Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
1.3. Блоковые коды
Все коды, описываемые в этой книге, за исключением кодов, рассматриваемых в гл. 12, являются блоковыми кодами. Именно для блоковых кодов Шеннон доказал свою фундаментальную теорему о дискретных каналах с шумом [119], в которой утверждается, что" канал имеет точно определяемую пропускную способность и что при помощи подходящих кодов можно передавать информацию с любой скоростью, не превосходящей пропускной способности канала, так, чтобы вероятность ошибки после декодирования была произвольно малой. Блоковые коды применяются не только в теории связи, но также покрайней мере еще в двух других областях. Они являются основой для распределения нагрузок при помощи переключательных матриц [40, 49, 78, 114], которые не только более эффективны, чем обычные системы адресов ячеек памяти, но и позволяют автоматически исправлять отдельные ошибки, произошедшие из-за неполадок устройства. Они аналогичны по математической структуре некоторым планам статистических экспериментов [5, 48].
Блоковый код — это код, в котором используются последовательности из  символов канала. Передаются только некоторые отобранные последовательности из символов канала. Передаются только некоторые отобранные последовательности из  символов, называемые кодовыми блоками или чаще кодовыми словами. На приемном конце на основе информации, содержащейся в полученной последовательности, принимается решение относительно переданного кодового слова. Это решение является статистическим, т. е. по своей природе оно является наилучшей гипотезой, исходящей из имеющейся информации, и поэтому оно не безошибочно. При использовании хорошего кода вероятность неверного решения может быть значительно меньше вероятности того, что первоначально поданные на вход канала символы безошибочно воспроизводятся на его выходе. символов, называемые кодовыми блоками или чаще кодовыми словами. На приемном конце на основе информации, содержащейся в полученной последовательности, принимается решение относительно переданного кодового слова. Это решение является статистическим, т. е. по своей природе оно является наилучшей гипотезой, исходящей из имеющейся информации, и поэтому оно не безошибочно. При использовании хорошего кода вероятность неверного решения может быть значительно меньше вероятности того, что первоначально поданные на вход канала символы безошибочно воспроизводятся на его выходе.
Процесс выбора решения может быть описан математически при помощи таблицы декодирования. Кодовые слова образуют первую строку этой таблицы. Если получено некоторое кодовое слово, логично предположить, что было передано именно это слово. Решения, принимаемые на приемном конце для других слов на выходе, описываются перечислением под каждым кодовым словом тех возможных слов на выходе, которые могут декодироваться в это
кодовое слово. Таким образом, каждое возможное слово на выходе появляется в таблице декодирования один и только один раз.
Пример. Предположим, что имеются четыре возможных сообщения a, b, с и d и что сообщение будет передаваться с помощью двоичного блокового кода длины 5. Тогда должны быть выбраны четыре кодовых слова, например 11000 для а, 00110 для  для для  для для 
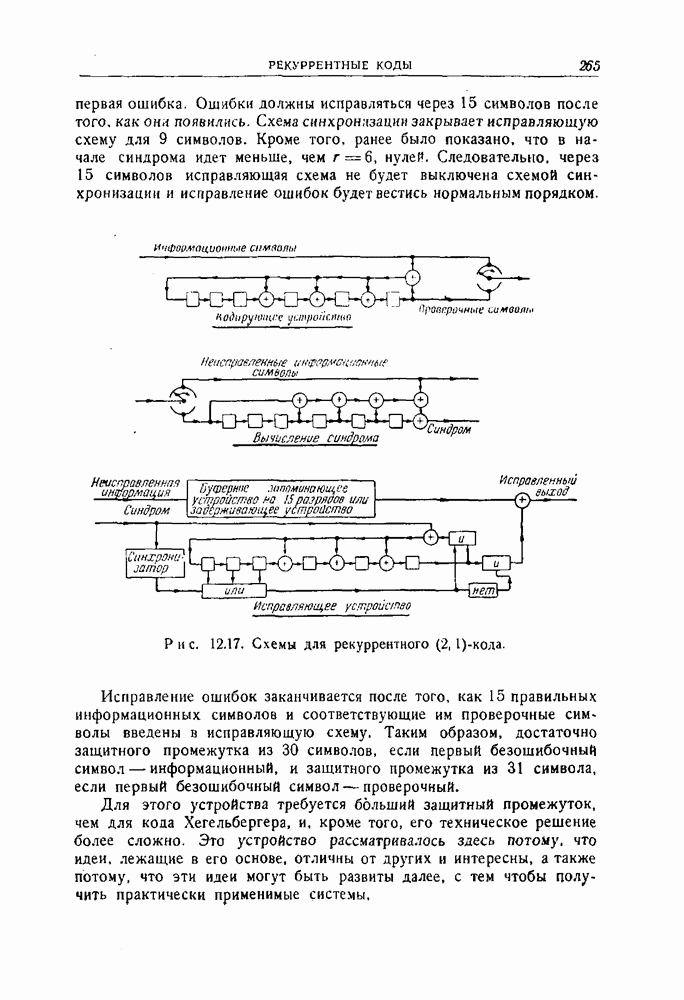
Кроме того, должны быть записаны решения, принимаемые на приемном конце для каждого из  слов, или последовательностей пяти символов, которые могут быть получены в результате передачи. Пример того, как это может быть сделано, приведен на рис. 1.3. слов, или последовательностей пяти символов, которые могут быть получены в результате передачи. Пример того, как это может быть сделано, приведен на рис. 1.3.

Рис. 1.3. Таблица декодирования для двоичного кода.
Код и схема декодирования, показанные на рис. 1.3, позволяют выполнять правильное декодирование, если в полученном векторе имеется не более чем одна ошибка, т. е. не более чем один искаженный символ. Действительно, все пять слов, которые получаются в результате ошибки в одном символе, расположены под соответствующим кодовым словом. Правильно декодируются и некоторые другие комбинации ошибок, хотя остальные комбинации могут декодироваться и неправильно. Например, если передавалось слово  и произошли две ошибки, в результате чего получилось слово и произошли две ошибки, в результате чего получилось слово  то декодирование будет произведено правильно, так как слово 11110 находится в столбце под то декодирование будет произведено правильно, так как слово 11110 находится в столбце под  Если же в результате двух ошибок получилось слово 110 11, то оно будет неправильно декодировано в слово Если же в результате двух ошибок получилось слово 110 11, то оно будет неправильно декодировано в слово  поскольку 110 11 в табл. 1.3 находится в столбце под 10 0 11. поскольку 110 11 в табл. 1.3 находится в столбце под 10 0 11.
Декодирование может допускать как одну из возможных альтернатив утверждение, что обнаружена ошибка, без каких-либо дополнительных гипотез относительно переданного слова. Осуществить такое декодирование можно, вводя в систему обнаружения ошибок, в которой устройство для декодирований двоичных символов в двоичные сигнализирует об ошибке, однако не делается никаких попыток принять какие-либо решения, если на выходе получено слово, не совпадающее с кодовым словом. С другой стороны, в системе могут сочетаться исправление и обнаружение ошибок. Например, для кода, изображенного на рис. 1.3, полученное слово, лежащее выше непрерывной линии, может декодироваться в кодовое слово в начале соответствующего столбца, но в то же время для слов на выходе, лежащих ниже непрерывной линии, декодирующее устройство может просто сигнализировать об "обнаружении ошибки". Это соответствует
исправлению единичных ошибок вместе с обнаружением некоторых комбинаций из двух или более ошибок.
Для того чтобы оценить возможности некоторого кода, нужно иметь более точные сведения о канале. Интенсивно исследовался двоичный симметричный канал, хотя многие реальные каналы связи описываются им не слишком точно. Этот канал схематически изображен на рис. 1.4. Для двоичного симметричного канала задается вероятность  того, что полученный символ совпадает с переданным. Вероятность того, что будет получен противоположный символ, того, что полученный символ совпадает с переданным. Вероятность того, что будет получен противоположный символ,  Предполагается, что Предполагается, что  и что каждый символ не зависит от всех других. и что каждый символ не зависит от всех других.

Рис. 1.4. Двоичный симметричный канал.

Рис. 1.5. Двоичный стирающий канал.
Заметим, что в терминах общей схемы, изображенной на рис. 1-2, этот "канал" включает а себя устройствокодирующее двоичные символы в сигналы на входе канала, собственно канал и устройство, декодирующее сигналы на выходе канала в двоичные символы.
Другим интенсивно изучавшимся идеализированным каналом является двоичный стирающий канал, изображенный на рис.  -Для этого канала задается вероятность -Для этого канала задается вероятность  того, что будет получен тот же символ, который передавался, и вероятность того, что будет получен тот же символ, который передавался, и вероятность  того, что передаваемый символ будет стерт. (Стертый символ обозначается через того, что передаваемый символ будет стерт. (Стертый символ обозначается через  Воздействия канала на различные символы предполагаются независимыми. Заметим, что на выходе этого канала известны положения искаженных символов, и этот факт делает обычно исправление стираний более легким, чем исправление ошибок. Обобщения стирающего канала включают недвоичный стирающий канал и канал со стираниями и ошибками. Стирающий канал является идеализацией системы, изображенной на рис. 1.2, в которой устройство, декодирующее сигналы на выходе канала в двоичные символы, выдает в сомнительных случаях символ, соответствующий стиранию и отличный от 0 и от 1. Воздействия канала на различные символы предполагаются независимыми. Заметим, что на выходе этого канала известны положения искаженных символов, и этот факт делает обычно исправление стираний более легким, чем исправление ошибок. Обобщения стирающего канала включают недвоичный стирающий канал и канал со стираниями и ошибками. Стирающий канал является идеализацией системы, изображенной на рис. 1.2, в которой устройство, декодирующее сигналы на выходе канала в двоичные символы, выдает в сомнительных случаях символ, соответствующий стиранию и отличный от 0 и от 1.
Если предположить, что рассматривается симметричный двоичный канал, по которому передается некоторое кодовое слово, то вероятность того, что не произойдет ни одной ошибки, равна  Вероятность того, что произойдет одна ошибка на заданном месте, равна Вероятность того, что произойдет одна ошибка на заданном месте, равна  Вероятность того, что слоу на выходе будет Вероятность того, что слоу на выходе будет
отличаться от переданного слова в  местах, равна местах, равна  Поскольку Поскольку  то получение на выходе блока без ошибок более вероятно, чем получение блока с ошибками. Получение любого слова с одной ошибкой более вероятно, чем получение любого слова с двумя или более ошибками, и т. д. В таком случае, в предположении, что отдельные кодовые слова с равными вероятностями могли передаваться по каналу, наилучшим решением на приемнике будет всегда декодирование в то кодовое слово, которое отличается от полученного слова в наименьшем числе мест. Такое декодирование называется декодированием по методу максимального правдоподобия. Схема декодирования, изображенная на рис. 1.3, удовлетворяет этому критерию. то получение на выходе блока без ошибок более вероятно, чем получение блока с ошибками. Получение любого слова с одной ошибкой более вероятно, чем получение любого слова с двумя или более ошибками, и т. д. В таком случае, в предположении, что отдельные кодовые слова с равными вероятностями могли передаваться по каналу, наилучшим решением на приемнике будет всегда декодирование в то кодовое слово, которое отличается от полученного слова в наименьшем числе мест. Такое декодирование называется декодированием по методу максимального правдоподобия. Схема декодирования, изображенная на рис. 1.3, удовлетворяет этому критерию.
Предполагая снова, что рассматривается симметричный двоичный канал, можно следующим образом вычислить вероятность правильного декодирования для кода, изображенного на рис. 1.3. Допустим, что передавалось слово  Оно будет правильно декодировано, если на выходе получено любое слово из соответствующего ему столбца. Одно из этих слов не отличается от переданного, пять отличаются в одном месте и два отличаются в двух местах. Поэтому вероятность правильного декодирования Оно будет правильно декодировано, если на выходе получено любое слово из соответствующего ему столбца. Одно из этих слов не отличается от переданного, пять отличаются в одном месте и два отличаются в двух местах. Поэтому вероятность правильного декодирования

Аналогичные вычисления могут быть сделаны для других кодовых слов.
Если этот код используется исключительно для обнаружения ошибок, то вероятность правильного приема равна  Вероятность необнаружения ошибки, если передавалось слово Вероятность необнаружения ошибки, если передавалось слово  равна вероятности того, что получено некоторое другое кодовое слово. Поскольку одно кодовое слово отличается от равна вероятности того, что получено некоторое другое кодовое слово. Поскольку одно кодовое слово отличается от  в четырех разрядах, а остальные кодовые слова - в трех разрядах каждое, то в четырех разрядах, а остальные кодовые слова - в трех разрядах каждое, то

|
1 |
Оглавление
- ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
- ГЛАВА 1. ПРОБЛЕМА КОДИРОВАНИЯ
- 1.2. Несколько замечаний о двоичных кодах, обнаруживающих и исправляющих ошибки
- 1.3. Блоковые коды
- 1.4. Расстояние Хэмминга
- 1.6. Проблема кодирования
- Замечания
- ГЛАВА 2. АЛГЕБРАИЧЕСКОЕ ВВЕДЕНИЕ
- 2.2. Кольца
- 2.3. Поля
- 2.4. Подгруппы и факторгруппы
- 2.5. Векторные пространства и линейные алгебры
- 2.6. Матрицы
- Замечания
- ГЛАВА 3. ЛИНЕЙНЫЕ КОДЫ
- 3.1. Определение линейного кода
- 3.2. Описание линейных кодов при помощи матриц
- 3.3. Стандартная расстановка
- 3.4. Поэтапное декодирование
- 3.5. Модулярное представление линейных кодов
- 3.6. Эквивалентность линейных кодов
- Замечания
- ГЛАВА 4. ВОЗМОЖНОСТИ ИСПРАВЛЕНИЯ ОШИБОК С ПОМОЩЬЮ ЛИНЕЙНЫХ КОДОВ
- 4.1. Граница Плоткина
- 4.2. Граница Варшамова-Гилберта
- 4.3. Граница, основанная на принципа плотной упаковки сфер
- 4.4. Граница, основанная на случайном выборе кода
- 4.5. Обсуждение границ
- 4.6. Границы для кодов, исправляющих или обнаруживающих пачки ошибок
- Замечания
- ГЛАВА 5. ВАЖНЕЙШИЕ ЛИНЕЙНЫЕ КОДЫ
- 5.1. Коды Хэмминга
- 5.2. Веса кодовых слов в коде Хэмминга
- 5.3. (23,12)-код Голея
- 5.4. Оптимальные коды для двоичного симметричного канала
- 5.5. Коды Рида — Маллера
- 5.6. Коды Макдональда
- 5.7. Коды, получаемые с помощью матриц Адамара
- 5.8. Итеративные коды
- Замечания
- ГЛАВА 6. КОЛЬЦА МНОГОЧЛЕНОВ И ПОЛЯ ГАЛУА
- 6.1. Идеалы, классы вычетов и кольцо классов вычетов
- 6.2. Идеалы и классы вычетов целых чисел
- 6.3. Идеалы многочленов и классы вычетов
- 6.4. Алгебра классов вычетов многочленов
- 6.5. Поля Галуа
- 6.6. Мультипликативная группа поля Галуа
- Замечания
- ГЛАВА 7. ЛИНЕЙНЫЕ ПЕРЕКЛЮЧАТЕЛЬНЫЕ СХЕМЫ
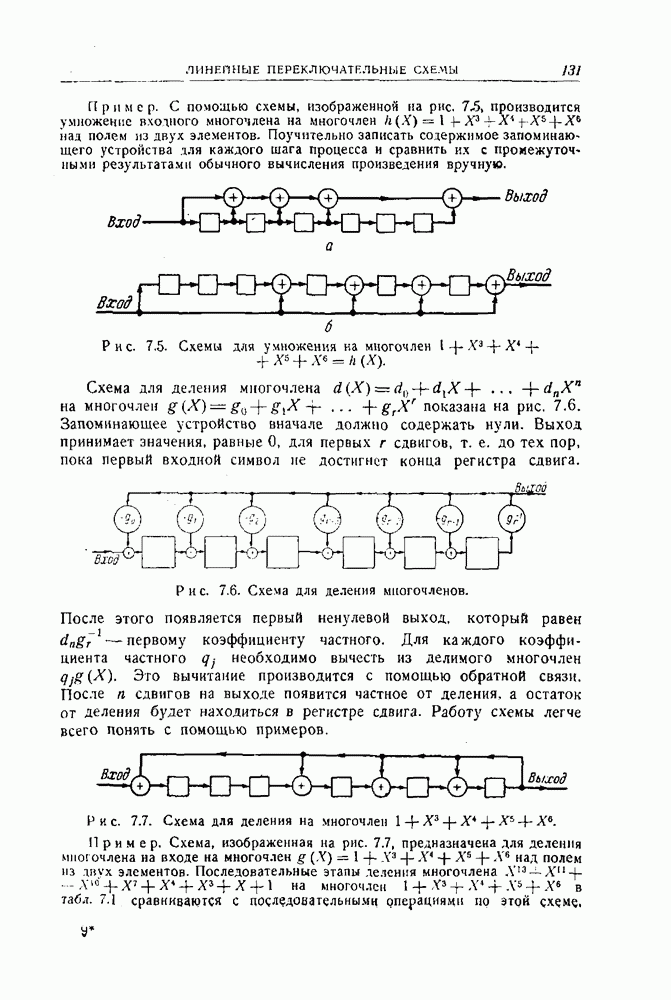
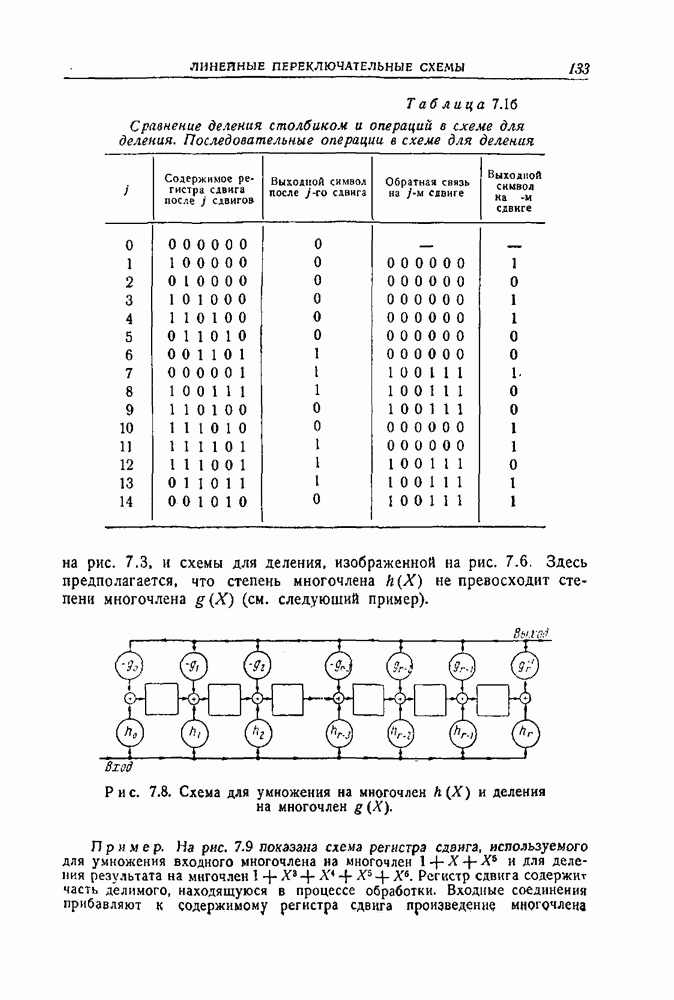
- 7.2. Умножение и деление многочленов
- 7.3. Вычисления в алгебрах многочленов и полях Галуа
- 7.4. Линейные рекуррентные соотношения и генераторы с регистром сдвига
- 7.5. Анализ линейных переключательных схем
- 7.6. Анализ общей линейной переключательной схемы с конечным числом состояний
- Замечания
- ГЛАВА 8. ЦИКЛИЧЕСКИЕ КОДЫ
- 8.1. Циклические коды и идеалы
- 8.2. Матричное описание циклических кодов
- 8.3. Последовательности максимальной длины
- 8.4. Кодирование с помощью регистра сдвига, содержащего k разрядов
- 8.5. Кодирование с помощью регистра сдвига, содержащего n — k разрядов
- 8.6. Обнаружение ошибок с помощью циклических кодов
- 8.7. Двоичные коды Хэмминга
- 8.8. Обобщенные коды Хэмминга
- 8.9. Укороченные циклические коды
- Замечания
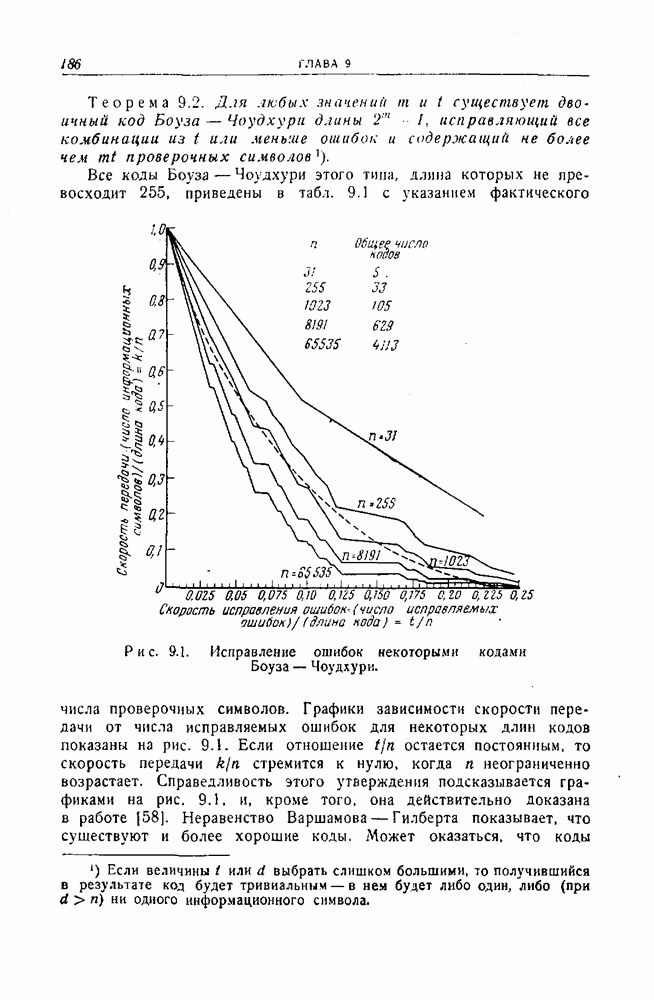
- ГЛАВА 9. КОДЫ БОУЗА — ЧОУДХУРИ
- 9.2. Двоичные коды
- 9.3. Коды Рида — Соломона
- 9.4. Метод исправления ошибок
- 9.5. Другой способ исправления ошибок для двоичных кодов
- 9.6. Обнаружение ошибок с помощью кодов Боуза — Чоудхури
- 9.7. Использование кодов Боуза — Чоудхури при передаче по стирающему каналу
- Замечания
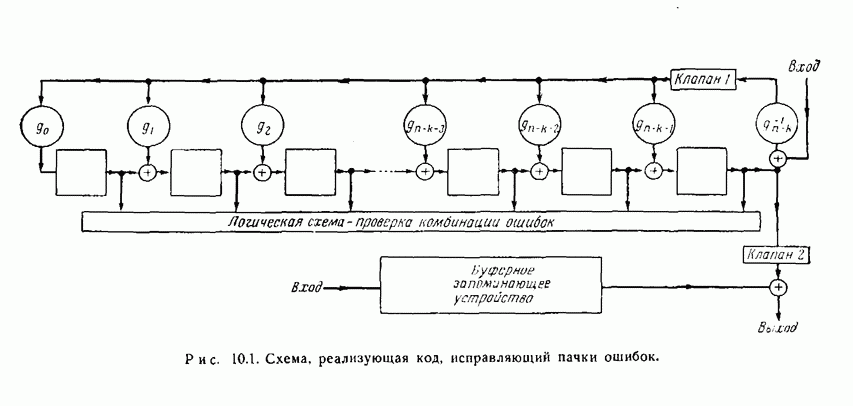
- ГЛАВА 10. ЦИКЛИЧЕСКИЕ КОДЫ, ИСПРАВЛЯЮЩИЕ ПАЧКИ ОШИБОК
- 10.1. Коды Файра
- 10.2. Возможности кодов Файра исправлять ошибки
- 10.3. Другие коды, исправляющие пачки ошибок
- 10.4. Двоичные коды, исправляющие пачки только с четным или только с нечетным числом ошибок
- 10.6. Практическая реализация кодов, исправляющих пачки ошибок
- 10.6. Другой метод исправления ошибок
- 10.7. Другой подход к задаче исправления пачек ошибок
- Замечания
- ГЛАВА 11. ДРУГИЕ СПОСОБЫ ДЕКОДИРОВАНИЯ
- 11.1. Общее декодирующее устройство для циклических кодов
- 11.2. Использование симметричности кода при поэтапном декодировании
- 11.3. Алгоритмы декодирования Рида
- Замечания
- ГЛАВА 12. РЕКУРРЕНТНЫЕ КОДЫ
- 12.1. Определение рекуррентного кода
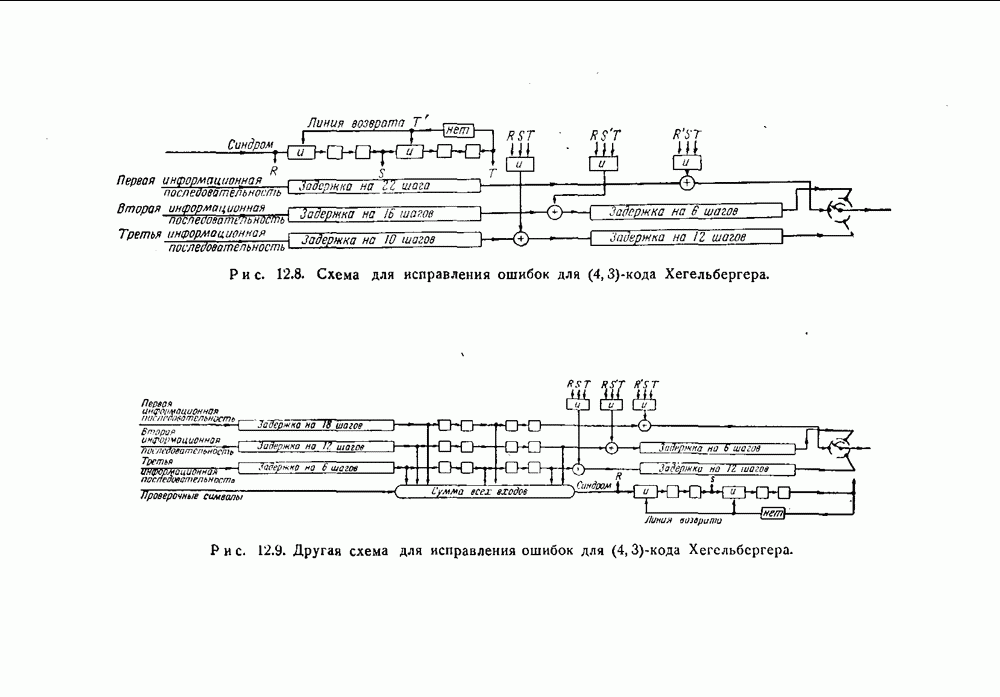
- 12.2. Коды Хегельбергера, исправляющие пачки ошибок
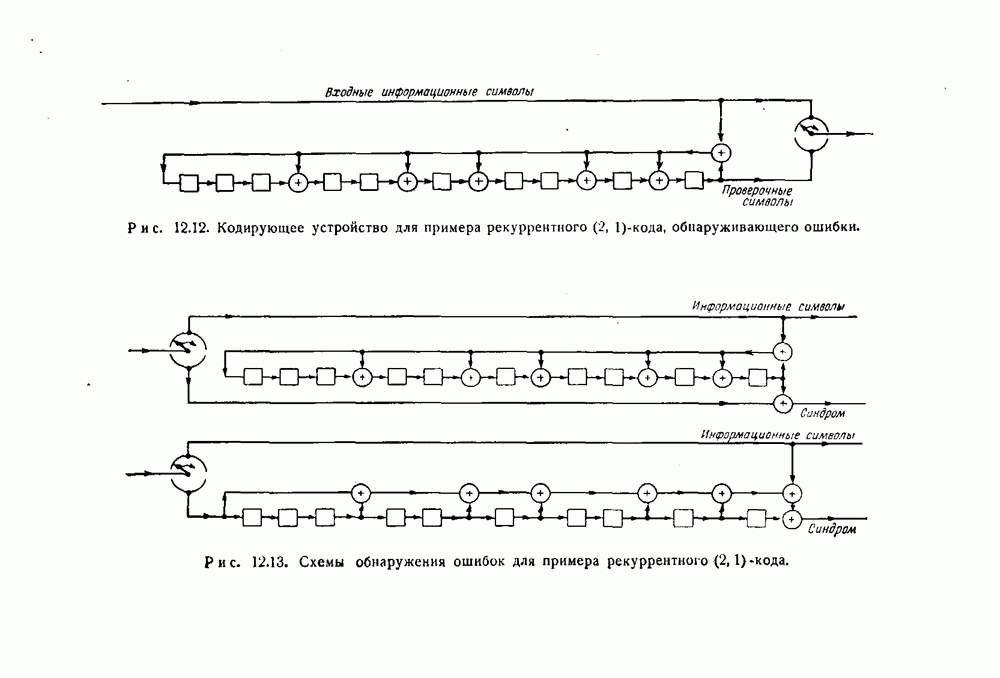
- 12.3. Обнаружение пачек ошибок с помощью рекуррентных кодов
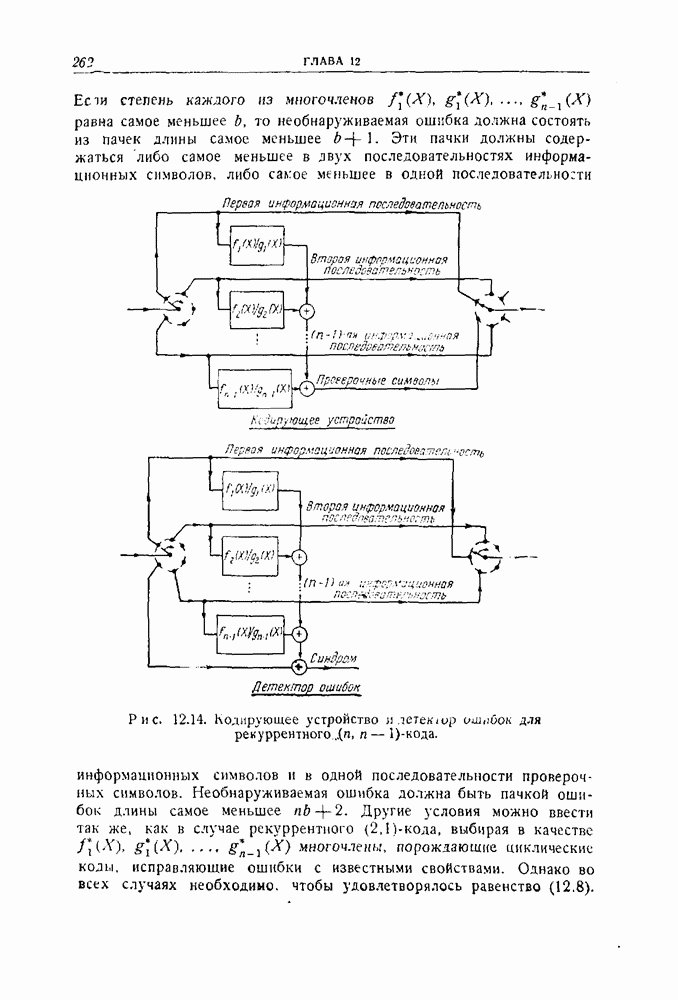
- 12.4. Рекуррентный код, исправляющий лачки ошибок и построенный на основе циклического кода
- 12.5. Последовательное декодирование
- ГЛАВА 13. КОДЫ ДЛЯ ПРОВЕРКИ АРИФМЕТИЧЕСКИХ ОПЕРАЦИЙ
- 13.2. AN-коды
- 13.3. Самодополняющиеся (AN+B)-коды
- 13.4. Реальное осуществление AN- и (AN+B)-кодов
- 13.6. Раздельные сумматор и проверяющее устройство
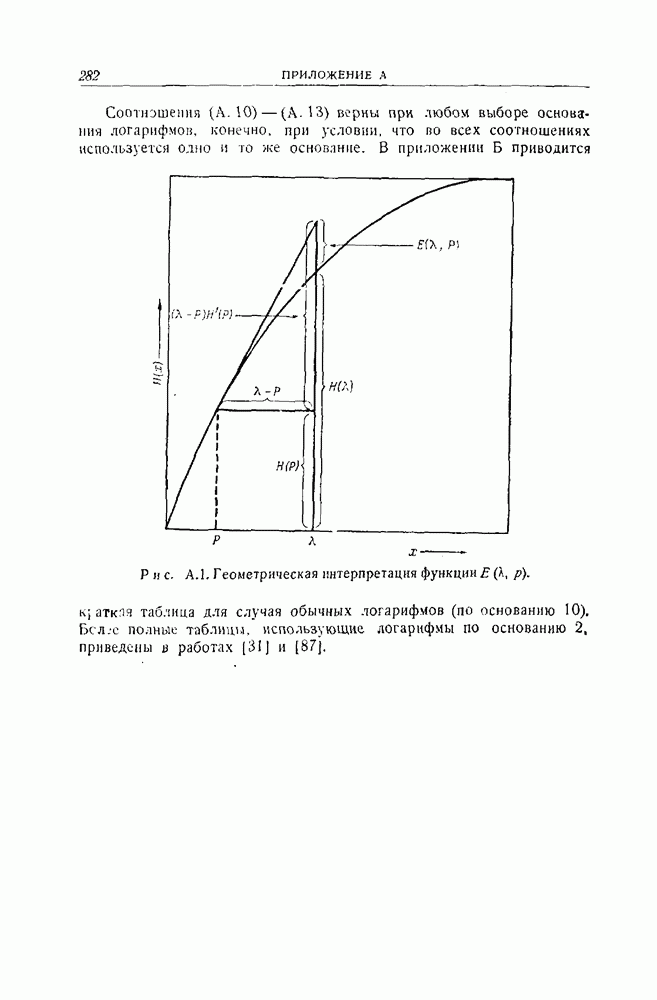
- ПРИЛОЖЕНИЕ А. НЕРАВЕНСТВА, ВКЛЮЧАЮЩИЕ БИНОМИАЛЬНЫЕ КОЭФФИЦИЕНТЫ
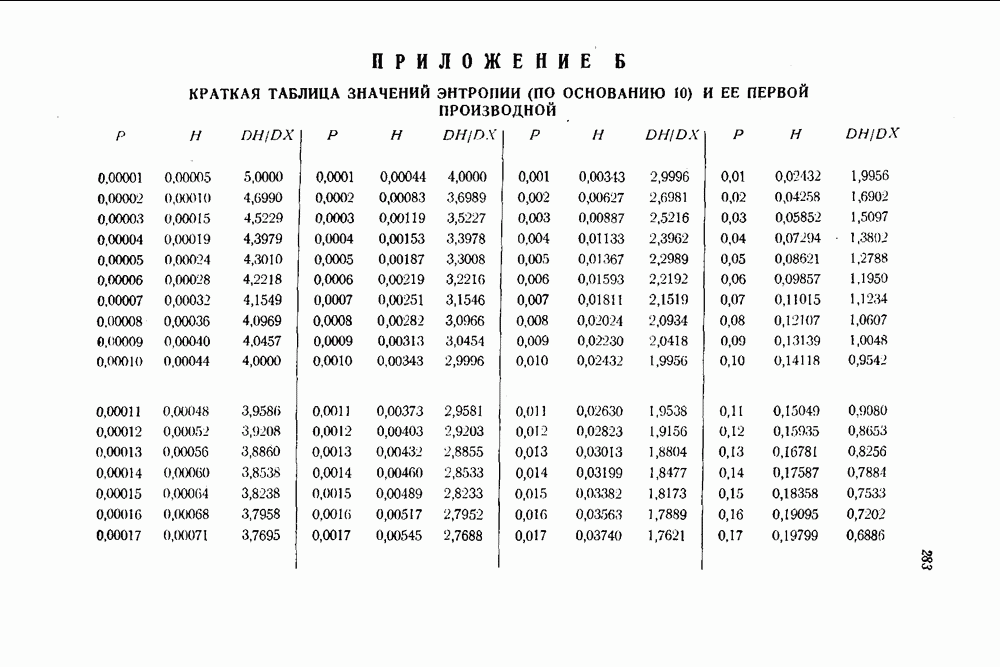
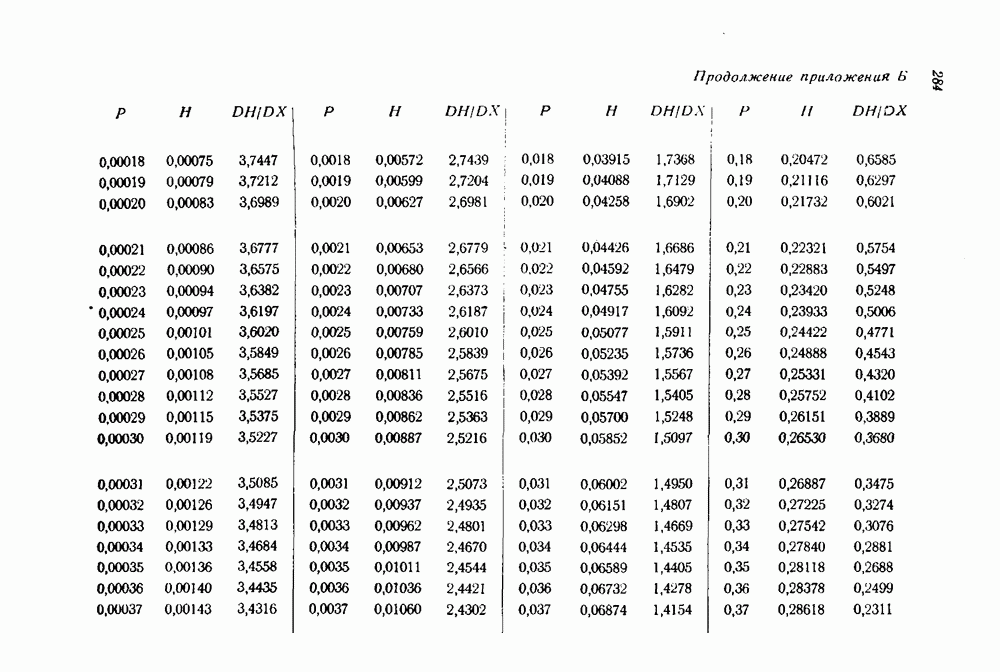
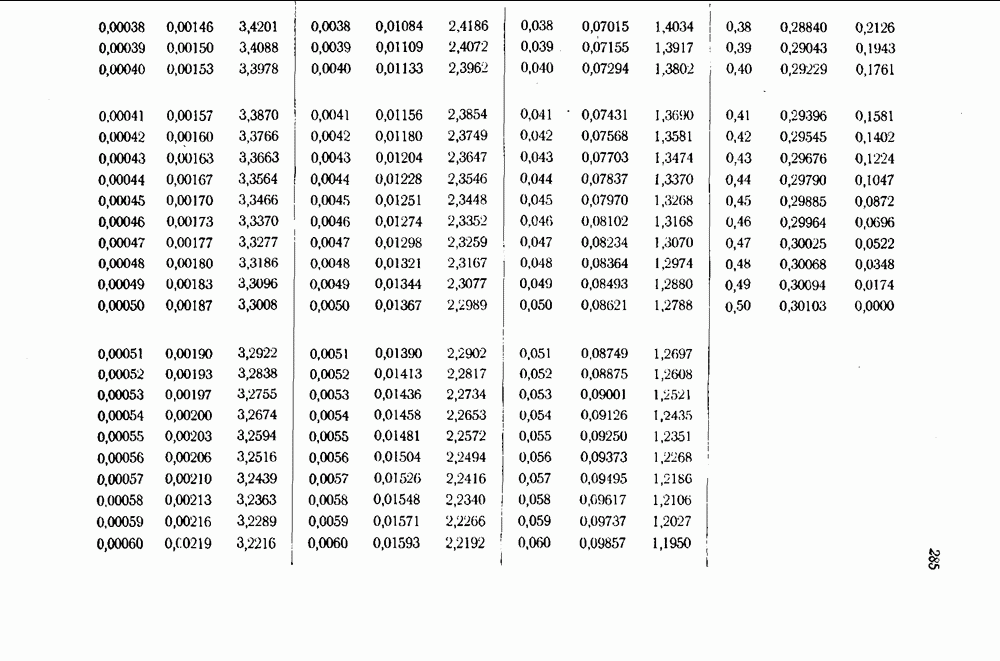
- ПРИЛОЖЕНИЕ Б. КРАТКАЯ ТАБЛИЦА ЗНАЧЕНИЙ ЭНТРОПИИ (ПО ОСНОВАНИЮ 10) И ЕЕ ПЕРВОЙ ПРОИЗВОДНОЙ
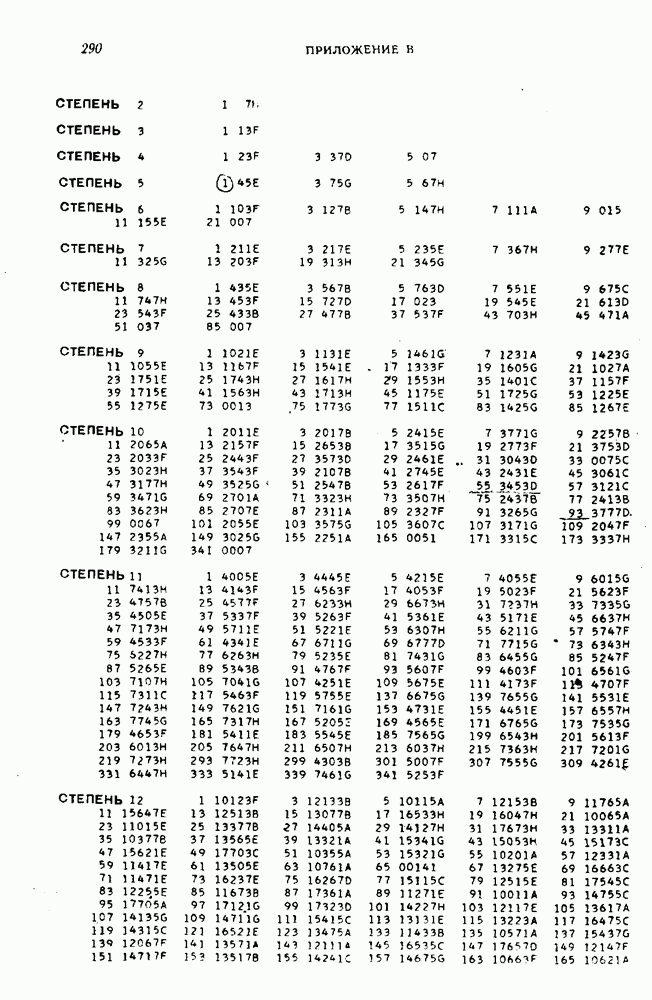
- ПРИЛОЖЕНИЕ В. ТАБЛИЦЫ НЕПРИВОДИМЫХ МНОГОЧЛЕНОВ НАД ПОЛЕМ GF(2)
|