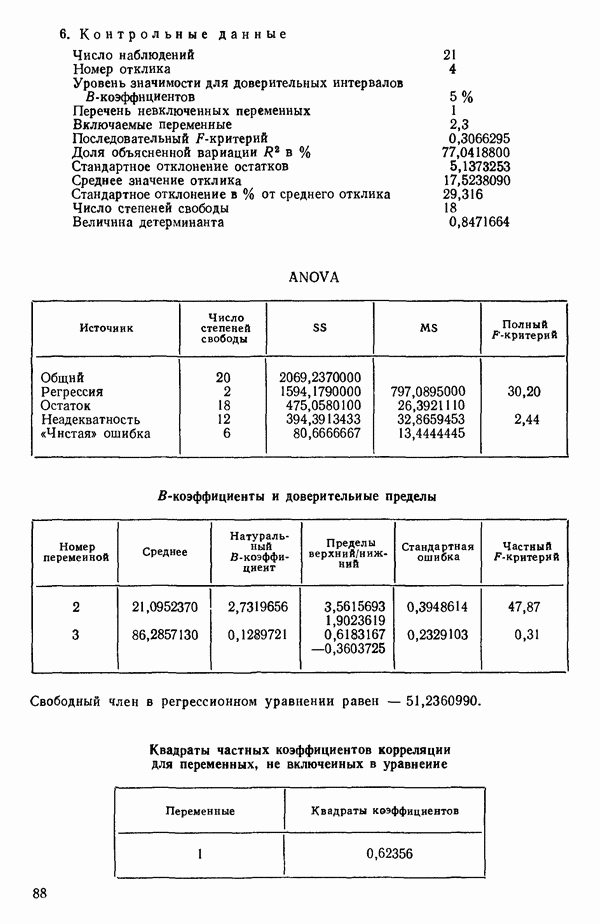
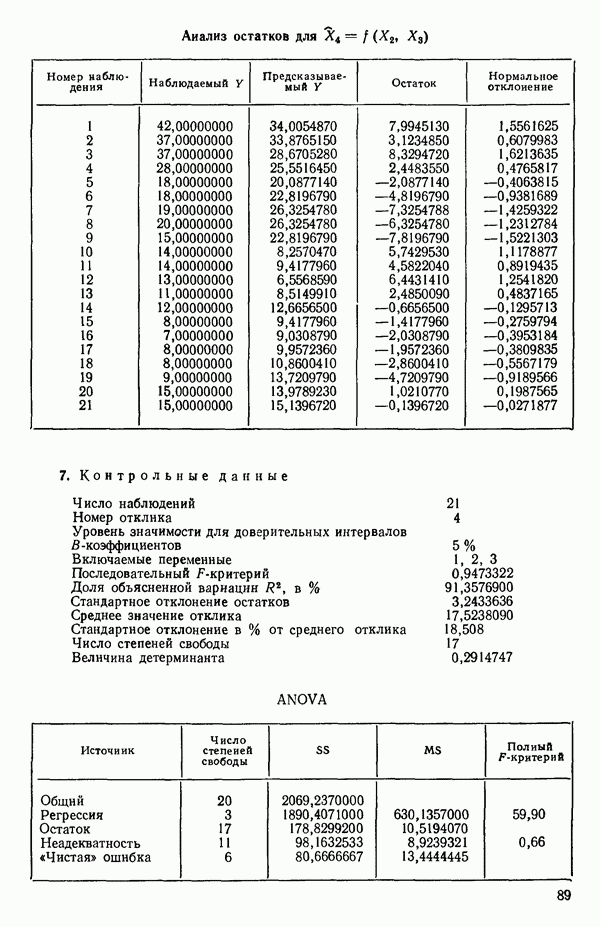
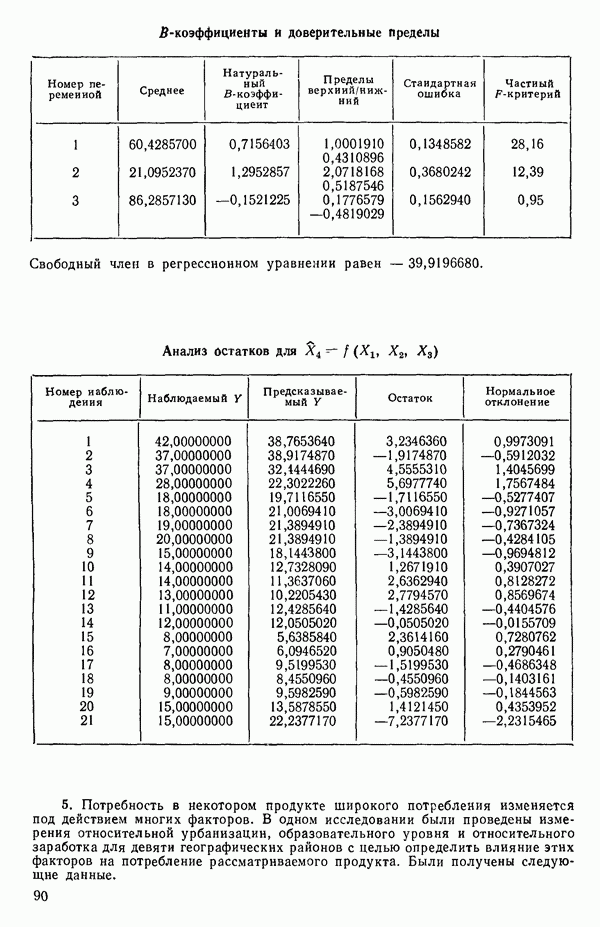
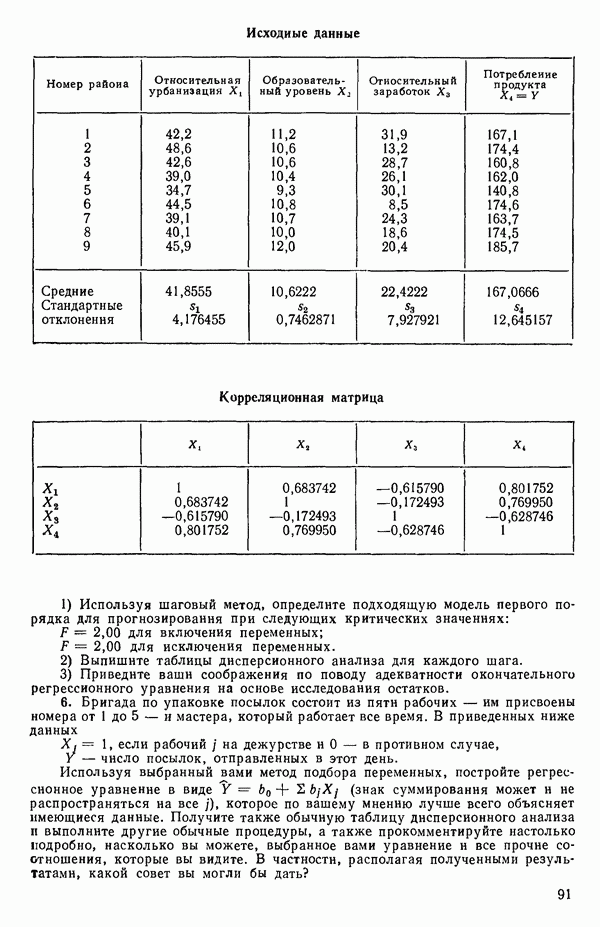
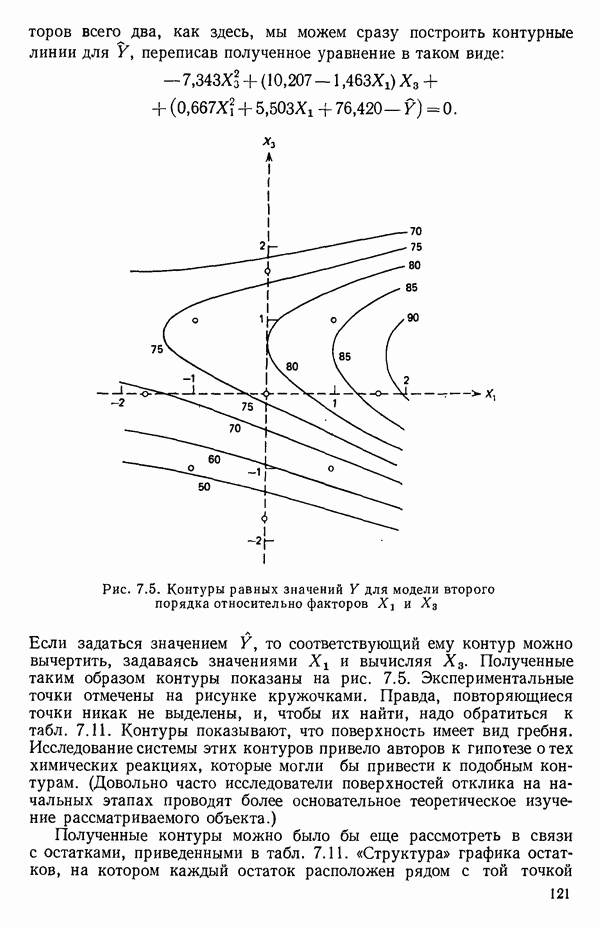
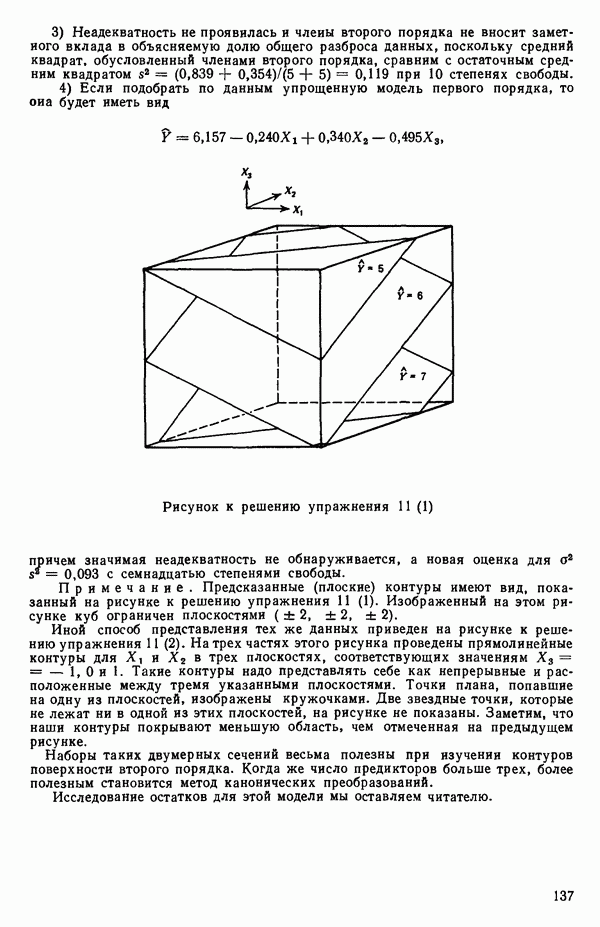
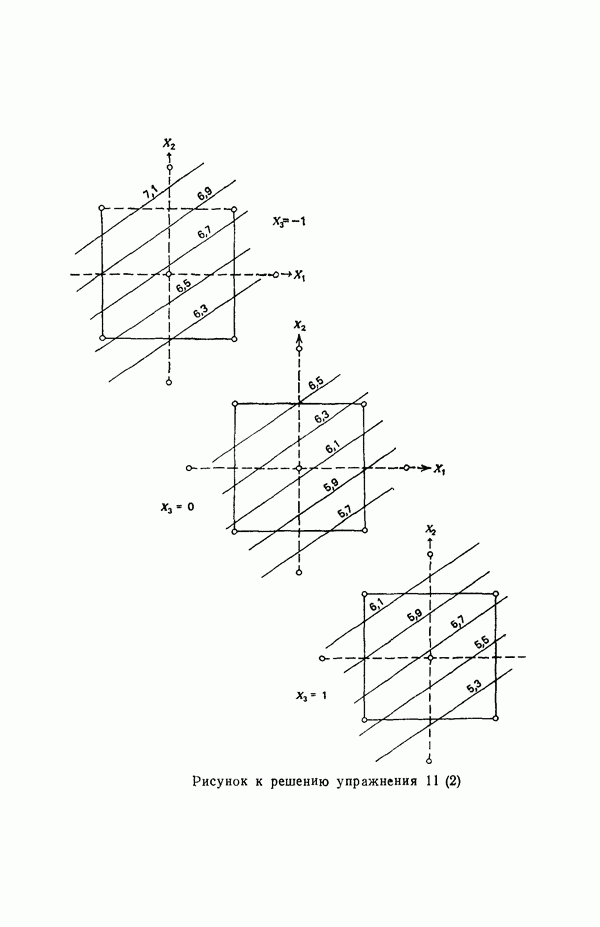
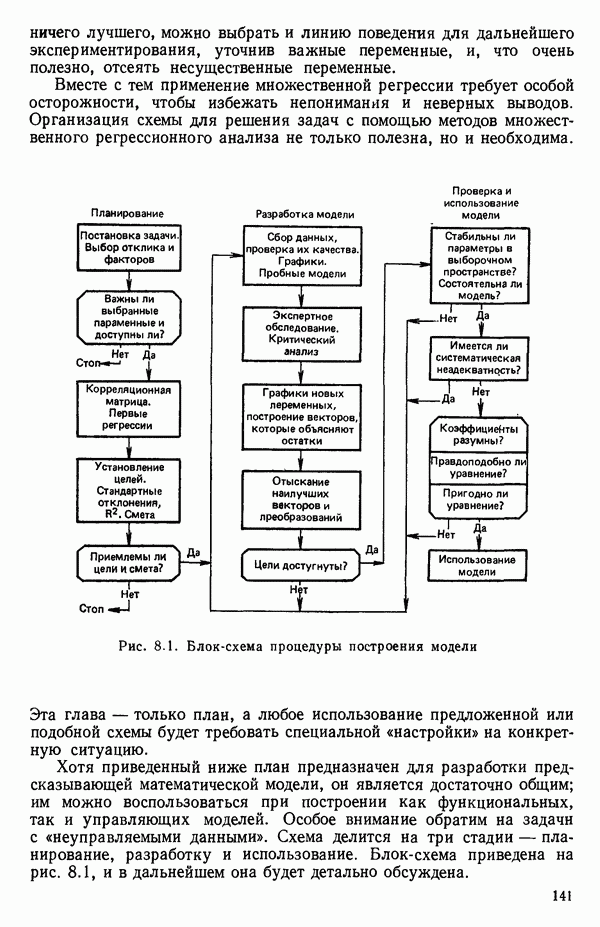
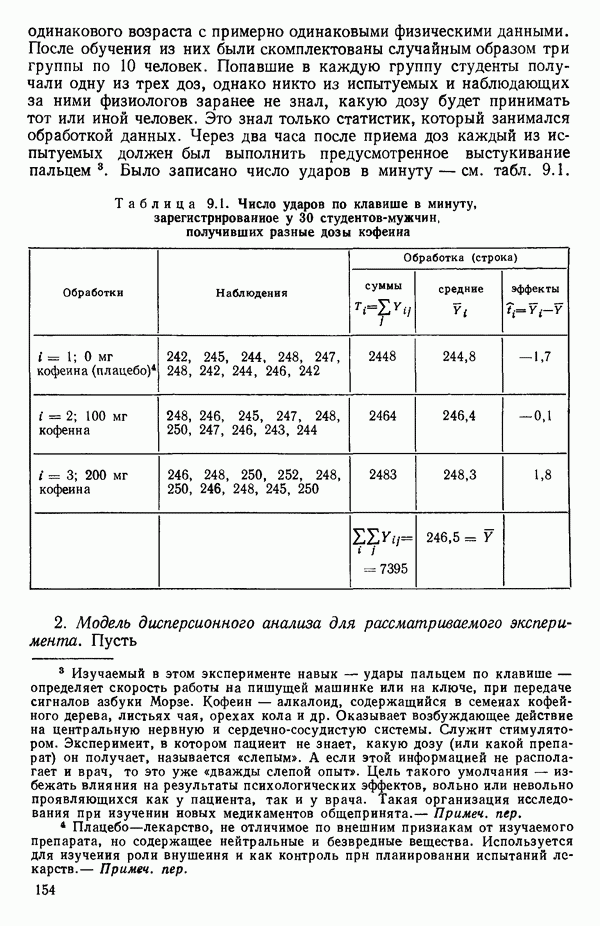
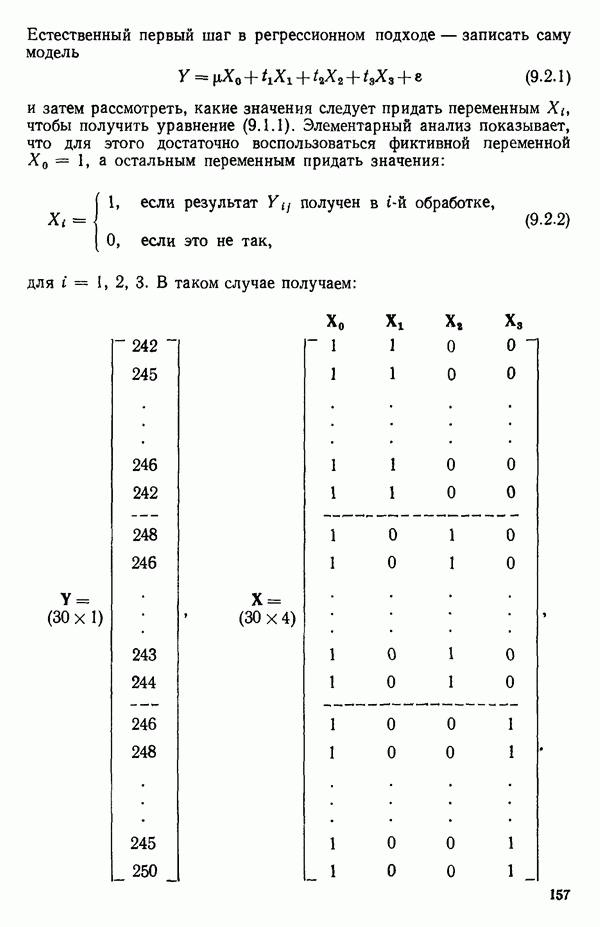
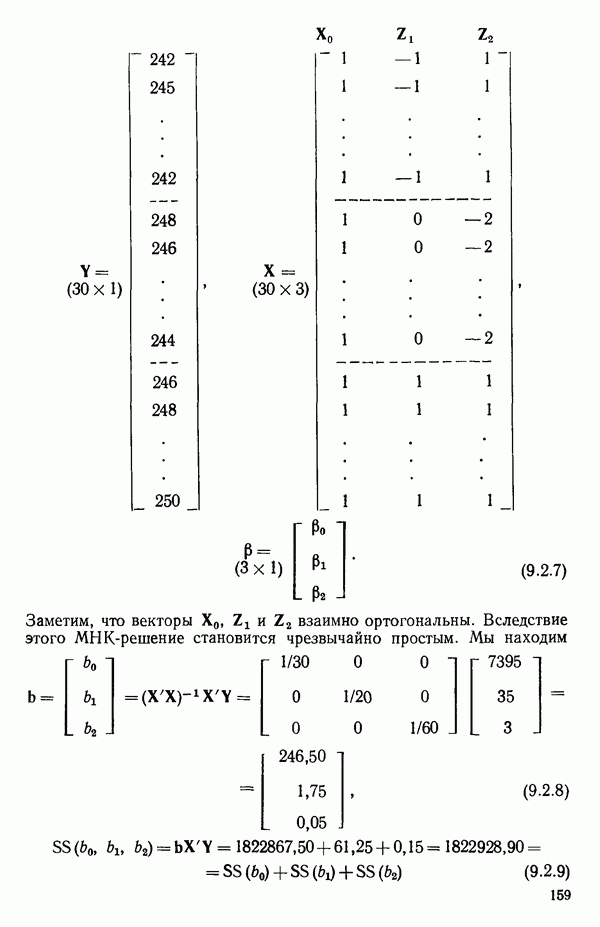
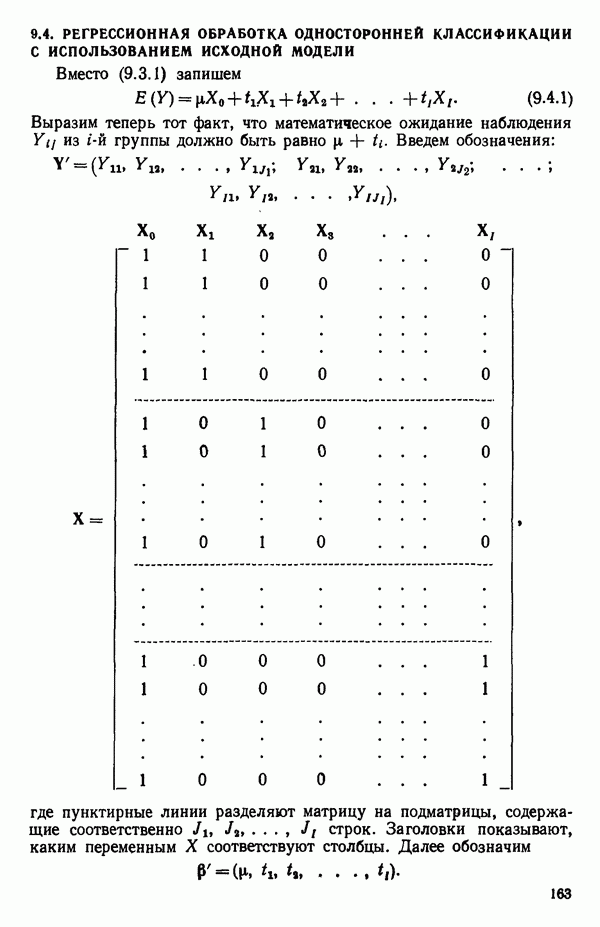
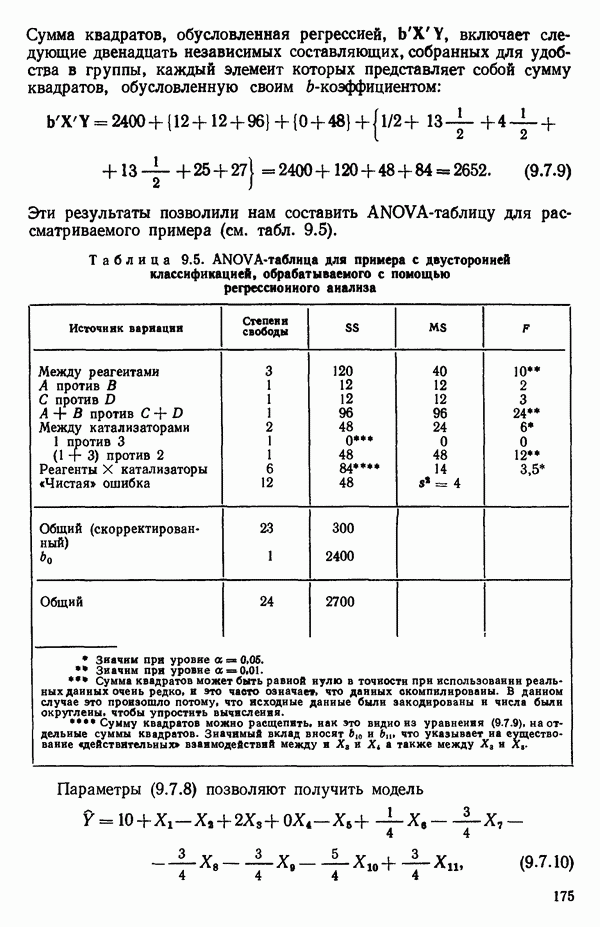
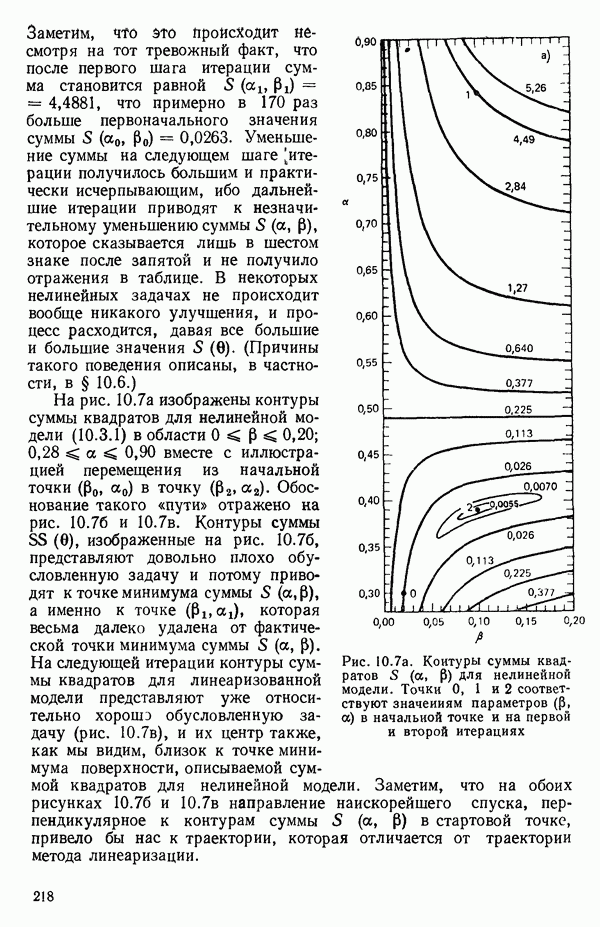
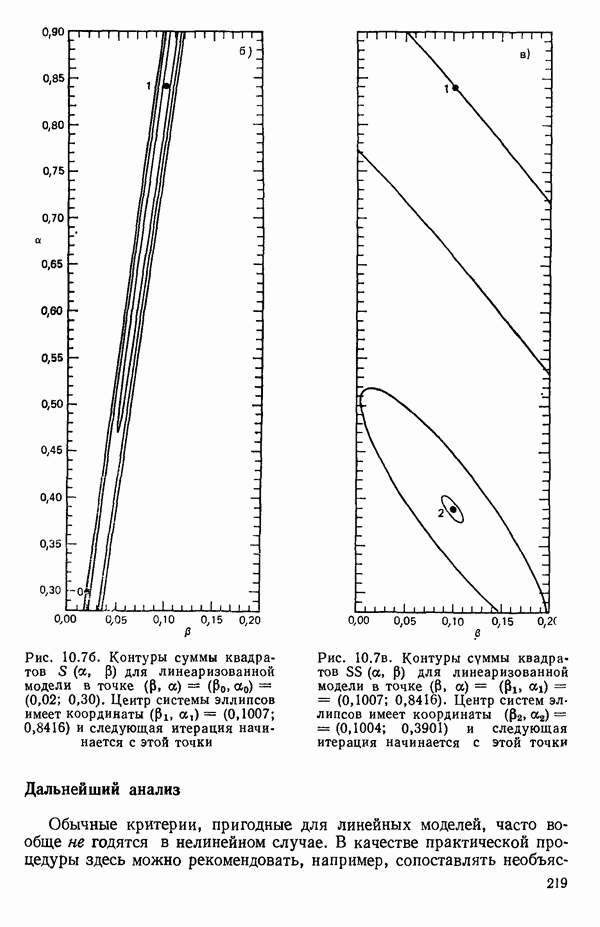
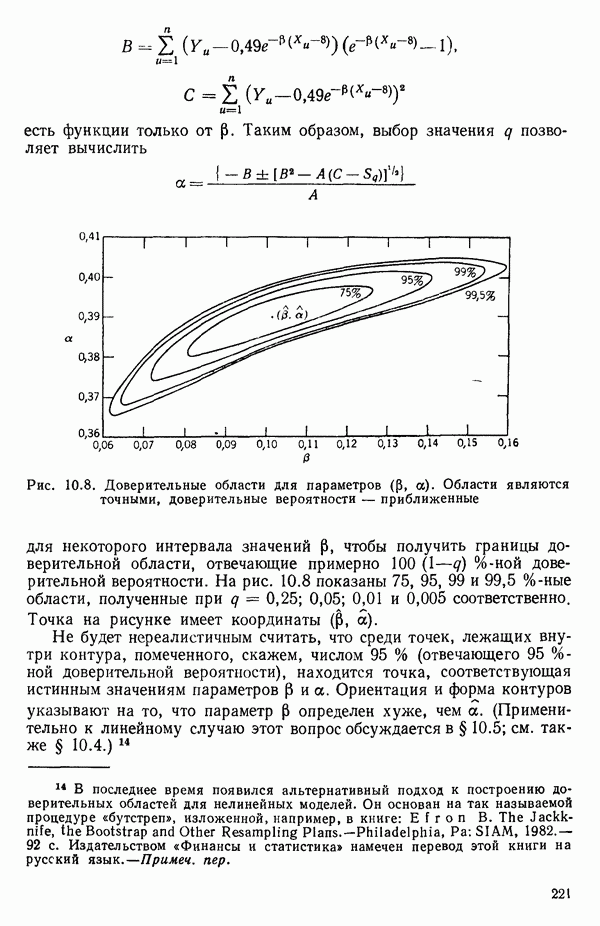
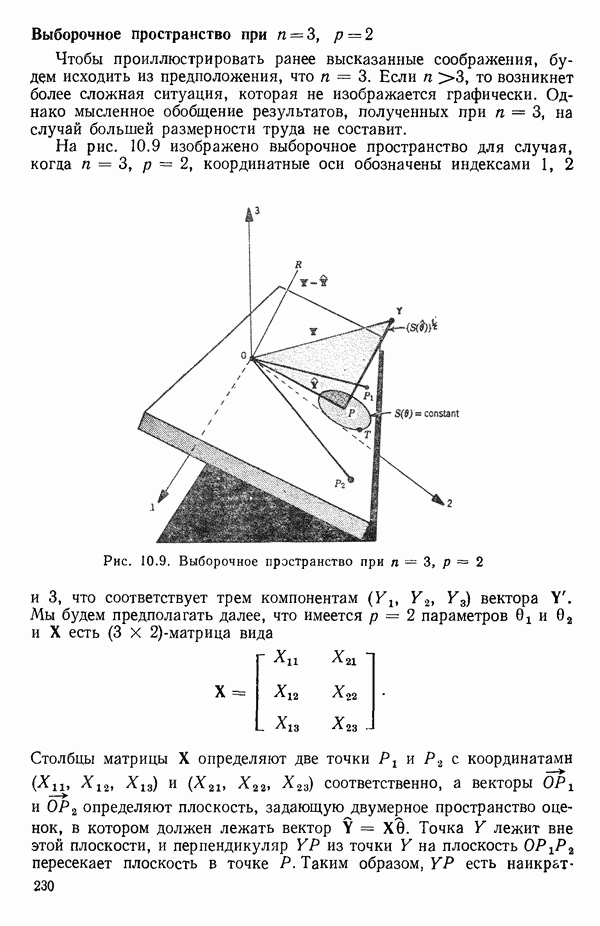
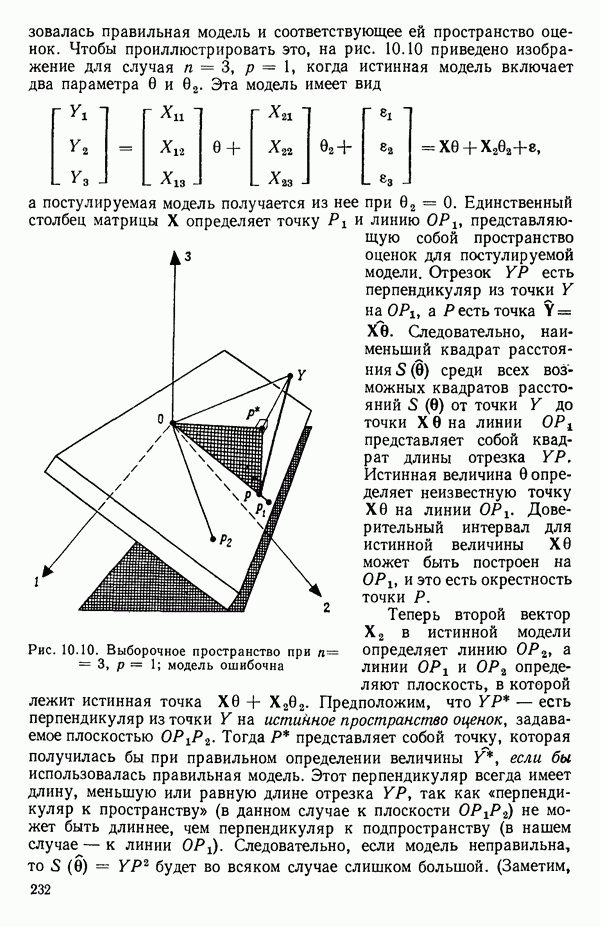
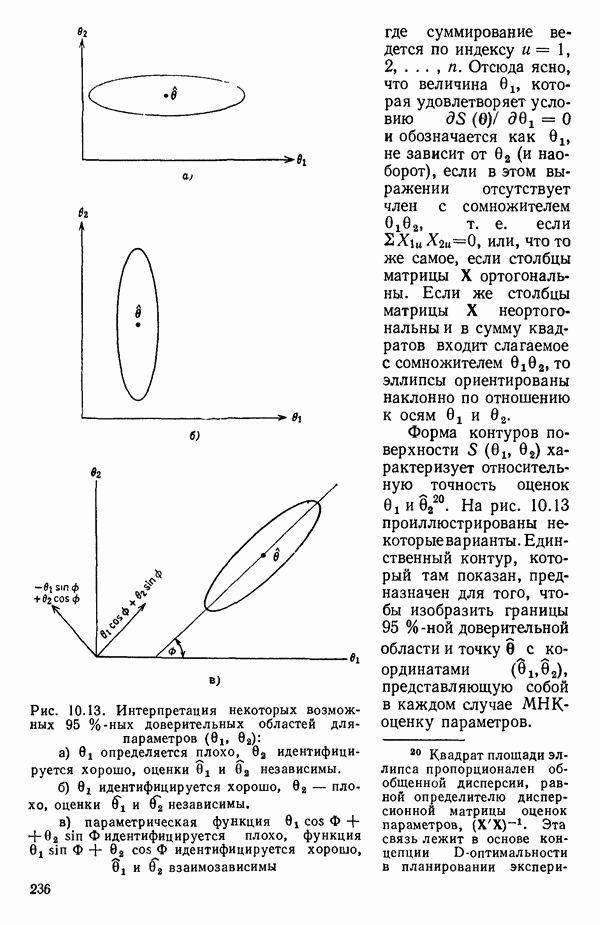
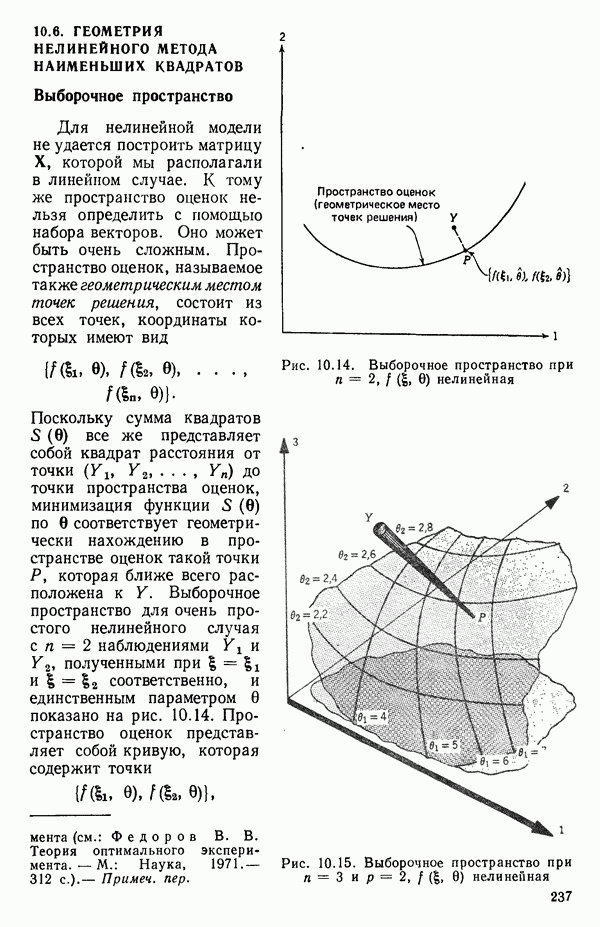
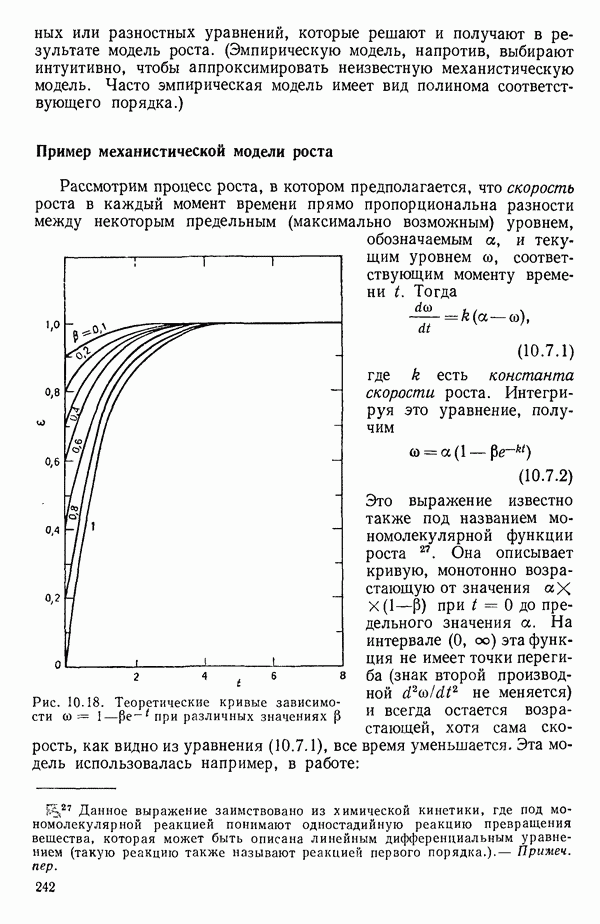
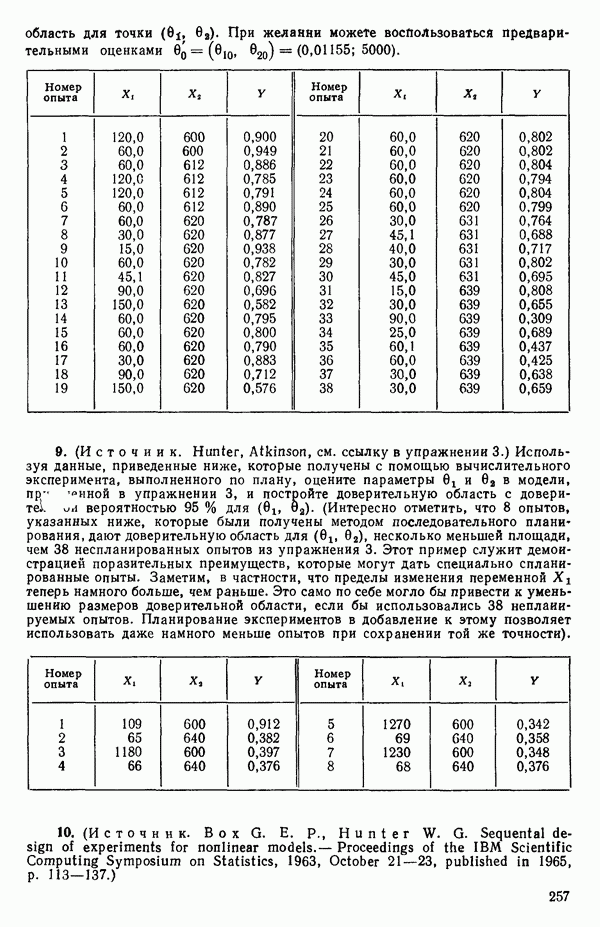
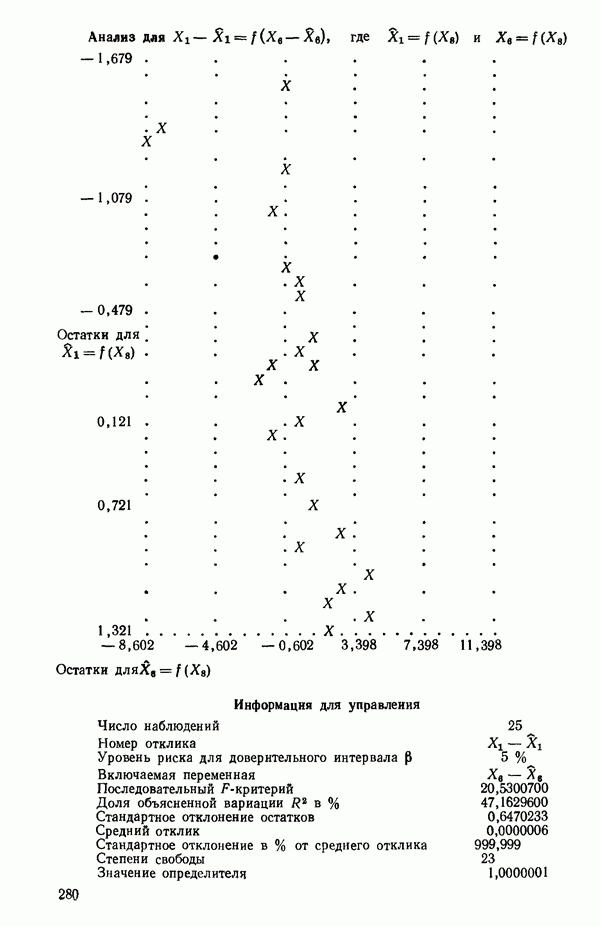
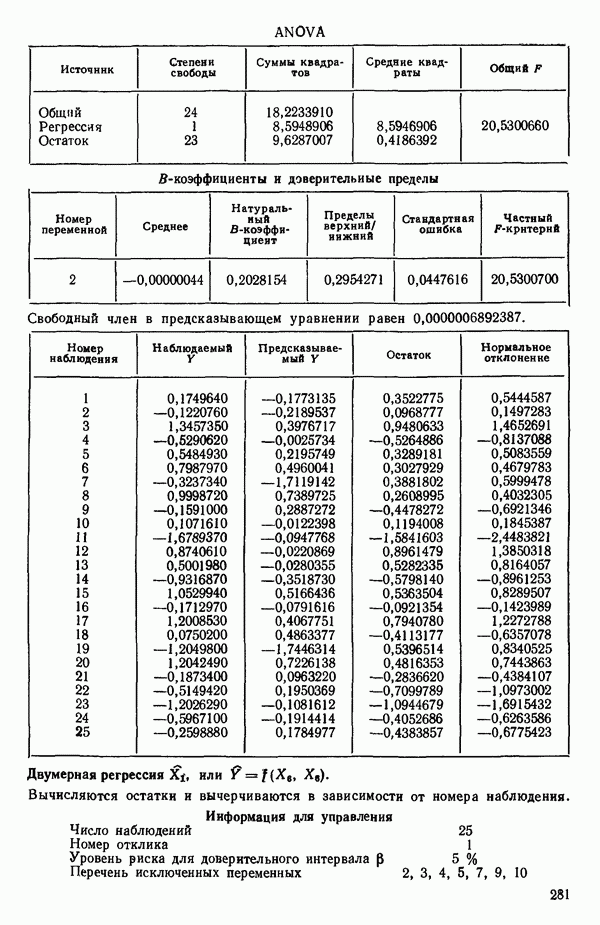
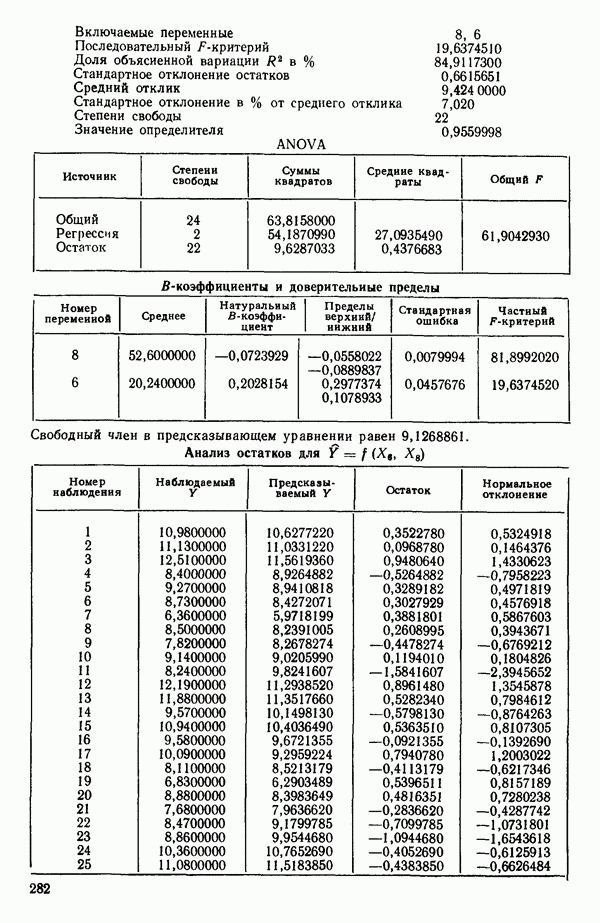
6.1. МЕТОД ВСЕХ ВОЗМОЖНЫХ РЕГРЕССИЙ
Это самая громоздкая процедура. Она вообще не реализуема без быстродействующих вычислительных машин. Поэтому данный метод стал применяться лишь после того, как появились быстродействующие ЭВМ. Он требует прежде всего построения каждого из всех возможных регрессионных уравнений, которые содержат  и некоторое число переменных
и некоторое число переменных  (где мы, как обычно, добавили фиктивную переменную
(где мы, как обычно, добавили фиктивную переменную  к набору величин
к набору величин  Поскольку для каждой переменной
Поскольку для каждой переменной  есть всего две возможности: либо входить, либо не входить в уравнение, и это относится ко всем
есть всего две возможности: либо входить, либо не входить в уравнение, и это относится ко всем  то всего будет
то всего будет  уравнений. (Будем предполагать, что член
уравнений. (Будем предполагать, что член  всегда содержится в уравнении). Если
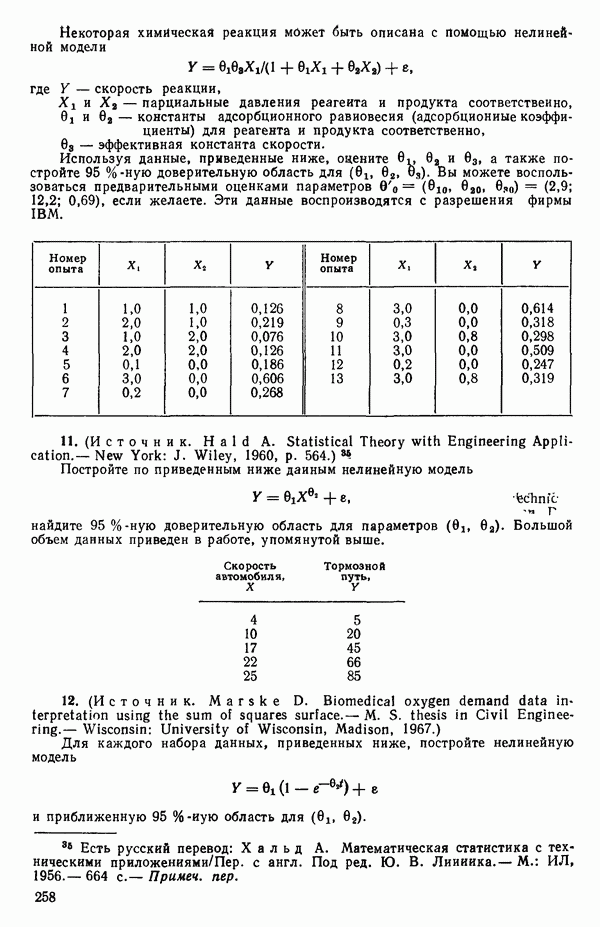
всегда содержится в уравнении). Если  это вовсе не так много, то надо исследовать
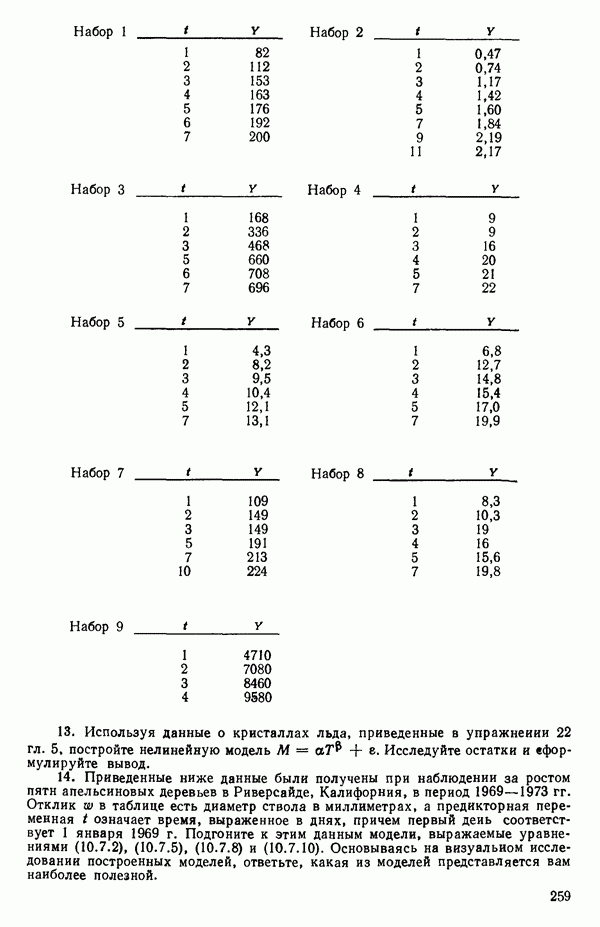
это вовсе не так много, то надо исследовать  уравнений. Каждое регрессионное уравнение оценивается с помощью некоторого критерия. Мы обсудим далее три критерия:
уравнений. Каждое регрессионное уравнение оценивается с помощью некоторого критерия. Мы обсудим далее три критерия:
1) величина  получаемая по методу наименьших квадратов,
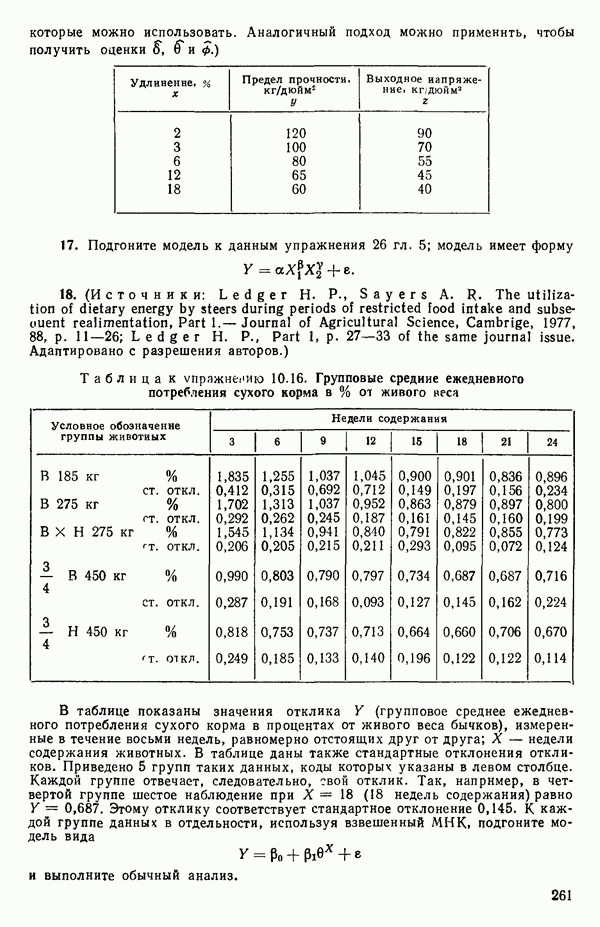
получаемая по методу наименьших квадратов,
2) величина  остаточный средний квадрат и
остаточный средний квадрат и
3)  -статистика.
-статистика.
(Все эти критерии фактически связаны друг с другом.) Выбор наилучшего уравнения в таком случае делается на основе оценки наблюдаемой картины, что мы покажем на примере.
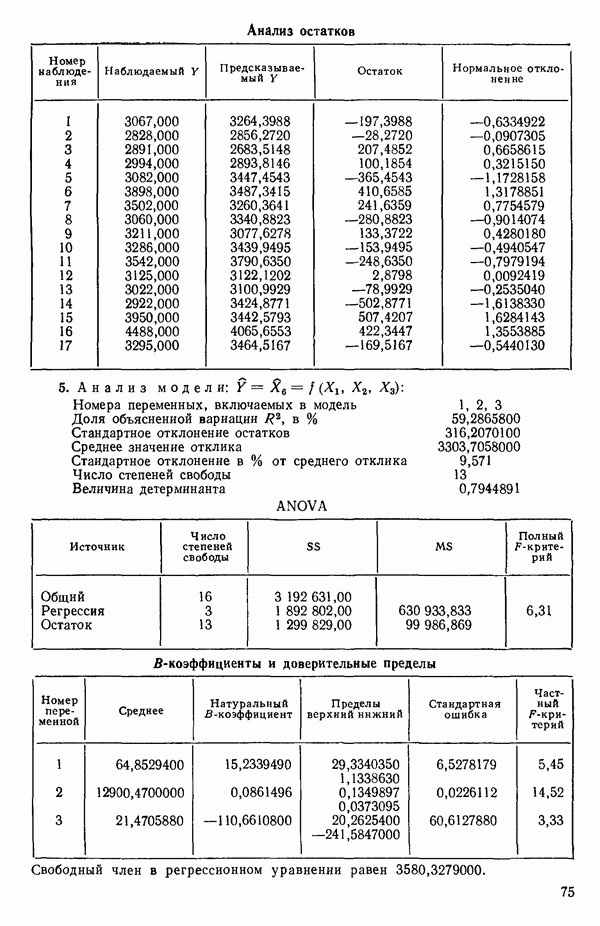
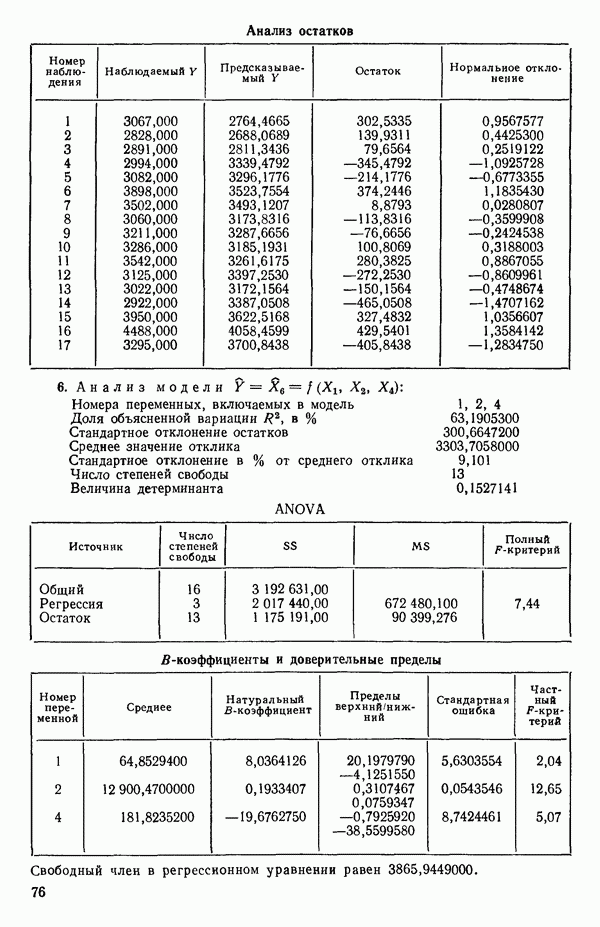
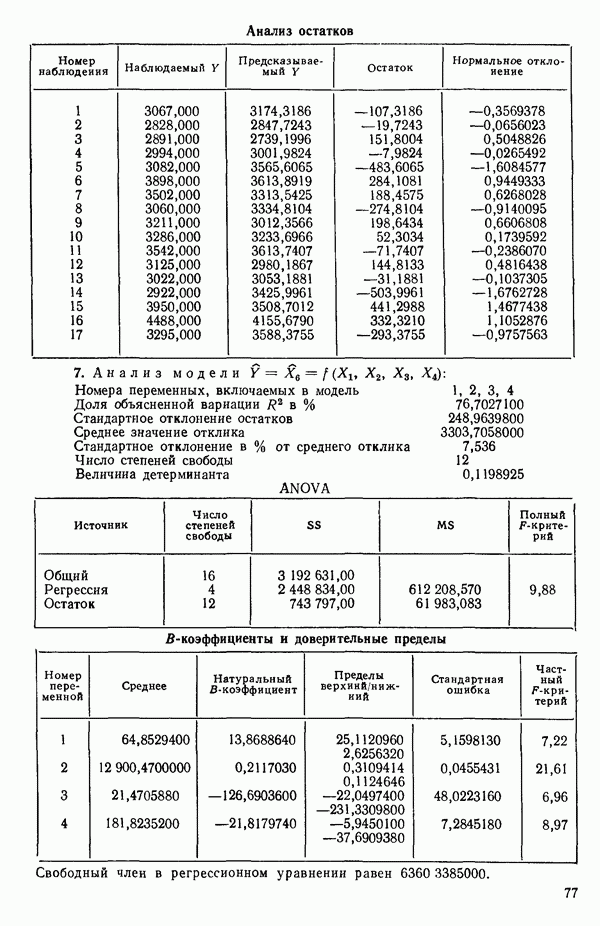
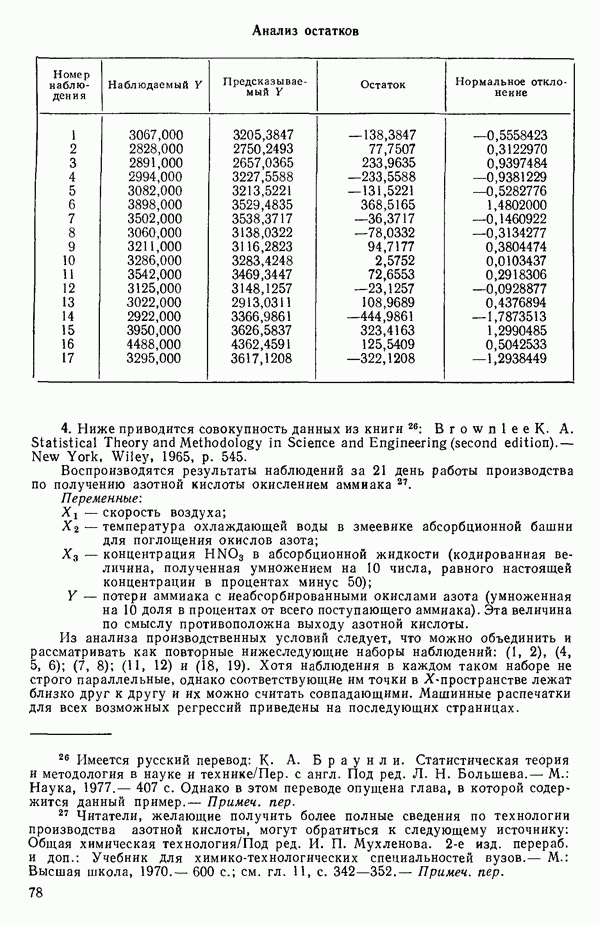
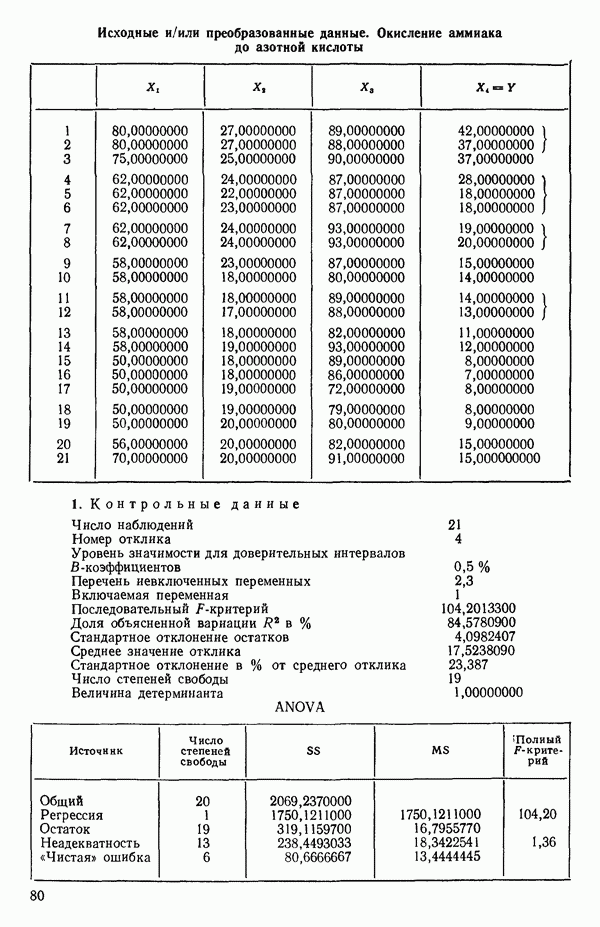
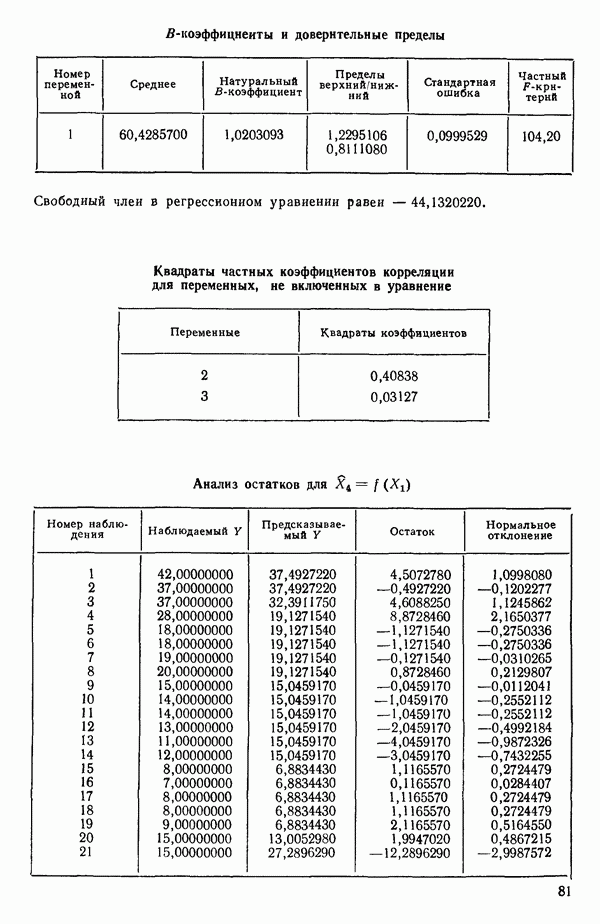
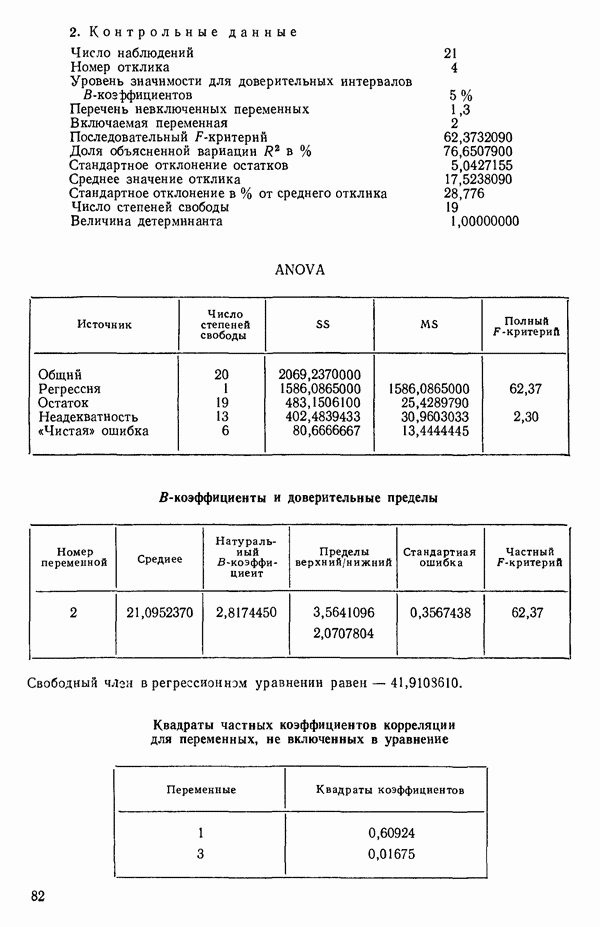
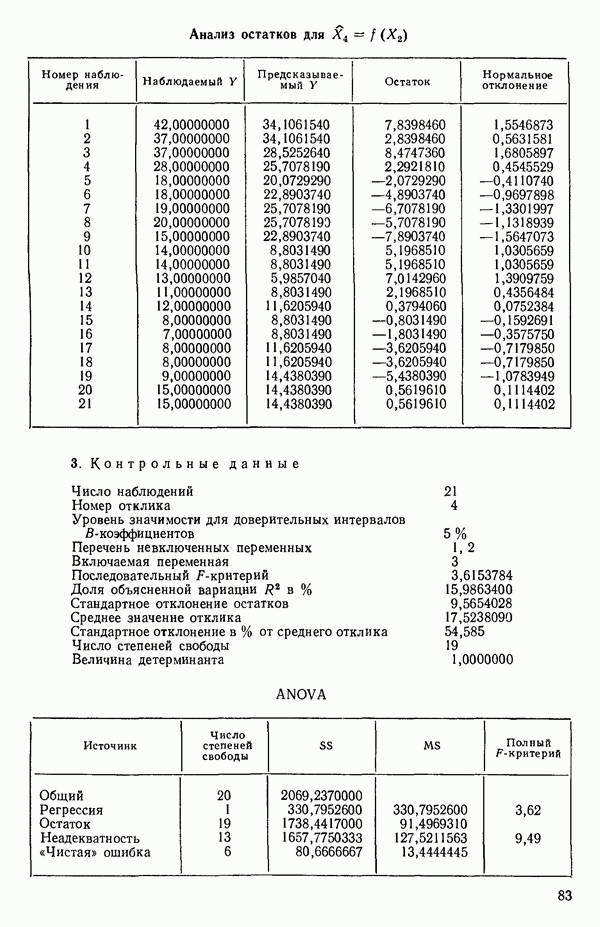
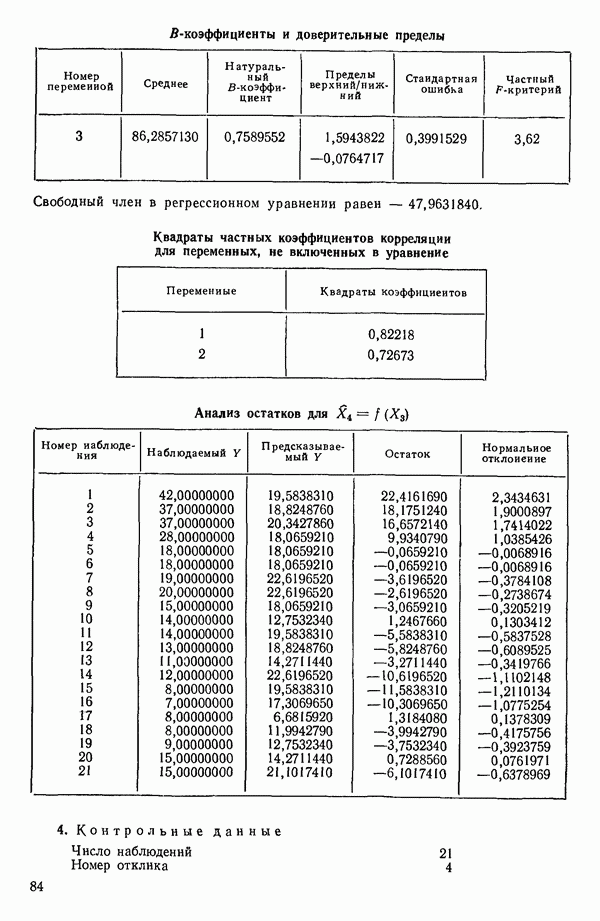
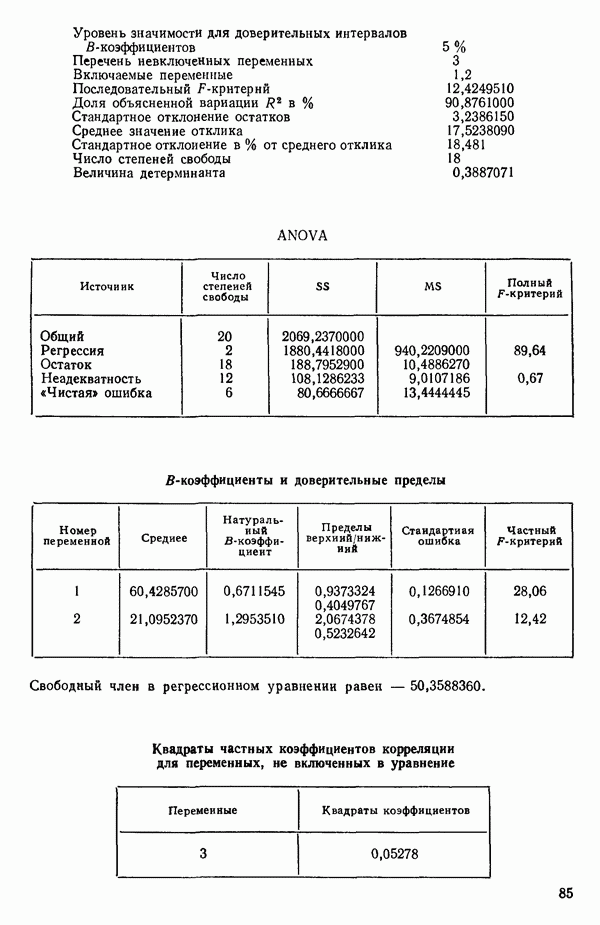
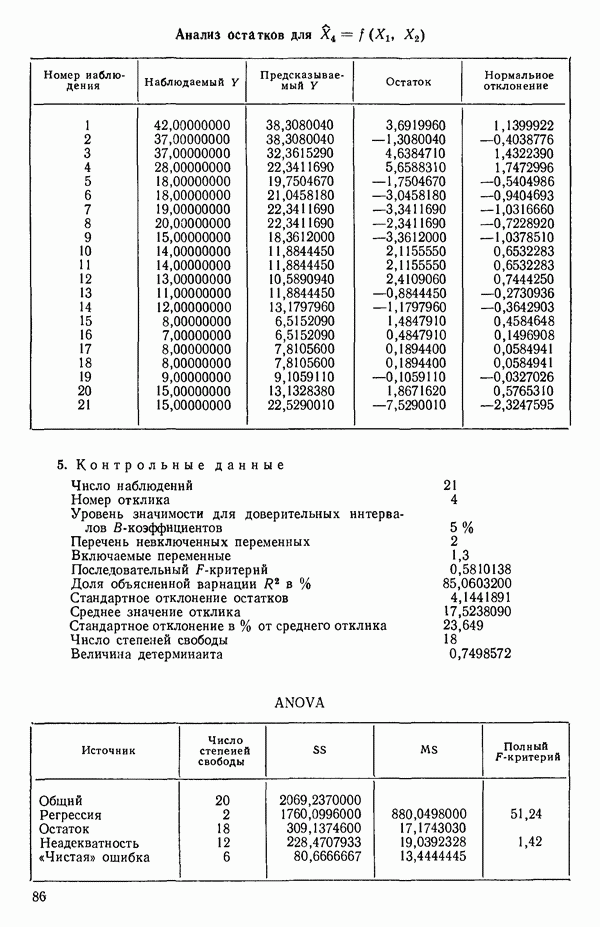
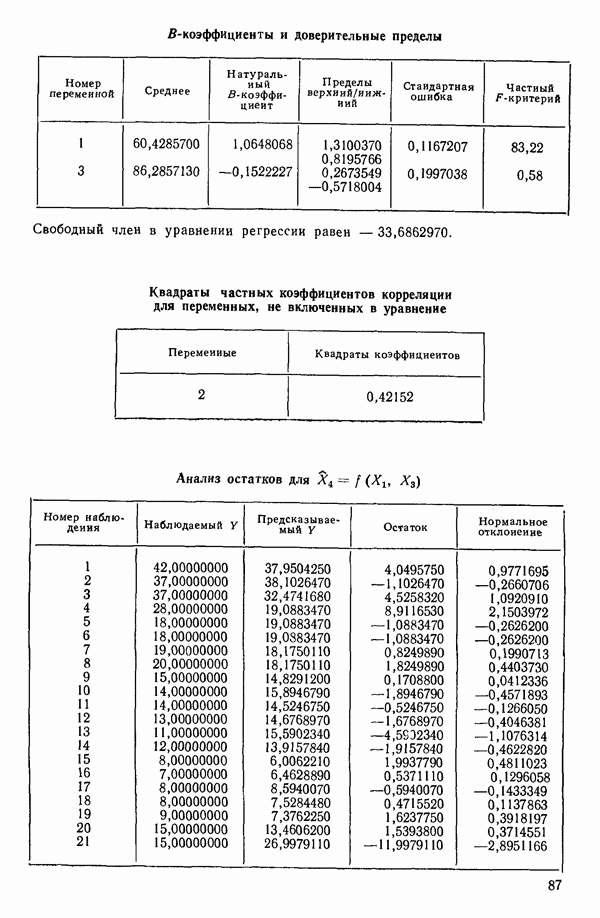
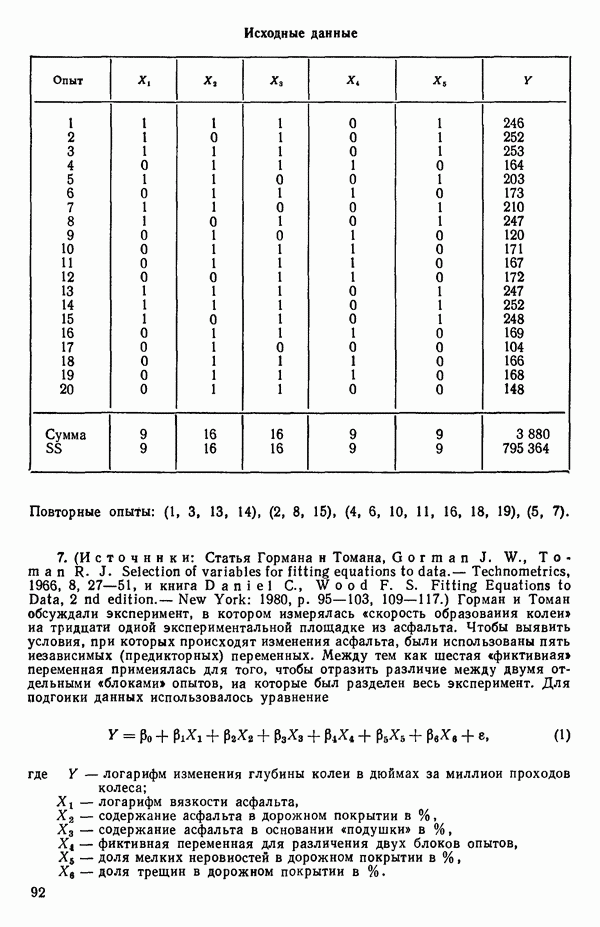
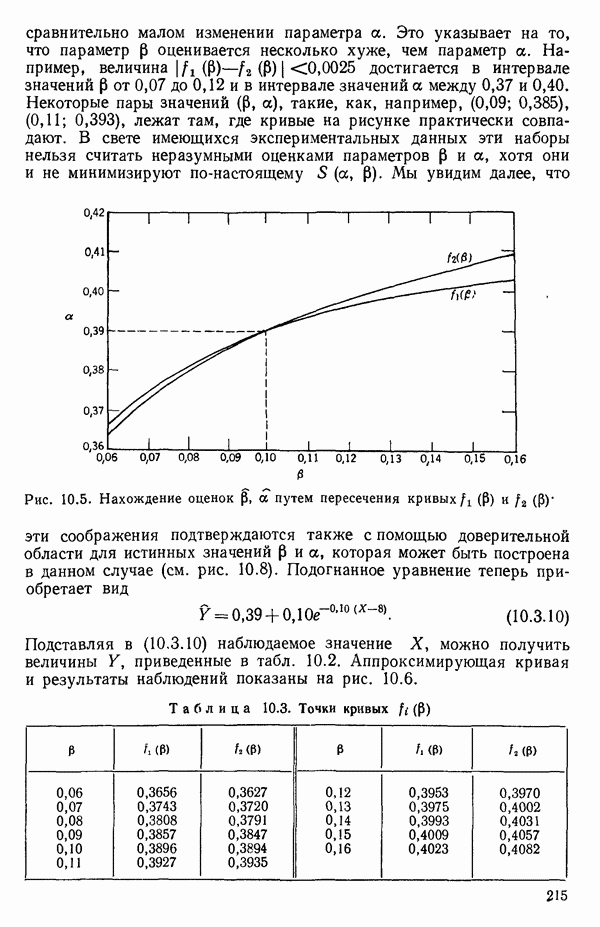
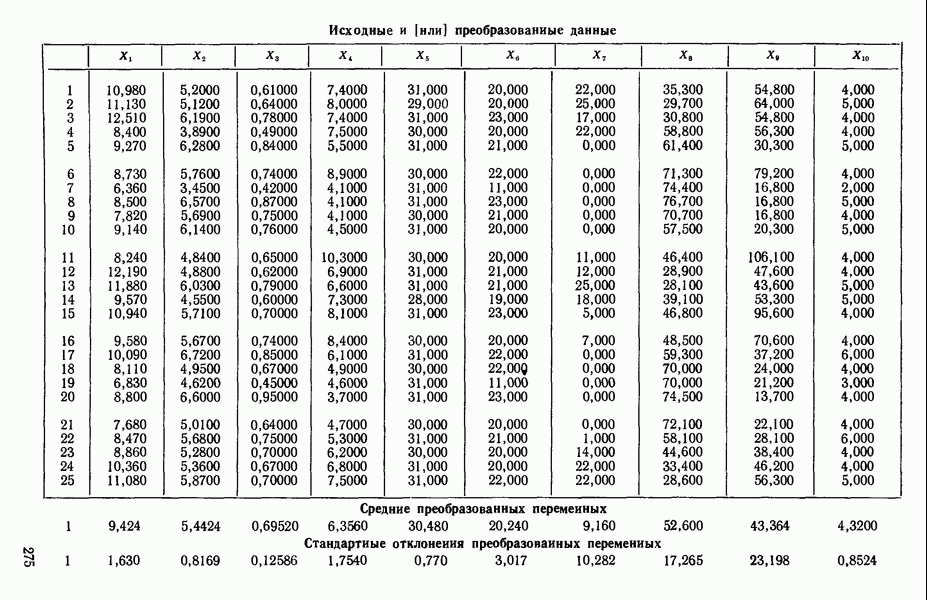
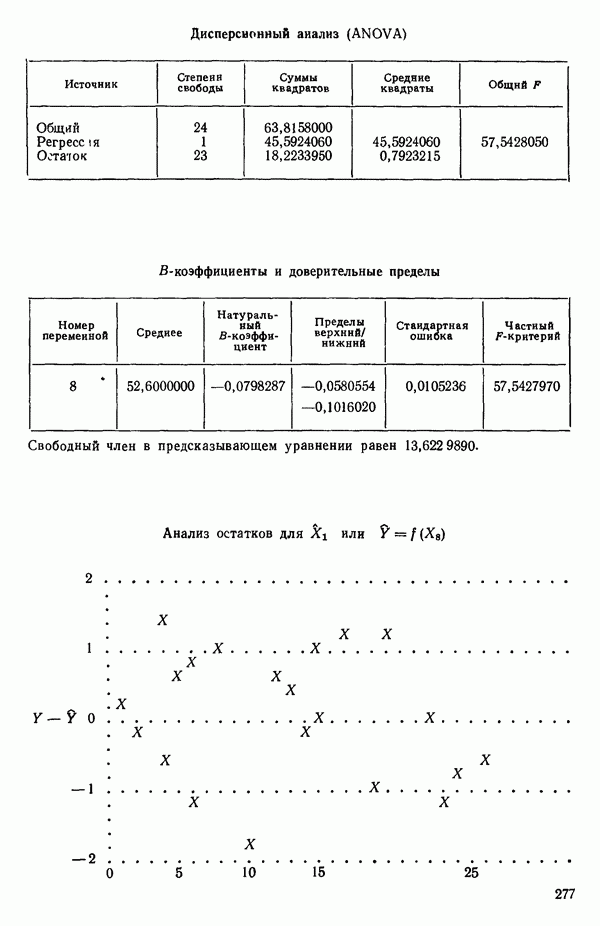
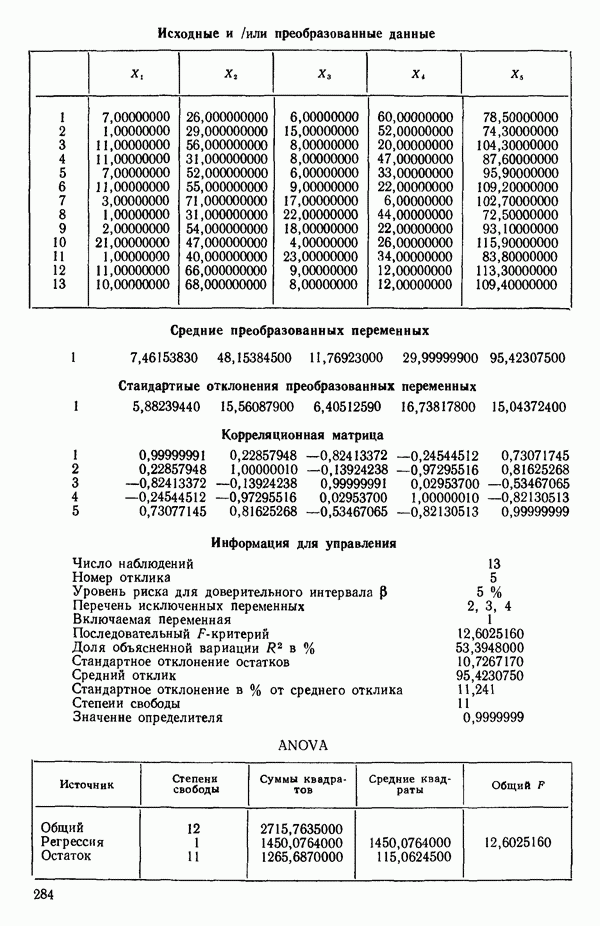
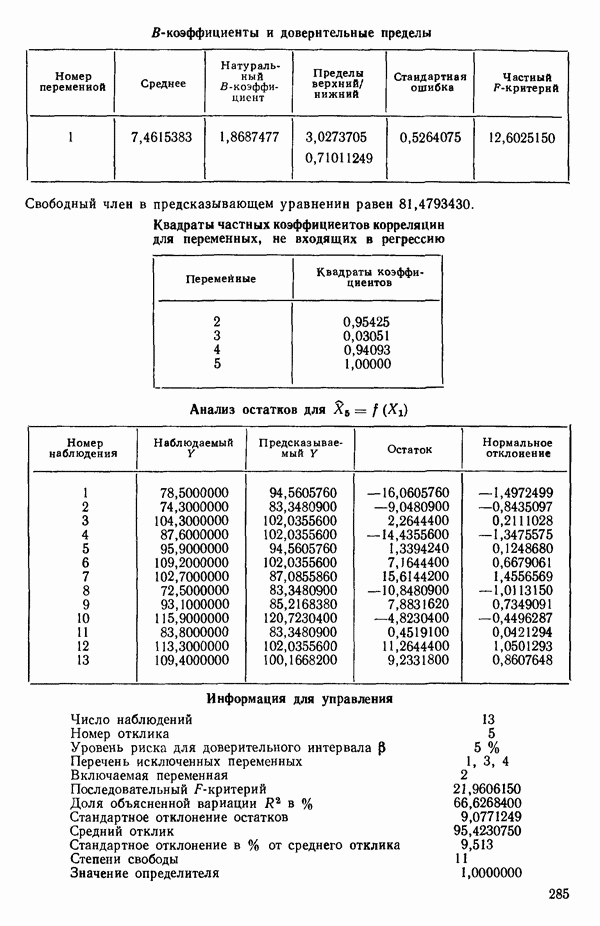
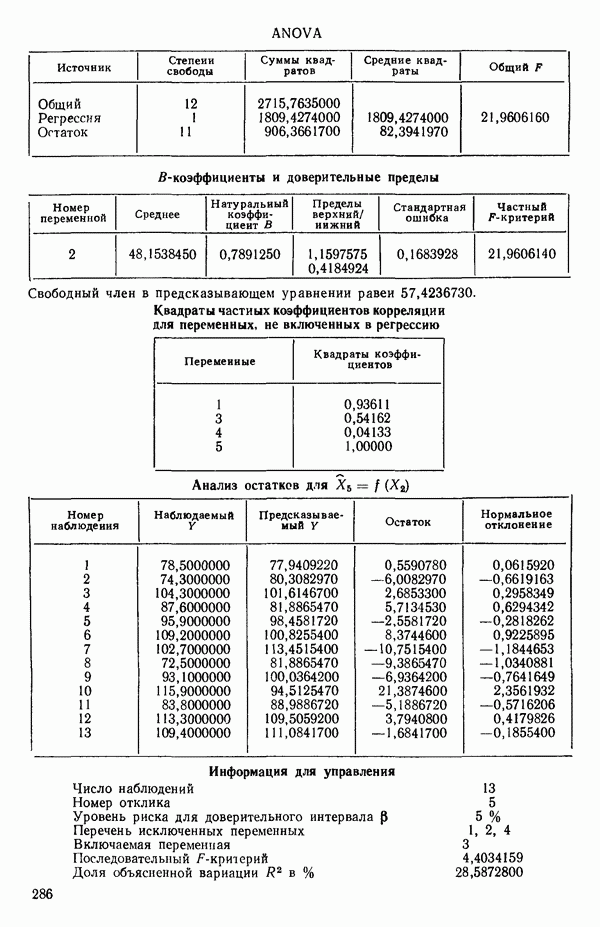
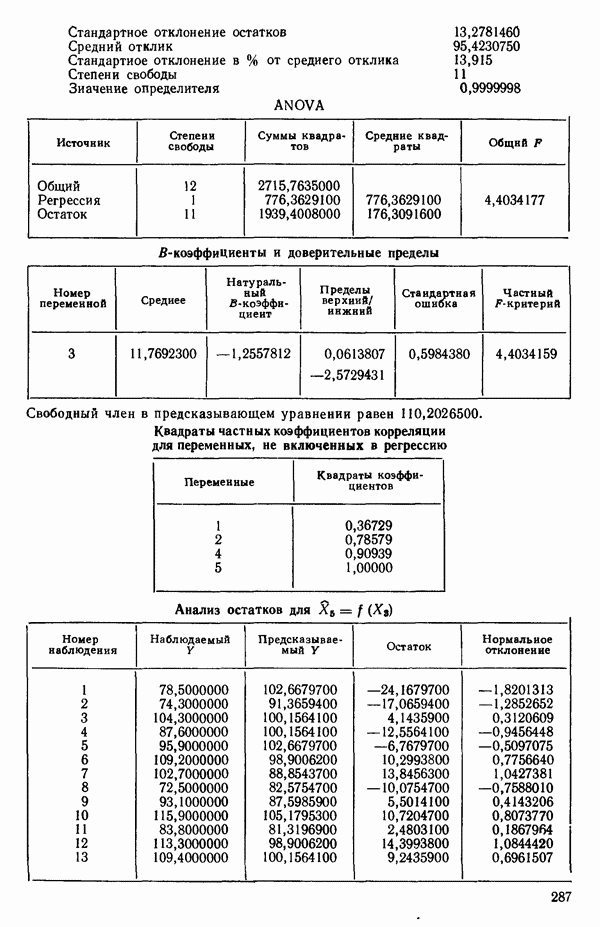
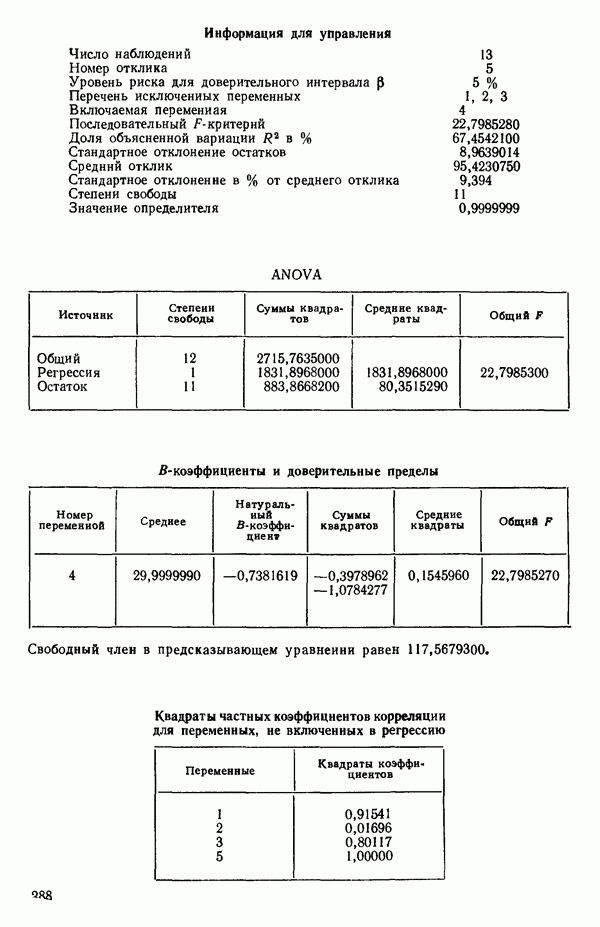
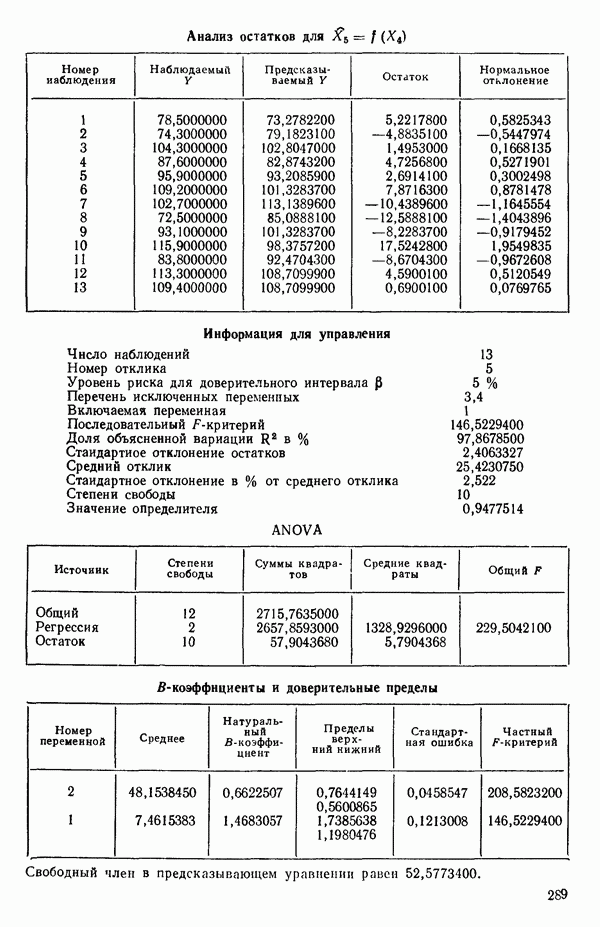
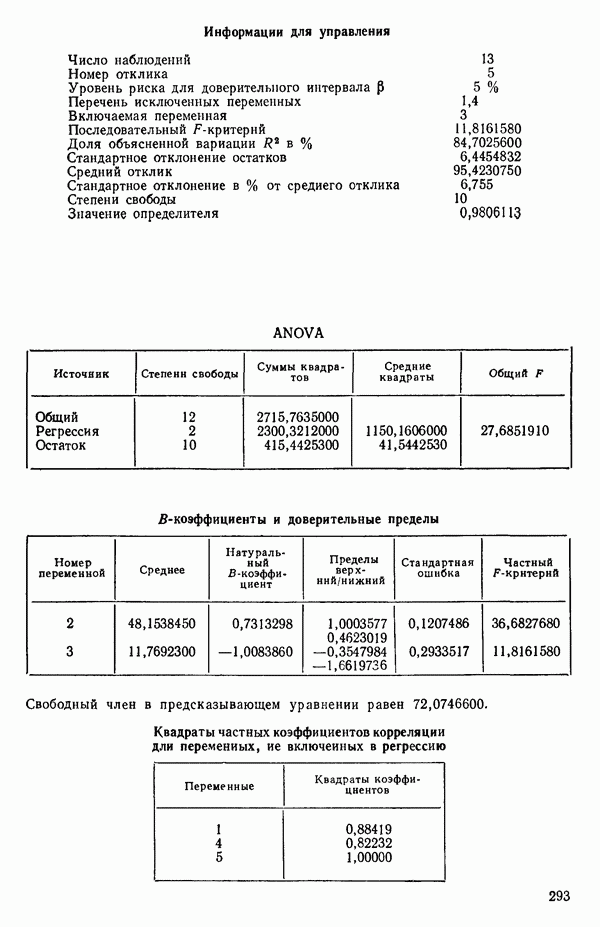
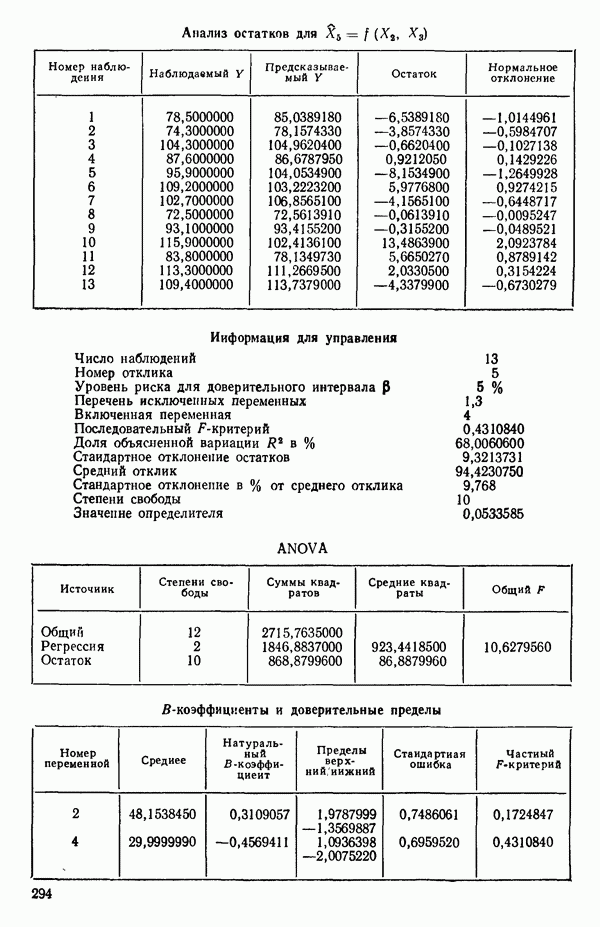
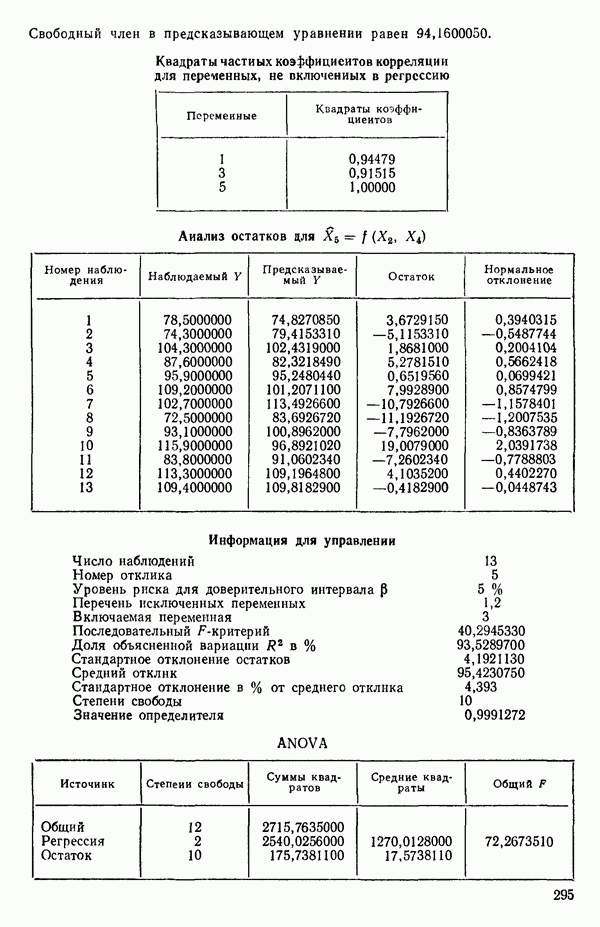
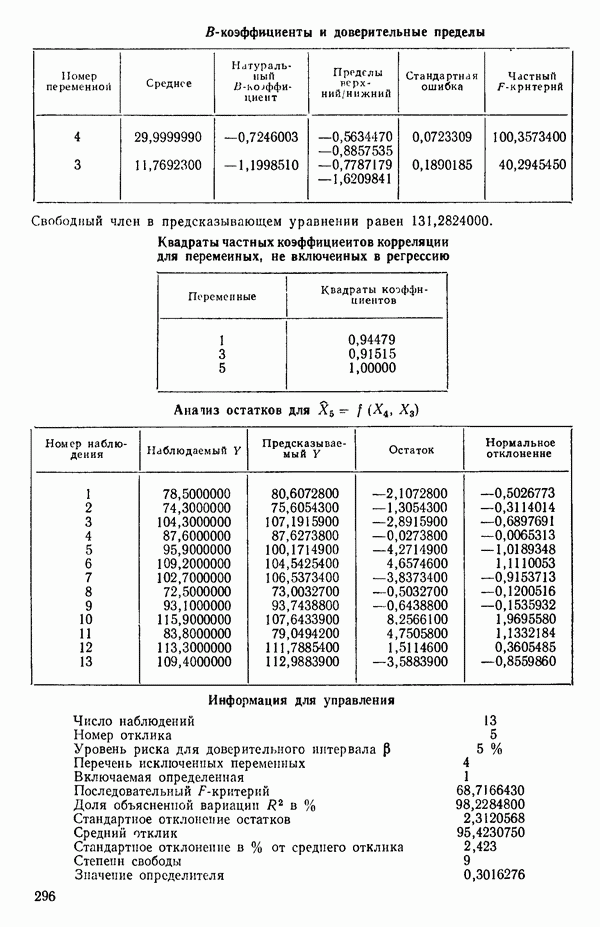
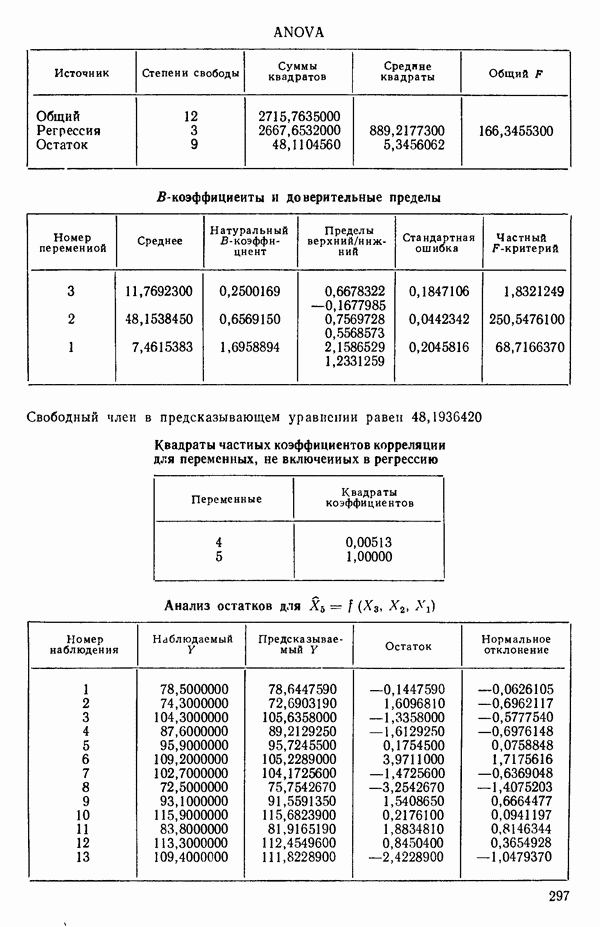
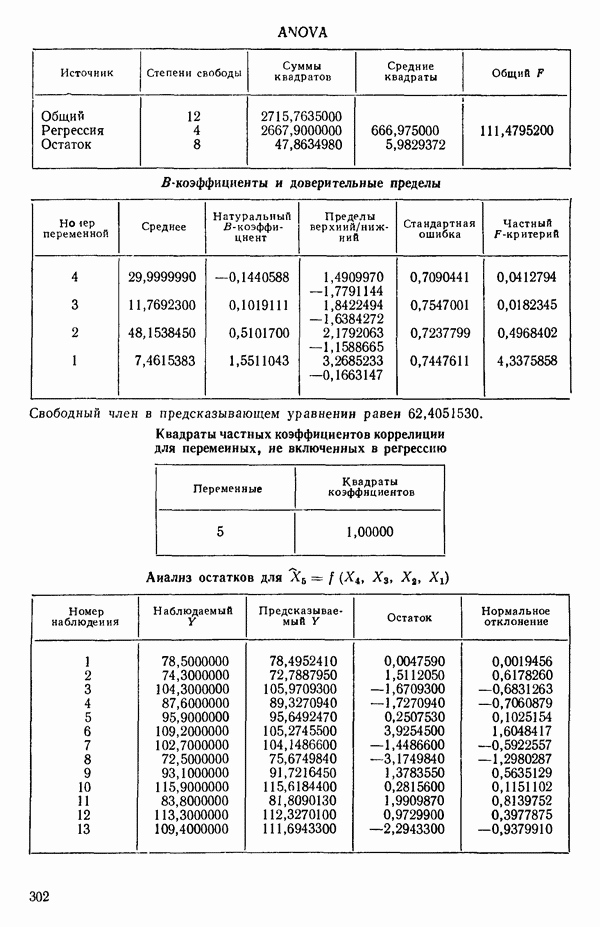
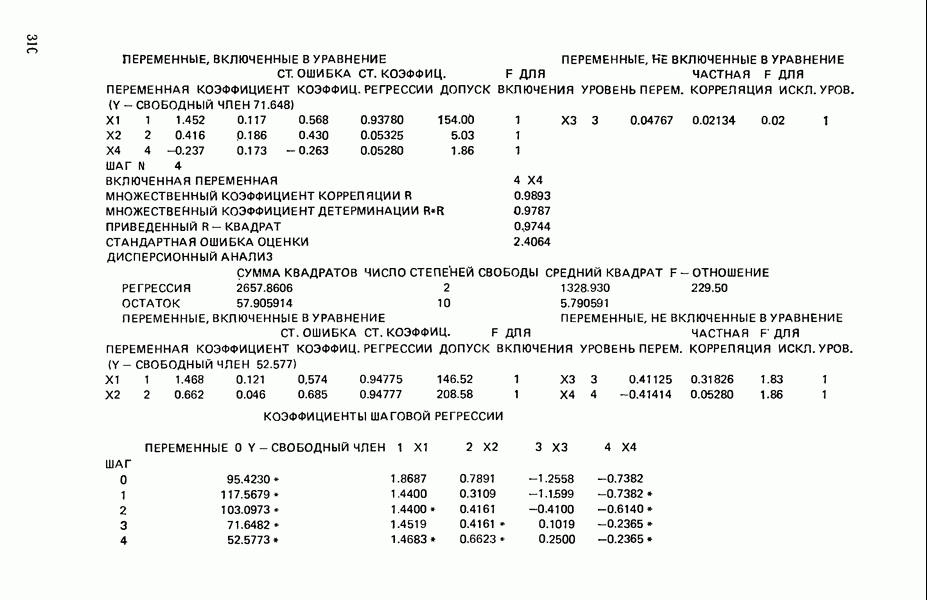
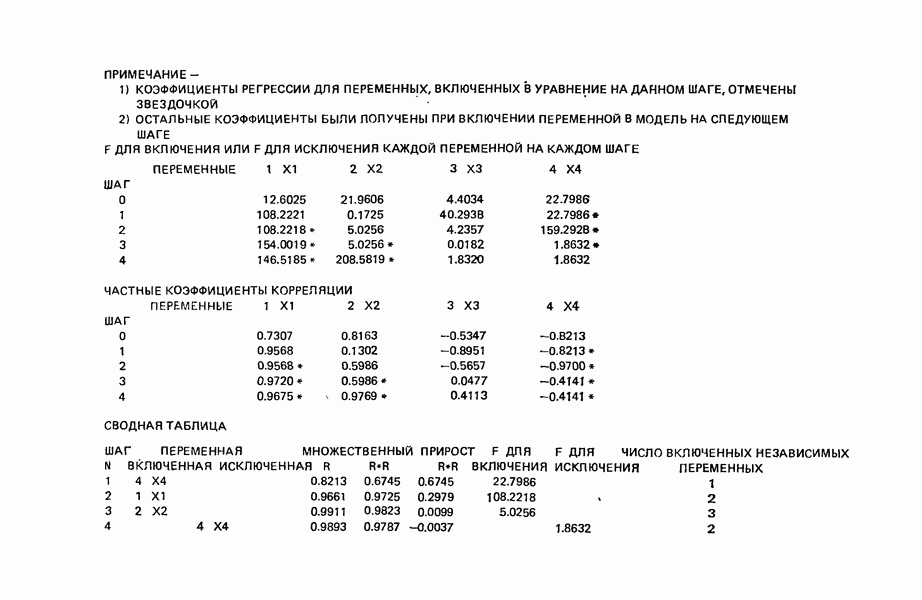
Воспользуемся данными для четырехфакторной задачи  , приведенной Хальдом на с. 647 его книги (см.: Hald A. Statistical Theory with Engineering Applications.- New York: J. Wiley, 1952). Именно эта задача была выбрана потому, что она иллюстрирует некоторые типичные трудности регрессионного анализа. Исходные данные приведены на машинных распечатках в приложении Б. Предикторные переменные здесь
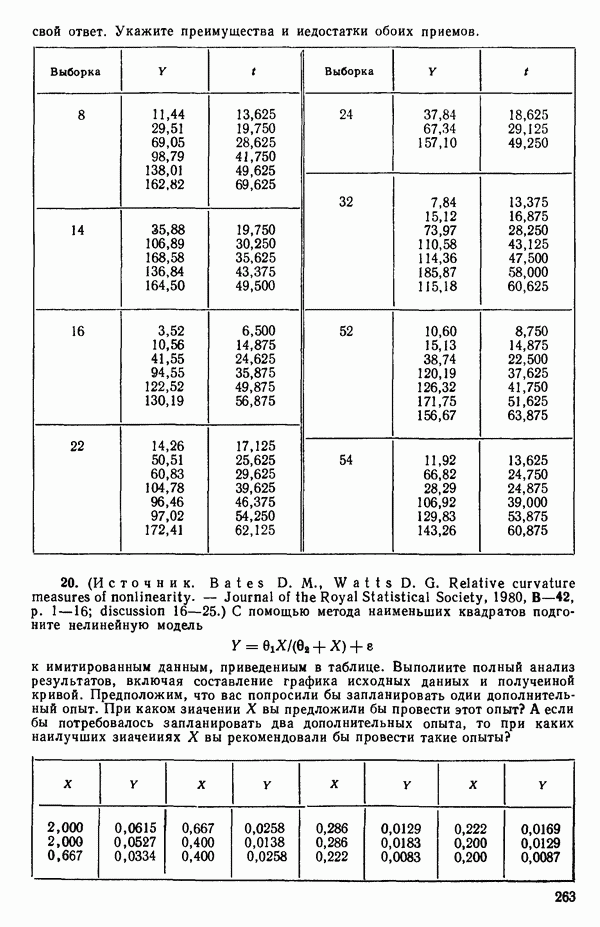
, приведенной Хальдом на с. 647 его книги (см.: Hald A. Statistical Theory with Engineering Applications.- New York: J. Wiley, 1952). Именно эта задача была выбрана потому, что она иллюстрирует некоторые типичные трудности регрессионного анализа. Исходные данные приведены на машинных распечатках в приложении Б. Предикторные переменные здесь  В данной задаче нет никаких преобразований, так что
В данной задаче нет никаких преобразований, так что  . Откликом служит переменная
. Откликом служит переменная  Член
Член  всегда включается в модель. Таким образом, имеется
всегда включается в модель. Таким образом, имеется  возможных регрессионных уравнений, которые включают
возможных регрессионных уравнений, которые включают  и
и  . Все они фигурируют в приложении Б. Теперь мы применим процедуры, указанные выше.
. Все они фигурируют в приложении Б. Теперь мы применим процедуры, указанные выше.
Статистика R2
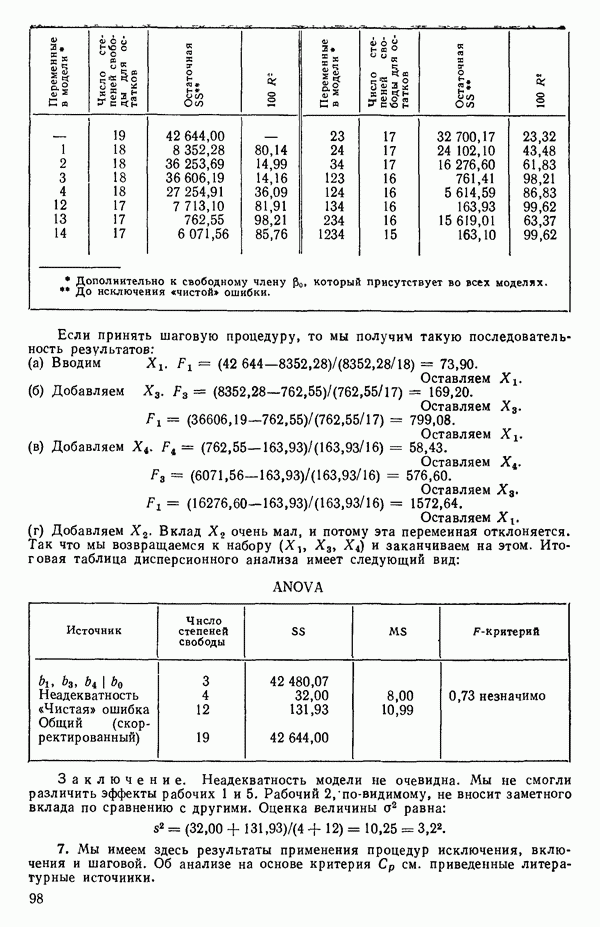
1. Разделим все варианты на 5 серий (наборов).
Серия А включает только один случай (модель 
Серия Б состоит из 4 однофакторных уравнений (модель  ).
).
Серия В включает все двухфакторные уравнения 
Серия Г состоит из всех трехфакторных уравнений (модель строится аналогично).
Серия  из всех уравнений с четырьмя факторами.
из всех уравнений с четырьмя факторами.
2. Упорядочим варианты внутри каждого набора по значению квадрата множественного коэффициента корреляции 
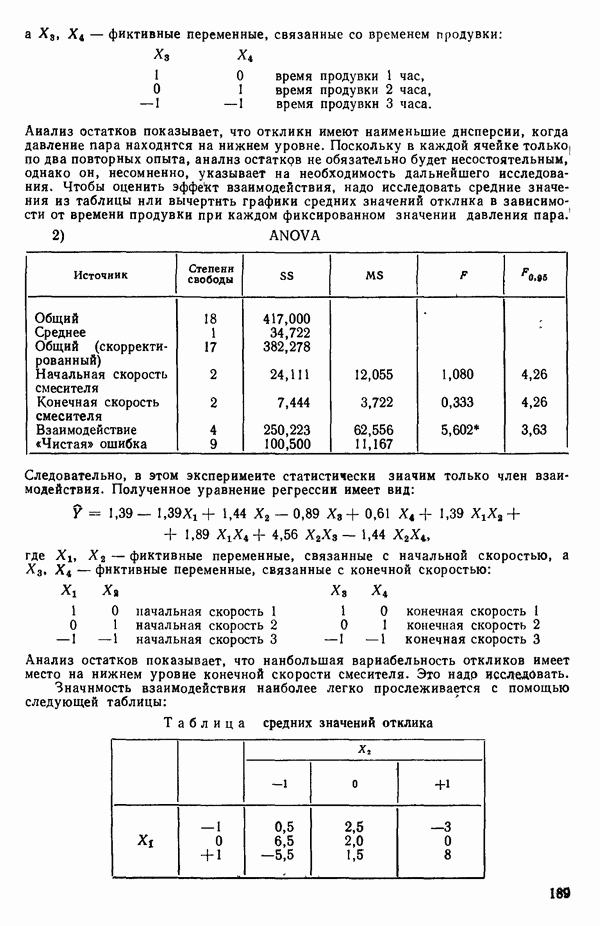
3. Выявим лидеров и рассмотрим, имеется ли какая-нибудь закономерность среди переменных, входящих в лидирующие уравнения каждой серии. В данном примере мы имеем:

(Заметим, что в серии В имеется 2 лидера с практически одинаковыми значениями величины  Если мы рассмотрим эти результаты, то увидим, что после введения двух переменных дальнейший прирост величины
Если мы рассмотрим эти результаты, то увидим, что после введения двух переменных дальнейший прирост величины  мал. Исследуя корреляционную матрицу для этих данных (приложение Б), можно обнаружить, что
мал. Исследуя корреляционную матрицу для этих данных (приложение Б), можно обнаружить, что  а также
а также  сильно коррелированы. В самом деле (если округлить до третьего знака после запятой)
сильно коррелированы. В самом деле (если округлить до третьего знака после запятой)

Следовательно, если  или
или  уже содержатся в регрессионном уравнении, дальнейшее добавление переменных очень мало снижает необъясненную вариацию отклика. Отсюда становится ясным, почему величина
уже содержатся в регрессионном уравнении, дальнейшее добавление переменных очень мало снижает необъясненную вариацию отклика. Отсюда становится ясным, почему величина  так слабо увеличивается при переходе от серии В к серии Г. Прирост
так слабо увеличивается при переходе от серии В к серии Г. Прирост  при переходе от серии Г к серии
при переходе от серии Г к серии  совсем уже мал. Это просто объясняется, если заметить, что X есть количества ингредиентов смеси и сумма их значений для любой заданной точки практически постоянна и заключена между 95 и 99.
совсем уже мал. Это просто объясняется, если заметить, что X есть количества ингредиентов смеси и сумма их значений для любой заданной точки практически постоянна и заключена между 95 и 99.
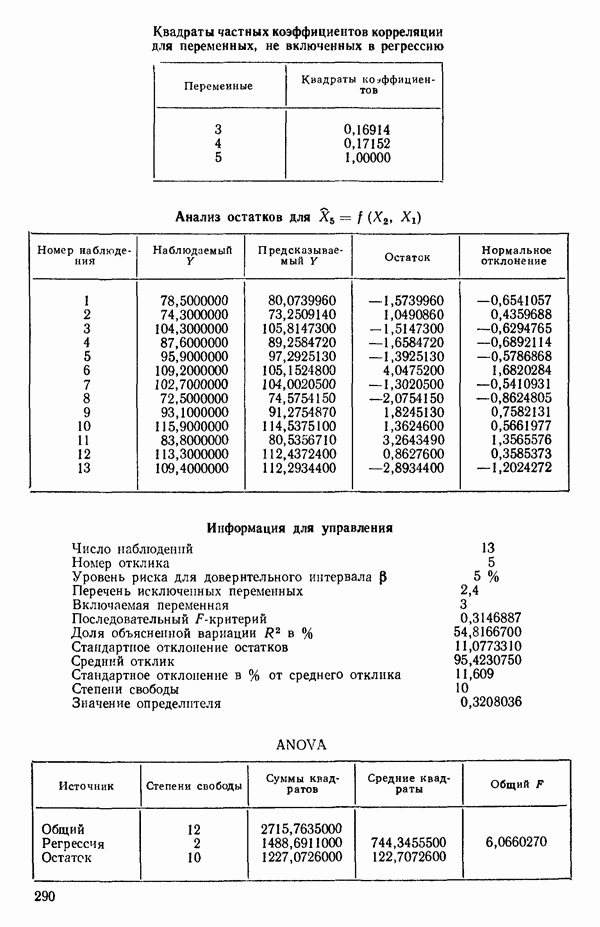
Какое уравнение следует отобрать для более внимательного рассмотрения. Одно из уравнений серии В, но какое? Если выбрать  то это не совсем оправдано, поскольку наилучшее однофакторное уравнение включает
то это не совсем оправдано, поскольку наилучшее однофакторное уравнение включает  По этой причине многие авторы отдали бы предпочтение зависимости
По этой причине многие авторы отдали бы предпочтение зависимости  Исследование всех возможных уравнений не дает четкого ответа на этот вопрос. Чтобы можно было принять решение, всегда требуется дополнительная
Исследование всех возможных уравнений не дает четкого ответа на этот вопрос. Чтобы можно было принять решение, всегда требуется дополнительная
информация, такая, как, например, сведения о характерных особенностях изучаемого продукта и о физической природе переменных 
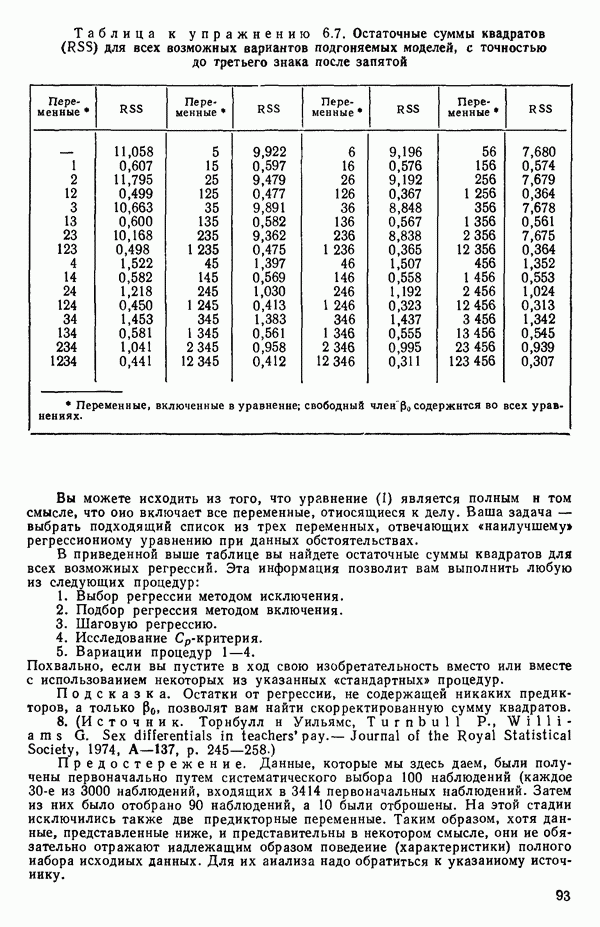
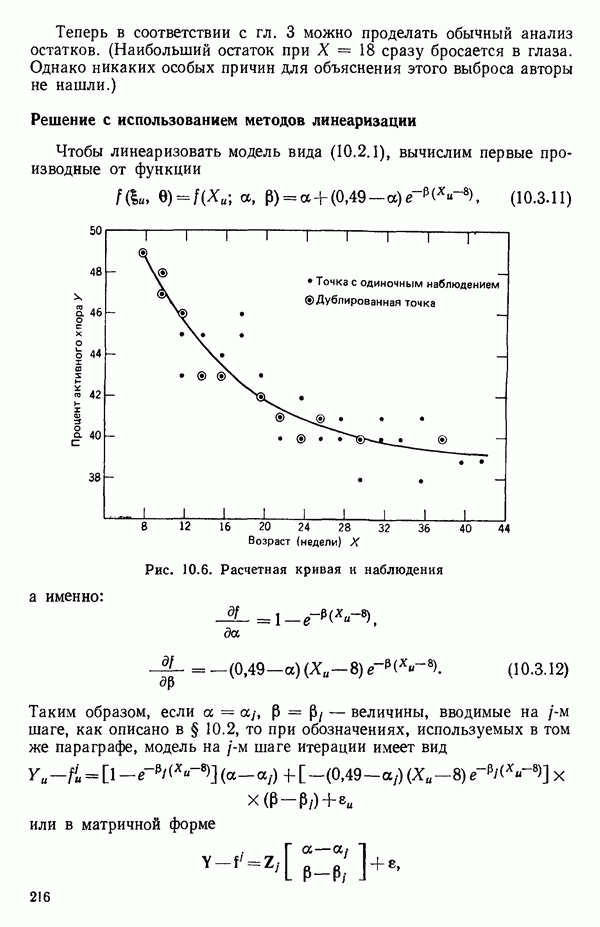
Алгоритм The (Algol 60) Algorithm AS 38 (из работы: Gar side M. J. Best subset search.- Applied statistics, 1971, 20, p. 112-115) позволяет быстро найти из всех возможных подмножеств регрессионных моделей те, которые имеют наибольший коэффициент множественной корреляции. Этот метод описан полностью Гарсайдом (Garside) в том же номере журнала на с. 8—15.
Остаточный средний квадрат s2
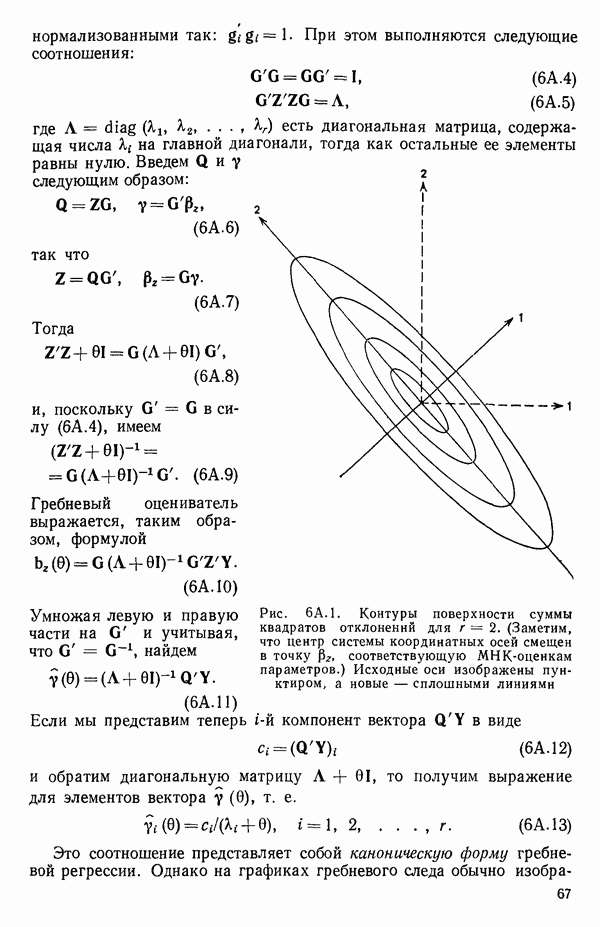
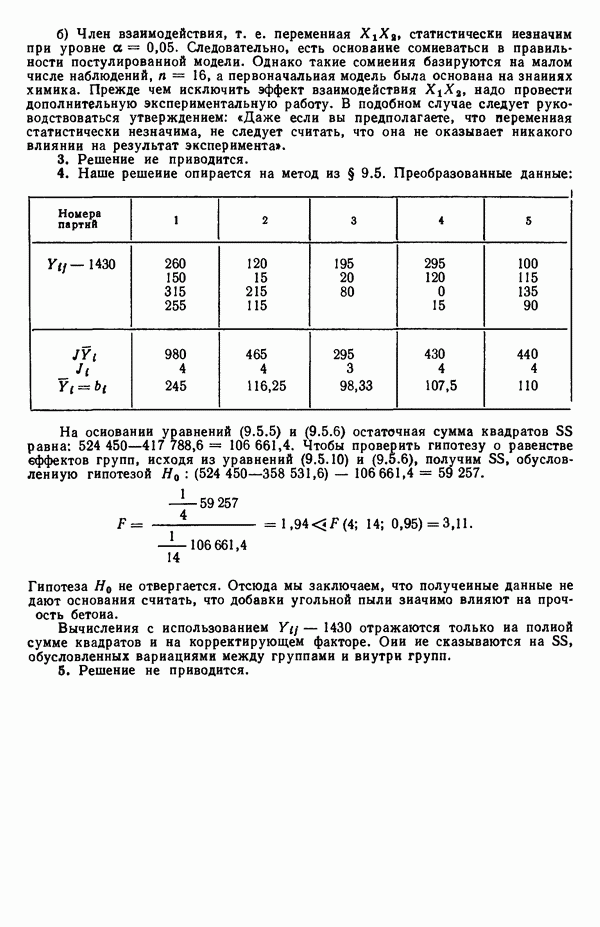
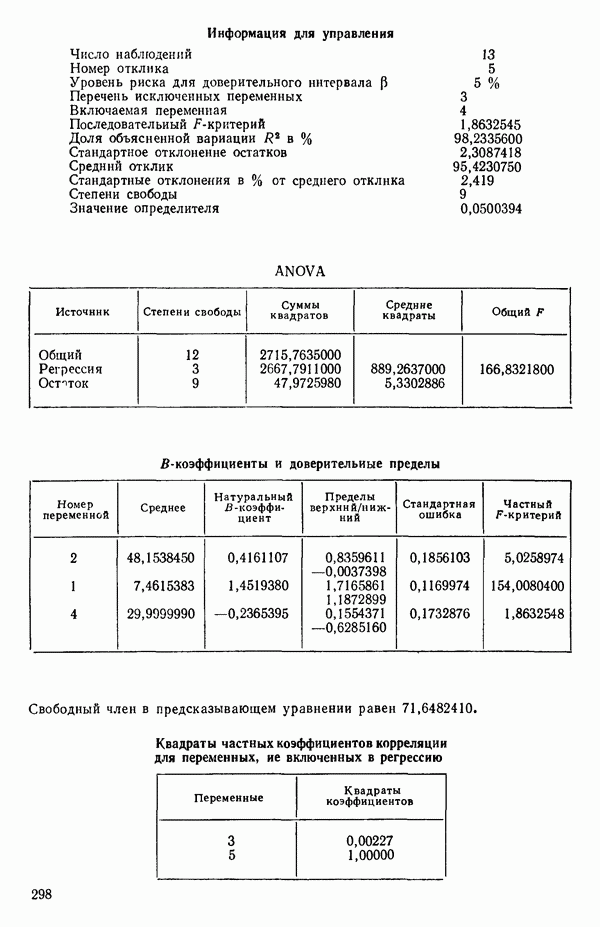
Если для некоторой большой задачи построены все регрессионные уравнения, то, рассматривая зависимость величины остаточного среднего квадрата от числа переменных, иногда можно наилучшим образом выбрать число переменных, которые следует сохранить в уравнении регрессии. Различные значения остаточного среднего квадрата по данным Хальда для всех наборов из  переменных, где
переменных, где  — число параметров в модели, включая
— число параметров в модели, включая  указаны в распечатках, приведенных в приложении Б.
указаны в распечатках, приведенных в приложении Б.

Если число потенциальных переменных для модели велико, скажем,  больше 10, и если число экспериментальных точек значительно больше
больше 10, и если число экспериментальных точек значительно больше  например от
например от  до Юг, то график
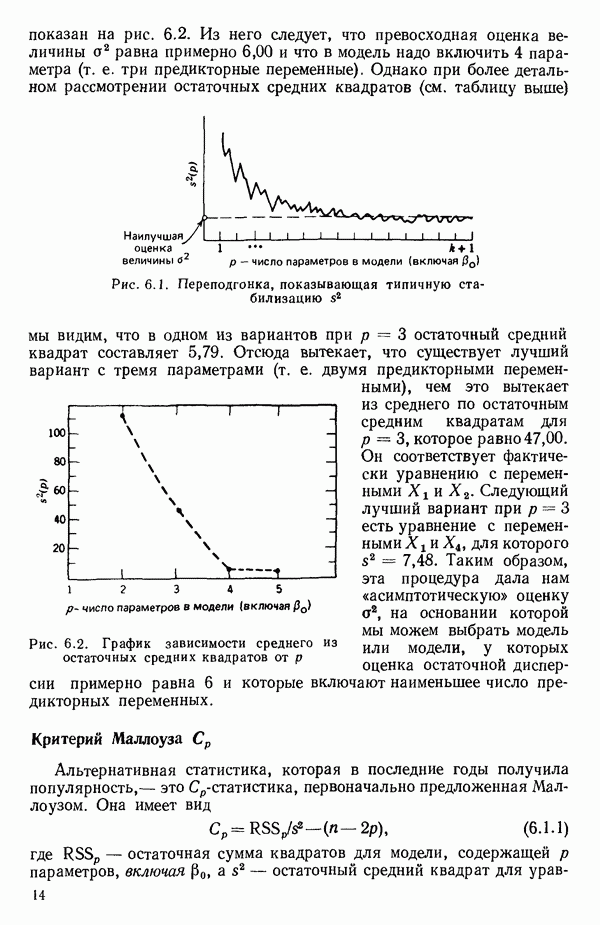
до Юг, то график  обычно довольно информативен. Подгонка регрессионных уравнений, которые включают больше предикторных переменных, чем нужно для удовлетворительного согласия экспериментальных и расчетных данных, называется переподгонкой (overfitting). По мере того как к «переподогнанному» уравнению добавляется все больше и больше предикторных переменных, остаточный средний квадрат имеет тенденцию стабилизироваться и приближается к истинной величине
обычно довольно информативен. Подгонка регрессионных уравнений, которые включают больше предикторных переменных, чем нужно для удовлетворительного согласия экспериментальных и расчетных данных, называется переподгонкой (overfitting). По мере того как к «переподогнанному» уравнению добавляется все больше и больше предикторных переменных, остаточный средний квадрат имеет тенденцию стабилизироваться и приближается к истинной величине  с ростом числа переменных (при условии, что все важные переменные включены в модель, а число наблюдений значительно, т. е. в пять — десять раз, как указано выше, превосходит число переменных в уравнении). Эта ситуация показана на рис. 6.1. При меньших по объему наборах данных, таких, как в нашем примере, мы не можем, конечно, ожидать, что эта идея окажется плодотворной, но она может привести к полезным заключениям. График зависимости средней величины
с ростом числа переменных (при условии, что все важные переменные включены в модель, а число наблюдений значительно, т. е. в пять — десять раз, как указано выше, превосходит число переменных в уравнении). Эта ситуация показана на рис. 6.1. При меньших по объему наборах данных, таких, как в нашем примере, мы не можем, конечно, ожидать, что эта идея окажется плодотворной, но она может привести к полезным заключениям. График зависимости средней величины  от
от 
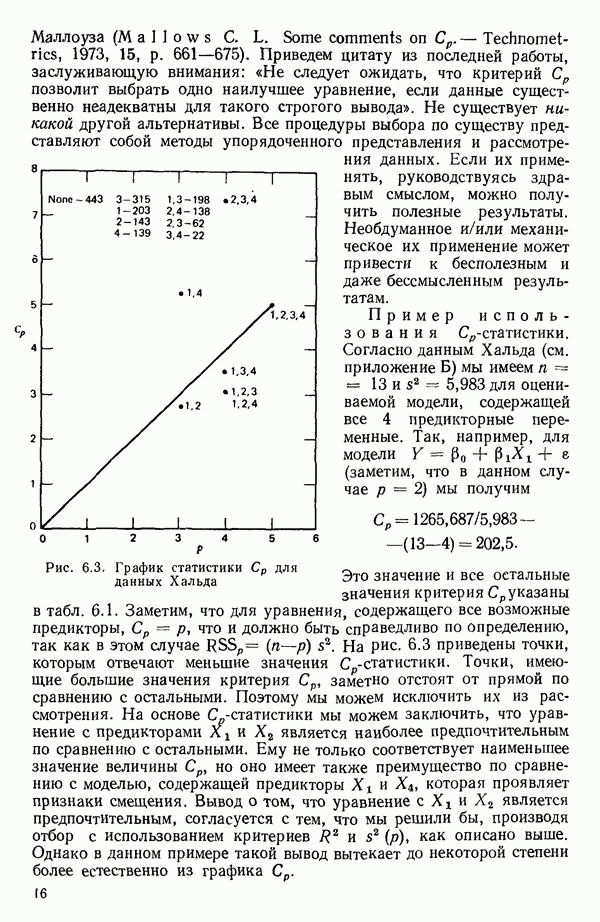
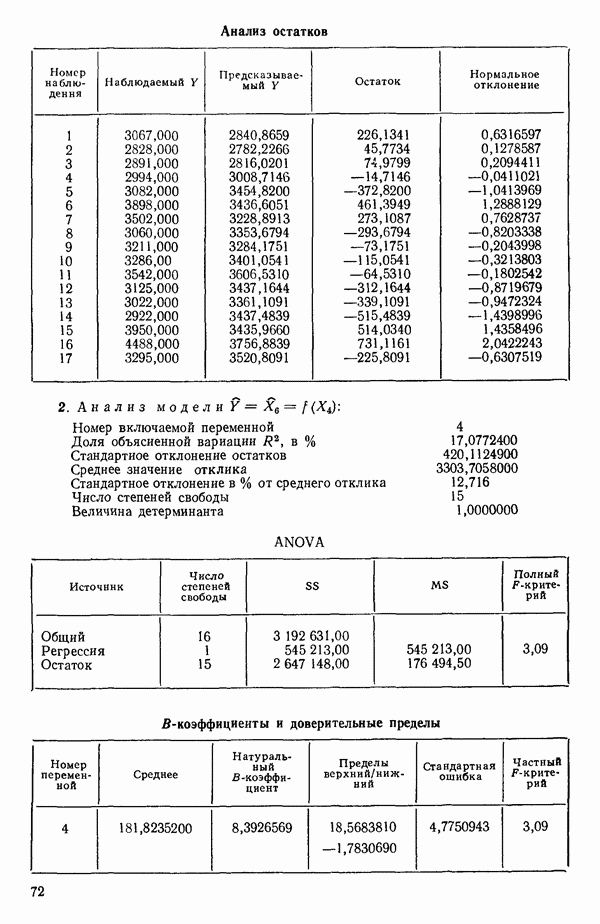
показан на рис. 6.2. Из него следует, что превосходная оценка величины  равна примерно 6,00 и что в модель надо включить 4 параметра (т. е. три предикторные переменные). Однако при более детальном рассмотрении остаточных средних квадратов (см. таблицу выше) мы видим, что в одном из вариантов при
равна примерно 6,00 и что в модель надо включить 4 параметра (т. е. три предикторные переменные). Однако при более детальном рассмотрении остаточных средних квадратов (см. таблицу выше) мы видим, что в одном из вариантов при  остаточный средний квадрат составляет 5,79.
остаточный средний квадрат составляет 5,79.

Рис. 6.1. Переподгонка, показывающая типичную стабилизацию 
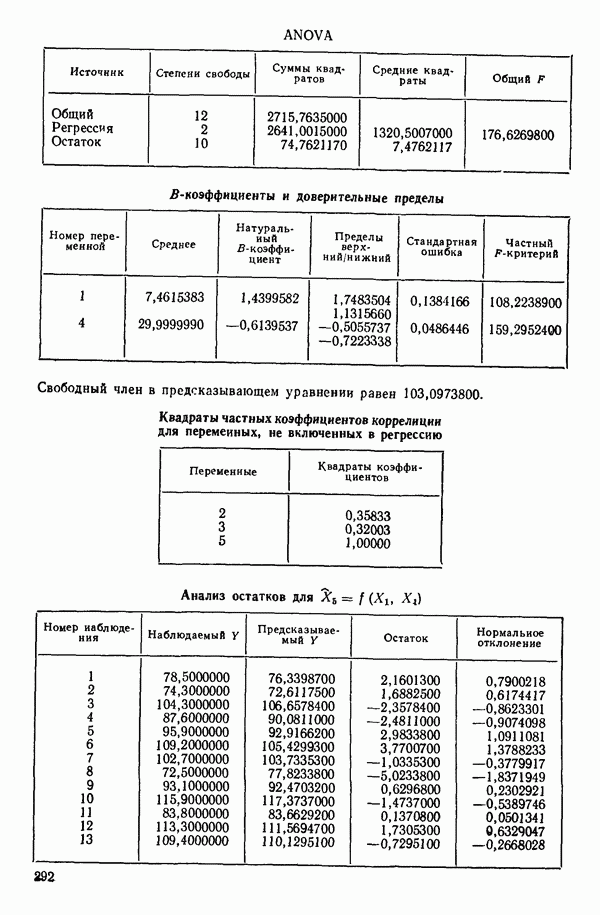
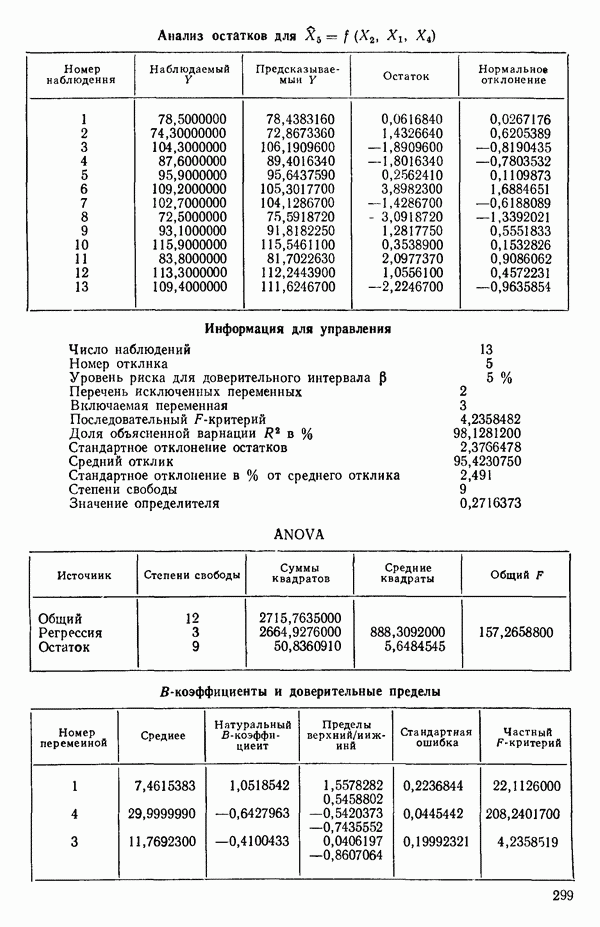
Отсюда вытекает, что существует лучший вариант с тремя параметрами (т. е. двумя предикторными переменными), чем это вытекает из среднего по остаточным средним квадратам для  которое равно 47,00. Он соответствует фактически уравнению с переменными
которое равно 47,00. Он соответствует фактически уравнению с переменными  Следующий лучший вариант при
Следующий лучший вариант при  есть уравнение с переменными
есть уравнение с переменными  для которого
для которого  Таким образом, эта процедура дала нам «асимптотическую» оценку
Таким образом, эта процедура дала нам «асимптотическую» оценку  на основании которой мы можем выбрать модель или модели, у которых оценка остаточной дисперсии примерно равна 6 и которые включают наименьшее число предикторных переменных.
на основании которой мы можем выбрать модель или модели, у которых оценка остаточной дисперсии примерно равна 6 и которые включают наименьшее число предикторных переменных.

Рис. 6.2. График зависимости среднего из остаточных средних квадратов от 
Критерий Маллоуза
Альтернативная статистика, которая в последние годы получила популярность, — это  -статистика, первоначально предложенная Маллоузом. Она имеет вид
-статистика, первоначально предложенная Маллоузом. Она имеет вид

где  остаточная сумма квадратов для модели, содержащей
остаточная сумма квадратов для модели, содержащей  параметров, включая
параметров, включая  остаточный средний квадрат для
остаточный средний квадрат для
уравнения, содержащего все переменные  При этом предполагается, что
При этом предполагается, что  является надежной несмещенной оценкой дисперсии
является надежной несмещенной оценкой дисперсии  Как показал Кеннард, величина
Как показал Кеннард, величина  тесно связана с приведенной
тесно связана с приведенной  -статистикой,
-статистикой,  и с самой
и с самой  -статистикой; см. уравнения (6.1.1), (2.6.116) и (2.6.11а). Кроме того, если уравнение с
-статистикой; см. уравнения (6.1.1), (2.6.116) и (2.6.11а). Кроме того, если уравнение с  параметрами адекватно, т. е. наблюдается удовлетворительное согласие экспериментальных и расчетных данных, то
параметрами адекватно, т. е. наблюдается удовлетворительное согласие экспериментальных и расчетных данных, то  Поскольку мы также предполагаем, что
Поскольку мы также предполагаем, что  приблизительно верно, что отношение
приблизительно верно, что отношение  имеет математическое ожидание, равное
имеет математическое ожидание, равное  откуда опять-таки вытекает, что для адекватной модели приблизительно верно соотношение
откуда опять-таки вытекает, что для адекватной модели приблизительно верно соотношение

Отсюда следует, что график зависимости  от
от  для адекватной модели будет иметь вид кривой, точки которой довольно близко примыкают к прямой
для адекватной модели будет иметь вид кривой, точки которой довольно близко примыкают к прямой  В случае уравнений с существенной неадекватностью, т. е. смещенных уравнений, возрастает число точек, которые расположены выше (а нередко и заметно выше) линии
В случае уравнений с существенной неадекватностью, т. е. смещенных уравнений, возрастает число точек, которые расположены выше (а нередко и заметно выше) линии  Благодаря случайным вариациям точки для хорошо подогнанных уравнений могут также оказаться ниже линии
Благодаря случайным вариациям точки для хорошо подогнанных уравнений могут также оказаться ниже линии  Фактическая величина
Фактическая величина  для каждой точки графика тоже имеет значение, поскольку (это можно показать) она представляет собой оценку полной суммы квадратов расхождений (обусловленных ошибками вариаций плюс ошибки смещения) расчетных значений откликов по подогнанной модели и откликов по истинной, но неизвестной модели. Когда к модели добавляют новые члены, чтобы уменьшить
для каждой точки графика тоже имеет значение, поскольку (это можно показать) она представляет собой оценку полной суммы квадратов расхождений (обусловленных ошибками вариаций плюс ошибки смещения) расчетных значений откликов по подогнанной модели и откликов по истинной, но неизвестной модели. Когда к модели добавляют новые члены, чтобы уменьшить  величина
величина  обычно возрастает. Наилучшая модель выбирается после визуального анализа графика
обычно возрастает. Наилучшая модель выбирается после визуального анализа графика  Мы будем искать регрессию с малым значением
Мы будем искать регрессию с малым значением  примерно равным
примерно равным  Если выбор не очевиден, то руководствуются частными соображениями или отдают предпочтение:
Если выбор не очевиден, то руководствуются частными соображениями или отдают предпочтение:
1) смешанному уравнению, которое не представляет фактические данные так же хорошо из-за того, что ему соответствует большее значение  (так что
(так что  но меньшая величина оценки
но меньшая величина оценки  общего расхождения (обусловленного ошибками вариаций и ошибками смещения) с откликами истинной, но неизвестной модели или
общего расхождения (обусловленного ошибками вариаций и ошибками смещения) с откликами истинной, но неизвестной модели или
2) уравнению с большим числом параметров, которое описывает фактические данные лучше (т. е.  но имеет большее общее расхождение (обусловленное ошибками вариаций и ошибками смещения) с откликами истинной, но неизвестной модели.
но имеет большее общее расхождение (обусловленное ошибками вариаций и ошибками смещения) с откликами истинной, но неизвестной модели.
Иными словами, «более короткая» модель имеет меньшую величину  но для «более длинной» модели (которая содержит больше членов) величина
но для «более длинной» модели (которая содержит больше членов) величина  ближе к
ближе к 
Дополнительные указания. Более детальное рассмотрение подобных ситуаций можно найти в книге Даниэля и Вуда (Daniel С., Wood F. S. Fitting Equations to Data. 2nd edition.- New York, J. Wiley, 1980) и в статье Гормана и Томана (Gorman J. W., Toman R. J. Selection of variables for fitting equations to data.- Technometrics, 1966, 8, p. 27-51); см. также работу
Маллоуза (Mallows С. L. Some comments on Cp.- Technomet-rics, 1973, 15, p. 661-675). Приведем цитату из последней работы, заслуживающую внимания: «Не следует ожидать, что критерий  позволит выбрать одно наилучшее уравнение, если данные существенно неадекватны для такого строгого вывода». Не существует никакой другой альтернативы. Все процедуры выбора по существу представляют собой методы упорядоченного представления и рассмотрения данных. Если их применять, руководствуясь здравым смыслом, можно получить полезные результаты. Необдуманное и/или механическое их применение может привести к бесполезным и даже бессмысленным результатам.
позволит выбрать одно наилучшее уравнение, если данные существенно неадекватны для такого строгого вывода». Не существует никакой другой альтернативы. Все процедуры выбора по существу представляют собой методы упорядоченного представления и рассмотрения данных. Если их применять, руководствуясь здравым смыслом, можно получить полезные результаты. Необдуманное и/или механическое их применение может привести к бесполезным и даже бессмысленным результатам.

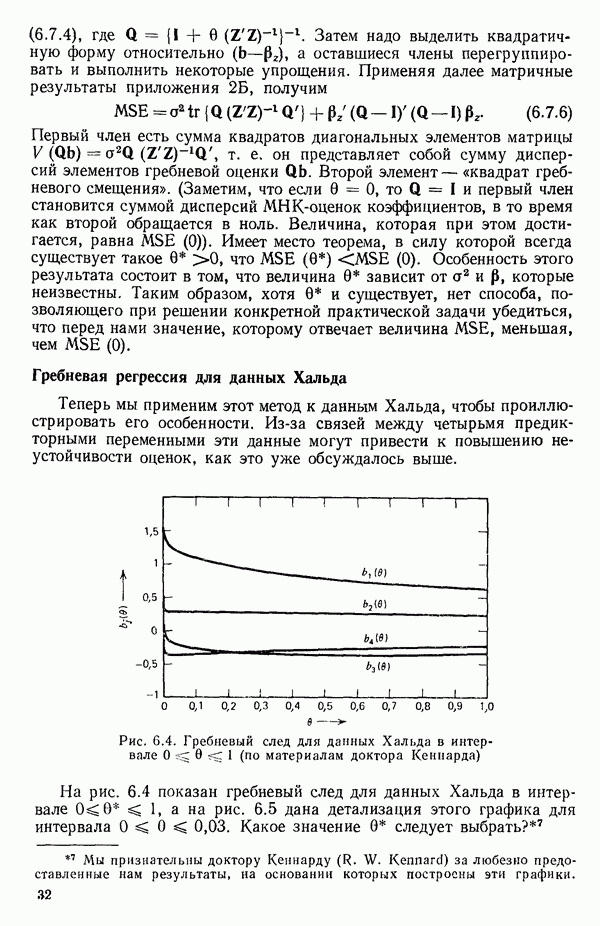
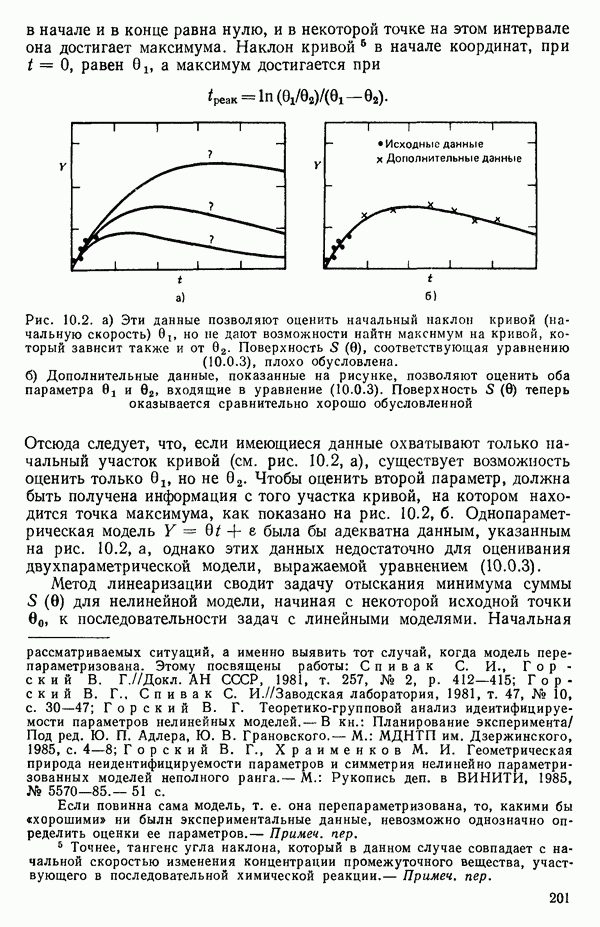
Рис. 6.3. График статистики  для данных Хальда
для данных Хальда
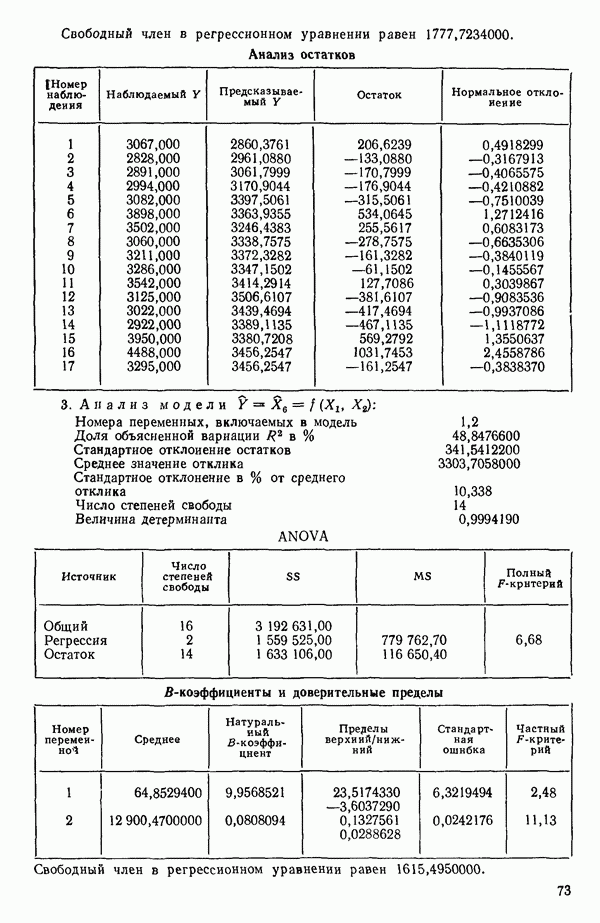
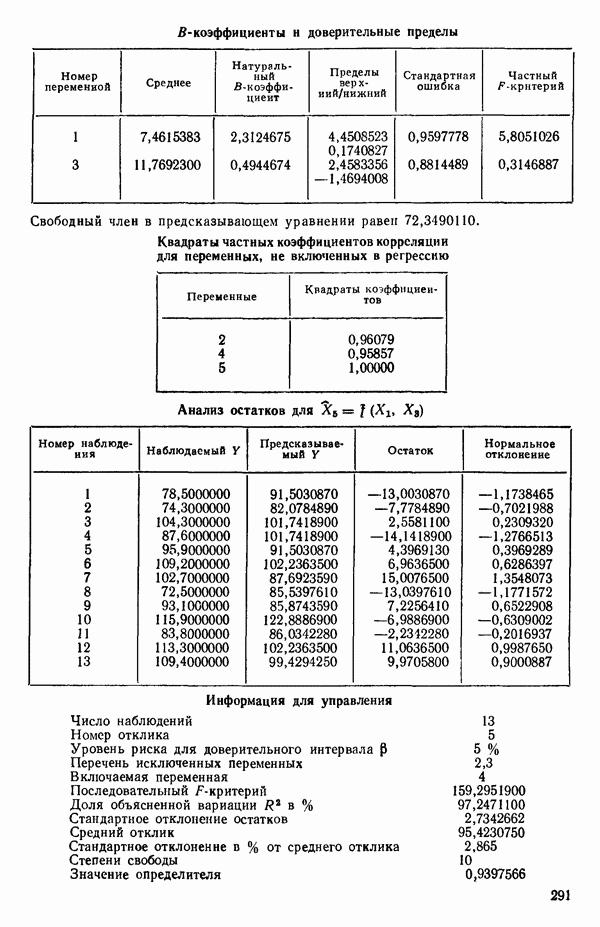
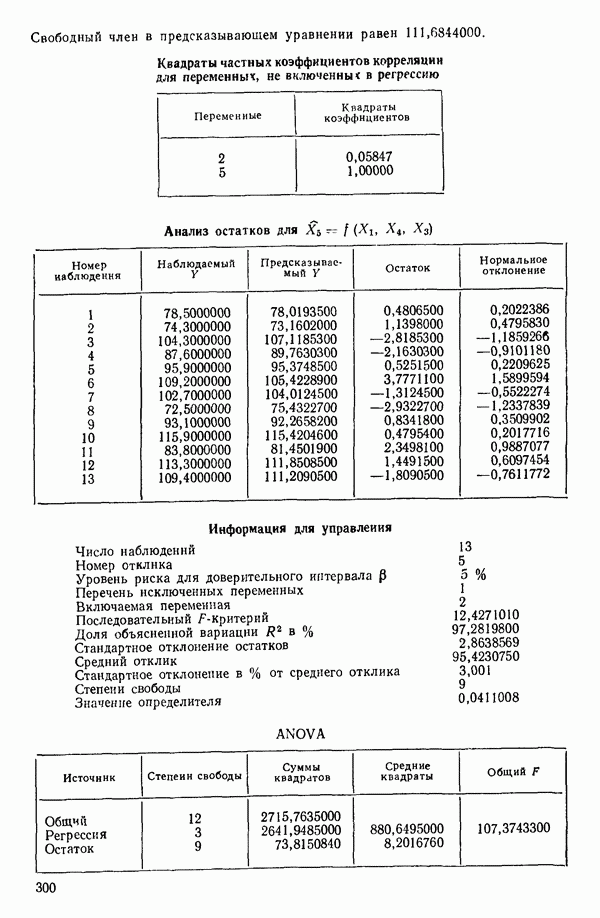
Пример использования  -статистики. Согласно данным Хальда (см. приложение Б) мы имеем
-статистики. Согласно данным Хальда (см. приложение Б) мы имеем  для оцениваемой модели, содержащей все 4 предикторные переменные. Так, например, для модели
для оцениваемой модели, содержащей все 4 предикторные переменные. Так, например, для модели  (заметим, что в данном случае
(заметим, что в данном случае  мы получим
мы получим

Это значение и все остальные значения критерия Сруказаны в табл. 6.1. Заметим, что для уравнения, содержащего все возможные предикторы,  что и должно быть справедливо по определению, так как в этом случае
что и должно быть справедливо по определению, так как в этом случае  На рис. 6.3 приведены точки, которым отвечают меньшие значения
На рис. 6.3 приведены точки, которым отвечают меньшие значения  -статистики. Точки, имеющие большие значения критерия
-статистики. Точки, имеющие большие значения критерия  заметно отстоят от прямой по сравнению с остальными. Поэтому мы можем исключить их из рассмотрения. На основе
заметно отстоят от прямой по сравнению с остальными. Поэтому мы можем исключить их из рассмотрения. На основе  -статистики мы можем заключить, что уравнение с предикторами
-статистики мы можем заключить, что уравнение с предикторами  является наиболее предпочтительным по сравнению с остальными. Ему не только соответствует наименьшее значение величины
является наиболее предпочтительным по сравнению с остальными. Ему не только соответствует наименьшее значение величины  но оно имеет также преимущество по сравнению с моделью, содержащей предикторы
но оно имеет также преимущество по сравнению с моделью, содержащей предикторы  которая проявляет признаки смещения. Вывод о том, что уравнение с
которая проявляет признаки смещения. Вывод о том, что уравнение с  является предпочтительным, согласуется с тем, что мы решили бы, производя отбор с использованием критериев
является предпочтительным, согласуется с тем, что мы решили бы, производя отбор с использованием критериев  как описано выше. Однако в данном примере такой вывод вытекает до некоторой степени более естественно из графика
как описано выше. Однако в данном примере такой вывод вытекает до некоторой степени более естественно из графика 
Таблица 6.1. Величины  для уравнений по данным Хальда
для уравнений по данным Хальда

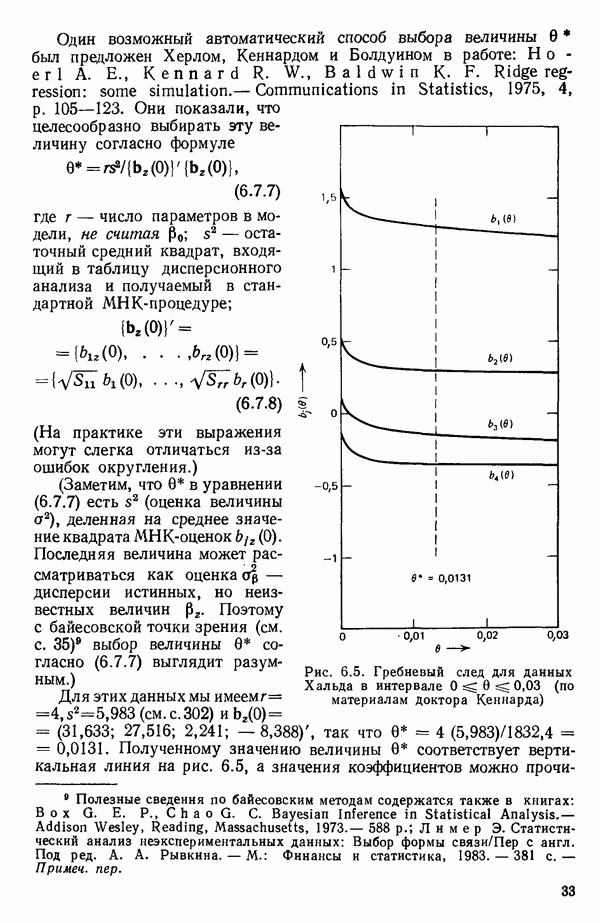
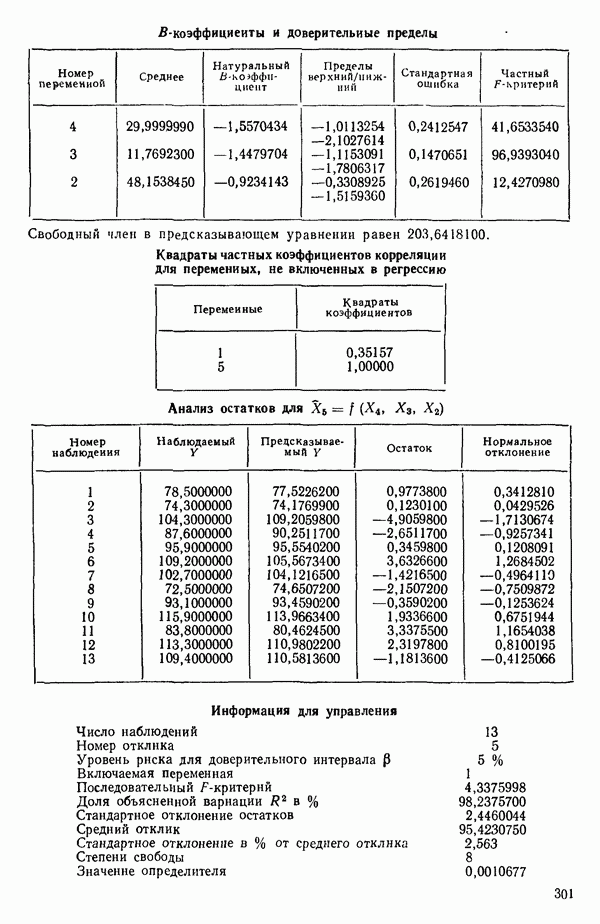
Общие замечания. Ранее упоминалось, что данные, использованные в этом примере, подвержены теоретическому ограничению  Из него вытекает, что
Из него вытекает, что  теоретически зависит от
теоретически зависит от  Следовательно, если бы в модель были включены все четыре фактора и ограничение выполнялось бы строго, то матрица
Следовательно, если бы в модель были включены все четыре фактора и ограничение выполнялось бы строго, то матрица  была бы вырожденной и имела бы детерминант, равный нулю, как до, так и после преобразования. Как мы видим из соответствующей машинной распечатки, см. с. 301, преобразованный детерминант действительно имеет очень малое значение,
была бы вырожденной и имела бы детерминант, равный нулю, как до, так и после преобразования. Как мы видим из соответствующей машинной распечатки, см. с. 301, преобразованный детерминант действительно имеет очень малое значение,
0,0010677. Когда детерминант имеет такое малое значение, нередко оказывается, что вычисления содержат главным образом ошибки округления и потому бессмысленны. И хотя в данном случае этого не произошло, появление малых значений детерминанта всегда должно настораживать (см. 5.5).
Избранные ссылки на работы, где отражены различные аспекты метода всех регрессий, приведены в библиографии.
Мнение. В общем анализ всех уравнений регрессии — довольно ненадежная процедура. Хотя она означает, что статистик «рассмотрел все возможности», но одновременно это значит, что он исследовал большое число регрессионных уравнений, многие из которых при здравом размышлении могли бы быть отвергнуты сразу. Если исследуется более пяти переменных, то затраты машинного времени становятся чрезмерными. Резко возрастают также усилия, связанные с анализом результатов всех вычислений, выведенных на печать. Поэтому более предпочтительны другие методы выбора регрессионного уравнения, которые менее трудоемки.