Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
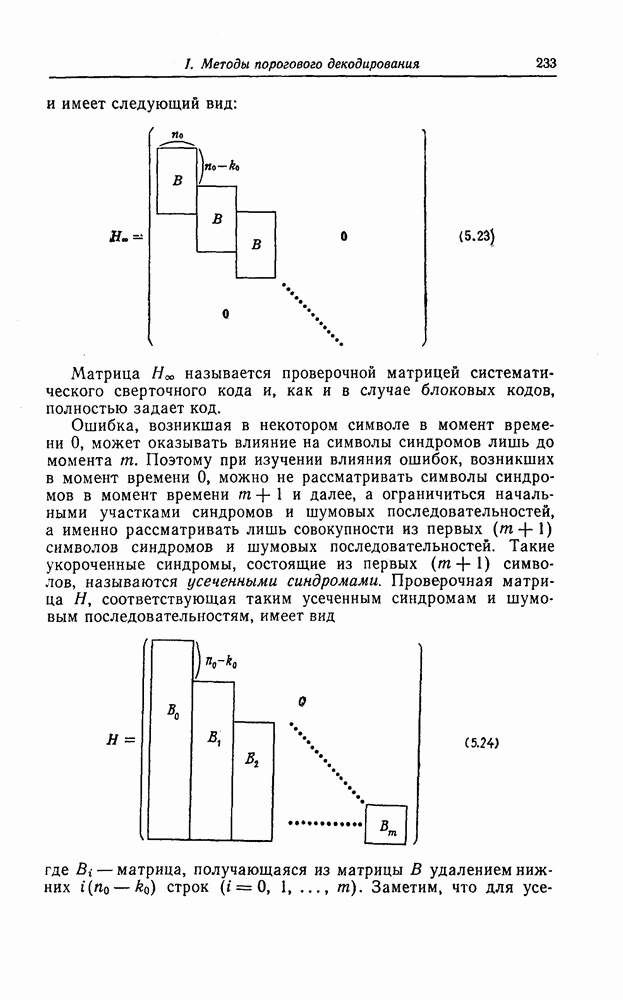
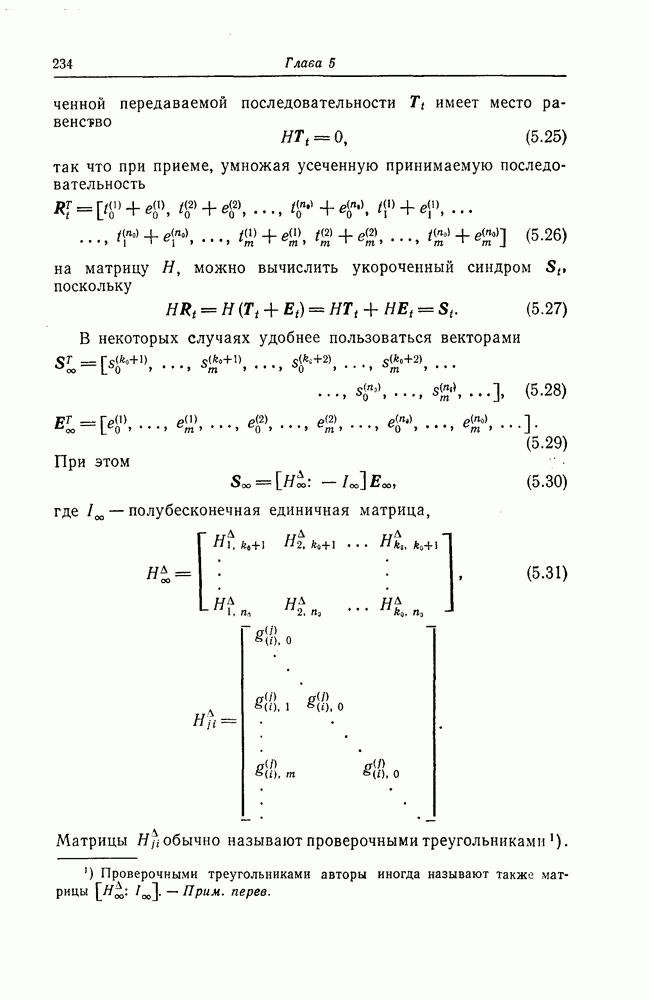
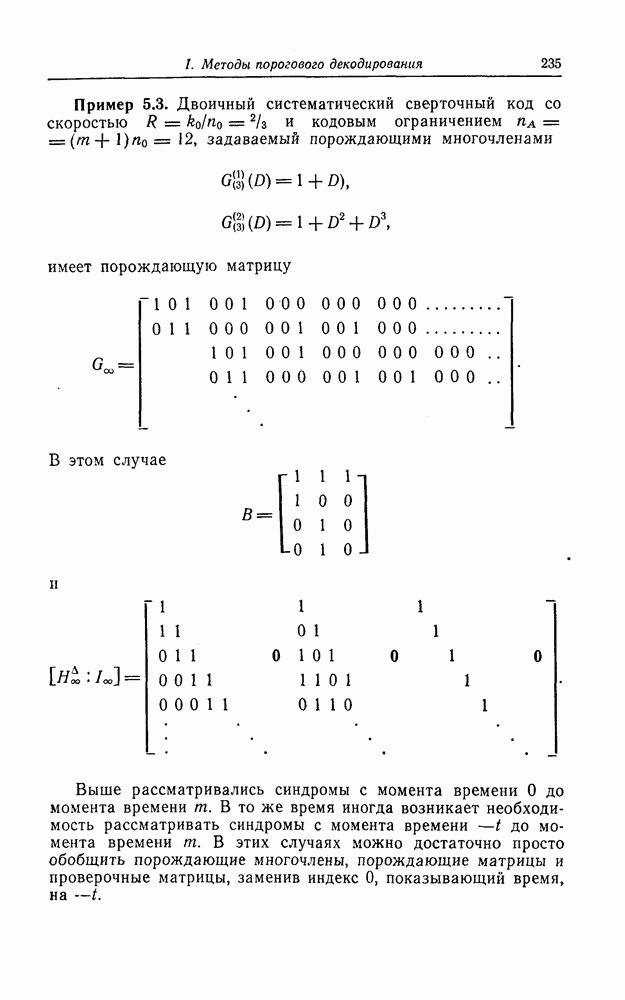
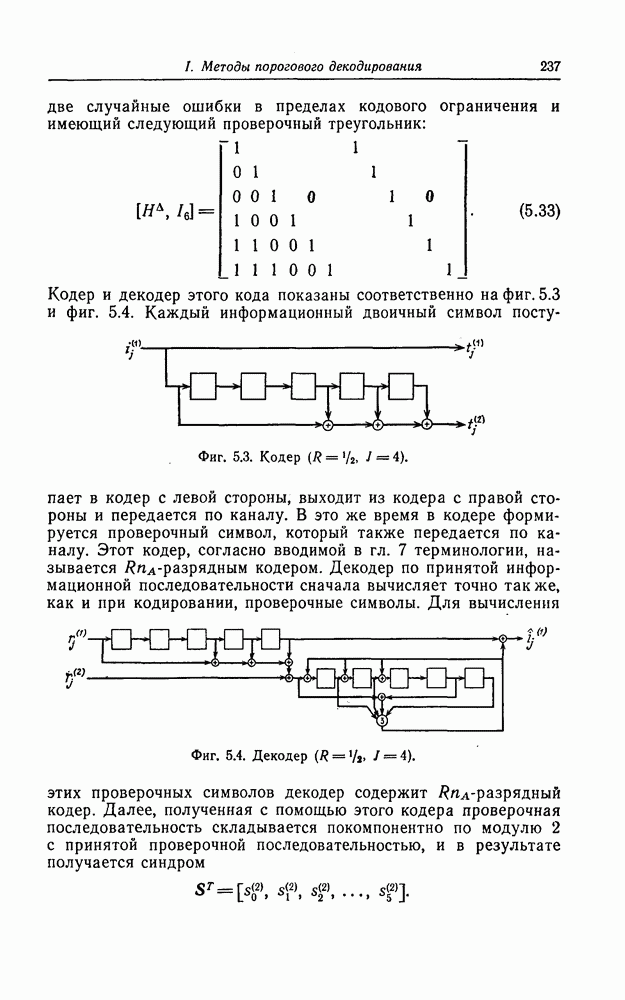
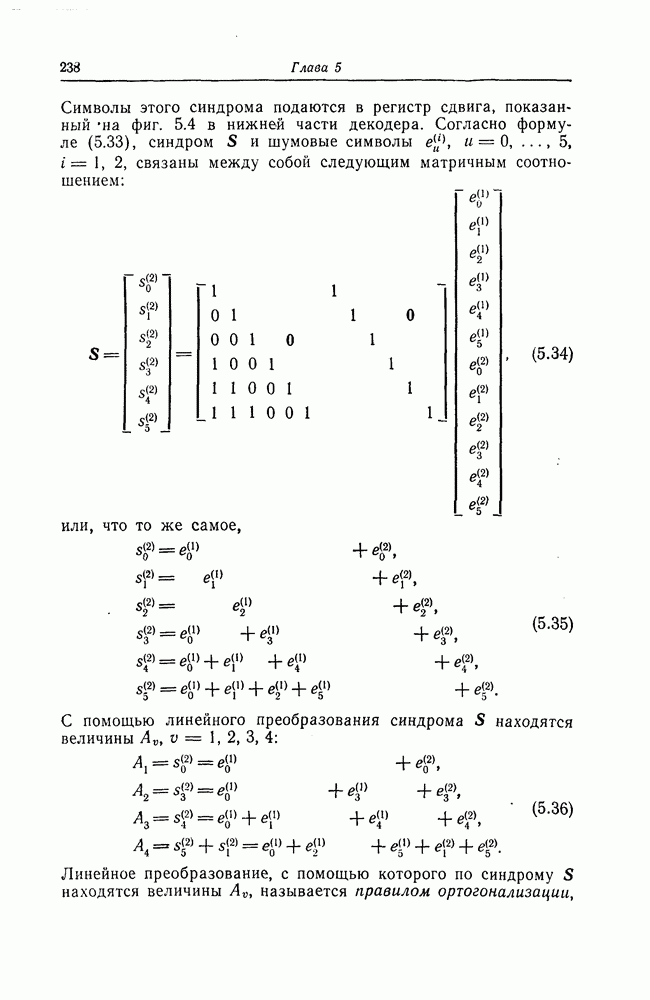
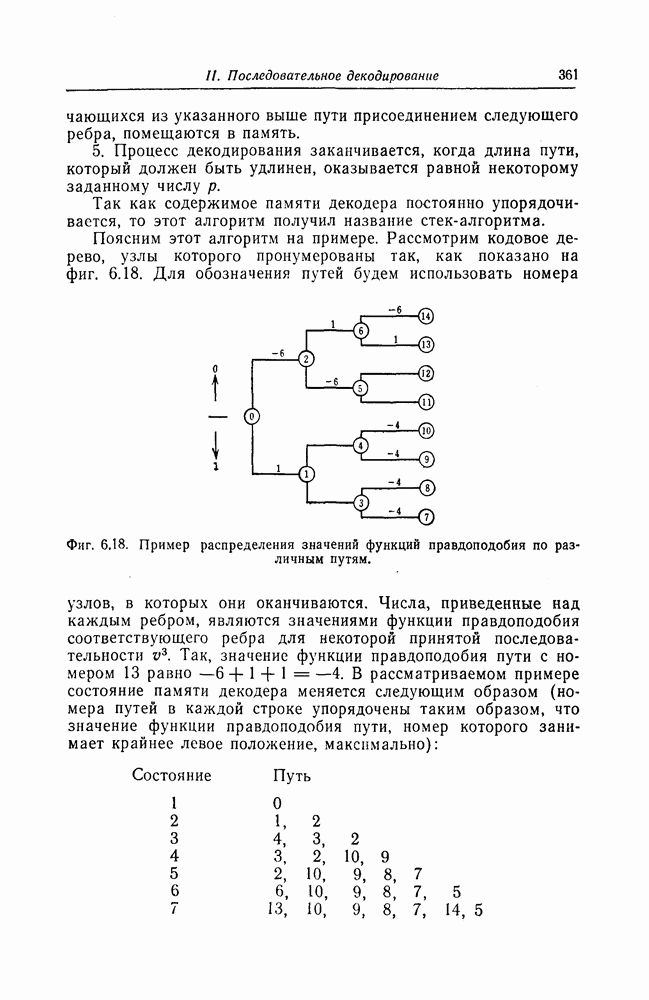
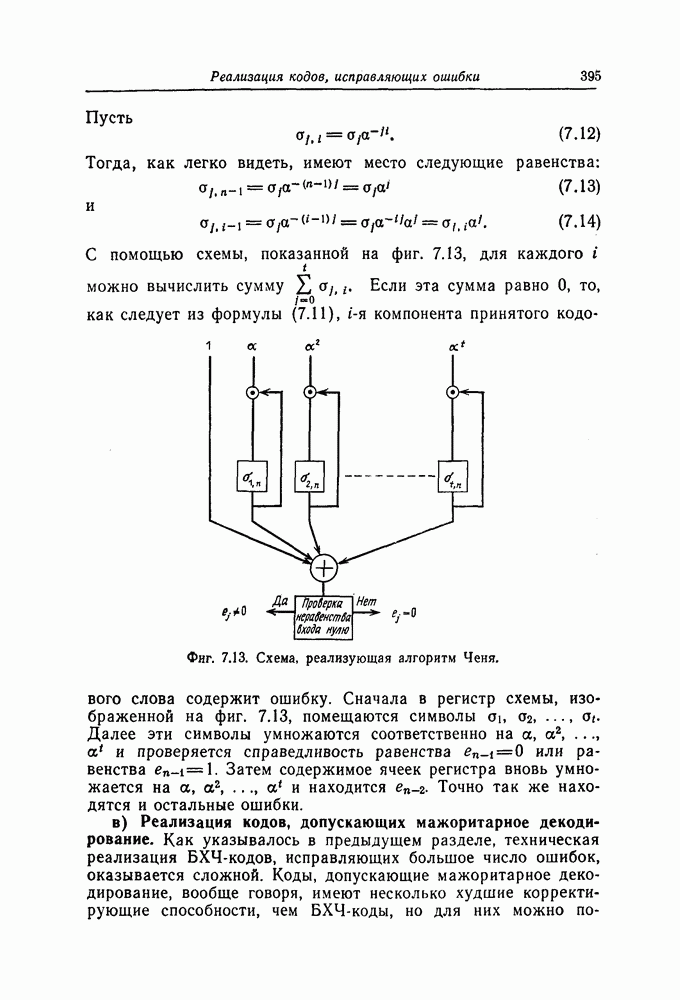
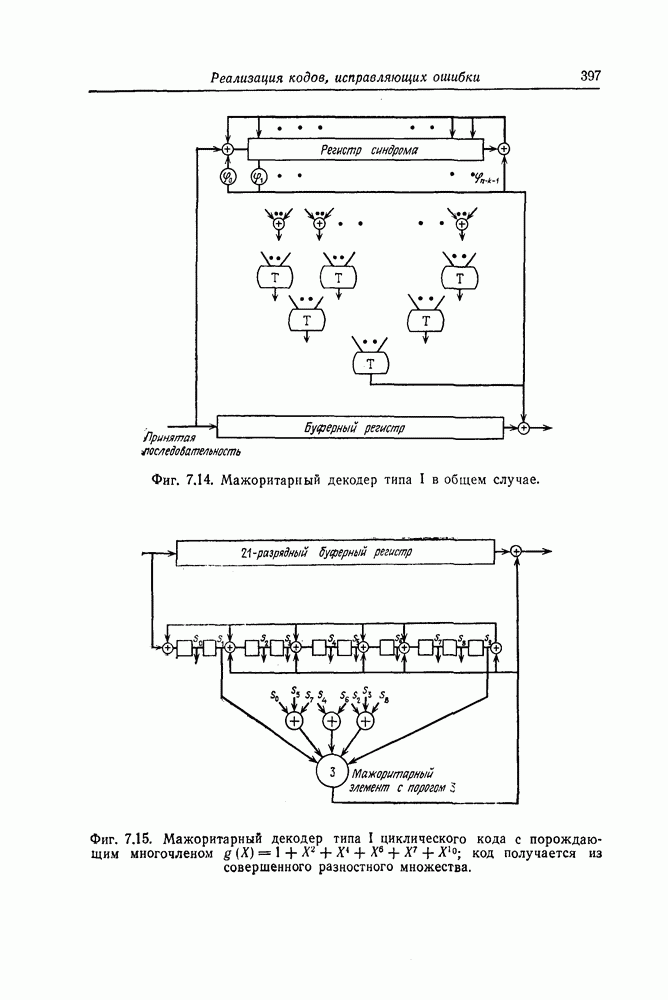
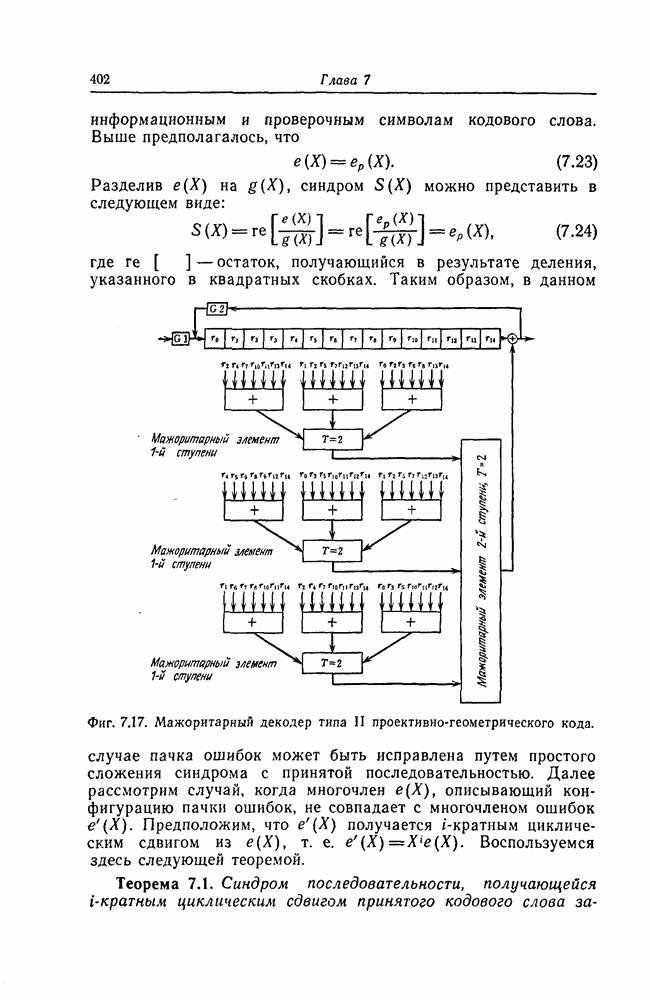
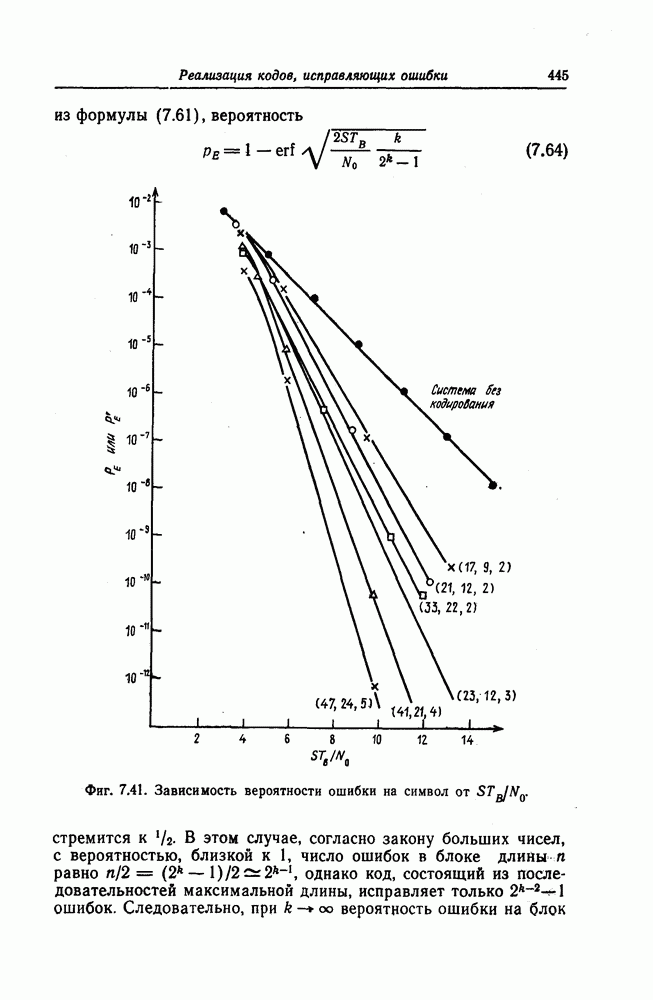
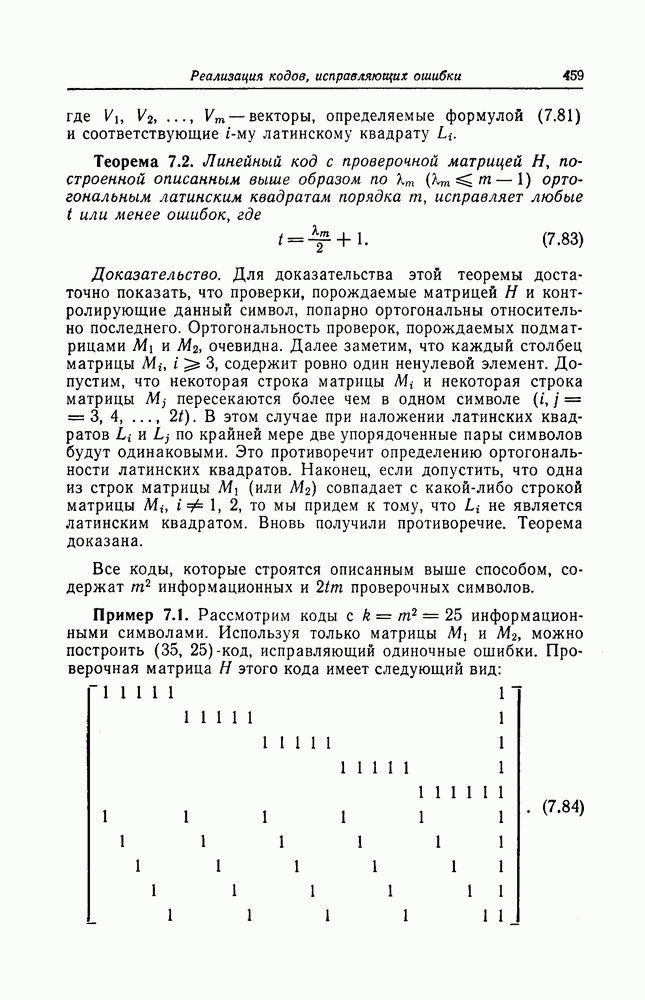
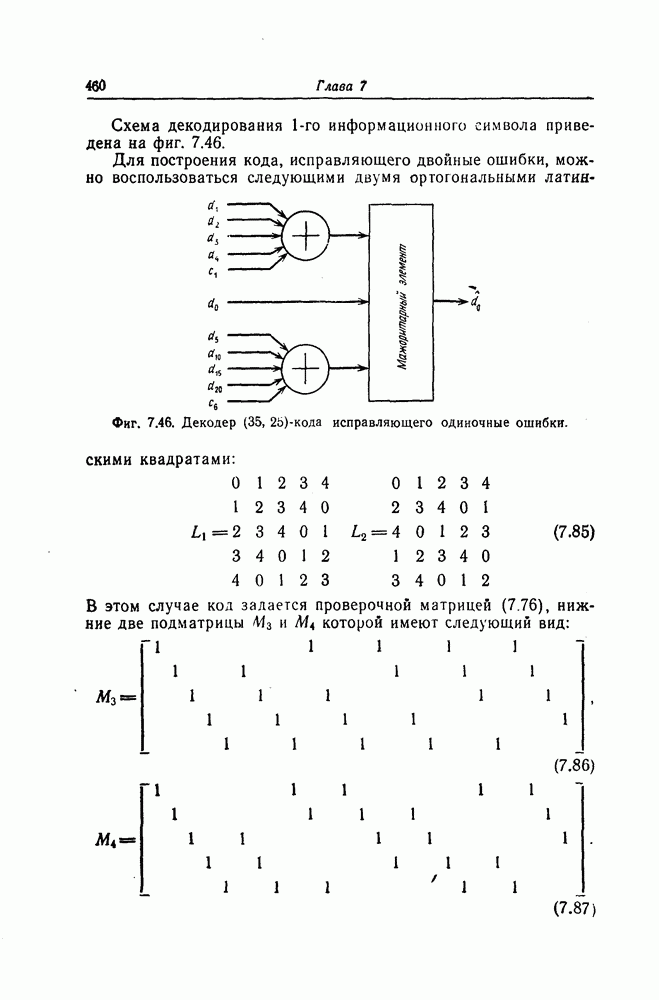
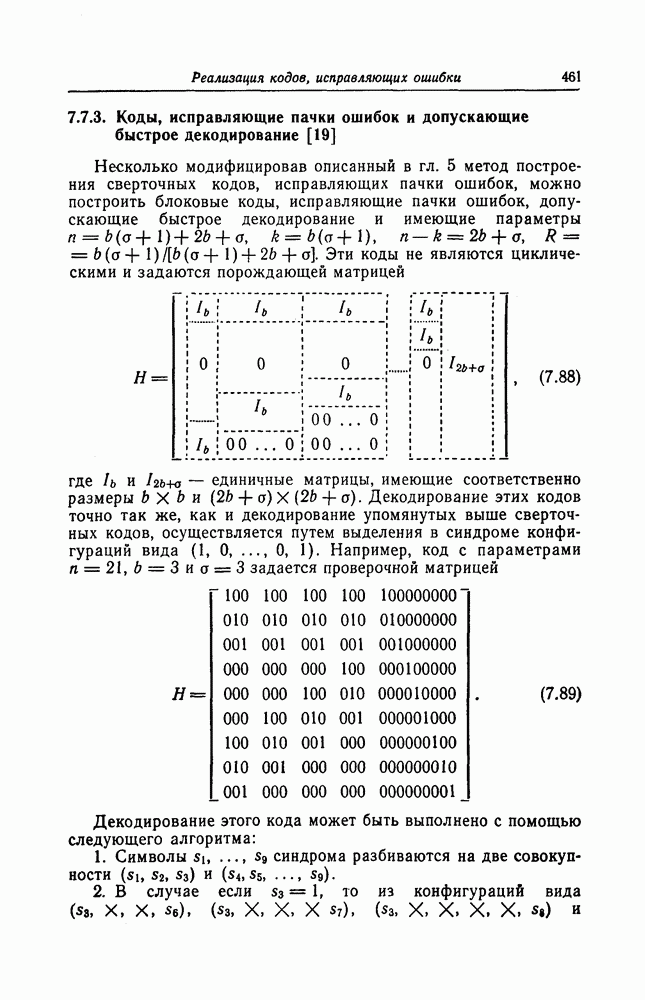
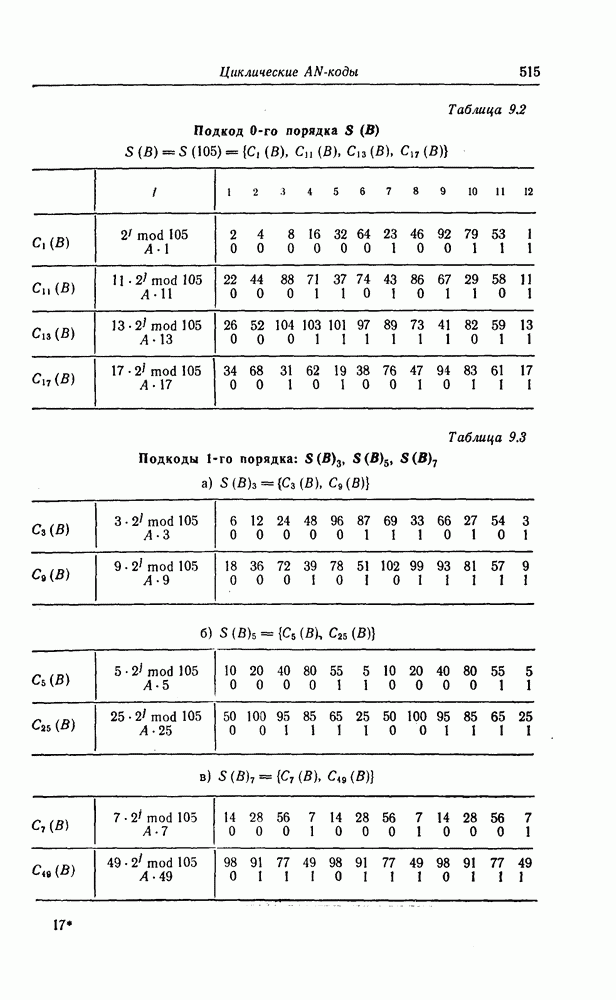
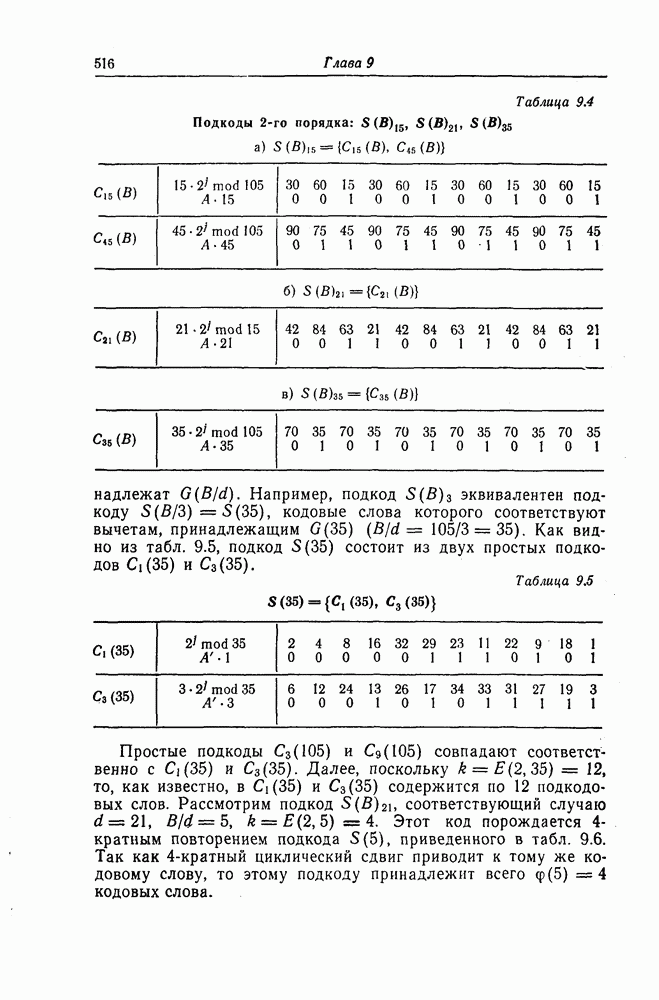
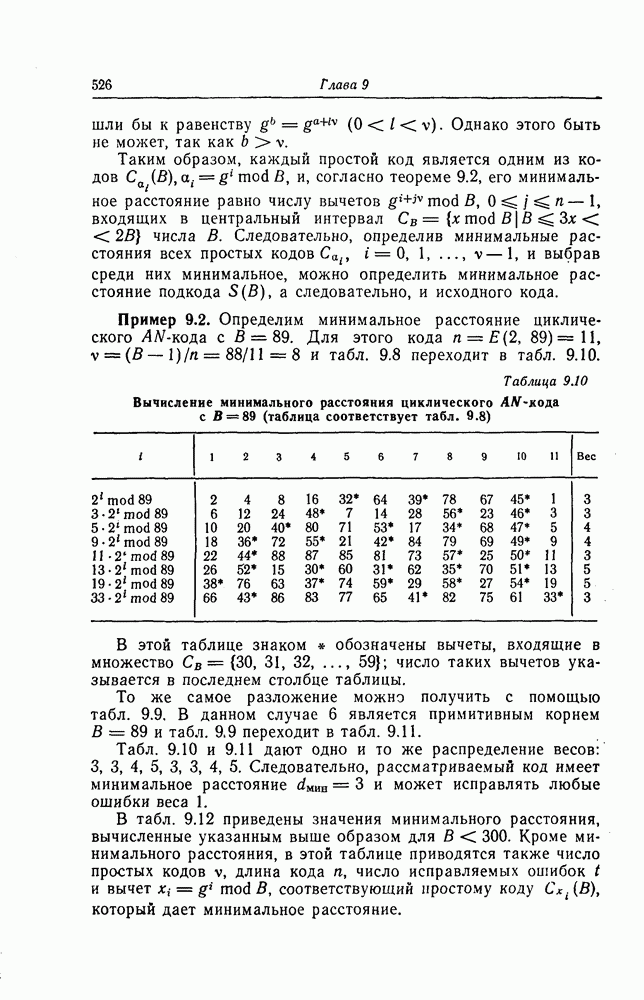
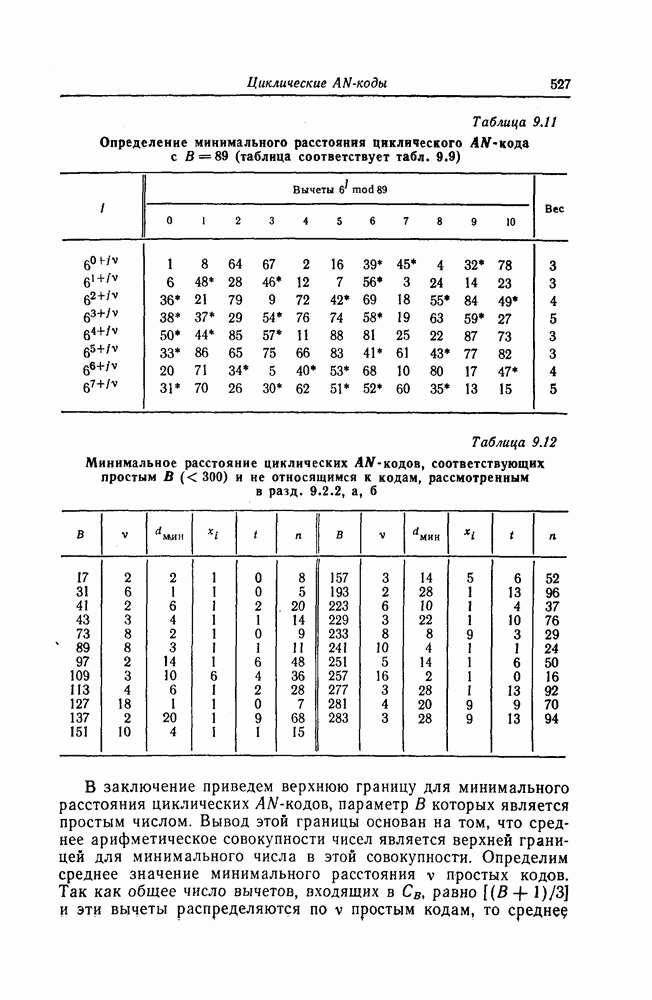
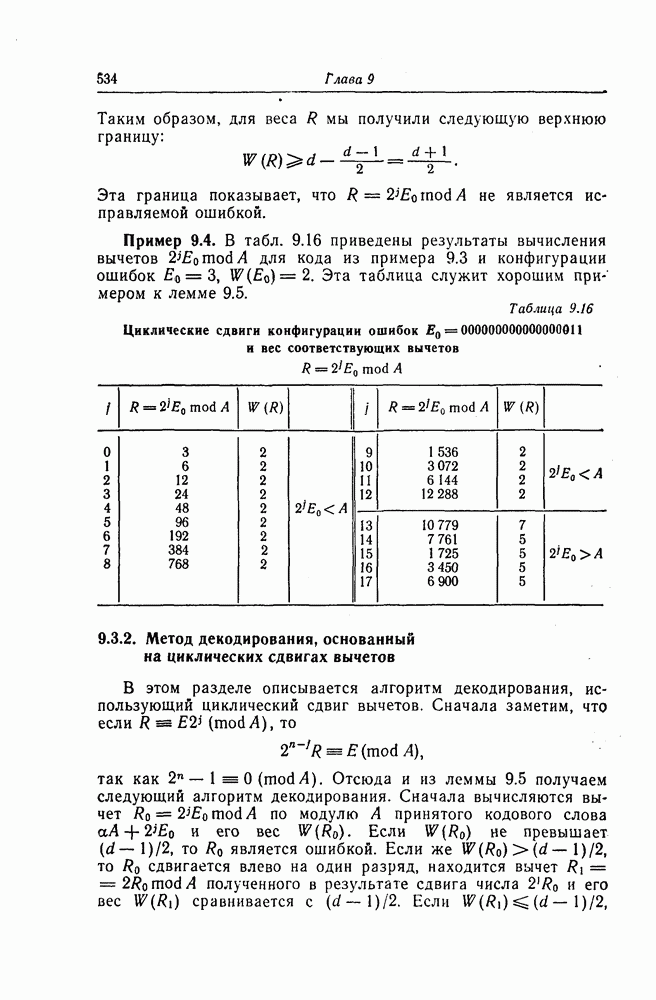
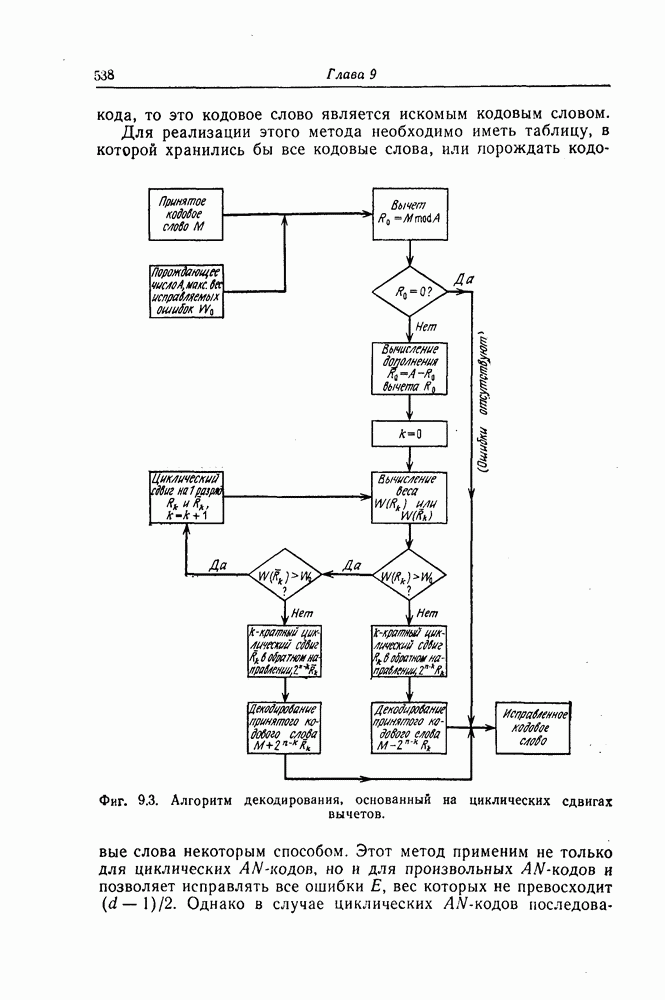
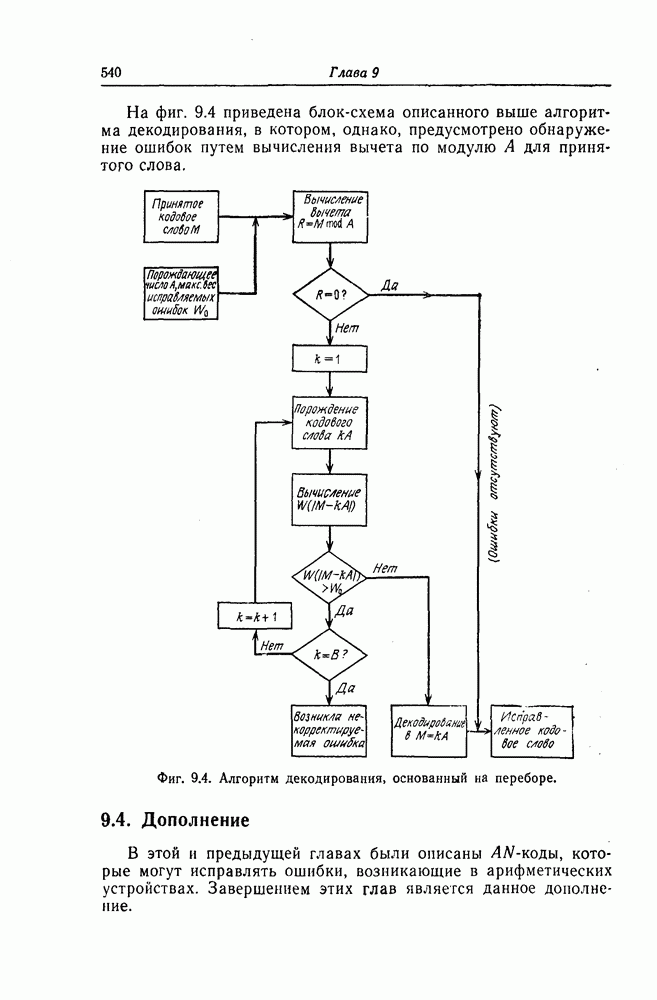
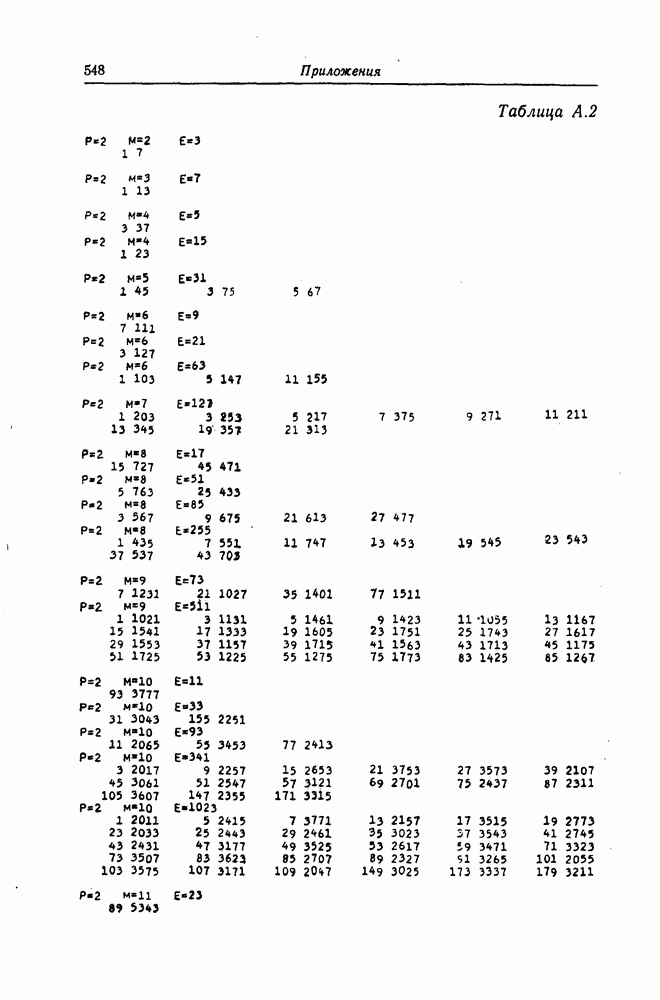
1. Основные понятия теории кодирования1.1. Коды, обнаруживающие и исправляющие ошибкиЕсли взять достаточно длинное предложение английского или японского текста и исказить его, заменив в некоторых местах одни буквы на другие, исключив ряд букв (символов) или добавив новые, то, используя знание структуры отдельных слов и предложения в целом, предыдущий и последующий тексты, а также наши обычные познания о предмете, о котором идет речь, можно в большом числе случаев полностью восстановить исходное предложение или по крайней мере безошибочно уловить его смысл. Это показывает, что английский, японский и другие естественные языки обладают очень большой избыточностью. В технике также часто устанавливают по два или три одинаковых устройства, чтобы при выходе из строя одного из них его можно было заменить другим. В некоторых случаях с помощью одного устройства выполняются дважды одни и те же вычисления, и если результаты этих вычислений совпадают, то принимается решение о том, что вычисления выполнены без ошибок. Если же результаты вычислений не совпадают, то это означает, что в процессе вычислений произошла ошибка. Вычисления проводятся еще раз, и обнаруженная ошибка устраняется. Во всех рассмотренных выше случаях наличие избыточности позволяет провести обнаружение ошибок и повысить надежность устройств. Однако проблема состоит не в том, чтобы просто повысить надежность за счет введения очень большой избыточности, а в том, как с помощью по возможности меньшей специальным образом вводимой избыточности достичь нужной степени надежности. В некоторых предложениях, взятых из естественного языка, достаточно сильно исказить небольшое число букв (например, считать эти буквы неопределенными), чтобы смысл был полностью искажен. Известно [I], что избыточность английского языка достигает 70%, однако нельзя сказать, что избыточность вводится в английский текст оптимально с точки зрения возможности исправления и обнаружения ошибок. Основной задачей теории кодирования в настоящее время является повышение надежности систем связи и вычислительных систем с помощью целенаправленного эффективного введения избыточности в процессе представления информации (в процессе преобразования информации). Введение избыточности приводит к снижению количества сообщений, которые могут быть переданы или обработаны за определенный период времени, а кроме того, предполагает использование в системе дополнительных устройств для целенаправленного введения избыточности (кодеров), устройств для обнаружения и исправления возникающих ошибок (декодеров) и ряда других дополнительных устройств. Само собой разумеется, что проектирование таких избыточных систем должно выполняться с учетом стоимости этих дополнительно вводимых устройств (см. гл. 7).
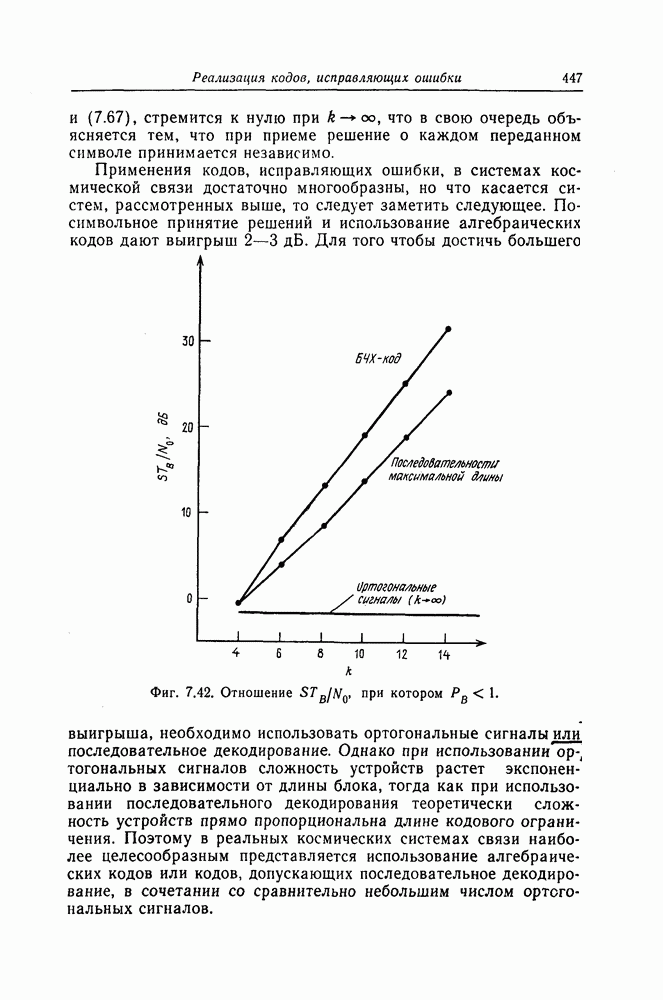
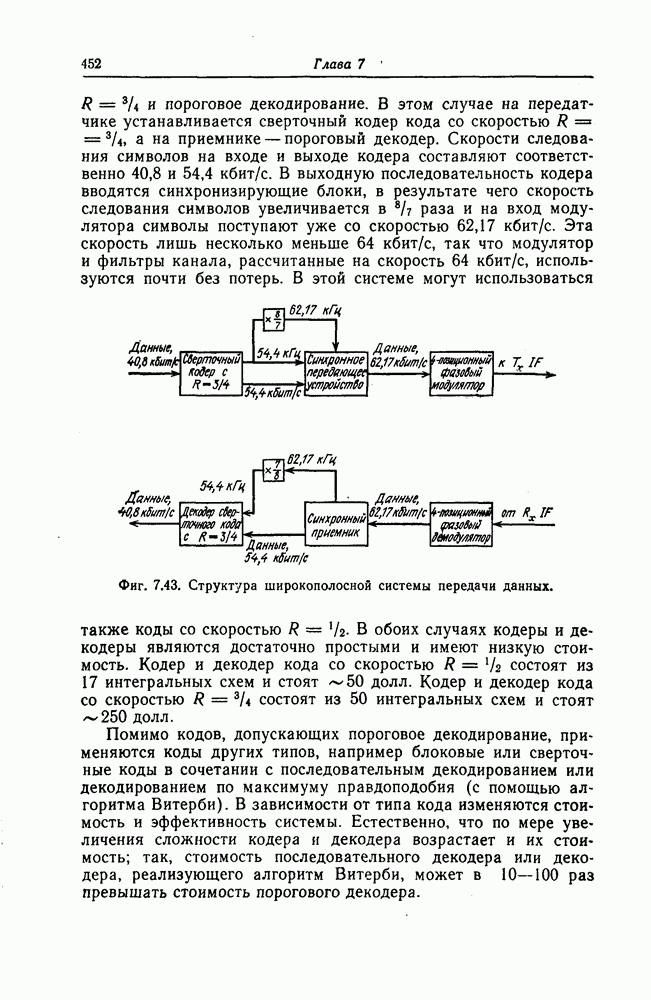
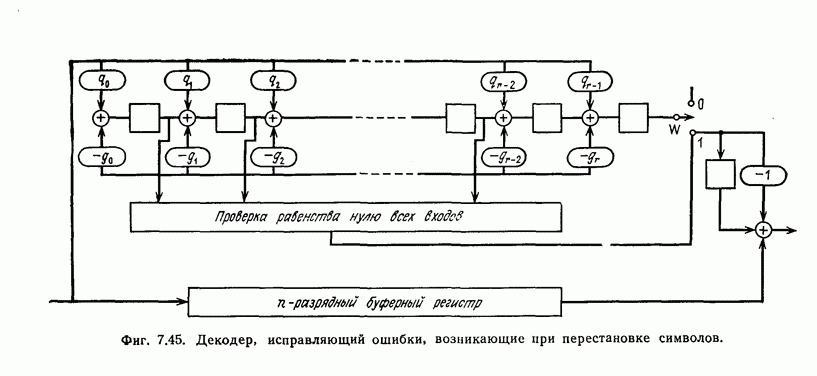
Фиг. 1.1. Модель системы связи. Поскольку в теории обычно рассматриваются идеализированные модели реальных систем, в которых из большого числа факторов, влияющих на поведение реальной системы, учитывается лишь часть, то теоретические результаты должны использоваться для решения задач, связанных с построением реальных систем, только после того, как будут определены границы применимости этих теоретических результатов. На фиг. 1.1 показана типичная модель системы связи, в которой используются коды, исправляющие ошибки [2]. В этой модели каналом является простейший двоичный канал. Эта же модель может быть использована и в качестве модели запоминающего устройства (например, запоминающего устройства на магнитной ленте или интегральной памяти), если среду, в которой хранится информация, рассматривать как канал связи. Поступающая от источника информация вначале с помощью преобразователя «источник информации — двоичная последовательность» преобразуется в последовательность двоичных символов, которая подается на вход кодера, где в нее вводится избыточность. Символы с выхода кодера с помощью модулятора преобразуются в сигналы, которые могут быть переданы по каналу. Эти сигналы поступают в канал, где они обычно искажаются шумами. На приемном конце искаженные сигналы ьлнала с помощью демодулятора преобразуются в последовательность двоичных символов, содержащую избыточные символы. Используя эту избыточность, декодер обнаруживает и исправляет возникшие ошибки. Двоичная последовательность символов на выходе декодера уже не является избыточной. Если воздействие шума в канале не слишком сильное и декодер может исправить все возникшие ошибки, то двоичная последовательность на выходе декодера будет совпадать с двоичной последовательностью на выходе преобразователя «источник информации — двоичная последовательность». И наконец, двоичная последовательность, получающаяся на выходе декодера, преобразуется в сигналы, приемлемые для получателя информации, и передается последнему. Ниже рассматривается несколько примеров простых кодов, обнаруживающих или исправляющих ошибки. Пример 1.1. Рассмотрим канал, по которому за время
Пример 1.2. В вычислительных машинах информация обычно представляется в виде двоичных последовательностей. При этом используется несколько способов представления десятичных цифр Таблица 1.1 (см. скан) Пример представления десятичных цифр символ 1» значительно больше (или значительно меньше), чем вероятность возникновения ошибки, типа «переход символа 1 в символ 0» (т. е. при так называемых несимметричных ошибках), а также в тех случаях, когда «убытки» из-за ошибочного принятия символа 1 вместо символа 0 значительно больше (меньше) убытков при принятии символа 0 вместо символа 1 [17—19]. Рассмотренные здесь коды являются примерами так называемых нелинейных кодов. Пример 1.3. Предположим, что некоторые
где в данном случае знак называют символом проверки на четность. Рассмотренный здесь метод обнаружения одиночных ошибок благодаря своей простоте применяется очень широко. В табл. 1.1 показан способ представления десятичных цифр с помощью пяти двоичных символов, первые четыре из которых являются двоичным разложением соответствующей десятичной цифры, а пятый — символом проверки на четность. Пример 1.4. Предположим, что имеется 16 сообщений, каждому из которых взаимно однозначно поставлена в соответствие двоичная последовательность
Здесь знак
где знак следующим образом:
Из формул (1.2) и (1.3) получаем
По предположению только один из символов Далее рассмотрим случай, когда
из левой части (1.4) различны, а во-вторых, что называемых обычно кодовыми векторами, называется кодом Хэмминга длины 7 [3]. Утверждение 1.1. Если последовательности Краткое доказательство. Число ненулевых компонент вектора называют весом этого вектора. Пусть Утверждение 1.2. Для любого двоичного вектора У длины 7 найдется такой кодовый вектор X, что Краткое доказательство. Если У — кодовый вектор, то Для представления в двоичной записи К различных сообщений достаточно Утверждение 1.3. В случае Краткое доказательство. Для того чтобы код исправлял одиночные ошибки, множества векторов, находящихся на расстоянии Хэмминга 1 и менее от каждого кодового слова, не должны пересекаться. Если длина кода равна По матрице
Совокупность всех двоичных векторов X длины 8, удовлетворяющих условию Утверждение 1.4. Расширение кода из примера 1.4 исправляет одиночные ошибки и в то же время обнаруживает двойные ошибки (т. е. ошибки в любых двух компонентах кодового вектора). Идея доказательства. Вначале, используя утверждение 1.1, нужно показать, что расстояние Хэмминга между любыми двумя различными кодовыми векторами не меньше четырех. Основываясь на этом, далее следует доказать, что рассматриваемый код исправляет одиночные и обнаруживает двойные ошибки (в общем случае связь между минимальным значением расстояния Хэмминга и способностью кода исправлять и обнаруживать ошибки устанавливается в разд. 1.3). При изучении корректирующей способности кода Хэмминга из примера 1.3 и его расширения из утверждения 1.4 для нас существенным было лишь то, что все столбцы матрицы
|
 |
Оглавление
|

















































































































































































































































































































































































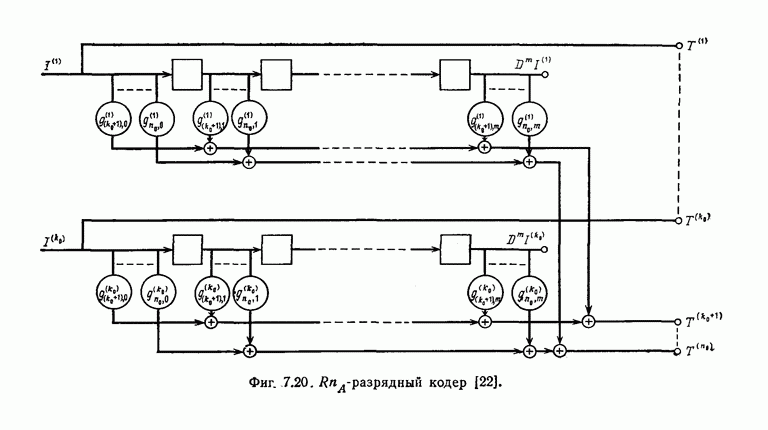

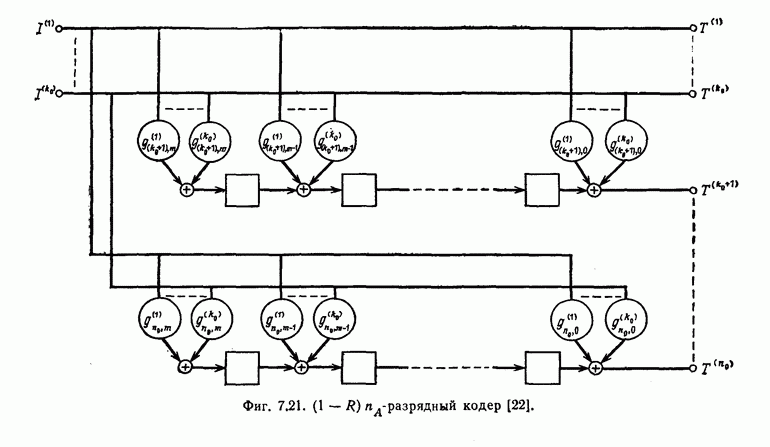
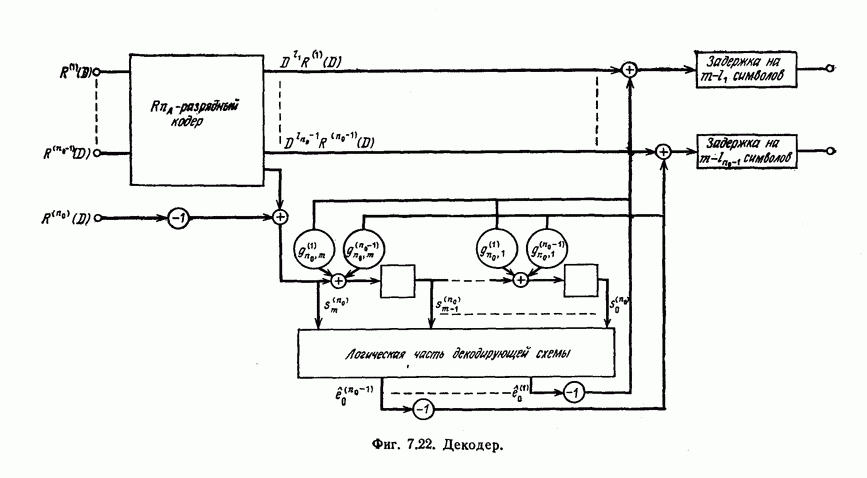



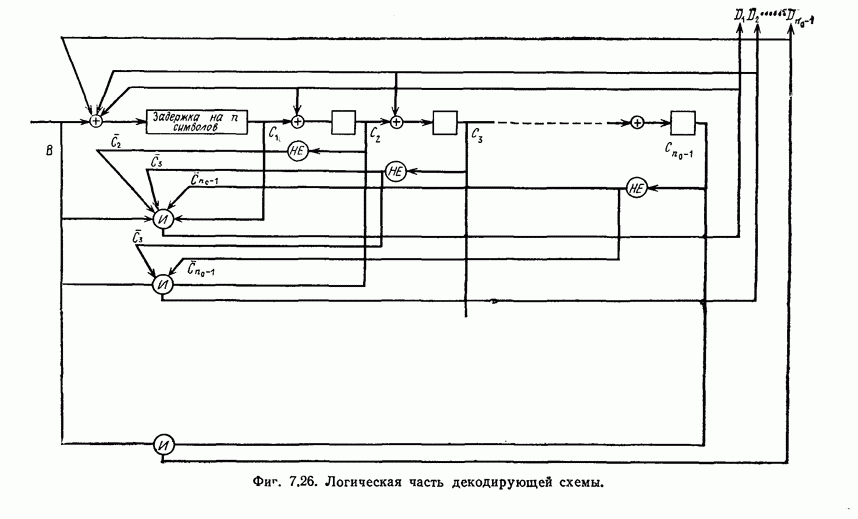
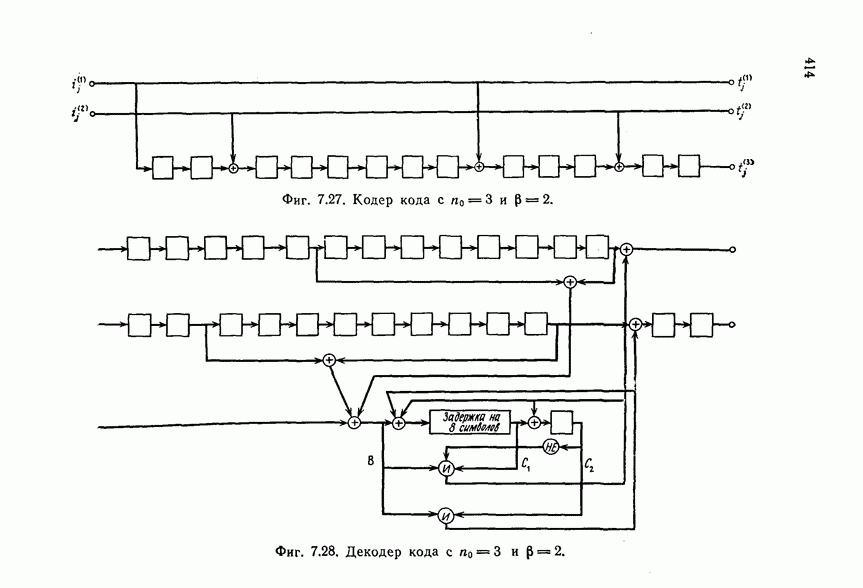





























































































































 может быть передан один импульс типа
может быть передан один импульс типа  или типа «1». Допустим, что при передаче могут происходить случайные ошибки, так что импульсы 0 и 1 могут быть приняты с некоторой вероятностью
или типа «1». Допустим, что при передаче могут происходить случайные ошибки, так что импульсы 0 и 1 могут быть приняты с некоторой вероятностью  соответственно как 1 и 0. Предположим, что ошибки при передаче различных импульсов возникают независимо. Пусть информацией, подлежащей передаче, является последовательность двоичных символов. Каждый символ
соответственно как 1 и 0. Предположим, что ошибки при передаче различных импульсов возникают независимо. Пусть информацией, подлежащей передаче, является последовательность двоичных символов. Каждый символ  этой последовательности передается по каналу с помощью последовательности из пяти импульсов 00000, если
этой последовательности передается по каналу с помощью последовательности из пяти импульсов 00000, если  и 11111, если
и 11111, если  На приемном конце принимаемая последовательность импульсов разбивается на группы по пять импульсов, называемые блоками, в соответствии с разбиением передаваемой последовательности. Если в принятом блоке содержится два и менее импульса 0, то принимается решение о том, что передавался символ
На приемном конце принимаемая последовательность импульсов разбивается на группы по пять импульсов, называемые блоками, в соответствии с разбиением передаваемой последовательности. Если в принятом блоке содержится два и менее импульса 0, то принимается решение о том, что передавался символ  Если в принятом блоке содержится три и более импульсов 0, то считается, что
Если в принятом блоке содержится три и более импульсов 0, то считается, что  Очевидно, что переданный символ а, будет декодирован верно тогда и только тогда, когда число ошибочно принятых импульсов в соответствующем блоке не больше двух. Следовательно, вероятность ошибочного декодирования любого символа а, равна)
Очевидно, что переданный символ а, будет декодирован верно тогда и только тогда, когда число ошибочно принятых импульсов в соответствующем блоке не больше двух. Следовательно, вероятность ошибочного декодирования любого символа а, равна)
 Этот метод передачи является простым, но для передачи одного бита информации он требует интервала времени длительностью
Этот метод передачи является простым, но для передачи одного бита информации он требует интервала времени длительностью  . В то же время существуют коды (см. теорему кодирования из разд. 1.5), которые позволяют передавать по тому же самому каналу один бит информации в среднем за меньший интервал времени с вероятностью ошибки, не превосходящей указанную выше величину. При этом, однако, процедуры кодирования и декодирования оказываются более сложными. В тех случаях, когда «убытки» из-за ошибочного декодирования оказываются больше убытков, возникающих из-за того, что часть символов а вообще не декодируется и считается неизвестной (как это имеет место, например, в системах с переспросом), часто оказывается более целесообразным использовать другой алгоритм декодирования. Этот алгоритм состоит в том, что если в блоке нет символов 1 или содержится только один символ 1, то считается, что
. В то же время существуют коды (см. теорему кодирования из разд. 1.5), которые позволяют передавать по тому же самому каналу один бит информации в среднем за меньший интервал времени с вероятностью ошибки, не превосходящей указанную выше величину. При этом, однако, процедуры кодирования и декодирования оказываются более сложными. В тех случаях, когда «убытки» из-за ошибочного декодирования оказываются больше убытков, возникающих из-за того, что часть символов а вообще не декодируется и считается неизвестной (как это имеет место, например, в системах с переспросом), часто оказывается более целесообразным использовать другой алгоритм декодирования. Этот алгоритм состоит в том, что если в блоке нет символов 1 или содержится только один символ 1, то считается, что  если же в блоке содержатся четыре или пять символов 1, то считается, что
если же в блоке содержатся четыре или пять символов 1, то считается, что  Во всех остальных случаях решение не принимается. Для этого алгоритма вероятность ошибочного декодирования равна
Во всех остальных случаях решение не принимается. Для этого алгоритма вероятность ошибочного декодирования равна  а вероятность отказа от декодирования равна
а вероятность отказа от декодирования равна 
 Одним из таких способов является код «два из пяти», показанный в табл. 1.1. Любая из цифр в этом коде представляется в виде двоичной последовательности длины 5, в которой два из пяти символов всегда равны 1 (заметим, что
Одним из таких способов является код «два из пяти», показанный в табл. 1.1. Любая из цифр в этом коде представляется в виде двоичной последовательности длины 5, в которой два из пяти символов всегда равны 1 (заметим, что  ) возникновении одиночной ошибки, т. е. при искажении одного из двоичных символов, последовательность содержит один или три символа, равных 1, а это позволяет обнаружить возникновение ошибки. В общем случае для представления каких-либо
) возникновении одиночной ошибки, т. е. при искажении одного из двоичных символов, последовательность содержит один или три символа, равных 1, а это позволяет обнаружить возникновение ошибки. В общем случае для представления каких-либо  сообщений могут использоваться двоичные последовательности длины
сообщений могут использоваться двоичные последовательности длины  каждая из которых содержит
каждая из которых содержит  символов 1. Совокупность таких двоичных последовательностей называется равновесным кодом. Коды этого типа оказываются эффективными, в частности, в тех случаях, когда вероятность возникновения ошибки типа «переход символа 0 в
символов 1. Совокупность таких двоичных последовательностей называется равновесным кодом. Коды этого типа оказываются эффективными, в частности, в тех случаях, когда вероятность возникновения ошибки типа «переход символа 0 в
 менее сообщений представлены в виде двоичных последовательностей
менее сообщений представлены в виде двоичных последовательностей  длины
длины  и это представление взаимно однозначно. Пусть
и это представление взаимно однозначно. Пусть

 означает сложение по модулю 2, т.е.
означает сложение по модулю 2, т.е.  если сумма в правой части (1.1) четна, и
если сумма в правой части (1.1) четна, и  если она нечетна. Предположим, что вместо последовательностей
если она нечетна. Предположим, что вместо последовательностей  длины
длины  используются последовательности
используются последовательности  длины
длины  Допустим, что в процессе передачи или обработки одной из таких последовательностей, содержащей один избыточный двоичный символ, возникла ошибка в одном из двоичных символов. Как видно из формулы (1.1), в неискаженной последовательности
Допустим, что в процессе передачи или обработки одной из таких последовательностей, содержащей один избыточный двоичный символ, возникла ошибка в одном из двоичных символов. Как видно из формулы (1.1), в неискаженной последовательности  число символов 1 всегда четно, а при возникновении ошибки в одном из символов это число становится нечетным. Это позволяет обнаруживать возникновение одиночных ошибок. Символ
число символов 1 всегда четно, а при возникновении ошибки в одном из символов это число становится нечетным. Это позволяет обнаруживать возникновение одиночных ошибок. Символ 
 длины 4. Вместо последовательности
длины 4. Вместо последовательности  для представления сообщений будем использовать двоичную последовательность
для представления сообщений будем использовать двоичную последовательность  длины 7, символы
длины 7, символы  которой определим следующим образом:
которой определим следующим образом:

 означает сложение по модулю 2, а остальные обозначения имеют тот же смысл, что и в обычных матричных соотношениях. Поскольку в процессе передачи или хранения последовательности
означает сложение по модулю 2, а остальные обозначения имеют тот же смысл, что и в обычных матричных соотношениях. Поскольку в процессе передачи или хранения последовательности  могут возникнуть ошибки, то принимаемая последовательность
могут возникнуть ошибки, то принимаемая последовательность  вообще говоря, будет отлична от исходной. Рассмотрим задачу восстановления исходной последовательности
вообще говоря, будет отлична от исходной. Рассмотрим задачу восстановления исходной последовательности  по известной последовательности
по известной последовательности  Предположим, что вероятность возникновения двух и более ошибок в двоичных символах одной последовательности длины 7 настолько мала, что этим событием можно пренебречь. Положим
Предположим, что вероятность возникновения двух и более ошибок в двоичных символах одной последовательности длины 7 настолько мала, что этим событием можно пренебречь. Положим

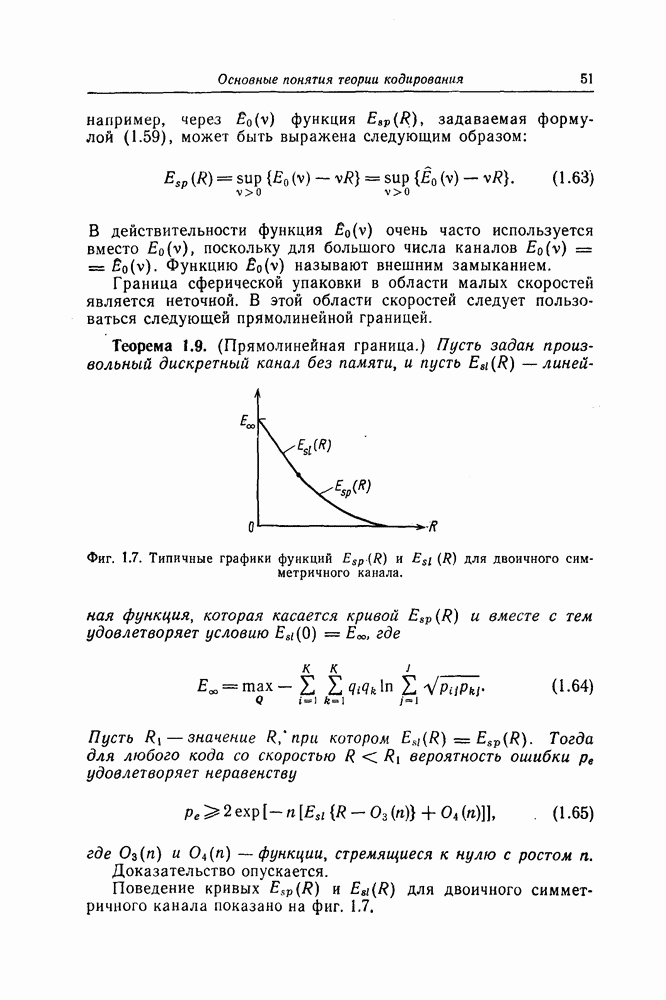
 обозначает сложение по модулю 2. Если
обозначает сложение по модулю 2. Если  то это означает, что в
то это означает, что в  двоичном символе произошла ошибка; если
двоичном символе произошла ошибка; если  то
то  двоичный символ передан без ошибок. Используя матрицу из левой части (1.2), определим
двоичный символ передан без ошибок. Используя матрицу из левой части (1.2), определим 


 может быть равен 1. При отсутствии ошибок, когда
может быть равен 1. При отсутствии ошибок, когда  имеем
имеем 
 а остальные шесть символов
а остальные шесть символов  равны 0. Заметим, во-первых, что все столбцы матрицы
равны 0. Заметим, во-первых, что все столбцы матрицы

 столбец этой матрицы представляет собой двоичную запись номера
столбец этой матрицы представляет собой двоичную запись номера  (самый младший разряд двоичного представления числа
(самый младший разряд двоичного представления числа  является верхним элементом столбца). При сделанных выше предположениях вектор-столбец
является верхним элементом столбца). При сделанных выше предположениях вектор-столбец  совпадает с
совпадает с  столбцом матрицы
столбцом матрицы  Следовательно, номер
Следовательно, номер  искаженного двоичного символа может быть найден следующим образом:
искаженного двоичного символа может быть найден следующим образом:  . С помощью равенства
. С помощью равенства  находим правильные двоичные символы
находим правильные двоичные символы  Множество двоичных последовательностей
Множество двоичных последовательностей  удовлетворяющих соотношению (1.2) и
удовлетворяющих соотношению (1.2) и
 удовлетворяют соотношению (1.2) (т. е.
удовлетворяют соотношению (1.2) (т. е.  то число
то число  значений индекса
значений индекса  таких, что
таких, что  (это число называется расстоянием Хэмминга [3] между векторами
(это число называется расстоянием Хэмминга [3] между векторами  не меньше трех (символ
не меньше трех (символ  означает транспонирование).
означает транспонирование).
 произвольный вектор веса 1 или 2. Так как все столбцы матрицы
произвольный вектор веса 1 или 2. Так как все столбцы матрицы  различны и ни один из них не является нулевым, то
различны и ни один из них не является нулевым, то  Вместе с тем по условиям утверждения
Вместе с тем по условиям утверждения  Наконец, заметим, что вес вектора
Наконец, заметим, что вес вектора  совпадает с
совпадает с  (здесь 0 — нулевой вектор).
(здесь 0 — нулевой вектор).

 Предположим, что У не является кодовым вектором. Пусть
Предположим, что У не является кодовым вектором. Пусть  двоичный вектор длины
двоичный вектор длины  Среди столбцов матрицы
Среди столбцов матрицы  существует ровно один столбец, в точности совпадающий с
существует ровно один столбец, в точности совпадающий с  Пусть
Пусть  номер этого столбца. Возьмем в качестве вектора X вектор, отличающийся от У только
номер этого столбца. Возьмем в качестве вектора X вектор, отличающийся от У только  компонентой. Тогда
компонентой. Тогда 
 двоичных символов
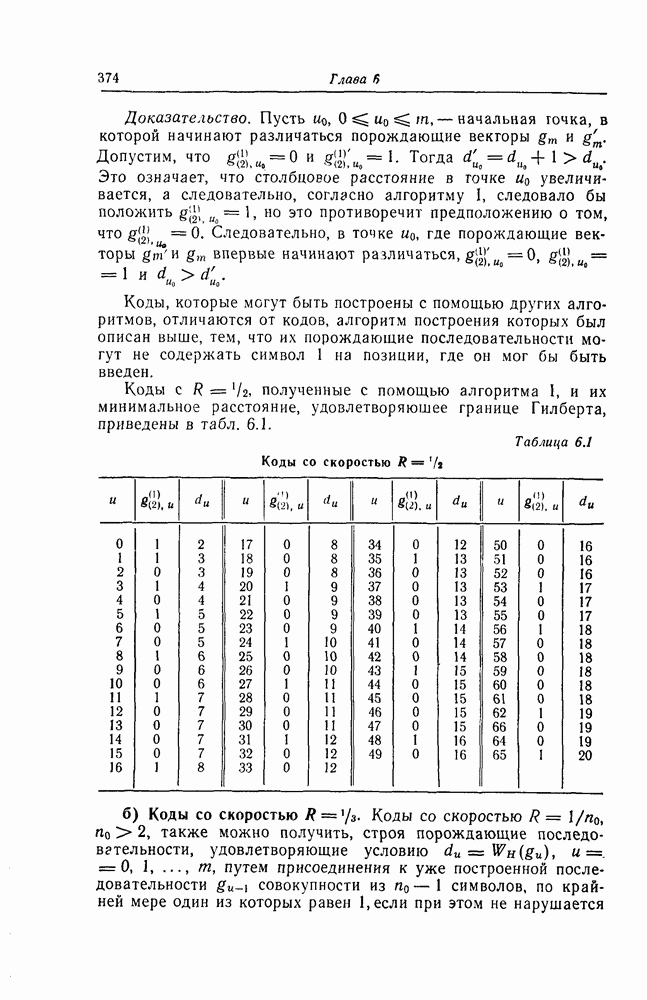
двоичных символов  минимальное целое число, не меньшее А). Однако, как показывают приведенные выше примеры, использование некоторого числа дополнительных избыточных символов позволяет осуществить исправление или обнаружение части возникающих ошибок или упростить схемы, осуществляющие обработку этих сообщений. Число
минимальное целое число, не меньшее А). Однако, как показывают приведенные выше примеры, использование некоторого числа дополнительных избыточных символов позволяет осуществить исправление или обнаружение части возникающих ошибок или упростить схемы, осуществляющие обработку этих сообщений. Число  где
где  общее число двоичных символов, используемых для представления каждого сообщения, называют числом проверочных или избыточных символов. Естественно, что всегда хотелось бы достичь нужных свойств кода (например, способности исправлять так называемые одиночные ошибки, т. е. ошибки в одном двоичном символе), используя по возможности меньшее число избыточных символов.
общее число двоичных символов, используемых для представления каждого сообщения, называют числом проверочных или избыточных символов. Естественно, что всегда хотелось бы достичь нужных свойств кода (например, способности исправлять так называемые одиночные ошибки, т. е. ошибки в одном двоичном символе), используя по возможности меньшее число избыточных символов.
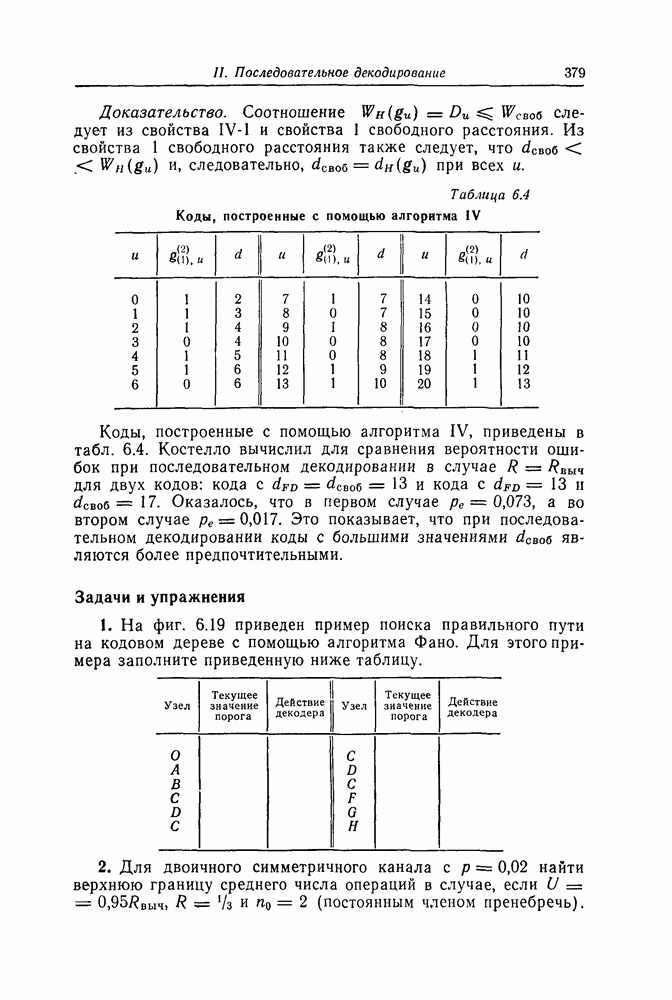
 никакой код, имеющий два или менее проверочных символа, не может исправлять одиночные ошибки. В этом смысле код Хэмминга длины 7 является наилучшим среди кодов, исправляющих одиночные ошибки.
никакой код, имеющий два или менее проверочных символа, не может исправлять одиночные ошибки. В этом смысле код Хэмминга длины 7 является наилучшим среди кодов, исправляющих одиночные ошибки.
 то число векторов, находящихся на расстоянии 1 и менее от кодового слова, равно
то число векторов, находящихся на расстоянии 1 и менее от кодового слова, равно  Так как общее число двоичных векторов длины
Так как общее число двоичных векторов длины  равно
равно  то для любого кода, исправляющего одиночные ошибки, должно выполняться неравенство откуда следует справедливость доказываемого утверждения.
то для любого кода, исправляющего одиночные ошибки, должно выполняться неравенство откуда следует справедливость доказываемого утверждения.
 из примера 1.4 построим матрицу
из примера 1.4 построим матрицу  следующим образом:
следующим образом:

 называется расширением кода из примера 1.4.
называется расширением кода из примера 1.4.
 различны и все они являются ненулевыми. Аналогично можно построить коды для любого
различны и все они являются ненулевыми. Аналогично можно построить коды для любого  . В общем случае коды Хэмминга и их расширения рассматриваются в задаче 3.2, примере 3.5 и разд. 4.1.
. В общем случае коды Хэмминга и их расширения рассматриваются в задаче 3.2, примере 3.5 и разд. 4.1.