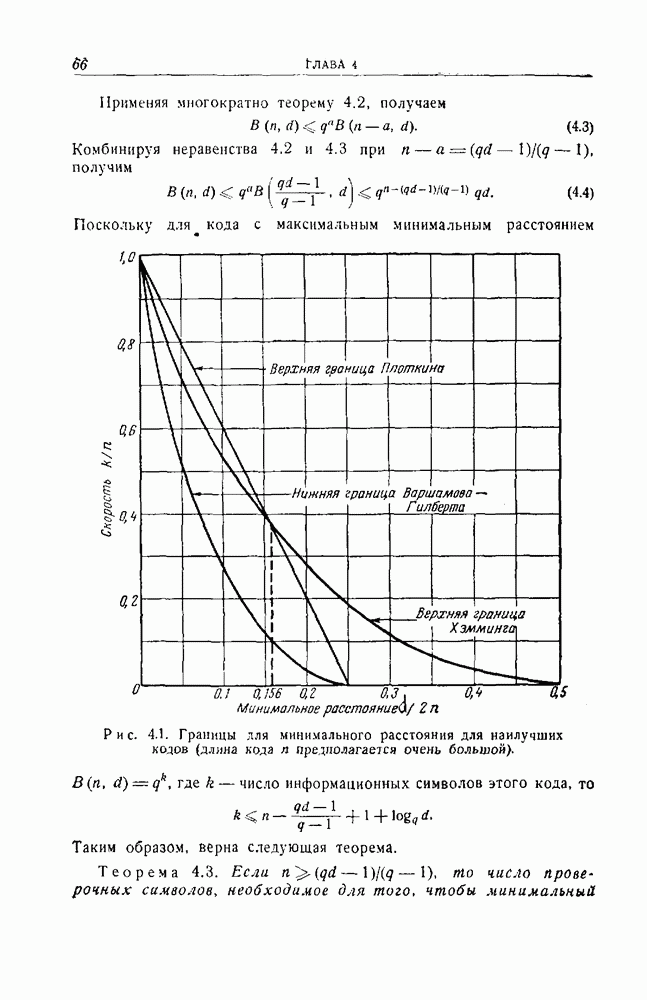
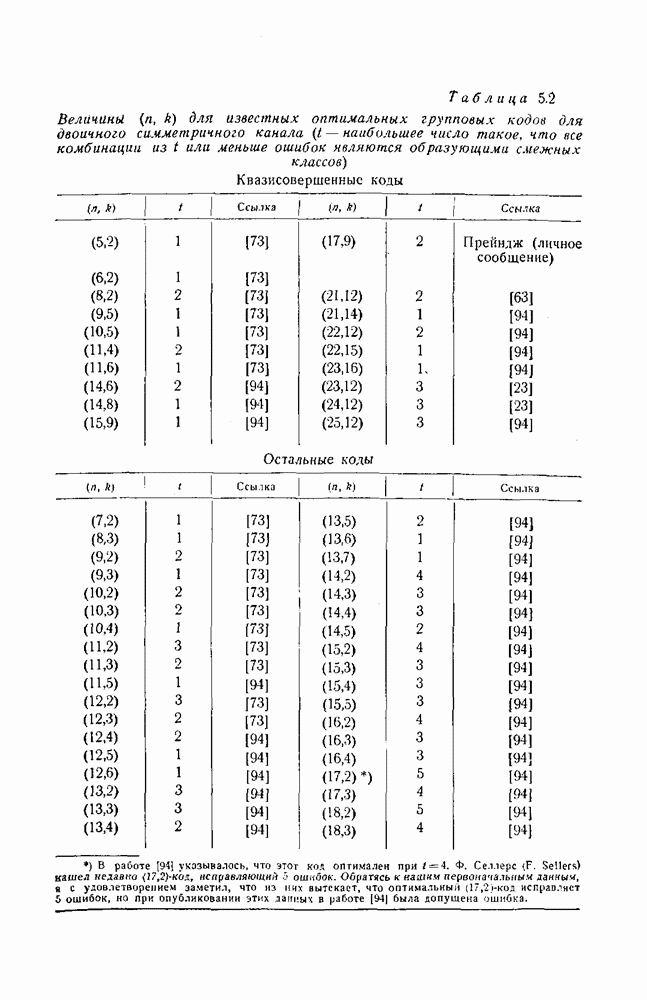
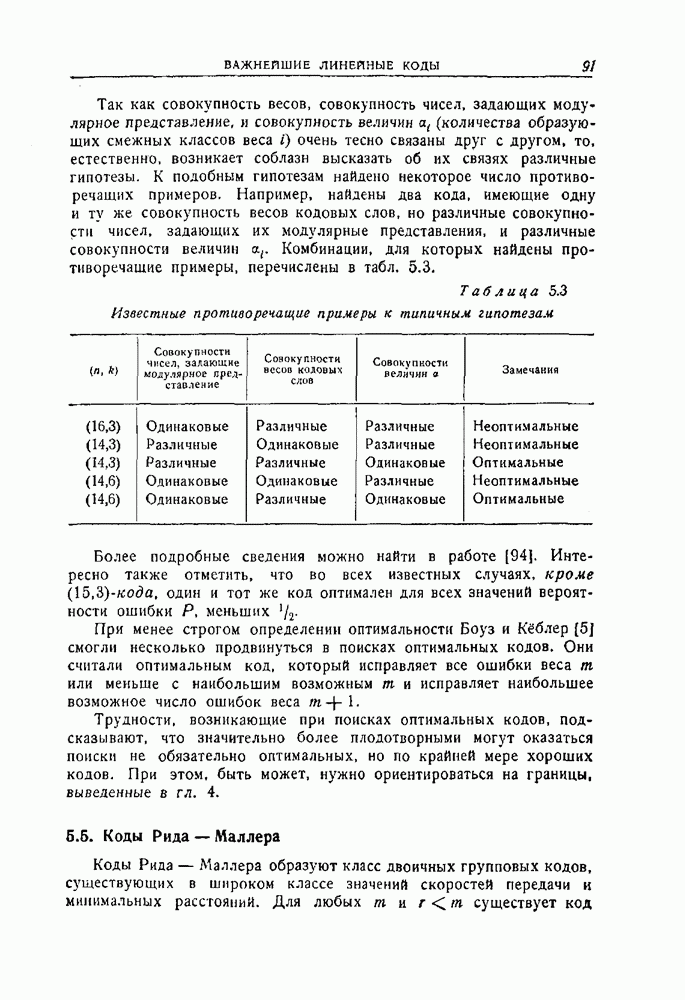
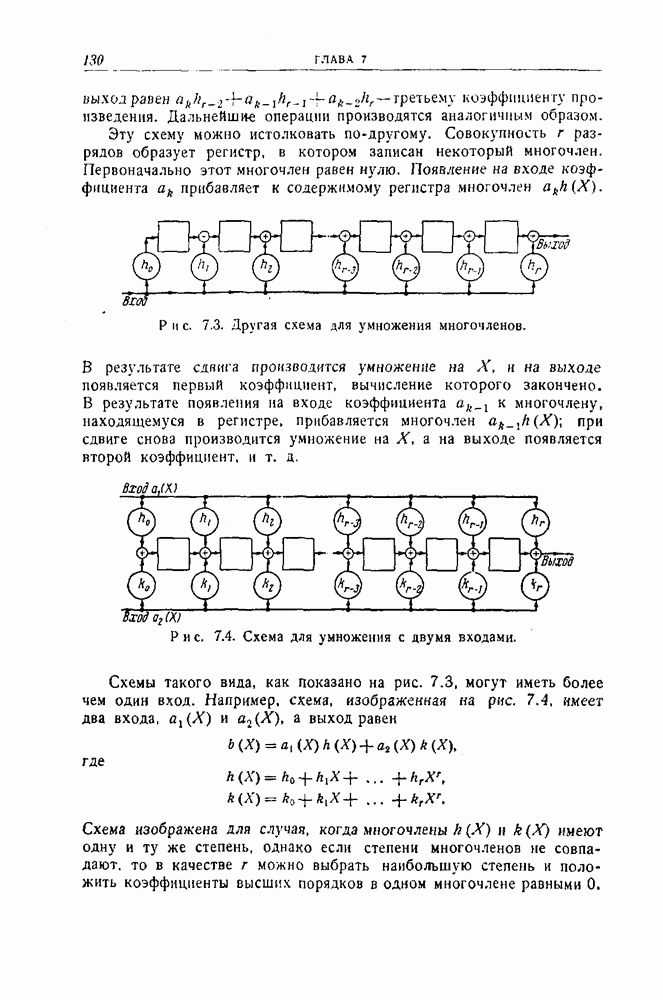
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
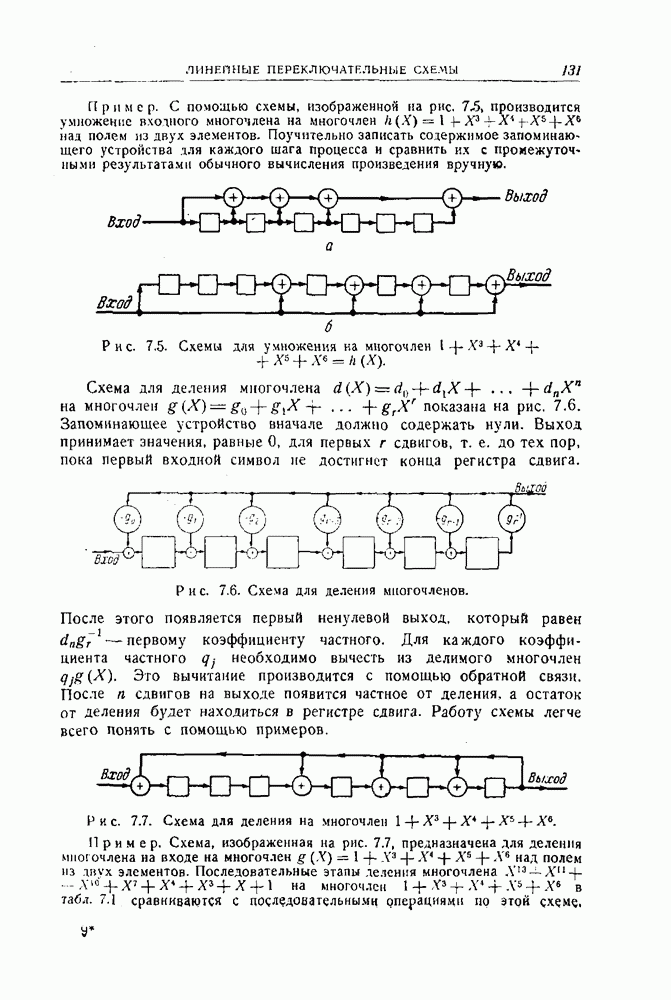
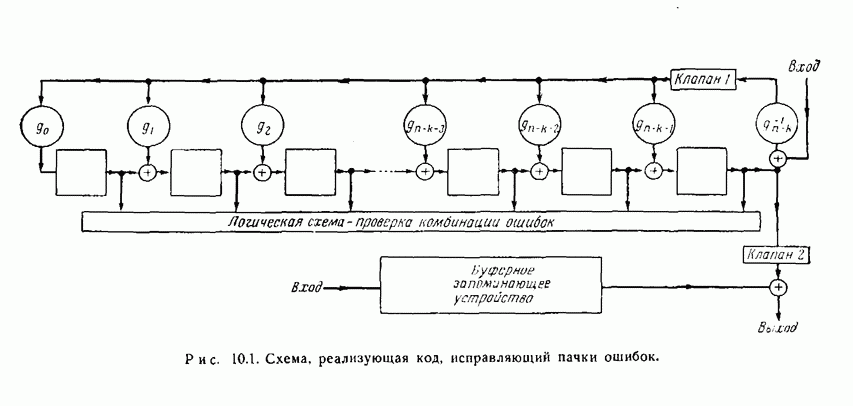
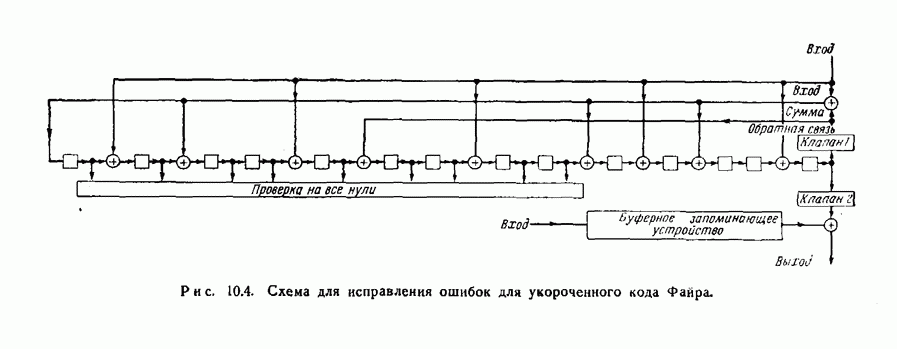
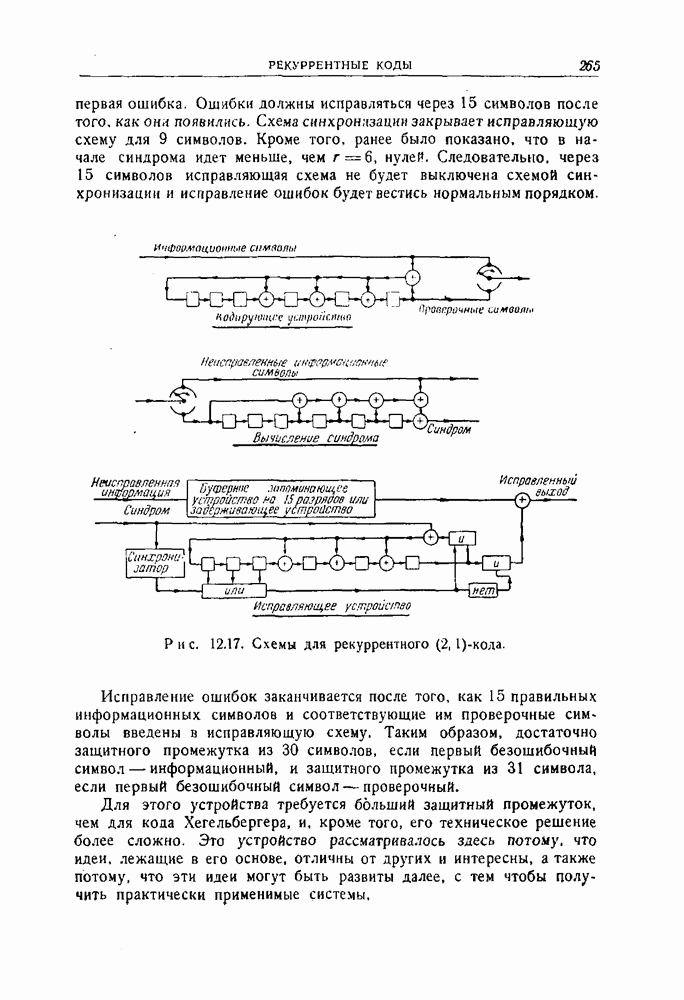
12.2. Коды Хегельбергера, исправляющие пачки ошибокКоды, описываемые в этом разделе, просты по структуре и поэтому легки для понимания. В то же время они удобны с точки зрения их технического осуществления и практически достаточно эффективны. Разбираемые здесь коды несколько отличаются от кодов, описанных в оригинальной статье Хегельбергера, который считал, что каждый проверочный символ является проверкой на четность для следующих за ним информационных символов. Здесь же предполагается, что все проверочные символы передаются после информационных символов, которые они проверяют. Такое расположение символов присолит к упрощению оборудования при практическом осуществлении кодов и меньшим суммарным задержкам для Чтобы проиллюстрировать основные идеи, рассмотрим сперва выходных последовательностей. Таким образом, для входной последовательности
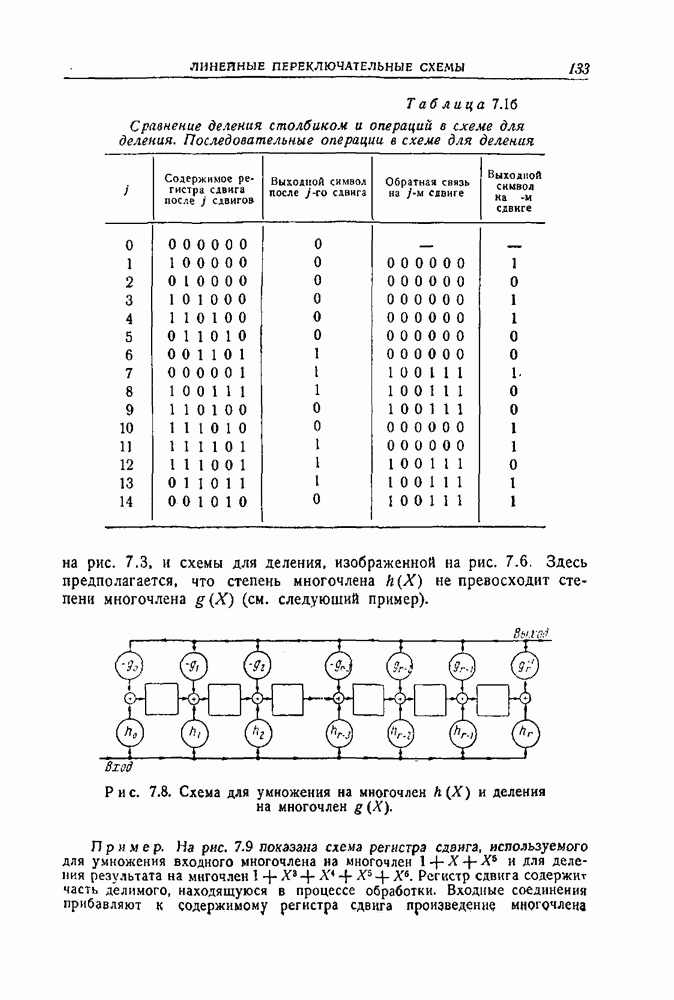
Рис. 12.2. Кодирующее устройство для простейшего рекуррентного На приемнике полученная последовательность разделяется на две последовательности, и по информационным символам вновь вычисляются проверочные символы. Они складываются по модулю 2 с полученными проверочными символами, в результате чего получается схема расположения неправильных проверок на четность, т. е. синдром. Если ошибки отсутствуют, то синдром равен последовательности нулей. Если при передаче появились ошибки, то в синдроме появляются единицы. Для рассматриваемого кода по синдрому можно исправить любую пачку ошибок, длина которой не превосходит 6. Чтобы увидеть, как это делается, предположим, что передавалась нулевая последовательность и что принята пачка ошибок длины 6: На рис. 12.3 изображена схема для исправления ошибок в информационных символах. Она основана на том. что если появляется ошибка, равная 1, то она повторяется обязательно три раза, а после этого обязательно появляются три нуля. Защитного промежутка из 9 правильных информационных символов и соответствующих им проверочных символов достаточно для того, чтобы исправить последующие пачки оштбок. Так, если защитный промежуток ничинается с информационного символа, то он должен состоять из 18 символов, хотя если защитный промежуток начинается с проверочного символа, то может потребоваться 19 правильных символов. Это вытекает из того факта, что достаточно (а иногда и необходимо), чтобы за последней единицей в синдроме следовали три нуля.
Рис. 12.3. Схема для вычисления синдрома и исправления ошибок для простейшего рекуррентного кода. Только после поступления шести правильных информационных символов и связанных с ними проверочных символов в схему, вычисляющую синдром, в ней будут содержаться только правильные символы, и после поступления еще трех пар правильных символов в синдроме появятся три нуля. Можно построить рекуррентный
Эта таблица содержит Эти векторы определяют соединения в регистре сдвига, в котором вычисляются проверочные символы. Число разрядоз в регистре сдвига на единицу меньше, чем число столбцов. Вектор определяет точки, в которых имеются соединения для первой информационной последовательности, вектор Если требуется чтобы код исправлял пачки длины 8, то этого можно достичь, образовывая новую совокупность векторов из векторов
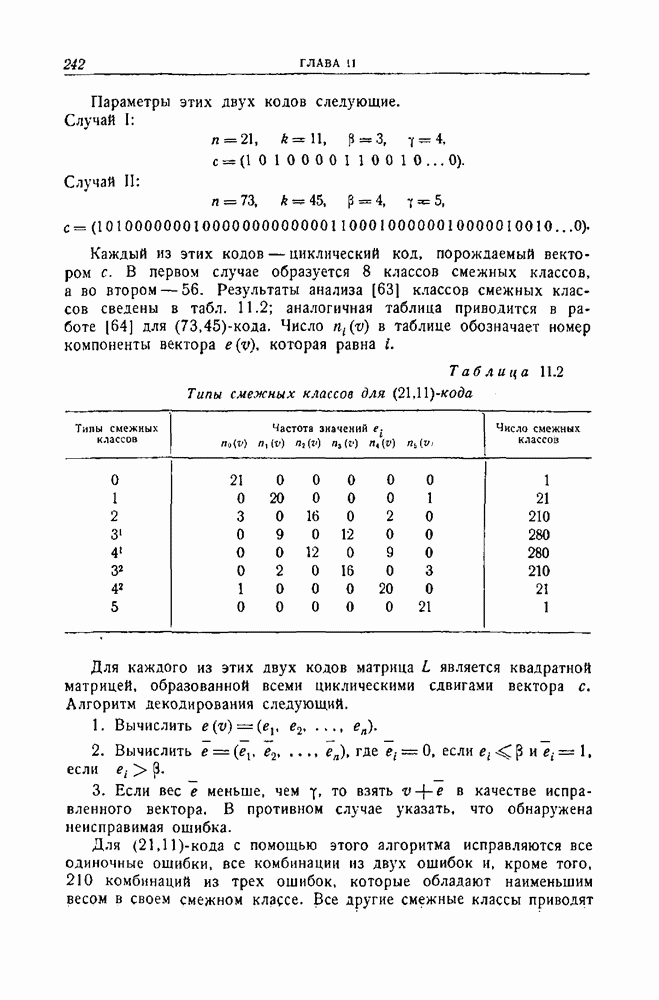
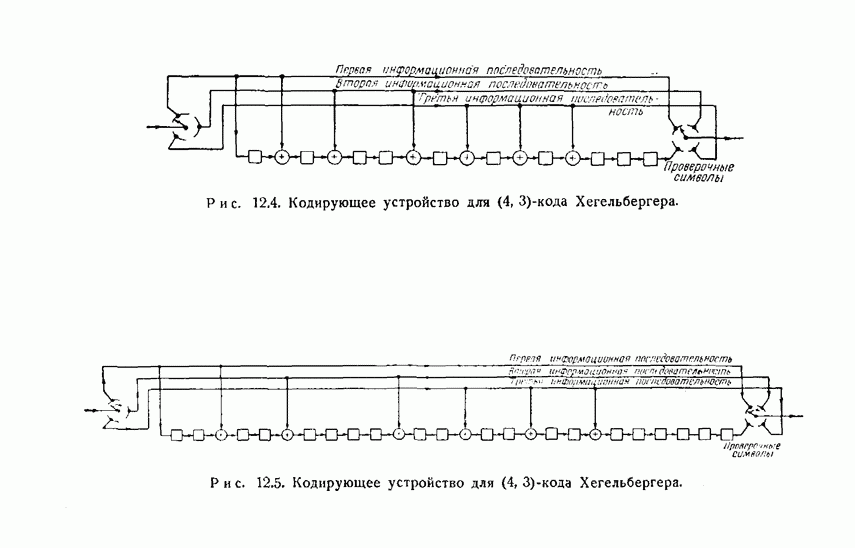
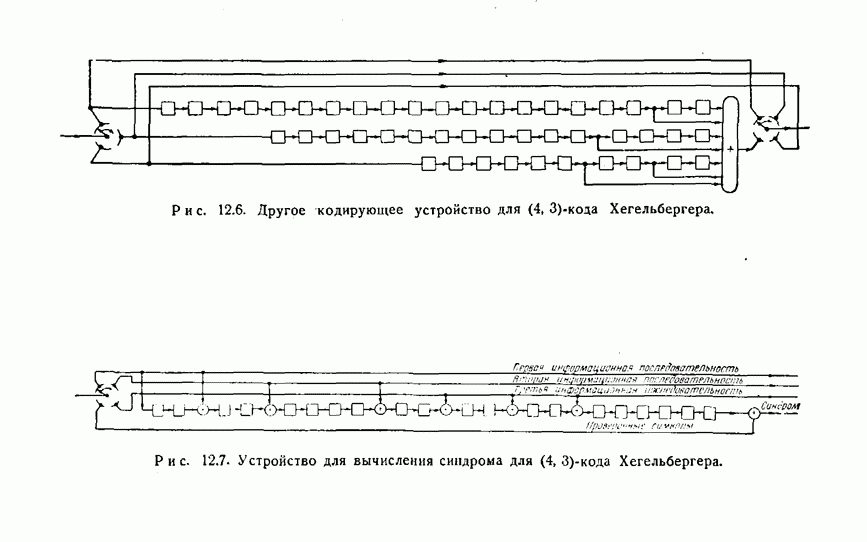
Кодирующее устройство для этого кода изображено на рис. 12.5, и еще одно эквивалентное ему кодирующее устройство изображено на рис. 12.6. По рис. 12.5 можно увидеть, что каждый проверочный символ является проверкой на четность некоторой совокупности из 7 ранее переданных информационных символов, по одному для каждого входного соединения регистра сдвига. Легко видеть, что в схеме, показанной на рис. 12.6, производятся те же самые вычисления. Теперь рассмотрим процесс исправления ошибок. Синдром можно вычислить, используя схему, изображенную на рис. 12.7. Синдром полностью определяется комбинацией ошибок, и если ошибок нет, то синдром состоит из одних нулей. Пачка общей длины 8 воздействует самое большее на два последовательно расположенных символа в любой отдельной информационной последовательности или в последовательности из проверочных символов. Если пачка ошибок
(кликните для просмотра скана)
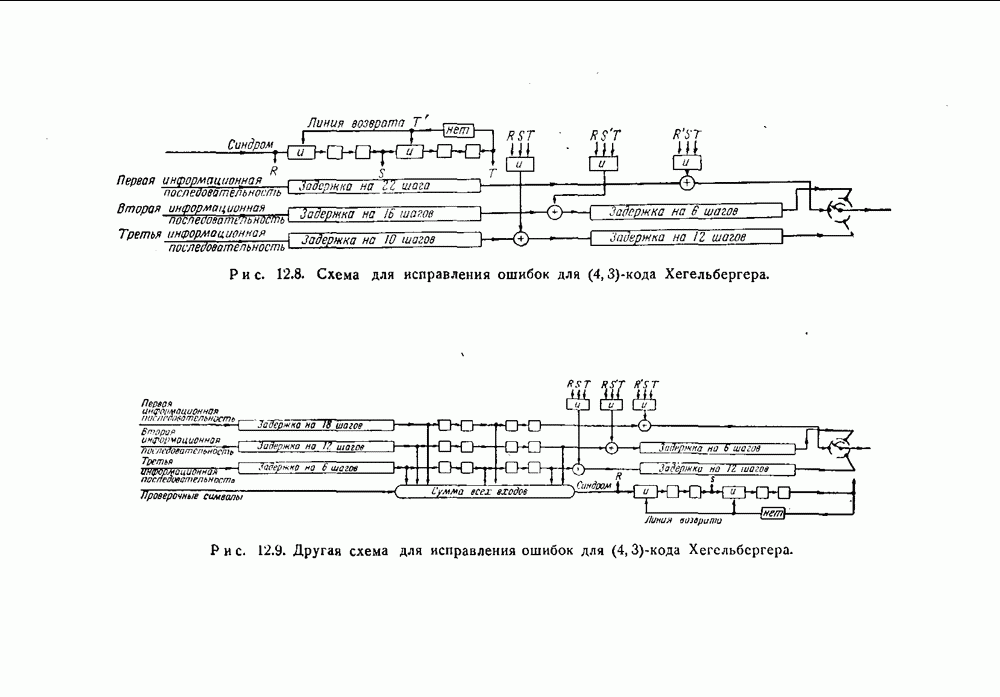
(кликните для просмотра скана) последовательности, и, наконец, на него начнут воздействовать ошибки из первой информационной последовательности. Таким образом, полный синдром, соответствующий рассматриваемой комбинации ошибок, будет равен По существу, ничего не изменится, если пачка начнется с другого места, например, пусть пачка ошибок Схема для исправления ошибок, которая может быть использована совместно с устройством для вычисления синдрома, изображенным на рис. 12.7, показана на рис. 12.8. Распознавание канала, Использование для вычисления синдрома схемы, изображенной на рис. 12.6, приводит к некоторому упрощению. Схема для исправления ошибок полностью показана на рис. 12.9. Для того чтобы устройство, исправляющее ошибки, было целиком заполнено правильными символами, достаточно 96 последовательных правильных символов. Следовательно, защитного промежутка из 95 правильных символов между пачками ошибок достаточно для того, чтобы можно было исправлять последовательные пачки. Рассматриваемый код достаточно систематичен для того, чтобы можно было получить формулы для расчета защитного промежутка, а также для расчета характеристик требуемых схем. Рассмотрим
(кликните для просмотра скана) устройства, изображенные на рис, 12.4 и 12.5, должны содержать
разрядов. В декодирующем устройстве, изображенном на рис. 12.9, регистр для вычисления синдрома должен содержать
разрядов. Общее число разрядов в линии первой информационной последовательности должно быть равно длине общей задержки по времени от момента появления ошибочного символа в первой информационной последовательности до тех
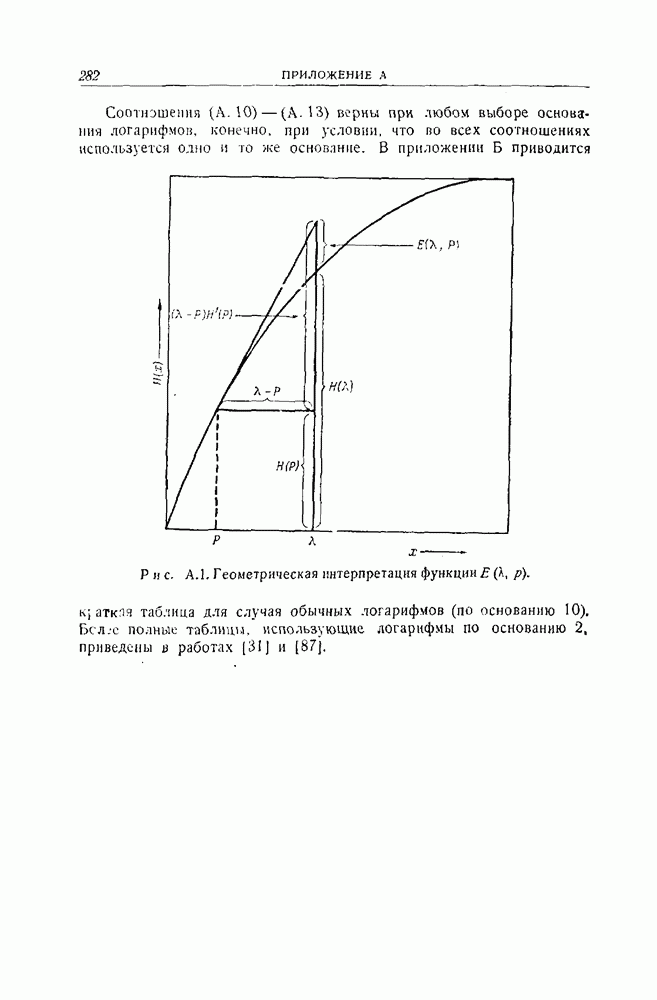
Что касается свободного от ошибок защитного промежутка, который должен помещаться между пачками ошибок, то наихудшая возможная комбинация состоит в появлении ошибки в первой информационной последовательности в конце первой пачки и одновременном появлении ошибки в проверочных символах в начале следующей пачки. Эта комбинация является наихудшей, потому что символы первой информационной последовательности оказывают влияние на синдром после наибольшей задержки, в то время как для проверочных символов задержки вообще не требуется. Промежуток от того момента, когда ошибка появилась в первой информационной последоватетельности, до того момента, когда соответствующая ей единица появляется из регистра для вычисления синдрома, равна сумме задержки в схеме, используемой для вычисления синдрома, и задержки в регистре для синдрома
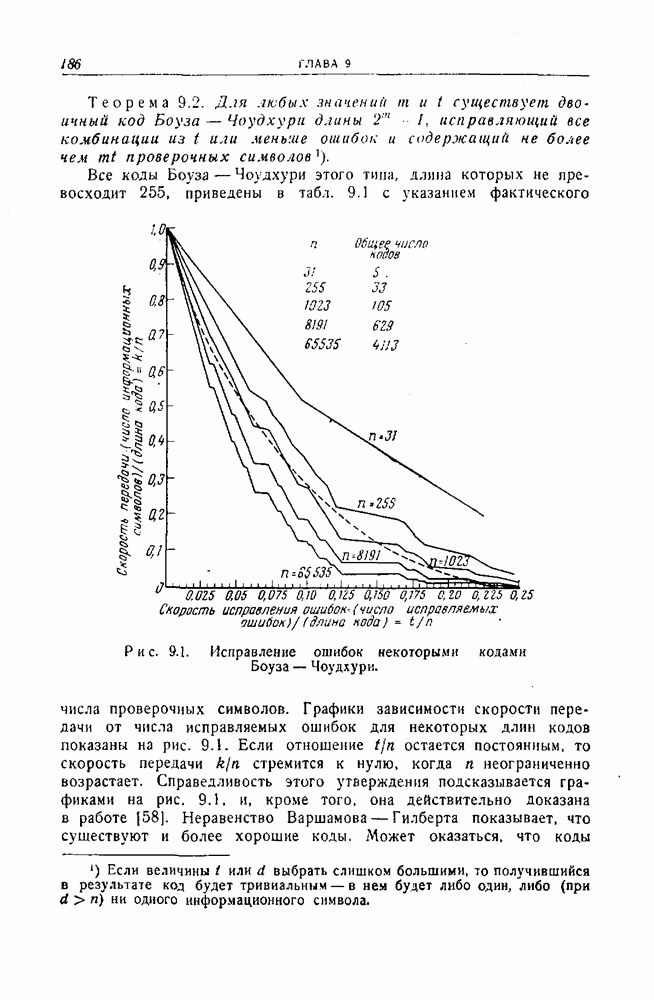
Схема будет содержать только правильные символы после того, как появится такое число блоков из
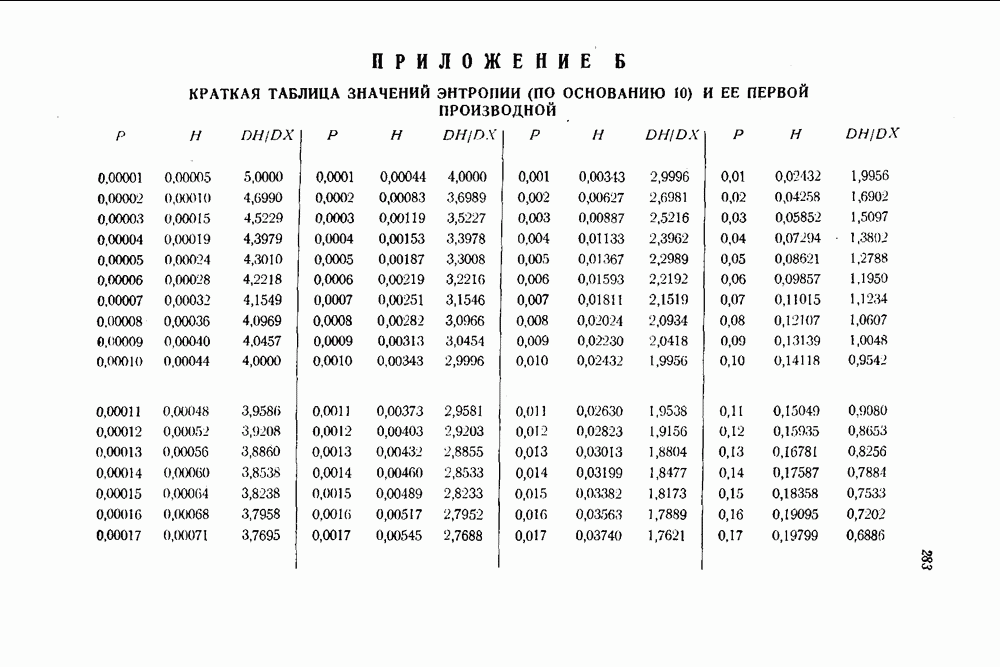
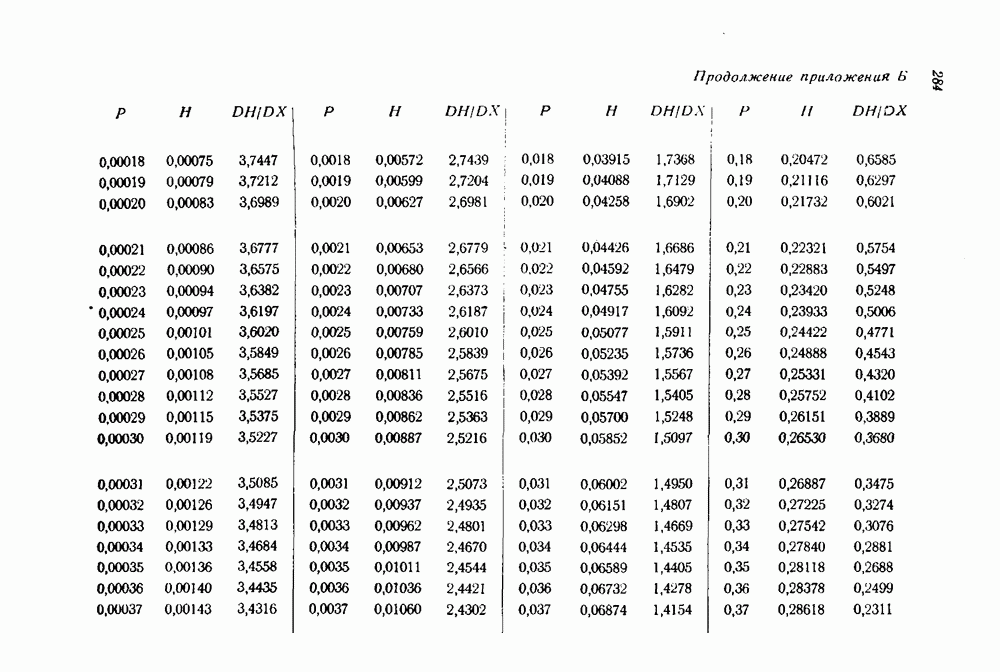
символов. С другой стороны, если в первой информационной последовательности появилась ошибка, за которой следуют Таблица 12.1 (см. скан) Характеристики сложности устройства и защитного промежутка для кодов Хегельбергера вычисления синдрома, которая неправильно интерпретируется как ошибка в другой последовательности информационных символов. Схемы, изображенные на рис. 12.2 и 12.3 для простейшего рекуррентного защитного промежутка, кодирующего и декодирующего устройства приводятся в табл. 12.1 Значения, приводимое в этой таблице, отличаются от значений, данных Хегельбергером [101], по двум причинам. Во-первых, схемы, приводимые здесь, неполностью совпадают со схемами, рассматриваемыми Хегельбергером, хотя в обоих случаях их построение основывается на одних и тех же принципах. Во-вторых, принятый здесь способ изображения схем отличается от способа, используемого Хегельбергером. На многих своих схемах Хегельбергер указывает на один разряд больше, чем здесь. Предполагается, что этот разряд относится к источнику сигнала. Таким образом, в некоторых случаях числа в табл. 12.1 на единицу меньше соответствующих чисел, приводимых Хегельбергером для совершенно эквивалентных схем.
|
 |
Оглавление
|





































































































































































































































































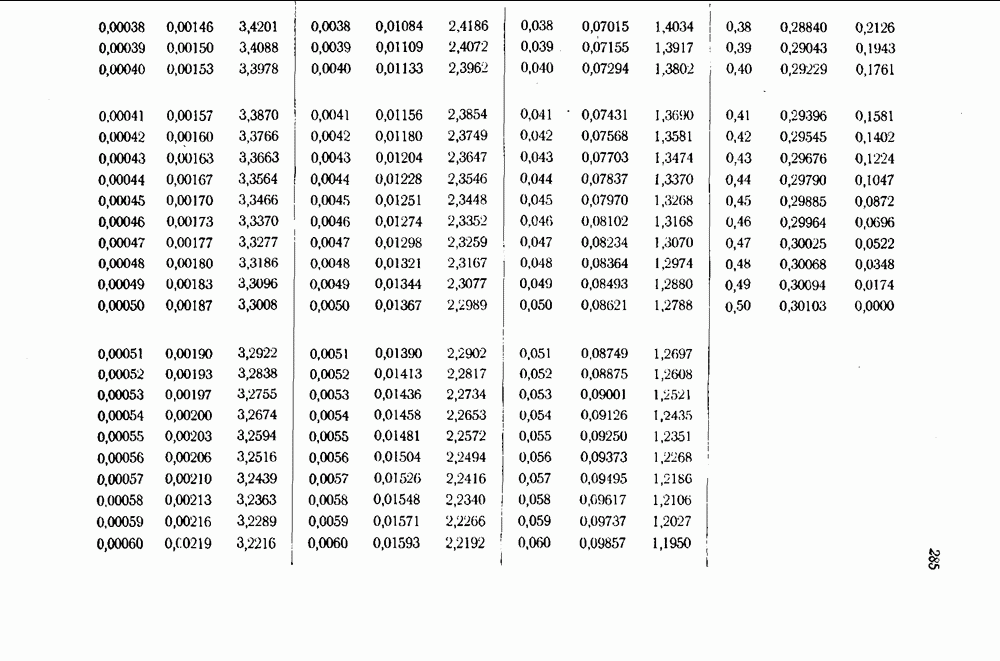




























 -кодов при
-кодов при 
 -рекуррентный код. Этот код исправляет любую пачку ошибок длины
-рекуррентный код. Этот код исправляет любую пачку ошибок длины  расположенную между двумя свободными от ошибок "защитными промежутками" длины 19. Кодирующее устройство показано на рис. 12.2. Имеется одна последовательность входных символов. Выходных последовательностей — две: одна из них дублирует входную информацию, а другая поступает из преобразователя типа регистра сдвига. Символы передаются попеременно из обеих
расположенную между двумя свободными от ошибок "защитными промежутками" длины 19. Кодирующее устройство показано на рис. 12.2. Имеется одна последовательность входных символов. Выходных последовательностей — две: одна из них дублирует входную информацию, а другая поступает из преобразователя типа регистра сдвига. Символы передаются попеременно из обеих
 первая выходная последовательность является дубликатом входной последовательности, а выходная последовательность проверочных символов, как нетрудно проверить, равна
первая выходная последовательность является дубликатом входной последовательности, а выходная последовательность проверочных символов, как нетрудно проверить, равна  (Предполагается, что регистр сдвига первоначально содержит только нули.) Передаваемая последовательность начинается с первого информационного символа, затем следует первый проверочный символ, затем второй информационный символ, второй проверочный символ и т. д. Для приведенных выше информационной последовательности и последовательности проверочных символов передаваемая последовательность имеет вид
(Предполагается, что регистр сдвига первоначально содержит только нули.) Передаваемая последовательность начинается с первого информационного символа, затем следует первый проверочный символ, затем второй информационный символ, второй проверочный символ и т. д. Для приведенных выше информационной последовательности и последовательности проверочных символов передаваемая последовательность имеет вид 

 -кода.
-кода.
 Если считать, что первый символ в этой последовательности — информационный, то переданная последовательность разбивается на информационную последовательность
Если считать, что первый символ в этой последовательности — информационный, то переданная последовательность разбивается на информационную последовательность  и последовательность из проверочных символов
и последовательность из проверочных символов  . С помощью схемы, изображенной на рис. 12.3, можно вычислить синдром, который оказывается равным
. С помощью схемы, изображенной на рис. 12.3, можно вычислить синдром, который оказывается равным  Синдром содержит комбинацию ошибок в последовательности проверочных символов, за которой следует подряд два раза комбинация ошибок в информационной последовательности. По структуре схемы для проверок на четность нетрудно увидеть, что так будет во всех случаях, когда общая длина пачки не превосходит 6. Поскольку синдром указывает одновременно комбинации ошибок и в проверочных и в информационных символах, то ошибки могут быть исправлены,
Синдром содержит комбинацию ошибок в последовательности проверочных символов, за которой следует подряд два раза комбинация ошибок в информационной последовательности. По структуре схемы для проверок на четность нетрудно увидеть, что так будет во всех случаях, когда общая длина пачки не превосходит 6. Поскольку синдром указывает одновременно комбинации ошибок и в проверочных и в информационных символах, то ошибки могут быть исправлены,

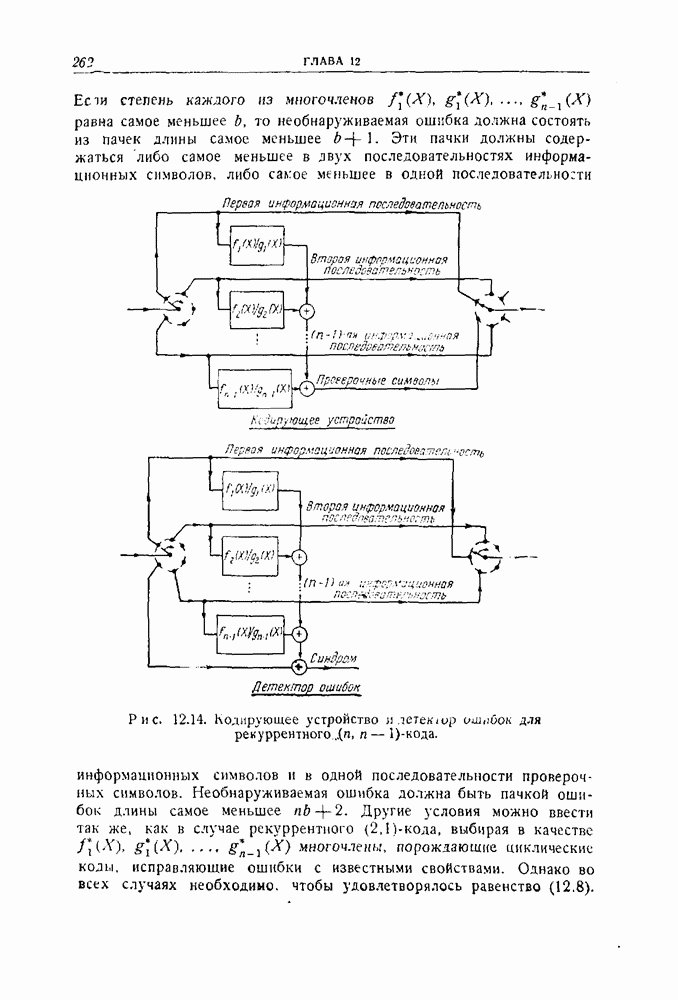
 -код такого же типа. Метод построения проиллюстрируем примером
-код такого же типа. Метод построения проиллюстрируем примером  -кода, исправляющего пачки ошибок длины 4. Первый шаг состоит в выборе
-кода, исправляющего пачки ошибок длины 4. Первый шаг состоит в выборе  двоичных векторов:
двоичных векторов:

 строк и
строк и  столбцов, элементами которых являются двоичные векторы. По диагонали стоят двоичные представления чисел
столбцов, элементами которых являются двоичные векторы. По диагонали стоят двоичные представления чисел  а все остальные места заняты нулями. Нули, с которых должны начинаться все векторы первого столбца, могут быть отброшены.
а все остальные места заняты нулями. Нули, с которых должны начинаться все векторы первого столбца, могут быть отброшены.
 определяет соединения для второй информационной последовательности и так далее, а последняя строка указывает соединения проверочных символов. Кодирующее устройство для
определяет соединения для второй информационной последовательности и так далее, а последняя строка указывает соединения проверочных символов. Кодирующее устройство для  -кода изображено на рис. 12.4,
-кода изображено на рис. 12.4,
 и
и  таким образом, чтобы между двумя столбцами из таблицы (12.1) появился нулевой столбец:
таким образом, чтобы между двумя столбцами из таблицы (12.1) появился нулевой столбец:

 начинается с символа, принадлежащего первой информационной последовательности, то символы
начинается с символа, принадлежащего первой информационной последовательности, то символы  принадлежат первой информационной последовательности,
принадлежат первой информационной последовательности,  -второй информационной последовательности,
-второй информационной последовательности,  третьей информационной последовательности,
третьей информационной последовательности,  ошибки в проверочных символах. При такой комбинации ошибок первые значащие символы в синдроме появятся под влиянием ошибочных проверочных символов
ошибки в проверочных символах. При такой комбинации ошибок первые значащие символы в синдроме появятся под влиянием ошибочных проверочных символов  Затем появятся подряд четыре нуля; третья информационная последовательность начинает воздействовать на синдром через 6 шагов после начала воздействия ошибок в проверочных символах, потому что она подается в регистр сдвига на 6 сдвигов позже. Поскольку третья информационная последовательность соединена с регистром сдвига в трех точках, то комбинация ошибок в третьей информационной последовательности повторится три раза. Лишь после этого на синдром воздействуют ошибки во второй информационной
Затем появятся подряд четыре нуля; третья информационная последовательность начинает воздействовать на синдром через 6 шагов после начала воздействия ошибок в проверочных символах, потому что она подается в регистр сдвига на 6 сдвигов позже. Поскольку третья информационная последовательность соединена с регистром сдвига в трех точках, то комбинация ошибок в третьей информационной последовательности повторится три раза. Лишь после этого на синдром воздействуют ошибки во второй информационной


 Комбинации ошибок, относящиеся к различным последовательностям, отделены друг от друга, и каждая из них повторяется в собственной, только ей присущей комбинации, что позволяет установить последовательность, к которой она относится.
Комбинации ошибок, относящиеся к различным последовательностям, отделены друг от друга, и каждая из них повторяется в собственной, только ей присущей комбинации, что позволяет установить последовательность, к которой она относится.
 начинается с третьей информационной последовательности. Тогда ошибки
начинается с третьей информационной последовательности. Тогда ошибки  появляются в третьей информационной последовательности,
появляются в третьей информационной последовательности,  в последовательности проверочных символов,
в последовательности проверочных символов,  в первой и
в первой и  во второй информационной последовательности. Можно проверить, что в этом случае синдром равен
во второй информационной последовательности. Можно проверить, что в этом случае синдром равен  Снова расположение повторений пар ошибок полностью характеризует канал, в котором эти ошибки появились.
Снова расположение повторений пар ошибок полностью характеризует канал, в котором эти ошибки появились.
 котором появились ошибки, производится на основе величин
котором появились ошибки, производится на основе величин  Например, если все три величины одновременно принимают значение 1, то соответствующая ошибка должна была появиться в третьем информационном канале. Задержка, необходимая для того, чтобы распознать полученный ошибочный символ и исправить его, различна для различных каналов, и, следовательно, регистры сдвига, изображенные на рис. 12.8, должны содержать дополнительные разряды для хранения информации в процессе различения ошибок. Задержка равна 22 единицам времени для первого информационного канала, 16 единицам времени для второго информационного канала и 10 единицам времени для третьего информационного канала.
Например, если все три величины одновременно принимают значение 1, то соответствующая ошибка должна была появиться в третьем информационном канале. Задержка, необходимая для того, чтобы распознать полученный ошибочный символ и исправить его, различна для различных каналов, и, следовательно, регистры сдвига, изображенные на рис. 12.8, должны содержать дополнительные разряды для хранения информации в процессе различения ошибок. Задержка равна 22 единицам времени для первого информационного канала, 16 единицам времени для второго информационного канала и 10 единицам времени для третьего информационного канала.
 -код, исправляющий пачки ошибок длины
-код, исправляющий пачки ошибок длины  для случая, когда b делится на
для случая, когда b делится на  . Пусть
. Пусть  обозначает наименьшее целое число, которое больше или равно
обозначает наименьшее целое число, которое больше или равно  Кодирующие
Кодирующие



 пока этот символ не повлияет впервые на содержимое последнего разряда регистра для вычисления синдрома. Под влиянием ошибочного символа на входе регистра для вычисления синдрома символ 1 появится впервые после
пока этот символ не повлияет впервые на содержимое последнего разряда регистра для вычисления синдрома. Под влиянием ошибочного символа на входе регистра для вычисления синдрома символ 1 появится впервые после  шагов. К этой величине следует прибавить еще длину регистра для вычисления синдрома. Так, для первой и для любой информационной линии потребуется
шагов. К этой величине следует прибавить еще длину регистра для вычисления синдрома. Так, для первой и для любой информационной линии потребуется  разрядов. Общее требуемое число разрядов в регистре сдвига и величина задержки равны поэтому
разрядов. Общее требуемое число разрядов в регистре сдвига и величина задержки равны поэтому


 правильных символов. Таким образом, требуемый защитный промежуток состоит из
правильных символов. Таким образом, требуемый защитный промежуток состоит из

 правильных символов, и ошибка, которая будет уже проверочным символом, то это приведет к комбинации символов в регистре для
правильных символов, и ошибка, которая будет уже проверочным символом, то это приведет к комбинации символов в регистре для
 -кода, отличаются от схем, изображенных на рис. 12.5 и 12.9. Простейший рекуррентный
-кода, отличаются от схем, изображенных на рис. 12.5 и 12.9. Простейший рекуррентный  -код может быть изменен так, чтобы он исправлял пачки ошибок других длин. При этом можно показать, что число требуемых сдвигов в регистре сдвига, или требуемая задержка, равны b для кодирующего устройства,
-код может быть изменен так, чтобы он исправлял пачки ошибок других длин. При этом можно показать, что число требуемых сдвигов в регистре сдвига, или требуемая задержка, равны b для кодирующего устройства,  для декодирующего устройства и что достаточно, чтобы длина защитного промежутка была равна
для декодирующего устройства и что достаточно, чтобы длина защитного промежутка была равна  Некоторые характеристики для
Некоторые характеристики для