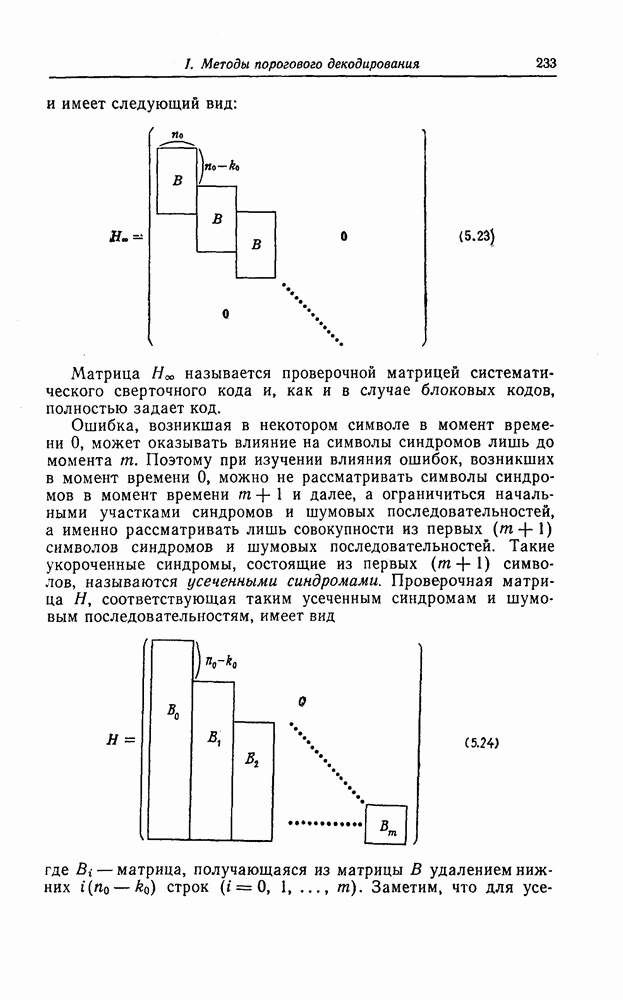
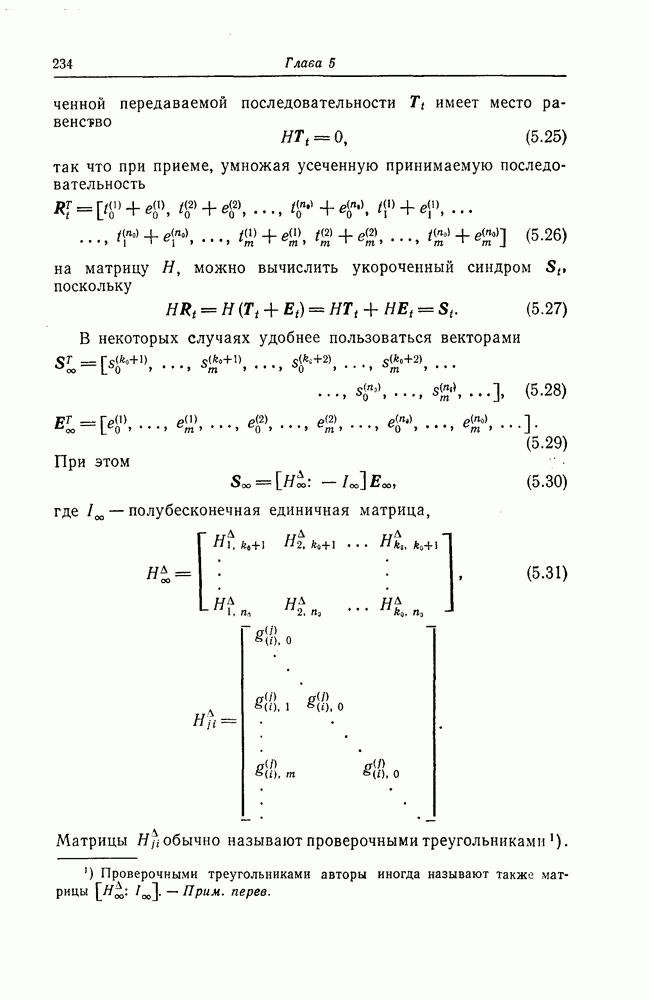
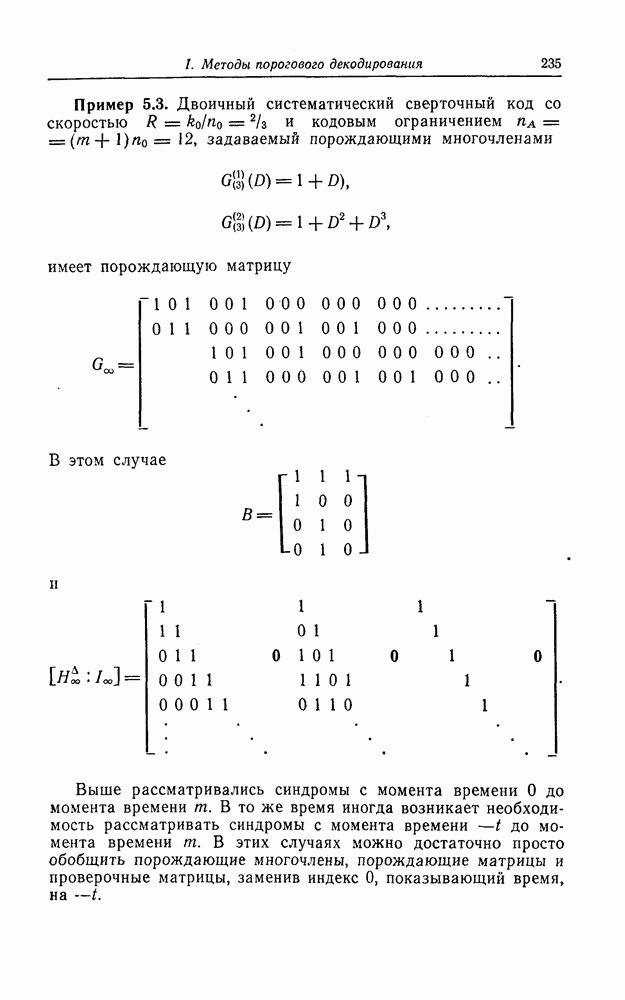
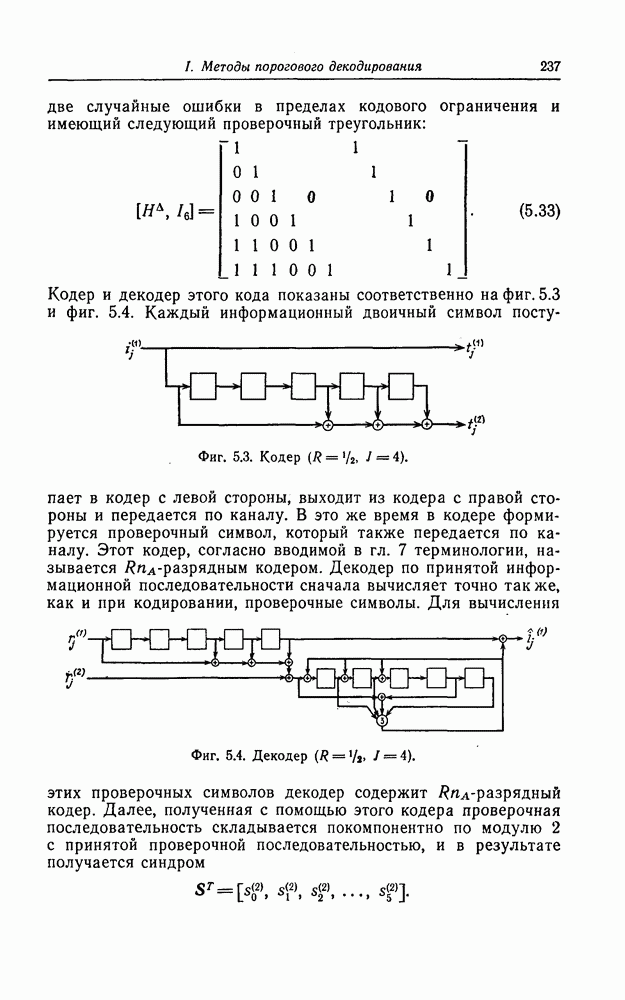
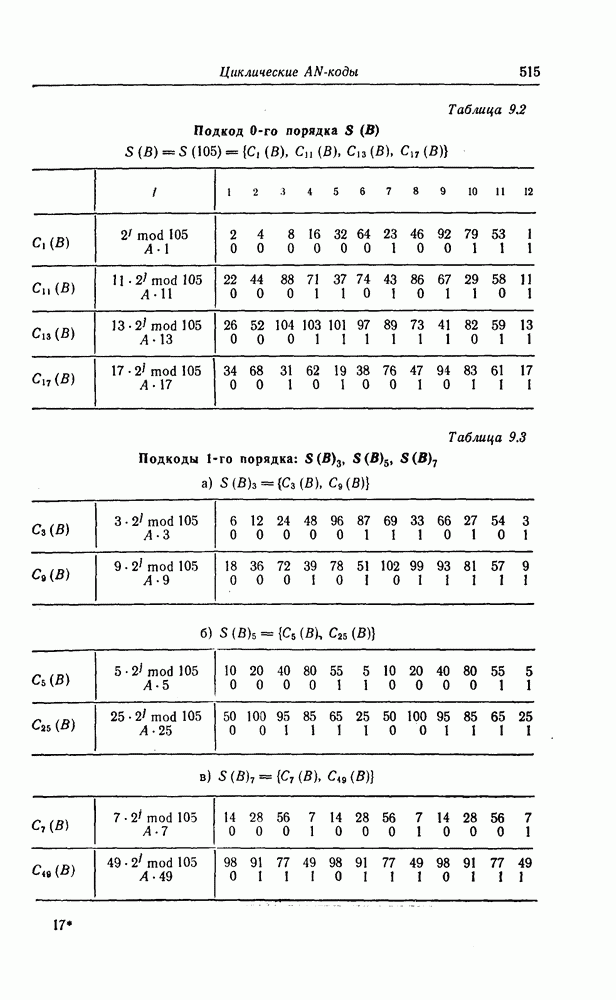
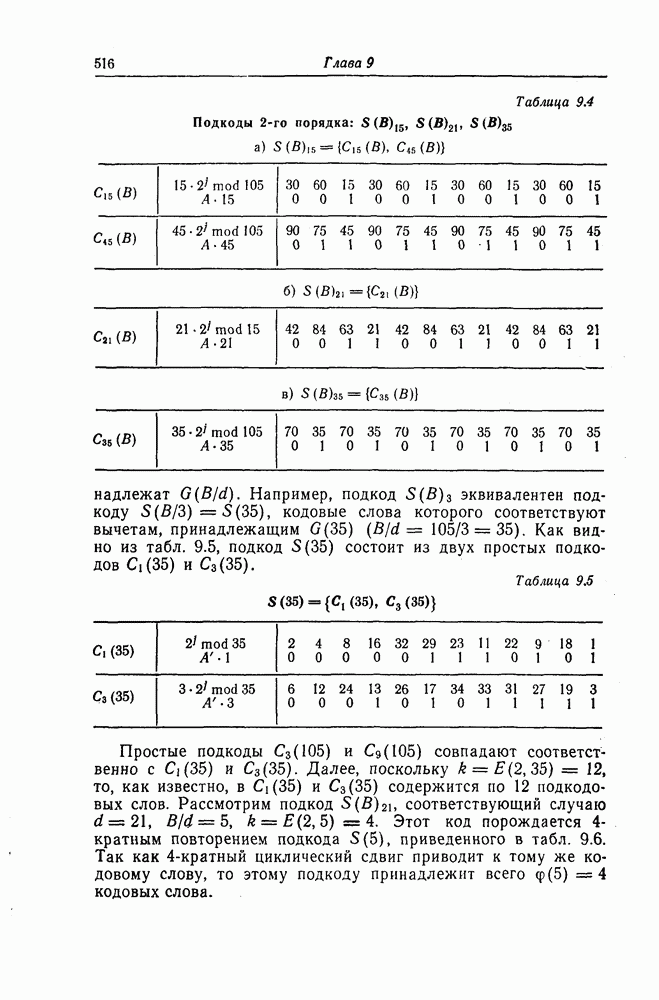
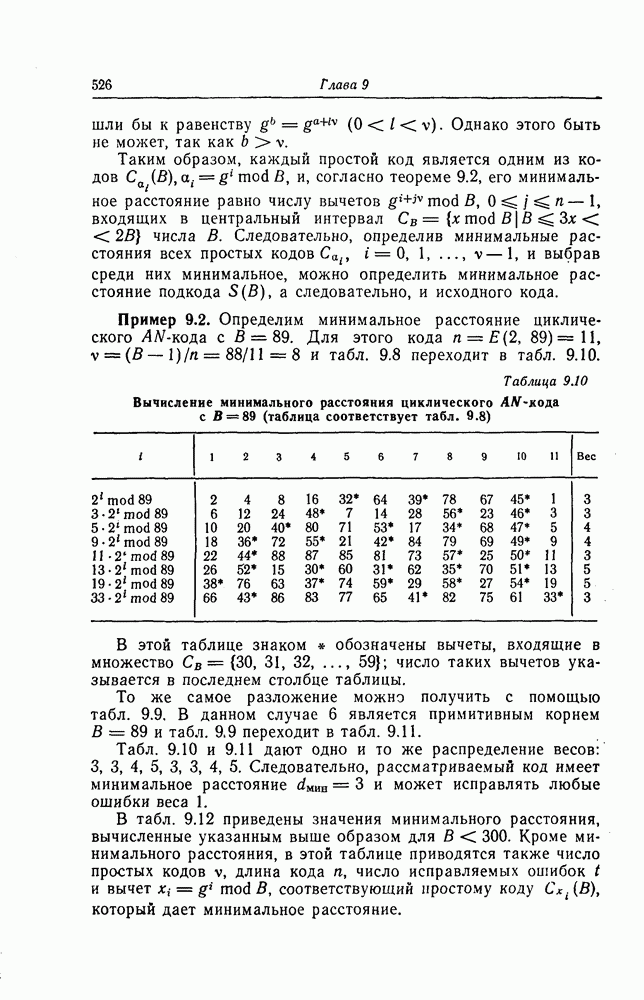
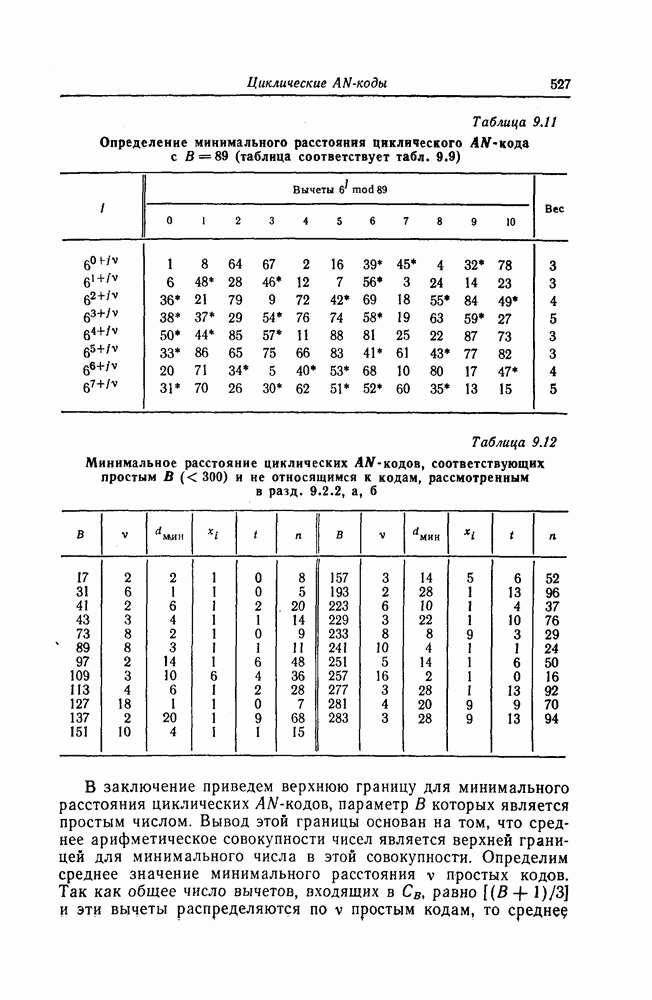
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
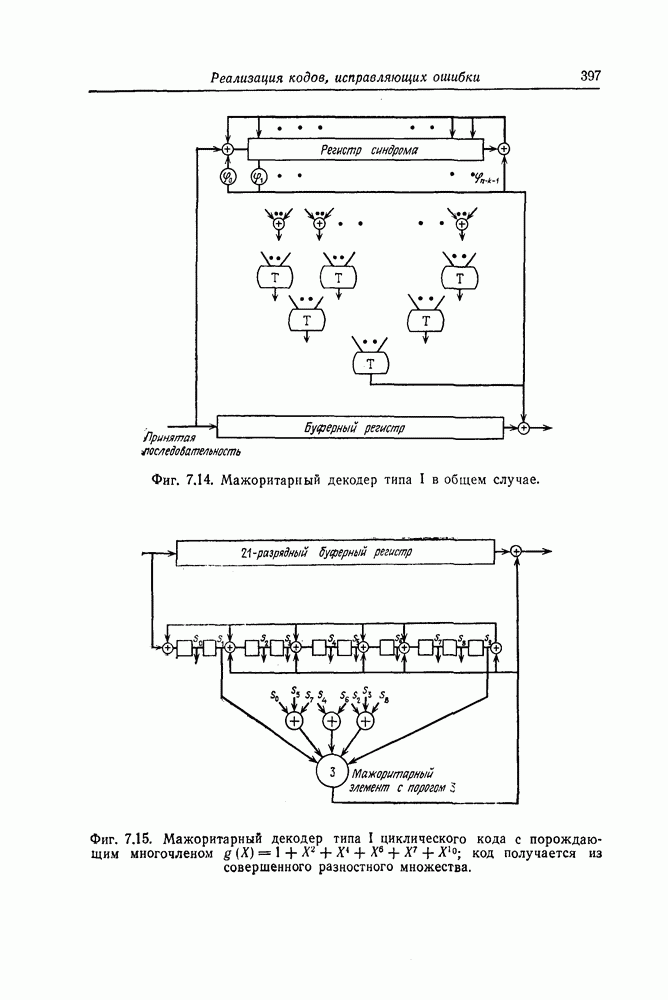
1.5.1. Граница случайного кодированияПоскольку верхняя граница для вероятности ошибки в (1.14) получается методом случайного кодирования, то она называется границей случайного кодирования. Теорема 1.4. (Шеннон, Галлагер). Пусть задан дискретный канал без памяти с входным алфавитом из К символов
где
Доказательство. Обозначим через Вначале рассмотрим некоторый фиксированный код, состоящий из А именно если принято слово V и целое число
то декодер максимального правдоподобия декодирует V в
где
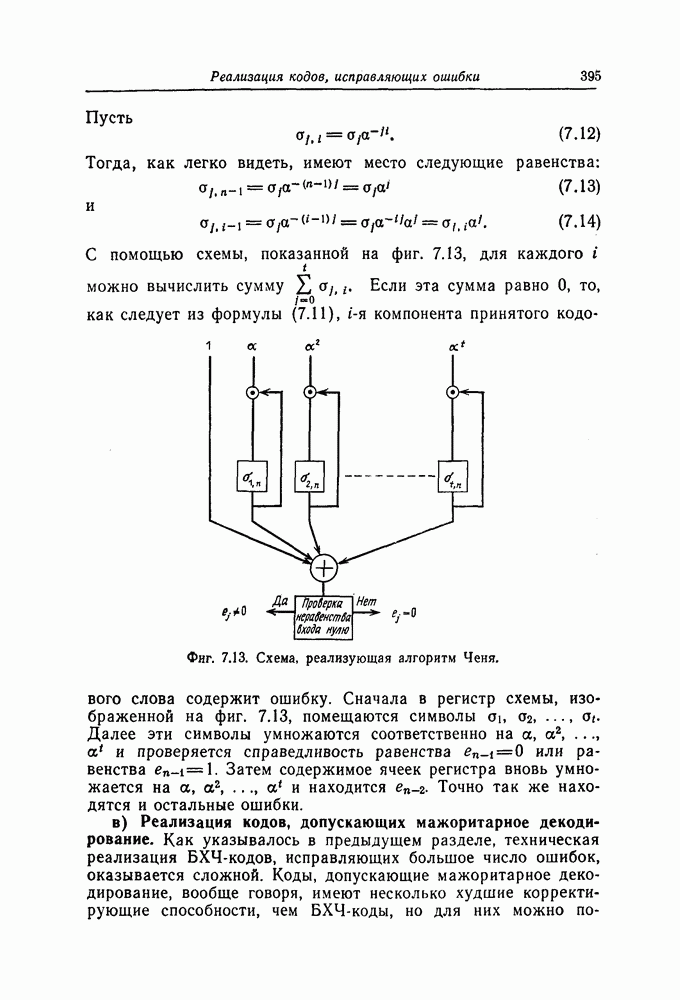
Первым шагом на пути вывода верхней границы для
В справедливости этого неравенства легко убедиться, если заметить, что 1) правая часть его всегда положительна, и, следовательно, оно выполняется всегда, когда 2) в случае когда Подставив (1.20) в (1.18), получим
Это неравенство дает границу сверху для Зададим вначале на множестве Итак, усредняя вероятность ошибки по ансамблю кодов, из формулы (1.21) получаем
где черта сверху означает усреднение. Ограничим область значений параметра 1) Все слагаемые под чертой в формуле (1.21) являются случайными величинами. А именно каждое из слагаемых является функцией случайно выбираемых кодовых слов, принимающей действительные значения. Поскольку среднее значение суммы случайных величин равно сумме средних значений, то
2) Аналогично, поскольку среднее значение произведения независимых случайных величин равно произведению средних значений сомножителей, то из формулы
3) Положим является выпуклой вверх функцией аргумента
4) Пользуясь опять тем, что среднее значение суммы случайных величин равно сумме средних значений слагаемых, получаем
Отсюда и из формулы
Поскольку кодовые слова в рассматриваемом ансамбле кодов выбираются с распределением
Правая часть последнего равенства не зависит от
Оценка (1.24) справедлива для произвольного дискретного канала, задаваемого распределением Пусть
Наложим на ансамбль кодов еще одно ограничение, а именно предположим, что символы кодовых слоз выбираются независимо с распределением
Подставляя формулы (1.25) и (1.26) в (1.24), получаем
Представляя далее сумму произведений в квадратных скобках в (1.27), как обычно, в виде произведения сумм, находим
Аналогично, вынося знак произведения в формуле (1.28) за квадратные скобки, имеем
Правую часть этой формулы можно упростить следующим образом. Совокупность К входных символов
Пусть
Поскольку правая часть (1.31) не зависит от Если провести минимизацию правой части формулы (1.31) по Следствие 1.2. При выполнении условий теоремы 1.4 существует код, для которого
где максимум берется по всем Функция
|
 |
Оглавление
|

































































































































































































































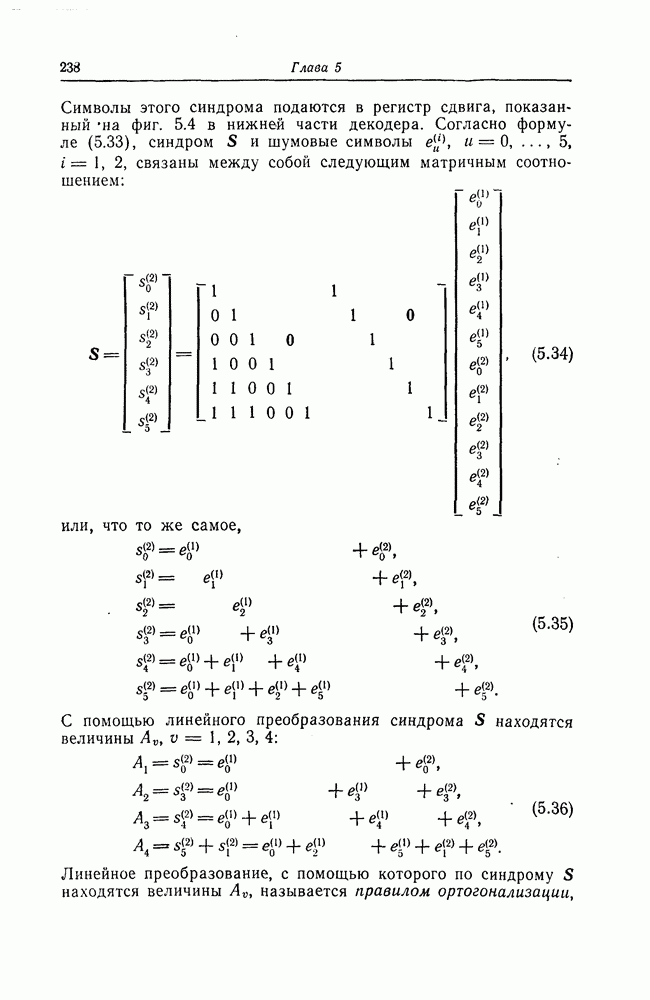














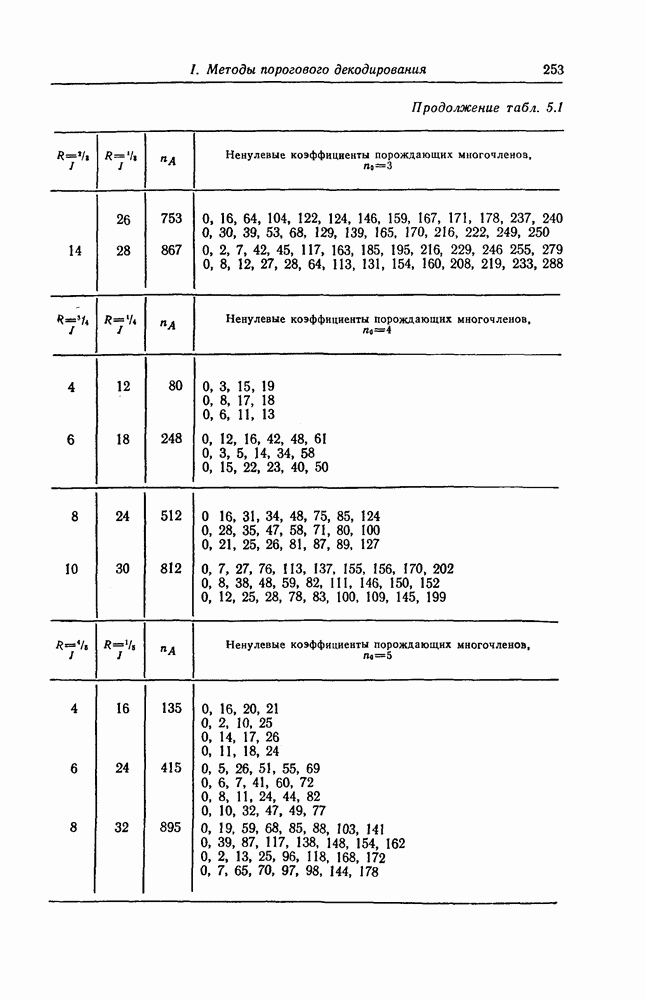





























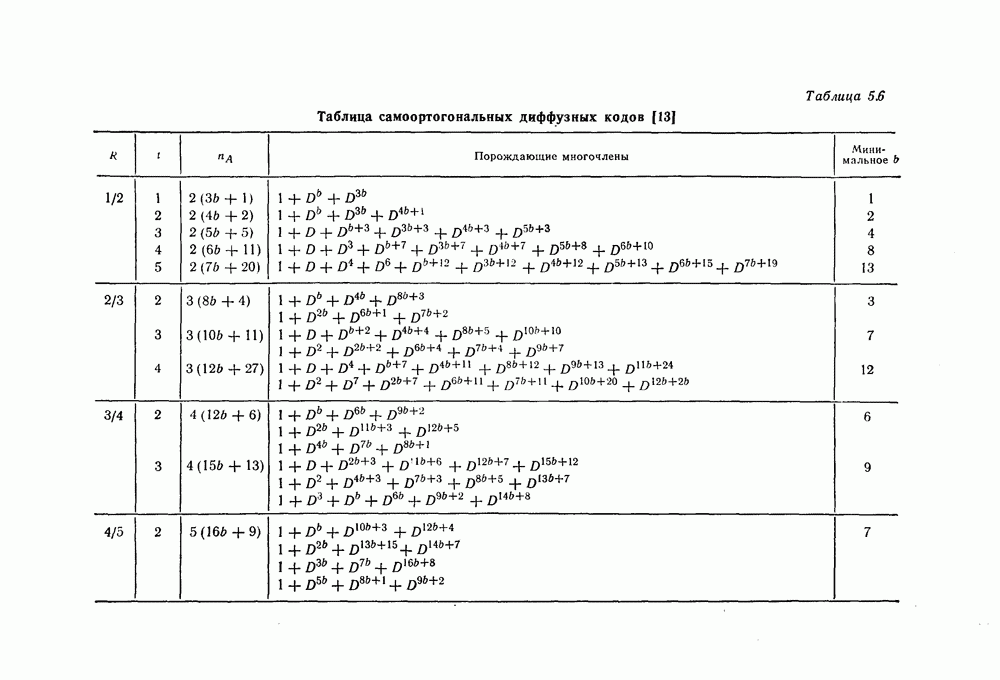

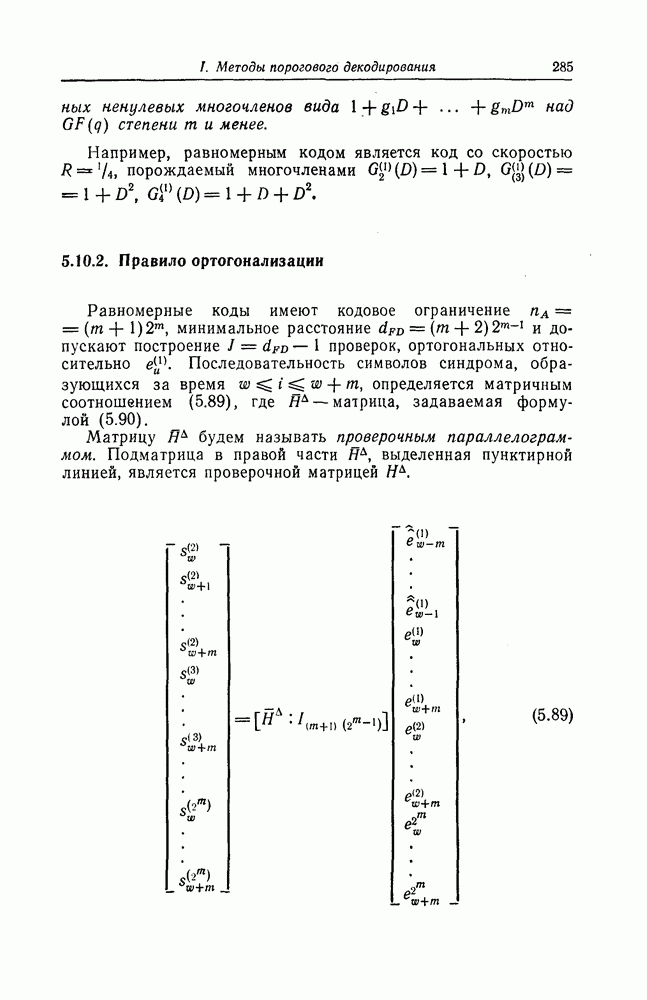




































































































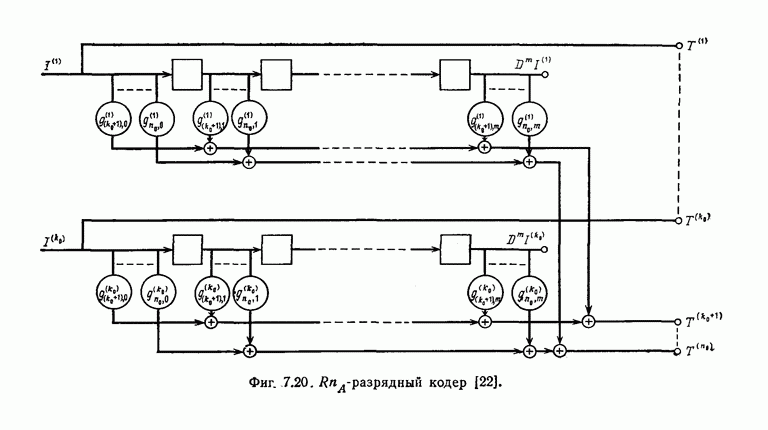

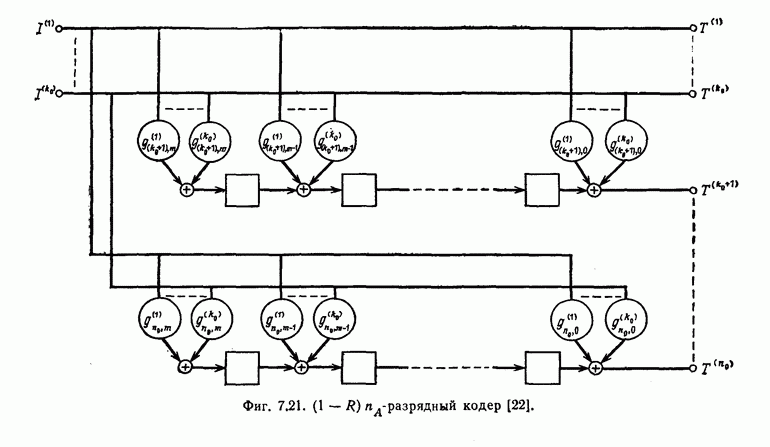
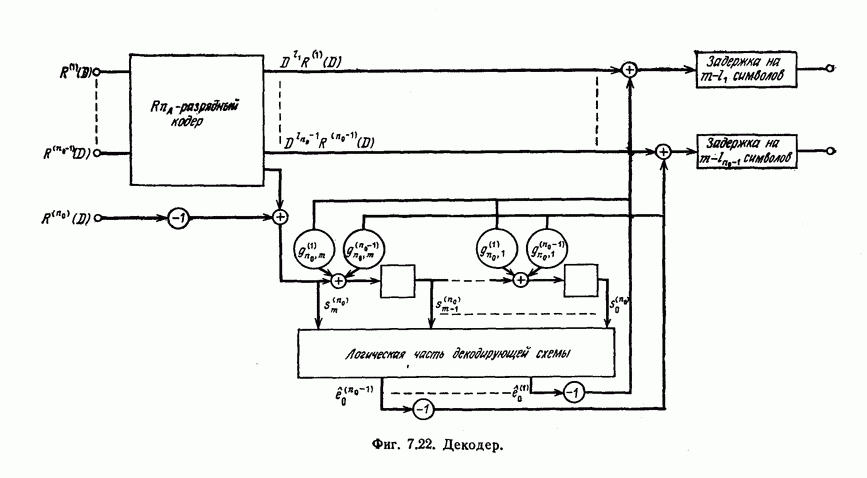



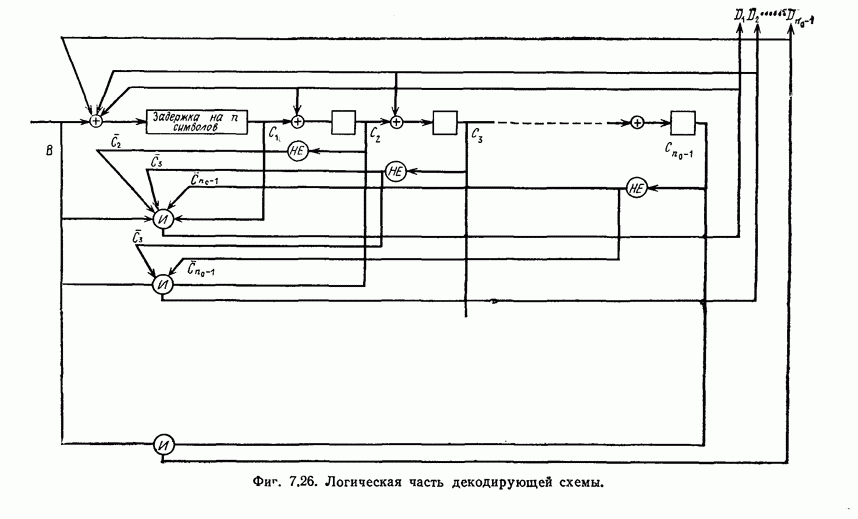




























































































































 выходным алфавитом из
выходным алфавитом из  символов
символов  переходными вероятностями
переходными вероятностями  Тогда для любой длины кода
Тогда для любой длины кода  любого числа кодовых слов
любого числа кодовых слов  и любого распределения вероятностей на множестве этих кодовых слов существует код длины
и любого распределения вероятностей на множестве этих кодовых слов существует код длины  вероятность ошибки для которого в указанном выше канале оценивается сверху следующим образом:
вероятность ошибки для которого в указанном выше канале оценивается сверху следующим образом:


 произвольное число из интервала
произвольное число из интервала  произвольный вероятностный вектор
произвольный вероятностный вектор 
 множество всех последовательностей длины
множество всех последовательностей длины  которые могут быть переданы по каналу, а через
которые могут быть переданы по каналу, а через  множество последовательностей длины
множество последовательностей длины  которые могут быть приняты на выходе канала. Пусть
которые могут быть приняты на выходе канала. Пусть  вероятность того, что на выходе канала принято слово
вероятность того, что на выходе канала принято слово  при условии, что было передано слово
при условии, что было передано слово 
 кодовых слов. Допустим, что целым числам
кодовых слов. Допустим, что целым числам  сопоставлены соответственно кодовые слова
сопоставлены соответственно кодовые слова  Предположим, что декодирование производится по максимуму правдоподобия.
Предположим, что декодирование производится по максимуму правдоподобия.
 таково, что при всех
таково, что при всех 

 Если же принято слово V, такое, что ни при каком
Если же принято слово V, такое, что ни при каком  неравенства (1.17) одновременно для всех
неравенства (1.17) одновременно для всех  не выпвлняюгся, то считается, что произошла ошибка декодирования. Вероятность возникновения ошибки декодирования при передаче
не выпвлняюгся, то считается, что произошла ошибка декодирования. Вероятность возникновения ошибки декодирования при передаче  кодового слова обозначим через
кодового слова обозначим через  Эта вероятность определяется равенством
Эта вероятность определяется равенством


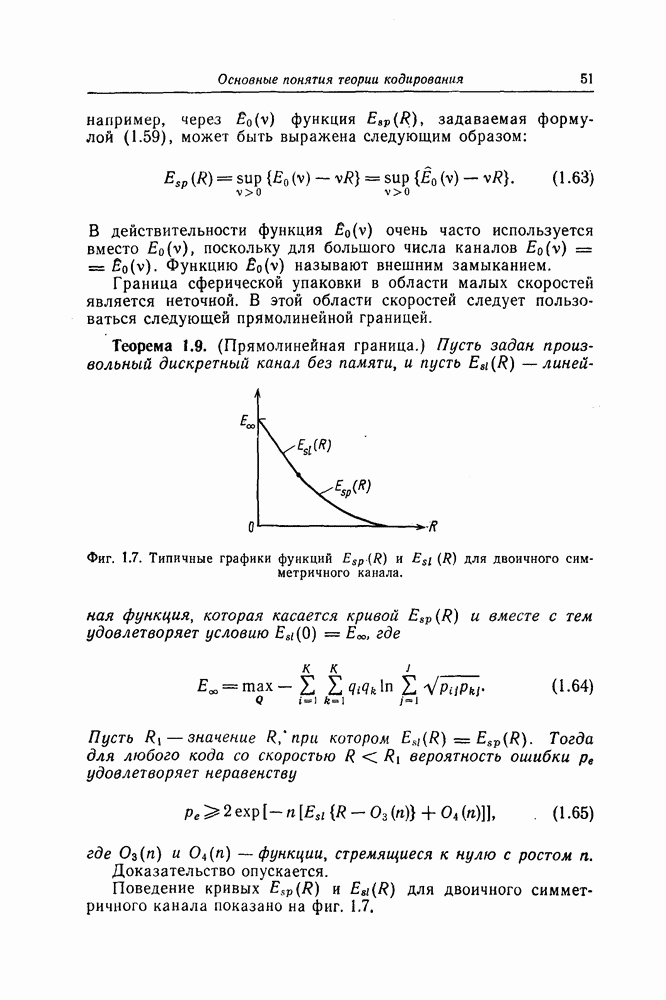
 является следующая оценка сверху для
является следующая оценка сверху для 


 одно из слагаемых в числителе правой части (1.20) больше знаменателя, а следовательно, и весь числитель больше знаменателя (при возведении числителя и знаменателя в
одно из слагаемых в числителе правой части (1.20) больше знаменателя, а следовательно, и весь числитель больше знаменателя (при возведении числителя и знаменателя в  степень по-прежнему первый остается больше второго).
степень по-прежнему первый остается больше второго).

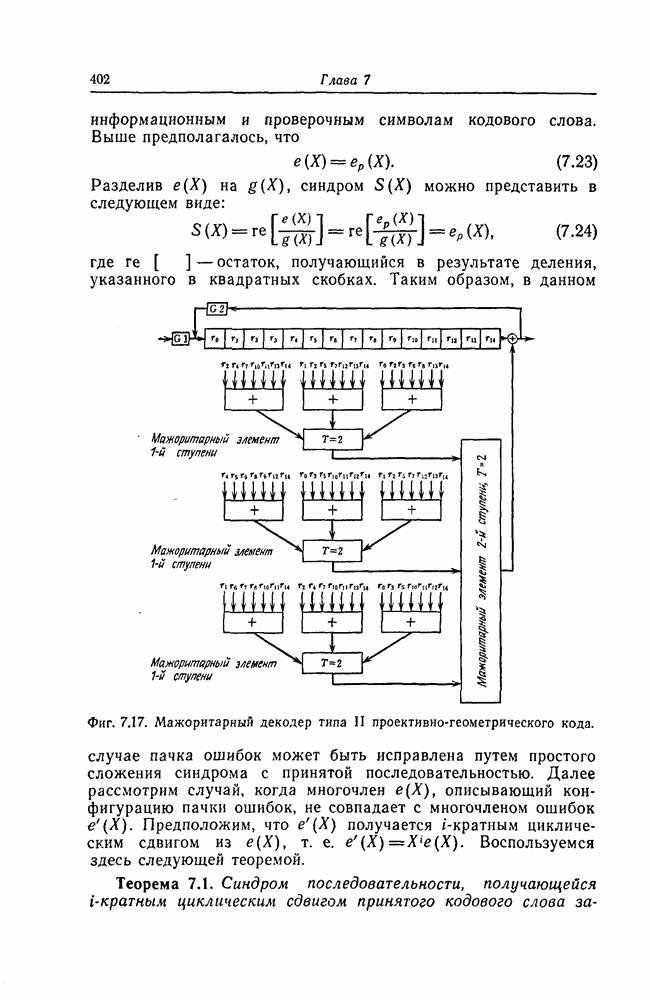
 в случае, когда множество кодовых слов задано, т.е. для фиксированного кода. Однако если число кодовых слов велико, то непосредственное вычисление границы (1.21) оказывается чрезвычайно затруднительным или вообще невозможным. В силу этого на следующем шаге осуществляется усреднение (1.21) по ансамблю кодов, выбранному некоторым специальным образом.
в случае, когда множество кодовых слов задано, т.е. для фиксированного кода. Однако если число кодовых слов велико, то непосредственное вычисление границы (1.21) оказывается чрезвычайно затруднительным или вообще невозможным. В силу этого на следующем шаге осуществляется усреднение (1.21) по ансамблю кодов, выбранному некоторым специальным образом.
 сообщений на входе канала распределение вероятностей
сообщений на входе канала распределение вероятностей  и рассмотрим ансамбль кодов, в котором каждое кодовое слово выбирается независимо с распределением вероятностей
и рассмотрим ансамбль кодов, в котором каждое кодовое слово выбирается независимо с распределением вероятностей  А именно рассмотрим ансамбль кодов, в котором код, состоящий из
А именно рассмотрим ансамбль кодов, в котором код, состоящий из  кодовых слов
кодовых слов  имеет вероятность
имеет вероятность  Оценим сверху среднюю по этому ансамблю вероятность ошибки. Поскольку в любом ансамбле кодов всегда существует по крайней мере один код, вероятность ошибки для которого не больше, чем средняя по ансамблю вероятность ошибки, то таким образом можно доказать существование кода, для которого вероятность ошибки по крайней мере не больше, чем вероятность ошибки, средняя по ансамблю.
Оценим сверху среднюю по этому ансамблю вероятность ошибки. Поскольку в любом ансамбле кодов всегда существует по крайней мере один код, вероятность ошибки для которого не больше, чем средняя по ансамблю вероятность ошибки, то таким образом можно доказать существование кода, для которого вероятность ошибки по крайней мере не больше, чем вероятность ошибки, средняя по ансамблю.

 интервалом
интервалом  и следующим образом упростим формулу
и следующим образом упростим формулу 

 получаем
получаем

 и воспользуемся тем, что
и воспользуемся тем, что  при
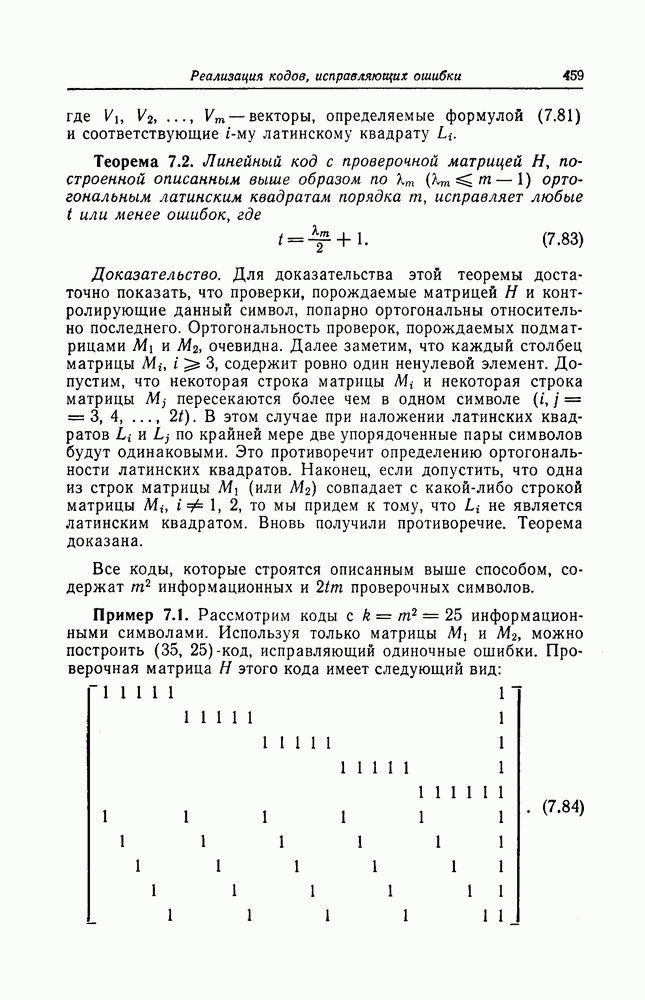
при  . В справедливости последнего неравенства легко убедиться, если заметить, что
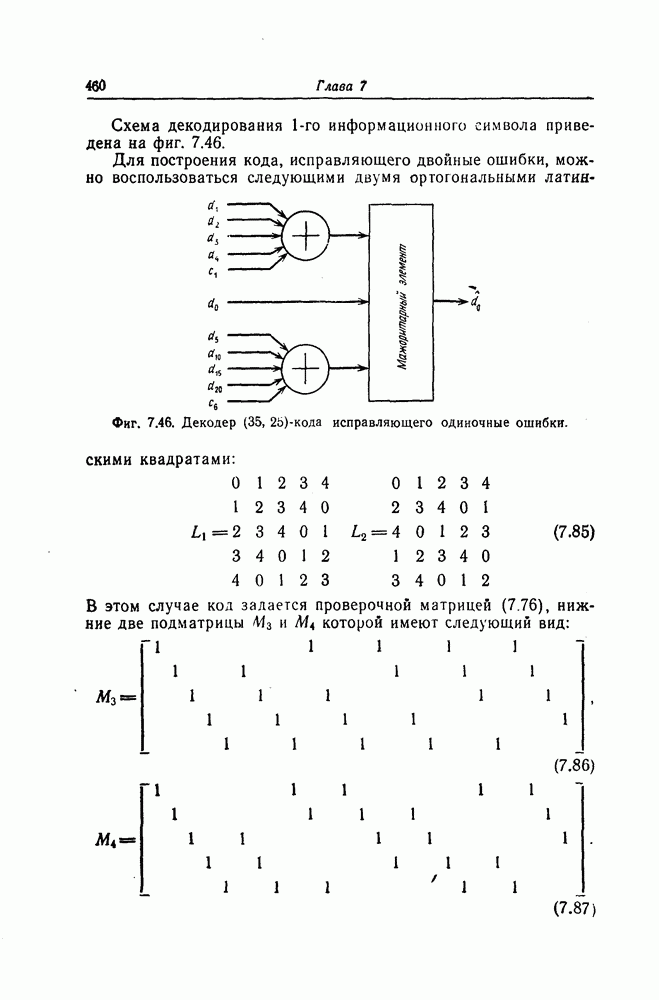
. В справедливости последнего неравенства легко убедиться, если заметить, что  при всех
при всех 
 Тогда
Тогда


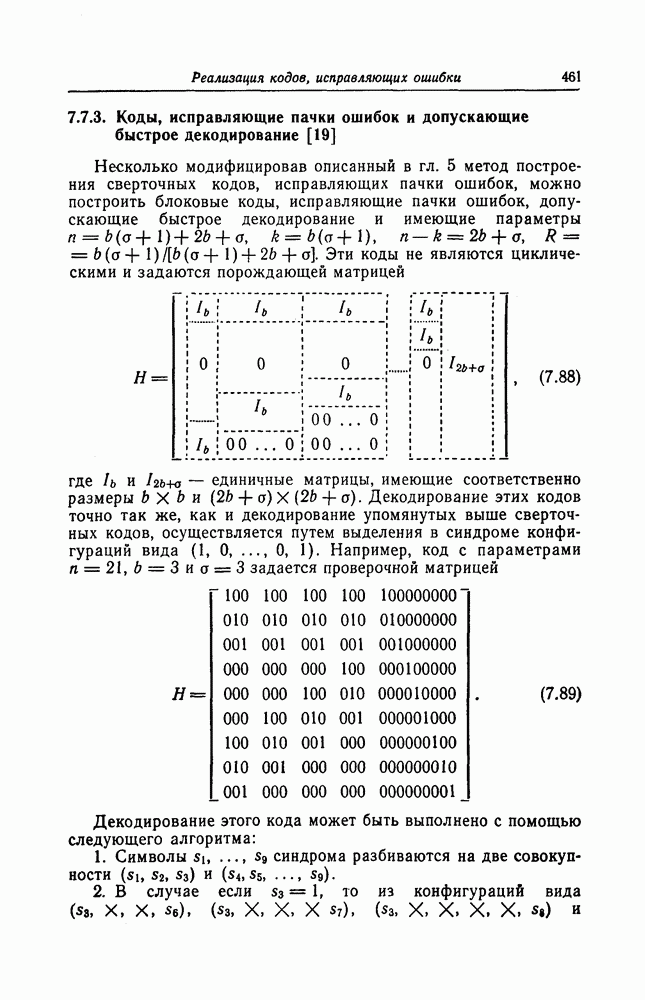
 следует, что
следует, что

 то
то

 следовательно, ее можно подставить в формулу (1.22) вместо соответствующих выражений как с индексом
следовательно, ее можно подставить в формулу (1.22) вместо соответствующих выражений как с индексом  так и с индексом
так и с индексом  Так как сумма по
Так как сумма по  в (1.22) является суммой
в (1.22) является суммой  одинаковых слагаемых, то
одинаковых слагаемых, то

 а также произвольного распределения
а также произвольного распределения  и любого
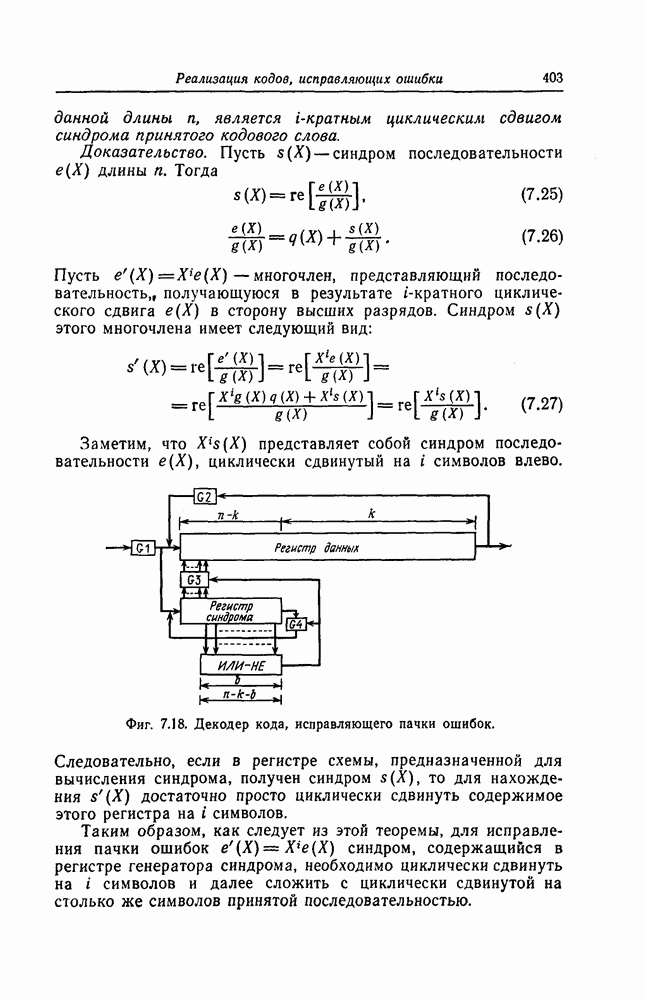
и любого  Если предположить дополнительно, что канал является каналом без памяти, то оценку (1.24) можно упростить.
Если предположить дополнительно, что канал является каналом без памяти, то оценку (1.24) можно упростить.
 компоненты входной последовательности
компоненты входной последовательности  компоненты выходной последовательности
компоненты выходной последовательности  По определению в канале без памяти для любых
По определению в канале без памяти для любых 

 входной алфавит канала). Тогда
входной алфавит канала). Тогда




 обозначим через
обозначим через  а совокупность
а совокупность  выходных символов
выходных символов  через
через  Обозначим также через
Обозначим также через  переходную вероятность канала
переходную вероятность канала  а через
а через  вероятность
вероятность  выбора символа
выбора символа  в ансамбле кодов. Эти обозначения подставим в формулу (1.29) и, заметив, что все сомножители произведения в правой части (1.29) равны, получим
в ансамбле кодов. Эти обозначения подставим в формулу (1.29) и, заметив, что все сомножители произведения в правой части (1.29) равны, получим

 скорость передачи информации в натуральных единицах (натах) на один символ канала (по определению
скорость передачи информации в натуральных единицах (натах) на один символ канала (по определению  Если оценить сверху
Если оценить сверху  величиной
величиной  то соотношение (1.30) можно представить в виде
то соотношение (1.30) можно представить в виде

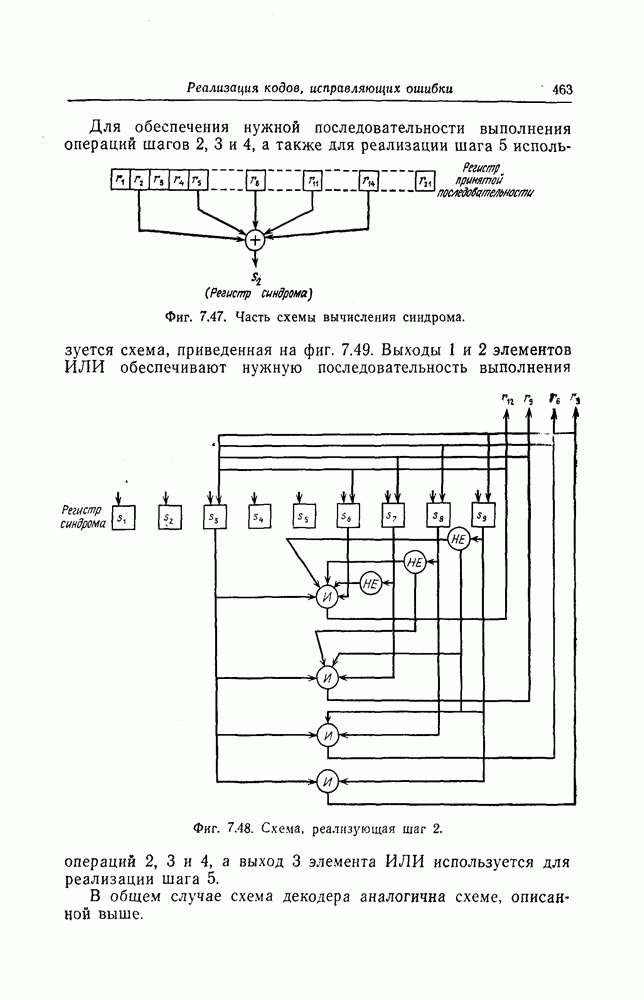
 то она является также границей сверху для средней по ансамблю кодов вероятности ошибки декодирования. Так как в ансамбле кодов имеется по крайней мере один код, вероятность ошибки декодирования для которого не больше средней по ансамблю вероятности ошибки декодирования, то таким образом теорема 1.4 доказана.
то она является также границей сверху для средней по ансамблю кодов вероятности ошибки декодирования. Так как в ансамбле кодов имеется по крайней мере один код, вероятность ошибки декодирования для которого не больше средней по ансамблю вероятности ошибки декодирования, то таким образом теорема 1.4 доказана.
 то можно получить более точную оценку для
то можно получить более точную оценку для 

 из интервала
из интервала  и всем вероятностным векторам
и всем вероятностным векторам 
 называется функцией надежности, и ее свойства оказывают большое влияние на поведение верхней границы для
называется функцией надежности, и ее свойства оказывают большое влияние на поведение верхней границы для 