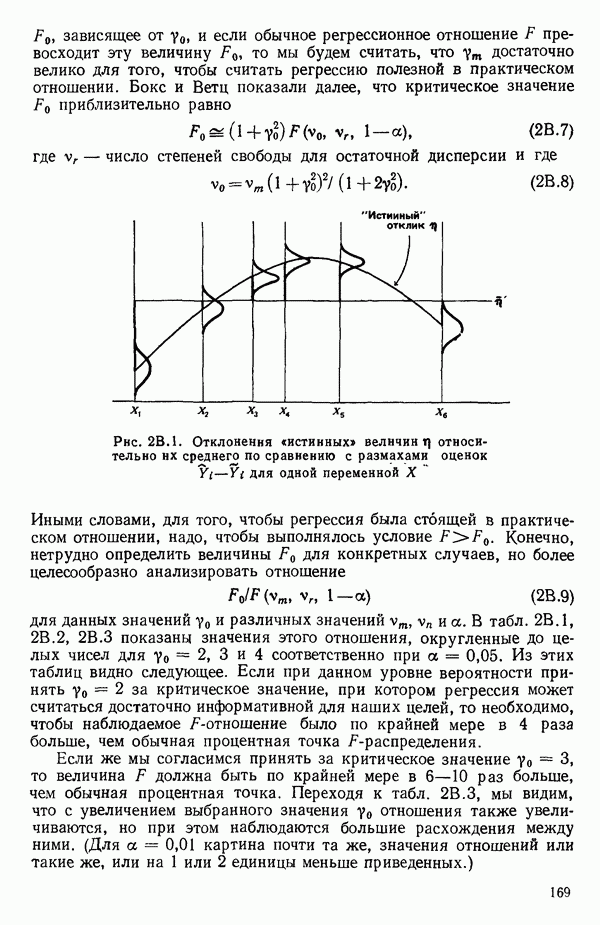
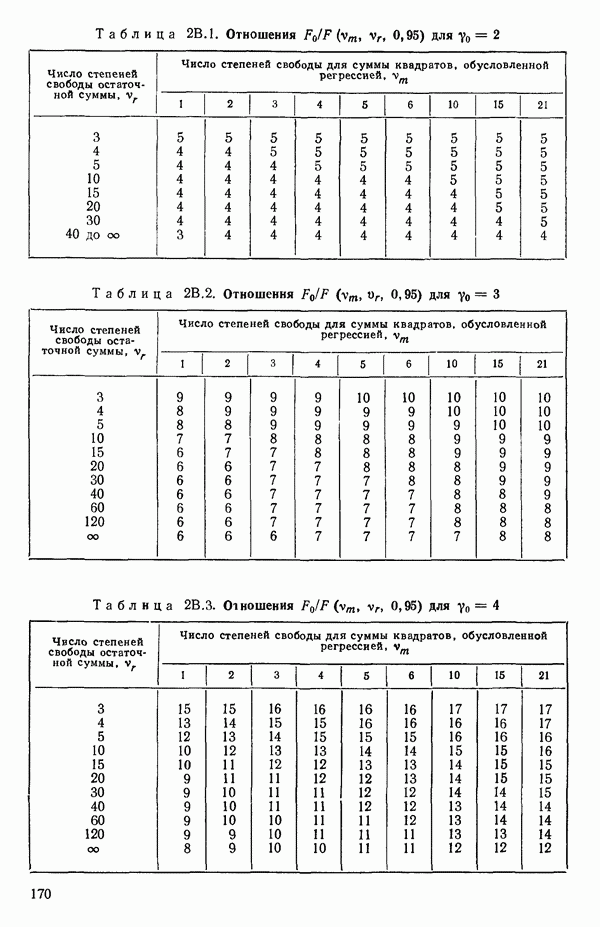
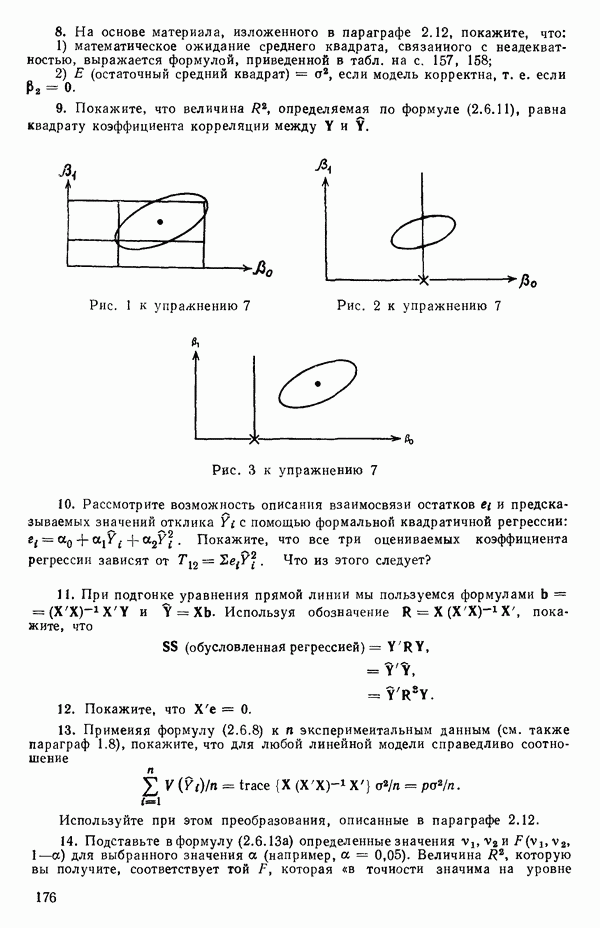
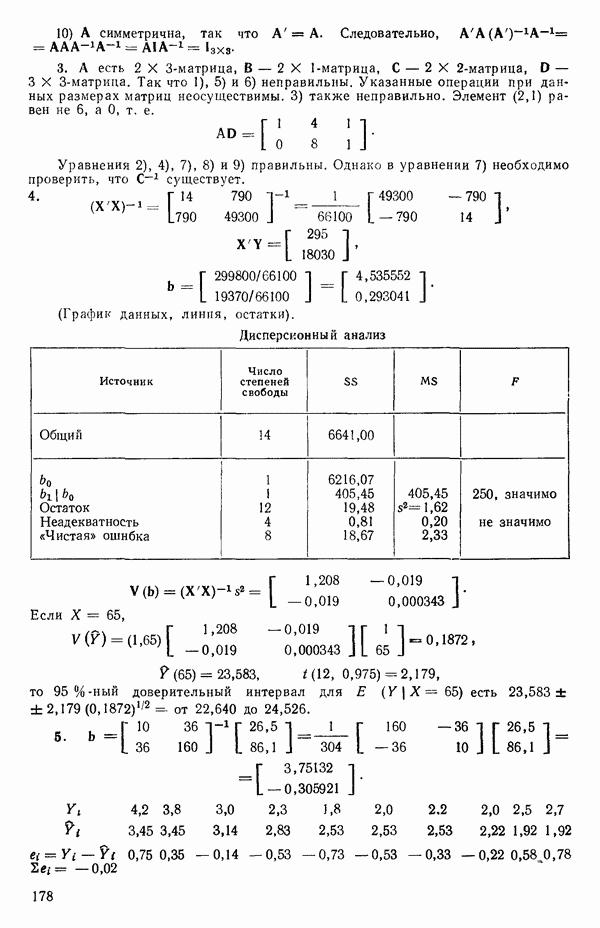
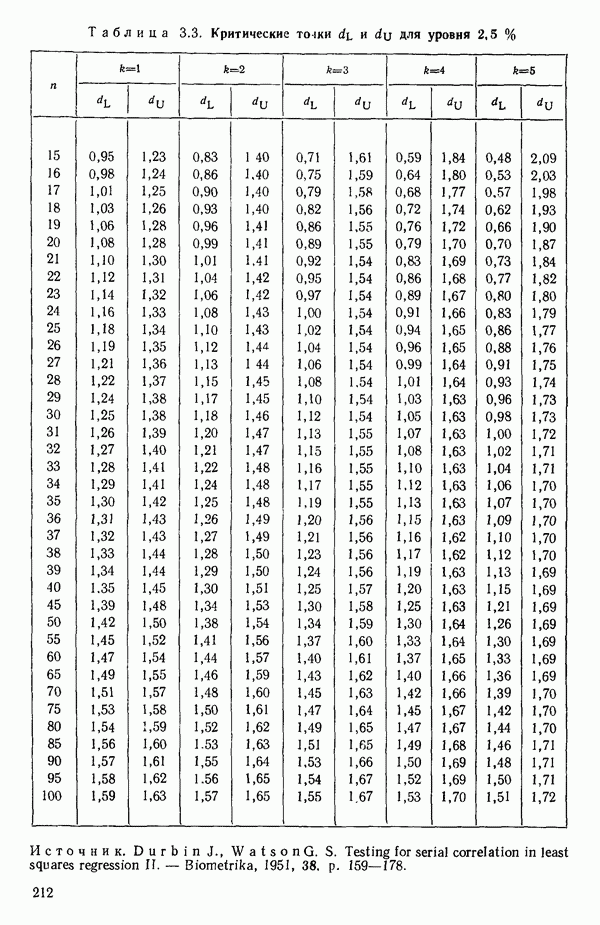
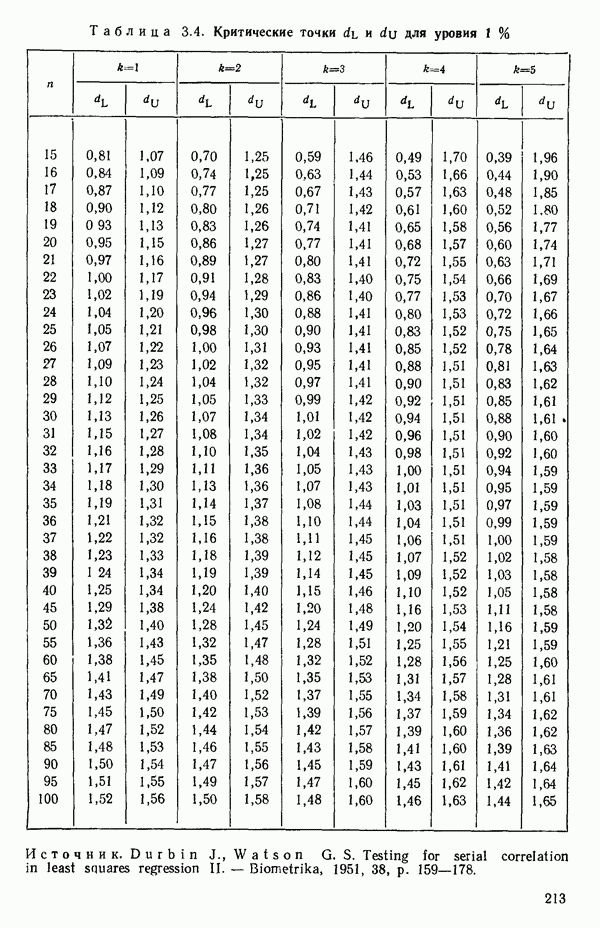
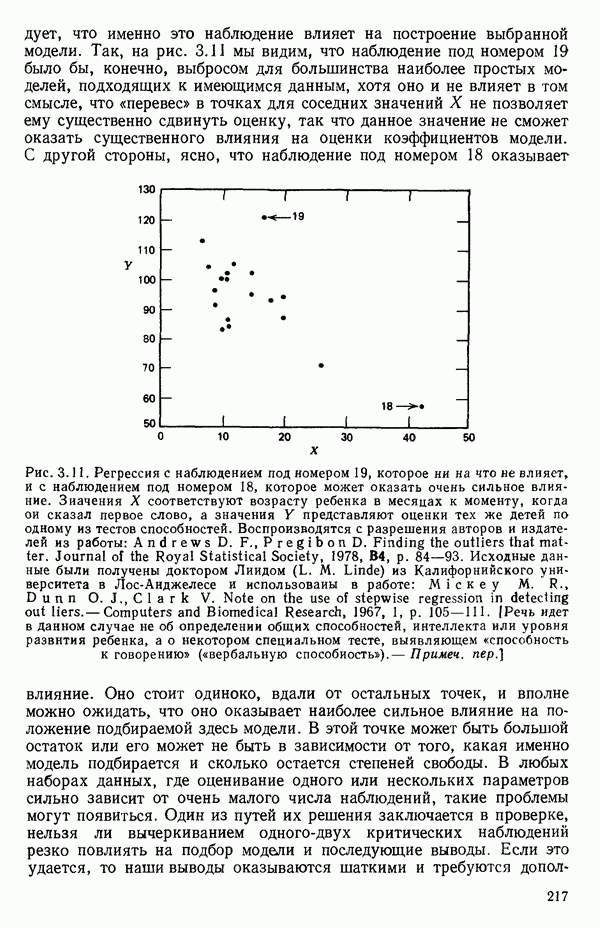
Пред.
След.
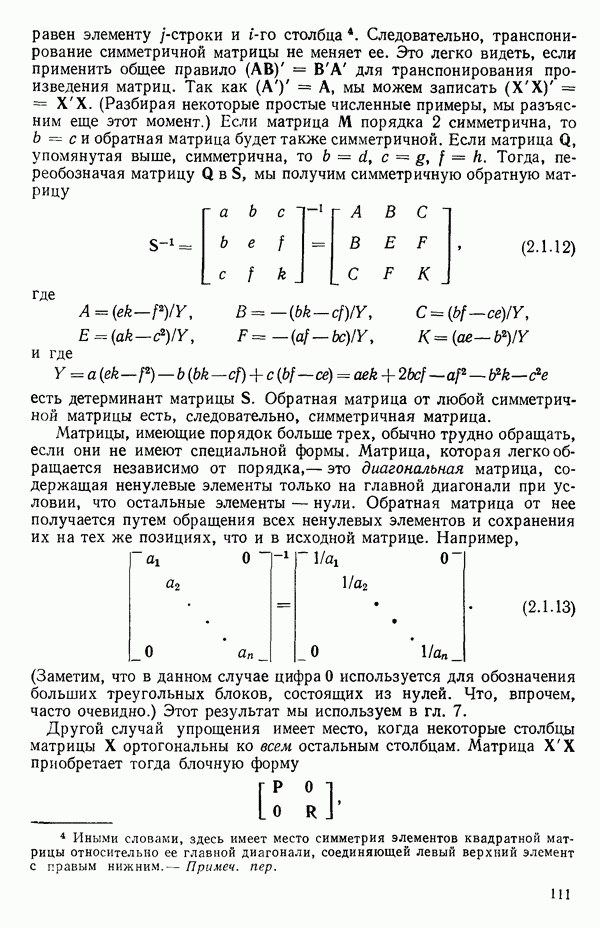
Макеты страниц
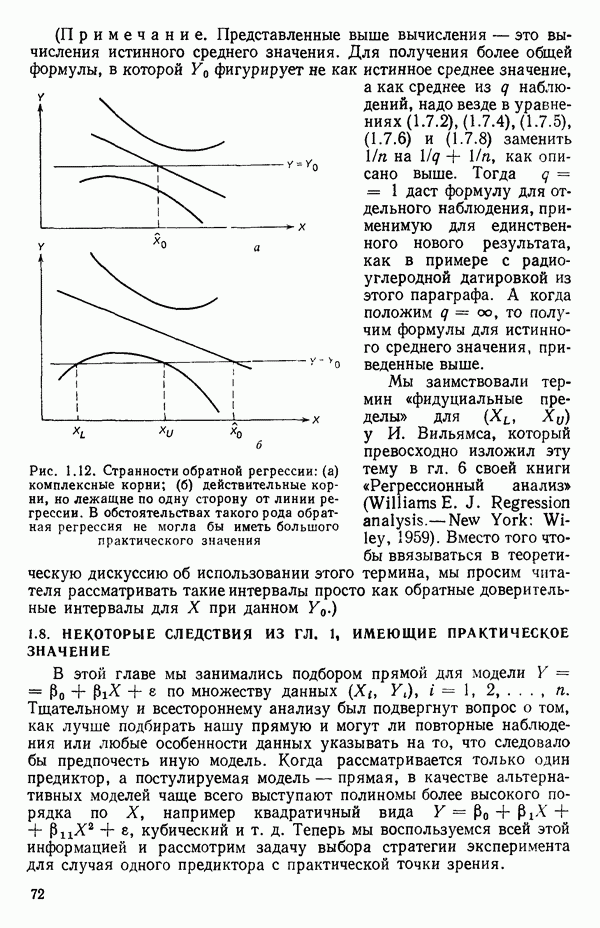
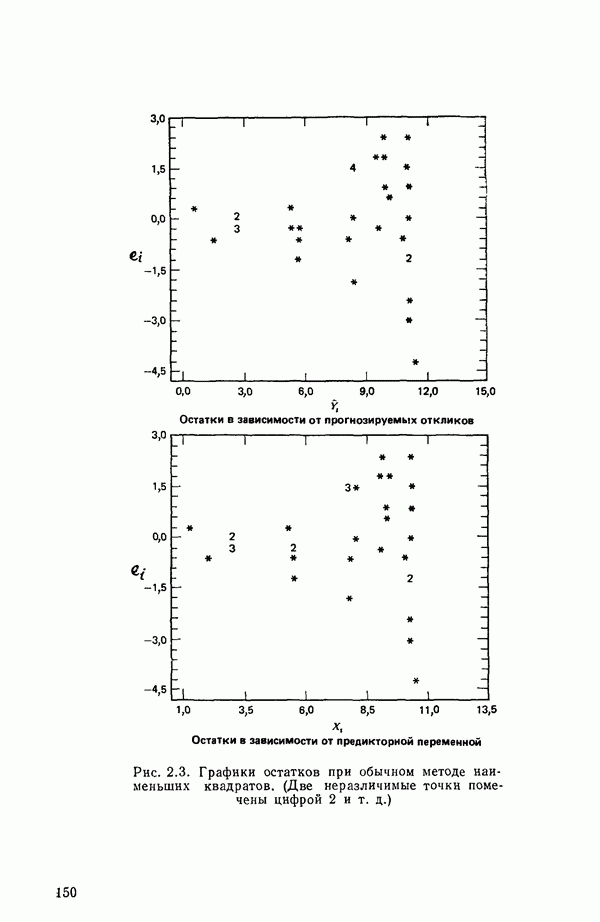
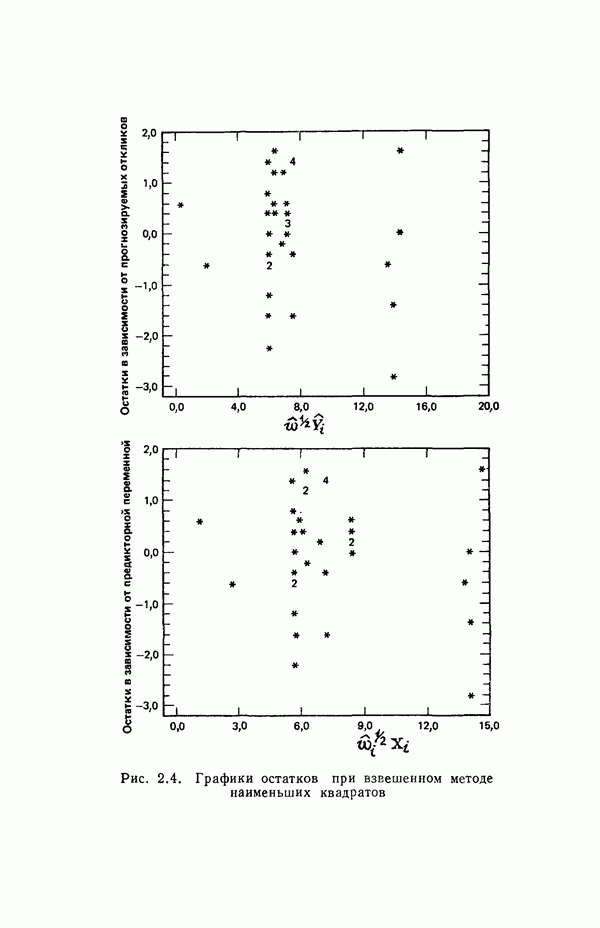
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
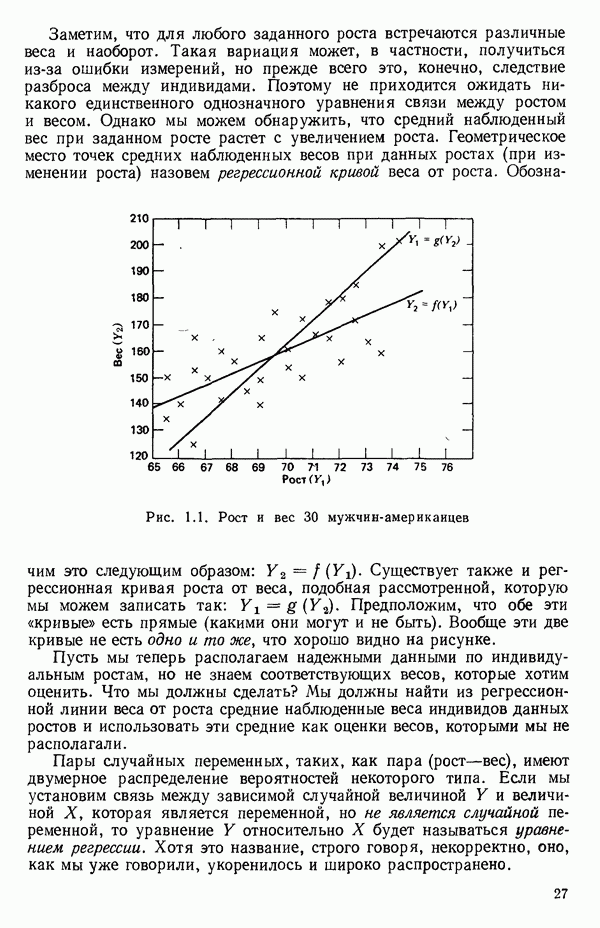
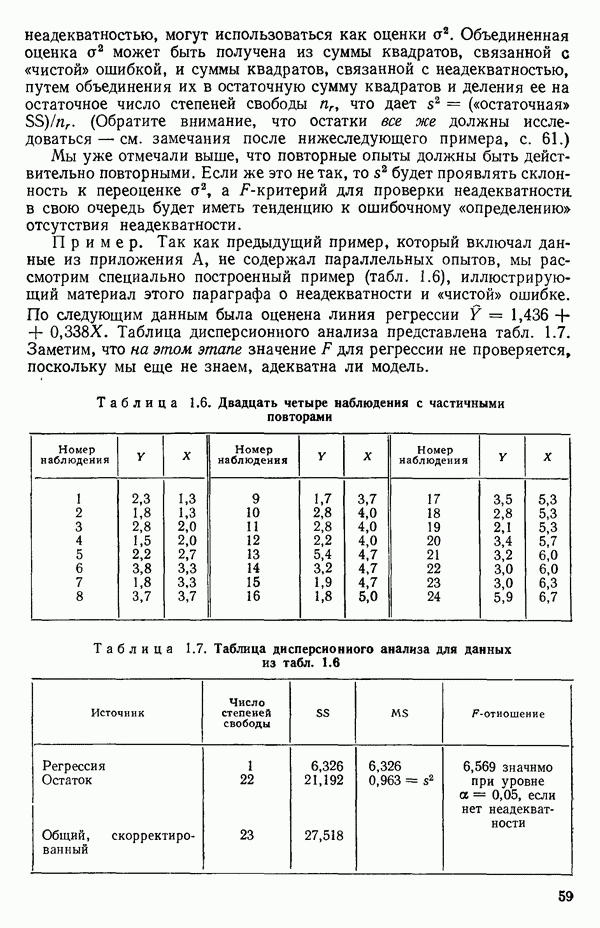
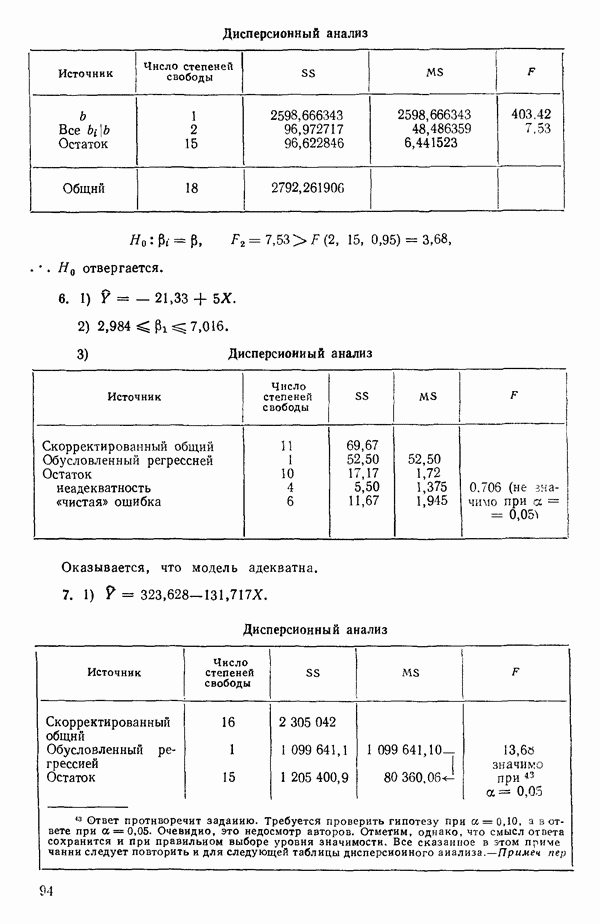
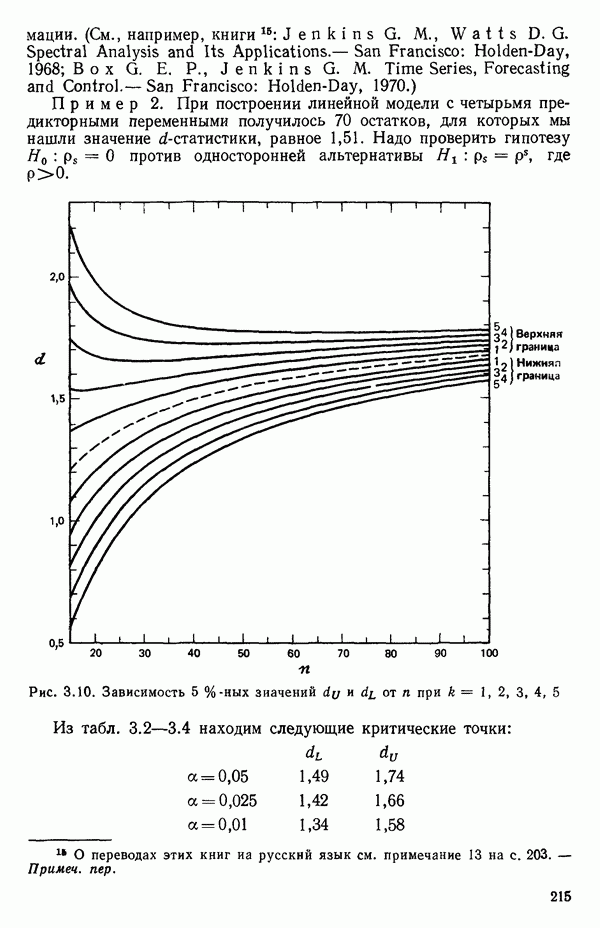
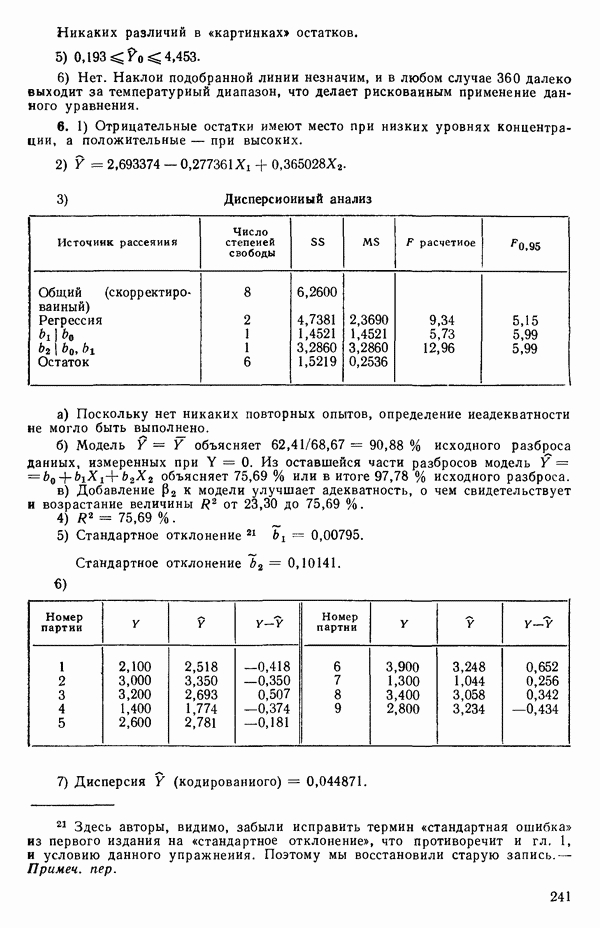
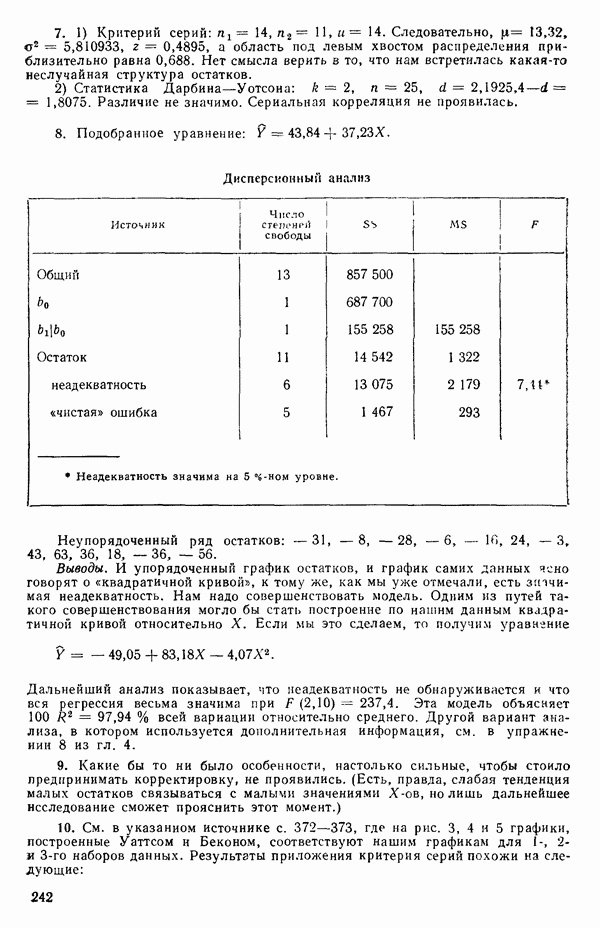
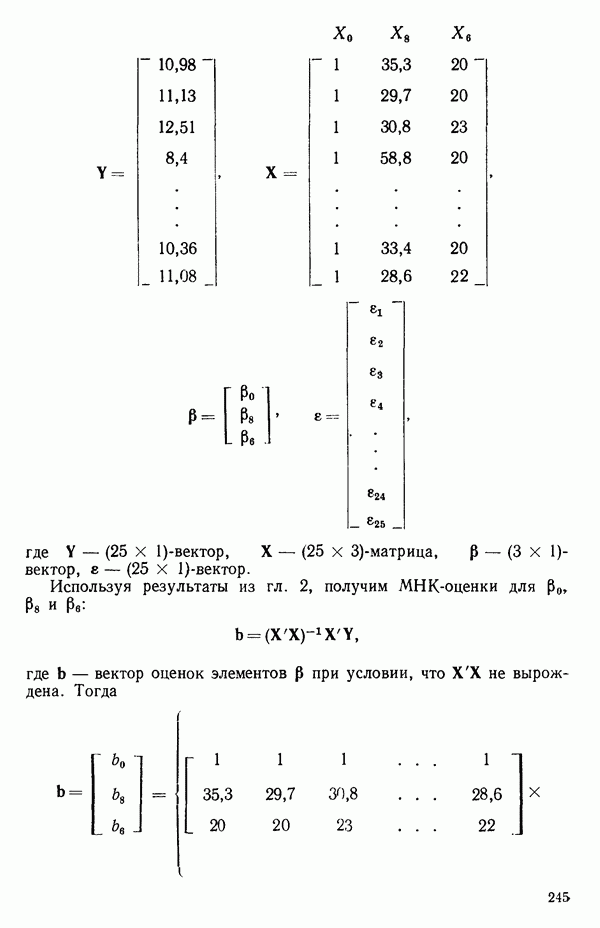
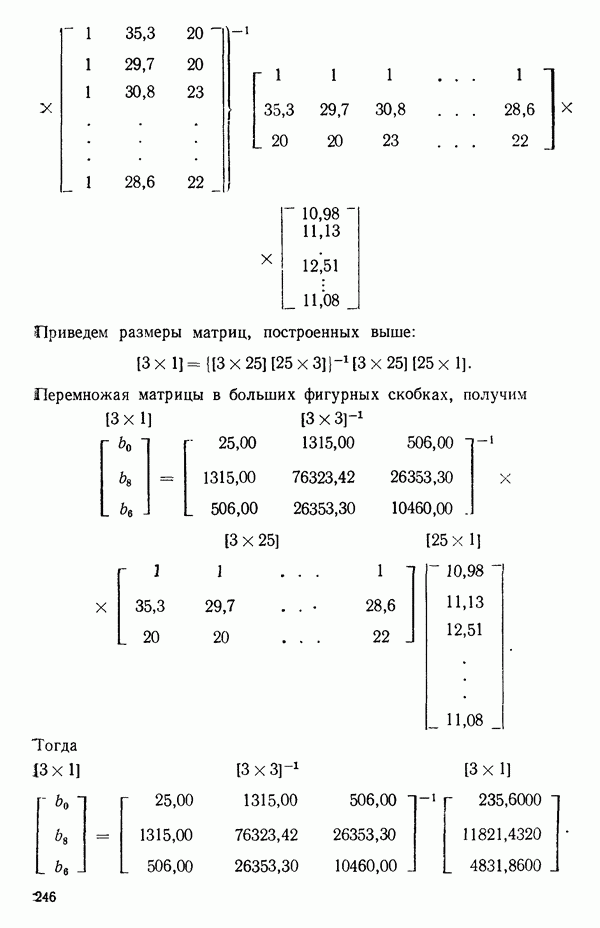
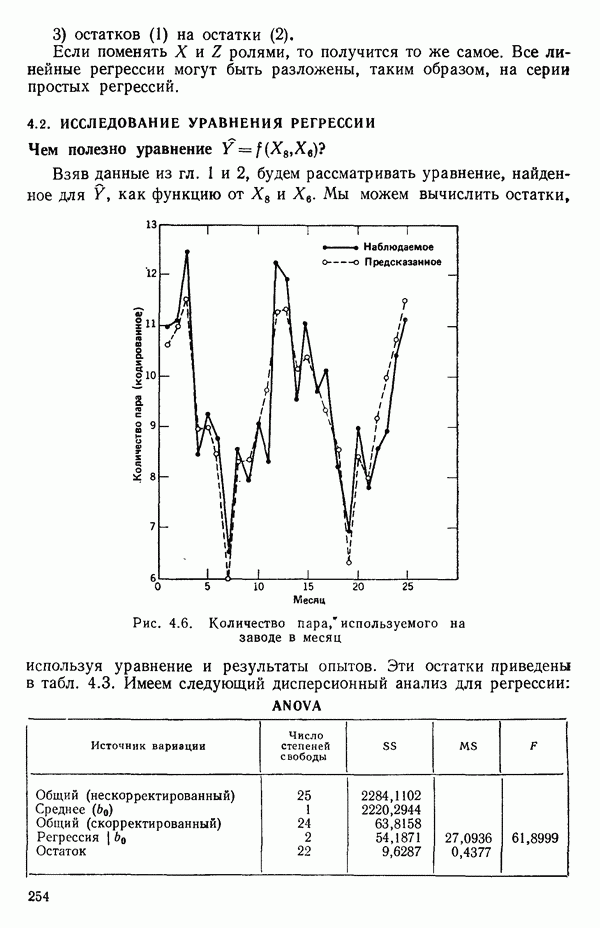
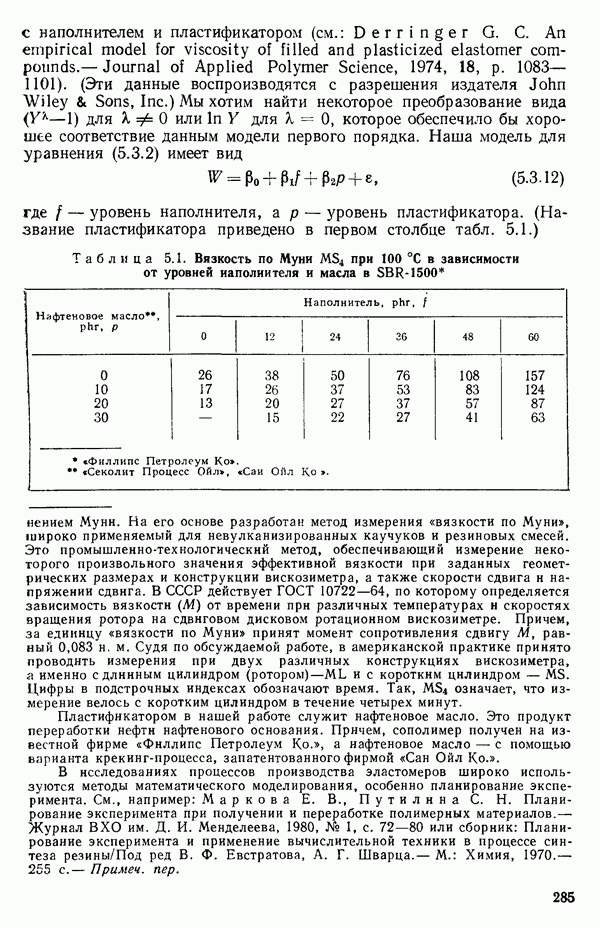
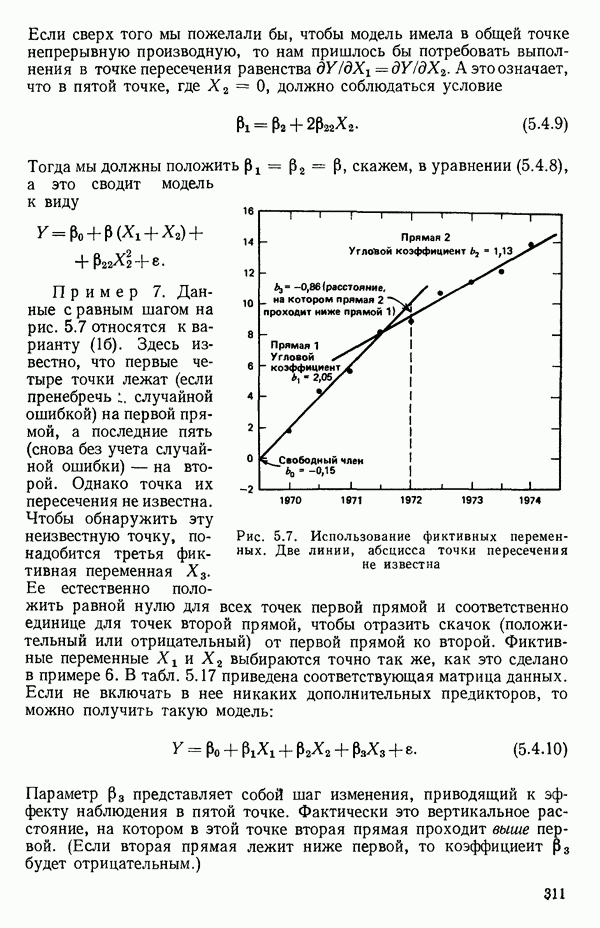
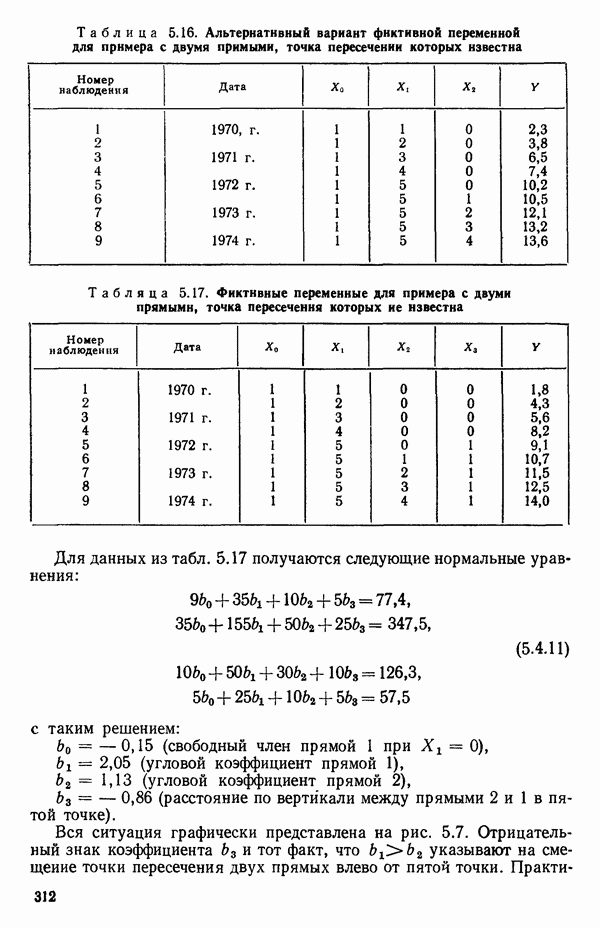
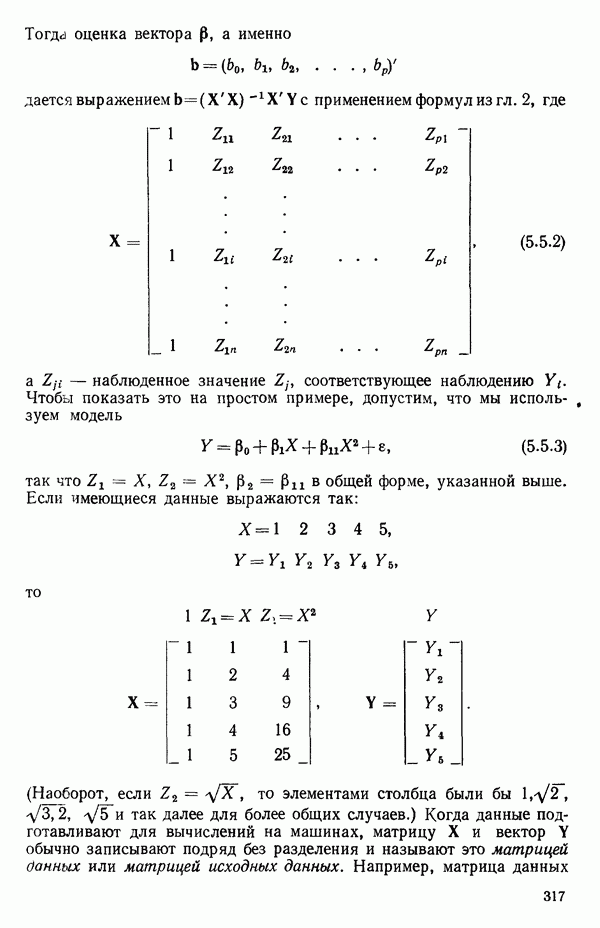
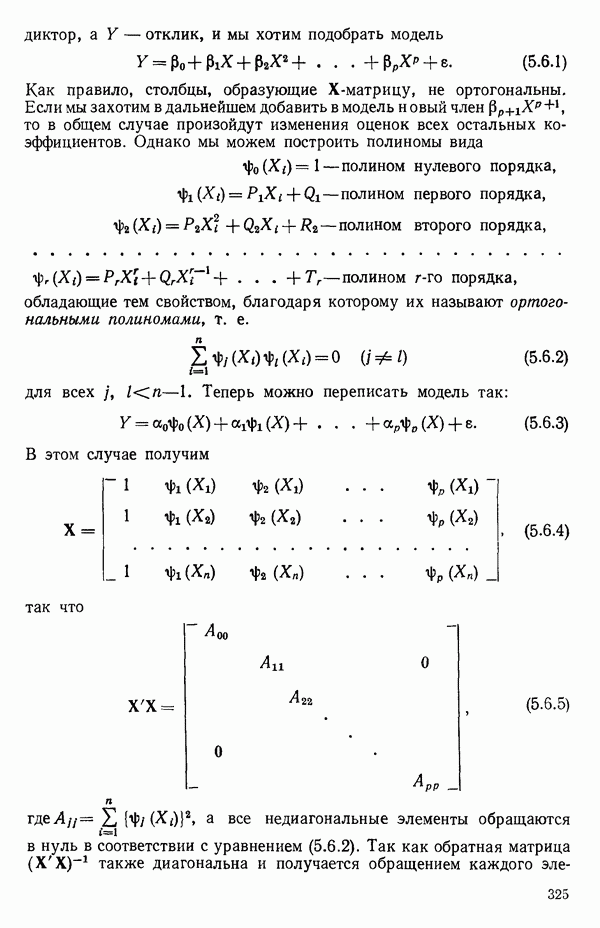
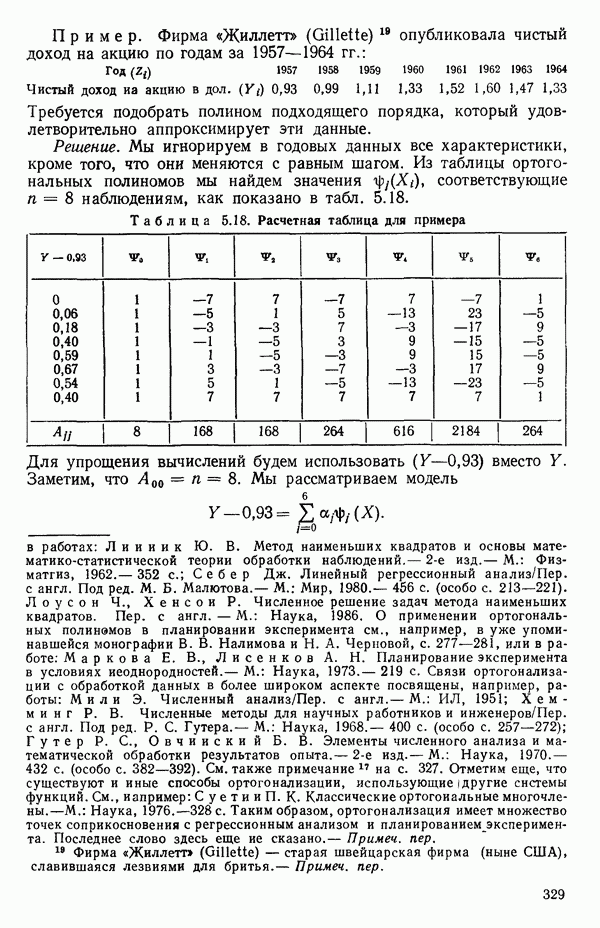
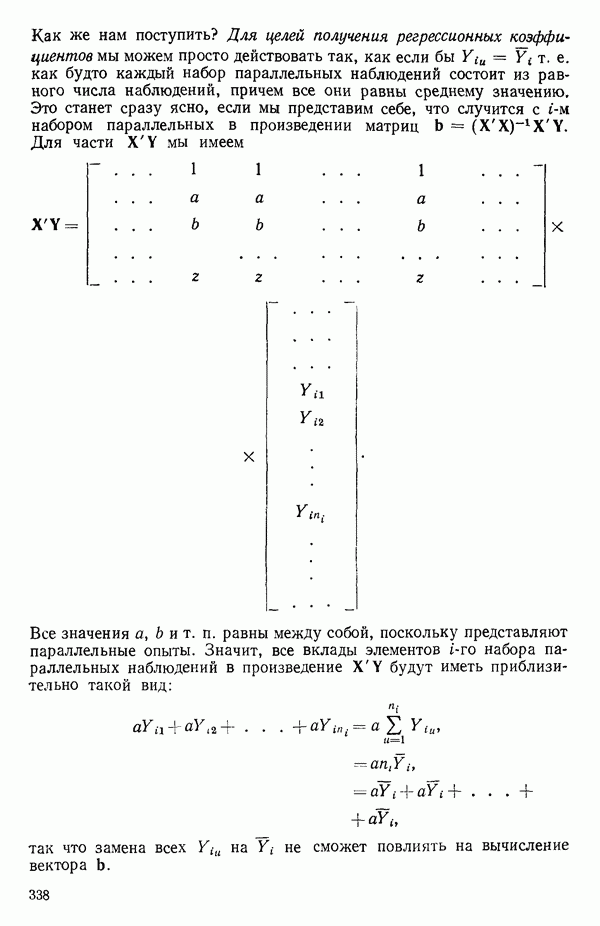
1.2. ЛИНЕЙНАЯ РЕГРЕССИЯ: ПОДБОР ПРЯМОЙМы упоминали, что уравнение прямой может быть полезно во многих ситуациях для обобщения наблюдаемой зависимости одной переменной от другой. Теперь покажем, как такое уравнение можно получить методом наименьших квадратов, когда имеются экспериментальные данные. Выделим в машинной распечатке на с. 30 двадцать пять наблюдений переменной 1 (количество пара (в фунтах), израсходованного за месяц) и переменной 8 (средняя температура воздуха в градусах Фаренгейта). Соответствующие пары наблюдений приведены в табл. 1.1 и нанесены на график рис. 1.4. Предположим, что линия регрессии переменной, которую мы обозначим
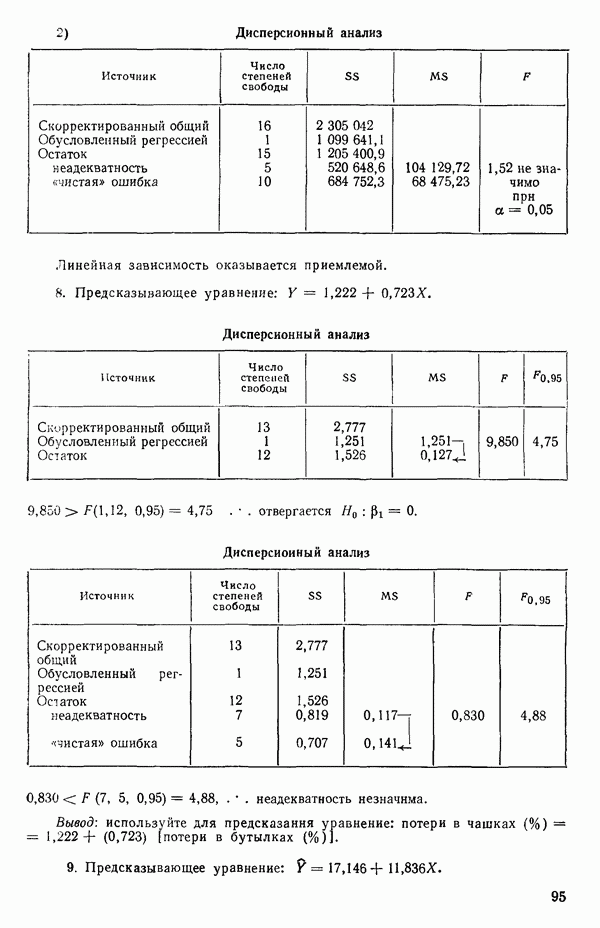
Рис. 1.4. Данные и подобранная прямая Тогда можно записать линейную модель:
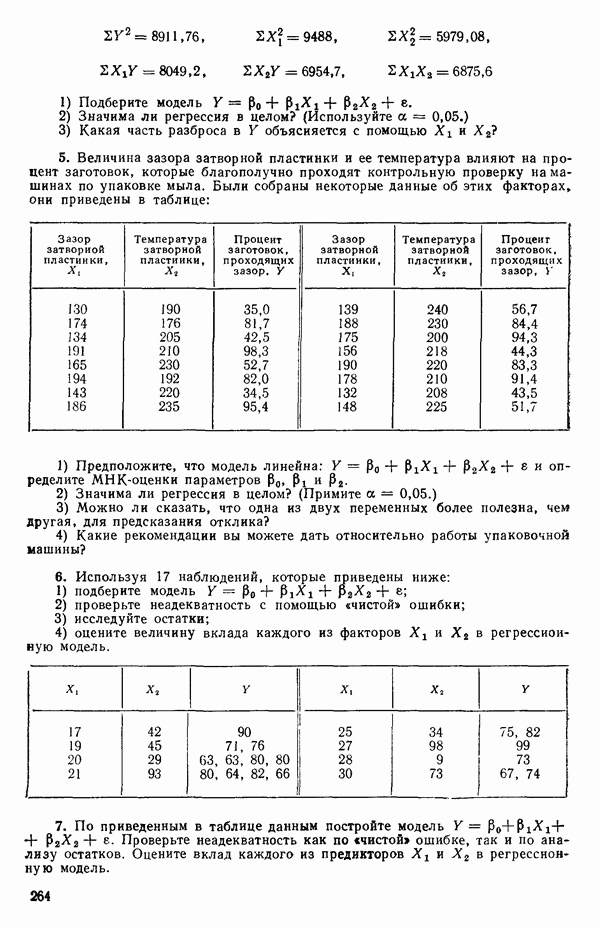
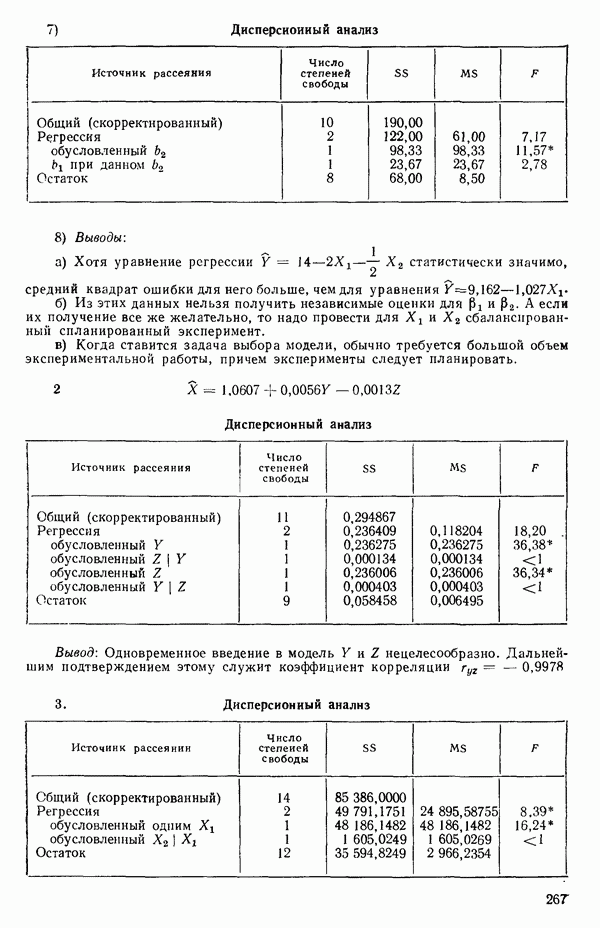
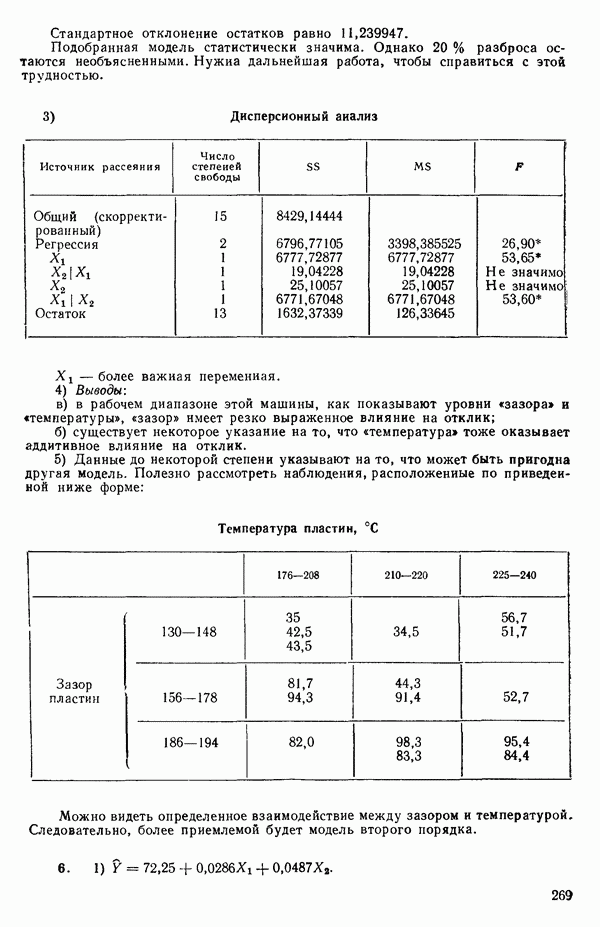
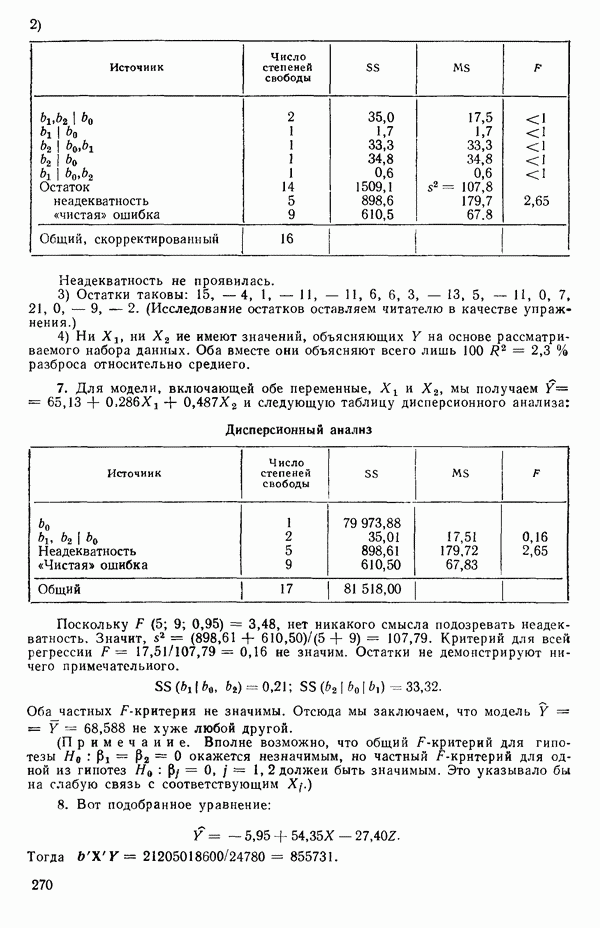
так что для данного X соответствующее значение Таблица 1.1. Двадцать пять наблюдений переменных 1 и 8
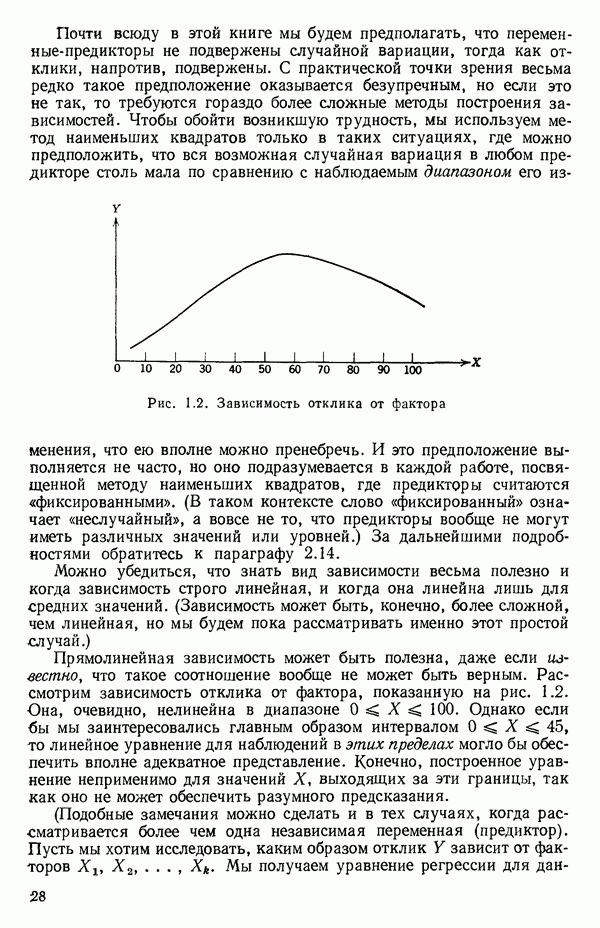
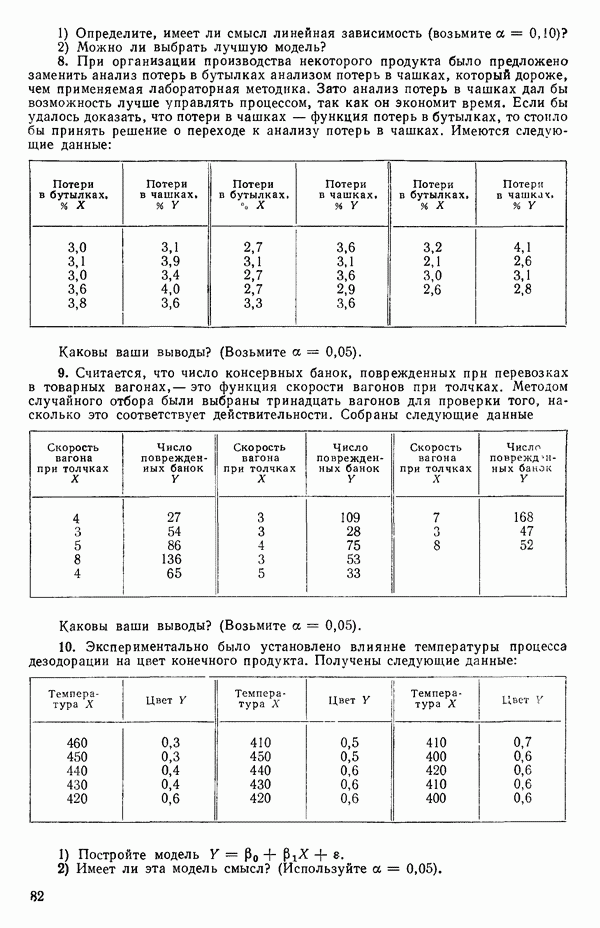
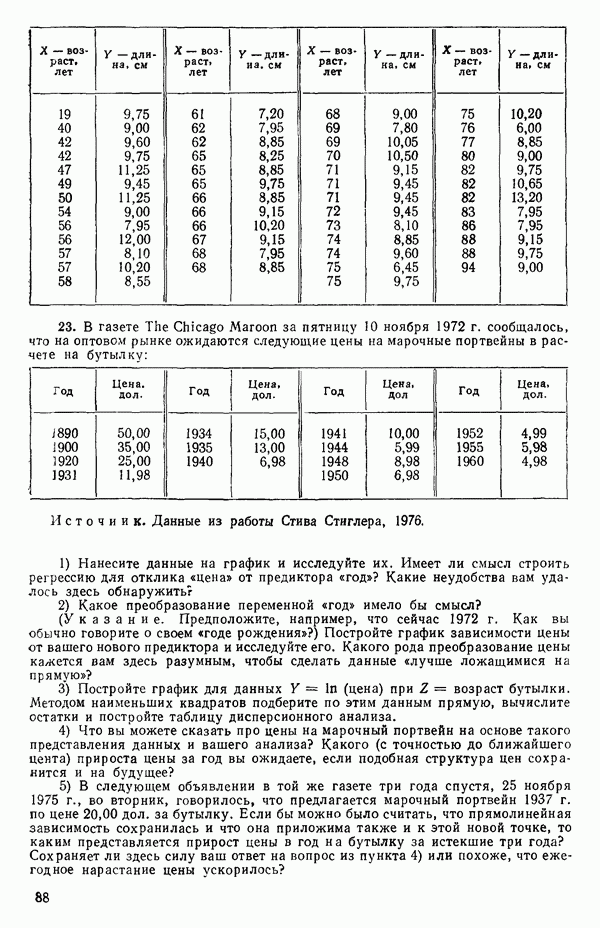
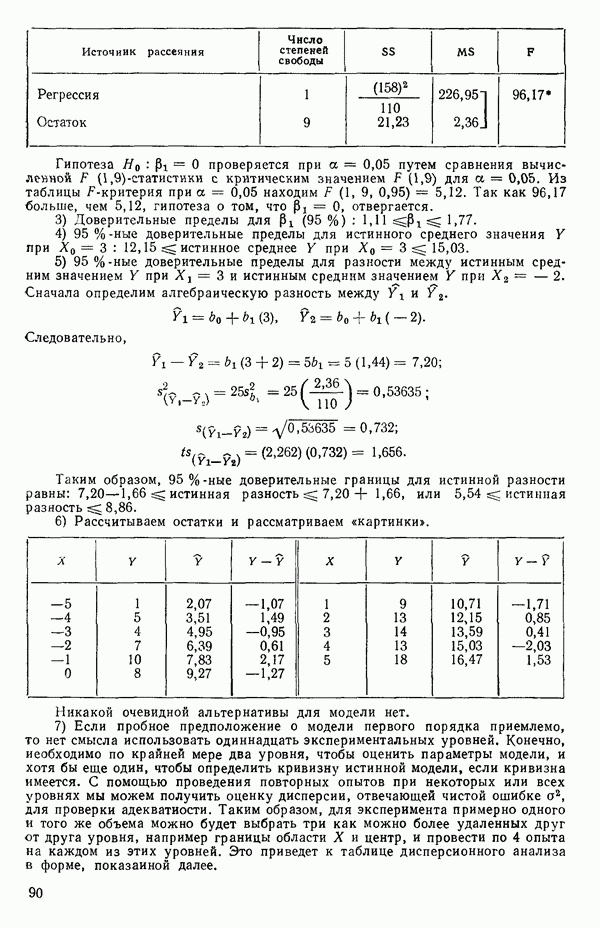
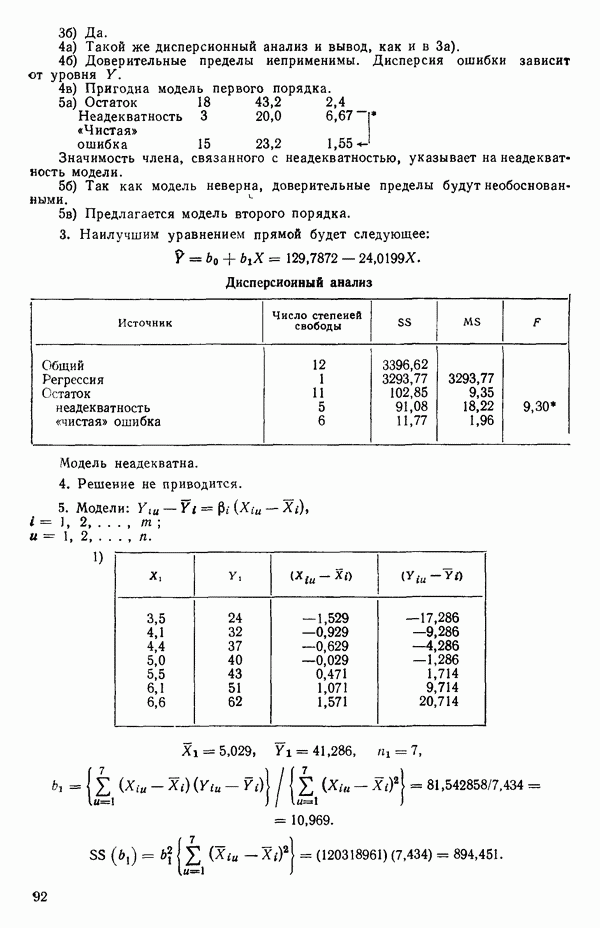
Уравнение (Примечание. Когда мы говорим, что модель линейна или нелинейна, мы имеем в виду линейность или нелинейность по параметрам. Величина наивысшей степени предиктора в модели называется порядком модели. Например,
есть регрессионная модель второго порядка (по X) и линейная (по Итак, в уравнении (1.2.1) величины
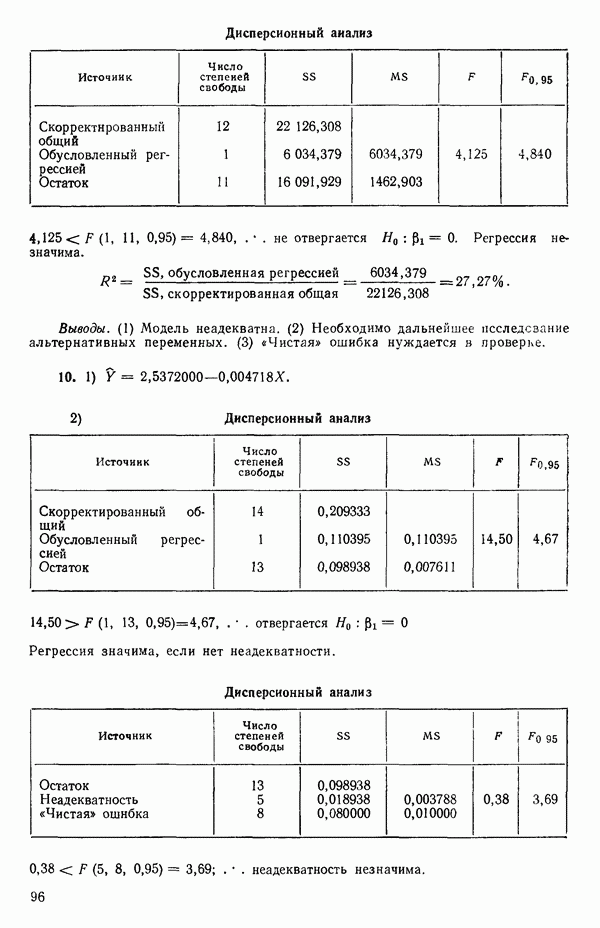
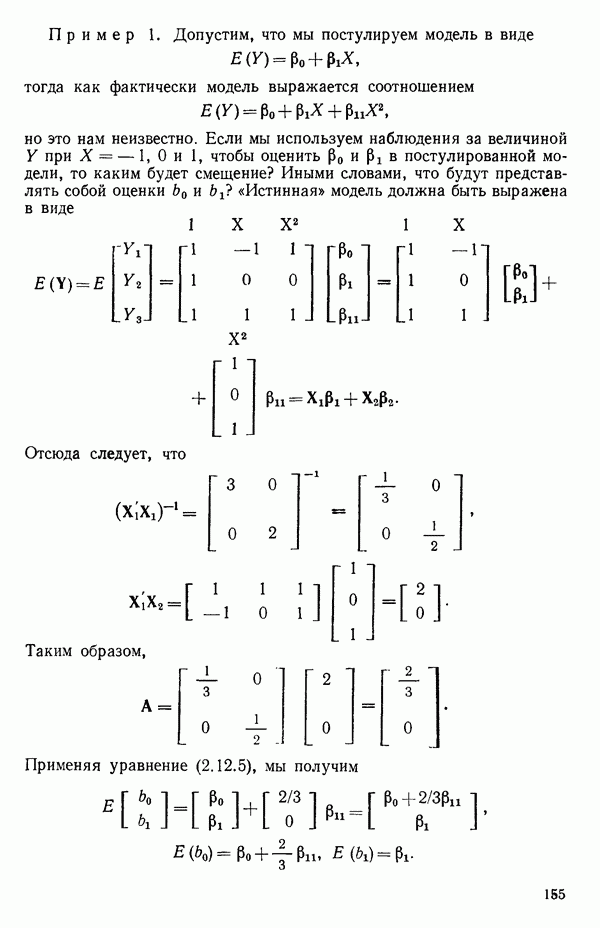
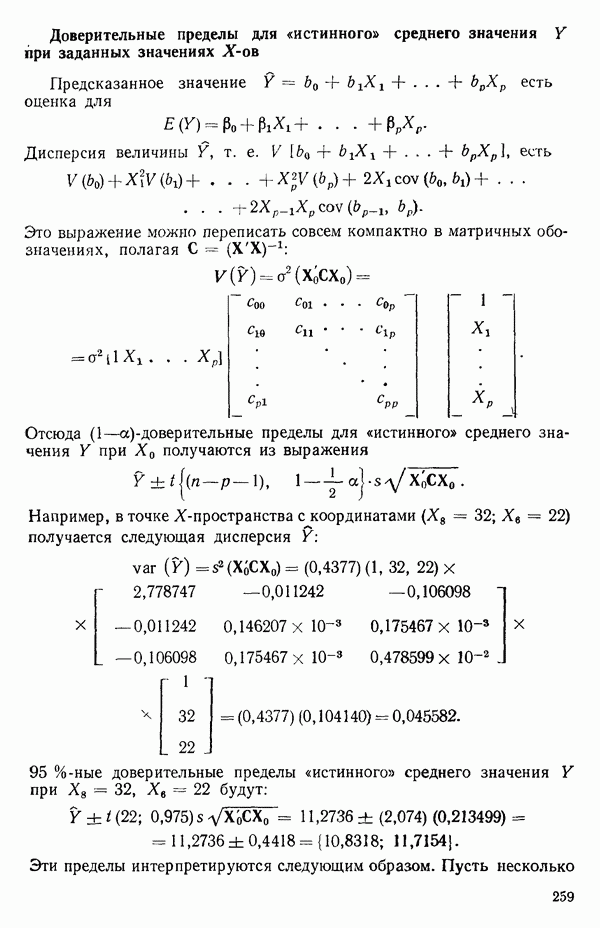
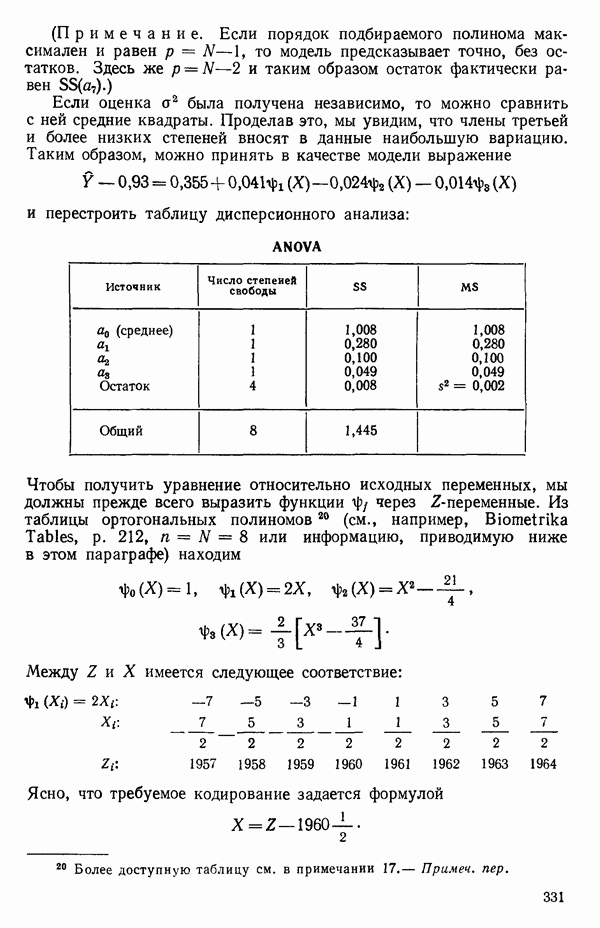
где Общепринято обозначение оценок параметров маленькими латинскими буквами, а самих параметров — греческими: обозначения для оценок: Нашей процедурой оценивания будет метод наименьших квадратов. Возник спор, насчет того, кто же первый предложил этот метод. По-видимому, он был разработан независимо Карлом Фридрихом Гауссом (1777—1855) и Адриеном Мари Лежандром (1752—1833), ибо Гаусс начал им пользоваться до 1803 г. (он настаивал на дате около 1795 г., но доказательств для этой более ранней даты нет), а Лежандр опубликовал первое сообщение в 1805 г. Когда Гаусс в 1809 г. написал, что он пользовался методом наименьших квадратов раньше, чем были опубликованы результаты Лежандра, началась ссора из-за приоритета. Эти данные тщательно изучены и обсуждены в работе Плэкетта из цикла «Исследования по истории теории вероятностей и статистики» (см.: Plackett R. L. Studies in the history of probability and statistics. XXIX. The discovery of the method of least squares.- Biometrika, 1972, 59, p. 239-251), которую мы настоятельно рекомендуем читателю. Еще рекомендуем публикации: Eisenhart С. The meaning of «least» in least squares.- Journal of the Washington Academy of Sciences. 1964, 54, p. 24-33 (перепечатано в Precision Measurement and Calibration, ed. H. H. Ku. National Bureau of Standards Special Publication 300, 1969, 1) и статью «Карл Фридрих Гаусс» из Международной энциклопедии социальных наук (Gauss, Carl Friedrich. International Encyclopedia of the Social Sciences.- New York: Macmillan Co., Free Press Div., 1968, 6, p. 74-81), а также связанную с этой проблемой работу: Stig1ег S. М. Gergonnes’s 1815 paper on the design and analysis of polynomial regression experiments. Historia Mathematica, 1974, 1, p. 431- 447 (cm. c. 433). При некоторых предположениях, которые обсуждаются в гл. 2, этот метод обладает определенными свойствами. Пусть мы имеем множество из
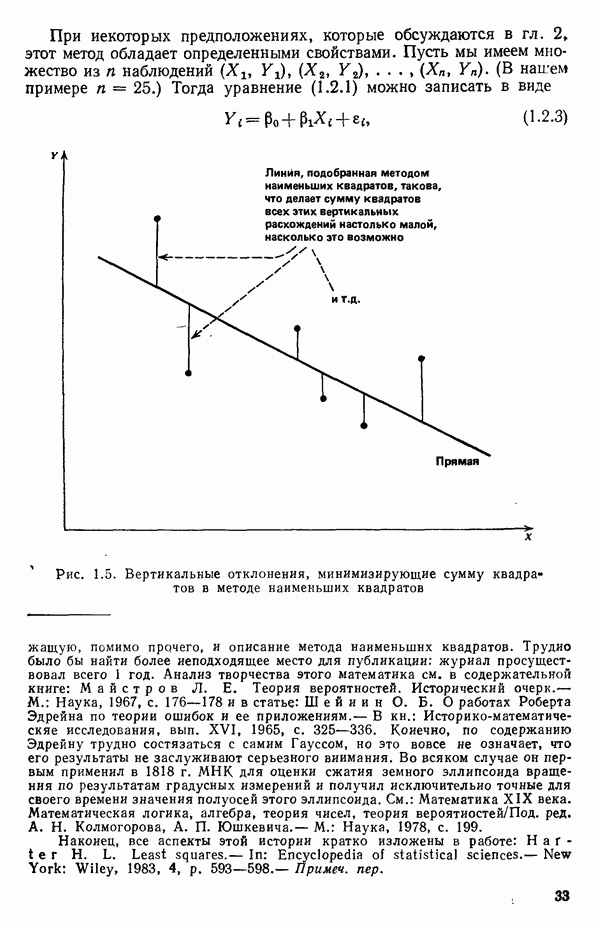
Рис. 1.5. Вертикальные отклонения, минимизирующие сумму квадратов в методе наименьших квадратов где
Будем подбирать значения оценок
так что для оценок
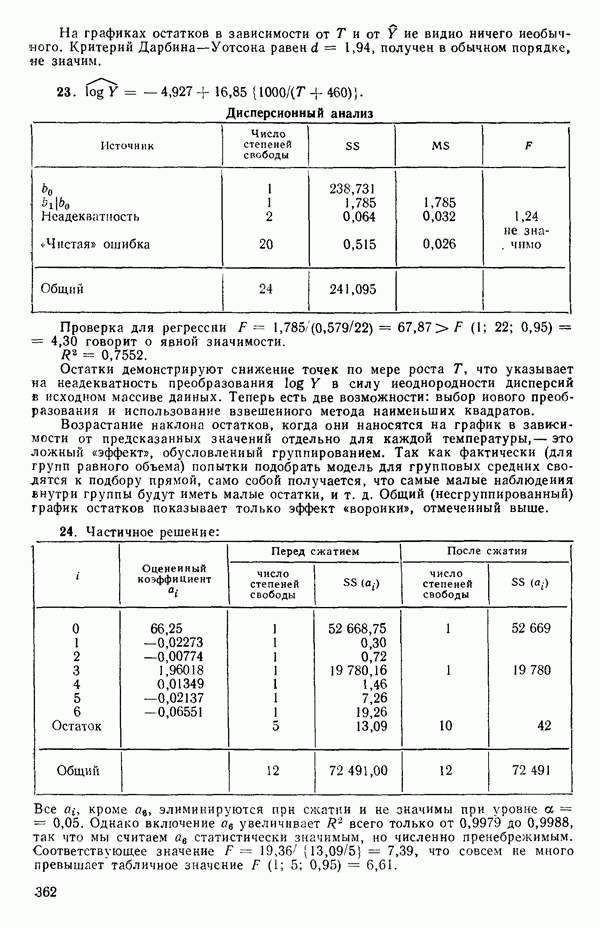
где при приравнивании выражений (1.2.5) к нулю мы подставили
или
Эти уравнения называют нормальными. Решение уравнений (1.2.8) относительно угла наклона прямой —
где суммирование всегда ведется от той же величины. Так как по определению
имеем:
Отсюда следует эквивалентность числителей в (1.2.9), а заодно, при замене Первая форма уравнения (1.2.9) обычно используется для вычисления Здесь и далее возьмем удобные обозначения и запишем:
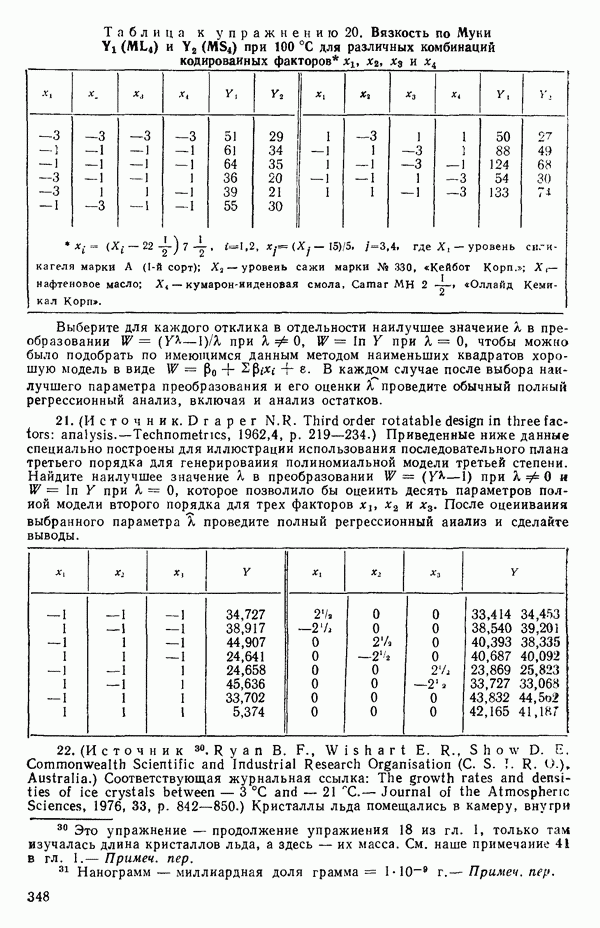
Заметим, что все эти выражения эквивалентны. Аналогично можно записать:
Вот легко запоминающаяся формула для
Решение уравнения (1.2.8) относительно свободного члена (отрезка на оси ординат при
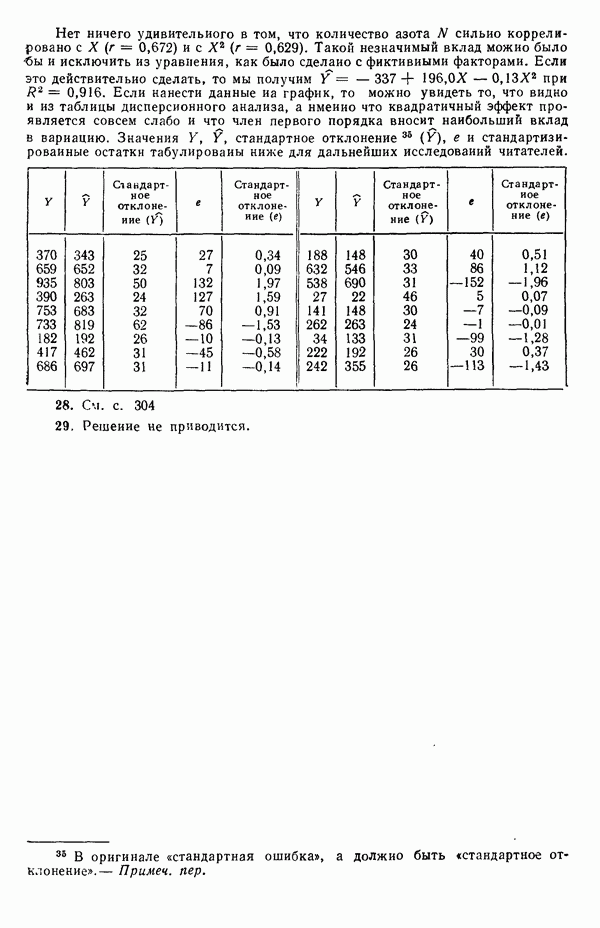
С помощью подстановки уравнения (1.2.10) в уравнение (1.2.2) можно получить оцениваемое уравнение регрессии:
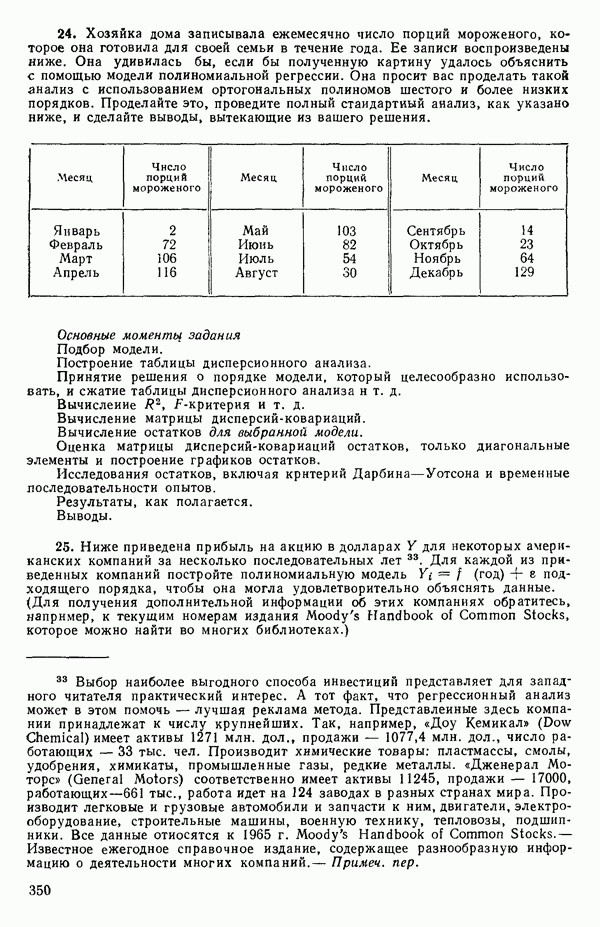
где определяется уравнением (1.2.9). Отметим, что если в (1.2.11) положить
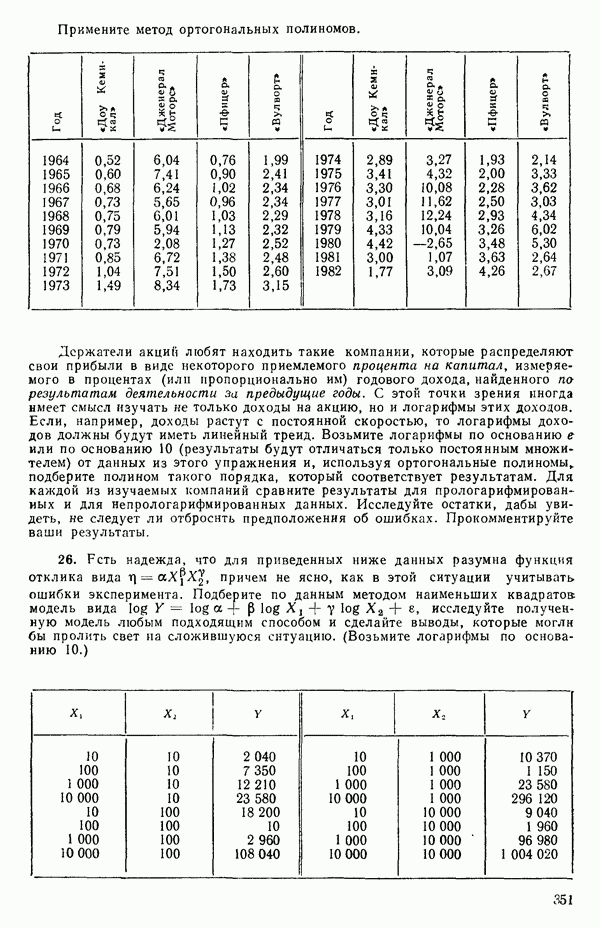
Поэтому подобранное уравнение есть
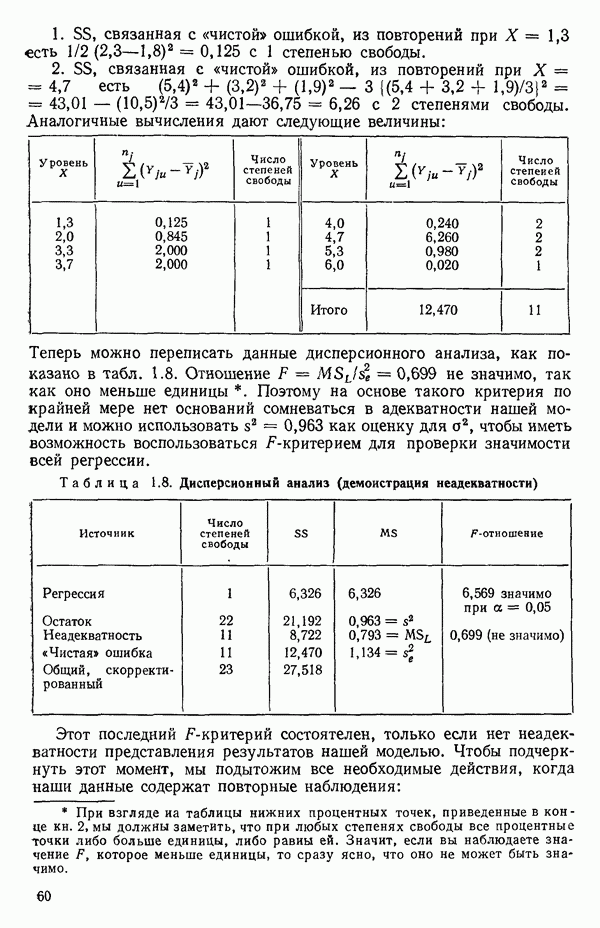
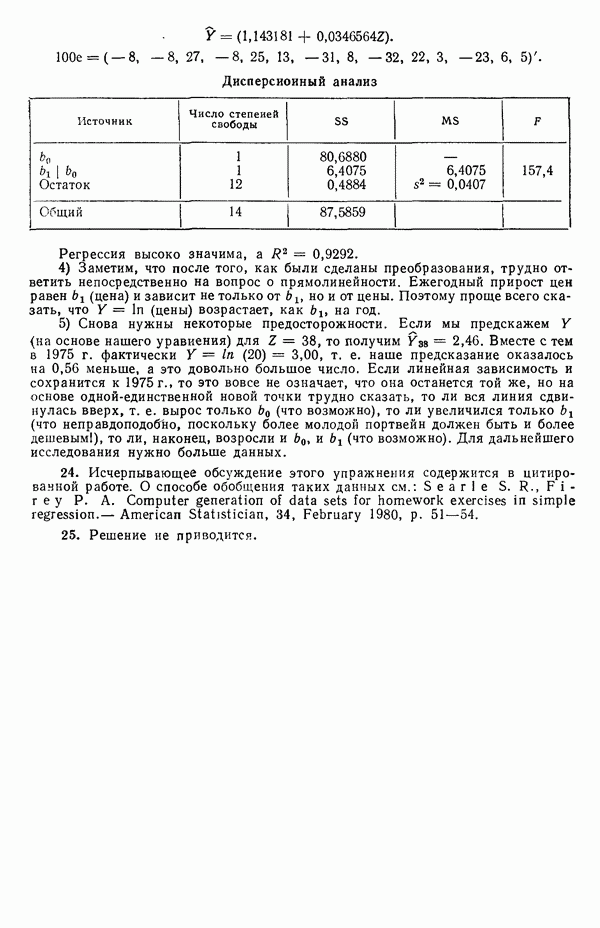
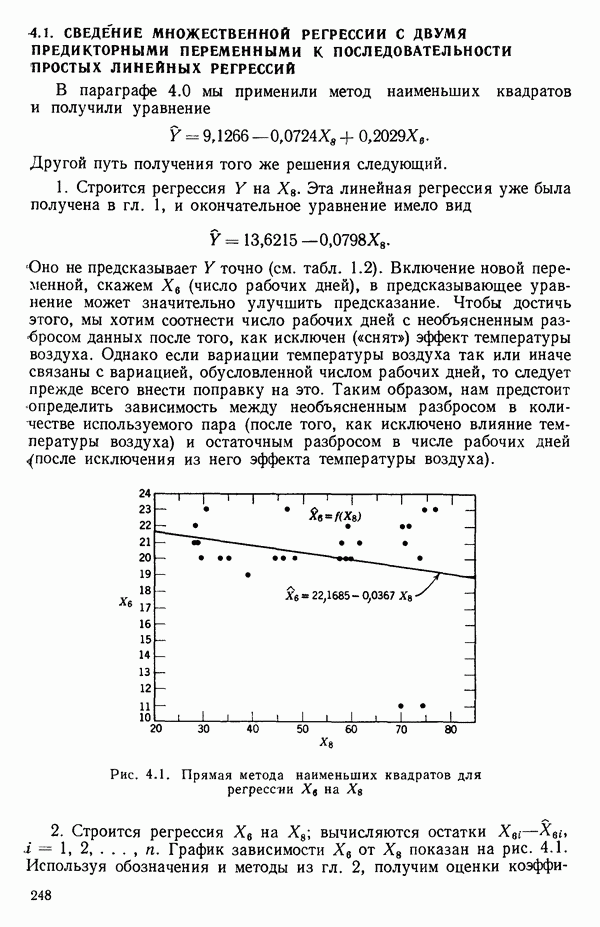
Построенная линия регрессии нанесена на рис. 1.4. Мы можем составить таблицу предсказанных значений Отметим, что так как
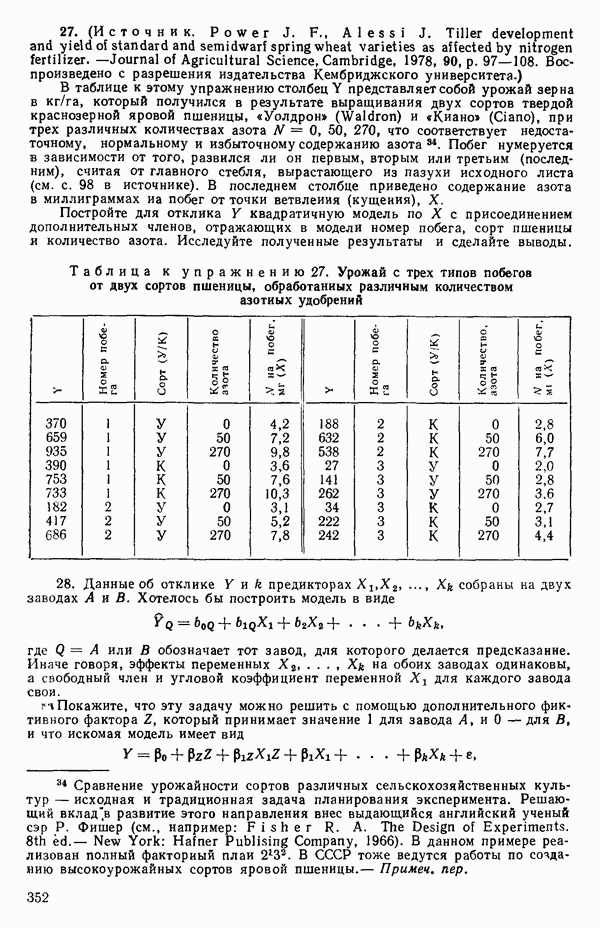
то
Значит и сумма остатков будет равна нулю. На практике из-за ошибок округления она может оказаться не точно равной нулю. Таблица 1.2. Результаты наблюдений, расчетные значения и остатки
В любой регрессионной задаче сумма остатков всегда равна нулю, если член (30 входит в модель. Это следствие первого из нормальных уравнений. Исключение
или
где
в соответствии с уравнением (1.2.9) и
так как
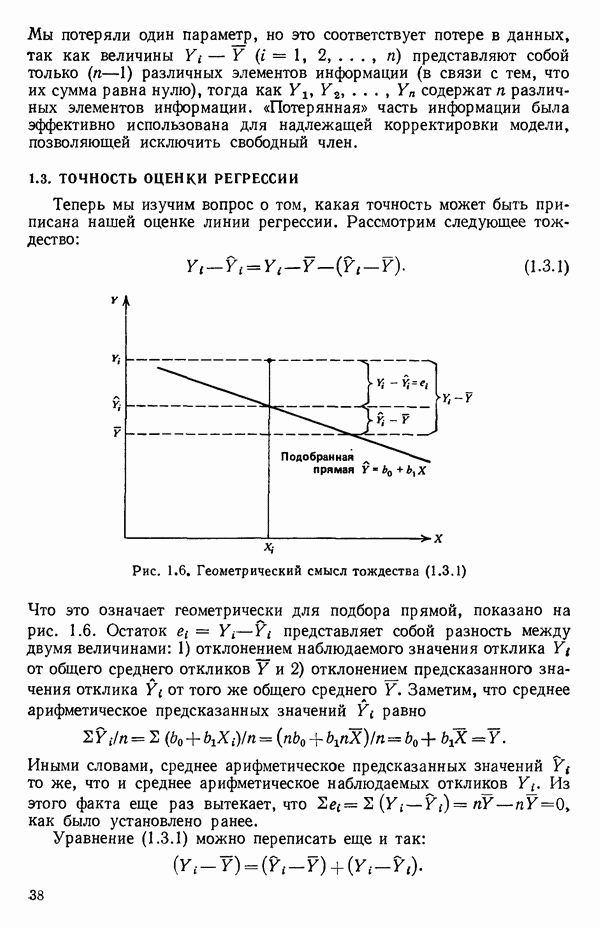
Мы потеряли один параметр, но это соответствует потере в данных, так как величины
|
 |
Оглавление
|












































































































































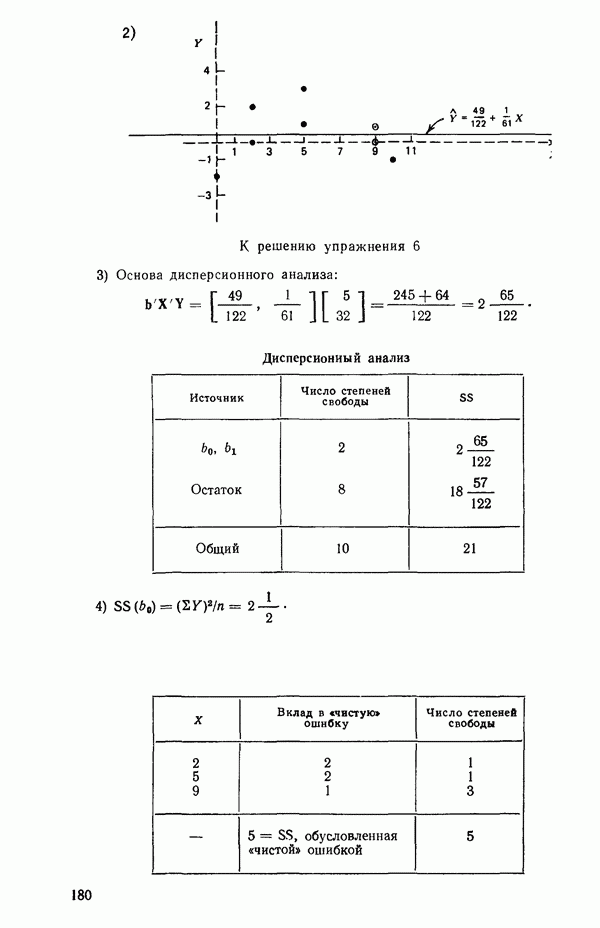



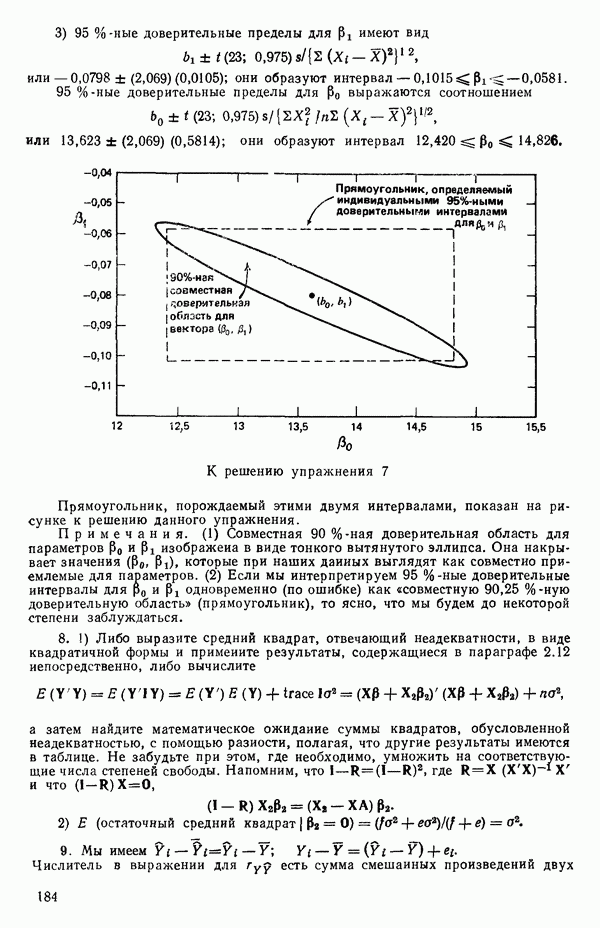






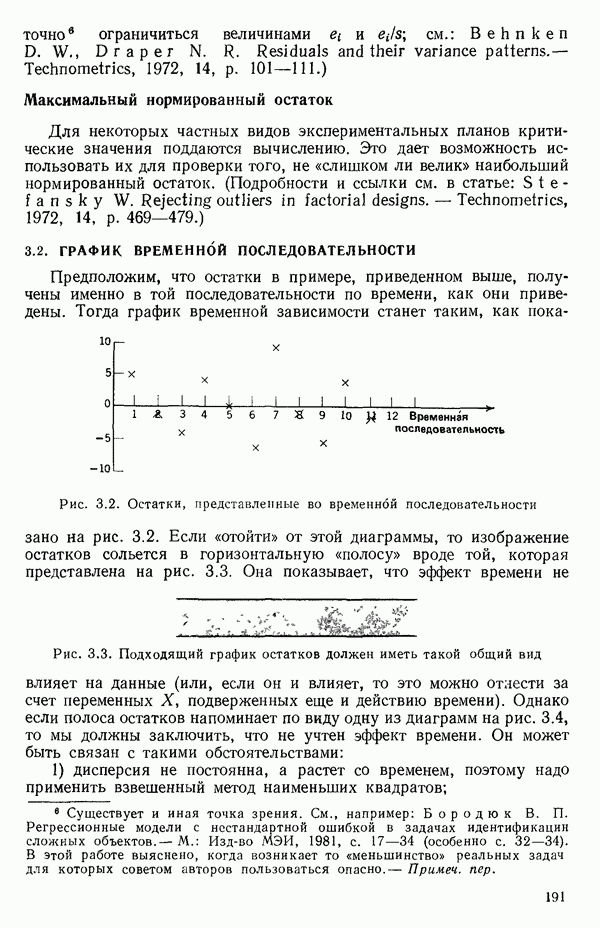








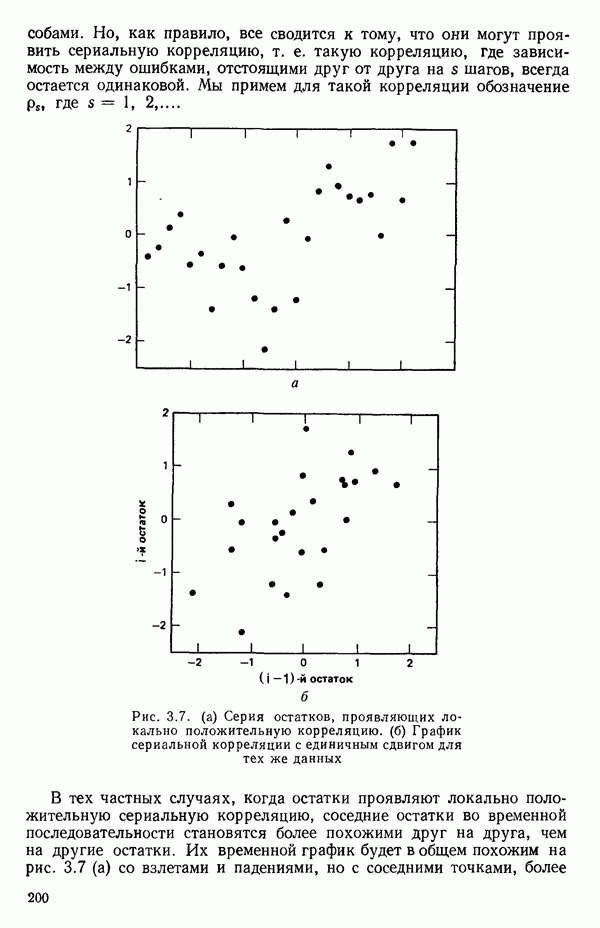
















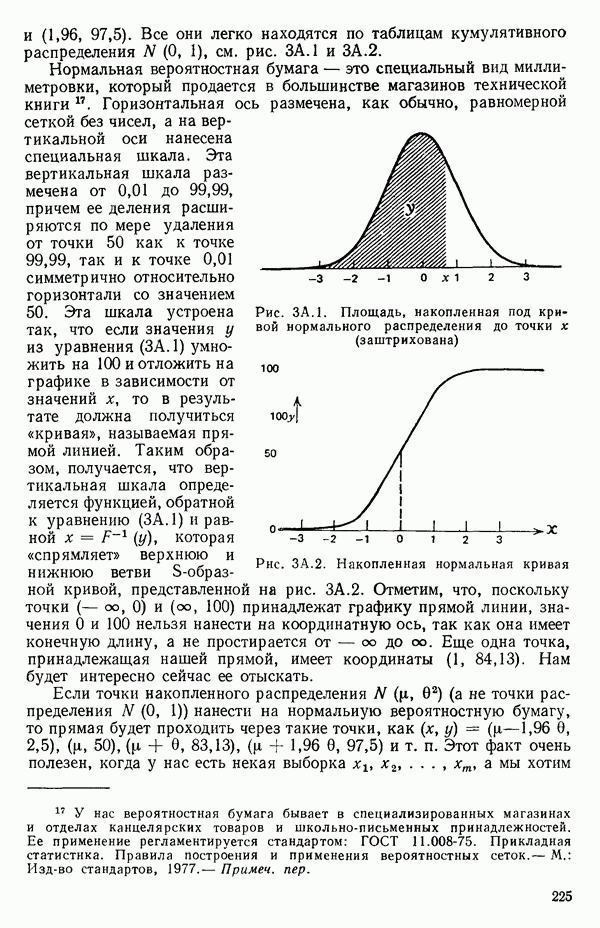
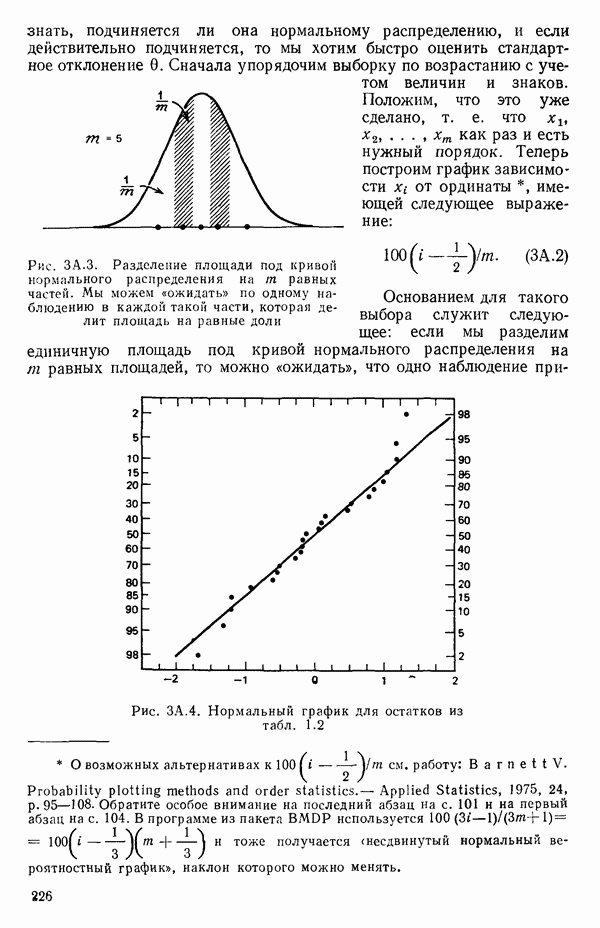


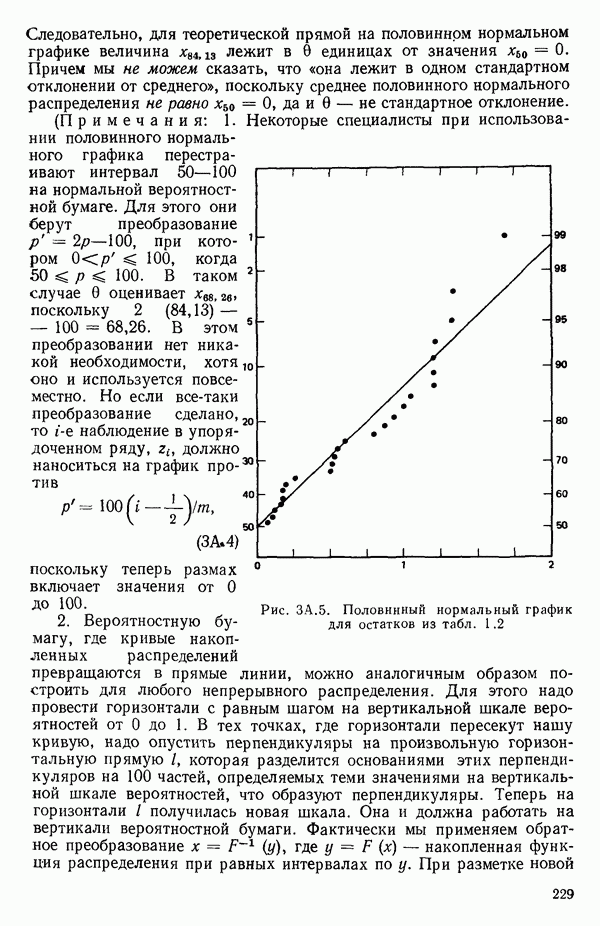





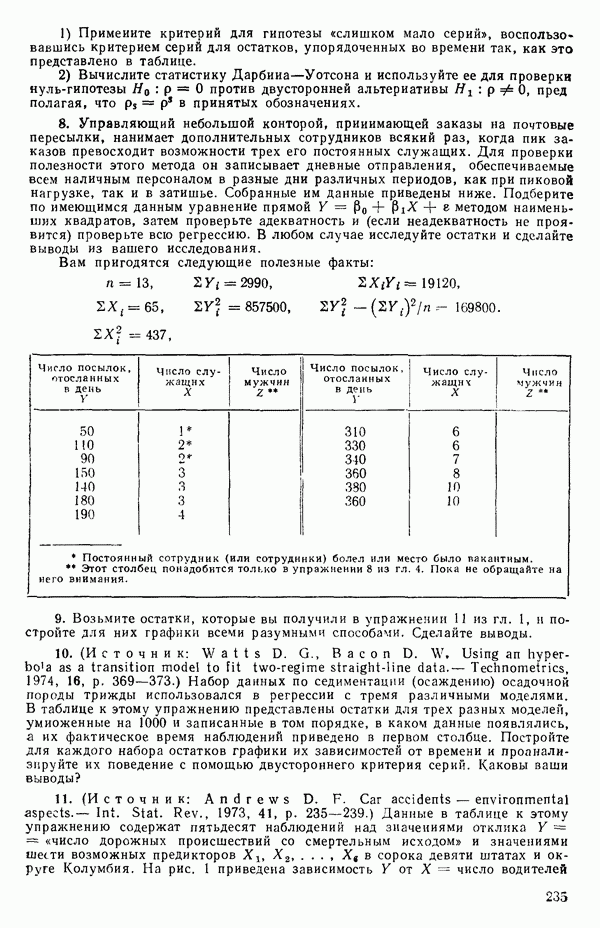
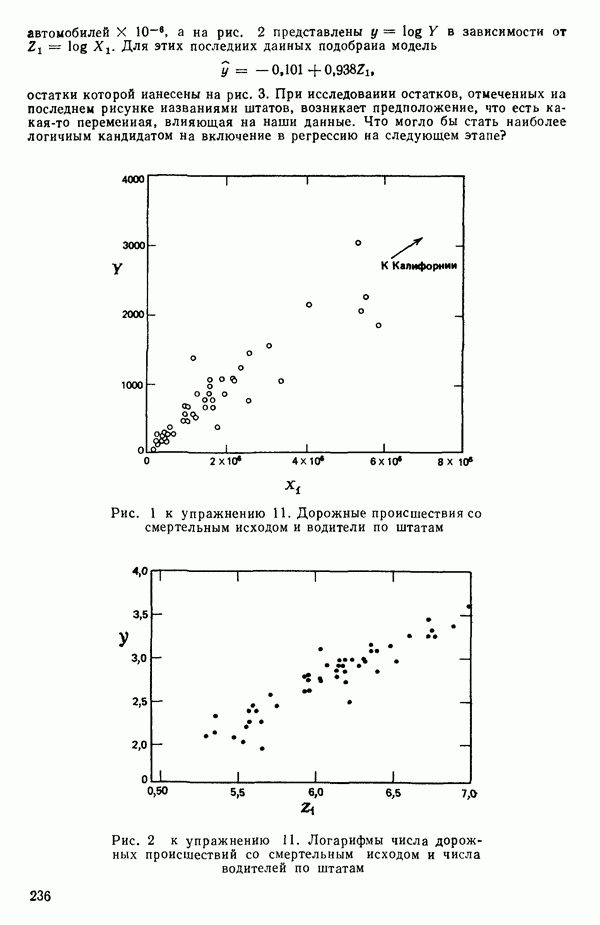
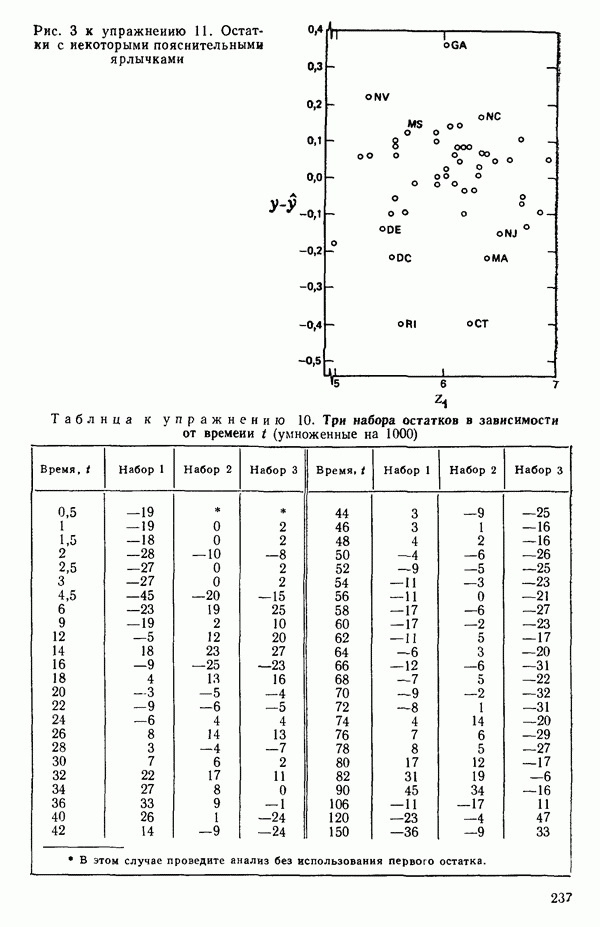
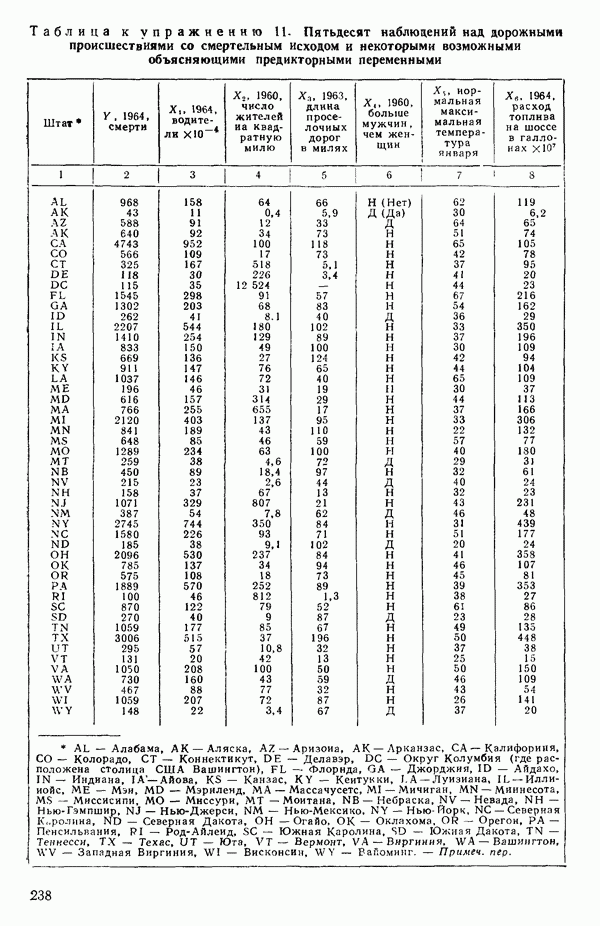

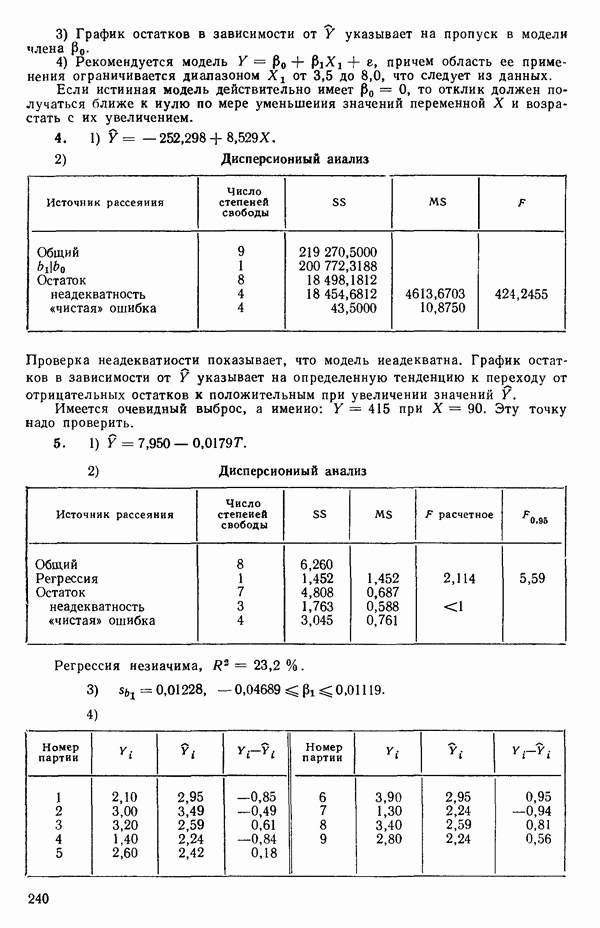



































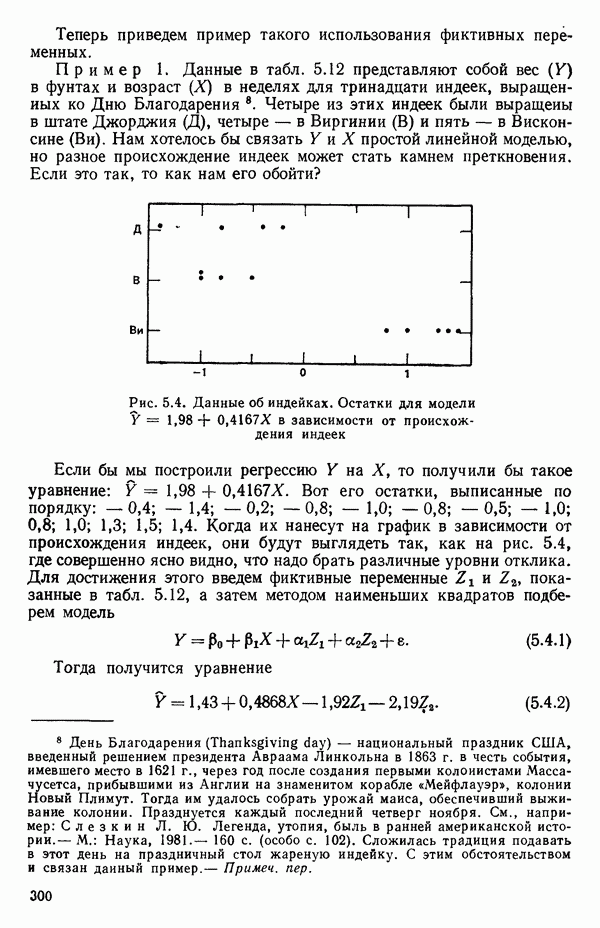
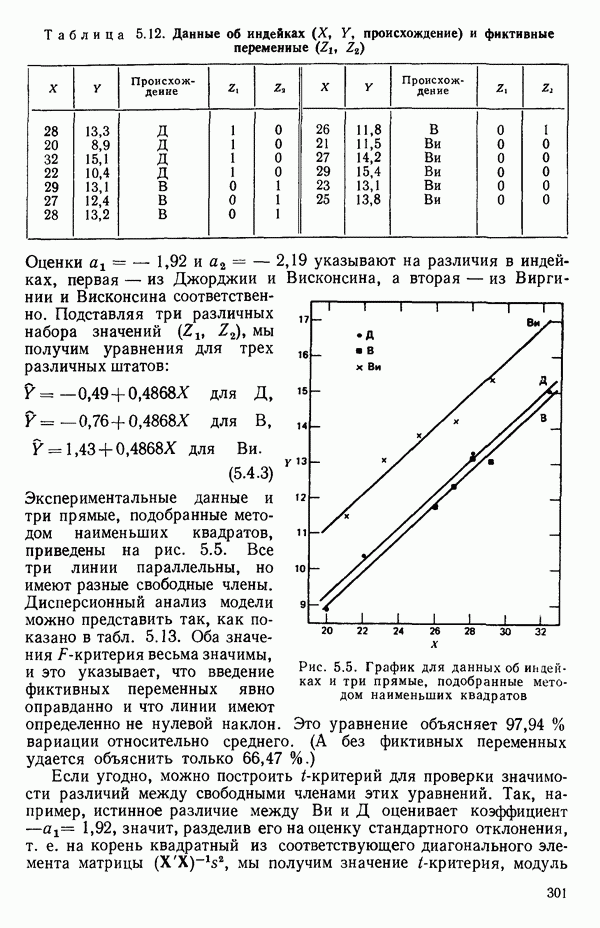




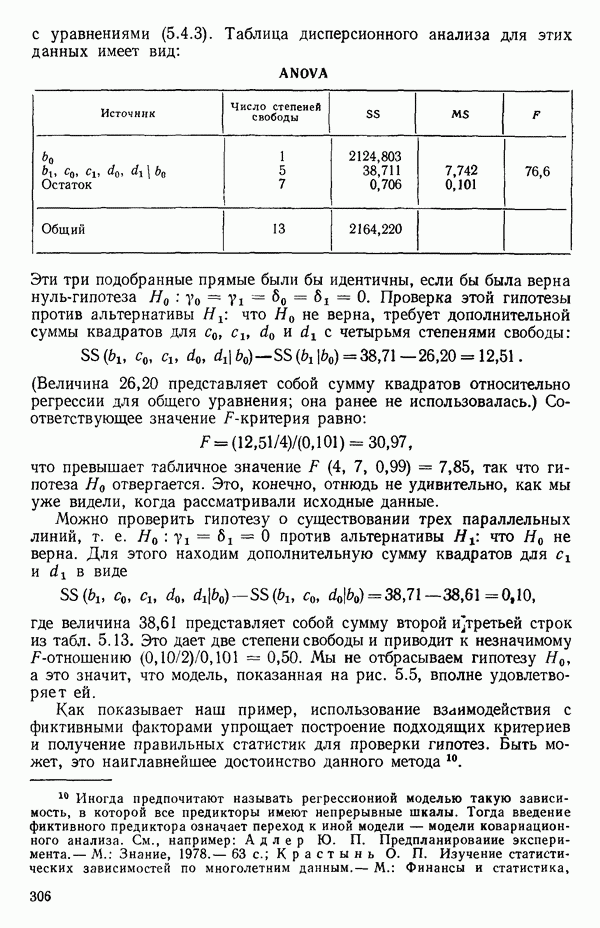


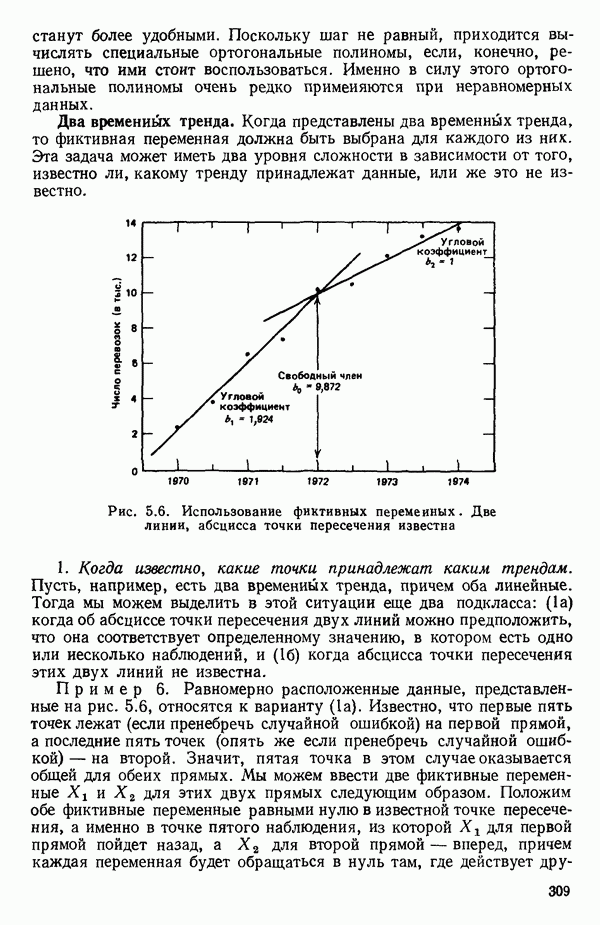




























 от переменной (X) имеет вид
от переменной (X) имеет вид 


 состоит из величины
состоит из величины  плюс добавка
плюс добавка  при учете которой любой индивидуальный У получает возможность не попасть на линию регрессии.
при учете которой любой индивидуальный У получает возможность не попасть на линию регрессии.

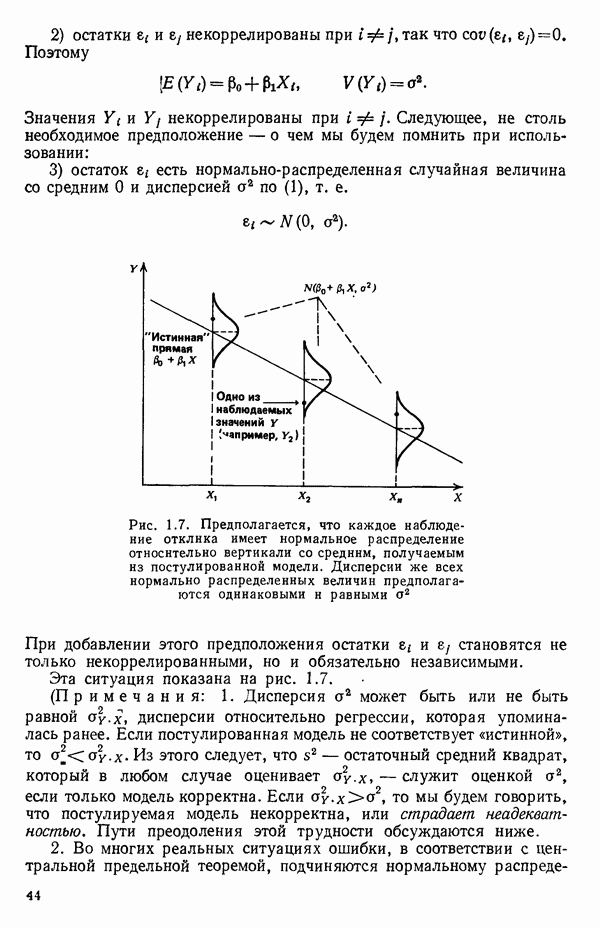
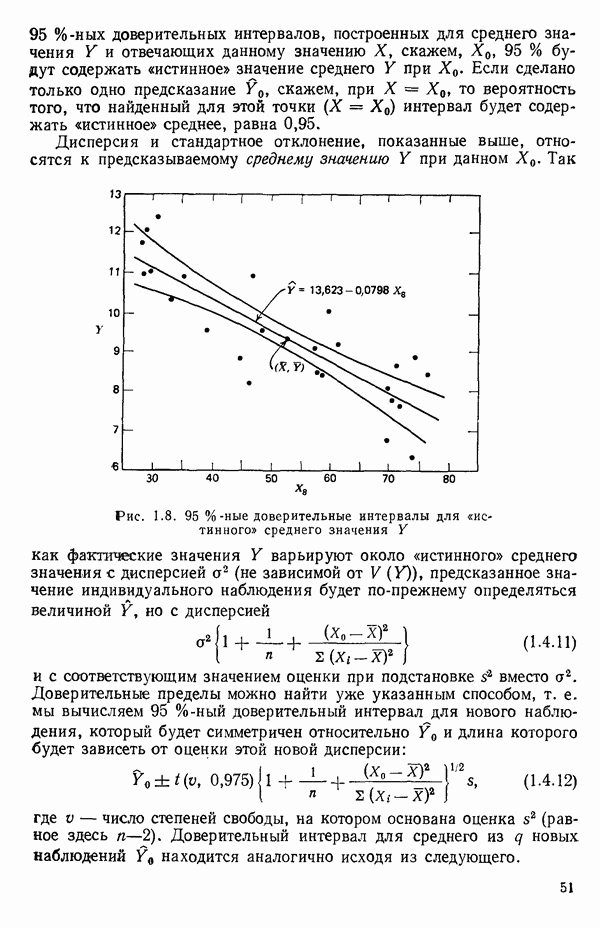
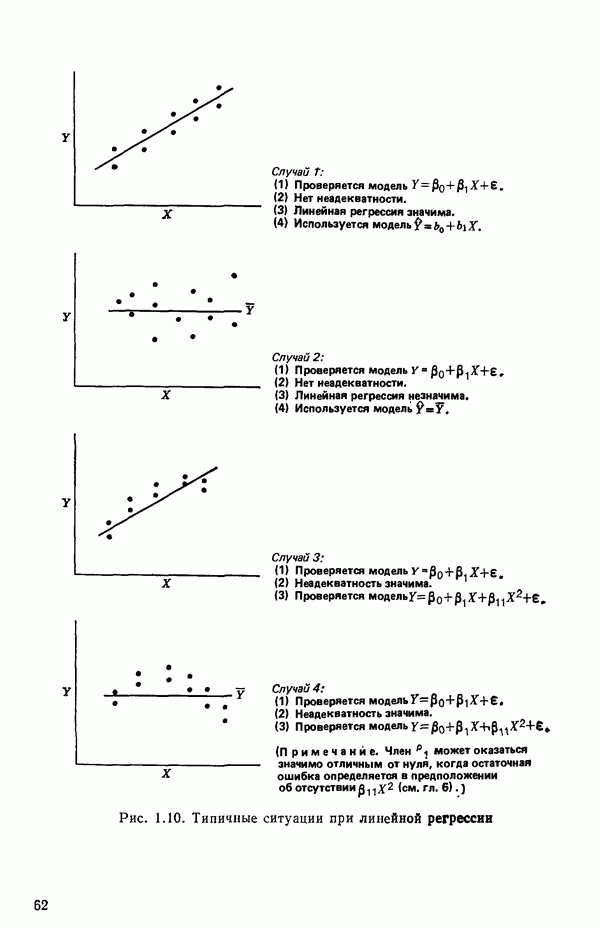
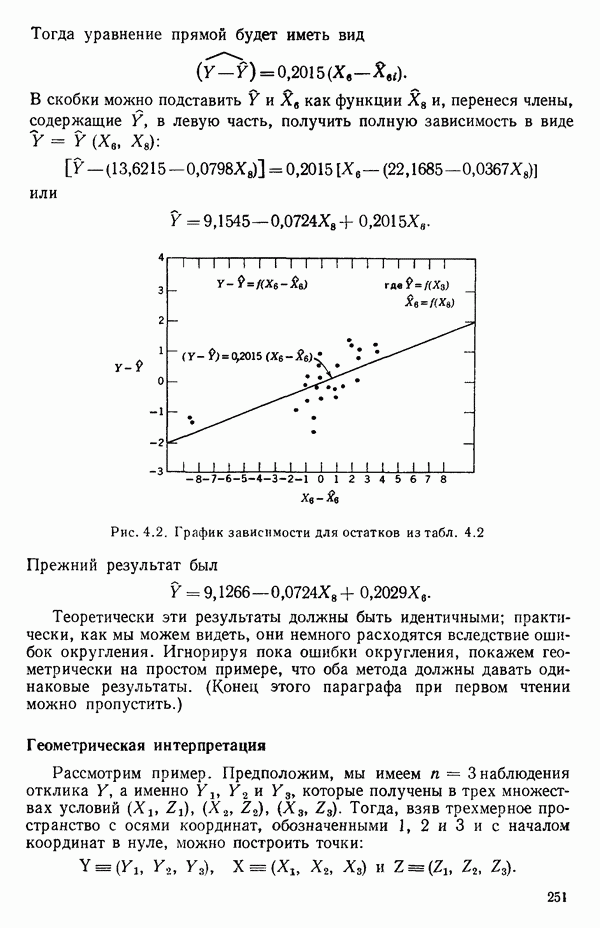
 - это модель, в которую мы верим. Начнем с предположения, что эта модель установлена, но на последующих стадиях будем проверять, так ли это на самом деле. Предположение о математической модели процесса необходимо с многих статистических точек зрения. Следует подчеркнуть, что то, что мы обычно делаем, есть постулирование модели либо предварительное допущение о ее правильности. Модель надо всесторонне критически исследовать в разных аспектах. Это наше «мнение» о ситуации на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины
- это модель, в которую мы верим. Начнем с предположения, что эта модель установлена, но на последующих стадиях будем проверять, так ли это на самом деле. Предположение о математической модели процесса необходимо с многих статистических точек зрения. Следует подчеркнуть, что то, что мы обычно делаем, есть постулирование модели либо предварительное допущение о ее правильности. Модель надо всесторонне критически исследовать в разных аспектах. Это наше «мнение» о ситуации на первой стадии исследования и это «мнение» может измениться, если мы найдем на более поздней стадии, что факты против него. Величины  называют параметрами модели.
называют параметрами модели.

 Если только специально не оговаривается, что модель нелинейна, а это может быть сделано, то имеется в виду линейная по параметрам модель, а слово «линейная» обычно опускается. Порядок модели может быть любым. Обозначение вида
Если только специально не оговаривается, что модель нелинейна, а это может быть сделано, то имеется в виду линейная по параметрам модель, а слово «линейная» обычно опускается. Порядок модели может быть любым. Обозначение вида  часто используется в полиномиальных моделях, где параметр
часто используется в полиномиальных моделях, где параметр  соотносится с X, в то время как соотносится с
соотносится с X, в то время как соотносится с  Естественное обобщение обозначений такого рода встречается, например, в параграфах 5.1 и 7.7.)
Естественное обобщение обозначений такого рода встречается, например, в параграфах 5.1 и 7.7.)
 неизвестны, причем величину
неизвестны, причем величину  на самом деле будет трудно исследовать, поскольку она меняется от наблюдения к наблюдению. Однако
на самом деле будет трудно исследовать, поскольку она меняется от наблюдения к наблюдению. Однако  остаются постоянными, и, хотя мы не умеем находить их точно без изучения всех возможных сочетаний
остаются постоянными, и, хотя мы не умеем находить их точно без изучения всех возможных сочетаний  , мы можем использовать информацию, содержащуюся в двадцати пяти наблюдениях табл. 1.1, для получения оценок
, мы можем использовать информацию, содержащуюся в двадцати пяти наблюдениях табл. 1.1, для получения оценок  и параметров
и параметров  Запишем это в таком виде:
Запишем это в таком виде:

 (читается «К с крышечкой») обозначает предсказанное значение
(читается «К с крышечкой») обозначает предсказанное значение  для данного X, когда
для данного X, когда  определены. Уравнение (1.2.2) можно использовать как предсказывающее уравнение; подстановка в него значения X позволяет предсказать «истинное» среднее значение
определены. Уравнение (1.2.2) можно использовать как предсказывающее уравнение; подстановка в него значения X позволяет предсказать «истинное» среднее значение  для этого
для этого 
 соответственно. Правда, довольно часто встречаются и такие
соответственно. Правда, довольно часто встречаются и такие
 Да мы и сами воспользуемся ими в гл. 10.
Да мы и сами воспользуемся ими в гл. 10.
 наблюдений
наблюдений  нашем примере
нашем примере  Тогда уравнение (1.2.1) можно записать в виде
Тогда уравнение (1.2.1) можно записать в виде


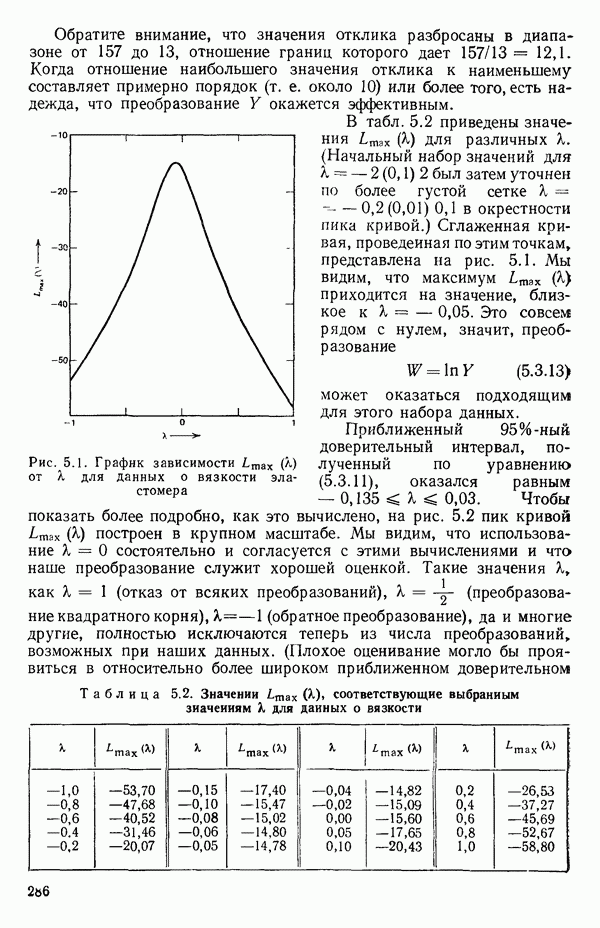
 Следовательно, сумма квадратов отклонений от «истинной» линии есть
Следовательно, сумма квадратов отклонений от «истинной» линии есть

 так, чтобы их подстановка вместо
так, чтобы их подстановка вместо  в уравнение (1.2.4) давала наименьшее возможное (минимальное) значение
в уравнение (1.2.4) давала наименьшее возможное (минимальное) значение  см. рис. 1.5. (Заметим, что
см. рис. 1.5. (Заметим, что  это фиксированные числа, которые нам известны.) Мы можем определить
это фиксированные числа, которые нам известны.) Мы можем определить  дифференцируя уравнение (1.2.4) сначала по
дифференцируя уравнение (1.2.4) сначала по  затем по
затем по  и приравнивая результаты к нулю. Тогда
и приравнивая результаты к нулю. Тогда

 имеем
имеем

 вместо
вместо  Из (1.2.6) имеем:
Из (1.2.6) имеем:


 дает
дает

 до
до  а два выражения для
а два выражения для  это обе правильные, но несколько различные формы одной и
это обе правильные, но несколько различные формы одной и


 на X, эквивалентность знаменателей. Величина
на X, эквивалентность знаменателей. Величина  называется нескорректированной суммой квадратов
называется нескорректированной суммой квадратов  коррекцией на среднее значение
коррекцией на среднее значение  Разность между ними называется скорректированной суммой квадратов
Разность между ними называется скорректированной суммой квадратов  Аналогично
Аналогично  называется нескорректированной суммой смешанных (парных) произведений, а
называется нескорректированной суммой смешанных (парных) произведений, а  коррекцией на среднее. Разность между ними называется скорректированной суммой произведений
коррекцией на среднее. Разность между ними называется скорректированной суммой произведений 
 на микрокалькуляторе, поскольку с ней гораздо легче работать и нет нужды в громоздких подсчетах для каждого
на микрокалькуляторе, поскольку с ней гораздо легче работать и нет нужды в громоздких подсчетах для каждого  выражений
выражений  и
и  соответственно. Полезно иметь в виду, что для уменьшения ошибок округления лучше всего сохранять в процессе счета столько знаков после запятой, сколько возможно. (Такая стратегия хороша и вообще. Округлять лучше всего на «стадии выдачи результатов», а не на промежуточных этапах.) Многие из цифровых компьютеров дадут более точные ответы, если воспользоваться второй формой уравнения (1.2.9). Это обусловлено машинной системой округления.
соответственно. Полезно иметь в виду, что для уменьшения ошибок округления лучше всего сохранять в процессе счета столько знаков после запятой, сколько возможно. (Такая стратегия хороша и вообще. Округлять лучше всего на «стадии выдачи результатов», а не на промежуточных этапах.) Многие из цифровых компьютеров дадут более точные ответы, если воспользоваться второй формой уравнения (1.2.9). Это обусловлено машинной системой округления.




 дает
дает


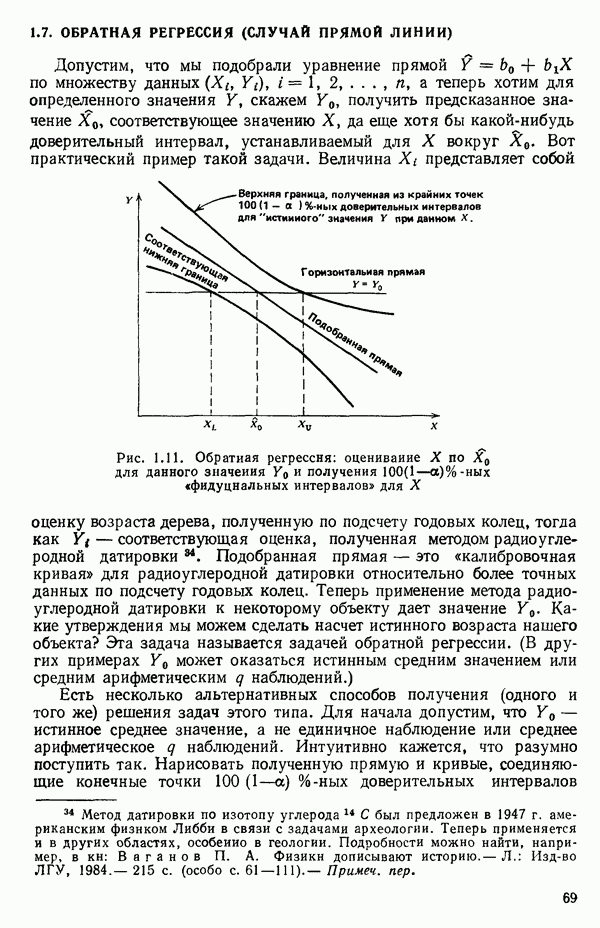
 то окажется, что
то окажется, что  . А это означает, что точка (
. А это означает, что точка ( лежит на подобранной прямой. Выполним теперь эти вычисления, пользуясь данными табл. 1.1. Мы найдем, что:
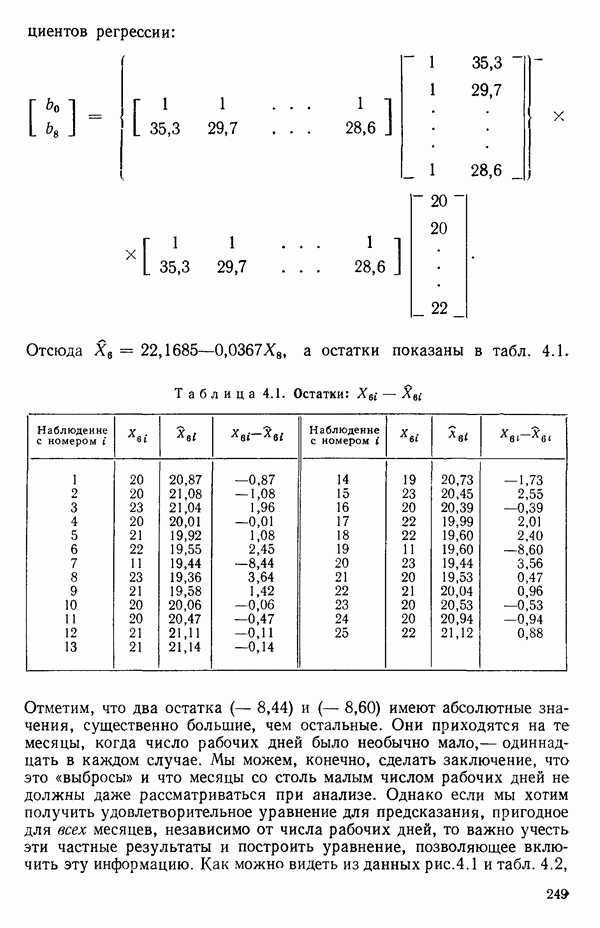
лежит на подобранной прямой. Выполним теперь эти вычисления, пользуясь данными табл. 1.1. Мы найдем, что:


 для каждого из 25 значений
для каждого из 25 значений  для которого известно наблюденное значение
для которого известно наблюденное значение  и найти остатки
и найти остатки  как это сделано в табл. 1.2. Остатков получается столько же, сколько исходных данных.
как это сделано в табл. 1.2. Остатков получается столько же, сколько исходных данных.



 из модели приводит к тому, что отклик обращается в нуль, когда все предикторы равны нулю. Такое предположение слишком сильно и потому обычно не справедливо. В линейной модели
из модели приводит к тому, что отклик обращается в нуль, когда все предикторы равны нулю. Такое предположение слишком сильно и потому обычно не справедливо. В линейной модели  в исключение
в исключение  означает, что линия проходит через точку
означает, что линия проходит через точку  т. е. что она отсекает нулевой отрезок
т. е. что она отсекает нулевой отрезок  при
при  Заметим здесь, до более подробного обсуждения в параграфе 5.4, что исключение
Заметим здесь, до более подробного обсуждения в параграфе 5.4, что исключение  из модели всегда возможно с помощью «центрирования» данных, но это совершенно не то же самое, что приравнивание
из модели всегда возможно с помощью «центрирования» данных, но это совершенно не то же самое, что приравнивание  Если, например, мы запишем уравнение (1.2.1) в виде
Если, например, мы запишем уравнение (1.2.1) в виде


 то оценки для
то оценки для  и
и  будут такими:
будут такими:


 при любом значении
при любом значении  Поэтому с полным успехом можно записать центрированную модель, совсем опуская свободный член
Поэтому с полным успехом можно записать центрированную модель, совсем опуская свободный член  (отрезок):
(отрезок):

 представляют собой только
представляют собой только  различных элементов информации (в связи с тем, что их сумма равна нулю), тогда как
различных элементов информации (в связи с тем, что их сумма равна нулю), тогда как  содержат
содержат  различных элементов информации. «Потерянная» часть информации была эффективно использована для надлежащей корректировки модели, позволяющей исключить свободный член.
различных элементов информации. «Потерянная» часть информации была эффективно использована для надлежащей корректировки модели, позволяющей исключить свободный член.