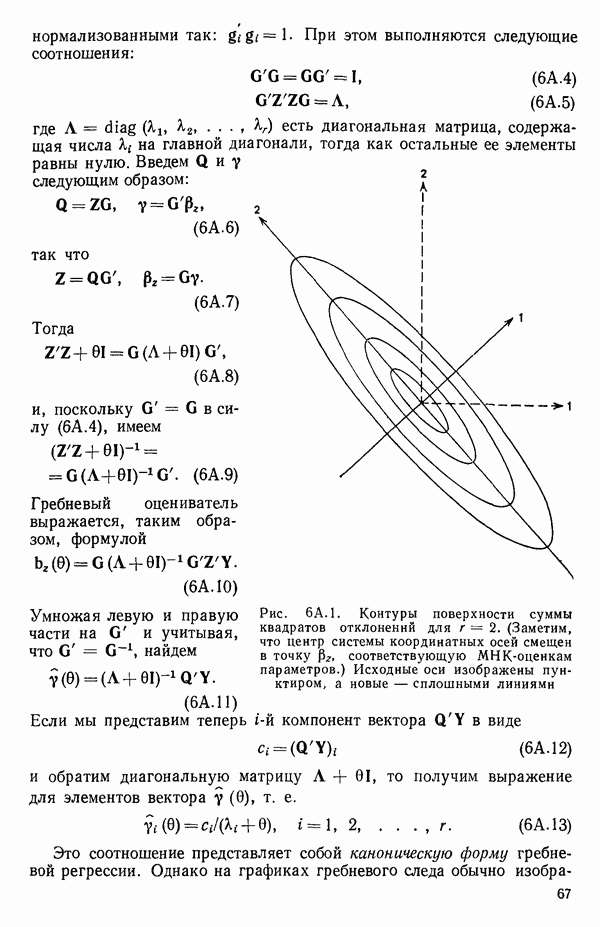
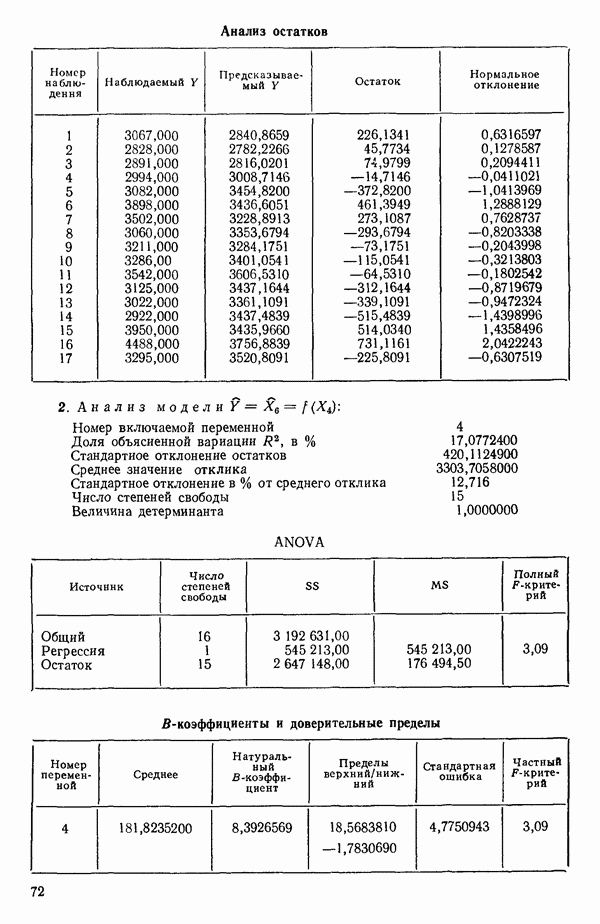
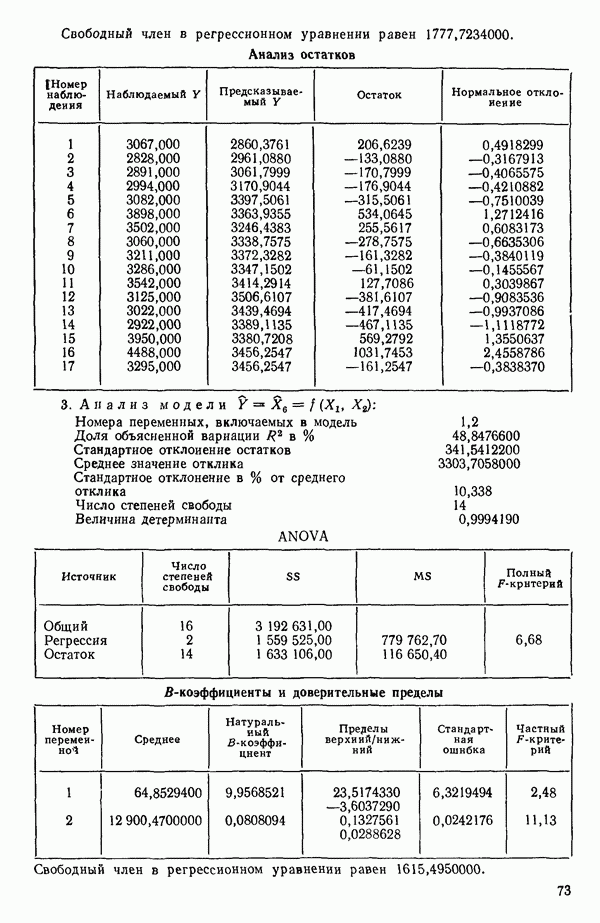
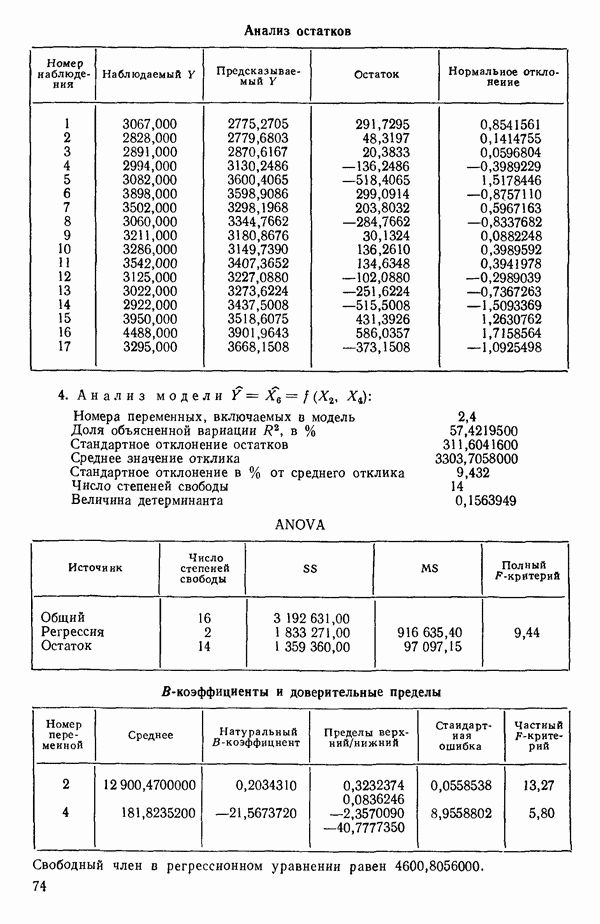
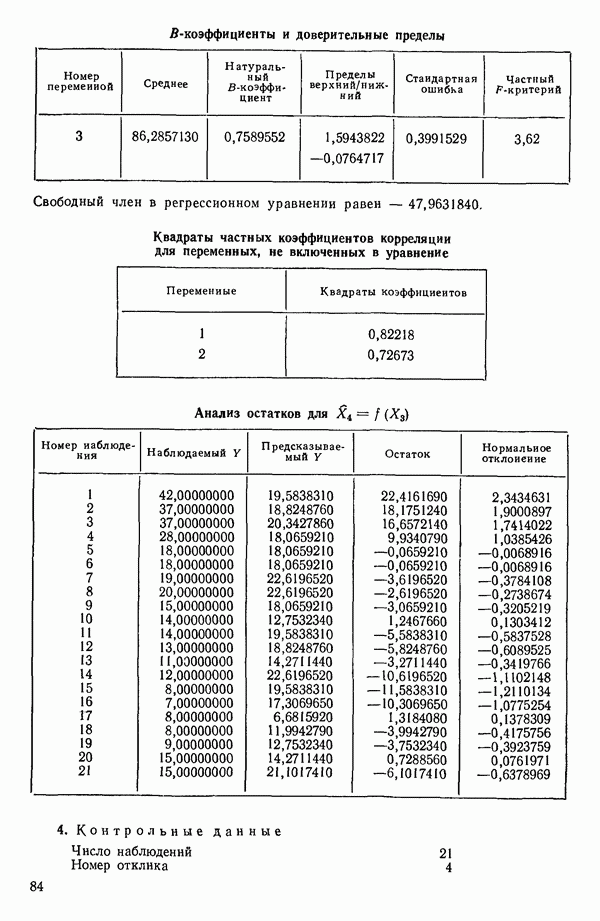
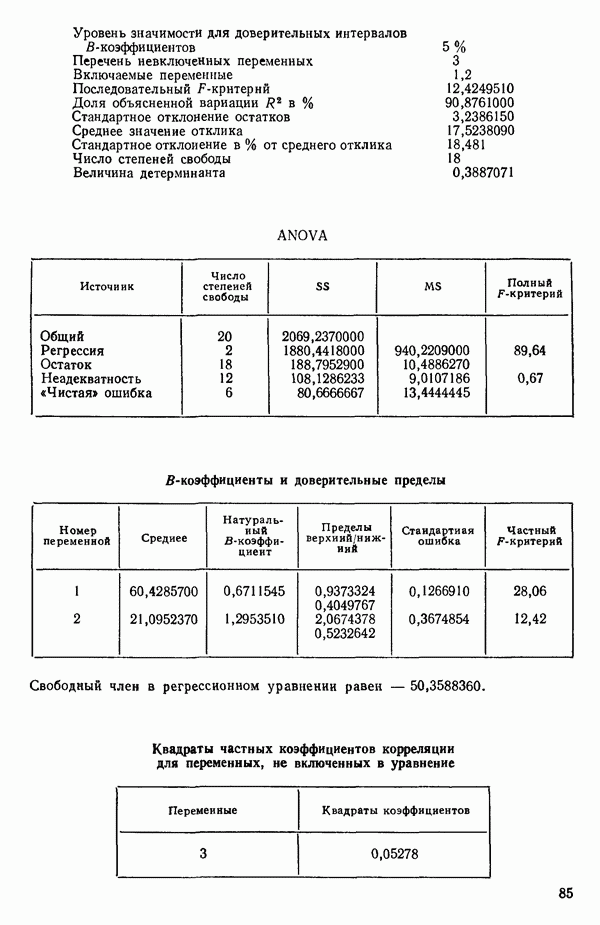
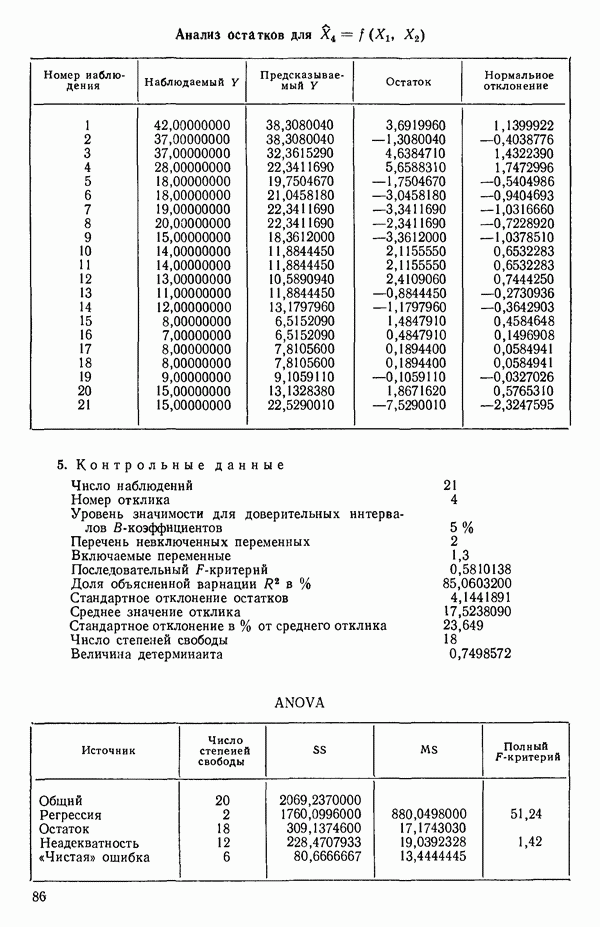
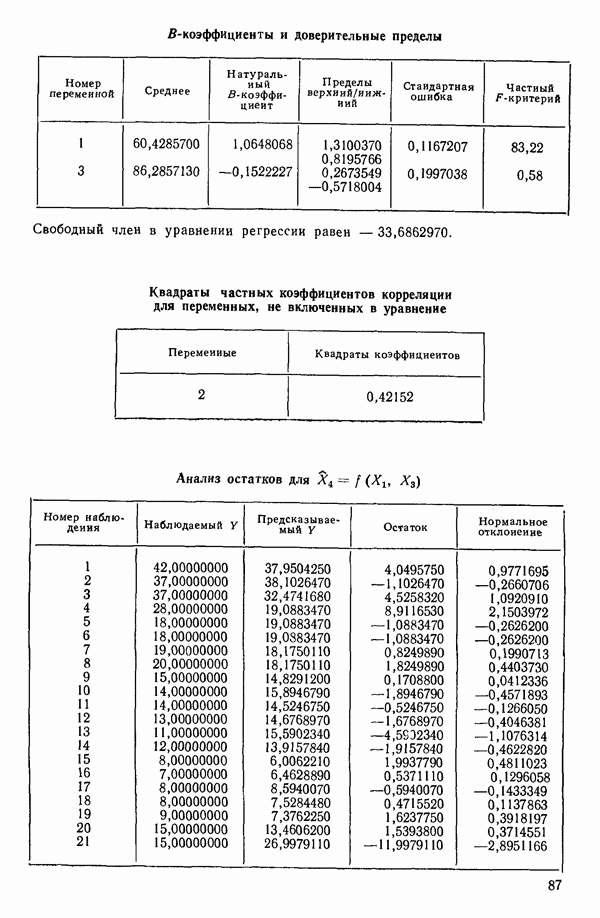
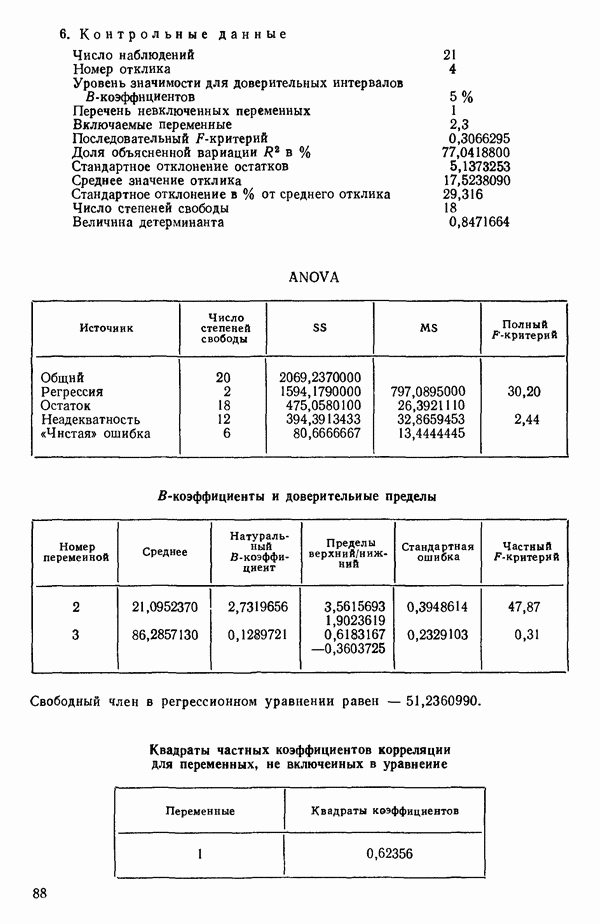
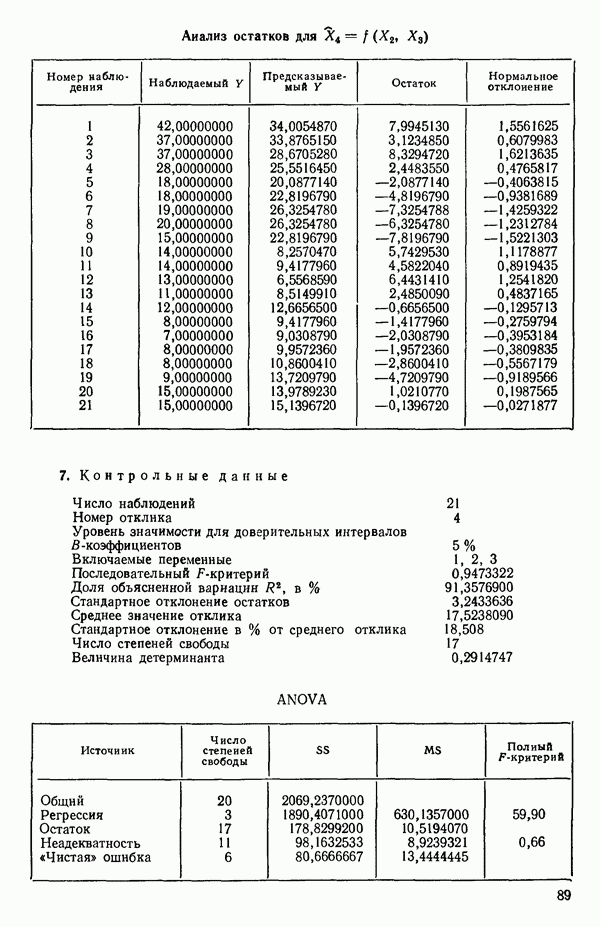
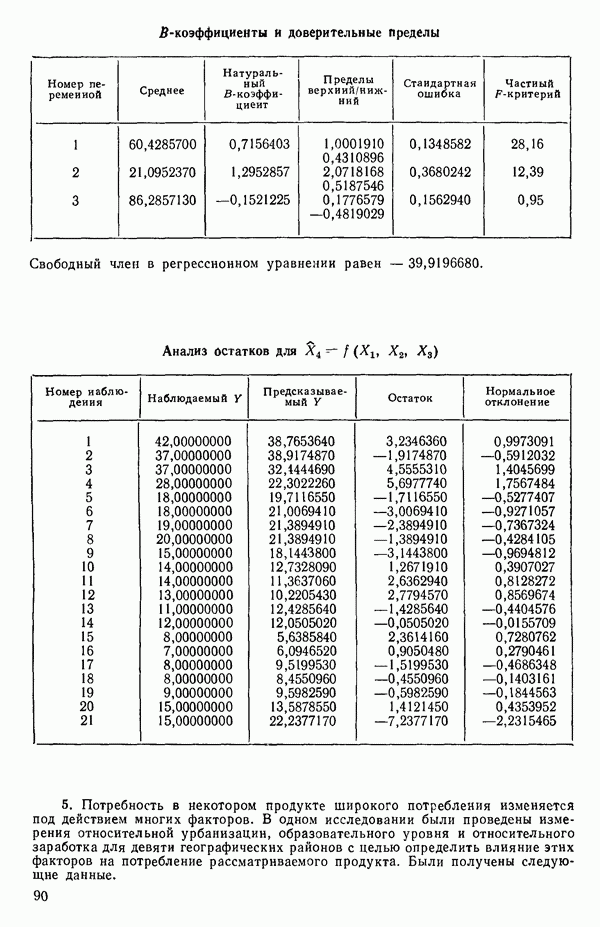
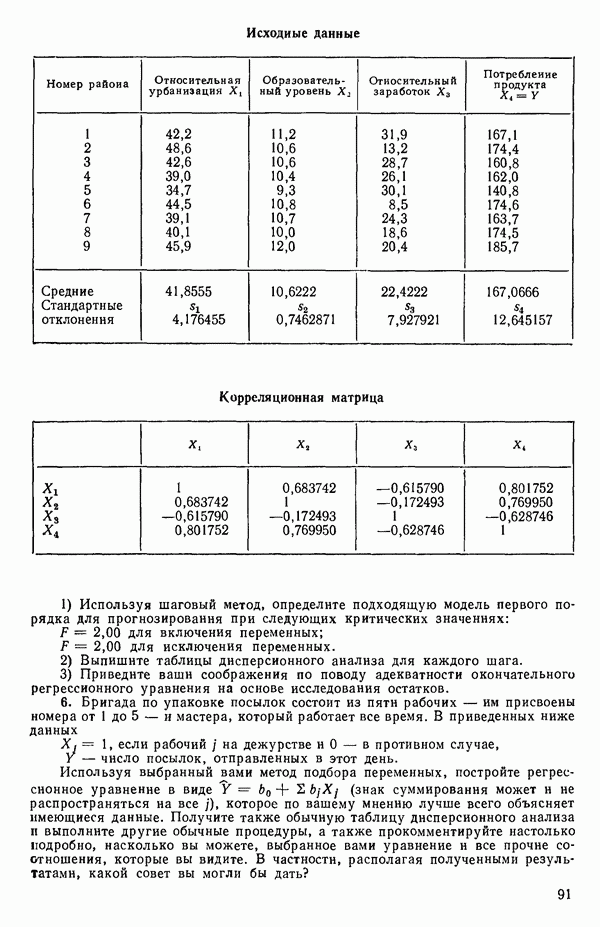
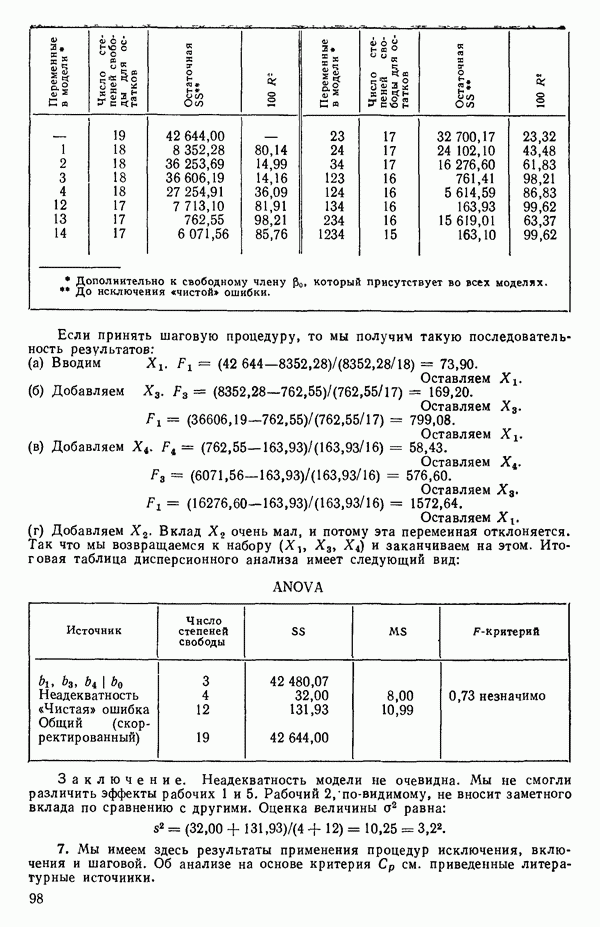
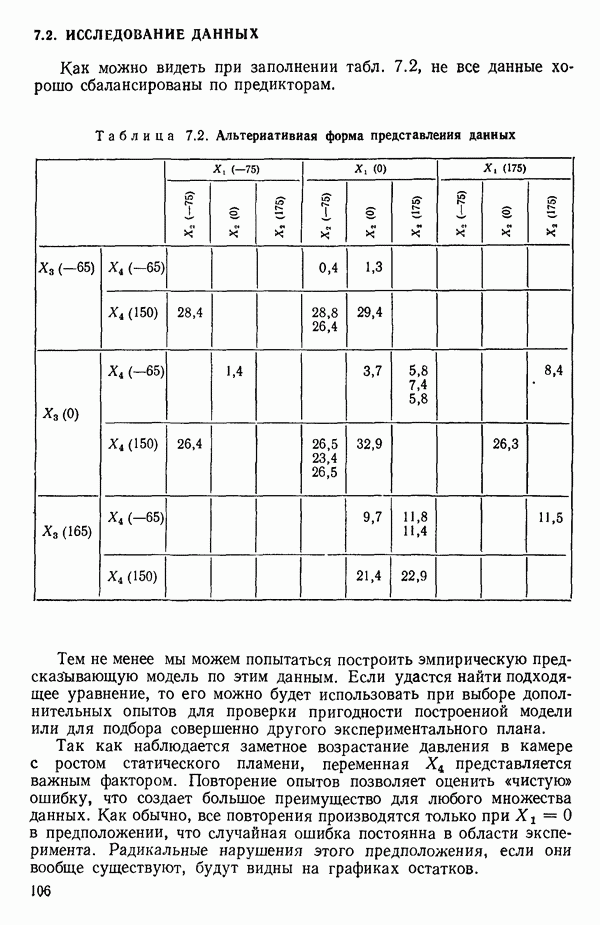
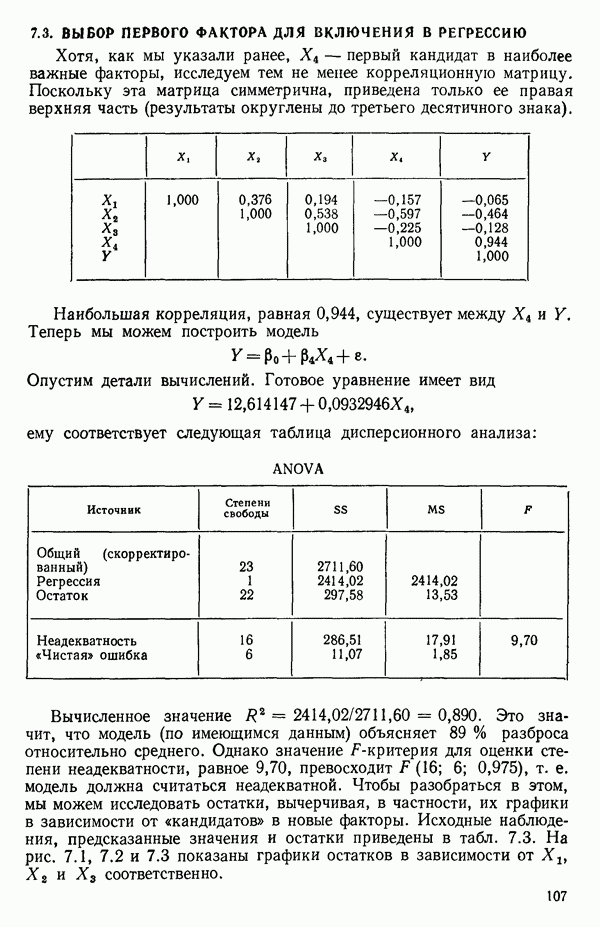
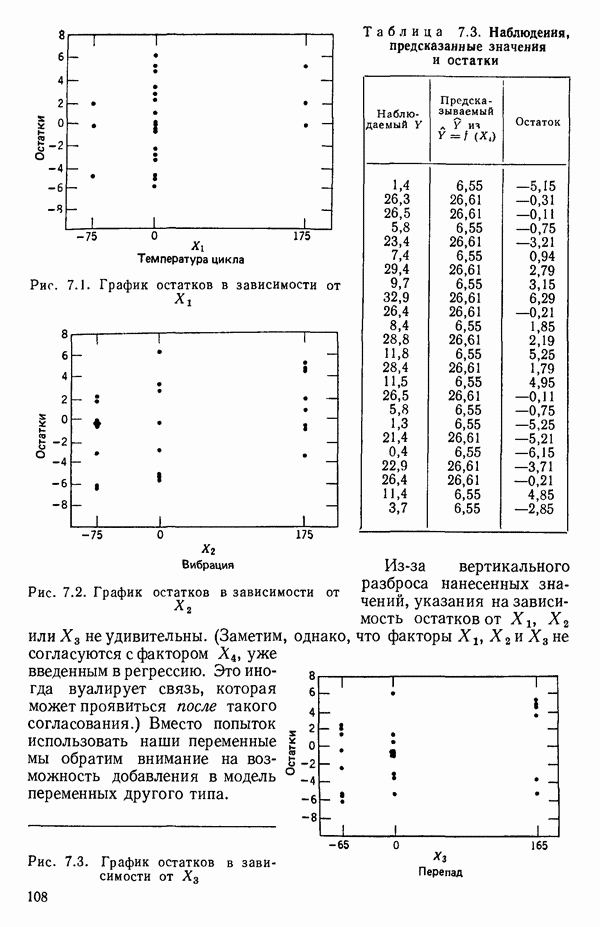
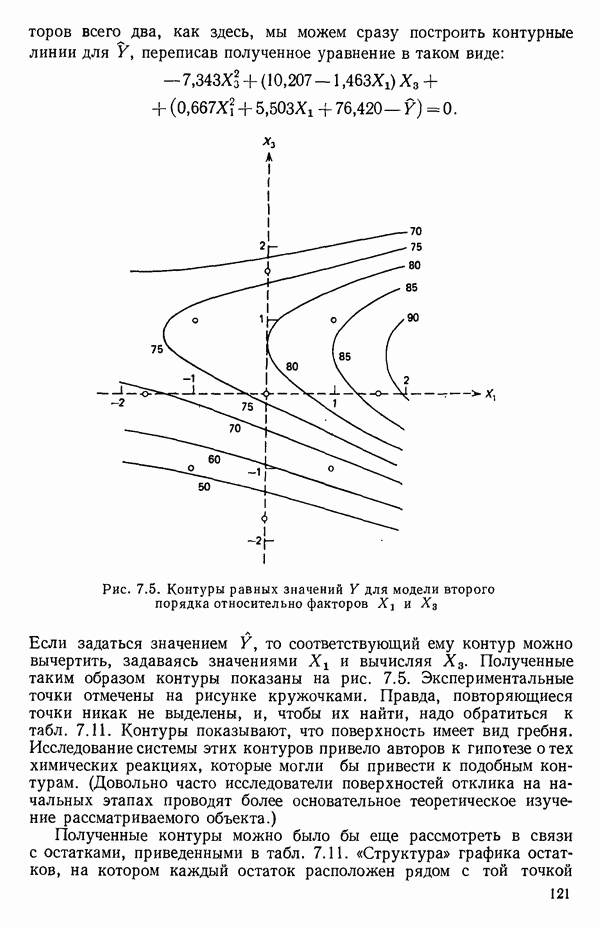
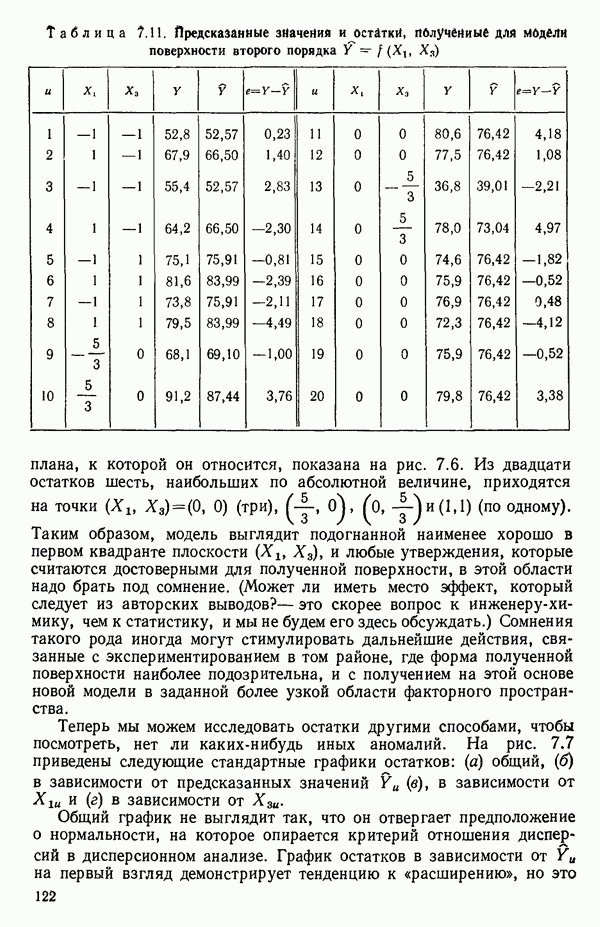
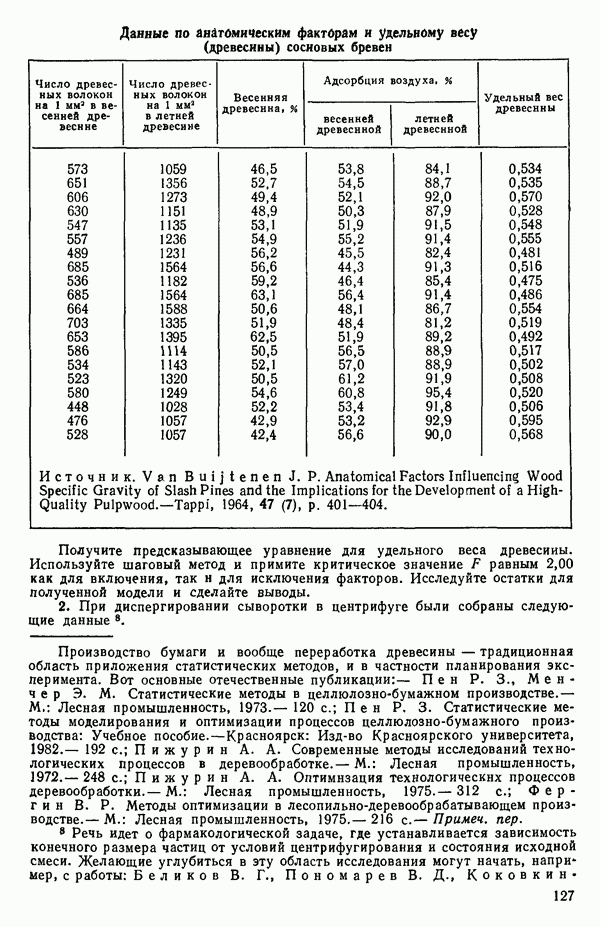
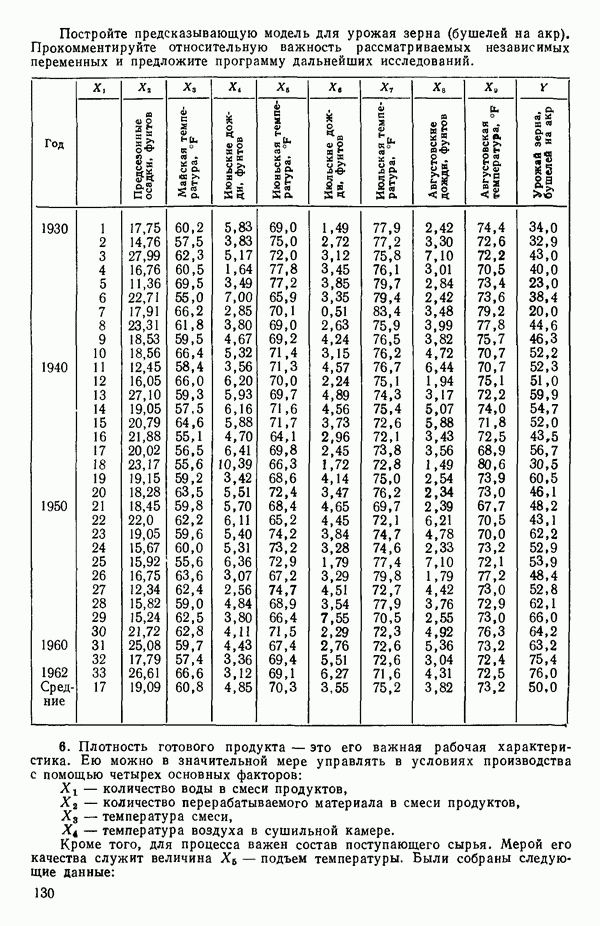
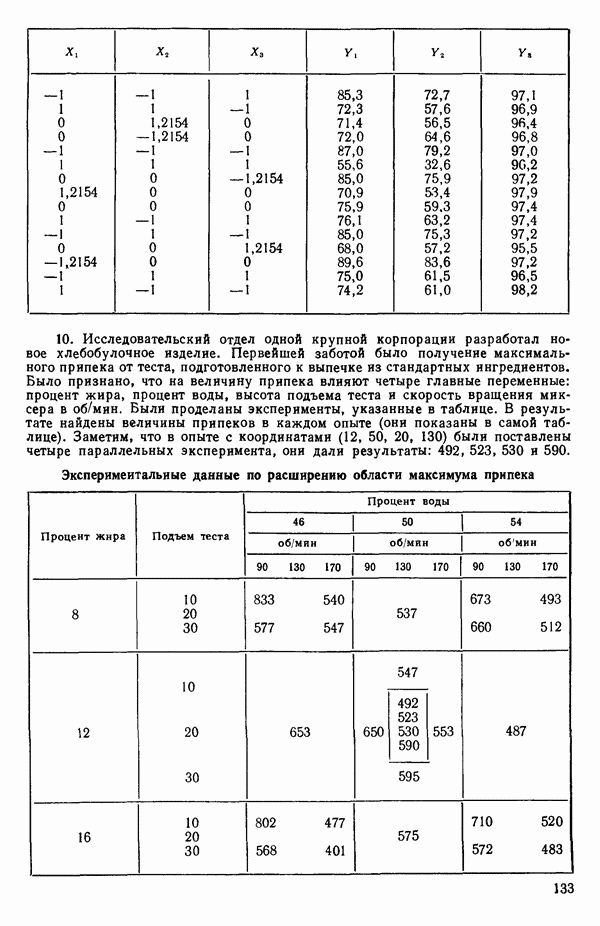
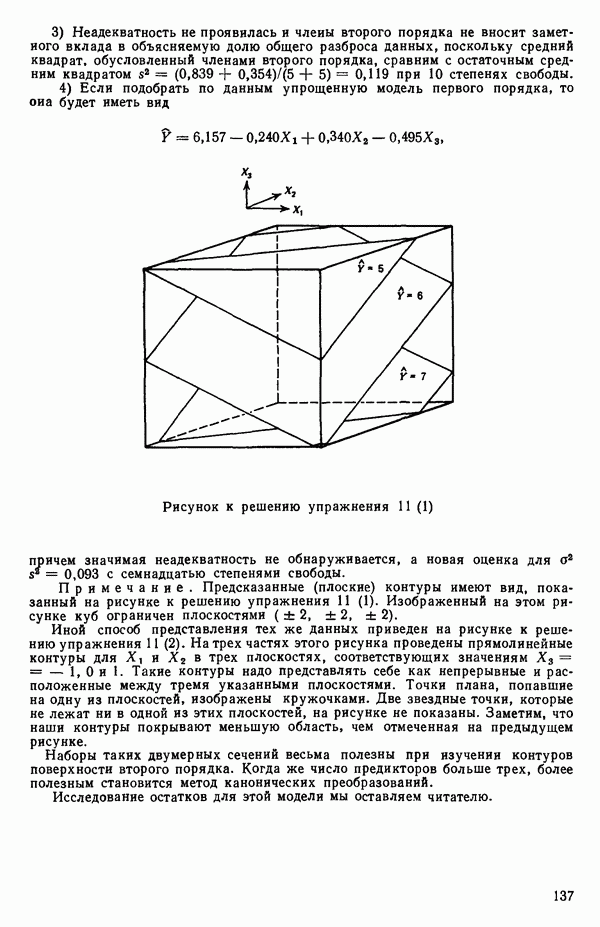
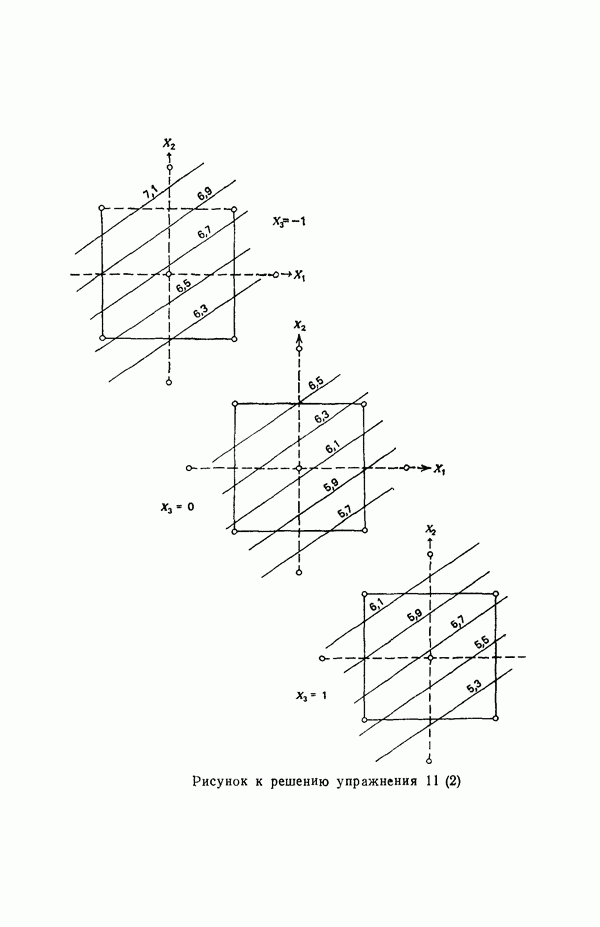
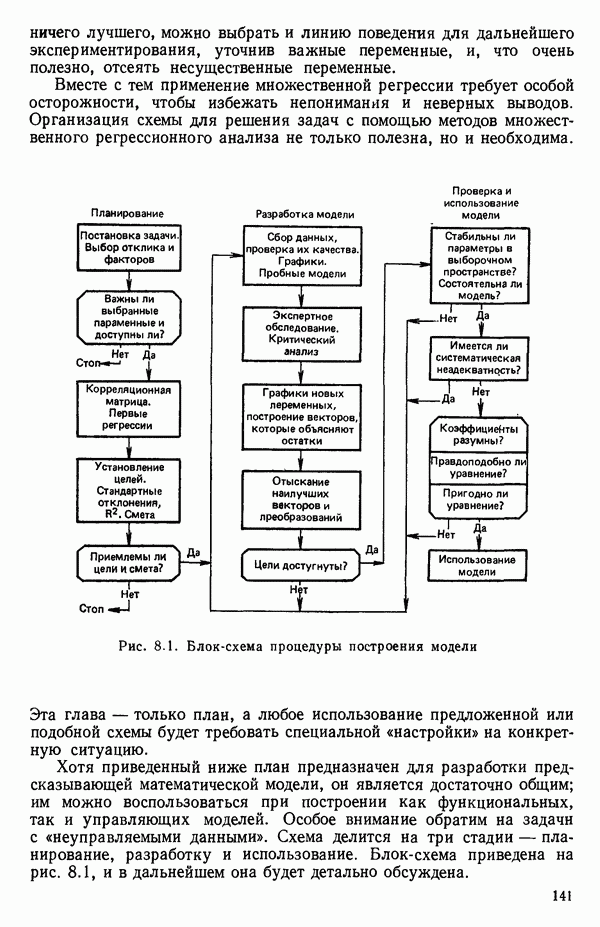
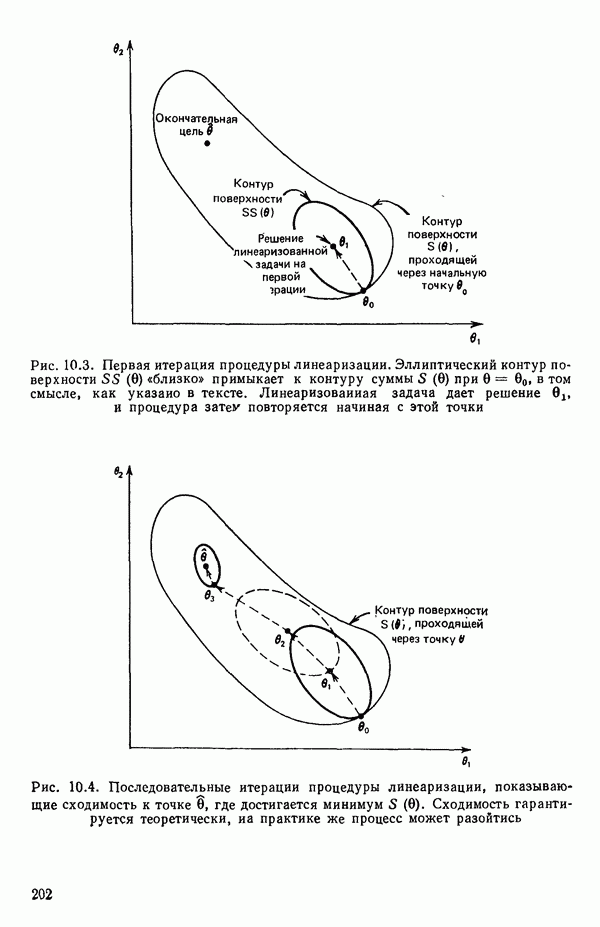
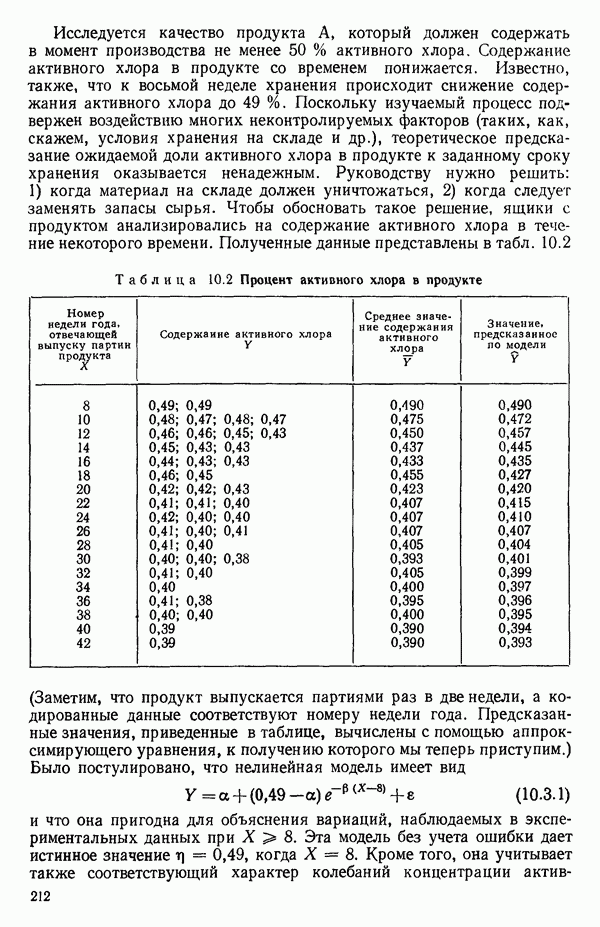
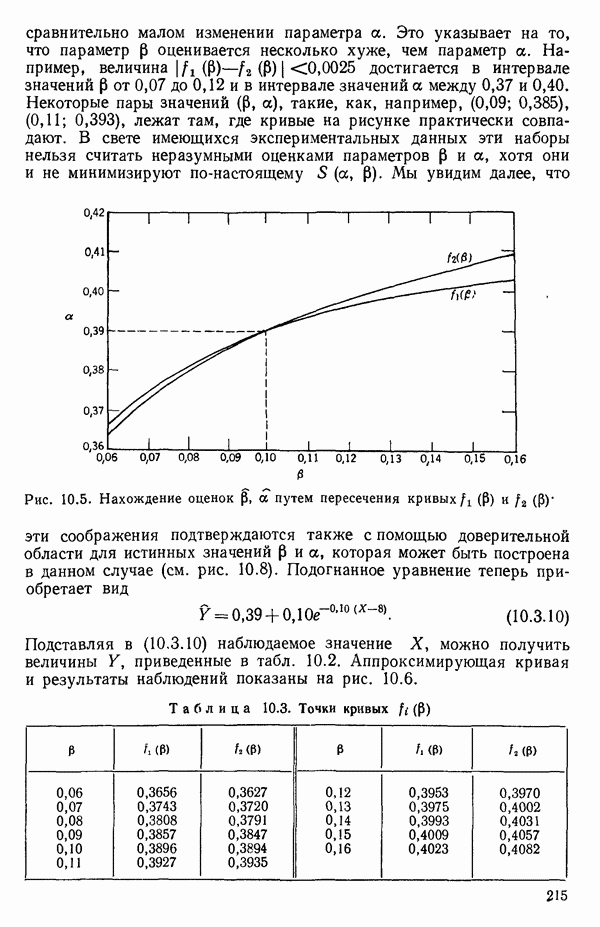
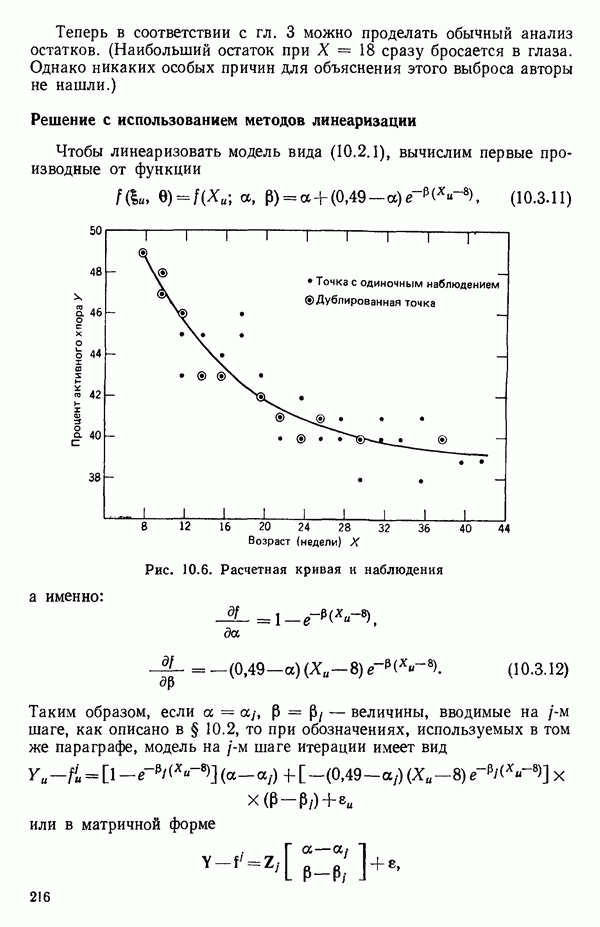
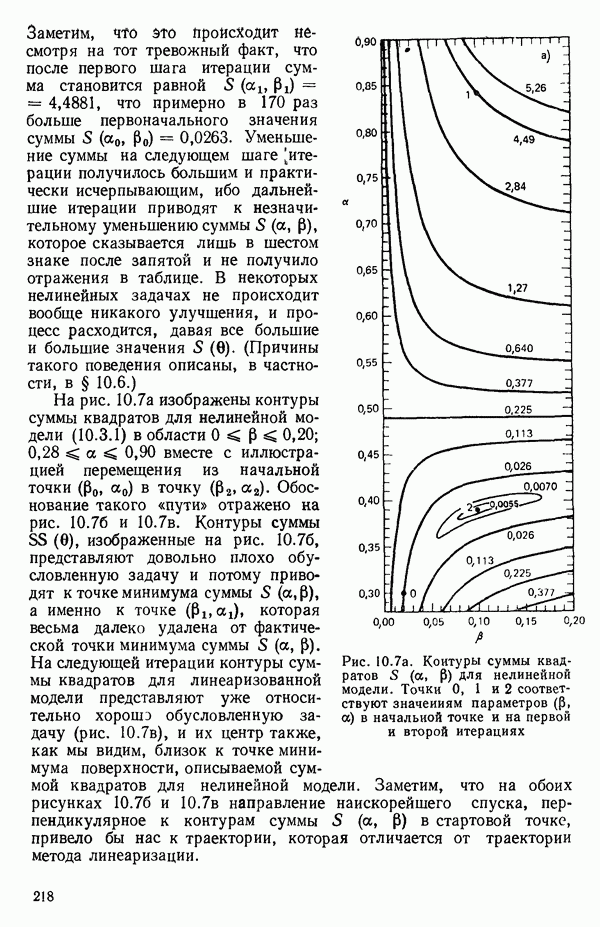
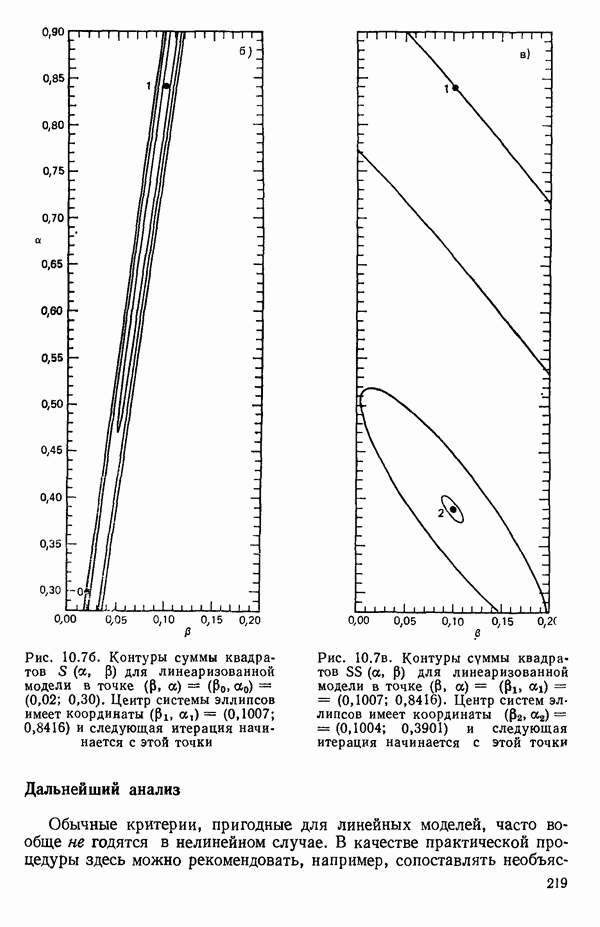
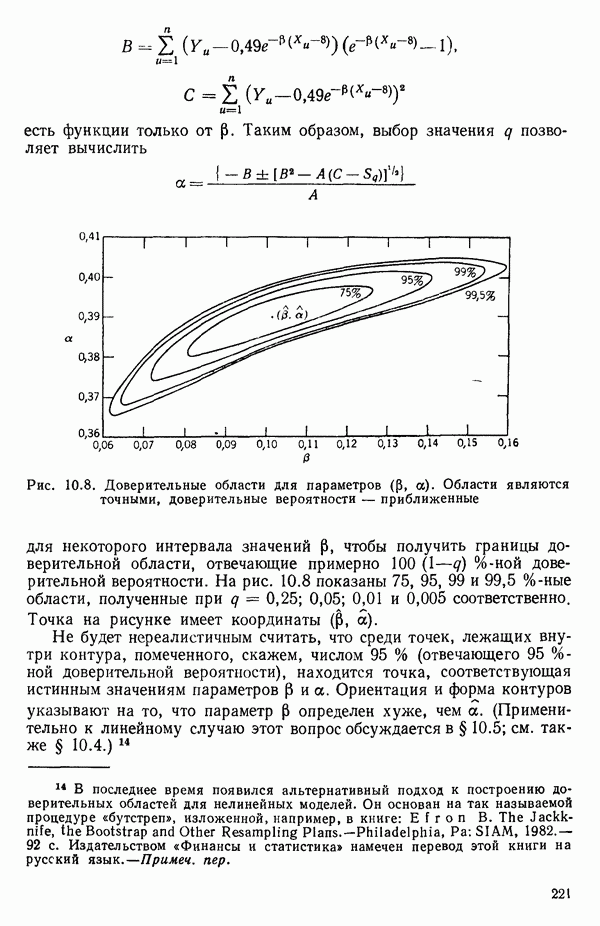
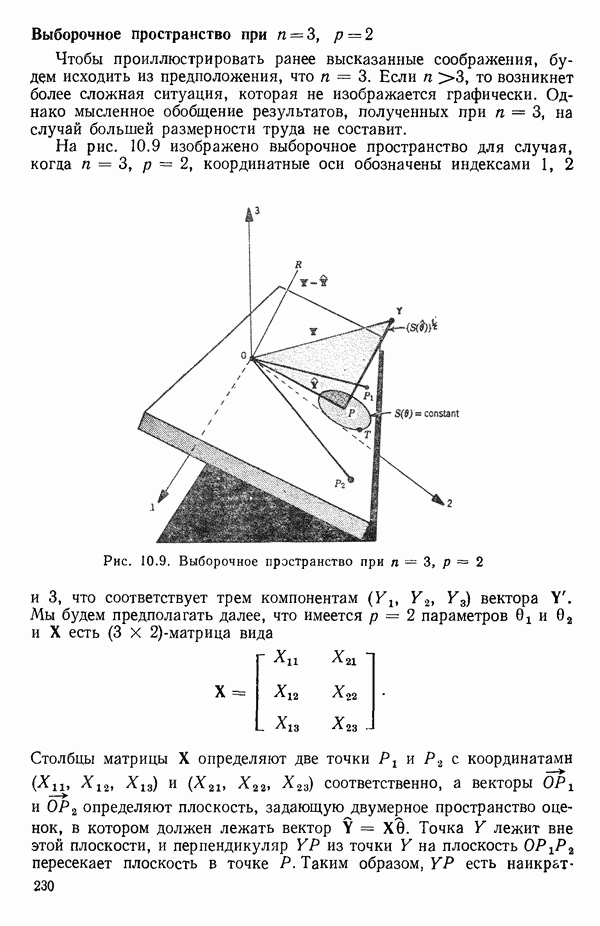
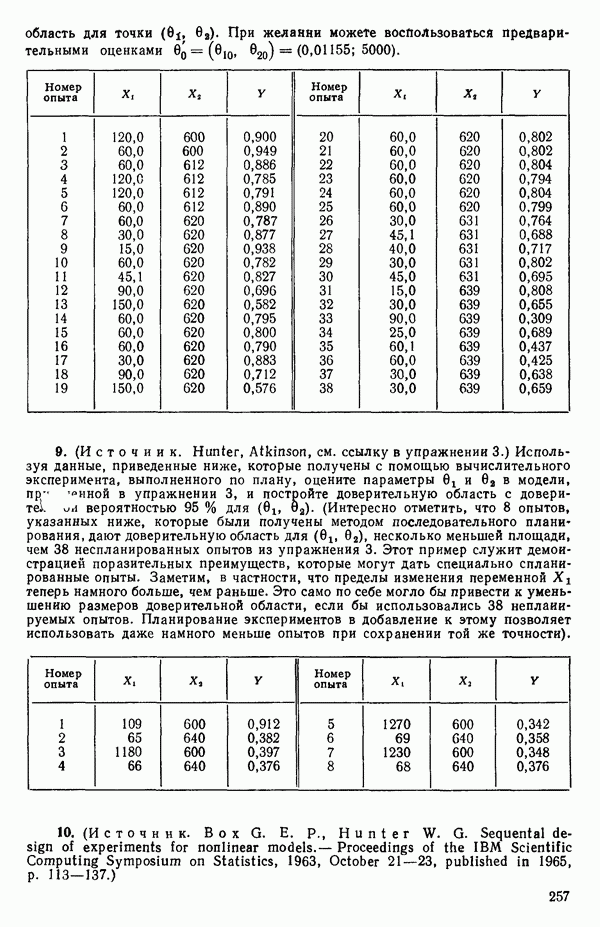
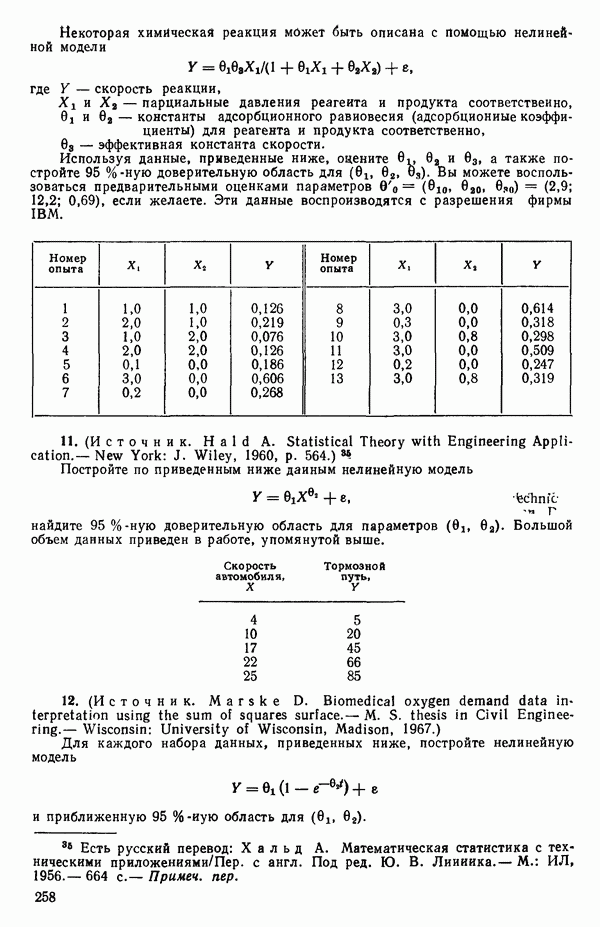
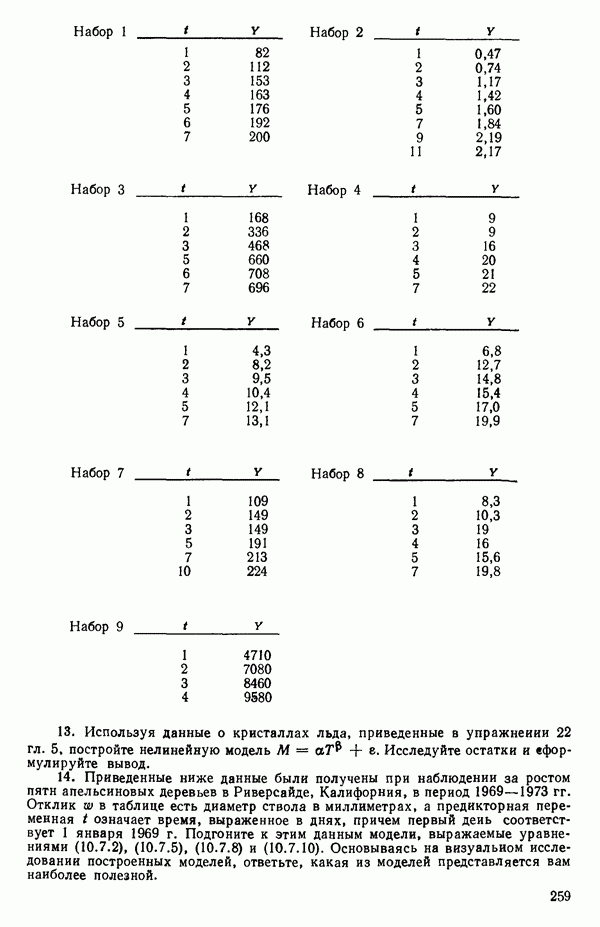
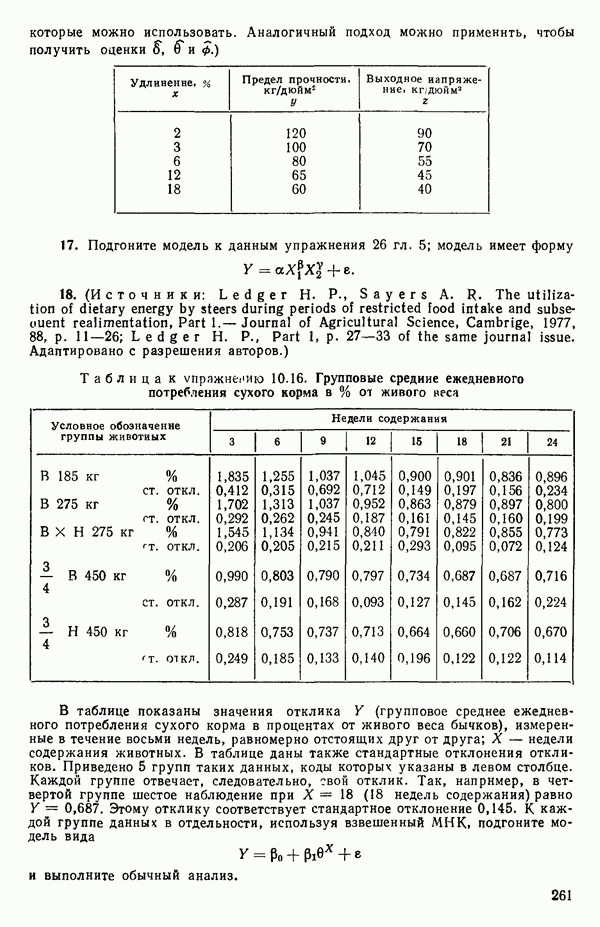
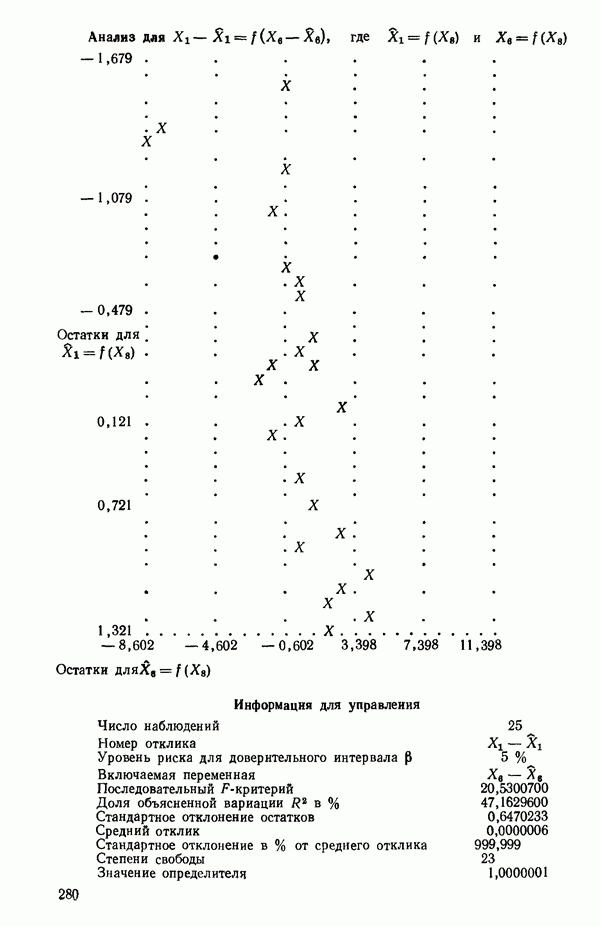
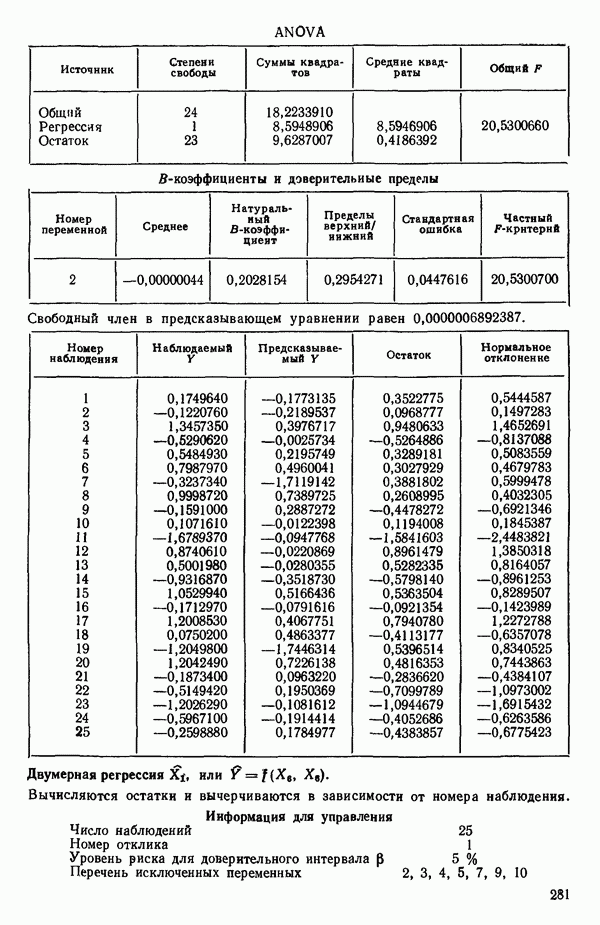
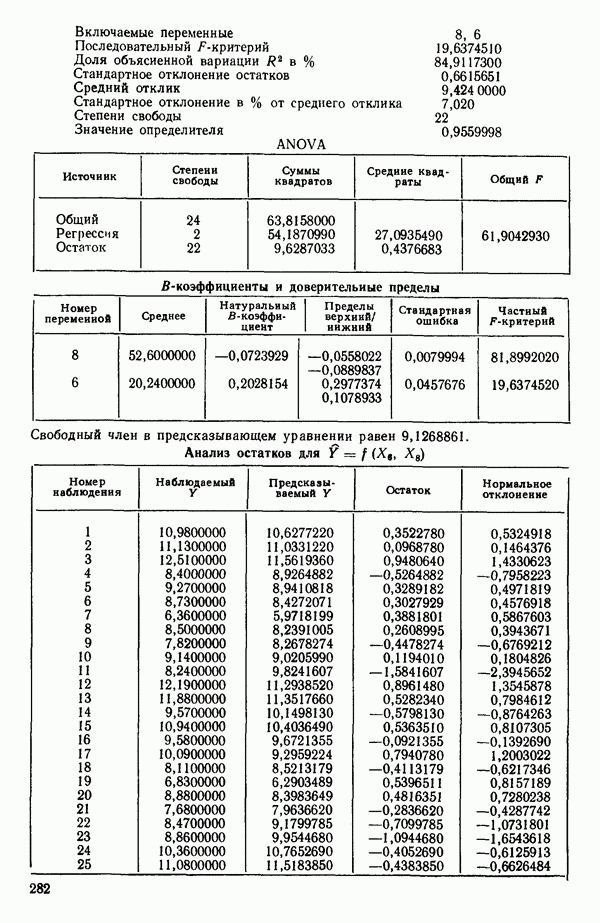
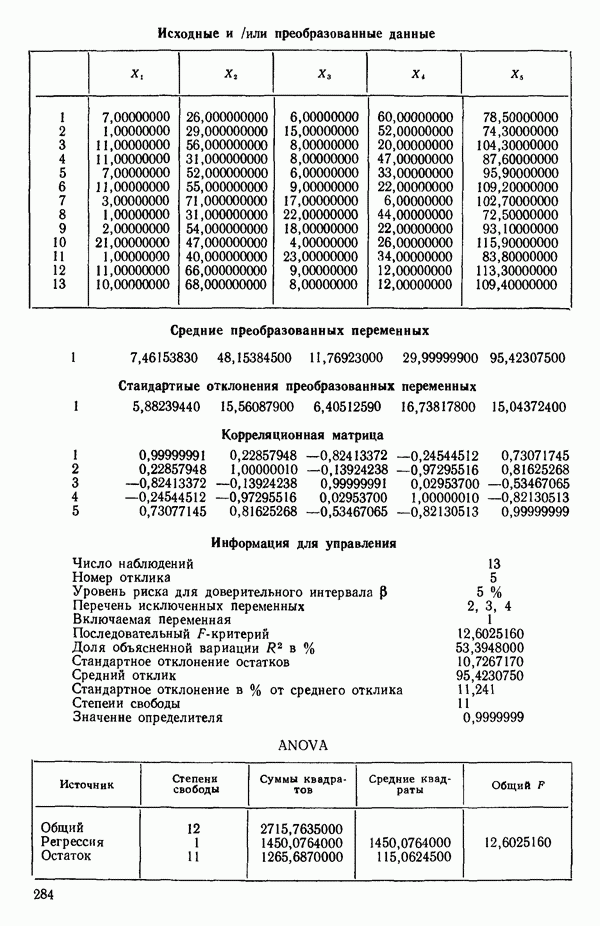
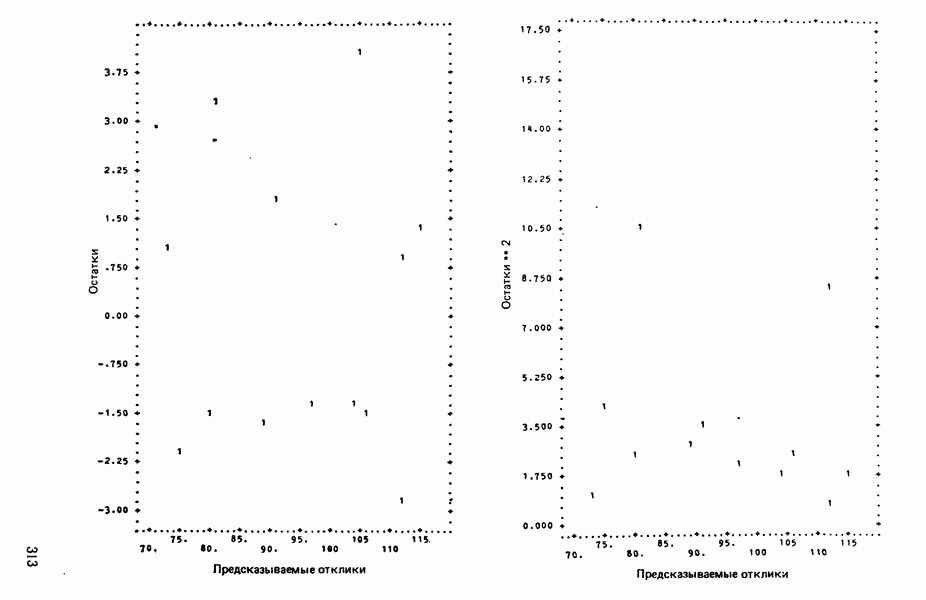
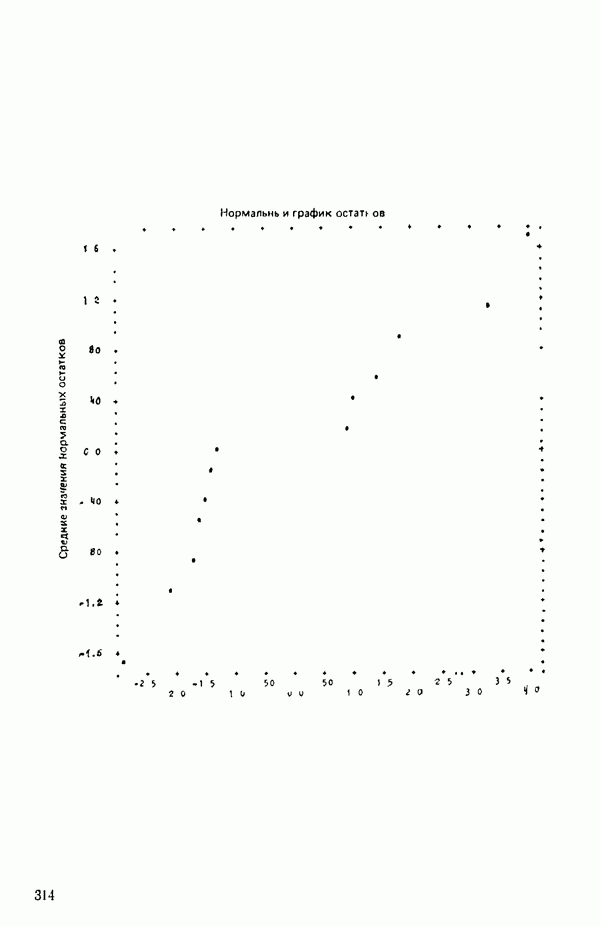
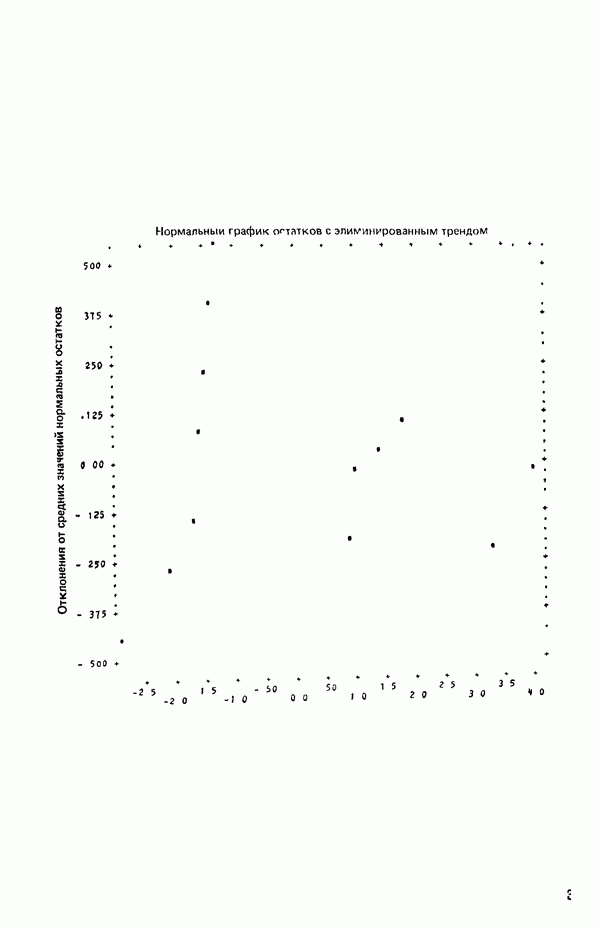
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
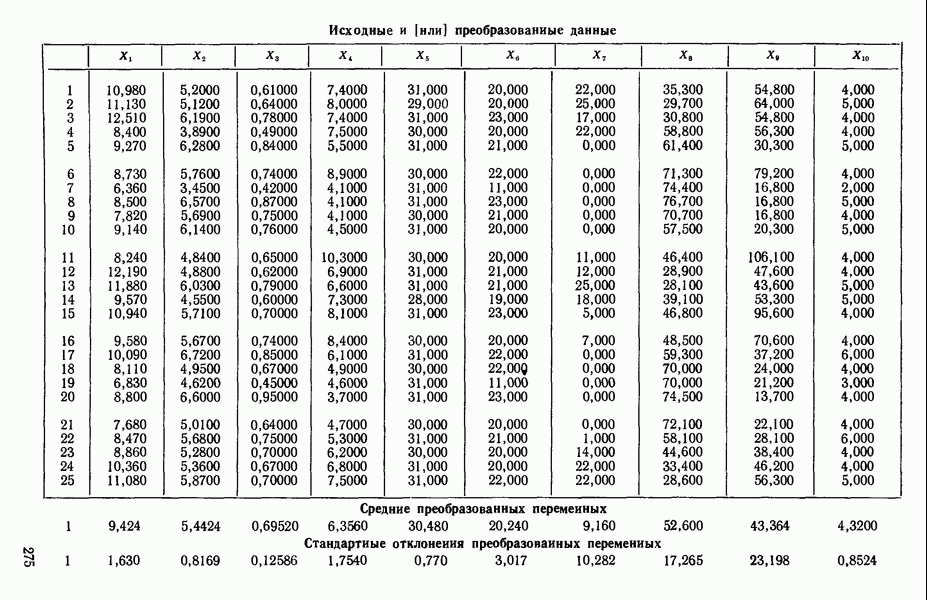
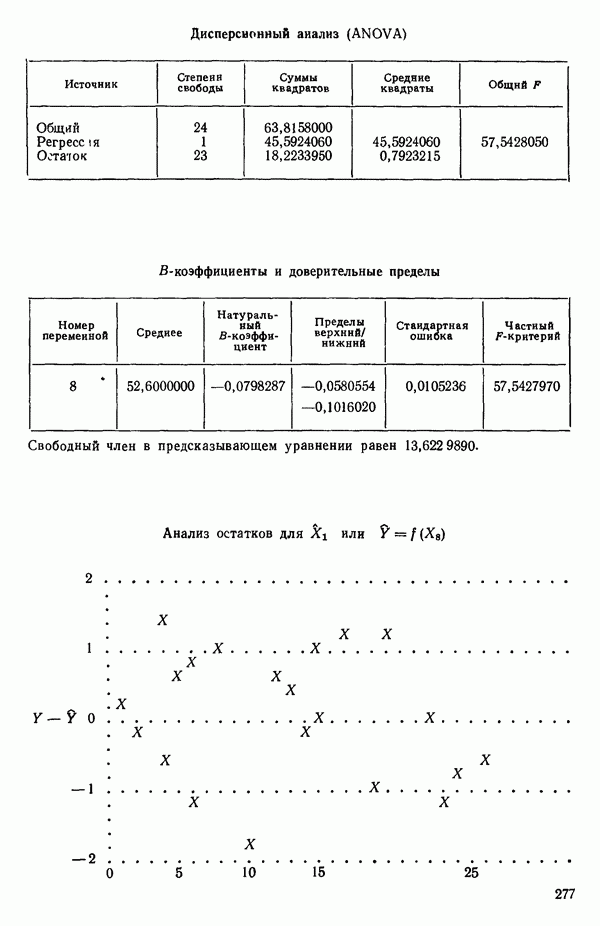
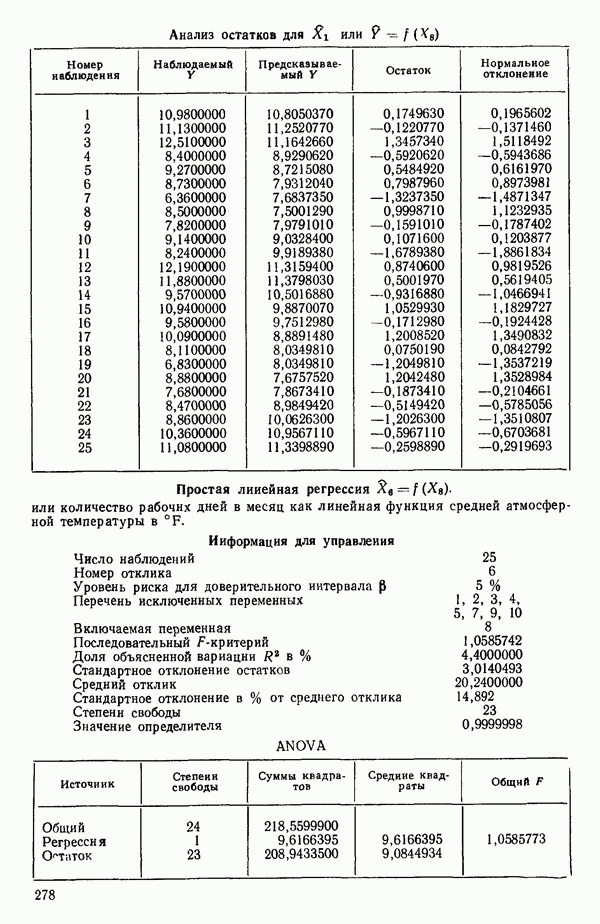
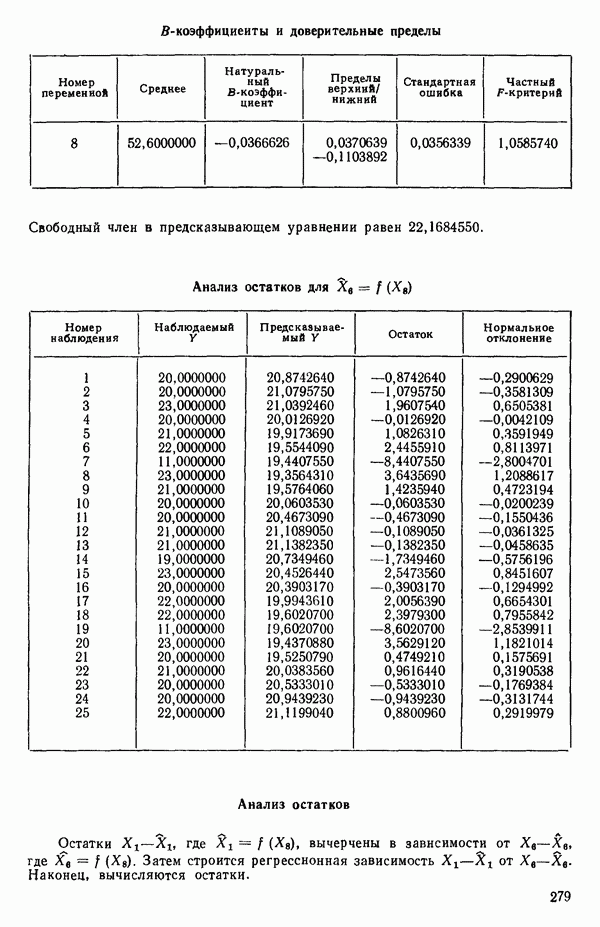
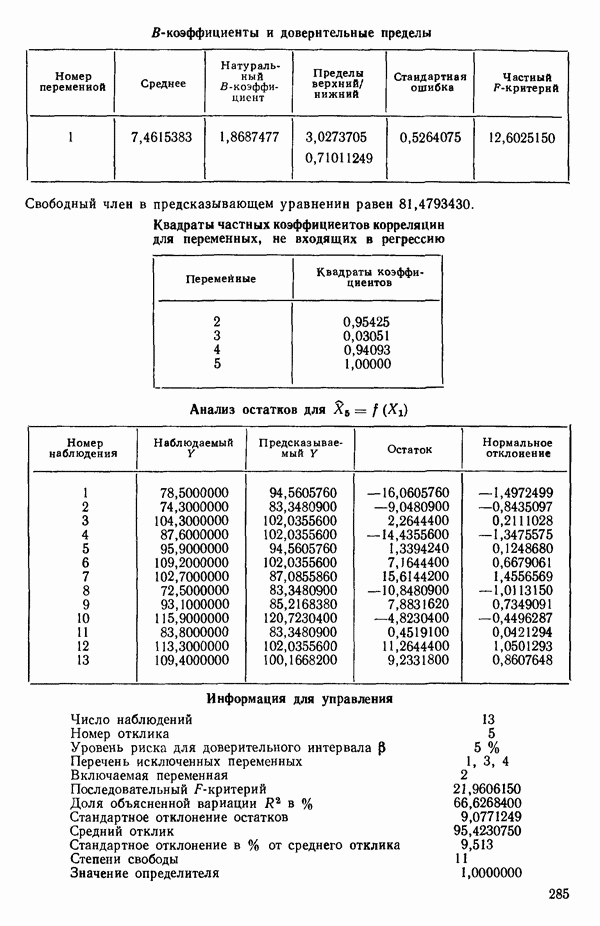
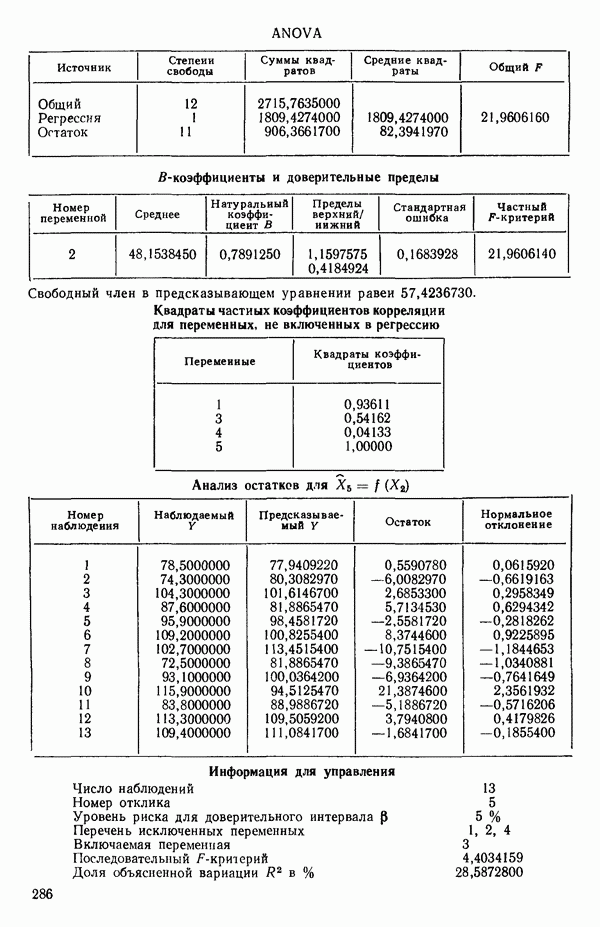
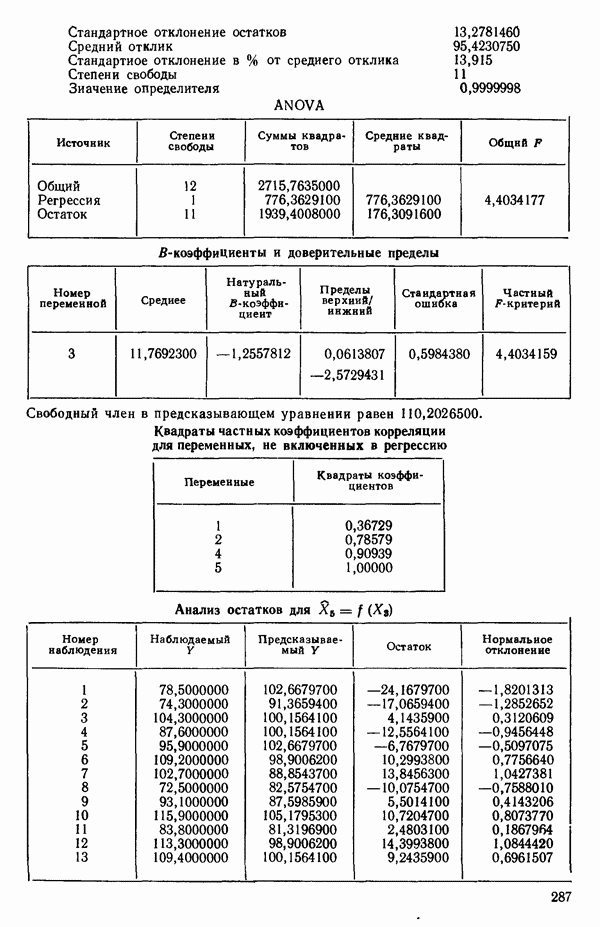
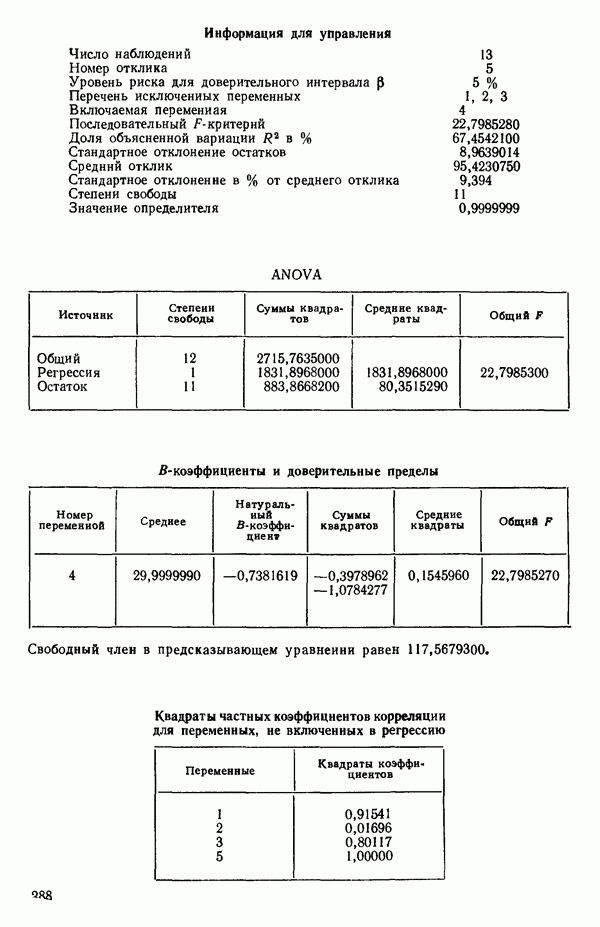
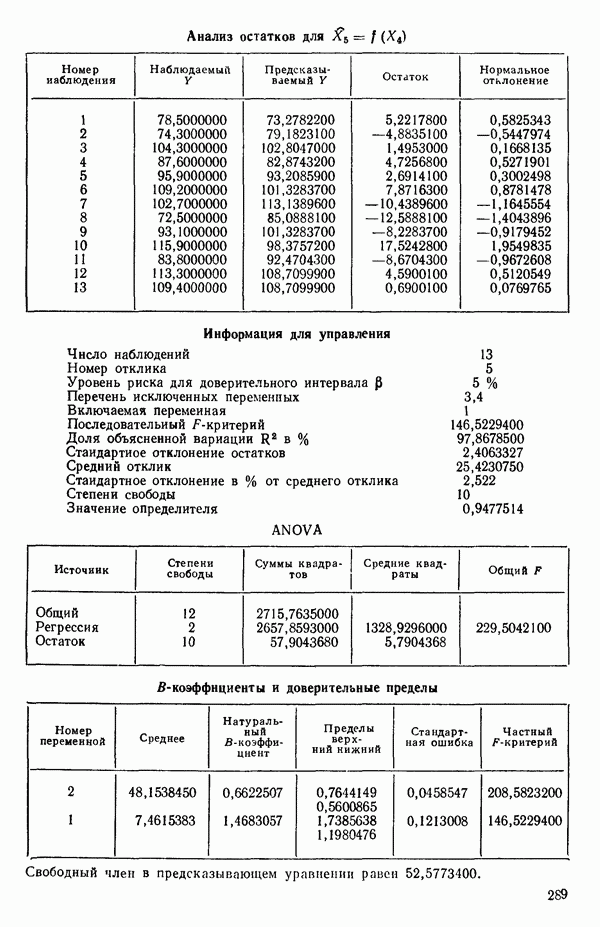
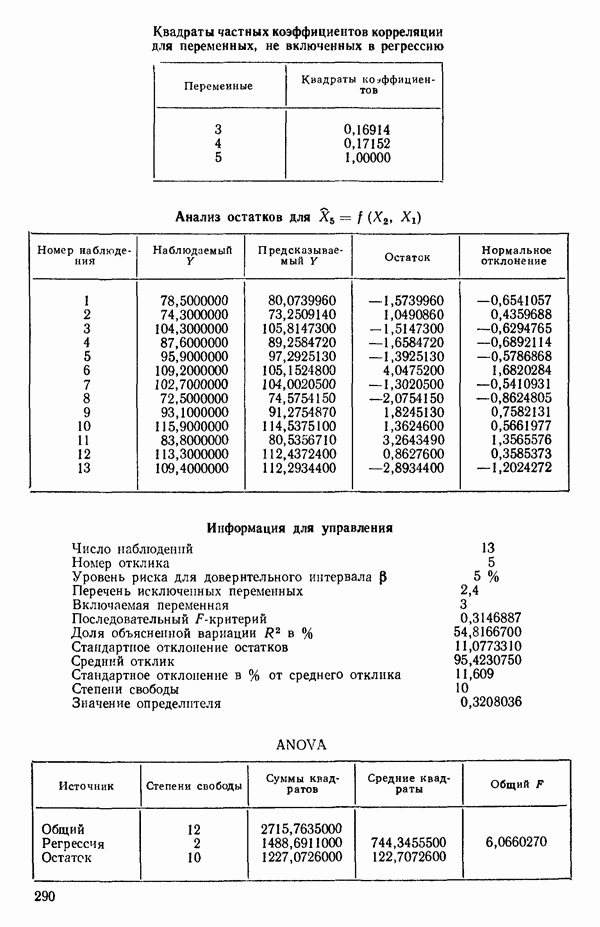
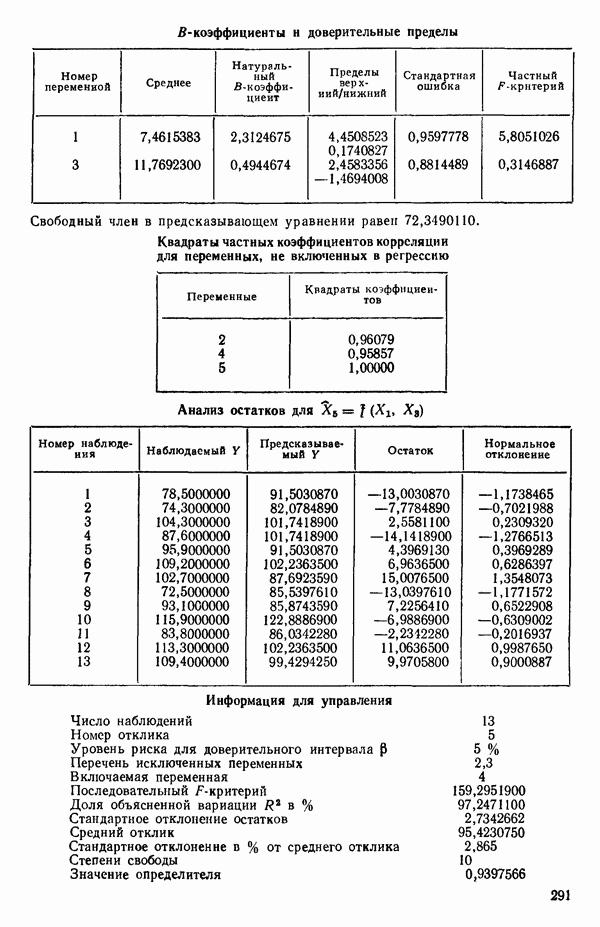
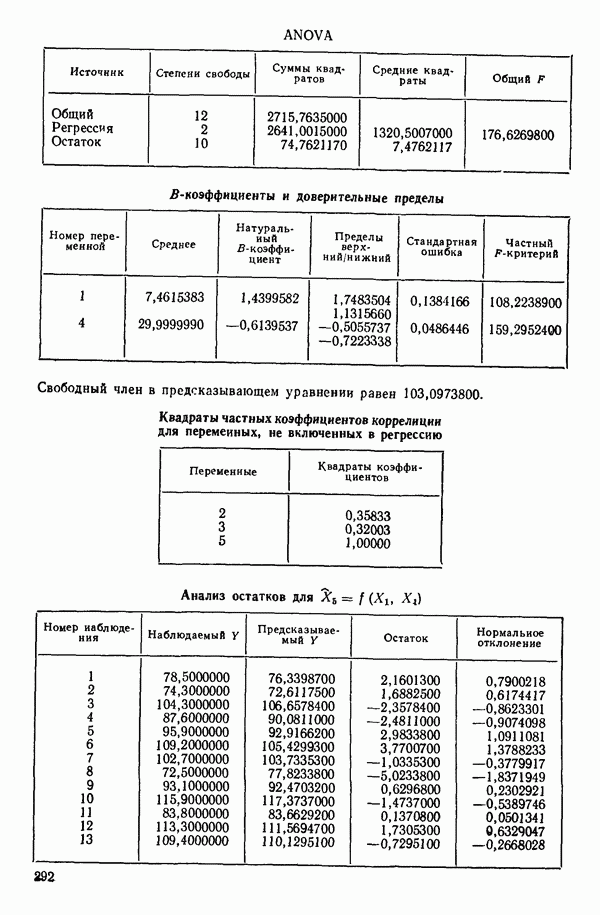
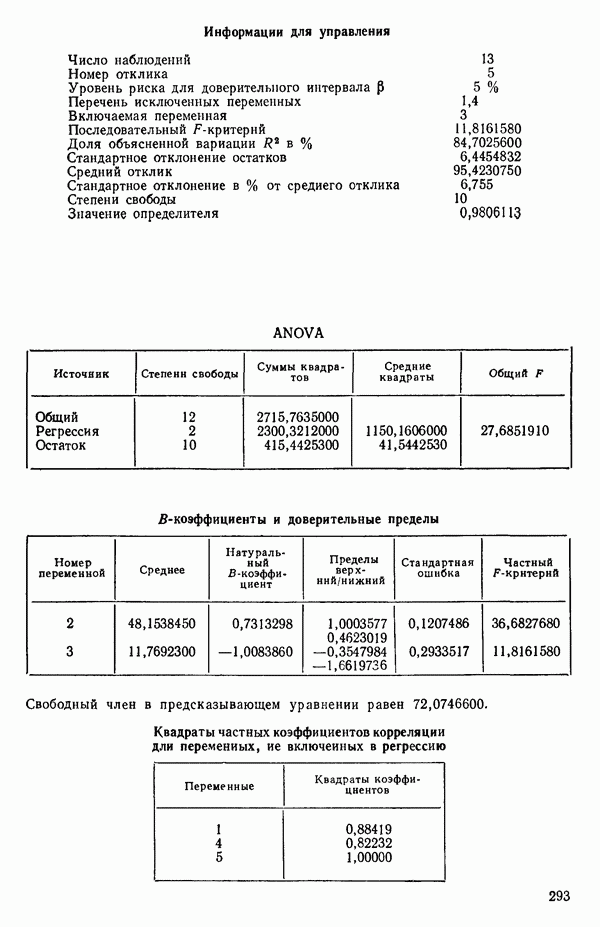
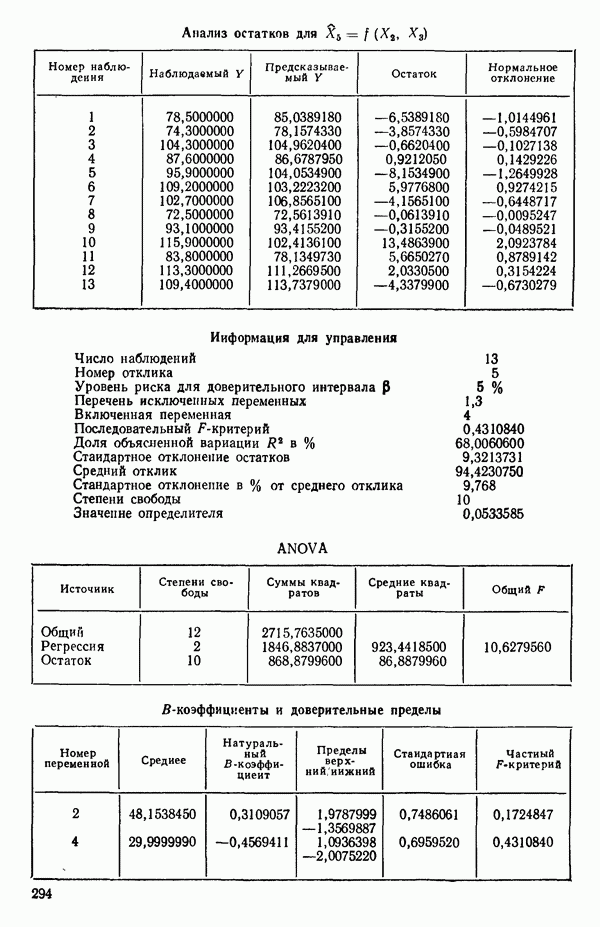
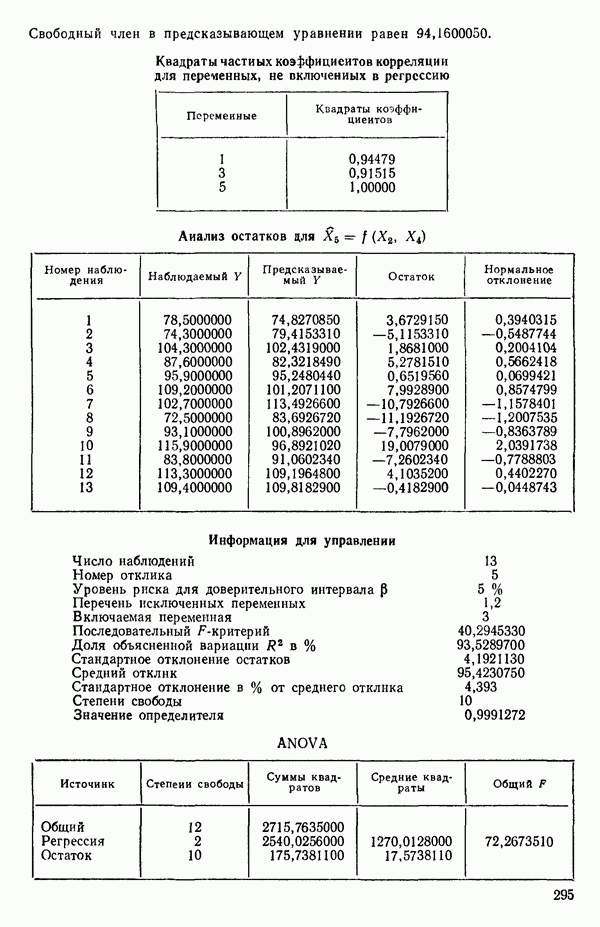
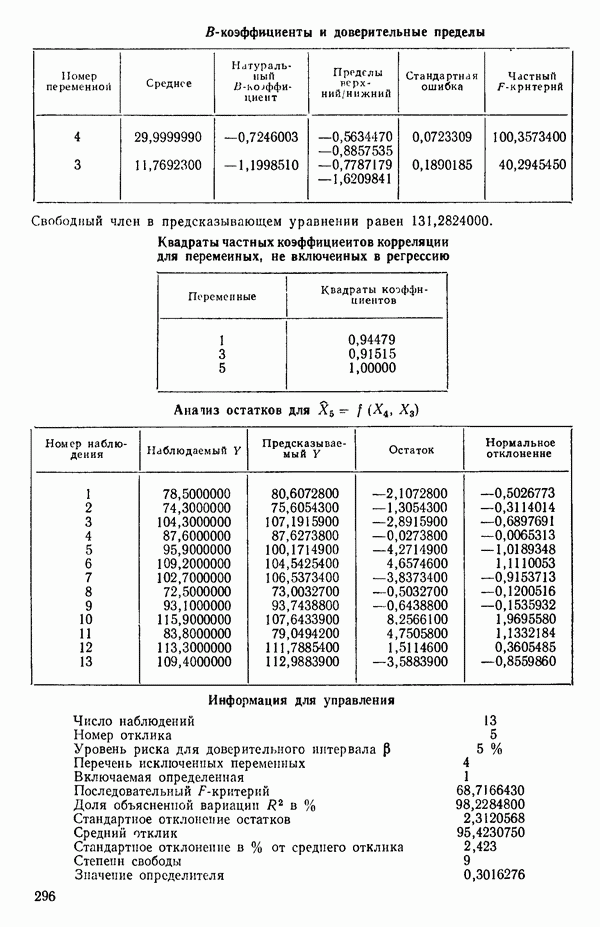
ПРЕДИСЛОВИЕ К РУССКОМУ ИЗДАНИЮВторая книга монографии Н. Дрейпера и Г. Смита «Прикладной регрессионный анализ» включает вычислительные аспекты регрессионного анализа, примеры его применения, принципы организации регрессионных исследований; в ней демонстрируется связь с дисперсионным анализом, рассмотрены вопросы нелинейного оценивания. Благодаря регрессионному анализу в вычислительной математике возникло целое направление, связанное главным образом с решением плохо обусловленных задач. Появилось огромное число подходов, алгоритмов и программ, позволяющих в этих нелегких условиях более или менее рационально организовать вычислительные процедуры. Интерес к вычислительным аспектам возник еще в «домашинную» эру, что привело к появлению схемы Дуллиттла, регрессии на ортогональные полиномы Чебышева, преобразованию с использованием метода Грама-Шмидта. С появлением современной вычислительной техники арсенал вычислительных методов резко расширился. Появились регрессия на главные компоненты, ридж-регрессия, регрессия на основе G-обращения, регуляризация по Тихонову, регрессия с использованием сингулярных разложений, схемы Холецкого и Хаусхолдера и т. д. Все эти методы нашли отражение на страницах данной книги. Если у читателя возникнет потребность ознакомиться с более подробным описанием конкретных процедур, он найдет соответствующие ссылки в примечаниях переводчиков к гл. 5. Подобные методы обычно основаны на преобразовании исходной задачи, на приведении ее к виду, удобному для вычислений. Как правило, их использование демонстрируется в применении к процедуре построения линейных регрессий. При оценивании параметров нелинейных регрессий приходится прибегать к поисковым методам, имеющим итерационный характер. Число таких методов и их модификаций столь велико, что даже для их перечисления и краткой характеристики потребовался бы значительный объем. В книге по существу речь идет лишь о градиентном методе и о методе Маркуардта. В последнее время на практике все более широкое применение находят методы без вычисления производных. К ним относятся, например, последовательный симплексный метод и его модификации, овражные методы и методы случайного поиска, тоже имеющие большое число модификаций. На первых этапах развития регрессионного анализа его широкое применение ограничивалось большим объемом вычислений, необходимых для получения результата. Развитие вычислительной техники кардинально изменило ситуацию. Появилась возможность автоматизировать регрессионные вычисления. Были созданы известные методы включения и исключения. На их базе были написаны многочисленные программы, развитие которых вылилось в метод всех возможных регрессий, а затем и в шаговый регрессионный анализ, ставший к настоящему времени наиболее массовым методом решения регрессионных задач. На этой основе были написаны многочисленные программы и пакеты программ для большинства известных типов вычислительных машин и на разных алгоритмических языках. Число таких пакетов только у нас в стране превосходит 1000. (Отечественные пакеты можно условно разделить на три большие группы: исследовательские пакеты, промышленные пакеты и пакеты многоцелевого назначения.) В данной книге описаны и охарактеризованы наиболее известные зарубежные пакеты, содержащие программы регрессионного анализа. В последние годы все большее распространение получают диалоговые системы, позволяющие работать с ЭВМ в интерактивном режиме. Несмотря на огромное число публикаций по регрессионному анализу, продолжается активное развитие этого направления. Проследим лишь некоторые из основных тенденций, предполагая, что читатель знаком с содержанием предисловия к книге 1, где об этом уже шла речь. Прежде всего надо отметить, что происходит пересмотр, размывание довольно жестких базовых предпосылок классического регрессионного анализа. Это касается таких предположений, как нормальность распределения ошибок, детерминированность факторов, аддитивность учитываемых в модели ошибок, однородность, независимость (точнее — отсутствие корреляции между ошибками). Отказ хотя бы от одного из перечисленных предположений фактически приводит к созданию новой модели. А последствия отказа сразу от нескольких предположений во многих случаях не исследованы. К тому же у каждого из базовых предположений есть не одна альтернатива, а целый спектр возможностей. Вторая тенденция состоит в вовлечении в регрессионный анализ более тонких математических методов. Это методы функционального анализа, теории групп, топологии и т. д. Так, например, представляет интерес обобщение регрессионной задачи на бесконечномерные пространства. При исследовании идентифицируемости моделей находят применение методы теории групп. Третья тенденция состоит в том, что развитие теории регрессионного анализа стимулируется, помимо всего прочего, обращением ко все более сложным объектам исследования. Помимо упоминавшихся ранее модификаций многомерной регрессии, речь идет, например, о моделях в форме обыкновенных дифференциальных уравнений, а также уравнений математической физики Сюда же относятся интегральные и интегро-дифференциальные уравнения, системы таких уравнений и вообще операторные уравнения. Кроме моделей, структуры которых выражаются формулами, в последнее время в рамках регрессионного анализа стали рассматриваться модели, которые задаются только алгоритмически. Это приводит к широкому внедрению имитационных моделей. Время ставит все более сложные задачи, и регрессионный анализ становится одним из первых инструментов, применяемых в процессе поиска их решения. Вот почему один из крупнейших современных специалистов по математической статистике Р. Рао назвал регрессионный анализ «методом века». Перейдем теперь к четвертой тенденции. Классический регрессионный анализ основан на том, что вид математической модели задан априори с точностью до параметров. Предполагается также, что уже реализован эксперимент, выполненный по некоторому плану. Таким образом, задача сводится к выбору наилучшей процедуры обработки этих данных. В последнее время получает развитие новый подход, в рамках которого предлагается одновременно выбирать наилучшую триаду: модель—план—метод оценивания, отвечающую, насколько возможно, рассматриваемой задаче. Не меньший интерес, с нашей точки зрения, представляет и концепция анализа данных, вытекающая из работ Дж. Тьюки. В отличие от предыдущего случая здесь предполагается, что выбор триады должен осуществляться не однажды, а многократно, поскольку процесс обработки данных предполагается перманентным: с появлением новых экспериментальных данных (как в модели текущего регрессионного анализа) возникают новые идеи, подходы и методы, уточняется понимание происходящих процессов и т. д. Анализ данных свел воедино изначально как бы несвязанные друг с другом элементы, подчинив их единому механизму решения задачи, открыв тем самым дорогу новому взгляду на возможности сбора (в том числе целенаправленного), анализа и интерпретации данных различной природы. Особого внимания заслуживают методы планирования эксперимента. Они образуют теперь целое направление в математической статистике. Наряду с регрессионным анализом их применяют в разнообразных областях современной науки от теории игр до распознавания образов. По мере развития теории планирования эксперимента усиливается ее воздействие на регрессионный анализ, благодаря чему создаются новые специальные процедуры обработки данных и проверки статистических гипотез, а иногда и новые подходы. Характерным примером может служить предложение пользоваться методами планирования эксперимента для выбора оптимального значения параметра регуляризации в ридж-регрессии (см.: Vuchkov I. А ridgetipe procedure for design of experiments.- Biometrika, 1977, 64, № 1, p. 147-150). Одно из естественных направлений развития планирования эксперимента приводит к идее управления выборкой в процессе обработки данных. Данные, собранные в связи с решением конкретной задачи, часто рассматриваются как выборка из некоторой генеральной совокупности, свойства которой и интересуют исследователя. Если эта выборка достаточно велика и представительна, то полученные на ее основе оценки могут характеризовать всю генеральную совокупность. Однако трудно найти критерий, который прояснил бы ситуацию для данной конкретной выборки и для избранного способа обобщения или прогноза. Остается ждать появления новой информации, чтобы сравнить ее с предсказаниями, полученными на основе модели. Расхождение между эмпирическими наблюдениями и прогнозом может служить естественной мерой качества прогноза, а значит, и модели. В тех случаях, когда оценка качества модели должна быть получена до поступления дополнительной информации, прибегают к делению имеющихся данных на две группы: первую используют для построения модели, а вторую для проверки ее качества. Хотя такой подход давно известен в теории распознавания образов, его проникновение в статистику было нелегким, поскольку искусственное уменьшение объема выборки ведет к уменьшению числа степеней свободы и потому отрицательно сказывается на мощности критериев, на величине доверительных интервалов и т. д., т. е. увеличивается неопределенность результатов. Более оправданная, но и более трудоемкая процедура, называемая методом «складного ножа», появилась в статистике в 50-е годы. Ее разработка связана с именами М. Кенуя и Дж. Тьюки. Эта процедура начинается с отбрасывания одного из наблюдений, построения модели на массиве оставшихся данных и ее проверки на отброшенном наблюдении. Так последовательно перебираются все наблюдения. Процесс можно продолжить, отбрасывая по два наблюдения, затем по три и так до тех пор, пока не останется «насыщенная» выборка. При этом нет необходимости в полном переборе всех вариантов, достаточно произвести рандомизированную случайную выборку. Слово «выборка» употребляется здесь не по отношению к эксперименту, который фиксирован, а по отношению к вариантам отбрасываемых наблюдений, т. е. происходит управление процессом обработки данных. Так возникла новая область планирования эксперимента. Это направление получило дополнительный импульс в 1979 г., когда Б. Эфроном был предложен метод «бутстреп», предполагающий многократное тиражирование эмпирической выборки и рандомизированный отбор из такой совокупности большого числа выборок того же объема, что и эмпирическая. По каждой из отобранных таким образом выборок решается та конкретная задача, ради которой проводился эксперимент, а на множестве решений строятся «эмпирические» распределения статистик, интересующих экспериментатора, что дает гораздо больше информации, чем непосредственная оценка. Таков краткий очерк проблем, связанных с развитием теории и практики регрессионного анализа. Предлагаемая вниманию читателя книга прежде всего предназначена для специалистов, связанных с приложениями регрессионного анализа. Вместе с тем она может представить интерес и для тех, кто ищет новые пути в такой более широкой и содержательной области, которой является анализ данных. Ю. АДЛЕР, В. ГОРСКИЙ
|
 |
Оглавление
|