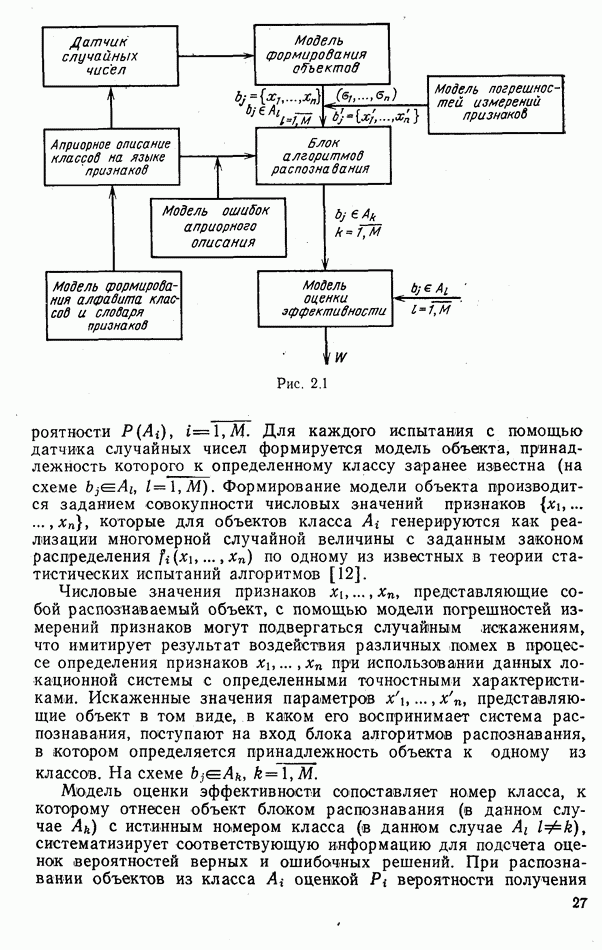
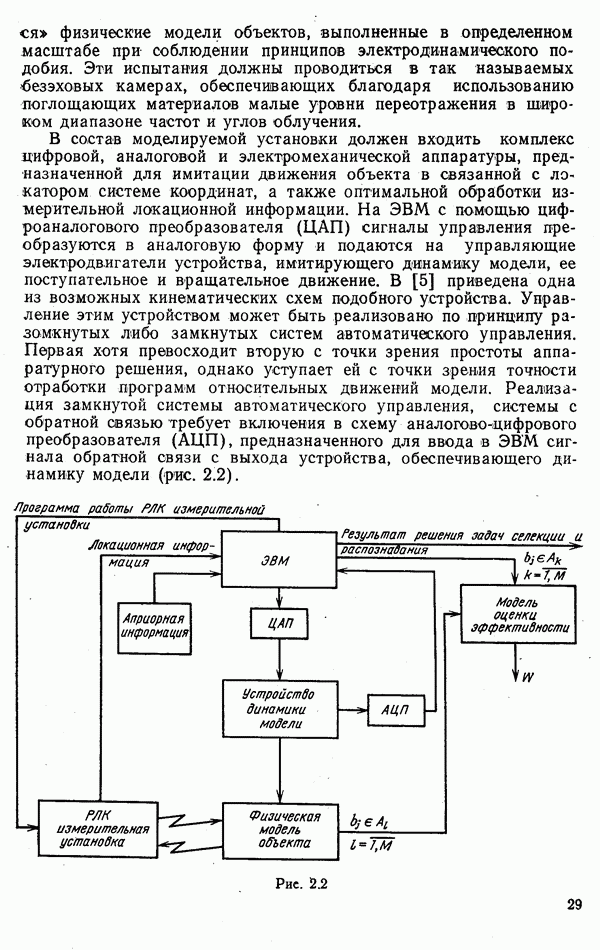
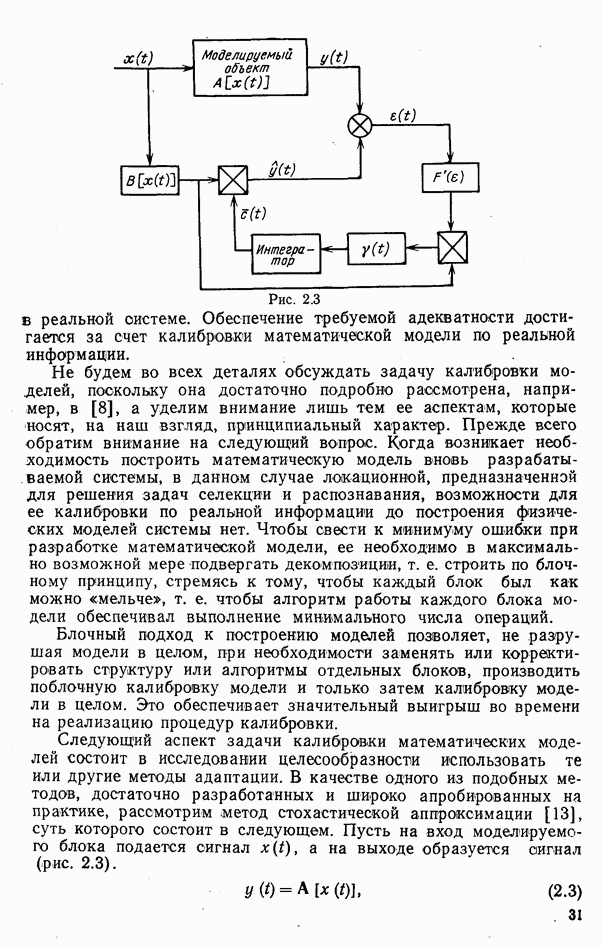
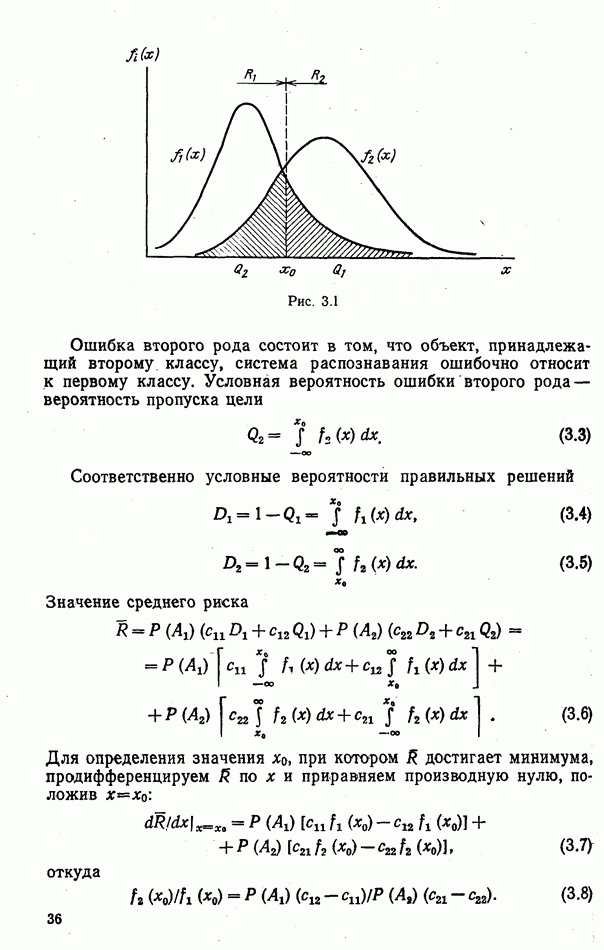
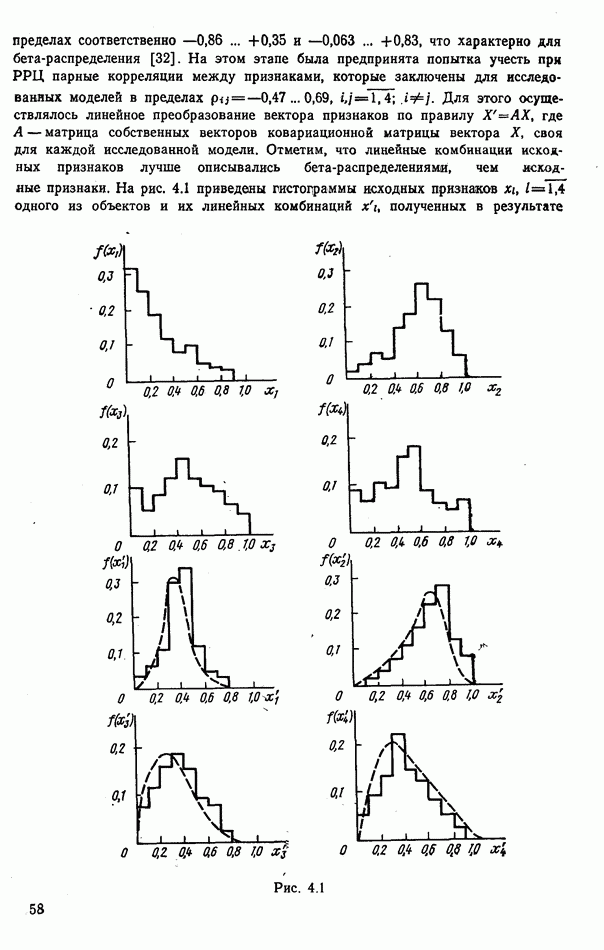
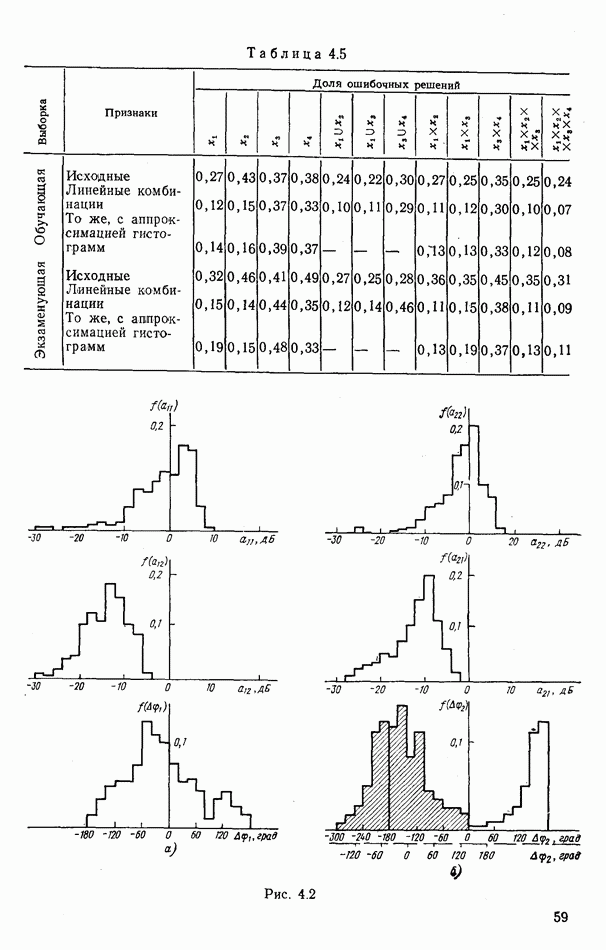
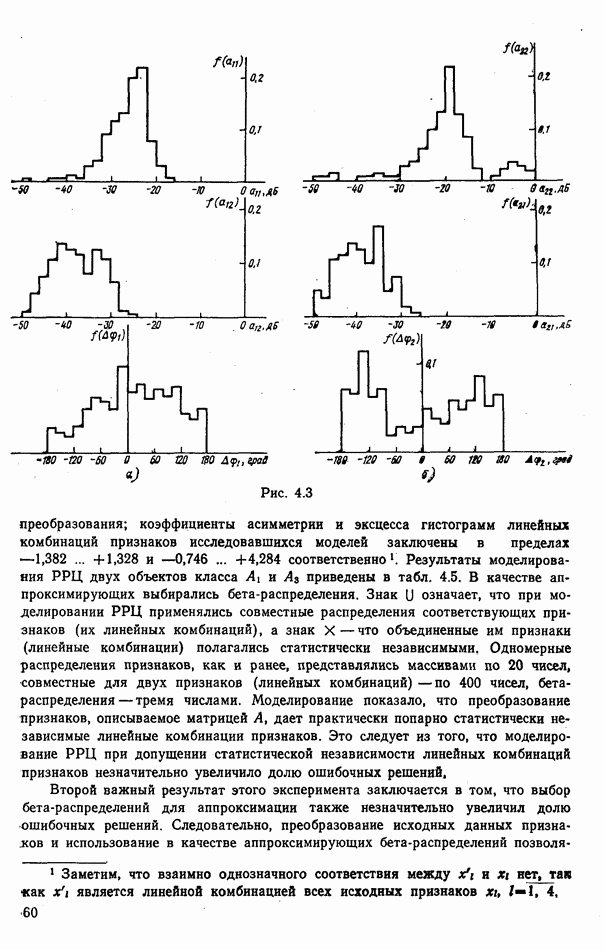
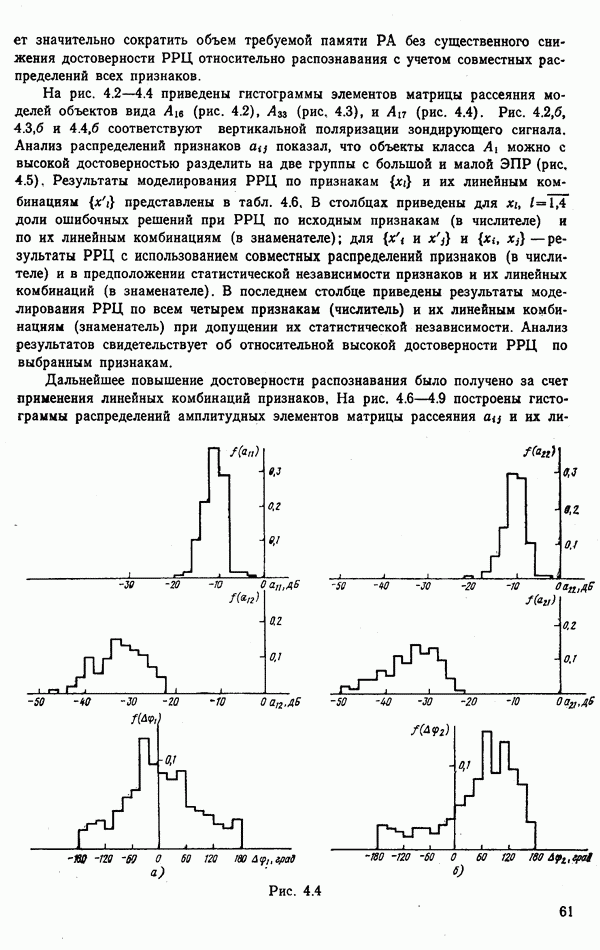
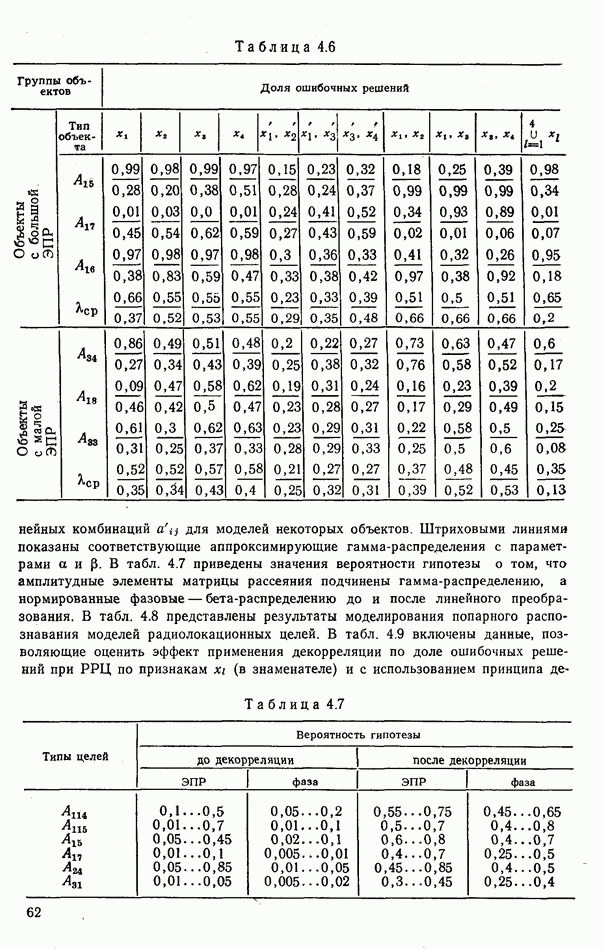
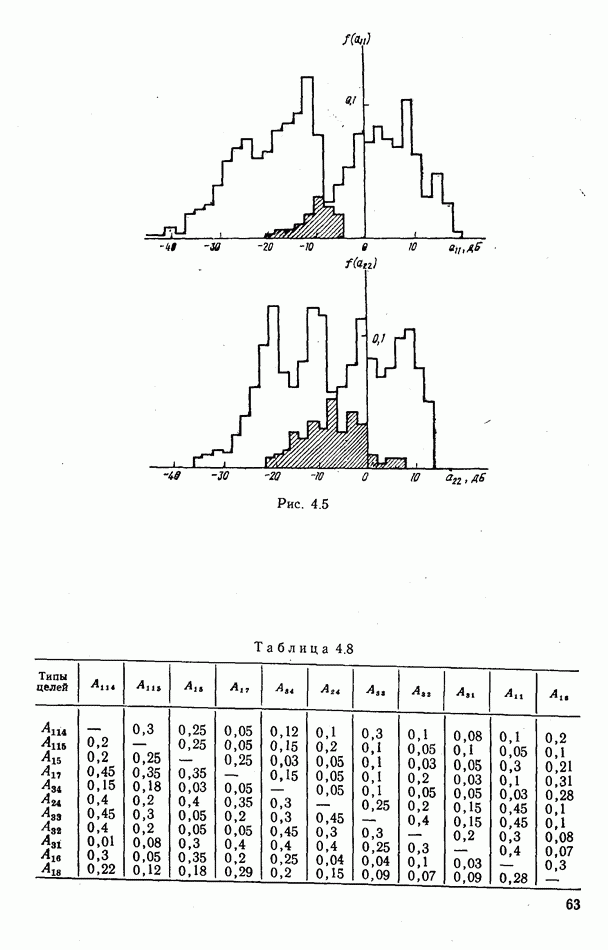
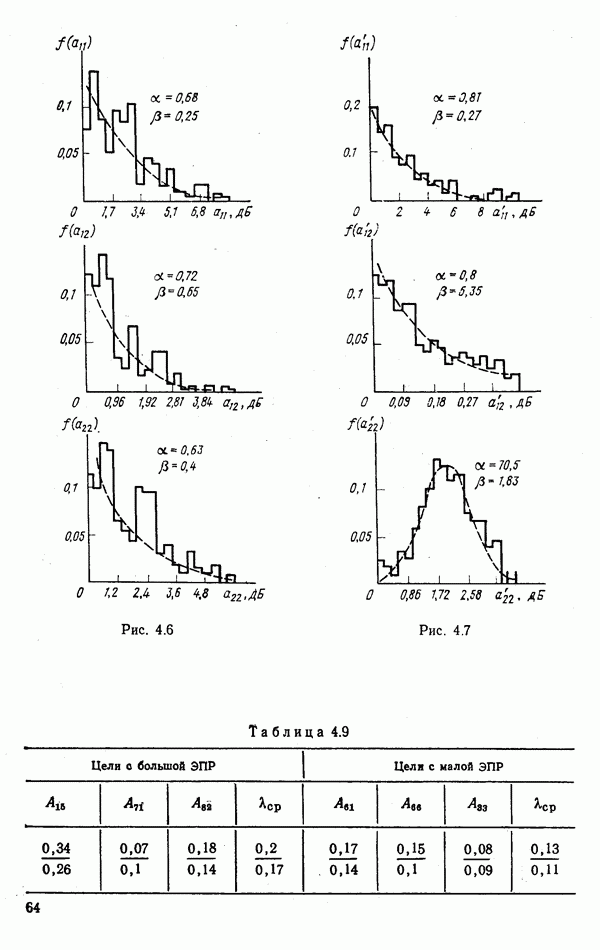
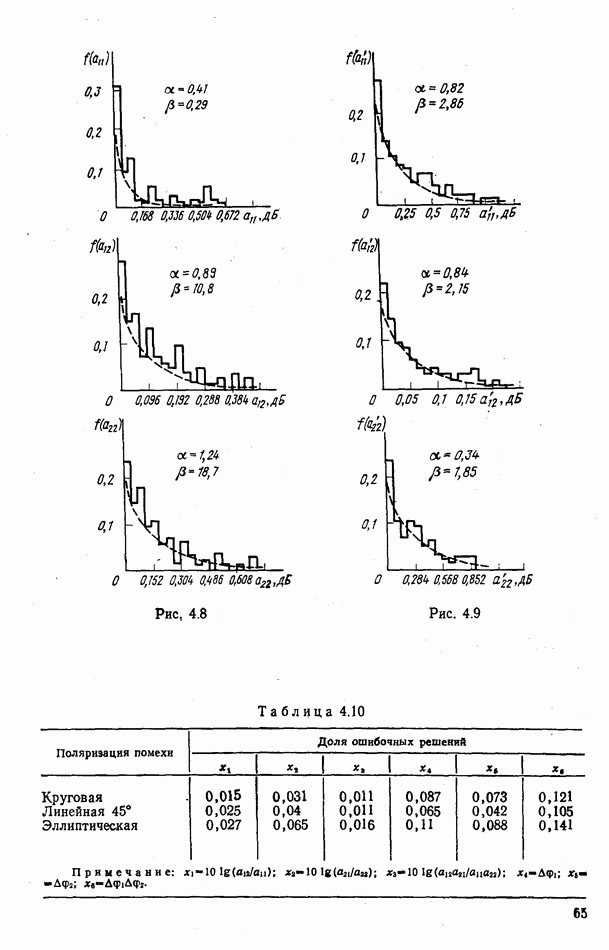
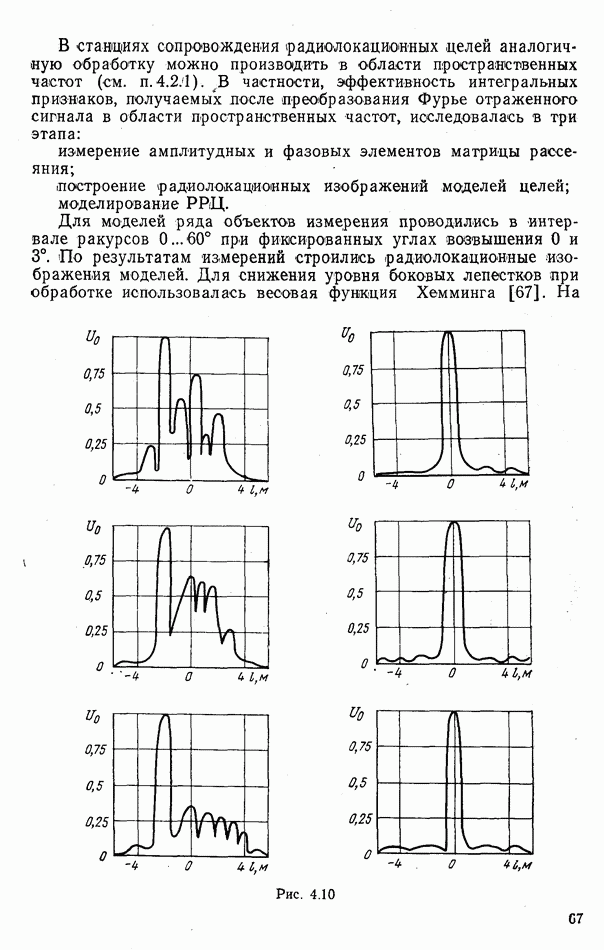
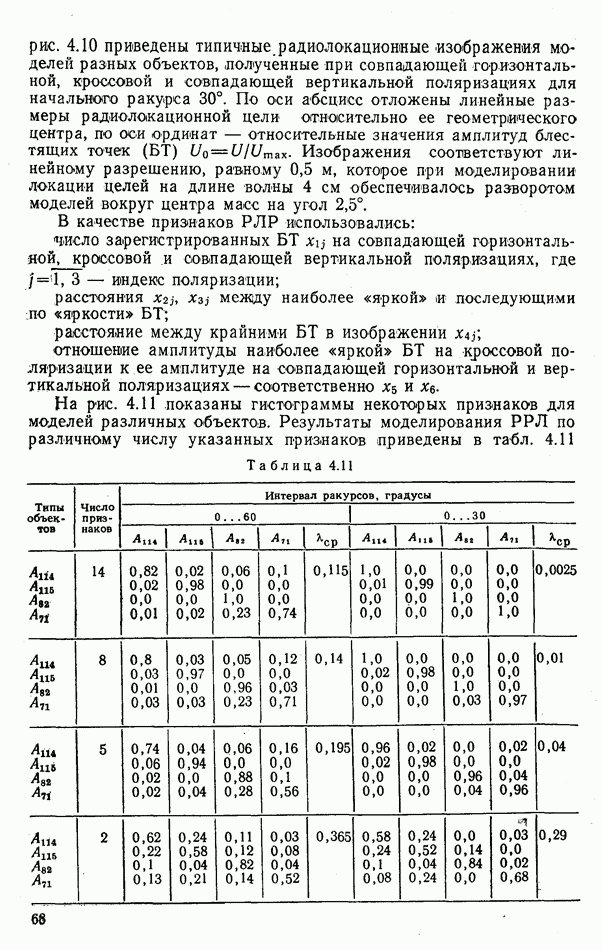
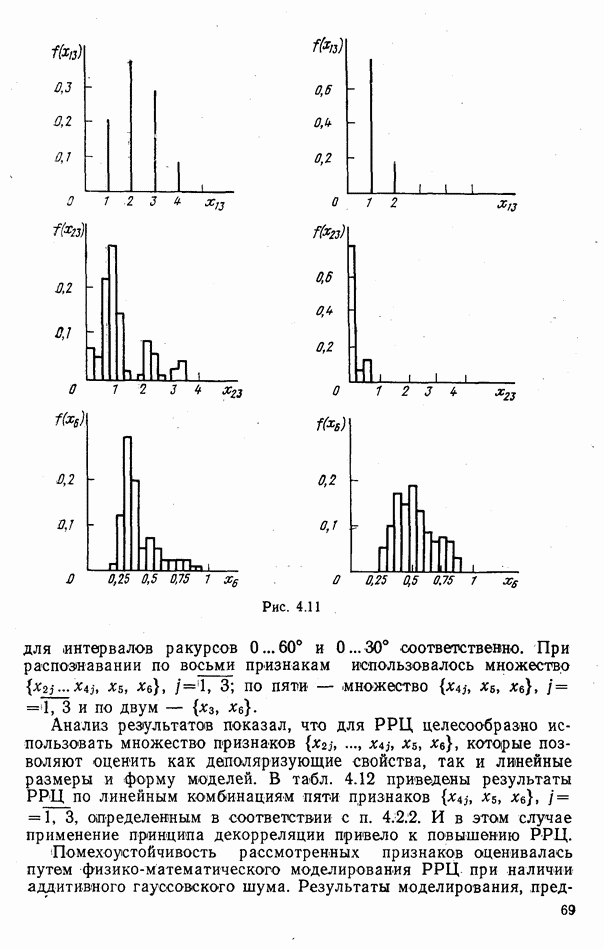
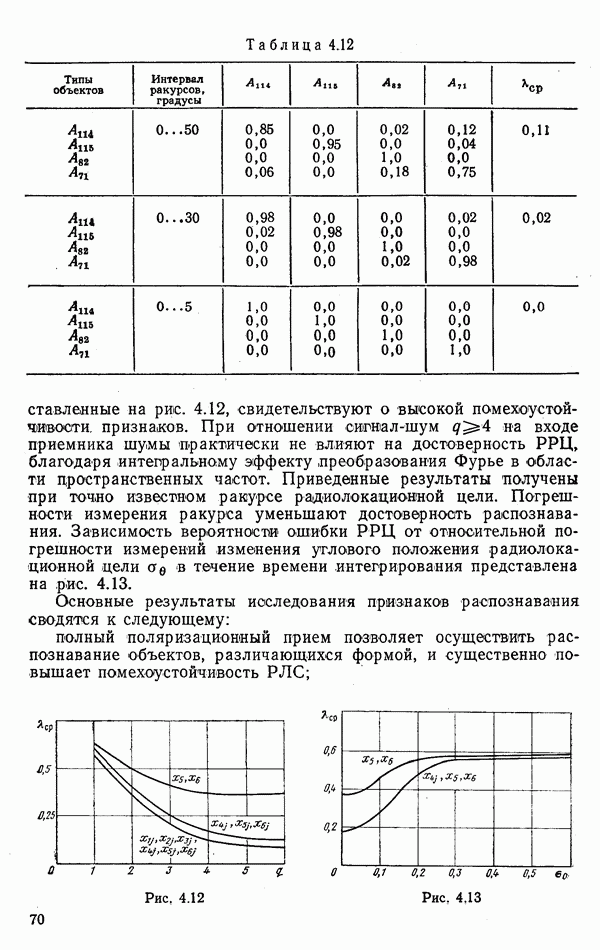
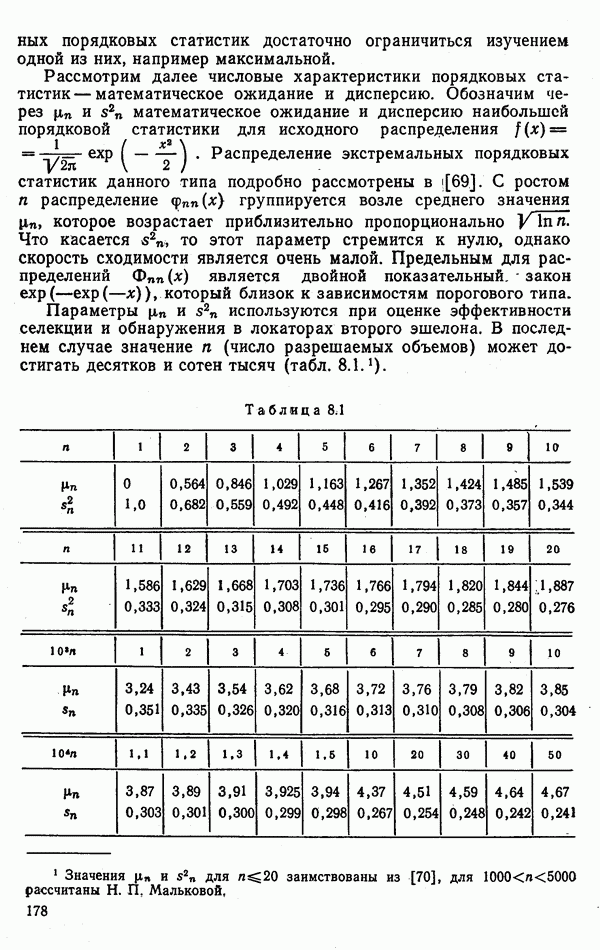
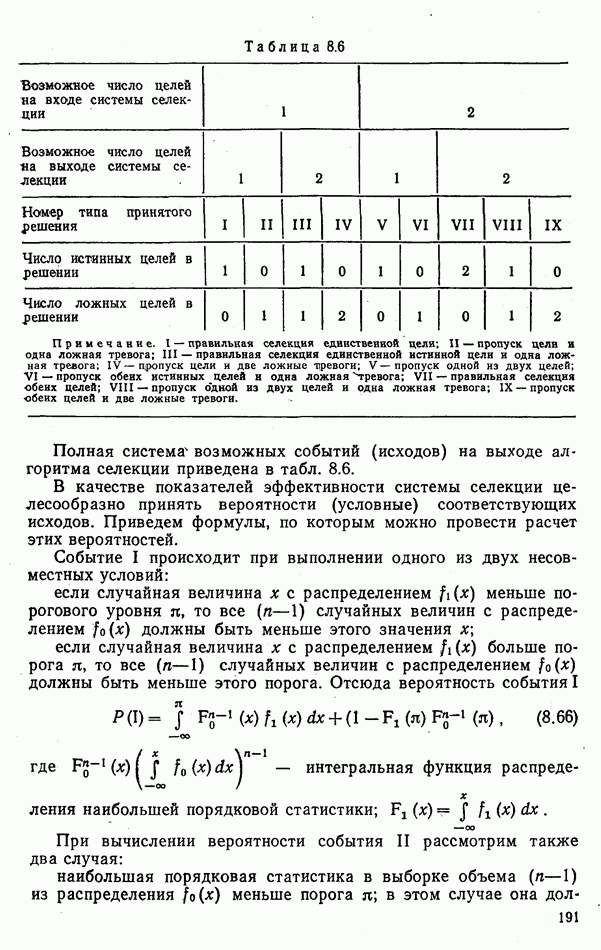
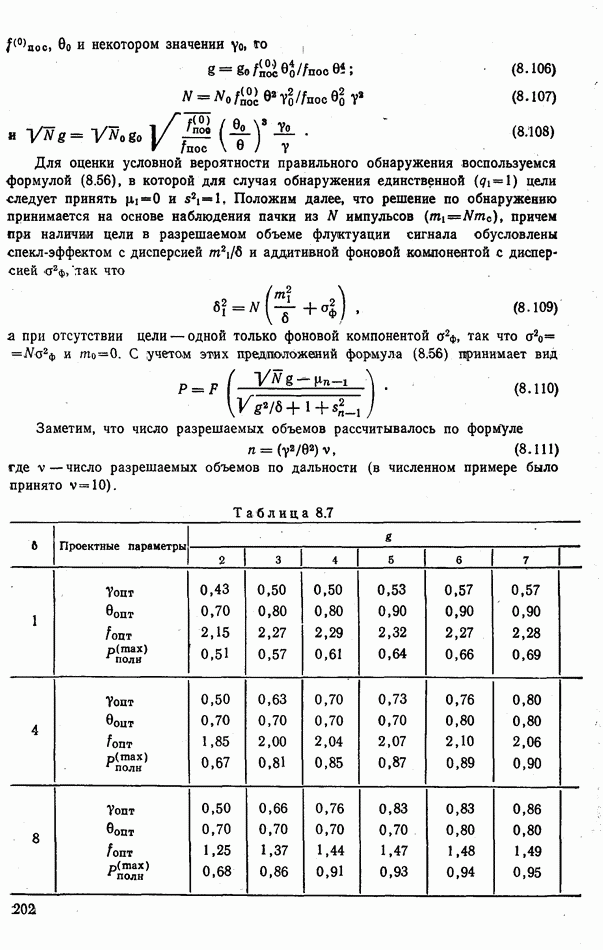
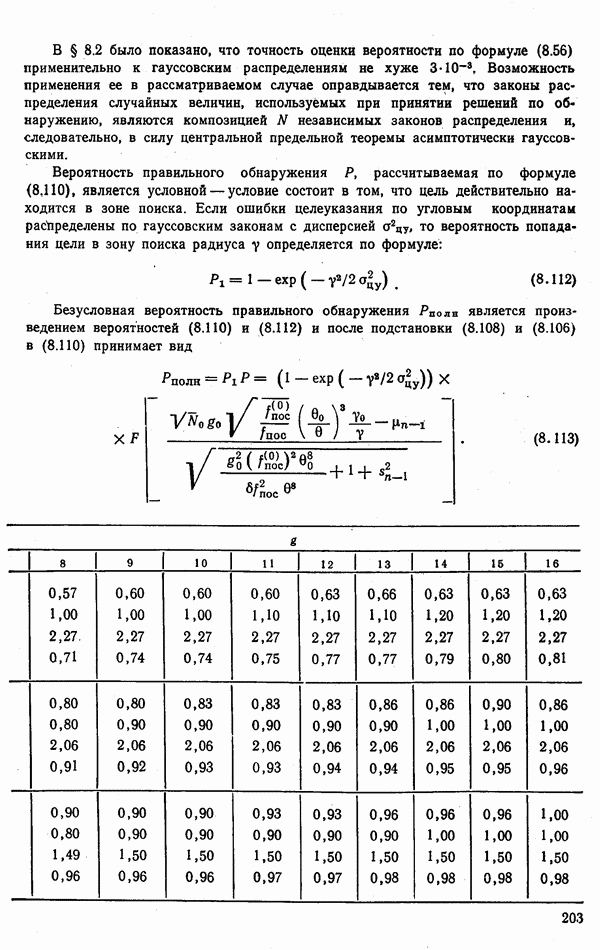
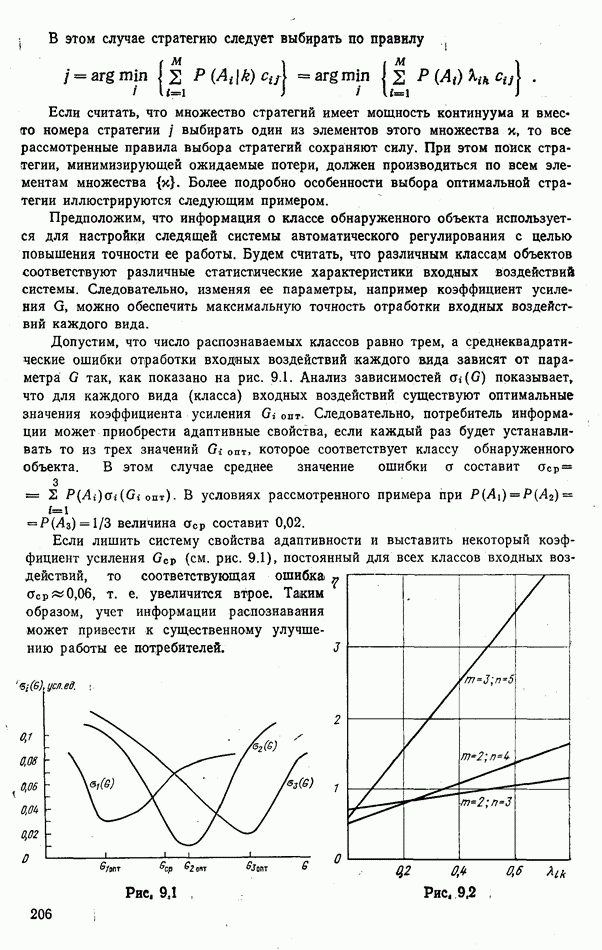
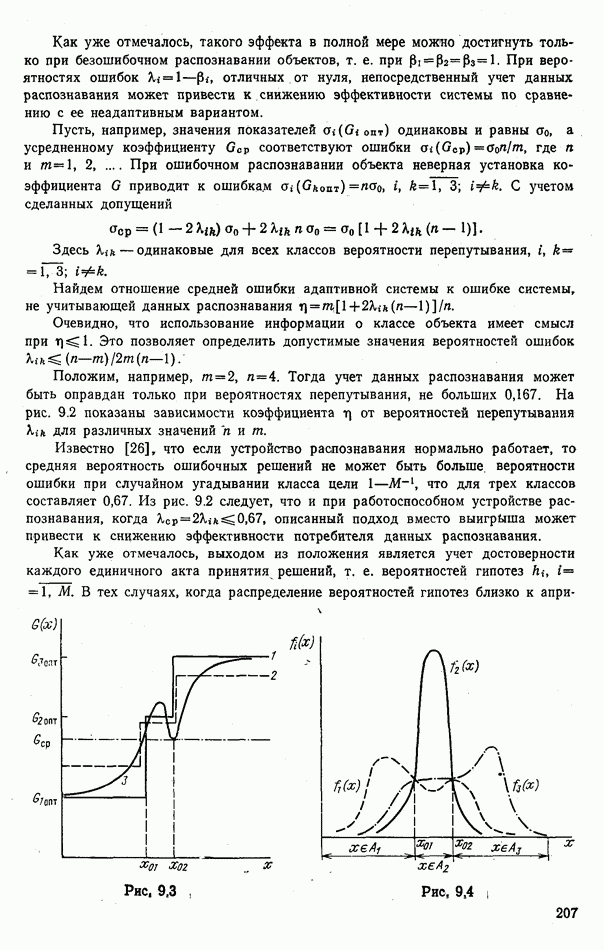
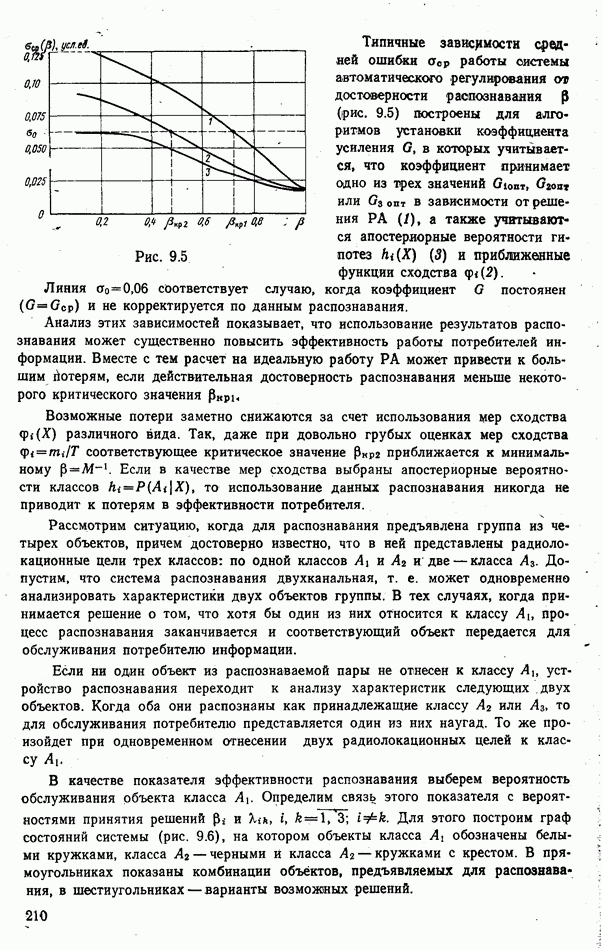
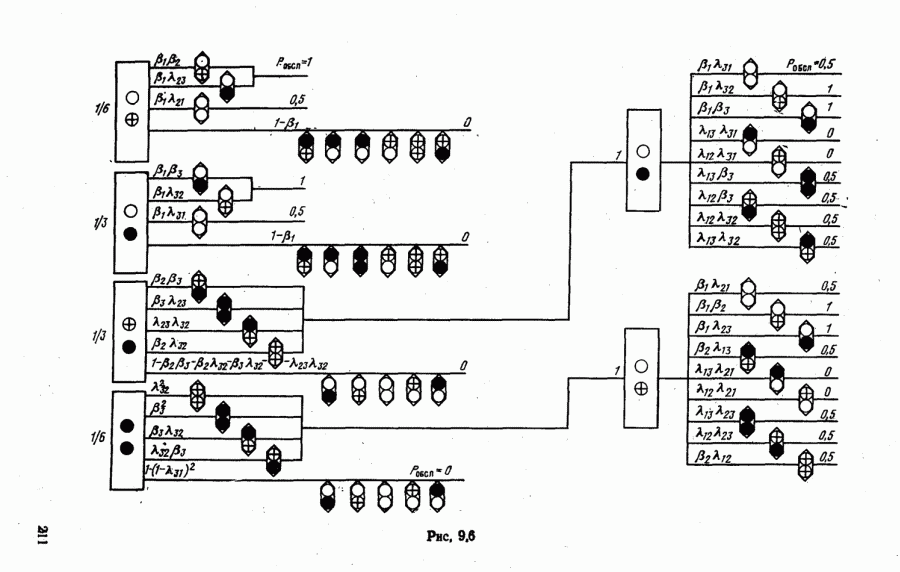
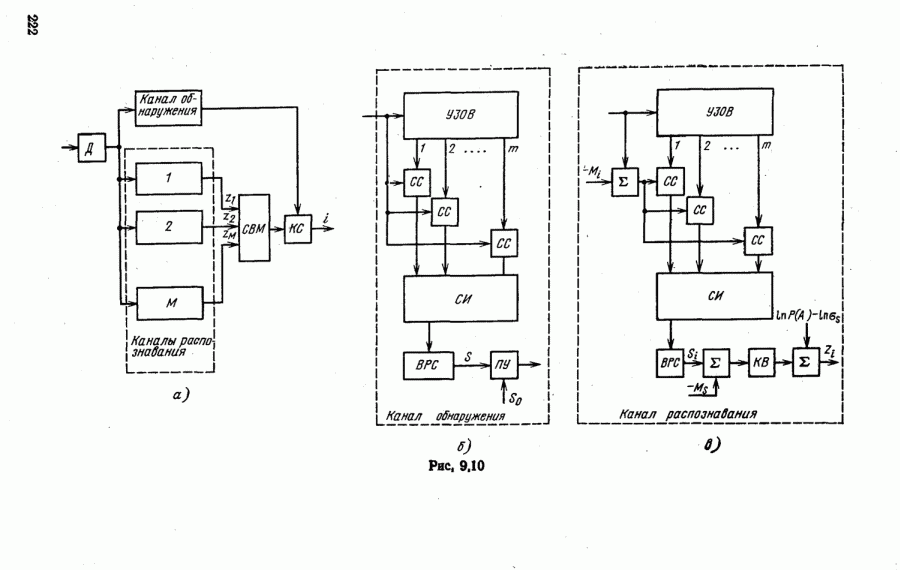
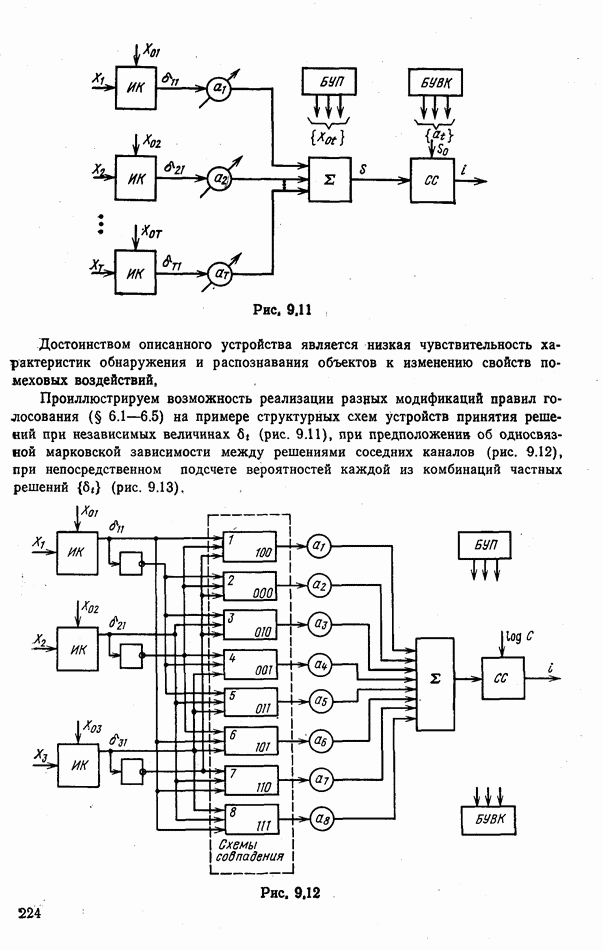
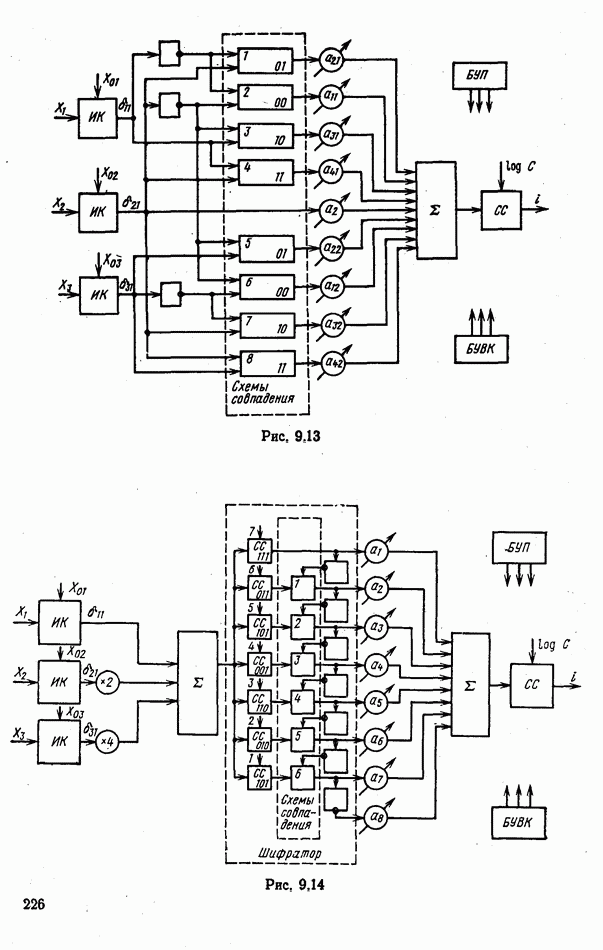
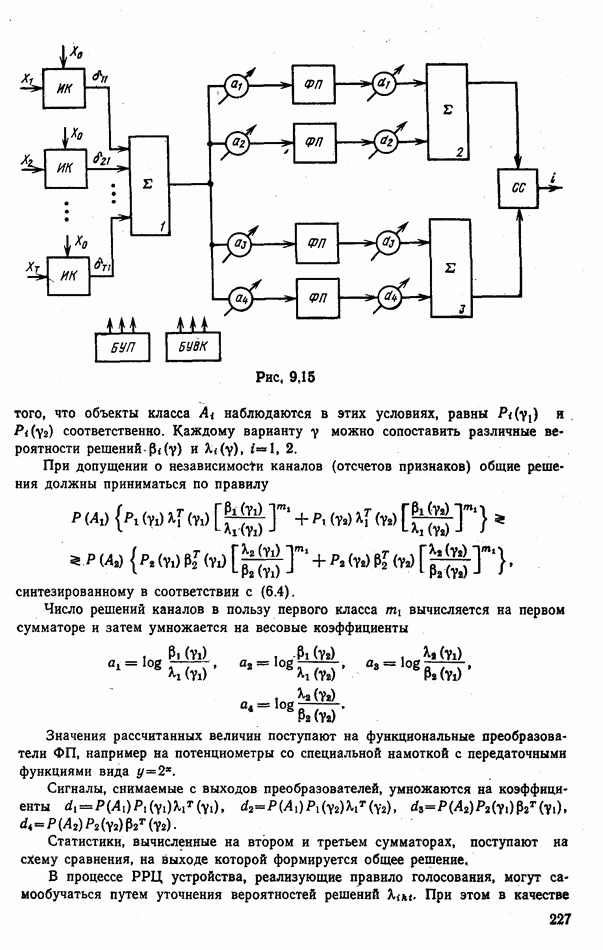
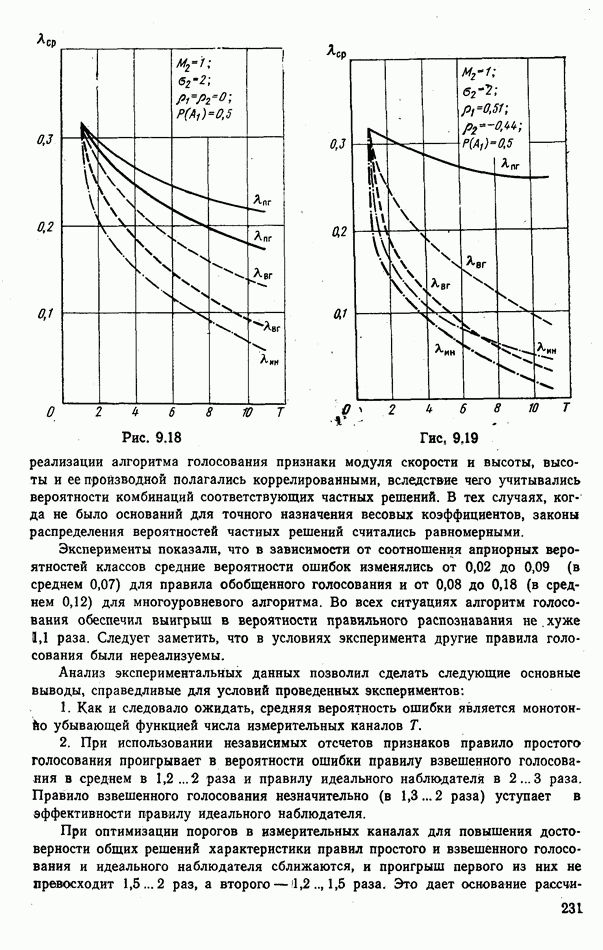
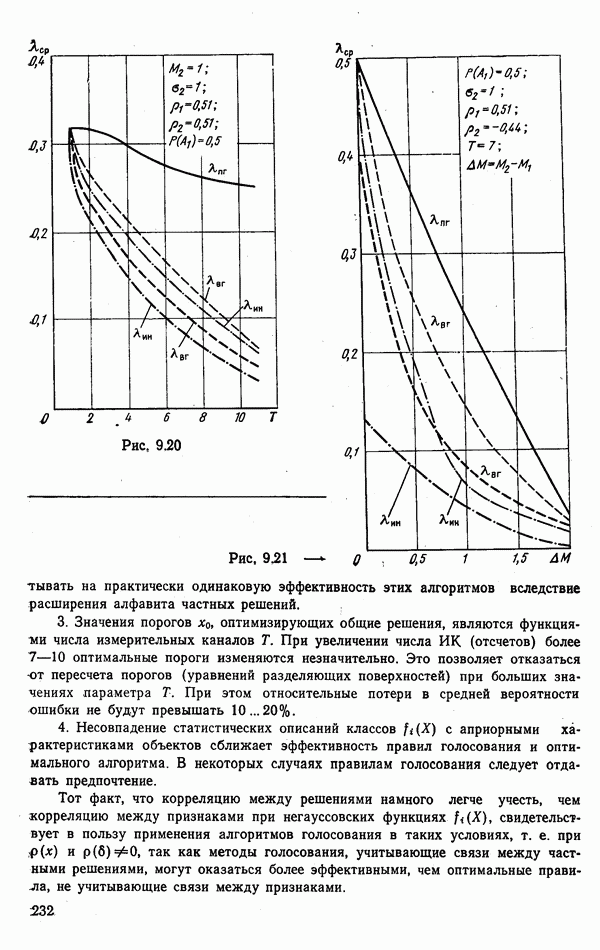
9.5.2. РАСПОЗНАВАНИЕ ОБЪЕКТОВ В ГРУППАХ
Для оценки эффективности алгоритмов распознавания групп объектов было проведено несколько серий экспериментов. В каждом из них моделировалось наблюдение групп численностью от двух до ста радиолокационных целей. Размеры групп задавались случайным образом, чаще всего в соответствии с гипотезой о пуассоновских потоках объектов. Значительное число экспериментов было посвящено моделированию распознавания групп однородного состава.
Измерение признаков объектов имитировалось обращением к записям сигналов, отраженных от радиолокационных целей, либо к машинным датчикам псевдослучайных чисел. В первом случае функции  (если они использовались) оценивались путем построения гистограмм; их значения хранились в памяти ЭВМ в табличном виде или аппроксимировались одним из известных законов распределений вероятностей. При использовании машинных датчиков законы
(если они использовались) оценивались путем построения гистограмм; их значения хранились в памяти ЭВМ в табличном виде или аппроксимировались одним из известных законов распределений вероятностей. При использовании машинных датчиков законы  полагались гауссовскими, рэлеевскими, логарифмически нормальными или экспоненциальными.
полагались гауссовскими, рэлеевскими, логарифмически нормальными или экспоненциальными.
При работе с записями сигналов радиолокационных целей использовались поляризационные признаки, описанные в гл. 4, и средние значения амплитуд эхо-сигналов на совпадающих поляризациях.
В наибольшем числе экспериментов была проверена эффективность одношаговых адаптивных алгоритмов при различных способах оценки составов групп. Моделирование показало, что независимо от способа измерения признаков и вида законов  эффективность проверявшихся алгоритмов определялась, главным образом, степенью колебания состава группы
эффективность проверявшихся алгоритмов определялась, главным образом, степенью колебания состава группы  относительно ожидаемого, размерами групп
относительно ожидаемого, размерами групп  близостью функций
близостью функций  при различных номерах классов
при различных номерах классов  .
.
Часть проводившихся экспериментов описана в [28]. Все они подтвердили теоретические заключения. В частности, были сделаны следующие выводы:
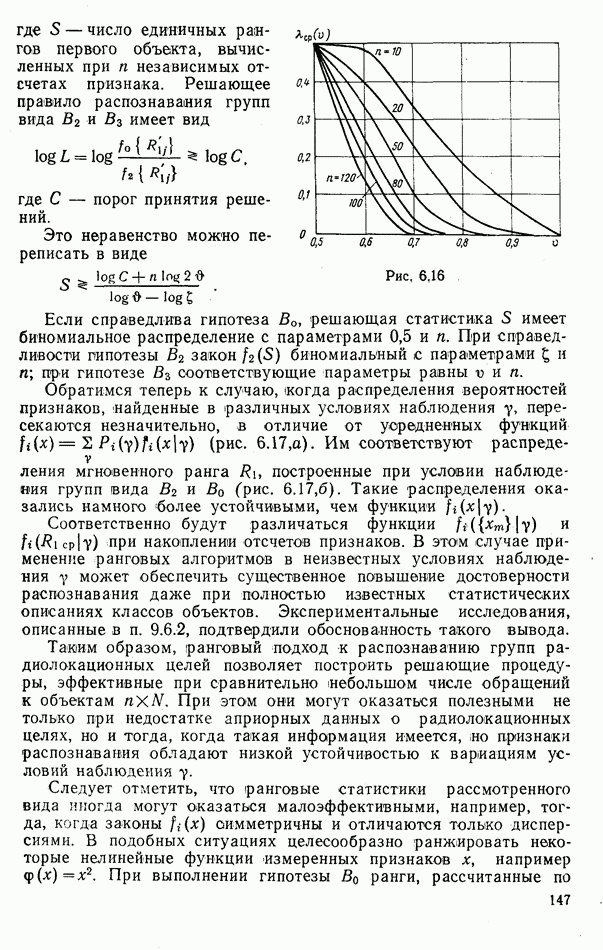
1. Применение адаптивных алгоритмов тем более оправдано, чем больше колеблются составы групп объектов относительно ожидаемых и чем больше размеры групп  При относительно стабильных составах групп наиболее предпочтительны оценки вида (6.19) и (6.21). При распознавании групп однородного состава в условиях неизвестных вероятностей
При относительно стабильных составах групп наиболее предпочтительны оценки вида (6.19) и (6.21). При распознавании групп однородного состава в условиях неизвестных вероятностей  наибольшую достоверность распознавания обеспечивают несмещенные оценки; при этом наиболее простые из них вида
наибольшую достоверность распознавания обеспечивают несмещенные оценки; при этом наиболее простые из них вида

оказались приблизительно эквивалентными.
2. При небольших размерах групп  адаптация может привести к некоторому снижению достоверности распознавания (см. рис. 9.22,а). При этом допустимый размер группы
адаптация может привести к некоторому снижению достоверности распознавания (см. рис. 9.22,а). При этом допустимый размер группы  зависит от способа ее формирования и от вида используемых оценок. С ростом числа классов М допустимые размеры групп увеличиваются. При независимом предъявлении объектов и параметре М, равном двум, допустимо
зависит от способа ее формирования и от вида используемых оценок. С ростом числа классов М допустимые размеры групп увеличиваются. При независимом предъявлении объектов и параметре М, равном двум, допустимо  объектов, в зависимости от вида функций
объектов, в зависимости от вида функций  используемых оценок и значений вероятностей
используемых оценок и значений вероятностей  Если эти вероятности не заданы, то допустимый размер группы уменьшается до
Если эти вероятности не заданы, то допустимый размер группы уменьшается до  объектов.
объектов.
3. Если составы группы сильно колеблются, то адаптация будет эффективна при  . В случае распознавания групп однородного состава она может быть оправдана и при
. В случае распознавания групп однородного состава она может быть оправдана и при 
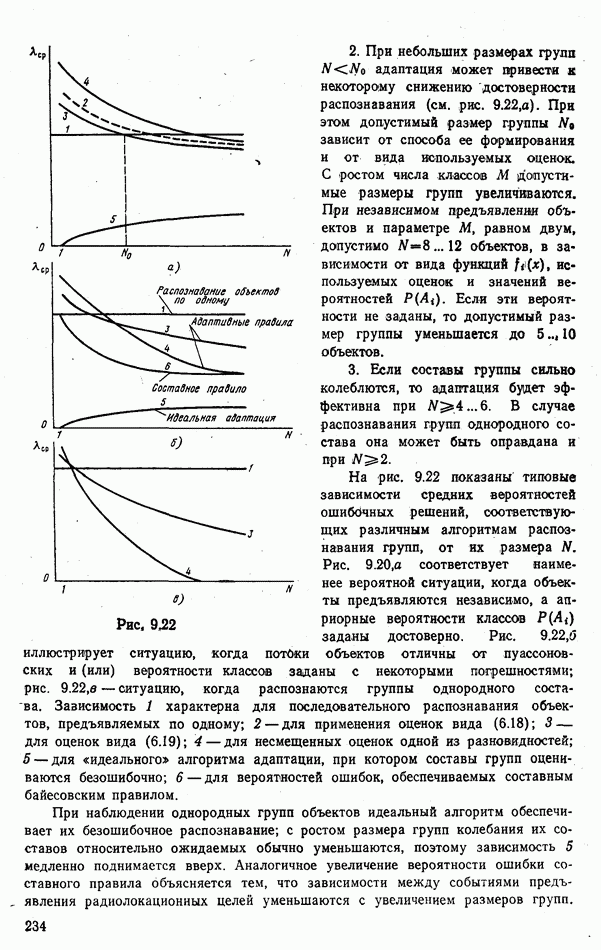
На рис. 9.22 показаны типовые зависимости средних вероятностей ошибочных решений, соответствующих различным алгоритмам распознавания групп, от их размера  Рис. 9.20, а соответствует наименее вероятной ситуации, когда объекты предъявляются независимо, а априорные вероятности классов
Рис. 9.20, а соответствует наименее вероятной ситуации, когда объекты предъявляются независимо, а априорные вероятности классов  заданы достоверно. Рис.
заданы достоверно. Рис.  иллюстрирует ситуацию, когда потоки объектов отличны от пуассоновских и (или) вероятности классов заданы с некоторыми погрешностями; рис. 9.22,в — ситуацию, когда распознаются группы однородного состава. Зависимость 1 характерна для последовательного распознавания объектов, предъявляемых по одному; 2 — для применения оценок вида (6.18); 3 — для оценок вида (6.19); 4 — для несмещенных оценок одной из разновидностей; 5 — для «идеального» алгоритма адаптации, при котором составы групп оцениваются безошибочно; 6 — для вероятностей ошибок, обеспечиваемых составным байесовским правилом.
иллюстрирует ситуацию, когда потоки объектов отличны от пуассоновских и (или) вероятности классов заданы с некоторыми погрешностями; рис. 9.22,в — ситуацию, когда распознаются группы однородного состава. Зависимость 1 характерна для последовательного распознавания объектов, предъявляемых по одному; 2 — для применения оценок вида (6.18); 3 — для оценок вида (6.19); 4 — для несмещенных оценок одной из разновидностей; 5 — для «идеального» алгоритма адаптации, при котором составы групп оцениваются безошибочно; 6 — для вероятностей ошибок, обеспечиваемых составным байесовским правилом.
При наблюдении однородных групп объектов идеальный алгоритм обеспечивает их безошибочное распознавание; с ростом размера групп колебания их составов относительно ожидаемых обычно уменьшаются, поэтому зависимость  медленно поднимается вверх. Аналогичное увеличение вероятности ошибки составного правила объясняется тем, что зависимости между событиями предъявления радиолокационных целей уменьшаются с увеличением размеров групп.
медленно поднимается вверх. Аналогичное увеличение вероятности ошибки составного правила объясняется тем, что зависимости между событиями предъявления радиолокационных целей уменьшаются с увеличением размеров групп.
Рис. 9.22 (см. скан)
Эксперименты показали, что комбинация составного и адаптивного алгоритмов может быть оправдана, если первый из них применять при  , а адаптивный алгоритм — при большем числе наблюдаемых объектов.
, а адаптивный алгоритм — при большем числе наблюдаемых объектов.
Эффективность ранговых алгоритмов оценивалась в условиях распознавания групп из  радиолокационных целей одного — трех классов. Число отсчетов признаков, характеризующих каждый объект группы, колебалось от
радиолокационных целей одного — трех классов. Число отсчетов признаков, характеризующих каждый объект группы, колебалось от  до
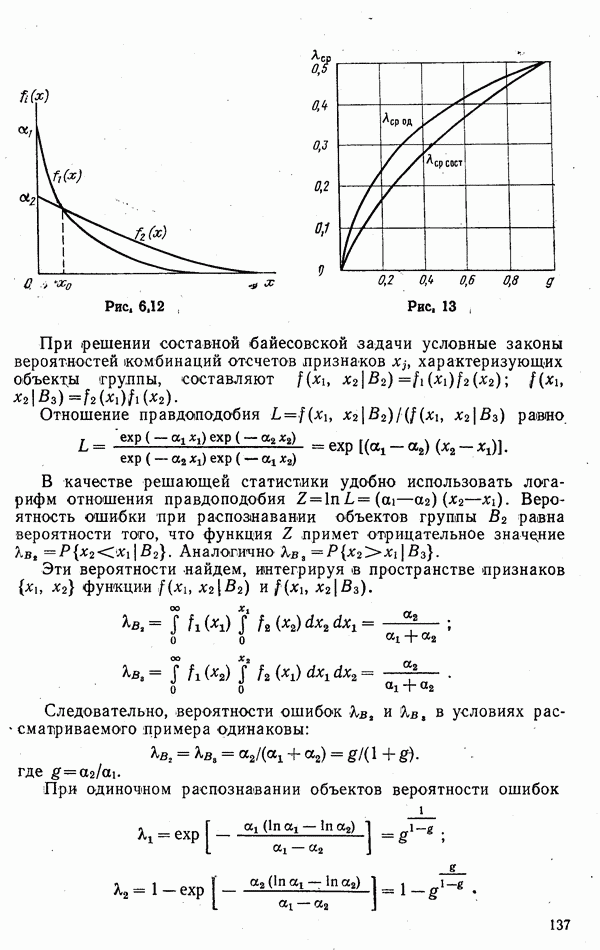
до  Эксперименты показали высокую эффективность ранговых правил. Интересно отметить, что в условиях примера, иллюстрируемого табл. 6.8 и рис. 6.12, применение составного байесовского правила и ранговых алгоритмов обеспечивает идентичные результаты. Действительно, сравнение рангов объектов группы и анализ составной статистики
Эксперименты показали высокую эффективность ранговых правил. Интересно отметить, что в условиях примера, иллюстрируемого табл. 6.8 и рис. 6.12, применение составного байесовского правила и ранговых алгоритмов обеспечивает идентичные результаты. Действительно, сравнение рангов объектов группы и анализ составной статистики  неизбежно приводят к одним и тем же решениям.
неизбежно приводят к одним и тем же решениям.
Эксперименты показали справедливость такого утверждения. Для этого были обработаны записи сигналов, отраженных от объектов сложной формы. Моделирование рангового распознавания групп, включающих по одной радиолокационной цели каждого из двух возможных классов, Привело к следующим оценкам вероятностей ошибок по одному отсчету признака (ранга)  Хер
Хер  Здесь первая вероятность соответствует ранговому алгоритму, а вторая — классическому правилу последовательного распознавания одиночных объектов. Несмотря на то, что значения выборочных распределений вероятностей признаков
Здесь первая вероятность соответствует ранговому алгоритму, а вторая — классическому правилу последовательного распознавания одиночных объектов. Несмотря на то, что значения выборочных распределений вероятностей признаков  плохо согласовывались с гипотезой об их экспоненциальной форме, вероятности ошибок хорошо совпали с расчетными для составного и последовательного правил при
плохо согласовывались с гипотезой об их экспоненциальной форме, вероятности ошибок хорошо совпали с расчетными для составного и последовательного правил при  (см. рис. 6.13).
(см. рис. 6.13).
Математическое моделирование кластерных методов распознавания групп объектов выполнялось в предположении о том, что число классов "алфавита М равно двум, а признаки классов гауссовские с распределениями  соответственно. Для распознавания предъявлялись группы по 100 объектов, причем число объектов класса
соответственно. Для распознавания предъявлялись группы по 100 объектов, причем число объектов класса  в них варьировалось от 10 до 90. От каждой из радиолокационных целей имитировалось получение трех отсчетов признаков. Порог распознавания выбирался в минимуме гистограммы, построенной по 300 точкам. Параметры
в них варьировалось от 10 до 90. От каждой из радиолокационных целей имитировалось получение трех отсчетов признаков. Порог распознавания выбирался в минимуме гистограммы, построенной по 300 точкам. Параметры  полагались равными 0,1 и 0,4 соответственно. Параметр
полагались равными 0,1 и 0,4 соответственно. Параметр  варьировался от 0,8 до 2, а параметр
варьировался от 0,8 до 2, а параметр  — от 2 до 4.
— от 2 до 4.
Результаты моделирования показали следующее: знание только того факта, что  позволило обеспечить практически безошибочное распознавание объектов в группах; ни в одной из серий экспериментов доля ошибочных решений не превзошла 0,10.
позволило обеспечить практически безошибочное распознавание объектов в группах; ни в одной из серий экспериментов доля ошибочных решений не превзошла 0,10.