Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
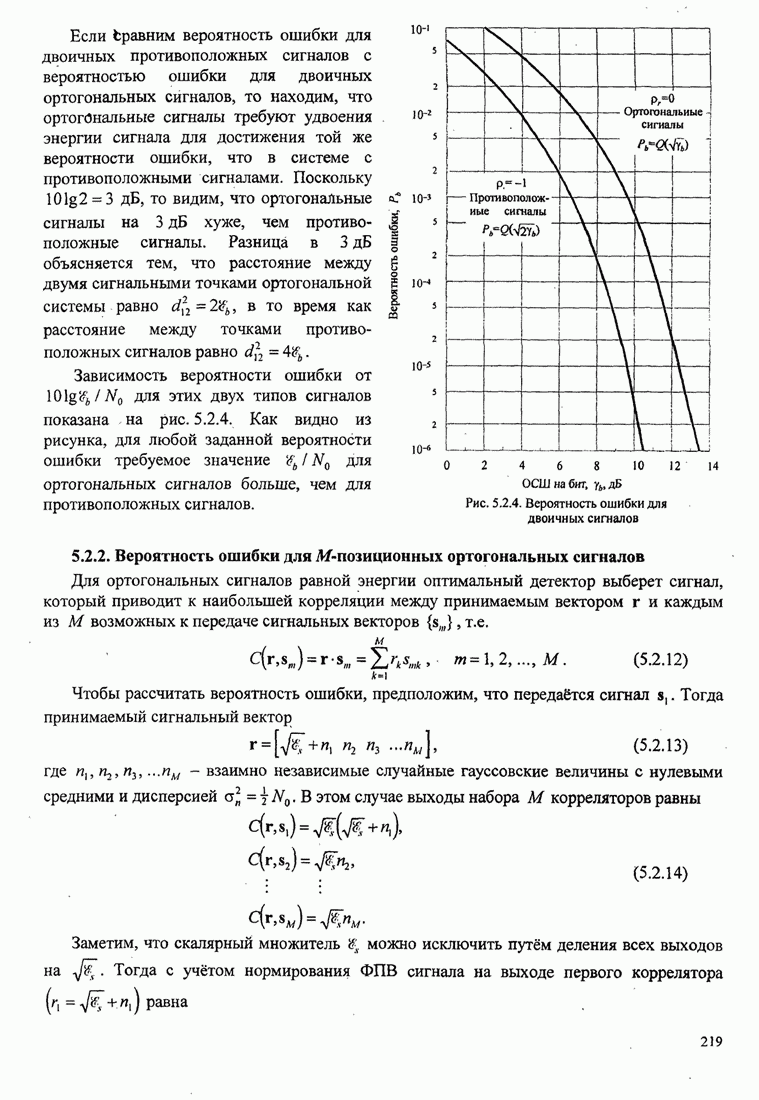
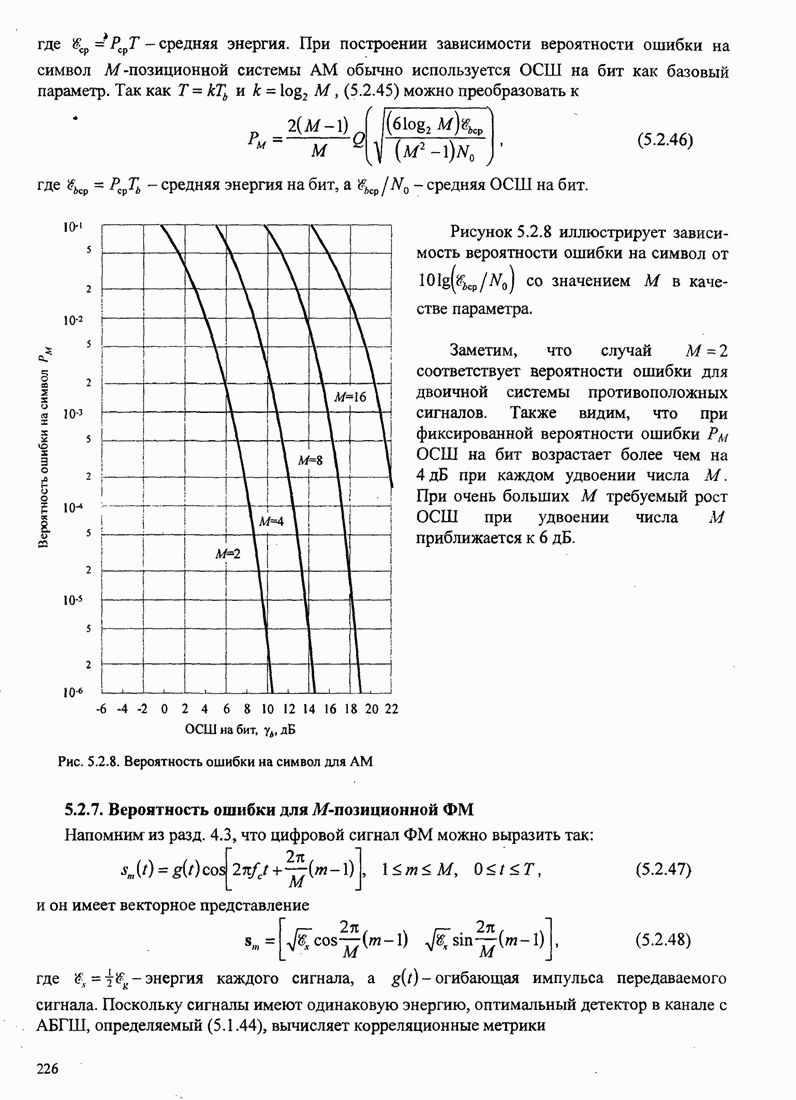
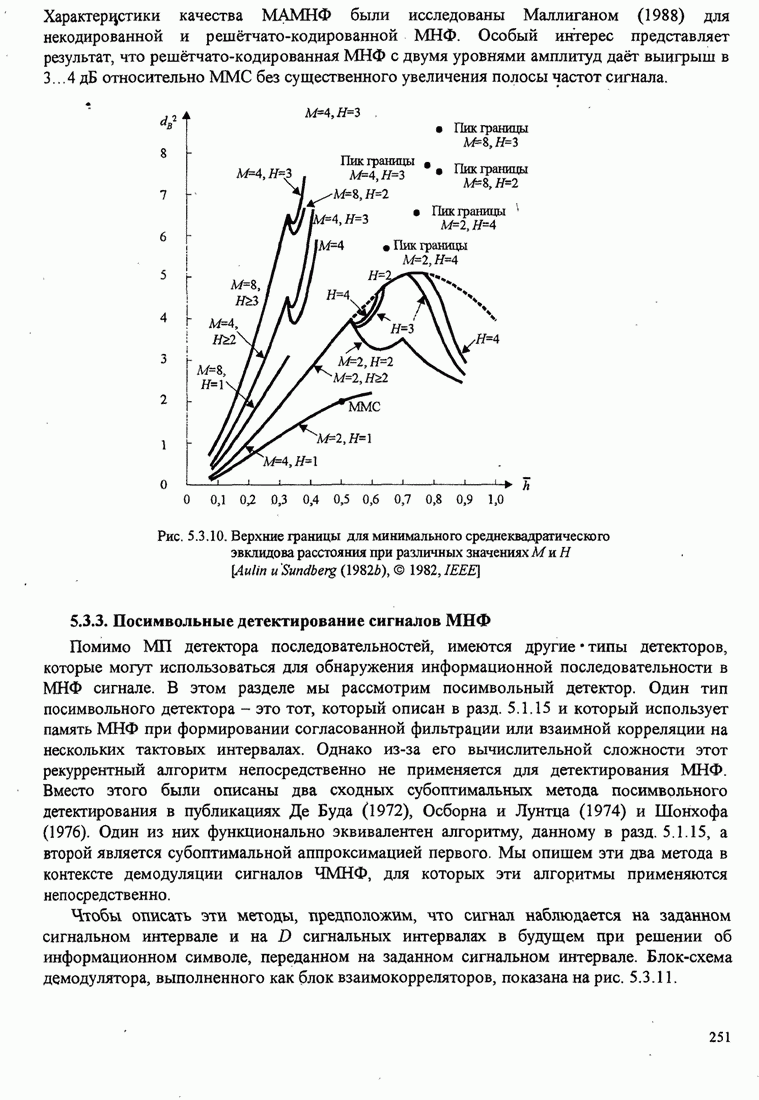
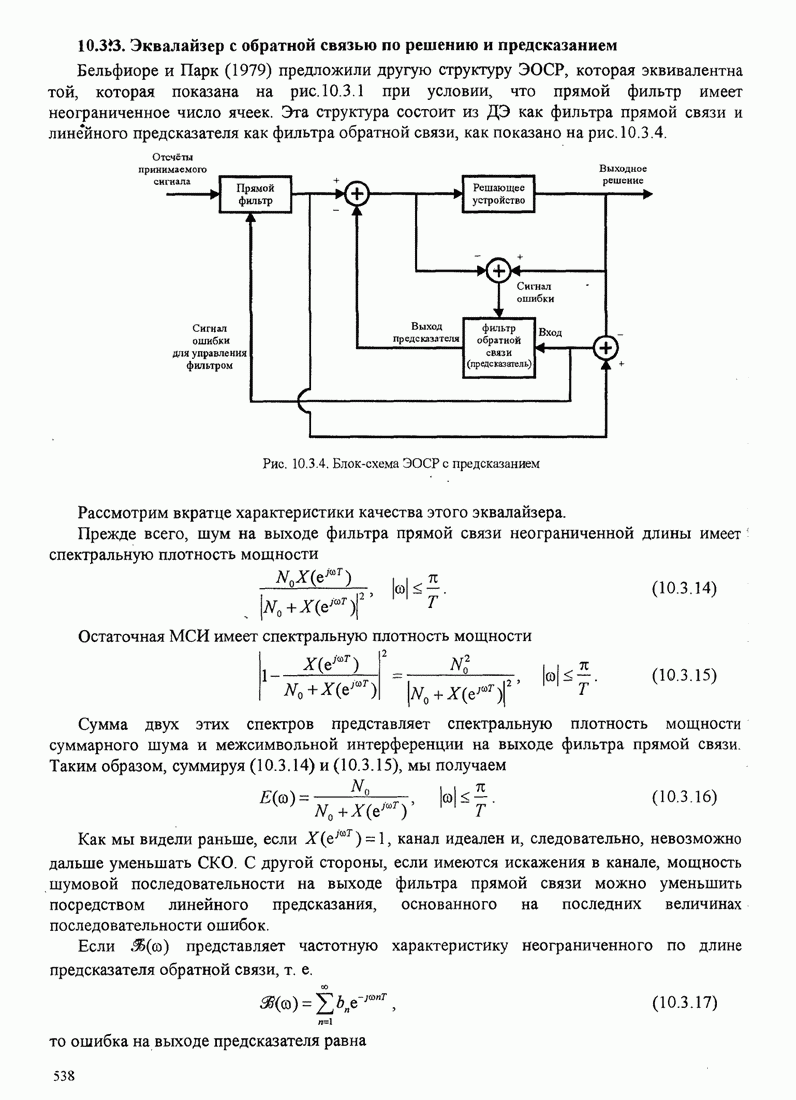
3.4.3. Векторное квантованиеВ предыдущих разделах мы рассмотрели квантование выходного сигнала непрерывного источника для случая, когда квантование выполняется последовательно по отдельным отсчётам, т.е. скалярное квантование. В этом разделе мы рассмотрим совместное квантование блока символьных отсчётов или блока сигнальных параметров. Этот вид квантования называется блоковым или векторным квантованием. Оно широко используется при кодировании речи в цифровых сотовых системах связи.
Фундаментальный результат теории искажения заключается в том, что лучшую характеристику можно достичь векторным, а не скалярным квантованием, даже если непрерывный источник без памяти. Если, кроме того, отсчёты сигнала или параметры сигнала статистически зависимы, мы можем использовать зависимость посредством совместного квантования блоков отсчётов или параметров и таким образом достичь большей эффективности (более низкой битовой скорости) по сравнению с той, которая достигается скалярным квантованием. Проблему
векторного квантования можно сформулировать так. Имеем
где
В
принципе векторное квантование блоков данных можно рассматривать как проблему
распознавания образов, включающую в себя классификацию блоков данных через
дискретное количество категорий или ячеек в соответствии с некоторым критерием
точности, таким, например, как среднеквадратическая погрешность. Для примера
рассмотрим квантование двумерных векторов
Рис. 3.4.3. Пример квантания в двухмерном пространстве В
общем, квантование
где
или, в более общем виде, взвешенная среднеквадратическая ошибка
где
Другая
мера искажений, которая иногда используется, является частным случаем
Частный
случай, когда Векторное
квантование не ограничивается квантованием блока сигнальных отсчётов источника
сигнала. Его можно использовать для квантования ряда параметров, извлечённых из
данных. Например, при линейном кодировании с предсказанием (ЛКП), описанном в
разделе 3.5.3, параметры, извлечённые из сигнала, являются коэффициентами
предсказания, которые являются коэффициентами для всеполюсной фильтровой модели
источника, который генерирует наблюдаемые данные. Эти параметры можно
рассматривать как блок и квантовать как блок символов, используя некоторую
подходящую меру искажений. В случае кодирования речи подходящей мерой
искажений, которую предложили Итакура и Саити (1986, 1975), является взвешенная
среднеквадратическая ошибка, где взвешивающая матрица При
кодировании речи альтернативным рядом параметров, которые могут быть квантованы
как блок и переданы к приёмнику, могут быть коэффициенты отражения (см. ниже) Еще
один ряд параметров, которые иногда используются для векторного квантования при
линейном кодировании с предсказанием речи, содержит логарифмические отношения
Теперь
вернемся к математической формулировке векторного квантования и рассмотрим
разбиение
если, и только если
Второе
условие, необходимое для оптимизации, заключается в том, что каждый выходной
вектор
Вектор
Таким
образом, эти условия оптимизации определяют разбиение В качестве верхней границы искажений векторного
квантования мы можем использовать величину искажений оптимального скалярного
квантователя, и эту границу можно применить для каждой компоненты вектора, как
было описано в предыдущем разделе. С другой стороны, наилучшие характеристики,
которые могут быть достигнуты оптимальным векторным квантователем, определяются
функцией скорость-искажение или, что эквивалентно, функцией искажение-скорость.
Функция искажение-скорость, которая была введена в предыдущем разделе, может
быть определена в контексте векторного квантования следующим образом.
Предположим, мы формируем вектор
Минимально достижимая средняя битовая скорость, с
которой могут быть переданы векторы
где
Для данной средней скорости
где
где Изложенный выше подход приемлем в предположении, что
СФПВ
Алгоритм K средних
Шаг 1.
Инициализируется начальный номер итерации Шаг 2.
Обучающие векторы
Шаг 3.
Пересчитываются (для
для обучающих векторов, которые попадают в каждую группу. Кроме того, рассчитывается результирующее искажение Шаг 4.
Заканчивается тестирование, если Алгоритм Если мы один раз выбрали выходные векторы
умножений и сложений на входной вектор. Если мы выбрали
Заметим, что число вычислений растёт экспоненциально с
параметром размерности п и битовой скорости Вычислительные затраты, связанные с полным поиском, можно уменьшить при помощи изящного субоптимального алгоритма (см. Чанг и др., 1984; Гершо, 1982). Чтобы продемонстрировать пользу векторного квантования по сравнению со скалярным квантованием, мы представим следующий пример, взятый у Макхоула и др. (1985). Пример 3.4.1. Пусть
где
Рис. 3.4.4. Равномерная ФПВ в двух измерениях (Макхоул и др., 1985) Если
мы квантуем
Следовательно,
для кодирования вектора
Таким образом, скалярное квантование каждой компоненты эквивалентно векторному квантованию с общим числом уровней
Видим,
что это приближение эквивалентно покрытию большой площади, которая охватывает прямоугольник посредством квадратных ячеек, причём каждая
ячейка представляет одну из Если же мы покроем только область, где
Следовательно, разница в битовой скорости при скалярном и векторном методах квантования равна
Для случая, когда
Следовательно, векторное квантование на 0,82 бит/отсчёт лучше, чем скалярное, при тех же искажениях. Интересно заметить, что линейное преобразование
(поворот на 45º) декоррелирует Векторное квантование применяется при различных
методах кодирования речи, включая сигнальные методы и методы базовых моделей,
которые рассматриваются в разд. 3.5. В методах, основанных на базовых моделях,
таких как линейное кодирование с предсказанием, векторное квантование делает
возможным кодирование речи на скоростях ниже 1000 бит/с (см. Бузо и др., 1980;
Роукос и др., 1982; Пауль, 1983). Если использовать методы кодирования
сигналов, возможно получить хорошее качество речи на скоростях передачи 16 000
бит/с, что эквивалентно скорости кодирования
|
 |
Оглавление
|













































































































































































































































































































































































































































































































































































































































































































































































































 (3.4.45)
(3.4.45)
