Пред.
След.
Макеты страниц
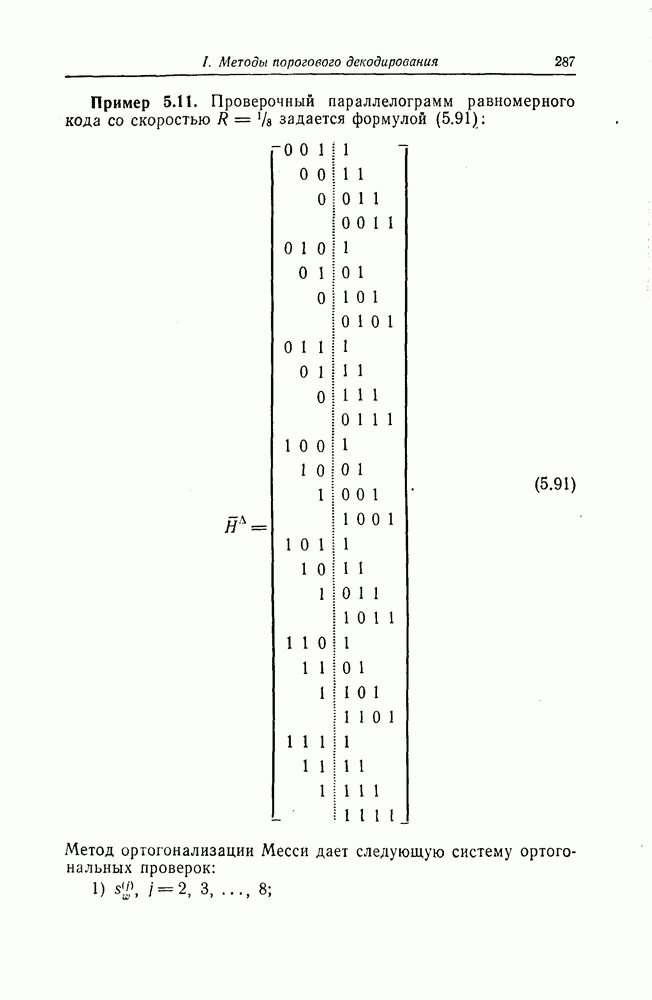
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
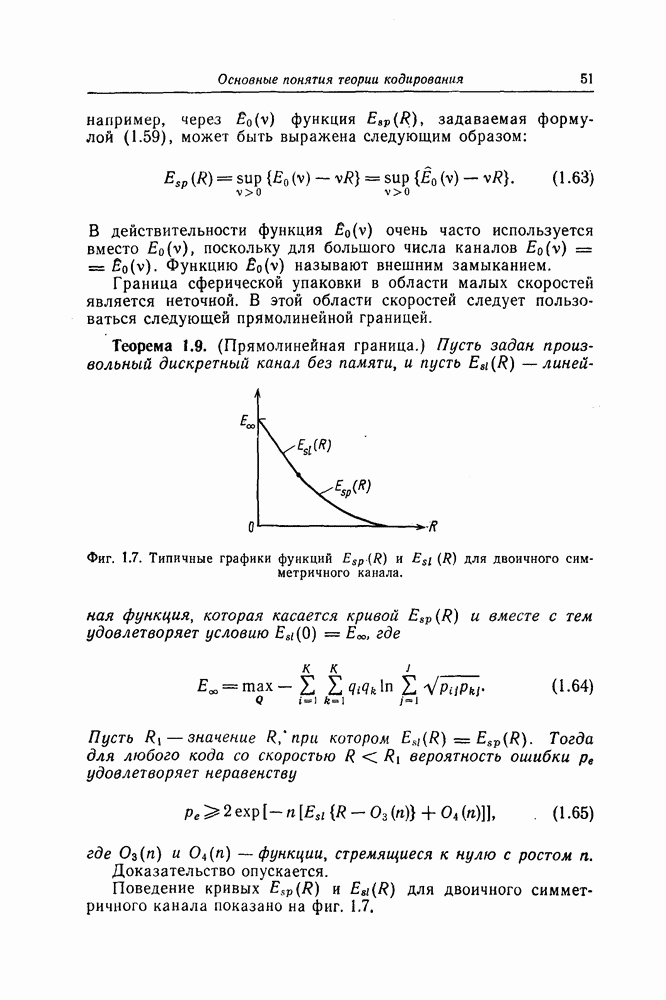
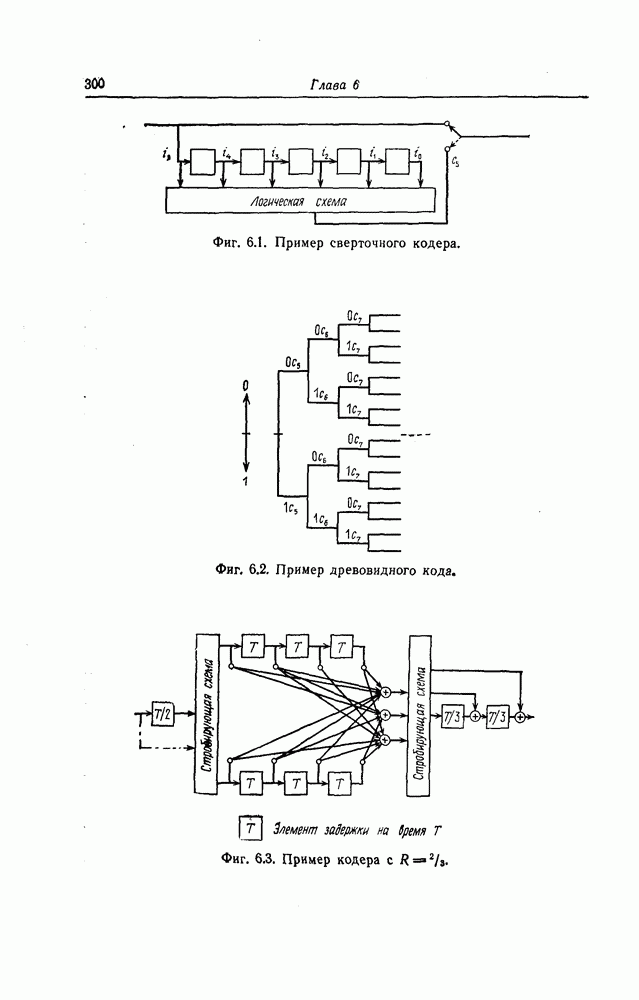
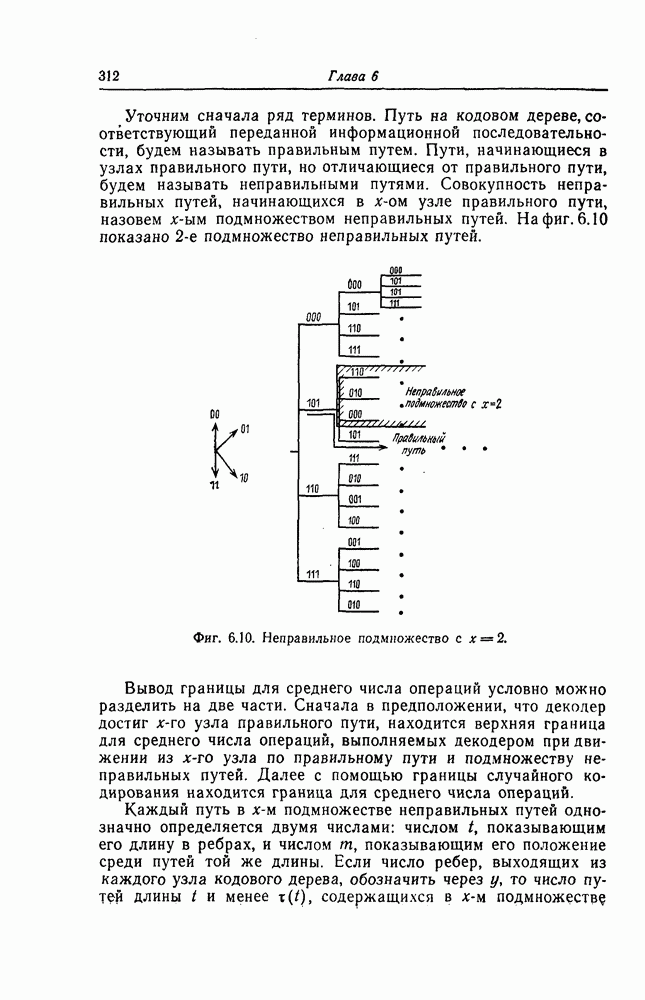
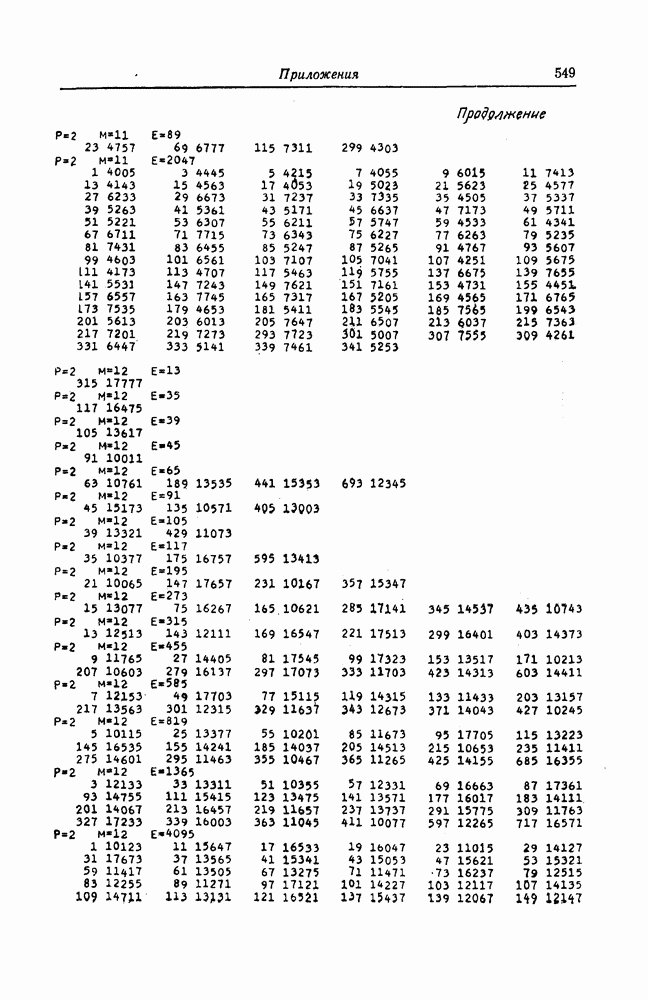
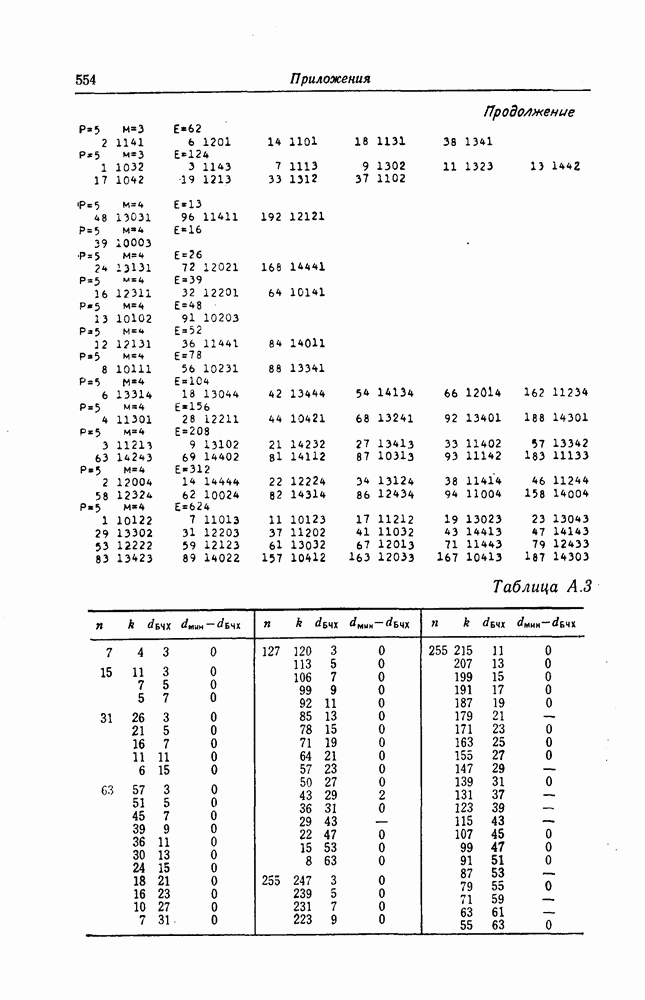
6.4. Коды, представляемые в виде кодового дерева, называются древовидными.Вообще говоря, древовидными кодами могут быть названы произвольные коды, имеющие древовидную структуру, подобную показанной на фиг. 6.2 или фиг. 6.4. При таком широком определении древовидных кодов коды, порождаемые сверточными кодерами, являются лишь подмножеством множества древовидных кодов. 6.1.2. Принцип последовательного декодированияПредположим, что задан некоторый древовидный код и попытаемся по принятой последовательности определить передававшуюся последовательность. Для этого сначала будем передвигаться поочередно вдоль каждого пути кодового дерева, сравнивая принятую последовательность с последовательностью, соответствующей пути, по которому мы движемся. Если при этом удается обнаружить некоторый путь, которому соответствует последовательность, почти совпадающая с принятой последовательностью, то естественно считать, что эта последовательность и передавалась. Метод декодирования, предложенный Возенкрафтом, предусматривает вначале поиск на кодовом дереве пути из
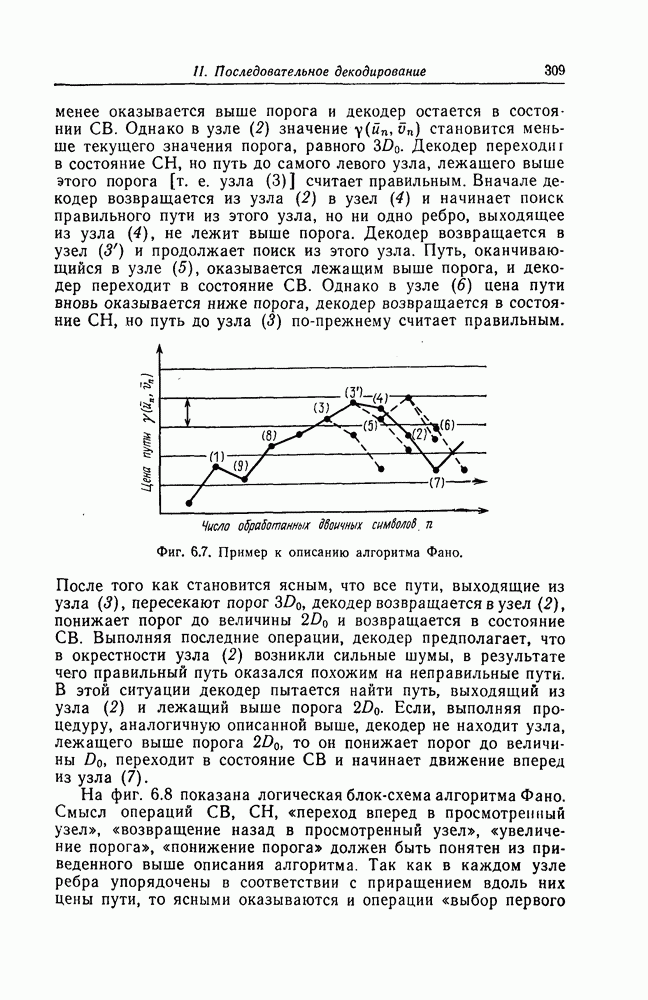
Фиг. 6.4. Пример древовидного кода скоростью Поскольку далее декодирование второго и последующих информационных символов осуществляется точно так же, как и первого информационного символа, то этот алгоритм был назван алгоритмом последовательного декодирования. Одним из критериев близости пути на кодовом дереве к принятой последовательности является расстояние Хэмминга между ними; если расстояние Хэмминга между последовательностями длины передававшейся и принятой последовательностями было больше чем Предположим, что этот метод декодирования используется в двоичном симметричном канале с вероятностью перехода
Фиг. 6.5. Число декодированных символов и расстояние Хэмминга для последовательного декодера. В тоже время расстояние Хэмминга, вычисляемое вдоль любого другого пути кодового дерева, будет возрастать со скоростью Этот алгоритм последовательного декодирования был обобщен Рейффеном [6] на случай произвольного дискретного канала без памяти. Обобщение было сделано путем замены расстояния Хэмминга на другую функцию, являющуюся обобщением расстояния Хэмминга. Дискретный канал без памяти с входным алфавитом из К символов и выходным алфавитом из где
где
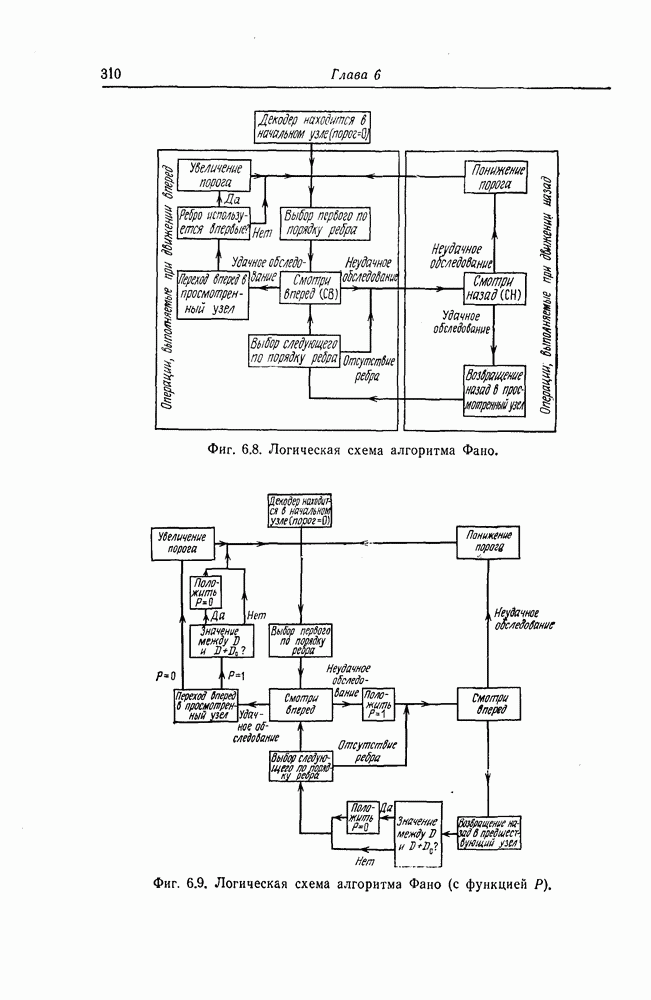
Величина Алгоритм последовательного декодирования, предложенный Фано [23], предусматривает вычисление и использование при декодировании наряду с ценой пути также некоторых порогов. Этот алгоритм является алгоритмом того же типа, что и алгоритм Возенкрафта, но если среднее число операций, необходимых для декодирования одного символа, в случае использования алгоритма Возенкрафта при скоростях передачи, меньших определенной скорости Фано. По тем же причинам алгоритм Фано будет детально рассмотрен в данной книге. В последние годы независимо Джели-нек [7] и Зигангиров [8] предложили алгоритм последовательного декодирования, часто называемый стек-алгоритмом. Нельзя сказать, что этот алгоритм во всех отношениях лучше алгоритма Фано, но так как его описание значительно проще описания алгоритма Фано и поскольку он хорошо иллюстрирует принцип последовательного декодирования, то этот алгоритм также будет кратко рассмотрен ниже.
|
 |
Оглавление
|

































































































































































































































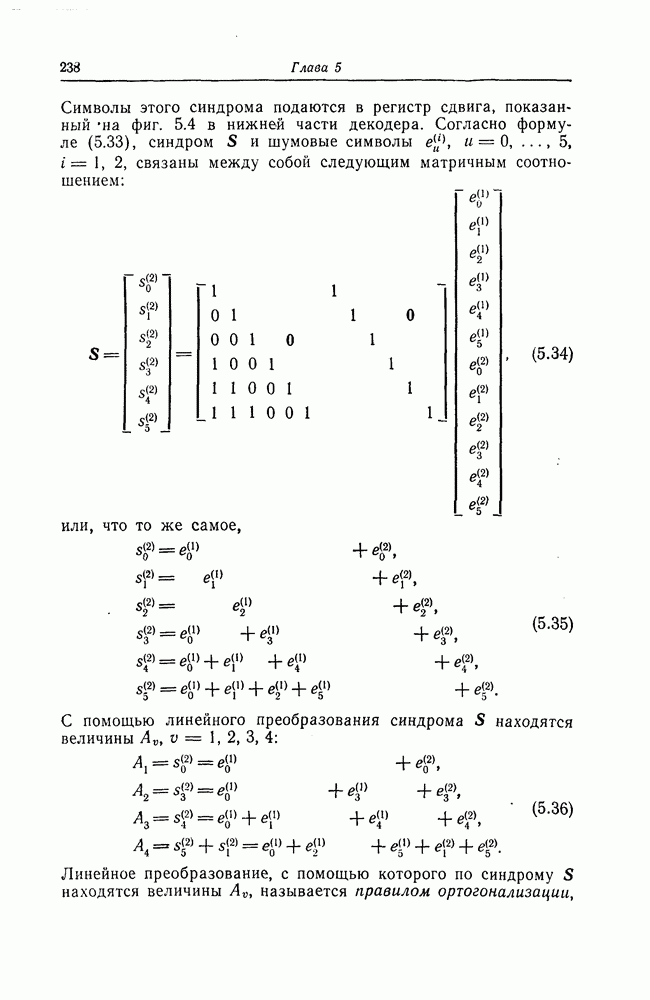














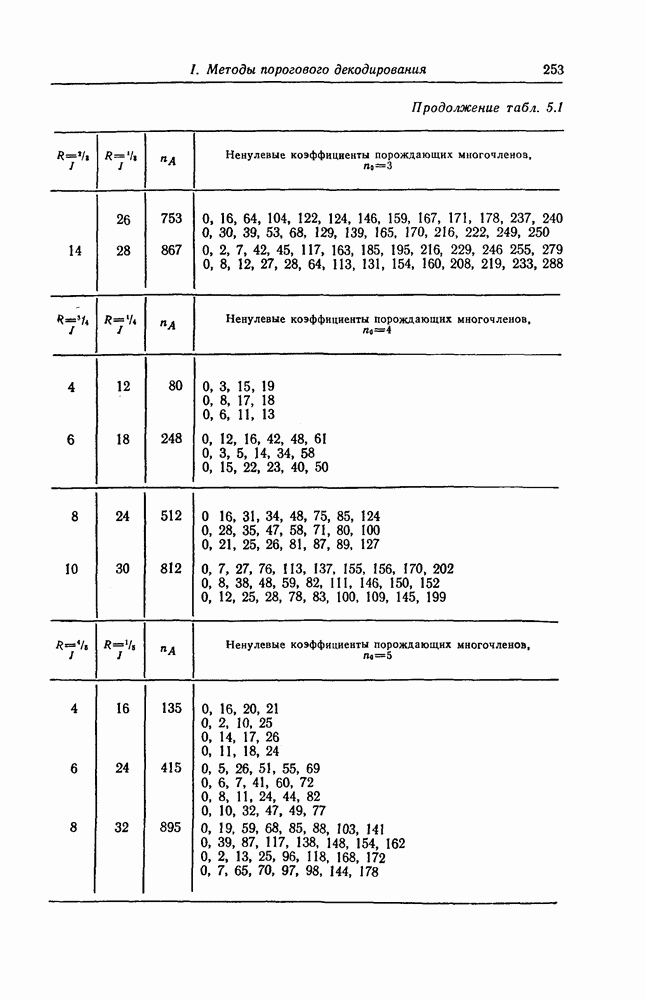





























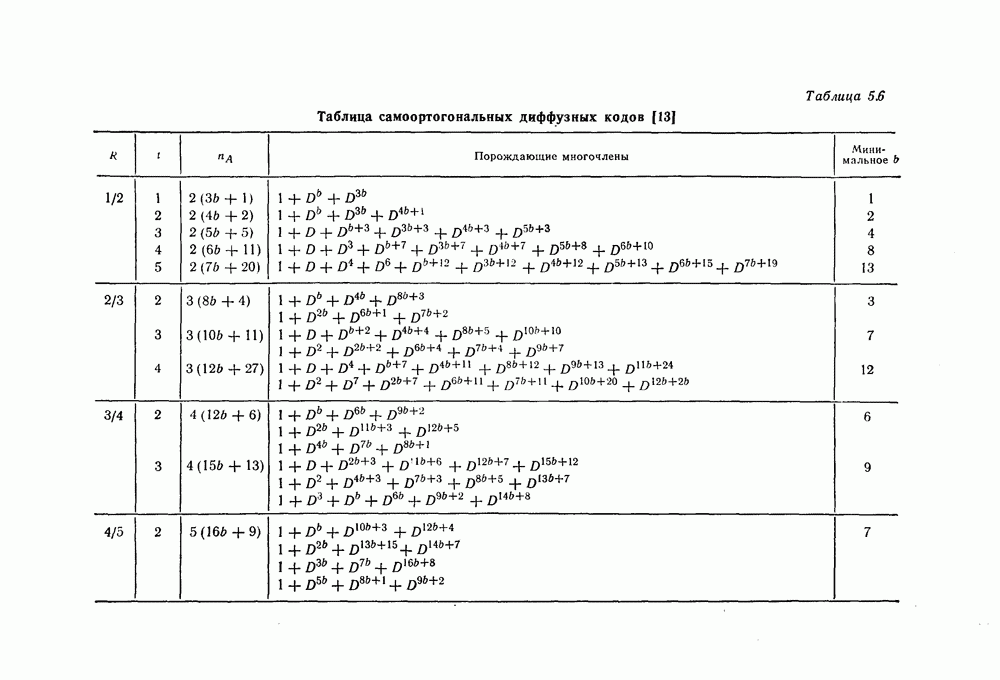

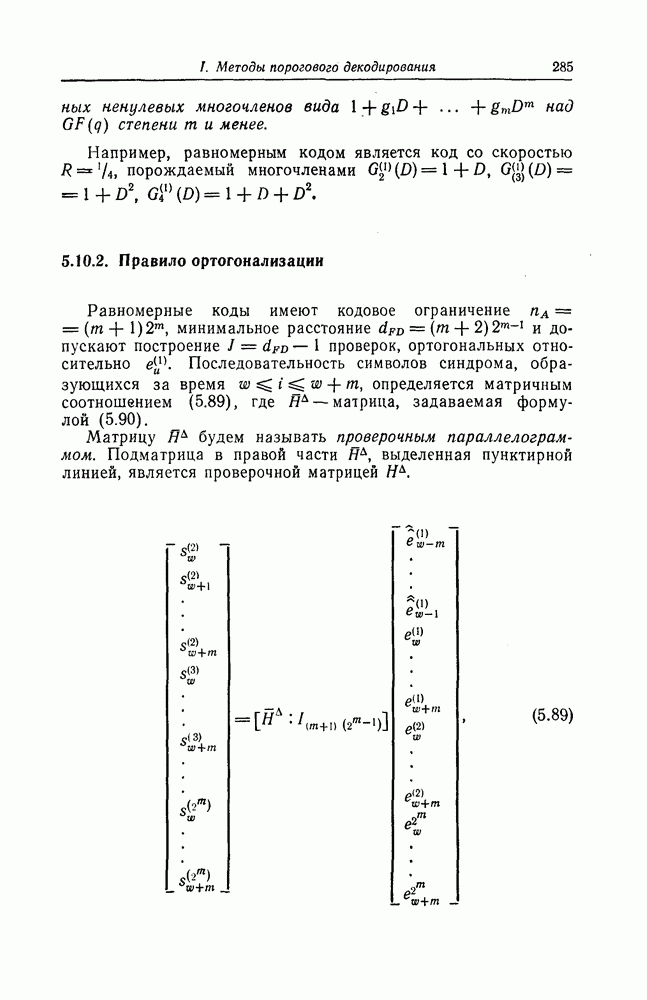


































































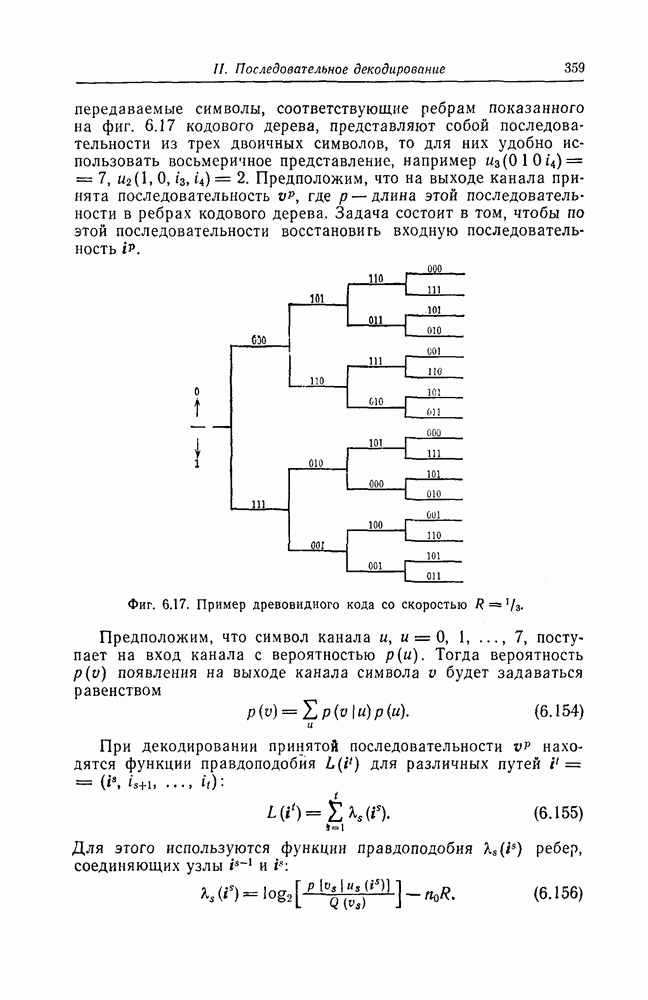

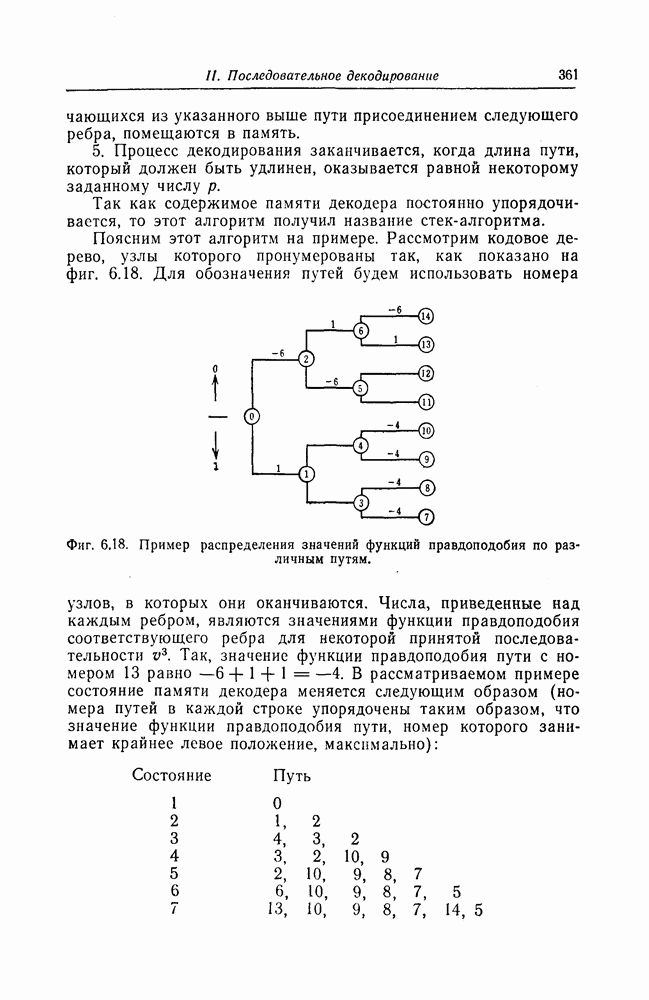












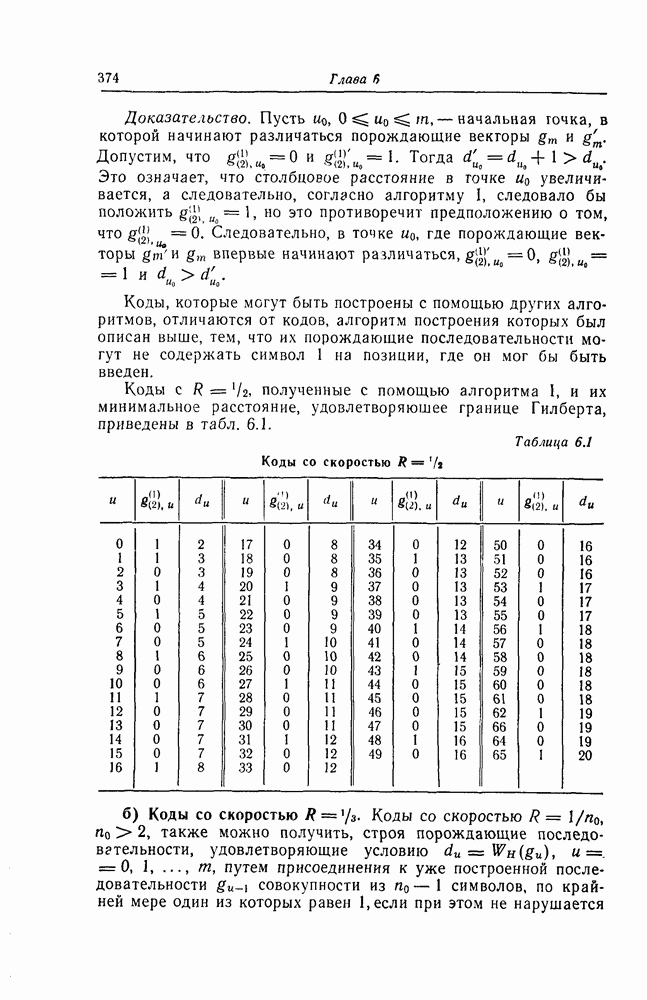




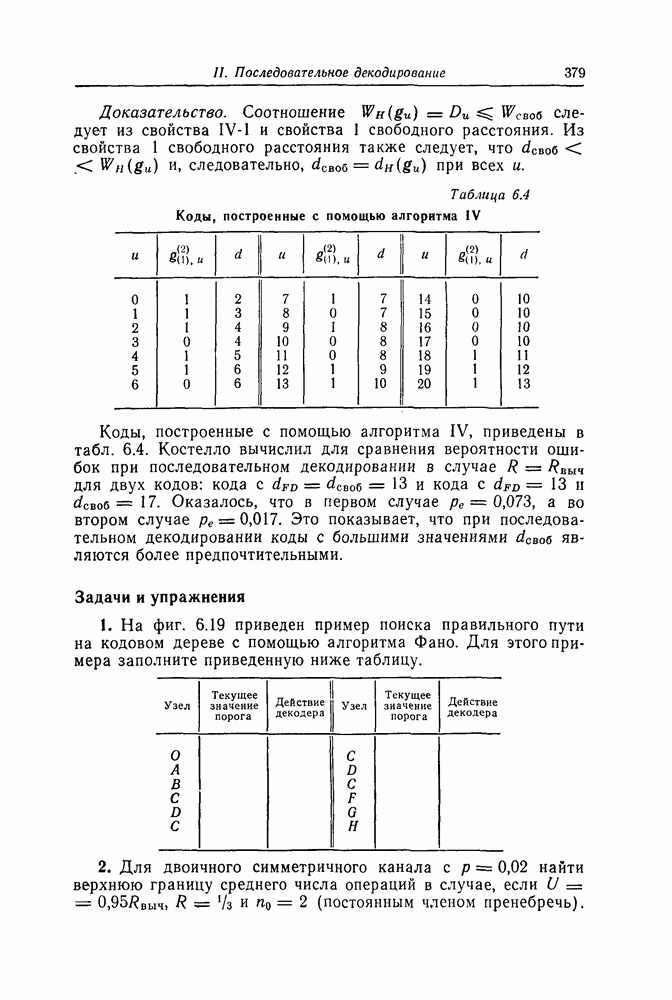
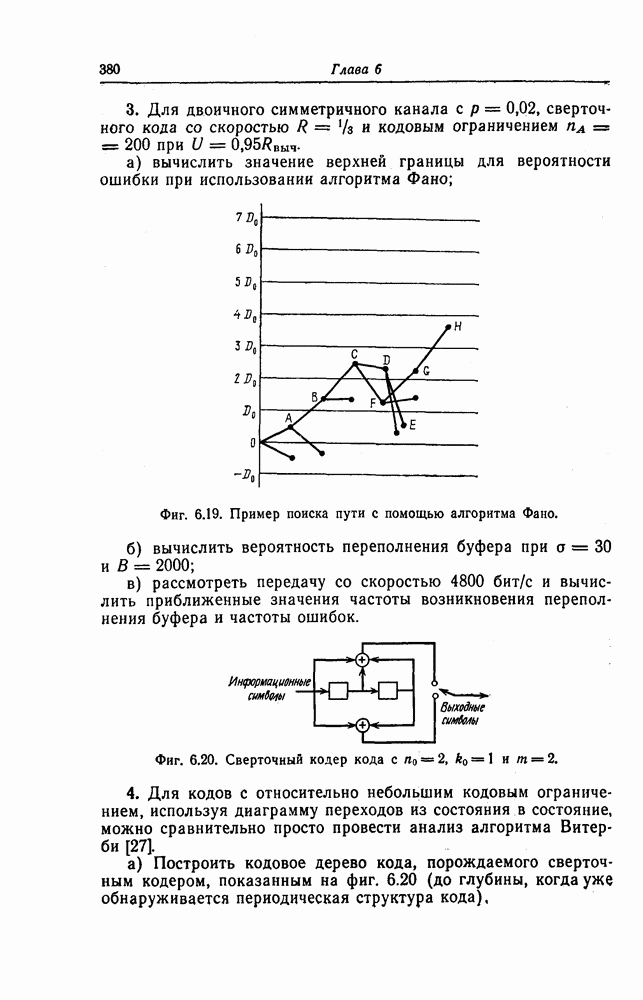





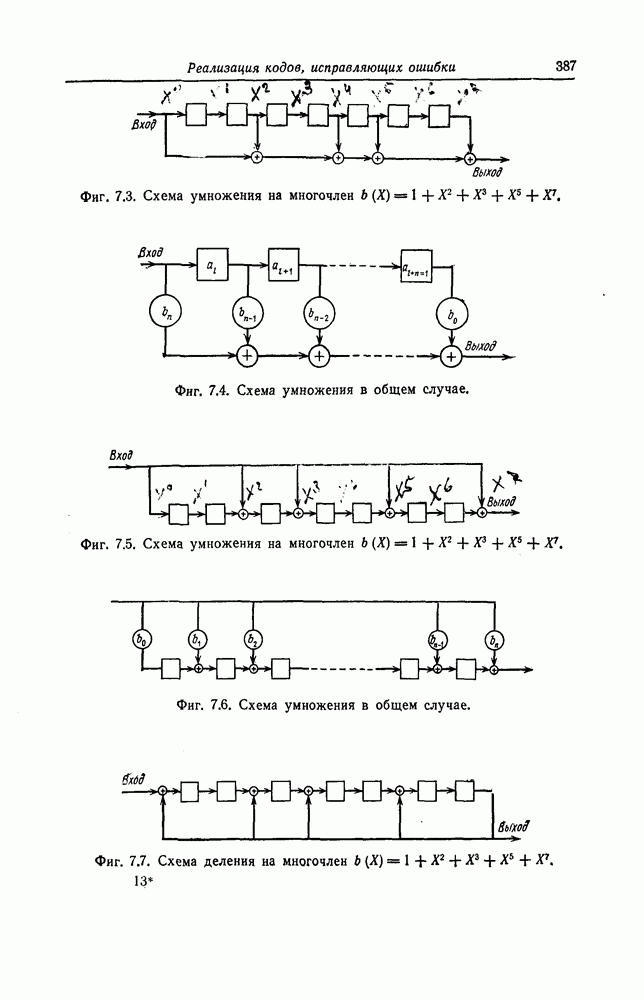

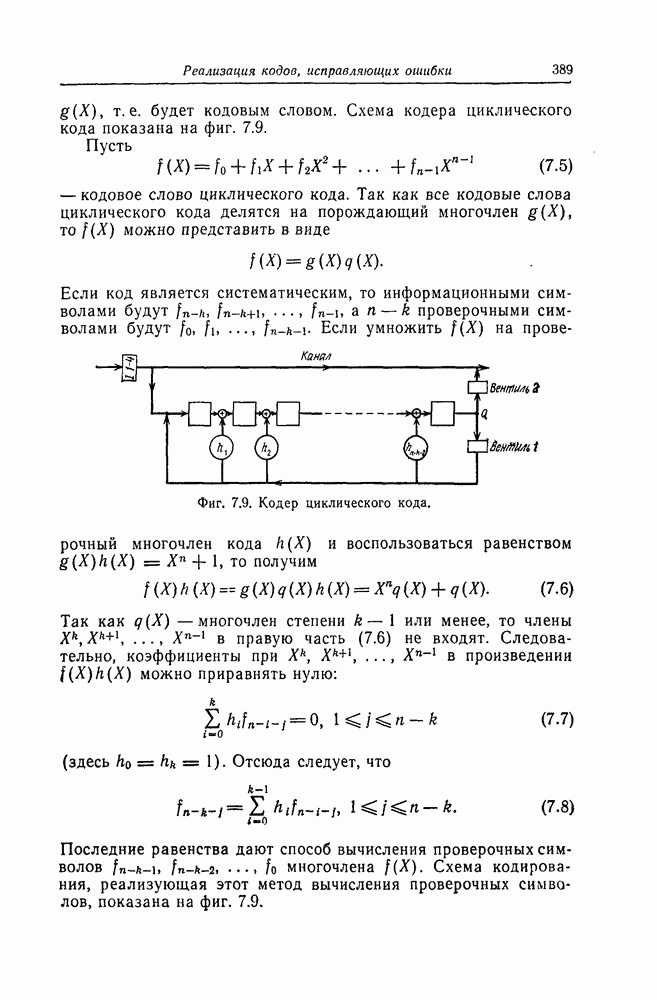
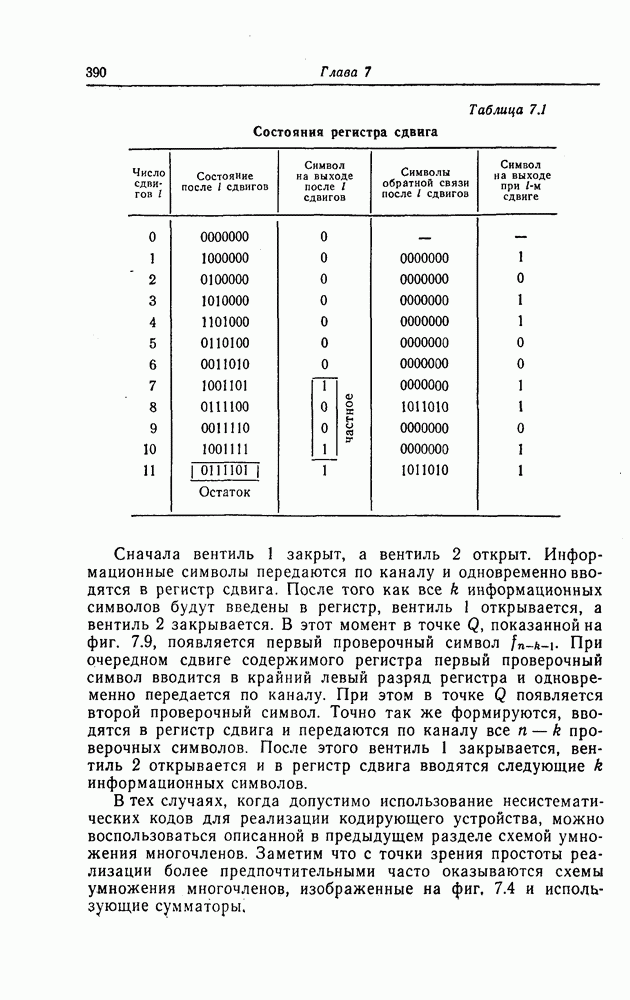




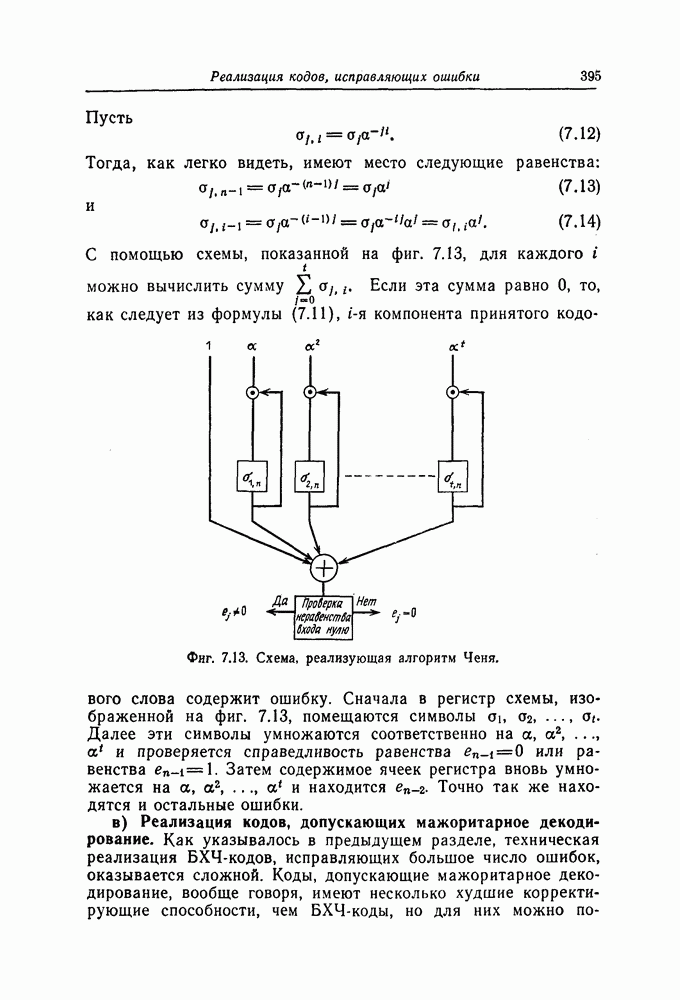

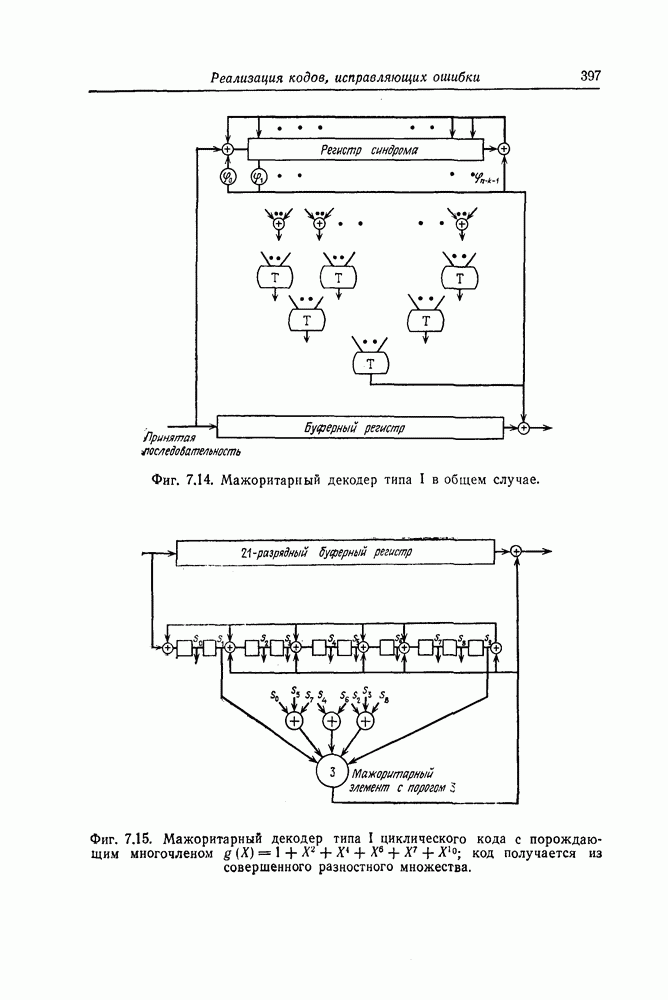




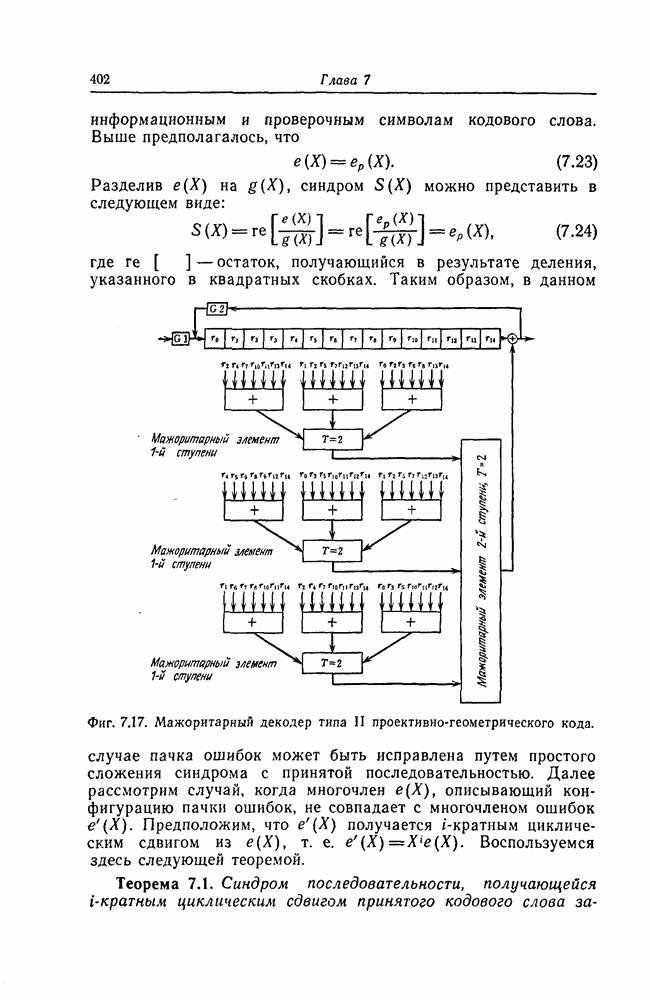
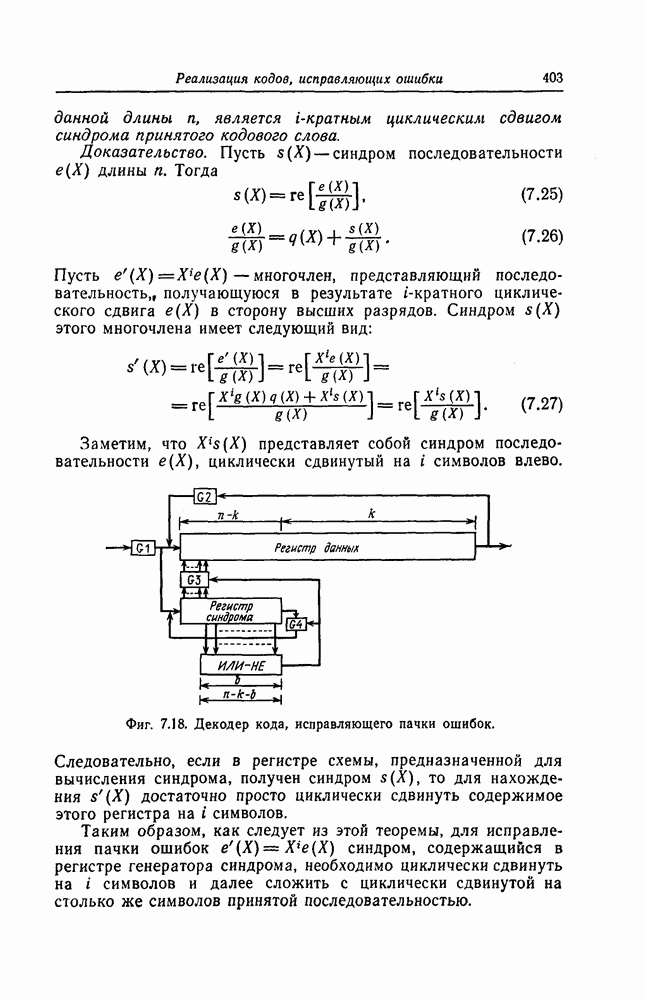


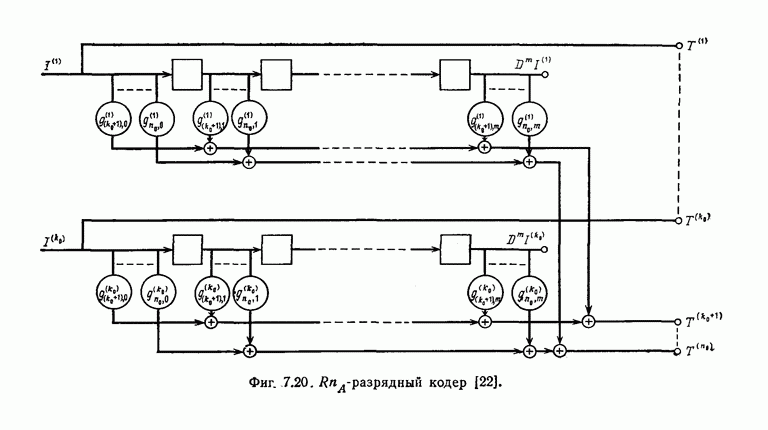

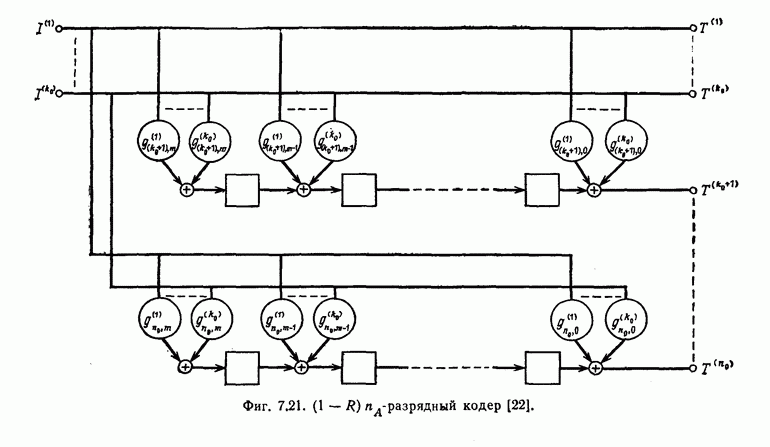
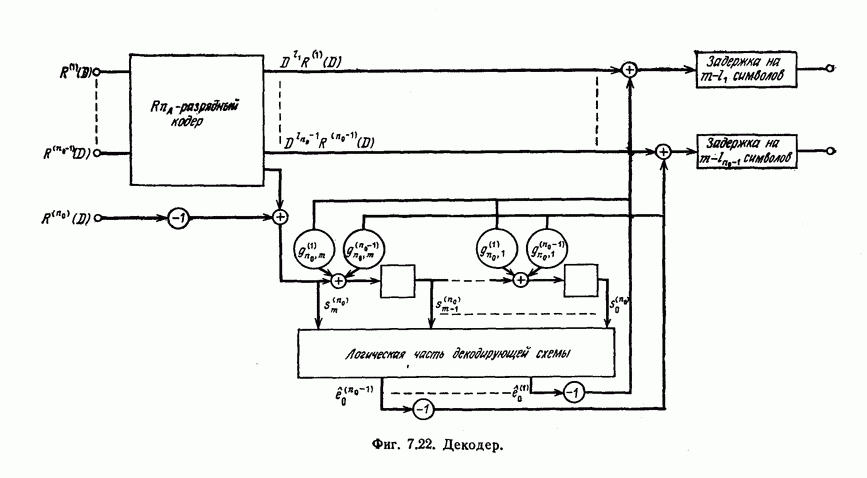



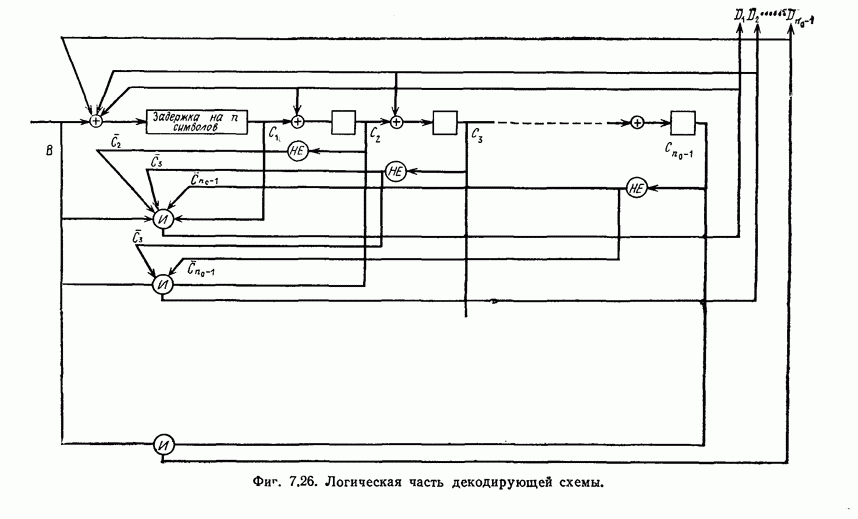
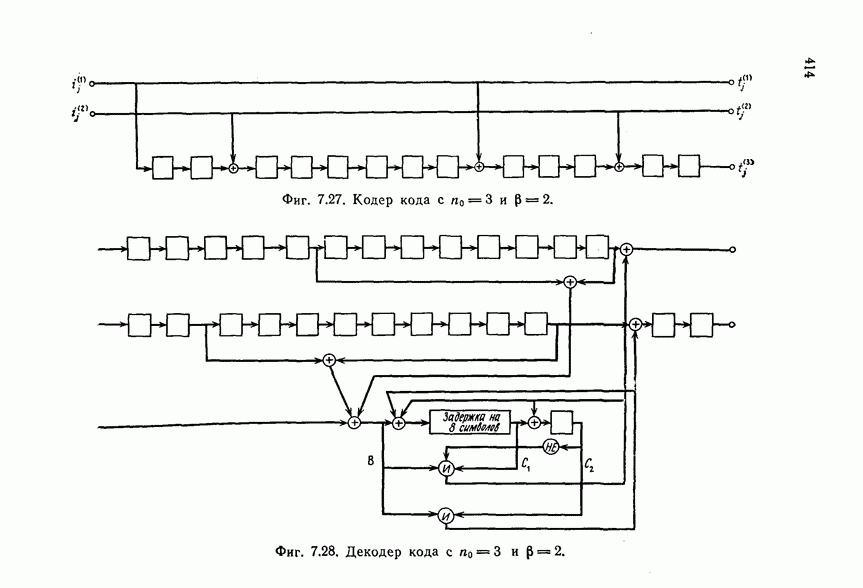


































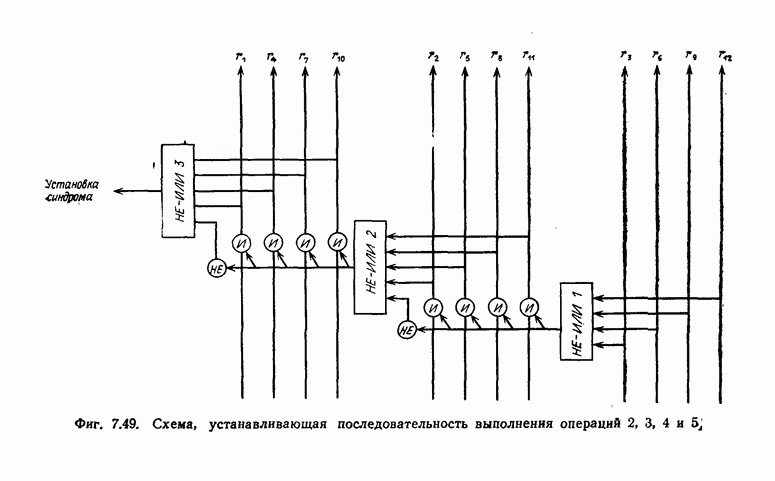



























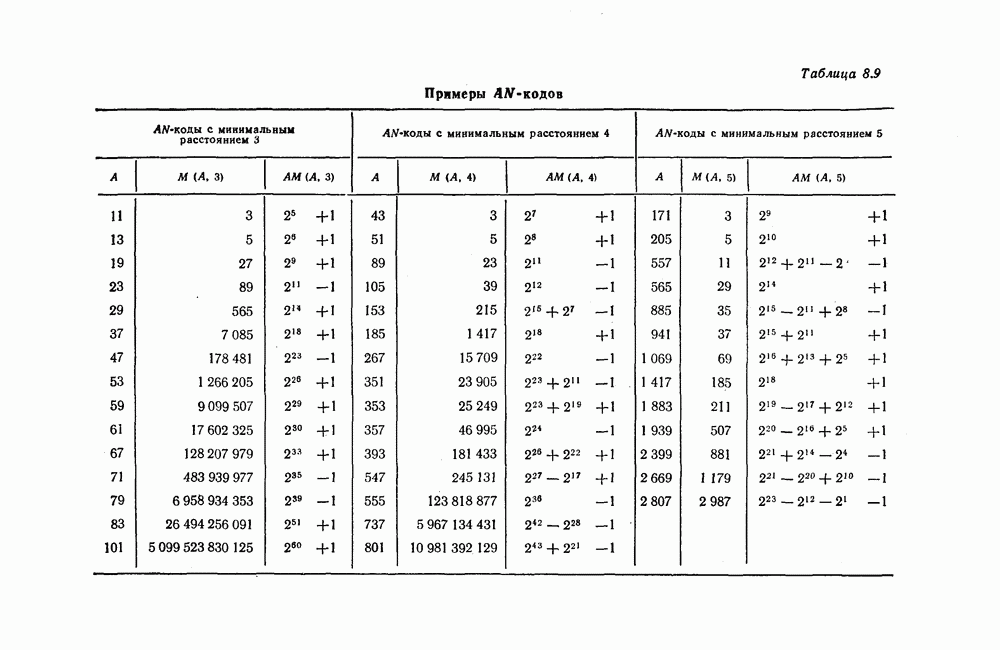



















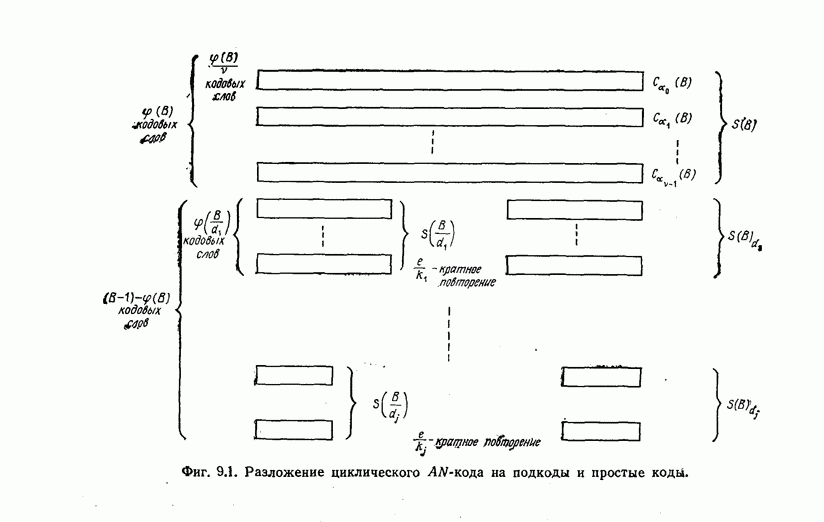

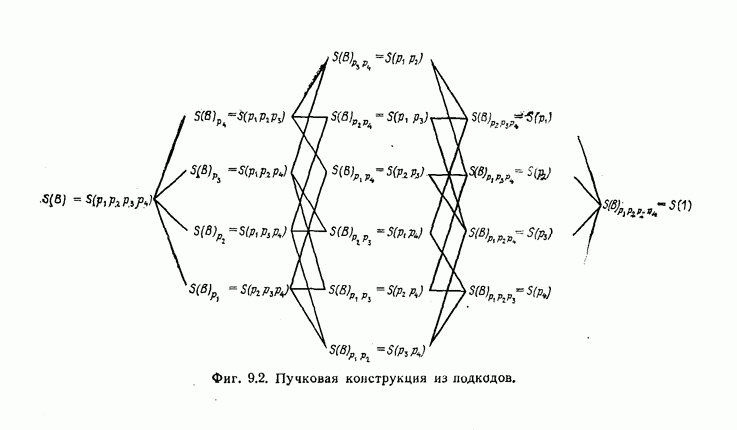











































 ребра, соответствующая которому кодовая последовательность находится на каком-то определенном расстоянии от переданной последовательности, и далее декодирование первого информационного символа (первым переданным информационным символом считается первый информационный символ первого ребра найденного пути).
ребра, соответствующая которому кодовая последовательность находится на каком-то определенном расстоянии от переданной последовательности, и далее декодирование первого информационного символа (первым переданным информационным символом считается первый информационный символ первого ребра найденного пути).


 не превышает определенный порог
не превышает определенный порог  то последовательности можно считать совпадающими. В случае двоичного симметричного канала порог
то последовательности можно считать совпадающими. В случае двоичного симметричного канала порог  выбирается таким образом, чтобы вероятность того, что расстояние Хэмминга между
выбирается таким образом, чтобы вероятность того, что расстояние Хэмминга между
 не превышала величины
не превышала величины  где
где  некоторая заданная постоянная. При этом вероятность того, что расстояние Хэмминга между правильным путем дерева и принятой последовательностью больше чем
некоторая заданная постоянная. При этом вероятность того, что расстояние Хэмминга между правильным путем дерева и принятой последовательностью больше чем  при больших
при больших  оказывается чрезвычайно малой.
оказывается чрезвычайно малой.
 Тогда, поскольку в этом случае в канале ошибки в различных символах возникают независимо с вероятностью перехода
Тогда, поскольку в этом случае в канале ошибки в различных символах возникают независимо с вероятностью перехода  то расстояние Хэмминга, вычисляемое вдоль правильного пути, как показано на фиг. 6.5, почти всегда будет возрастать со скоростью
то расстояние Хэмминга, вычисляемое вдоль правильного пути, как показано на фиг. 6.5, почти всегда будет возрастать со скоростью  вместе с числом обработанных символов.
вместе с числом обработанных символов.

 поскольку различные пути кодового дерева отличаются друг от друга приблизительно в половине символов. Таким образом, расстояния Хэмминга, вычисленные вдоль правильного и ошибочного пути кодового дерева, оказываются различными. При этом, даже если на начальном этапе декодирования путь кодового дерева был выбран неправильно, то через некоторое время ошибка будет обнаружена, поиск правильного пути будет продолжен и в конце концов правильный путь будет найден.
поскольку различные пути кодового дерева отличаются друг от друга приблизительно в половине символов. Таким образом, расстояния Хэмминга, вычисленные вдоль правильного и ошибочного пути кодового дерева, оказываются различными. При этом, даже если на начальном этапе декодирования путь кодового дерева был выбран неправильно, то через некоторое время ошибка будет обнаружена, поиск правильного пути будет продолжен и в конце концов правильный путь будет найден.
 символов определяется совокупностью переходных вероятностей
символов определяется совокупностью переходных вероятностей 
 -вероятность того, что при передаче входного символа
-вероятность того, что при передаче входного символа  на выходе канала будет принят символ
на выходе канала будет принят символ  Расстояние между путем кодового дерева
Расстояние между путем кодового дерева  содержащим
содержащим  символов, и принятой последовательностью
символов, и принятой последовательностью  определяется равенством
определяется равенством


 представляет собой вероятность появления на выходе канала символа и, в случае, если на входе канала символ
представляет собой вероятность появления на выходе канала символа и, в случае, если на входе канала символ  появляется с вероятностью
появляется с вероятностью  Расстояние, определяемое формулой (6.1), является количеством информации между последовательностями
Расстояние, определяемое формулой (6.1), является количеством информации между последовательностями  и
и  в случае, когда пары
в случае, когда пары  статистически независимы и символы
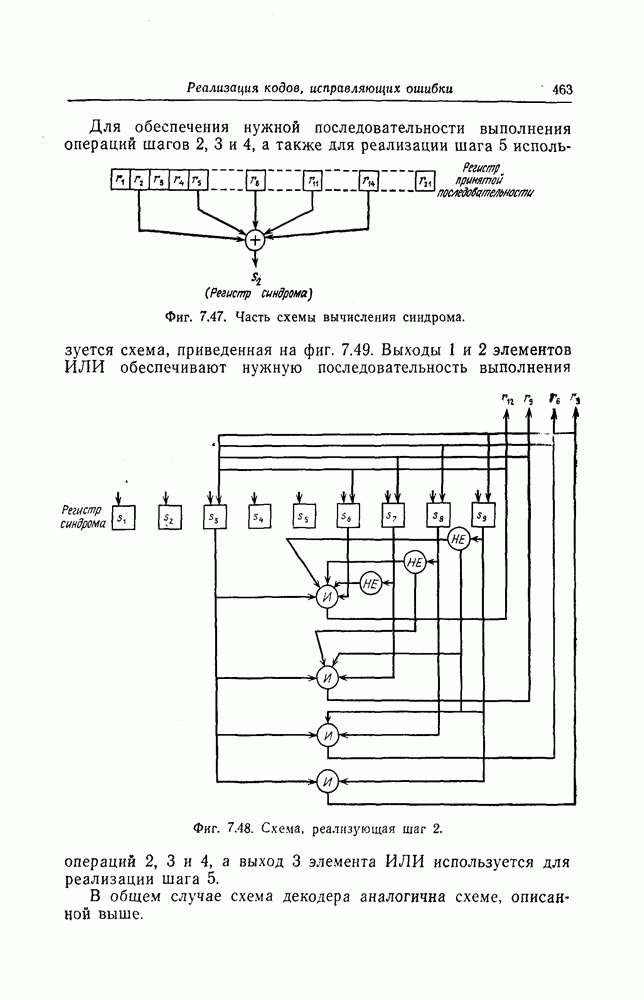
статистически независимы и символы  на входе канала появляются с вероятностями
на входе канала появляются с вероятностями  Если правую часть (6.1) представить в виде логарифма произведения, то можно заметить, что величина
Если правую часть (6.1) представить в виде логарифма произведения, то можно заметить, что величина  определяется вероятностью
определяется вероятностью  которая в случае двоичного симметричного канала является монотонно убывающей функцией расстояния Хэмминга между последовательностями
которая в случае двоичного симметричного канала является монотонно убывающей функцией расстояния Хэмминга между последовательностями  Следовательно, в случае двоичного симметричного канала введенное выше расстояние эквивалентно расстоянию Хэмминга. Однако поскольку в случае произвольного дискретного канала без памяти введенная функция не может быть интерпретирована в терминах расстояния Хэмминга, то будем называть ее в дальнейшем ценой пути.
Следовательно, в случае двоичного симметричного канала введенное выше расстояние эквивалентно расстоянию Хэмминга. Однако поскольку в случае произвольного дискретного канала без памяти введенная функция не может быть интерпретирована в терминах расстояния Хэмминга, то будем называть ее в дальнейшем ценой пути.
 растет как небольшая степень кодового ограничения, то для алгоритма Фано это среднее число в тех же условиях не зависит от длины кодового ограничения. Это упрощает анализ алгоритма декодирования Фано. Кроме того, достоинством алгоритма Фано является также то, что он допускает более простую техническую реализацию, чем алгоритм Возенкрафта. В силу этого приблизительно с 1964 г. исследования алгоритмов последовательного декодирования в значительной степени были связаны с исследованием алгоритма
растет как небольшая степень кодового ограничения, то для алгоритма Фано это среднее число в тех же условиях не зависит от длины кодового ограничения. Это упрощает анализ алгоритма декодирования Фано. Кроме того, достоинством алгоритма Фано является также то, что он допускает более простую техническую реализацию, чем алгоритм Возенкрафта. В силу этого приблизительно с 1964 г. исследования алгоритмов последовательного декодирования в значительной степени были связаны с исследованием алгоритма