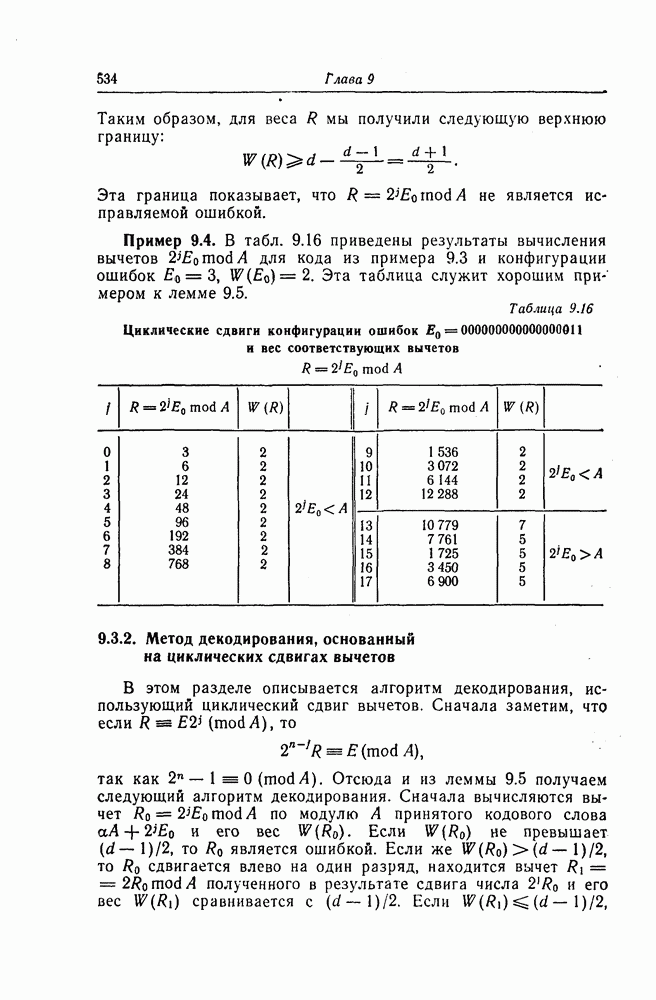
а  вероятность ошибки при принятии решения о каждом отдельном символе.
вероятность ошибки при принятии решения о каждом отдельном символе.
Чтобы строго определить эквивалентную вероятность ошибки на символ, необходимо знать полные статистические свойства ошибок, а не только то, что среди  двоичных символов возникает
двоичных символов возникает  или более ошибок. Вместе с тем каких-либо алгебраических законов, описырающих поведение ошибок для алгебраических кодов, не существует, и поэтому должны исследоваться и определяться вероятности различных конфигураций ошибок. Однако даже при использовании вычислительных машин эта задача весьма трудоемкая, так как требует очень большого числа операций. В данном разделе будет получена верхняя граница для вероятности ошибки на символ при следующих предположениях.
или более ошибок. Вместе с тем каких-либо алгебраических законов, описырающих поведение ошибок для алгебраических кодов, не существует, и поэтому должны исследоваться и определяться вероятности различных конфигураций ошибок. Однако даже при использовании вычислительных машин эта задача весьма трудоемкая, так как требует очень большого числа операций. В данном разделе будет получена верхняя граница для вероятности ошибки на символ при следующих предположениях.
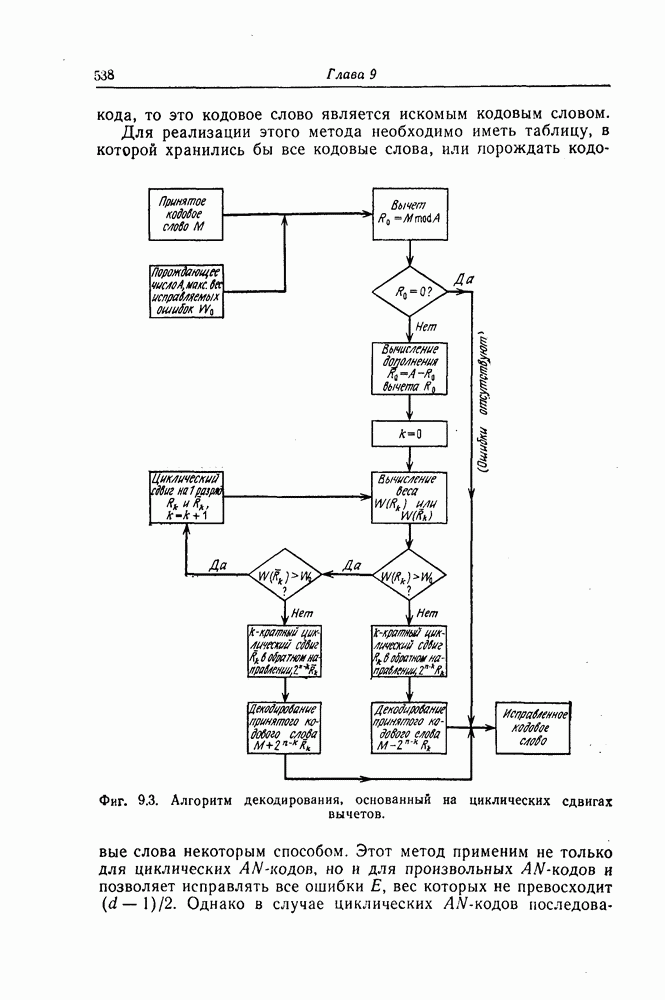
В случае возникновения  или более ошибок в результате ошибочных действий декодер может породить еще
или более ошибок в результате ошибочных действий декодер может породить еще  ошибок.
ошибок.
Если среди  символов появилось
символов появилось  и более ошибок, то
и более ошибок, то  или более ошибок возникают случайно. Предположение о случайном возникновении
или более ошибок возникают случайно. Предположение о случайном возникновении  или более ошибок вводится по следующим причинам:
или более ошибок вводится по следующим причинам:
I. Почти для всех алгебраических кодов при таком декодировании не существует каких-либо оснований к тому, чтобы результат ошибочных действий сказывался на каких-либо выделенных символах.
II. В процессе декодирования почти всех алгебраических кодов ошибки в информационных символах и ошибки в проверочных символах не разделяются. Следовательно, если результат ошибочных действий связать с некоторыми определенными символами и вероятности ошибок в символах считать различными, то путем расположения проверочных символов на позициях с высокой вероятностью ошибки можно понизить среднюю вероятность ошибки в информационных символах в случае, когда распределение вероятностей ошибок в символах неизвестно.
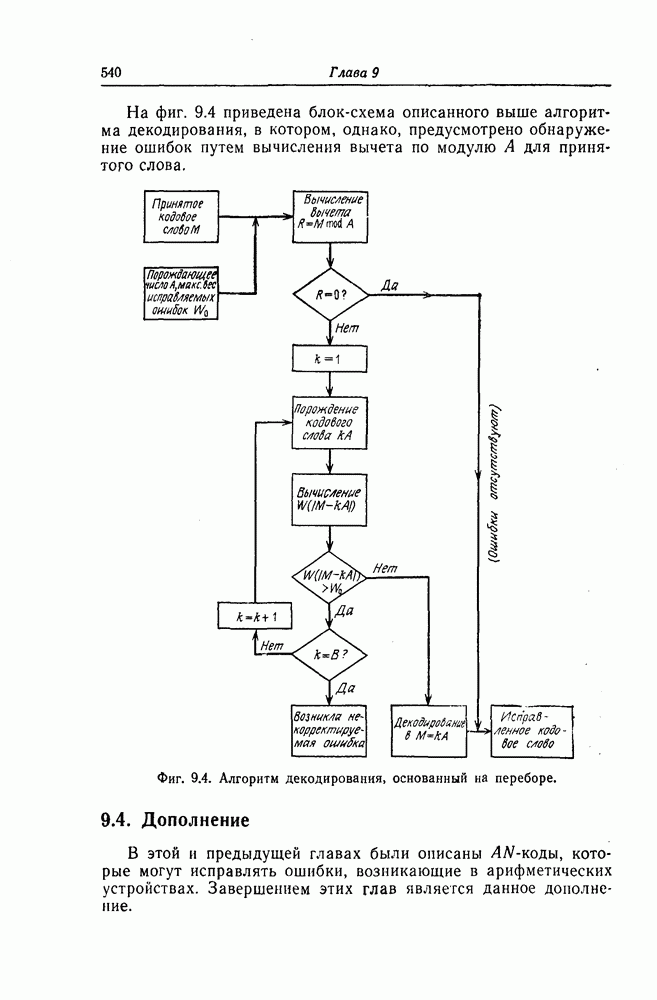
Итак, при сделанных выше предположениях  ошибок в
ошибок в  символах возникают независимо, так что среднее число ошибок в информационных символах равно
символах возникают независимо, так что среднее число ошибок в информационных символах равно  Отсюда следует, что среднее число (математическое ожидание) ошибочных информационных символов равно
Отсюда следует, что среднее число (математическое ожидание) ошибочных информационных символов равно

Следовательно, для эквивалентной вероятности ошибки на символ  (после деления на
(после деления на  и замены
и замены  на 1)
на 1)
получаем следующую верхнюю границу:

Вероятность  в реальных системах обычно имеет значения порядка
в реальных системах обычно имеет значения порядка  В случае когда
В случае когда  т.е. при
т.е. при  правые части формул (7.35) и (7.37) достаточно точно аппроксимируются их первыми или несколькими первыми членами.
правые части формул (7.35) и (7.37) достаточно точно аппроксимируются их первыми или несколькими первыми членами.
Вероятность возникновения ошибки в отдельном символе при передаче по каналу (входящая в эти формулы) зависит от модуляции и должна определяться для каждой системы отдельно.

































































































































































































































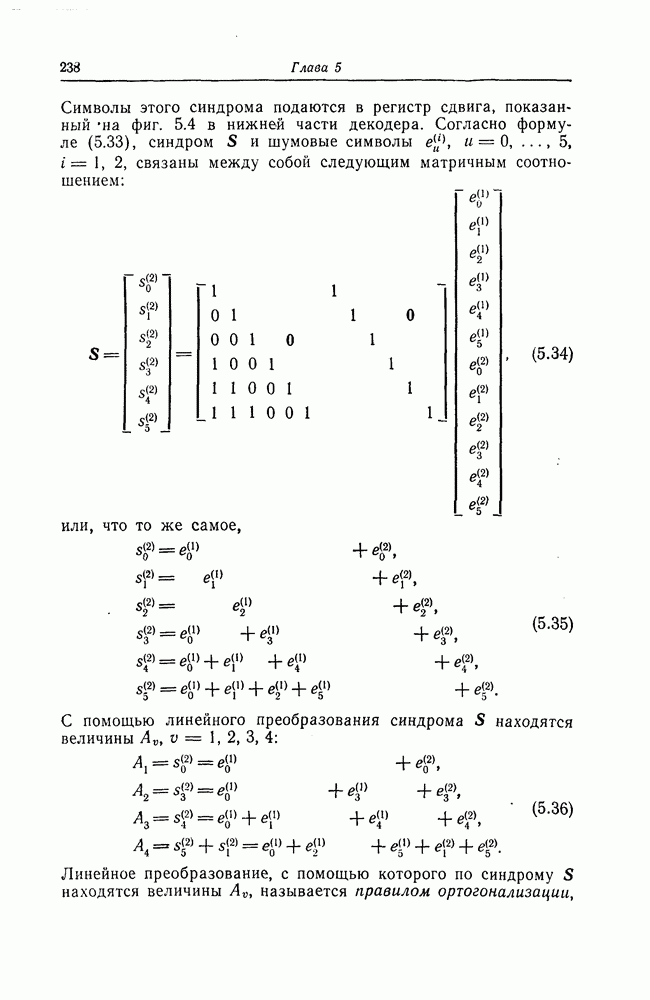














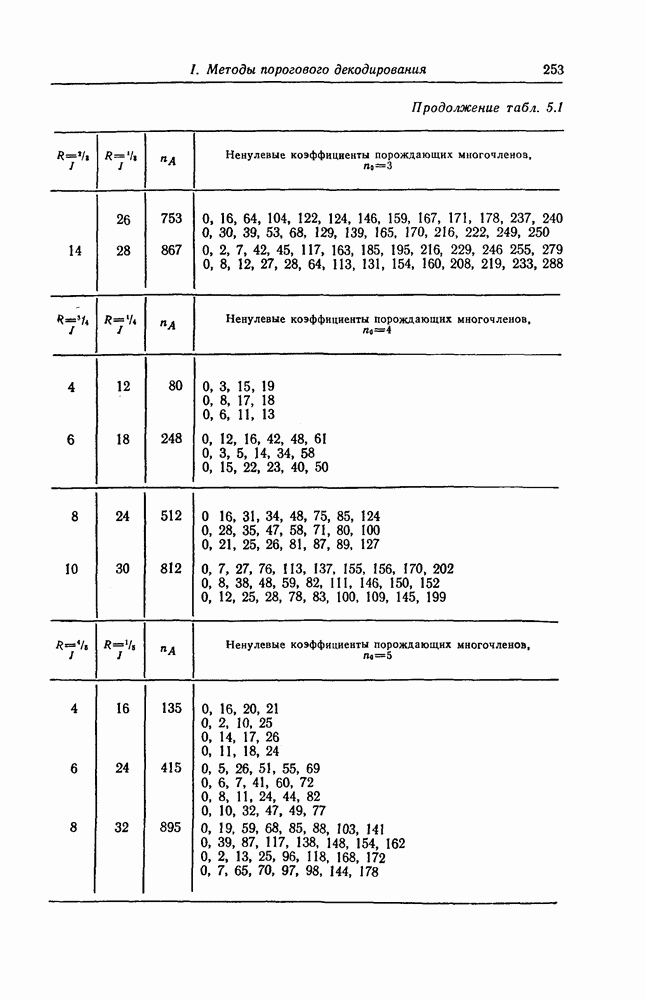





























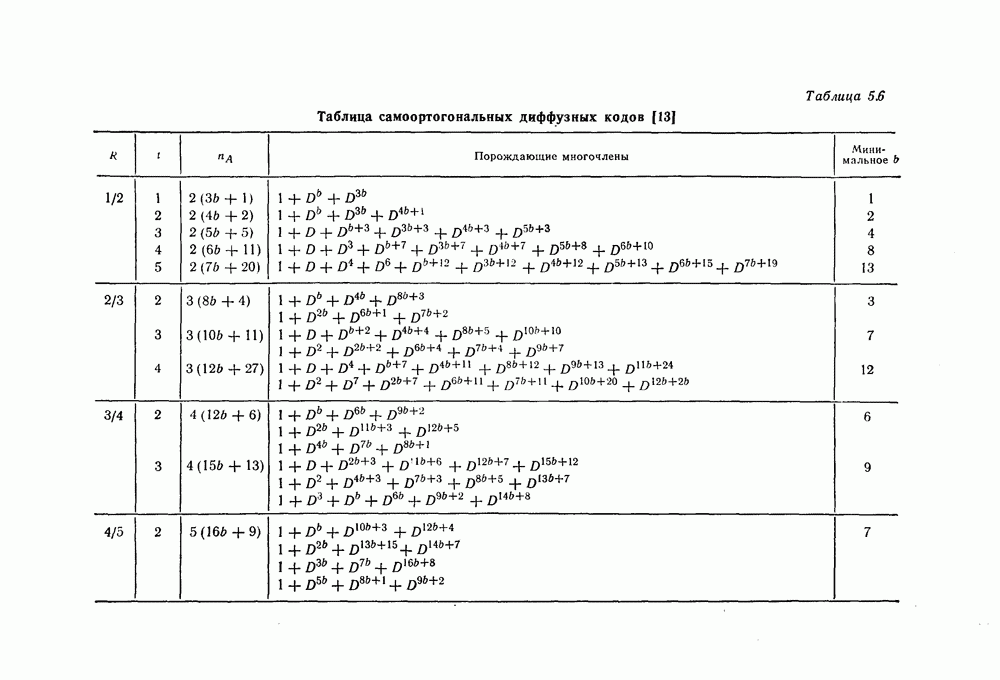

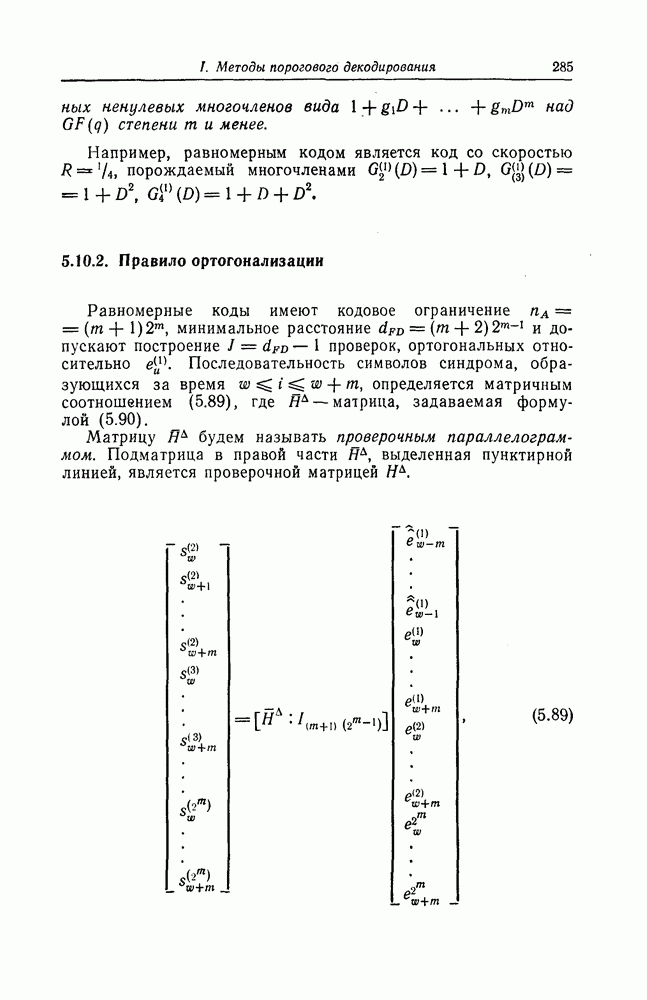





























































































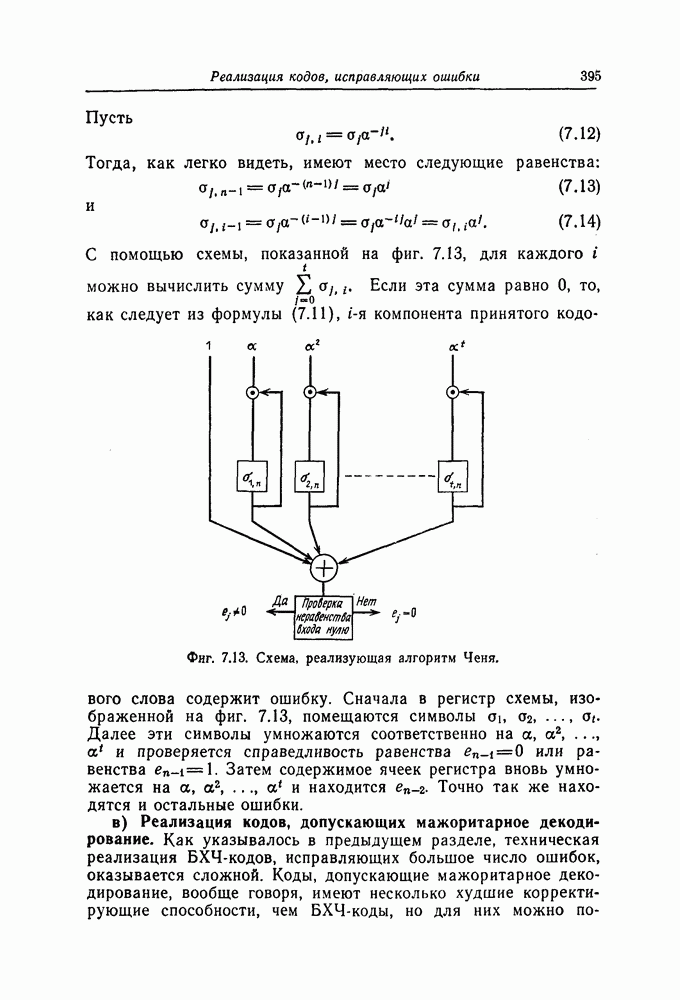

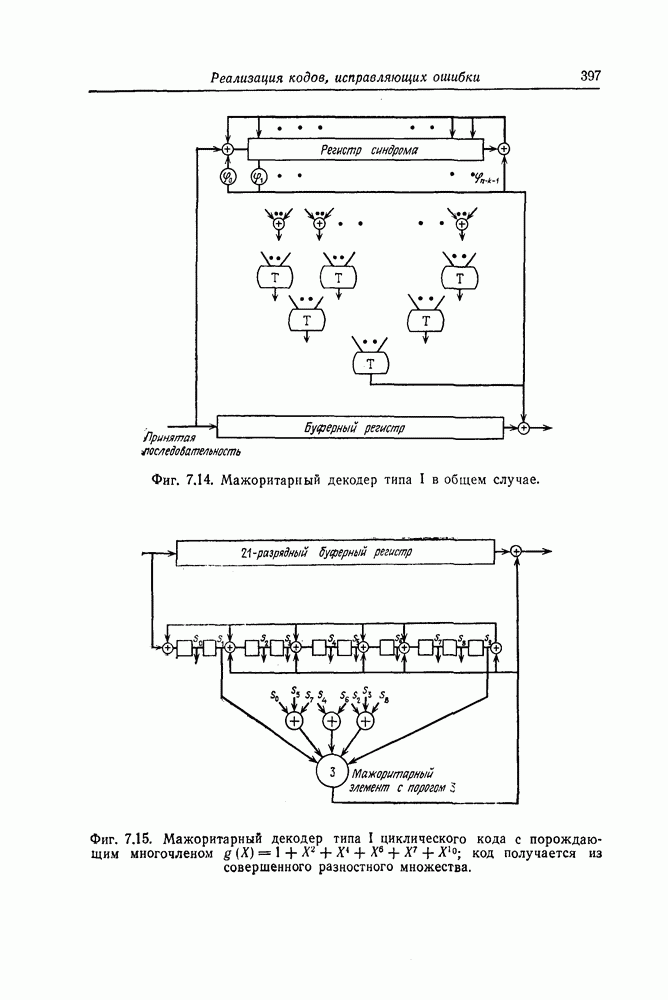




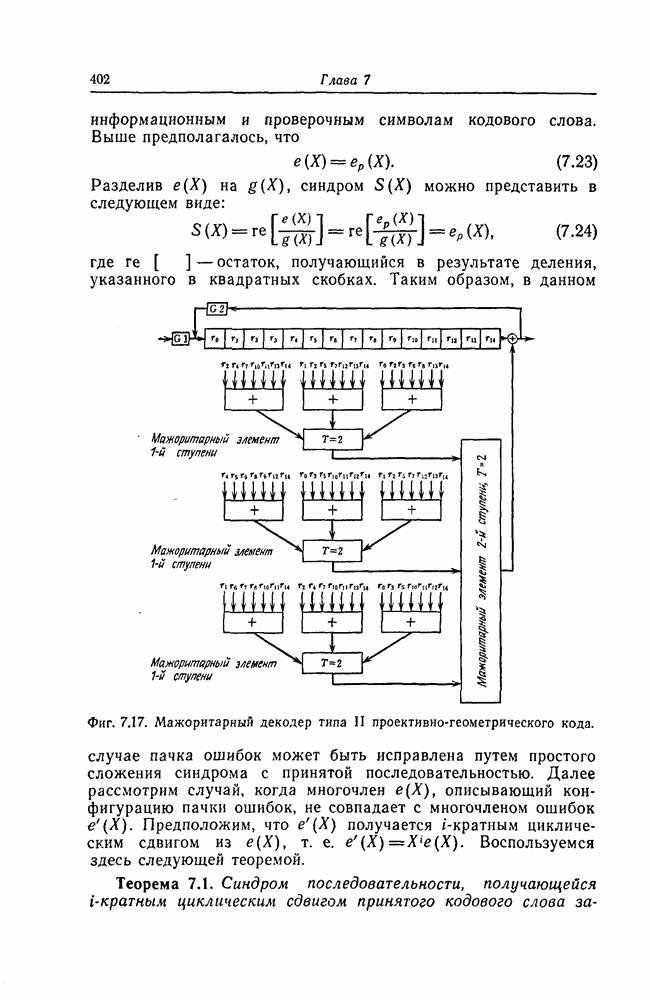
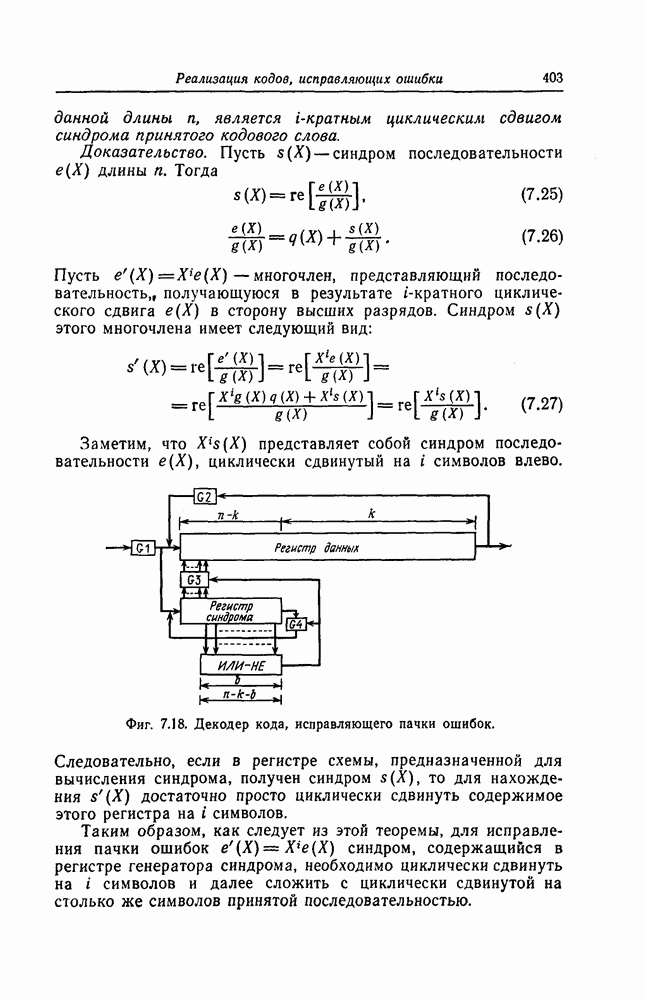


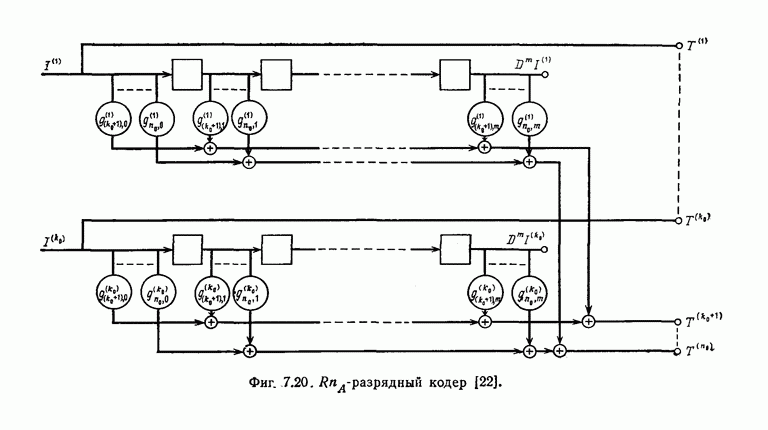

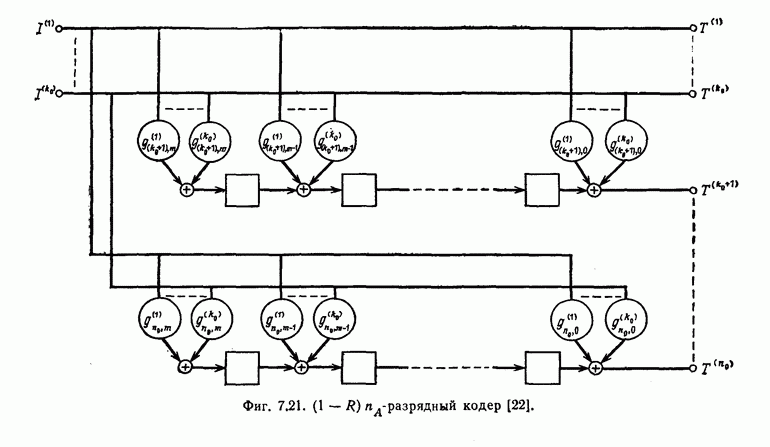
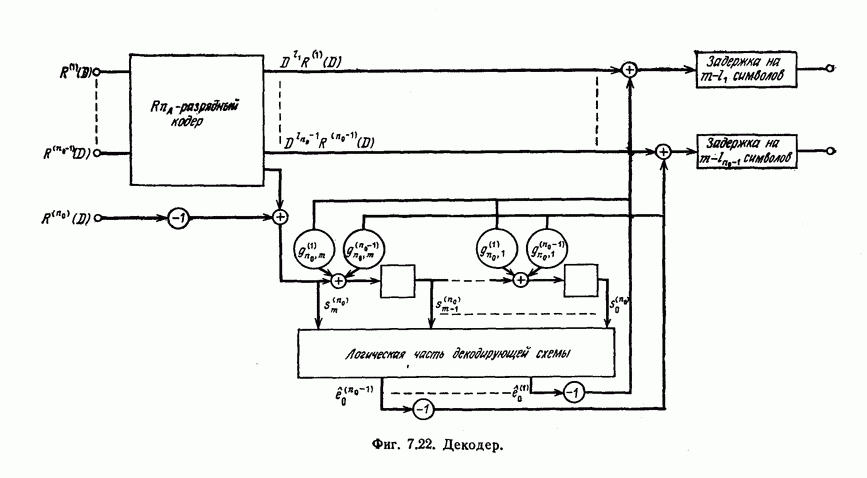



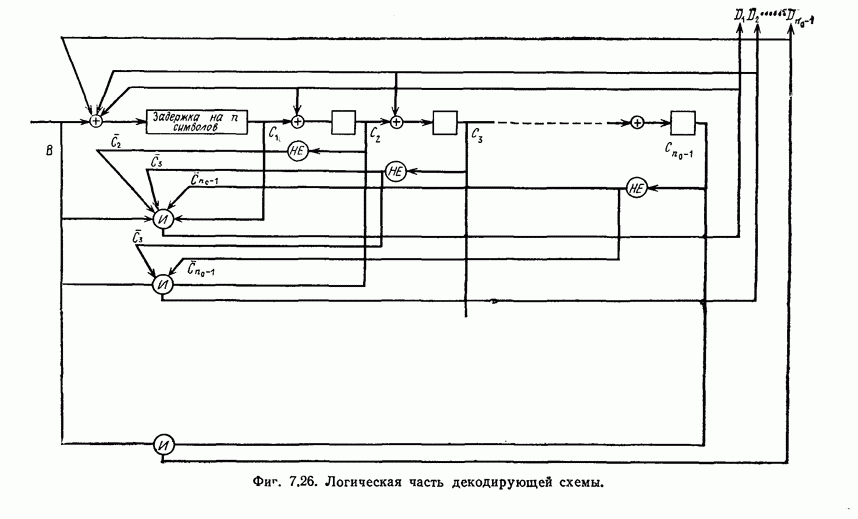


















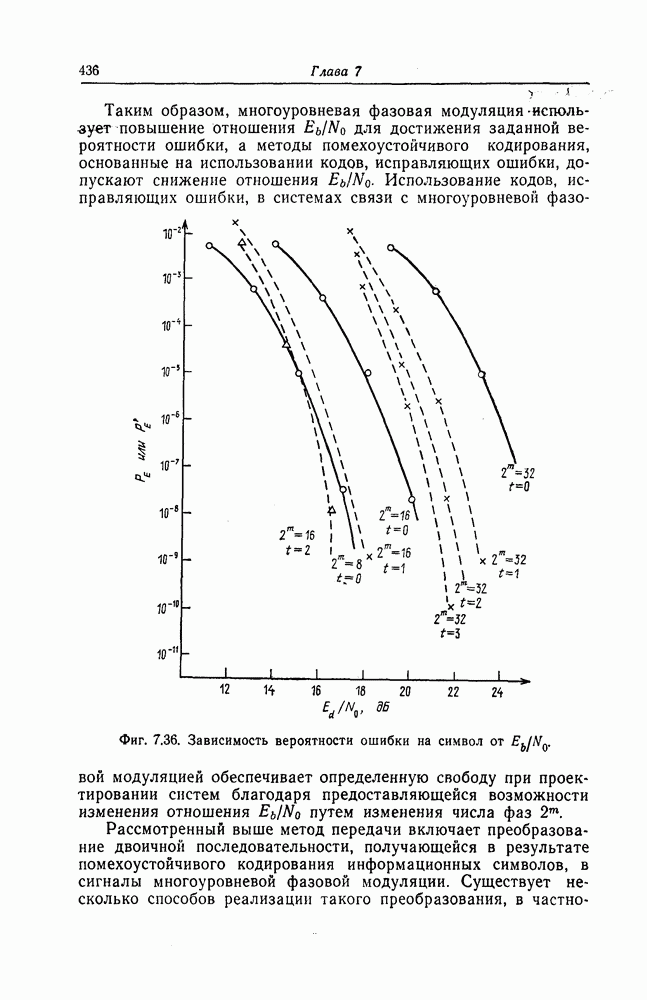



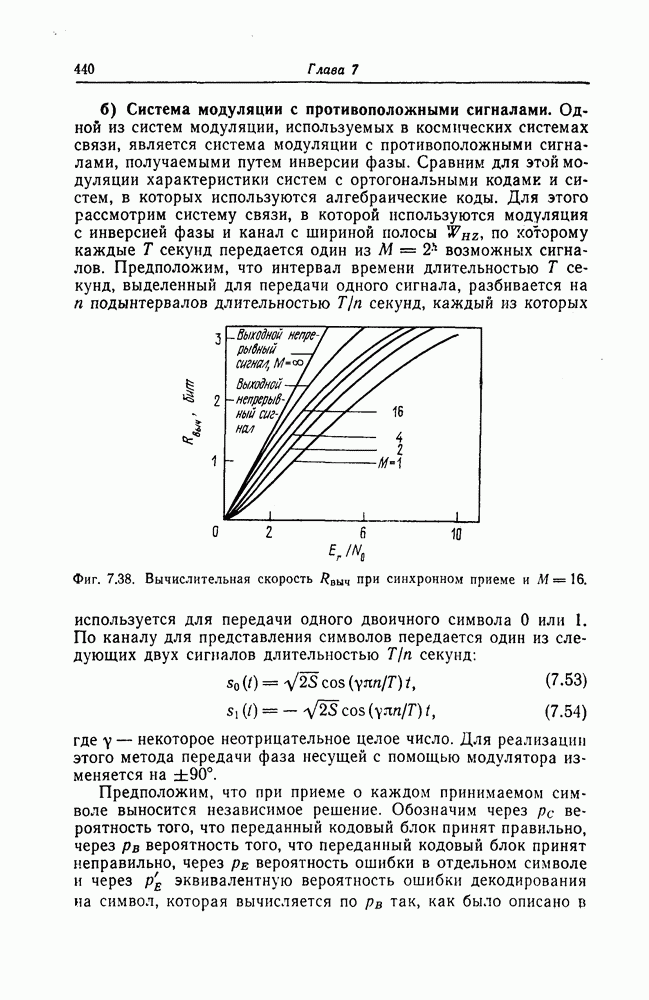

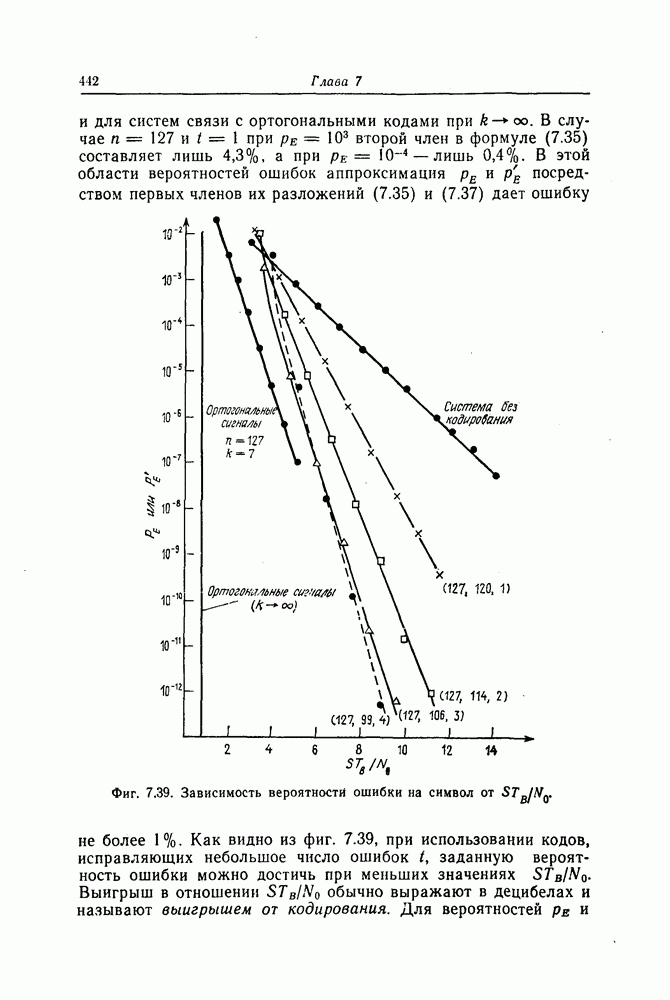

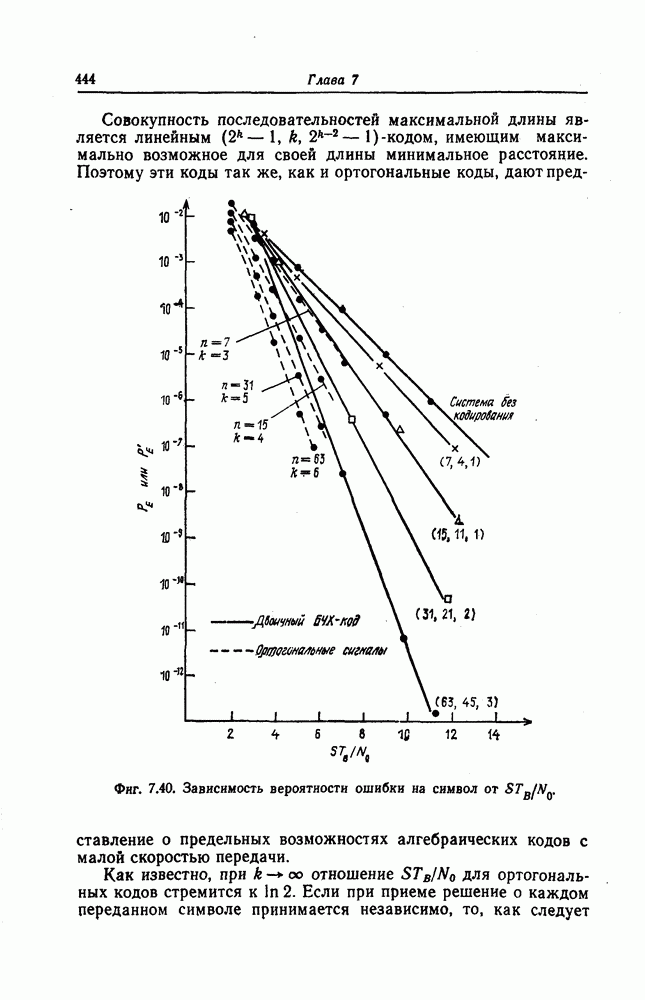
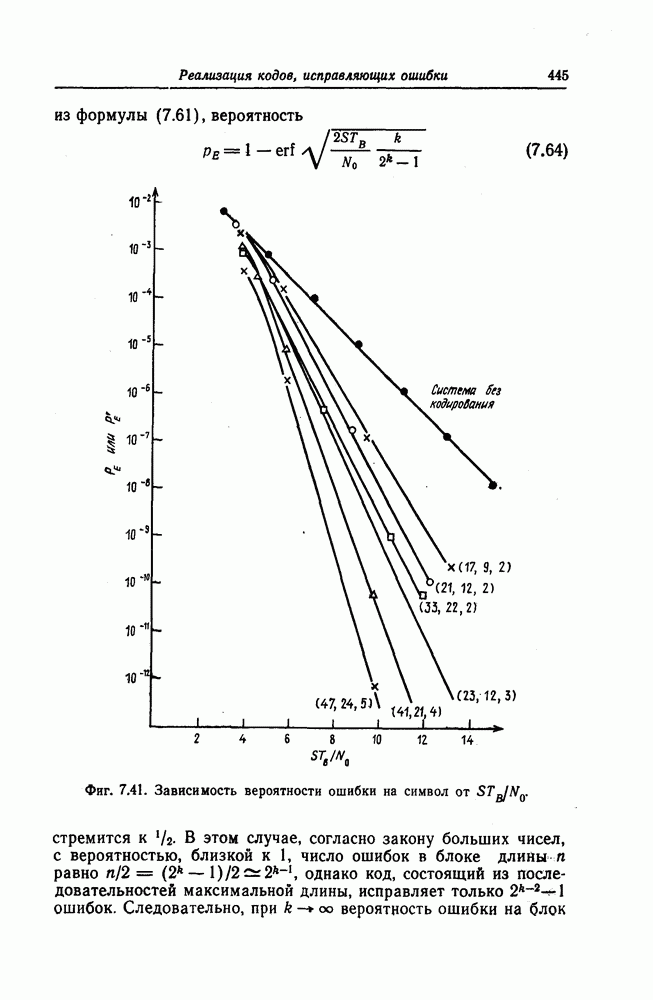

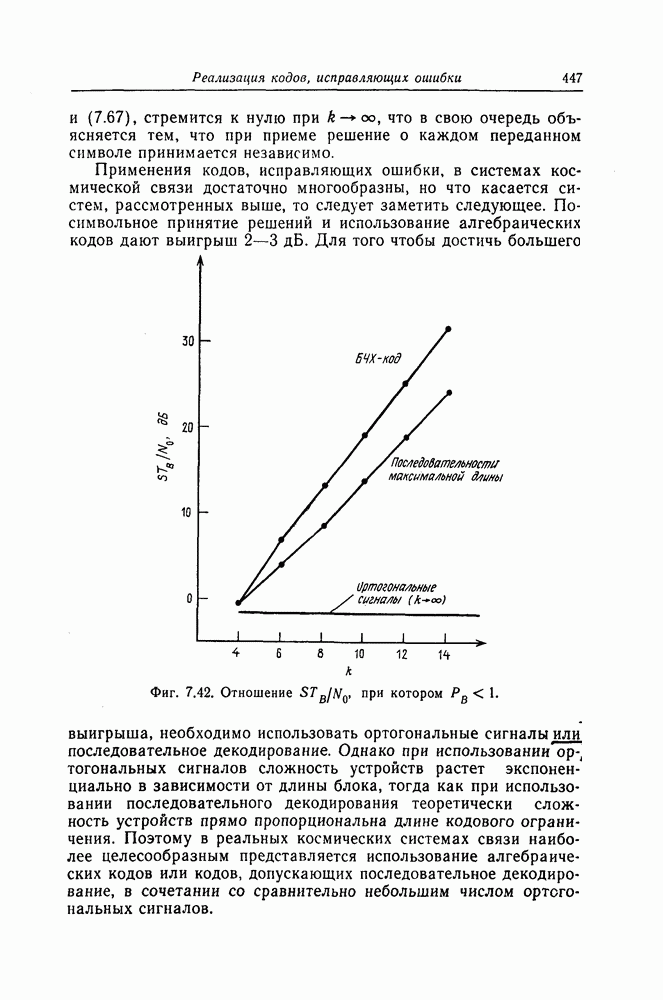




































































































 и эквивалентную вероятность ошибки на символ
и эквивалентную вероятность ошибки на символ  которые понадобятся в дальнейшем [6].
которые понадобятся в дальнейшем [6].
 информационными символами, исправляющие ошибки кратности
информационными символами, исправляющие ошибки кратности  и менее, будем называть
и менее, будем называть  -кодами. Предположим, что при приеме о каждом переданном символе принимается независимое решение. В этом случае вероятность
-кодами. Предположим, что при приеме о каждом переданном символе принимается независимое решение. В этом случае вероятность  ошибки в кодовом слове
ошибки в кодовом слове  -кода определяется равенством
-кода определяется равенством


