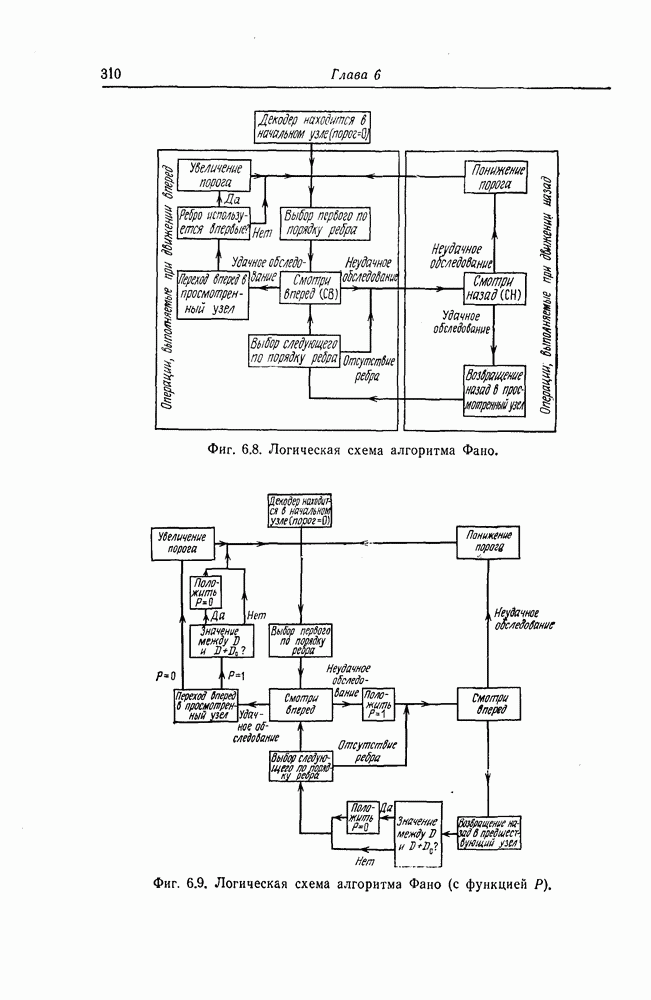
 выбирается та, которая имеет наибольшую длину (знаком X обозначены символы, значения которых на данном этапе не существенны). С помощью этой конфигурации исправляются ошибки в
выбирается та, которая имеет наибольшую длину (знаком X обозначены символы, значения которых на данном этапе не существенны). С помощью этой конфигурации исправляются ошибки в  символах. После исправления указанных символов полагаются равными нулю и соответствующие символы синдрома.
символах. После исправления указанных символов полагаются равными нулю и соответствующие символы синдрома.
3. Из конфигураций вида  выбирается та, которая имеет наибольшую длину. С помощью этой конфигурации исправляются ошибки в
выбирается та, которая имеет наибольшую длину. С помощью этой конфигурации исправляются ошибки в  символах, после чего также осуществляется коррекция синдрома.
символах, после чего также осуществляется коррекция синдрома.
4. Из конфигураций  выбирается та, которая имеет наибольшую длину. С помощью этой конфигурации исправляются ошибки в
выбирается та, которая имеет наибольшую длину. С помощью этой конфигурации исправляются ошибки в  символах, после чего осуществляется коррекция синдрома.
символах, после чего осуществляется коррекция синдрома.
5. Если некоторые символы синдрома отличны от нуля, то осуществляется восстановление.
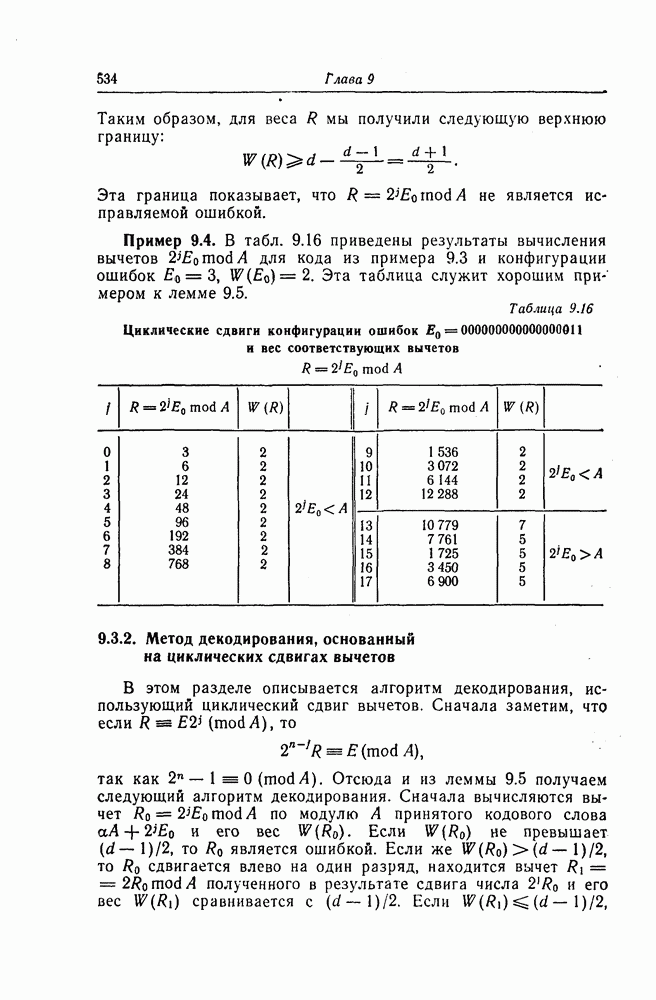
Предположим, например, что ошибки возникли в  символах
символах  и кодового слова кода, задаваемого порождающей матрицей (7.89). Обозначим через
и кодового слова кода, задаваемого порождающей матрицей (7.89). Обозначим через  значение ошибки в 1-й компоненте кодового слова. В данном случае синдром имеет следующий вид:
значение ошибки в 1-й компоненте кодового слова. В данном случае синдром имеет следующий вид:

При декодировании принятого кодового слова с помощью описанного выше алгоритма на шаге 2 выделяется конфигурация  и осуществляется исправление ошибки
и осуществляется исправление ошибки  На шаге 3 выделяется конфигурация
На шаге 3 выделяется конфигурация  и исправляется ошибка
и исправляется ошибка 
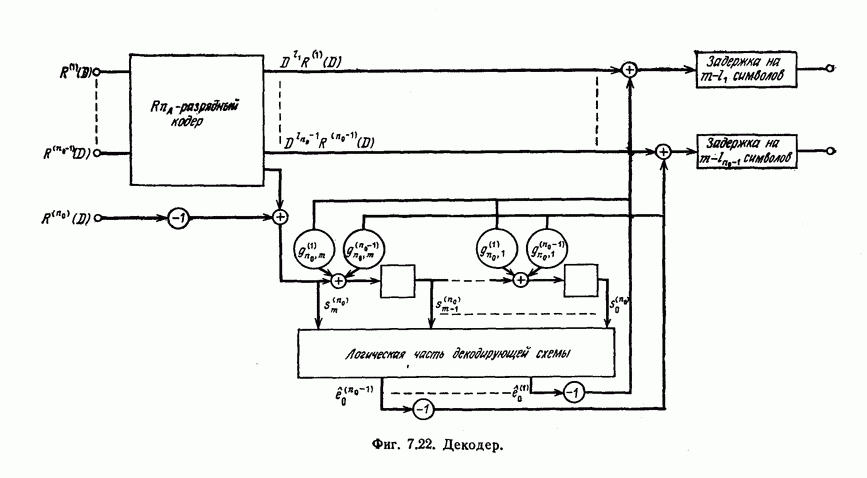
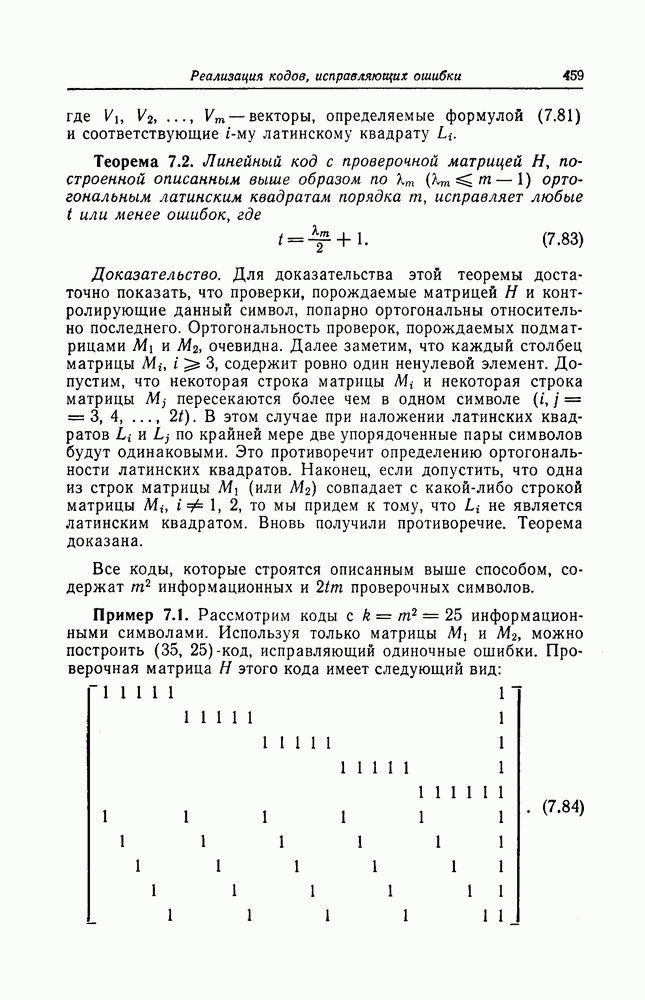
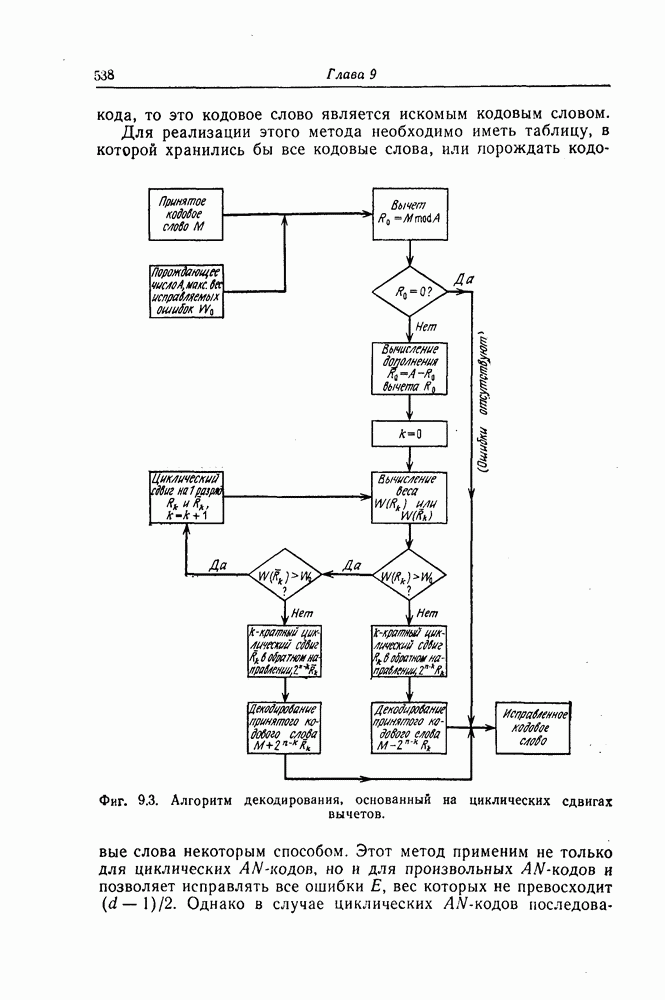
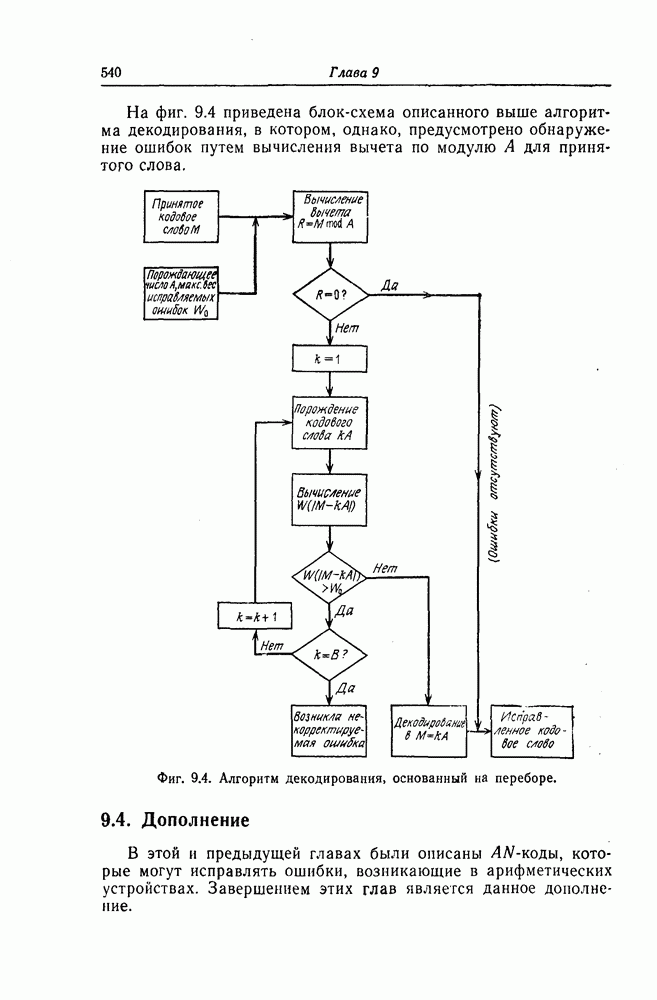
Рассмотрим декодер, реализующий описанный выше алгоритм декодирования. Этот декодер состоит из схемы вычисления синдрома, схемы исправления ошибок и схемы коррекции синдрома. Схемы кодеров здесь рассматривать не будем, поскольку они аналогичны соответствующим схемам вычисления синдрома, входящим в состав декодеров.
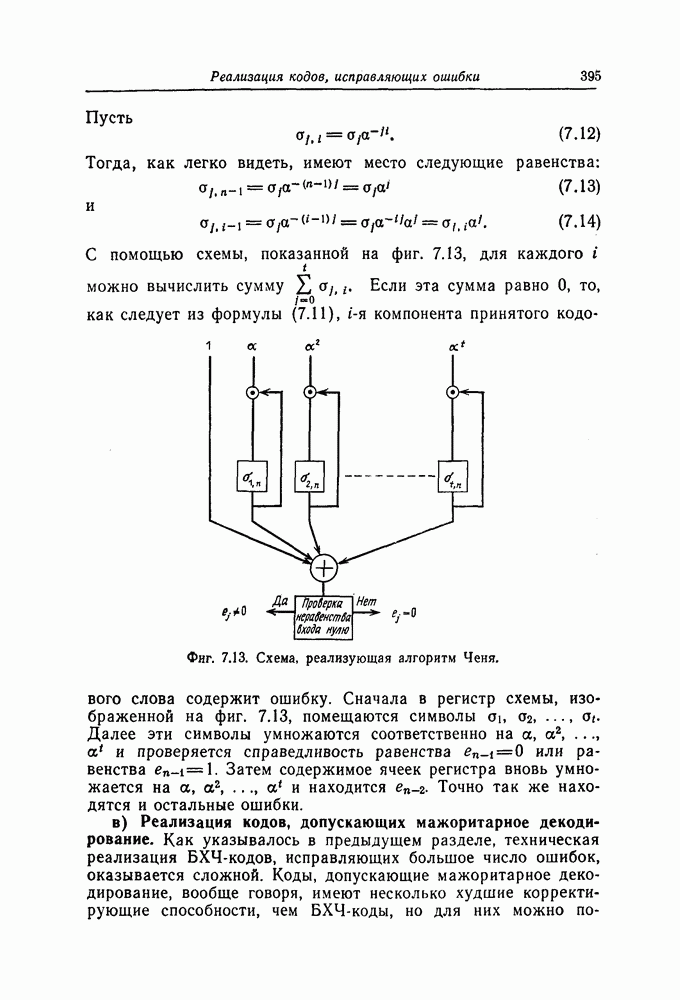
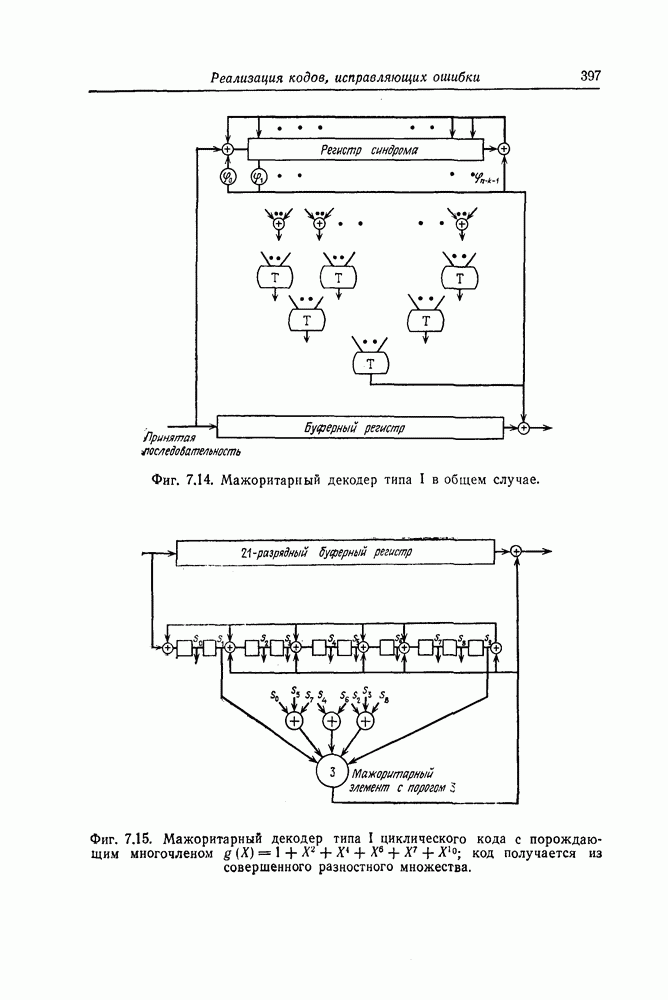
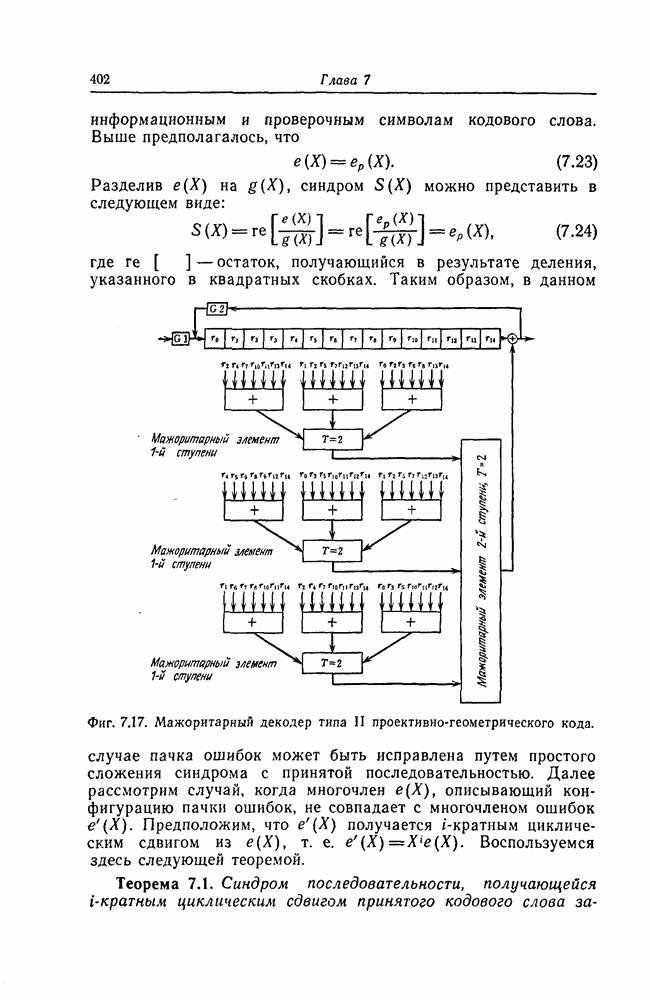
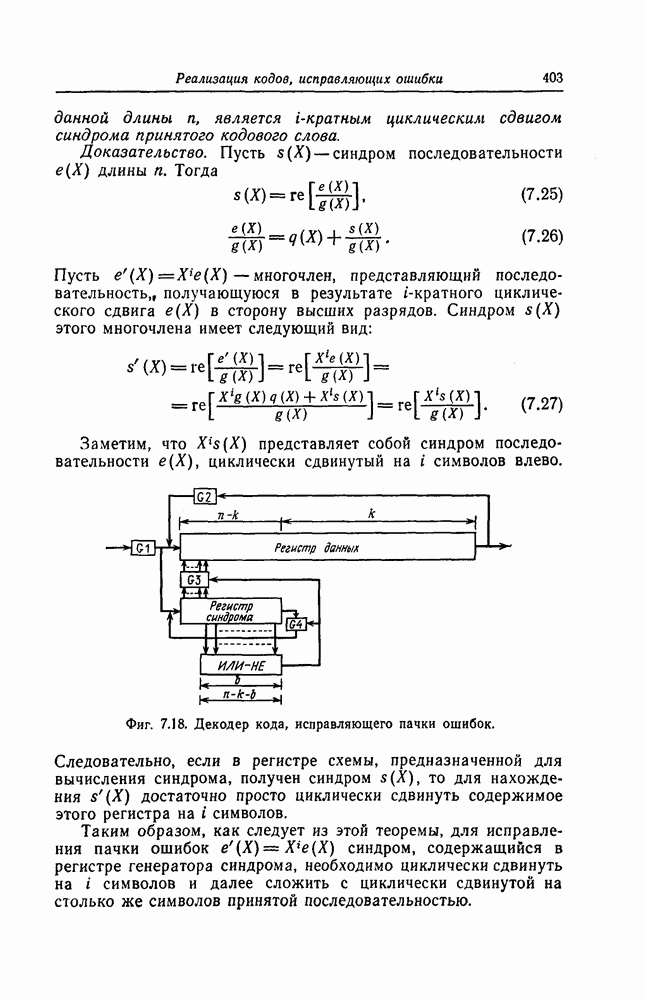
Часть схемы вычисления синдрома, используемая для вычисления символа 52, приведена на фиг. 7.47. Остальные символы синдрома вычисляются с помощью аналогичных схем.
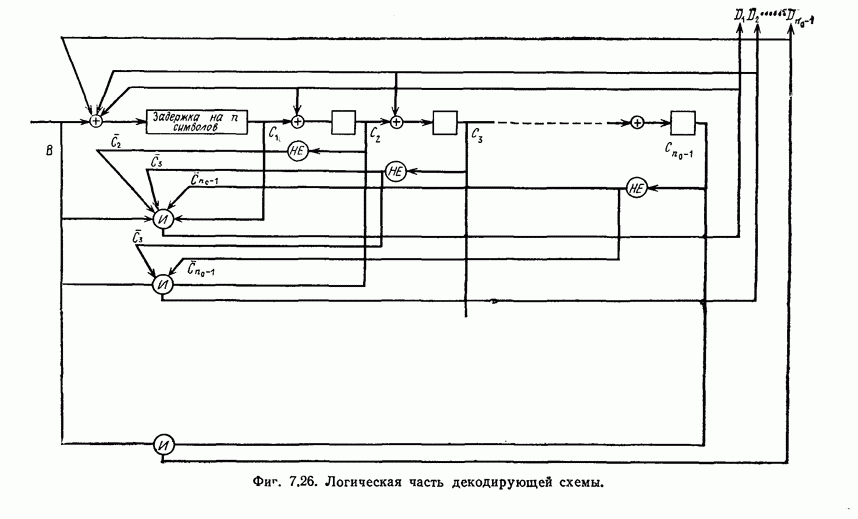
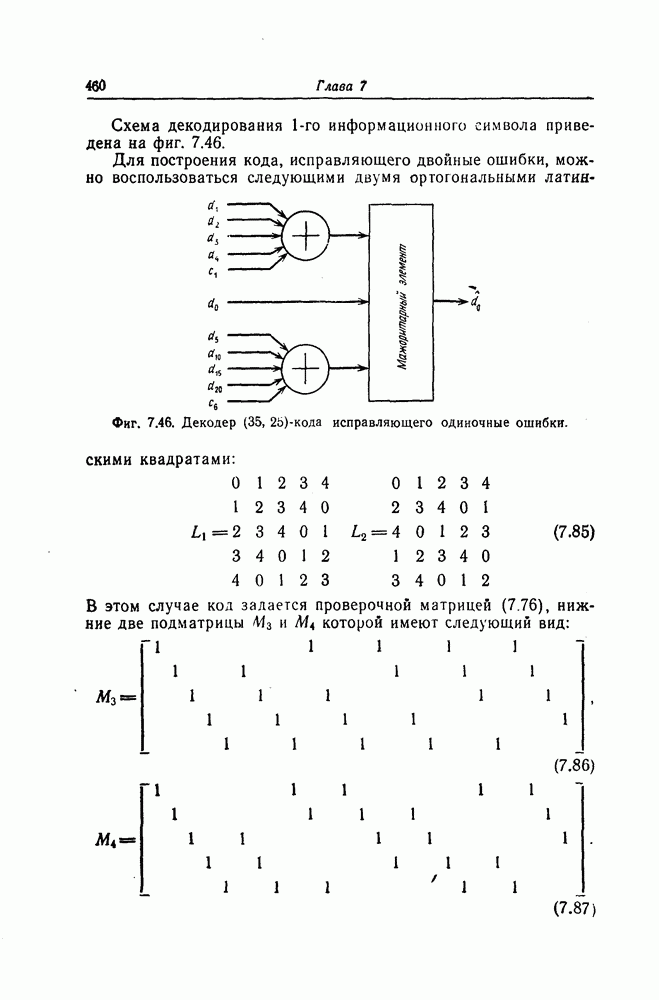
Для реализации шагов 2, 3, и 4 описанного алгоритма используются почти идентичные схемы На фиг. 7 48 приведена схема, используемая для реализации шага 2. В этой схеме элементы И используются для выделения конфигураций вида ( ). а элементы НЕ - для определения наиболее длинной из них.
). а элементы НЕ - для определения наиболее длинной из них.
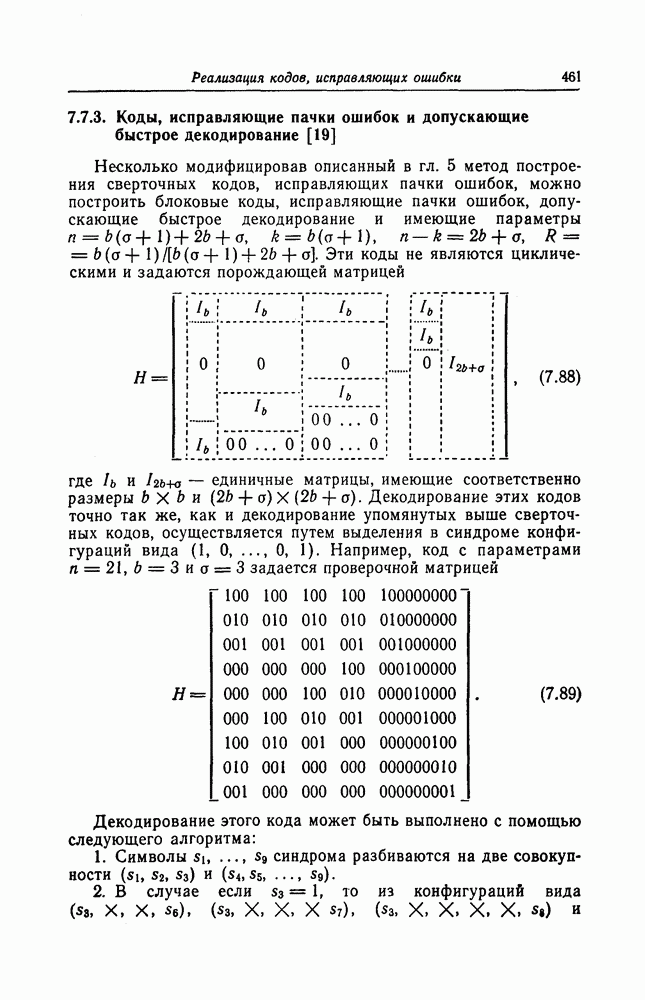
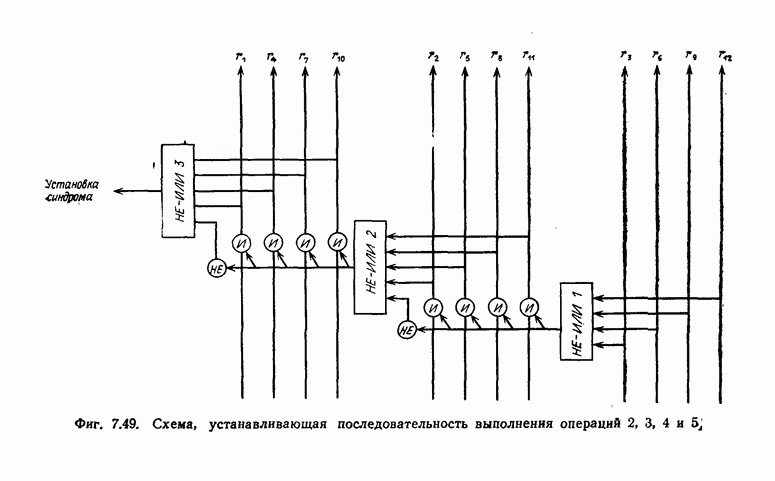
Для обеспечения нужной последовательности выполнения операций шагов 2, 3 и 4, а также для реализации шага 5 используется схема, приведенная на фиг. 7.49.

Фиг. 7.47. Часть схемы вычисления синдрома.
Выходы 1 и 2 элементов ИЛИ обеспечивают нужную последовательность выполнения операций 2, 3 и 4, а выход 3 элемента ИЛИ используется для реализации шага 5.

Фиг. 7.48. Схема, реализующая шаг 2.
В общем случае схема декодера аналогична схеме, описавной выше.

(кликните для просмотра скана)
Так как рассмотренные здесь коды, исправляющие пачки ошибок, допускают быстрое декодирование, то они могут использоваться в вычислительных машинах. В качестве кодов, исправляющих пачки ошибок и допускающих быстрое декодирование, могут также использоваться коды Файра и их обобщения (алгоритм быстрого декодирования этих кодов предложен Ченем [20]).
Задачи
(см. скан)
































































































































































































































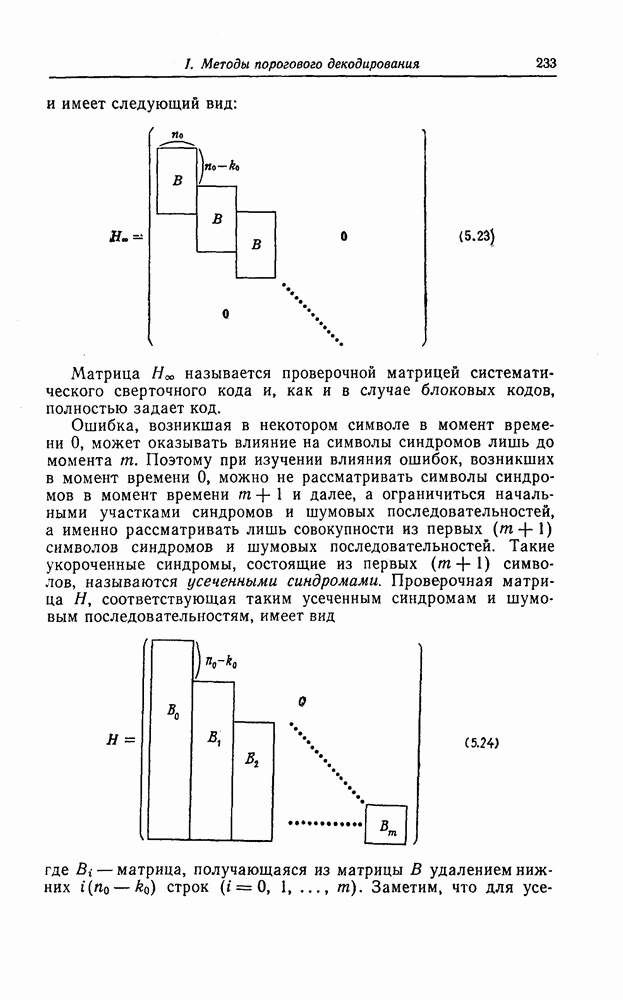
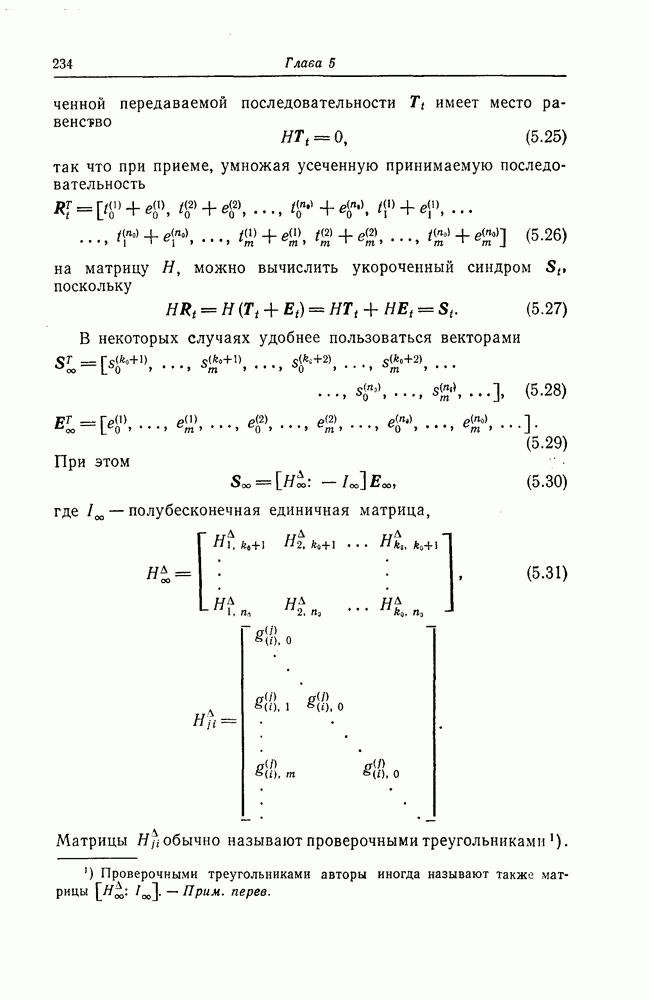














































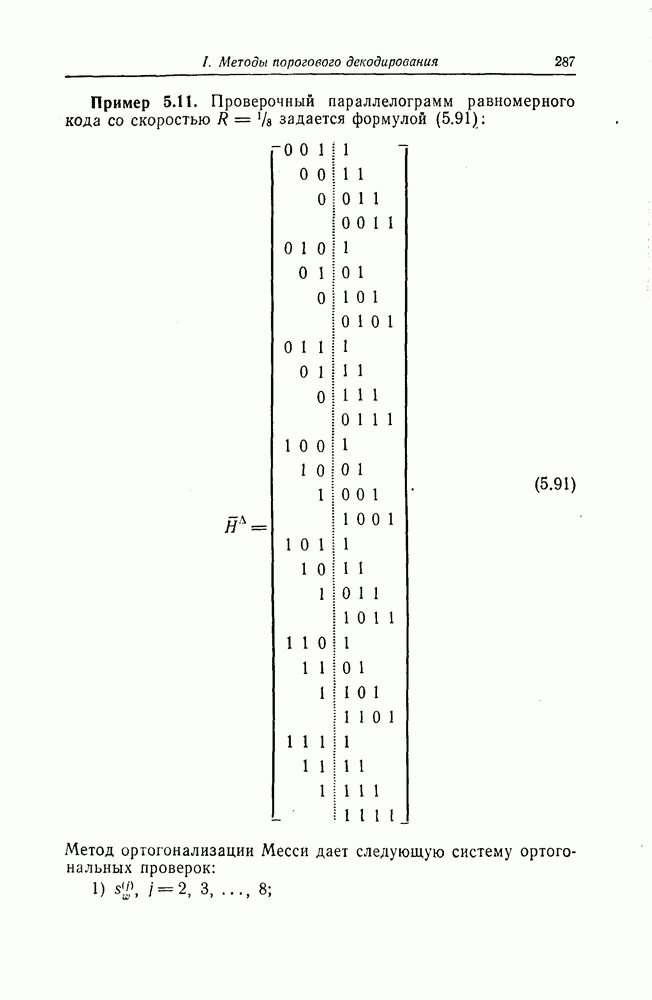


































































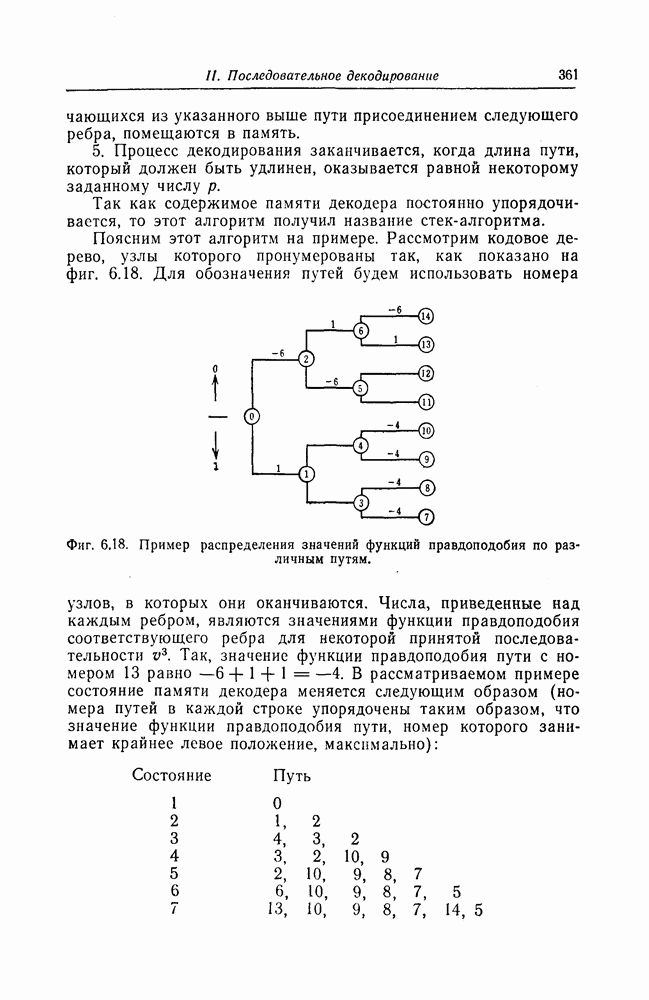












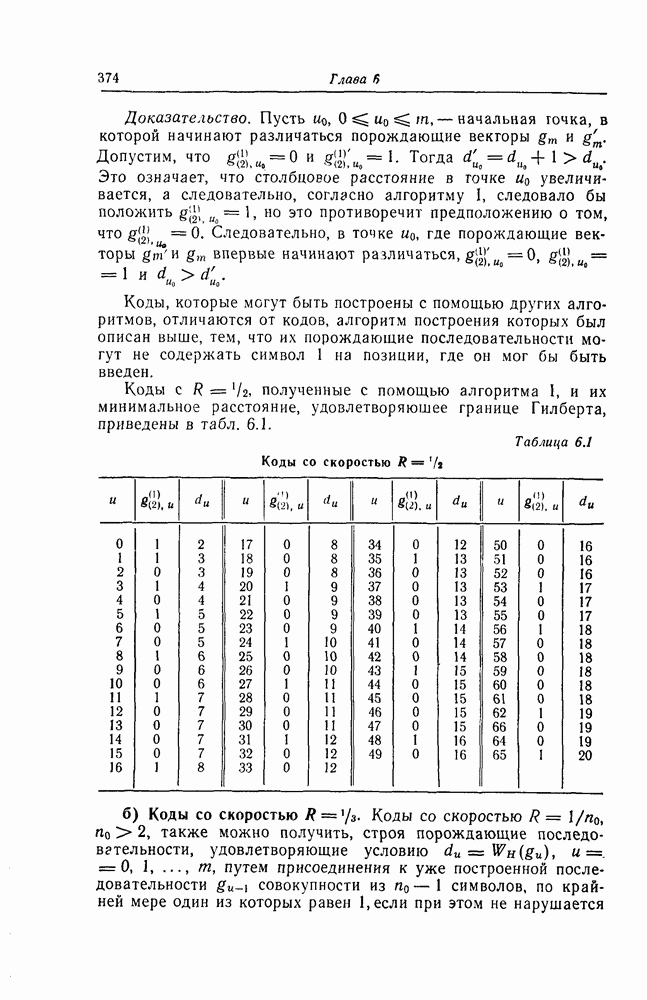




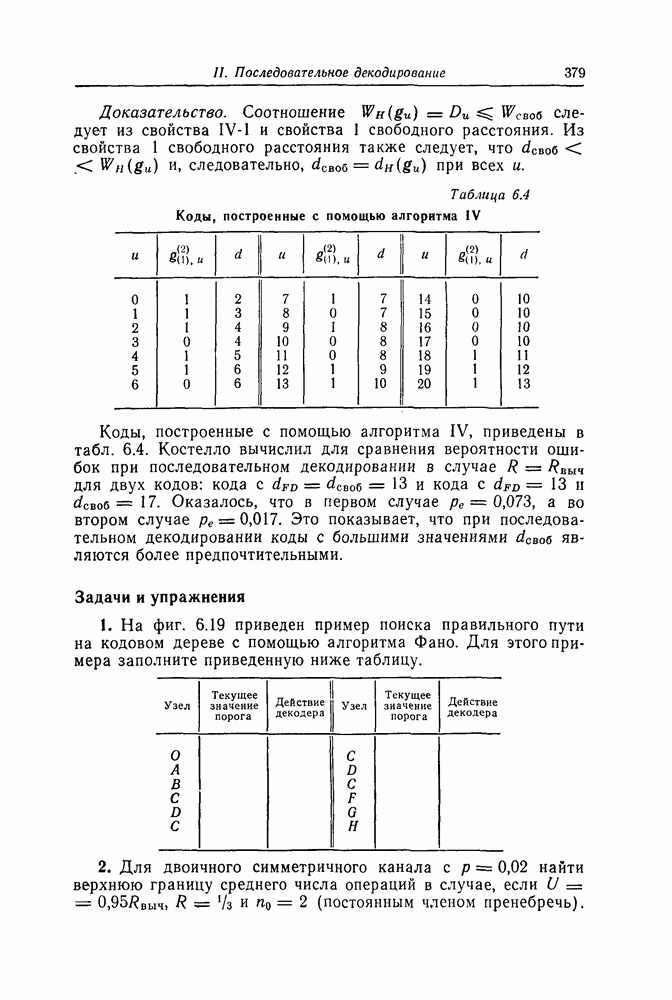
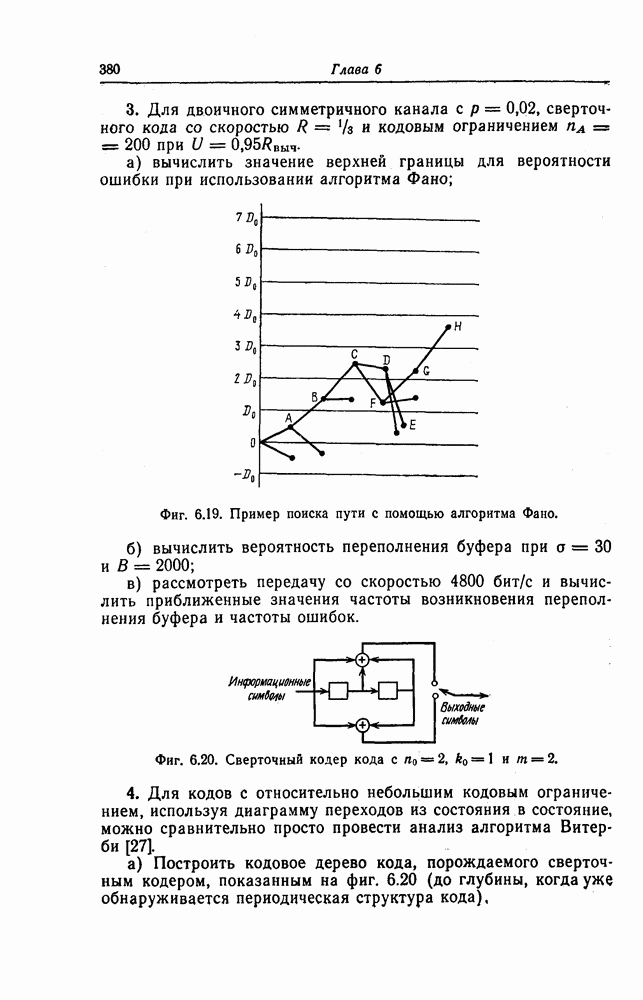

















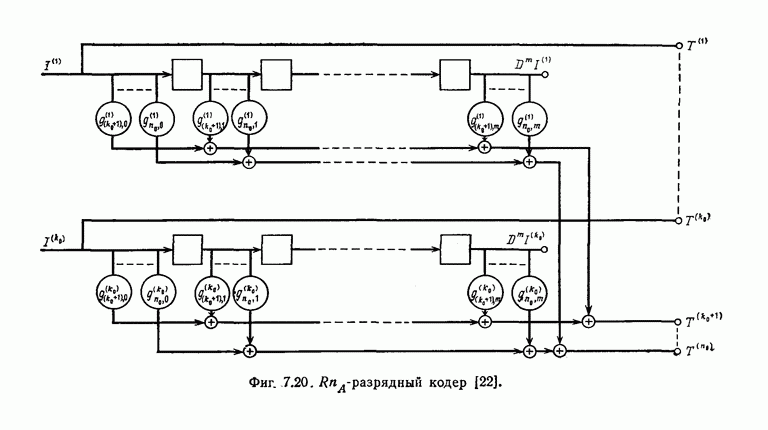

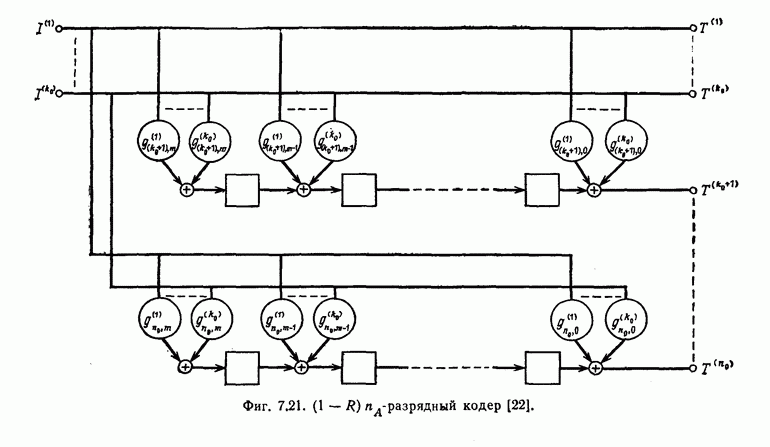
































































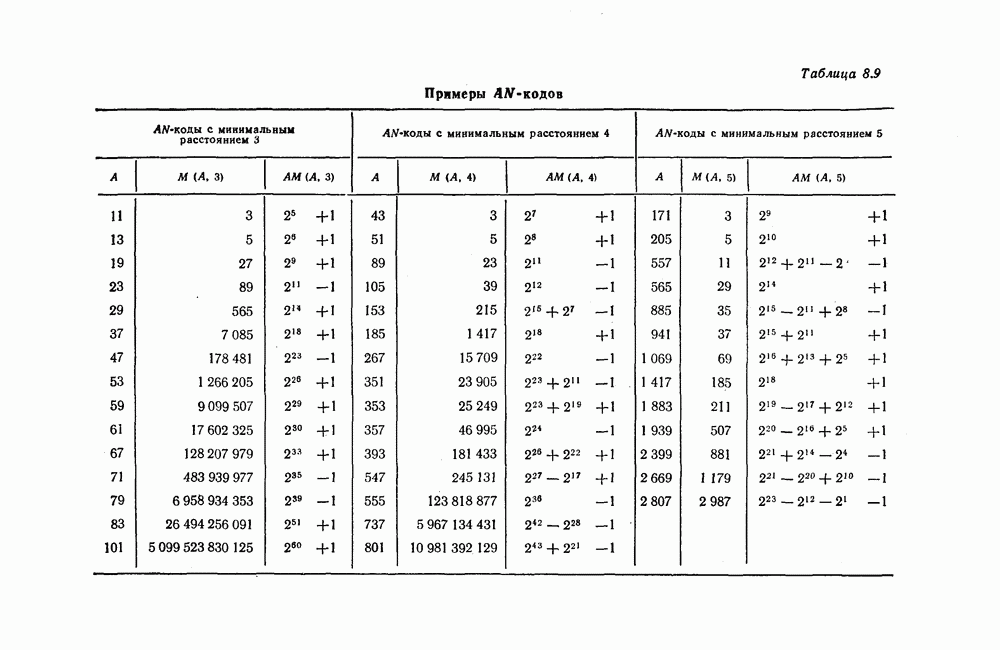




















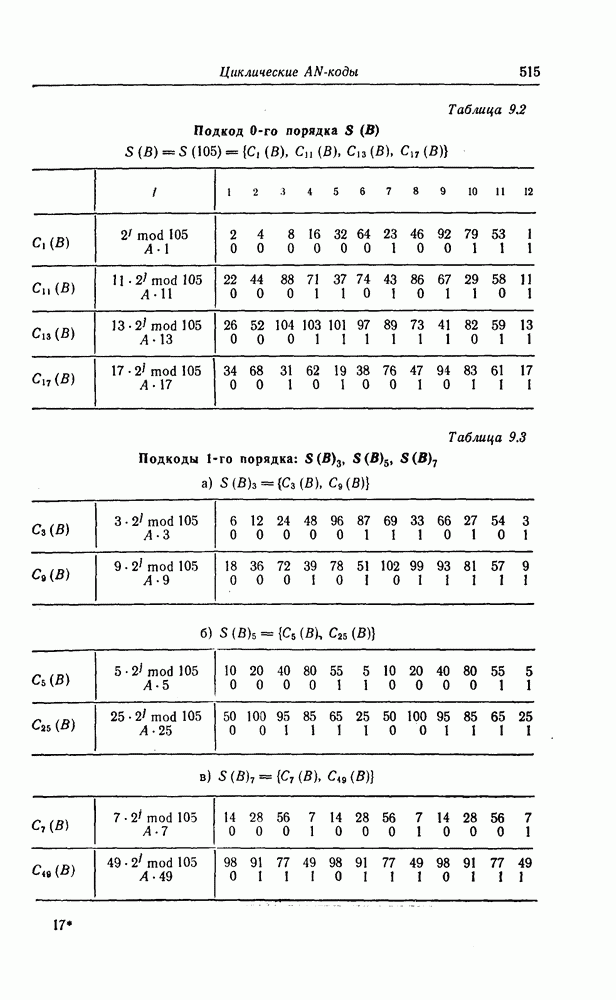
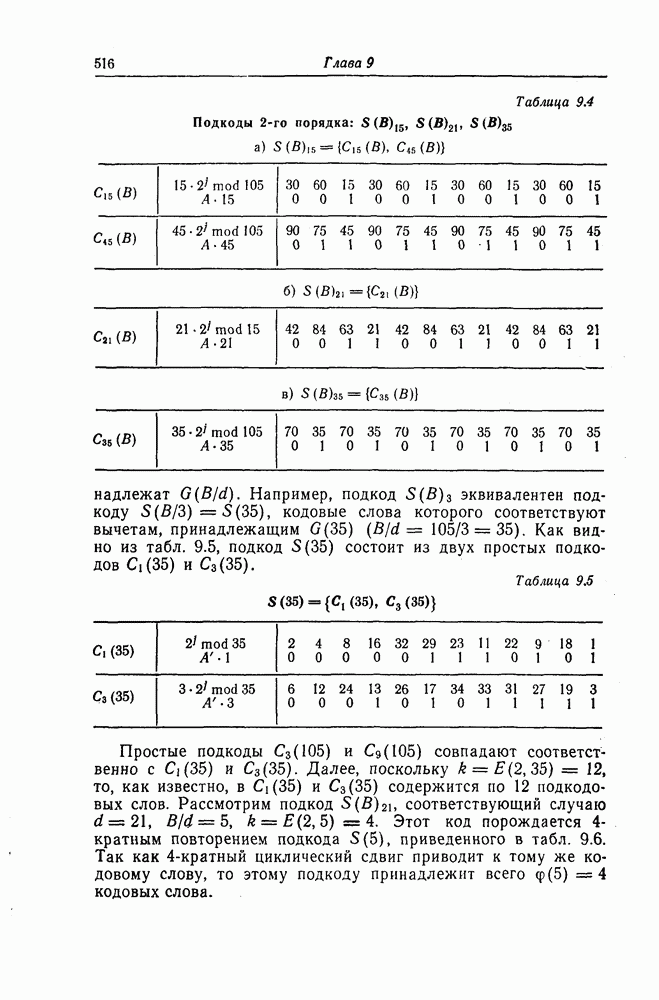









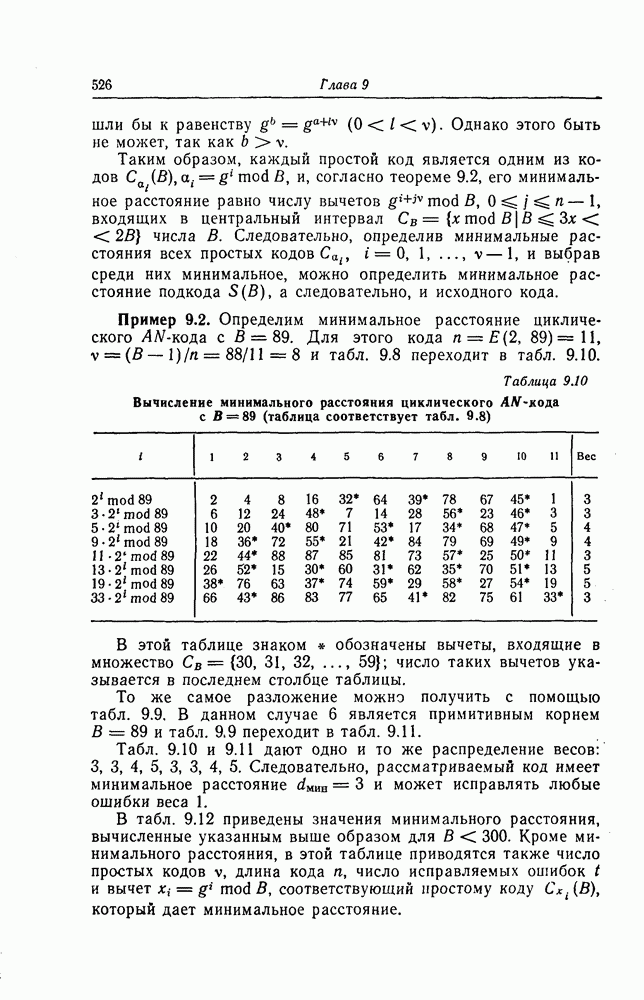
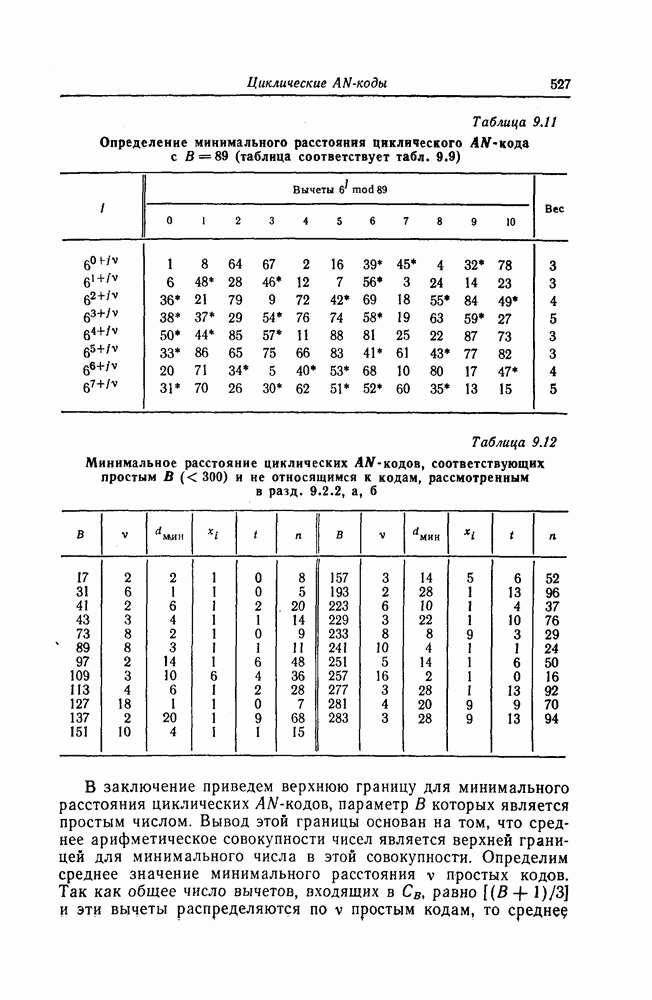


































 Эти коды не являются циклическими и задаются порождающей матрицей
Эти коды не являются циклическими и задаются порождающей матрицей

 единичные матрицы, имеющие соответственно размеры
единичные матрицы, имеющие соответственно размеры  Декодирование этих кодов точно так же, как и декодирование упомянутых выше сверточных кодов, осуществляется путем выделения в синдроме конфигураций вида (
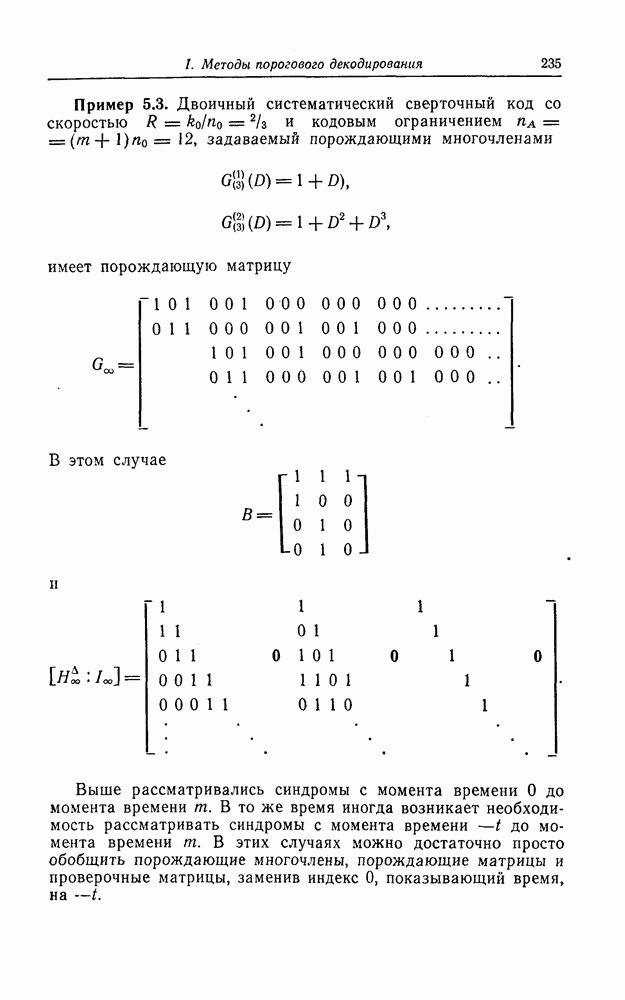
Декодирование этих кодов точно так же, как и декодирование упомянутых выше сверточных кодов, осуществляется путем выделения в синдроме конфигураций вида ( Например, код с параметрами
Например, код с параметрами  задается проверочной матрицей
задается проверочной матрицей

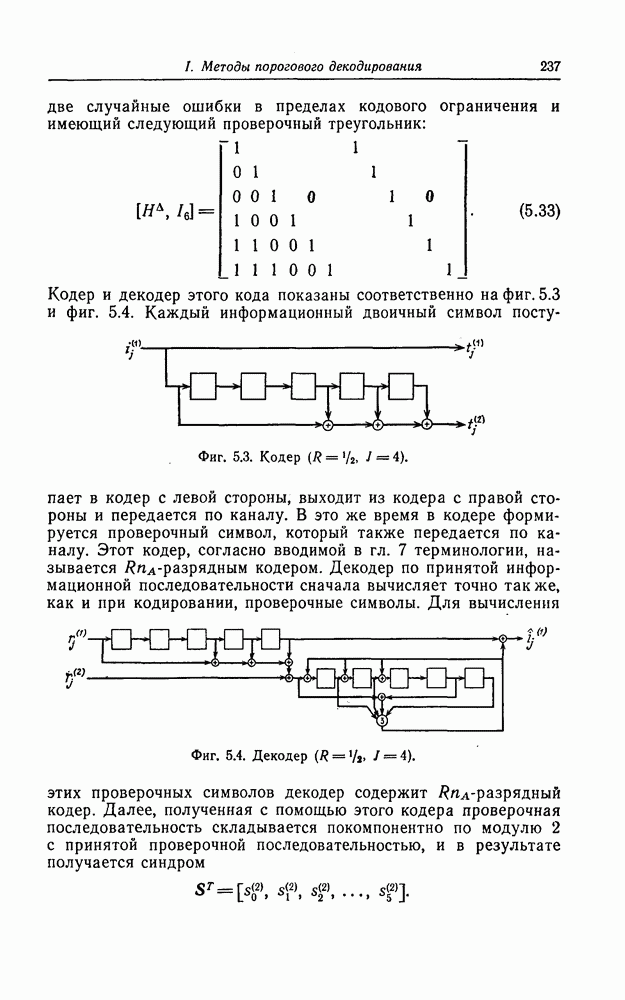
 синдрома разбиваются на две совокупности
синдрома разбиваются на две совокупности 
 то из конфигураций вида
то из конфигураций вида  и
и
