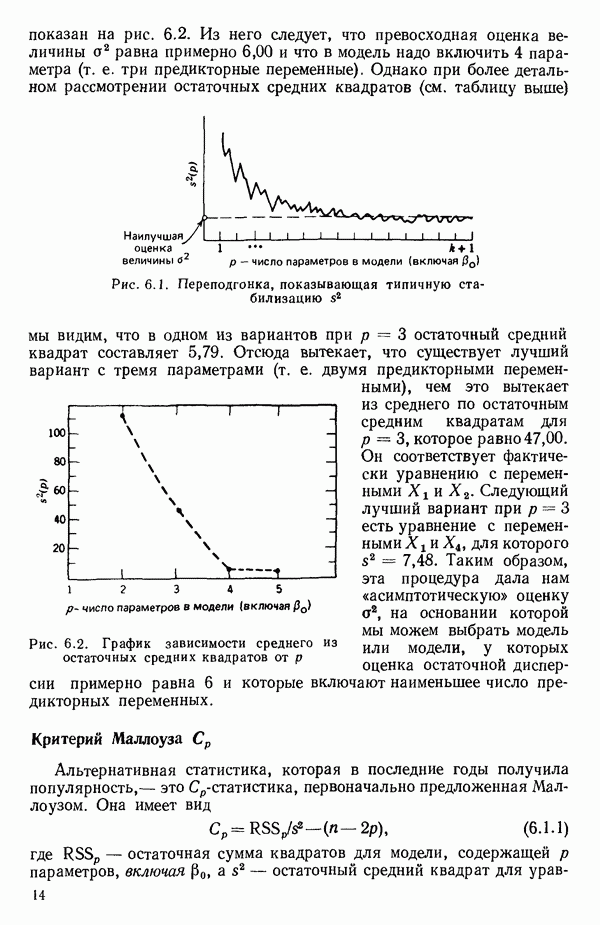
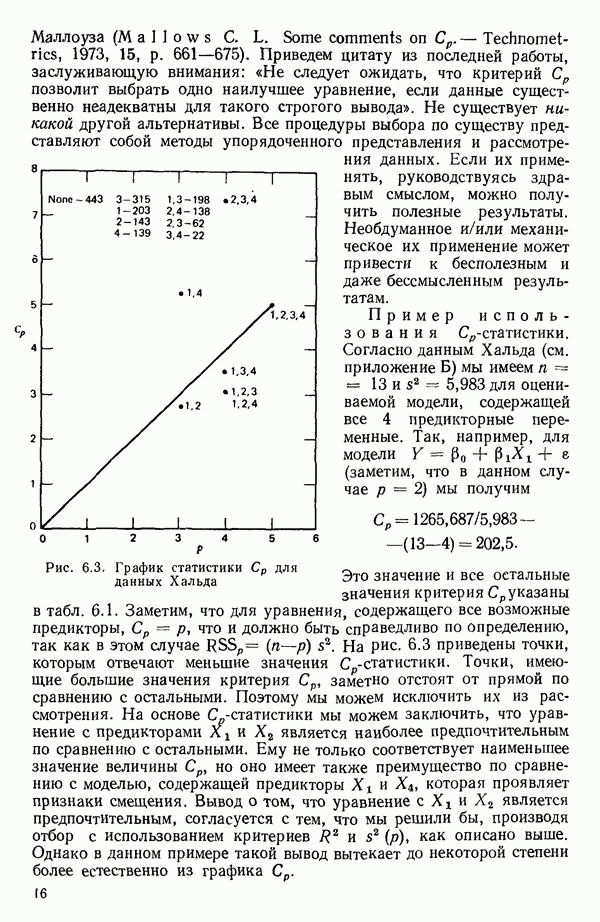
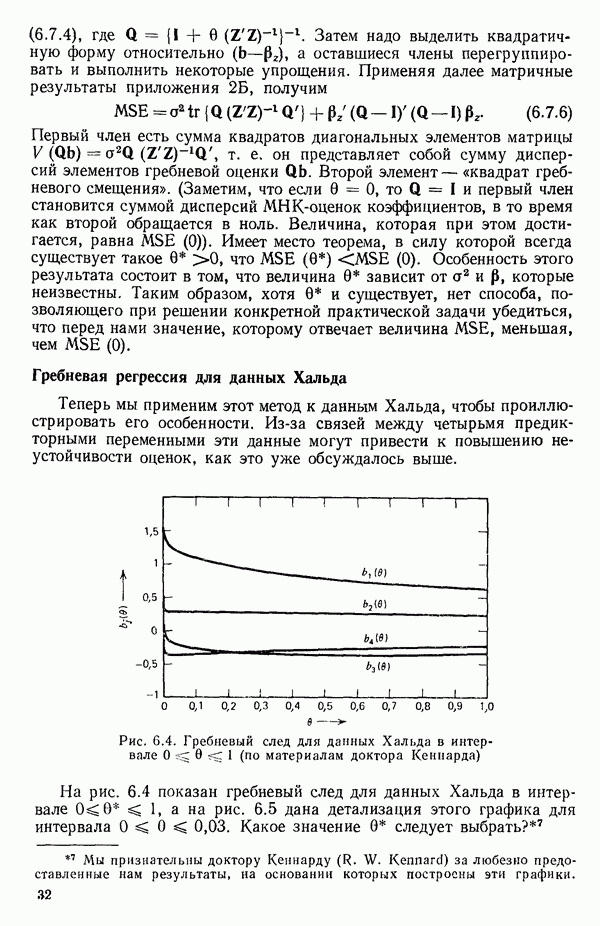
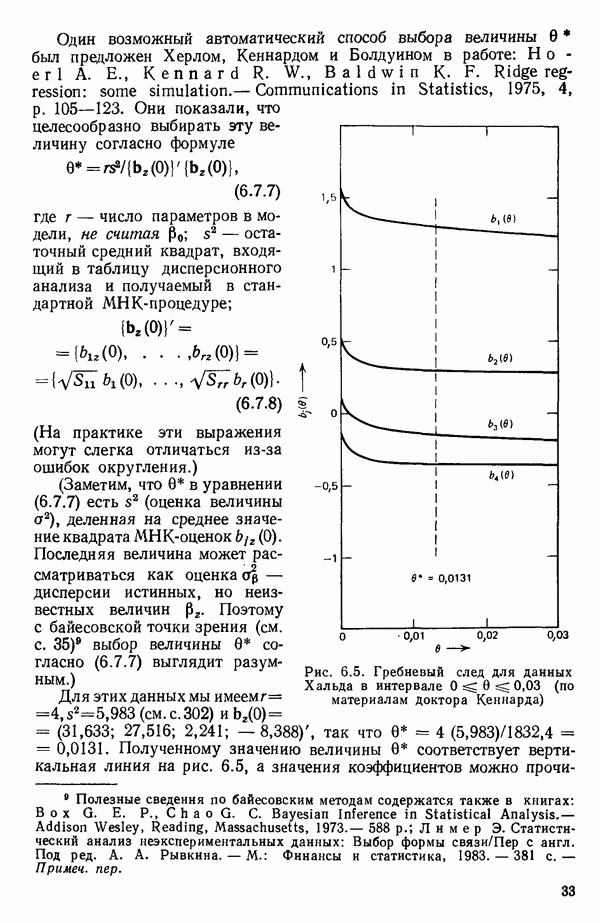
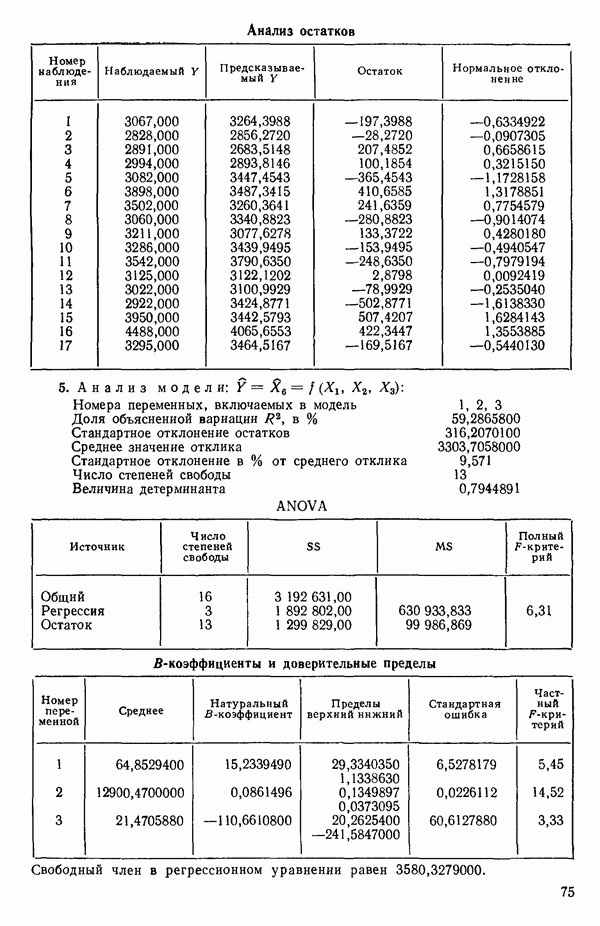
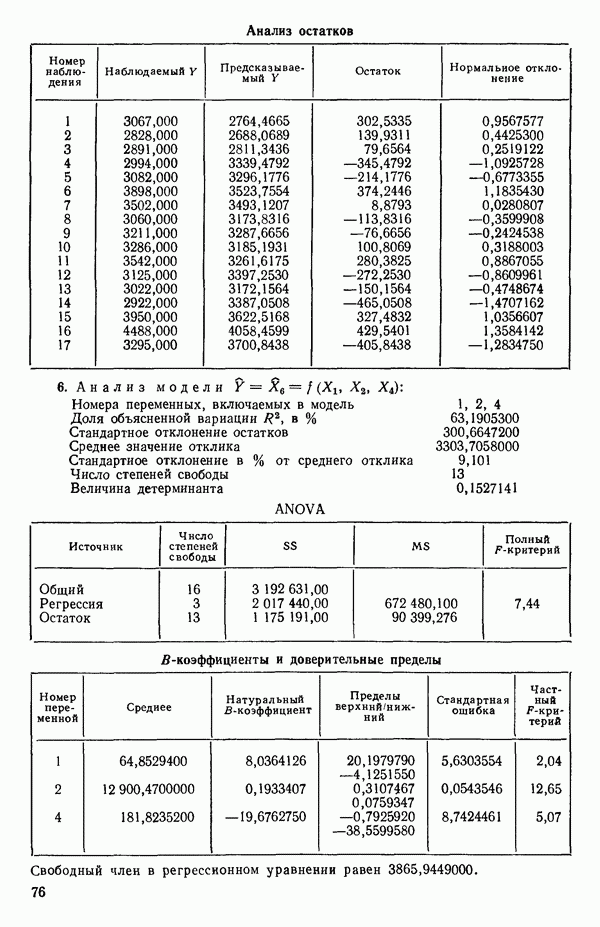
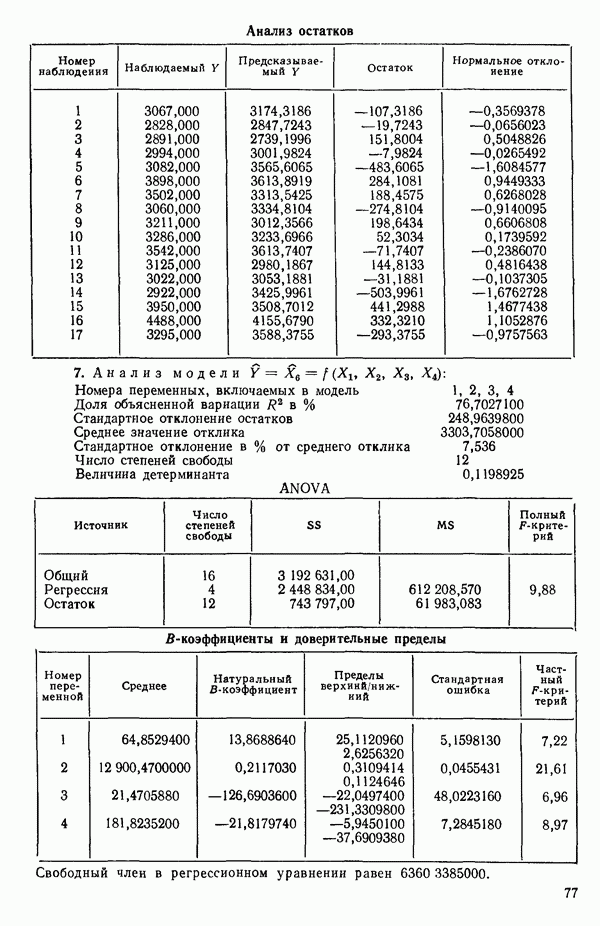
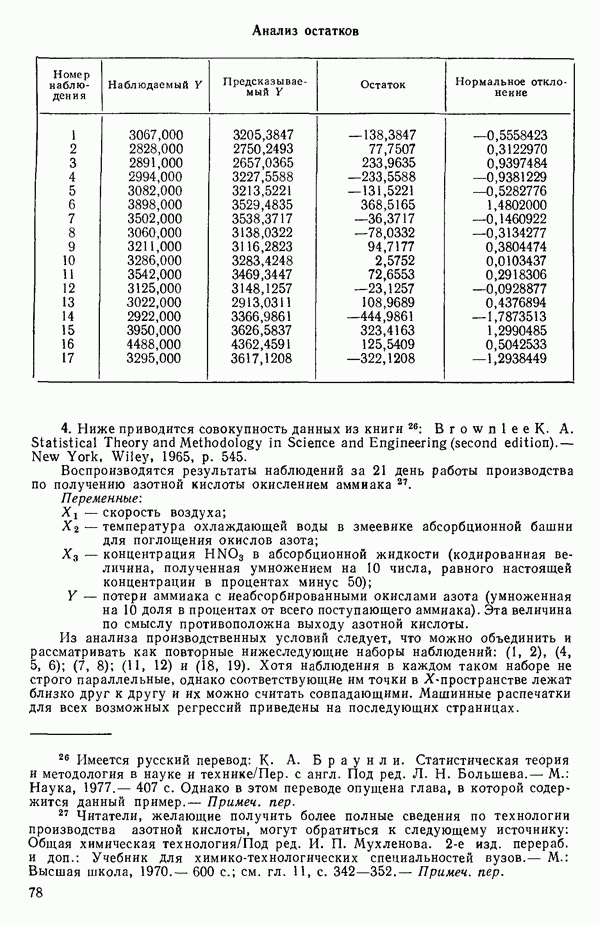
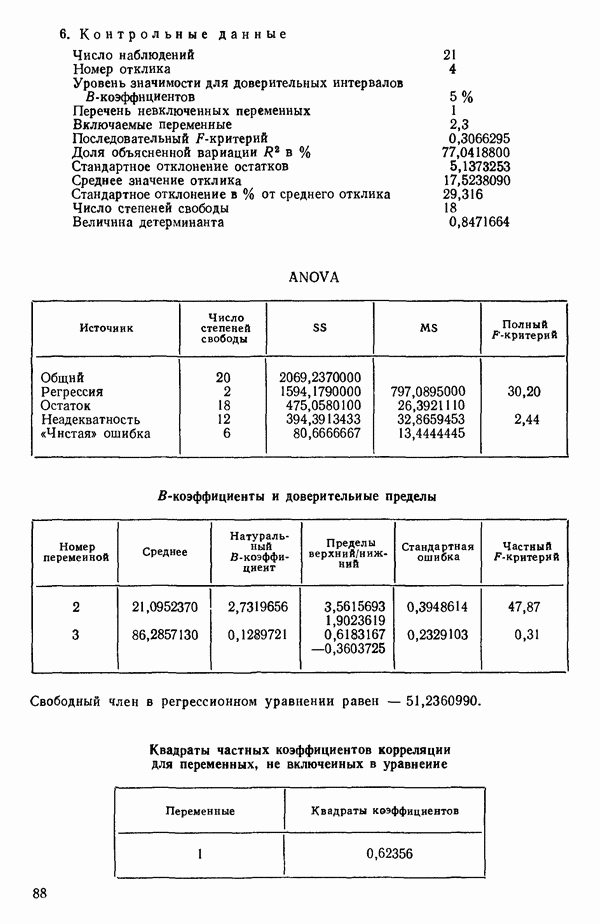
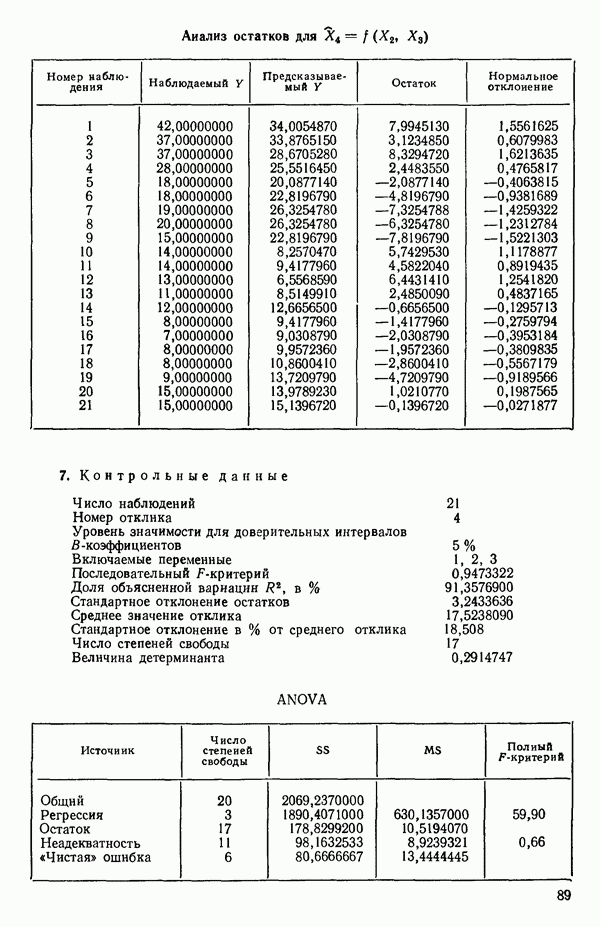
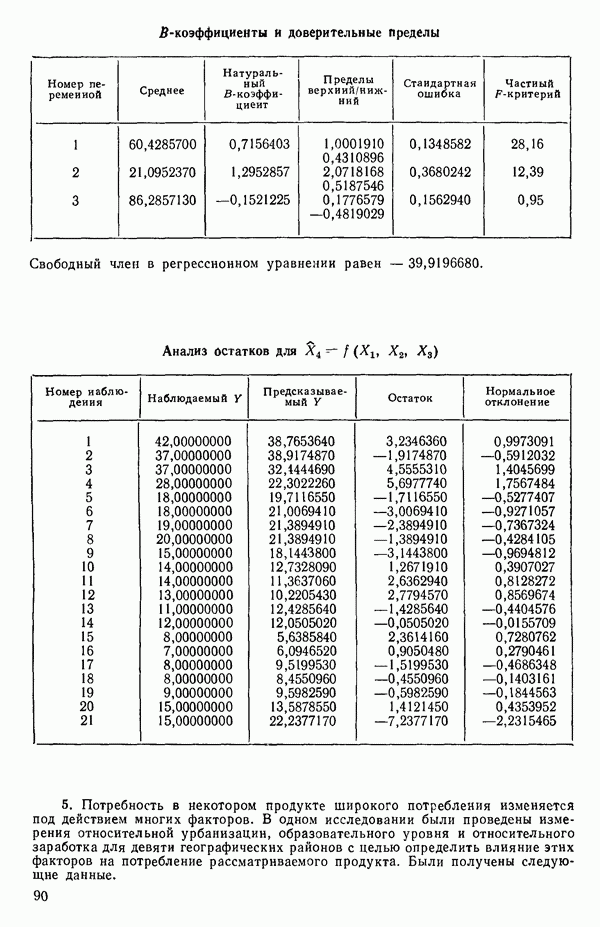
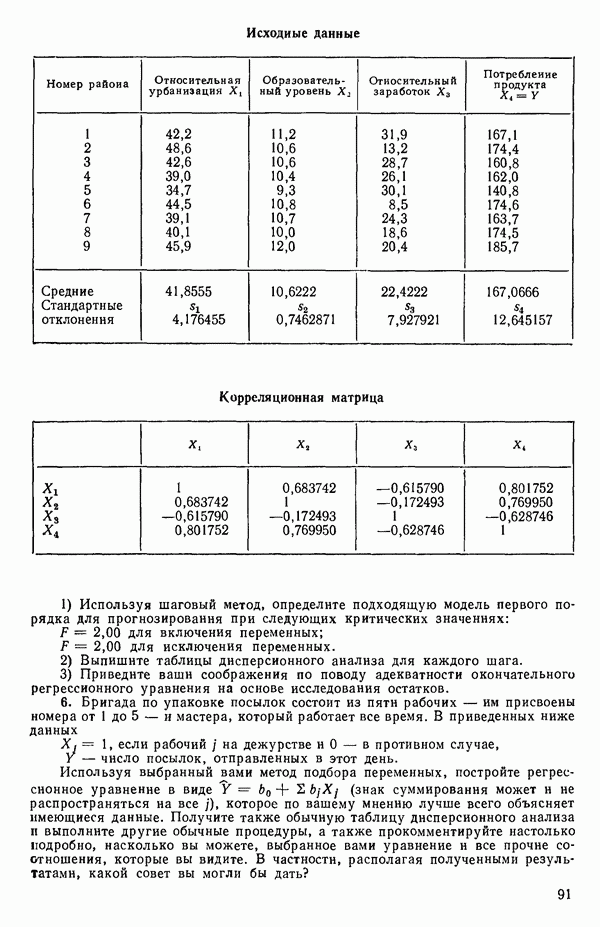
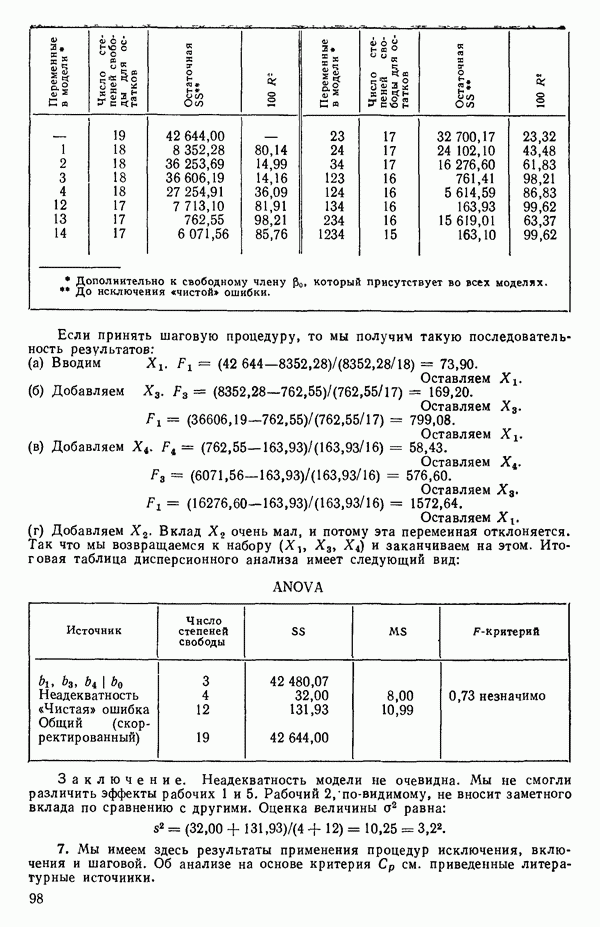
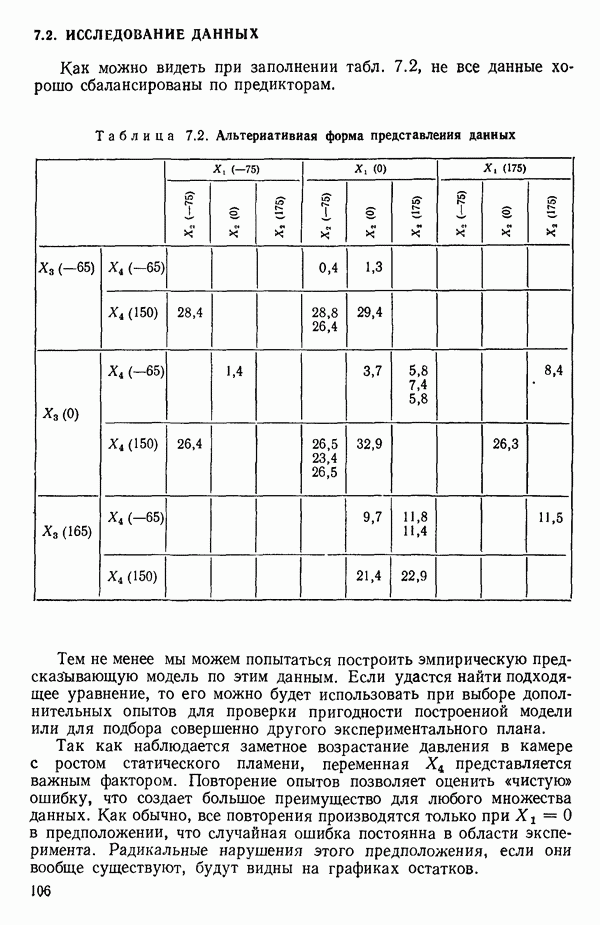
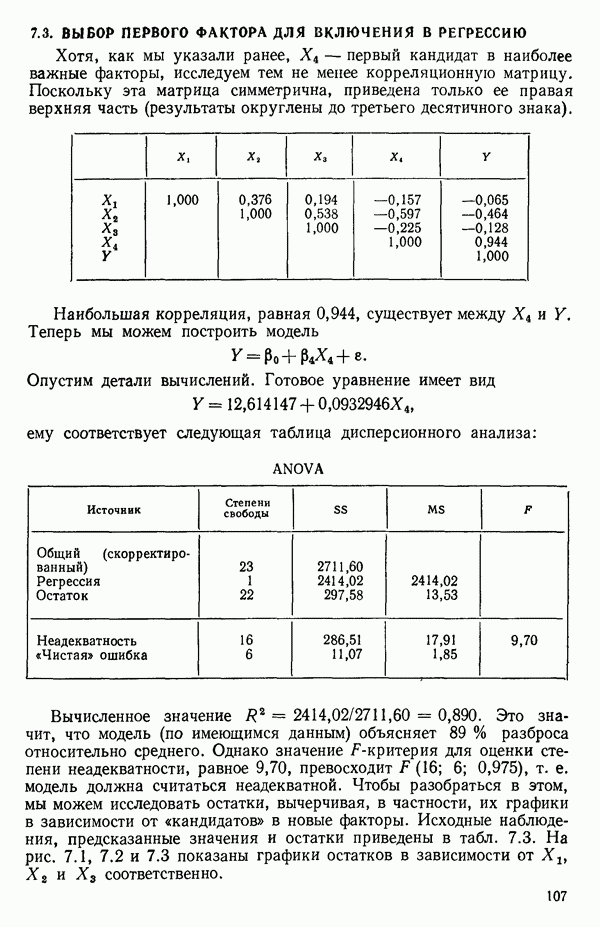
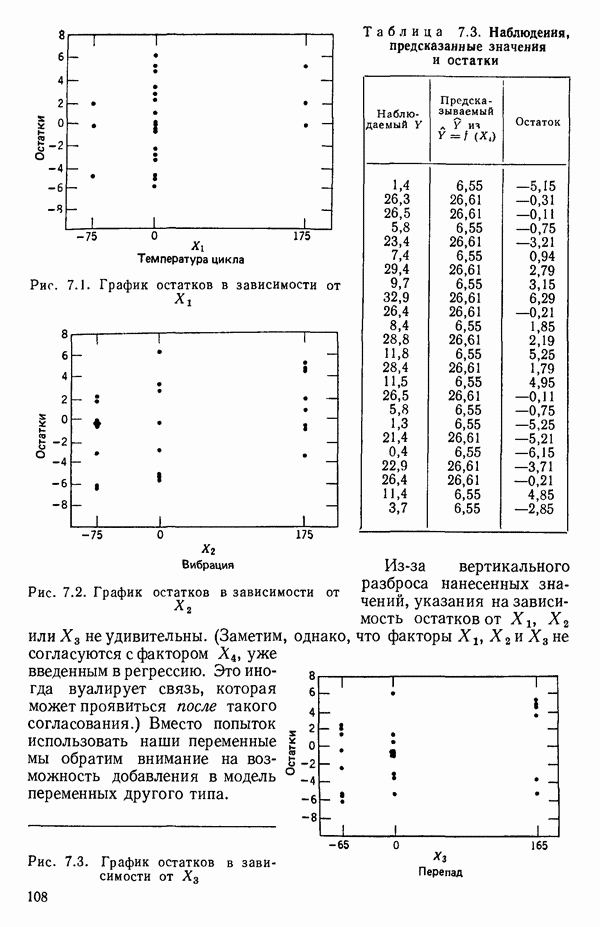
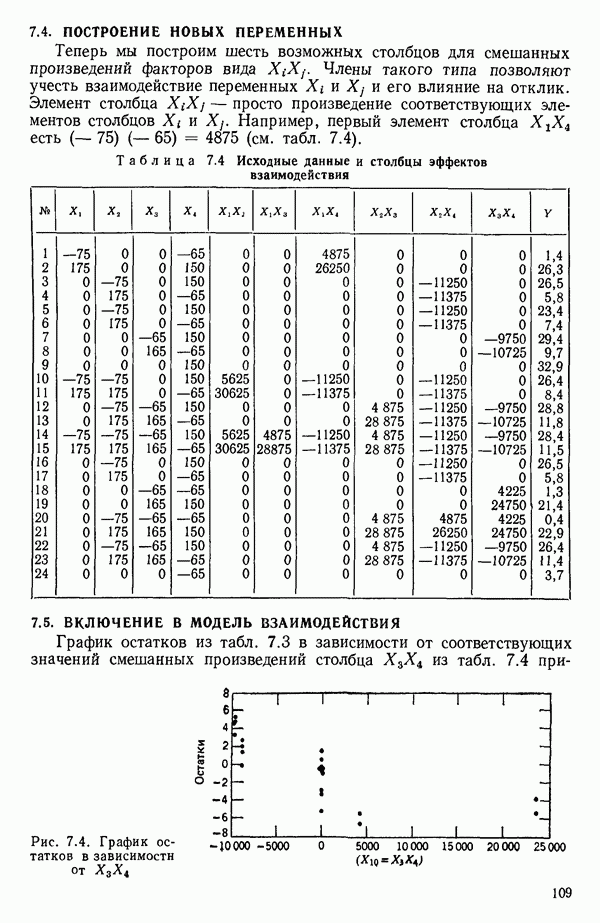
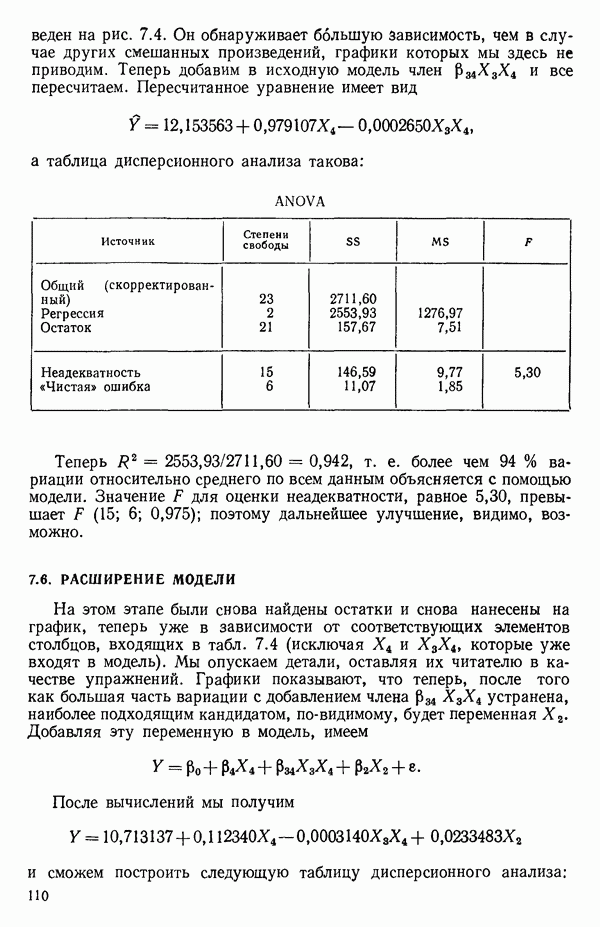
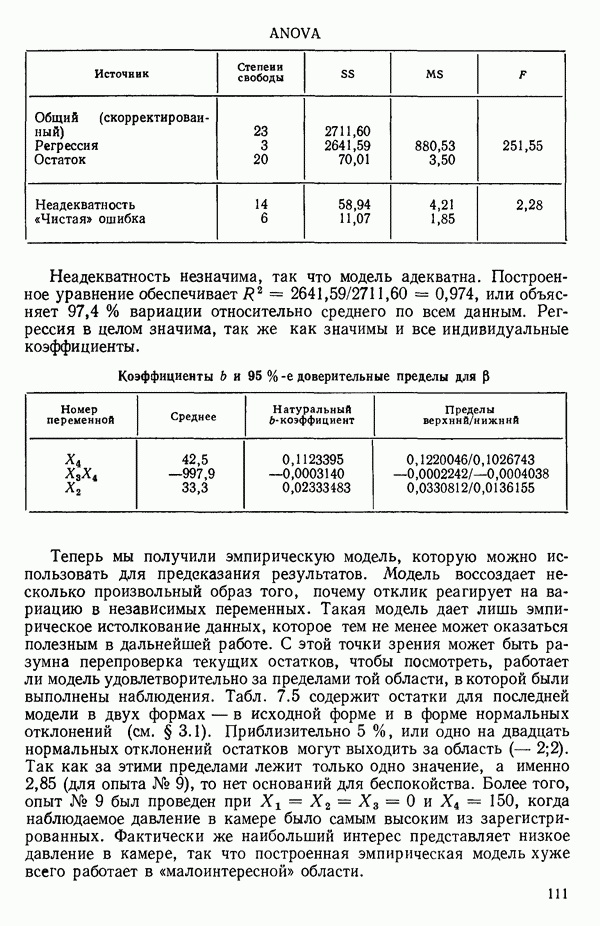
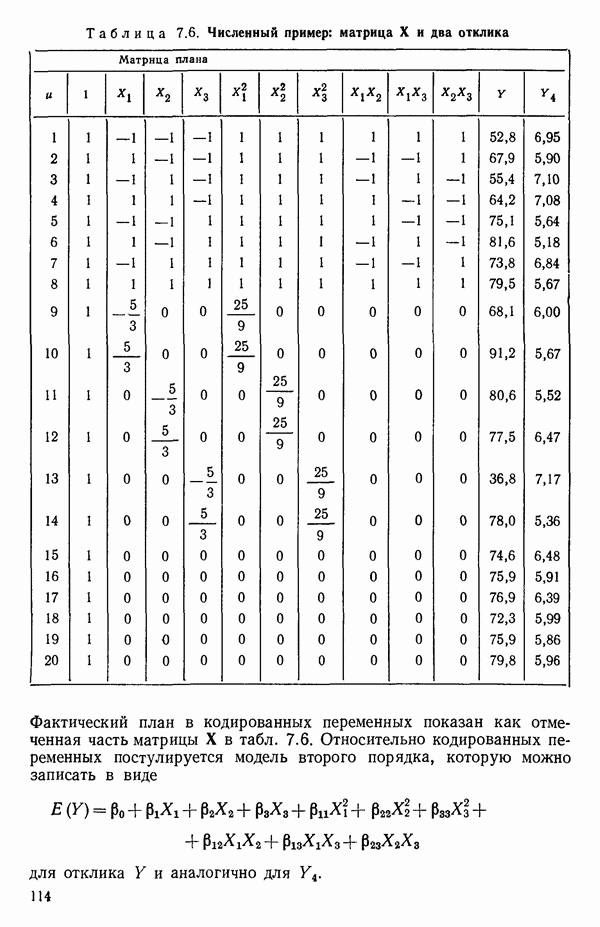
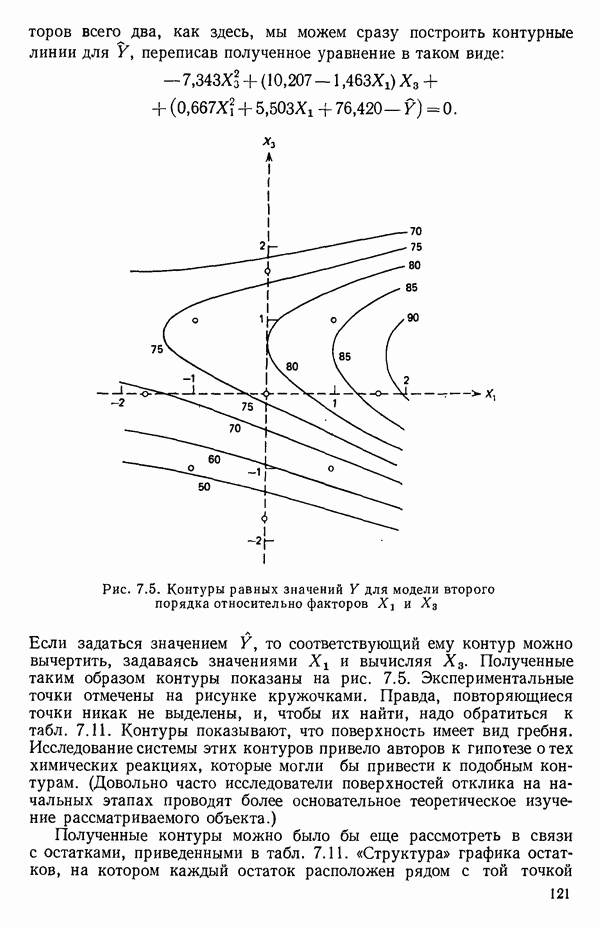
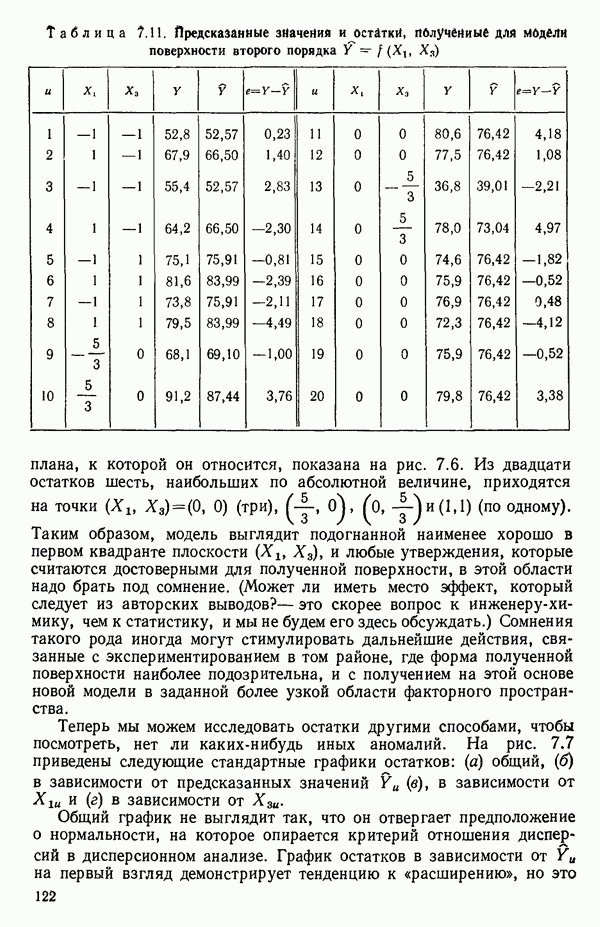
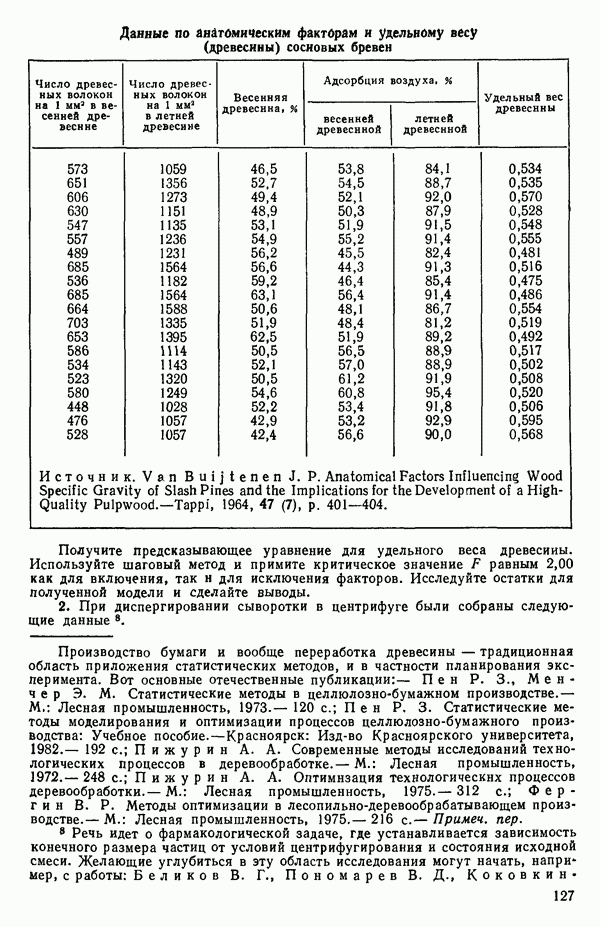
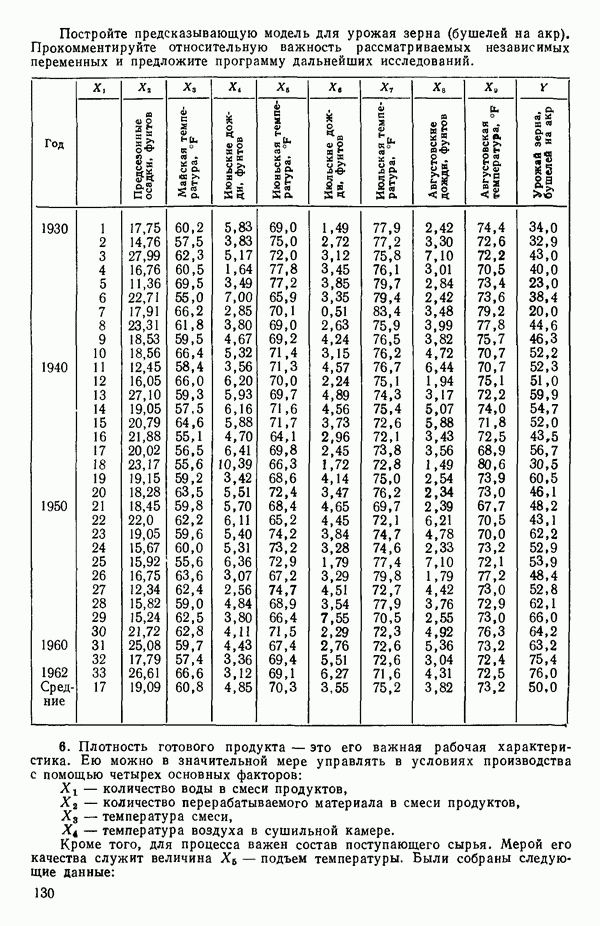
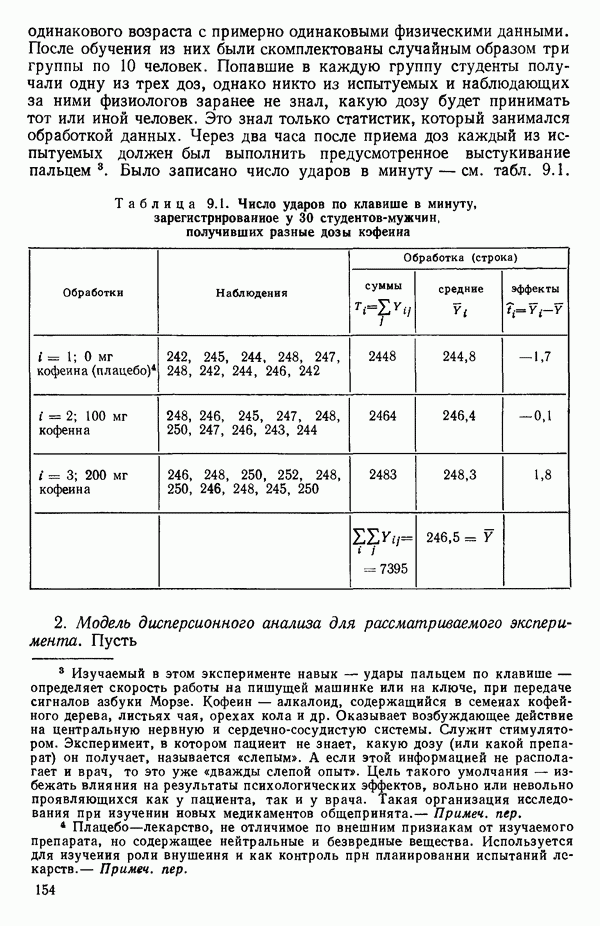
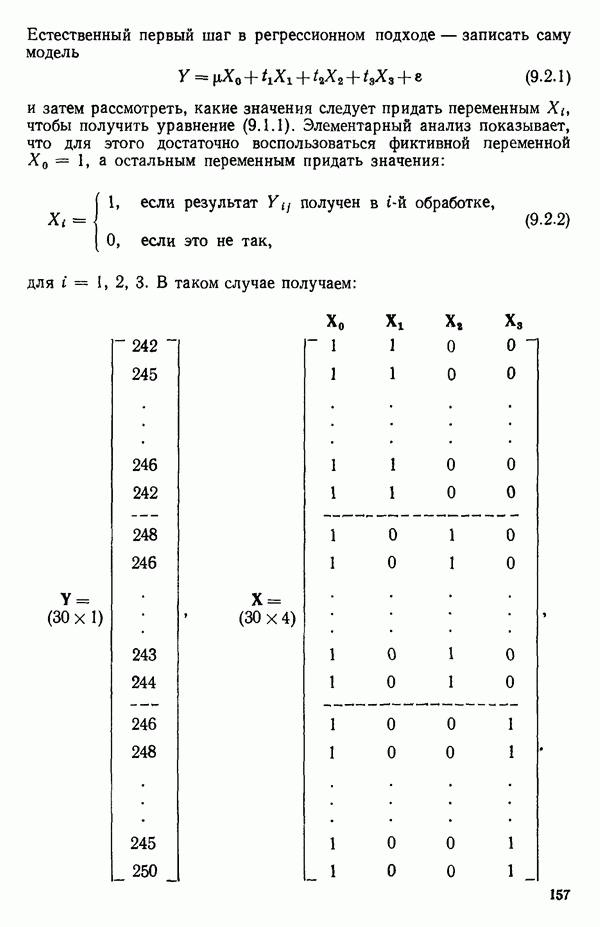
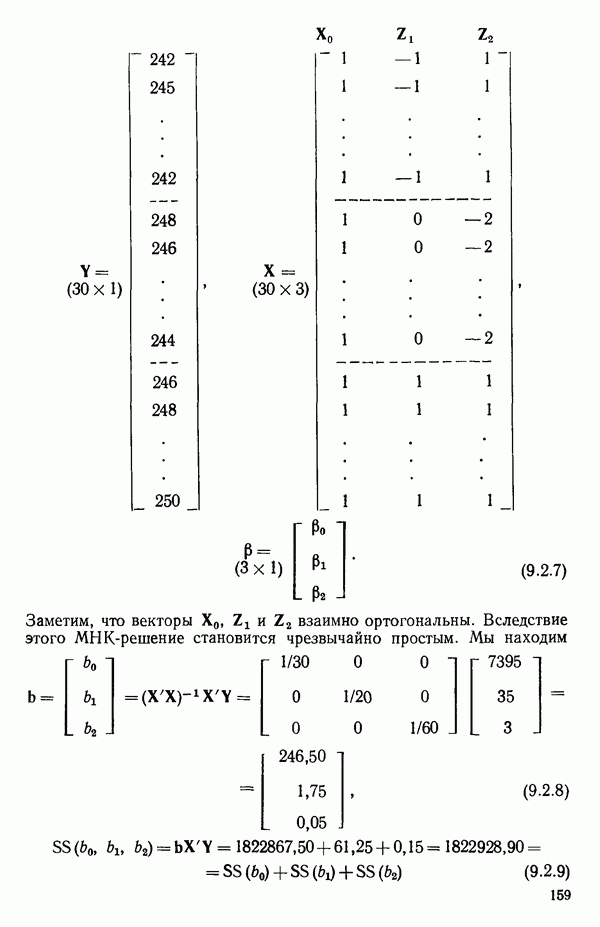
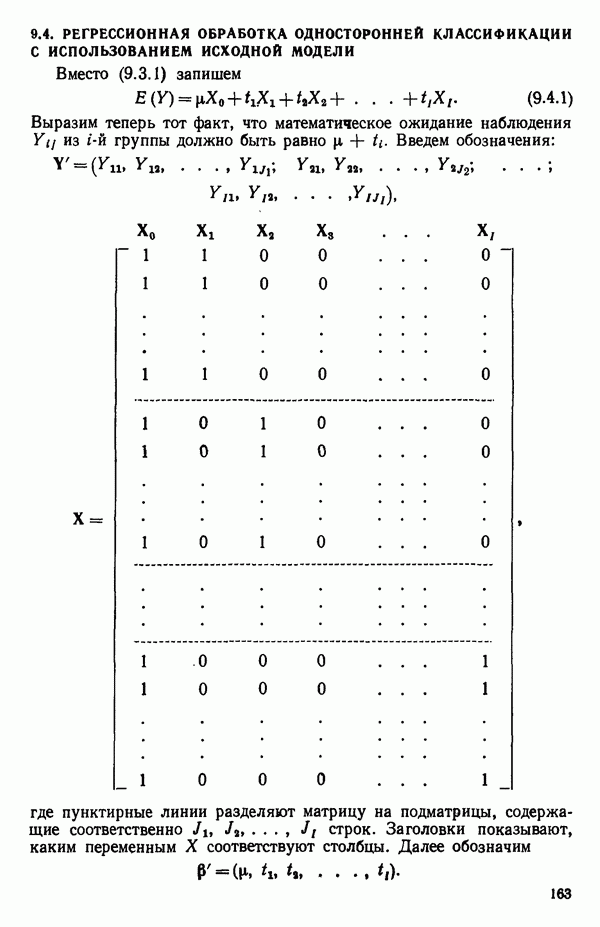
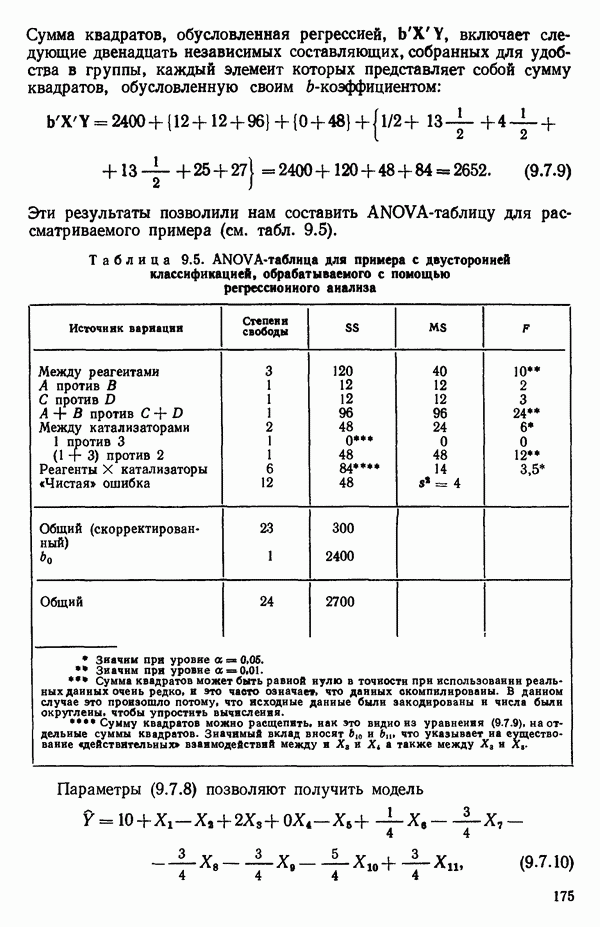
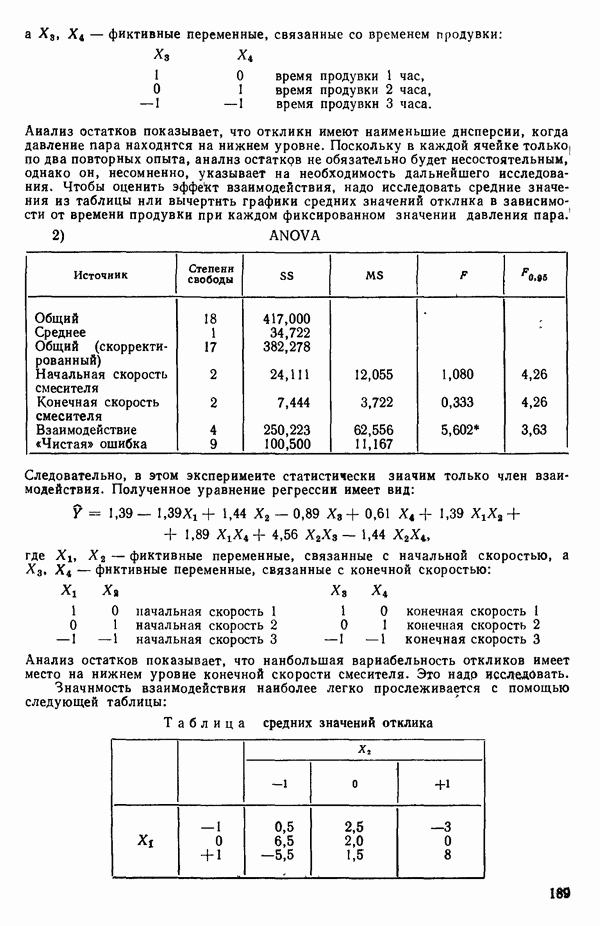
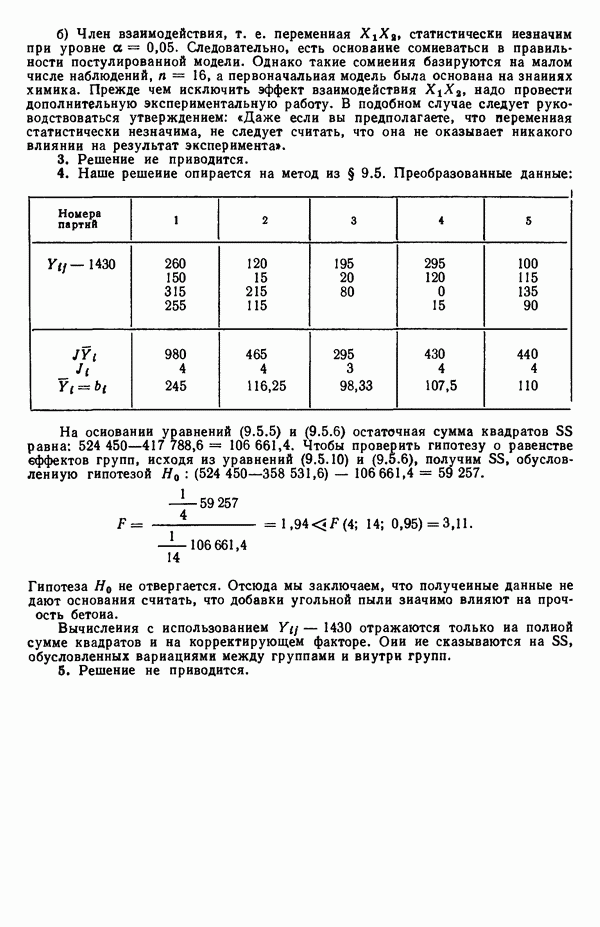
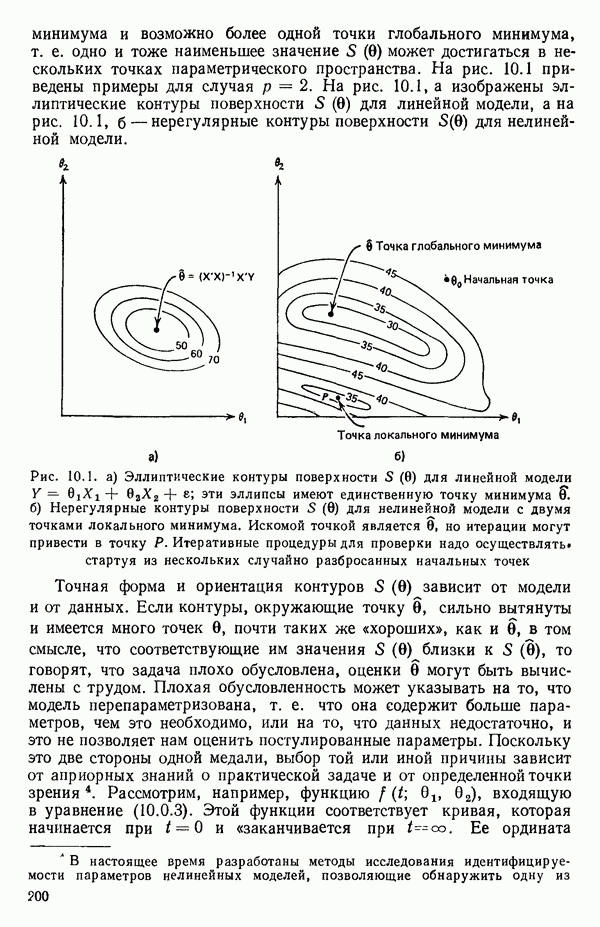
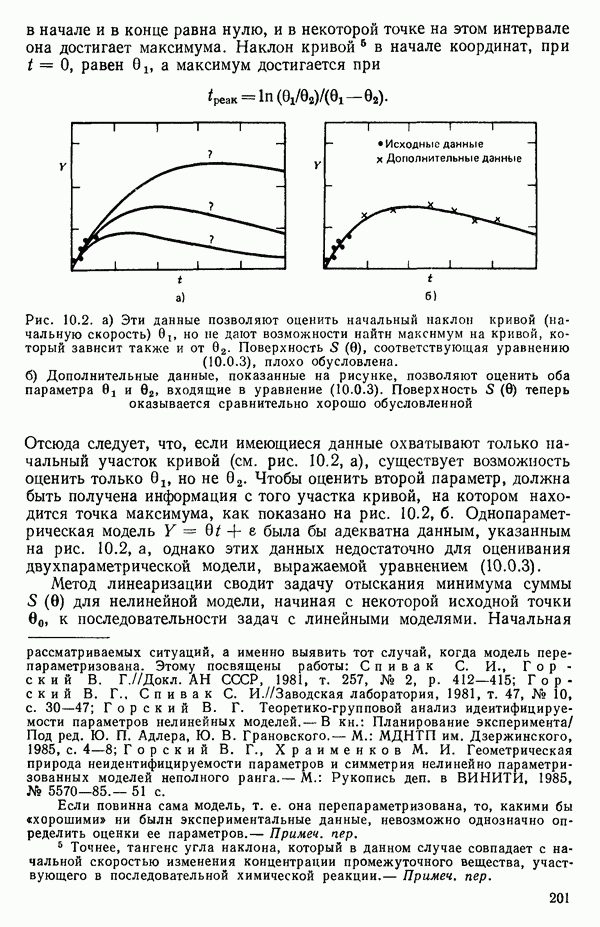
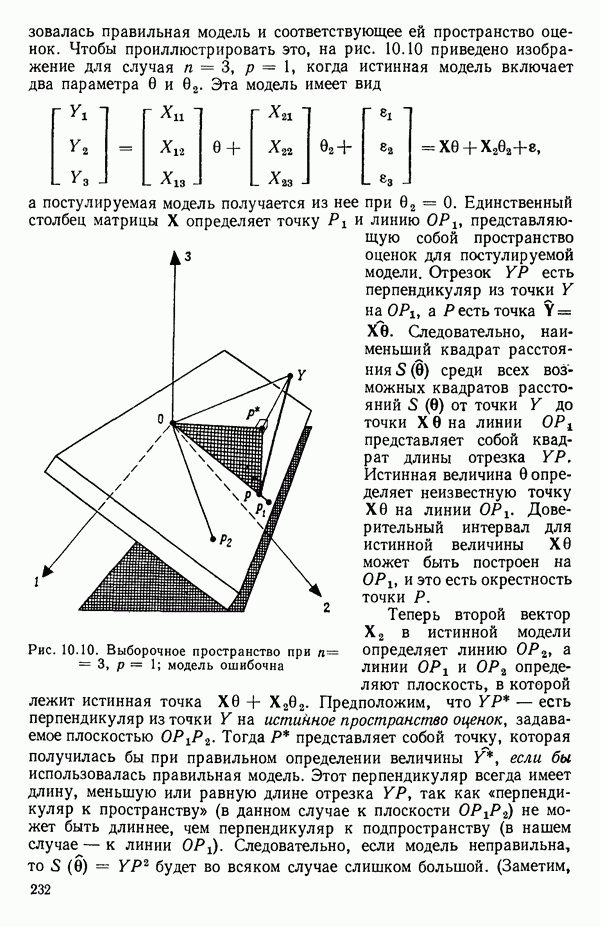
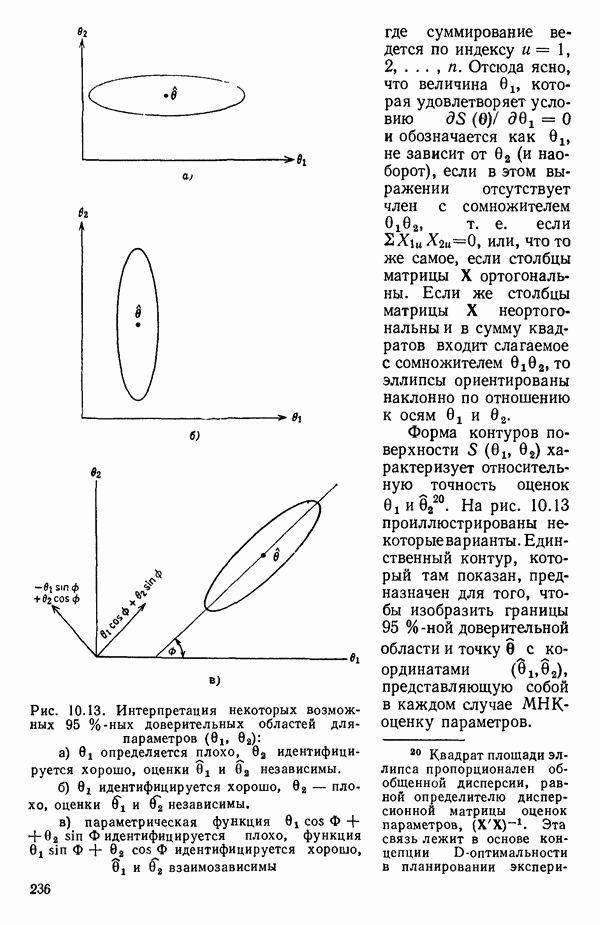
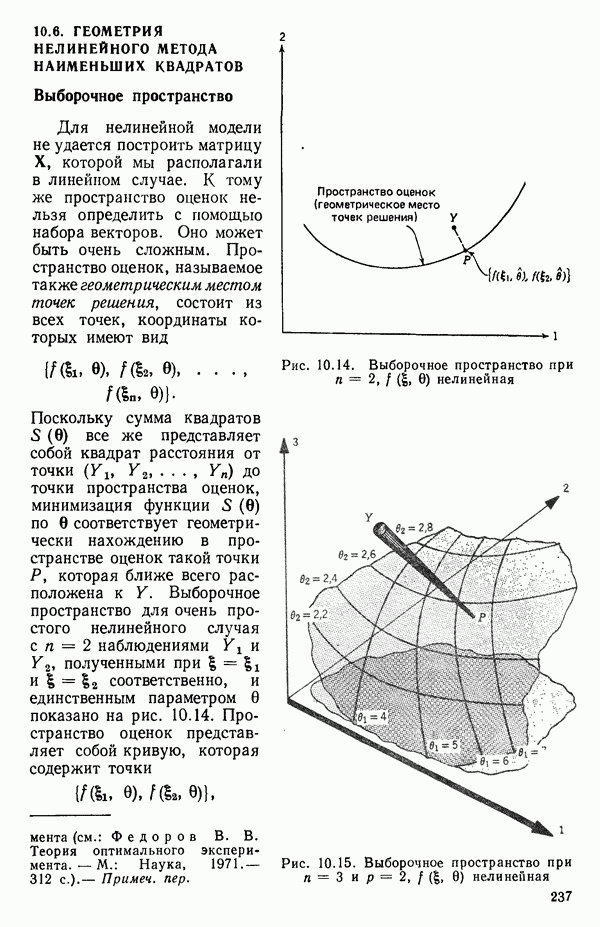
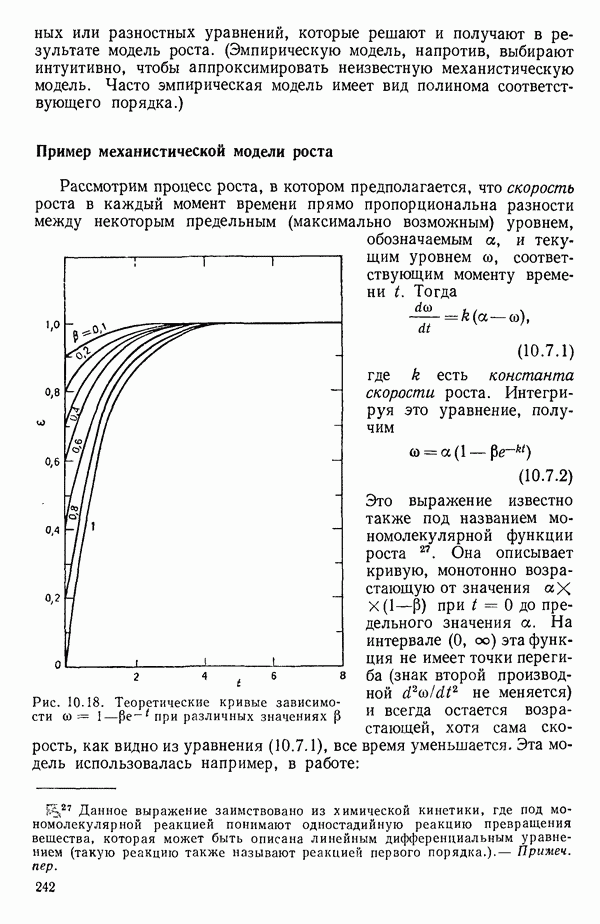
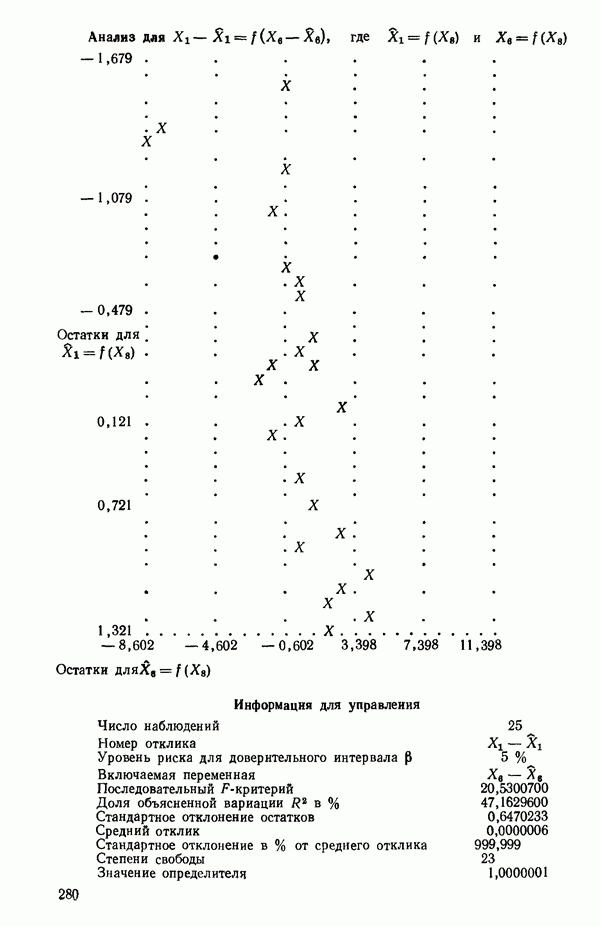
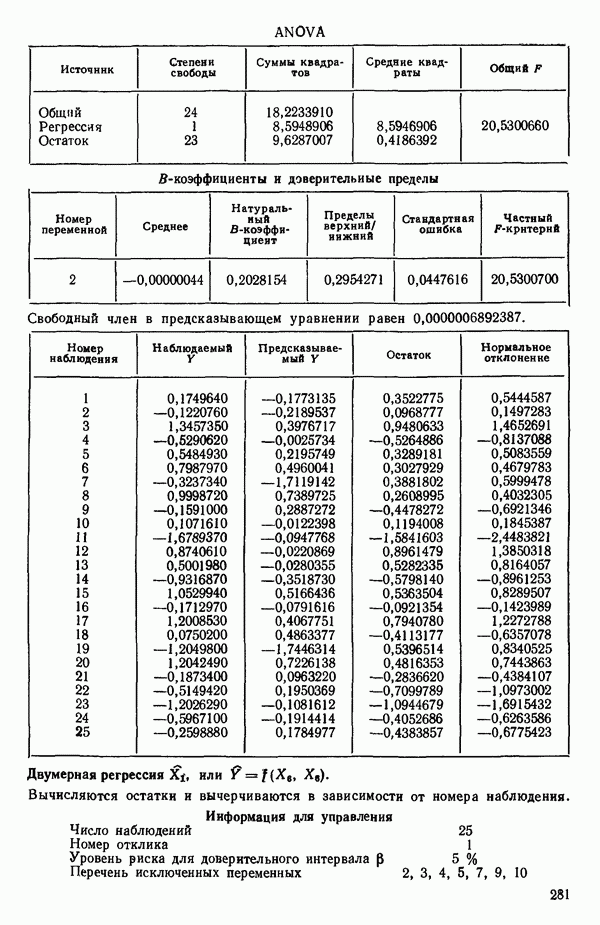
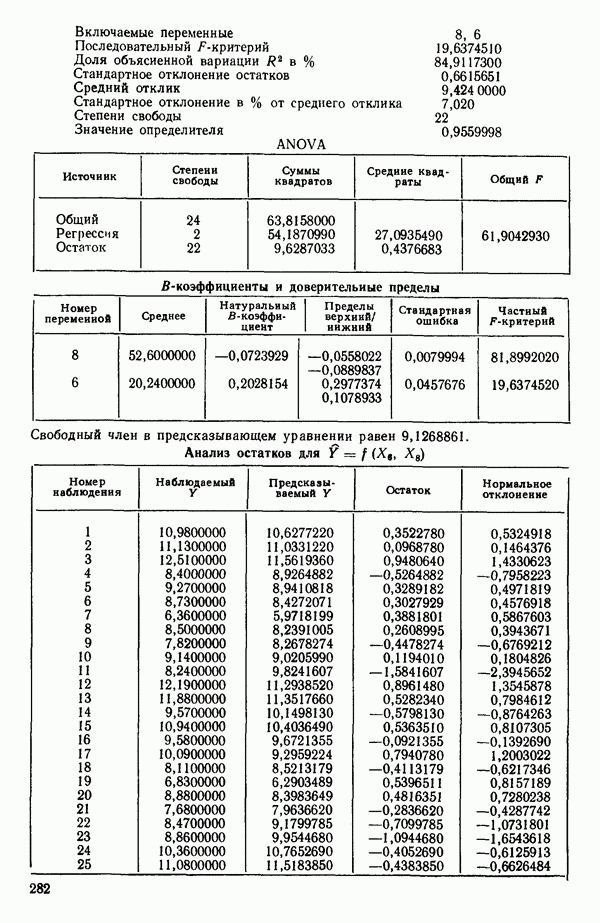
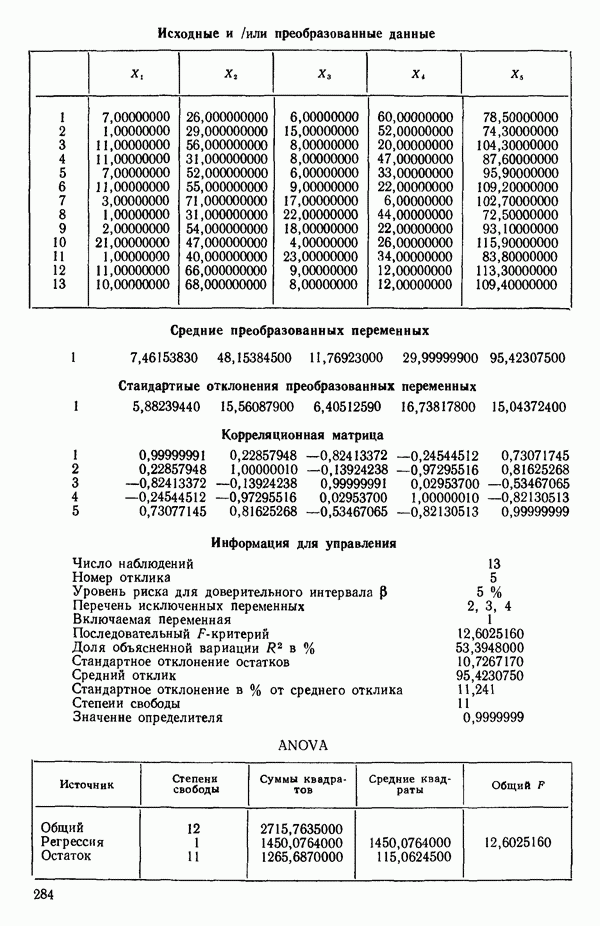
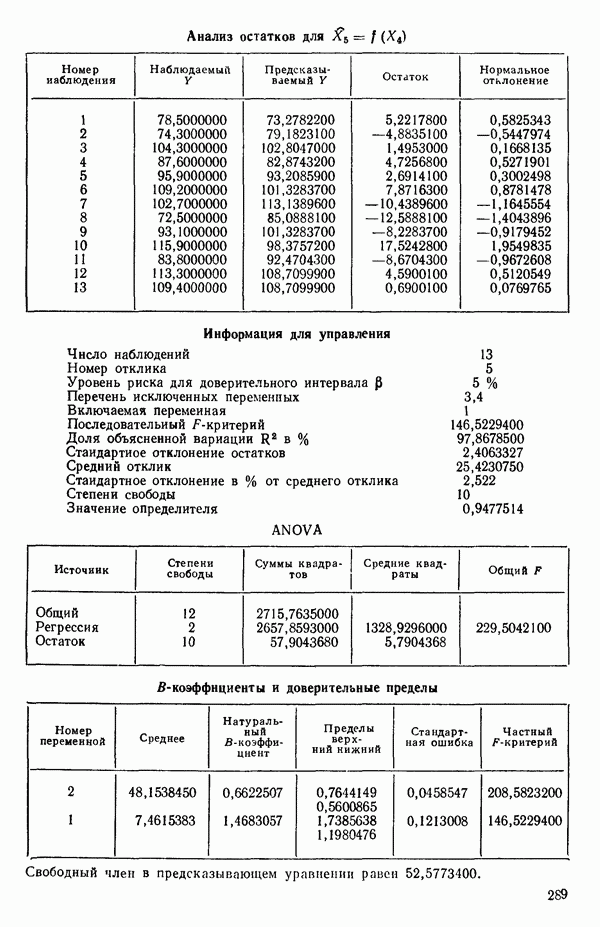
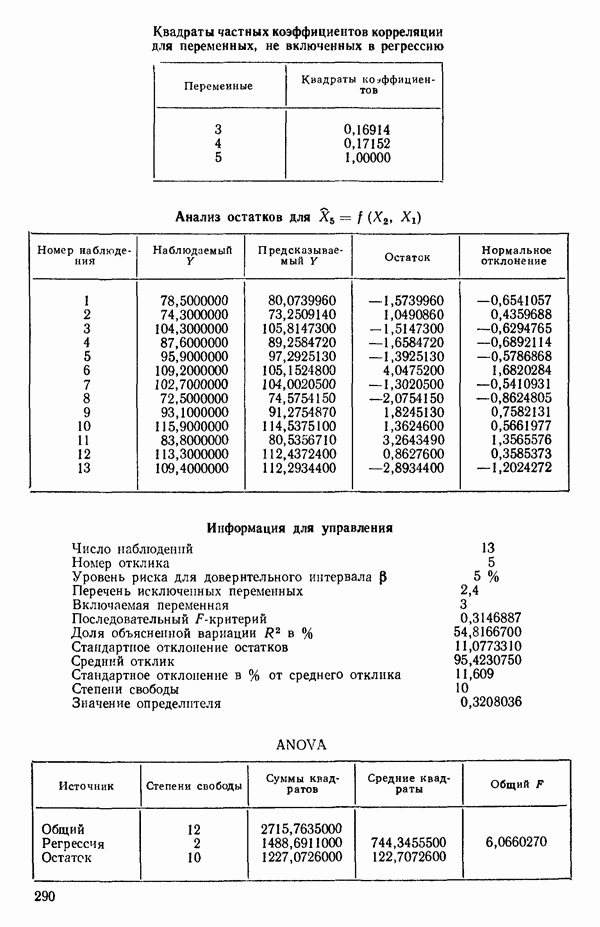
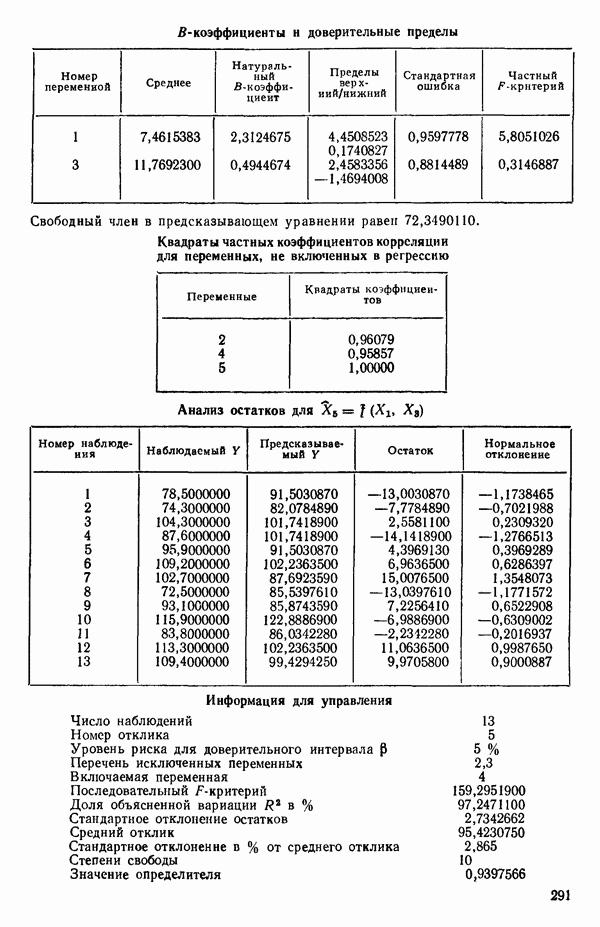
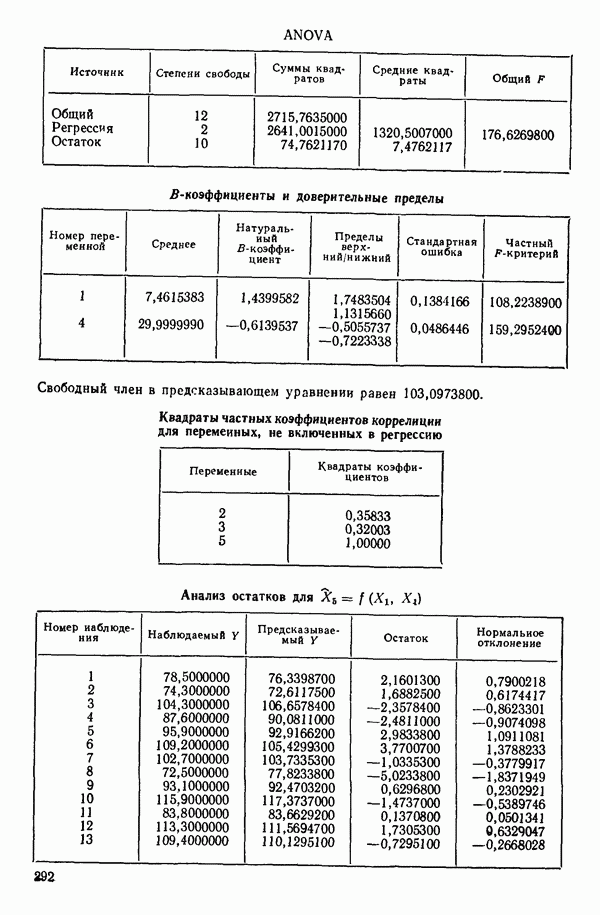
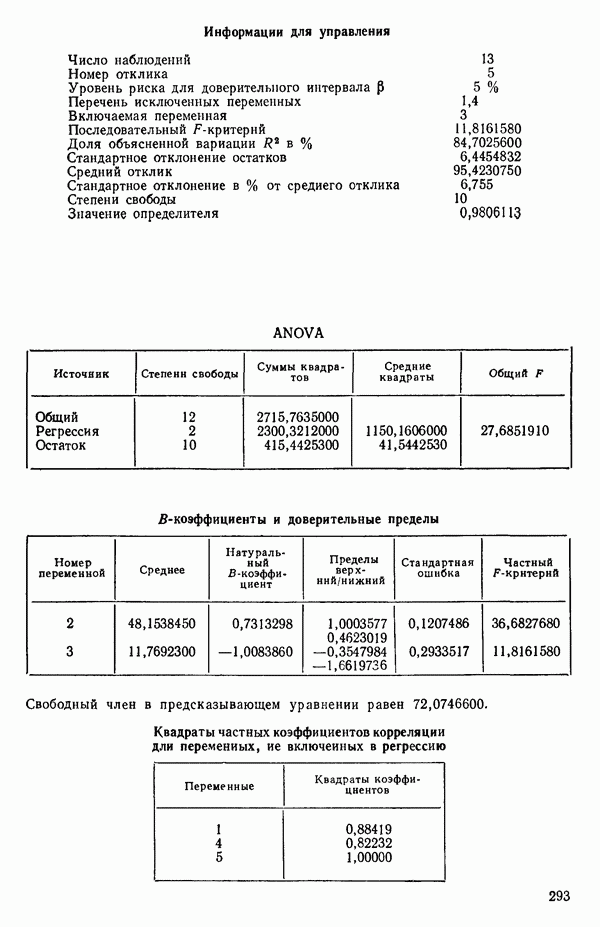
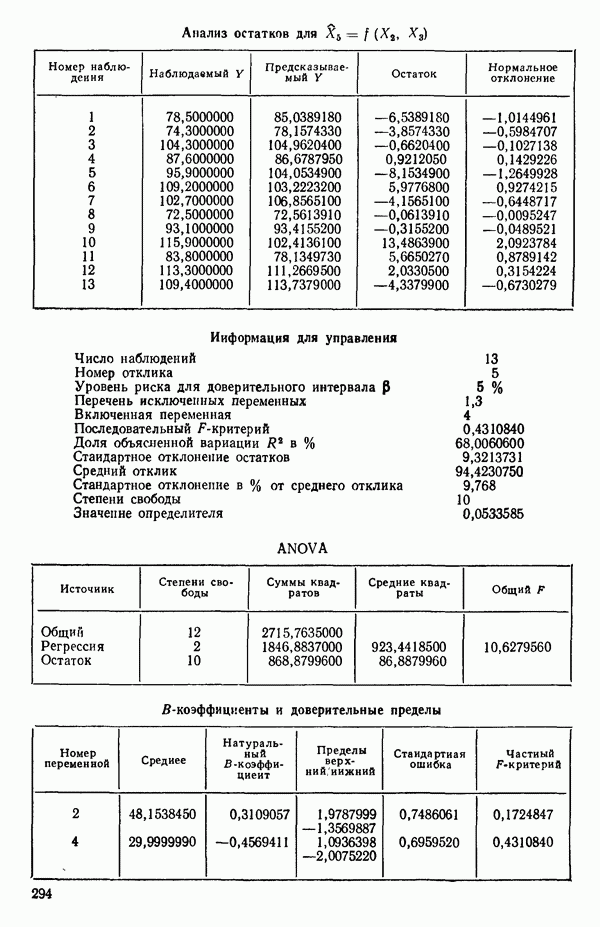
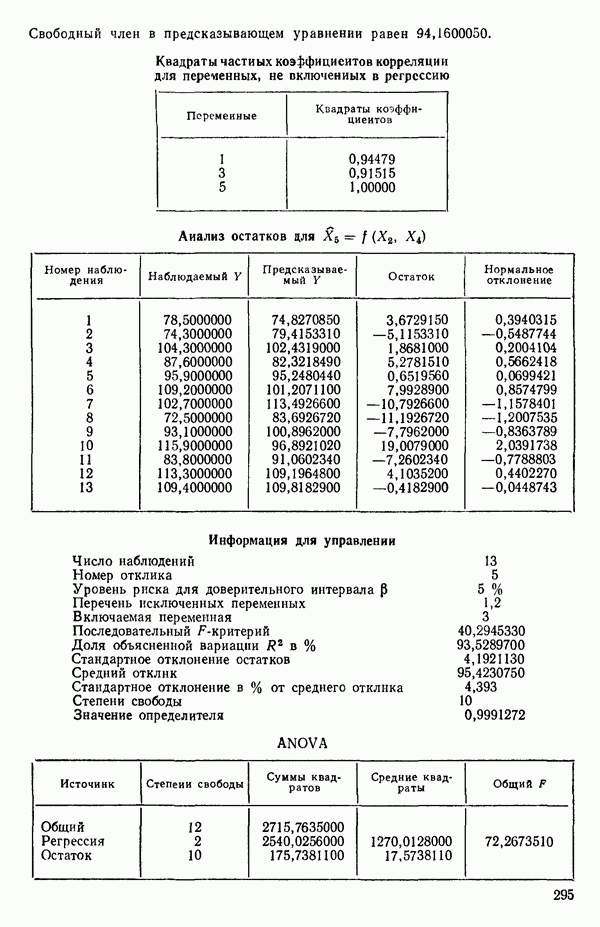
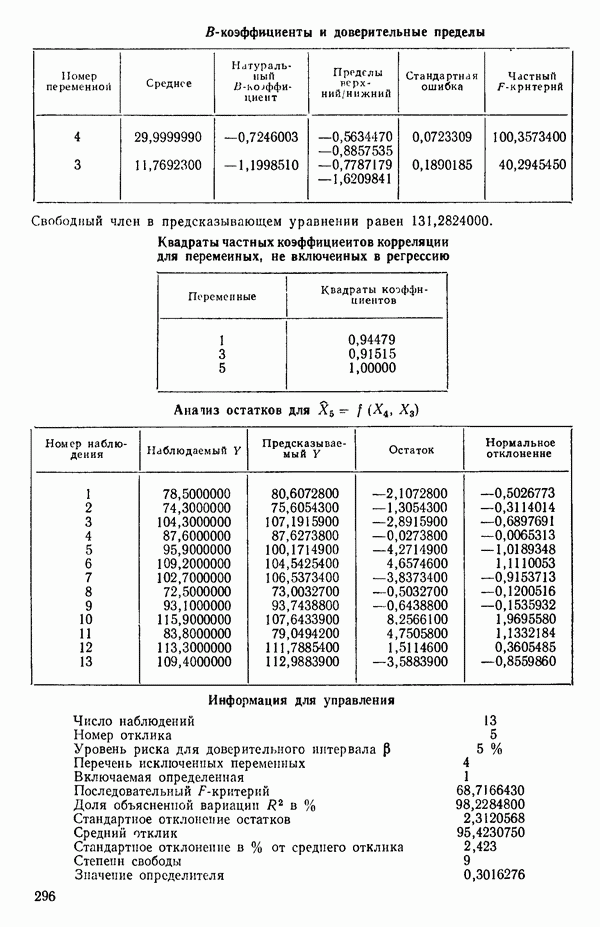
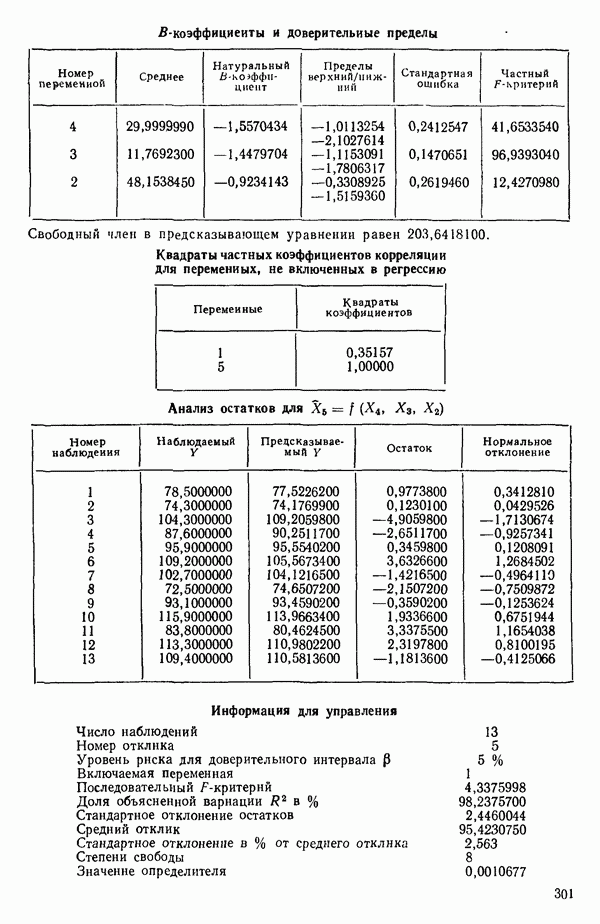
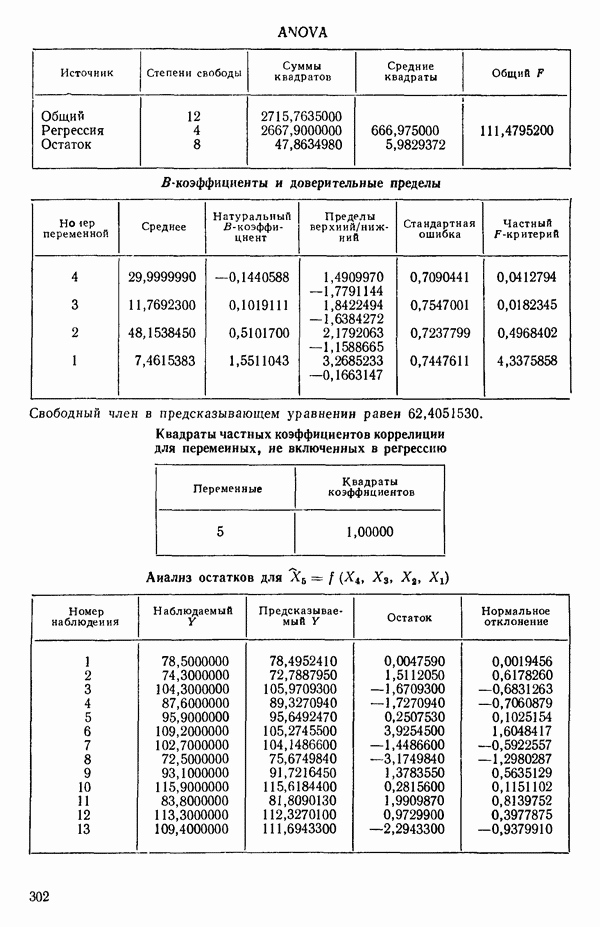
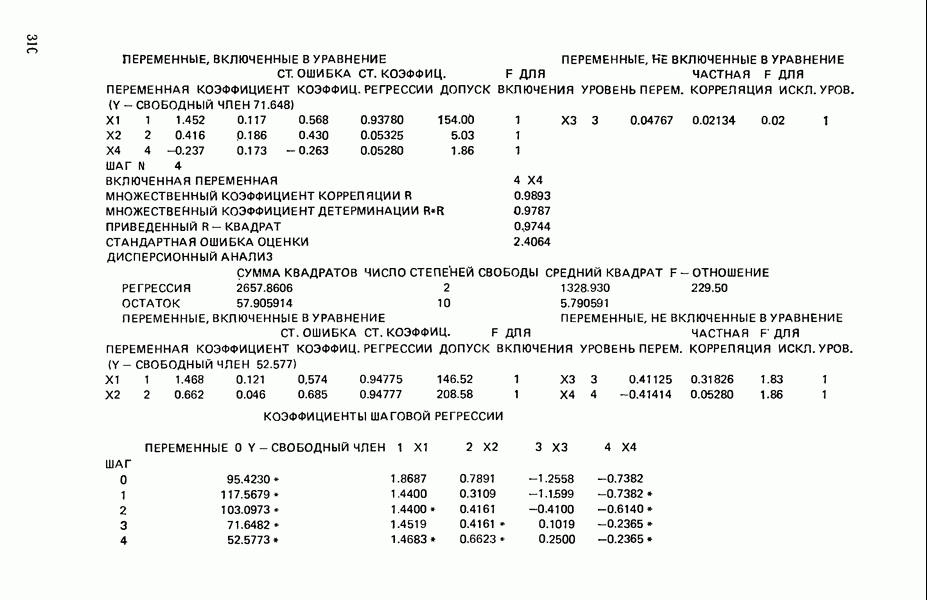
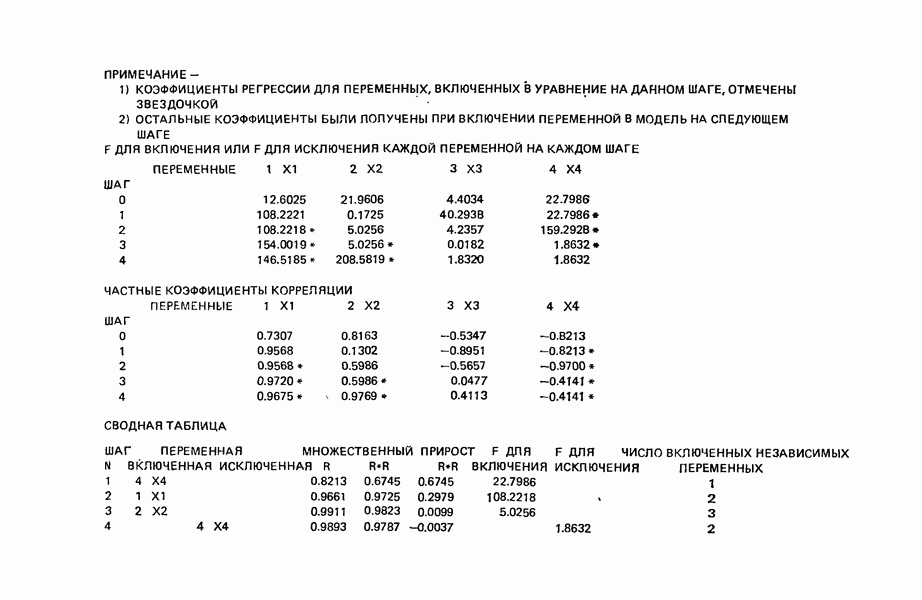
6.5. НЕДОСТАТОК, КОТОРЫЙ СЛЕДУЕТ ПОНЯТЬ, НЕ ПРИДАВАЯ ЕМУ СЛИШКОМ БОЛЬШОГО ЗНАЧЕНИЯ
Как метод исключения, так и шаговый регрессионный метод страдают недостатком, который не очевиден на первый взгляд. Так, например, в шаговой процедуре проверка по частному  -критерию на стадии включения переменной производится для того предиктора, который имеет наибольшее значение частного F среди всех предикторов, не входящих в регрессию в данный момент. Корректное «нуль-распределение» (т. е. распределение в случае справедливости нулевой гипотезы) этой статистики, как мы полагаем, будет отнюдь не обычным
-критерию на стадии включения переменной производится для того предиктора, который имеет наибольшее значение частного F среди всех предикторов, не входящих в регрессию в данный момент. Корректное «нуль-распределение» (т. е. распределение в случае справедливости нулевой гипотезы) этой статистики, как мы полагаем, будет отнюдь не обычным  -распределением и для выборочной, и для теоретической статистики, а получить его очень трудно, за исключением нескольких простейших ситуаций. Исследования показывают, например, что в некоторых случаях, когда проверка с помощью
-распределением и для выборочной, и для теоретической статистики, а получить его очень трудно, за исключением нескольких простейших ситуаций. Исследования показывают, например, что в некоторых случаях, когда проверка с помощью  -критерия при включении переменных производилась при уровне значимости а, соответствующая вероятность была равна
-критерия при включении переменных производилась при уровне значимости а, соответствующая вероятность была равна  где
где  число кандидатов на включение, которые имелись на этой стадии. Что можно сделать в связи с этим? Одна возможность состоит в определении правильных уровней значимости для любого данного случая. Другая заключается в использовании иных статистических критериев вместо частного
число кандидатов на включение, которые имелись на этой стадии. Что можно сделать в связи с этим? Одна возможность состоит в определении правильных уровней значимости для любого данного случая. Другая заключается в использовании иных статистических критериев вместо частного  -критерия. Обе эти возможности обсуждались в недавних публикациях, но к моменту написания нашей книги проблема полностью и надлежащим образом еще не была решена, в том смысле, чтобы можно было гарантировать улучшение процедуры. Пока такое решение не найдено, мы предлагаем читателю применять процедуры в описанном виде, не придавая слишком большого значения действительным уровням вероятности, а просто рассматривая весь метод как проведение серии сравнений, которые позволяют выявлять, по-видимому, наиболее полезные наборы предикторов. Для тех, кто желает углубиться в проблему более основательно, мы приводим в конце книги некоторые избранные ссылки. Этим читателям следует также просмотреть последние выпуски основных статистических журналов, где могут содержаться другие работы.
-критерия. Обе эти возможности обсуждались в недавних публикациях, но к моменту написания нашей книги проблема полностью и надлежащим образом еще не была решена, в том смысле, чтобы можно было гарантировать улучшение процедуры. Пока такое решение не найдено, мы предлагаем читателю применять процедуры в описанном виде, не придавая слишком большого значения действительным уровням вероятности, а просто рассматривая весь метод как проведение серии сравнений, которые позволяют выявлять, по-видимому, наиболее полезные наборы предикторов. Для тех, кто желает углубиться в проблему более основательно, мы приводим в конце книги некоторые избранные ссылки. Этим читателям следует также просмотреть последние выпуски основных статистических журналов, где могут содержаться другие работы.
Преодолеть указанную выше трудность проще всего, назначив в программах заранее значения  для включения и исключения (так, например, можно принять
для включения и исключения (так, например, можно принять  Такой подход описывается Форсайтом в сборнике программ (BMDP-79, Biomedical Computer Programs, P-Series/Diхоп W. J., Brown М. B., Eds.-Berkeley: University of California Press, 1979, Appendix C, p. 855) следующим образом:
Такой подход описывается Форсайтом в сборнике программ (BMDP-79, Biomedical Computer Programs, P-Series/Diхоп W. J., Brown М. B., Eds.-Berkeley: University of California Press, 1979, Appendix C, p. 855) следующим образом:
«Некоторые пользователи, применяющие программы шагового регрессионного и дискриминантного анализа, спрашивают: почему мы всюду используем термины  для включения» и
для включения» и  для исключения» вместо того, чтобы просто называть их величинами
для исключения» вместо того, чтобы просто называть их величинами  Другие
Другие
предлагают, чтобы мы запрашивали у пользователя уровень значимости а и имели программу, позволяющую преобразовать эту величину в соответствующее значение  Составить такую программу для ЭВМ в принципе достаточно просто, но это нелегко сделать статистически корректно, поскольку при выборе «наилучшей» переменной обычные таблицы
Составить такую программу для ЭВМ в принципе достаточно просто, но это нелегко сделать статистически корректно, поскольку при выборе «наилучшей» переменной обычные таблицы  -критерия неприменимы. Подходящее критическое значение есть функция числа вариантов, числа переменных и, к несчастью, характера коррелированности предикторных переменных. Это означает, что уровень значимости, соответствующий
-критерия неприменимы. Подходящее критическое значение есть функция числа вариантов, числа переменных и, к несчастью, характера коррелированности предикторных переменных. Это означает, что уровень значимости, соответствующий  -критерию для включения, зависит от конкретного набора данных. Так, например, в случае нескольких сотен опытов и 50 потенциальных предикторов
-критерию для включения, зависит от конкретного набора данных. Так, например, в случае нескольких сотен опытов и 50 потенциальных предикторов  -критерий для включения, равный 11, приближенно соответствовал бы
-критерий для включения, равный 11, приближенно соответствовал бы  если бы все 50 предикторов были некоррелированными. В обычно используемых
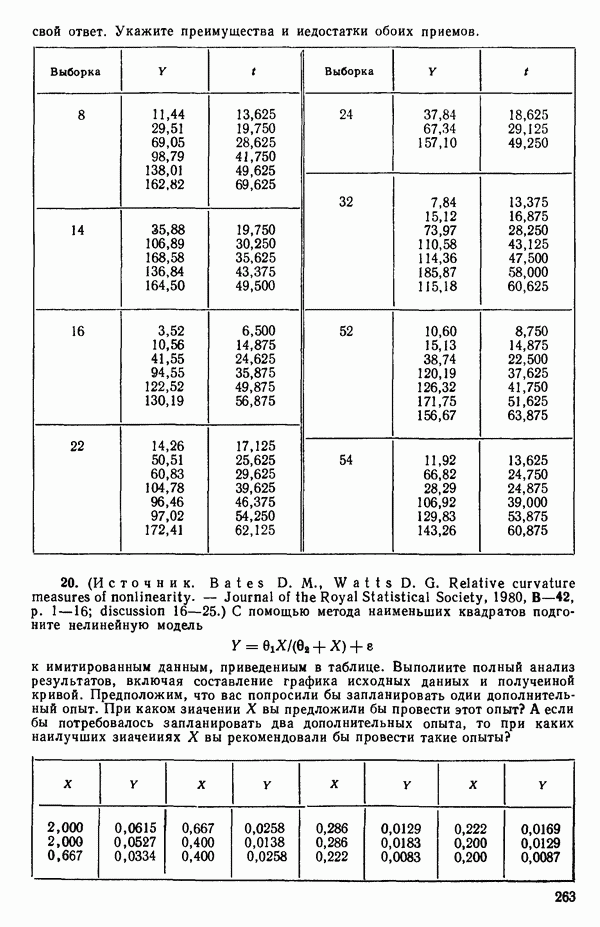
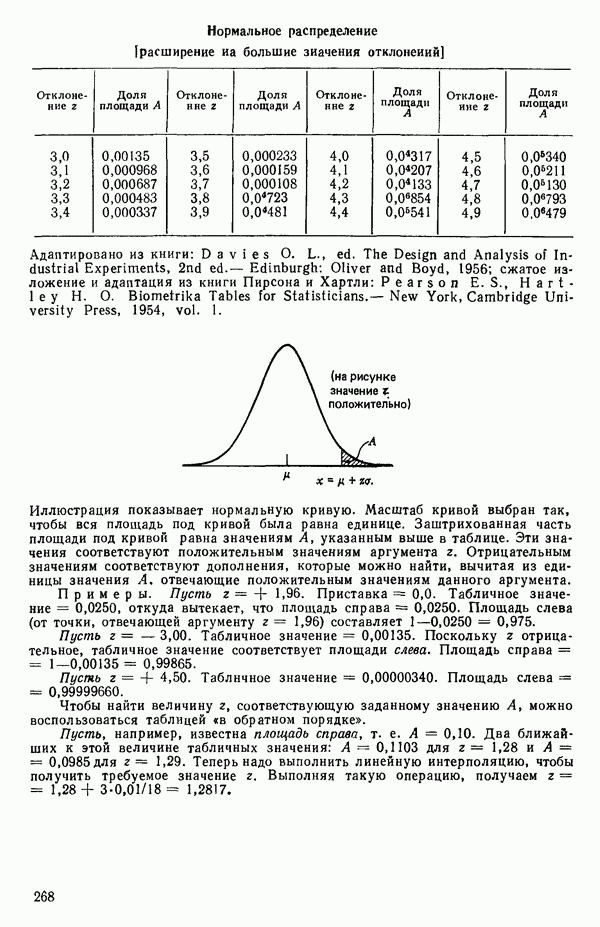
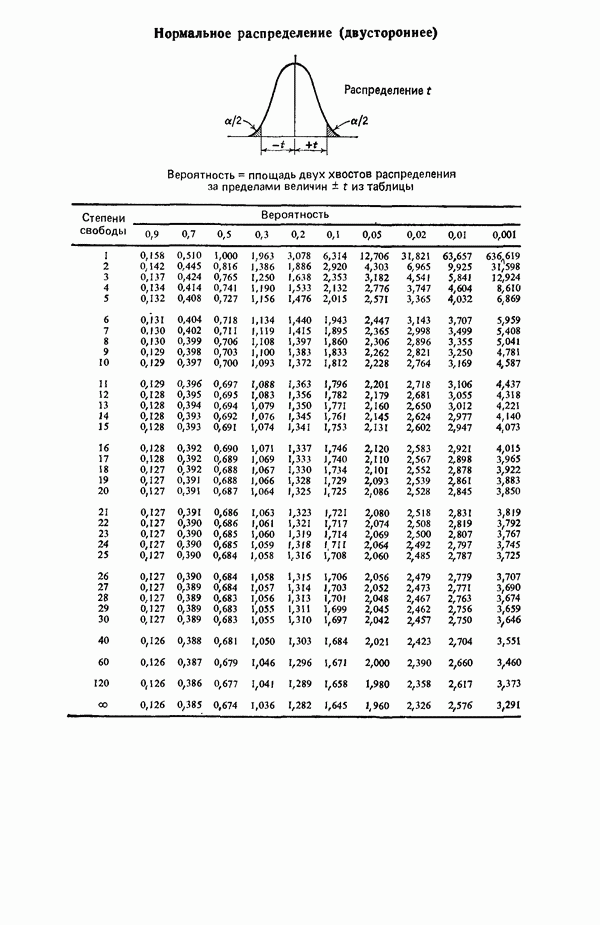
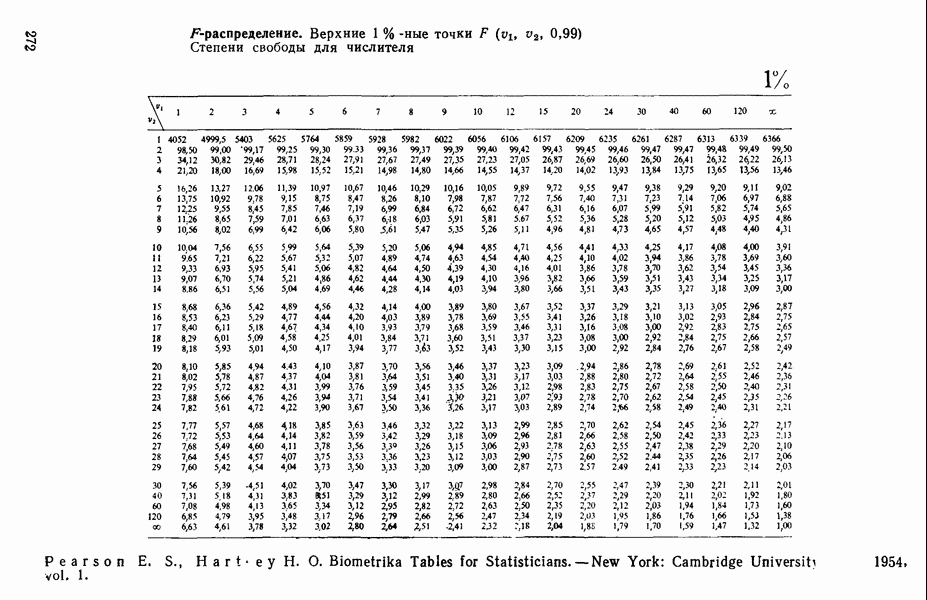
если бы все 50 предикторов были некоррелированными. В обычно используемых  -таблицах ошибочно предлагается величина
-таблицах ошибочно предлагается величина  , равная 4.»
, равная 4.»
(Добавим к этому, что использование значения, равного 4, не будет неправильным, если просто принимать а более высоким, чем мы обсуждали ранее. Однако зачастую принимают значения по существу более высокие. Так, например, в указанном выше случае при номинальном значении  (50 некоррелированных предикторов) «действительная» величина а, определяемая по формуле 1 —
(50 некоррелированных предикторов) «действительная» величина а, определяемая по формуле 1 —  равнялась бы 0,923. Эта формула может быть полезна в качестве грубого ориентира. Заметим, что пакет программ BMDP периодически пересматривается. В более поздних версиях учитываются возможные изменения метода.)
равнялась бы 0,923. Эта формула может быть полезна в качестве грубого ориентира. Заметим, что пакет программ BMDP периодически пересматривается. В более поздних версиях учитываются возможные изменения метода.)