Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
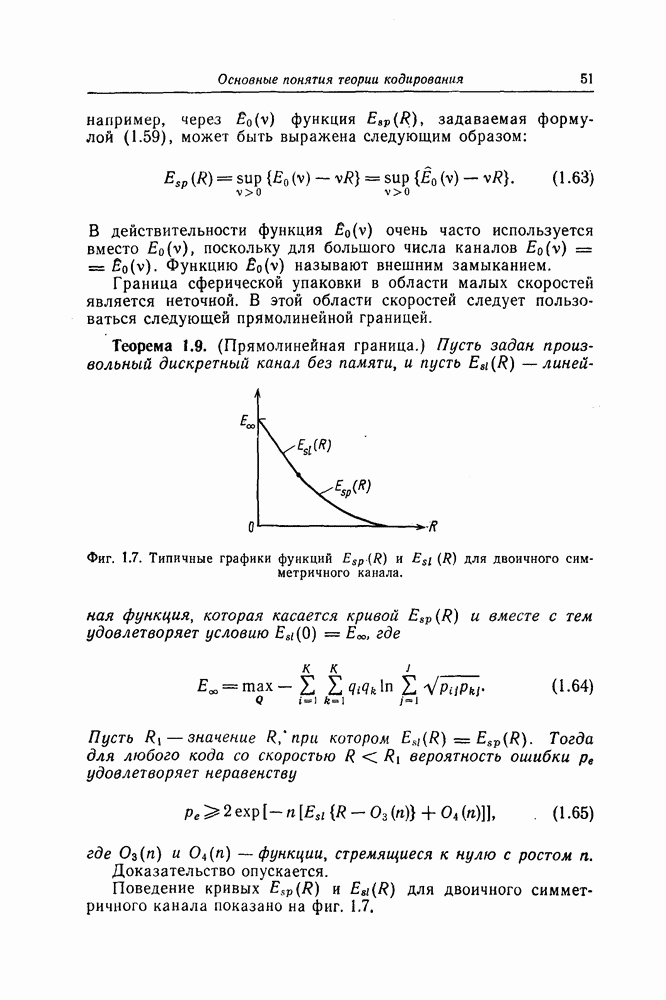
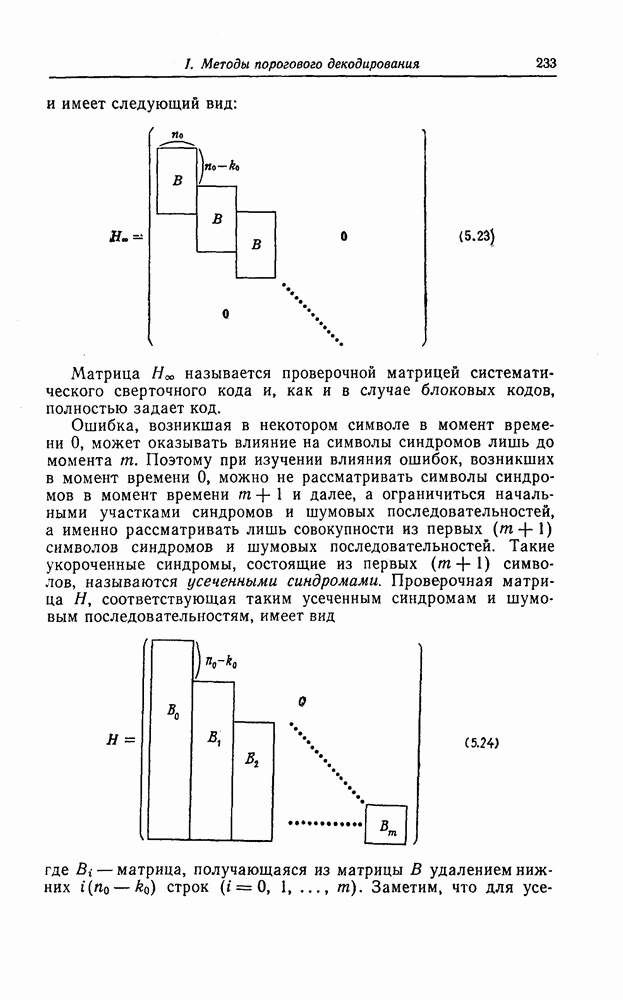
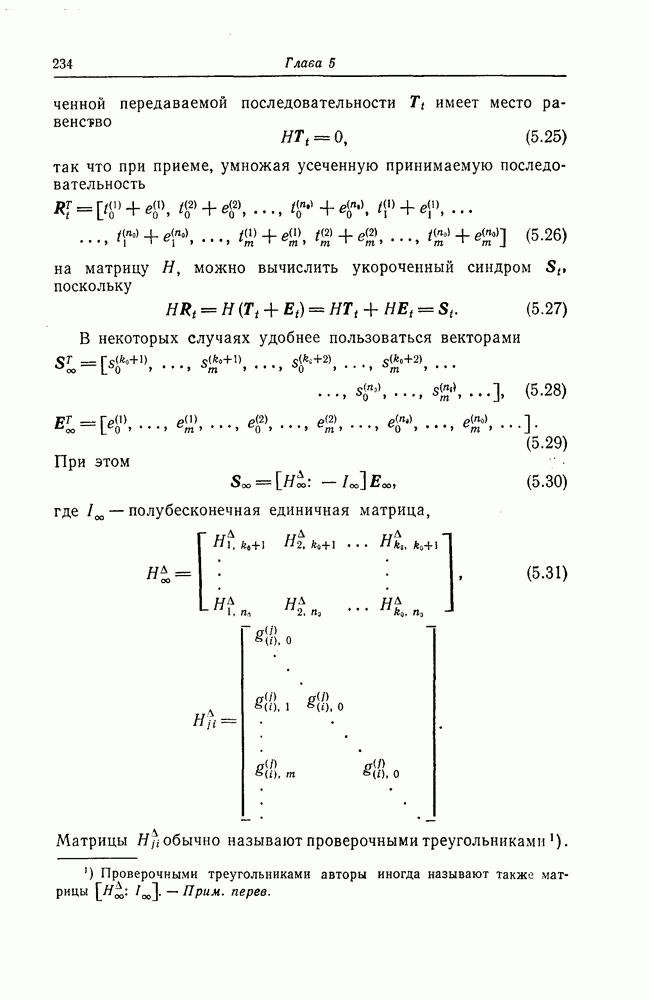
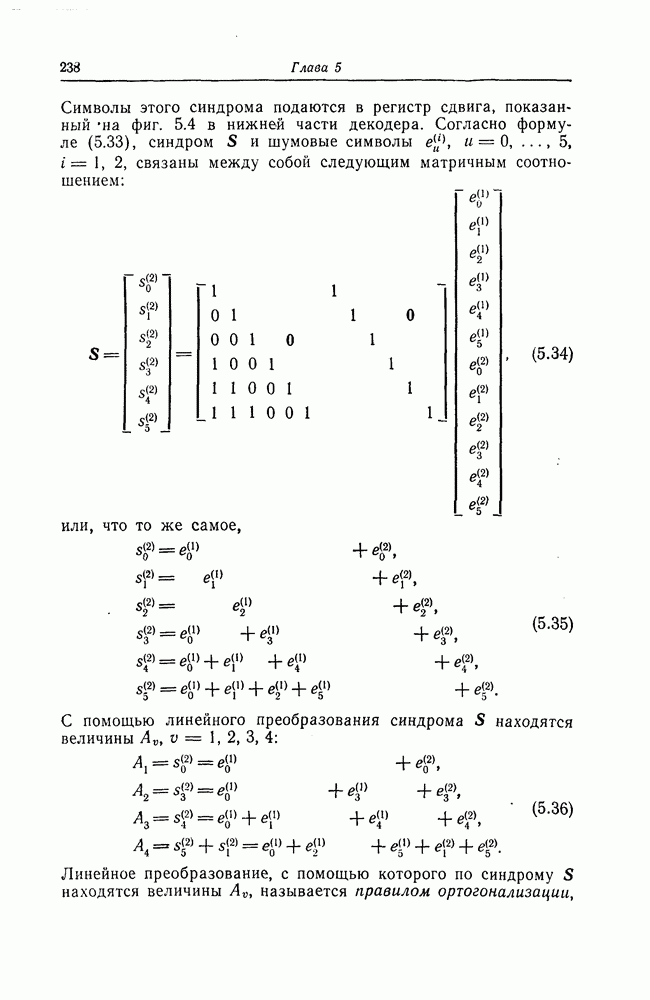
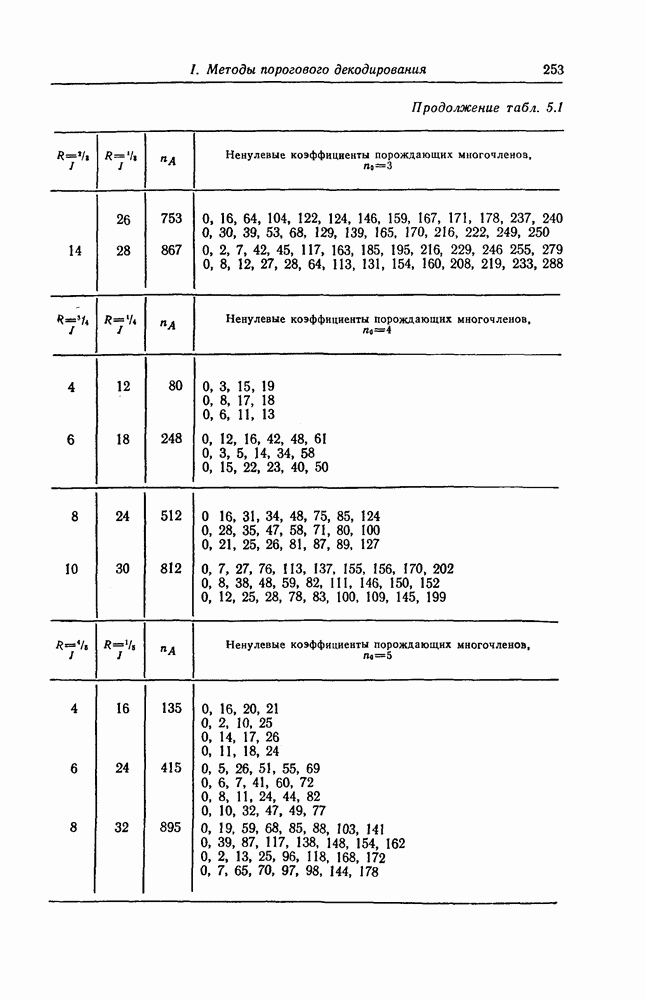
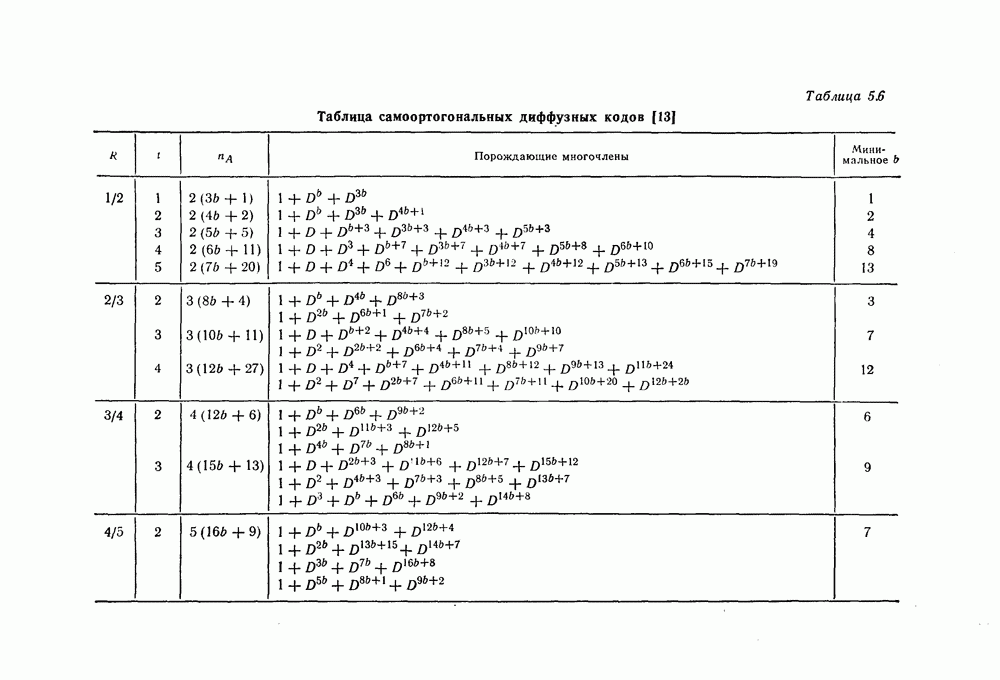
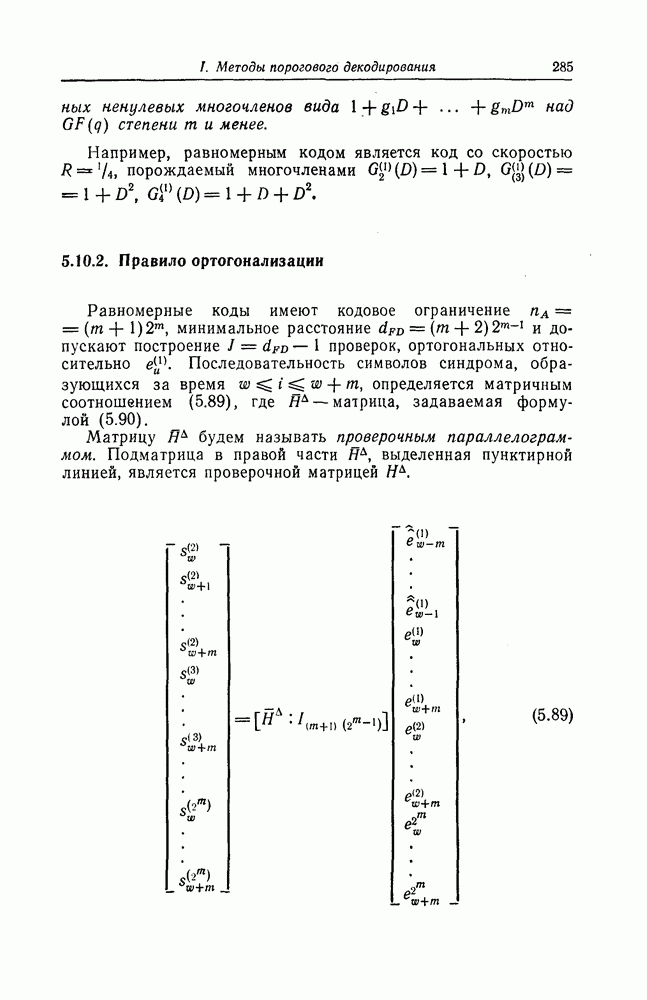
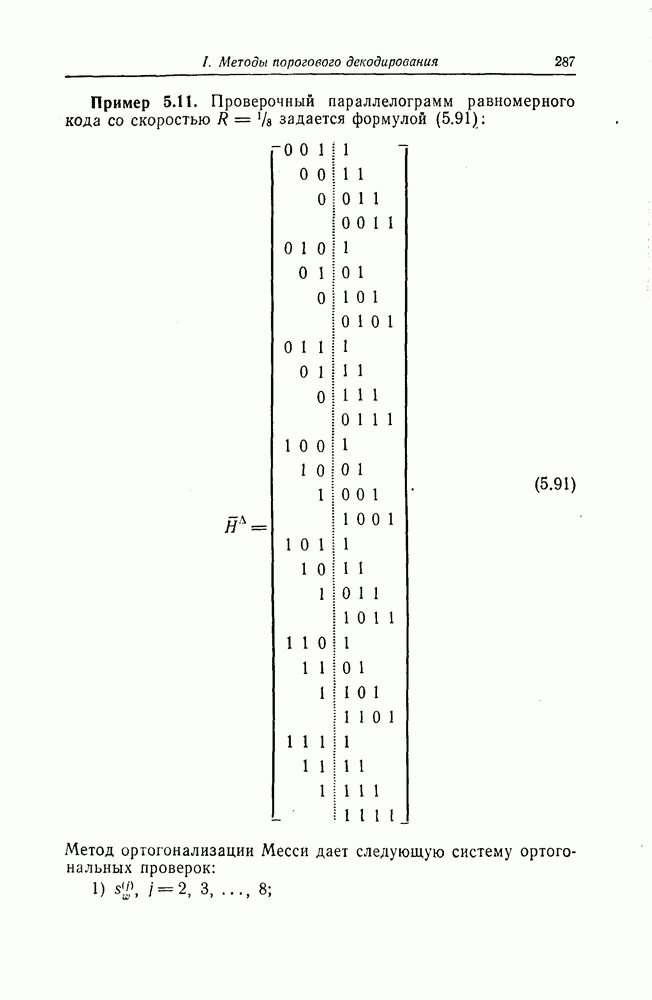
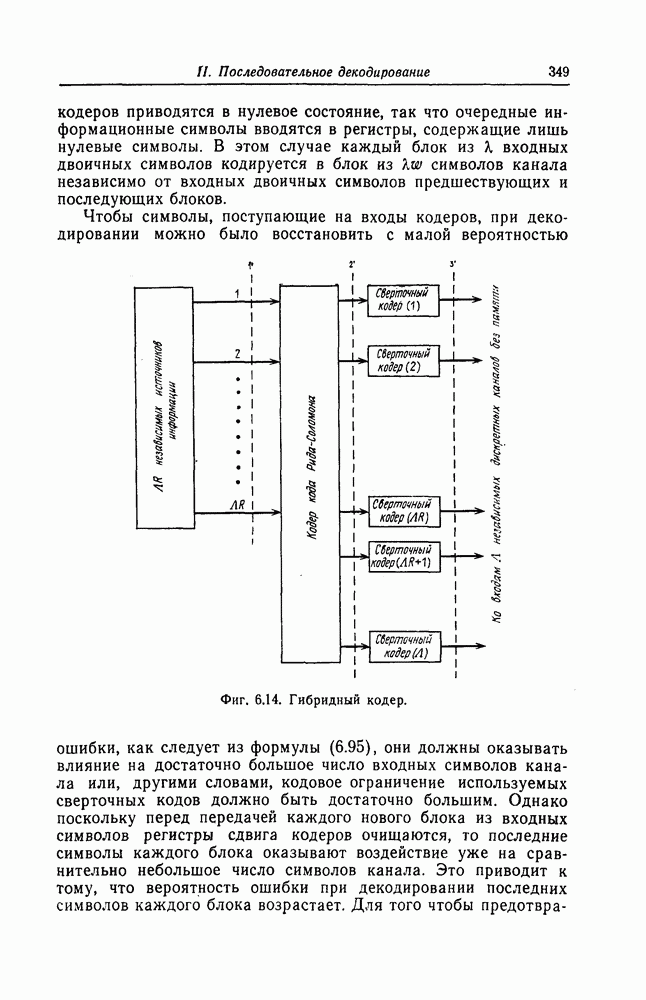
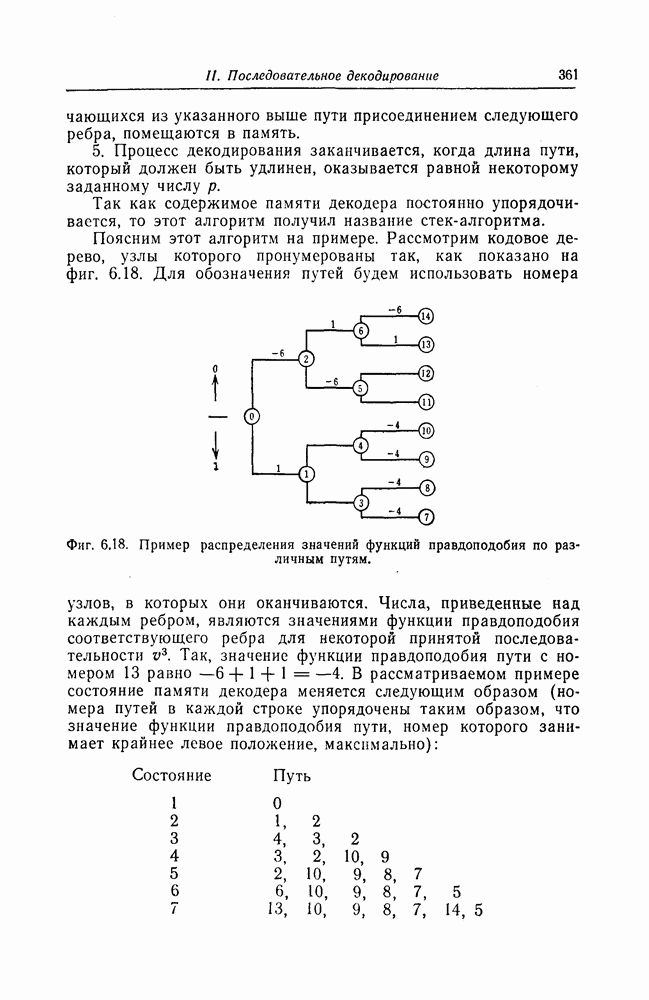
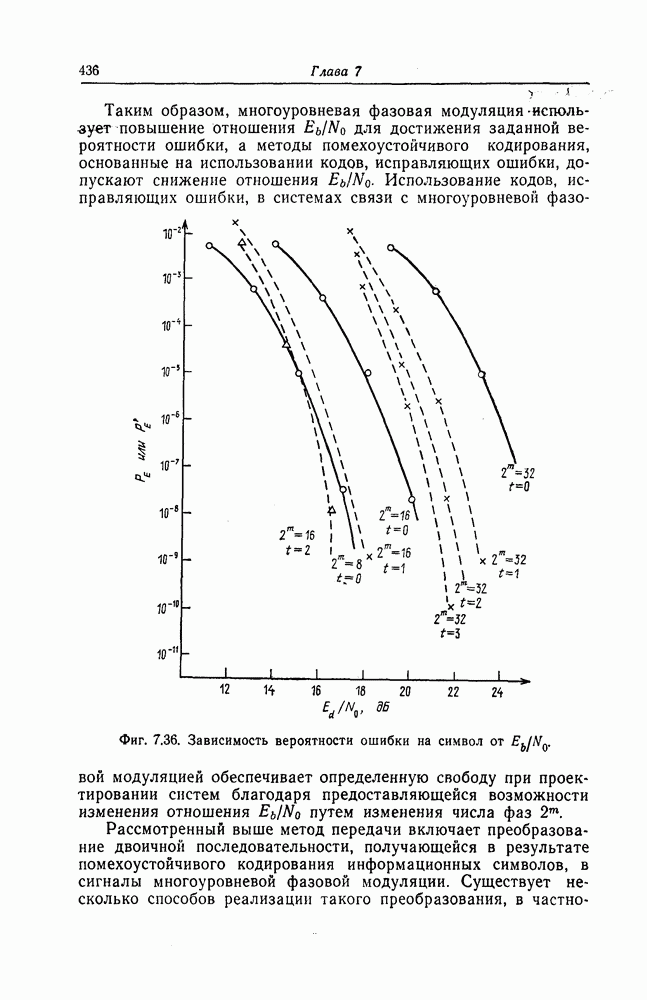
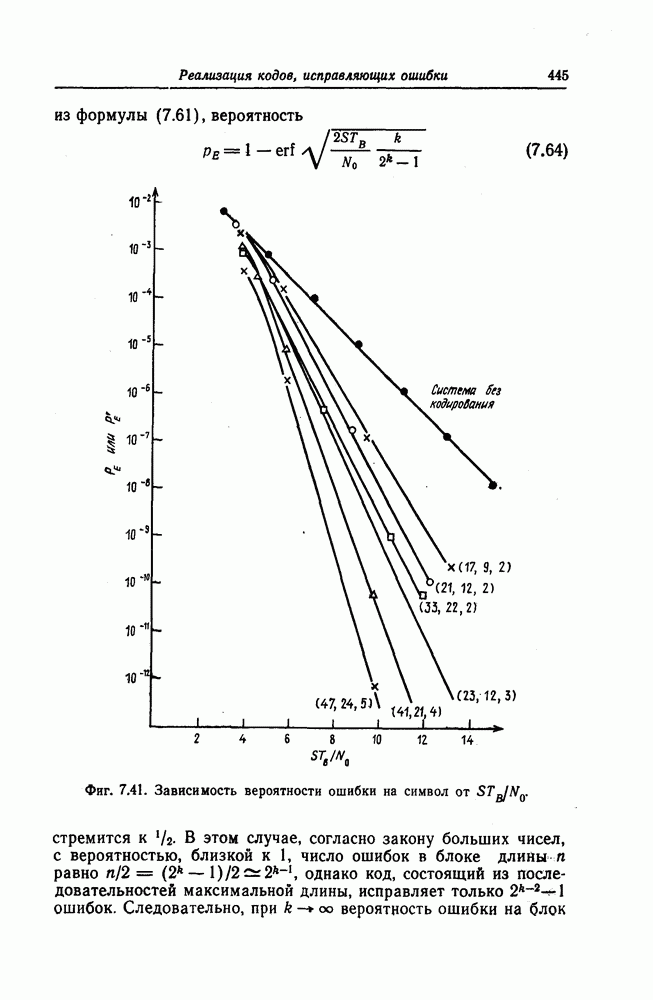
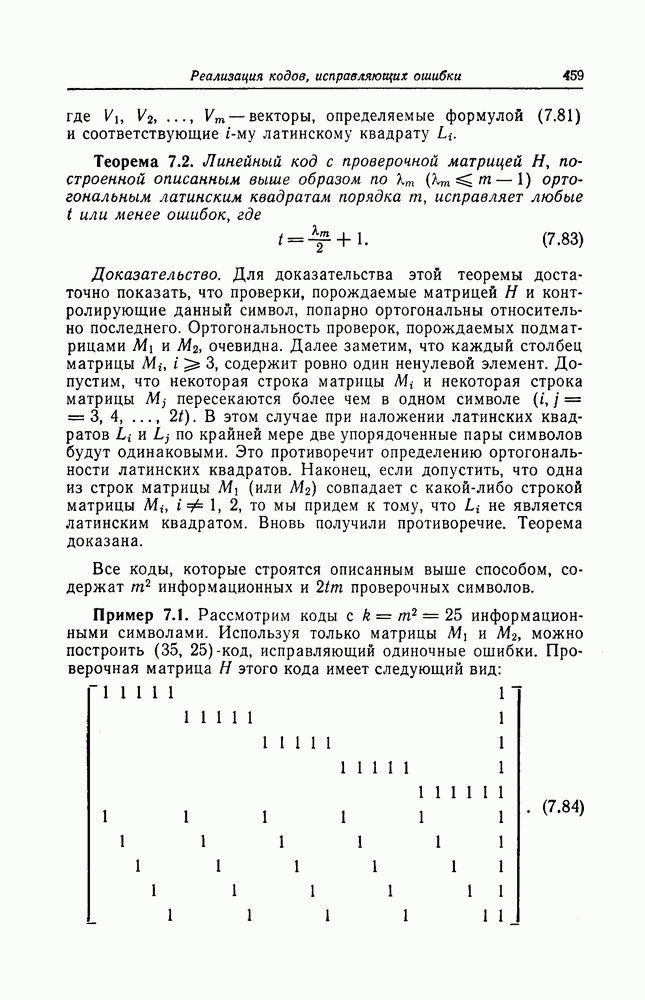
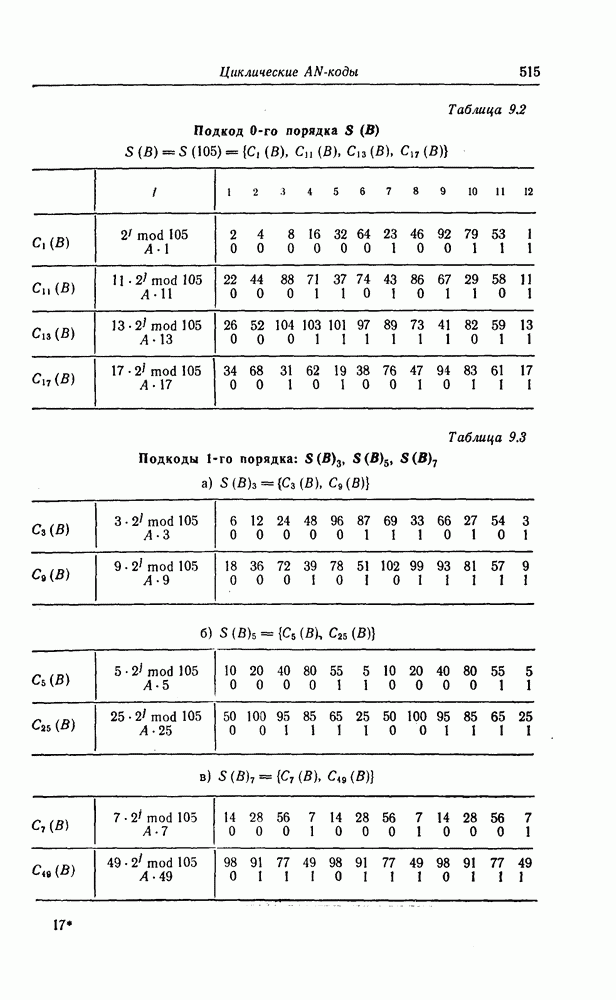
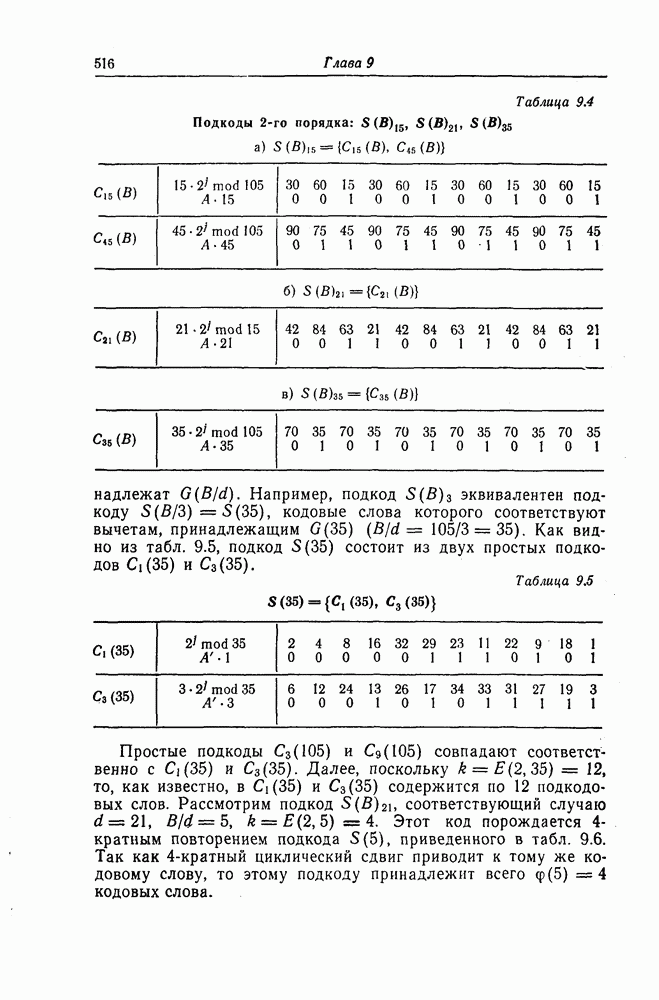
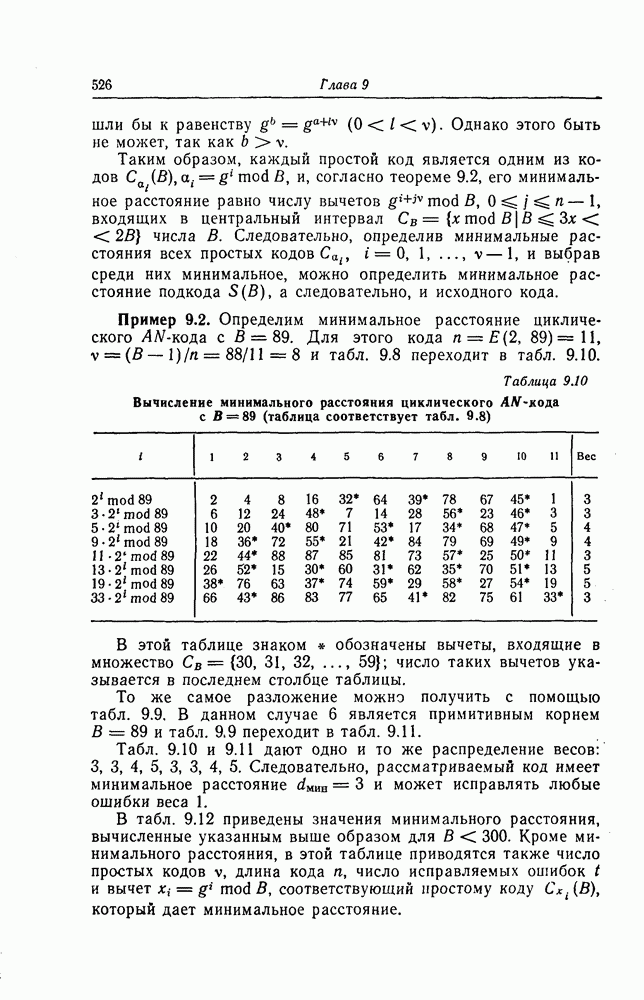
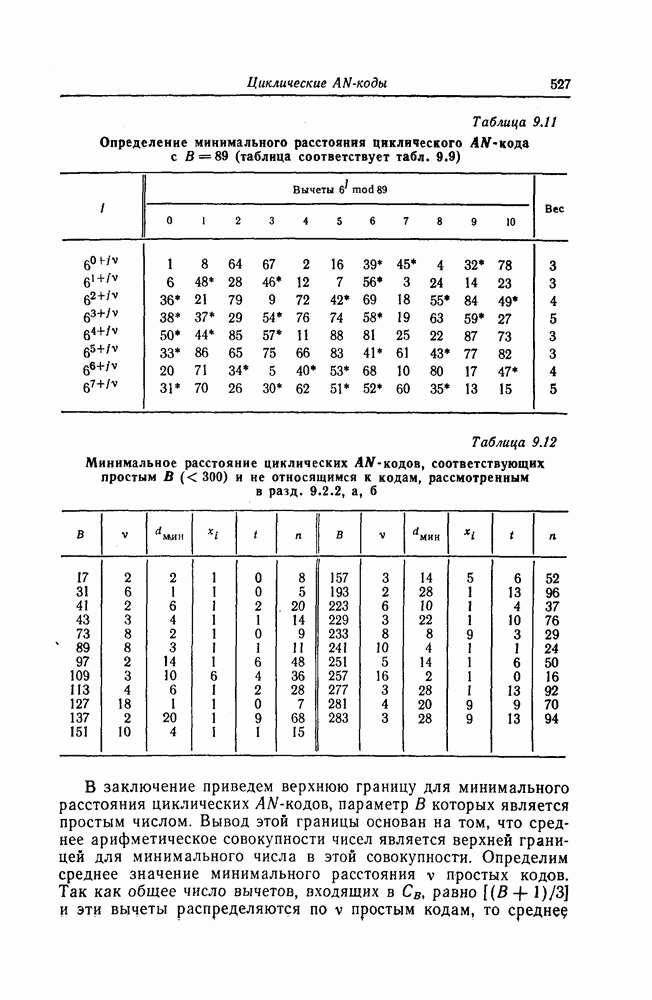
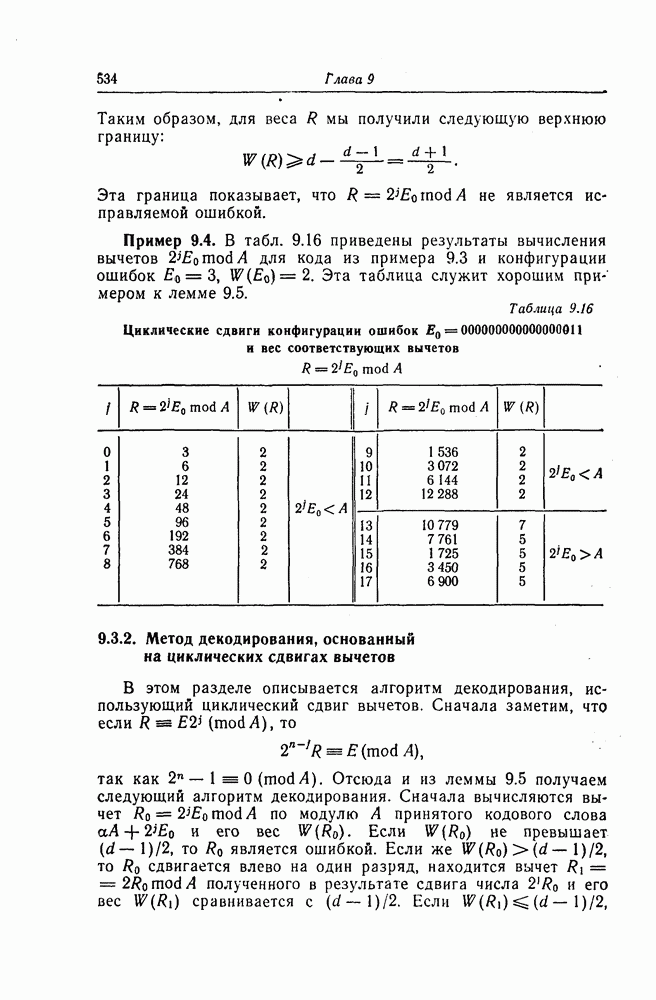
6.4. Распределение числа операций и вероятность переполнения буфераКак будет показано ниже, при последовательном декодировании в некоторой области скоростей передачи вероятность ошибки стремится экспоненциально к нулю с ростом длины кодового ограничения. Однако вероятность ошибки при декодировании не является тем параметром, который определяет поведение алгоритмов последовательного декодирования. Чтобы найти правильный путь при наличии сильных шумов, приемник должен обследовать большое число ребер, а для этого он должен хранить в памяти достаточно большое число принятых символов. Емкость памяти декодера в реальных системах ограничена, и поэтому при возникновении пачки шумов все элементы памяти могут оказываться занятыми, т. е. возникает так называемое переполнение буфера. Вероятность переполнения буфера является обычно тем параметром, который определяет поведение алгоритмов последовательного декодирования. В предыдущем разделе было найдено среднее число операций, необходимых для декодирования одного ребра, однако величиной, определяющей переполнение буфера, является не среднее число операций, а распределение числа операций, а именно вероятность операций при декодировании является распределением Парето, а именно Исследование вероятности переполнения буфера проведем в три этапа. Сначала рассмотрим структуру буфера и его функционирование, затем получим верхнюю и нижнюю границы для вероятности 6.4.1. Структура и функционирование буфераСтруктура буфера показана на фиг. 6.12.
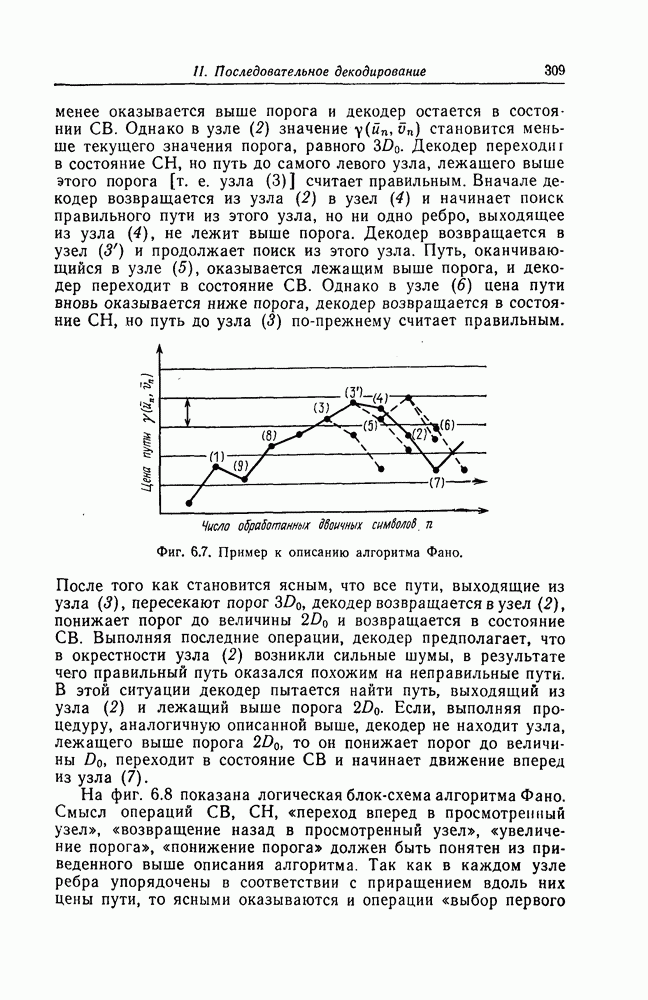
Фиг. 6.12. Стандартная структура буфера. Как видно из этой фигуры, часть емкости буфера используется для хранения символов принимаемых последовательностей, которые вводятся в буфер слева блоками в порядке поступления последних (каждый блок соответствует определенному ребру кодового дерева), а другая часть емкости буфера используется для хранения результатов предварительного декодирования принятых блоков. Буфер содержит два указателя Один из них, так называемый указатель предела, указывает первое слева ребро, обследованное декодером. Другой указатель, так называемый указатель поиска, указывает положение, в котором в данный момент времени декодер осуществляет поиск. Согласно фиг. 6.12, декодер может хранить В ребер. Защитная память, показанная на фиг. 6.12 справа, устанавливается для того, чтобы при переполнении буфера можно было выделить ненадежно декодированные данные. При слабых шумах оба указателя находятся, как правило, вблизи левого конца буфера, а также близко друг к другу. По мере возрастания уровня шумов, действующих в канале, оба указателя обычно смещаются вправо. При этом указатель поиска всегда располагается справа от указателя предела и расстояние между этими указателями возрастает медленнее, чем расстояние между указателем предела и левым концом буфера. Так как при малом уровне шумов цены правильного и неправильного путей сильно различаются, то в результате проводимого поиска сразу удается разделить правильный и неправильный пути. При пачке шумов цены правильного пути начинают падать и декодер, исследуя как падающий участок правильного пути, так и неправильные пути, цены которых лежат выше минимальной цены правильного пути, постепенно понижает порог. С уменьшением уровня шумов цены правильного пути начинают возрастать и декодер движется вперед, вновь повышая значения порога. Однако, возвращаясь к фиг. 6.7, заметим, что до этого декодер должен обследовать неправильные пути между узлами (7) и (9). Так как число ребер неправильных путей, лежащих в этой области, растет экспоненциально с ростом длины этого участка, то резко возрастает и объем проводимых вычислений. В результате указатель предела перемещается вправо на значительное расстояние от левого конца буфера, однако при этом расстояние между указателями предела и поиска оказывается несколько меньшим. 6.4.2. Нижняя граница для ...Распределение
Точнее, ими была получена нижняя граница для распределения Пусть задан дискретный канал без памяти, и пусть
Верхнюю огибающую Рассмотрим передачу по дискретному каналу без памяти
то, согласно формулам (1.68) и (1.69),
где Прежде чем применить эту границу для нахождения распределения числа операций при декодировании, введем следующие величины:
Покажем, что вероятность Для этого рассмотрим блоковый код со скоростью
Далее, подставим
Пусть X — некоторая постоянная и
При этом справедливы также неравенства (6.36) и (6.37). Подставляя выражение (6.39) в (6.37), получаем
Возьмем натуральный логарифм от обеих частей (6.42):
Используя эту формулу, преобразуем неравенство (6.43) к виду
Как следует из формулы (6.44),
Используя это соотношение, запишем формулу (6.45) в виде
Эта оценка может быть использована следующим образом. Предположим, что в начале принятой последовательности возникла пачка ошибок длины Условная вероятность того, что при передаче последовательности
и, следовательно, при декодировании списком по максимуму правдоподобия вероятность ошибки определяется равенством
Неравенство (6.47) представляет собой нижнюю границу для этой вероятности. Далее, предположим, что принята последовательность 1) Поиск ребер осуществляется последовательно. Если в некотором узле кодового дерева декодер выберет ребро, которое раньше не обследовалось, то это решение не зависит от принятой последовательности, соответствующей ребрам, лежащим на кодовом дереве глубже. 2) Декодер выполняет по крайней мере одну операцию на каждом обследуемом пути. В результате этого поиска передаваемые последовательности На время допустим, что на месте Результат упорядочения зависит от принятой последовательности последовательного декодирования. Однако результирующий порядок, согласно особенности 1, не зависит от символов передаваемой и принятой последовательностей, находящихся на расстоянии Согласно особенности 2 последовательного декодирования, в любом узле кодового дерева, который обследуется в процессе декодирования, декодер должен выполнить по крайней мере одну операцию. Следовательно, в случае, если передается последовательность, индекс которой принадлежит Таким образом, вероятность
Для каждой фиксированной последовательности
и, следовательно,
Эта оценка показывает, что распределение числа операций при декодировании является распределением Парето. Заметим, что полученная оценка является оценкой снизу числа операций, выполняемых декодером в узлах кодового дерева, лежащих на глубине
Таким образом, нижняя оценка для 6.4.3. Верхняя граница для ...Для вывода верхней границы для 1) Неравенство Чебышева. Пусть
Справедливо также следующее неравенство:
где 2) Неравенство Минковского. Пусть
и, кроме того,
Используя эти два неравенства и верхнюю границу для числа операций при декодировании, даваемую соотношением (6.15), Сэвадж [9] получил следующую верхнюю границу для Теорема 6.2. (Сэвадж). Существует сверточный код со скоростью передачи
Доказательство. Рассматривая суммы по
как суммы по
где черта сверху означает усреднение по принимаемым последовательностям и ансамблю кодов. Здесь воспользуемся ансамблем кодов, в котором все символы кодовых слов являются независимыми величинами с распределением
где
При
Это доказывает существование по крайней мере одного кода, распределение величины с для которого удовлетворяет (6.57). Таким образом, мы получили верхнюю и нижнюю границы распределения 6.4.4. Связь с вероятностью переполнения буфераУстановить связь между распределением Операции, которые выполняются декодером в узлах неправильного подмножества кодового дерева, обычно являются операциями, связанными с обследованием коротких путей этого неправильного подмножества. Действительно, длинные пути имеют цены, значительно отличающиеся от цен правильного пути. В силу этого вероятность того, что выполняемые декодером операции связаны с обследованием длинного пути, является очень малой. Это позволяет предположить, что операции, выполняемые декодером в неправильных подмножествах кодового дерева, являются операциями, которые, как правило, декодер выполняет в небольших локальных «впадинах», образующихся на траектории правильного пути. Поэтому, если некоторая впадина правильного пути содержит
Предположим, что пики числа операций, обусловленные этими неправильными подмножествами, появляются независимо. Пусть
Обозначим через а число операций, выполняемых декодером за время получения одного ребра, и через В — объем регистра в ребрах. Тогда
и, следовательно,
Приведенные выше качественные рассуждения подтверждаются результатами моделирования. Кроме того, теоретическим подтверждением правильности этих качественных рассуждений является нижняя граница для (6.50). В оставшейся части этого раздела остановимся на этой нижней границе. Предположим, что емкость памяти декодера такова, что в ней могут храниться все данные, необходимые для декодирования 0 двоичных информационных символов. Тогда, если за время поступления и
и
где Далее рассмотрим случай декодирования
Так как в данном случае рассматривается канал без памяти, то шумы, действующие на тот или иной фиксированный подблок, не зависят от шумов, действующих на другие подблоки. Поскольку вероятность ошибки при обработке то, используя разложение бинома, для вероятности
Далее рассмотрим случай декодера без учителя. Всякий раз, когда декодер с учителем переполняет буфер, декодер без учителя либо также переполняет буфер, либо возникает ошибка. (При отсутствии ошибки декодер без учителя выполняет все операции, которые выполняет декодер с учителем, и, кроме того, при выходе за пределы начальных подблоков неправильных путей он должен также выполнять операции на последующих подблоках. Эти операции выполняют функции учителя и при отсутствии ошибок указывают декодеру на то, что он вышел из подблока неправильного пути.) Следовательно, вероятность переполнения буфера декодером с учителем является границей сверху для вероятности переполнения буфера декодером без учителя или возникновения ошибки, т. е.
Следующее неравенство следует непосредственно из (6.42):
Из формул (6.65) и (6.66) для
(Здесь мы воспользовались также тем, что
Из формул (6.69) и (6.71) непосредственно следует, что
Объединяя слагаемые, содержащие
Отсюда следует, что если
то
Заметим, что условие (6.73) в большинстве практически интересных случаев выполняется. Согласно формулам (6.66) и (6.73),
Отсюда, а также из формул (6.52), (6.65), неравенства со
Предположим, что (о и
Таким образом, сравнительно просто была получена нижняя граница для вероятности ошибки или переполнения буфера. Этот результат не является столь же сильным, как верхняя граница. Нижняя граница и верхняя граница, полученная с помощью качественных рассуждений, похожи друг на друга. Из формул (6.64) и (6.57) следует, что
Полагая в нижней границе
Таким образом, вероятность переполнения буфера линейно возрастает с
|
 |
Оглавление
|

















































































































































































































































































































































































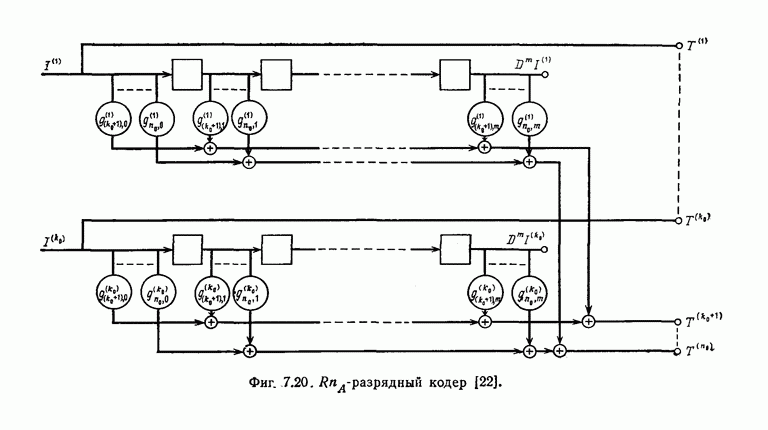

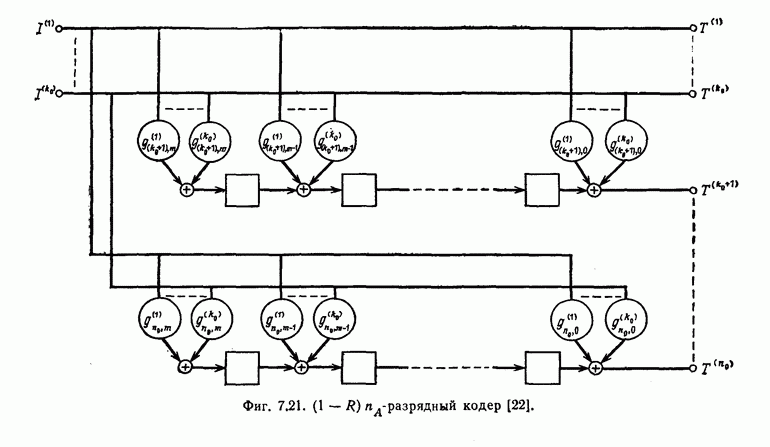
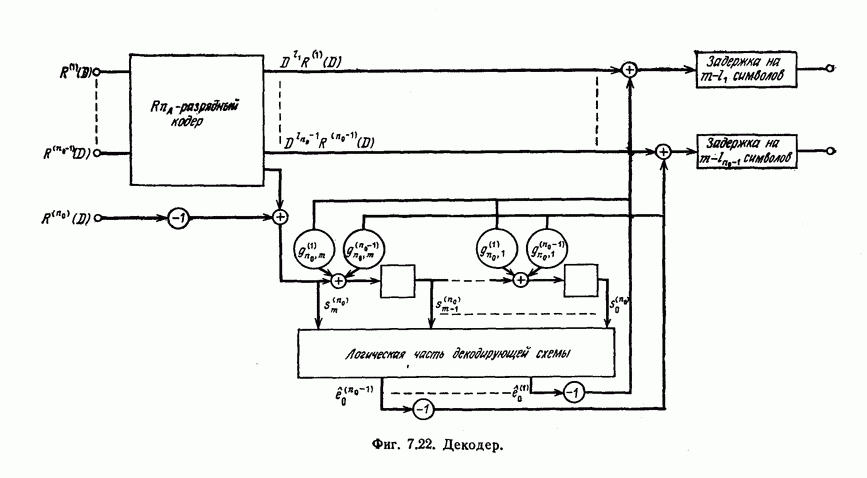



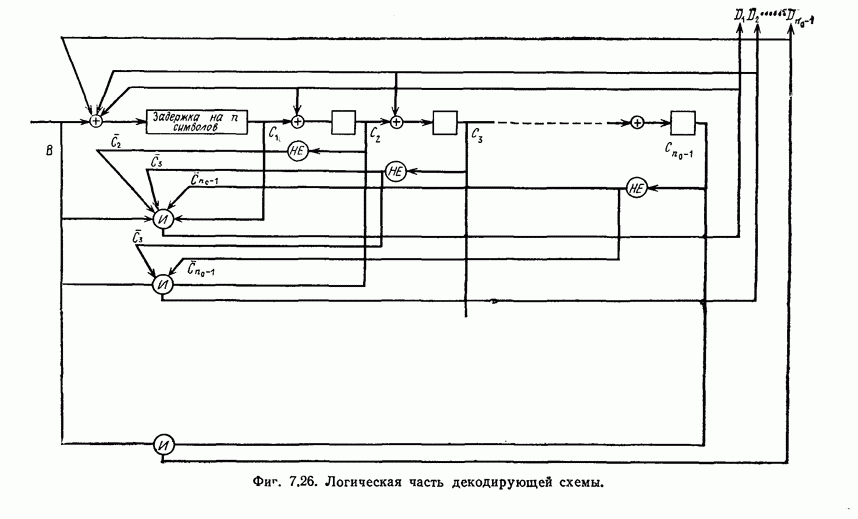




























































































































 того, что число операций при декодировании с превысит значение
того, что число операций при декодировании с превысит значение  Как уже было показано выше, случайная величина с, определяющая число операций, выполняемых декодером в неправильных подмножествах кодового дерева, связана с ценами путей всех возможных длин; поскольку эти пути являются зависимыми, то нахождение точных значений вероятности
Как уже было показано выше, случайная величина с, определяющая число операций, выполняемых декодером в неправильных подмножествах кодового дерева, связана с ценами путей всех возможных длин; поскольку эти пути являются зависимыми, то нахождение точных значений вероятности  является трудной задачей. Поэтому очень важно попытаться обойти статистическую зависимость неправильных путей кодового дерева и получить верхнюю и нижнюю границы для вероятности
является трудной задачей. Поэтому очень важно попытаться обойти статистическую зависимость неправильных путей кодового дерева и получить верхнюю и нижнюю границы для вероятности  которые бы достаточно точно описывали ее поведение. Ниже такие границы будут получены, и из этих границ будет следовать, что распределение числа
которые бы достаточно точно описывали ее поведение. Ниже такие границы будут получены, и из этих границ будет следовать, что распределение числа

 и наконец установим связь между вероятностью переполнения буфера и вероятностью
и наконец установим связь между вероятностью переполнения буфера и вероятностью 

 числа операций при декодировании
числа операций при декодировании  двоичных информационных символов было найдено Джекобсом и Берлекэмпом [12]:
двоичных информационных символов было найдено Джекобсом и Берлекэмпом [12]:

 числа операций с, необходимых декодеру для декодирования
числа операций с, необходимых декодеру для декодирования  первых информационных символов, из которой следовало приведенное выше приближенное равенство. Эта нижняя граница была получена методом, в основных чертах совпадающим с методом получения нижней границы для вероятности ошибки при декодировании списком, использованным Шенноном, Галлагером и Берлекэмпом [5].
первых информационных символов, из которой следовало приведенное выше приближенное равенство. Эта нижняя граница была получена методом, в основных чертах совпадающим с методом получения нижней границы для вероятности ошибки при декодировании списком, использованным Шенноном, Галлагером и Берлекэмпом [5].

 будем обозначать через
будем обозначать через  Для большого числа реальных каналов
Для большого числа реальных каналов  и вместо
и вместо  всегда можно использовать
всегда можно использовать  Использование
Использование  в подобных случаях позволяет упростить нижнюю границу.
в подобных случаях позволяет упростить нижнюю границу.
 равновероятных сообщений с помощью блокового кода из
равновероятных сообщений с помощью блокового кода из  кодовых слов, каждое из которых состоит из
кодовых слов, каждое из которых состоит из  входных символов канала. Приемник обрабатывает последовательности длины
входных символов канала. Приемник обрабатывает последовательности длины  поступающие с выхода канала, и сопоставляет каждой из них список из
поступающие с выхода канала, и сопоставляет каждой из них список из  сообщений. Вероятность того, что в этом списке сообщений отсутствует действительно передававшееся сообщение, обозначается через
сообщений. Вероятность того, что в этом списке сообщений отсутствует действительно передававшееся сообщение, обозначается через  Пусть
Пусть  произвольное целое число. Если число кодовых слов
произвольное целое число. Если число кодовых слов  и число сообщений
и число сообщений  включаемых при декодировании в список, удовлетворяют неравенству
включаемых при декодировании в список, удовлетворяют неравенству


 функции, стремящиеся к нулю с ростом
функции, стремящиеся к нулю с ростом  Эта граница справедлива для произвольного блокового кода длины
Эта граница справедлива для произвольного блокового кода длины  и произвольного декодера со списком объема
и произвольного декодера со списком объема 

 можно оценить сверху функцией, которая имеет тот же вид, что и распределение Парето.
можно оценить сверху функцией, которая имеет тот же вид, что и распределение Парето.
 зафиксируем
зафиксируем  и выберем некоторым специальным указанным ниже образом
и выберем некоторым специальным указанным ниже образом  так, чтобы выполнялось неравенство (6.36). Сначала запишем неравенство (6.36) в следующем виде:
так, чтобы выполнялось неравенство (6.36). Сначала запишем неравенство (6.36) в следующем виде:

 в правую часть (6.40) вместо
в правую часть (6.40) вместо  и выберем минимально возможное
и выберем минимально возможное  такое, что
такое, что

 минимальное кратное X, для которого выполняется неравенство (6.41). При таком выборе
минимальное кратное X, для которого выполняется неравенство (6.41). При таком выборе  наряду с (6.41) имеет место и другое неравенство:
наряду с (6.41) имеет место и другое неравенство:





 имеет порядок
имеет порядок 


 Допустим, что длина этой пачки является целым числом, кратным некоторой постоянной X и удовлетворяющим неравенствам (6.41) и (6.42). Обозначим через
Допустим, что длина этой пачки является целым числом, кратным некоторой постоянной X и удовлетворяющим неравенствам (6.41) и (6.42). Обозначим через  совокупность передаваемых последовательностей длины
совокупность передаваемых последовательностей длины  выходящих из начального узла кодового дерева. Эту совокупность, содержащую
выходящих из начального узла кодового дерева. Эту совокупность, содержащую  последовательностей, можно рассматривать как блоковый код длины
последовательностей, можно рассматривать как блоковый код длины  со скоростью
со скоростью  Обозначим через
Обозначим через  первые
первые  символов принятой последовательности. Для каждой фиксированной последовательности
символов принятой последовательности. Для каждой фиксированной последовательности  совокупность
совокупность  вероятностей
вероятностей  упорядочим в порядке их убывания. Пусть
упорядочим в порядке их убывания. Пусть  -совокупность индексов
-совокупность индексов  последних вероятностей из этого списка. Если принята последовательность
последних вероятностей из этого списка. Если принята последовательность  то
то  указывает
указывает  наименее правдоподобных сообщений или, другими словами,
наименее правдоподобных сообщений или, другими словами,  выделяет совокупность сообщений, которые при декодировании списком по максимуму правдоподобия не включаются в список.
выделяет совокупность сообщений, которые при декодировании списком по максимуму правдоподобия не включаются в список.
 индекс 1 которой принадлежит
индекс 1 которой принадлежит  будет принята последовательность
будет принята последовательность  равна
равна


 и рассмотрим, каким образом последовательный декодер осуществляет поиск правильного пути, выходящего из начального узла кодового дерева. Поведение любого последовательного декодера характеризуется следующими особенностями:
и рассмотрим, каким образом последовательный декодер осуществляет поиск правильного пути, выходящего из начального узла кодового дерева. Поведение любого последовательного декодера характеризуется следующими особенностями:
 обследуются до полной длины
обследуются до полной длины  и декодер после
и декодер после  символа продолжает двигаться вперед; здесь мы рассмотрим лишь пути кодового дерева длины
символа продолжает двигаться вперед; здесь мы рассмотрим лишь пути кодового дерева длины 
 символа имеется некий учитель, который указывает декодеру, выбрал ли он правильную последовательность
символа имеется некий учитель, который указывает декодеру, выбрал ли он правильную последовательность  или некоторую неправильную последовательность. Если последовательность
или некоторую неправильную последовательность. Если последовательность  является неправильным путем, то декодер установленным для данного алгоритма порядком возвращается назад и начинает обследование другого пути
является неправильным путем, то декодер установленным для данного алгоритма порядком возвращается назад и начинает обследование другого пути  до длины
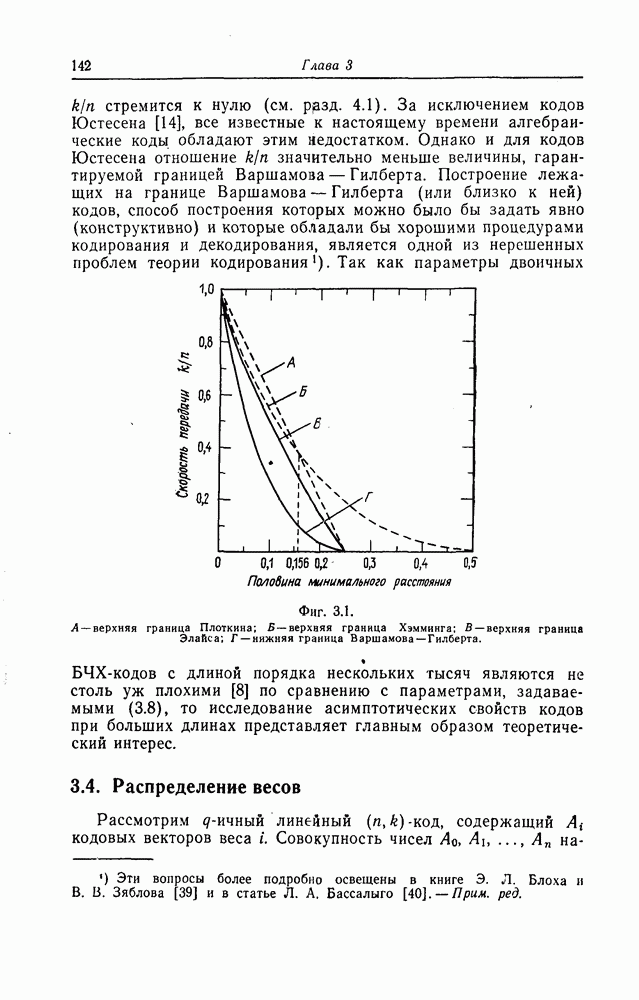
до длины  Если и этот путь является неправильным, то учитель вторично указывает декодеру на ошибку. Декодер вновь возвращается назад в исходное состояние и начинает обследование третьей последовательности и т. д. Другими словами, эти действия декодера для каждой фиксированной принятой последовательности
Если и этот путь является неправильным, то учитель вторично указывает декодеру на ошибку. Декодер вновь возвращается назад в исходное состояние и начинает обследование третьей последовательности и т. д. Другими словами, эти действия декодера для каждой фиксированной принятой последовательности  длины
длины  можно интерпретировать как один из способов упорядочения последовательностей из
можно интерпретировать как один из способов упорядочения последовательностей из 
 передаваемых последовательностей
передаваемых последовательностей  и алгоритма
и алгоритма
 и более от начального узла кодового дерева. Пусть
и более от начального узла кодового дерева. Пусть  -множество индексов
-множество индексов  последних
последних  последовательностей из
последовательностей из  упорядоченных указанным выше образом.
упорядоченных указанным выше образом.
 а принята последовательность
а принята последовательность  то декодер с учителем на глубине
то декодер с учителем на глубине  кодового. дерева должен выполнить по крайней мере
кодового. дерева должен выполнить по крайней мере  операций.
операций.
 того, что декодер с учителем выполнит по крайней мере
того, что декодер с учителем выполнит по крайней мере  операций при обследовании кодового дерева до глубины
операций при обследовании кодового дерева до глубины  должна удовлетворять неравенству
должна удовлетворять неравенству

 наборы
наборы  задают подмножества из
задают подмножества из  кодовых слов множества
кодовых слов множества  Так как
Так как  определяет подмножество наименее правдоподобных кодовых слов, то
определяет подмножество наименее правдоподобных кодовых слов, то


 и менее. Так как в число этих операций входят также и операции, выполняемые декодером в подмножестве неправильных путей, то левая часть (6 51) также является оценкой снизу для распределения числа операций с, выполняемых в подмножестве неправильных путей, т. е.
и менее. Так как в число этих операций входят также и операции, выполняемые декодером в подмножестве неправильных путей, то левая часть (6 51) также является оценкой снизу для распределения числа операций с, выполняемых в подмножестве неправильных путей, т. е.

 получена.
получена.
 потребуются следующие два неравенства:
потребуются следующие два неравенства:
 произвольная случайная величина,
произвольная случайная величина,  ее среднее значение и
ее среднее значение и  дисперсия. Тогда
дисперсия. Тогда


 случайная величина, принимающая только отрицательные значения.
случайная величина, принимающая только отрицательные значения.
 неотрицательные случайные величины, принимающие с вероятностью
неотрицательные случайные величины, принимающие с вероятностью  соответственно значения а
соответственно значения а  Тогда для любого
Тогда для любого 



 для которого распределение
для которого распределение  числа операций с для типичного подмножества неправильных путей в дискретном канале без памяти удовлетворяет неравенству
числа операций с для типичного подмножества неправильных путей в дискретном канале без памяти удовлетворяет неравенству

 в (6.15), т. е. в неравенстве
в (6.15), т. е. в неравенстве

 неравенства (6.56), получаем
неравенства (6.56), получаем

 Аналогично тому, как было получено неравенство (6.33), можно показать, что
Аналогично тому, как было получено неравенство (6.33), можно показать, что 


 величина и, следовательно,
величина и, следовательно,  сходятся. Это означает, что существует код, для которого момент
сходятся. Это означает, что существует код, для которого момент  порядка величины с не превышает некоторую константу
порядка величины с не превышает некоторую константу  Из неравенств
Из неравенств  получаем, что
получаем, что  Согласно неравенству Чебышева, типичное для ансамбля кодов распределение
Согласно неравенству Чебышева, типичное для ансамбля кодов распределение  величины с должно удовлетворять неравенству
величины с должно удовлетворять неравенству

 числа операций при декодировании с. Эти границы показывают, что рассматриваемое распределение является распределением Парето.
числа операций при декодировании с. Эти границы показывают, что рассматриваемое распределение является распределением Парето.
 и вероятностью переполнения буфера точно очень трудно. Поэтому здесь сначала обсудим эту связь качественно, а затем покажем, как, следуя подобным качественным рассуждениям, можно получить нижнюю границу для вероятности переполнения буфера.
и вероятностью переполнения буфера точно очень трудно. Поэтому здесь сначала обсудим эту связь качественно, а затем покажем, как, следуя подобным качественным рассуждениям, можно получить нижнюю границу для вероятности переполнения буфера.
 неправильных подмножеств, то суммарное число операций, выполняемых декодером при обследовании этой впадины, является суммой чисел операций, выполняемых декодером в каждом из неправильных подмножеств, а поэтому естественно предположить, что эта сумма имеет то же распределение, что и число операций, выполняемых декодером в каждом из упомянутых выше неправильных подмножеств. Обозначим через
неправильных подмножеств, то суммарное число операций, выполняемых декодером при обследовании этой впадины, является суммой чисел операций, выполняемых декодером в каждом из неправильных подмножеств, а поэтому естественно предположить, что эта сумма имеет то же распределение, что и число операций, выполняемых декодером в каждом из упомянутых выше неправильных подмножеств. Обозначим через  суммарное число операций, необходимых для обследования каждой впадины, и пусть с — число операций, выполняемых декодером в одном неправильном подмножестве кодового дерева. Тогда в силу вышеизложенного при больших значениях с и
суммарное число операций, необходимых для обследования каждой впадины, и пусть с — число операций, выполняемых декодером в одном неправильном подмножестве кодового дерева. Тогда в силу вышеизложенного при больших значениях с и  имеем
имеем

 вероятность того, что буфер переполнится при декодировании
вероятность того, что буфер переполнится при декодировании  ребра или ранее,
ребра или ранее,  число операций, необходимых для заполнения пустого буфера. Тогда, так как всего образуется
число операций, необходимых для заполнения пустого буфера. Тогда, так как всего образуется  пиков числа операций, то
пиков числа операций, то



 полученная с их помощью Джекобсом и Берлекэмпом [12] на основании оценки
полученная с их помощью Джекобсом и Берлекэмпом [12] на основании оценки
 двоичных информационных символов по крайней мере и символов оказались не декодированными, то возникает переполнение буфера. За время поступления и
двоичных информационных символов по крайней мере и символов оказались не декодированными, то возникает переполнение буфера. За время поступления и  двоичных информационных символов декодер может выполнить не более чем
двоичных информационных символов декодер может выполнить не более чем  операций. Следовательно, всегда, когда для декодирования и двоичных информационных символов необходимо выполнить более чем
операций. Следовательно, всегда, когда для декодирования и двоичных информационных символов необходимо выполнить более чем  операций, возникает переполнение буфера. Пусть
операций, возникает переполнение буфера. Пусть

 — число двоичных информационных символов, соответствующих
— число двоичных информационных символов, соответствующих  символам канала. Тогда при любой скорости передачи
символам канала. Тогда при любой скорости передачи  имеет место следующее равенство:
имеет место следующее равенство:

 целое число, удовлетворяющее соотношениям (6.41) и (6.42) (через
целое число, удовлетворяющее соотношениям (6.41) и (6.42) (через  здесь и ниже обозначается минимальное (максимальное) целое число, большее (меньшее) или равное
здесь и ниже обозначается минимальное (максимальное) целое число, большее (меньшее) или равное 
 двоичных информационных символов. Эти символы можно разбить на
двоичных информационных символов. Эти символы можно разбить на  подблоков по и двоичных символов в каждом
подблоков по и двоичных символов в каждом  символов канала). Предположим, что декодер имеет учителя, и всякий раз, когда он начинает декодирование подблока неправильного пути, учитель указывает на это. Декодер возвращается по этому подблоку назад, начинает обследование следующего пути и, таким образом, в конце концов обнаруживает правильный подблок. Другими словами, предположим, что декодер с учителем всегда следует по
символов канала). Предположим, что декодер имеет учителя, и всякий раз, когда он начинает декодирование подблока неправильного пути, учитель указывает на это. Декодер возвращается по этому подблоку назад, начинает обследование следующего пути и, таким образом, в конце концов обнаруживает правильный подблок. Другими словами, предположим, что декодер с учителем всегда следует по  подблокам правильного пути. Таким образом, в случае декодера с учителем вероятность
подблокам правильного пути. Таким образом, в случае декодера с учителем вероятность  возникновения переполнения буфера во время декодирования любого из
возникновения переполнения буфера во время декодирования любого из  подблоков ограничена снизу вероятностью того, что для обнаружения правильного пути для этого подблока потребуется
подблоков ограничена снизу вероятностью того, что для обнаружения правильного пути для этого подблока потребуется  или более операций, т. е.
или более операций, т. е.

 двоичных информационных символов равна нулю для декодера с учителем,
двоичных информационных символов равна нулю для декодера с учителем,
 переполнения буфера для одного подблока получаем следующую оценку:
переполнения буфера для одного подблока получаем следующую оценку:



 получаем следующую оценку:
получаем следующую оценку:

 Разлагая второе слагаемое в правой части последнего неравенства, получаем
Разлагая второе слагаемое в правой части последнего неравенства, получаем


 имеем
имеем




 и формулы (6.75) получаем
и формулы (6.75) получаем

 таковы, что
таковы, что  При этих предположениях из формул (6.68) и (6.69) получаем
При этих предположениях из формул (6.68) и (6.69) получаем


 получаем
получаем

 и убывает с ростом
и убывает с ростом 