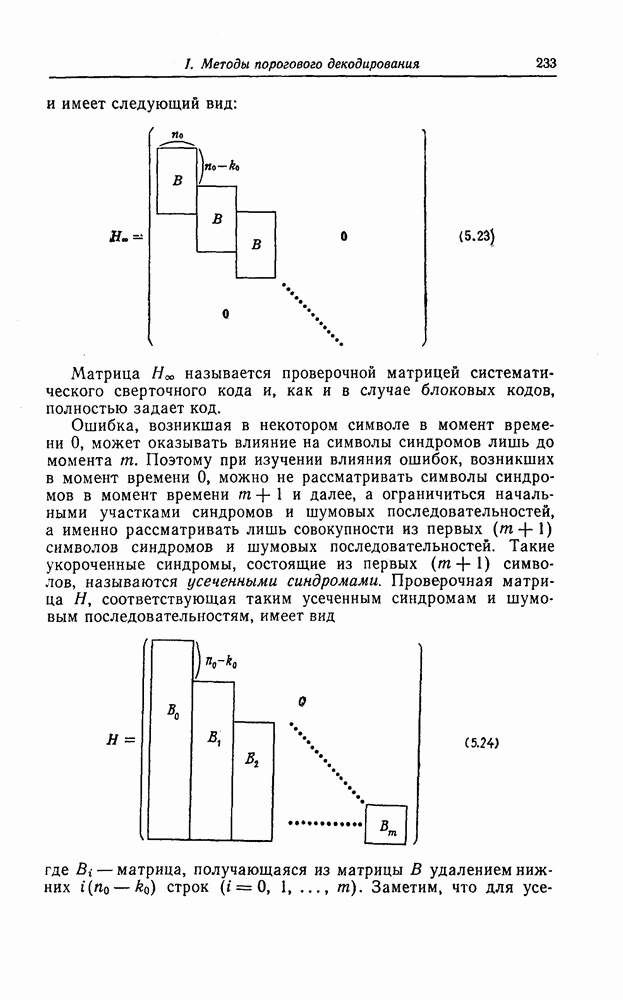
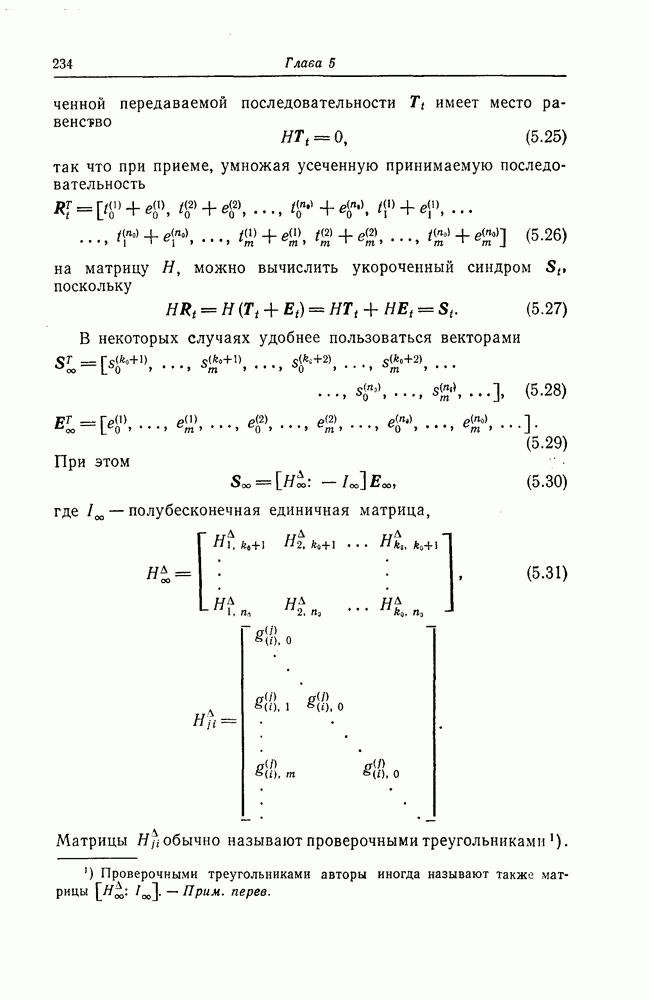
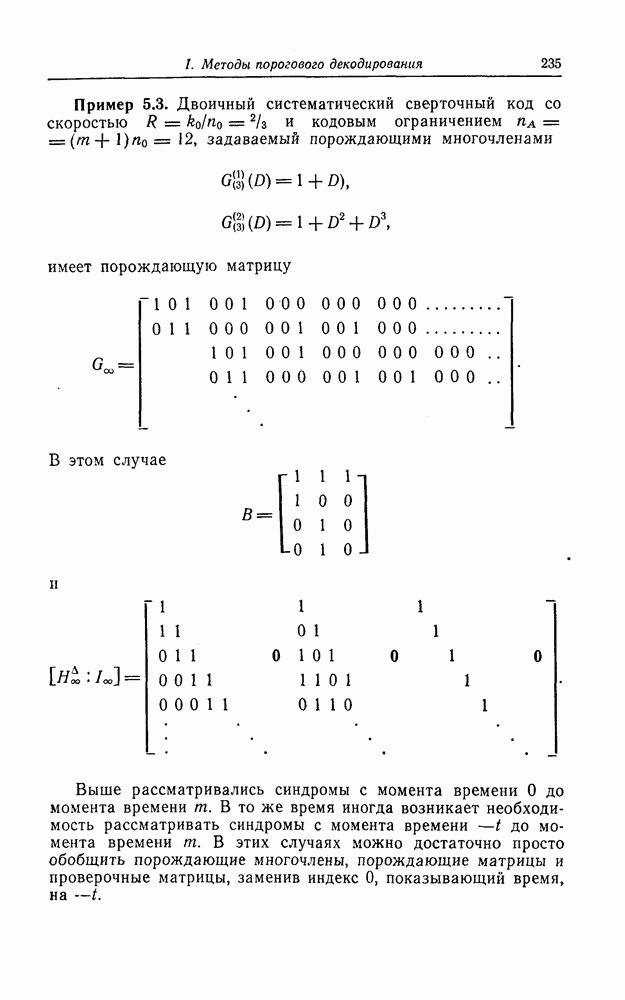
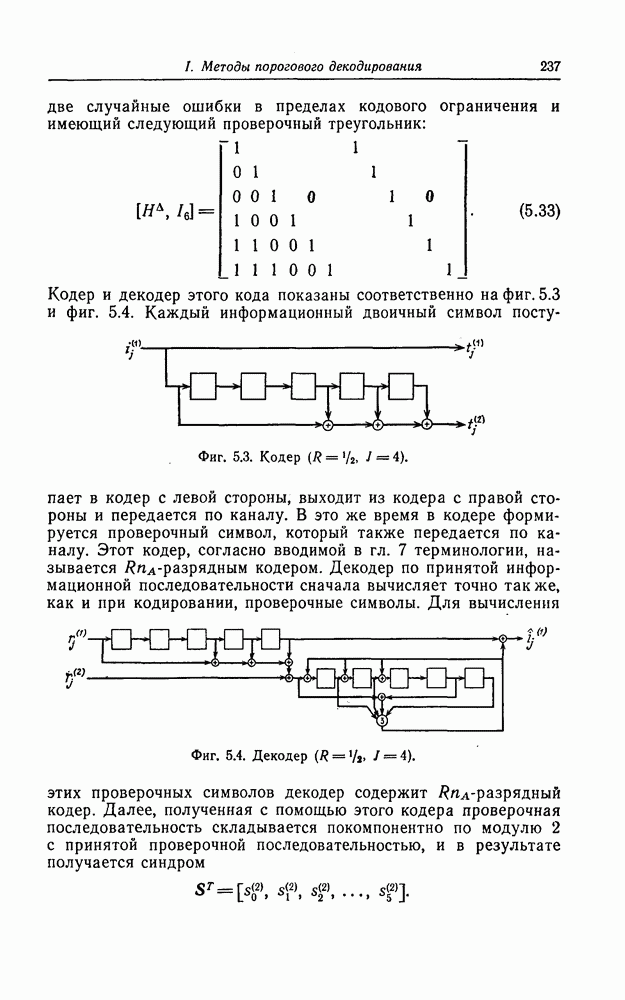
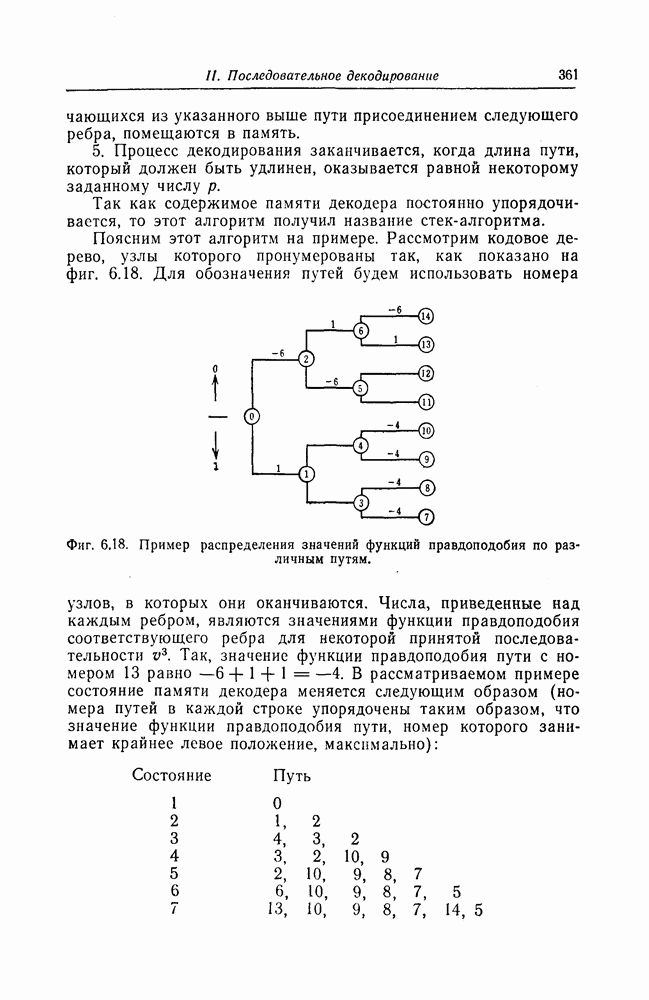
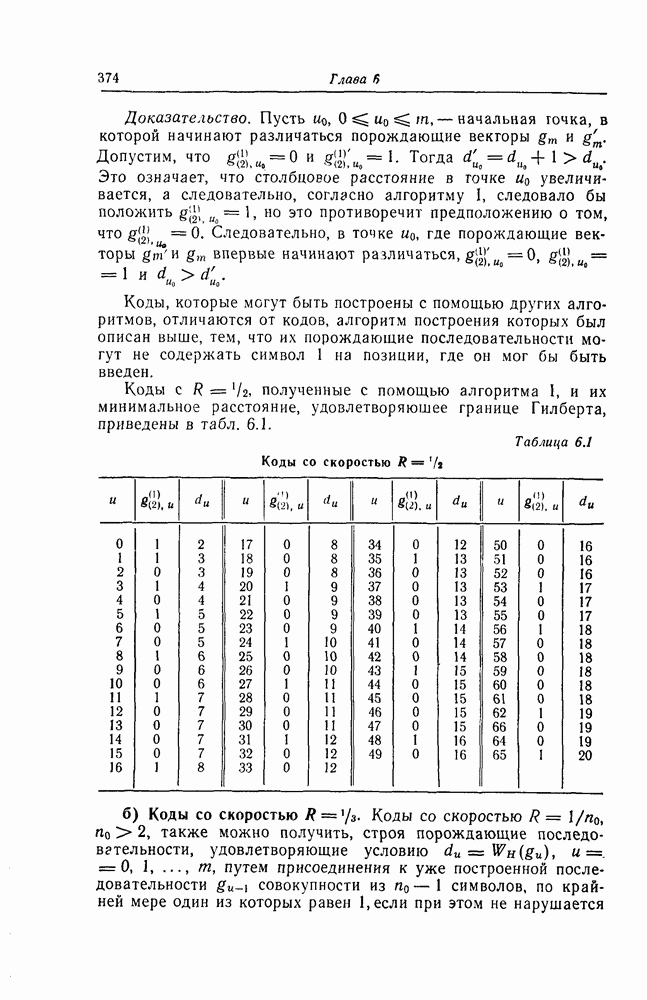
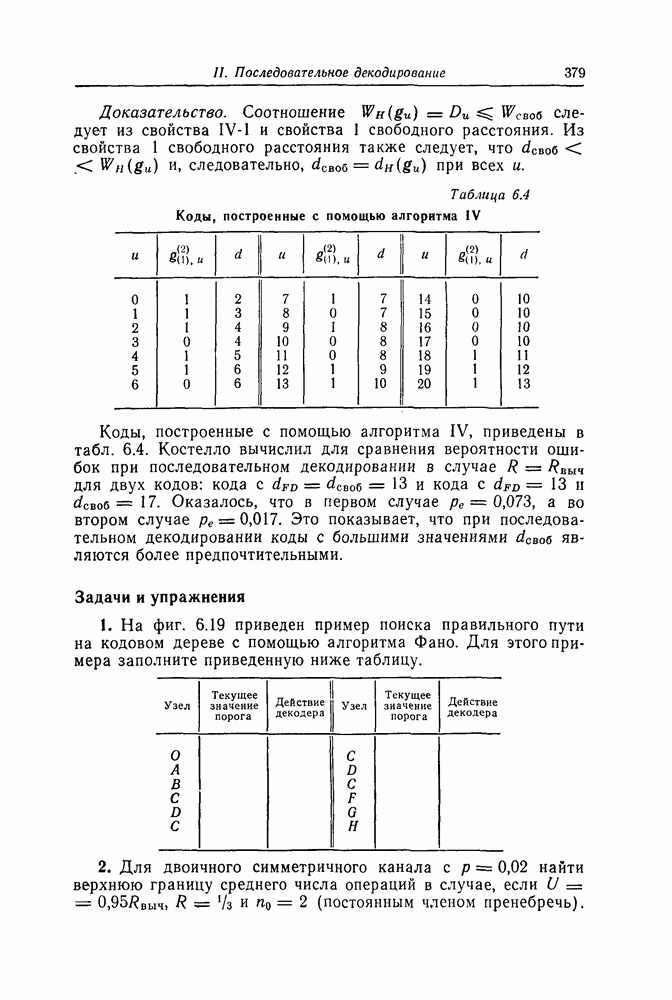
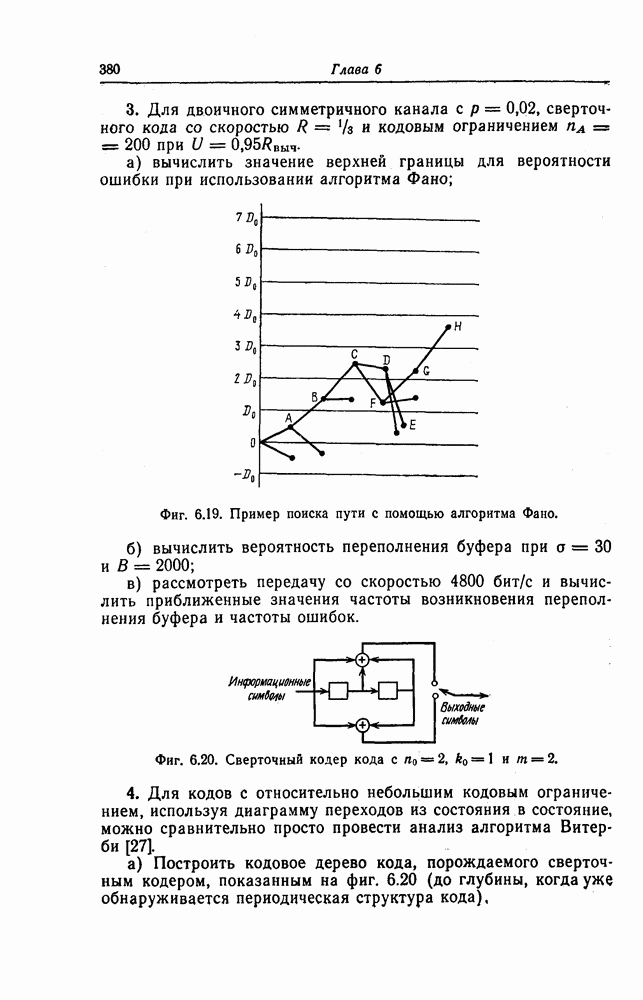
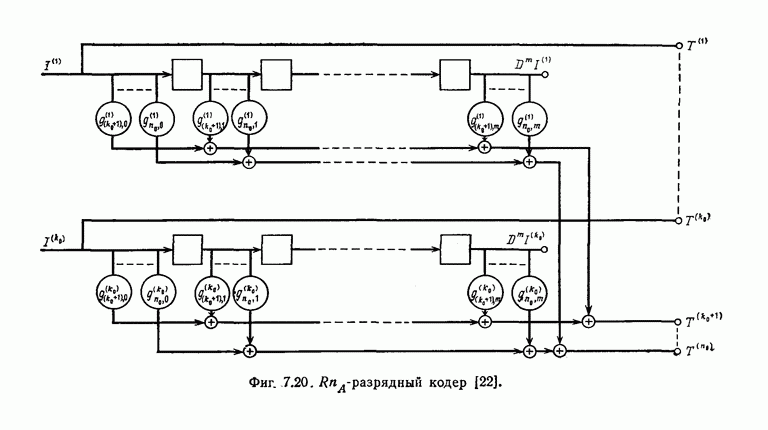
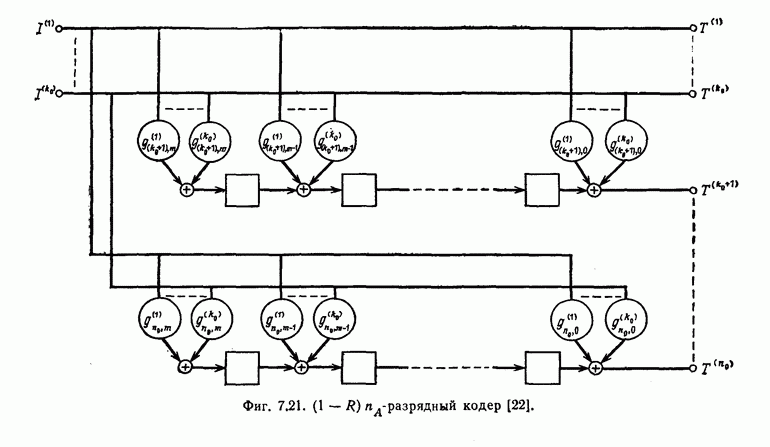
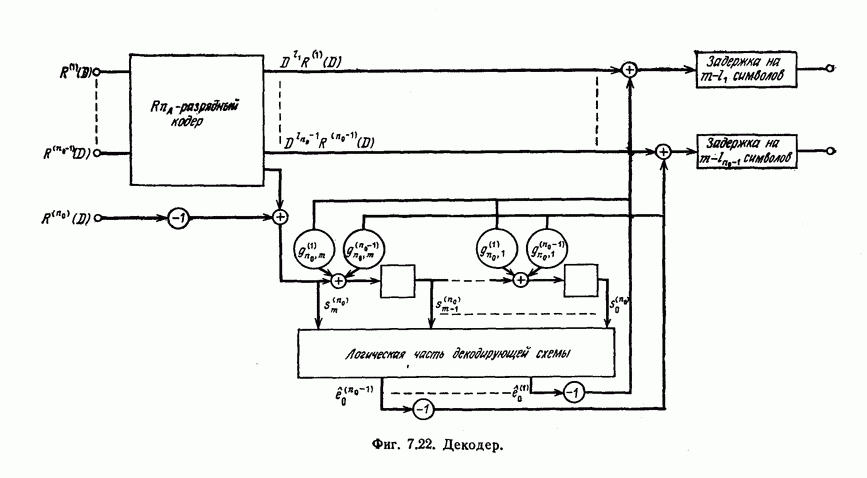
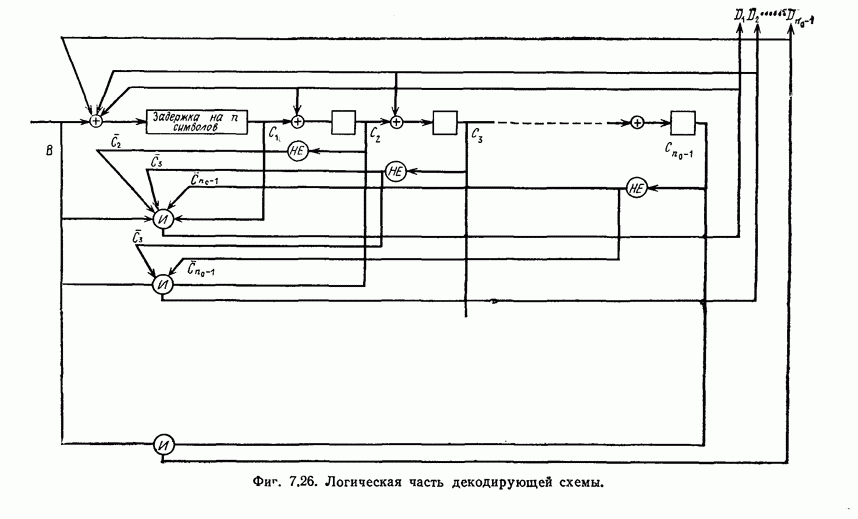
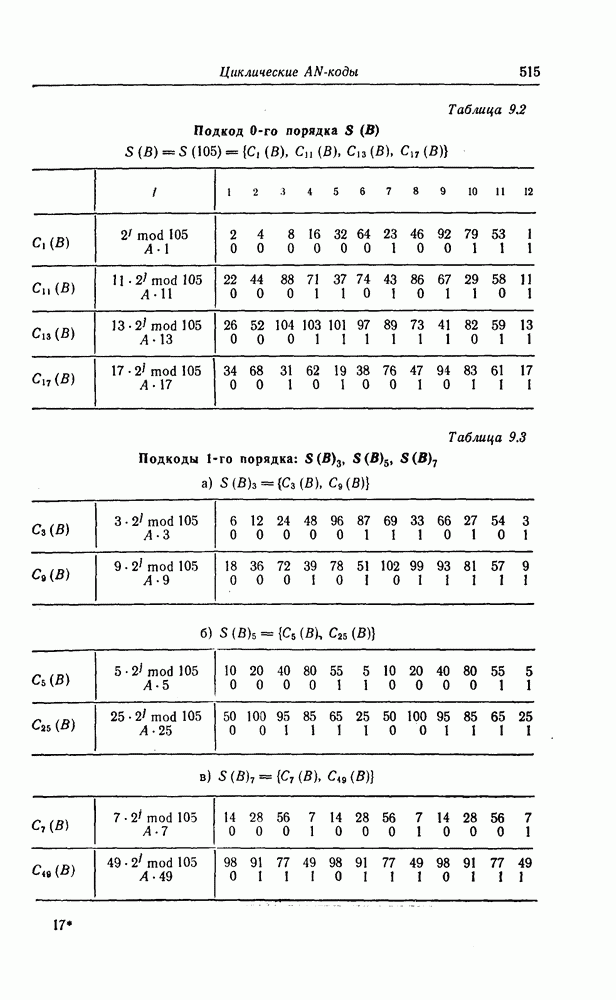
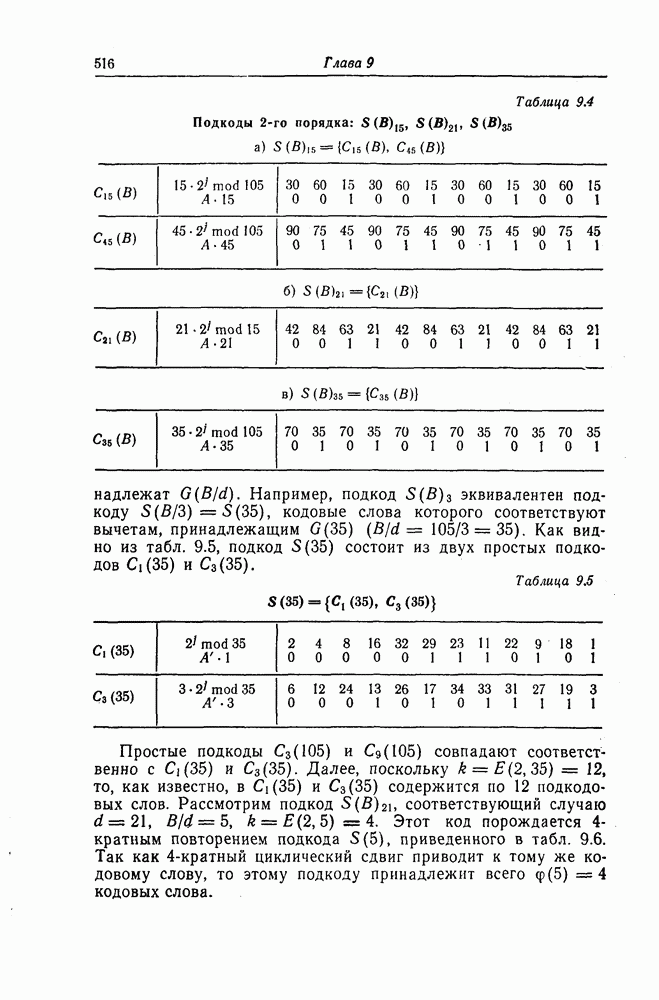
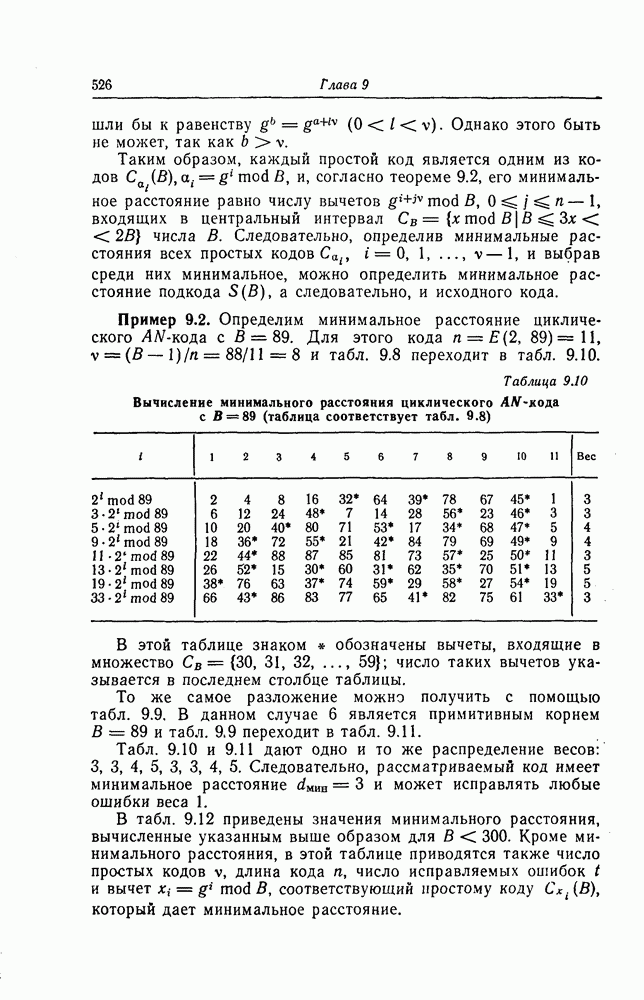
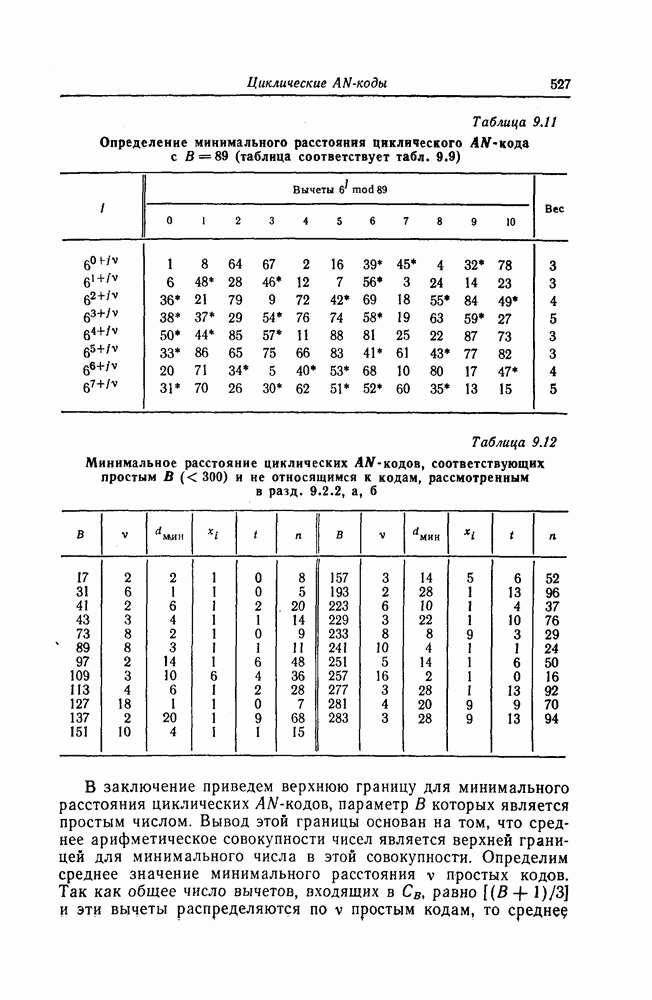
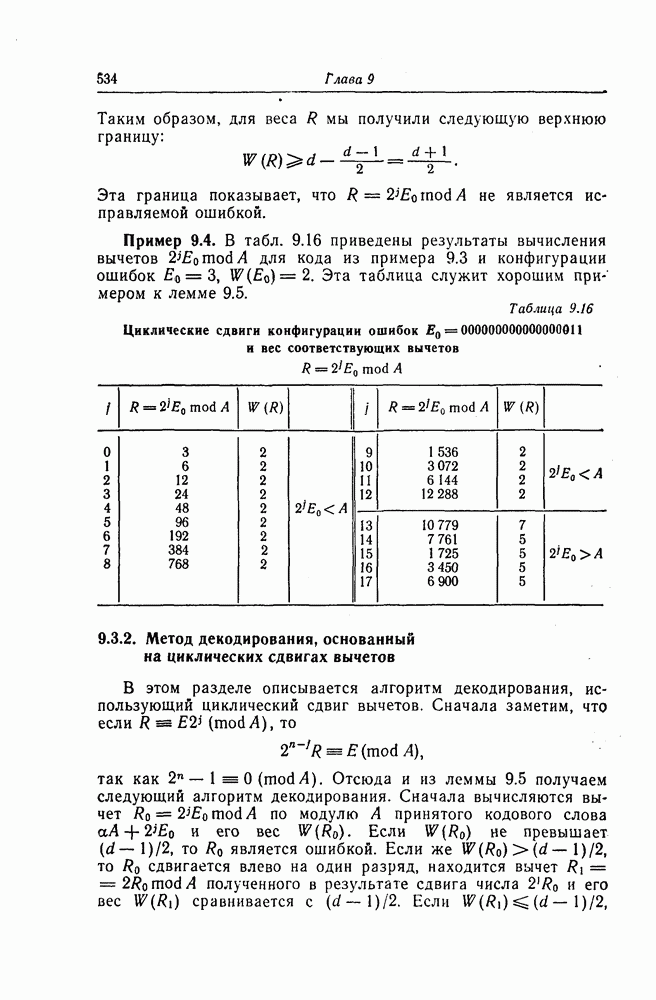
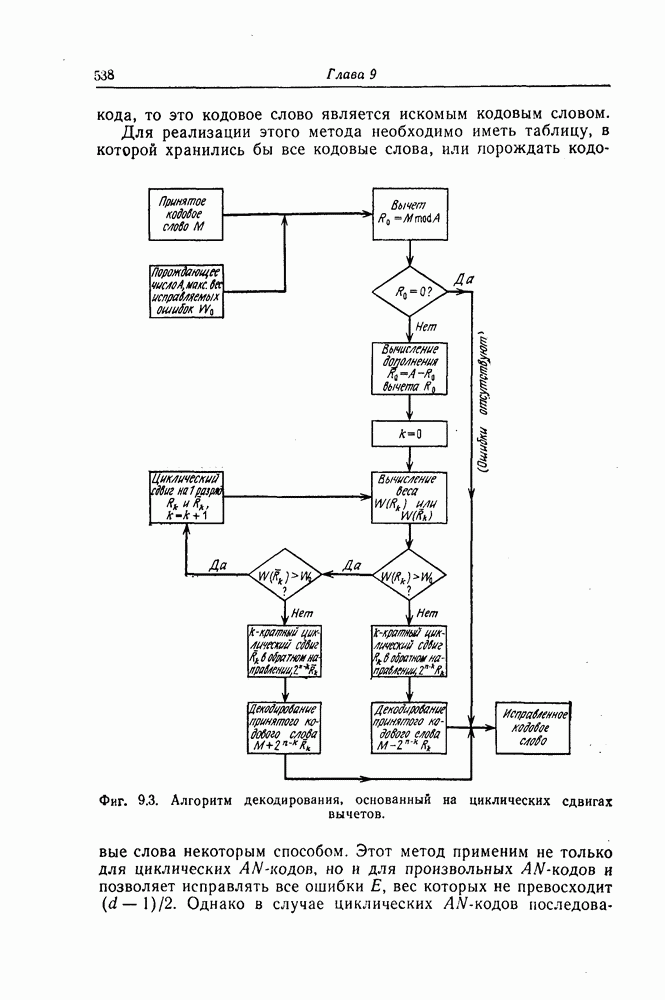
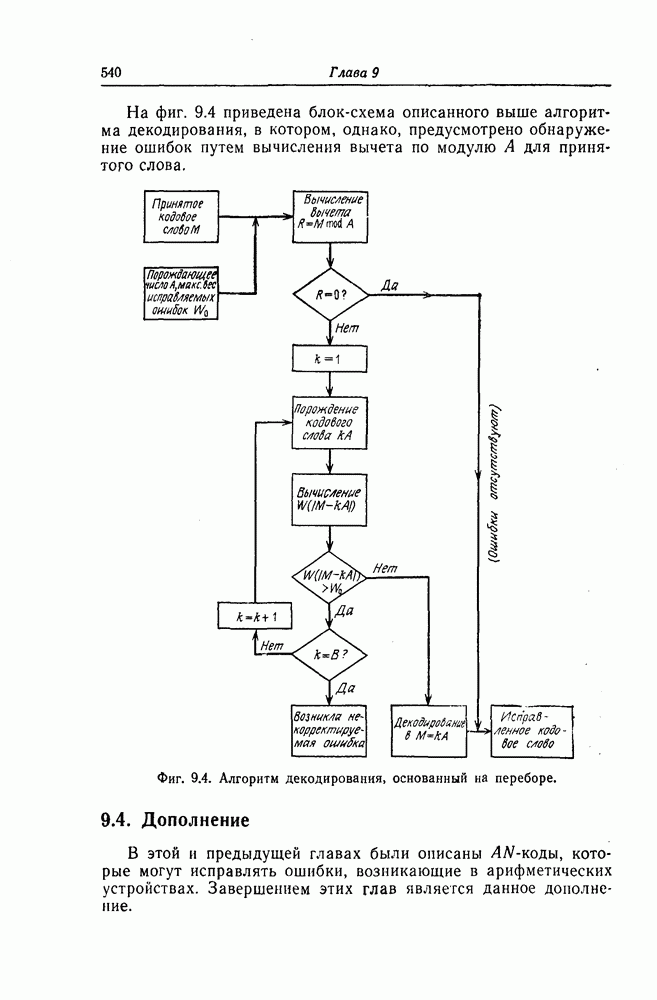
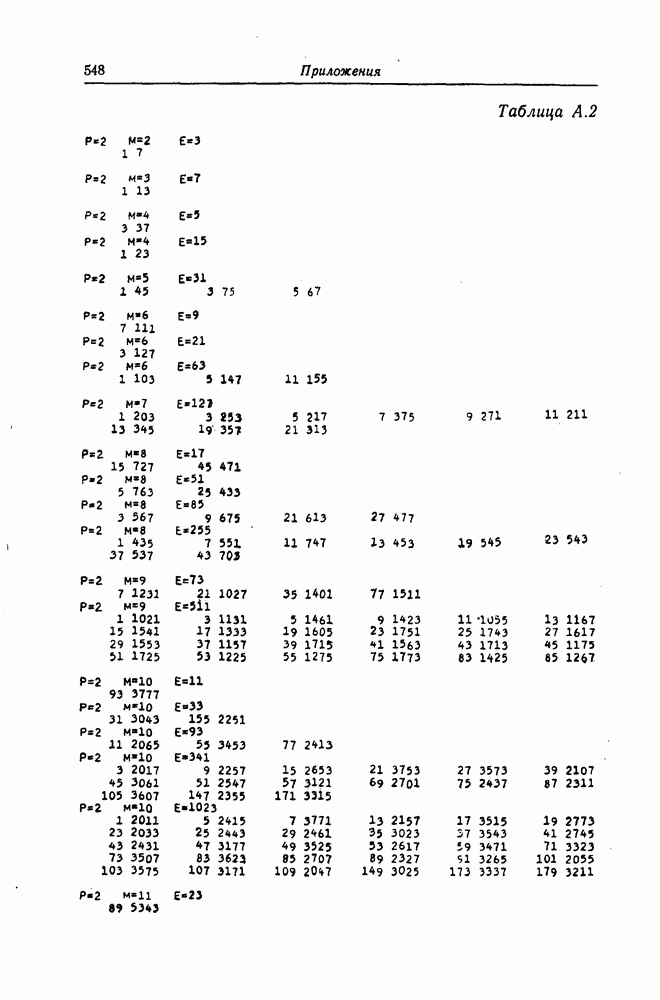
1.5.4. Декодирование списком
В основе концепций, развиваемых в предыдущем разделе, лежит декодирование по максимуму правдоподобия, когда принятой последовательности символов сопоставляется одно из целых чисел. В данном разделе рассматривается более общая концепция декодирования, а именно декодирование списком. При декодировании списком принятой последовательности символов ставится в соответствие некоторый набор (список) целых чисел из интервала от 1 до  Если целое число, соответствующее переданному сообщению, не входит в список целых чисел, полученный в результате декодирования, то говорят, что произошла ошибка при декодировании списком.
Если целое число, соответствующее переданному сообщению, не входит в список целых чисел, полученный в результате декодирования, то говорят, что произошла ошибка при декодировании списком.
Допустим, что код и декодирование списком заданы. Пусть  совокупность последовательностей длины
совокупность последовательностей длины  которые могут быть приняты и которым сопоставляются списки сообщений, содержащие целое число
которые могут быть приняты и которым сопоставляются списки сообщений, содержащие целое число  пусть
пусть  дополнение
дополнение  Тогда условная вероятность возникновения ошибки при передаче сообщения
Тогда условная вероятность возникновения ошибки при передаче сообщения  и декодировании списком определяется равенством
и декодировании списком определяется равенством

Полагая, что подлежащие передаче сообщения имеют равные вероятности и усредняя  по
по  можно ввести среднюю вероятность ошибки
можно ввести среднюю вероятность ошибки  для заданных кода и декодирования списком.
для заданных кода и декодирования списком.
Пусть  минимальная вероятность ошибки, которая может быть достигнута в заданном канале при декодировании списком из
минимальная вероятность ошибки, которая может быть достигнута в заданном канале при декодировании списком из  сообщений и при использовании кодов длины
сообщений и при использовании кодов длины  содержащих
содержащих  кодовых слов. В этих обозначениях
кодовых слов. В этих обозначениях  минимальная вероятность ошибки при обычном декодировании. Скорость передачи при декодировании списком определяется равенством
минимальная вероятность ошибки при обычном декодировании. Скорость передачи при декодировании списком определяется равенством

При  это определение совпадает с обычным определением скорости передачи.
это определение совпадает с обычным определением скорости передачи.
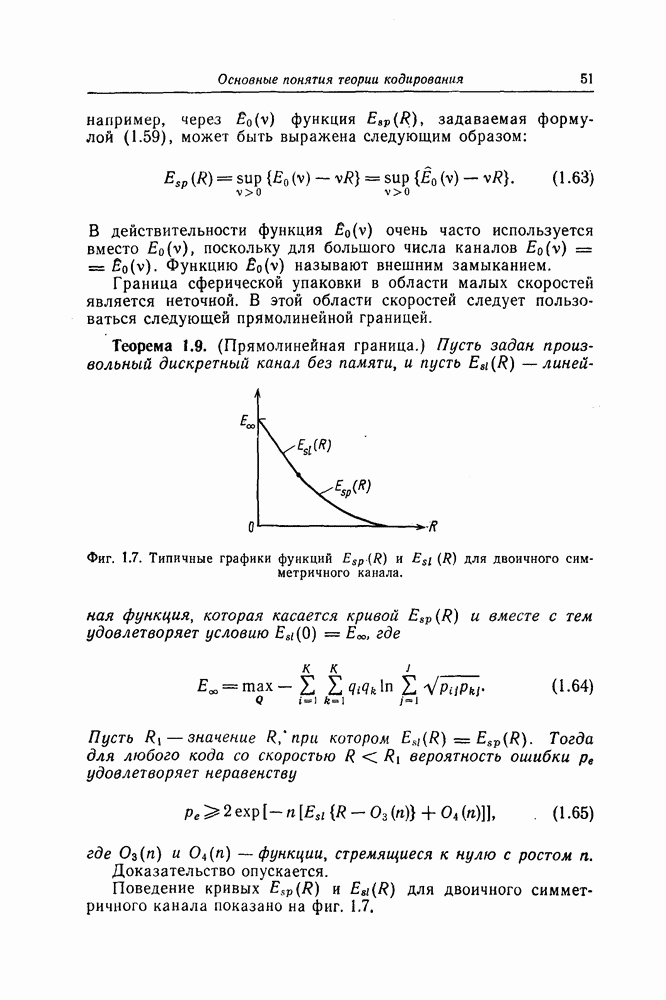
Таким образом, декодирование списком является одним из методов принятия промежуточных «мягких» решений. Для декодирования списком Шенноном, Галлагером и Берлекэмпом [13] была получена следующая граница сферической упаковки.
Теорема 1.10. В дискретном канале без памяти с переходными вероятностями 

где

Доказательство опускается.
Эта граница будет использована в дальнейшем при определении различных границ, характеризующих поведение алгоритмов последовательного декодирования.
Метод, основанный на построении границ для средних по некоторому ансамблю кодов характеристик и используемый при доказательстве теоремы кодирования и исследовании алгоритмов последовательного декодирования, является полезным по следующим причинам. Обычно с увеличением длины кода  число кодовых слов возрастает экспоненциально. При этом, как правило, ничего нельзя сказать о поведении характеристик каждого кода в отдельности. В то же время, вычислив средние по некоторому ансамблю кодов характеристики, можно утверждать, что характеристики по крайней мере одного из кодов этого ансамбля не хуже средних характеристик. Таким образом, метод исследования, основанный на вычислении границ для средних характеристик некоторого ансамбля кодов, оказывается полезным при анализе систем связи, характеристики которых зависят от очень большого числа случайных величин. В последние годы этот метод широко используется, кроме того, для получения оценок вероятности ошибки в системах Передачи данных с межсимвольной интерференцией [22, 25].
число кодовых слов возрастает экспоненциально. При этом, как правило, ничего нельзя сказать о поведении характеристик каждого кода в отдельности. В то же время, вычислив средние по некоторому ансамблю кодов характеристики, можно утверждать, что характеристики по крайней мере одного из кодов этого ансамбля не хуже средних характеристик. Таким образом, метод исследования, основанный на вычислении границ для средних характеристик некоторого ансамбля кодов, оказывается полезным при анализе систем связи, характеристики которых зависят от очень большого числа случайных величин. В последние годы этот метод широко используется, кроме того, для получения оценок вероятности ошибки в системах Передачи данных с межсимвольной интерференцией [22, 25].