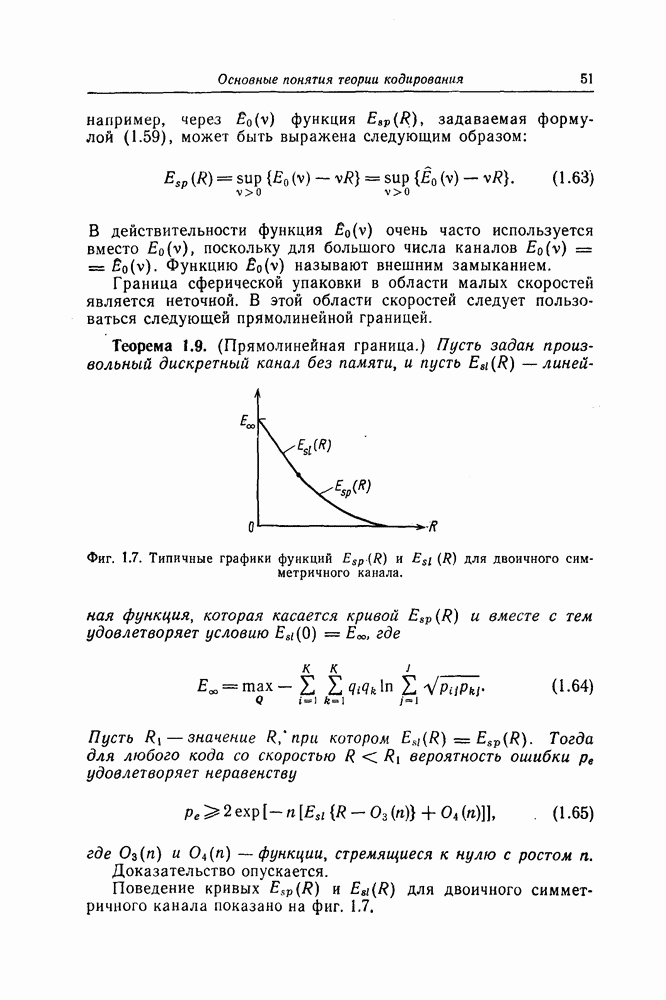
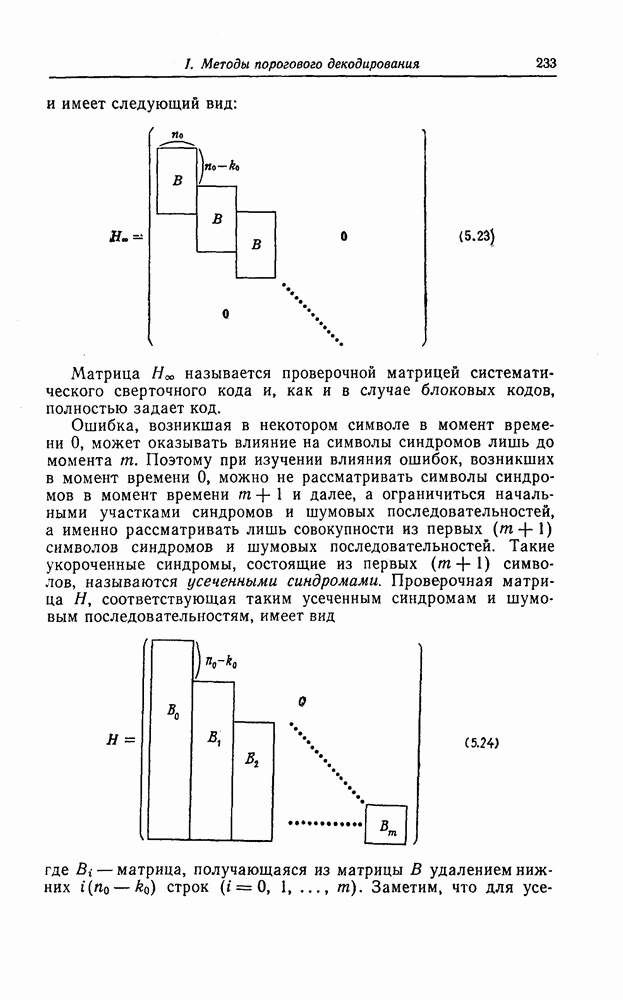
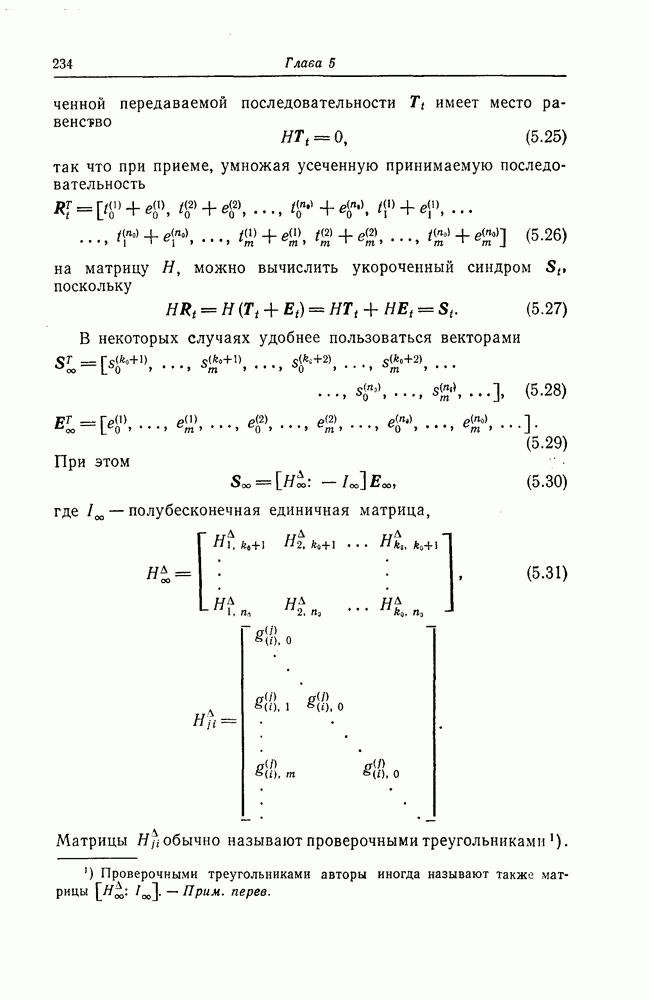
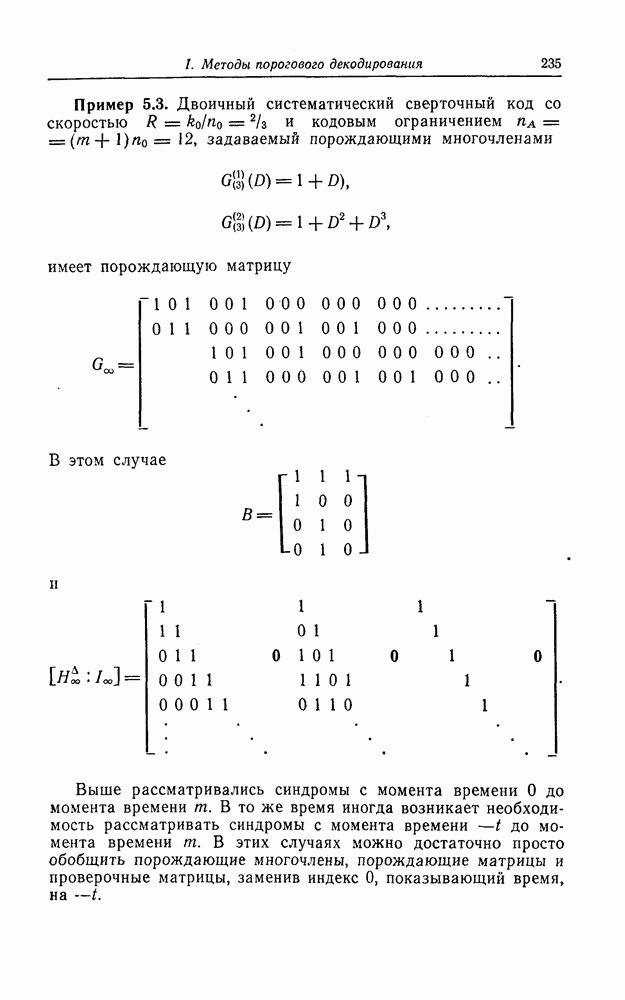
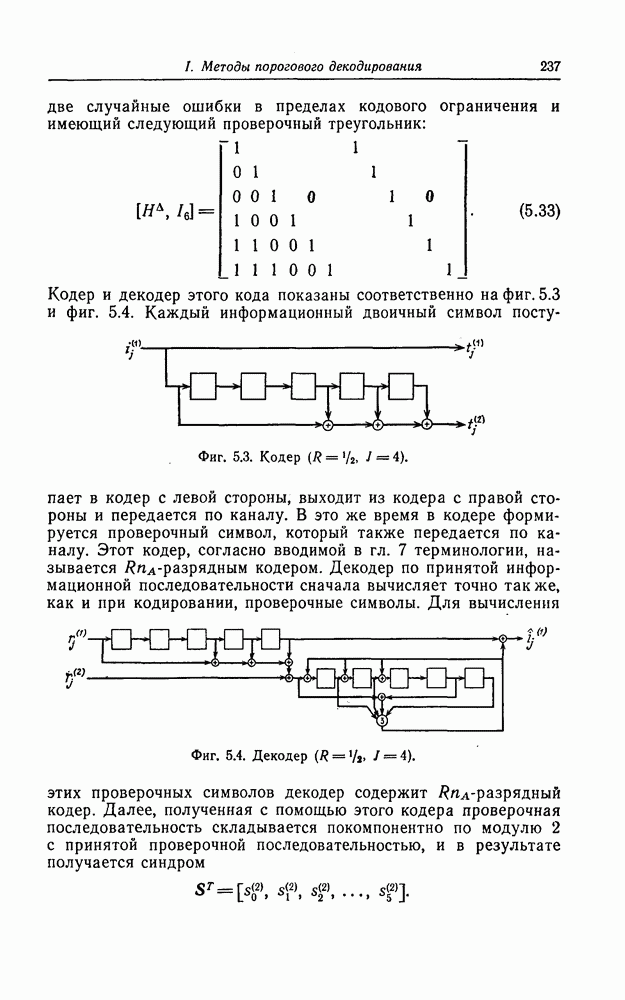
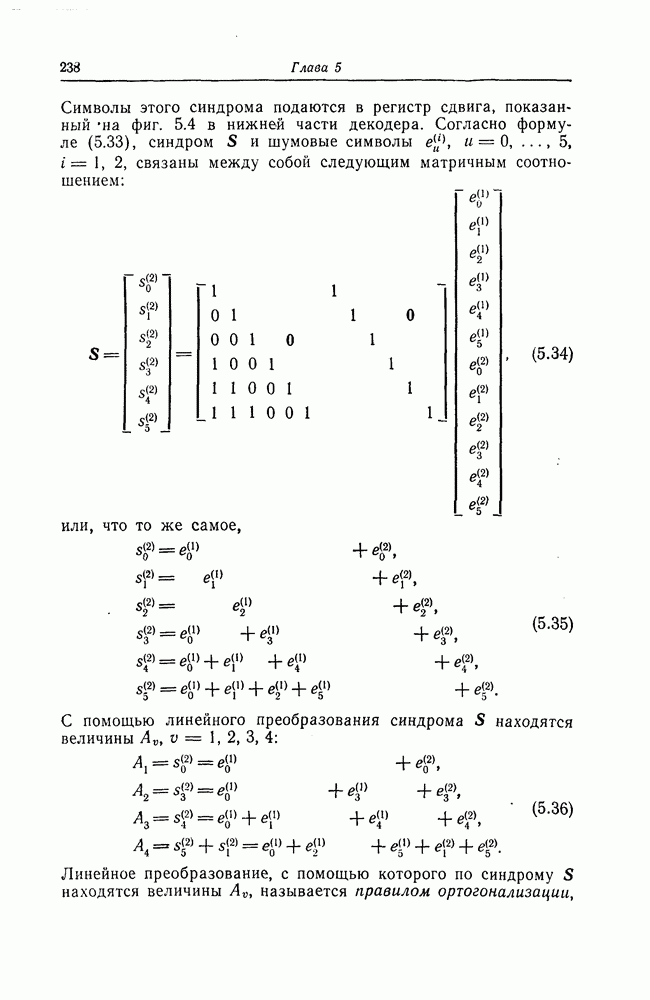
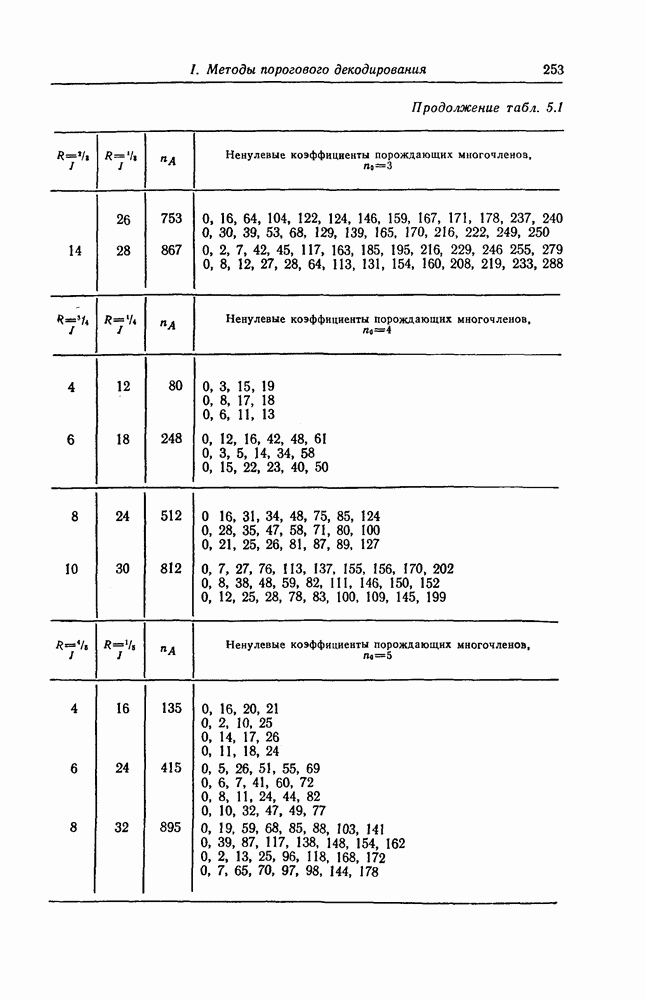
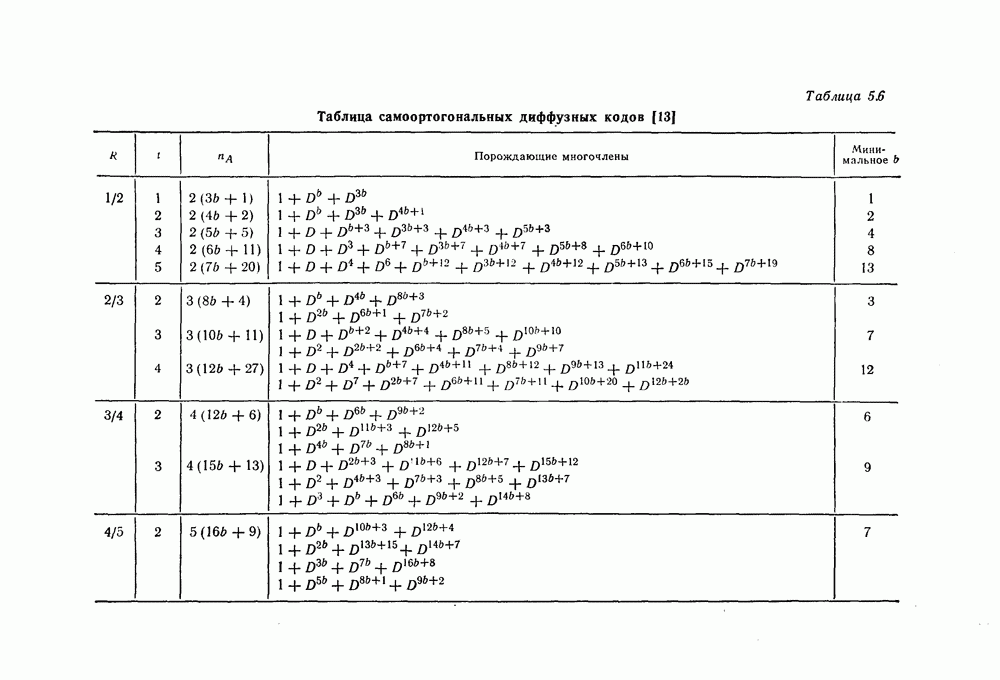
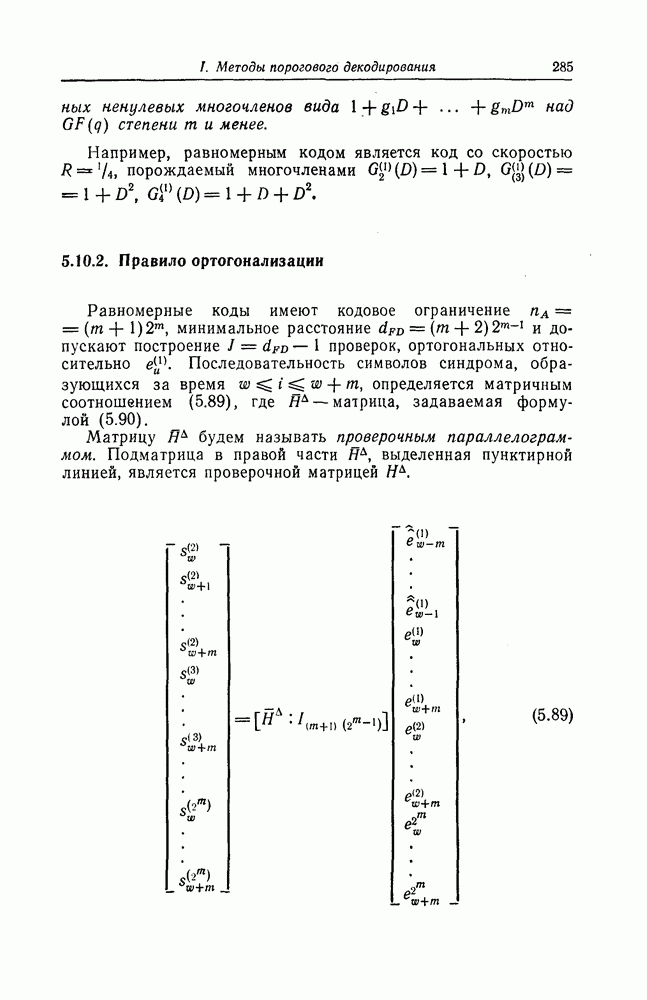
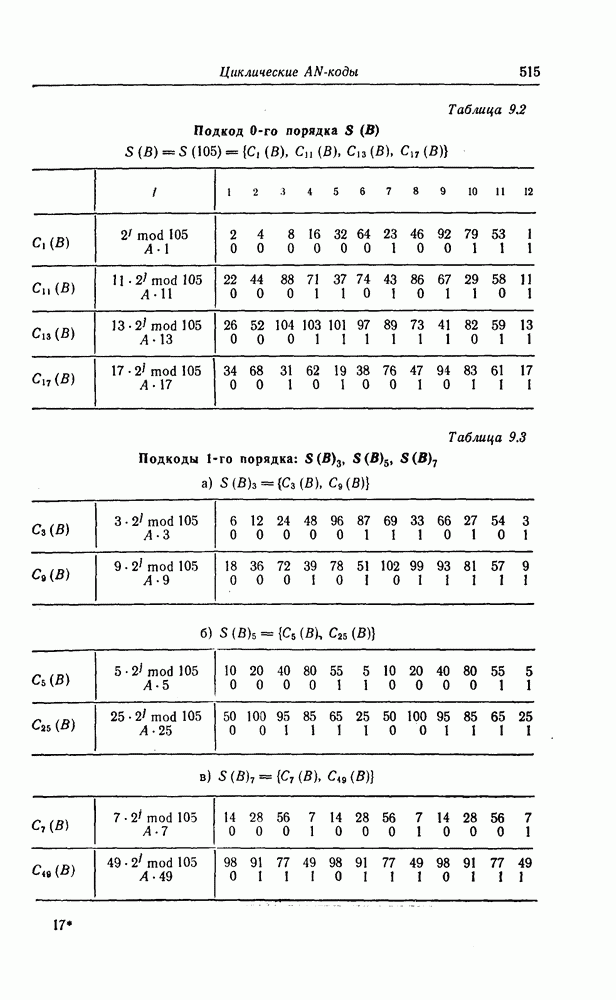
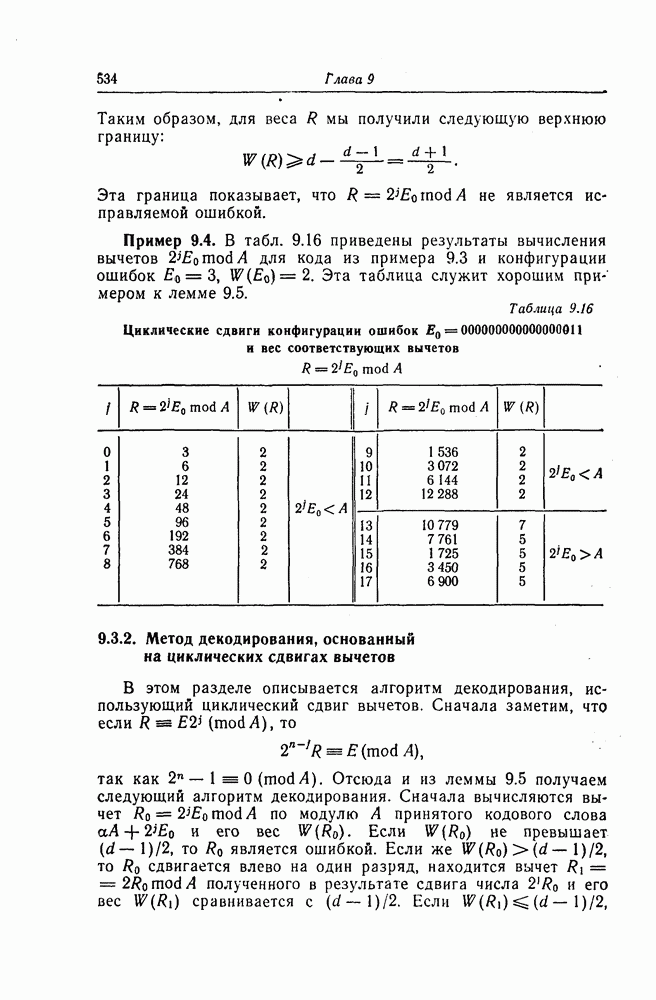
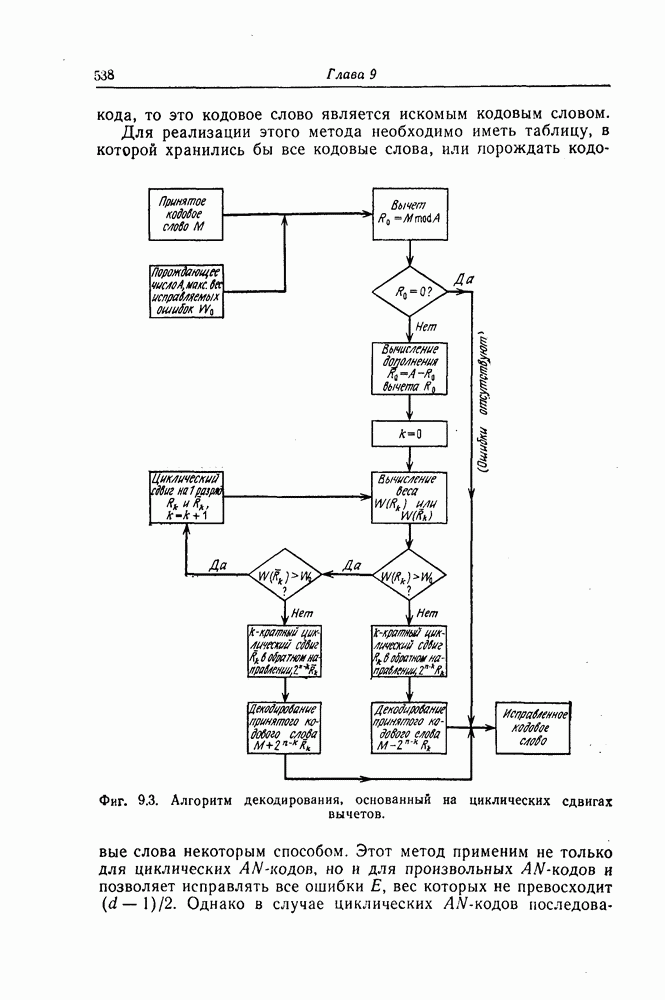
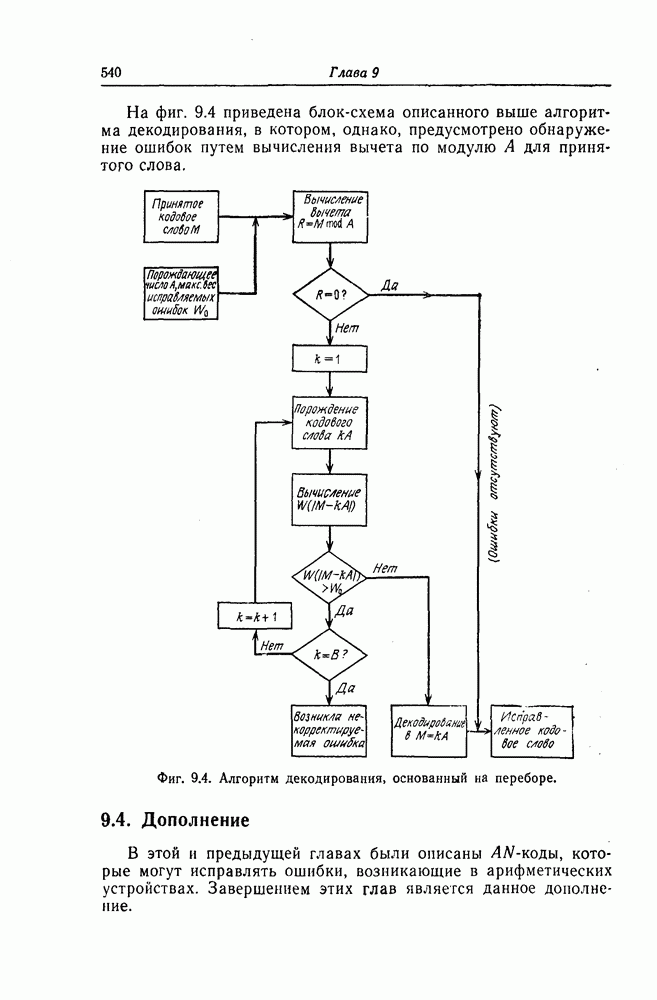
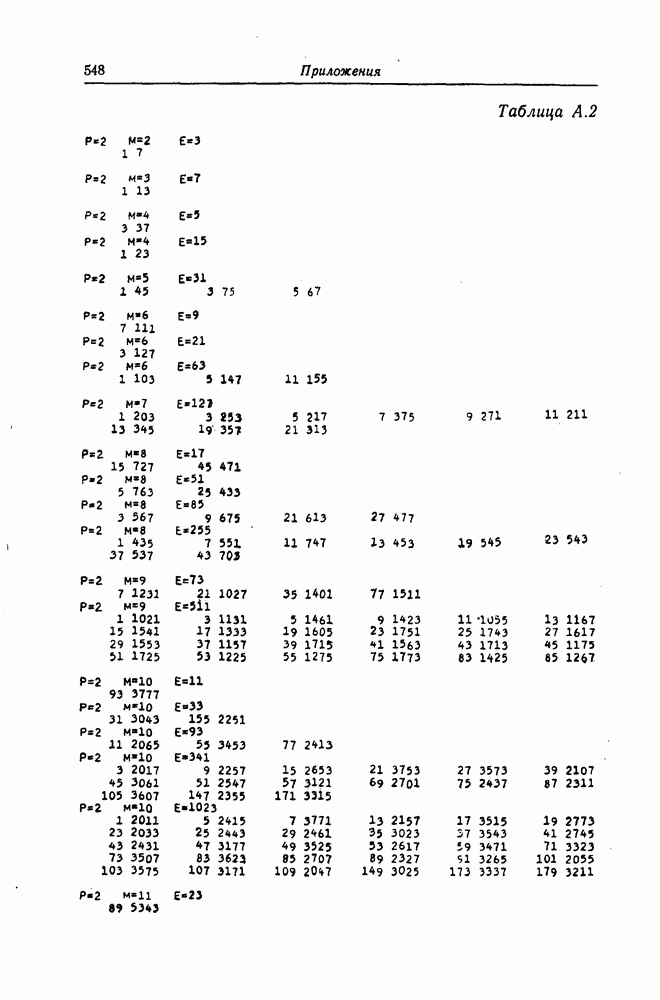
6.6. Границы Витерби и декодирование по максимуму правдоподобия
Начало этой главы, за исключением вывода нижней границы для вероятности переполнения буфера, посвящено исследованию вероятности ошибки, среднего числа операций и распределения числа операций для алгоритма последовательного декодирования, предложенного Фано. В этом разделе находятся верхняя и нижняя границы для вероятности ошибки при декодировании методом Витерби, который не связан с алгоритмом Фано. Верхняя граница будет получена с помощью вероятностного (но не последовательного) алгоритма декодирования, предложенного Витерби, а вывод нижней границы вообще не связан с каким-либо конкретным алгоритмом декодирования, и нижняя
граница справедлива для произвольного сверточного кода. Полученные ниже границы Витерби показывают, что характеристики сверточных кодов лучше, чем у блоковых кодов той же длины. Это утверждение неоднократно высказывалось после введения Элайсом сверточных кодов, но строгое доказательство оно получило лишь с появлением границ Витерби.
Форни [14] показал, что использованный Витерби для получения верхней границы алгоритм декодирования является алгоритмом декодирования по максимуму правдоподобия, и таким образом еще раз отметил его важность.
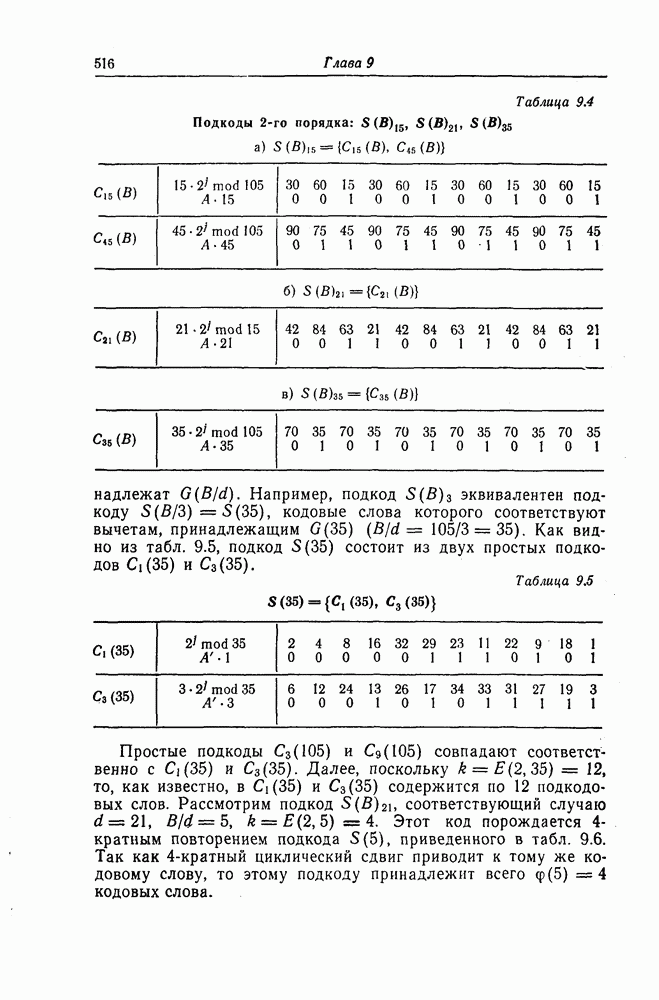
6.6.1. Верхняя граница для вероятности ошибки
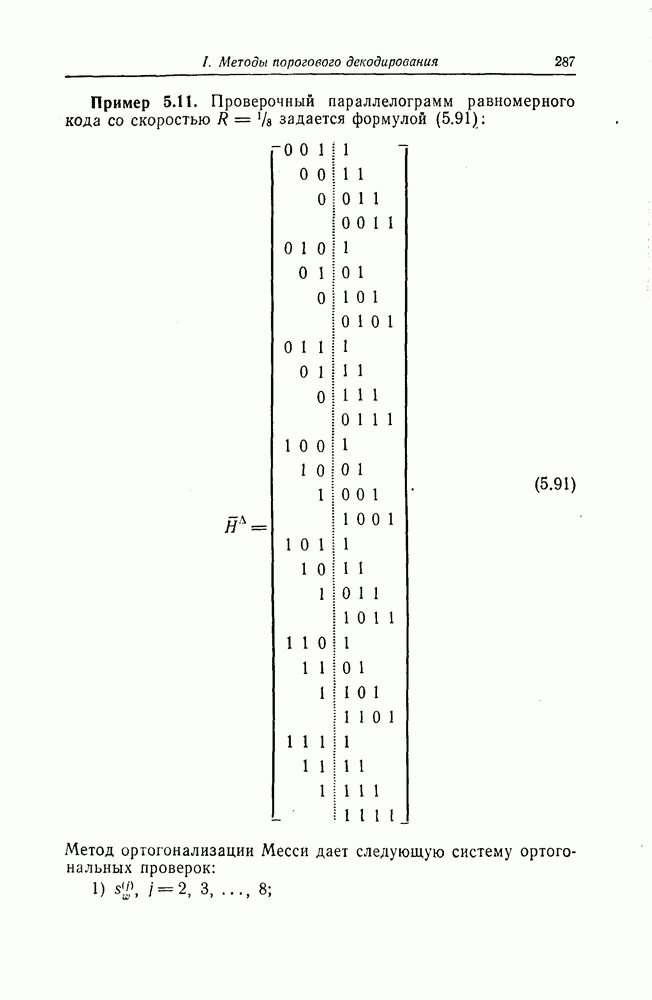
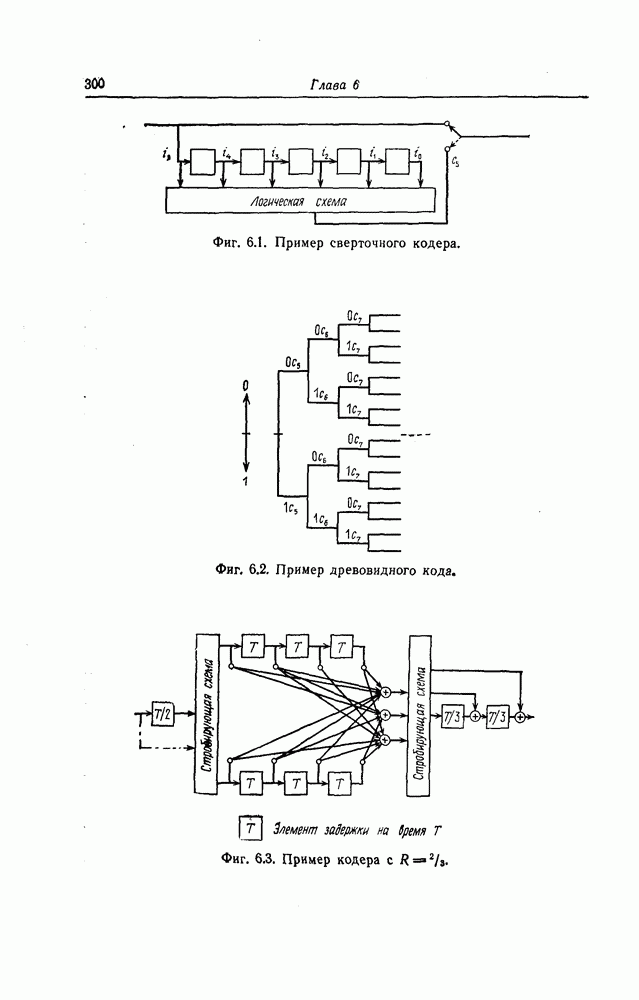
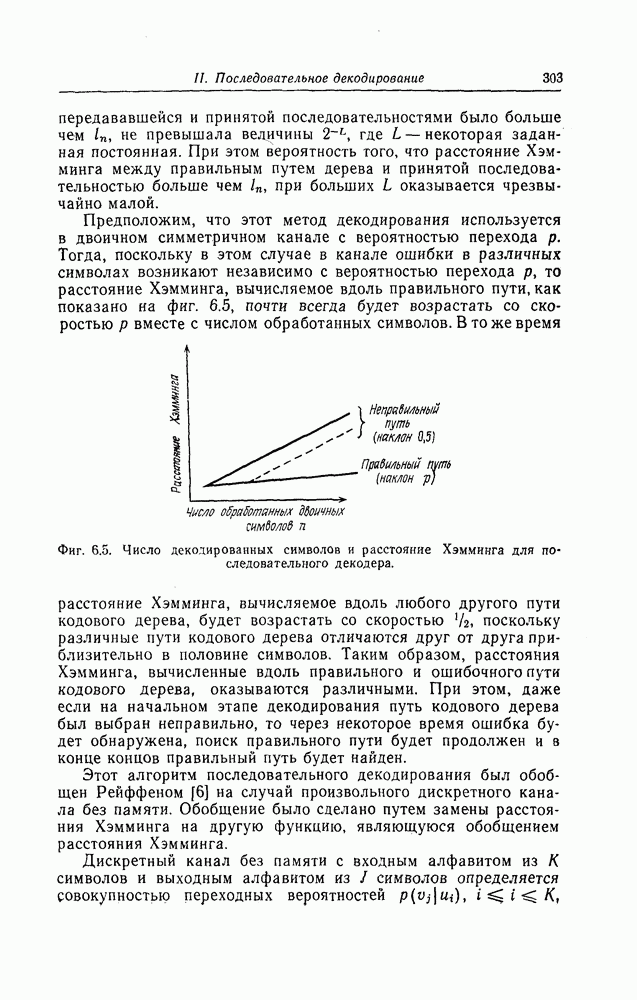
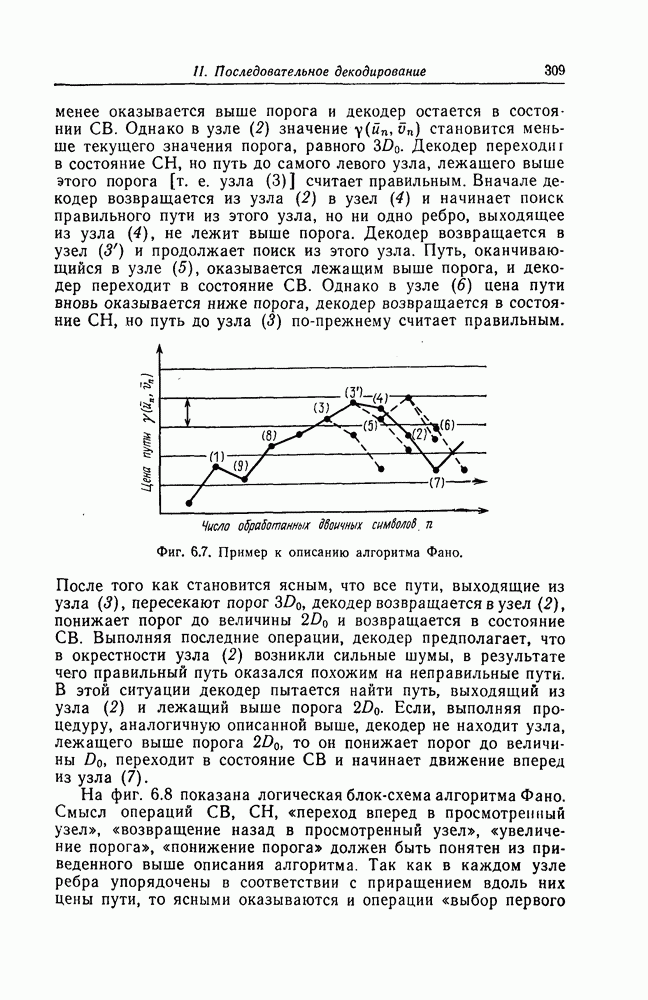
Верхняя граница Витерби так же, как и полученная выше верхняя граница вероятности ошибки для алгоритма Фано, выводится методом случайного кодирования.

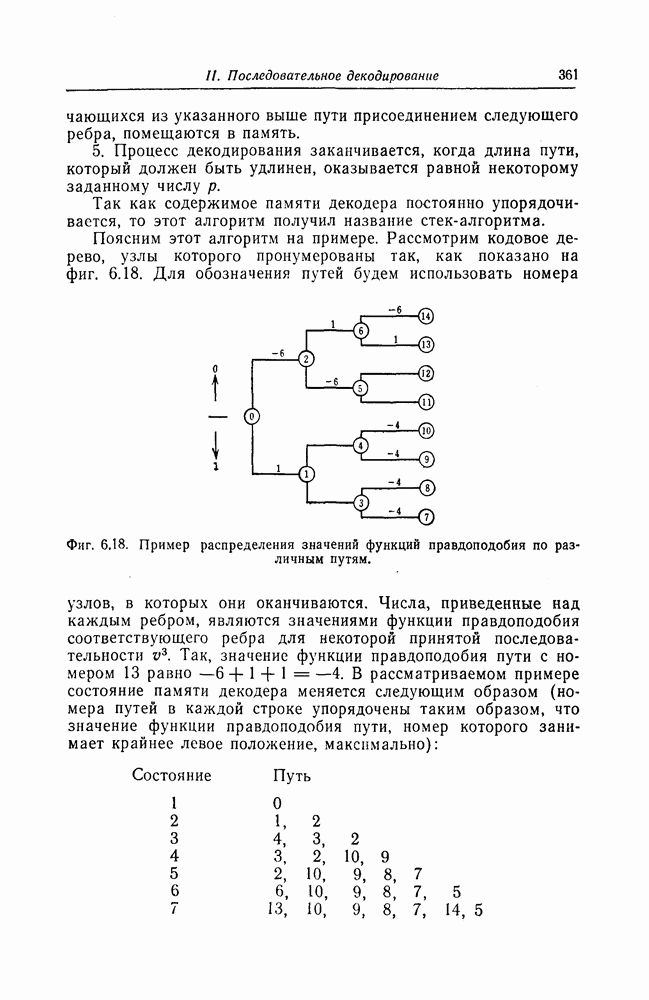
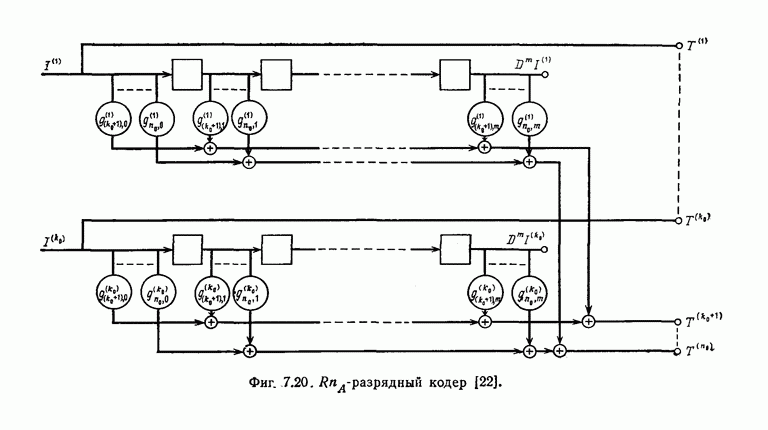
Фиг. 6.13. Кодер.
Использованный в разд. 6.6 ансамбль сверточных кодов можно построить также следующим образом.
Входная последовательность, символами которой являются элементы поля  как показано на фиг. 6.13, подается на вход
как показано на фиг. 6.13, подается на вход  -разрядного регистра сдвига, входящего в состав кодера. С каждым поступлением в регистр сдвига очередного входного символа с помощью схемы вычисления скалярных произведений формируется
-разрядного регистра сдвига, входящего в состав кодера. С каждым поступлением в регистр сдвига очередного входного символа с помощью схемы вычисления скалярных произведений формируется  выходных символов. Схема вычисления скалярных произведений выбирается случайным образом с помощью ансамбля
выходных символов. Схема вычисления скалярных произведений выбирается случайным образом с помощью ансамбля  матриц с равномерным распределением. Выходная последовательность
матриц с равномерным распределением. Выходная последовательность  складывается со
складывается со
случайной последовательностью  независимых равновероятных символов. В результате все символы на выходе устройства формирования символов канала оказываются равновероятными. После того как на вход кодера будет подано в информационных символов, сюда подается последовательность из
независимых равновероятных символов. В результате все символы на выходе устройства формирования символов канала оказываются равновероятными. После того как на вход кодера будет подано в информационных символов, сюда подается последовательность из  нулей. Порождаемый таким кодером код обладает следующими свойствами:
нулей. Порождаемый таким кодером код обладает следующими свойствами:
1. Если  информационных символов двух различных путей кодового дерева совпадают, эти информационные символы порождают одну и ту же последовательность из
информационных символов двух различных путей кодового дерева совпадают, эти информационные символы порождают одну и ту же последовательность из  символов.
символов.
2. Все символы канала вдоль любого пути кодового дерева являются равновероятными.
3. Символы канала вдоль любого пути кодового дерева статистически независимы.
4. Если с вводом в регистр сдвига каждого информационного символа матрица из  элементов, используемых для вычисления скалярных произведений, выбирается случайно и независимо, то символы канала различных двух произвольных путей кодового дерева оказываются независимыми.
элементов, используемых для вычисления скалярных произведений, выбирается случайно и независимо, то символы канала различных двух произвольных путей кодового дерева оказываются независимыми.
Поскольку каждому информационному символу описанный выше кодер сопоставляет  символов канала, то порождаемые этим кодером коды имеют скорость передачи
символов канала, то порождаемые этим кодером коды имеют скорость передачи

и кодовое ограничение 
Далее, как было сказано, будем предполагать, что после введения в регистр сдвига в информационных символов в него вводятся  нулей. При выводе верхней границы для вероятности ошибки будет использоваться следующий алгоритм декодирования.
нулей. При выводе верхней границы для вероятности ошибки будет использоваться следующий алгоритм декодирования.
Каждое ребро заданного пути кодового дерева будет обозначаться посредством соответствующего информационного символа  а соответствующие этому ребру символы принятой последовательности — через
а соответствующие этому ребру символы принятой последовательности — через 
1) Для каждого из  путей кодового дерева, образованных первыми
путей кодового дерева, образованных первыми  ребрами, вычисляются значения
ребрами, вычисляются значения  функций правдоподобия
функций правдоподобия  Далее проводится сравнение значений функций правдоподобия путей
Далее проводится сравнение значений функций правдоподобия путей

для всех  возможных векторов
возможных векторов  При проведении каждого из этих
При проведении каждого из этих  сравнений путь, имеющий
сравнений путь, имеющий
наибольшее значение функции правдоподобия, оставляется, а другой путь отбрасывается. После выполнения  сравнений остается
сравнений остается  векторов, и для каждого из них вектор
векторов, и для каждого из них вектор  определяется однозначно.
определяется однозначно.
2) Для каждого из оставленных на шаге I путей вычисляются значения функций правдоподобия двух ребер, выходящих из  узла кодового дерева; полученные значения умножаются на значение функции правдоподобия исходного пути, и таким образом находятся
узла кодового дерева; полученные значения умножаются на значение функции правдоподобия исходного пути, и таким образом находятся  значений функций правдоподобия путей, состоящих из
значений функций правдоподобия путей, состоящих из  ребер. Эти последовательности
ребер. Эти последовательности  определяются однозначно. Пусть
определяются однозначно. Пусть  символ «1 последовательности, оставленной на 1-м шаге. Для различных пар путей
символ «1 последовательности, оставленной на 1-м шаге. Для различных пар путей

находятся  значений функций правдоподобия. Далее, как и на 1-м шаге,
значений функций правдоподобия. Далее, как и на 1-м шаге,  из этих путей оставляются, а остальные отбрасываются.
из этих путей оставляются, а остальные отбрасываются.
Этот шаг процедуры декодирования повторяется  раз. В частности, на
раз. В частности, на  шаге декодер выполняет
шаге декодер выполняет  сравнений функций правдоподобия для следующих пар путей:
сравнений функций правдоподобия для следующих пар путей:

где  символы, полученные в результате сравнений на предыдущих шагах декодирования.
символы, полученные в результате сравнений на предыдущих шагах декодирования.
3) На  шаге на вход декодера подается символ 0, проводится сравнение значений функций правдоподобия следующих
шаге на вход декодера подается символ 0, проводится сравнение значений функций правдоподобия следующих  пар путей:
пар путей:

при всевозможных векторах  и по результатам этих сравнений оставляются
и по результатам этих сравнений оставляются  путей. Так как на вход регистра сдвига с момента
путей. Так как на вход регистра сдвига с момента  подаются нулевые символы, то число выполняемых сравнений с каждым шагом уменьшается вдвое. Перед
подаются нулевые символы, то число выполняемых сравнений с каждым шагом уменьшается вдвое. Перед  шагом остаются два
шагом остаются два 

На  шаге из этих двух путей выбирается тот, который имеет большее значение функции правдоподобия, и этот путь оставляется как правильный.
шаге из этих двух путей выбирается тот, который имеет большее значение функции правдоподобия, и этот путь оставляется как правильный.
При использовании этого алгоритма декодирования ошибка при декодировании возникает в том случае, если при проведении 6 сравнений для пар путей, содержащих правильный путь, оказывается, что значение функции правдоподобия правильного пути меньше, чем значение функции правдоподобия некоторого другого сравниваемого пути. В целях упрощения предположим, что правильный путь является последовательностью, состоящей из одних нулей. Рассмотрим случай, когда ошибка возникает на  шаге декодирования. На
шаге декодирования. На  шаге декодирования первые
шаге декодирования первые  ребер правильного пути обозначим через
ребер правильного пути обозначим через  Векторы, сравнение которых проводится на этом шаге декодирования, задаются формулами (6.99), но правильный путь входит лишь в следующие пары:
Векторы, сравнение которых проводится на этом шаге декодирования, задаются формулами (6.99), но правильный путь входит лишь в следующие пары:

где  символы, найденные на предыдущих шагах и являющиеся элементами поля
символы, найденные на предыдущих шагах и являющиеся элементами поля  Следовательно, число путей, которые сравниваются на
Следовательно, число путей, которые сравниваются на  шаге с правильным путем, равно
шаге с правильным путем, равно  Эти
Эти  путей можно разбить на группы следующим образом.
путей можно разбить на группы следующим образом.
Пусть  вектор, обозначающий путь, ответвляющийся от правильного пути в
вектор, обозначающий путь, ответвляющийся от правильного пути в  узле, а (
узле, а ( вектор, обозначающий путь, ответвляющийся от правильного пути в
вектор, обозначающий путь, ответвляющийся от правильного пути в  узле. По аналогии пусть
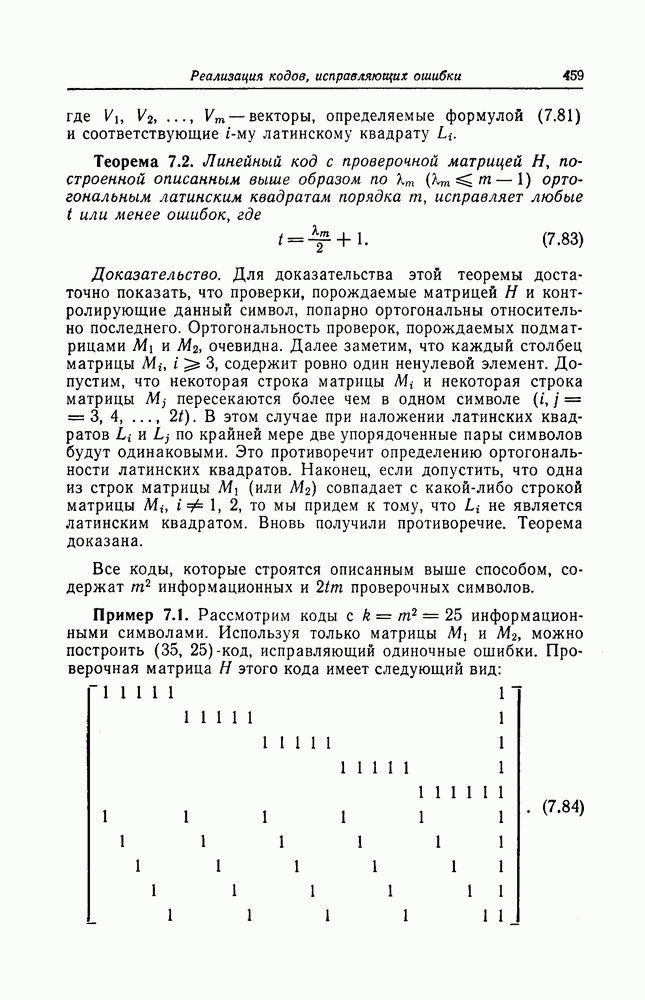
узле. По аналогии пусть  -вектор,обозначающий путь, отвевляющийся от правильного пути в
-вектор,обозначающий путь, отвевляющийся от правильного пути в  узле
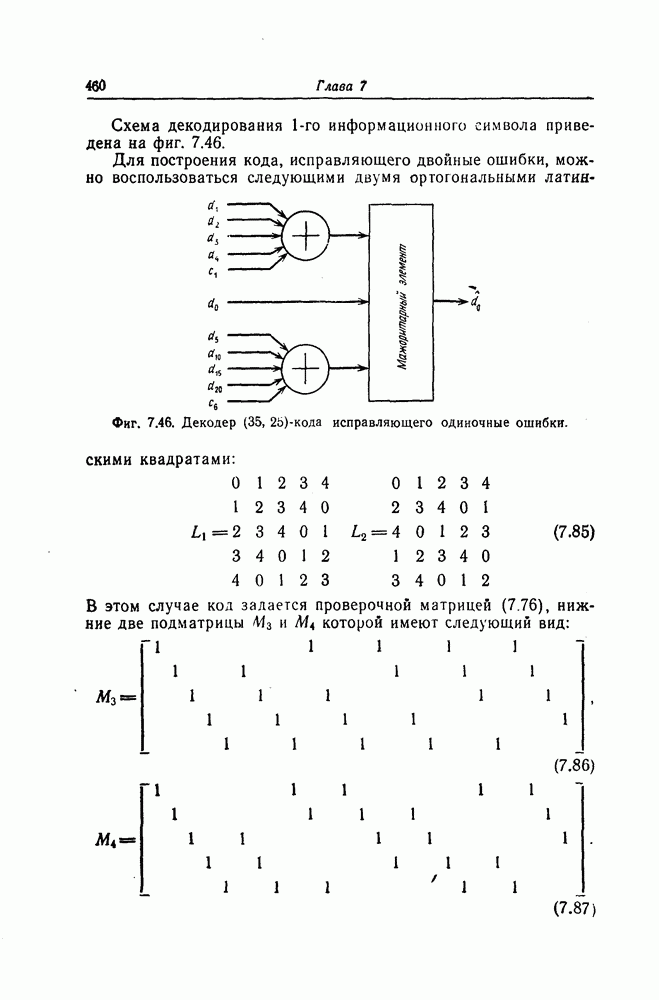
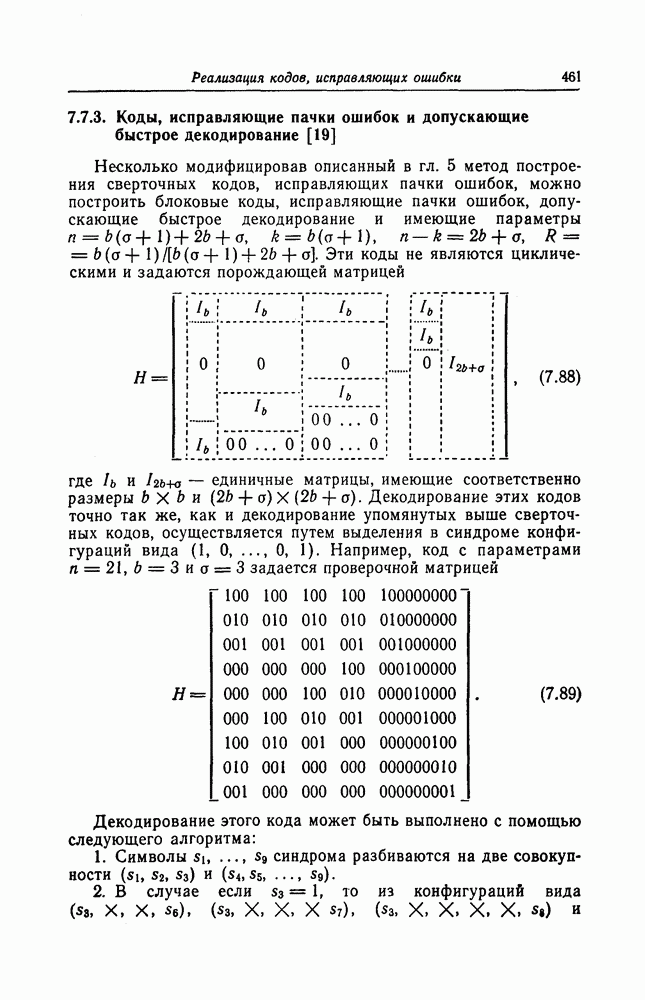
узле  ; всего имеются два таких пути. В общем случае число путей, ответвляющихся от правильного пути
; всего имеются два таких пути. В общем случае число путей, ответвляющихся от правильного пути  узле, равно
узле, равно  а число путей, ответвляющихся в
а число путей, ответвляющихся в  узле, равно 1. Общее число указанных выше путей равно
узле, равно 1. Общее число указанных выше путей равно  и оно является общим числом векторов, которые могут составлять вторую строку (6.102).
и оно является общим числом векторов, которые могут составлять вторую строку (6.102).
Однако все эти векторы не имеют прямого отношения к выбору правильного пути. В силу свойства 1 кодера, если два пути, отличающиеся в некотором заданном ребре, совпадают в последующих  информационных символах, то они также совпадают в следующем за ними ребре. Если два пути с
информационных символах, то они также совпадают в следующем за ними ребре. Если два пути с
произвольными фиксированными информационными символами не имеют никаких  совпадающих подряд идущих информационных символов, то они не имеют совпадающих ребер. Такие пути будем называть полностью несовпадающими. В силу этого свойства кодера при рассматриваемом алгоритме декодирования векторами, которые сравниваются с правильным путем на
совпадающих подряд идущих информационных символов, то они не имеют совпадающих ребер. Такие пути будем называть полностью несовпадающими. В силу этого свойства кодера при рассматриваемом алгоритме декодирования векторами, которые сравниваются с правильным путем на  шаге, являются не все векторы вида (6.99), а только те из них, которые полностью не совпадают с правильным путем. Следовательно, математическое ожидание вероятности ошибки при проведении сравнений на
шаге, являются не все векторы вида (6.99), а только те из них, которые полностью не совпадают с правильным путем. Следовательно, математическое ожидание вероятности ошибки при проведении сравнений на  шаге можно оценить сверху суммой математических ожиданий вероятностей возникновения ошибок при проведении сравнений с векторами, отличающимися от правильного пути соответственно в
шаге можно оценить сверху суммой математических ожиданий вероятностей возникновения ошибок при проведении сравнений с векторами, отличающимися от правильного пути соответственно в  ребрах:
ребрах:

Слагаемое с  в правой части этого неравенства можно оценить сверху вероятностью ошибки для блокового кода длиной
в правой части этого неравенства можно оценить сверху вероятностью ошибки для блокового кода длиной  состоящего из одного кодового слова;
состоящего из одного кодового слова;  слагаемое в правой части (6.103) можно оценить сверху вероятностью ошибки для блокового кода длиной
слагаемое в правой части (6.103) можно оценить сверху вероятностью ошибки для блокового кода длиной  символов канала, состоящего из
символов канала, состоящего из  кодовых слов. Используя свойства 2—4 кодера и границу случайного кодирования, получаем
кодовых слов. Используя свойства 2—4 кодера и границу случайного кодирования, получаем

где

Верхняя граница для вероятности ошибки при декодировании древовидного кода  длиной В получается суммированием (6.104) по
длиной В получается суммированием (6.104) по  Так как правая часть неравенства (6.104) не зависит от до, то имеем
Так как правая часть неравенства (6.104) не зависит от до, то имеем

В силу того что в ансамбле кодов, для которого справедливы неравенства (6.106), существует по крайней мере один код,
для которого  , а
, а  является монотонно возрастающей функцией
является монотонно возрастающей функцией  получаем следующую теорему.
получаем следующую теорему.
Теорема 6.4. (Витерби) В дискретном канале без памяти вероятность ошибки при декодировании В ребер двоичного древовидного кода удовлетворяет следующему неравенству:

где

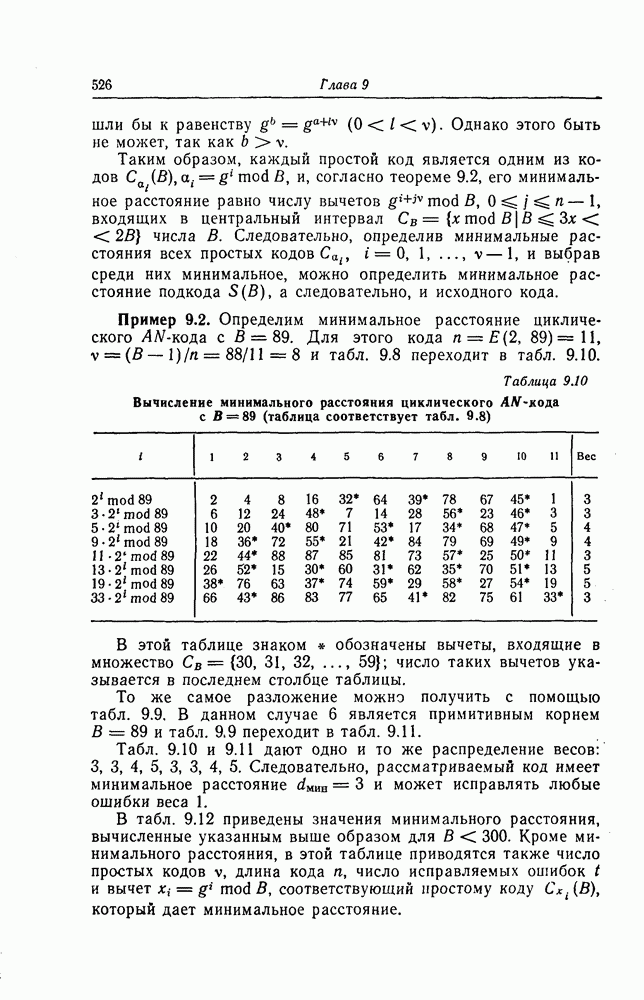
6.6.2. Нижняя граница для вероятности ошибки
В этом разделе получим нижнюю границу для вероятности ошибки. Для этого воспользуемся декодером с учителем, для исследования которого применим границу сферической упаковки и прямолинейную границу.
В данном случае будем предполагать, что учитель указывает декодеру все ребра правильного пути кодового дерева, за исключением I следующих друг за другом ребер  Другими словами, учитель указывает все передаваемые информационные символы
Другими словами, учитель указывает все передаваемые информационные символы  за исключением
за исключением  символов, соответствующих указанным выше ребрам. Таким образом, задача декодера сводится к тому, чтобы по принятой последовательности
символов, соответствующих указанным выше ребрам. Таким образом, задача декодера сводится к тому, чтобы по принятой последовательности  состоящей из
состоящей из  символов, определить, какая из
символов, определить, какая из  двоичных последовательностей передавалась. (Здесь
двоичных последовательностей передавалась. (Здесь  совокупность принятых символов, соответствующих
совокупность принятых символов, соответствующих  ребру.) Итак, поскольку в данном случае символы, передаваемые в моменты времени
ребру.) Итак, поскольку в данном случае символы, передаваемые в моменты времени  даются учителем, то декодеру необходимо исследовать лишь символы
даются учителем, то декодеру необходимо исследовать лишь символы  до
до  Исследуемые 2 путей могут различаться лишь в
Исследуемые 2 путей могут различаться лишь в  и последующих ребрах, но если рассматривать только информационные последовательности, имеющие одни и те же символы
и последующих ребрах, но если рассматривать только информационные последовательности, имеющие одни и те же символы  при
при  то состояния регистра сдвига при порождении
то состояния регистра сдвига при порождении  и последующих ребер будут совпадать и, следовательно, при
и последующих ребер будут совпадать и, следовательно, при  кодер будет порождать всегда одну и ту же последовательность. Таким образом, исследуемые 2 путей могут отличаться друг от друга самое большее в
кодер будет порождать всегда одну и ту же последовательность. Таким образом, исследуемые 2 путей могут отличаться друг от друга самое большее в  ребрах.
ребрах.
Будем считать, что приемник для каждого из этих 2 путей, имеющих равные априорные вероятности, вычисляет значение
функции правдоподобия  и выбирает из них тот путь, для которого значение функции правдоподобия максимально. Здесь и — вектор, определяющий путь. Полагая
и выбирает из них тот путь, для которого значение функции правдоподобия максимально. Здесь и — вектор, определяющий путь. Полагая

из равенства

получаем

Длина вектора  равна
равна  Следовательно, вероятность ошибки для указанного выше декодера можно оценить снизу любой нижней границей для вероятности ошибки блокового кода длиной
Следовательно, вероятность ошибки для указанного выше декодера можно оценить снизу любой нижней границей для вероятности ошибки блокового кода длиной  содержащего 21 — екодовых слов.
содержащего 21 — екодовых слов.
Как следует из соотношений (1.59) и (1.63) первой главы, граница сферической упаковки для блокового кода длиной  со скоростью
со скоростью  имеет следующий вид:
имеет следующий вид:

где  верхняя огибающая
верхняя огибающая  Так как
Так как

и параметр  здесь является некоторой фиксированной постоянной, то
здесь является некоторой фиксированной постоянной, то  стремится к нулю с ростом
стремится к нулю с ростом  следовательно,
следовательно,

Подставляя  получаем
получаем

Так как аргумент  функции
функции  удовлетворяет неравенству
удовлетворяет неравенству

то

Как следует из результатов Шеннона, Галлагера и Берлекэмпа [5], функция  может быть задана параметрически:
может быть задана параметрически:

где  любое из чисел
любое из чисел  . Проводя максимизацию
. Проводя максимизацию  по
по  получаем следующую нижнюю границу для вероятности ошибки
получаем следующую нижнюю границу для вероятности ошибки 

Здесь необходимо найти функцию

Для этого, выбрав  достаточно большим, сначала проведем минимизацию по всем действительным положительным числам
достаточно большим, сначала проведем минимизацию по всем действительным положительным числам  , а после этого ограничим область минимизации для чисел
, а после этого ограничим область минимизации для чисел  кратных
кратных 
Дифференцируя  по
по  получаем
получаем

Из равенства (6.118) имеем

Подставляя последнее равенство в формулу (6.121) и приравнивая далее (6.121) к нулю, находим 

Повторно дифференцируя равенство (6.121), используя (6.118) и то, что вторая производная  выпуклой вверх функции
выпуклой вверх функции  отрицательна, получаем
отрицательна, получаем

Следовательно, в точке, определяемой соотношением (6.123), достигается минимум исследуемой функции. Подставляя  из
из
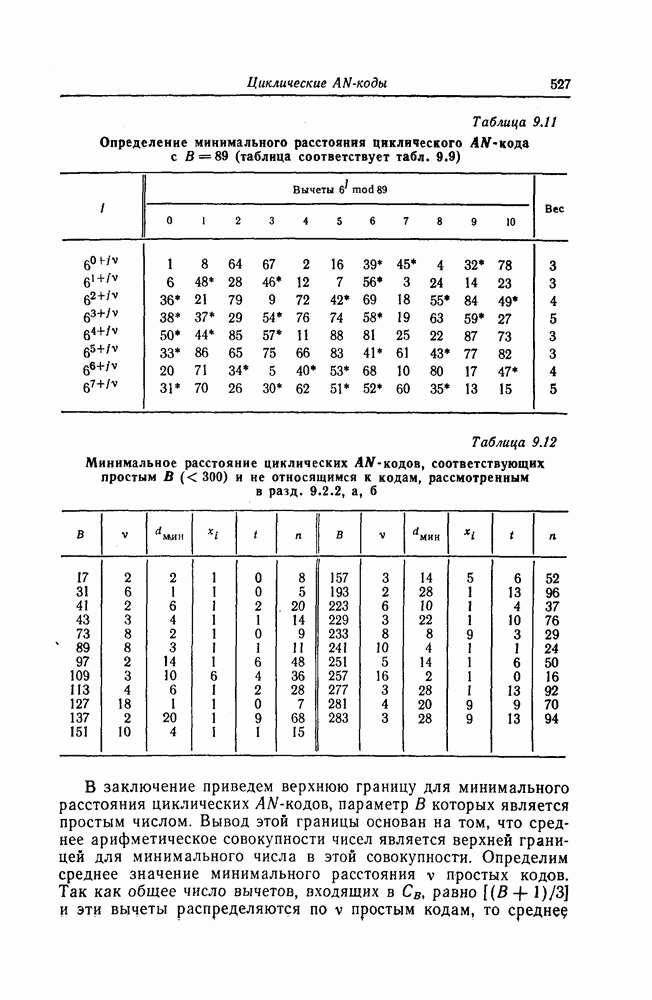
В случае малых скоростей, используя прямолинейную границу, для  можно получить более сильную нижнюю границу. Эту границу мы приведем здесь без доказательства.
можно получить более сильную нижнюю границу. Эту границу мы приведем здесь без доказательства.
Утверждение 6.1. В области малых скоростей имеет место следующая граница:

где  - решение уравнения
- решение уравнения  и
и






















































































































































































































































































































































































































































































































 выпуклая вверх функция, то
выпуклая вверх функция, то  следовательно,
следовательно,

 - неотрицательная величина. Из формул (6.117), (6.123) и (6.126) получаем
- неотрицательная величина. Из формул (6.117), (6.123) и (6.126) получаем

 кратно
кратно  введем «корректирующее слагаемое»
введем «корректирующее слагаемое»  и исследуем его влияние. Изменение
и исследуем его влияние. Изменение  на величину порядка
на величину порядка  приводит к изменению показателя экспоненты на величину порядка
приводит к изменению показателя экспоненты на величину порядка  Обозначим
Обозначим  через
через  Величина
Величина  связана с
связана с  следующим образом:
следующим образом:

 в показатель экспоненты оценки для
в показатель экспоненты оценки для  достаточно ввести слагаемое
достаточно ввести слагаемое  Из формул (6.119), (6.120), (6.126) и (6.128) получаем следующую теорему.
Из формул (6.119), (6.120), (6.126) и (6.128) получаем следующую теорему.
 ограничена снизу следующим образом:
ограничена снизу следующим образом:

