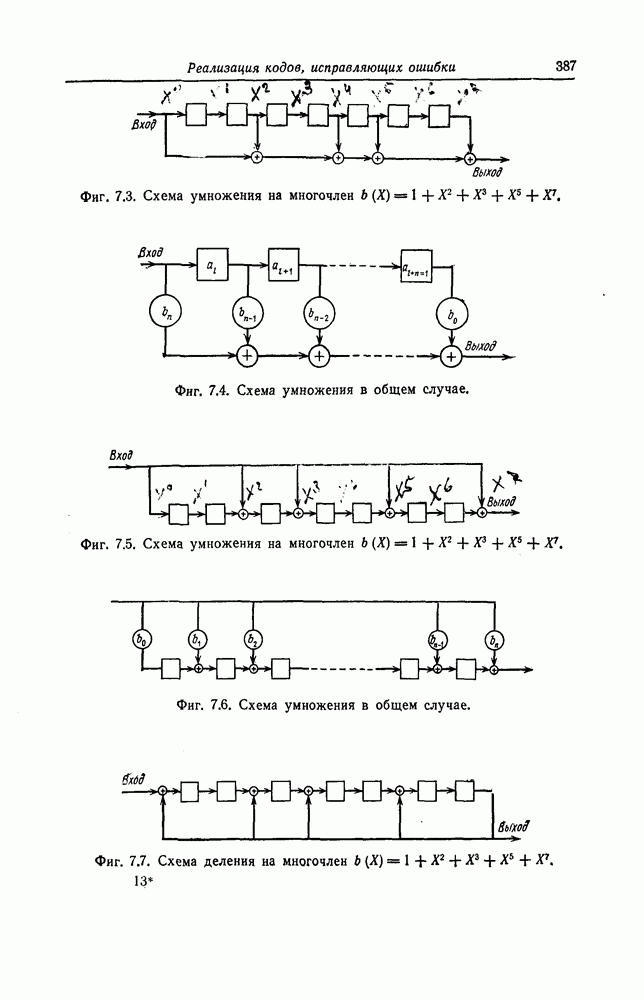
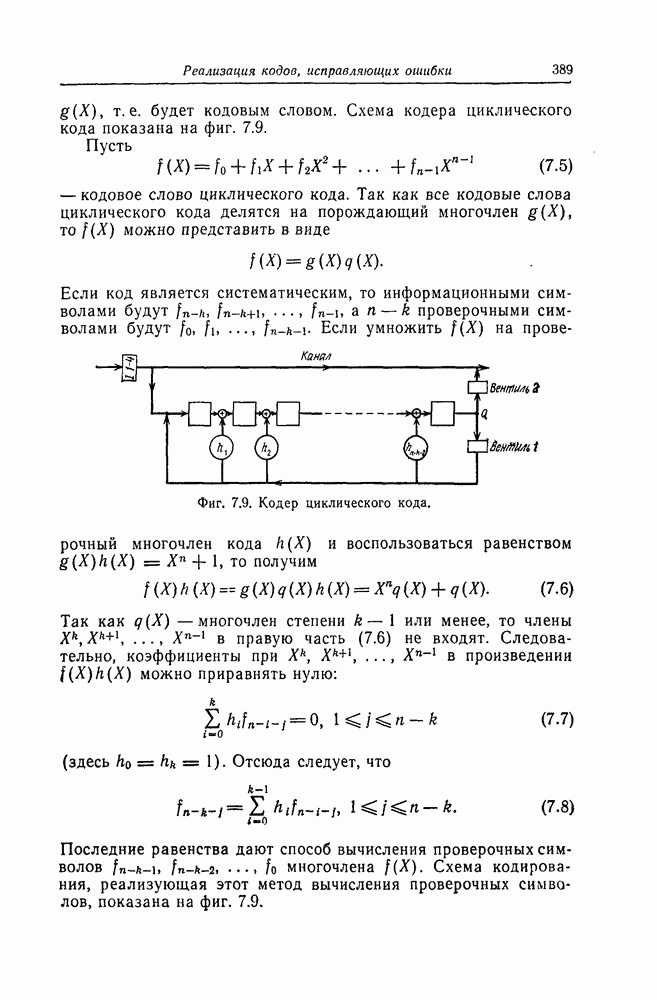
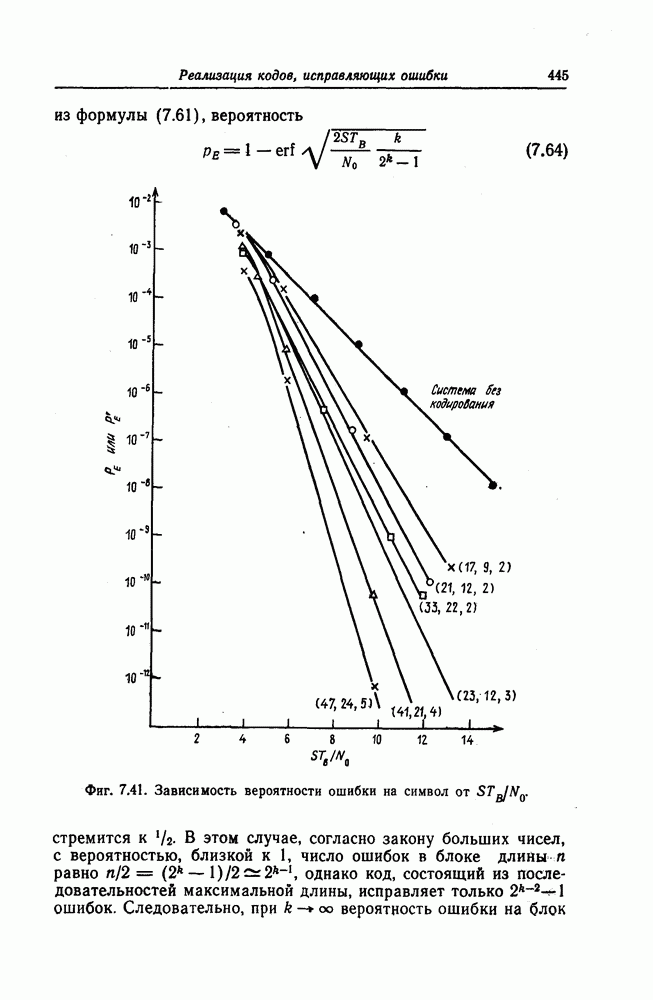
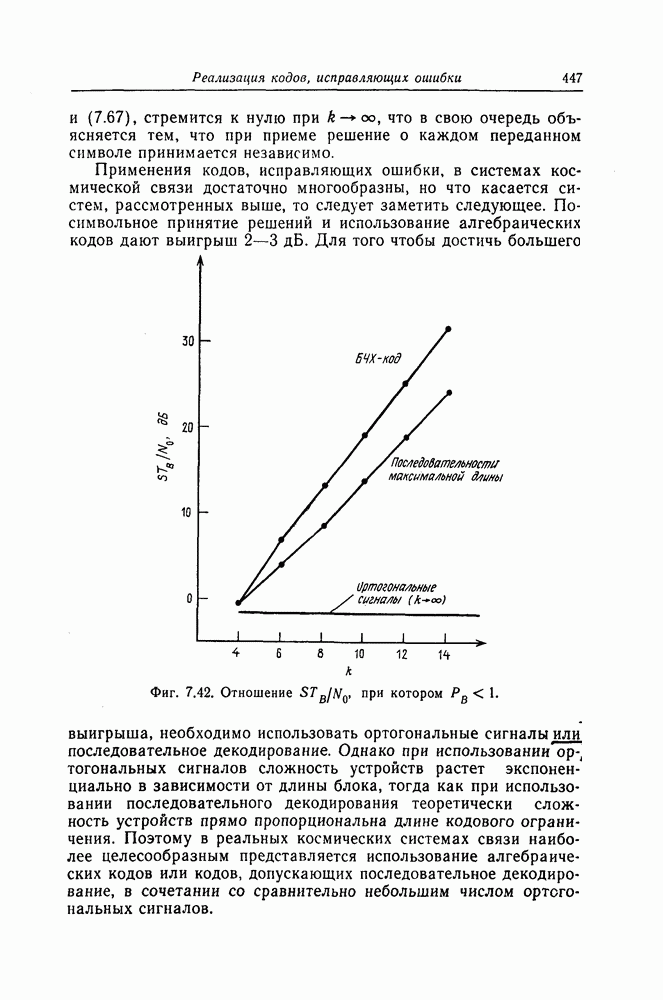
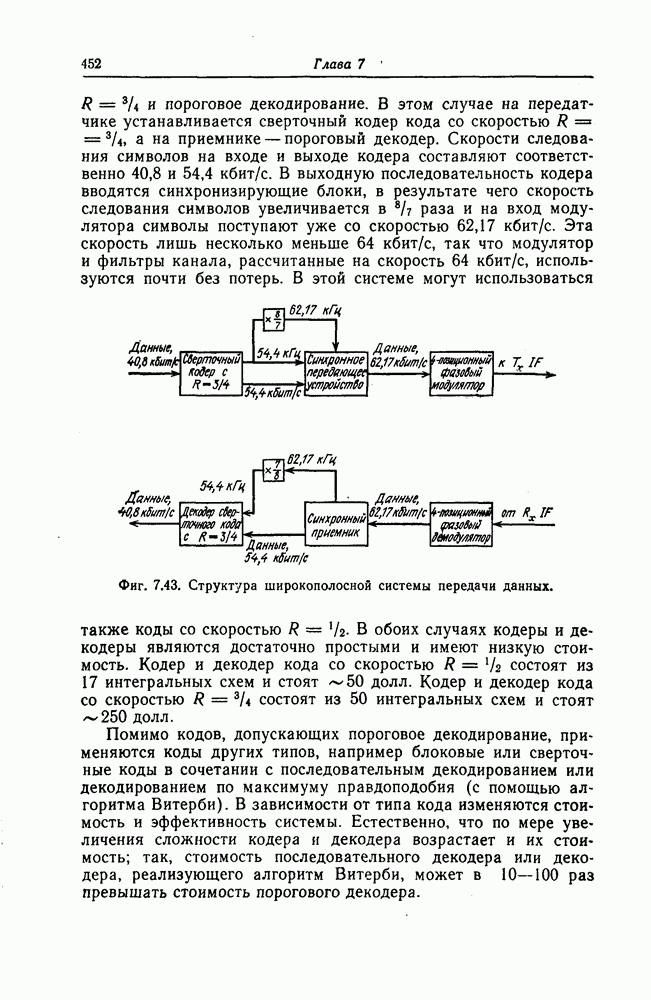
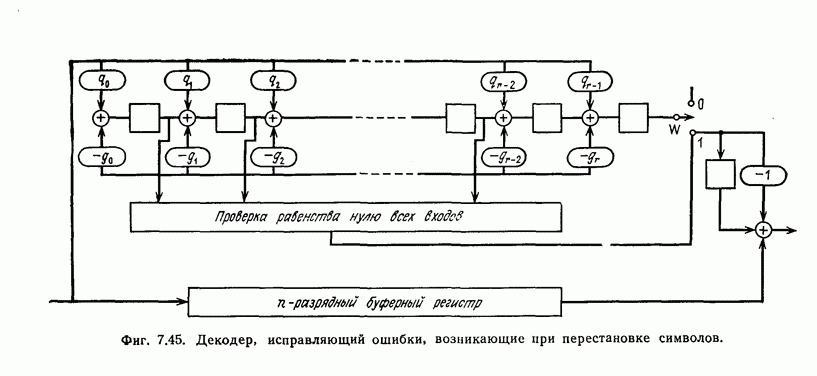
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
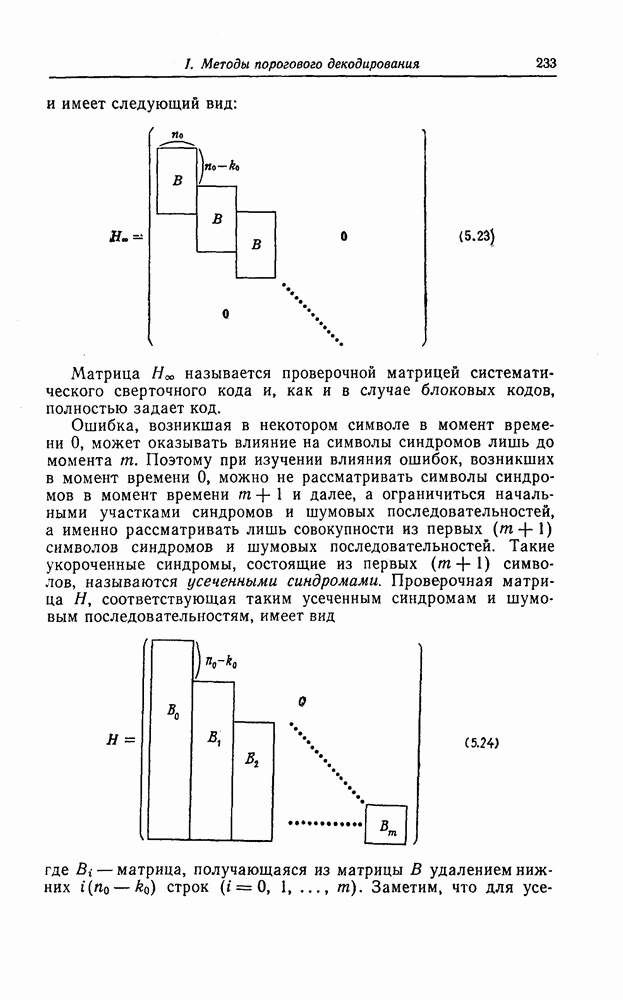
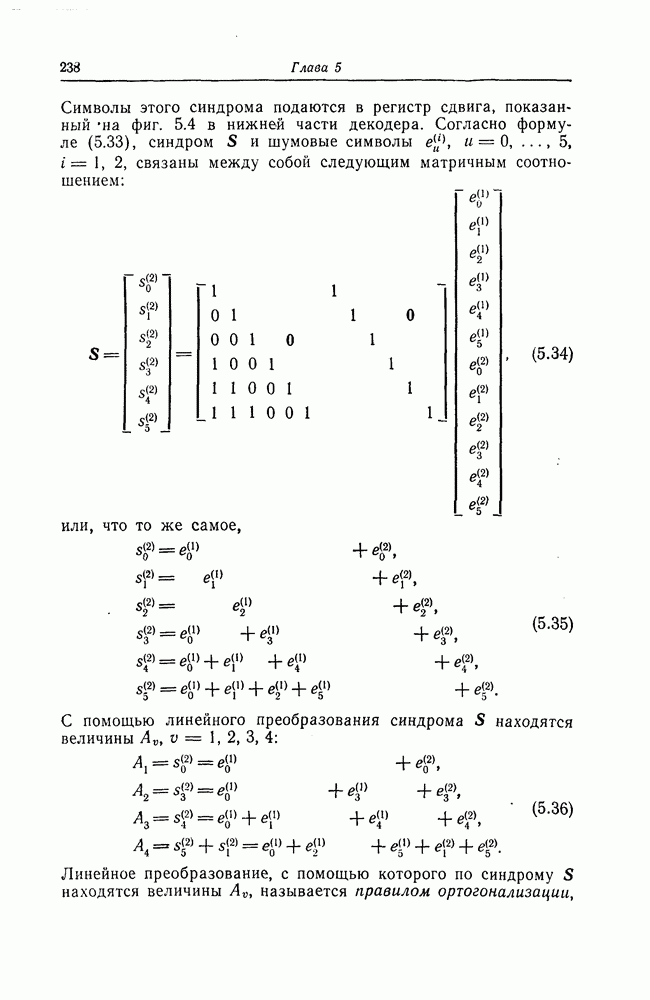
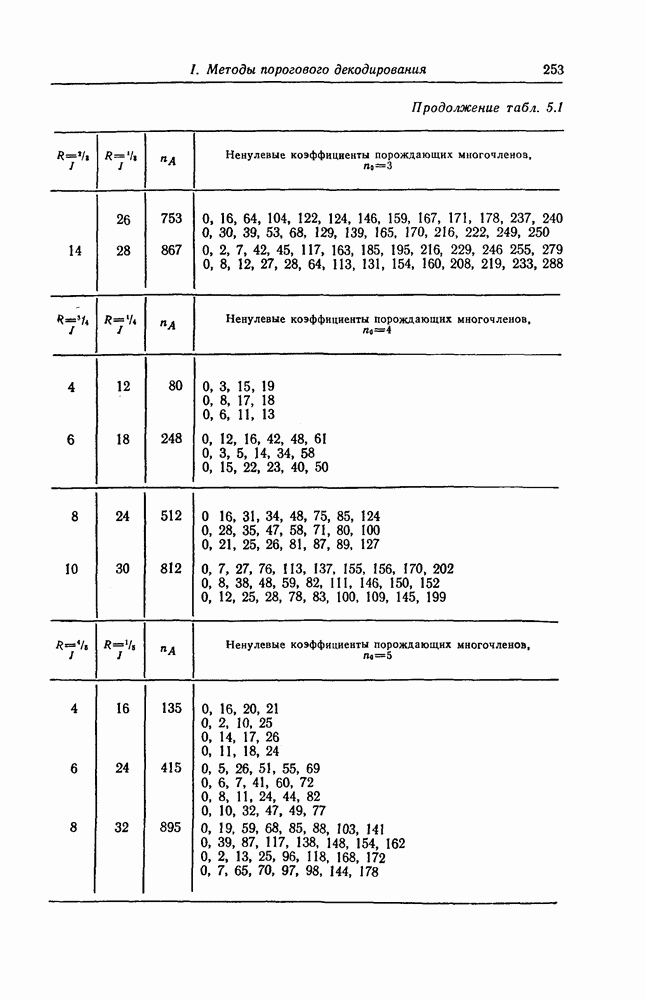
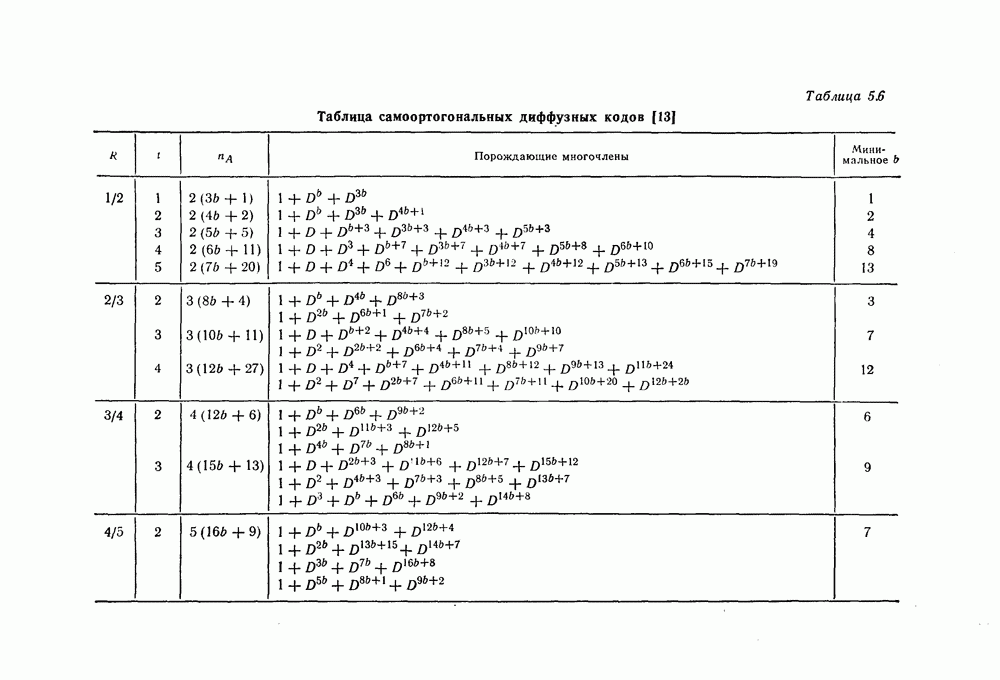
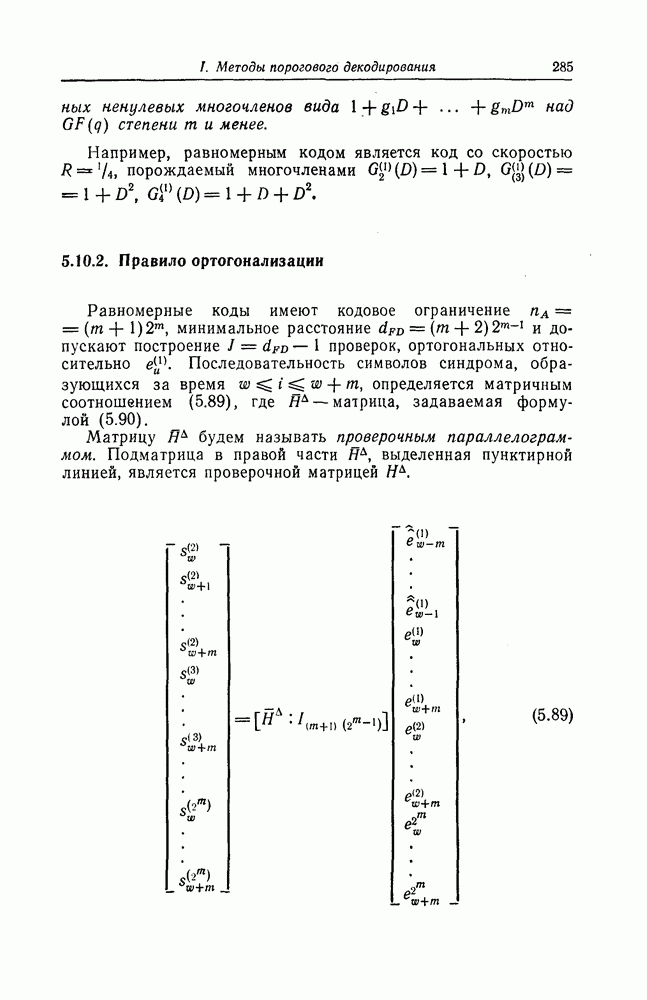
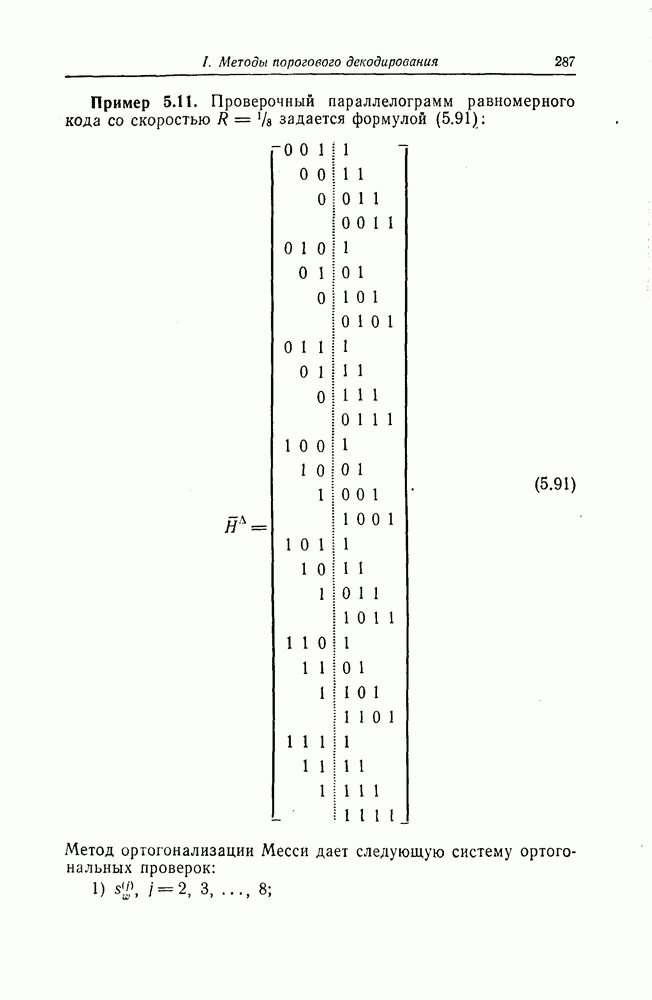
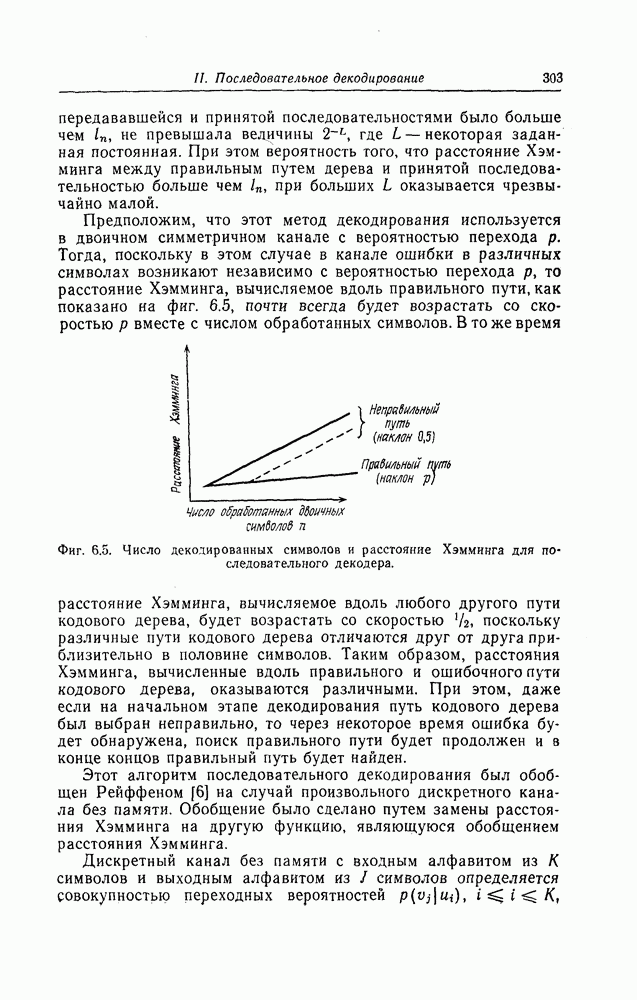
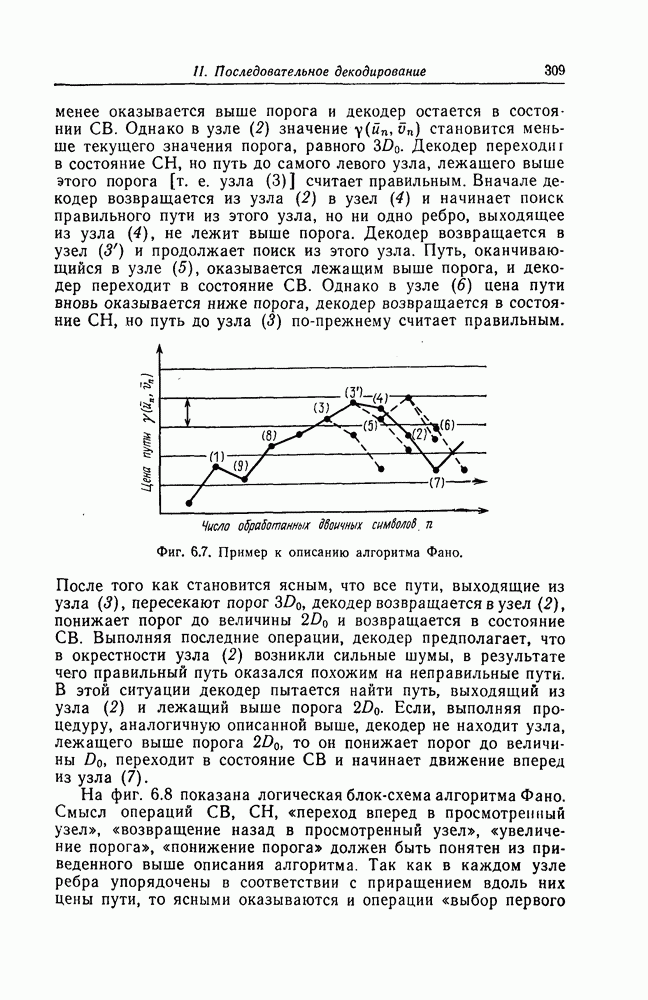
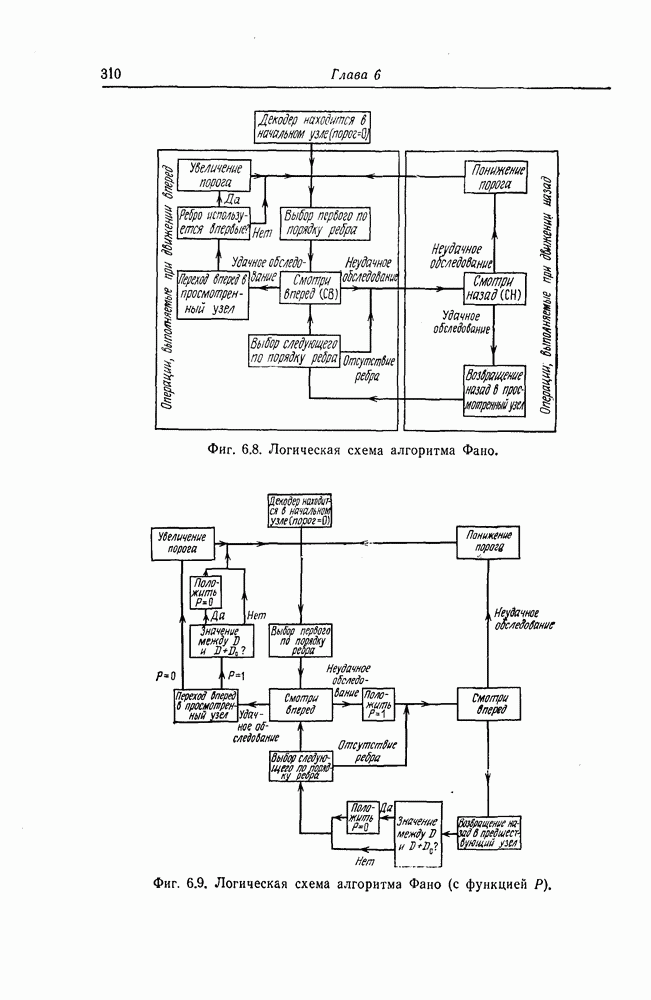
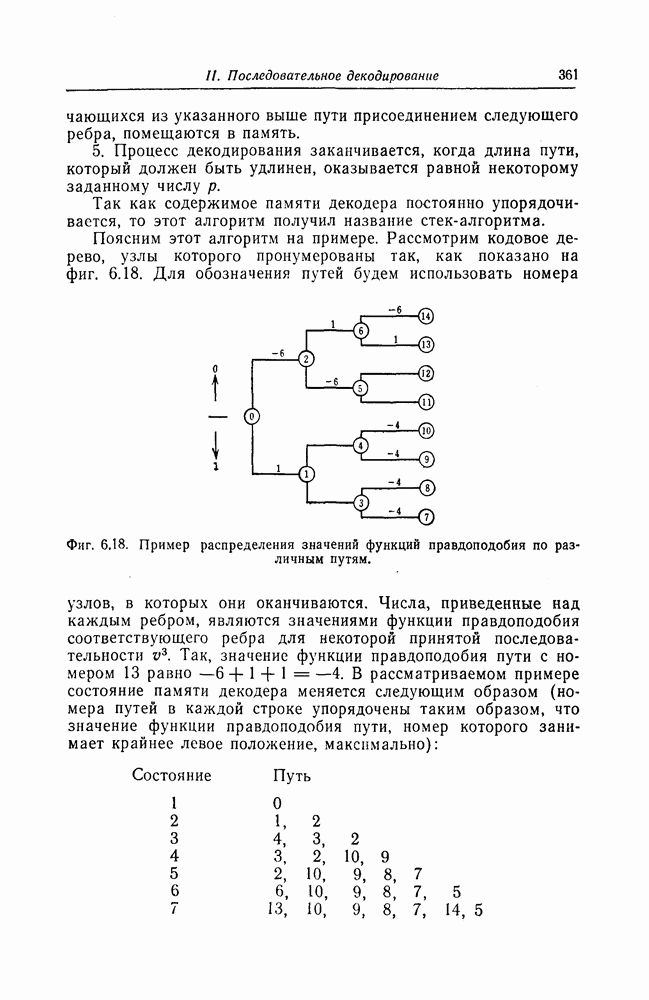
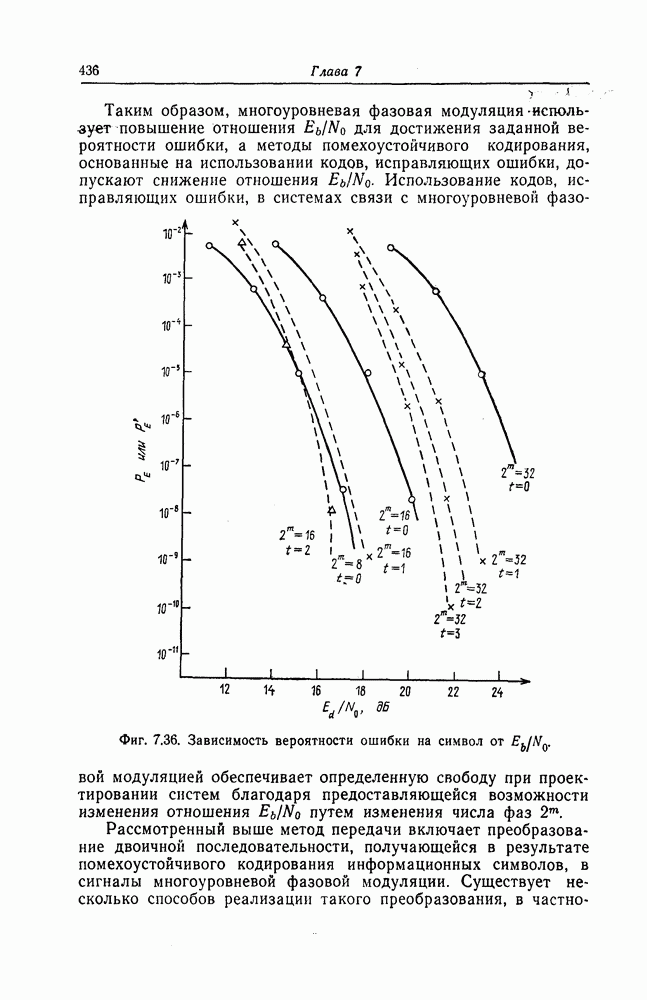
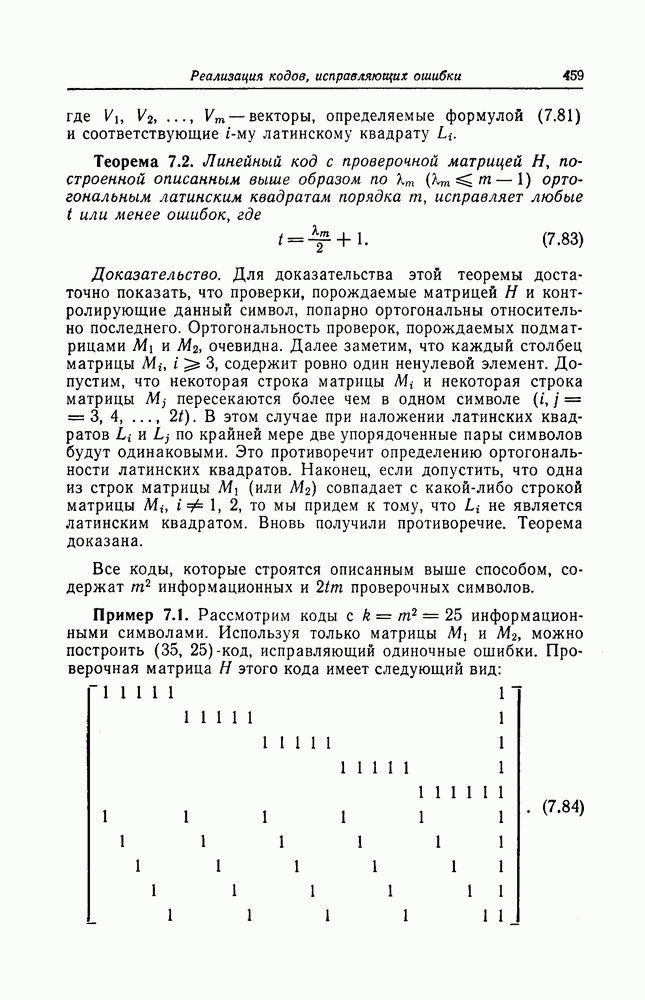
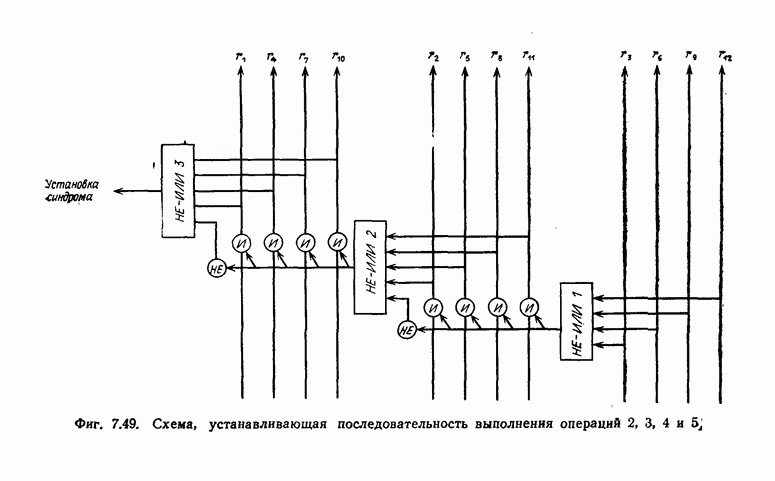
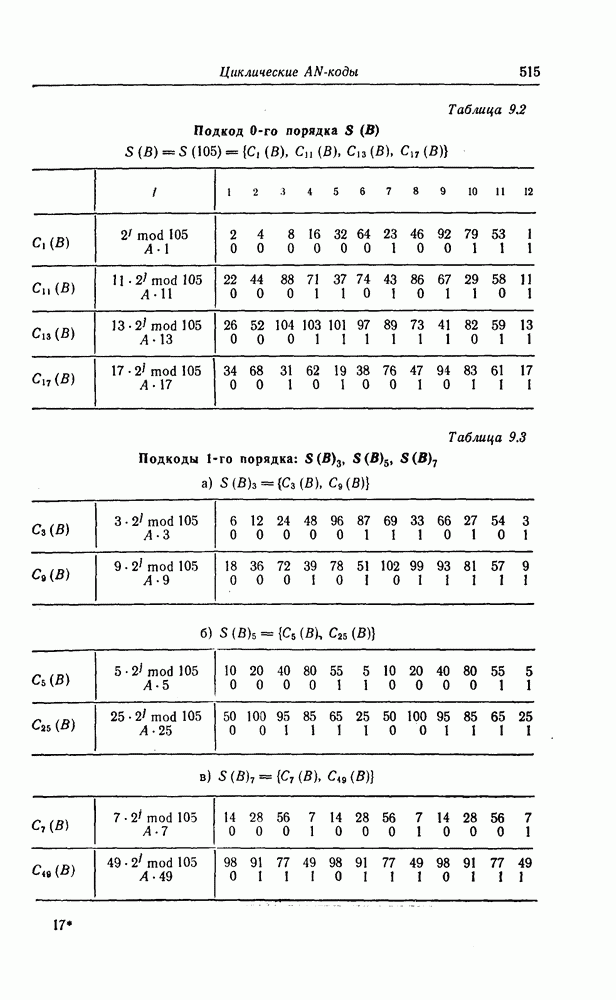
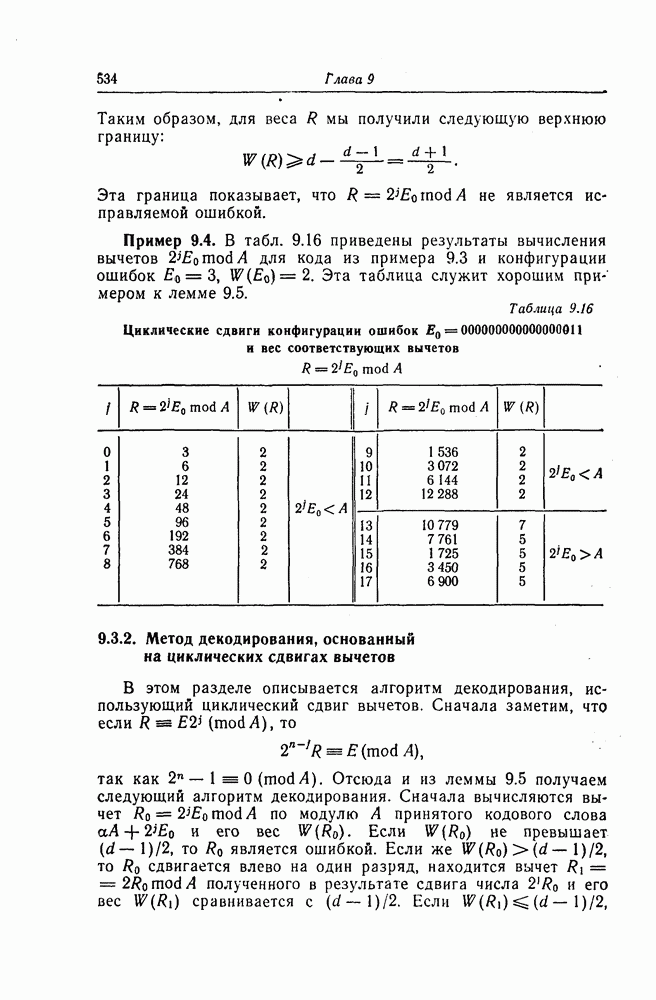
7.1.3. Декодеры циклических кодовЕсли кодеры обычно относительно просты и однотипны, то декодеры, как правило, гораздо сложнее кодеров и их структура сильно зависит от используемых кодов. В этом разделе сначала рассматриваются простейшие декодеры, а именно декодеры кодов, обнаруживающих ошибки. Далее рассматриваются декодеры БХЧ-кодов, декодеры для кодов, допускающих пороговое декодирование, декодеры для кодов, исправляющих пачки ошибок, и некоторые другие декодеры. а) Декодеры, обнаруживающие ошибки. Декодер этого типа состоит обычно из буферного регистра, предназначенного для хранения принятого кодового слова, и схемы деления принятого слова на порождающий многочлен кода
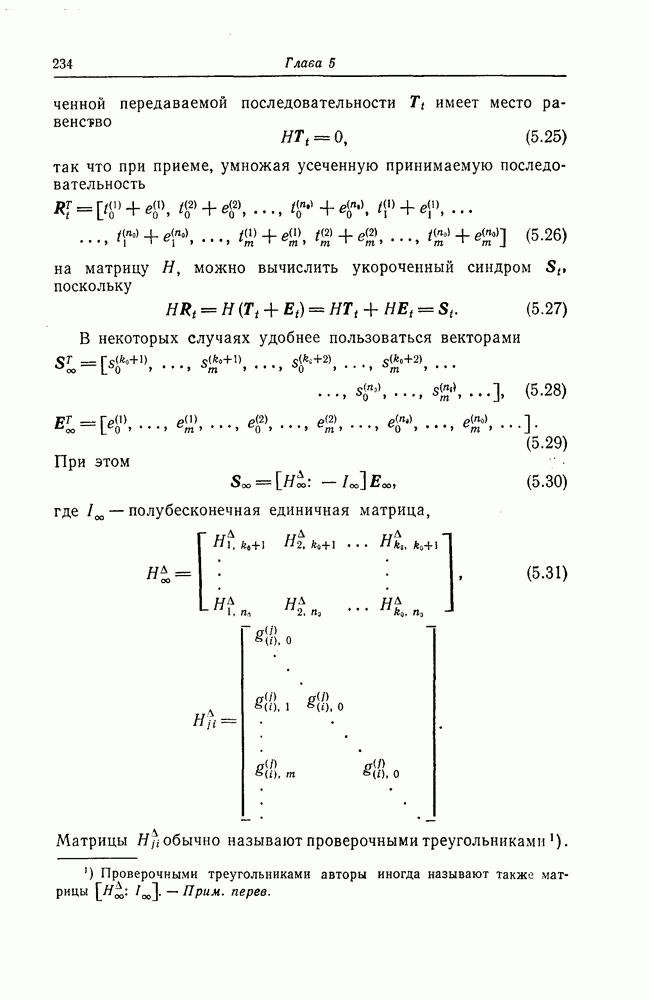
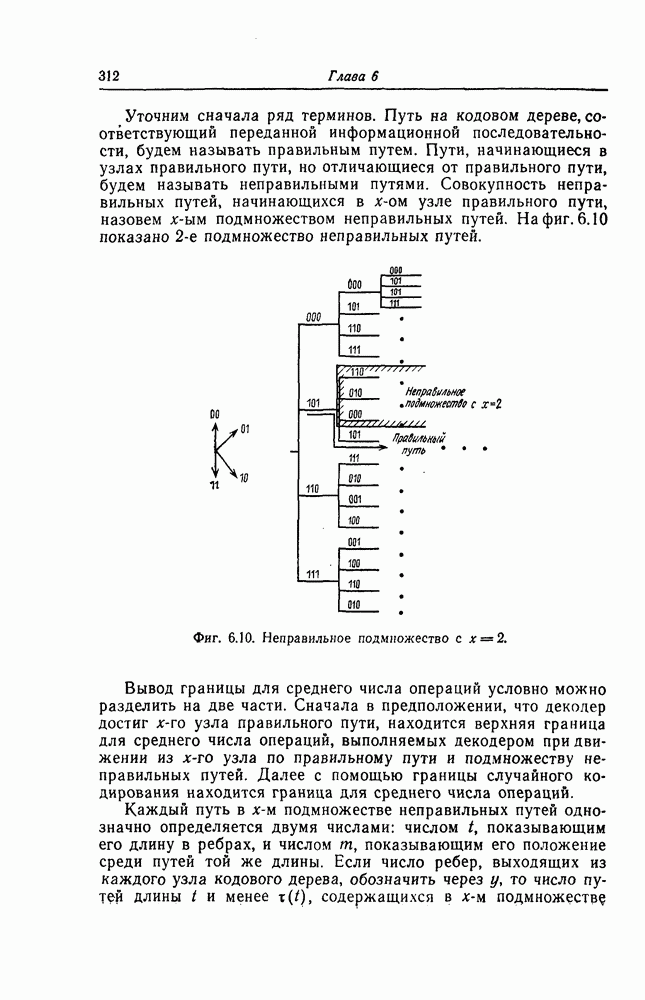
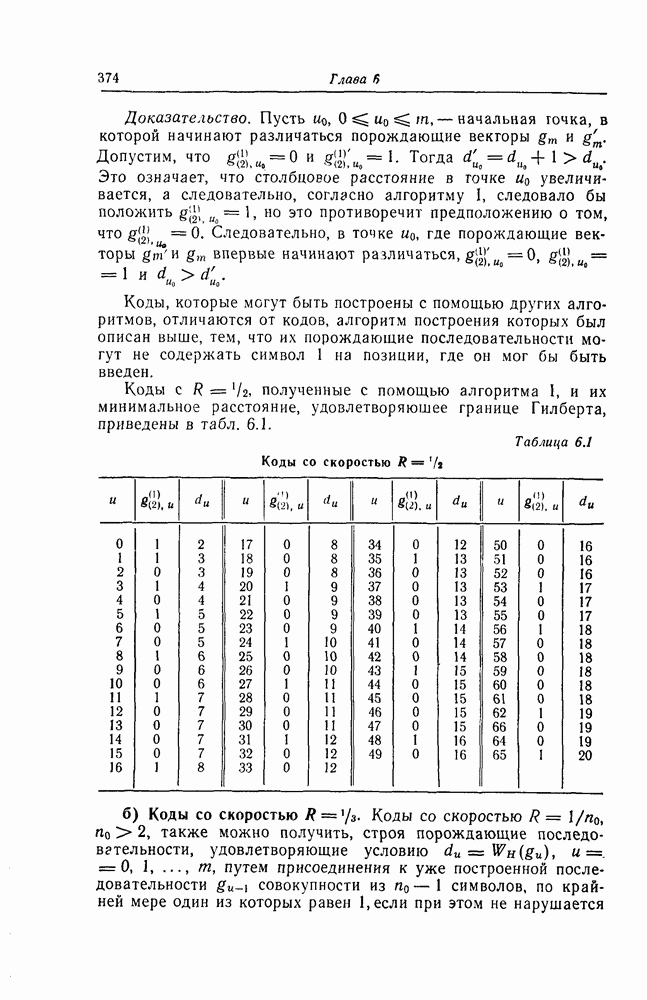
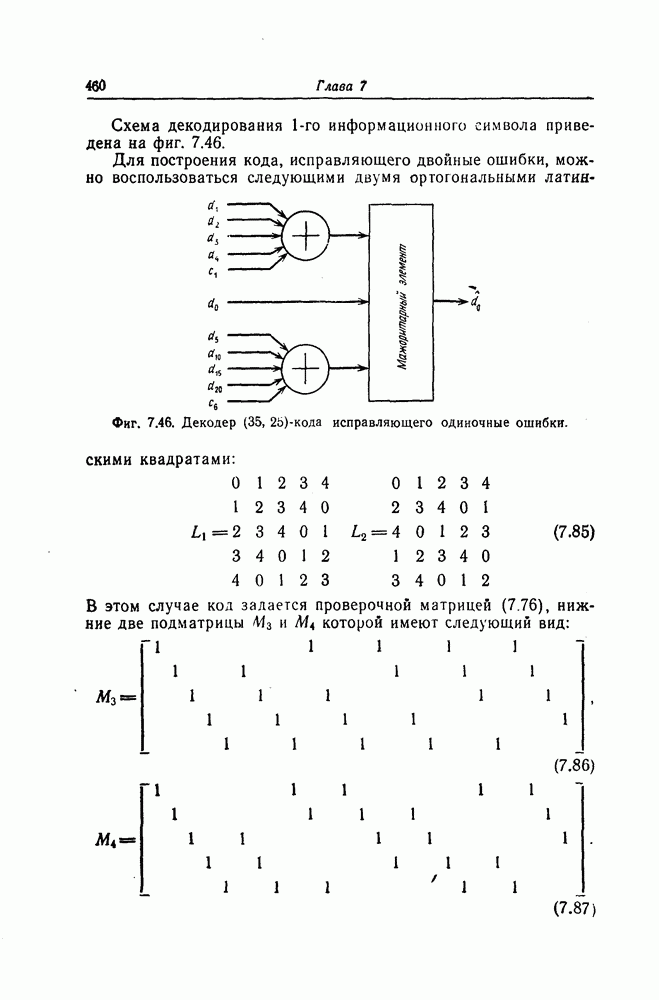
Фиг. 7.10. Декодер, обнаруживающий ошибки. В противном случае, т. е. если хотя бы один из коэффициентов остатка отличен от нуля, принимается решение о том, что произошла ошибка при передаче; при этом прием прекращается и на передающую сторону посылается запрос на повторную передачу этого кодового слова. В показанном на фиг. 7.10 декодере принятое кодовое слово одновременно вводится в буферный регистр и изображенную под регистром схему деления многочленов. После введения принятого слова в схему деления в регистре сдвига последней оказывается остаток от деления принятого слова на порождающий многочлен кода; в зависимости от того, равен ли остаток нулю или нет, принимается решение об отсутствии или наличии ошибок в принятом слове. Эта схема обнаружения ошибок очень проста, и устройства обнаружения ошибок с этой схемой широко используются в реальных системах. Следует заметить, что при использовании этой схемы необходим канал обратной связи, буферное запоминающее устройство для хранения данных и ряд других устройств. б) Декодер БЧХ-кода. Как уже указывалось выше, БЧХ-коды могут иметь достаточно большое кодовое расстояние. Однако их техническая реализация оказывается сравнительно сложной. Алгоритм декодирования БЧХ-кода включает следующие пять операций: I. Вычисление синдрома. II. Вычисление многочлена, имеющего своими корнями локаторы ошибок. III. Нахождение корней этого многочлена. IV. Вычисление значений ошибок (в двоичном случае эта операция не нужна). V. Исправление ошибок. В двоичном случае операции III и V могут выполняться одновременно с помощью описанного ниже алгоритма Ченя.
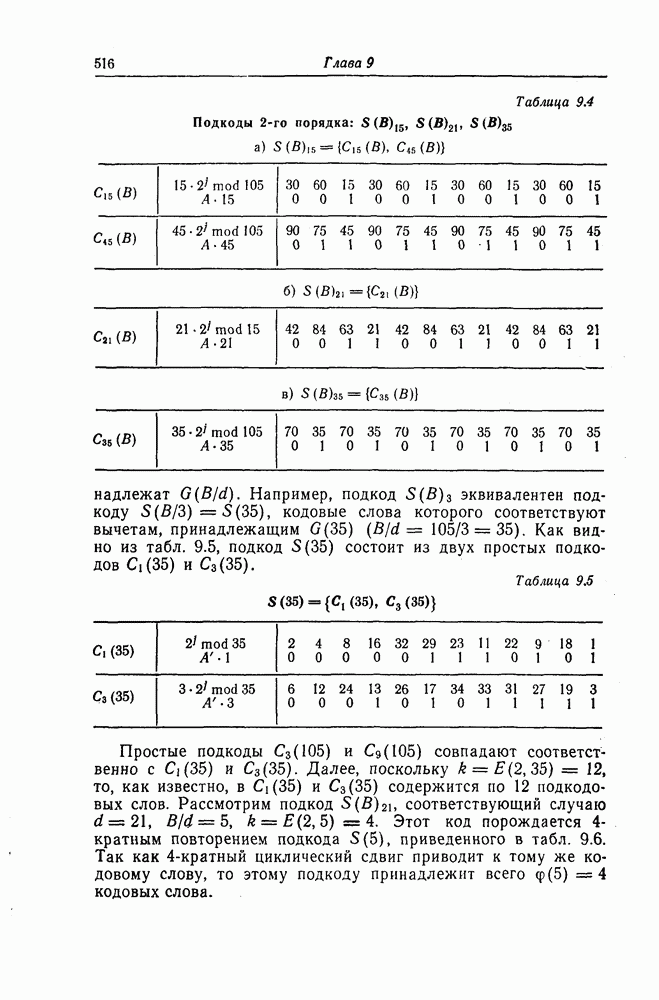
Фиг. 7.11. Схема для вычисления При декодировании БЧХ-кодов сначала находится синдром; эта операция может быть реализована с помощью схемы, осуществляющей вычисления в поле Галуа. Чтобы найти синдром, необходимо для принятого слова
вычислить его значение Рассмотрим схему вычисления синдрома для кода, корни порождающего многочлена которого лежат в поле
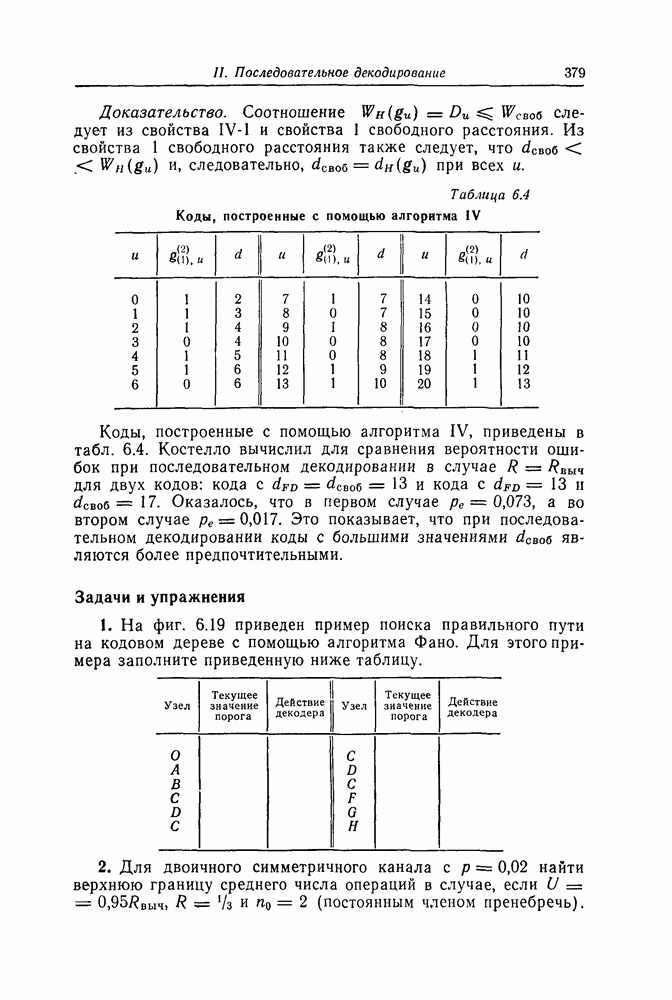
в рассмотренную схему следует последовательно ввести символы Далее рассмотрим случай, когда GF(2^4)]. Так как, согласно таблице умножения в поле
то
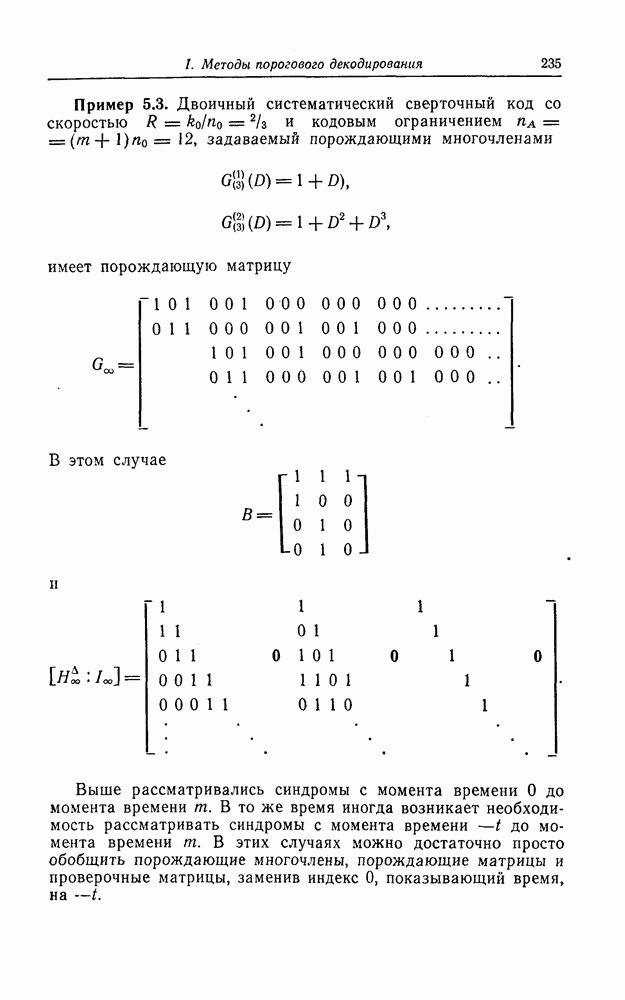
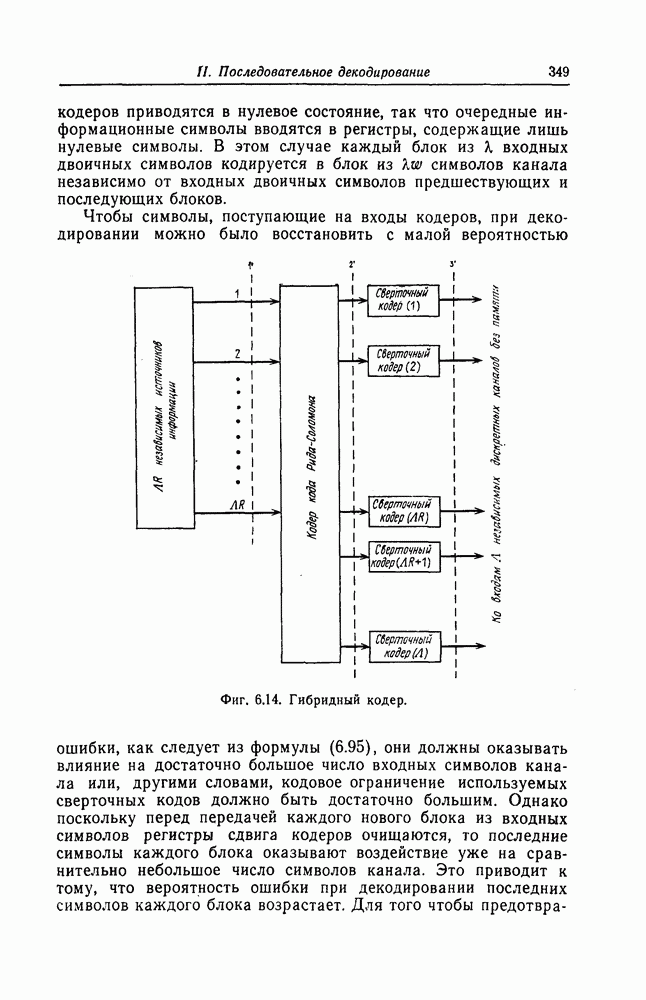
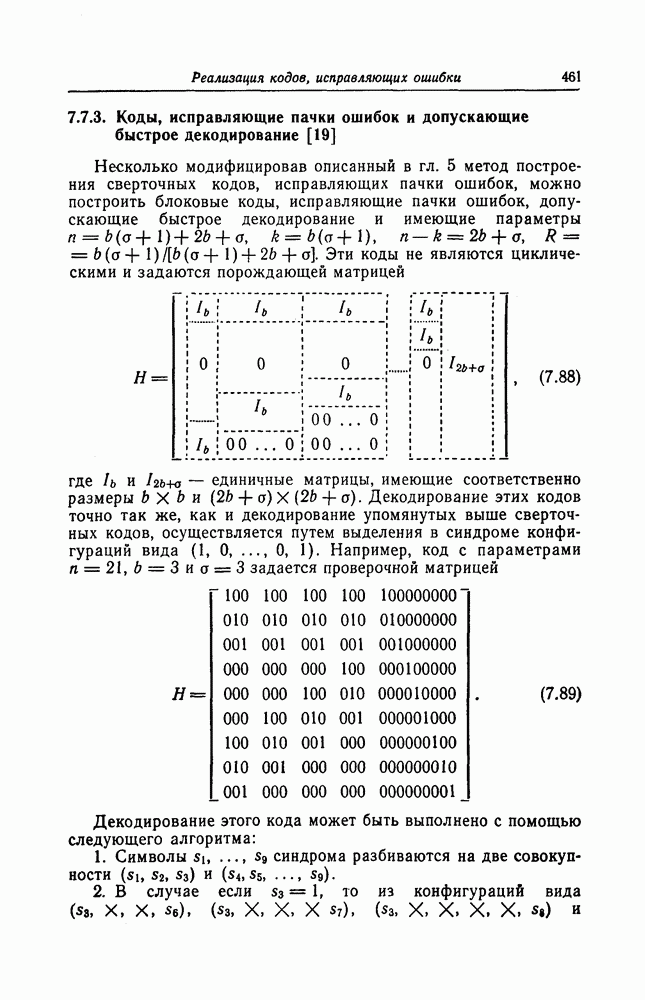
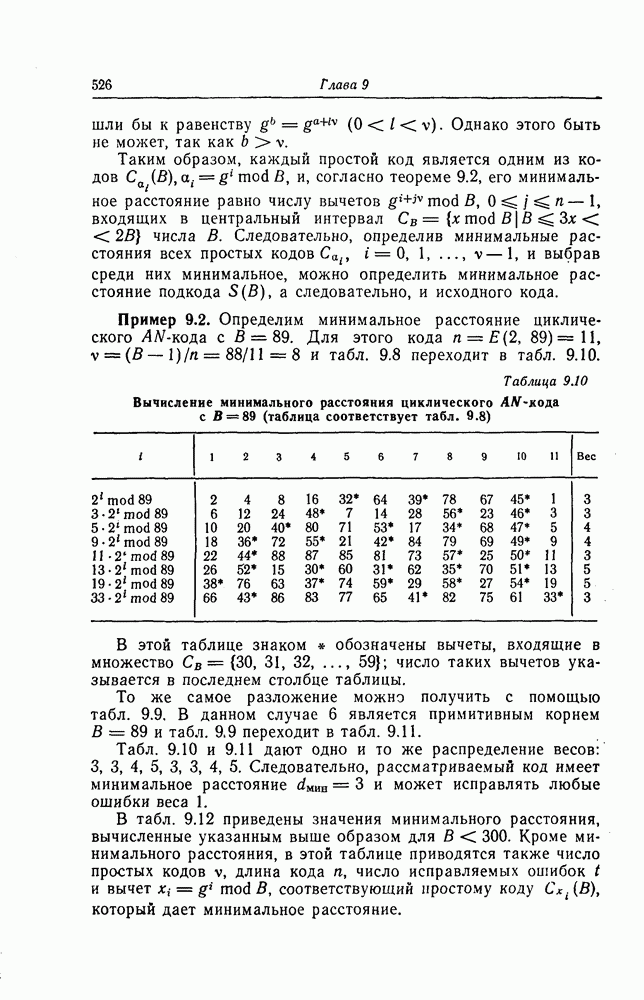
Фиг. 7.12. Схема для вычисления Если обозначить через
Эти суммы могут быть вычислены с помощью изображенной на фиг. 7.12 схемы, представляющей собой регистр сдвига с обратной связью. Таким образом, если ввести последовательно в этот регистр символы принятой последовательности После того как синдром вычислен, следующей операцией при декодировании БЧХ-кодов является нахождение многочлена, корнями которого являются локаторы ошибок. Эта операция является наиболее сложной при технической реализации. При использовании для этой цели как алгоритма Питерсона, так и предложенного позже алгоритма Берлекэмпа — Месси при большом числе исправляемых ошибок достаточно простого устройства, реализующего эту операцию, построить не удается. В то же время как в том, так и другом случаях математически сложные расчеты могут быть относительно легко выполнены программными методами. Поэтому использование постоянных и полупостоянных памятей и других подобных устройств для построения специализированных вычислительных устройств, предназначенных для декодирования БЧХ-кодов, позволяет снизить стоимость и упростить структуру декодеров. Однако, когда скорость передачи информации велика, быстродействие универсальной вычислительной машины может оказаться недостаточным для выполнения декодирования поступающих слов. В этих случаях для реализации декодирования часто применяются специализированные устройства. Вопрос о том, какой из алгоритмов — Питерсона или Берлекэмпа — Месси — в этом случае лучше, должен в каждом конкретном случае исследоваться специально. Как уже указывалось выше, вычисление синдрома осуществляется параллельно с приемом слова и завершается после ввода последнего в буферный регистр. Как будет показано ниже, определение положения ошибок при использовании алгоритма Ченя выполняется при считывании принятого слова из буфера. Такйм образом, нахождение многочлена, корнями которого являются локаторы ошибок, должно выполняться независимо от приема переданного слова и считывания последнего из буфера. Поэтому к быстроте выполнения этой операции, а именно времени вычисления многочлена локаторов ошибок, предъявляются повышенные требования. Если число исправляемых ошибок невелико, коэффициенты многочлена локаторов ошибок сравнительно просто определить, выразив их через символы синдрома и подставив в полученные формулы конкретные значения символов синдрома. При этом соответствующие схемы оказываются не очень сложными. Если многочлен
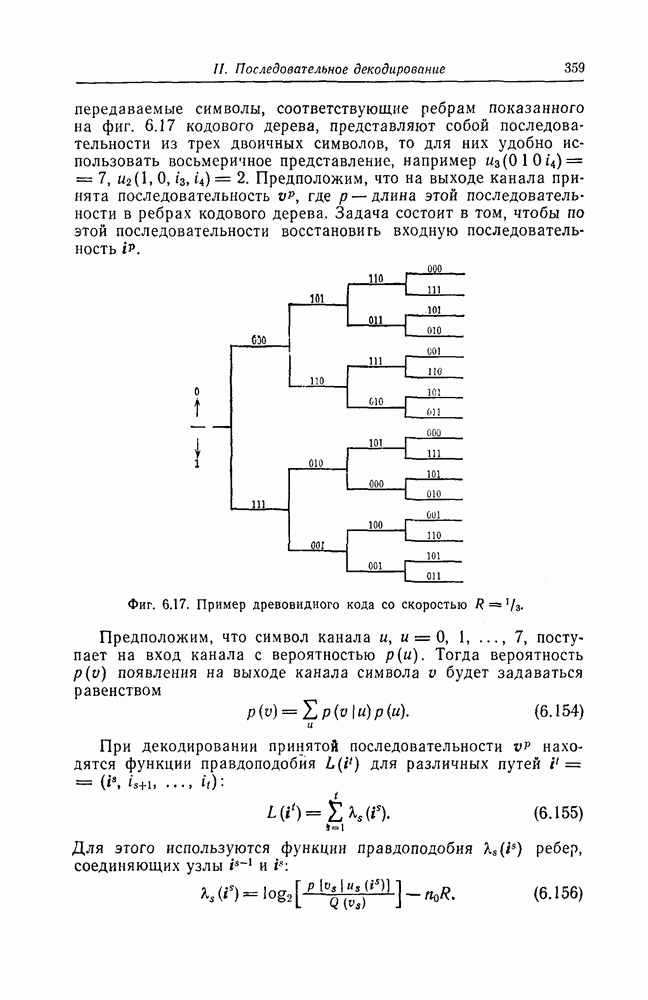
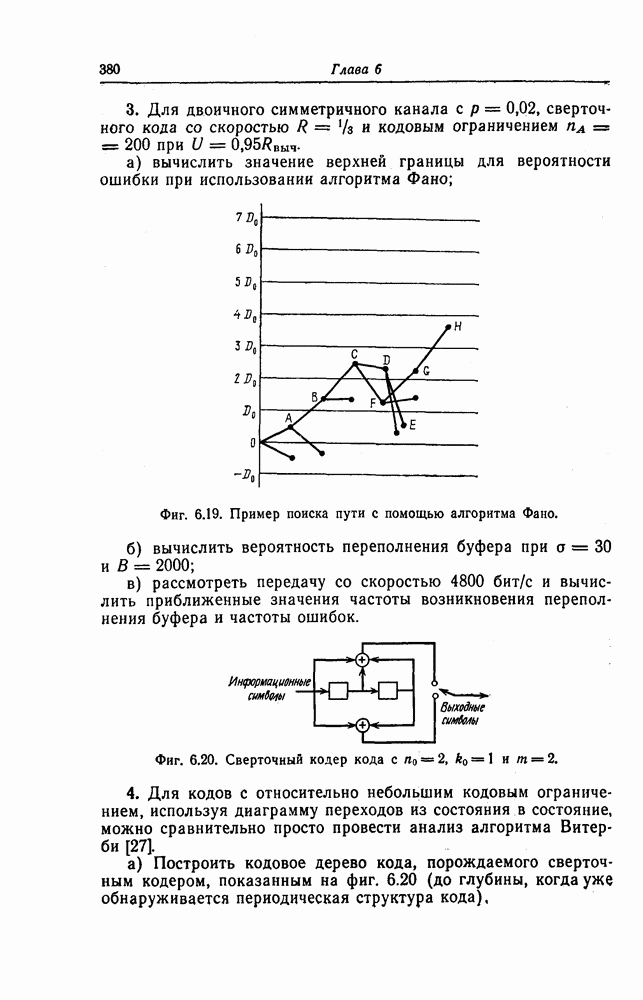
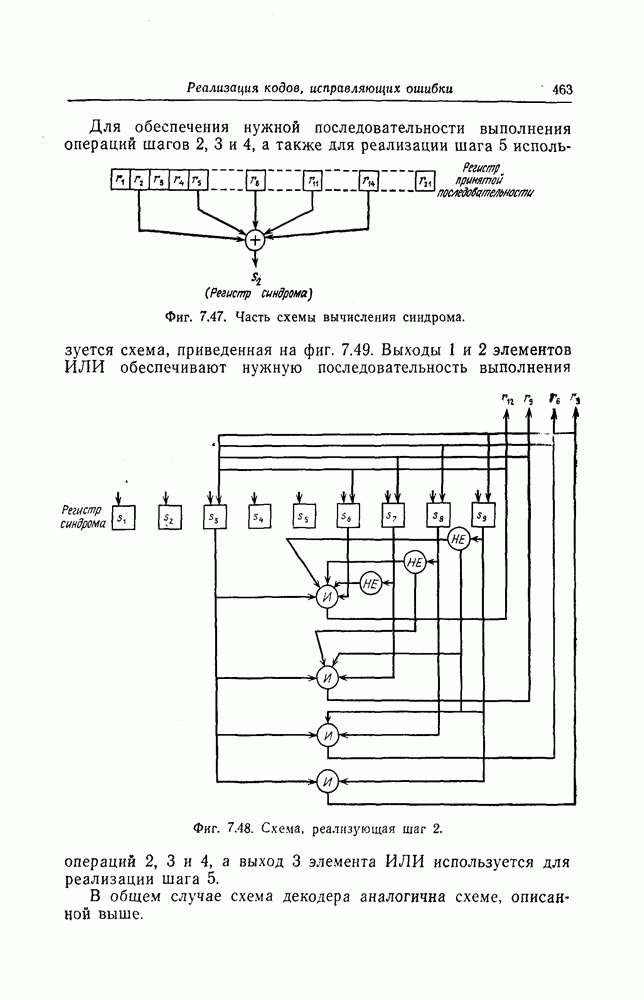
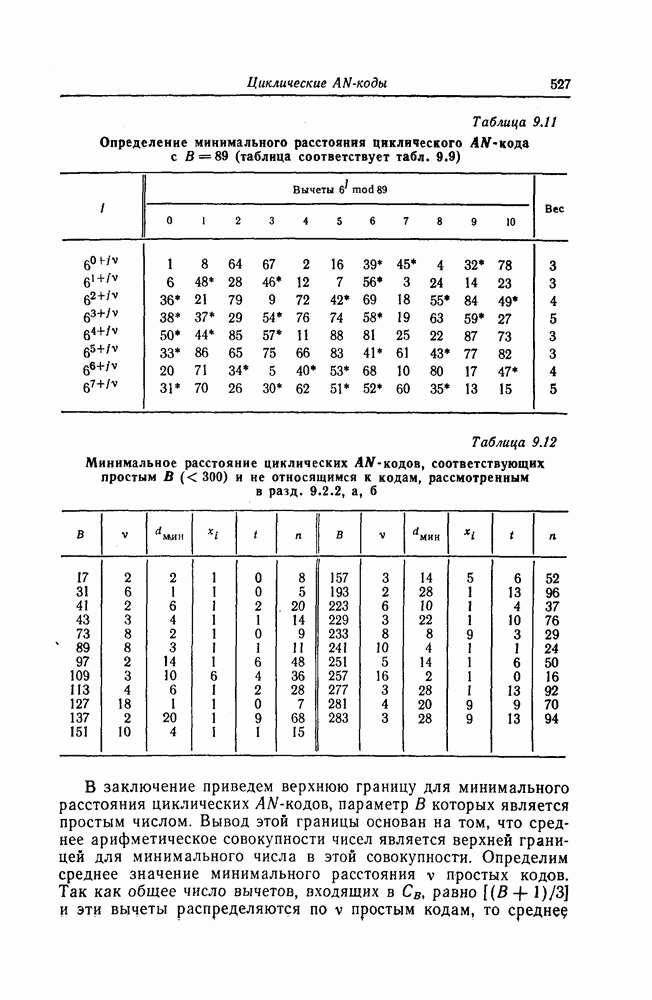
корнями которого являются локаторы ошибок, найден, то непосредственное исправление ошибок можно осуществить, например, воспользовавшись следующим алгоритмом Ченя. Предположим, что при передаче кодового слова БЧХ-кода произошло
Пусть
Тогда, как легко видеть, имеют место следующие равенства:
и
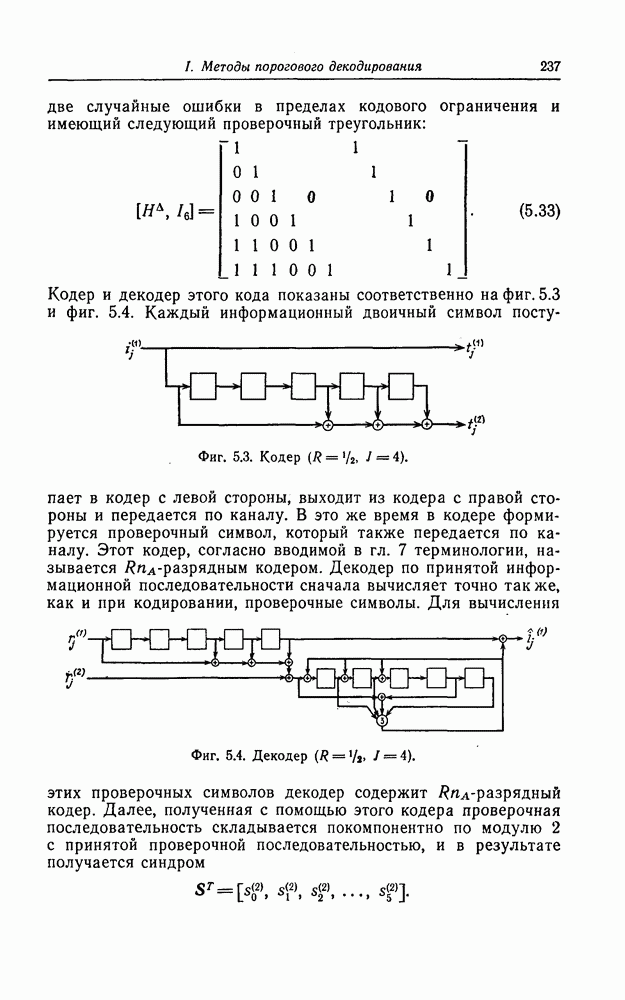
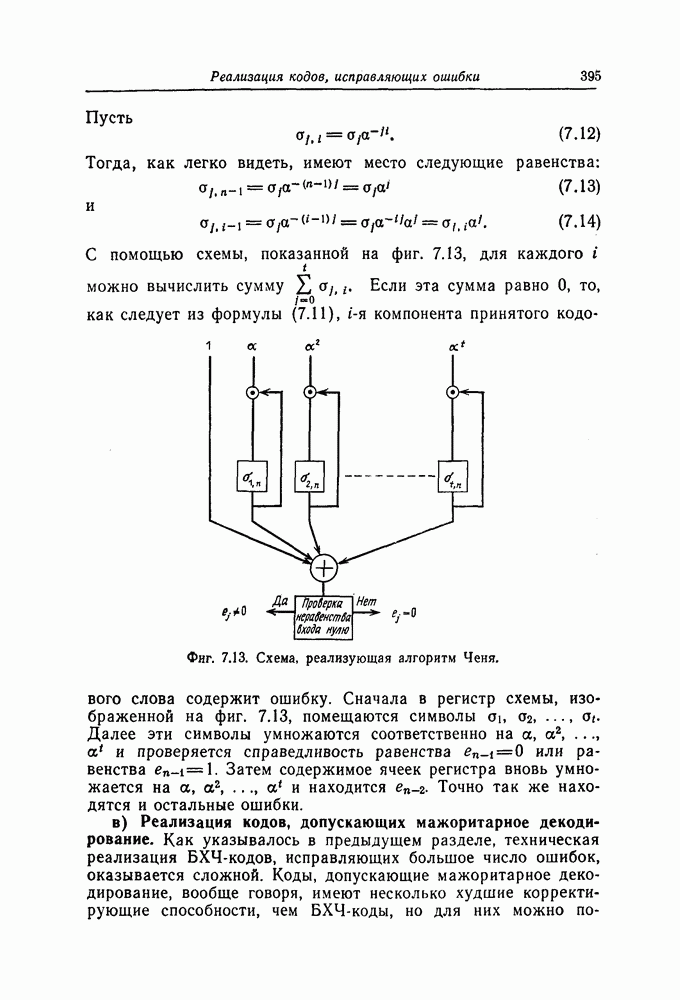
С помощью схемы, показанной на фиг. 7.13, для каждого
Фиг. 7.13. Схема, реализующая алгоритм Ченя. Сначала в регистр схемы, изображенной на фиг. 7.13, помещаются символы в) Реализация кодов, допускающих мажоритарное декодирование. Как указывалось в предыдущем разделе, техническая реализация БХЧ-кодов, исправляющих большое число ошибок, оказывается сложной. Коды, допускающие мажоритарное декодирование, вообще говоря, имеют несколько худшие корректирующие способности, чем БХЧ-коды, но для них можно построить простые декодирующие устройства. Заметим, что эти коды также являются циклическими. Поэтому будем считать, что в принятой последовательности Шаг 1. Вычисляется синдром. Шаг 2. По Шаг 3. Первый символ принятой последовательности считывается из буфера и складывается по модулю 2 с выходным символом последнего мажоритарного элемента; этим завершается исправление ошибки в первом символе. Шаг 4. Осуществляется сдвиг синдрома и буферного регистра. На этом шаге необходимо устранить воздействие
(здесь
представляющим собой остаток от деления Шаг 5. Новый синдром, полученный на шаге 4, используется для декодирования 2-го символа принятой последовательности. Вновь выполняя операции 2, 3 и 4, можно декодировать 2-й символ принятой последовательности точно так же, как и 1-й символ.
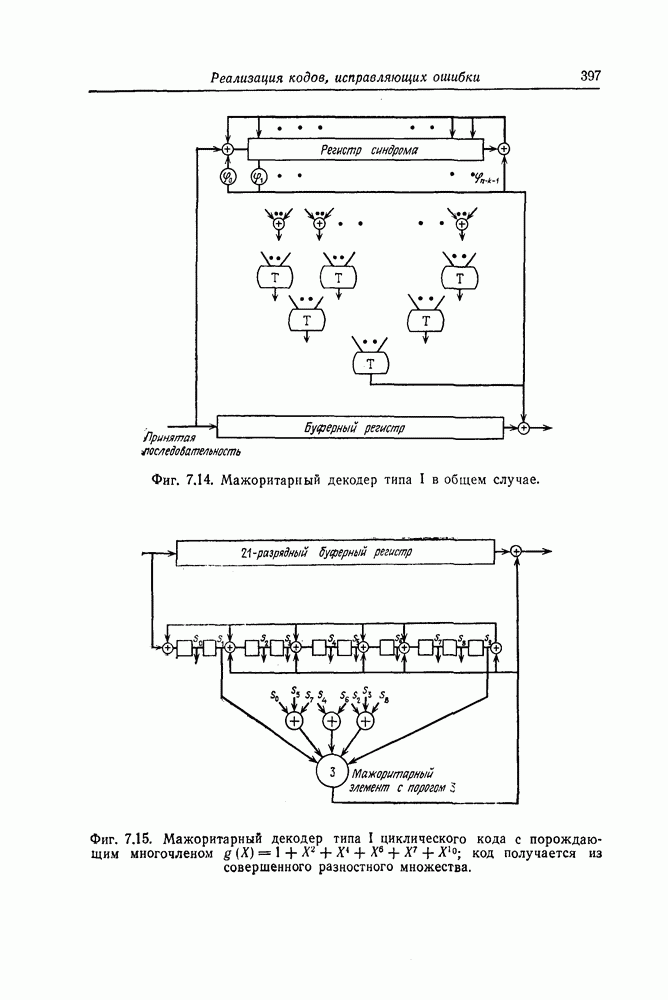
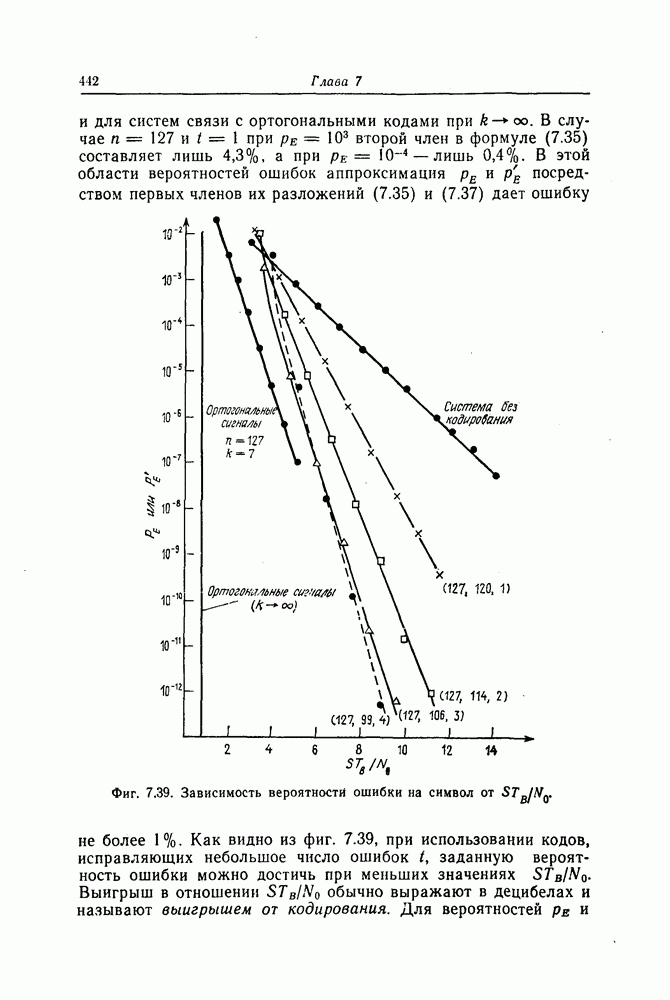
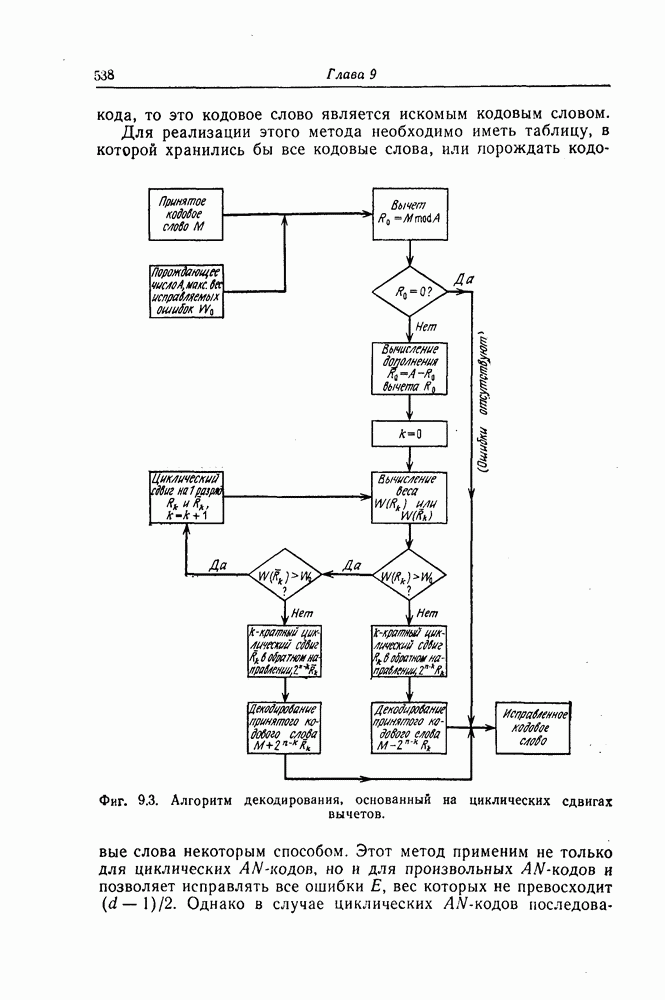
(кликните для просмотра скана) Шаг 6. Точно так же декодер осуществляет декодирование остальных символов принятой последовательности. Блок-схема декодера, осуществляющего декодирование принятой последовательности описанным выше образом, приведена на фиг. 7.14. Изображенный на фиг. 7.14 декодер называют декодером типа Еще один споособ декодирования рассматриваемых кодов можно получить, построив составные проверки на основе проверочной матрицы кода
элементы пространства строк проверочной матрицы
соответственно передаваемый кодовый вектор, вектор ошибок и принятый вектор. Скалярное произведение
Так как
или, что то же самое,
Как видно, отыскание
Декодер, осуществляющий декодирование на основе описанных выше составных проверок, называют декодером типа II. Декодер типа II в общем виде изображен на фиг. 7.16 и функционирует следующим образом: Шаг 1. Вентиль 1 открыт, вентиль 2 закрыт, и принятая последовательность вводится в буферный регистр. После ввода принятой последовательности вентиль 1 закрывается, а вентиль 2 открывается.
Фиг. 7.16. Мажоритарный декодер типа II в общем случае Шаг 2. Строятся составные проверки, ортогональные относительно Шаг Шаг 4. После выполнения шага 3 содержимое буферного регистра сдвигается на один символ вправо. При этом 2-й принятый символ переходит на место 1-го принятого символа и декодируется точно так же, как и 1-й принятый символ. Шаг 5. Повторяя указанные выше операции 2, 3 и 4, декодер точно так же декодирует остальные принятые символы. После окончания декодирования всех принятых символов в буферном регистре содержится кодовый вектор и на входы мажоритарных элементов подаются символы 0. В качестве примера декодера типа II рассмотрим декодер кода над
Заметим, что каждой строке матрицы
Среди подпространств матрицы
и подавая их на вход порогового элемента с порогом 2, получаем составную проверку, ортогональную относительно
получаем составную проверку, ортогональную относительно
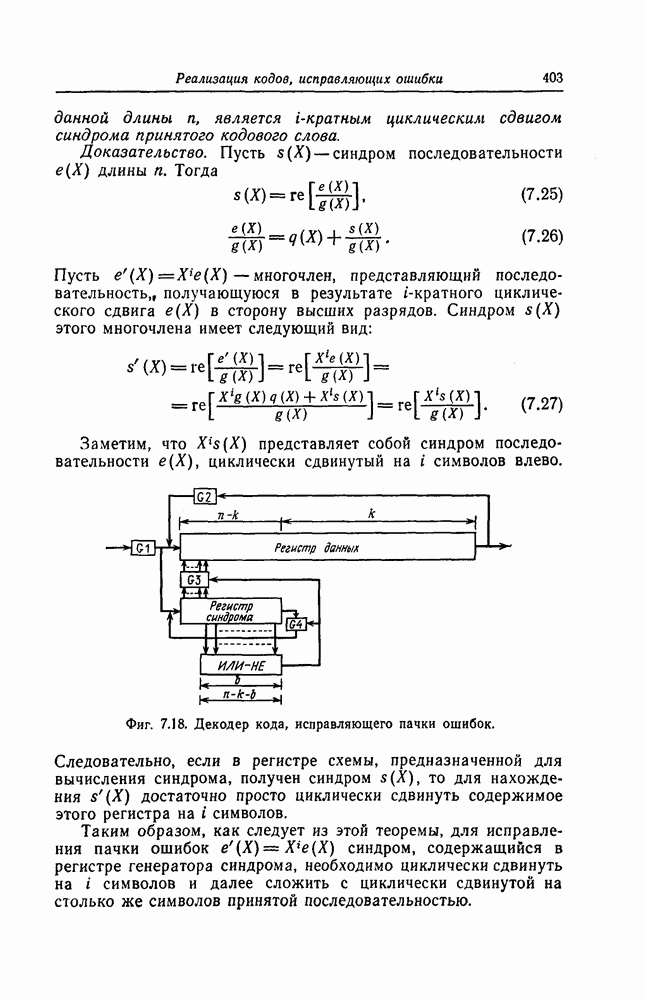
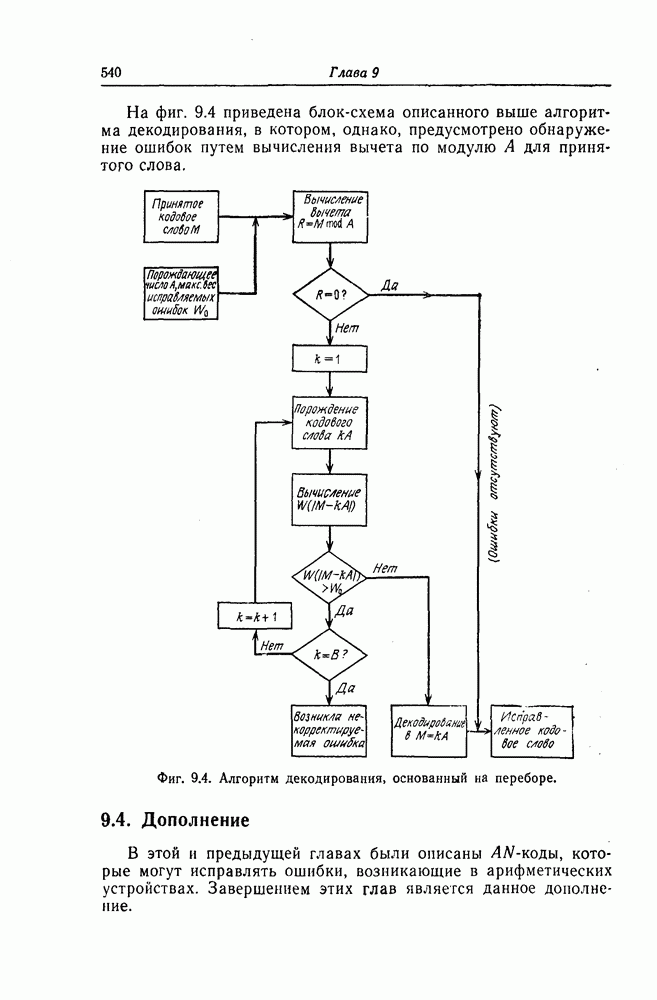
получаем составную проверку, ортогональную относительно г) Декодирование циклических кодов, исправляющих пачки ошибок. Как циклические коды, так и укороченные циклические коды, предложенные Касами и другими авторами для исправления пачек ошибок, задаются либо порождающим многочленом Декодирование таких кодов, исправляющих пачки ошибок, осуществляется следующим образом. Предположим, что корректируемая пачка ошибок длины информационным и проверочным символам кодового слова. Выше предполагалось, что
Разделив
где
Фиг. 7.17. Мажоритарный декодер типа II проективно-геометрического кода. Таким образом, в данном случае пачка ошибок может быть исправлена путем простого сложения синдрома с принятой последовательностью. Далее рассмотрим случай, когда многочлен Теорема 7.1. Синдром последовательности, получающейся заданной длины Доказательство. Пусть
Пусть
Заметим, что
Фиг. 7.18. Декодер кода, исправляющего пачки ошибок. Следовательно, если в регистре схемы, предназначенной для вычисления синдрома, получен синдром то для нахождения Таким образом, как следует из этой теоремы, для исправления пачки ошибок Декодер кода, исправляющего пачки ошибок описанным выше образом, показан на фиг. 7.18. Элемент ИЛИ-НЕ этого декодера имеет Для примера рассмотрим код длины
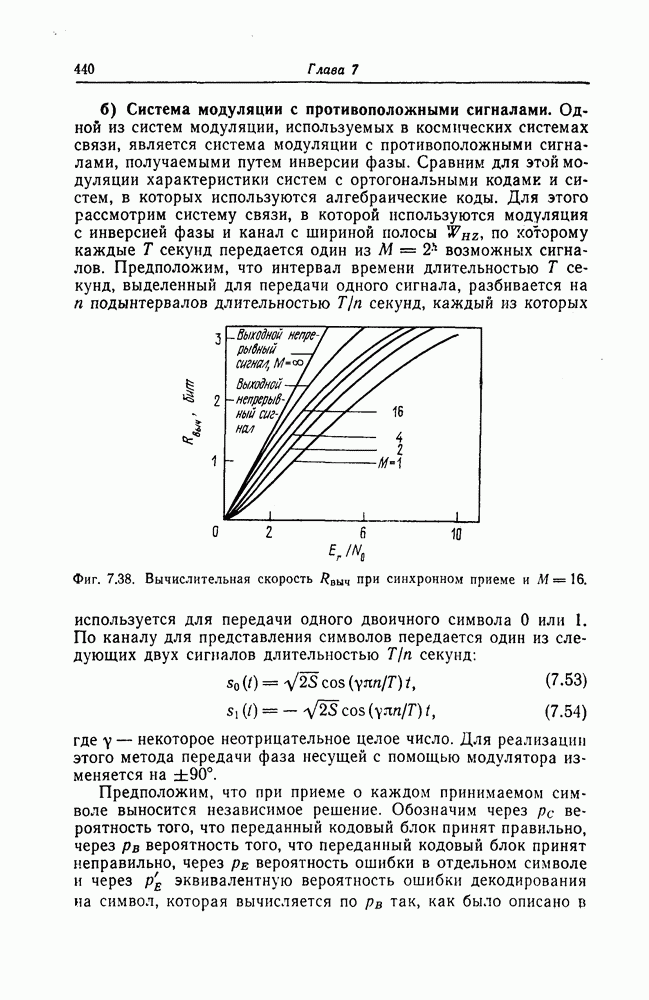
Для исправления пачек ошибок длины 9 и менее этот код следует «проредить» с шагом 3. В этом случае код будет задаваться порождающим многочленом
Рассмотрим код, задаваемый многочленом Предположим, что передавалось нулевое кодовое слово и при передаче возникли ошибки в
а синдром
Далее предположим, что при передаче возникла пачка ошибок длины 3 в
а синдром
Если этот синдром сдвигать влево, в сторону младших разрядов, то содержимое регистра будет изменяться следующим образом:
После
Фиг. 7.19. Декодер кода с порождающим многочленом Следовательно, сдвигая принятую последовательность циклически на 5 символов в сторону младших разрядов и складывая ее по модулю 2 с содержимым регистра, предназначенным для хранения синдрома, можно исправить возникшую пачку ошибок. Декодер, выполняющий эти операции, показан на фиг. 7.19.
|
 |
Оглавление
|

















































































































































































































































































































































































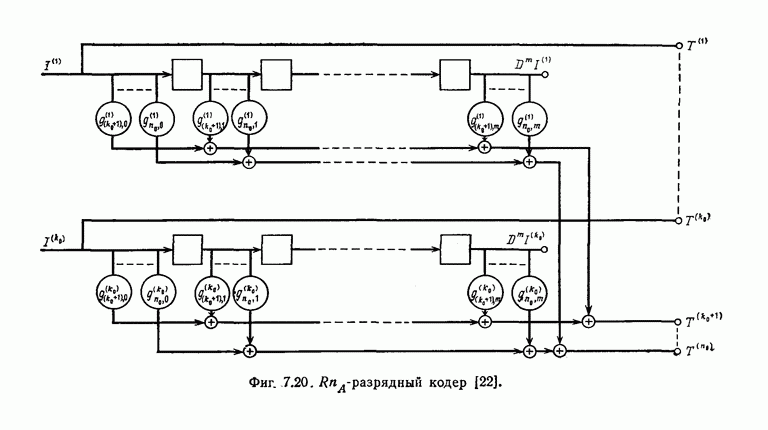

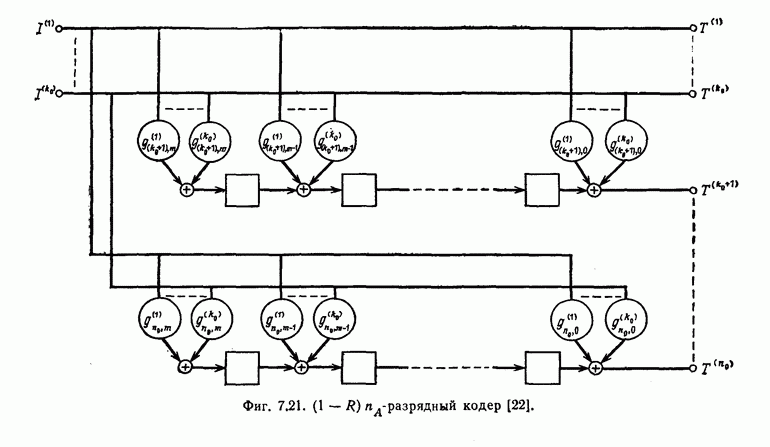
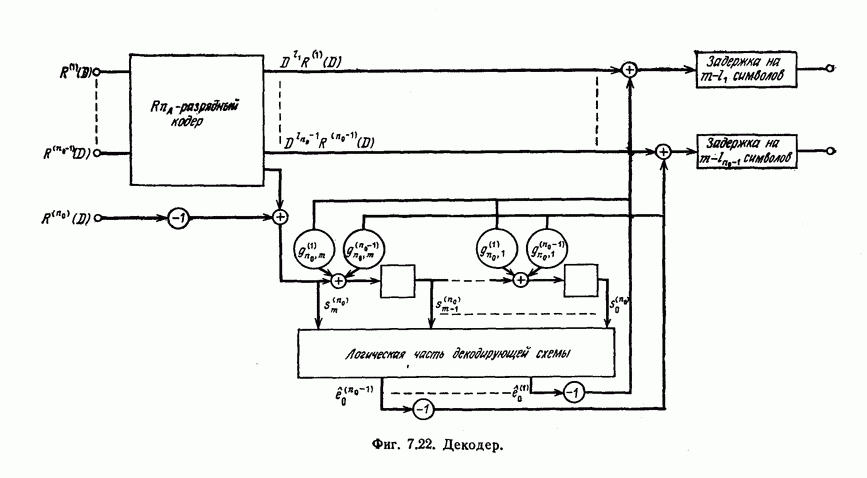



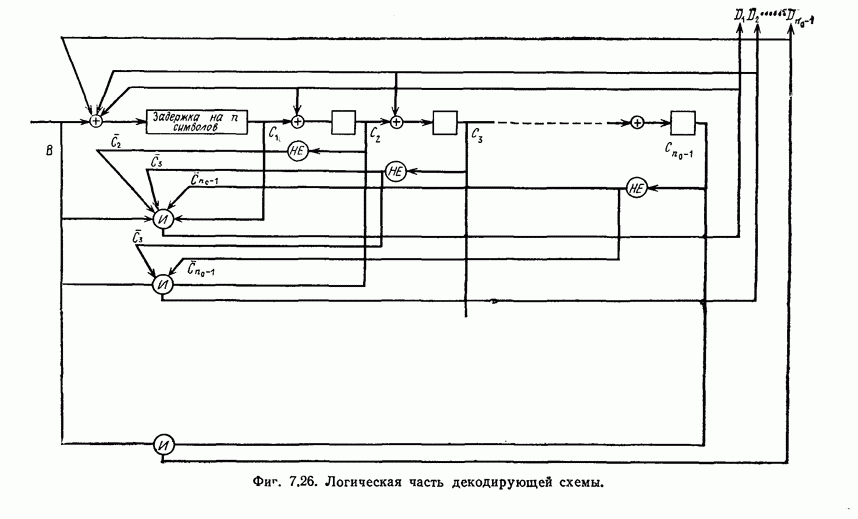
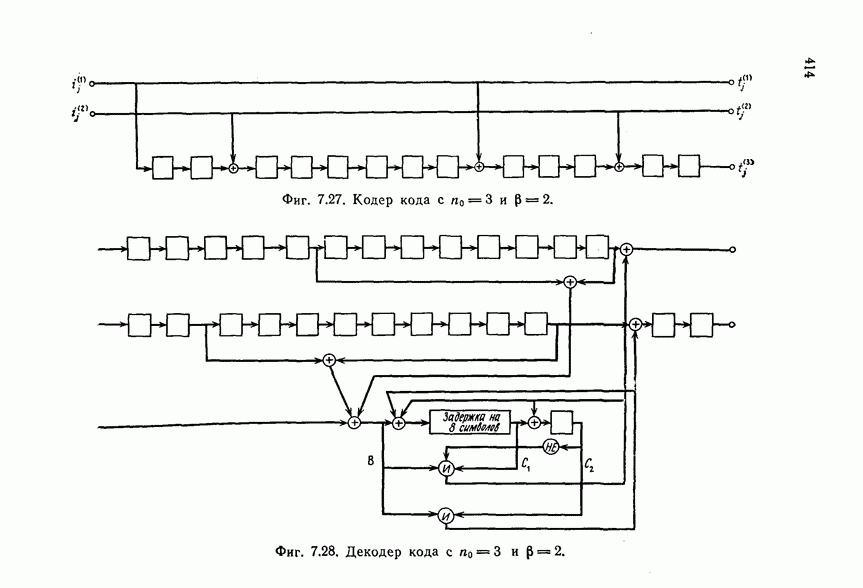




























































































































 Если полученный в результате деления остаток равен нулю, то считается, что ошибок при передаче не было.
Если полученный в результате деления остаток равен нулю, то считается, что ошибок при передаче не было.




 в некоторых точках
в некоторых точках  Эту операцию можно выполнить посредством следующей последовательной схемы.
Эту операцию можно выполнить посредством следующей последовательной схемы.
 . Сначала рассмотрим схему вычисления
. Сначала рассмотрим схему вычисления  Пусть а — примитивный элемент поля
Пусть а — примитивный элемент поля  являющийся корнем многочлена
являющийся корнем многочлена  Если в крайний левый разряд регистра схемы, изображенной на фиг. 7.11, ввести символ 1 и начать его сдвигать, то, как легко проверить, благодаря цепи обратной связи в разрядах регистра последовательно будут формироваться двоичные представления
Если в крайний левый разряд регистра схемы, изображенной на фиг. 7.11, ввести символ 1 и начать его сдвигать, то, как легко проверить, благодаря цепи обратной связи в разрядах регистра последовательно будут формироваться двоичные представления  Таким образом, чтобы вычислить
Таким образом, чтобы вычислить


 На фиг. 7.12 приведен пример схемы вычисления
На фиг. 7.12 приведен пример схемы вычисления  с помощью регистра сдвига с четырьмя разрядами [а — примитивный элемент поля
с помощью регистра сдвига с четырьмя разрядами [а — примитивный элемент поля




 .
.
 соответственно коэффициенты векторного представления
соответственно коэффициенты векторного представления  элемента поля
элемента поля  после умножения последнего на
после умножения последнего на  то будем иметь
то будем иметь

 то в результате в регистре окажется
то в результате в регистре окажется  При использовании этой схемы вычисление синдрома кончается в тот момент, когда завершается прием слова.
При использовании этой схемы вычисление синдрома кончается в тот момент, когда завершается прием слова.

 ошибок. Тогда, если
ошибок. Тогда, если  компонента принятого слова является ошибочной, то
компонента принятого слова является ошибочной, то




 можно вычислить сумму
можно вычислить сумму  Если эта сумма равно 0, то, как следует из формулы (7.11),
Если эта сумма равно 0, то, как следует из формулы (7.11),  компонента принятого кодового слова содержит ошибку.
компонента принятого кодового слова содержит ошибку.

 . Далее эти символы умножаются соответственно на
. Далее эти символы умножаются соответственно на  а и проверяется справедливость равенства
а и проверяется справедливость равенства  или равенства
или равенства  Затем содержимое ячеек регистра вновь умножается на
Затем содержимое ячеек регистра вновь умножается на  а и находится
а и находится  Точно так же находятся и остальные ошибки.
Точно так же находятся и остальные ошибки.
 символы
символы  являются информационными, а символы
являются информационными, а символы  проверочными. При декодировании таких кодов удобно вначале вычислять составные проверки, ортогональные относительно шумового символа
проверочными. При декодировании таких кодов удобно вначале вычислять составные проверки, ортогональные относительно шумового символа  воздействующего на принятый символ
воздействующего на принятый символ  При этом декодирование происходит следующим образом:
При этом декодирование происходит следующим образом:
 символам синдрома строятся
символам синдрома строятся  составных проверок, ортогональных относительно
составных проверок, ортогональных относительно  полученные
полученные  составных проверок подаются на входы мажоритарного элемента. Эта операция повторяется
составных проверок подаются на входы мажоритарного элемента. Эта операция повторяется  раз, и если выход последнего мажоритарного элемента оказывается равным 1, то декодер принимает решение о том, что в первом символе принятой последовательности содержится ошибка. Если же выход последнего мажоритарного элемента равен 0, то декодер принимает решение о том, что первый символ принятой последовательности является правильным.
раз, и если выход последнего мажоритарного элемента оказывается равным 1, то декодер принимает решение о том, что в первом символе принятой последовательности содержится ошибка. Если же выход последнего мажоритарного элемента равен 0, то декодер принимает решение о том, что первый символ принятой последовательности является правильным.
 на синдром. Если обозначить шумовую последовательность через
на синдром. Если обозначить шумовую последовательность через  сумму членов
сумму членов  степени
степени  и менее через
и менее через  то синдром
то синдром  можно представить в виде
можно представить в виде

 остаток выражения, стоящего в квадратных скобках). Следовательно, воздействие
остаток выражения, стоящего в квадратных скобках). Следовательно, воздействие  на синдром можно устранить, сложив синдром с многочленом
на синдром можно устранить, сложив синдром с многочленом

 на
на  Эту операцию называют коррекцией синдрома. После коррекции синдрома в регистре синдрома содержится синдром принятой последовательности, сдвинутой на один символ.
Эту операцию называют коррекцией синдрома. После коррекции синдрома в регистре синдрома содержится синдром принятой последовательности, сдвинутой на один символ.

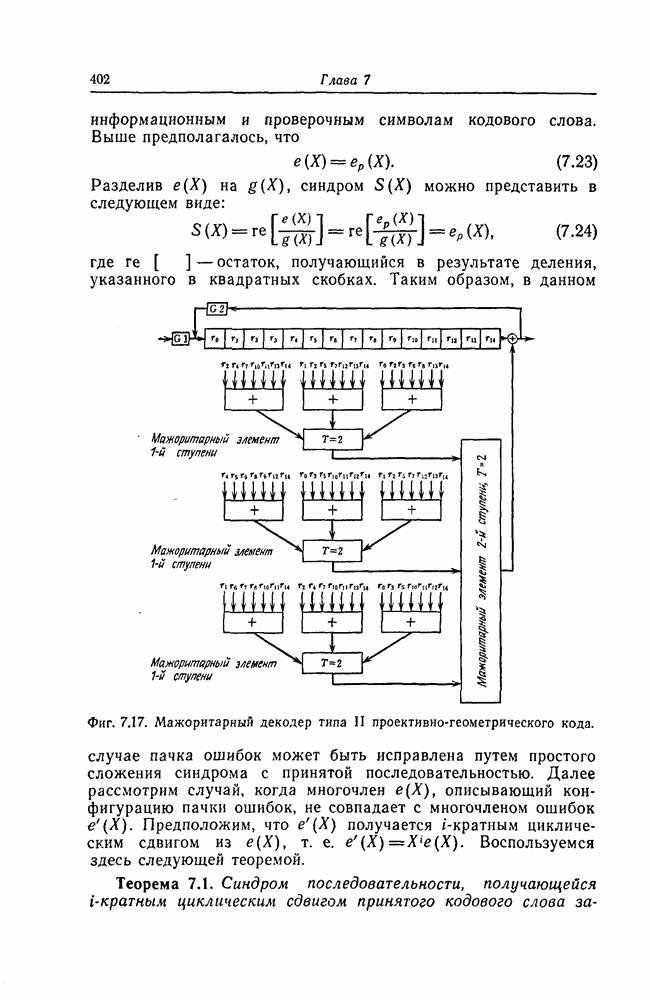
 На фиг. 7.15 показан декодер типа I циклического кода с порождающим многочленом
На фиг. 7.15 показан декодер типа I циклического кода с порождающим многочленом  получающегося из совершенного разностного множества.
получающегося из совершенного разностного множества.
 Обозначим здесь через
Обозначим здесь через

 а черео
а черео

 имеет вид:
имеет вид:

 , то
, то


 составных проверок, ортогональных относительно
составных проверок, ортогональных относительно  эквивалентно отысканию
эквивалентно отысканию  векторов
векторов  в пространстве строк матрицы
в пространстве строк матрицы  элементы
элементы  строк равны 1, и строки таковы, что ни при каком
строк равны 1, и строки таковы, что ни при каком  среди элементов
среди элементов  нет двух единиц. Согласно формуле (7.15), в качестве составных проверок, ортогональных относительно
нет двух единиц. Согласно формуле (7.15), в качестве составных проверок, ортогональных относительно  можно взять следующие проверки:
можно взять следующие проверки:

 составных проверок представляют собой
составных проверок представляют собой  сумм принятых символов. Векторы показывают, какие из принятых символов нужно сложить, чтобы получить проверки
сумм принятых символов. Векторы показывают, какие из принятых символов нужно сложить, чтобы получить проверки 

 или совокупности символов, содержащих
или совокупности символов, содержащих  Для этого определенные принятые символы подаются на входы сумматоров по модулю 2.
Для этого определенные принятые символы подаются на входы сумматоров по модулю 2.
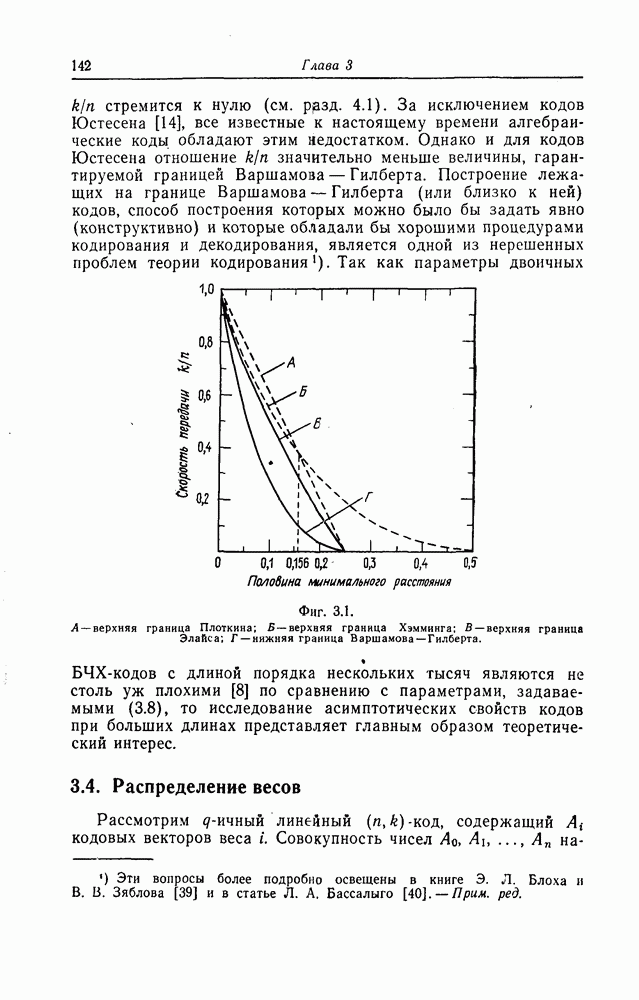
 составных проверок подаются на входы мажоритарных элементов 1-й ступени. Символы с выходов мажоритарных элементов 1-й ступени подаются на входы мажоритарных элементов 2-й ступени и т.д. Символ с выхода мажоритарного элемента
составных проверок подаются на входы мажоритарных элементов 1-й ступени. Символы с выходов мажоритарных элементов 1-й ступени подаются на входы мажоритарных элементов 2-й ступени и т.д. Символ с выхода мажоритарного элемента  ступени складывается по модулю 2 с первым принятым символом
ступени складывается по модулю 2 с первым принятым символом  считываемым из буферного регистра, и таким образом исправление ошибки в
считываемым из буферного регистра, и таким образом исправление ошибки в  завершается,
завершается,
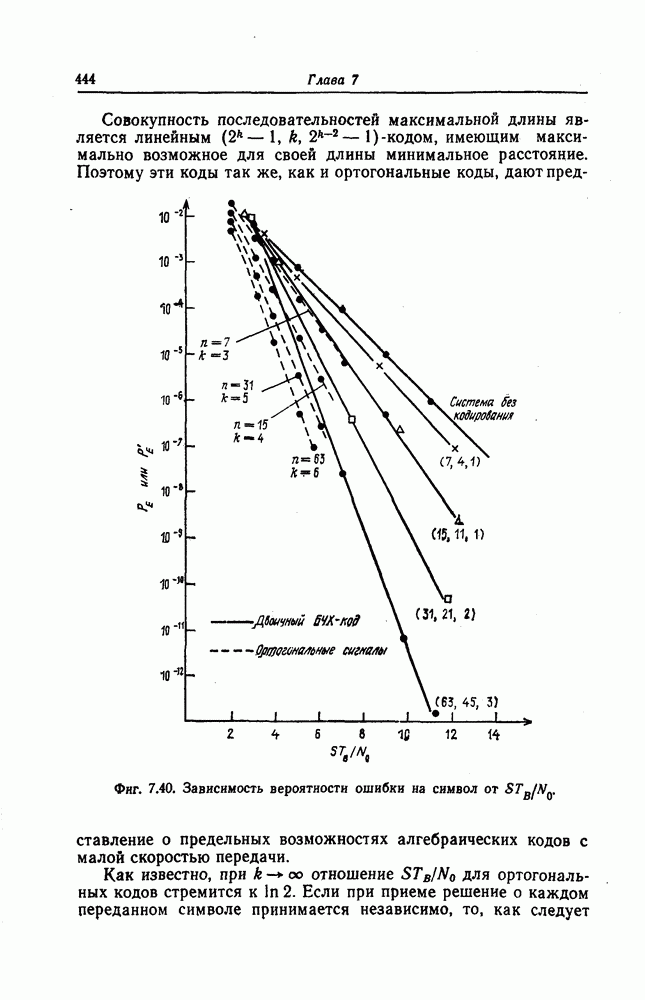
 с параметрами
с параметрами  ортогонализируемого в два шага. Этот код задается нуль-матрицей (проверочной матрицей), в качестве которой берется матрица инцидентности
ортогонализируемого в два шага. Этот код задается нуль-матрицей (проверочной матрицей), в качестве которой берется матрица инцидентности  строками которой являются в свою очередь всевозможные циклические сдвиги последовательности коэффициентов многочлена 4
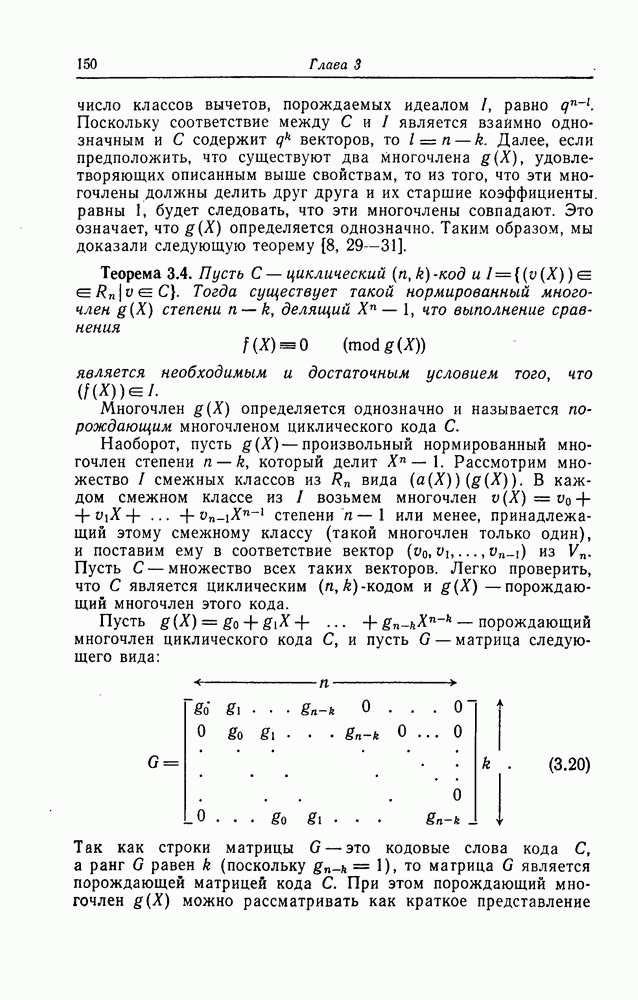
строками которой являются в свою очередь всевозможные циклические сдвиги последовательности коэффициентов многочлена 4

 соответствует одно из 15 проективных пространств
соответствует одно из 15 проективных пространств  содержащихся в
содержащихся в  :
:

 существуют три подпространства
существуют три подпространства  содержащие элемент
содержащие элемент  соответствующий Гц. Следовательно, строками
соответствующий Гц. Следовательно, строками
 ортогональными относительно
ортогональными относительно  являются 10, 13 и 14-я строки. Кроме того, 5, 11 и 13-я строки матрицы
являются 10, 13 и 14-я строки. Кроме того, 5, 11 и 13-я строки матрицы  ортогональны относительно
ортогональны относительно  и 11-я строки ортогональны относительно
и 11-я строки ортогональны относительно  Вычисляя следующие три суммы по модулю 2, в каждую из которых входит по 7 символов:
Вычисляя следующие три суммы по модулю 2, в каждую из которых входит по 7 символов:

 Вычисляя суммы
Вычисляя суммы

 Аналогично, вычисляя суммы
Аналогично, вычисляя суммы

 Если выходы этих трех пороговых элементов подать на вход четвертого порогового элемента, порог которого также равен 2, то на выходе последнего порогового элемента получим проверку, ортогональную относительно
Если выходы этих трех пороговых элементов подать на вход четвертого порогового элемента, порог которого также равен 2, то на выходе последнего порогового элемента получим проверку, ортогональную относительно  Схема декодера, выполняющего описанные выше операции, приведена на фиг. 7.17.
Схема декодера, выполняющего описанные выше операции, приведена на фиг. 7.17.
 либо порождающим многочленом
либо порождающим многочленом  получающимся перемежением
получающимся перемежением  с шагом
с шагом 
 возникла в проверочных символах кодового слова. Пусть
возникла в проверочных символах кодового слова. Пусть  -многочлен, описывающий конфигурацию данной пачки ошибок, а
-многочлен, описывающий конфигурацию данной пачки ошибок, а  и
и  - многочлены ошибок, соответствующие соответственно
- многочлены ошибок, соответствующие соответственно

 на
на  синдром
синдром  можно представить в следующем виде:
можно представить в следующем виде:

 остаток, получающийся в результате деления, указанного в квадратных скобках.
остаток, получающийся в результате деления, указанного в квадратных скобках.

 описывающий конфигурацию пачки ошибок, не совпадает с многочленом ошибок
описывающий конфигурацию пачки ошибок, не совпадает с многочленом ошибок  Предположим, что
Предположим, что  получается
получается  -кратным циклическим сдвигом из
-кратным циклическим сдвигом из  т. е.
т. е.  Воспользуемся здесь следующей теоремой.
Воспользуемся здесь следующей теоремой.
 -кратным циклическим сдвигом принятого кодового слова
-кратным циклическим сдвигом принятого кодового слова
 является
является  -кратным циклическим сдвигом синдрома принятого кодового слова.
-кратным циклическим сдвигом синдрома принятого кодового слова.
 синдром последовательности
синдром последовательности  длины
длины  Тогда
Тогда

 -многочлен, представляющий последовательность, получающуюся в результате
-многочлен, представляющий последовательность, получающуюся в результате  -кратного циклического сдвига
-кратного циклического сдвига  в сторону высших разрядов. Синдром
в сторону высших разрядов. Синдром  этого многочлена имеет следующий вид:
этого многочлена имеет следующий вид:

 представляет собой синдром последовательности
представляет собой синдром последовательности  циклически сдвинутый на
циклически сдвинутый на  символов влево.
символов влево.

 достаточно просто циклически сдвинуть содержимое этого регистра на
достаточно просто циклически сдвинуть содержимое этого регистра на  символов.
символов.
 синдром, содержащийся в регистре генератора синдрома, необходимо циклически сдвинуть на
синдром, содержащийся в регистре генератора синдрома, необходимо циклически сдвинуть на  символов и далее сложить с циклически сдвинутой на столько же символов принятой последовательностью.
символов и далее сложить с циклически сдвинутой на столько же символов принятой последовательностью.
 входов, на которые подаются символы с выходов регистра синдрома. Если все эти символы равны нулю, то это означает, что
входов, на которые подаются символы с выходов регистра синдрома. Если все эти символы равны нулю, то это означает, что  младших разрядов синдрома представляют собой пачку ошибок длины
младших разрядов синдрома представляют собой пачку ошибок длины  или менее, которая может быть исправлена. В этом случае цепь обратной связи регистра синдрома с помощью вентиля
или менее, которая может быть исправлена. В этом случае цепь обратной связи регистра синдрома с помощью вентиля  разрывается, принятая последовательность, сдвинутая циклически на нужное число символов, складывается с синдромом, и таким образом пачка ошибок оказывается исправленной.
разрывается, принятая последовательность, сдвинутая циклически на нужное число символов, складывается с синдромом, и таким образом пачка ошибок оказывается исправленной.
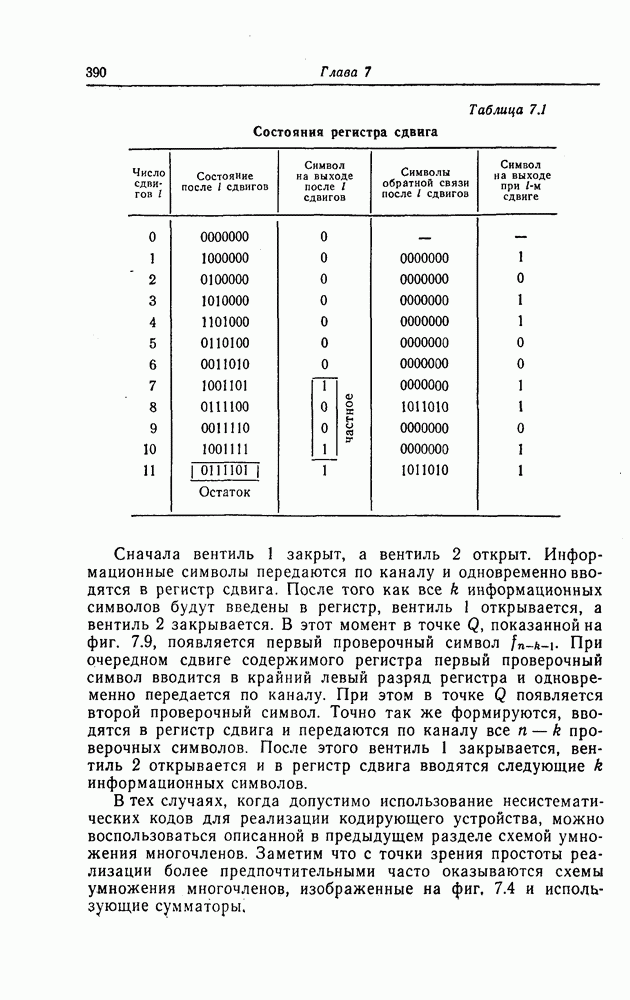
 информационными символами, исправляющий пачки ошибок длины 3 и менее. Согласно табл. 7.1, этот код имеет следующий порождающий многочлен:
информационными символами, исправляющий пачки ошибок длины 3 и менее. Согласно табл. 7.1, этот код имеет следующий порождающий многочлен:


 символах. В этом случае
символах. В этом случае


 символах. В этом случае
символах. В этом случае



 -кратного сдвига старшие
-кратного сдвига старшие  разряда синдрома оказываются равными нулю, а в младших разрядах формируется вектор ошибок.
разряда синдрома оказываются равными нулю, а в младших разрядах формируется вектор ошибок.

