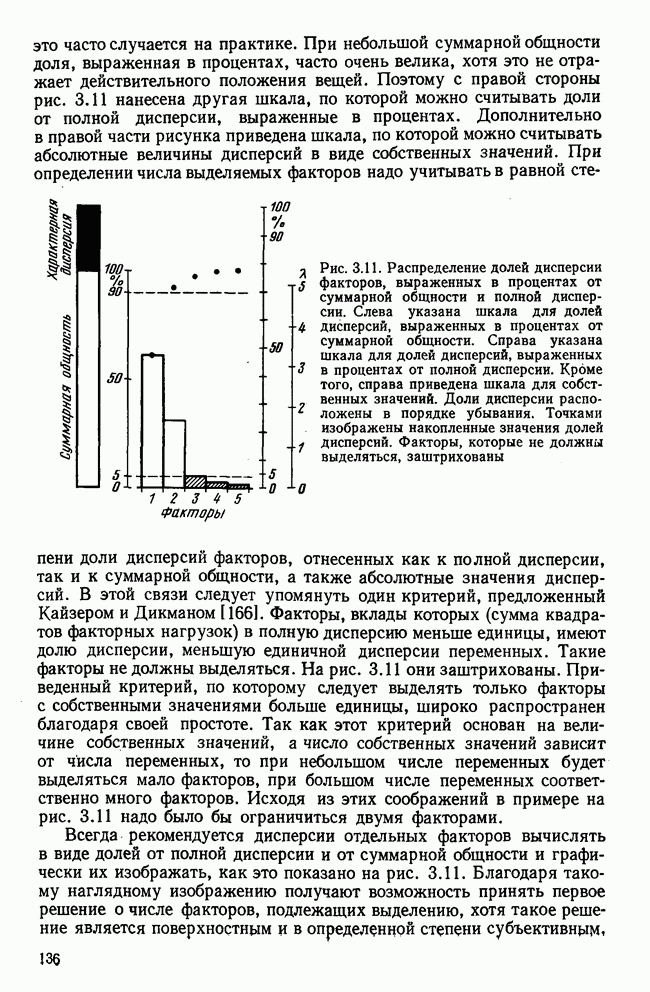
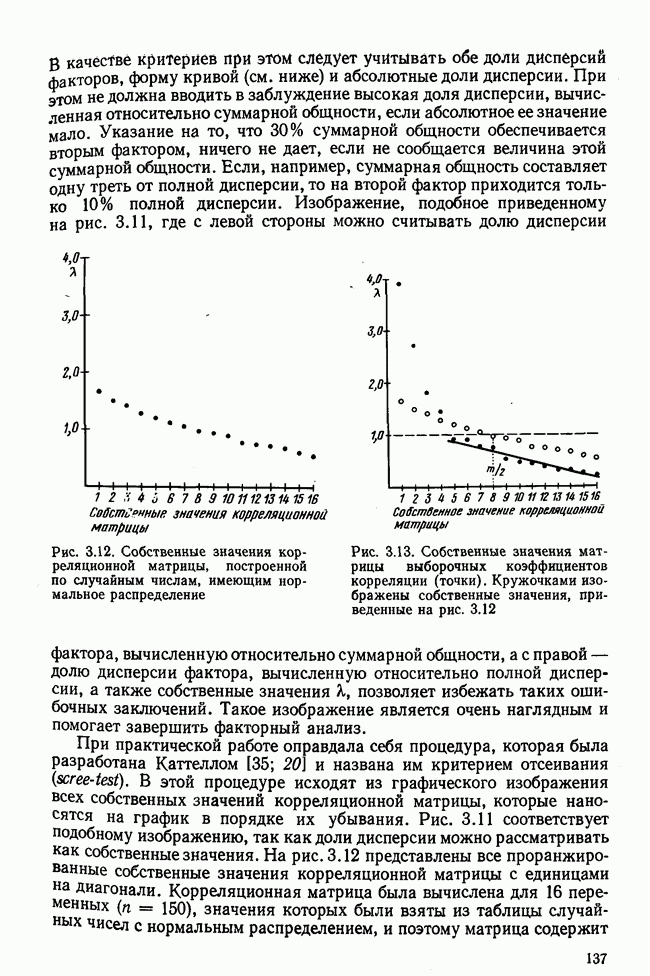
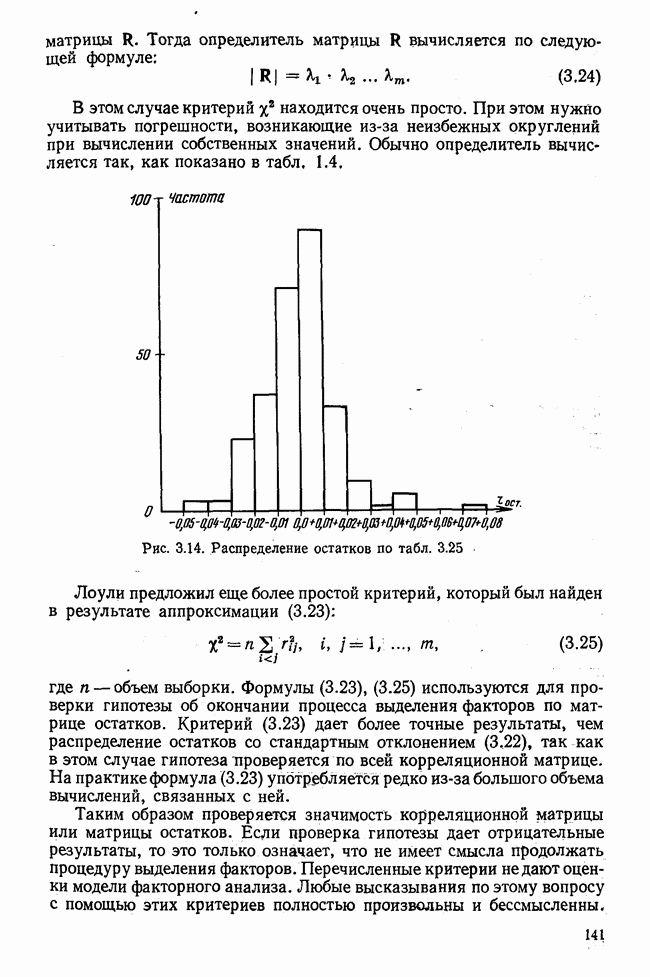
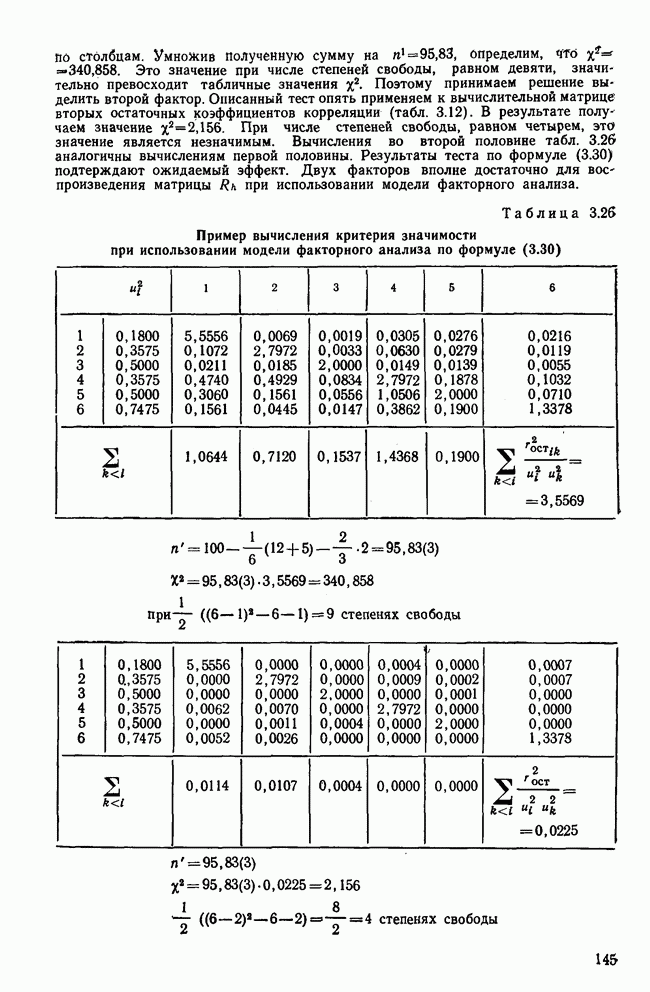
Пред.
След.
Макеты страниц
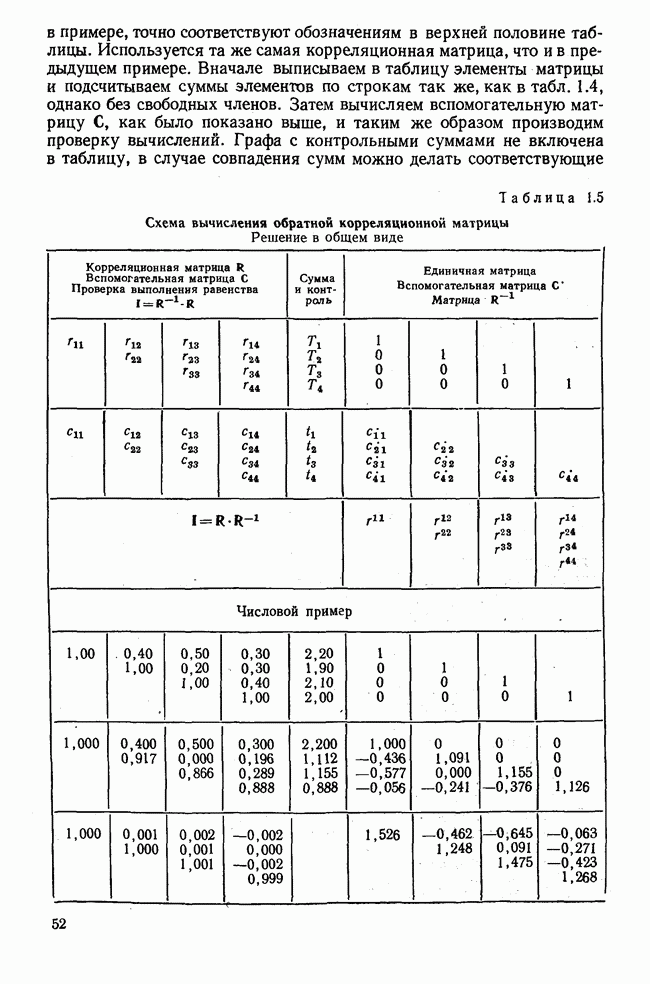
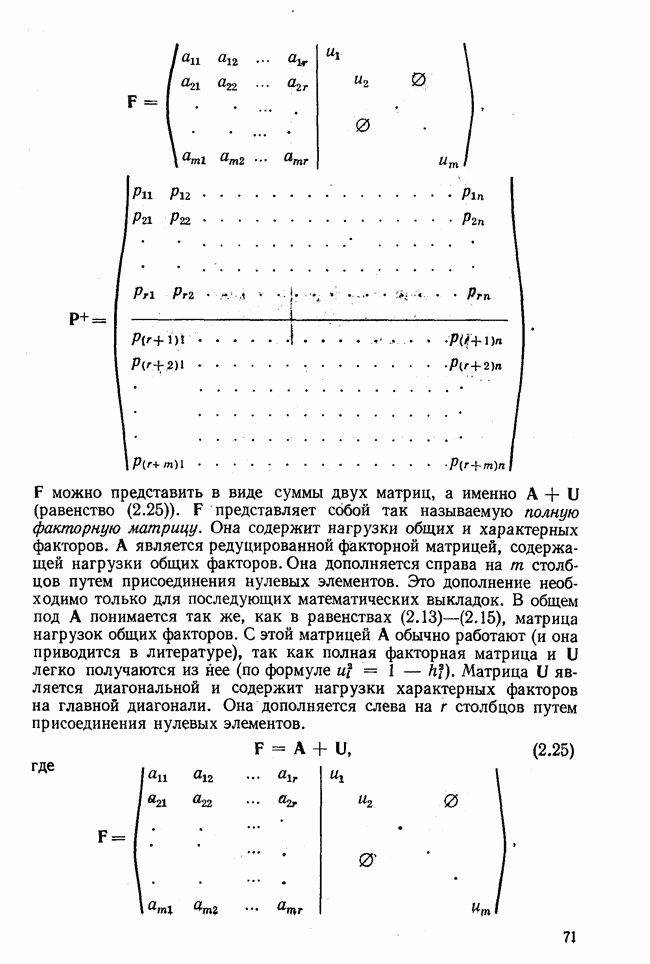
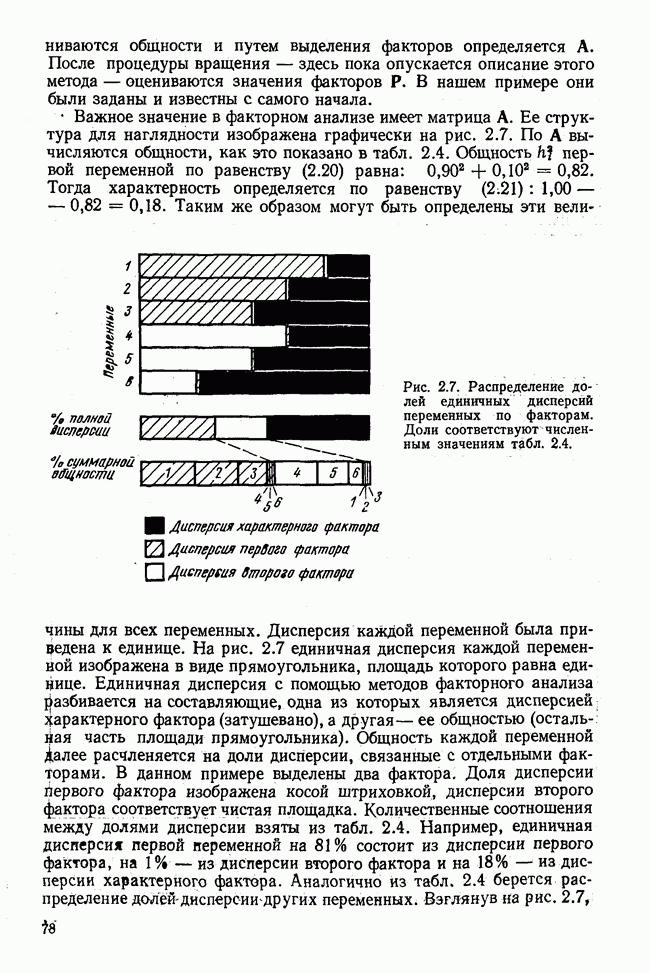
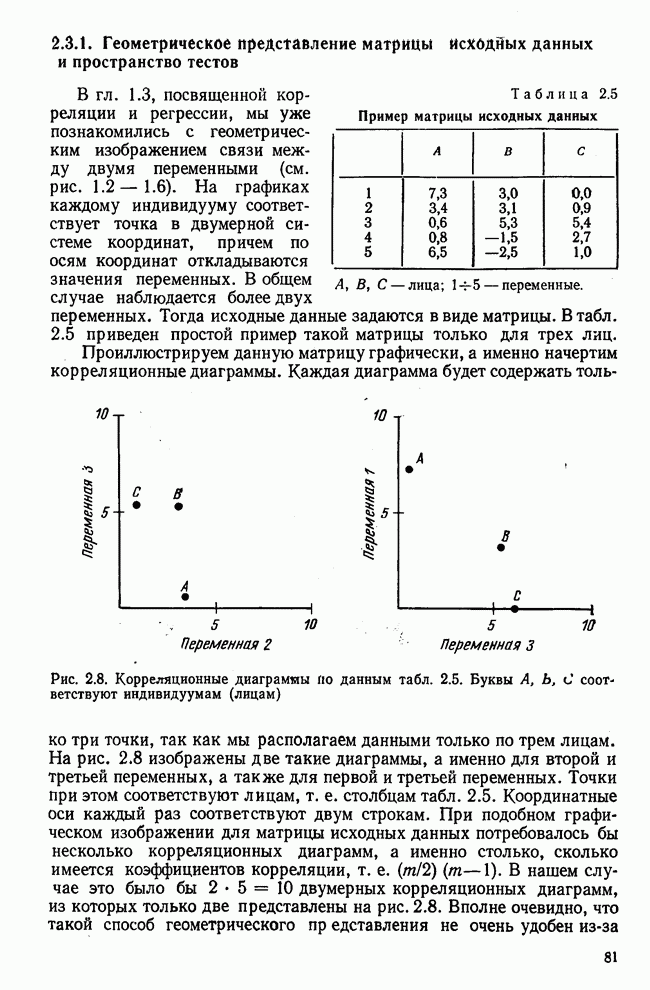
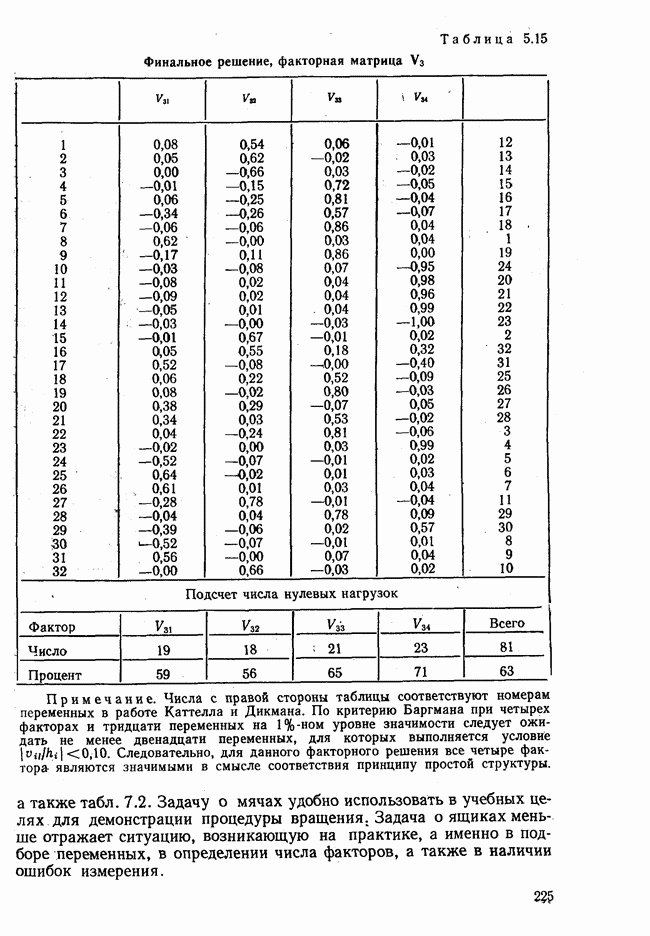
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
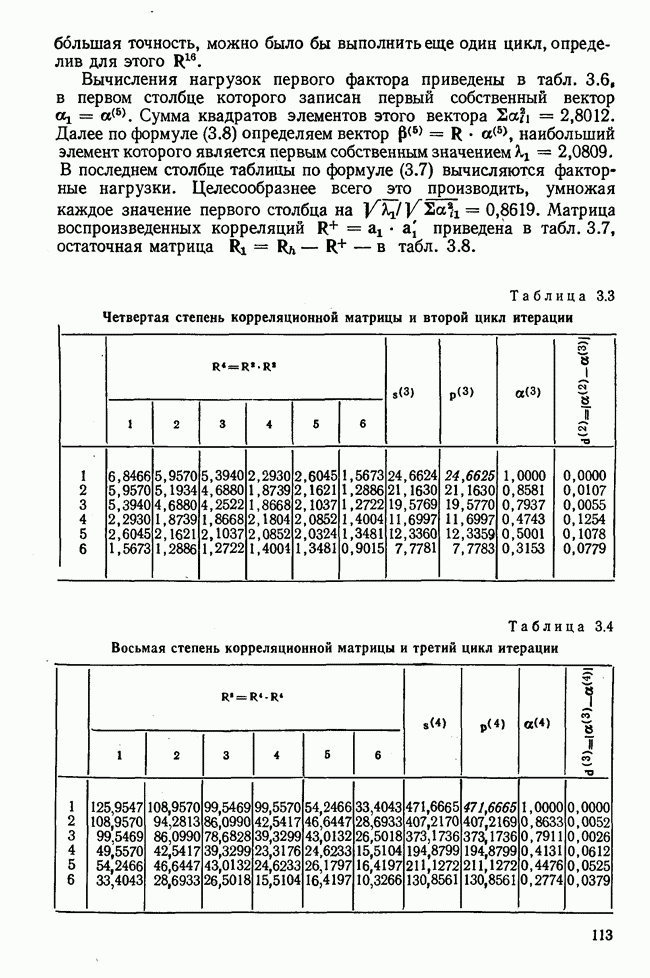
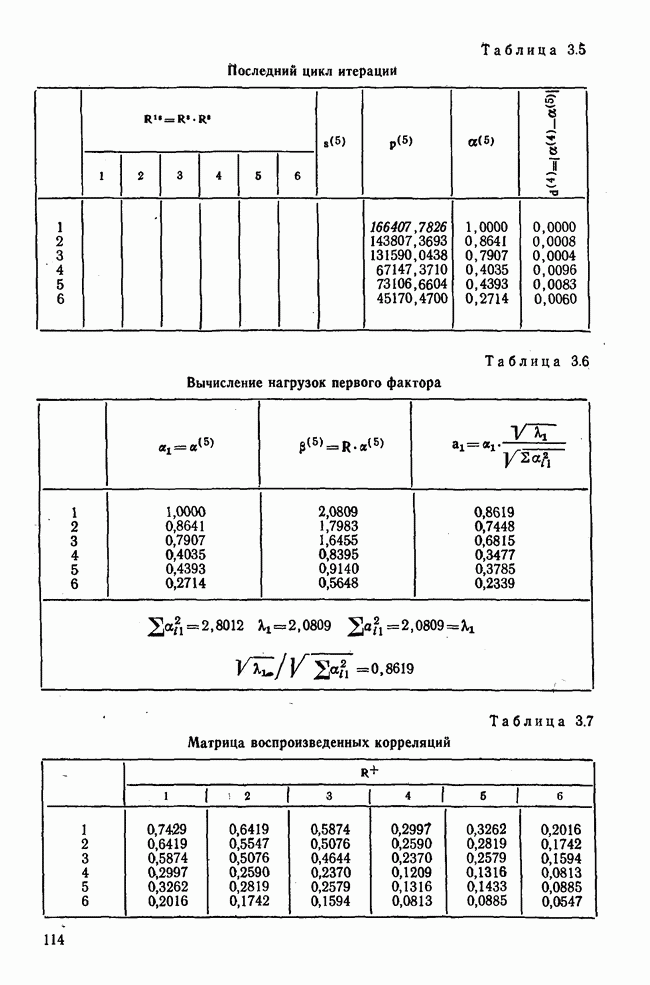
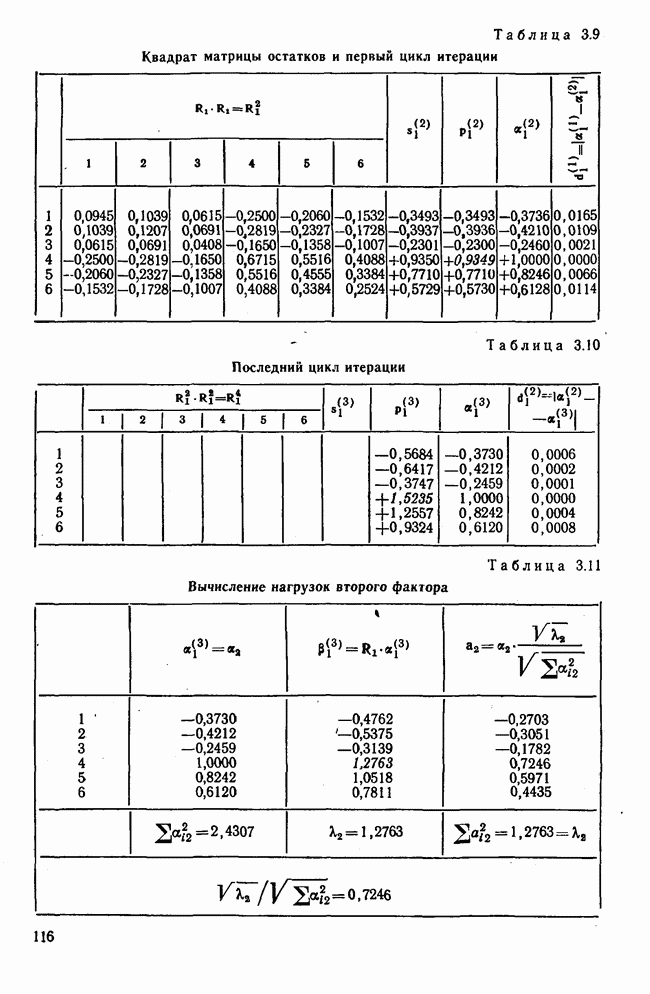
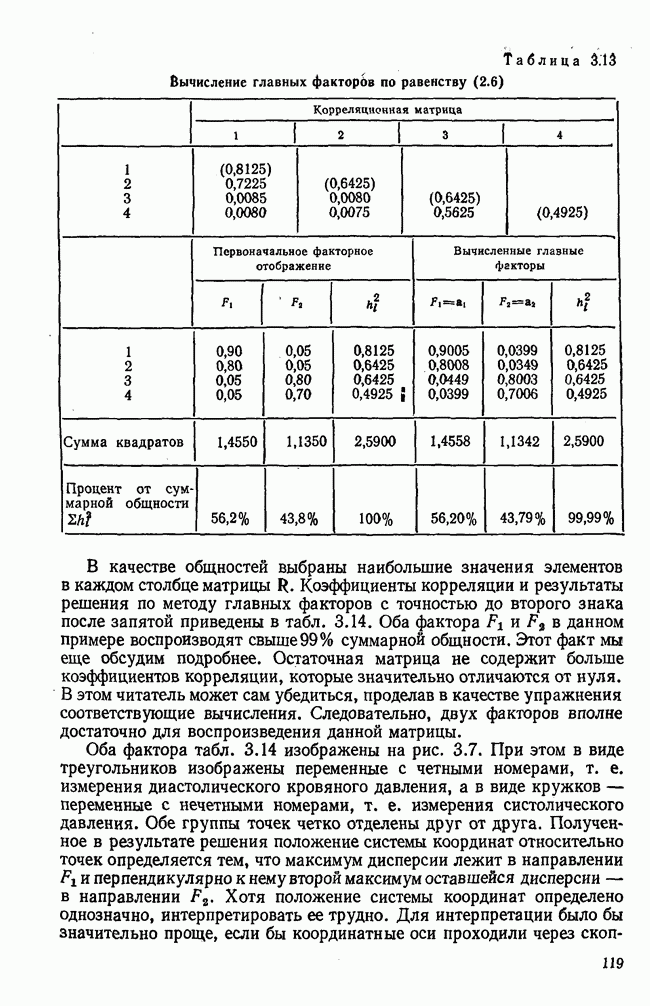
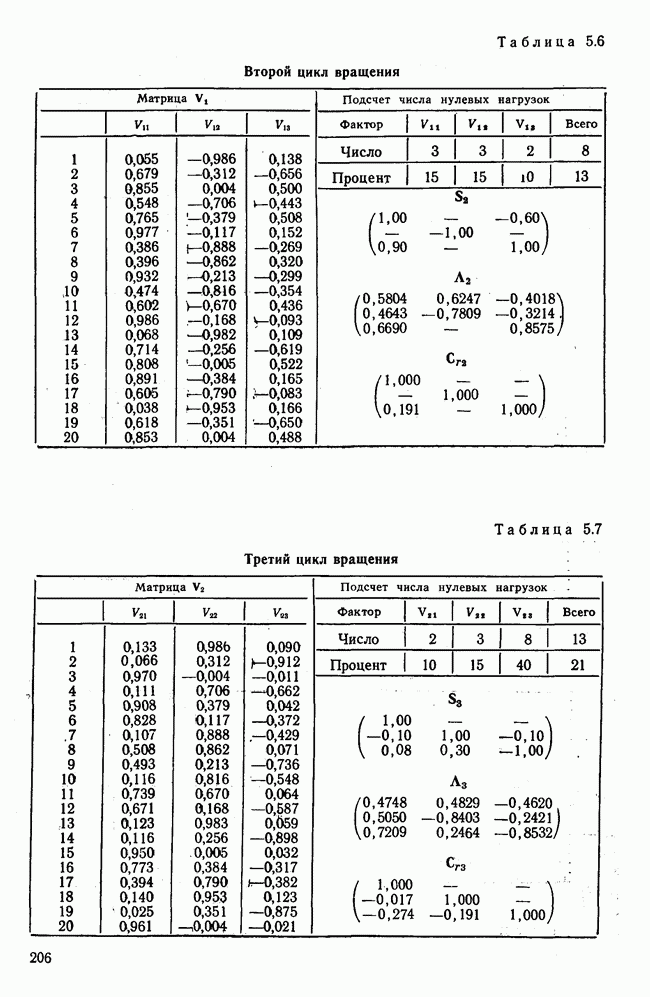
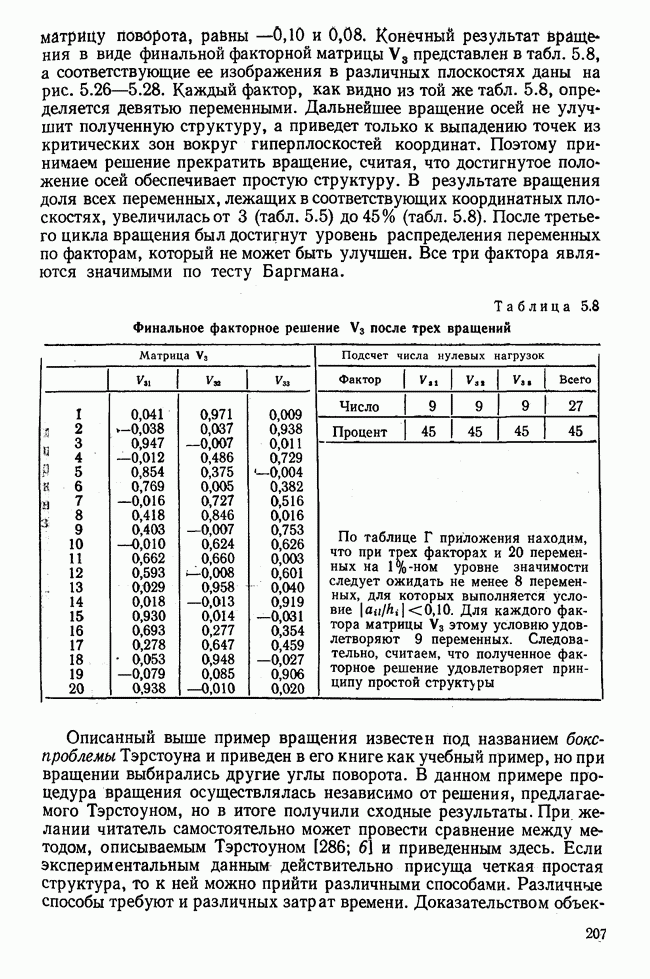
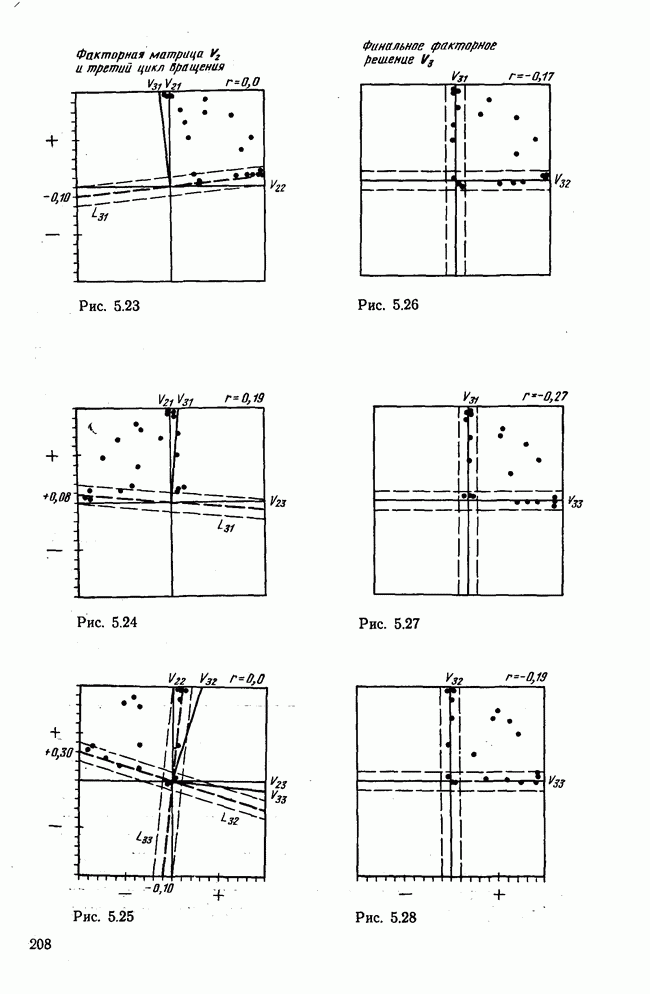
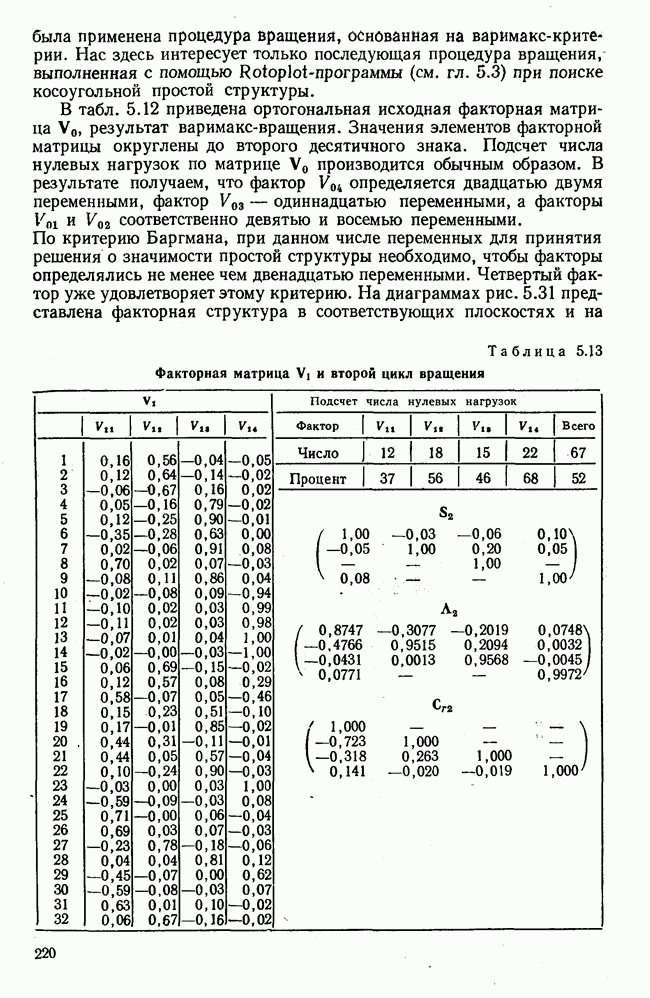
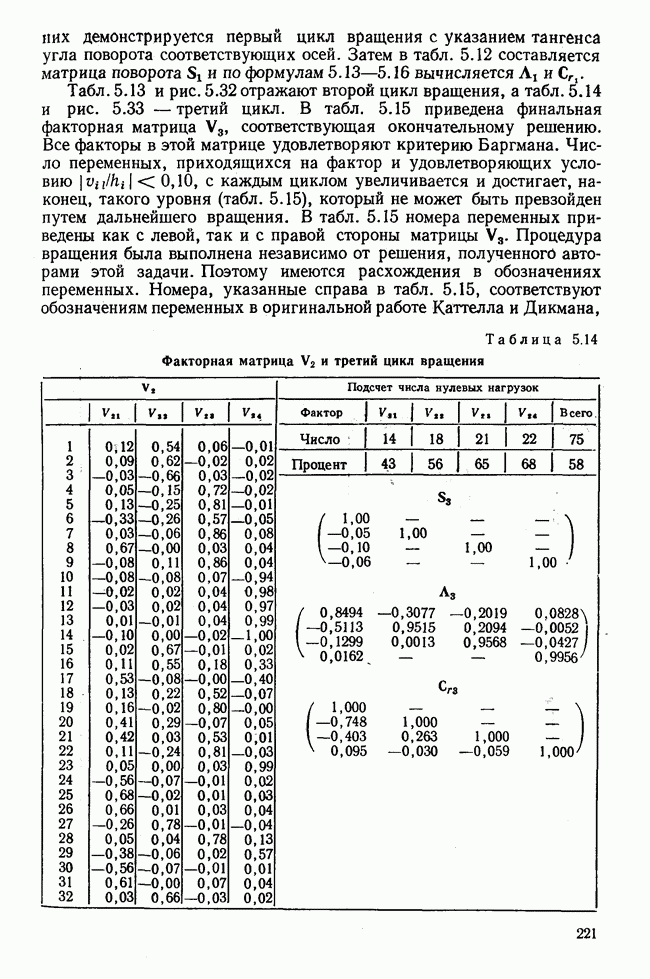
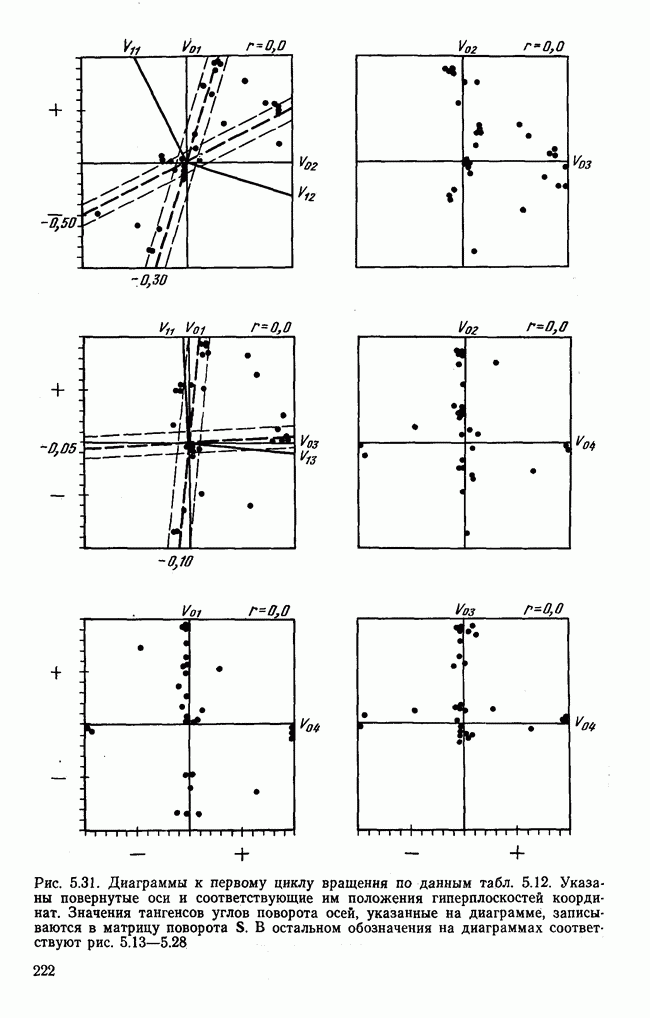
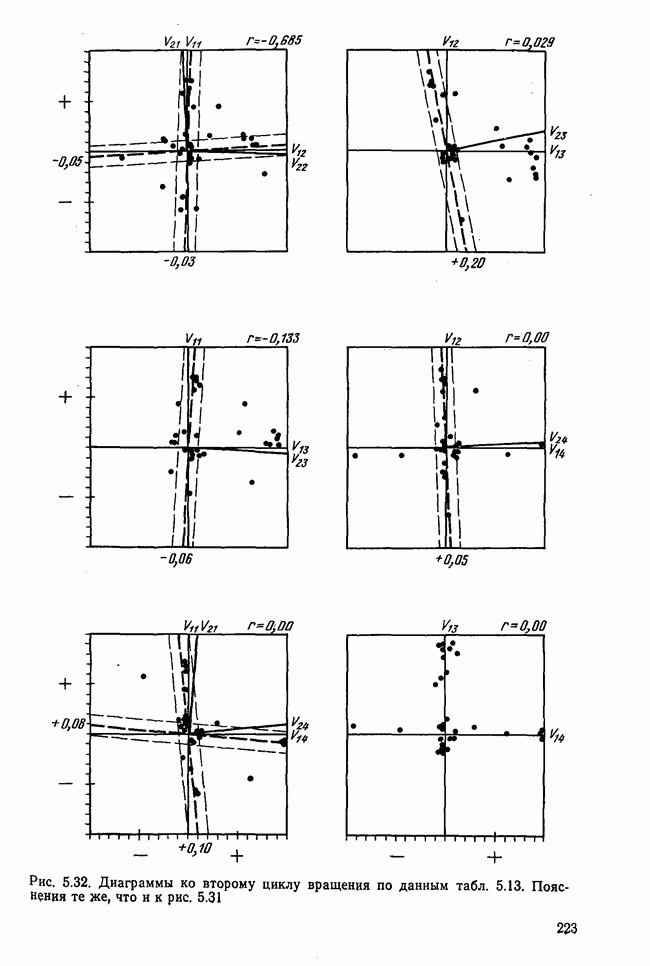
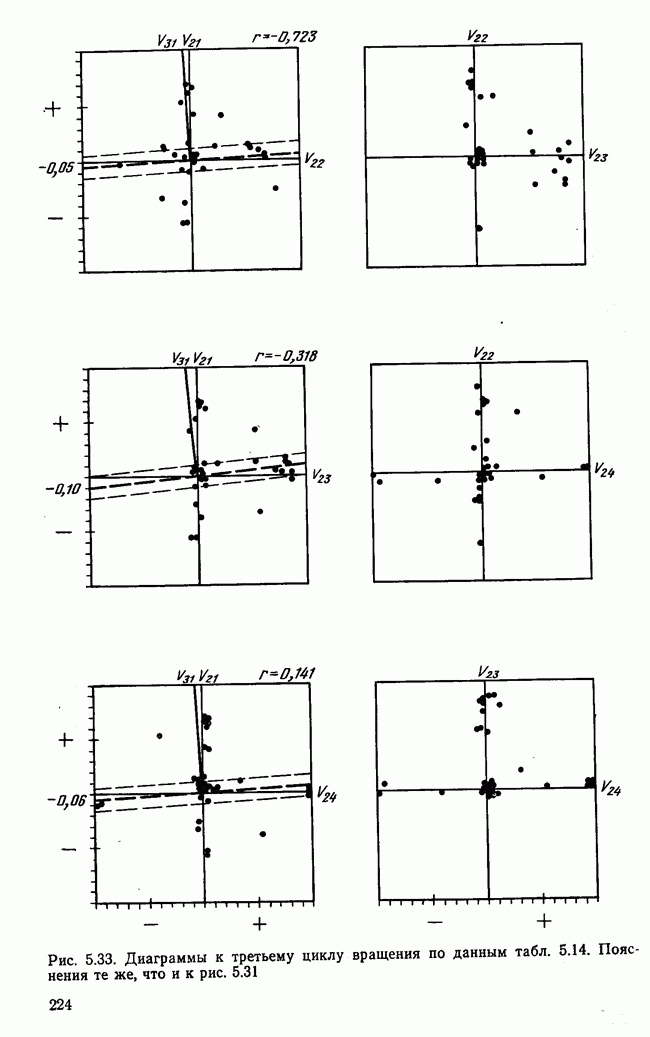
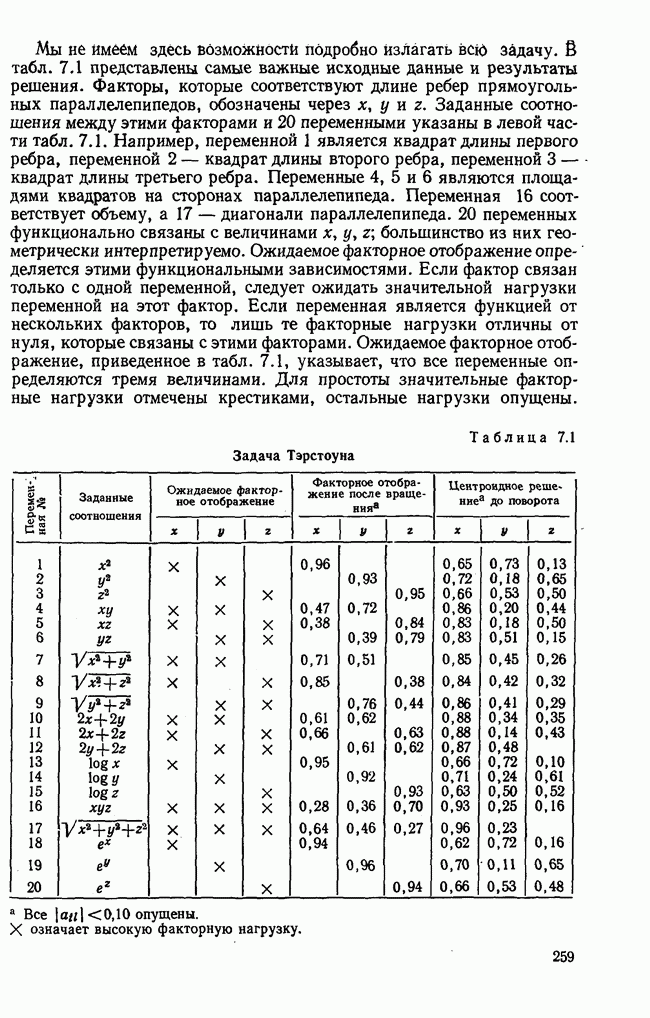
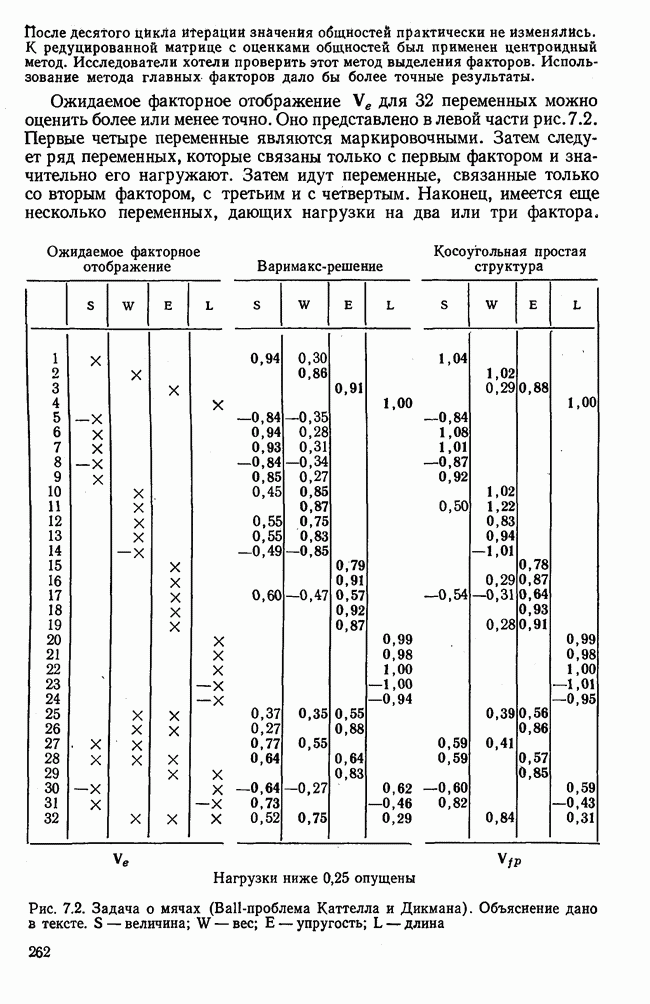
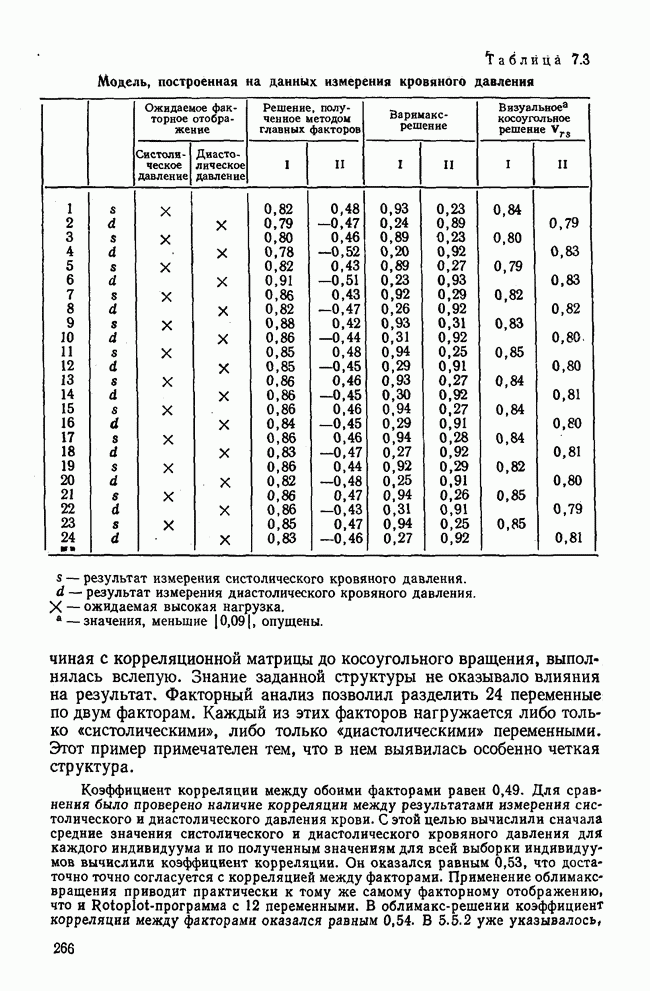
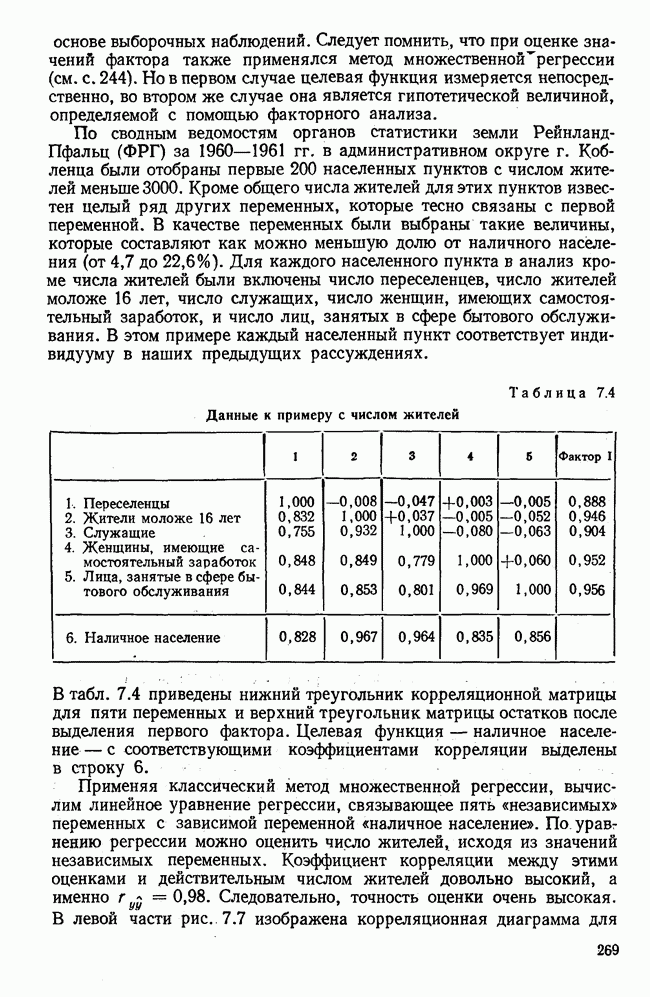
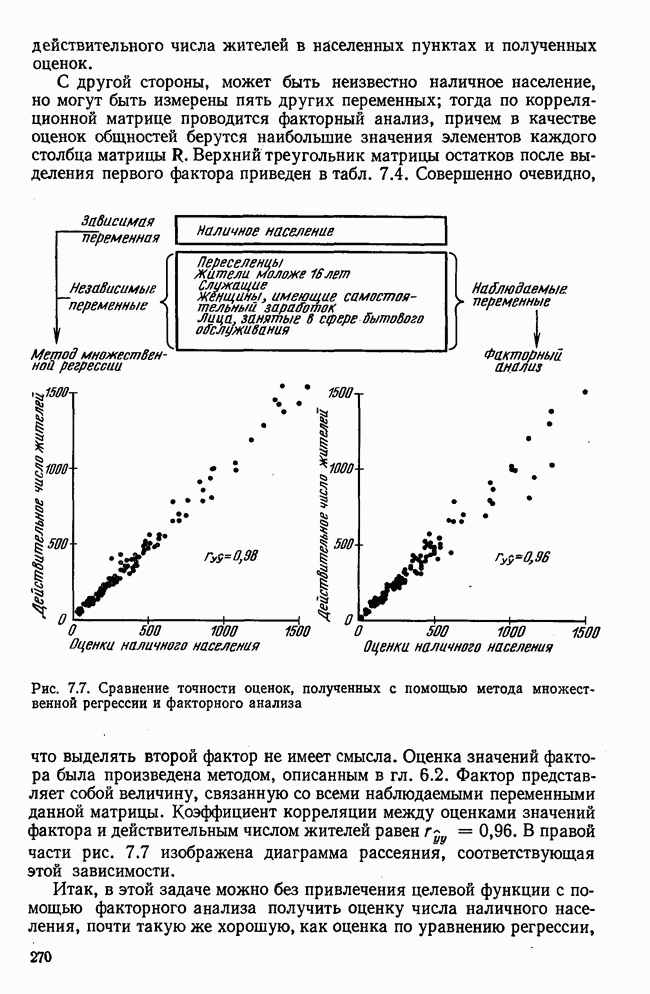
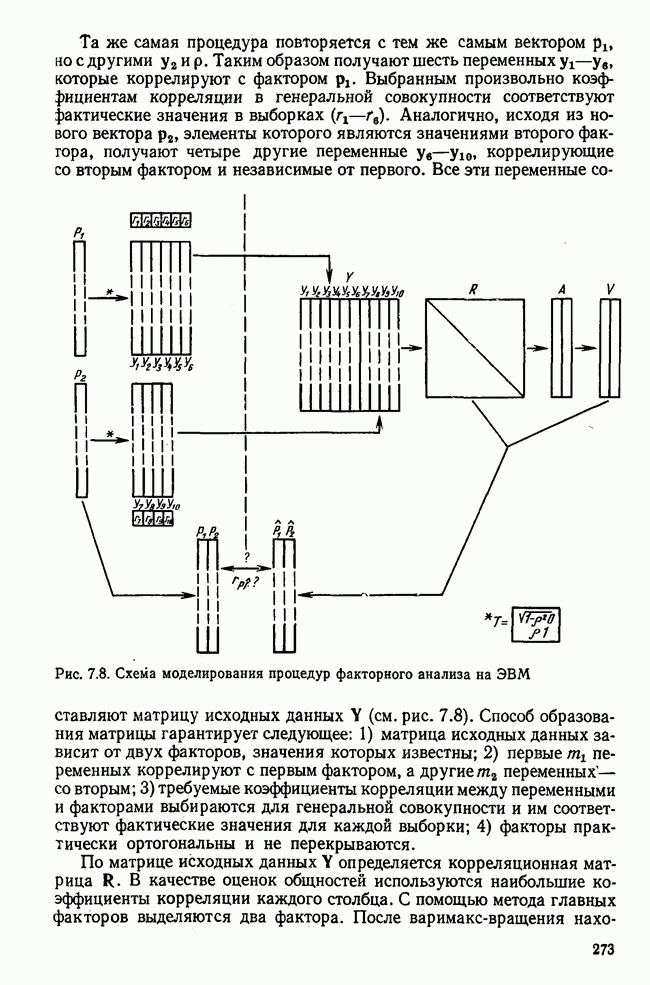
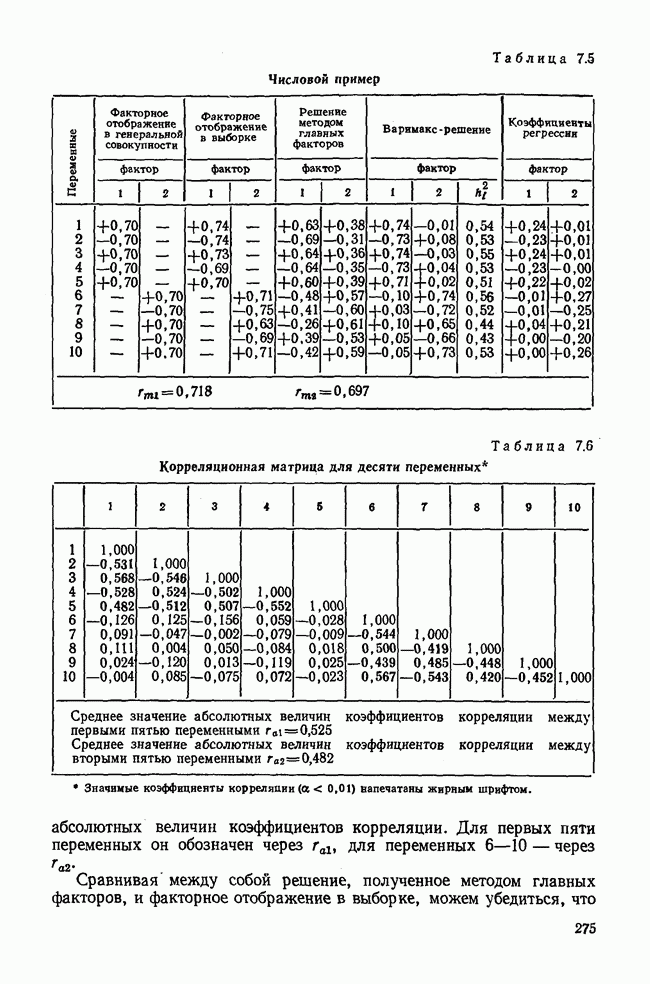
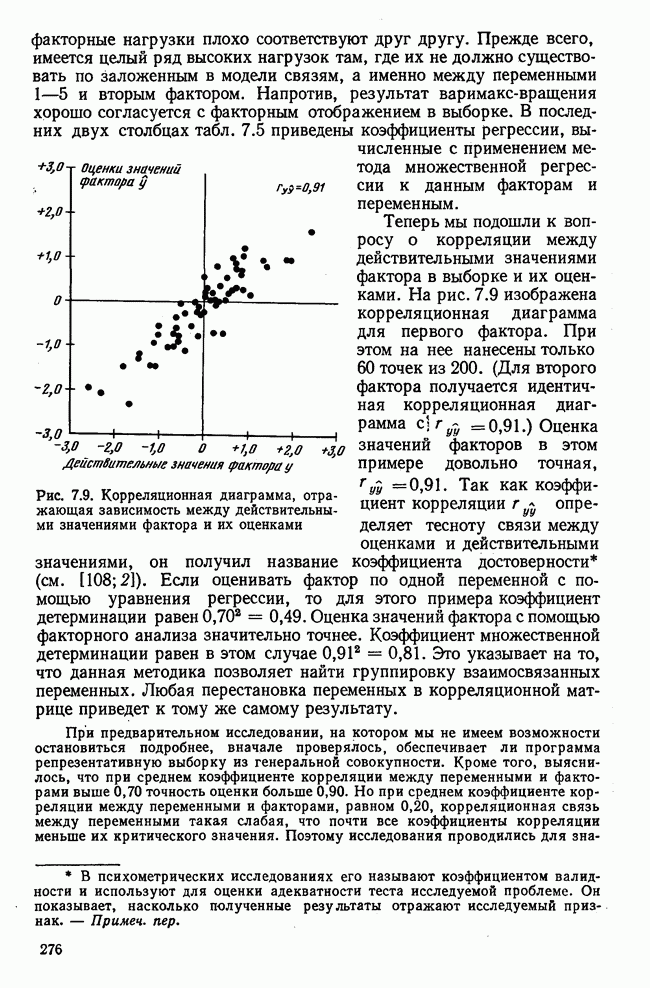
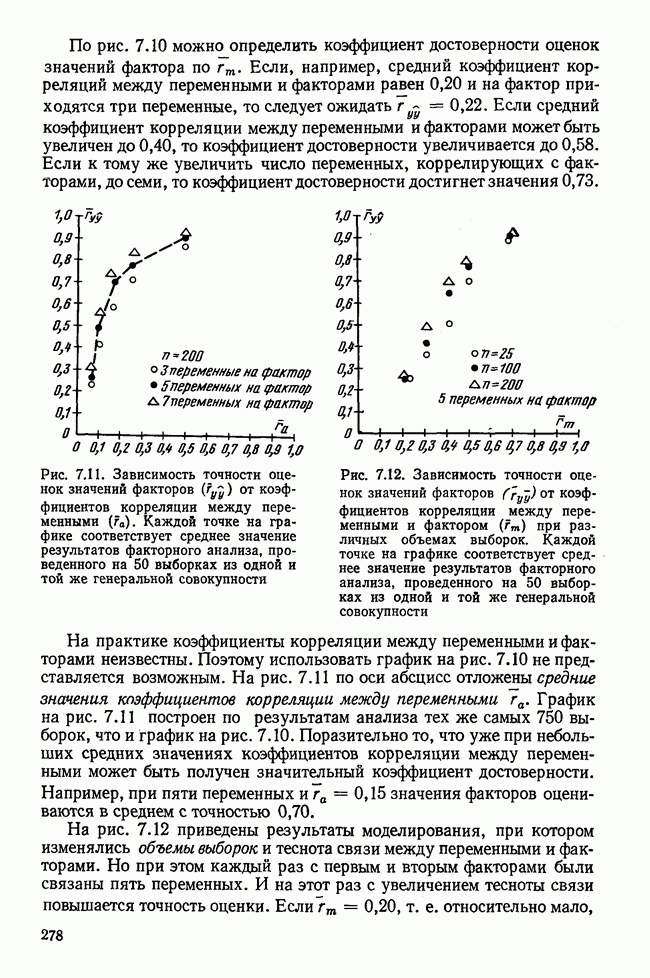
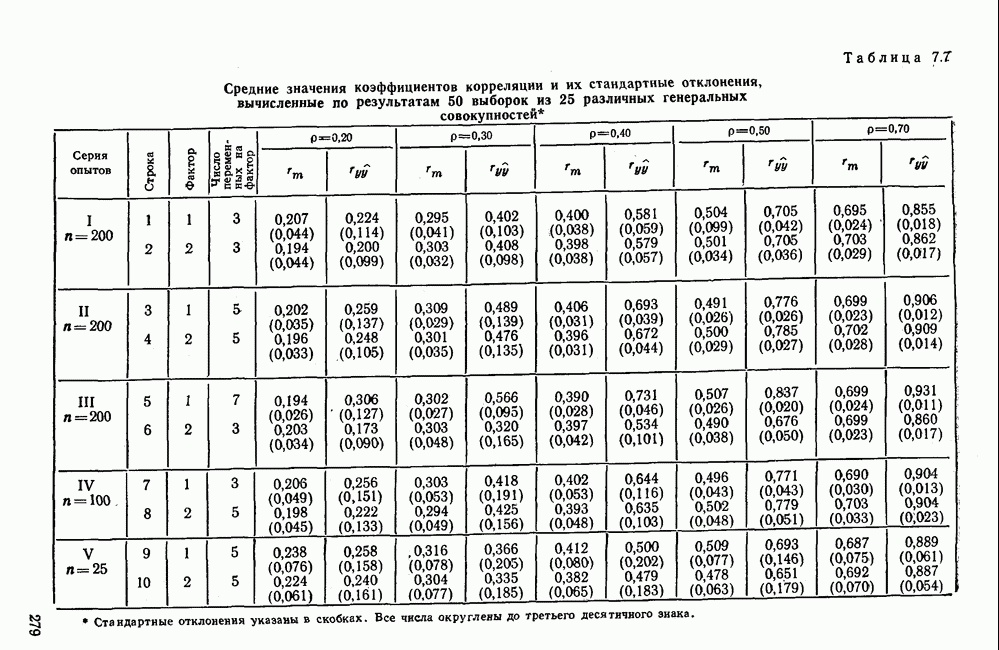
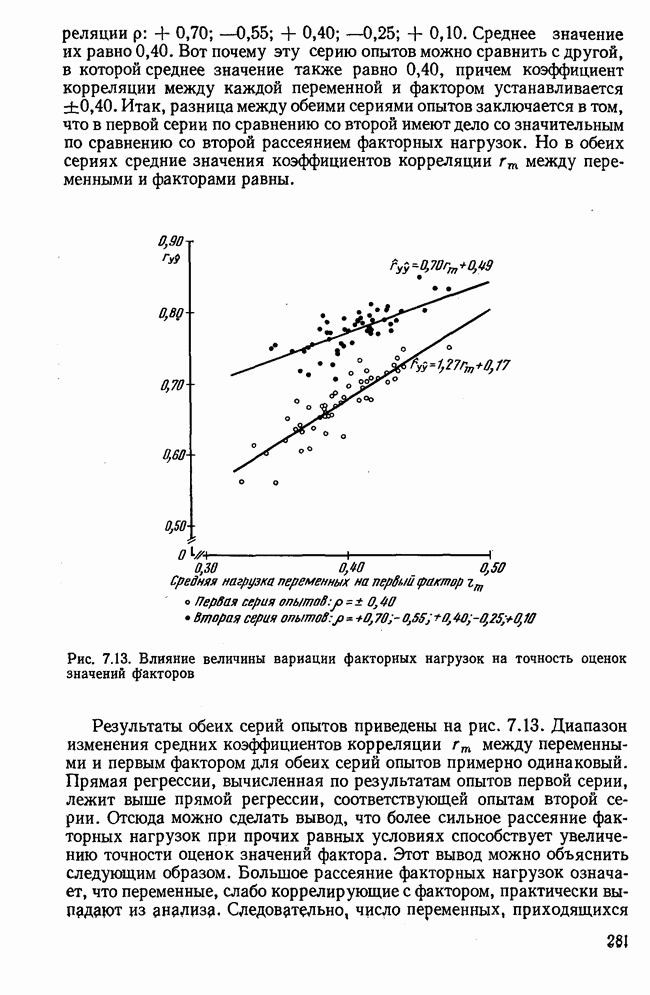
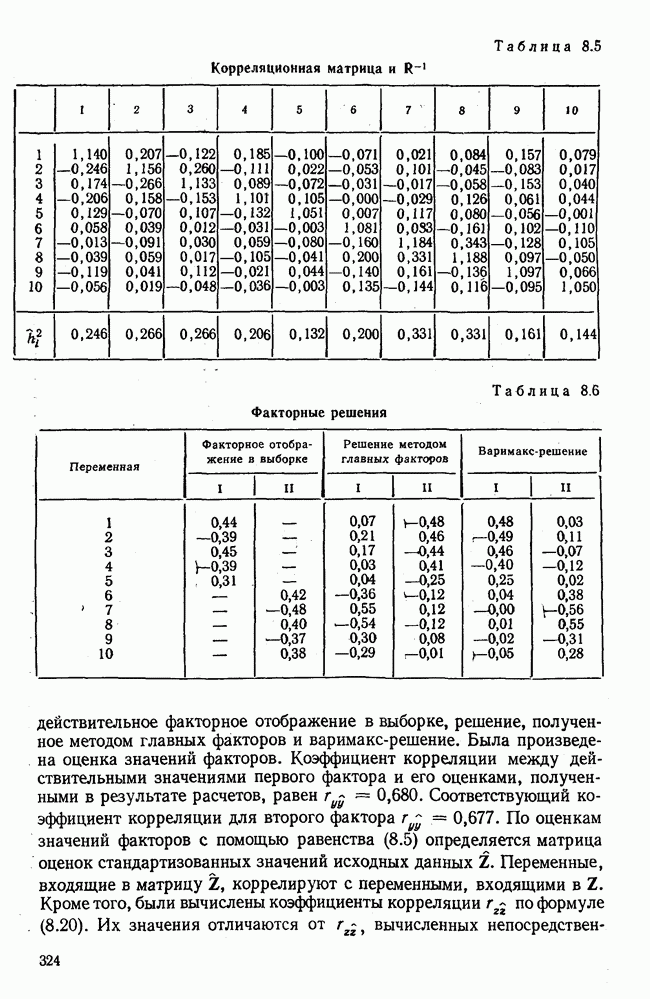
1.3. КОРРЕЛЯЦИЯ И РЕГРЕССИЯПроведение факторного анализа предполагает определенный базис статистических знаний, например умение вычислять среднее значение и стандартное отклонение, использовать статистические критерии, а также знакомство с корреляционным и регрессионным анализом. Большинство книг по статистике обсуждает эти вопросы. В этой главе кратко описываются основные понятия корреляционного и регрессионного анализа. Факторный анализ исходит в большинстве случаев непосредственно из коэффициентов корреляции, поэтому мы также начнем с обсуждения метода их вычисления. Предположим, у группы, состоящей из Если из контекста ясно, что Кроме среднего значения вычисляют меру отклонения значений каждой переменной от этой средней. Для этого сначала определяют так называемую сумму квадратов отклонений отдельных значений от среднего (сокращенно СКО). В табл. 1.1 в строке 3 приведено выражение суммы квадратов отклонений, обозначенное До этого момента каждая переменная рассматривалась отдельно, по значениям каждой были вычислены среднее значение и стандартное отклонение. Теперь поставим вопрос: как можно по одной из этих величин делать заключение о другой? Этот вопрос, заключающийся, по существу, в том, как по величине Таблица 1.1. Формулы корреляционного и регрессионного исчисления
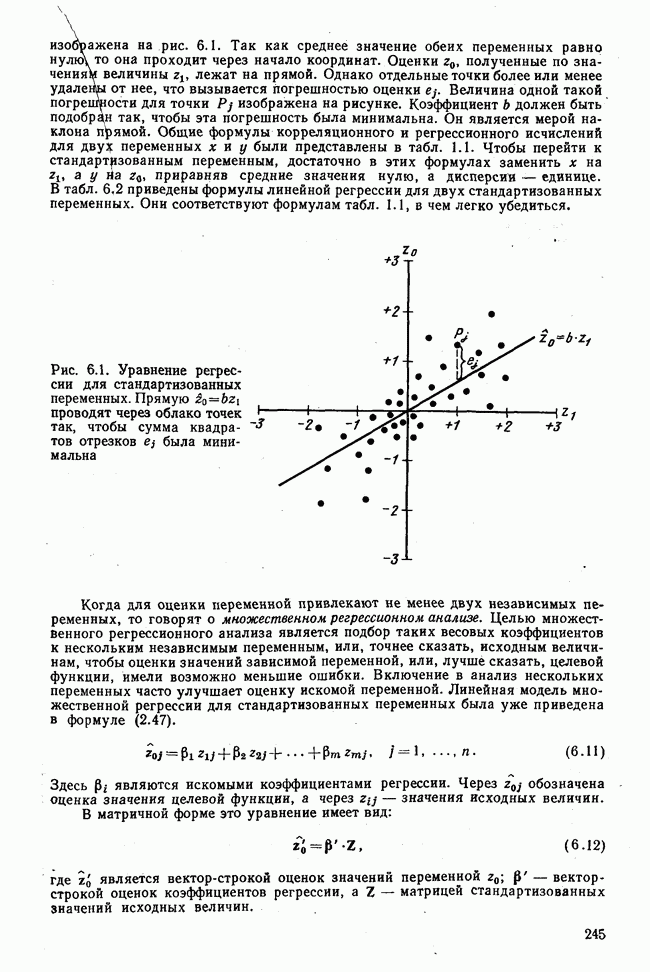
Теперь нужно провести через это скопление точек прямую так, чтобы исходя из х «как можно точнее» оценить значение у. Эти оценки у по принятому методу оценивания являются тогда наиболее точными, если сумма квадратов их вертикальных отклонений от действительных значений по возможности является наименьшей. Итак, требуется найти параметры прямой
из условия
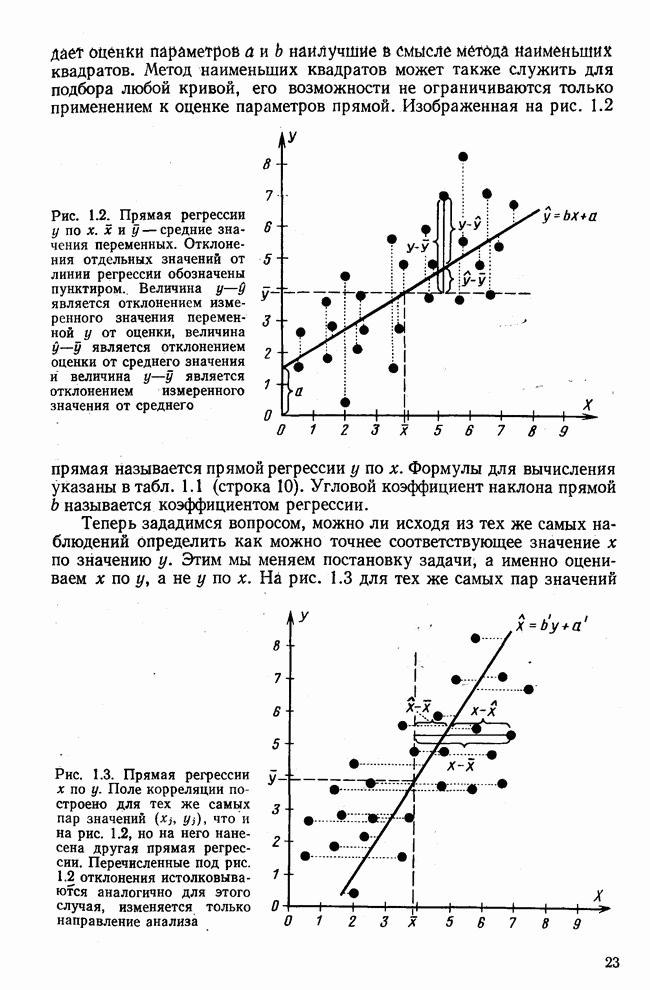
Такая прямая изображена на рис. 1.2. Как и для любой прямой, параметр b здесь характеризует наклон прямой к оси 0, а параметр а является аддитивной постоянной. Условие (1.2) соответствует требованию метода наименьших квадратов, так как сумма квадратов отклонений должна обращаться в минимум. Применение этого метода дает оценки параметров а и b наилучшие в смысле метода наименьших квадратов. Метод наименьших квадратов может также служить для подбора любой кривой, его возможности не ограничиваются только применением к оценке параметров прямой. Изображенная на рис. 1.2 прямая называется прямой регрессии у по
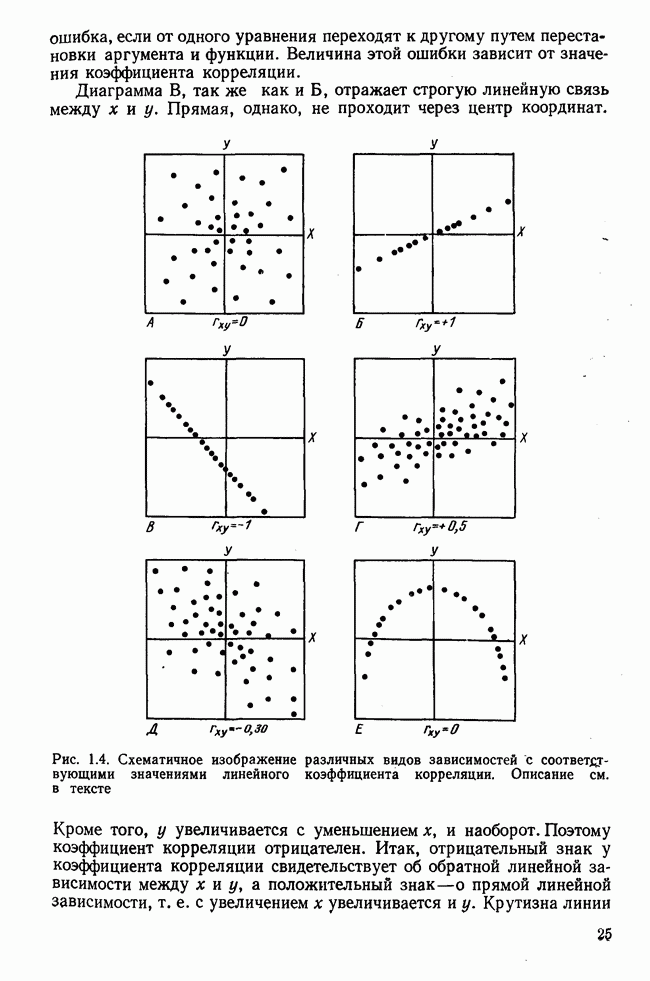
Рис. 1.2. Прямая регрессии у по х. х и у — средние значения переменных. Отклонения отдельных значений от линии регрессии обозначены пунктиром. Величина Формулы для вычисления указаны в табл. 1.1 (строка 10). Угловой коэффициент наклона прямой b называется коэффициентом регрессии. Теперь зададимся вопросом, можно ли исходя из тех же самых наблюдений Определить как можно точнее соответствующее значение
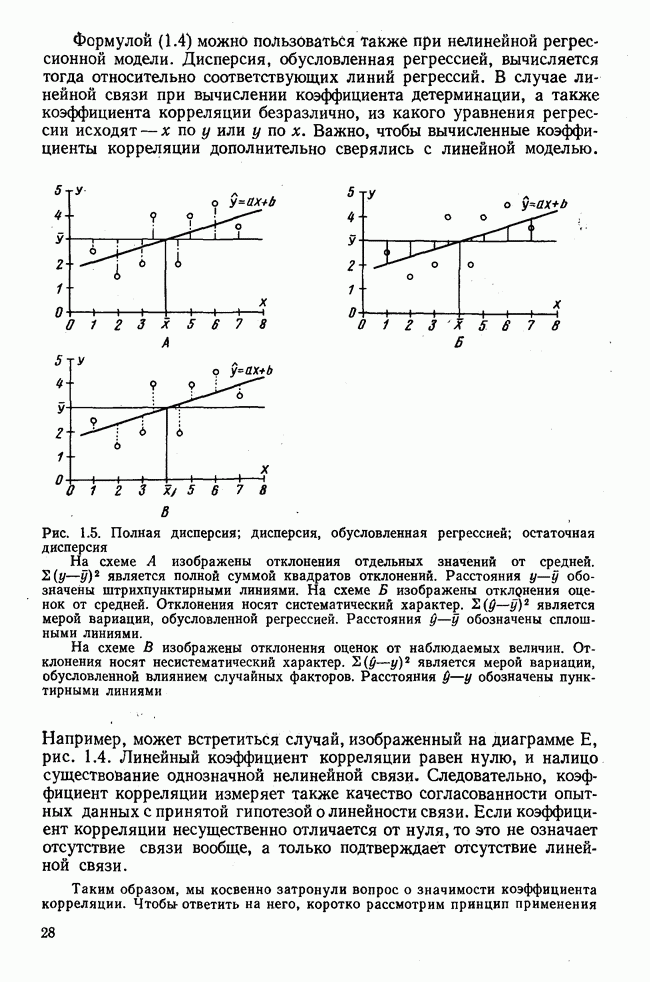
Рис. 1.3. Прямая регрессии х по у. Поле корреляции построено для тех же самых пар значений На рис. 1.3 для тех же самых пар значений При определении взаимосвязи всегда предполагается, что известно, какая величина является исходной, а какая — целевой функцией. Прежде чем составлять уравнение регрессии, выясняют для себя, какую переменную выбрать в качестве аргумента, а какую — в виде функции. Допустима другая постановка задачи, при которой не интересуются направлением и формой зависимости, а хотели бы знать, как сильна связь между двумя рядами наблюдений, относящихся к одним и тем же объектам. Это уже задача корреляционного исчисления. Коэффициент корреляции служит мерой линейной взаимосвязи между двумя измеряемыми величинами. Он может принимать значения между +1 и -1. Если он равен нулю, то линейная связь между х и у отсутствует. Если он равен +1 или —1, то связь строго линейная. На рис. 1.4 схематично изображены возможные поля корреляций при различных значениях коэффициентов корреляции. На диаграмме А точки случайно разбросаны на координатной плоскости. По величине Допускается ошибка, если от одного уравнения переходят к другому путем перестановки аргумента и функции. Величина этой ошибки зависит от значения коэффициента корреляции. Диаграмма В, так же как и Б, отражает строгую линейную связь между х и у. Прямая, однако, не проходит через центр координат.
Рис. 1.4. Схематичное изображение различных видов зависимостей с соответствующими значениями линейного коэффициента корреляции. Описание см. в тексте Кроме того, у увеличивается с уменьшением х, и наоборот. Поэтому коэффициент корреляции отрицателен. Итак, отрицательный знак у коэффициента корреляции свидетельствует об обратной линейной зависимости между х и у, а положительный знак — о прямой линейной зависимости, т. е. с увеличением х увеличивается и у. Крутизна линии регрессии не оказывает влияния на величину коэффициента корреляции или его знак. Знак коэффициента корреляции отражает лишь направление связи между обеими переменными. На диаграмме Д также схематично показано поле корреляции при отрицательном коэффициенте корреляции. Формулы для вычисления коэффициента корреляции приведены в табл. 1.1. При этом сначала определяется сумма произведений отклонений. Мы уже познакомились с суммой квадратов отклонений для каждой переменной. Вместо того, чтобы возводить в квадрат эти отклонения, а затем суммировать, как указано в строке 3 табл. 1.1, отклонение отдельного значения от средней арифметической одной переменной умножают на соответствующее отклонение другой переменной, а затем суммируют. Таким образом, получают сумму произведений отклонений По аналогии с дисперсией, которую получают делением суммы квадратов отклонений на В литературе на английском языке по регрессионному анализу полную дисперсию разлагают на две составляющие: дисперсию переменной, обусловленную регрессией, и остаточную дисперсию, вызванную ошибками наблюдений. Из рис. 1.2 видно, что расстояние
Второе слагаемое в правой части равенства является удвоенным произведением систематической и случайной составляющих и при суммировании оно обращается в нуль, если (
или
Левая часть равенства (1.3) называется полной дисперсией переменной у. Первый член правой части является дисперсией, связанной с регрессией. Эта дисперсия характеризует рассеивание за счет исследуемого фактора, т. е. является так называемой «объяснимой» дисперсией. Второй член правой части равенства является «необъяснимой» дисперсией, известной под названием остаточной дисперсии. Происхождение этих названий объясняется следующим образом. Отклонения Отклонения, изображенные на схеме А, входят в полную дисперсию величины у. На схеме Б изображены отклонения, которые носят систематический характер. Они соответствуют дисперсии, обусловленной регрессией. На схеме В представлены отклонения эмпирических точек от регрессионной прямой, которые носят несистематический характер. Частное от деления дисперсии, обусловленной регрессией, на полную дисперсию называют коэффициентом детерминации. Коэффициент детерминации используют как характеристику доли вариации в полной дисперсии, обусловленной влиянием фактора
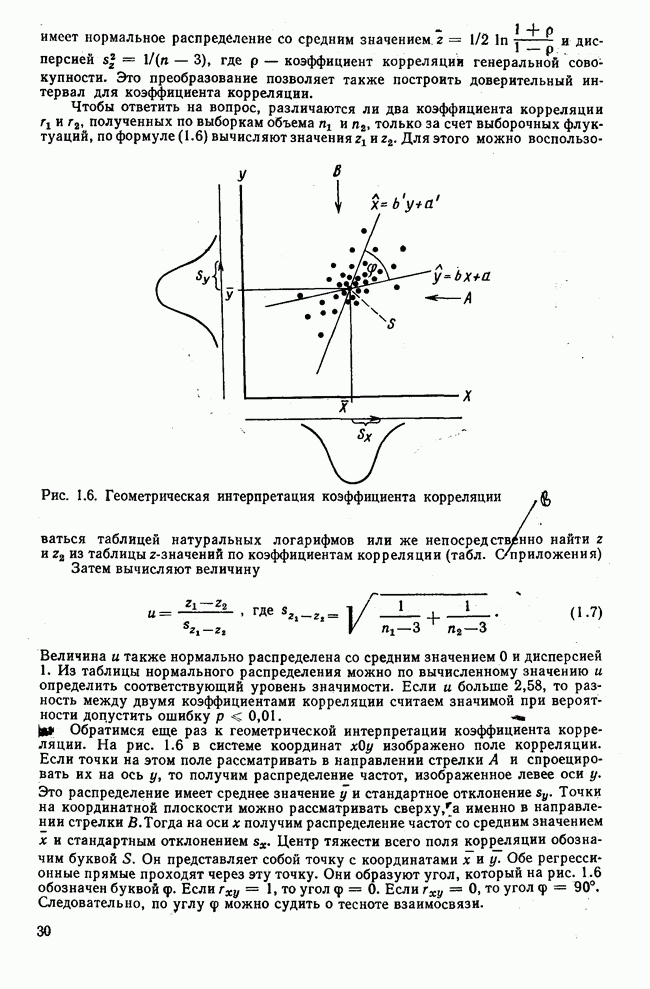
Коэффициент детерминации изменяется от 0 до 1. Извлекая квадратный корень из этого коэффициента, получим коэффициент корреляции Формулой (1.4) можно пользоваться также при нелинейной регрессионной модели. Дисперсия, обусловленная регрессией, вычисляется тогда относительно соответствующих линий регрессий. В случае линейной связи при вычислении коэффициента детерминации, а также коэффициента корреляции безразлично, из какого уравнения регрессии исходят — х по у или у по х. Важно, чтобы вычисленные коэффициенты корреляции дополнительно сверялись с линейной моделью.
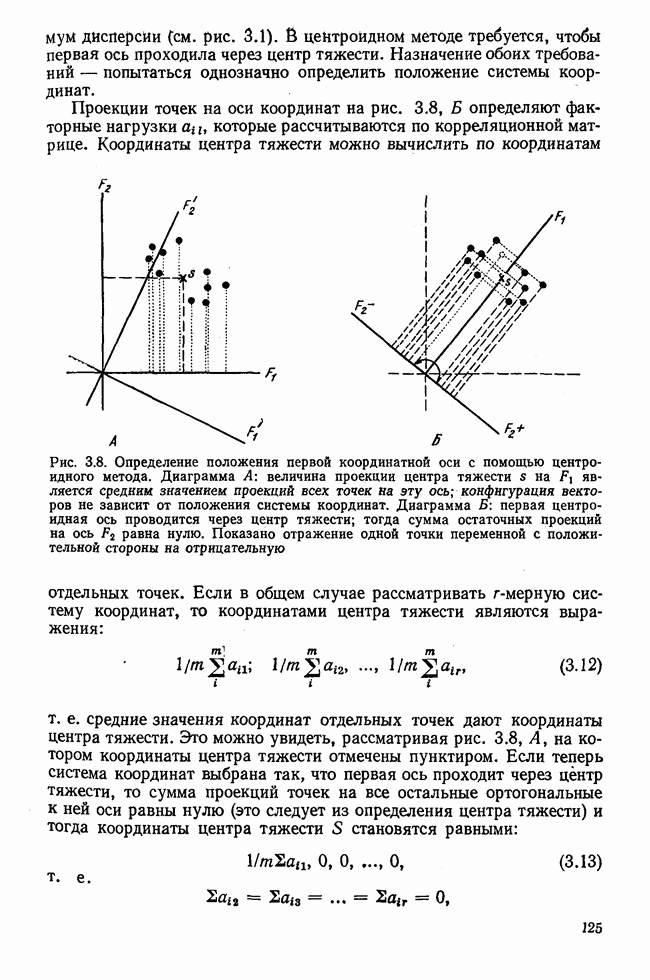
Рис. 1.5. Полная дисперсия; дисперсия, обусловленная регрессией; остаточная дисперсия На схеме А изображены отклонения отдельных значений от средней. На схеме В изображены отклонения оценок от наблюдаемых величин. Отклонения носят несистематический характер. Например, может встретиться случай, изображенный на диаграмме Е, рис. 1.4. Линейный коэффициент корреляции равен нулю, и налицо существование однозначной нелинейной связи. Следовательно, коэффициент корреляции измеряет также качество согласованности опытных данных с принятой гипотезой о линейности связи. Если коэффициент корреляции несущественно отличается от нуля, то это не означает отсутствие связи вообще, а только подтверждает отсутствие линейной связи. Таким образом, мы косвенно затронули вопрос о значимости коэффициента корреляции. Чтобы ответить на него, коротко рассмотрим принцип применения статистических критериев. Формулируется нулевая гипотеза
Вероятность ошибки 1-го рода обозначается через а, ошибки 2-го рода — через
превысит критическое значение, которое следует ожидать менее чем в 1% случаев при данном объеме выборки. Величина t при условии Если хотят проверить гипотезу о том, относятся ли оба вычисленных коэффициента корреляции к одной и той же совокупности, то используют
имеет нормальное распределение со средним значением Это преобразование позволяет также построить доверительный интервал для коэффициента корреляции. Чтобы ответить на вопрос, различаются ли два коэффициента корреляции и полученных по выборкам объема
Рис. 1.6. Геометрическая интерпретация коэффициента корреляции Затем вычисляют величину
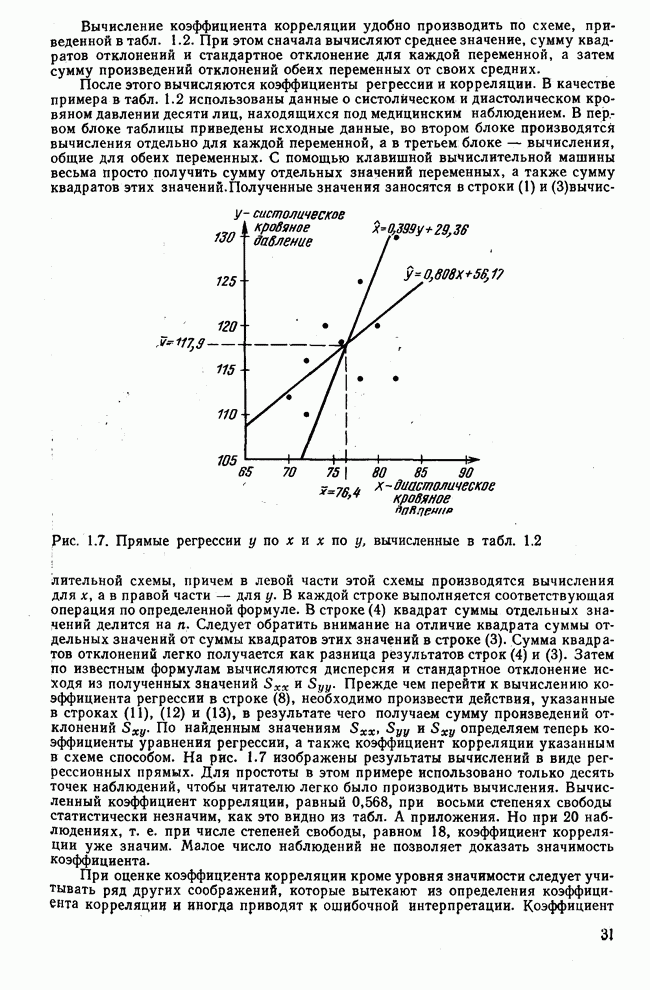
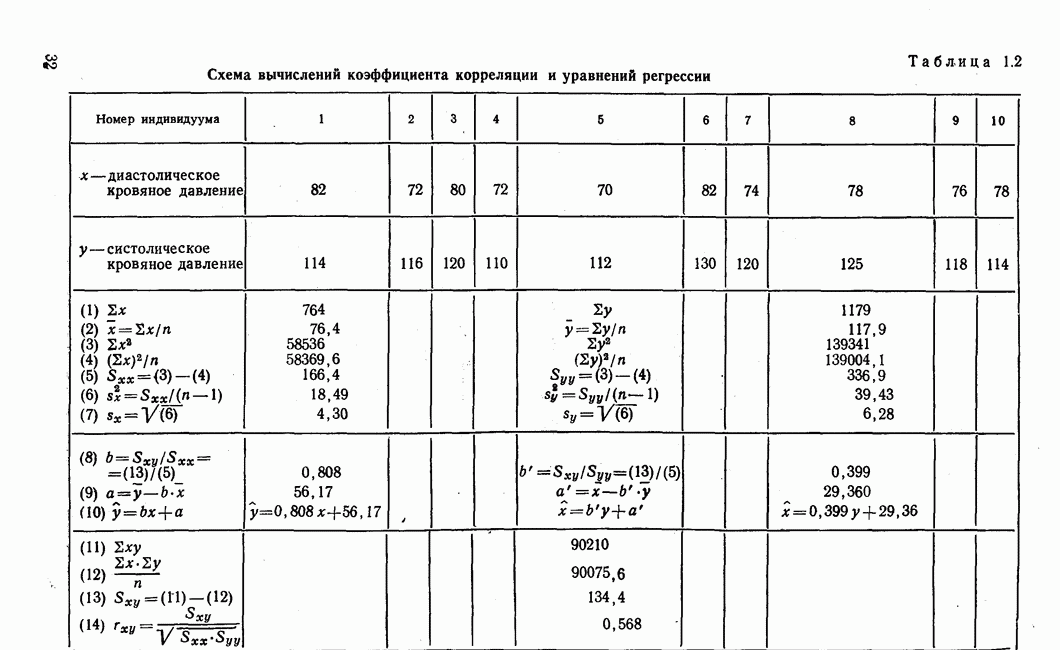
Величина и также нормально распределена со средним значением 0 и дисперсией 1. Из таблицы нормального распределения можно по вычисленному значению и определить соответствующий уровень значимости. Если и больше 2,58, то разность между двумя коэффициентами корреляции считаем значимой при вероятности допустить ошибку Обратимся еще раз к геометрической интерпретации коэффициента корреляции. На рис. 1.6 в системе координат Вычисление коэффициента корреляции удобно производить по схеме, приведенной в табл. 1.2. При этом сначала вычисляют среднее значение, сумму квадратов отклонений и стандартное отклонение для каждой переменной, а затем сумму произведений отклонений обеих переменных от своих средних. После этого вычисляются коэффициенты регрессии и корреляции. В качестве примера в табл. 1.2 использованы данные о систолическом и диастолическом кровяном давлении десяти лиц, находящихся под медицинским наблюдением. В первом блоке таблицы приведены исходные данные, во втором блоке производятся вычисления отдельно для каждой переменной, а в третьем блоке — вычисления, общие для обеих переменных. С помощью клавишной вычислительной машины весьма просто получить сумму отдельных значений переменных, а также сумму квадратов этих значений.
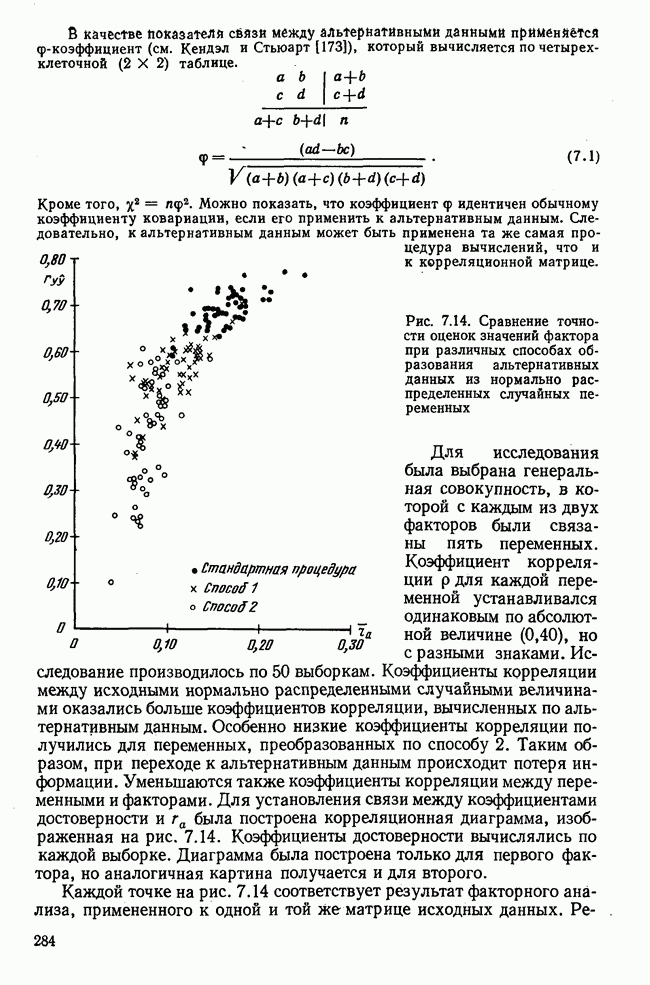
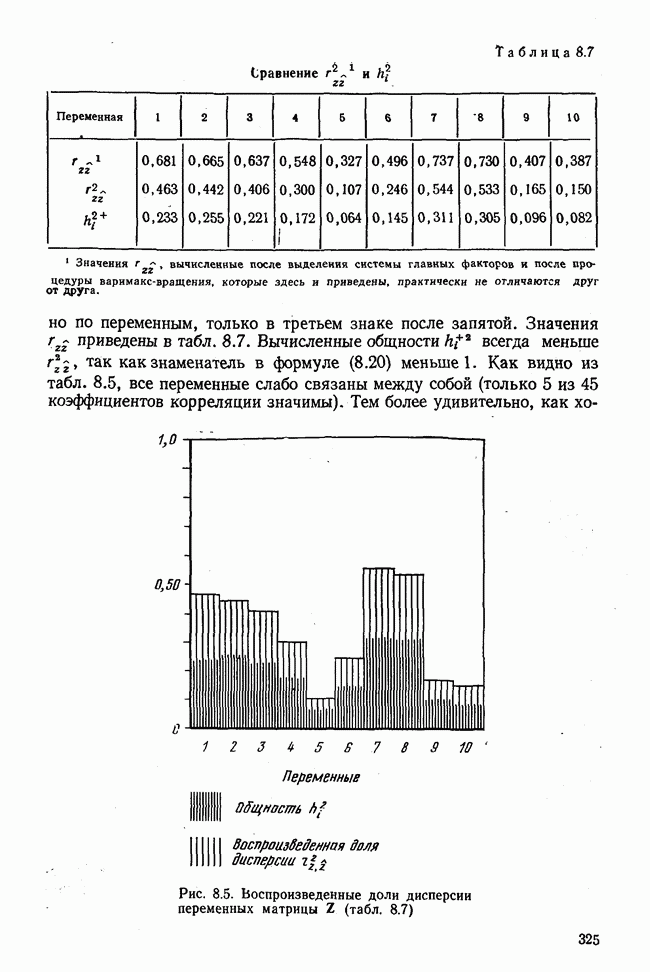
Рис. 1.7. Прямые регрессии у по х и х по у, вычисленные в табл. 1.2 Полученные значения заносятся в строки (1) и (3) вычислительной схемы, причем в левой части этой схемы производятся вычисления для х, а в правой части — для у. В каждой строке выполняется соответствующая операция по определенной формуле. В строке (4) квадрат суммы отдельных значений делится на При оценке коэффициента корреляции кроме уровня значимости следует учитывать ряд других соображений, которые вытекают из определения коэффициента корреляции И иногда приводят к ошибочной интерпретации. Таблица 1.2. Схема вычислений коэффициента корреляции и уравнений регрессии (см. скан) Коэффициент корреляции является параметром двумерного нормального распределения. Но если случайные величины имеют другое совместное распределение, отличное от нормального, то коэффициент корреляции не входит непосредственно в выражение этого закона распределения и поэтому не имеет четкого истолкования. Но даже в этом случае его используют как общепринятый статистический показатель, наподобие стандартного отклонения, которое является параметром одномерного нормального распределения. Для альтернативных и качественных признаков такие показатели, как ковариация и коэффициент корреляции, должны применяться с большой осторожностью. Имеются другие показатели взаимосвязи между переменными, более подходящие в этом случае, которые тоже можно оценивать на значимость. Как это отражается на факторном анализе, если элементами исходной матрицы являются другие показатели взаимосвязи или неправильно вычисленные коэффициенты корреляции, — предмет особого разговора. Перед вычислением коэффициента корреляции следует проверить гипотезу о нормальности обоих распределений и линейности связи между ними. В общем достаточно внимательно всмотреться в поле корреляции. В крайнем случае линейность регрессии можно проверить по схеме, предложенной Б. Уолкером, которую можно найти также в [176; 3]. Проверку гипотезы о нормальности распределения производят с помощью критерия
|
 |
Оглавление
|
































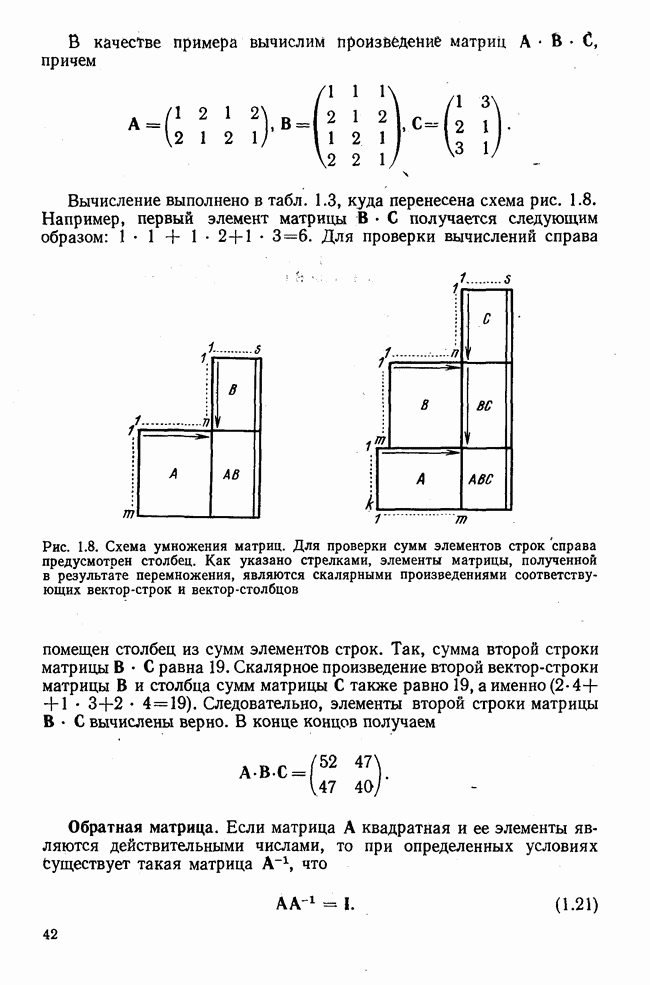






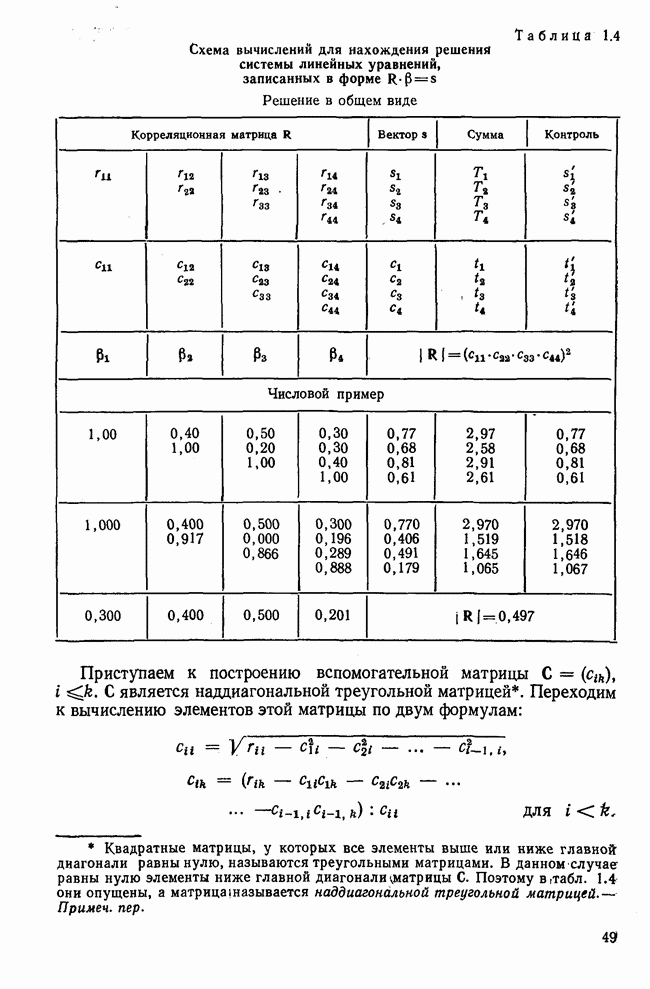




























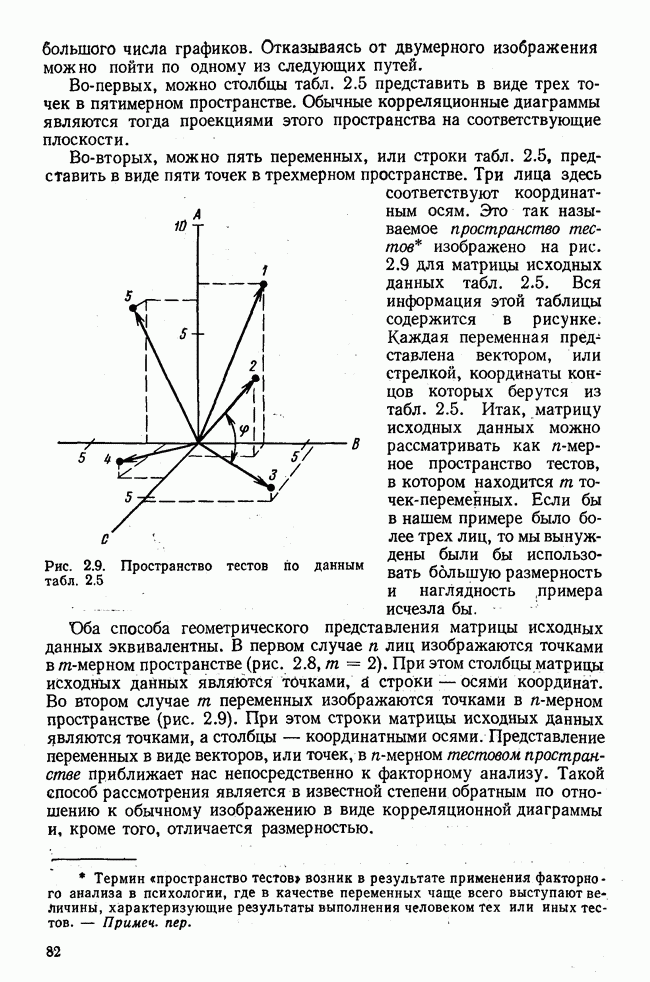


























































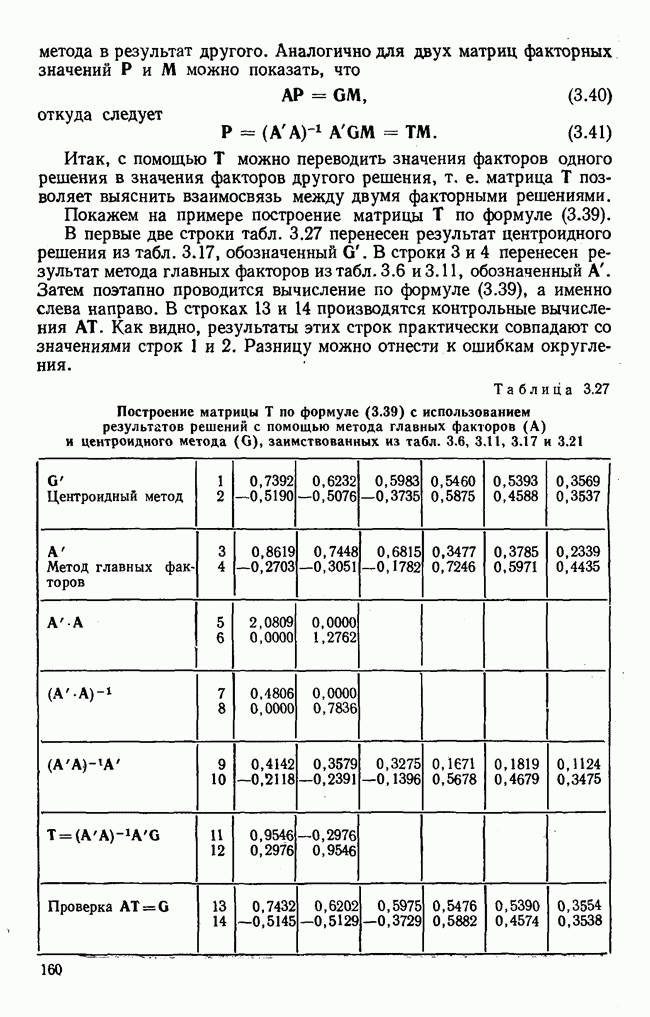










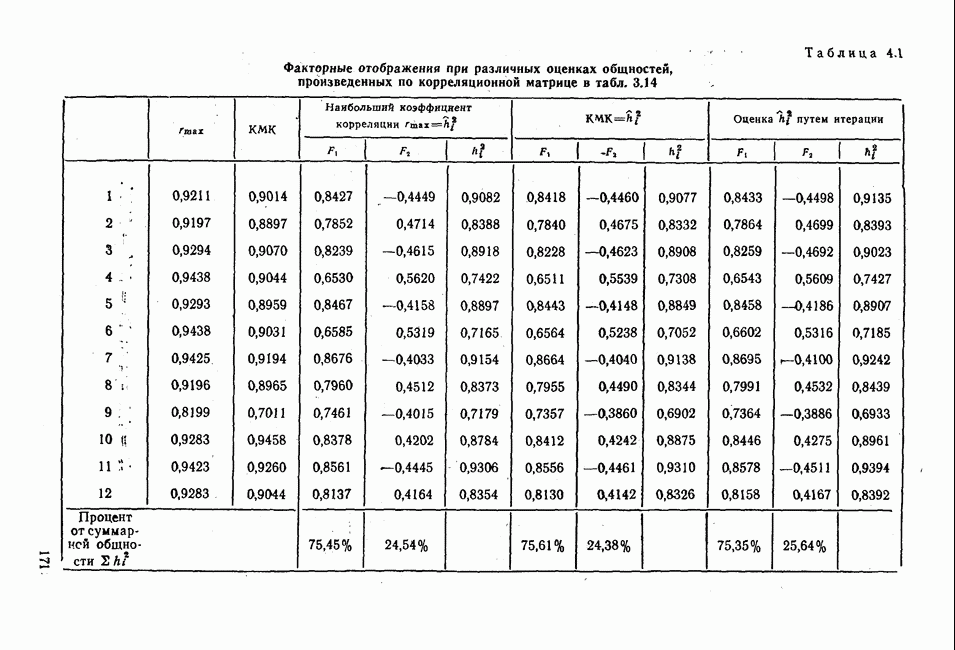


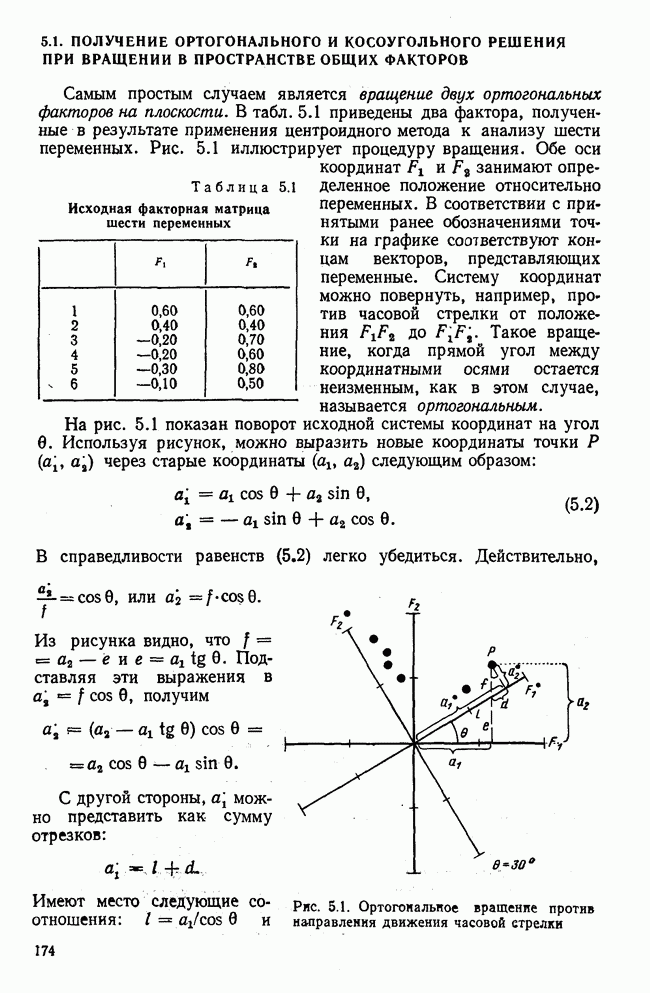






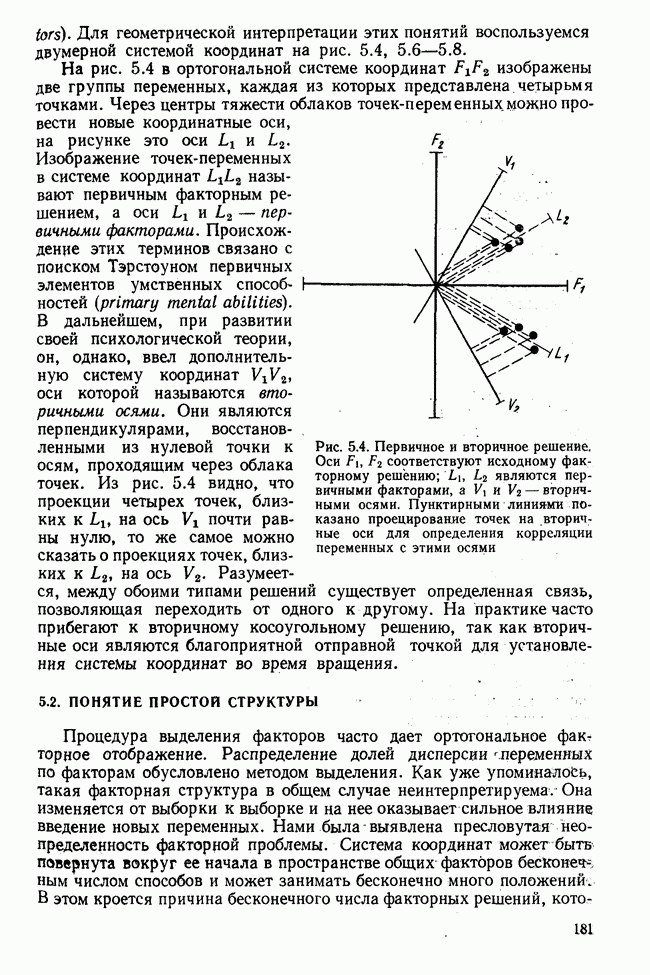












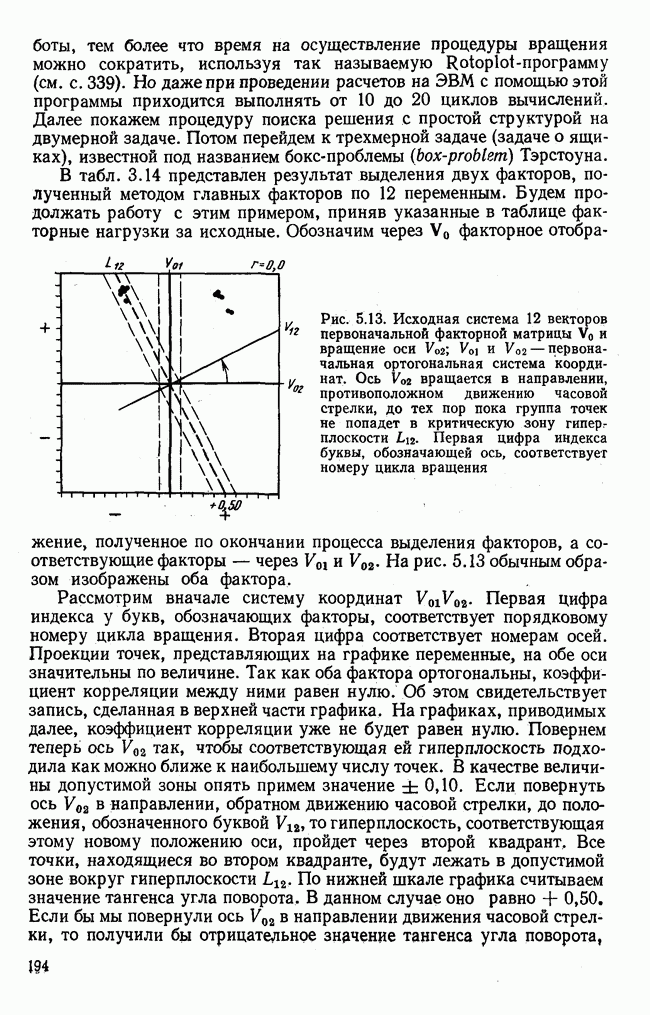


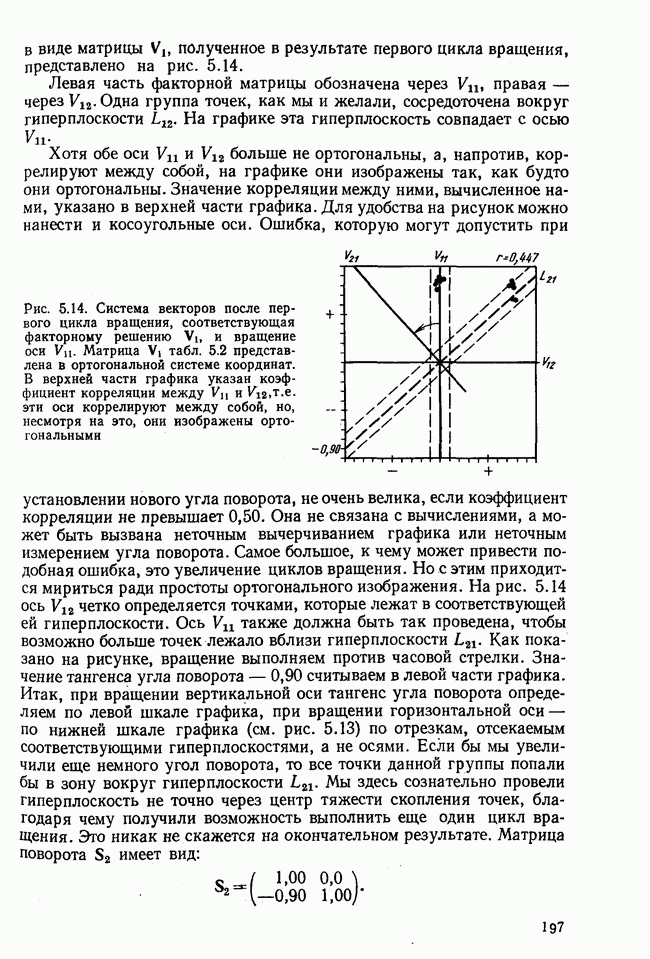

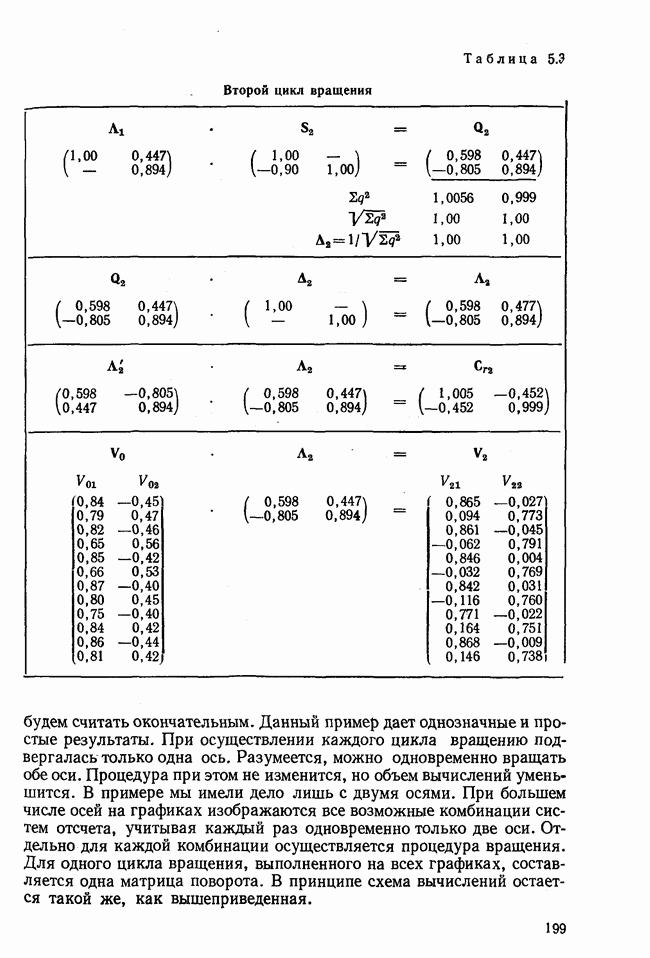

















































































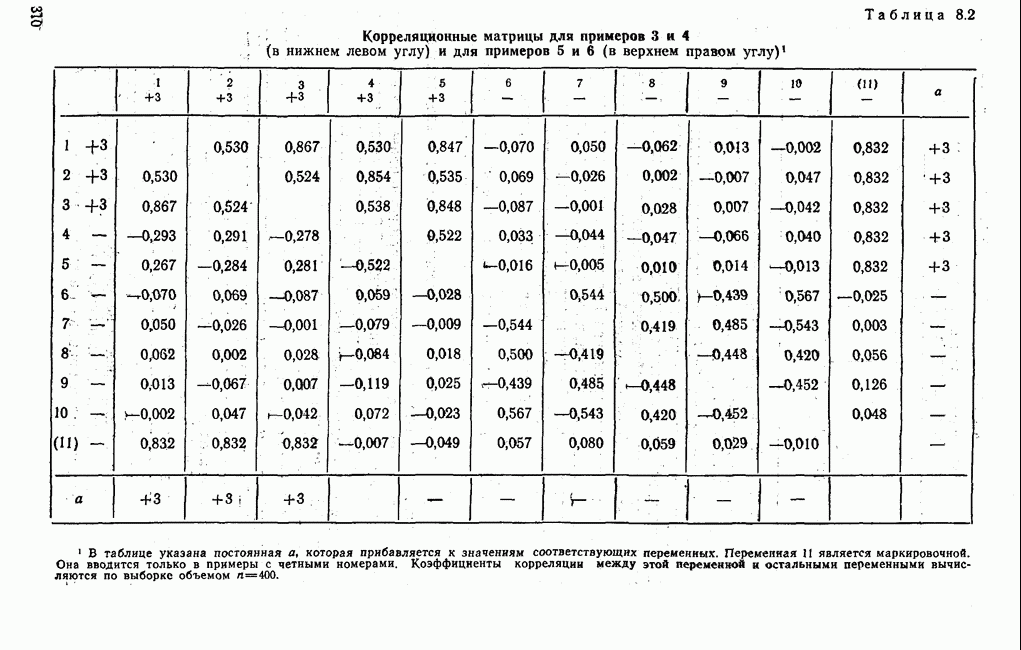

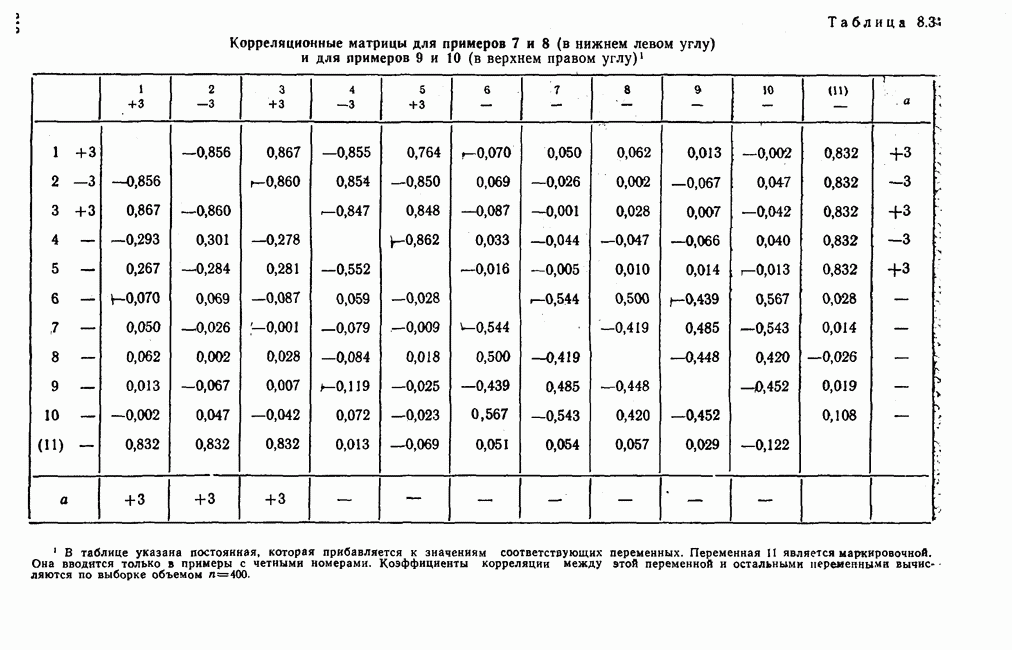







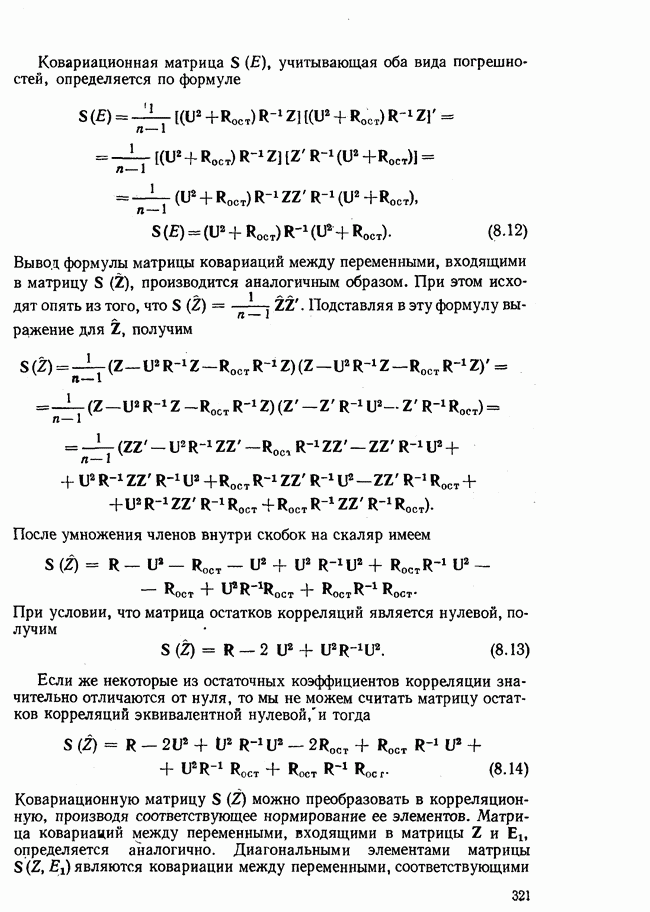






















































 лиц, или у
лиц, или у  объектов, измеряются два признака или переменные х и у. В результате имеем отдельные значения
объектов, измеряются два признака или переменные х и у. В результате имеем отдельные значения  . Вначале оба ряда наблюдения рассматриваем раздельно и для каждого из них вычисляем статистические характеристики. Важнейшей из этих характеристик является среднее значение
. Вначале оба ряда наблюдения рассматриваем раздельно и для каждого из них вычисляем статистические характеристики. Важнейшей из этих характеристик является среднее значение  , которое получают, разделив сумму отдельных значений на
, которое получают, разделив сумму отдельных значений на  . Соответствующая формула приведена в строке 2 табл. 1.1. Для обозначения сложения применяется знак суммы с соответствующими индексами
. Соответствующая формула приведена в строке 2 табл. 1.1. Для обозначения сложения применяется знак суммы с соответствующими индексами 
 пробегает значения от 1 до
пробегает значения от 1 до  , то иногда суммирование обозначают таким образом:
, то иногда суммирование обозначают таким образом:  или
или  или
или  .
.
 или
или  но для вычислений более удобна формула в строке 4. Если разделить сумму квадратов отклонений на
но для вычислений более удобна формула в строке 4. Если разделить сумму квадратов отклонений на  так называемое число степеней свободы, то получим дисперсию (строка 5). Извлекая корень квадратный из дисперсии, получим характеристику, называемую стандартным отклонением (строка 6). Стандартное отклонение является мерой среднего отклонения отдельных значений от их средней.
так называемое число степеней свободы, то получим дисперсию (строка 5). Извлекая корень квадратный из дисперсии, получим характеристику, называемую стандартным отклонением (строка 6). Стандартное отклонение является мерой среднего отклонения отдельных значений от их средней.
 судить о величине у, является задачей регрессионного исчисления. Для графического изображения обеих переменных используется прямоугольная система координат
судить о величине у, является задачей регрессионного исчисления. Для графического изображения обеих переменных используется прямоугольная система координат  Любой паре значений
Любой паре значений  для каждого объекта соответствует точка на графике рис. 1.2. Если рассматривать скопление точек на графике, то можно увидеть, что в общем с увеличением
для каждого объекта соответствует точка на графике рис. 1.2. Если рассматривать скопление точек на графике, то можно увидеть, что в общем с увеличением  значения у также увеличиваются.
значения у также увеличиваются.





 является отклонением измеренного значения переменной у от оценки, величина
является отклонением измеренного значения переменной у от оценки, величина  является отклонением оценки от среднего значения и величина
является отклонением оценки от среднего значения и величина  является отклонением измеренного значения от среднего
является отклонением измеренного значения от среднего
 по значению у. Этим мы меняем постановку задачи, а именно оцениваем х по у, а не у по х.
по значению у. Этим мы меняем постановку задачи, а именно оцениваем х по у, а не у по х.

 , что и на рис. 12, но на него нанесена другая прямая регрессии. Перечисленные под рис. 1.2 отклонения истолковываются аналогично для этого случая, изменяется только направление анализа
, что и на рис. 12, но на него нанесена другая прямая регрессии. Перечисленные под рис. 1.2 отклонения истолковываются аналогично для этого случая, изменяется только направление анализа
 построена прямая регрессий х по у. При этом минимизируется сумма квадратов отклонений опытных точек, измеренных по горизонтальной оси. Поэтому в результате получается прямая, не согласующаяся с регрессией у по х. Но обозначение и вычисление параметров этой прямой полностью аналогичны (табл. 1.1, строка 11). Выбор вида прямой регрессии определяется содержательной постановкой задачи анализа. Регрессия у по х не идентична регрессии х по у. Из уравнения
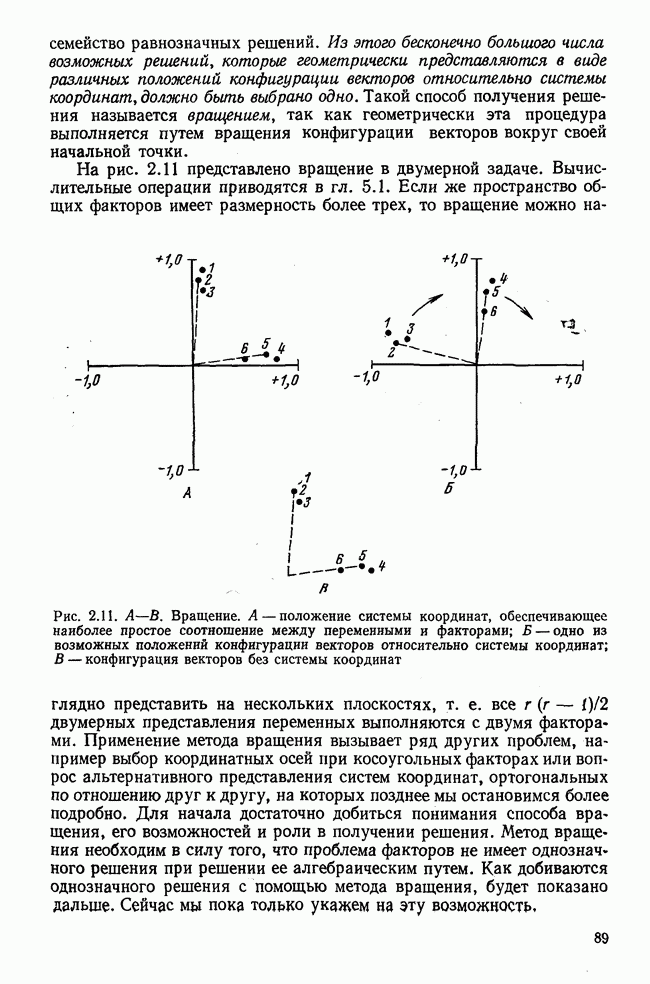
построена прямая регрессий х по у. При этом минимизируется сумма квадратов отклонений опытных точек, измеренных по горизонтальной оси. Поэтому в результате получается прямая, не согласующаяся с регрессией у по х. Но обозначение и вычисление параметров этой прямой полностью аналогичны (табл. 1.1, строка 11). Выбор вида прямой регрессии определяется содержательной постановкой задачи анализа. Регрессия у по х не идентична регрессии х по у. Из уравнения  а нельзя выразить х через у. Если, например, хотят приблизительно оценить рост человека по весу, а также решить обратную задачу — сделать вывод о весе человека по росту, то нельзя пользоваться одним и тем же уравнением. Две разные постановки задачи приводят к двум разным регрессионным прямым. Если же на одном графике начертить обе регрессионные прямые, то они образуют между собой угол (см. рис. 1.6). Только в случае совершенно однозначной линейной связи между х и у обе прямые регрессии совпадают и угол между ними становится равным нулю.
а нельзя выразить х через у. Если, например, хотят приблизительно оценить рост человека по весу, а также решить обратную задачу — сделать вывод о весе человека по росту, то нельзя пользоваться одним и тем же уравнением. Две разные постановки задачи приводят к двум разным регрессионным прямым. Если же на одном графике начертить обе регрессионные прямые, то они образуют между собой угол (см. рис. 1.6). Только в случае совершенно однозначной линейной связи между х и у обе прямые регрессии совпадают и угол между ними становится равным нулю.
 нельзя сделать вывод об у. Связь между
нельзя сделать вывод об у. Связь между  и у отсутствует,
и у отсутствует,  или незначимо отличается от нуля. На диаграмме Б все точки лежат на прямой. Каждому значению х можно однозначно поставить в соответствие значение у. Чем больше х, тем больше у. Если эта прямая соответствует уравнению регрессии, выражающему зависимость между исследуемым и результативным признаками, то уравнение можно использовать для нахождения как у по
или незначимо отличается от нуля. На диаграмме Б все точки лежат на прямой. Каждому значению х можно однозначно поставить в соответствие значение у. Чем больше х, тем больше у. Если эта прямая соответствует уравнению регрессии, выражающему зависимость между исследуемым и результативным признаками, то уравнение можно использовать для нахождения как у по  так их по у. Такой крайний случай, когда коэффициент корреляции точно равен
так их по у. Такой крайний случай, когда коэффициент корреляции точно равен  практически не встречается. На поле корреляции, изображенном на диаграмме Г, точки разбросаны не случайно, а имеют тенденцию стабилизироваться в определенном направлении. Такая ситуация возникает часто. Чем больше х, тем в общем случае больше у. Линейность этой связи выражается величиной коэффициента корреляции, который в данном случае приблизительно равен +0,50. По сравнению с диаграммой Б линейная связь под действием несистематических помех расплывается так, что картина кажется затушеванной. В таком случае в зависимости от постановки задачи вычисляется уравнение регрессии либо у по
практически не встречается. На поле корреляции, изображенном на диаграмме Г, точки разбросаны не случайно, а имеют тенденцию стабилизироваться в определенном направлении. Такая ситуация возникает часто. Чем больше х, тем в общем случае больше у. Линейность этой связи выражается величиной коэффициента корреляции, который в данном случае приблизительно равен +0,50. По сравнению с диаграммой Б линейная связь под действием несистематических помех расплывается так, что картина кажется затушеванной. В таком случае в зависимости от постановки задачи вычисляется уравнение регрессии либо у по  либо х по у.
либо х по у.

 (строка 7).
(строка 7).
 можно вычислить так называемую ковариацию, разделив
можно вычислить так называемую ковариацию, разделив  на
на  Ковариация
Ковариация  так же как коэффициент корреляции, является мерой взаимосвязи двух переменных. Но этот показатель не нормирован, т. е. величина ковариации зависит от физической размерности переменных. Коэффициент корреляции является безразмерной величиной. Он представляет собой нормированную ковариацию. Ковариация между ростом в дюймах и весом в фунтах численно отличается от ковариации, подсчитанной между ростом в сантиметрах и весом в килограммах для тех же самых лиц. Однако коэффициент корреляции в обоих случаях будет один и тот же. На величину коэффициента корреляции не оказывают влияния линейные преобразования измерительной шкалы, т. е. если результаты измерения увеличить на постоянную величину или умножить на нее, то значение коэффициента корреляции не изменится. Напротив, коэффициенты регрессии и ковариация от подобных преобразований изменяются, но только от мультипликативных членов, а не от аддитивных.
так же как коэффициент корреляции, является мерой взаимосвязи двух переменных. Но этот показатель не нормирован, т. е. величина ковариации зависит от физической размерности переменных. Коэффициент корреляции является безразмерной величиной. Он представляет собой нормированную ковариацию. Ковариация между ростом в дюймах и весом в фунтах численно отличается от ковариации, подсчитанной между ростом в сантиметрах и весом в килограммах для тех же самых лиц. Однако коэффициент корреляции в обоих случаях будет один и тот же. На величину коэффициента корреляции не оказывают влияния линейные преобразования измерительной шкалы, т. е. если результаты измерения увеличить на постоянную величину или умножить на нее, то значение коэффициента корреляции не изменится. Напротив, коэффициенты регрессии и ковариация от подобных преобразований изменяются, но только от мультипликативных членов, а не от аддитивных.
 состоит из отрезков
состоит из отрезков  и
и  . Следовательно, имеет место равенство
. Следовательно, имеет место равенство  . Если обе части этого равенства возвести в квадрат и просуммировать по всем точкам, то получим
. Если обе части этого равенства возвести в квадрат и просуммировать по всем точкам, то получим

 ) и (
) и ( ) некоррелированы. Независимость этих составляющих является необходимым условием модели. Итак,
) некоррелированы. Независимость этих составляющих является необходимым условием модели. Итак,


 зависят от уравнения регрессии, следовательно, представляют собой эффект от регрессионной связи. Таким образом, эта часть вариации объясняется регрессионной моделью. Напротив, отклонения
зависят от уравнения регрессии, следовательно, представляют собой эффект от регрессионной связи. Таким образом, эта часть вариации объясняется регрессионной моделью. Напротив, отклонения  варьируют случайным образом и не могут быть объяснены моделью, в нашем случае — линейной, т. е. эти отклонения отражают влияние случайных факторов. Для наглядности три вида отклонений схематично изображены на рис. 1.5. На всех трех схемах этого рисунка изображена одна и та же регрессионная прямая, одни и те же эмпирические точки на одной и той же координатной плоскости.
варьируют случайным образом и не могут быть объяснены моделью, в нашем случае — линейной, т. е. эти отклонения отражают влияние случайных факторов. Для наглядности три вида отклонений схематично изображены на рис. 1.5. На всех трех схемах этого рисунка изображена одна и та же регрессионная прямая, одни и те же эмпирические точки на одной и той же координатной плоскости.
 в случае линейной регрессии.
в случае линейной регрессии.



 является полной суммой квадратов отклонений. Расстояния
является полной суммой квадратов отклонений. Расстояния  обозначены штрихпунктирными линиями. На схеме Б изображены отклонения оценок от средней. Отклонения носят систематический характер.
обозначены штрихпунктирными линиями. На схеме Б изображены отклонения оценок от средней. Отклонения носят систематический характер.  является мерой вариации, обусловленной регрессией. Расстояния
является мерой вариации, обусловленной регрессией. Расстояния  обозначены сплошными линиями.
обозначены сплошными линиями.
 является мерой вариации, обусловленной влиянием случайных факторов. Расстояния
является мерой вариации, обусловленной влиянием случайных факторов. Расстояния  обозначены пунктирными линиями
обозначены пунктирными линиями
 которая, например, заключается в том, что наблюдавшийся коэффициент корреляции целиком обусловлен случайными колебаниями выборки, на основании которой он вычислен. Альтернативная гипотеза
которая, например, заключается в том, что наблюдавшийся коэффициент корреляции целиком обусловлен случайными колебаниями выборки, на основании которой он вычислен. Альтернативная гипотеза  состоит в том, что коэффициент корреляции больше, чем можно было бы ожидать при случайном осуществлении выборки. Только одна из гипотез может быть правильна и только одна из них должна быть принята на основе имеющихся эмпирических данных. При этом возможны четыре случая:
состоит в том, что коэффициент корреляции больше, чем можно было бы ожидать при случайном осуществлении выборки. Только одна из гипотез может быть правильна и только одна из них должна быть принята на основе имеющихся эмпирических данных. При этом возможны четыре случая:

 . Большей частью при проверке статистических гипотез задаются лишь вероятностью а. Принимают решение отвергнуть гипотезу
. Большей частью при проверке статистических гипотез задаются лишь вероятностью а. Принимают решение отвергнуть гипотезу  и принять гипотезу
и принять гипотезу  , если в результате вычислений появляется такой по величине коэффициент корреляции, что мы могли бы ожидать его только на уровне значимости
, если в результате вычислений появляется такой по величине коэффициент корреляции, что мы могли бы ожидать его только на уровне значимости  Тогда мы в 5% или 1% случаев ошибочно принимаем гипотезу о наличии линейной связи, хотя в действительности ее нет. Выбор уровня значимости а для ошибки 1-го рода весьма произволен. Он должен устанавливаться в зависимости от важности вытекающих из принятого решения последствий. В общем случае рекомендуется
Тогда мы в 5% или 1% случаев ошибочно принимаем гипотезу о наличии линейной связи, хотя в действительности ее нет. Выбор уровня значимости а для ошибки 1-го рода весьма произволен. Он должен устанавливаться в зависимости от важности вытекающих из принятого решения последствий. В общем случае рекомендуется  -ный уровень значимости и коэффициент корреляции будет тогда считаться значимым, если величина
-ный уровень значимости и коэффициент корреляции будет тогда считаться значимым, если величина

 распределена по закону Стьюдента с
распределена по закону Стьюдента с  степенями свободы. Для удобства табулировано непосредственно распределение выборочного коэффициента корреляции при
степенями свободы. Для удобства табулировано непосредственно распределение выборочного коэффициента корреляции при  для различных степеней свободы и уровней значимости (табл. А приложения). Таблица сокращает объем вычислений, так как сравнение вычисленного по наблюдениям значения
для различных степеней свободы и уровней значимости (табл. А приложения). Таблица сокращает объем вычислений, так как сравнение вычисленного по наблюдениям значения  с указанным в таблице его критическим значением дает возможность непосредственно судить о значимости или незначимости обнаруженной связи.
с указанным в таблице его критическим значением дает возможность непосредственно судить о значимости или незначимости обнаруженной связи.
 -преобразование Фишера. С помощью этого преобразования переходим от распределения коэффициента корреляции к нормальному распределению. Величина
-преобразование Фишера. С помощью этого преобразования переходим от распределения коэффициента корреляции к нормальному распределению. Величина

 и дисперсией
и дисперсией  где
где  — коэффициент корреляции генеральной совокупности.
— коэффициент корреляции генеральной совокупности.
 , только за счет выборочных флуктуаций, по формуле (1.6) вычисляют значения
, только за счет выборочных флуктуаций, по формуле (1.6) вычисляют значения  . Для этого можно воспользоваться таблицей натуральных логарифмов или же непосредственно найти
. Для этого можно воспользоваться таблицей натуральных логарифмов или же непосредственно найти  из таблицы
из таблицы  -значений по коэффициентам корреляции (табл. О приложения)
-значений по коэффициентам корреляции (табл. О приложения)



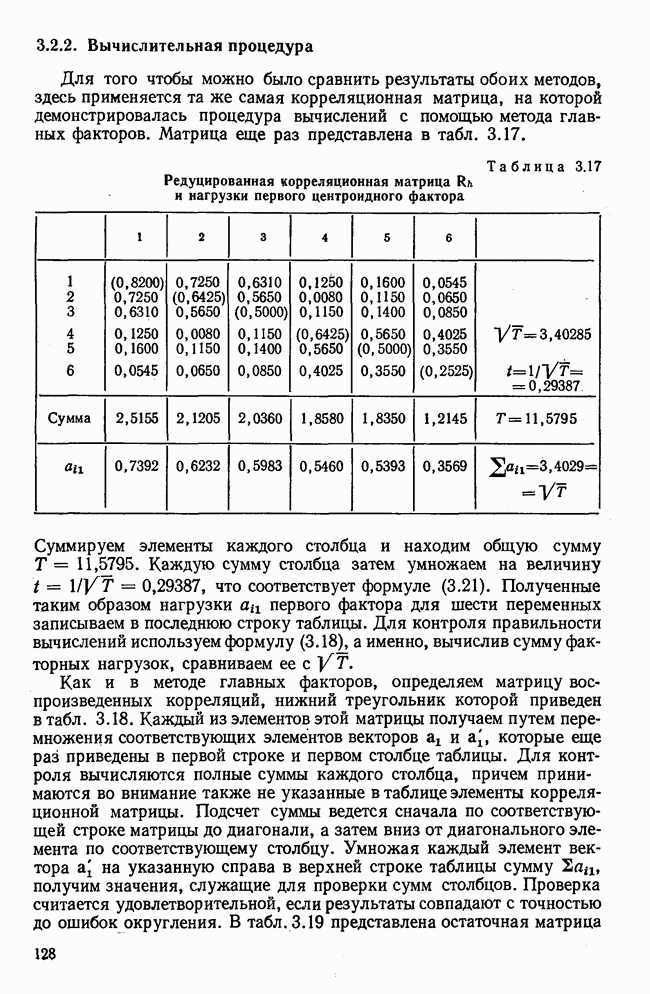
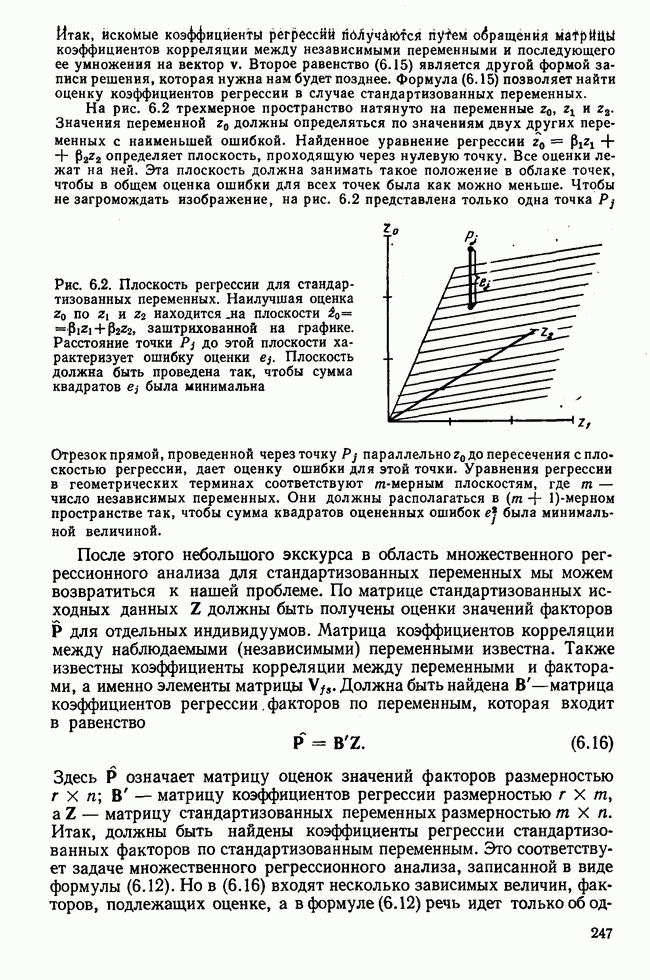
 изображено поле корреляции. Если точки на этом поле рассматривать в направлении стрелки А и спроецировать их на ось у, то получим распределение частот, изображенное левее оси у. Это распределение имеет среднее значение у и стандартное отклонение
изображено поле корреляции. Если точки на этом поле рассматривать в направлении стрелки А и спроецировать их на ось у, то получим распределение частот, изображенное левее оси у. Это распределение имеет среднее значение у и стандартное отклонение  Точки на координатной плоскости можно рассматривать сверху, а именно в направлении стрелки В. Тогда на оси х получим распределение частот со средним значением х и стандартным отклонением
Точки на координатной плоскости можно рассматривать сверху, а именно в направлении стрелки В. Тогда на оси х получим распределение частот со средним значением х и стандартным отклонением  . Центр тяжести всего поля корреляции обозначим буквой S. Он представляет собой точку с координатами х и у. Обе регрессионные прямые проходят через эту точку. Они образуют угол, который на рис. 1.6 обозначен буквой
. Центр тяжести всего поля корреляции обозначим буквой S. Он представляет собой точку с координатами х и у. Обе регрессионные прямые проходят через эту точку. Они образуют угол, который на рис. 1.6 обозначен буквой  . Если
. Если  , то угол
, то угол  . Если
. Если  , то угол
, то угол  . Следовательно, по углу
. Следовательно, по углу  можно судить о тесноте взаимосвязи.
можно судить о тесноте взаимосвязи.

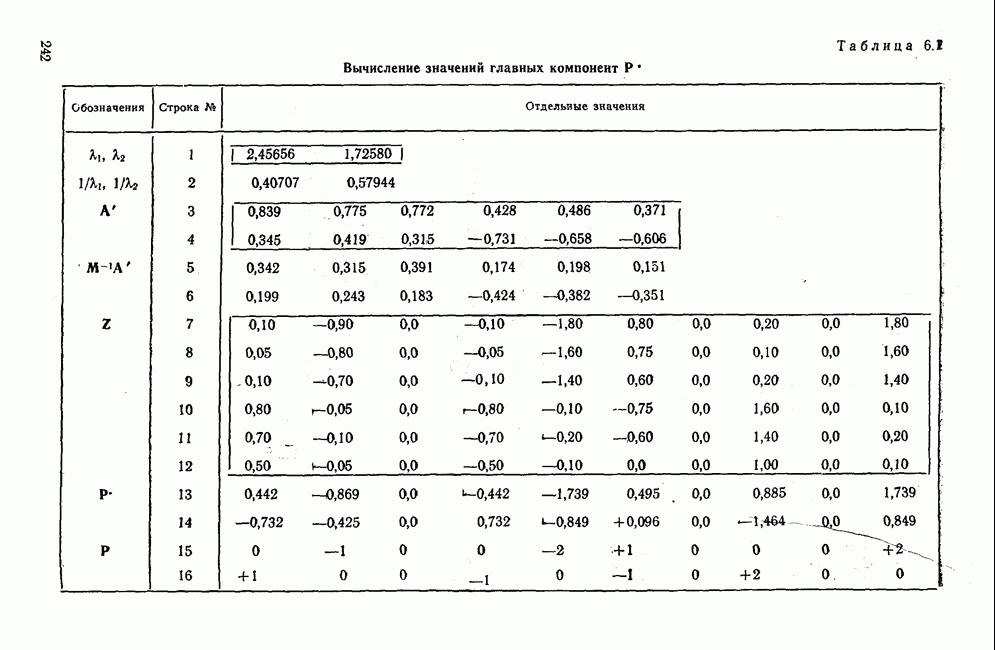
 . Следует обратить внимание на отличие квадрата суммы отдельных значений от суммы квадратов этих значений в строке (3). Сумма квадратов отклонений легко получается как разница результатов строк (4) и (3). Затем по известным формулам вычисляются дисперсия и стандартное отклонение исходя из полученных значений
. Следует обратить внимание на отличие квадрата суммы отдельных значений от суммы квадратов этих значений в строке (3). Сумма квадратов отклонений легко получается как разница результатов строк (4) и (3). Затем по известным формулам вычисляются дисперсия и стандартное отклонение исходя из полученных значений  Прежде чем перейти к вычислению коэффициента регрессии в строке (8), необходимо произвести действия, указанные в строках (11), (12) и (13), в результате чего получаем сумму произведений отклонений
Прежде чем перейти к вычислению коэффициента регрессии в строке (8), необходимо произвести действия, указанные в строках (11), (12) и (13), в результате чего получаем сумму произведений отклонений  По найденным значениям
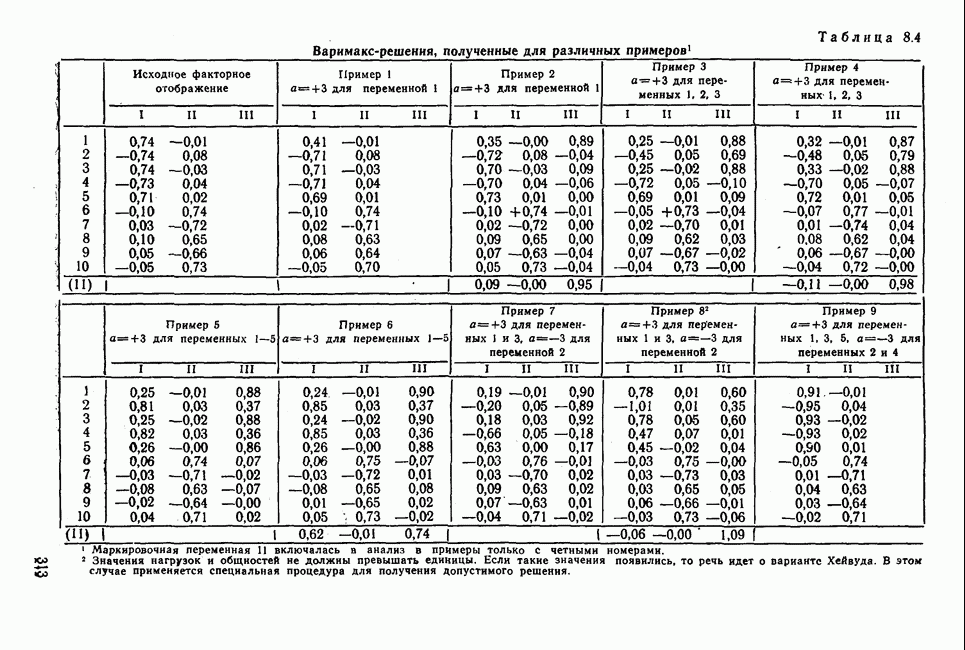
По найденным значениям  определяем теперь коэффициенты уравнения регрессии, а также коэффициент корреляции указанным в схеме способом. На рис. 1.7 изображены результаты вычислений в виде регрессионных прямых. Для простоты в этом примере использовано только десять точек наблюдений, чтобы читателю легко было производить вычисления. Вычисленный коэффициент корреляции, равный 0,568, при восьми степенях свободы статистически незначим, как это видно из табл. А приложения. Но при 20 наблюдениях, т. е. при числе степеней свободы, равном 18, коэффициент корреляции уже значим. Малое число наблюдений не позволяет доказать значимость коэффициента.
определяем теперь коэффициенты уравнения регрессии, а также коэффициент корреляции указанным в схеме способом. На рис. 1.7 изображены результаты вычислений в виде регрессионных прямых. Для простоты в этом примере использовано только десять точек наблюдений, чтобы читателю легко было производить вычисления. Вычисленный коэффициент корреляции, равный 0,568, при восьми степенях свободы статистически незначим, как это видно из табл. А приложения. Но при 20 наблюдениях, т. е. при числе степеней свободы, равном 18, коэффициент корреляции уже значим. Малое число наблюдений не позволяет доказать значимость коэффициента.
 Описание этого критерия имеется почти во всех учебниках по статистике, например в учебнике Линдера [190; 2]. В заключение следует указать на то, что при интерпретации коэффициента корреляции нужно быть как можно осторожнее. Можно привести многочисленные примеры, где высокий коэффициент корреляции появляется при отсутствии причинной связи между явлениями только за счет неоднородности материала, на что особенно обращал внимание еще Коллер [176; 1, 2, 4]. При проведении исследования Коллер [176; 2] предлагал исключать все возможности, приводящее к ложной корреляции. Факторный анализ является методом, который продвинулся значительно дальше в интерпретации коэффициента корреляции. Факторный анализ исходит из матрицы, элементами которой являются коэффициенты корреляции.
Описание этого критерия имеется почти во всех учебниках по статистике, например в учебнике Линдера [190; 2]. В заключение следует указать на то, что при интерпретации коэффициента корреляции нужно быть как можно осторожнее. Можно привести многочисленные примеры, где высокий коэффициент корреляции появляется при отсутствии причинной связи между явлениями только за счет неоднородности материала, на что особенно обращал внимание еще Коллер [176; 1, 2, 4]. При проведении исследования Коллер [176; 2] предлагал исключать все возможности, приводящее к ложной корреляции. Факторный анализ является методом, который продвинулся значительно дальше в интерпретации коэффициента корреляции. Факторный анализ исходит из матрицы, элементами которой являются коэффициенты корреляции.