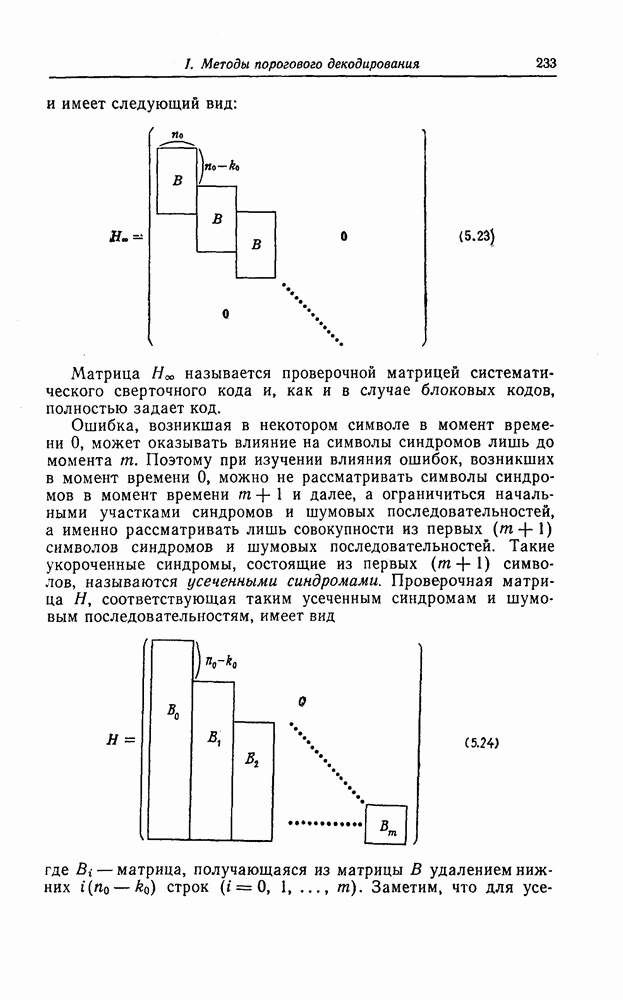
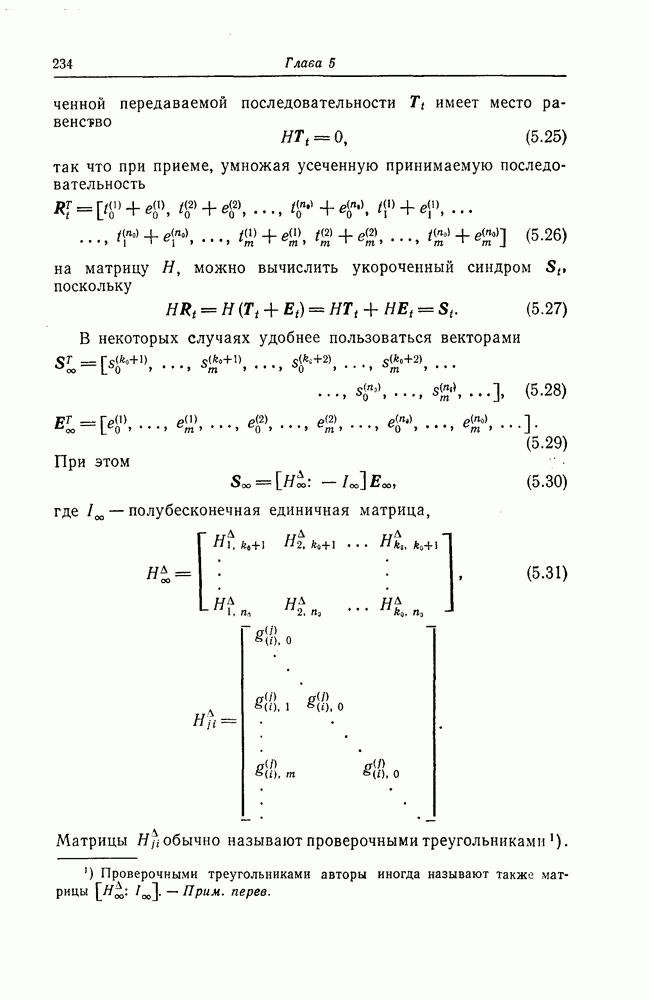
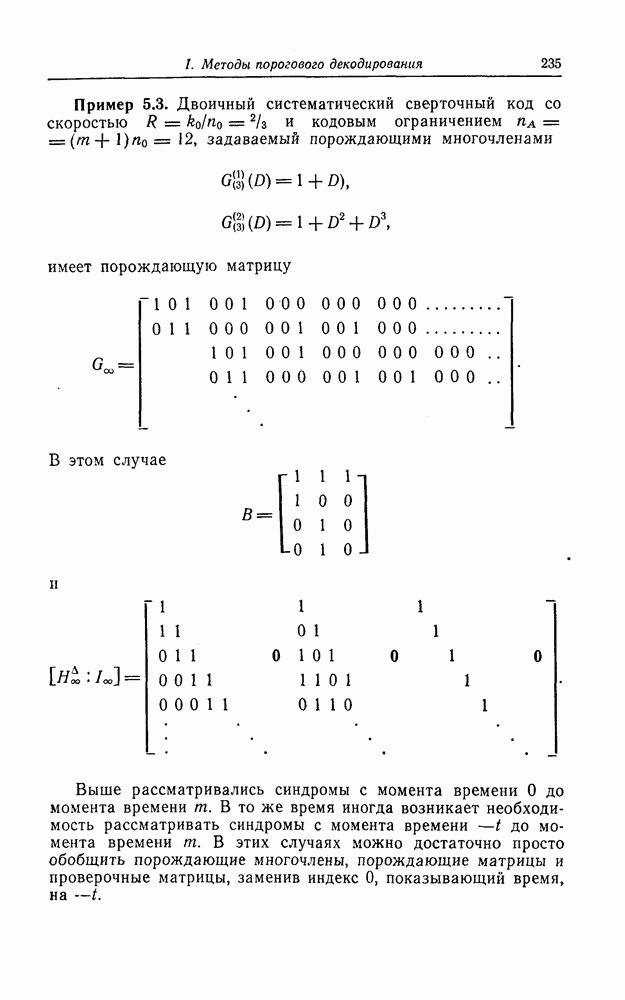
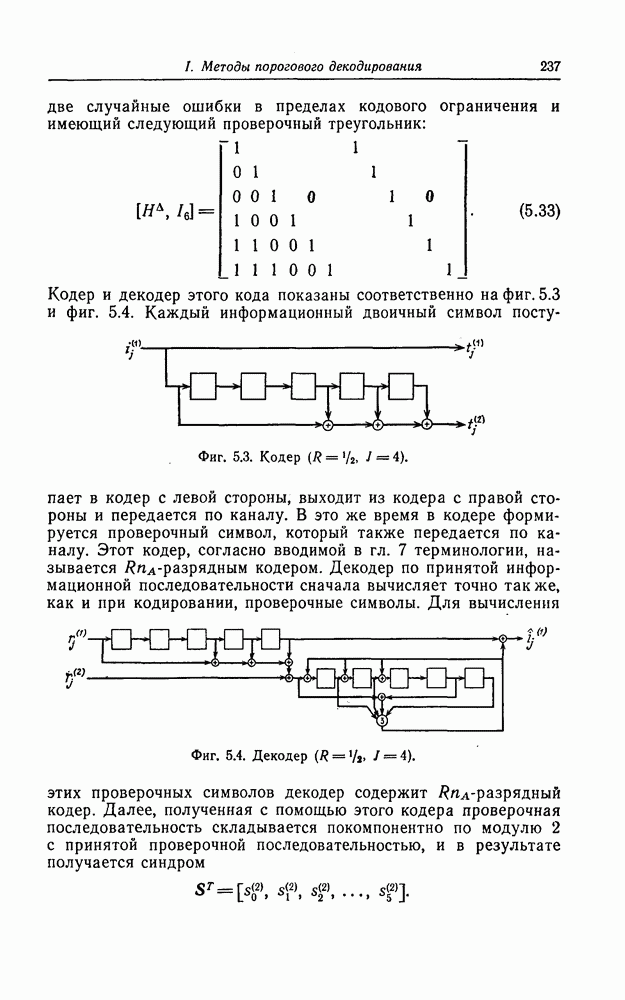
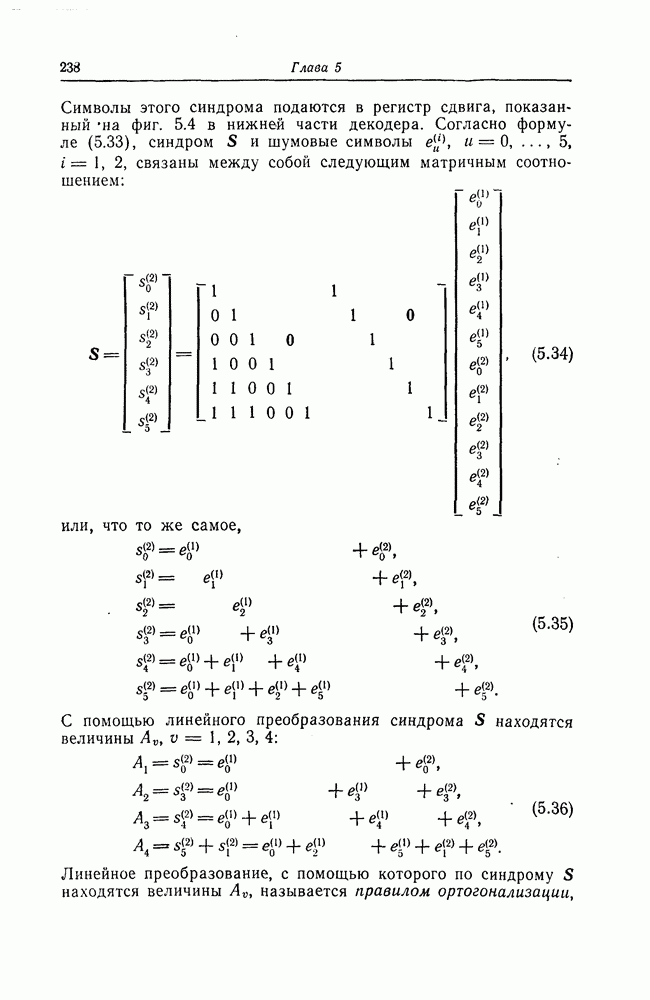
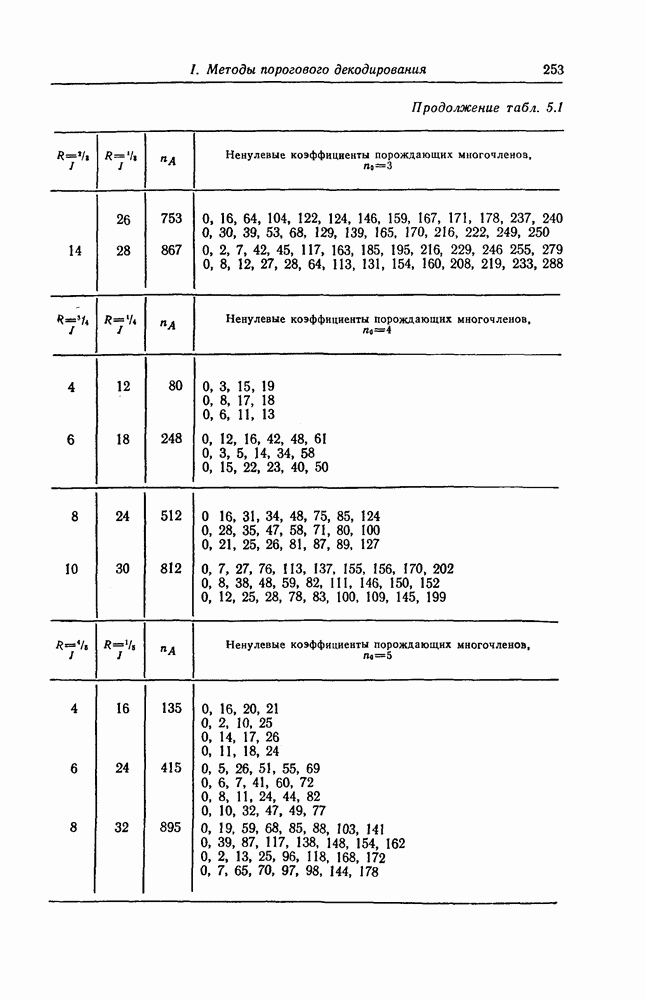
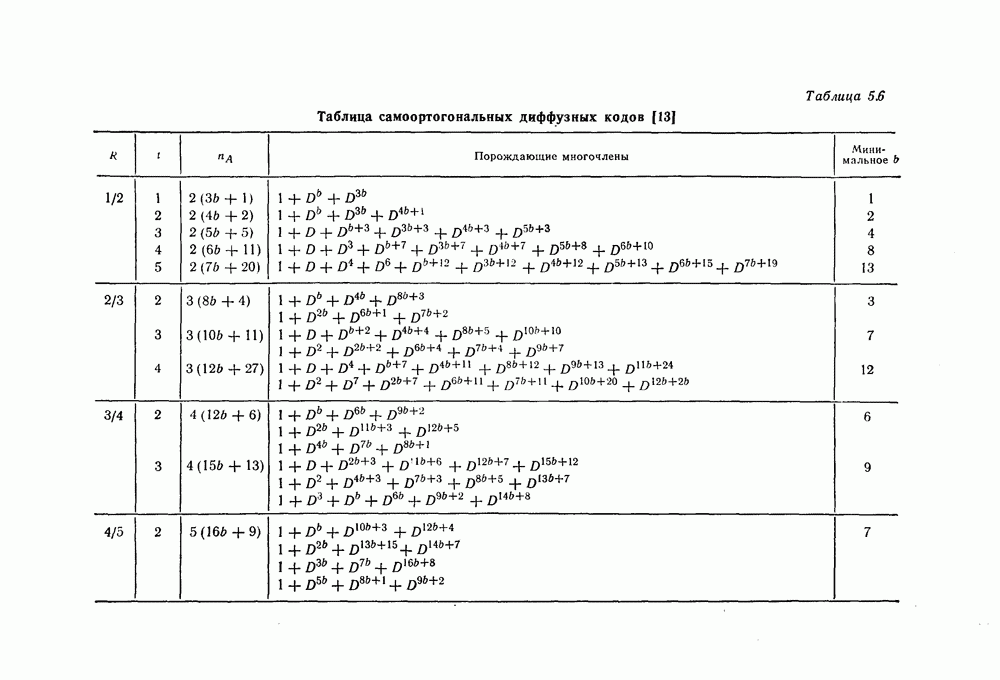
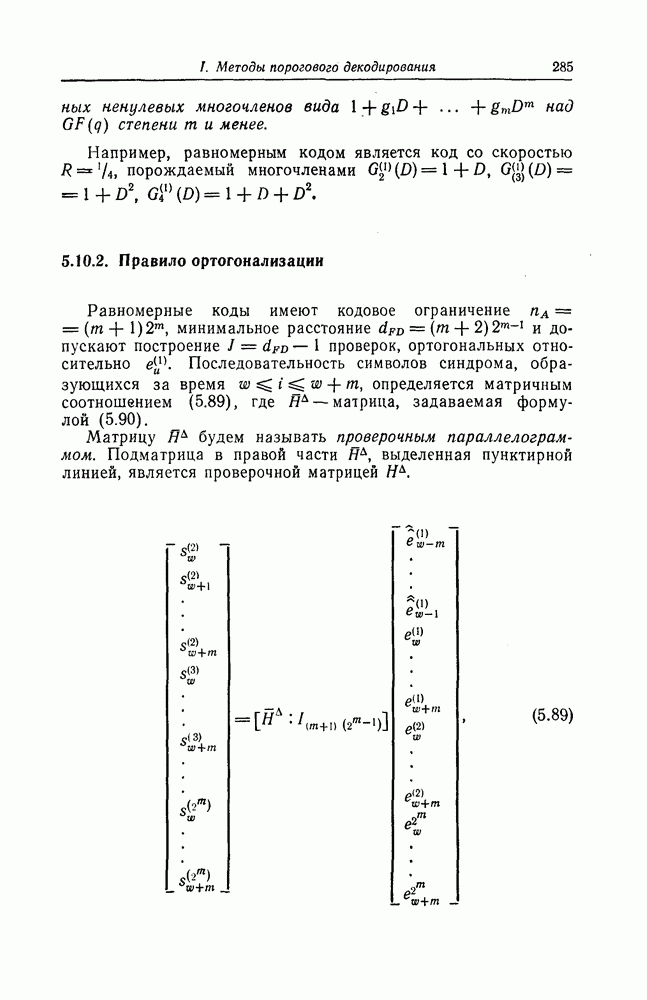
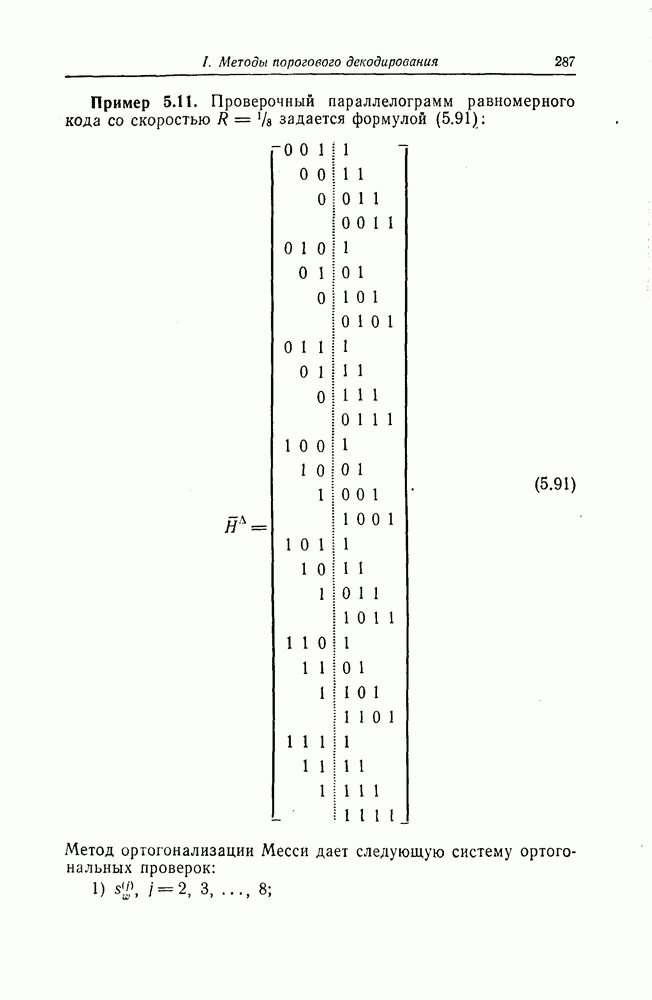
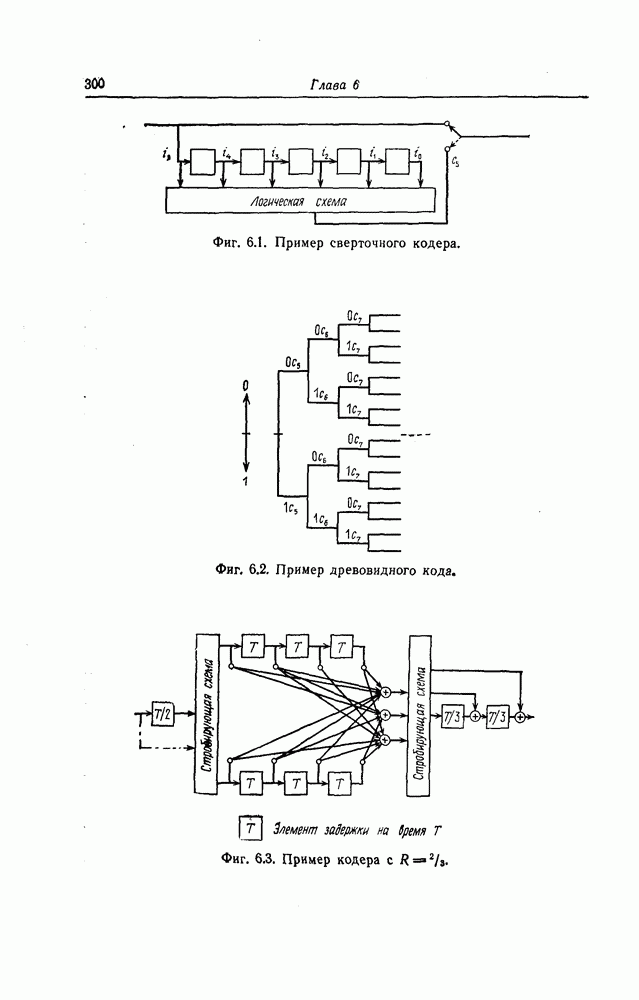
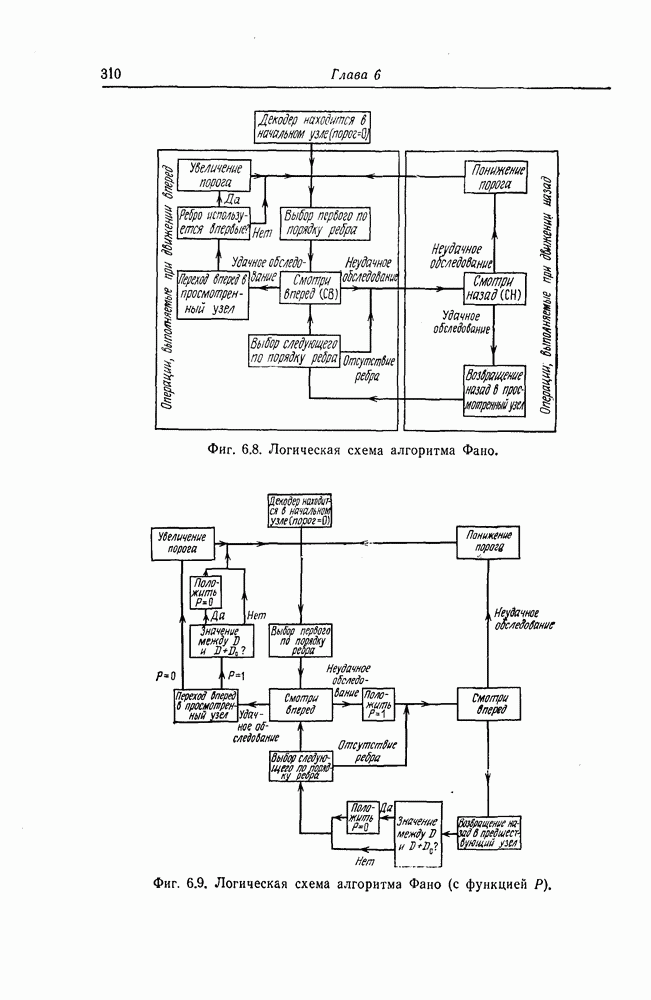
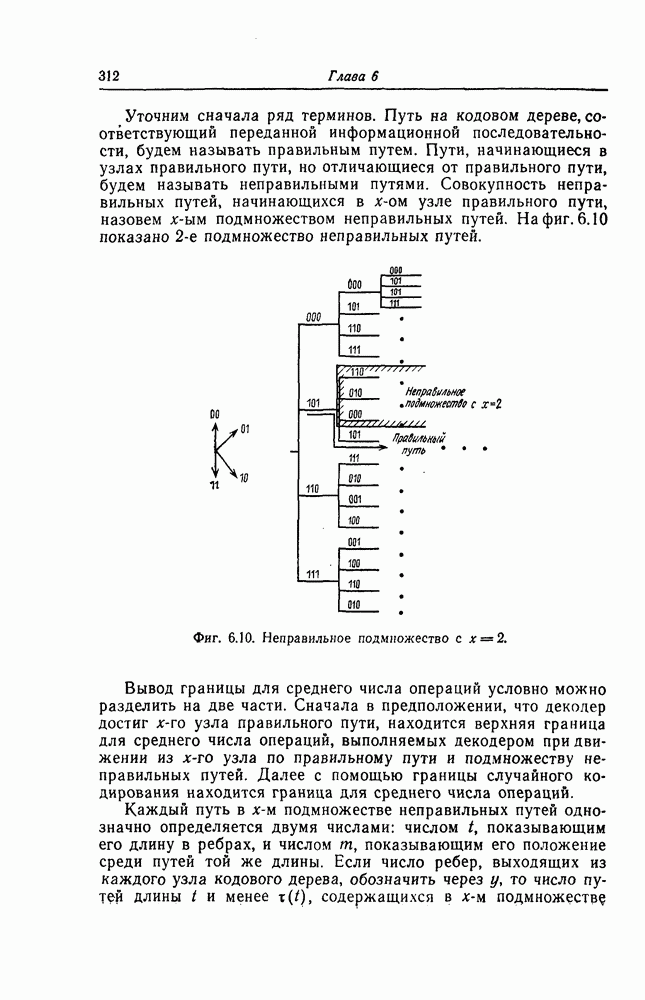
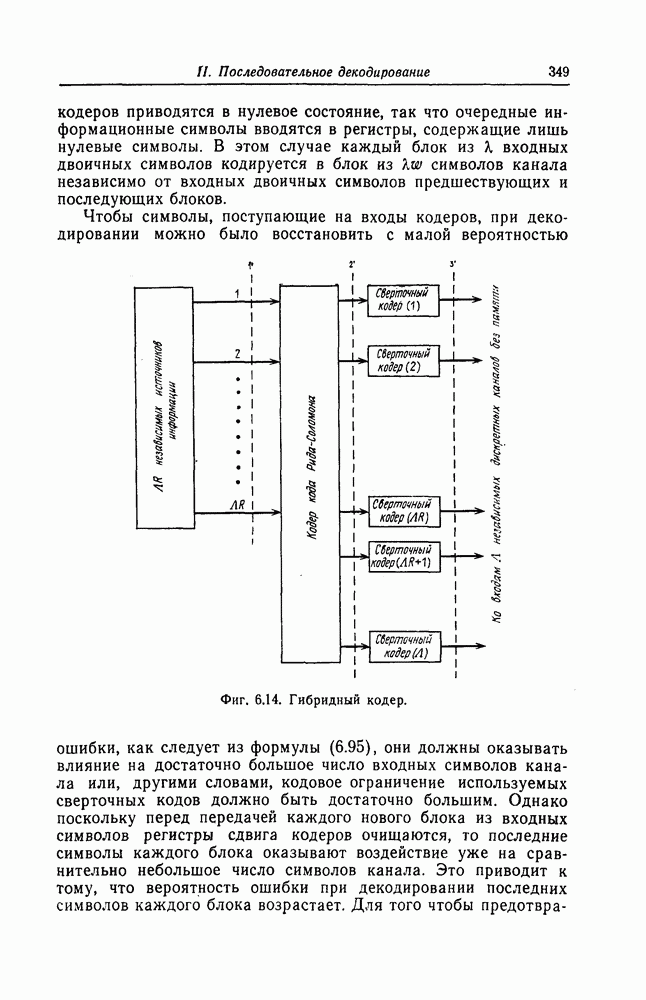
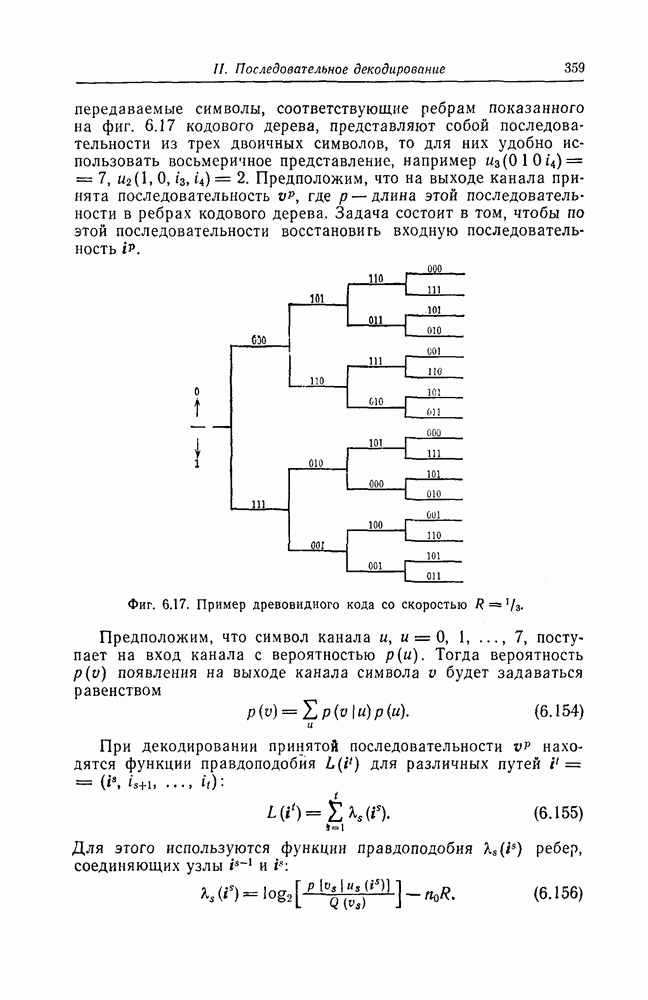
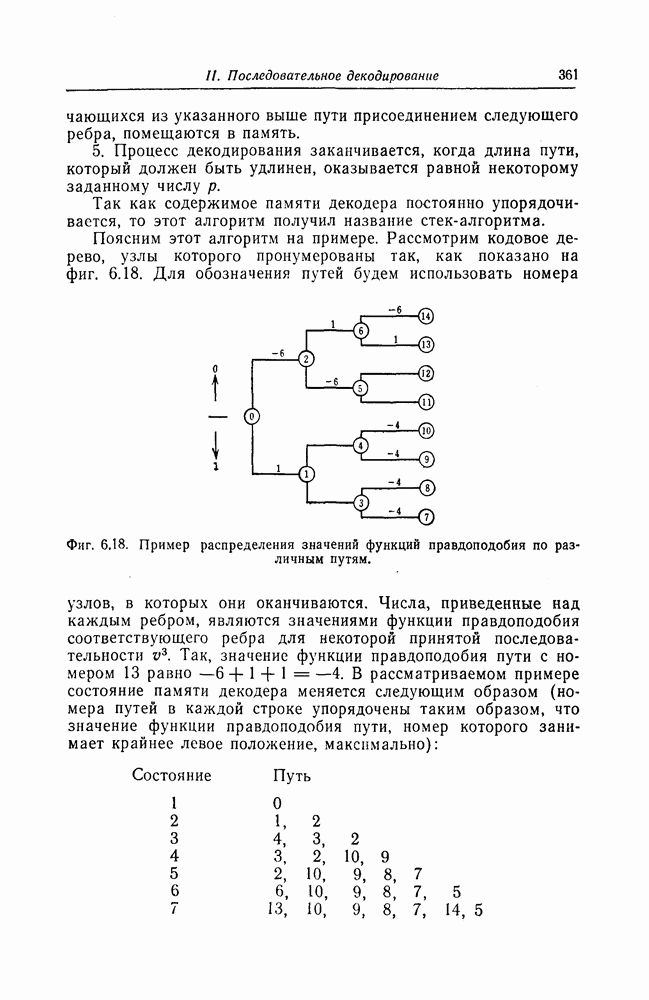
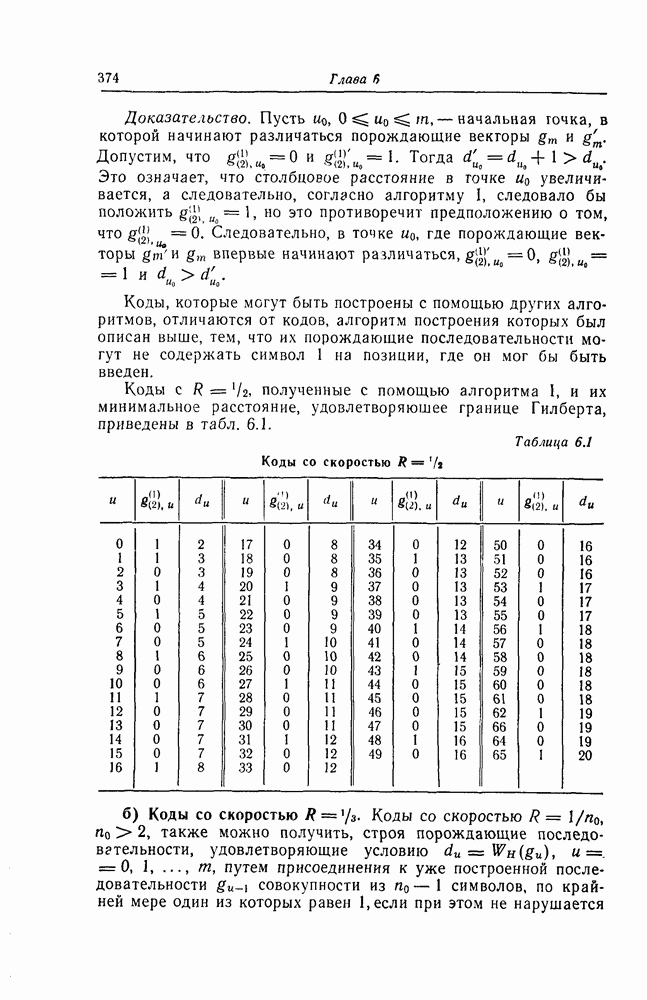
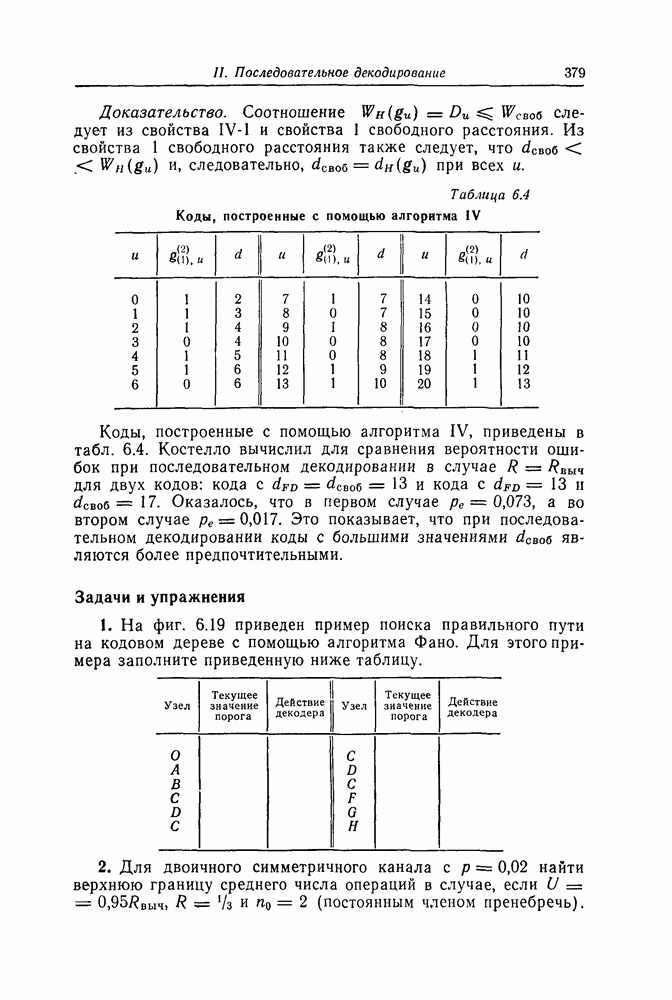
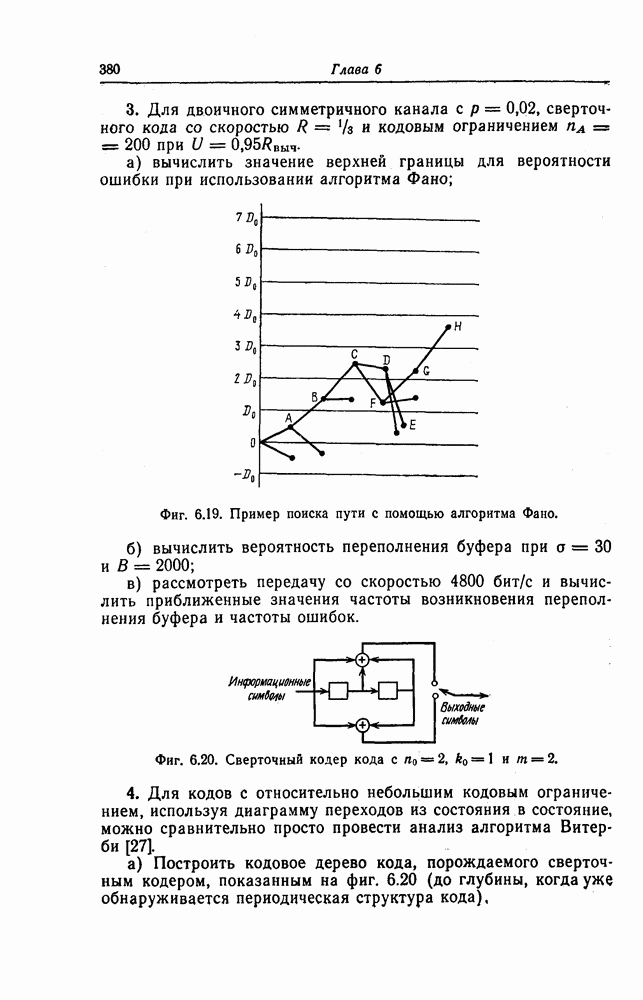
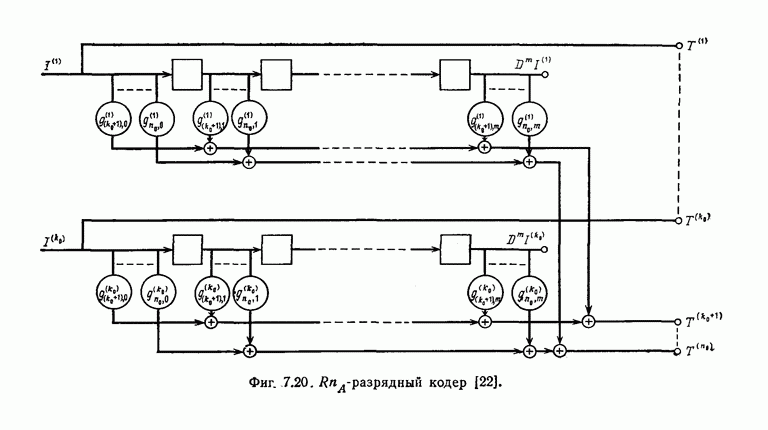
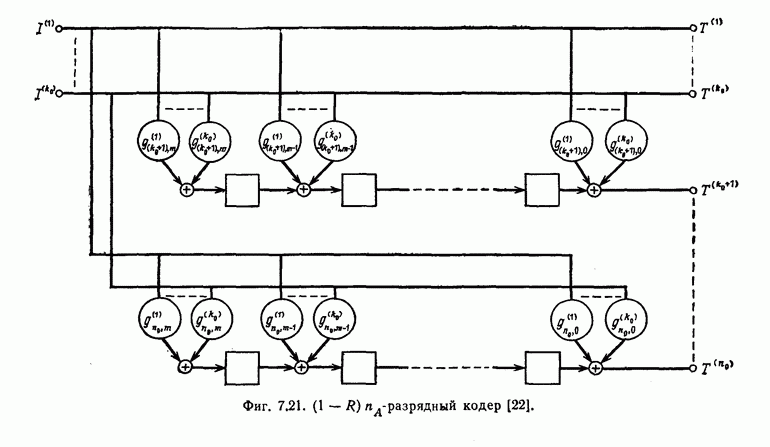
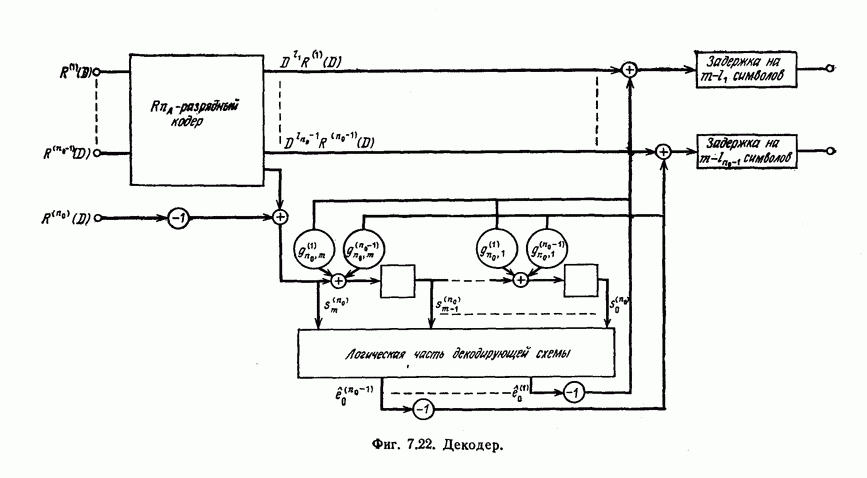
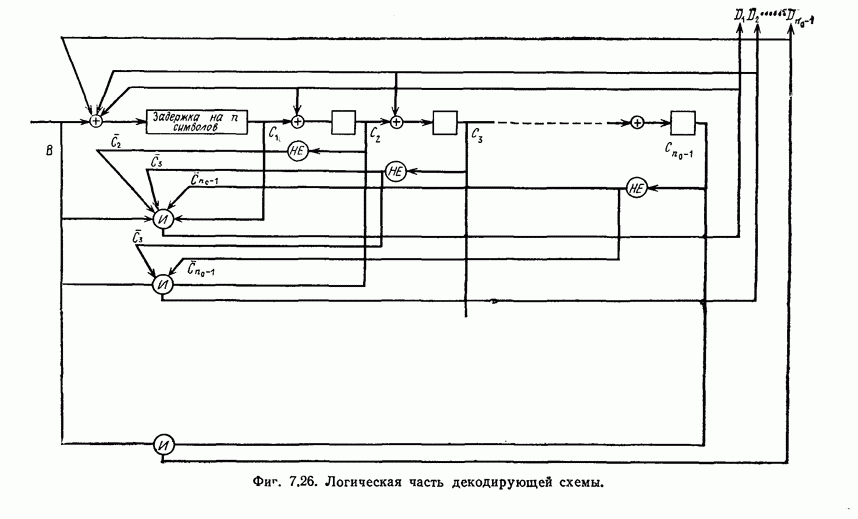
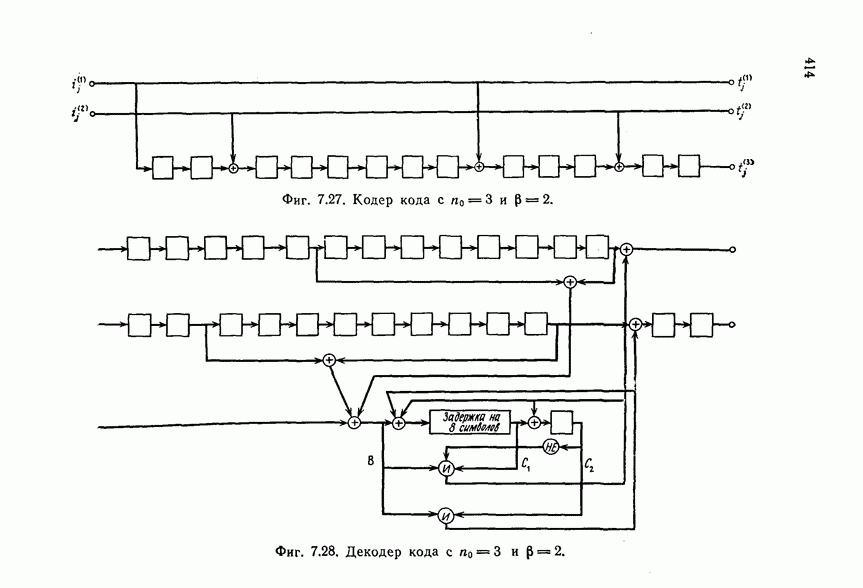
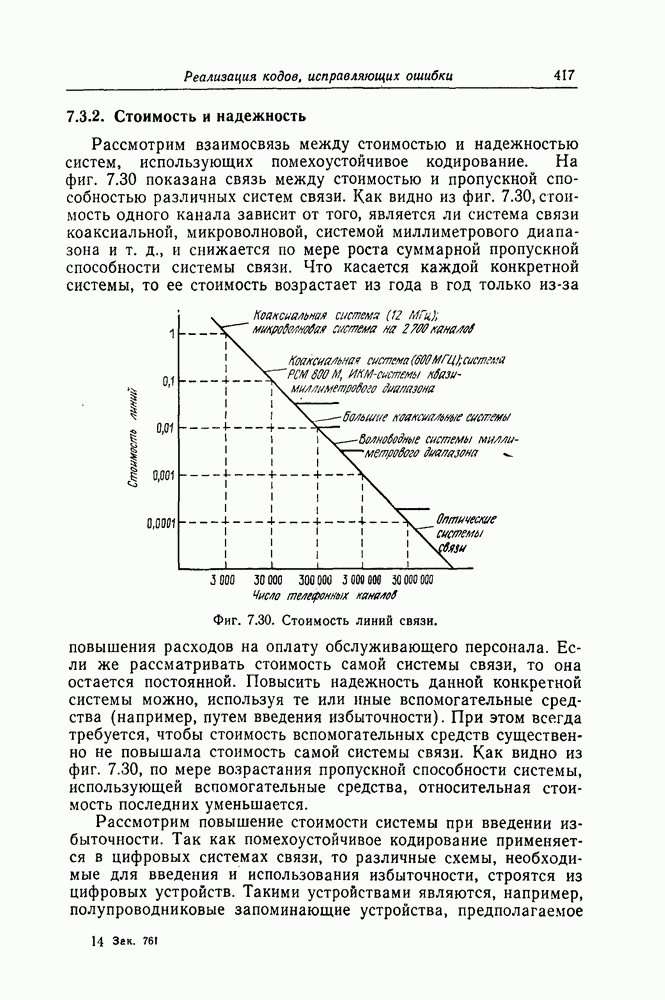
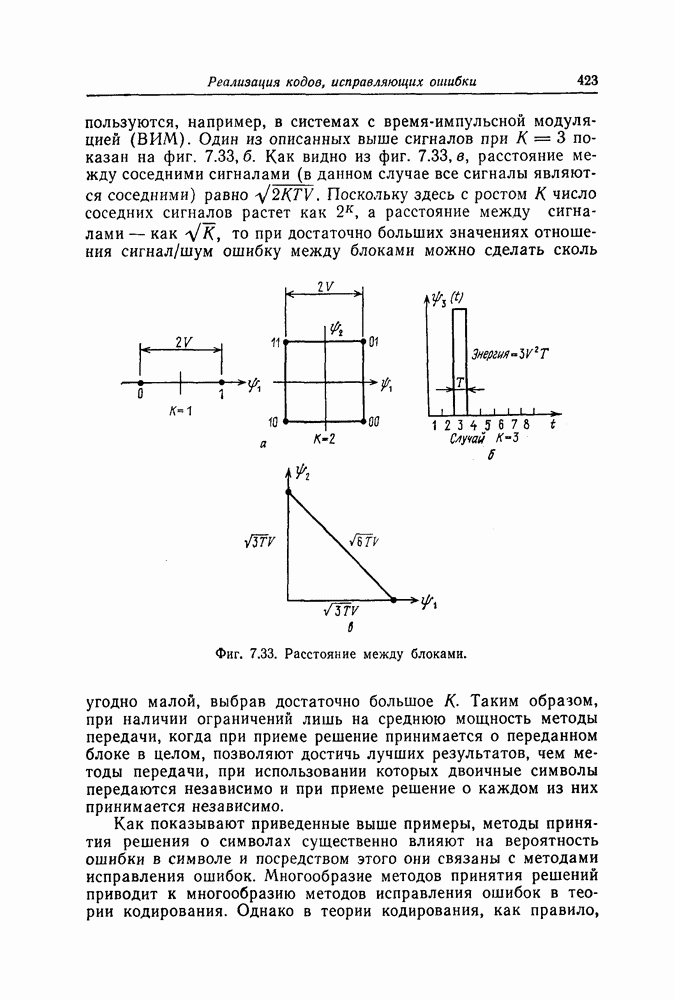
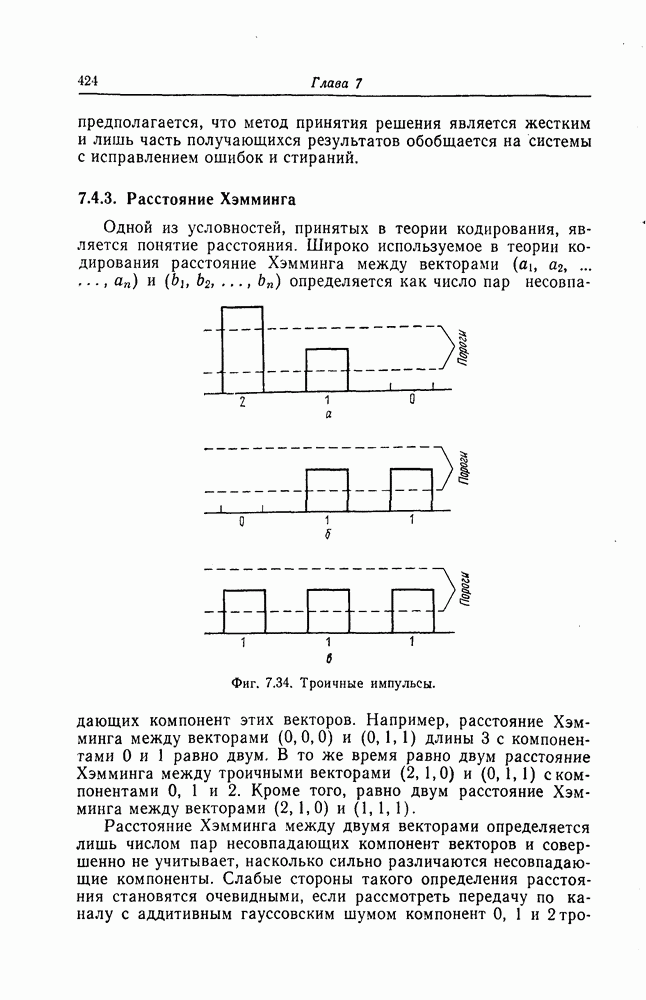
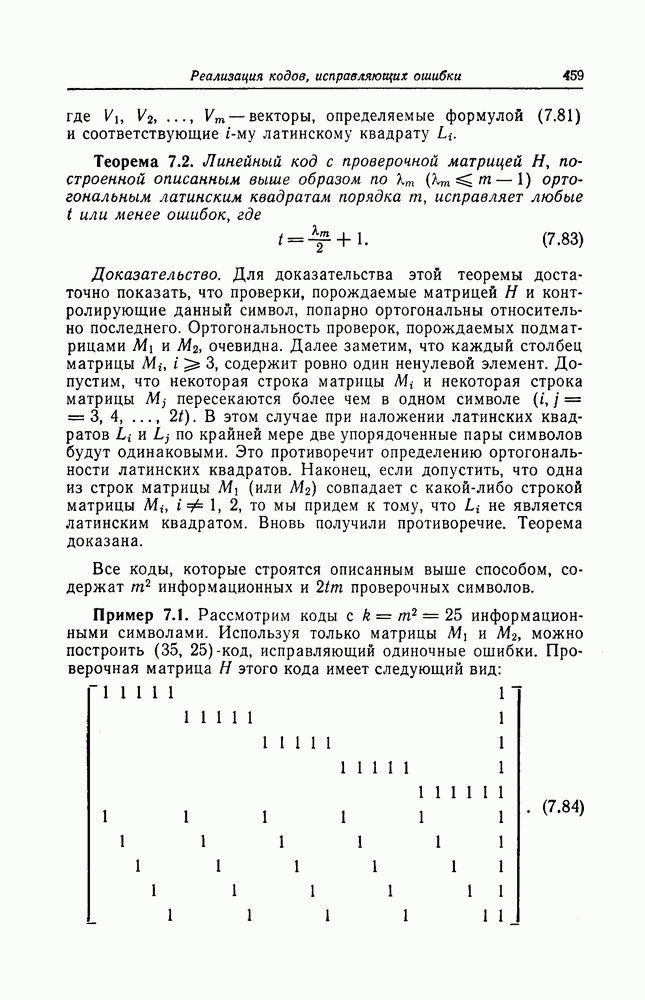
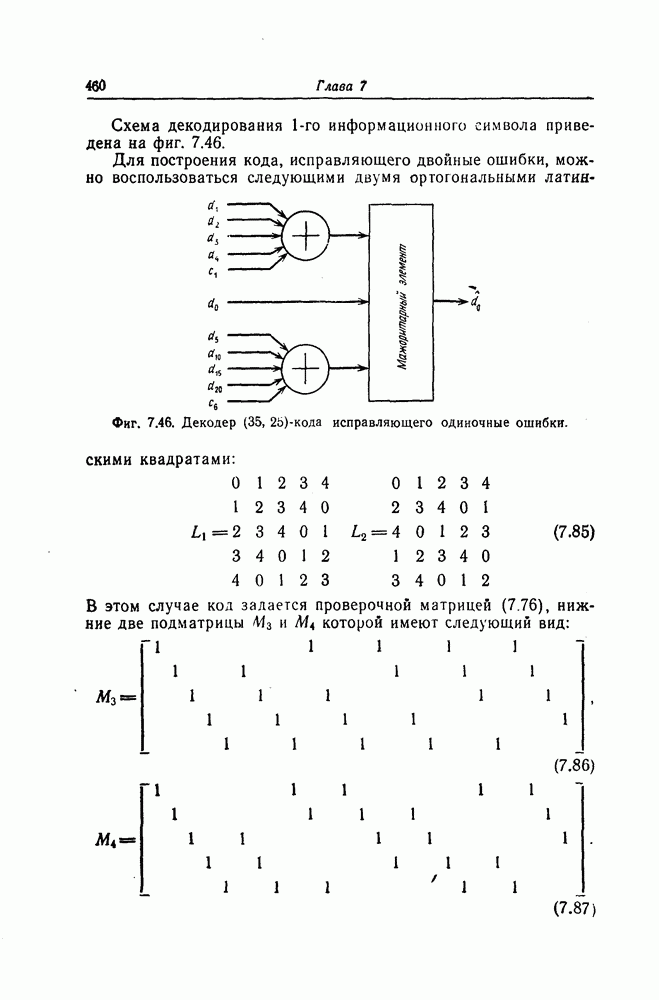
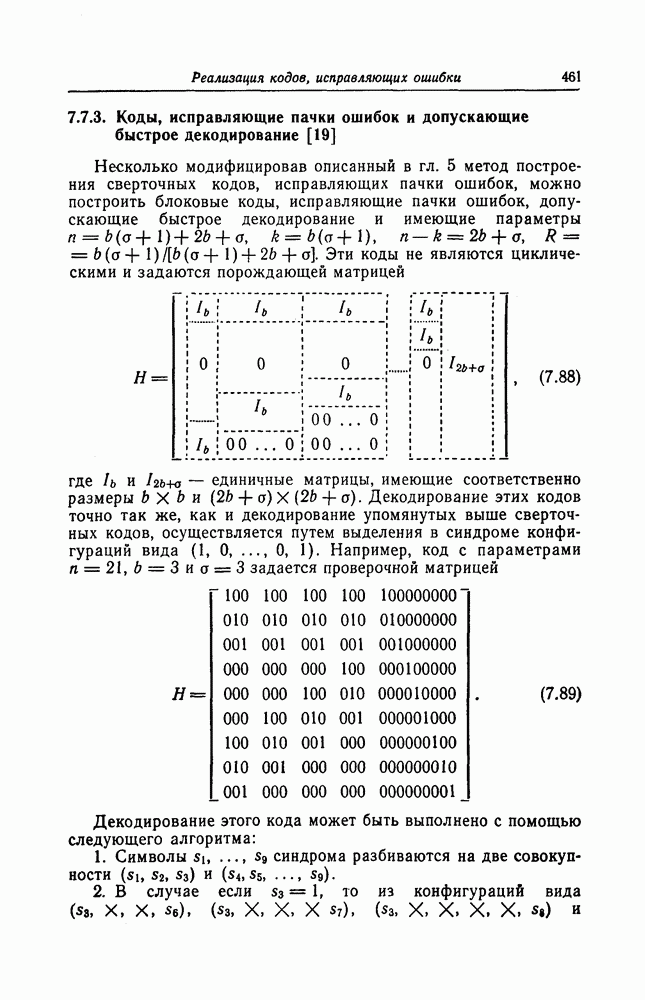
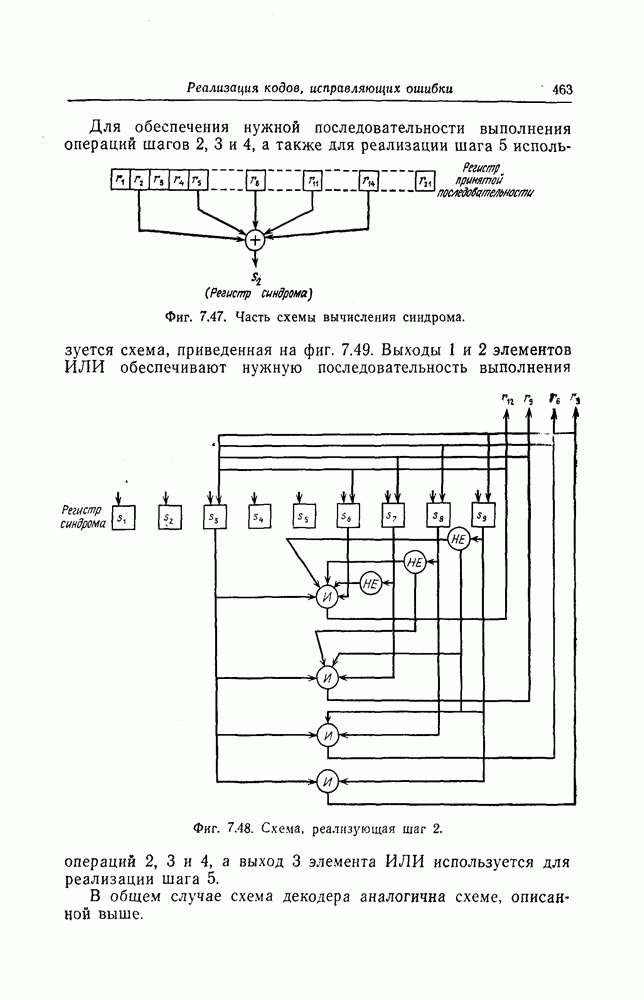
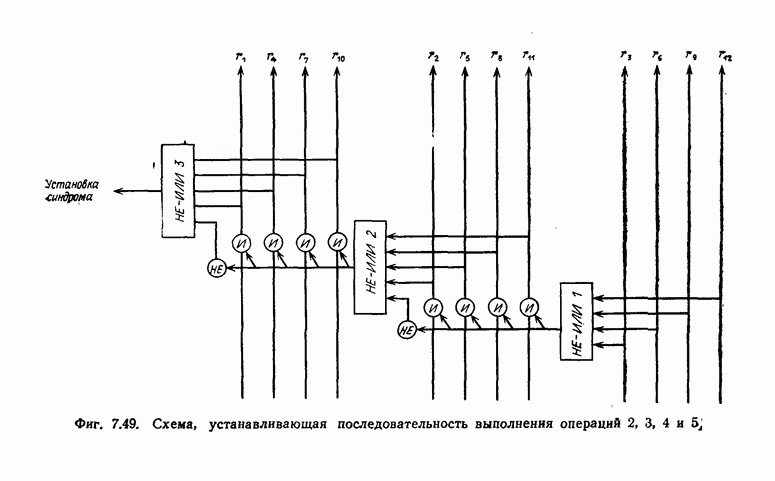
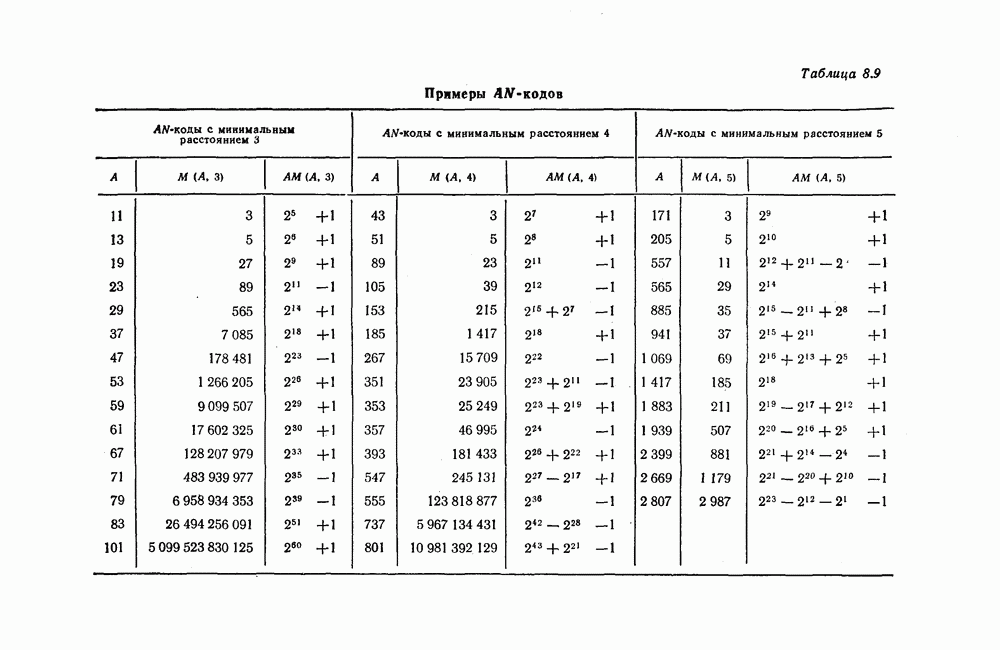
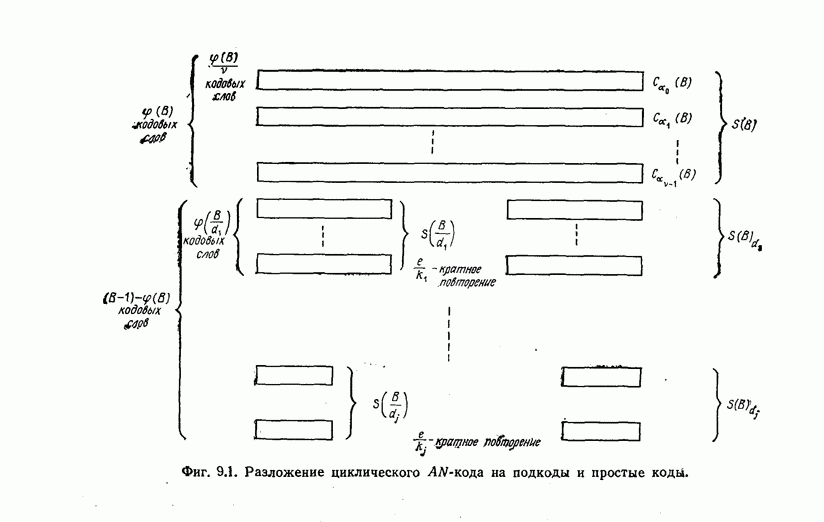
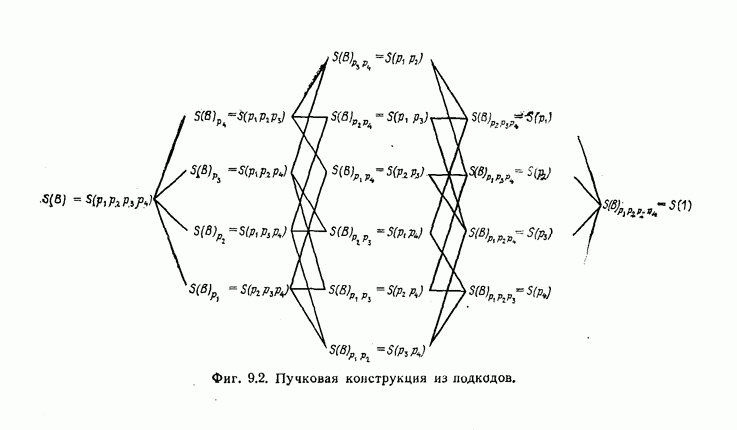
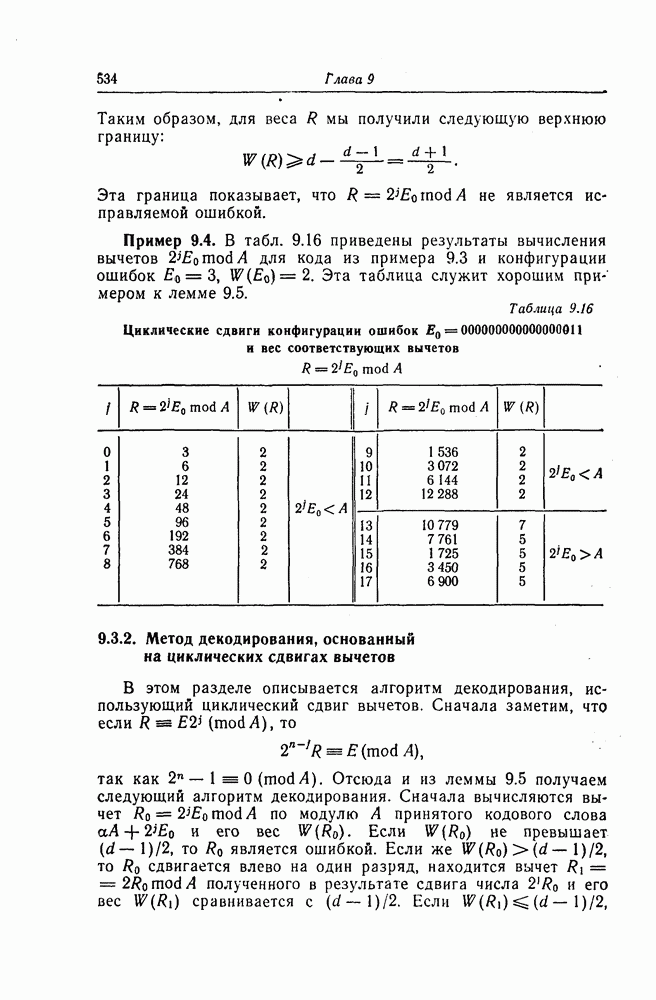
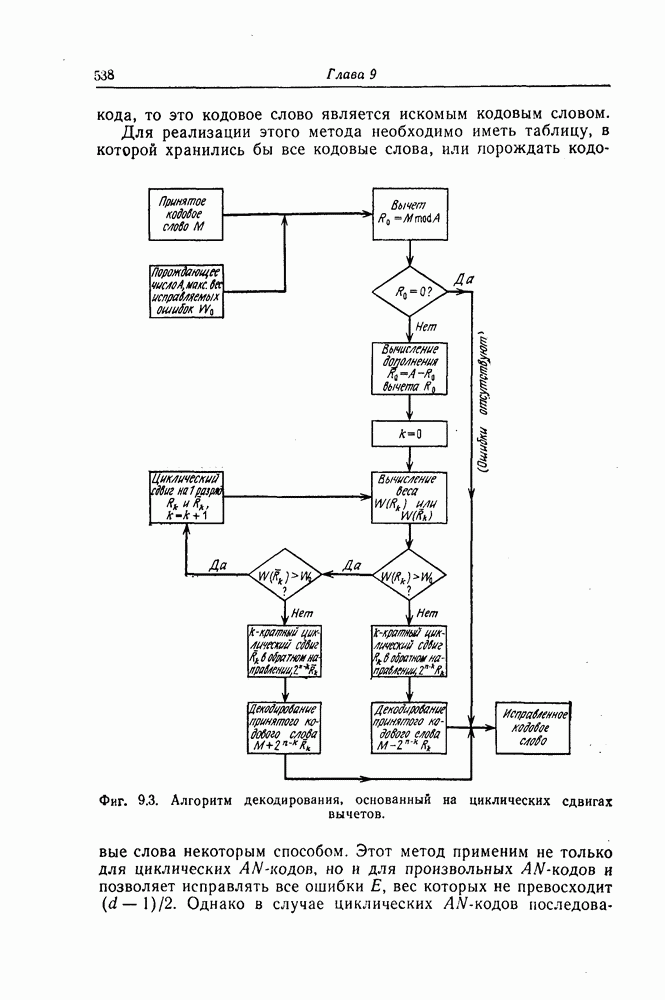
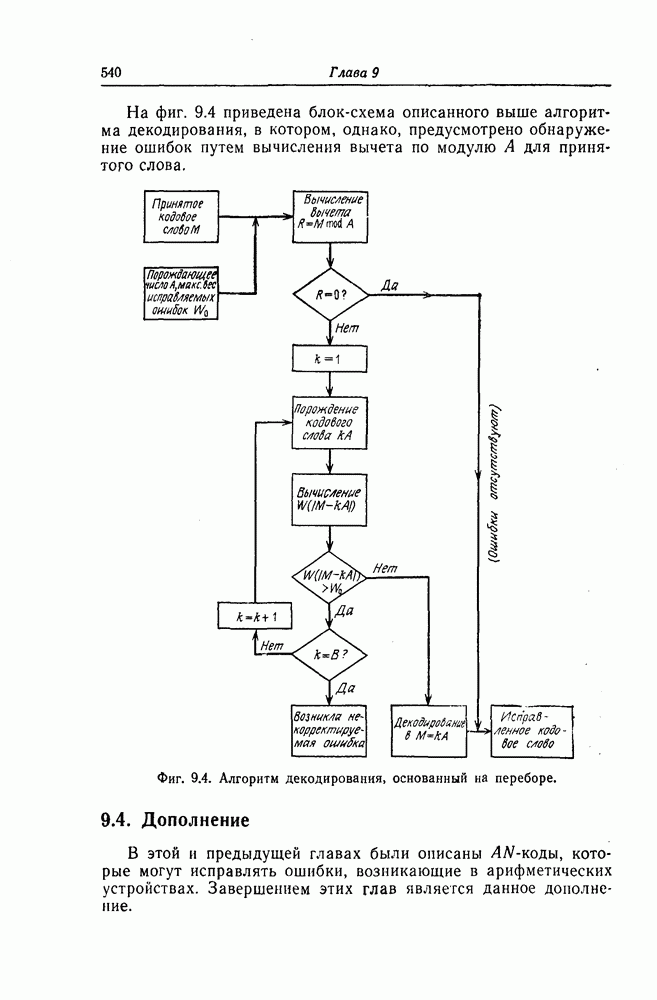
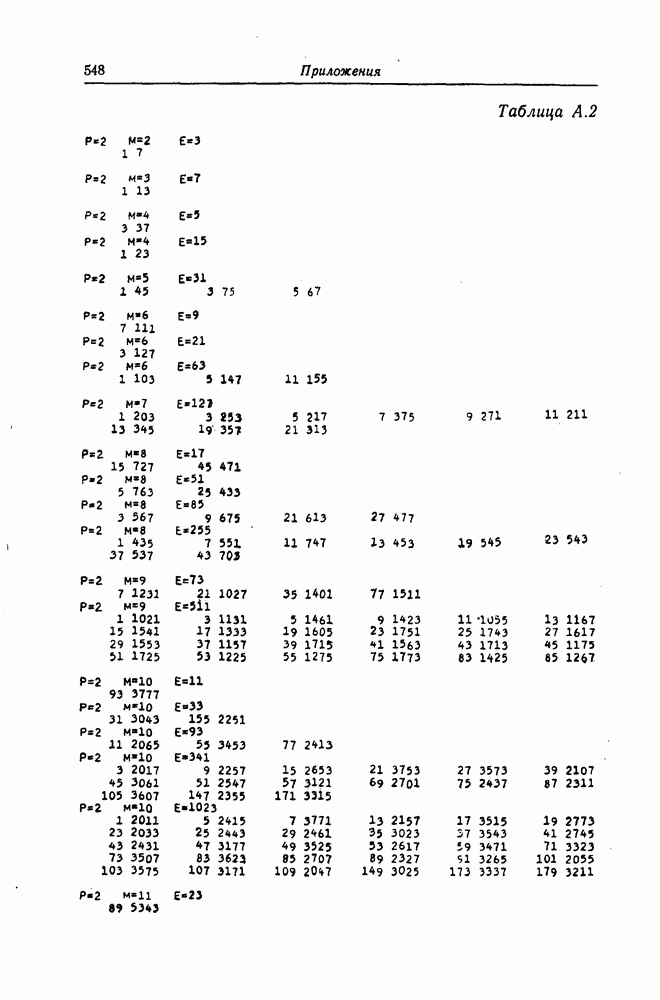
6. Сверточные коды II. Последовательное декодирование
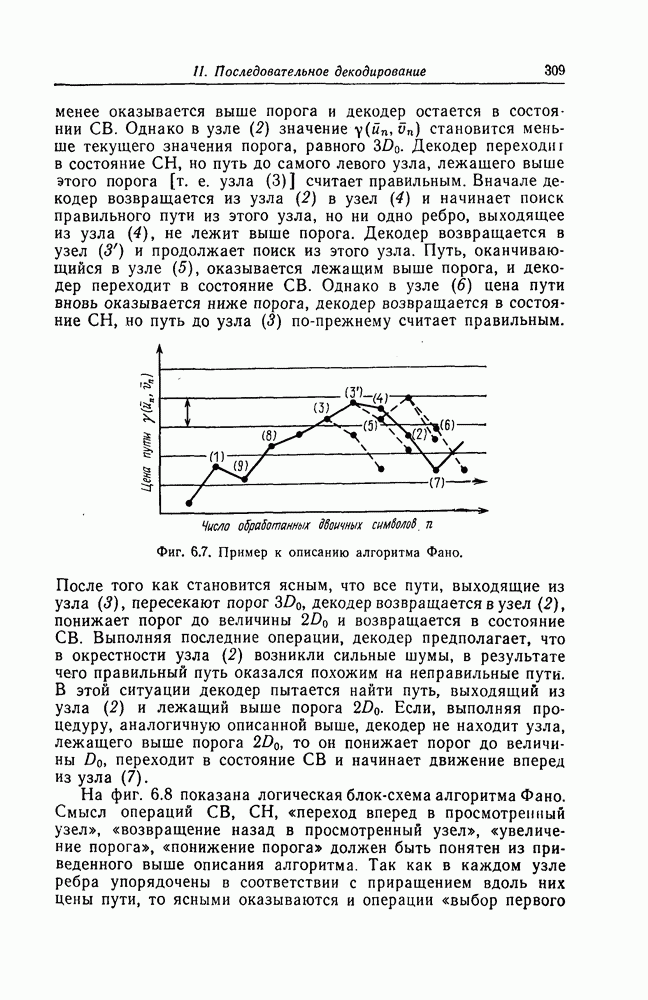
Последовательное декодирование было предложено Возенкрафтом [1], и, как уже указывалось выше, на начальном этапе исследования в этой области велись главным образом в Массачусетсом технологическом институте. Кодирование и декодирование блоковых кодов и рассматривавшихся до сих пор сверточных кодов основано главным образом на использовании алгебраических методов. Основные достоинства метода последовательного декодирования связаны с тем, что при этом методе число операций, необходимых для декодирования одного символа, является случайной величиной в отличие от того, что имеет место при алгебраических методах.
Если простота алгоритмов порогового декодирования и, следовательно, простота их реализации стимулировали исследования сравнительно коротких кодов и повышение их корректирующих способностей, то проводившиеся параллельно исследования методов последовательного декодирования имели одной из своих главных целей практическую реализацию теоремы Шеннона для канала с шумами [2]. При доказательстве теоремы кодирования Шеннон и Галлагер [3] использовали декодирование по максимуму правдоподобия. Алгоритм декодирования по максимуму правдоподобия применительно к сверточным кодам предложен Витерби [4]. Однако при декодировании по максимуму правдоподобия сложность устройств с увеличением длины кода растет экспоненциально. Достоинством методов последовательного декодирования является то, что они требуют для своей реализации приемлемого по стоимости оборудования и при этом позволяют достичь приблизительно той же вероятности ошибки, что и методы оптимального декодирования по максимуму правдоподобия, стоимость реализации которых является очень высокой. Это связано с тем, что при последовательном декодировании число операций, которые должен выполнить декодер для того, чтобы декодировать один символ, изменяется в зависимости от уровня шумов в канале. Число операций при последовательном декодировании является функцией скорости передачи и шумов в канале. При всех скоростях передачи, меньших определенной скорости  среднее число операций при декодировании оказывается небольшим. Последовательный декодер состоит из логической схемы, позволяющей проводить вычисления со средней скоростью, в несколько раз большей
среднее число операций при декодировании оказывается небольшим. Последовательный декодер состоит из логической схемы, позволяющей проводить вычисления со средней скоростью, в несколько раз большей
скорости передачи символов, и буферного запоминающего устройства, предназначенного для хранения поступающих данных при повышении уровня шумов в канале. В случае если число возникших в канале ошибок превысит корректирующую способность кода, при последовательном декодировании и других методах декодирования могут возникать ошибки. Однако при последовательном декодировании ошибки могут возникать также и из-за того, что оказываются занятыми все ячейки памяти буферного запоминающего устройства, т.е., другими словами, из-за переполнения буфера. Конечно, если вероятность возникновения ошибки из-за переполнения буфера оказывается значительно больше, чем вероятность возникновения ошибки из-за невозможности исправить или обнаружить ошибку, то именно она и будет определять характеристики алгоритма последовательного декодирования.
Число операций, необходимых для декодирования одного символа, при последовательном декодировании является случайной величиной, и поэтому важным методом анализа последовательного декодирования является метод, использованный Галлагером [3], а также Шенноном, Галлагером и Берлекэмпом [5] для получения границы случайного кодирования. Однако даже при использовании этого эффективного метода провести полный теоретический анализ не удается, и поэтому важным методом анализа последовательного декодирования остается его моделирование.