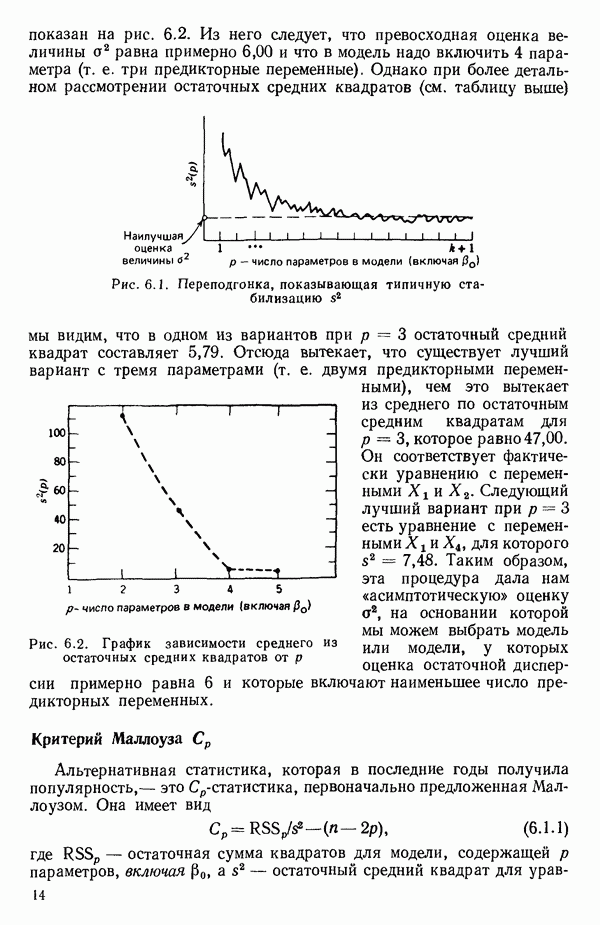
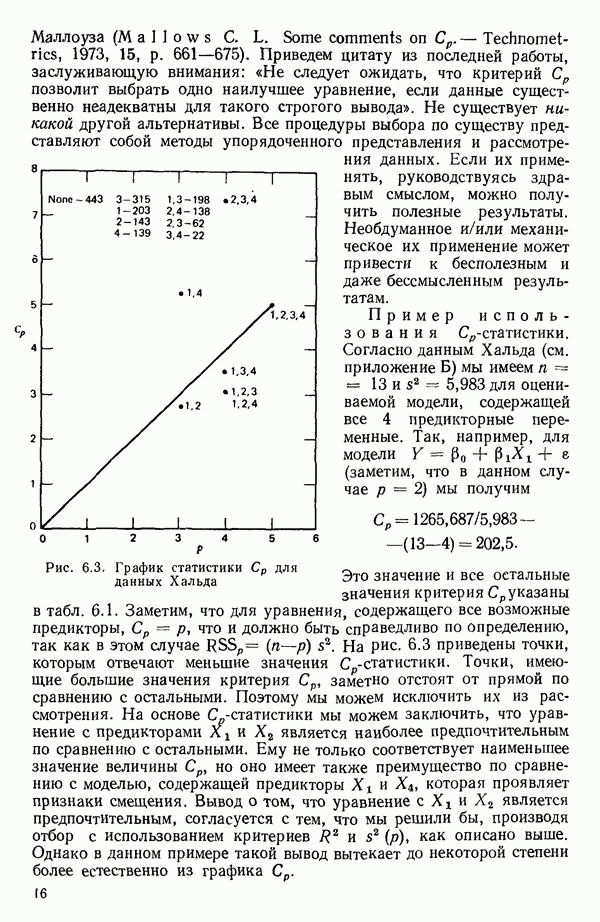
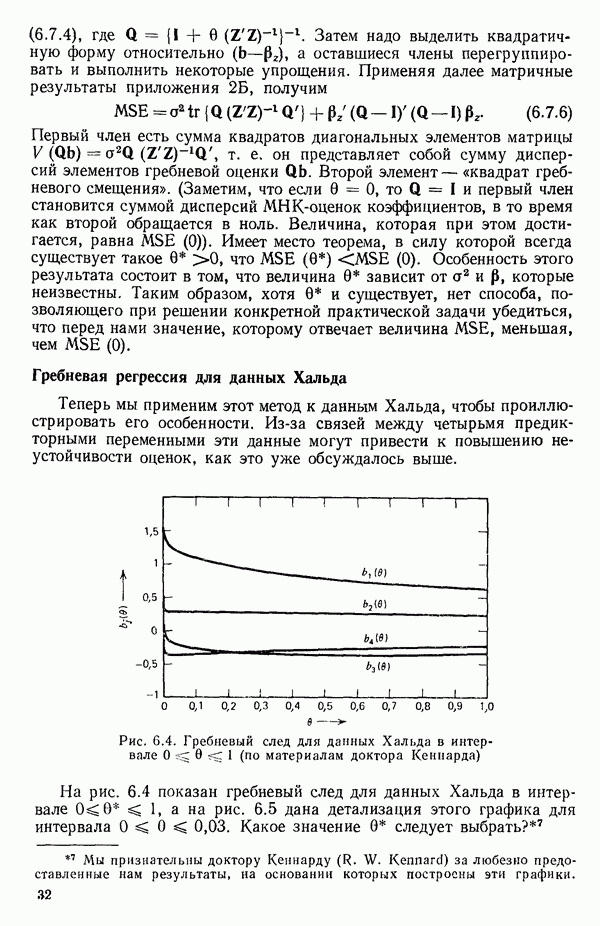
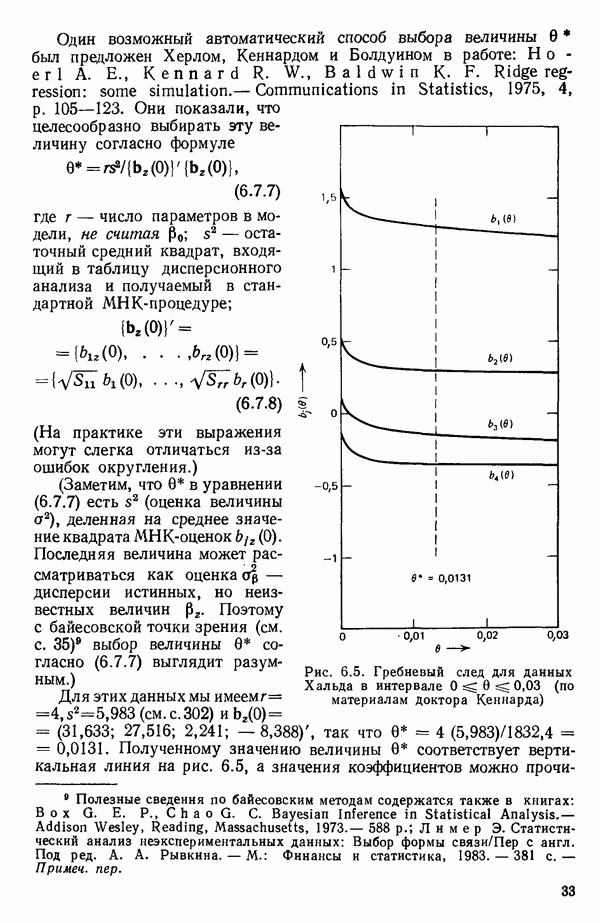
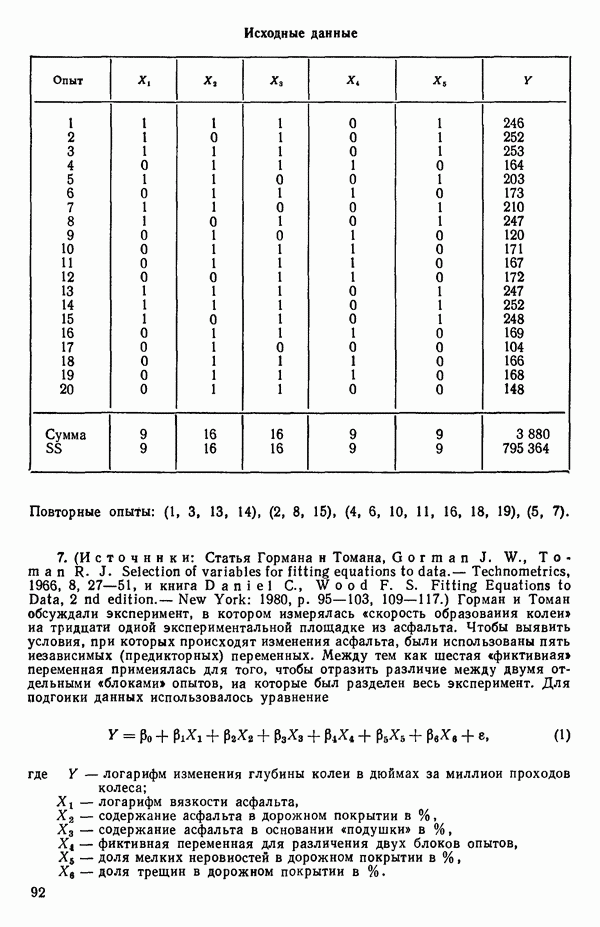
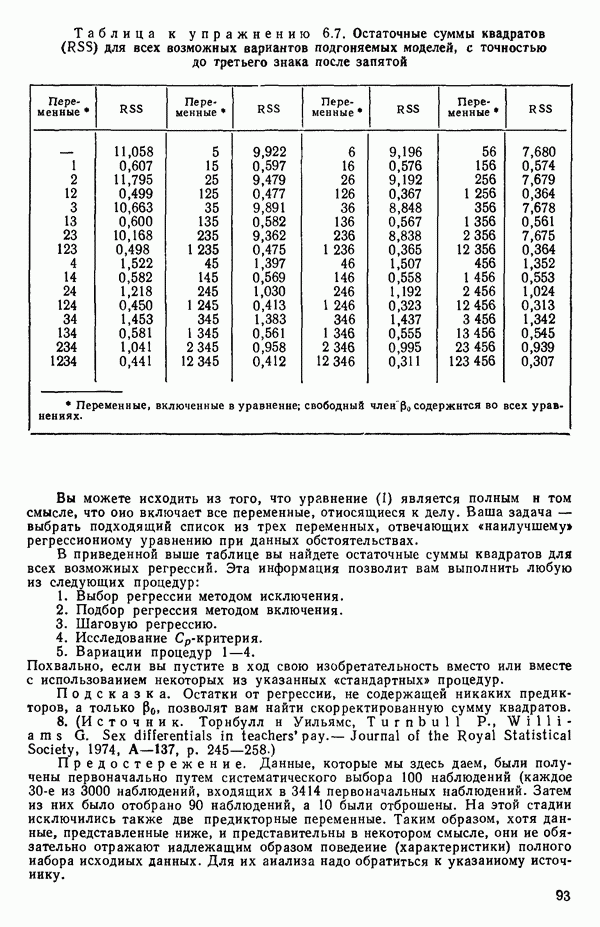
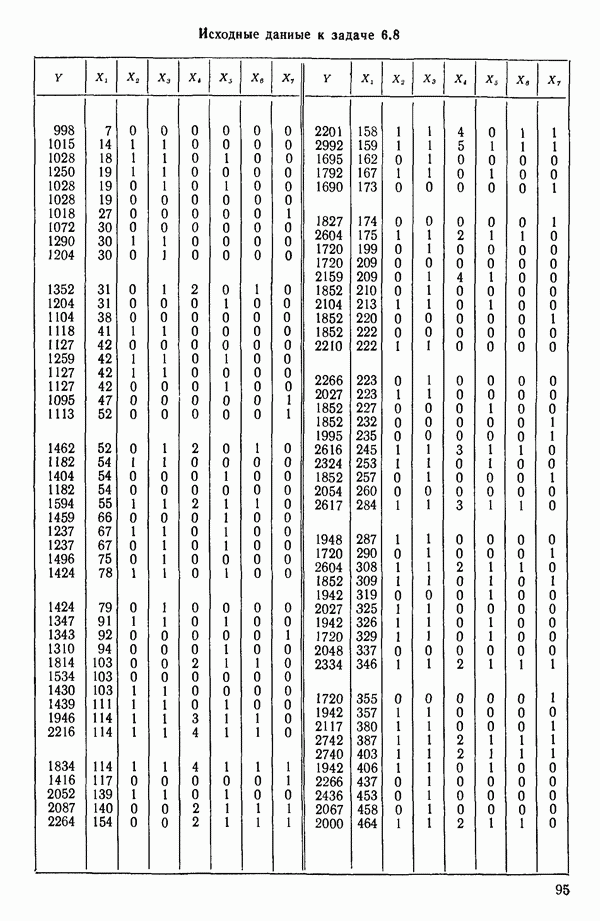
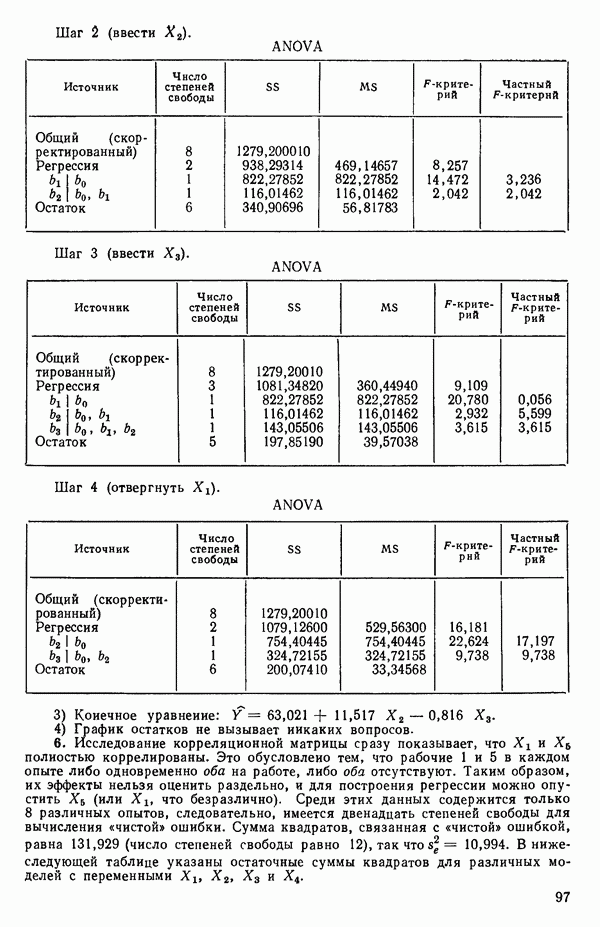
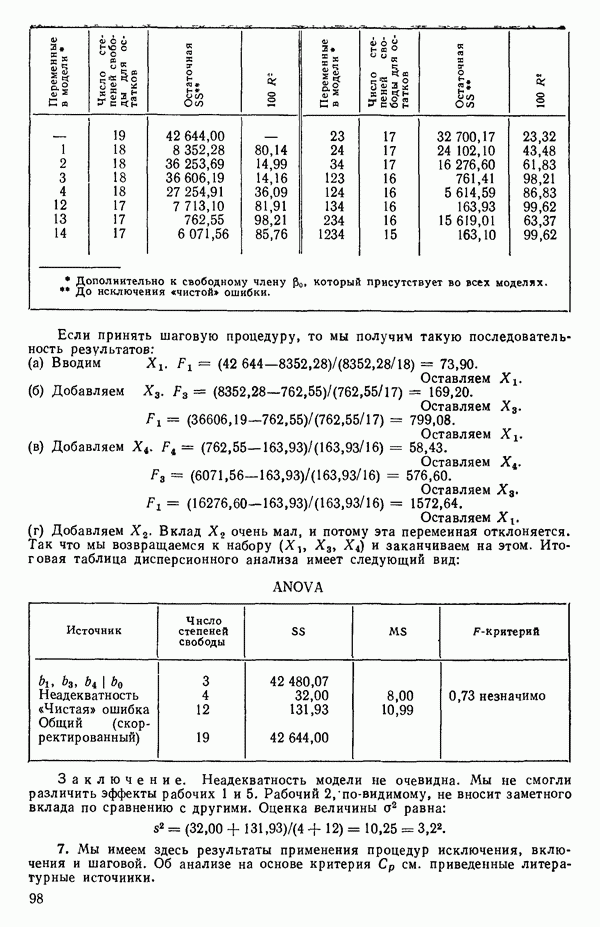
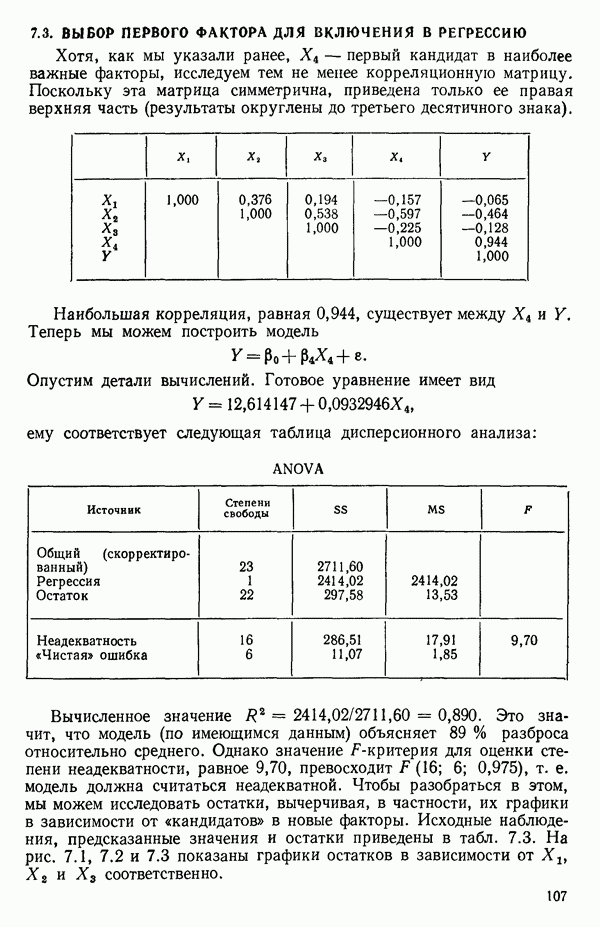
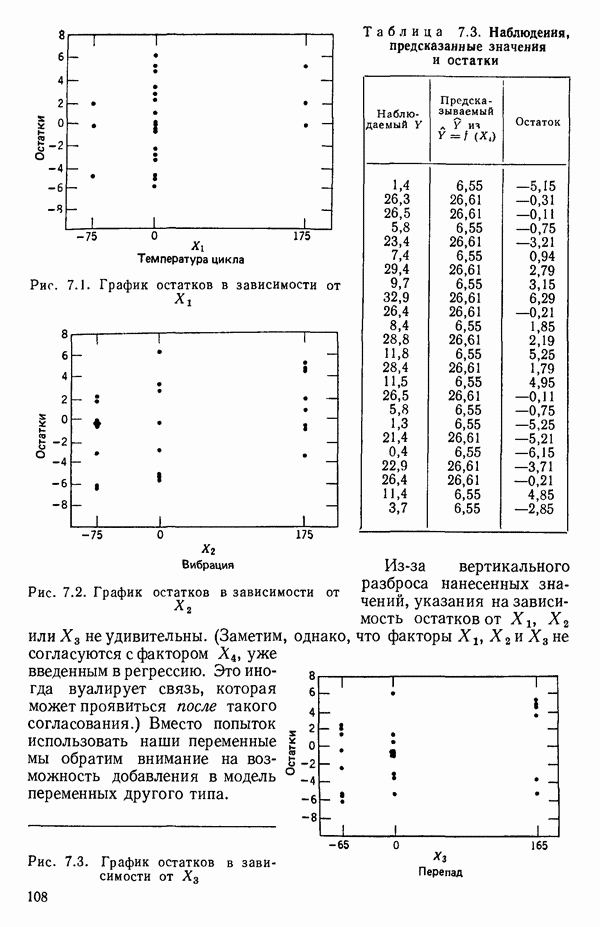
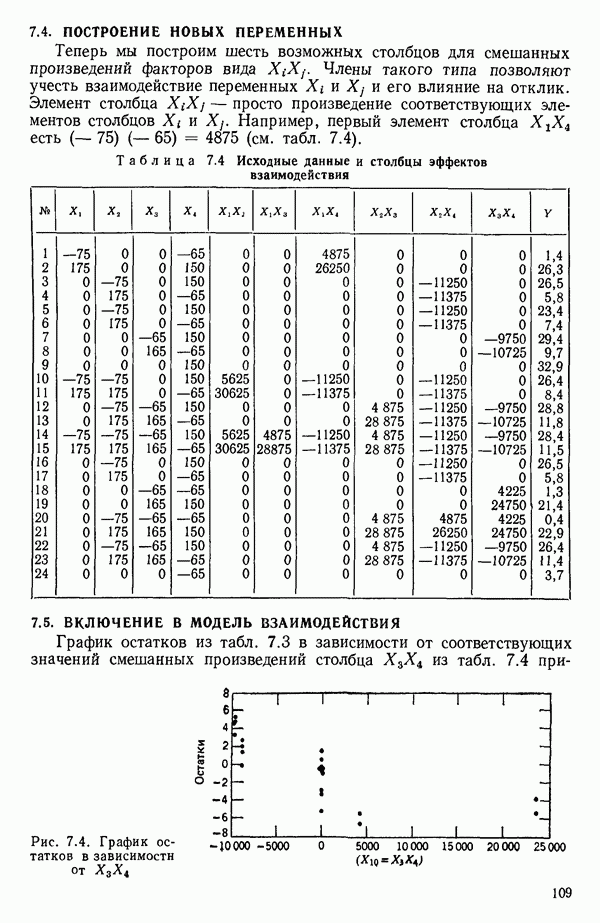
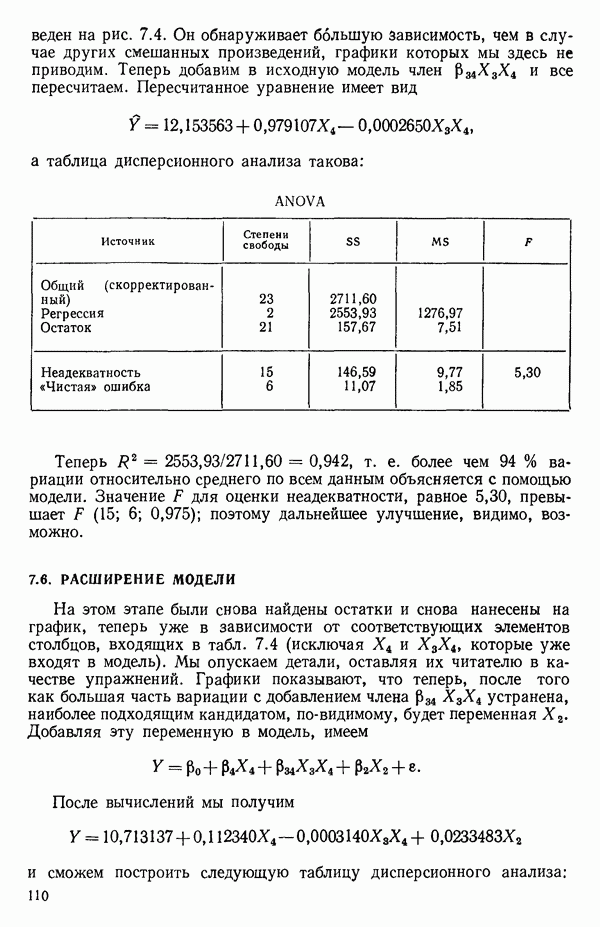
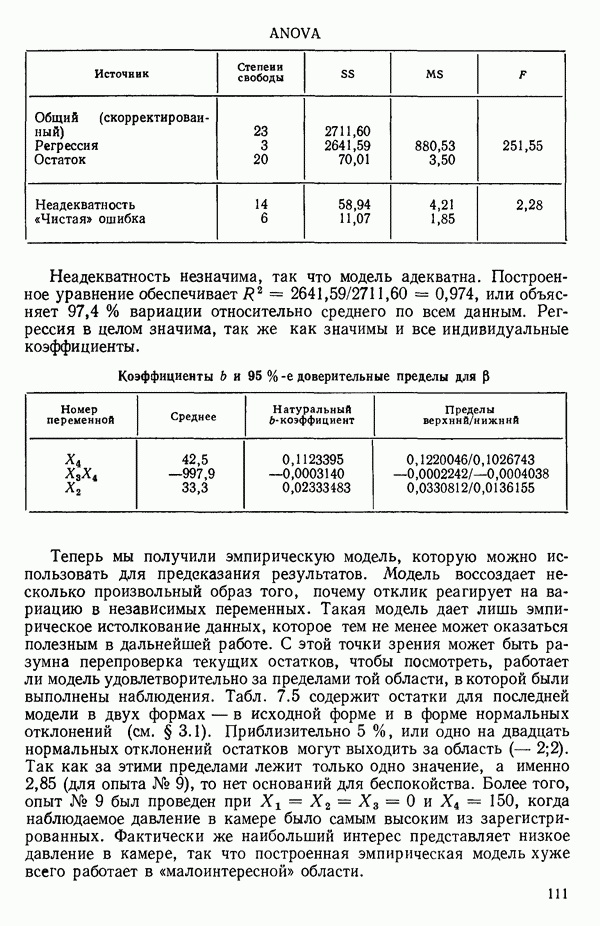
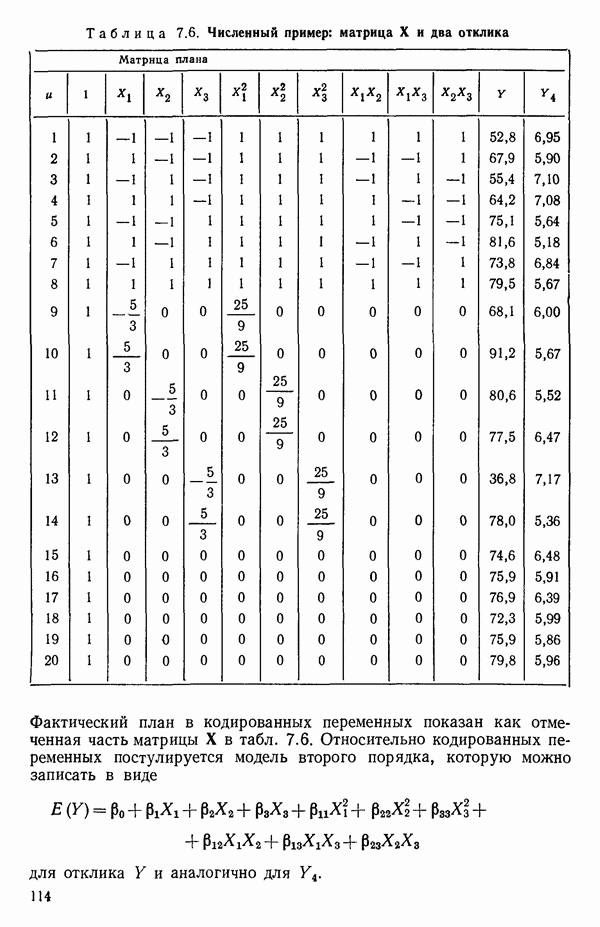
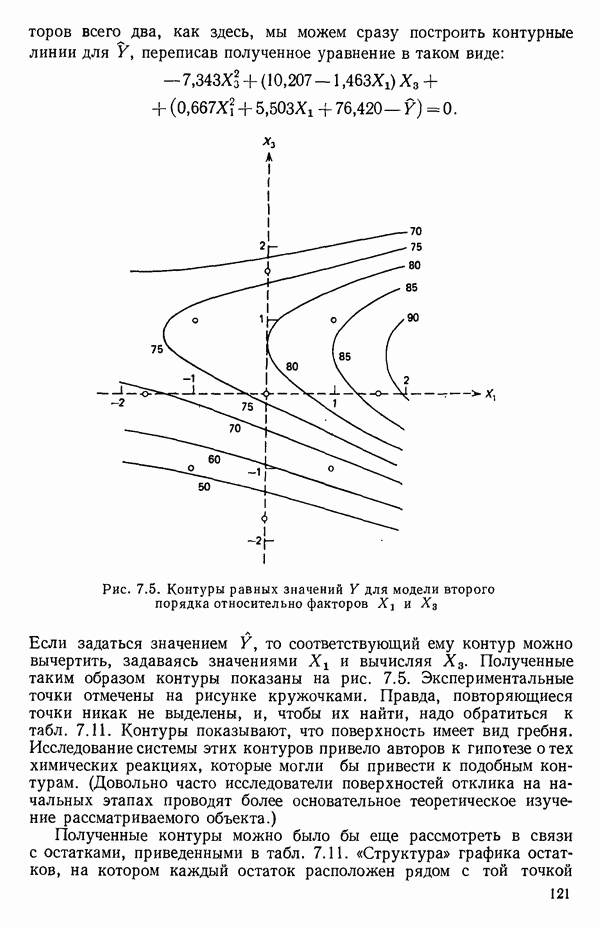
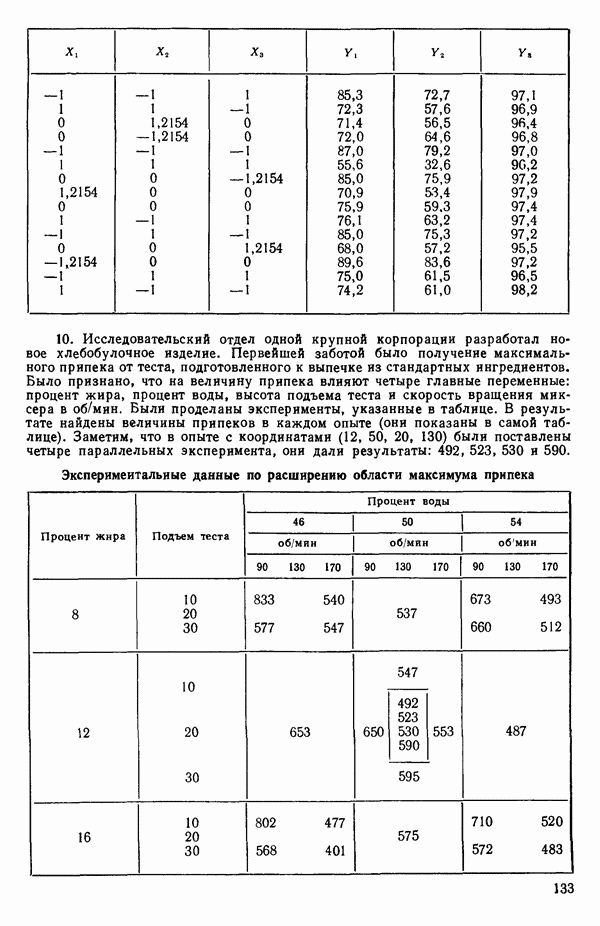
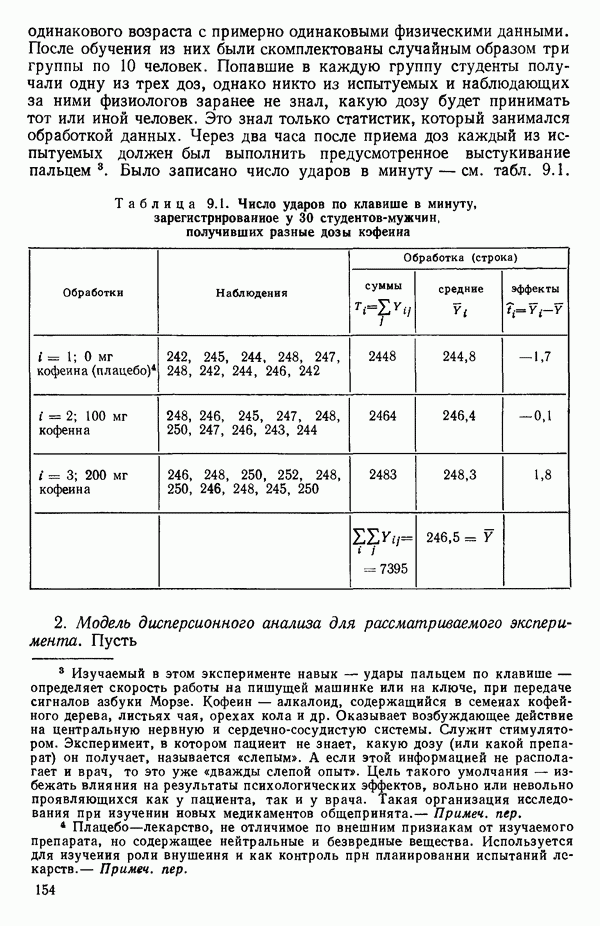
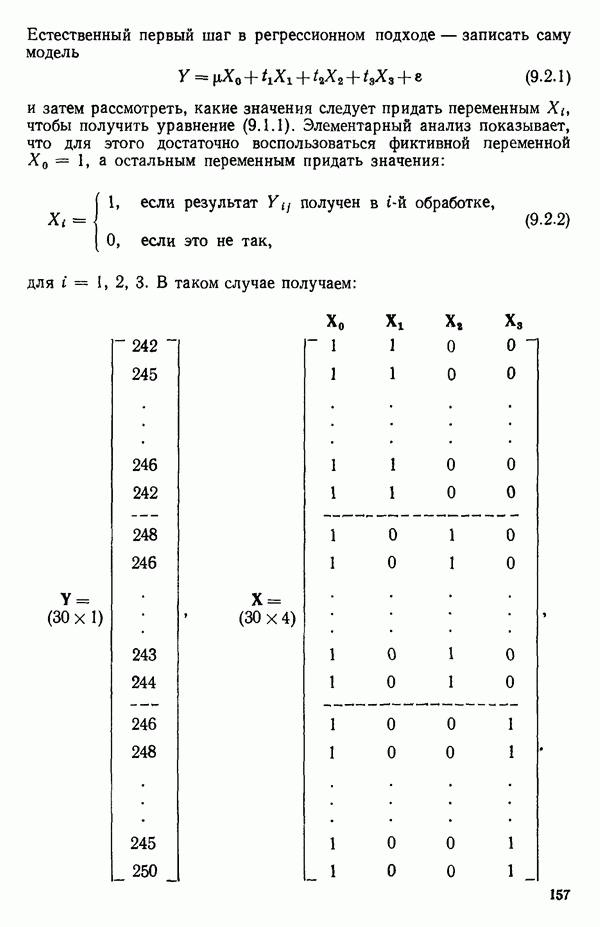
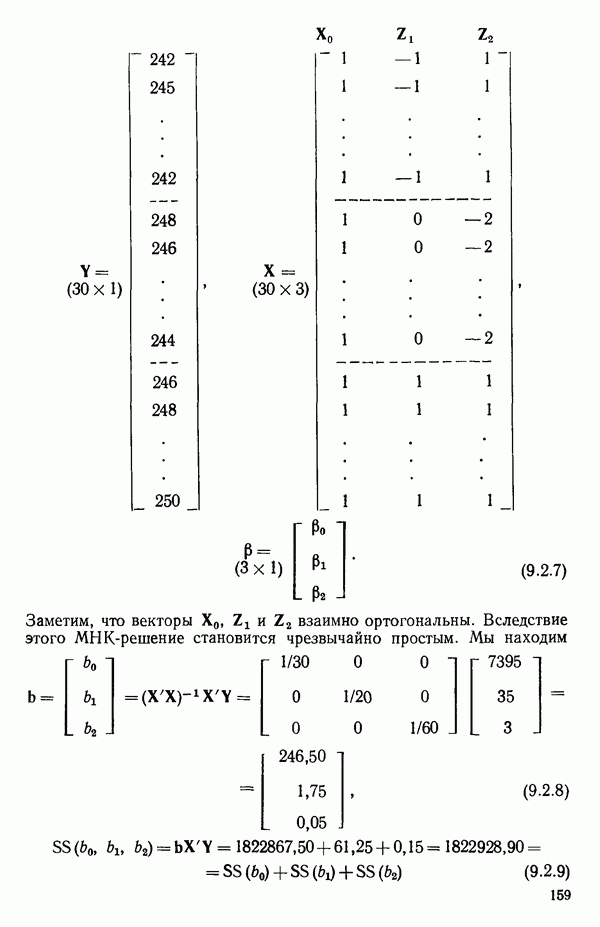
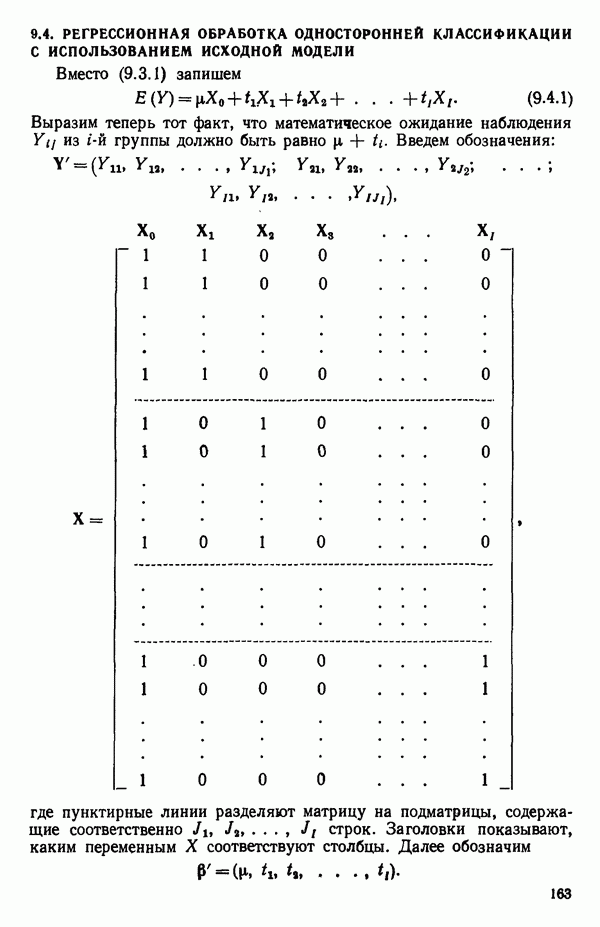
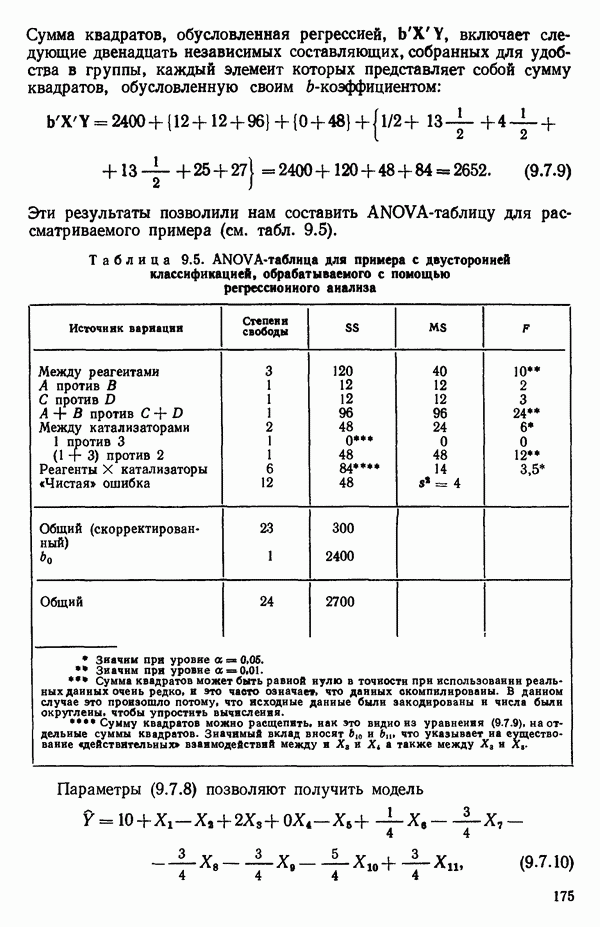
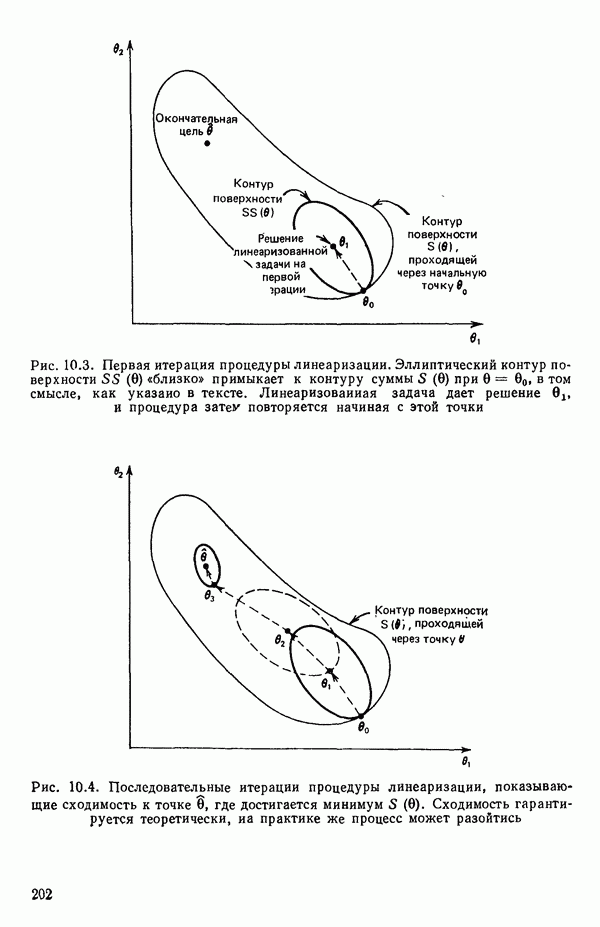
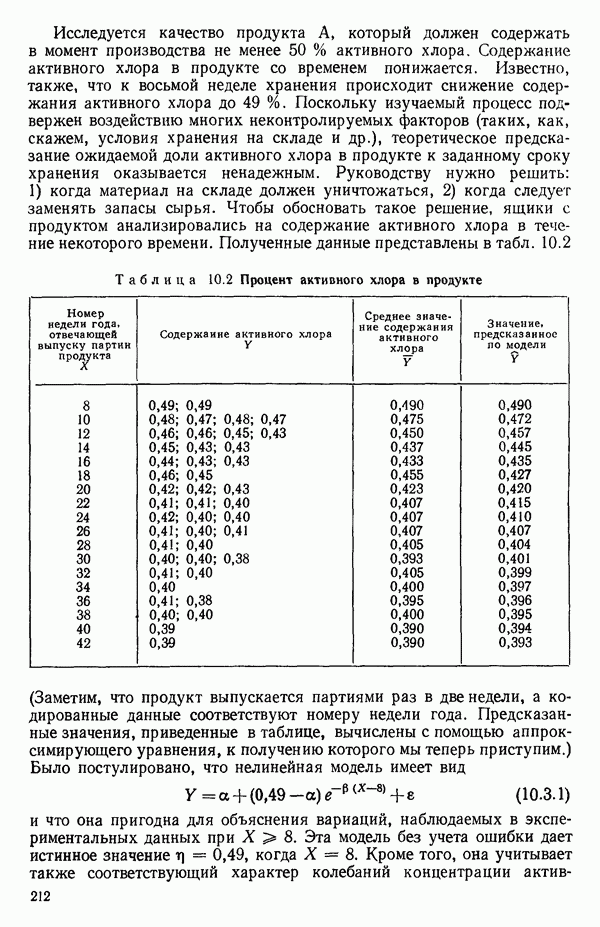
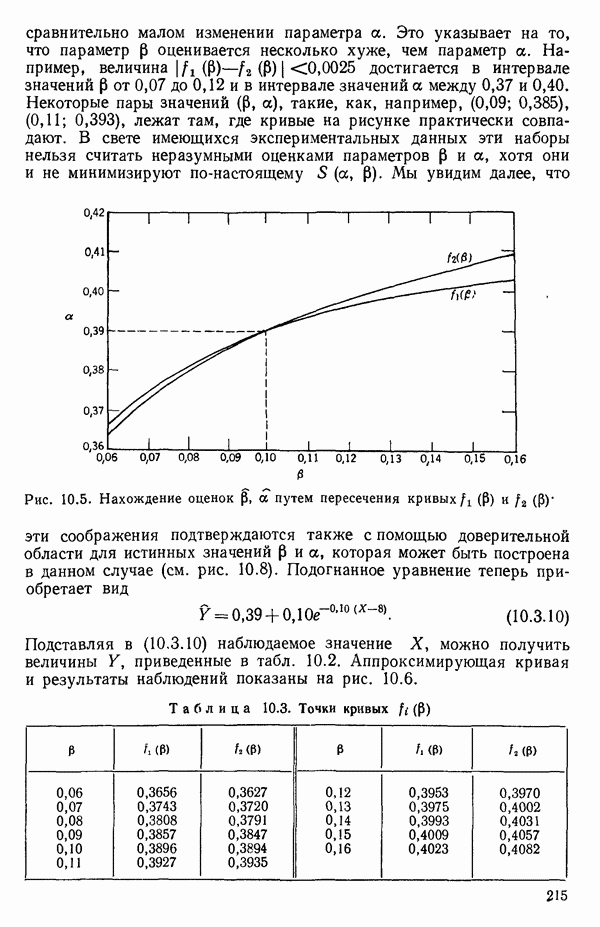
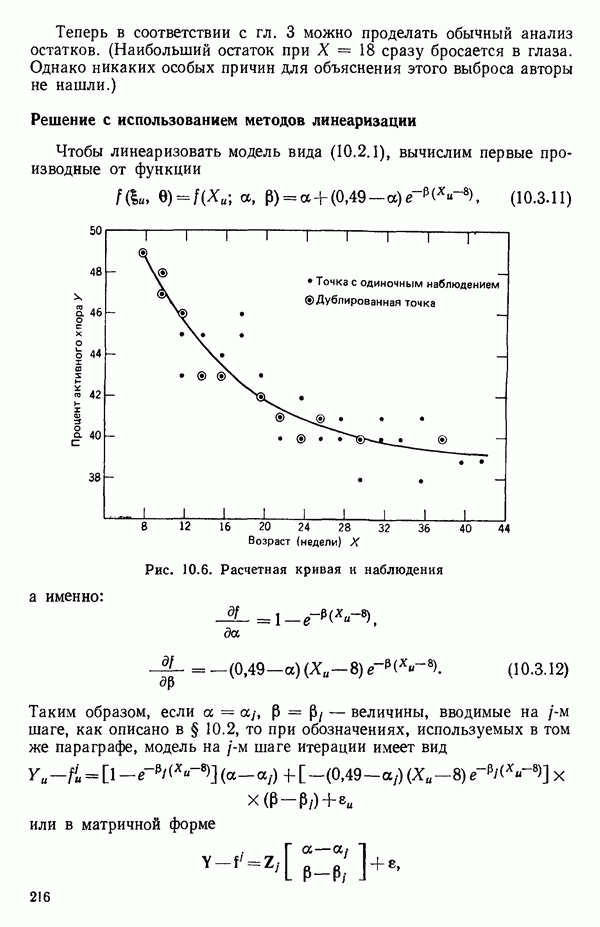
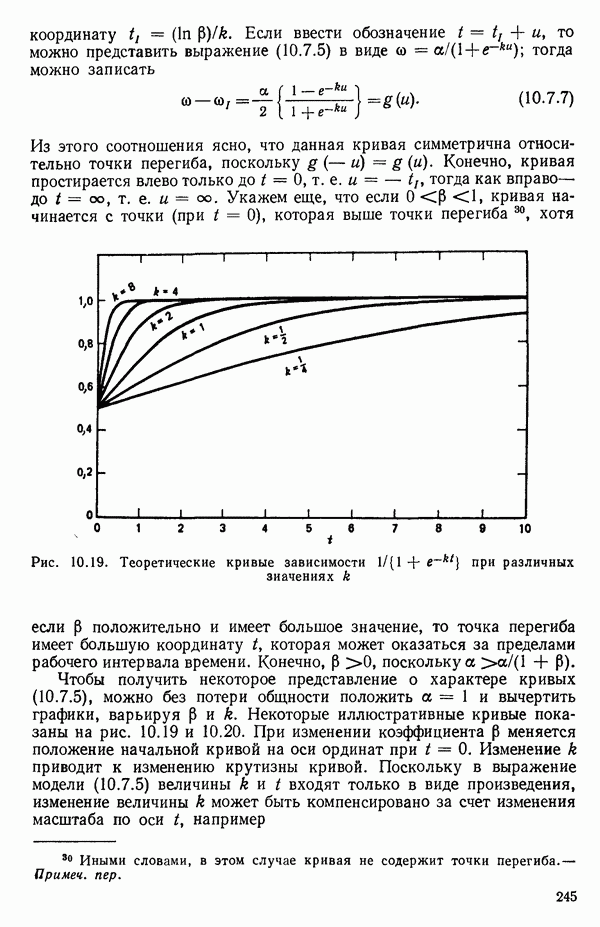
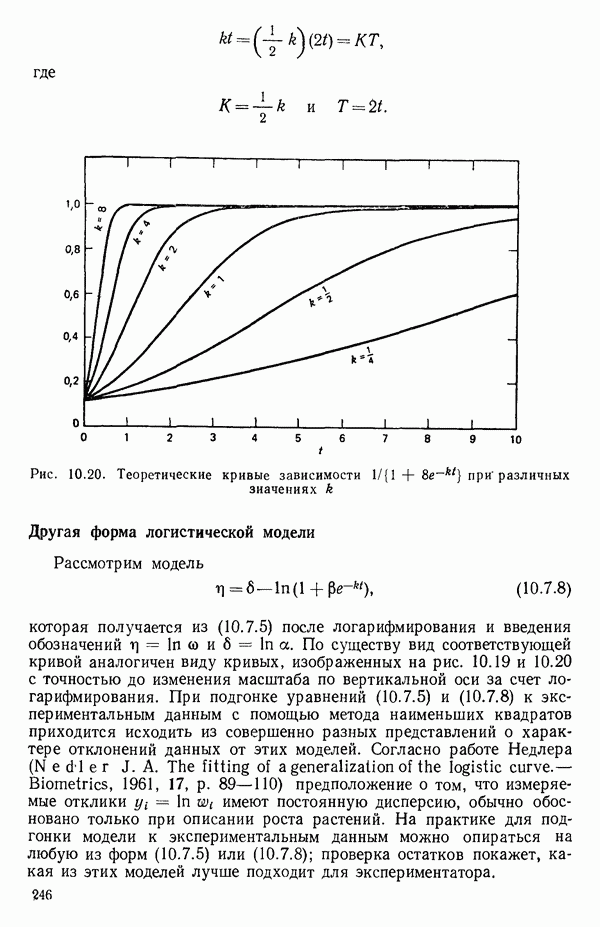
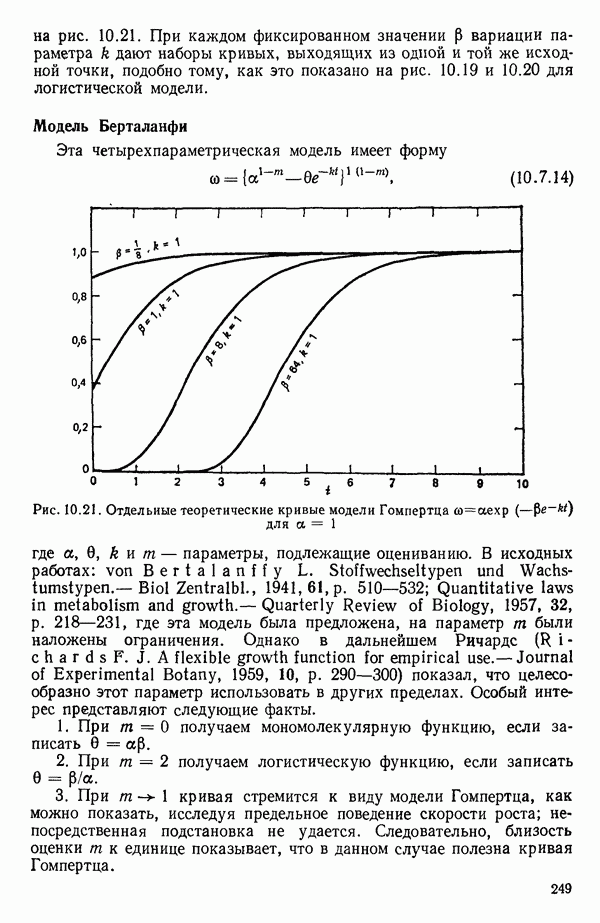
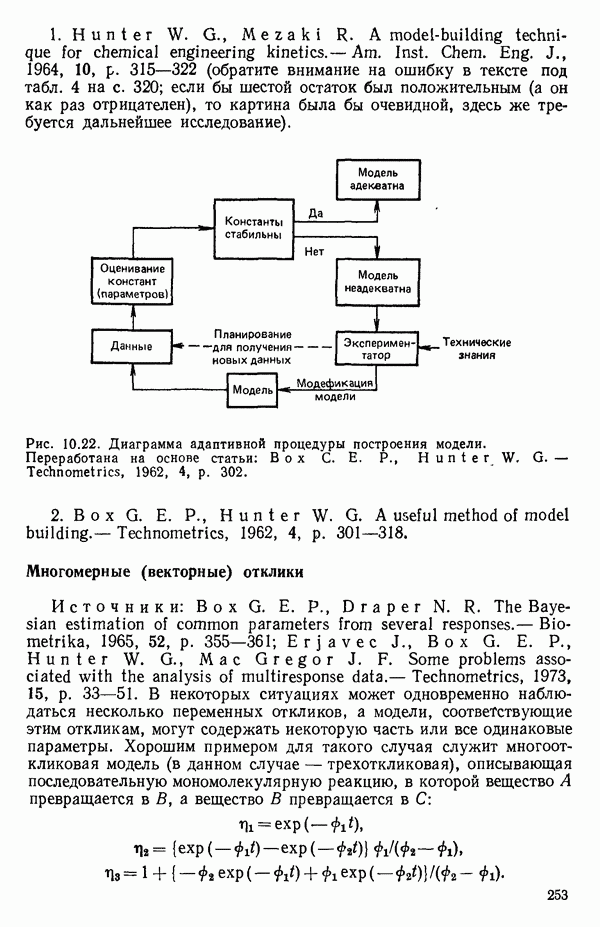
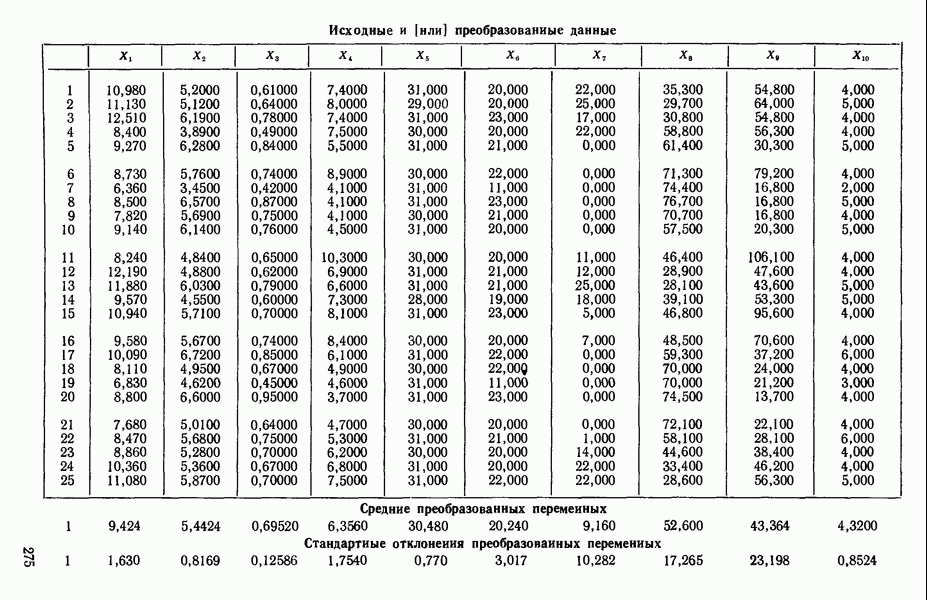
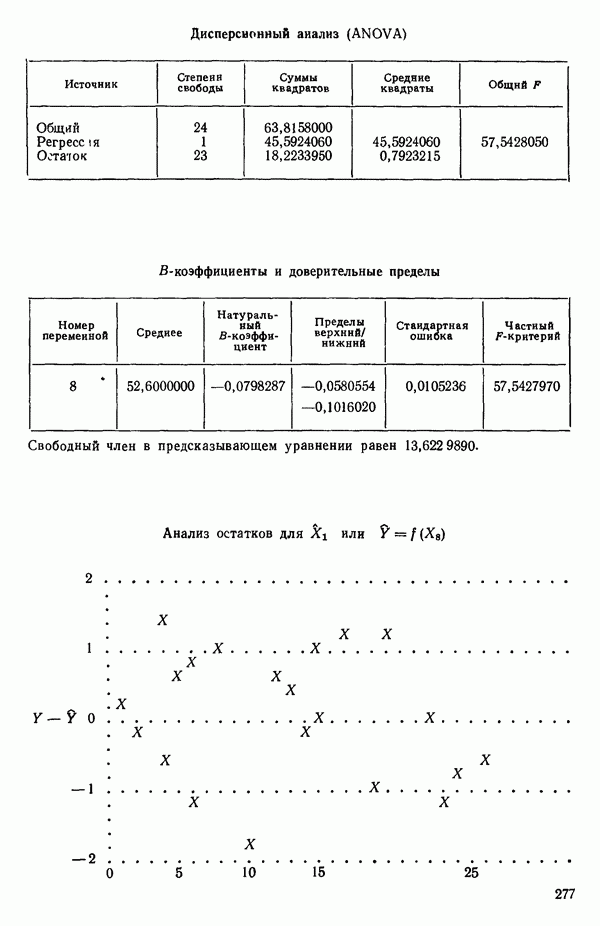
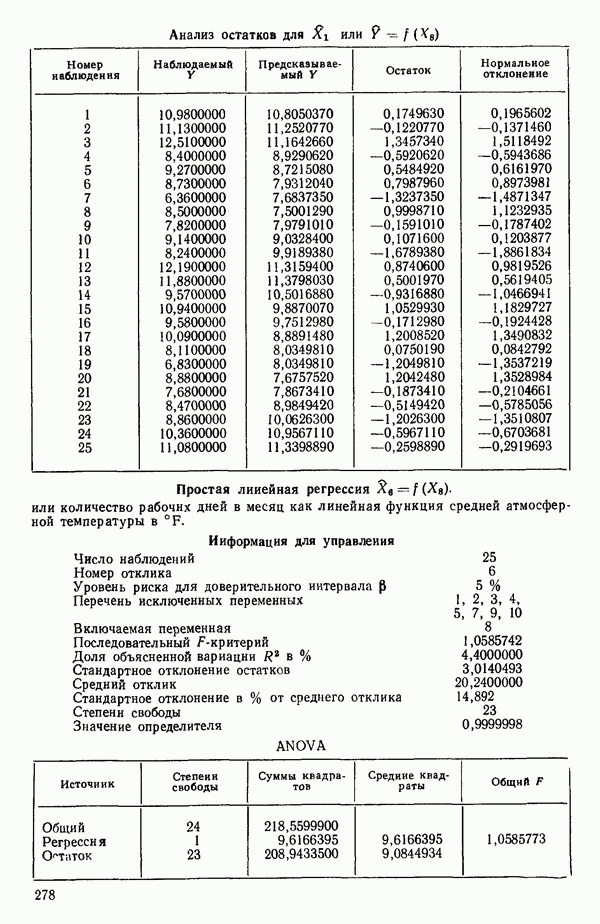
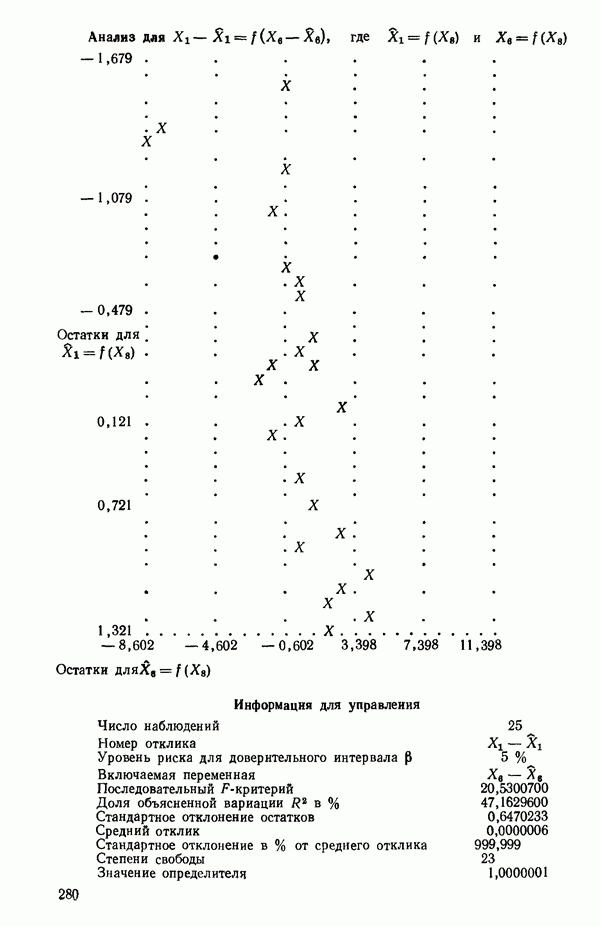
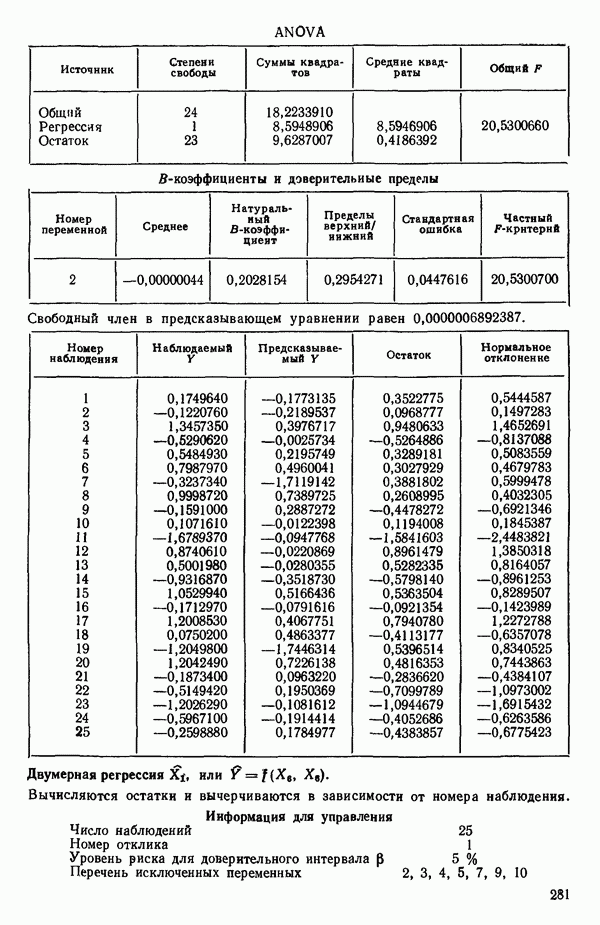
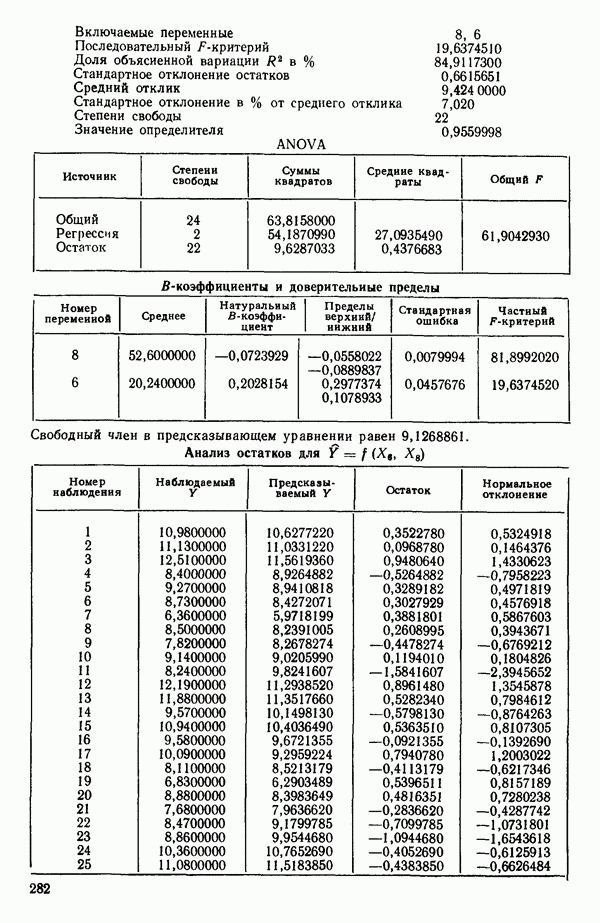
6.4. ШАГОВЫЙ РЕГРЕССИОННЫЙ МЕТОД
Метод исключения начинается с наиболее полного уравнения, включающего все переменные, и состоит в последовательном уменьшении числа переменных до тех пор, пока не принимается решение об использовании уравнения с оставшимися членами. Шаговый метод представляет собой попытку прийти к тем же результатам, действуя в обратном направлении, т. е. включая переменные по очереди в уравнение до тех пор, пока уравнение не станет удовлетворительным. Порядок включения определяется с помощью частного коэффициента корреляции как меры важности переменных, еще не включенных в
уравнение. Основная процедура состоит в следующем. Прежде всего выбирается величина  наиболее сильно коррелированная с Y (предположим, что это
наиболее сильно коррелированная с Y (предположим, что это  и находится линейное, первого порядка регрессионное уравнение
и находится линейное, первого порядка регрессионное уравнение  Затем мы проверяем, значима ли эта переменная. Если это не так, то мы должны согласиться с выводом, что наилучшая модель выражается уравнением
Затем мы проверяем, значима ли эта переменная. Если это не так, то мы должны согласиться с выводом, что наилучшая модель выражается уравнением  В противном случае мы должны найти вторую предикторную переменную
В противном случае мы должны найти вторую предикторную переменную  которую следует включить в модель. Мы определяем частные коэффициенты корреляции для всех предикторов, не включенных в уравнение на этом шаге, а именно для
которую следует включить в модель. Мы определяем частные коэффициенты корреляции для всех предикторов, не включенных в уравнение на этом шаге, а именно для  с учетом поправки на
с учетом поправки на  В математическом отношении это эквивалентно нахождению корреляции между (1) остатками от регрессии
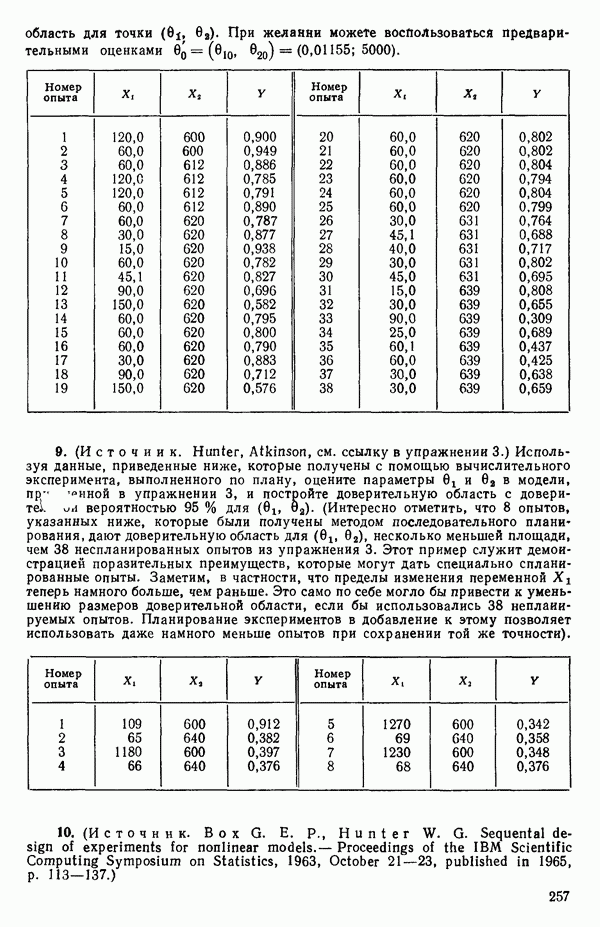
В математическом отношении это эквивалентно нахождению корреляции между (1) остатками от регрессии  и (2) остатками от каждой из регрессий
и (2) остатками от каждой из регрессий  (которые мы фактически не определяли). Теперь выбирается величина
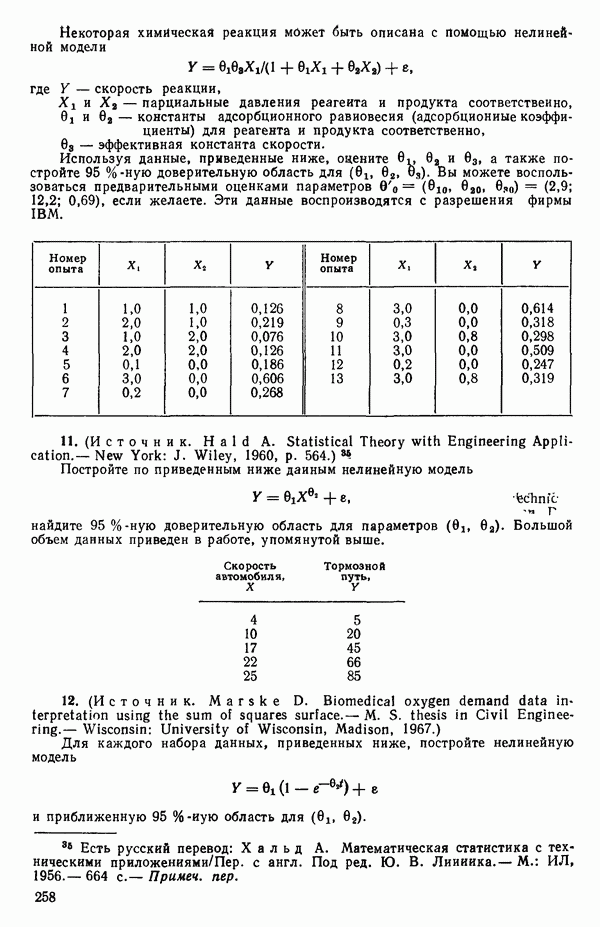
(которые мы фактически не определяли). Теперь выбирается величина  (предположим, что это
(предположим, что это  которая имеет наибольшее значение частного коэффициента корреляции с
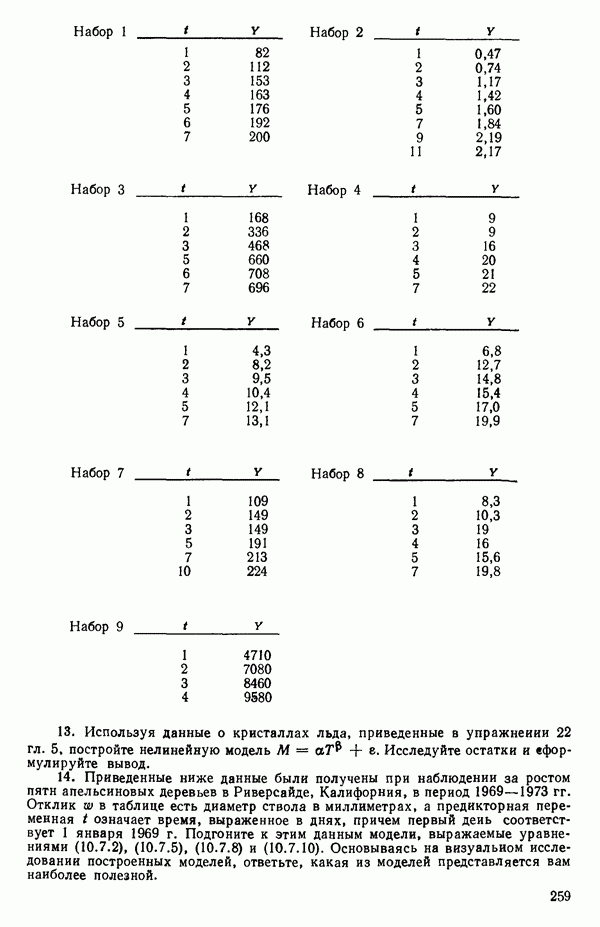
которая имеет наибольшее значение частного коэффициента корреляции с  и находится второе регрессионное уравнение
и находится второе регрессионное уравнение  Полное уравнение проверяется на значимость. Отмечается улучшение величины
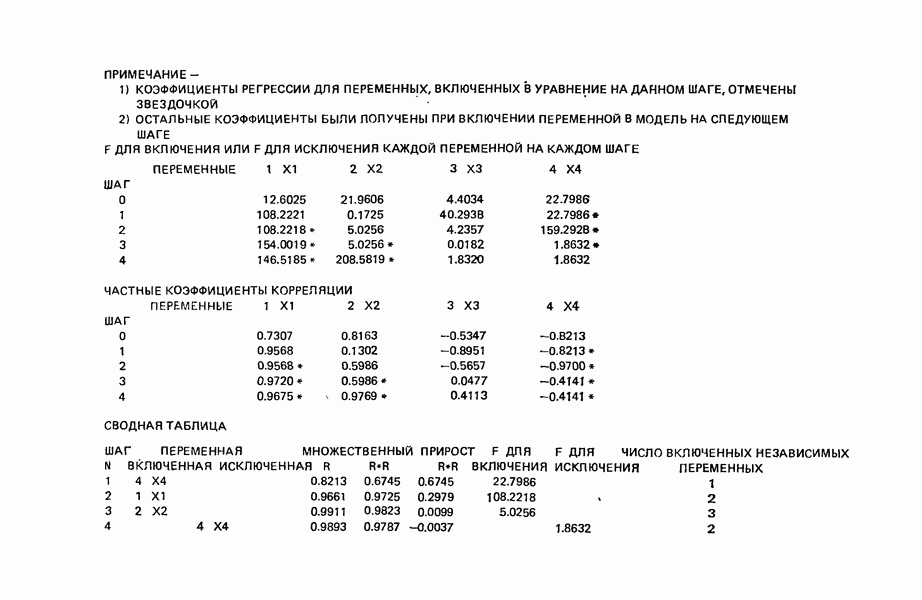
Полное уравнение проверяется на значимость. Отмечается улучшение величины  и исследуются частные F-критерии для обеих переменных, содержащихся в уравнении, а не только для той, которая только что была введена в уравнение. Наименьшая величина из этих двух частных F-критериев сравнивается затем с подходящей процентной точкой F-распределения. Соответствующая предикторная переменная сохраняется в уравнении или исключается из него в зависимости от результатов проверки. Такая проверка «наименее полезного предиктора в уравнении на данном этапе» проводится на каждом шаге этого метода. Может оказаться, что предиктор, который на предыдущем шаге был наилучшим кандидатом для включения в уравнение, на более позднем шаге оказывается ненужным. Это может быть вызвано теми связями, которые существуют между этой и другими переменными, содержащимися теперь в уравнении. Чтобы проверить это, на каждом шаге для каждой предикторной переменной, содержащейся в уравнении, вычисляется частный F-критерий и находится наименьший из них (он может быть связан с любой предикторной переменной, включенной в модель только что или ранее),
и исследуются частные F-критерии для обеих переменных, содержащихся в уравнении, а не только для той, которая только что была введена в уравнение. Наименьшая величина из этих двух частных F-критериев сравнивается затем с подходящей процентной точкой F-распределения. Соответствующая предикторная переменная сохраняется в уравнении или исключается из него в зависимости от результатов проверки. Такая проверка «наименее полезного предиктора в уравнении на данном этапе» проводится на каждом шаге этого метода. Может оказаться, что предиктор, который на предыдущем шаге был наилучшим кандидатом для включения в уравнение, на более позднем шаге оказывается ненужным. Это может быть вызвано теми связями, которые существуют между этой и другими переменными, содержащимися теперь в уравнении. Чтобы проверить это, на каждом шаге для каждой предикторной переменной, содержащейся в уравнении, вычисляется частный F-критерий и находится наименьший из них (он может быть связан с любой предикторной переменной, включенной в модель только что или ранее),
который затем сравнивается с заранее выбранной процентной точкой соответствующего  -распределения. Это позволяет судить о вкладе наименее ценной переменной в регрессию на данном шаге в предположении, что она только что была введена в модель безотносительно к тому, как это было на самом деле. Если проверяемая переменная показывает незначимый вклад в регрессию, она исключается из уравнения. После этого регрессионное уравнение пересчитывается с учетом всех оставшихся в нем предикторных переменных. Наилучшие переменные из тех, которые не вошли на данном шаге в модель (т. е. те, для которых коэффициент частной корреляции с
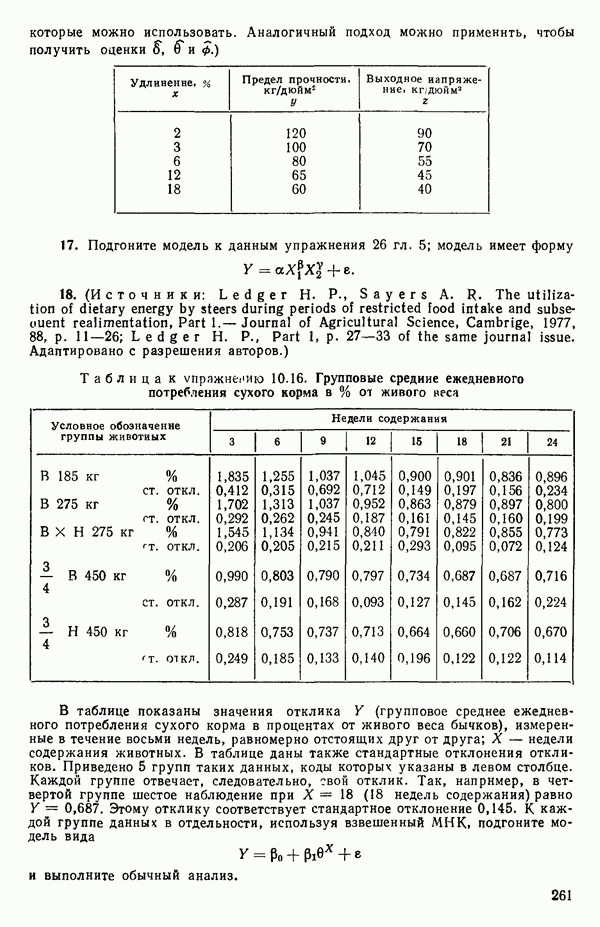
-распределения. Это позволяет судить о вкладе наименее ценной переменной в регрессию на данном шаге в предположении, что она только что была введена в модель безотносительно к тому, как это было на самом деле. Если проверяемая переменная показывает незначимый вклад в регрессию, она исключается из уравнения. После этого регрессионное уравнение пересчитывается с учетом всех оставшихся в нем предикторных переменных. Наилучшие переменные из тех, которые не вошли на данном шаге в модель (т. е. те, для которых коэффициент частной корреляции с  при наличии предикторов в уравнении получился наибольшим), затем проверяются, чтобы убедиться, удовлетворяют ли они частному
при наличии предикторов в уравнении получился наибольшим), затем проверяются, чтобы убедиться, удовлетворяют ли они частному  -критерию для включения. Если удовлетворяют, их включают в уравнение и снова возвращаются к проверке всех частных
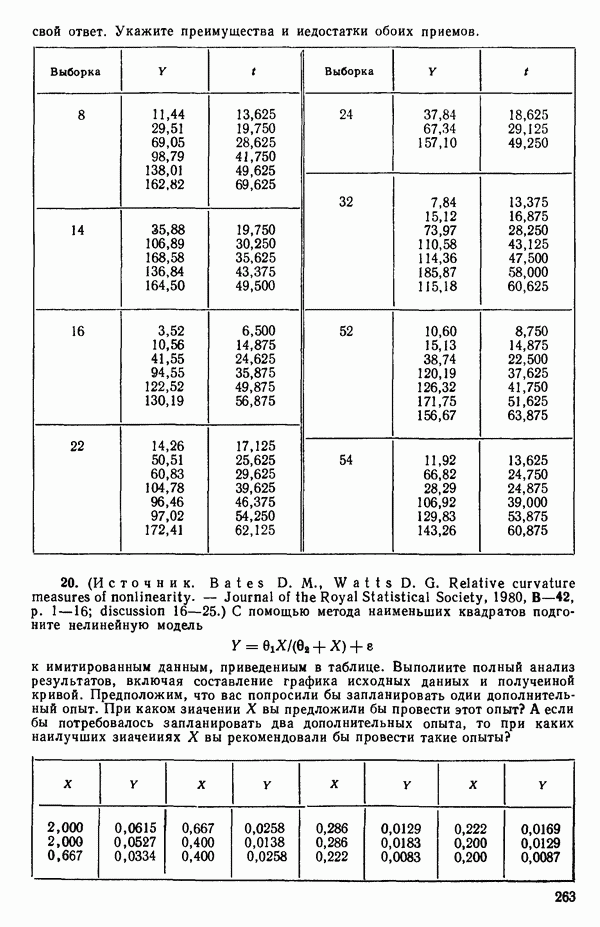
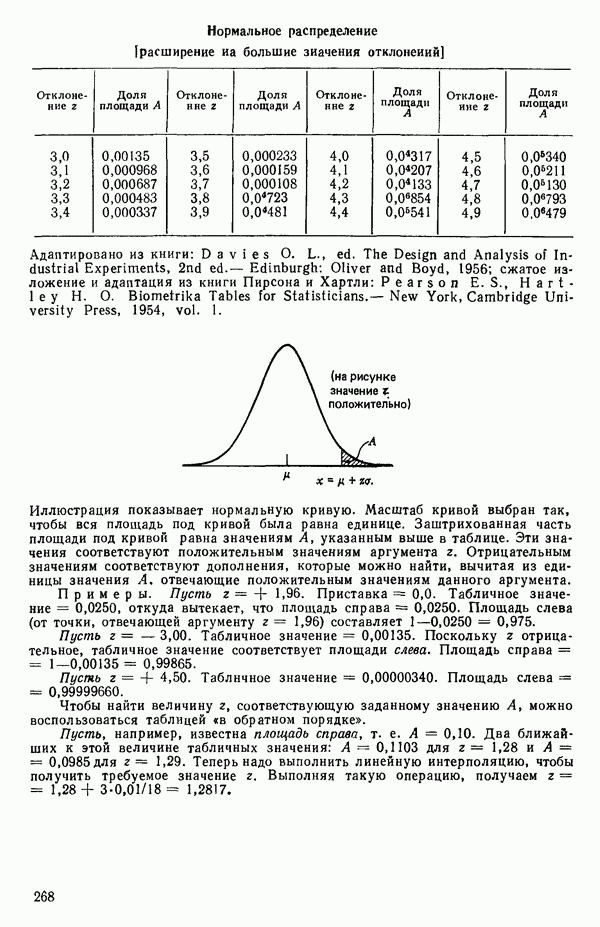
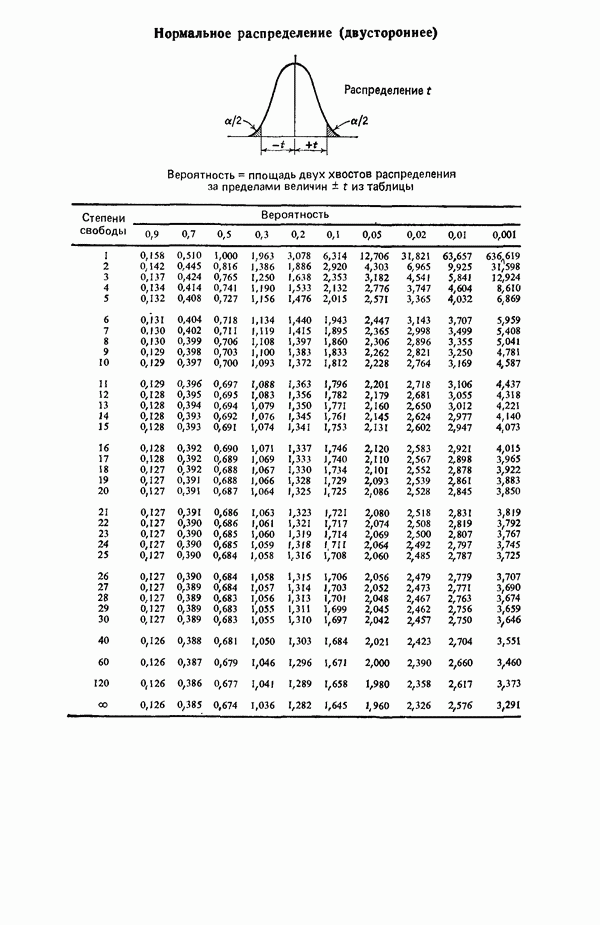
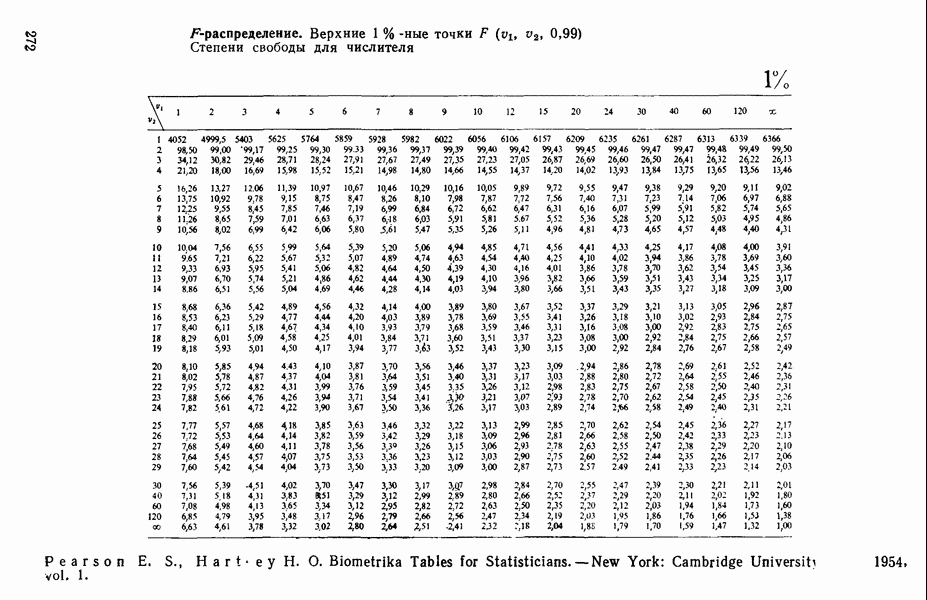
-критерию для включения. Если удовлетворяют, их включают в уравнение и снова возвращаются к проверке всех частных  для переменных. Если же они не выдерживают этой проверки, переходят к следующей операции исключения. В конечном счете (если только уровень значимости а не выбран плохо, что приводит к зацикливанию) процесс прекращается, если никакие из переменных, содержащихся в текущем уравнении, не удается исключить из него, а ближайший наилучший предиктор-претендент не в состоянии занять место в уравнении. Когда переменная включается в регрессию, ее влияние на
для переменных. Если же они не выдерживают этой проверки, переходят к следующей операции исключения. В конечном счете (если только уровень значимости а не выбран плохо, что приводит к зацикливанию) процесс прекращается, если никакие из переменных, содержащихся в текущем уравнении, не удается исключить из него, а ближайший наилучший предиктор-претендент не в состоянии занять место в уравнении. Когда переменная включается в регрессию, ее влияние на  квадрат множественного коэффициента корреляции, обычно указывается в машинной распечатке.
квадрат множественного коэффициента корреляции, обычно указывается в машинной распечатке.
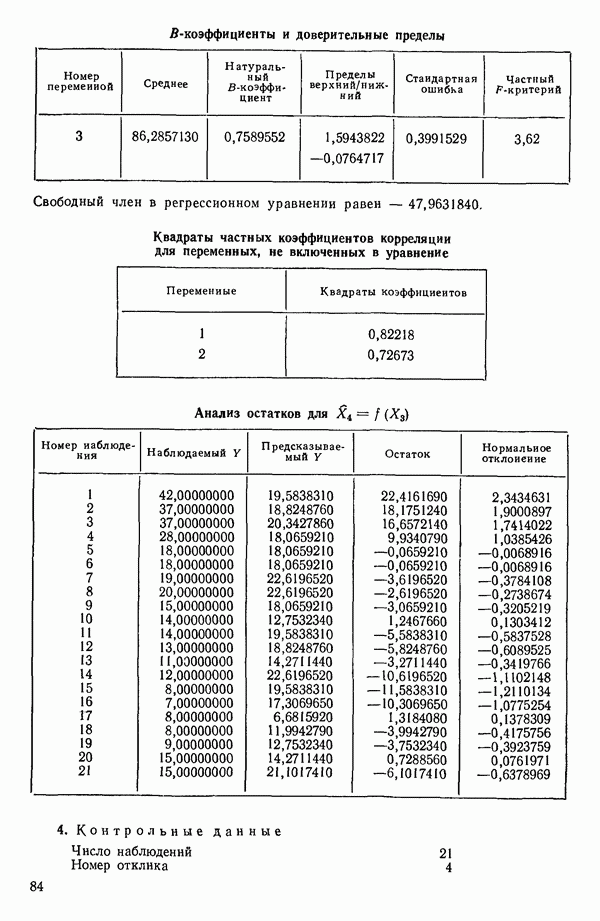
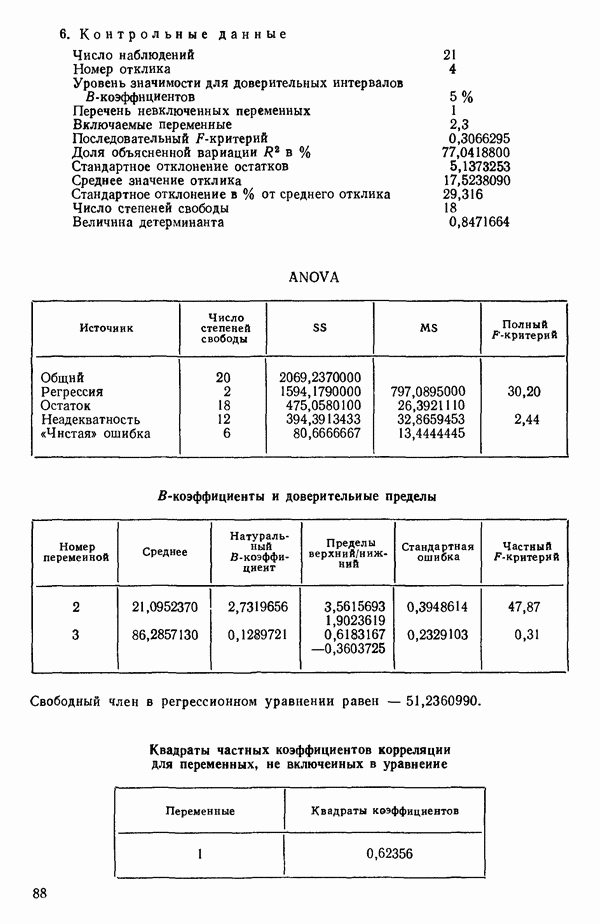
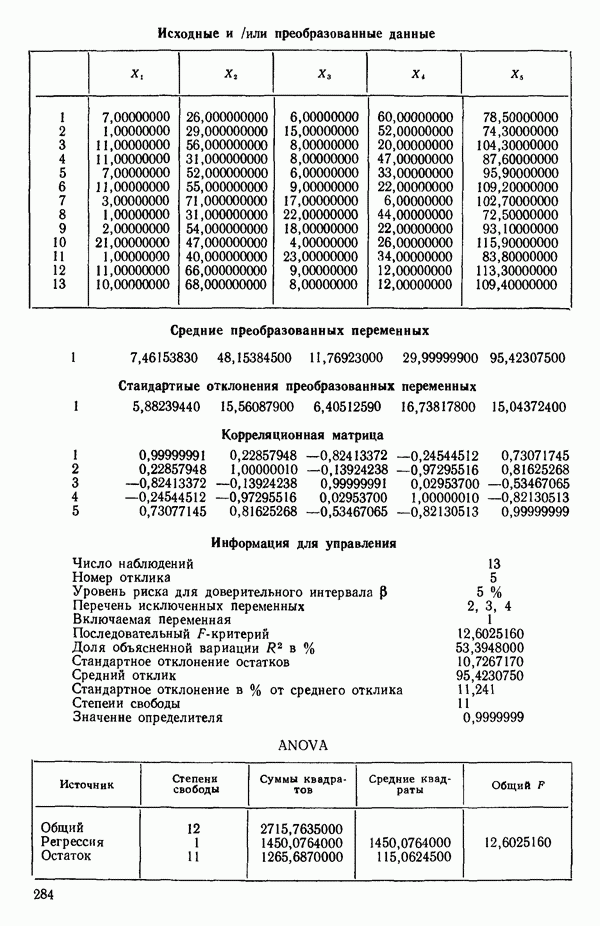
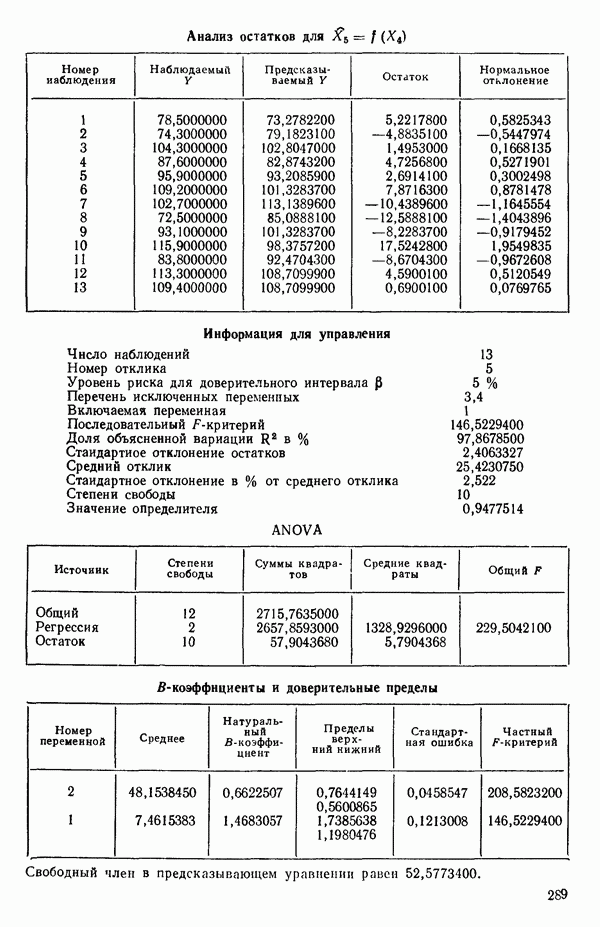
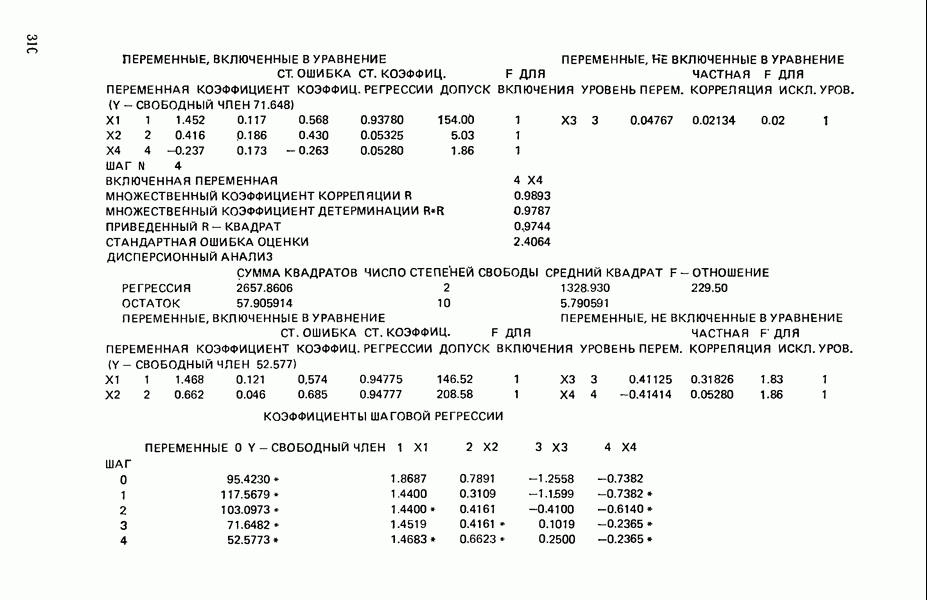
Мы снова воспользуемся данными Хальда, чтобы проиллюстрировать, как работает шаговая процедура. (См. распечатку, где указано, что  ) Для обоих критериев включения и исключения принят уровень значимости
) Для обоих критериев включения и исключения принят уровень значимости 
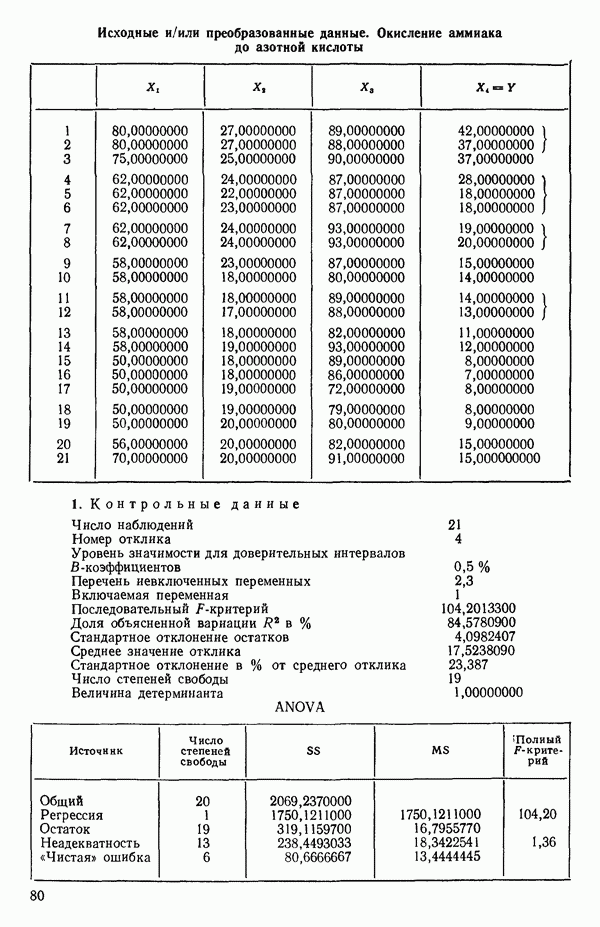
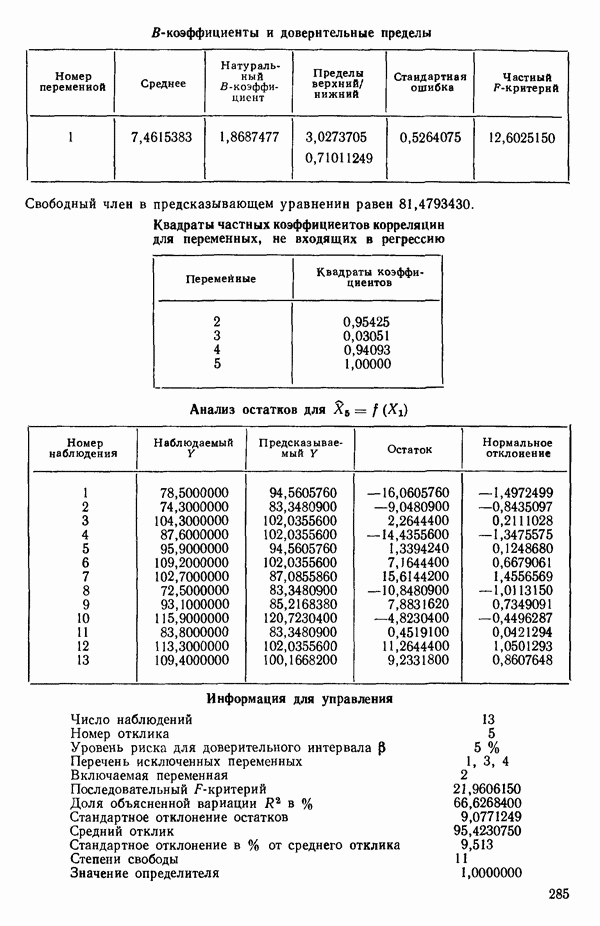
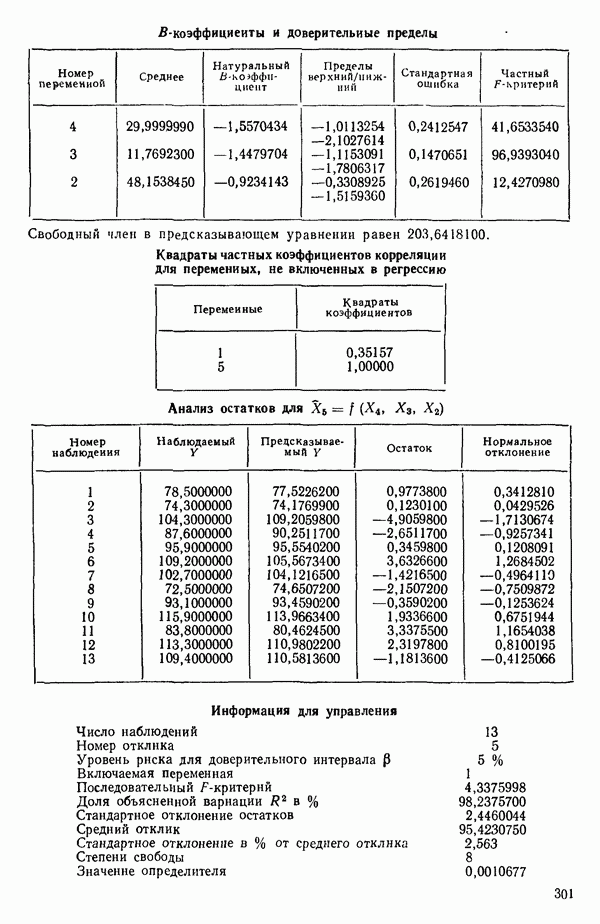
1. Вычислим коэффициенты корреляции между каждой предикторной переменной и откликом. Выберем в качестве первой переменной для включения в регрессию ту, которая коррелирована с откликом наиболее сильно. Исследование корреляционной матрицы в приложении Б показывает, что  наиболее сильно коррелирована с откликом
наиболее сильно коррелирована с откликом  или
или  Следовательно,
Следовательно,  это первая переменная, которая должна быть включена в регрессионное уравнение.
это первая переменная, которая должна быть включена в регрессионное уравнение.
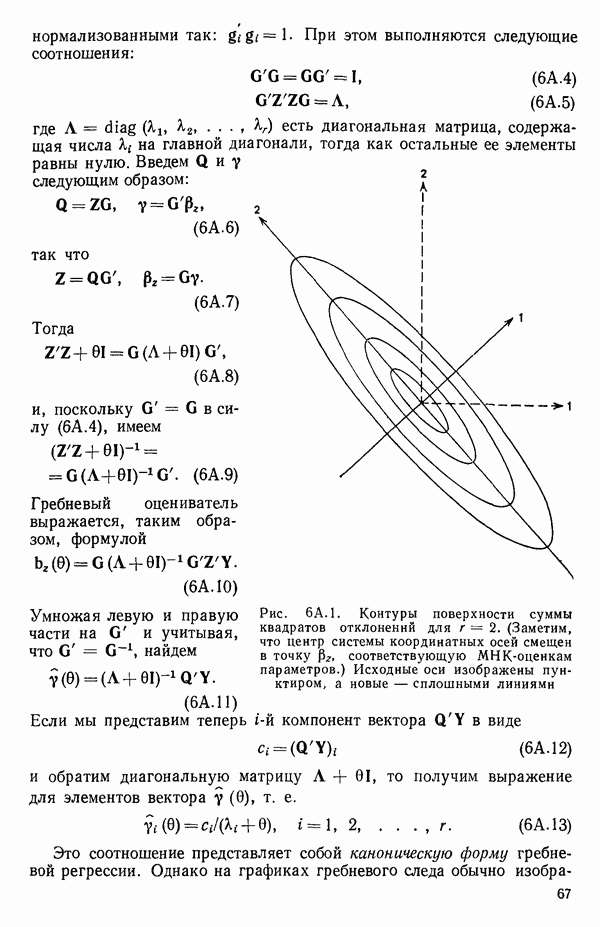
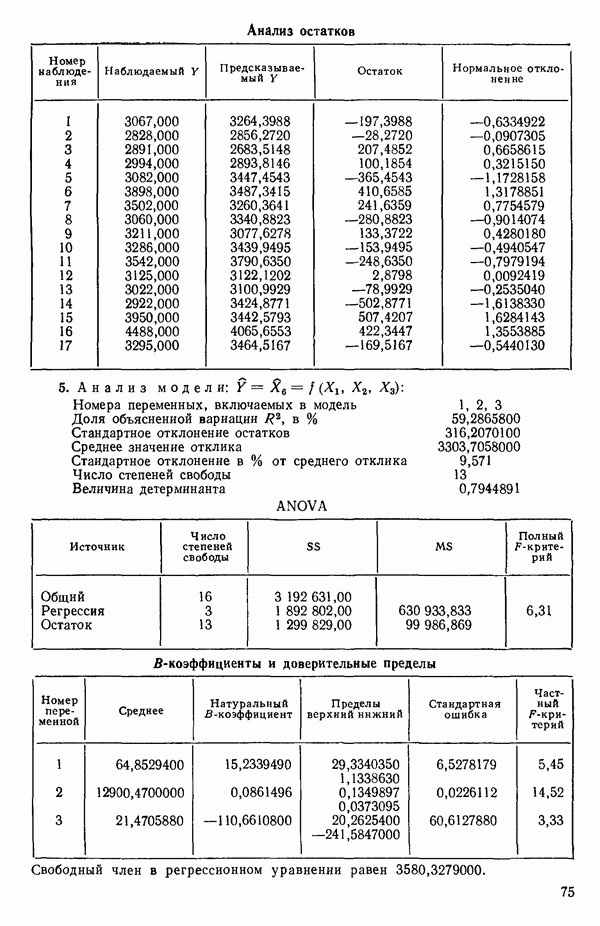
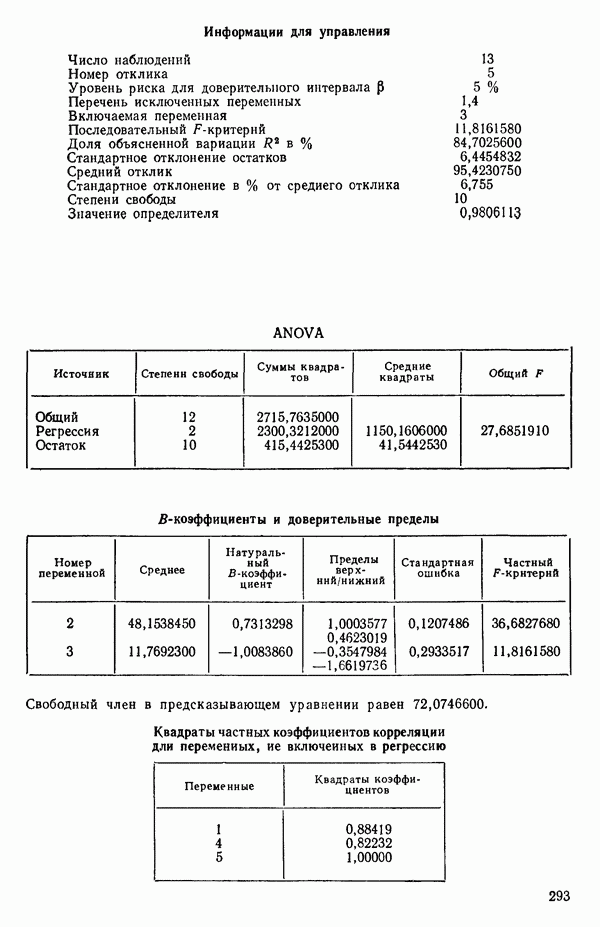
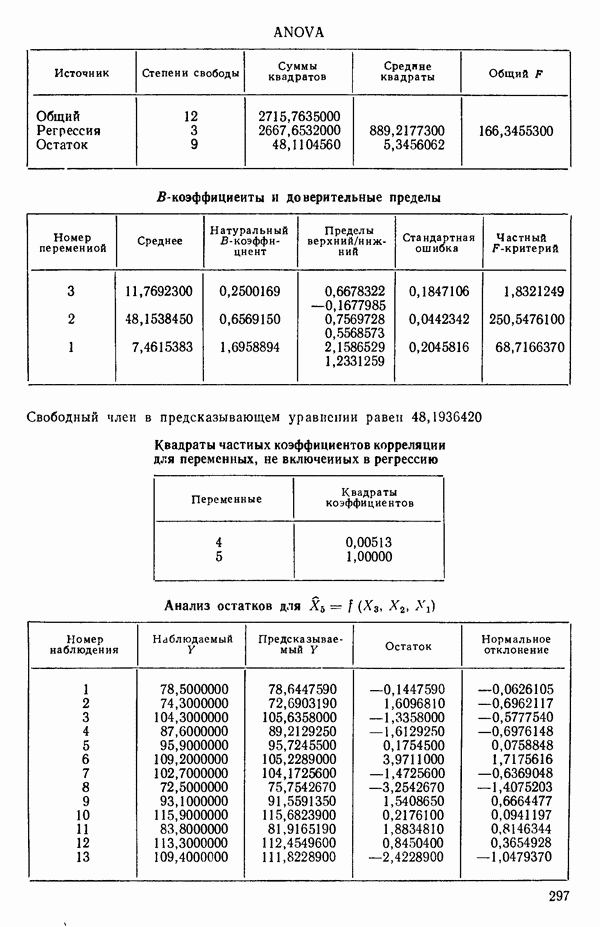
2. Построим регрессию  в зависимости от
в зависимости от  и получим МНК-уравнение, приведенное на с. 288. Полный
и получим МНК-уравнение, приведенное на с. 288. Полный  -критерий показывает, что регрессия значима. Таким образом, переменная
-критерий показывает, что регрессия значима. Таким образом, переменная  сохраняется в уравнении.
сохраняется в уравнении.
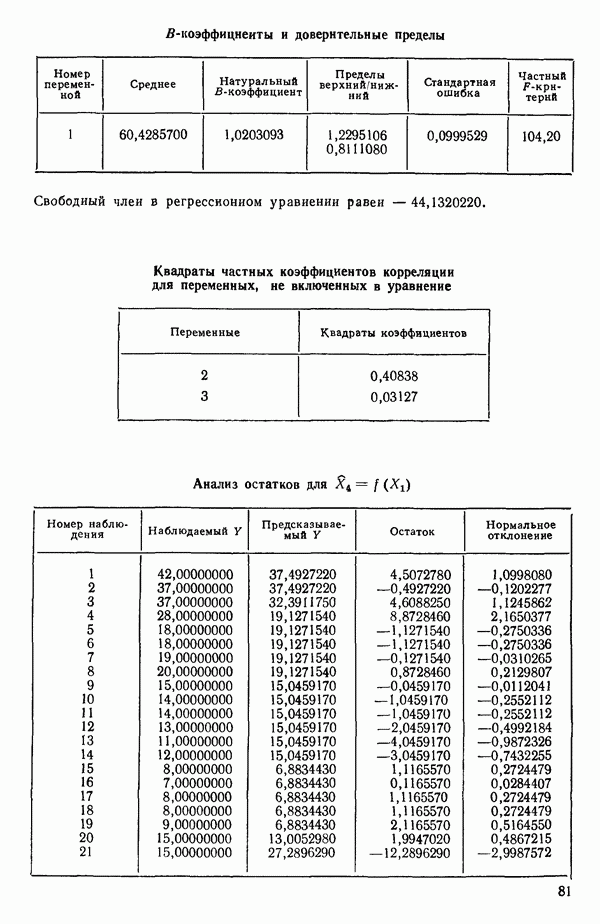
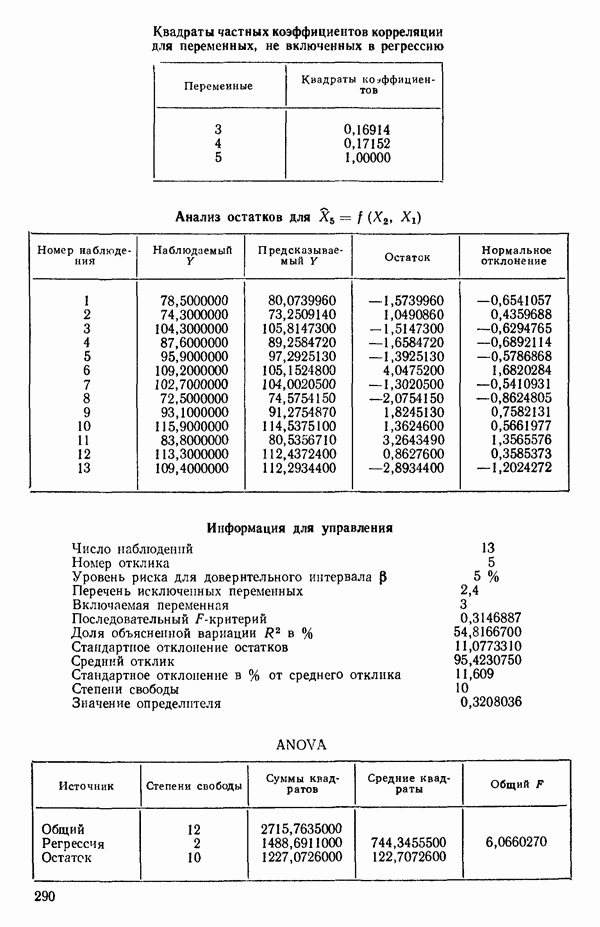
3. Вычислим частные коэффициенты корреляции между всеми переменными, не входящими в уравнение, и откликом. Их квадраты указаны внизу на с. 288. Выберем в качестве следующей переменной
для включения в регрессионное уравнение переменную с наибольшим значением частного коэффициента корреляции. Это переменная 
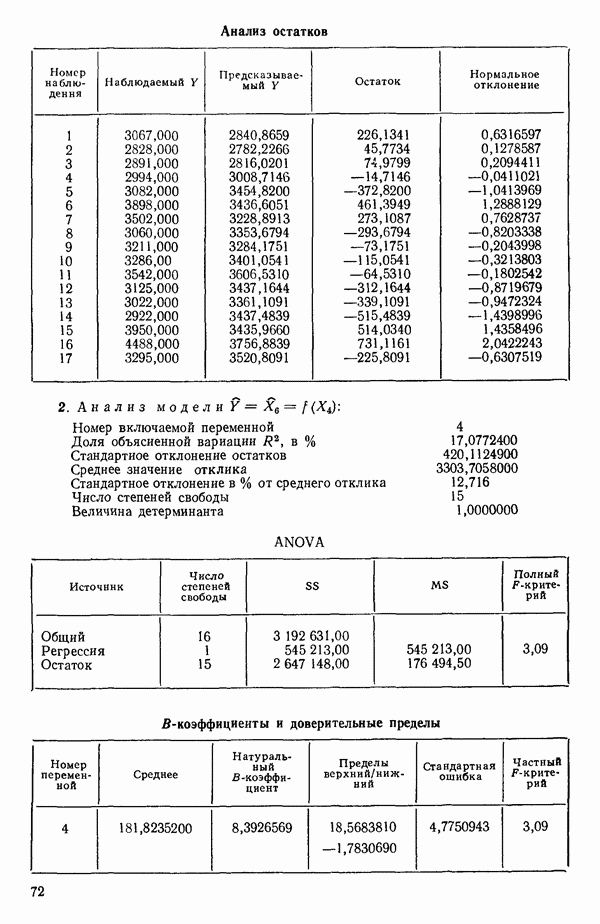
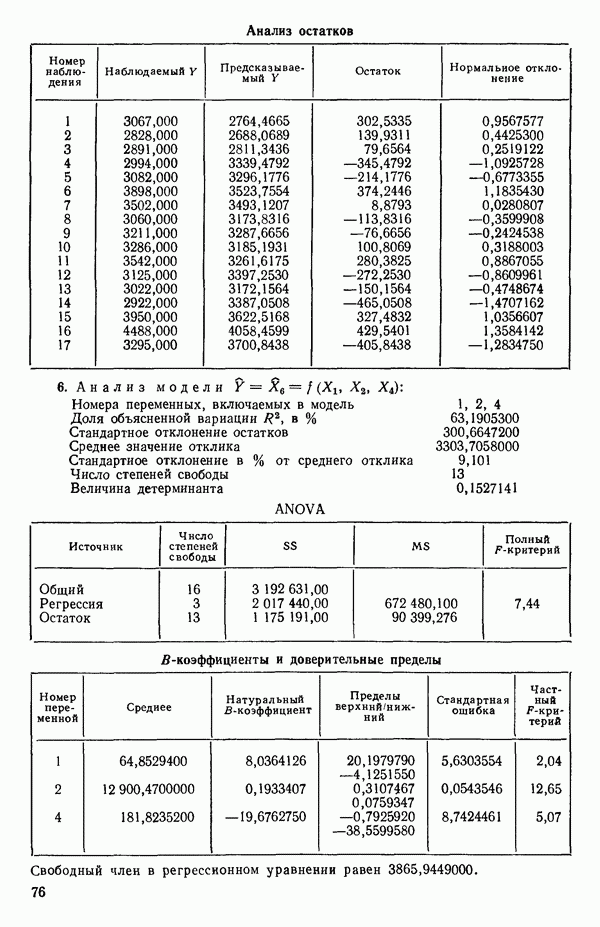
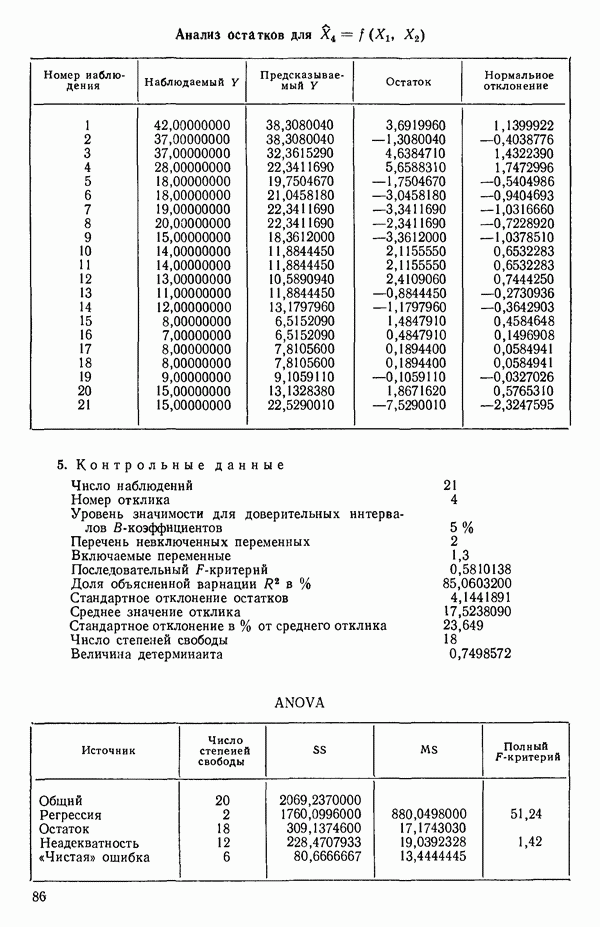
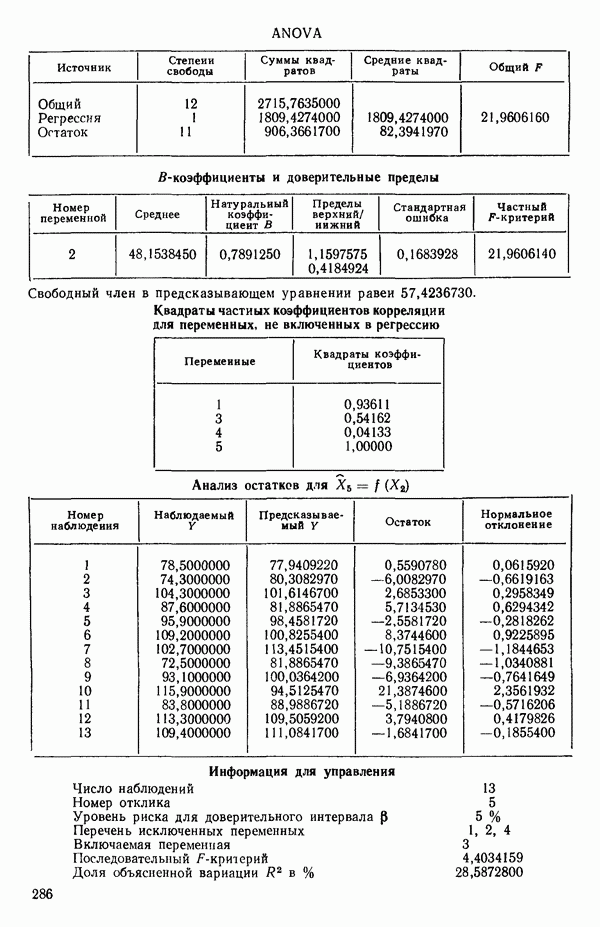
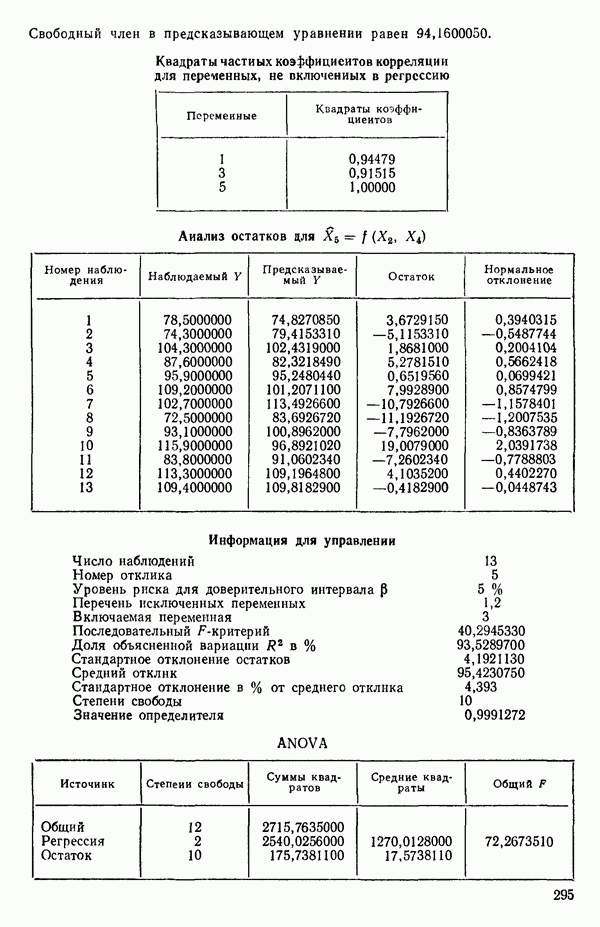
4. Получим МНК-уравнение  содержащее как
содержащее как  так и
так и  см. с. 291. Этому уравнению соответствует
см. с. 291. Этому уравнению соответствует  и оно явно значимо, поскольку величина полного
и оно явно значимо, поскольку величина полного  -критерия равна
-критерия равна  . А это превосходит
. А это превосходит  То, что новая переменная
То, что новая переменная  дает значимое снижение остаточной суммы квадратов, показывает ее частный
дает значимое снижение остаточной суммы квадратов, показывает ее частный  -критерий, который равен 108,22, что превосходит величину
-критерий, который равен 108,22, что превосходит величину  Таким образом,
Таким образом,  остается в уравнении. Мы проверим также вклад
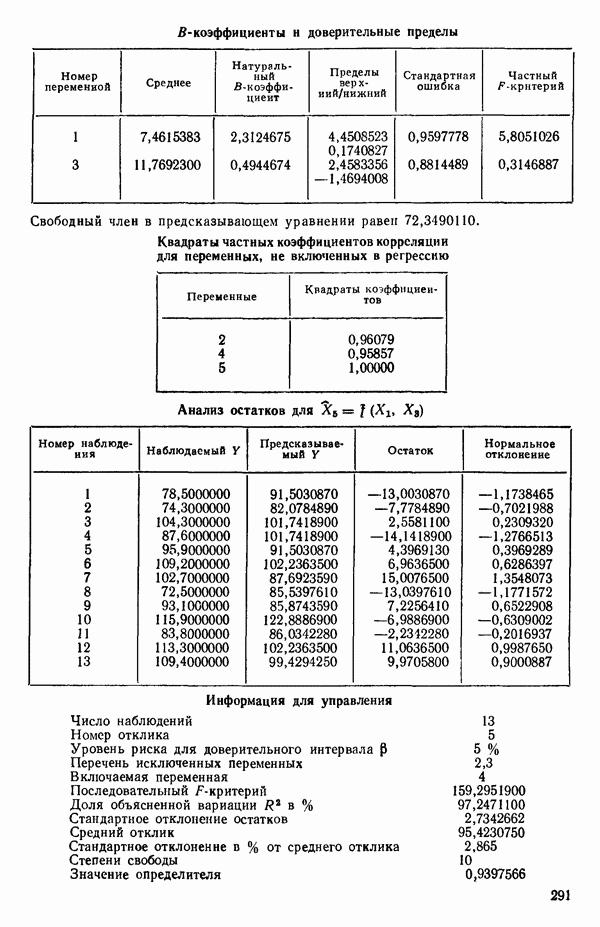
остается в уравнении. Мы проверим также вклад  в предположении, что величина
в предположении, что величина  будто бы была включена в модель первой, а переменная
будто бы была включена в модель первой, а переменная  второй. Поскольку величина частного
второй. Поскольку величина частного  -критерия равна 159,295 (см. с. 291), что значительно превосходит
-критерия равна 159,295 (см. с. 291), что значительно превосходит  переменная
переменная  сохраняется в уравнении. (На практике в большинстве программ не проверяются обе переменные, как это делается здесь, а выбирают переменную с наименьшим значением частного
сохраняется в уравнении. (На практике в большинстве программ не проверяются обе переменные, как это делается здесь, а выбирают переменную с наименьшим значением частного  -критерия и проверяют ее. Принимается решение об исключении или сохранении соответствующей предикторной переменной. При исключении уравнение пересчитывается, а при сохранении ищется следующий кандидат.)
-критерия и проверяют ее. Принимается решение об исключении или сохранении соответствующей предикторной переменной. При исключении уравнение пересчитывается, а при сохранении ищется следующий кандидат.)
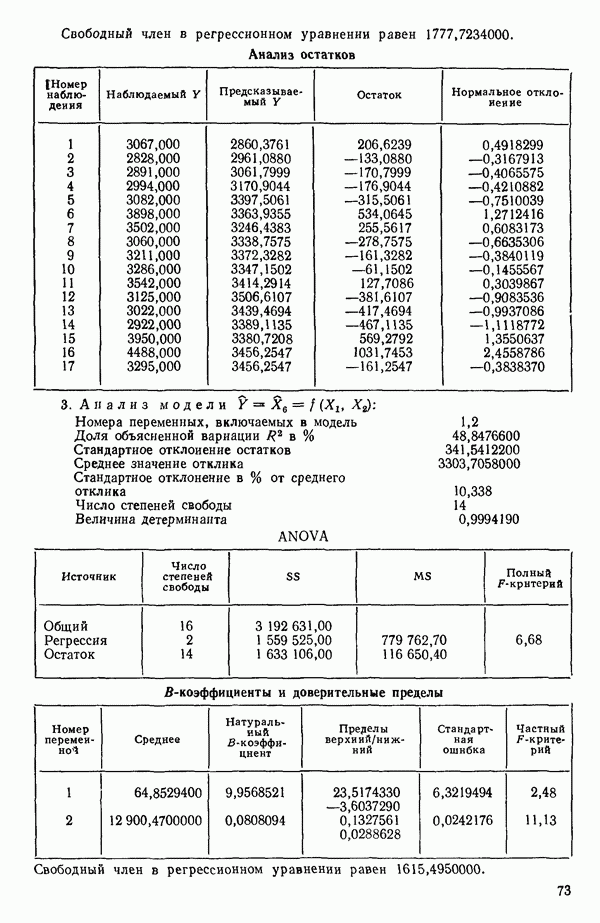
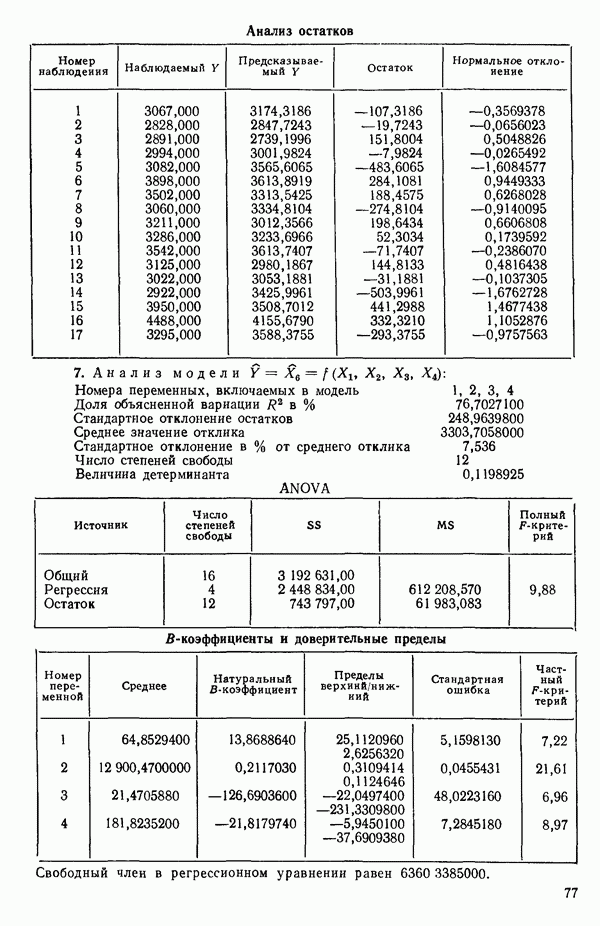
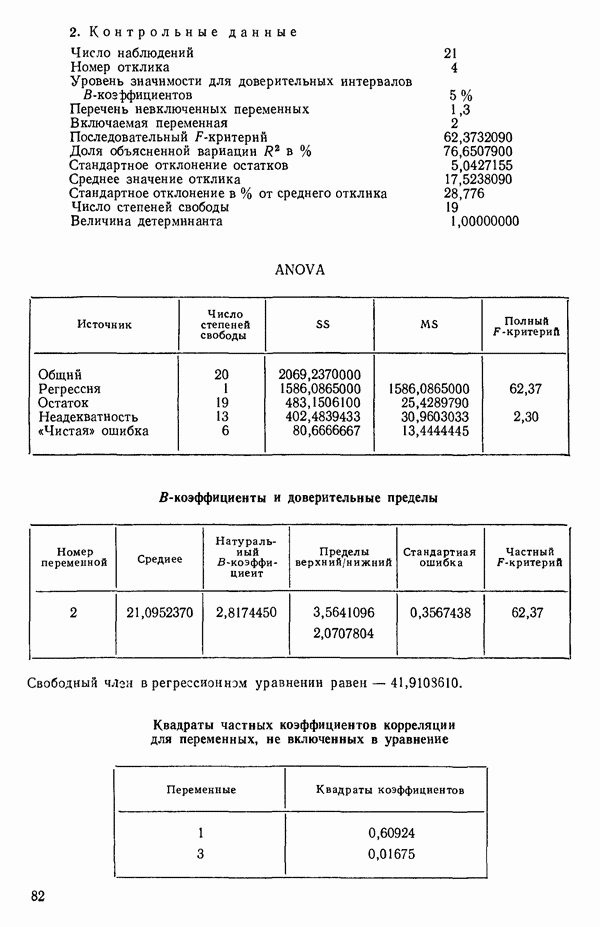
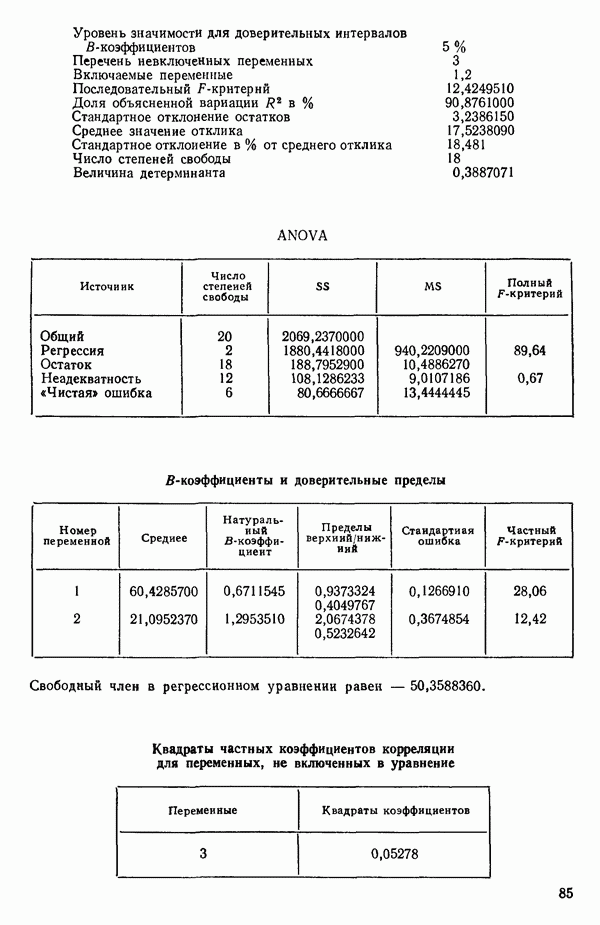
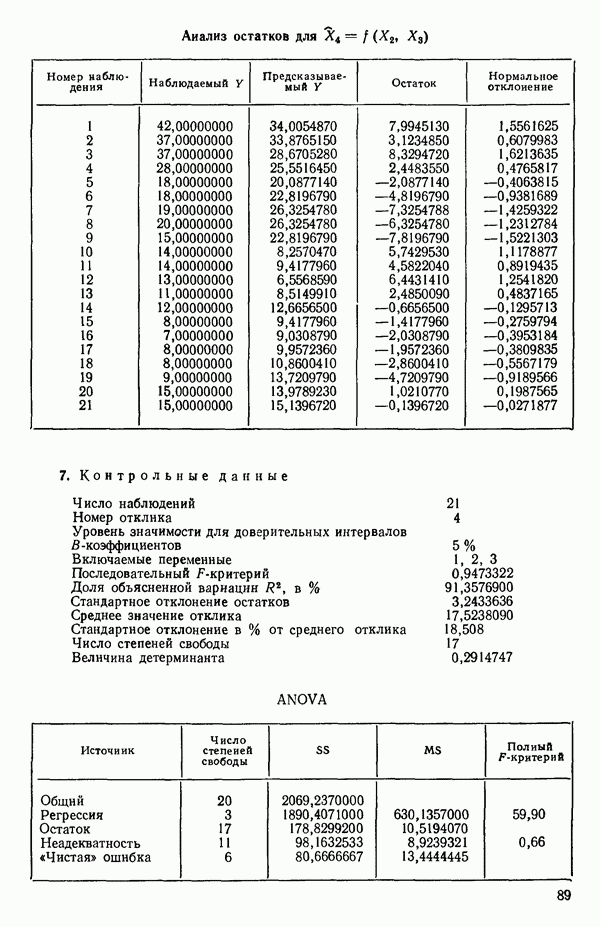
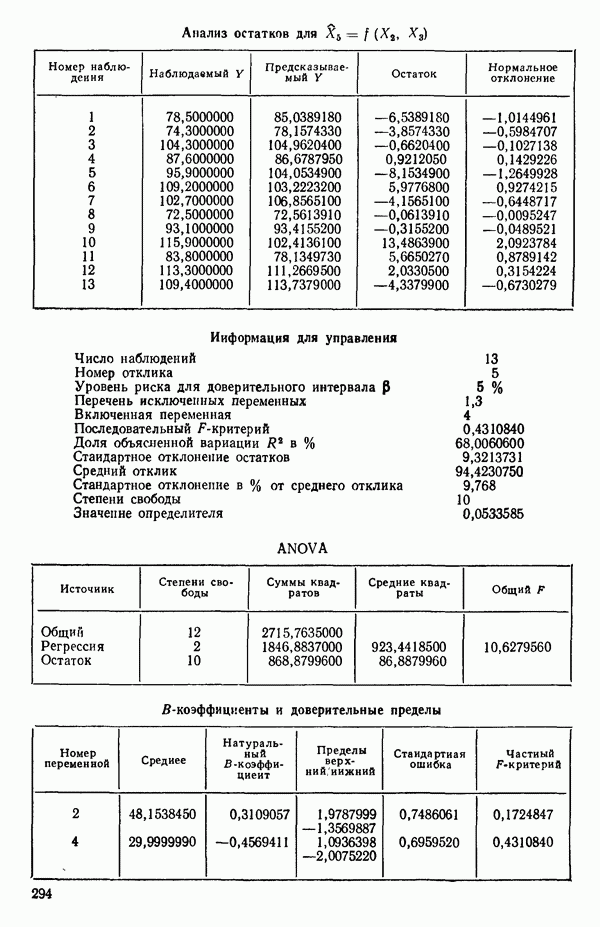
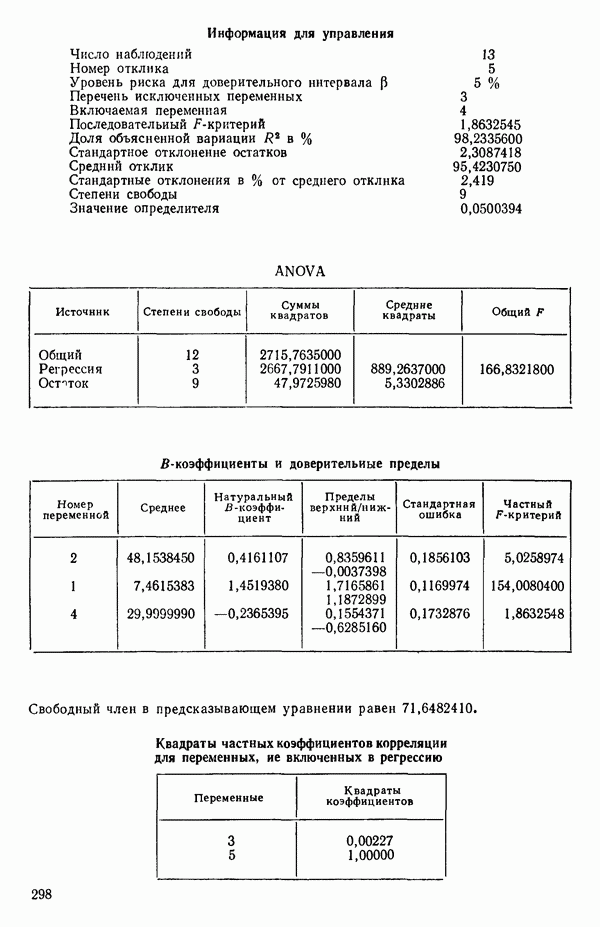
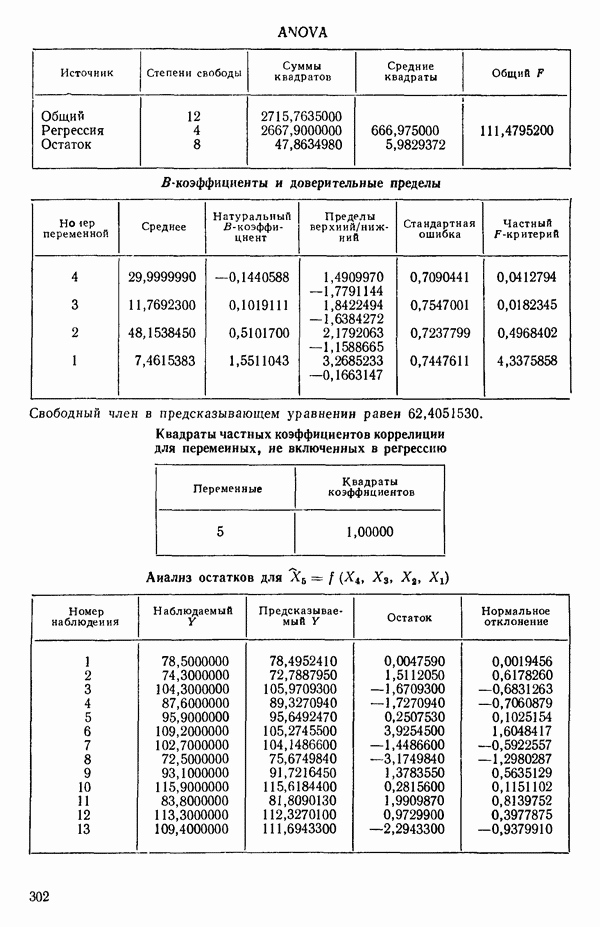
5. Согласно шаговому методу теперь для включения в уравнение выбирается следующая переменная, которая имеет наиболее высокий частный коэффициент корреляции с откликом (при условии, что переменные  уже содержатся в регрессии). Как видно, это переменная
уже содержатся в регрессии). Как видно, это переменная  (Квадрат частного коэффициента корреляции предиктора
(Квадрат частного коэффициента корреляции предиктора  с откликом равен 0,358 — см. с. 291.)
с откликом равен 0,358 — см. с. 291.)
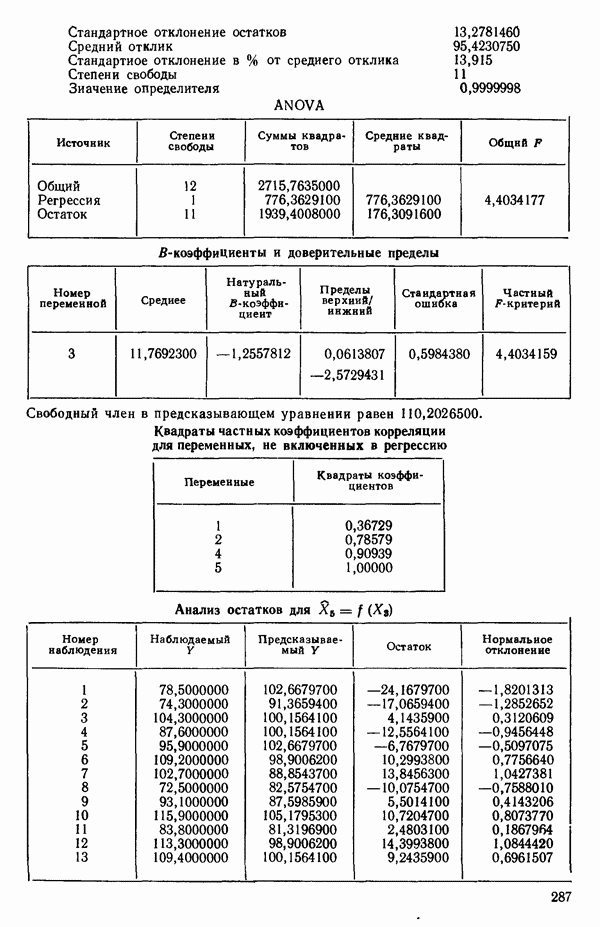
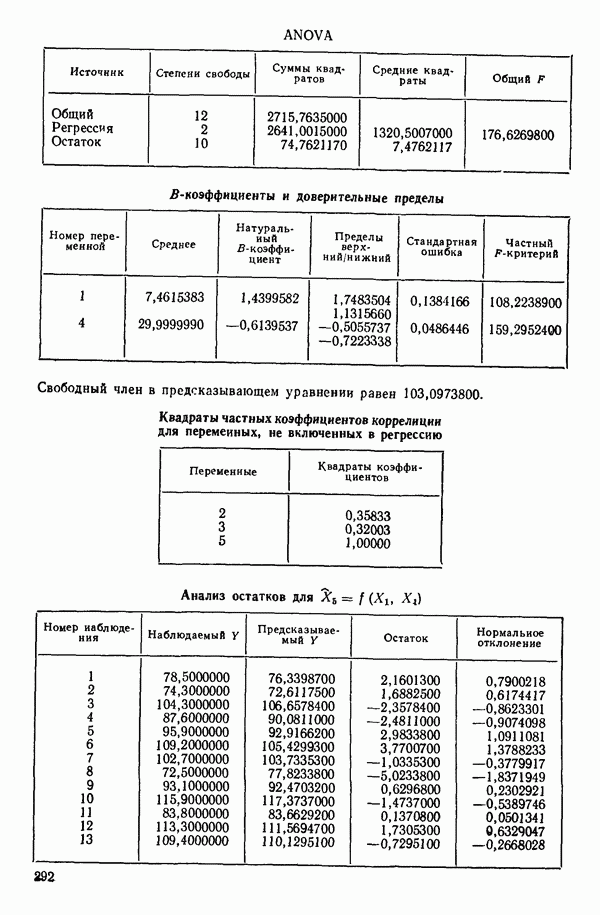
6. Новое уравнение  приведено на с. 298. Квадрат множественного коэффициента корреляции,
приведено на с. 298. Квадрат множественного коэффициента корреляции,  выраженный в
выраженный в  увеличился с 97,2 до 98,2 %. Затем на этом шаге исследовались частные
увеличился с 97,2 до 98,2 %. Затем на этом шаге исследовались частные  -критерии для переменных
-критерии для переменных  Наименьшее значение
Наименьшее значение  (см. с. 298) соответствует
(см. с. 298) соответствует  И поскольку эта величина меньше, чем
И поскольку эта величина меньше, чем  переменная
переменная  отвергается. В уравнении, которое пересчитывается
отвергается. В уравнении, которое пересчитывается  , сохраняются переменные
, сохраняются переменные  как значимые.
как значимые.
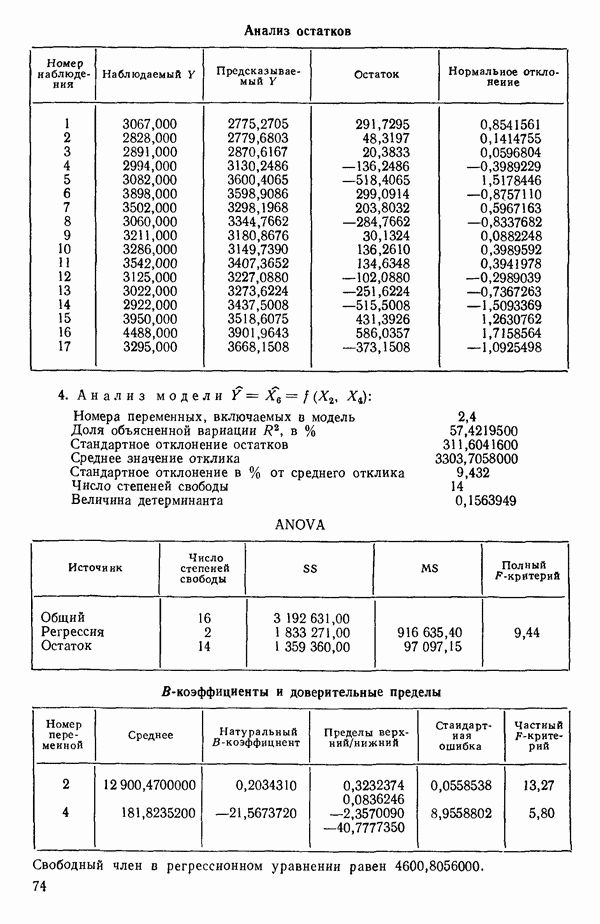
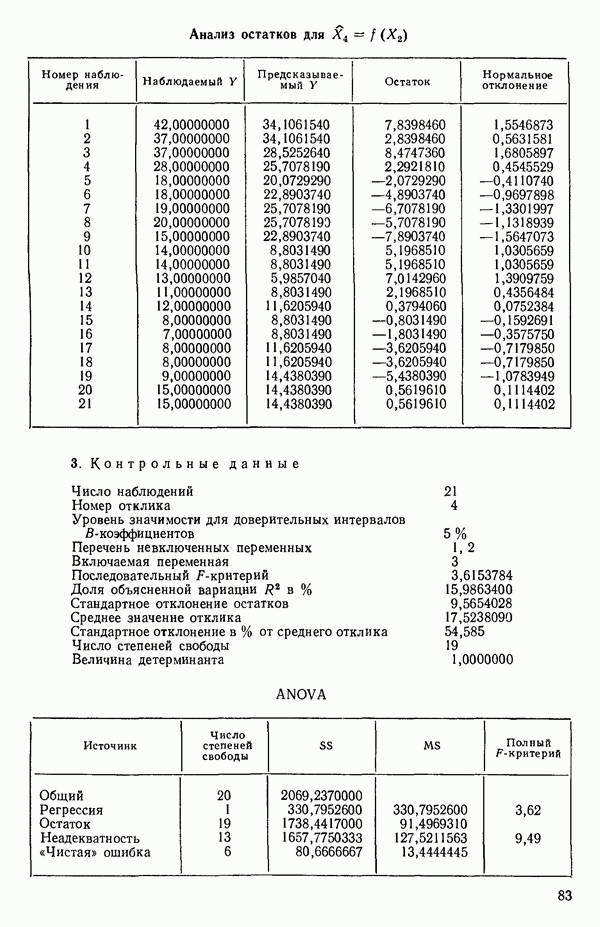
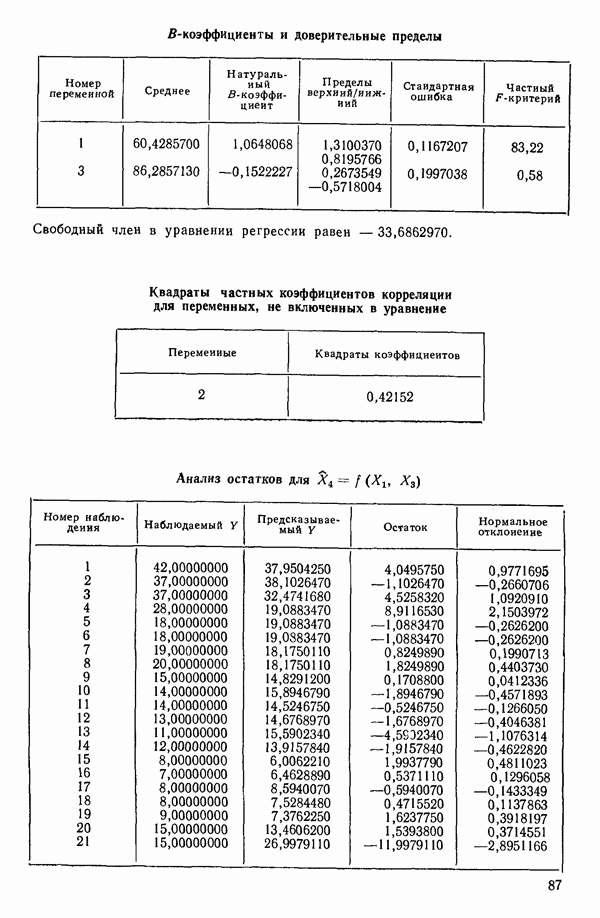
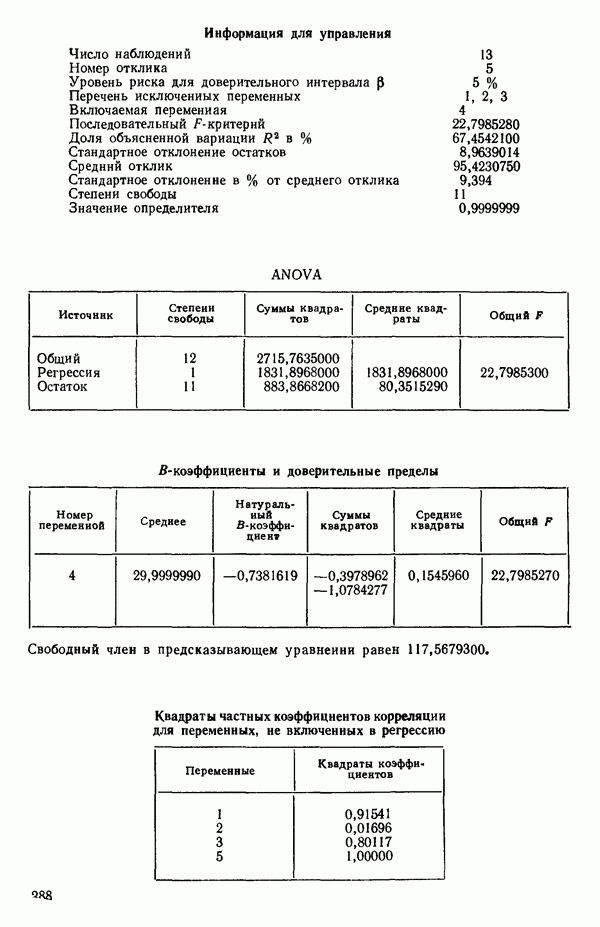
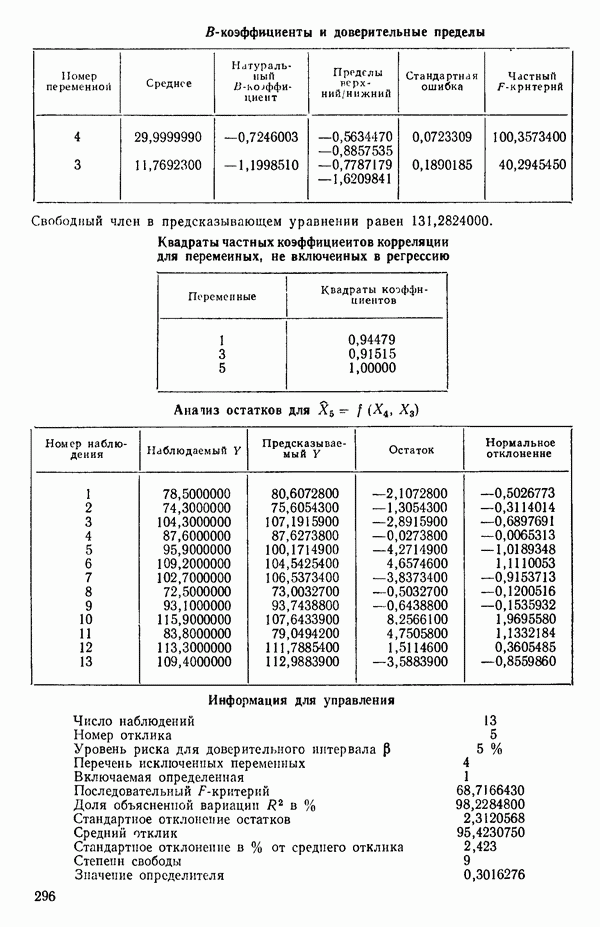
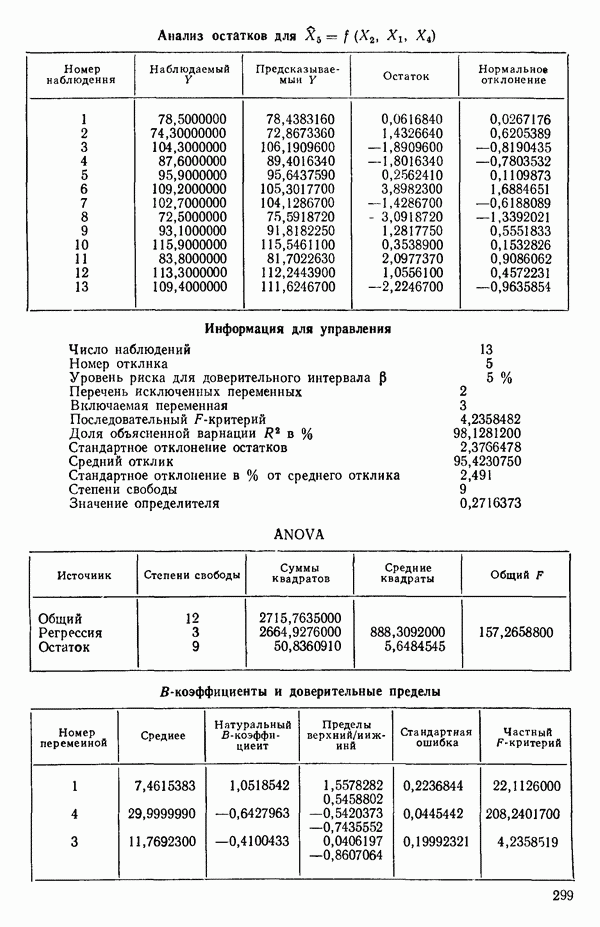
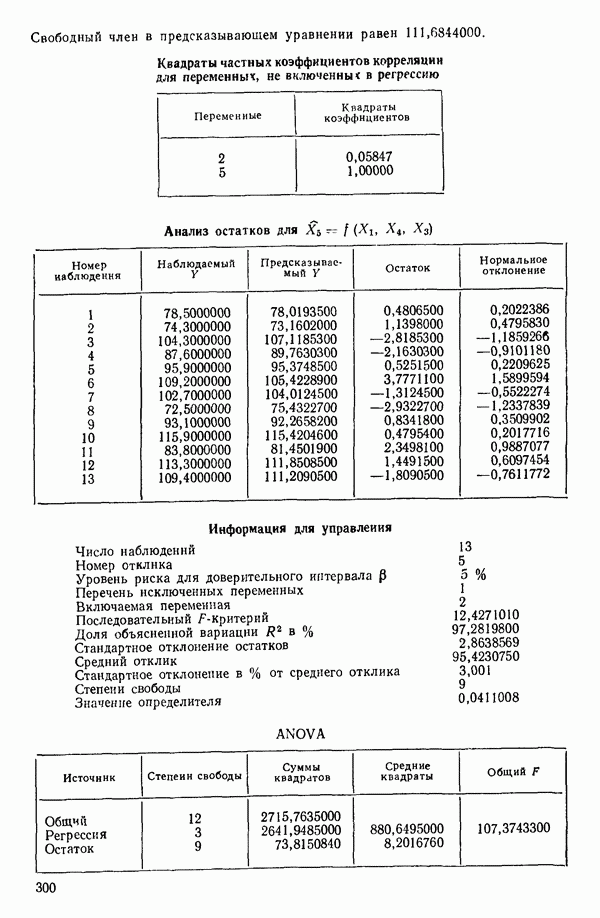
7. Единственная остающаяся переменная, которая может рассматриваться на этом этапе, есть  Поскольку эта переменная немедленно отвергается, шаговая регрессионная процедура заканчивается, и как наилучшее выбирается уравнение
Поскольку эта переменная немедленно отвергается, шаговая регрессионная процедура заканчивается, и как наилучшее выбирается уравнение  показанное на с. 289, а именно
показанное на с. 289, а именно

Мнение. Мы считаем этот метод одним из лучших среди обсуждавшихся выше и рекомендуем его применять. Он наиболее экономичен при обработке данных на ЭВМ. К тому же он позволяет избежать манипуляций с большим числом предикторов, чем это необходимо, хотя уравнение продолжает улучшаться с каждым шагом. Однако шаговый метод может легко стать обузой для
профессионального статистика. Как и во всех других обсуждавшихся методах, здесь требуются все же разумные суждения при первоначальном выборе переменных и при критическом анализе модели путем исследования остатков. Можно полагать, что использование этого метода для автоматического выбора наилучшего уравнения с помощью ЭВМ будет слишком затруднительным. Обсуждение этого метода дано в статье: Efroymson М. A. Multiple regression analysis, в книге: Mathematical Methods for Digital Computers/Ralston A. and Wilf H. S., ed.- New York: J. Wiley, 1962.