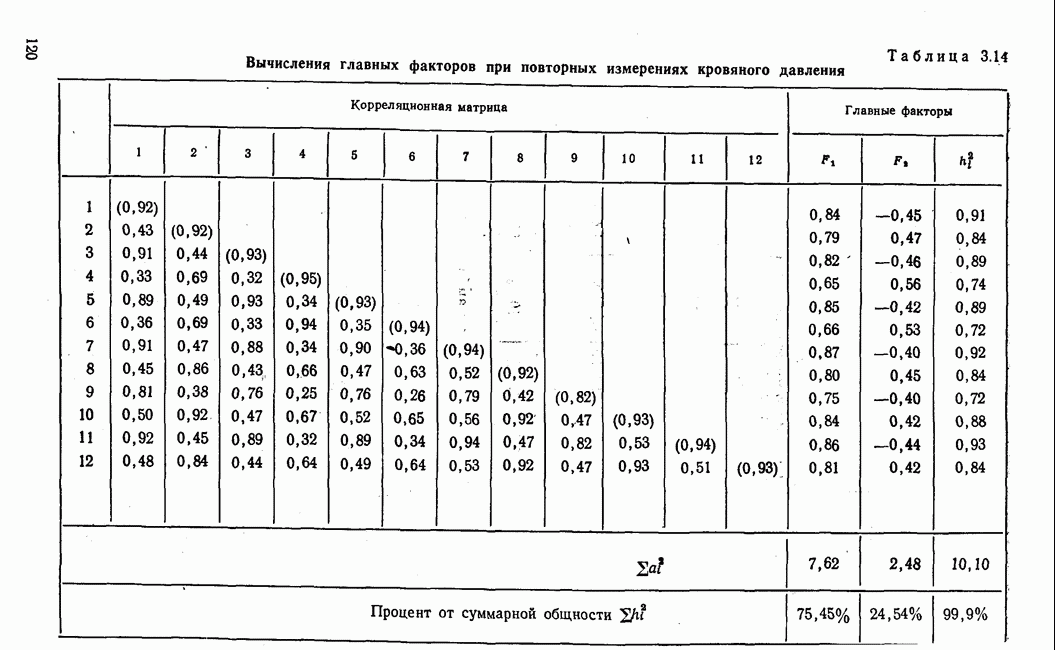
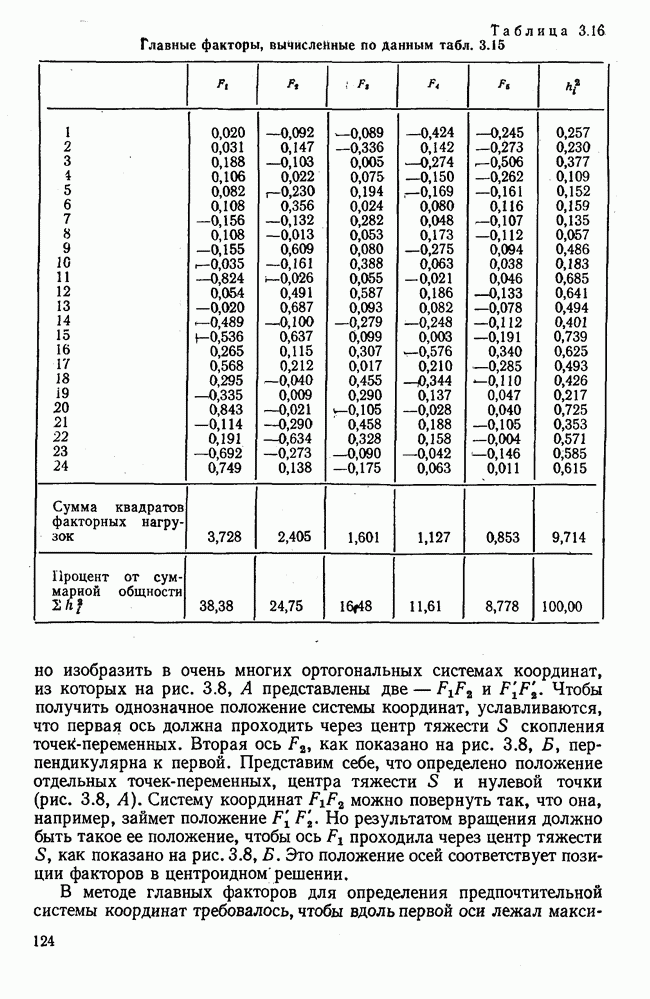
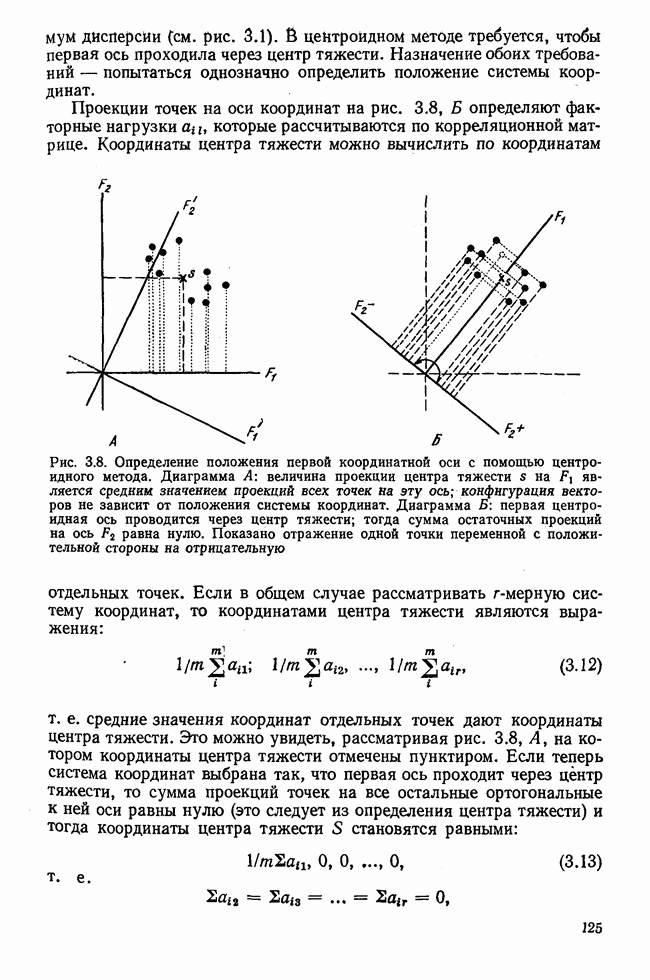
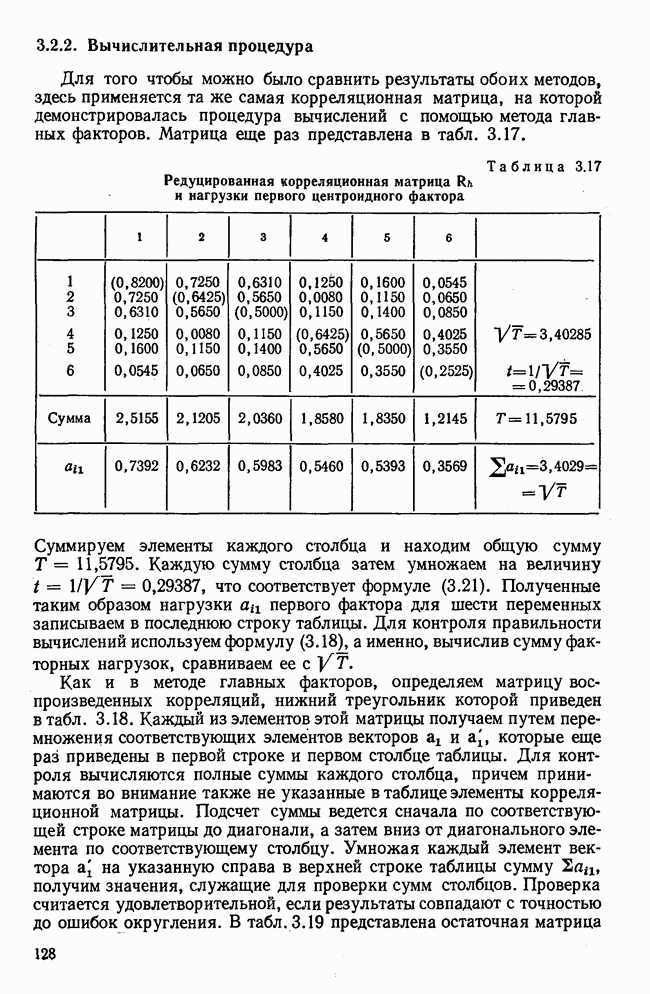
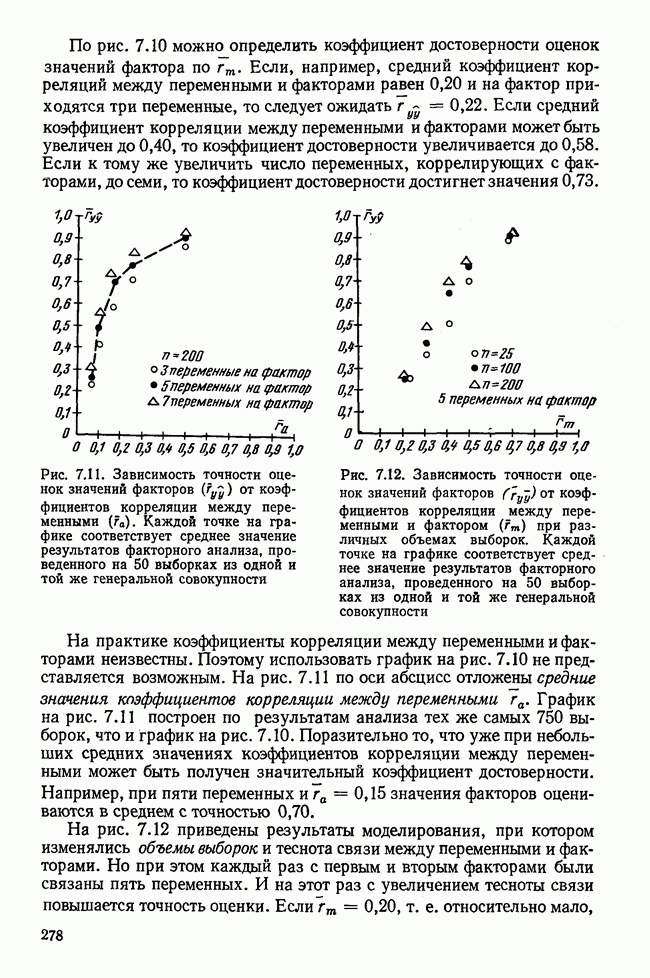
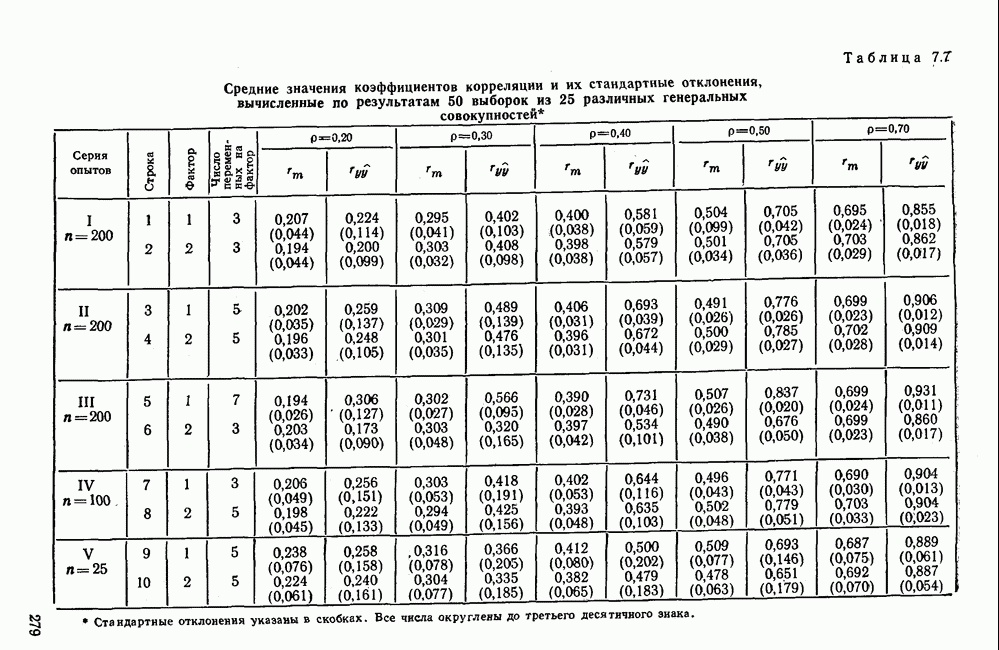
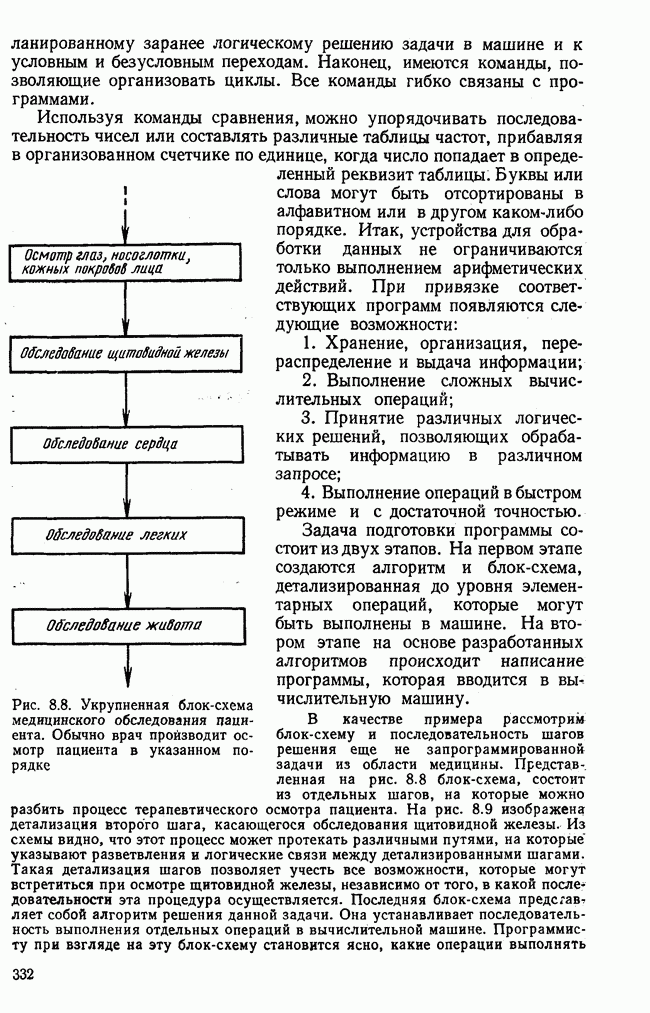
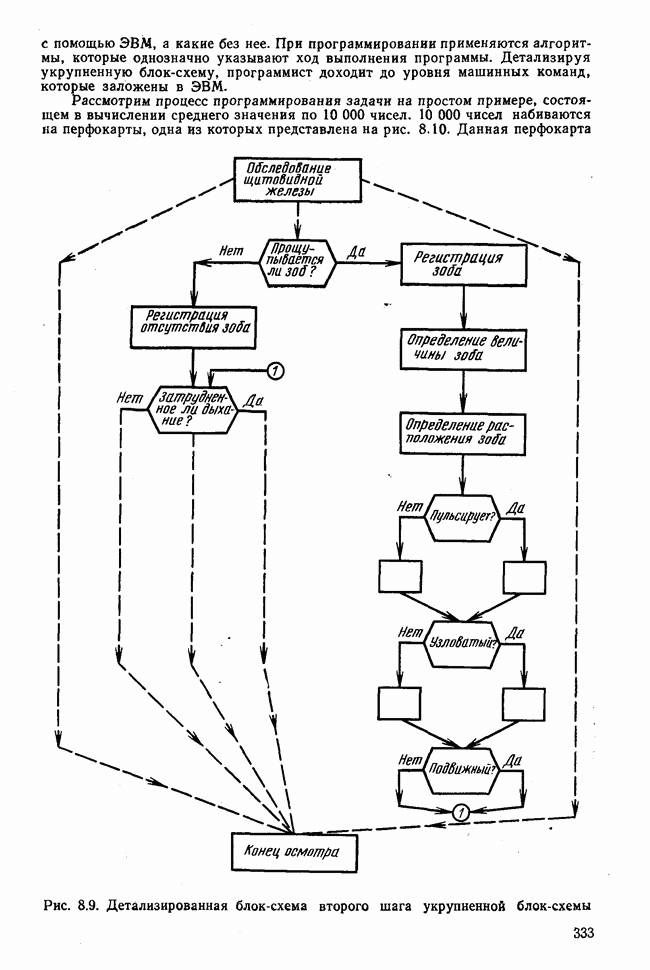
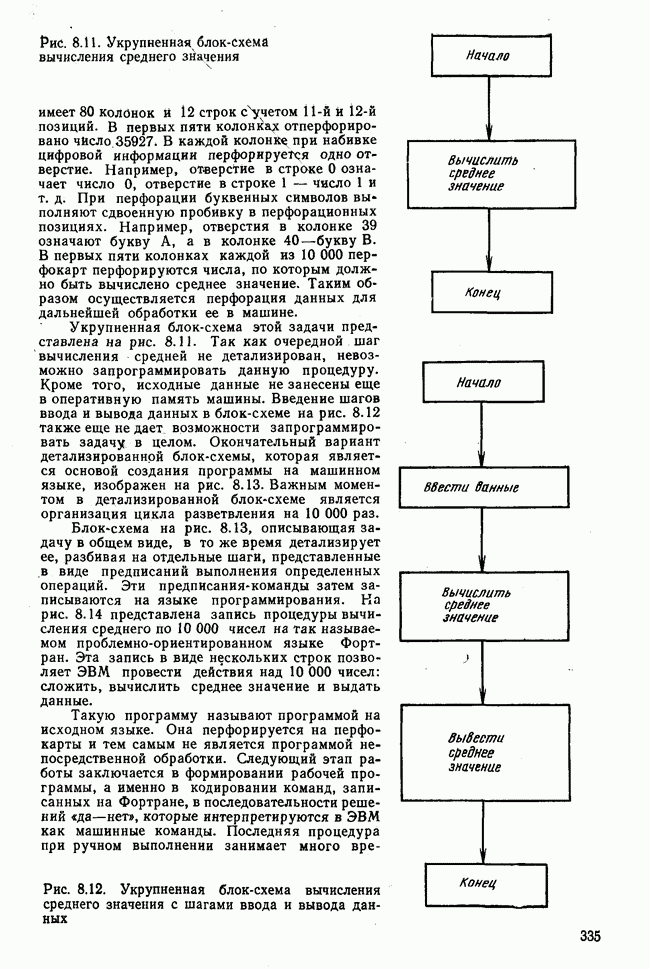
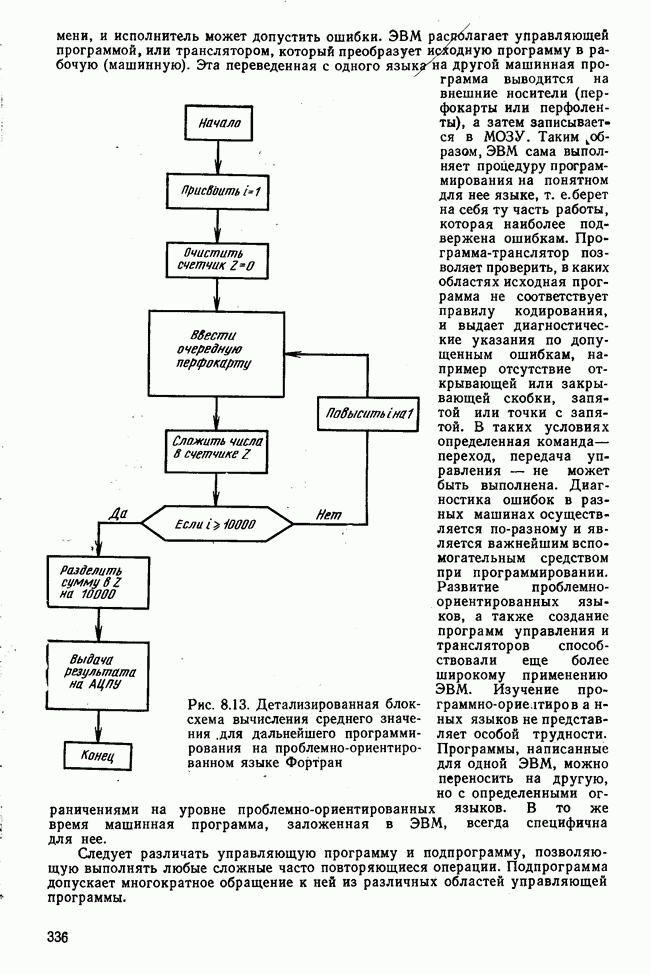
Пред.
След.
Макеты страниц
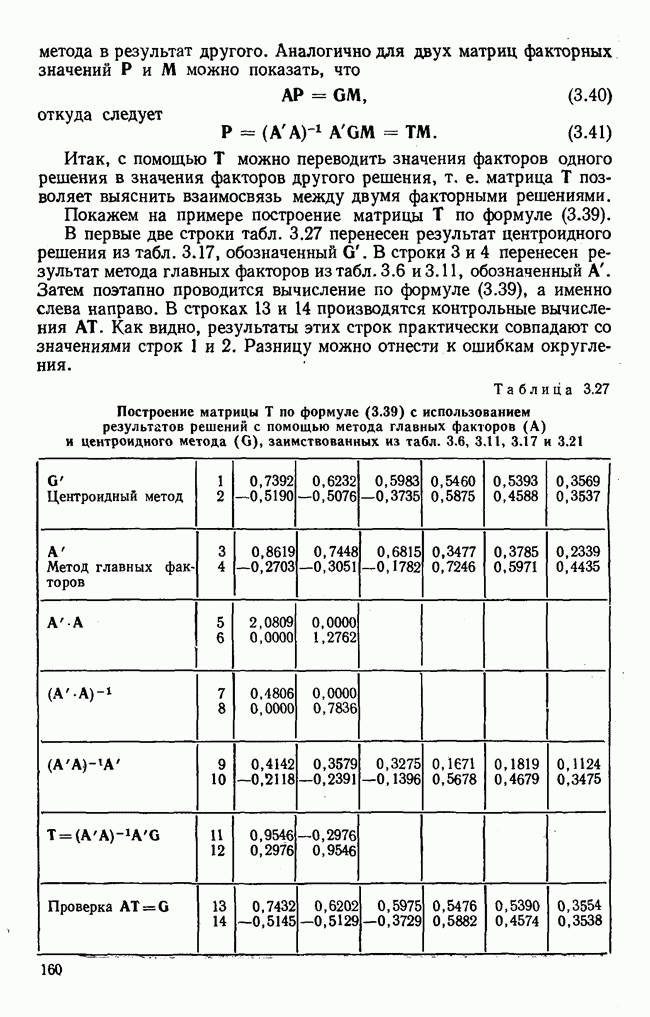
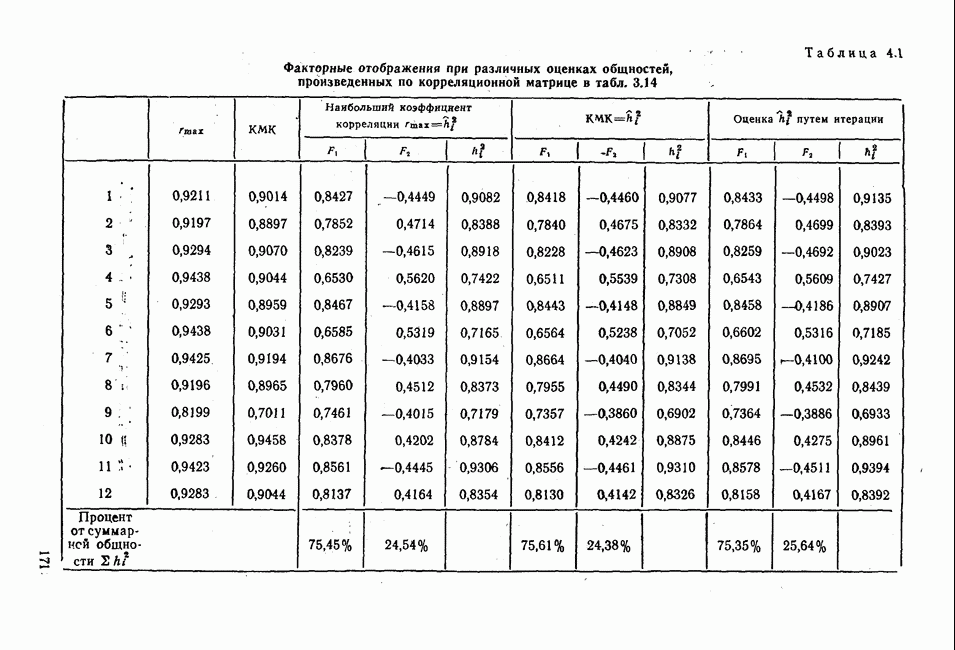
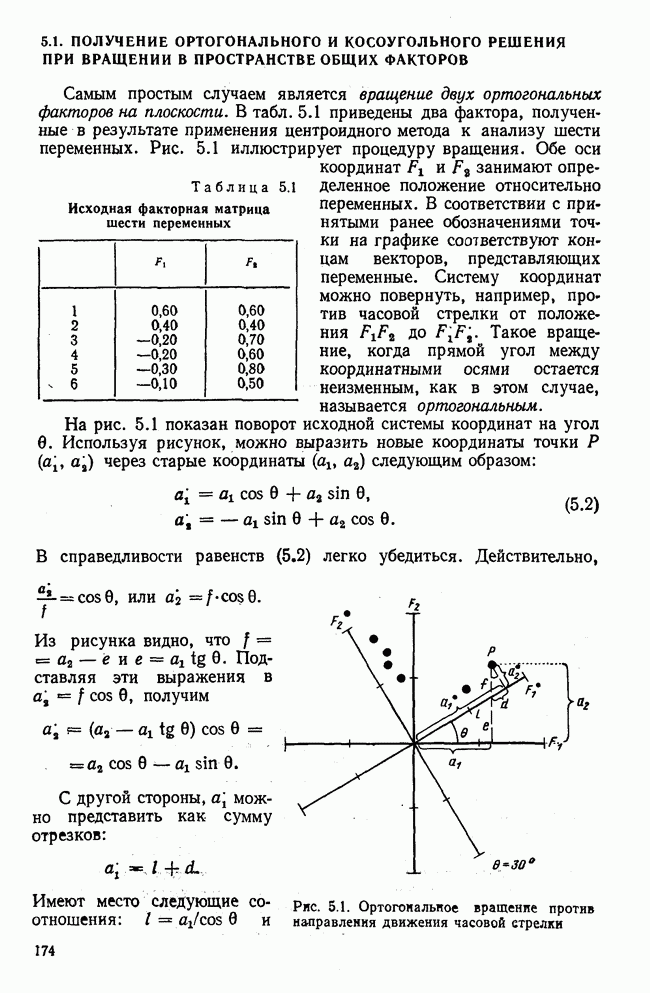
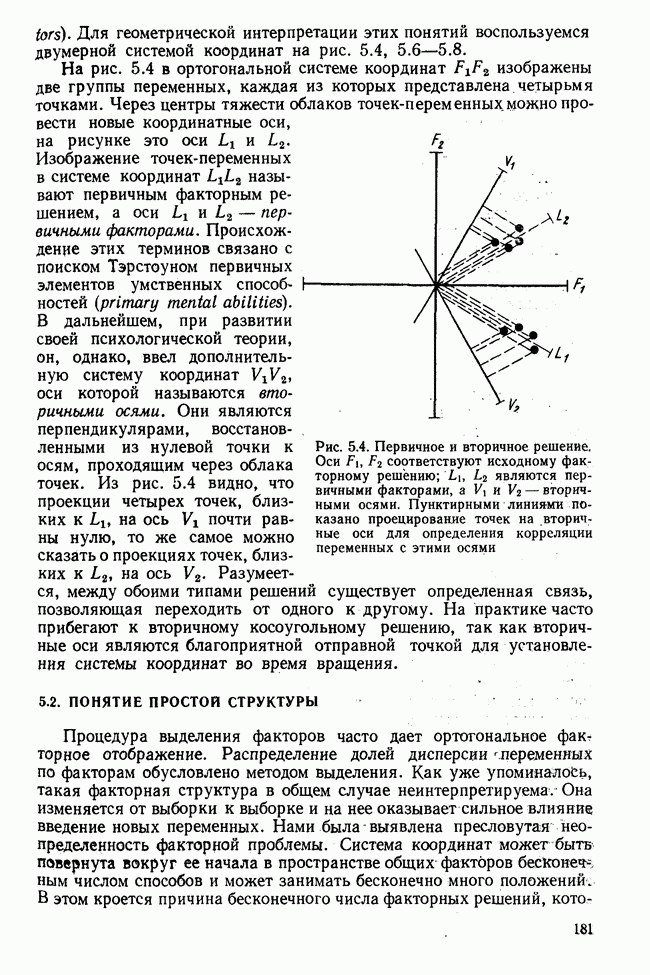
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
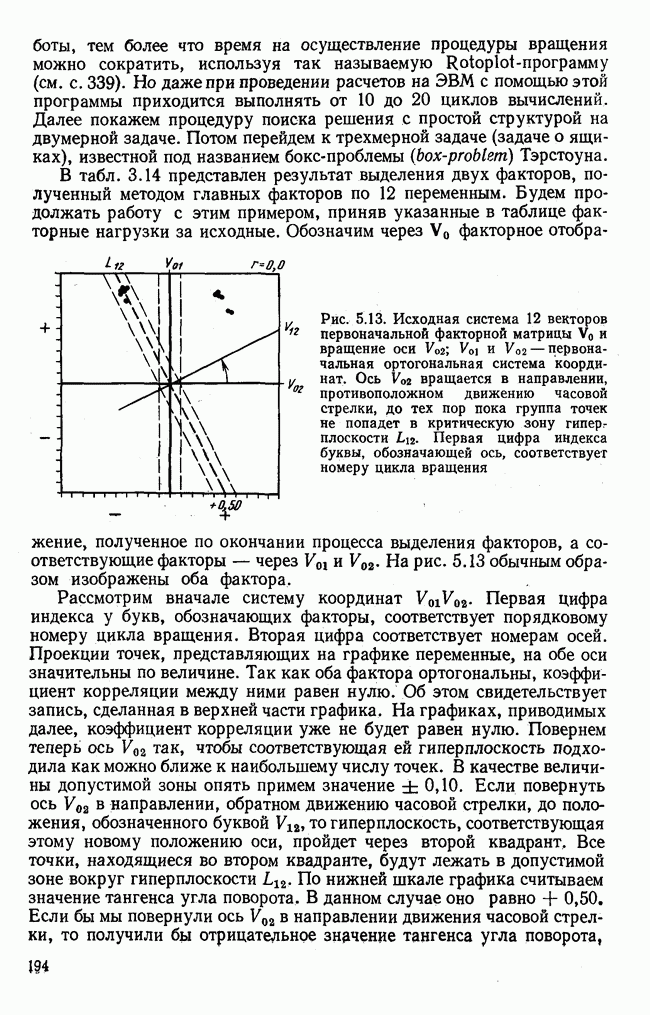
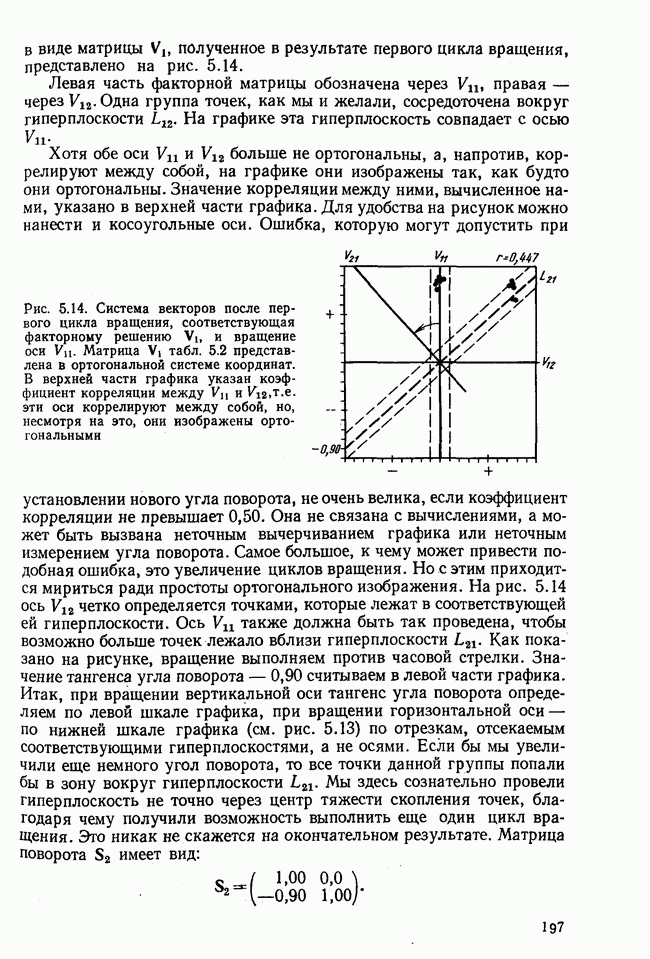
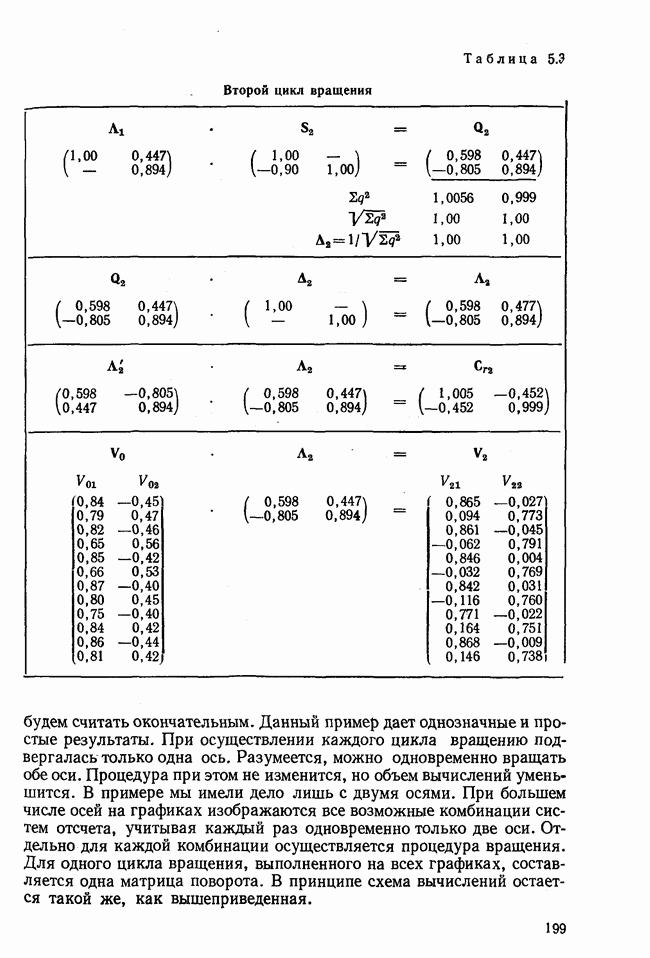
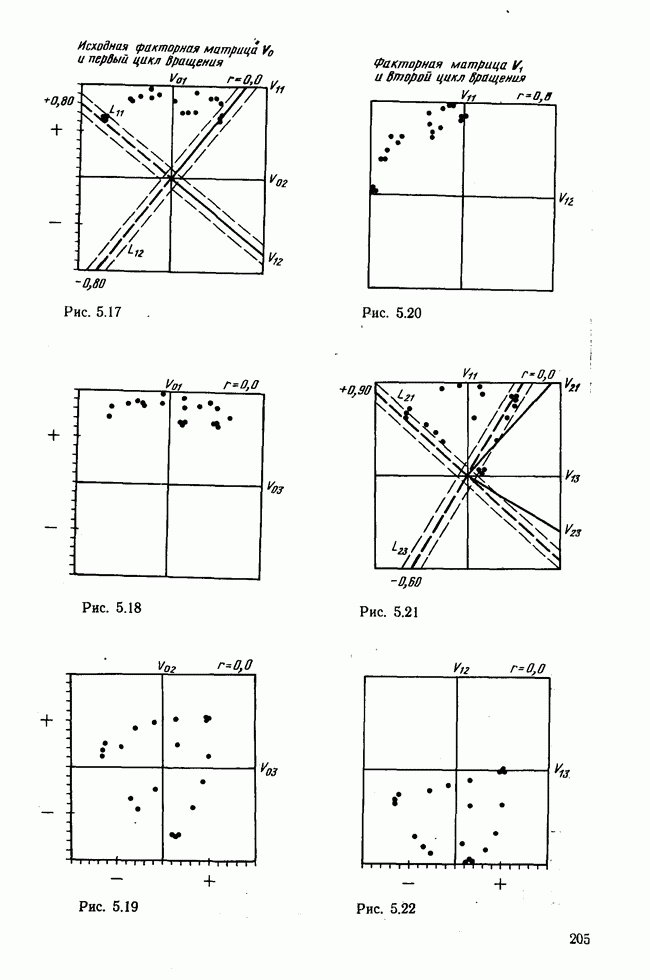
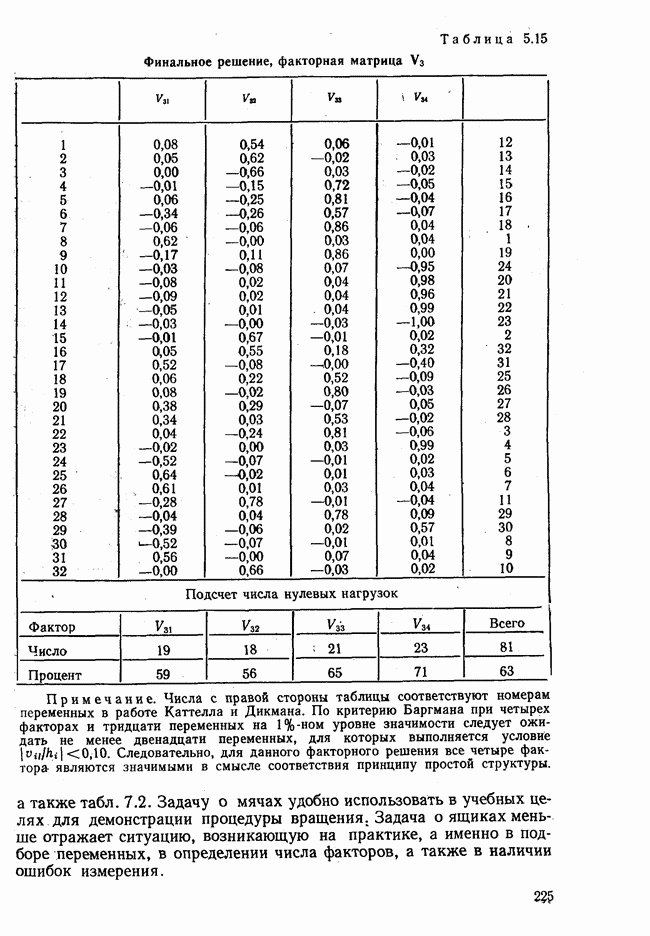
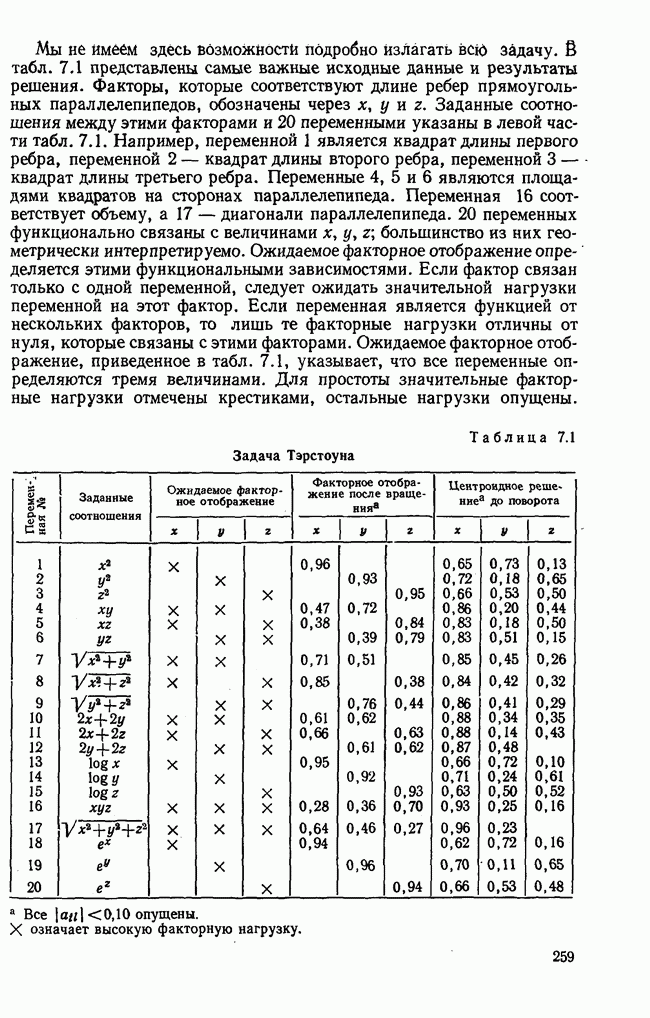
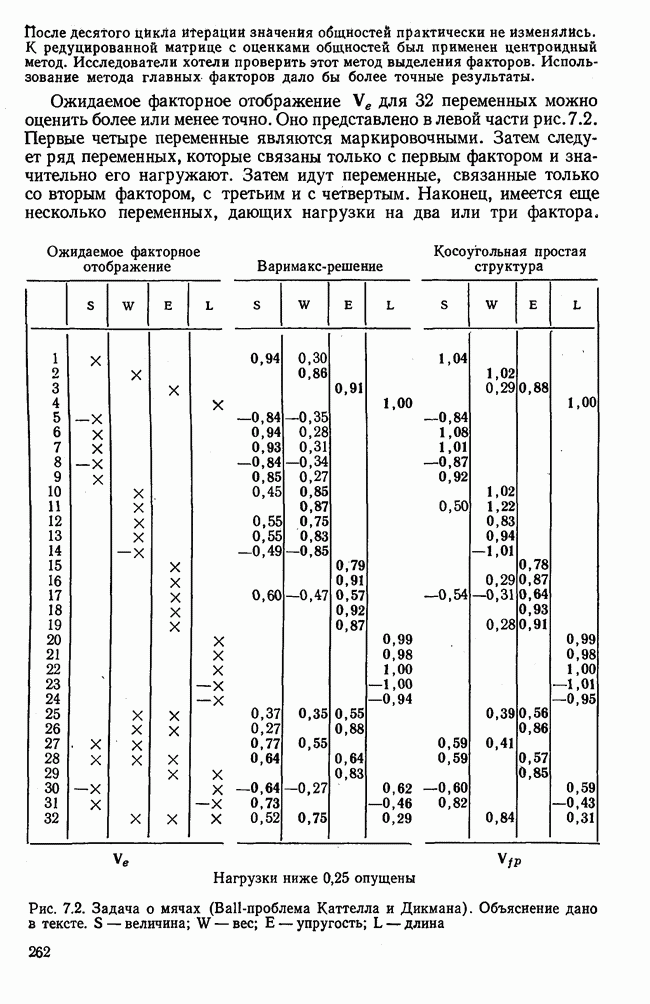
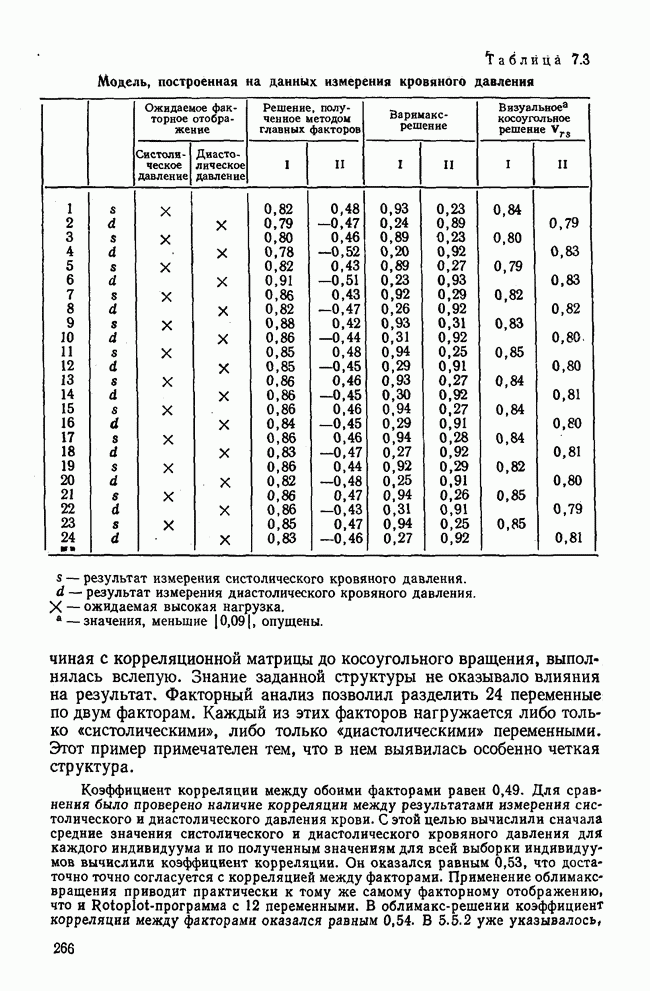
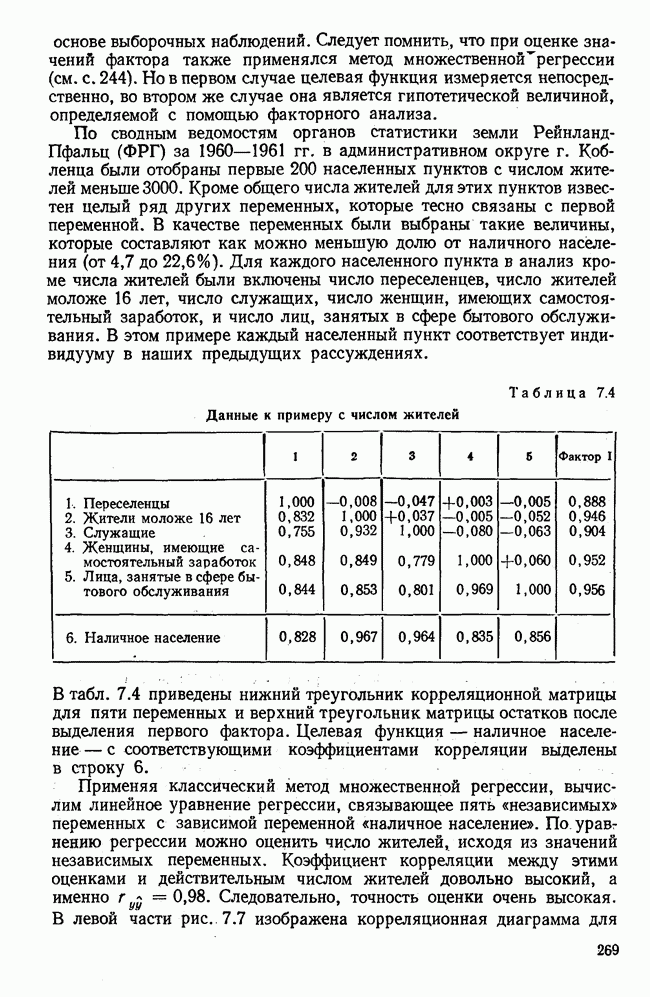
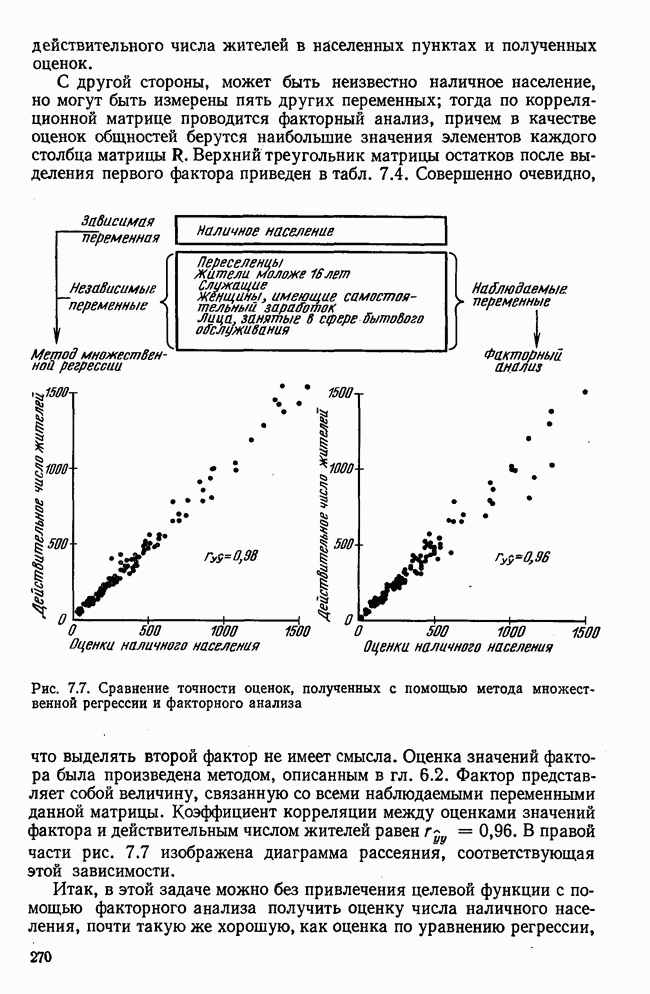
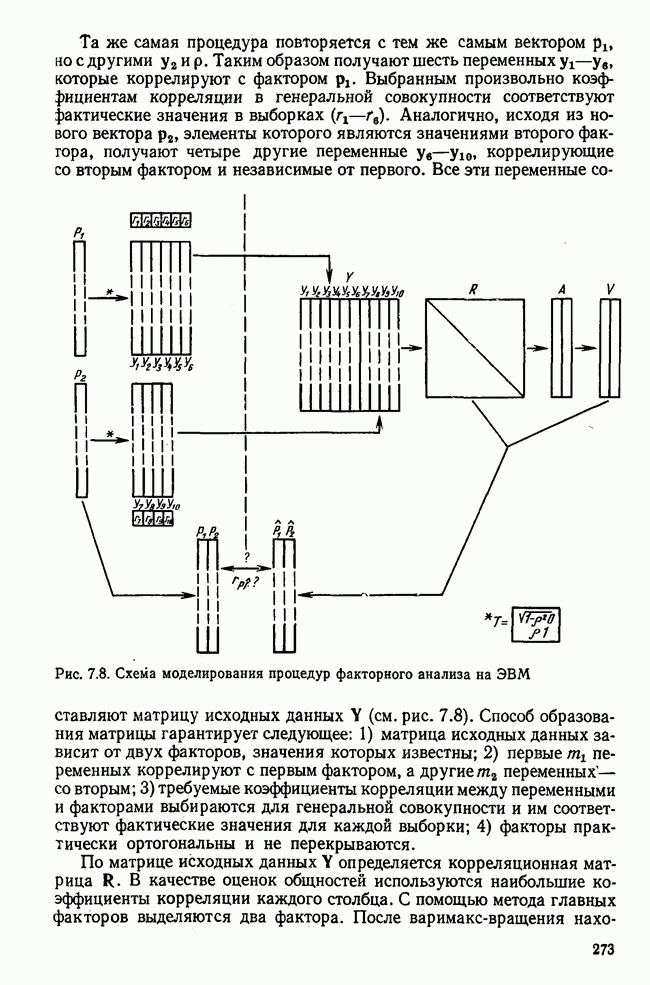
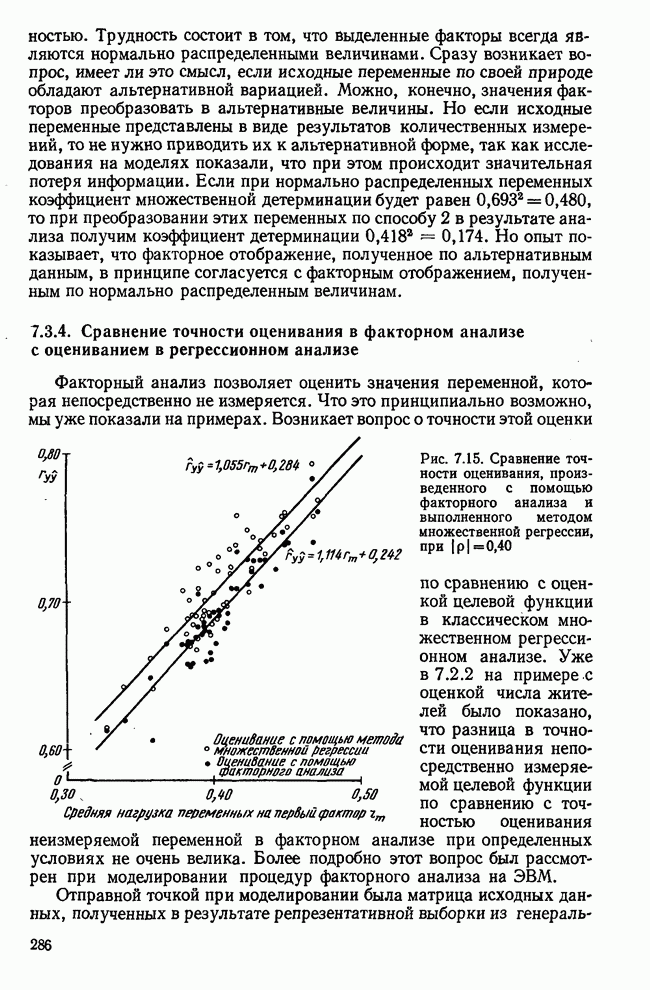
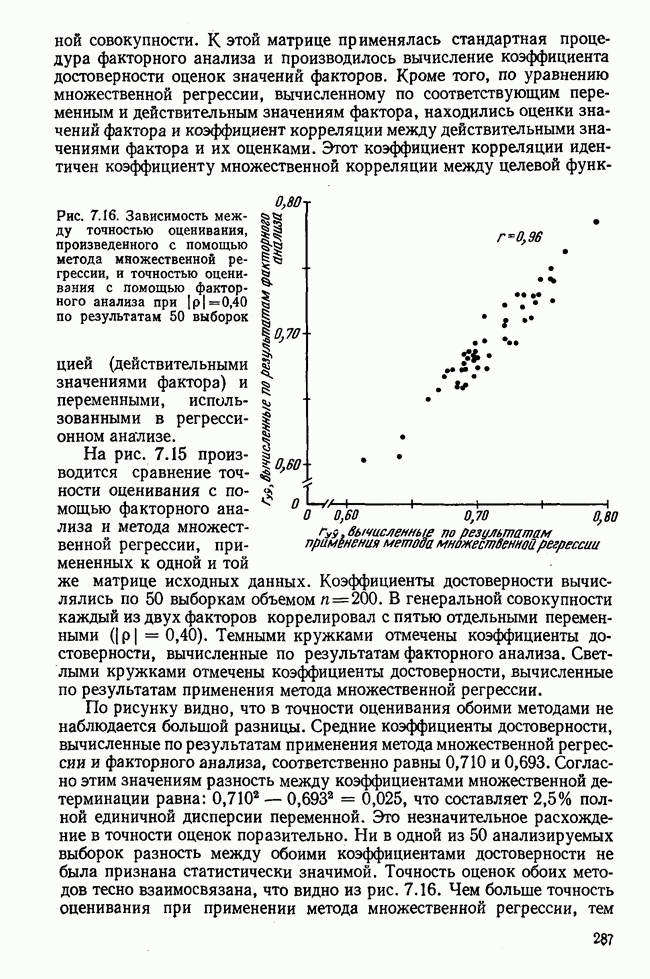
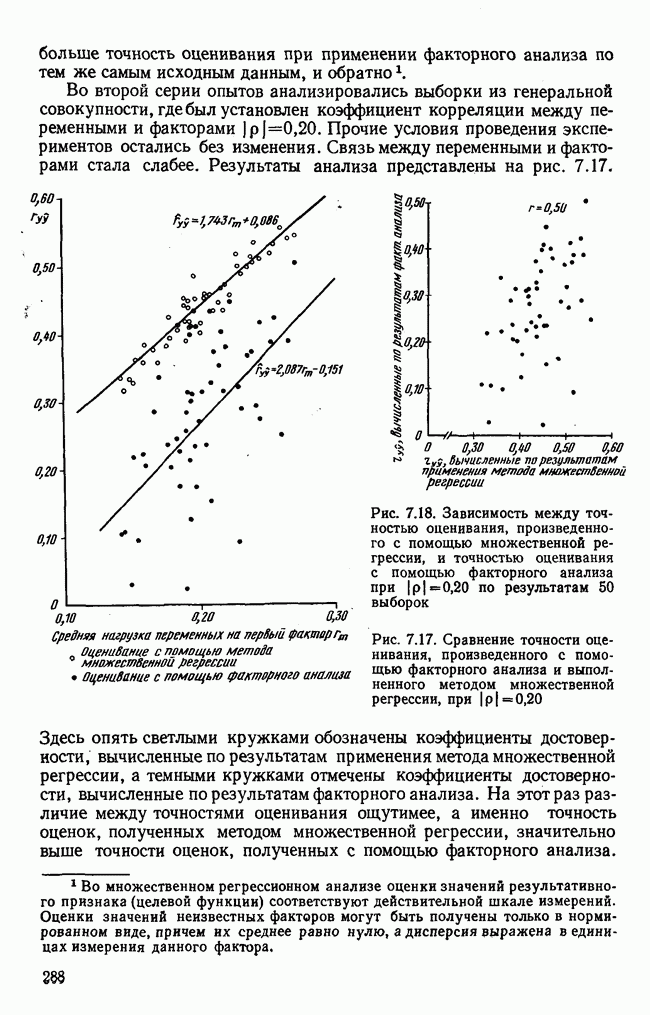
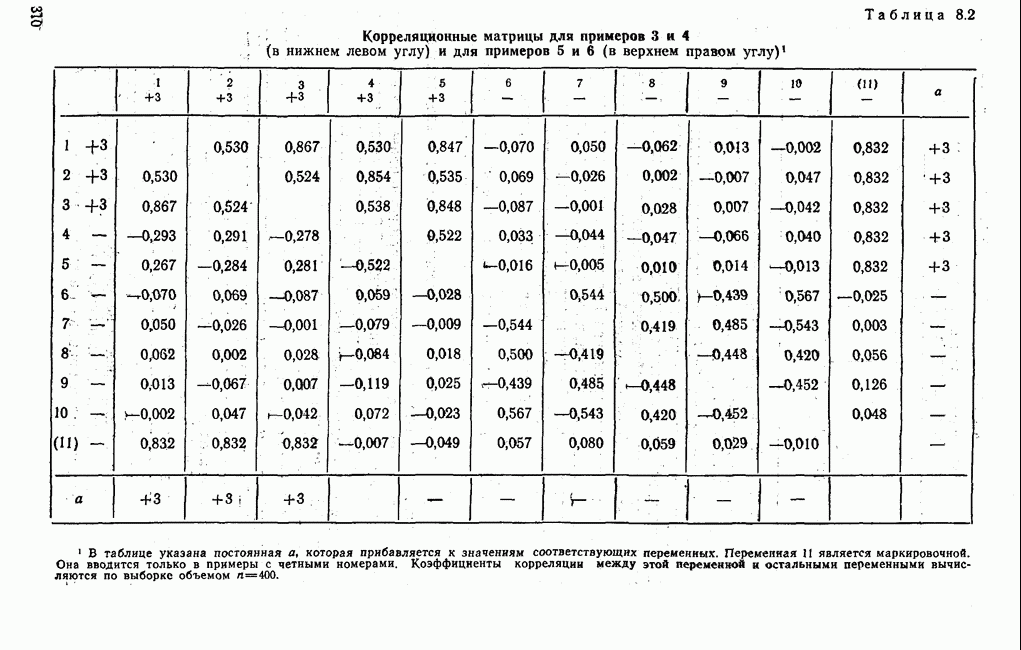
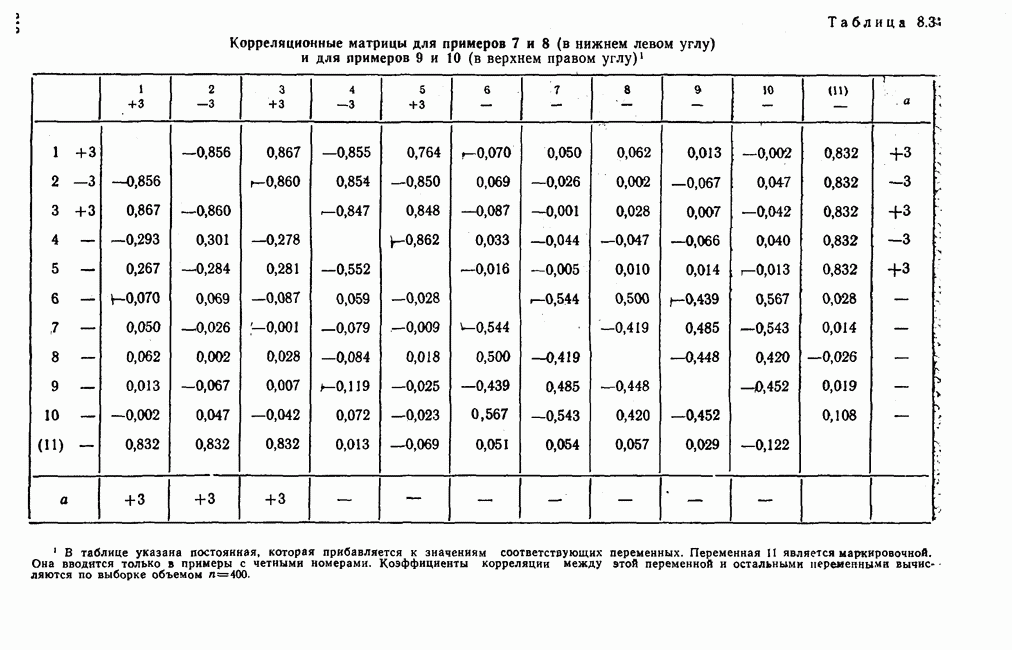
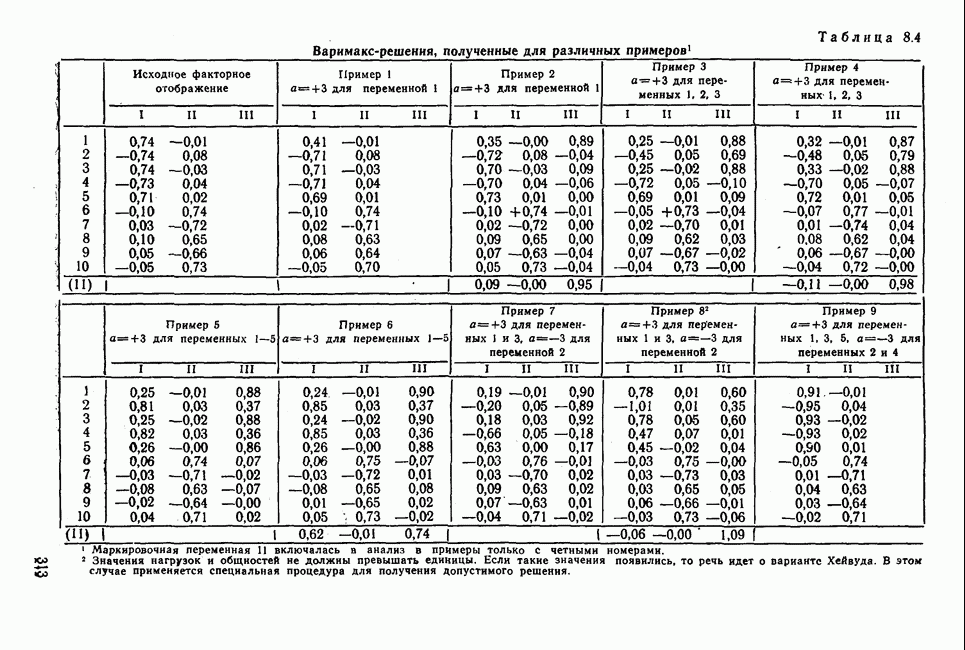
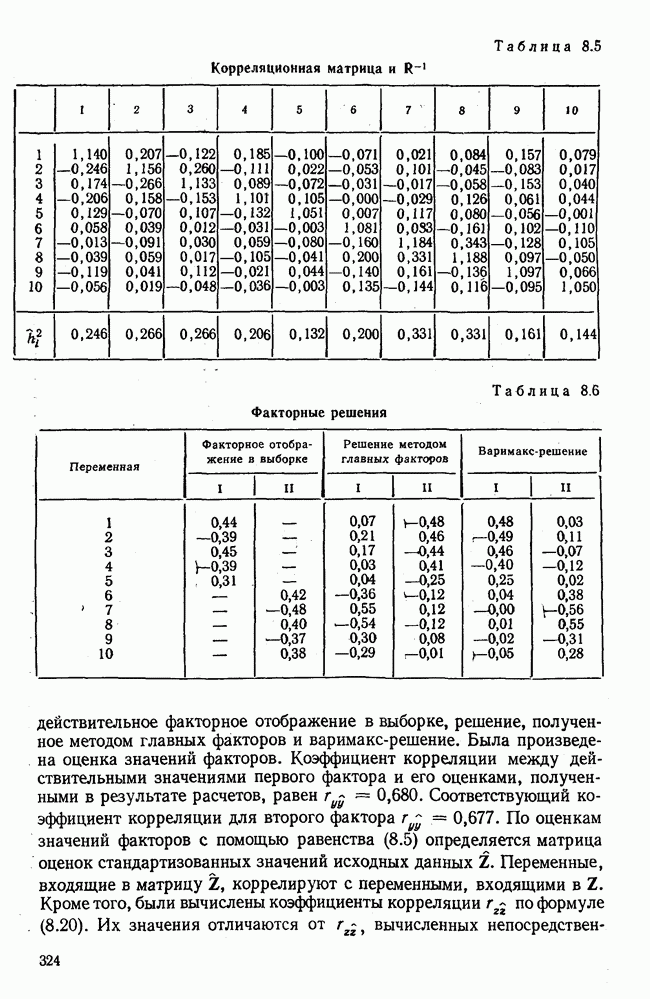
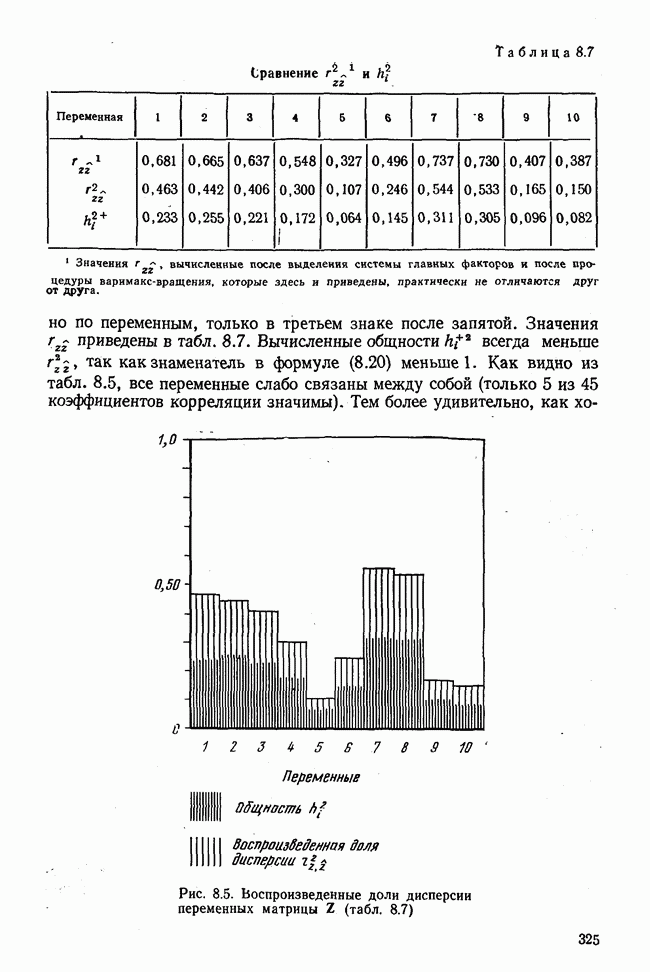
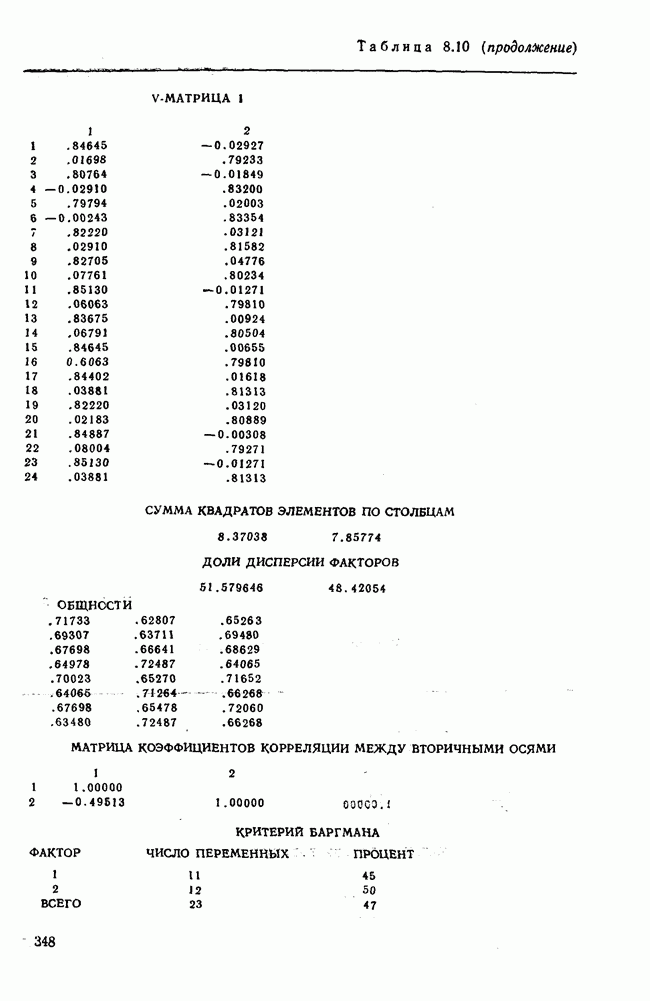
7.3.3. Точность результатов факторного анализа при альтернативных данныхНе всегда переменные, по которым проводится факторный анализ, могут быть измерены количественно. Имеется целый ряд переменных, например пол, которые обладают только альтернативной вариацией. Некоторые общие положения при работе с качественными признаками приведены в гл. 8.2. Используемые нами формула коэффициента корреляции или формула коэффициента ковариации пригодны только для количественных величин. Так как факторный анализ исходит из корреляционной матрицы, то возникает вопрос: каким образом преобразовать альтернативные значения переменных, чтобы по ним можно было выполнить процедуру факторного анализа? Это вызывает большие затруднения. Обычно альтернативным значениям переменной приписывают с помощью факторных нагрузок определенные веса. К каким ошибкам это приводит, неизвестно. Так как альтернативные данные на практике встречаются довольно часто, было проведено исследование результатов факторного анализа с такими данными при моделировании необходимых для этого процедур на ЭВМ. С помощью моделирования было проверено, где происходит потеря информации при переходе к альтернативным данным. При данном исследовании использовали ту же самую матрицу данных, по которой раньше проводился факторный анализ, т. е. исходили из нормально распределенных случайных величин. Процедура факторного анализа, выполняемая по нормально распределенным случайным величинам, далее будет называться стандартной процедурой. После преобразования этой матрицы в матрицу альтернативных данных по ней строилась корреляционная матрица и проводился факторный анализ. Преобразование матрицы было выполнено двумя способами. При первом способе разделения значений переменных на две альтернативные группы использовалась медиана, т. е. все значения меньше нуля обозначались через 1, все значения больше нуля — через 2. Этот способ классификации данных в дальнейшем будет фигурировать как способ 1. При этом в среднем 50% значений переменных приходится на каждую из альтернативных групп. При втором способе классификации в качестве разделяющего элемента использовали значение переменной, равное — 1, т. е. все значения меньше — 1 обозначались через 1, все значения больше — 1 — через 2. Тогда в среднем 84% значений переменных попадало в одну группу, а 16% значений — в другую, так как первоначальная матрица исходных данных содержит значения нормально распределенных стандартизованных переменных. Этот способ классификации в дальнейшем называется способом 2. К одним и тем же выборкам из одной и той же генеральной совокупности была три раза применена процедура факторного анализа, включая вычисление 1) стандартную процедуру факторного анализа, примененную к нормально распределенным случайным величинам; 2) процедуру факторного анализа, примененную к данным, полученным способом 1. При этом предполагается, что значения факторов нормально распределены, а переменные обладают альтернативной вариацией, причем при преобразовании переменной в качестве разделяющего элемента использовалась медиана; 3) процедуру факторного анализа, примененную к данным, полученным способом 2. При этом предполагается, что значения факторов нормально распределены, а переменные обладают альтернативной вариацией. В качестве разделяющего элемента при преобразовании переменных служила величина, значительно отличающаяся от медианы. Это было сделано для того, чтобы приблизиться к реальной ситуации, часто возникающей на практике, когда классификация выполняется произвольно. В качестве показателя связи между альтернативными данными прмменйётся
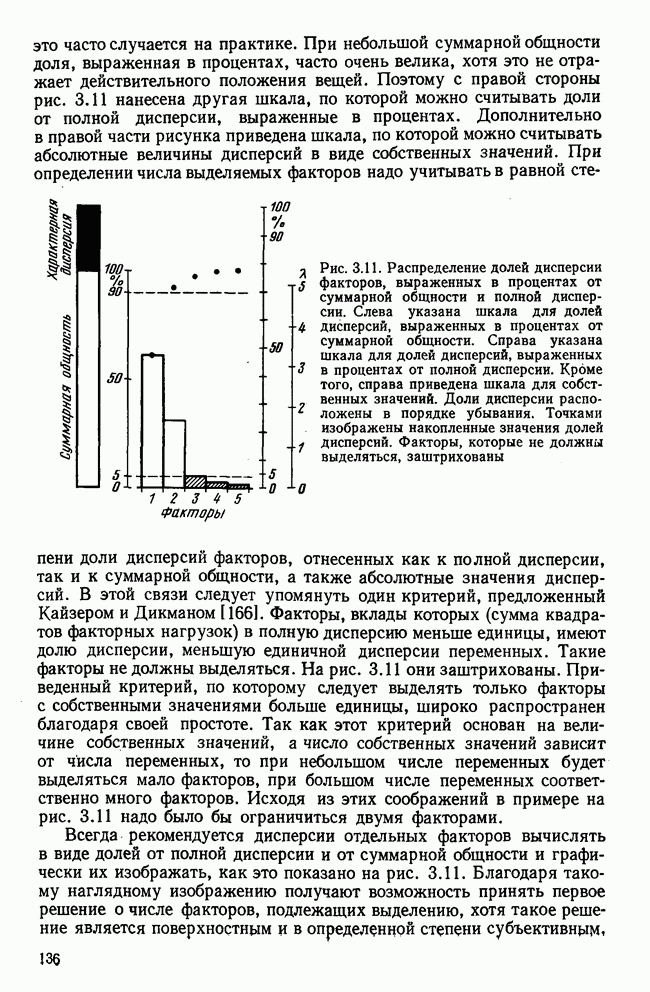
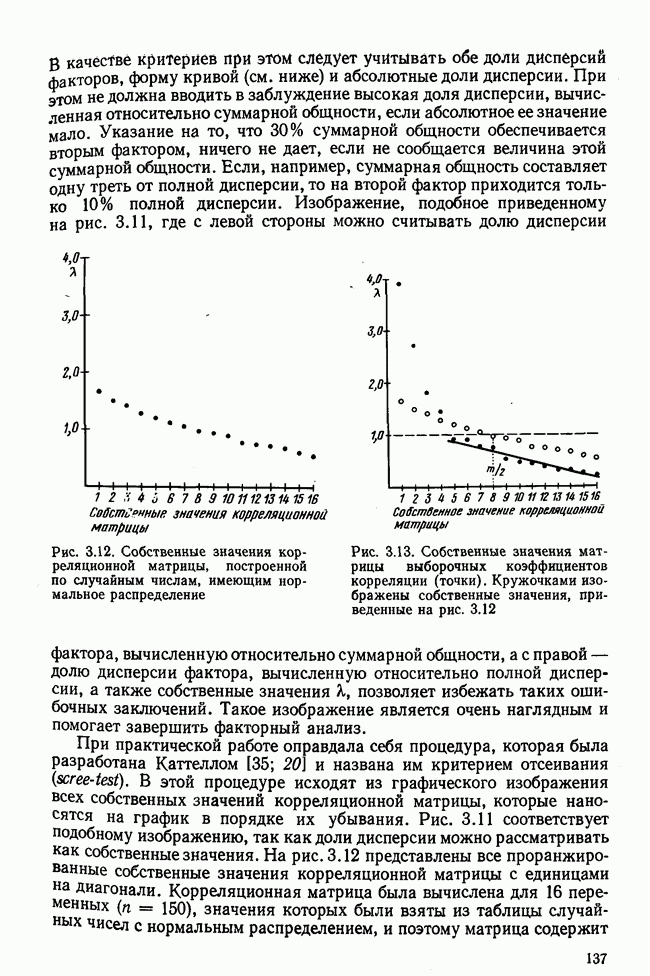
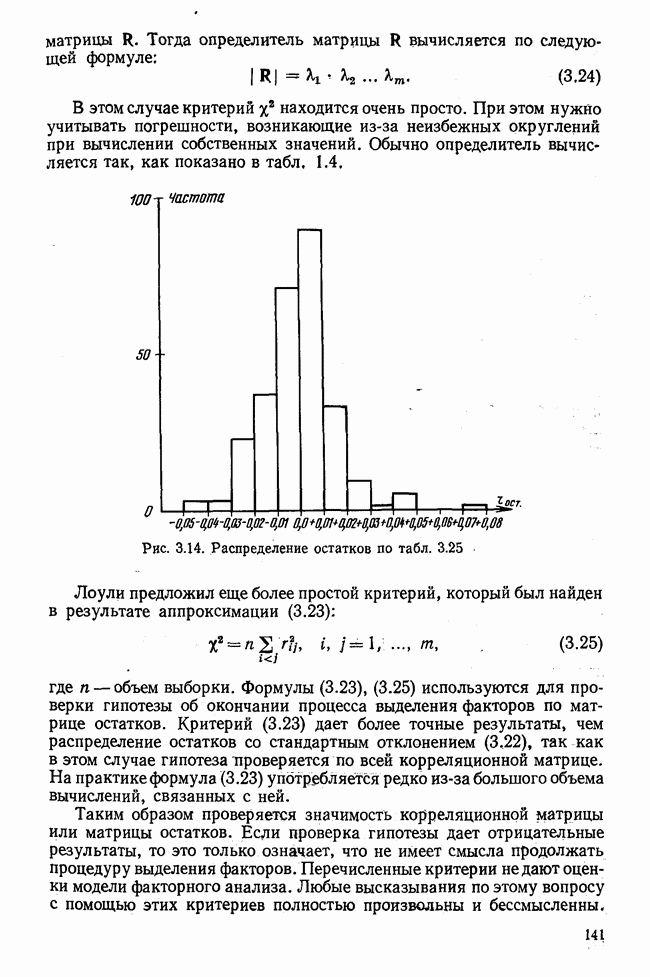
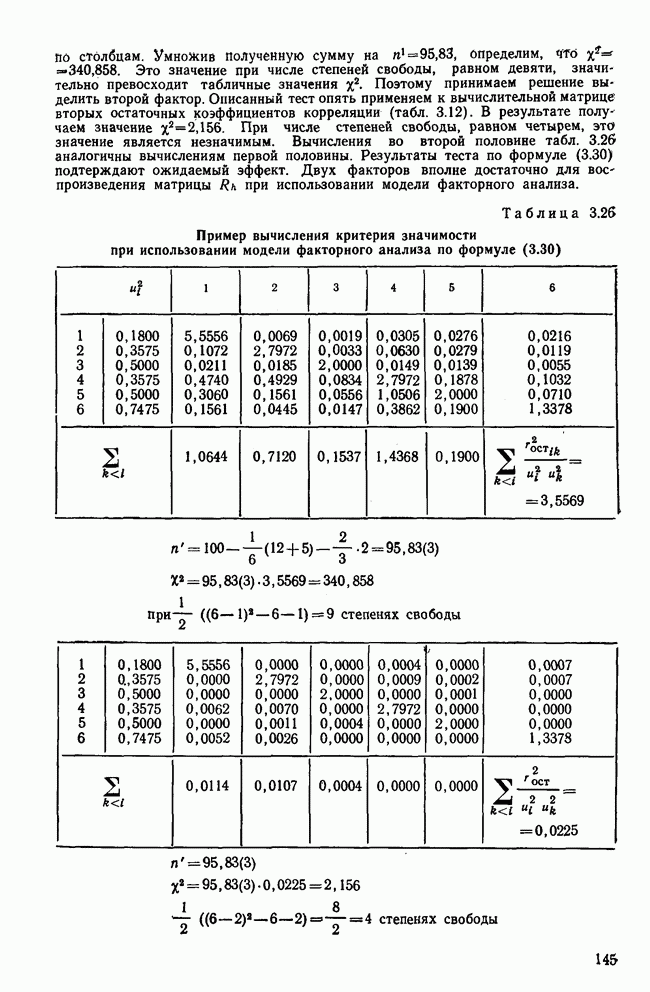
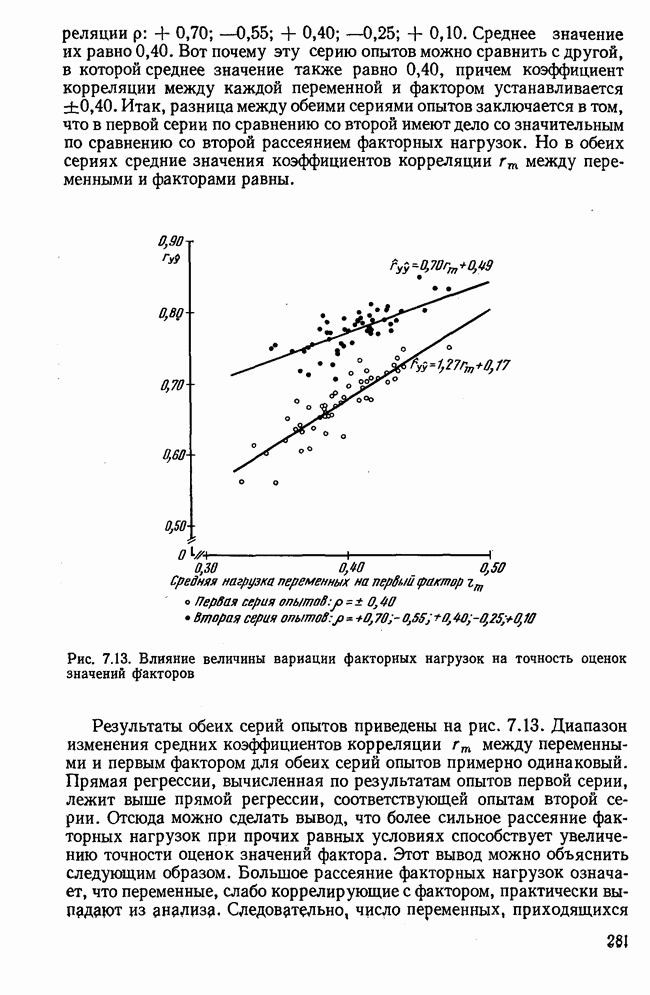
Кроме того,
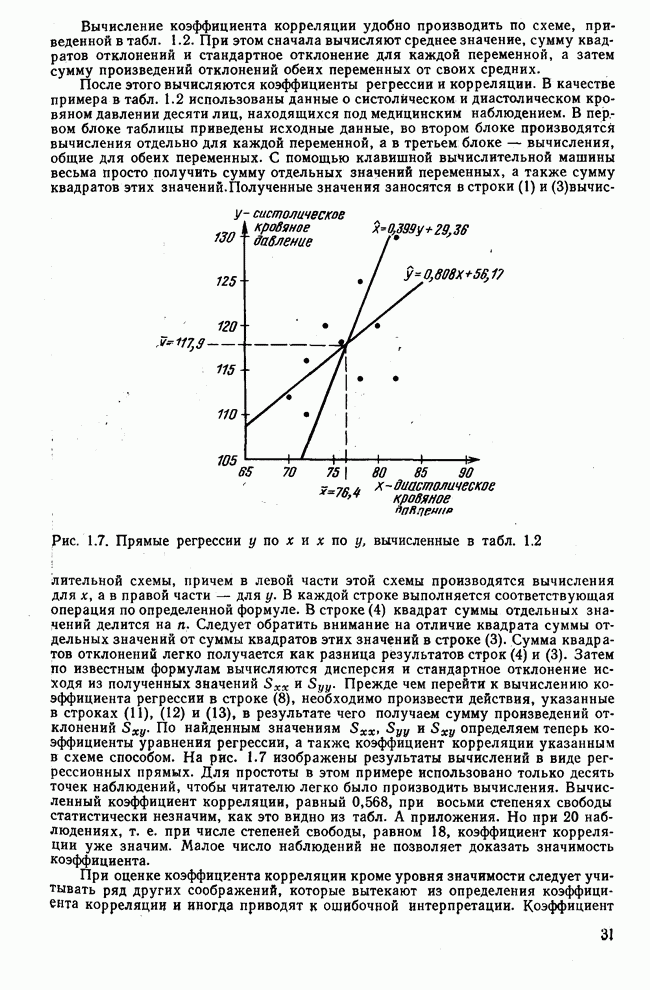
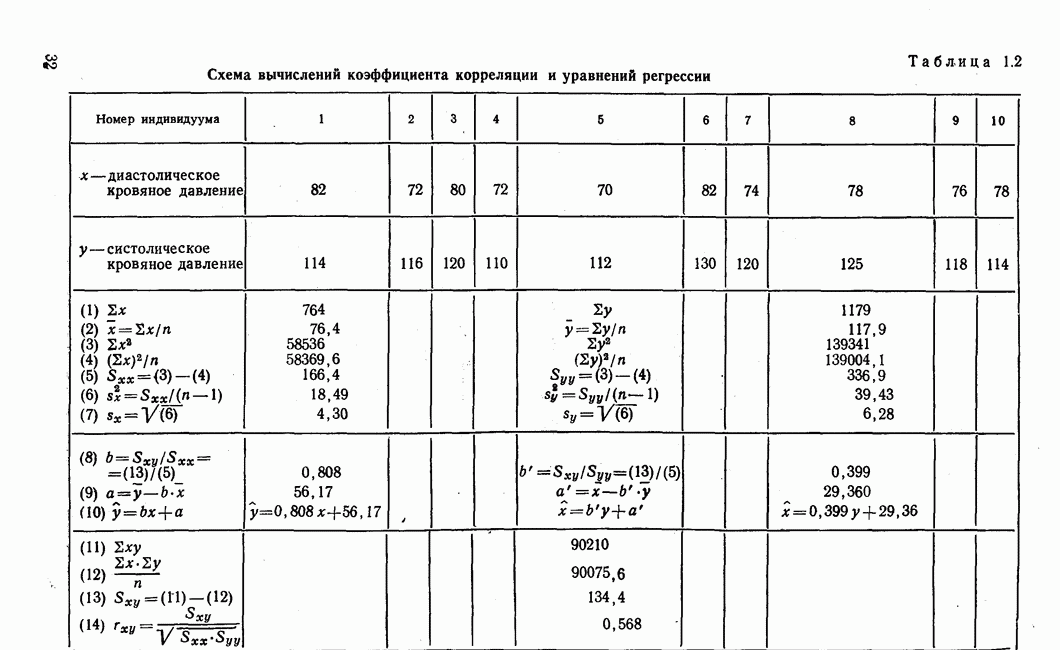
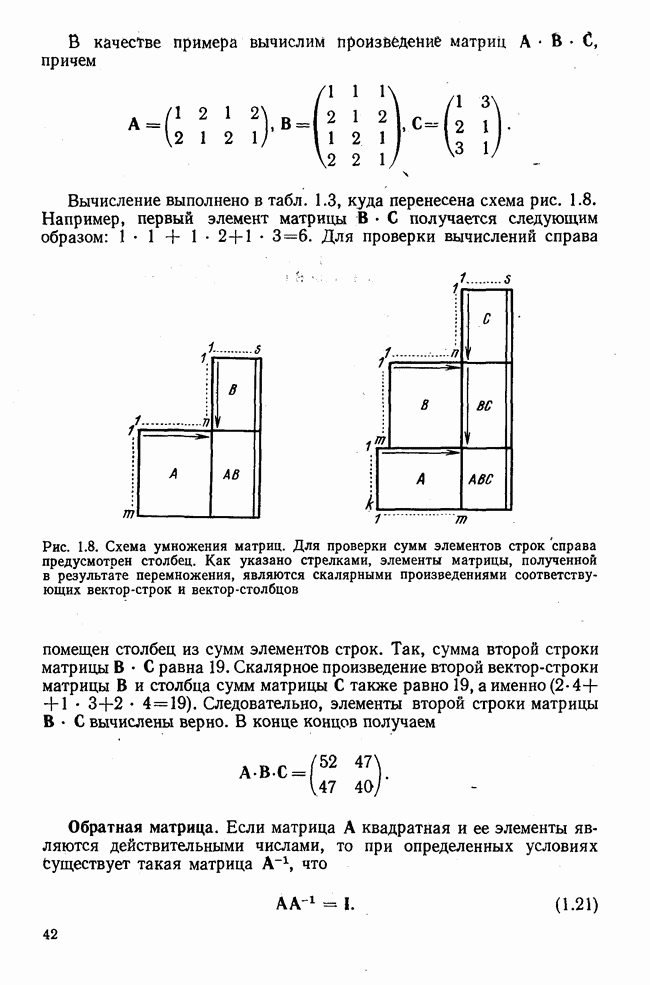
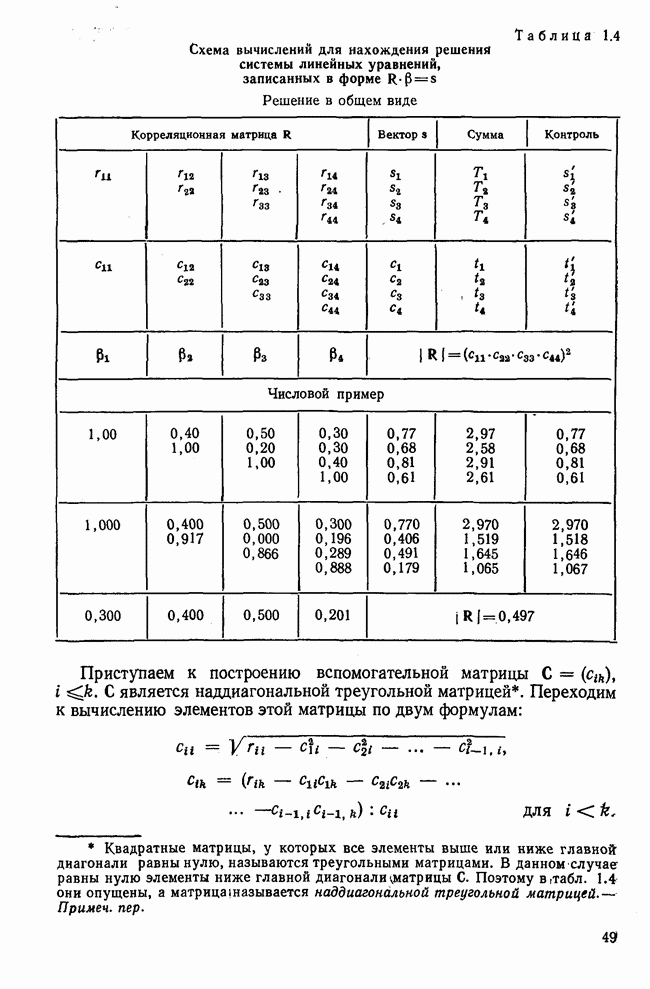
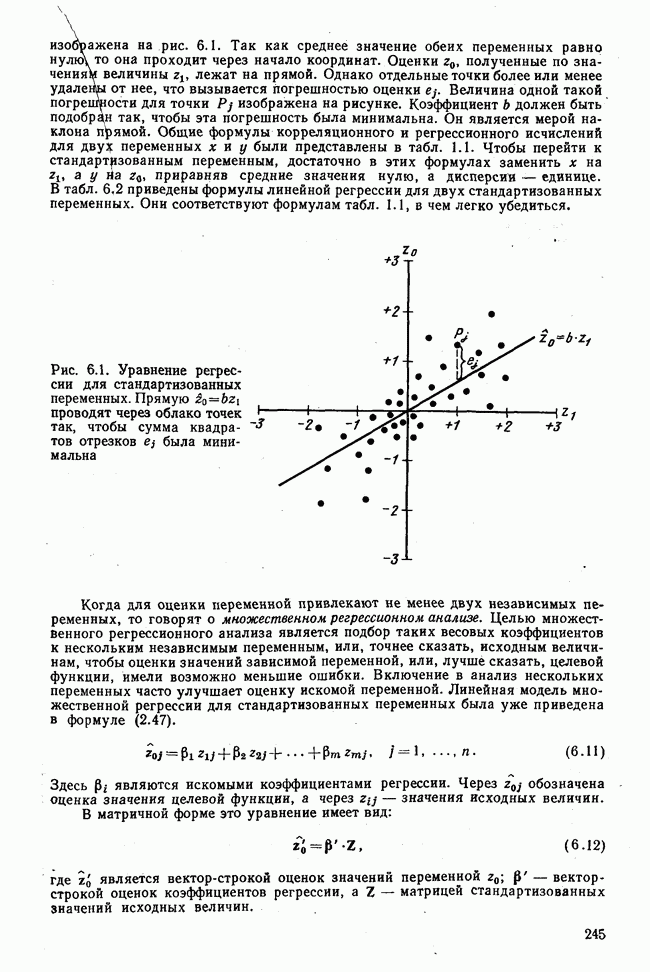
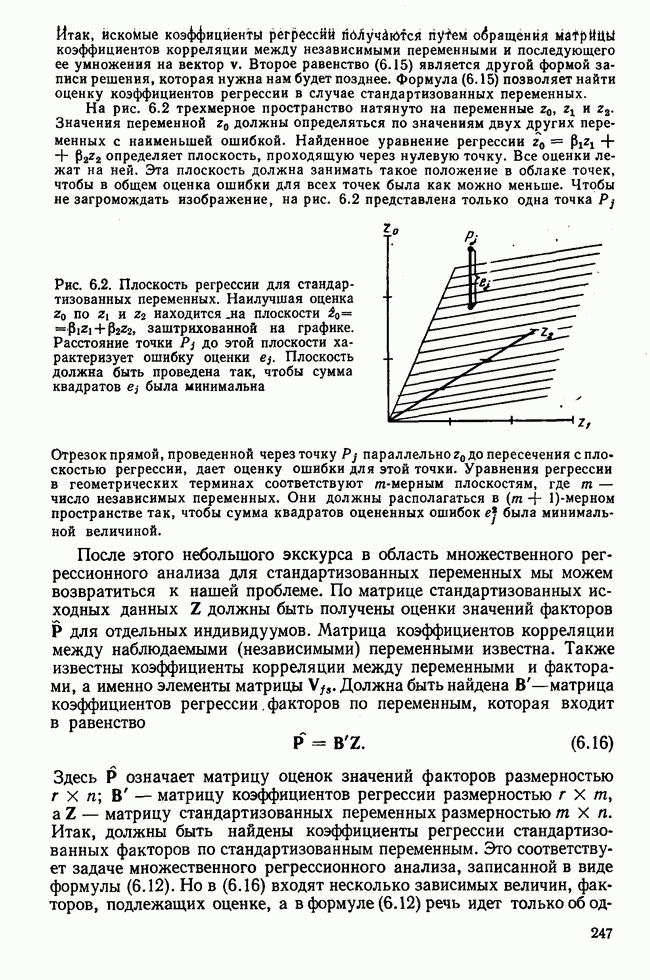
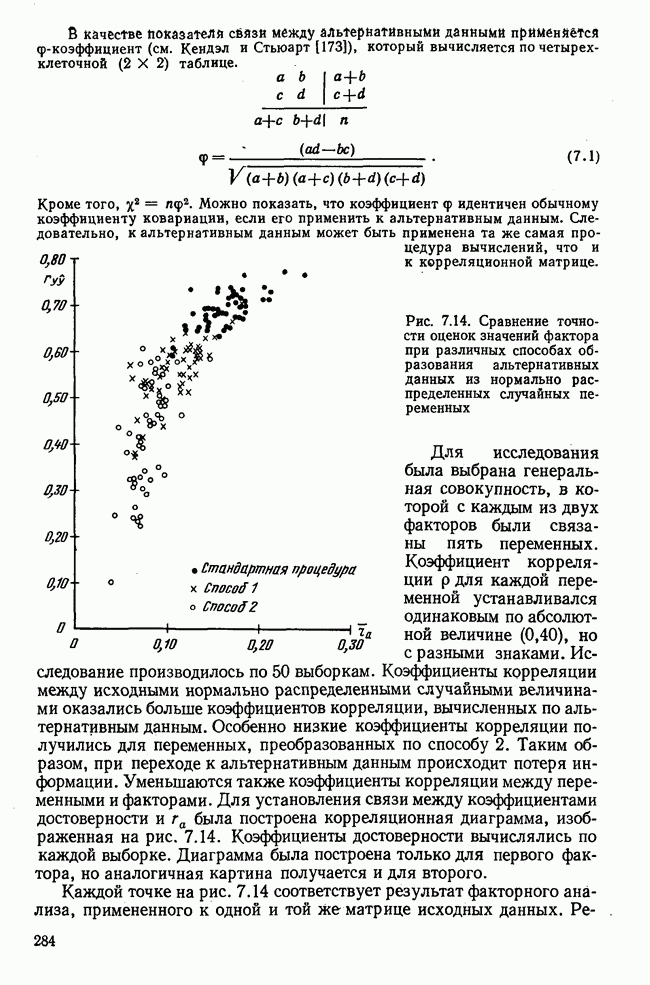
Рис. 7.14. Сравнение точности оценок значений фактора при различных способах образования альтернативных данных из нормально распределенных случайных переменных Для исследования была выбрана генеральная совокупность, в которой с каждым из двух факторов были связаны пять переменных. Коэффициент корреляции Каждой точке на рис. 7.14 соответствует результат факторного анализа, примененного к одной и той же матрице исходных данных. Результаты стандартной процедуры факторного анализа отмечены тем ными точками. Результаты факторного анализа по данным, преобразованным способом 1, отмечены крестиками. Результаты факторного анализа по данным, преобразованным способом 2, отмечены на диаграмме светлыми кружочками. По оси абсцисс отложены средние значения абсолютных величин коэффициентов корреляции между пятью переменными Вообще говоря, сравнивать между собой средние значения коэффициентов достоверности не совсем корректно, так как они вычислены по различным матрицам данных. Уже корреляционные матрицы значительно различаются между собой, что видно по значениям Итак, при альтернативных данных коэффициенты корреляции между переменными уменьшаются по сравнению с количественными данными, т. е. связь между переменными ослабевает. Если имеют дело с настоящими альтернативными данными, например, при исследовании такого признака, как пол, то приходится мириться с этим. Если переменные с альтернативной вариацией имеют такую же высокую корреляцию, как и нормально распределенные величины, то, как следует из рис. 7.14 и 7.11, значения факторов будут оценены с не меньшей точностью. Трудность состоит в том, что выделенные факторы всегда являются нормально распределенными величинами. Сразу возникает вопрос, имеет ли это смысл, если исходные переменные по своей природе обладают альтернативной вариацией. Можно, конечно, значения факторов преобразовать в альтернативные величины. Но если исходные переменные представлены в виде результатов количественных измерений, то не нужно приводить их к альтернативной форме, так как исследования на моделях показали, что при этом происходит значительная потеря информации. Если при нормально распределенных переменных коэффициент множественной детерминации будет равен
|
 |
Оглавление
|



















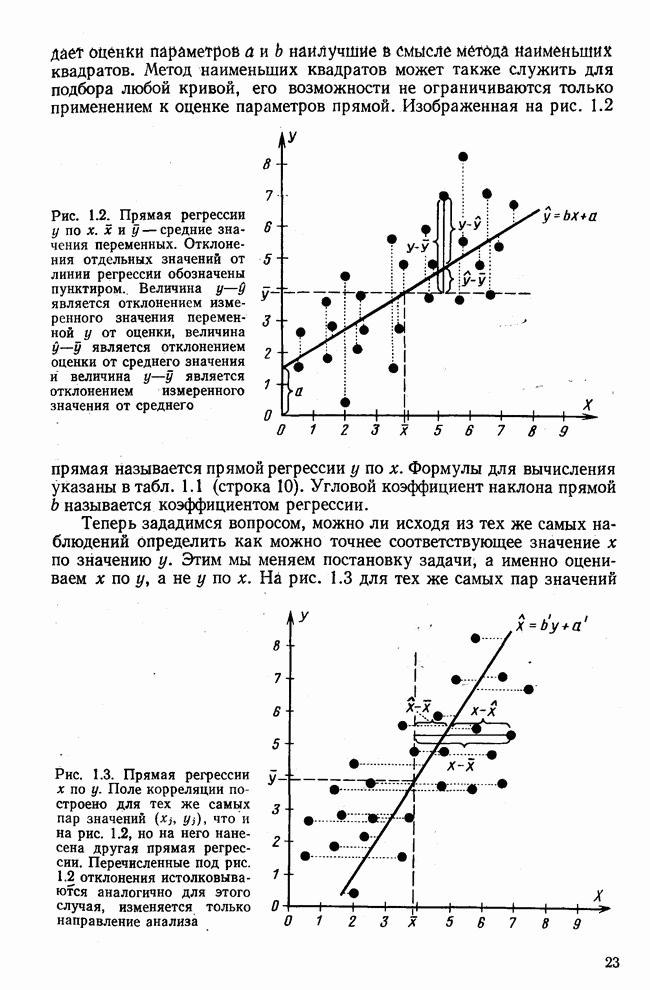

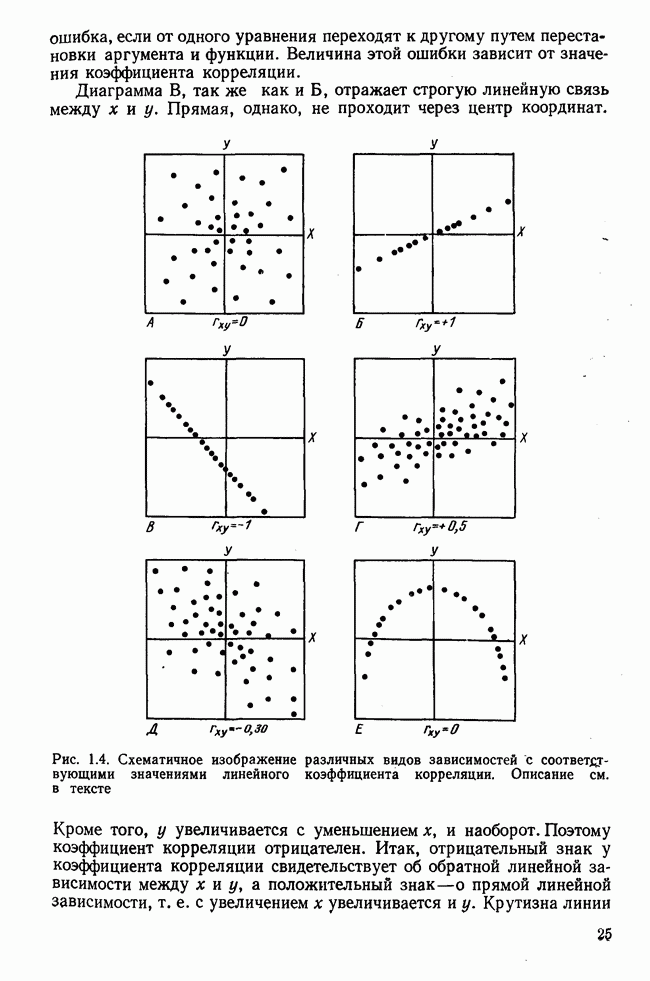


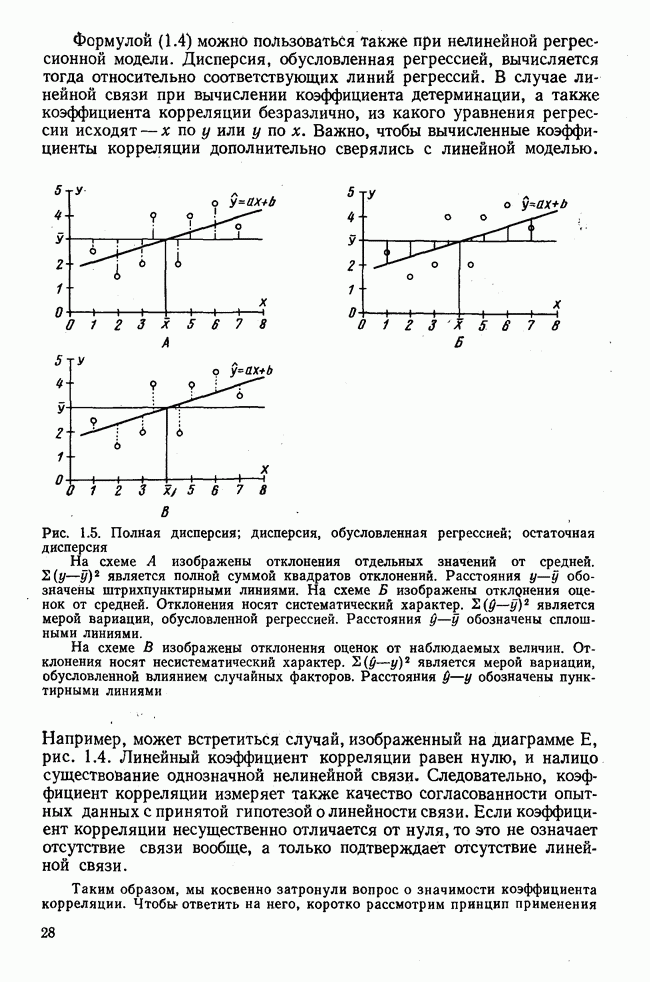

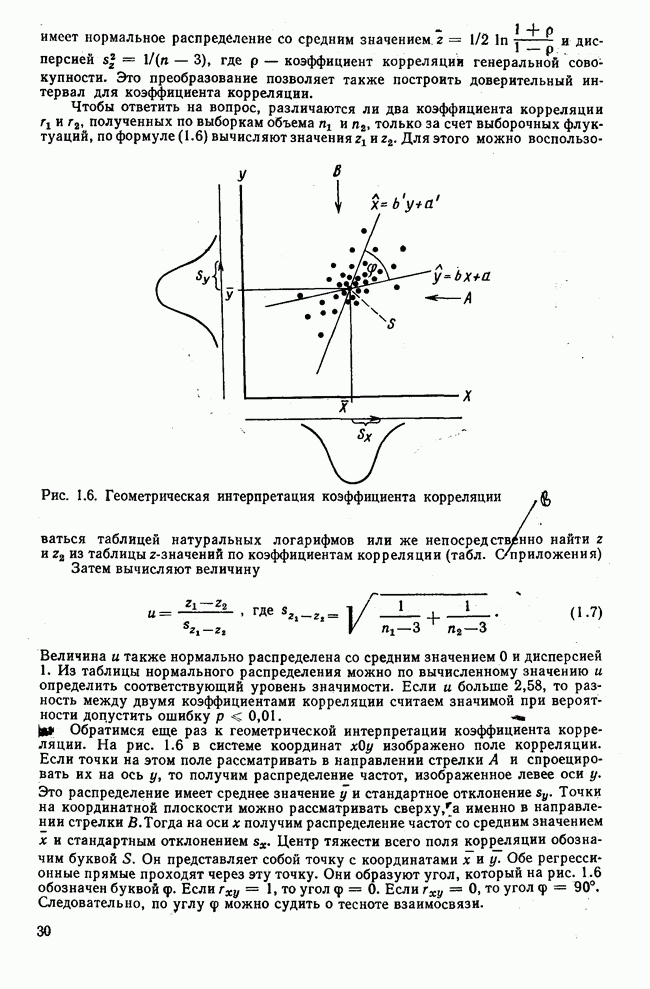











































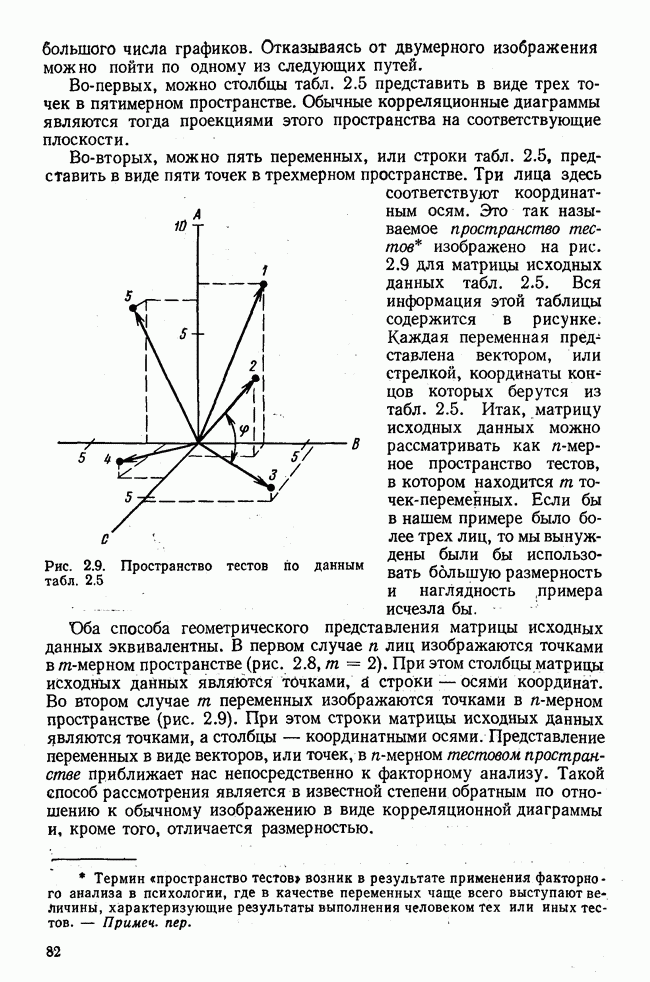






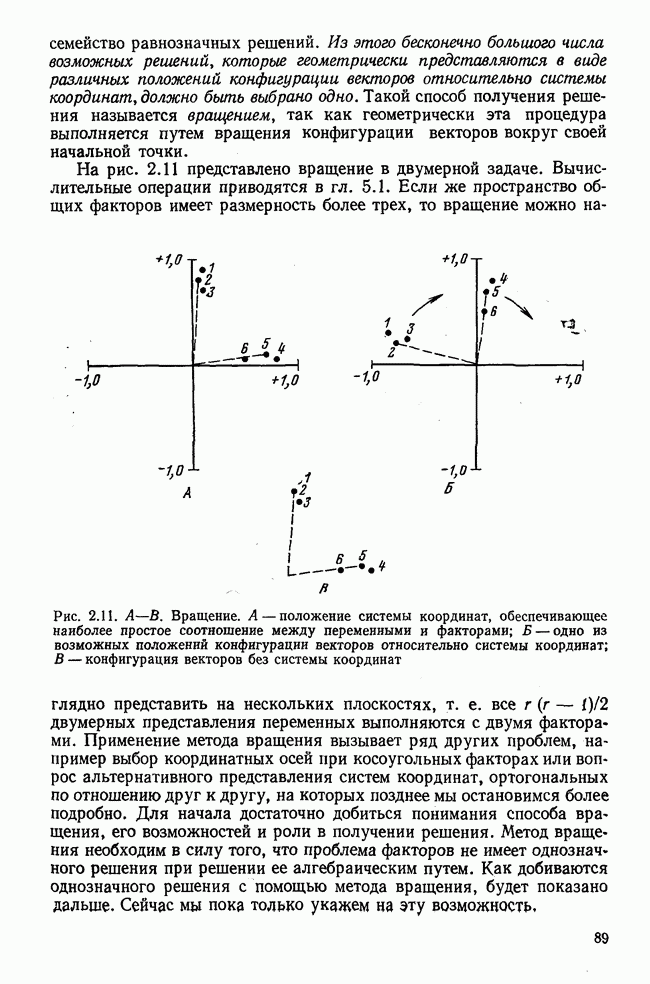














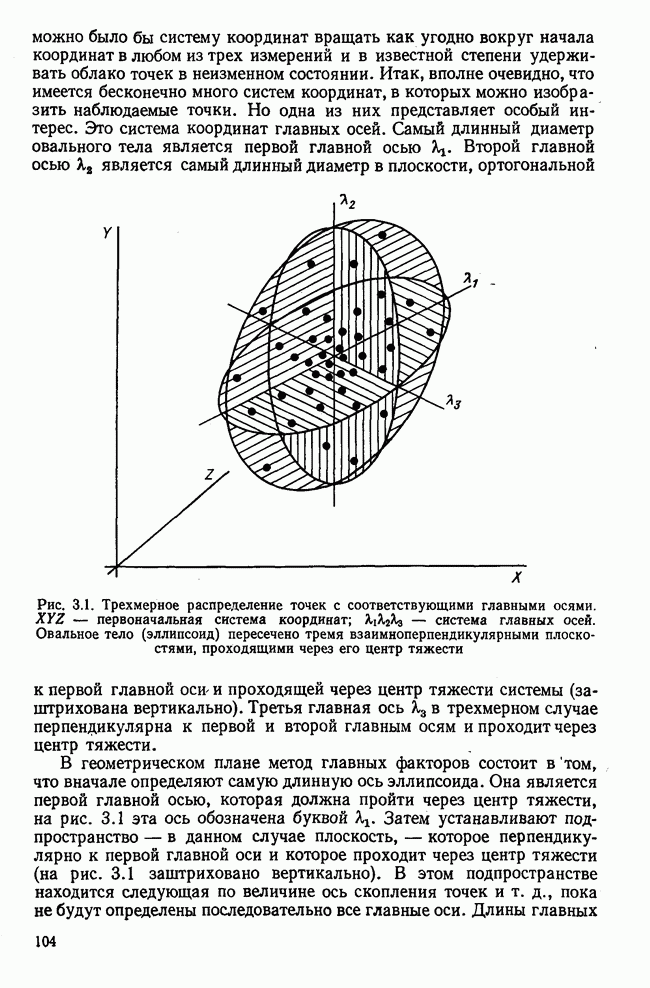


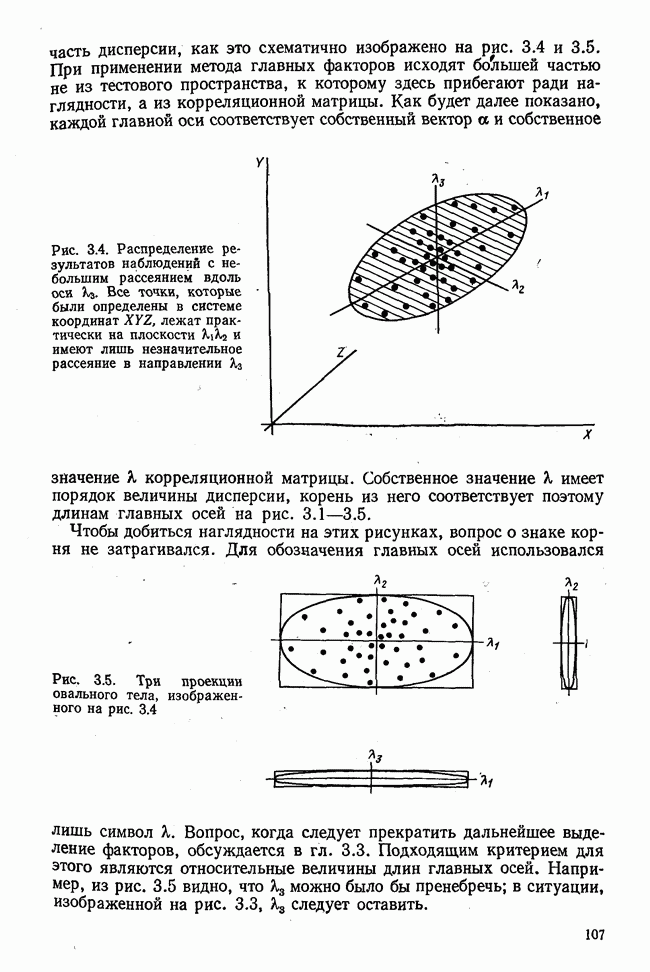













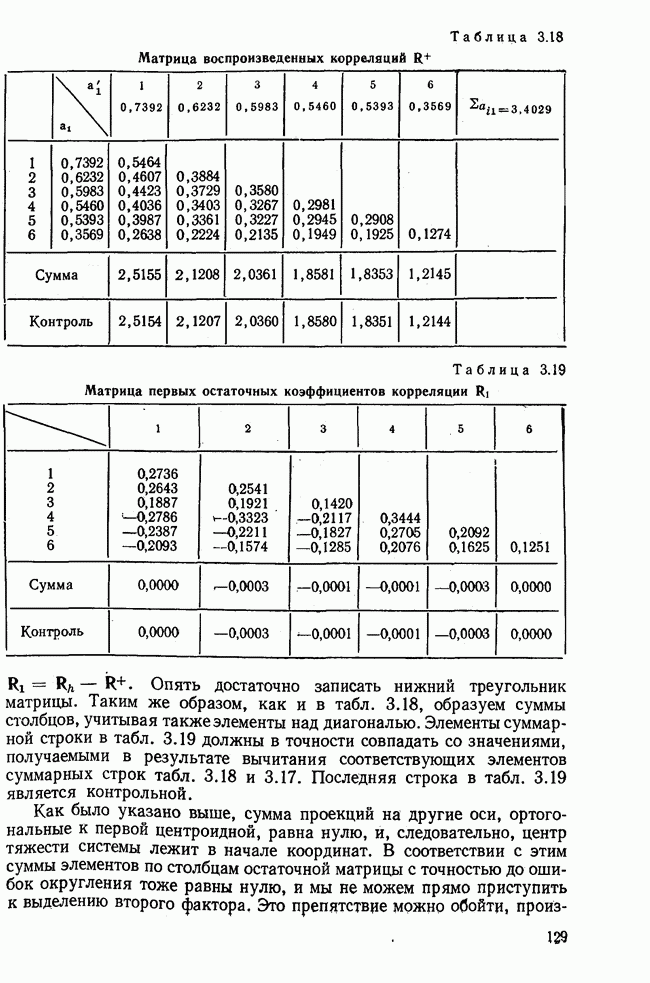


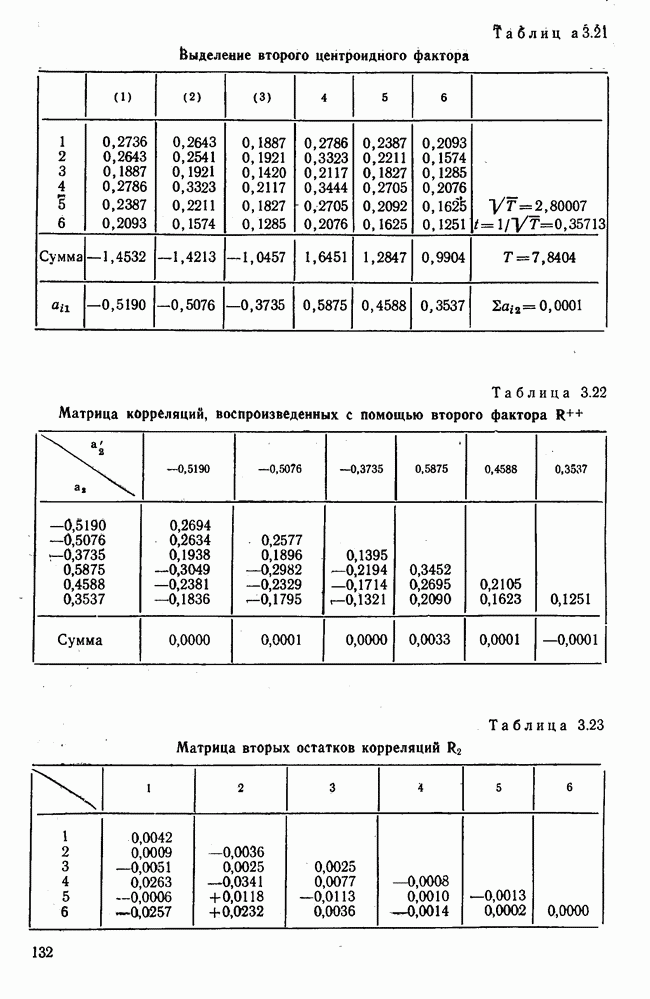
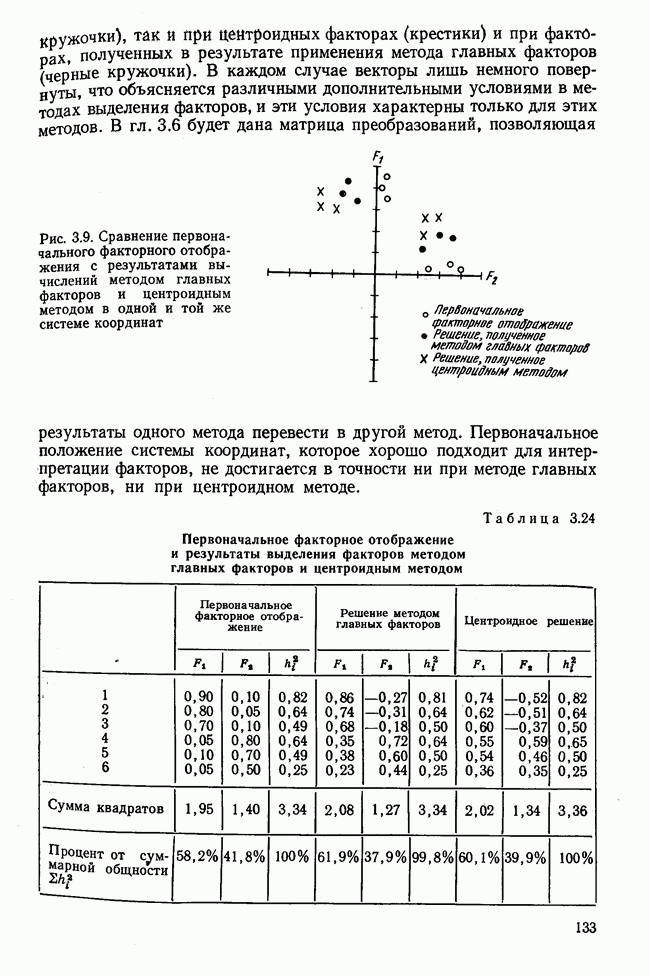

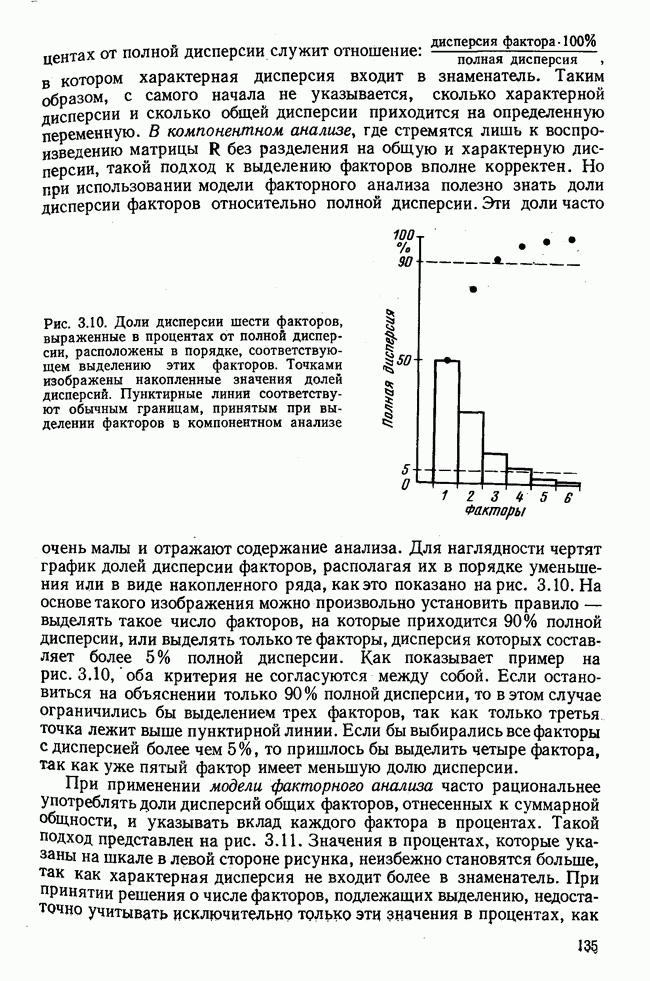























































































































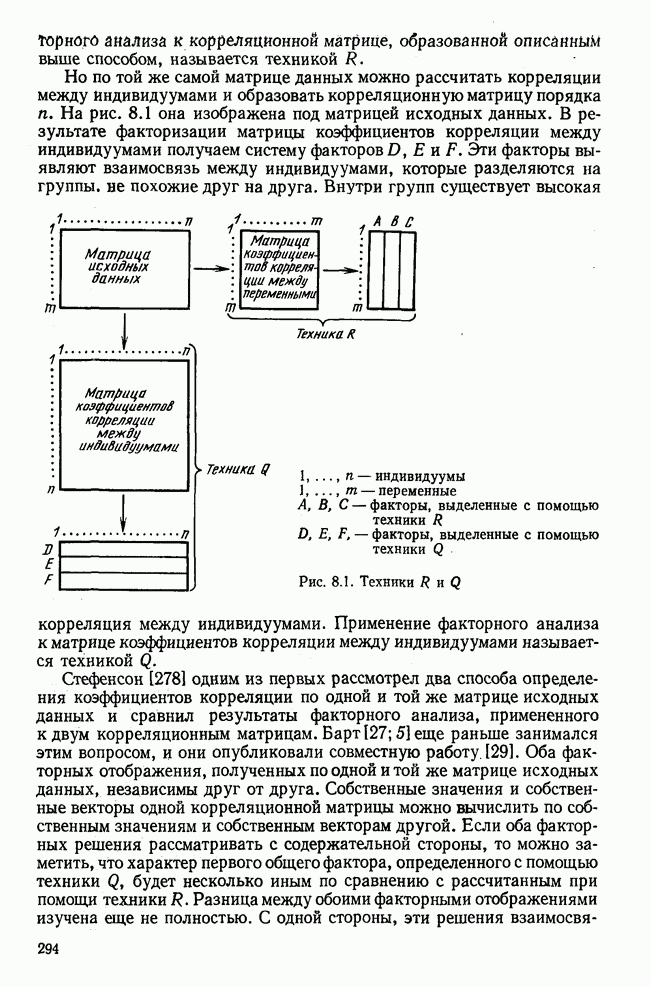













































































 Итак, будем различать:
Итак, будем различать:
 -коэффициент (см. Кендэл и Стьюарт [173]), который вычисляется по четырехклеточной (2 X 2) таблице.
-коэффициент (см. Кендэл и Стьюарт [173]), который вычисляется по четырехклеточной (2 X 2) таблице.

 Можно показать, что коэффициент
Можно показать, что коэффициент  идентичен обычному коэффициенту ковариации, если его применить к альтернативным данным. Следовательно, к альтернативным данным может быть применена та же самая процедура вычислений, что и к корреляционной матрице.
идентичен обычному коэффициенту ковариации, если его применить к альтернативным данным. Следовательно, к альтернативным данным может быть применена та же самая процедура вычислений, что и к корреляционной матрице.

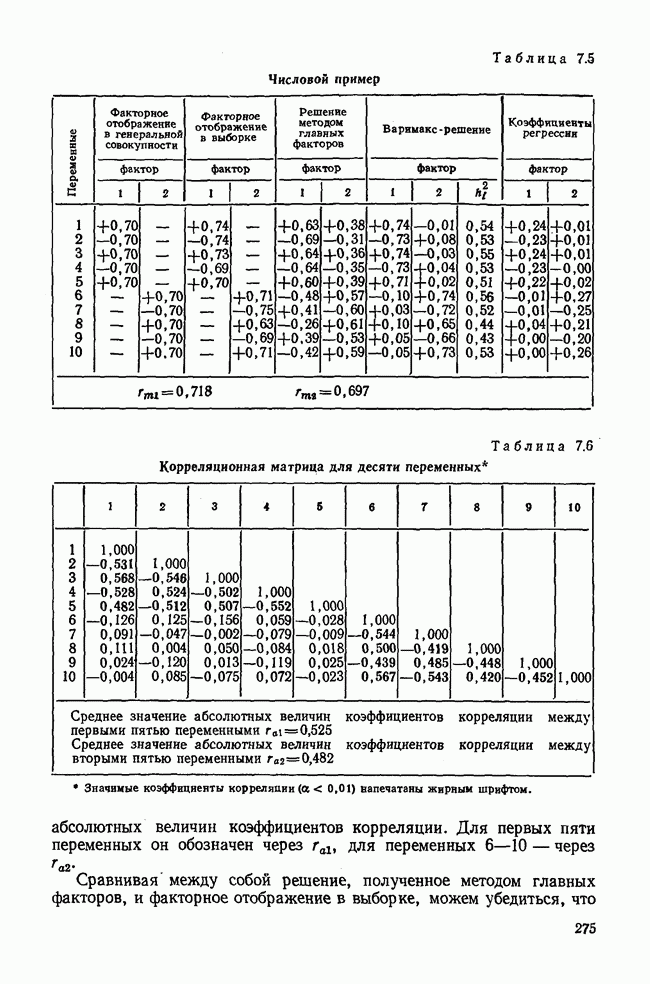
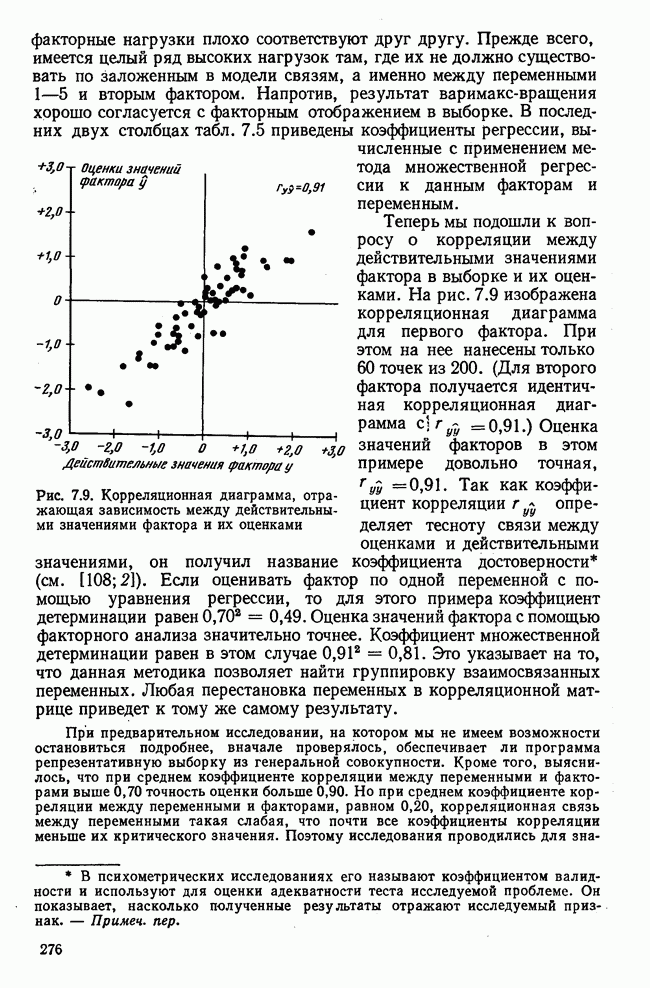
 для каждой переменной устанавливался одинаковым по абсолютной величине (0,40), но с разными знаками. Исследование производилось по 50 выборкам. Коэффициенты корреляции между исходными нормально распределенными случайными величинами оказались больше коэффициентов корреляции, вычисленных по альтернативным данным. Особенно низкие коэффициенты корреляции получились для переменных, преобразованных по способу 2. Таким образом, при переходе к альтернативным данным происходит потеря информации. Уменьшаются также коэффициенты корреляции между переменными и факторами. Для установления связи между коэффициентами достоверности и
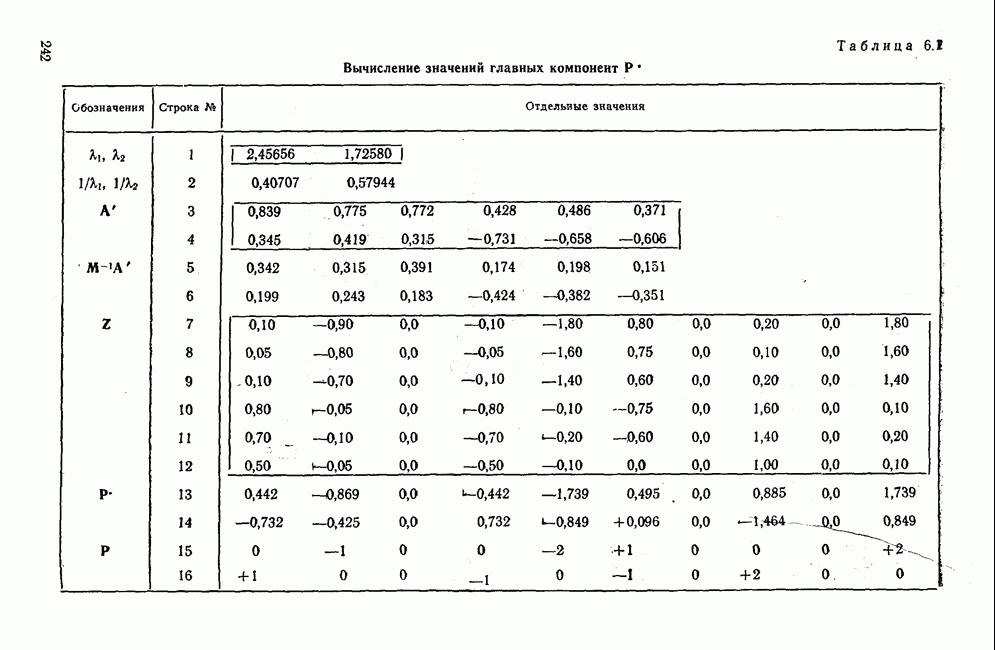
для каждой переменной устанавливался одинаковым по абсолютной величине (0,40), но с разными знаками. Исследование производилось по 50 выборкам. Коэффициенты корреляции между исходными нормально распределенными случайными величинами оказались больше коэффициентов корреляции, вычисленных по альтернативным данным. Особенно низкие коэффициенты корреляции получились для переменных, преобразованных по способу 2. Таким образом, при переходе к альтернативным данным происходит потеря информации. Уменьшаются также коэффициенты корреляции между переменными и факторами. Для установления связи между коэффициентами достоверности и  была построена корреляционная диаграмма, изображенная на рис. 7.14. Коэффициенты достоверности вычислялись по каждой выборке. Диаграмма была построена только для первого фактора, но аналогичная картина получается и для второго.
была построена корреляционная диаграмма, изображенная на рис. 7.14. Коэффициенты достоверности вычислялись по каждой выборке. Диаграмма была построена только для первого фактора, но аналогичная картина получается и для второго.
 по оси ординат — значения
по оси ординат — значения  . Из рисунка видно, что при переходе к альтернативным данным коэффициенты корреляции в R уменьшаются. При стандартной процедуре факторного анализа средний коэффициент корреляции между переменными
. Из рисунка видно, что при переходе к альтернативным данным коэффициенты корреляции в R уменьшаются. При стандартной процедуре факторного анализа средний коэффициент корреляции между переменными  (стандартное отклонение равно 0,029), средний коэффициент достоверности
(стандартное отклонение равно 0,029), средний коэффициент достоверности  (стандартное отклонение равно 0,04). Потеря информации при переходе к альтернативным данным приводит к уменьшению соответствующих коэффициентов. Так, при проведении факторного анализа по данным, полученным способом 1, имеем
(стандартное отклонение равно 0,04). Потеря информации при переходе к альтернативным данным приводит к уменьшению соответствующих коэффициентов. Так, при проведении факторного анализа по данным, полученным способом 1, имеем  (стандартное отклонение равно 0,028), а
(стандартное отклонение равно 0,028), а  (стандартное отклонение равно 0,066). При проведении факторного анализа по альтернативным данным, полученным способом 2, наблюдается дальнейшее уменьшение среднего коэффициента корреляции между переменными и среднего коэффициента достоверности, а именно
(стандартное отклонение равно 0,066). При проведении факторного анализа по альтернативным данным, полученным способом 2, наблюдается дальнейшее уменьшение среднего коэффициента корреляции между переменными и среднего коэффициента достоверности, а именно  (стандартное отклонение равно 0,018) и
(стандартное отклонение равно 0,018) и  (стандартное отклонение равно 0,119).
(стандартное отклонение равно 0,119).
 на рис. 7.14. Потеря информации происходит перед вычислением корреляционной матрицы. Факторный анализ как таковой не может возместить эту потерянную информацию. Если коэффициенты корреляции между переменными с альтернативной вариацией равны коэффициентам корреляции между нормально распределенными переменными, то точность оценок значений факторов будет не хуже. Характер расположения точек на рис. 7.14 приблизительно соответствует кривой, изображенной на рис. 7.11. При
на рис. 7.14. Потеря информации происходит перед вычислением корреляционной матрицы. Факторный анализ как таковой не может возместить эту потерянную информацию. Если коэффициенты корреляции между переменными с альтернативной вариацией равны коэффициентам корреляции между нормально распределенными переменными, то точность оценок значений факторов будет не хуже. Характер расположения точек на рис. 7.14 приблизительно соответствует кривой, изображенной на рис. 7.11. При  и при пяти нормально распределенных переменных следует ожидать значения коэффициента достоверности от 0,40 до 0,50. Если обратиться к рис. 7.14, то можно убедиться, что при
и при пяти нормально распределенных переменных следует ожидать значения коэффициента достоверности от 0,40 до 0,50. Если обратиться к рис. 7.14, то можно убедиться, что при  среднее значение коэффициента достоверности для результатов 50 анализов по данным, полученным способом 2, попадает в этот интервал.
среднее значение коэффициента достоверности для результатов 50 анализов по данным, полученным способом 2, попадает в этот интервал.
 то при преобразовании этих переменных по способу 2 в результате анализа получим коэффициент детерминации 0,4182 — 0,174. Но опыт показывает, что факторное отображение, полученное по альтернативным данным, в принципе согласуется с факторным отображением, полученным по нормально распределенным величинам.
то при преобразовании этих переменных по способу 2 в результате анализа получим коэффициент детерминации 0,4182 — 0,174. Но опыт показывает, что факторное отображение, полученное по альтернативным данным, в принципе согласуется с факторным отображением, полученным по нормально распределенным величинам.