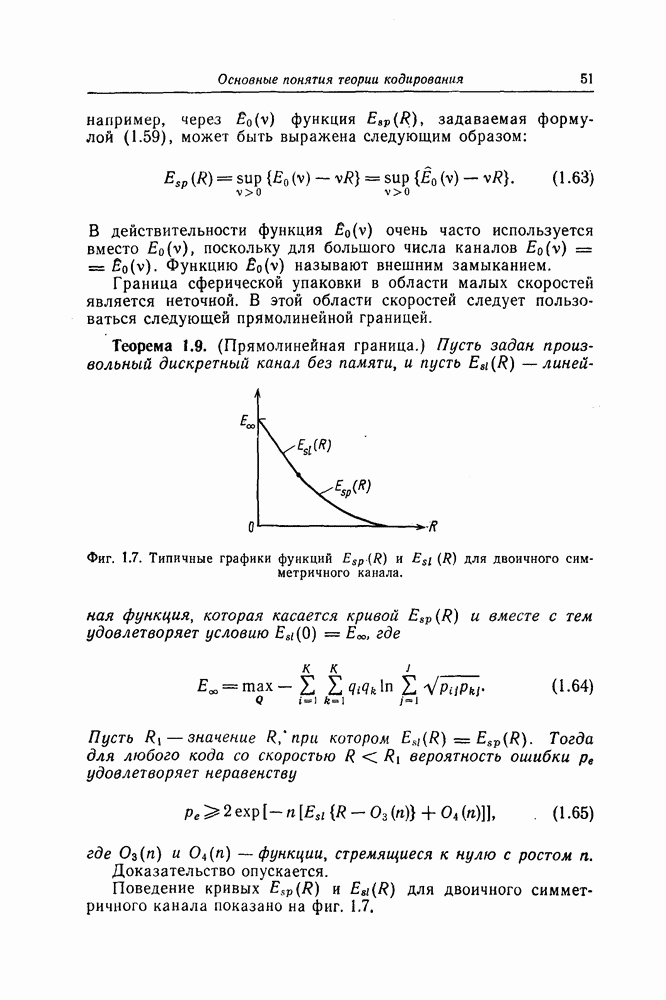
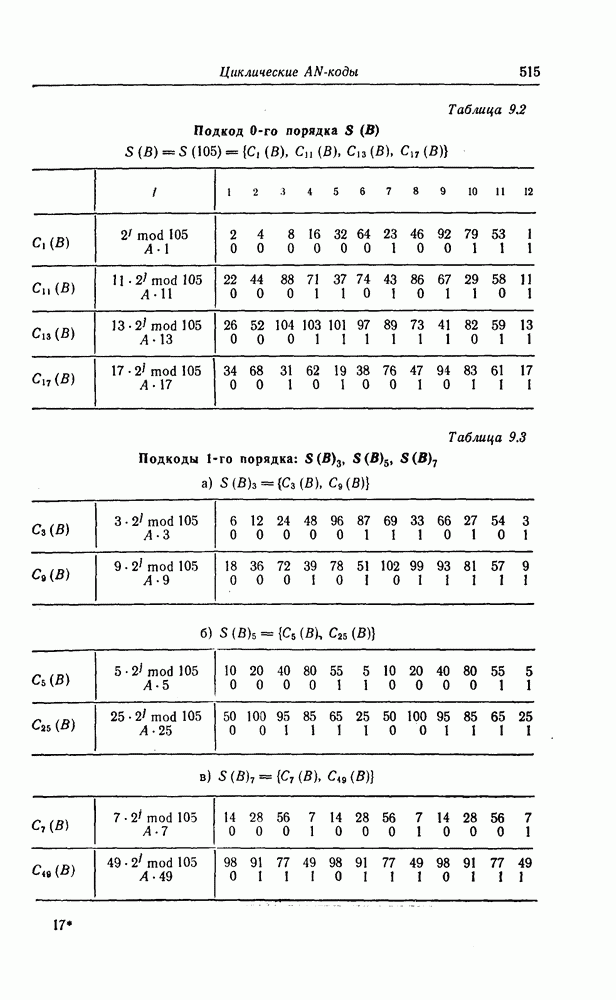
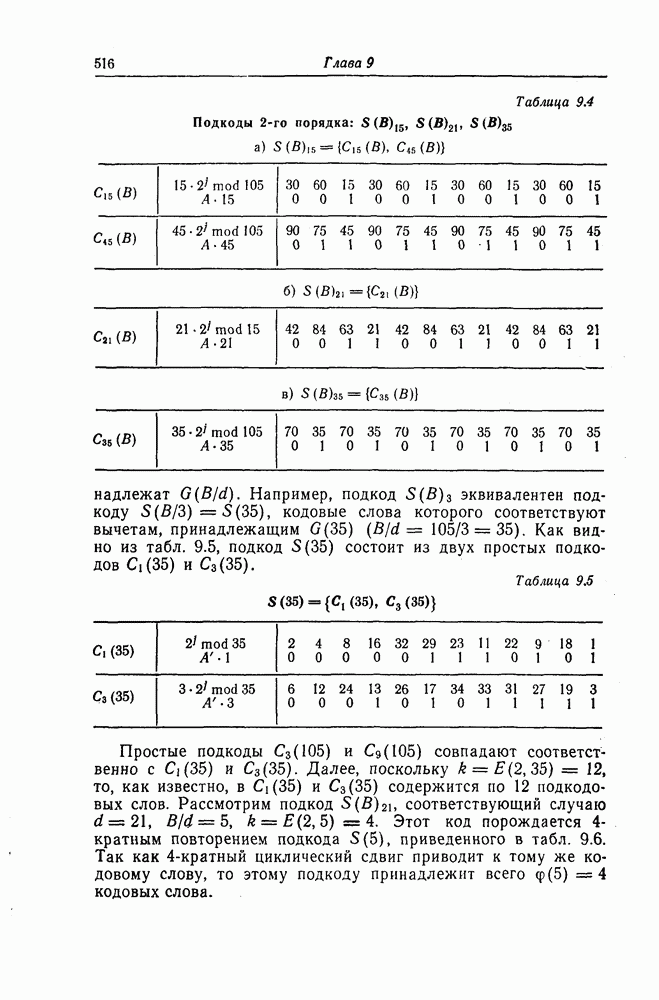
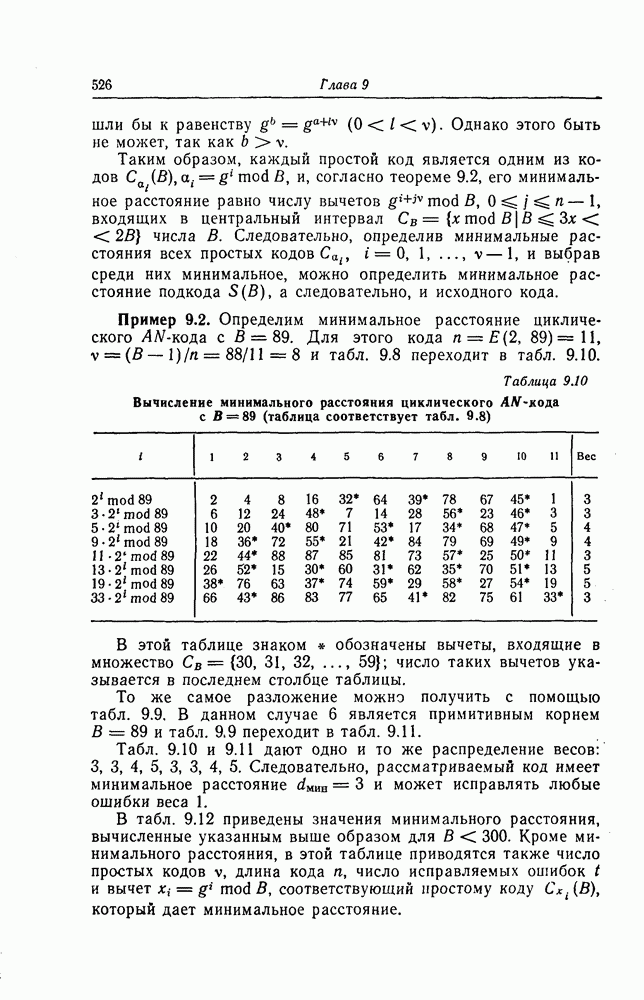
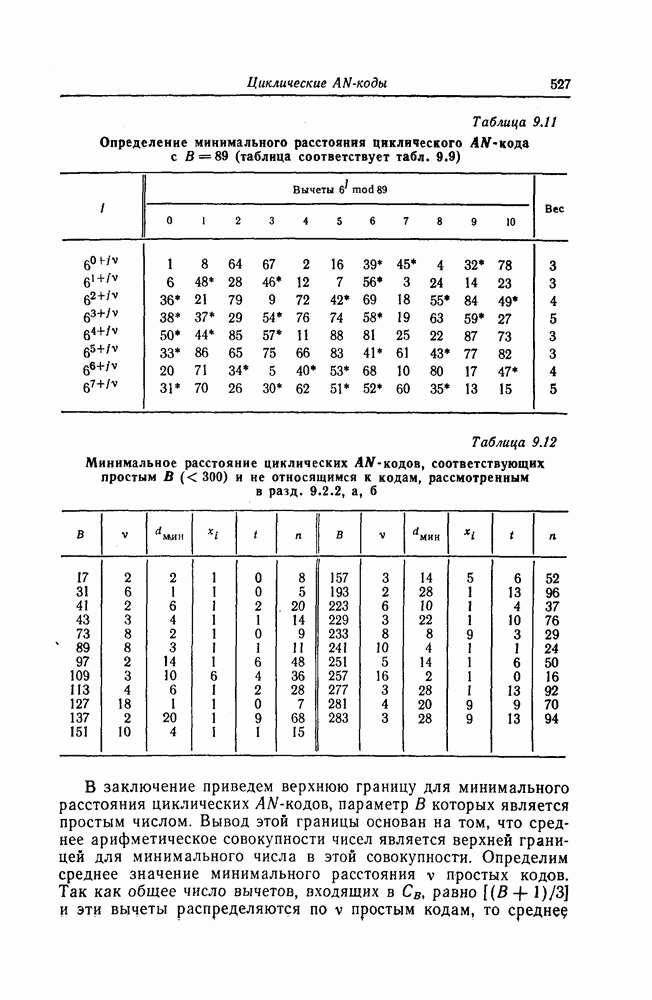
Пред.
След.
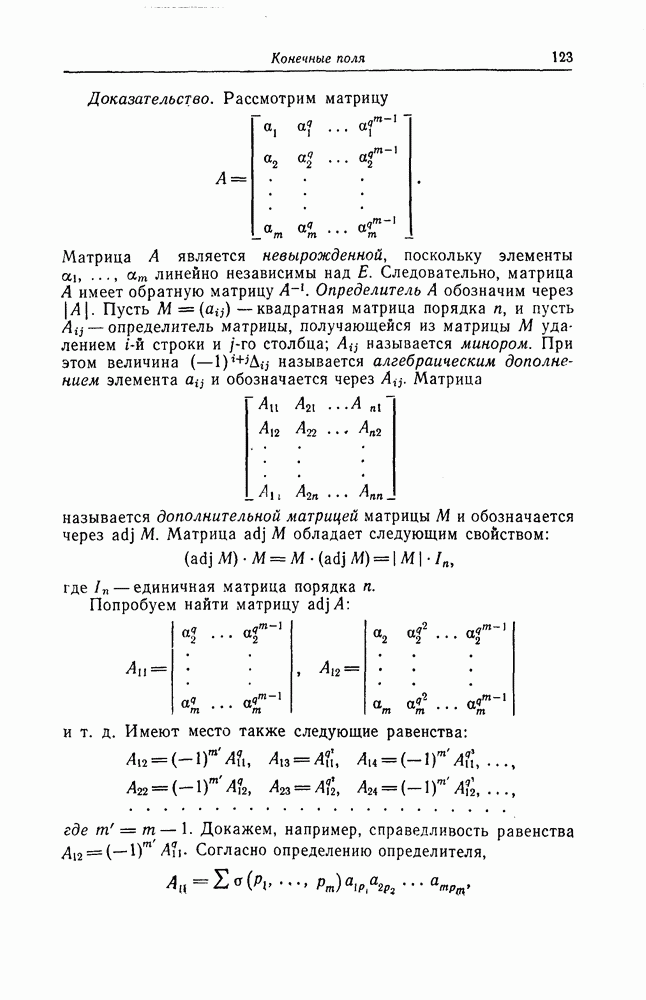
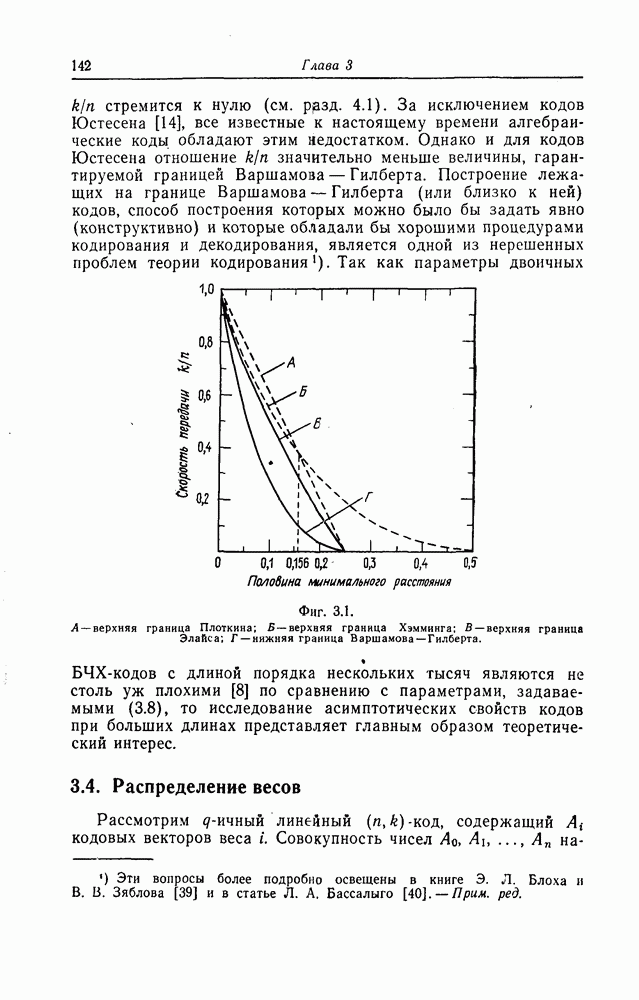
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
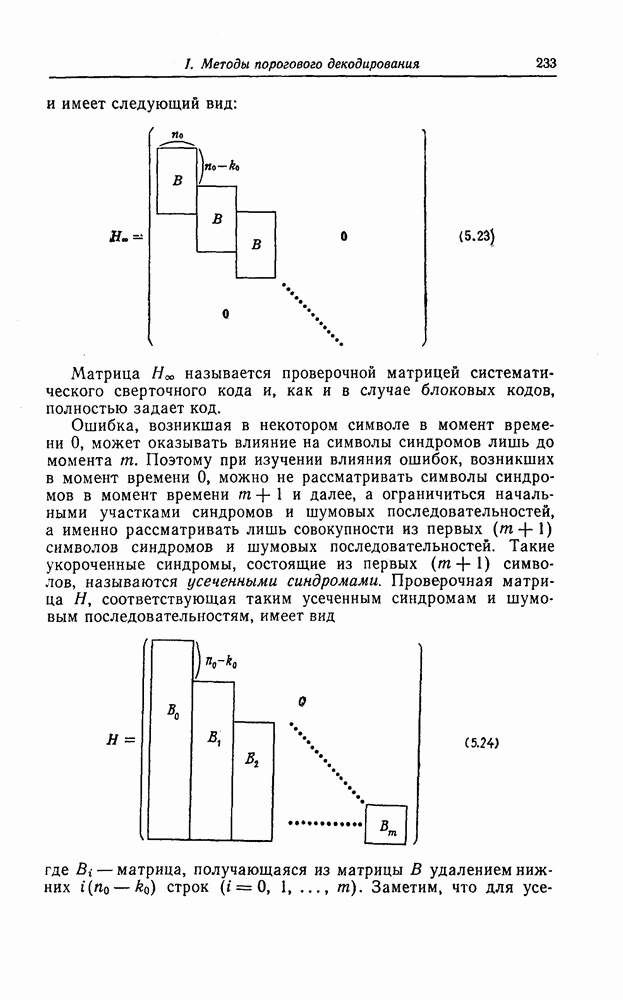
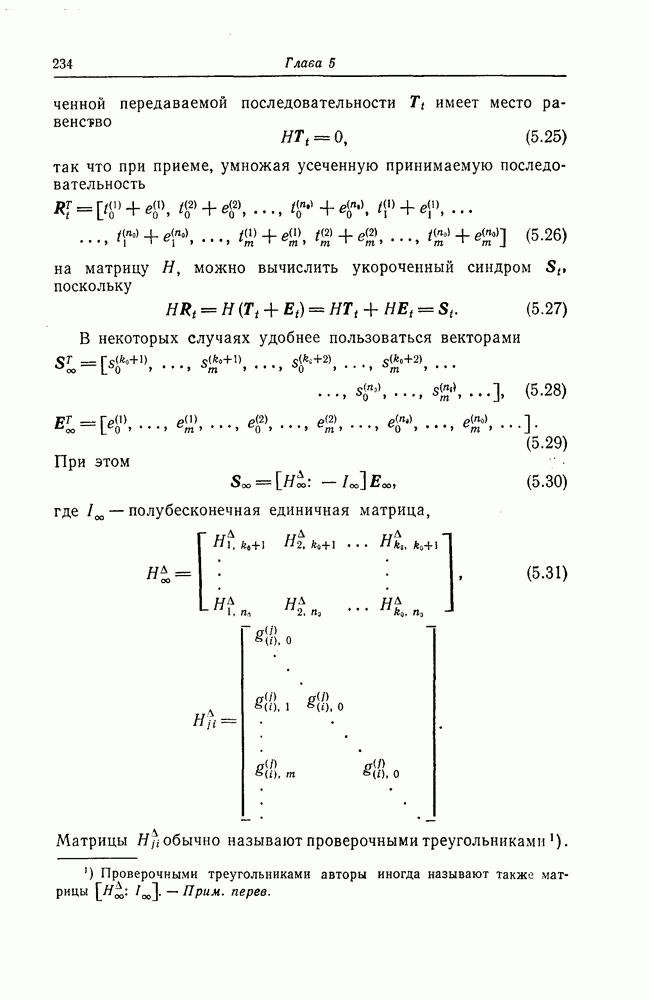
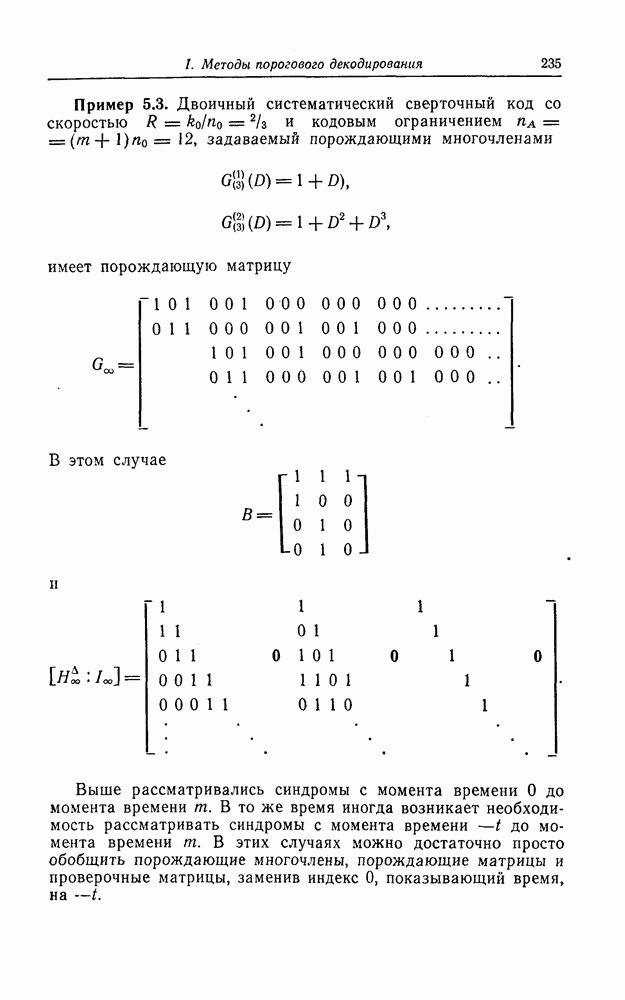
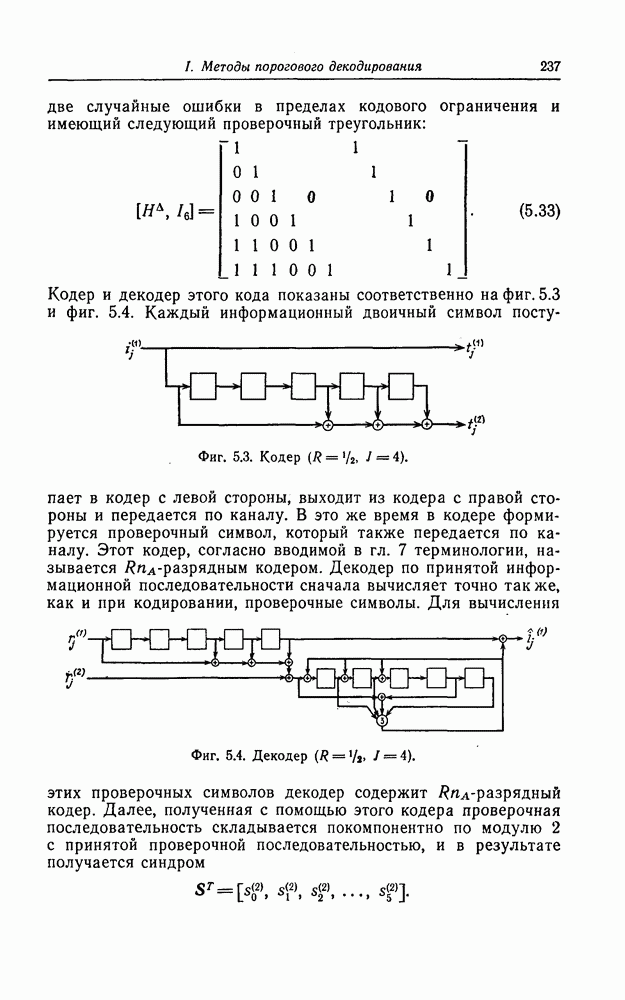
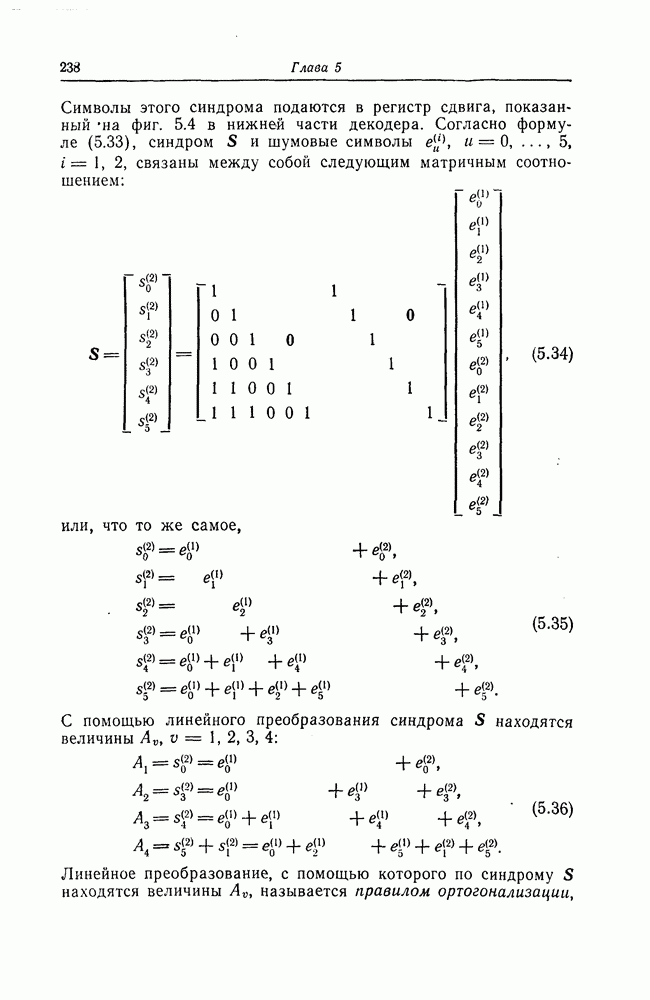
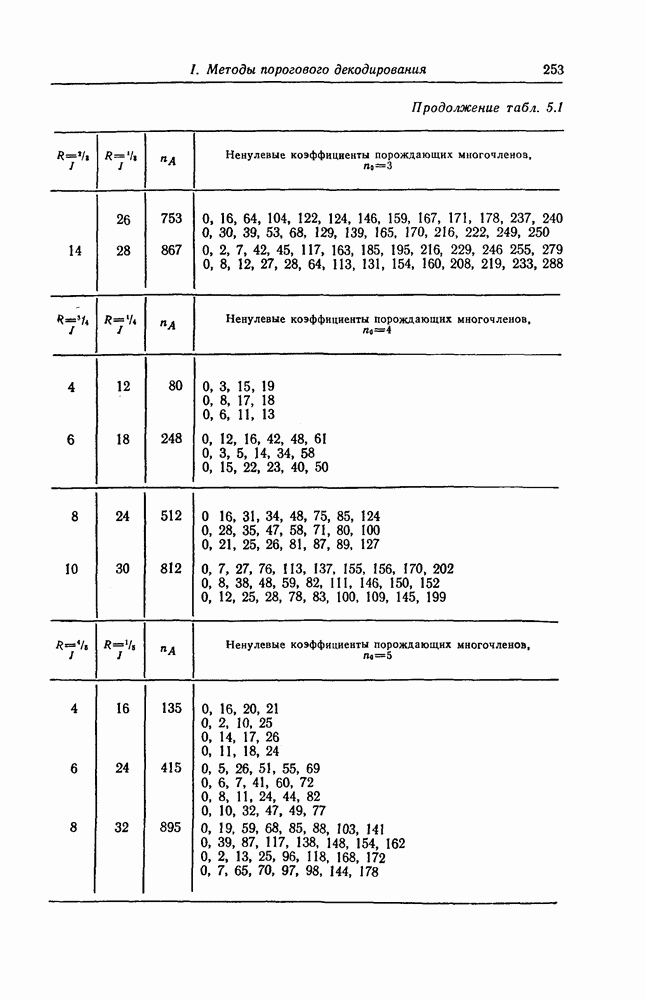
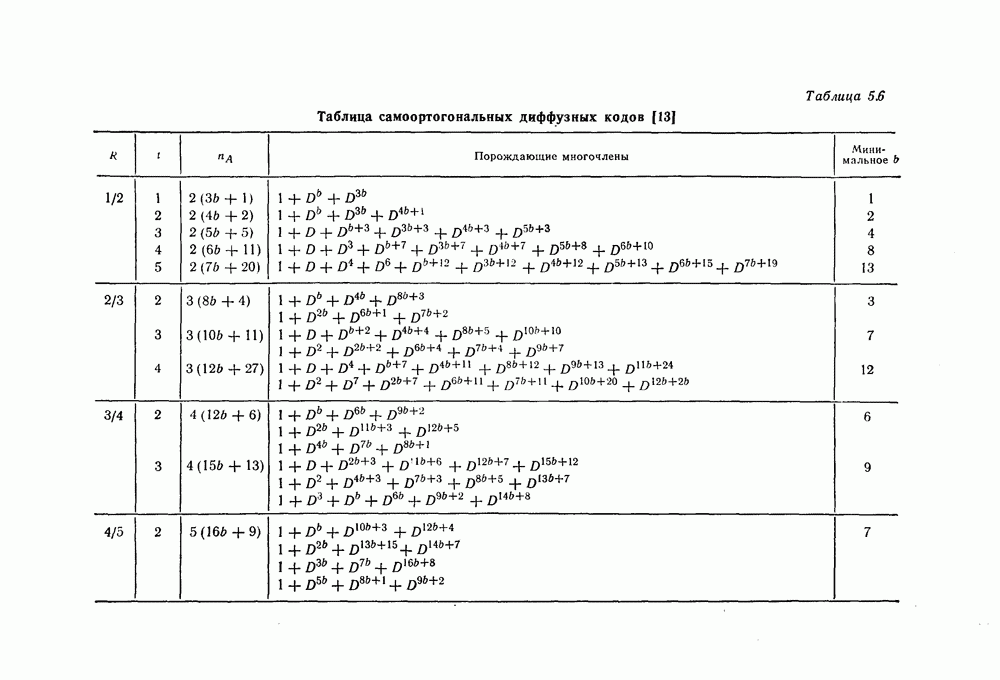
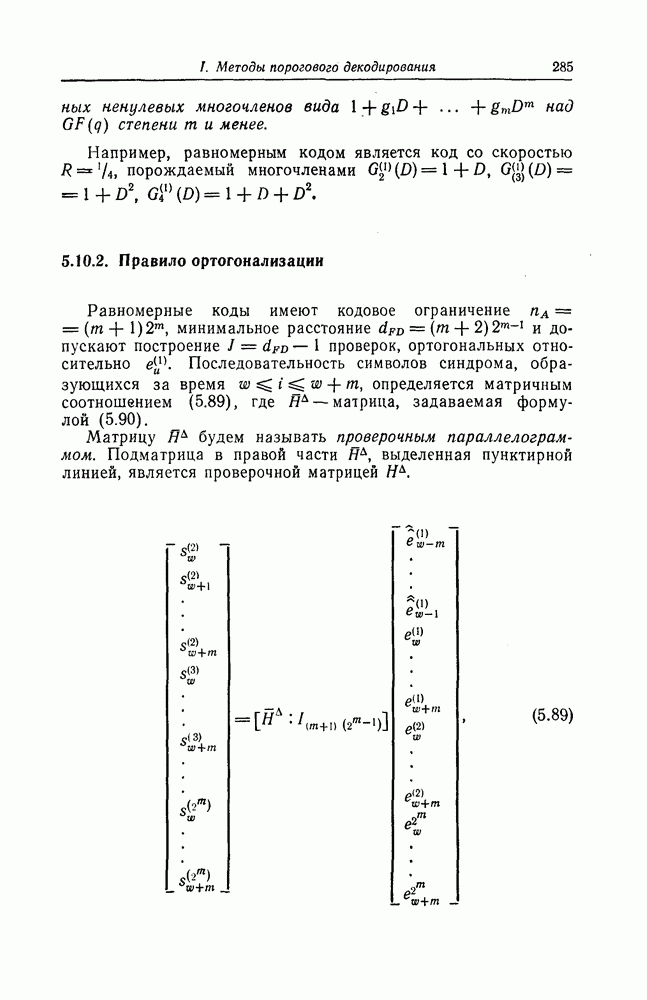
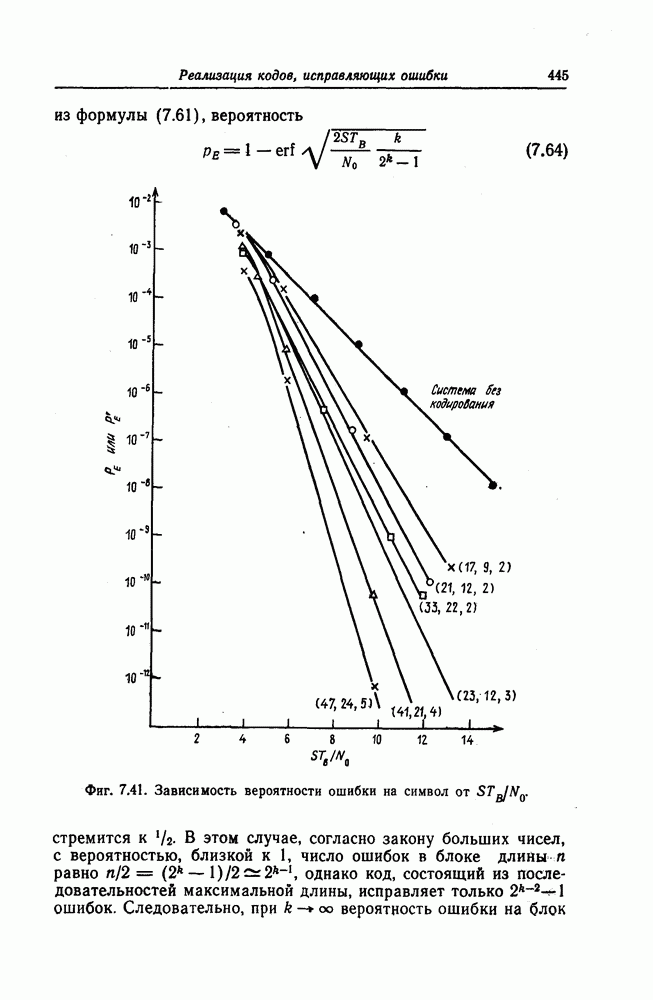
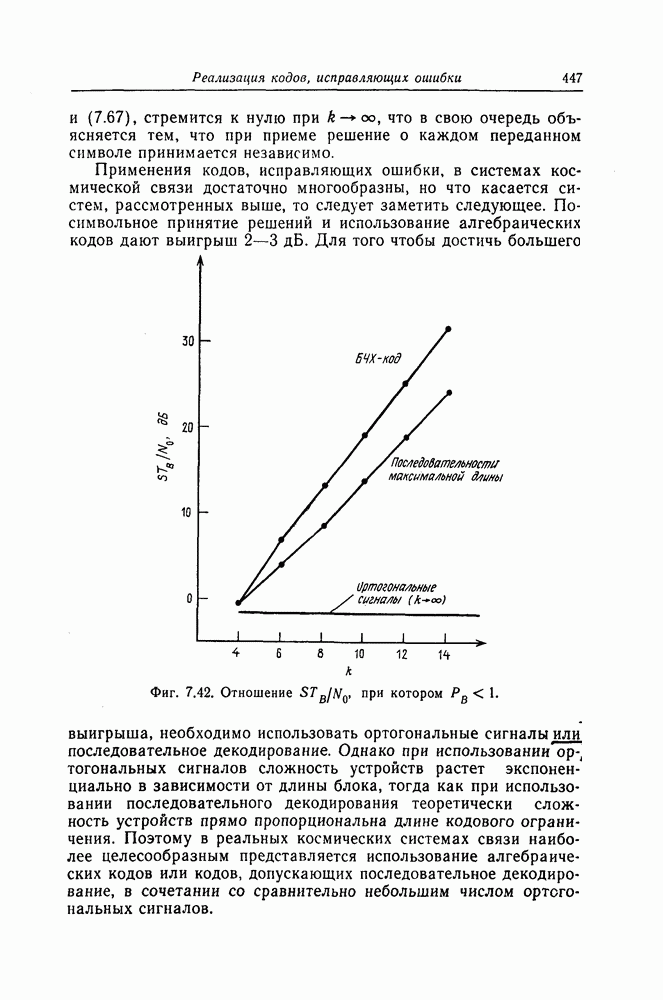
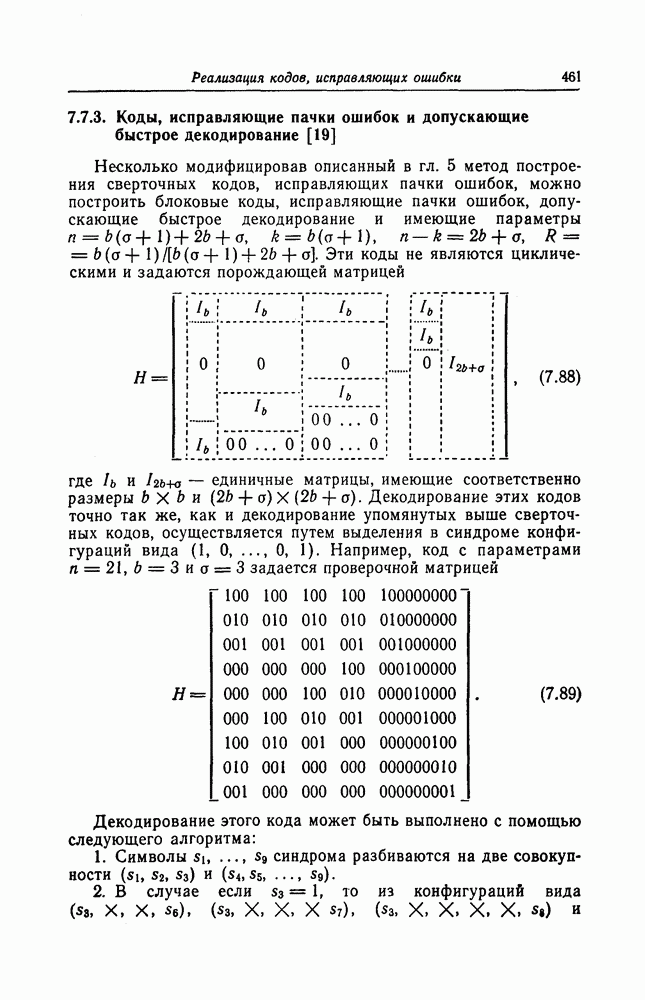
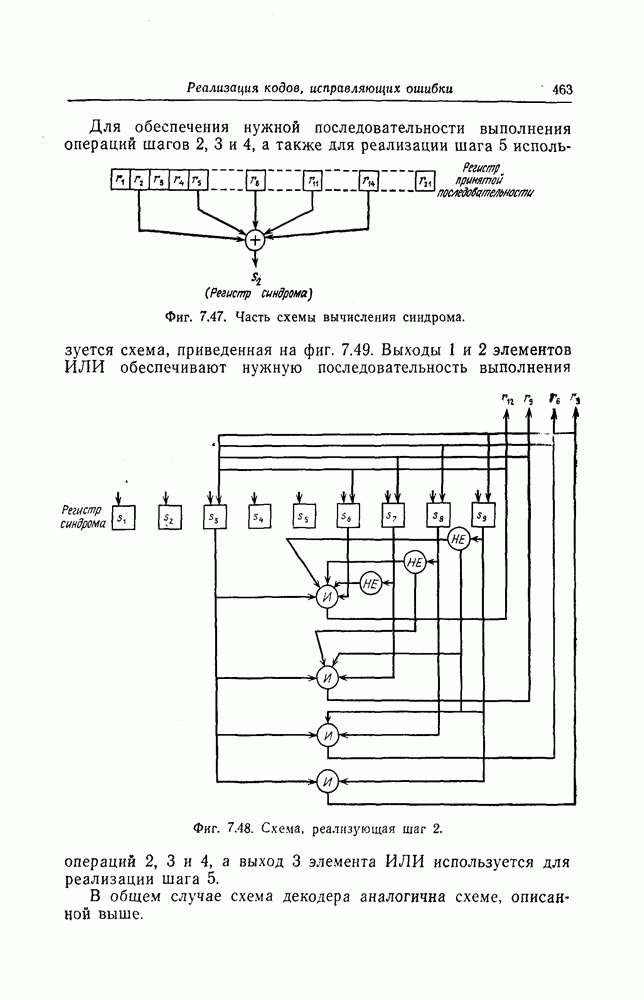
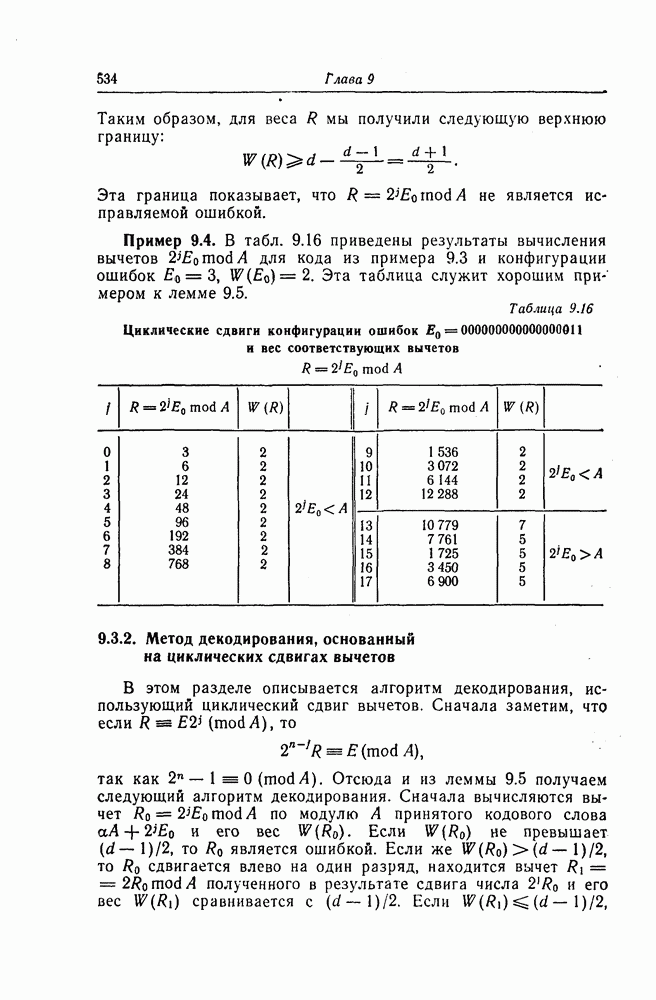
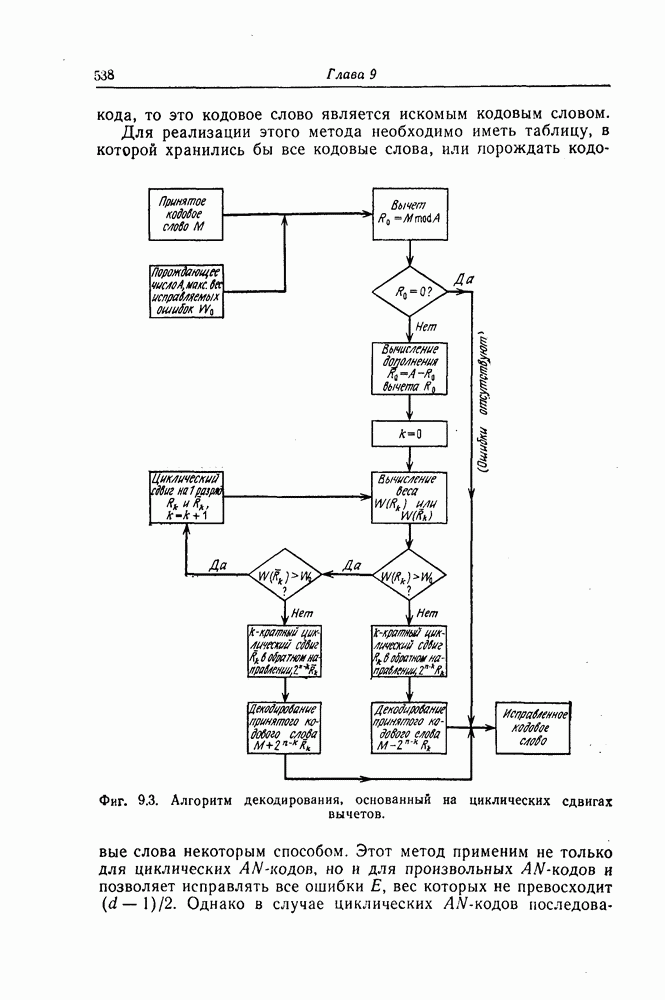
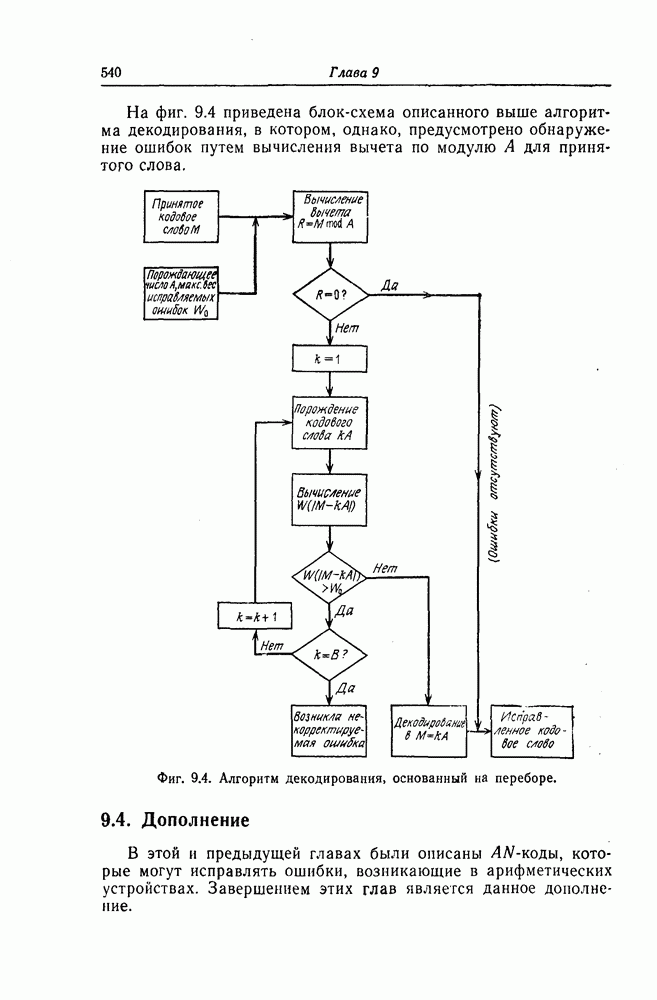
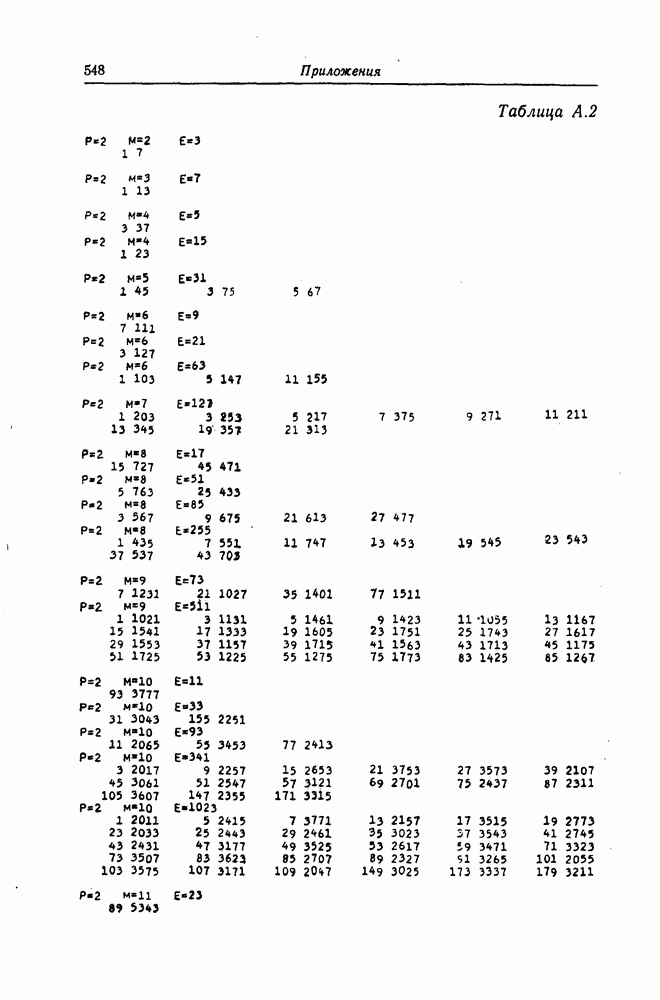
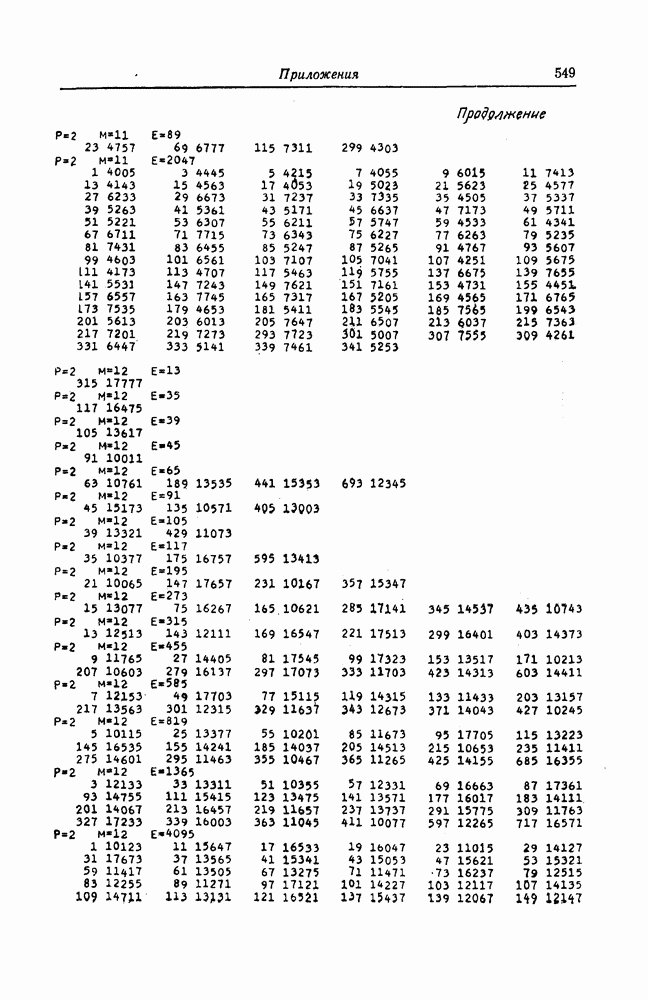
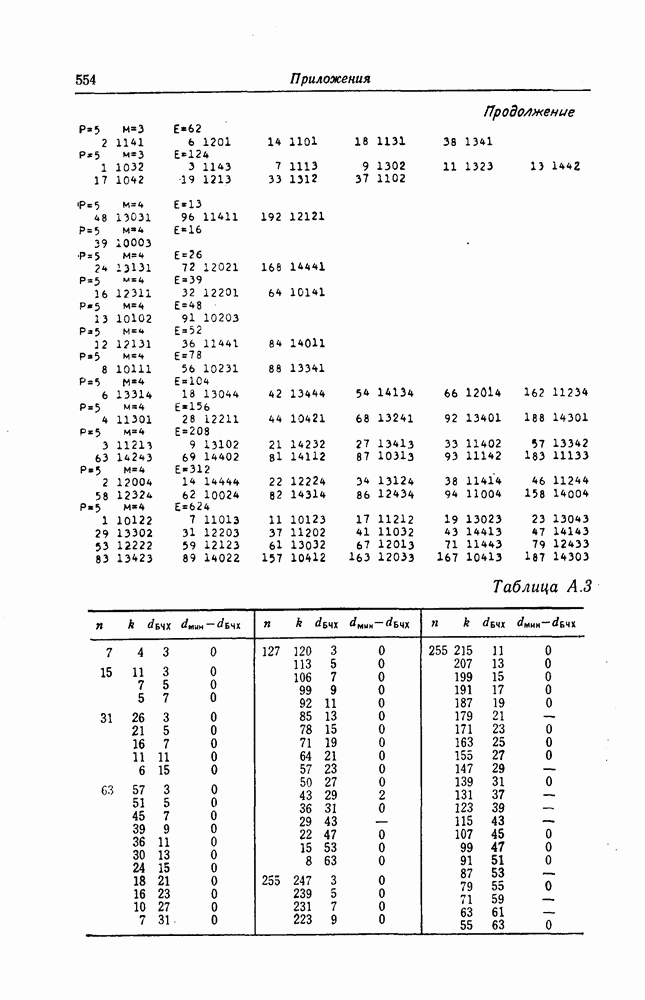
5.10. Равномерные сверточные кодыДругим классом кодов, допускающих пороговое декодирование, является класс равномерных сверточных кодов. Эти коды имеют низкую скорость передачи, но их минимальное расстояние совпадает со средним расстоянием. Обладая приблизительно такой же корректирующей способностью, как и блоковые коды максимальной длины, они тем не менее имеют небольшую глубину распространения ошибок. Однако этот класс кодов является небольшим, поскольку строится лишь для скоростей вида 5.10.1. Определение равномерного кодаОпределение 5.6. Двоичным равномерным кодом называется код со скоростью различных ненулевых многочленов вида Например, равномерным кодом является код со скоростью 5.10.2. Правило ортогонализацииРавномерные коды имеют кодовое ограничение Матрицу
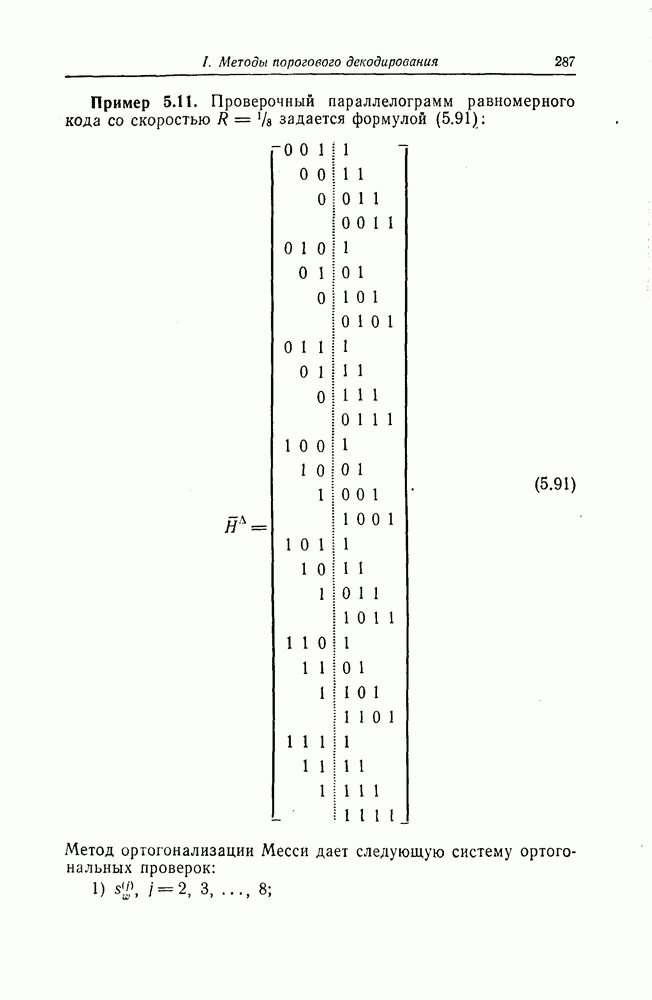
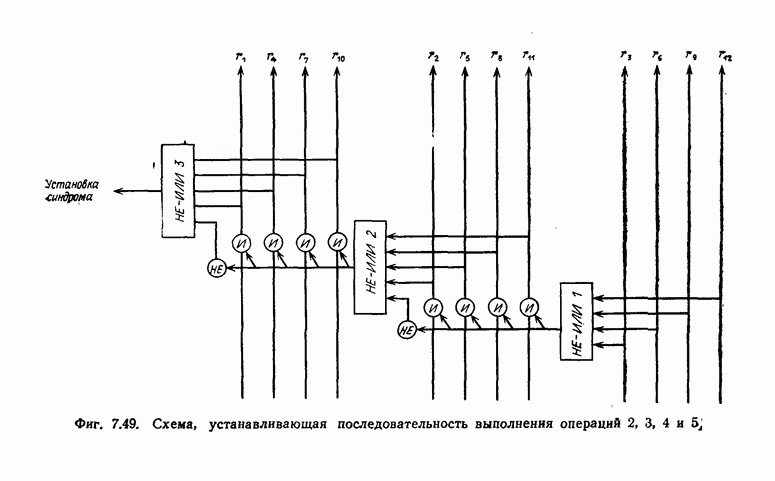
Величины Месси предложил следующее правило ортогональности равномерных кодов, позволяющее построить систему составных проверок, ортогональных относительно 1. В качестве 2. Пусть 3. В качестве остальных Пример 5.11. Проверочный параллелограмм равномерного кода со скоростью (см. скан) Метод ортогонализации Месси дает следующую систему ортогональных проверок:
5.10.3. Метод ортогонализации, обеспечивающий небольшую глубину распространения ошибокОдной из характеристик равномерных кодов является глубина распространения ошибок. Анализируя явление распространения ошибок, Салливан [35] разработал следующий алгоритм ортогонализации, позволяющий минимизировать глубину распространения ошибок: 1) В качестве 2) Пусть 3) В качестве остальных Пример 5.12. Если применить метод Салливана для ортогонализации кода из примера 5.11, то получим следующую систему составных проверок:
Метод ортогонализации Салливана является частным случаем метода ортогонализации Месси, но он выгодно отличается от последнего следующим. Использование метода ортогонализации Месси в примере 5.11 приводит, например, к тому, что от Поскольку при использовании метода ортогонализации Салливана величины
где Будем говорить, что декодер в момент времени Теорема 5.8. Пусть при использовании равномерного сверточного кода и оптимального правила ортогонализации некоторая некорректируемая совокупность ошибок в канале приводит к ошибочному декодированию символа
Тогда декодер к моменту времени Доказательство. Сначала предположим, что Далее предположим, что Из доказанной теоремы следует, в частности, что декодер кода из примера 5.11 принимает правильное решение о
|
 |
Оглавление
|










































































































































































































































































































































































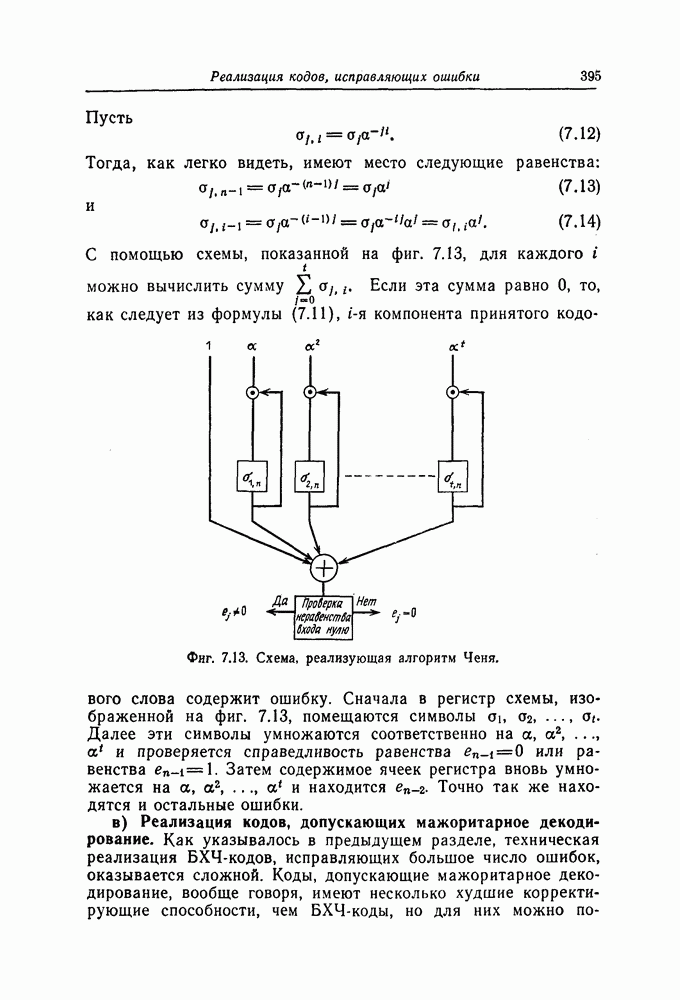

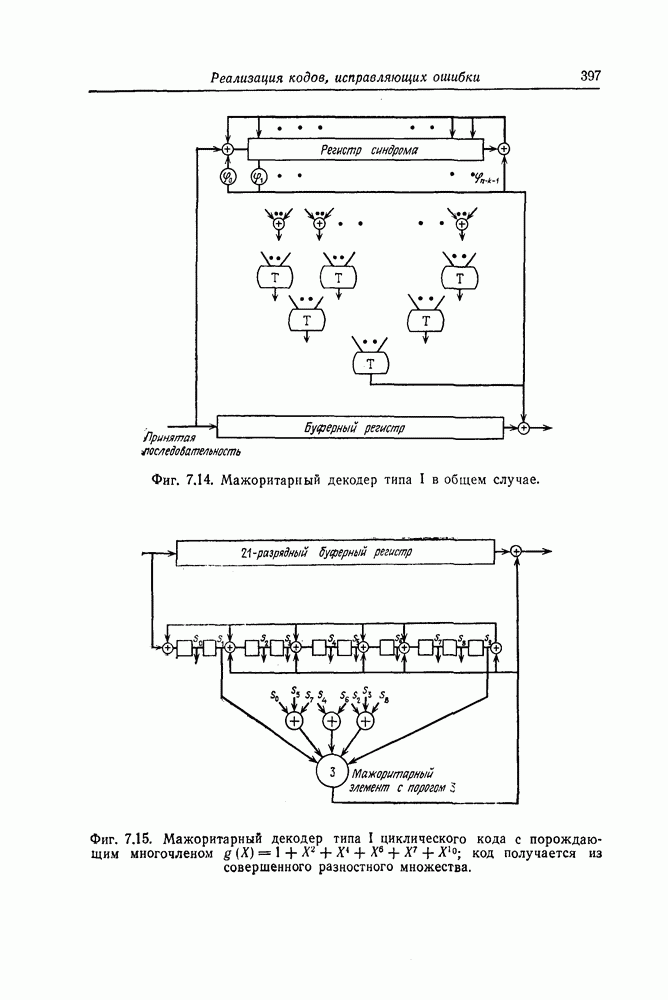




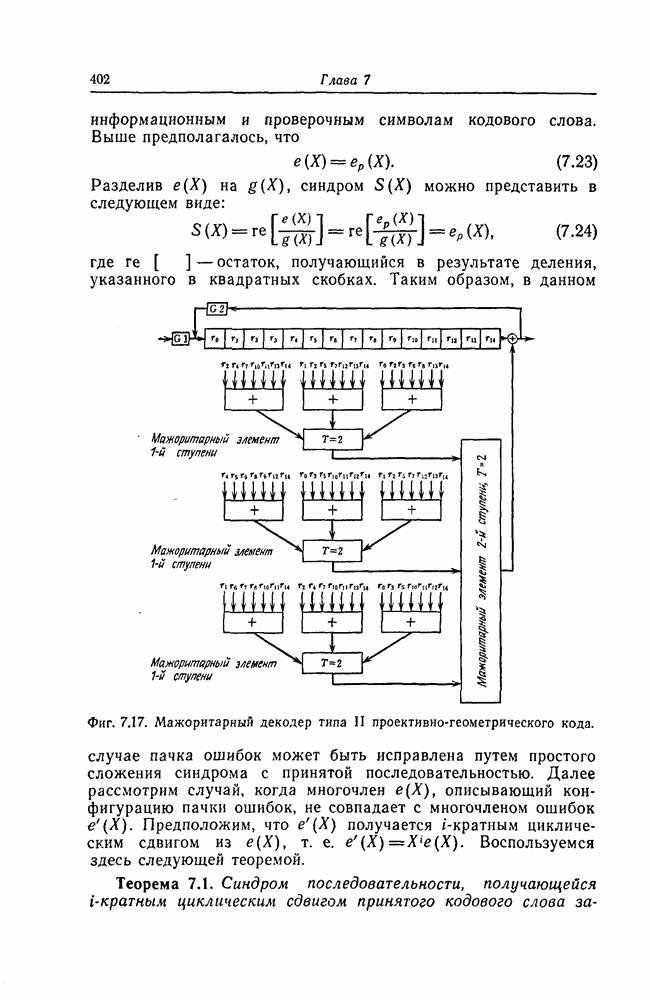
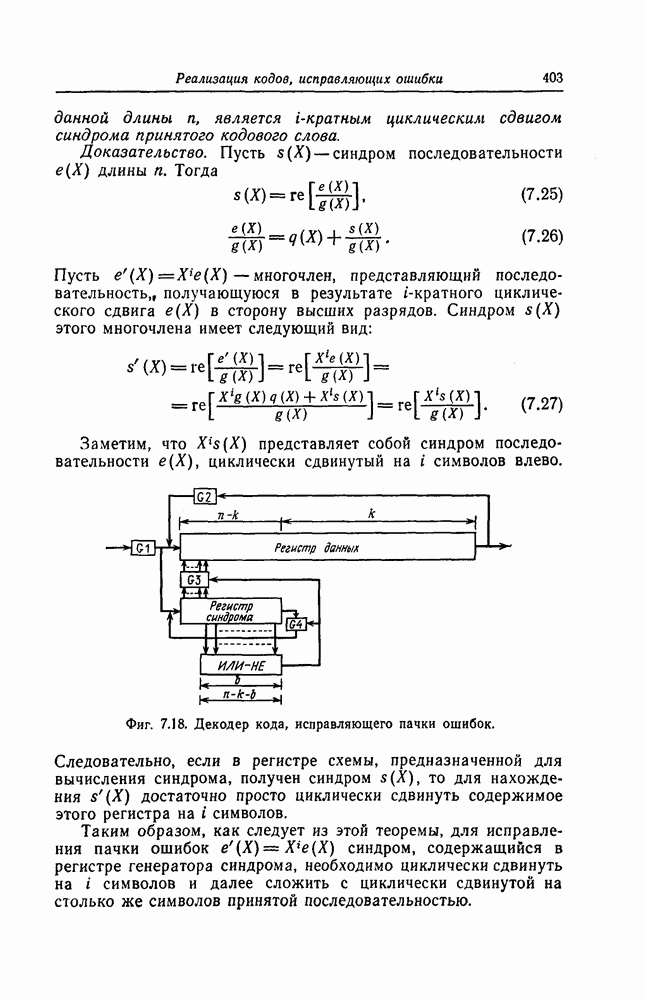


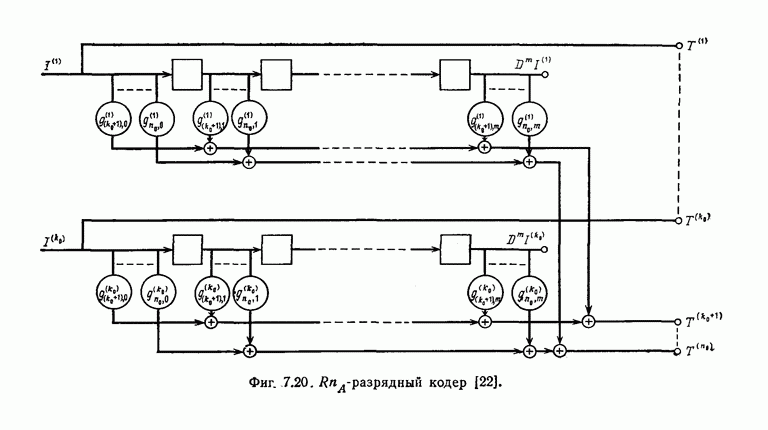

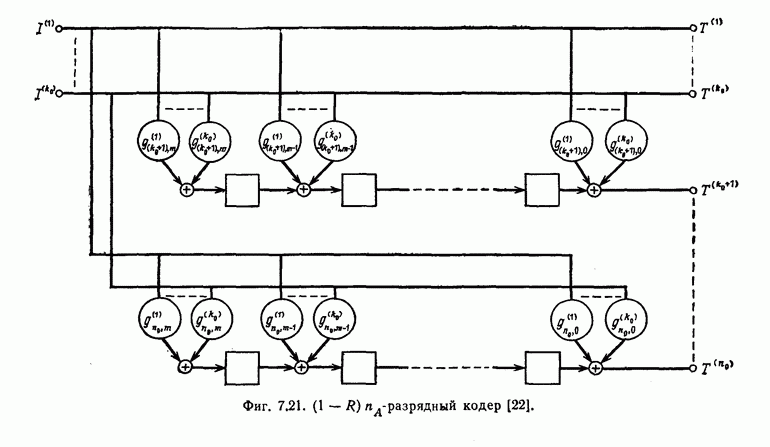
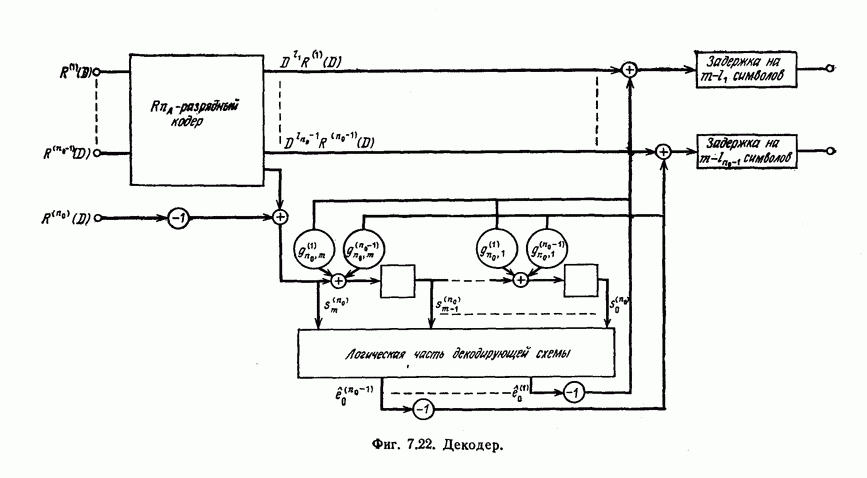



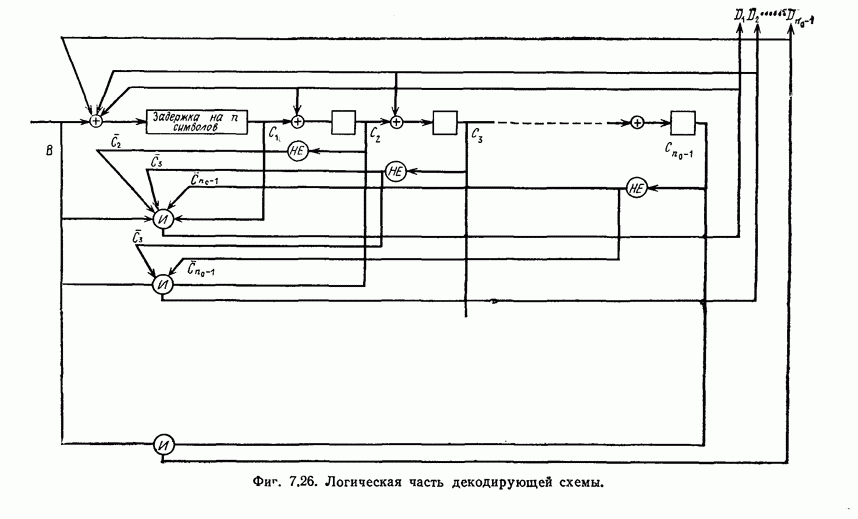
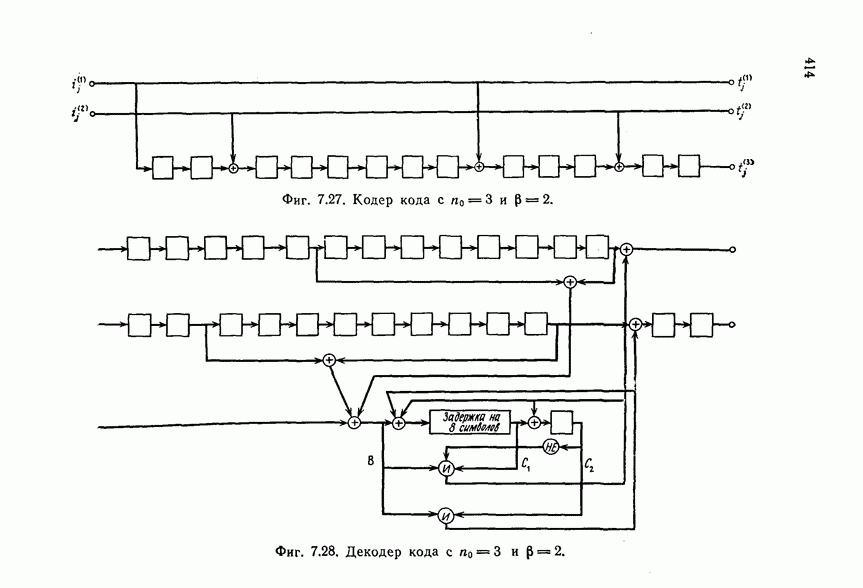


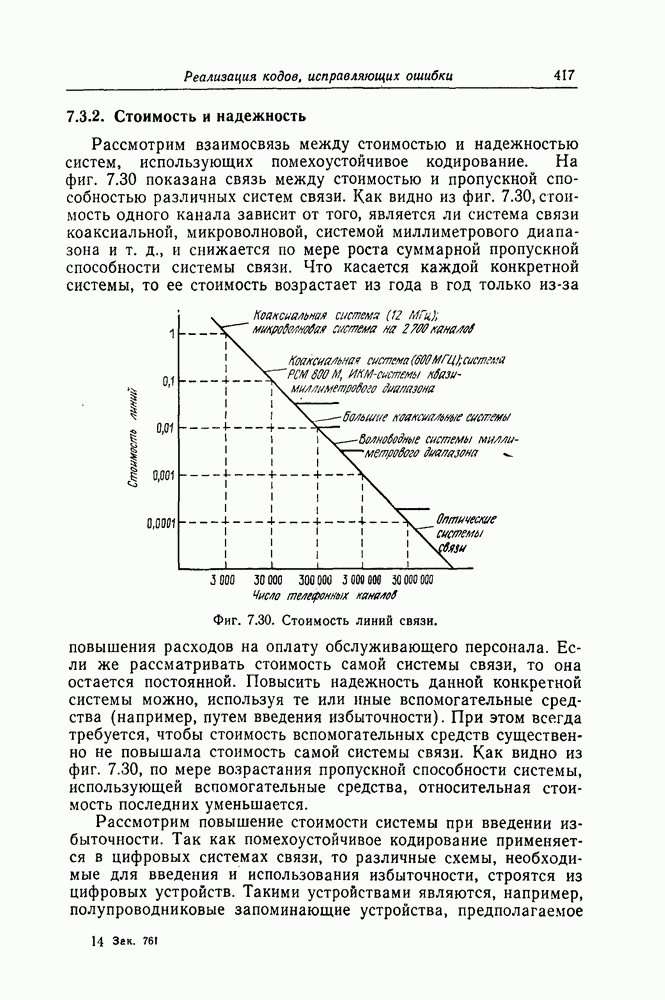
















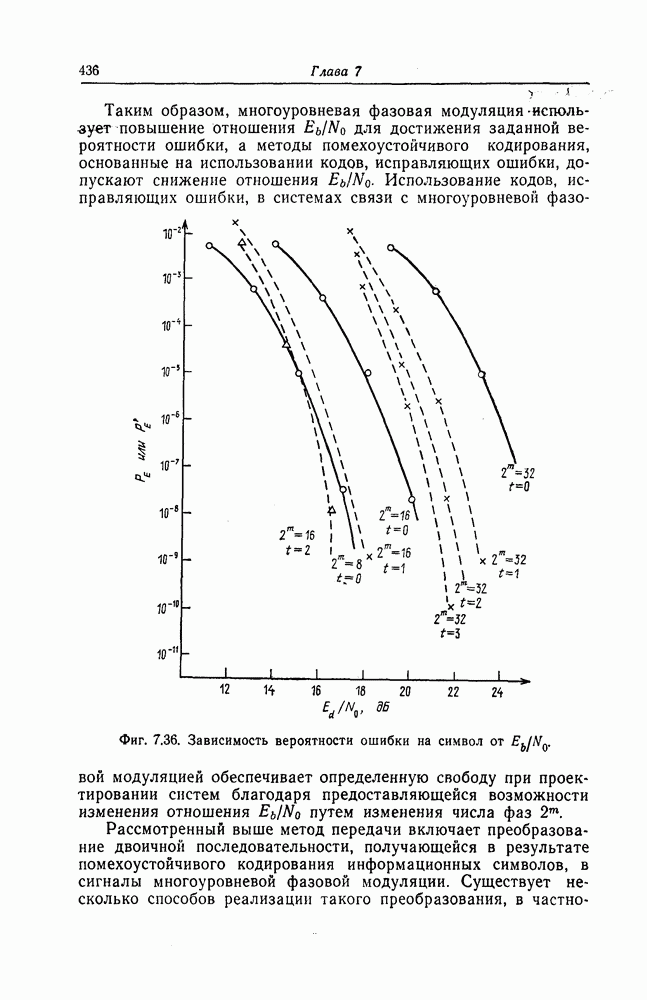



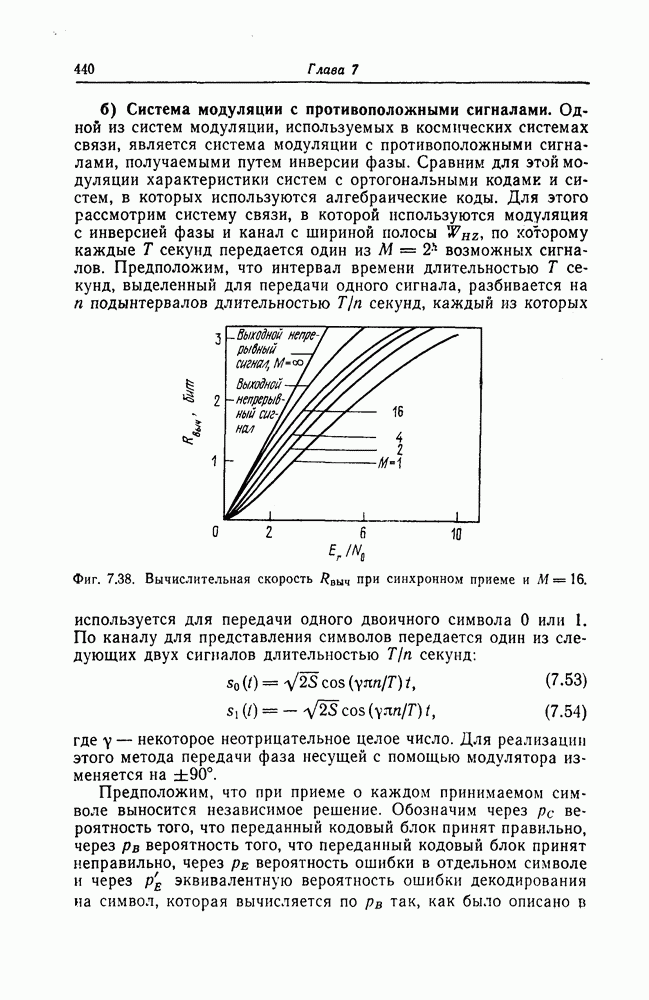

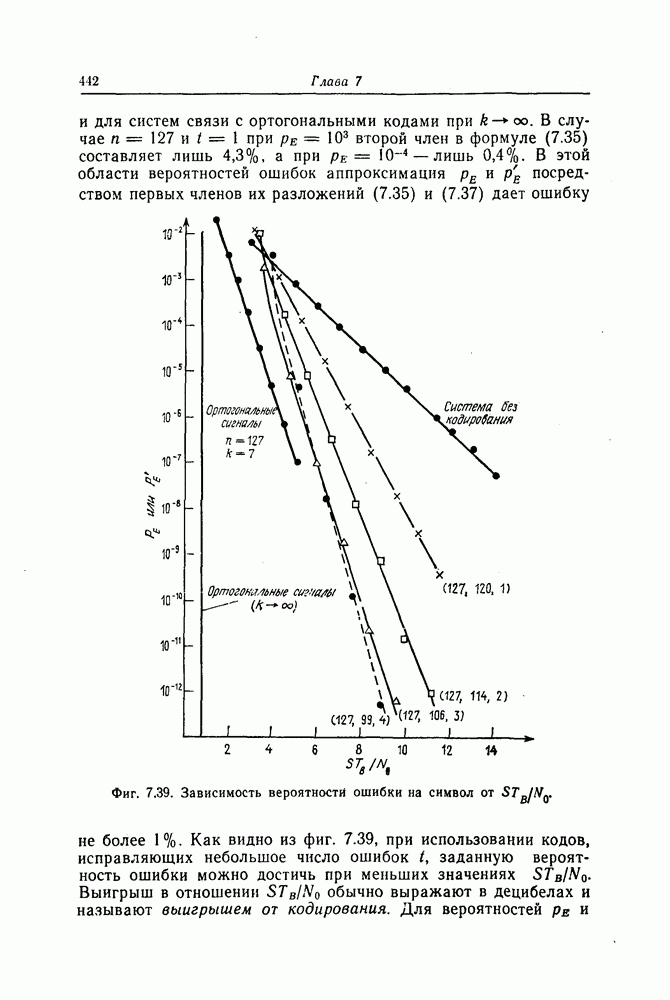

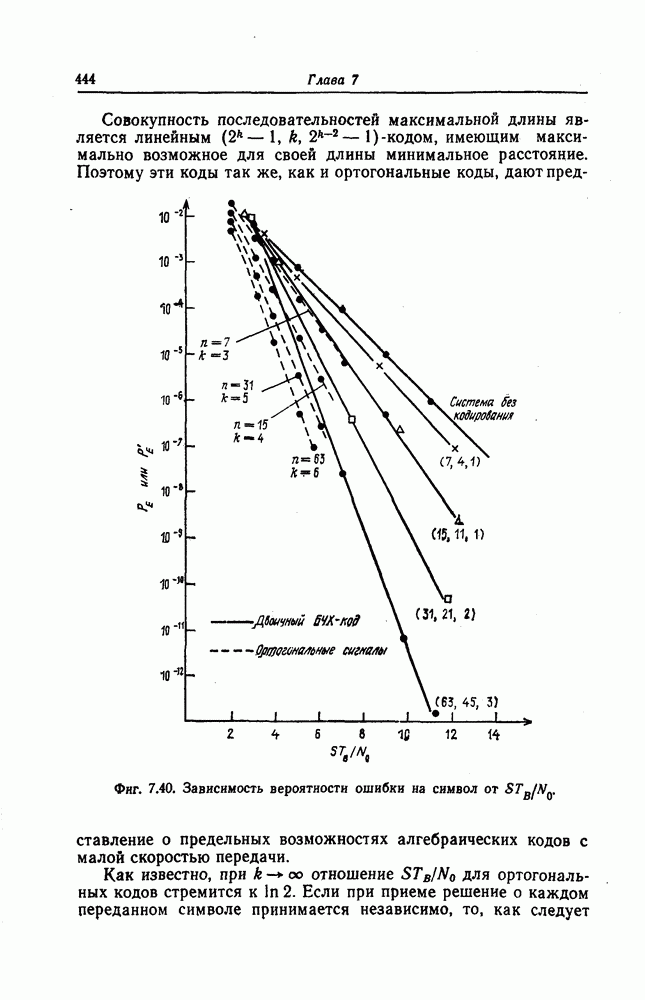






































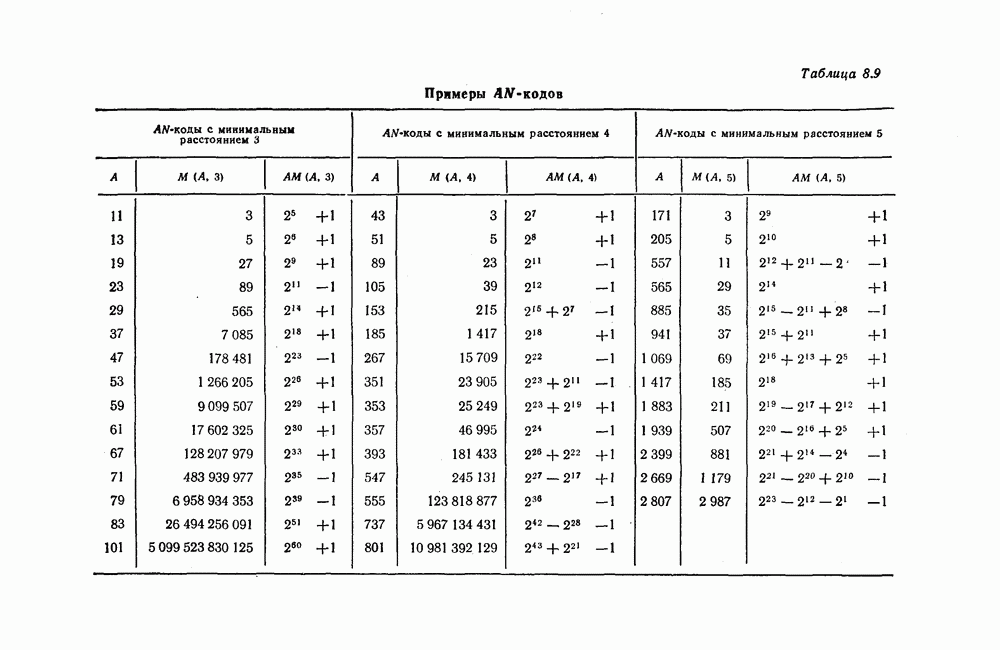































































 Эти коды, впервые построенные Месси [2] для
Эти коды, впервые построенные Месси [2] для  в дальнейшем были обобщены Робинсоном [36] и на случай
в дальнейшем были обобщены Робинсоном [36] и на случай  Однако здесь в целях упрощения мы ограничимся рассмотрением только кодов над
Однако здесь в целях упрощения мы ограничимся рассмотрением только кодов над 
 порождающими многочленами
порождающими многочленами  которого являются все
которого являются все 
 над
над  степени
степени  и менее.
и менее.
 порождаемый многочленами
порождаемый многочленами 
 минимальное расстояние
минимальное расстояние  и допускают построение
и допускают построение  проверок, ортогональных относительно
проверок, ортогональных относительно  Последовательность символов синдрома, образующихся за время
Последовательность символов синдрома, образующихся за время  определяется матричным соотношением (5.89), где
определяется матричным соотношением (5.89), где  матрица, задаваемая формулой (5.90).
матрица, задаваемая формулой (5.90).
 будем называть проверочным параллелограммом. Подматрица в правой части
будем называть проверочным параллелограммом. Подматрица в правой части  выделенная пунктирной линией, является проверочной матрицей
выделенная пунктирной линией, является проверочной матрицей 


 в (5.89) будучи суммами
в (5.89) будучи суммами  предшествующих шумовых информационных символов
предшествующих шумовых информационных символов  и оценок последних, равны 0, если
и оценок последних, равны 0, если  т. е. если символ
т. е. если символ  был декодирован верно, равны 1 в противном случае и отражают воздействие на символы синдрома ошибок декодирования.
был декодирован верно, равны 1 в противном случае и отражают воздействие на символы синдрома ошибок декодирования.
 первых составных проверок выбираются
первых составных проверок выбираются 
 — символ синдрома, которому соответствует строка
— символ синдрома, которому соответствует строка  матрицы
матрицы  последовательность из
последовательность из  символов 0 и 1, оканчивающаяся символом 1). Тогда найдется по крайней мере один символ
символов 0 и 1, оканчивающаяся символом 1). Тогда найдется по крайней мере один символ  которому в матрице
которому в матрице  соответствует строка
соответствует строка  Все суммы
Все суммы  относятся к числу искомых составных проверок.
относятся к числу искомых составных проверок.
 составных проверок берутся символы
составных проверок берутся символы  которым соответствуют строки матрицы
которым соответствуют строки матрицы  вида
вида  где
где  последовательность символов 0 длины
последовательность символов 0 длины  Заметим, что каждый из шумовых символов
Заметим, что каждый из шумовых символов  контролирует только одну составную проверку.
контролирует только одну составную проверку.
 задается формулой (5.91):
задается формулой (5.91):


 первых составных проверок берутся символы синдрома
первых составных проверок берутся символы синдрома 
 символ синдрома, которому соответствует строка
символ синдрома, которому соответствует строка  матрицы
матрицы  содержащая не менее трех символов 1 (здесь
содержащая не менее трех символов 1 (здесь  последовательность из
последовательность из  символов 0 и 1). Тогда среди строк матрицы
символов 0 и 1). Тогда среди строк матрицы  всегда можно найти строку вида
всегда можно найти строку вида  соответствующую некоторому символу синдрома
соответствующую некоторому символу синдрома  Действительно, это всегда можно сделать, поскольку все заканчивающиеся символом 1 строки с номером
Действительно, это всегда можно сделать, поскольку все заканчивающиеся символом 1 строки с номером  проверочных параллелограммов образуют совокупность, в которую каждая двоичная последовательность длины
проверочных параллелограммов образуют совокупность, в которую каждая двоичная последовательность длины  содержащая не менее двух единиц, входит ровно один раз. Суммы
содержащая не менее двух единиц, входит ровно один раз. Суммы  образуют составные проверки, которые содержат только символ
образуют составные проверки, которые содержат только символ 
 составных проверок берутся символы синдрома, которым в матрице
составных проверок берутся символы синдрома, которым в матрице  соответствуют строки вида
соответствуют строки вида 

 оказываются зависящими восемь составных проверок. Но в этом случае возникновение ошибки декодирования, когда
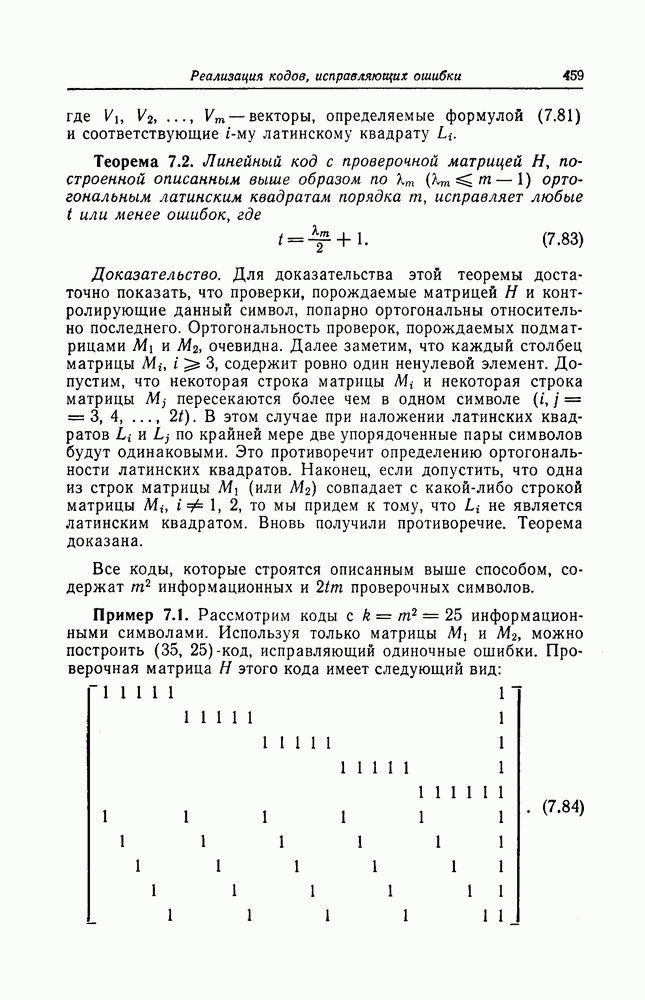
оказываются зависящими восемь составных проверок. Но в этом случае возникновение ошибки декодирования, когда  эквивалентно появлению пачки ошибок длины 8, что резко ухудшает корректирующую способность кода по отношению к символу
эквивалентно появлению пачки ошибок длины 8, что резко ухудшает корректирующую способность кода по отношению к символу  . В то же время при использовании метода ортогонализации Салливана ни одна из составных проверок, полученных на втором и третьем шагах, не содержит ни один из символов
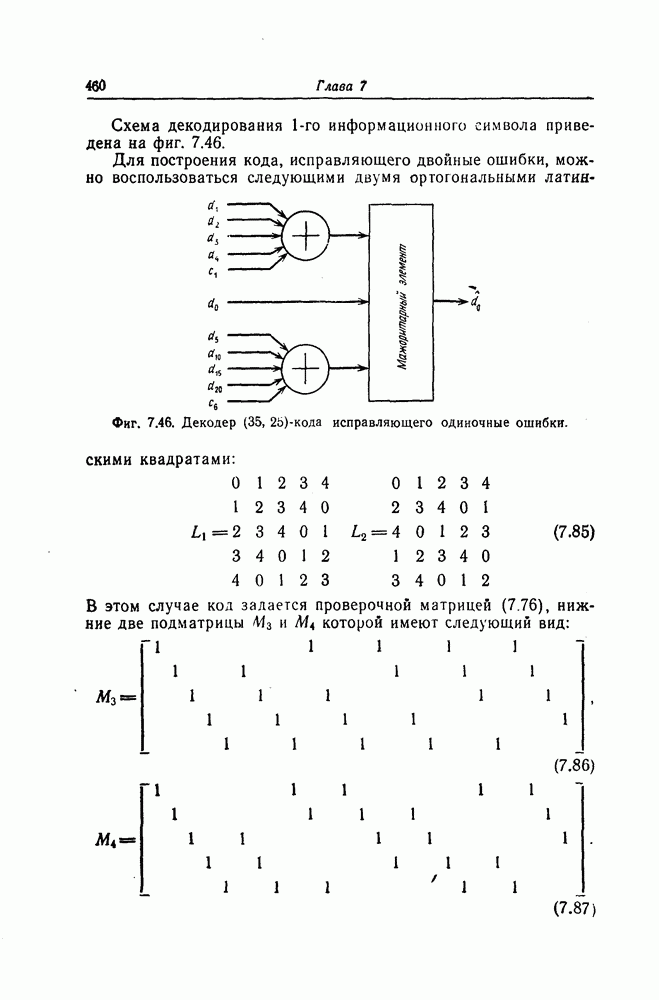
. В то же время при использовании метода ортогонализации Салливана ни одна из составных проверок, полученных на втором и третьем шагах, не содержит ни один из символов  Поэтому с точки зрения уменьшения глубины распространения ошибок метод Салливана является оптимальным методом ортогонализации.
Поэтому с точки зрения уменьшения глубины распространения ошибок метод Салливана является оптимальным методом ортогонализации.
 контролируются лишь проверками
контролируются лишь проверками  то их воздействие на составные проверки может быть задано следующим простым соотношением:
то их воздействие на составные проверки может быть задано следующим простым соотношением:

 матрица размера
матрица размера  строками которой являются всевозможные ненулевые последовательности длины
строками которой являются всевозможные ненулевые последовательности длины 
 находится в нормальном рабочем состоянии, если
находится в нормальном рабочем состоянии, если  Пусть
Пусть  множество ошибок, контролируемых составными проверками, т. е.
множество ошибок, контролируемых составными проверками, т. е. 
 Пусть
Пусть  минимальное целое число, такое, что ни одно из множеств
минимальное целое число, такое, что ни одно из множеств  содержит
содержит  или более символов 1
или более символов 1

 перейдет в нормальное рабочее состояние.
перейдет в нормальное рабочее состояние.
 и ни один из элементов
и ни один из элементов  не равен 1. В этом случае в правой части (5.92) ненулевым является только первый вектор, а следовательно, ровно
не равен 1. В этом случае в правой части (5.92) ненулевым является только первый вектор, а следовательно, ровно  символов множеств
символов множеств  будут равны единице. Допустим, что в
будут равны единице. Допустим, что в  равны 1 не более
равны 1 не более  символов
символов  Тогда изменить свое значение с 0 на 1 могут самое большее
Тогда изменить свое значение с 0 на 1 могут самое большее  составных проверок. Следовательно, общее число составных проверок, принимающих значение 1, не больше, чем целая часть
составных проверок. Следовательно, общее число составных проверок, принимающих значение 1, не больше, чем целая часть  и решение о принимается правильно.
и решение о принимается правильно.
 и все элементы
и все элементы  за исключением равны нулю. Тогда среди элементов множества
за исключением равны нулю. Тогда среди элементов множества  будут равны 0 самое большее
будут равны 0 самое большее  элементов. Если допустить, что среди символов
элементов. Если допустить, что среди символов  равны 1 не больше чем
равны 1 не больше чем  то число символов
то число символов  равных 1 и отличных от
равных 1 и отличных от  строго меньше чем
строго меньше чем  а следовательно, строго меньше чем
а следовательно, строго меньше чем  составных проверок изменяют свое значение с 1 на 0. В этом случае не менее
составных проверок изменяют свое значение с 1 на 0. В этом случае не менее  составных проверок по-прежнему будут оставаться равными единице и решение о
составных проверок по-прежнему будут оставаться равными единице и решение о  опять будет принято правильно.
опять будет принято правильно.
 при наличии в
при наличии в  не более девяти символов 1, если ошибок декодирования раньше не было, и при наличии в
не более девяти символов 1, если ошибок декодирования раньше не было, и при наличии в  не более пяти символов 1, если перед этим произошла ошибка декодирования.
не более пяти символов 1, если перед этим произошла ошибка декодирования.