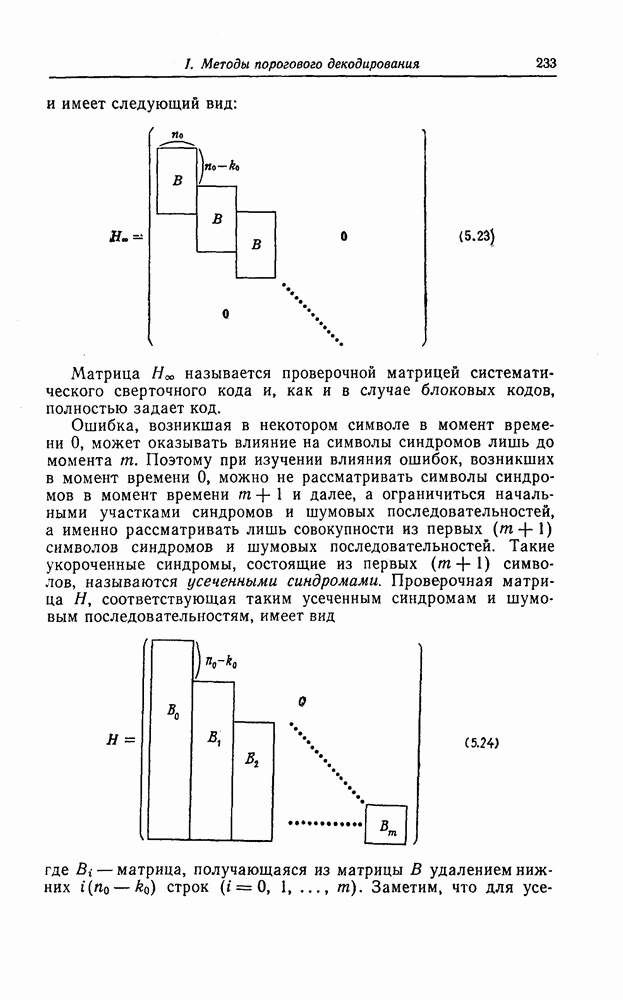
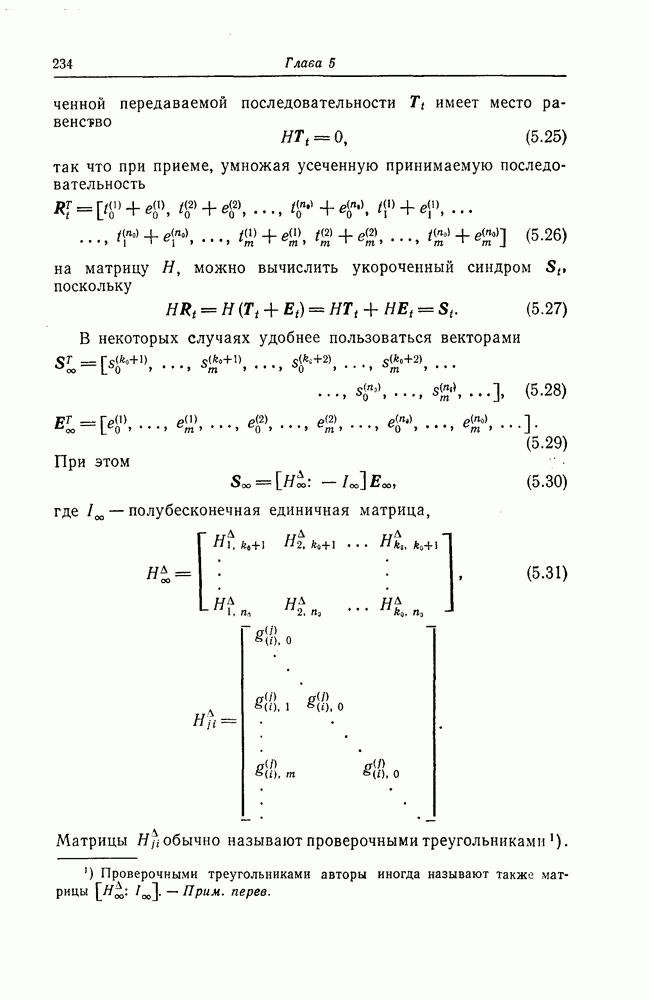
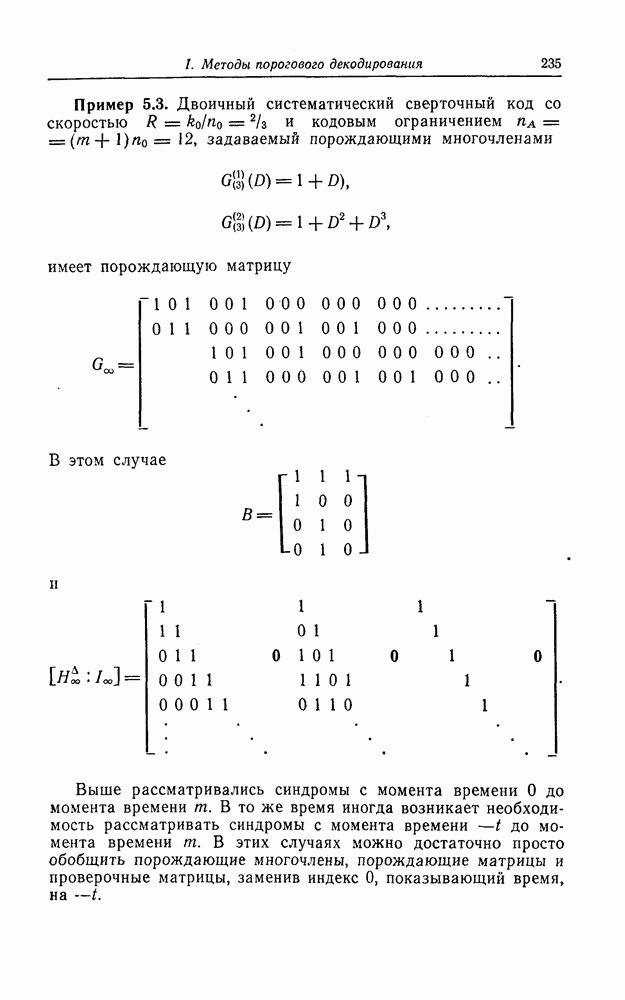
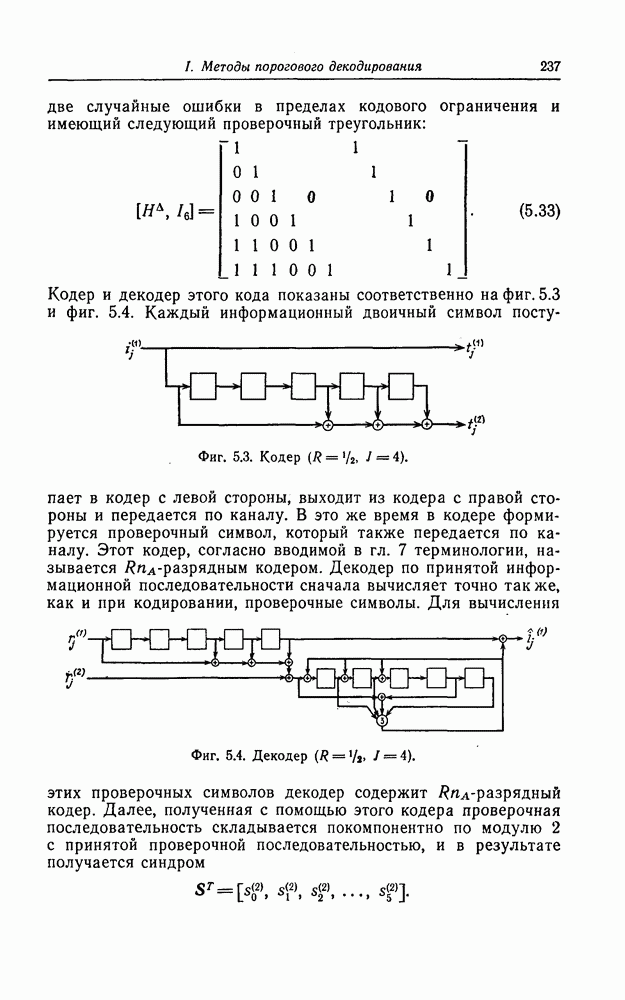
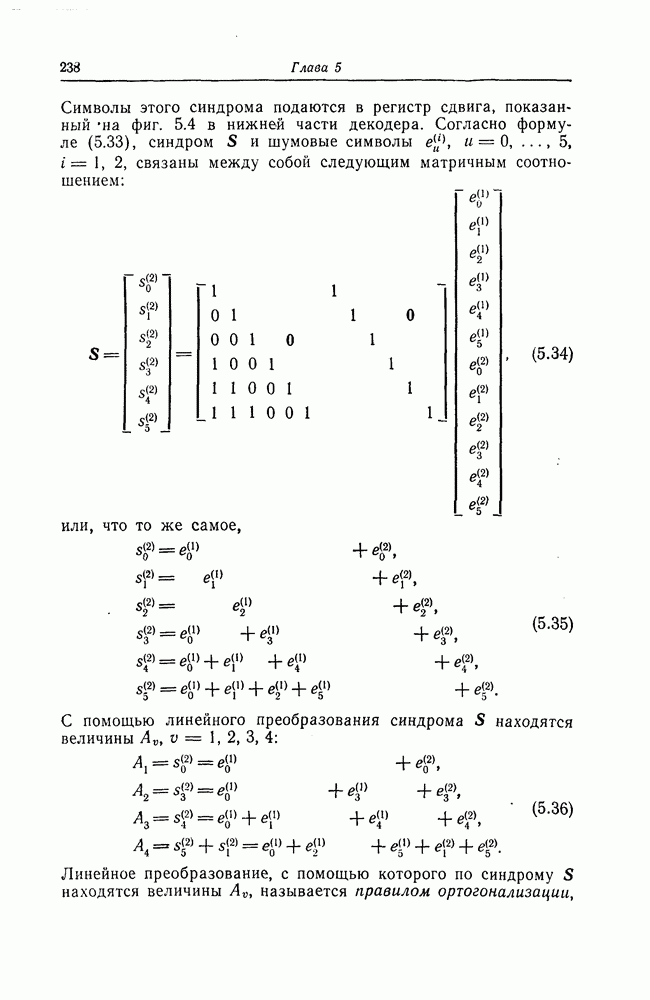
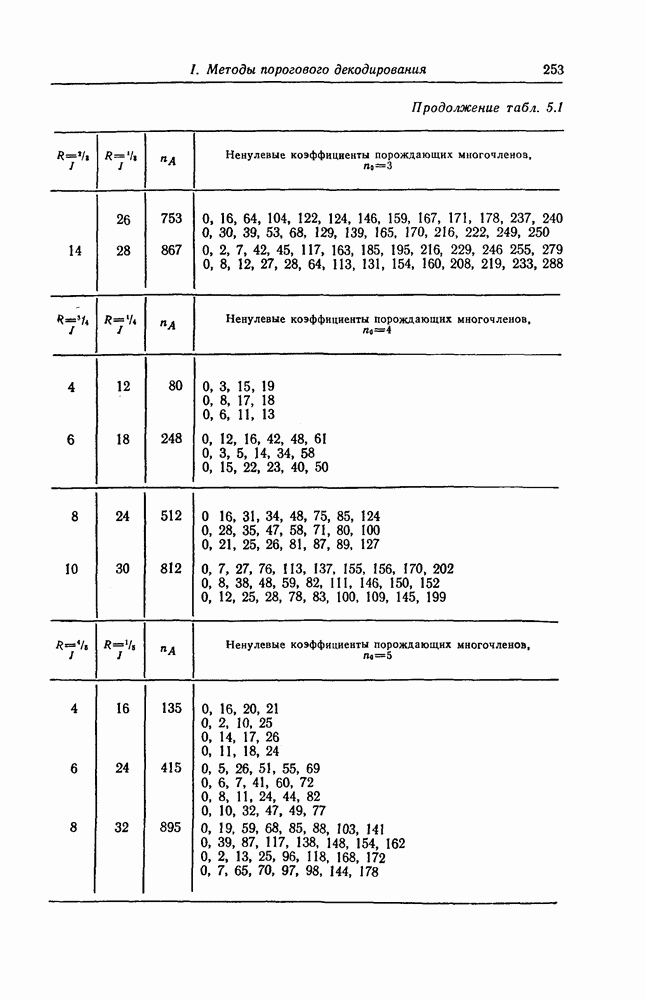
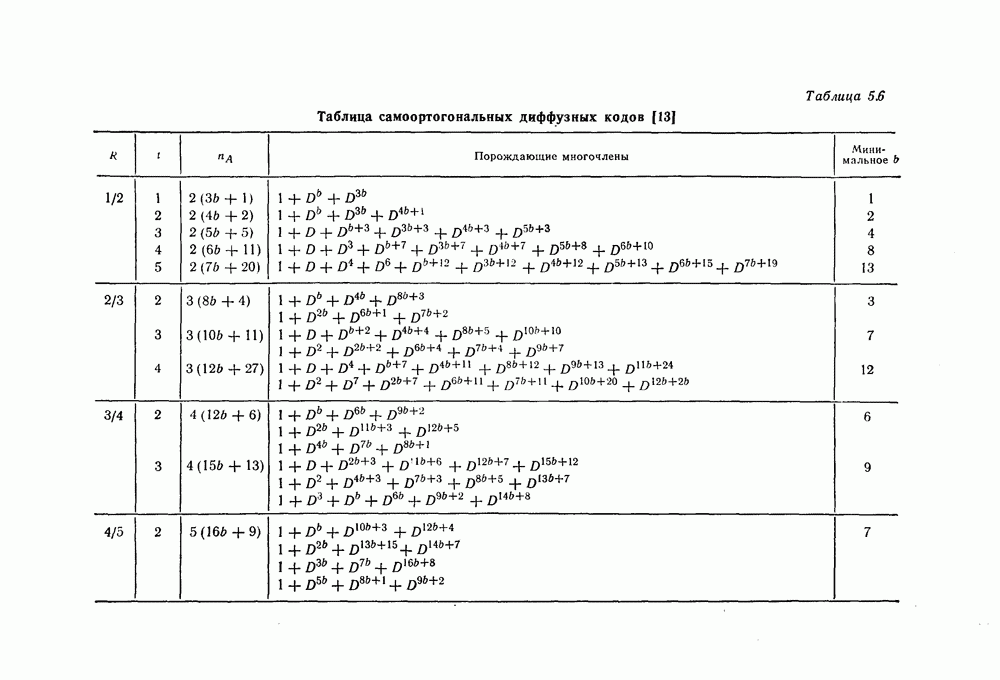
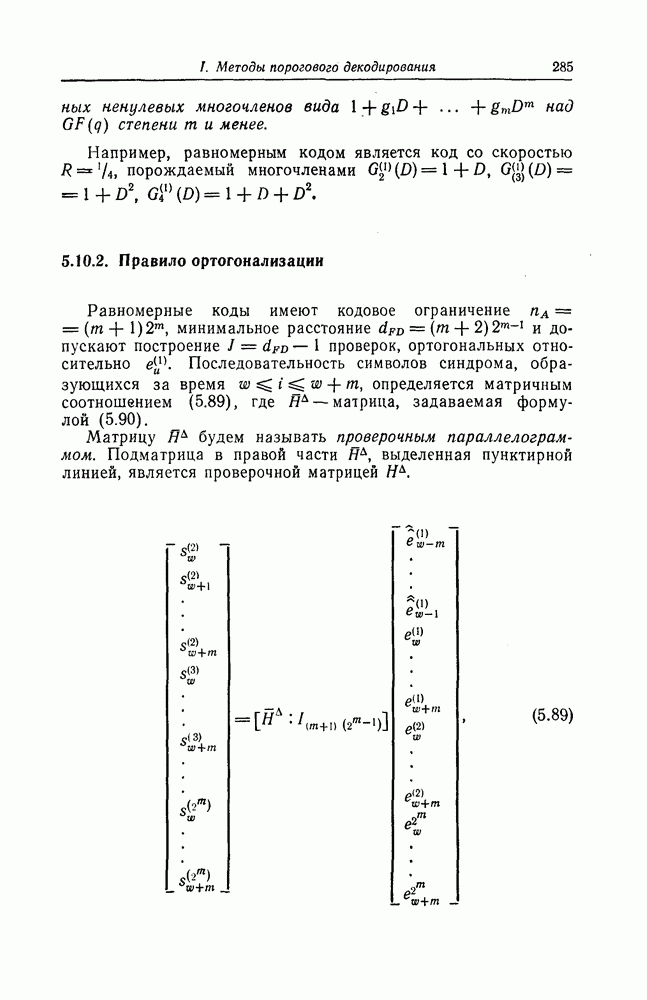
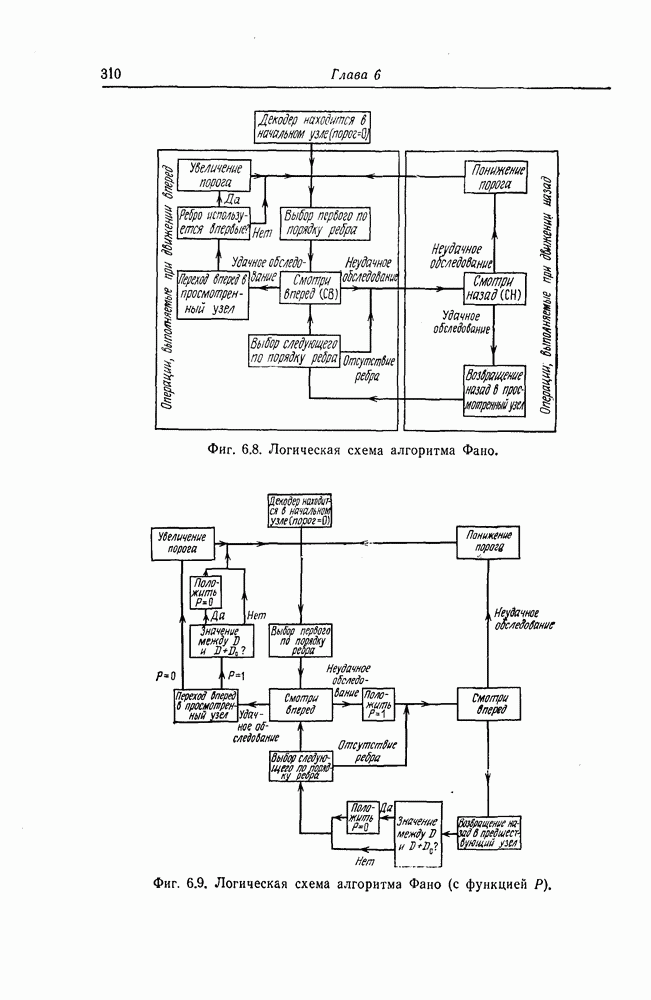
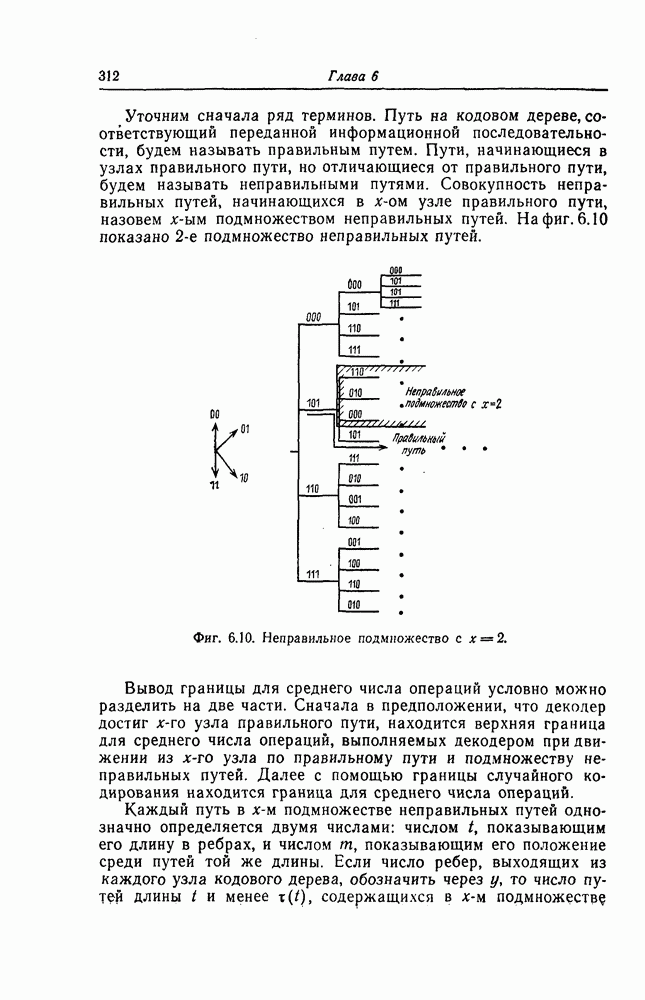
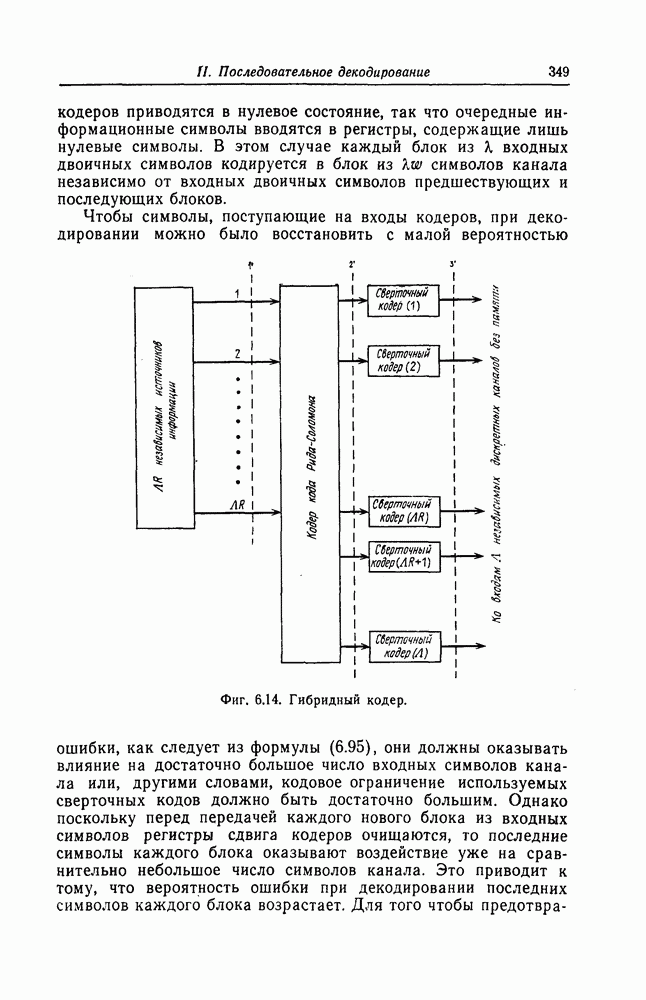
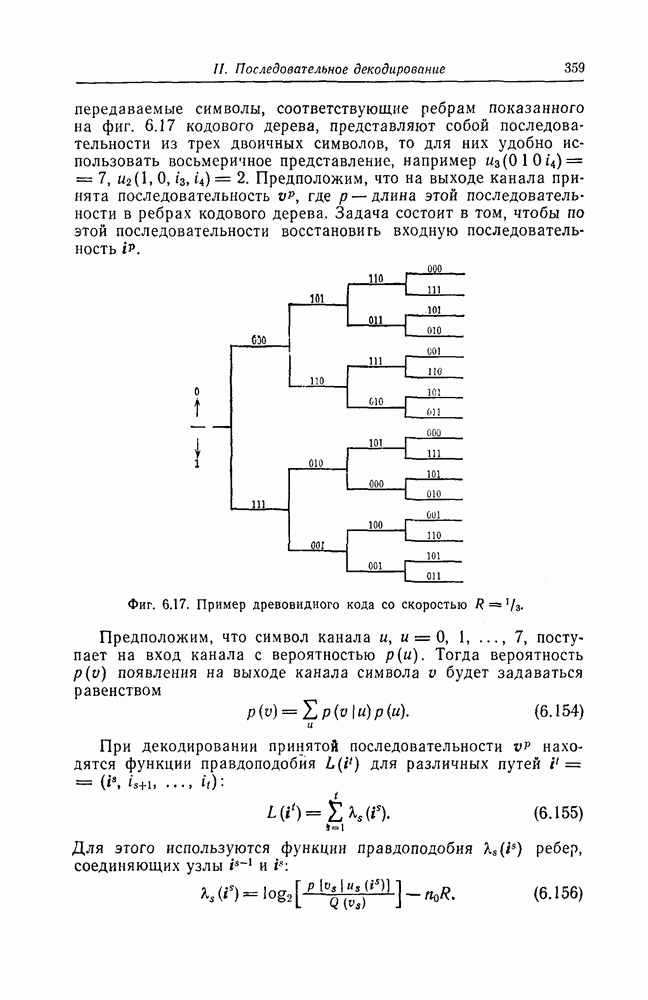
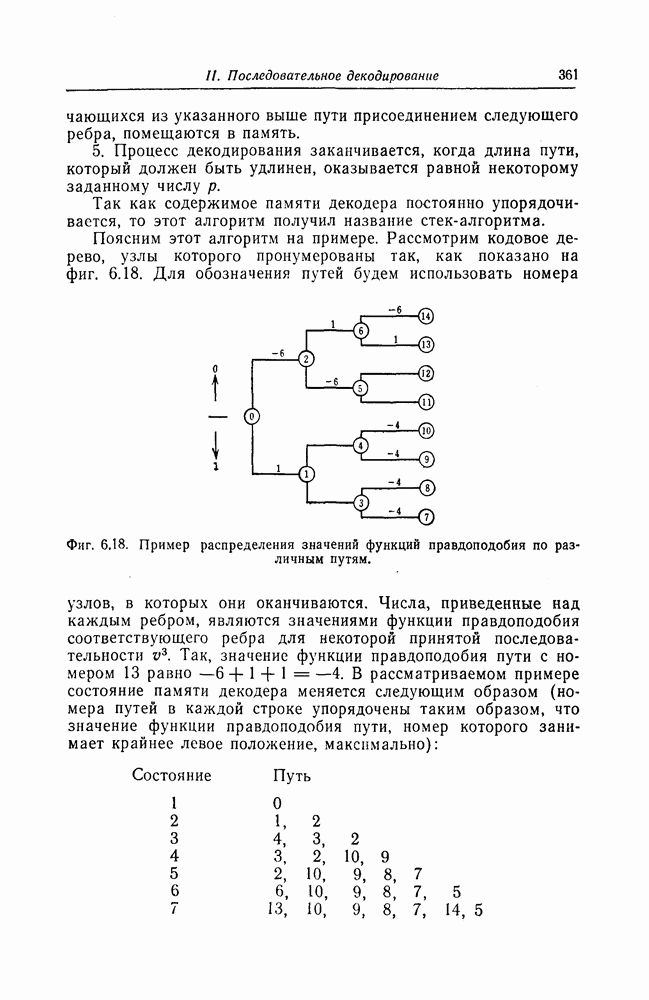
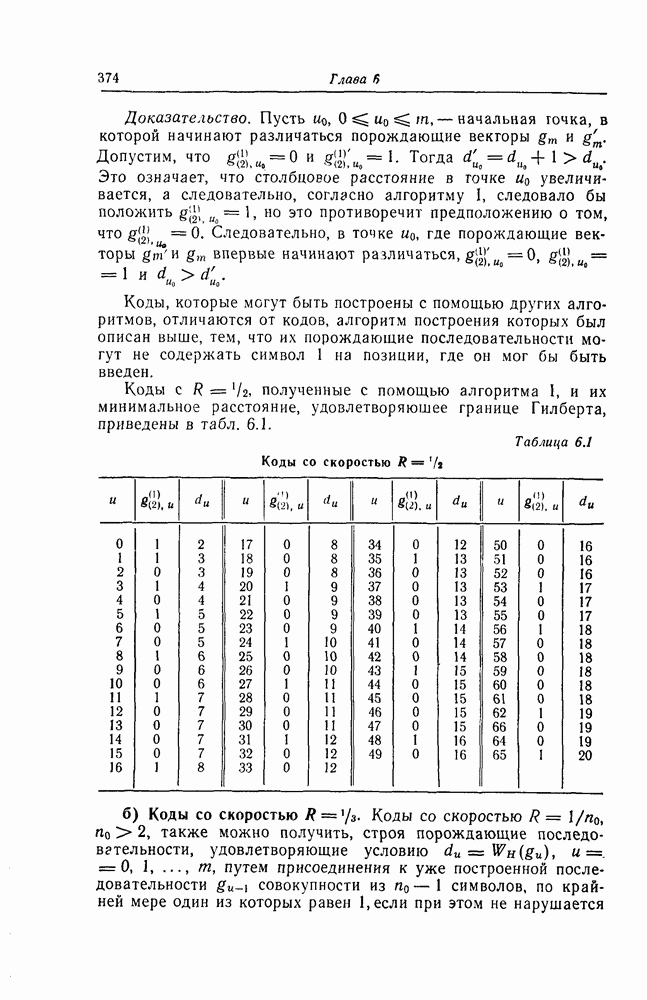
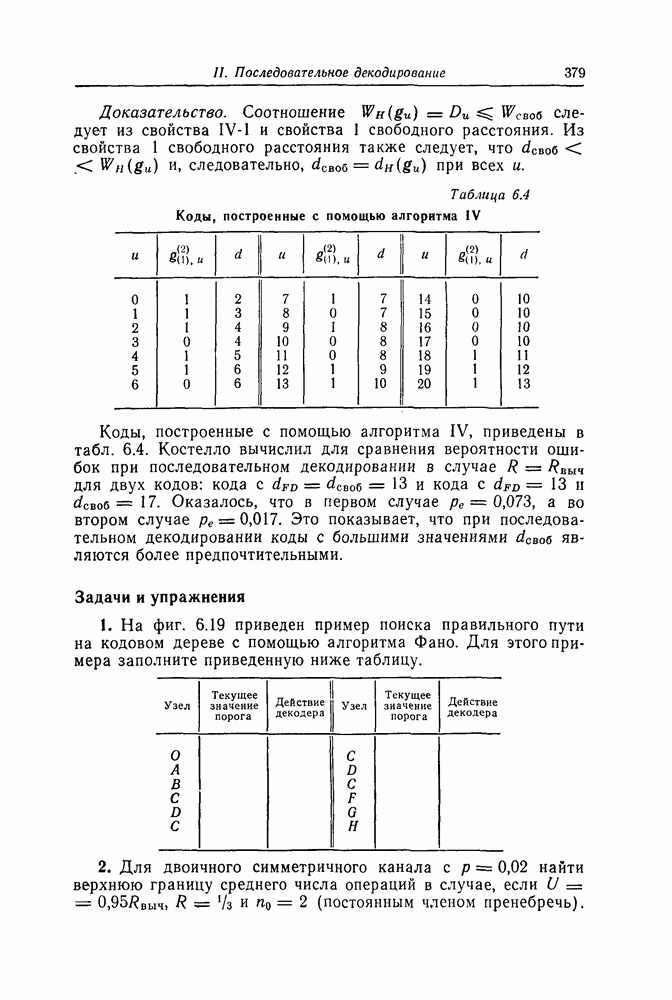
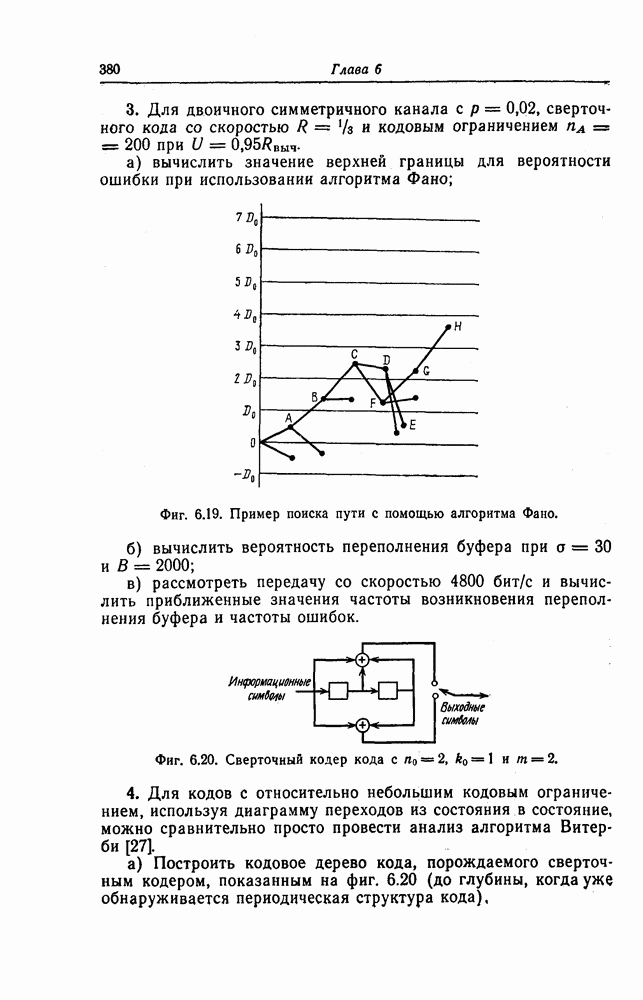
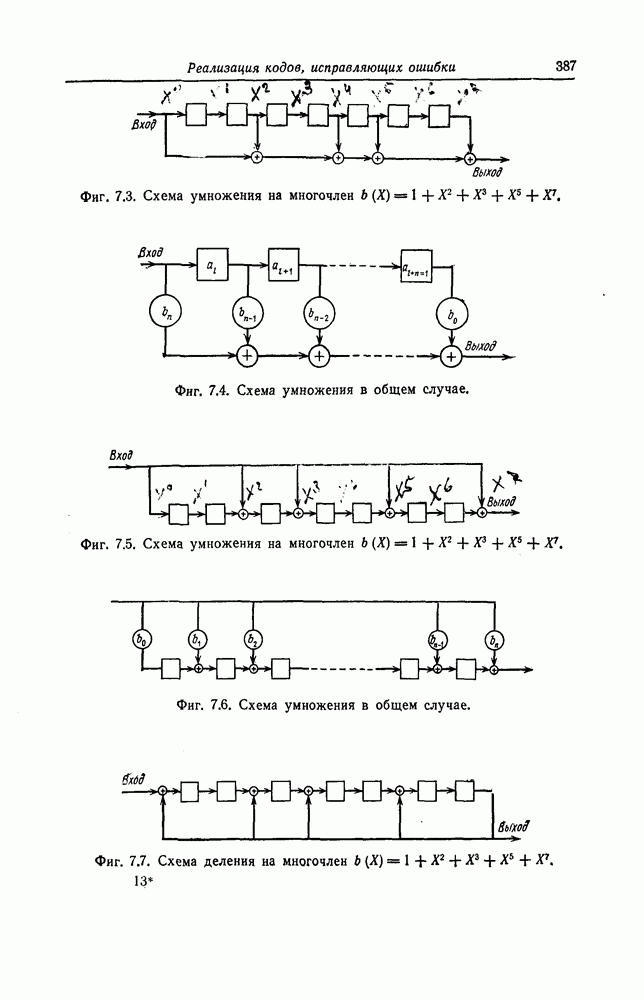
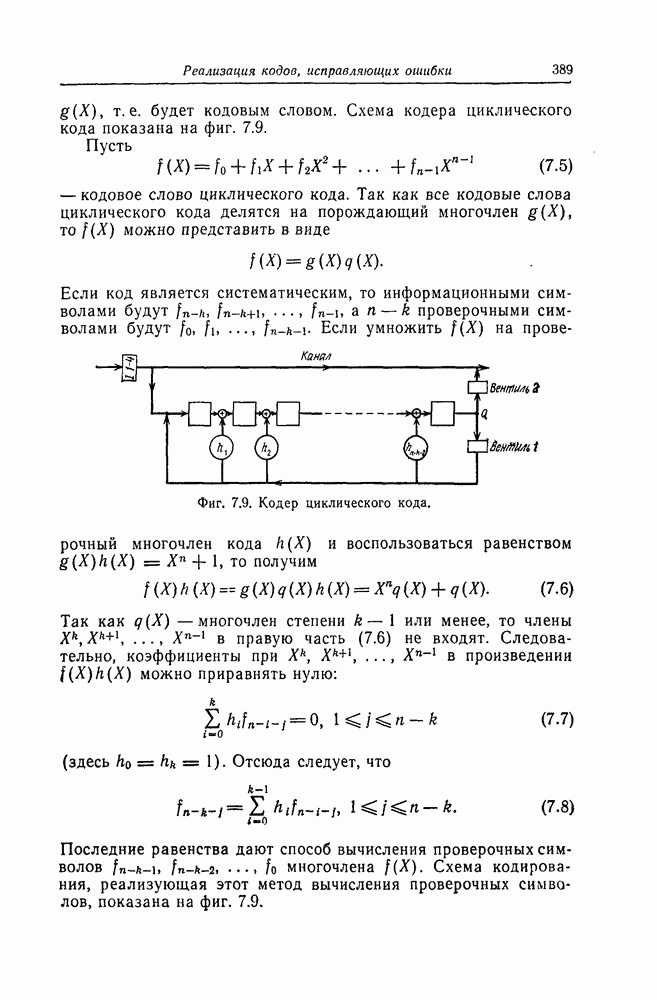
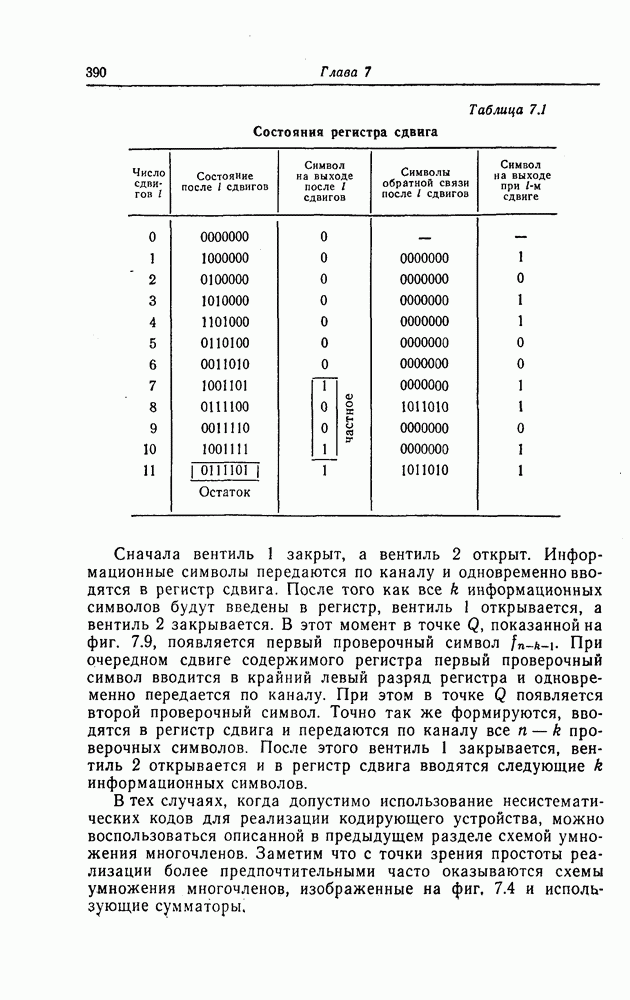
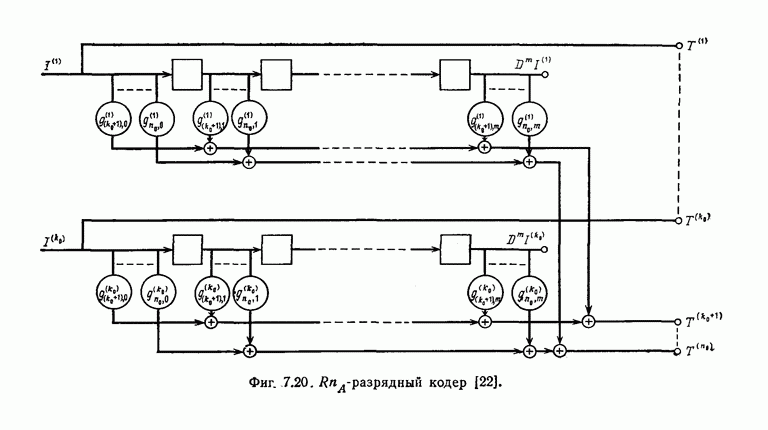
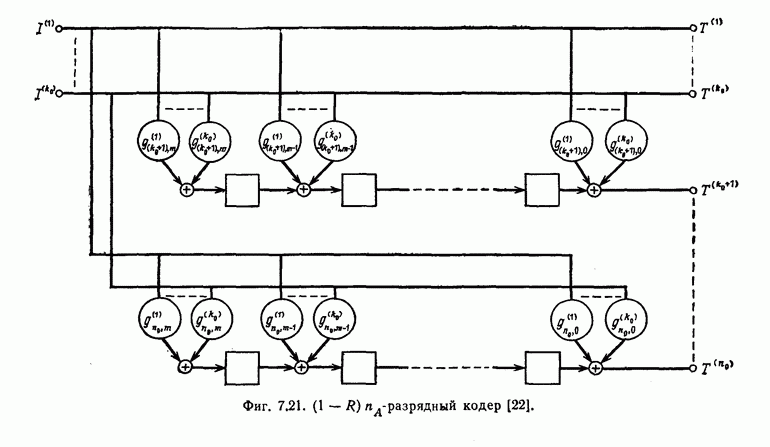
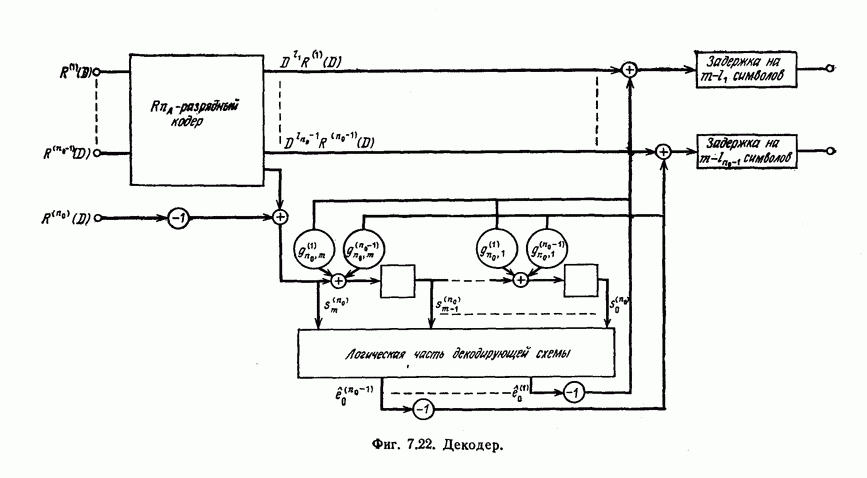
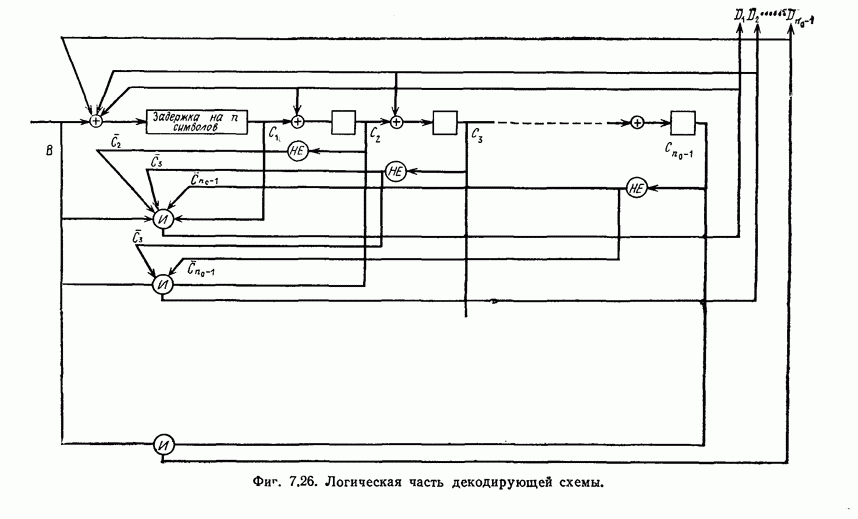
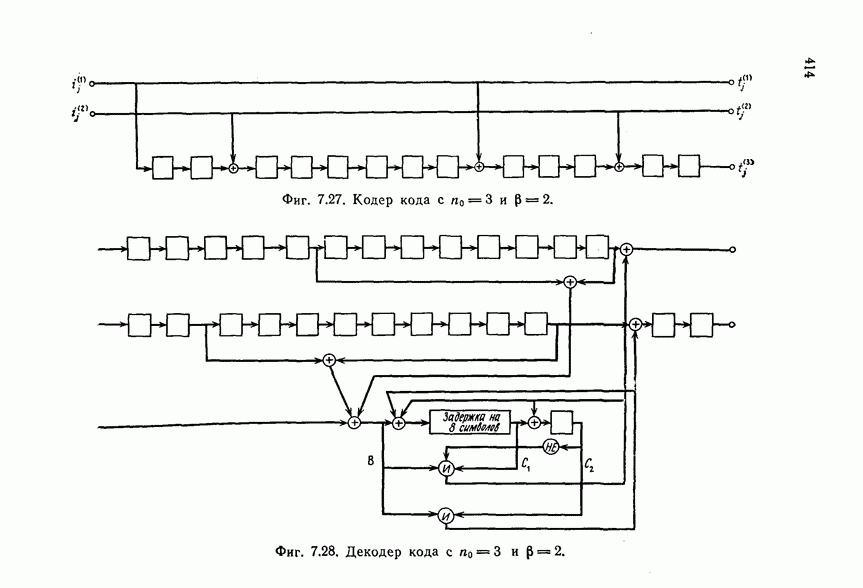
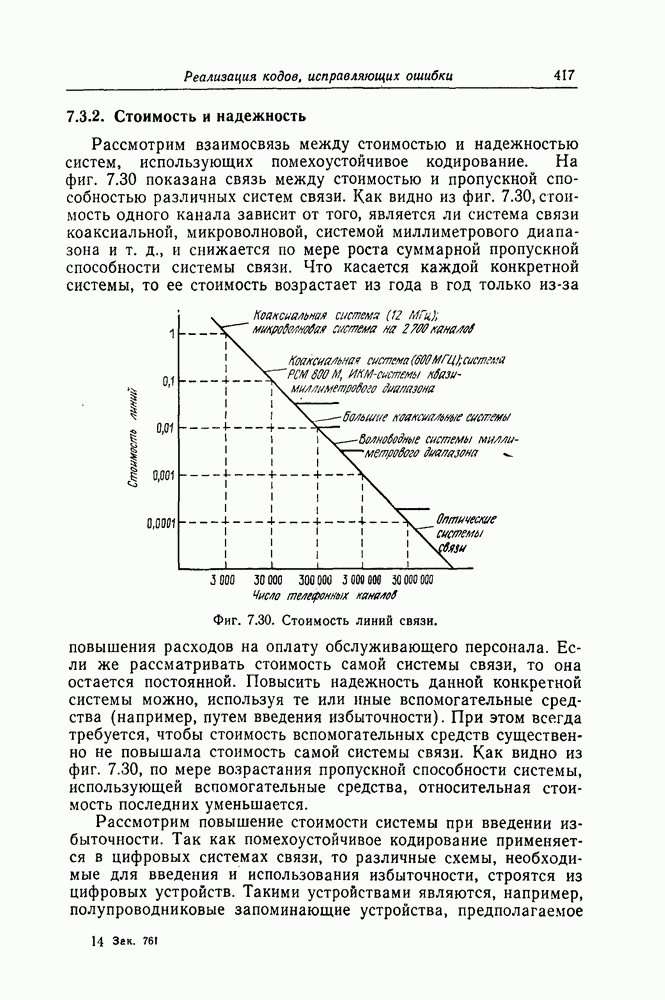
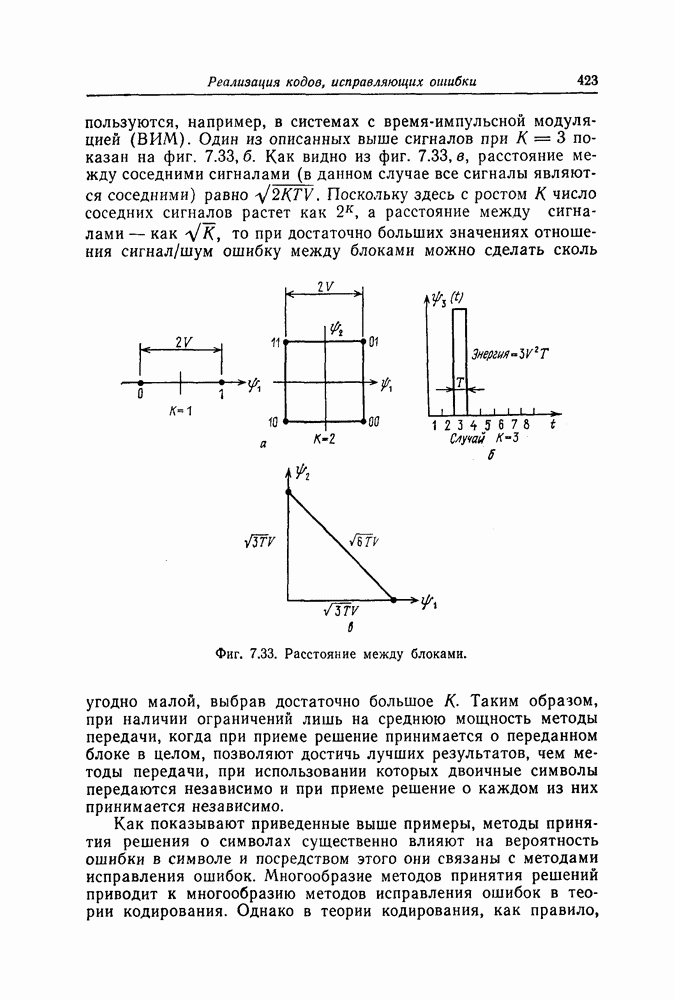
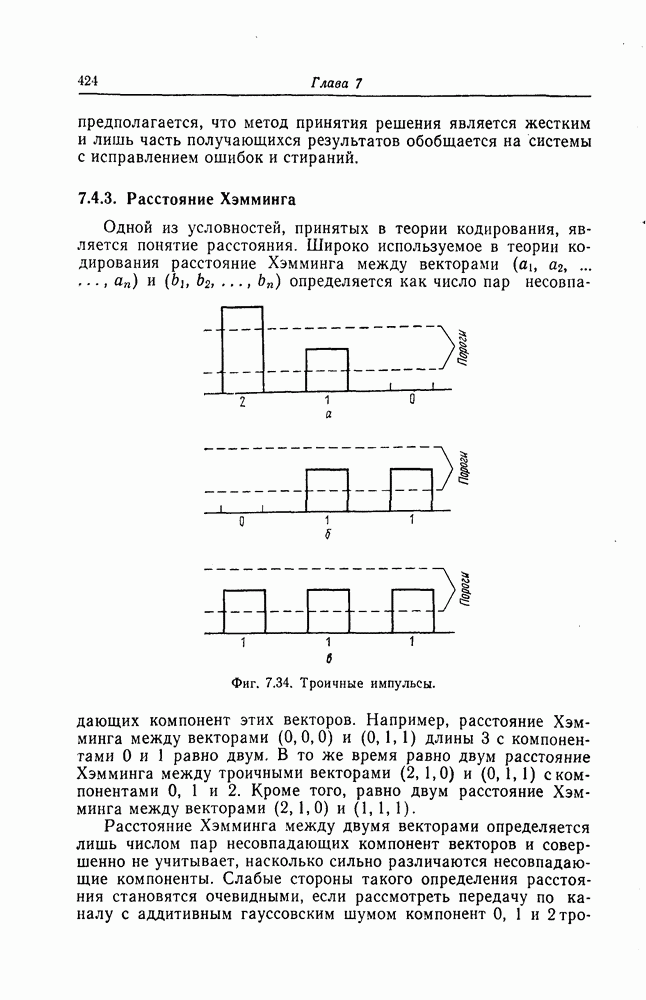
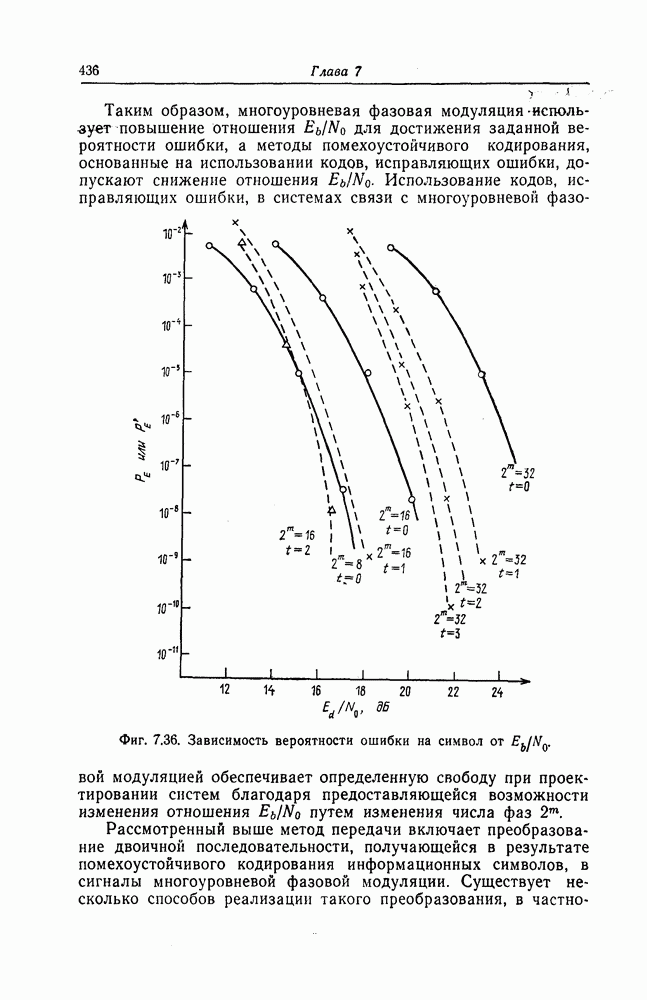
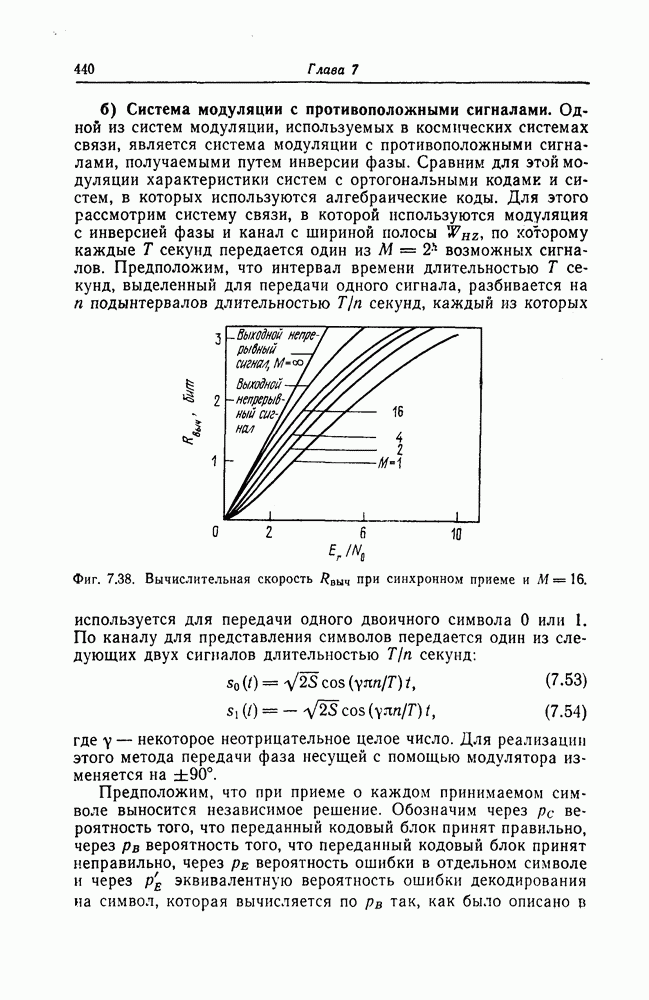
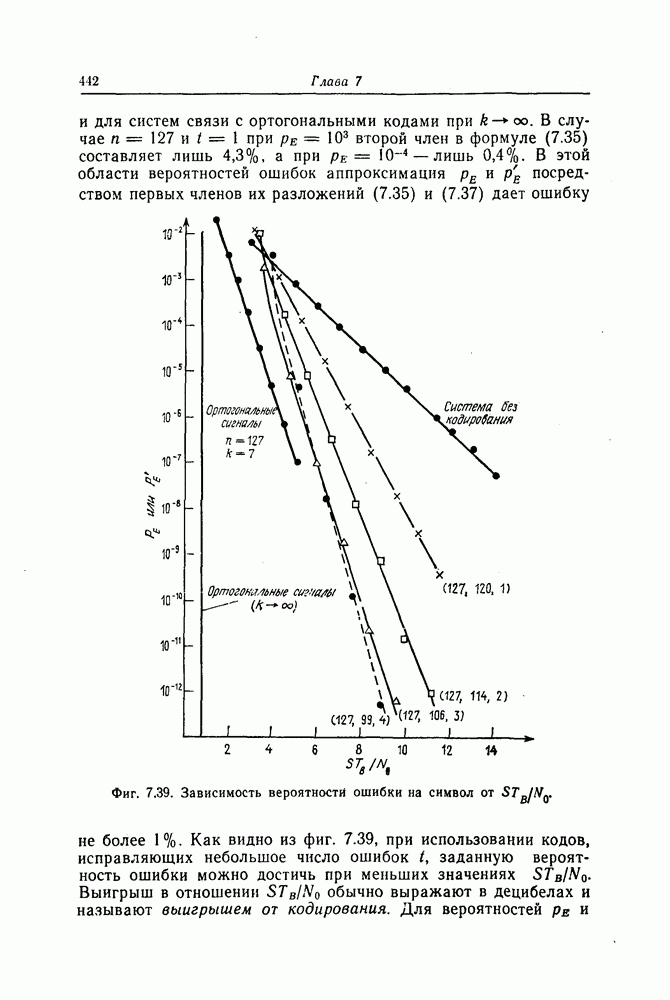
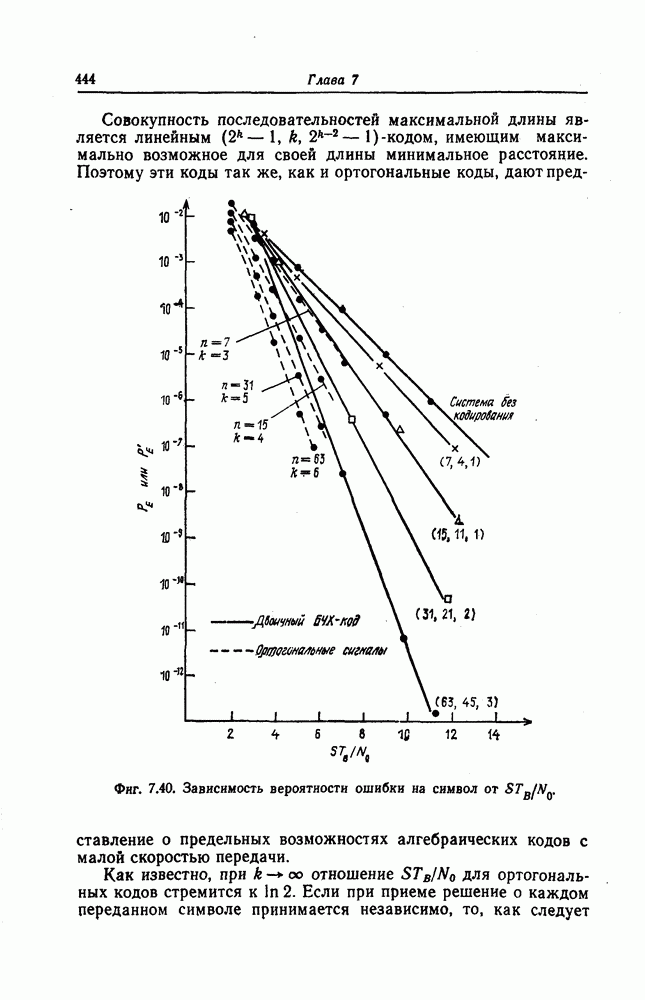
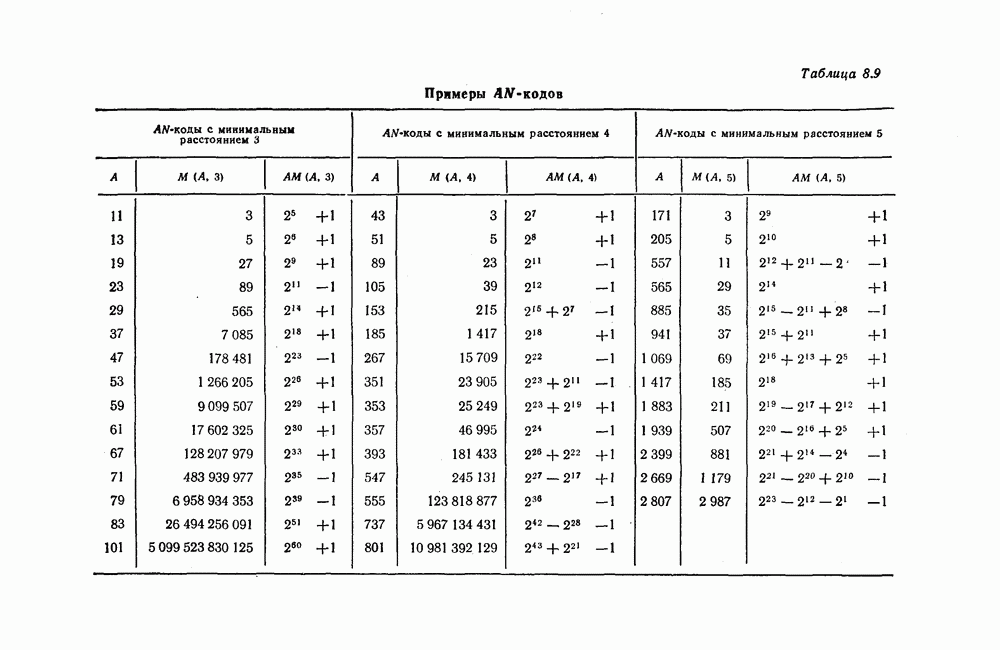
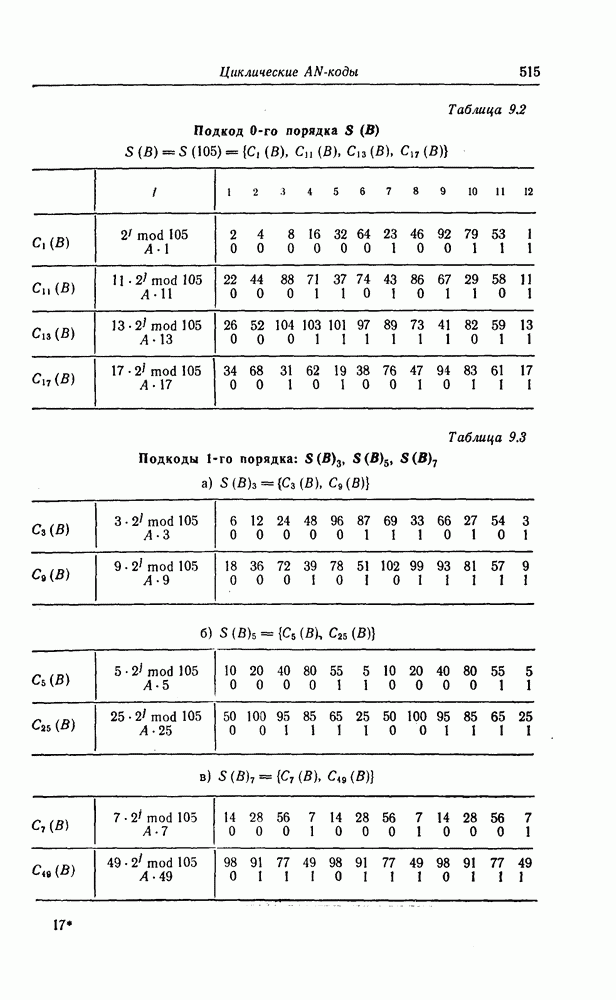
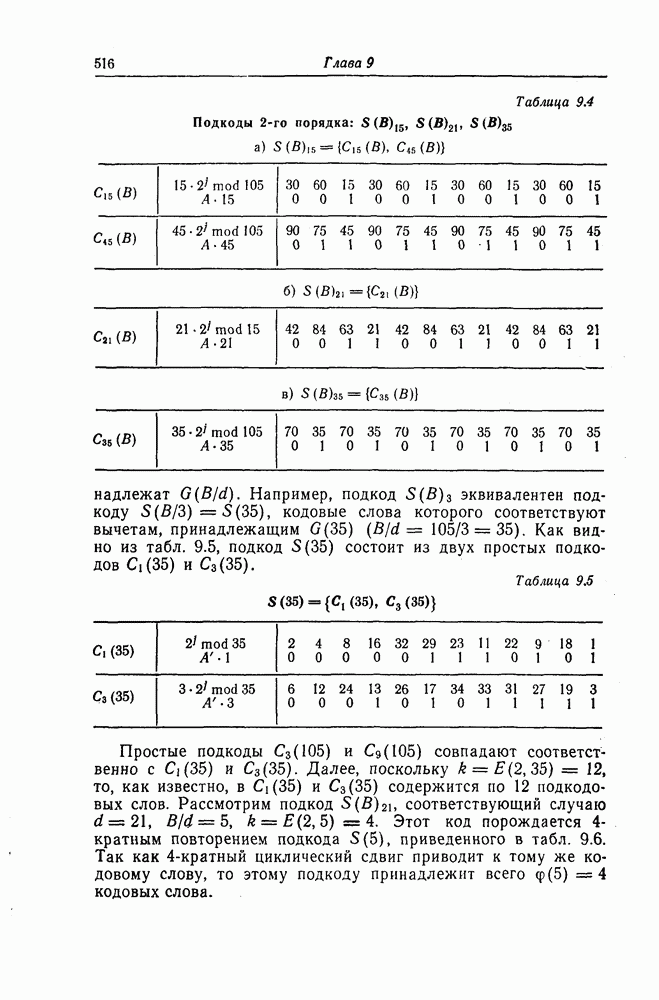
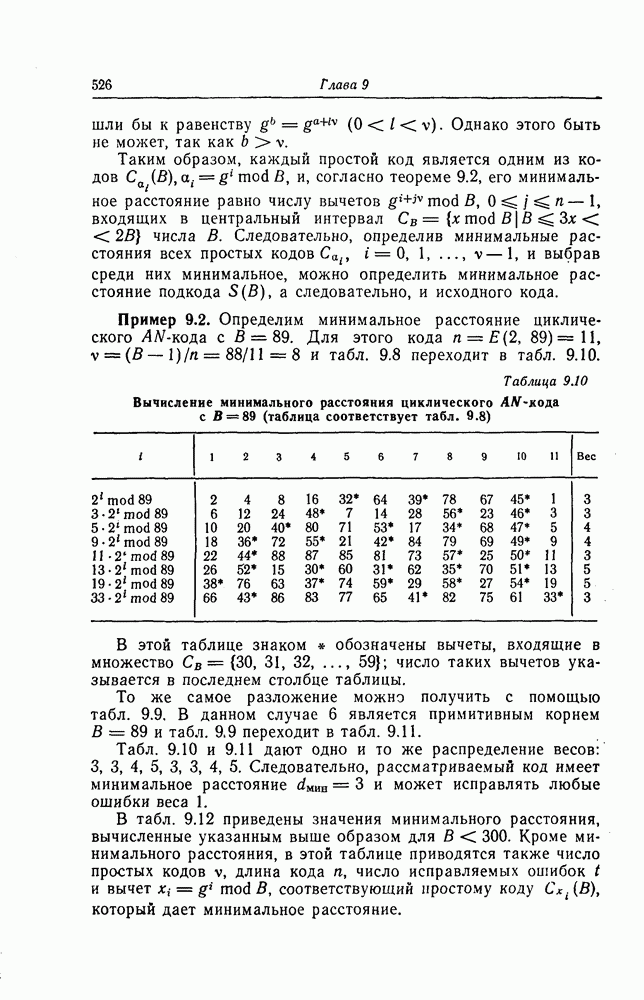
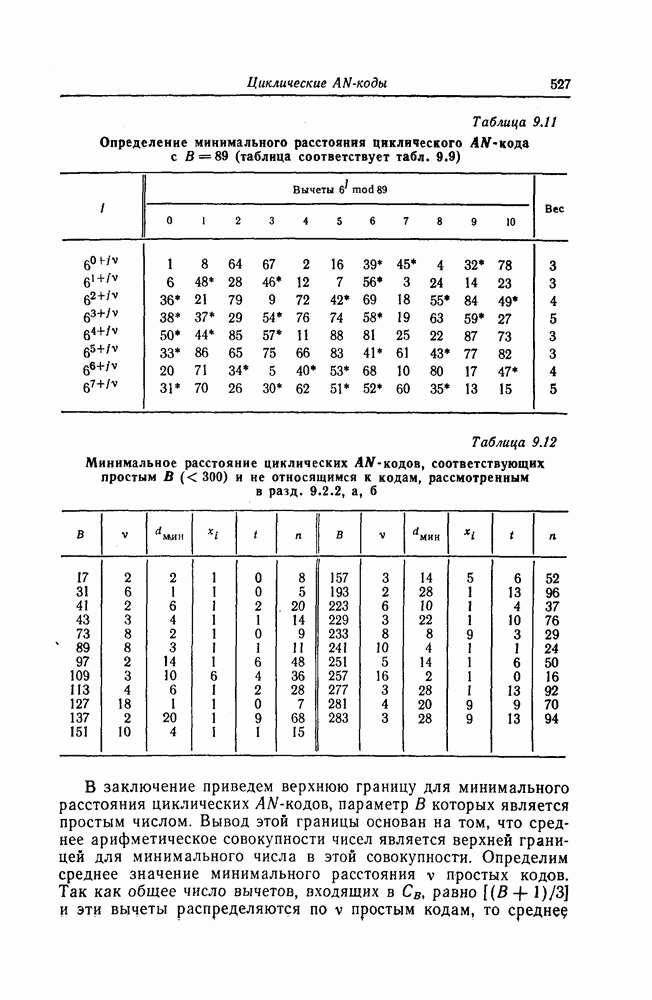
7.7. Применение в системах обработки информации
Алгебраические коды, используемые в вычислительных машинах, можно условно разбить на следующие два типа:
1. Коды, исправляющие специфичные для вычислительных машин ошибки, такие, например, как перестановки соседних символов, возникающие при общении человека с машиной, и др.
2. Коды допускающие быстрое декодирование.
К числу кодов типа 1 относятся, в частности, коды Рида — Соломона и некоторые другие хорошо известные коды, которые
используются на практике для исправления различных специфичных для вычислительных машин ошибок [16]. В тех случаях, когда необходимы коды, допускающие быстрое декодирование, циклические коды, занимающие в теории кодирования центральное место, не всегда оказываются наилучшими. Это связано с тем, что алгоритмы декодирования циклических кодов, как правило, являются последовательными, т. е. они сначала исправляют ошибку в некотором одном символе, далее осуществляют циклический сдвиг декодируемого слова, затем исправляют ошибку в следующем символе и т. д. Устройства, реализующие такие алгоритмы, являются очень простыми, но проведение  циклических сдвигов значительно увеличивает время декодирования, что при использовании этих алгоритмов в вычислительной машине снижает эффективность работы последней. В этом разделе будут рассмотрены класс кодов, предназначенных для использования при общении человека с машиной, и класс кодов, допускающих быстрое декодирование.
циклических сдвигов значительно увеличивает время декодирования, что при использовании этих алгоритмов в вычислительной машине снижает эффективность работы последней. В этом разделе будут рассмотрены класс кодов, предназначенных для использования при общении человека с машиной, и класс кодов, допускающих быстрое декодирование.
7.7.1. Применение кодов при общении человека с машиной
В процессе общения человека с машиной иногда не удается точно установить источник возникновения ошибок и принять соответствующие меры к их устранению; в этом случае для повышения надежности обычно используются коды, исправляющие ошибки. Модель процесса общения человека с машиной сложнее, чем модель канала связи.
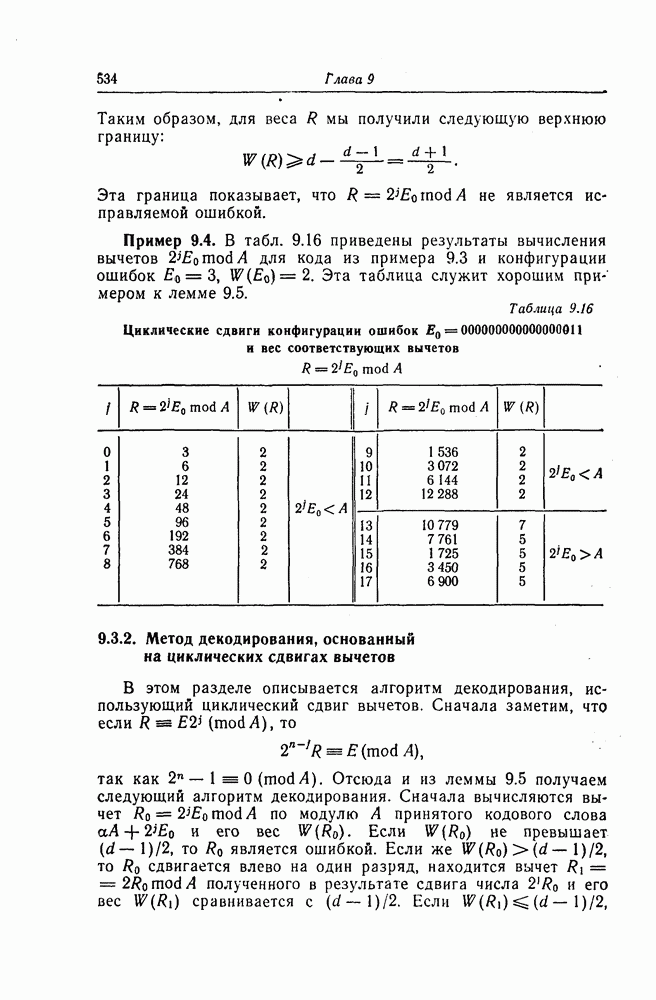
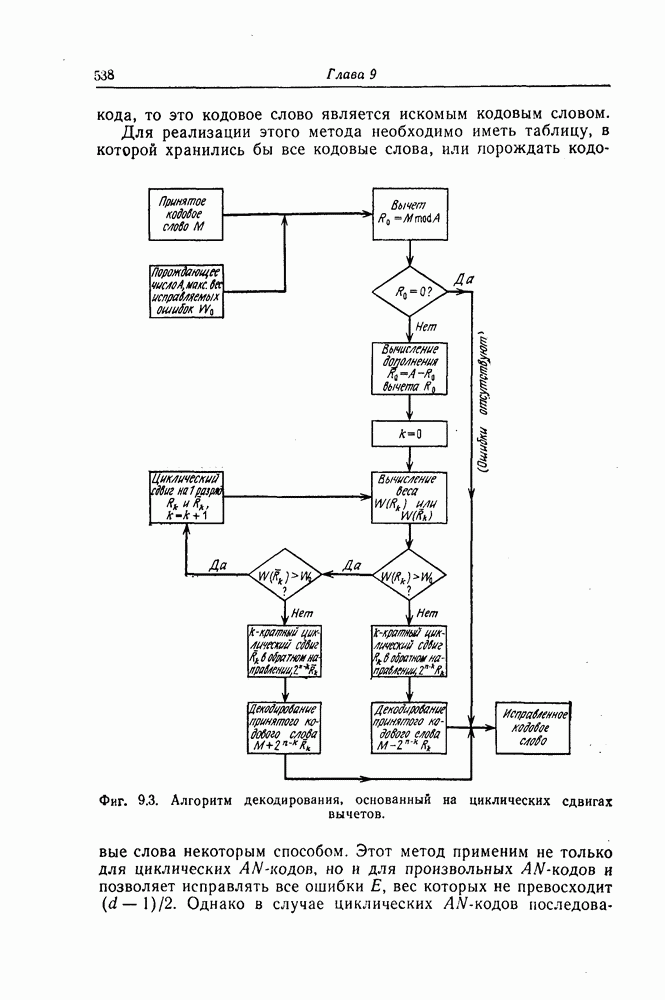
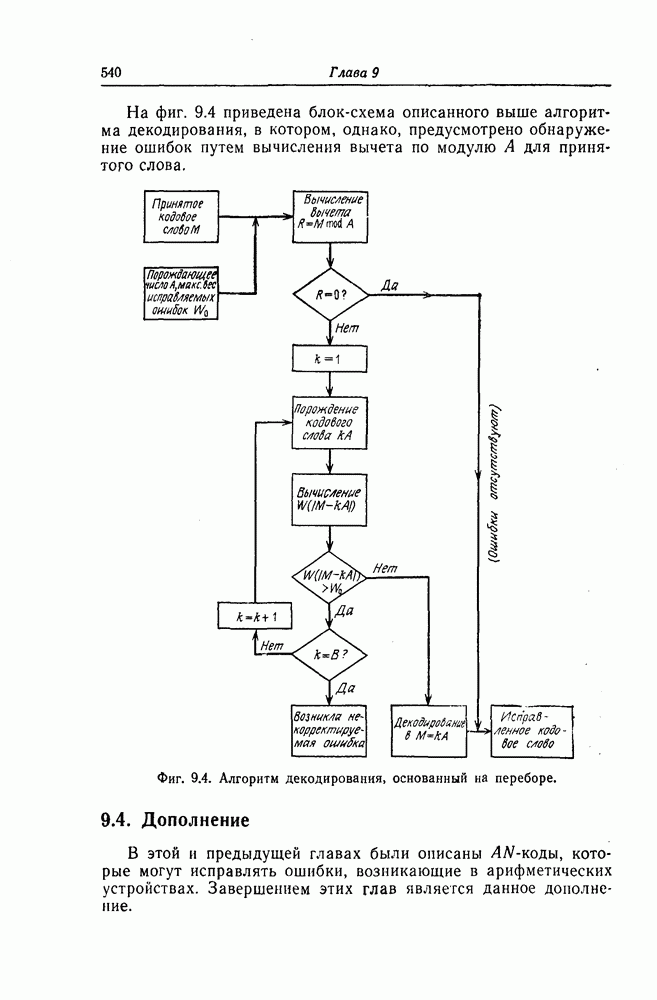
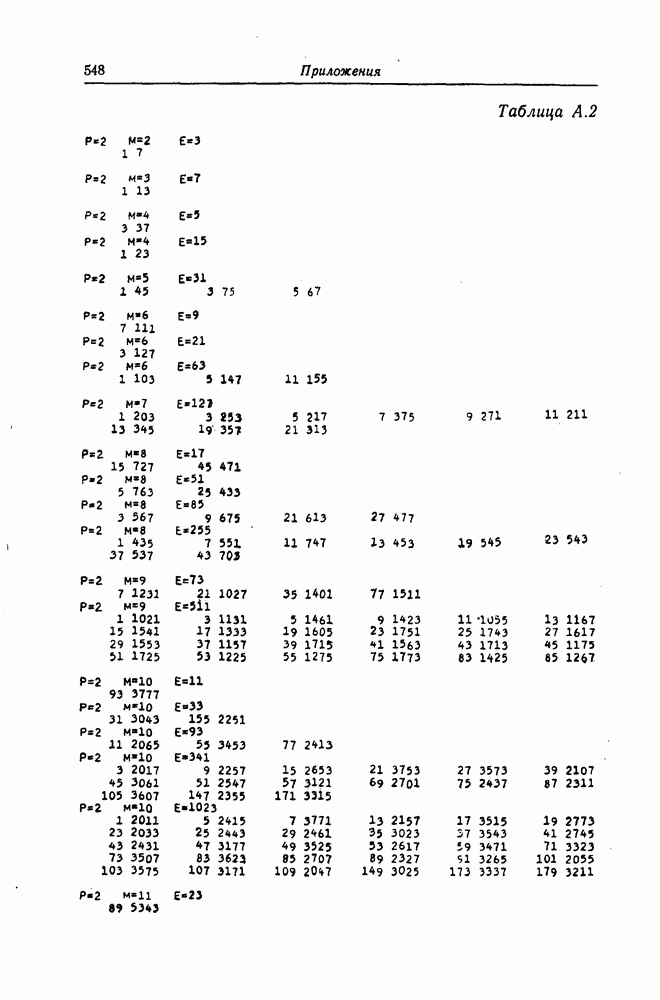
К числу наиболее типичных ошибок, возникающих в процессе общения человека с машиной, можно отнести следующие: перестановки соседних символов, замена символов, вставки символов, выпадения символов и др.
Рассмотрим класс кодов, исправляющих перестановки соседних символов [13]. Перестановку соседних символов всегда можно рассматривать как пачку ошибок длины 2. Так как при перестановке соседних символов значения ошибок в них всегда совпадают, то эти ошибки можно исправить значительно проще, чем обычные пачки ошибок длины 2. Описанные ниже коды являются кодами, которые исправляют ошибку из-за перестановки символов как обычную одиночную ошибку.
Предположим, что передаваемые и принимаемые символы являются элементами поля  Рассмотрим
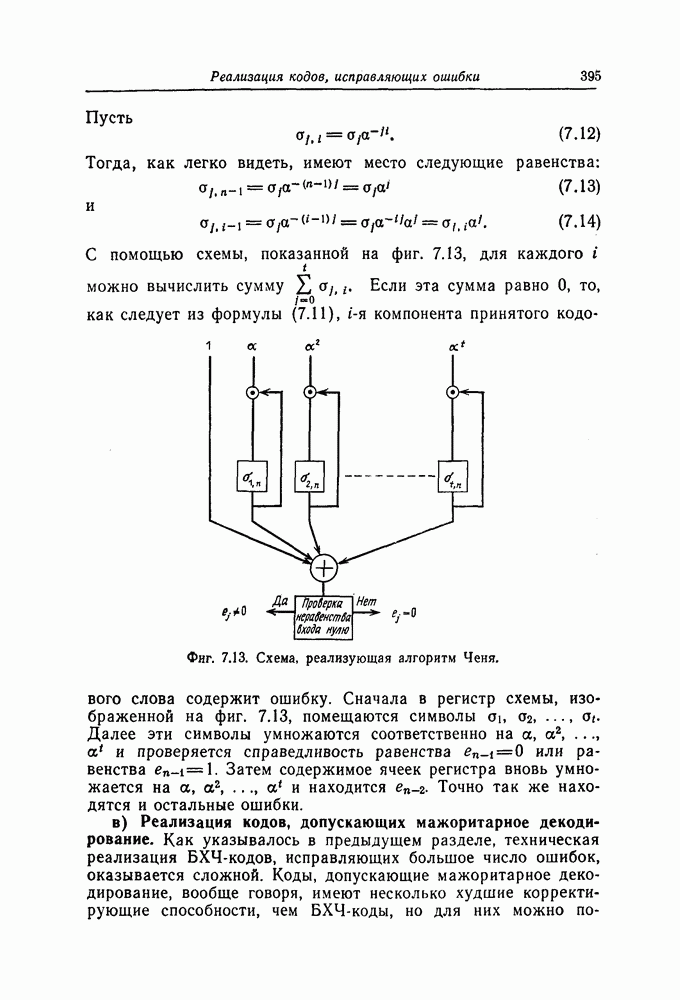
Рассмотрим  -ичный циклический код длины
-ичный циклический код длины  задаваемый порождающим многочленом
задаваемый порождающим многочленом  степени
степени  Кодовыми словами этого кода являются многочлены степени
Кодовыми словами этого кода являются многочлены степени  или менее, которые делятся на
или менее, которые делятся на  Пусть
Пусть  является неприводимым многочленом, корнем которого является элемент
является неприводимым многочленом, корнем которого является элемент  где а — примитивный элемент
где а — примитивный элемент 
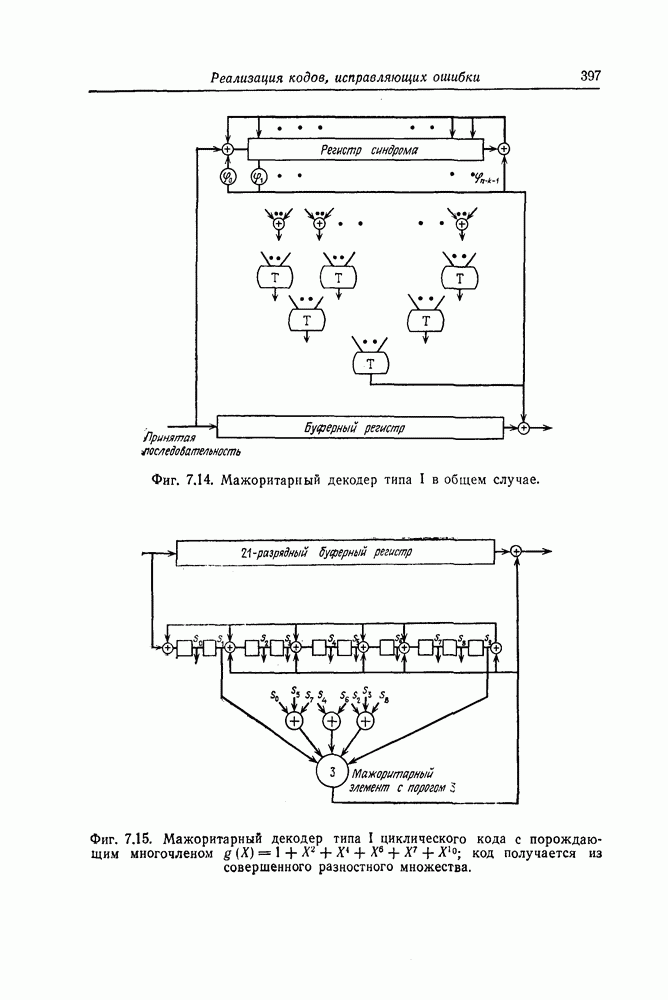
Так как произвольный вектор-столбец из  символов поля
символов поля  всегда можно представить в виде произведения элемента поля
всегда можно представить в виде произведения элемента поля  и одного из столбцов проверочной матрицы рассматриваемого кода, то существуют единственный элемент
и одного из столбцов проверочной матрицы рассматриваемого кода, то существуют единственный элемент  поля
поля  и целое положительное число
и целое положительное число  такие, что
такие, что

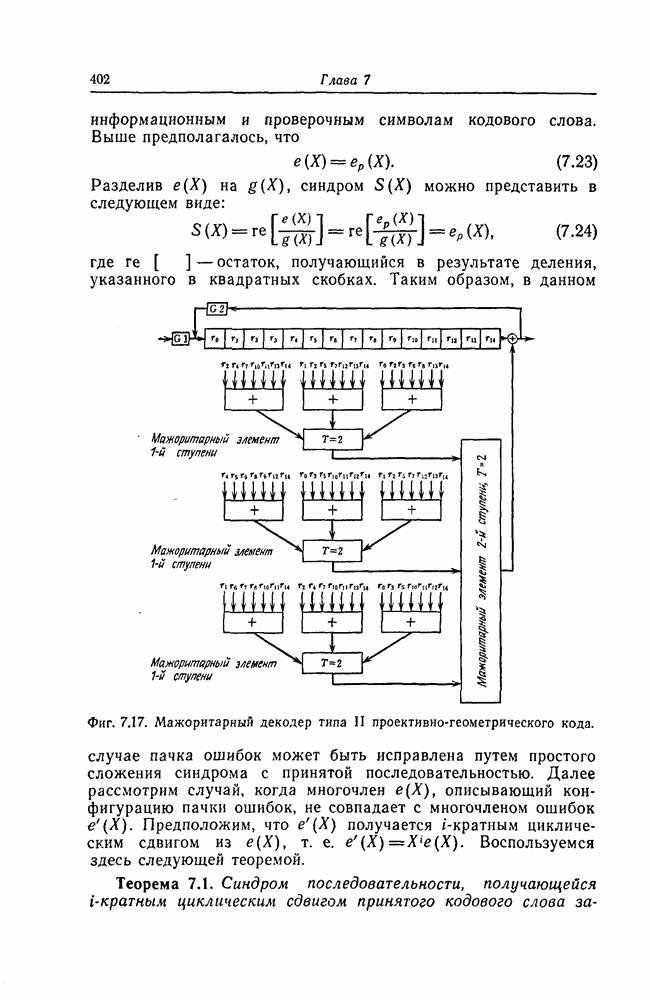
Это сравнение можно переписать в виде

Так как ошибкам из-за перестановки символов соответствует многочлен ошибок вида

то синдром определяется равенством

Поскольку  являются взаимно простыми многочленами, то можно установить взаимно однозначное соответствие между значениями синдрома, соответствующими различным пачкам ошибок, возникающим при перестановке символов, и значениями синдрома, соответствующими простым одиночным ошибкам. Чтобы схему исправления одиночных ошибок можно было использовать для исправления ошибок, возникающих из-за перестановки символов, достаточно воспользоваться следующим соотношением:
являются взаимно простыми многочленами, то можно установить взаимно однозначное соответствие между значениями синдрома, соответствующими различным пачкам ошибок, возникающим при перестановке символов, и значениями синдрома, соответствующими простым одиночным ошибкам. Чтобы схему исправления одиночных ошибок можно было использовать для исправления ошибок, возникающих из-за перестановки символов, достаточно воспользоваться следующим соотношением:

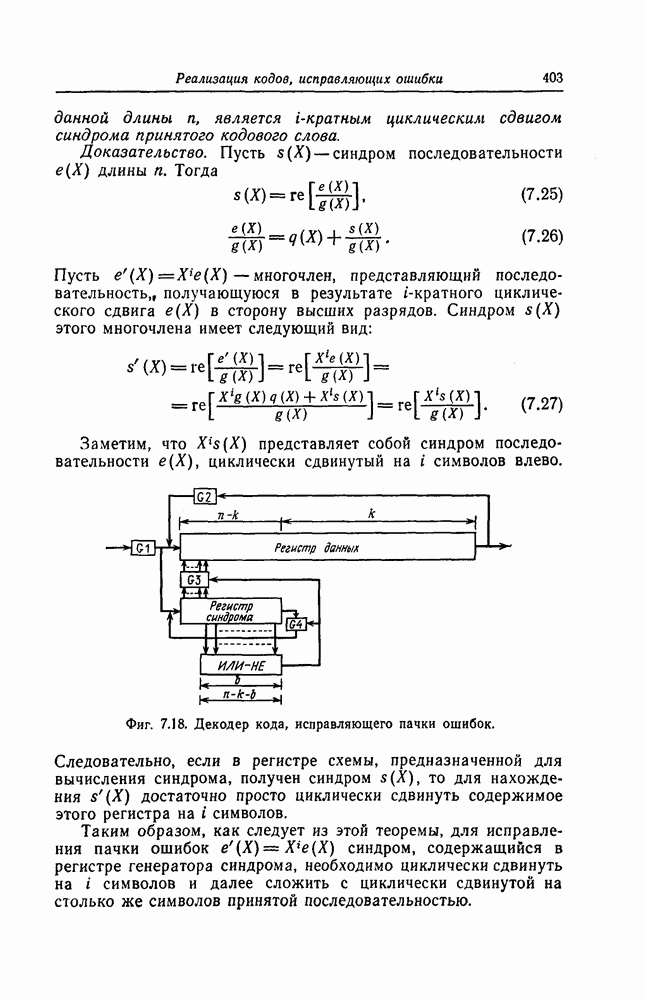
При этом синдром  можно получить умножением синдрома
можно получить умножением синдрома  вычисленного по принятому кодовому вектору, на многочлен
вычисленного по принятому кодовому вектору, на многочлен

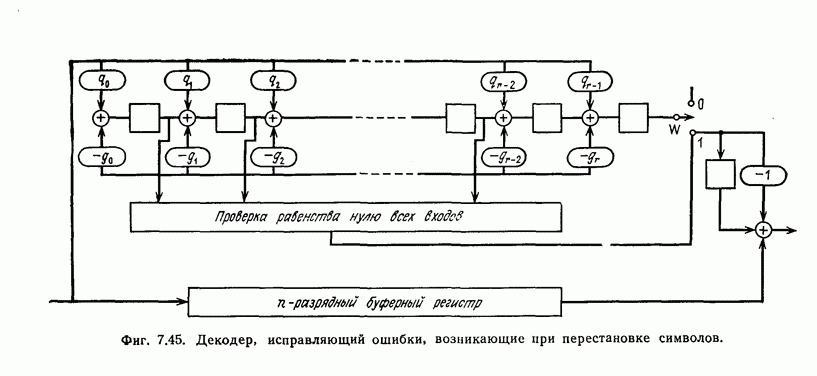
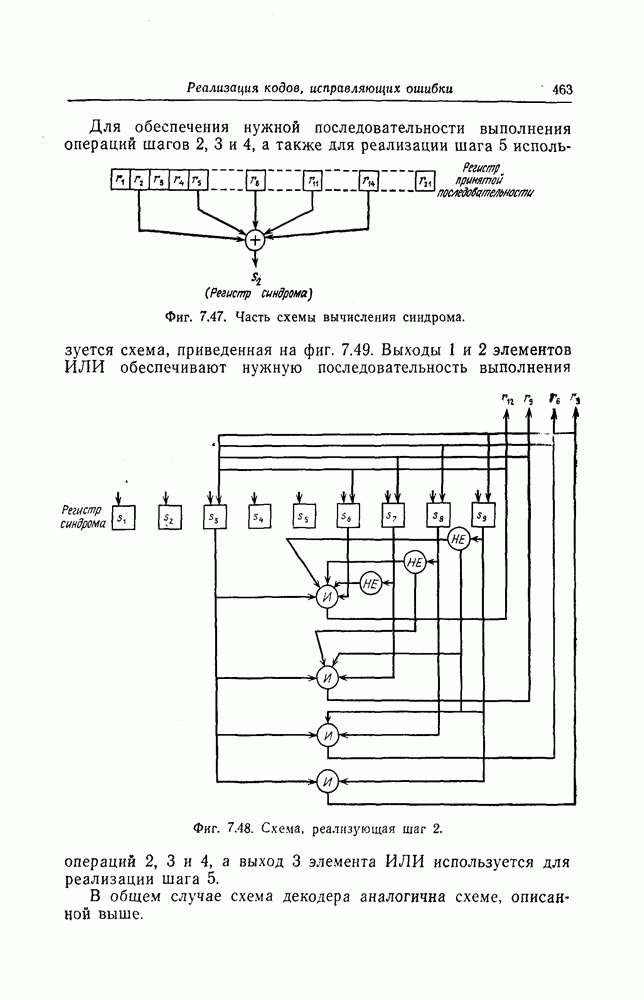
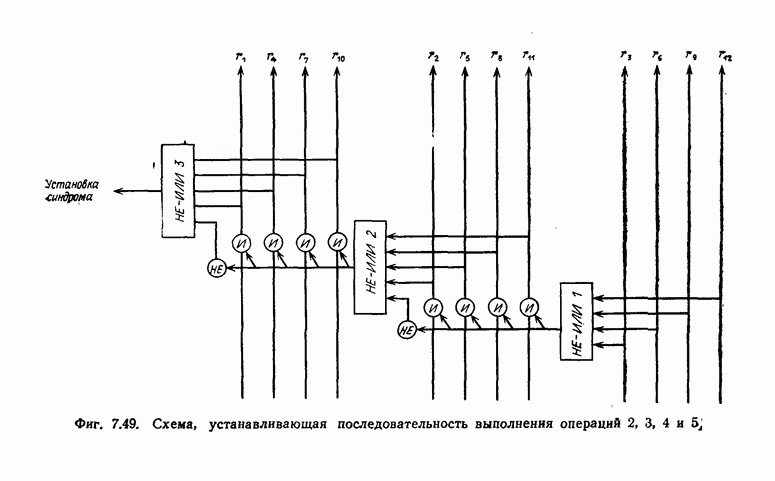
Декодер, реализующий описанный выше алгоритм исправления ошибок, возникающих при перестановке символов, показан на фиг. 7.45. Переключатель  находится в положении 0 до тех пор, пока левые
находится в положении 0 до тех пор, пока левые  разрядов регистра сдвига не будут содержать нулевые символы.
разрядов регистра сдвига не будут содержать нулевые символы.

(кликните для просмотра скана)