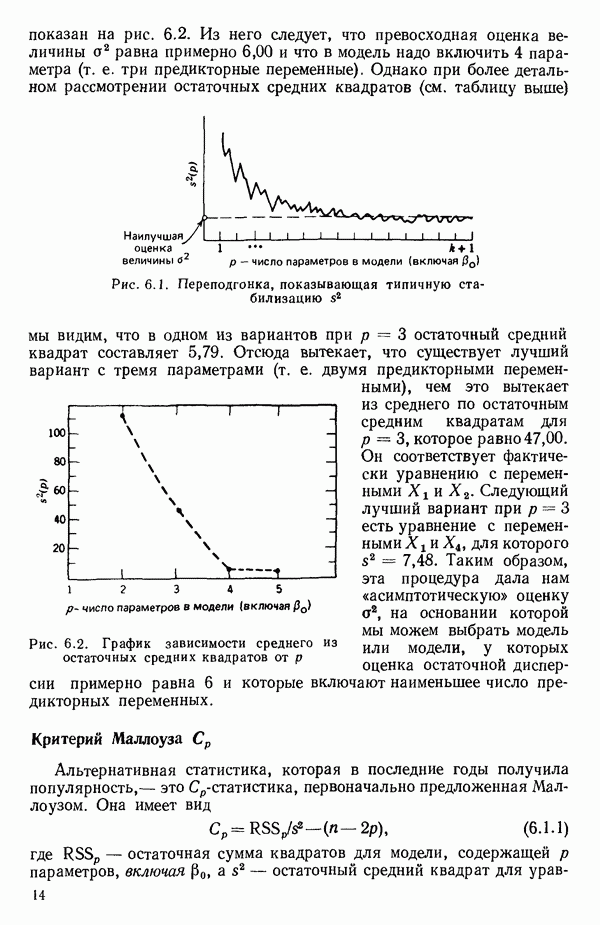
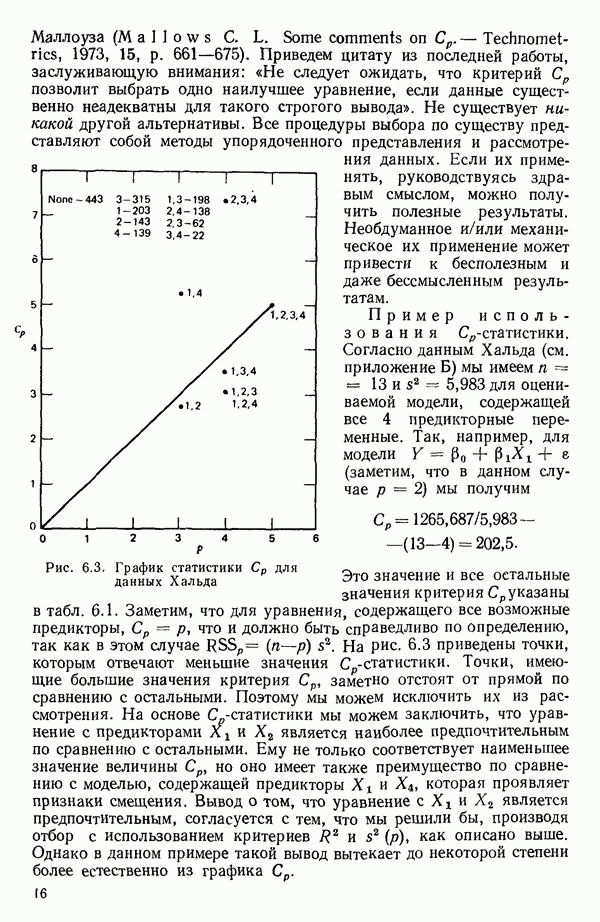
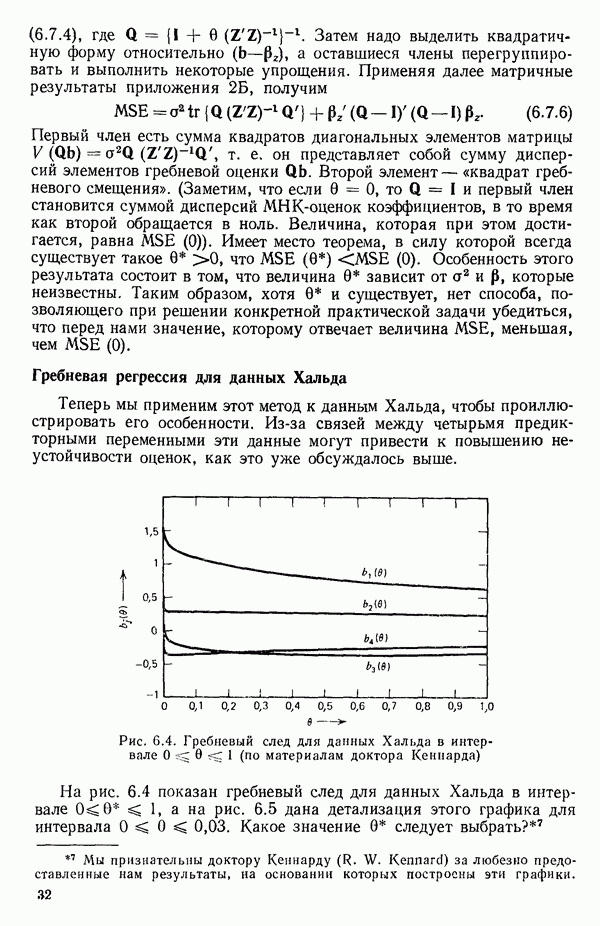
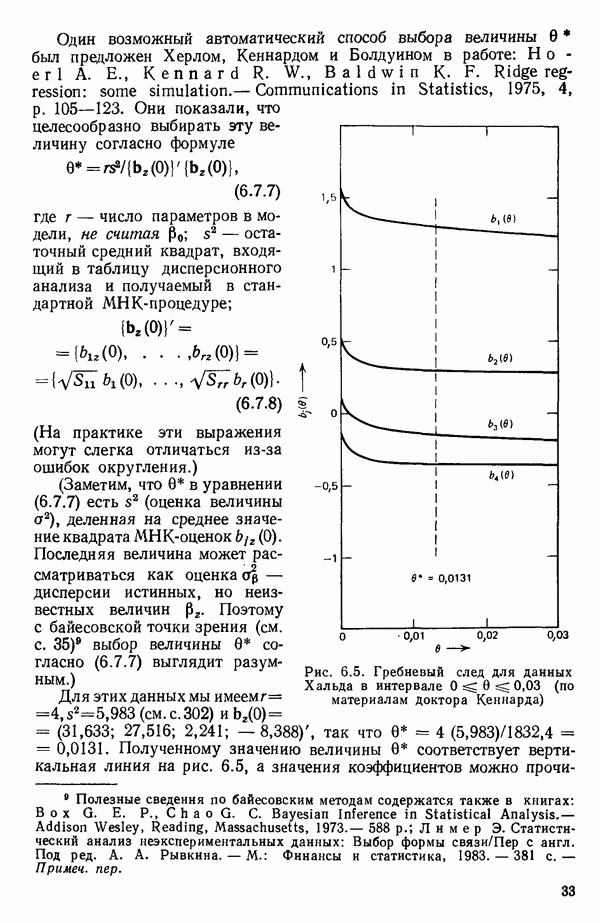
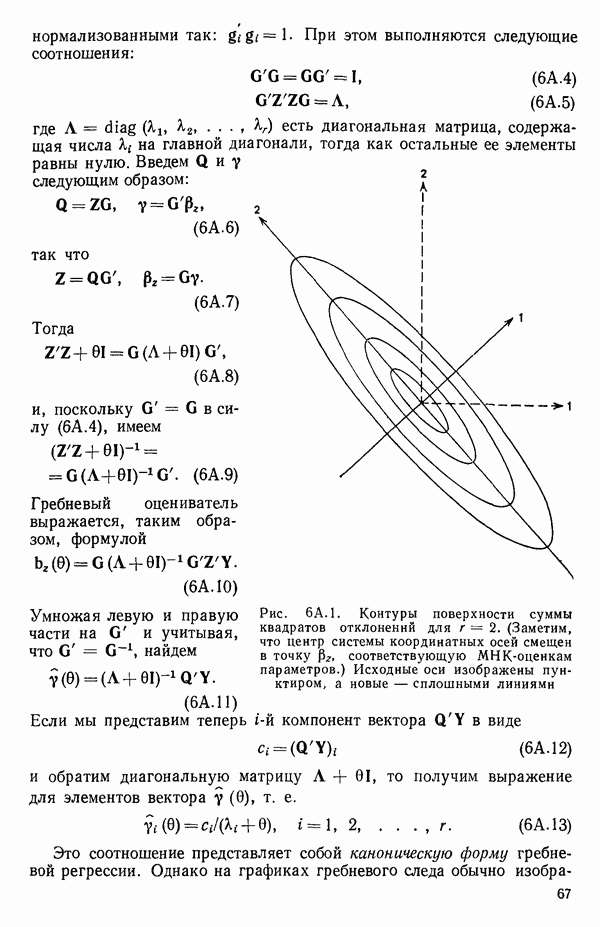
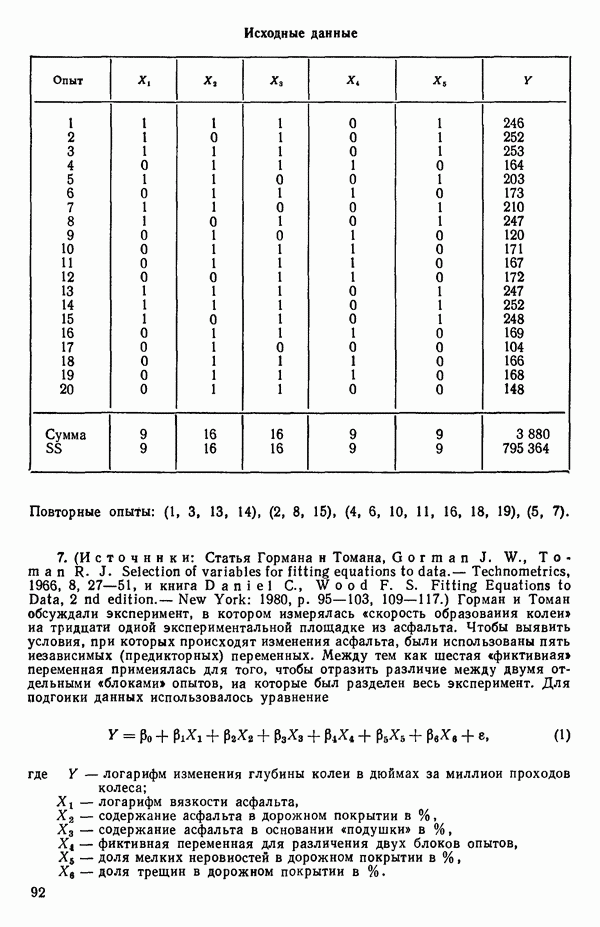
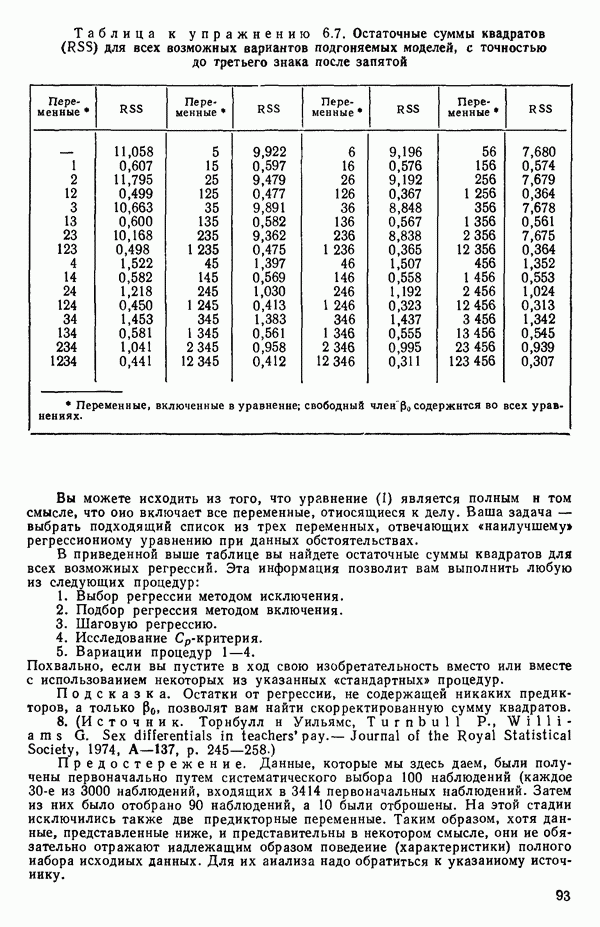
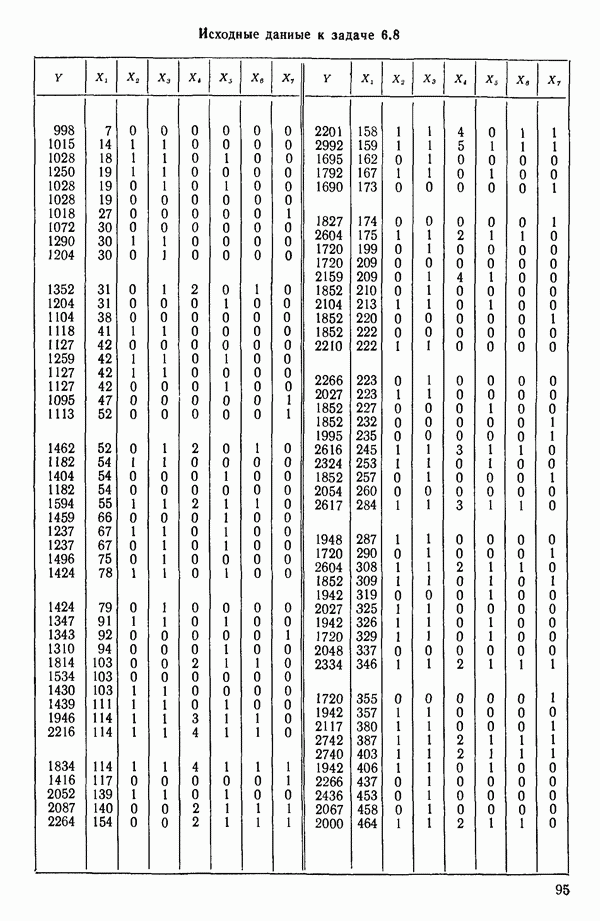
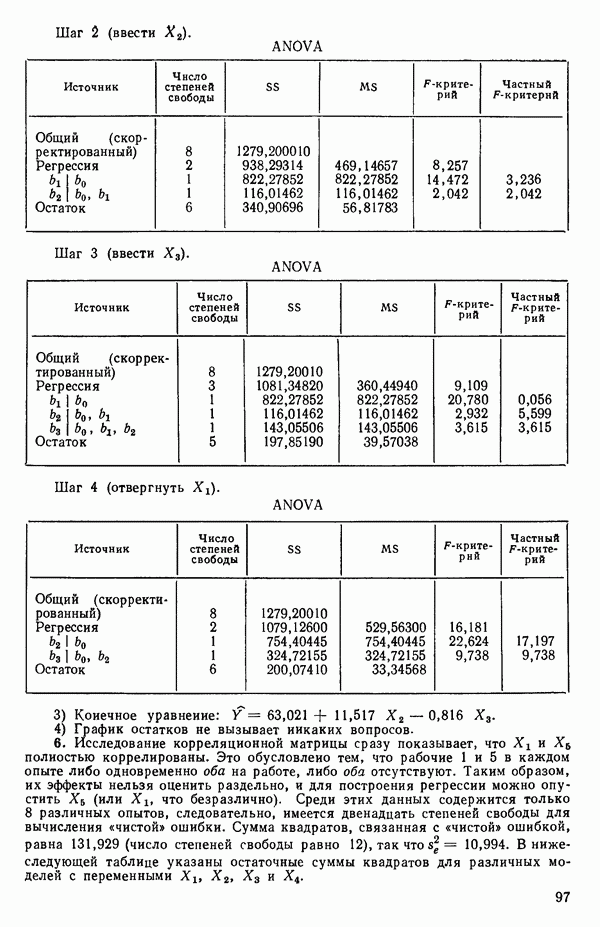
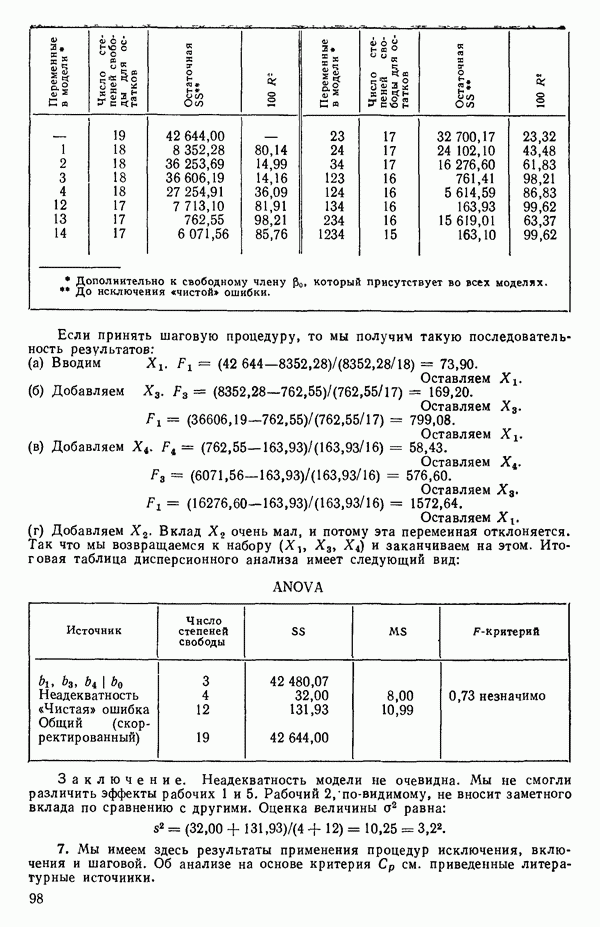
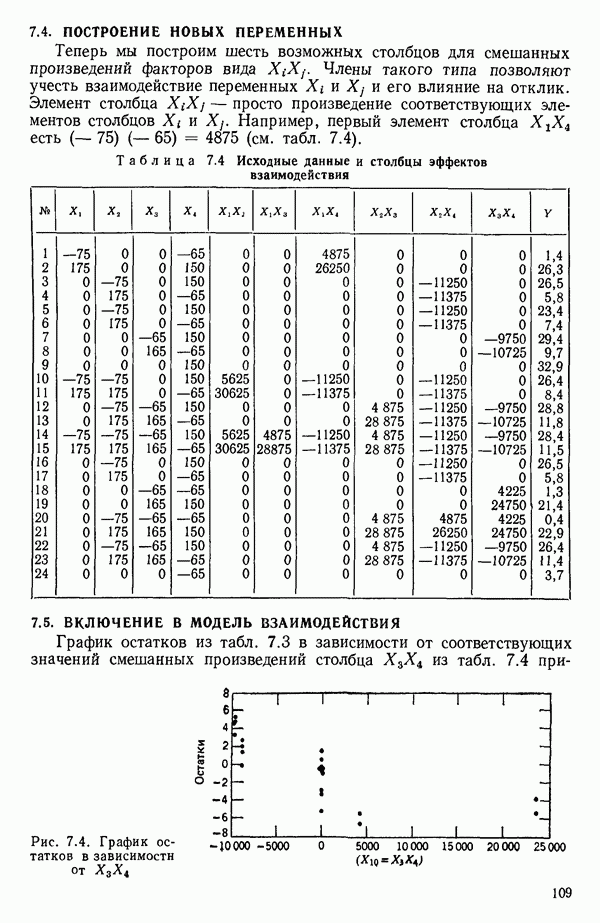
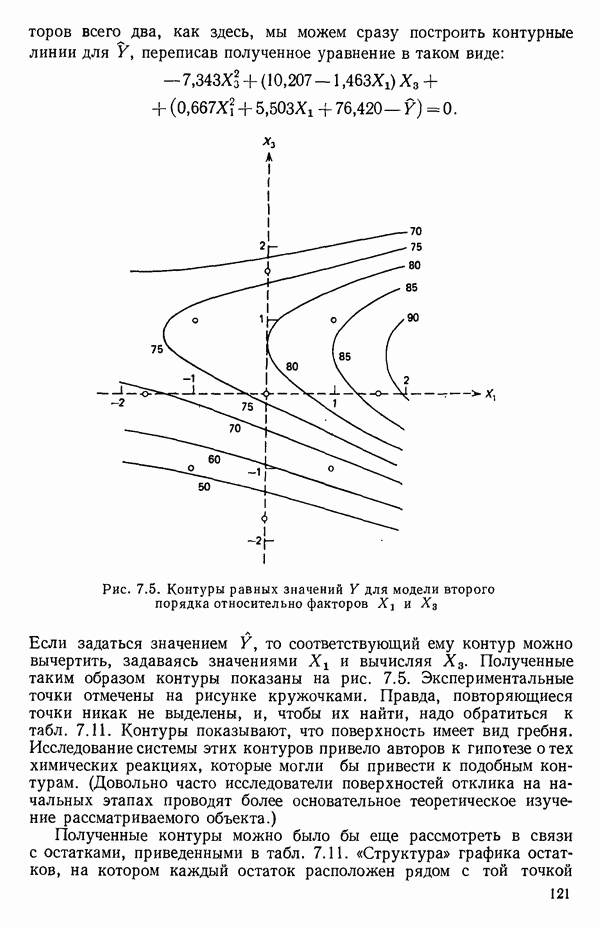
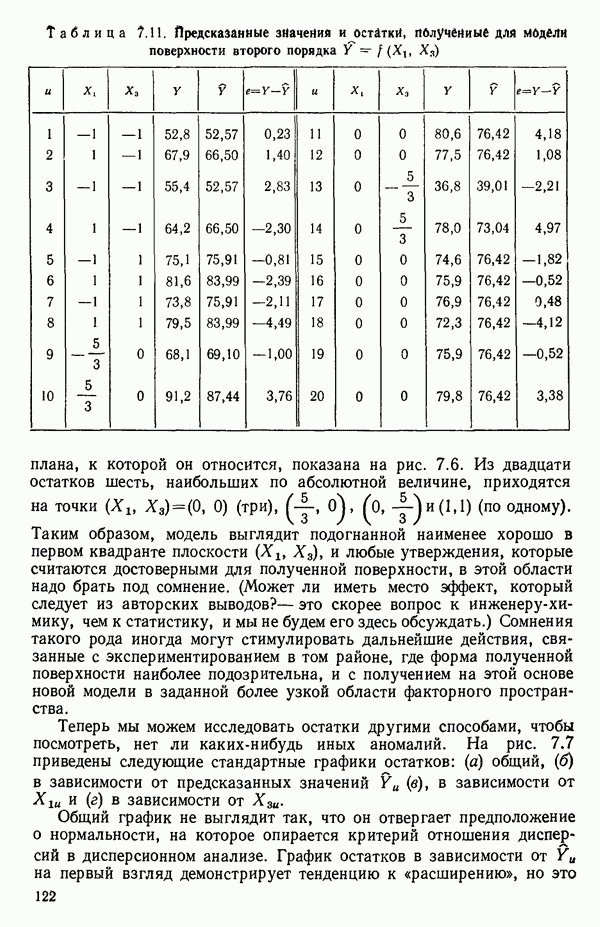
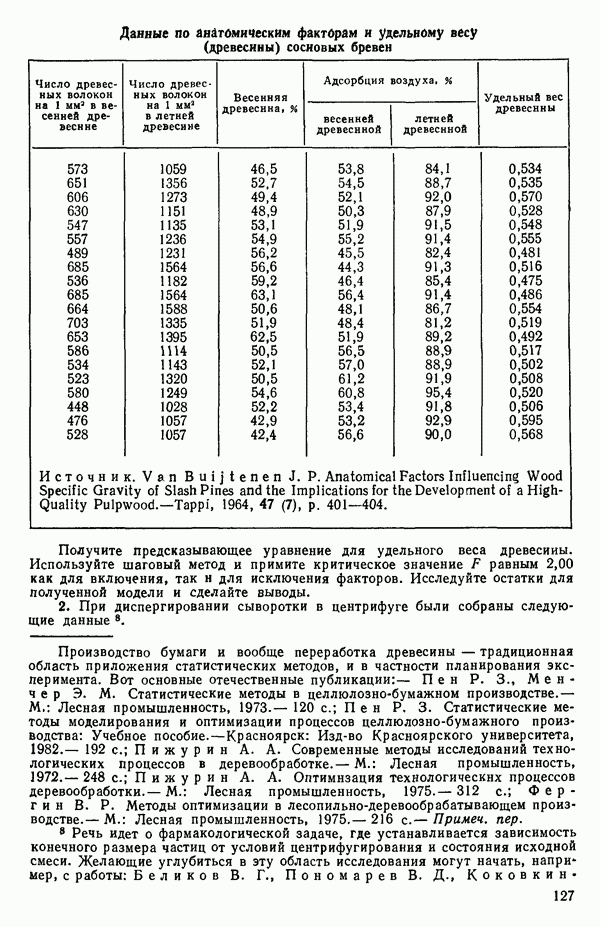
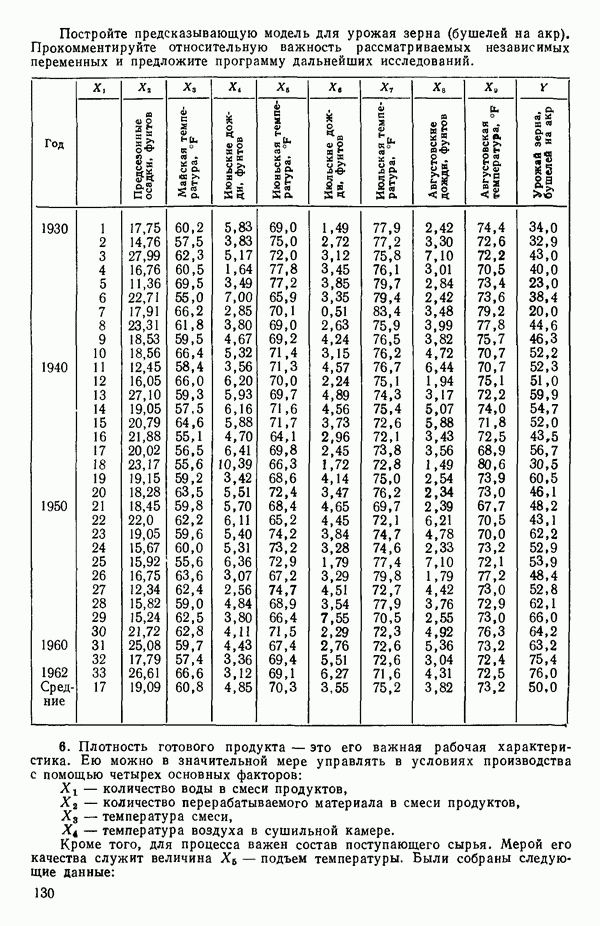
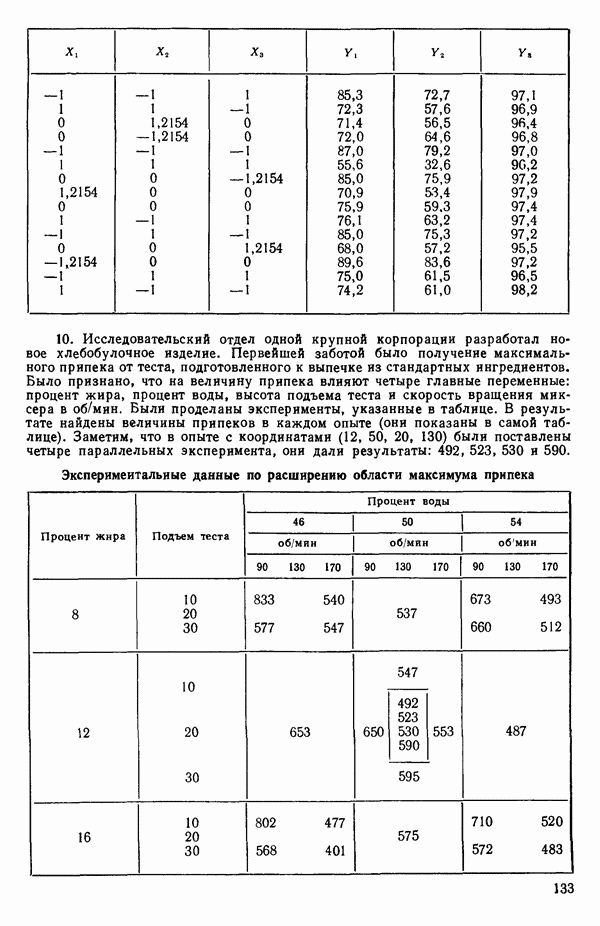
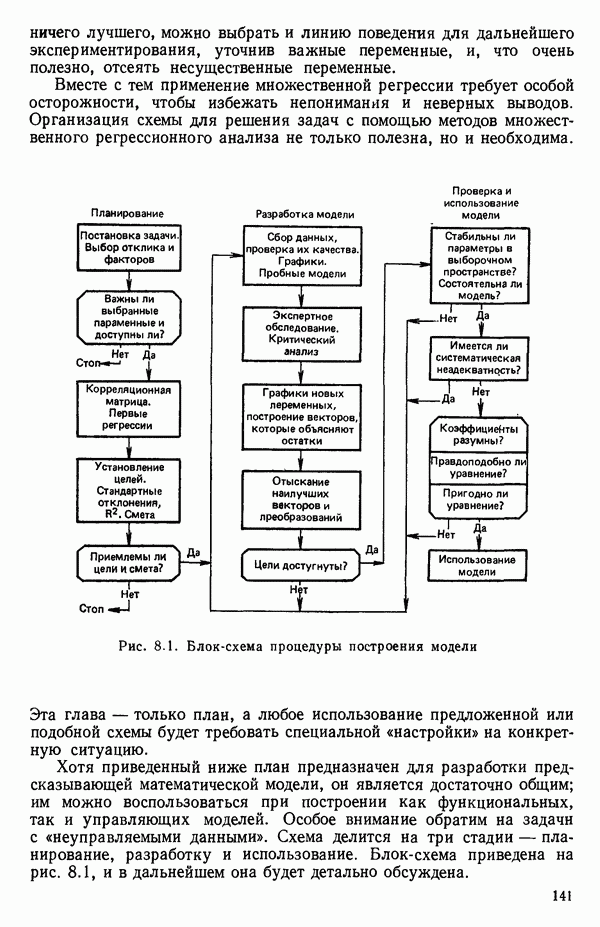
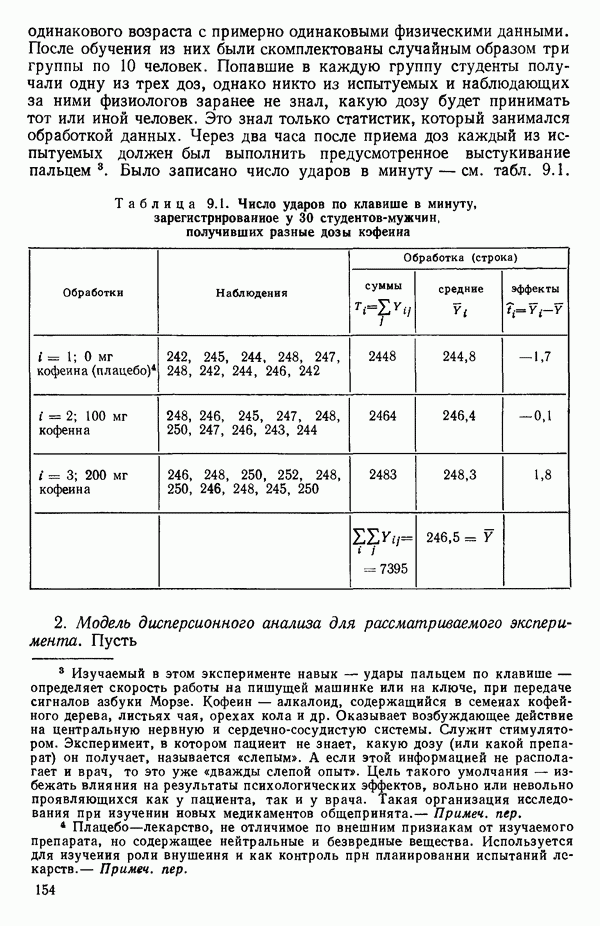
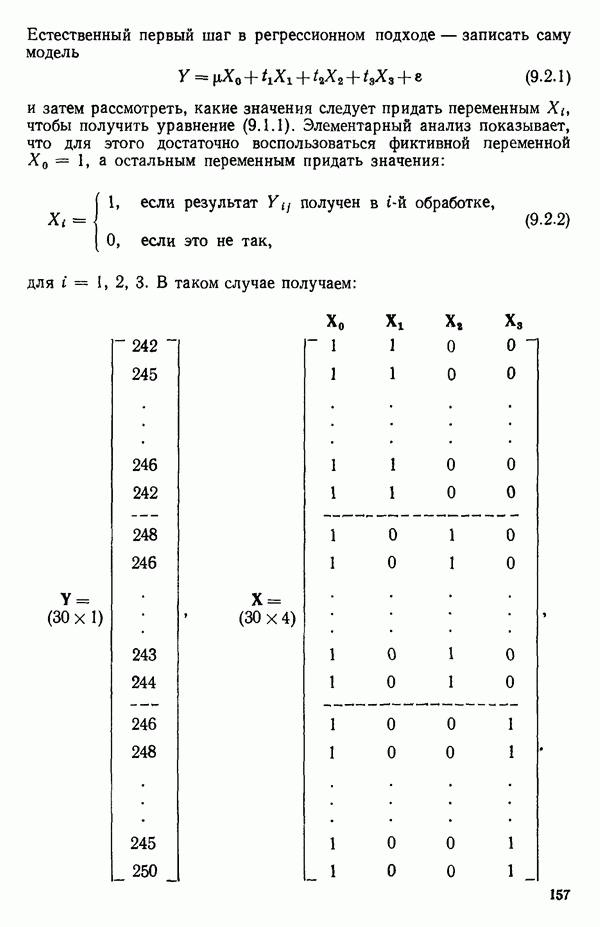
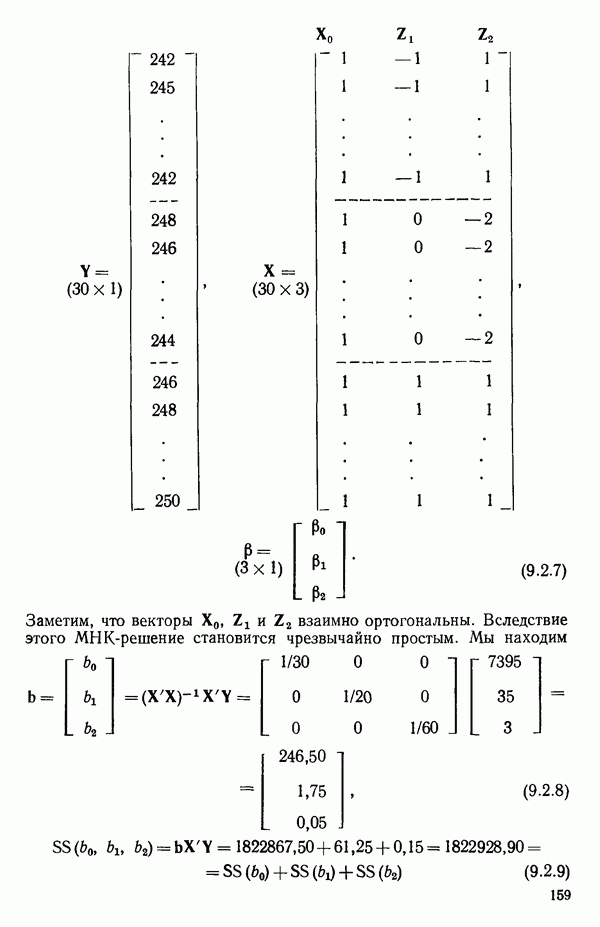
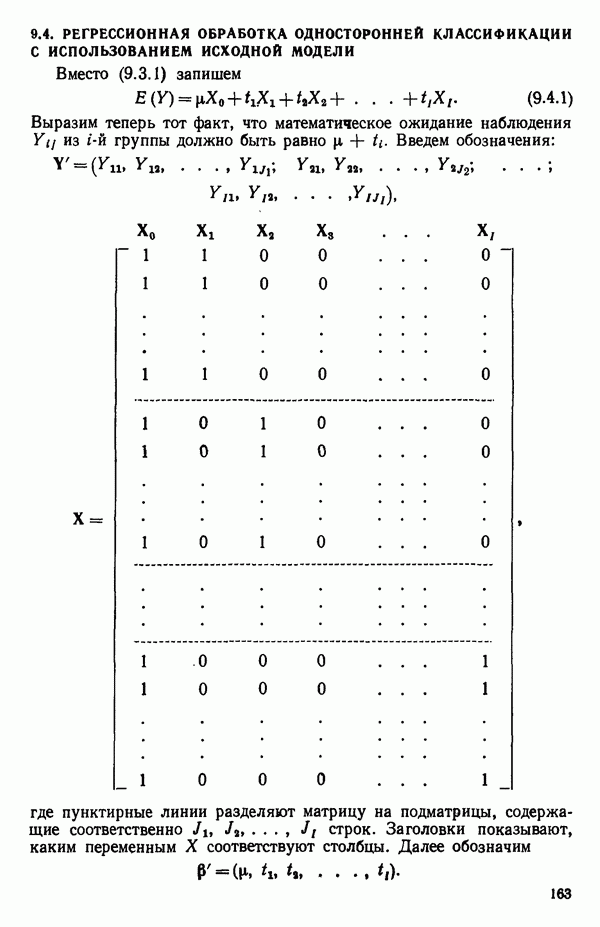
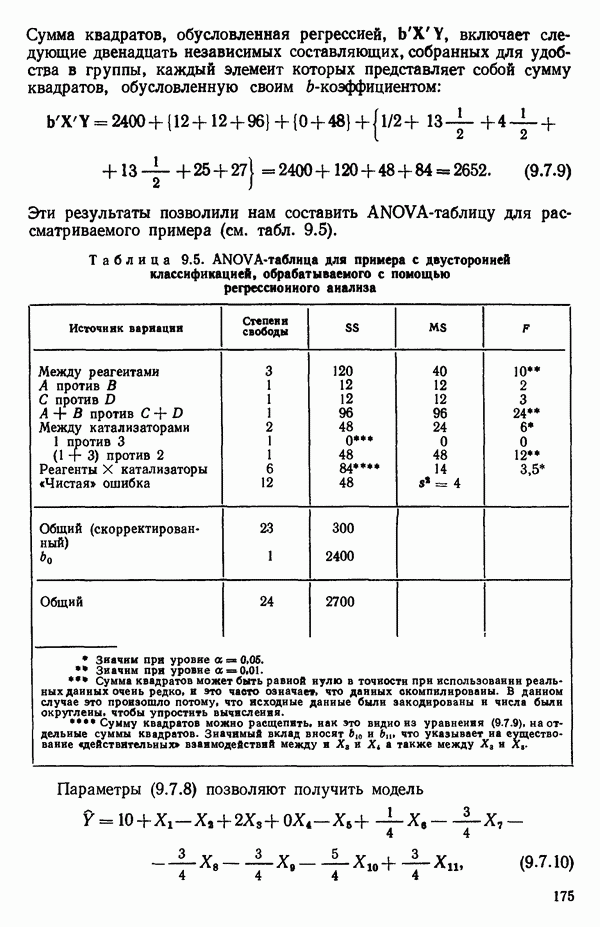
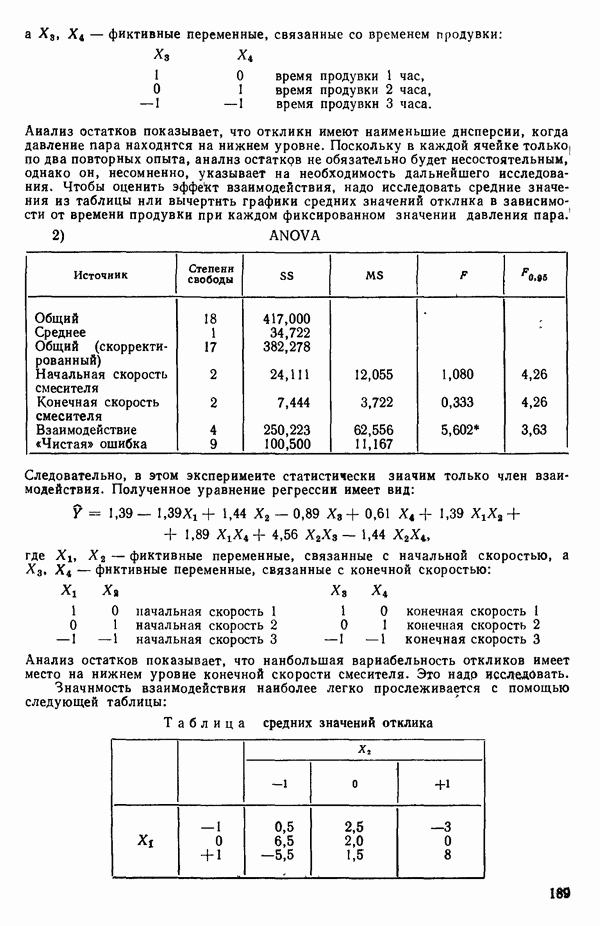
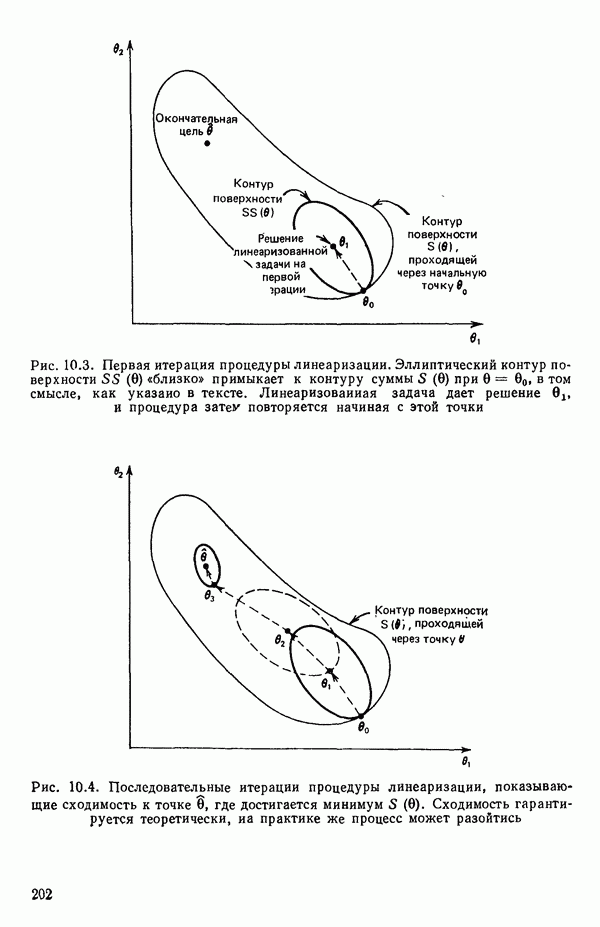
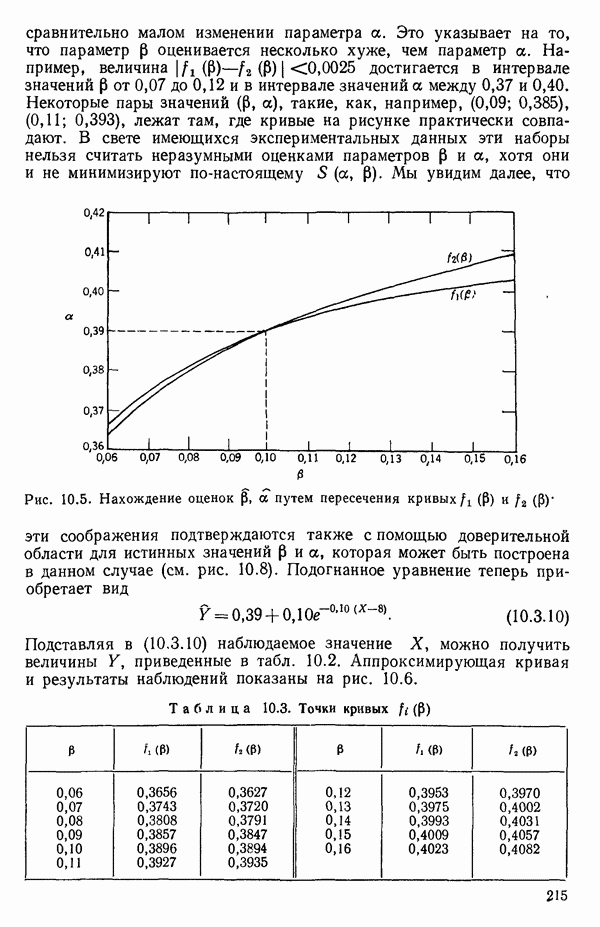
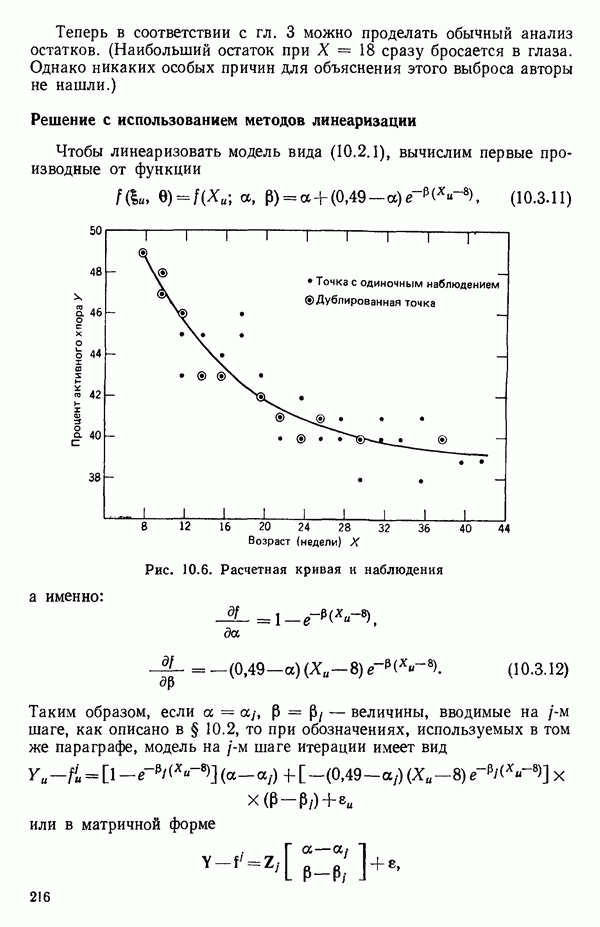
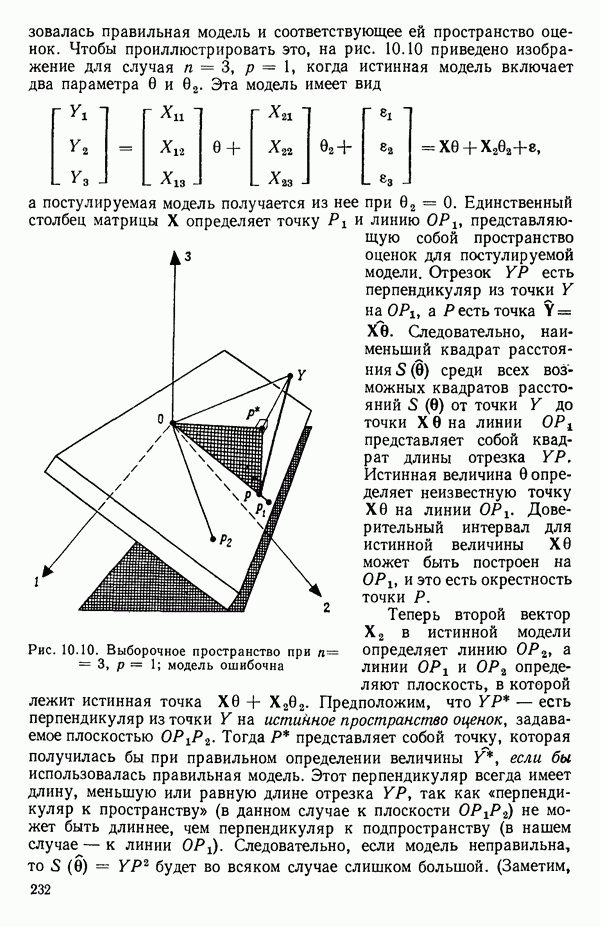
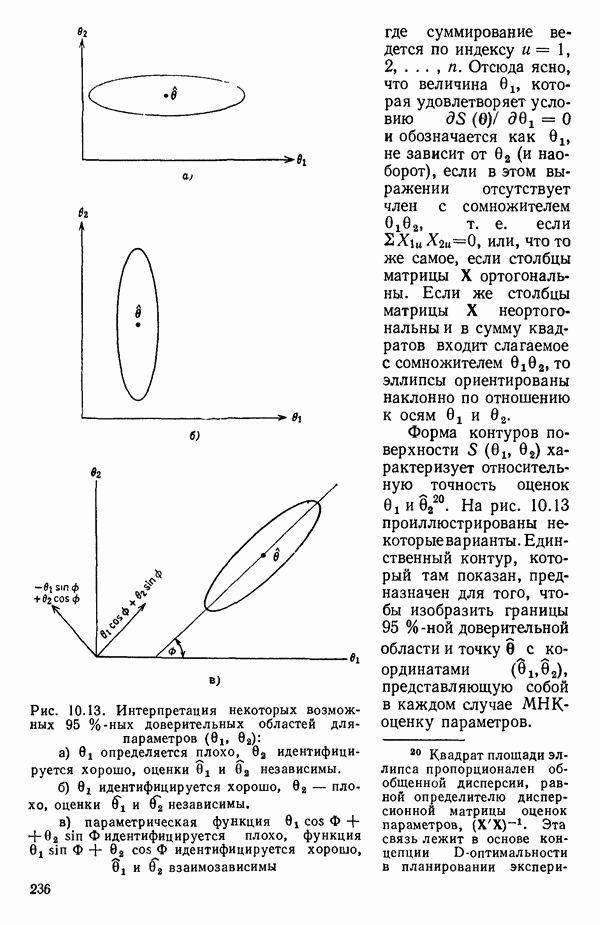
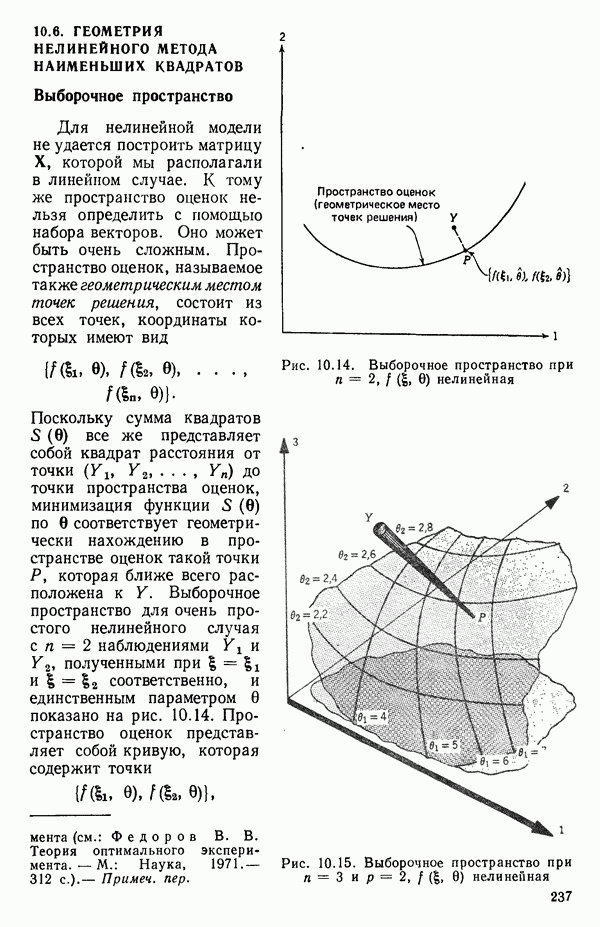
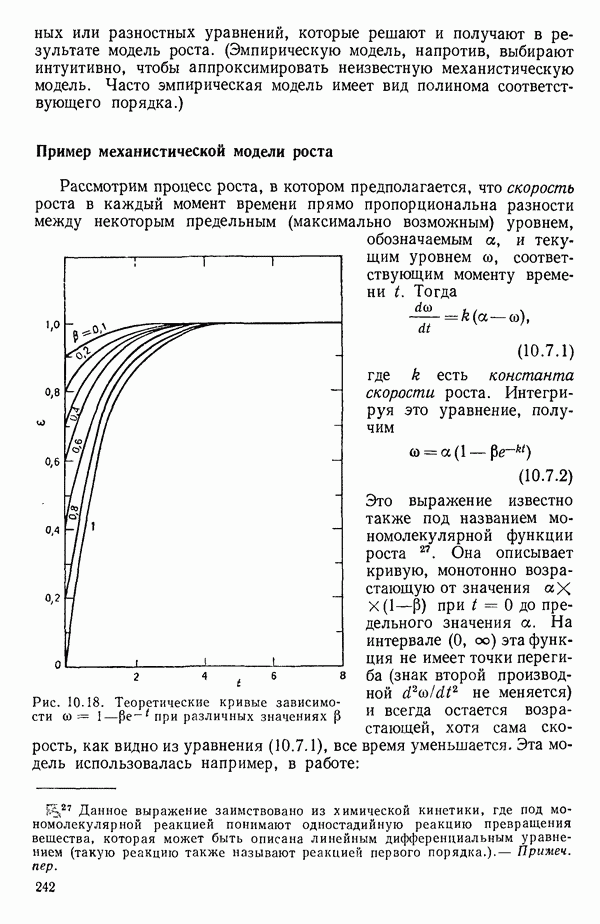
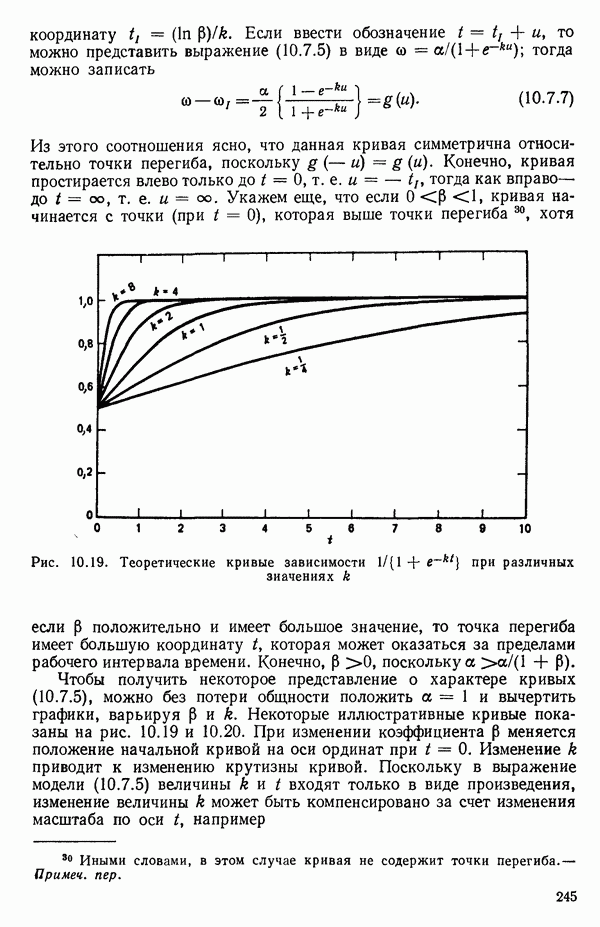
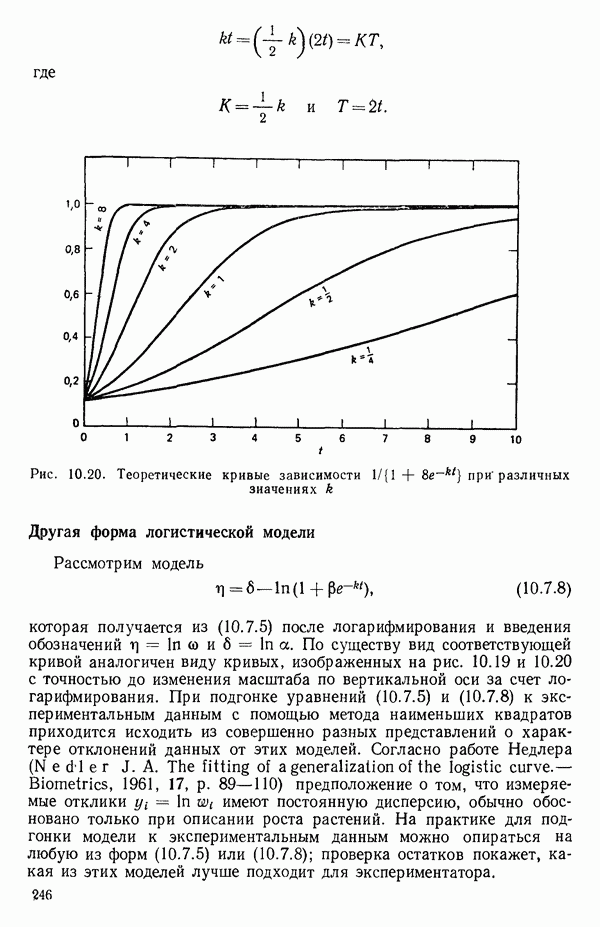
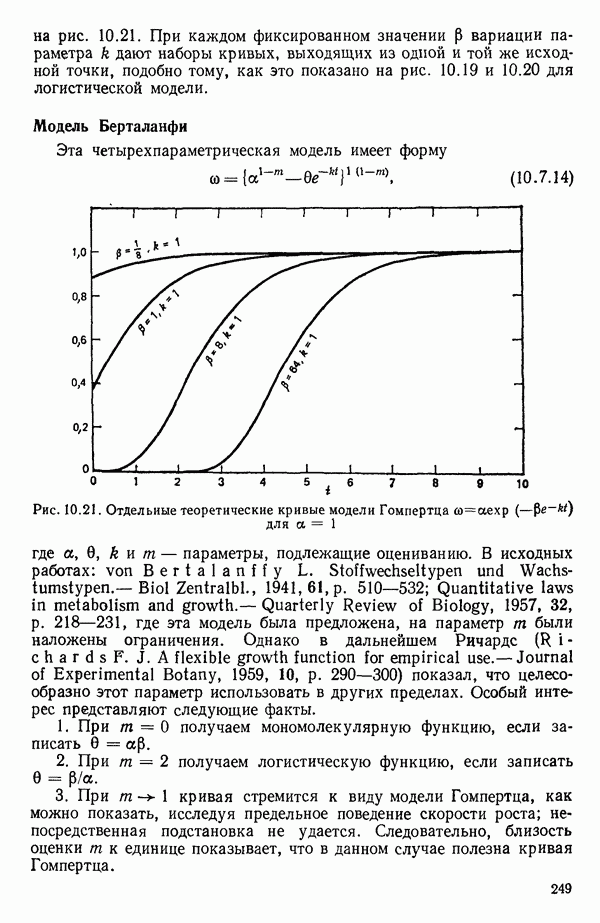
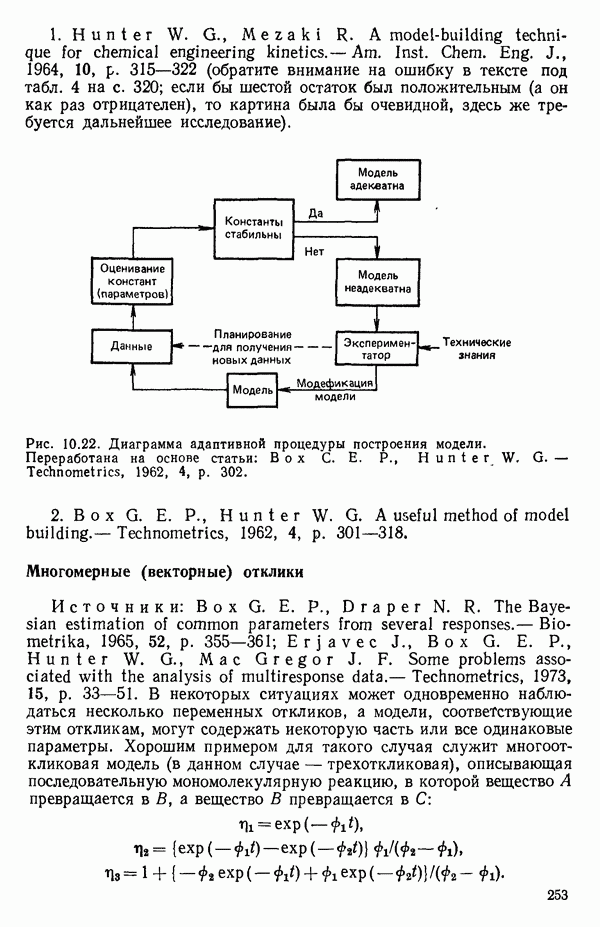
6.9. РЕГРЕССИЯ НА ГЛАВНЫХ КОМПОНЕНТАХ
До сих пор в этой главе, посвященной методам выбора предикторов, мы имели дело с моделями предсказания, используя только переменные  в качестве основы для представления исходных данных. Возникавшие при этом трудности обычно ограничивались тем, что мы не знали значение величины
в качестве основы для представления исходных данных. Возникавшие при этом трудности обычно ограничивались тем, что мы не знали значение величины  а также наблюдалась высокая степень коррелированности переменных
а также наблюдалась высокая степень коррелированности переменных  (проблема мультиколлинеарности). Гребневая регрессия представлялась как метод, позволяющий преодолеть последнее затруднение. Альтернативная процедура, которая основана на детальном анализе корреляционной структуры, была впервые предложена Хотеллингом в его ставшей уже классической работе: Ноttе1ing Harold. Analysis of a complex of statistical variables into principal components.- Journal of Educational Psychology, 1933, 24, p. 417-441, 489—520.
(проблема мультиколлинеарности). Гребневая регрессия представлялась как метод, позволяющий преодолеть последнее затруднение. Альтернативная процедура, которая основана на детальном анализе корреляционной структуры, была впервые предложена Хотеллингом в его ставшей уже классической работе: Ноttе1ing Harold. Analysis of a complex of statistical variables into principal components.- Journal of Educational Psychology, 1933, 24, p. 417-441, 489—520.
Используя обозначения, ранее применявшиеся в 6.7, посвященном гребневой регрессии, начнем с введения «центрированной и нормированной матрицы X», которую мы будем теперь называть «матрицей Z». В таком случае  будет корреляционной матрицей. Характеристические корни (нередко их называют скрытыми (латентными) корнями или собственными числами) корреляционной матрицы представляют собой
будет корреляционной матрицей. Характеристические корни (нередко их называют скрытыми (латентными) корнями или собственными числами) корреляционной матрицы представляют собой  решений
решений  детерминантного уравнения
детерминантного уравнения

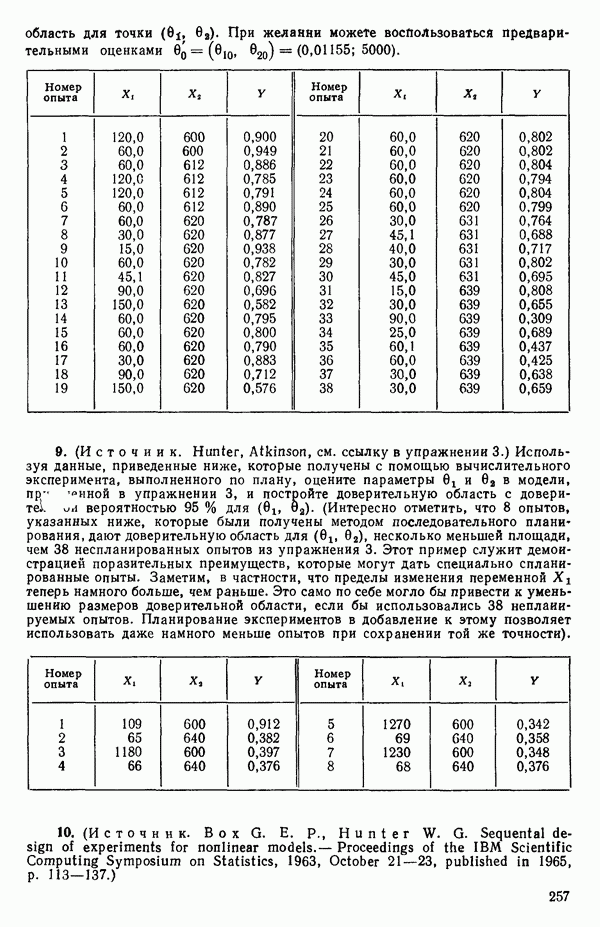
Можно показать, что сумма характеристических корней корреляционной матрицы равна следу  т. е. сумме ее диагональных элементов. Она равна:
т. е. сумме ее диагональных элементов. Она равна:  если использовать обозначения, применяемые в данной главе. (Напомним, что
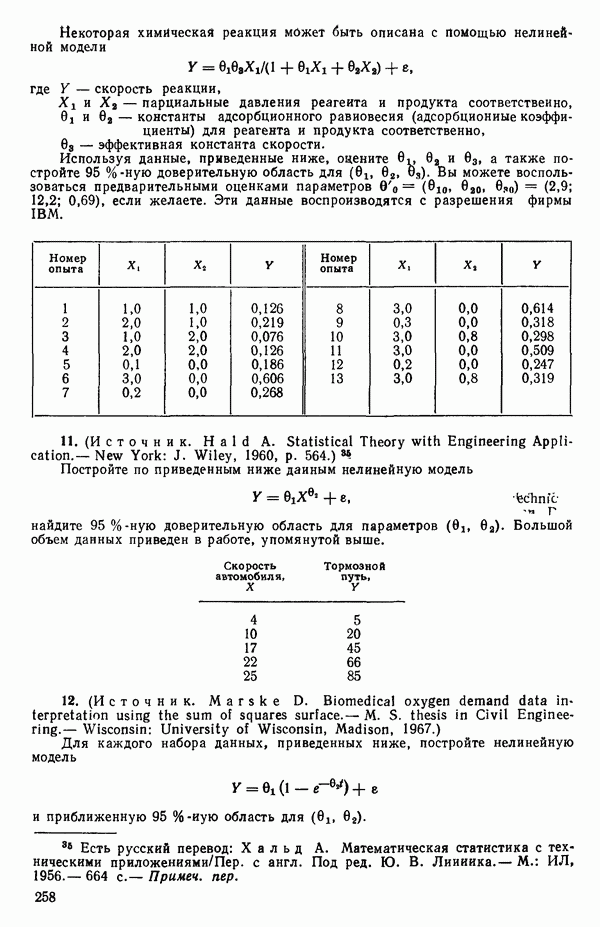
если использовать обозначения, применяемые в данной главе. (Напомним, что  есть число параметров в модели, включая
есть число параметров в модели, включая  Стандартизируем данные, т. е. перейдем к новым переменным, из которых формируются вектор-столбцы матрицы:
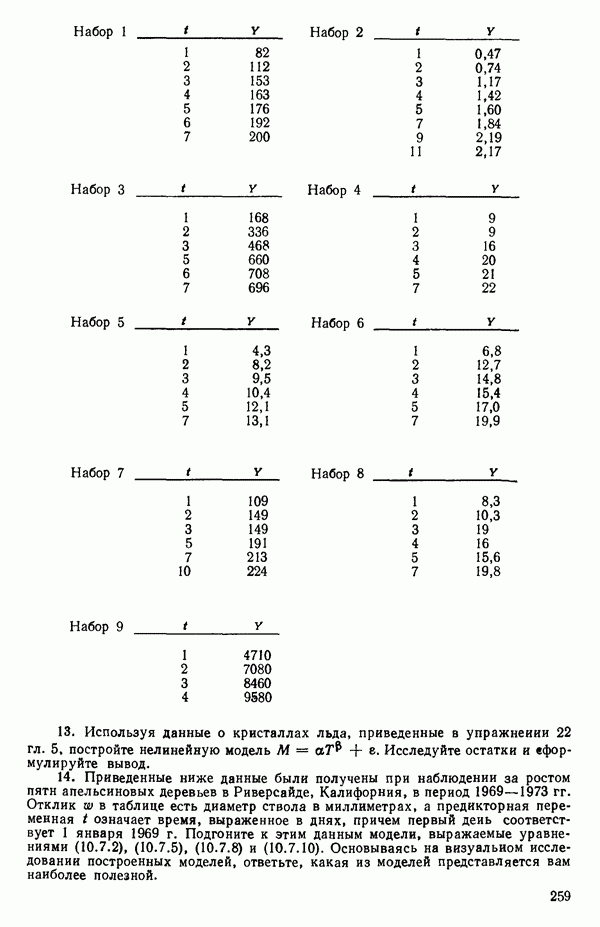
Стандартизируем данные, т. е. перейдем к новым переменным, из которых формируются вектор-столбцы матрицы:

где

Сумма элементов каждого такого столбца равна нулю, а сумма квадратов элементов — единице. В результате мы ортогонализировали новый  коэффициент и перевели предикторы в «корреляционную форму». Ранг невырожденной корреляционной матрицы равен:
коэффициент и перевели предикторы в «корреляционную форму». Ранг невырожденной корреляционной матрицы равен:  Очевидно, сумма всех сумм квадратов элементов по
Очевидно, сумма всех сумм квадратов элементов по
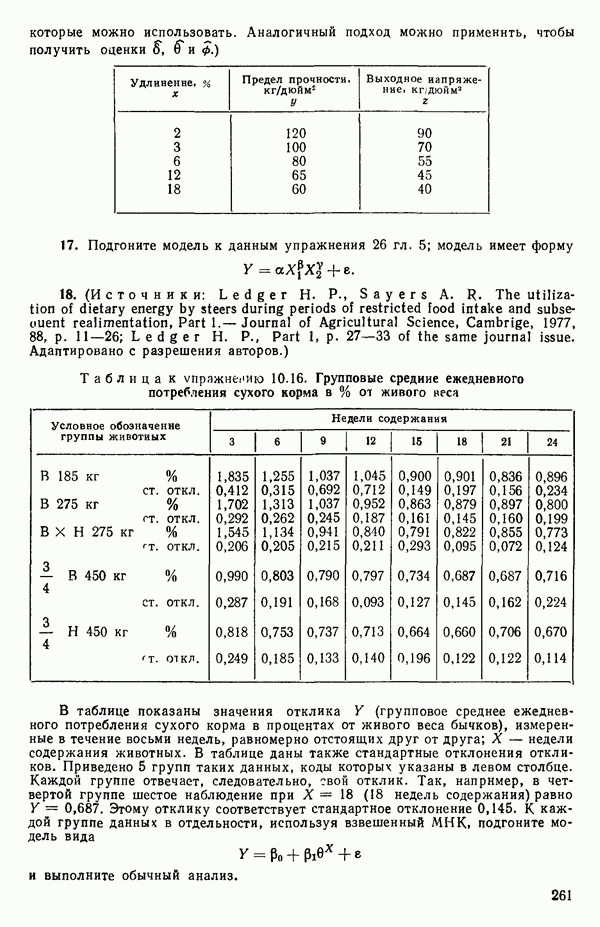
столбцам  равна
равна  Назовем ее полной дисперсией переменных. Разложим эту величину, используя преобразованные переменные
Назовем ее полной дисперсией переменных. Разложим эту величину, используя преобразованные переменные 
С каждым характеристическим корнем  связан характеристический вектор
связан характеристический вектор  который удовлетворяет системе однородных уравнений:
который удовлетворяет системе однородных уравнений:

Решения  выбираются из бесконечного множества «пропорциональных» решений, соответствующих каждому
выбираются из бесконечного множества «пропорциональных» решений, соответствующих каждому  таким образом, чтобы соблюдалось условие
таким образом, чтобы соблюдалось условие  Можно показать далее, что если все
Можно показать далее, что если все  различны, то характеристические векторы попарно ортогональны. (Если не все
различны, то характеристические векторы попарно ортогональны. (Если не все  различны, то надо выполнить некоторые преобразования, которые мы здесь не обсуждаем, поскольку такой случай обычно не возникает при обработке реальных данных.) Векторы
различны, то надо выполнить некоторые преобразования, которые мы здесь не обсуждаем, поскольку такой случай обычно не возникает при обработке реальных данных.) Векторы  используются для того, чтобы перейти от переменных
используются для того, чтобы перейти от переменных  к главным компонентам
к главным компонентам  в форме
в форме

Сумма квадратов элементов  из которых формируются вектор-столбцы
из которых формируются вектор-столбцы  равна
равна  Иными словами, каждой главной компоненте
Иными словами, каждой главной компоненте  соответствует величина
соответствует величина  представляющая собой часть полной дисперсии переменных:
представляющая собой часть полной дисперсии переменных: 
Таким образом, при реализации этой процедуры формируются новые искусственные переменные  с помощью линейного преобразования исходных переменных, выражаемого уравнением (6.9.5), причем так, что вектор-столбцы
с помощью линейного преобразования исходных переменных, выражаемого уравнением (6.9.5), причем так, что вектор-столбцы  взаимно ортогональны. Переменная
взаимно ортогональны. Переменная  соответствующая наибольшему характеристическому корню
соответствующая наибольшему характеристическому корню  называется первой главной компонентой. Она «объясняет» наибольшую часть вариации в наборе стандартизированных данных. Последующие главные компоненты
называется первой главной компонентой. Она «объясняет» наибольшую часть вариации в наборе стандартизированных данных. Последующие главные компоненты  объясняют все меньшие и меньшие доли вариации. В итоге
объясняют все меньшие и меньшие доли вариации. В итоге

Обычно используют не все главные компоненты, а выбирают некоторые из них по определенному правилу. Однако не существует универсальной процедуры, которой придерживались бы все. Некоторые психологи используют, например, правило, согласно которому принимаются в расчет лишь компоненты, для которых собственные числа больше единицы. Моррисон (Morrison D. F.) во 2-м издании Multivariate Statistical Methods (New York: Me Graw-Hill, 1976,
p. 273) отмечает, что  компоненты целесообразно вычислять до тех пор, пока они не «объяснят» некоторую заранее назначенную большую долю (скажем, 75 % или более того) суммарной дисперсии». Иными словами, мы выбираем первые
компоненты целесообразно вычислять до тех пор, пока они не «объяснят» некоторую заранее назначенную большую долю (скажем, 75 % или более того) суммарной дисперсии». Иными словами, мы выбираем первые  главных компонент, для которых выполняется условие
главных компонент, для которых выполняется условие  В некоторых таких правилах автоматически получается набор из
В некоторых таких правилах автоматически получается набор из  главных компонент, и исходные переменные
главных компонент, и исходные переменные  представляются теперь с помощью этого набора из
представляются теперь с помощью этого набора из  новых предикторных переменных. Метод наименьших квадратов используется затем для получения уравнения, связывающего
новых предикторных переменных. Метод наименьших квадратов используется затем для получения уравнения, связывающего  с выбранными главными компонентами. Порядок их включения в уравнение роли не играет, так как все они «ортогональны» друг к другу. Коль скоро такое уравнение получено в виде функции от выбранных главных компонентов
с выбранными главными компонентами. Порядок их включения в уравнение роли не играет, так как все они «ортогональны» друг к другу. Коль скоро такое уравнение получено в виде функции от выбранных главных компонентов  его можно преобразовать и выразить через исходные предикторы
его можно преобразовать и выразить через исходные предикторы  если это желательно, или проинтерпретировать в терминах выбранных переменных
если это желательно, или проинтерпретировать в терминах выбранных переменных 
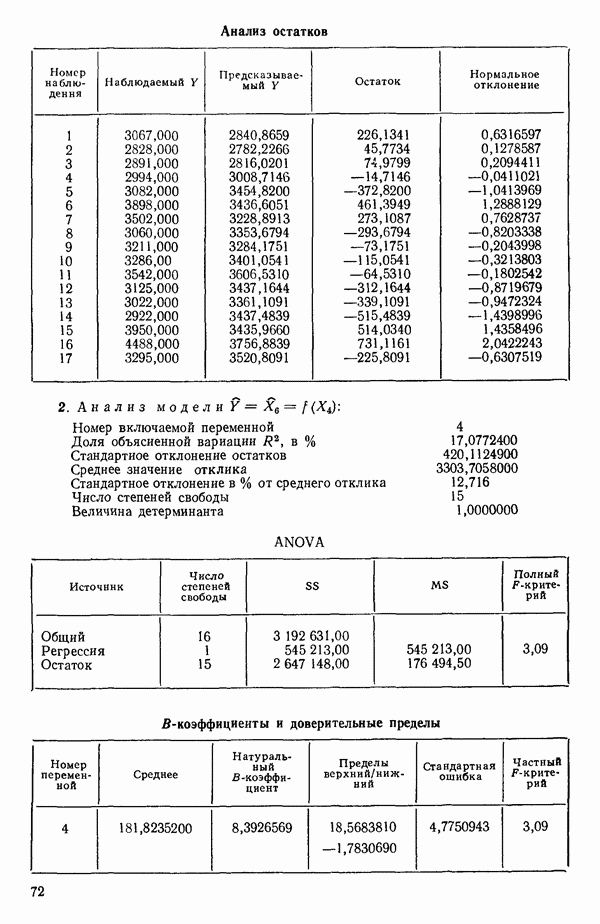
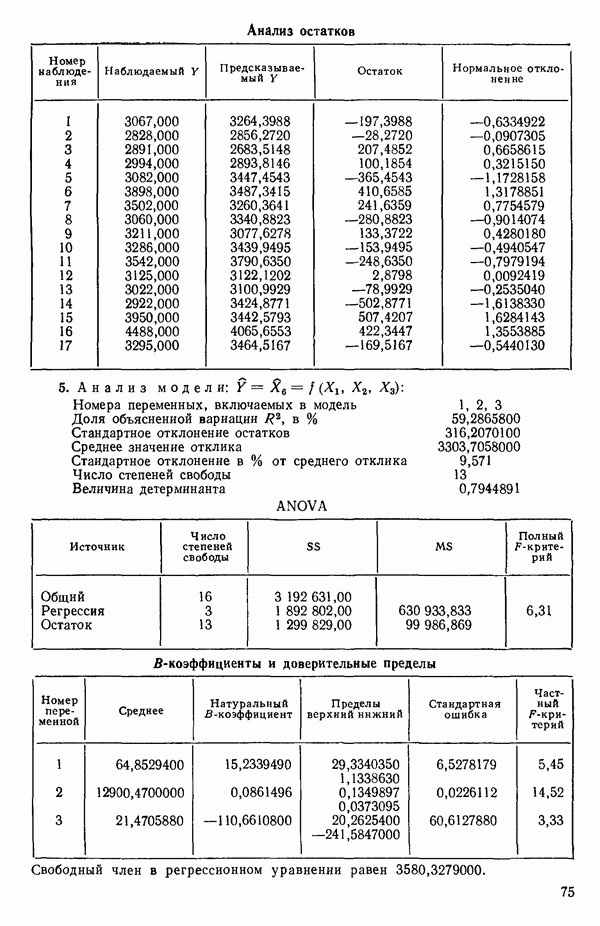
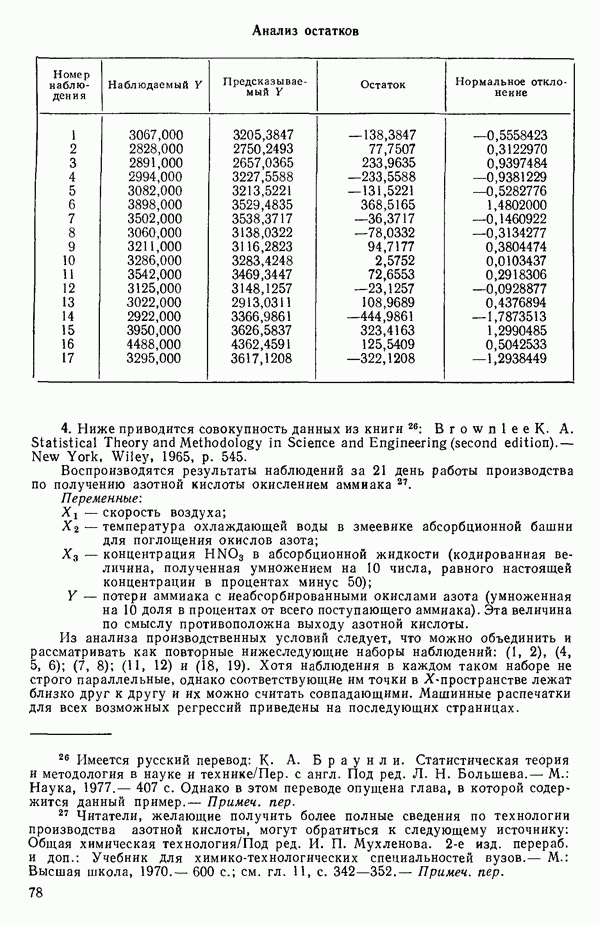
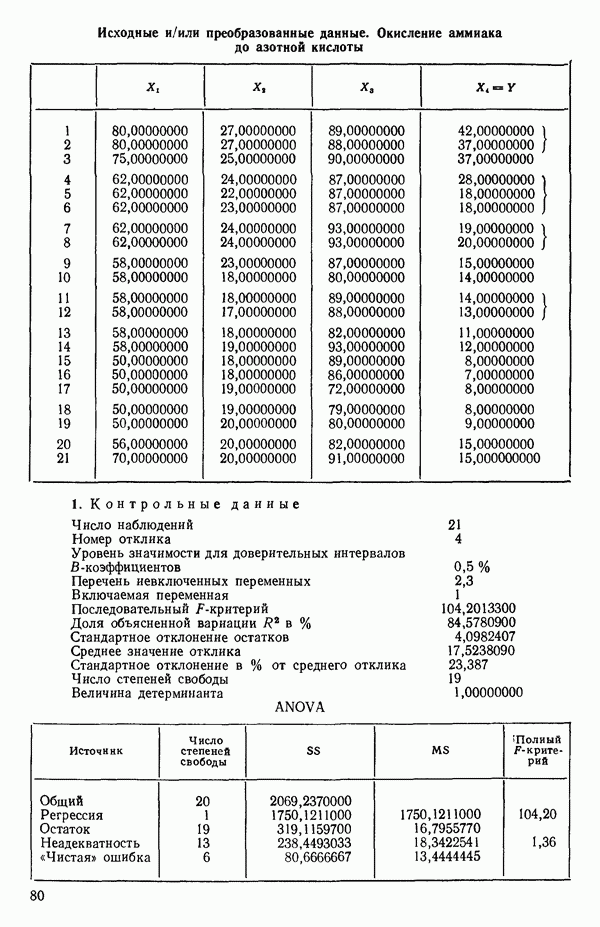
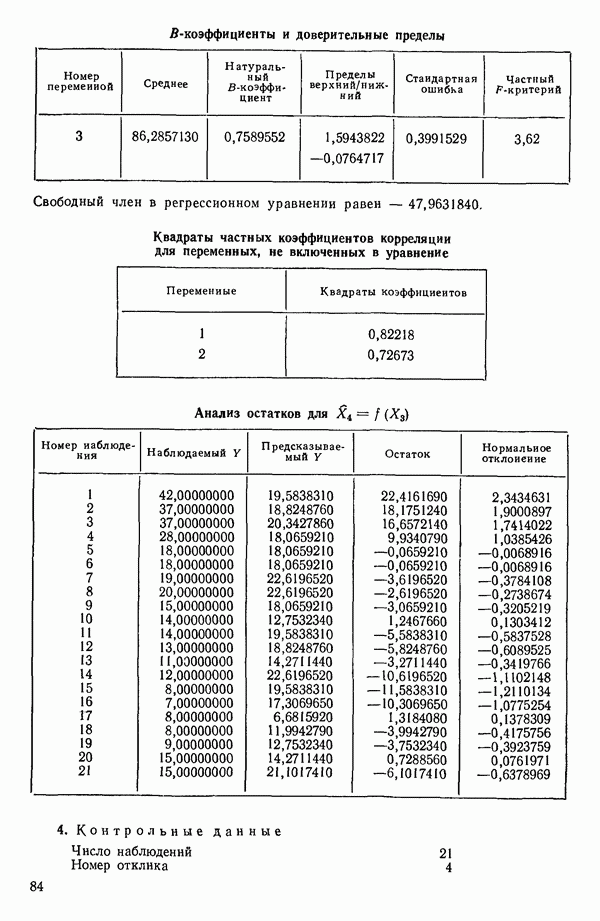
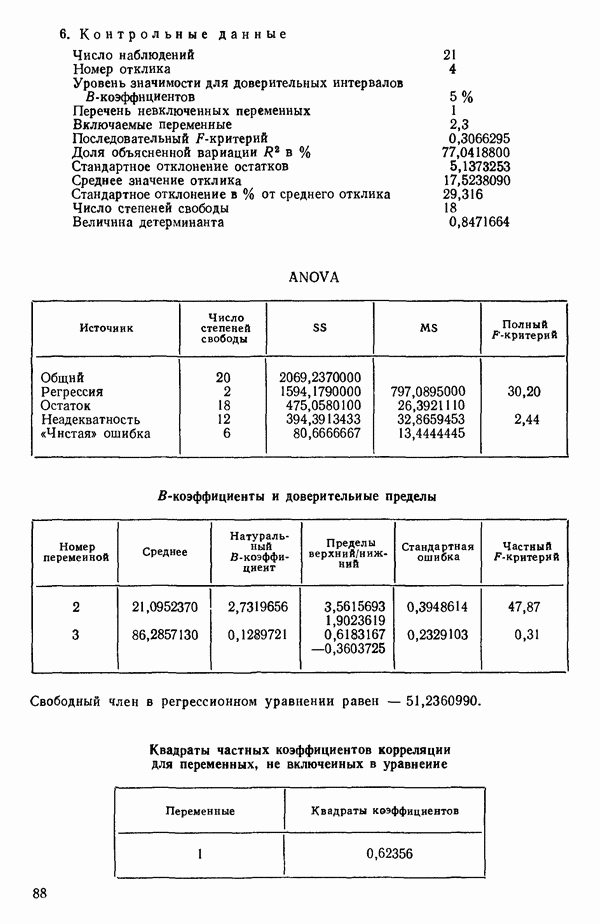
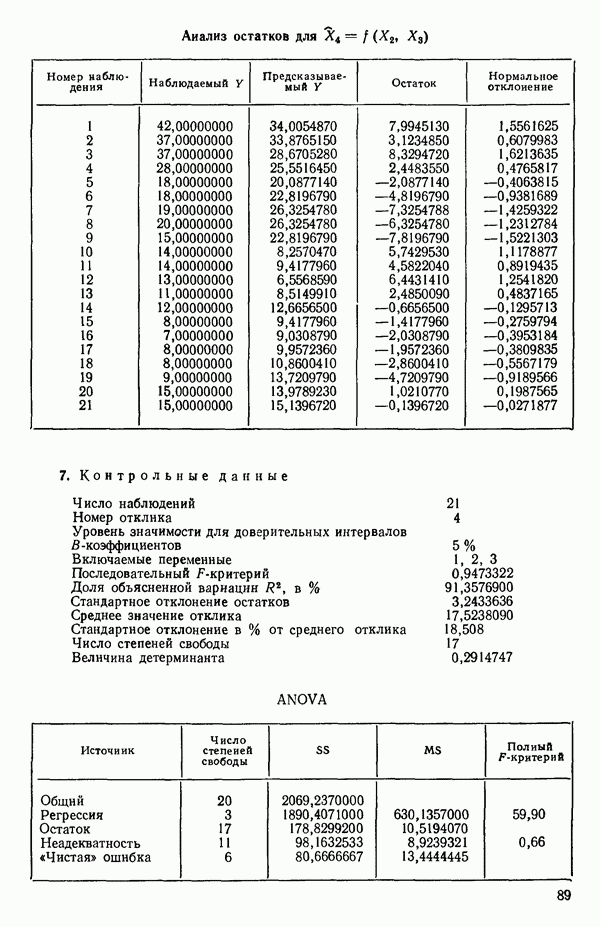
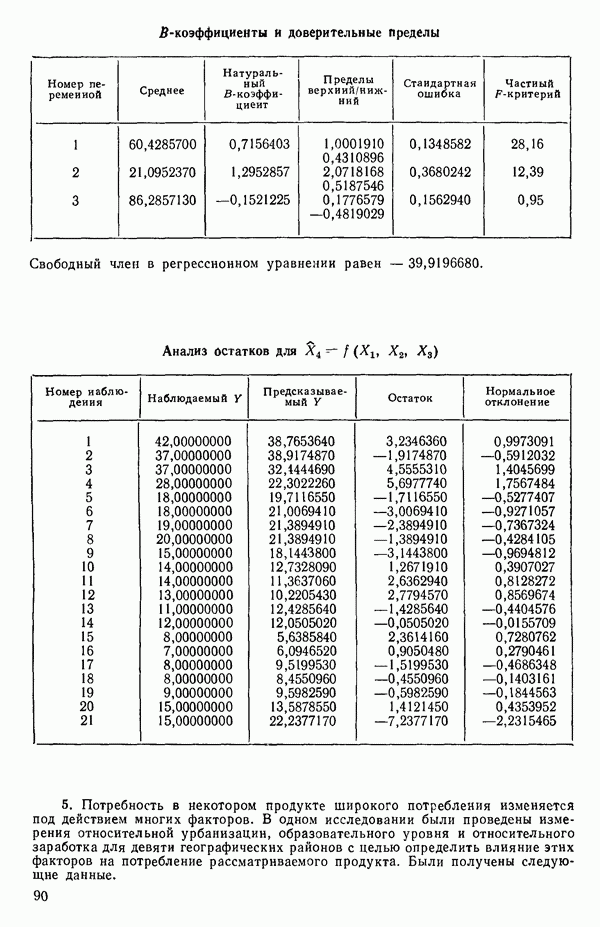
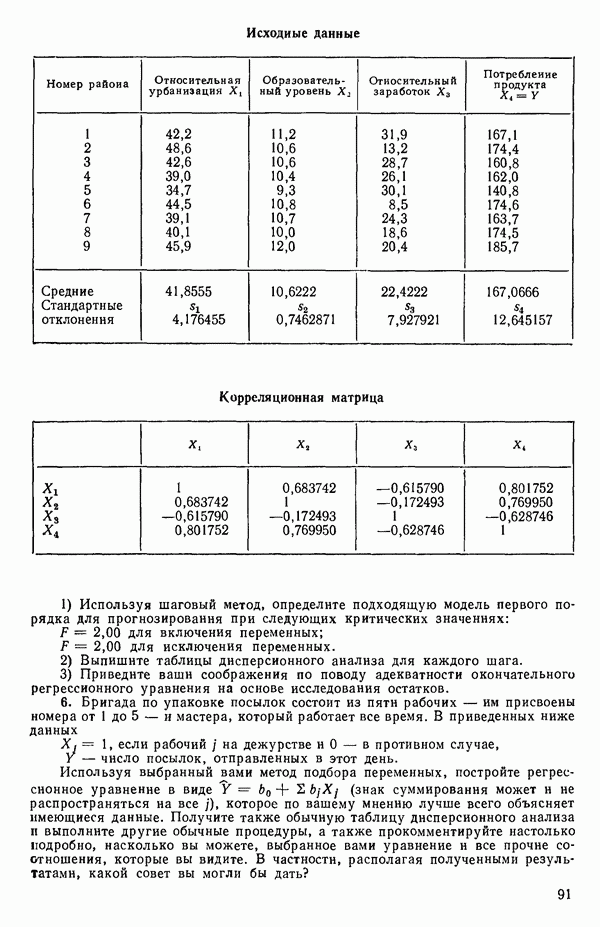
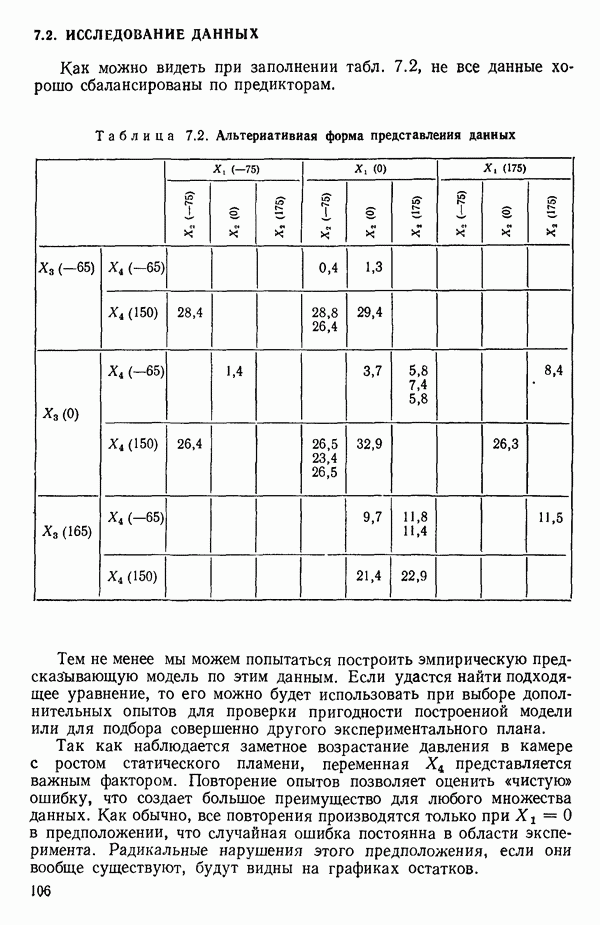
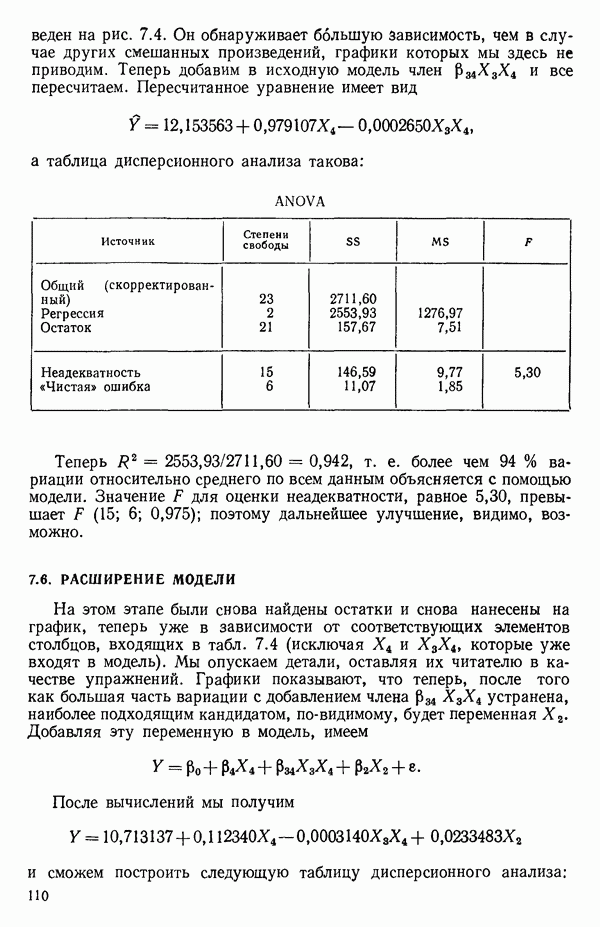
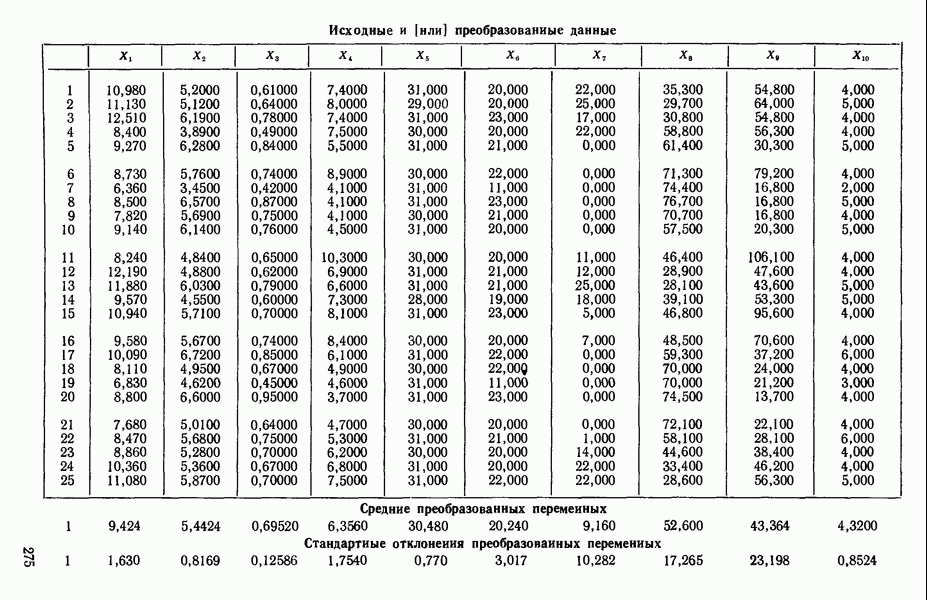
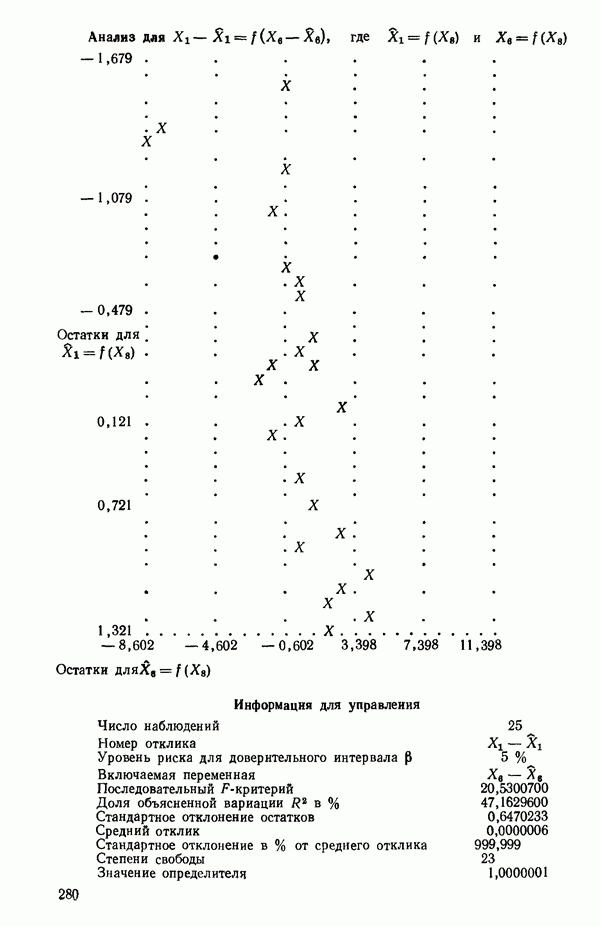
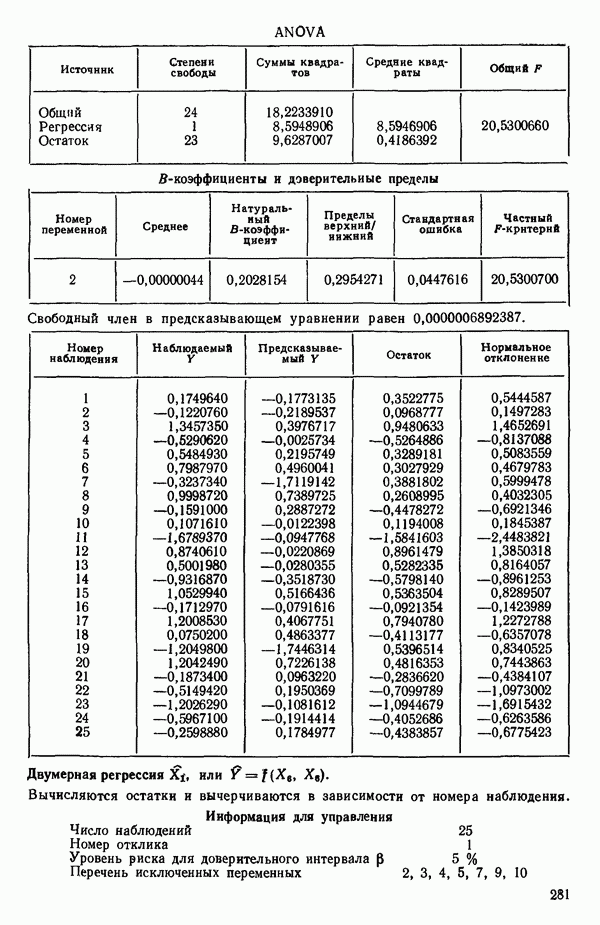
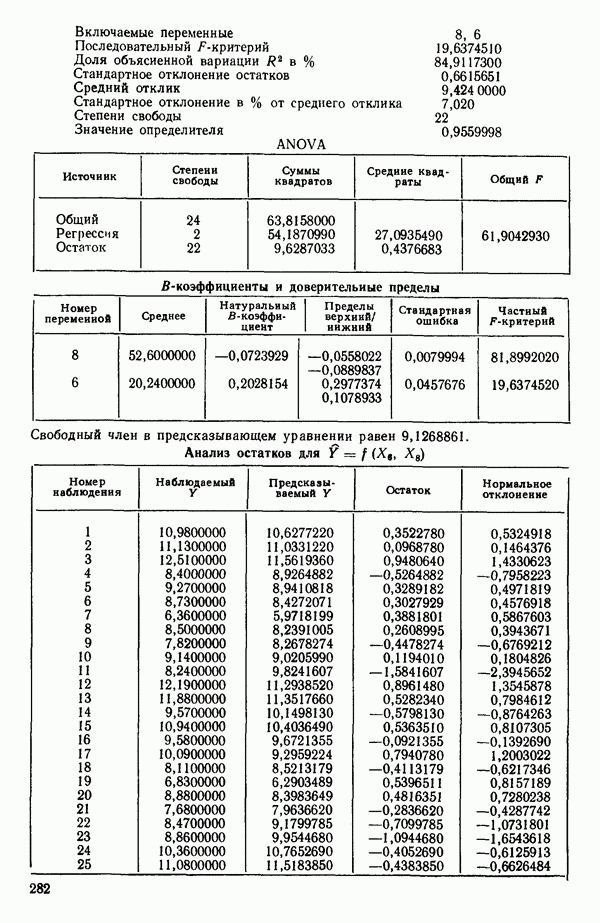
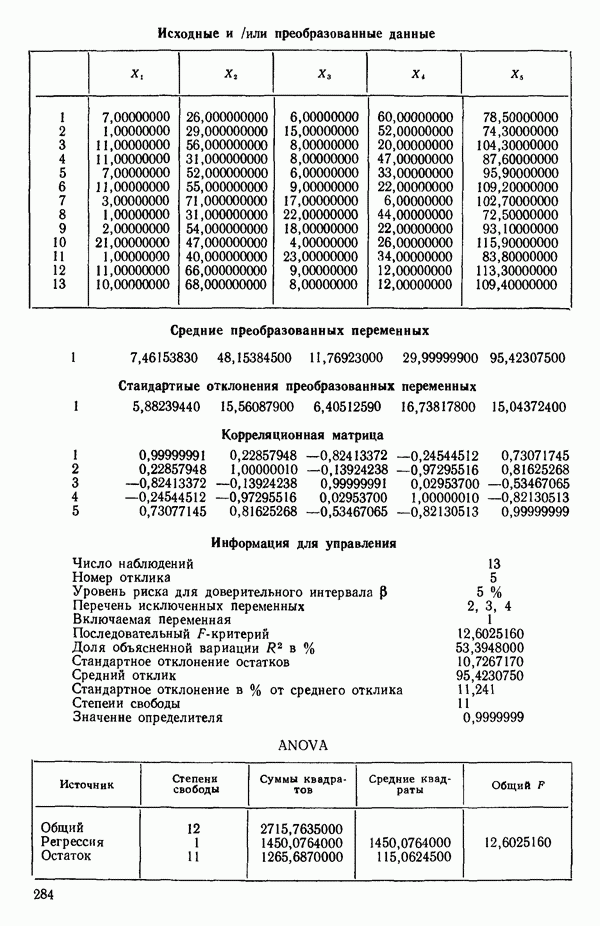
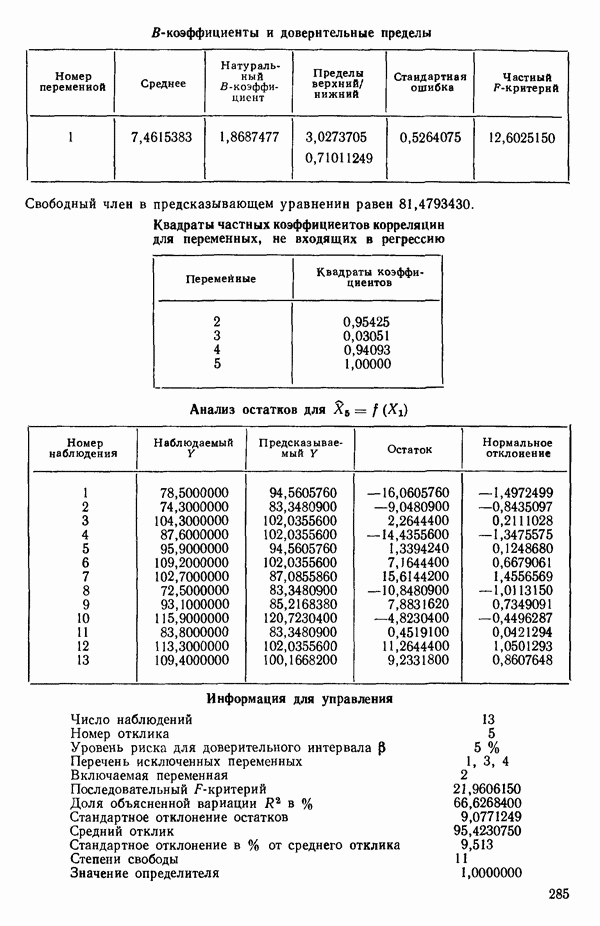
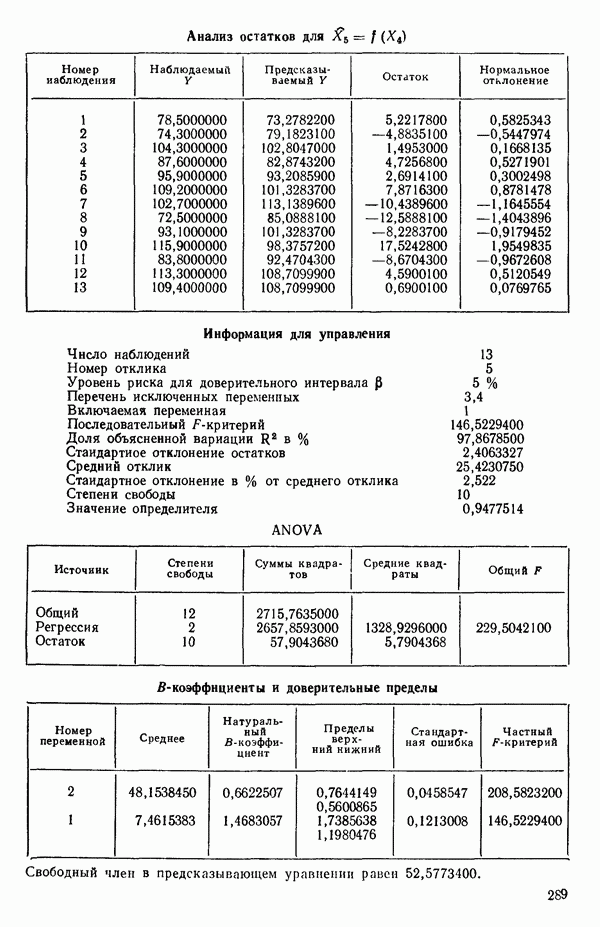
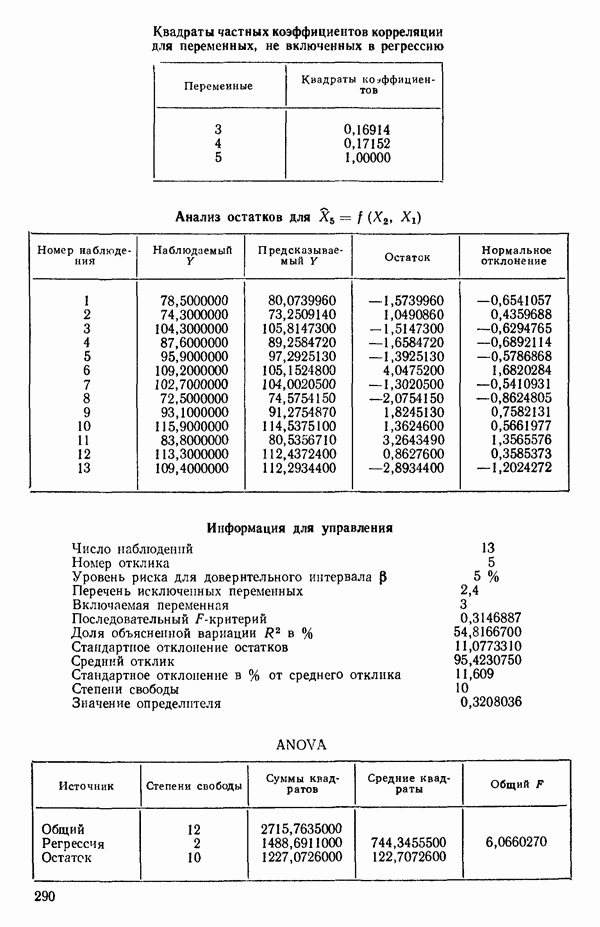
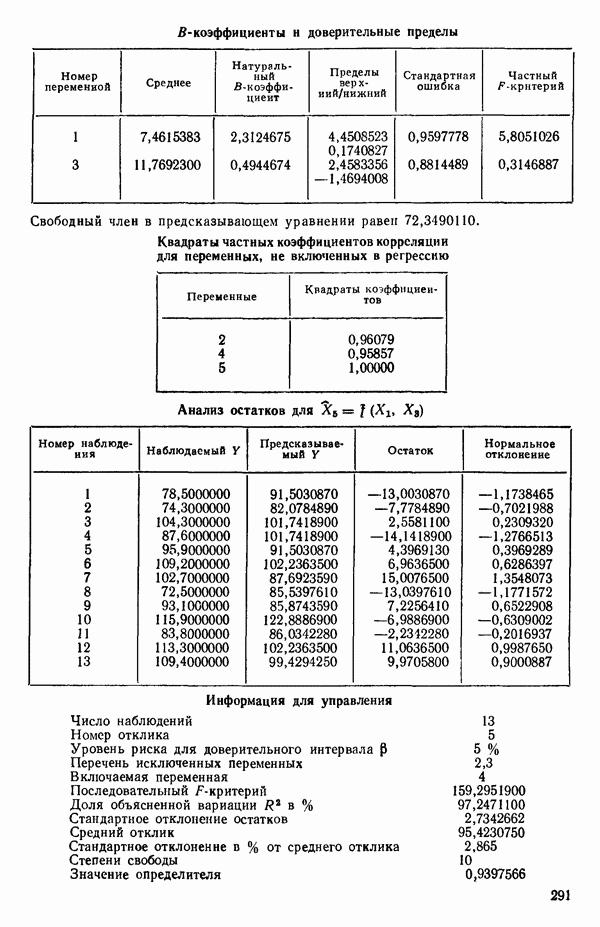
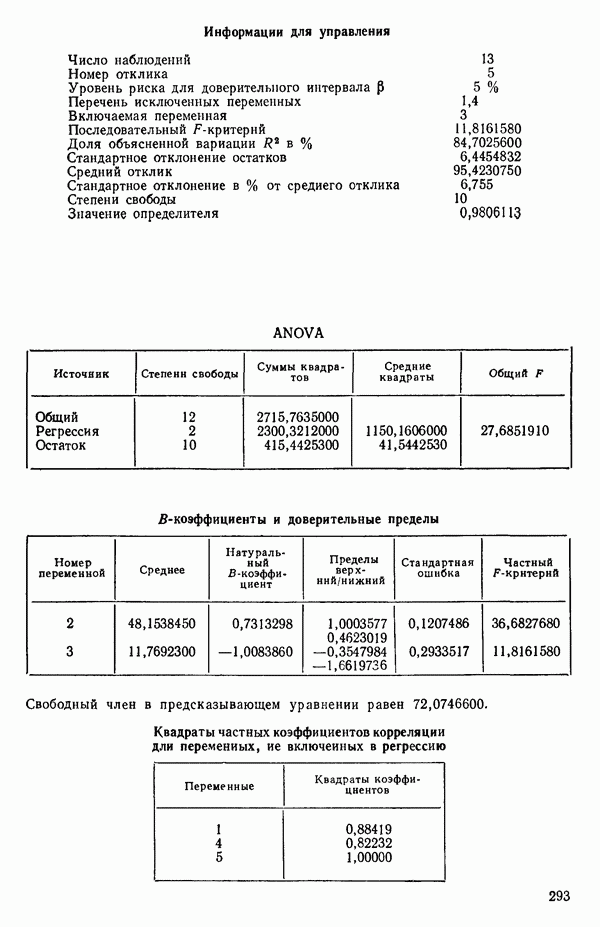
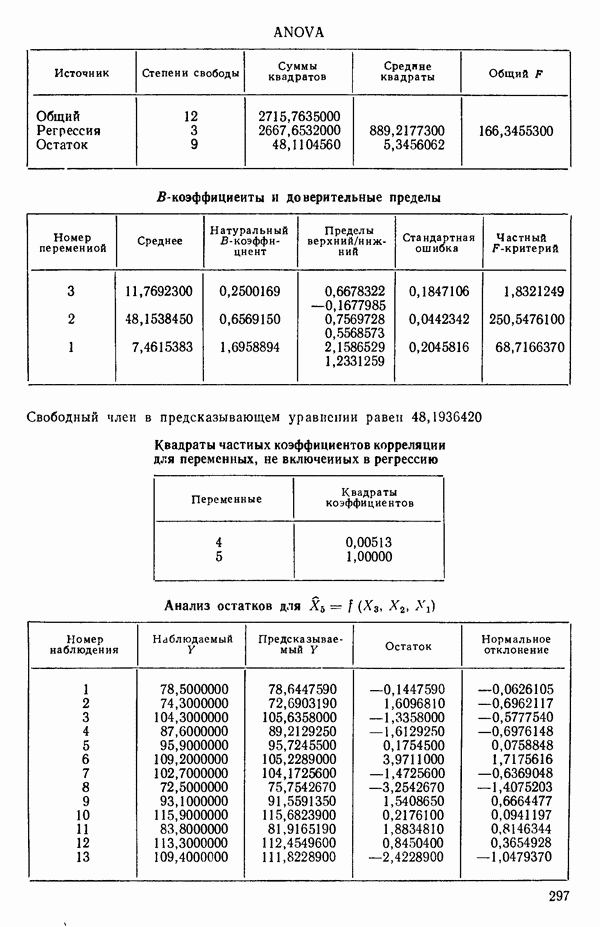
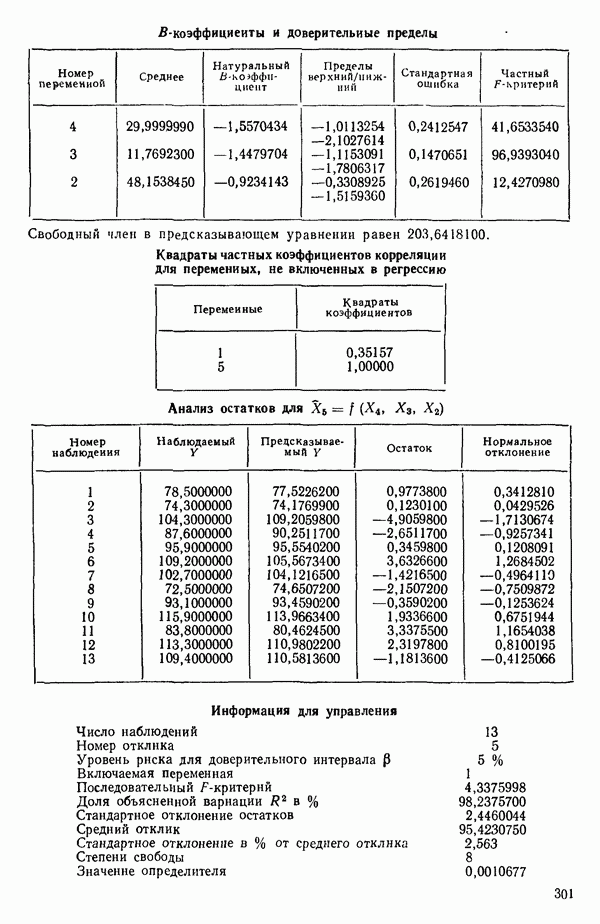
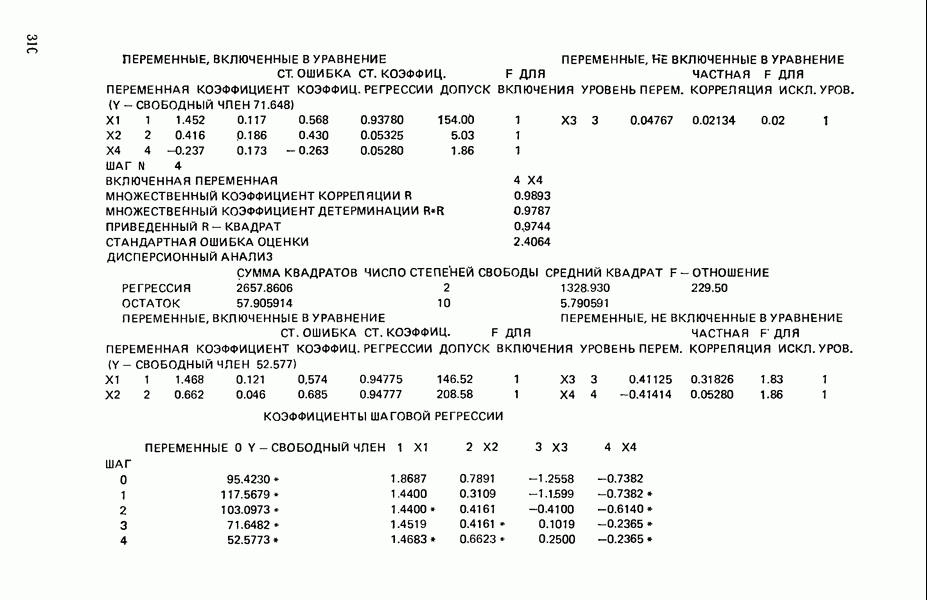
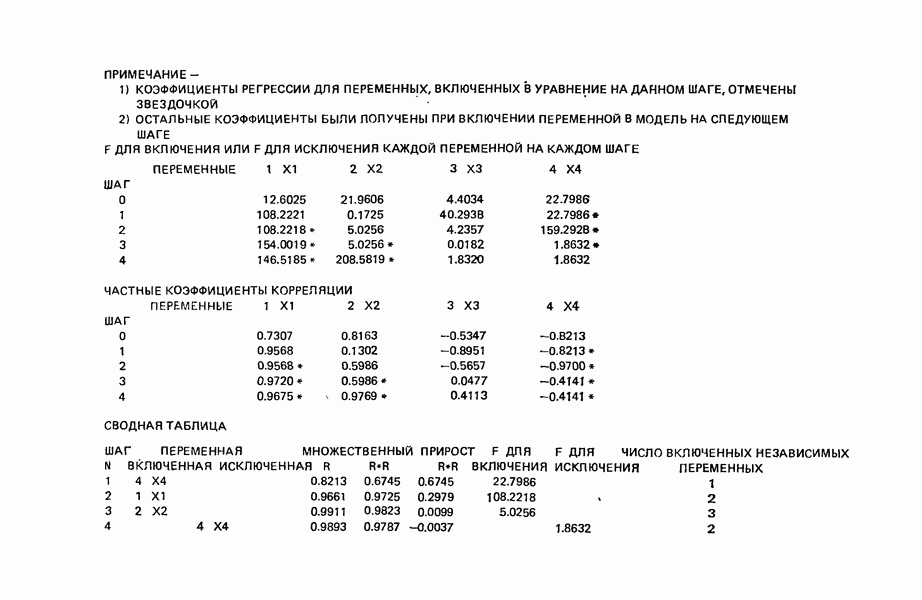
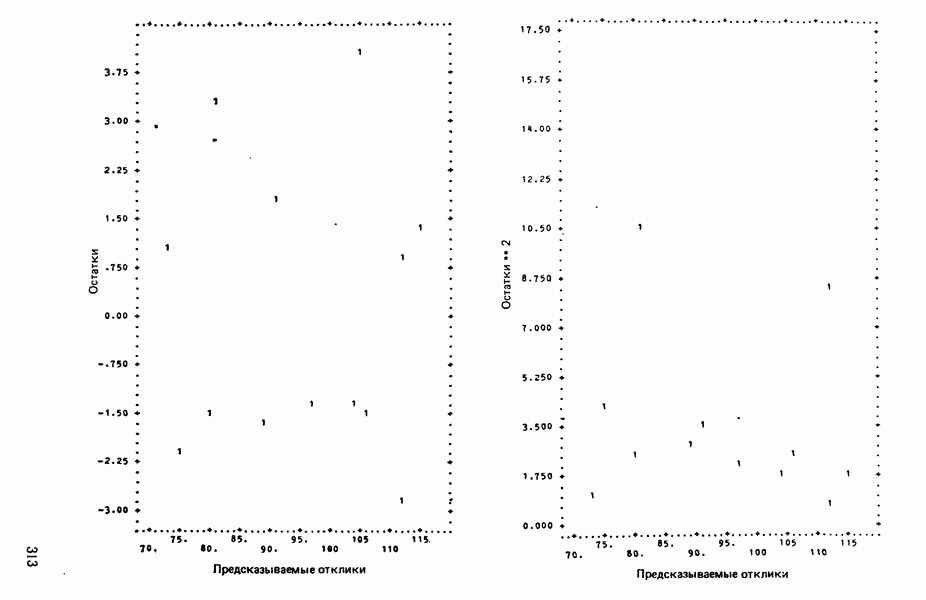
Мы проиллюстрируем этот метод, используя данные Хальда (с. 283) и программу BMDP4R programs, Regression on Principal Components. Машинная распечатка сокращена. Сначала приведем контрольные данные.
(см. скан)
Для удобства приведем суммарные статистики исходных данных и корреляционную матрицу.
(см. скан)
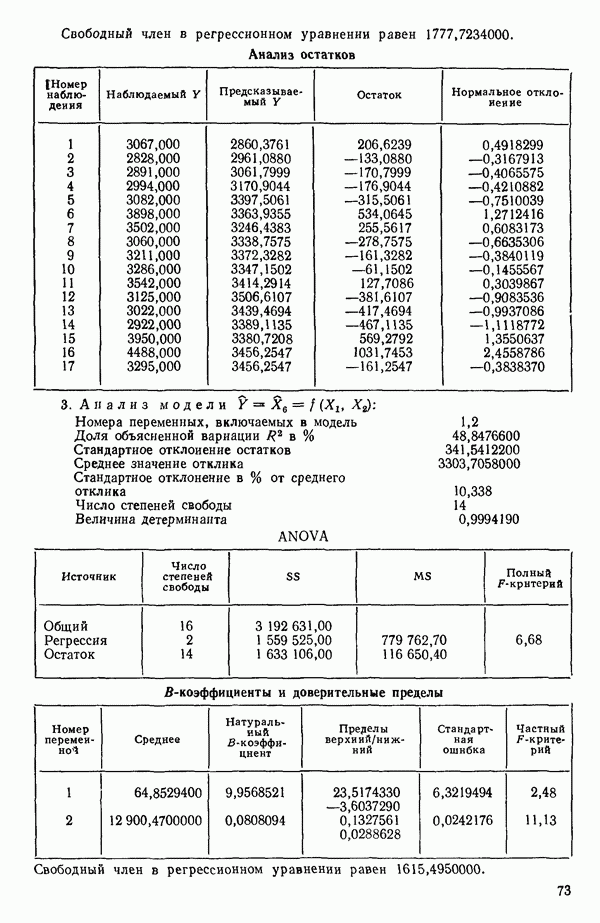
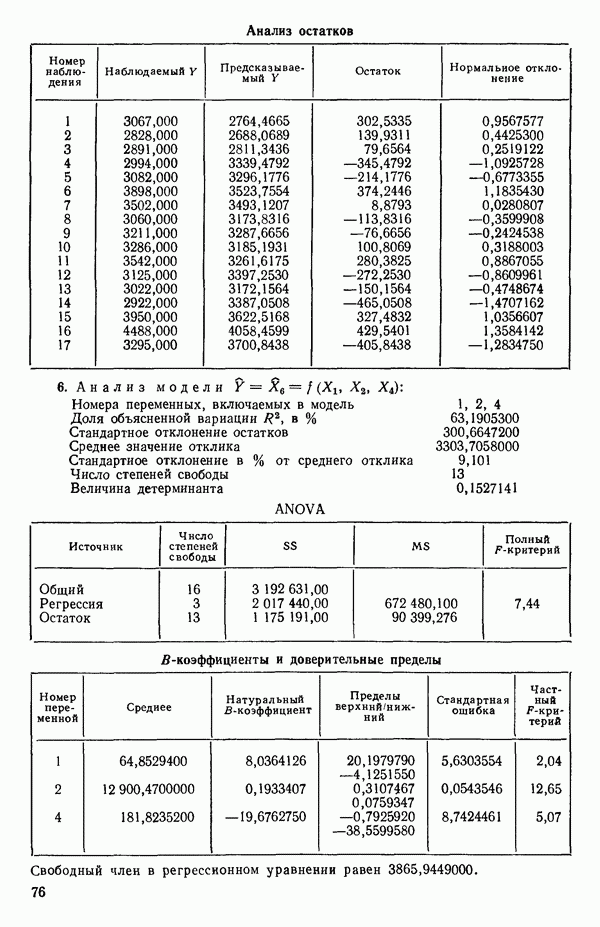
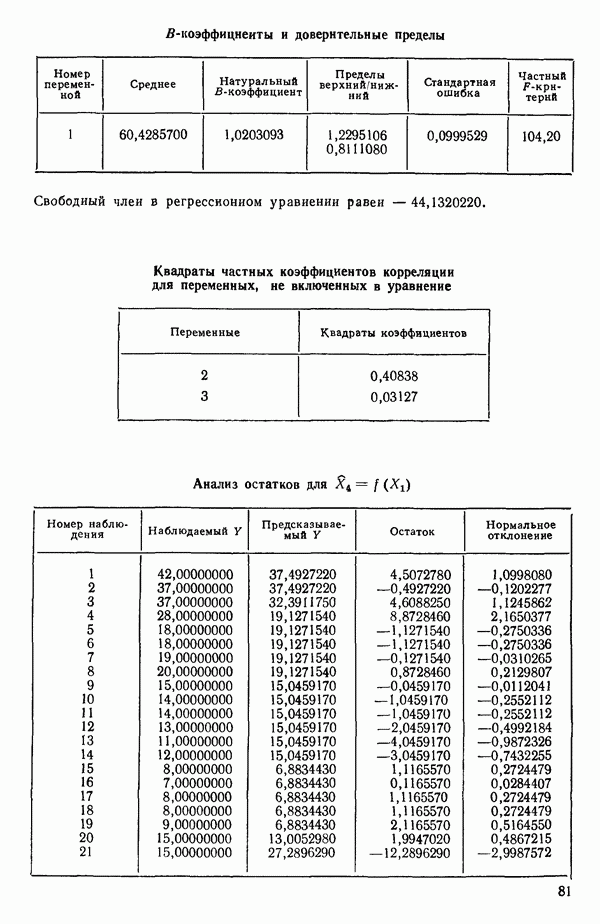
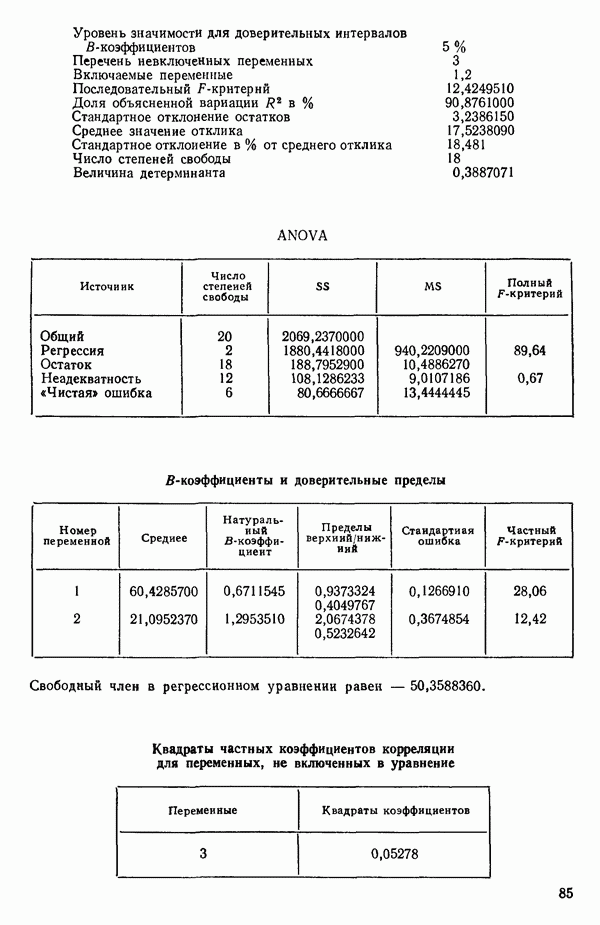
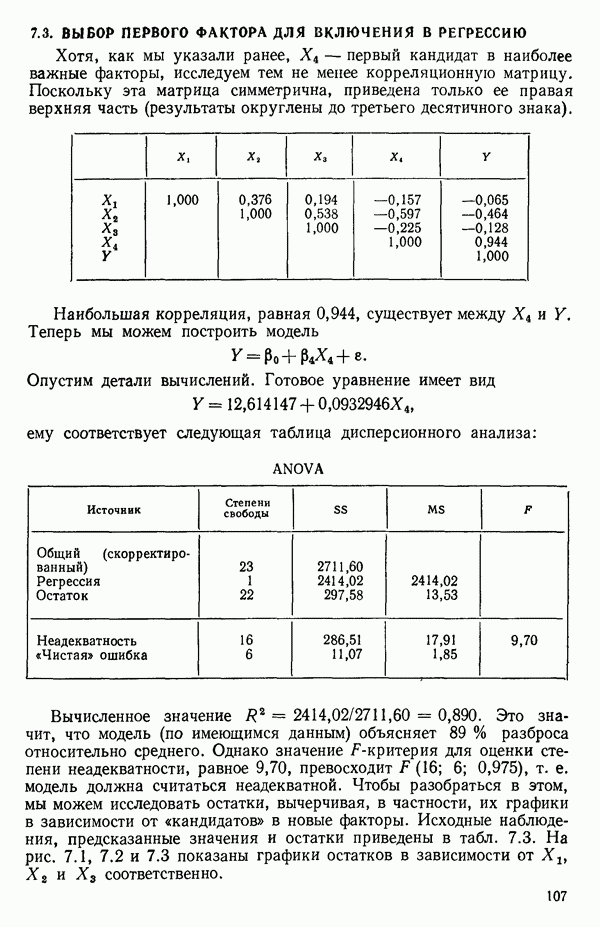
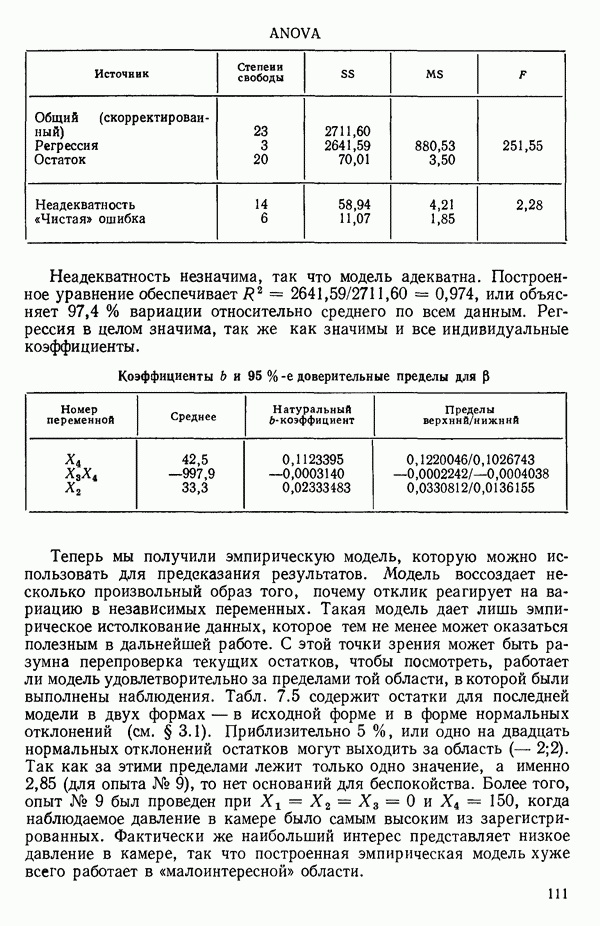
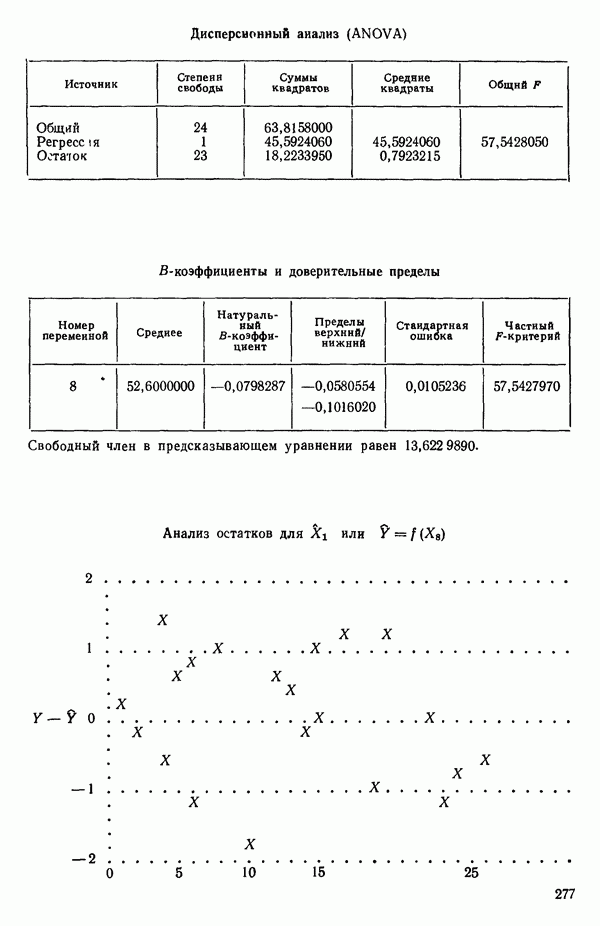
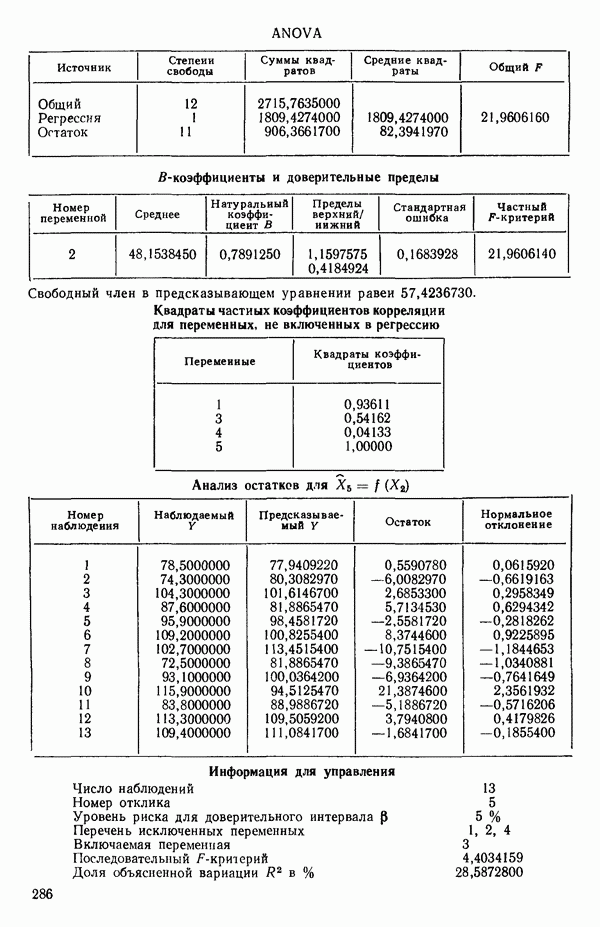
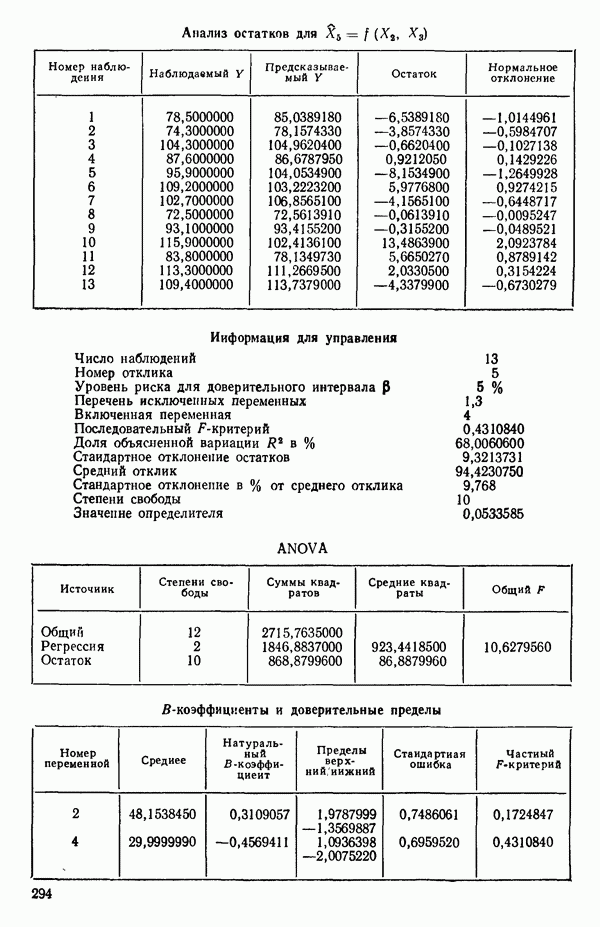
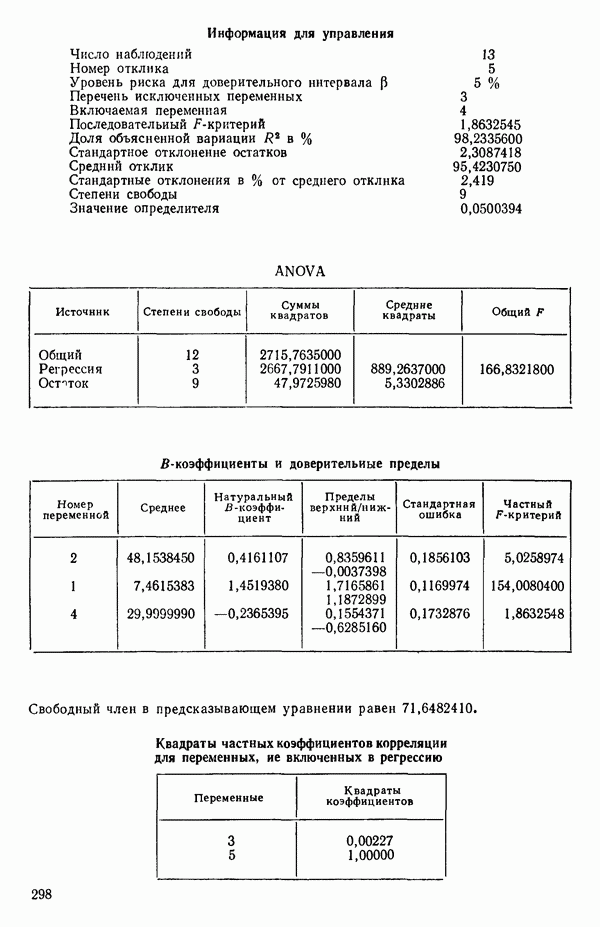
Далее приводятся собственные числа и соответствующие им собственные векторы. Здесь лишь только три собственных числа, которые превышают установленный порог 0,01. Показано также, какая часть суммарной дисперсии независимых переменных  объясняется собственными числами.
объясняется собственными числами.
(см. скан)
Интерпретация приведенных выше результатов такова:

и т. д. Заметим, кстати, что это есть преобразование, позволяющее перейти от  Для того чтобы получить зависимость
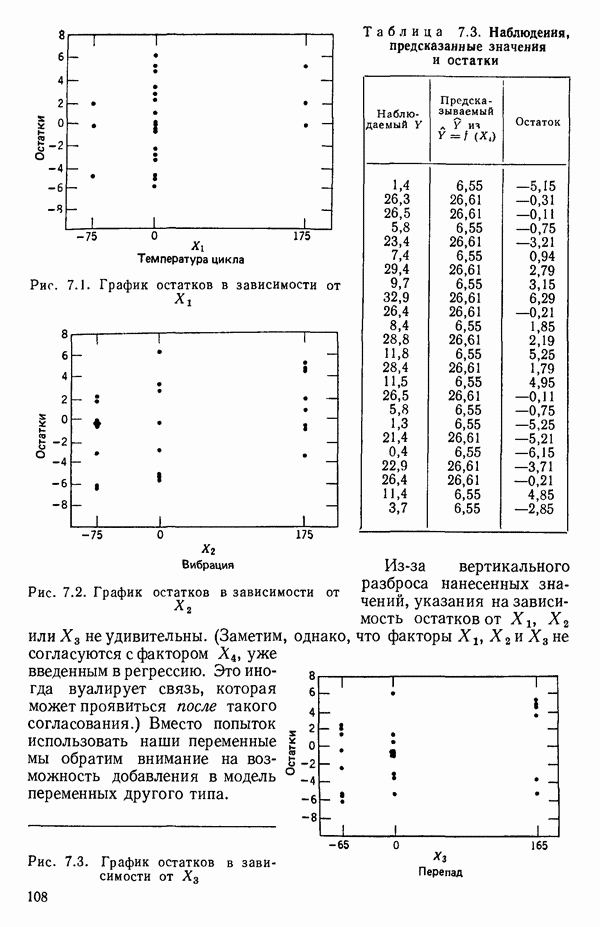
Для того чтобы получить зависимость  от
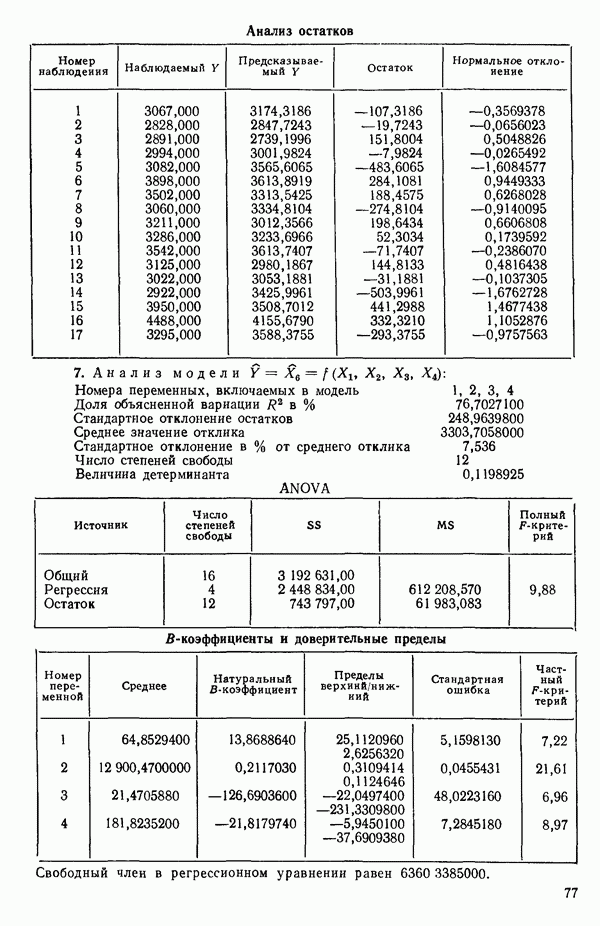
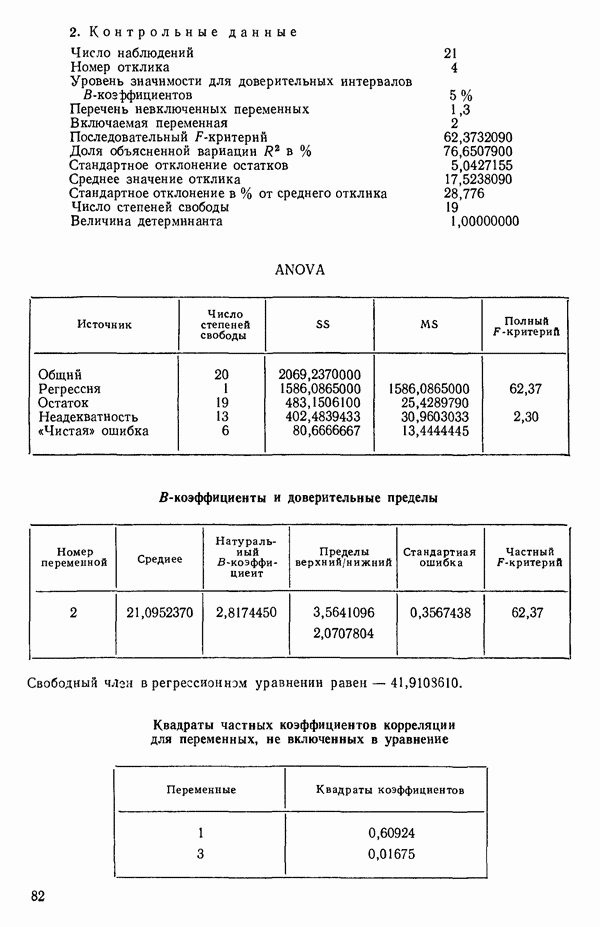
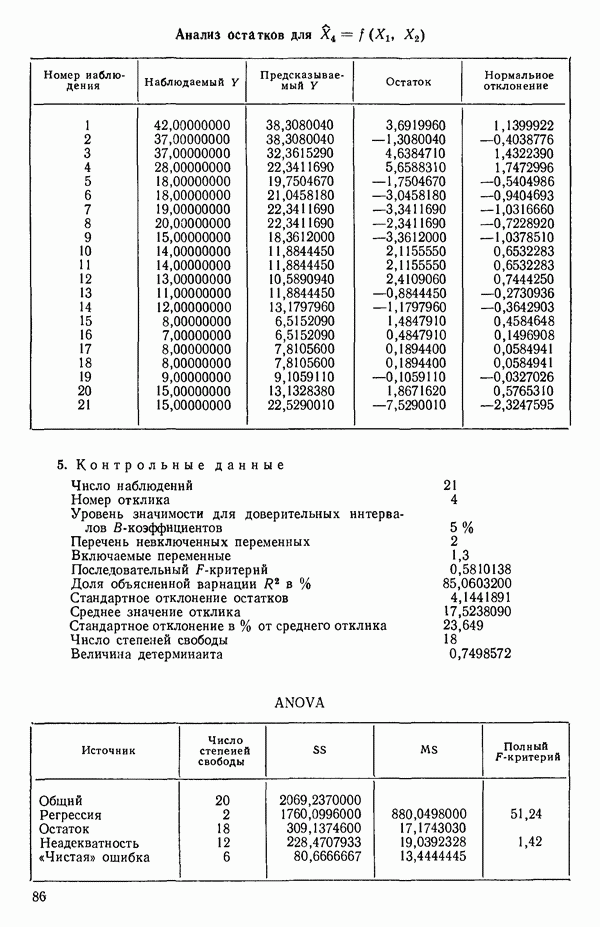
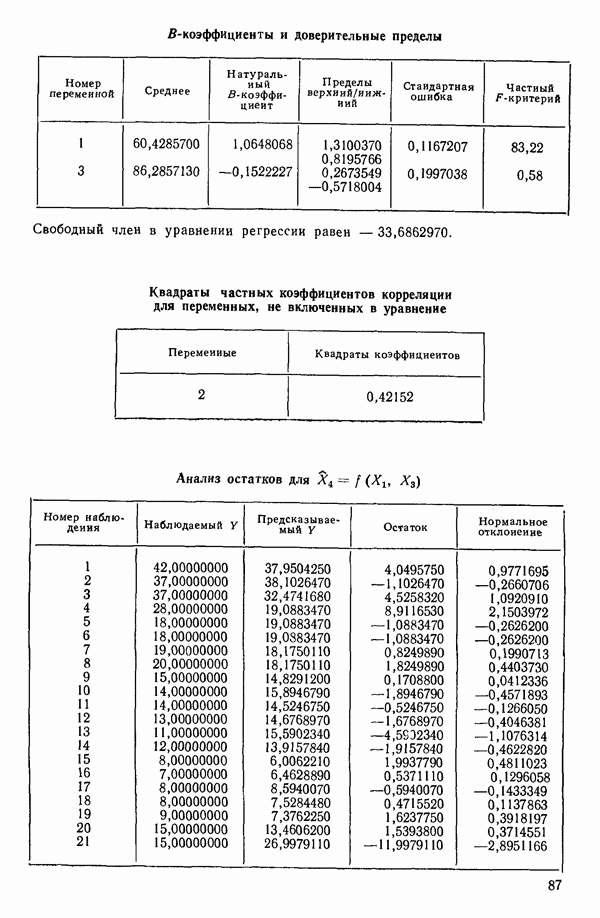
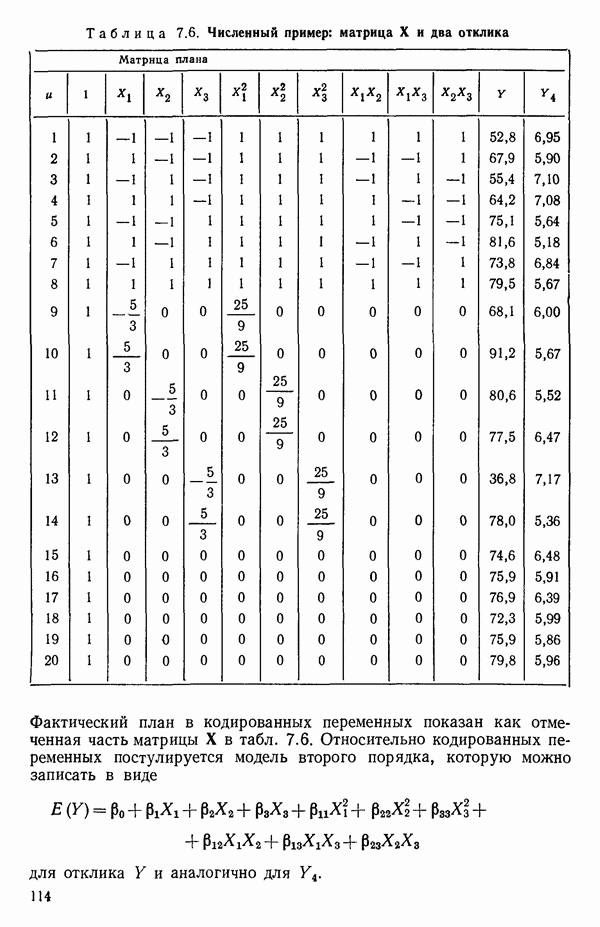
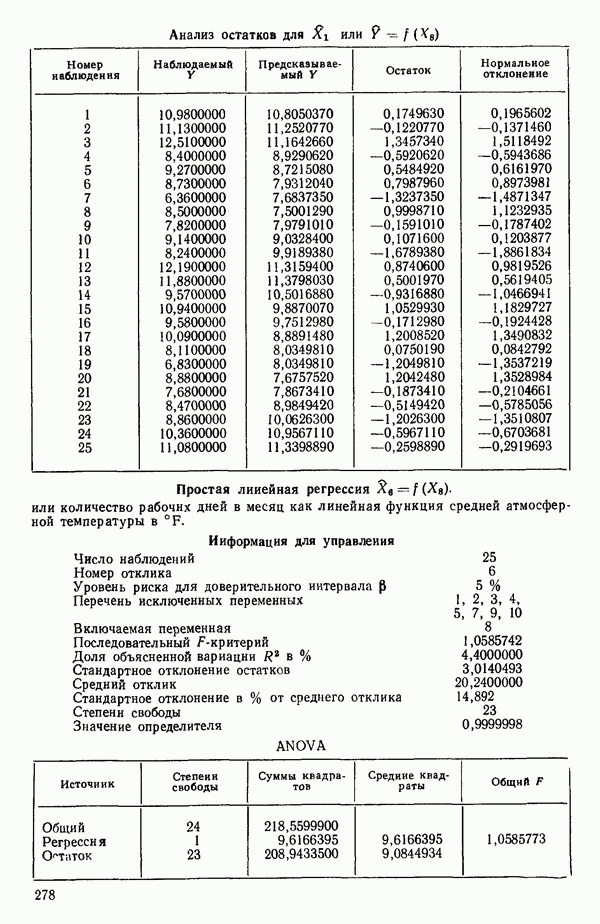
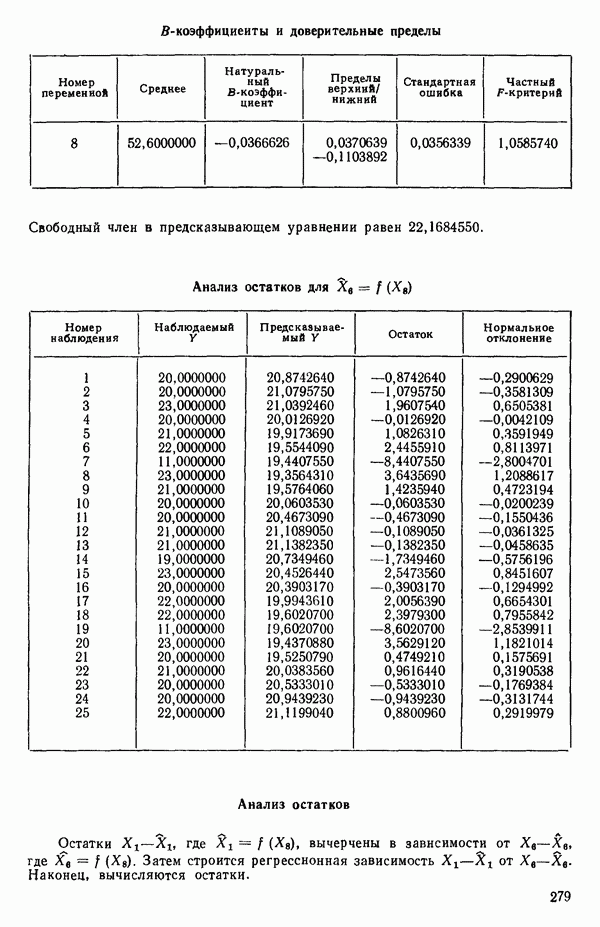
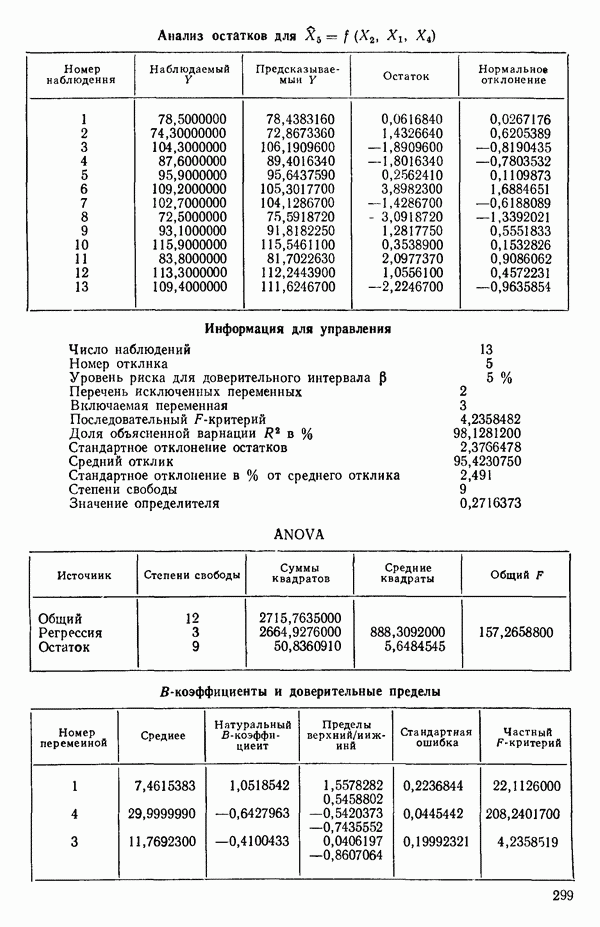
от  надо воспользоваться соотношением типа (6.9.2). Значения главных компонент вычисляются для каждой точки исходных данных и печатаются построчно вместе со значениями откликов.
надо воспользоваться соотношением типа (6.9.2). Значения главных компонент вычисляются для каждой точки исходных данных и печатаются построчно вместе со значениями откликов.
(см. скан)
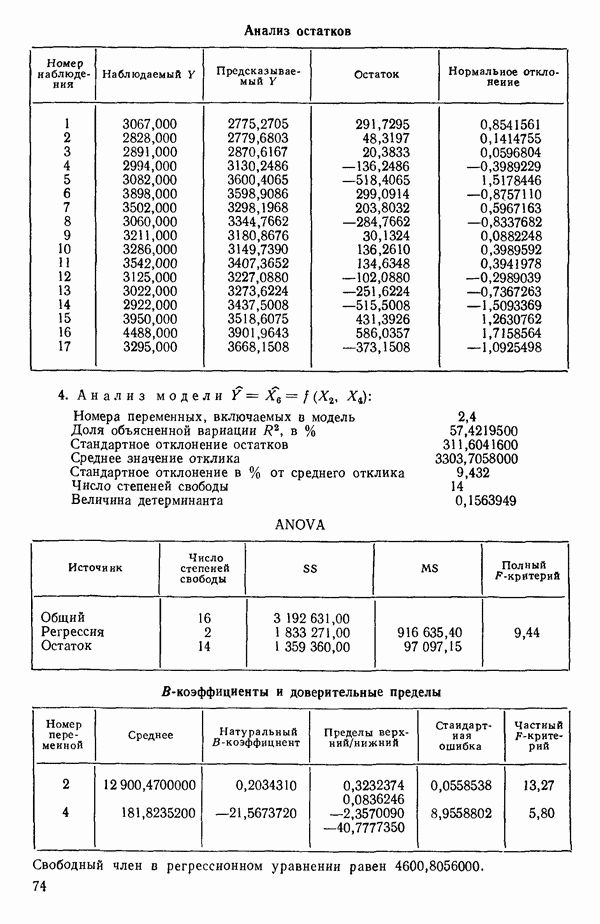
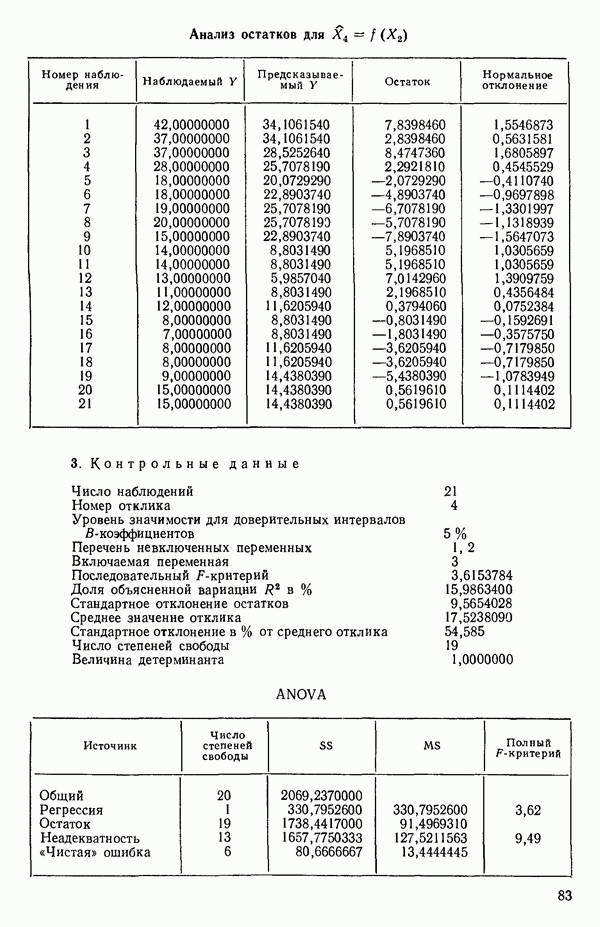
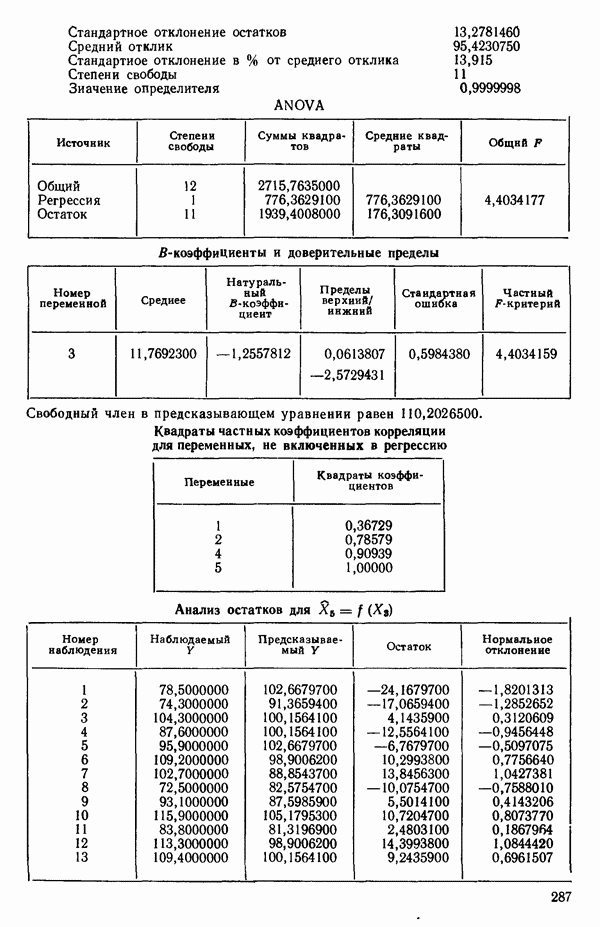
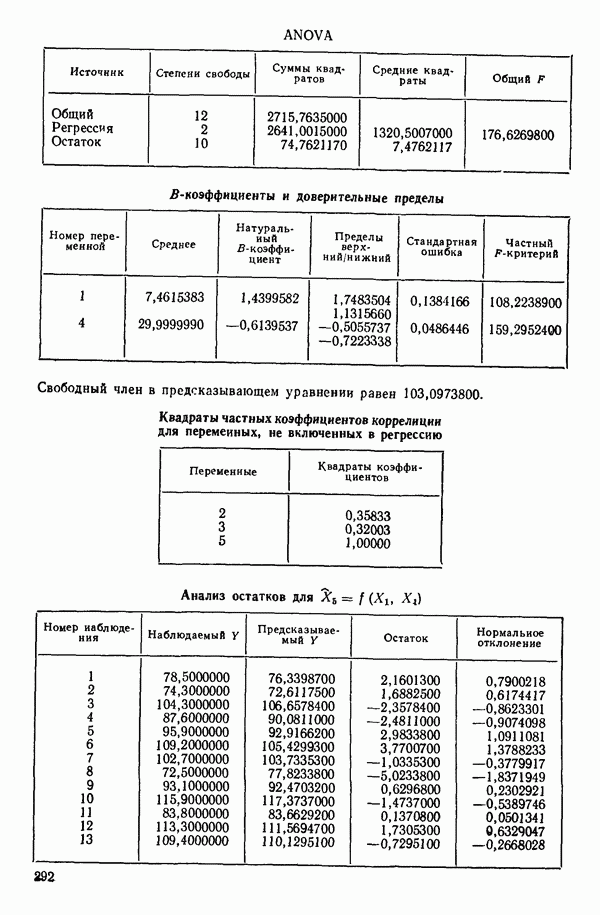
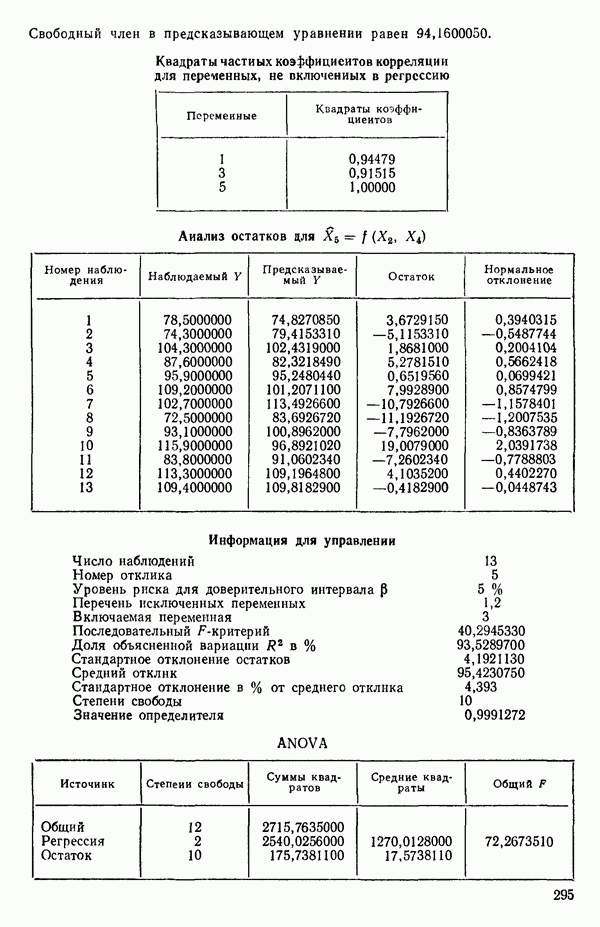
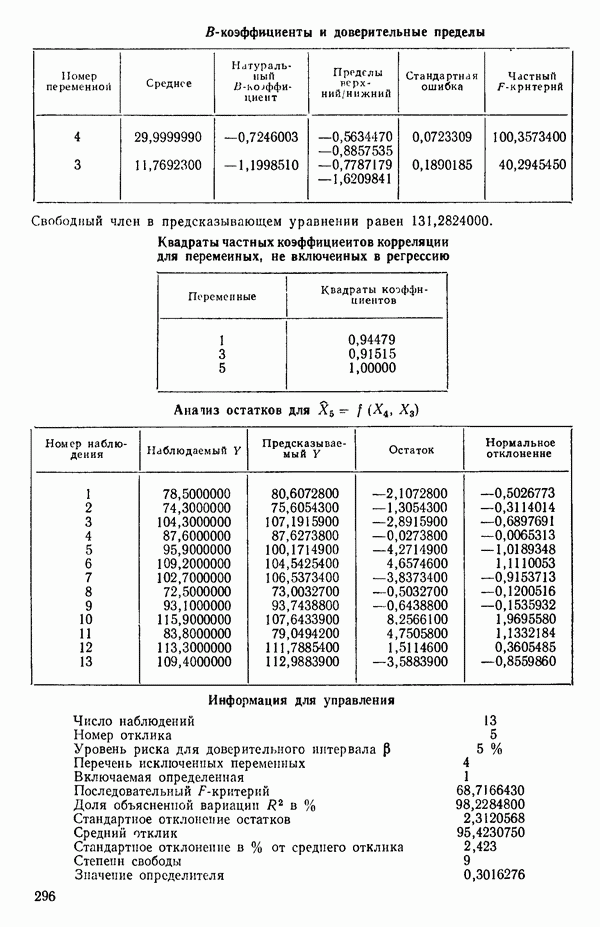
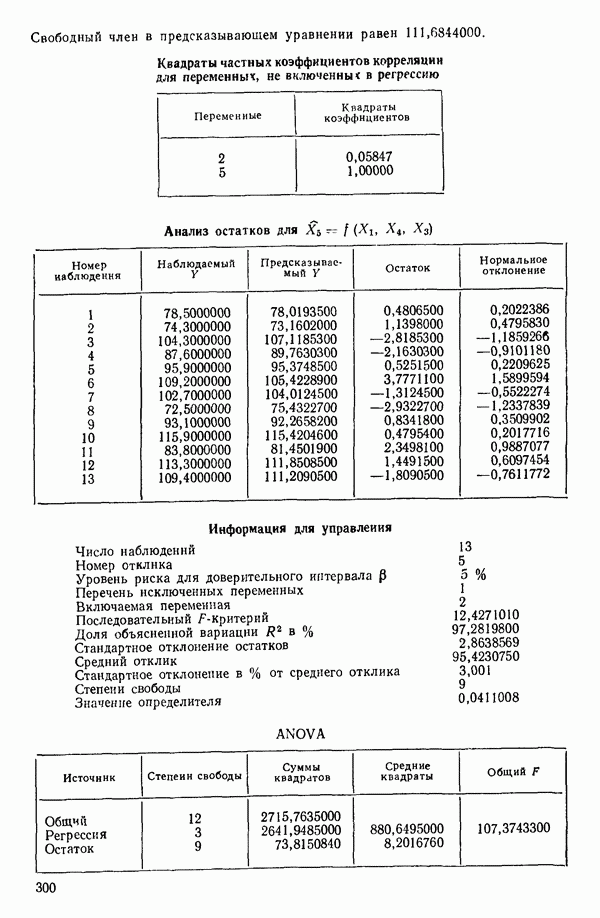
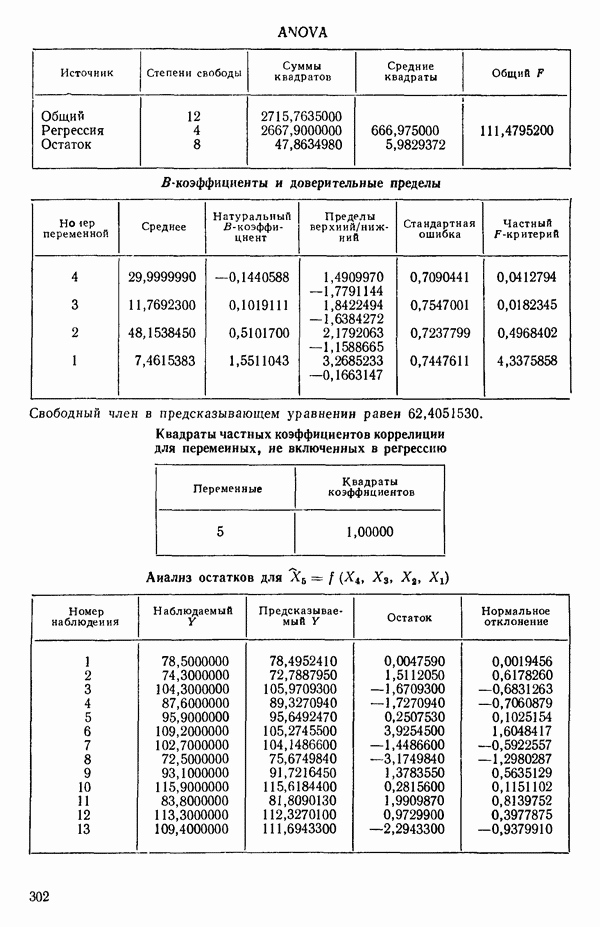
Таблица 6.4. Таблица дисперсионного анализа данных Хальда, обработанных методом главных компонент

Коэффициенты корреляции  и У таковы:
и У таковы:

Модель

была подогнана к исходным данным по методу наименьших квадратов. В итоге получили

Табл. 6.4 соответствует этой модели. В последнем столбце приведены значения  -критерия, полученные при введении компонент
-критерия, полученные при введении компонент  в модель поодиночке, последовательно в порядке расположения их вкладов. Так, например, если в модель вводится только одна первая компонента, остаточная сумма квадратов равна:
в модель поодиночке, последовательно в порядке расположения их вкладов. Так, например, если в модель вводится только одна первая компонента, остаточная сумма квадратов равна:

с 11 степенями свободы. Величина последовательного  -критерия в таком случае равна:
-критерия в таком случае равна:

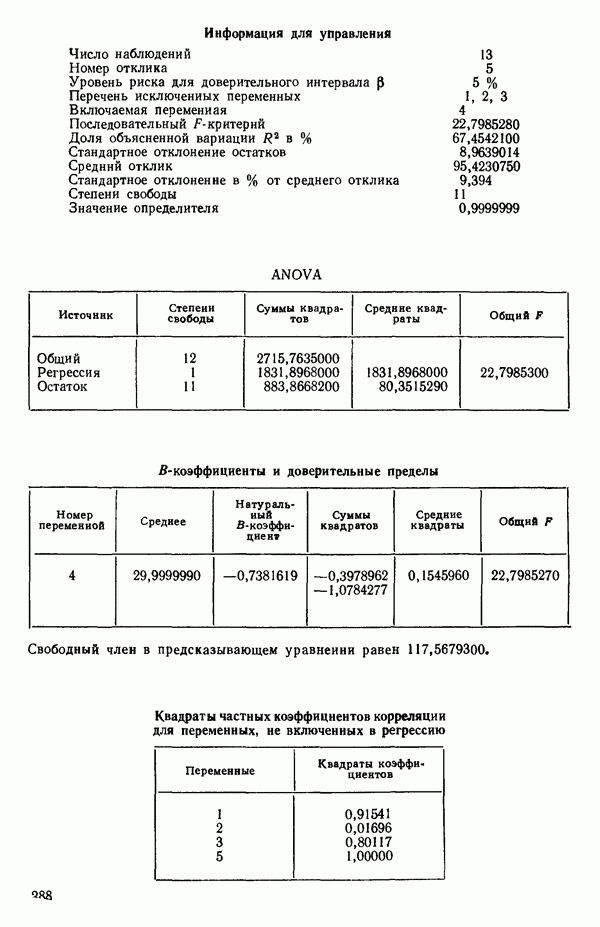
Величина  растет от 0,9649 до 0,9820 и до 0,9821 по мере того, как добавляются ортогональные переменные
растет от 0,9649 до 0,9820 и до 0,9821 по мере того, как добавляются ортогональные переменные  Переходя обратно от переменных
Переходя обратно от переменных  к переменным
к переменным  для этих трех случаев получим следующие подогнанные уравнения.
для этих трех случаев получим следующие подогнанные уравнения.
Только с компонентой 

С компонентами и 

С компонентами 

Из всего приведенного выше анализа ясно, что только две компоненты и  играют существенную роль в подбираемом уравнении. В силу этого целесообразно принять уравнение (6.9.11). Заметим, что во всех полученных уравнениях участвуют все переменные
играют существенную роль в подбираемом уравнении. В силу этого целесообразно принять уравнение (6.9.11). Заметим, что во всех полученных уравнениях участвуют все переменные  ни одна из них не исключается при реализации данной процедуры. Укажем также, что уравнения, выраженные через
ни одна из них не исключается при реализации данной процедуры. Укажем также, что уравнения, выраженные через  имеют смещенные оценки параметров, тогда как применяя метод наименьших квадратов непосредственно к уравнению, выраженному через исходные переменные
имеют смещенные оценки параметров, тогда как применяя метод наименьших квадратов непосредственно к уравнению, выраженному через исходные переменные  получим несмещенные оценки.
получим несмещенные оценки.
Мнение. Основной вопрос, который возникает здесь, таков: имеют или нет реальный смысл переменные  или по крайней мере имеют ли они больший смысл, чем переменные
или по крайней мере имеют ли они больший смысл, чем переменные  для тех систем, для которых получены данные? Если да или в том случае, когда переменные
для тех систем, для которых получены данные? Если да или в том случае, когда переменные  могут использоваться при эксплуатации системы, регрессия на главных компонентах чрезвычайно полезна. Если же переменные
могут использоваться при эксплуатации системы, регрессия на главных компонентах чрезвычайно полезна. Если же переменные  не несут в себе большего смысла, чем
не несут в себе большего смысла, чем  то метод главных компонент не настолько ценен, чтобы его рекомендовать. В целом этот метод, по-видимому, малоприменим в физических, технических и биологических науках. Он может быть полезным иногда в общественных науках как метод отыскания эффективных комбинаций переменных.
то метод главных компонент не настолько ценен, чтобы его рекомендовать. В целом этот метод, по-видимому, малоприменим в физических, технических и биологических науках. Он может быть полезным иногда в общественных науках как метод отыскания эффективных комбинаций переменных.
Попытки улучшить регрессию на главных компонентах обсуждаются в § 6.10.