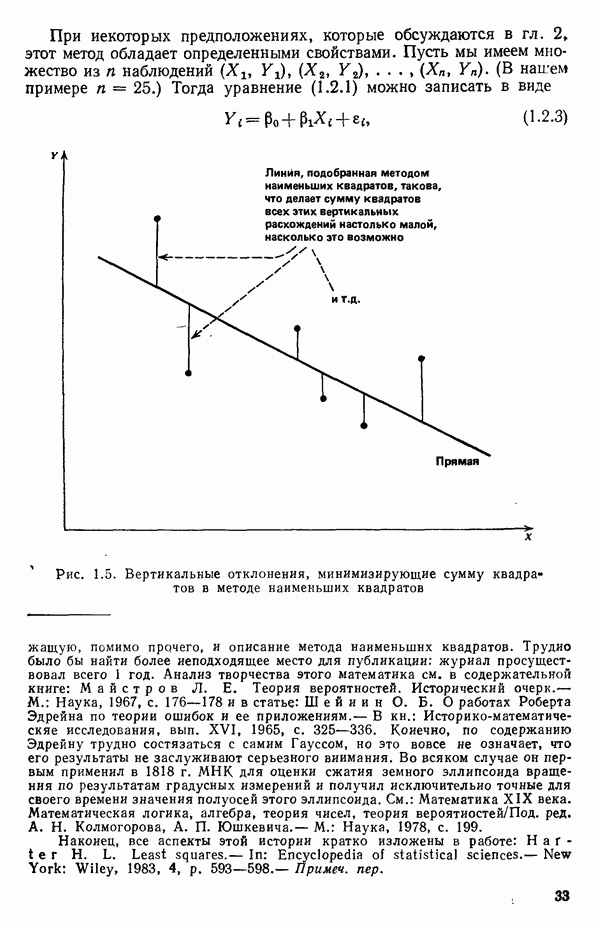
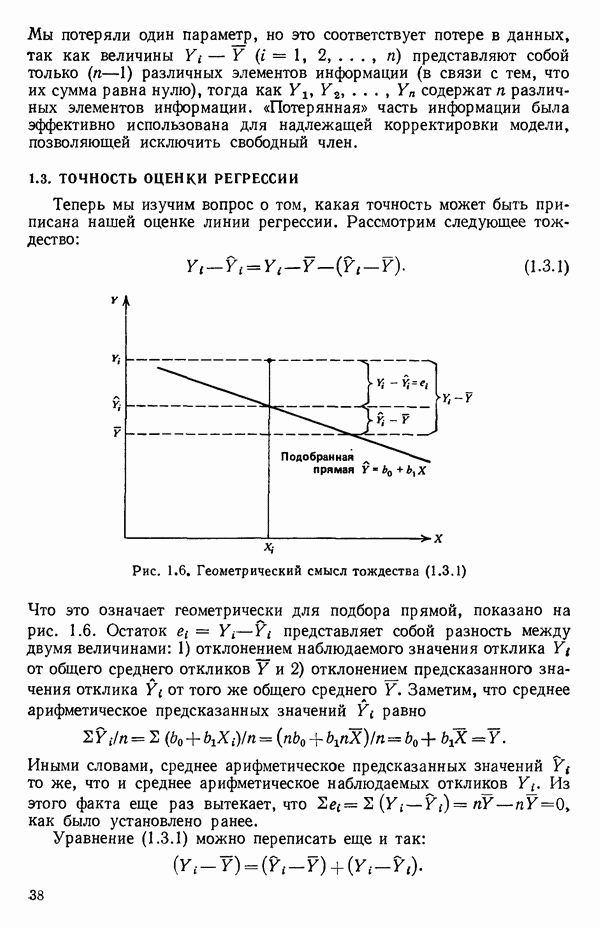
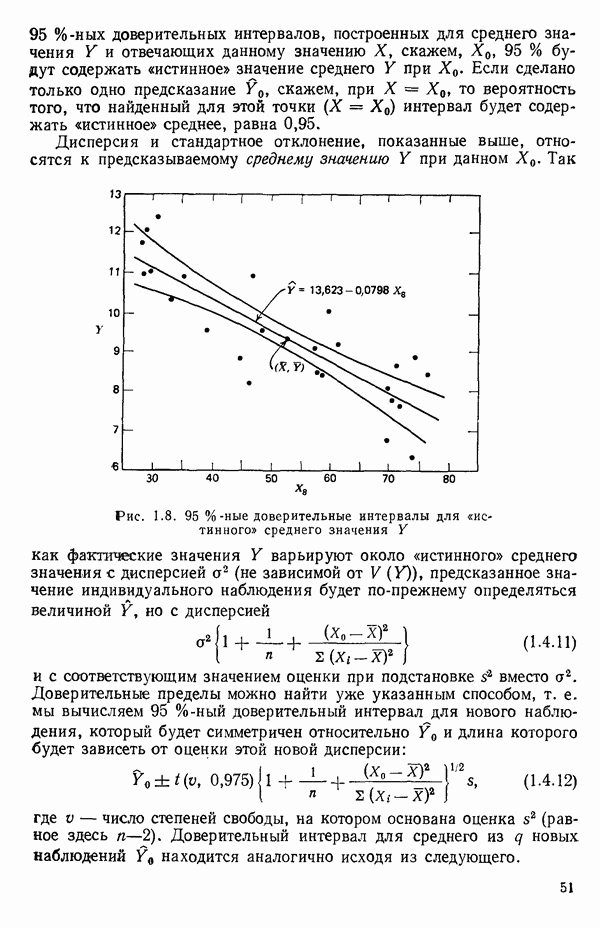
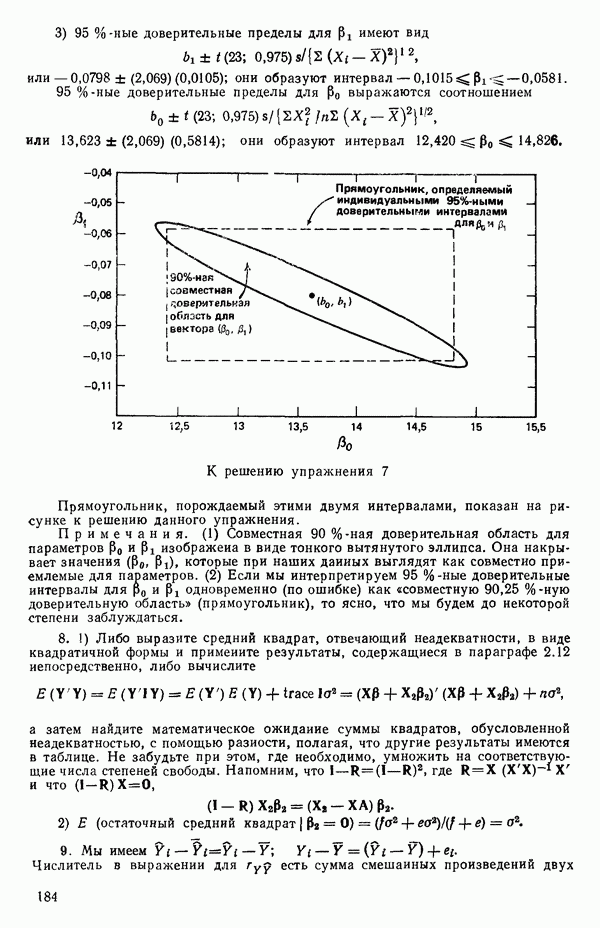
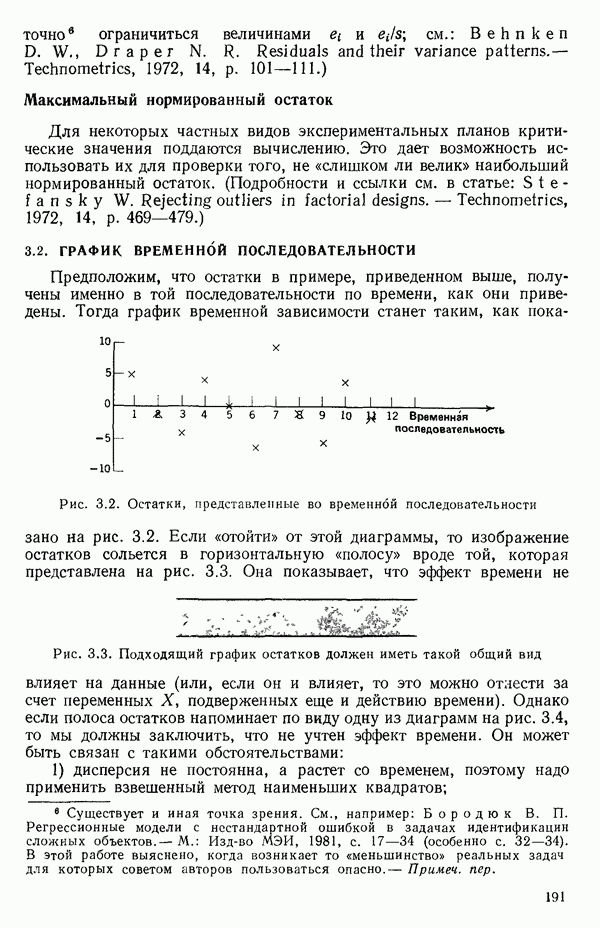
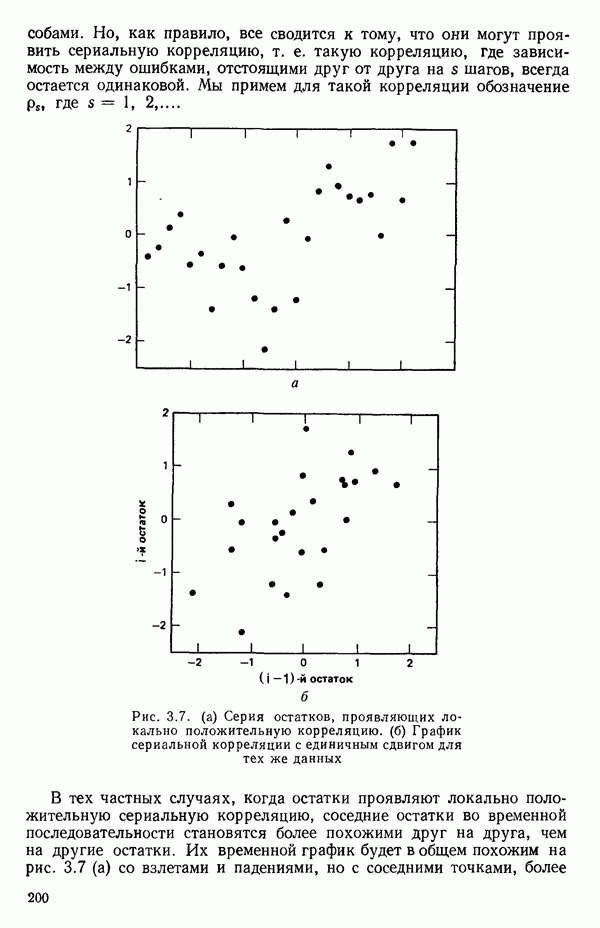
Пред.
След.
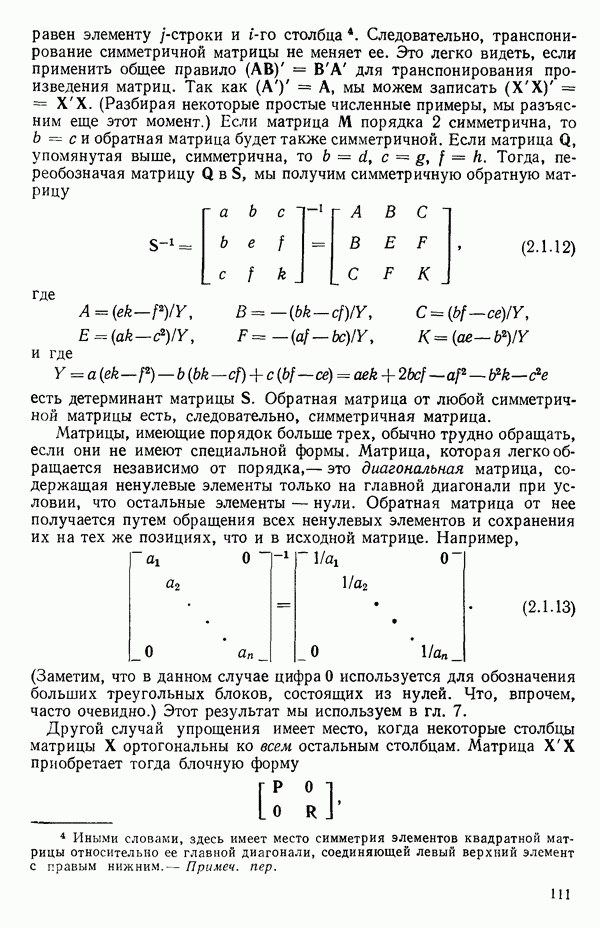
Макеты страниц
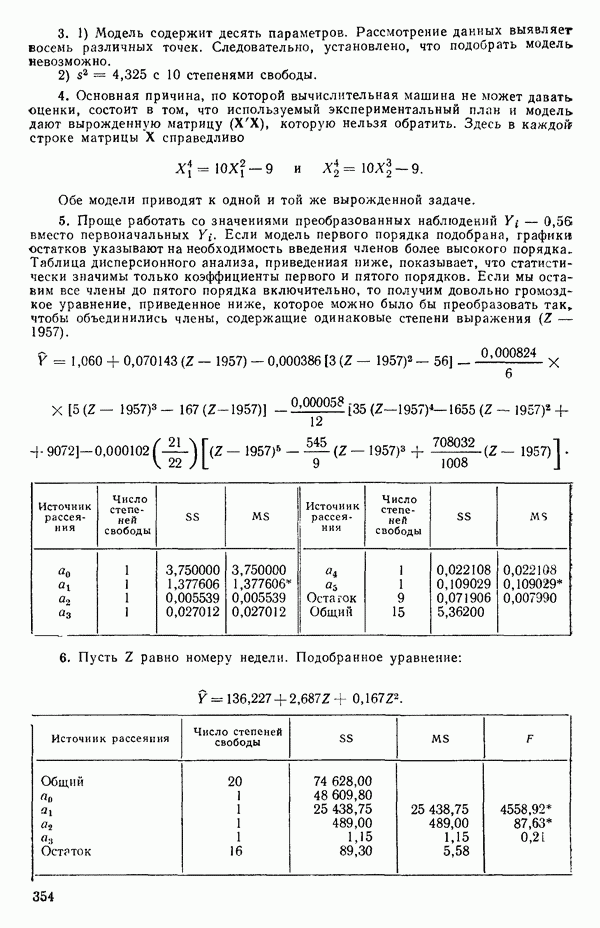
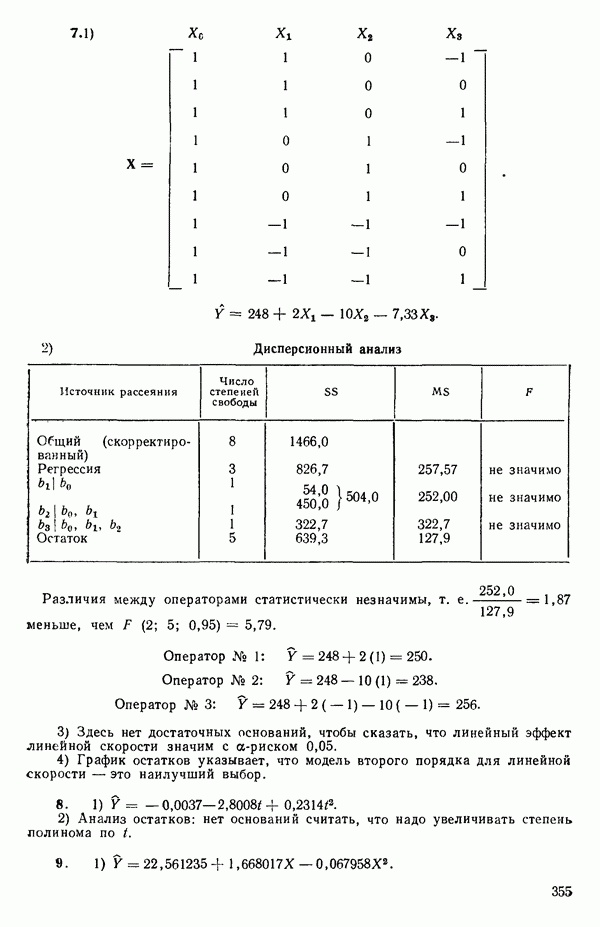
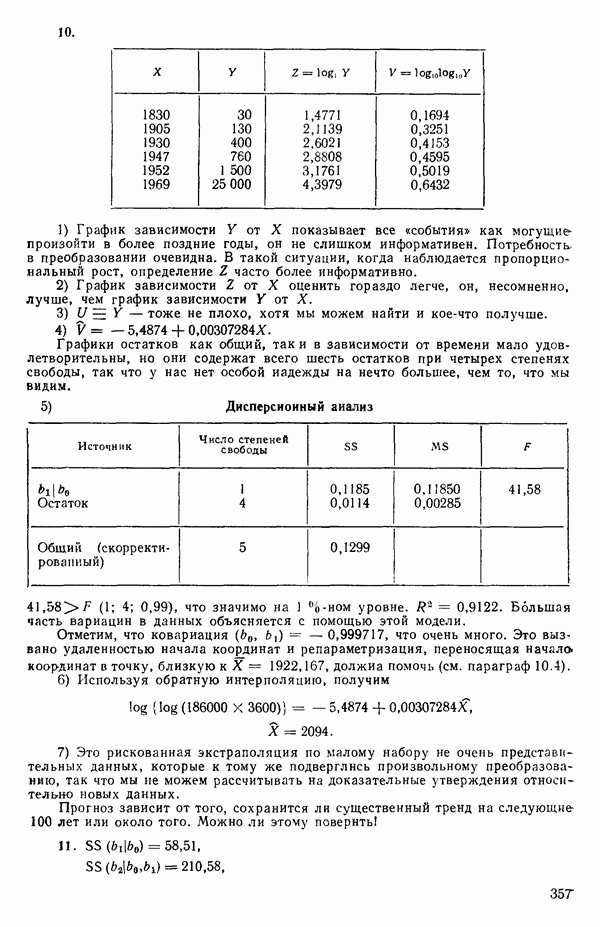
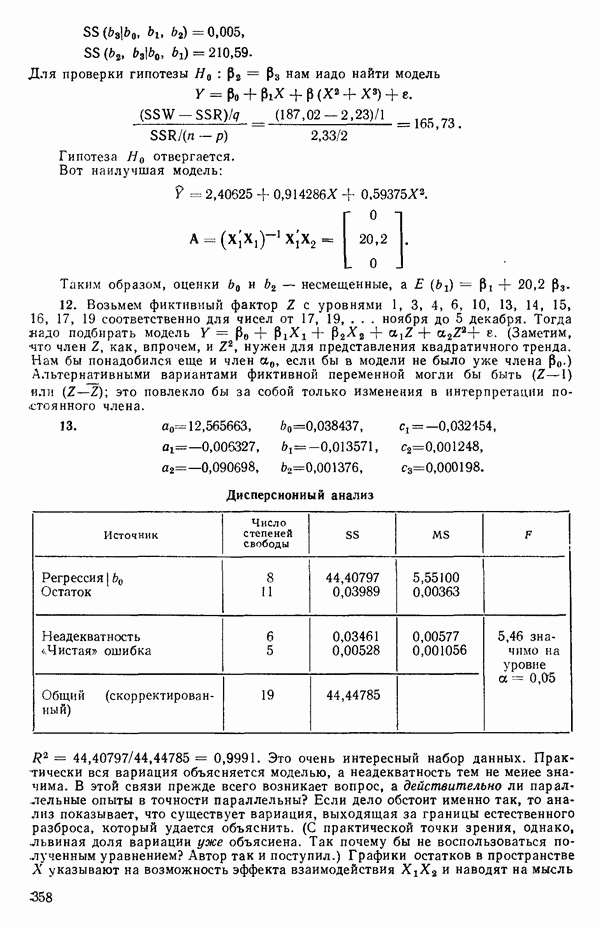
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
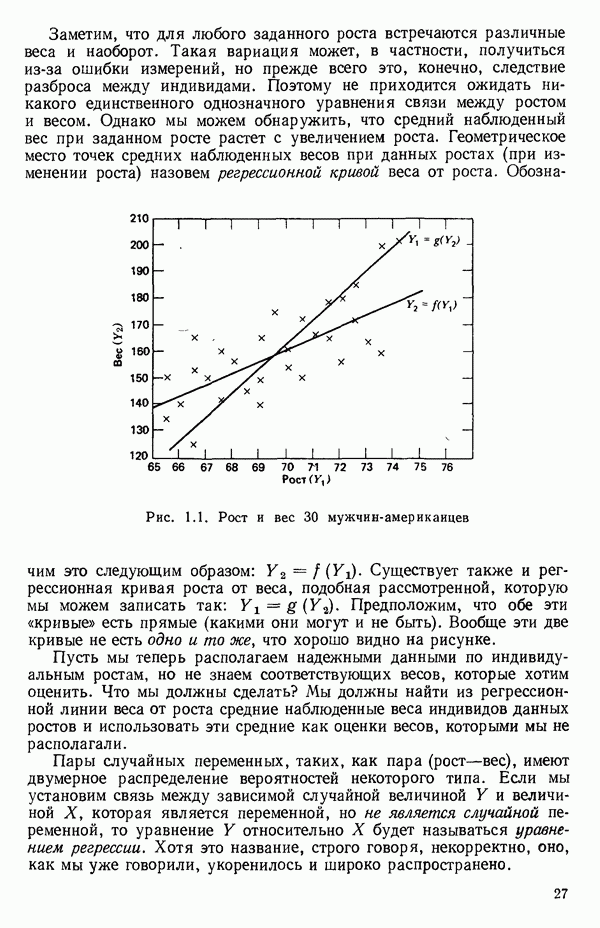
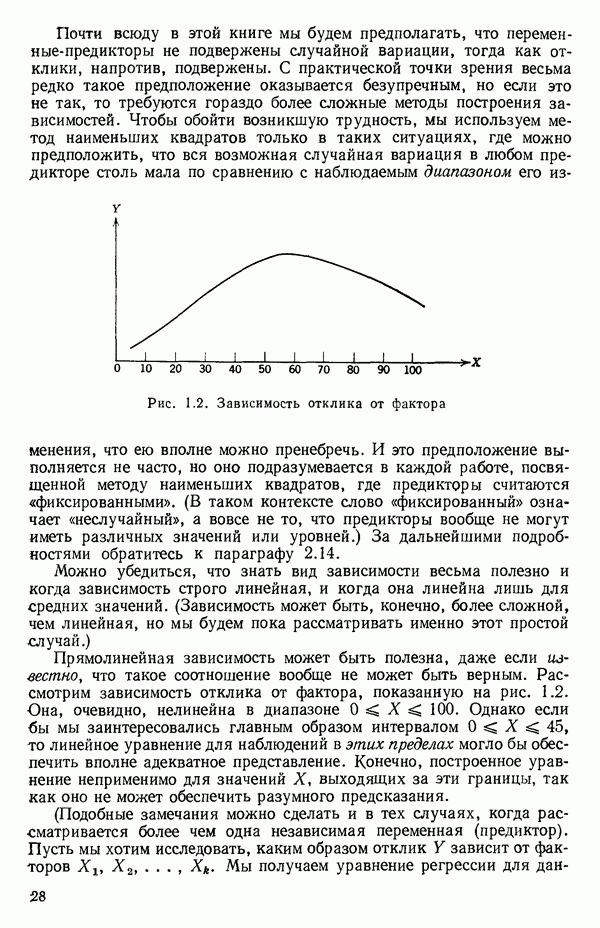
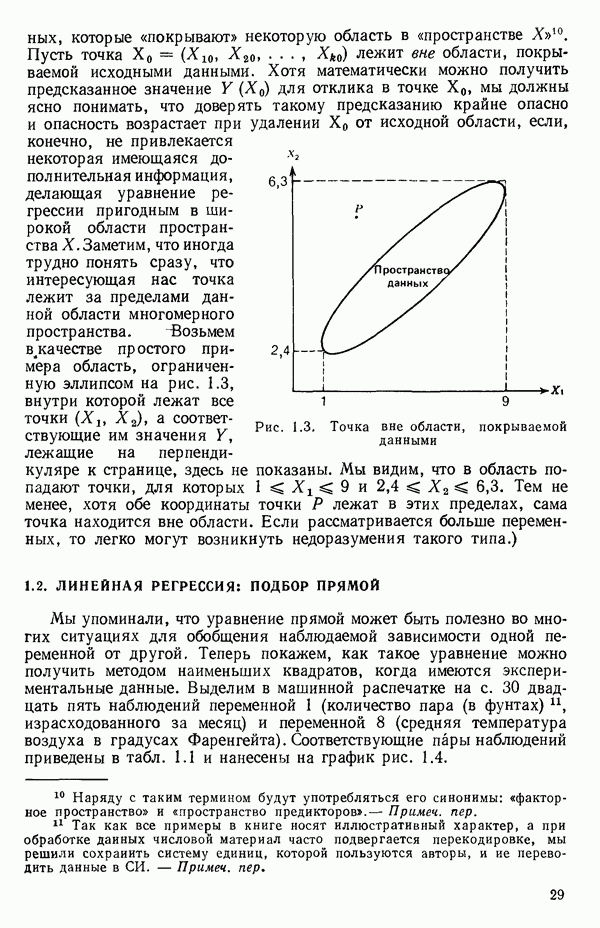
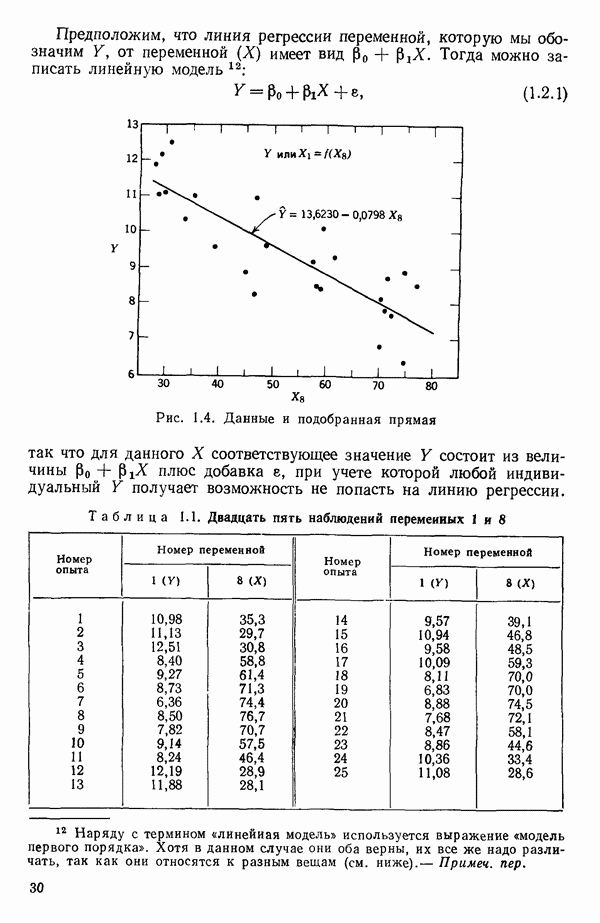
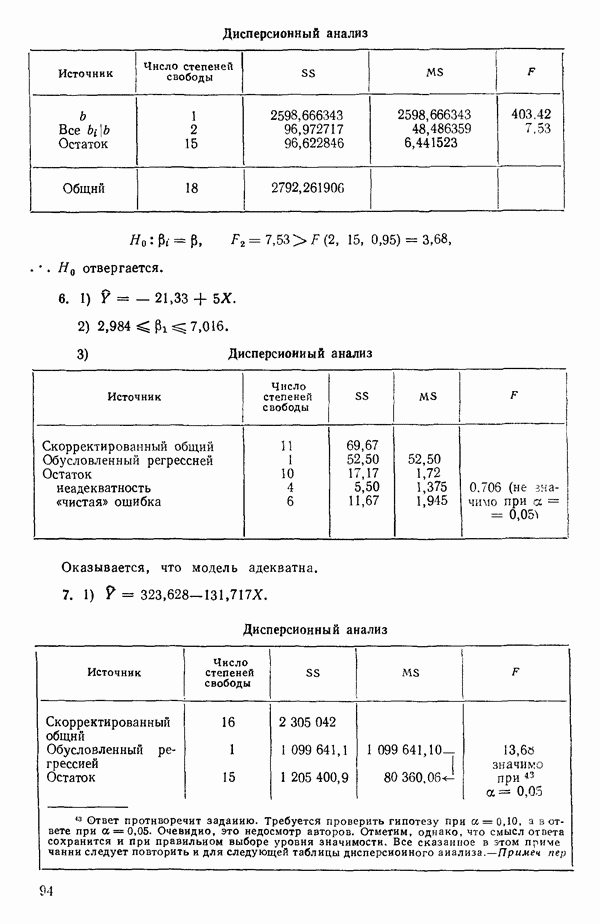
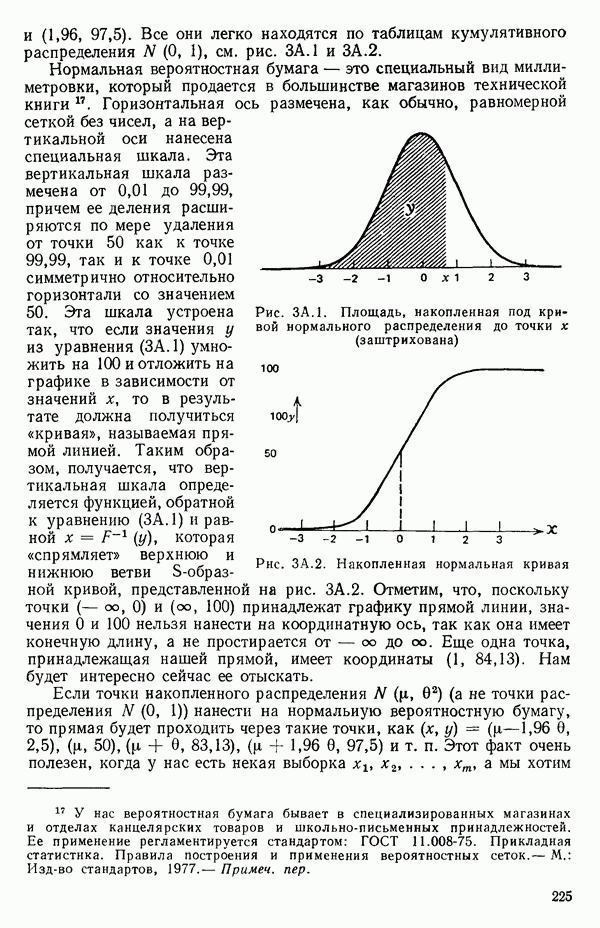
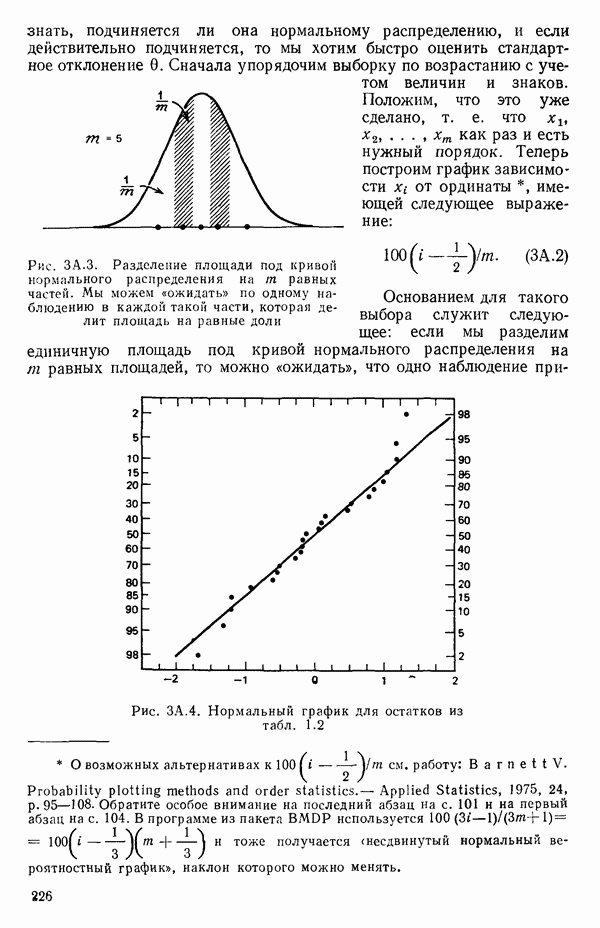
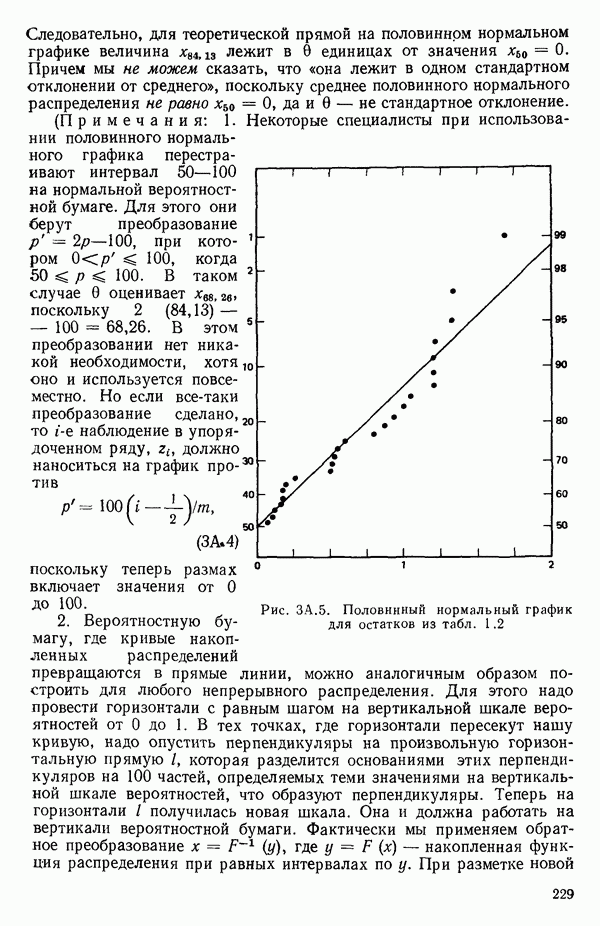
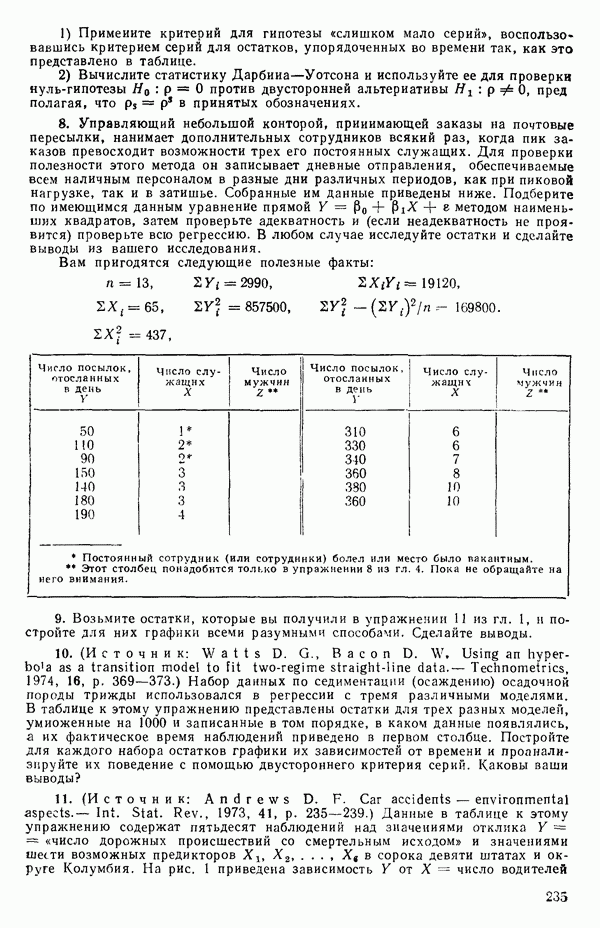
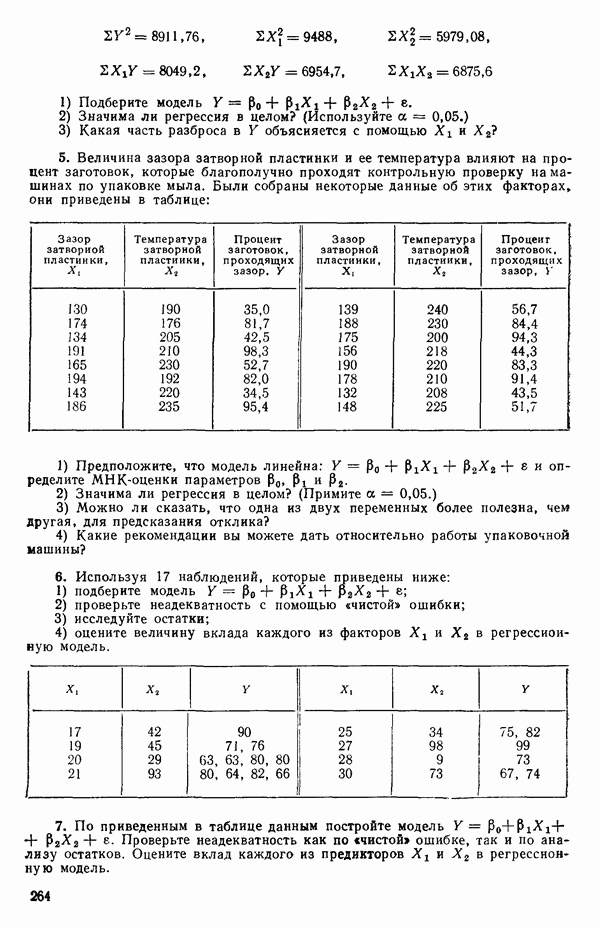
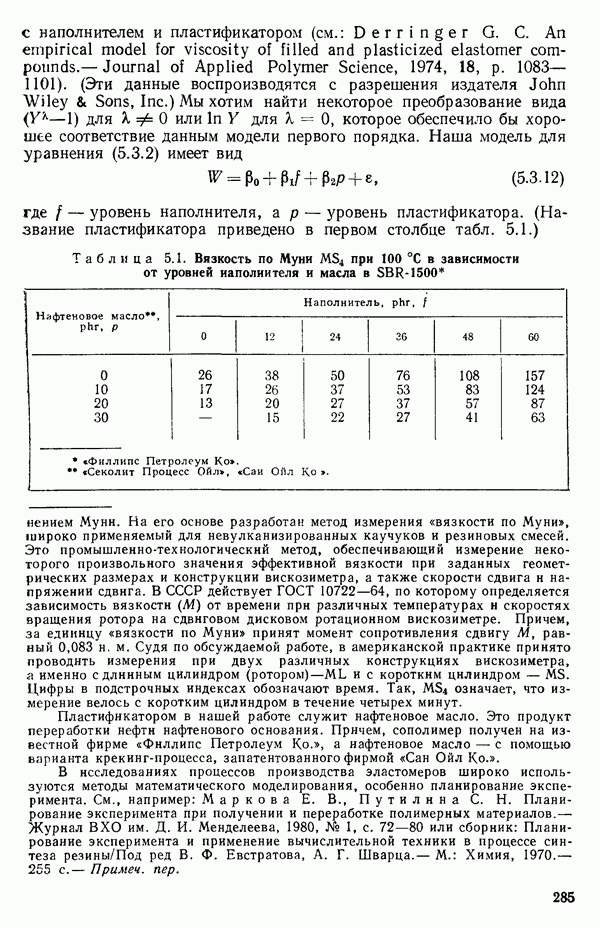
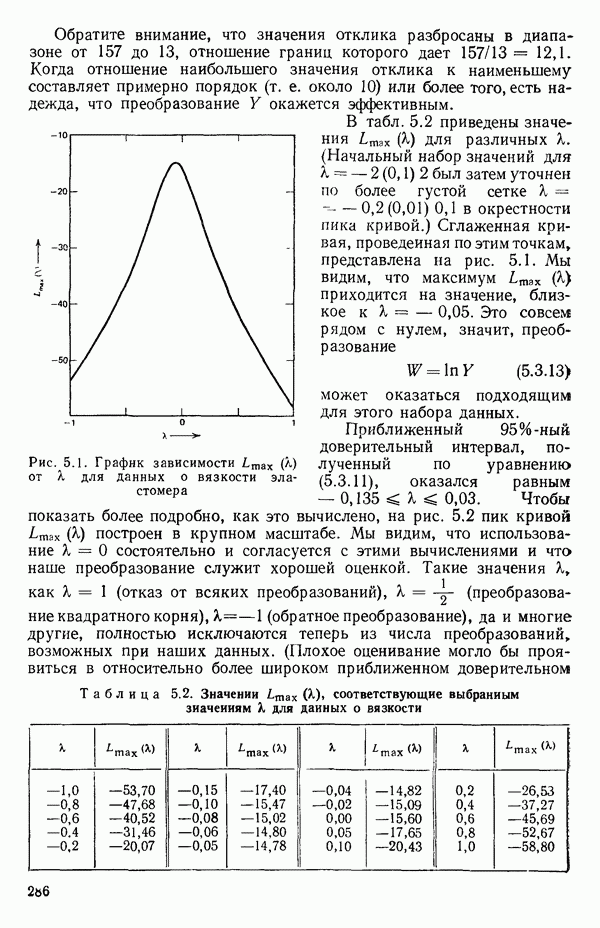
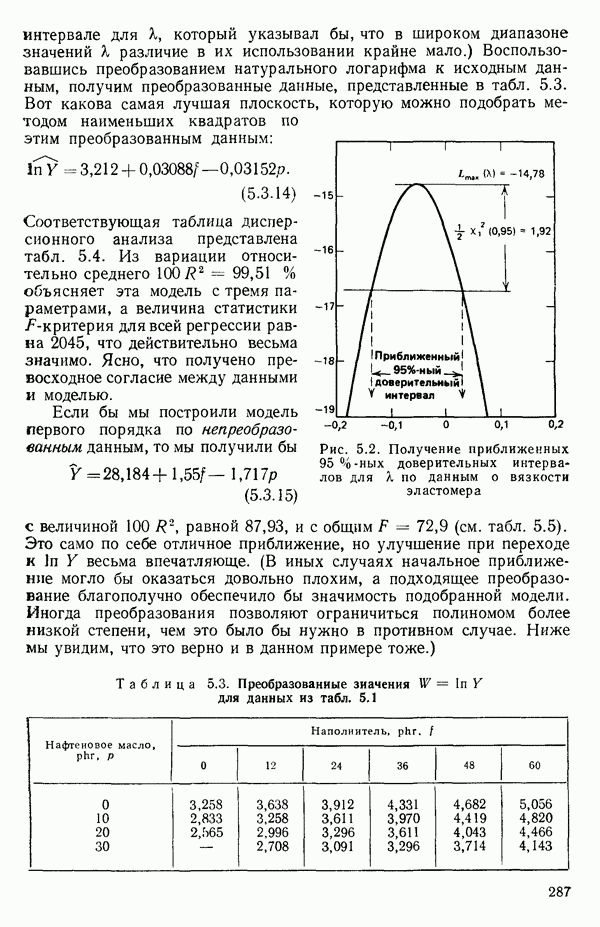
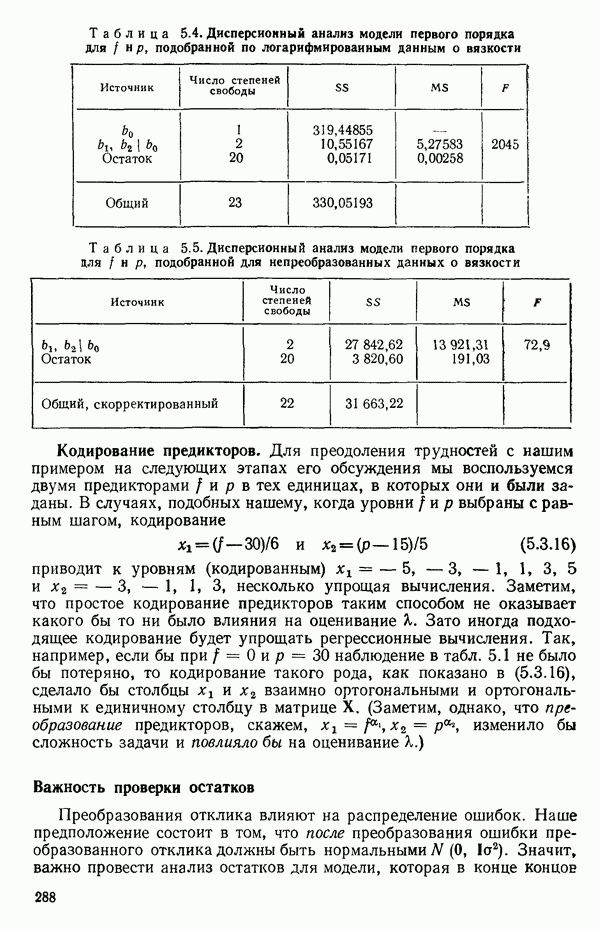
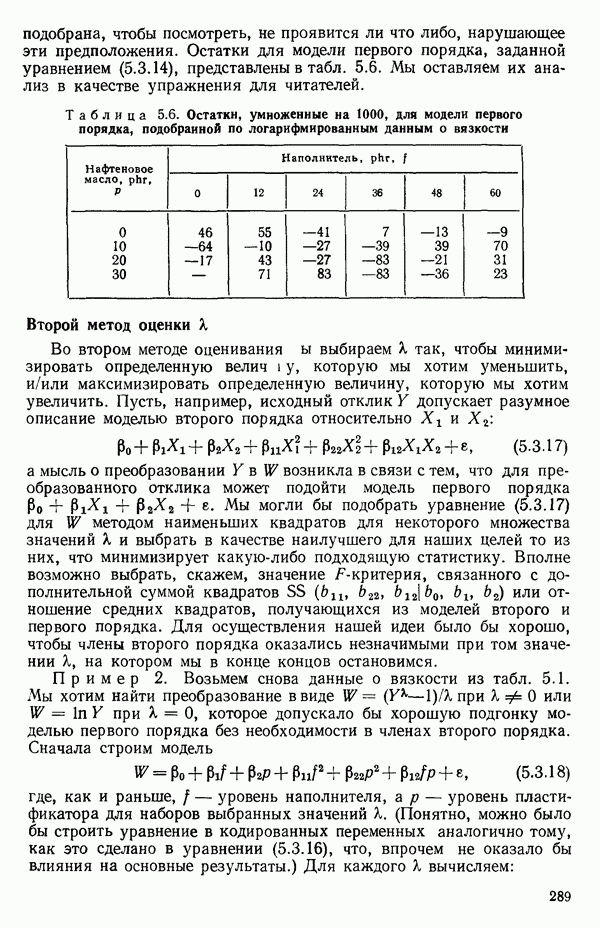
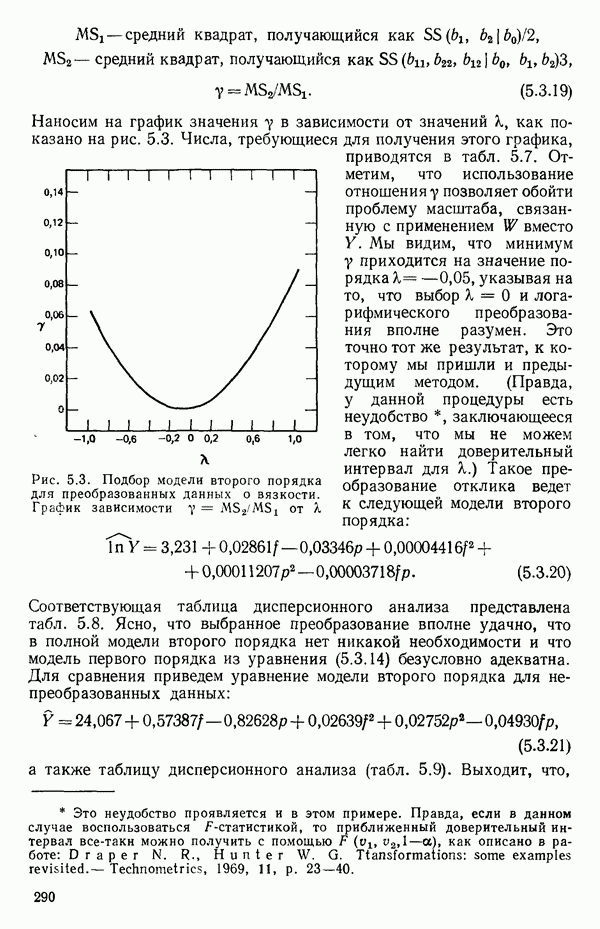
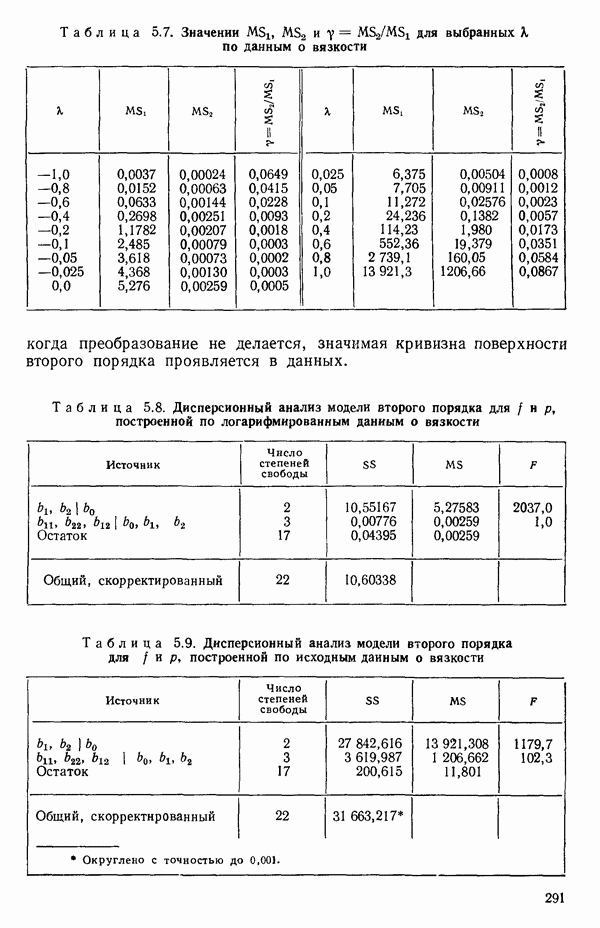
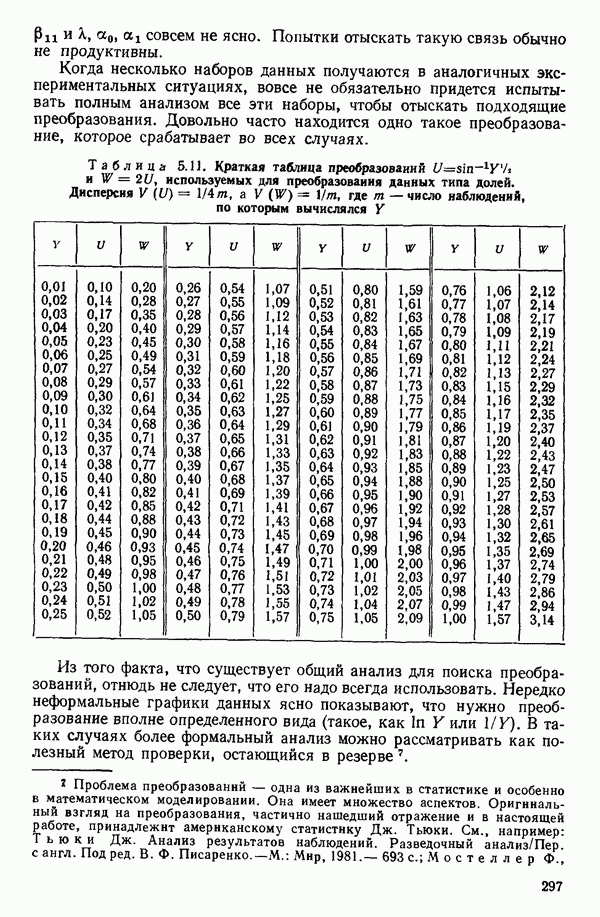
1.5. НЕАДЕКВАТНОСТЬ И «ЧИСТАЯ» ОШИБКАМы уже отмечали, что построенная линия регрессии — это расчетная линия, основанная на некоторой модели или предположениях. Но предположения мы не можем принимать слепо, а должны рассматривать их как предварительные. При некоторых обстоятельствах (условиях) можно проверить, корректна ли наша модель. Прежде всего мы можем изучить проявления предполагаемой некорректности модели. Вспомним, что информацию относительно того, почему построенная модель недостаточна правильно объясняет наблюдаемый разброс значений зависимой переменной
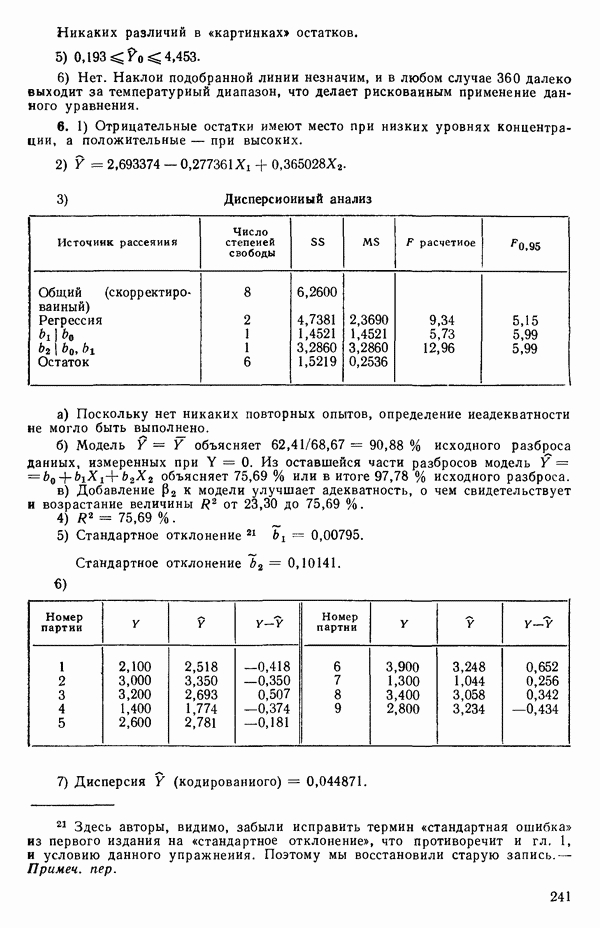
где
Величина
и это верно независимо от того, будет ли модель правильна Можно показать, что
имеет математическое ожидание, или среднее значение Однако если модель не корректна, т. е. В простом случае подбора прямой обычно можно определить ошибку смещения, непосредственно исследуя график с данными (см., например, рис. 1.10). Если модель более сложна и (или) включает больше переменных, то это невозможно. Если существует априорная оценка (Примечание. Важно понимать, что повторение опытов может быть в некотором смысле верным и неверным. Пусть, например, мы будем пытаться применять регрессионный метод к зависимости Когда в данных содержатся повторные опыты, нам нужны дополнительные обозначения для множества наблюдений к
Всего получается
наблюдений. Вклад суммы квадратов, связанной с «чистой» ошибкой для
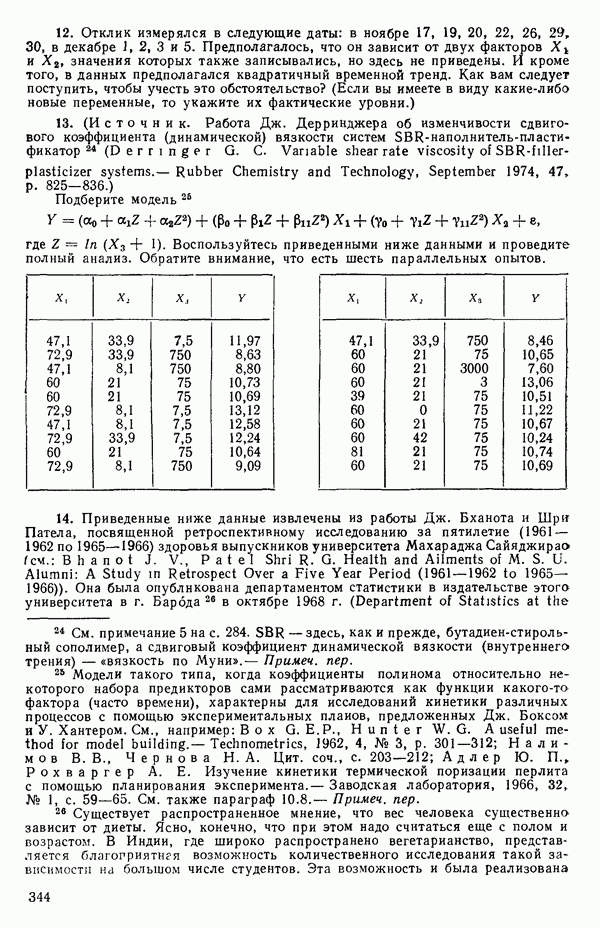
Объединяя внутренние суммы квадратов для всех серий повторных опытов, мы получим общую сумму квадратов «чистых» ошибок в виде
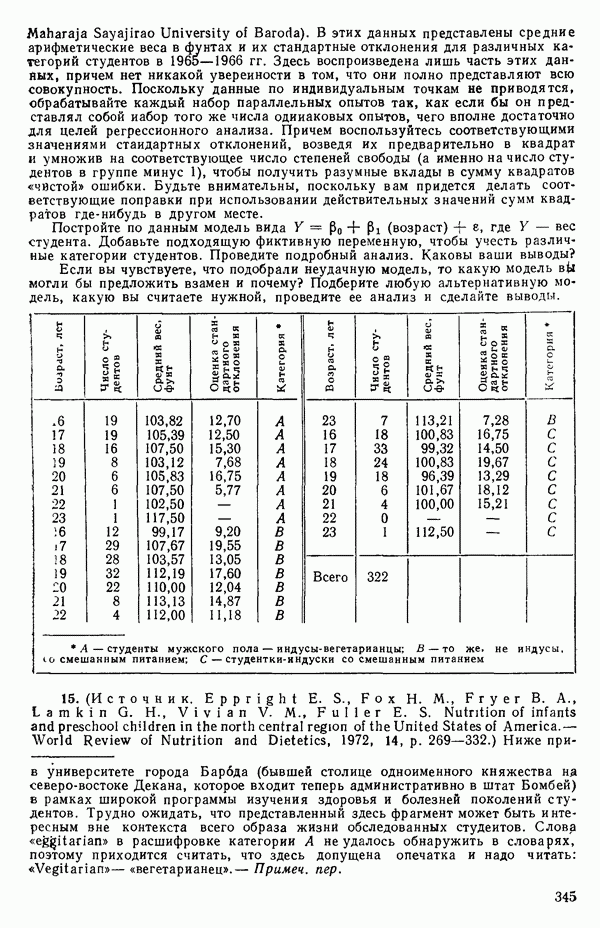
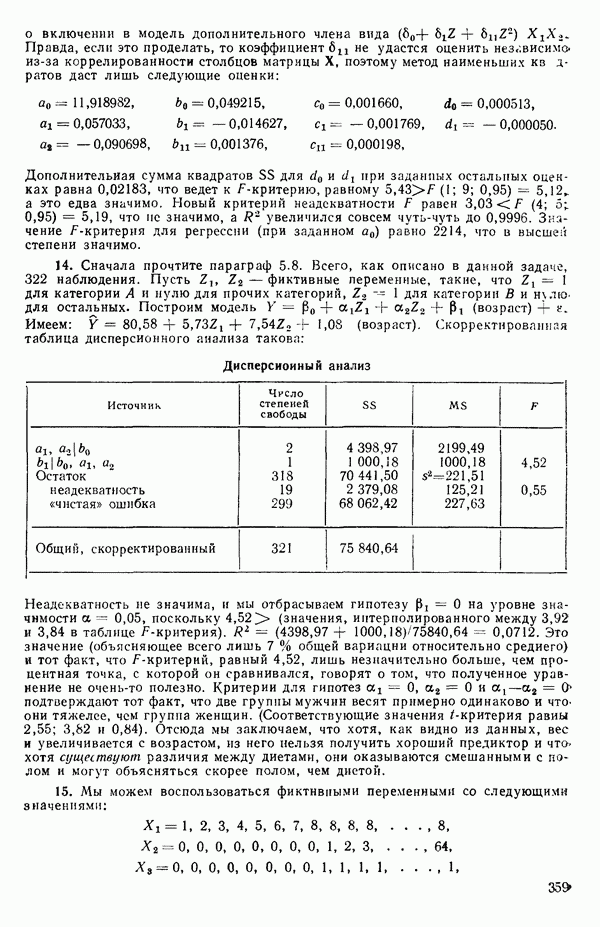
со степенями свободы
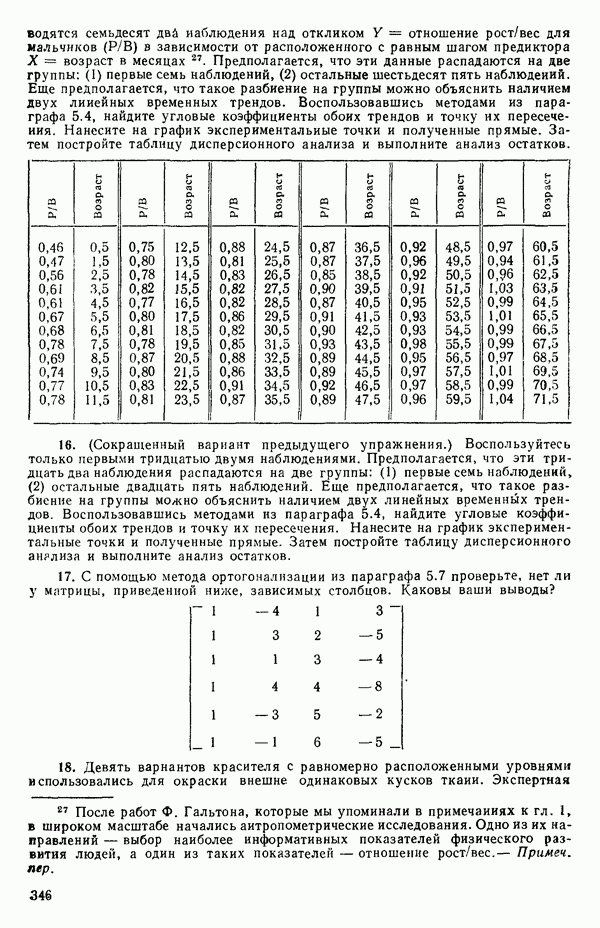
Отсюда средний квадрат «чистых» ошибок равен:
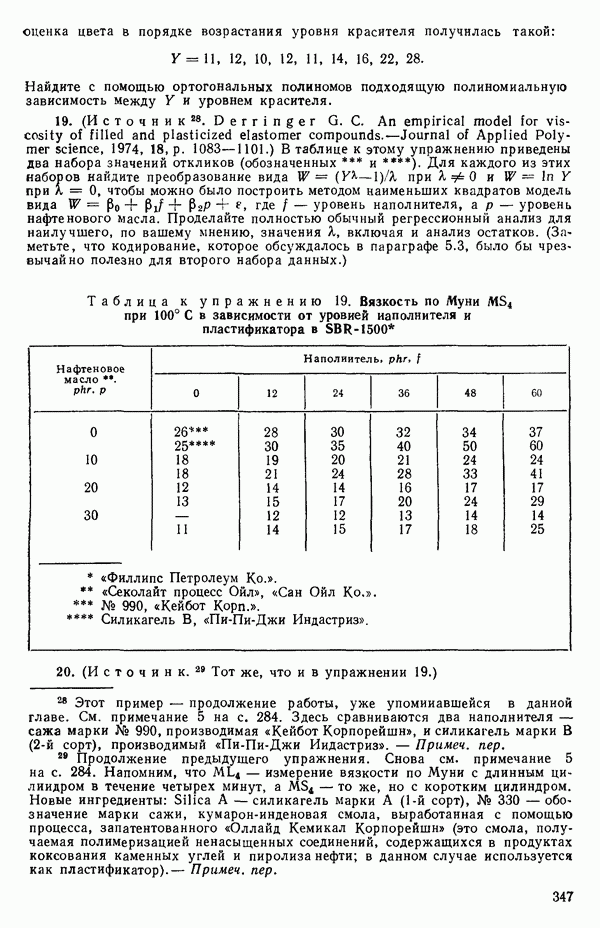
и он служит оценкой (Примечание. Если имеются только два наблюдения
Это удобная форма для вычислений. Такая Таким образом, сумма квадратов «чистых» ошибок фактически оказывается частью остаточной суммы квадратов, что мы теперь и покажем. Остаток для
воспользовавшись тем обстоятельством, что все повторные точки при любом
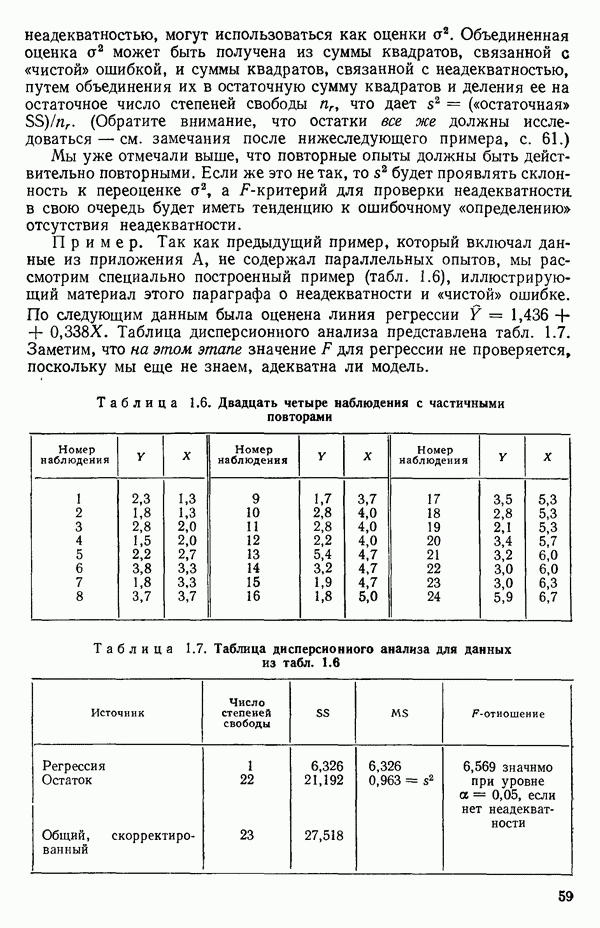
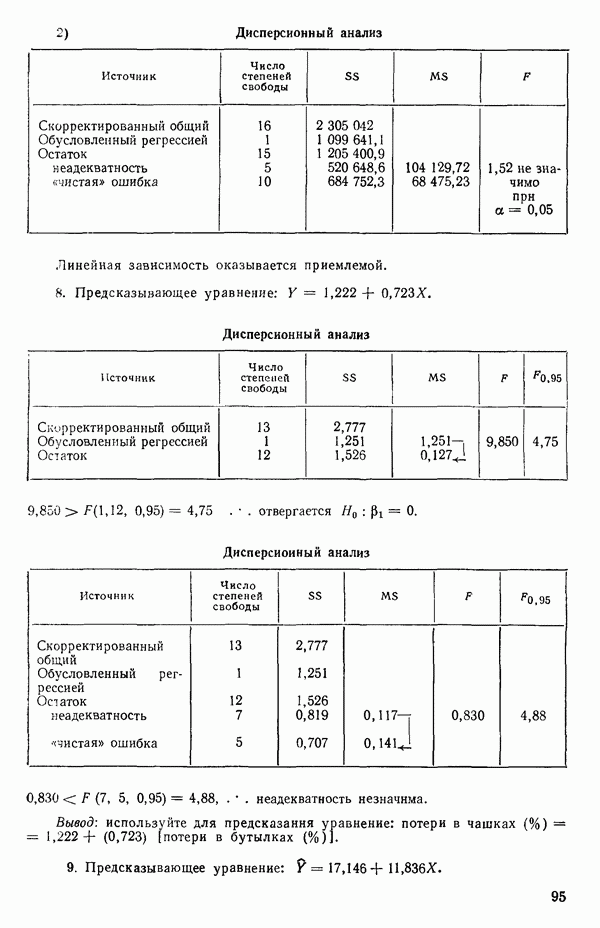
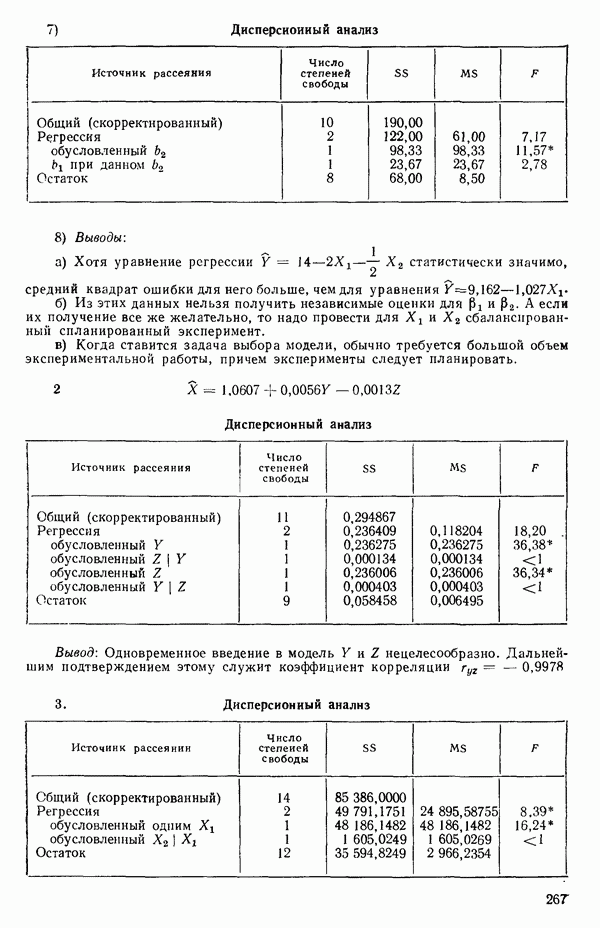
Рис. 1.9. Разложение остаточной суммы квадратов на суммы квадратов, обусловленные неадекватностью и «чистой» ошибкой Слева в уравнении (1.5.8) стоит остаточная сумма квадратов. Первый член в правой части — это сумма квадратов чистых ошибок. Последний член мы называем суммой квадратов неадекватности. Отсюда следует, что сумму квадратов, обусловленную «чистой» ошибкой, можно ввести в таблицу дисперсионного анализа, как показано на рис. 1.9. Обычный прием — это сравнение отношений 1) значимым, то это показывает, что модель, по-видимому, неадекватна. Можно попытаться изучить, когда и как встречается неадекватность. (См. комментарии к различным графикам остатков в гл. 3. Заметим, однако, что графики остатков — стандартная процедура, которая должна применяться в любом регрессионном анализе, а не только в тех случаях, когда неадекватность может быть продемонстрирована с помощью этого критерия.); 2) незначимым, то это показывает, что, по-видимому, нет оснований сомневаться в адекватности модели и что как средний квадрат, связанный с «чистой» ошибкой, так и средний квадрат, обусловленный неадекватностью, могут использоваться как оценки Мы уже отмечали выше, что повторные опыты должны быть действительно повторными. Если же это не так, то Пример. Так как предыдущий пример, который включал данные из приложения А, не содержал параллельных опытов, мы рассмотрим специально построенный пример (табл. 1.6), иллюстрирующий материал этого параграфа о неадекватности и «чистой» ошибке. По следующим данным была оценена линия регрессии Таблица 1.6. Двадцать четыре наблюдения с частичными повторами
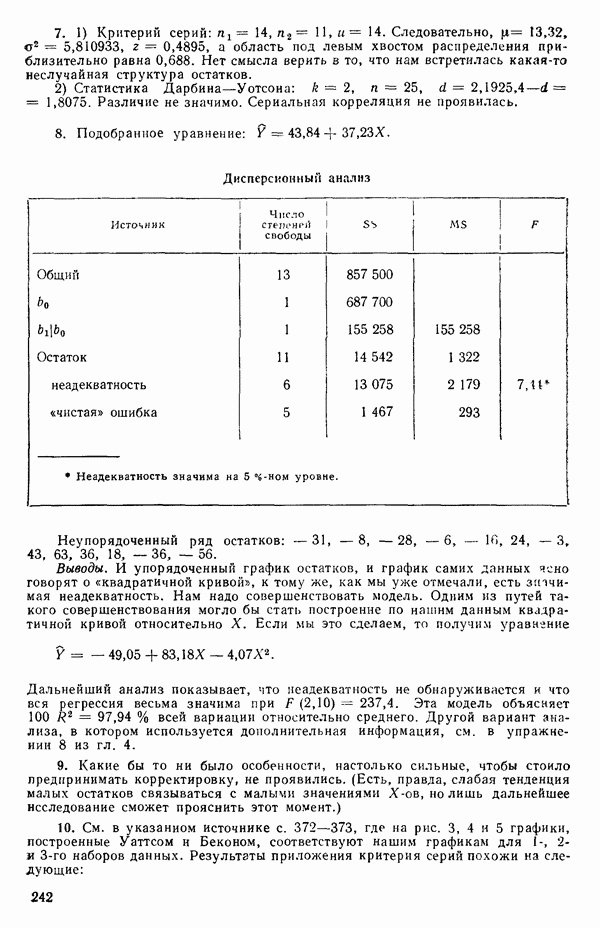
Таблица 1.7. Таблица дисперсионного анализа для данных из табл. 1.6
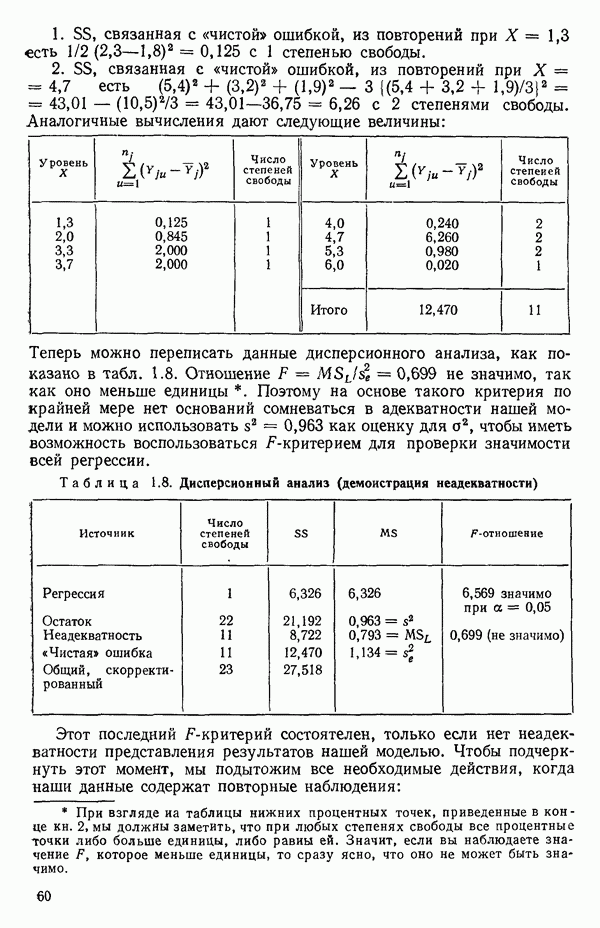
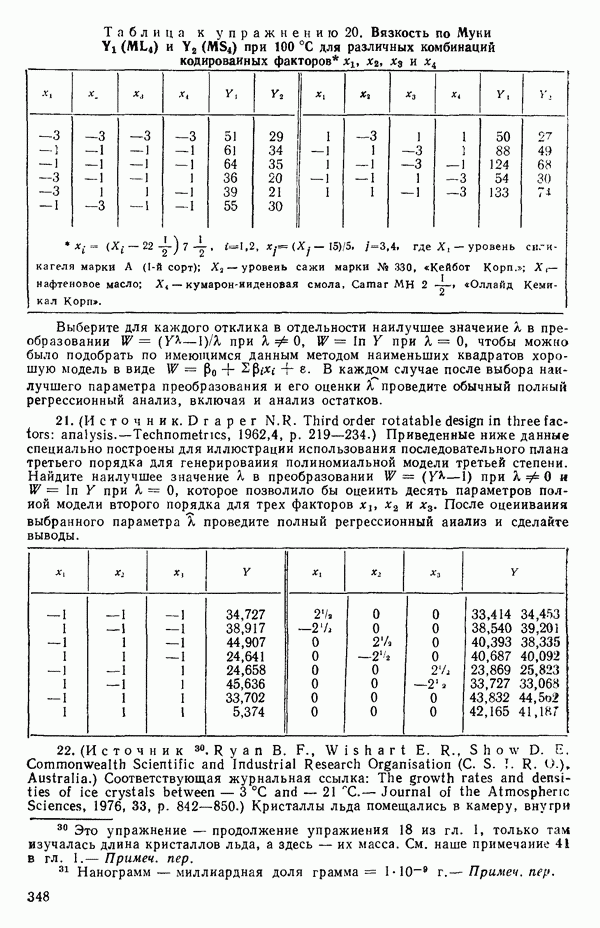
1. 2.
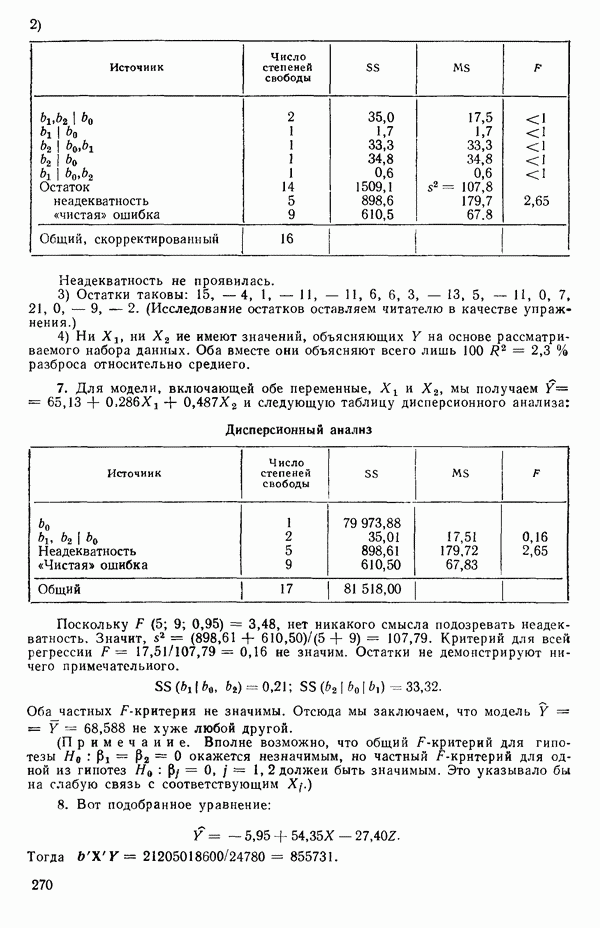
Теперь можно переписать данные дисперсионного анализа, как показано в табл. 1.8. Отношение Таблица 1.8. Дисперсионный анализ (демонстрация неадекватности)
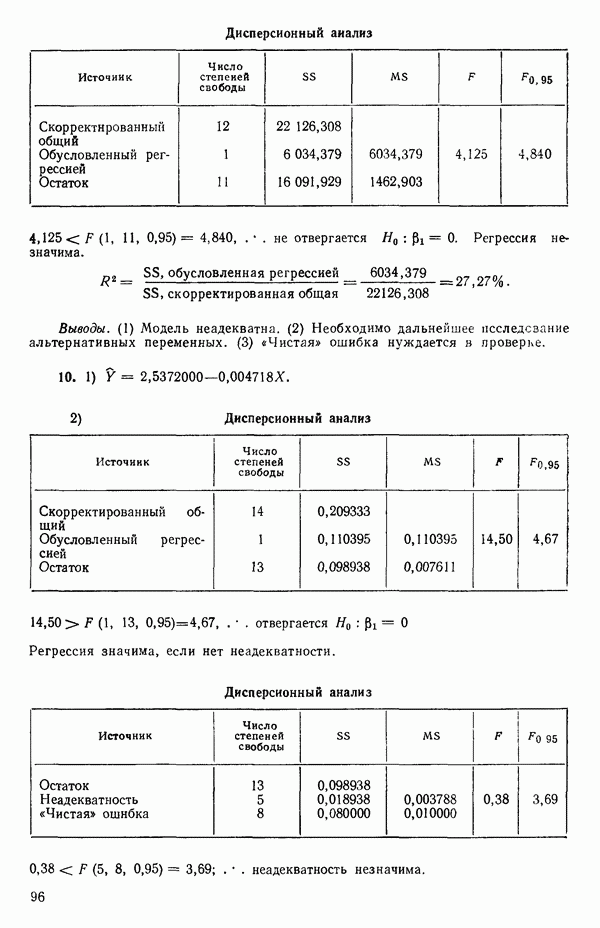
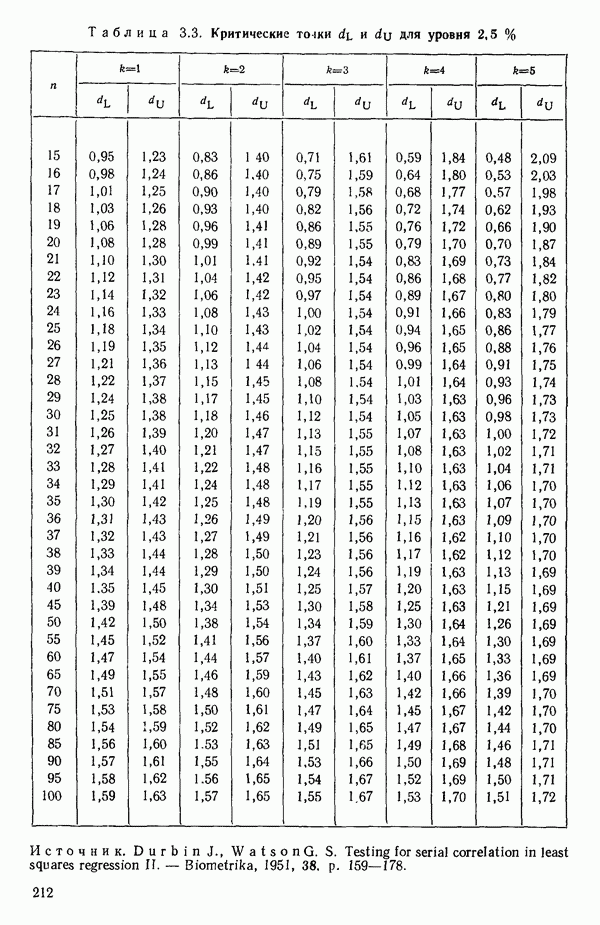
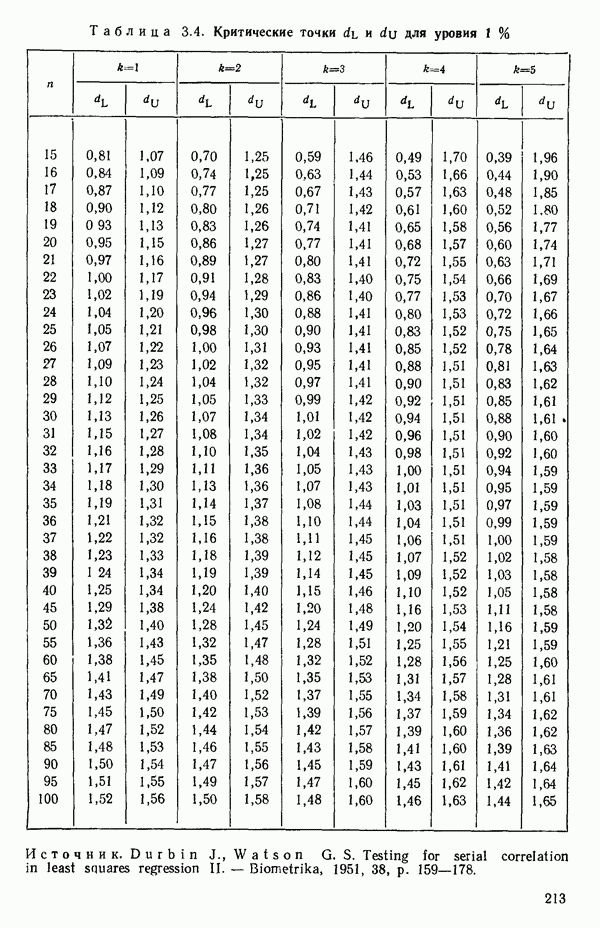
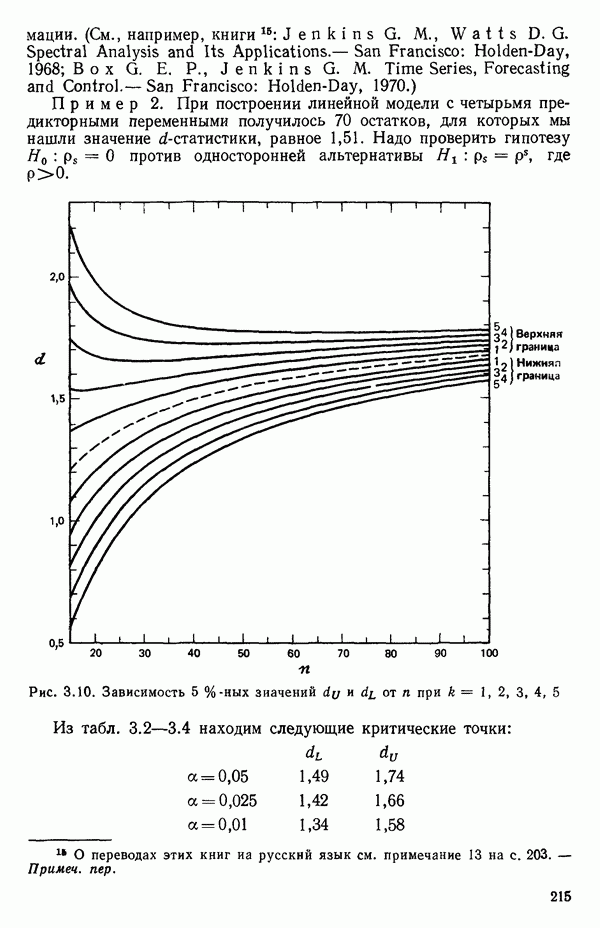
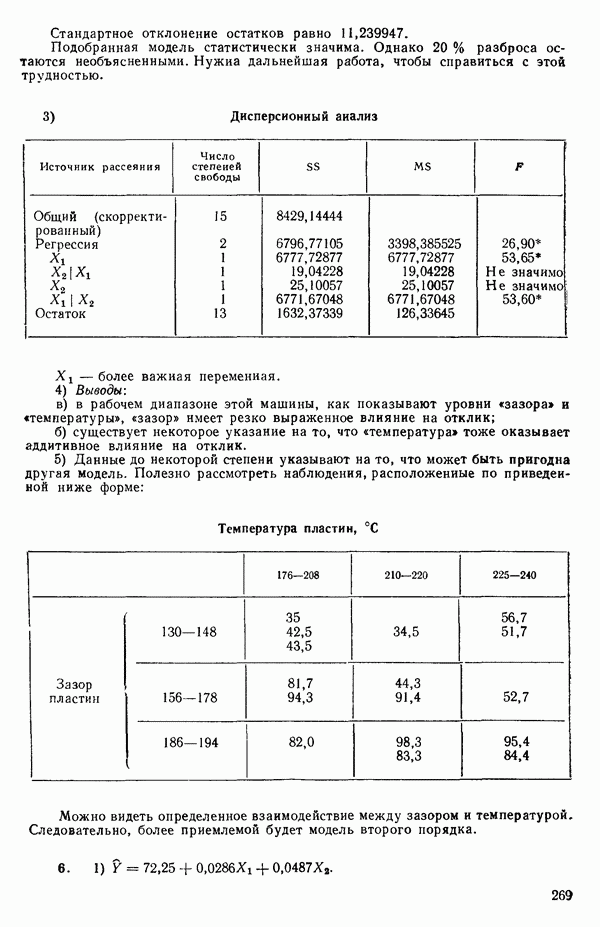
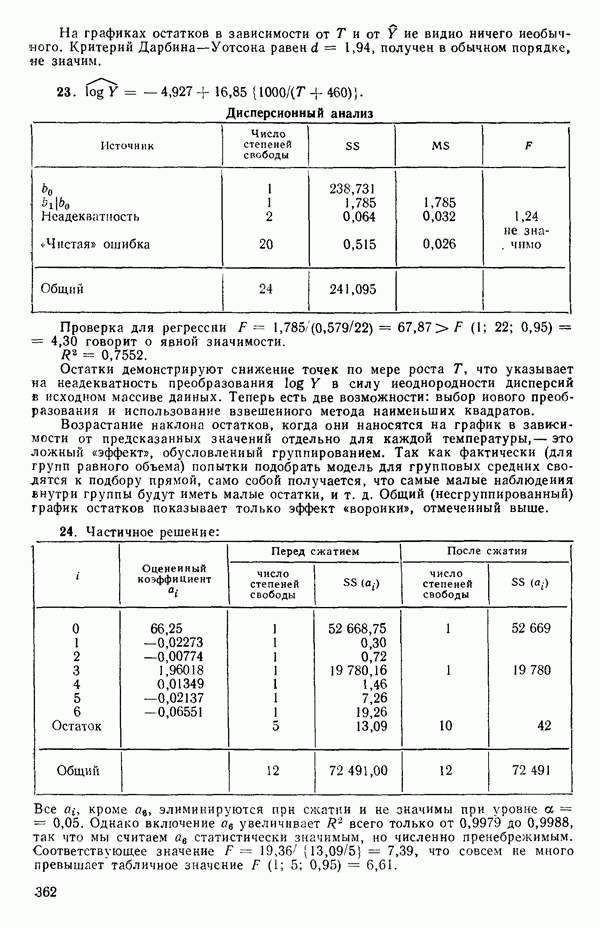
Этот последний 1. Подобрать модель, составить простую таблицу дисперсионного анализа с двумя входами: регрессией и остатком. Но для общей регрессии пока не использовать 2. Вычислить сумму квадратов, связанную с «чистой» ошибкой и разложить остаточную сумму квадратов, как на рис. 1.9. (Ну а если «чистой» ошибки нет, то остается проверять неадекватность посредством анализа графиков остатков (см. гл. 3).) 3. Применить 4а. Значимая неадекватность. Прекратить анализ подобранной модели и искать пути улучшения модели методами анализа остатков (см. гл. 3). Не применять 46. Неадекватность не значима. Снова объединить суммы квадратов для «чистых» ошибок и неадекватности в остаточную сумму квадратов. Использовать остаточный средний квадрат Заметим, что если модель «проходит через все барьеры», это еще не означает, что она правильна; просто нет оснований считать ее неадекватной имеющимся данным. Если неадекватность обнаружена, то может понадобиться другая модель, возможно, квадратичная вида Влияние повторных опытов на R2Как мы отмечали в параграфе 1.4, невозможно, чтобы величина Для демонстрации этого в нашем последнем примере напомним, что сумма квадратов, обусловленная «чистой» ошибкой, равна 12,470 при 11 степенях свободы. То, что модель подогнана к этим данным, не имеет значения, все равно величина 12,470 остается неизменяемой и необъясняемой. Следовательно, максимум
(кликните для просмотра скана) или 54,68 %. Однако то значение
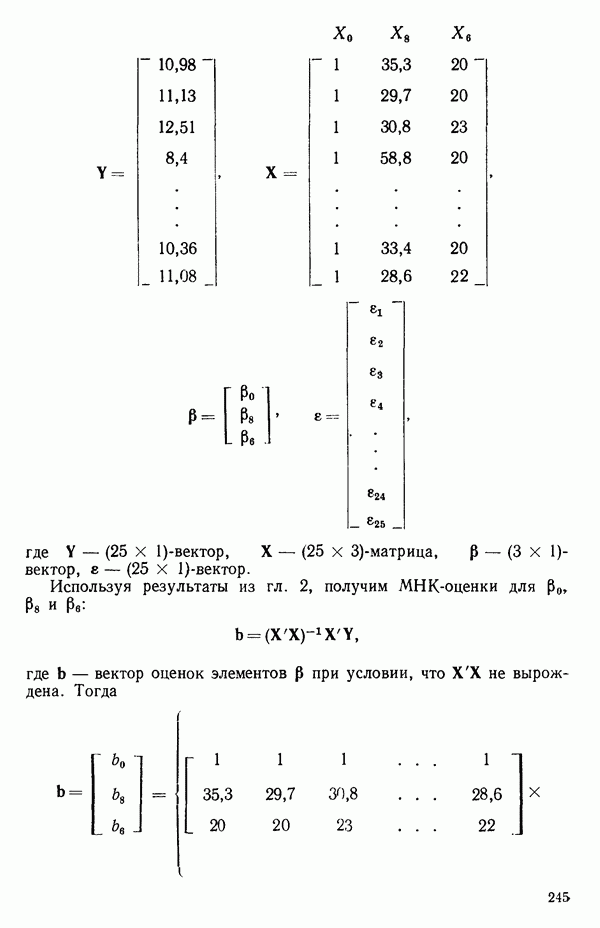
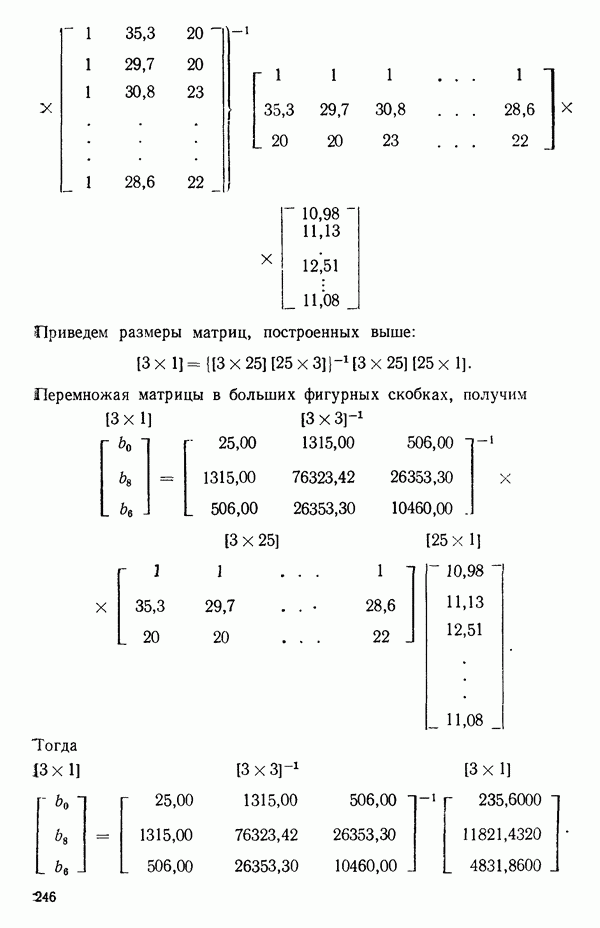
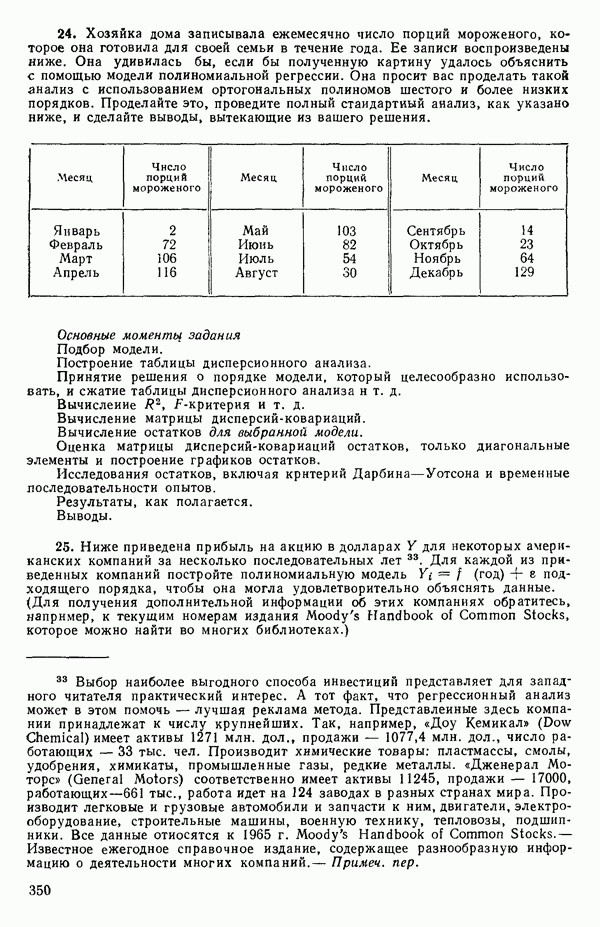
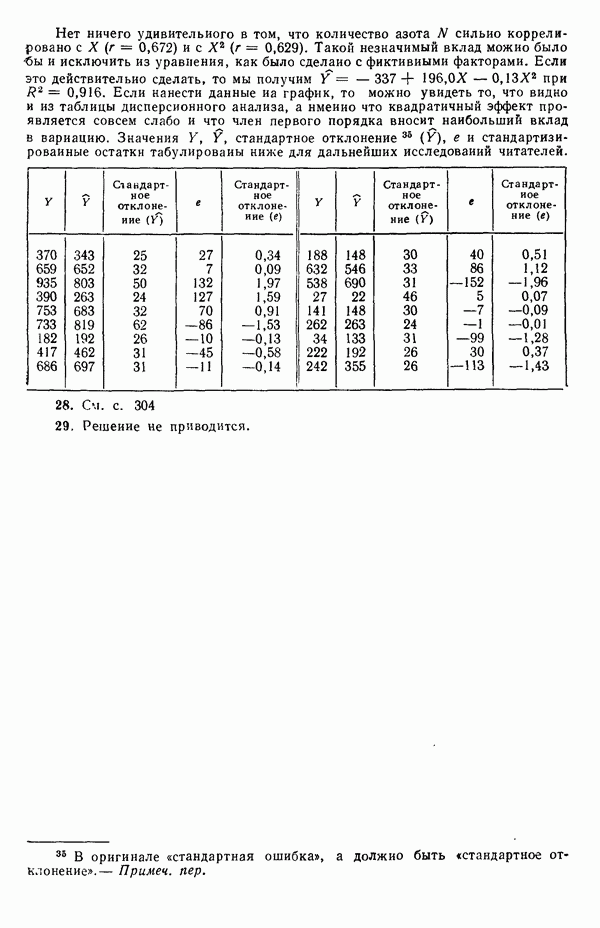
Иными словами, мы можем объяснить «Чистая» ошибка в многофакторном случаеПриведенные выше для случая одной переменной формулы применимы и в общем, сколько бы предикторов
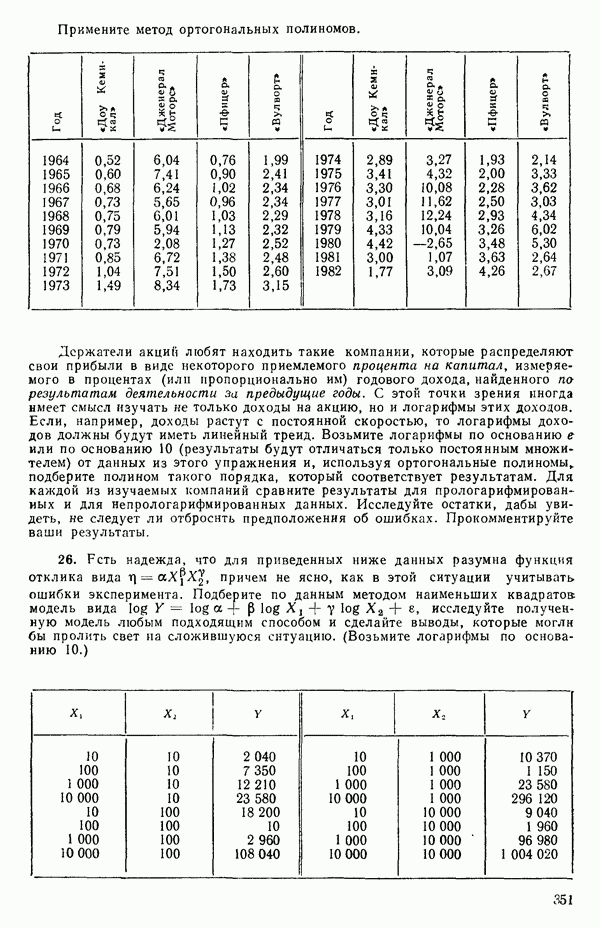
дают повторные опыты. Однако 4 точки
уже не дают повторных опытов, поскольку координаты Приблизительные повторыНекоторые наборы данных не имеют или имеют очень мало повторных опытов, зато в них есть приблизительные повторы, т. е. множества опытов, которые очень близки друг к другу в пространстве X по сравнению с общим разбросом точек в этом пространстве. В таких случаях мы можем воспользоваться этими псевдоповторами так, как будто они обычные повторы и вычислить по ним приближенную сумму квадратов, связанную с «чистой» ошибкой. Тогда ее можно использовать в анализе стандартным способом. Пример такого использования приведен в упражнении 12 из гл. 1.
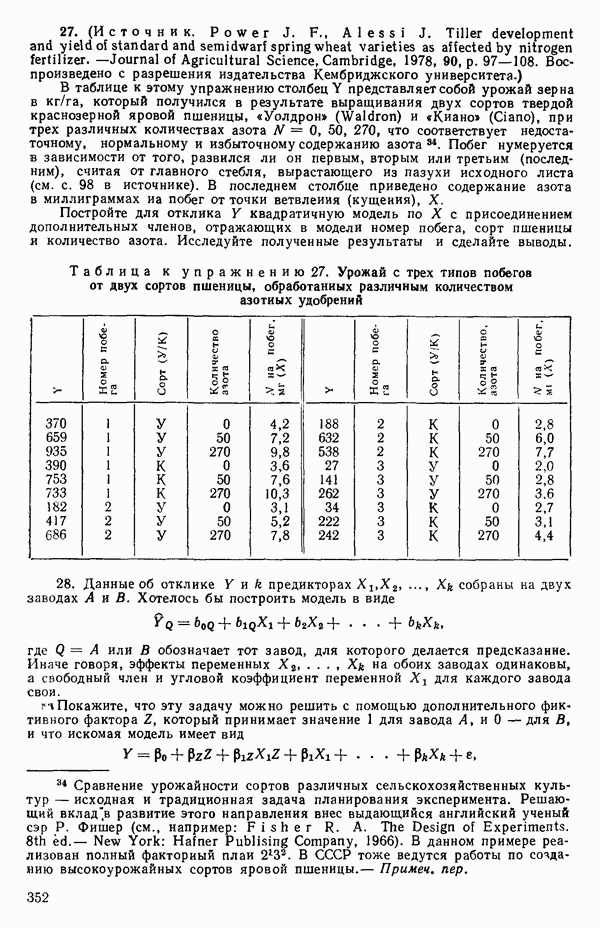
|
 |
Оглавление
|






















































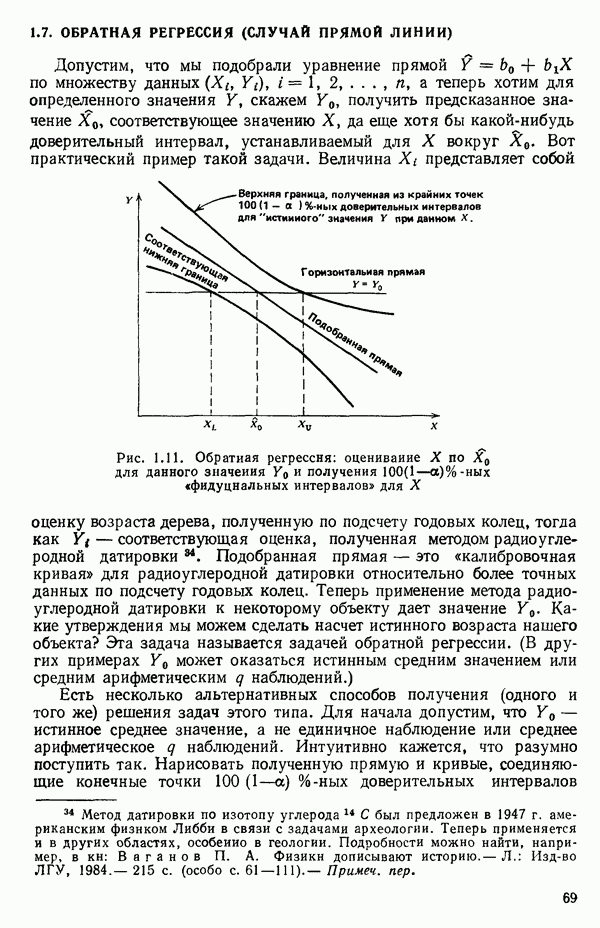


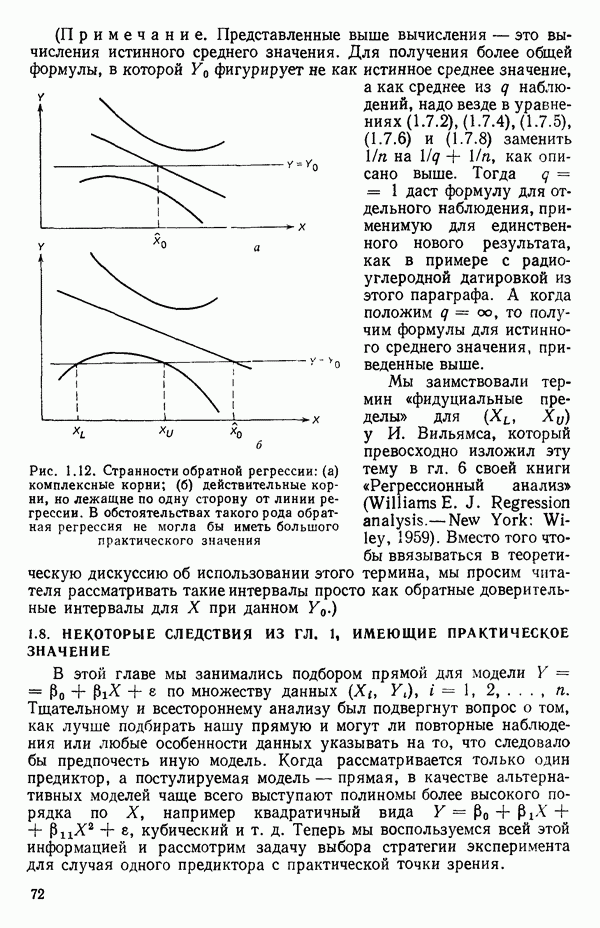




















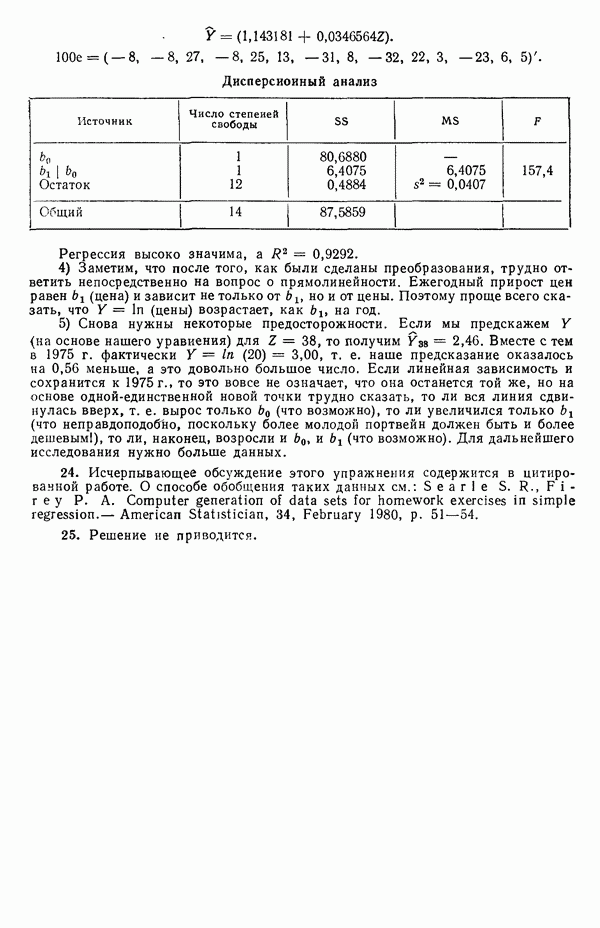










































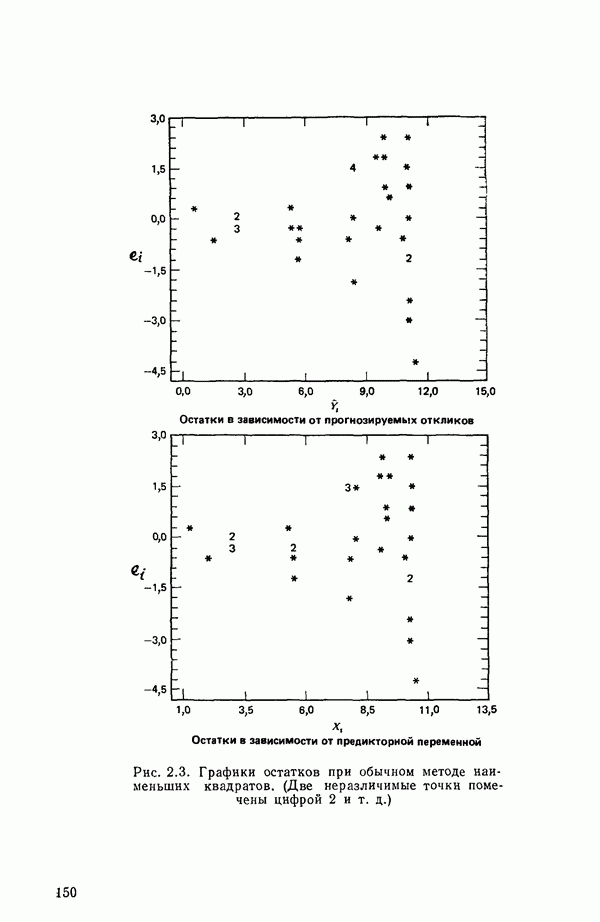

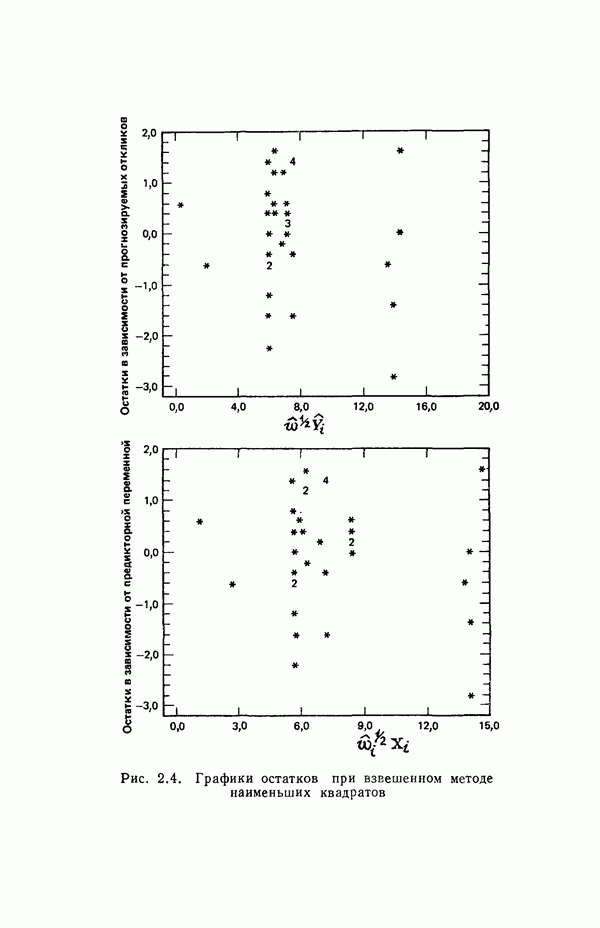














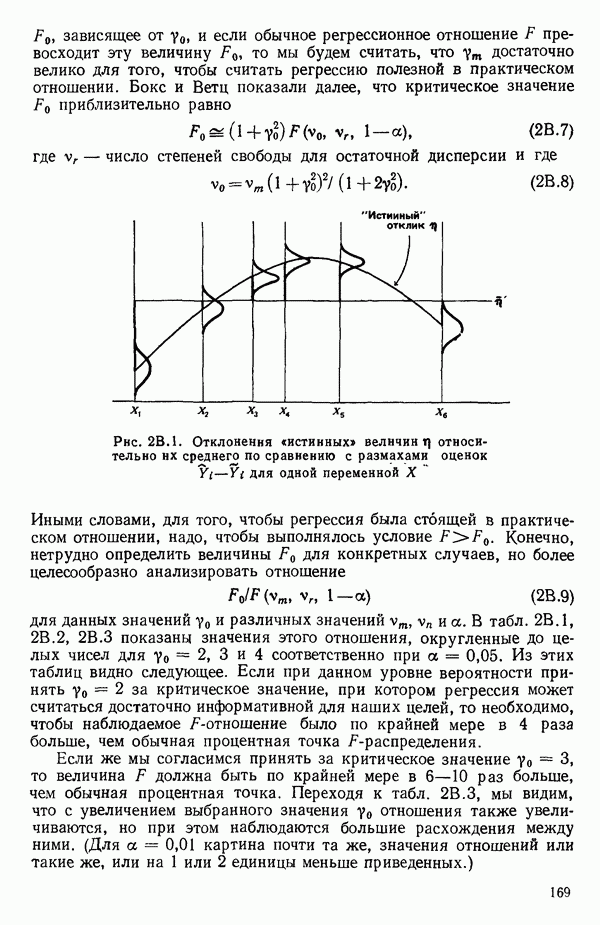







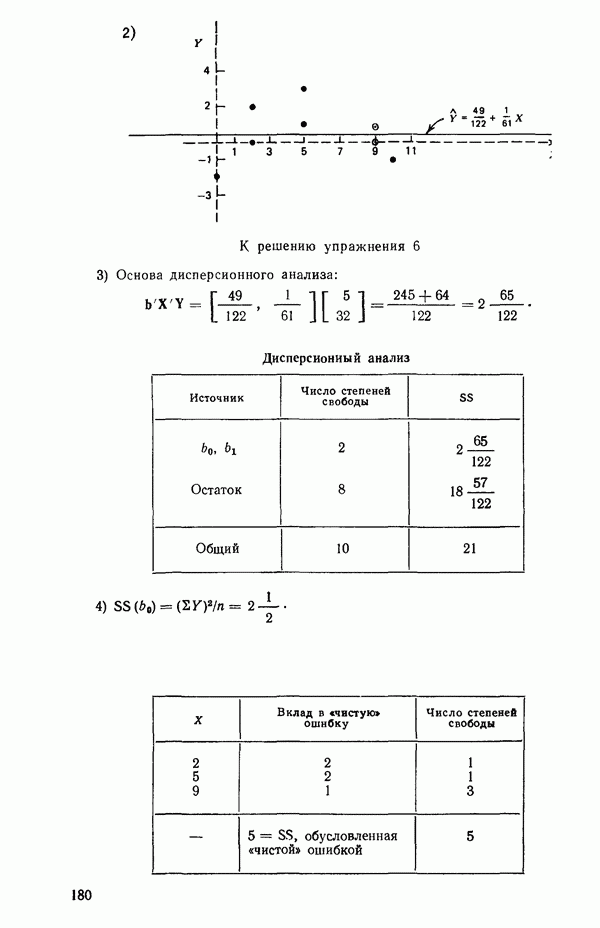

















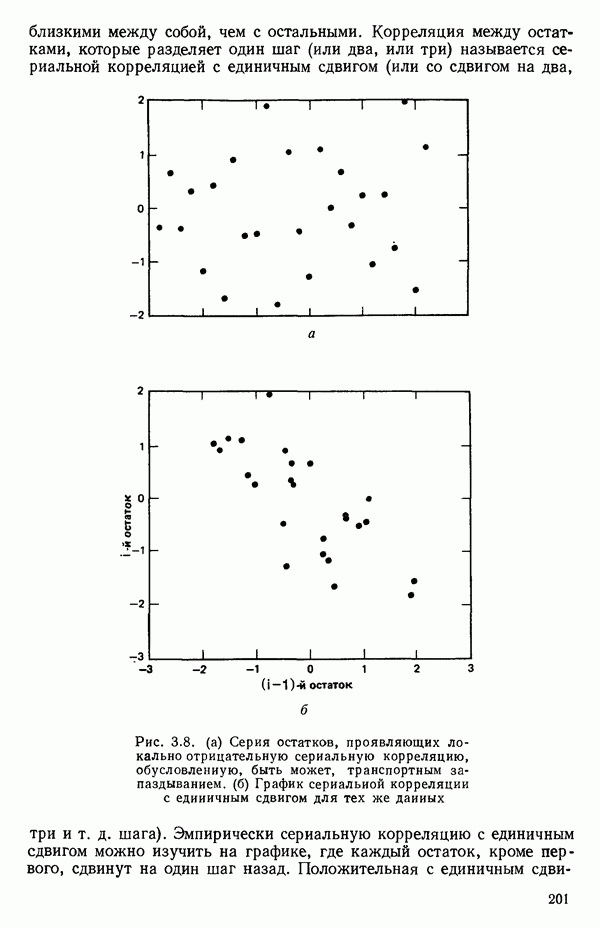
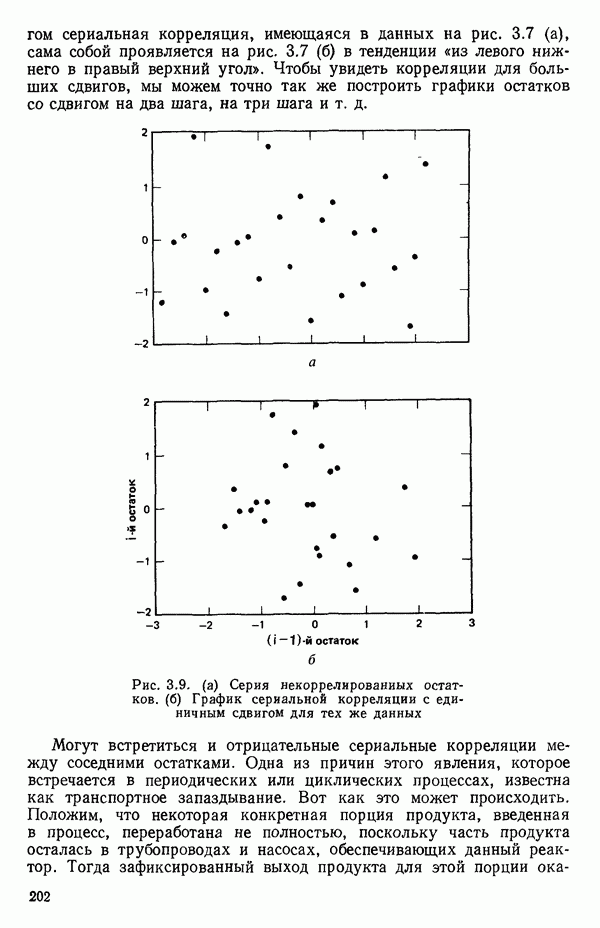























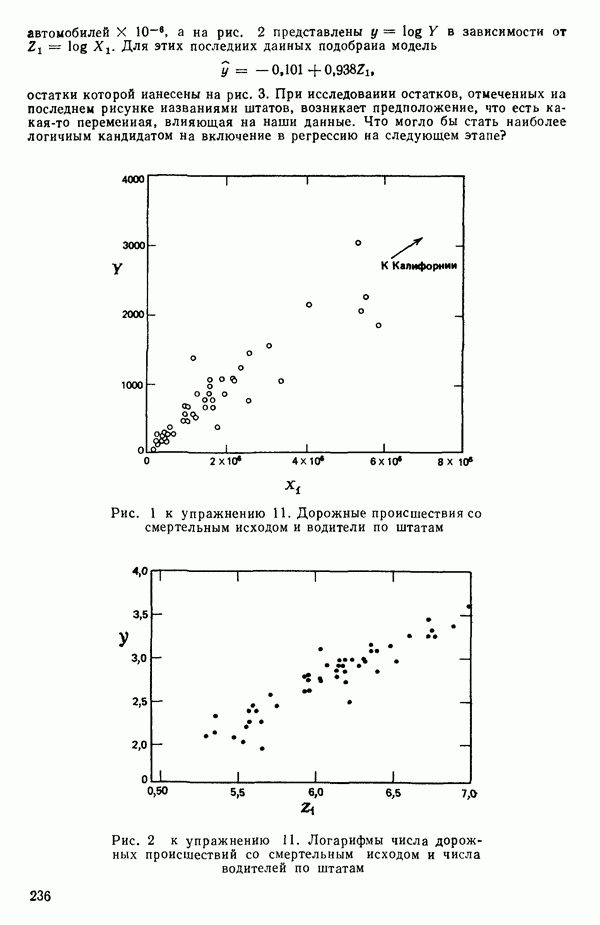
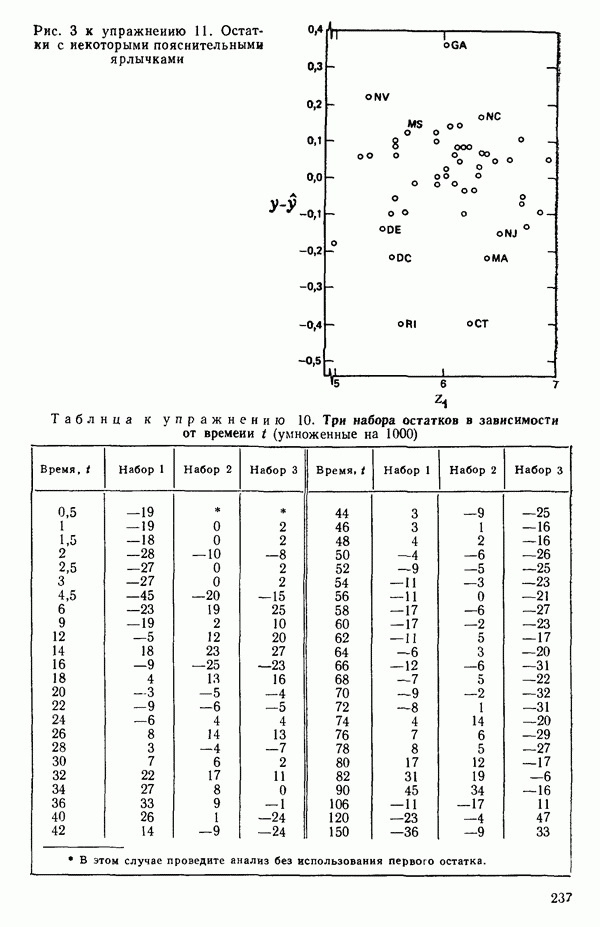
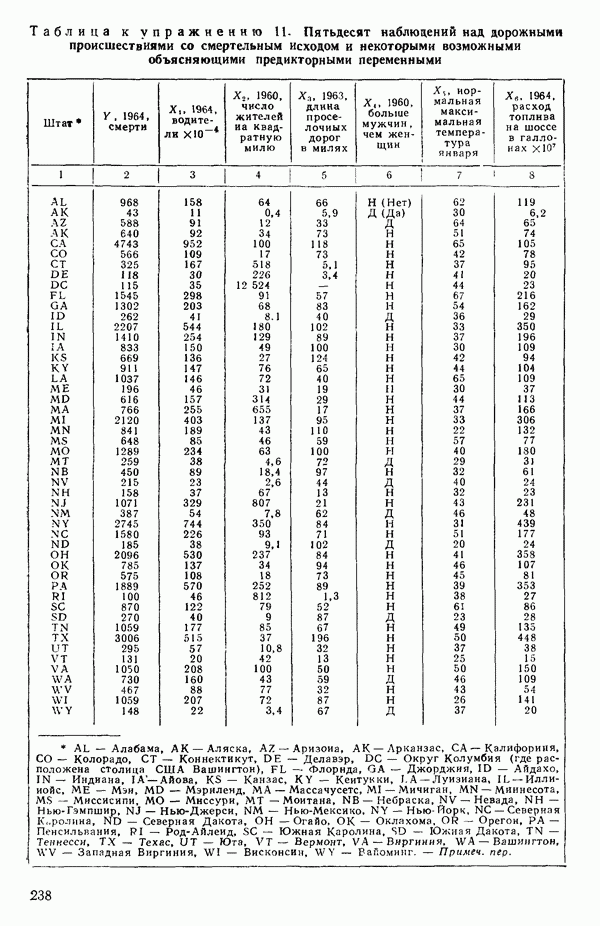




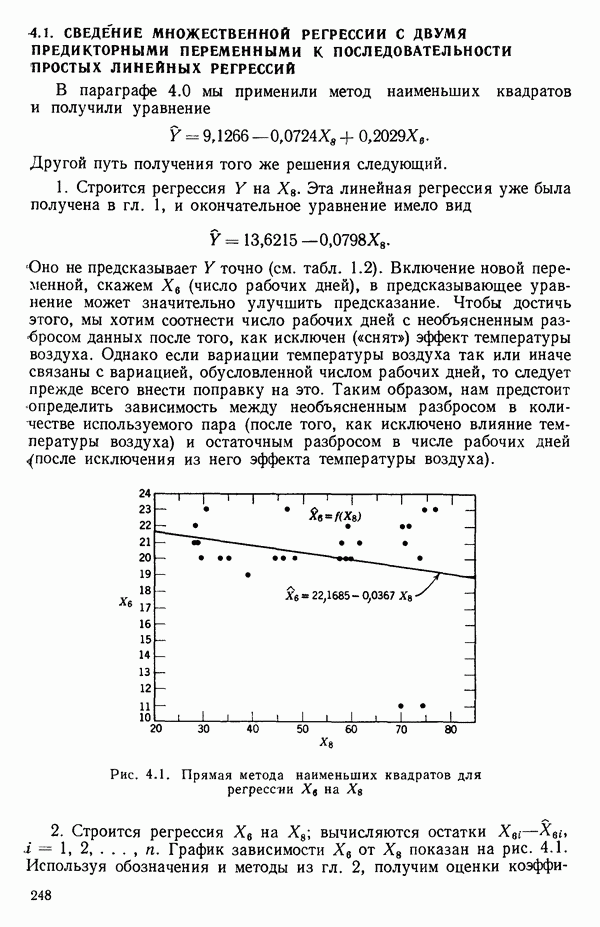
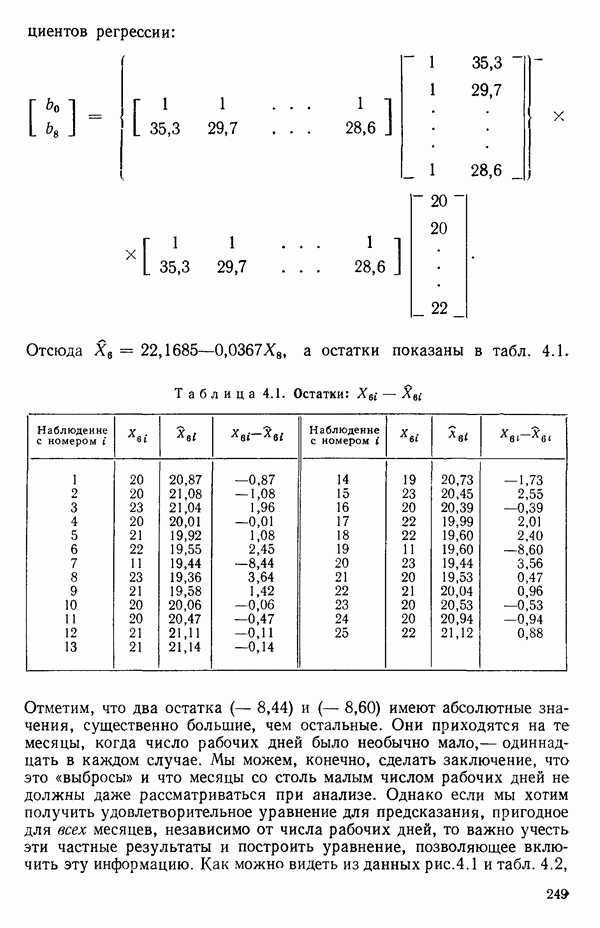

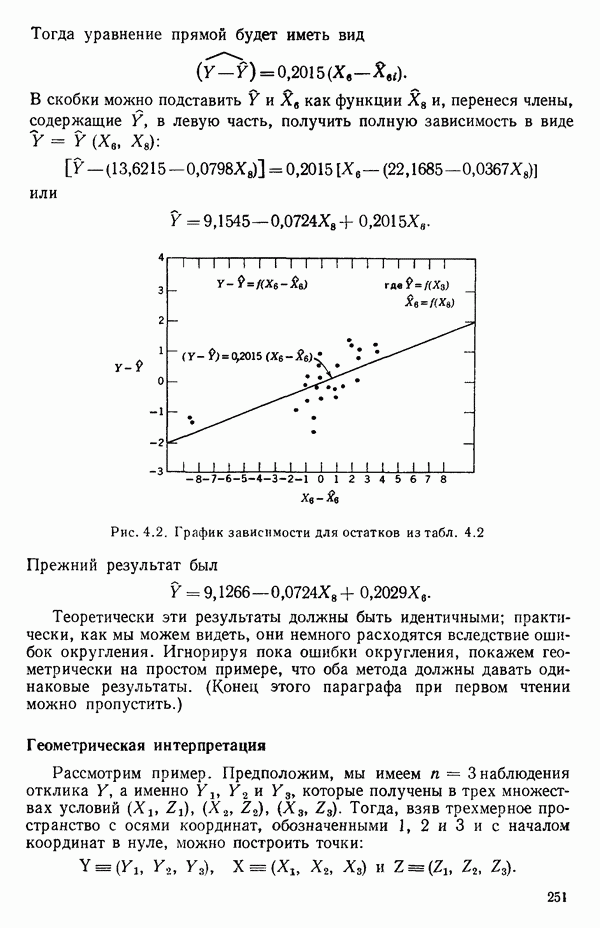

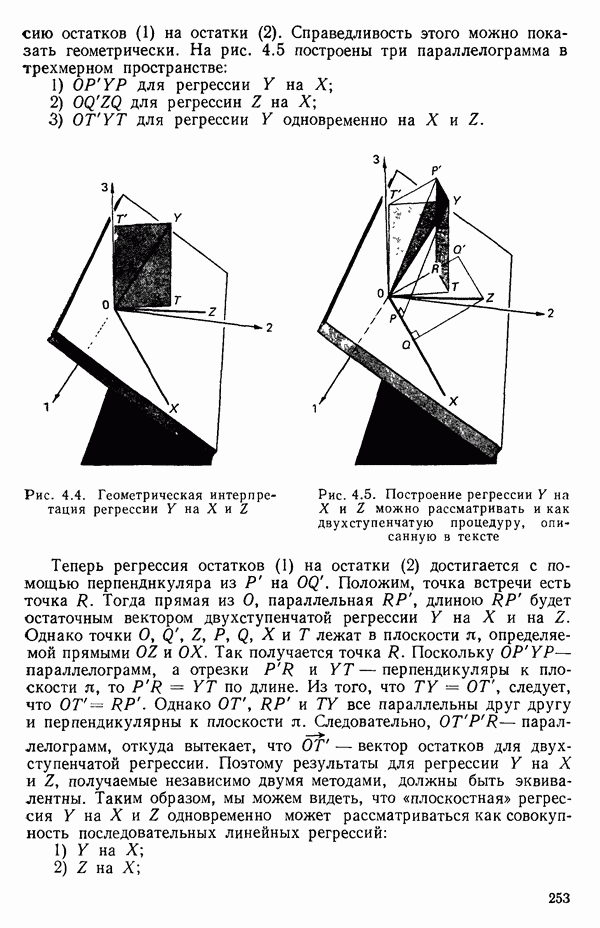
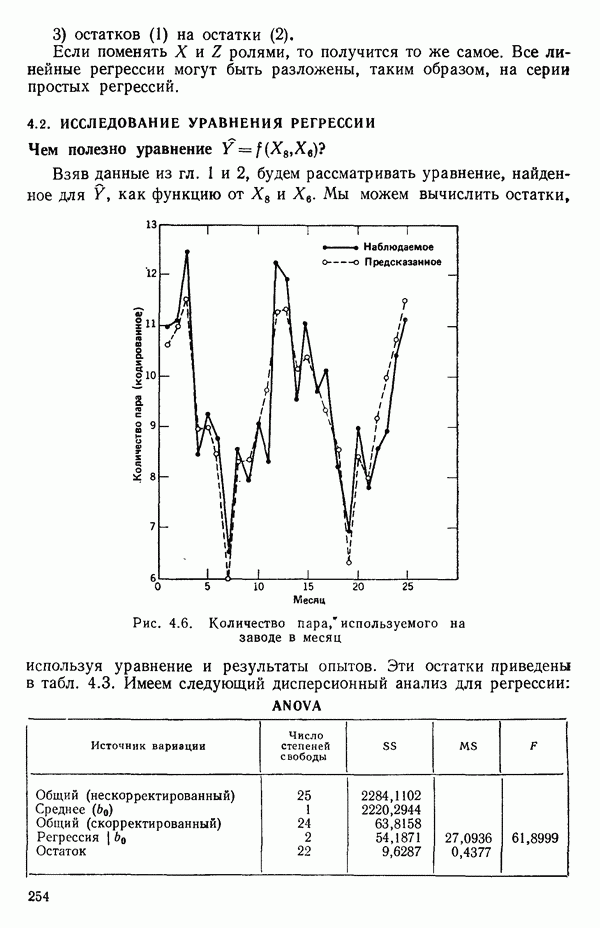






























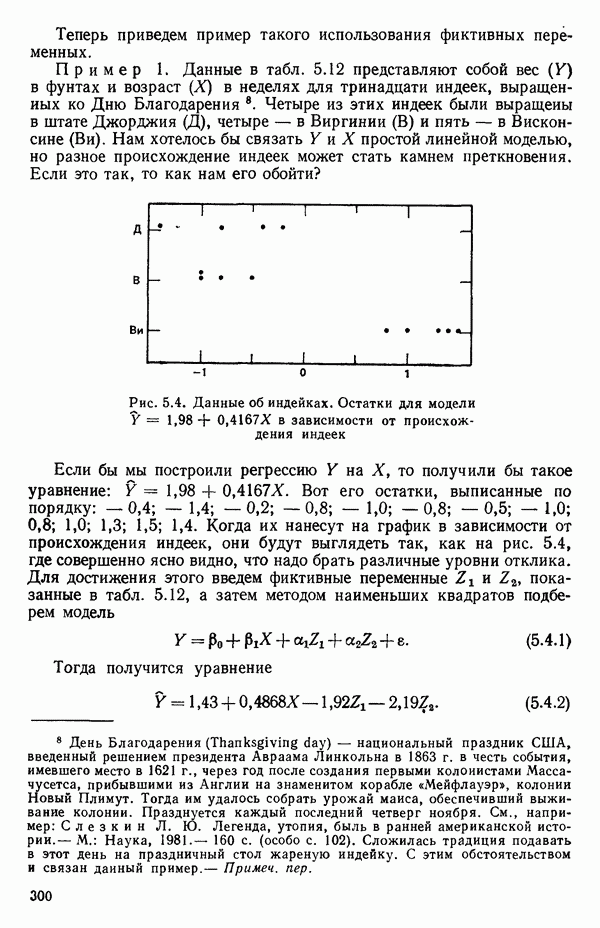
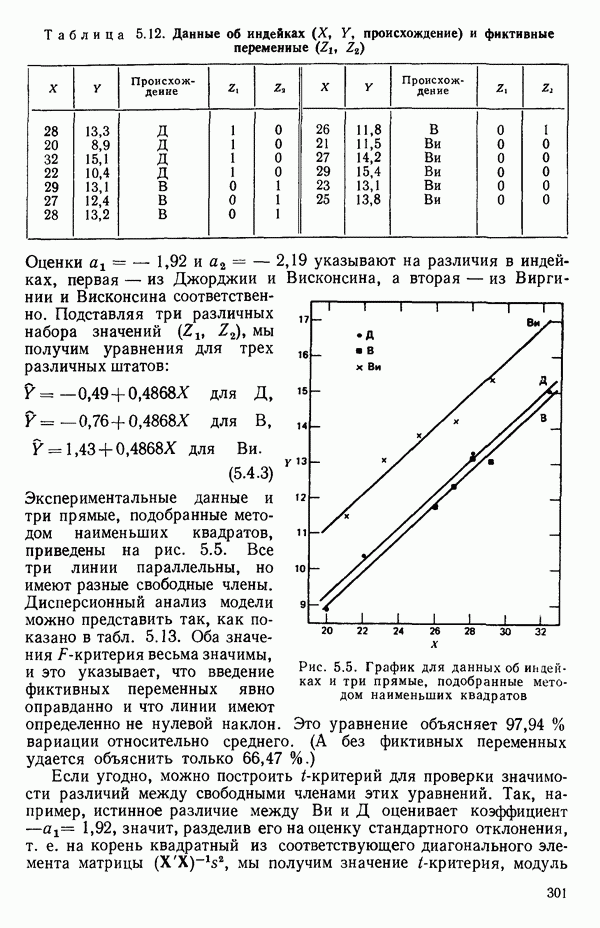




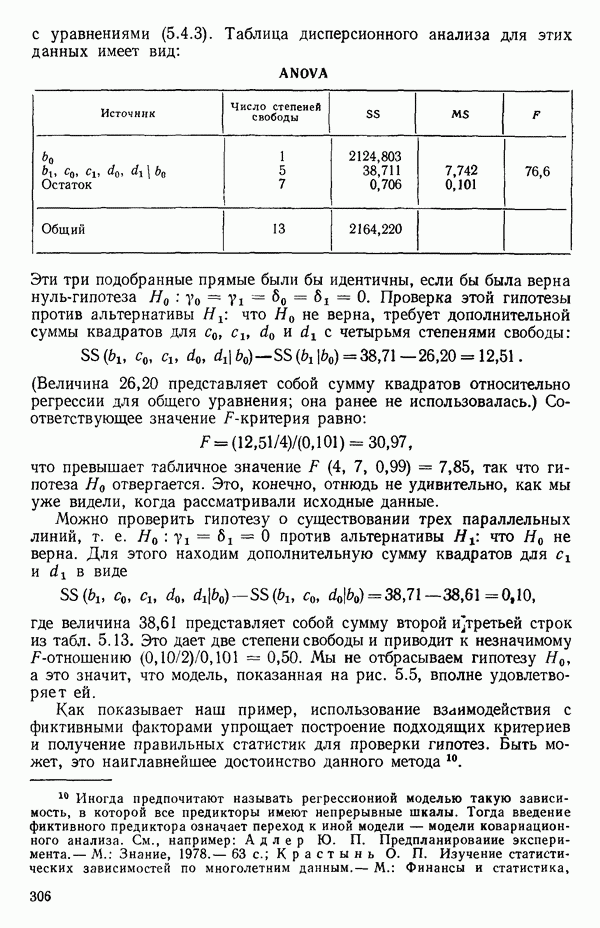


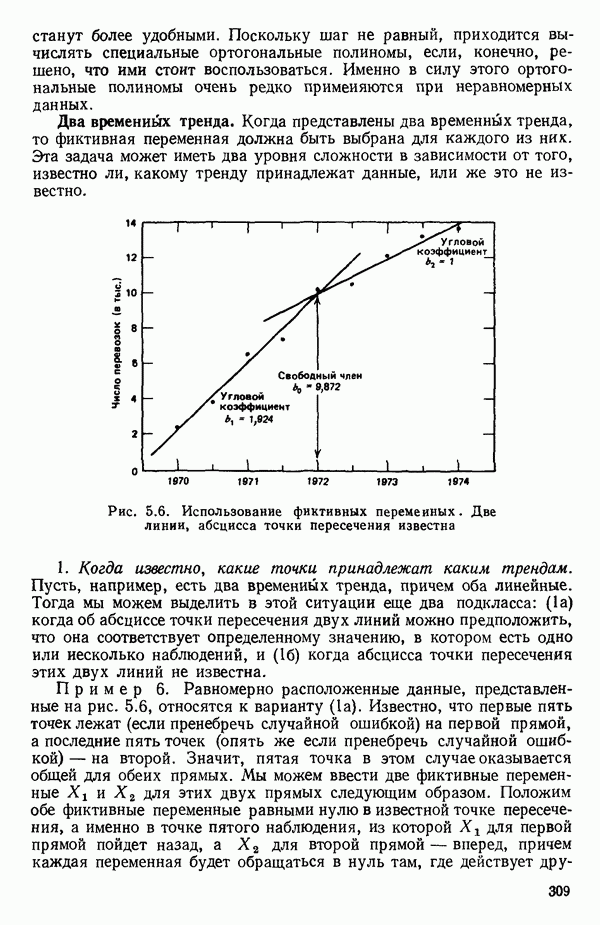















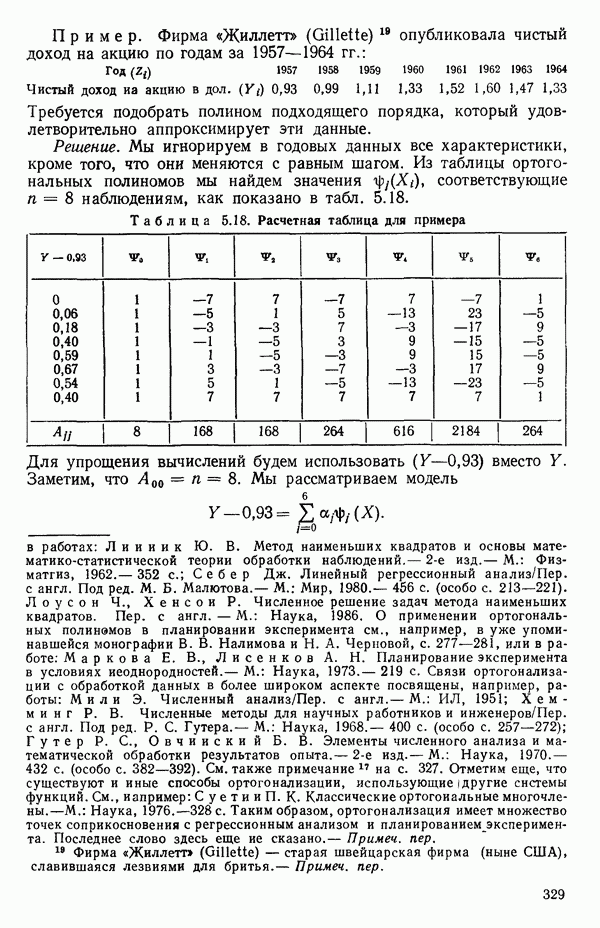

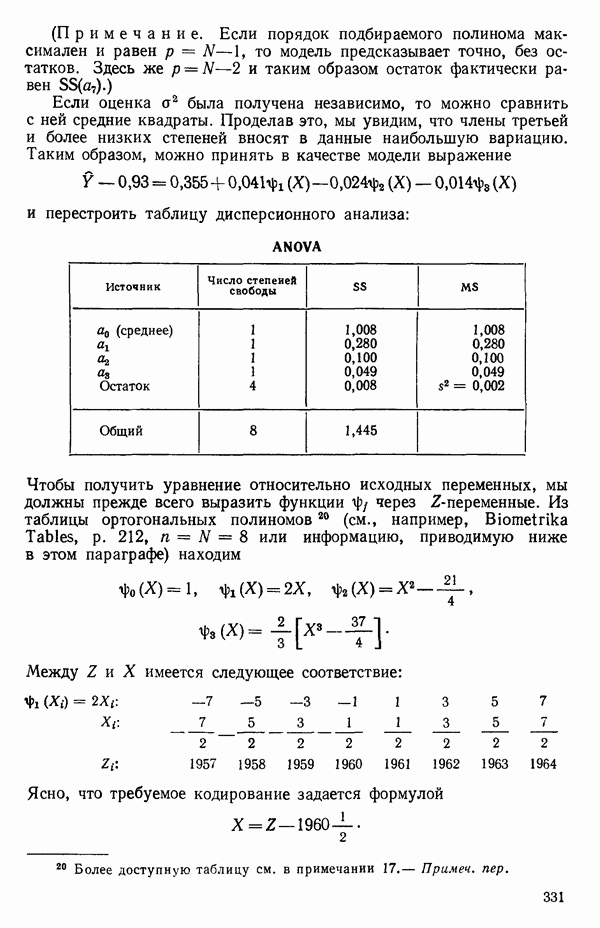

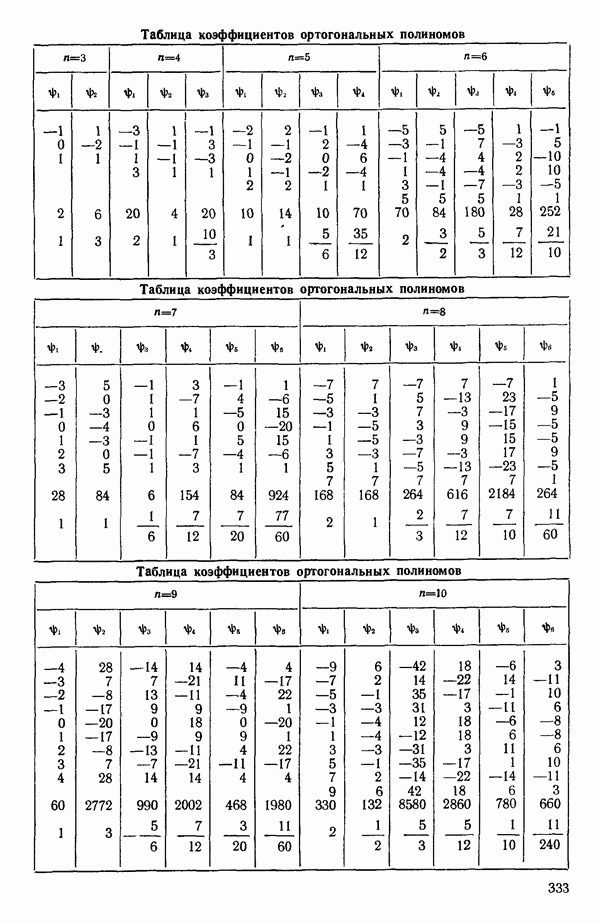
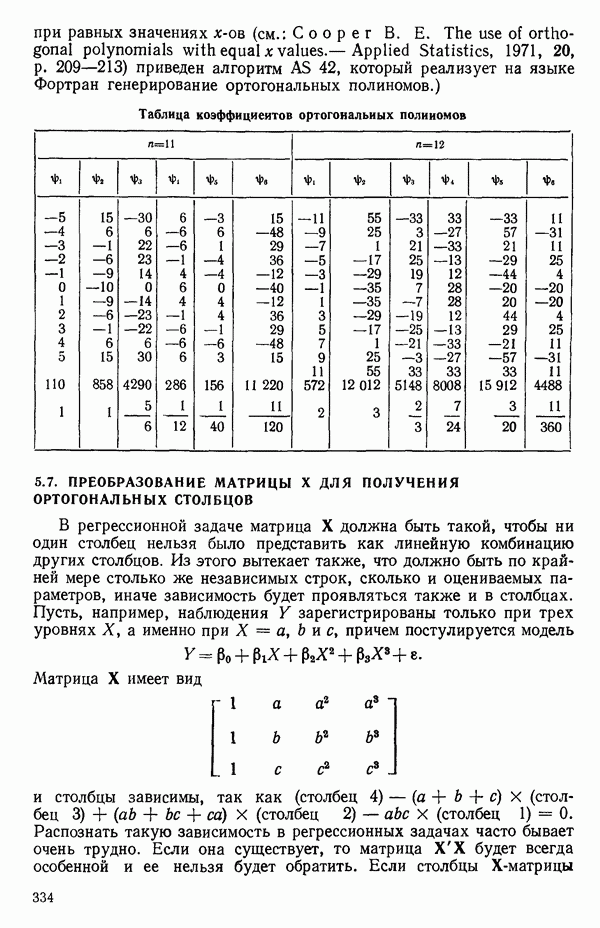



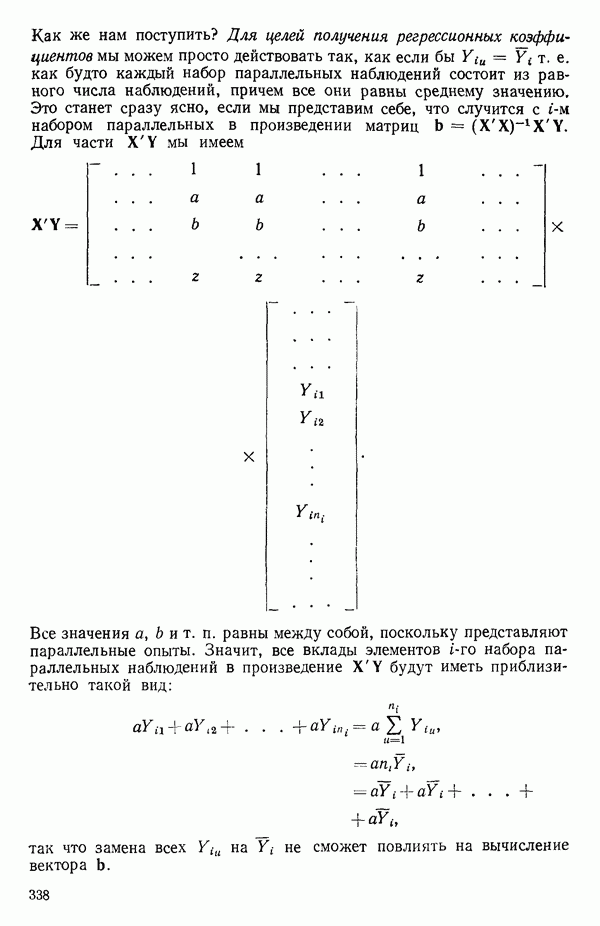








 остатки при
остатки при  Это величины, на которые действительные наблюдаемые значения
Это величины, на которые действительные наблюдаемые значения  отличаются от значений
отличаются от значений  вычисленных по уравнению. Как показано в параграфе 1.2,
вычисленных по уравнению. Как показано в параграфе 1.2,  . Остатки содержат всю мыслимую
. Остатки содержат всю мыслимую
 исследовании остатков см. гл. 3.) Пусть
исследовании остатков см. гл. 3.) Пусть  обозначает величину среднего для «истинной» модели при
обозначает величину среднего для «истинной» модели при  Тогда мы можем записать:
Тогда мы можем записать:


 это ошибка смещения при
это ошибка смещения при  Если модель верна, то
Если модель верна, то  Если же модель не верна, то
Если же модель не верна, то  и его значение зависит от «истинной» модели и значения
и его значение зависит от «истинной» модели и значения  Переменная
Переменная  это случайная величина, имеющая нулевое среднее, так как
это случайная величина, имеющая нулевое среднее, так как

 будет ли
будет ли  равно
равно 
 коррелированны и величина
коррелированны и величина  имеет математическое ожидание, или среднее значение
имеет математическое ожидание, или среднее значение  где
где  дисперсия ошибки. Исходя из этого можно далее показать, что остаточный средний квадрат, т. е. величина
дисперсия ошибки. Исходя из этого можно далее показать, что остаточный средний квадрат, т. е. величина

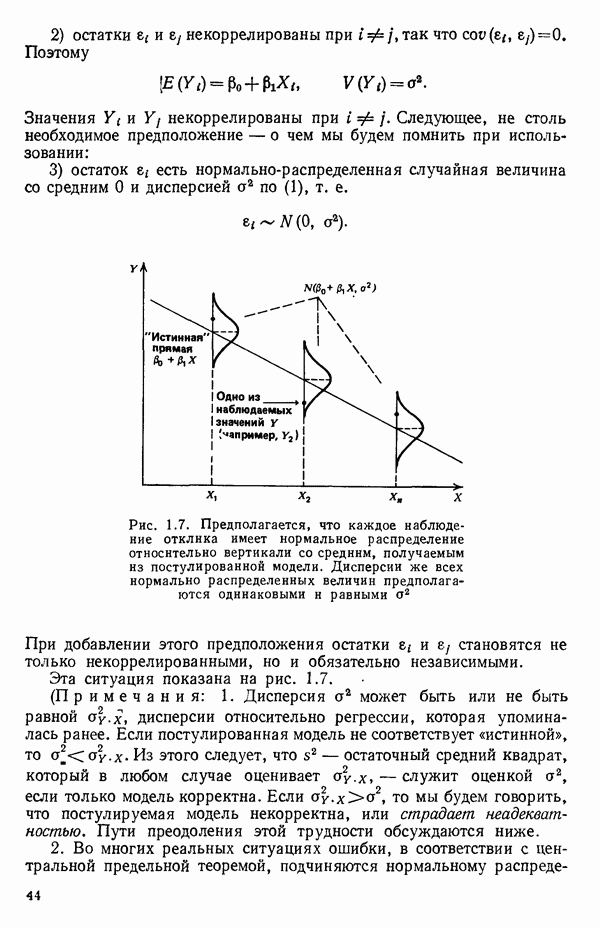
 если постулированная модель корректна, и
если постулированная модель корректна, и  если модель не корректна. Если модель корректна, т. е.
если модель не корректна. Если модель корректна, т. е.  то остатки будут (коррелированными) случайными отклонениями
то остатки будут (коррелированными) случайными отклонениями  и остаточный средний квадрат можно использовать как оценку дисперсии ошибки
и остаточный средний квадрат можно использовать как оценку дисперсии ошибки 
 то остатки содержат оба компонента: случайный
то остатки содержат оба компонента: случайный  и систематический
и систематический  Мы можем рассматривать их соответственно как случайную ошибку разброса и систематическую ошибку смещения. Таким образом, остаточная сумма квадратов будет иметь тенденцию к разбуханию и перестанет служить удовлетворительной мерой случайных вариаций, имеющихся в наблюдениях. Однако так как средний квадрат есть случайная величина, то может оказаться, что он не будет иметь большого значения, даже если смещение существует. С некоторыми аналогичными задачами в общей проблеме регрессии можно познакомиться в параграфе 2.12.
Мы можем рассматривать их соответственно как случайную ошибку разброса и систематическую ошибку смещения. Таким образом, остаточная сумма квадратов будет иметь тенденцию к разбуханию и перестанет служить удовлетворительной мерой случайных вариаций, имеющихся в наблюдениях. Однако так как средний квадрат есть случайная величина, то может оказаться, что он не будет иметь большого значения, даже если смещение существует. С некоторыми аналогичными задачами в общей проблеме регрессии можно познакомиться в параграфе 2.12.
 (под «априорной оценкой» мы понимаем оценку, полученную на основе ранее выполненных опытов, в которых варьировались изучаемые условия), то можно увидеть (или проверить по F-критерию), значимо ли остаточная сумма квадратов превышает нашу априорную оценку. Если она значимо больше, то мы говорим, что имеет место неадекватность и следует пересмотреть модель, поскольку в данной форме она непригодна. Если априорной оценки
(под «априорной оценкой» мы понимаем оценку, полученную на основе ранее выполненных опытов, в которых варьировались изучаемые условия), то можно увидеть (или проверить по F-критерию), значимо ли остаточная сумма квадратов превышает нашу априорную оценку. Если она значимо больше, то мы говорим, что имеет место неадекватность и следует пересмотреть модель, поскольку в данной форме она непригодна. Если априорной оценки  нет, но измерения
нет, но измерения  повторялись (два раза или более) при одинаковых значениях X, то мы можем использовать эти повторения для получения оценки
повторялись (два раза или более) при одинаковых значениях X, то мы можем использовать эти повторения для получения оценки  Про такую оценку говорят, что она представляет «чистую» ошибку, потому что если сделать X одинаковыми для двух наблюдений, то только случайные вариации могут влиять на результаты и создавать разброс между ними. Такие различия обычно будут обеспечивать получение оценки
Про такую оценку говорят, что она представляет «чистую» ошибку, потому что если сделать X одинаковыми для двух наблюдений, то только случайные вариации могут влиять на результаты и создавать разброс между ними. Такие различия обычно будут обеспечивать получение оценки  которая более надежна, чем оценки, получаемые из любых других источников. По этой причине имеет смысл при планировании экспериментов ставить опыты с повторениями.
которая более надежна, чем оценки, получаемые из любых других источников. По этой причине имеет смысл при планировании экспериментов ставить опыты с повторениями.
 (тест на коэффициент интеллекта
(тест на коэффициент интеллекта  от X (рост человека). Можно получить верные повторные точки, если измерять отдельно
от X (рост человека). Можно получить верные повторные точки, если измерять отдельно  у двух людей абсолютно одинакового роста. Если, однако, мы измеряем дважды
у двух людей абсолютно одинакового роста. Если, однако, мы измеряем дважды  одного человека, то сможем получить вовсе не правильные повторные точки в нашем смысле, а только «переподтвержденную» единственную точку. Она будет содержать информацию о разбросе метода испытаний, являющемся составной частью разброса
одного человека, то сможем получить вовсе не правильные повторные точки в нашем смысле, а только «переподтвержденную» единственную точку. Она будет содержать информацию о разбросе метода испытаний, являющемся составной частью разброса  но не сможет обеспечить информацию относительно разброса в
но не сможет обеспечить информацию относительно разброса в  между людьми с одинаковым ростом, определяющим
между людьми с одинаковым ростом, определяющим  в нашей задаче. В химических экспериментах последовательные наблюдения, выполненные при установившемся состоянии, тоже не дают верных повторных точек. Если же, однако, некоторое множество условий проведения опыта устанавливать заново после промежуточных опытов при других уровнях X и в отсутствии дрейфа уровня отклика, то удается получить верные повторные опыты. Имея это в виду, к повторяющимся опытам, обнаруживающим вопреки ожиданиям заметное согласие, следует всегда относиться с осторожностью и подвергать их дополнительному исследованию.)
в нашей задаче. В химических экспериментах последовательные наблюдения, выполненные при установившемся состоянии, тоже не дают верных повторных точек. Если же, однако, некоторое множество условий проведения опыта устанавливать заново после промежуточных опытов при других уровнях X и в отсутствии дрейфа уровня отклика, то удается получить верные повторные опыты. Имея это в виду, к повторяющимся опытам, обнаруживающим вопреки ожиданиям заметное согласие, следует всегда относиться с осторожностью и подвергать их дополнительному исследованию.)
 при одном и том же значении
при одном и том же значении  Пусть мы имеем
Пусть мы имеем  различных значений X и
различных значений X и
 из этих значений
из этих значений  где
где  относятся
относятся  наблюдений. Тогда мы говорим, что
наблюдений. Тогда мы говорим, что


 наблюдений при
наблюдений при  будет равен внутренней сумме квадратов
будет равен внутренней сумме квадратов  относительно их среднего
относительно их среднего 




 безотносительно к тому, корректна ли подобранная модель. Словом, эта величина — полная сумма квадратов «между повторениями (параллельными опытами)», деленная на общее число степеней свободы.
безотносительно к тому, корректна ли подобранная модель. Словом, эта величина — полная сумма квадратов «между повторениями (параллельными опытами)», деленная на общее число степеней свободы.
 в точке
в точке  то
то

 имеет одну степень свободы.)
имеет одну степень свободы.)
 наблюдения при
наблюдения при  можно записать в виде
можно записать в виде

 имеют одно и то же предсказанное значение
имеют одно и то же предсказанное значение  Если мы возведем в квадрат обе части этого выражения, а затем просуммируем их по
Если мы возведем в квадрат обе части этого выражения, а затем просуммируем их по  и по
и по  то получим причем парные произведения исчезают при суммировании по и для каждого
то получим причем парные произведения исчезают при суммировании по и для каждого 


 со
со  -ной точкой
-ной точкой  -распределения при
-распределения при  и
и  степенях свободы. Если это отношение является:
степенях свободы. Если это отношение является:
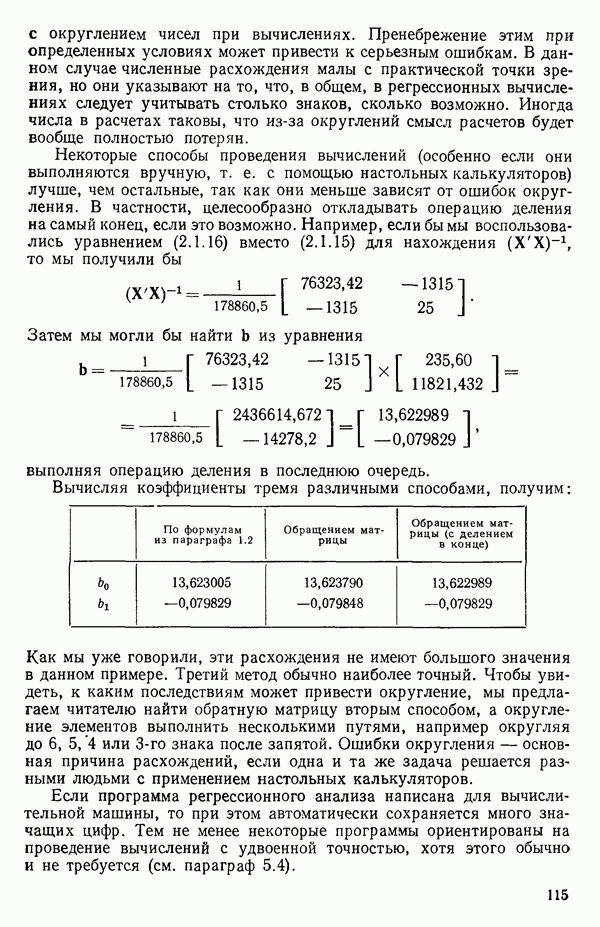
 Объединенная оценка
Объединенная оценка  может быть получена из суммы квадратов, связанной с «чистой» ошибкой, и суммы квадратов, связанной с неадекватностью, путем объединения их в остаточную сумму квадратов и деления ее на остаточное число степеней свободы
может быть получена из суммы квадратов, связанной с «чистой» ошибкой, и суммы квадратов, связанной с неадекватностью, путем объединения их в остаточную сумму квадратов и деления ее на остаточное число степеней свободы  что дает
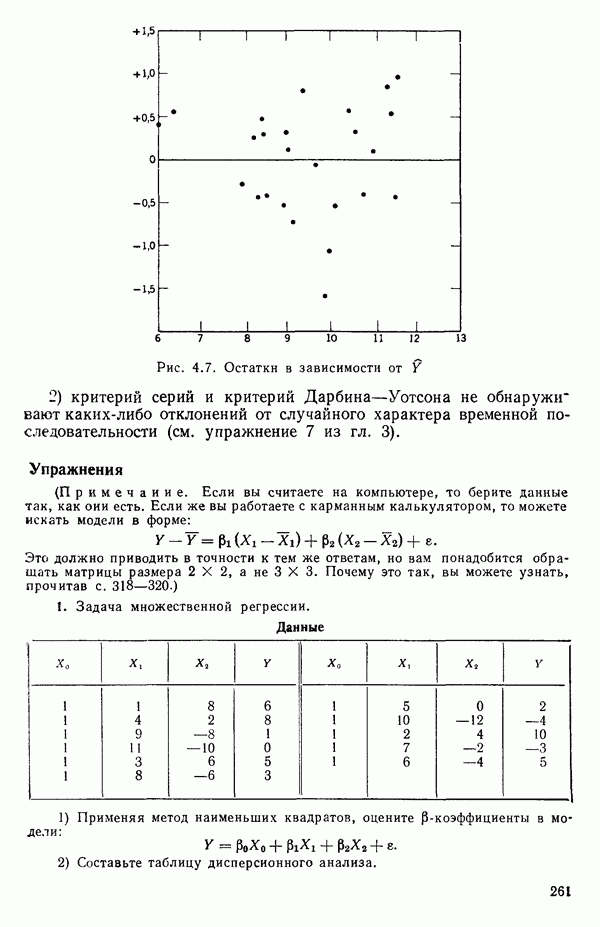
что дает  внимание, что остатки все же должны исследоваться — см. замечания после нижеследующего примера, с. 61.)
внимание, что остатки все же должны исследоваться — см. замечания после нижеследующего примера, с. 61.)
 будет проявлять склонность к переоценке
будет проявлять склонность к переоценке  а
а  -критерий для проверки неадекватности в свою очередь будет иметь тенденцию к ошибочному «определению» отсутствия неадекватности.
-критерий для проверки неадекватности в свою очередь будет иметь тенденцию к ошибочному «определению» отсутствия неадекватности.
 Таблица дисперсионного анализа представлена табл. 1.7. Заметим, что на этом этапе значение F для регрессии не проверяется, поскольку мы еще не знаем, адекватна ли модель.
Таблица дисперсионного анализа представлена табл. 1.7. Заметим, что на этом этапе значение F для регрессии не проверяется, поскольку мы еще не знаем, адекватна ли модель.


 связанная с «чистой» ошибкой, из повторений при
связанная с «чистой» ошибкой, из повторений при  есть
есть  с 1 степенью свободы.
с 1 степенью свободы.
 связанная с «чистой» ошибкой, из повторений при
связанная с «чистой» ошибкой, из повторений при  есть
есть  с 2 степенями свободы. Аналогичные вычисления дают следующие величины:
с 2 степенями свободы. Аналогичные вычисления дают следующие величины:

 не значимо, так как оно меньше единицы
не значимо, так как оно меньше единицы  Поэтому на основе такого критерия по крайней мере нет оснований сомневаться в адекватности нашей модели и можно использовать
Поэтому на основе такого критерия по крайней мере нет оснований сомневаться в адекватности нашей модели и можно использовать  как оценку для
как оценку для  чтобы иметь возможность воспользоваться
чтобы иметь возможность воспользоваться  -критерием для проверки значимости всей регрессии.
-критерием для проверки значимости всей регрессии.

 -критерий состоятелен, только если нет неадекватности представления результатов нашей моделью. Чтобы подчеркнуть этот момент, мы подытожим все необходимые действия, когда наши данные содержат повторные наблюдения:
-критерий состоятелен, только если нет неадекватности представления результатов нашей моделью. Чтобы подчеркнуть этот момент, мы подытожим все необходимые действия, когда наши данные содержат повторные наблюдения:
 -критерий.
-критерий.
 -критерий для неадекватности. Если критерий неадекватности не значим, т. е. нет смысла сомневаться в адекватности модели, то перейти к пункту 46.
-критерий для неадекватности. Если критерий неадекватности не значим, т. е. нет смысла сомневаться в адекватности модели, то перейти к пункту 46.
 -критерий для общей регрессии (см. с. 157) и не пытаться строить доверительные интервалы. Если нет адекватности подобранной модели, то не верны предпосылки, которые лежат в основе этих операций.
-критерий для общей регрессии (см. с. 157) и не пытаться строить доверительные интервалы. Если нет адекватности подобранной модели, то не верны предпосылки, которые лежат в основе этих операций.
 в качестве оценки для
в качестве оценки для  применить
применить  -критерий для общей регрессии, получить доверительные пределы для «истинного» среднего значения
-критерий для общей регрессии, получить доверительные пределы для «истинного» среднего значения  вычислить
вычислить  и т. д. А графики для остатков все-таки надо строить и надо исследовать их особенности (см. гл. 3).
и т. д. А графики для остатков все-таки надо строить и надо исследовать их особенности (см. гл. 3).
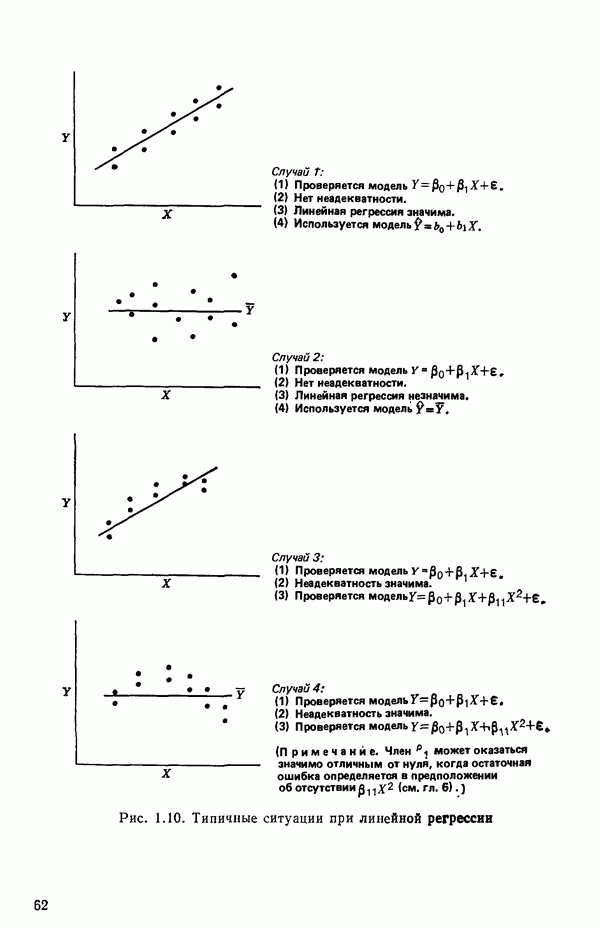
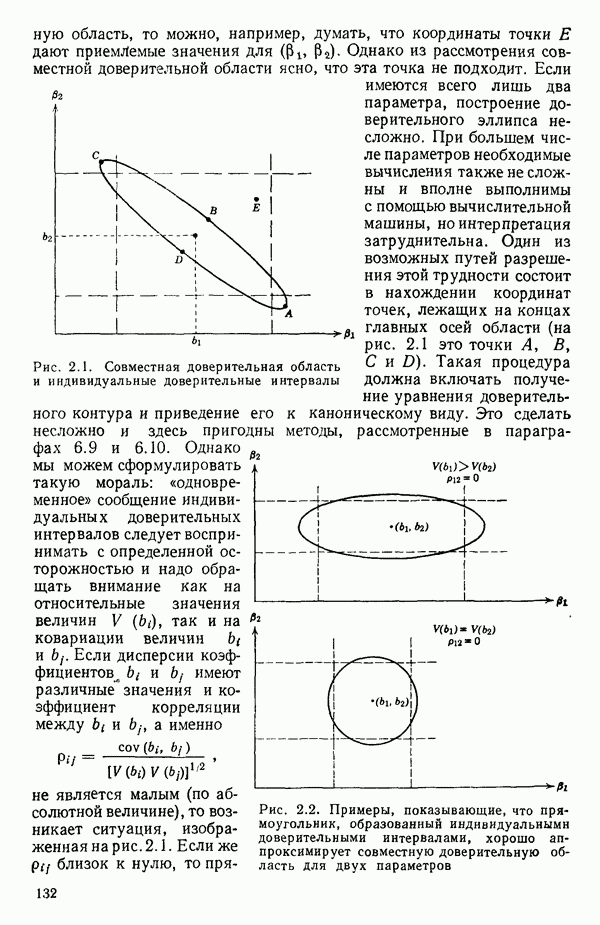
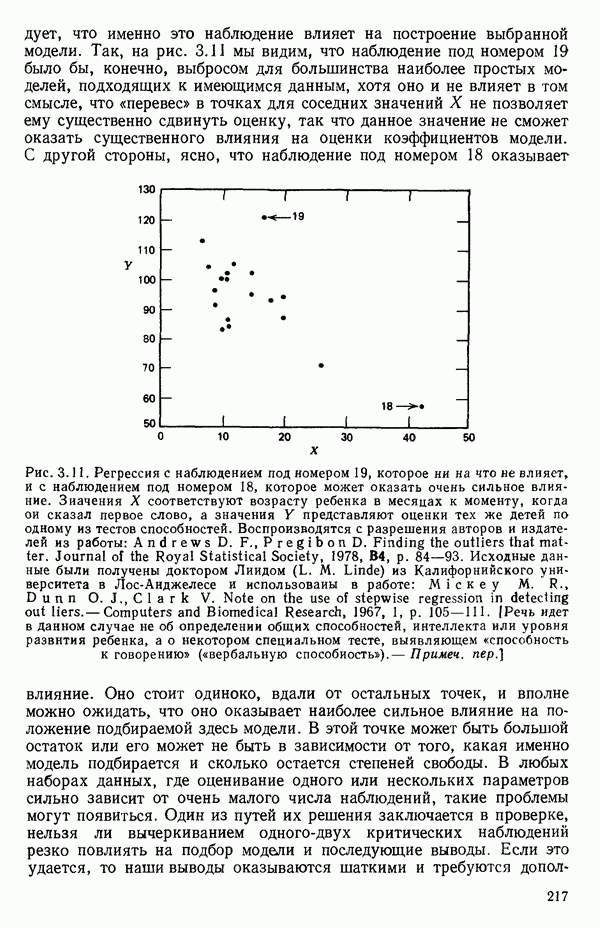
 На рис. 1.10 показаны некоторые ситуации, которые могут возникнуть, когда прямая строится по данным шаг за шагом
На рис. 1.10 показаны некоторые ситуации, которые могут возникнуть, когда прямая строится по данным шаг за шагом
 достигла 1, если есть повторные опыты, сколько бы членов ни использовалось в модели. (Тривиальное исключение появляется, когда
достигла 1, если есть повторные опыты, сколько бы членов ни использовалось в модели. (Тривиальное исключение появляется, когда  что случается крайне редко при повторении опытов.) Никакая модель не может изменить вариацию, обусловленную «чистой» ошибкой (см. решение упражнения 13 из гл. 1).
что случается крайне редко при повторении опытов.) Никакая модель не может изменить вариацию, обусловленную «чистой» ошибкой (см. решение упражнения 13 из гл. 1).
 достижимый при этих данных, есть
достижимый при этих данных, есть


 что фактически достигнуто для подобранной модели, равно:
что фактически достигнуто для подобранной модели, равно:

 или около
или около  того, что вообще может быть объяснено. Этот результат, хоть он и не слишком впечатляющ, выглядит привлекательнее. Такие расчеты часто позволяют глубже понять, чего модель действительно стоит по сравнению с тем, что она могла бы стоить в лучшем случае.
того, что вообще может быть объяснено. Этот результат, хоть он и не слишком впечатляющ, выглядит привлекательнее. Такие расчеты часто позволяют глубже понять, чего модель действительно стоит по сравнению с тем, что она могла бы стоить в лучшем случае.
 ни оказалось в данных. Единственный момент, который надо иметь в виду, состоит в том, что у повторных опытов должны совпадать все координаты, т. е. они должны иметь одни и те же значения для
ни оказалось в данных. Единственный момент, который надо иметь в виду, состоит в том, что у повторных опытов должны совпадать все координаты, т. е. они должны иметь одни и те же значения для  совпадающие значения для и т. д. Например, следующие 4 отклика для 4 точек
совпадающие значения для и т. д. Например, следующие 4 отклика для 4 точек


 во всех этих случаях различны.
во всех этих случаях различны.