Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
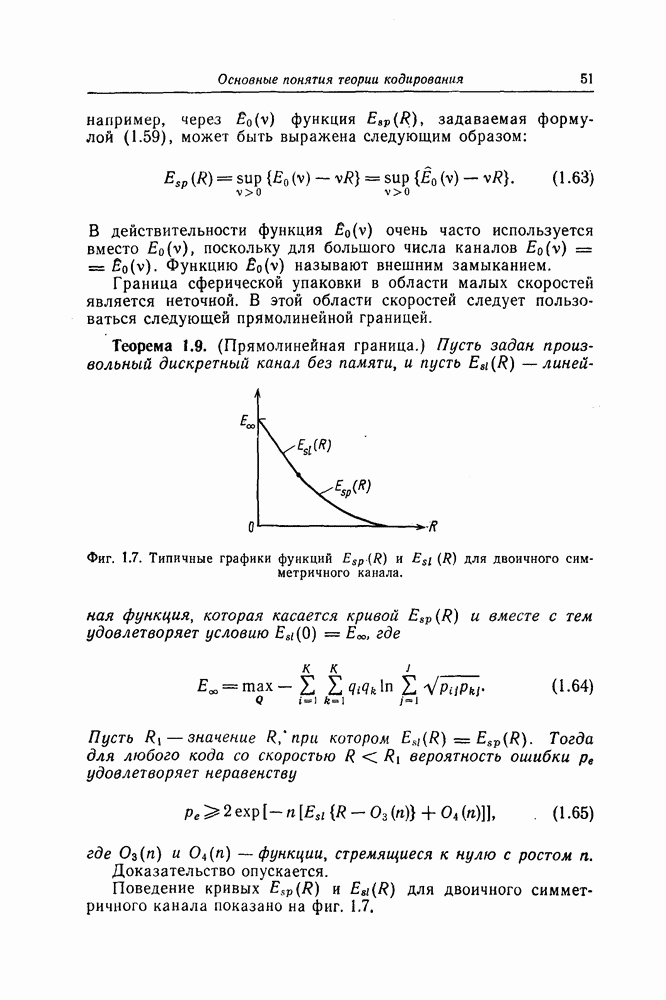
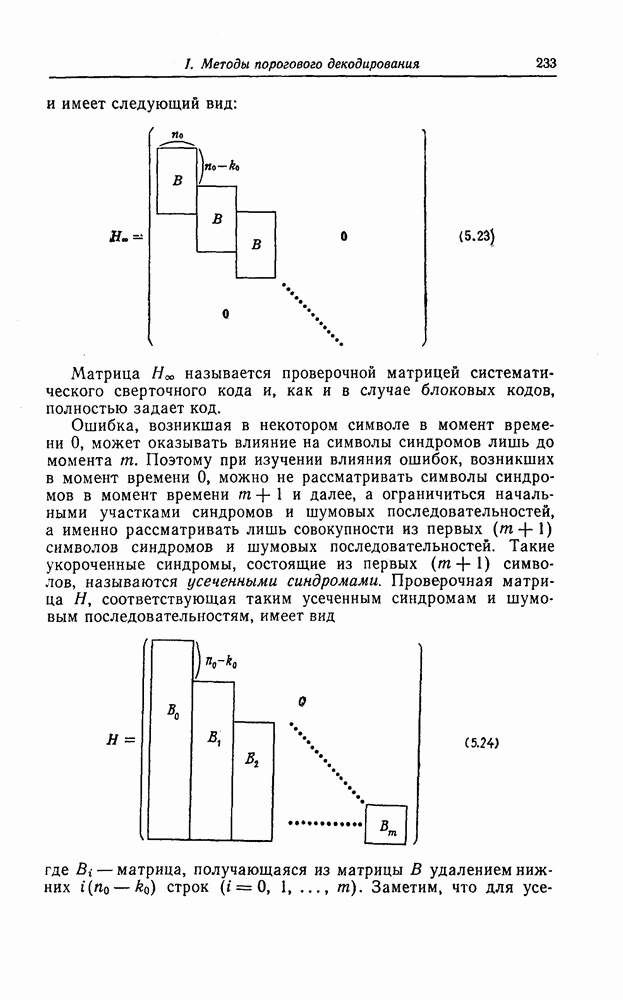
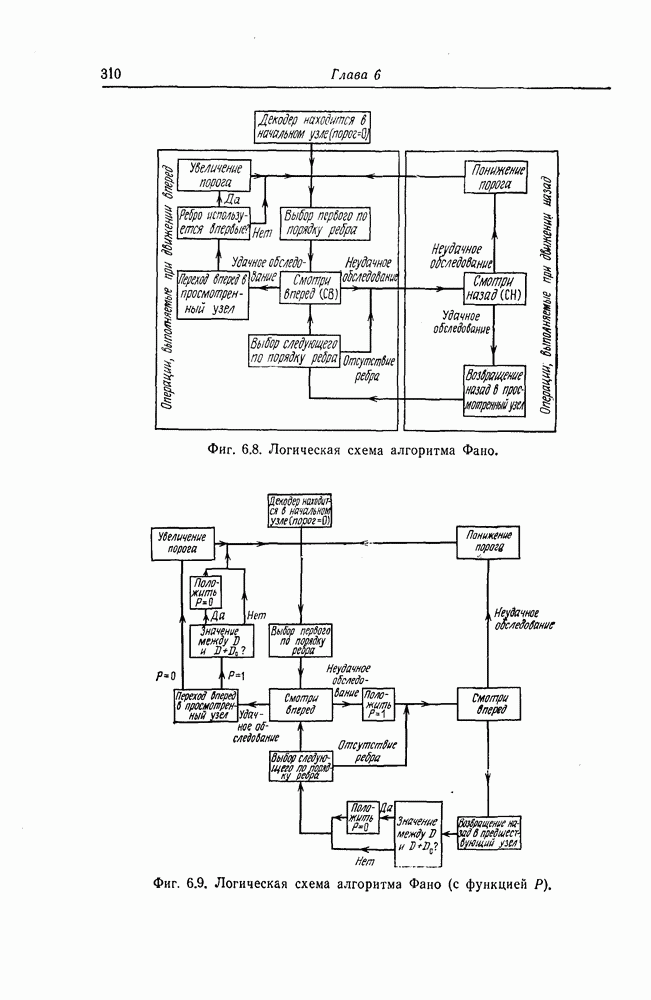
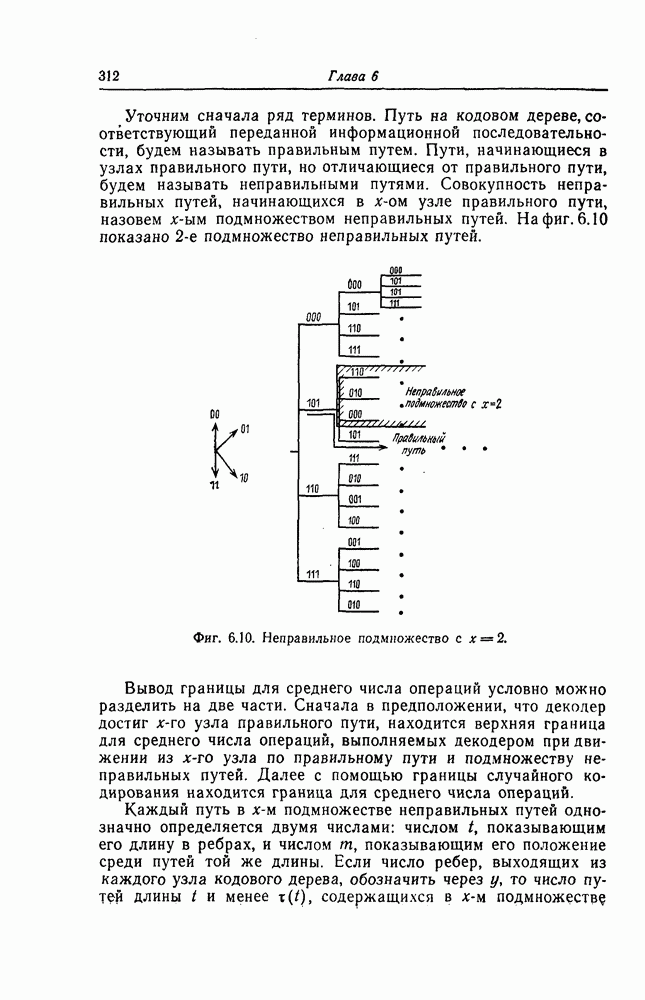
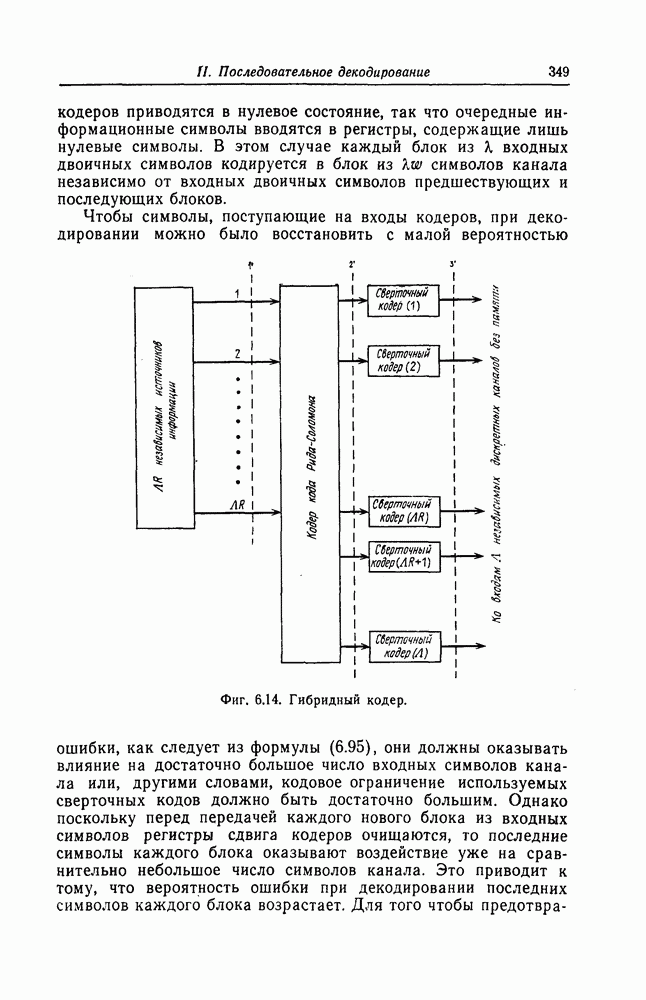
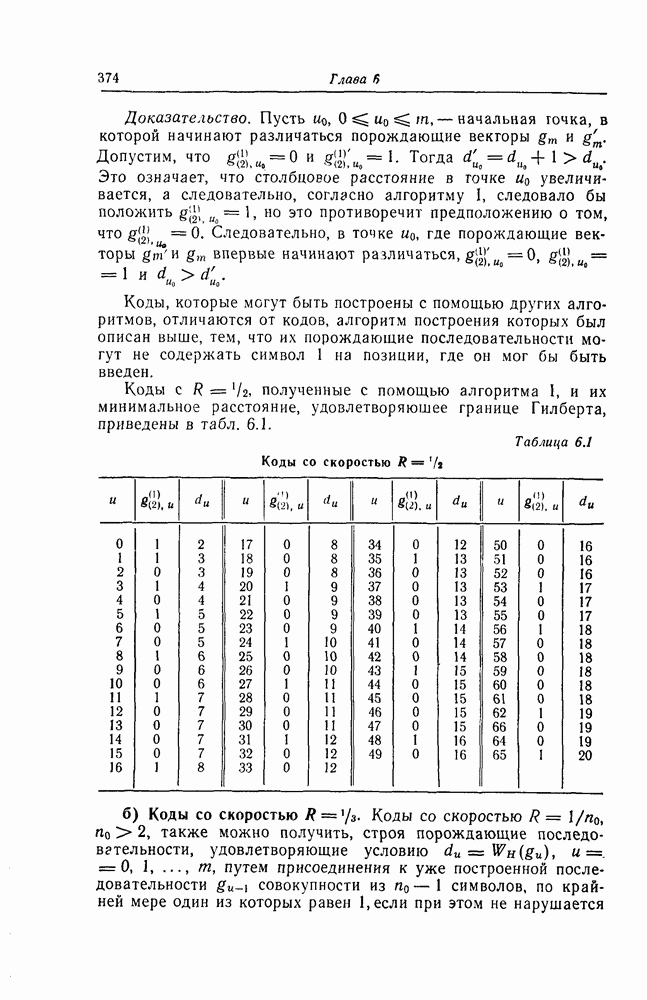
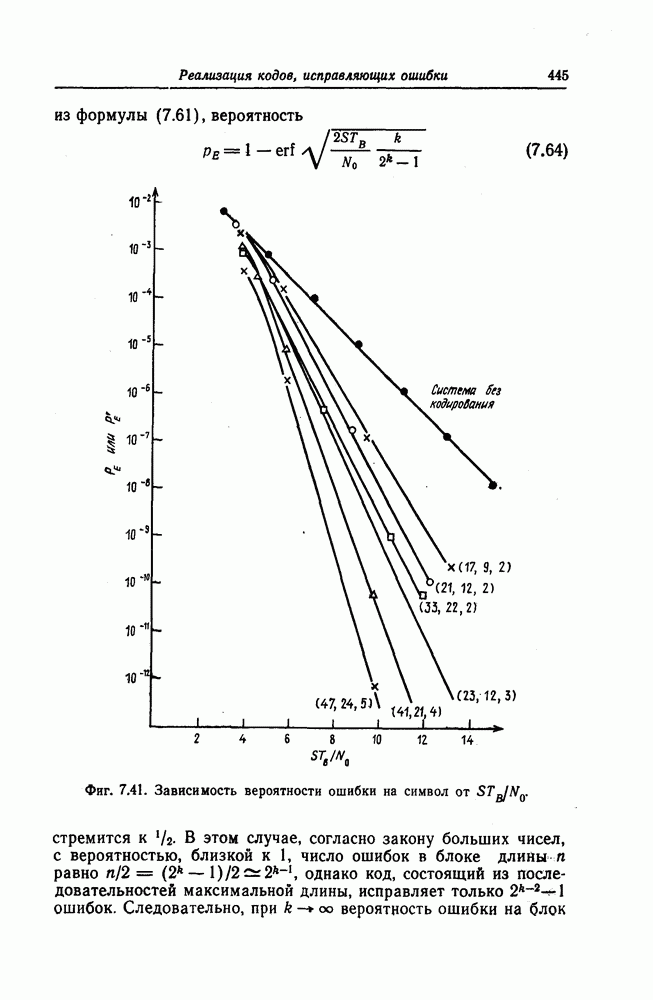
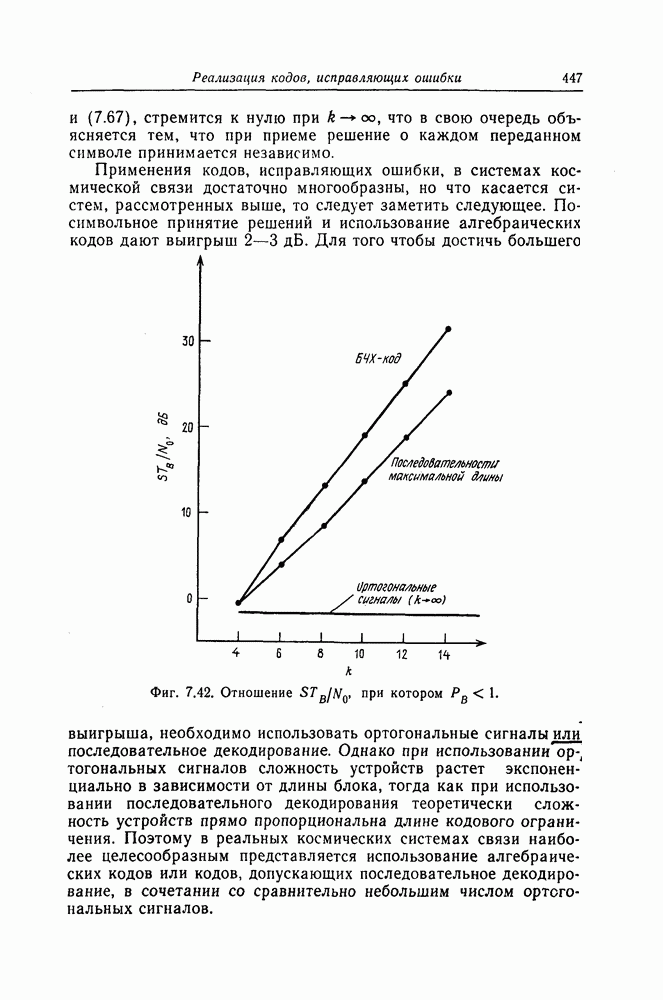
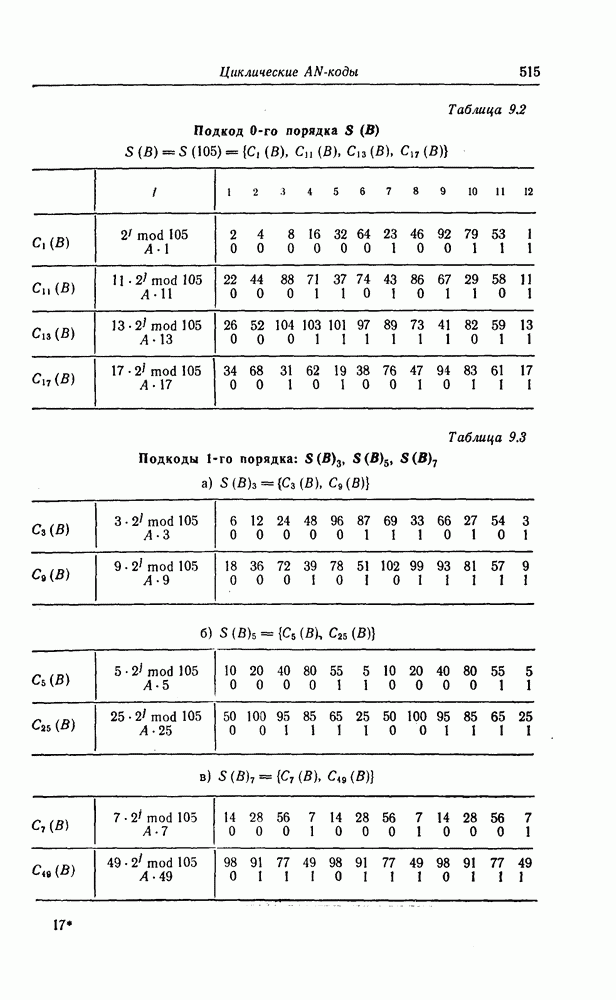
6.8. Стек-алгоритмВыше было проведено детальное исследование алгоритма Фано. Этот алгоритм обладает рядом несомненных достоинств, но, как можно было убедиться выше, анализ многих его характеристик очень сложен. Рассматриваемый в этом разделе так называемый стек-алгоритм, найденный независимо Джелинеком [7] и Зигангировым [8], по сравнению с алгоритмом Фано может быть описан гораздо проще, а кроме того, он достаточно прост для понимания. Этот алгоритм не всегда лучше алгоритма Фано (Гейст [15]), но благодаря своей простоте он позволяет глубже понять сущность последовательного декодирования. Для простоты рассмотрим здесь этот алгоритм применительно к двоичным кодам. Для пояснений будем использовать двоичный древовидный код со скоростью передаваемые символы, соответствующие ребрам показанного на фиг. 6.17 кодового дерева, представляют собой последовательности из трех двоичных символов, то для них удобно использовать восьмеричное представление, например
Фиг. 6.17. Пример древовидного кода со скоростью Предположим, что символ канала
При декодировании принятой последовательности
Для этого используются функции правдоподобия
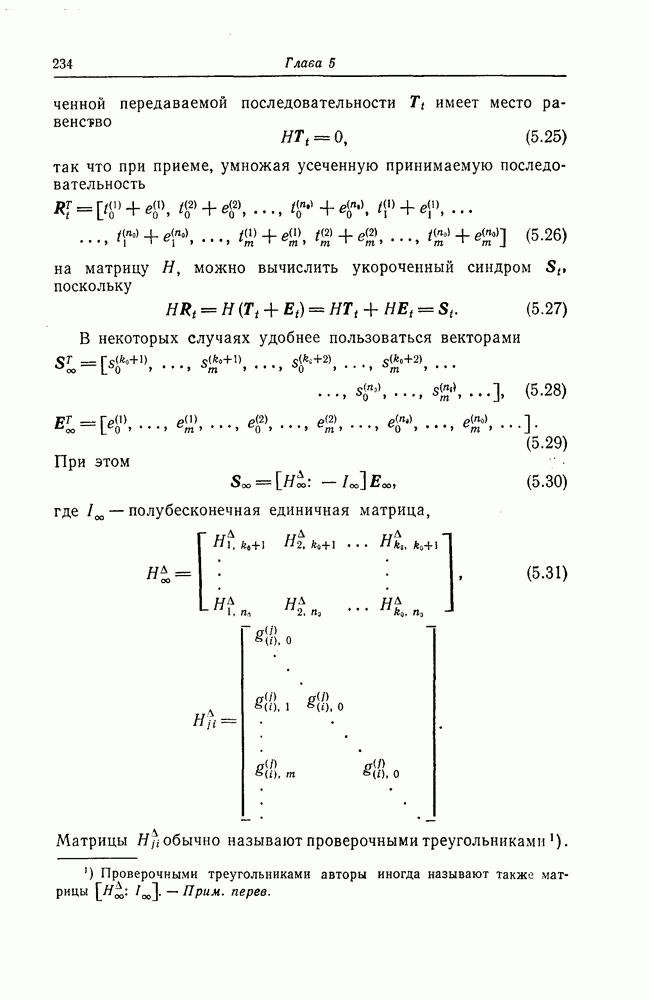
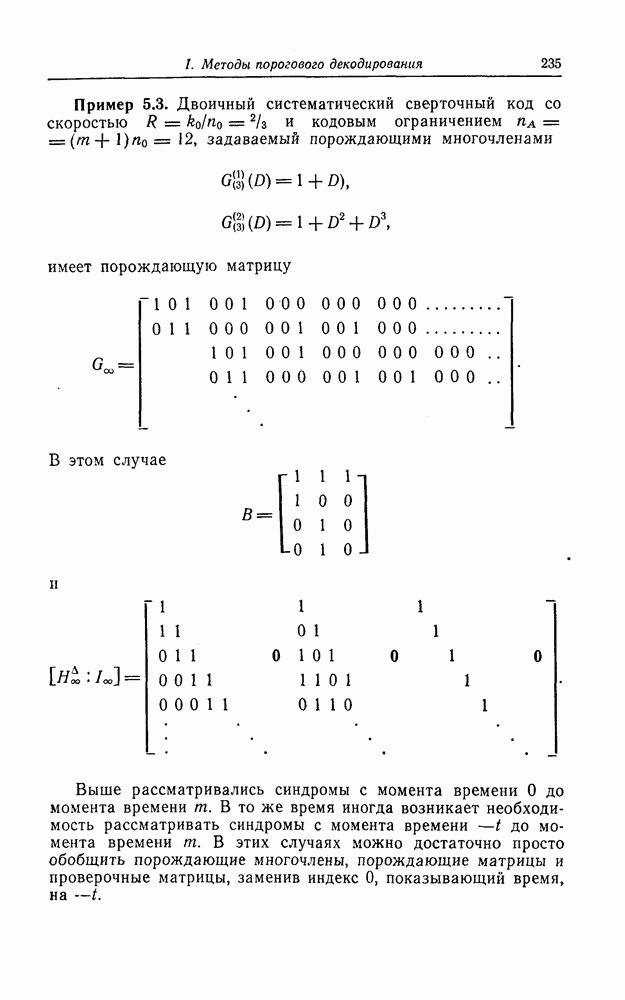
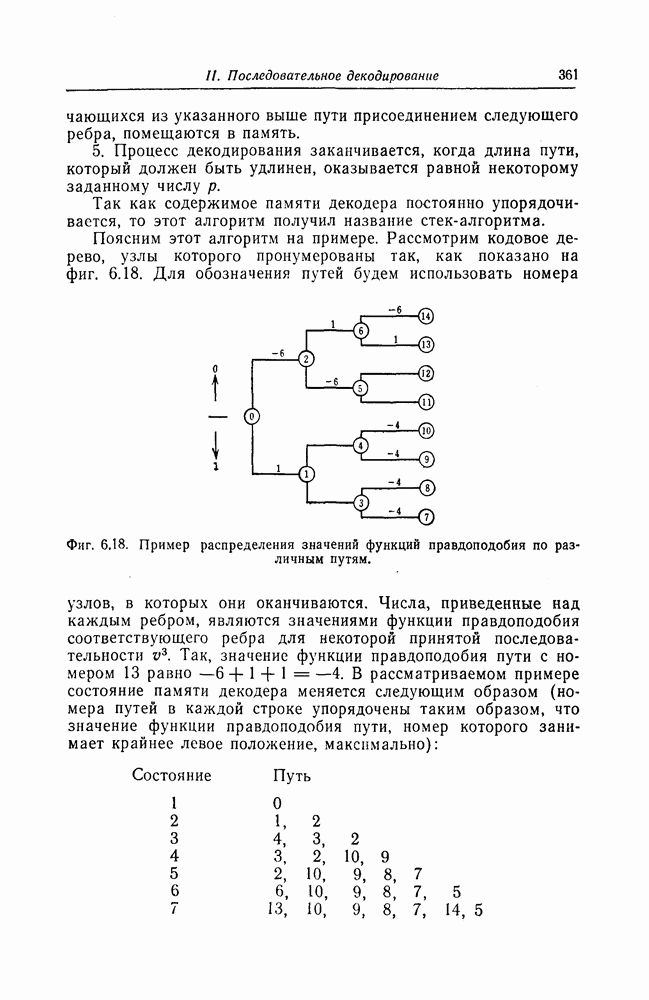
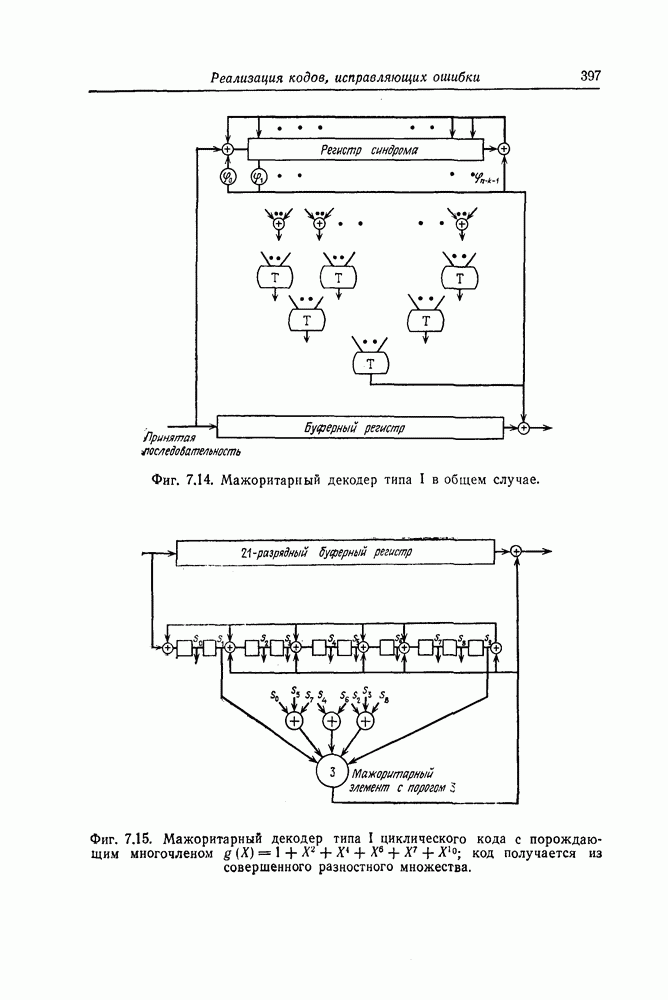
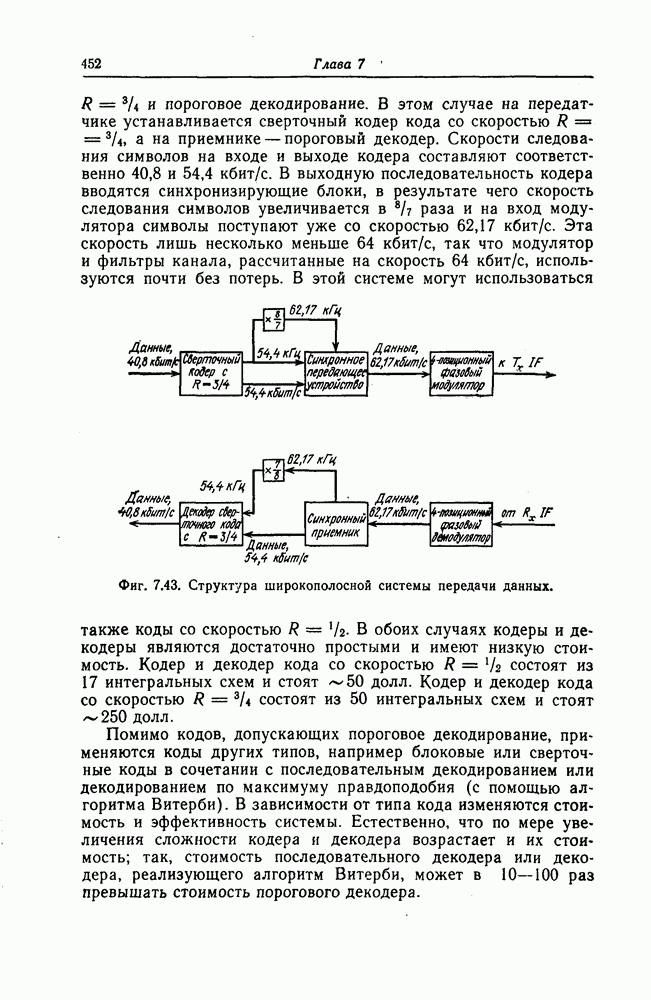
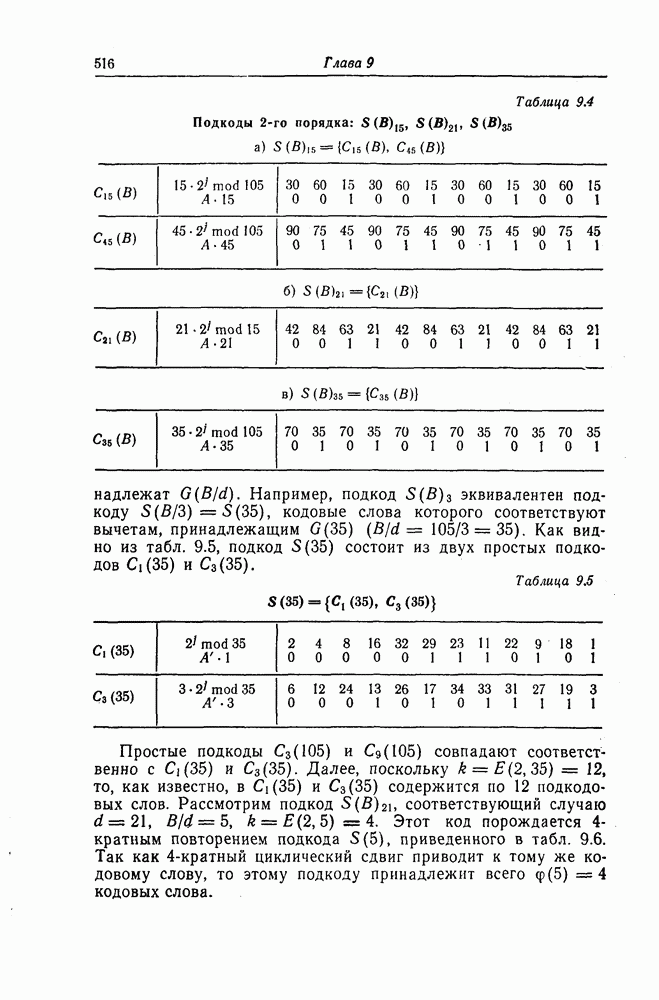
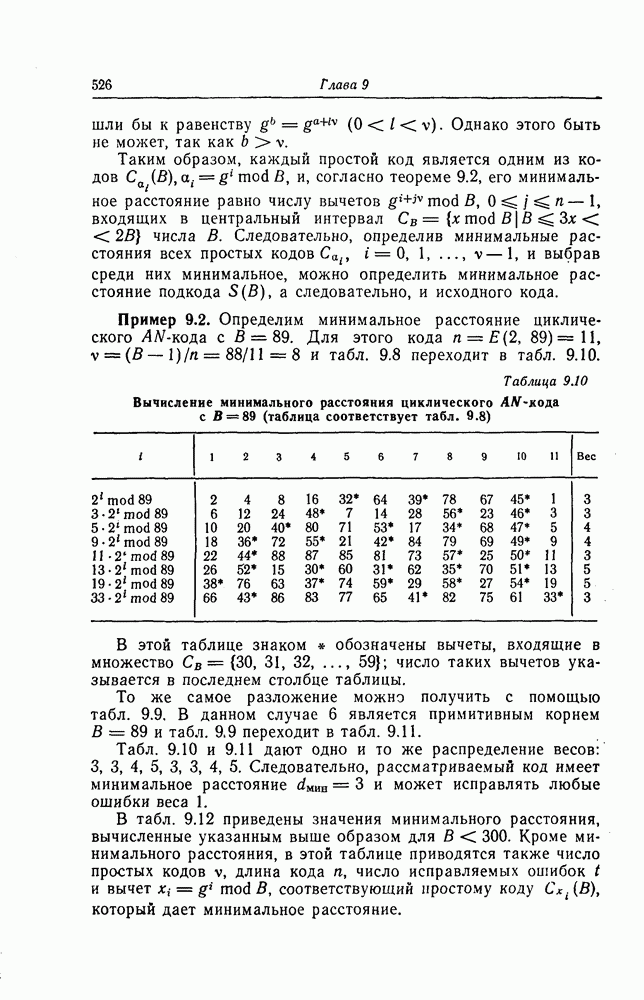
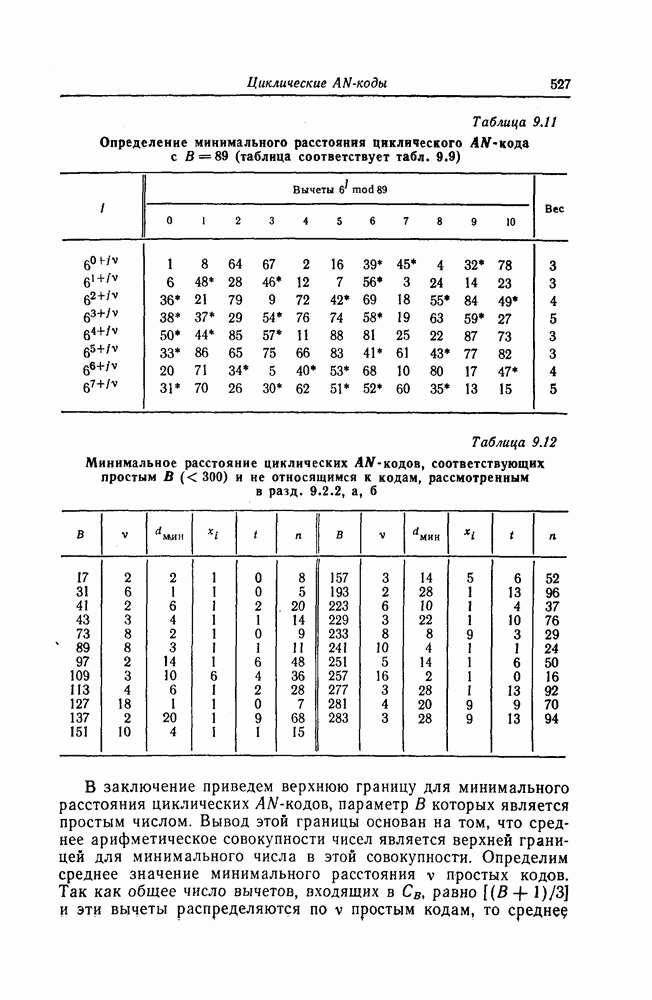
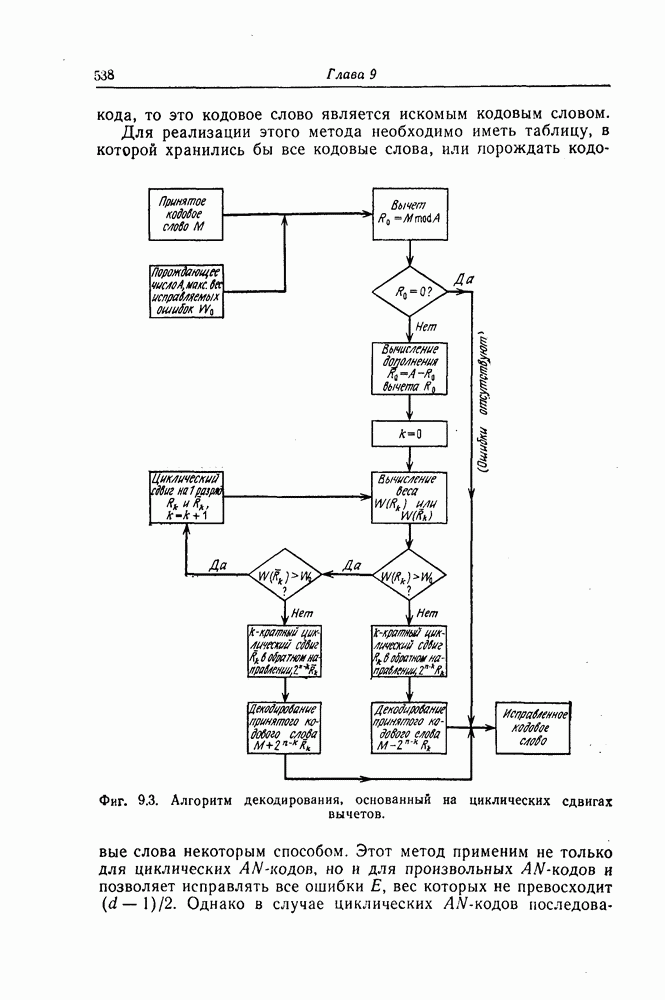
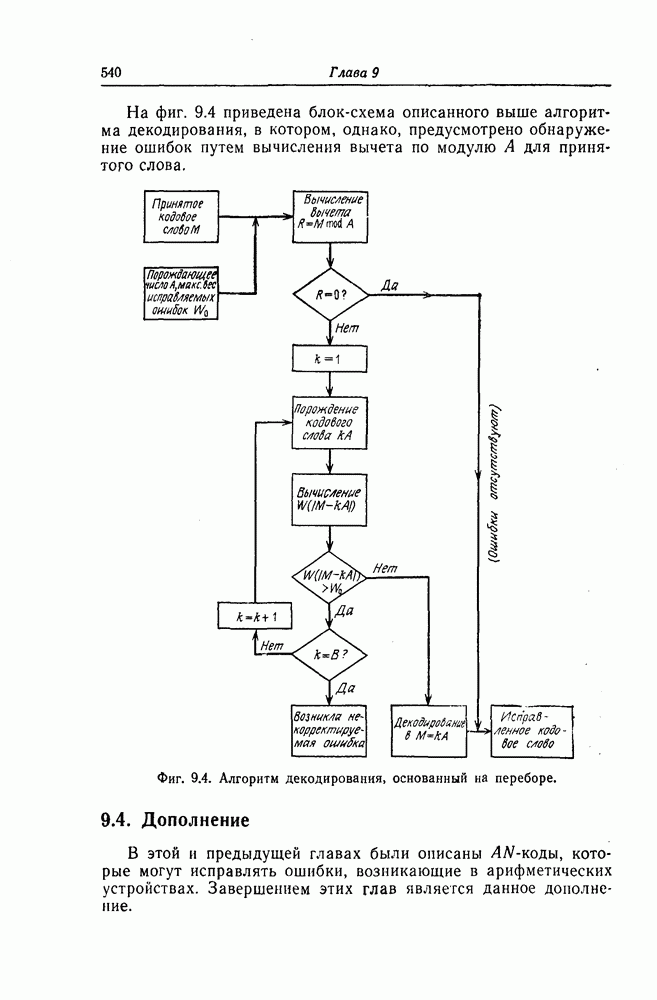
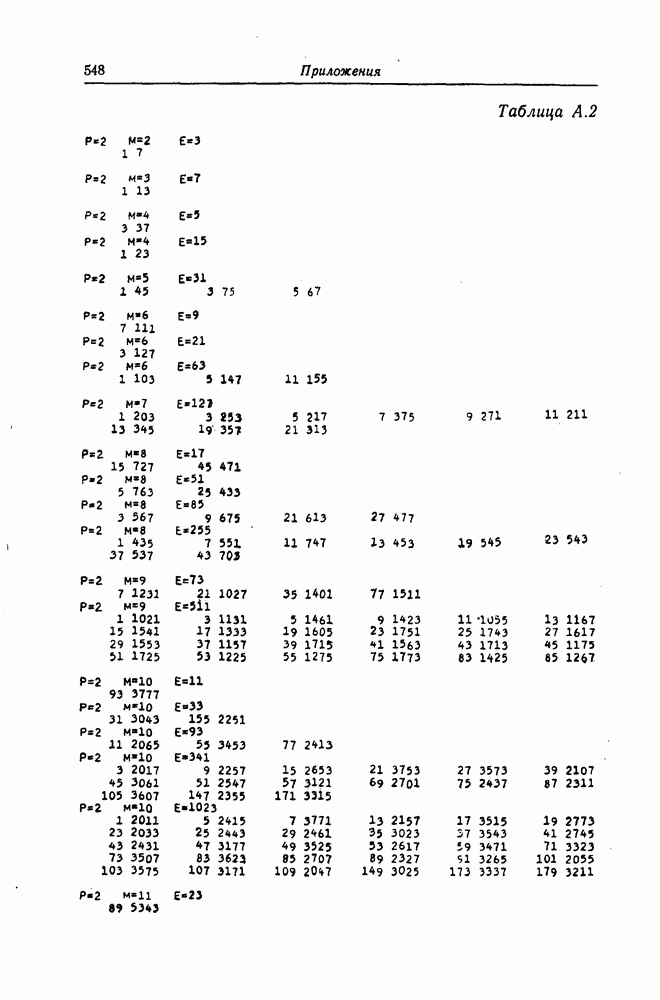
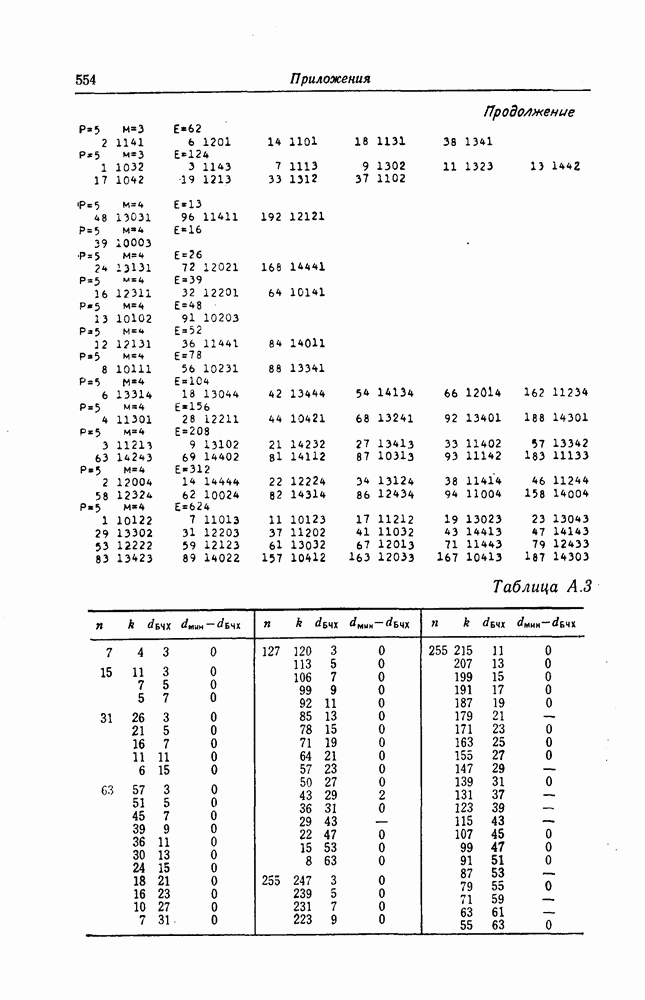
Поскольку в процессе декодирования последовательность 1. Вычисляются функции правдоподобия 2. Если 3. Значения функций правдоподобия трех путей, хранящиеся в памяти декодера, упорядочиваются в порядке их убывания, после чего находится путь, соответствующий наибольшему из этих значений. Для двух путей, которые получаются из указанного выше пути присоединением следующего ребра, вычисляются значения функции правдоподобия. Значение функции правдоподобия пути, который был только что удлинен, из памяти удаляется, а в память помещаются вновь вычисленные значения функций правдоподобия. Например, предположим, что в памяти декодера хранятся значения 4. Каждый последующий шаг алгоритма декодирования аналогичен описанным выше шагам. После получающихся из указанного выше пути присоединением следующего ребра, помещаются в память. 5. Процесс декодирования заканчивается, когда длина пути, который должен быть удлинен, оказывается равной некоторому заданному числу Так как содержимое памяти декодера постоянно упорядочивается, то этот алгоритм получил название стек-алгоритма. Поясним этот алгоритм на примере. Рассмотрим кодовое дерево, узлы которого пронумерованы так, как показано на фиг. 6.18.
Фиг. 6.18. Пример распределения значений функций правдоподобия по различным путям. Для обозначения путей будем использовать номера узлов, в которых они оканчиваются. Числа, приведенные над каждым ребром, являются значениями функции правдоподобия соответствующего ребра для некоторой принятой последовательности
Так как путь с номером 13, занимающим крайнее левое положение в последней строке, имеет длину 3, то декодер на шаге 7 декодирование прекращает. Таким образом, стек-алгоритм действительно значительно проще алгоритма Фано. В работе [7] приведено обобщение этого алгоритма на случай недвоичных кодов. Анализ вероятности ошибки и среднего числа операций при декодировании можно найти в работе [25]. Методы расчета этих характеристик для стек-алгоритма аналогичны методам расчета соответствующих характеристик алгоритма Фано и здесь рассматриваться не будут.
|
 |
Оглавление
|















































































































































































































































































































































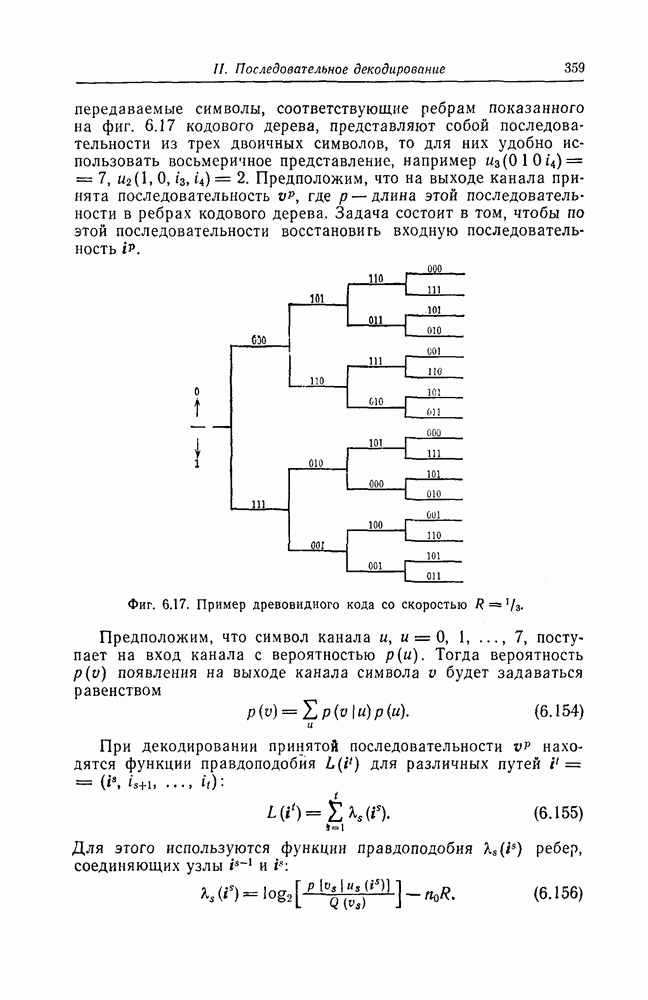



























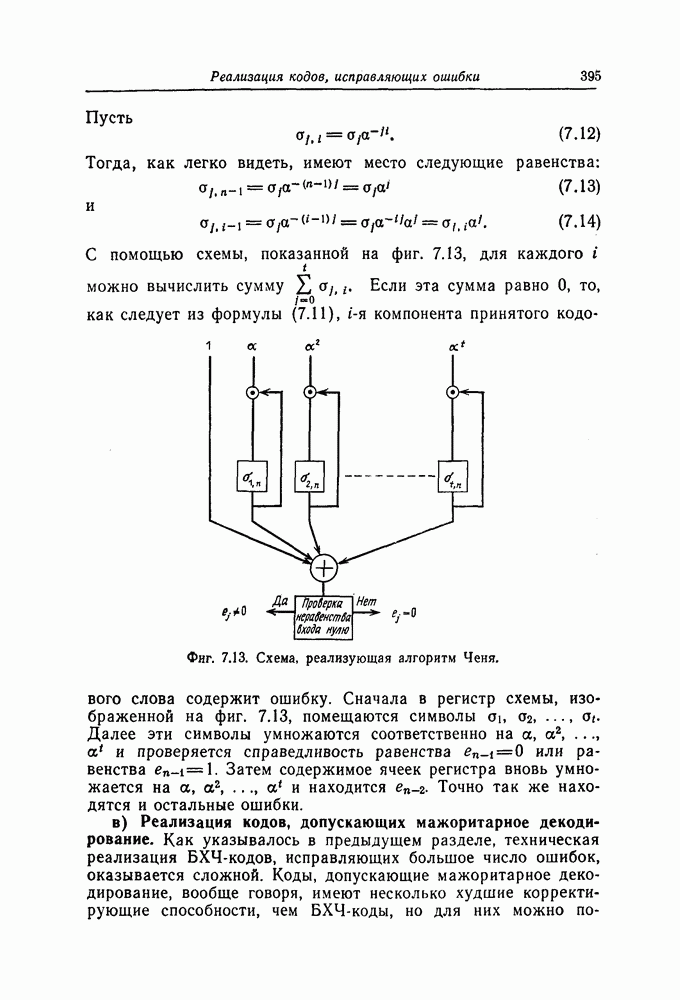











































































































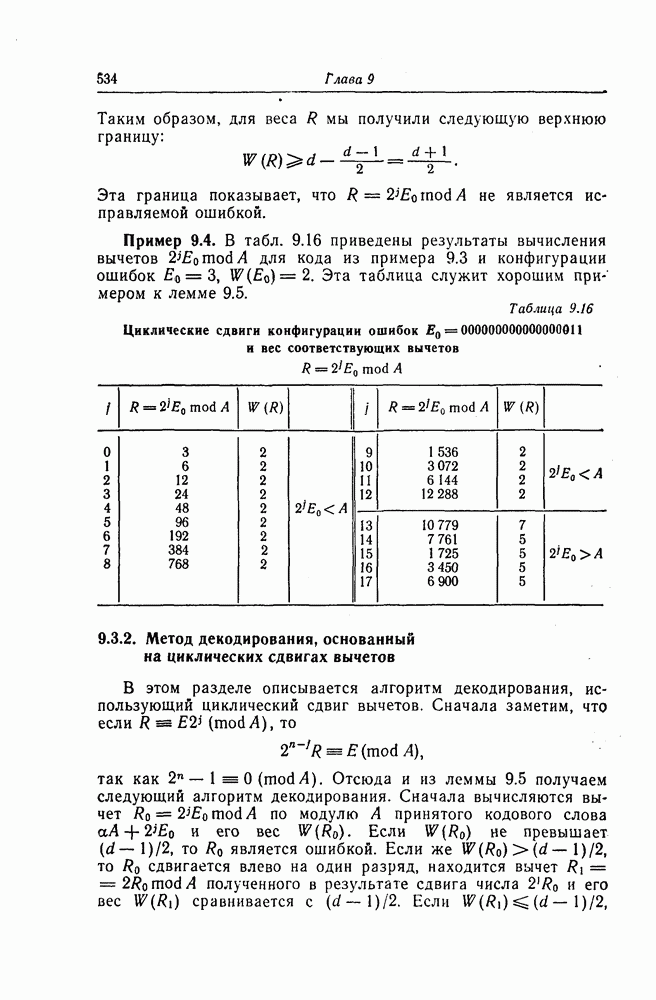











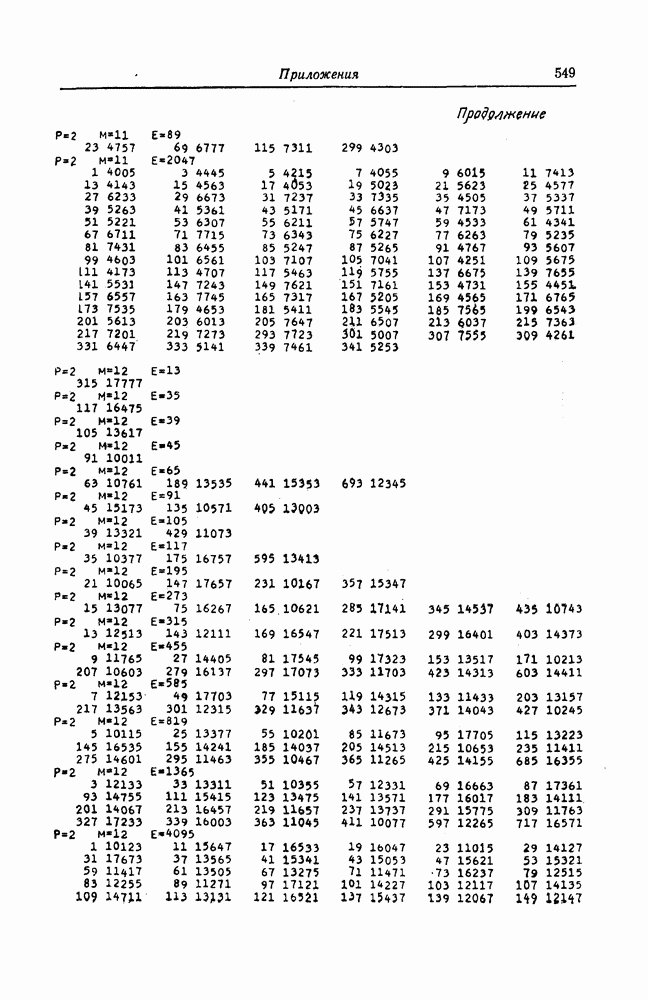

















 кодовое дерево которого изображено на фиг. 6.17. Пусть
кодовое дерево которого изображено на фиг. 6.17. Пусть  двоичный информационный символ, поступающий в момент времени
двоичный информационный символ, поступающий в момент времени  на вход кодера. Пути длины
на вход кодера. Пути длины  будем обозначать с помощью соответствующих им векторов
будем обозначать с помощью соответствующих им векторов  Через
Через  обозначим символы, используемые для передачи по каналу
обозначим символы, используемые для передачи по каналу  ребра пути
ребра пути  Так как
Так как
 Предположим, что на выходе канала принята последовательность
Предположим, что на выходе канала принята последовательность  где
где  длина этой последовательности в ребрах кодового дерева. Задача состоит в том, чтобы по этой последовательности восстановить входную последовательность
длина этой последовательности в ребрах кодового дерева. Задача состоит в том, чтобы по этой последовательности восстановить входную последовательность 


 поступает на вход канала с вероятностью
поступает на вход канала с вероятностью  Тогда вероятность
Тогда вероятность  появления на выходе канала символа
появления на выходе канала символа  будет задаваться равенством
будет задаваться равенством

 находятся функции правдоподобия
находятся функции правдоподобия  для различных путей
для различных путей 

 ребер, соединяющих узлы
ребер, соединяющих узлы 

 не изменяется и символы
не изменяется и символы  для каждого
для каждого  определяются кодовым деревом, которое считается заданным, то величины
определяются кодовым деревом, которое считается заданным, то величины  являются функциями только путей. Рассмотрим следующий алгоритм декодирования:
являются функциями только путей. Рассмотрим следующий алгоритм декодирования:
 двух ребер, выходящих из начального узла кодового дерева. Эти значения помещаются в память декодера.
двух ребер, выходящих из начального узла кодового дерева. Эти значения помещаются в память декодера.
 то
то  извлекается из памяти декодера и вычисляются значения
извлекается из памяти декодера и вычисляются значения  Если
Если  то из памяти извлекается
то из памяти извлекается  и вычисляются значения
и вычисляются значения  Величина
Величина  удаляется из памяти декодера, а вновь найденные значения функций правдоподобия помещаются в память декодера. На этом шаг 2 заканчивается. Таким образом, перед следующим шагом в памяти декодера хранятся значения функций правдоподобия трех путей, а именно двух путей длиной 2 и одного пути длиной 1.
удаляется из памяти декодера, а вновь найденные значения функций правдоподобия помещаются в память декодера. На этом шаг 2 заканчивается. Таким образом, перед следующим шагом в памяти декодера хранятся значения функций правдоподобия трех путей, а именно двух путей длиной 2 и одного пути длиной 1.
 . В этом случае из памяти удаляется
. В этом случае из памяти удаляется  а помещаются в память значения функций правдоподобия
а помещаются в память значения функций правдоподобия  На этом шаг декодирования заканчивается. Перед следующим шагом декодирования в памяти декодера хранятся значения функций правдоподобия четырех путей, среди которых два пути имеют длину 3, один — длину 1, и еще один — длину 2 (возможно, что все четыре пути будут иметь длину 2).
На этом шаг декодирования заканчивается. Перед следующим шагом декодирования в памяти декодера хранятся значения функций правдоподобия четырех путей, среди которых два пути имеют длину 3, один — длину 1, и еще один — длину 2 (возможно, что все четыре пути будут иметь длину 2).
 шага в памяти декодера хранятся
шага в памяти декодера хранятся  значений функций правдоподобия
значений функций правдоподобия  путей, которые могут иметь различную длину, но ни один из которых не является началом другого. На
путей, которые могут иметь различную длину, но ни один из которых не является началом другого. На  шаге находятся наибольшее содержащееся в памяти значение функции правдоподобия и соответствующий этому значению путь. Значение функции правдоподобия этого пути из памяти декодера удаляется, а значения функций правдоподобия двух путей,
шаге находятся наибольшее содержащееся в памяти значение функции правдоподобия и соответствующий этому значению путь. Значение функции правдоподобия этого пути из памяти декодера удаляется, а значения функций правдоподобия двух путей,


 Так, значение функции правдоподобия пути с номером 13 равно
Так, значение функции правдоподобия пути с номером 13 равно  . В рассматриваемом примере состояние памяти декодера меняется следующим образом (номера путей в каждой строке упорядочены таким образом, что значение функции правдоподобия пути, номер которого занимает крайнее левое положение, максимально):
. В рассматриваемом примере состояние памяти декодера меняется следующим образом (номера путей в каждой строке упорядочены таким образом, что значение функции правдоподобия пути, номер которого занимает крайнее левое положение, максимально):
