Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
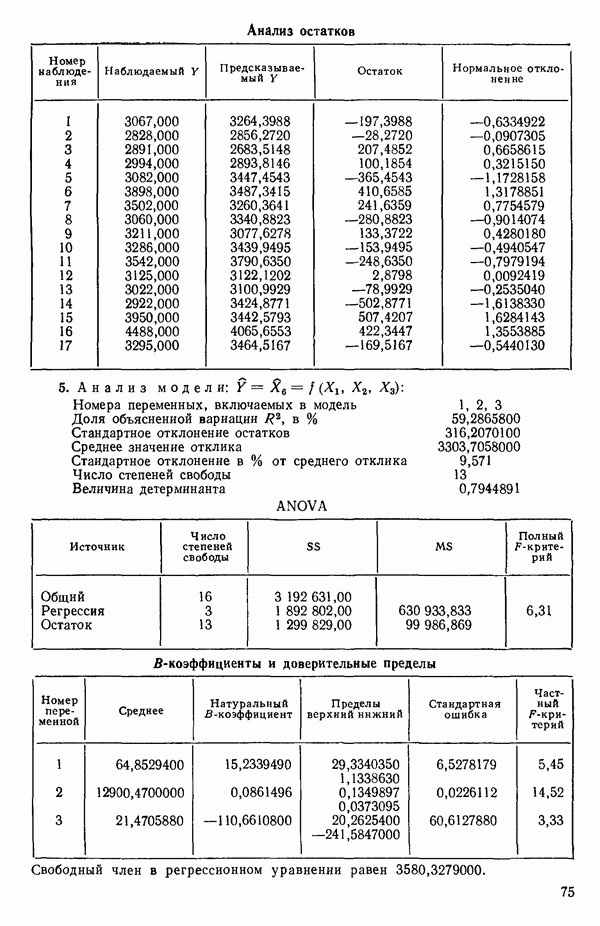
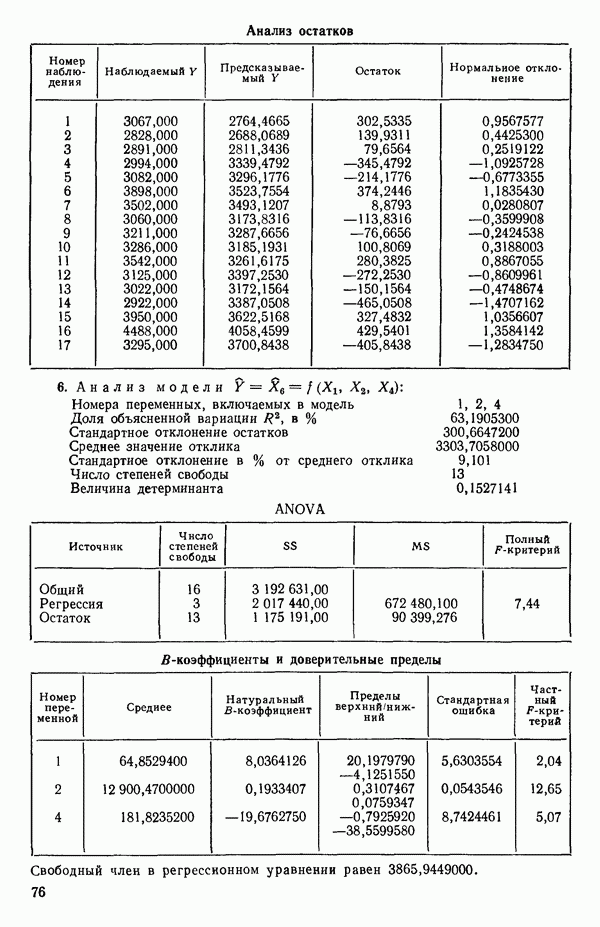
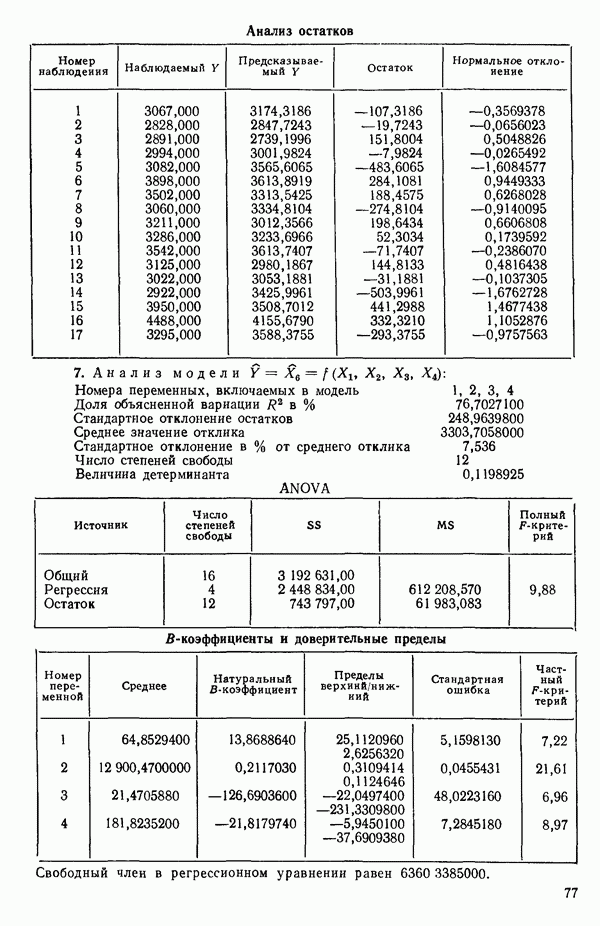
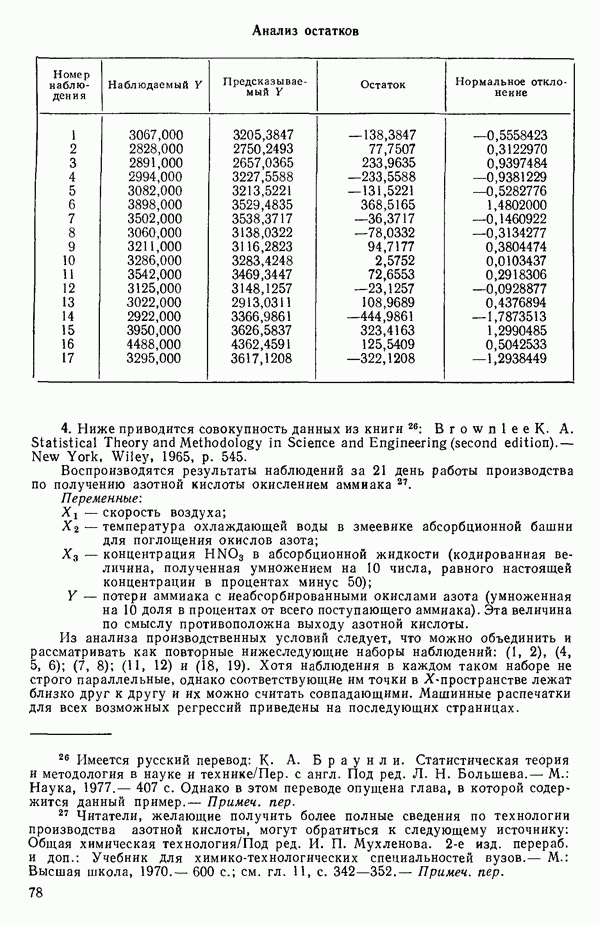
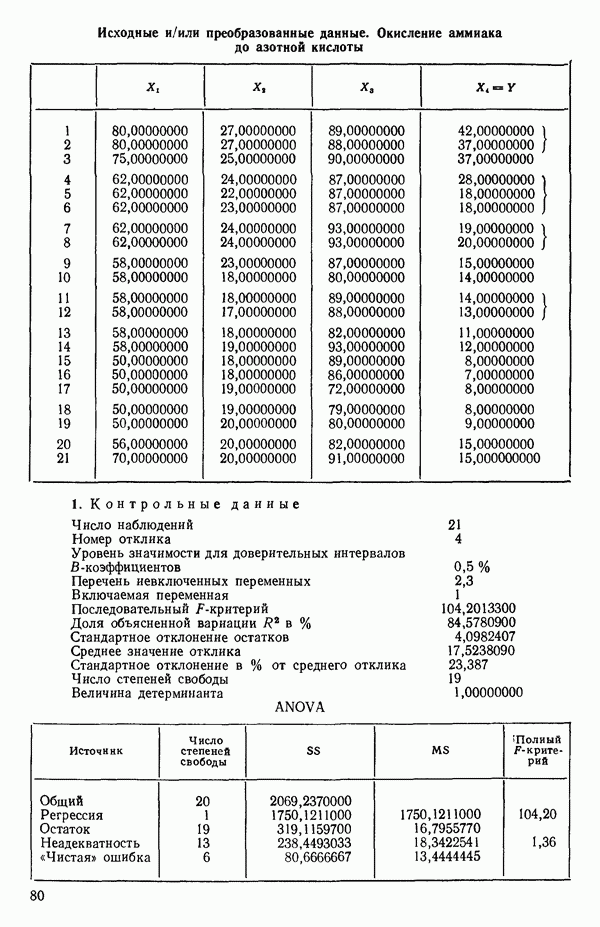
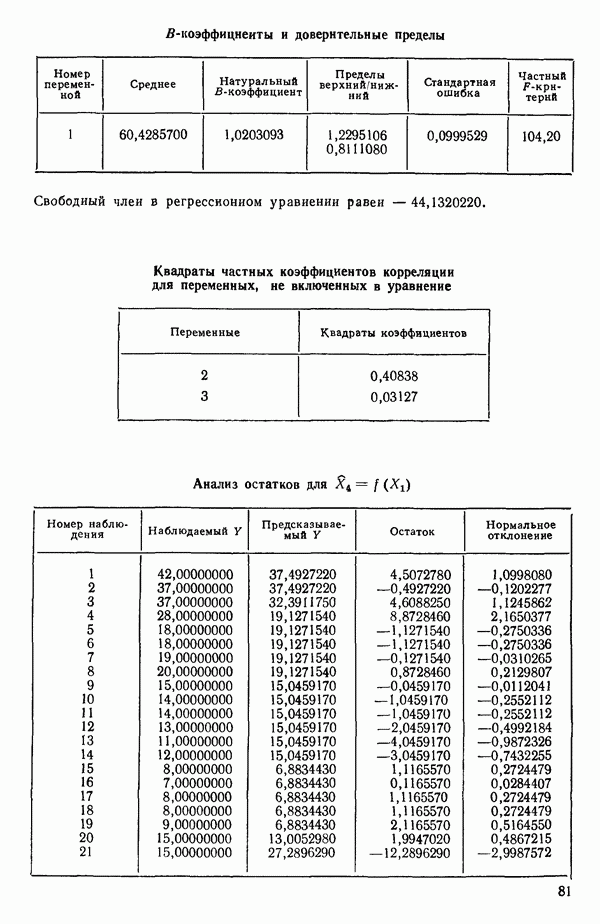
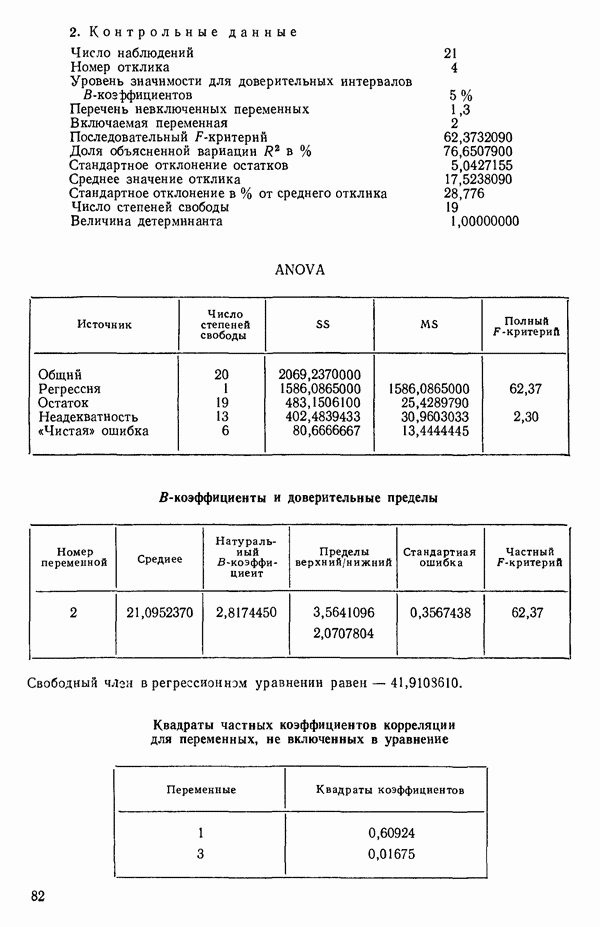
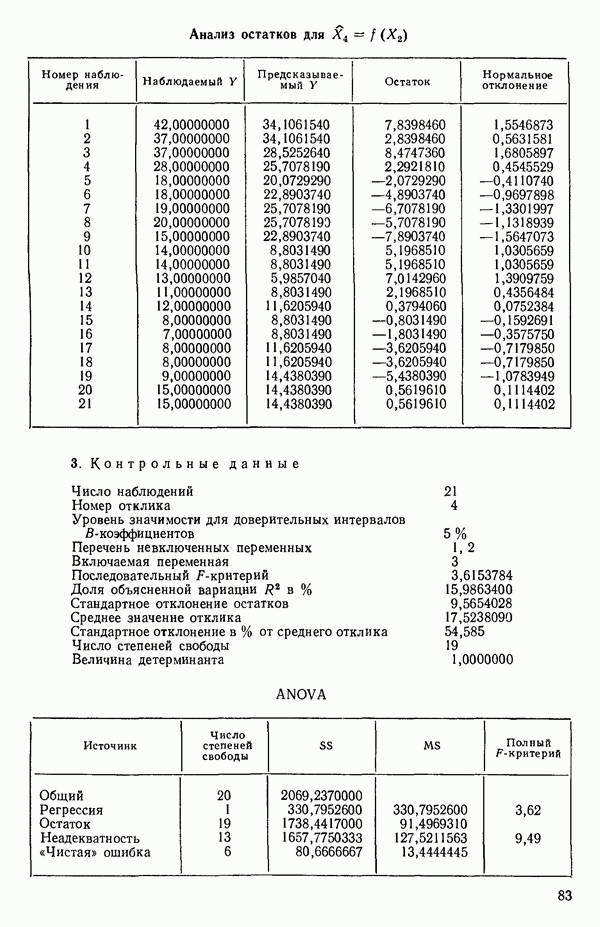
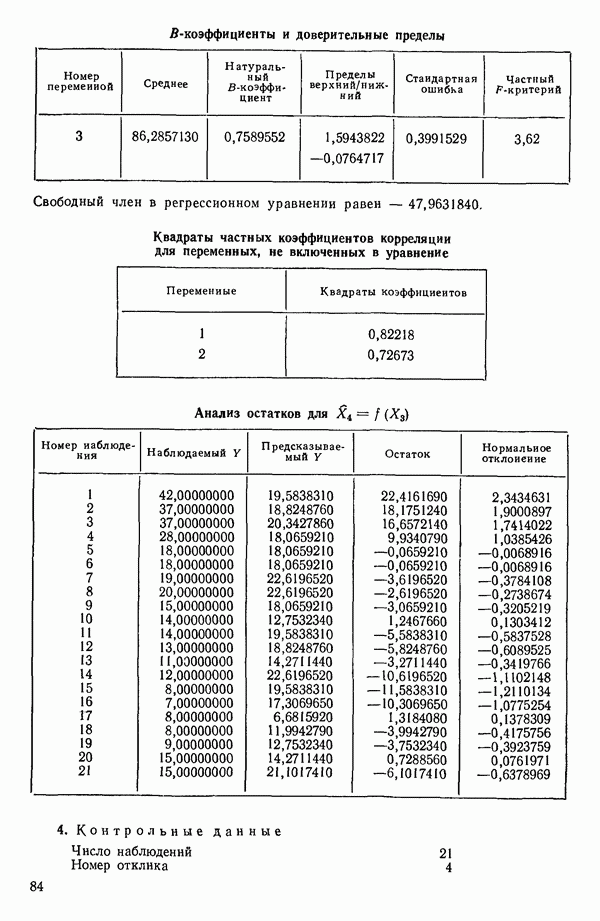
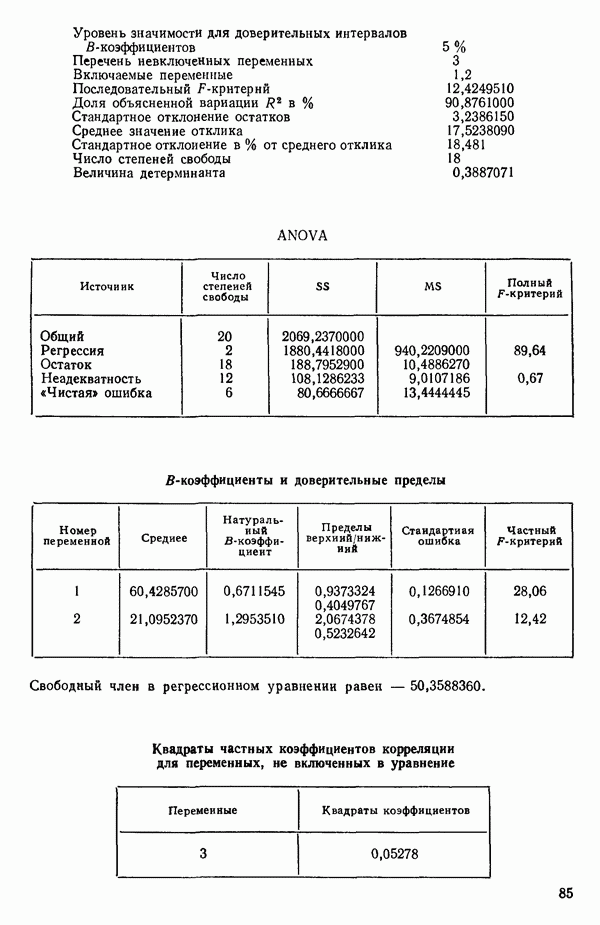
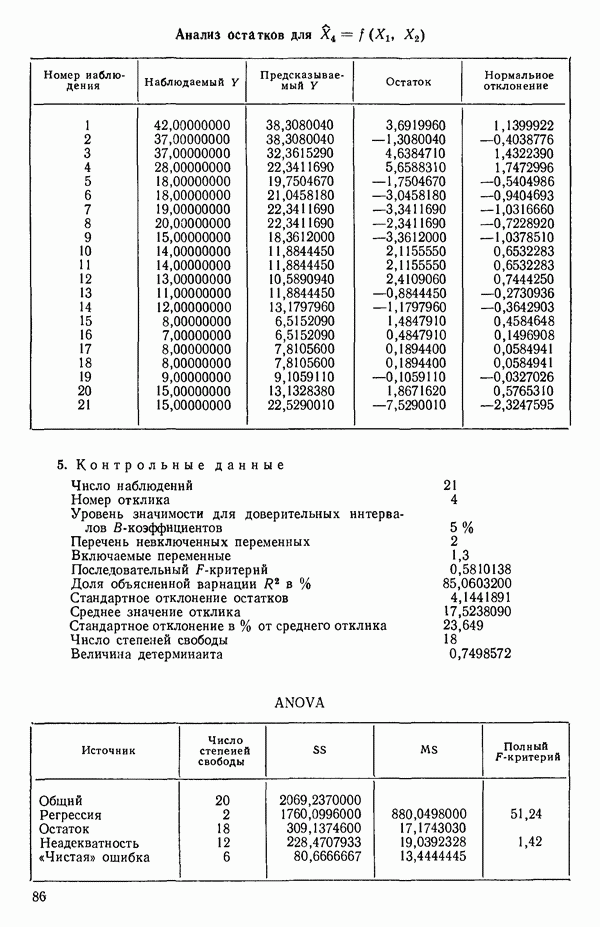
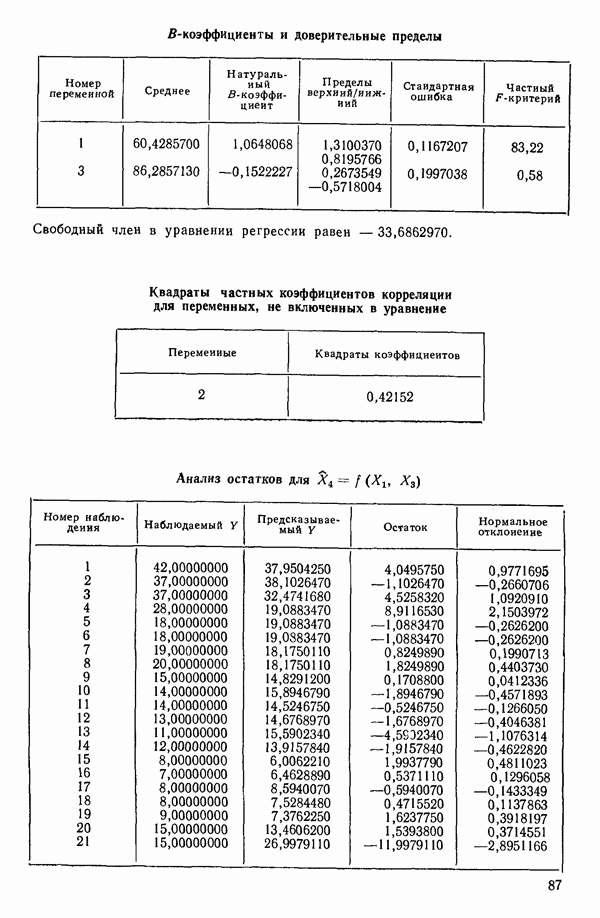
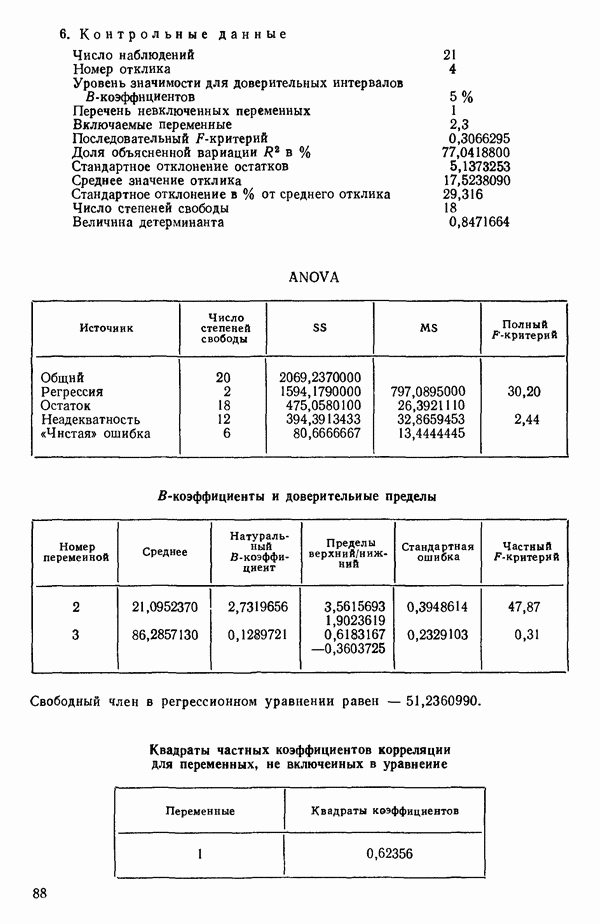
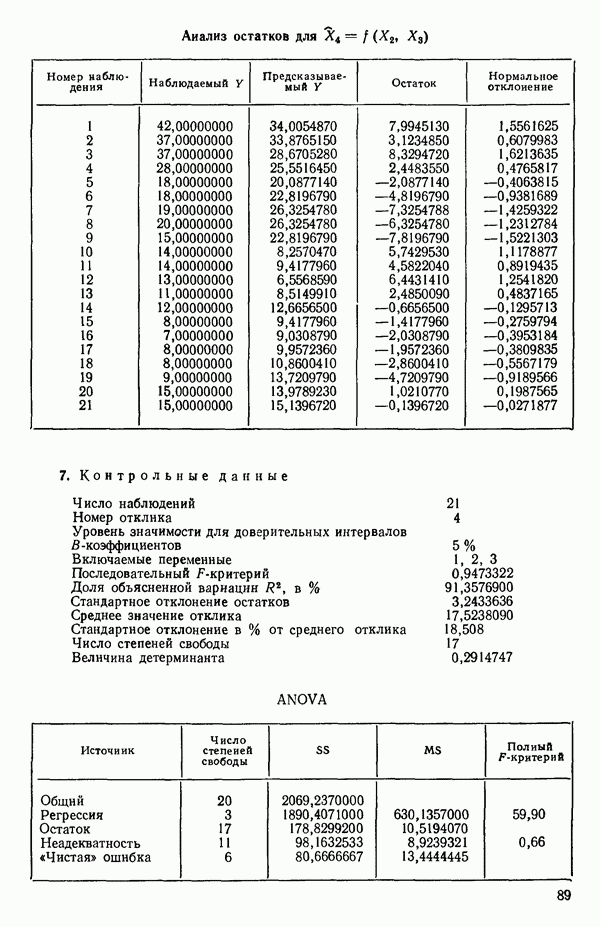
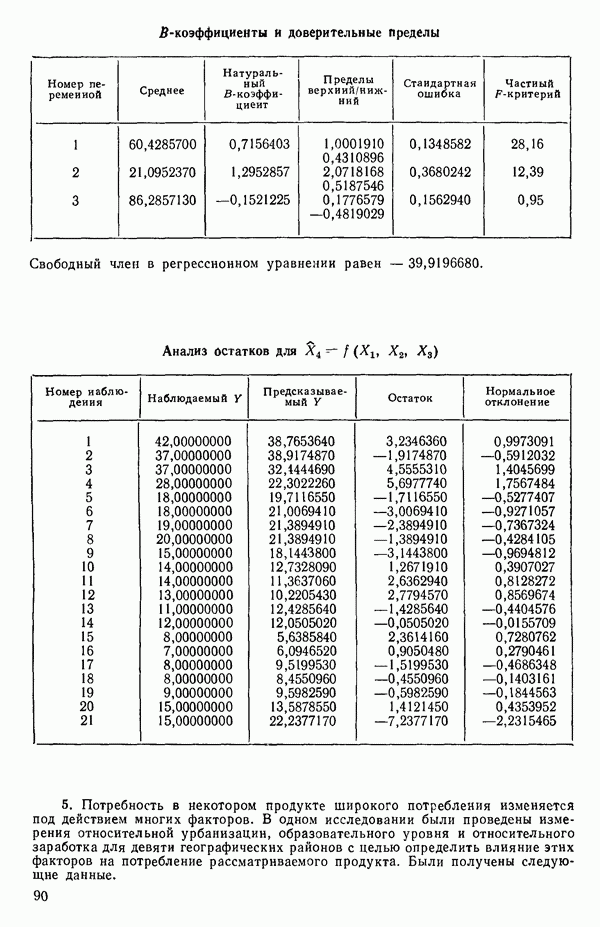
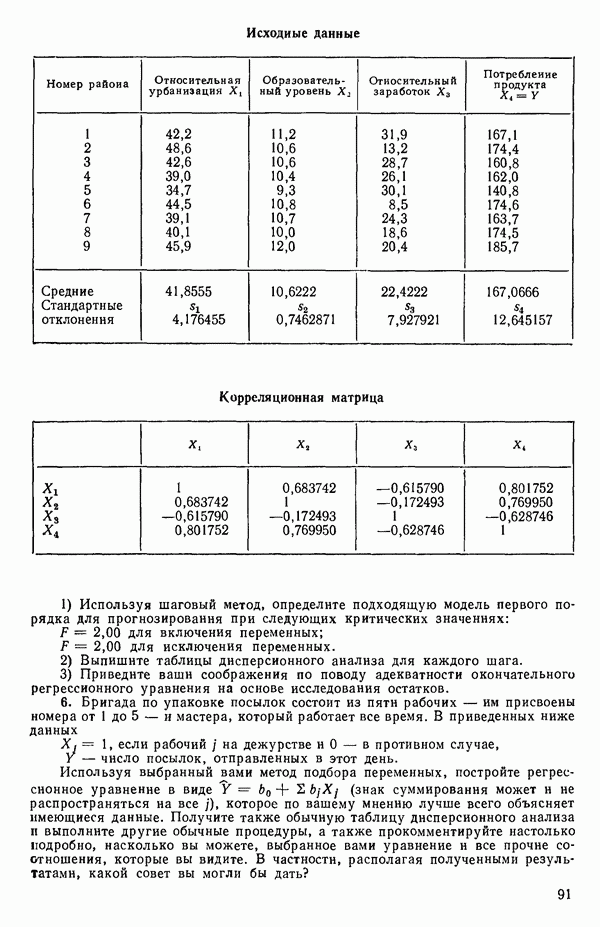
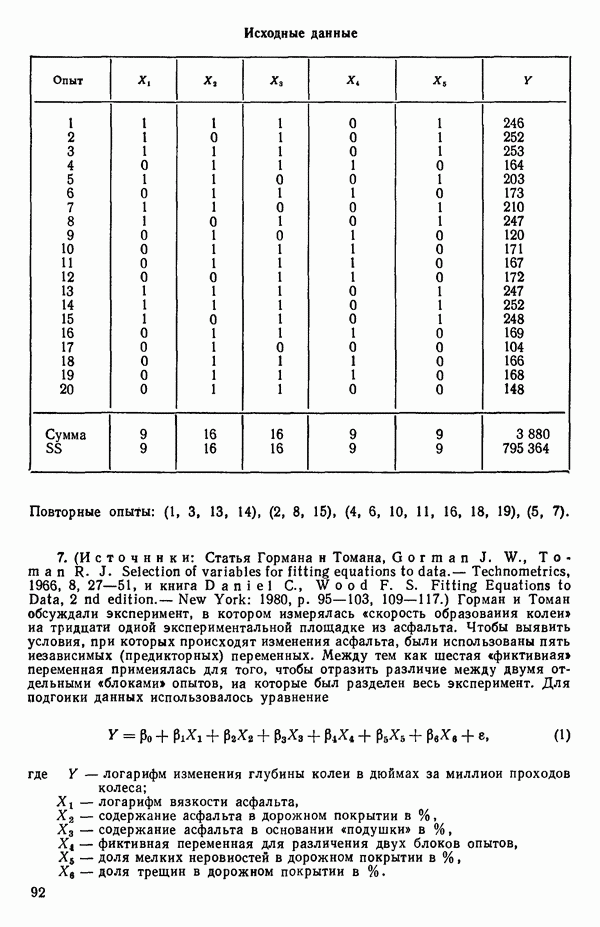
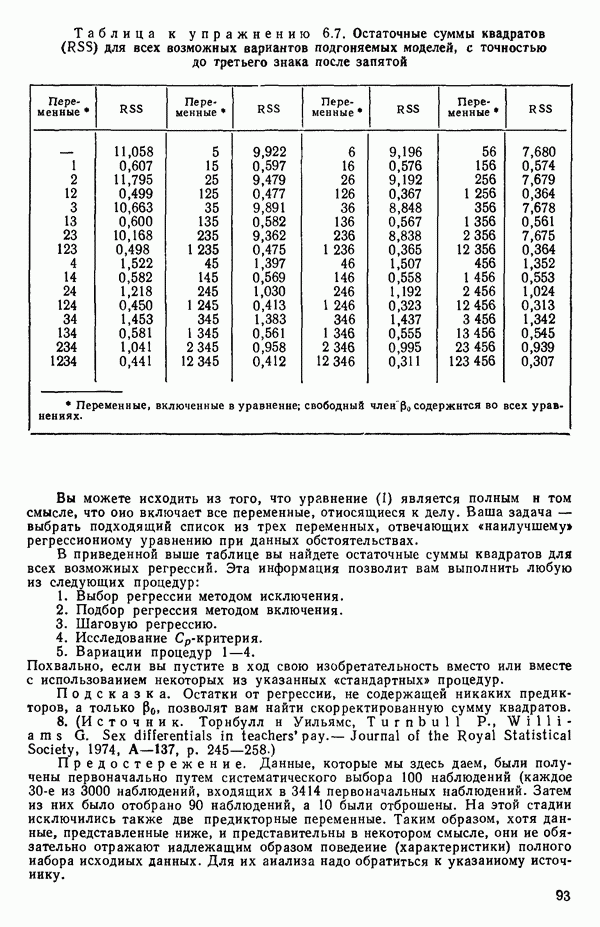
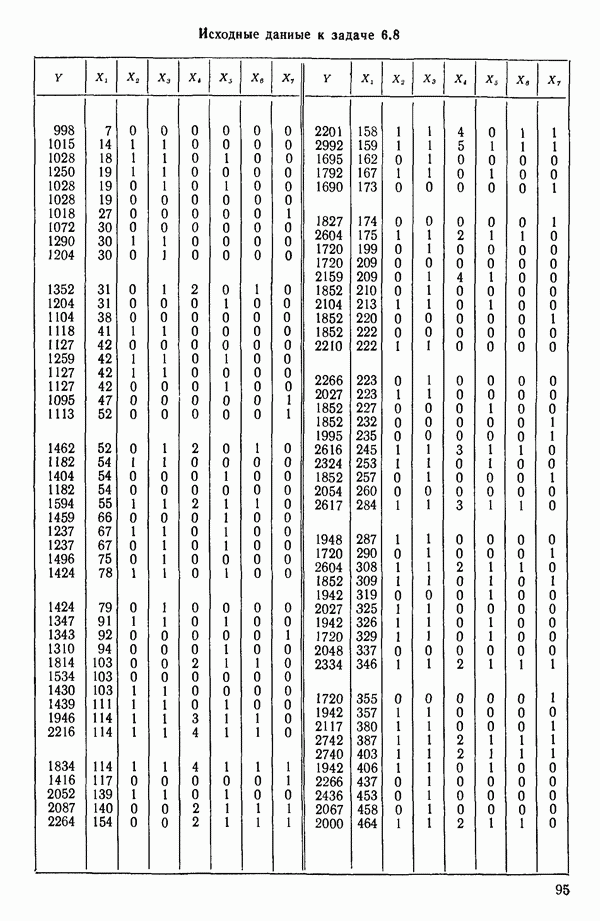
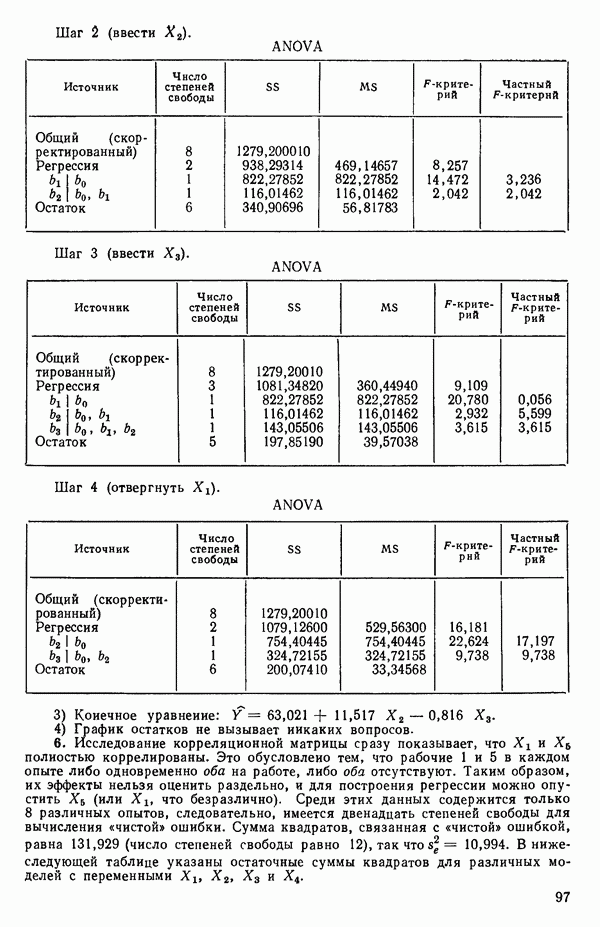
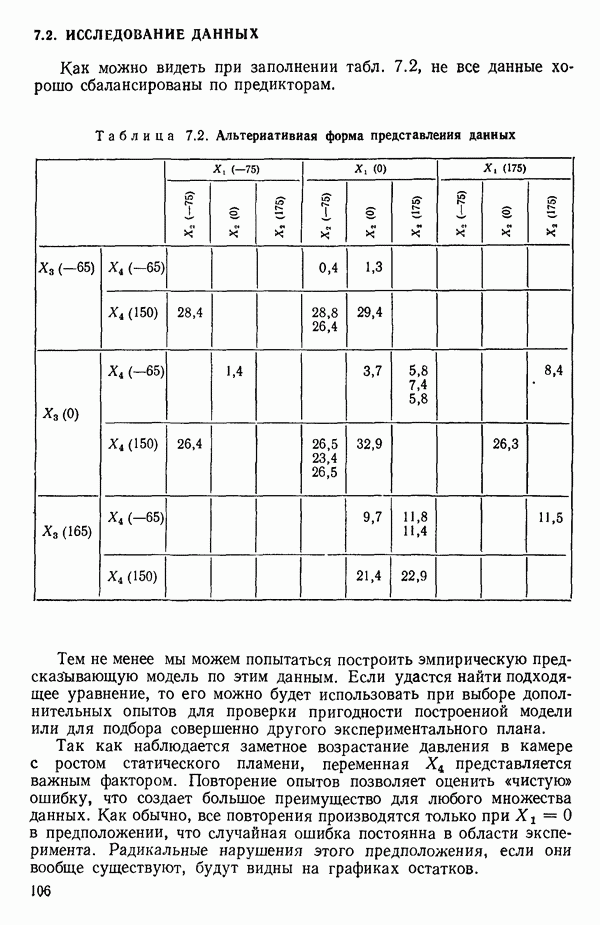
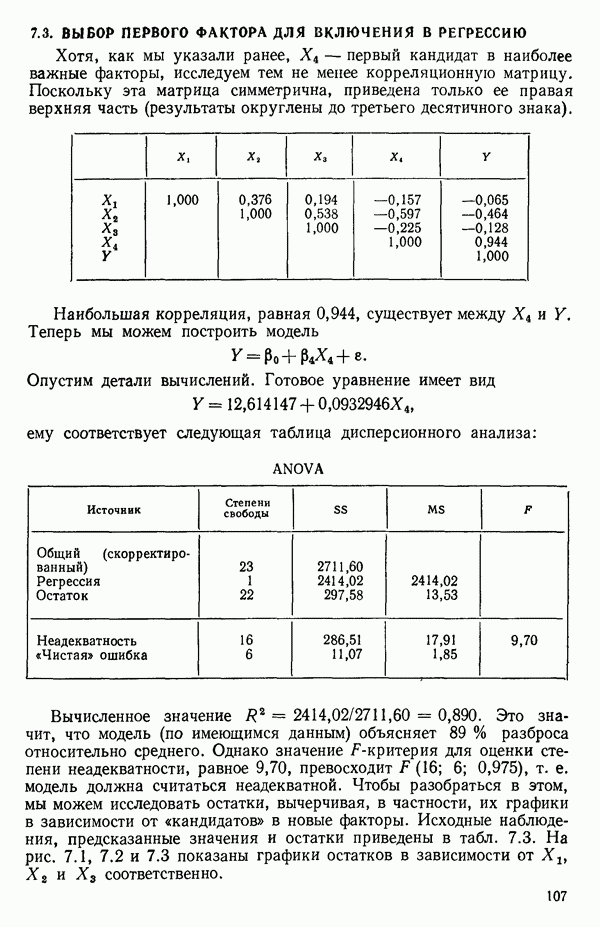
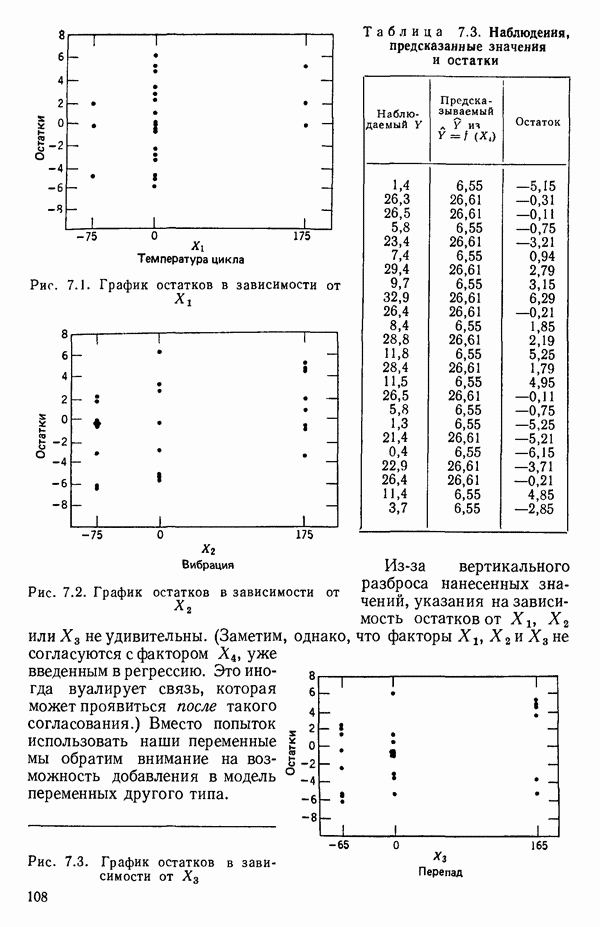
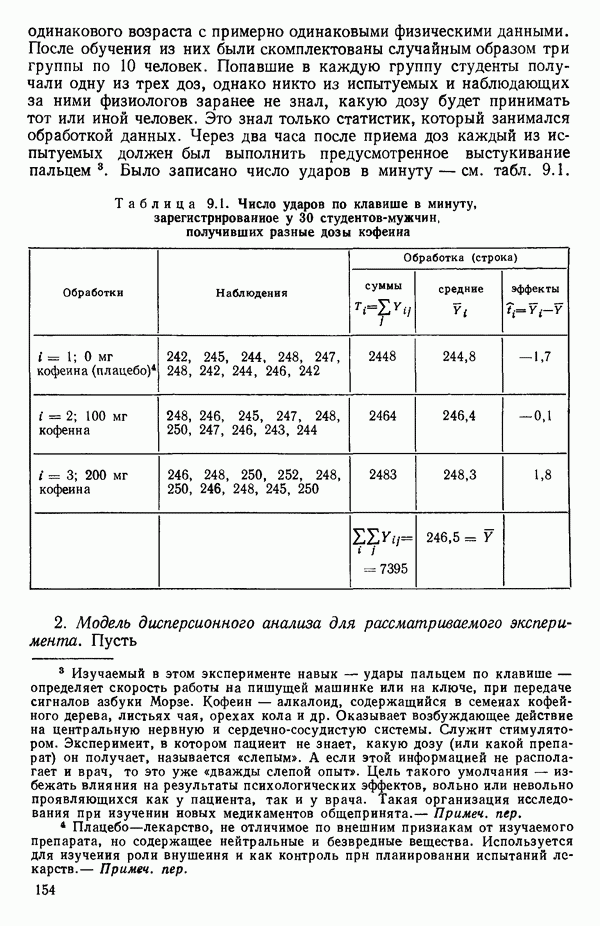
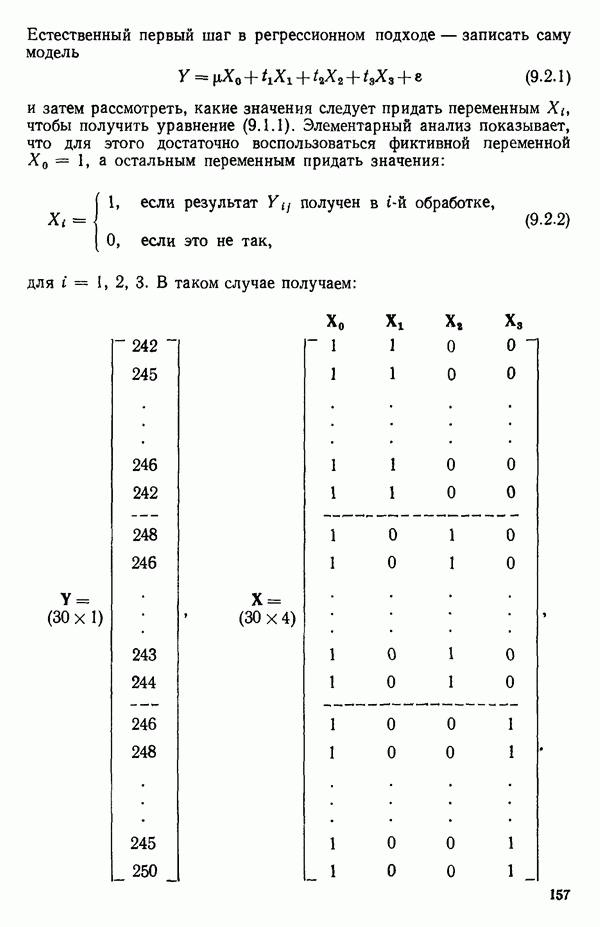
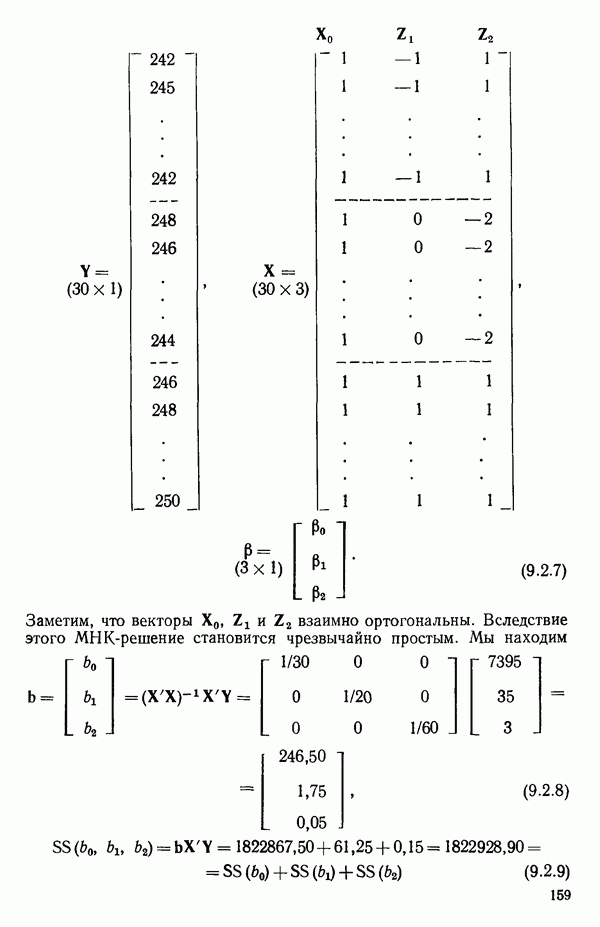
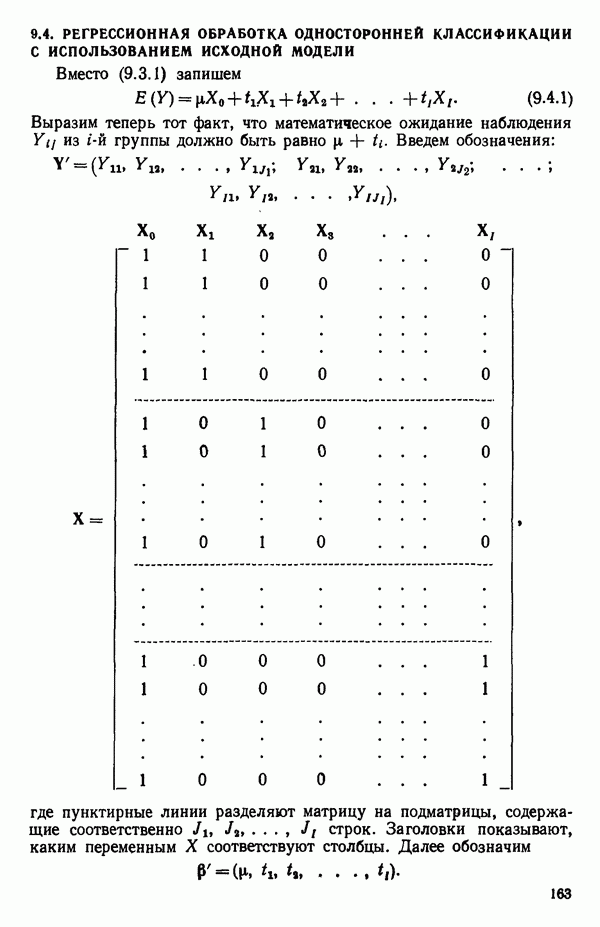
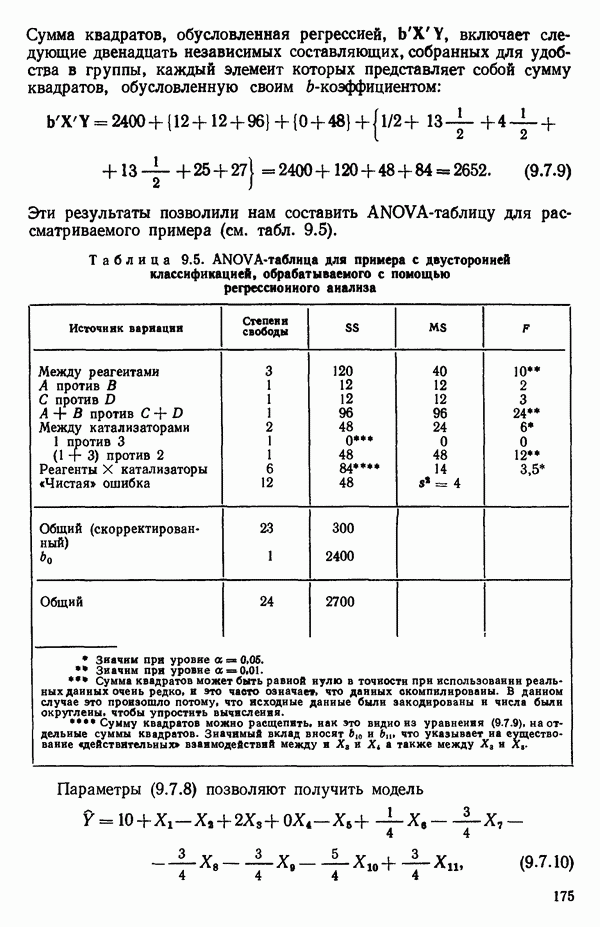
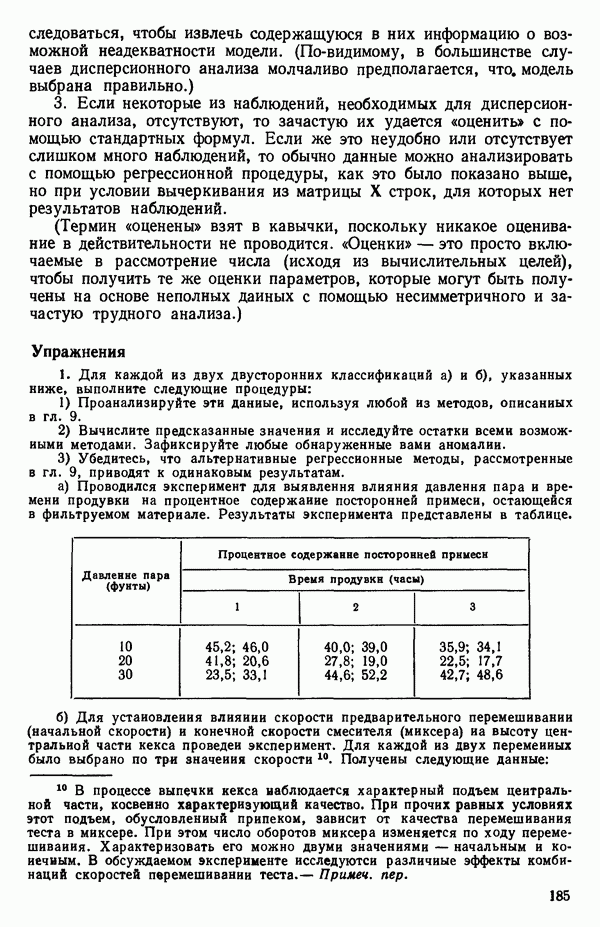
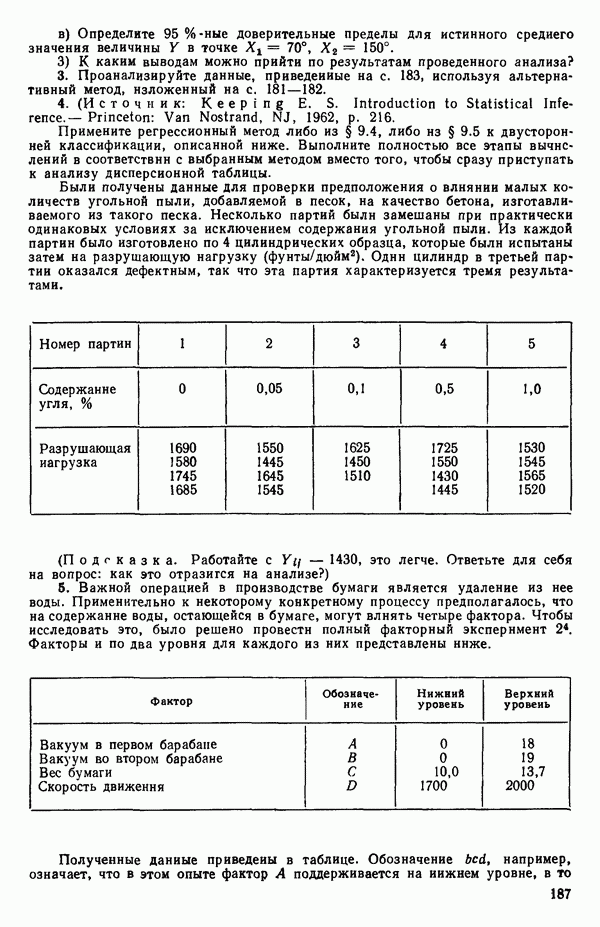
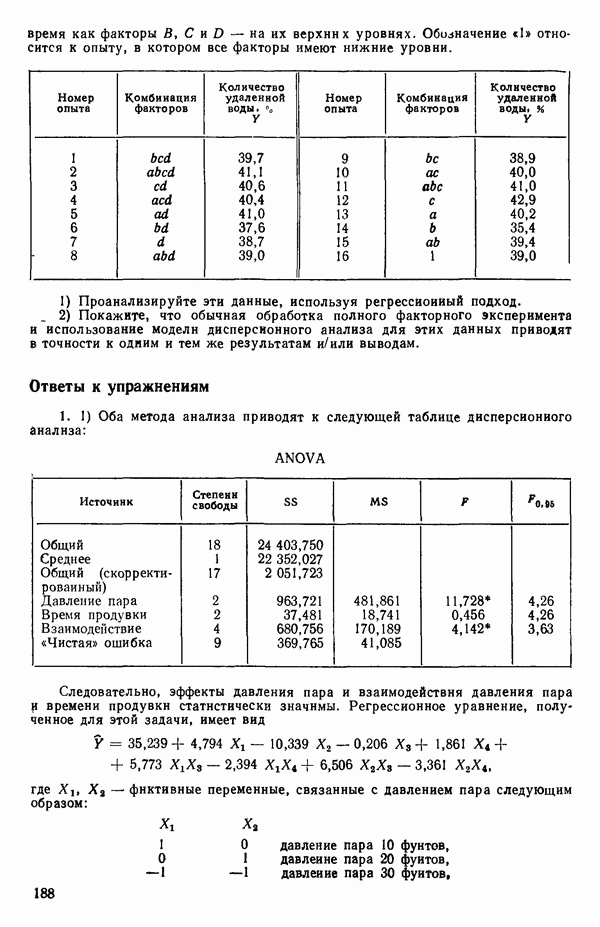
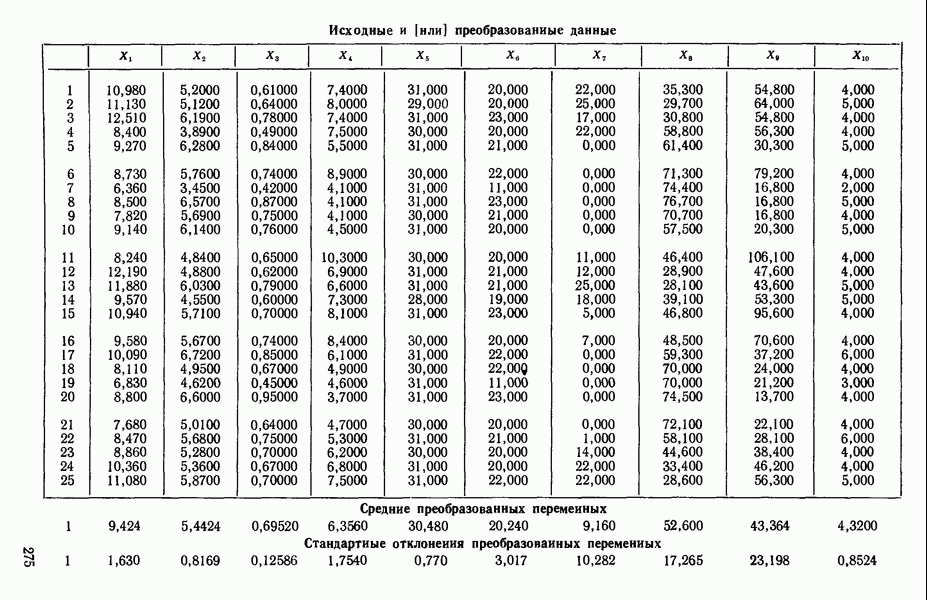
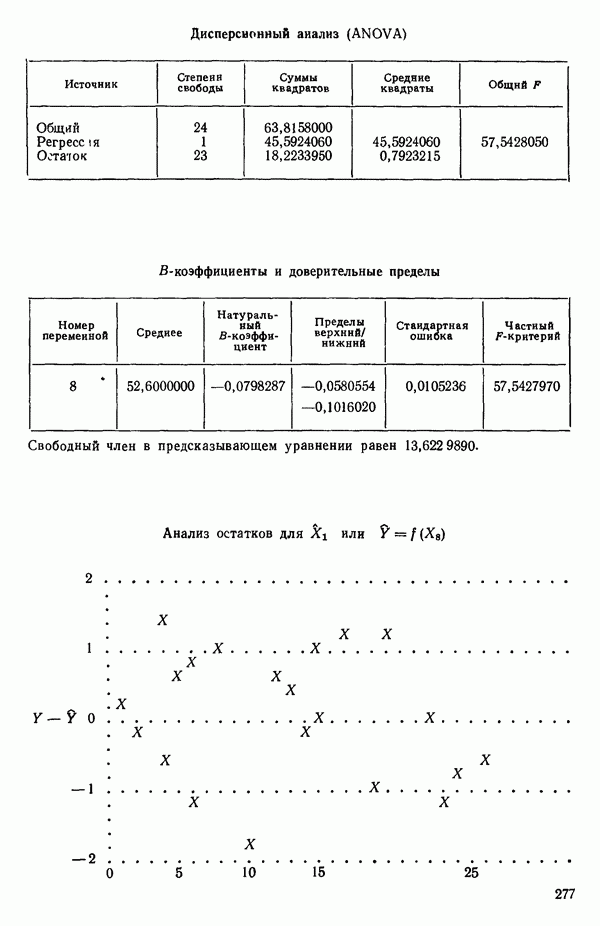
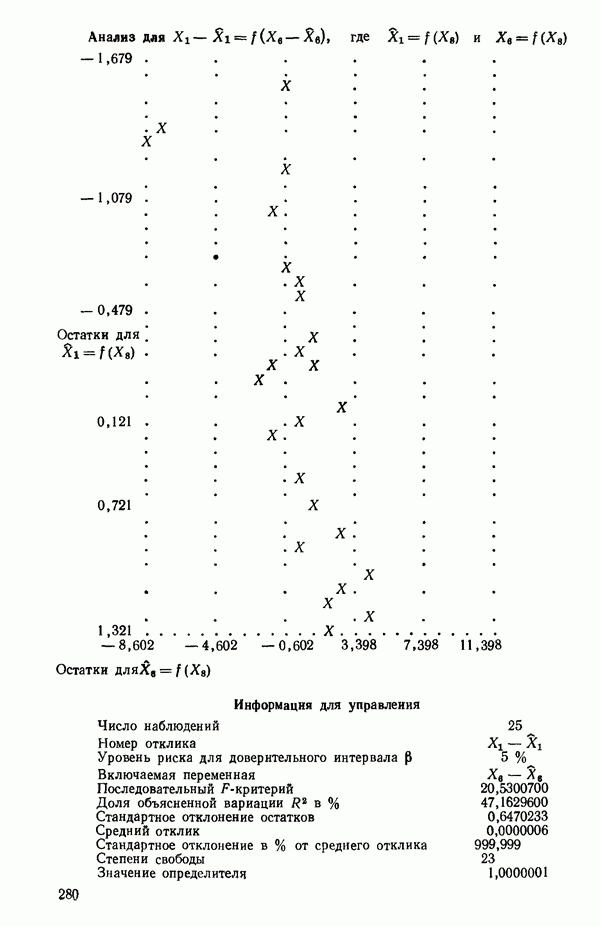
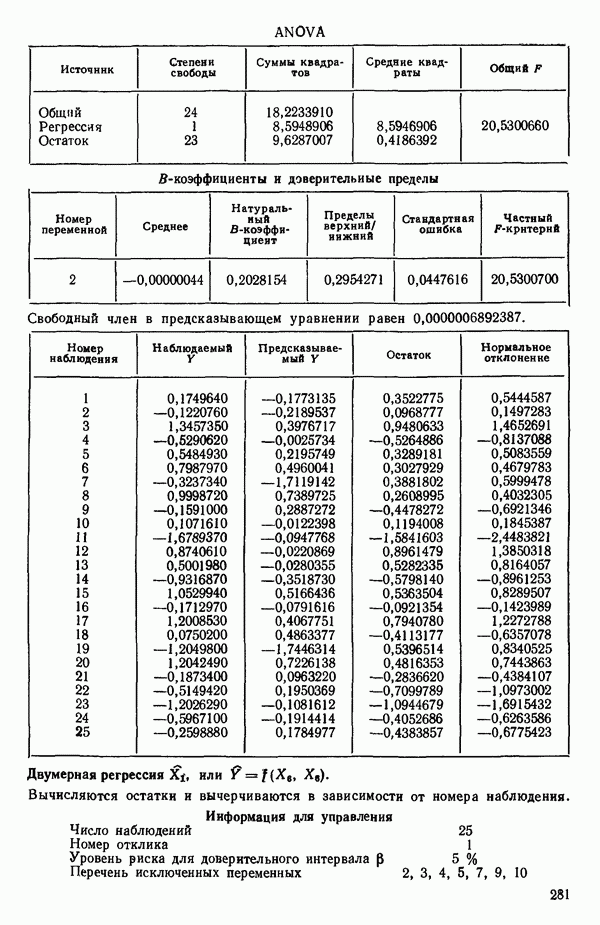
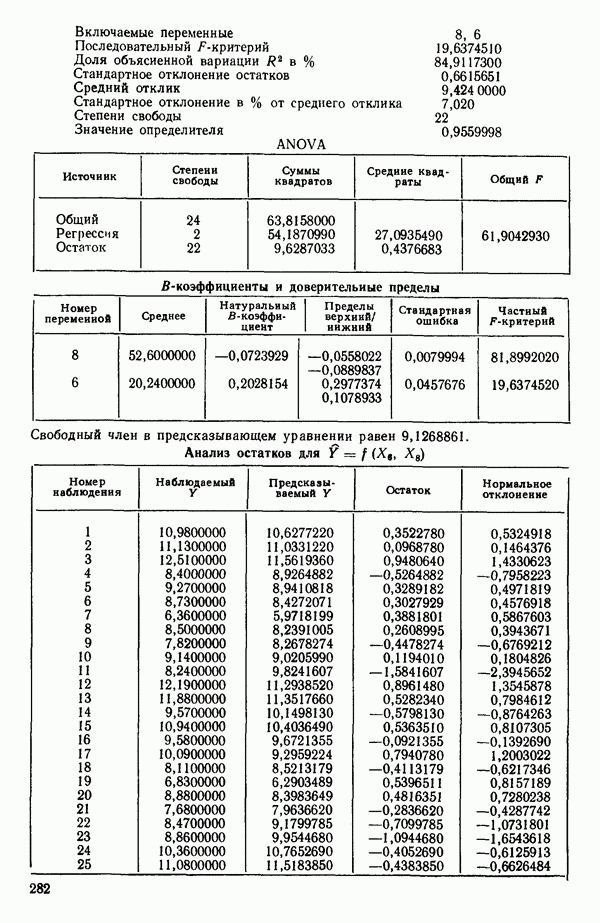
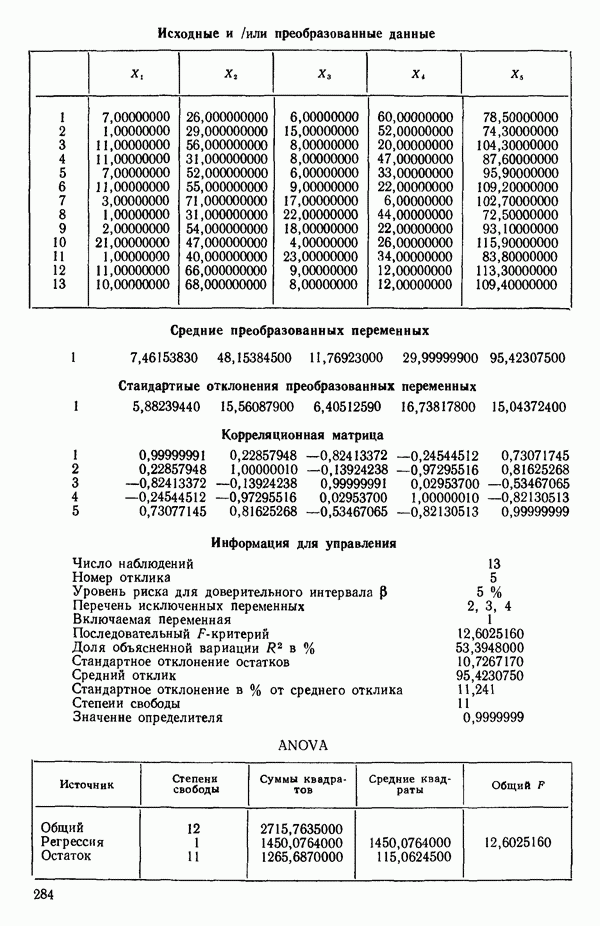
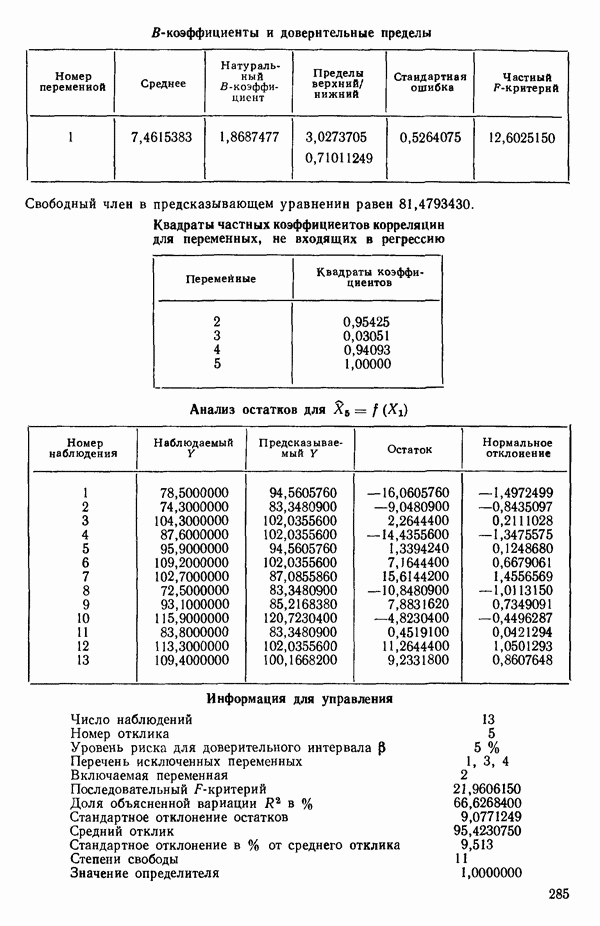
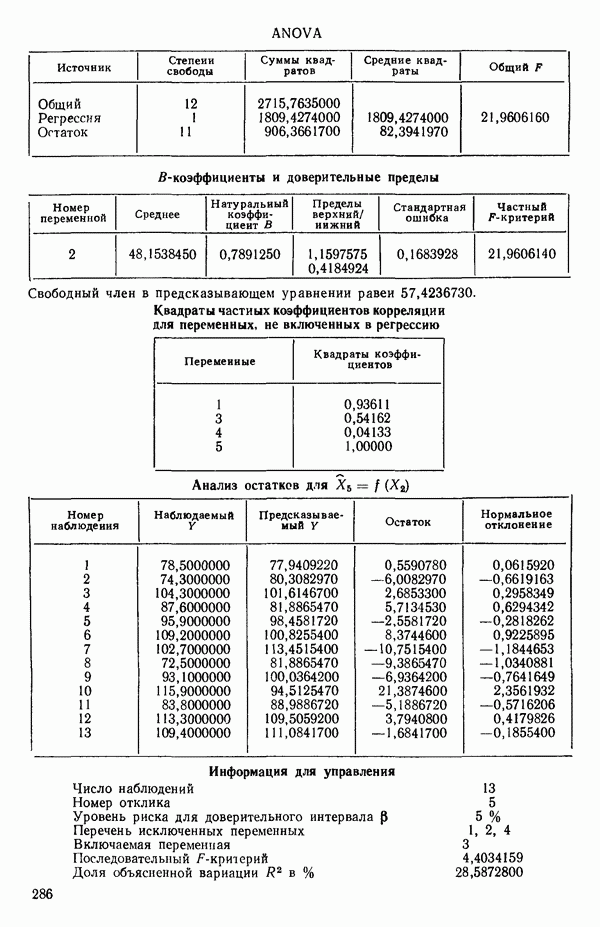
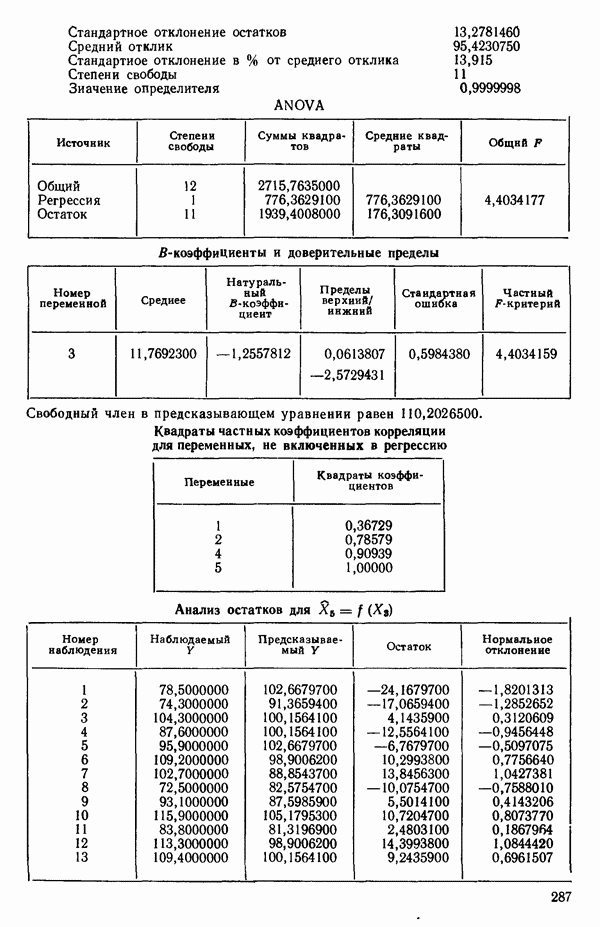
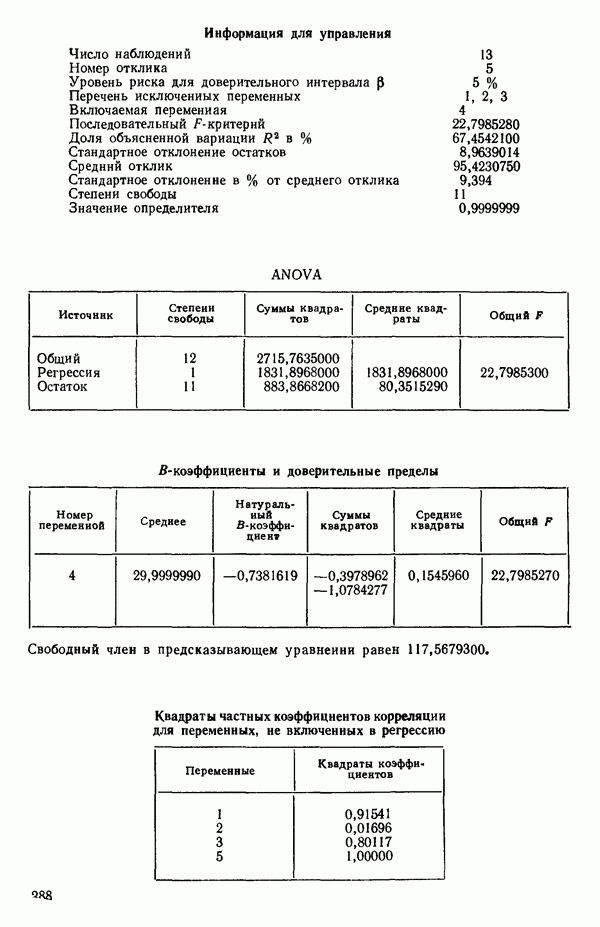
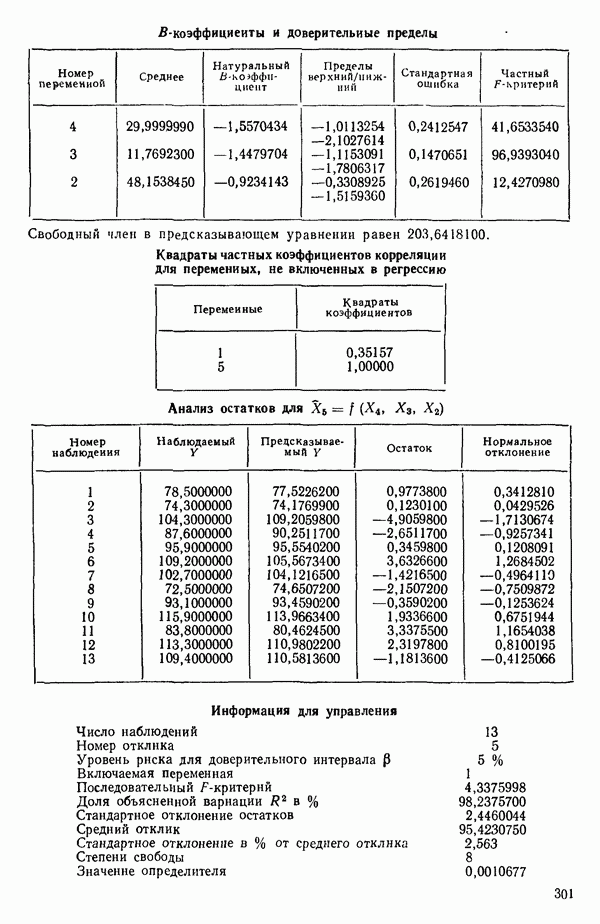
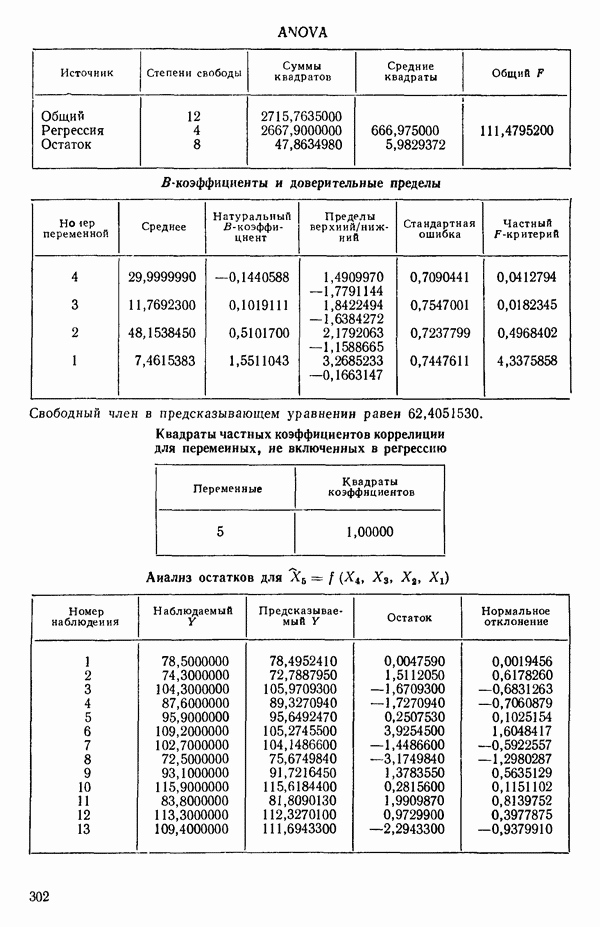
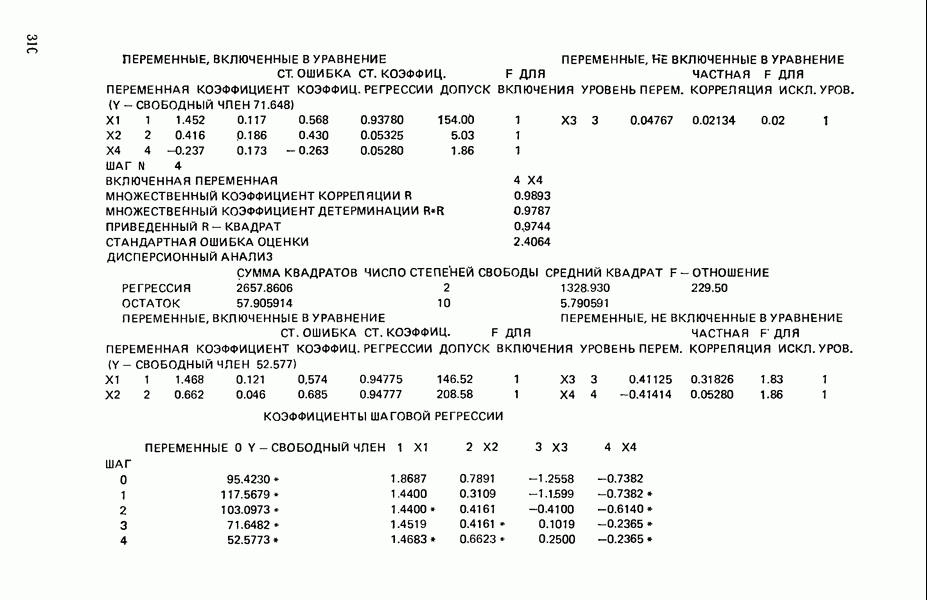
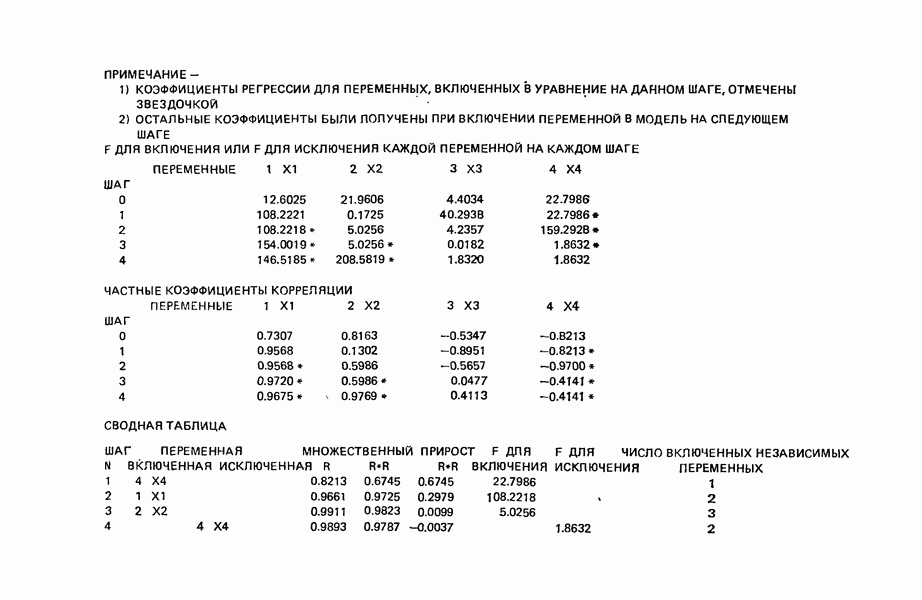
ПРИЛОЖЕНИЯПРИЛОЖЕНИЕ А. ОБЪЯСНЕНИЕ ДАННЫХ И СИМВОЛОВ В ПРИЛОЖЕНИЯХОпределение переменных Каждое приложение начинается с названия регрессионной задачи, за которым следует определение используемых переменных. Первоначальные и/или преобразованные данные Затем перечисляются входные данные. Каждая строка представляет совокупность одновременных наблюдений над всеми независимыми и зависимой переменными (опыт). Номеру опыта соответствует номер строки слева от матрицы исходных данных. Средние преобразованных переменных Строка средних значений каждого столбца. Стандартные отклонения преобразованных переменных Каждый элемент этой строки является стандартным отклонением столбца исходных данных. Корреляционная матрица Матрица вычисленных коэффициентов корреляции гц. Диагональные элементы должны быть в точности единицами. Нарушение этого условия объясняется ошибками округления, возникающими при машинном счете. Информация для управления Информация для управления включает: а) Число наблюдений — равно числу наблюдений отклика в данной задаче. б) Номер, соответствующий переменной-отклику. Номер обозначает, какой столбец матрицы исходных данных следует рассматривать как отклик. Например, № 4 будет указывать, что данные столбца 4 следует рассматривать как отклик или переменную У. в) Уровень риска г) Перечень исключенных переменных. Это номера, определяющие, какие векторы не должны рассматриваться при подборе регрессионной модели. д) Включаемые переменные. Независимые переменные, которые выбраны для введения в регрессию на определенном шаге. е) Последовательный F-критерий. F-критерий служит для проверки того, существенно ли влияет последняя переменная, включенная в регрессию, на понижение величины необъясненной вариации. Детально обсуждается в гл. 2 и 4. ж) Доля объясненной вариации в з) Стандартное отклонение остатков. Корень квадратный и) Средний отклик. Арифметическое среднее всех наблюденных значений отклика. к) Стандартное отклонение в процентах от среднего отклика. Мера величины стандартного отклонения остатков относительно среднего отклика рассчитывается как отношение стандартного отклонения остатков к среднему отклику. л) Степени свободы. Число степеней свободы, используемое для расчета стандартного отклонения остатков. м) Значение определителя. Значение определителя корреляционной матрицы всех переменных в регрессии на каждом шаге машинного счета. Дисперсионный анализ (ANOVA) Это таблица дисперсионного анализа для регрессионных задач. Источник. Под заголовком «Источник» перечисляются все источники рассеяния в данной задаче. Н Степени свободы. Столбец, показывает число степеней свободы для каждого из источников рассеяния. SS - сумма квадратов. В столбце с таким заголовком указываются суммы квадратов для каждого источника рассеяния. MS-средний квадрат. Столбец «средний квадрат» получается при делении каждой суммы квадратов на соответствующее ей число степеней свободы. Общий
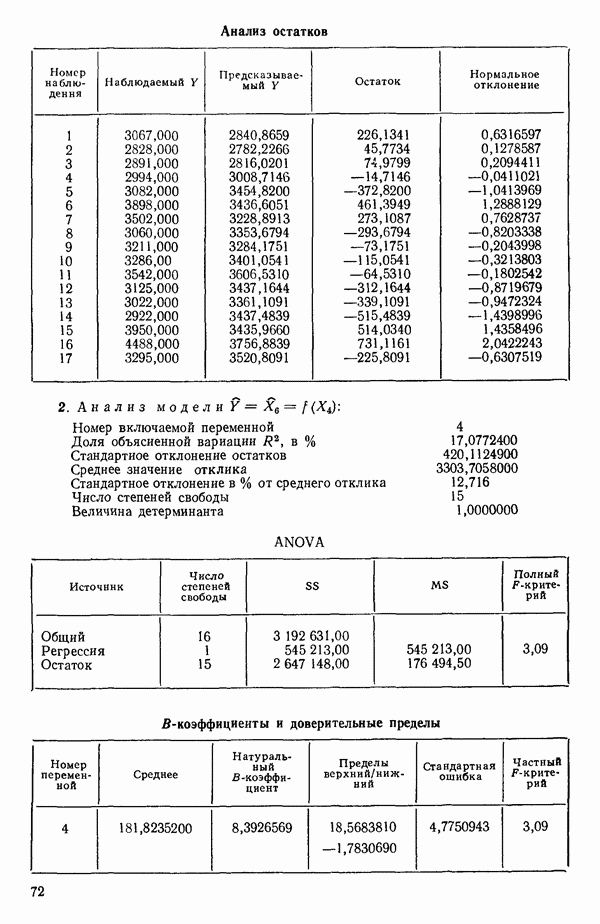
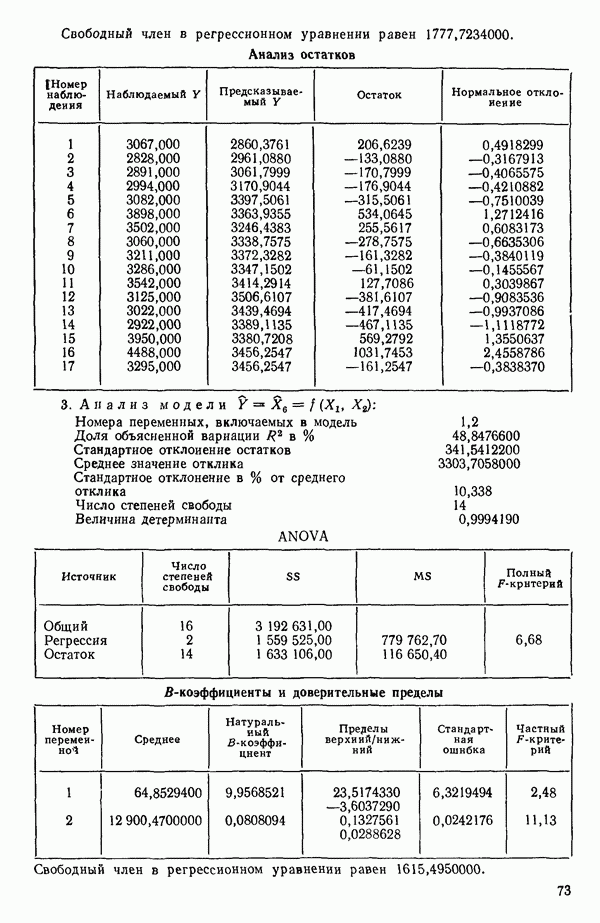
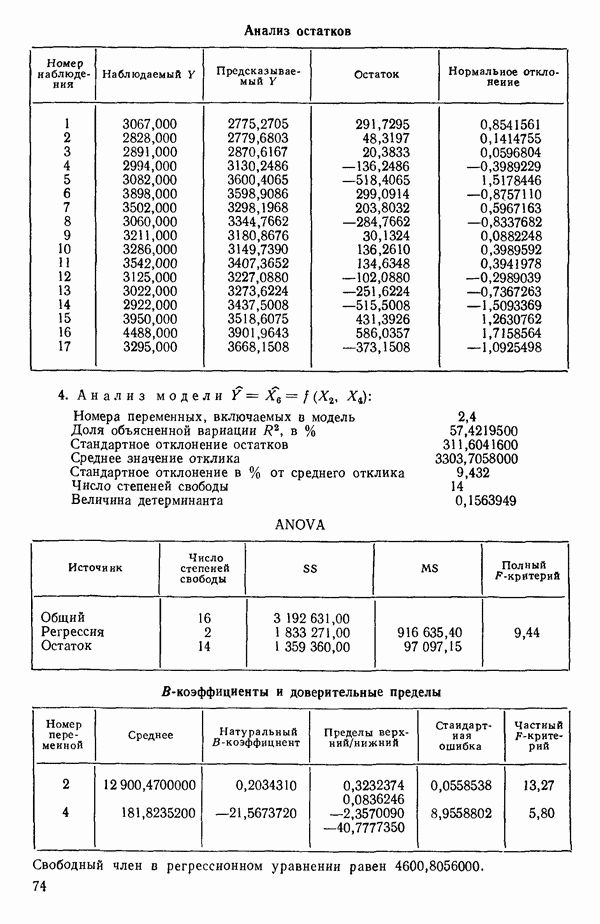
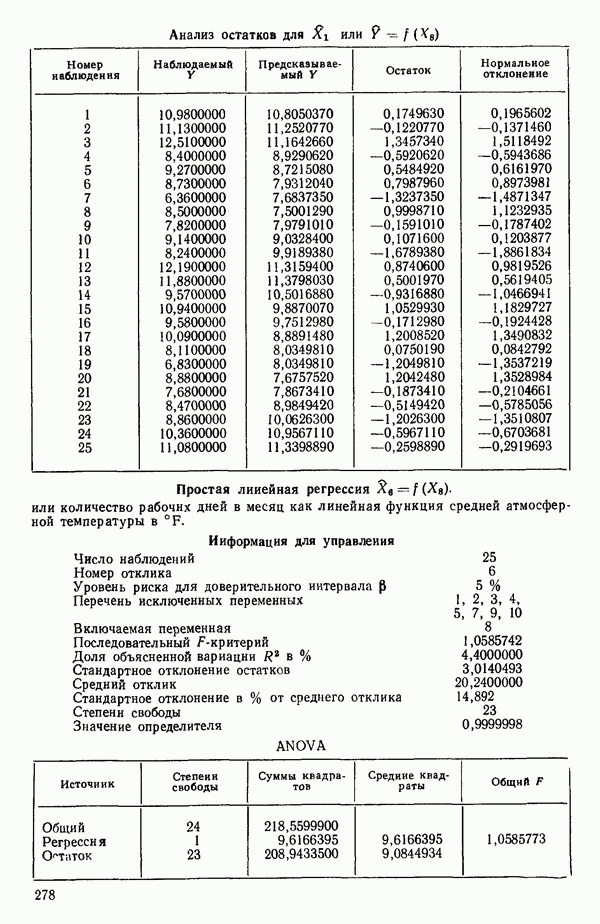
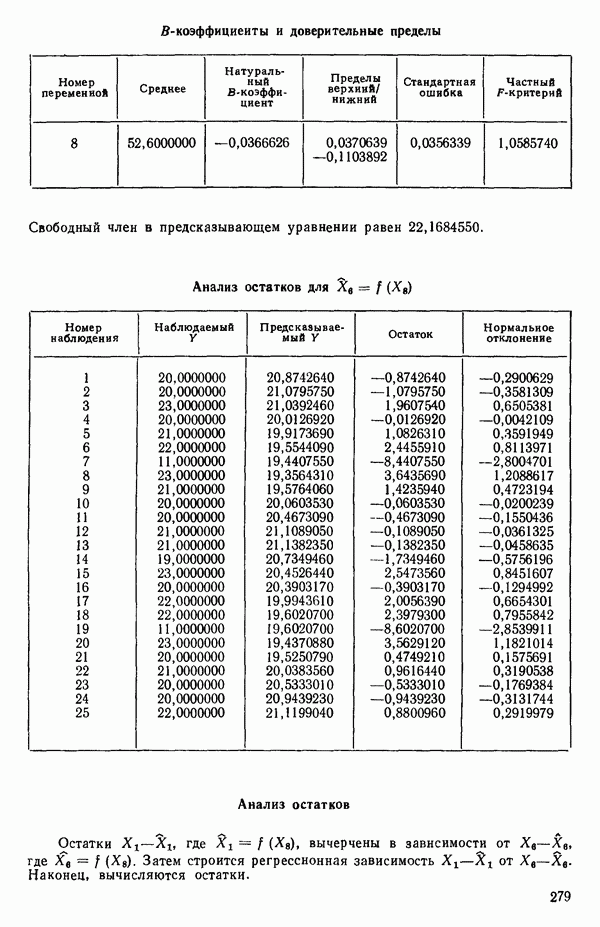
Номер переменной. Указывается номер каждой независимой переменной в регрессионной модели. Среднее. Среднее значение всех наблюдений для независимой переменной. Натуральный Пределы (верхннй/нижний). Имеются в виду Стандартная ошибка. Стандартная ошибка коэффициента Частный F-критерий. Свободный член в предсказывающем уравнении. МНК-оценка коэффициента Квадраты частных коэффициентов корреляции переменных, не введенных в уравнение регрессии Частный коэффициент корреляции между каждой переменной, не введенной в регрессию, и откликом вычисляется и возводится в квадрат. Обсуждение этого статистического показателя дано в гл. 5 и 6. Анализ остатков Под этим заголовком записываются результаты подбора модели для «сглаживания» всех данных. Наблюдаемый Предсказываемый У. Значение предсказанного У, или Остаток. Разность между наблюденным и предсказанным значениями Нормальное отклонение. Разность
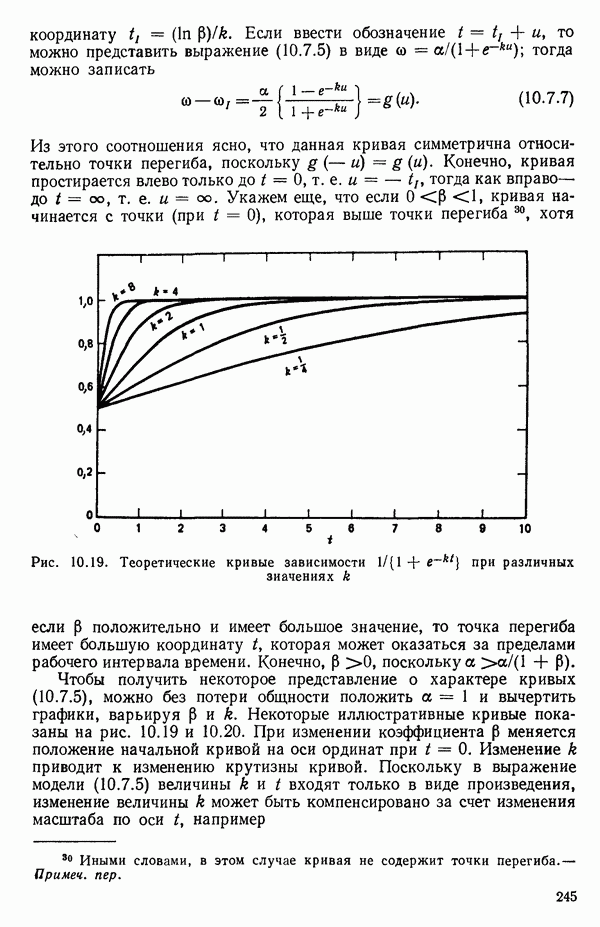
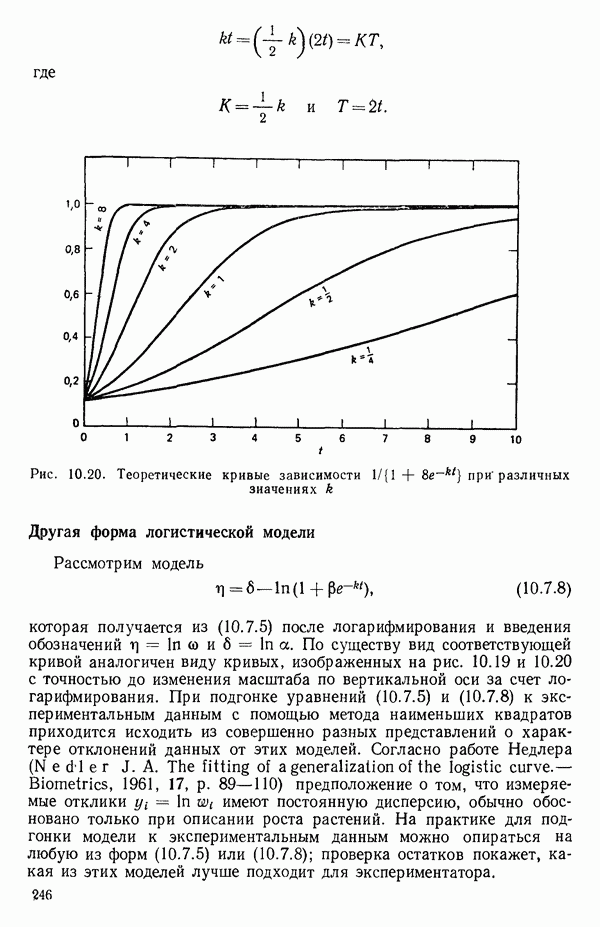
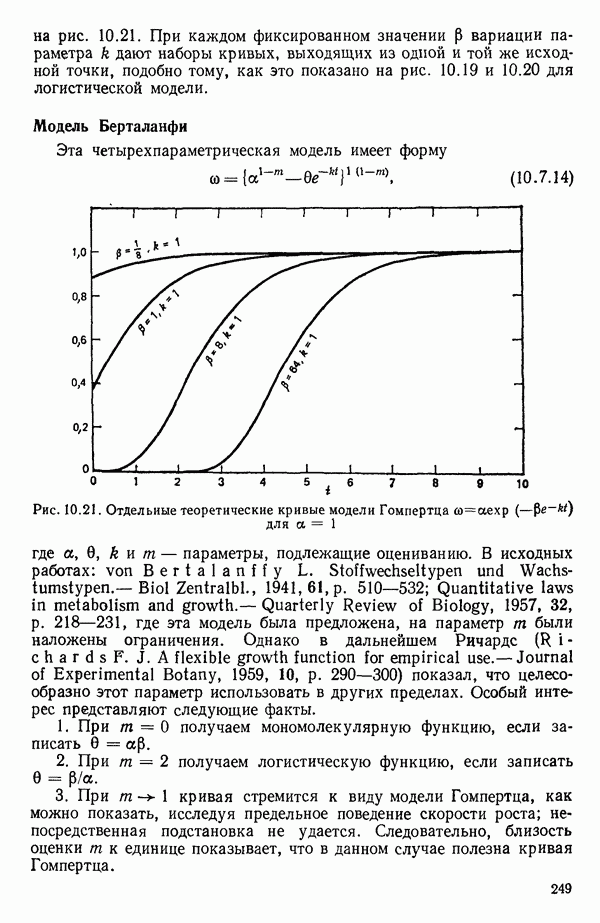
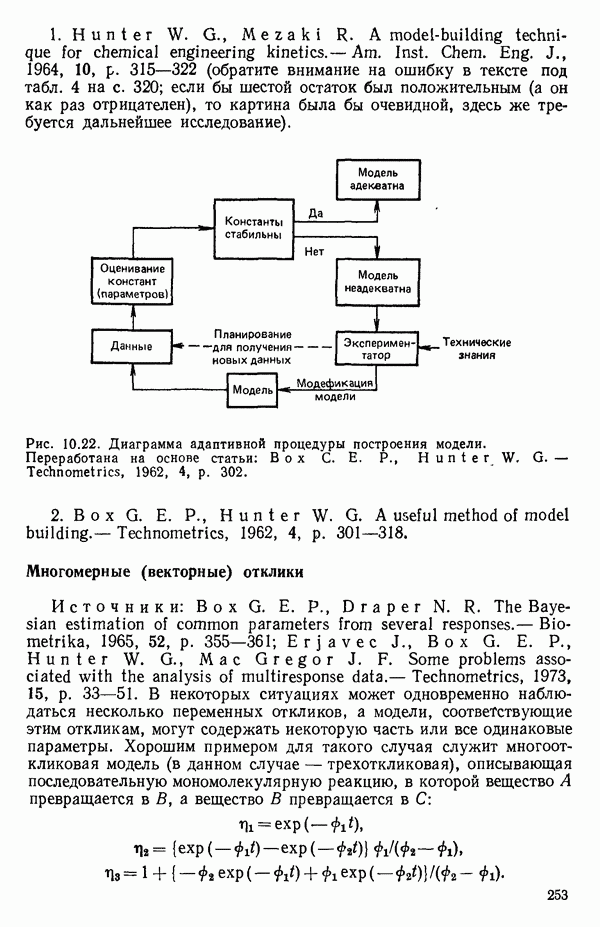
(кликните для просмотра скана) (см. скан)
(кликните для просмотра скана)
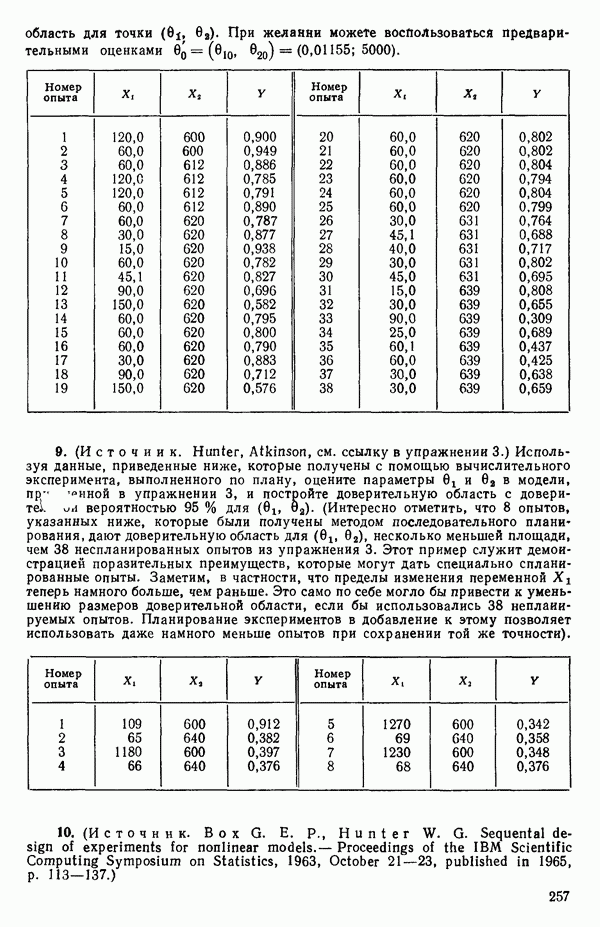
(кликните для просмотра скана) (см. скан)
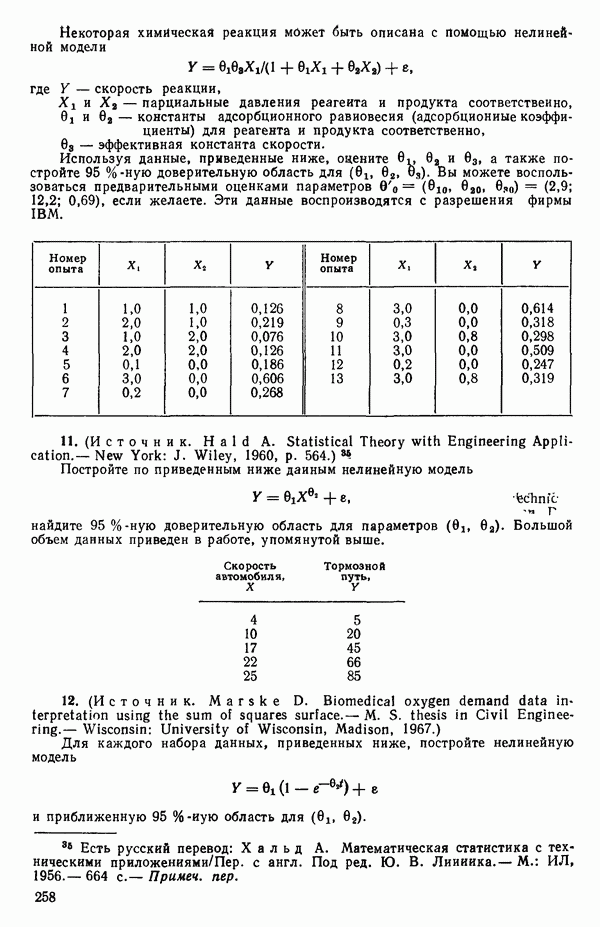
(кликните для просмотра скана)
(кликните для просмотра скана) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан) (см. скан)
|
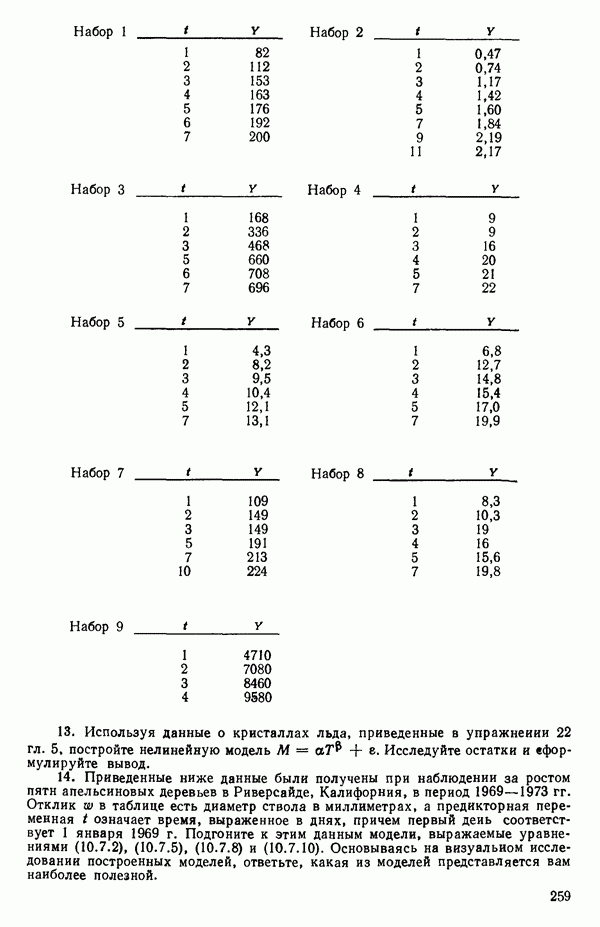
 |
Оглавление
|



























































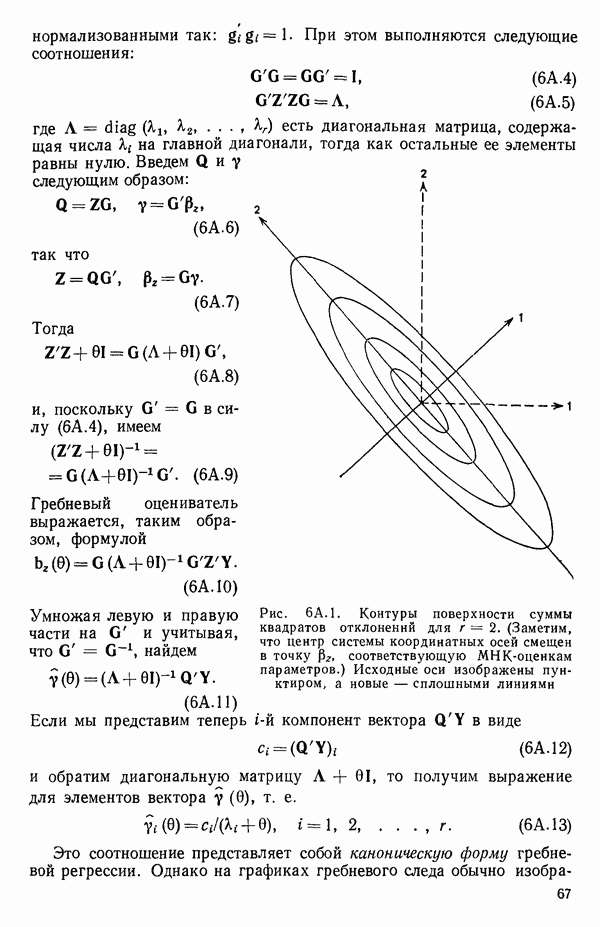







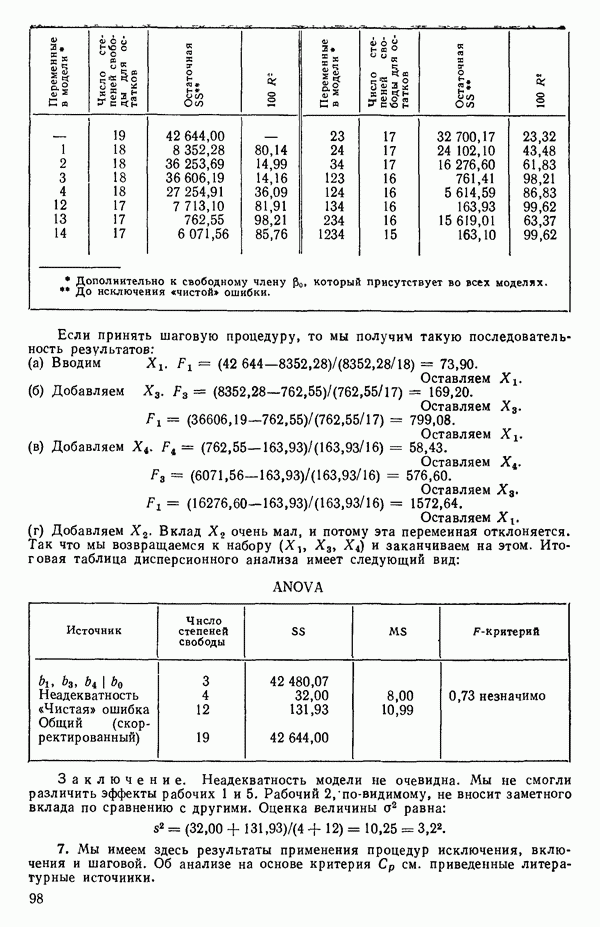















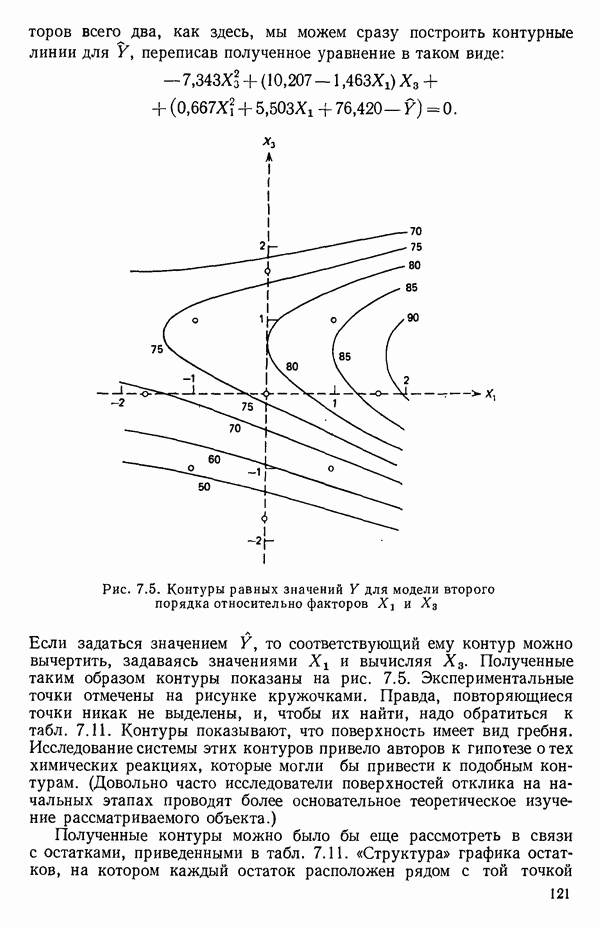
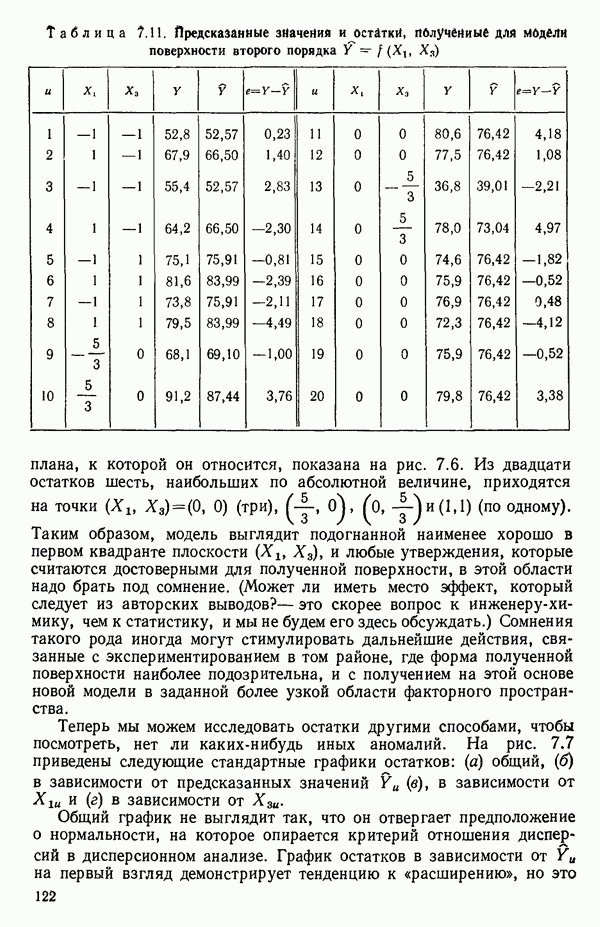




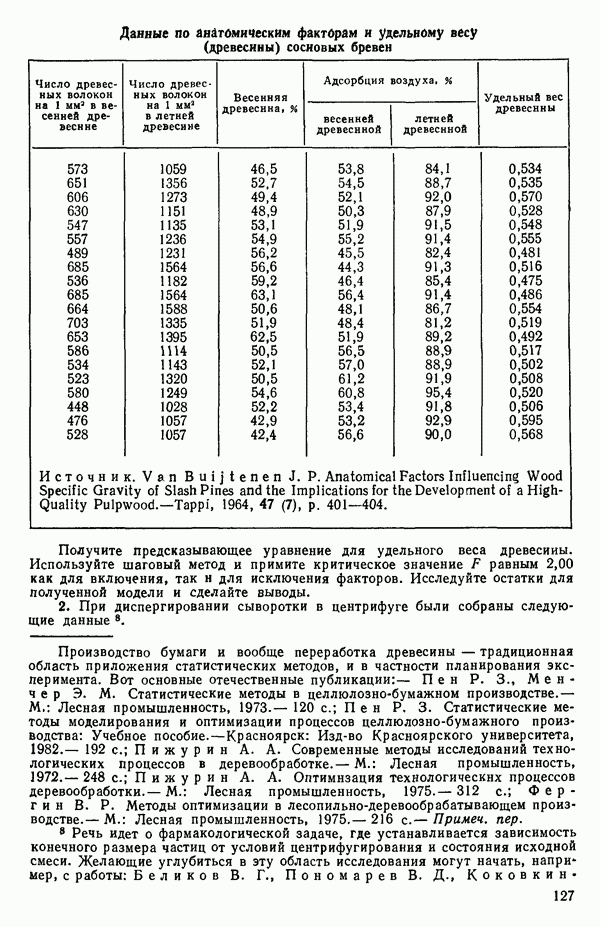


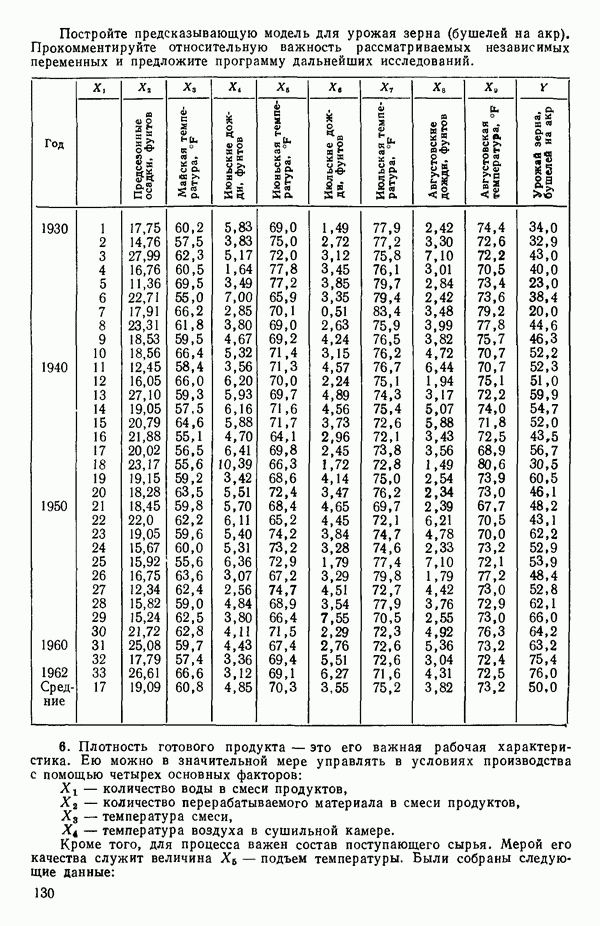














































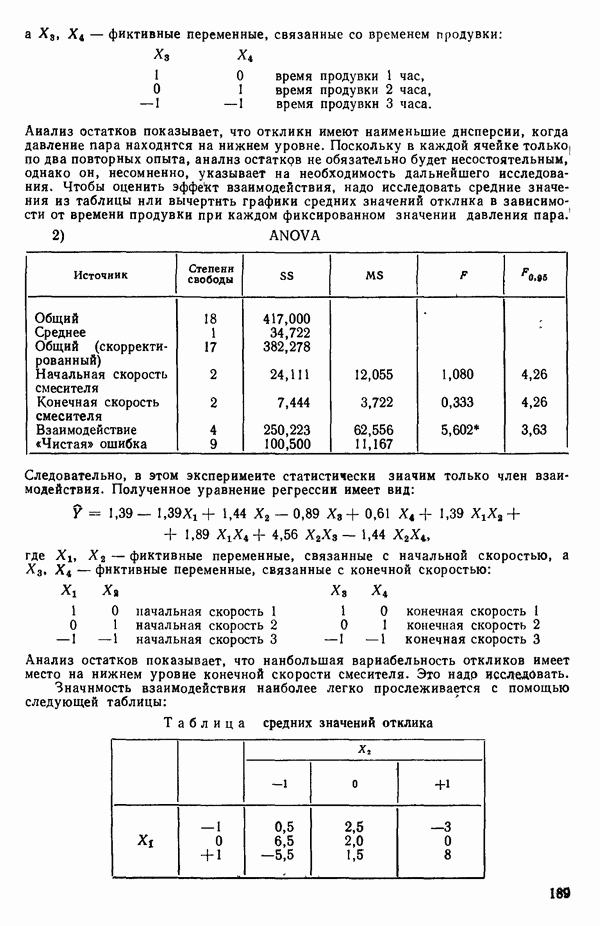

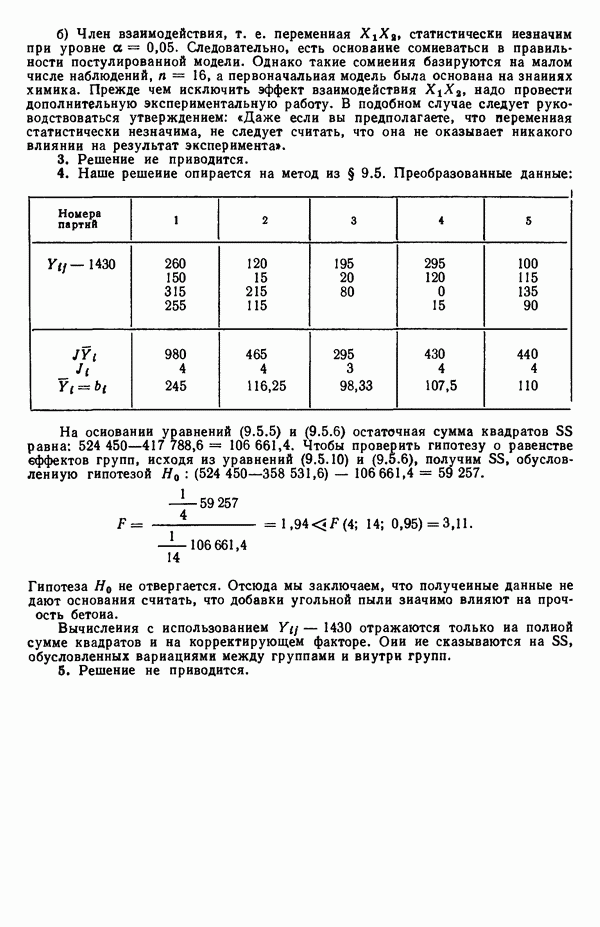








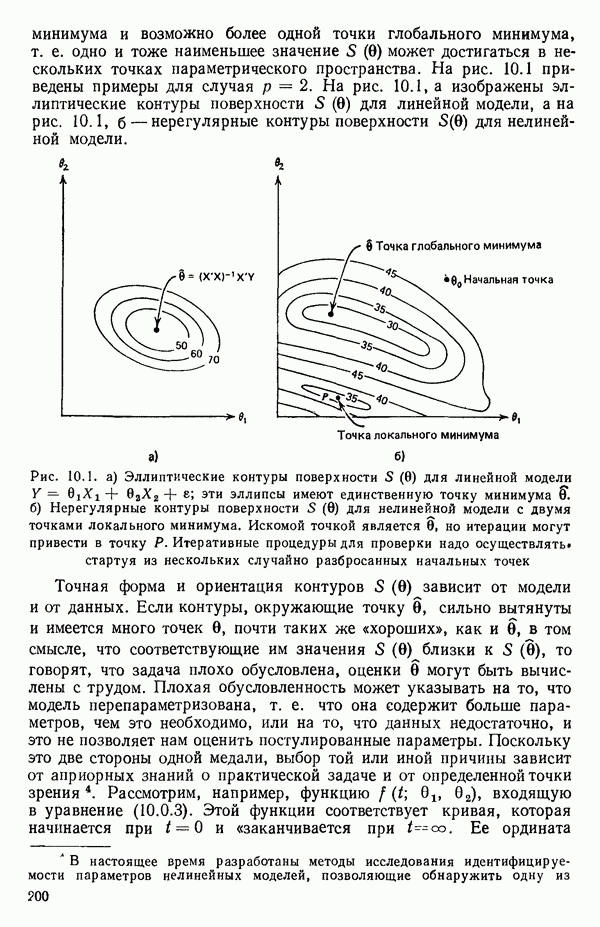
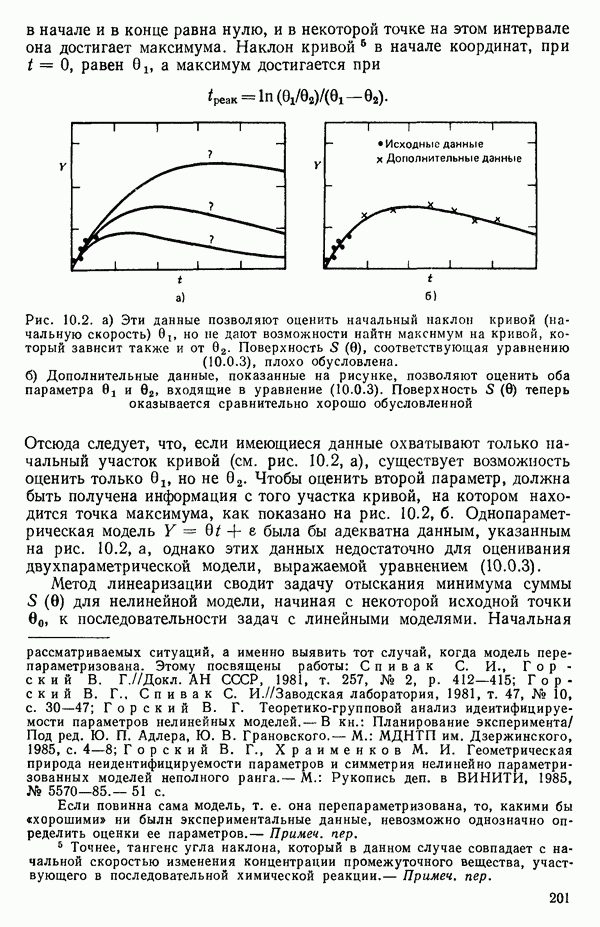












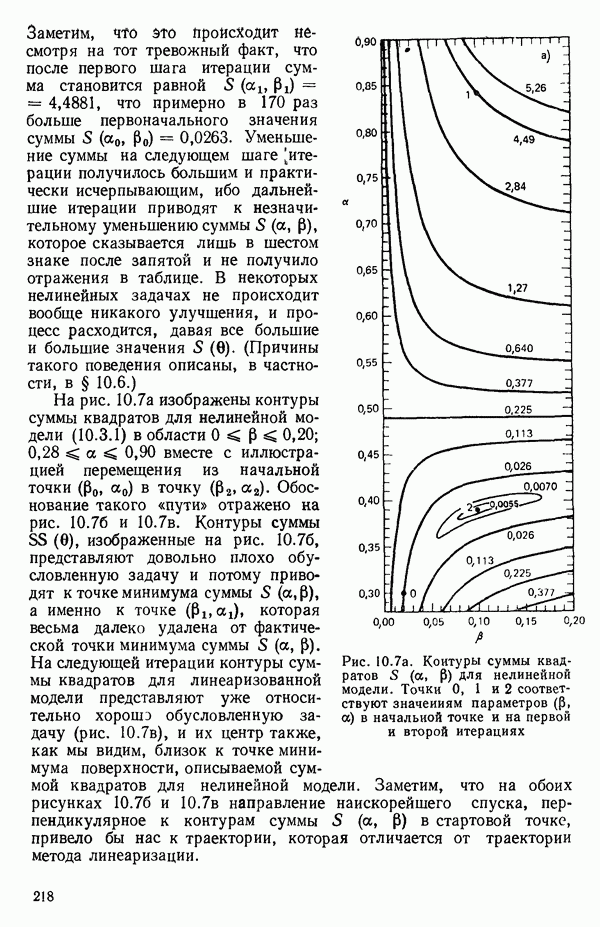
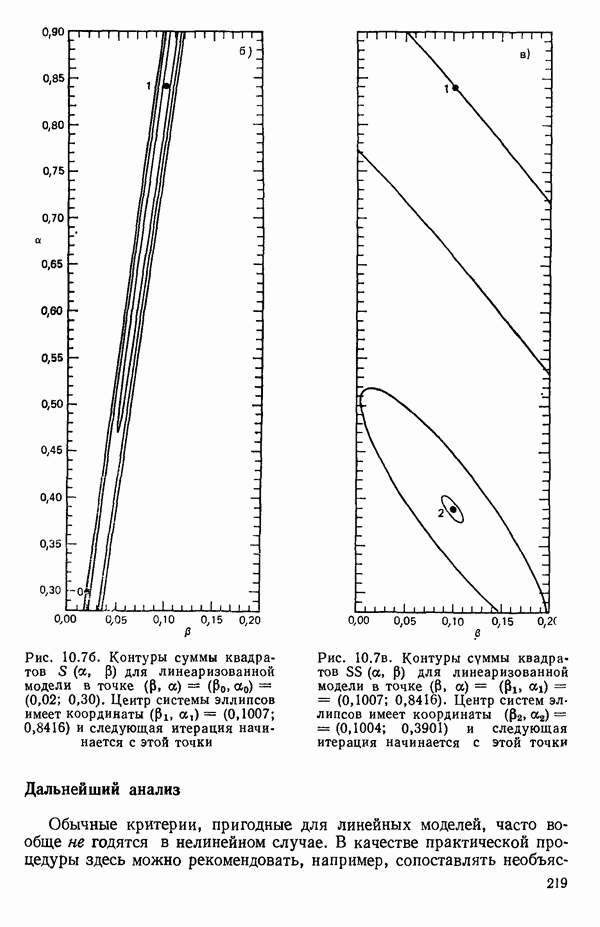

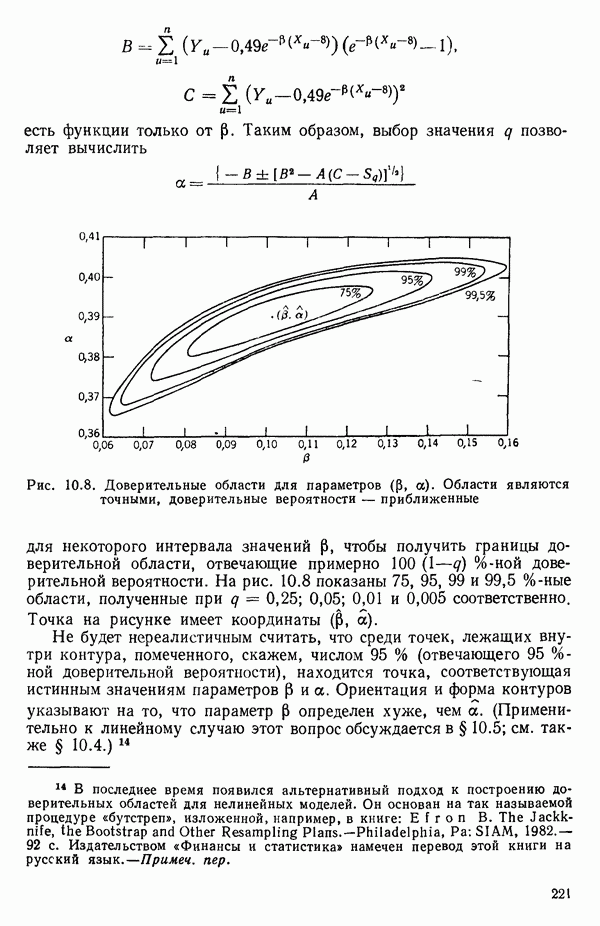








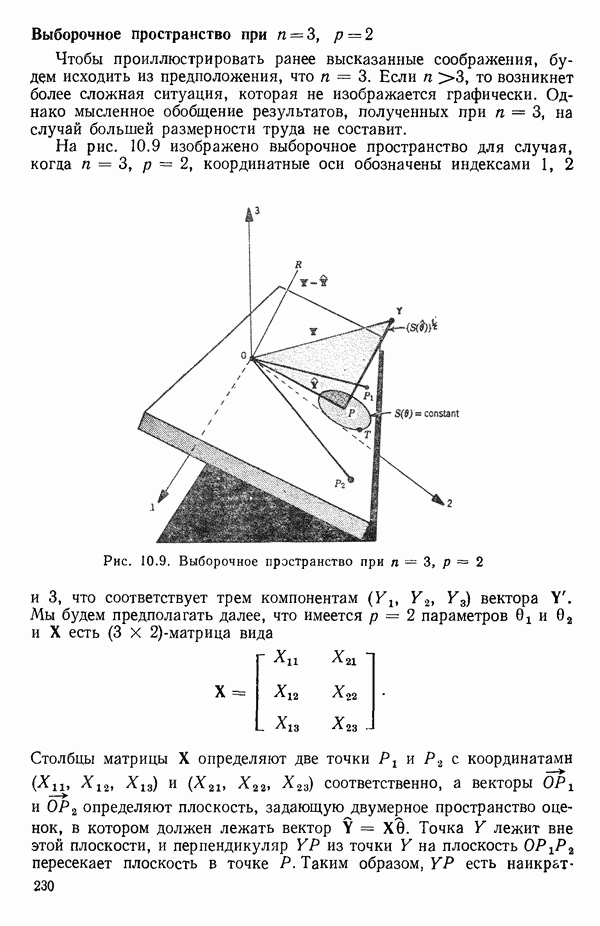






























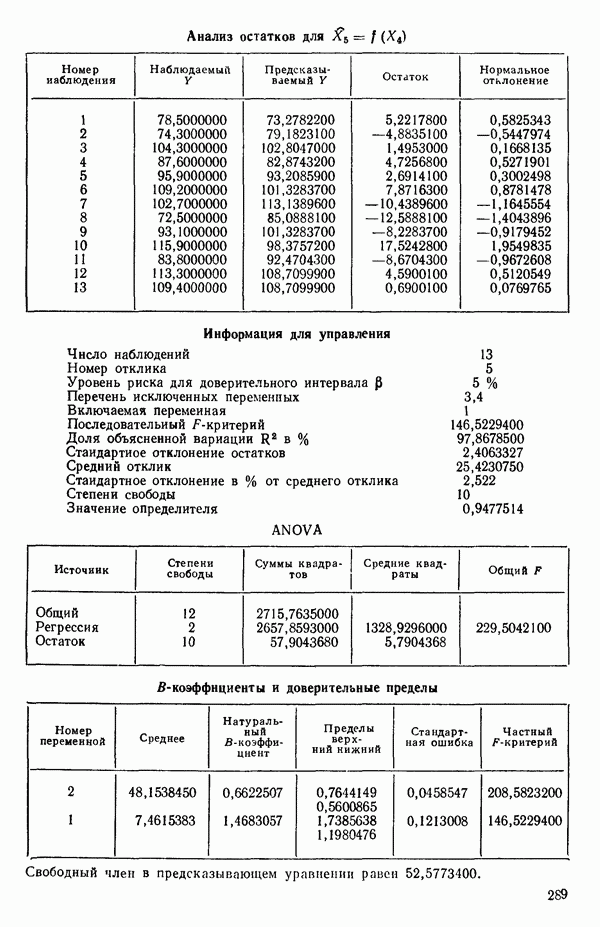
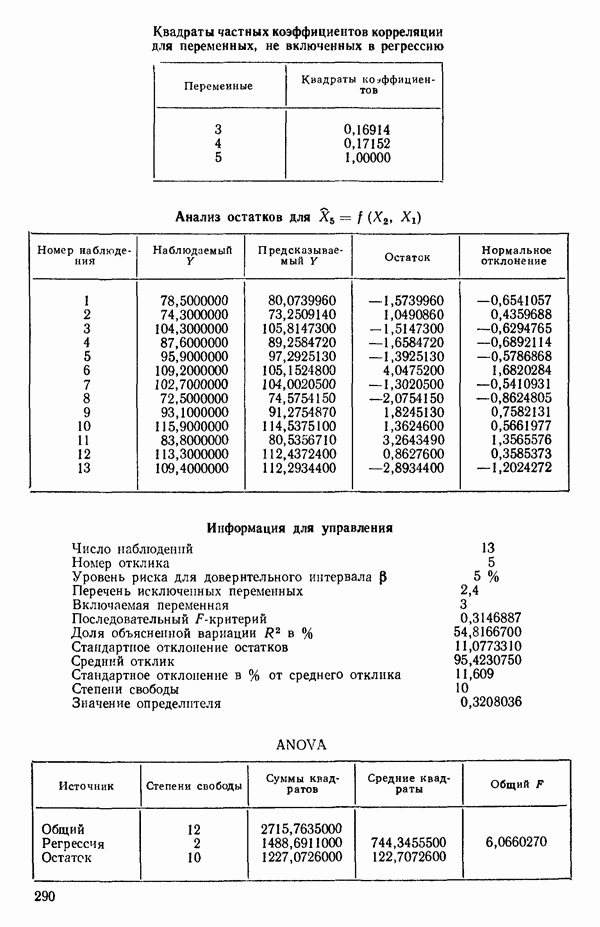
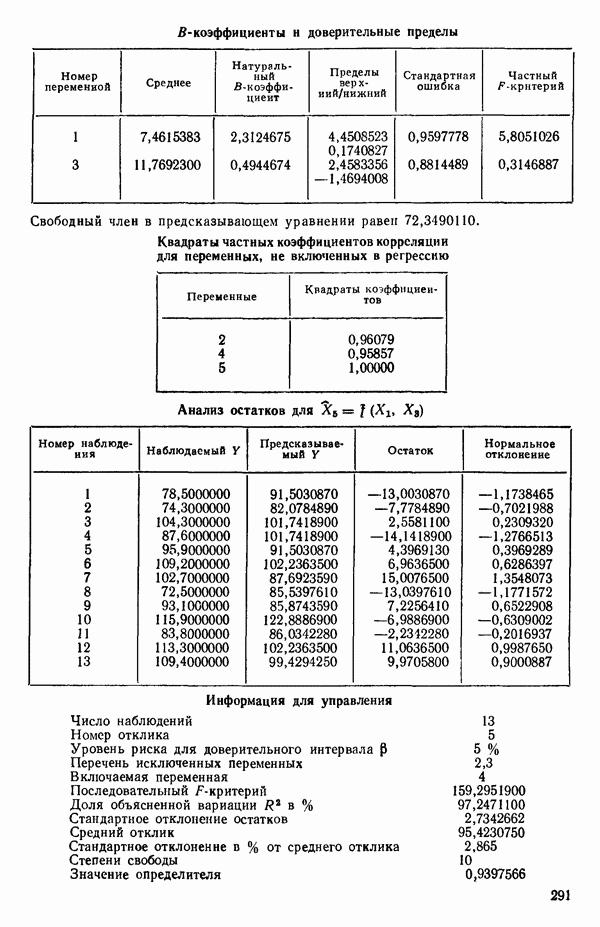
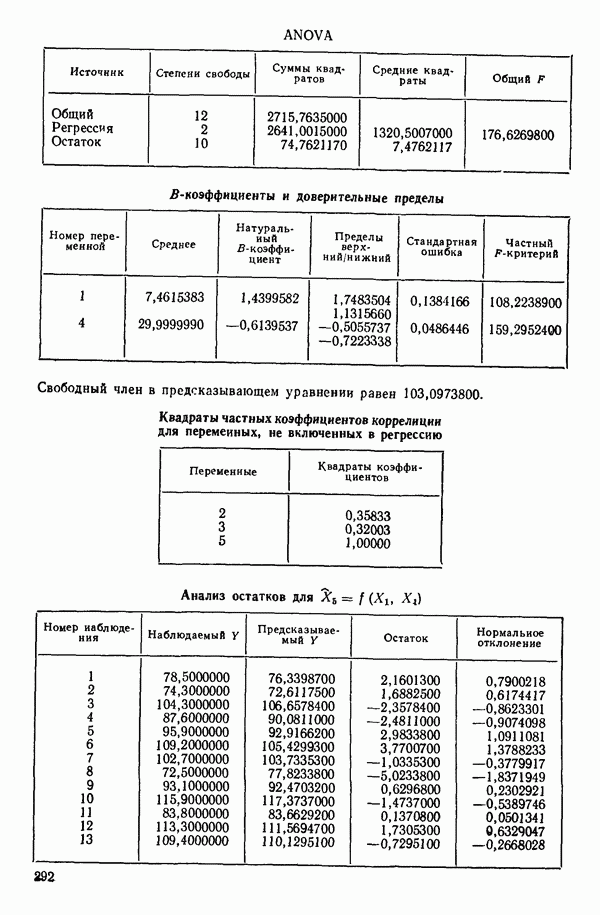
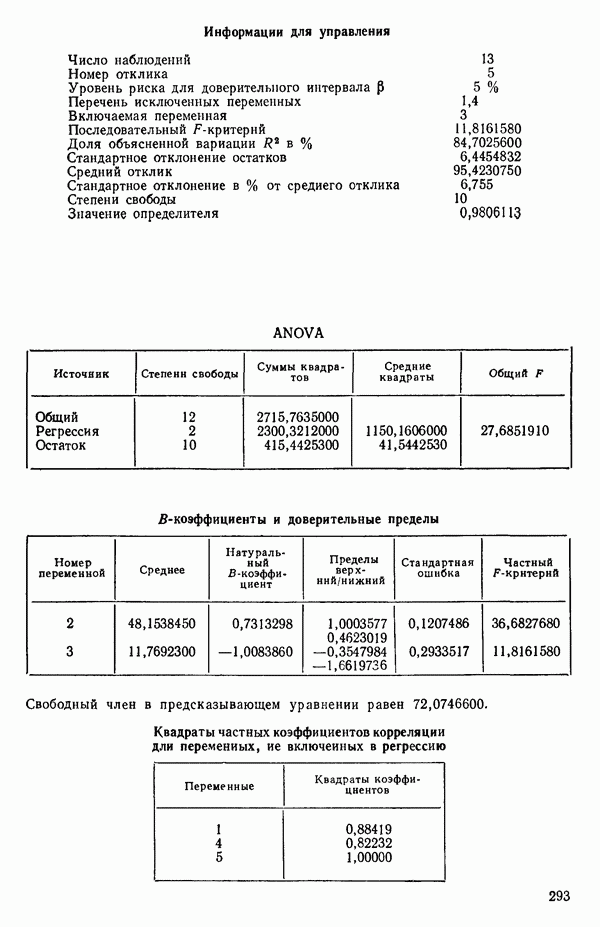
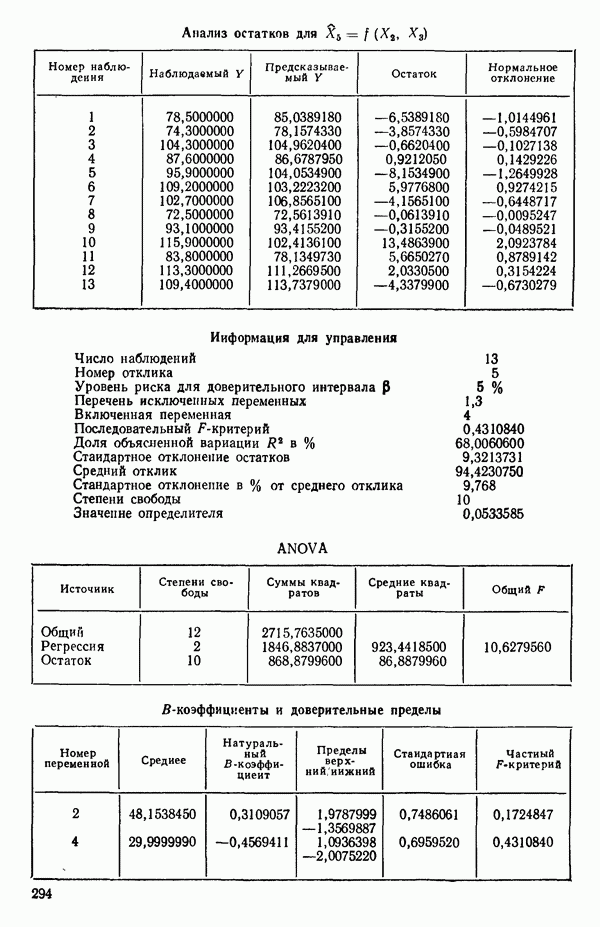
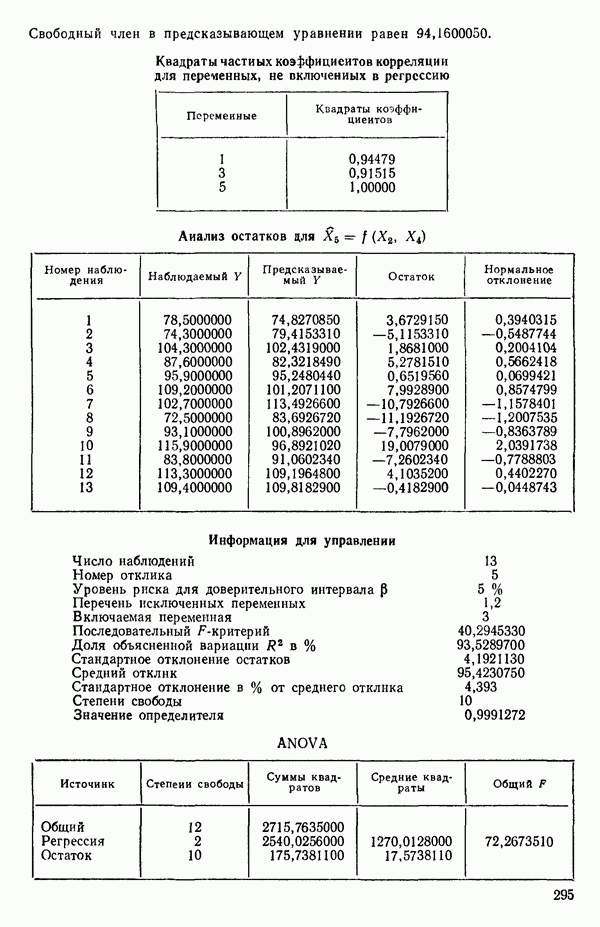
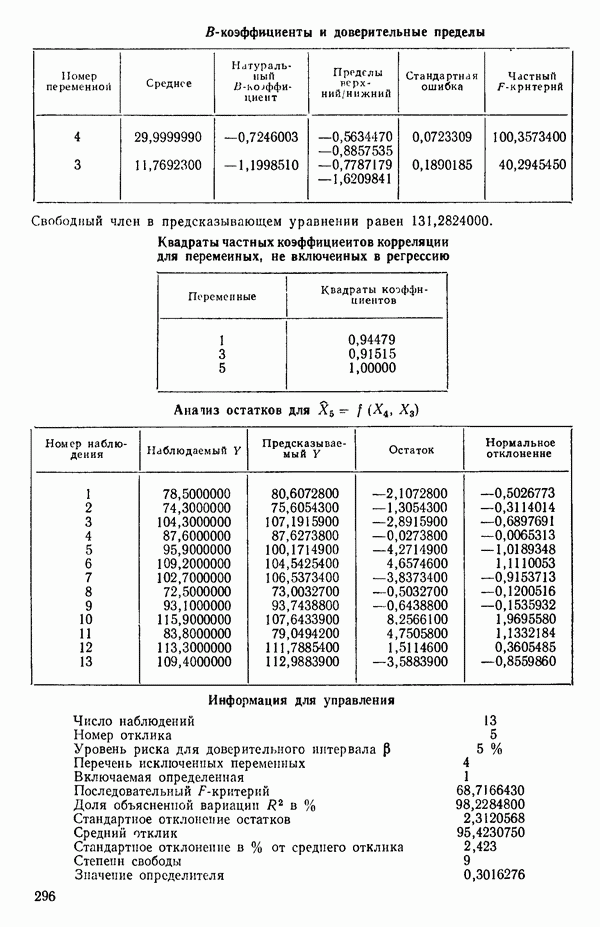
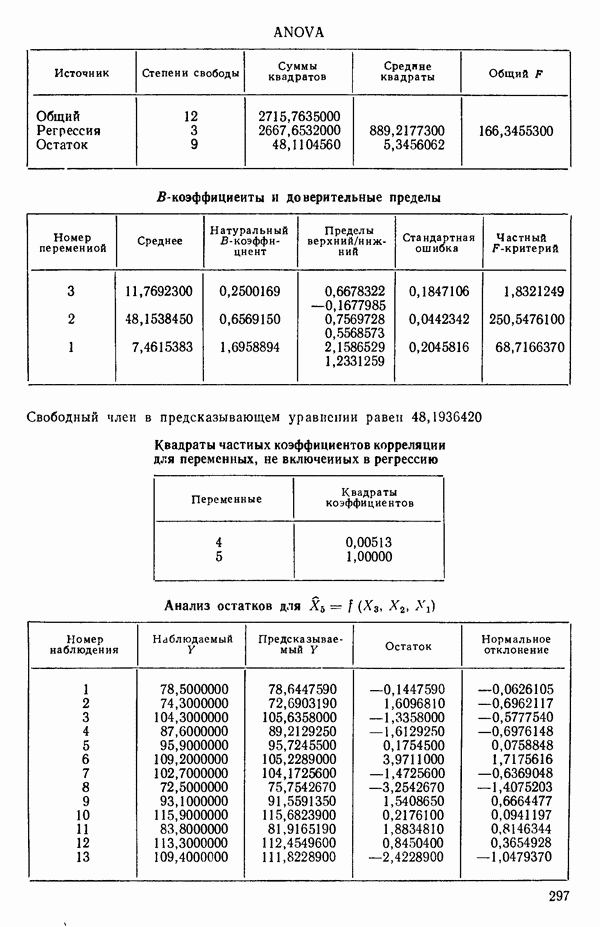
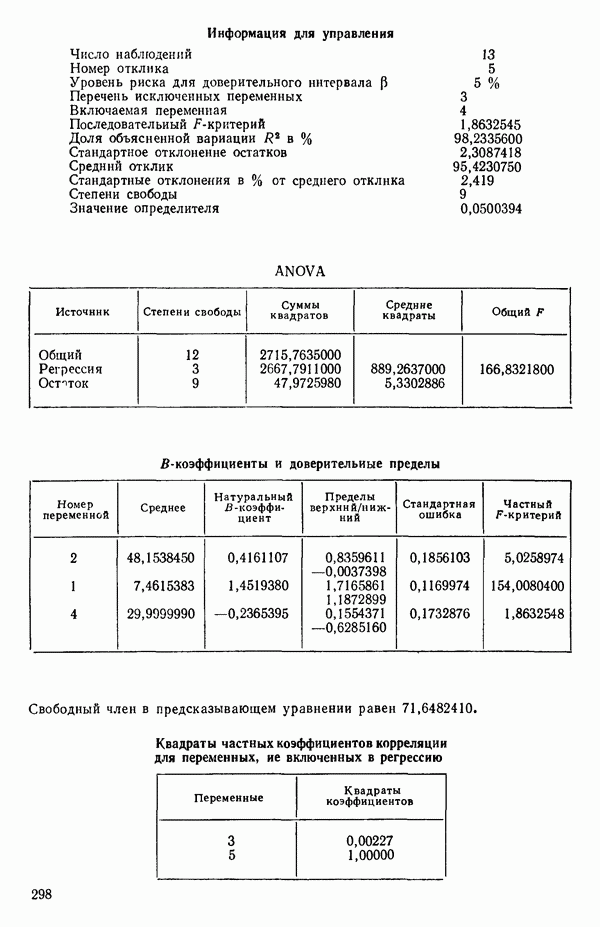
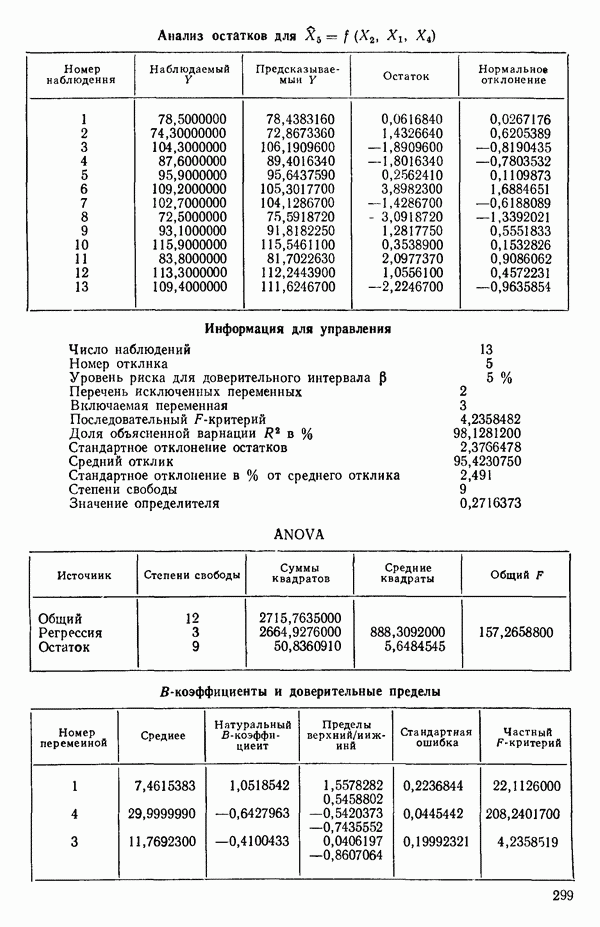
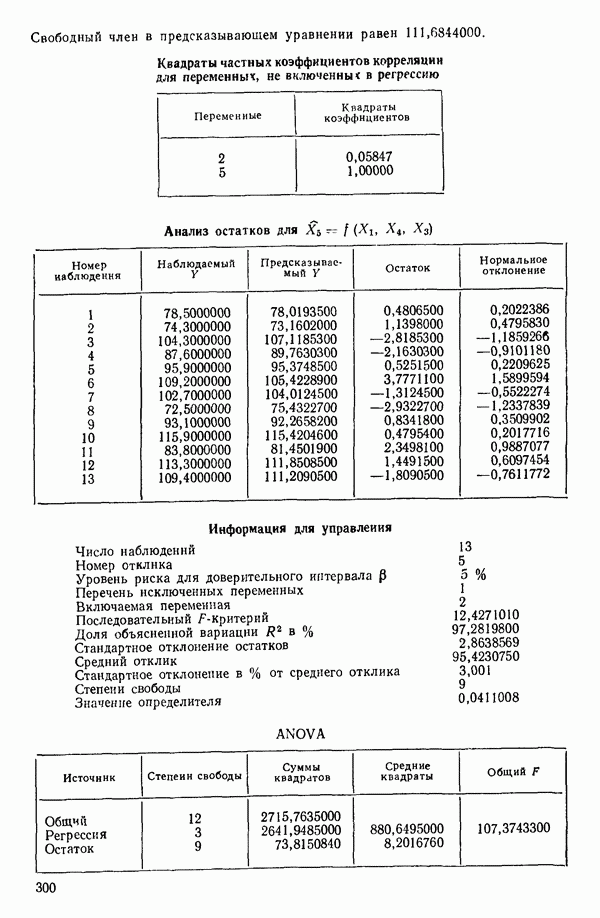








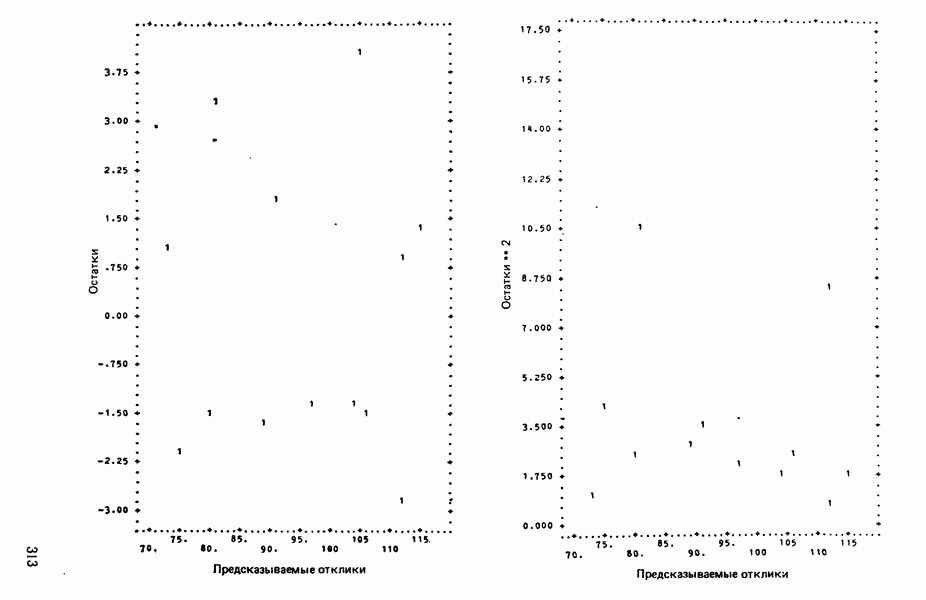
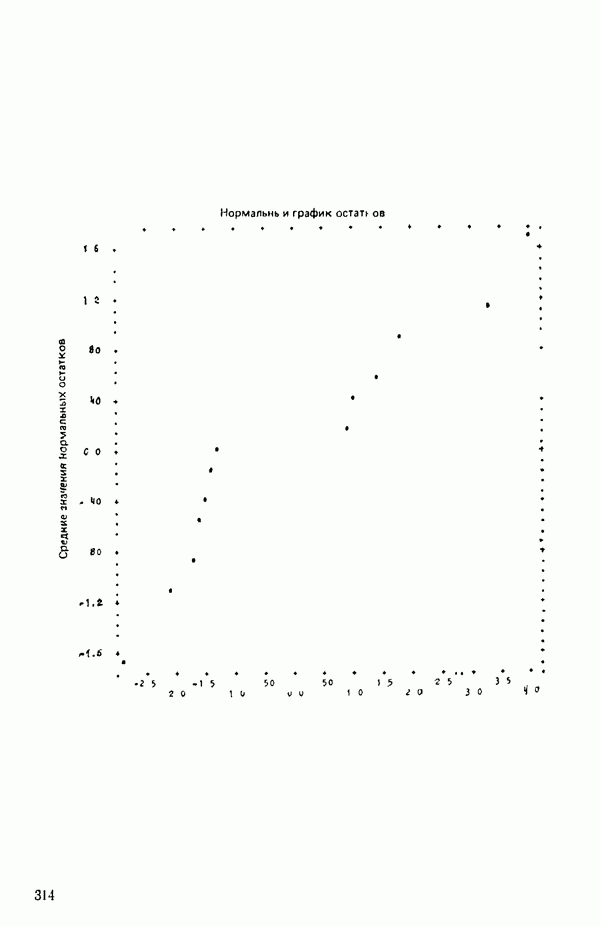
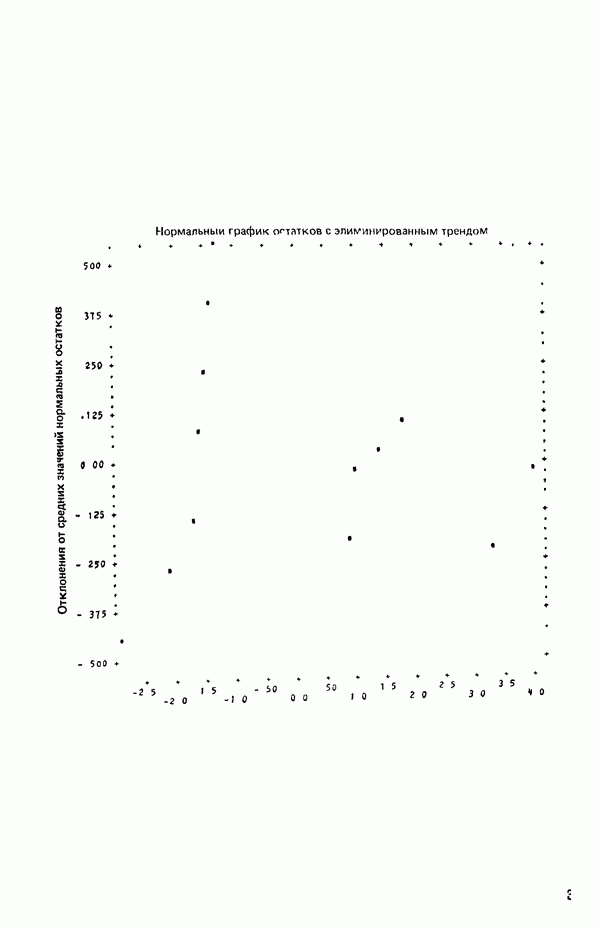




























 для доверительного интервала. Эта строка обозначает вероятность а совершения ошибки первого рода. Используется для расчета доверительных интервалов уровня 1—а коэффициентов регрессии.
для доверительного интервала. Эта строка обозначает вероятность а совершения ошибки первого рода. Используется для расчета доверительных интервалов уровня 1—а коэффициентов регрессии.
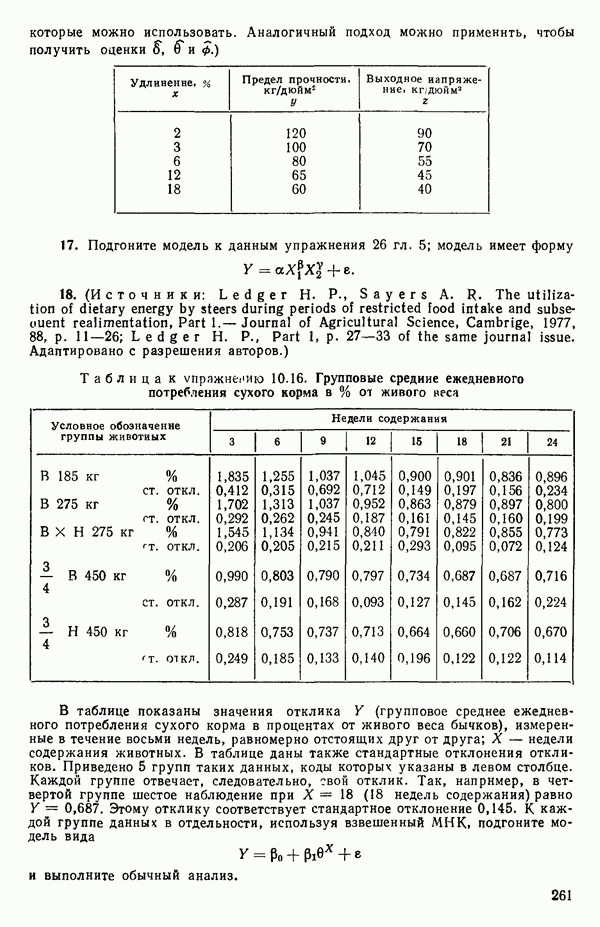
 Это квадрат коэффициента множественной корреляции,
Это квадрат коэффициента множественной корреляции,  Объяснение этой статистики дается в гл. 1, 2 и 4.
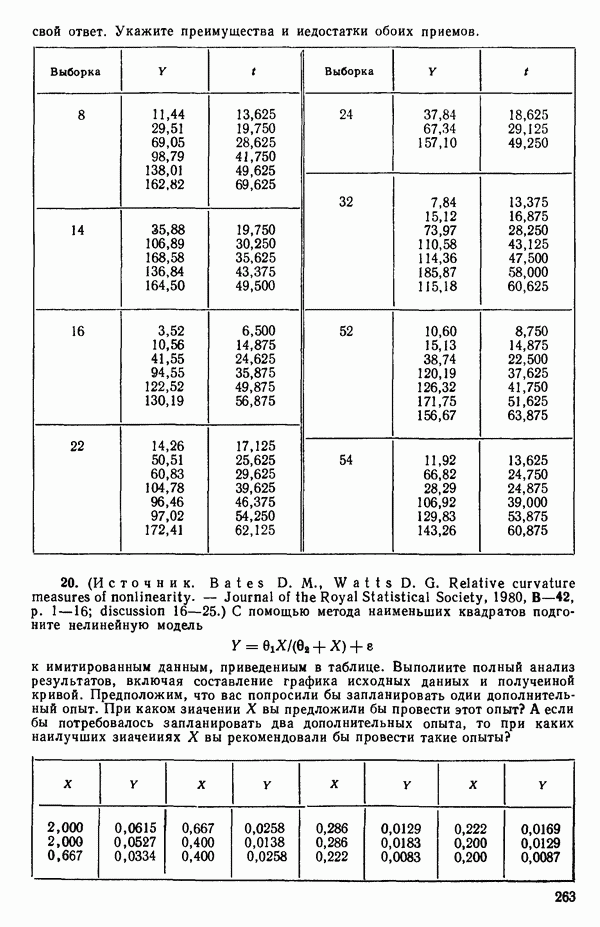
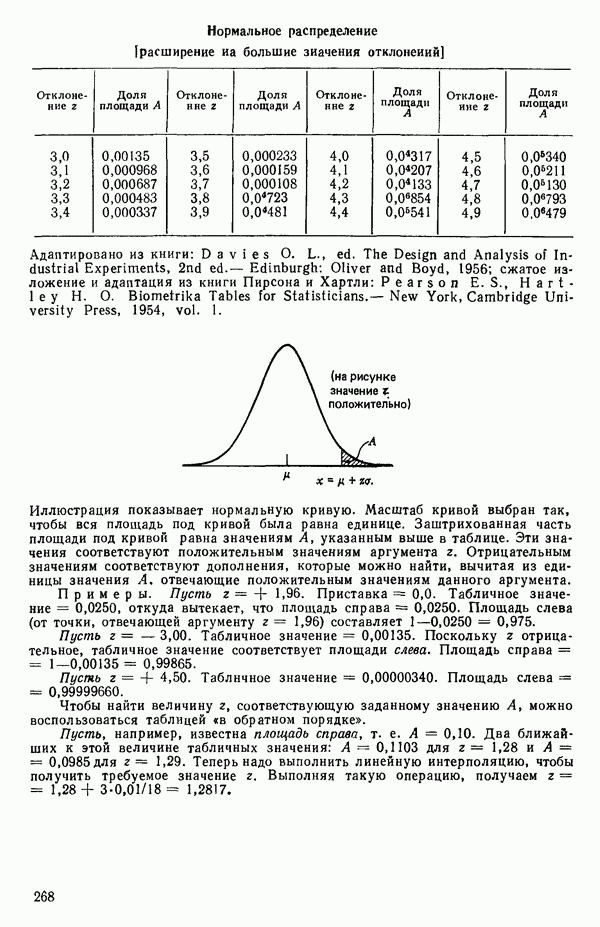
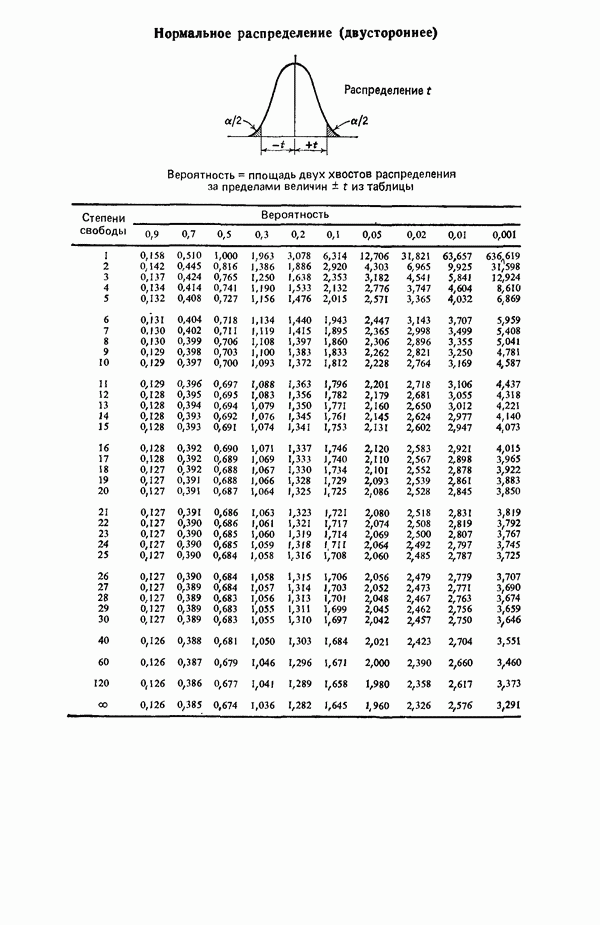
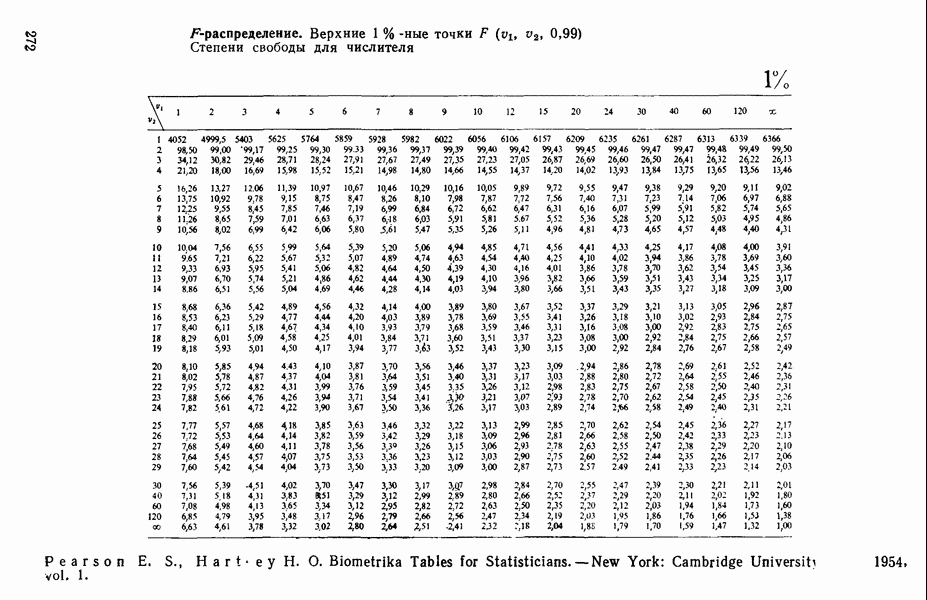
Объяснение этой статистики дается в гл. 1, 2 и 4.
 среднего квадрата ошибки в таблице дисперсионного анализа.
среднего квадрата ошибки в таблице дисперсионного анализа.
 -статистика служит для определения статистической значимости регрессионной модели, рассматриваемой на каждом этапе. Рассчитывается следующим образом:
-статистика служит для определения статистической значимости регрессионной модели, рассматриваемой на каждом этапе. Рассчитывается следующим образом:

 -коэффициенты и доверительные пределы.
-коэффициенты и доверительные пределы.
 оэффициент. Если при вводе данных в вычислительную машину производилось любое кодирование, программа декодирует
оэффициент. Если при вводе данных в вычислительную машину производилось любое кодирование, программа декодирует  -коэффициент в первоначальные единицы и напечатает его.
-коэффициент в первоначальные единицы и напечатает его.
 -ные доверительные пределы истинного коэффициента регрессии,
-ные доверительные пределы истинного коэффициента регрессии,  Расчетные формулы для этих пределов приведены в гл. 1 и 4.
Расчетные формулы для этих пределов приведены в гл. 1 и 4.
 Формула для ее вычисления дается в гл. 1 и 4.
Формула для ее вычисления дается в гл. 1 и 4.
 -критерий для каждой переменной в предположении, что она была последней переменной, включенной в регрессию. Обсуждение этой статистики дается в гл. 5 и 6.
-критерий для каждой переменной в предположении, что она была последней переменной, включенной в регрессию. Обсуждение этой статистики дается в гл. 5 и 6.

 Наблюдение отклика У для каждой данной точки, показанной в матрице исходных данных.
Наблюдение отклика У для каждой данной точки, показанной в матрице исходных данных.
 полученное при использовании подобранной модели.
полученное при использовании подобранной модели.
 или
или 
 деленная на стандартное отклонение остатков
деленная на стандартное отклонение остатков  или
или 




