Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
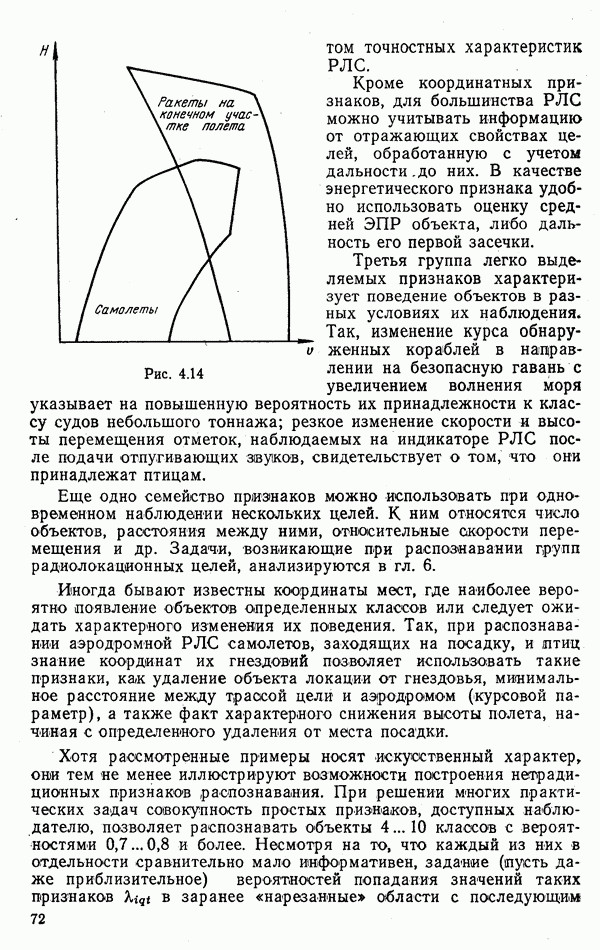
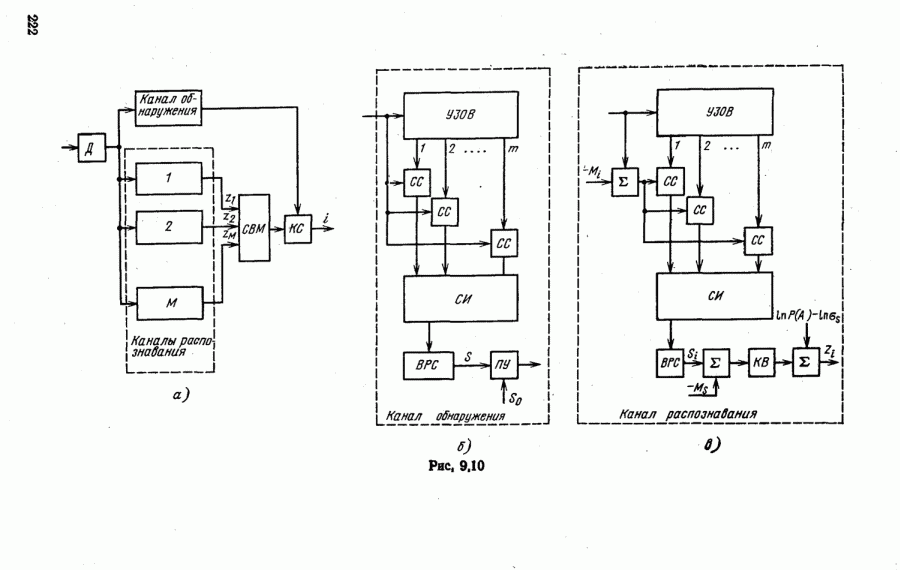
ГЛАВА 6. ПРИНЯТИЕ РЕШЕНИИ ПРИ РАСПОЗНАВАНИИ РАДИОЛОКАЦИОННЫХ ЦЕЛЕЙ6.1. ПОСТАНОВКА ЗАДАЧИНеобходимость специального рассмотрения решающих процедур обусловлена тем, что в значительном большинстве возникающих на практике задач классические методы теории статистических решений мало пригодны из-за ряда особенностей и ограничений, характерных для распознавания радиолокационных целей. Основными из них являются: жесткие ограничения времени расчетов, объема памяти запоминающих устройств, пропускной способности каналов передачи информации; высокий уровень априорной неопределенности. Так, далеко не всегда можно считать известными вероятности классов воздействие разного рода помех, большое разнообразие характеристик целей, объединенных в один и тот же класс. Параметры РЛС (например, мощность и несущая частота зондирующих сигналов) не всегда удовлетворяют требованиям высокой стабильности, ракурсы целей относительно РЛС могут изменяться в широких пределах и в большинстве случаев неизвестны наблюдателю. Все эти факторы могут приводить к существенной нестационарности распознавание объектов зачастую будет производиться системой РЛС, объединенных общим пунктом обработки информации. Частные решения каждой РЛС о классе наблюдаемой цели будут поступать на такой пункт для принятия общего решения; возможность одновременного наблюдения и распознавания нескольких объектов, составляющих группу. В такой ситуации распознавание каждой цели по одиночке не является оптимальным. В зависимости от выполнимости тех или иных перечисленных факторов могут быть построены решающие схемы, оптимальные или близкие к оптимальным в конкретных условиях функционирования систем РРЦ. Будем считать, что информация о наблюдаемой цели поступает на вход устройства распознавания, включающего Т измерительных каналов Каждый Результатом обработки признака
или расчет вероятностей гипотез
Признаки Множество результатов измерений всех
где Если не оговорено противное, будем считать, что распознавание каждой цели (при наличии необходимой априорной информации) производится по правилу идеального наблюдателя. Полученные результаты нетрудно распространить на другие критерии эффективности РРЦ. Наивысшую достоверность распознавания можно обеспечить при использовании условных В противном случае неизбежна потеря информации о цели и «основная задача разработчика систем РРЦ сводится к минимизации таких потерь. Потери могут соответствовать и преобразованию вида Если избежать потерь информации в Когда статистическими связями между признаками Из всех способов преобразования В задачах РРЦ частные решения принимают, например, Если алфавиты классов, используемых разными Величины
Иногда вместо обозначений и В зависимости от того, какие преобразования Оптимальные процедуры. Решающая схема, обладающая наибольшей мощностью, имеет вид
К сожалению, в таком виде она практически неприменима при: решении большинства задач РРЦ. Главная причина — это трудности в задании Зачастую отсутствует возможность априорного анализа сигналов, характеризующих объекты локации, и их описания оказываются весьма приблизительными. Наконец, отдельные признаки целей, например поведенческие, нельзя считать случайными величинами в строго математическом смысле. Поэтому их описание с помощью функций Правила голосования. Известен [28, 57, 61] ряд решающих схем, позволяющих принимать общие решения путем анализа функций Допустим независимость решений
где При статистической зависимости частных решений каналов следует их предварительно декоррелировать либо учитывать условные вероятности «выпадения» разных комбинаций решений при распознавании целей каждого класса Упрощенным вариантом рассмотренного правила является алгоритм простого голосования, когда все коэффициенты
В этом случае общее решение принимается в пользу того класса, который собрал наибольшее число «голосов» каналов. Серьезный недостаток этого правила — возможность отказов, когда большинство голосов делит два или более класса. В таких случаях общее решение проще всего разыгрывать между ними по жребию. В общем случае коэффициенты
Общие решения, принимаемые в соответствии с этим правилом, совпадают с решениями, полученными по правилу идеального наблюдателя, примененному к множеству признаков X, поступающих на входы измерительных каналов, при независимости подмножеств Еще два эмпирических алгоритма голосования рассмотрены в [28, 57]. Первый из них можно назвать алгоритмом голосования коллектива решающих правил. При этом предполагается, что на все
Областью компетентности Очевидно, что отказ от анализа решений остальных Еще один способ повысить эффективность голосования коллектива решающих правил — это учет не только значений признаков X, но и условий наблюдения у. Действительно, допустим, что одни и те же эхосигналы радиолокационной цели поступают на два устройства принятия решений. Первое из них распознает объекты на основании расчета функций Второй эмпирический алгоритм называется правилом максимальной уверенности. Он напоминает алгоритм голосования коллектива решающих правил и отличается предположением о том, что множества признаков
Непараметрические алгоритмы. Эти алгоритмы можно реализовать при недостаточных априорных сведениях об объектах локации, однако их эффективность обычно далека от потенциально достижимой. Кроме того, некоторые из них довольно сложны в реализации (например, правило «к ближайших соседей»), что ставит под сомнение возможность их применения при РРЦ. Из множества непараметрических схем выделим правила, основанные на измерении расстояний между «портретом» распознаваемой цели Расстояния можно оценивать, например, методом средних квадратов: Очевидно, что один из недостатков такого подхода — одинаковый вклад в расстояние Методы, основанные на локальных оценках плотностей распределения вероятностей признаков, предполагают запоминание обучающей выборки и распознавание каждой новой цели с учетом результатов классификации объектов, участвовавших в обучении Многоуровневые решающие схемы Признаки
и цель относится к тому классу, который не был исключен ни. на одном из этапов анализа, т. е. ни одним ИК. Многоуровневые алгоритмы привлекательны своей простотой, но обладают и рядом недостатков. Основной из них состоит в том, что ошибка, допущенная вследствие анализа одного признака, непоправима даже тогда, когда все остальные признаки прямо указывают на исключенный класс. Это ограничивает множество признаков, которыми оперируют многоуровневые РА, небольшим числом наиболее информативных характеристик радиолокационной цели. Очевидно, что такой прием снижает общий объем анализируемых сведений об объекте распознавания, а вместе с тем и вероятность его правильной классификации. Кроме того, следует отметить сложность принятия окончательных решений при многократном повторении процесса распознавания, а также трудность учета информации о важности объектов разных классов, априорных вероятностей их наблюдения. Проведенный анализ решающих схем позволяет рекомендовать для практического решения задач РРЦ компромиссный подход, исключающий необходимость точного знания законов Рассмотрим теперь коротко процесс обработки признаков целей в Обратим внимание на то, что преобразование Еще один подход к построению вторичных признаков определяется стремлением повысить их статистическую устойчивость (см. § 4.5, 9.4). При этом В дальнейшем будем считать, что в каждом Положим сначала, что в каждом Как будет показано, выделение областей решений не должно быть произвольным. От того, как оно произведено, существенно зависит эффективность общих решений. При этом области Совпадение алфавита частных решений с алфавитом классов — традиционное условие синтеза процедур голосования. При этом каждый С другой стороны, если разные РЛС используют отличающиеся алфавиты классов, то совместная обработка их частных решений с помощью рассмотренных правил голосования невозможна. Предположение о совпадении алфавитов общих и частных решений оказывается излишним и в тех случаях, когда хотя бы часть ИК входит в состав одного и того же устройства распознавания. Отказ от него позволяет заметно повысить эффективность распознавания, а иногда и упростить решающие процедуры. Для доказательства сделанного утверждения рассмотрим следующий пример. Пусть распознаются объекты двух равновероятных классов по нескольким отсчетам равномерно распределенных признаков (рис. 6.1). Порог принятия решений по одному отсчету признака
Произведем два независимых отсчета признаков
Рис. 6.1 Таблица 6.1 (см. скан) решений Обратим внимание на то, что ошибочные решения могут приниматься только при попадании отсчетов признаков в область [0,5; 1,5]. Рассмотрим, к чему приведет рассмотрение нового алфавита частных решений (табл. 6.2 и рис. 6.1). Составим возможные комбинации новых частных решений и рассчитаем их условные вероятности Как следует из анализа табл. 6.3, увеличение размерности алфавита первичных решений с двух до трех обеспечило снижение вероятностей ошибок от Таблица 6.2 (см. скан) Таблица 6.3 (см. скан) Таким образом, в общем случае алфавит классов частных решений измерительных каналов Это оказывается удобным, в частности когда каждый из каналов принимает бинарные решения в пользу одного из двух классов <он или Если бесконечно увеличивать число классов частных решений При использовании признаков с высокой степенью статистической устойчивости расширение алфавита частных решений позволяет повышать достоверность РРЦ. В этом случае следует считаться только с ограничениями технического или стоимостного характера. Когда признаки объектов обладают низкой устойчивостью, расширение алфавита частных решений следует производить осторожно. Это связано с тем, что решения да, используемые как вторичные признаки при принятии общих решений, могут оказаться намного более устойчивыми, чем признаки X или частные решения, полученные при расширении алфавитов В самом деле, при обучении намного труднее оценить вероятность попадания признака Выбор алфавитов частных решений достаточно сложен и требует учета специфики каждой конкретной задачи РРЦ. Выбирая области принятия частных решений и подбирая весовые коэффициенты так, чтобы каждый соответствующих частных решений и их весовом суммировании, может совпадать с большинством из рассмотренных алгоритмов. Это дает основание присвоить ему наименование правила обобщенногоголосования (подробнее см. § 6.3).
|
 |
Оглавление
|

























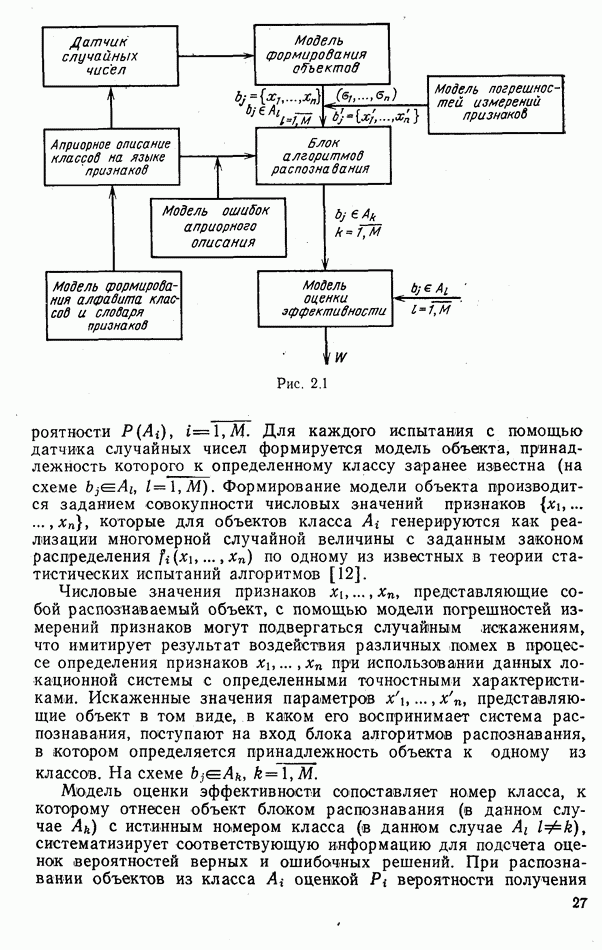

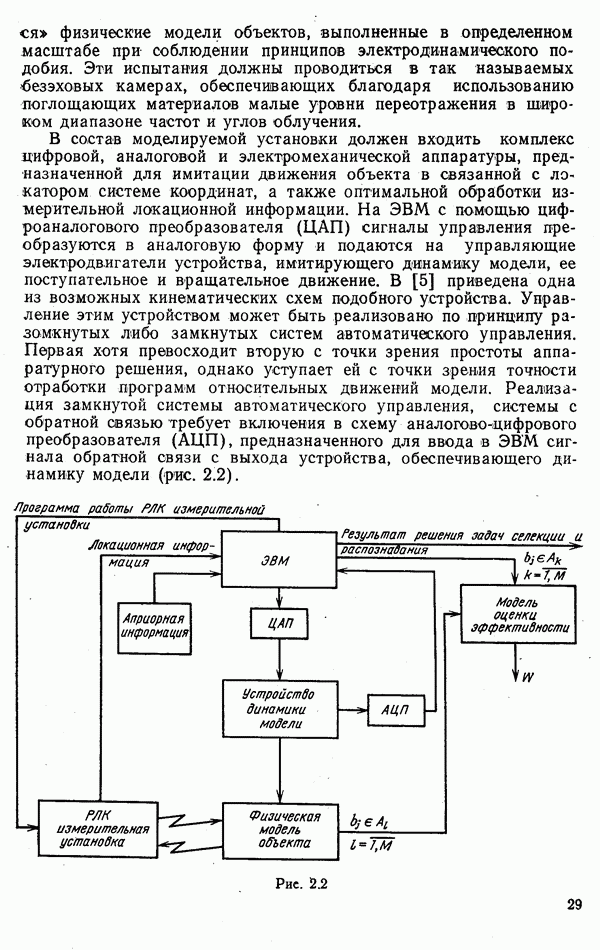

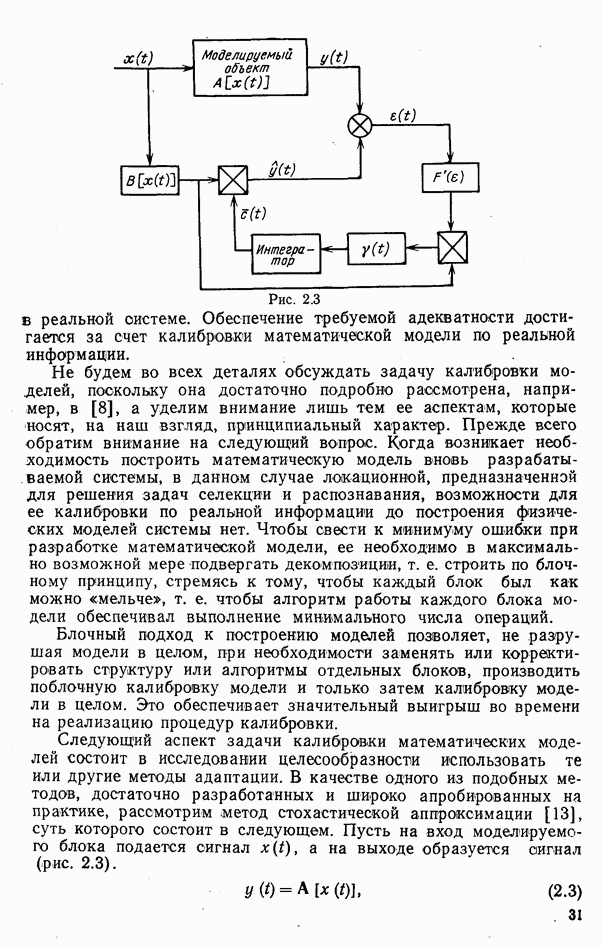




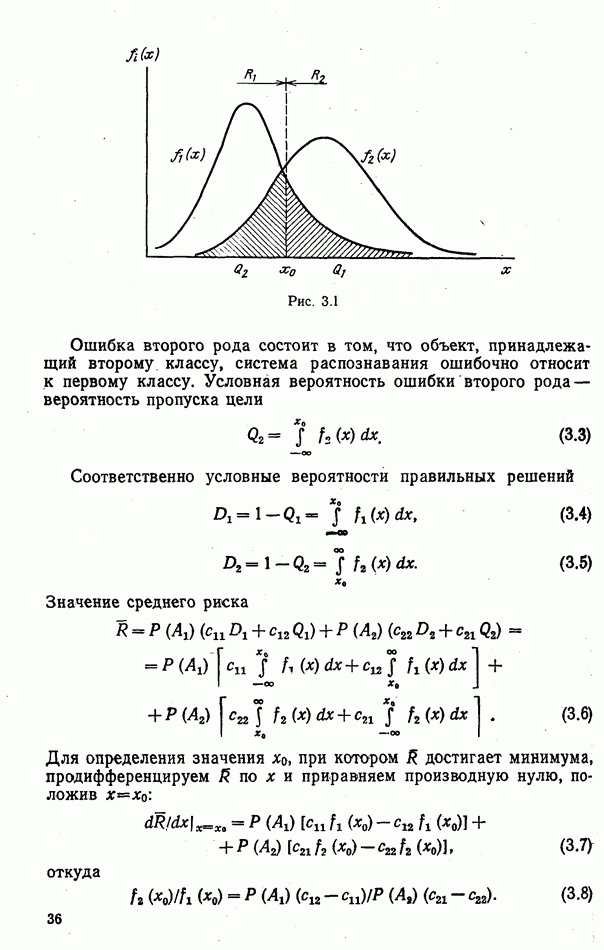





















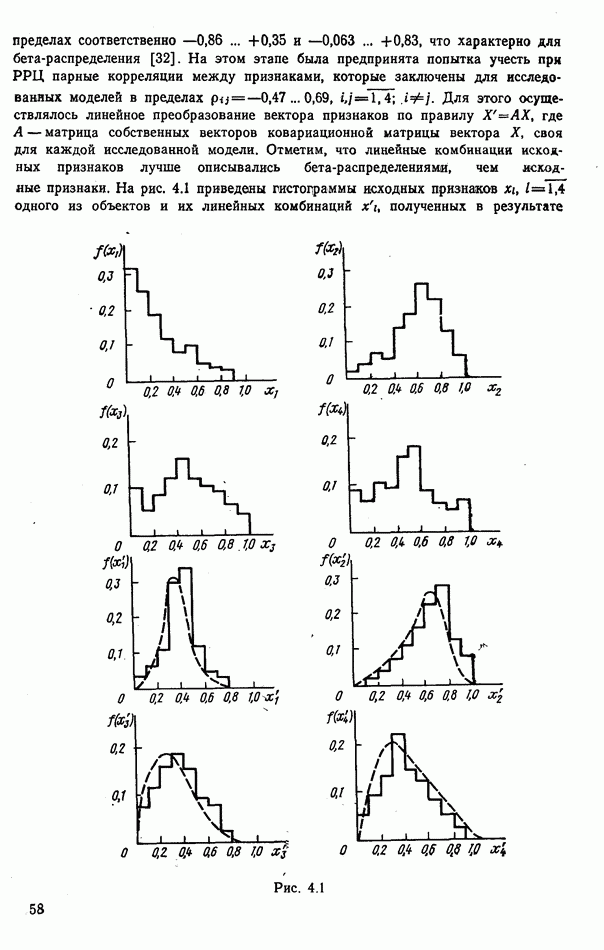
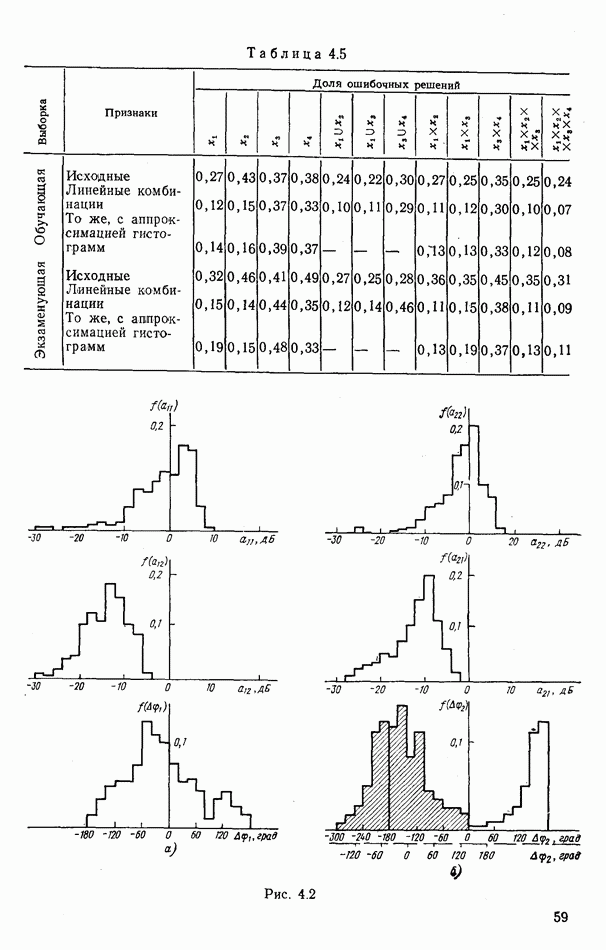
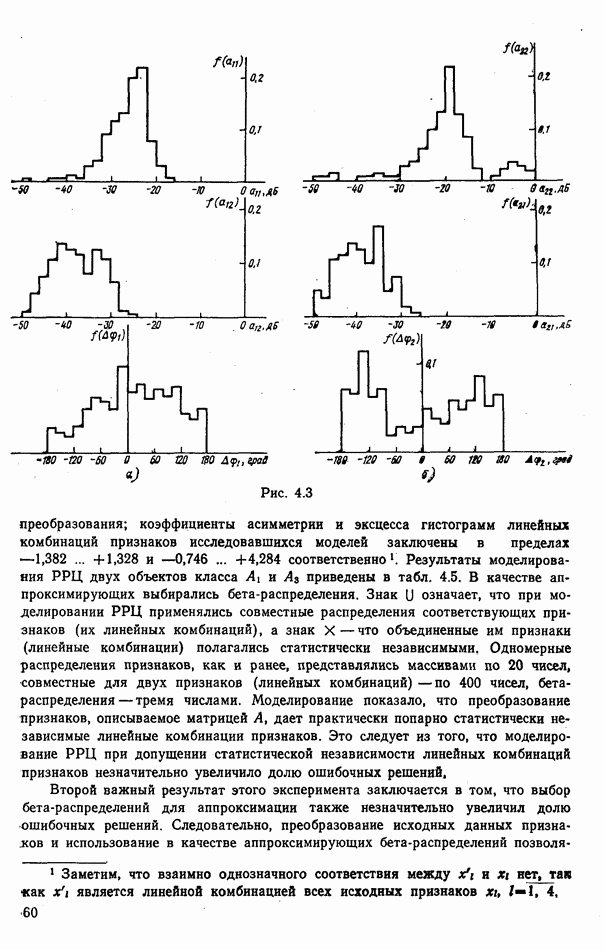
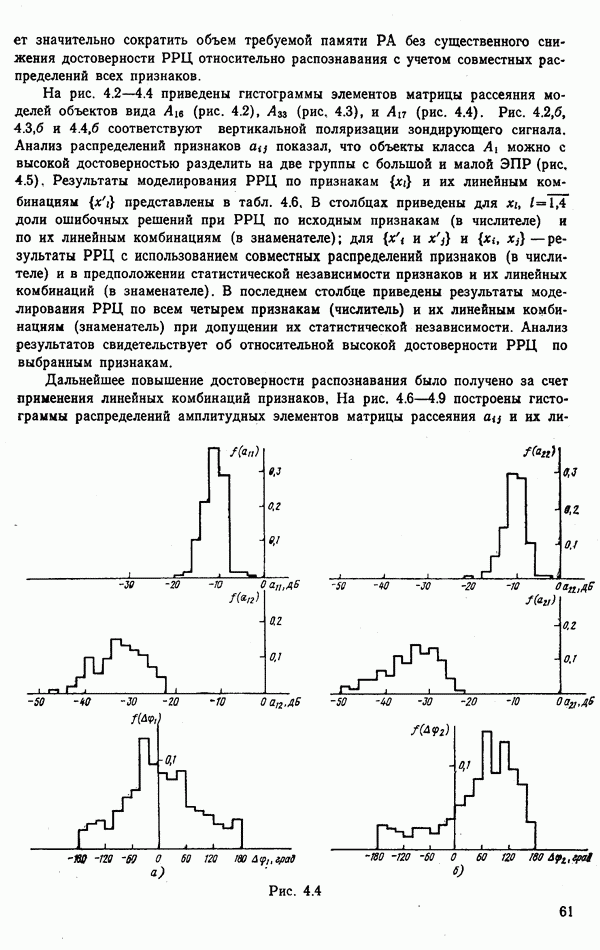
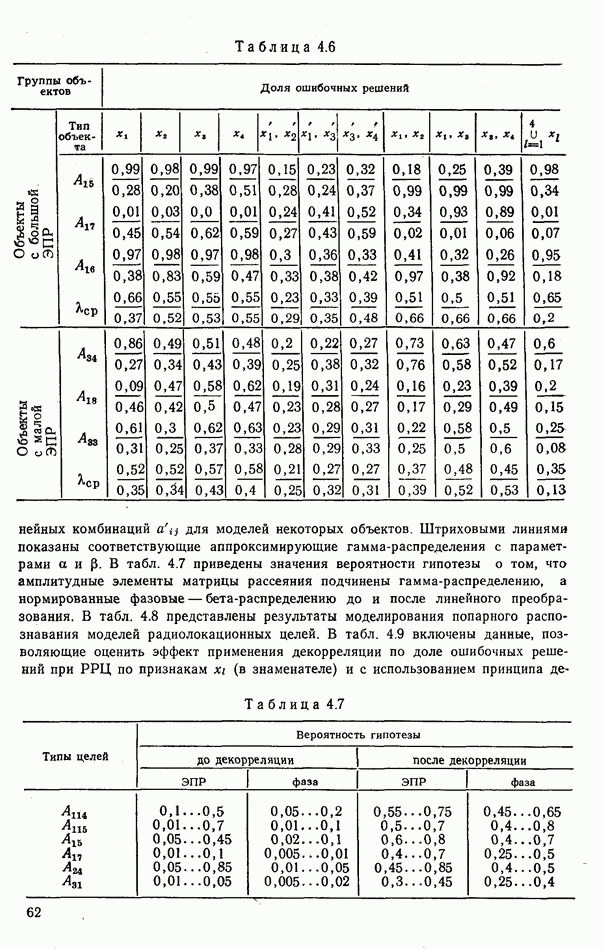
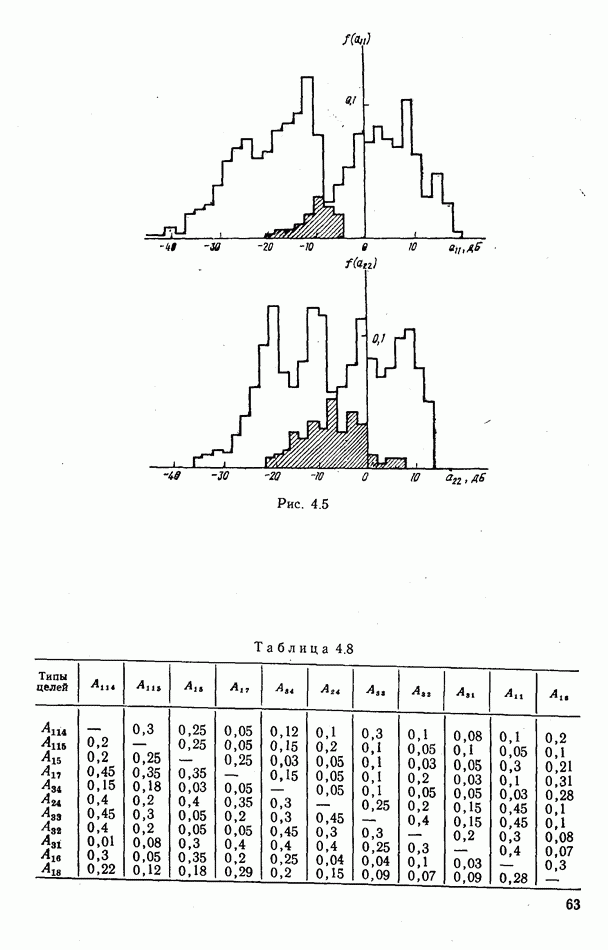

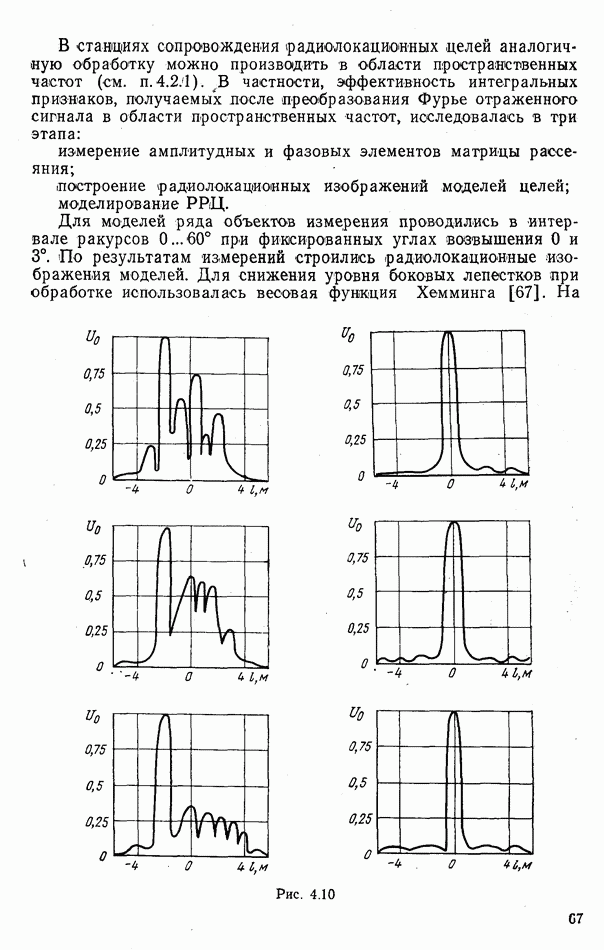
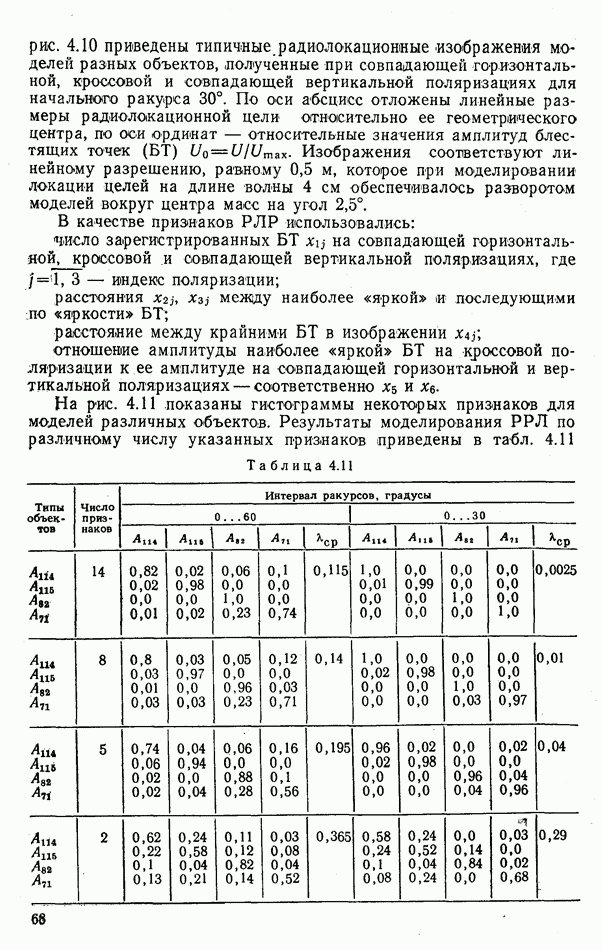
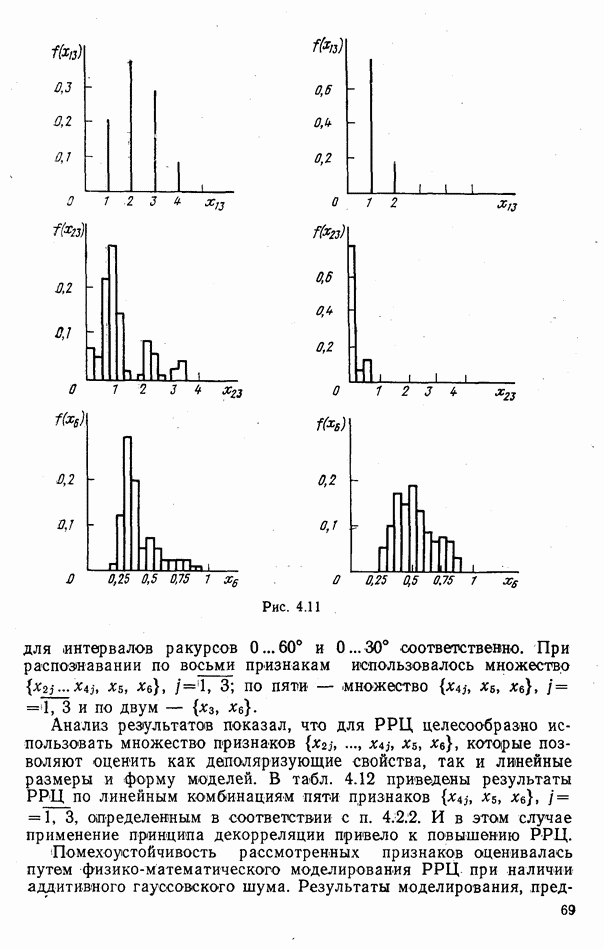
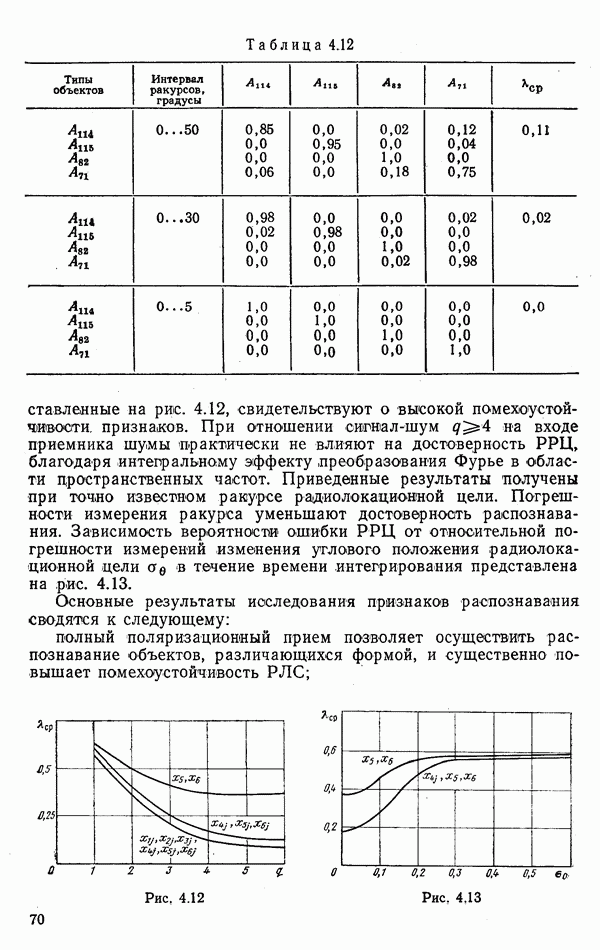






























































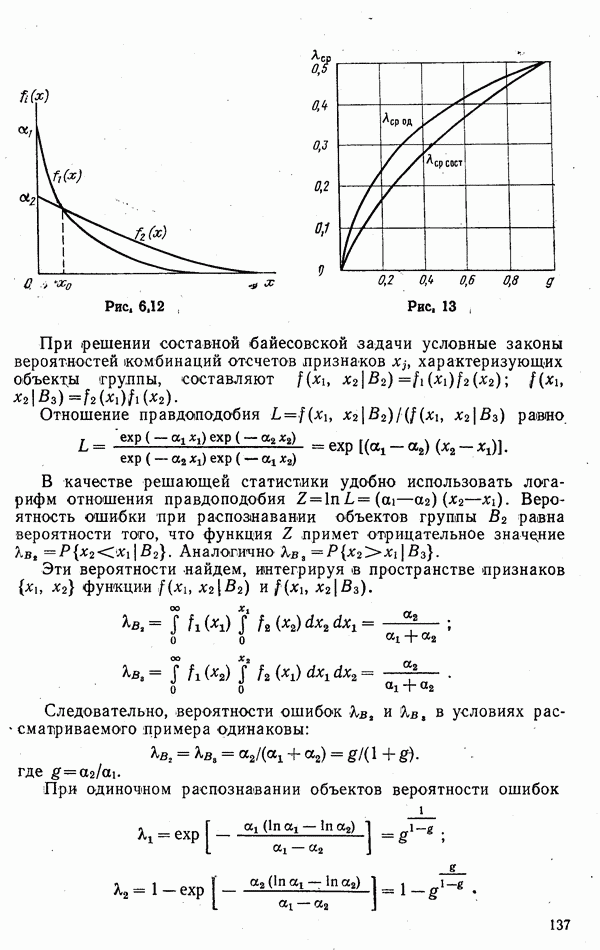









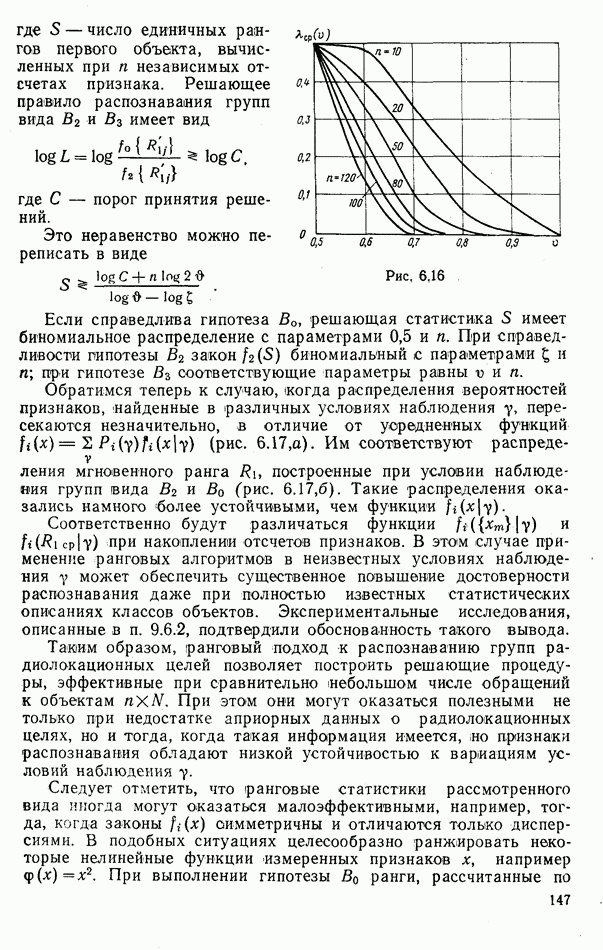
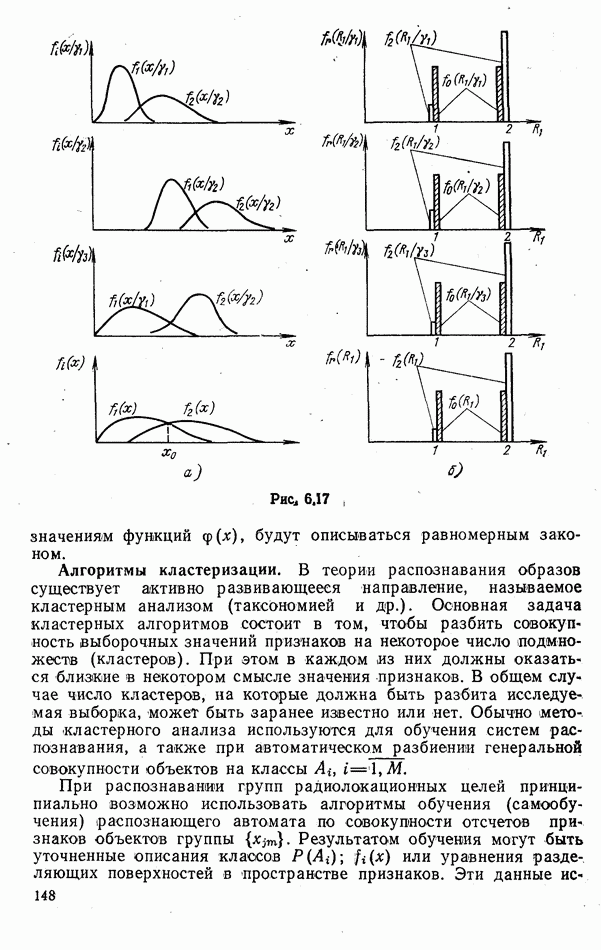




























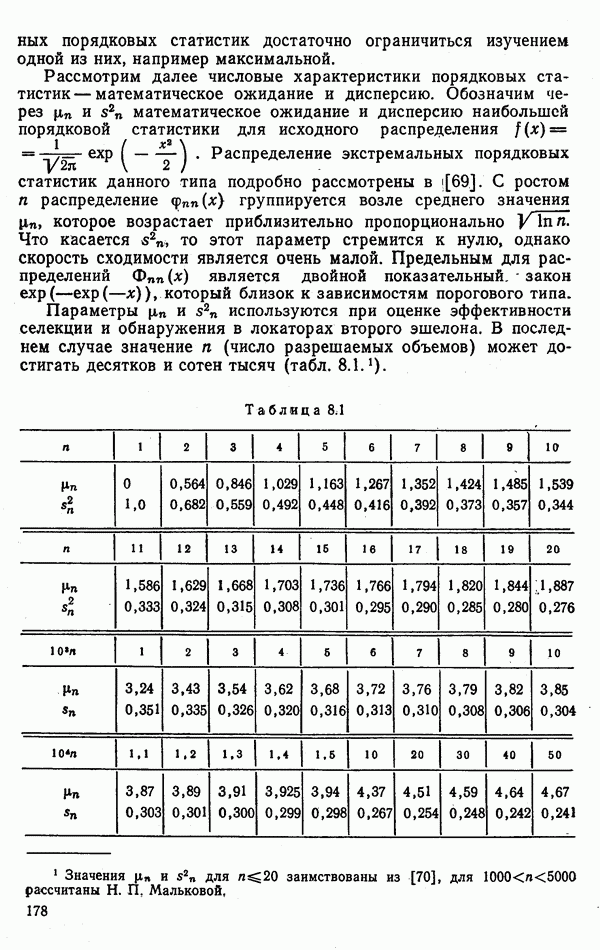












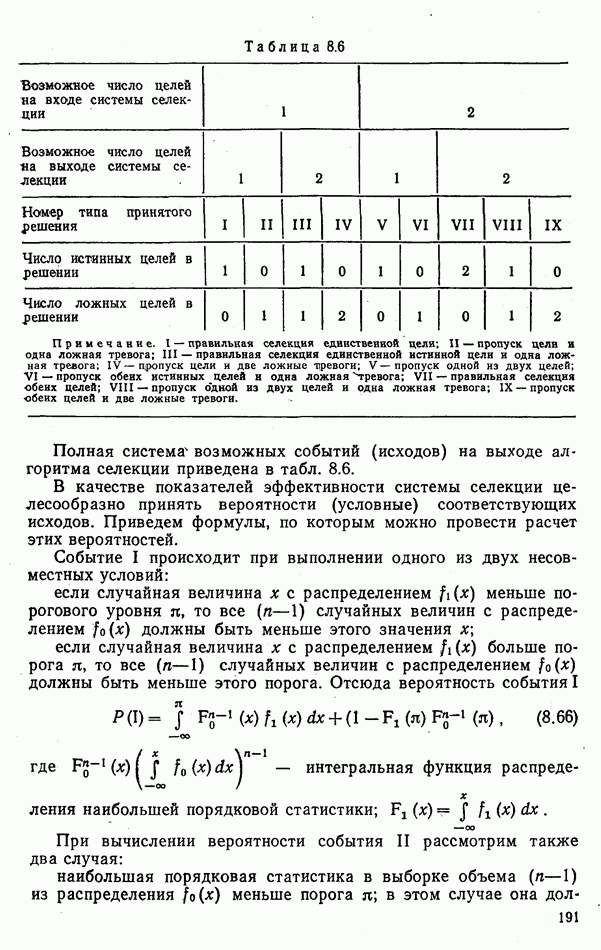










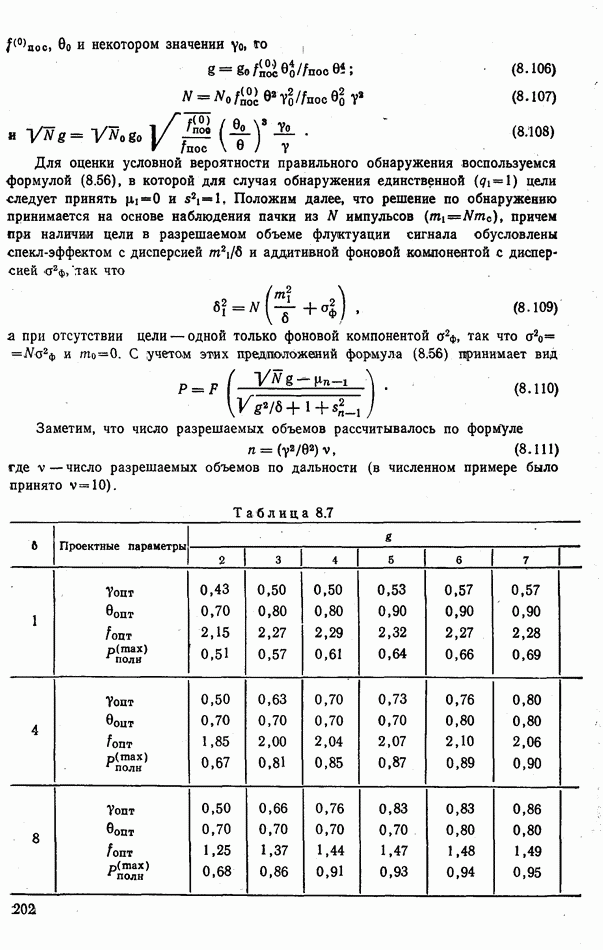
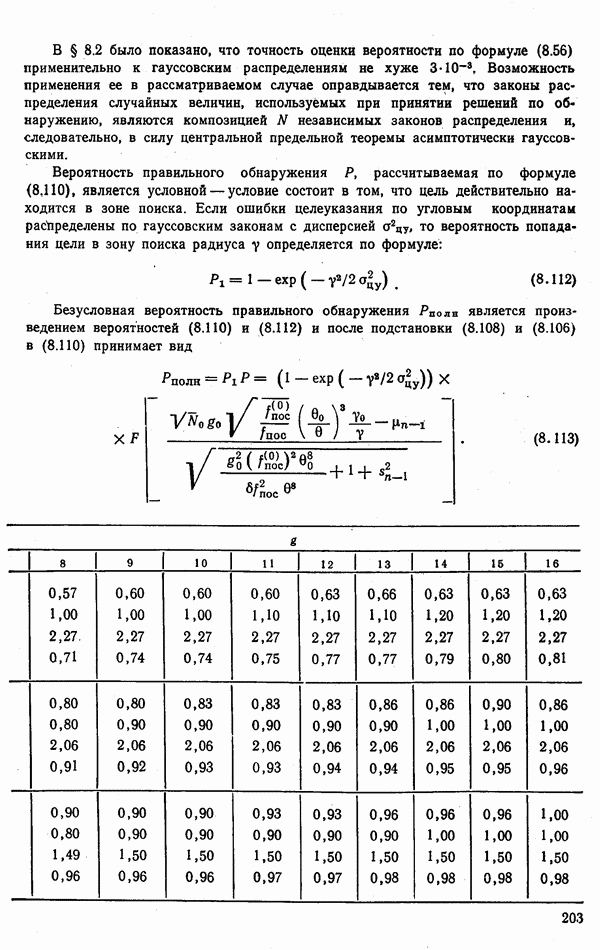


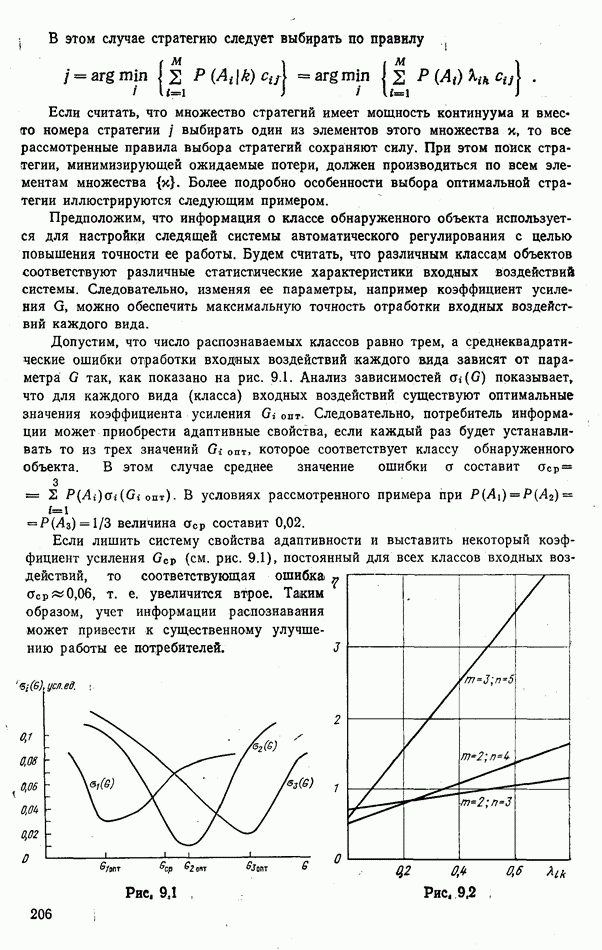
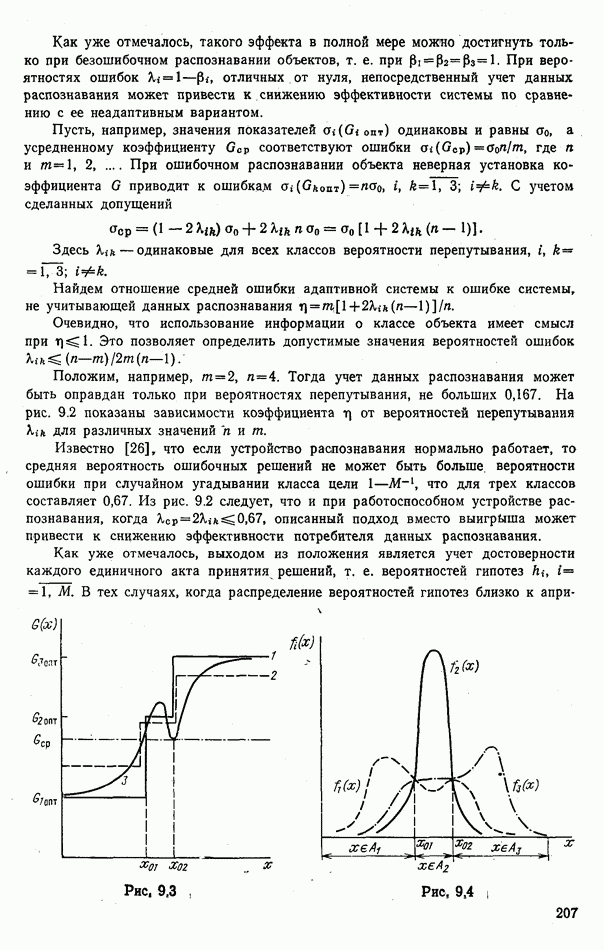


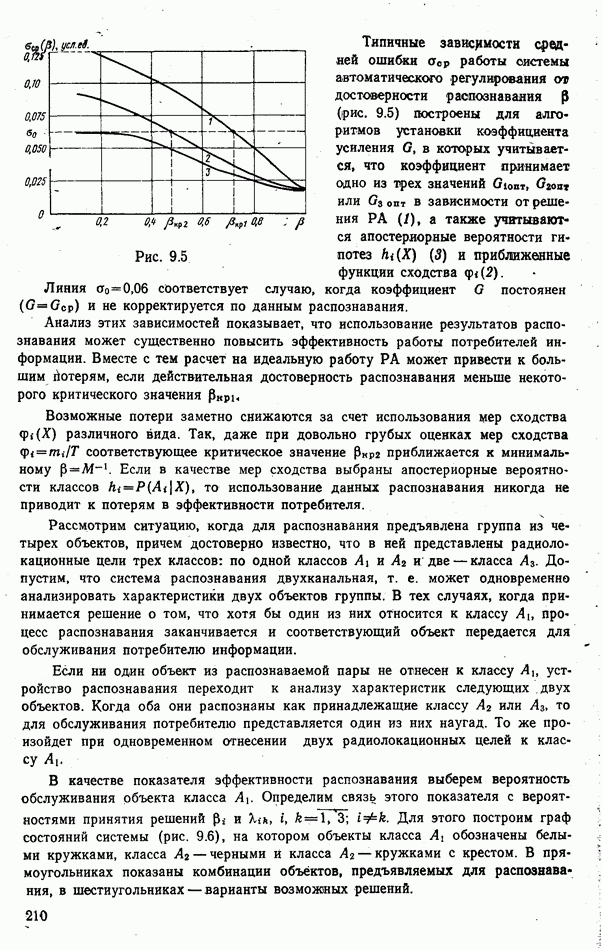
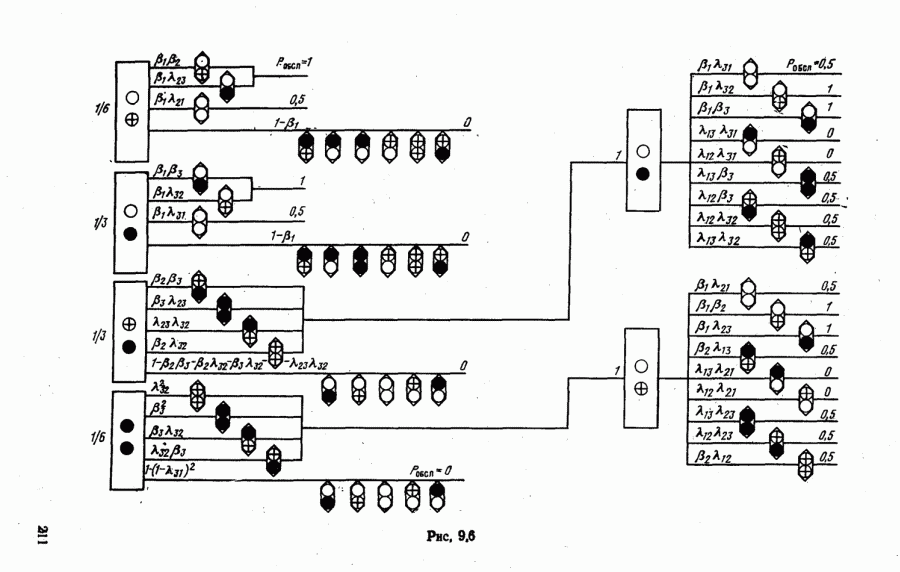















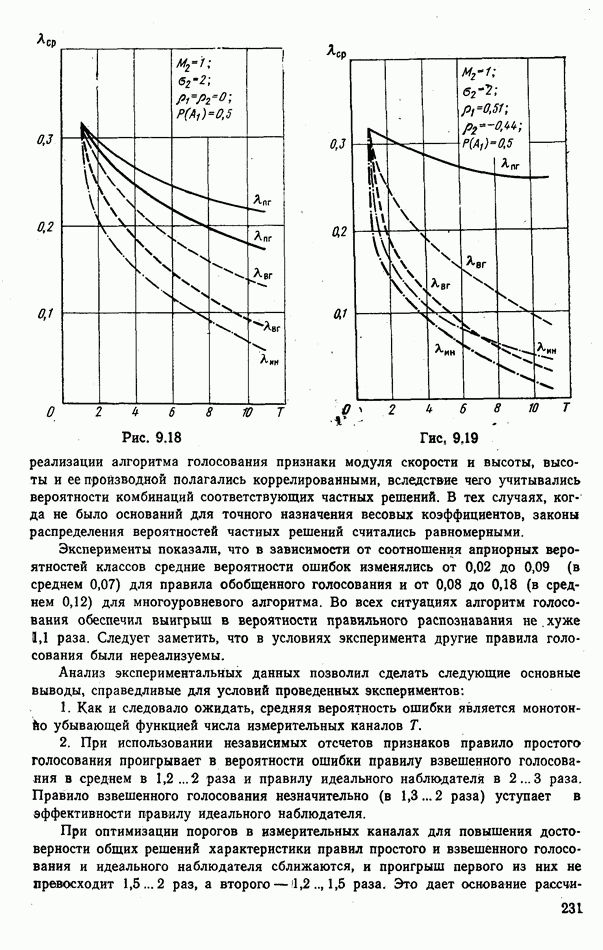
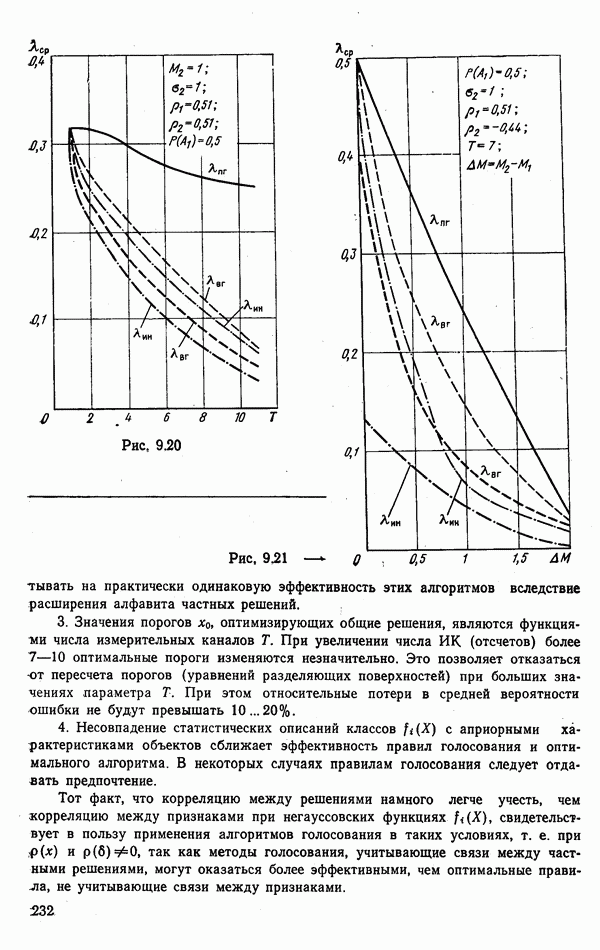

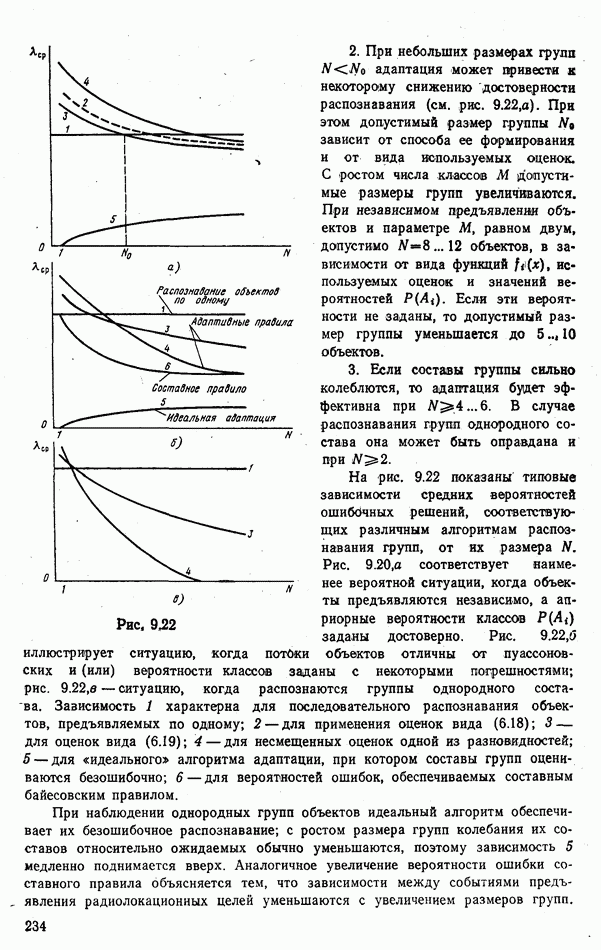




 стоимости принятия решений, законы распределения вероятностей
стоимости принятия решений, законы распределения вероятностей  . Иногда отсутствует возможность набора обучающей статистики о распознаваемых объектах, поэтому описание их характеристик носит качественный характер;
. Иногда отсутствует возможность набора обучающей статистики о распознаваемых объектах, поэтому описание их характеристик носит качественный характер;
 и во многих случаях исключают возможность их аналитической аппроксимации;
и во многих случаях исключают возможность их аналитической аппроксимации;
 Измерительным каналом в общем случае может быть как отдельный
Измерительным каналом в общем случае может быть как отдельный  объединенный вместе с другими автоматами и пунктом обработки информации в единую систему, так и схема, оценивающая значение конкретного признака распознавания, например, амплитуды эхосигнала цели.
объединенный вместе с другими автоматами и пунктом обработки информации в единую систему, так и схема, оценивающая значение конкретного признака распознавания, например, амплитуды эхосигнала цели.
 анализирует значение одного признака
анализирует значение одного признака  или множества
или множества  признаков цели. Объединение подмножеств
признаков цели. Объединение подмножеств  измеренных всеми
измеренных всеми  составляет признак X цели;
составляет признак X цели;
 является величина (множество)
является величина (множество)  . В простейшем случае
. В простейшем случае  хотя возможны и более сложные преобразования, например принятие частных решений
хотя возможны и более сложные преобразования, например принятие частных решений


 могут измеряться разными
могут измеряться разными  одновременно или последовательно. Последнему предположению с математической; точки зрения эквивалентно многократное измерение одного и того же признака X в моменты
одновременно или последовательно. Последнему предположению с математической; точки зрения эквивалентно многократное измерение одного и того же признака X в моменты  .
.
 подается: на устройство принятия общих решений. По отношению к нему множество У служит вторичным признаком цели. Общее решение принимается после анализа множества У и состоит в отнесении цели к одному из классов заданного алфавита
подается: на устройство принятия общих решений. По отношению к нему множество У служит вторичным признаком цели. Общее решение принимается после анализа множества У и состоит в отнесении цели к одному из классов заданного алфавита  или
или  расчете М апостериорных вероятностей гипотез
расчете М апостериорных вероятностей гипотез

 — условный
— условный  множества Y.
множества Y.
 или достаточных статистик признаков цели. Для этого необходимо оценивать значения
или достаточных статистик признаков цели. Для этого необходимо оценивать значения  или достаточных статистик путем анализа множества
или достаточных статистик путем анализа множества  Так, если возможны взаимно однозначные преобразования
Так, если возможны взаимно однозначные преобразования  то указанную задачу можно решить известными способами нахождения
то указанную задачу можно решить известными способами нахождения  функции случайной величины [32, 66].
функции случайной величины [32, 66].
 затрудняющему учет статистических связей между элементами множества X. Здесь
затрудняющему учет статистических связей между элементами множества X. Здесь  вероятности гипотез, рассчитанные в
вероятности гипотез, рассчитанные в 
 невозможно, то общие решения лучше всего принимать путем расчета и анализа
невозможно, то общие решения лучше всего принимать путем расчета и анализа  вторичных признаков
вторичных признаков 
 можно пренебречь (например, после выполнения декоррелирующего преобразования), функцию
можно пренебречь (например, после выполнения декоррелирующего преобразования), функцию  принято определять как произведение условных
принято определять как произведение условных  . В § 6.2 показано, что непосредственное использование этой формулы иногда приводит к некорректным результатам.
. В § 6.2 показано, что непосредственное использование этой формулы иногда приводит к некорректным результатам.
 особого внимания заслуживает преобразование вида
особого внимания заслуживает преобразование вида  формирующее частное решение
формирующее частное решение  . Такие решения широко используют в устройствах бинарного обнаружения сигналов и технической диагностики.
. Такие решения широко используют в устройствах бинарного обнаружения сигналов и технической диагностики.
 объединении в единую систему нескольких однотипных РЛС. Если распознавание производит один
объединении в единую систему нескольких однотипных РЛС. Если распознавание производит один  выдающий решения через некоторый промежуток времени, отведенный для РРЦ, то при увеличении времени контакта с целью может появиться необходимость принятия общего решения по совокупности частных решений, сформированных ранее.
выдающий решения через некоторый промежуток времени, отведенный для РРЦ, то при увеличении времени контакта с целью может появиться необходимость принятия общего решения по совокупности частных решений, сформированных ранее.
 не совпадают, задача усложняется. Примером может служить использование доплеровской РЛС, распознающей три класса целей по скорости:
не совпадают, задача усложняется. Примером может служить использование доплеровской РЛС, распознающей три класса целей по скорости:  — неподвижная;
— неподвижная;  — малоскороствая;
— малоскороствая;  совместно со второй РЛС, оценивающей размеры целей:
совместно со второй РЛС, оценивающей размеры целей:  — малые;
— малые;  — средние;
— средние;  Общее решение должно быть принято в пользу одного из классов главного алфавита:
Общее решение должно быть принято в пользу одного из классов главного алфавита:  — дирижабли;
— дирижабли;  вертолеты;
вертолеты;  — транспортные самолеты;
— транспортные самолеты;  — истребители;
— истребители;  — местные предметы. Очевидно, что решения
— местные предметы. Очевидно, что решения  принятые в соответствии с алфавитами
принятые в соответствии с алфавитами  заданными каждой
заданными каждой  несут информацию, полезную для разделения целей в соответствии с алфавитом общих решений
несут информацию, полезную для разделения целей в соответствии с алфавитом общих решений 
 как
как  , будем называть частными решениями измерительных каналов. Разница между ними состоит только в том, что бинарная переменная
, будем называть частными решениями измерительных каналов. Разница между ними состоит только в том, что бинарная переменная  фиксирует факт отнесения цели в
фиксирует факт отнесения цели в  и к одному из
и к одному из  вспомогательных классов
вспомогательных классов  из М классов основного алфавита:
из М классов основного алфавита:

 будем использовать
будем использовать  отождествляя эту переменную с номером класса
отождествляя эту переменную с номером класса  (или q), к которому цель отнес 1-й канал.
(или q), к которому цель отнес 1-й канал.
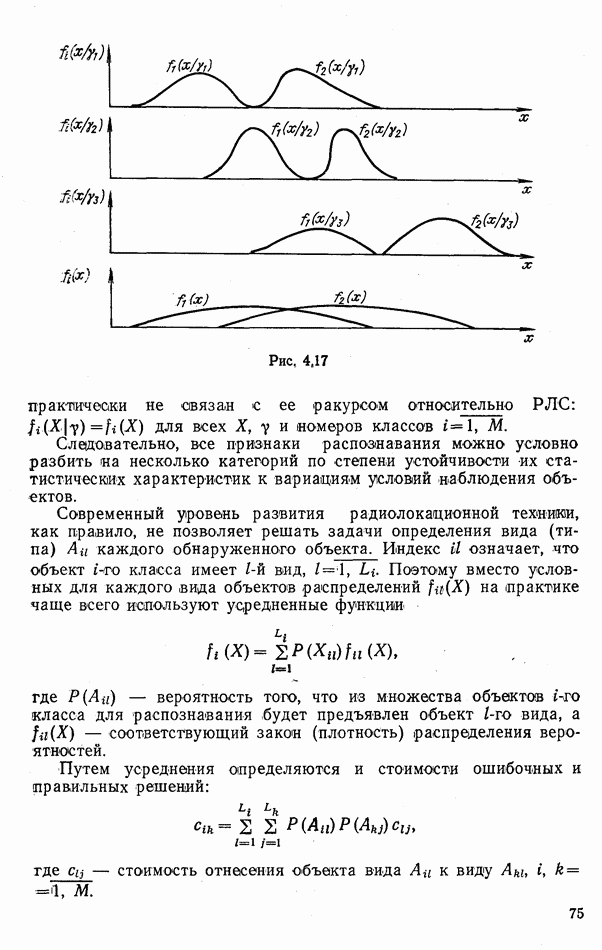
 производятся в измерительных каналах, различают оптимальные алгоритмы, основанные на использовании
производятся в измерительных каналах, различают оптимальные алгоритмы, основанные на использовании  или соответствующих достаточных статистик; алгоритмы голосования частных решений; непараметрические процедуры. Рассмотрим их последовательно.
или соответствующих достаточных статистик; алгоритмы голосования частных решений; непараметрические процедуры. Рассмотрим их последовательно.

 . Особенно сложна аналитическая аппроксимация многомерных функций
. Особенно сложна аналитическая аппроксимация многомерных функций  которые, как правило, многомодальны, их параметры могут существенно изменяться, при вариации условий наблюдения целей, а составляющие
которые, как правило, многомодальны, их параметры могут существенно изменяться, при вариации условий наблюдения целей, а составляющие  иногда имеют высокую степень статистических связей.
иногда имеют высокую степень статистических связей.
 оказывается не совсем корректным.
оказывается не совсем корректным.
 Рассмотрим основные из них.
Рассмотрим основные из них.
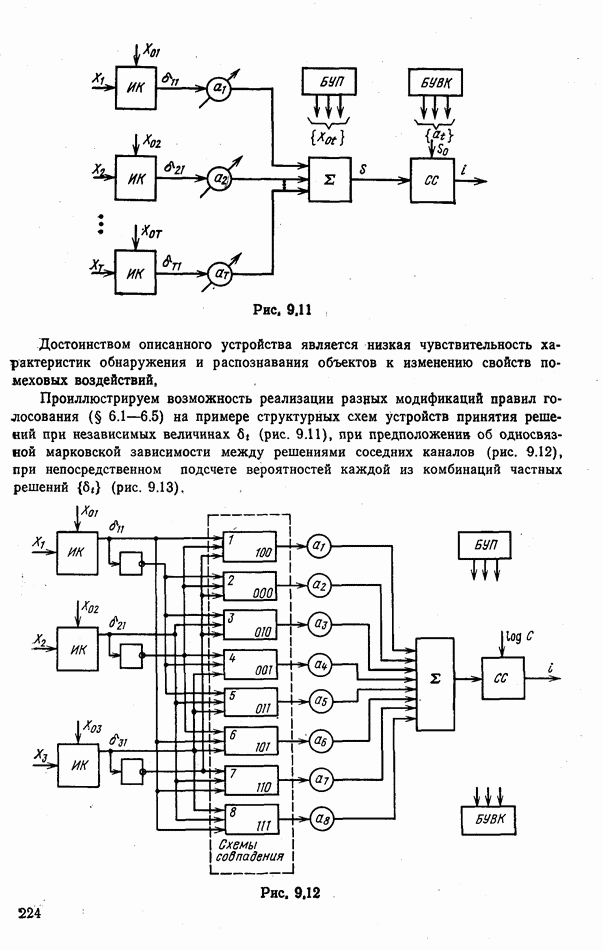
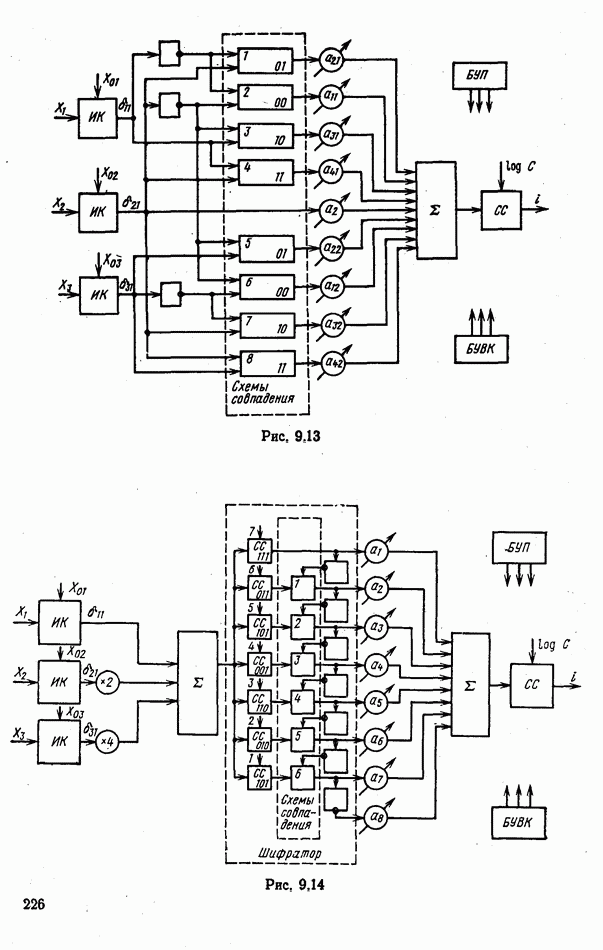
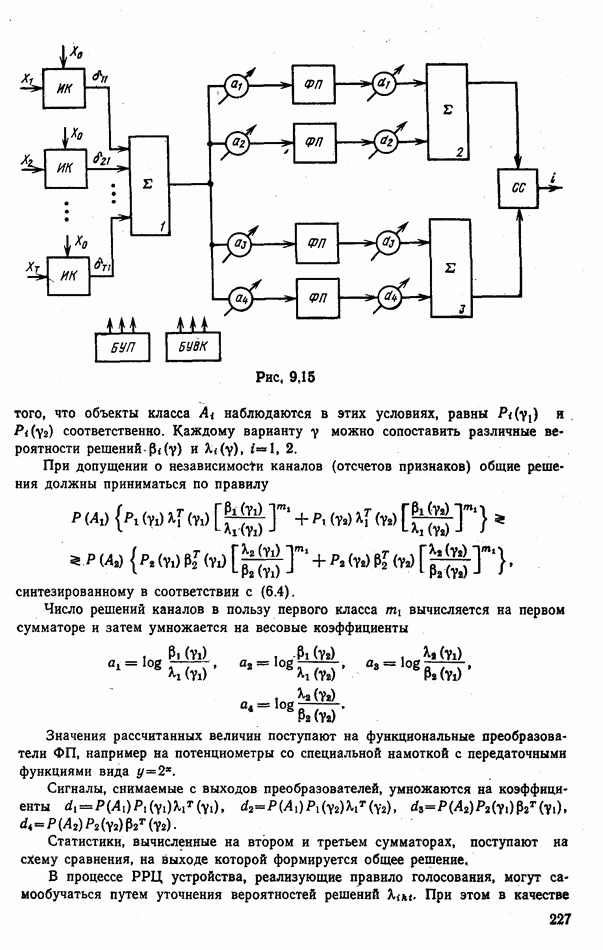
 При этом, как будет показано, оптимальное общее решение должно приниматься по правилу взвешенного голосования
При этом, как будет показано, оптимальное общее решение должно приниматься по правилу взвешенного голосования

 — вероятность того, что в
— вероятность того, что в  ИК объект класса
ИК объект класса  будет отнесен к классу
будет отнесен к классу  .
.
 , (см. § 6.5).
, (см. § 6.5).
 считаются нулевыми, а
считаются нулевыми, а  — единичными:
— единичными:

 могут зависеть от текущих значений признаков
могут зависеть от текущих значений признаков  Примером может служить алгоритм оптимального голосования [28]
Примером может служить алгоритм оптимального голосования [28]


 поступают одни и те же значения признаков
поступают одни и те же значения признаков  . В каждом из каналов реализован «свой» способ формирования частных решений
. В каждом из каналов реализован «свой» способ формирования частных решений  . В соответствии с этим весовые коэффициенты
. В соответствии с этим весовые коэффициенты

 канала называется множество значений признаков, при котором этот канал обеспечивает наивысшую достоверность частных решений
канала называется множество значений признаков, при котором этот канал обеспечивает наивысшую достоверность частных решений  среди всех Т измерительных каналов.
среди всех Т измерительных каналов.
 каналов связан с потерей информации. Если положить весовые коэффициенты всех каналов отличными от нуля и вычислить их с учетом вероятностей ошибочных и правильных решений каждого
каналов связан с потерей информации. Если положить весовые коэффициенты всех каналов отличными от нуля и вычислить их с учетом вероятностей ошибочных и правильных решений каждого  для всех Т областей компетентности, то этот недостаток рассмотренного алгоритма может быть устранен.
для всех Т областей компетентности, то этот недостаток рассмотренного алгоритма может быть устранен.
 , а второе вычисляет функции т. е. способно учитывать условия наблюдения объекта. Если параметр у не оценивается, то решения обоих устройств идентичны. Если информация об условиях наблюдения задана, то при всех значениях признака X решения второго устройства будут более достоверными.
, а второе вычисляет функции т. е. способно учитывать условия наблюдения объекта. Если параметр у не оценивается, то решения обоих устройств идентичны. Если информация об условиях наблюдения задана, то при всех значениях признака X решения второго устройства будут более достоверными.
 обрабатываемых в разных
обрабатываемых в разных  не пересекаются. При этом общее решение отождествляется с частным решением того канала, которому соответствует максимальное из всех
не пересекаются. При этом общее решение отождествляется с частным решением того канала, которому соответствует максимальное из всех  значений вероятностей гипотез
значений вероятностей гипотез

 и эталонами
и эталонами  каждого из классов.
каждого из классов.
 где
где  .
.
 каждого из Т вторичных признаков
каждого из Т вторичных признаков  хотя они обычно имеют разную информативность.
хотя они обычно имеют разную информативность.
 Такой подход вряд ли можно рекомендовать для большинства задач РРЦ ввиду его сложности и трудностей априорного обучения
Такой подход вряд ли можно рекомендовать для большинства задач РРЦ ввиду его сложности и трудностей априорного обучения  по реальным объектам.
по реальным объектам.
 можно применять для отдельных простых задач РРЦ. Они предполагают разбиение множества классов
можно применять для отдельных простых задач РРЦ. Они предполагают разбиение множества классов  на ряд подмножеств
на ряд подмножеств 
 согласно
согласно  анализируются последовательно. В зависимости от того, в какую
анализируются последовательно. В зависимости от того, в какую  из
из  областей попало значение t-го признака, распознаваемая цель считается относящейся к алфавиту
областей попало значение t-го признака, распознаваемая цель считается относящейся к алфавиту  который получен из алфавита
который получен из алфавита  путем исключения одного или нескольких классов
путем исключения одного или нескольких классов  После анализа последнего
После анализа последнего  признака каждый из М возможных алфавитов
признака каждый из М возможных алфавитов  включает только по одному классу целей
включает только по одному классу целей  . В зависимости от величины
. В зависимости от величины  объект относится к одному из них. Математически
объект относится к одному из них. Математически  описывается выражением
описывается выражением

 но сохраняющий ряд преимуществ байесовских процедур. Такой подход может быть реализован с, помощью процедуры обобщенного голосования, рассматриваемой далее. При этом в зависимости от уровня априорной неопределенности решающее правило будет приближаться
но сохраняющий ряд преимуществ байесовских процедур. Такой подход может быть реализован с, помощью процедуры обобщенного голосования, рассматриваемой далее. При этом в зависимости от уровня априорной неопределенности решающее правило будет приближаться  оптимальной параметрической (при известных
оптимальной параметрической (при известных  ) или непараметрической (при полностью неизвестных
) или непараметрической (при полностью неизвестных  процедуре.
процедуре.
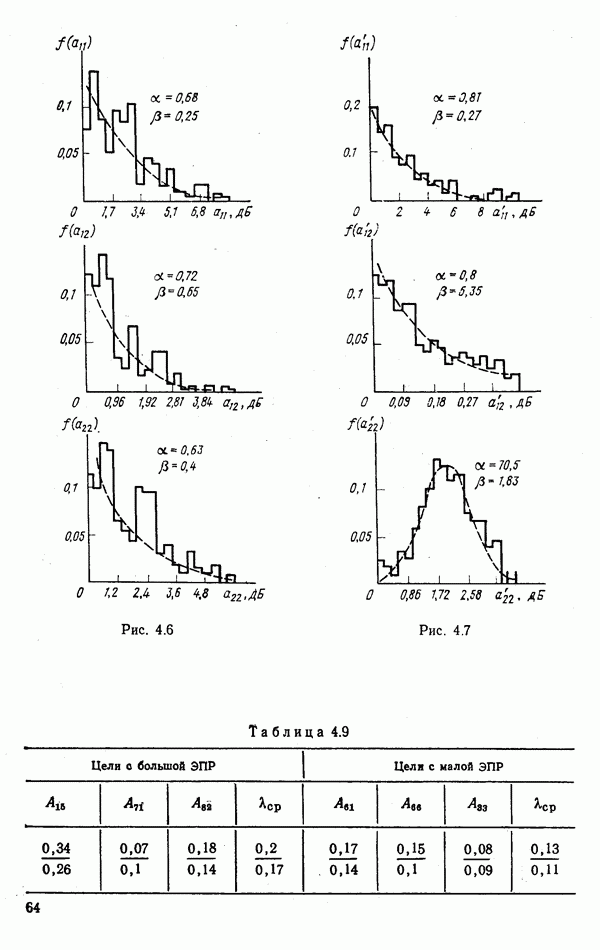
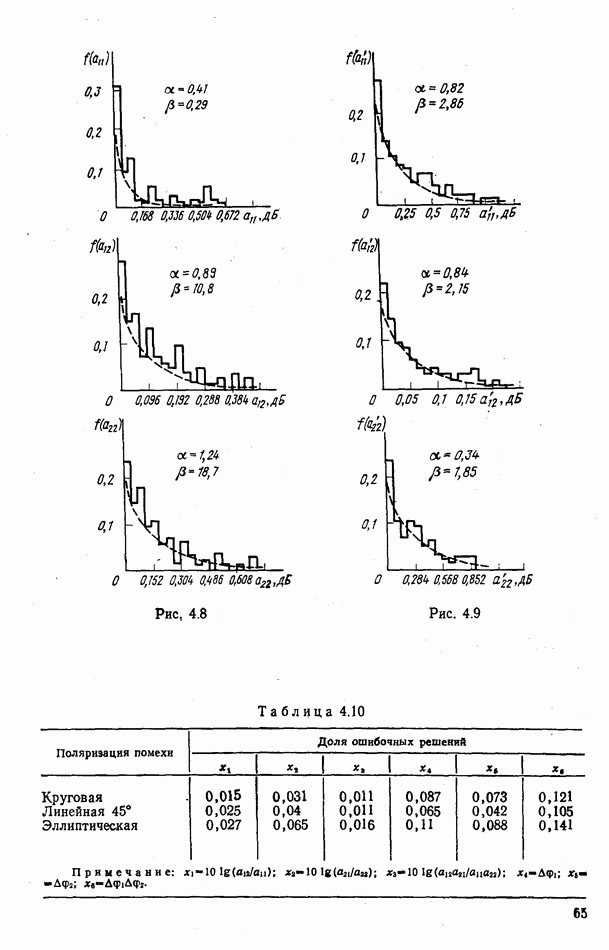
 . Особого внимания заслуживают декоррелирующие преобразования вида
. Особого внимания заслуживают декоррелирующие преобразования вида  где
где  — специально подобранные постоянные коэффициенты, позволяющие в некоторых случаях получить некоррелированную систему вторичных признаков
— специально подобранные постоянные коэффициенты, позволяющие в некоторых случаях получить некоррелированную систему вторичных признаков  . При этом облегчается расчет
. При этом облегчается расчет 
 проводится индивидуально для каждого класса
проводится индивидуально для каждого класса  При
При  иногда возможна одновременная декорреляция признаков целей обоих классов
иногда возможна одновременная декорреляция признаков целей обоих классов 
 удается достаточно точно оценить, в отличие от
удается достаточно точно оценить, в отличие от  параметры которых могут неопределенным образом изменяться в широких пределах.
параметры которых могут неопределенным образом изменяться в широких пределах.
 производится квантование множества признаков
производится квантование множества признаков  на некоторое число областей
на некоторое число областей  Значение
Значение  может изменяться от двух (при бинарном квантовании) до
может изменяться от двух (при бинарном квантовании) до  когда множество
когда множество  воспроизводит входное воздействие
воспроизводит входное воздействие  без потери информации.
без потери информации.
 производится квантование множества значений
производится квантование множества значений  на М областей
на М областей  по числу классов распознаваемых объектов. Для реализации правила взвешенного голосования должны быть заданы вероятности попадания признаков целей разных классов в каждую из таких областей принятия частных решений.
по числу классов распознаваемых объектов. Для реализации правила взвешенного голосования должны быть заданы вероятности попадания признаков целей разных классов в каждую из таких областей принятия частных решений.
 обеспечивающие оптимальность частных решений каждого
обеспечивающие оптимальность частных решений каждого  канала при его автономной работе, как правило, не будут наилучшими при работе этого канала в составе системы ИК.
канала при его автономной работе, как правило, не будут наилучшими при работе этого канала в составе системы ИК.
 «обязан» отнести объект к одному из классов
«обязан» отнести объект к одному из классов  Такое требование оправдано, например, при объединении на общем пункте обработки результатов распознавания цели несколькими однотипными РЛС.
Такое требование оправдано, например, при объединении на общем пункте обработки результатов распознавания цели несколькими однотипными РЛС.
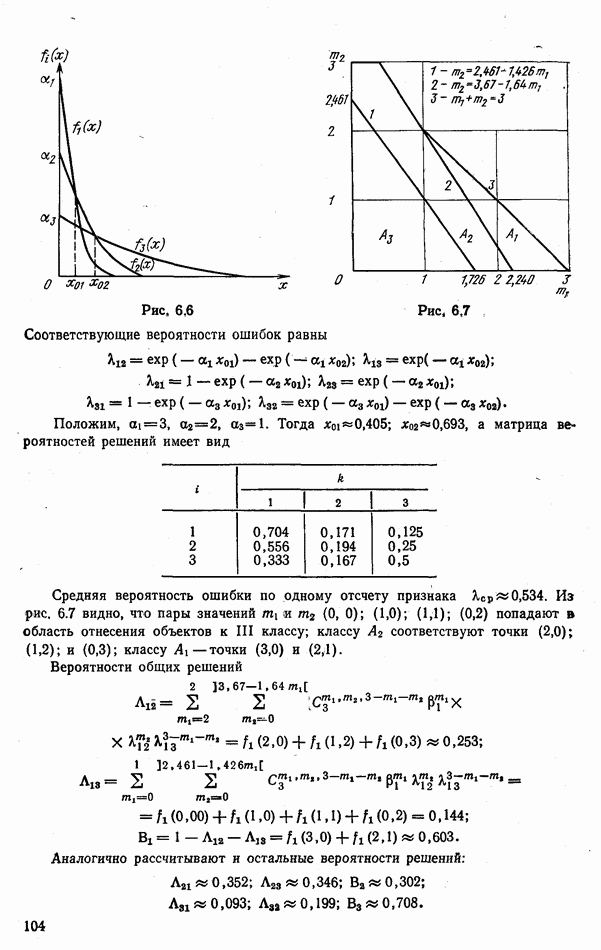
 положим равным единице. Тогда вероятности ошибок каждого из каналов (т. е. по каждому отсчету) составят
положим равным единице. Тогда вероятности ошибок каждого из каналов (т. е. по каждому отсчету) составят

 и проанализируем возможные варианты соответствующих комбинаций
и проанализируем возможные варианты соответствующих комбинаций

 (табл. 6.1). При одинаковых вероятностях комбинаций решений объекты в одном случае
(табл. 6.1). При одинаковых вероятностях комбинаций решений объекты в одном случае  будем относить к классу
будем относить к классу  во втором случае
во втором случае  — к классу
— к классу  . Средняя вероятность ошибки общих решений
. Средняя вероятность ошибки общих решений  совпала со средней вероятностью ошибки по одному отсчету.
совпала со средней вероятностью ошибки по одному отсчету.
 где
где  — номера вспомогательных классов
— номера вспомогательных классов  (табл. 6.3). При равенстве вероятностей
(табл. 6.3). При равенстве вероятностей  общие решения будем распределять поровну между классами.
общие решения будем распределять поровну между классами.
 т. е. примерно в 1,33 раза. Интересно отметить, что более сложный алгоритм идеального наблюдателя в условиях рассмотренного примера приводит к той же вероятности ошибки
т. е. примерно в 1,33 раза. Интересно отметить, что более сложный алгоритм идеального наблюдателя в условиях рассмотренного примера приводит к той же вероятности ошибки  что и легко реализуемое правило голосования.
что и легко реализуемое правило голосования.
 не должен совпадать с алфавитом классов общих решений
не должен совпадать с алфавитом классов общих решений  Более того, в каждом из
Более того, в каждом из  может быть задан «свой» алфавит решений
может быть задан «свой» алфавит решений  .
.
 причем множества
причем множества  не совпадают хотя бы частично. В этом случае общие решения могут приниматься в пользу любого из
не совпадают хотя бы частично. В этом случае общие решения могут приниматься в пользу любого из  классов
классов  Такое построение системы измерительных каналов легко реализуемо и может получить распространение на практике.
Такое построение системы измерительных каналов легко реализуемо и может получить распространение на практике.
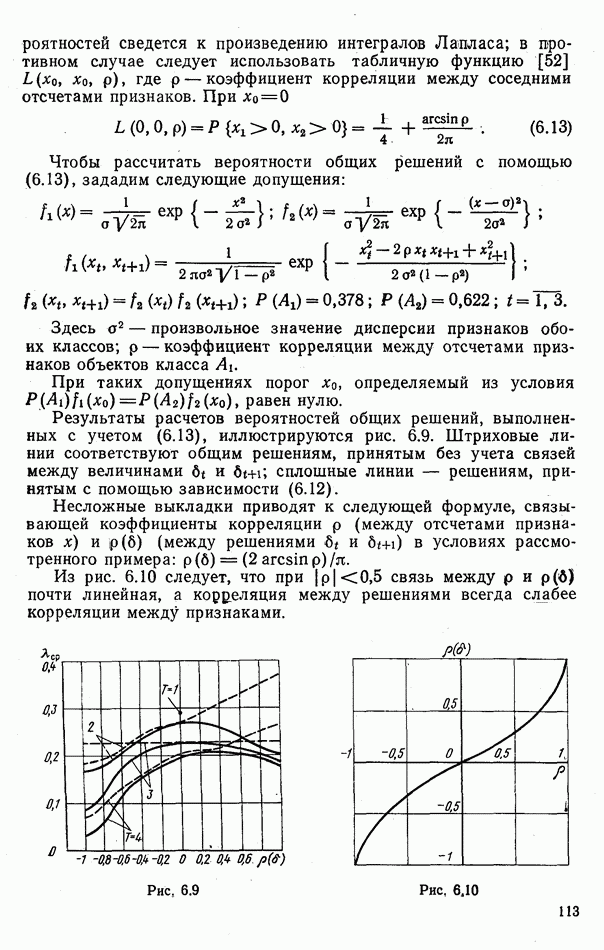
 стремясь снизить потери информации, связанные с квантованием признаков, то в пределе получим алгоритм, эквивалентный алгоритму идеального наблюдателя, примененному к вектору входных воздействий каналов X. Действительно, уменьшим область квантования признака
стремясь снизить потери информации, связанные с квантованием признаков, то в пределе получим алгоритм, эквивалентный алгоритму идеального наблюдателя, примененному к вектору входных воздействий каналов X. Действительно, уменьшим область квантования признака  до
до  Вероятность попадания значения признака, характеризующего объект класса
Вероятность попадания значения признака, характеризующего объект класса  в эту область равна
в эту область равна  Соответственно весовые коэффициенты при голосовании окажутся зависящими от логарифмов функций
Соответственно весовые коэффициенты при голосовании окажутся зависящими от логарифмов функций  что приведет к рассмотренному правилу оптимального голосования.
что приведет к рассмотренному правилу оптимального голосования.

 в область
в область  чем вероятность его попадания в область справа или слева от некоторого порога
чем вероятность его попадания в область справа или слева от некоторого порога  При изменении условий наблюдения у первая из этих вероятностей
При изменении условий наблюдения у первая из этих вероятностей  может измениться весьма значительно, в то время как приращение второй вероятности будет небольшим. В этом случае преимущества более сложного решающего правила могут быть обесценены.
может измениться весьма значительно, в то время как приращение второй вероятности будет небольшим. В этом случае преимущества более сложного решающего правила могут быть обесценены.
 исключал из рассмотрения один или несколько классов
исключал из рассмотрения один или несколько классов  алгоритм голосования можно отождествлять с многоуровневой решающей схемой. Таким образом, решающее правило, основанное на квантовании признаков X на некоторое, не жестко определенное число областей, принятии
алгоритм голосования можно отождествлять с многоуровневой решающей схемой. Таким образом, решающее правило, основанное на квантовании признаков X на некоторое, не жестко определенное число областей, принятии