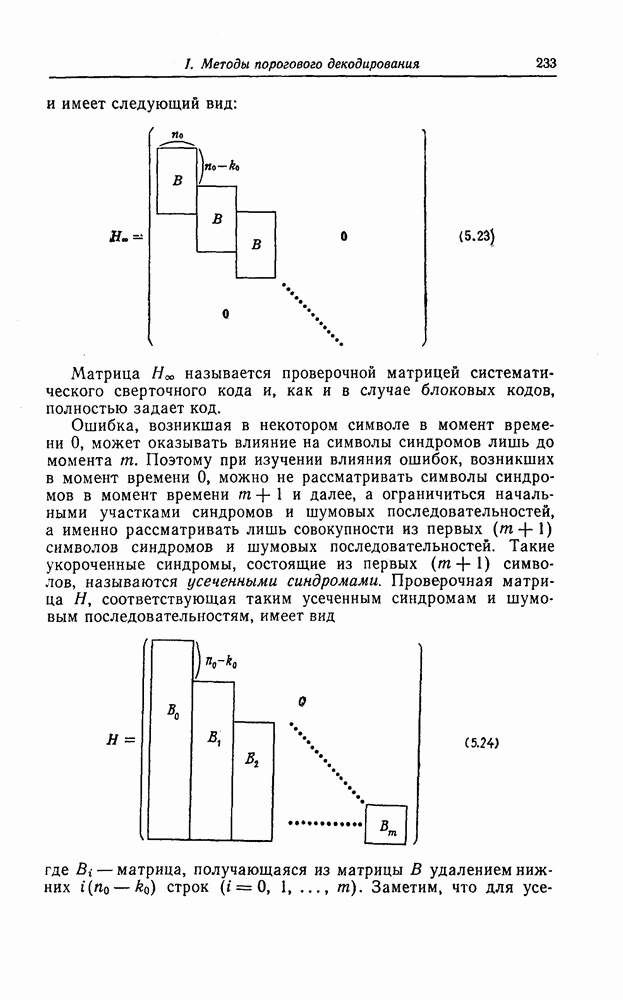
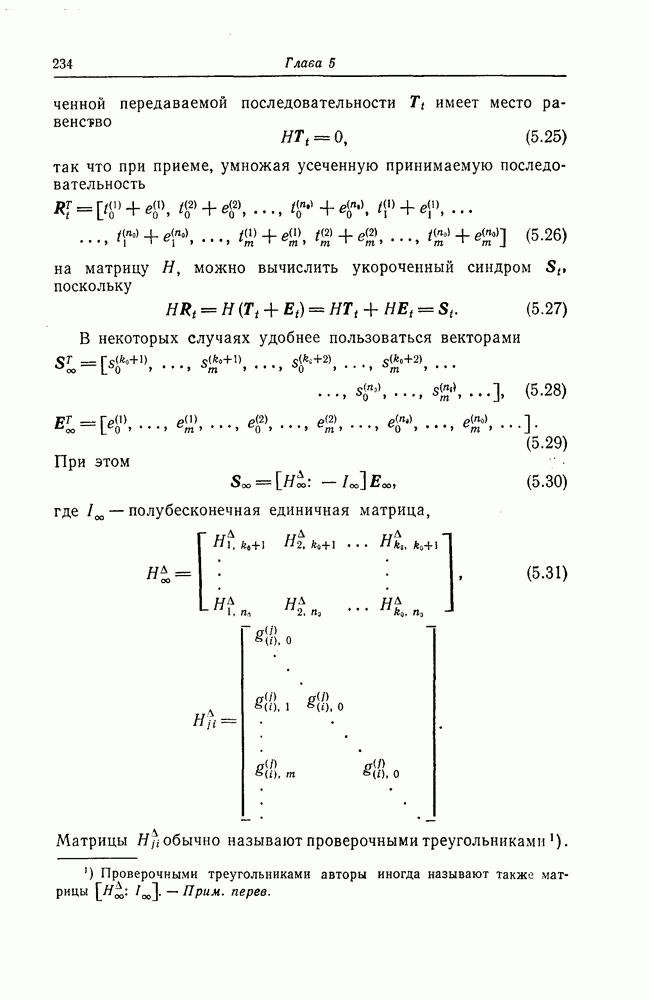
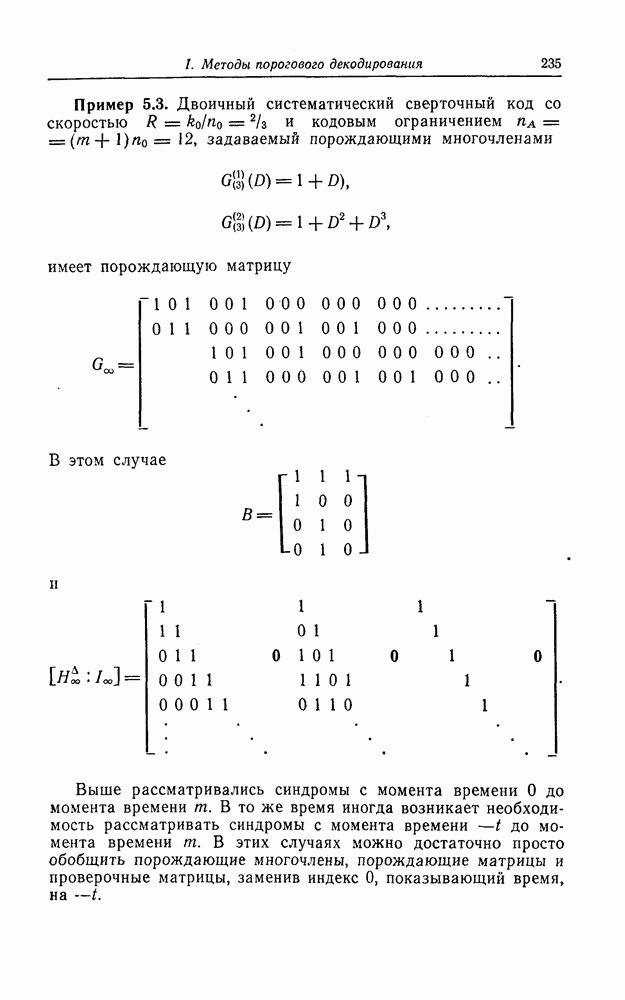
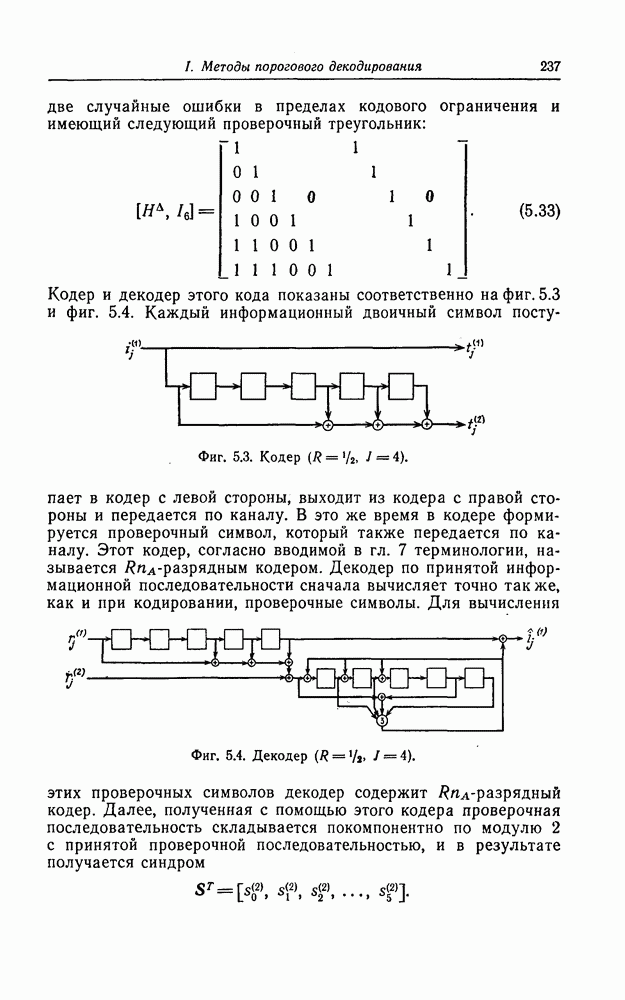
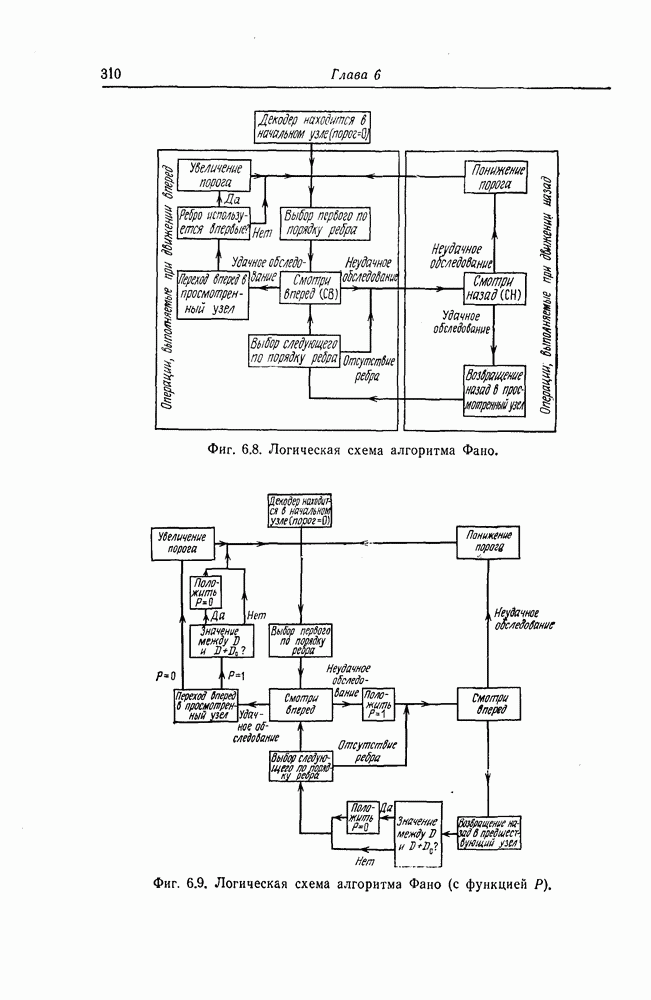
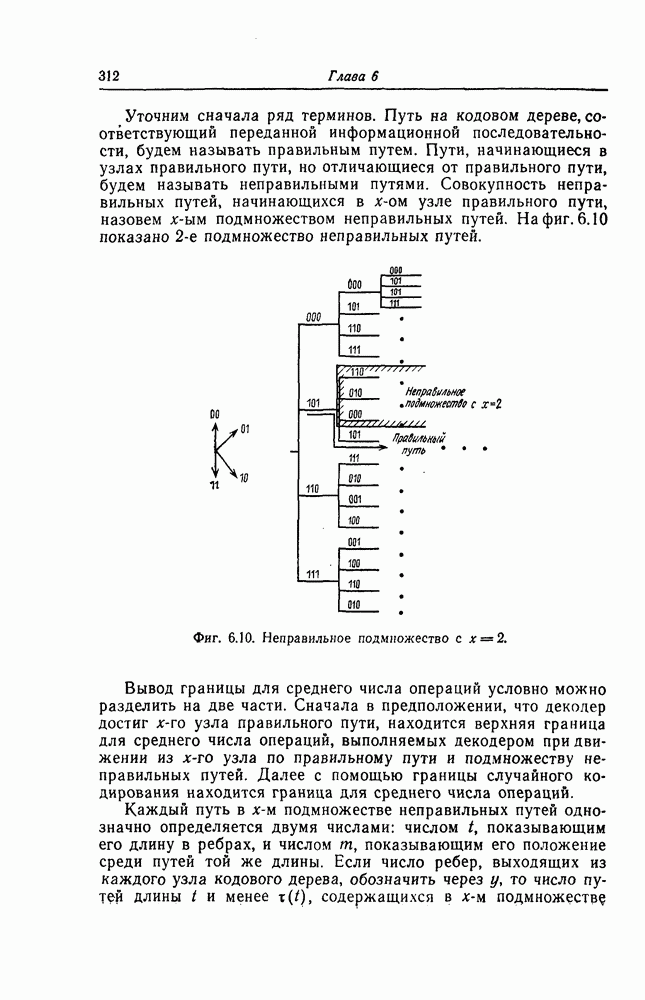
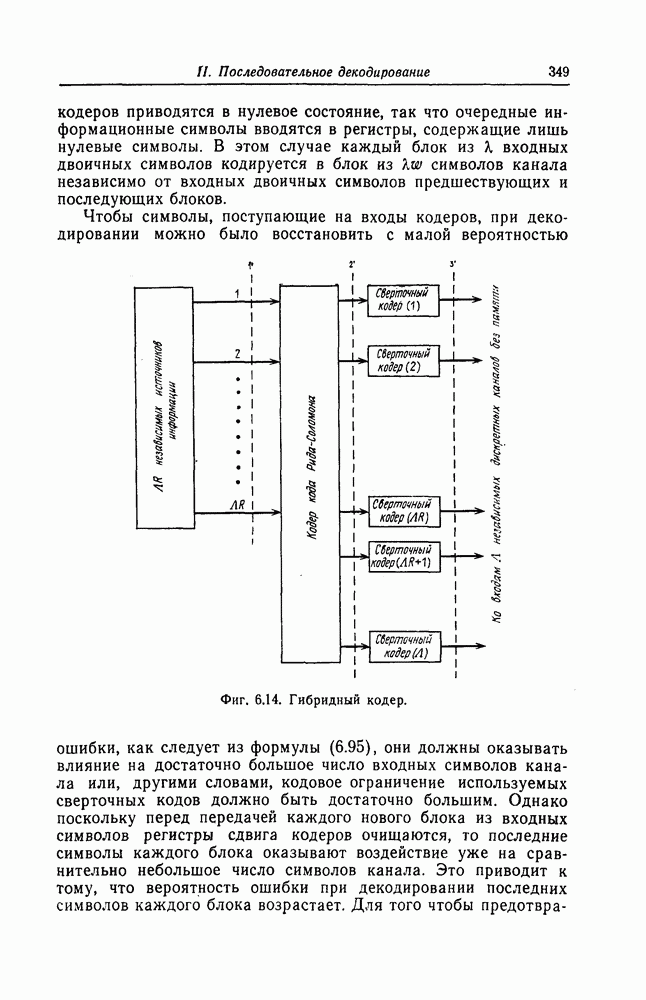
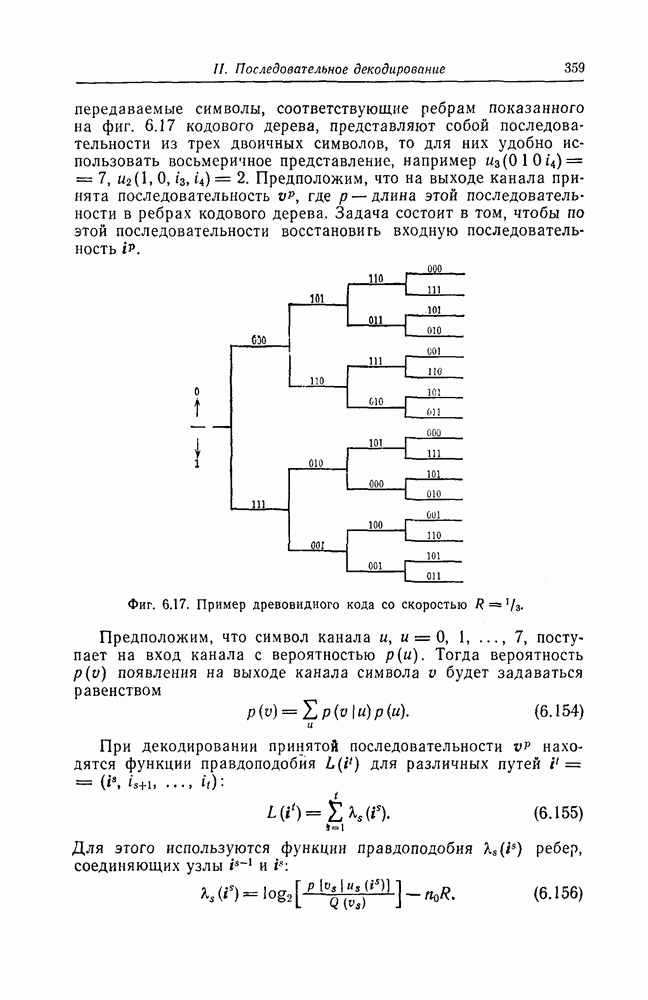
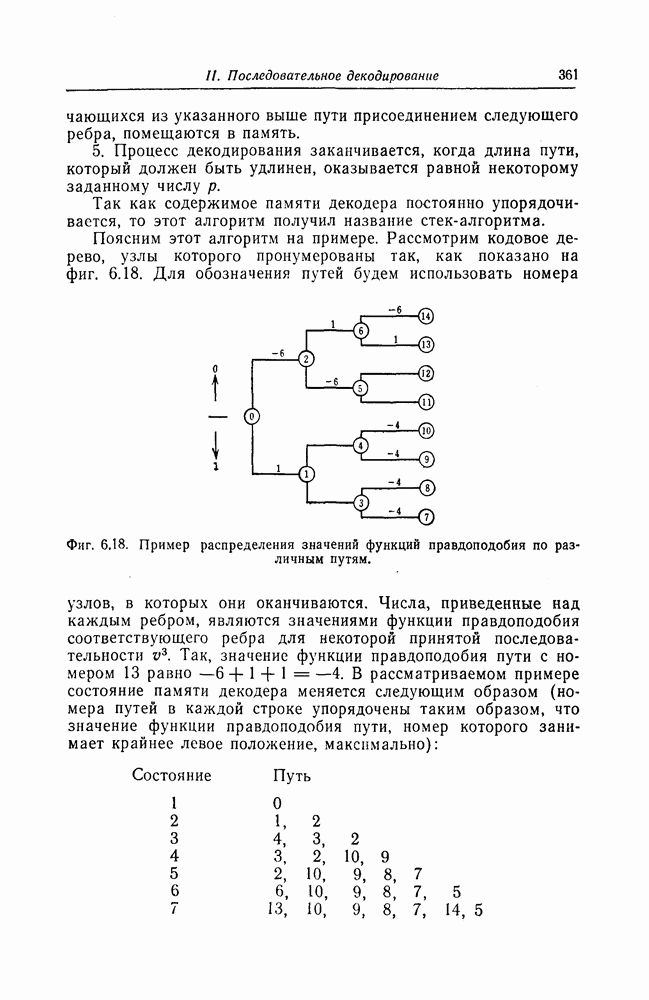
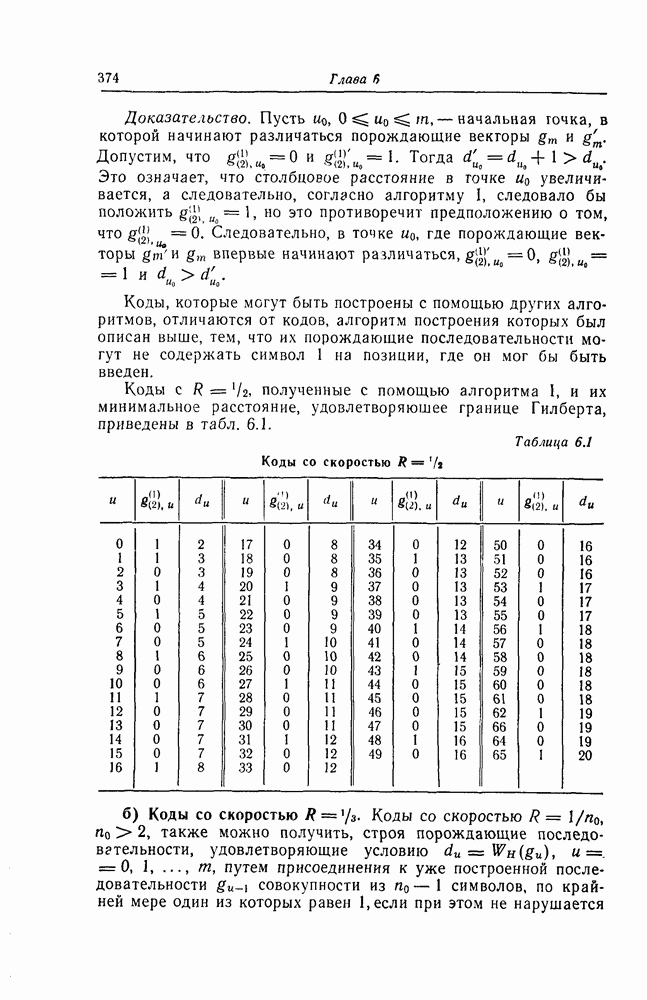
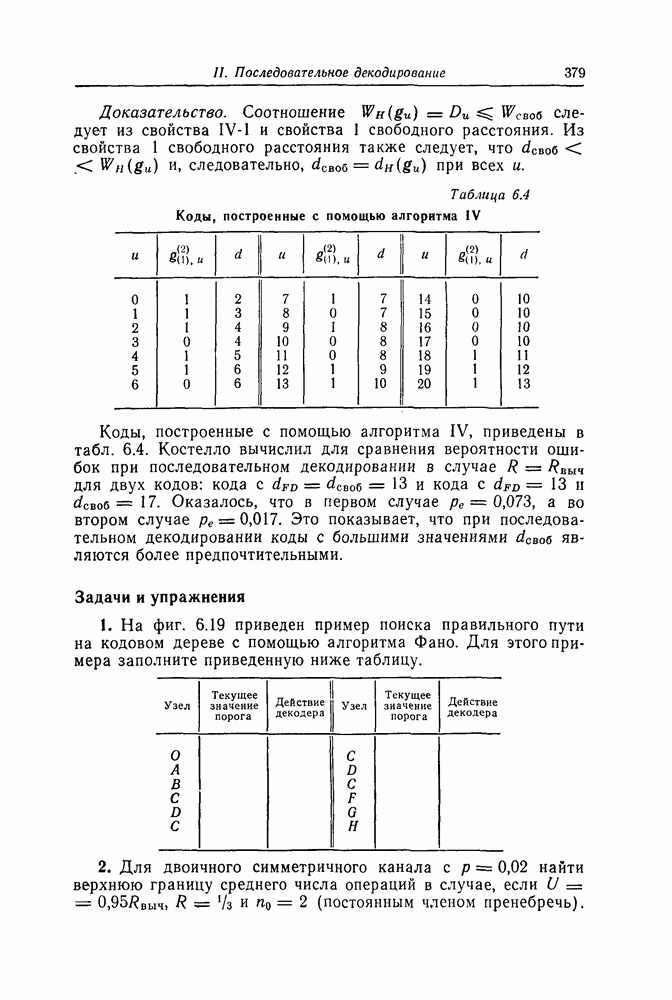
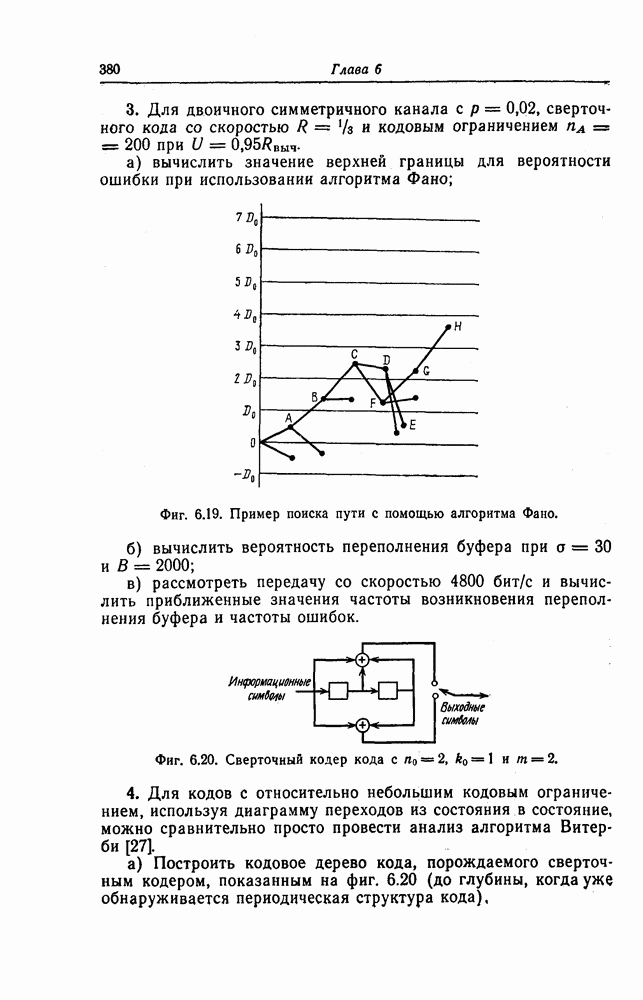
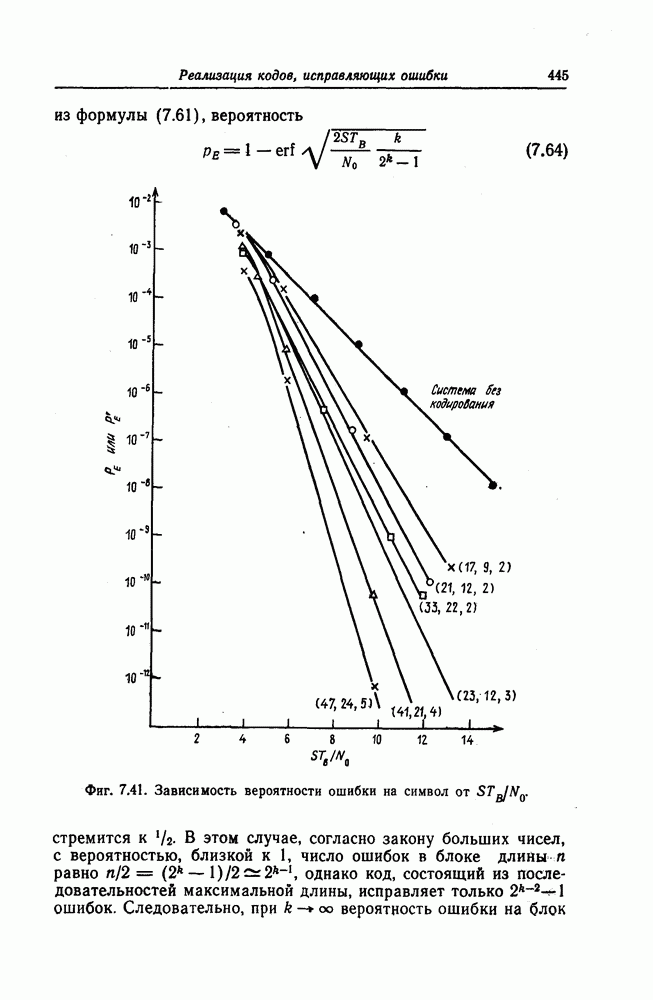
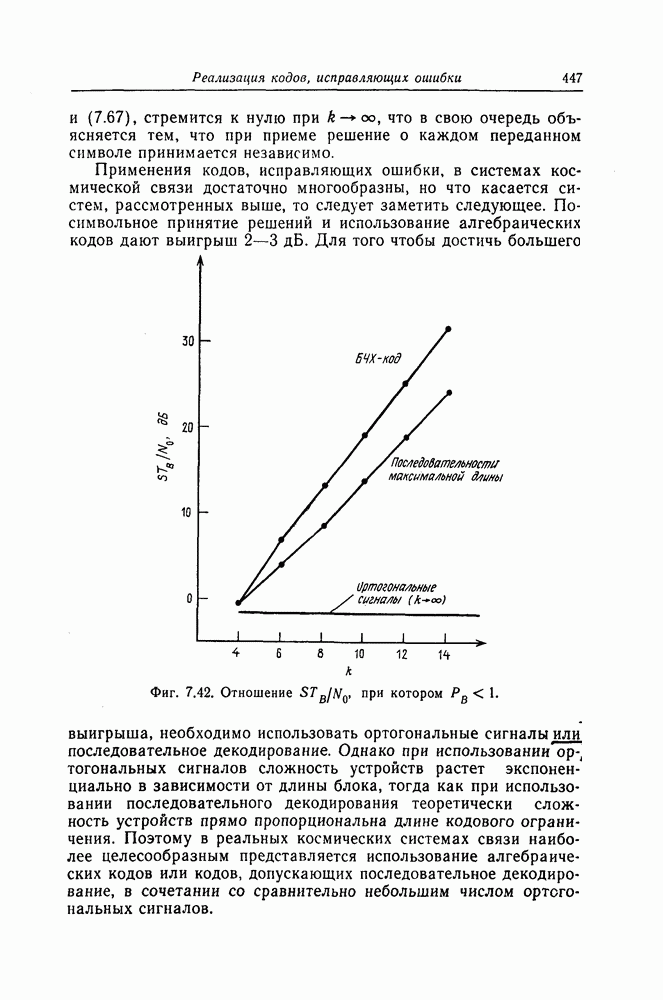
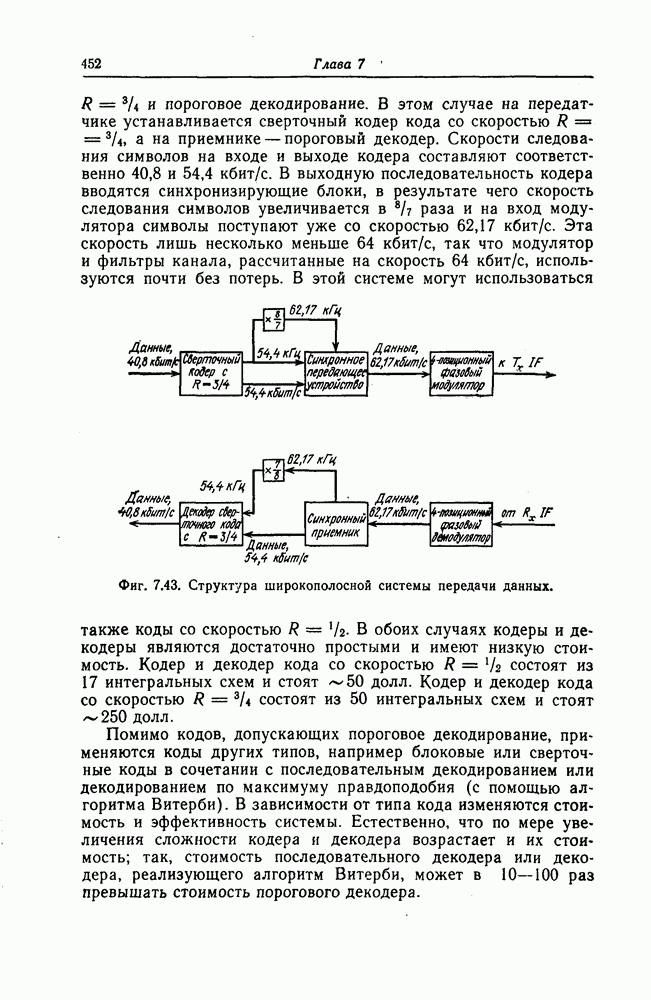
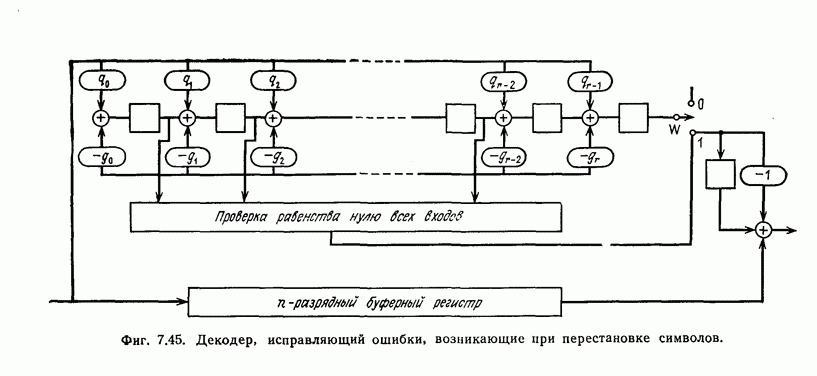
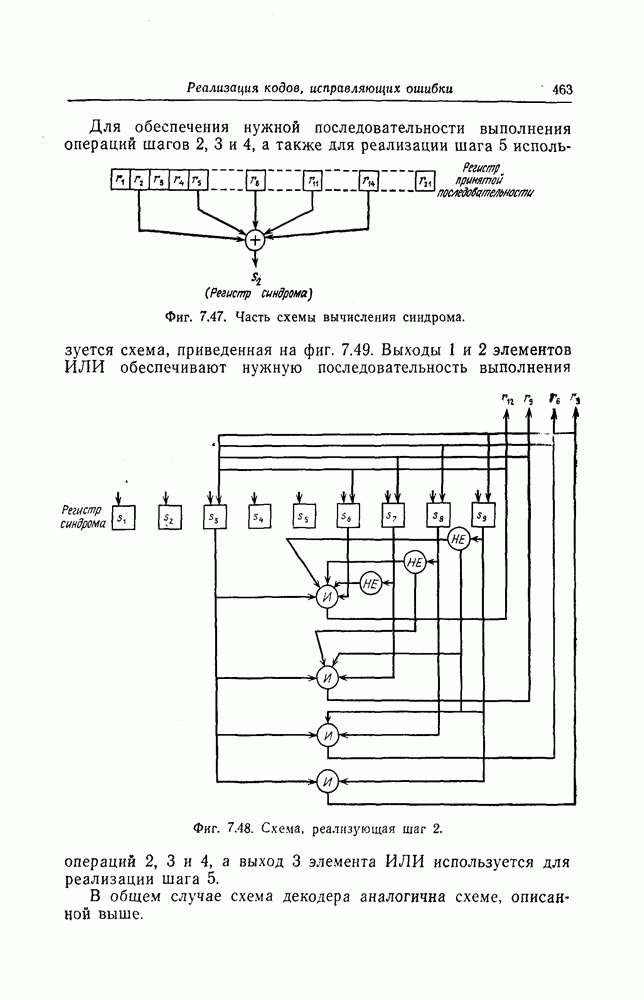
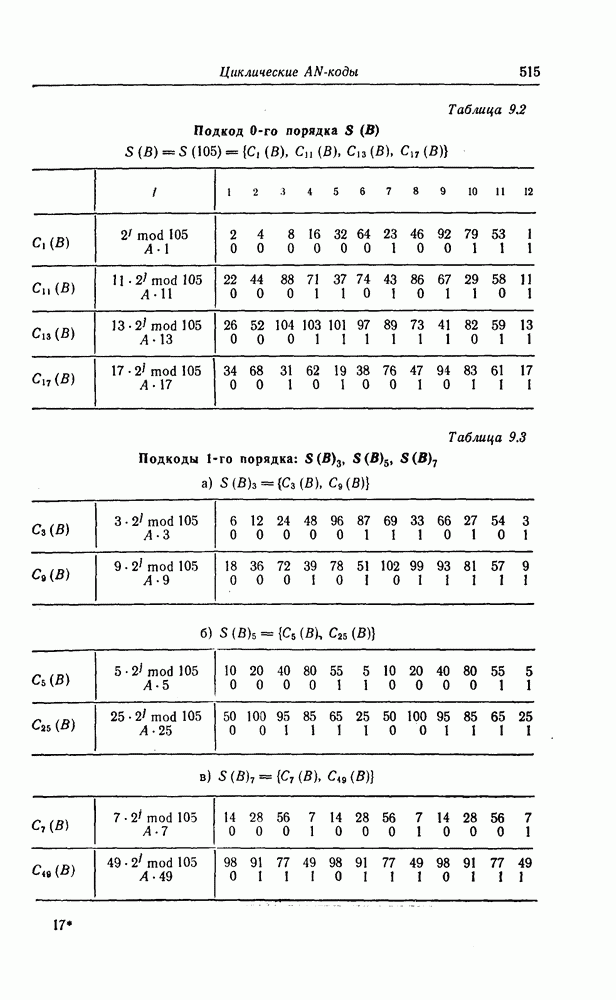
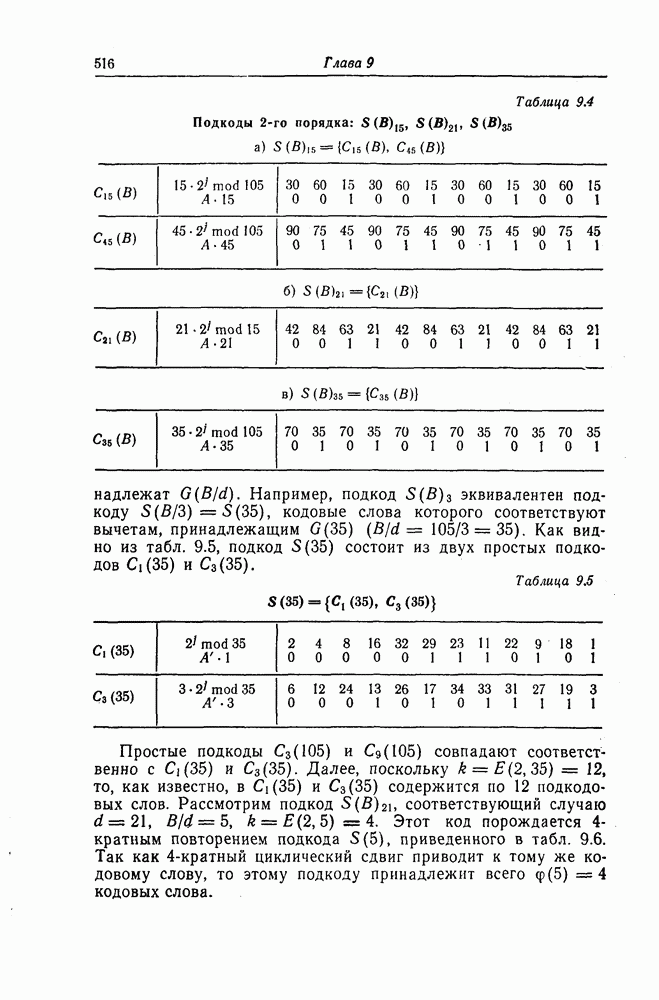
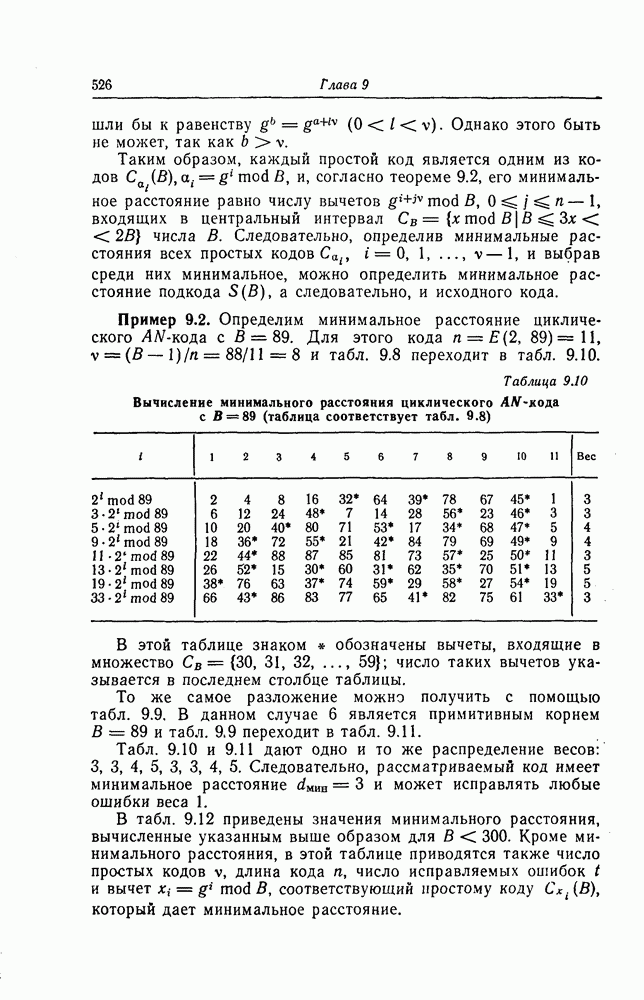
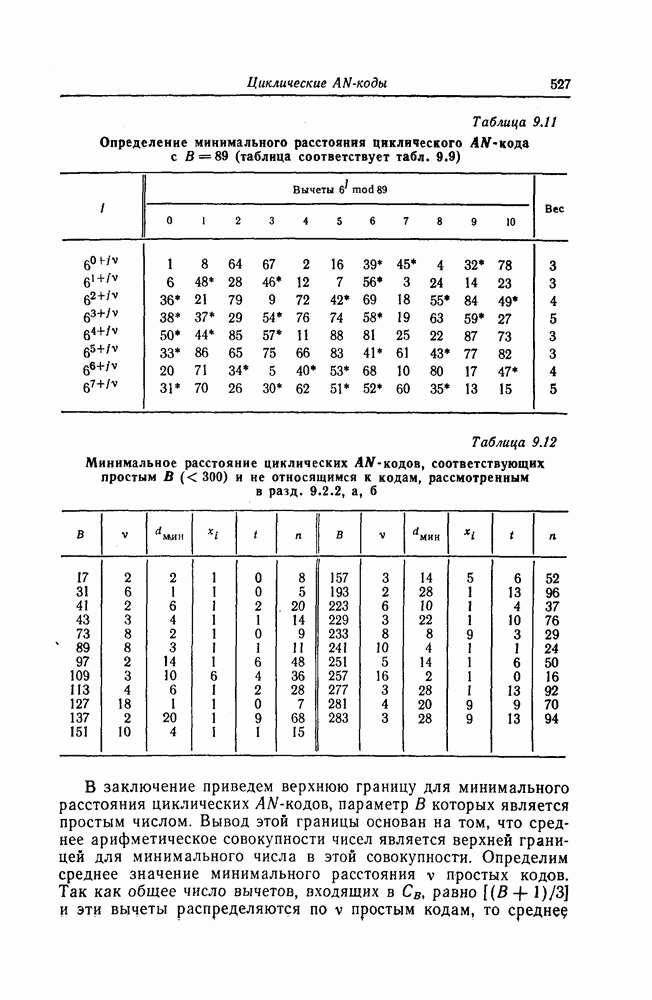
6.5. Вероятность необнаружения ошибки
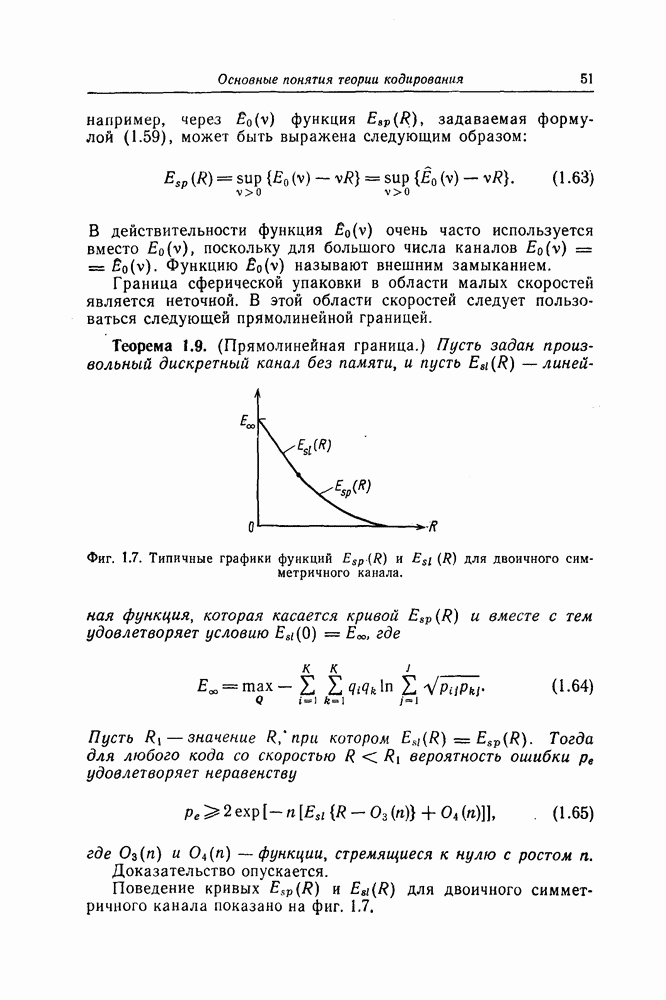
При исследовании среднего числа операций для алгоритма Фано использовалось предположение о бесконечности кодового ограничения сверточного кода, но полученная в результате верхняя граница для среднего числа операций оказалась независящей от длины кодового ограничения, и это позволило сделать вывод о том, что предположение о бесконечности кодового ограничения допустимо.
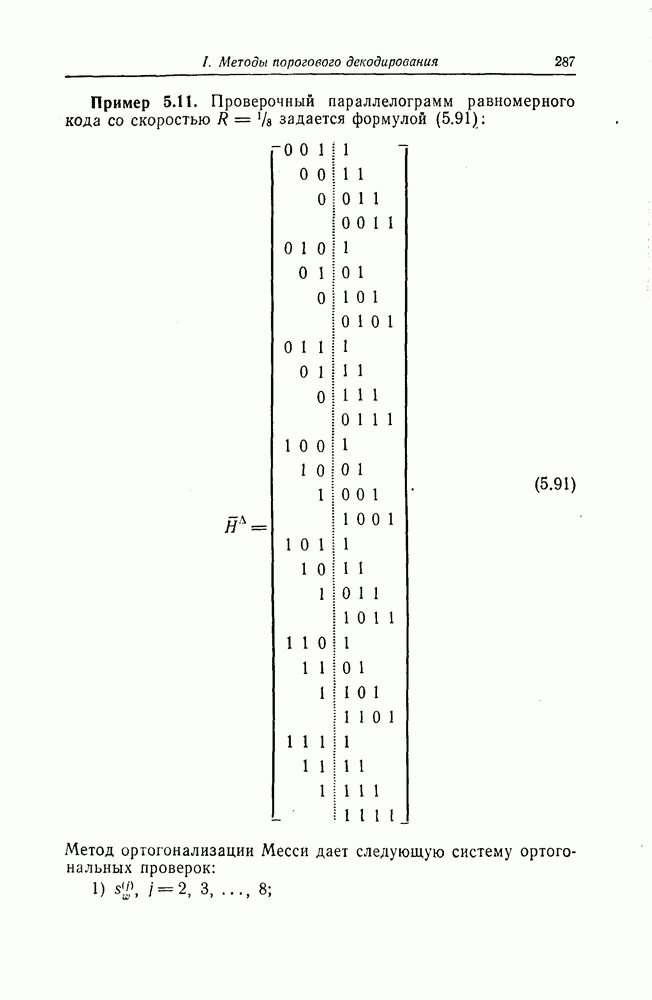
Однако кодовое ограничение сверточных кодов, порождаемых реальными кодерами, конечно и поэтому могут возникать необнаруживаемые ошибки. Например, вернемся к показанному на фиг. 6.1 сверточному кодеру кода со скоростью 1/2. Этот кодер содержит  -разрядный регистр сдвига, и информационный символ, поступающий в момент времени
-разрядный регистр сдвига, и информационный символ, поступающий в момент времени  еще влияет на проверочный символ, формируемый в момент времени
еще влияет на проверочный символ, формируемый в момент времени  но уже не оказывает влияния на последующие проверочные символы. В силу этого две выходные последовательности кодера, соответствующие двум двоичным входным последовательностям, отличающимся в первых
но уже не оказывает влияния на последующие проверочные символы. В силу этого две выходные последовательности кодера, соответствующие двум двоичным входным последовательностям, отличающимся в первых  символах и совпадающим в остальных символах, могут отличаться лишь в первых
символах и совпадающим в остальных символах, могут отличаться лишь в первых  символах, но обязательно совпадают в последующих символах. Предположим, что при передаче одной из этих выходных последовательностей по каналу шумы исказили первые
символах, но обязательно совпадают в последующих символах. Предположим, что при передаче одной из этих выходных последовательностей по каналу шумы исказили первые  символов таким образом, что эта выходная последовательность перешла в другую указанную выше последовательность. В этом случае возникшую ошибку декодер не может ни обнаружить, ни исправить. Такие ошибки называют необнаруживаемыми ошибками.
символов таким образом, что эта выходная последовательность перешла в другую указанную выше последовательность. В этом случае возникшую ошибку декодер не может ни обнаружить, ни исправить. Такие ошибки называют необнаруживаемыми ошибками.
Известно несколько границ вероятности ошибки для алгоритма Фано. В частности, для всех скоростей, меньших пропускной способности канала, верхняя граница для вероятности ошибки была получена Юдкиным [13]. Однако здесь мы рассмотрим верхнюю границу для вероятности ошибки, полученную Сэваджем [9] из соотношений, приведенных в разд. 6.3.
Вообще говоря, двоичная последовательность длины  поступающая на вход сверточного кодера, содержащего k
поступающая на вход сверточного кодера, содержащего k  -разрядных
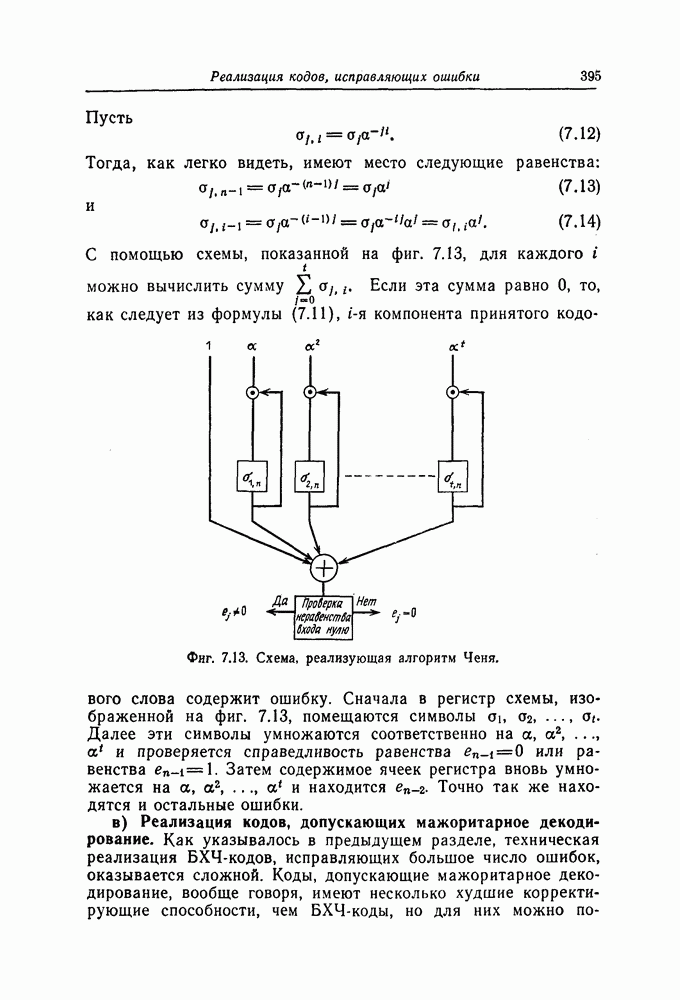
-разрядных
рядных регистров сдвига, порождает  ребер и оказывает влияние на формирование
ребер и оказывает влияние на формирование  ребер. Предположим, что задан некоторый фиксированный правильный путь, и попробуем найти число
ребер. Предположим, что задан некоторый фиксированный правильный путь, и попробуем найти число  путей в первом неправильном подмножестве, отличающихся от заданного правильного пути в первых ребрах и совпадающих с ним в последующих ребрах. Сначала заметим, что из каждого узла кодового дерева выходит
путей в первом неправильном подмножестве, отличающихся от заданного правильного пути в первых ребрах и совпадающих с ним в последующих ребрах. Сначала заметим, что из каждого узла кодового дерева выходит  ребер. Чтобы путь принадлежал первому неправильному подмножеству, его первое ребро должно отличаться от первого ребра правильного пути. При этом для того, чтобы путь отличался от правильного пути самое большее в
ребер. Чтобы путь принадлежал первому неправильному подмножеству, его первое ребро должно отличаться от первого ребра правильного пути. При этом для того, чтобы путь отличался от правильного пути самое большее в  ребрах, его
ребрах, его  ребро должно отличаться от
ребро должно отличаться от  ребра правильного пути. Отсюда следует, что
ребра правильного пути. Отсюда следует, что

В случае если путь  длины
длины  ребер, лежащих в неправильном подмножестве, начинающемся в начальном узле кодового дерева, имеет цену, превышающую максимальное значение порога, которое лежит ниже минимальной цены правильных путей длины
ребер, лежащих в неправильном подмножестве, начинающемся в начальном узле кодового дерева, имеет цену, превышающую максимальное значение порога, которое лежит ниже минимальной цены правильных путей длины  или менее символов, декодер Фано может по ошибке идентифицировать путь
или менее символов, декодер Фано может по ошибке идентифицировать путь  как правильный и породить таким образом
как правильный и породить таким образом  или менее ошибок. Другими словами, если путь
или менее ошибок. Другими словами, если путь  такой, что
такой, что

то декодер Фано может декодировать этот путь ошибочно. Следовательно, вероятность  возникновения
возникновения  или менее необнаруживаемых ошибок при передаче правильного пути можно найти, используя почти те же рассуждения, что и в разд. 6.3. Пусть
или менее необнаруживаемых ошибок при передаче правильного пути можно найти, используя почти те же рассуждения, что и в разд. 6.3. Пусть  ступенчатая функция, определенная выше [см. формулу (6.12)]. Тогда
ступенчатая функция, определенная выше [см. формулу (6.12)]. Тогда

Далее, точно так же, как и в разд. 6.3, воспользуемся границей Чернова

подставим

в правую часть (6.83) и проведем усреднение по ансамблю кодов. Здесь следует заметить, что в разд. 6.3 допускались бесконечные кодовые ограничения, а среднее значение по ансамблю
вычислялось для ансамбля кодов бесконечно большой длины. В данном же случае кодовое ограничение кода  равно
равно  а длина кодов в ансамбле, по которому производится усреднение, составляет
а длина кодов в ансамбле, по которому производится усреднение, составляет  символов. Если на длине
символов. Если на длине  символов кодовые последовательности из этого ансамбля статистически независимы, то в других местах эти последовательности оказываются, вообще говоря, уже статистически зависимыми. Как показал Галлагер [11], ансамбль кодов, обладающих этими свойствами, можно построить, выбирая всякий раз, когда в регистры сдвига кодера поступают новые информационные символы, случайным образом связи и осуществляя сложение выходной последовательности кодера с некоторой случайной последовательностью.
символов кодовые последовательности из этого ансамбля статистически независимы, то в других местах эти последовательности оказываются, вообще говоря, уже статистически зависимыми. Как показал Галлагер [11], ансамбль кодов, обладающих этими свойствами, можно построить, выбирая всякий раз, когда в регистры сдвига кодера поступают новые информационные символы, случайным образом связи и осуществляя сложение выходной последовательности кодера с некоторой случайной последовательностью.
Теорема 6.3. Для любого  существует сверточный код со скоростью передачи
существует сверточный код со скоростью передачи  и вероятностью необнаружения ошибки, экспоненциально убывающей с ростом длины кодового ограничения
и вероятностью необнаружения ошибки, экспоненциально убывающей с ростом длины кодового ограничения  Показатель экспоненты этой вероятности меньше чем
Показатель экспоненты этой вероятности меньше чем 
Доказательство. Подставляя  в (6.83), получаем
в (6.83), получаем

Проводя усреднение по ансамблю кодов, полагая

и используя соотношения  получаем
получаем

Согласно неравенству Шварца,

Далее, вводя  с помощью равенств (6.30) и (6.31) и проводя суммирование по
с помощью равенств (6.30) и (6.31) и проводя суммирование по  находим
находим

Если это неравенство усреднить по  то получим границу для средней вероятности ошибки
то получим границу для средней вероятности ошибки  Однако правая часть (6.91) не зависит от
Однако правая часть (6.91) не зависит от  следовательно, (6.91) дает верхнюю границу также для
следовательно, (6.91) дает верхнюю границу также для  Вводя величины
Вводя величины  получаем
получаем

Вероятность  возникновения по крайней мере одной необнаруживаемой ошибки в неправильном подмножестве, начинающемся в начальном узле кодового дерева, ограничена сверху суммой по
возникновения по крайней мере одной необнаруживаемой ошибки в неправильном подмножестве, начинающемся в начальном узле кодового дерева, ограничена сверху суммой по  вероятностей
вероятностей 

Правая часть этого неравенства сходится, если  . В случае, если
. В случае, если  , то, как видно из разд. 6.3, среднее число операций расходится. Если положить
, то, как видно из разд. 6.3, среднее число операций расходится. Если положить  то при
то при  правая часть неравенства (6.93) будет сходиться. Если в этой области значений
правая часть неравенства (6.93) будет сходиться. Если в этой области значений  суммирование по
суммирование по  и 5 в правой части (6.93) провести независимо, положив верхние пределы равными бесконечности, то получим следующее неравенство:
и 5 в правой части (6.93) провести независимо, положив верхние пределы равными бесконечности, то получим следующее неравенство:

Обозначив через А произведение первых трех сомножителей в правой части (6.94), последнее неравенство перепишем в виде

Отсюда следует справедливость доказываемой теоремы.
Таким образом, для алгоритма Фано в случае  были найдены границы для вероятности ошибки, среднего числа операций и вероятности переполнения буфера. Чтобы получить представление о порядке этих параметров, рассмотрим следующий пример.
были найдены границы для вероятности ошибки, среднего числа операций и вероятности переполнения буфера. Чтобы получить представление о порядке этих параметров, рассмотрим следующий пример.
Пример 6.1. Рассмотрим двоичный симметричный канал с вероятностью ошибки  и сверточный код со скоростью передачи
и сверточный код со скоростью передачи  и кодовым ограничением
и кодовым ограничением  Пусть
Пусть  При
При  получаем
получаем

Верхняя граница для вероятности ошибки имеет следующий вид:

Пусть  Полагая
Полагая  из формулы (6.78) находим вероятность переполнения буфера
из формулы (6.78) находим вероятность переполнения буфера

При передаче со скоростью 2400 бит/с переполнение буфера возникает в среднем один раз за 460 000/2400 200 с. В то же время ошибка появляется в среднем один раз за 1014 с.
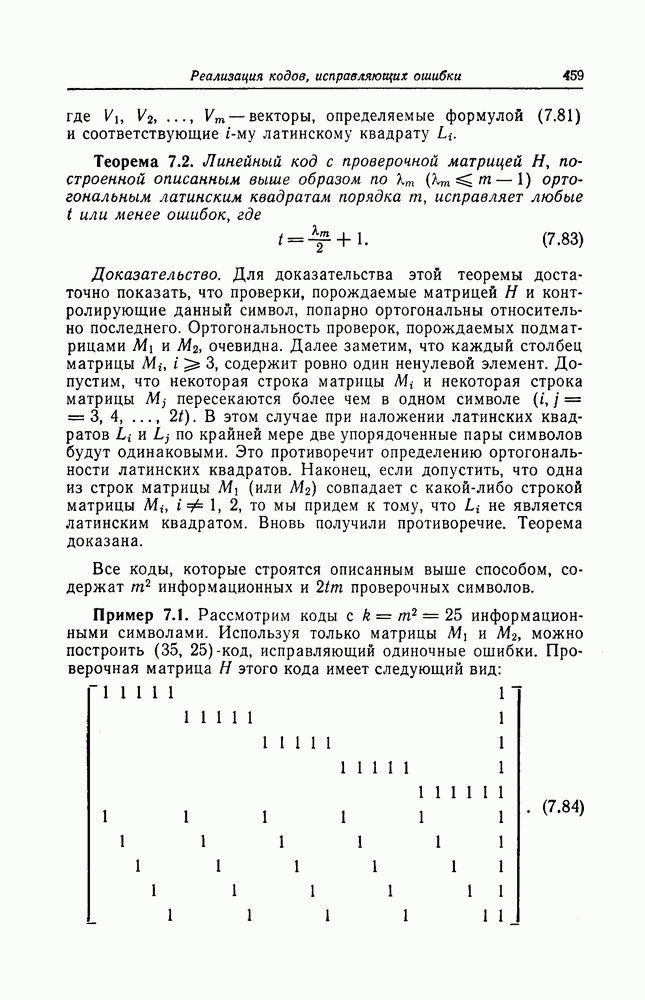
Как показывают приведенные выше численные результаты, поведение алгоритмов последовательного декодирования определяется главным образом вероятностью переполнения буфера.