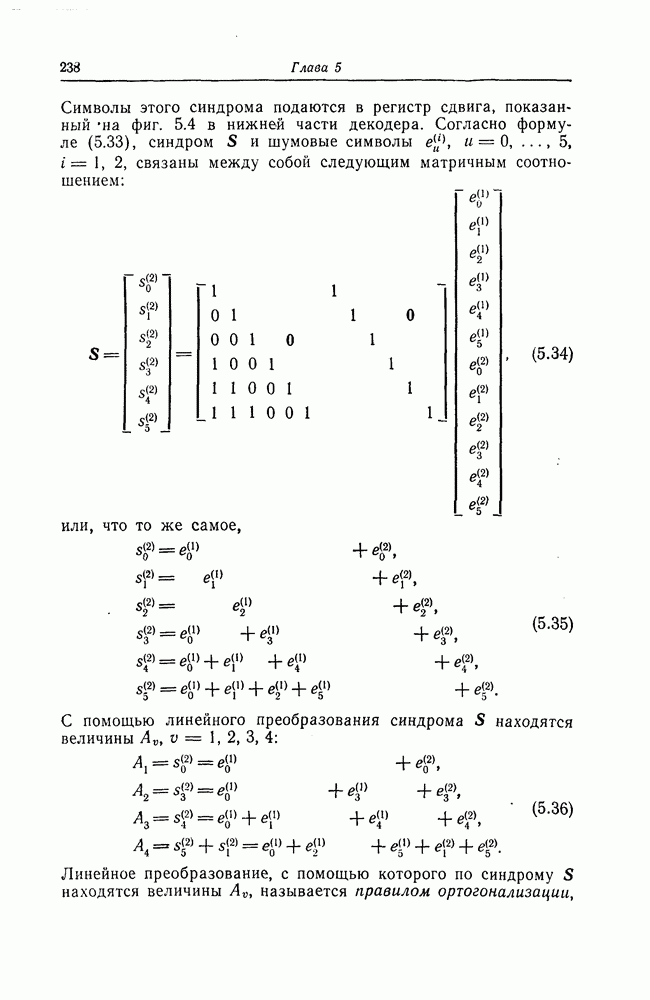
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
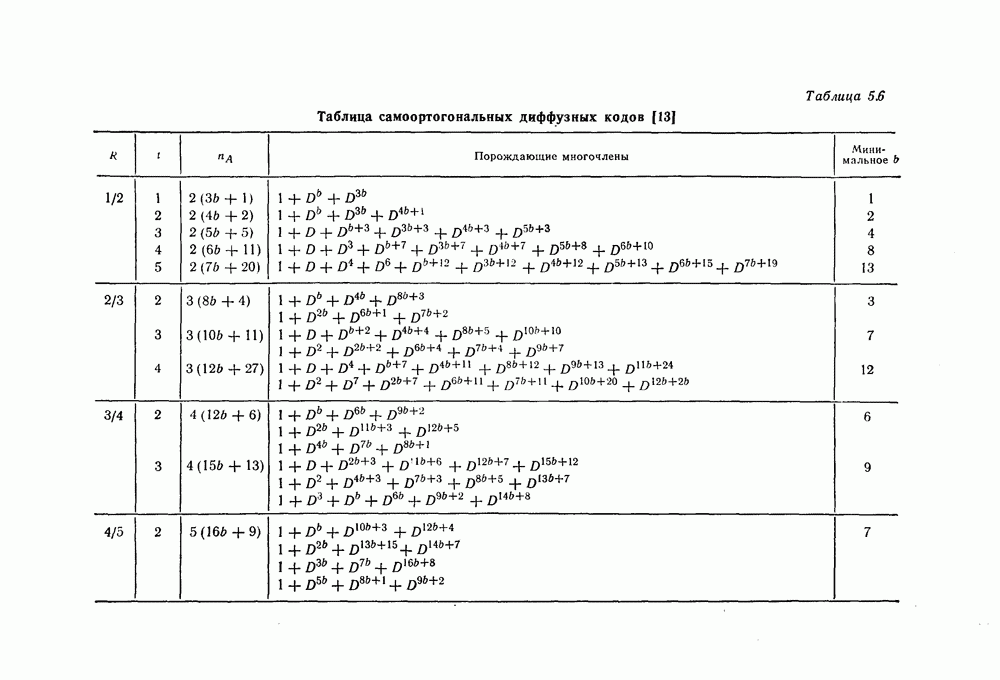
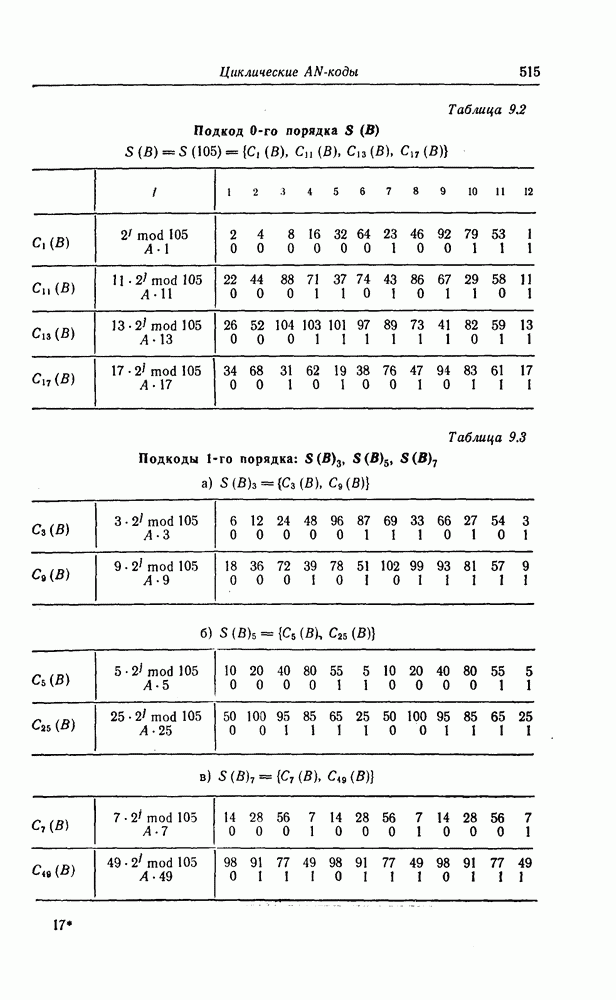
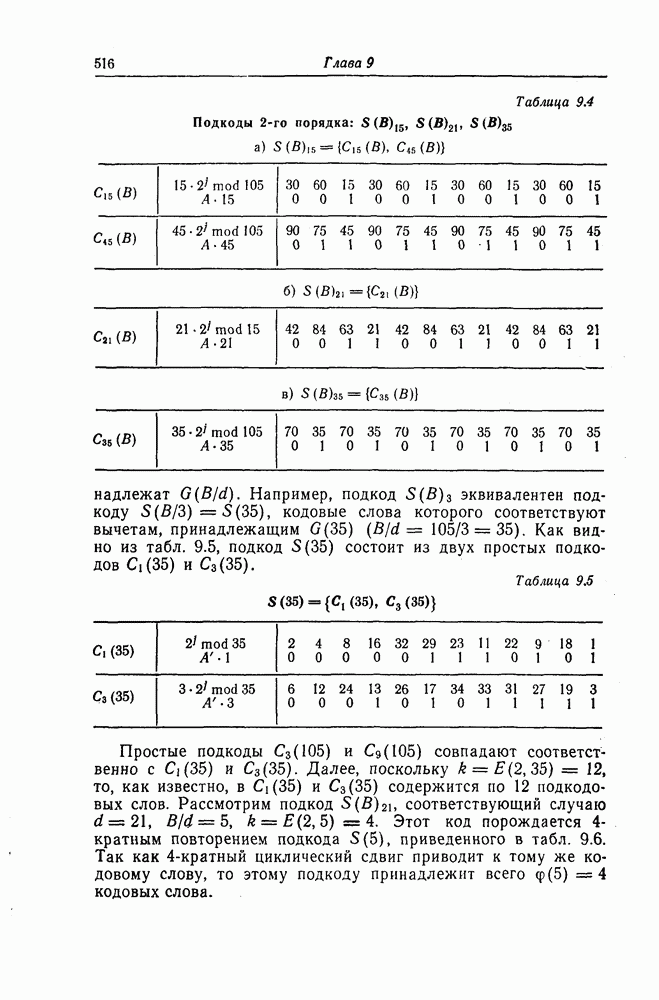
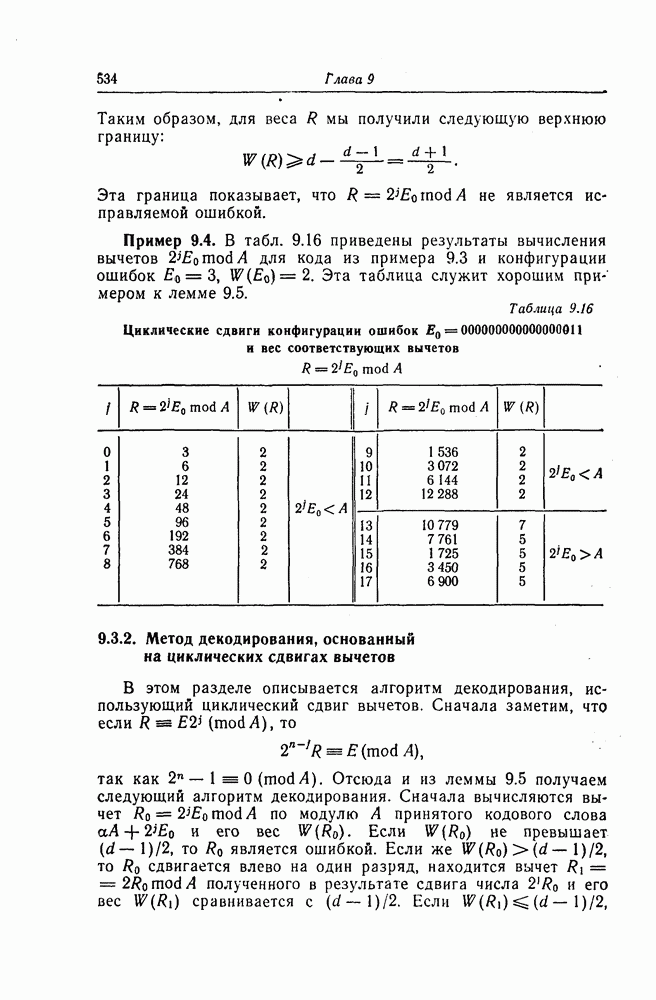
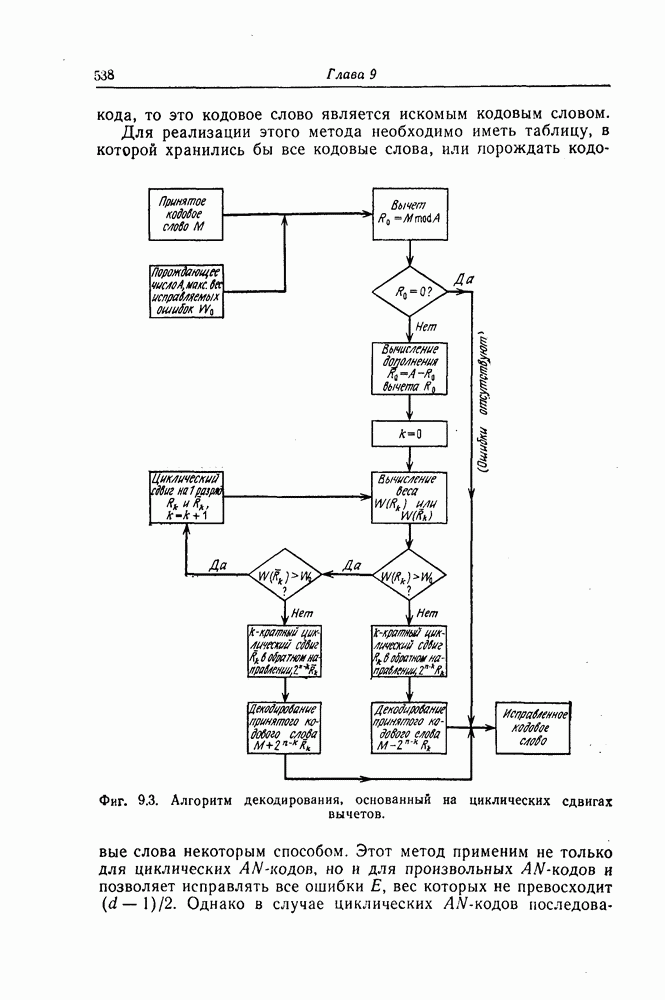
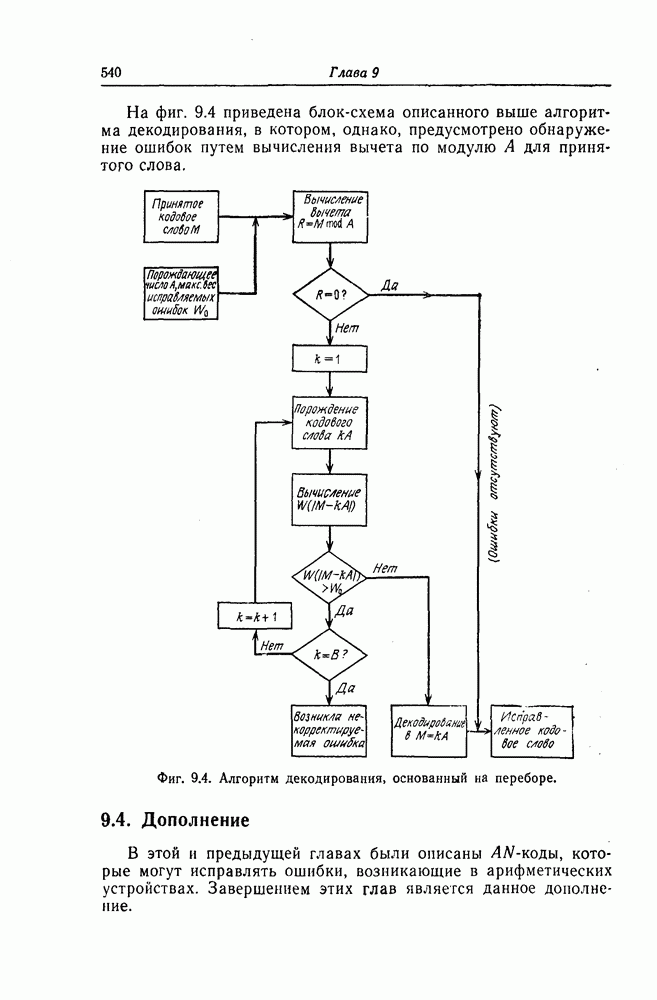
5.8. Сверточные коды, исправляющие пачки ошибокНесколько раньше, чем было введено пороговое декодирование, Хегельбергер [4] построил сверточные коды, исправляющие пачки ошибок. В дальнейшем Вайнер и Эш [6], Препарата [7], Берлекэмп [5] и Месси [8] получили нижние границы для длины свободного от ошибок защитного интервала, необходимого для исправления ошибок, разработали методы кодирования, основанные на теории матриц, и методы декодирования, использующие структуру систематических кодов. В данном разделе будут рассмотрены Так называемые коды Ивадари, исправляющие пачки ошибок и асимптотически достигающие нижней границы для кодового ограничения (или для длины защитного интервала) кодов, исправляющих пачки ошибок [10—12]. Эти коды могут быть очень просто реализованы, поскольку метод их декодирования является самым простым, который только может быть при пороговом декодировании. При построении кодов, исправляющих пачки ошибок, как и в случае блоковых кодов, очень важно иметь нижнюю границу для кодового ограничения
Рассматриваемые в этом разделе коды Ивадари представляют собой подкласс сверточных кодов, в котором для любых целых чисел 5.8.1. Метод чередованияСуществуют два типа метода чередования: простой и обобщенный. При простом чередовании с периодом х кода с порождающими многочленами Пример 5.9. Рассмотрим сверточный код из примера 5.6 со скоростью
Матрица
В результате простого чередования с периодом 2 этого кода получается код с порождающим многочленом
Этот код имеет следующую матрицу:
При обобщенном чередовании исходного кода, а именно при чередовании членов с нулевой, второй и третьей степенью, получается код с порождающим многочленом
Матрица
Как видно из этого примера, при обобщенном чередовании нужно всегда указывать, какие слагаемые порождающего многочлена или какие строки матрицы участвуют в чередовании. 5.8.2. Принцип построения кодовОсновная идея, использованная Ивадари, заключалась в том, чтобы построить коды, удовлетворяющие следующим требованиям. При отсутствии ошибок в канале синдром должен быть нулевым. Любая ошибка, возникшая в любой передаваемой последовательности, должна иметь в синдроме так называемую собственную часть, не пересекающуюся с собственными частями других ошибок. Кроме того, код должен быть построен таким образом, чтобы декодер мог выделить собственную часть любой ошибки, а следовательно, обнаружить и исправить эти ошибки. При построении кодов Ивадари по — 1 информационным последовательностям сопоставляются различные последовательности веса 2 вида Проще всего коды Ивадари можно ввести, если описать структуру синдрома этих кодов. Поскольку при возникновении пачки ошибок длины последовательностей может оказаться
где 5.8.3. Способ построения кодовРассматриваемые в этом разделе коды большей частью строятся методом проб и ошибок; общим достоинством этих кодов является то, что их структура позволяет сначала исправлять ошибки, возникшие в Сначала рассмотрим коды типа I, на основе которых строятся коды типа II. Сопоставив синдром следующим образом:
Заметим, что в эту формулу входят все пр конфигураций ошибок. Предполагая, что используется метод декодирования с обратной связью, выберем параметр х таким образом, чтобы в синдроме можно было при декодировании выделить без ошибок собственные конфигурации каждой передаваемой последовательности. Чтобы разложить при декодировании ненулевой синдром на по — 1 различных единичных конфигураций, используется следующий алгоритм декодирования. С появлением каждого ненулевого символа в синдроме начинается поиск единичных конфигураций, образованных этим и предшествующими ненулевыми символами, хранящимися в ячейках памяти декодирующей логической схемы. 1) Если ни одну из 2) Если обнаружена одна из 3) Если одновременно можно построить несколько единичных конфигураций, то с помощью указанного ниже правила запрета выбирается одна из этих конфигураций и осуществляется переход к шагу 2. Правило запрета: «Если обнаружено несколько единичных конфигураций, то выбирается та, которая имеет большую длину». Последовательность ошибок 5.8.4. Конкретные кодыКод типа I [10—12]:
Порождающими многочленами этого кода являются многочлены
Используя тот же самый метод декодирования, что и для кода типа I, но несколько изменяя расположение в синдроме последовательностей
Порождающими многочленами кода типа II являются многочлены
Принцип декодирования кодов типа I и типа II один и тот же, но тем не менее эти коды несколько отличаются друг от друга. Пример 5.10 иллюстрирует процесс декодирования рассмотренных выше кодов. Пример 5.10. Рассмотрим код Ивадари типа II с параметрами
Предположим, что возникли следующие ошибки:
Конечно, на приемном конце эти многочлены неизвестны, но может быть вычислен синдром, который, согласно формулам (5.81) — (5.83), в данном случае имеет следующий вид:
Из формул (5.81) и (5.82) следует, что единичные конфигурации второй и первой информационных последовательностей имеют длину соответственно 10 и 9. Согласно шагу 1 алгоритма декодирования, до появления 2-го символа
Разлагая этот синдром дальше, можно исправить оставшиеся ошибки. 5.8.5. Оценки кодов и сравнение их параметровОбычно используются следующие критерии оценки качества кодов, исправляющих пачки ошибок: 1) Достигает (быть может, асимптотически) или нет кодовое ограничение (или длина защитного интервала) нижней границы (5.72). Свойства сверточных кодов таковы, что соотношения (5.72) для этих величин со знаком равенства выполняться не могут. Так, Вайнер и Эш [3], рассматривая случай, когда пачка ошибок начинается за первой информационной последовательностью, получили следующую более точную границу для сверточных кодов:
и назвали оптимальными коды, для которых эти соотношения выполняются со знаком равенства. Следуя этому определению, будем называть квазиоптимальными коды, для которых
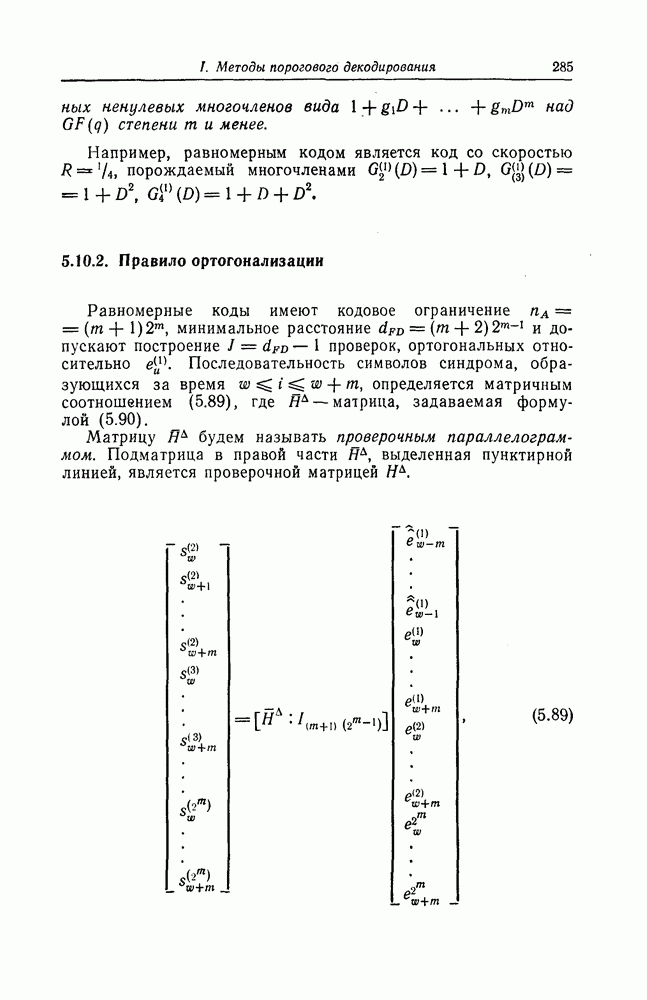
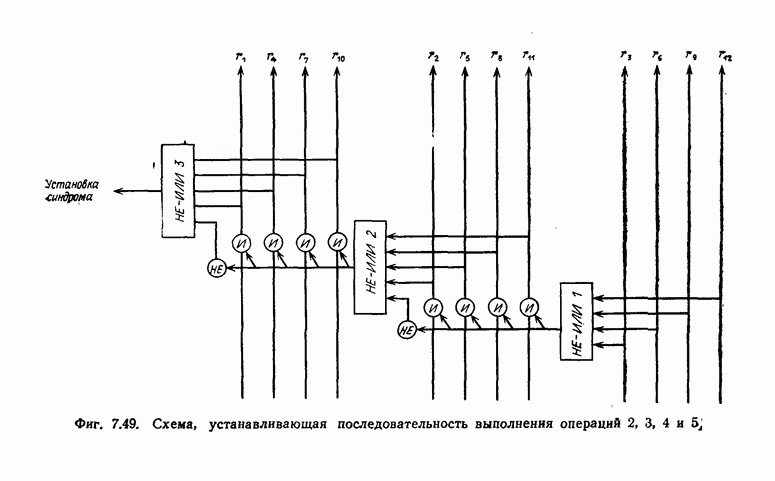
т. е. нижняя граница (5.85) достигается асимптотически при большой длине исправляемых пачек ошибок. 2) Экономичность можно характеризовать числом каскадов регистров сдвига, используемых в кодере и декодере. 3) В случае возникновения ошибки декодирования глубина распространения последней должна быть по возможности меньшей. При декодировании рассматриваемых здесь кодов решение о наличии или отсутствии ошибки в символе принимается элементом И. Поскольку этот элемент можно рассматривать как пороговый элемент с двумя входами и порогом 1,5, то в данном случае можно воспользоваться критерием устойчивости пороговой декодирующей логической схемы. Так как при каждом срабатывании декодирующей логической схемы вес внутреннего состояния этой схемы уменьшается на 1 или 2, то, следовательно, схема устойчива. Что касается глубины распространения ошибок, то обычный защитный интервал длины Таблица 5.5 (см. скан) Необходимое число ячеек регистров сдвига и длина защитных интервалов кодов, исправляющих пачки ошибок Следовательно, глубина распространения ошибок не превышает В табл. 5.5 приведены значения указанных выше характеристик для кодов типа I и II. 5.8.6. Другие кодыВыше был описан метод построения кодов со скоростью Рассмотренные коды позволяют исправлять любые пачки ошибок длины Найти регулярный метод построения циклических кодов с числом проверочных символов
|
 |
Оглавление
|
































































































































































































































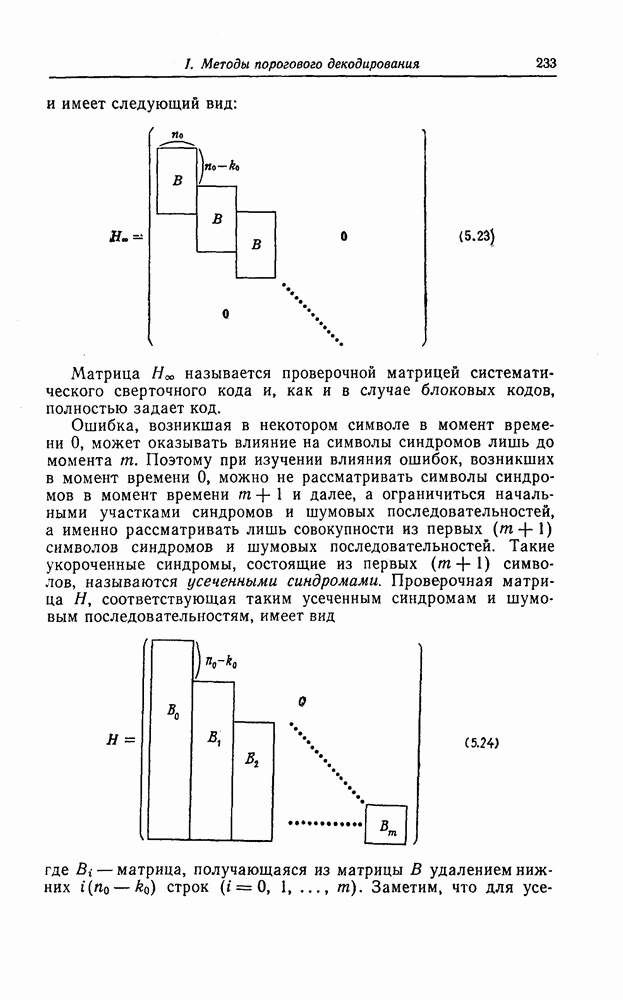
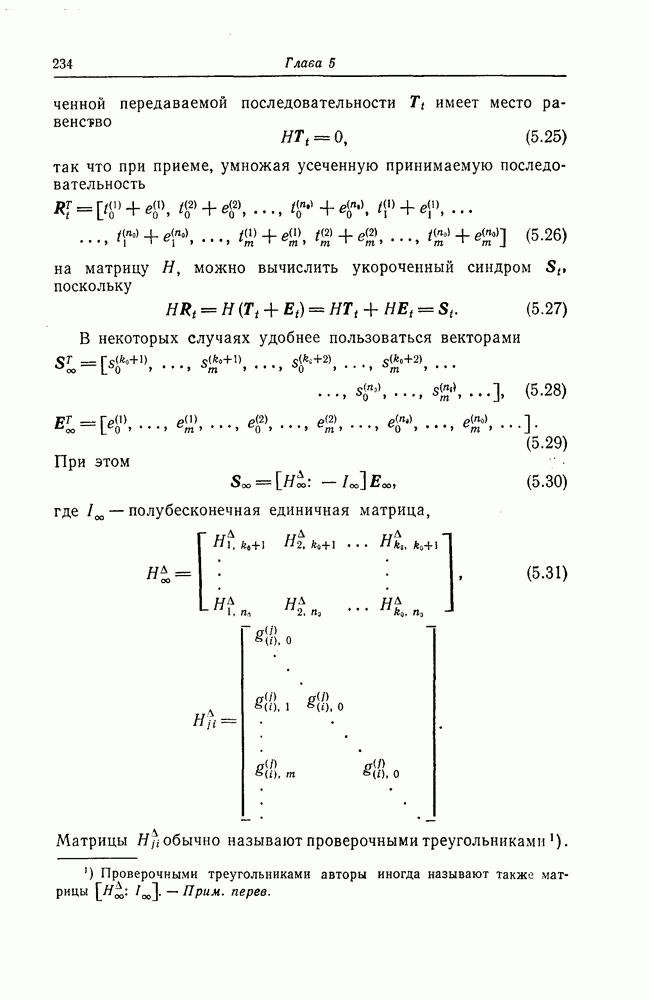
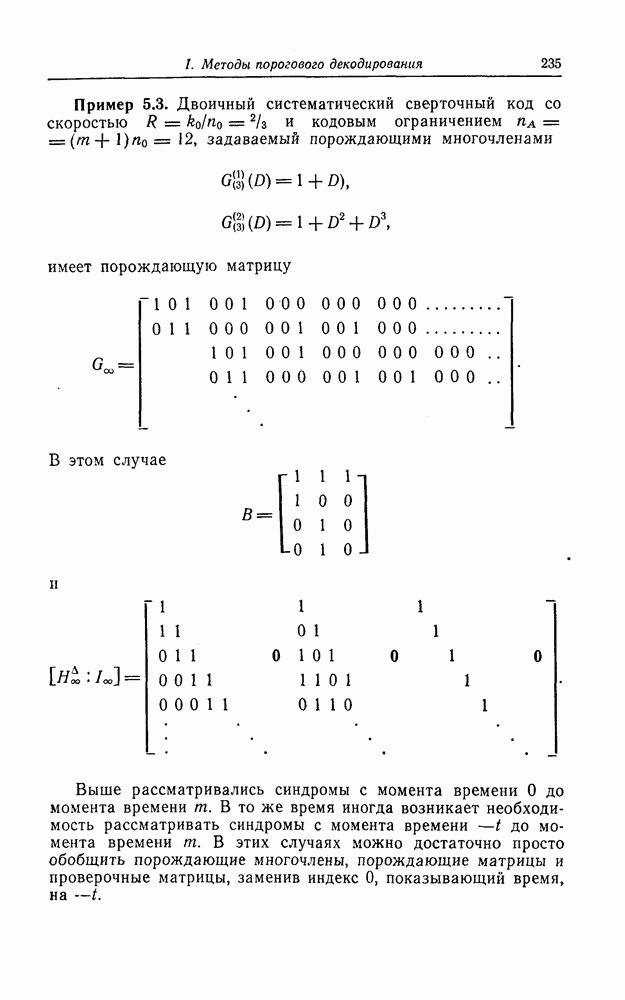

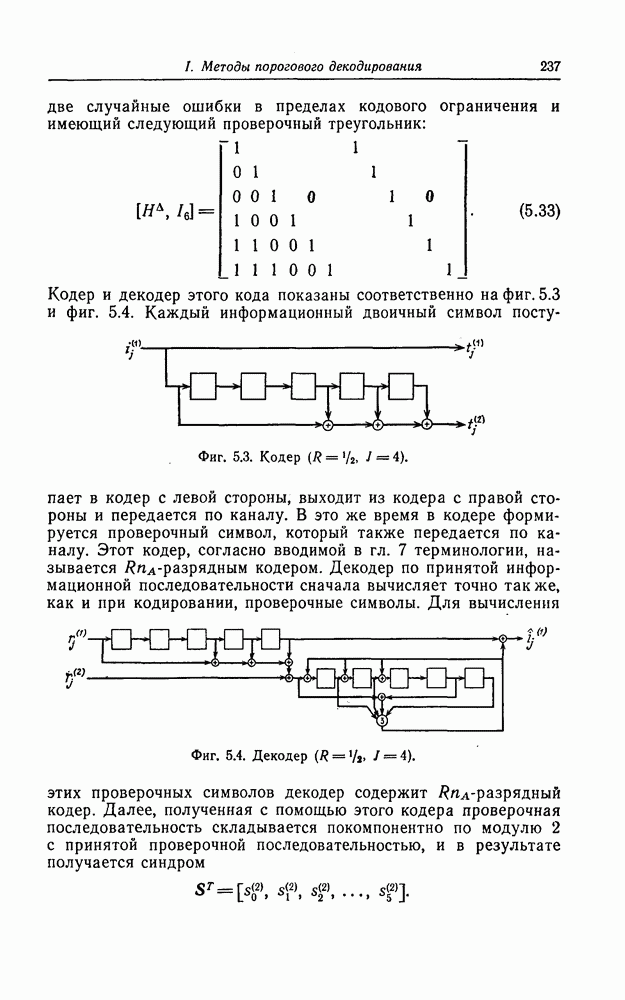















































































































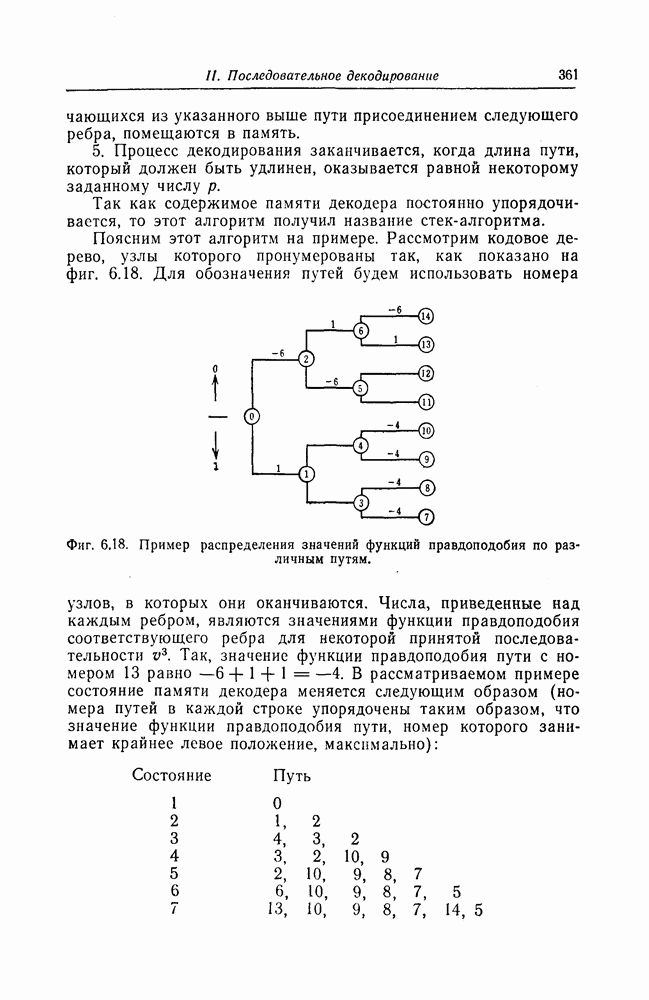












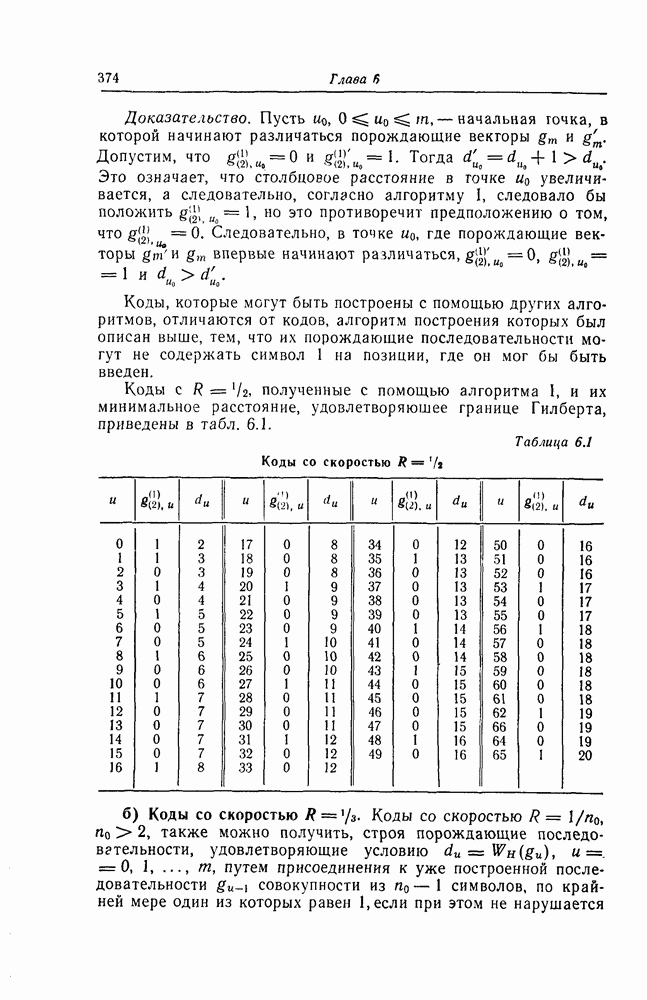




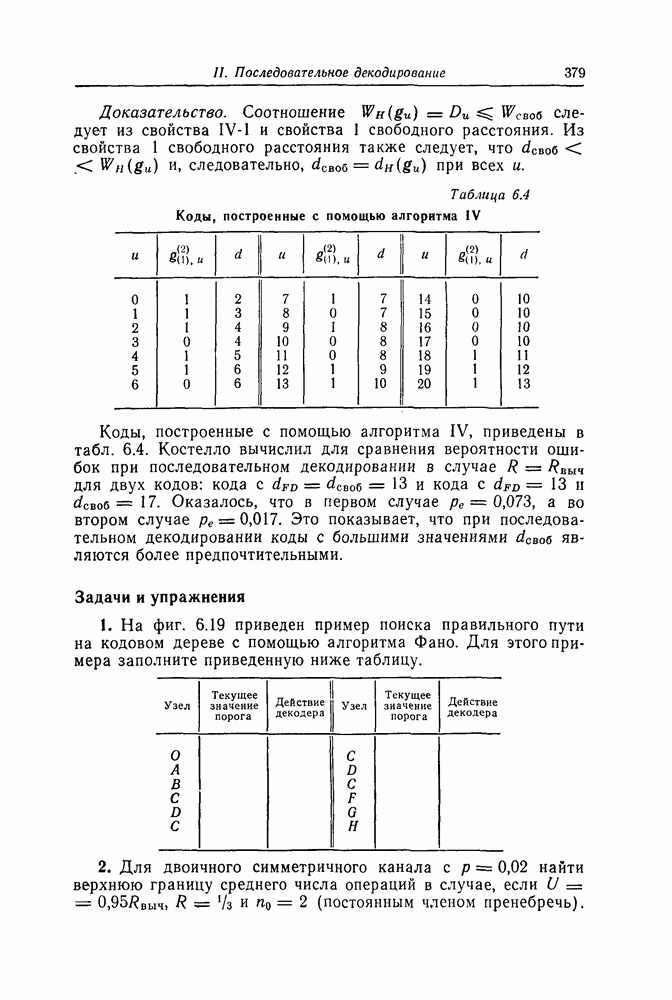
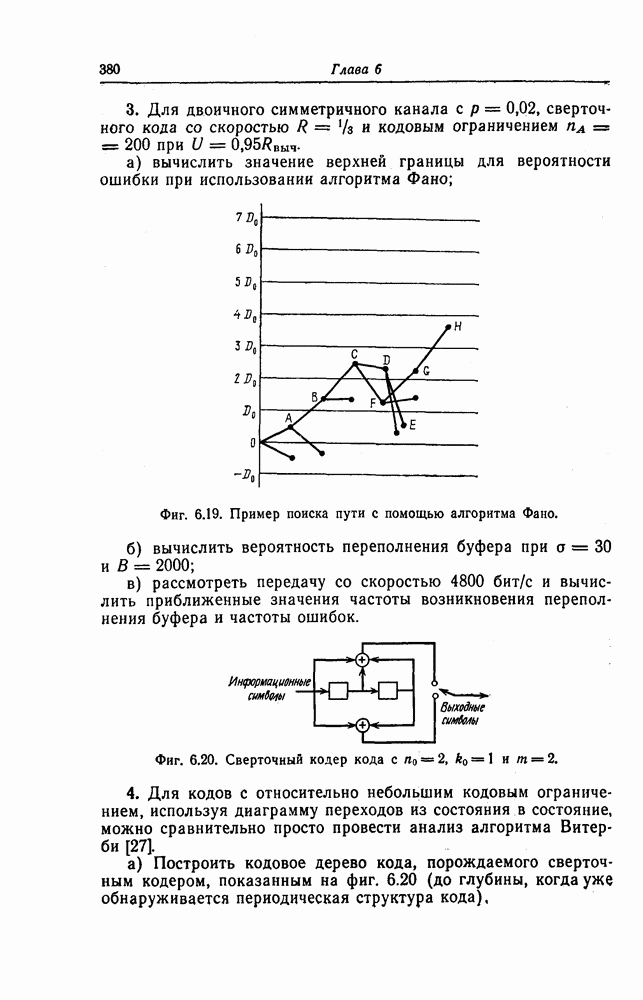










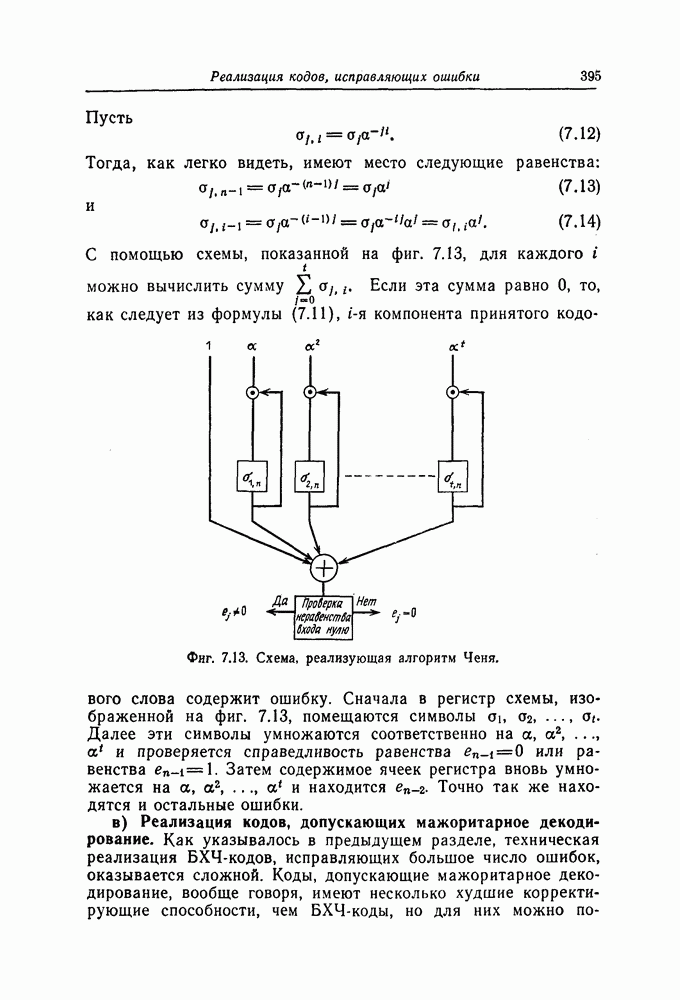

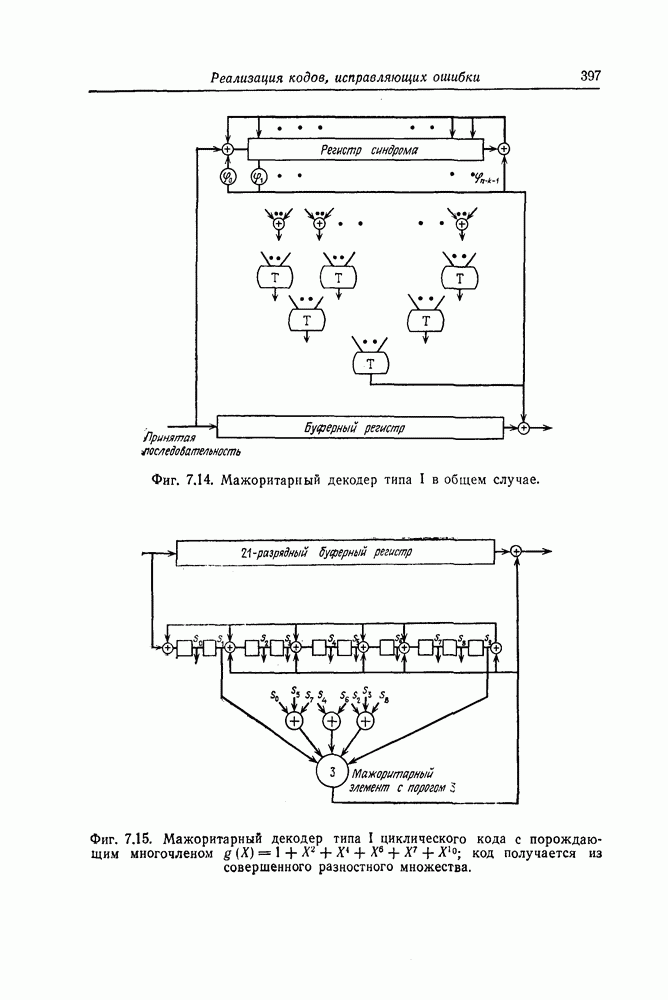






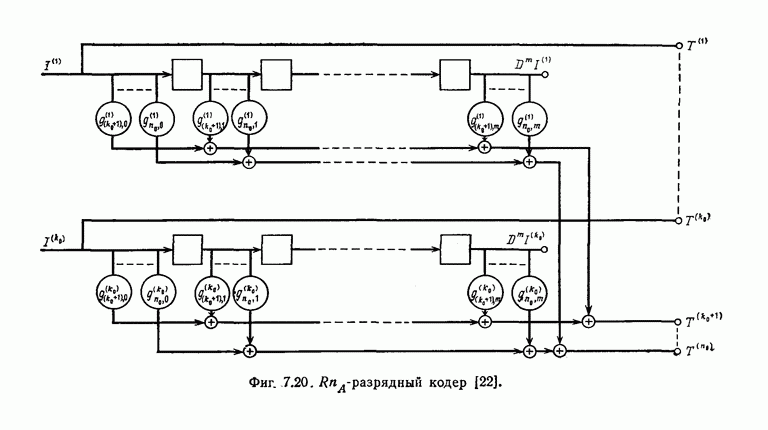

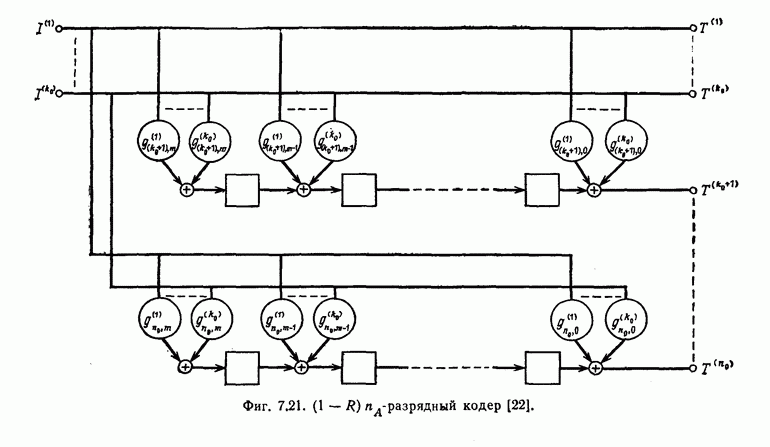
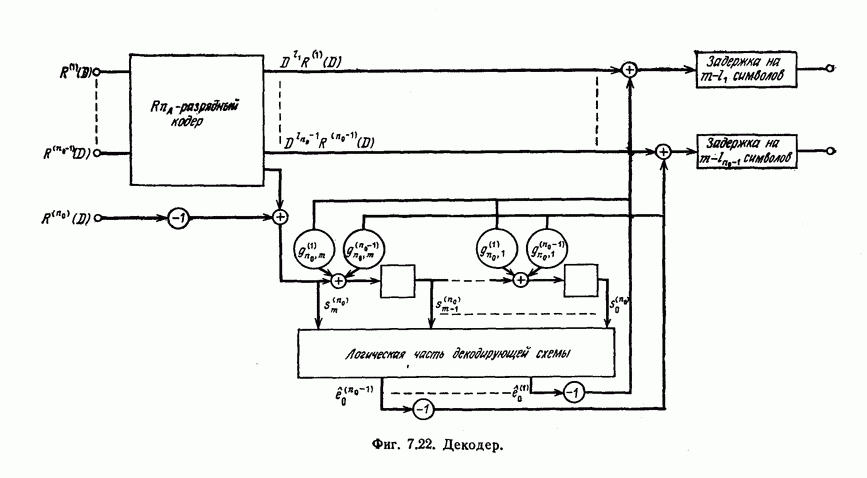



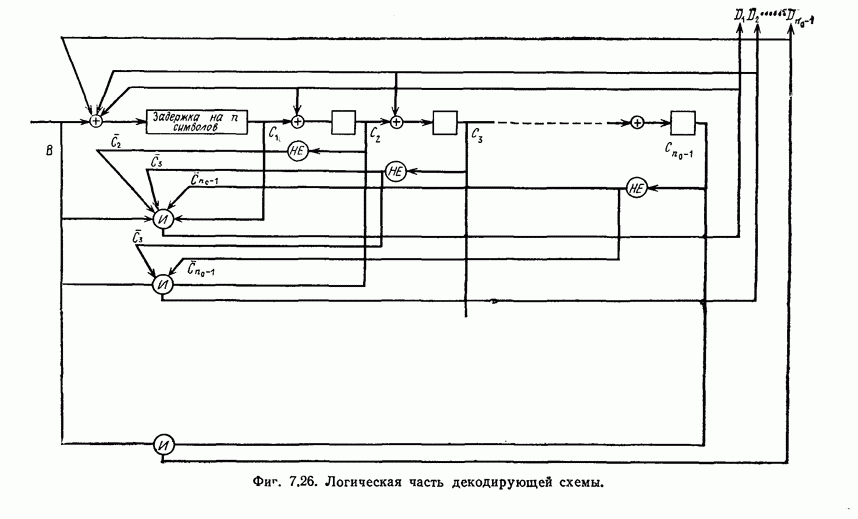


















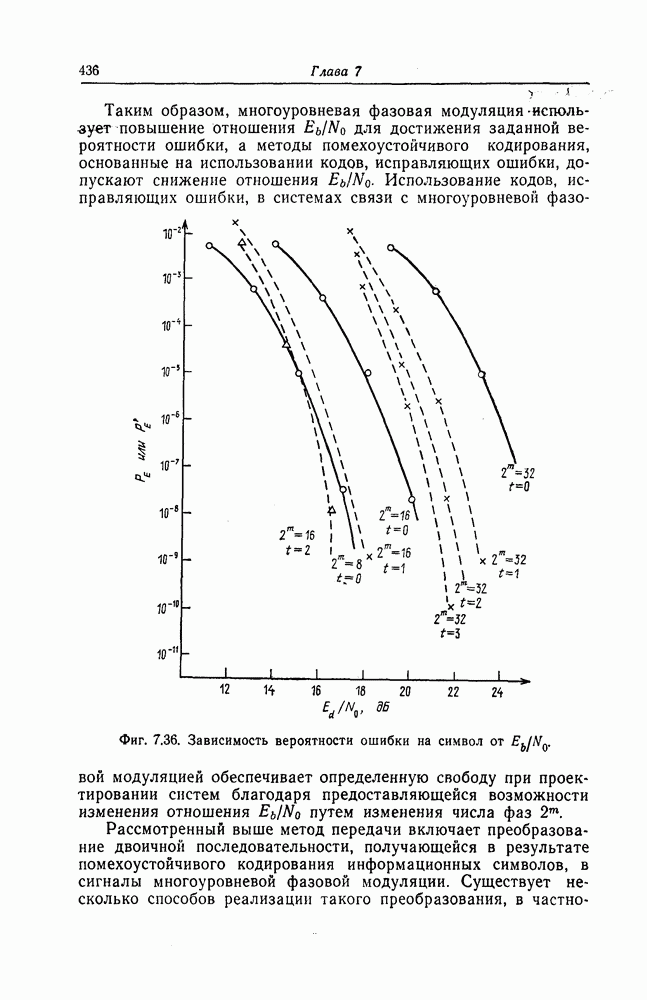





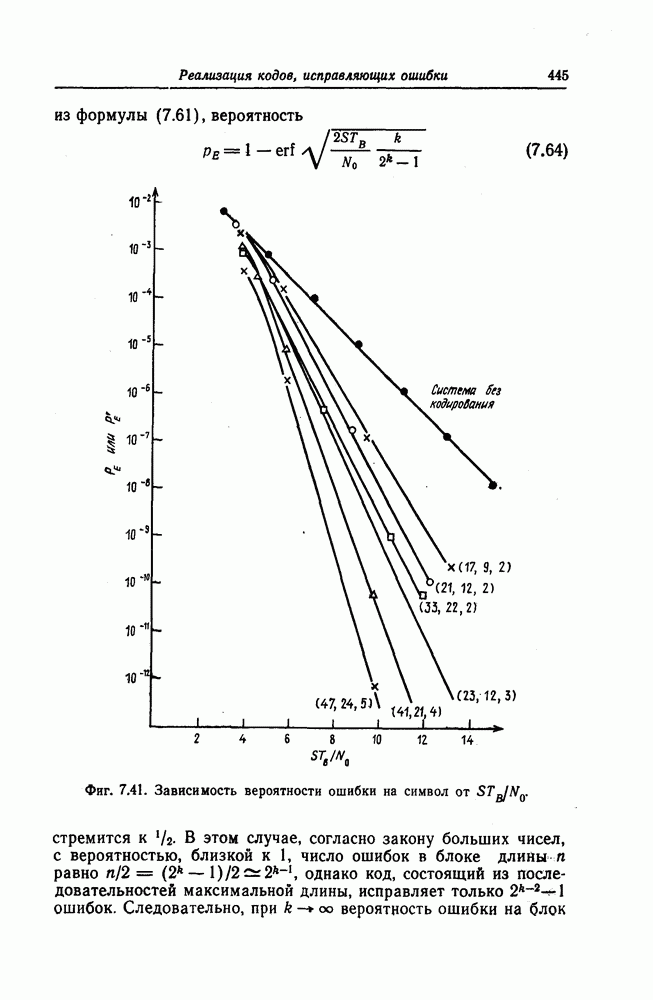

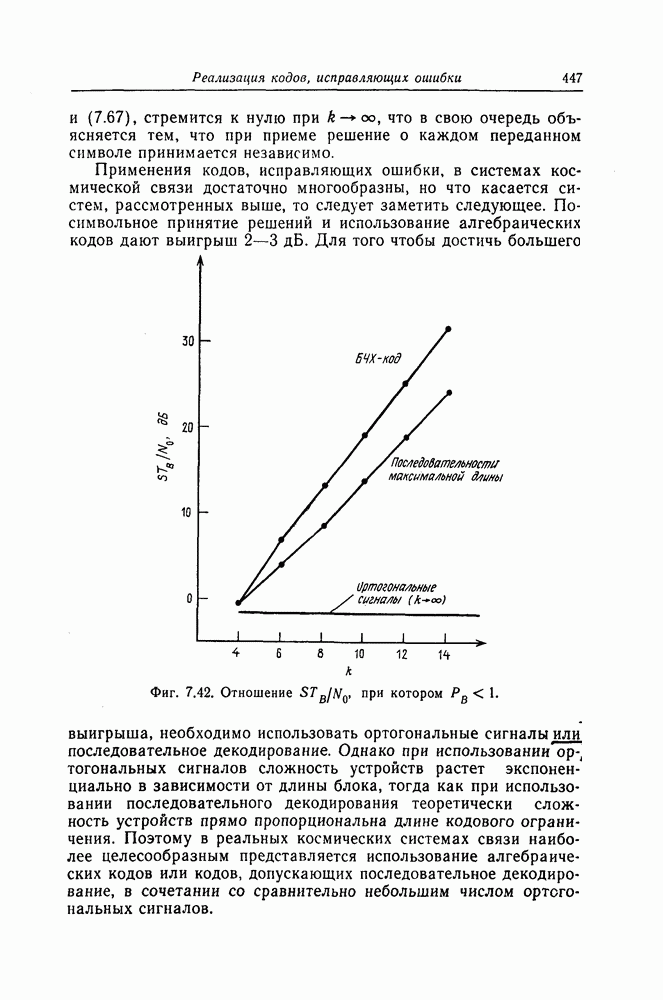




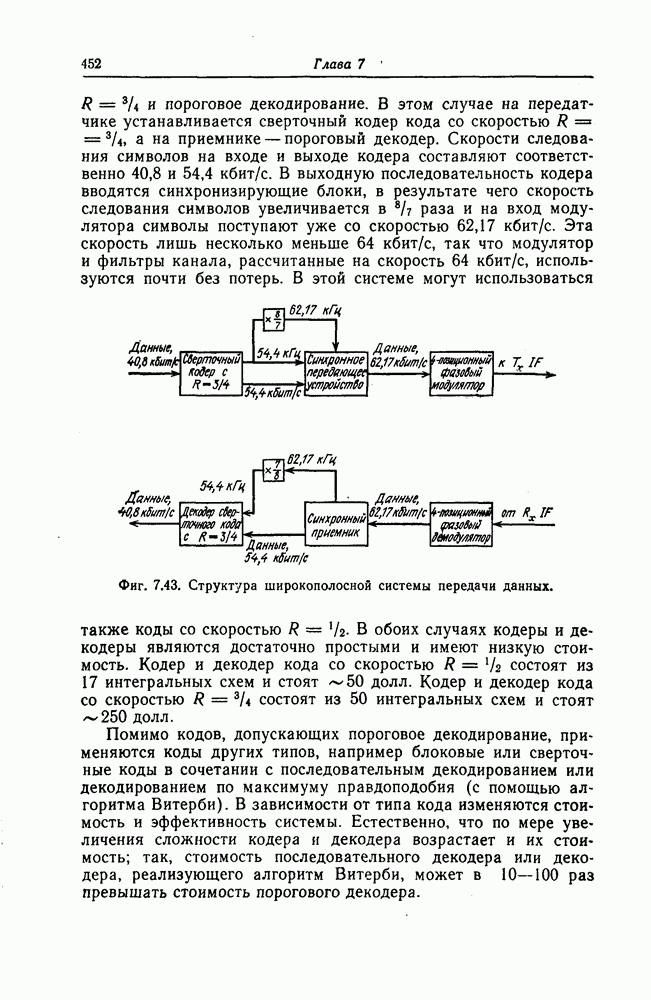



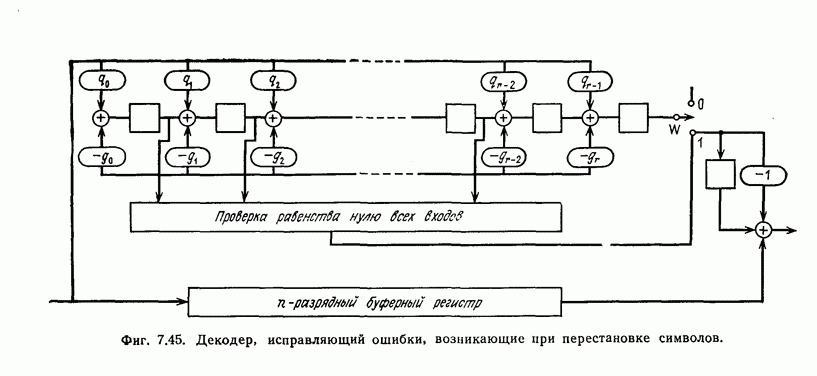





























































































 (или длины защитного интервала). Защитным интервалом называют последовательность свободных от ошибок символов, следующих за пачкой ошибок. Защитный интервал необходим для того, чтобы пачки ошибок можно было исправлять. Вайнер и Эш [6] получили следующую границу для кодового ограничения (и длины защитного интервала
(или длины защитного интервала). Защитным интервалом называют последовательность свободных от ошибок символов, следующих за пачкой ошибок. Защитный интервал необходим для того, чтобы пачки ошибок можно было исправлять. Вайнер и Эш [6] получили следующую границу для кодового ограничения (и длины защитного интервала  кода, исправляющего пачки ошибок длины
кода, исправляющего пачки ошибок длины 

 существует код со скоростью
существует код со скоростью  исправляющий любые пачки ошибок длины
исправляющий любые пачки ошибок длины  и менее. Любой код из этого класса, исправляющий пачки ошибок длины
и менее. Любой код из этого класса, исправляющий пачки ошибок длины  называется основным кодом. Коды со скоростью
называется основным кодом. Коды со скоростью  исправляющие пачки ошибок длины
исправляющие пачки ошибок длины  получаются из основного кода методом чередования.
получаются из основного кода методом чередования.
 все показатели степеней в каждом порождающем многочлене умножаются на число х. В результате простого чередования кода с проверочной матрицей
все показатели степеней в каждом порождающем многочлене умножаются на число х. В результате простого чередования кода с проверочной матрицей  получается новый код, проверочная матрица которого может быть получена из матрицы
получается новый код, проверочная матрица которого может быть получена из матрицы  путем введения между любыми двумя соседними строками последней
путем введения между любыми двумя соседними строками последней  нулевых строк. Если же на х умножаются не все показатели степеней в порождающих многочленах, а только те, которые принадлежат некоторому заданному множеству, то такое чередование называется обобщенным. При обобщенном чередовании проверочная матрица получающегося кода строится из проверочной матрицы исходного кода путем введения
нулевых строк. Если же на х умножаются не все показатели степеней в порождающих многочленах, а только те, которые принадлежат некоторому заданному множеству, то такое чередование называется обобщенным. При обобщенном чередовании проверочная матрица получающегося кода строится из проверочной матрицы исходного кода путем введения  нулевых строк между каждой строкой из некоторого заданного подмножества строк и следующей строкой.
нулевых строк между каждой строкой из некоторого заданного подмножества строк и следующей строкой.
 и кодовым ограничением
и кодовым ограничением  который задается порождающим многочленом
который задается порождающим многочленом

 для этого кода имеет следующий вид:
для этого кода имеет следующий вид:




 получающегося кода имеет следующий вид:
получающегося кода имеет следующий вид:

 где
где  элемент поля
элемент поля  единственной проверочной последовательности при этом сопоставляется последовательность
единственной проверочной последовательности при этом сопоставляется последовательность  веса 1. Последовательности
веса 1. Последовательности  длины
длины  называются единичными конфигурациями длины
называются единичными конфигурациями длины  а последовательности
а последовательности  длины
длины  проверочными конфигурациями длины
проверочными конфигурациями длины  Если информационным последовательностям сопоставить двоичные представления
Если информационным последовательностям сопоставить двоичные представления  нечетных целых чисел, а проверочной последовательности — проверочную конфигурацию, то точно так же, как и коды Ивадари, можно построить коды Хегельбергера. Метод декодирования всех этих кодов один и тот же.
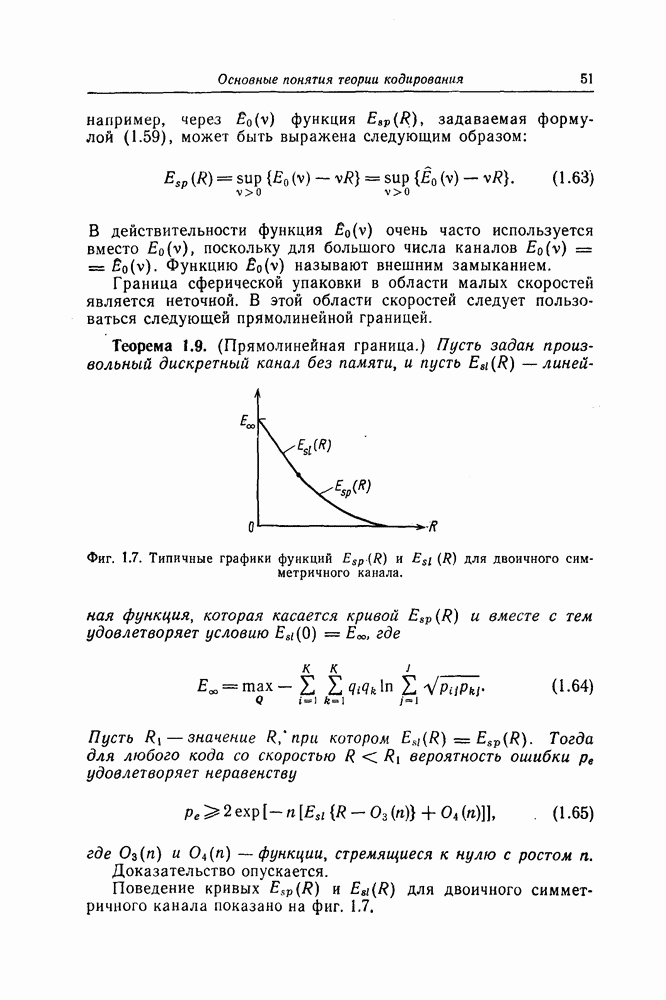
нечетных целых чисел, а проверочной последовательности — проверочную конфигурацию, то точно так же, как и коды Ивадари, можно построить коды Хегельбергера. Метод декодирования всех этих кодов один и тот же.
 в каждой из передаваемых
в каждой из передаваемых
 ошибок, то при возникновении такой пачки ошибок
ошибок, то при возникновении такой пачки ошибок  собственных конфигураций ошибок для каждой из
собственных конфигураций ошибок для каждой из  передаваемых последовательностей должны появиться в синдроме. Задача построения кода, удовлетворяющего указанным выше требованиям, сводится к тому, чтобы разместить эти конфигурации в синдроме так, чтобы они не накладывались друг на друга и при декодировании их можно было бы безошибочно выделить. В целях упрощения последовательность ошибок, возникающих в
передаваемых последовательностей должны появиться в синдроме. Задача построения кода, удовлетворяющего указанным выше требованиям, сводится к тому, чтобы разместить эти конфигурации в синдроме так, чтобы они не накладывались друг на друга и при декодировании их можно было бы безошибочно выделить. В целях упрощения последовательность ошибок, возникающих в  передаваемой последовательности с момента времени 0 до момента времени
передаваемой последовательности с момента времени 0 до момента времени  будем обозначать в дальнейшем как
будем обозначать в дальнейшем как

 ошибка в момент времени
ошибка в момент времени  передаваемой последовательности.
передаваемой последовательности.
 информационной последовательности, затем ошибки, появившиеся в
информационной последовательности, затем ошибки, появившиеся в  информационной последовательности, и наконец ошибки, возникшие в 1-й информационной последовательности. Это позволяет правильно исправить ошибки даже в случае, если они возникли за пределами 1-й информационной последовательности. При этом используется свойство ошибок возникать пачками. Следует также обратить внимание на то, что если при декодировании рассматриваемых здесь кодов ошибки различных информационных последовательностей исправляются раздельно, то при декодировании рассмотренных ранее самоортогональных и ортогонализируемых кодов, предназначенных для исправления случайных ошибок, сначала исправляются ошибки, возникшие в момент времени 0 во всех по — 1 информационных последовательностях, затем одновременно исправляются ошибки, возникшие в
информационной последовательности, и наконец ошибки, возникшие в 1-й информационной последовательности. Это позволяет правильно исправить ошибки даже в случае, если они возникли за пределами 1-й информационной последовательности. При этом используется свойство ошибок возникать пачками. Следует также обратить внимание на то, что если при декодировании рассматриваемых здесь кодов ошибки различных информационных последовательностей исправляются раздельно, то при декодировании рассмотренных ранее самоортогональных и ортогонализируемых кодов, предназначенных для исправления случайных ошибок, сначала исправляются ошибки, возникшие в момент времени 0 во всех по — 1 информационных последовательностях, затем одновременно исправляются ошибки, возникшие в  информационных последовательностях в момент времени 1, и т. д.
информационных последовательностях в момент времени 1, и т. д.
 передаваемой последовательности проверочную конфигурацию длины
передаваемой последовательности проверочную конфигурацию длины  передаваемой последовательности единичную конфигурацию длины
передаваемой последовательности единичную конфигурацию длины  сформируем
сформируем

 единичных конфигураций обнаружить не удается, то этот ненулевой символ синдрома сдвигается в регистр.
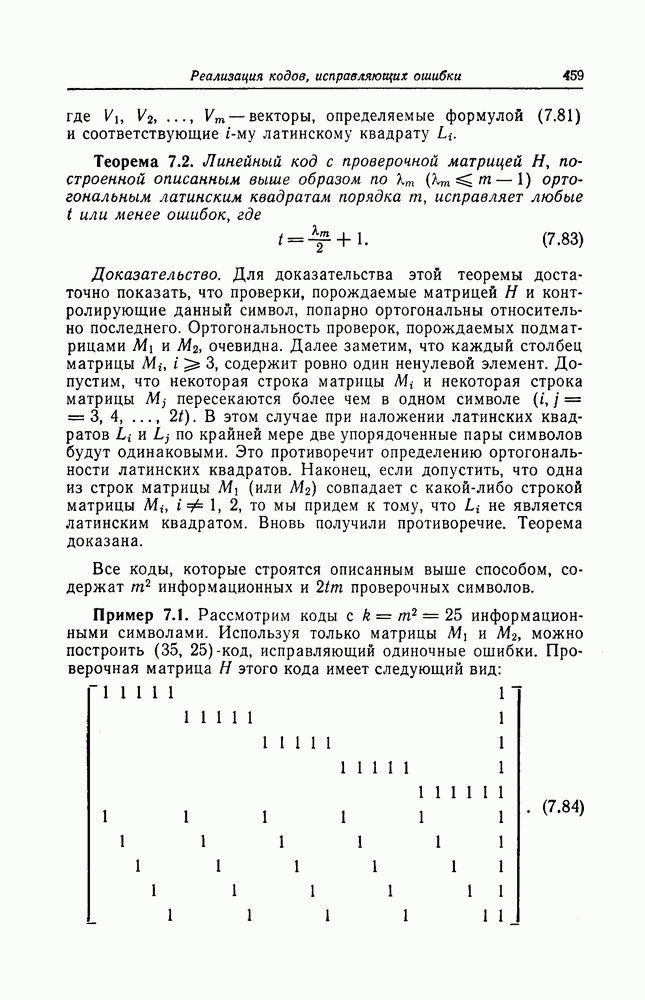
единичных конфигураций обнаружить не удается, то этот ненулевой символ синдрома сдвигается в регистр.
 единичных конфигураций, по длине этой конфигурации определяется номер переданной последовательности, в которой возникла ошибка, породившая эту конфигурацию, а символ, входящий в эту конфигурацию, дает значение ошибки. Это позволяет исправить обнаруженную ошибку и провести исправление синдрома.
единичных конфигураций, по длине этой конфигурации определяется номер переданной последовательности, в которой возникла ошибка, породившая эту конфигурацию, а символ, входящий в эту конфигурацию, дает значение ошибки. Это позволяет исправить обнаруженную ошибку и провести исправление синдрома.
 возникших в
возникших в  передаваемой последовательности (проверочной последовательности), для исправления ошибок в информационных передаваемых последовательностях не используется. Величину х следует выбрать так, чтобы указанные выше операции 1—3 выполнялись без ошибок и длина синдрома была бы по возможности минимальной. Этим условиям удовлетворяет
передаваемой последовательности (проверочной последовательности), для исправления ошибок в информационных передаваемых последовательностях не используется. Величину х следует выбрать так, чтобы указанные выше операции 1—3 выполнялись без ошибок и длина синдрома была бы по возможности минимальной. Этим условиям удовлетворяет  Таким образом строятся коды типа I,
Таким образом строятся коды типа I,


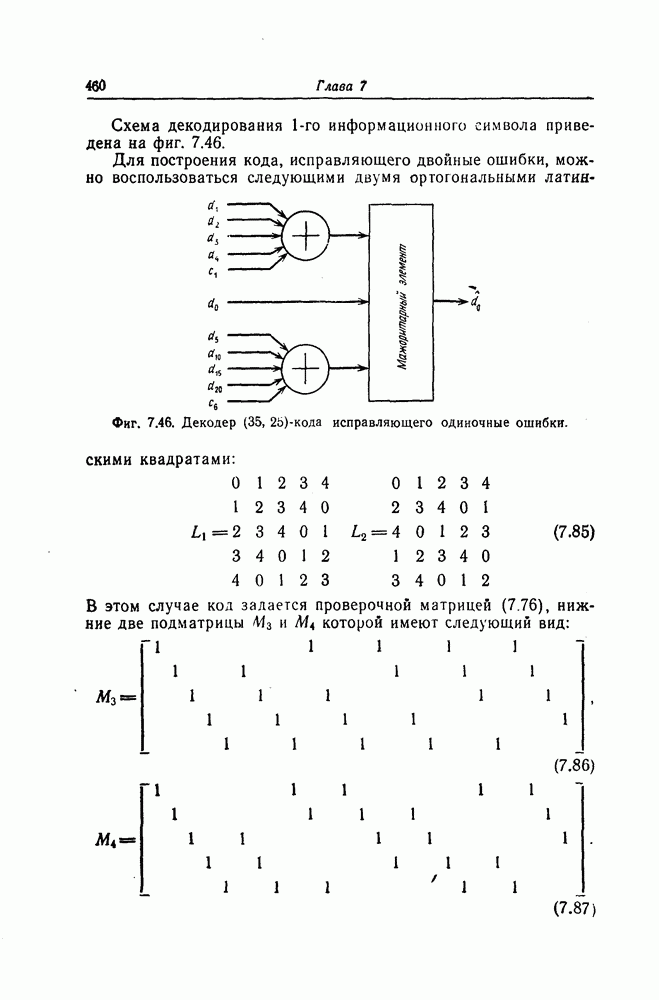
 можно получить следующий код. Код типа II [11, 12]:
можно получить следующий код. Код типа II [11, 12]:


 Согласно формуле (5.80), этот код задается порождающими многочленами
Согласно формуле (5.80), этот код задается порождающими многочленами



 его единичная конфигурация образована быть не может и до этого момента поступающие символы ошибок просто направляются в регистр сдвига. При появлении 2-го символа
его единичная конфигурация образована быть не может и до этого момента поступающие символы ошибок просто направляются в регистр сдвига. При появлении 2-го символа  алгоритм обнаружит две единичные конфигурации длины 10 и 9, образованные этим символом соответственно с 1-м символом
алгоритм обнаружит две единичные конфигурации длины 10 и 9, образованные этим символом соответственно с 1-м символом  символом
символом  Согласно правилу запрета, алгоритм выбирает конфигурацию длины 10, исправляет
Согласно правилу запрета, алгоритм выбирает конфигурацию длины 10, исправляет  и устраняет воздействие
и устраняет воздействие  на
на  После этого синдром принимает следующий вид:
После этого синдром принимает следующий вид: 



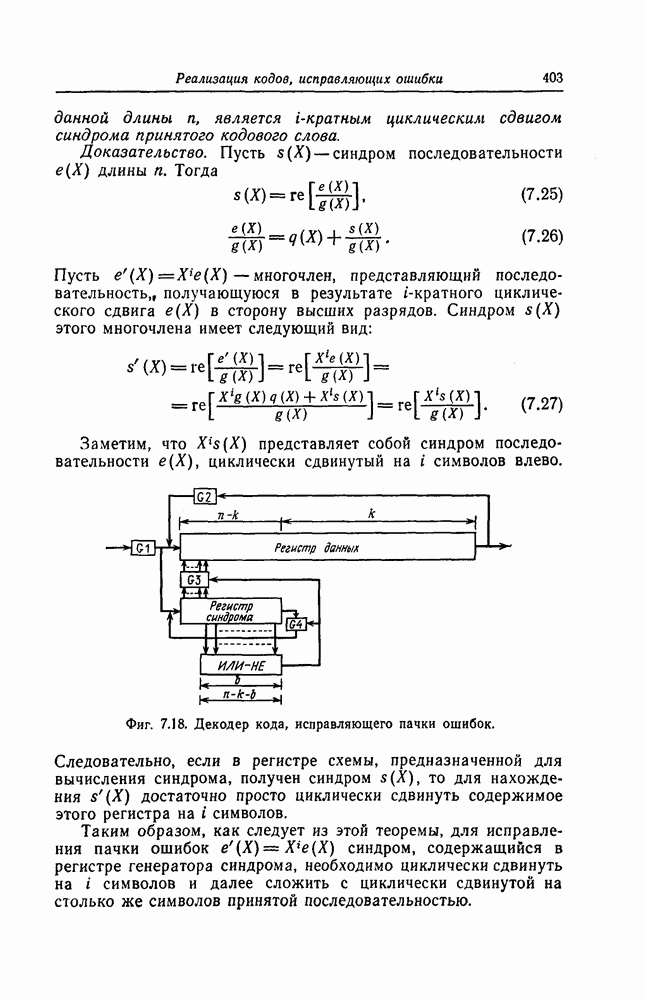
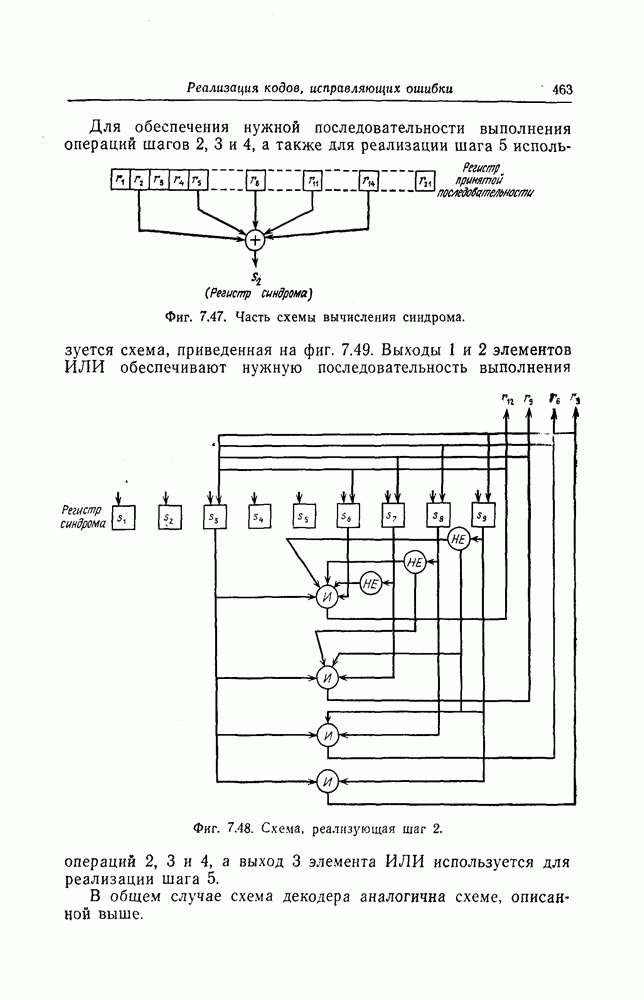
 гарантирует, что влияние возникшей ошибки распространяется только на последующие ошибки в синдроме, а дополнительный защитный интервал доп гарантирует, что все ненулевые символы будут из декодирующей логической схемы удалены.
гарантирует, что влияние возникшей ошибки распространяется только на последующие ошибки в синдроме, а дополнительный защитный интервал доп гарантирует, что все ненулевые символы будут из декодирующей логической схемы удалены.

 Известно, что при
Известно, что при  эти коды оказываются почти тривиальными, допускающими мажоритарное декодирование [10, 12].
эти коды оказываются почти тривиальными, допускающими мажоритарное декодирование [10, 12].
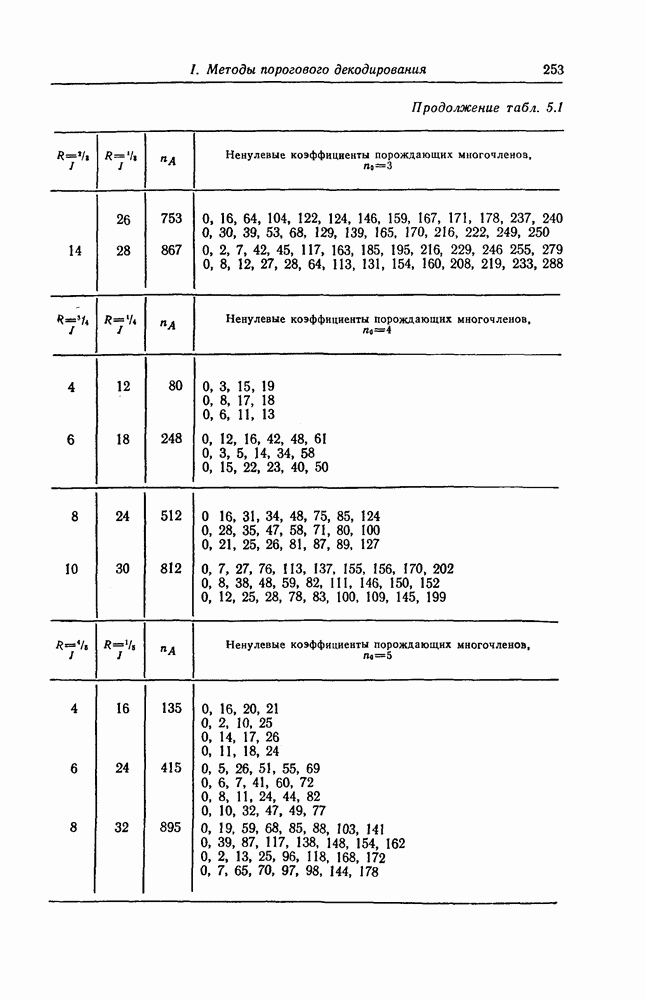
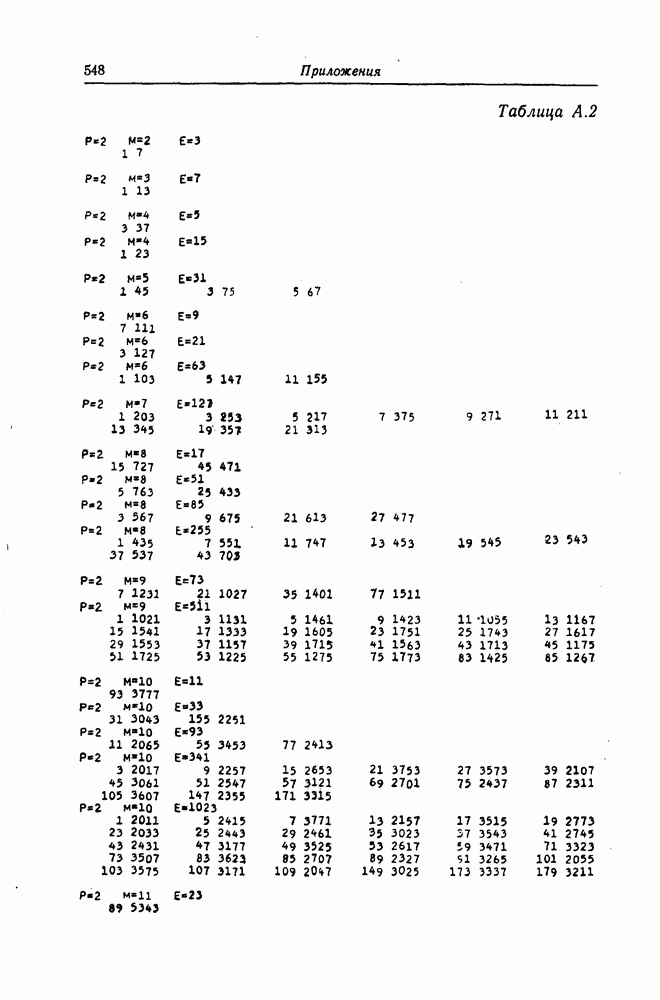
 и менее. Однако известны коды [41], которые позволяют исправлять почти все пачки ошибок длины до
и менее. Однако известны коды [41], которые позволяют исправлять почти все пачки ошибок длины до  имеют скорость
имеют скорость  и защитный интервал, несколько больший чем
и защитный интервал, несколько больший чем  Эти коды имеют несколько лучшие корректирующие способности, благодаря чему необходим меньший защитный интервал. Кроме того, эти коды позволяют исправлять также и случайные ошибки.
Эти коды имеют несколько лучшие корректирующие способности, благодаря чему необходим меньший защитный интервал. Кроме того, эти коды позволяют исправлять также и случайные ошибки.
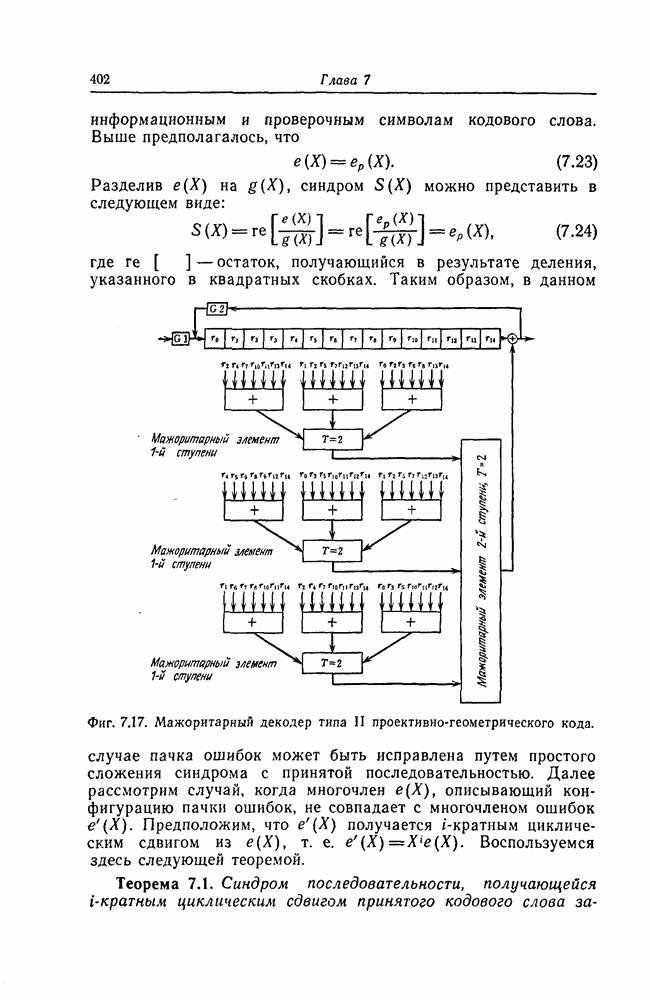
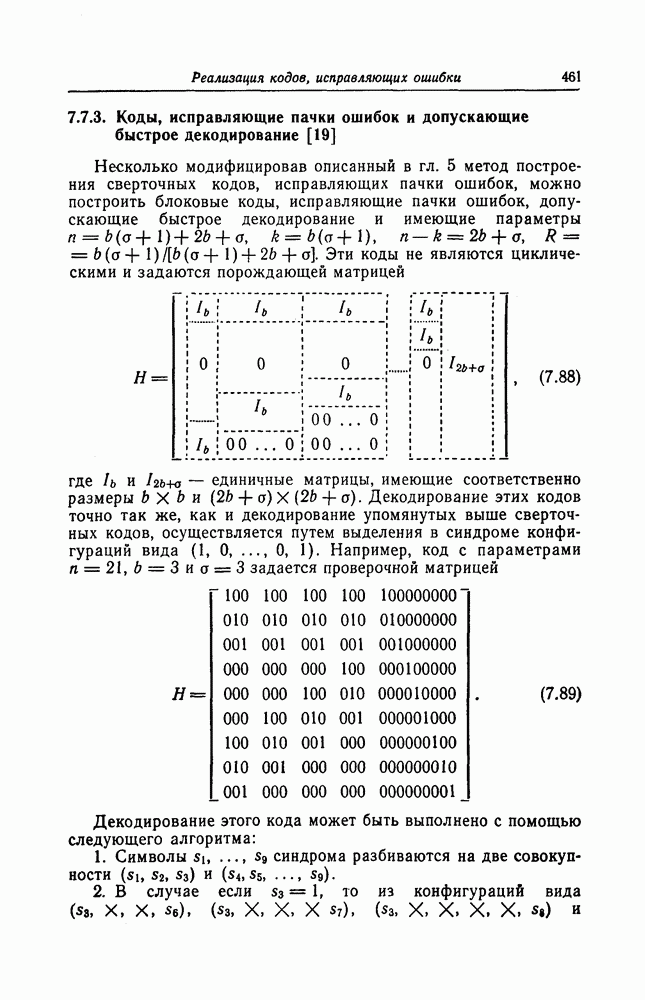
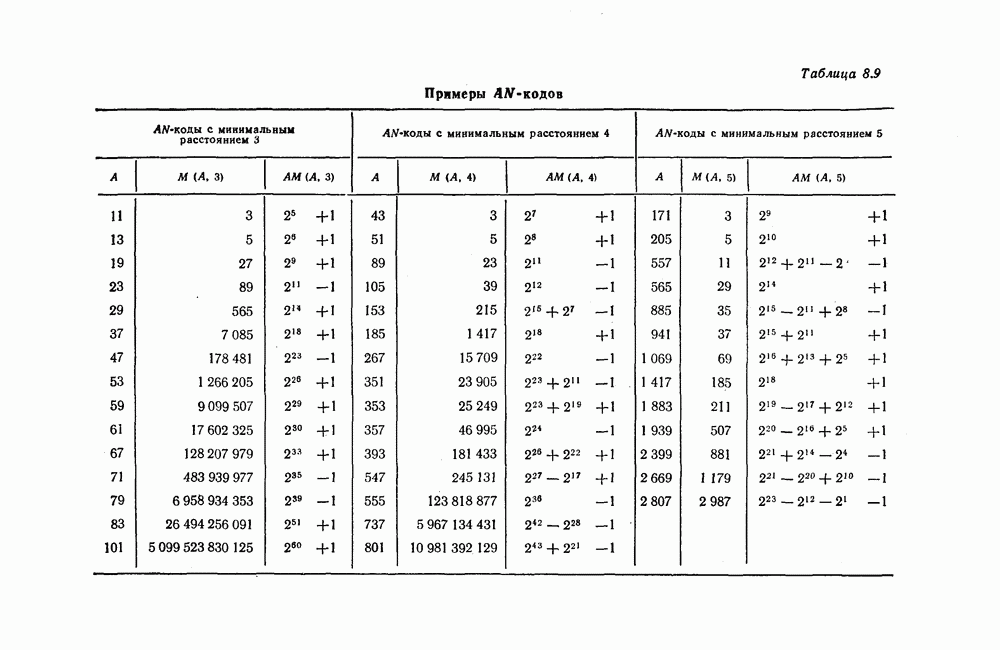
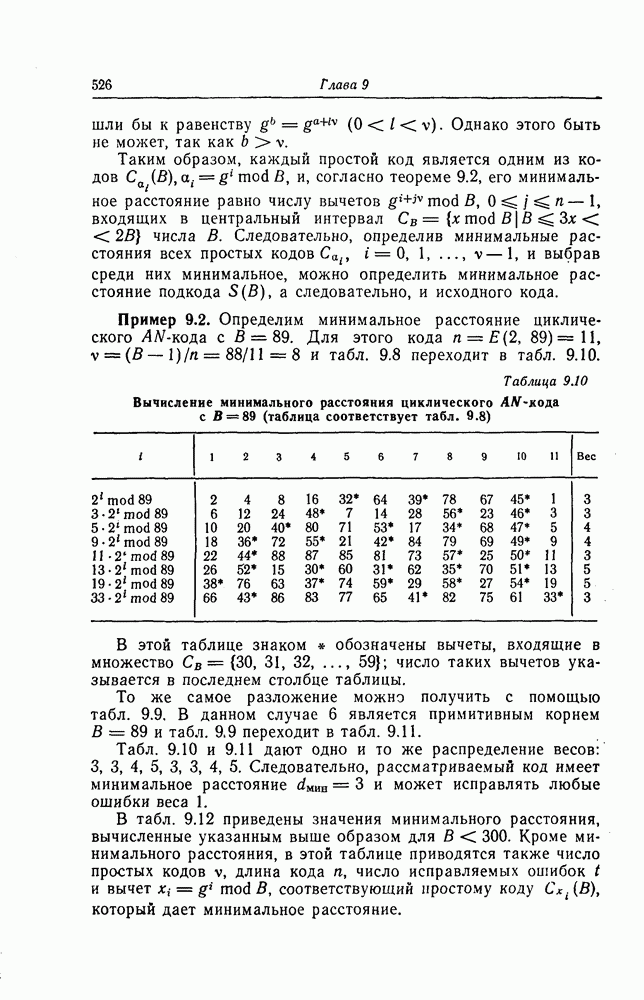
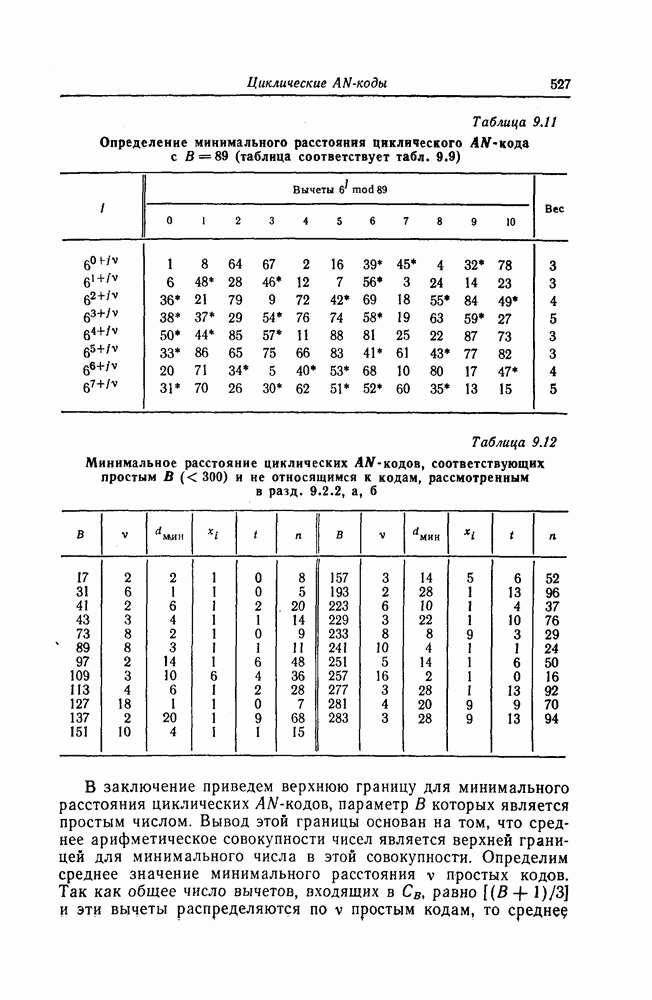
 а 26, довольно трудно. Как указывается в гл. 7 и как в этом действительно нетрудно убедиться, рассмотренные коды соответствуют блоковым кодам с числом проверочных символов
а 26, довольно трудно. Как указывается в гл. 7 и как в этом действительно нетрудно убедиться, рассмотренные коды соответствуют блоковым кодам с числом проверочных символов  То, что эти коды можно строить регулярным методом, объясняется тем, что они имеют очень простые алгоритмы кодирования и декодирования и, кроме того, позволяют изменять избыточность. Коды с числом избыточных символов
То, что эти коды можно строить регулярным методом, объясняется тем, что они имеют очень простые алгоритмы кодирования и декодирования и, кроме того, позволяют изменять избыточность. Коды с числом избыточных символов  являются наилучшими среди кодов, имеющих ту же длину и исправляющих пачки ошибок длины
являются наилучшими среди кодов, имеющих ту же длину и исправляющих пачки ошибок длины  Известно, что если число проверочных символов больше
Известно, что если число проверочных символов больше  то вероятность возникновения в пределах одного блока или кодового ограничения двух пачек ошибок становится большой, а следовательно, становится большой и вероятность ошибочного декодирования.
то вероятность возникновения в пределах одного блока или кодового ограничения двух пачек ошибок становится большой, а следовательно, становится большой и вероятность ошибочного декодирования.