Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ГЛАВА 9. ПРИКЛАДНЫЕ ЗАДАЧИ РАДИОЛОКАЦИОННОГО РАСПОЗНАВАНИЯ9.1. ЭФФЕКТИВНОСТЬ ПОТРЕБИТЕЛЕЙ ИНФОРМАЦИИ РАСПОЗНАВАНИЯПроиллюстрируем возможные пути использования результатов РРЦ тремя примерами. Во всех случаях качество распознавания будем оценивать показателем эффективности потребителя информации. Обычно решение При отсутствии текущей информации распознавания ее потребитель может выбрать либо минимаксную стратегию
Будем считать, что в результате измерения признака объекта
Во многих случаях устройство распознавания неспособно рассчитать вероятности гипотез Лучшим решением в таких условиях будет вычисление и использование апостериорных вероятностей классов на основании имеющихся данных о номере класса объекта k. В этом случае стратегию следует выбирать по правилу
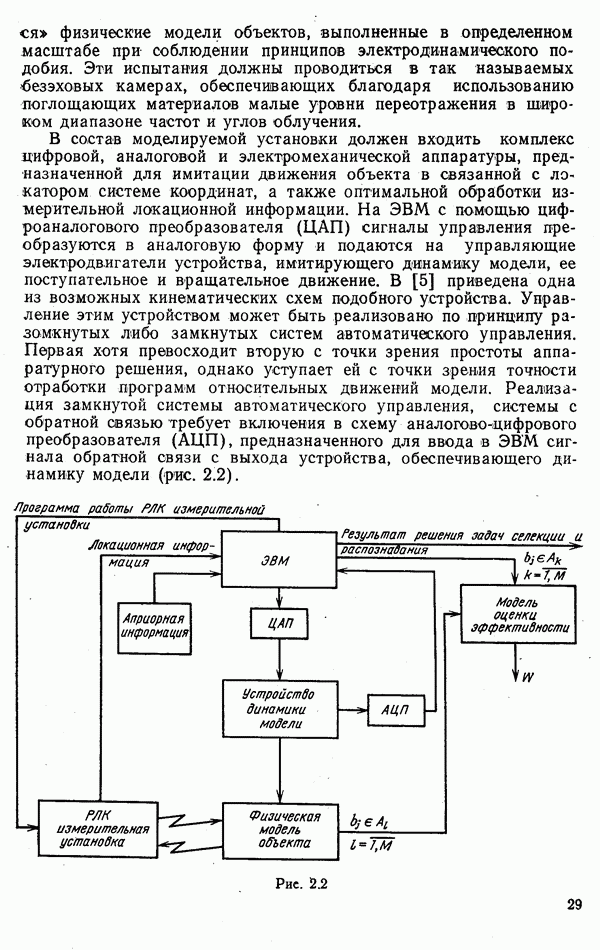
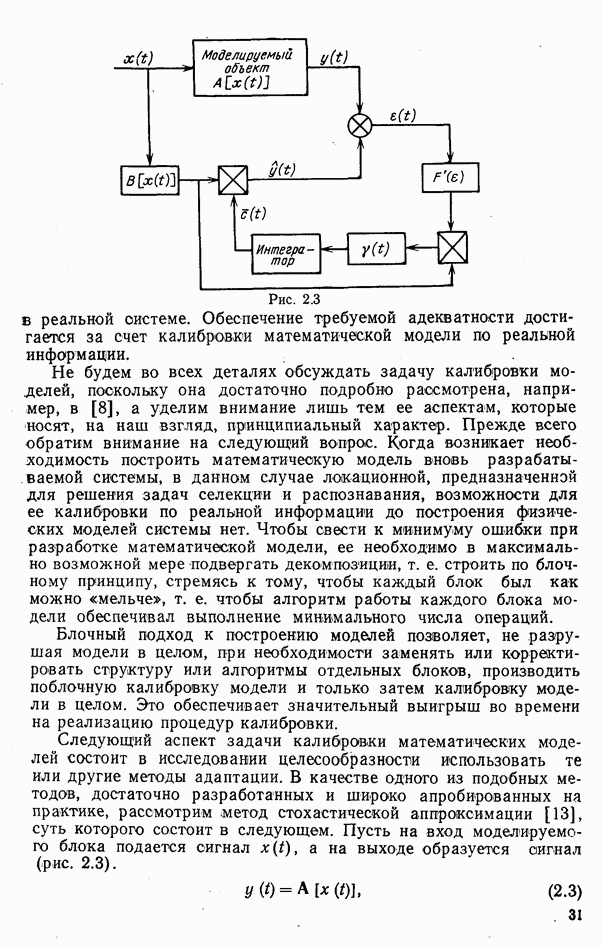
Если считать, что множество стратегий имеет мощность континуума и вместо номера стратегии Предположим, что информация о классе обнаруженного объекта используется для настройки следящей системы автоматического регулирования с целью повышения точности ее работы. Будем считать, что различным классам объектов соответствуют различные статистические характеристики входных воздействий системы. Следовательно, изменяя ее параметры, например коэффициент усиления Допустим, что число распознаваемых классов равно трем, а среднеквадратические ошибки отработки входных воздействий каждого вида зависят от параметра В условиях рассмотренного примера при Если лишить систему свойства адаптивности и выставить некоторый коэффициент усиления
Рис. 9.1.
Рис. 9.2. Как уже отмечалось, такого эффекта в полной мере можно достигнуть только при безошибочном распознавании объектов, т. е. при Пусть, например, значения показателей
Здесь Найдем отношение средней ошибки адаптивной системы к ошибке системы, не учитывающей данных распознавания Очевидно, что использование информации о классе объекта имеет смысл при 1. Это позволяет определить допустимые значения вероятностей ошибок Положим, например, Известно [26], что если устройство распознавания нормально работает, то средняя вероятность ошибочных решений не может быть больше, вероятности ошибки при случайном угадывании класса цели Как уже отмечалось, выходом из положения является учет достоверности каждого единичного акта принятия решений, т. е. вероятностей гипотез
Рис. 9.3
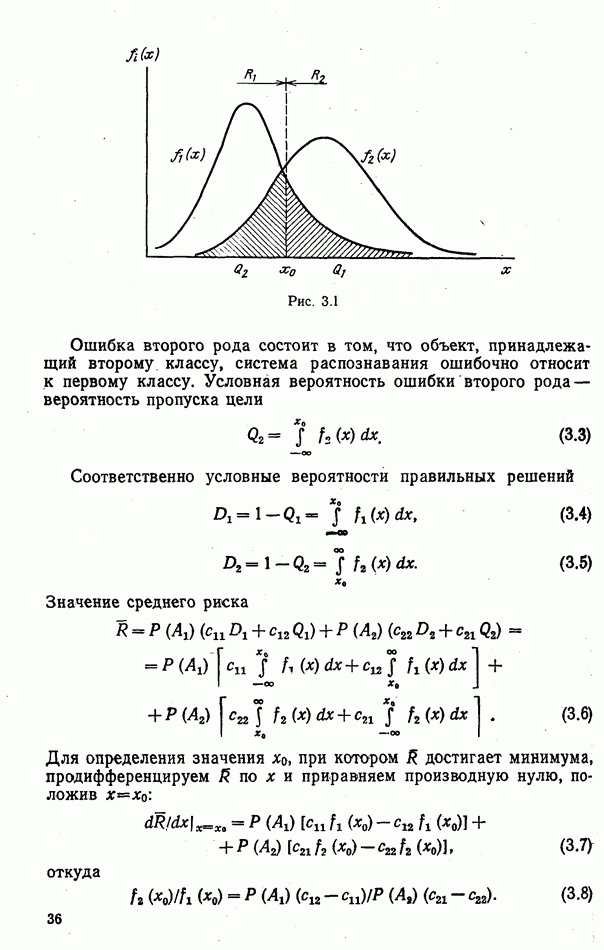
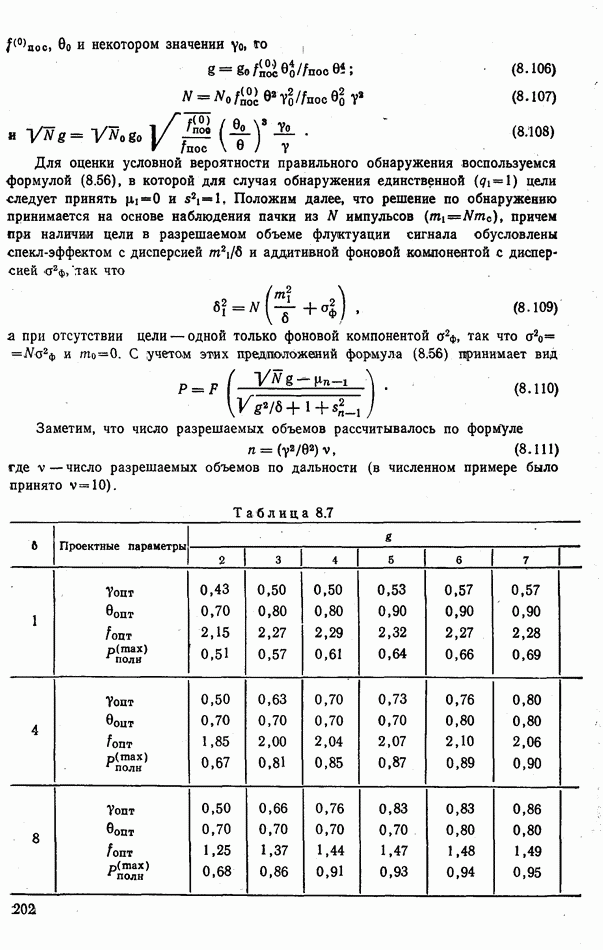
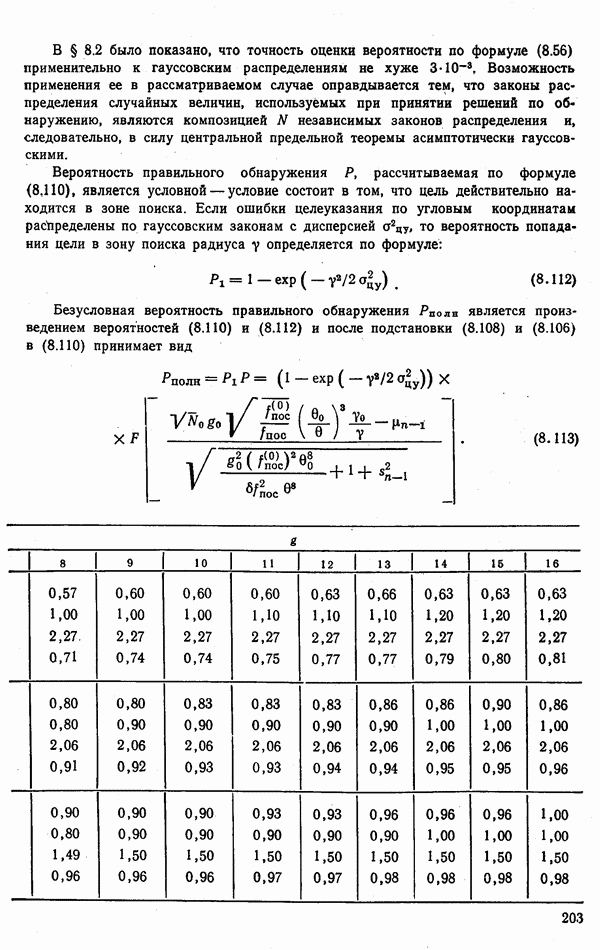
Рис. 9.4. распределению вероятностей классов, начальное значение коэффициента Для вычисления вероятностей гипотез должны быть известны априорные вероятности классов Если решения о классе объекта принимаются в результате измерения
где
При этом коэффициент усиления
Более грубо оценки мер сходства можно вычислять в виде
Первому и второму подходам соответствуют ожидаемые значения ошибок регулирования
для третьего подхода
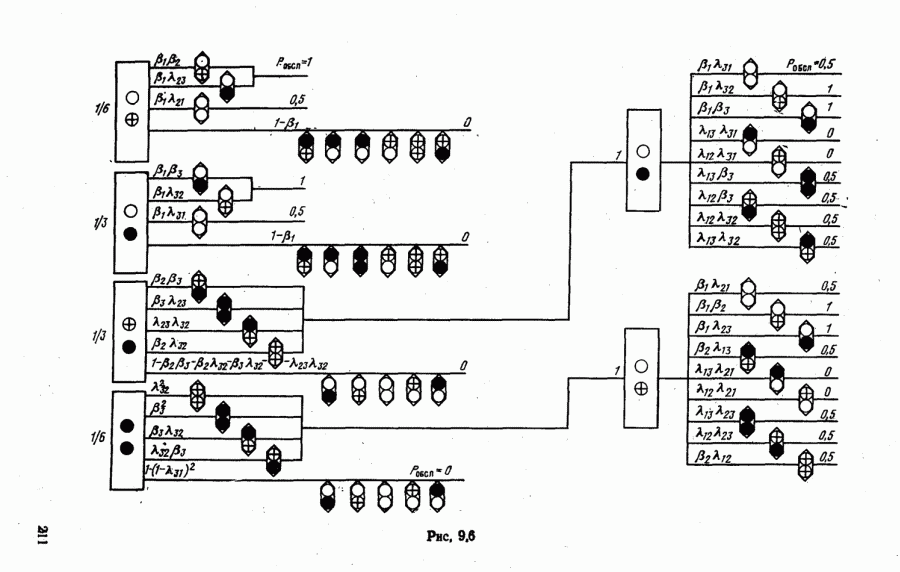
На рис. 9.4 показаны функции Обратившись к выражению для стср, заметим, что эффективность потребителя информации распознавания зависит от характеристик матрицы вероятностей перепутывания Значения ее элементов определяются не только функциями
Так, если реализован второй подход к использованию результатов распознавания, то систему «распознающий автомат + потребитель информации» можно оптимизировать оптимальной настройкой
Таким образом, в тех случаях, когда потребитель информации использует решения о классе объекта для выбора наиболее выгодного режима работы (структурных связей, параметров схем), возможна оптимизация системы «устройство распознавания В тех случаях, когда выдача мер сходства невозможна, в устройстве распознавания должно быть задано оптимальное множество порогов Если установить различные пороги в одном и том же устройстве трудно, то следует выбирать компромиссный вариант, более или менее удовлетворяющий интересам каждого из потребителей информации распознавания. Если это возможно, лучше всего выдавать им весь набор апостериорных вероятностей классов.
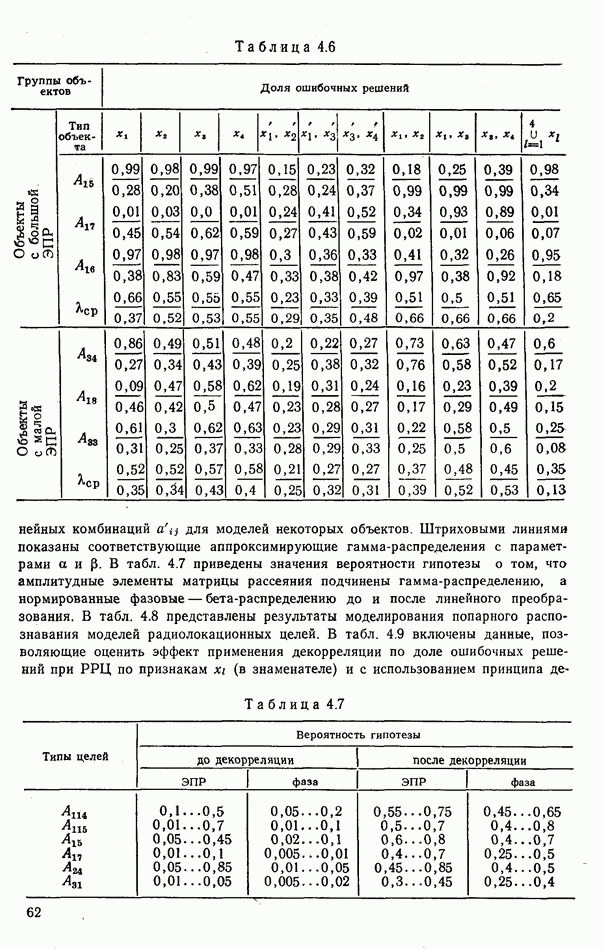
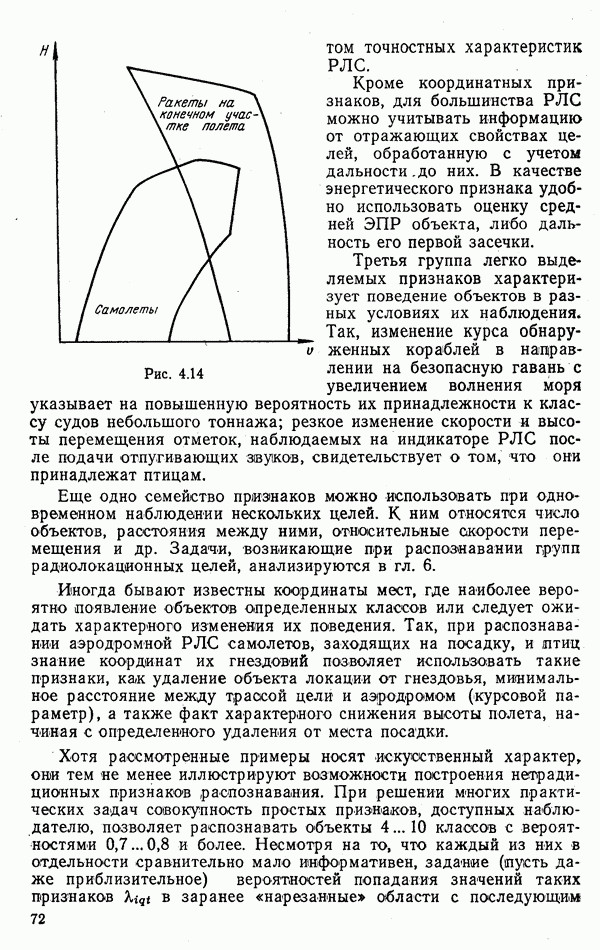
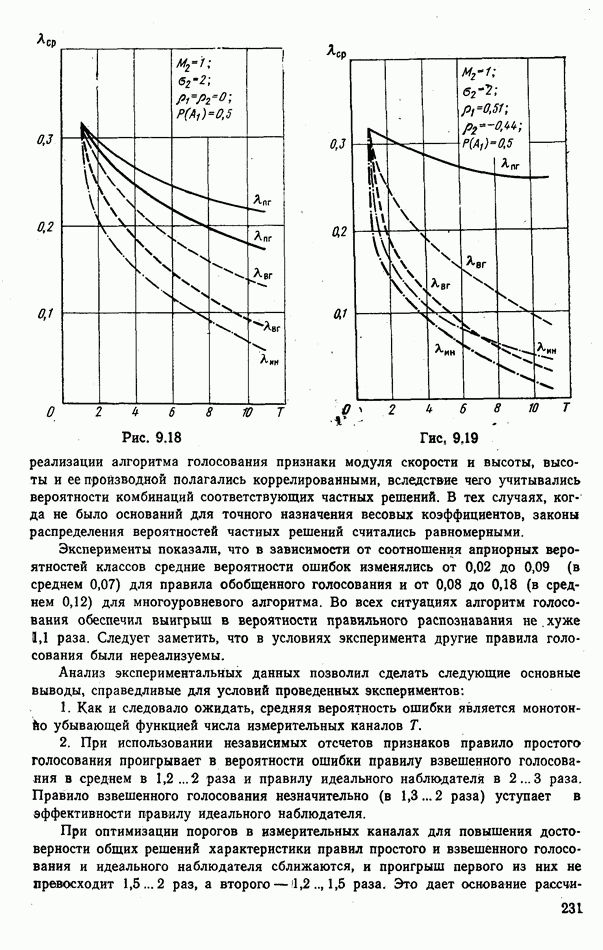
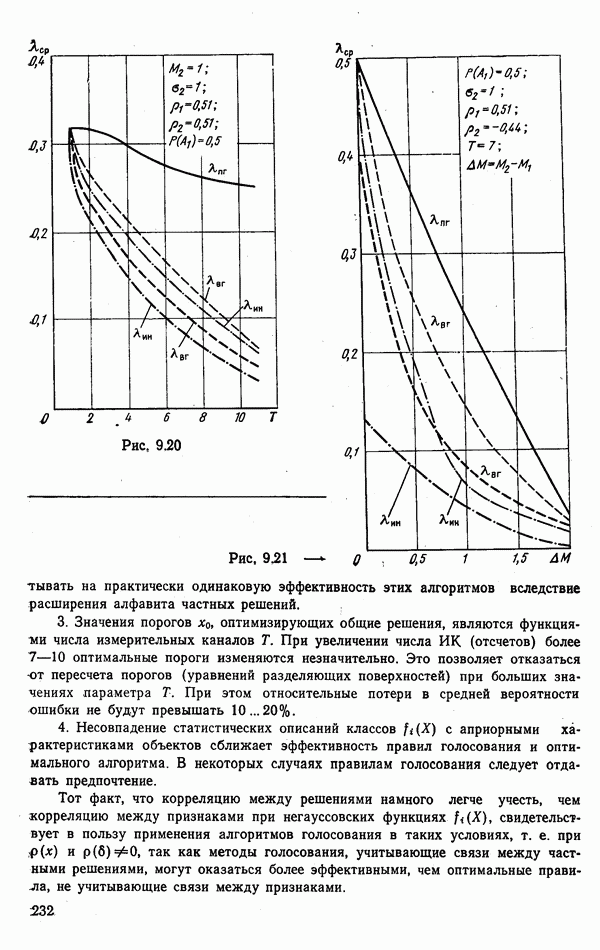
Рис. 9.5 Типичные зависимости средней ошибки Линия Анализ этих зависимостей показывает, что использование результатов распознавания может существенно повысить эффективность работы потребителей информации. Вместе с тем расчет на идеальную работу Возможные потери заметно снижаются за счет использования мер сходства Рассмотрим ситуацию, когда для распознавания предъявлена группа из четырех объектов, причем достоверно известно, что в ней представлены радиолокационные цели трех классов: по одной классов Если ни один объект из распознаваемой пары не отнесен к классу В качестве показателя эффективности распознавания выберем вероятность обслуживания объекта класса
(кликните для просмотра скана) Около прямоугольников указаны вероятности предъявления комбинаций объектов, около шестиугольников — вероятности соответствующих решений, в конце каждой ветви — соответствующая ей вероятностть обслуживания объекта первого класса. Анализ построенной схемы позволяет найти вероятность обслуживания, радиолокационных целей класса
Из этого выражения видно, что специфика решаемой задачи приводит к показателю эффективности, нелинейно зависящему от верояткостей принятия решений
Применительно к рассмотренной задаче можно положить стоимости решений
Это приводит к зависимости
Очевидно, что как бы мы ни подбирали постоянные Совпадения выражений для среднего риска и вероятности обслуживания Робе можно добиться, рассматривая вероятности распознавания не отдельных объектов Одна из основных задач, стоящих перед системами массового обслуживания, — установка очередности удовлетворения поступающих заявок. При разной важности заявок задача обычно оказывается многокритериальной, что затрудняет поиск оптимального решения. Лучший способ его отыскания — свертка нескольких критериев в один. Допустим, что РЛС обнаружила и распознала несколько приближающихся объектов, подлежащих последовательному обслуживанию. Каждый Время обслуживания каждого объекта линейно зависит от его дальности Необходимо максимизировать вероятность успешного обслуживания всех
Рис. 9.7 При решении подобных задач и отсутствии данных о классах радиолокационных целей очередность их обслуживания обычно определяется порядком их приближения на дальность Ее значение определяется по формуле
где Дальности
т. е. номера объектов пересмотрены в соответствии с установленной очередью Поиск оптимальной очередности обслуживания объектов при небольших размерах группы возможен методом прямого перебора; при больших Если
Отождествление объектов. Если несколько РЛС передают на общий пункт обработки информации разными РЛС на индикаторе Пусть, например, две РЛС наблюдают цели, с отличающимися на Если при выборе перечисленных гипотез стоимости ошибок одинаковы, то следует выбрать наиболее правдоподобную из них. Для этого следует рассчитать совместные законы распределения вероятностей Если решения В некоторых случаях составляющая При справедливости гипотез 1—4 закон Закон Таблица 9.1 (см. скан) следует принять гипотезу 1. В остальных случаях для расчета Анализ законов При определении истинных координат объектов по данным нескольких РЛС может оказаться полезной методика комбинаций оценок, рассмотренная в п. 6.7.4. Анализ сложных гипотез о координатах объектов и номерах их классов может быть рекомендован при завязке трасс радиолокационных целей, экстраполяции их положения в пространстве и поиске объектов по данным целеуказания. При этом размеры пространственных стробов, в которых анализируется радиолокационная обстановка, целесообразно выбирать с учетом маневренных возможностей обнаруженных целей. Рассмотренные примеры показали целесообразность и необходимость совместного решения задач обнаружения и определения координат радиолокационных целей и задач их распознавания.
|
 |
Оглавление
|

























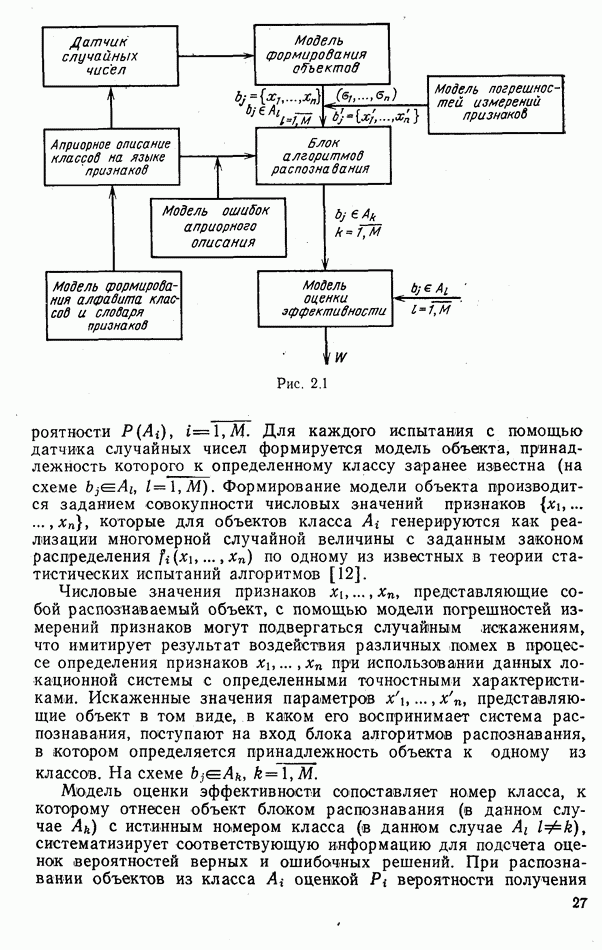



























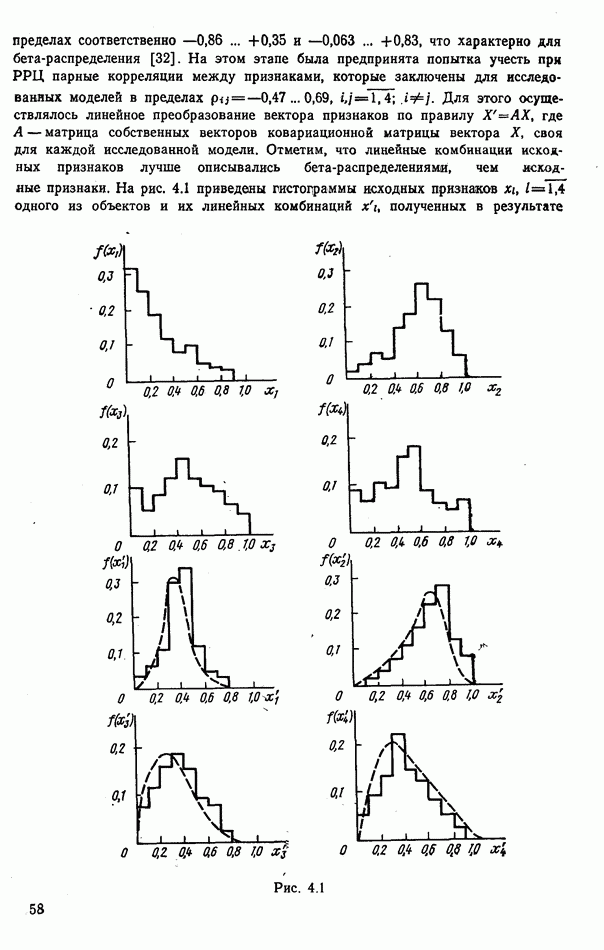
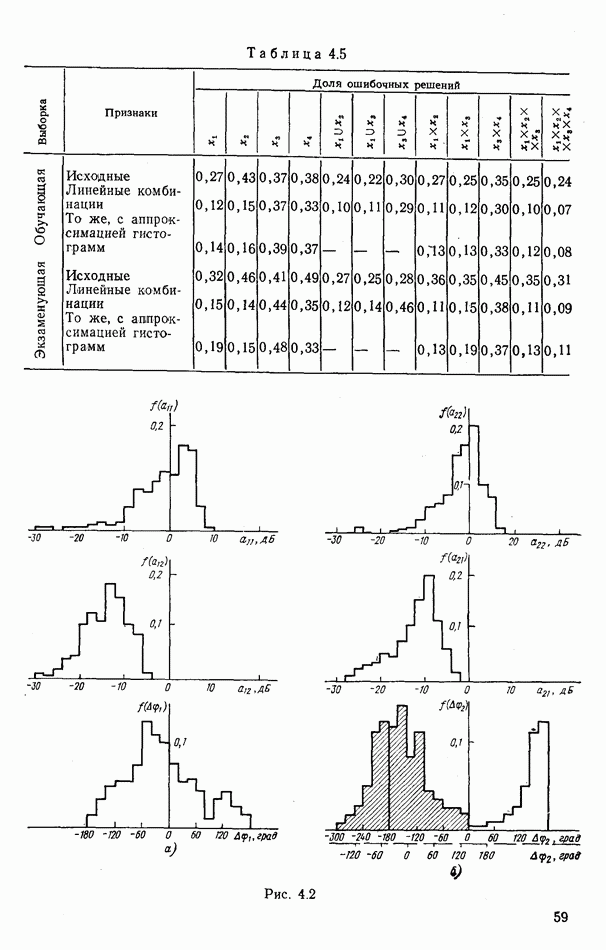
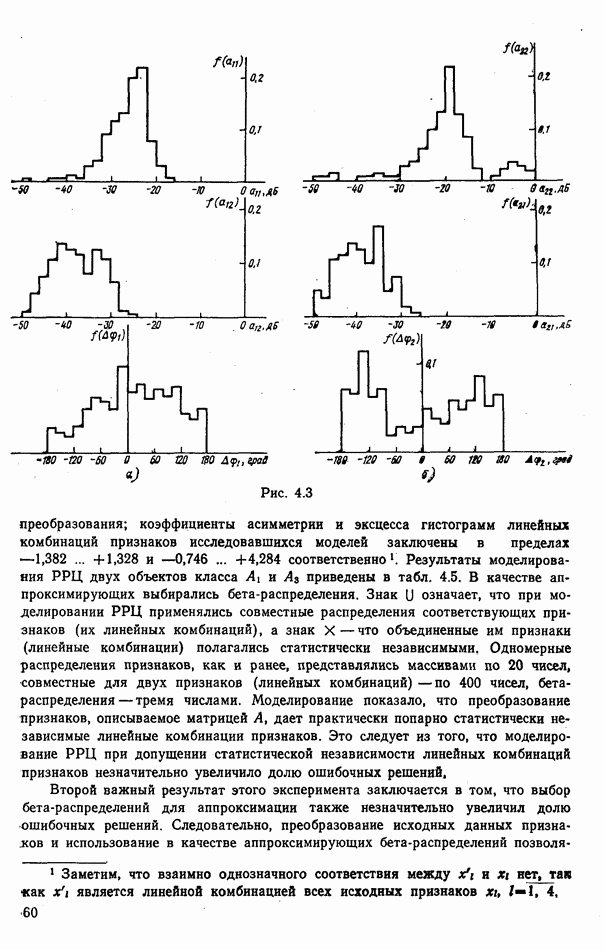
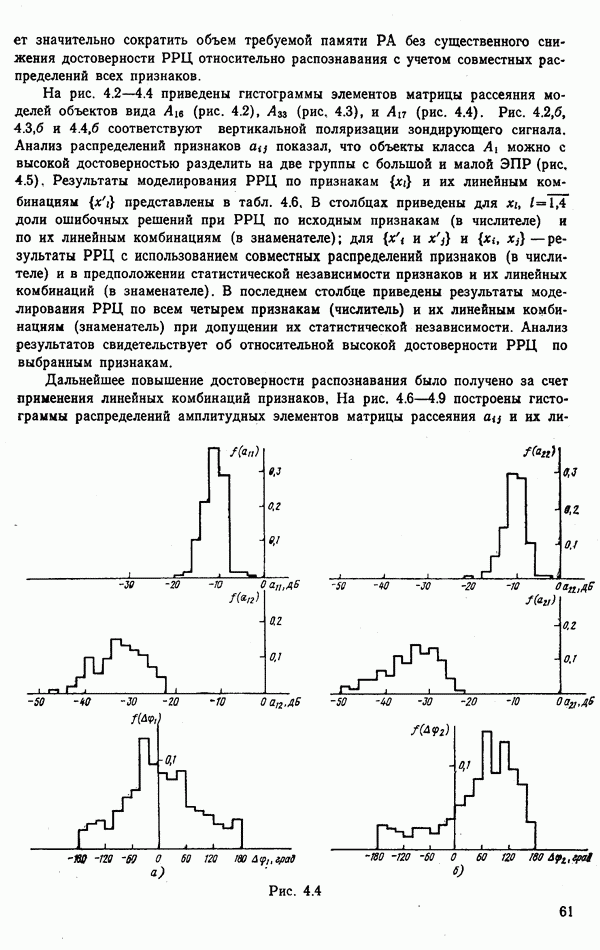

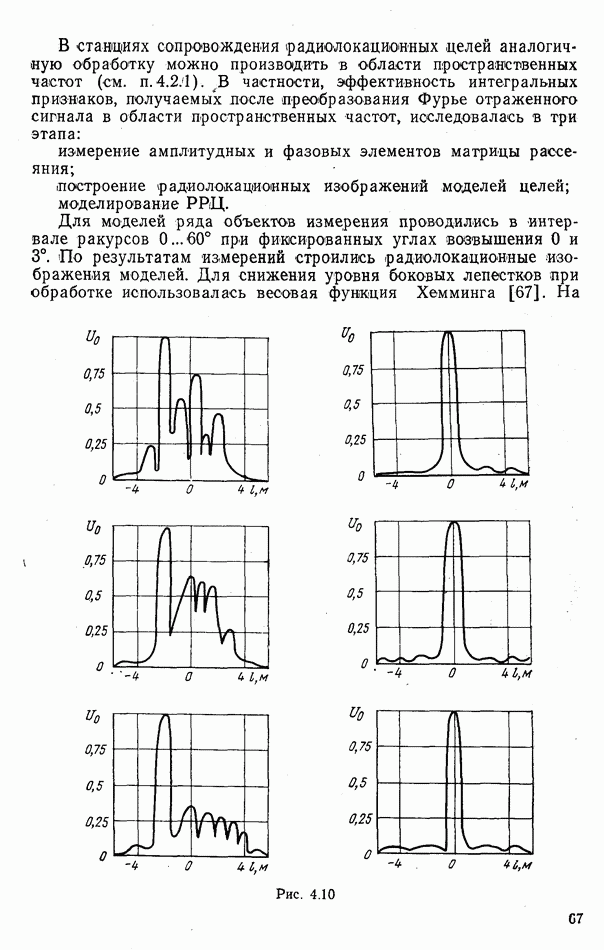
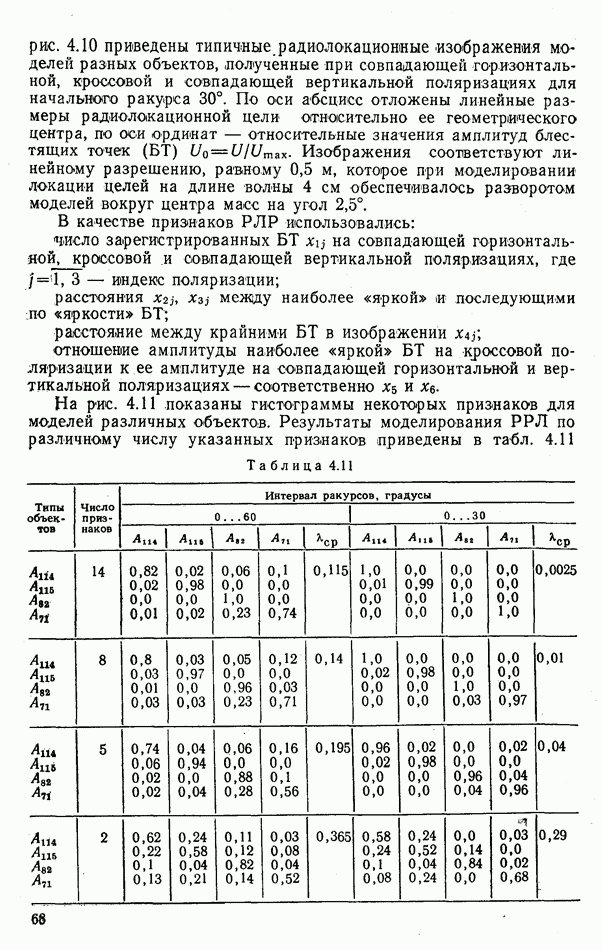
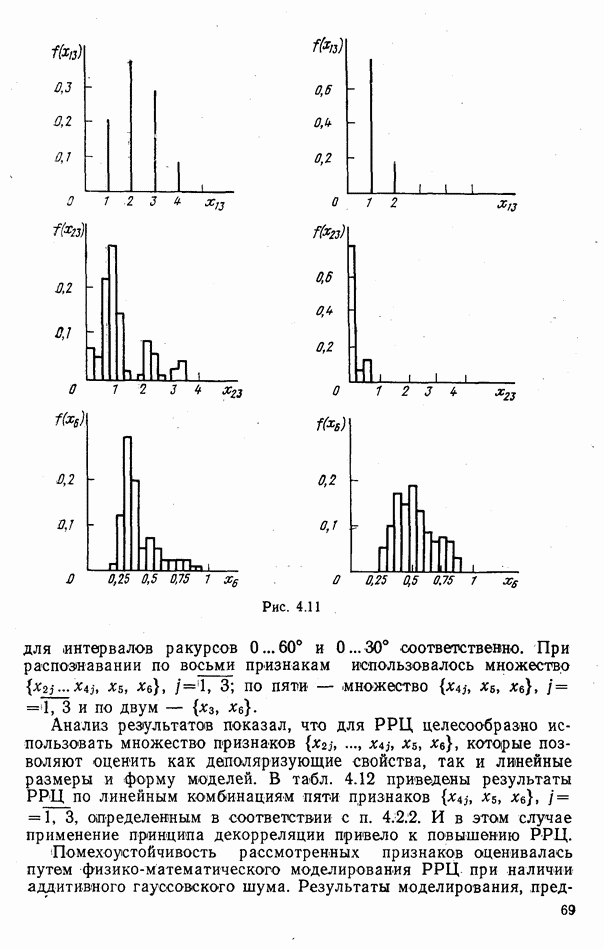
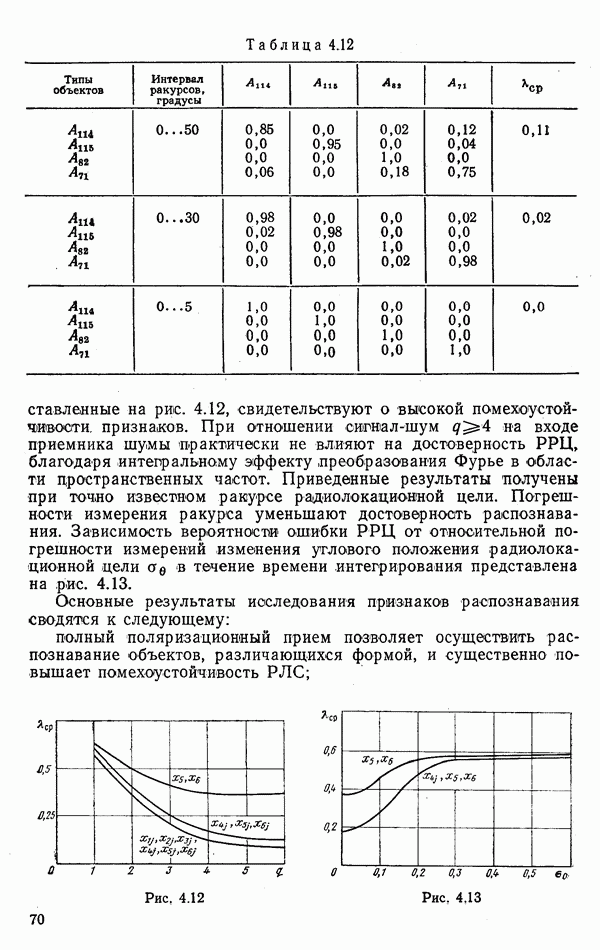







































































































































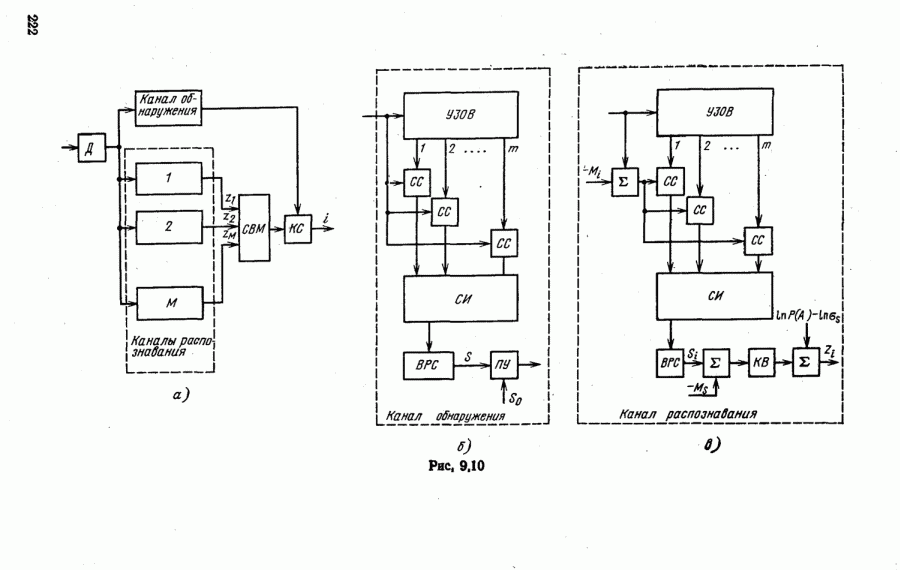

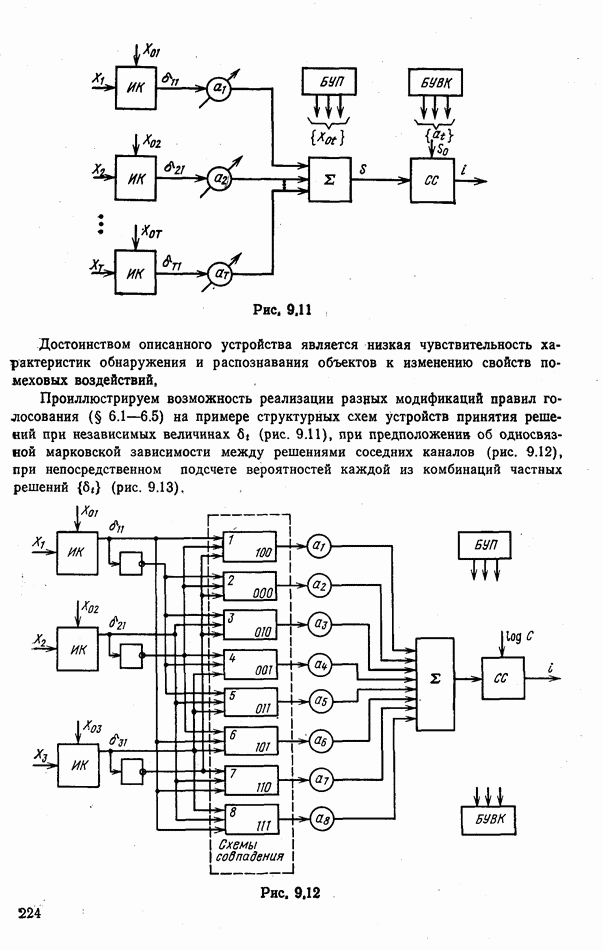

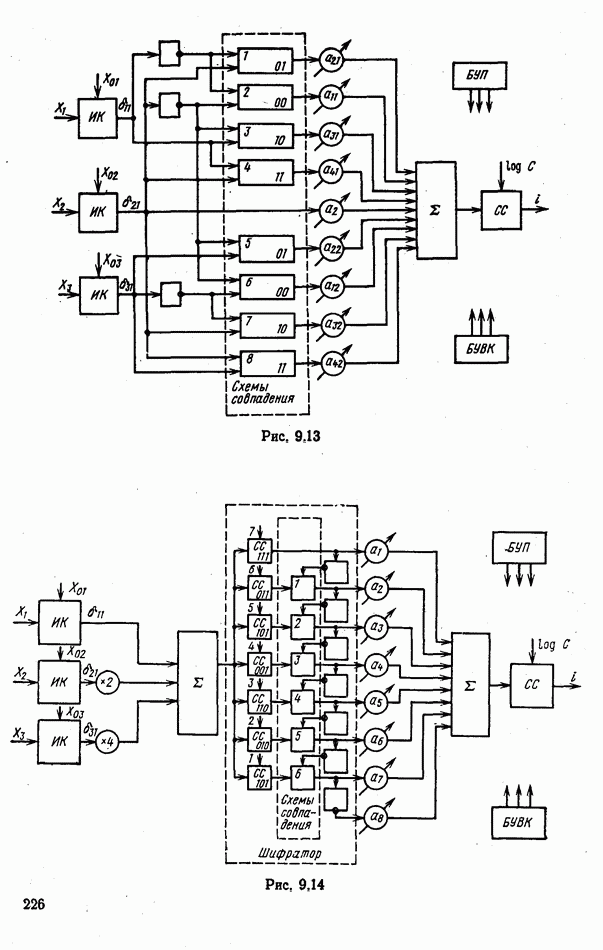








 номере класса объекта
номере класса объекта  выданное распознающим автоматом
выданное распознающим автоматом  используется потребителем его информации для выбора того или иного режима работы. Пронумеруем такие режимы индексами
используется потребителем его информации для выбора того или иного режима работы. Пронумеруем такие режимы индексами  Тогда задача выбора режима работы будет эквивалентна задаче выбора оптимальной стратегии в игре с платежной матрицей
Тогда задача выбора режима работы будет эквивалентна задаче выбора оптимальной стратегии в игре с платежной матрицей  размера
размера 
 либо стратегию, минимизирующую средний риск
либо стратегию, минимизирующую средний риск 

 вычислил апостериорное распределение вероятностей классов
вычислил апостериорное распределение вероятностей классов  Тогда естественным будет выбор оптимальной стратегии по правилу
Тогда естественным будет выбор оптимальной стратегии по правилу

 и выдает потребителю лишь номер класса
и выдает потребителю лишь номер класса  к которому отнесена радиолокационная цель. В такой ситуации потребитель информации может выбирать стратегию по правилу
к которому отнесена радиолокационная цель. В такой ситуации потребитель информации может выбирать стратегию по правилу  Очевидно, что такой подход будет оправдан только при полном доверии к решениям распознающего автомата, Это соответствует распределению вероятностей гипотез
Очевидно, что такой подход будет оправдан только при полном доверии к решениям распознающего автомата, Это соответствует распределению вероятностей гипотез  для всех
для всех  . В тех случаях, когда решения о классе объекта иногда принимаются с ошибками, рассмотренному правилу могут сопутствовать значительные потери.
. В тех случаях, когда решения о классе объекта иногда принимаются с ошибками, рассмотренному правилу могут сопутствовать значительные потери.

 выбирать один из элементов этого множества
выбирать один из элементов этого множества  то все рассмотренные правила выбора стратегий сохраняют силу. При этом поиск стратегии, минимизирующей ожидаемые потери, должен производиться по всем элементам множества
то все рассмотренные правила выбора стратегий сохраняют силу. При этом поиск стратегии, минимизирующей ожидаемые потери, должен производиться по всем элементам множества  Более подробно особенности выбора оптимальной стратегии иллюстрируются следующим примером.
Более подробно особенности выбора оптимальной стратегии иллюстрируются следующим примером.
 можно обеспечить максимальную точность отработки входных воздействий каждого вида.
можно обеспечить максимальную точность отработки входных воздействий каждого вида.
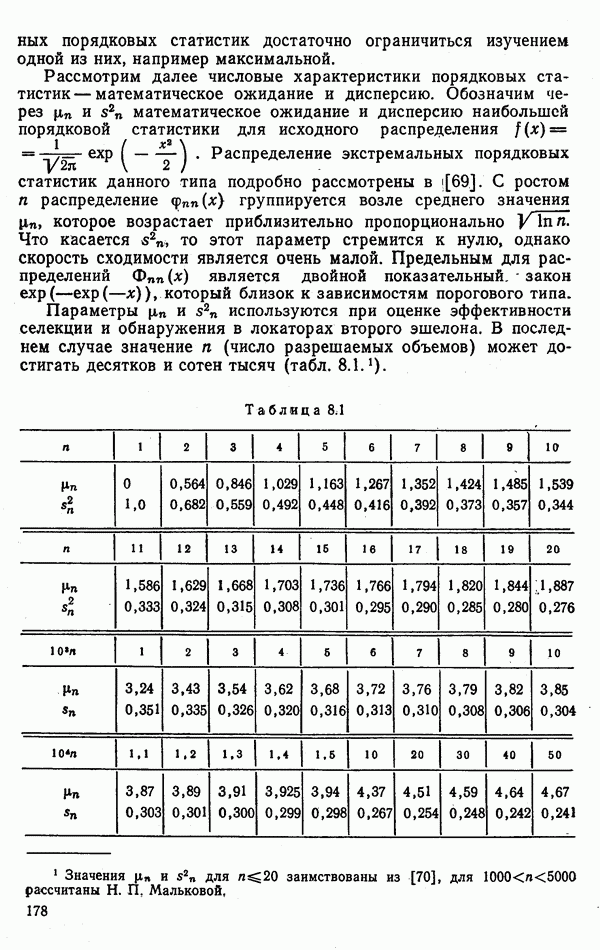
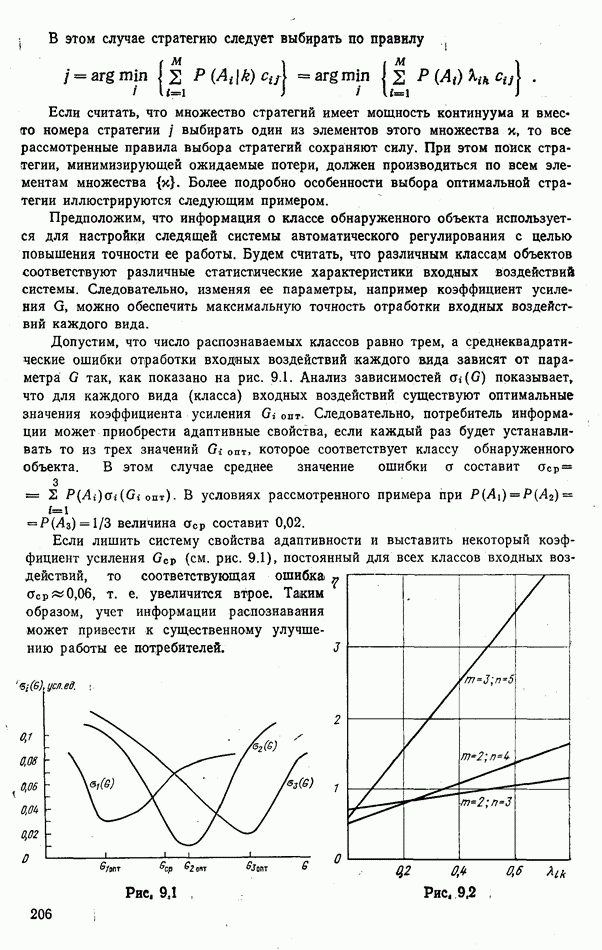
 так, как показано на рис. 9.1. Анализ зависимостей
так, как показано на рис. 9.1. Анализ зависимостей  показывает, что для каждого вида (класса) входных воздействий существуют оптимальные значения коэффициента усиления
показывает, что для каждого вида (класса) входных воздействий существуют оптимальные значения коэффициента усиления  опт. Следовательно, потребитель информации может приобрести адаптивные свойства, если каждый раз будет устанавливать то из трех значений
опт. Следовательно, потребитель информации может приобрести адаптивные свойства, если каждый раз будет устанавливать то из трех значений  которое соответствует классу обнаруженного объекта. В этом случае среднее значение ошибки а составит
которое соответствует классу обнаруженного объекта. В этом случае среднее значение ошибки а составит 
 величина
величина  составит 0,02.
составит 0,02.
 (см. рис. 9.1), постоянный для всех классов входных воздействий, то соответствующая ошибка
(см. рис. 9.1), постоянный для всех классов входных воздействий, то соответствующая ошибка  , т. е. увеличится втрое. Таким образом, учет информации распознавания может привести к существенному улучшению работы ее потребителей.
, т. е. увеличится втрое. Таким образом, учет информации распознавания может привести к существенному улучшению работы ее потребителей.


 При вероятностях ошибок
При вероятностях ошибок  отличных от нуля, непосредственный учет данных распознавания может привести к снижению эффективности системы по сравнению с ее неадаптивным вариантом.
отличных от нуля, непосредственный учет данных распознавания может привести к снижению эффективности системы по сравнению с ее неадаптивным вариантом.
 одинаковы и равны
одинаковы и равны  , а усредненному коэффициенту
, а усредненному коэффициенту  соответствуют ошибки
соответствуют ошибки  где
где  . При ошибочном распознавании объекта неверная установка коэффициента
. При ошибочном распознавании объекта неверная установка коэффициента  приводит к ошибкам
приводит к ошибкам  . С учетом сделанных допущений
. С учетом сделанных допущений

 — одинаковые для всех классов вероятности перепутывания,
— одинаковые для всех классов вероятности перепутывания,  .
.


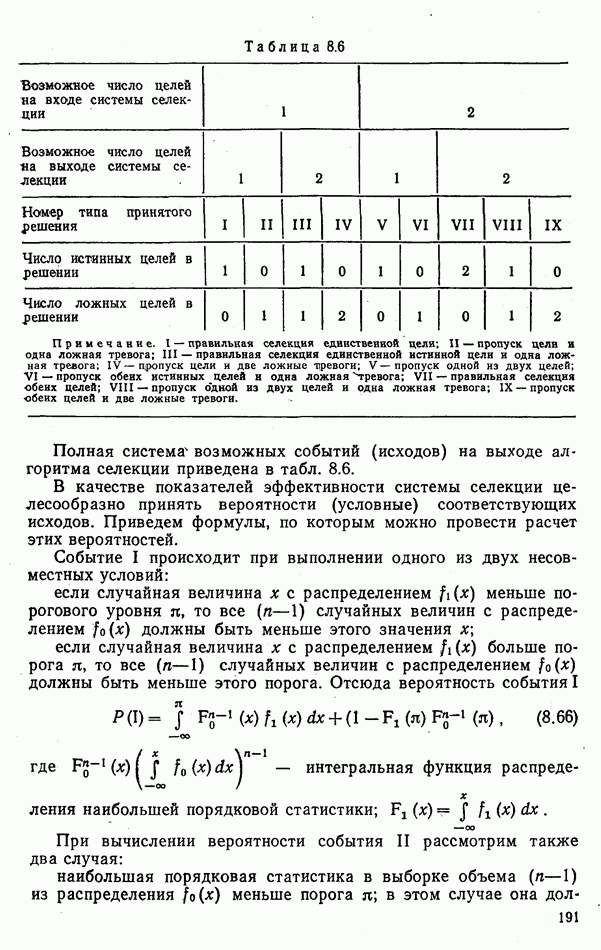
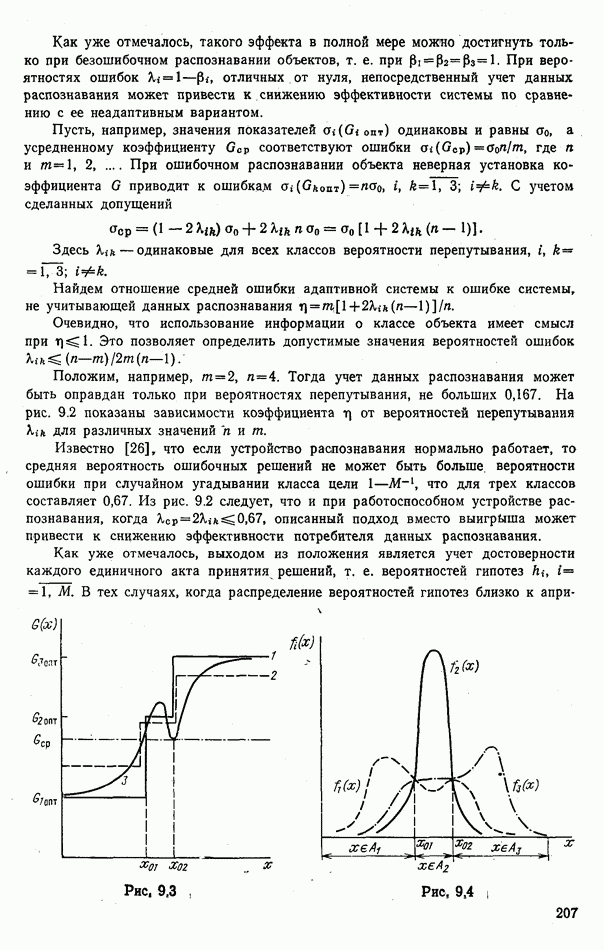
 Тогда учет данных распознавания может быть оправдан только при вероятностях перепутывания, не больших 0,167. На рис. 9.2 показаны зависимости коэффициента
Тогда учет данных распознавания может быть оправдан только при вероятностях перепутывания, не больших 0,167. На рис. 9.2 показаны зависимости коэффициента  от вероятностей перепутывания
от вероятностей перепутывания  для различных значений
для различных значений  .
.
 что для трех классов составляет 0,67. Из рис. 9.2 следует, что и при работоспособном устройстве распознавания, когда
что для трех классов составляет 0,67. Из рис. 9.2 следует, что и при работоспособном устройстве распознавания, когда  описанный подход вместо выигрыша может привести к снижению эффективности потребителя данных распознавания.
описанный подход вместо выигрыша может привести к снижению эффективности потребителя данных распознавания.
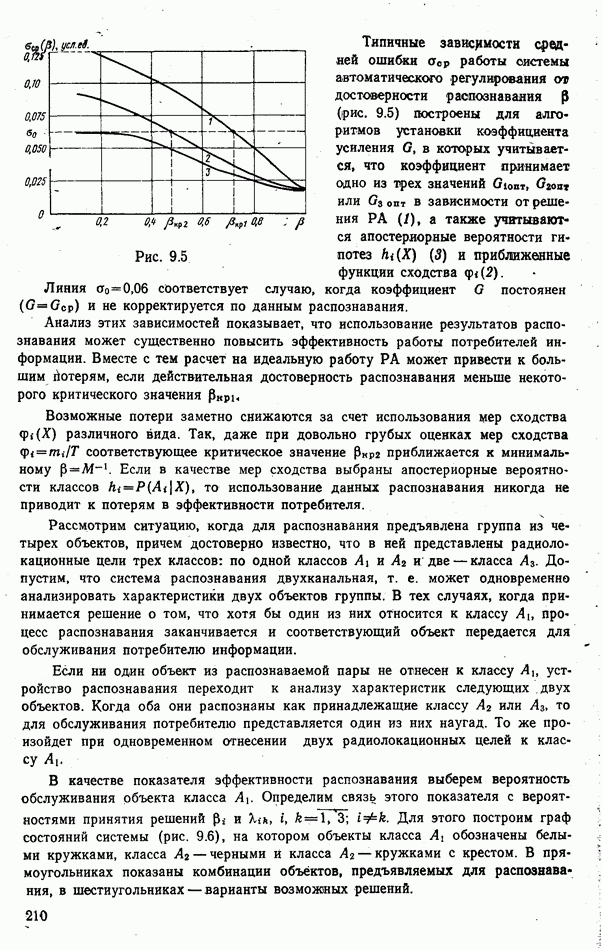
 . В тех случаях, когда распределение вероятностей гипотез близко к априорному
. В тех случаях, когда распределение вероятностей гипотез близко к априорному


 следует изменять весьма незначительно. Наоборот, сигналы, которым соответствуют близкие к единице вероятности гипотез
следует изменять весьма незначительно. Наоборот, сигналы, которым соответствуют близкие к единице вероятности гипотез  сдвигают коэффициент
сдвигают коэффициент  к одному из оптимальных значений
к одному из оптимальных значений  .
.
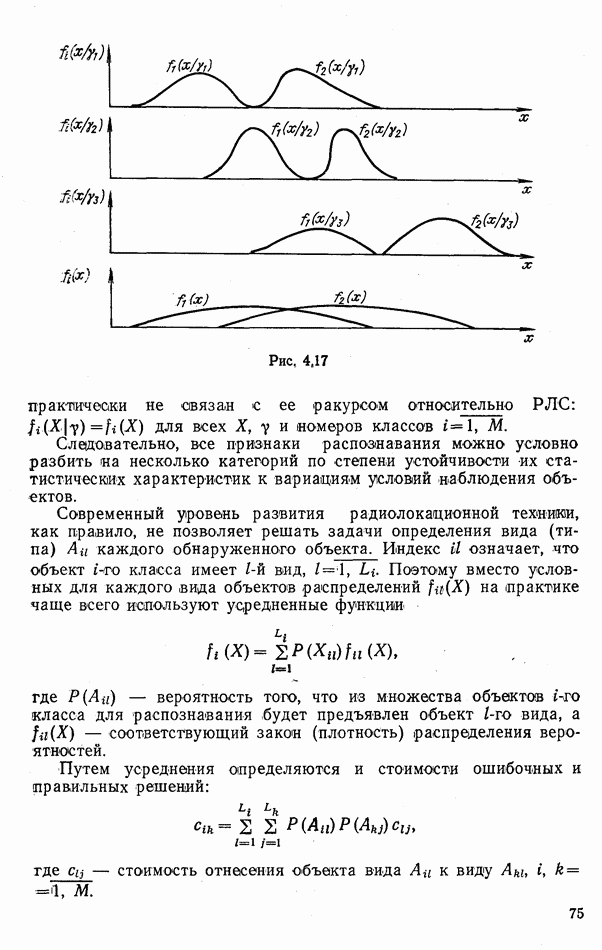
 и законы распределения
и законы распределения  Если такая информация не задана, эффективным может оказаться использование других мер сходства распознаваемого объекта с эталонными образами: махалонобисовых расстояний, коэффициентов корреляции между принятым и эталонным сигналами
Если такая информация не задана, эффективным может оказаться использование других мер сходства распознаваемого объекта с эталонными образами: махалонобисовых расстояний, коэффициентов корреляции между принятым и эталонным сигналами 
 независимых отсчетов признаков (см. гл. 6), вероятности гипотез можно записать в виде
независимых отсчетов признаков (см. гл. 6), вероятности гипотез можно записать в виде

 - число «голосов» в пользу класса
- число «голосов» в пользу класса 

 следует выбирать по правилу
следует выбирать по правилу

 а коэффициент
а коэффициент  выбирать по правилу
выбирать по правилу  Таким образом, можно выделить три основных способа учета данных распознавания в соответствии с правилами установки коэффициента
Таким образом, можно выделить три основных способа учета данных распознавания в соответствии с правилами установки коэффициента 



 и соответствующие области принятия решений.
и соответствующие области принятия решений.
 (рис. 9.4), но и видом разделяющих поверхностей (множеством порогов
(рис. 9.4), но и видом разделяющих поверхностей (множеством порогов  Следовательно,
Следовательно,  причем оптимальную пару аргументов можно найти путем решения системы уравнений
причем оптимальную пару аргументов можно найти путем решения системы уравнений

 и выбором множества
и выбором множества  по правилу
по правилу

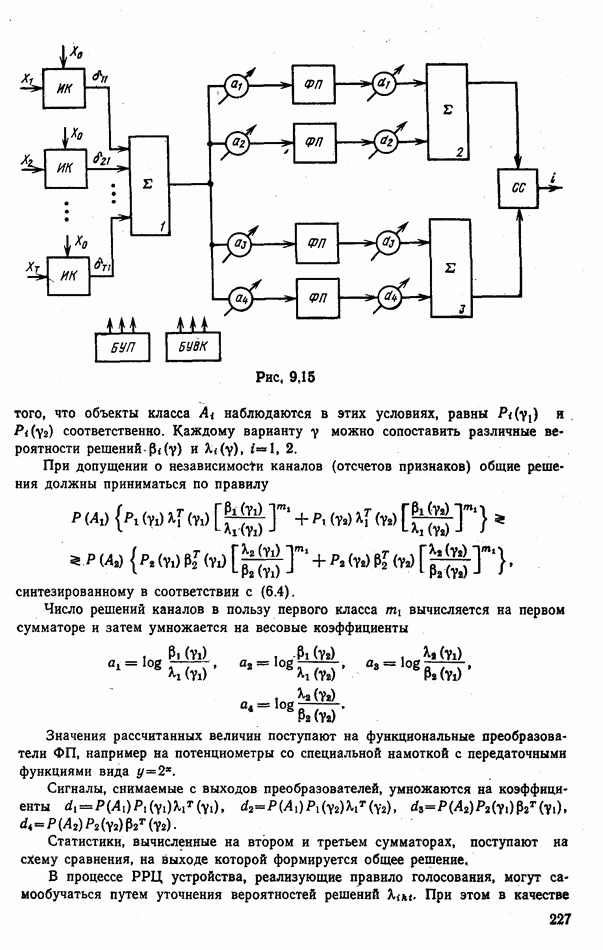
 потребитель информации». Для этого
потребитель информации». Для этого  должен выдавать потребителю не номера классов объектов, а меры сходства с каждым из М эталонов.
должен выдавать потребителю не номера классов объектов, а меры сходства с каждым из М эталонов.
 и определено правило выбора режима работы потребителя для каждого из возможных решений
и определено правило выбора режима работы потребителя для каждого из возможных решений  При этом может возникнуть неожиданный эффект. Если одно и то же устройство распознавания поставляет информацию нескольким потребителям, то для каждого из них может быть задан «свой» набор разделяющих поверхностей (множество
При этом может возникнуть неожиданный эффект. Если одно и то же устройство распознавания поставляет информацию нескольким потребителям, то для каждого из них может быть задан «свой» набор разделяющих поверхностей (множество  ). Следовательно,
). Следовательно,  может отнести одну и ту же радиолокационную цель к нескольким непересекающимся классам одновременно в зависимости от того, к какому потребителю информации поступают соответствующие решения. Необходимость установки различных порогов возникает и тогда, когда алфавиты классов «интересующих» различных потребителей, не совпадают.
может отнести одну и ту же радиолокационную цель к нескольким непересекающимся классам одновременно в зависимости от того, к какому потребителю информации поступают соответствующие решения. Необходимость установки различных порогов возникает и тогда, когда алфавиты классов «интересующих» различных потребителей, не совпадают.

 работы системы автоматического регулирования от достоверности распознавания
работы системы автоматического регулирования от достоверности распознавания  (рис. 9.5) построены для алгоритмов установки коэффициента усиления
(рис. 9.5) построены для алгоритмов установки коэффициента усиления  в которых учитывается, что коэффициент принимает одно из трех значений Оюпт,
в которых учитывается, что коэффициент принимает одно из трех значений Оюпт,  или
или  в зависимости от решения
в зависимости от решения  а также учитываются апостериорные вероятности гипотез
а также учитываются апостериорные вероятности гипотез  и приближенные функции сходства
и приближенные функции сходства 
 соответствует случаю, когда коэффициент
соответствует случаю, когда коэффициент  постоянен
постоянен  и не корректируется по данным распознавания.
и не корректируется по данным распознавания.
 может привести к большим потерям, если действительная достоверность распознавания меньше некоторого критического значения
может привести к большим потерям, если действительная достоверность распознавания меньше некоторого критического значения 
 различного вида. Так, даже при довольно грубых оценках мер сходства
различного вида. Так, даже при довольно грубых оценках мер сходства  соответствующее критическое значение
соответствующее критическое значение  приближается к минимальному
приближается к минимальному  Если в качестве мер сходства выбраны апостериорные вероятности классов
Если в качестве мер сходства выбраны апостериорные вероятности классов  то использование данных распознавания никогда не приводит к потерям в эффективности потребителя.
то использование данных распознавания никогда не приводит к потерям в эффективности потребителя.
 и две — класса
и две — класса  Допустим, что система распознавания двухканальная, т. е. может одновременно анализировать характеристики двух объектов группы. В тех случаях, когда принимается решение о том, что хотя бы один из них относится к классу
Допустим, что система распознавания двухканальная, т. е. может одновременно анализировать характеристики двух объектов группы. В тех случаях, когда принимается решение о том, что хотя бы один из них относится к классу  процесс распознавания заканчивается и соответствующий объект передается для обслуживания потребителю информации.
процесс распознавания заканчивается и соответствующий объект передается для обслуживания потребителю информации.
 устройство распознавания переходит к анализу характеристик следующих двух объектов. Когда оба они распознаны как принадлежащие классу
устройство распознавания переходит к анализу характеристик следующих двух объектов. Когда оба они распознаны как принадлежащие классу  или
или  то для обслуживания потребителю представляется один из них наугад. То же произойдет при одновременном отнесении двух радиолокационных целей к классу
то для обслуживания потребителю представляется один из них наугад. То же произойдет при одновременном отнесении двух радиолокационных целей к классу 
 Определим связь этого показателя с вероятностями принятия решений и
Определим связь этого показателя с вероятностями принятия решений и  Для этого построим граф состояний системы (рис. 9.6), на котором объекты класса
Для этого построим граф состояний системы (рис. 9.6), на котором объекты класса  обозначены белыми кружками, класса
обозначены белыми кружками, класса  — черными И класса
— черными И класса  — кружками с крестом. В прямоугольниках показаны комбинации объектов, предъявляемых для распознавания, в шестиугольниках — варианты возможных решений.
— кружками с крестом. В прямоугольниках показаны комбинации объектов, предъявляемых для распознавания, в шестиугольниках — варианты возможных решений.



 и не совпадающему по форме с выражением для среднего риска распознавания
и не совпадающему по форме с выражением для среднего риска распознавания



 пороговое множество
пороговое множество  минимизирующее функцию
минимизирующее функцию  не будет совпадать с множеством
не будет совпадать с множеством  минимизирующим средний риск. Соответственно будут отличаться и решения, принимаемые согласно каждому из этих критериев.
минимизирующим средний риск. Соответственно будут отличаться и решения, принимаемые согласно каждому из этих критериев.
 а их комбинаций, показанных на рис. 9.6. Но в этом случае задача распознавания радиолокационных целей заменяется задачей распознавания ситуаций. Некоторые пути ее решения рассматриваются в гл. 6 и в части 3.
а их комбинаций, показанных на рис. 9.6. Но в этом случае задача распознавания радиолокационных целей заменяется задачей распознавания ситуаций. Некоторые пути ее решения рассматриваются в гл. 6 и в части 3.
 объект характеризуется номером класса
объект характеризуется номером класса  к которому его отнес
к которому его отнес  начальной дальностью
начальной дальностью  и скоростью
и скоростью  Все объекты подлежат обслуживанию на участке дальностей от
Все объекты подлежат обслуживанию на участке дальностей от  до
до  Вероятность успешного обслуживания объекта
Вероятность успешного обслуживания объекта  зависит от его класса и дальности обслуживания
зависит от его класса и дальности обслуживания  (рис. 9.7).
(рис. 9.7).
 где
где  — время перехода к обслуживанию нового объекта,
— время перехода к обслуживанию нового объекта,  постоянная, имеющая размерность скорости.
постоянная, имеющая размерность скорости.
 обнаруженных объектов
обнаруженных объектов 

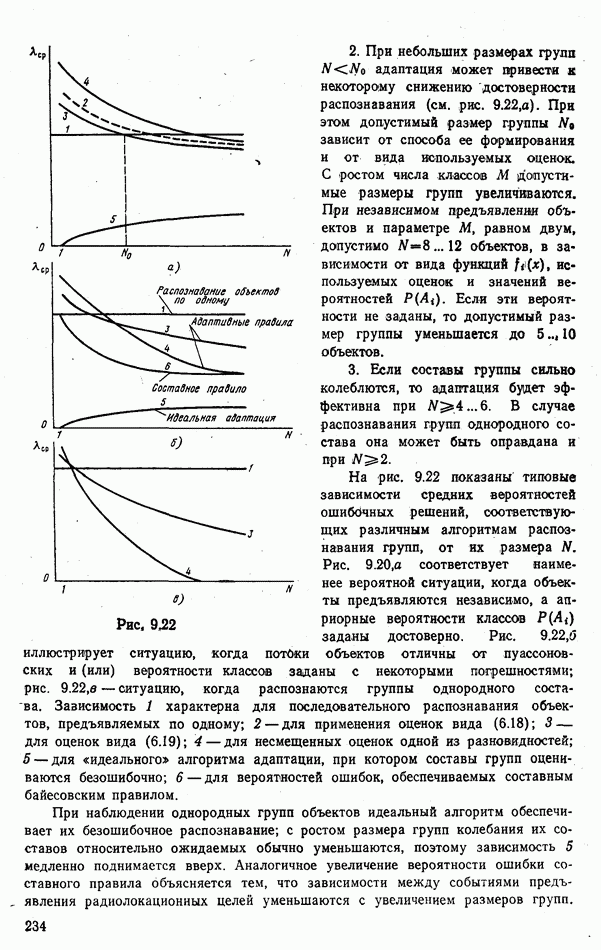
 . Очевидно, что это не лучшее решение задачи; с другой стороны, мало что обещает учет только классов объектов и пренебрежение их положением в пространстве. В общем случае возможны
. Очевидно, что это не лучшее решение задачи; с другой стороны, мало что обещает учет только классов объектов и пренебрежение их положением в пространстве. В общем случае возможны  вариантов очередности обслуживания объектов. Пронумеруем эти варианты индексами
вариантов очередности обслуживания объектов. Пронумеруем эти варианты индексами  Наиболее эффективный
Наиболее эффективный  вариант очередности обслуживания, очевидно будет удовлетворять условию
вариант очередности обслуживания, очевидно будет удовлетворять условию  т. е. максимизировать
т. е. максимизировать  .
.


 - вероятность успешного обслуживания
- вероятность успешного обслуживания  объекта, найденная с учетом дальности его обслуживания, номера его класса и очередности
объекта, найденная с учетом дальности его обслуживания, номера его класса и очередности  обслуживания, определяемой значением
обслуживания, определяемой значением 
 удобно оценивать с помощью рекуррентной зависимости
удобно оценивать с помощью рекуррентной зависимости

 обслуживания. Расчеты показывают, что правильный учет результатов распознавания обеспечивает ощутимый (обычно в
обслуживания. Расчеты показывают, что правильный учет результатов распознавания обеспечивает ощутимый (обычно в  раза) выигрыш в значении
раза) выигрыш в значении 
 необходимо применять специальные приемы. Можно, например, запрещать рассмотрение вариантов, предусматривающих перестановку очередей однотипных объектов с близкими скоростями. Другие способы решения задачи основаны на применении алгоритмов случайного поиска и др. Выбор конкретной методики зависит от специфики задачи.
необходимо применять специальные приемы. Можно, например, запрещать рассмотрение вариантов, предусматривающих перестановку очередей однотипных объектов с близкими скоростями. Другие способы решения задачи основаны на применении алгоритмов случайного поиска и др. Выбор конкретной методики зависит от специфики задачи.
 может ошибаться, то вероятность
может ошибаться, то вероятность  следует рассчитывать по формуле
следует рассчитывать по формуле

 — найденные тем или иным способом апостериорные вероятности гипотез о принадлежности
— найденные тем или иным способом апостериорные вероятности гипотез о принадлежности  объекта к
объекта к  классу,
классу,
 координаты распознаваемых объектов и решения о номерах их классов, то может возникнуть задача отождествления (инден-тификации) данных. При этом необходимо определить, какому истинному числу радиолокационных целей принадлежат близко расположенные отметки, создаваемые
координаты распознаваемых объектов и решения о номерах их классов, то может возникнуть задача отождествления (инден-тификации) данных. При этом необходимо определить, какому истинному числу радиолокационных целей принадлежат близко расположенные отметки, создаваемые
 Обычно для ответа на этот вопрос учитывают возможные погрешности измерения координат объектов каждой из станций. Покажем, что задачи отождествления и распознавания объектов следует решать совместно.
Обычно для ответа на этот вопрос учитывают возможные погрешности измерения координат объектов каждой из станций. Покажем, что задачи отождествления и распознавания объектов следует решать совместно.
 прямоугольными координатами. Первая станция отнесла свой объект к классу
прямоугольными координатами. Первая станция отнесла свой объект к классу  а вторая — к классу
а вторая — к классу  . В такой ситуации следует рассмотреть шесть гипотез — см. первые две колонки табл. 9.1.
. В такой ситуации следует рассмотреть шесть гипотез — см. первые две колонки табл. 9.1.
 координат
координат  и решений
и решений  и
и  при условии справедливости каждой из шести гипотез.
при условии справедливости каждой из шести гипотез.
 принимались без учета координат, объектов, то закон
принимались без учета координат, объектов, то закон  можно разбить на два сомножителя;
можно разбить на два сомножителя; 
 может быть описана нормальным двумерным законом. При справедливости гипотез
может быть описана нормальным двумерным законом. При справедливости гипотез  удобно считать математические ожидания
удобно считать математические ожидания  нулевыми, ошибки
нулевыми, ошибки  независимыми с с одинаковыми дисперсиями
независимыми с с одинаковыми дисперсиями  определяемыми ошибками топогеодезической привязки и точностью работы РЛС.
определяемыми ошибками топогеодезической привязки и точностью работы РЛС.
 можно считать равномерным в некоторых пределах, или гауссовским. В последнем случае математические ожидания координат
можно считать равномерным в некоторых пределах, или гауссовским. В последнем случае математические ожидания координат  следует выбирать равными типовым взаимным удалениям двух соседних радиолокационных целей. Дисперсии этих величин будут равны
следует выбирать равными типовым взаимным удалениям двух соседних радиолокационных целей. Дисперсии этих величин будут равны  где
где  — составляющая, характеризующая стабильность расстояний между соседними объектами.
— составляющая, характеризующая стабильность расстояний между соседними объектами.
 определяется вероятностями ошибок и правильных решений каждой из РЛС. Так, если распознавание всегда безошибочно, то однозначна
определяется вероятностями ошибок и правильных решений каждой из РЛС. Так, если распознавание всегда безошибочно, то однозначна
 следует использовать методику, описанную в 6 гл.
следует использовать методику, описанную в 6 гл.
 вычисленных для различных номеров гипотез
вычисленных для различных номеров гипотез  показал, что принимать следует ту из них, для которой некоторая решающая статистика
показал, что принимать следует ту из них, для которой некоторая решающая статистика  будет максимальна. В последнем столбце табл. 9.1 приведены выражения для статистики
будет максимальна. В последнем столбце табл. 9.1 приведены выражения для статистики  найденные в предположении равновероятности всех гипотез и равенстве нулю дисперсии
найденные в предположении равновероятности всех гипотез и равенстве нулю дисперсии  Через и
Через и  обозначены соответственно вероятности правильного и ошибочного распознавания целей i-го класса t-й РЛС.
обозначены соответственно вероятности правильного и ошибочного распознавания целей i-го класса t-й РЛС.
