Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
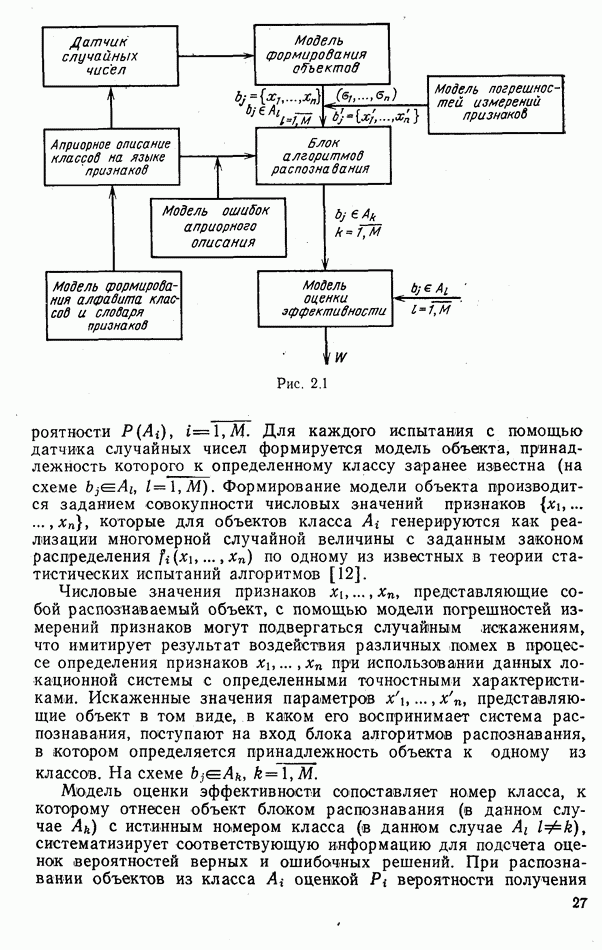
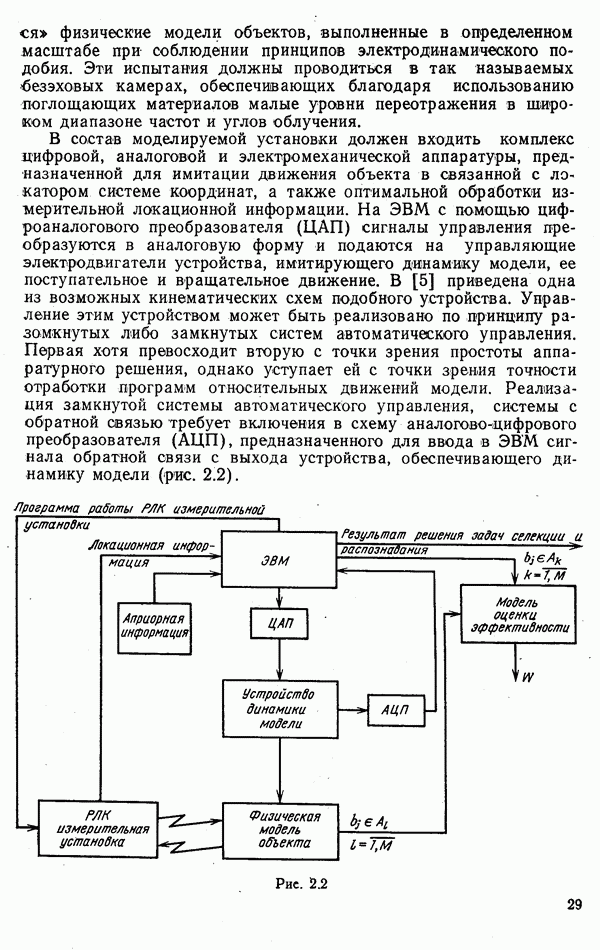
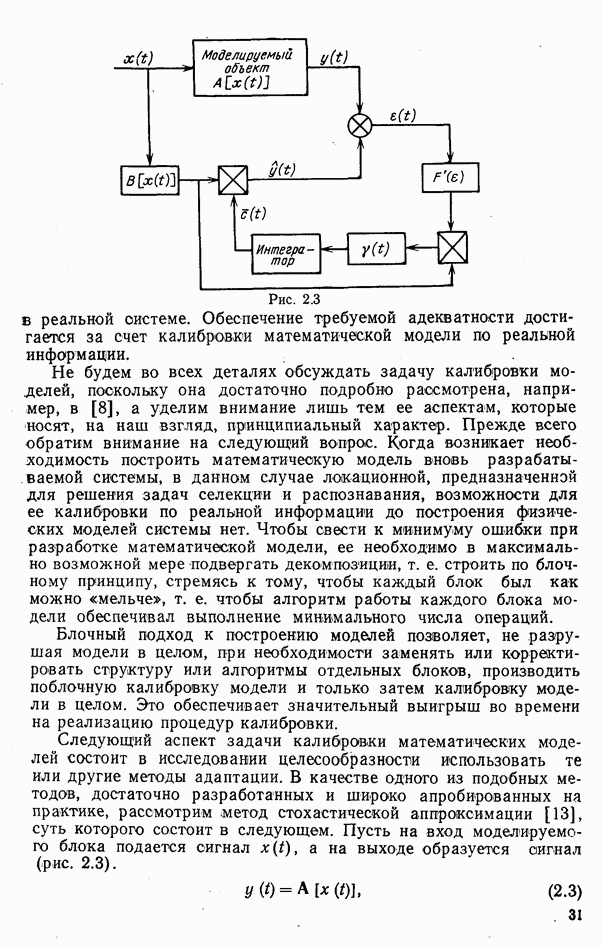
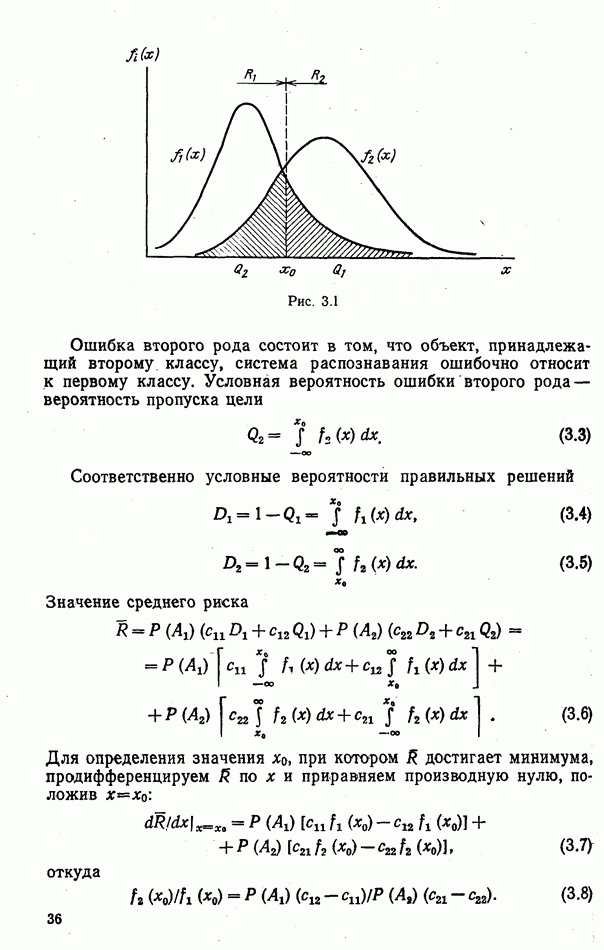
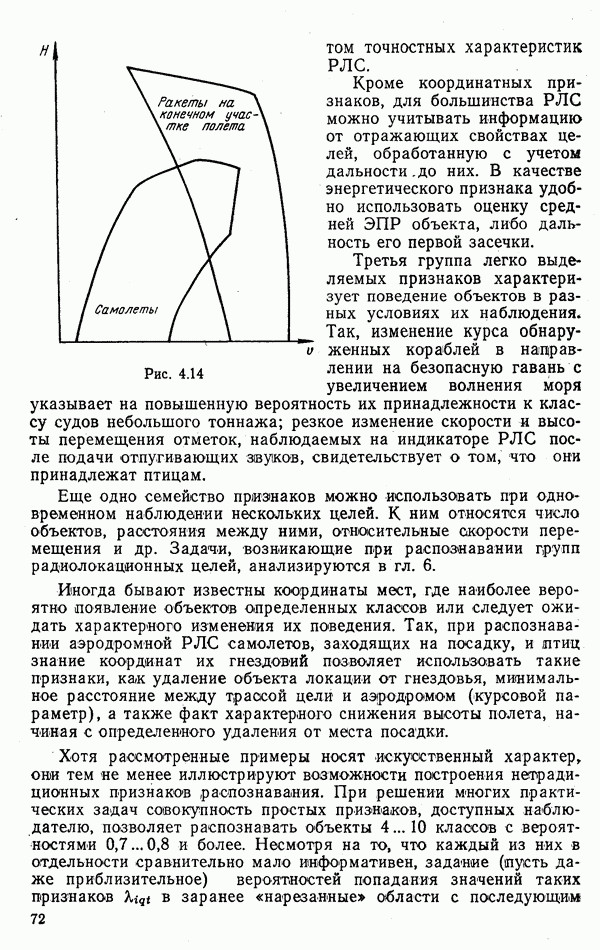
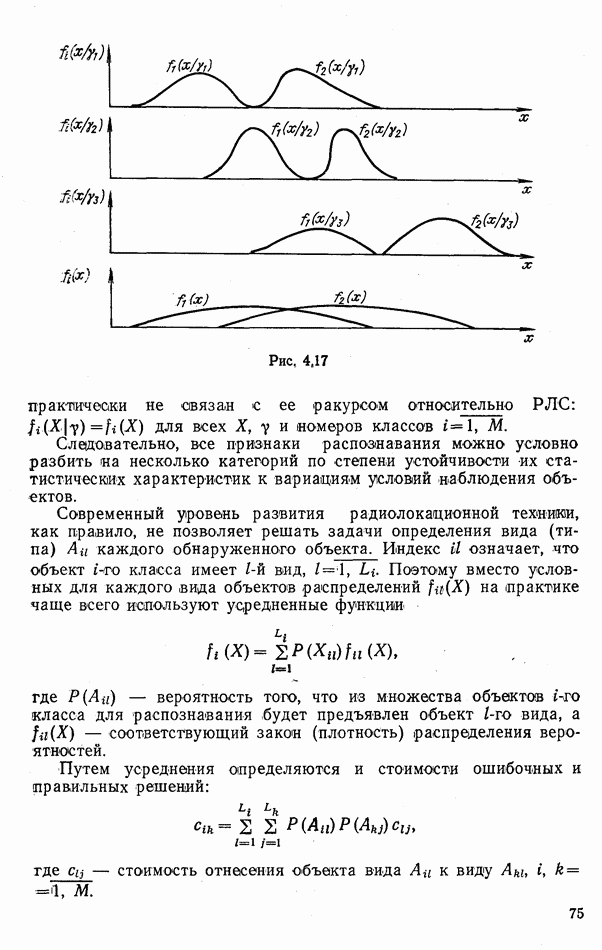
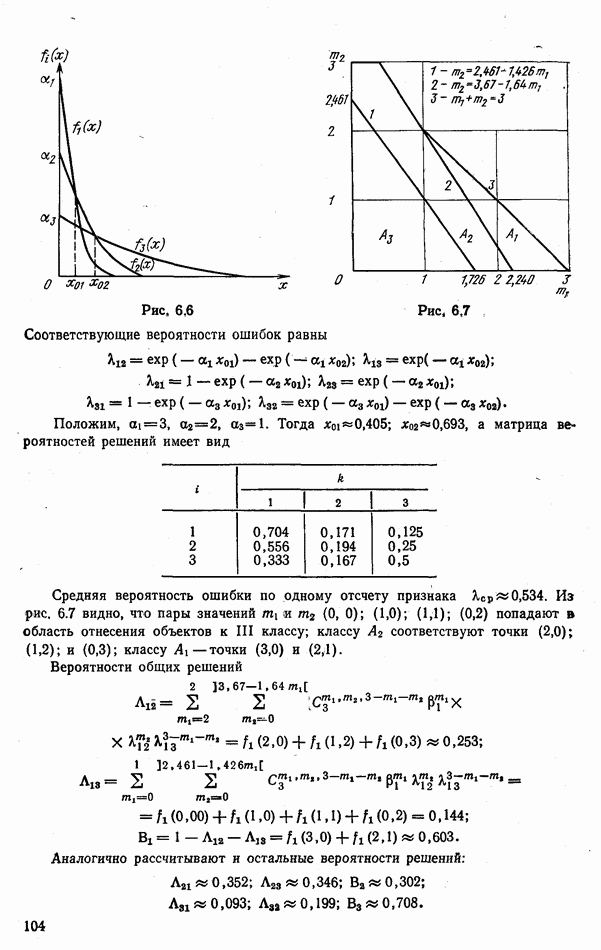
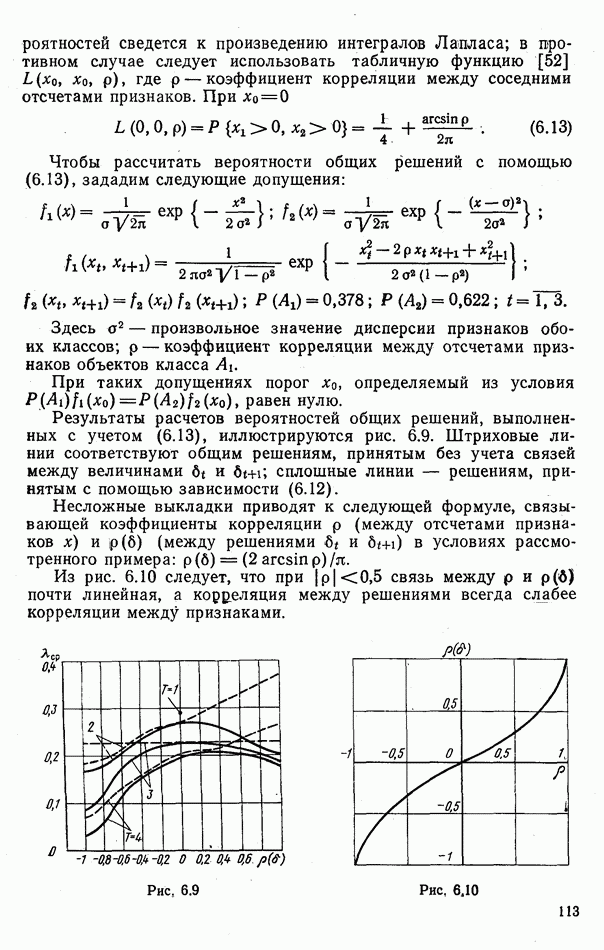
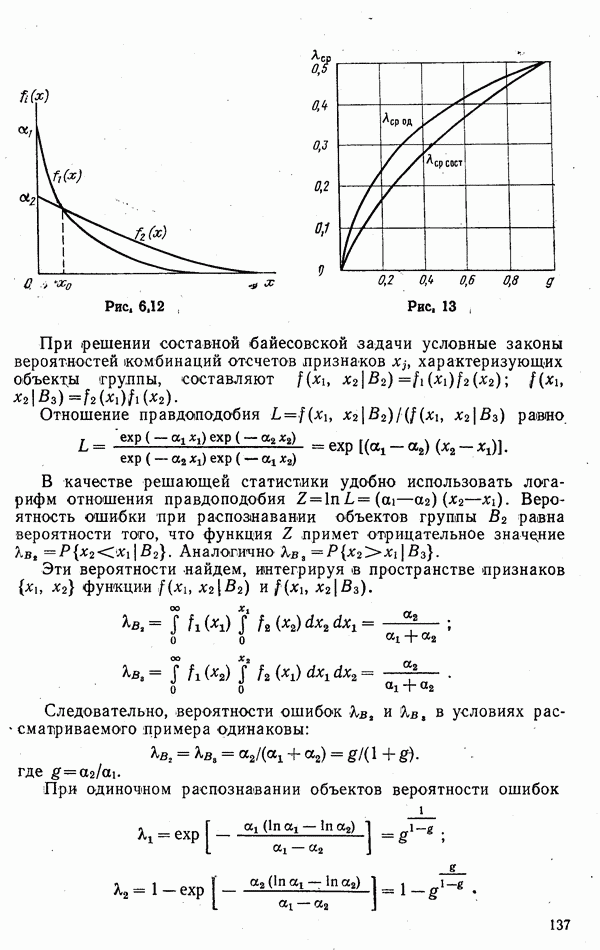
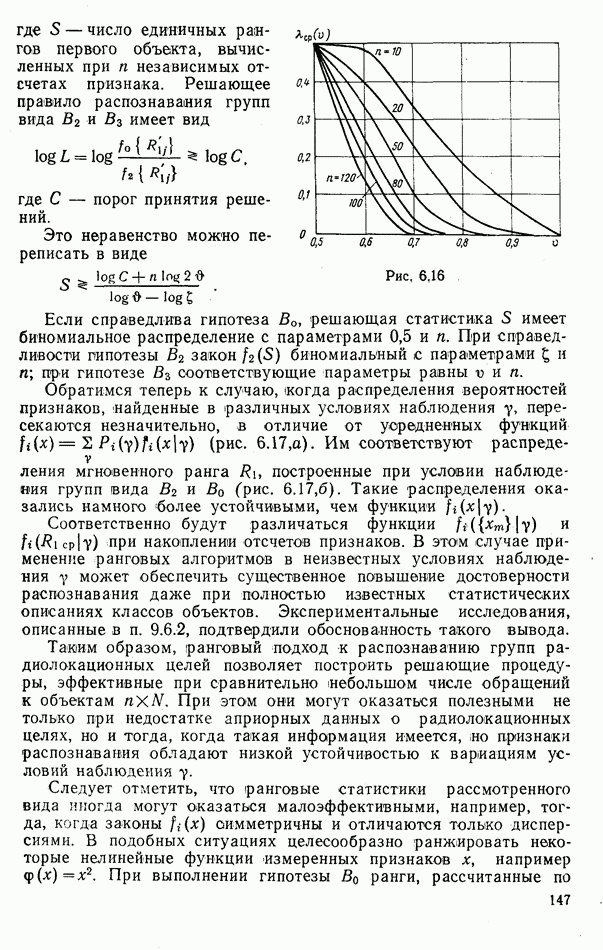
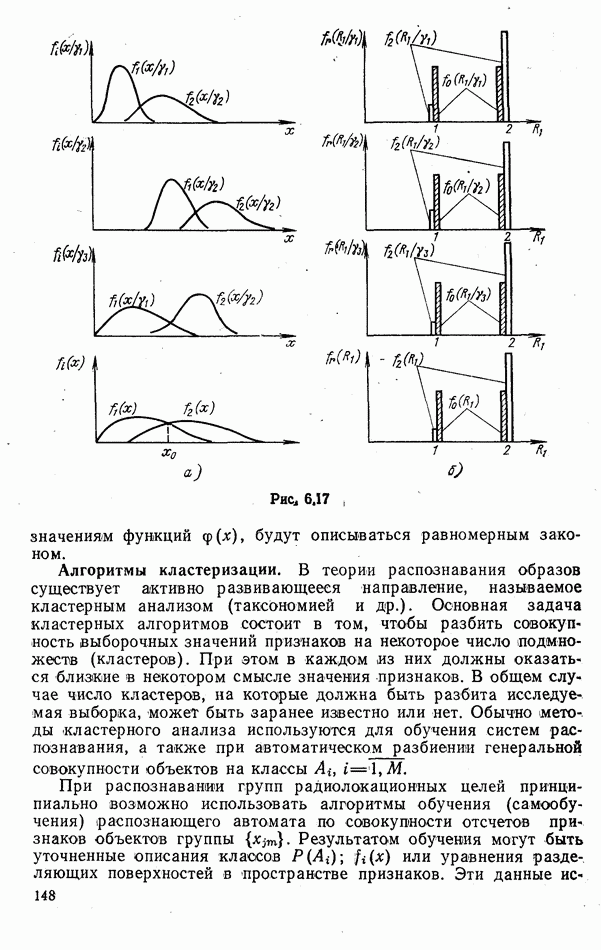
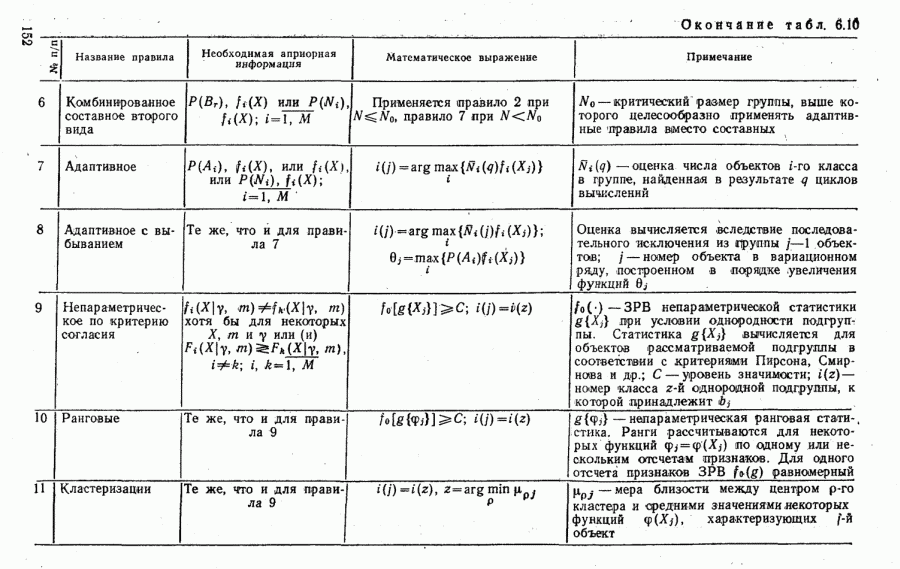
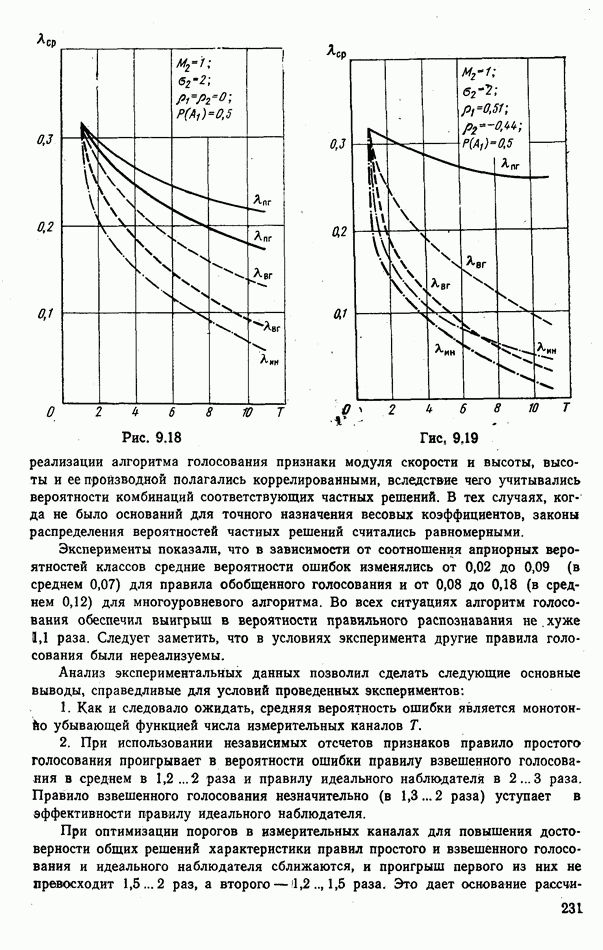
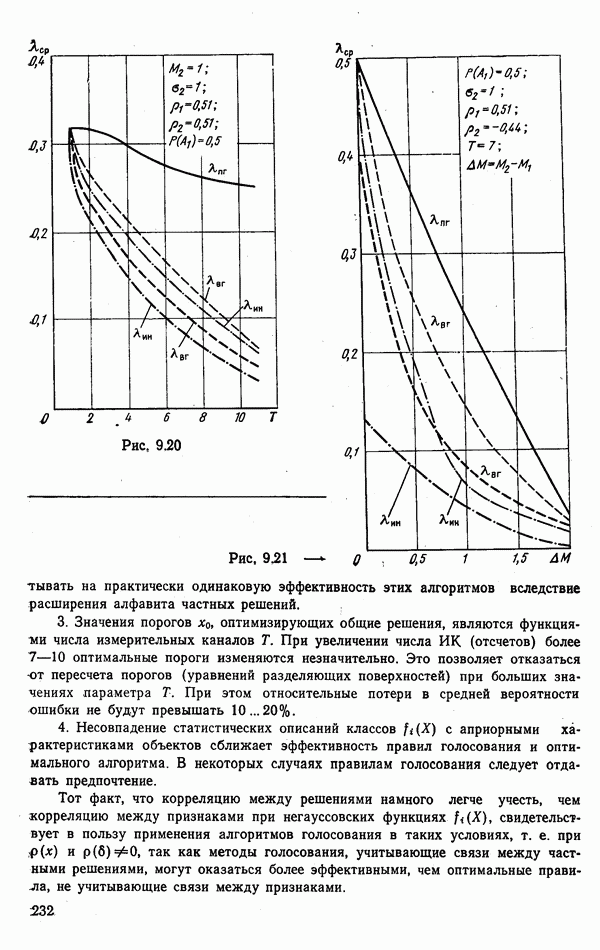
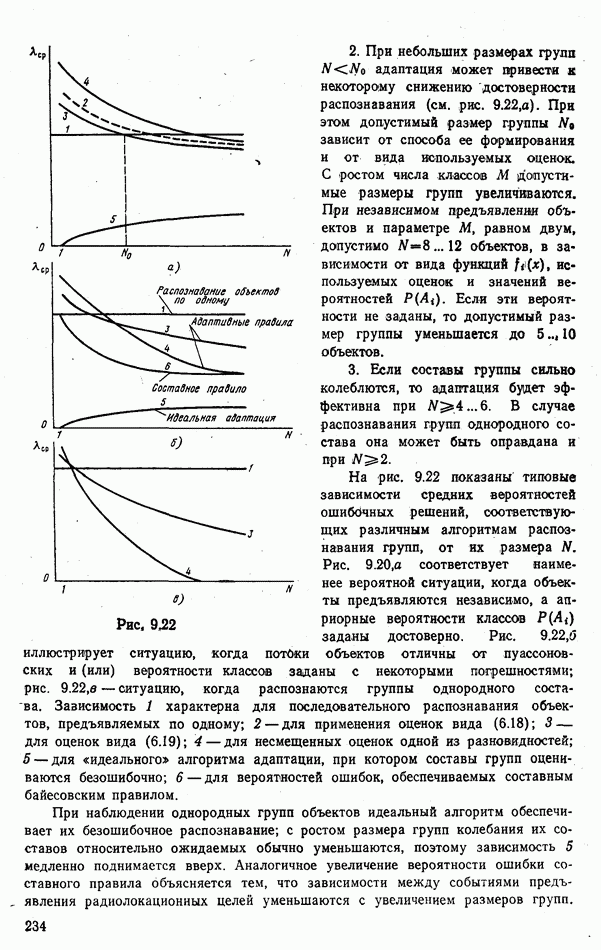
ЧАСТЬ 3. СЕЛЕКЦИЯ КАК ЗАДАЧА ТЕОРИИ СТАТИСТИЧЕСКИХ РЕШЕНИЙГЛАВА 7. СИНТЕЗ АЛГОРИТМОВ СЕЛЕКЦИИ7.1. РАСПОЗНАВАНИЕ И СЕЛЕКЦИЯ: СХОДСТВО И ОТЛИЧИЯ7.1.1. ПОСТАНОВКА ЗАДАЧИ СЕЛЕКЦИИ. ФОРМУЛИРОВАНИЕ СТАТИСТИЧЕСКИХ ГИПОТЕЗТеория статистических решений является общей методологической основой решения многих задач локации. Наряду с распознаванием типа или класса целей (классификацией) и обнаружением целей в локаторах, работающих в ждущем режиме, большой практический интерес представляют такие задачи, как оценка состояния цели (оценка момента перехода цели из одного состояния в другое), селекция истинной цели в группе ложных, обнаружение целей в локаторах, работающих по целеуказаниям, и некоторые другие. На отличия между процессами обнаружения в локаторах указанных двух типов (в дальнейшем будем их называть локаторами первого и второго эшелонов) обращается внимание, например, в [58, с. 406], где отмечено, что «задача синтеза оптимального алгоритма обнаружения объектов требует специальных критериев и специального математического аппарата». Последнее справедливо и для селекции. Более того, отличия между обнаружением в локаторах второго эшелона и селекцией, с одной стороны, и обнаружением в локаторах первого эшелона и распознаванием — с другой, существенны и касаются практически всех сторон этих процессов; постановки задачи, априорной информации и априорной энтропии, формулируемых статистических гипотез, применяемых решающих правил, критериев оптимальности, показателей эффективности и методов их оценивания. Воспользуемся определениями распознавания и селекции, приведенными в [71]: «Распознавание цели — определение типа и, государственной принадлежности воздушно-космической цели. Осуществляется путем анализа данных о параметрах движения и поведении в полете, характере излучений, месте и времени пуска и других данных (конфигурация, размер и т. п.), полученных от РЛС различного назначения и друшх средств контроля воздушно-космического пространства» (стр. 625). «Селекция воздушно-космических целей (от латинского selection — выбор, отбор) - выделение космических и авиационно-космических аппаратов, головных частей баллистических ракет, крылатых ракет, самолетов и т. п. в воздушном и космическом пространстве на фоне ложных целей, искусственных или естественных помех. Для селекции применяются радиолокационные, радиотехнические, оптические, оптико-электронные, акустические, теплолокационные и другие специальные средства» (стр. 666). Естественно, что различные задачи (определение типа цели и выделение истинной цели на фоне ложных) требуют применения различных методов решения. Принято, однако, считать, что задачу селекции можно решить, применяя алгоритмы распознавания к различным объектам наблюдаемого множества. Распознавание цели (обнаружение цели в локаторе первого эшелона можно рассматривать как двухальтернативное распознавание) при любом из критериев качества основано на вычислении отношения правдоподобия для наблюдаемой выборки (функционала отношения правдоподобия для непрерывной реализации сигнала). Отношение правдоподобия (функционал отношения правдоподобия) является достаточной статистикой, т. е. такой функцией выборки (реализации), с помощью которой осуществляется редукция данных, используемых при принятии решения без потери информации [66, т. III]. В результате редукции эвклидово пространство выборок (гильбертово пространство реализаций) отображается на одномерную совокупность значений одной неотрицательной случайной величины. Решение при обнаружении выносится при превышении этой случайной величиной некоторого порога, зависящего от выбранного критерия, а ее распределение вероятностей определяет качество принимаемых решений (вероятности ошибок того или иного рода). Это позволяет еще до начала наблюдений разделить пространство выборок (реализаций) на две взаимно непересекающиеся области, одна из которых соответствует тем случаям, когда следует принимать решение о наличии цели, а другая — об отсутствии цели. Аналогично обстоит дело и при многоальтернативной классификации, когда наблюдаемая цель может относиться к одному из N классов объектов, а решение принимается в пользу того из классов, для которого отношение правдоподобия приняло наибольшее значение. При этом также возможно априорное разбиение пространства выборок (реализаций) на N взаимно непересекающихся областей, разделяемых дискриминантными поверхностями, так что применяемое решающее правило является, по существу, правилом порогового типа. При любых других критериях качества (минимум среднего риска, максимум апостериорной вероятности и др.) изменяются лишь уравнения, определяющие дискриминантные функции, однако пороговый характер решающих правил остается неизменным. Матрица возможных исходов при распознавании имеет размерность NXN. Такую же размерность имеет матрица вероятностей, характеризующих качество системы распознавания, причем N(N—1) из этих показателей независимы и определяют параметры уравнений для дискриминантных функций поверхностей. Проанализируем последствия, к которым приводит применение правил порогового типа к решению задачи селекции. Вследствие воздействия шумов измеряемые значения реализаций сигналов являются случайными функциями и при любом априорном разбиении пространства реализаций в области, соответствующей «истинным» целям, может оказаться больше одной реализации либо не оказаться ни одной. Оба эти случая не соответствуют постановке задачи селекции, поскольку в результате ее решения необходимо выбрать единственную истинную цель в группе ложных. Во всяком случае (Полученное решение не является окончательным, так что данное правило «решающим» в собственном смысле этого слова не является. При селекции существует единственный вид правильного решения: истинная цель выбрана правильно, а все виды ошибочных решений образуют вместе с ним полную группу несовместных событий. Отсюда следует, что вероятности правильного и ошибочного решений в сумме равны 1 [73], а эффективность селекции можно охарактеризовать единственным независимым показателем эффективности, поскольку для потребителя информации системы селекции безразлично, какая именно из ложных целей принята в качестве истинной, а «ложная тревога» означает одновременно и «пропуск цели». Поскольку при селекции решение принимается по информации обо всех объектах наблюдаемой группы, одна и та же реализация может быть отнесена к классу «истинных» или «ложных» в зависимости от того, какие значения приняли все остальные реализации. Приведенные соображения со всей определенностью показывают, что отличия между селекцией и распознаванием выходят за рамки чисто терминологических. Обнаружение целей в локаторах второго эшелона имеет много общих черт с селекцией, что позволяет рассматривать их в рамках единой методологической концепции. Задачу селекции можно сформулировать следующим образом: при известных отличиях между распределениями значений признаков объектов различных классов и составе конкретной выборки объектов необходимо по измеренным значениям признаков всех наблюдаемых объектов принять решение о том, какой именно из этих объектов относится к интересующему классу. В постановке этой задачи имеются следующие особенности по сравнению с задачей распознавания: предполагаются известными не сами распределения значений признаков, а соотношения между этими распределениями (например, объект интересующего нас класса по своим геометрическим размерам превосходит объекты других классов); решение задачи селекции оказывается возможным и тогда, когда известно только распределение значений признаков для интересующего нас класса и даже тогда, когда ни одно из этих распределений априори неизвестно, однако постулируется сам факт существования таких отличий; предполагаются известными не статистические свойства генеральной совокупности объектов, характеризуемые априорными вероятностями появления объектов различных классов, а состав конкретной выборки наблюдаемых объектов: решения о селекции принимаются не для каждого объекта в отдельности (что может привести к неоднозначным решениям, либо решениям, не согласующимся с исходной постановкой), а по выборке в целом на основе всей совокупной информации. Постановку задачи селекции рассмотрим вначале применительно к простейшей, однако довольно распространенной на практике ситуации, когда в выборке из При первоначальном анализе плотности распределения значений признака Пусть в результате измерения значений признака Сравним рассмотренную постановку задачи селекции с постановкой задачи обнаружения цели в локаторе второго эшелона, т.е. в локаторе, работающем при внешних целеуказаниях. Предположим вначале, что в зоне поиска локатора находится ровно одна цель и необходимо правильно указать номер разрешаемого объема, в котором она находится. Конечно, эта постановка является некоторой идеализацией реального процесса измерения координат цели. Строго говоря, она применима лишь к локаторам, в которых обзор зоны поиска цели по угловым координатам осуществляется с помощью некоторого числа парциальных каналов, а поиск цели по дальности или радиальной скорости — с помощью некоторого числа согласованных с сигналом фильтров. При непрерывном последовательном обзоре пространства одноканальной системой подобный подход является удобной математической идеализацией. Под «разрешаемым объемом» можно понимать элементарный многомерный параллелепипед, границы которого соответствуют разрешающим способностям по измеренным координатам. С учетом этого полная зона поиска разбивается на Как и при селекции, статистические гипотезы Хотя до сих пор мы предполагали, что в наблюдаемой группе объектов в поле зрения информационного средства находится единственная цель, это ограничение существенного значения не имеет. Далее будет показана возможность обобщения рассматриваемой методологии на случай произвольного, но априори известного наибольшего или наименьшего возможного числа целей, подлежащих обнаружению или селекции, а также на случай, когда это число задается соответствующим вероятностным распределением. Рассматриваемую методологию можно применять и тогда, когда информация такого рода наблюдателю неизвестна, однако проектируемое информационное средство обладает ограниченной пропускной способностью.
|
 |
Оглавление
|




















































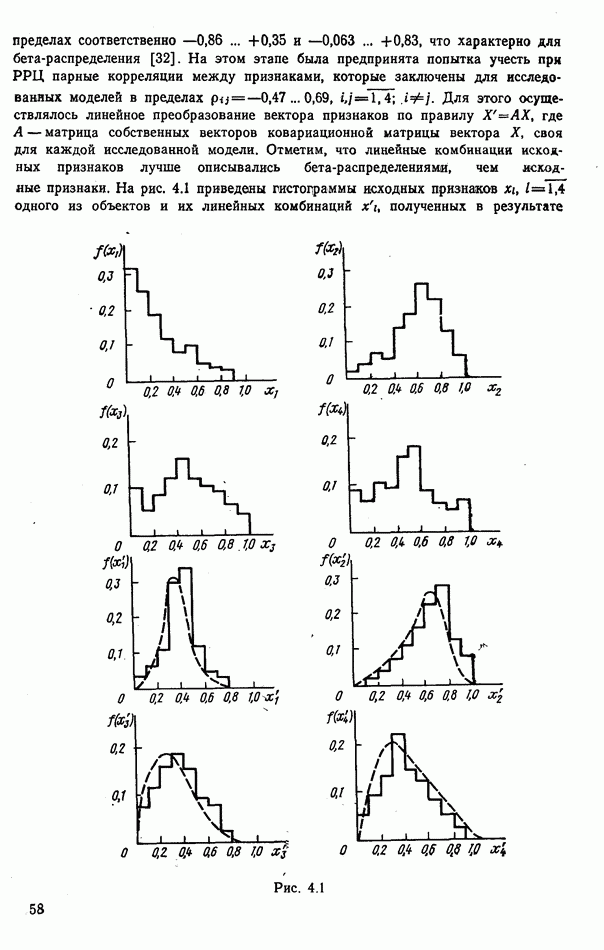
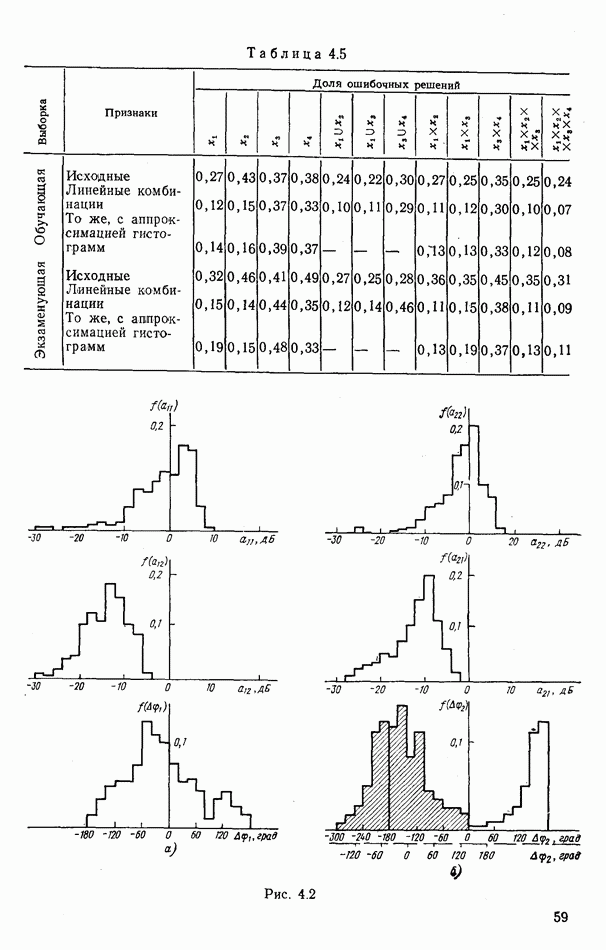
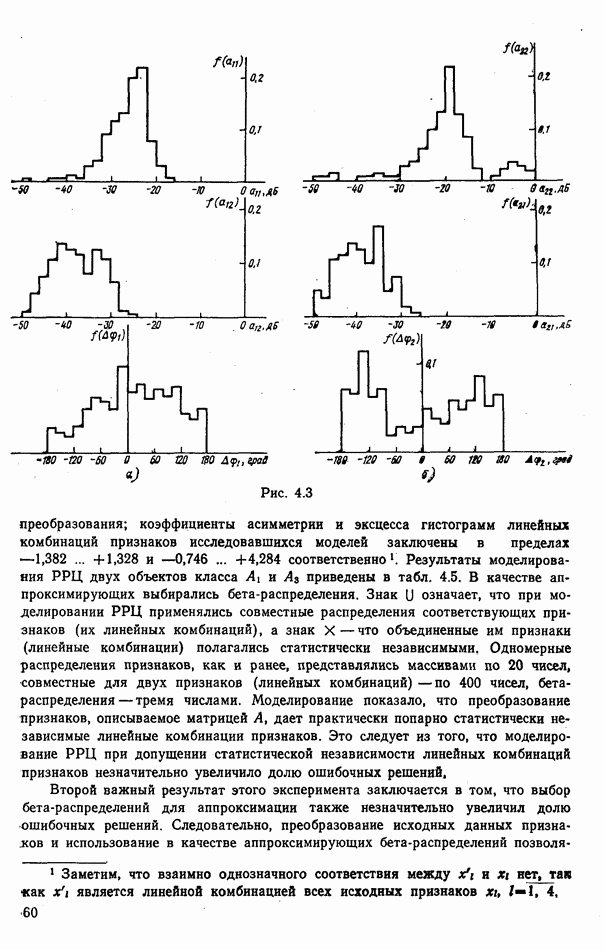
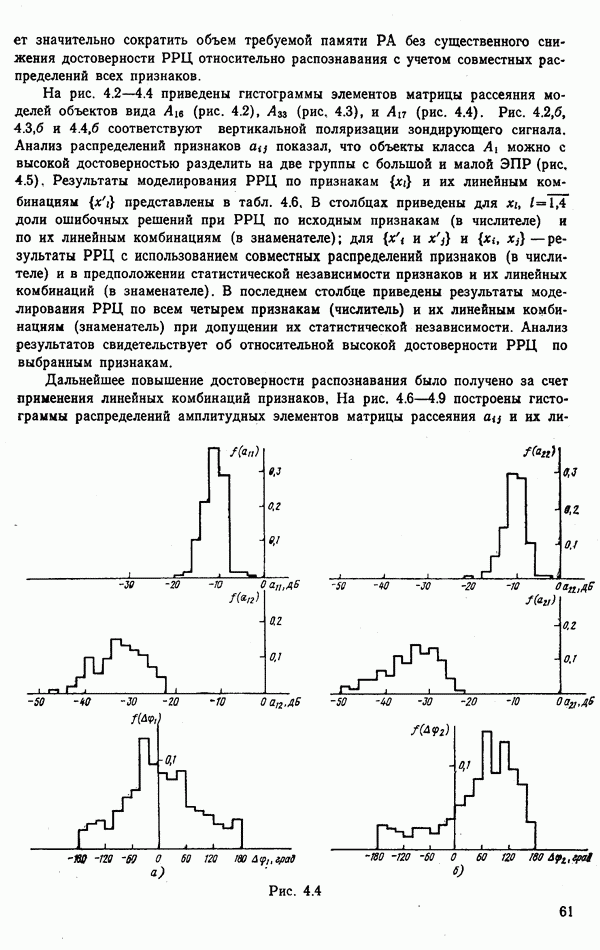
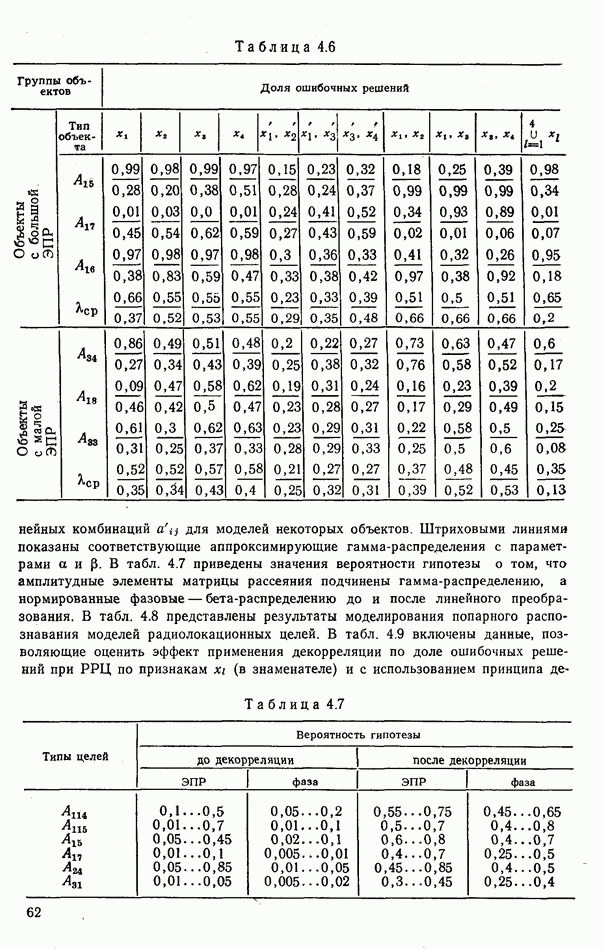
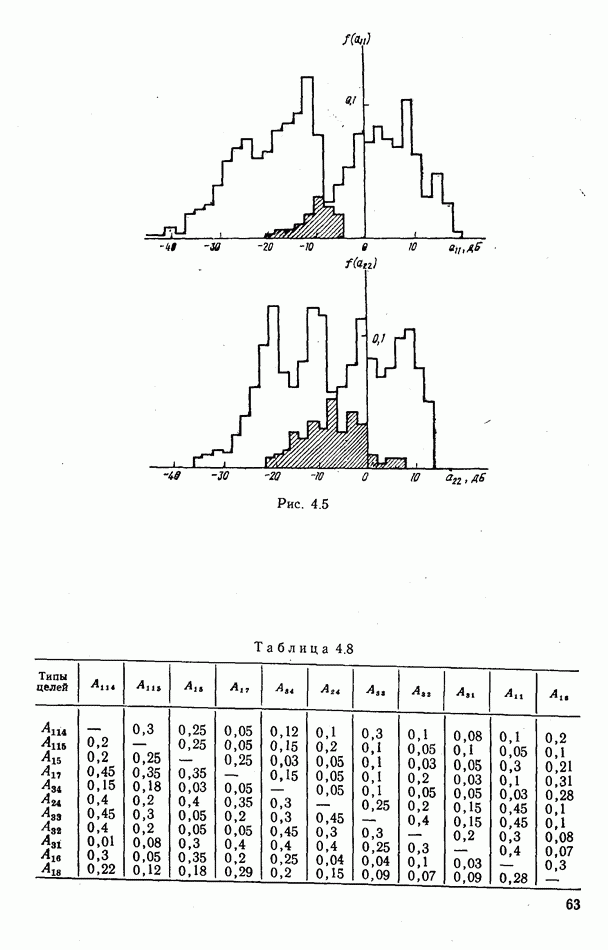
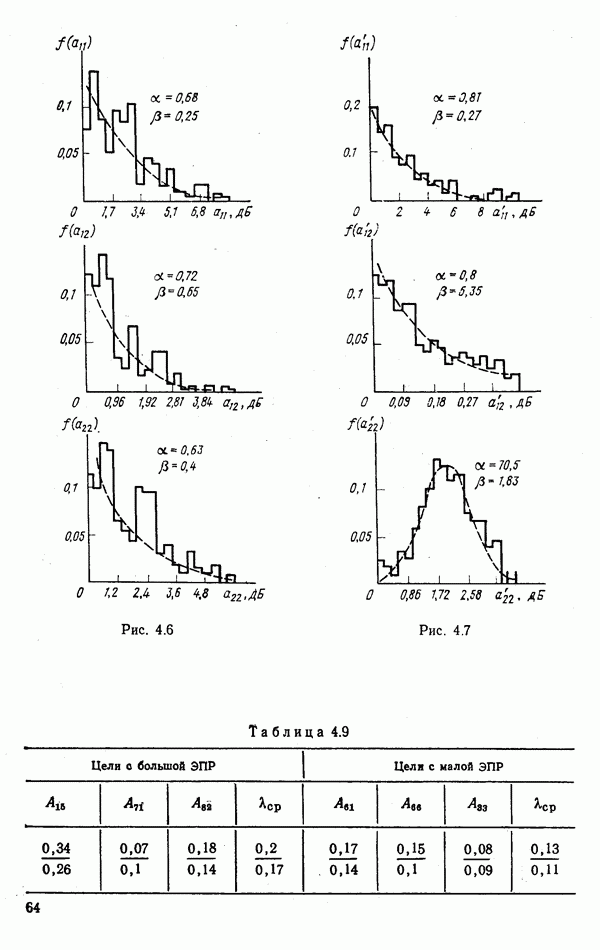
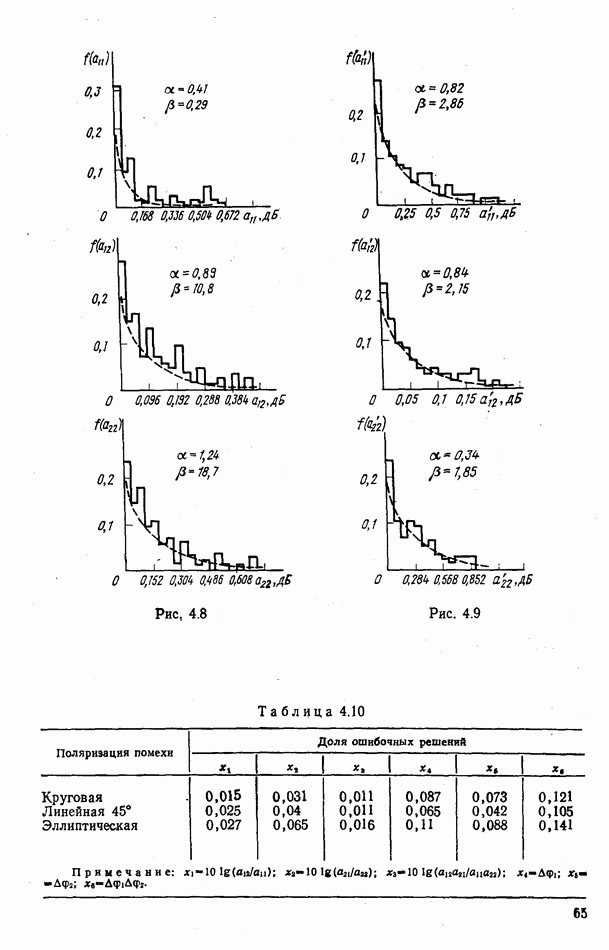

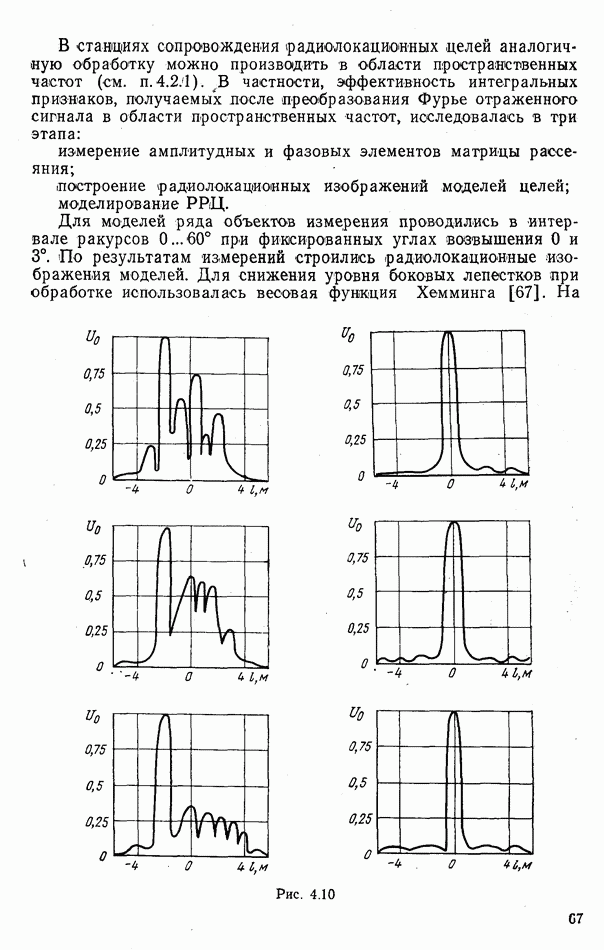
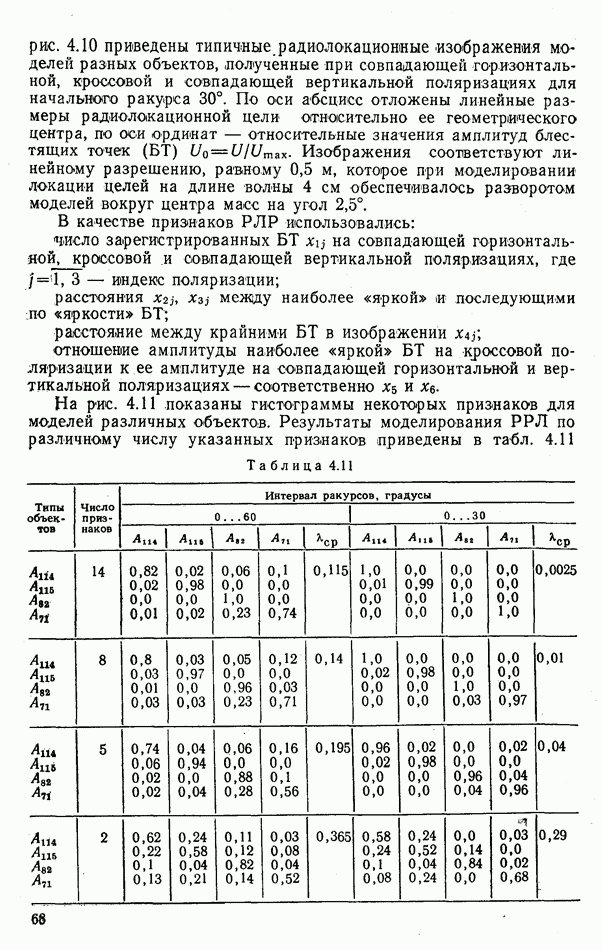
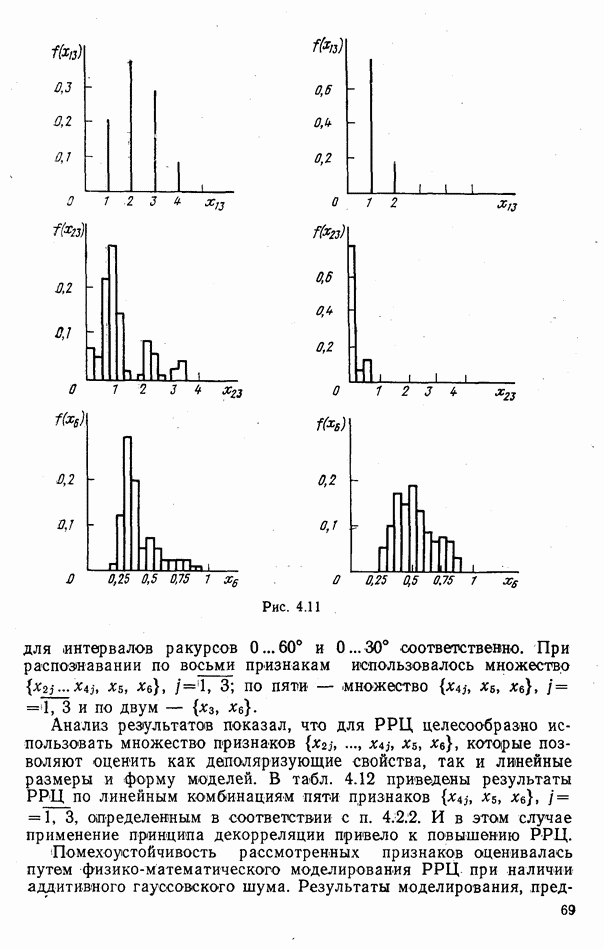
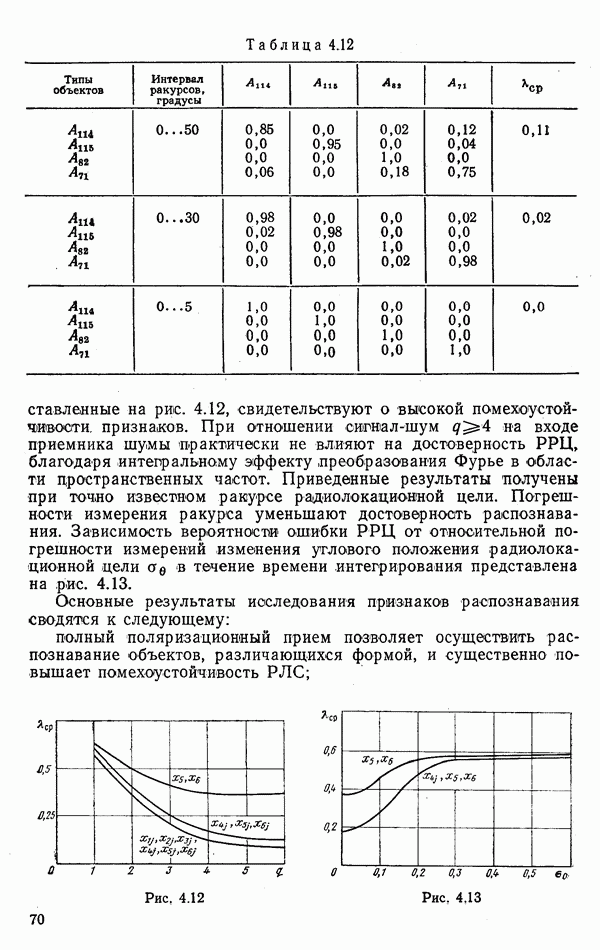



























































































































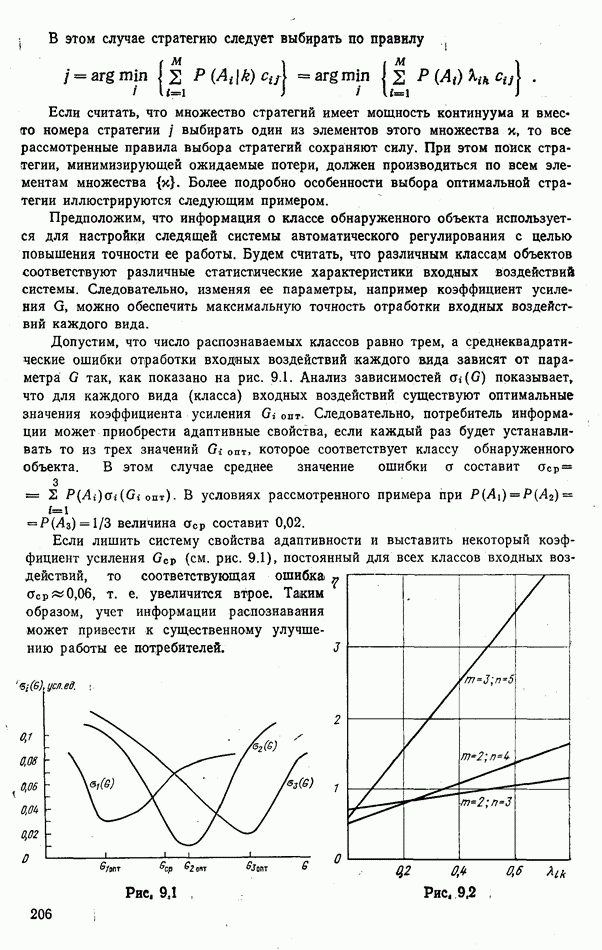
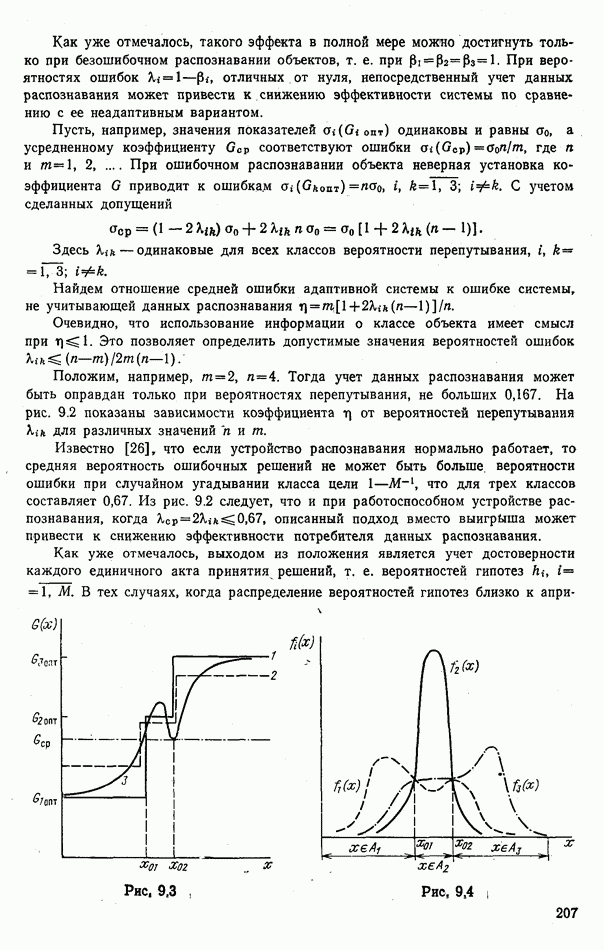


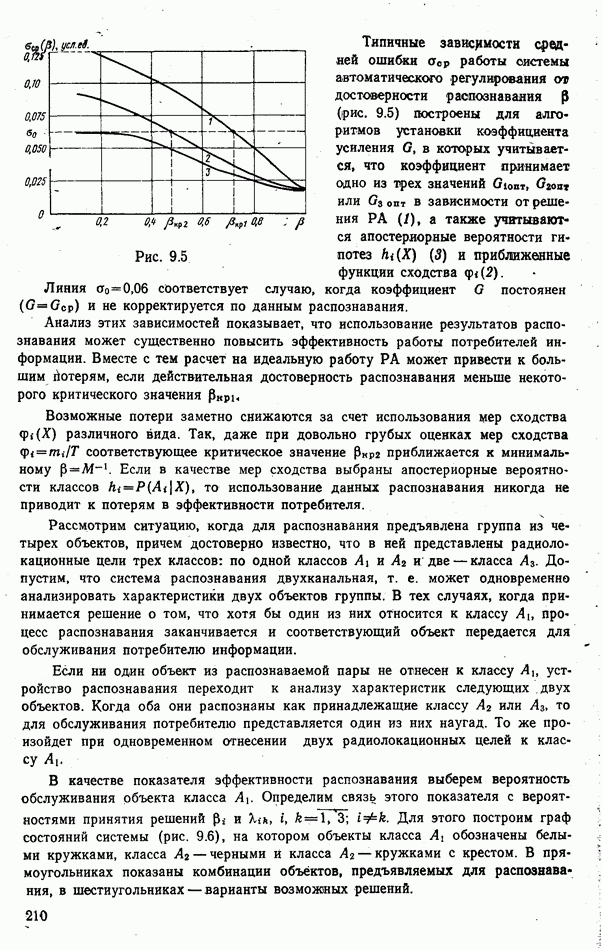
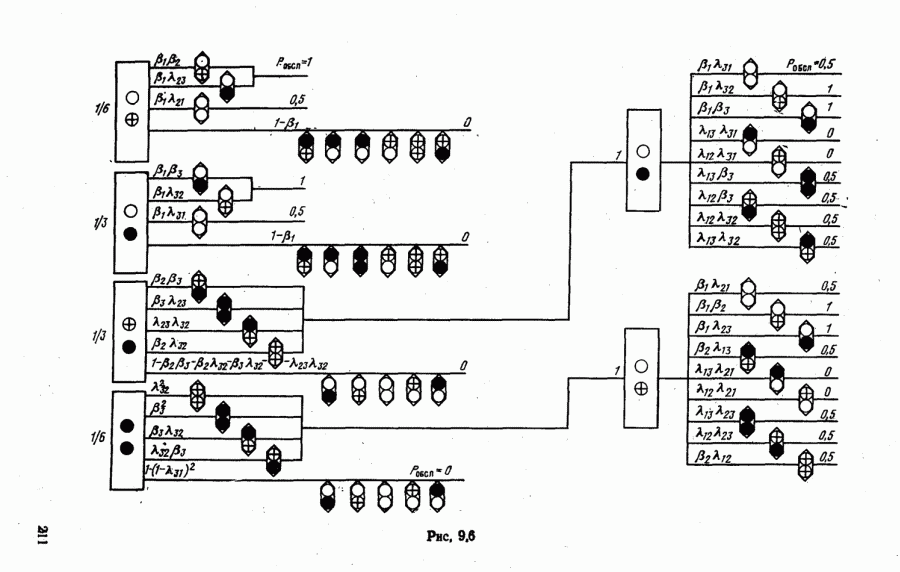










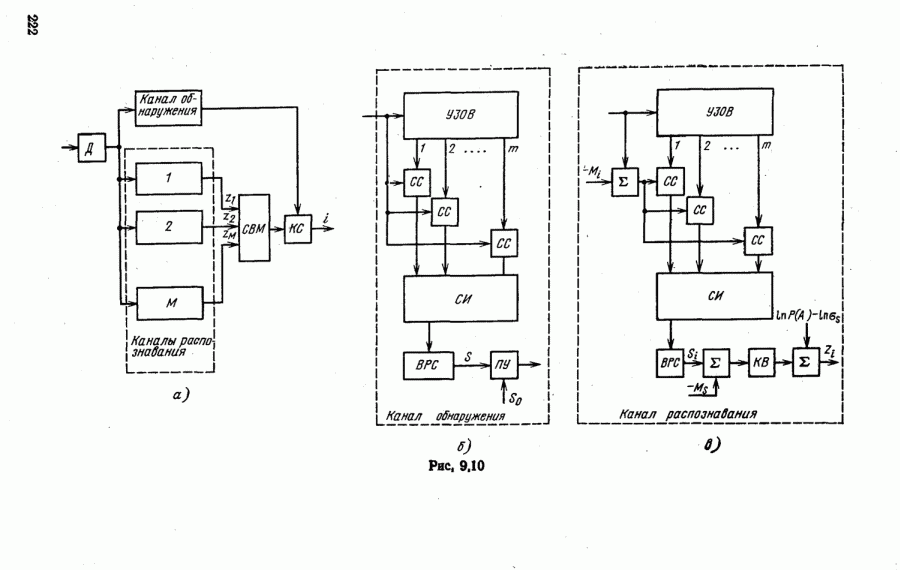

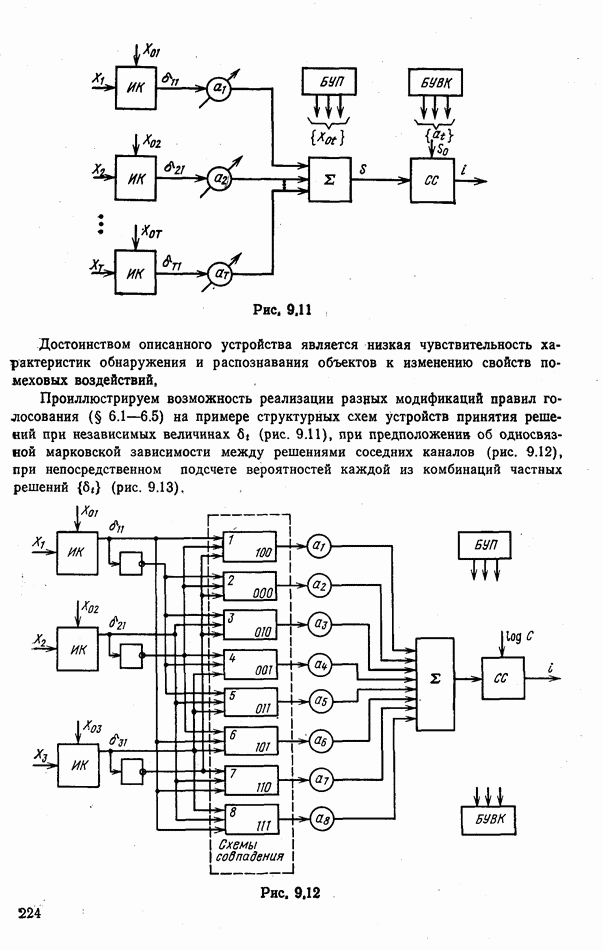

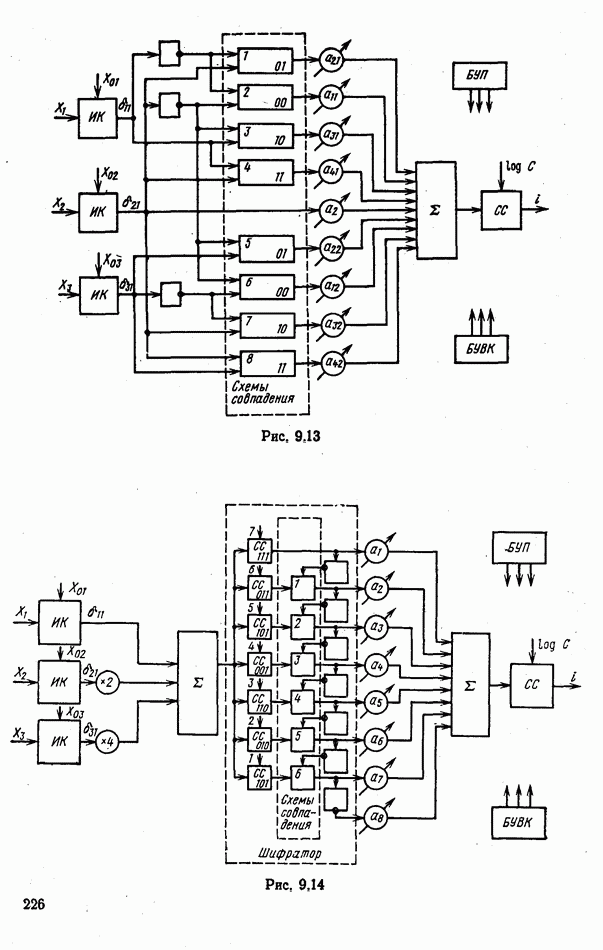
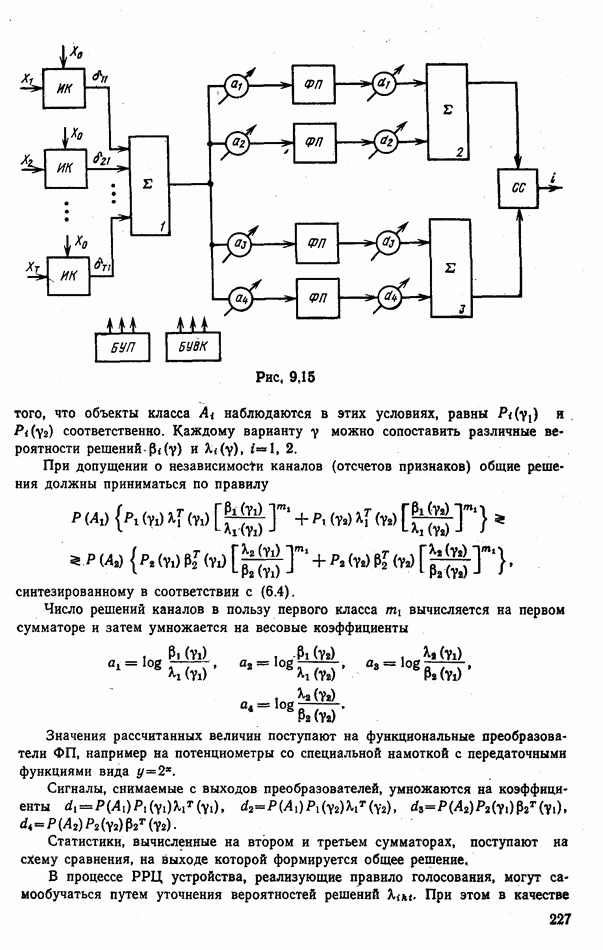








 объектов находится ровно один объект первого класса, который и надлежит отселектировать от объектов нулевого (фонового) класса.
объектов находится ровно один объект первого класса, который и надлежит отселектировать от объектов нулевого (фонового) класса.
 для первого
для первого  и нулевого
и нулевого  классов предполагаются известными. В ходе дальнейшего рассмотрения установим, какого рода априорная информация необходима для решения задачи селекции, и приведем некоторое уточнение и обобщение первоначальной постановки.
классов предполагаются известными. В ходе дальнейшего рассмотрения установим, какого рода априорная информация необходима для решения задачи селекции, и приведем некоторое уточнение и обобщение первоначальной постановки.
 для каждого из
для каждого из  объектов получены значения оценки
объектов получены значения оценки  где
где  — номер объекта. При наличии этой информации проверяемые статистические гипотезы сформулируем следующим образом: гипотеза
— номер объекта. При наличии этой информации проверяемые статистические гипотезы сформулируем следующим образом: гипотеза  состоит в том, что именно
состоит в том, что именно  объект относится к первому классу и, следовательно, все остальные объекты относятся к нулевому классу. Задача синтеза алгоритма селекции состоит в том, чтобы определить наилучшее с точки зрения некоторого критерия эффективности решающее правило, в соответствии с которым следует принимать одну из гипотез
объект относится к первому классу и, следовательно, все остальные объекты относятся к нулевому классу. Задача синтеза алгоритма селекции состоит в том, чтобы определить наилучшее с точки зрения некоторого критерия эффективности решающее правило, в соответствии с которым следует принимать одну из гипотез
 элементарных объемов, а задача обнаружения состоит в том, чтобы выбрать элементарный параллелепипед (измерить координаты его центра), в котором находится цель.
элементарных объемов, а задача обнаружения состоит в том, чтобы выбрать элементарный параллелепипед (измерить координаты его центра), в котором находится цель.
 будем формулировать таким образом; из предположения, что цель находится в
будем формулировать таким образом; из предположения, что цель находится в  разрешаемом объеме, следует, что в других разрешаемых объемах цели нет.
разрешаемом объеме, следует, что в других разрешаемых объемах цели нет.