Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
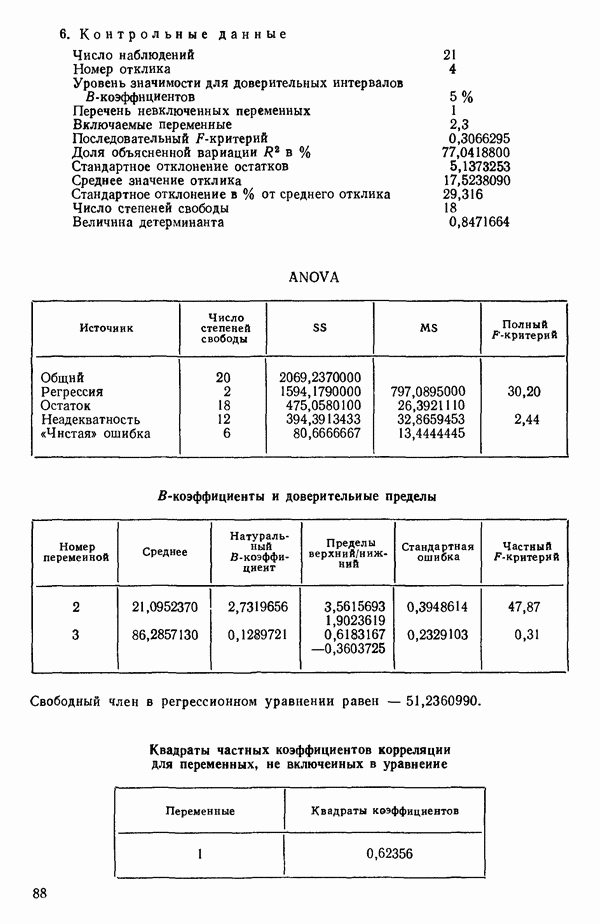
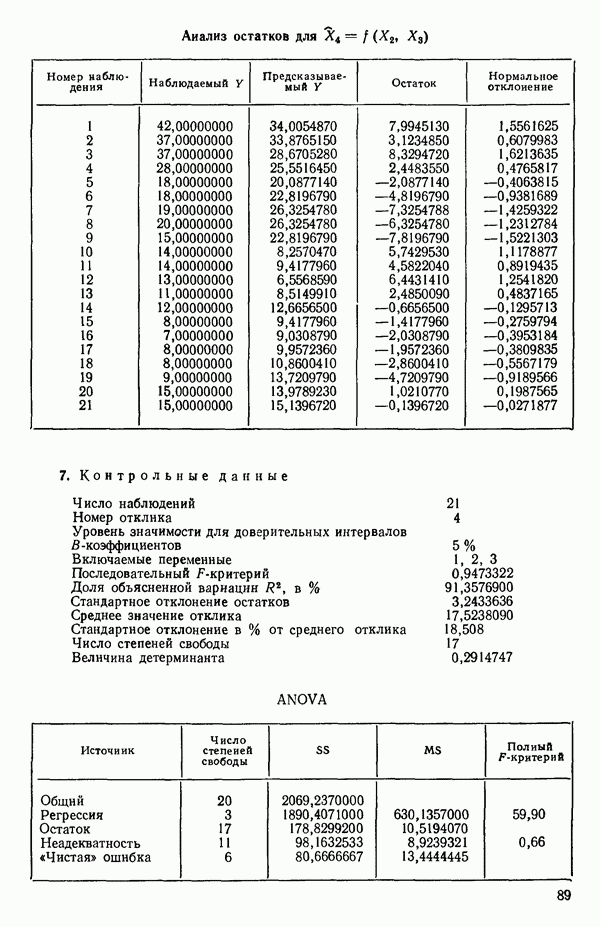
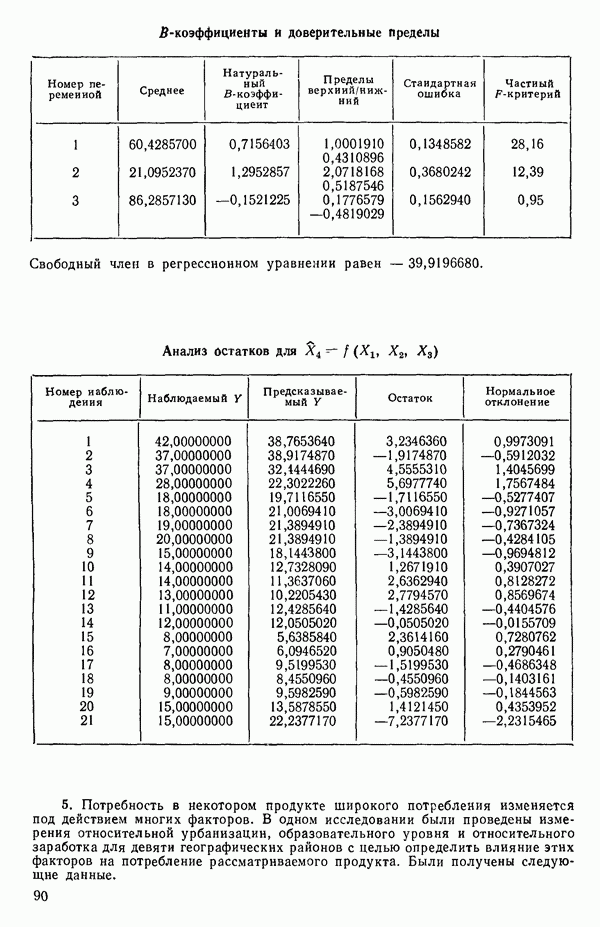
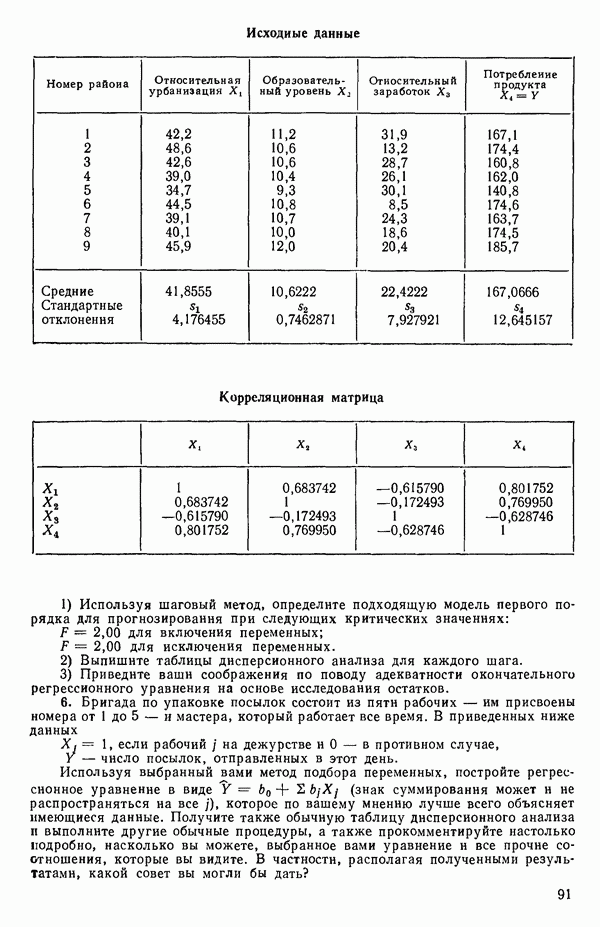
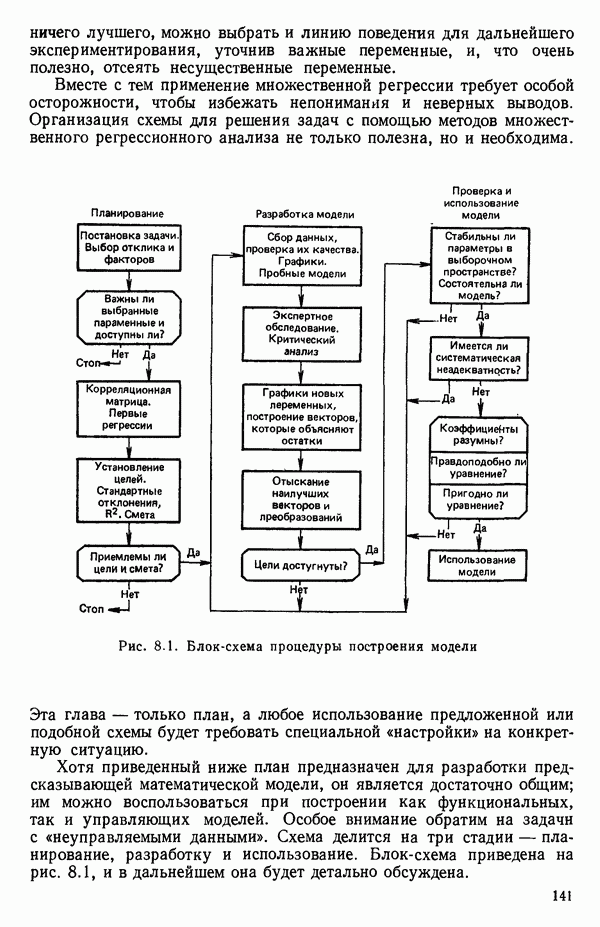
Глава 6. ВЫБОР «НАИЛУЧШЕГО» УРАВНЕНИЯ РЕГРЕССИИ6.0. ВведениеМы отложим обсуждение общей процедуры построения модели до гл. 8, а в данной главе ограничимся рассмотрением только нескольких статистических методов отбора переменных в регрессионном анализе. Предположим, что мы хотим построить линейное регрессионное уравнение для некоторого отклика 1. Если мы хотим сделать уравнение полезным для прогноза, мы должны стремиться включить в него как можно больше переменных 2. Поскольку затраты, связанные с получением информации и ее последующим контролем при большом числе переменных Компромисс между этими крайностями как раз и есть то, что обычно называется выбором «наилучшего» уравнения регрессии. Для реализации такого выбора нет однозначной статистической процедуры. Если бы мы знали величину применением критериев Некоторые предостережения относительно использования данных пассивного эксперимента Если регрессионный анализ проводится по данным пассивного эксперимента (т. е. по данным, которые получаются при обычном функционировании объекта, а не в результате специально спланированных экспериментов), то могут возникать некоторые потенциально опасные ситуации, описанные в статье: Box G. Е. P. Use and abuse of regression. Technometrics, 8, 1966, p. 625-629. Ошибка в модели может не быть случайной, а оказаться следствием совместного влияния нескольких переменных, не содержащихся в регрессионном уравнении, а возможно, и вовсе неизмеряемых (они называются скрытыми (латентными) переменными). Из-за возможного смещения оценок параметров (см. 2.12) наблюдаемый ложный эффект некоторой переменной может провоцироваться фактически неизмеряемой скрытой переменной. Если система продолжает действовать в том же режиме, в котором производилась запись данных, это не вводит в заблуждение. Однако поскольку эта скрытая переменная не измерялась, ее изменения не были видны и не регистрировались; в дальнейшем они могут привести к тому, что предсказания по модели станут ненадежными. Другой дефект данных пассивного эксперимента зачастую состоит в том, что наиболее существенные предикторные переменные изменяются в весьма узких пределах, вследствие чего отклики поддерживаются в определенных границах. Малость этих изменений может стать причиной того, что некоторые коэффициенты регрессии окажутся «статистически незначимыми». Подобный вывод к тому же не удовлетворит и практиков, поскольку они «знают», что эти переменные существенны. Обе точки зрения, конечно совместимы: если эффективная предикторная переменная не варьируется сильно, она будет выглядеть малоэффективной или неэффективной. Третья проблема, возникающая при использовании данных пассивного эксперимента, состоит в том, что распространенная на практике стратегия управления объектами (например, если предикторами. В тех случаях, когда планирование экспериментов невозможно, данные случайного происхождения все же можно анализировать с помощью регрессионных методов. Однако надо иметь в виду, что при этом появляются дополнительные обстоятельства, благоприятствующие ошибочным заключениям.
|
 |
Оглавление
|










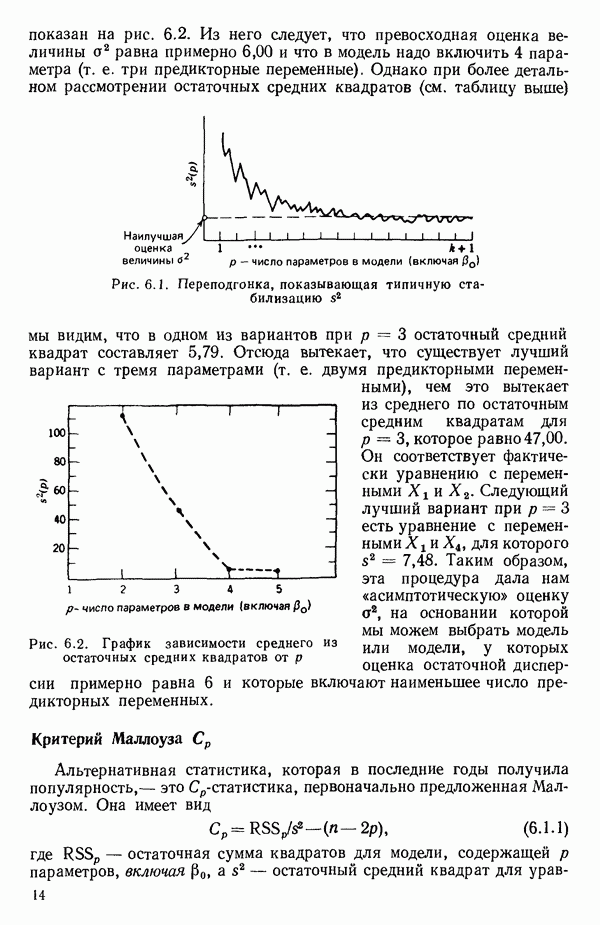

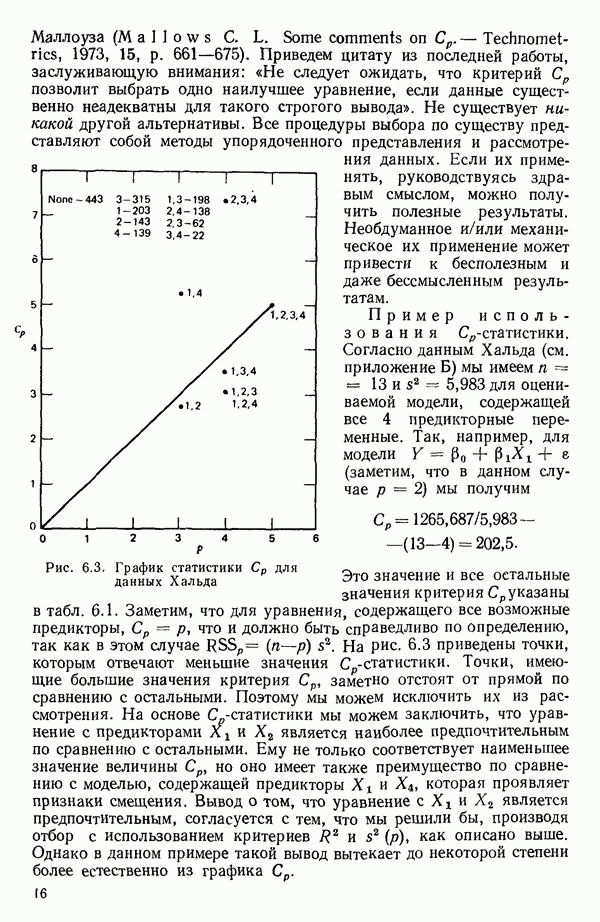















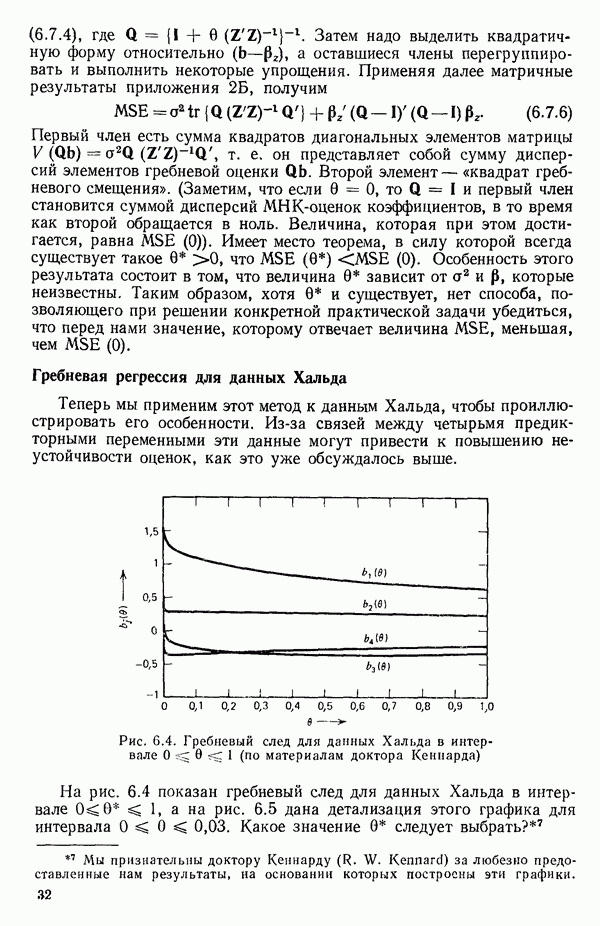
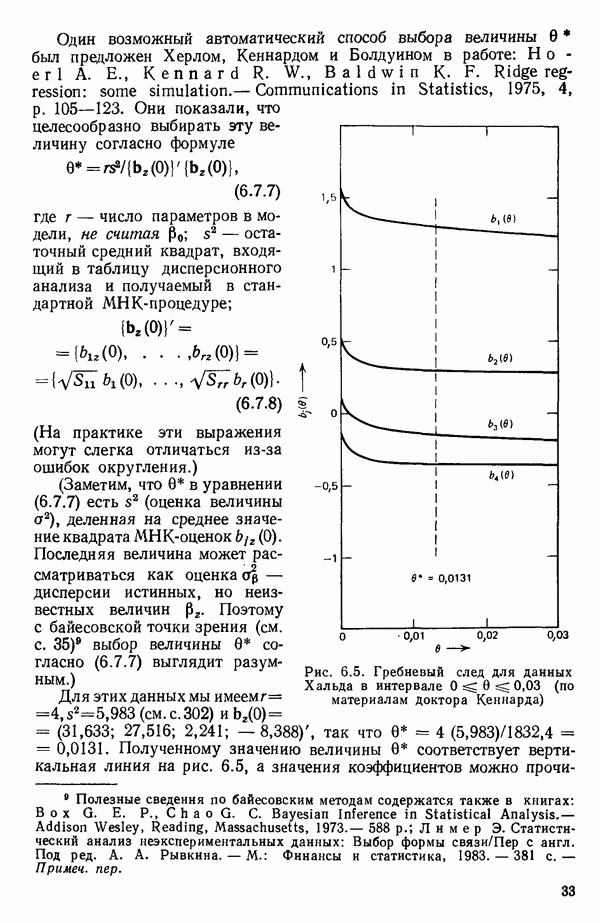





































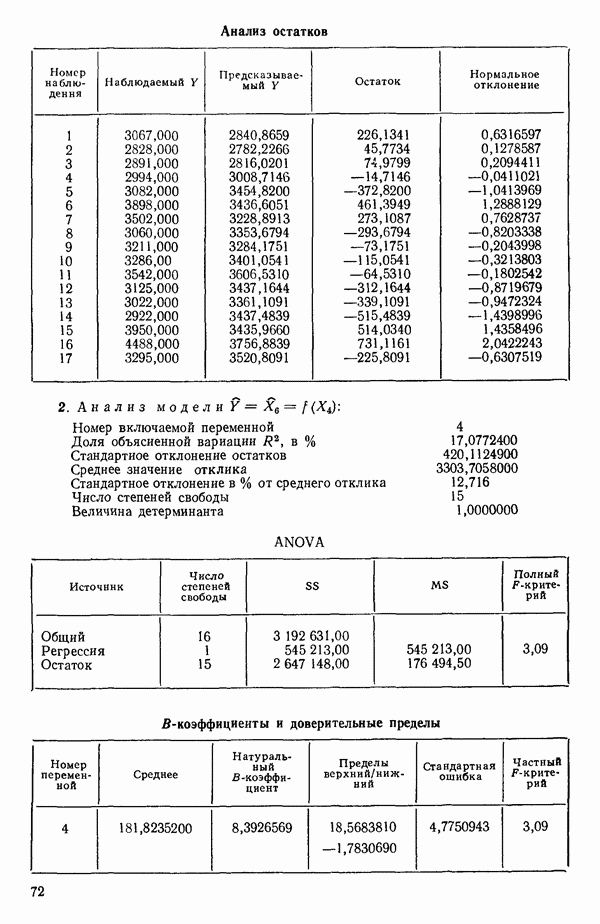
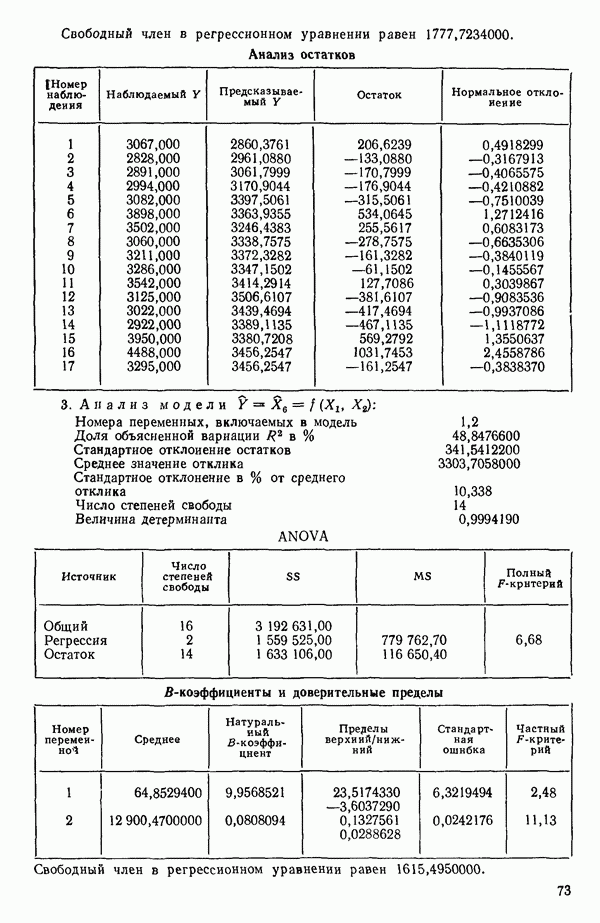
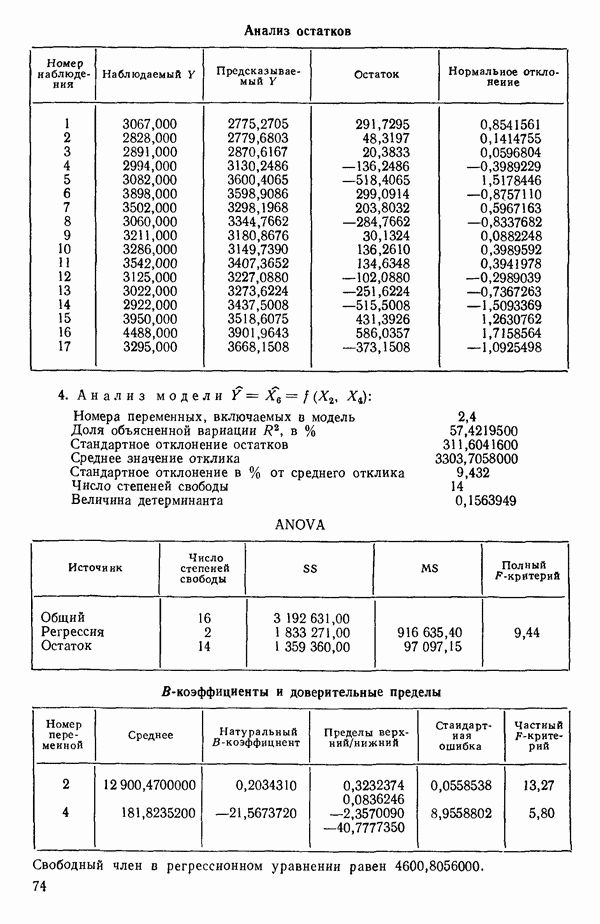
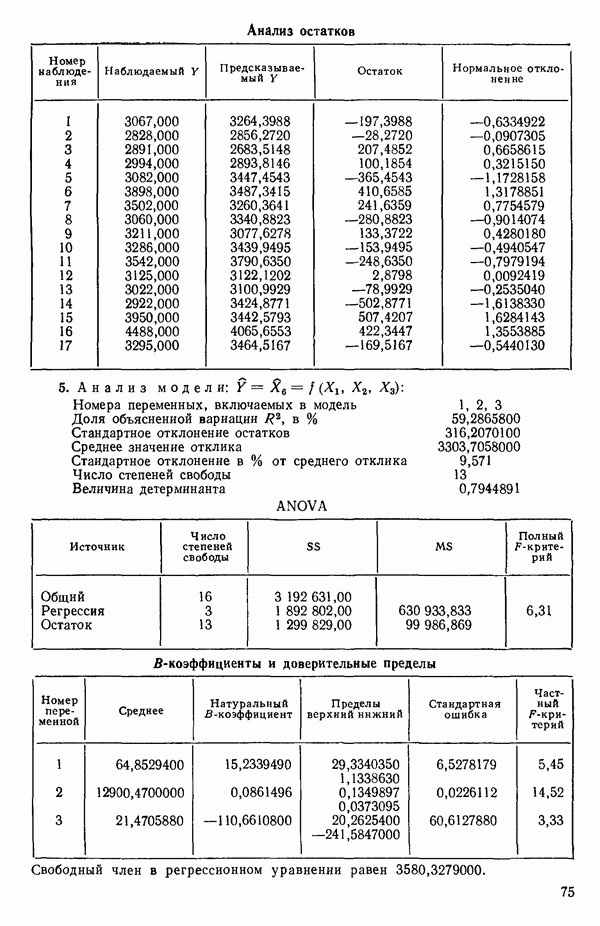
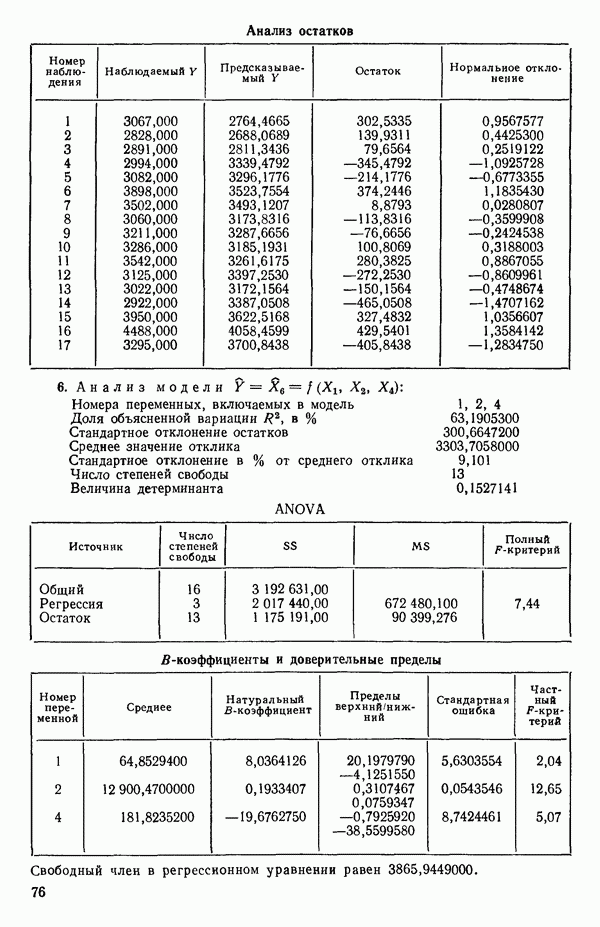
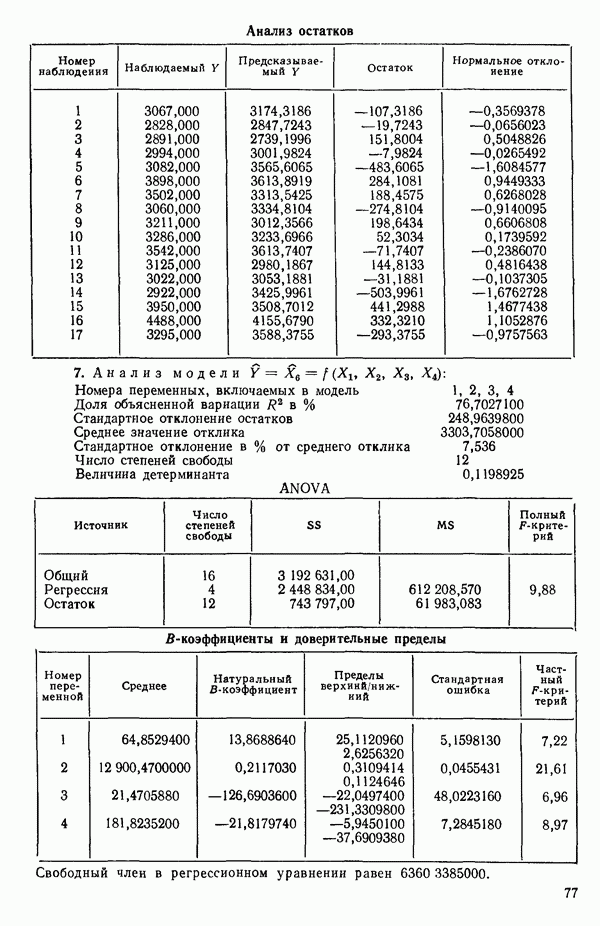
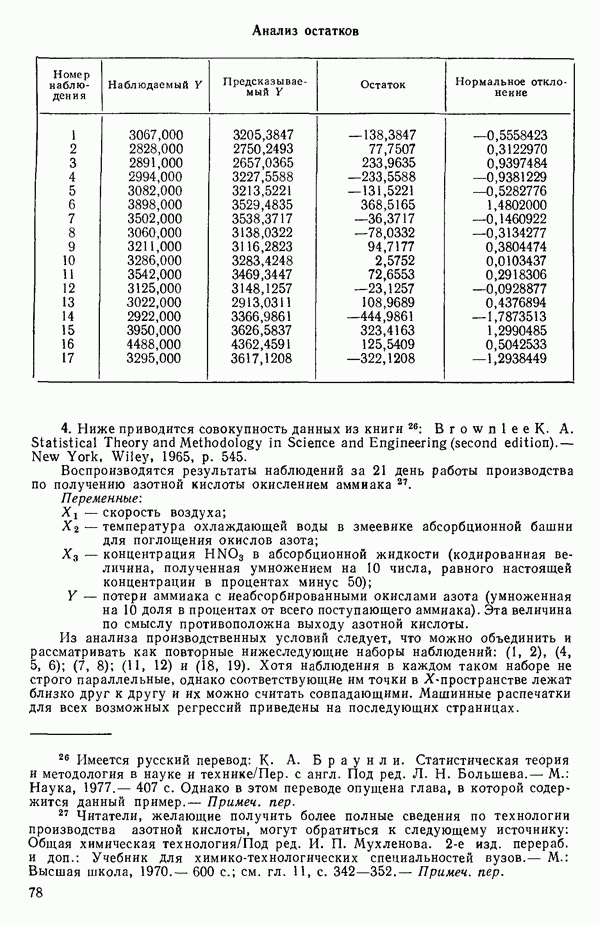

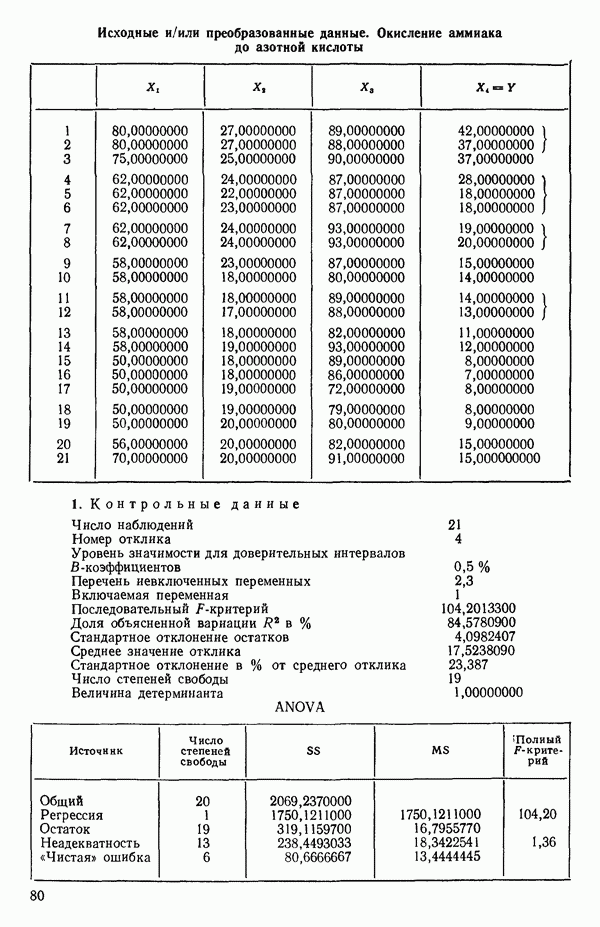
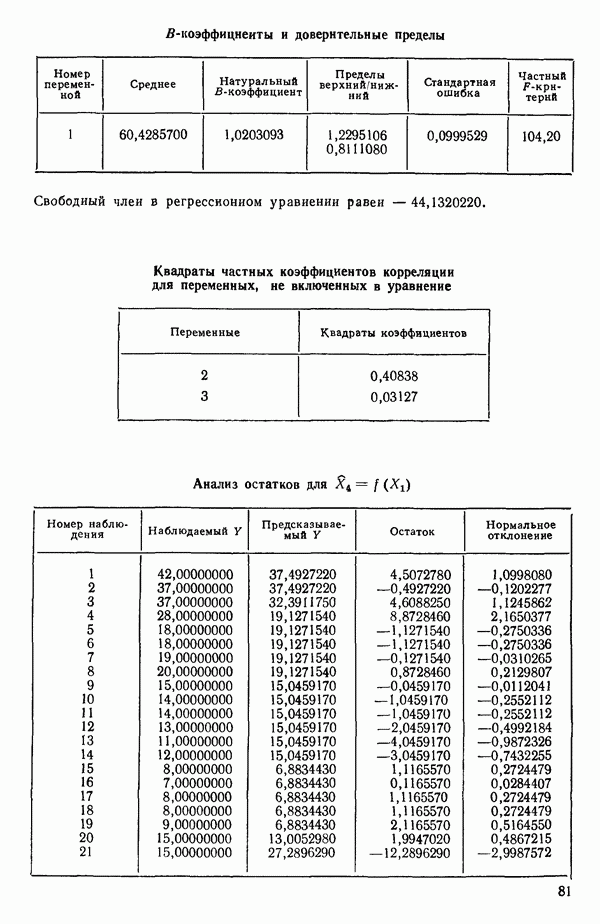
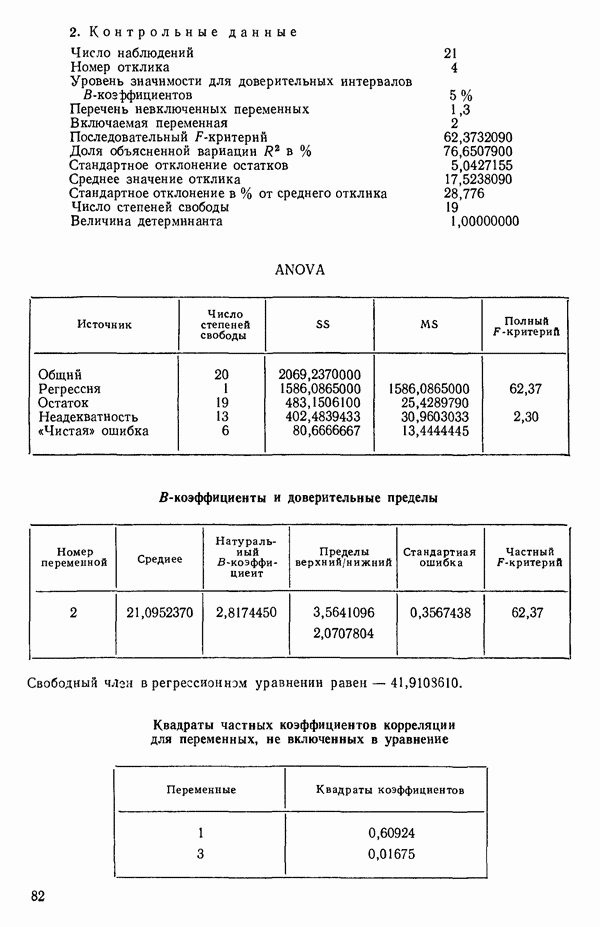
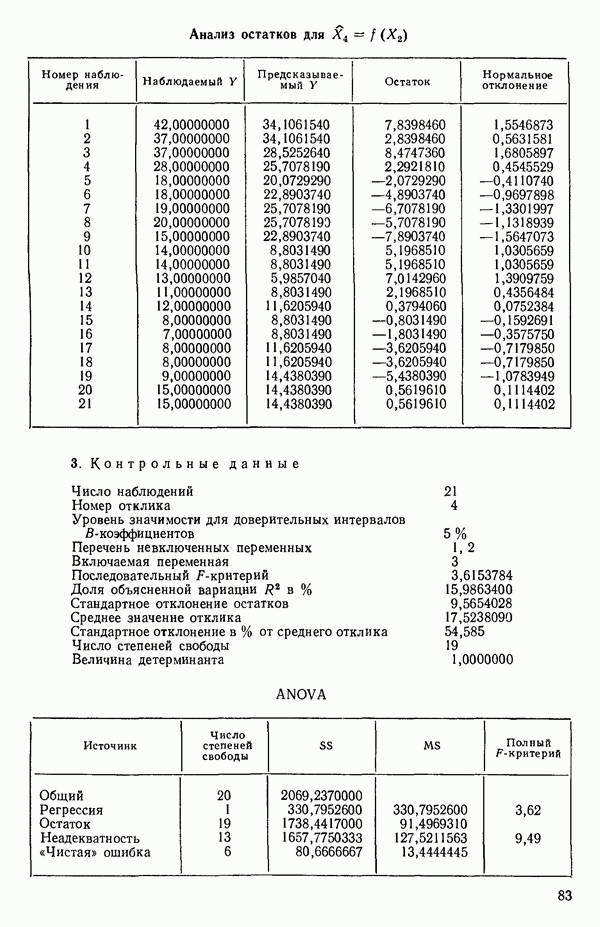
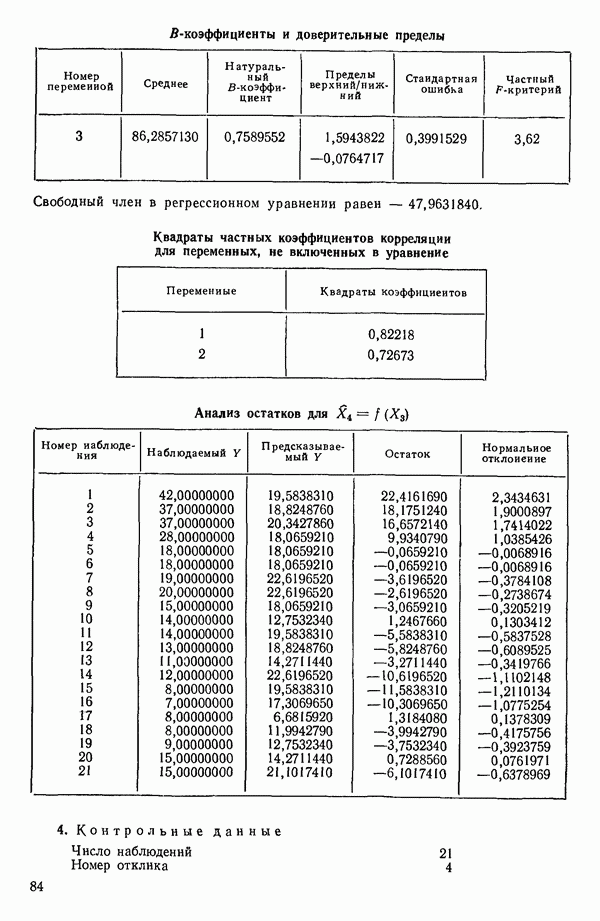
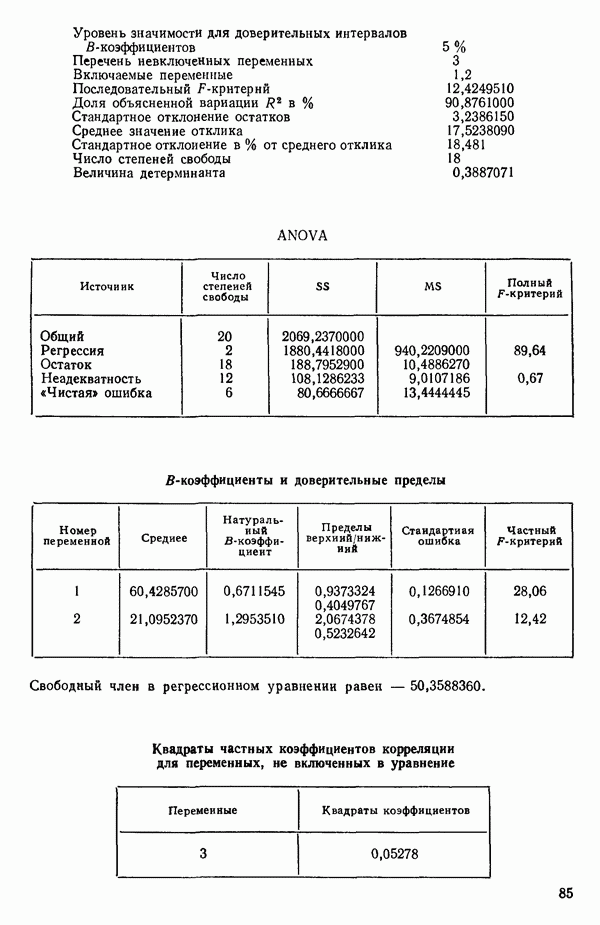
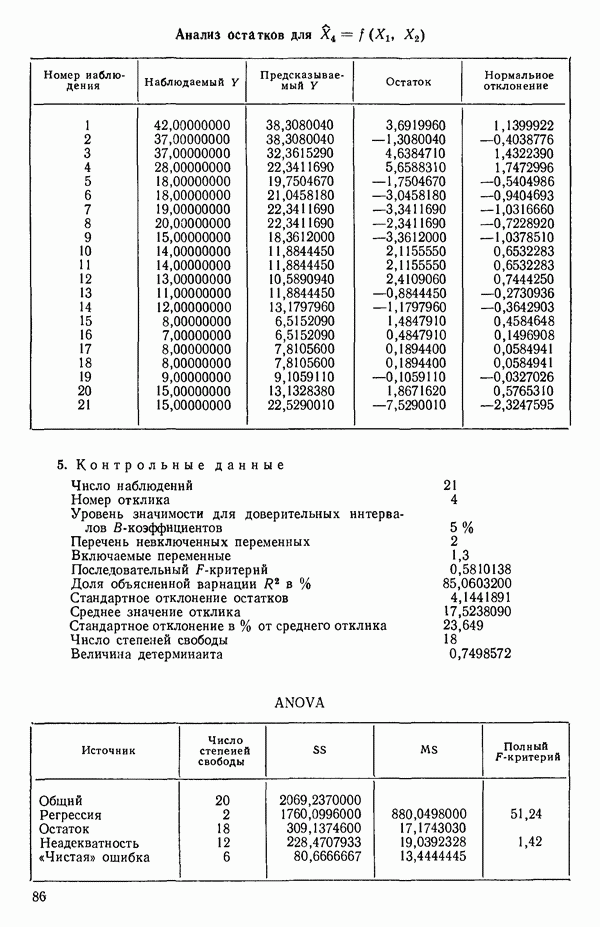
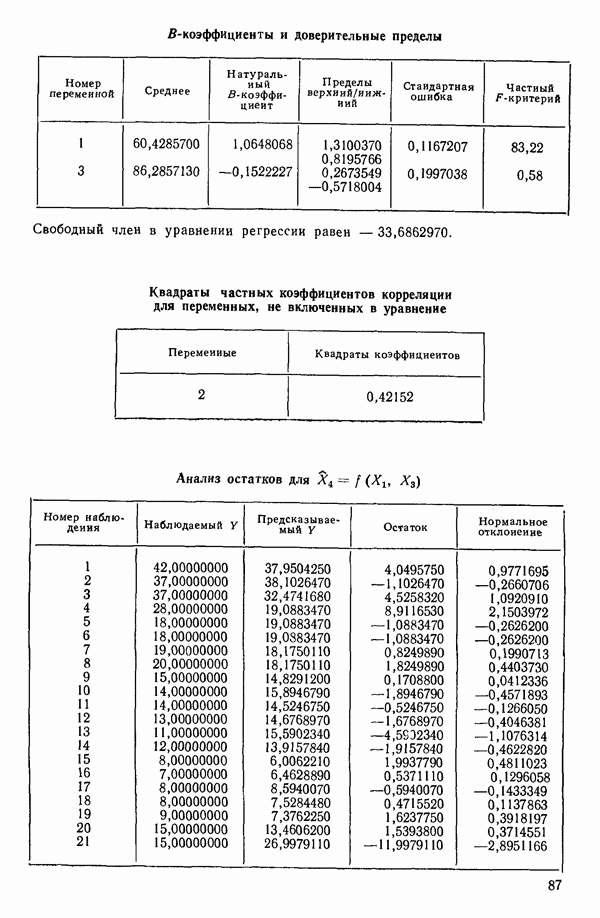
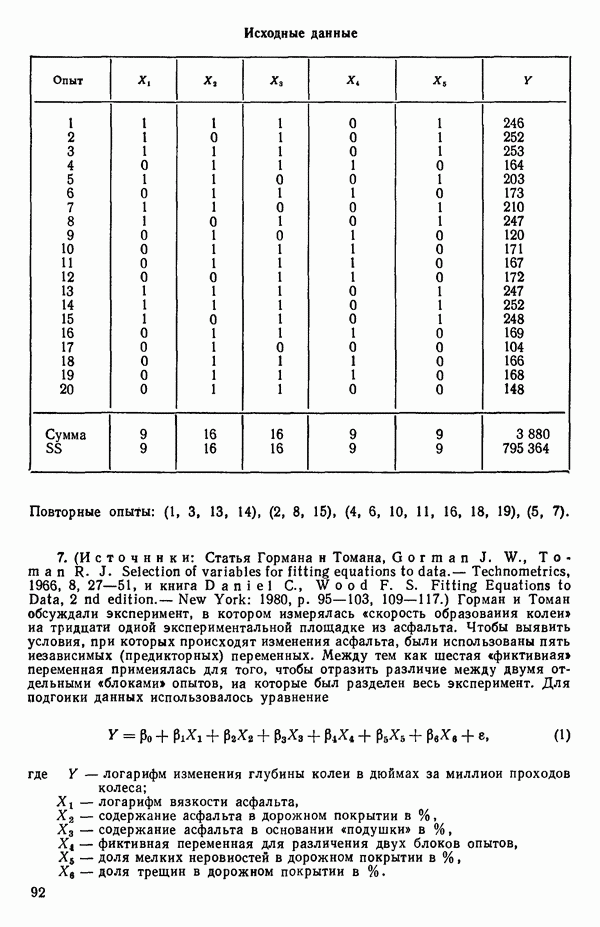
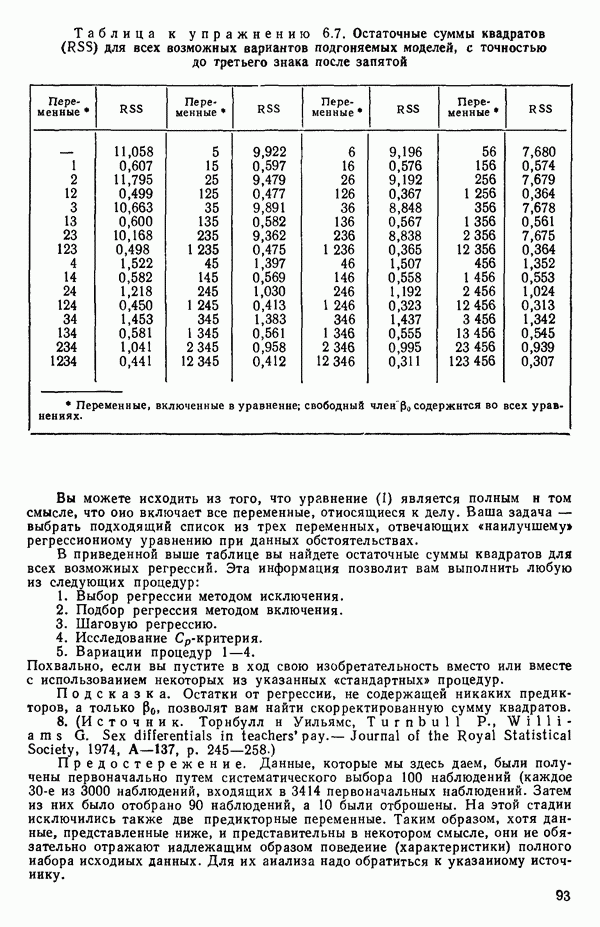

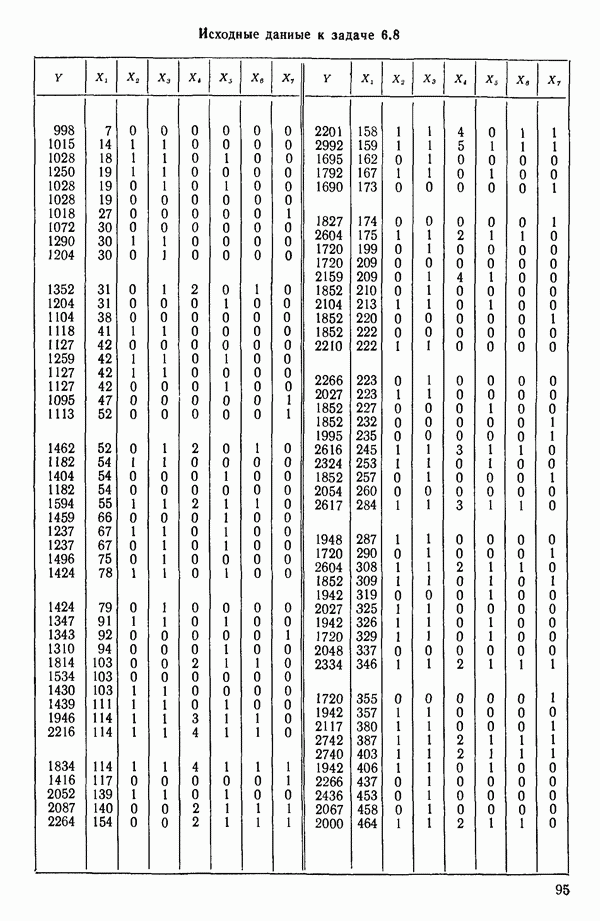

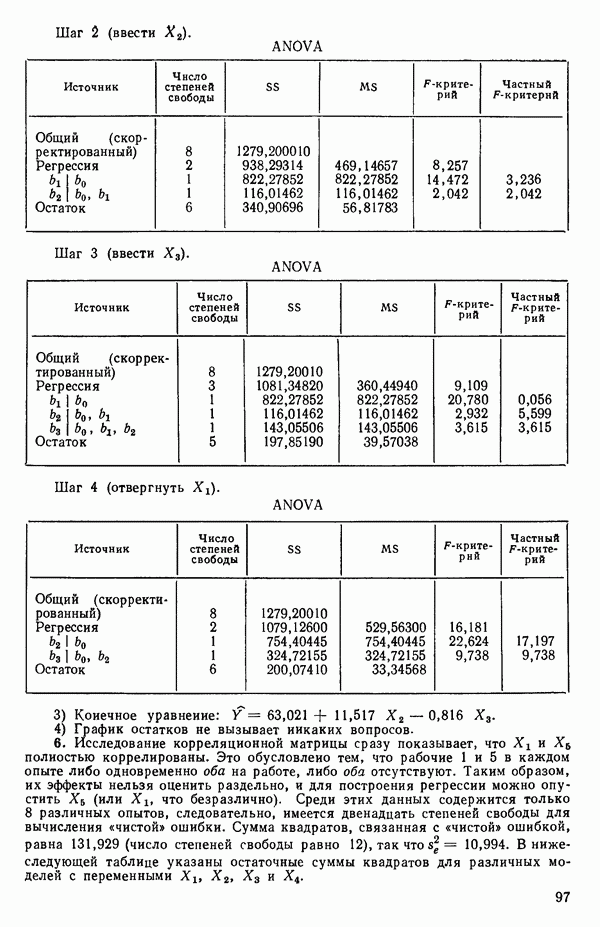
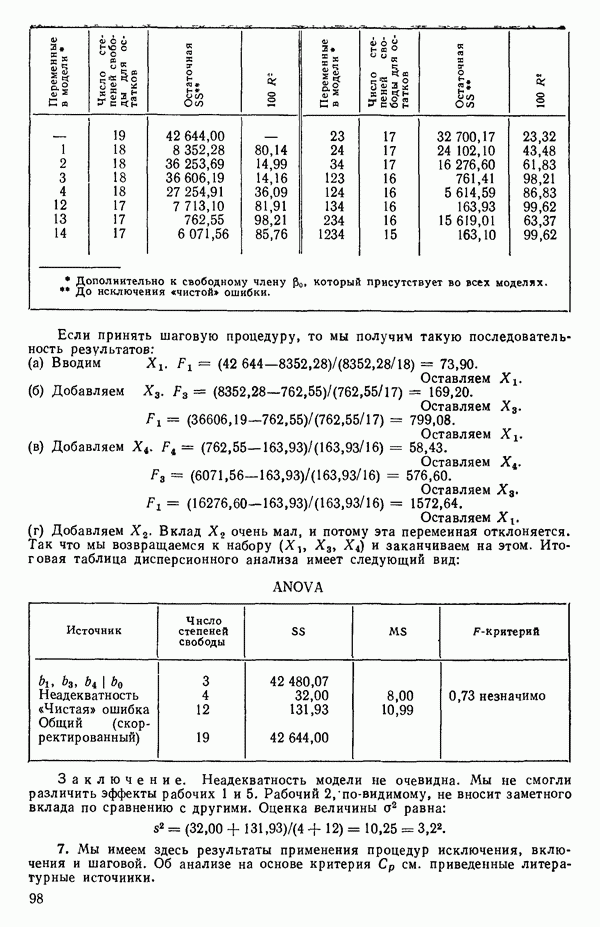







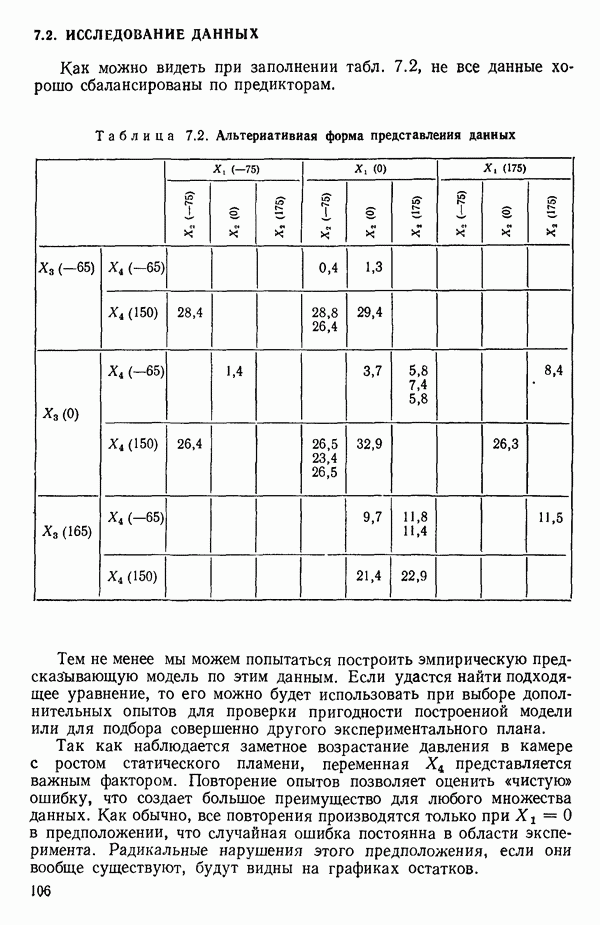
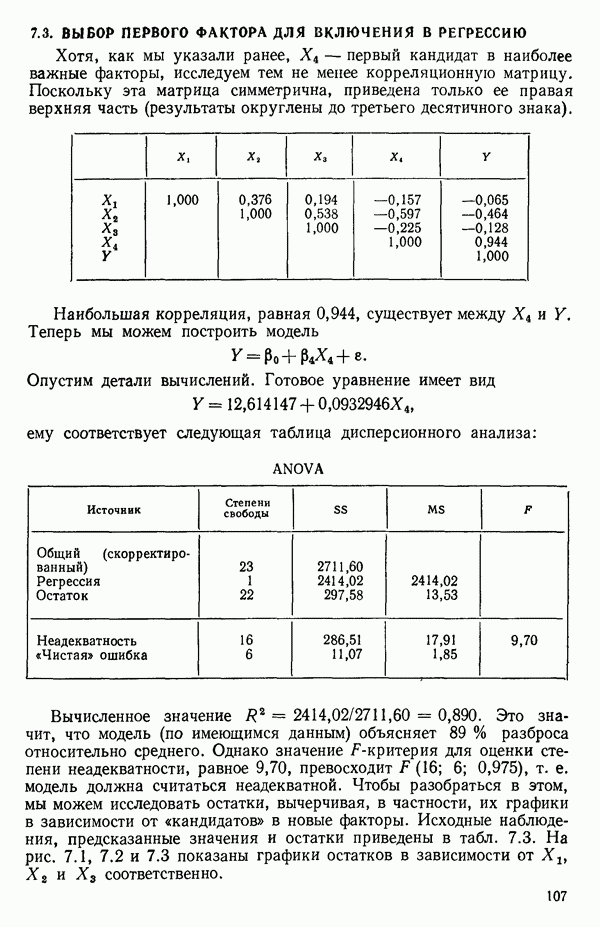
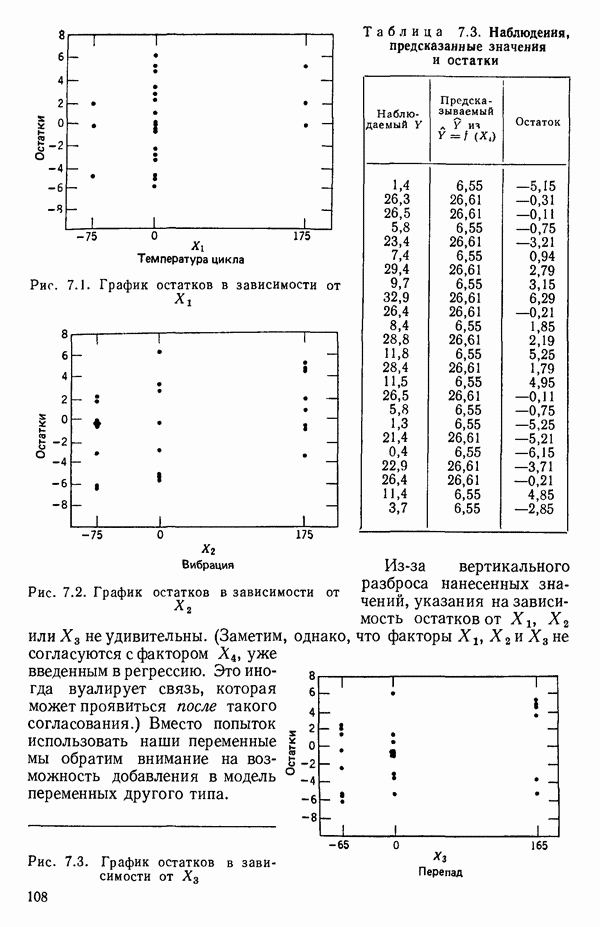
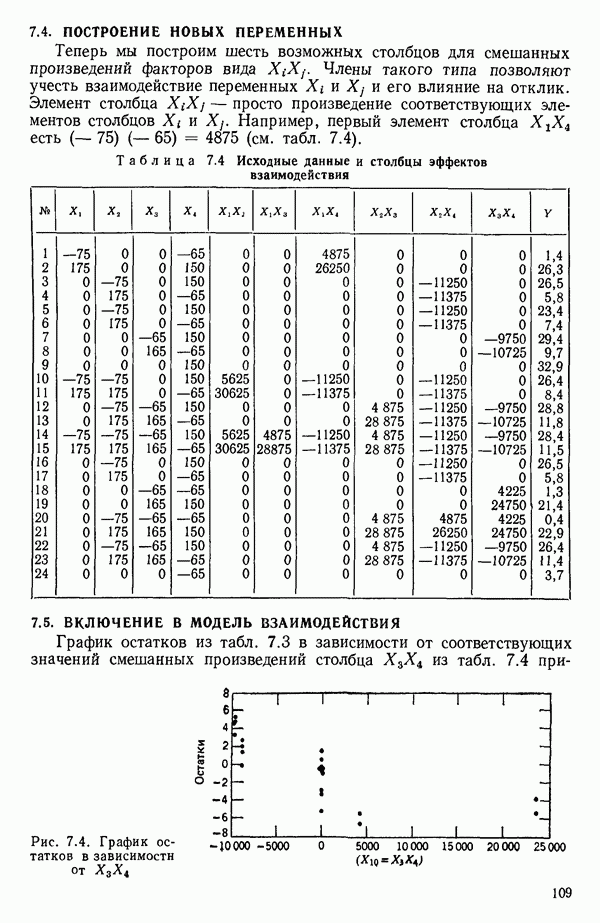
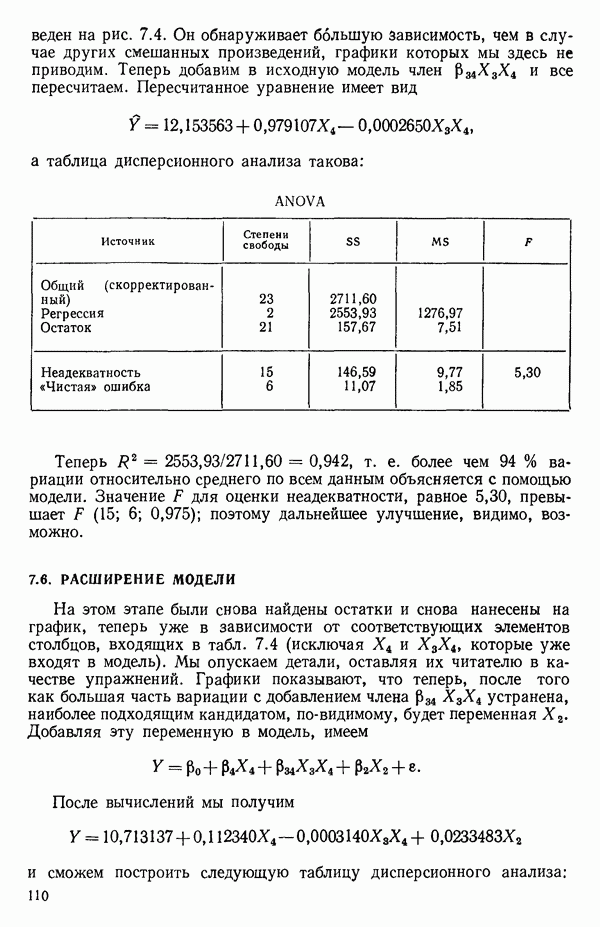
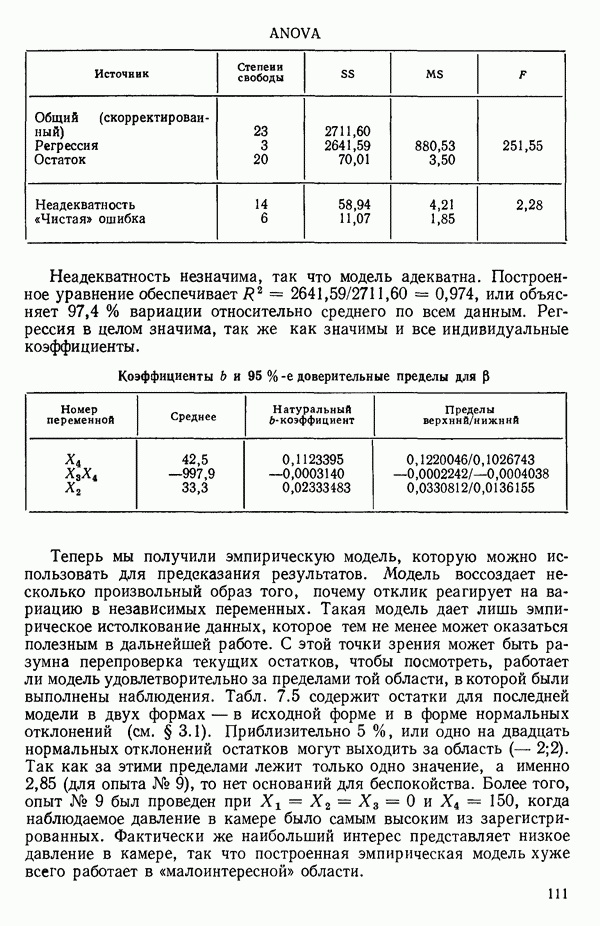


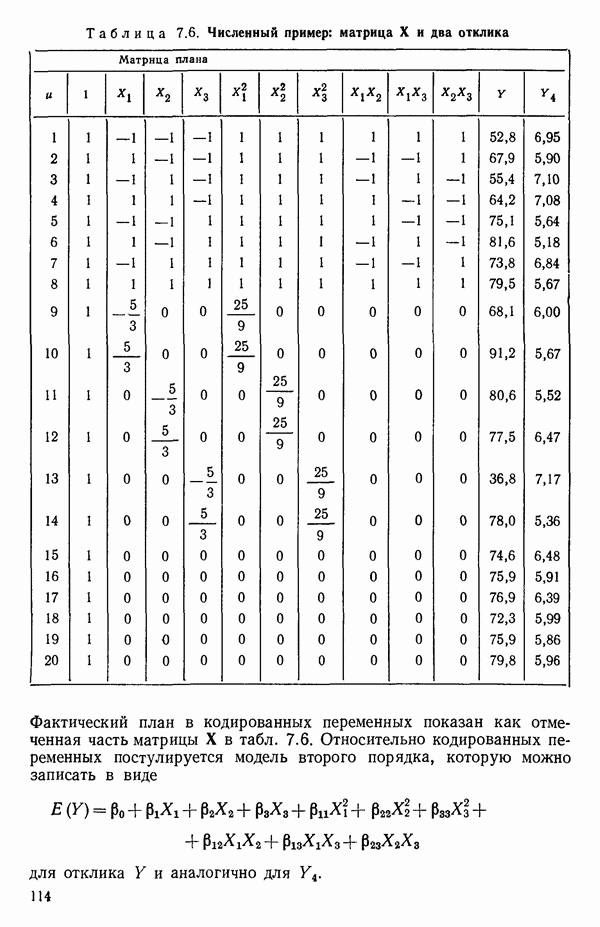






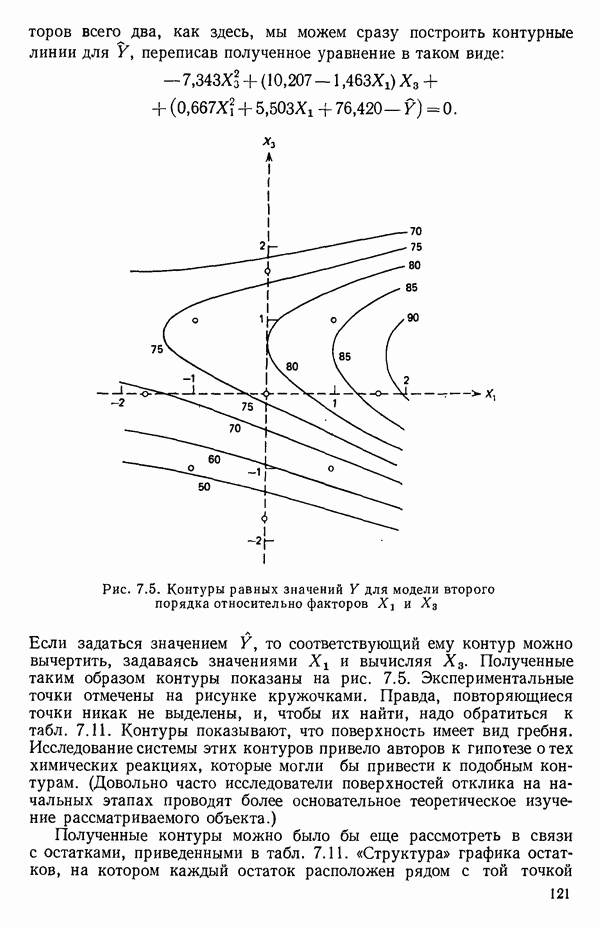
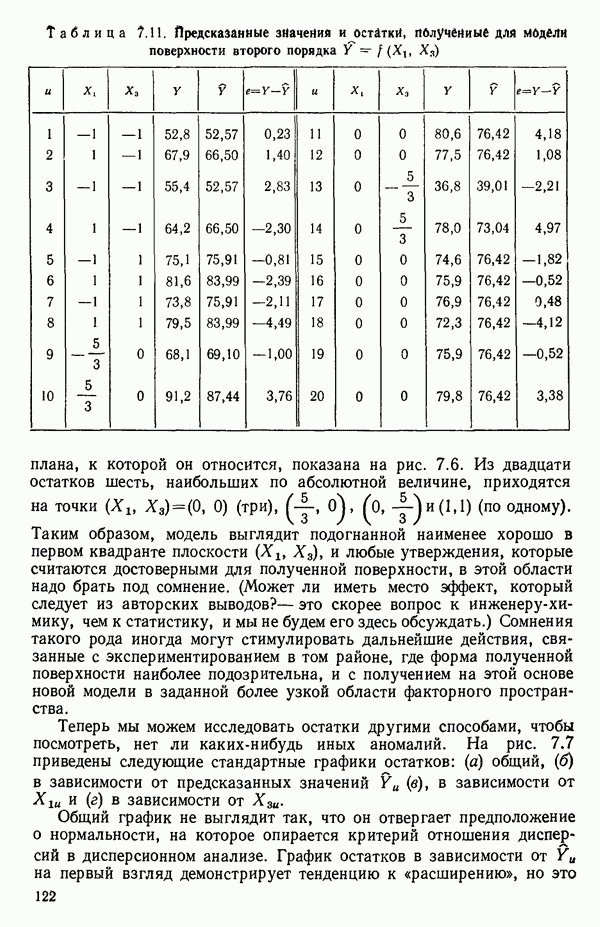




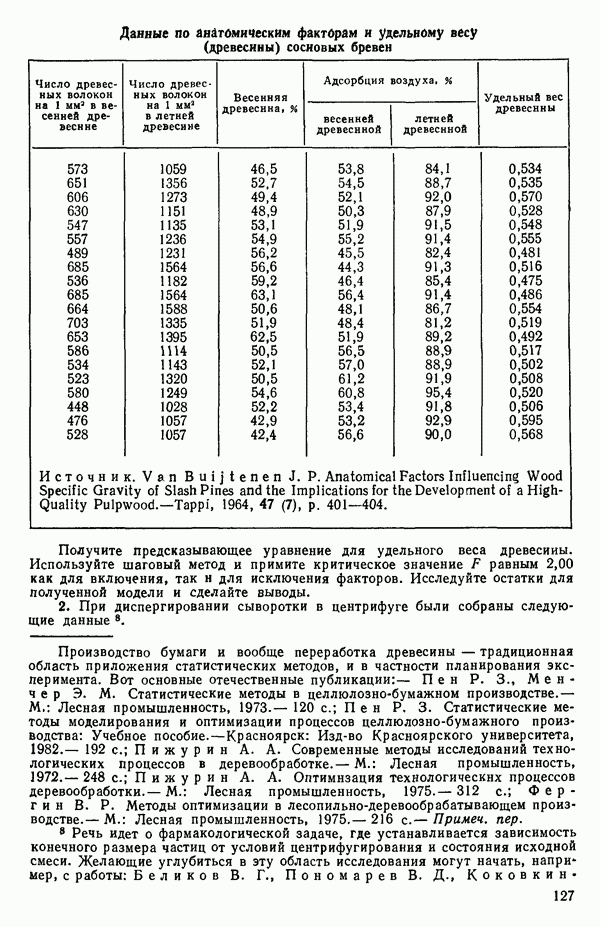


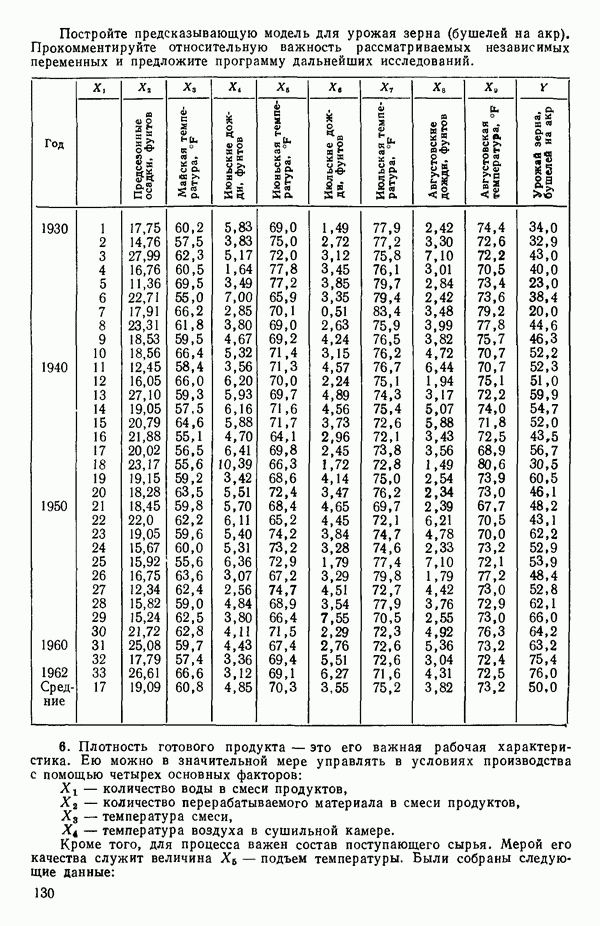


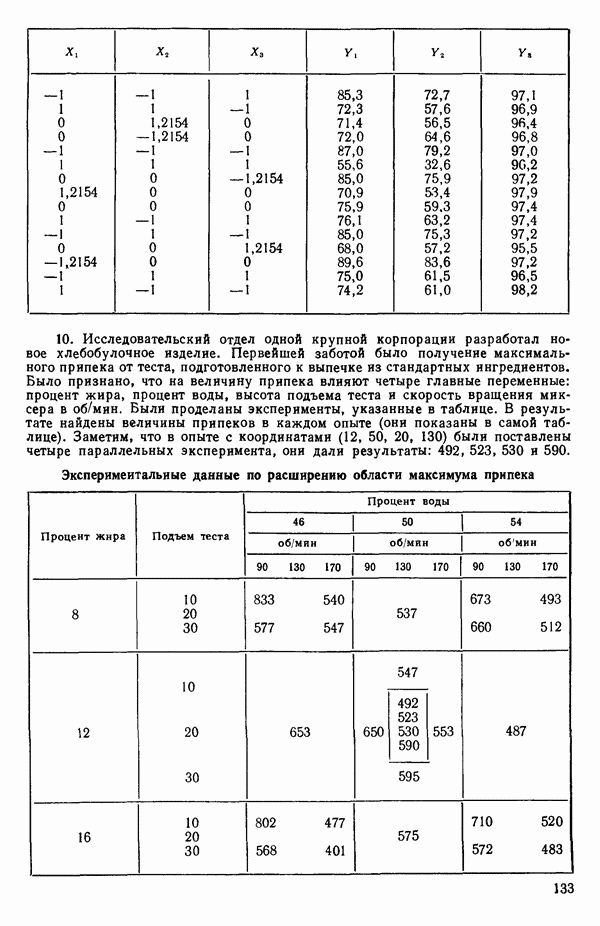



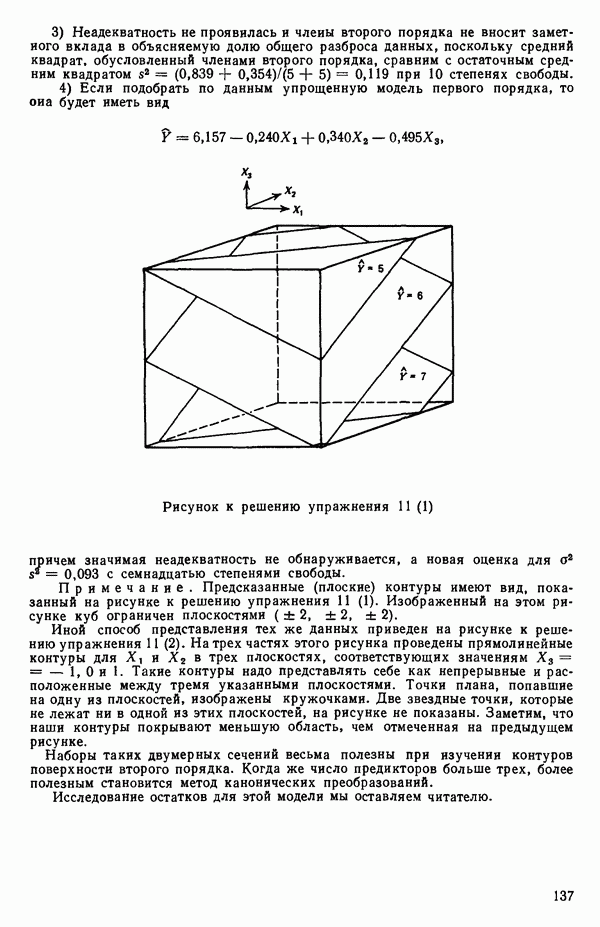
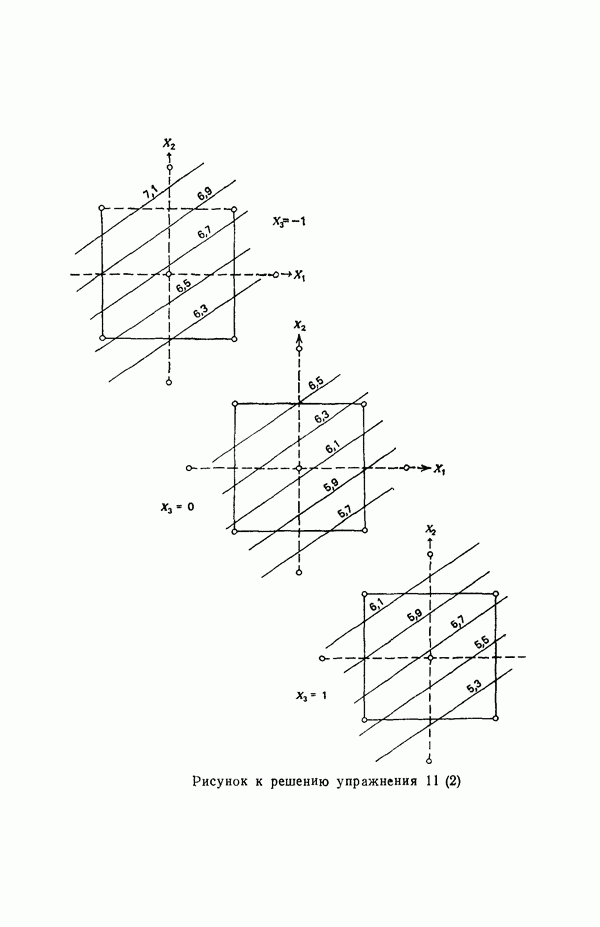














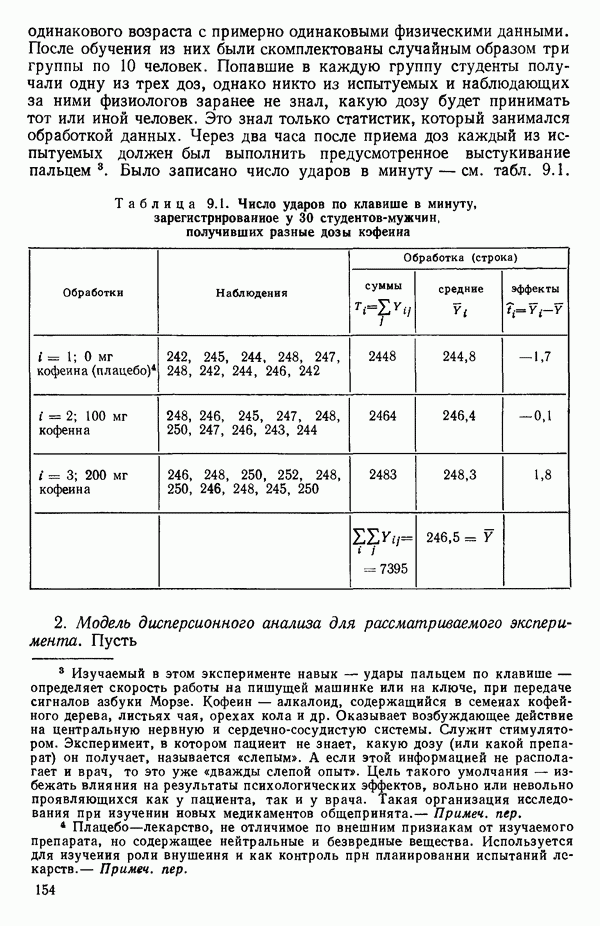


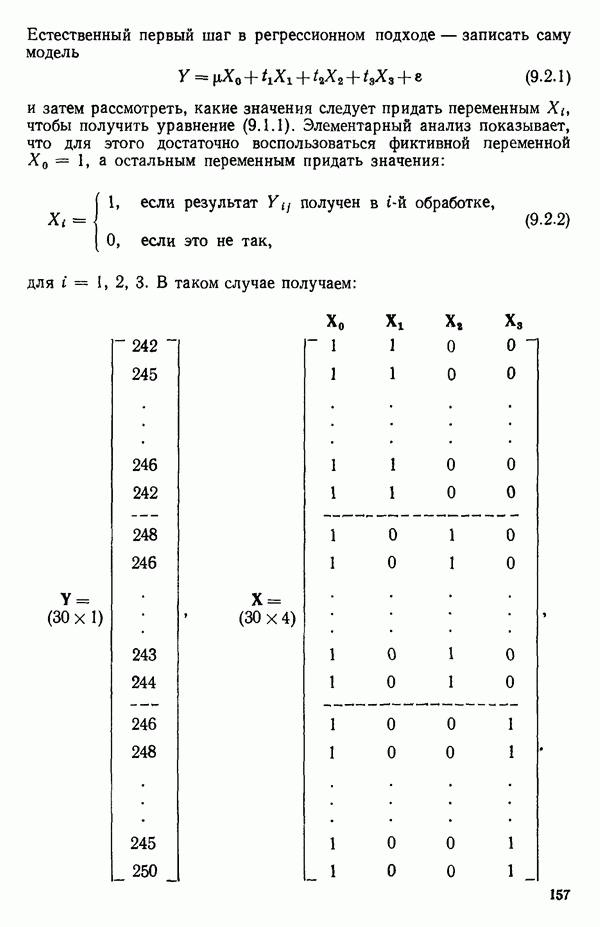

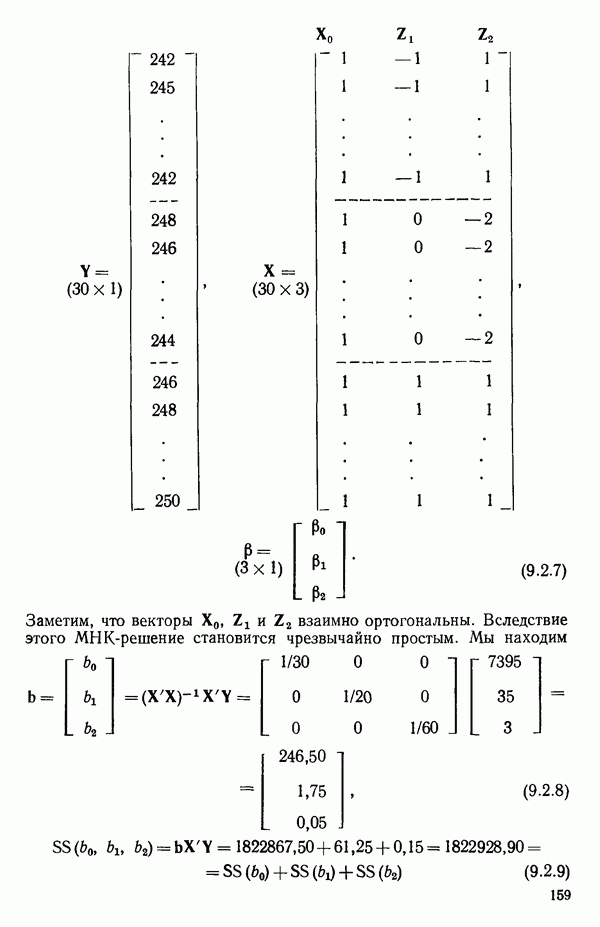



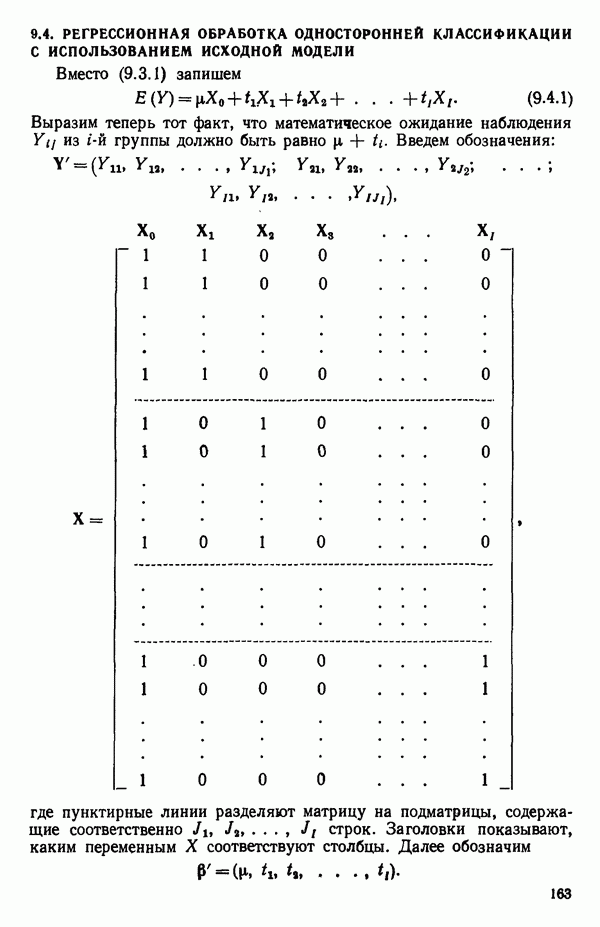











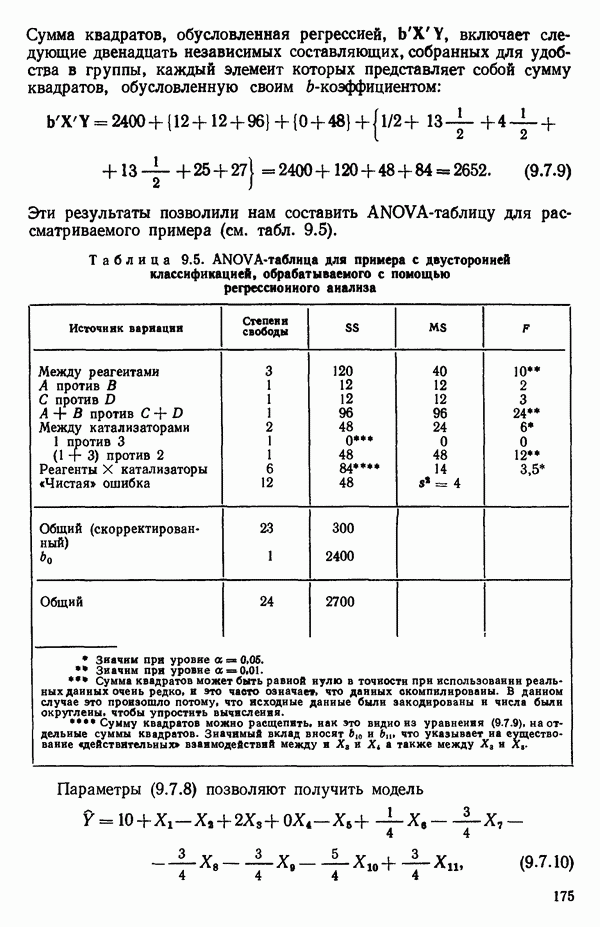































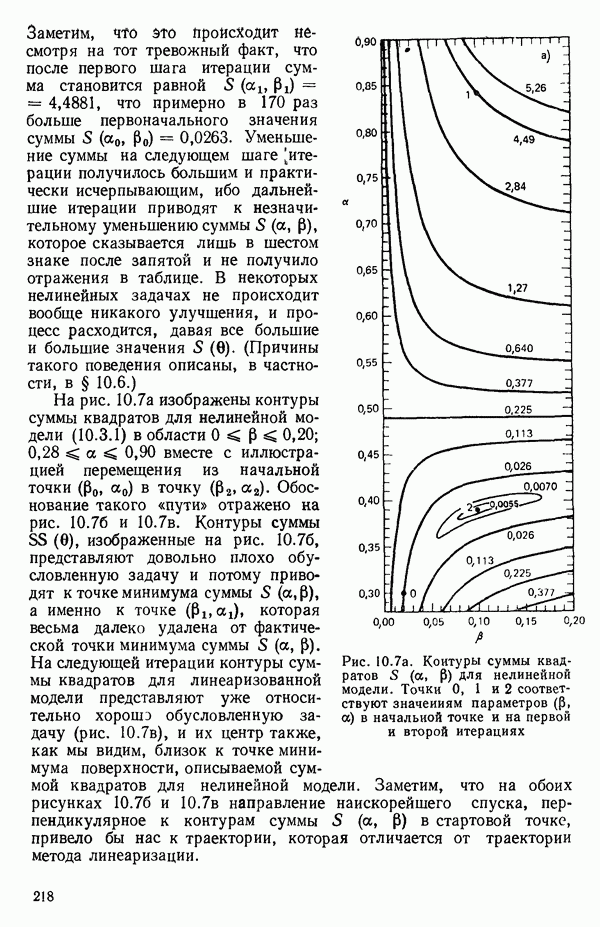
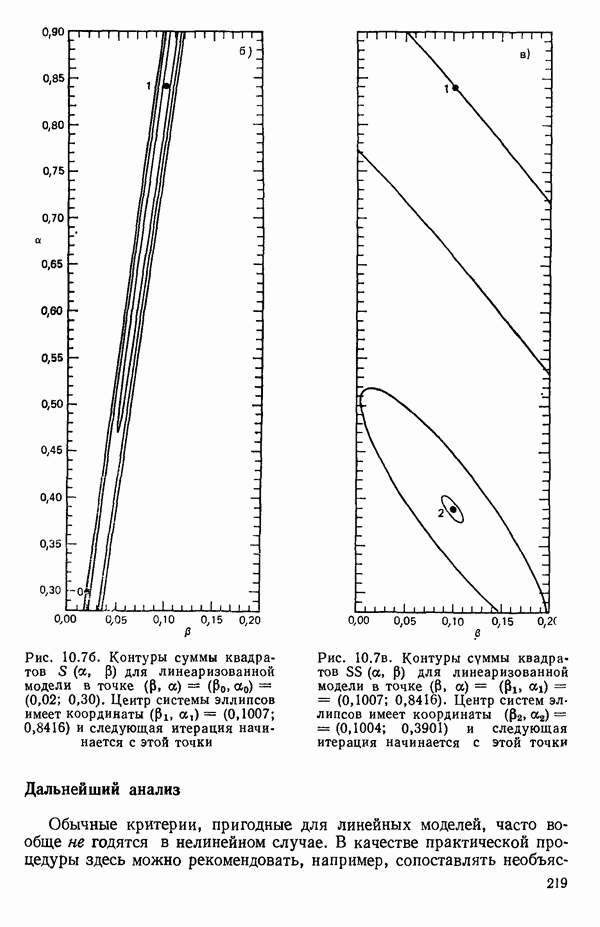

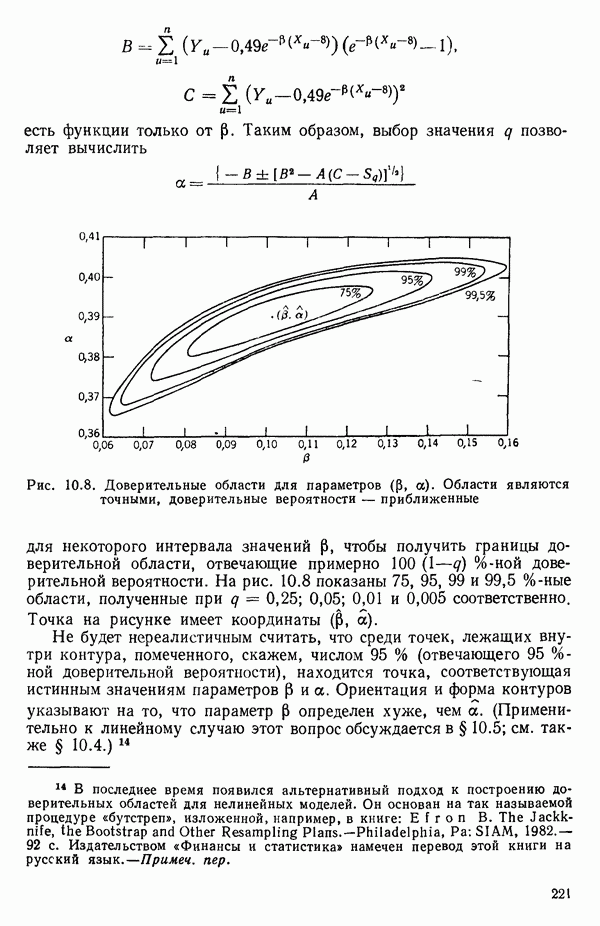








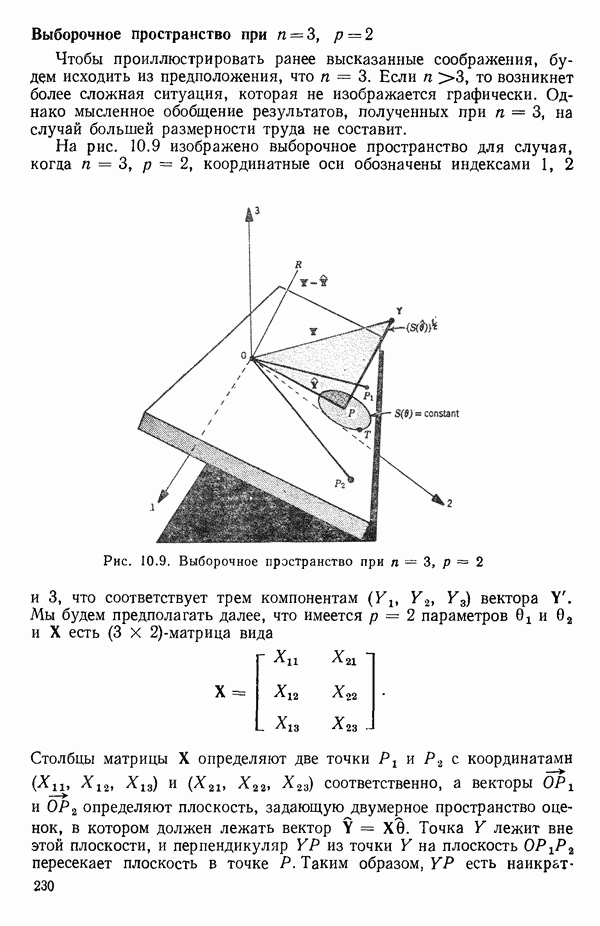










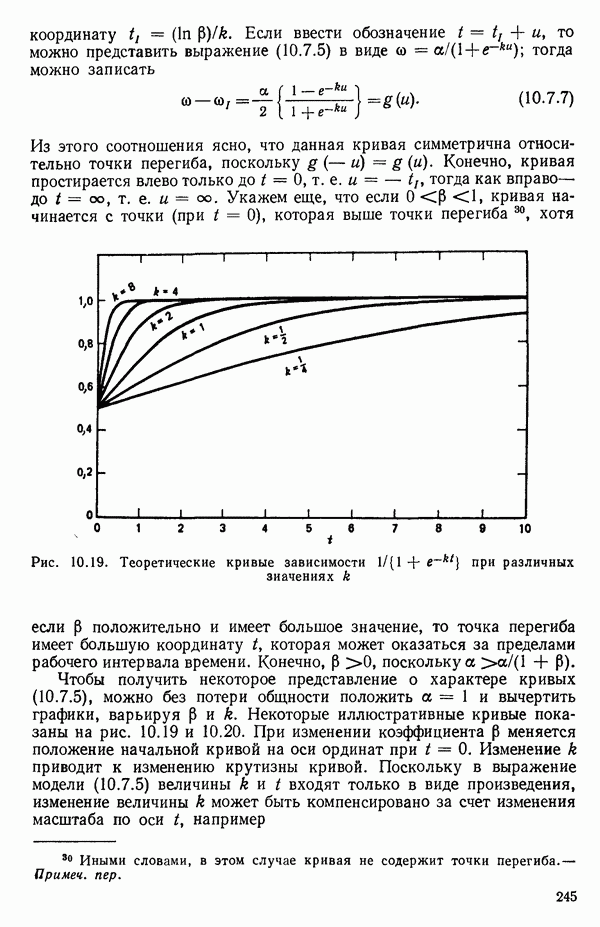
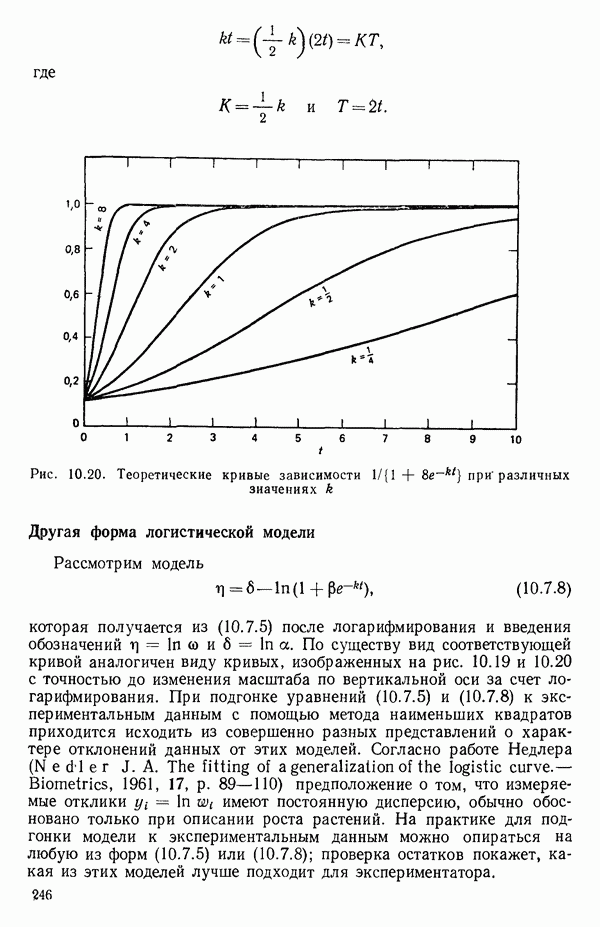


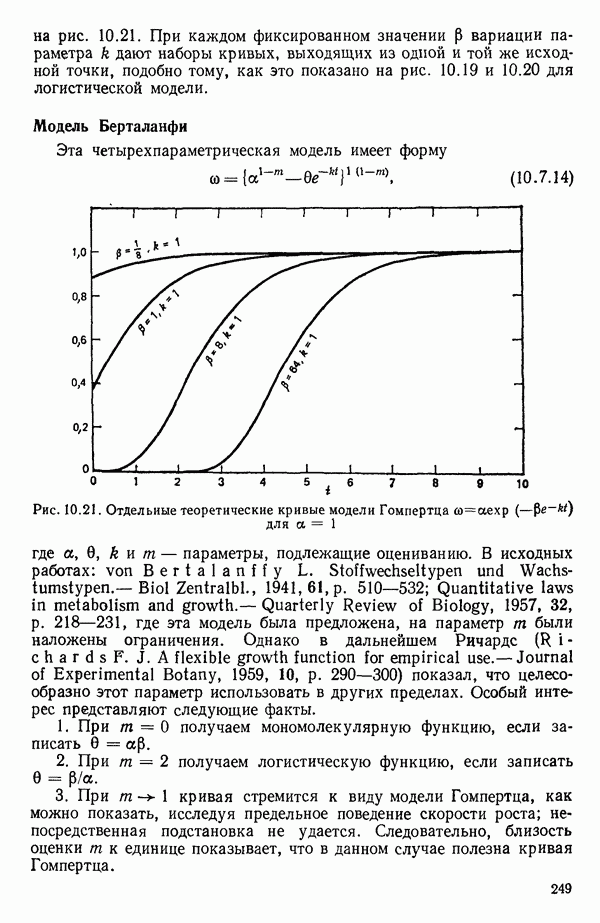



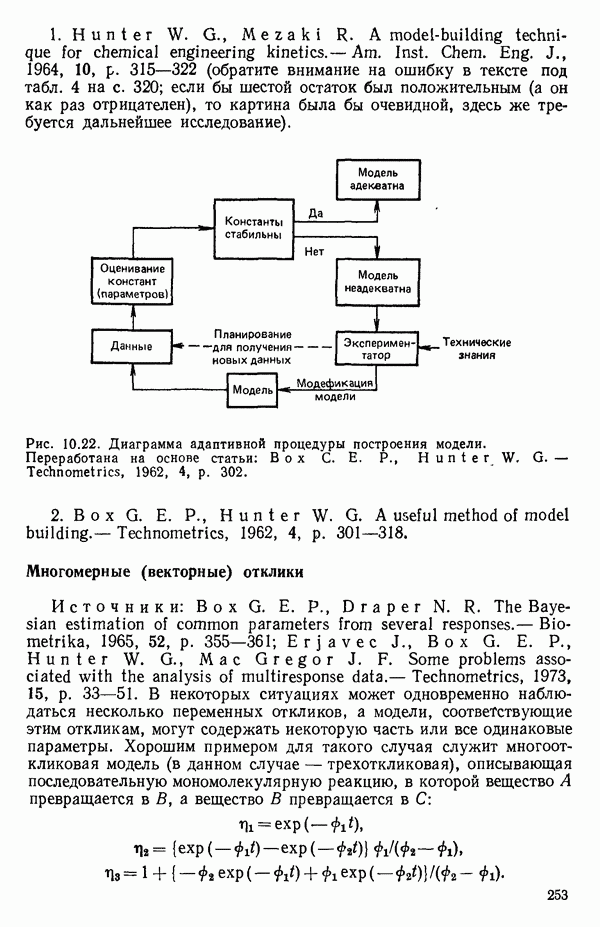





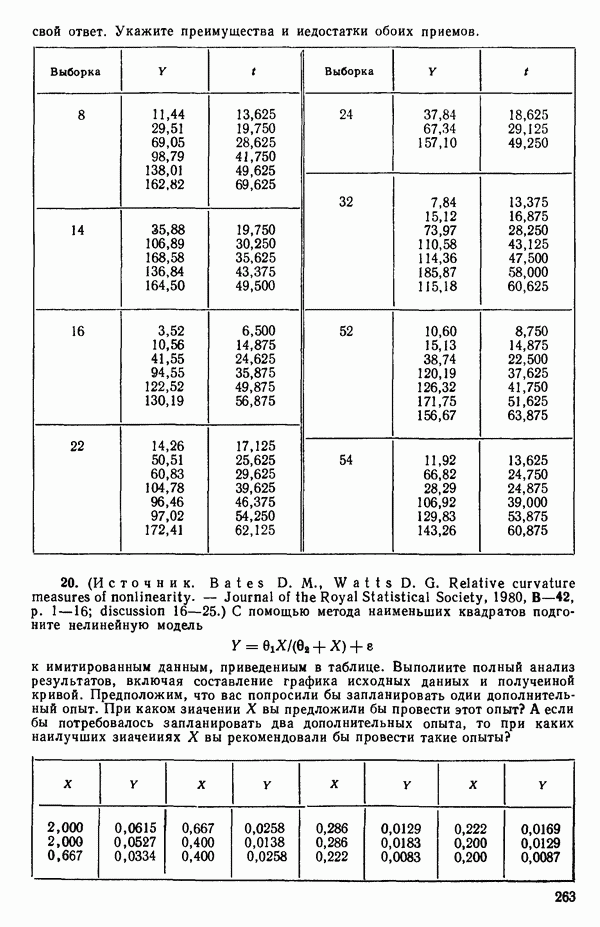




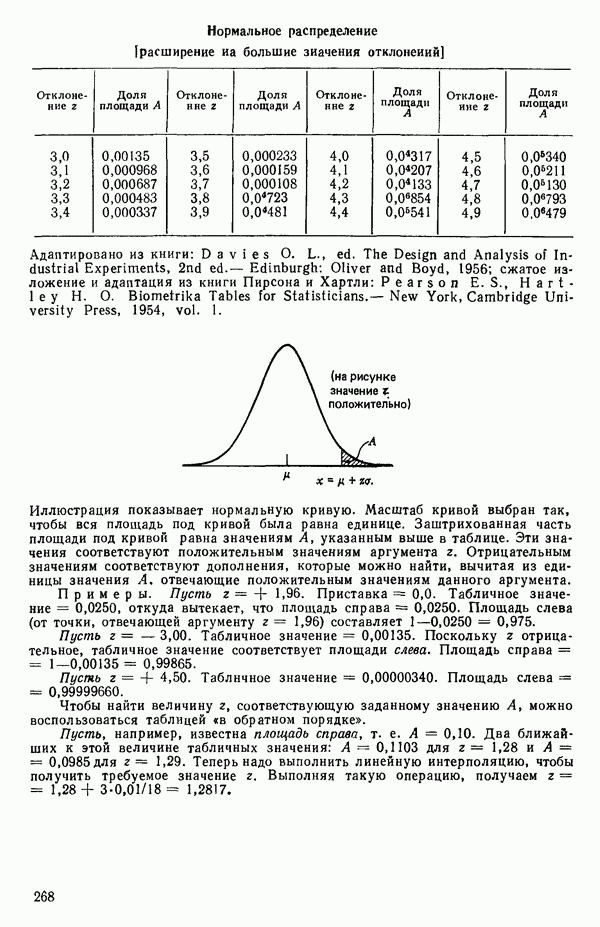
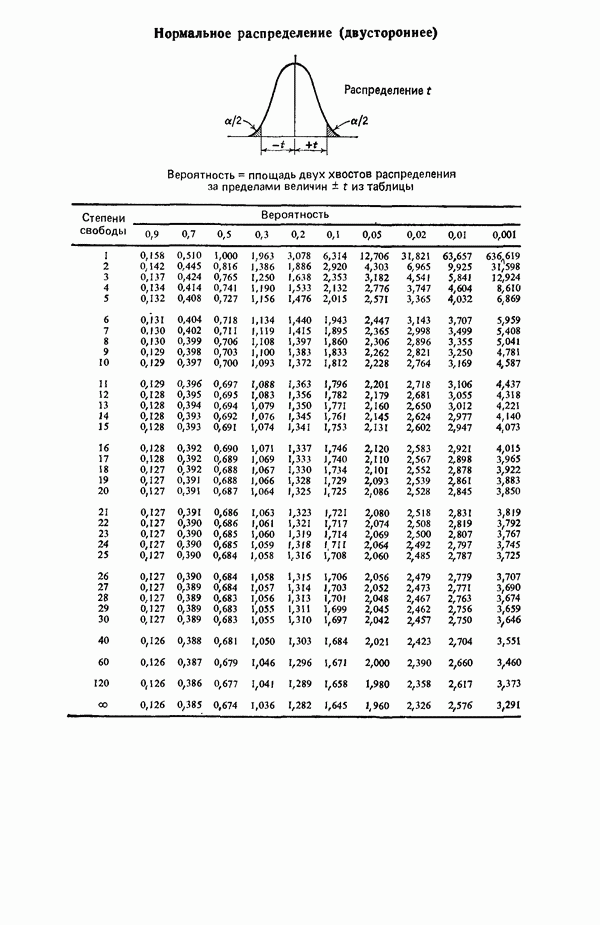


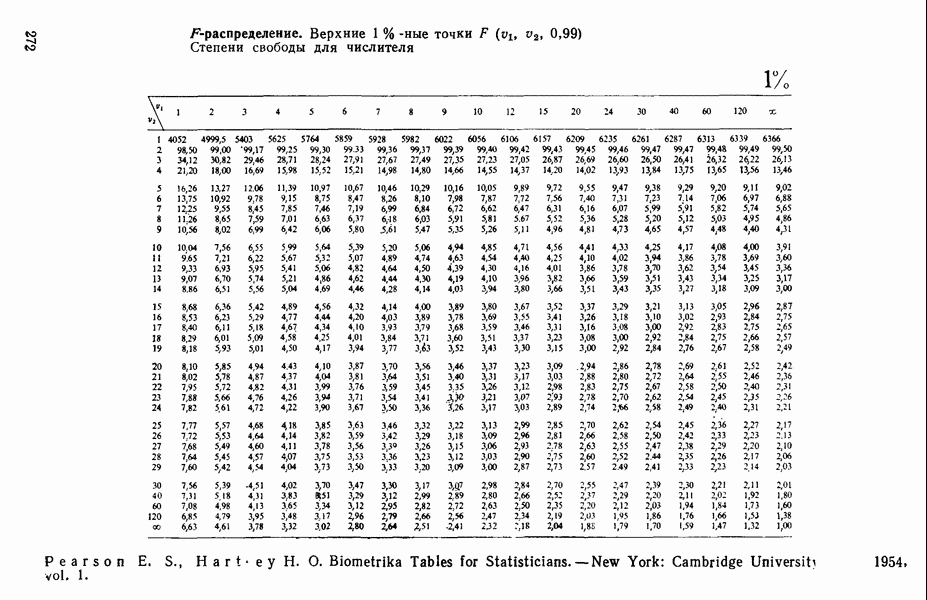


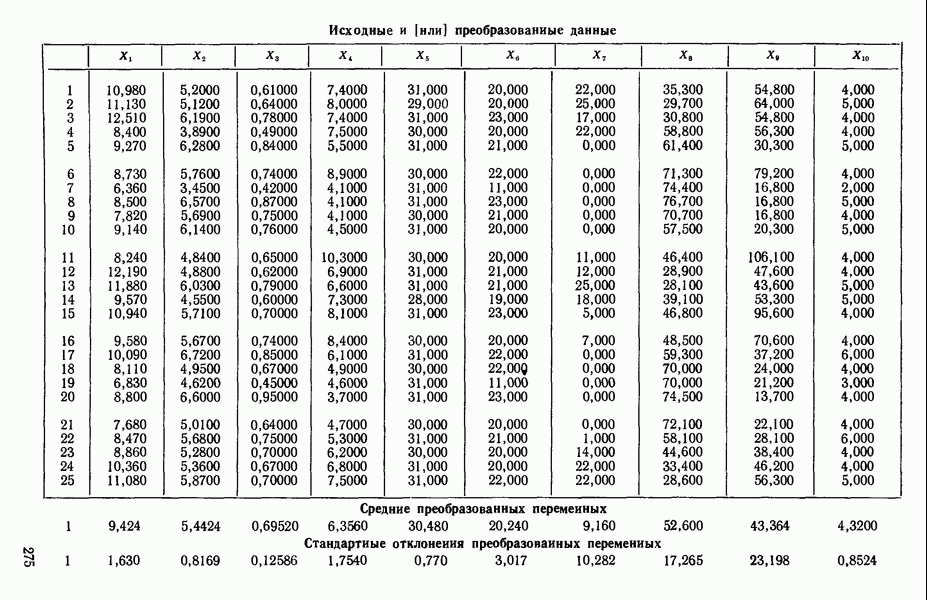

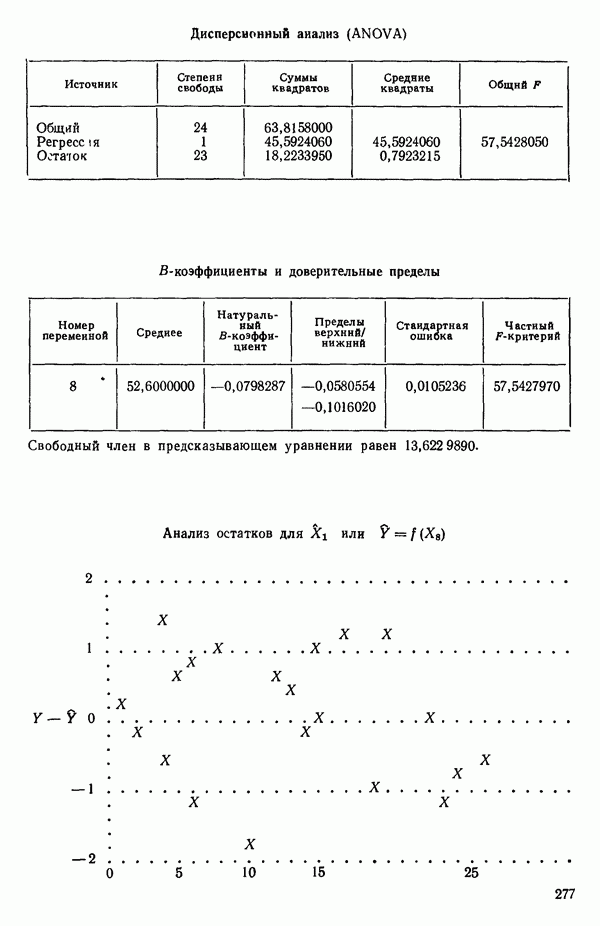
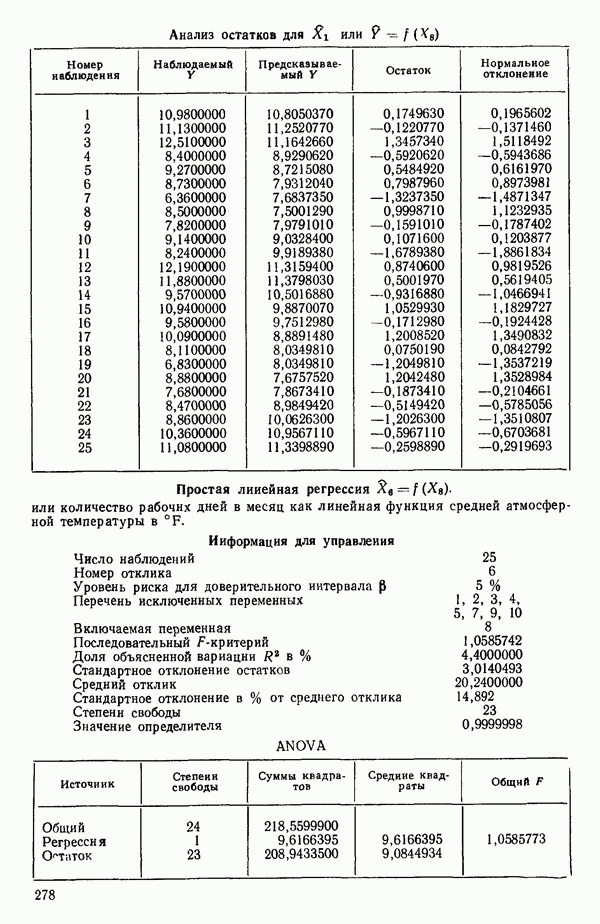
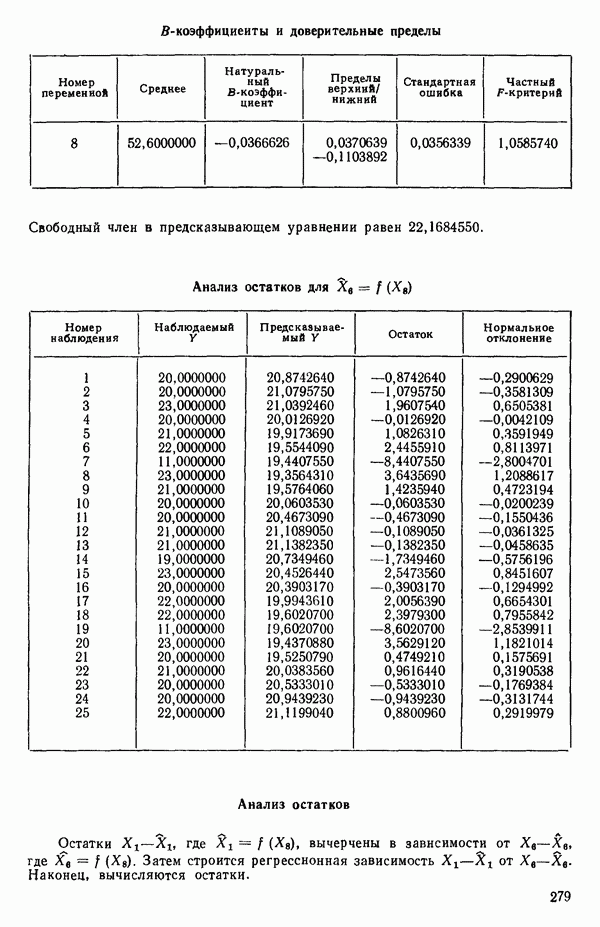
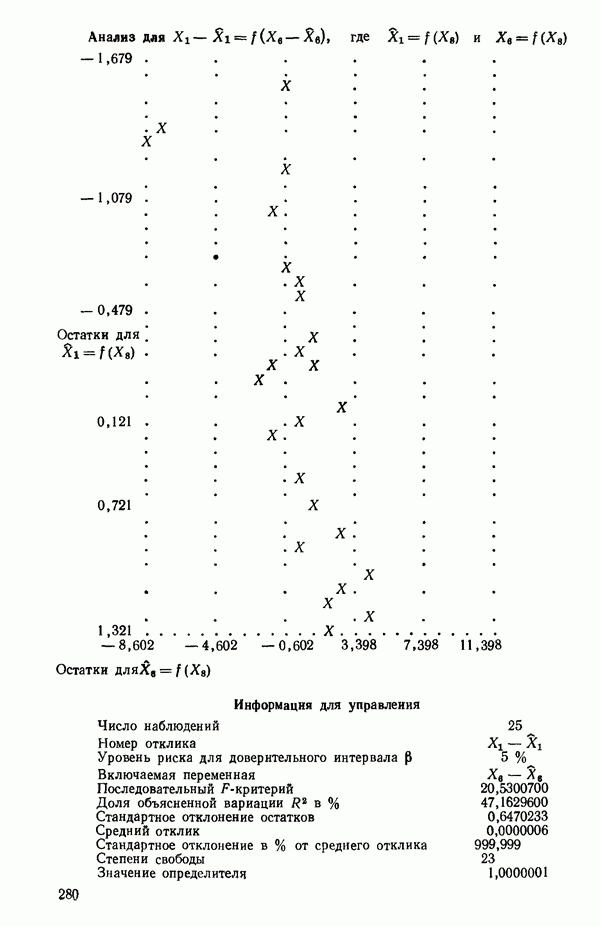
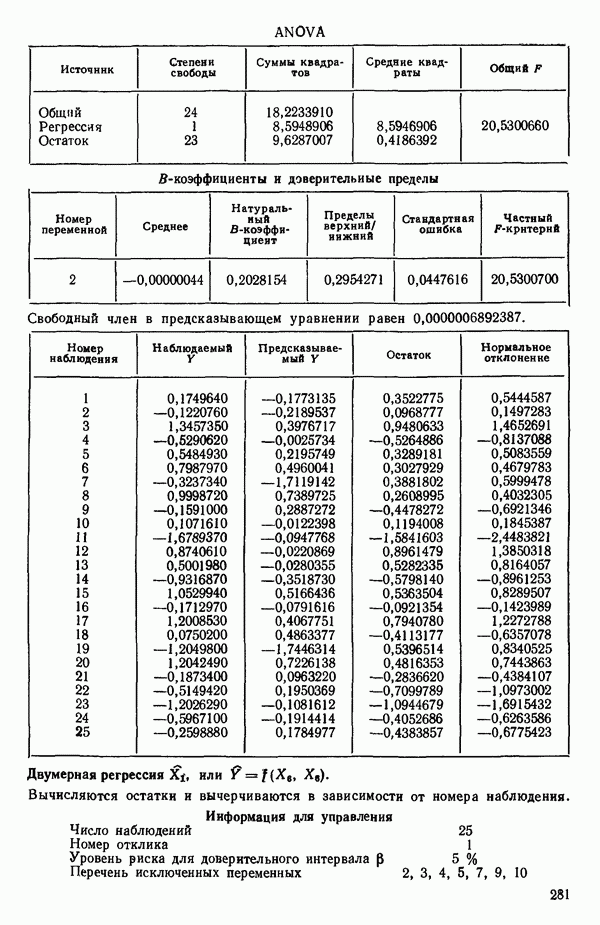
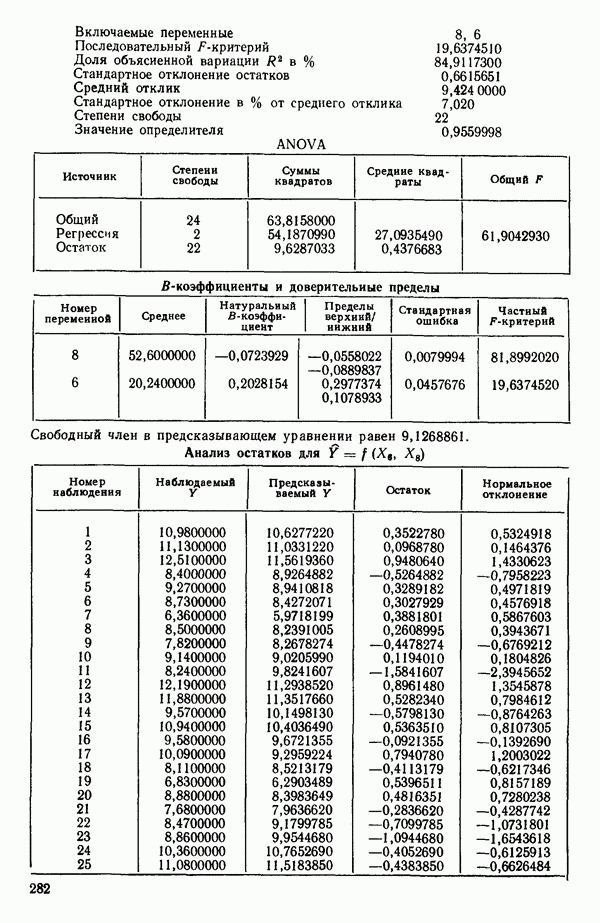

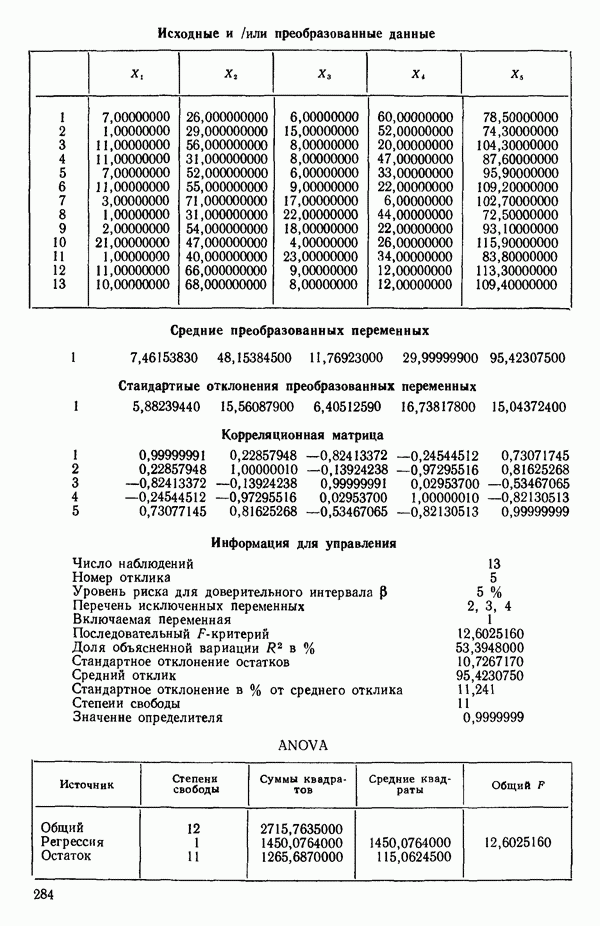
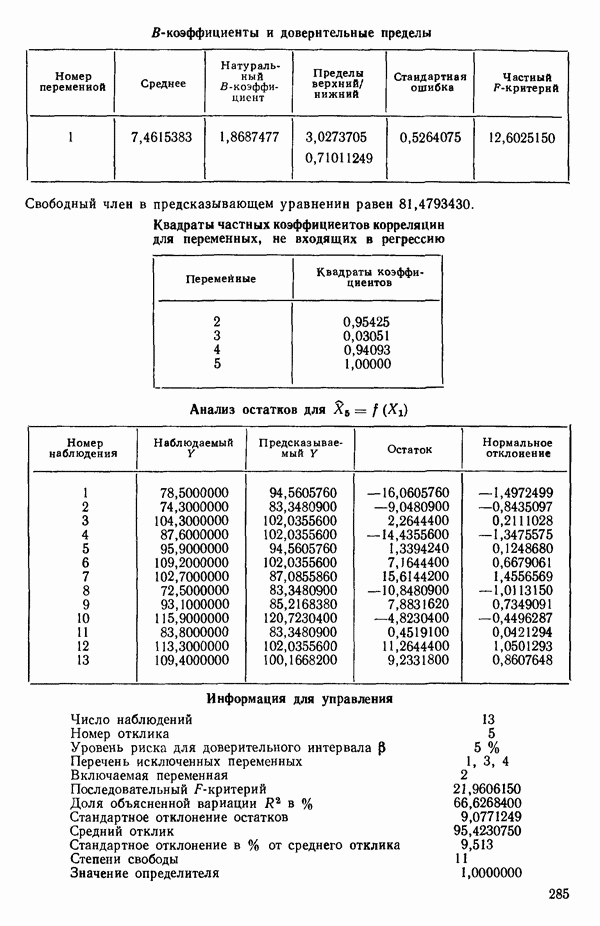
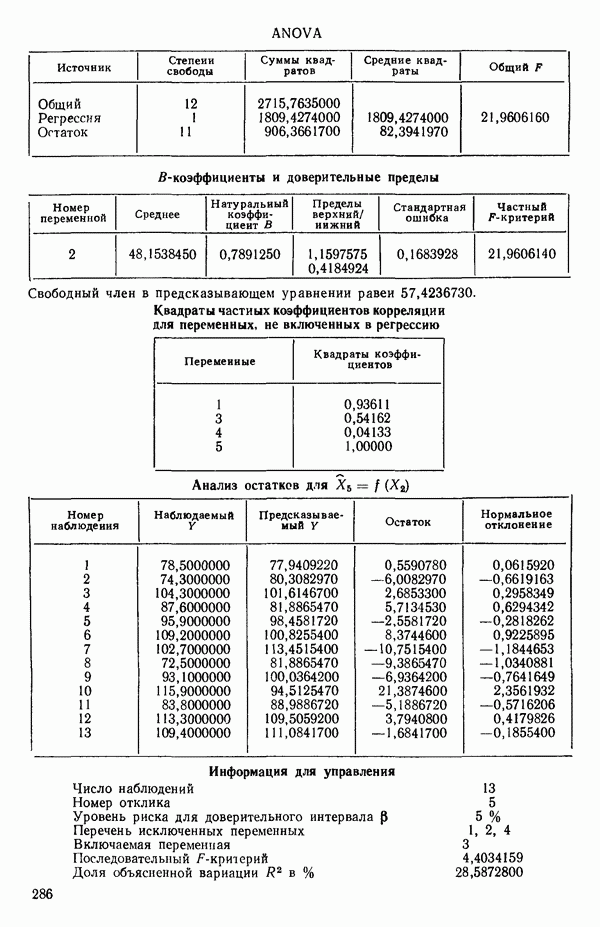
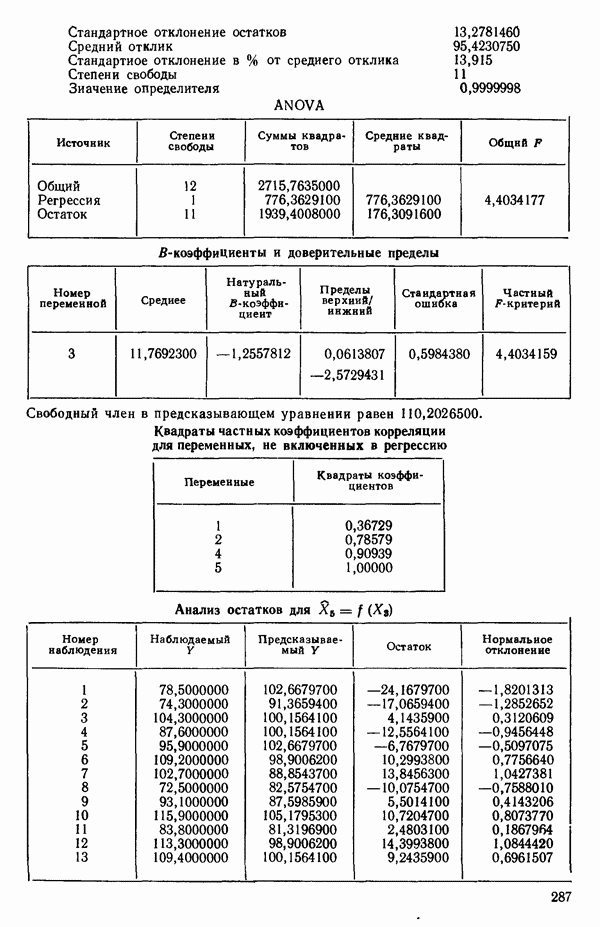
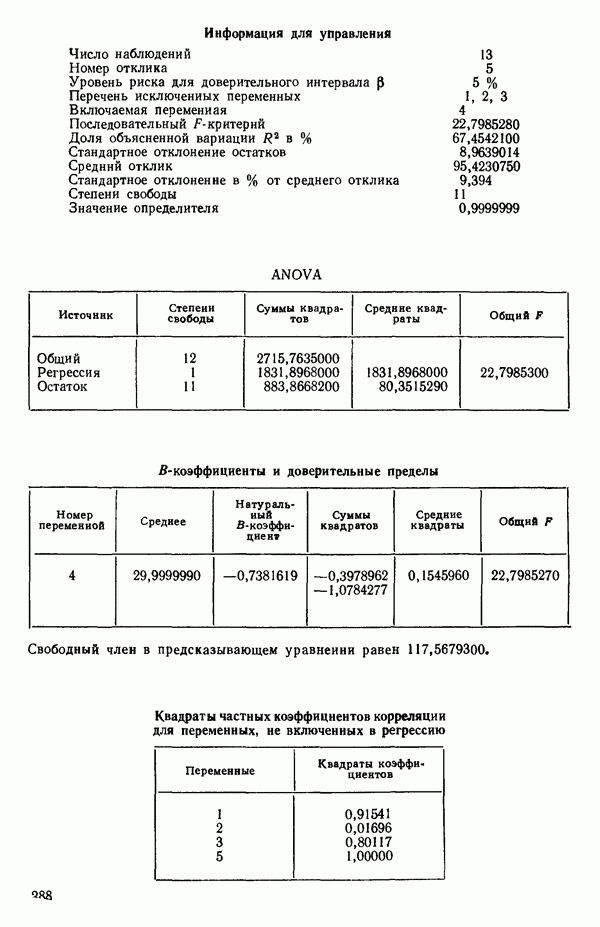
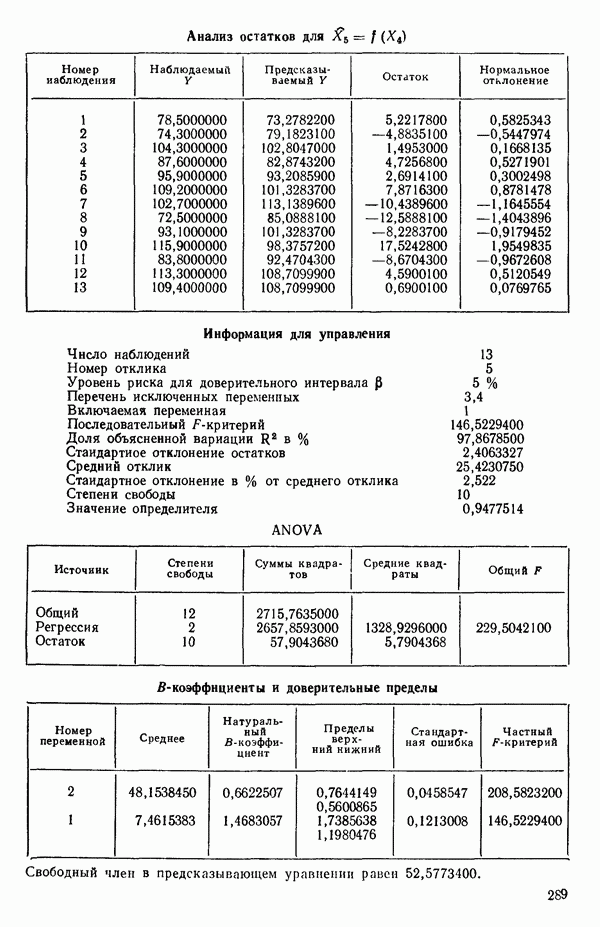
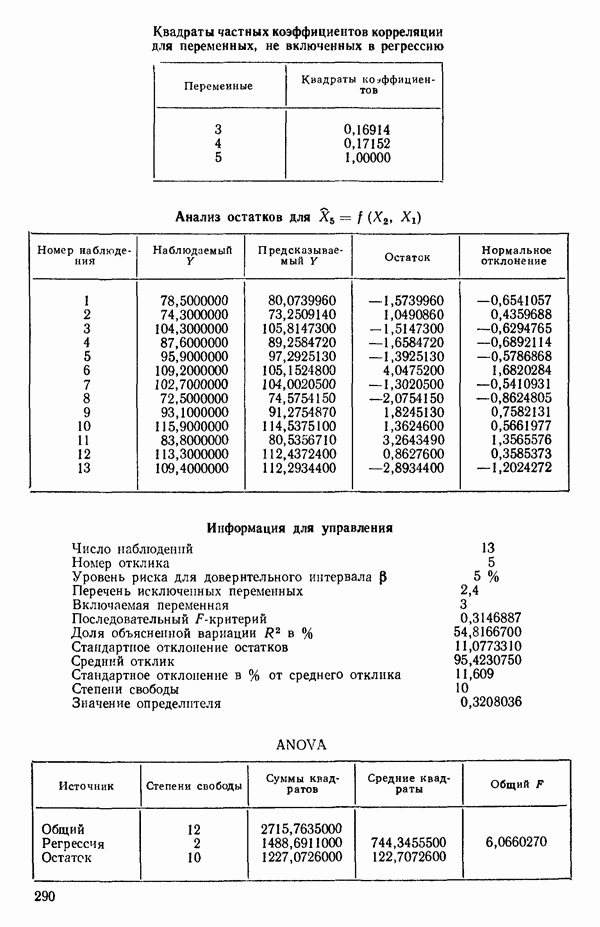
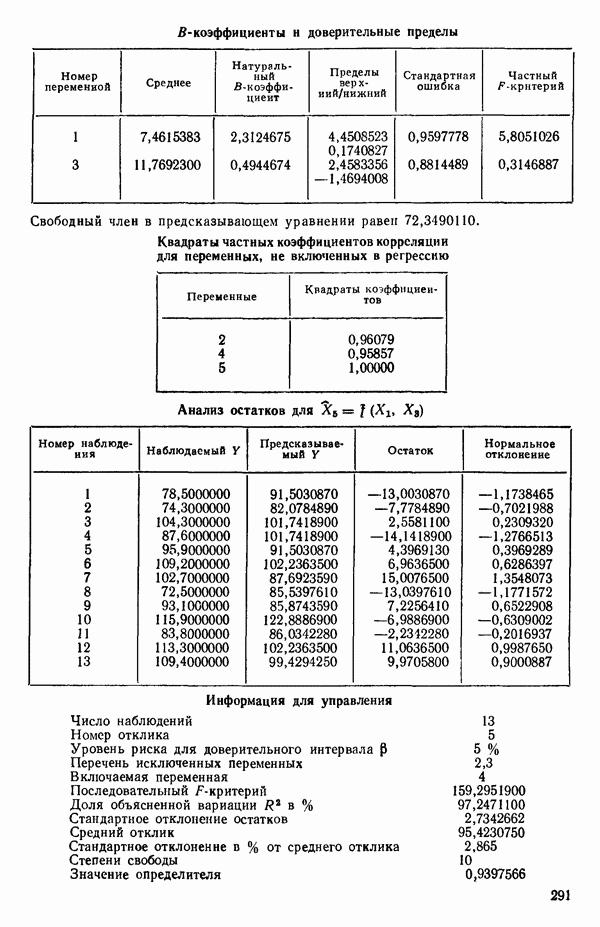
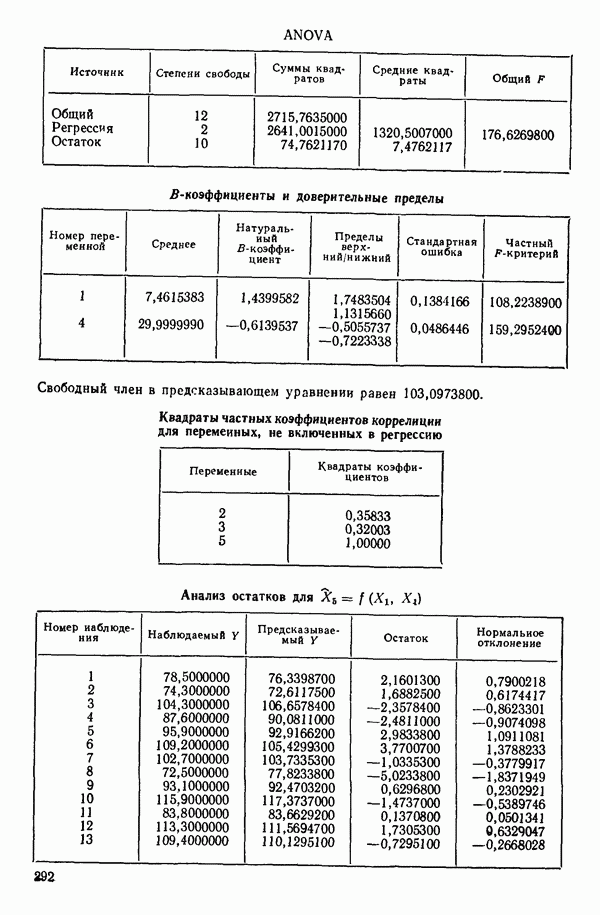
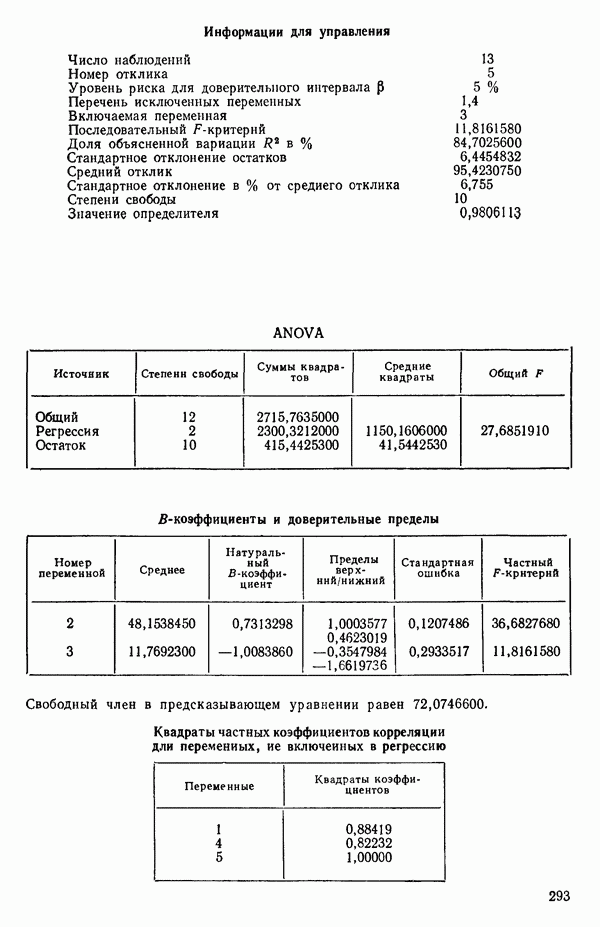
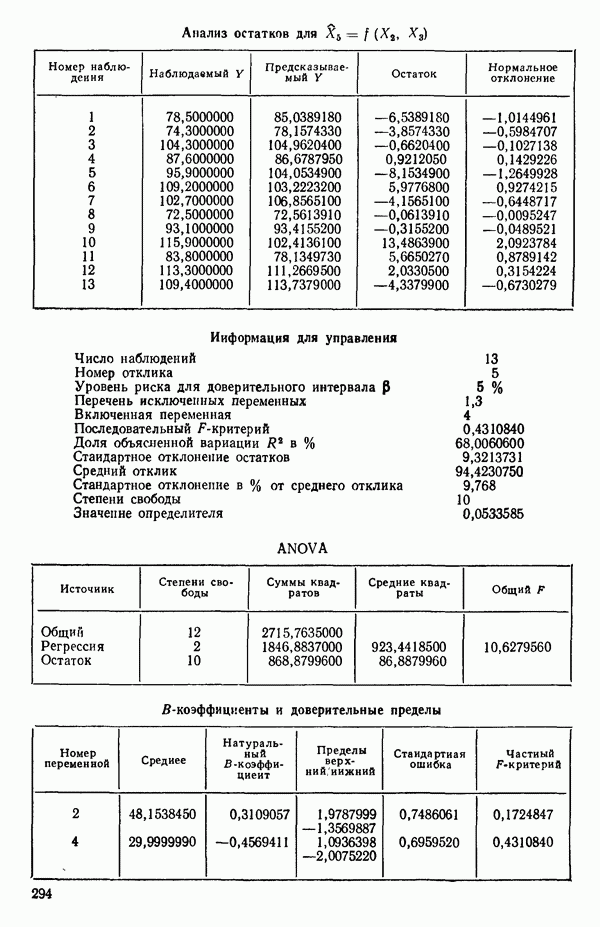
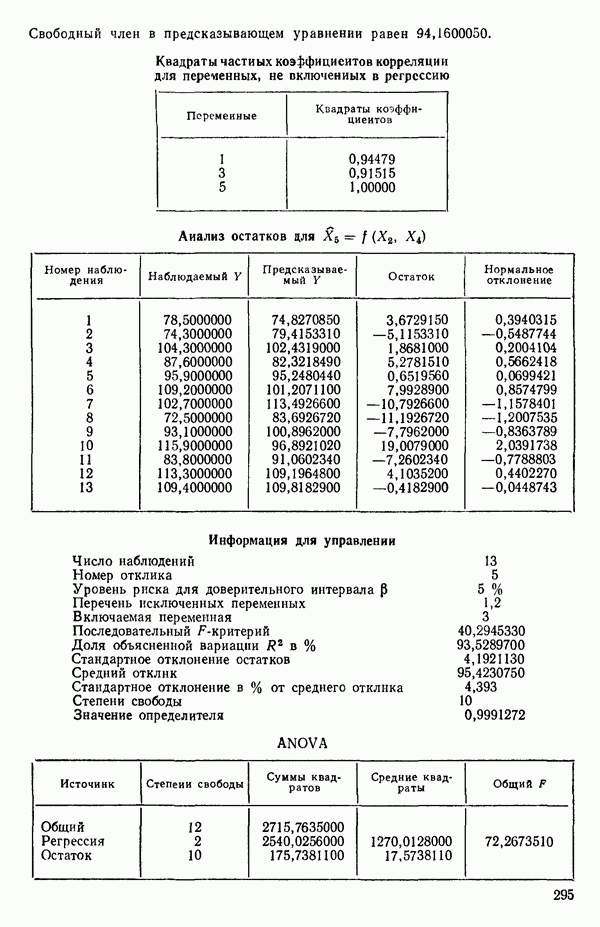
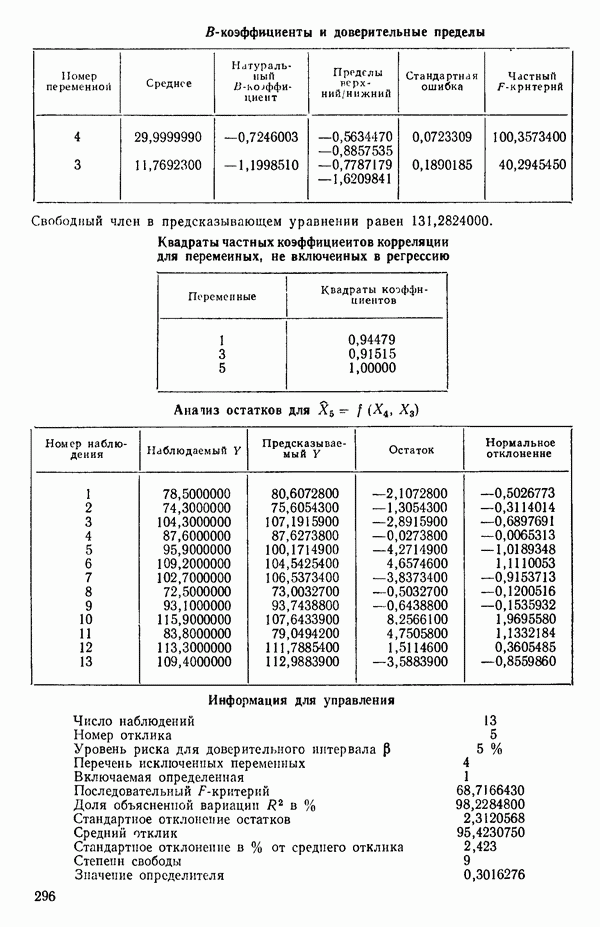
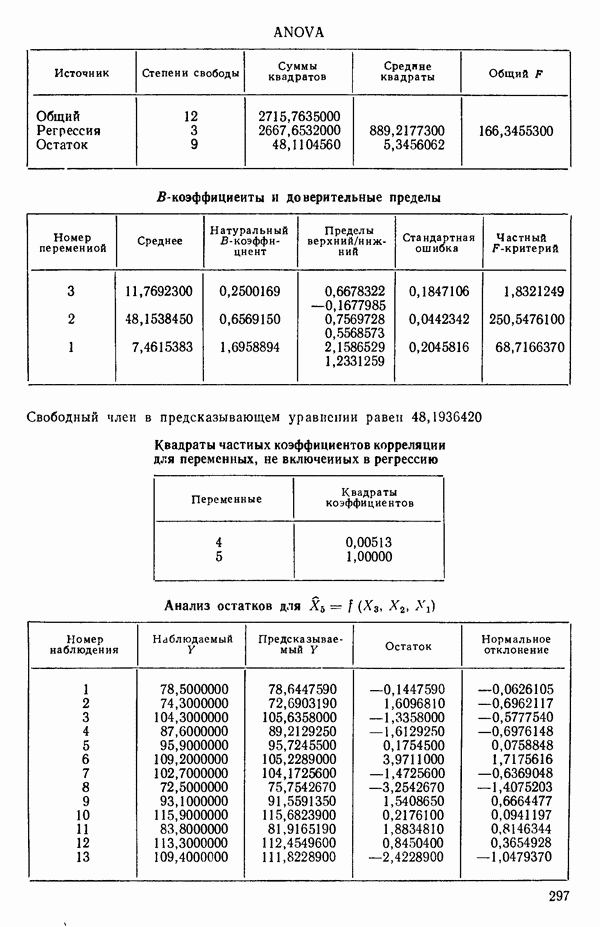
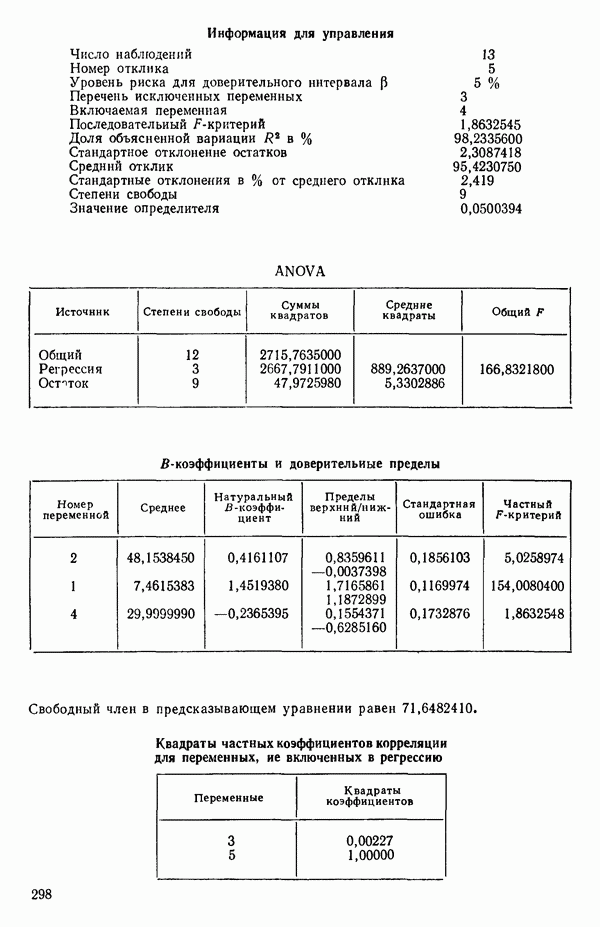
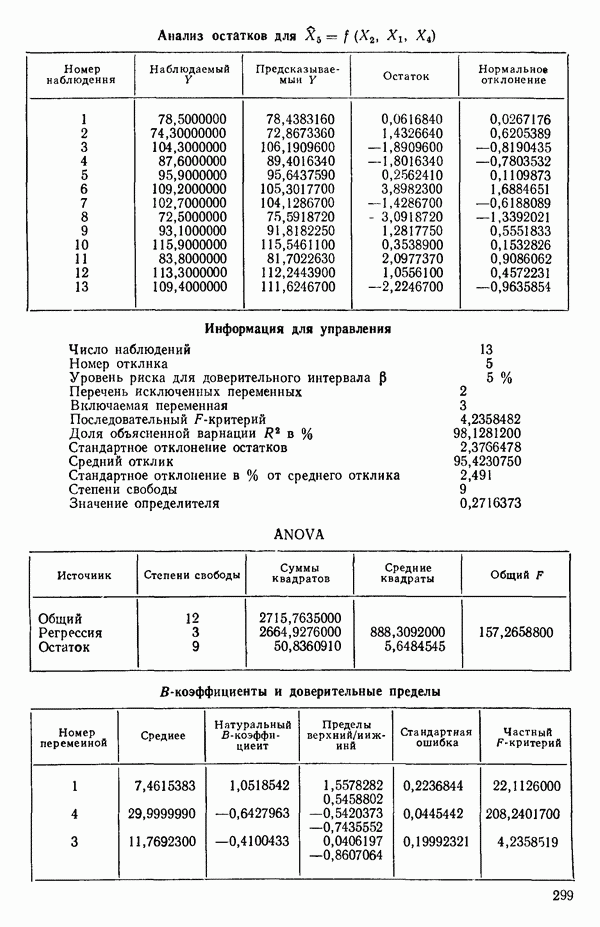
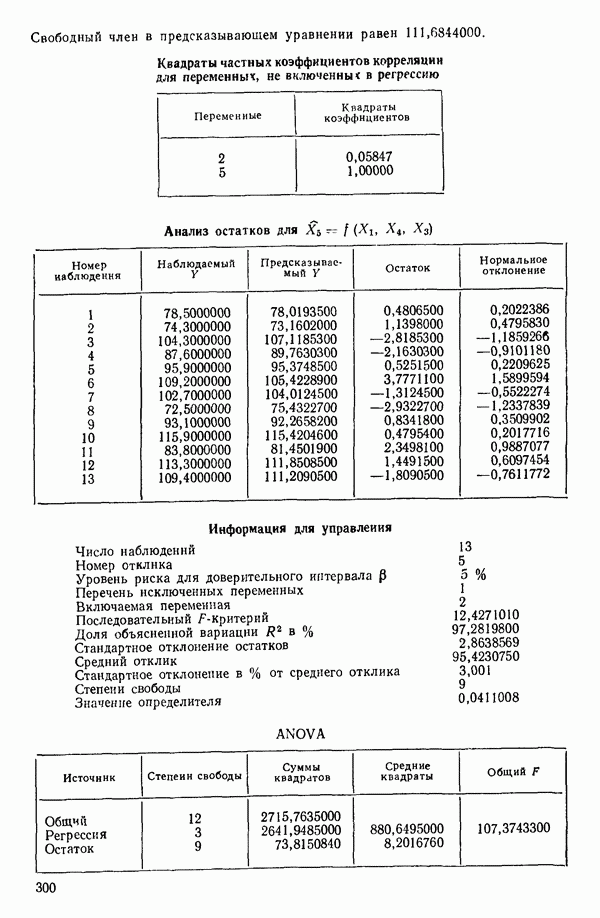
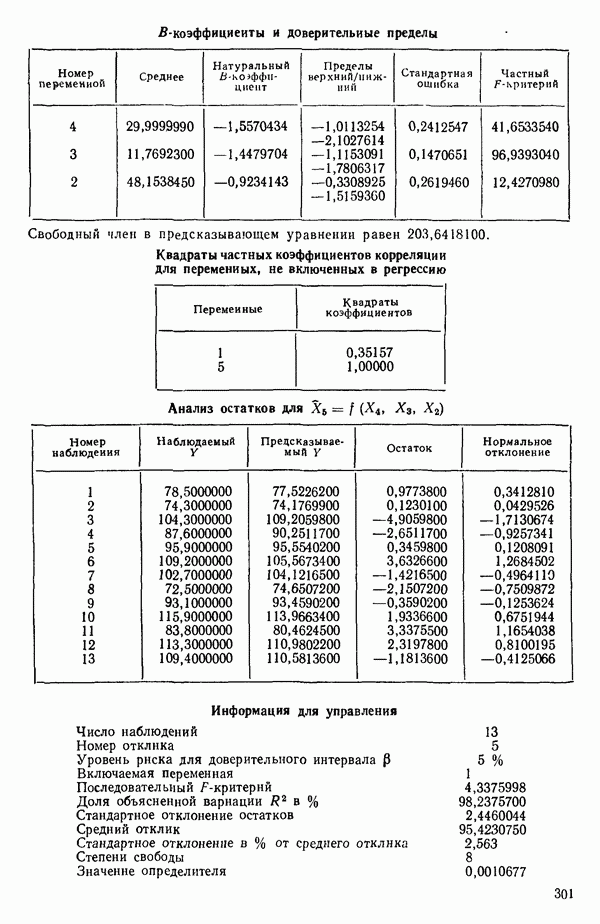
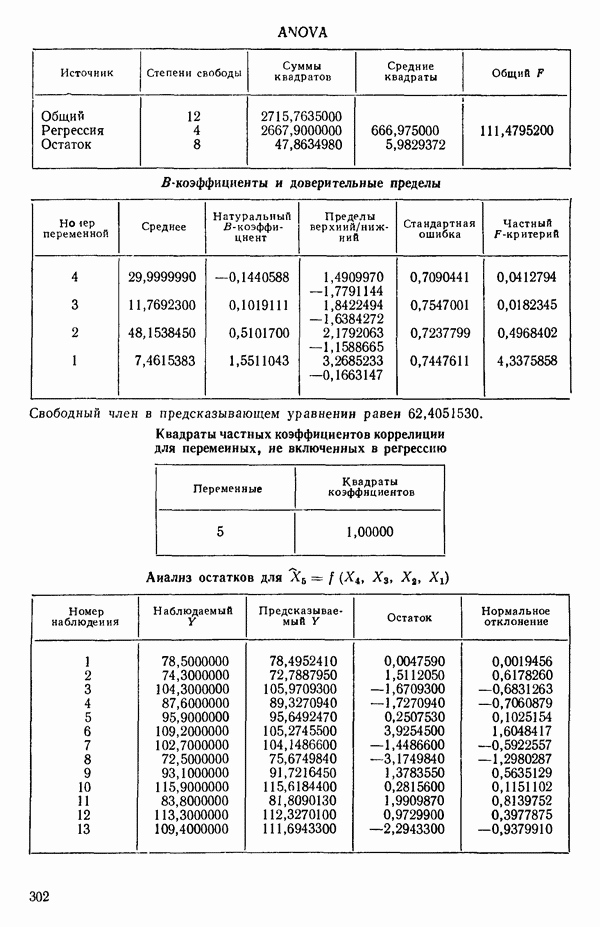







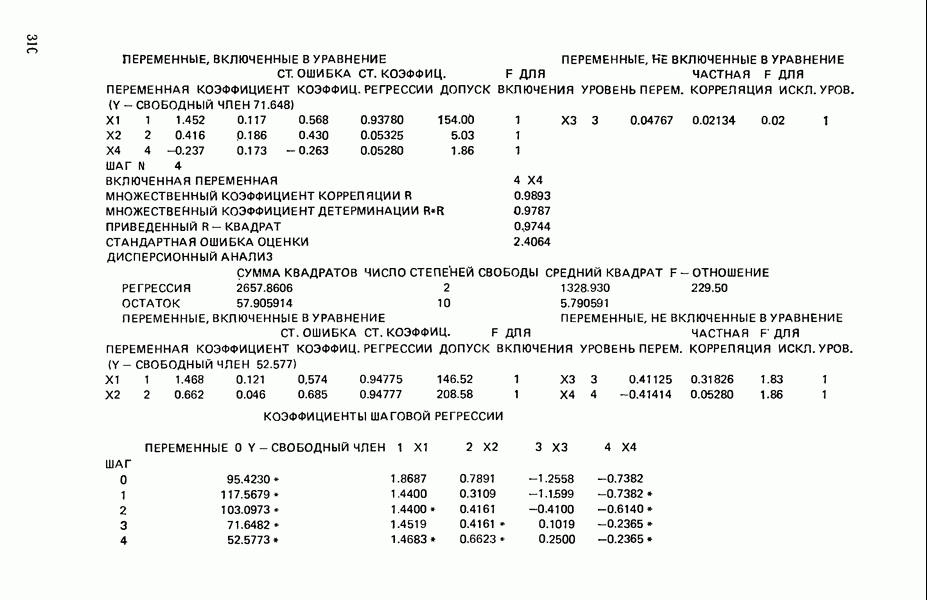
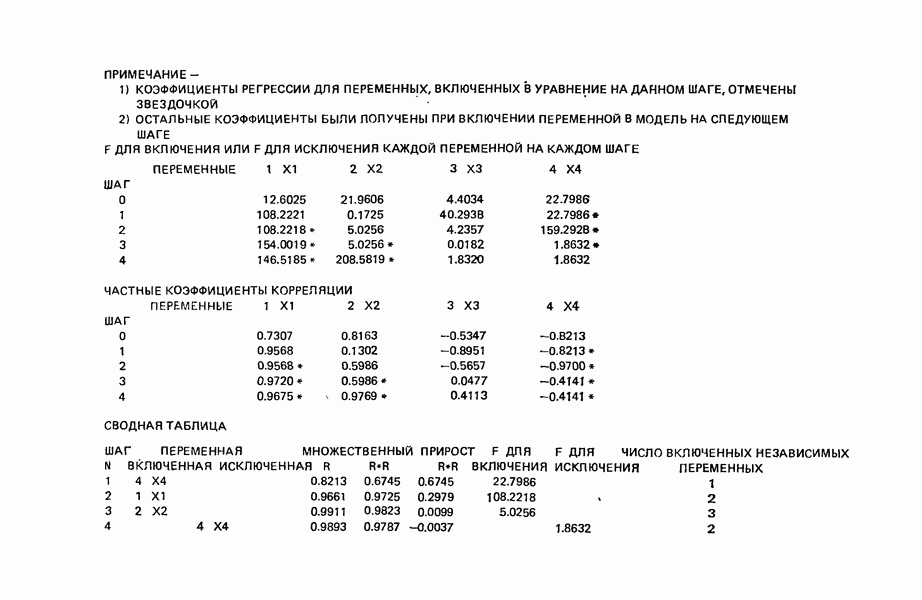

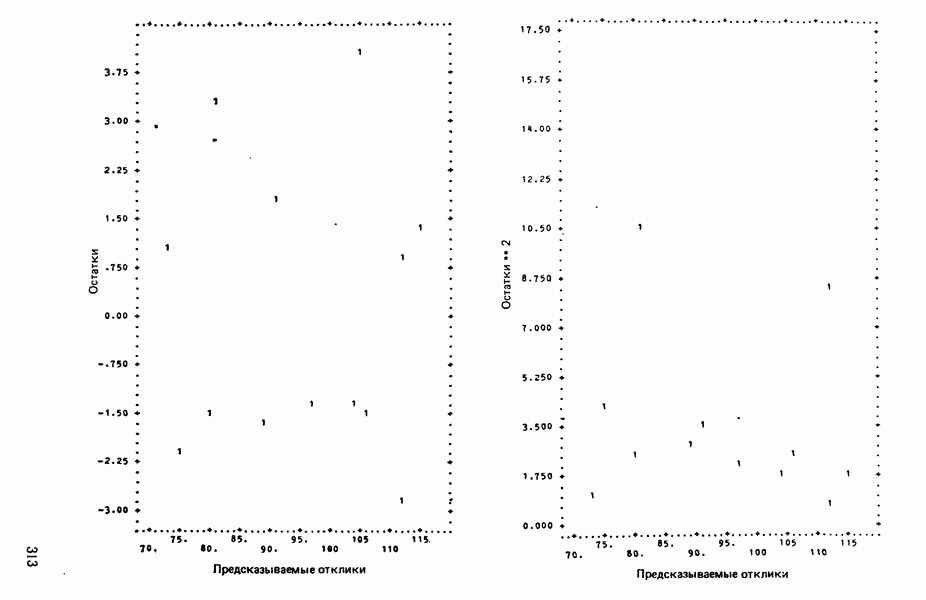
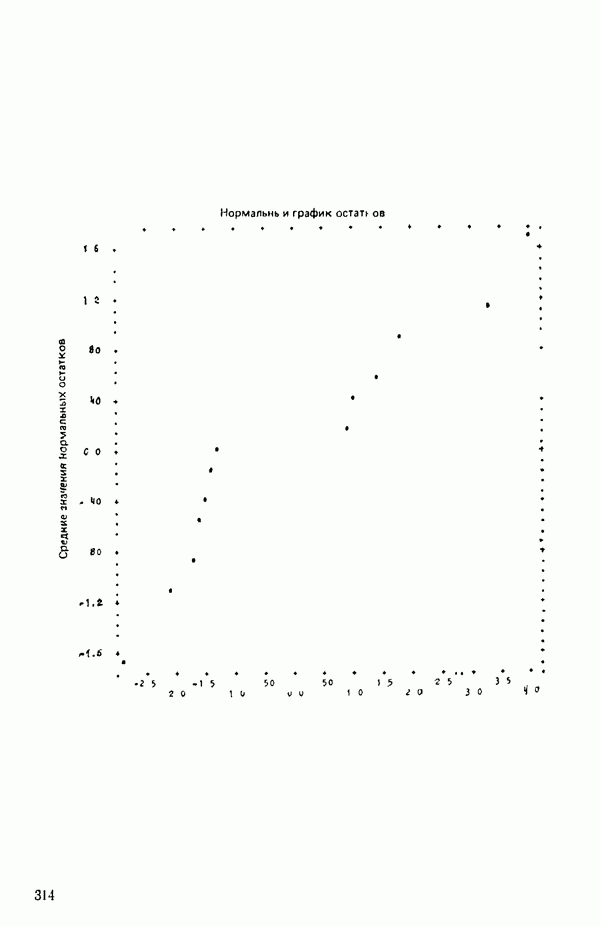
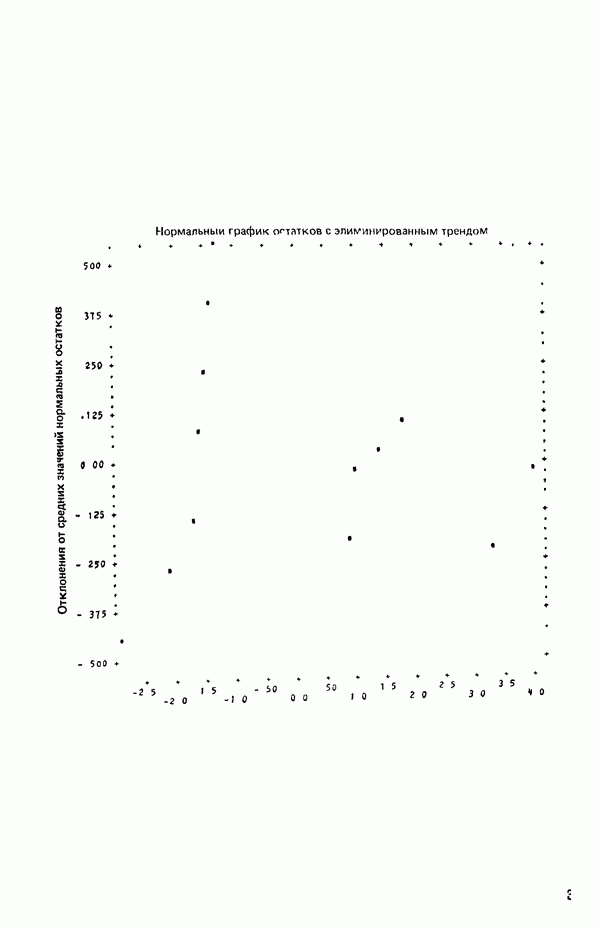




























 связанного с главными «независимыми» или предикторными переменными
связанного с главными «независимыми» или предикторными переменными  Предположим далее, что
Предположим далее, что  все функции от одной или нескольких переменных X и эти функции образуют полный набор переменных, из которых должно формироваться уравнение. Допустим еще, что этот набор включает любые функции, скажем, такие, как квадраты, парные произведения, логарифмы, обратные величины и степени, которые, как можно предположить, желательны и необходимы. Существует два противоположных по смыслу критерия для выбора окончательного уравнения.
все функции от одной или нескольких переменных X и эти функции образуют полный набор переменных, из которых должно формироваться уравнение. Допустим еще, что этот набор включает любые функции, скажем, такие, как квадраты, парные произведения, логарифмы, обратные величины и степени, которые, как можно предположить, желательны и необходимы. Существует два противоположных по смыслу критерия для выбора окончательного уравнения.
 с тем чтобы определение прогнозируемых величин стало более надежным.
с тем чтобы определение прогнозируемых величин стало более надежным.
 велики, мы должны стремиться к тому, чтобы модель включала как можно меньше величин
велики, мы должны стремиться к тому, чтобы модель включала как можно меньше величин 
 (истинную дисперсию наблюдений, т. е. дисперсию воспроизводимости) для некоторой хорошо определенной задачи, то выбор наилучшего уравнения регрессии был бы намного легче. К сожалению, мы этого никогда не знаем, и потому субъективные суждения оказываются необходимой составной частью любого из рассматриваемых статистических методов. В этой главе мы опишем несколько предложенных методов. Все они, по-видимому, применяются в настоящее время. Для полноты картины добавим также, что в одной и той же задаче их применение не обязательно ведет к получению одинакового решения, хотя во многих случаях будет получаться тот же самый ответ. Мы обсудим: 1) метод всех возможных регрессий с использованием трех критериев:
(истинную дисперсию наблюдений, т. е. дисперсию воспроизводимости) для некоторой хорошо определенной задачи, то выбор наилучшего уравнения регрессии был бы намного легче. К сожалению, мы этого никогда не знаем, и потому субъективные суждения оказываются необходимой составной частью любого из рассматриваемых статистических методов. В этой главе мы опишем несколько предложенных методов. Все они, по-видимому, применяются в настоящее время. Для полноты картины добавим также, что в одной и той же задаче их применение не обязательно ведет к получению одинакового решения, хотя во многих случаях будет получаться тот же самый ответ. Мы обсудим: 1) метод всех возможных регрессий с использованием трех критериев:  и критерия Маллоуза
и критерия Маллоуза  метод наилучшего подмножества регрессий с
метод наилучшего подмножества регрессий с
 (приведенного) и Ср; 3) метод исключения; 4) шаговый регрессионный метод; 5) некоторые вариации предыдущих методов; 6) гребневую регрессию; 7) ПРЕСС; 8) регрессию на главные компоненты; 9) регрессию на собственные числа и 10) ступенчатый регрессионный анализ. После обсуждения каждого метода мы сформулируем наше мнение о нем.
(приведенного) и Ср; 3) метод исключения; 4) шаговый регрессионный метод; 5) некоторые вариации предыдущих методов; 6) гребневую регрессию; 7) ПРЕСС; 8) регрессию на главные компоненты; 9) регрессию на собственные числа и 10) ступенчатый регрессионный анализ. После обсуждения каждого метода мы сформулируем наше мнение о нем.
 повышается, то надо для компенсации снижать
повышается, то надо для компенсации снижать  зачастую вызывает значительные корреляции предикторов. Из-за этого невозможно понять, с
зачастую вызывает значительные корреляции предикторов. Из-за этого невозможно понять, с  или
или  или с той и другой переменными связано изменение
или с той и другой переменными связано изменение  Тщательно спланированный эксперимент может избавить от этих неприятностей. Эффекты скрытых переменных могут быть «рандомизированы», можно выбрать эффективные пределы изменения предикторных переменных и можно избежать корреляций между
Тщательно спланированный эксперимент может избавить от этих неприятностей. Эффекты скрытых переменных могут быть «рандомизированы», можно выбрать эффективные пределы изменения предикторных переменных и можно избежать корреляций между