Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
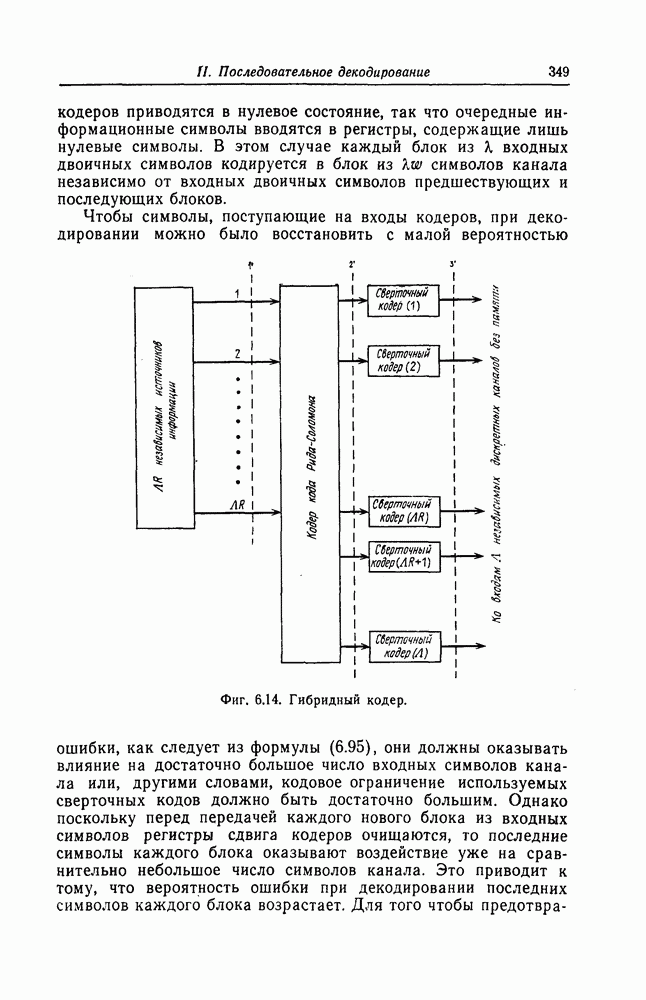
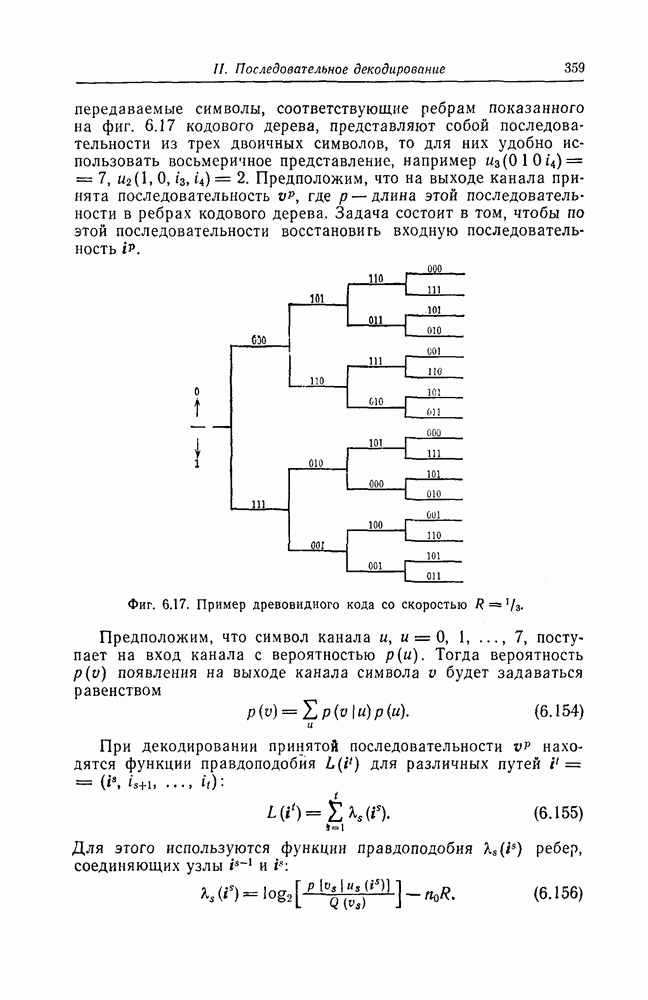
5.1.2. Методы последовательного декодированияПоследовательное декодирование было введено Возенкрафтом [14] раньше, чем пороговое декодирование, и на начальном этапе исследования в этой области велись главным образом в МТИ. Этот метод, приближающийся по своим характеристикам к методу декодирования по максимуму правдоподобия, требует для декодирования одного символа тем меньше операций, чем меньше уровень шума в канале; в отличие от этого при декодировании по максимуму правдоподобия число операций постоянно и достаточно велико, поскольку оно определяется максимальным уровнем шума в канале. Это свойство последовательного декодирования позволяет упростить требующиеся для его реализации устройства. Предложенный Возенкрафтом алгоритм был положен в основу экспериментов по передаче данных по телефонным каналам, проводившихся в Линкольновской лаборатории МТИ и получивших название SECO [15]. Алгоритм Возенкрафта, предназначавшийся первоначально для двоичного симметричного канала, был обобщен Рейффеном [16] на случай произвольного дискретного канала без памяти. Крупным успехом исследований в этом направлении было открытие алгоритма Фано [17]. Среднее число операций, требующееся для декодирования одного символа при использовании алгоритма Фано, не зависит от кодового ограничения. Допуская простую техническую реализацию, а также обладая рядом других достоинств, этот алгоритм до настоящего времени остается одним из основных алгоритмов. Поскольку алгоритмы последовательного декодирования являются вероятностными, то анализ их работы связан с рядом сложностей. Один из путей преодоления этих сложностей заключается в том, чтобы, как и при доказательстве теоремы кодирования Шеннона для канала с шумом, найти характеристики алгоритма, средние по некоторому ансамблю кодов, и далее, воспользовавшись тем, что по крайней мере для одного из кодов в этом ансамбле характеристики алгоритма не хуже средних, сделать вывод об эффективности того или иного алгоритма. Метод определения границы случайного кодирования, предложенный Галлагером и подробно рассмотренный в гл. 1, также широко применяется для анализа алгоритмов последовательного декодирования. Этим методом вначале Севадж [18] нашел среднее число операций для алгоритма Фано; затем вновь Севадж [19], Джекобе и Берлекэмп [20] и др. показали, что распределение числа операций при декодировании является распределением Парето. Еще одним способом анализа сложных алгоритмов является их моделирование на вычислительной машине. Большая работа по моделированию алгоритмов последовательного декодирования была выполнена Джорданом [21] и др. Кроме этих методов для исследования поведения алгоритмов последовательного декодирования используются также качественные и общие методы. При последовательном декодировании желательно использовать коды с большим минимальным расстоянием и по возможности меньшим кодовым ограничением. Удобно представлять коды в виде кодового дерева. Буссганг [22] опубликовал список кодов со скоростями При последовательном декодировании число операций, необходимых для декодирования одного символа, возрастает по мере увеличения уровня шума в канале. При сильном шуме принятые, но еще не декодированные символы накапливаются в буферной памяти декодера. В тех случаях, когда ожидающая обработки последовательность символов переполняет буферную память, декодер перестает работать правильно. Это явление характерно для последовательного декодирования и известно под названием переполнения буфера. Вероятность переполнения буфера можно вычислить или оценить с помощью распределения Парето для числа операций при декодировании, полученного Севаджем [18], а также Джекобсом и Берлекэмпом [20]. В действительности вероятность переполнения буфера часто оказывается гораздо больше, чем вероятность ошибочного декодирования, и именно она определяет возможности последовательного декодирования. Фальконер [38] предложил гибридный метод декодирования каскадных кодов, сочетающий в себе элементы алгебраического и последовательного декодирования. В качестве внешних кодов он использовал коды Рида — Соломона, а в качестве внутренних кодов — коды, допускающие последовательное декодирование. При этом в случае, если при последовательном декодировании число операций превышает некоторый определенный порог, то соответствующий символ внешнего кода считается стертым. Как показал Фальконер, такой метод декодирования позволяет уменьшить вероятность переполнения буфера. Как уже указывалось выше, алгоритм Фано занимает центральное положение среди алгоритмов последовательного декодирования. Зигангировым [27] и Джелинеком [26] независимо был предложен другой алгоритм последовательного декодирования, известный под названием стек-алгоритма. Этот алгоритм во многих случаях лучше алгоритма Фано; он очень просто описывается и помогает проникнуть в существо различных принципиальных вопросов последовательного декодирования.
|
 |
Оглавление
|
































































































































































































































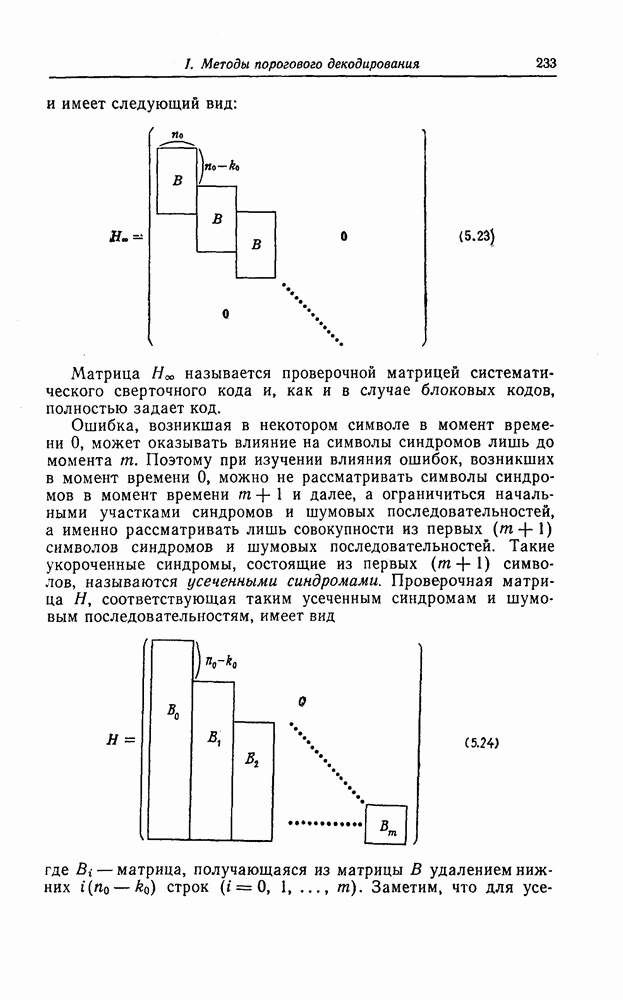
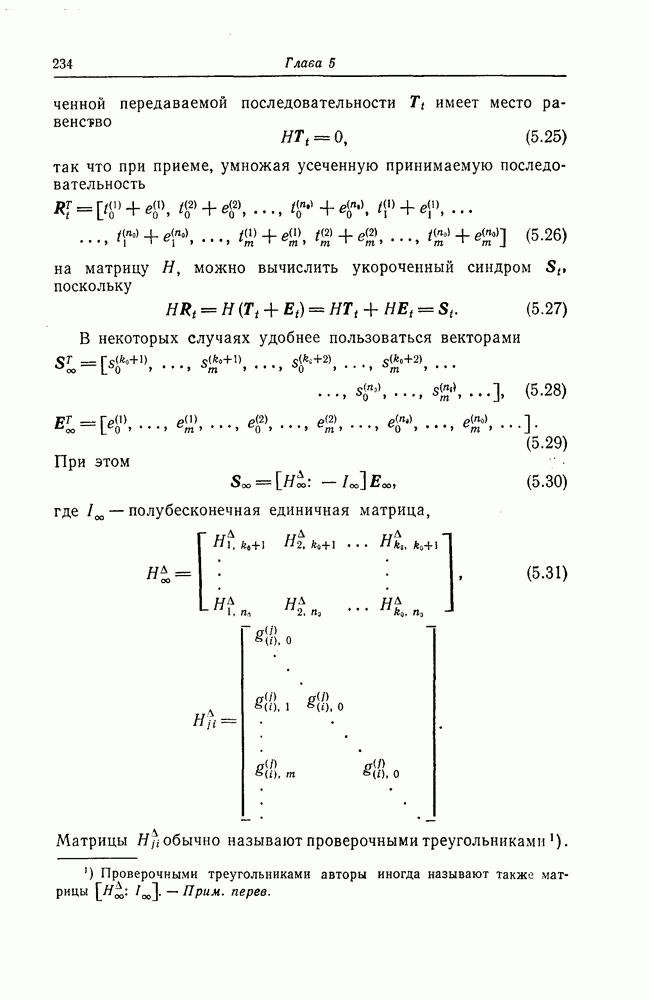
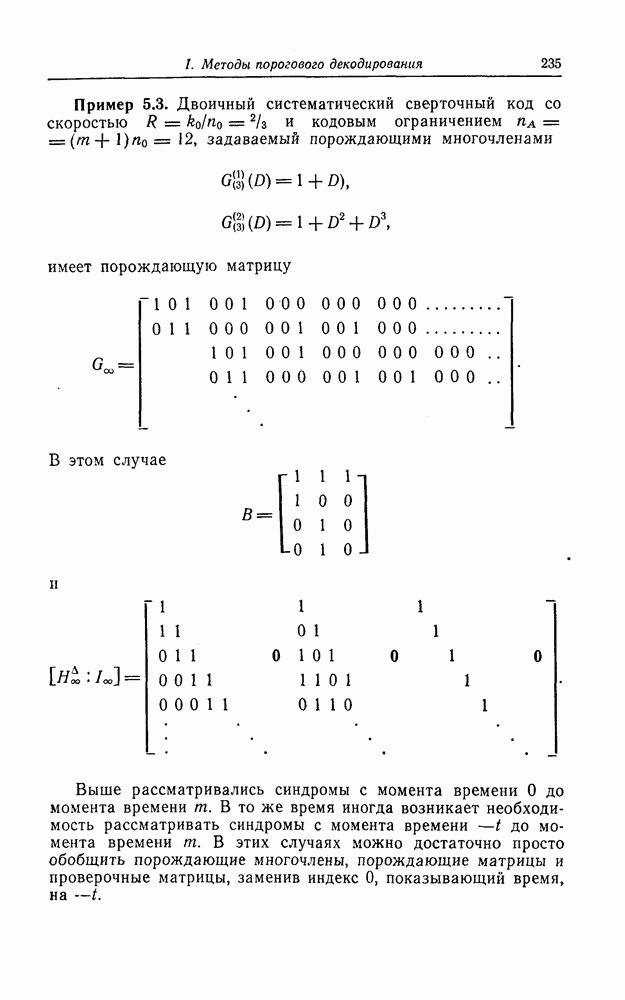

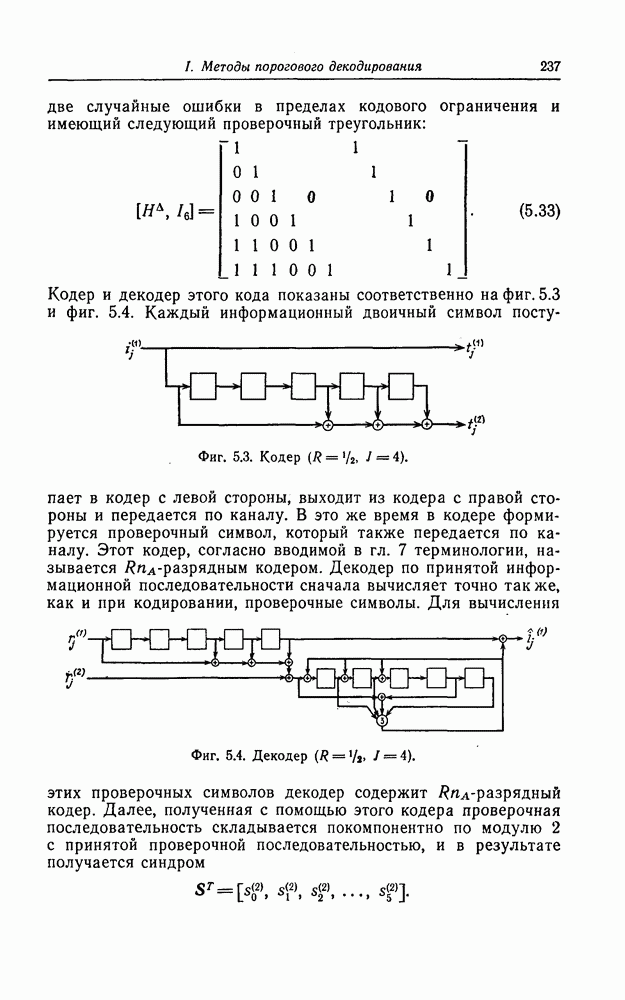
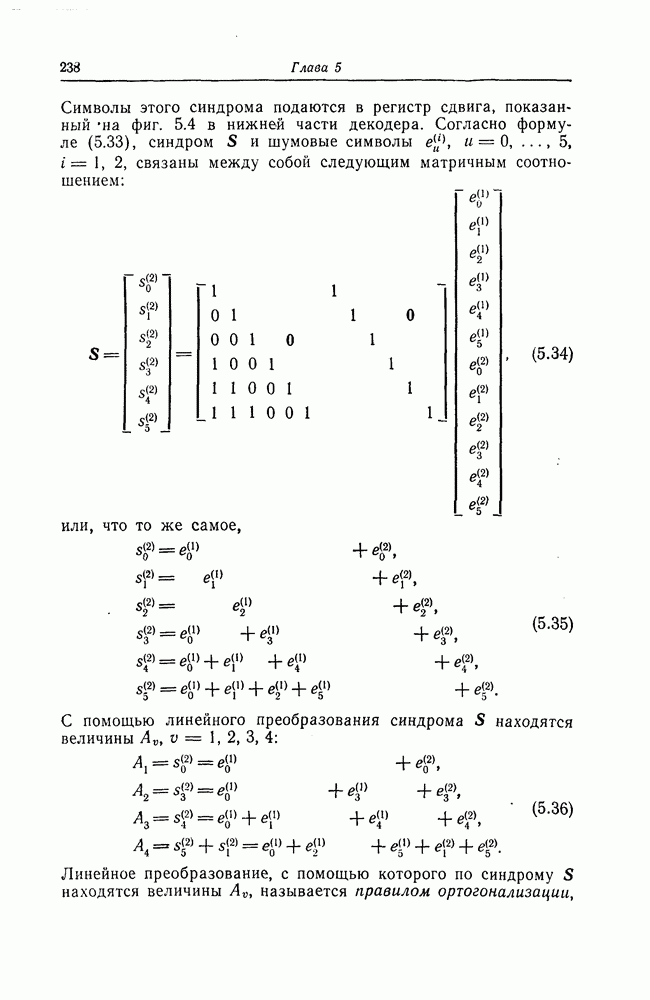














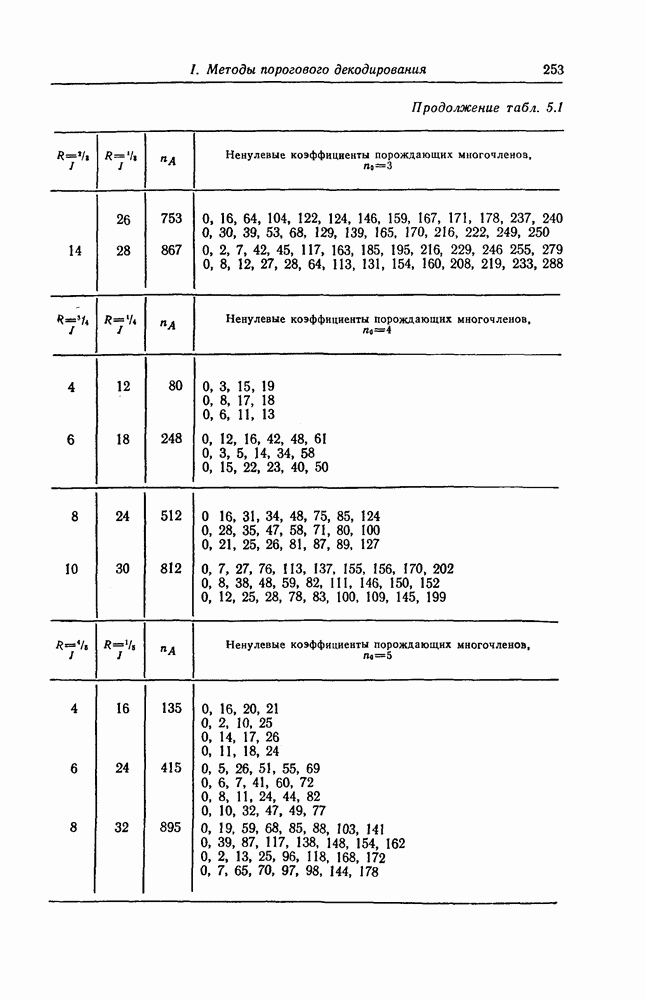





























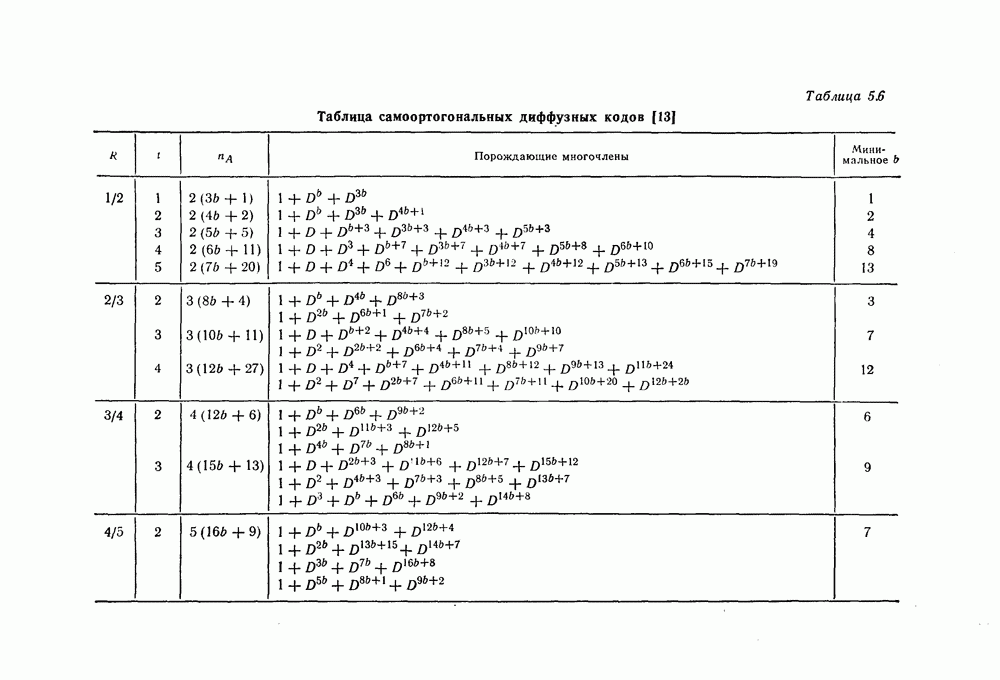

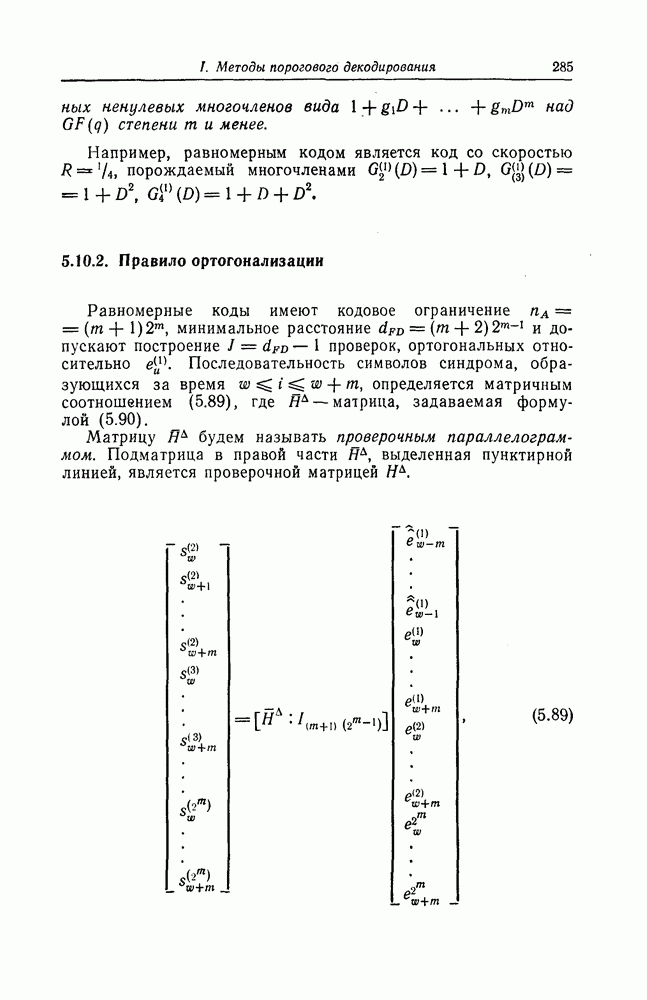

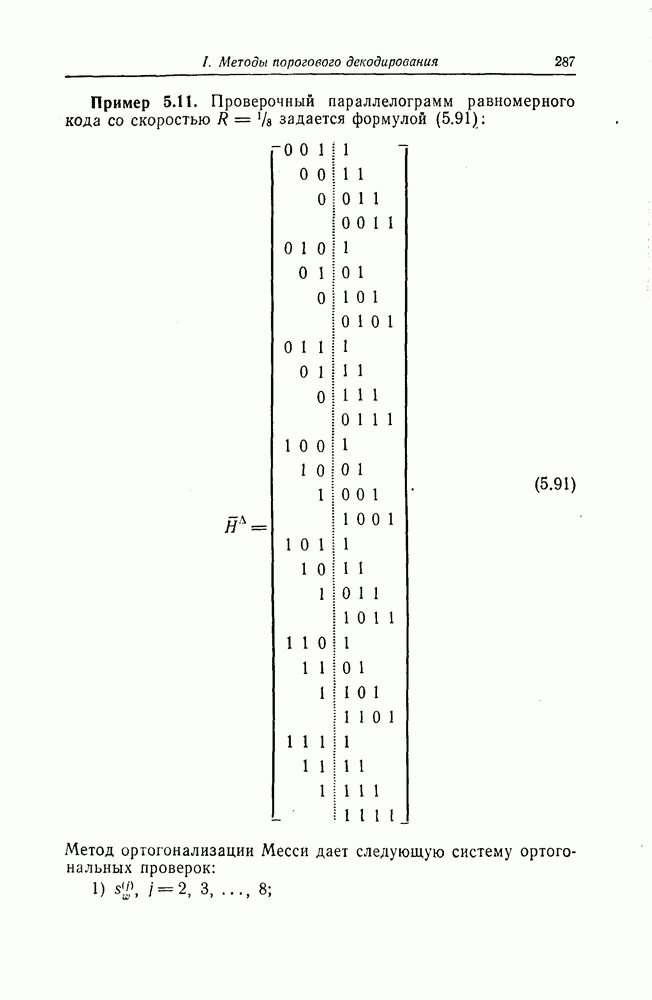












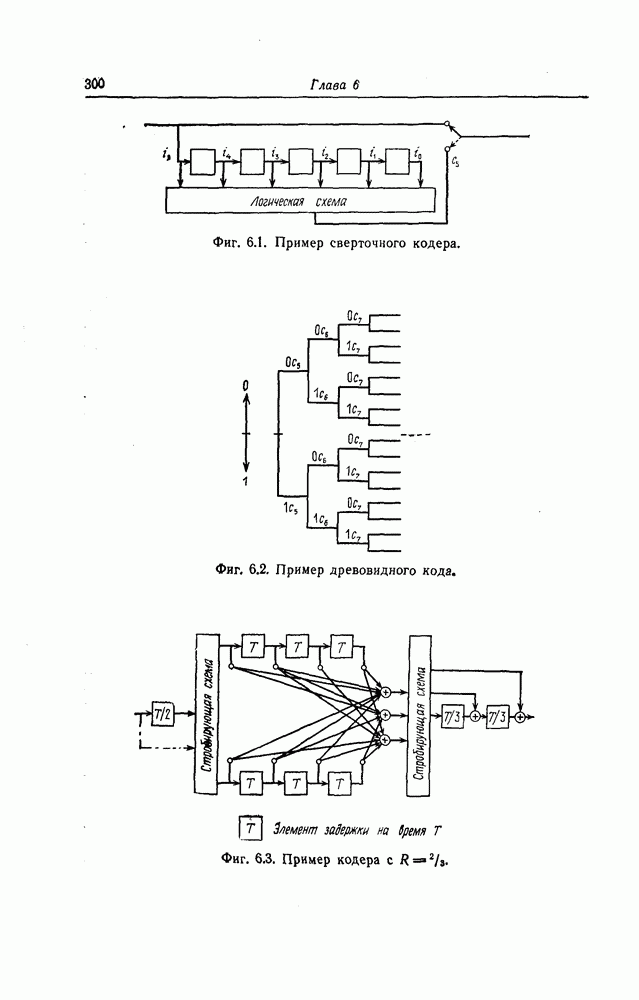


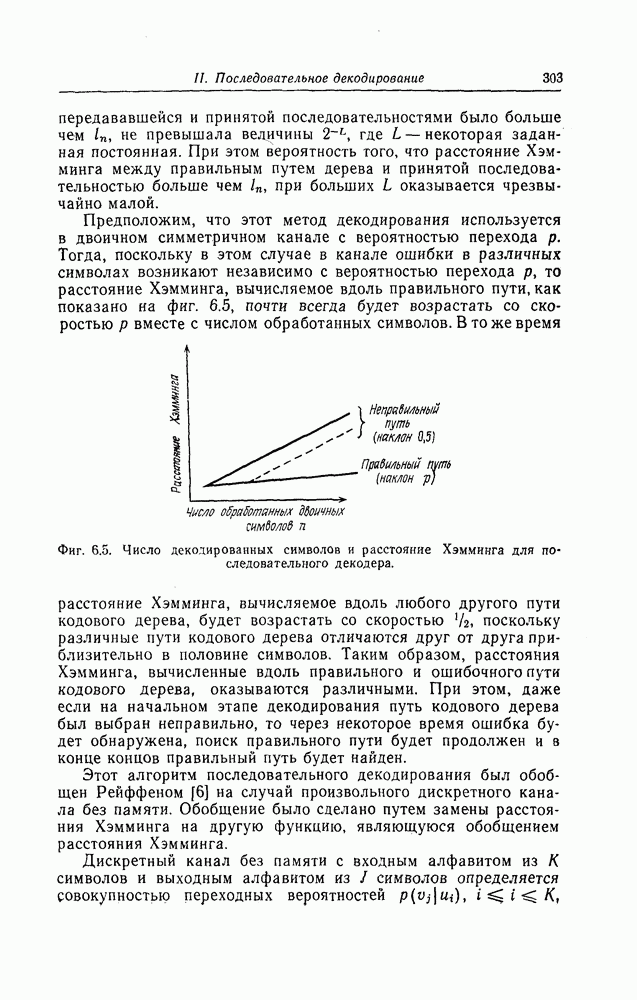





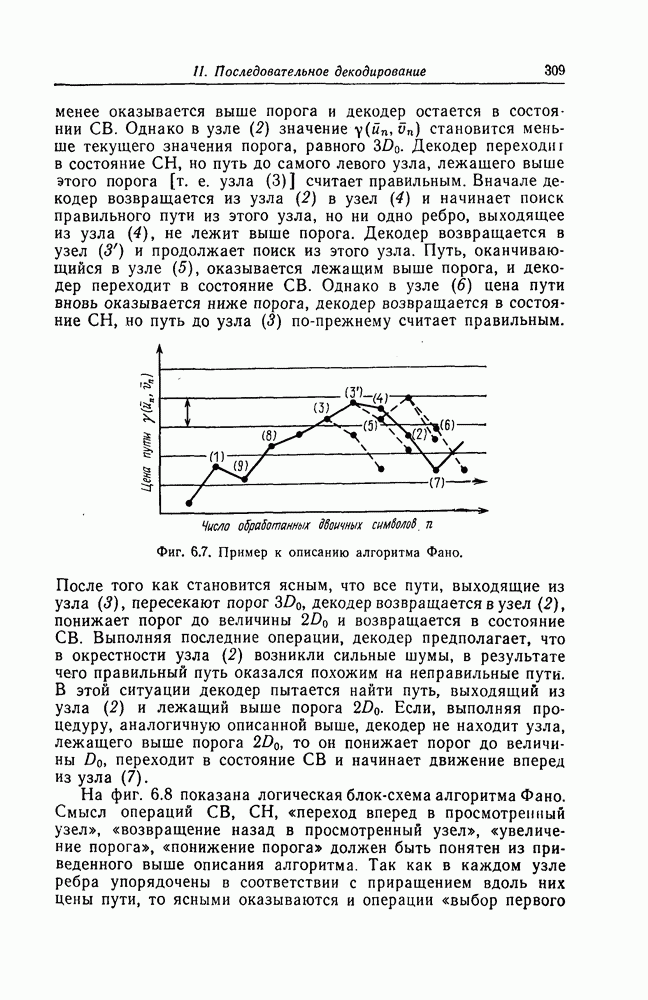
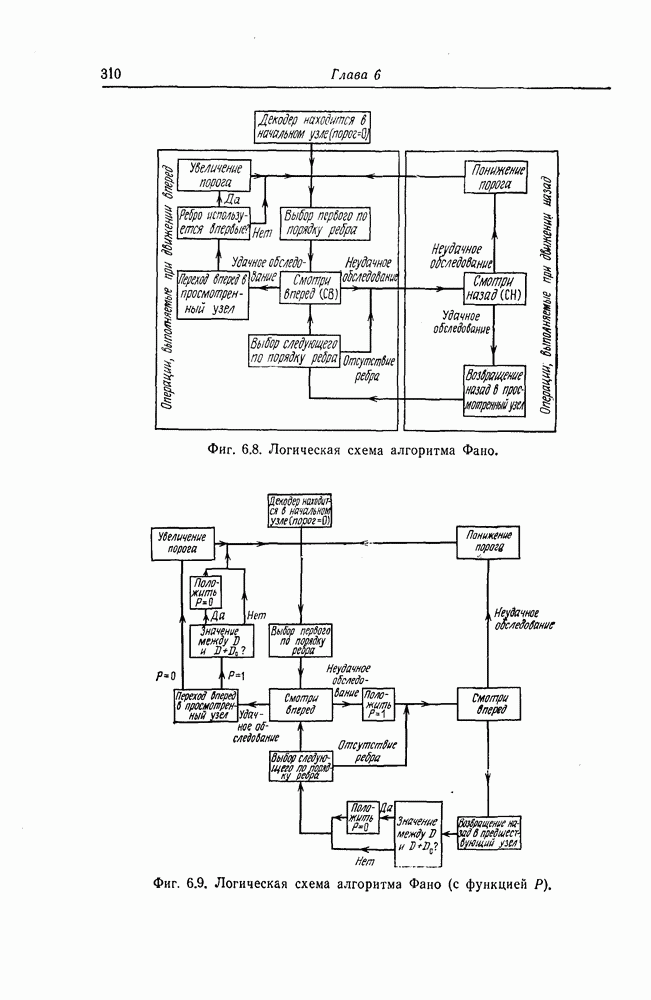

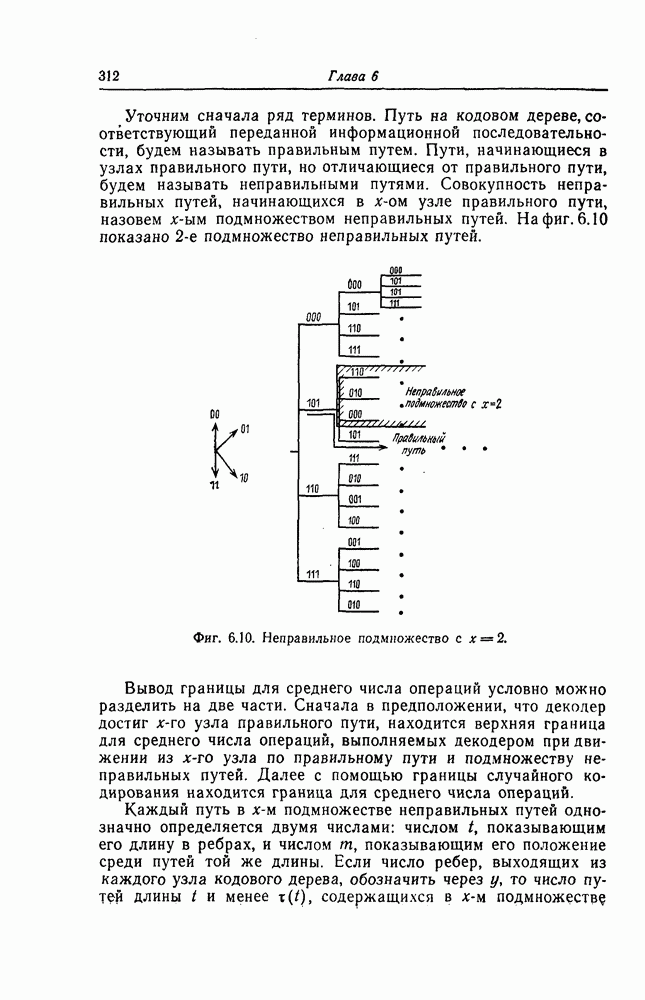














































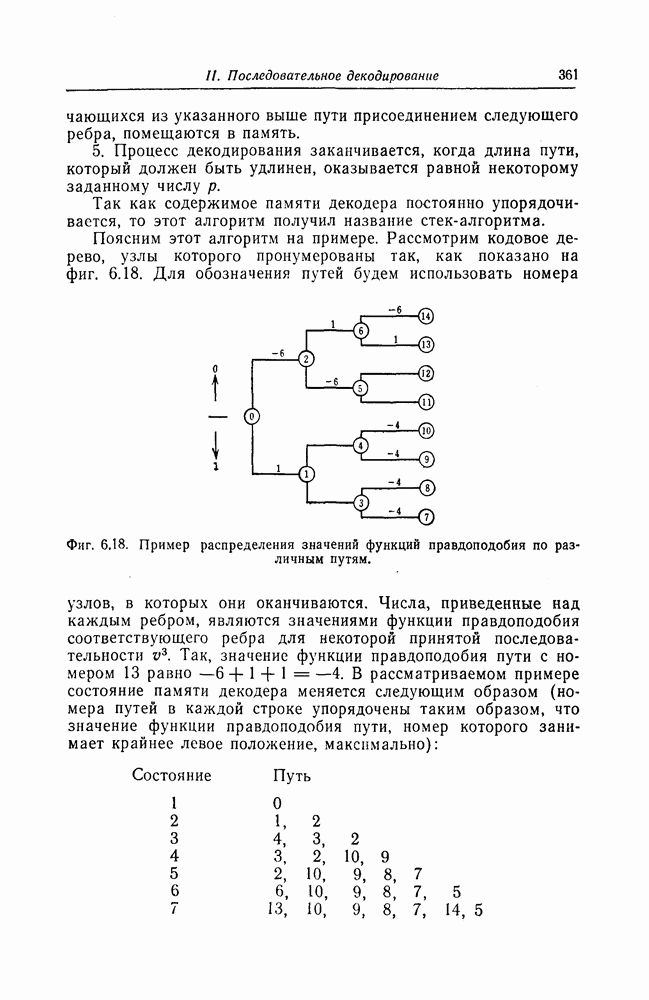












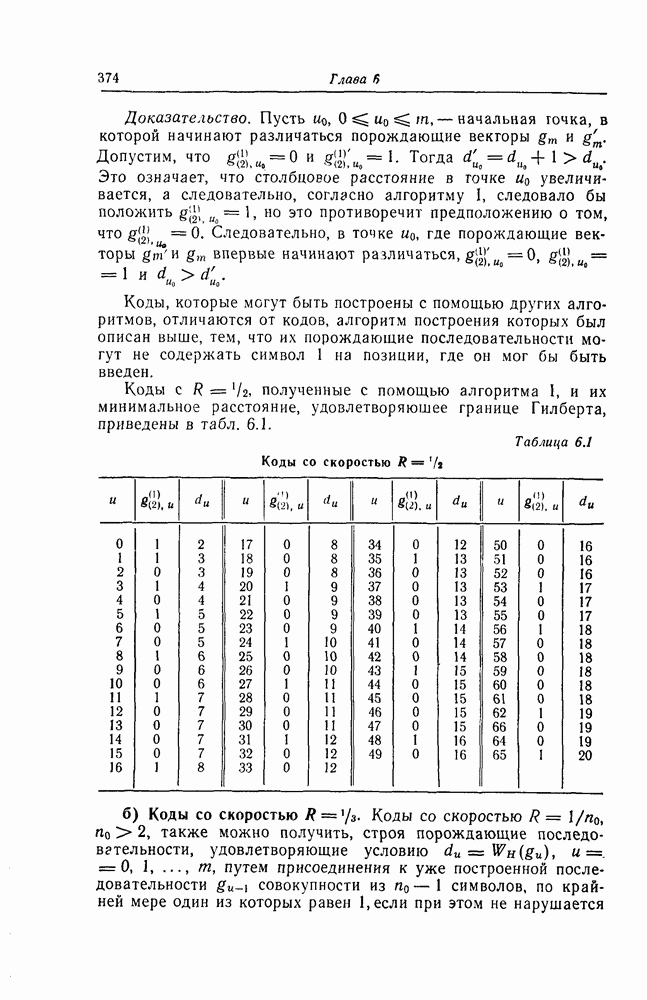




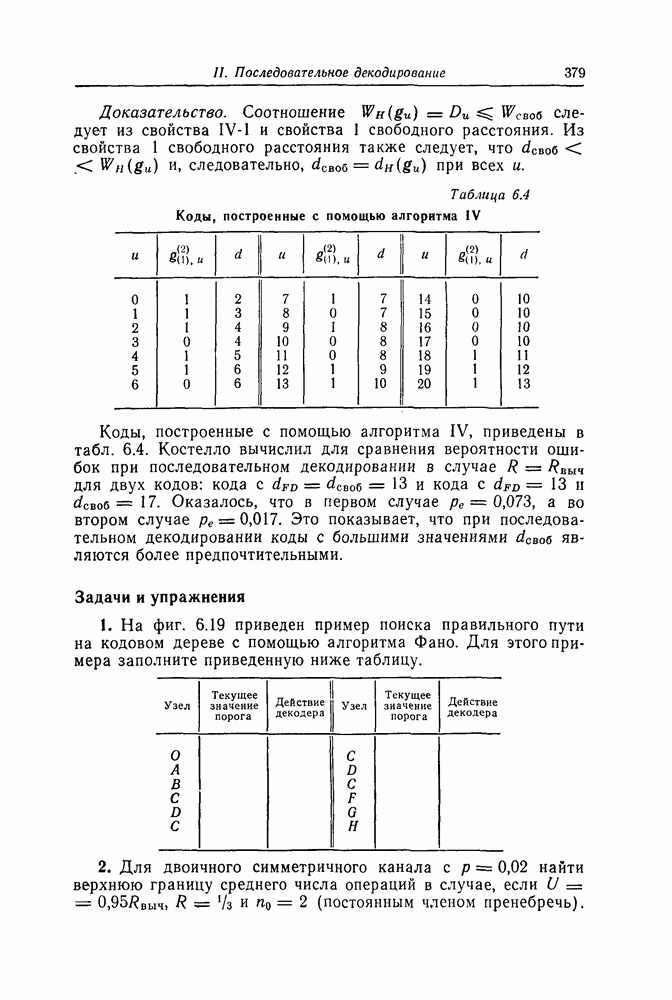
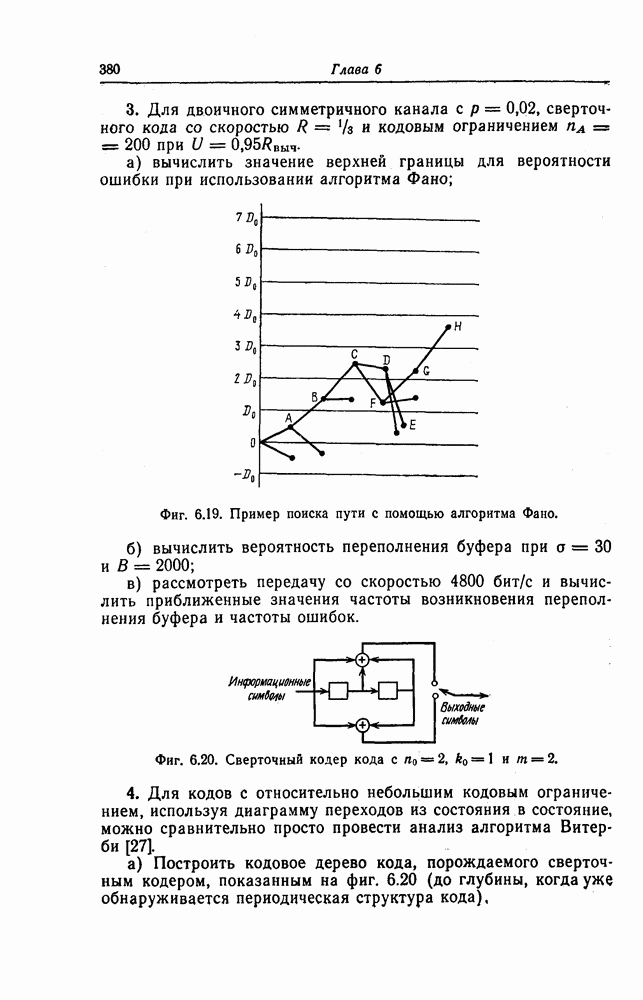










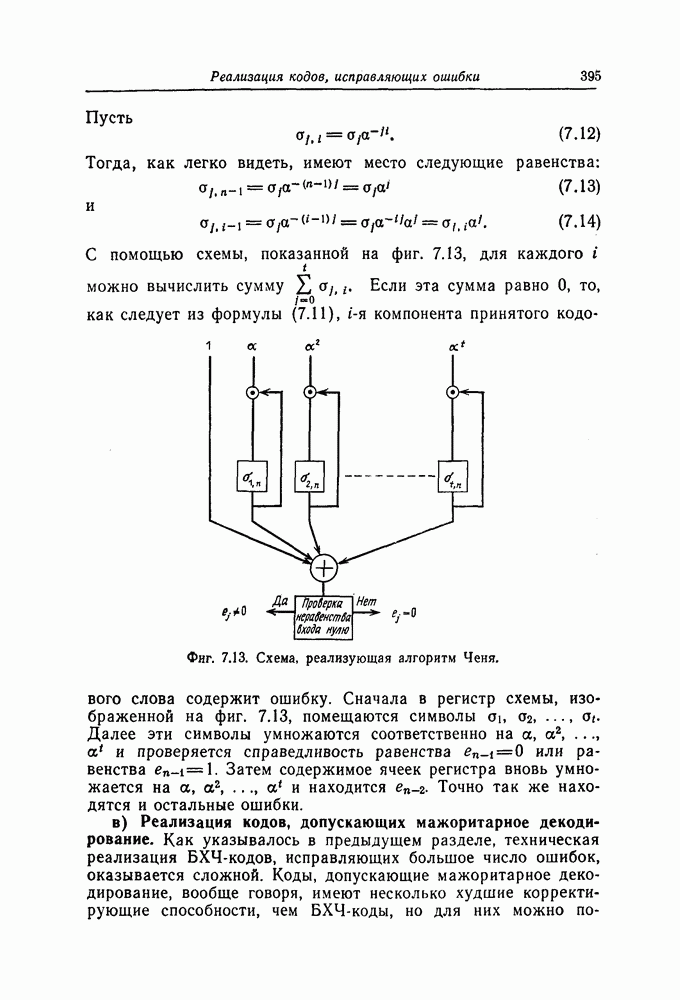

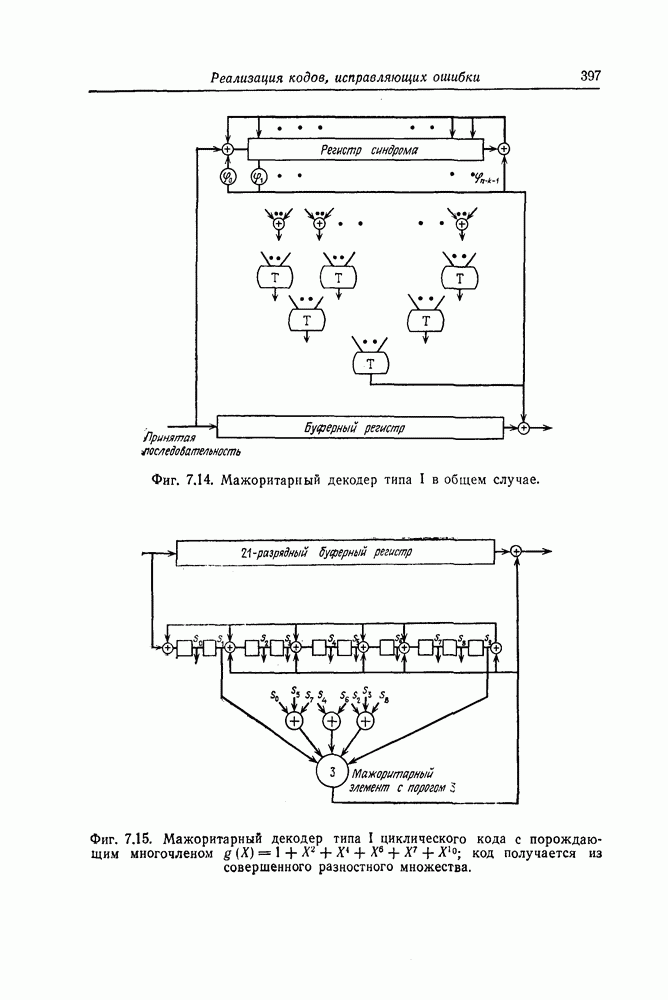




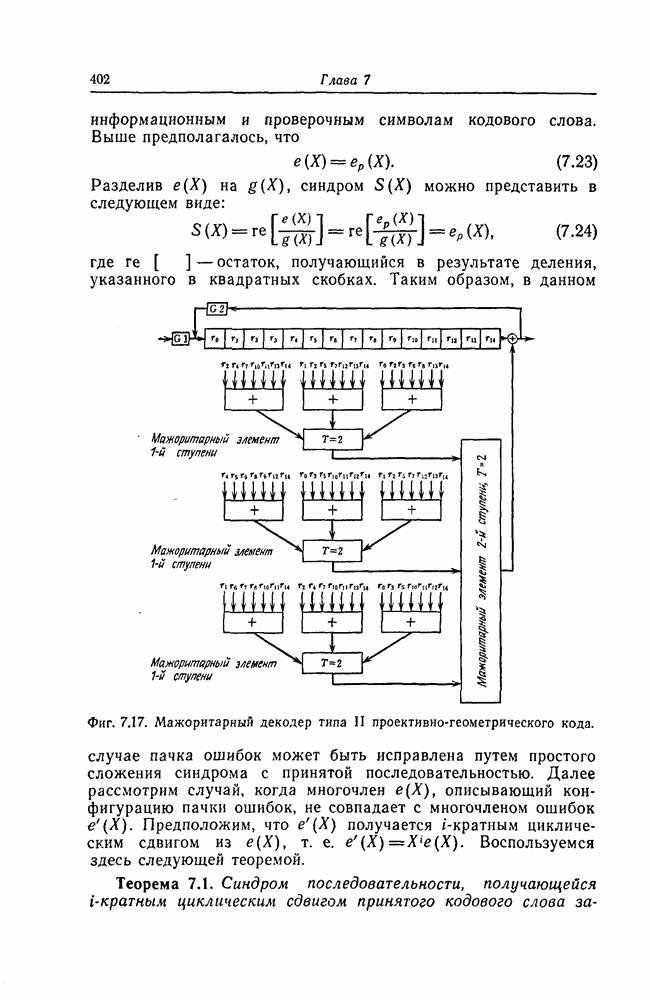
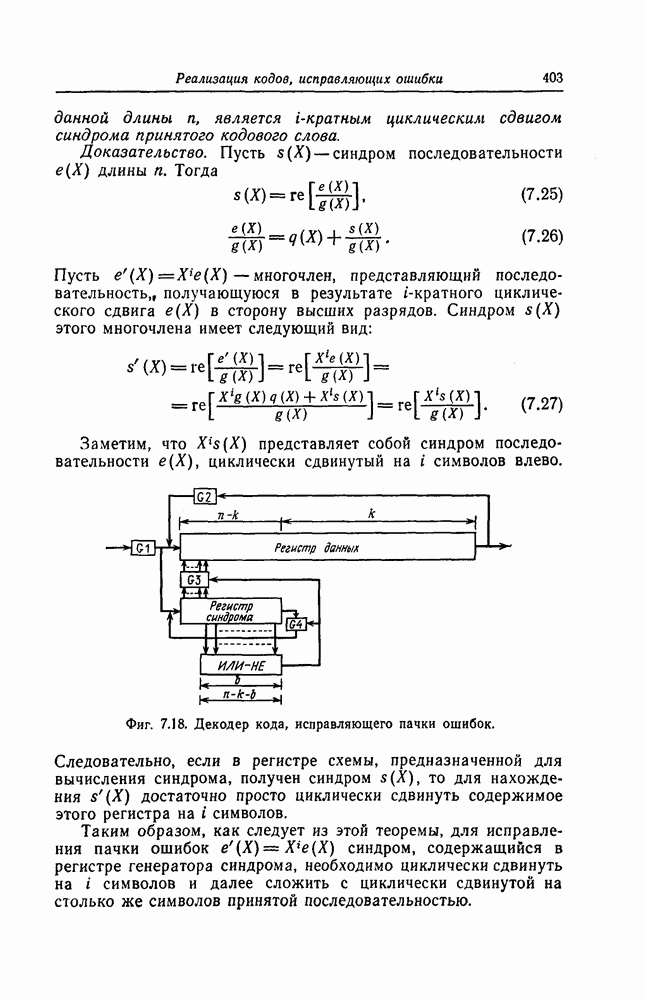


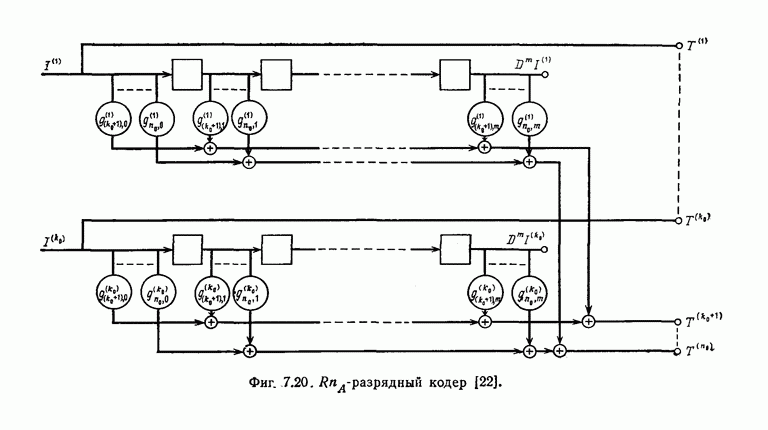

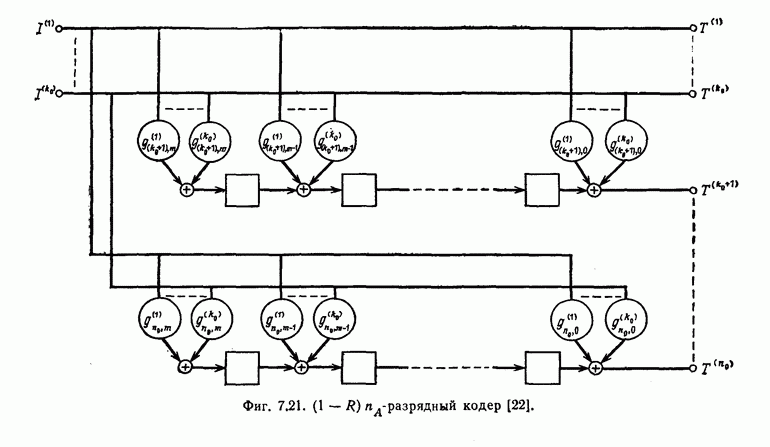
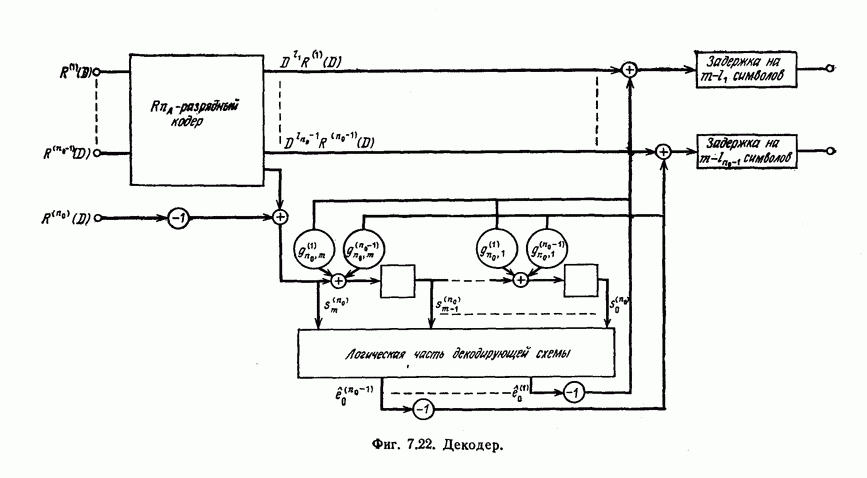



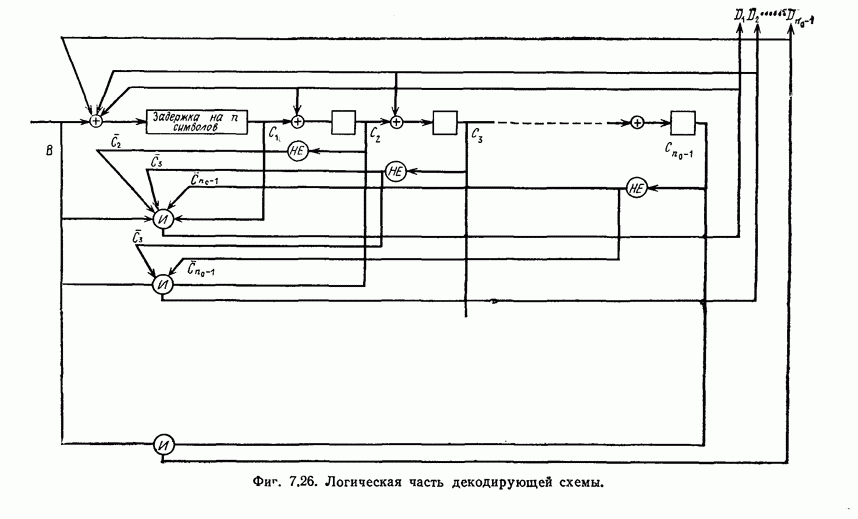
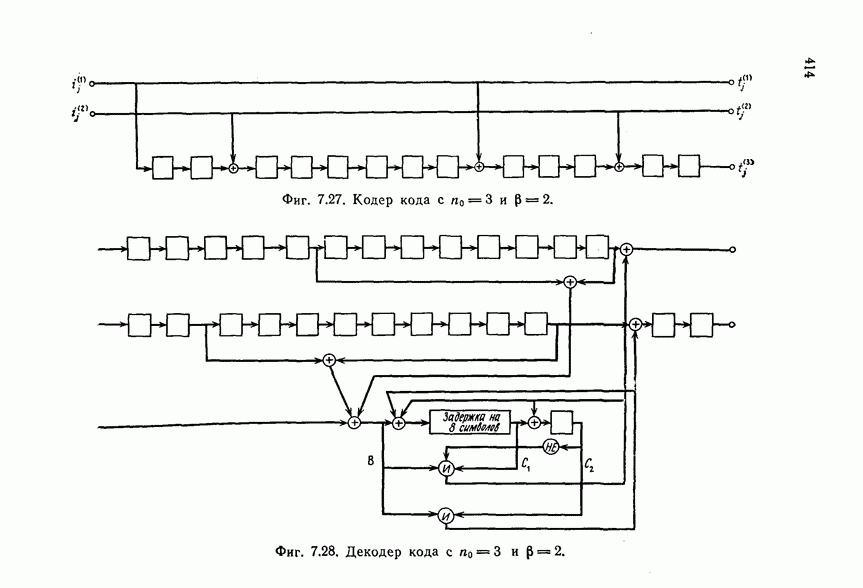


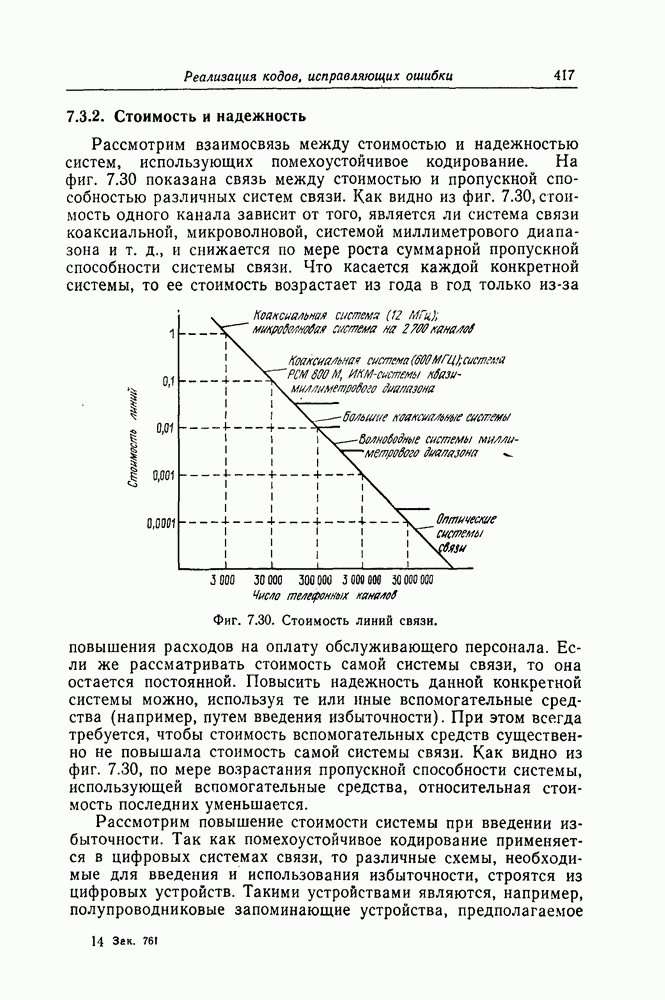





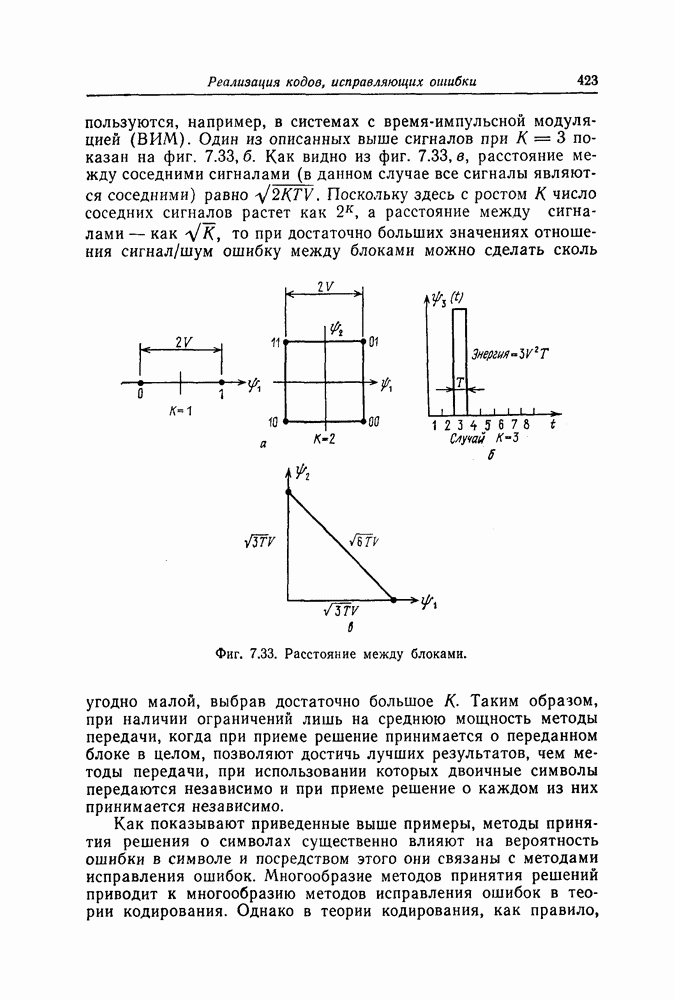
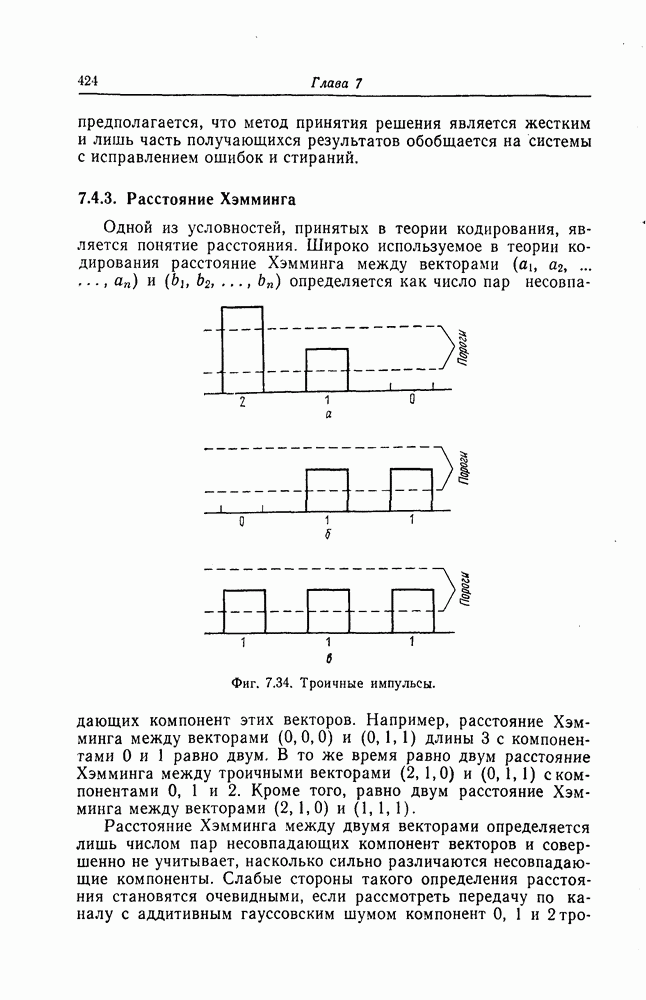











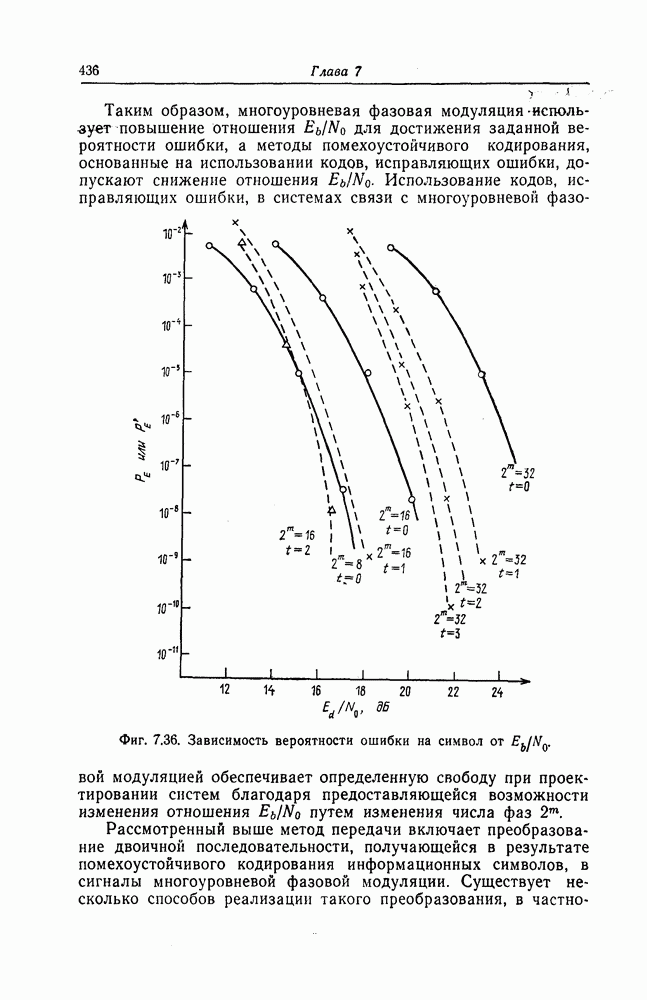



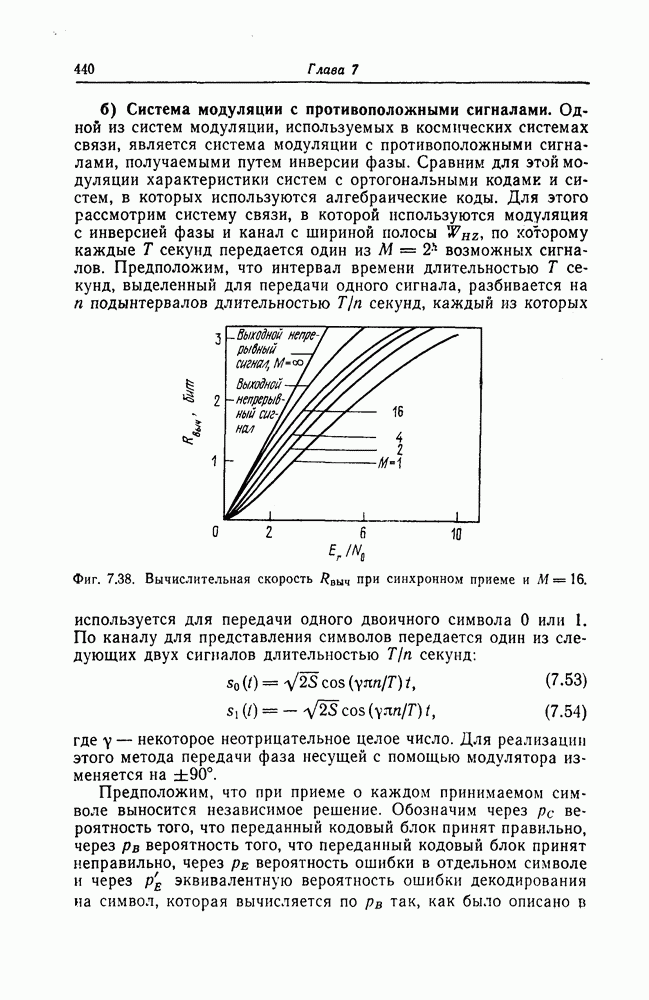

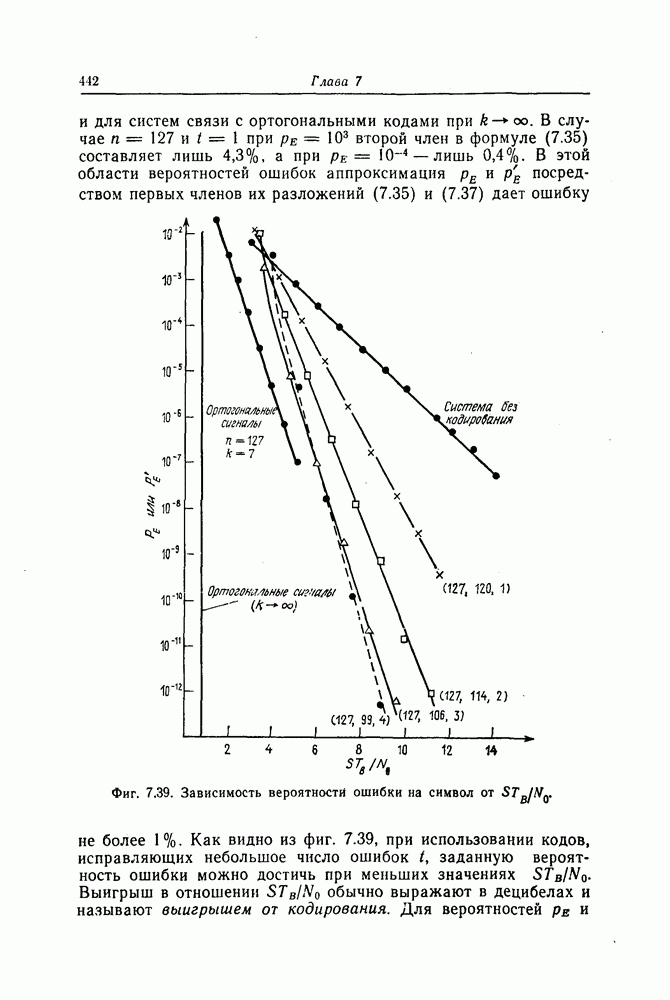

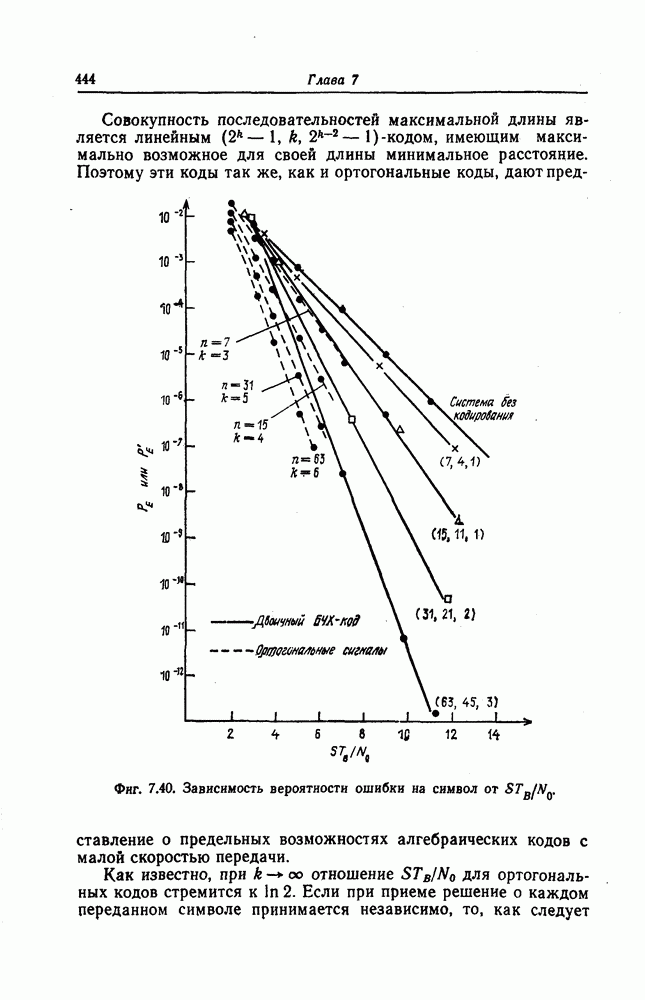









































































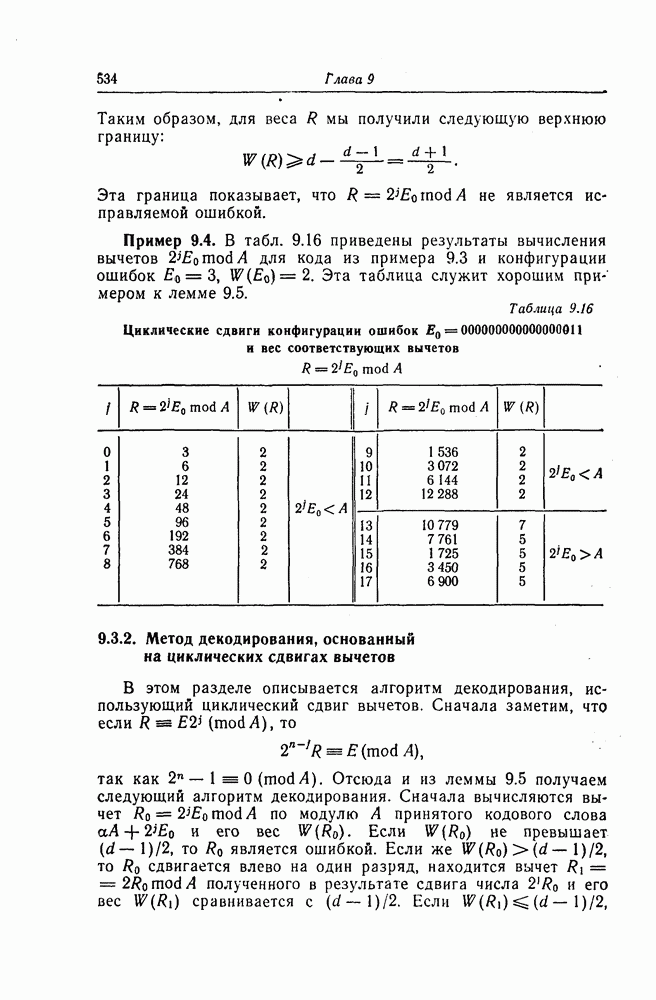



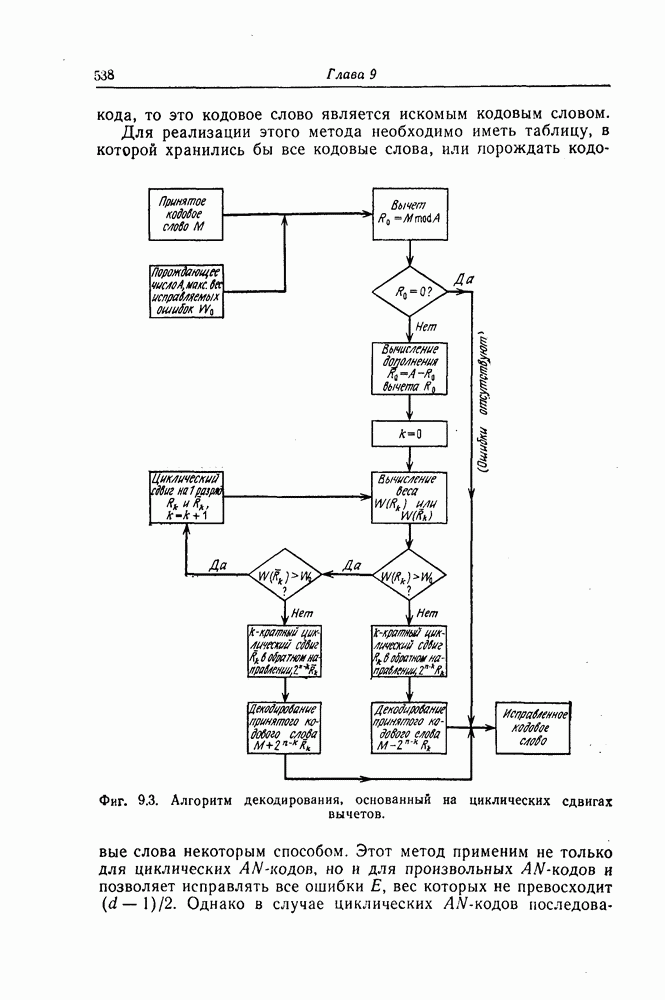

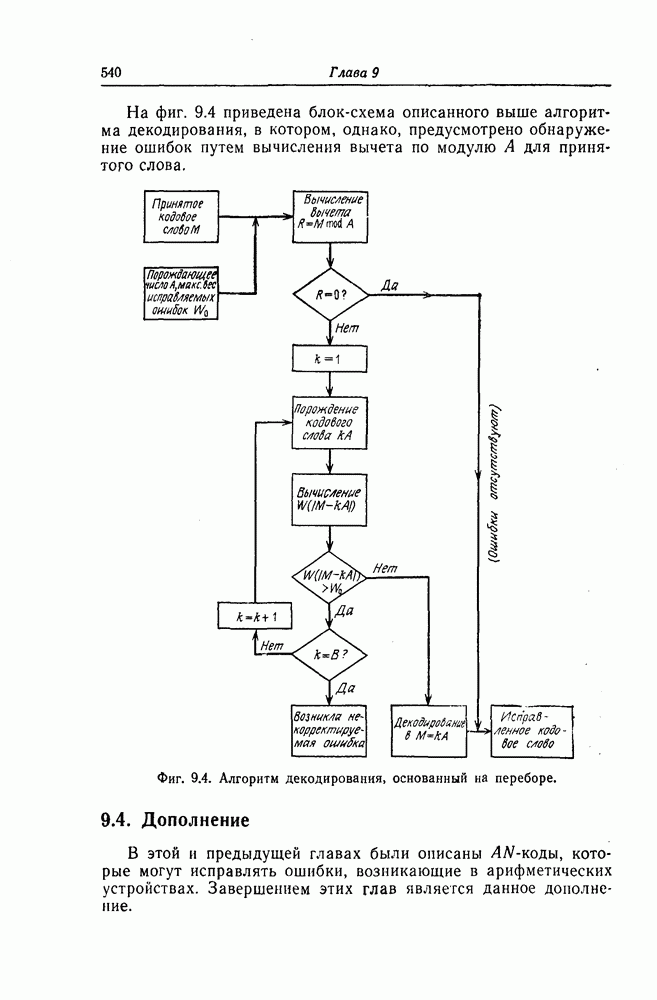







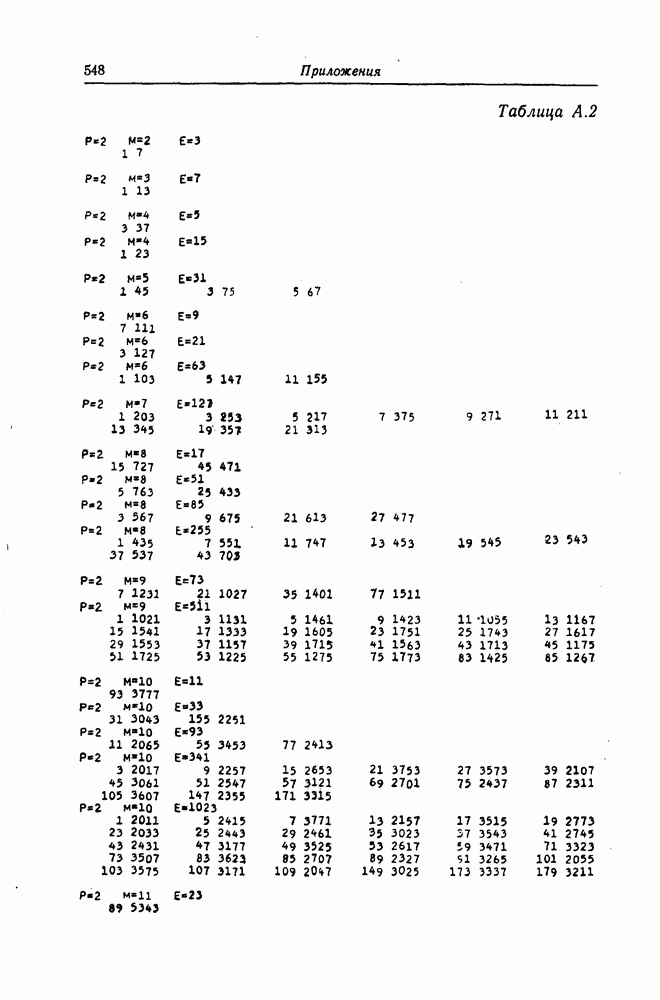
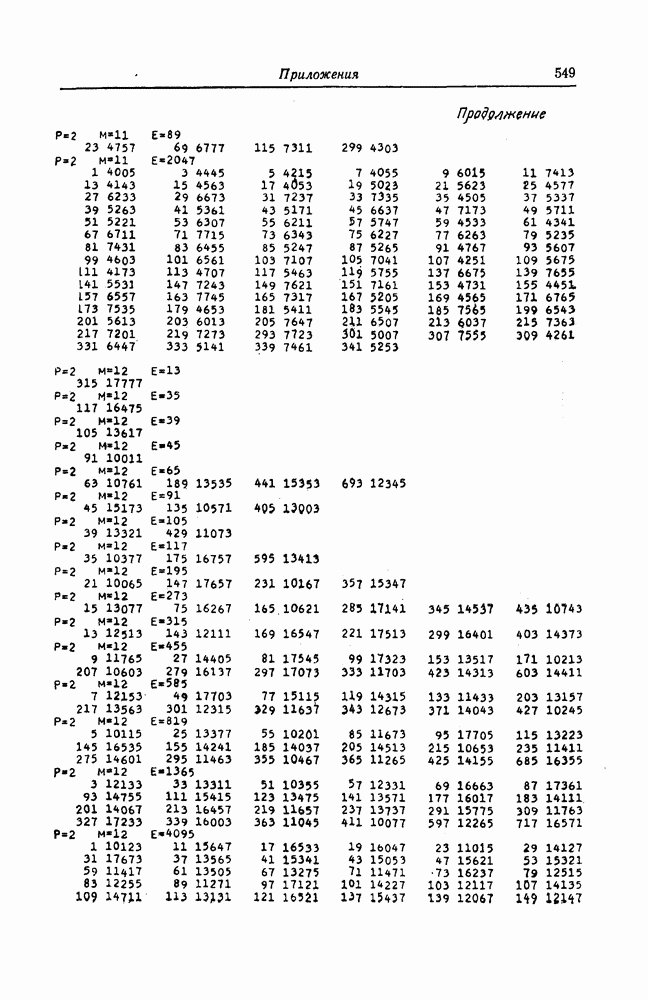




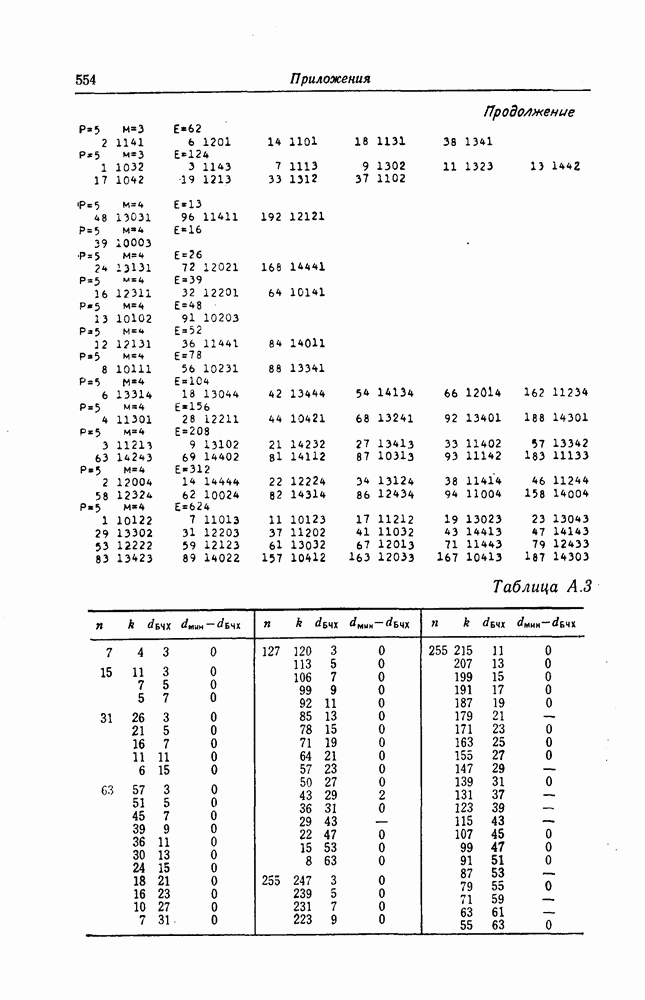













 которые могут использоваться в сочетании с последовательным декодированием, а Лин [23] предложил регулярный метод построения таких кодов. Кроме того, Костелло [24] предложил простой алгоритм, при использовании которого с помощью вычислительной машины можно строить коды с большим минимальным расстоянием.
которые могут использоваться в сочетании с последовательным декодированием, а Лин [23] предложил регулярный метод построения таких кодов. Кроме того, Костелло [24] предложил простой алгоритм, при использовании которого с помощью вычислительной машины можно строить коды с большим минимальным расстоянием.