Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
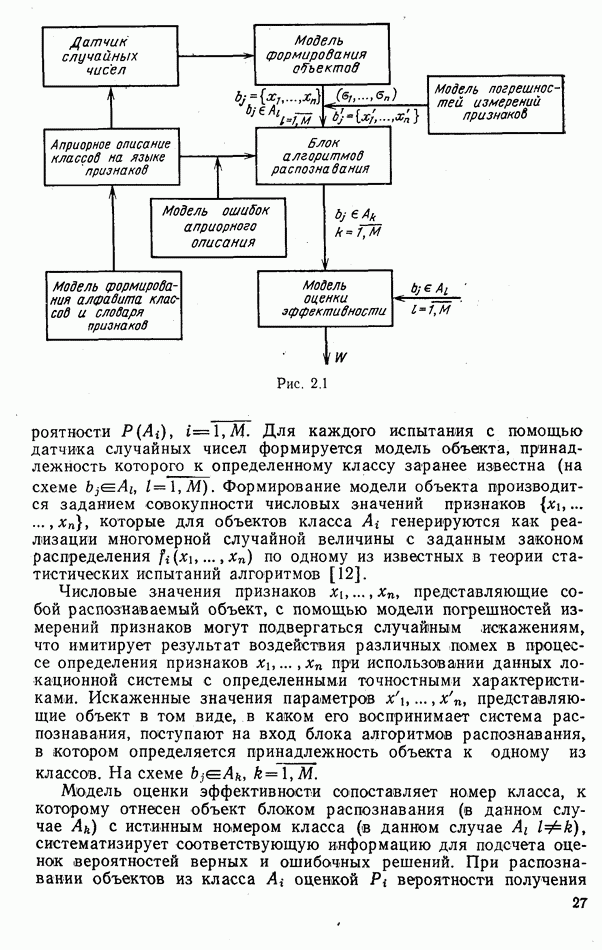
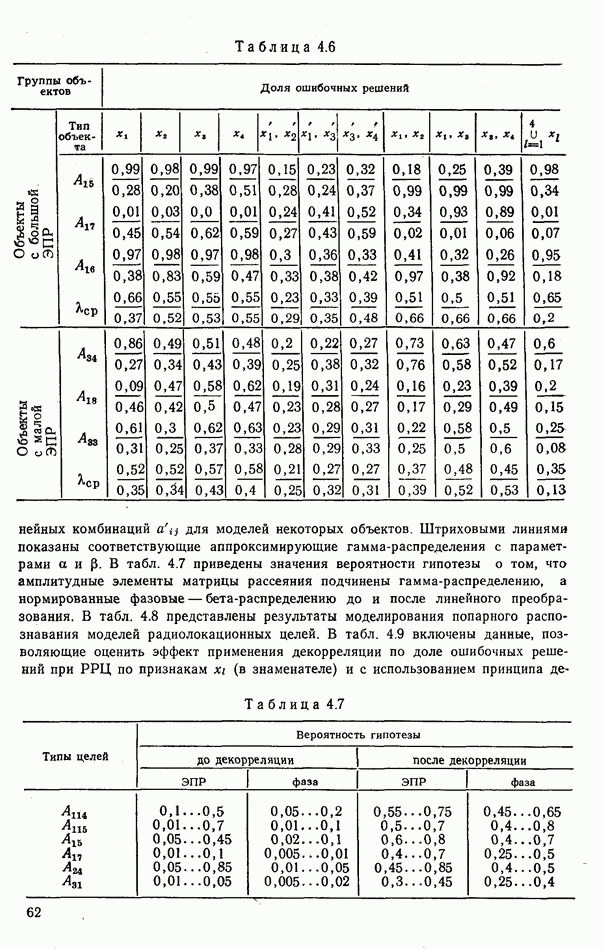
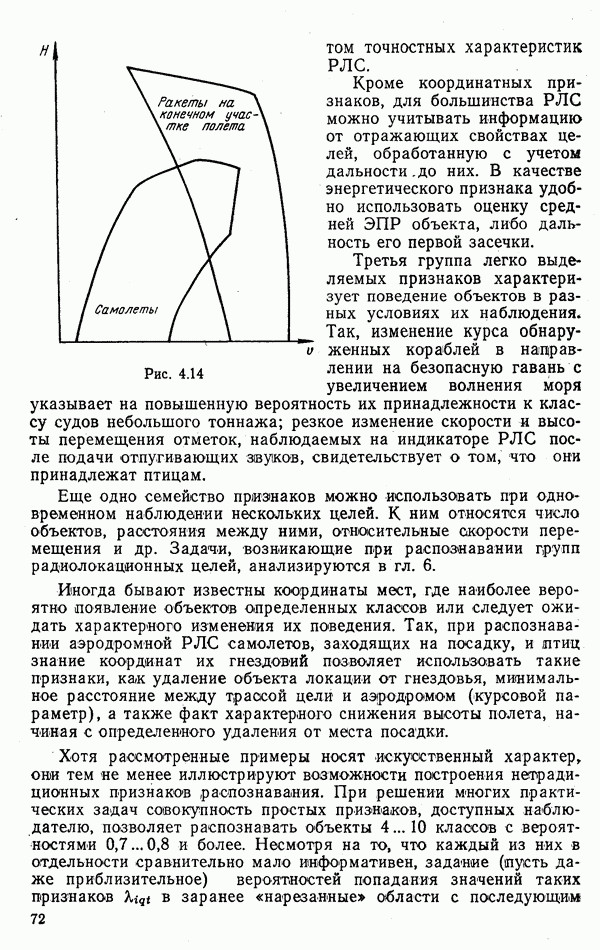
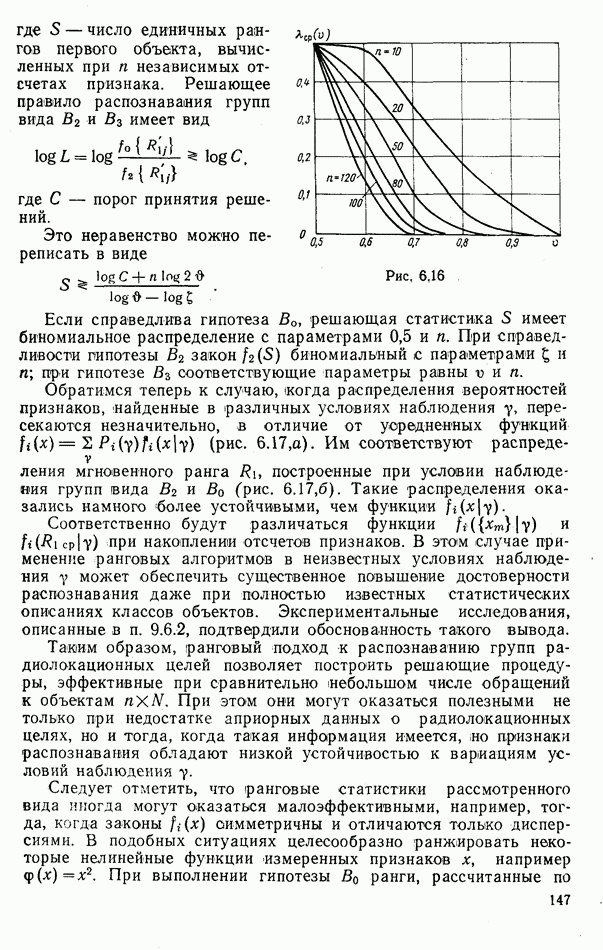
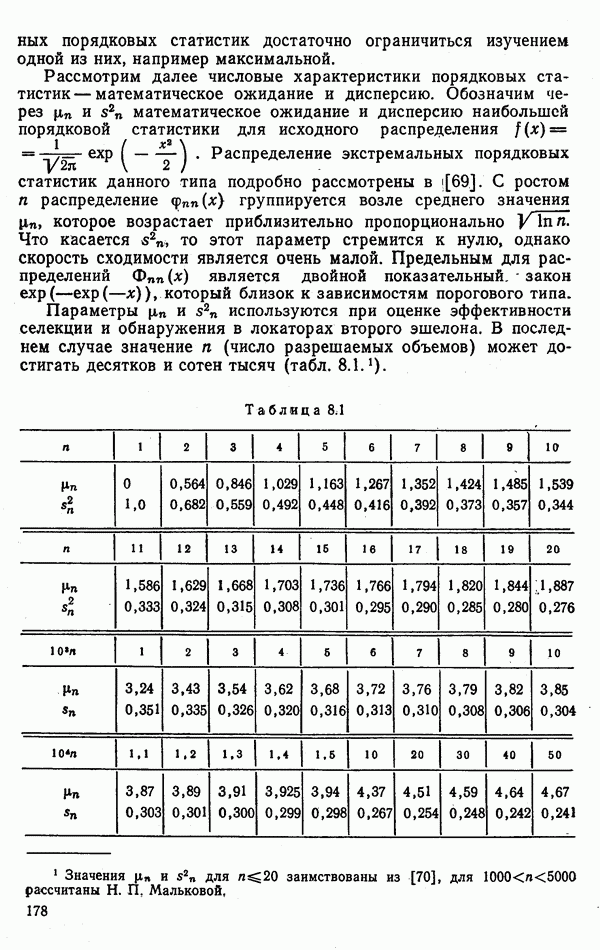
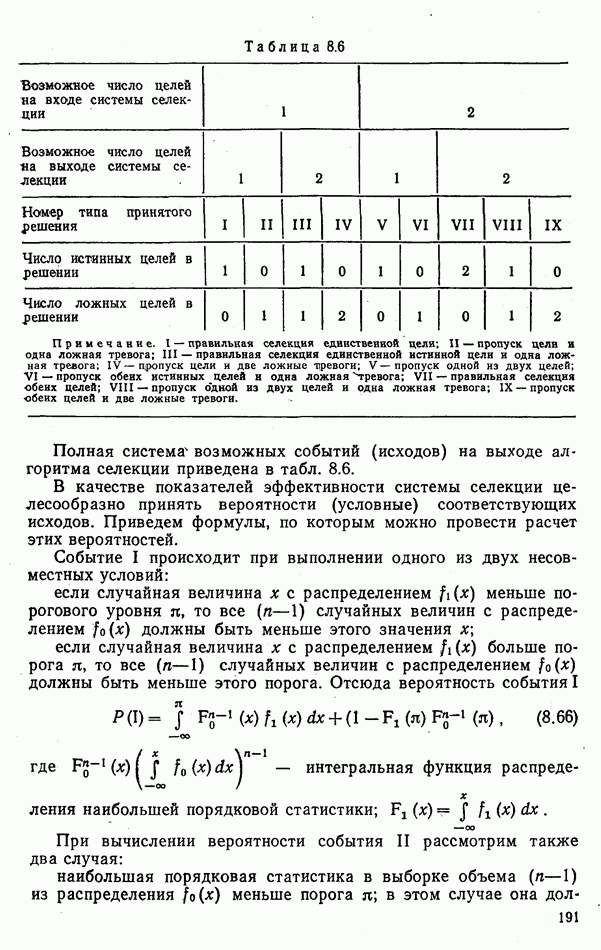
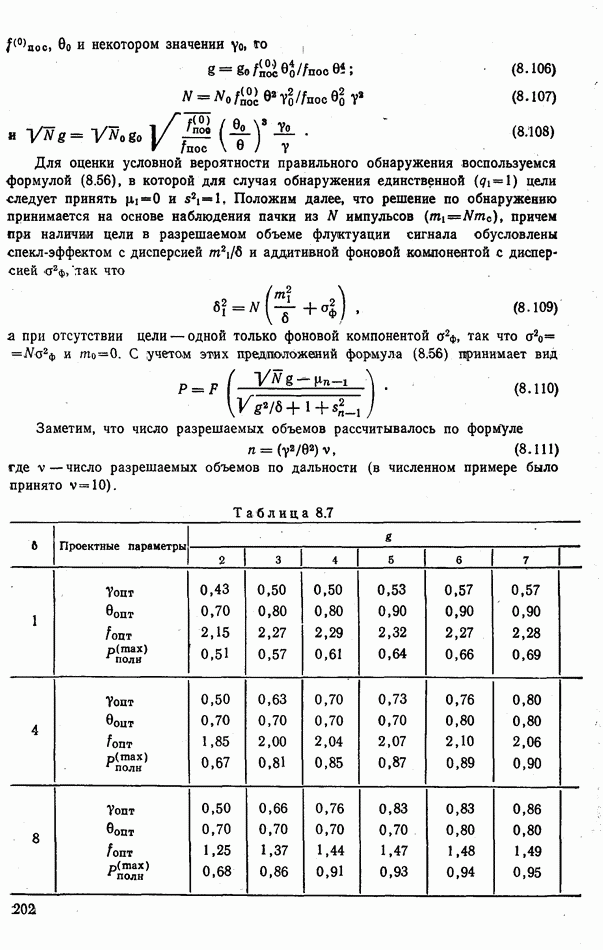
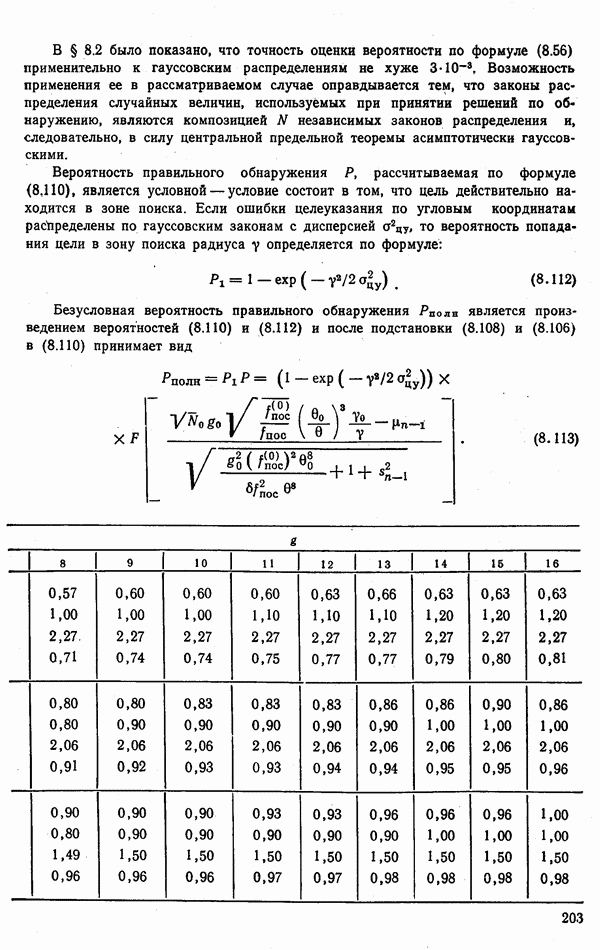
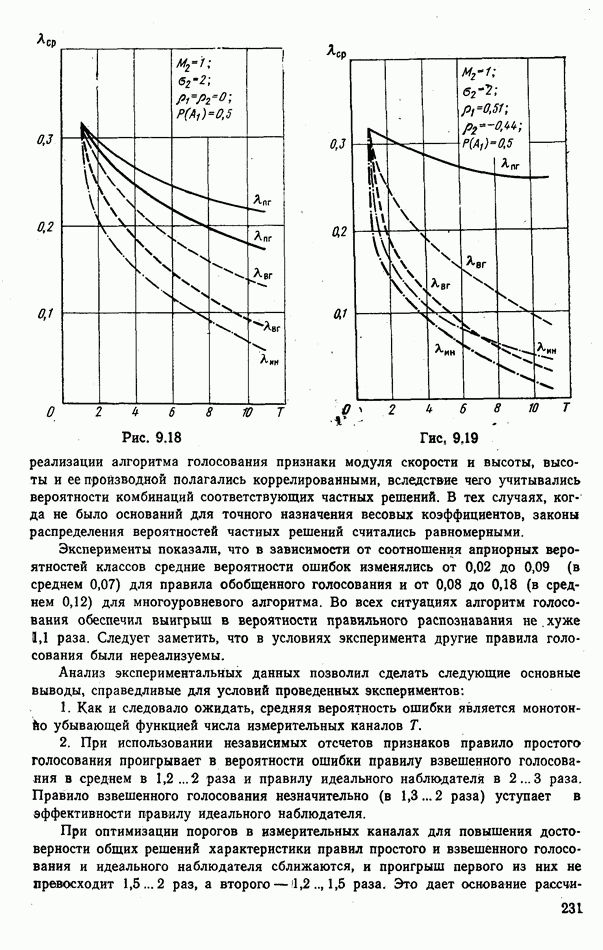
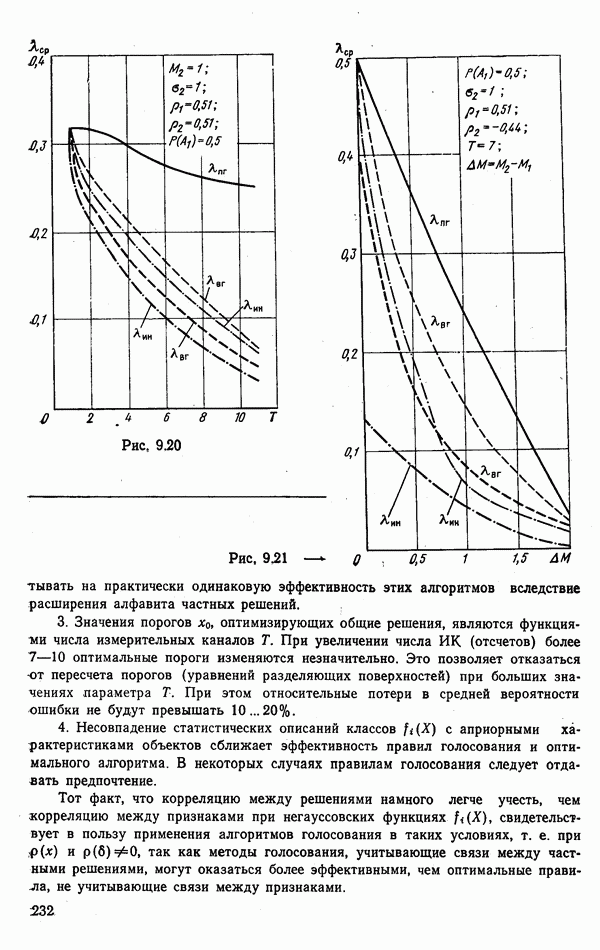
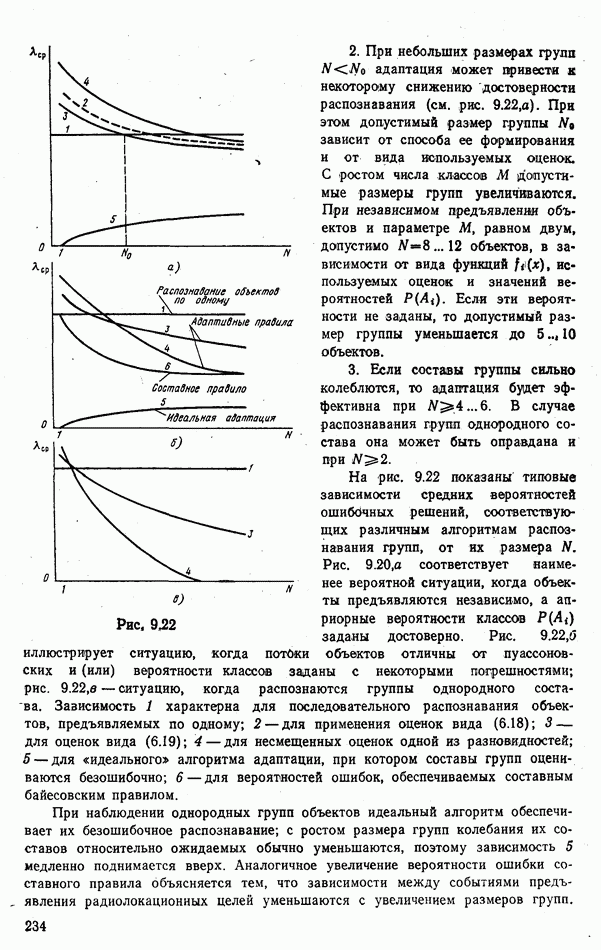
6.9. НЕПАРАМЕТРИЧЕСКИЕ ПРОЦЕДУРЫ РАСПОЗНАВАНИЯ ГРУПП ОБЪЕКТОВРассматриваемые алгоритмы сходны с непараметрическими процедурами обнаружения сигналов, теория которых сейчас интенсивно развивается. Основные отличия между теми и другими заключается в том, что, во-первых, задача распознавания решается при числе альтернатив М, большем двух, и, во-вторых, анализ сигналов, приходящих из различных участков пространства (на разных частотах), заменен анализом признаков, характеризующих каждый объект распознаваемой группы. В практике РРЦ группы наблюдаемых объектов весьма часто будут иметь однородный состав. Сказанное означает, что все оказаться на вероятности принятия правильных (решений. В этом легко убедиться, если предположить, что в однородные группы размера N могут объединяться радиолокационные цели не всех видов или классов. Кроме того, к однородным группам могут быть применены наиболее эффективные в таких условиях разновидности одношаговых адаптивных алгоритмов или правила принятия составных решений. Установление факта однородности группы может иметь и важное самостоятельное значение, связанное со способом действий потребителя информации. Так, в примере, разобранном в § 9.1, однородная группа заведомо включает два объекта третьего класса и, стало быть, обслуживанию не подлежит. Таким образом, в перечень задач, решаемых при РРЦ, можно включить и оценку гипотезы об однородности состава группы обнаруженных объектов. Специфика рассматриваемых далее непараметрических алгоритмов такова, что именно эту задачу можно с их помощью решить наиболее эффективно. Для принятия решения об однородности наблюдаемой группы следует сконструировать какую-либо меру сходства ее с группами из множества однородных. В идеальном случае в качестве такой меры сходства должна использоваться вероятность гипотезы
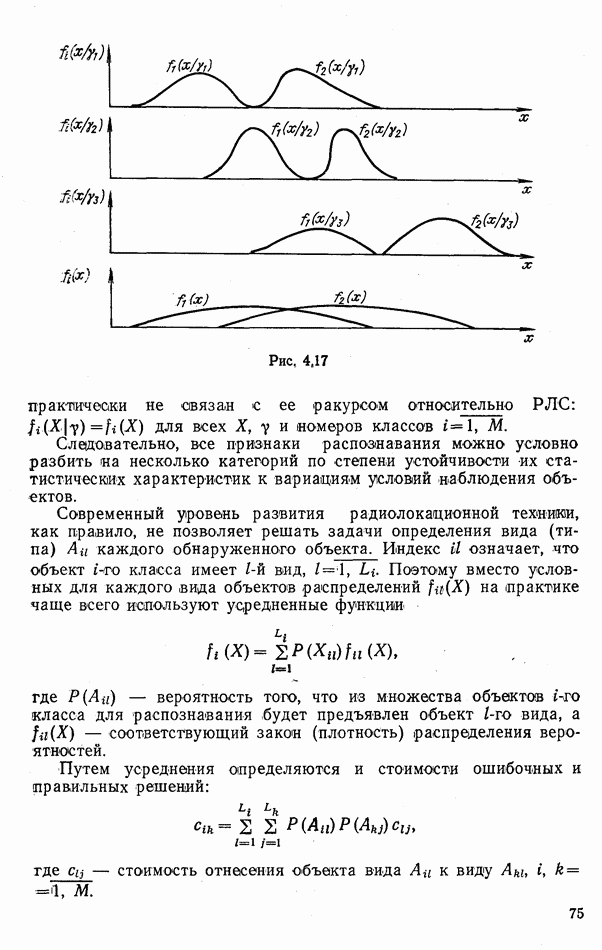
где Рассматриваемые далее непараметрические процедуры позволяют оценить функцию В практике радиолокационного распознавания одинаково редко встречаются случаи как полностью известных, так и полностью неизвестных статистических описаний классов. Поэтому зачастую приближенное задание законов найти функции С помощью аппарата распознавания однородных групп можно разбить наблюдаемую группу объектов Проанализируем более подробно непараметрические процедуры, которые используют для распознавания групп радиолокационных целей. Среди них различают три разновидности алгоритмов: основанные на использовании статистических критериев согласия, ранговые и кластеризации. Рассмотрим последовательно каждый из них. Алгоритмы, основанные на использовании статистических критериев согласий. Допустим, что у наблюдателя нет никаких достоверных сведений о распознаваемых классах, кроме информации о том, что их статистические характеристики не совпадают: Правдоподобие первой гипотезы можно оценить с помощью хорошо известных непараметрических критериев согласия: Пирсона, Мизеса, Колмогорова и др. [54, 63]. Для примера остановимся на одном из них — часто применяемом в статистике критерии Пирсона Допустим, что для каждого Статистика Пирсона
(для удобства в обозначениях Если гипотеза
где При этом математическое ожидание статистики
где Выберем некоторое пороговое значение Пусть распределение
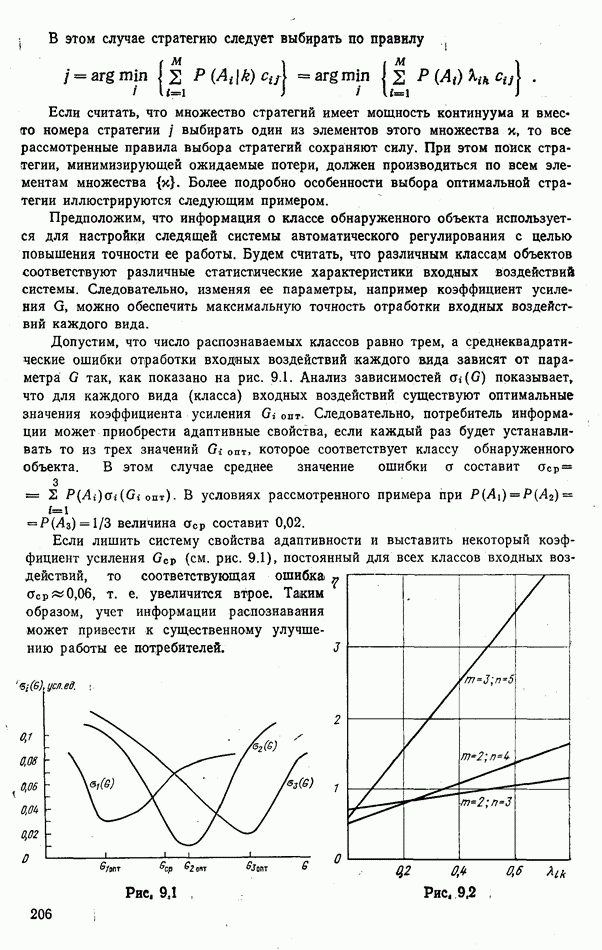
Рис. 6.14 Предположим, что при всех
Поскольку, отвергая гипотезу
при условии, что Если положить
Полученный результат остается справедливым и для других непараметрических статистик, не совпадающих со статистикой Пирсона. Так, если распределения такой статистики (обозначим ее через Ранговые алгоритмы распознавания групп объектов. Проанализируем значения признаков Если сделать по
При числе отсчетов В теории обнаружения сигналов гауссовская аппроксимация закона Если в группе из
где Существует немало разновидностей ранговых алгоритмов обнаружения сигналов, которые можно использовать при распознавании групп радиолокационных целей [50, 61, 58]. Остановимся на одном из них, так называемом модифицированном правиле Вилкоксона. В соответствии с этим правилом в качестве непараметрической статистики выбирается сумма рангов Достоинства ранговых правил заключаются в том, что они позволяют принимать решения при небольшом числе Это позволяет отказаться от знания точного вида этих функций, ограничившись расчетом вероятностей того, что значение признака Проиллюстрируем возможности ранговых решающих процедур следующим примером. Предположим, что необходимо распознать группу из двух объектов, каждый из которых может относиться к классу
где индексы Легко убедиться в том, что для групп однородного состава
т. е. для таких групп ранг первого объекта равномерно распределен. Пусть в качестве признаков используются текущие оценки ЭПР наблюдаемых объектов, которые можно считать экспоненциально распределенными: Обозначим вероятность того, что первый объект группы получит первый ранг через а вероятность противоположного события — через и. Тогда для группы вида
Аналогично находятся и другие законы Предположим, что Если в качестве решающей статистики использовать средний ранг первого объекта Таблица 6.9 (см. скан)
Рис. 6.15
Задаваясь параметрами и и числом отсчетов
Вычисления вероятностей ошибок в предположении, что законы На меньшие потери информации можно рассчитывать, если накапливать не значения рангов, а соответствующие отношения правдоподобия. Преобразуем используемую систему координат, присвоив объекту с рангом
Рис. 6.16 где
где С — порог принятия решений. Это неравенство можно переписать в виде
Если справедлива гипотеза Обратимся теперь к случаю, когда распределения вероятностей признаков, найденные в различных условиях наблюдения у, пересекаются незначительно, в отличие от усредненных функций Соответственно будут различаться функции Таким образом, ранговый подход к распознаванию групп радиолокационных целей позволяет построить решающие процедуры, эффективные при сравнительно небольшом числе обращений к объектам Следует отметить, что ранговые статистики рассмотренного вида иногда могут оказаться малоэффективными, например, тогда, когда законы Рис. 6.17 (см. скан) значениям функций Алгоритмы кластеризации. В теории распознавания образов существует активно развивающееся направление, называемое кластерным анализом (таксономией и др.). Основная задача кластерных алгоритмов состоит в том, чтобы разбить совокупность выборочных значений признаков на некоторое число подмножеств (кластеров). При этом в каждом из них должны оказаться близкие в некотором смысле значения признаков. В общем случае число кластеров, на которые должна быть разбита исследуемая выборка, может быть заранее известно или нет. Обычно методы кластерного анализа используются для обучения систем распознавания, а также при автоматическом разбиении генеральной совокупности объектов на классы При распознавании групп радиолокационных целей принципиально возможно использовать алгоритмы обучения (самообучения) распознающего автомата по совокупности отсчетов признаков объектов группы затем для отнесения каждого объекта группы к одному из М классов алфавита Кроме оценки вероятностей
Но соответствующие решающие правила могут быть реализованы только на базе параметрических моделей функций Несмотря на отказ от обязательного задания законов Предположим, что при распознавании некоторой группы из пяти объектов было выполнено по три обращения к каждому из них. Допустим также, что полученные в результате значения признаков Анализ полученной выборки Привлечение дополнительной информации, например сведений о том, что число классов
Рис. 6.18 Достоинством рассмотренного подхода является то, что он позволяет безошибочно распознавать радиолокационные цели тогда, когда плотности Процедуры кластеризации носят преимущественно эвристический характер [24, 25, 48, 34]. Для решения задачи распознавания групп радиолокационных целей может быть применено большинство из них. Пусть, например, было принято решение о применении одного из самых простых способов кластеризации — методе гистограмм — к анализу выборки Если заранее известно, что в группе представлены три класса объектов, то выбрать пороги Значения признаков отдельных объектов, измеренные при разных отсчетах, могут оказаться по разные стороны от порога. При этом самое простое — отнести радиолокационную цель к тому классу, которому соответствует большее число отсчетов признака Если число классов объектов в группе заранее не задано, то многое зависит от числа мод законов
Рис. 6.19 Таблица 6.10 (см. скан) Окончание табл. 6.16 (см. скан) радиолокационной цели. Допустим, что они «дружно» колеблются от одного максимума гистограммы к другому. Естественно, что в этом случае наличие таких максимумов нельзя истолковывать как Долю субъективизма, свойственную описанному подходу, можно уменьшить, реализовав двухэтажную процедуру принятия решений. Сначала оценивается степень однородности группы, например, с помощью ранговых правил. Если гипотеза об однородности отвергается, естественно будет поставить в соответствие каждому из максимумов гистограммы свой класс объектов. Потенциальные возможности кластерных алгоритмов были проверены методом математического моделирования (подробнее см. п. 9.5.2). Как уже отмечалось, при использовании кластерных методов в задачах распознавания групп радиолокационных целей появляется возможность присвоить отсчетам признаков номера наблюдаемых объектов. Другая особенность — это возможность учета данных о составе группы Пусть, например, требуется выделить Если выполняются неравенства вида В табл. 6.10 приведена краткая сводка основных правил распознавания целей в группах. В ней отражены некоторые разновидности рассмотренных процедур. Основное внимание уделена крупным семействам решающих правил и наиболее характерным; для этих семейств алгоритмам.
|
 |
Оглавление
|




















































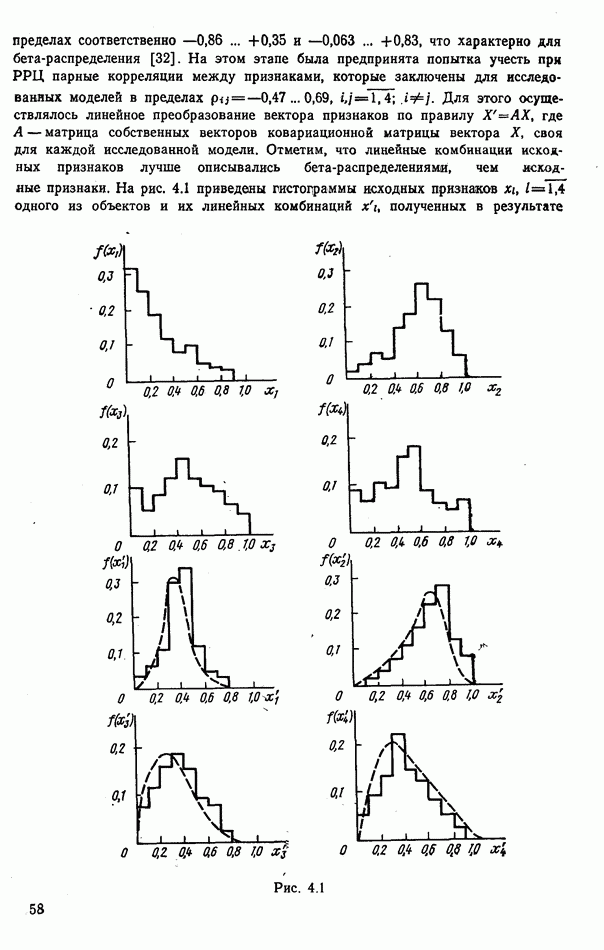
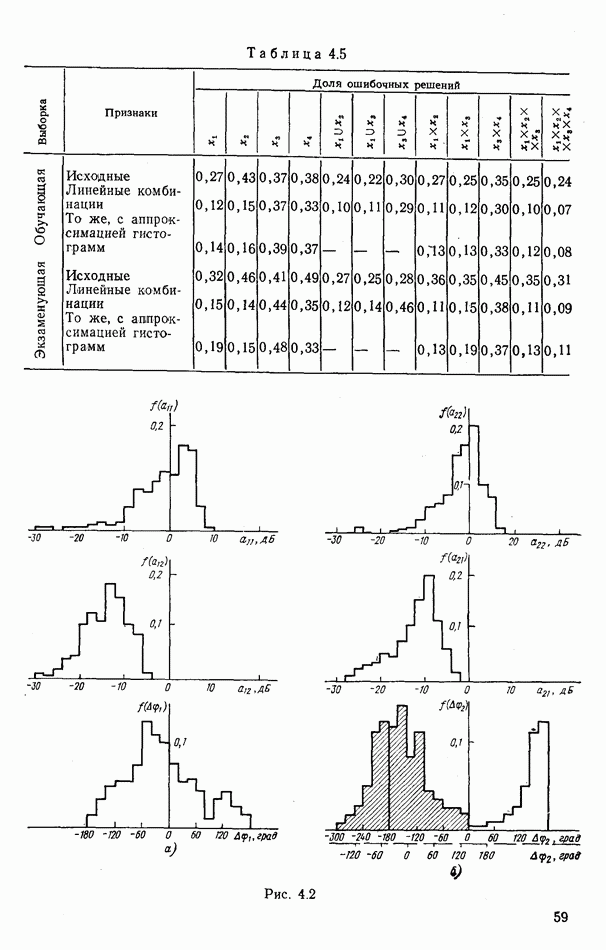
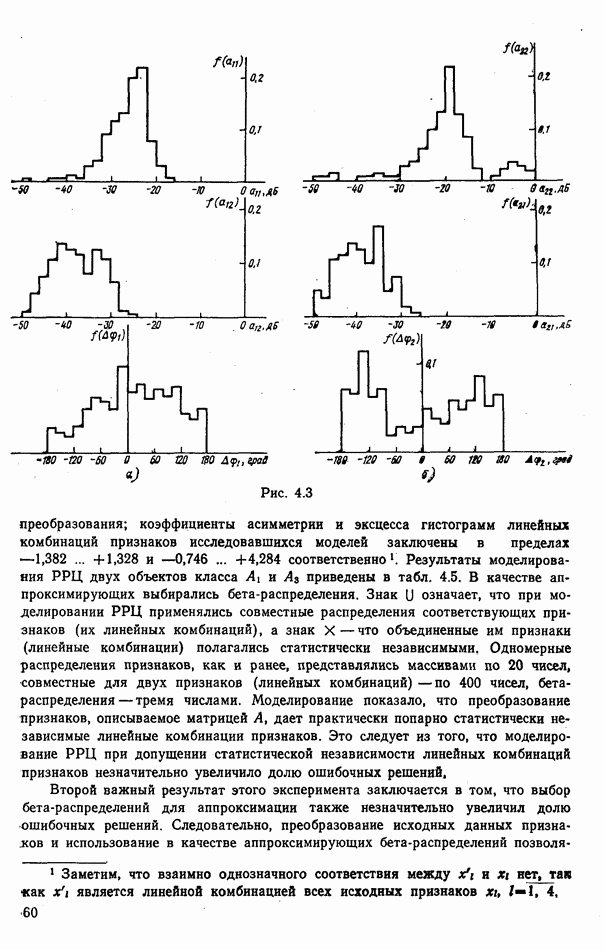
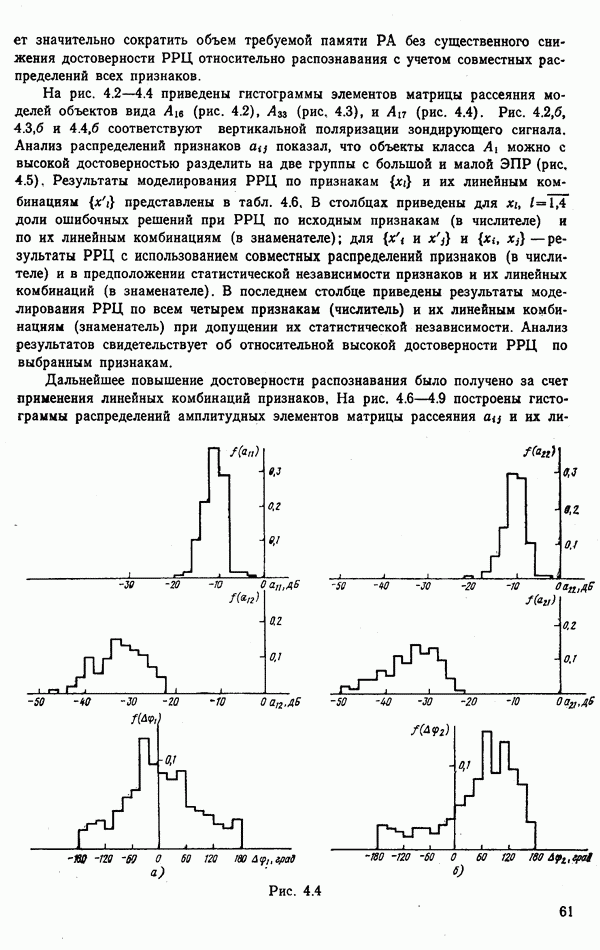

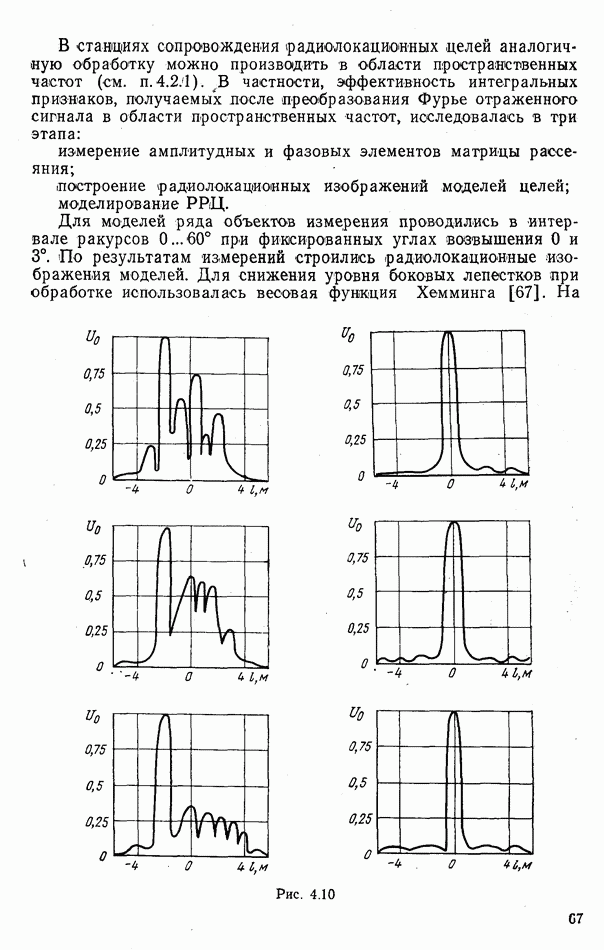
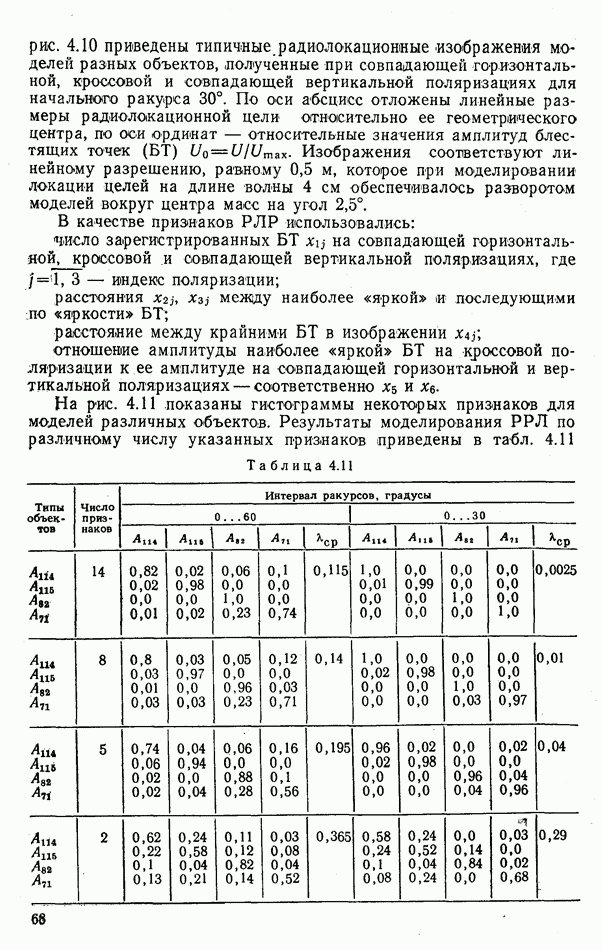
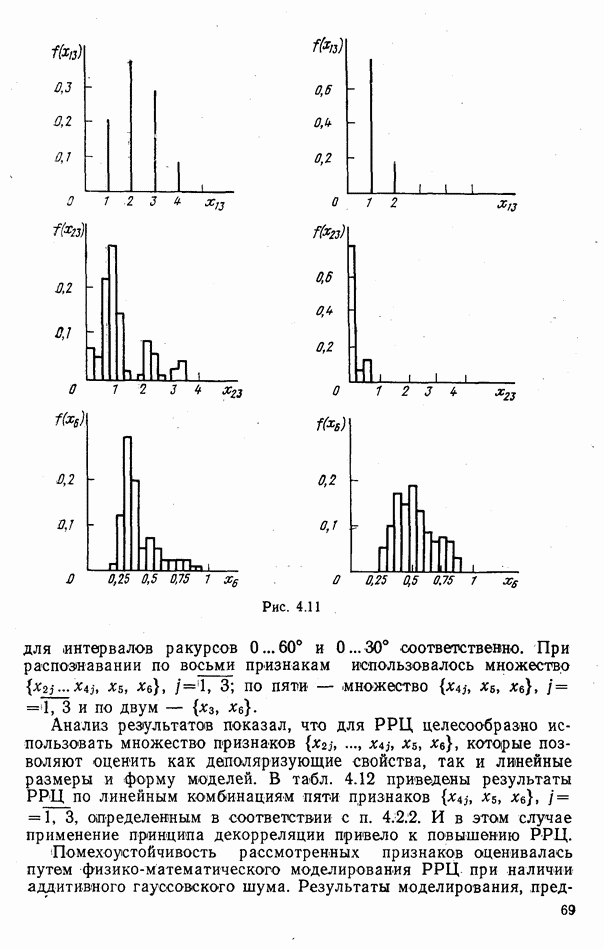
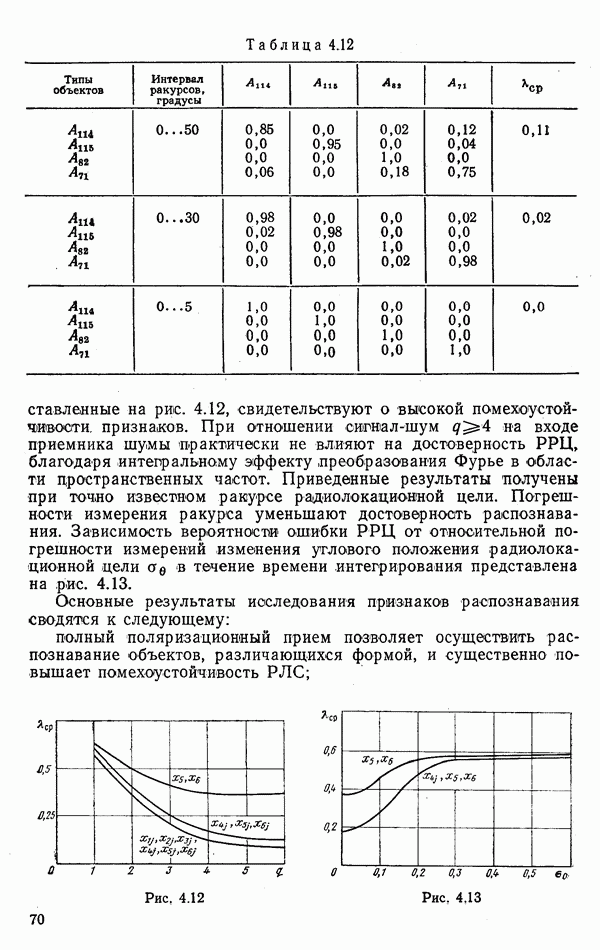

















































































































































 объектов группы будут принадлежать к одному классу
объектов группы будут принадлежать к одному классу  , или даже виду
, или даже виду  но неизвестно, к какому именно. В этом случае определение факта однородности группы может очень существенно
но неизвестно, к какому именно. В этом случае определение факта однородности группы может очень существенно

 — априорные вероятности предъявления групп однородного (индекс О) или неоднородного (индекс Н) составов;
— априорные вероятности предъявления групп однородного (индекс О) или неоднородного (индекс Н) составов;  — соответствующие условные законы распределения вероятностей множества признаков
— соответствующие условные законы распределения вероятностей множества признаков  характеризующих объекты группы
характеризующих объекты группы  Если законы распределения вероятностей признаков
Если законы распределения вероятностей признаков  для объектов каждого класса
для объектов каждого класса  заданы точно, то расчет функций
заданы точно, то расчет функций  а следовательно и вероятности
а следовательно и вероятности  принципиально возможен.
принципиально возможен.
 и тогда, когда о законах
и тогда, когда о законах  почти ничего не известно, кроме того, что
почти ничего не известно, кроме того, что  при
при  . К сожалению, в общем случае расчет значений функций
. К сожалению, в общем случае расчет значений функций  при таких скудных априорных сведениях невозможен. Это приводит к необходимости использовать приближенные оценки вероятности
при таких скудных априорных сведениях невозможен. Это приводит к необходимости использовать приближенные оценки вероятности  или косвенно связанные с ней показатели, например коэффициенты ранговой корреляции Чупрова, Кендэла или коэффициент конкордации [50, 49]. Каждая из этих мер, наряду с вероятностью
или косвенно связанные с ней показатели, например коэффициенты ранговой корреляции Чупрова, Кендэла или коэффициент конкордации [50, 49]. Каждая из этих мер, наряду с вероятностью  может служить оценкой доли одинаковых объектов в группе с последующим применением адаптивных решающих правил (см. п. 6.7.1).
может служить оценкой доли одинаковых объектов в группе с последующим применением адаптивных решающих правил (см. п. 6.7.1).
 позволяет приближенно же
позволяет приближенно же
 что необходимо для синтеза правил распознавания однородных групп объектов. Иногда для этого удается использовать сведения о законах формирования групп.
что необходимо для синтеза правил распознавания однородных групп объектов. Иногда для этого удается использовать сведения о законах формирования групп.
 на несколько подгрупп
на несколько подгрупп  каждая из которых имеет однородный состав. В этом случае привлечение небольшого объема дополнительных априорных данных о характеристиках классов
каждая из которых имеет однородный состав. В этом случае привлечение небольшого объема дополнительных априорных данных о характеристиках классов  позволит отнести к одному из них каждую однородную подгруппу
позволит отнести к одному из них каждую однородную подгруппу  Такими дополнительными данными могут служить сведения о возможном числе объектов разных классов в группах, соотношении их средних ЭПР и т.
Такими дополнительными данными могут служить сведения о возможном числе объектов разных классов в группах, соотношении их средних ЭПР и т. 
 Сформулируем две взаимоисключающие гипотезы:
Сформулируем две взаимоисключающие гипотезы:  — все объекты рассматриваемой группы принадлежат к одному и тому же классу;
— все объекты рассматриваемой группы принадлежат к одному и тому же классу;  — в группе представлены объекты разных классов.
— в группе представлены объекты разных классов.

 объекта группы
объекта группы  измерены по
измерены по  отсчетов признака
отсчетов признака  Это позволяет построить гистограмму значений признака
Это позволяет построить гистограмму значений признака  характеризующую данную радиолокационную цель. Для этого необходимо весь диапазон значений признака
характеризующую данную радиолокационную цель. Для этого необходимо весь диапазон значений признака  разбить на
разбить на  разрядов с номерами
разрядов с номерами  и оценить частоту
и оценить частоту  попаданий значений признака в каждый из них. Если у всех объектов группы эти частоты будут близки
попаданий значений признака в каждый из них. Если у всех объектов группы эти частоты будут близки  то ее состав может быть признан однородным.
то ее состав может быть признан однородным.
 учитывает отклонения частот
учитывает отклонения частот  от средних значений
от средних значений 

 индекс
индекс  заменен индексами
заменен индексами  ).
).
 об однородности группы справедлива, то закон распределения статистики
об однородности группы справедлива, то закон распределения статистики  при условии, что отношения
при условии, что отношения  достаточно велики, имеет распределение
достаточно велики, имеет распределение  степенями свободы
степенями свободы

 — гамма-функция.
— гамма-функция.


 .
.
 и будем относить к классу
и будем относить к классу  все группы, для которых
все группы, для которых  а остальные группы отнесем к множеству групп неоднородного состава
а остальные группы отнесем к множеству групп неоднородного состава  При этом, подбирая порог
При этом, подбирая порог  можно обеспечить любую наперед заданную вероятность неверного распознавания
можно обеспечить любую наперед заданную вероятность неверного распознавания  однородных групп радиолокационных целей. К сожалению, оценить вероятность ошибки второго рода К, т. е. вероятность отнести группу смешанного состава к разряду однородных, довольно трудно, если функции
однородных групп радиолокационных целей. К сожалению, оценить вероятность ошибки второго рода К, т. е. вероятность отнести группу смешанного состава к разряду однородных, довольно трудно, если функции  не заданы. Лучшее, что иногда удается сделать в этой ситуации, — это рассчитать ее предельное значение. Укажем на один из способов получения такой оценки.
не заданы. Лучшее, что иногда удается сделать в этой ситуации, — это рассчитать ее предельное значение. Укажем на один из способов получения такой оценки.
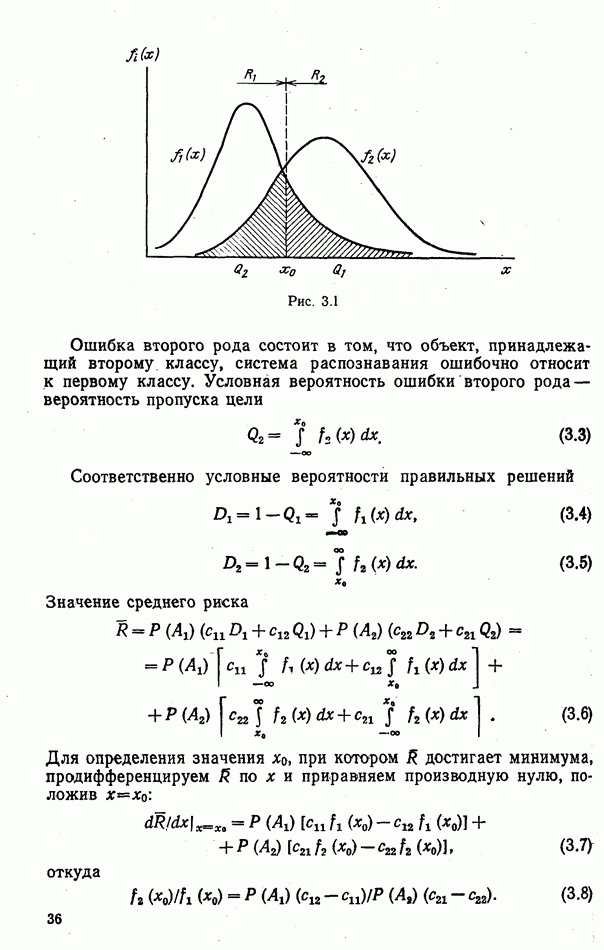
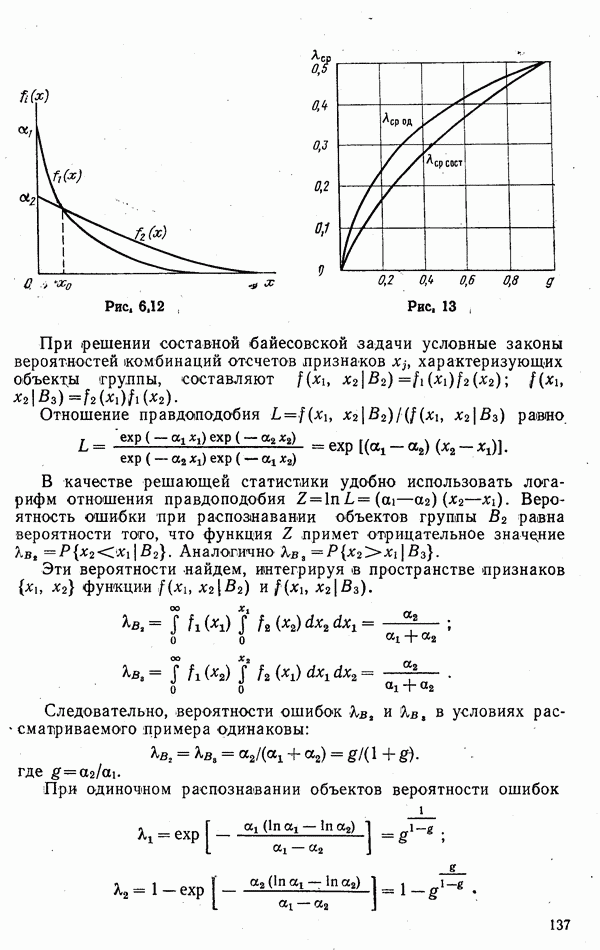
 одномодальное и имеет вид, показанный на рис. 6.14. Произвольному значению функции
одномодальное и имеет вид, показанный на рис. 6.14. Произвольному значению функции  попавшему слева от порога
попавшему слева от порога  соответствует вероятность гипотезы
соответствует вероятность гипотезы


 значение функции
значение функции  не превосходит некоторого предела
не превосходит некоторого предела  Тогда
Тогда

 мы ошибаемся с вероятностью
мы ошибаемся с вероятностью  можно утверждать, что рассмотренный алгоритм будет характеризоваться вероятностью ошибки распознавания однородных групп
можно утверждать, что рассмотренный алгоритм будет характеризоваться вероятностью ошибки распознавания однородных групп  и вероятностью ошибки второго рода
и вероятностью ошибки второго рода

 для всех
для всех 
 то можно записать
то можно записать

 дискретны, то параметр
дискретны, то параметр  не может быть больше единицы.
не может быть больше единицы.
 измеренных после
измеренных после  обращения к каждому объекту
обращения к каждому объекту  наблюдаемой группы. Расположим объекты
наблюдаемой группы. Расположим объекты  в порядке возрастания значений их признаков. Тогда после
в порядке возрастания значений их признаков. Тогда после  отсчета в сформированном вариационном ряду первым окажется объект с наименьшим значением признака, вторым — объект со следующим по значению в возрастающем порядке признаком
отсчета в сформированном вариационном ряду первым окажется объект с наименьшим значением признака, вторым — объект со следующим по значению в возрастающем порядке признаком  Новые номера объектов в таком ряду называются их рангами. Обозначим ранг
Новые номера объектов в таком ряду называются их рангами. Обозначим ранг  радиолокационной цели, найденный после
радиолокационной цели, найденный после  отсчета признака, через
отсчета признака, через  Совокупность рангов
Совокупность рангов  можно рассматривать как новые признаки распознавания, обладающие рядом полезных свойств.
можно рассматривать как новые признаки распознавания, обладающие рядом полезных свойств.
 отсчетов признаков каждого объекта
отсчетов признаков каждого объекта  и сопоставить этому объекту сумму рангов
и сопоставить этому объекту сумму рангов  , то распределение статистики
, то распределение статистики  будет определяться путем
будет определяться путем  -кратной свертки равномерного закона
-кратной свертки равномерного закона  при условии, что наблюдаемая группа однородна, а отсчеты признаков независимы [58]:
при условии, что наблюдаемая группа однородна, а отсчеты признаков независимы [58]:

 функция
функция  хорошо аппроксимируется гауссовским законом [68] с параметрами
хорошо аппроксимируется гауссовским законом [68] с параметрами  .
.
 не всегда удачна, так как она может приводить к неправильной оценке допустимой вероятности ложной тревоги, задаваемой обычно на уровне
не всегда удачна, так как она может приводить к неправильной оценке допустимой вероятности ложной тревоги, задаваемой обычно на уровне  При распознавании групп объектов допустимые вероятности ошибок обычно выше
При распознавании групп объектов допустимые вероятности ошибок обычно выше  что делает указанную аппроксимацию вполне приемлемой даже при небольших
что делает указанную аппроксимацию вполне приемлемой даже при небольших  к
к 
 объектов
объектов  из них относятся к классу
из них относятся к классу  а один объект — к классу
а один объект — к классу  то закон распределения «мгновенного» ранга
то закон распределения «мгновенного» ранга  Имеет вид
Имеет вид

 — функции распределения, определяемые законами
— функции распределения, определяемые законами  соответственно [68].
соответственно [68].
 , которая при распознавании каждого
, которая при распознавании каждого  объекта должна сравниваться с некоторыми порогами
объекта должна сравниваться с некоторыми порогами  При
При  нимается решение о том, что радиолокационная цель по своим статистическим свойствам не отличается от большинства объектов группы. В противном случае принимается конкурирующая гипотеза. Значения порогов
нимается решение о том, что радиолокационная цель по своим статистическим свойствам не отличается от большинства объектов группы. В противном случае принимается конкурирующая гипотеза. Значения порогов  выбираются из условия обеспечения требуемого уровня вероятности ошибочного отнесения однородной группы к разряду смешанных.
выбираются из условия обеспечения требуемого уровня вероятности ошибочного отнесения однородной группы к разряду смешанных.
 объектов
объектов  группе и
группе и  обращений к ним. Другие непараметрические процедуры предполагают существенный объем выборочных данных. Кроме того, можно показать, что законы распределения ранговых статистик зависят в основном от взаимного расположения функций
обращений к ним. Другие непараметрические процедуры предполагают существенный объем выборочных данных. Кроме того, можно показать, что законы распределения ранговых статистик зависят в основном от взаимного расположения функций  в пространстве признаков
в пространстве признаков 
 объекта класса
объекта класса  , окажется большим, чем значение того же признака, характеризующего объект
, окажется большим, чем значение того же признака, характеризующего объект  класса,
класса,  . Соответствующие распределения ранговых статистик зачастую оказываются намного более устойчивыми, чем функции
. Соответствующие распределения ранговых статистик зачастую оказываются намного более устойчивыми, чем функции  определенные на исходном множестве признаков. Так будет, например, при неизвестных аддитивных и мультипликативных погрешностях измерений признаков.
определенные на исходном множестве признаков. Так будет, например, при неизвестных аддитивных и мультипликативных погрешностях измерений признаков.
 либо к классу
либо к классу  (см. табл. 6.8). Допустим вероятности групп
(см. табл. 6.8). Допустим вероятности групп  одинаковыми. Задача выделения однородных групп сводится к поиску групп вида
одинаковыми. Задача выделения однородных групп сводится к поиску групп вида  Найдем законы распределения ранга первого объекта наблюдаемой группы
Найдем законы распределения ранга первого объекта наблюдаемой группы 

 и
и  определяются номером группы
определяются номером группы  например, для группы
например, для группы  для группы
для группы  — значения признаков, характеризующие соответственно первый и второй объекты группы;
— значения признаков, характеризующие соответственно первый и второй объекты группы; 
 и
и 





 Тогда распределения мгновенных рангов будут определяться вероятностями
Тогда распределения мгновенных рангов будут определяться вероятностями  (табл. 6.9), где
(табл. 6.9), где 

 распределения
распределения  будут зависеть от числа отсчетов признаков
будут зависеть от числа отсчетов признаков  Функции
Функции  имеют биномиальное распределение, которое с ростом
имеют биномиальное распределение, которое с ростом  хорошо аппроксимируется гауссовским законом
хорошо аппроксимируется гауссовским законом  или
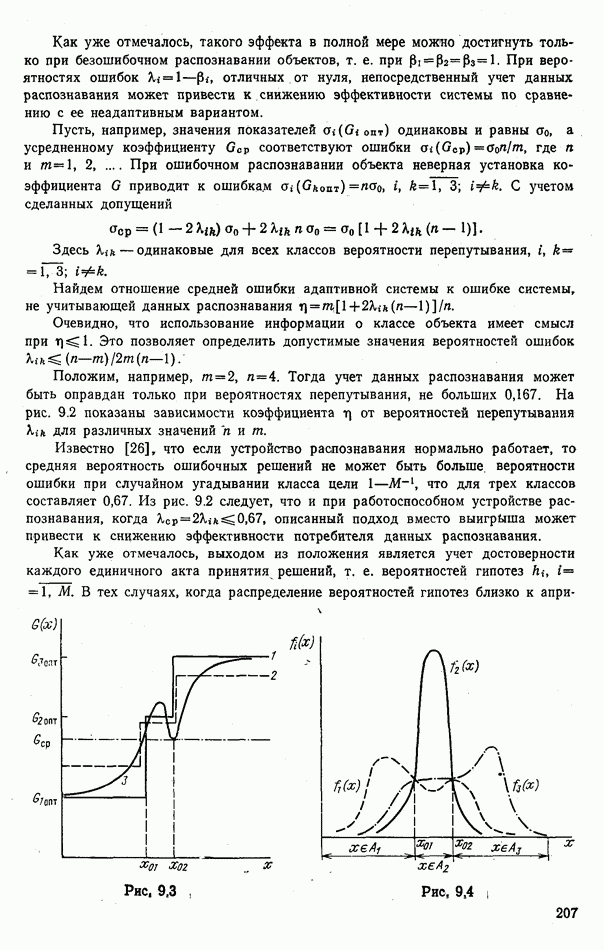
или  Соответствующие графики представлены на рис. 6.15.
Соответствующие графики представлены на рис. 6.15.
 и значениями порогов
и значениями порогов  можно оценить вероятности ошибок определения составов групп. Группы будем считать однородными, если значение среднего ранга лежит между порогами
можно оценить вероятности ошибок определения составов групп. Группы будем считать однородными, если значение среднего ранга лежит между порогами  Вероятности ошибочных решений
Вероятности ошибочных решений

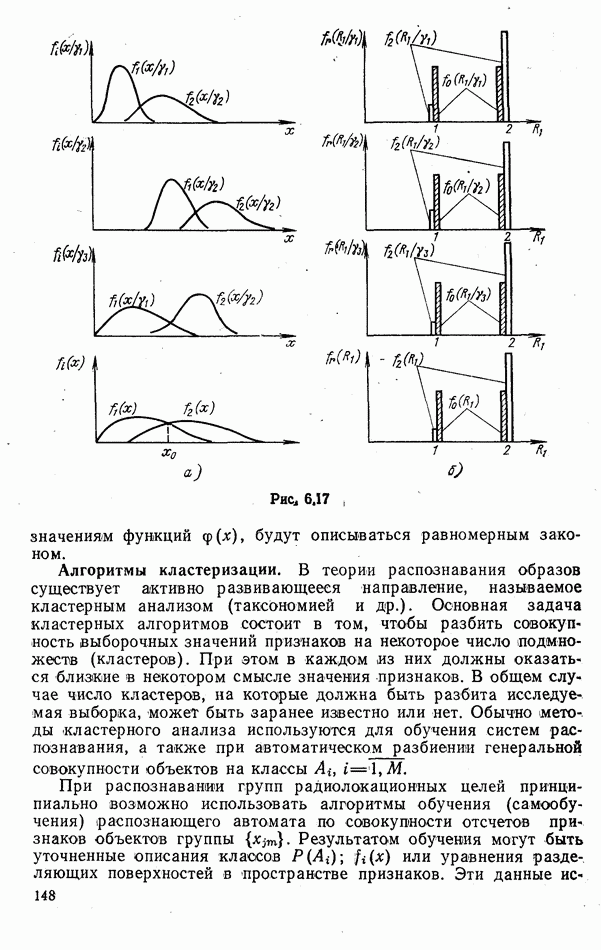
 гауссовские (рис. 6.16), показали что при низкой информативности признаков, когда вероятность ошибки по одному отсчету равна около 0,4, сходимость алгоритмов принятия решений низкая. При уменьшении параметра
гауссовские (рис. 6.16), показали что при низкой информативности признаков, когда вероятность ошибки по одному отсчету равна около 0,4, сходимость алгоритмов принятия решений низкая. При уменьшении параметра  эффективность ранговых правил быстро возрастает с увеличением числа отсчетов признаков
эффективность ранговых правил быстро возрастает с увеличением числа отсчетов признаков 
 нулевой ранг
нулевой ранг  Тогда
Тогда


 — число единичных рангов первого объекта, вычисленных при
— число единичных рангов первого объекта, вычисленных при  независимых отсчетах признака. Решающее правило распознавания групп вида
независимых отсчетах признака. Решающее правило распознавания групп вида  имеет вид
имеет вид


 решающая статистика
решающая статистика  имеет биномиальное распределение с параметрами 0,5 и
имеет биномиальное распределение с параметрами 0,5 и  При справедливости гипотезы
При справедливости гипотезы  закон
закон  биномиальный с параметрами
биномиальный с параметрами  и и; при гипотезе
и и; при гипотезе  соответствующие параметры равны и и
соответствующие параметры равны и и 
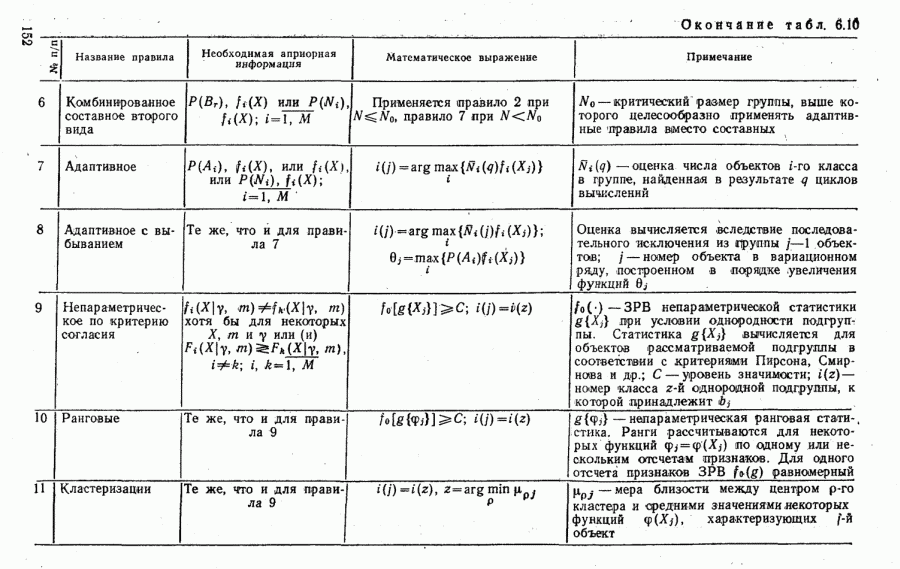
 (рис. 6.17,а). Им соответствуют распределения мгновенного ранга
(рис. 6.17,а). Им соответствуют распределения мгновенного ранга  построенные при условии наблюдения групп вида
построенные при условии наблюдения групп вида  (рис. 6.17,б). Такие распределения оказались намного более устойчивыми, чем функции
(рис. 6.17,б). Такие распределения оказались намного более устойчивыми, чем функции  .
.
 при накоплении отсчетов признаков. В этом случае применение ранговых алгоритмов в неизвестных условиях наблюдения у может обеспечить существенное повышение достоверности распознавания даже при полностью известных статистических описаниях классов объектов. Экспериментальные исследования, описанные в
при накоплении отсчетов признаков. В этом случае применение ранговых алгоритмов в неизвестных условиях наблюдения у может обеспечить существенное повышение достоверности распознавания даже при полностью известных статистических описаниях классов объектов. Экспериментальные исследования, описанные в  подтвердили обоснованность такого вывода.
подтвердили обоснованность такого вывода.
 При этом они могут оказаться полезными не только при недостатке априорных данных о радиолокационных целях, но и тогда, когда такая информация имеется, но признаки распознавания обладают низкой устойчивостью к вариациям условий наблюдения у.
При этом они могут оказаться полезными не только при недостатке априорных данных о радиолокационных целях, но и тогда, когда такая информация имеется, но признаки распознавания обладают низкой устойчивостью к вариациям условий наблюдения у.
 симметричны и отличаются только дисперсиями. В подобных ситуациях целесообразно ранжировать некоторые нелинейные функции измеренных признаков
симметричны и отличаются только дисперсиями. В подобных ситуациях целесообразно ранжировать некоторые нелинейные функции измеренных признаков  например
например  При выполнении гипотезы
При выполнении гипотезы  ранги, рассчитанные по
ранги, рассчитанные по
 будут описываться равномерным законом.
будут описываться равномерным законом.
 .
.
 Результатом обучения могут быть уточненные описания классов
Результатом обучения могут быть уточненные описания классов  или уравнения разделяющих поверхностей в пространстве признаков. Эти данные используются
или уравнения разделяющих поверхностей в пространстве признаков. Эти данные используются
 .
.
 алгоритмы обучения в принципе позволяют строить и приближения функций
алгоритмы обучения в принципе позволяют строить и приближения функций  путем непосредственной оценки их моментов
путем непосредственной оценки их моментов

 известных далеко не всегда. В отличие от алгоритмов адаптации рассматриваемые процедуры не ограничиваются оценкой числа объектов каждого класса в группе
известных далеко не всегда. В отличие от алгоритмов адаптации рассматриваемые процедуры не ограничиваются оценкой числа объектов каждого класса в группе  а также не предполагают знания параметрических моделей функций
а также не предполагают знания параметрических моделей функций 
 и вероятностей
и вероятностей  кластерные методы можно с успехом применять для оценки функций
кластерные методы можно с успехом применять для оценки функций  или уравнений разделяющих поверхностей. При этом необходимый объем априорных сведений о распознаваемых объектах может быть близок к минимуму. Для доказательства рассмотрим следующий пример.
или уравнений разделяющих поверхностей. При этом необходимый объем априорных сведений о распознаваемых объектах может быть близок к минимуму. Для доказательства рассмотрим следующий пример.
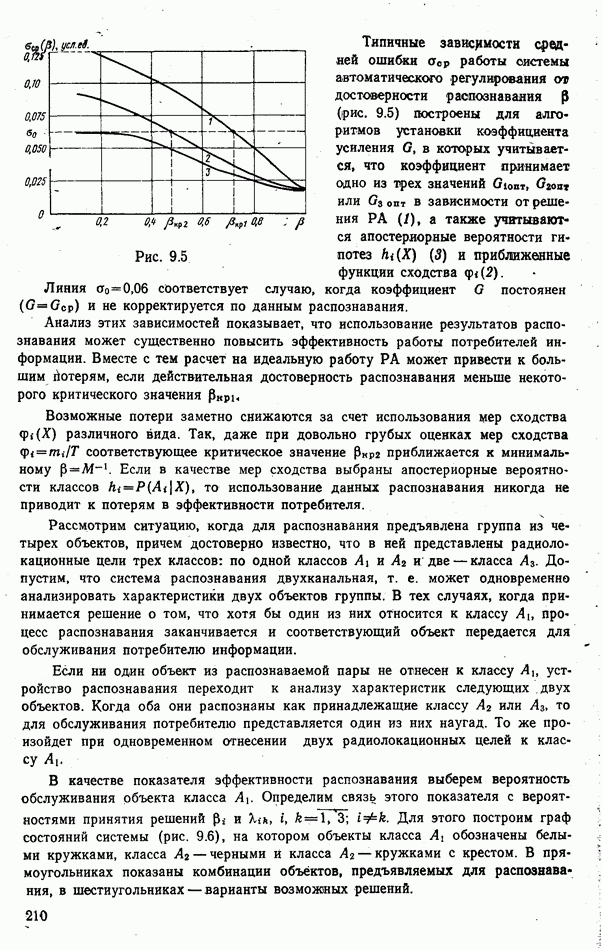
 разместились на оси
разместились на оси  так, как показано на рис. 6.18.
так, как показано на рис. 6.18.
 позволяет предположить, что в распознаваемой группе три объекта с номерами
позволяет предположить, что в распознаваемой группе три объекта с номерами  относятся к одному и тому же классу (виду), а объекты с номерами 2 и 3 принадлежат еще к двум классам (видам).
относятся к одному и тому же классу (виду), а объекты с номерами 2 и 3 принадлежат еще к двум классам (видам).
 а среднее значение признака
а среднее значение признака  растет с увеличением номера класса
растет с увеличением номера класса  даст основание отнести объекты
даст основание отнести объекты  и
и  к первому классу, а объекты
к первому классу, а объекты  — к классам
— к классам  соответственно. Вместо этих сведений можно использовать априорную информацию о возможном соотношении числа объектов каждого класса в наблюдаемой группе.
соответственно. Вместо этих сведений можно использовать априорную информацию о возможном соотношении числа объектов каждого класса в наблюдаемой группе.

 не пересекаются, но условия наблюдения у учесть невозможно. Знание числа классов, представленных (в группе, намного облегчает построение эффективных решающих правил. Недостатком многих алгоритмов кластеризации служит допущение о мономодальности законов
не пересекаются, но условия наблюдения у учесть невозможно. Знание числа классов, представленных (в группе, намного облегчает построение эффективных решающих правил. Недостатком многих алгоритмов кластеризации служит допущение о мономодальности законов  .
.
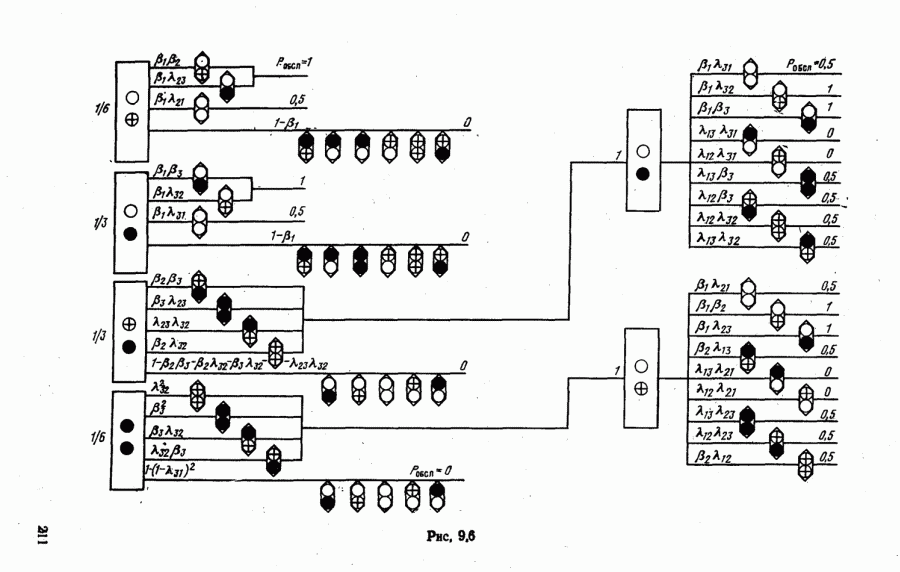
 характеризующей объекты наблюдаемой группы. Разобъем для этого диапазон выборочных значений признаков на
характеризующей объекты наблюдаемой группы. Разобъем для этого диапазон выборочных значений признаков на  интервалов с номерами
интервалов с номерами  Определим относительную частоту
Определим относительную частоту  попаданий значений признаков в каждый из них и построим соответствующую гистограмму (рис. 6.19).
попаданий значений признаков в каждый из них и построим соответствующую гистограмму (рис. 6.19).
 нетрудно. Естественно будет все объекты, значения признаков которых попали слева от
нетрудно. Естественно будет все объекты, значения признаков которых попали слева от  отнести к классу с наименьшим средним значением признака
отнести к классу с наименьшим средним значением признака  допустим к классу
допустим к классу  объекты с максимальными значениями признаков
объекты с максимальными значениями признаков  — отнести к классу
— отнести к классу  а признаки, значения которых оказались между порогами, считать порожденными объектами второго класса.
а признаки, значения которых оказались между порогами, считать порожденными объектами второго класса.
 Другой способ заключается в расчете статистики, основанной на сумме
Другой способ заключается в расчете статистики, основанной на сумме  отклонений значений признаков от порога
отклонений значений признаков от порога  и классификации объекта в зависимости от ее знака.
и классификации объекта в зависимости от ее знака.
 При работе с группами радиолокационных целей многомодальность функции
При работе с группами радиолокационных целей многомодальность функции  не мешает построению алгоритмов кластеризации. Это обусловлено тем, что, во-первых, все объекты наблюдаются в одних и тех же условиях. Поэтому существенное различие их выборочных характеристик, измеренных в течение короткого промежутка времени, мало вероятно. Во-вторых, можно «проследить» за поведением признаков, измеренных от одной и той же
не мешает построению алгоритмов кластеризации. Это обусловлено тем, что, во-первых, все объекты наблюдаются в одних и тех же условиях. Поэтому существенное различие их выборочных характеристик, измеренных в течение короткого промежутка времени, мало вероятно. Во-вторых, можно «проследить» за поведением признаков, измеренных от одной и той же

 присутствие в группе объектов с различными статистическим» свойствами.
присутствие в группе объектов с различными статистическим» свойствами.
 если он, конечно, определен.
если он, конечно, определен.
 объектов первого класса из состава наблюдаемой группы размера
объектов первого класса из состава наблюдаемой группы размера  Измерим, признаки объектов группы и разместим их в вариационном ряду в порядке роста выборочных средних некоторых функций,
Измерим, признаки объектов группы и разместим их в вариационном ряду в порядке роста выборочных средних некоторых функций,  Вид этих функций определяется спецификой решаемой задачи.
Вид этих функций определяется спецификой решаемой задачи.
 и известны их знаки для всех
и известны их знаки для всех  , то можно найти центр кластера первого класса. К классу
, то можно найти центр кластера первого класса. К классу  следует отнести
следует отнести  объектов, наиболее близких к этому центру. Если знаки таких неравенств не заданы, то к классу
объектов, наиболее близких к этому центру. Если знаки таких неравенств не заданы, то к классу  следует отнести тот кластер, число объектов в котором наиболее близко к
следует отнести тот кластер, число объектов в котором наиболее близко к  Разумеется, при
Разумеется, при  задача не решается однозначно.
задача не решается однозначно.