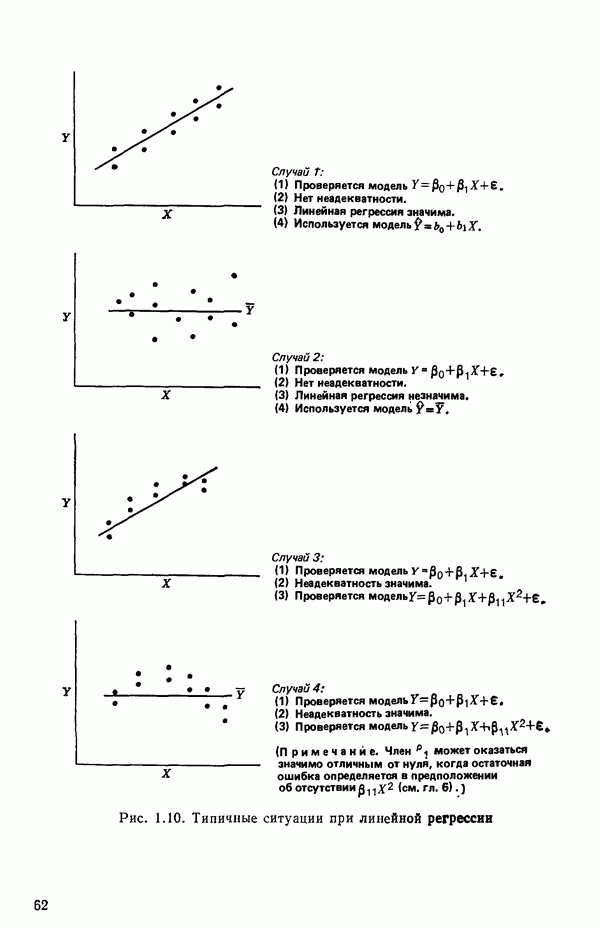
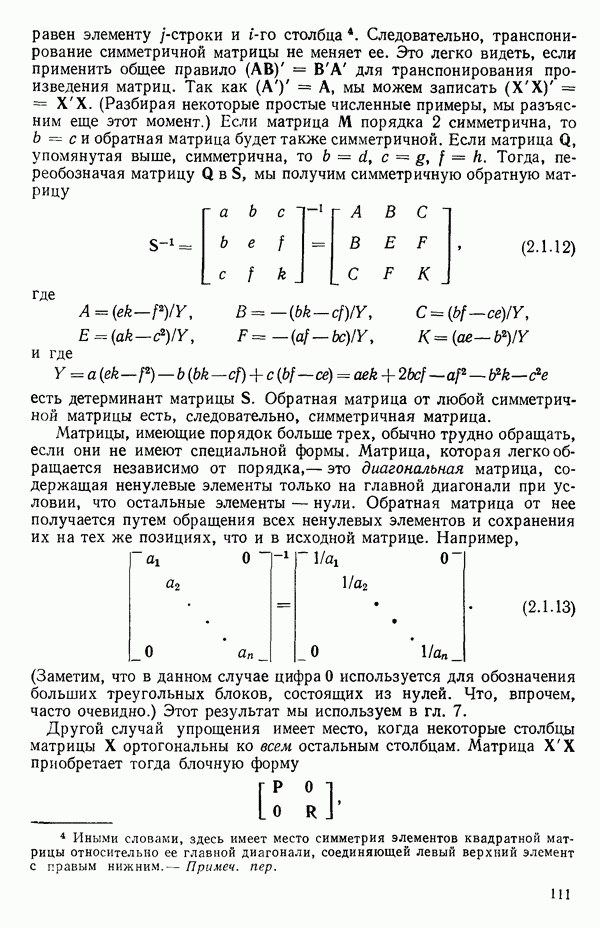
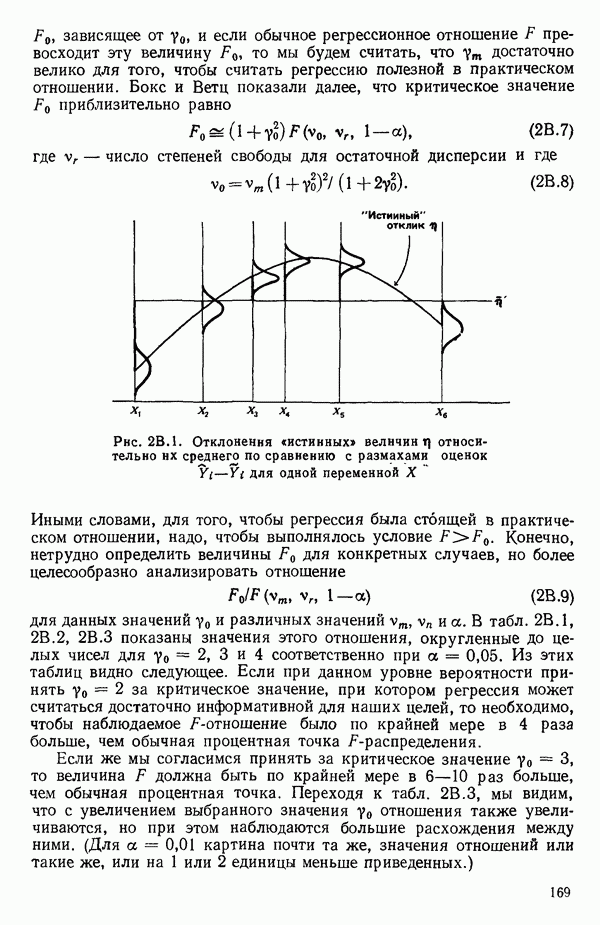
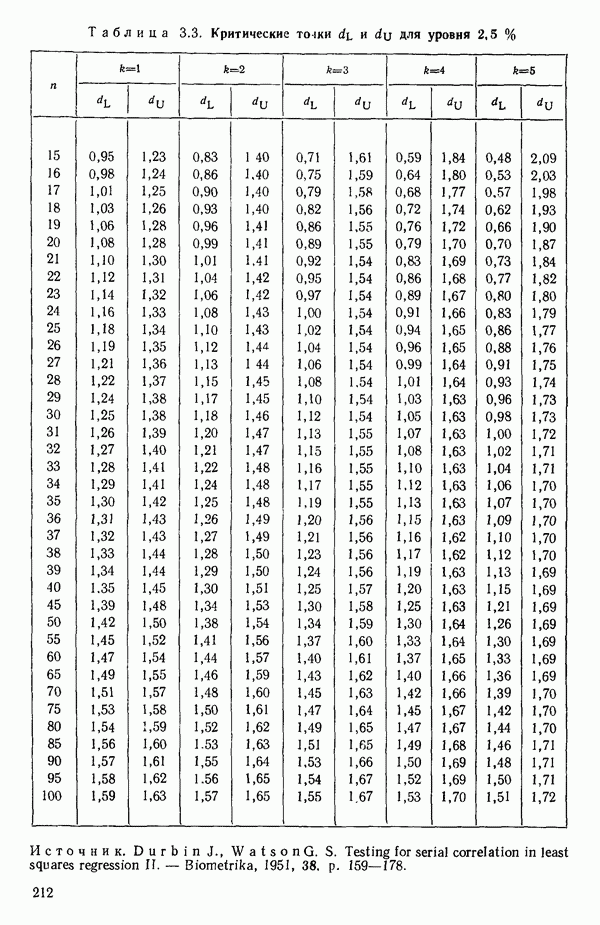
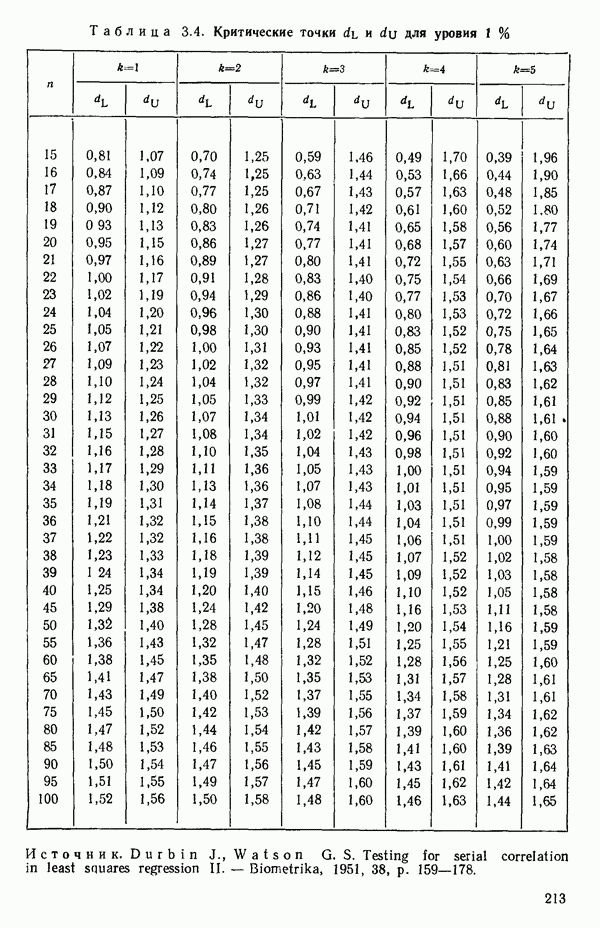
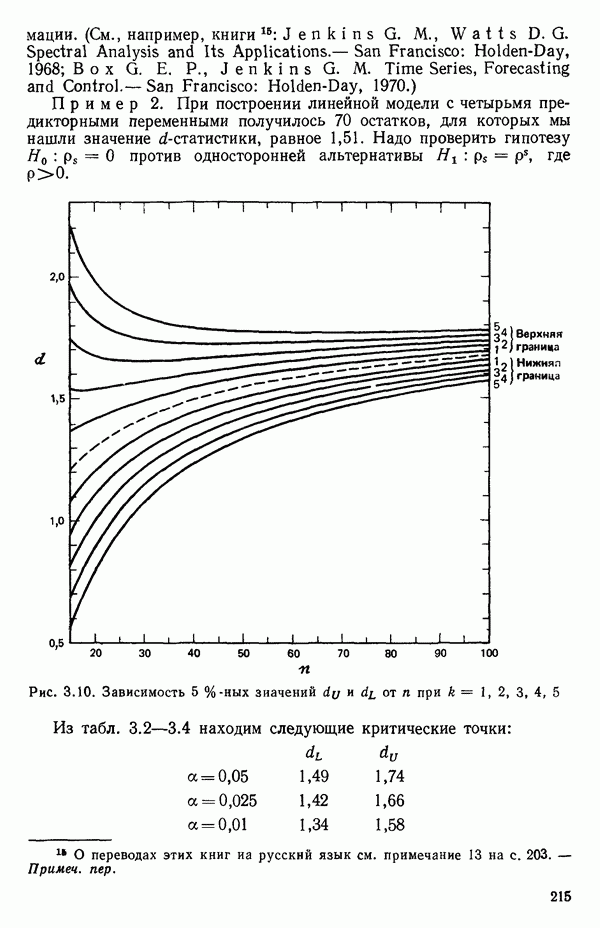
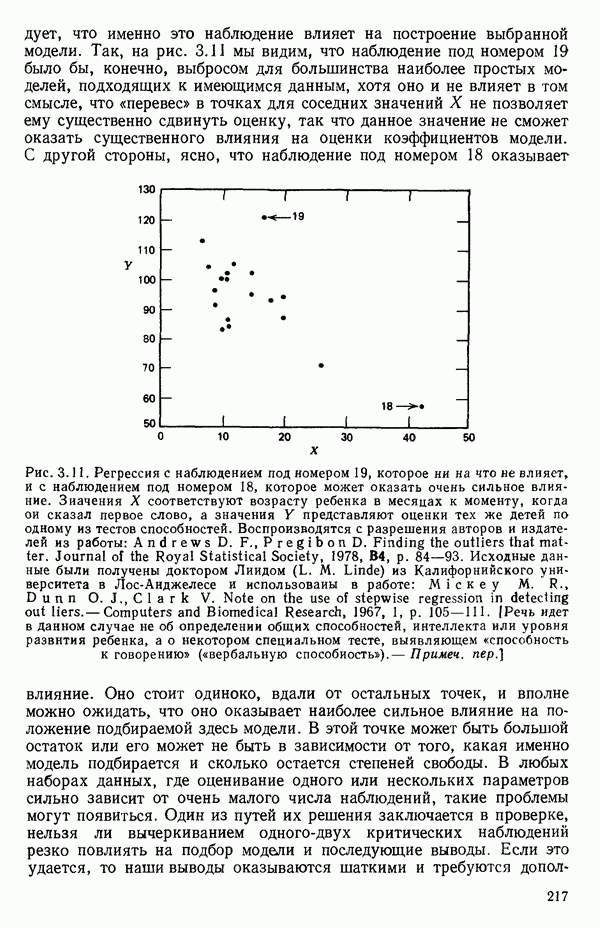
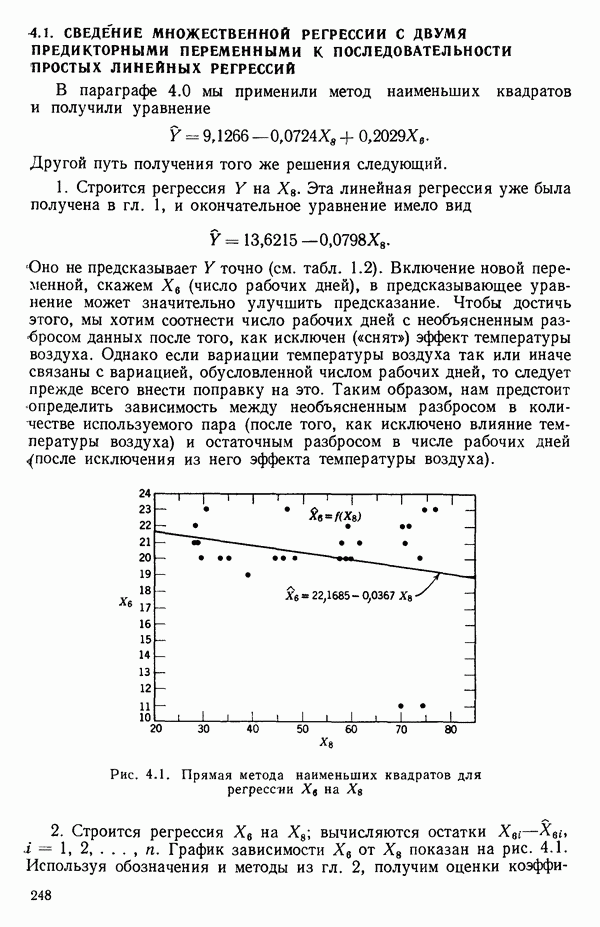
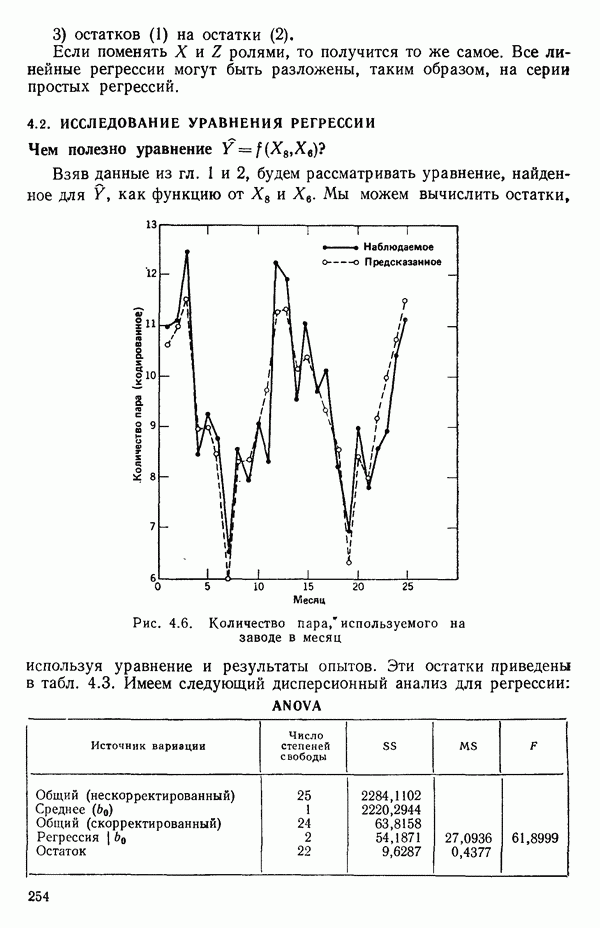
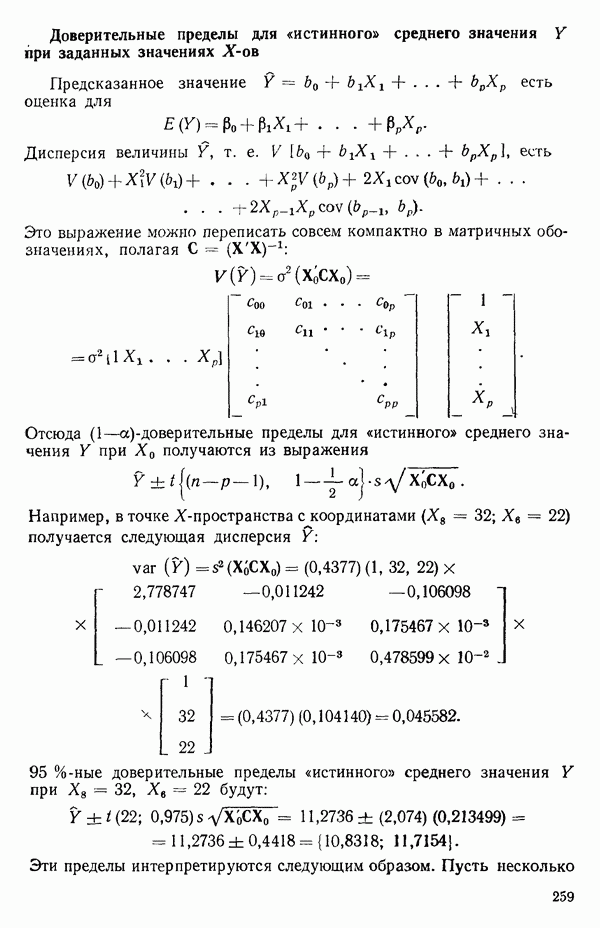
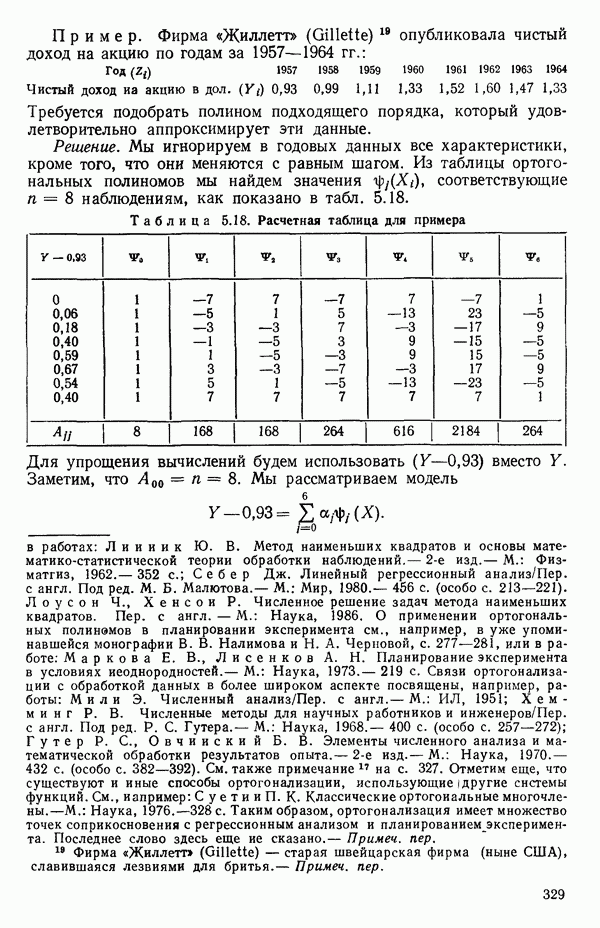
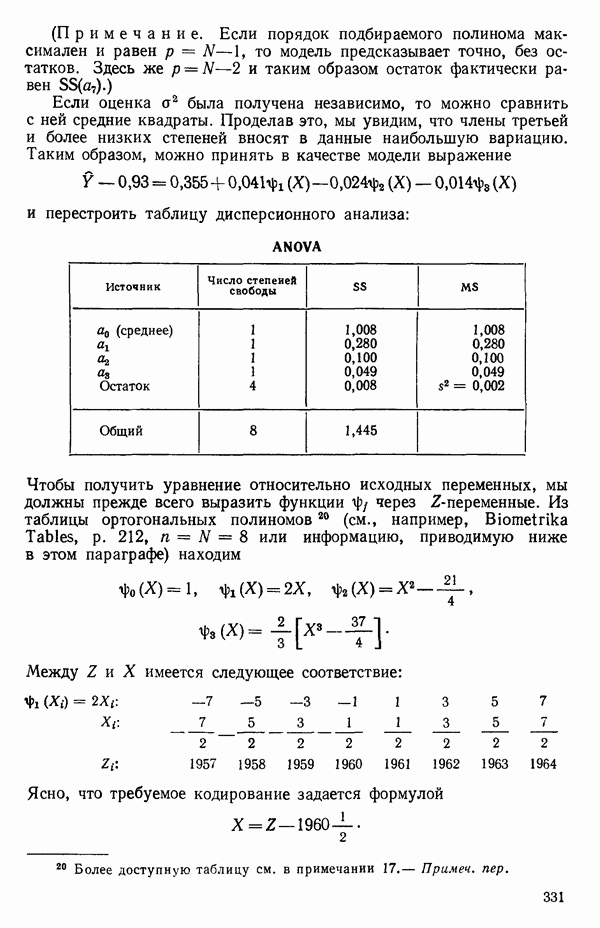
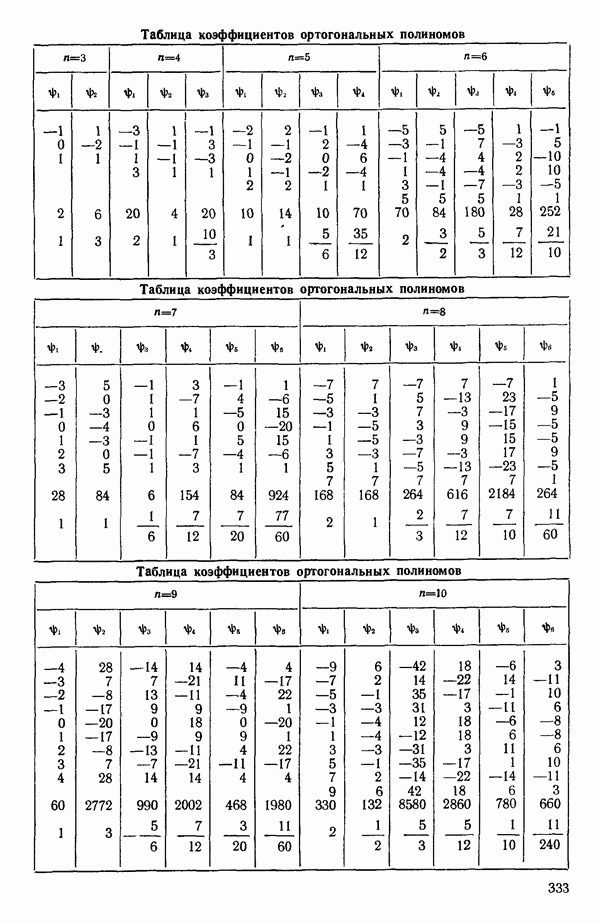
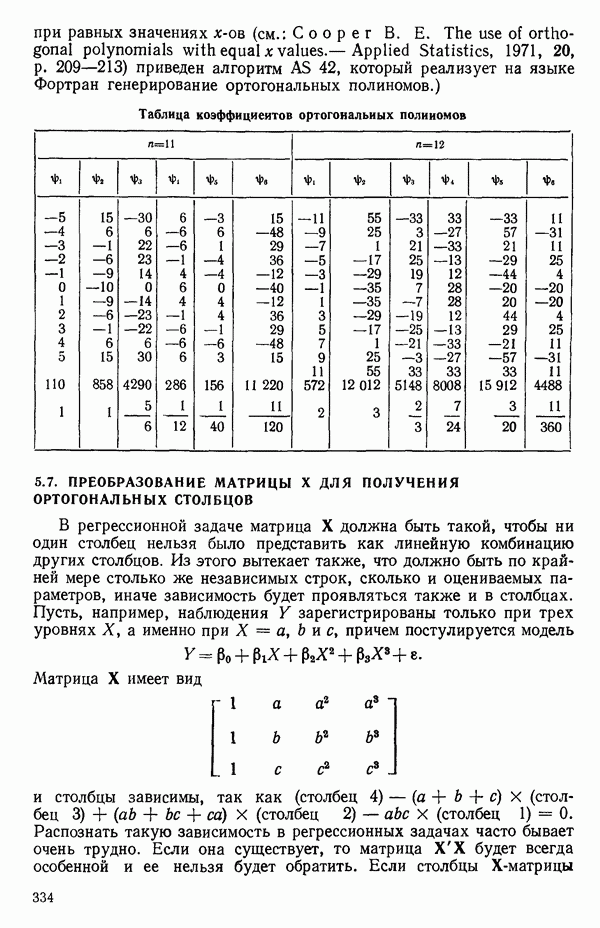
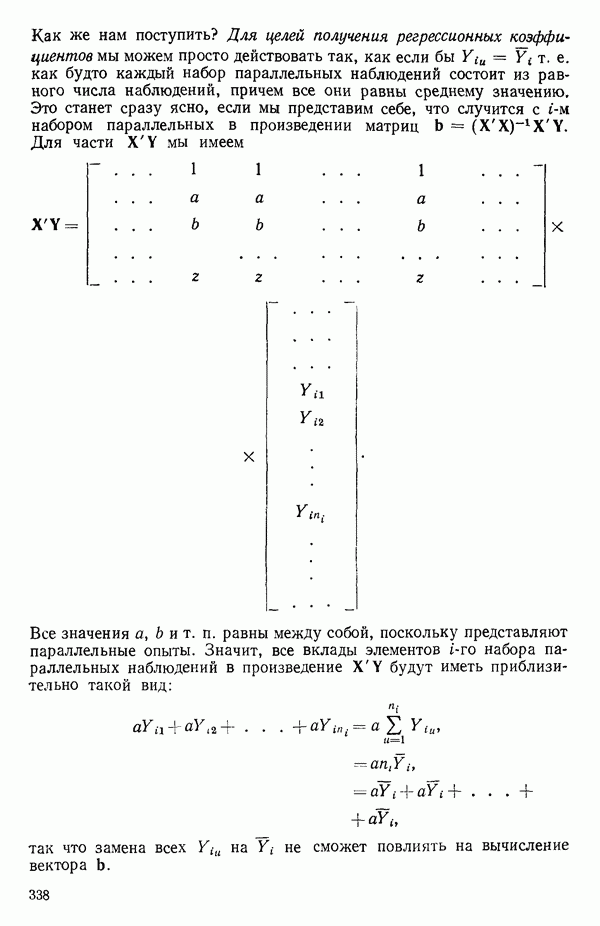
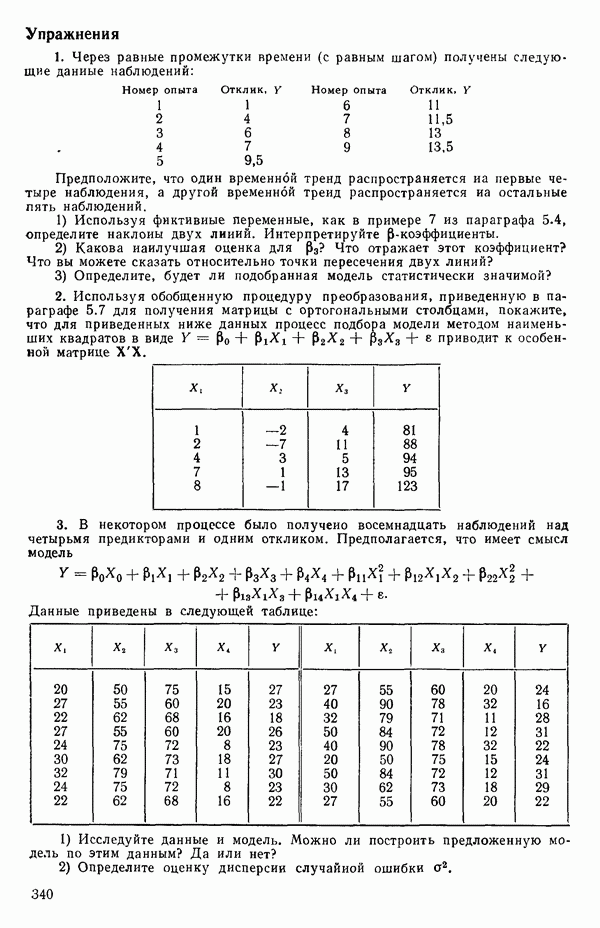
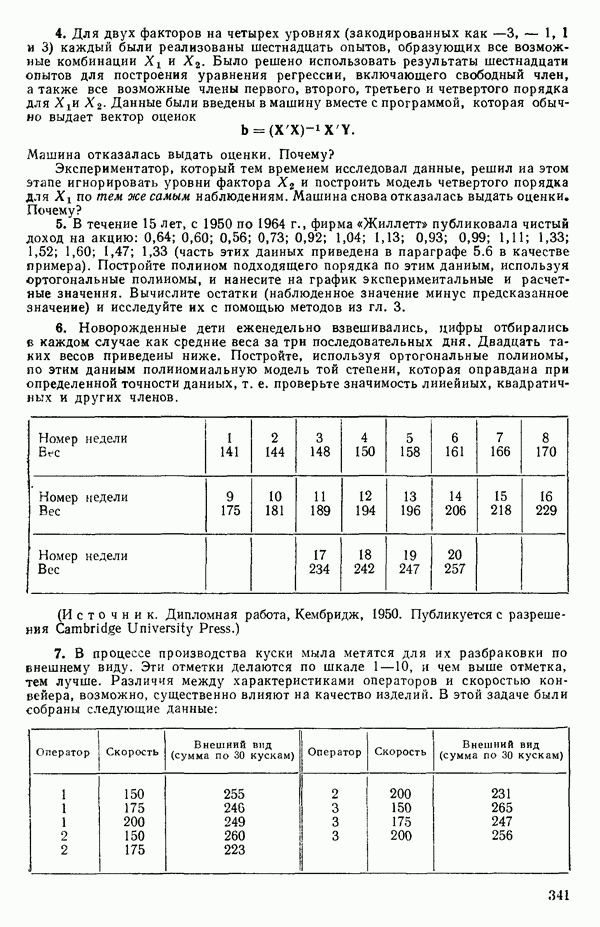
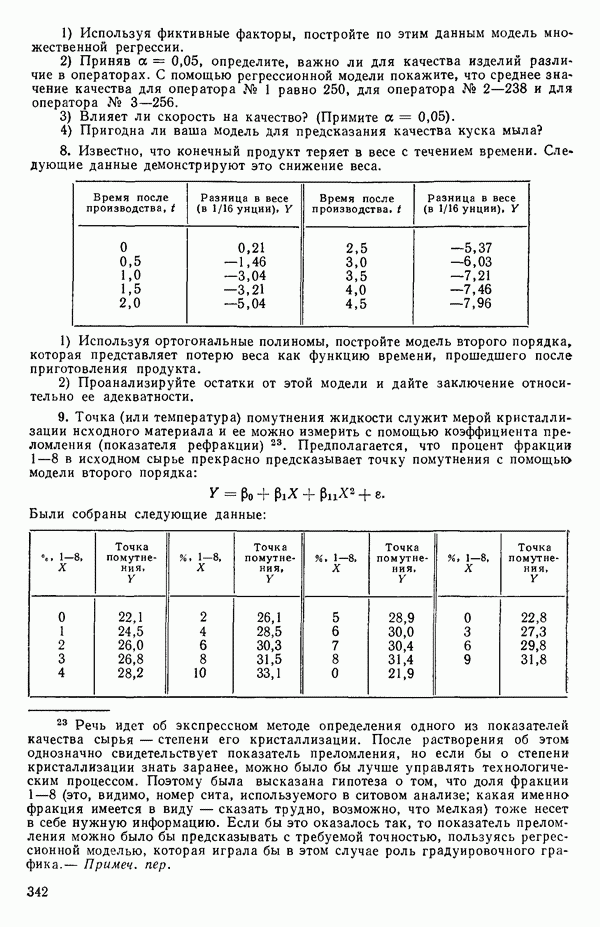
5.3. СЕМЕЙСТВА ПРЕОБРАЗОВАНИЙ
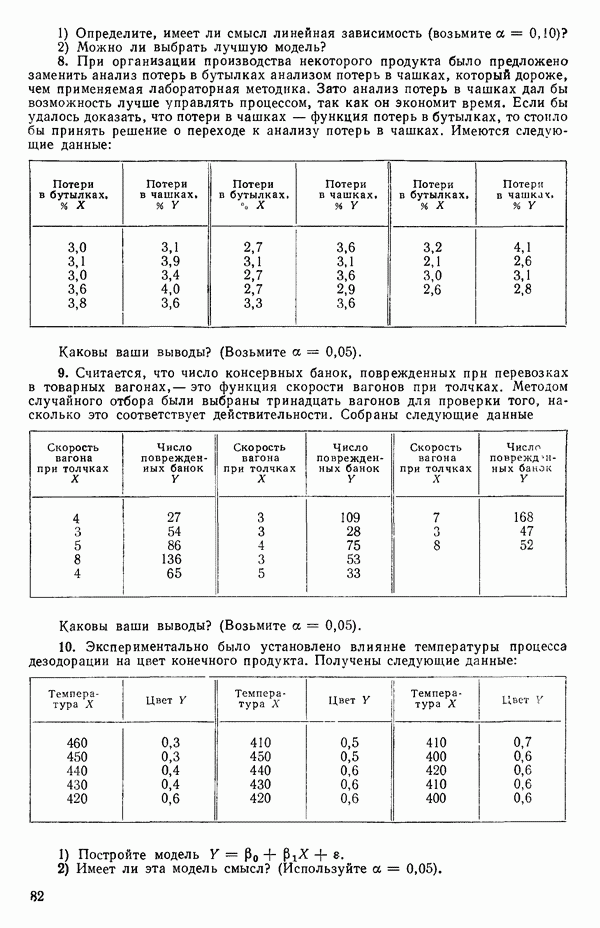
Преобразование отклика
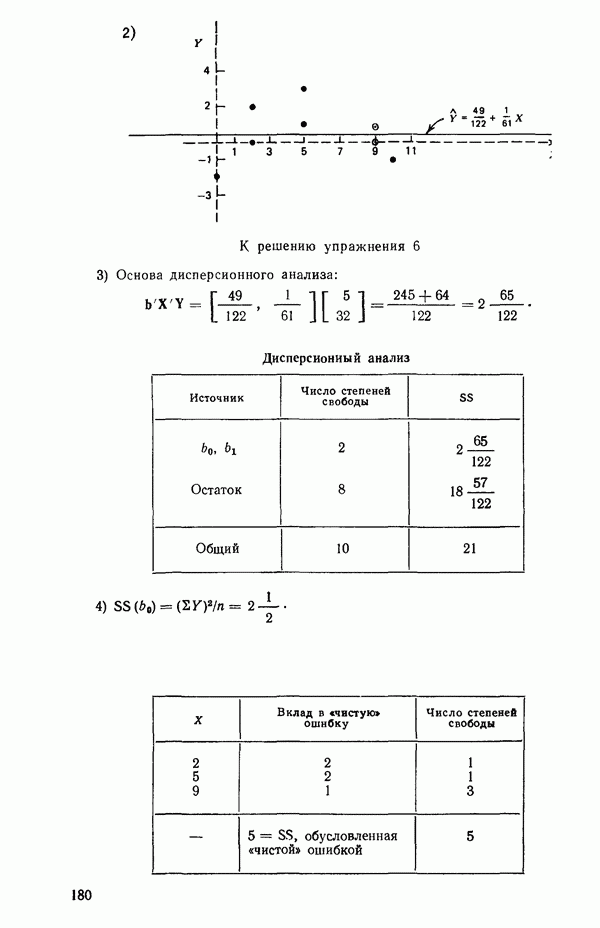
Одно из полезных семейств преобразований для (обязательна положительного) отклика  степенные преобразования:
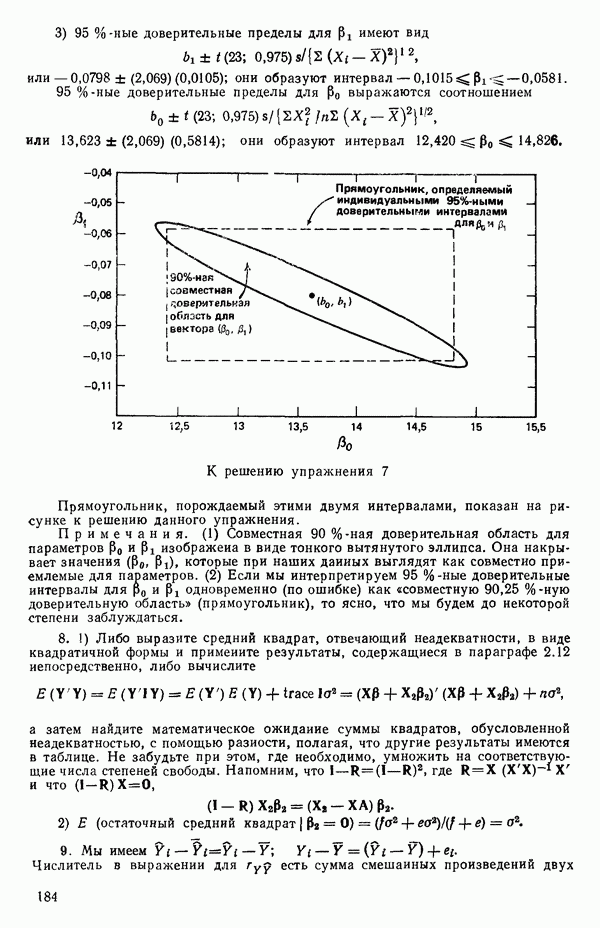
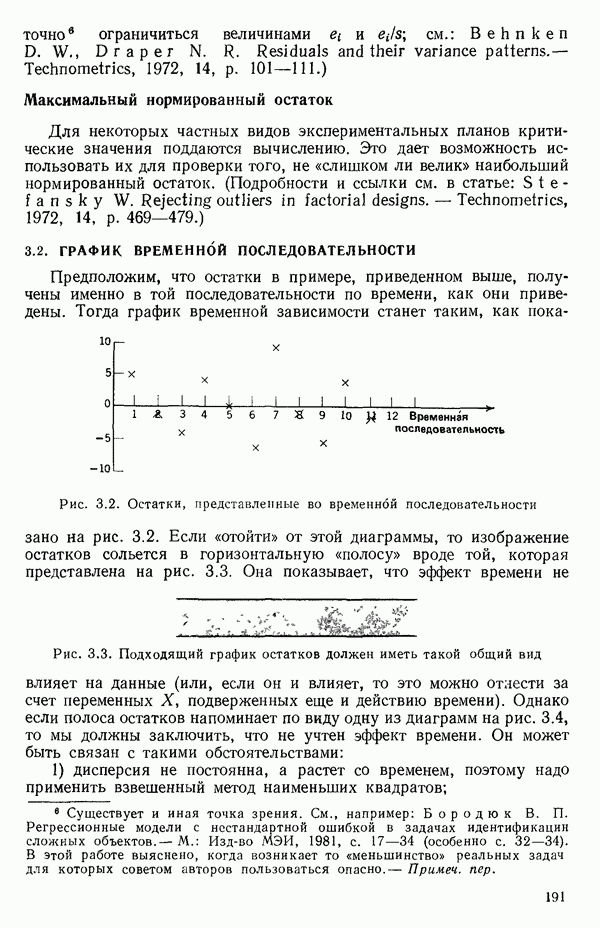
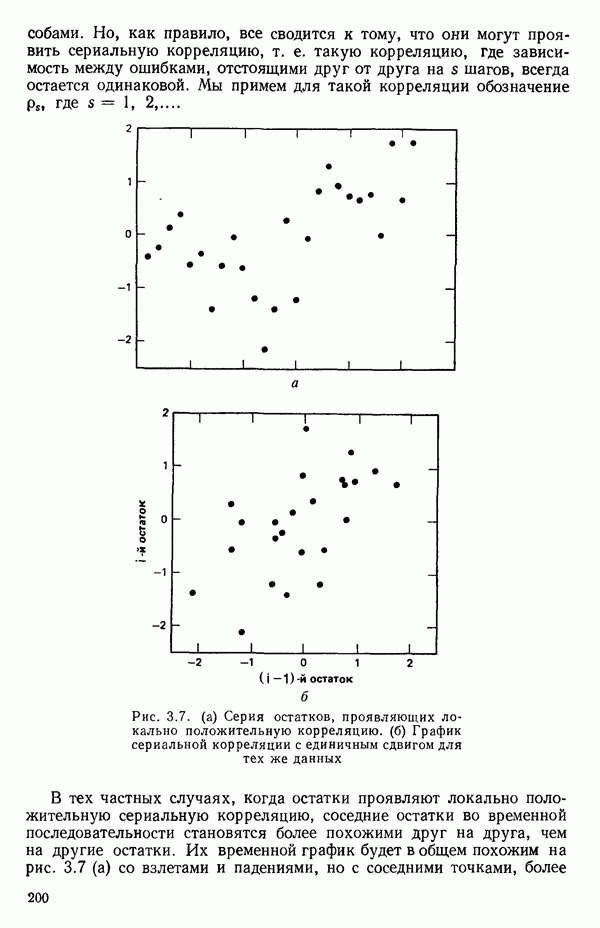
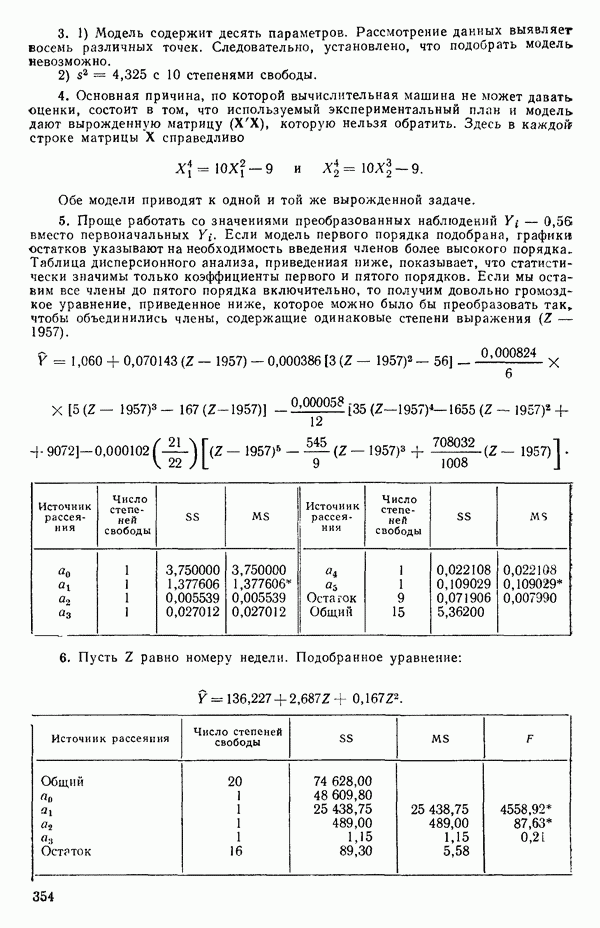
степенные преобразования:

Это непрерывное семейство, зависящее от единственного параметра  Мы можем воспользоваться для оценки этого параметра имеющимися данными точно так же, как мы оцениваем вектор параметров
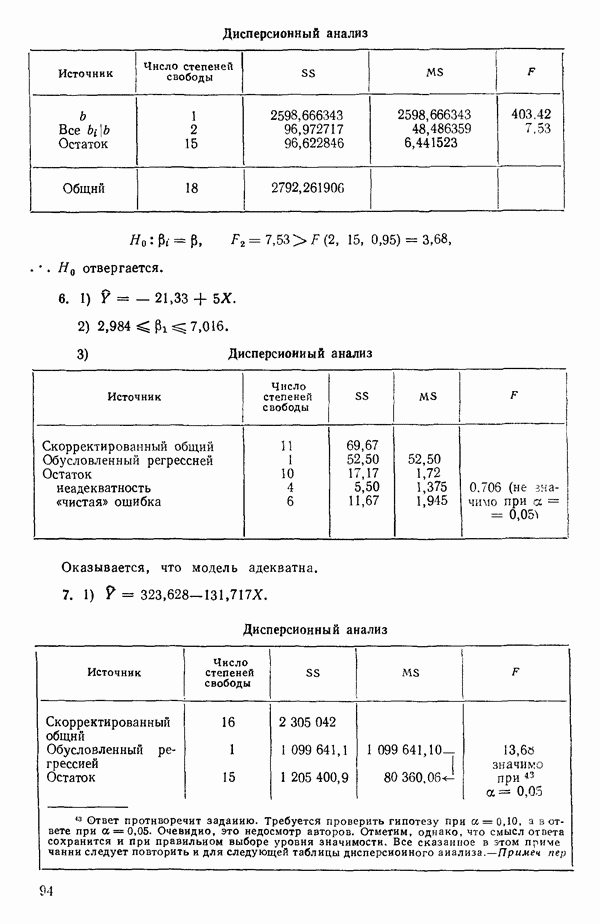
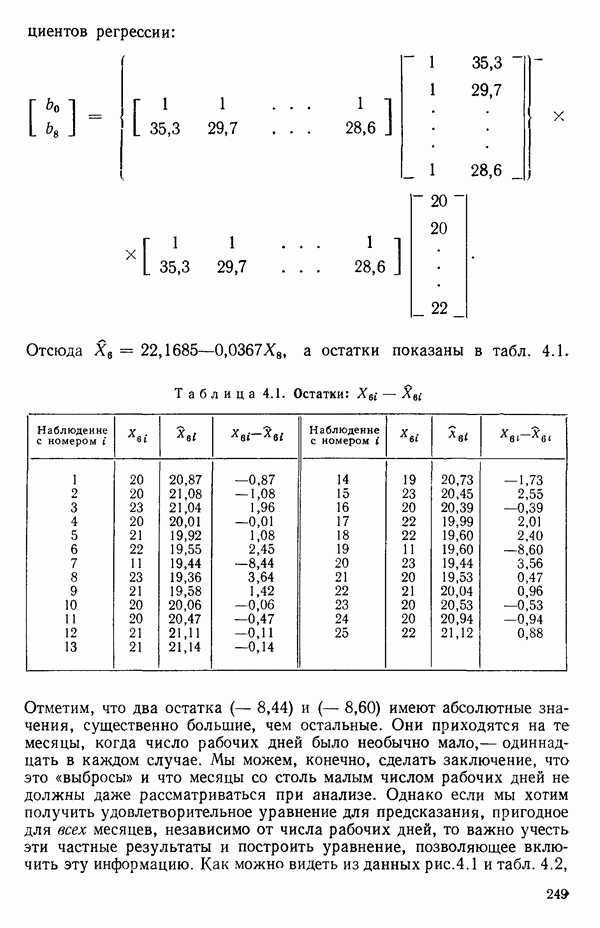
Мы можем воспользоваться для оценки этого параметра имеющимися данными точно так же, как мы оцениваем вектор параметров  в модели, которую строим, скажем
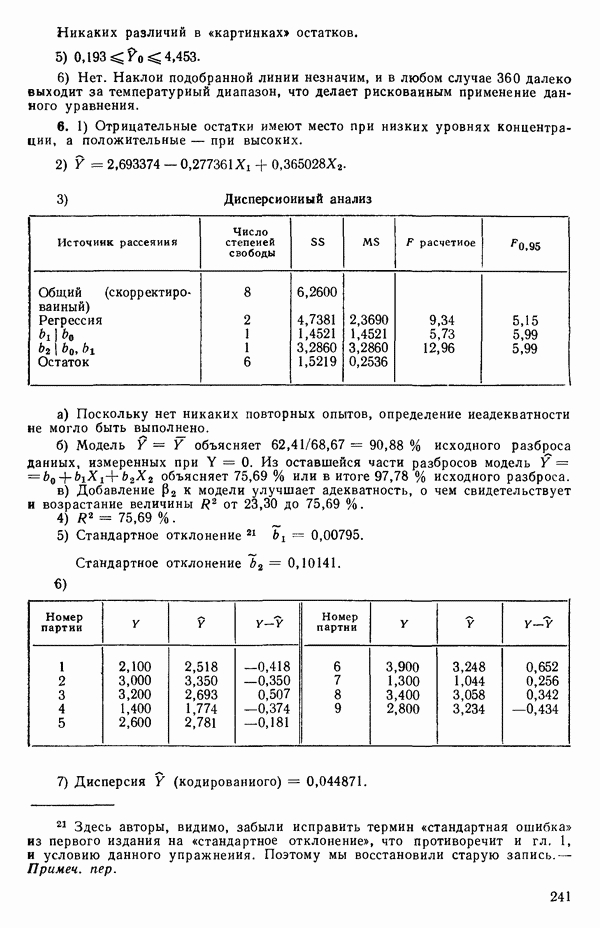
в модели, которую строим, скажем

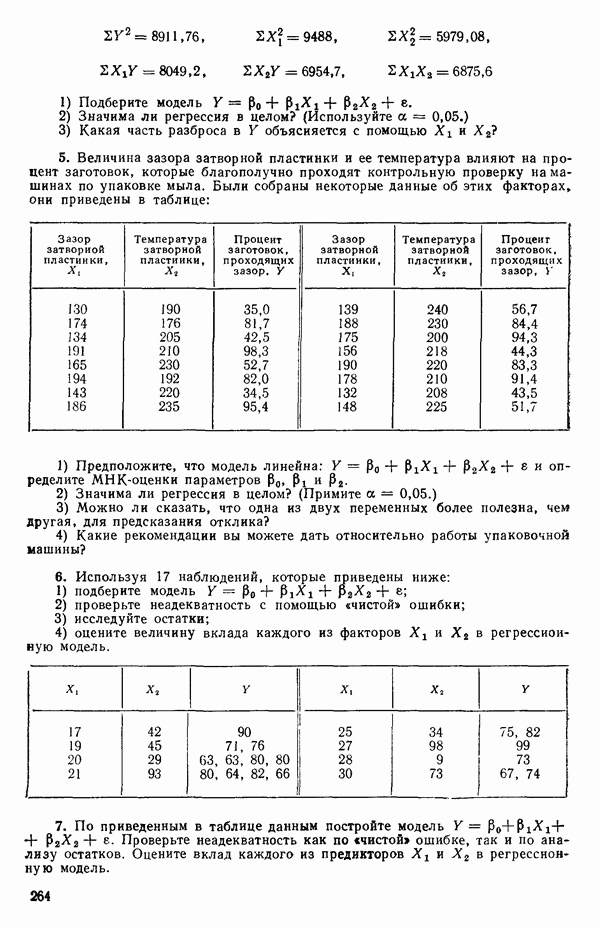
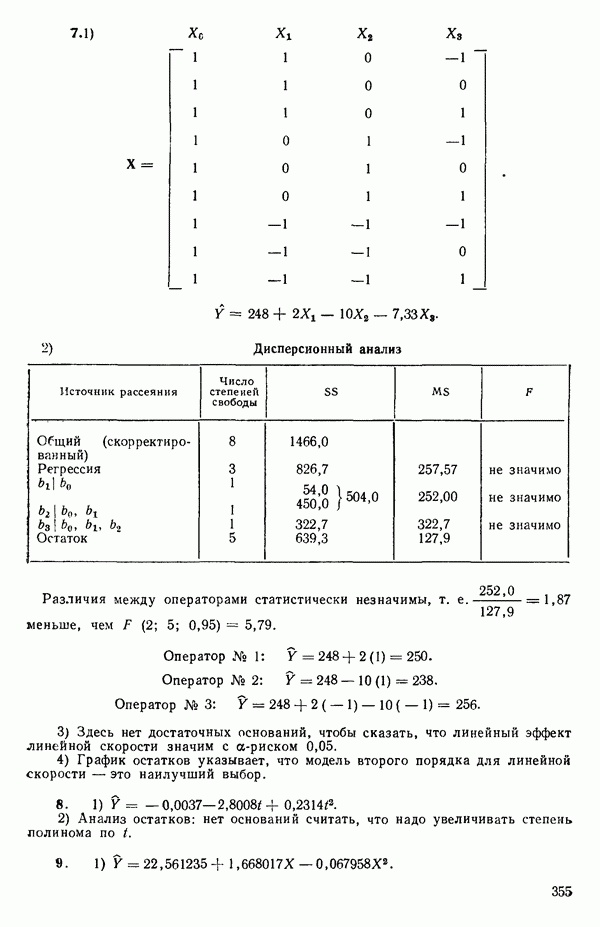
где  Существуют два главных способа оценки. Один из них основан на методе максимума правдоподобия в предположении, что остатки распределены нормально
Существуют два главных способа оценки. Один из них основан на методе максимума правдоподобия в предположении, что остатки распределены нормально  для подходящего выбора к. Этот подход (так же, как и его байесовский эквивалент) хорош для любого семейства преобразований, в том числе и для упомянутого выше, что отмечали Дж. Бокс и Д. Кокс еще в своей работе, вышедшей в 1964 г. Ниже перечислены необходимые шаги этого метода.
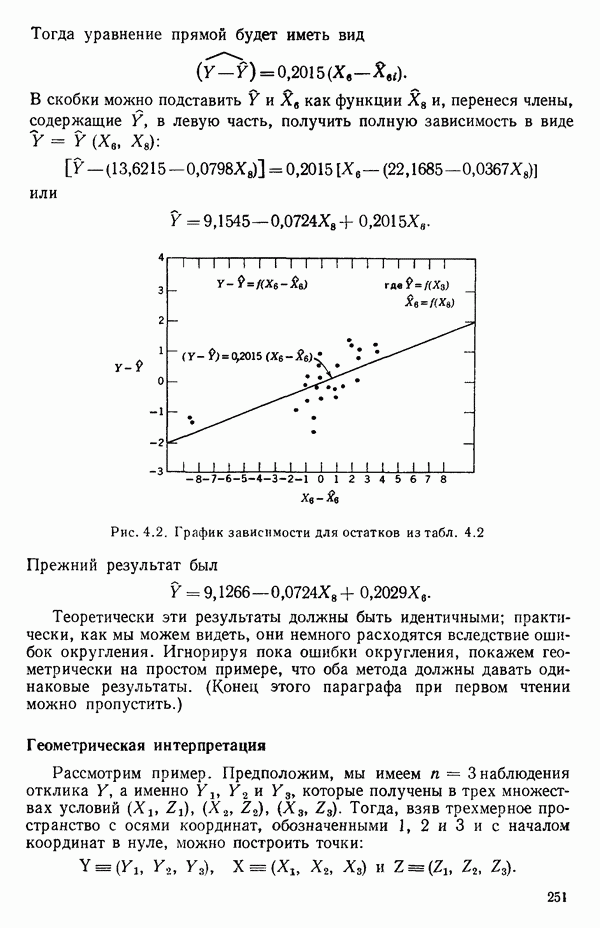
для подходящего выбора к. Этот подход (так же, как и его байесовский эквивалент) хорош для любого семейства преобразований, в том числе и для упомянутого выше, что отмечали Дж. Бокс и Д. Кокс еще в своей работе, вышедшей в 1964 г. Ниже перечислены необходимые шаги этого метода.
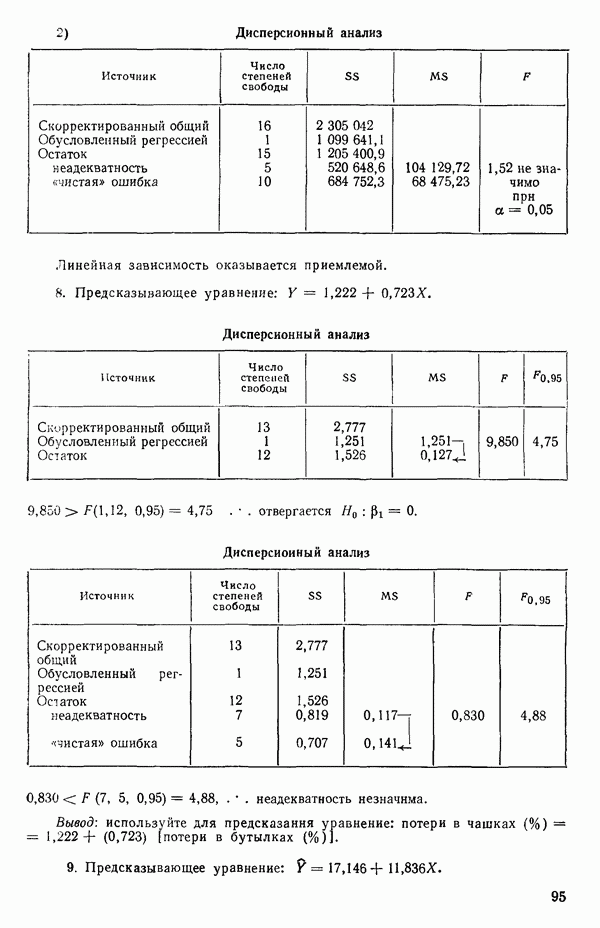
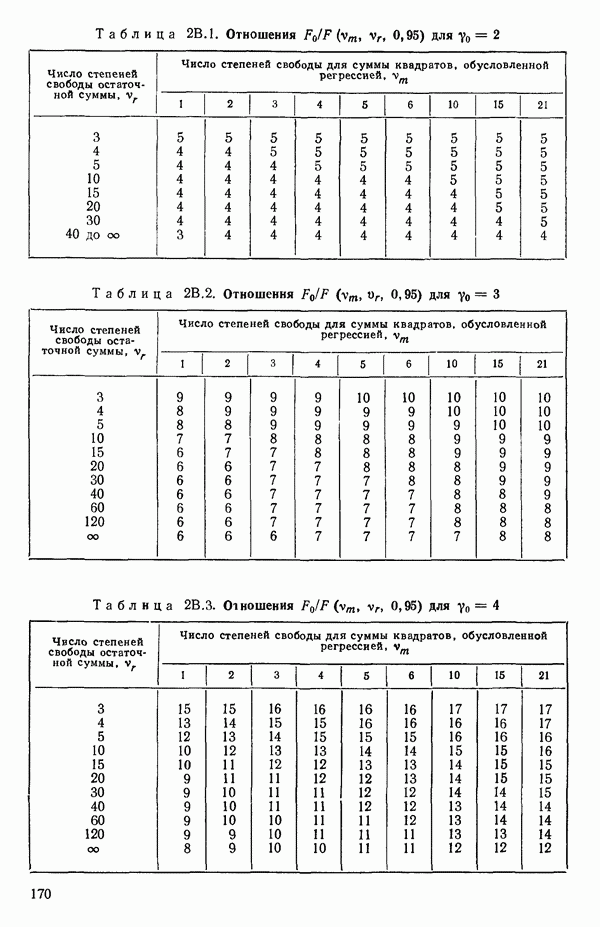
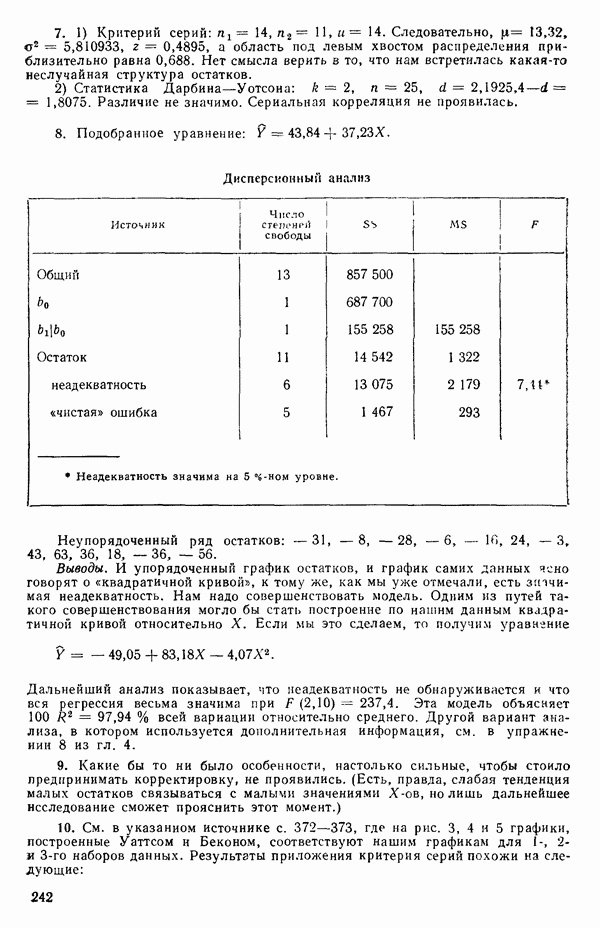
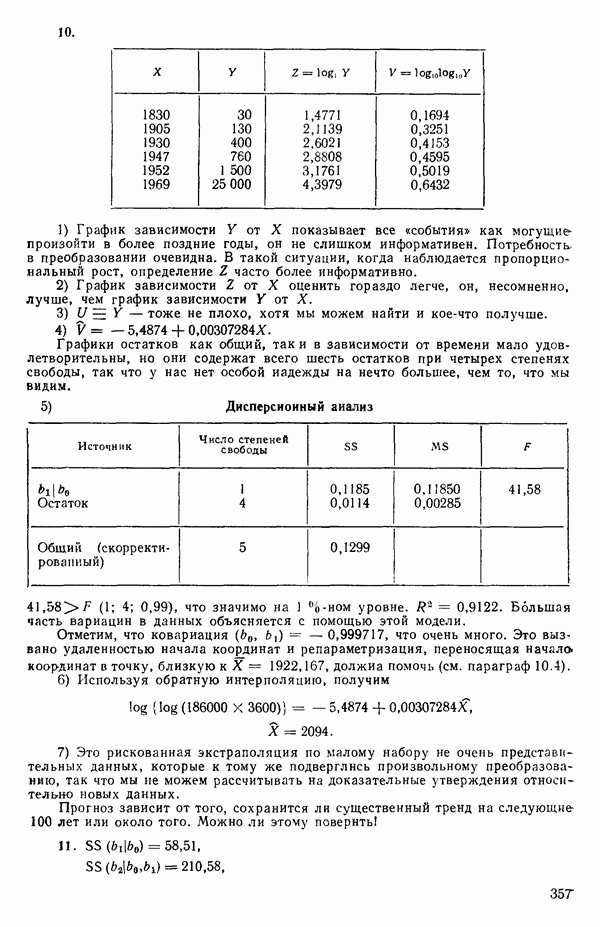
Оценка «лямбда» методом максимума правдоподобия
1. Берем какое-нибудь значение X из заданного диапазона. (Обычно мы начинаем подбор X с просмотра диапазона  или даже
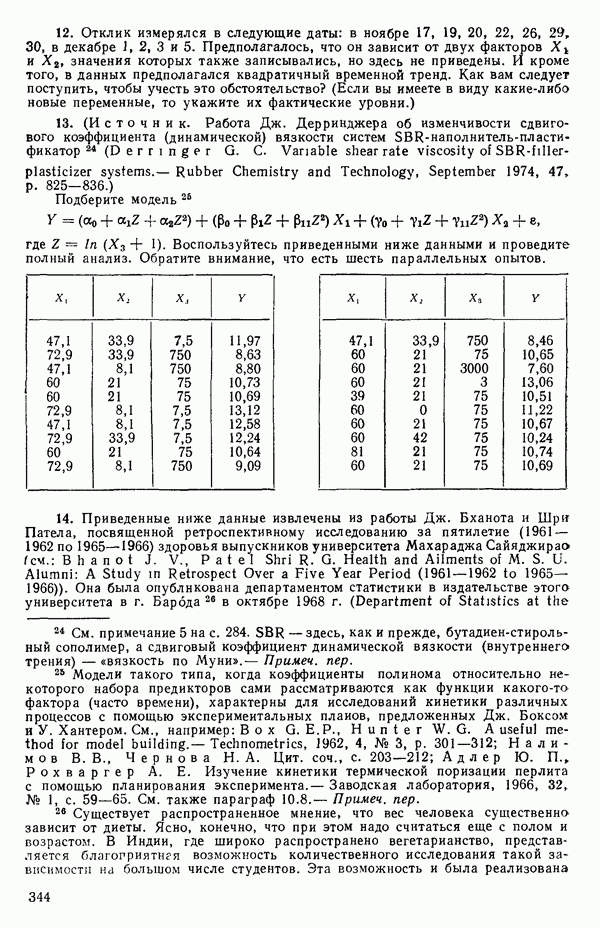
или даже  , постепенно расширяя диапазон настолько, насколько это окажется необходимым. Как правило, в заданном диапазоне выбирается от одиннадцати до двадцати одного значения
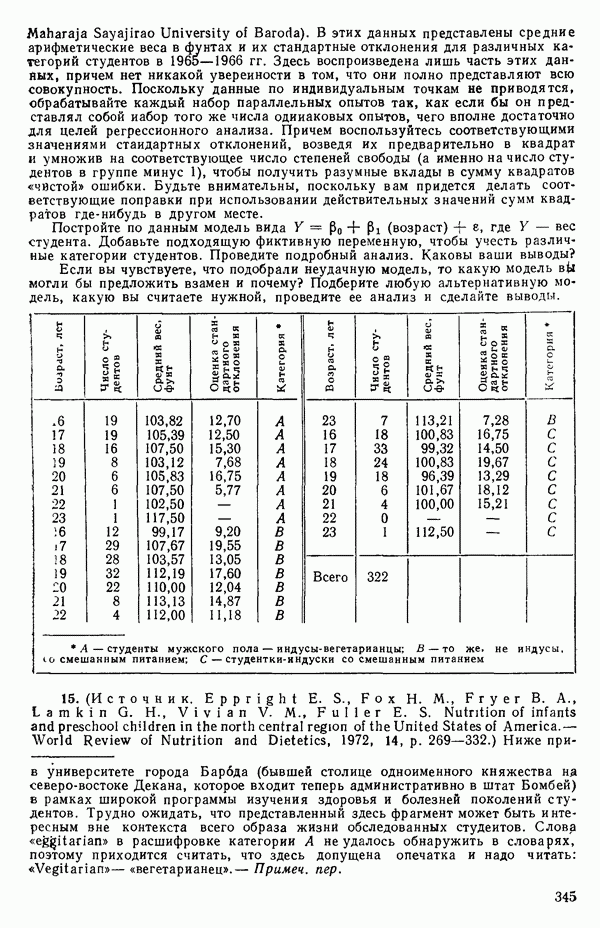
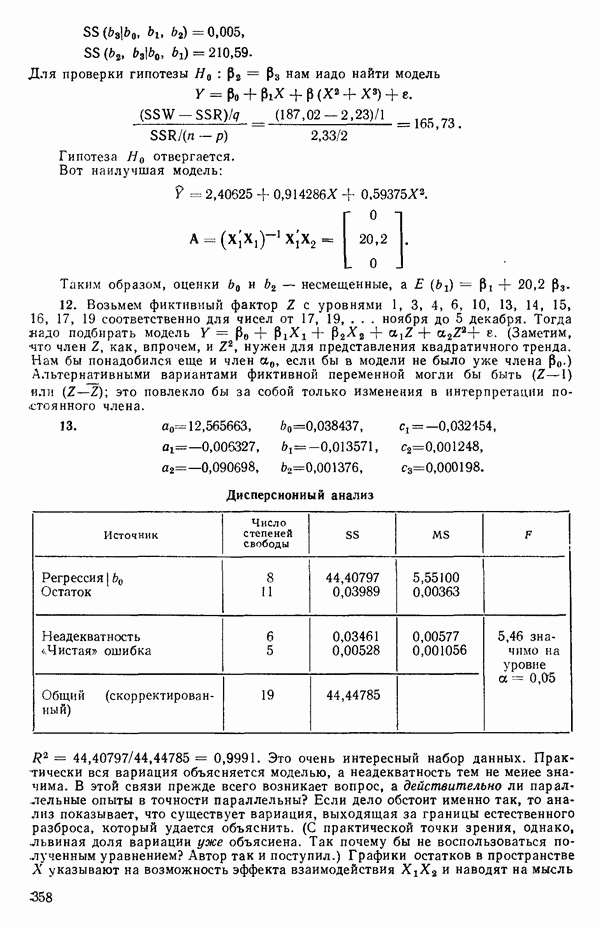
, постепенно расширяя диапазон настолько, насколько это окажется необходимым. Как правило, в заданном диапазоне выбирается от одиннадцати до двадцати одного значения  . В
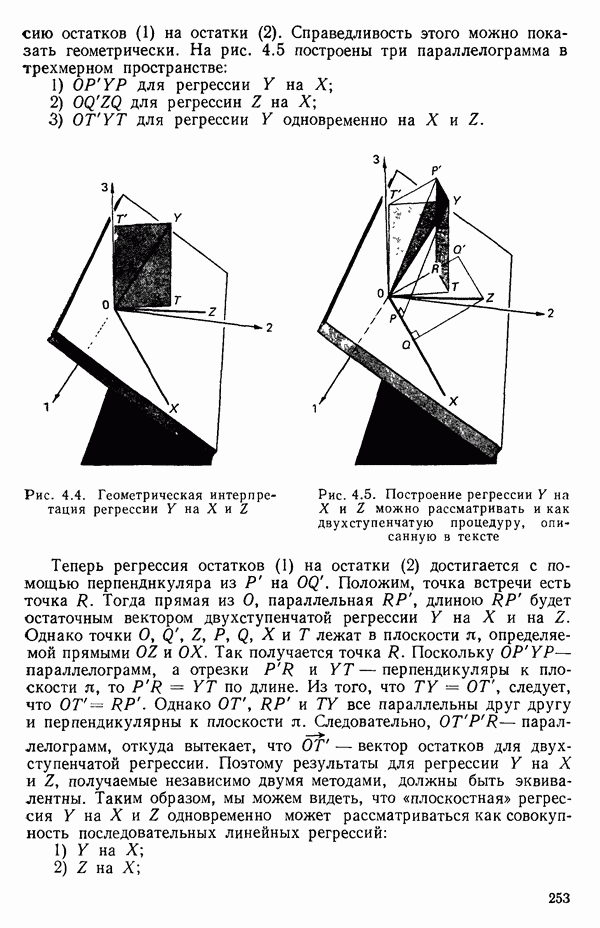
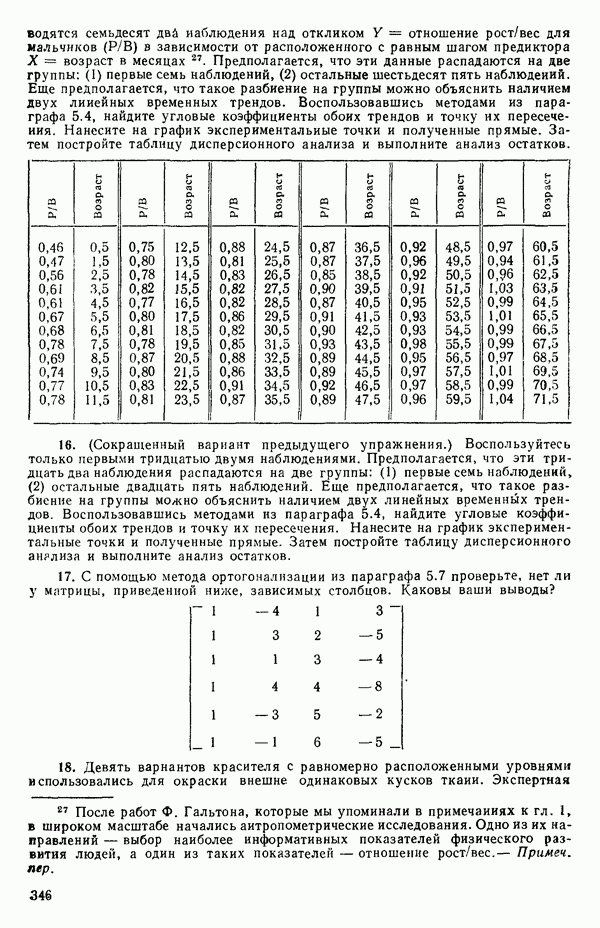
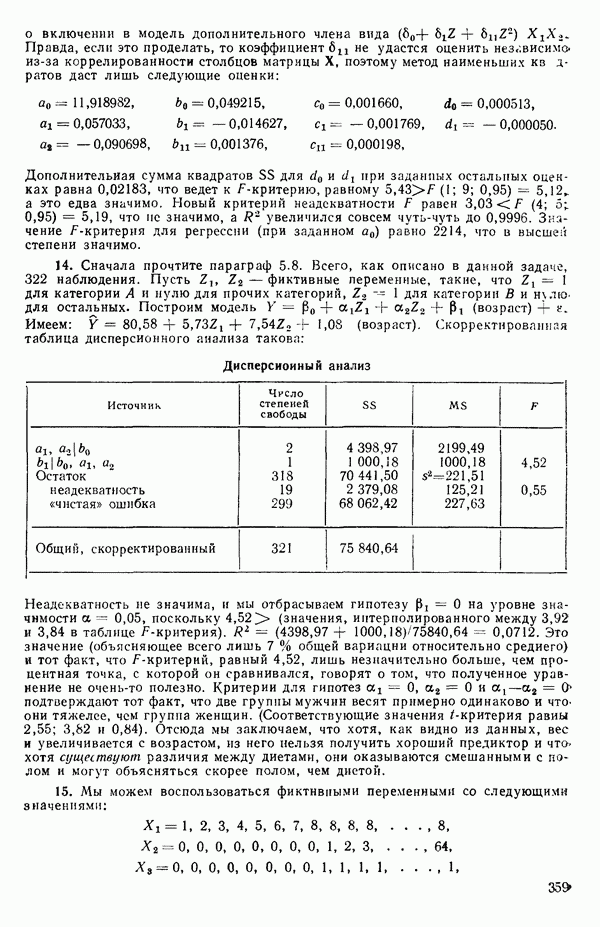
. В
дальнейшем мы можем дробить интервал и на более мелкие части, если потребуются дополнительные подробности, но необходимость в этом возникает нечасто, см. пункт 3 ниже.)
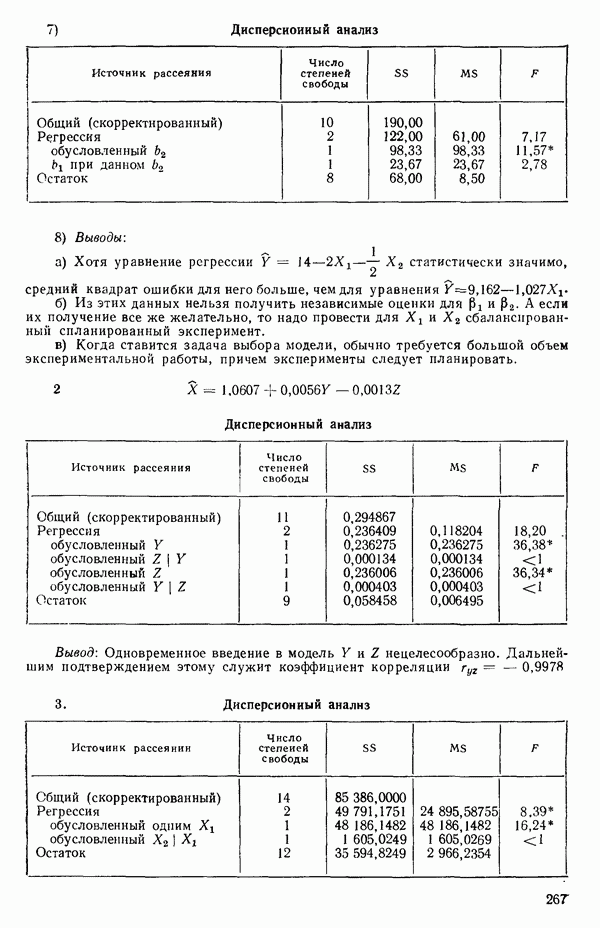
2. Для выбранного значения  вычисляем
вычисляем

где  общее число наблюдений,
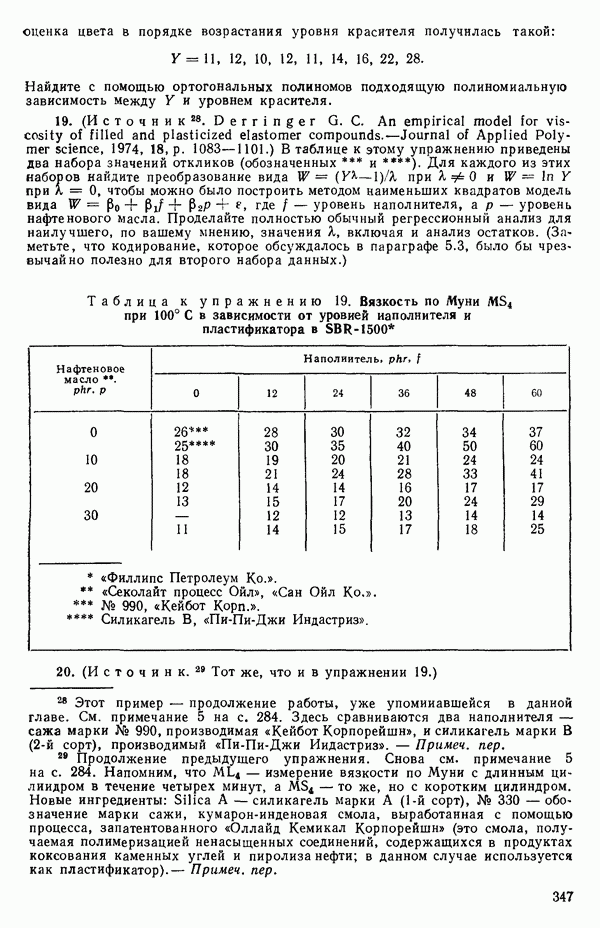
общее число наблюдений,

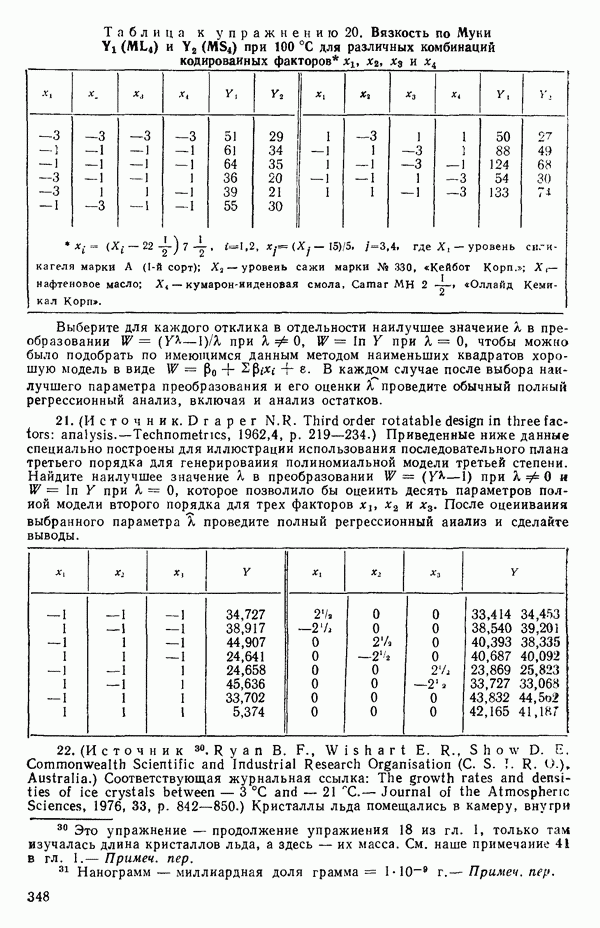
(т. е. остаточная сумма квадратов от уравнения регрессии, подобранного по модели (5.3.2) при выбранном значении  , взятая
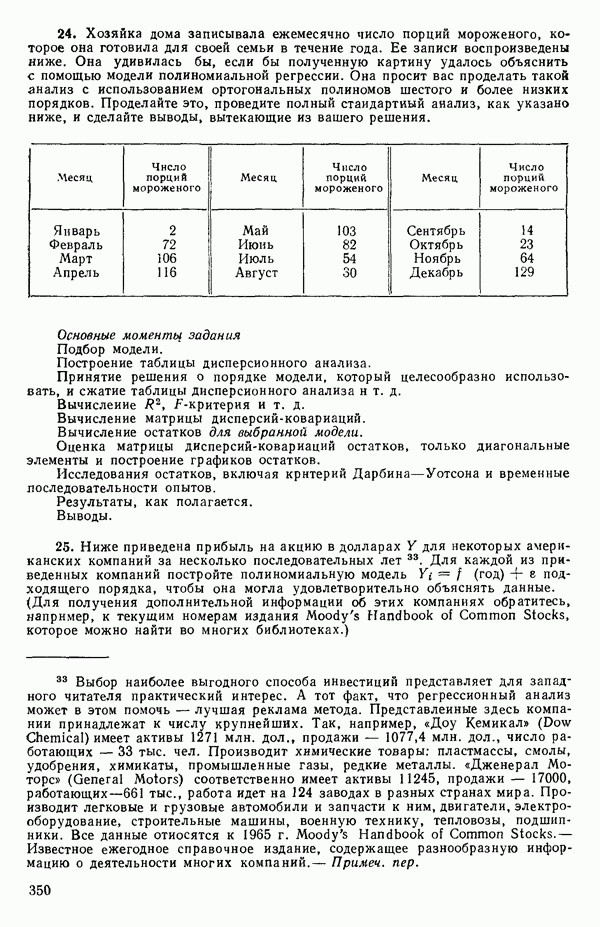
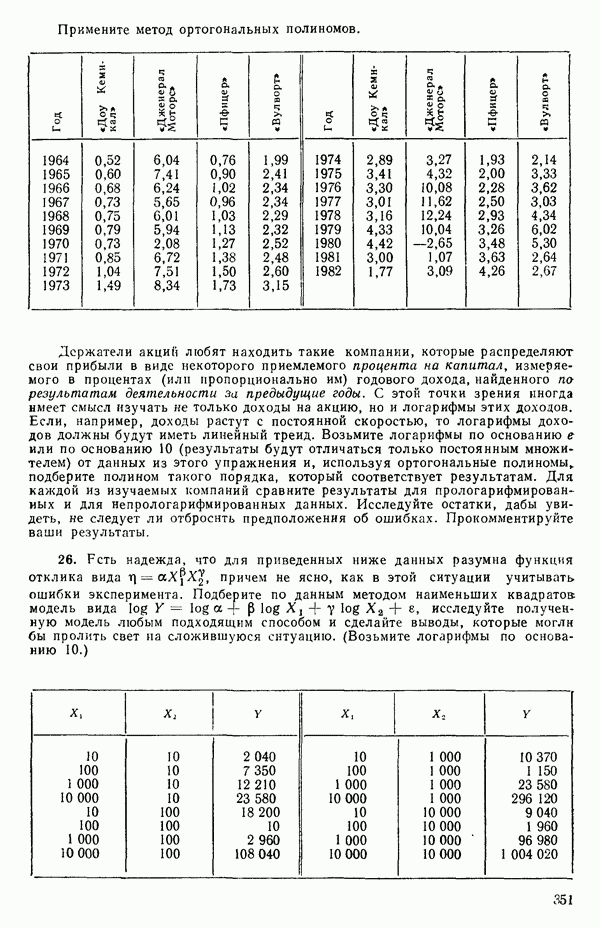
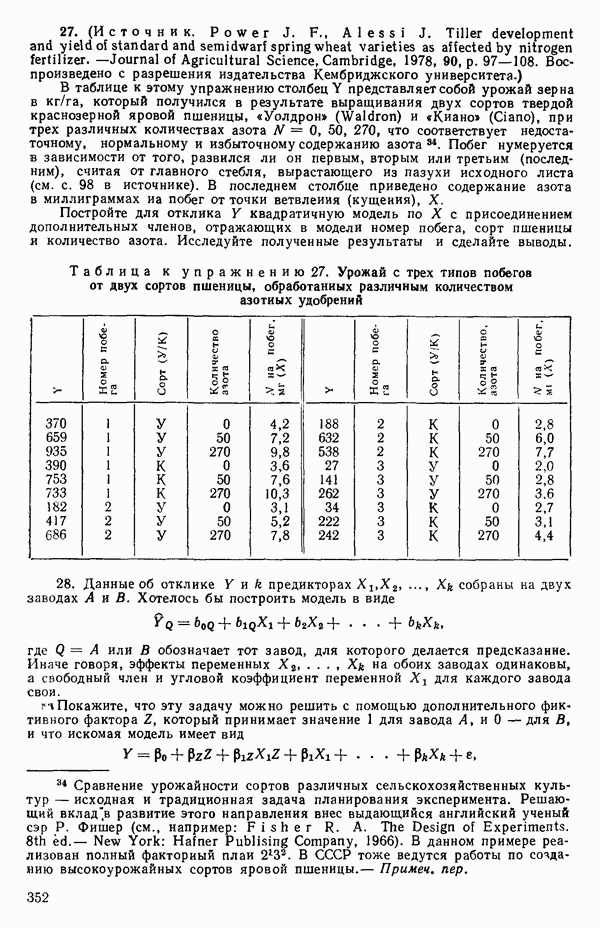
, взятая  раз), а
раз), а

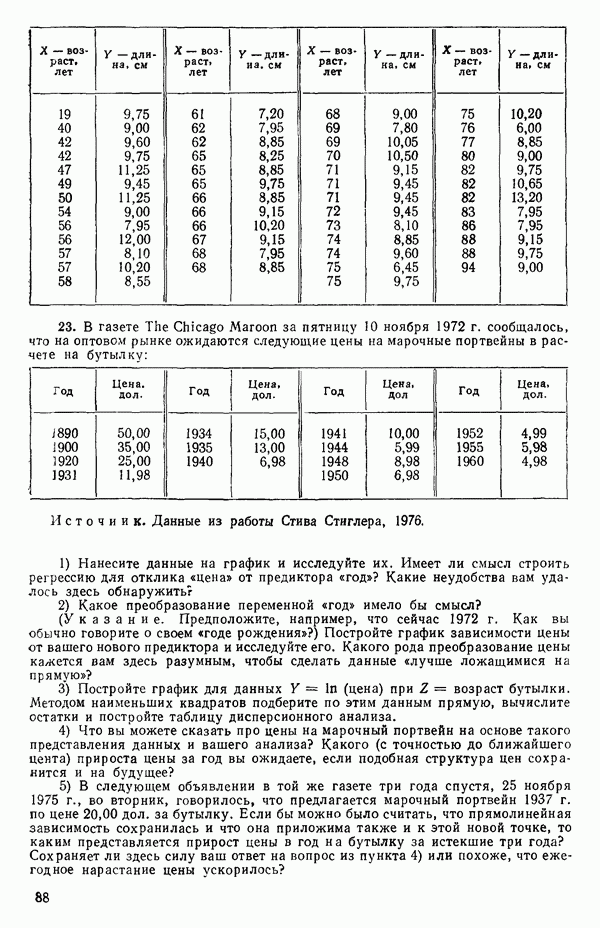
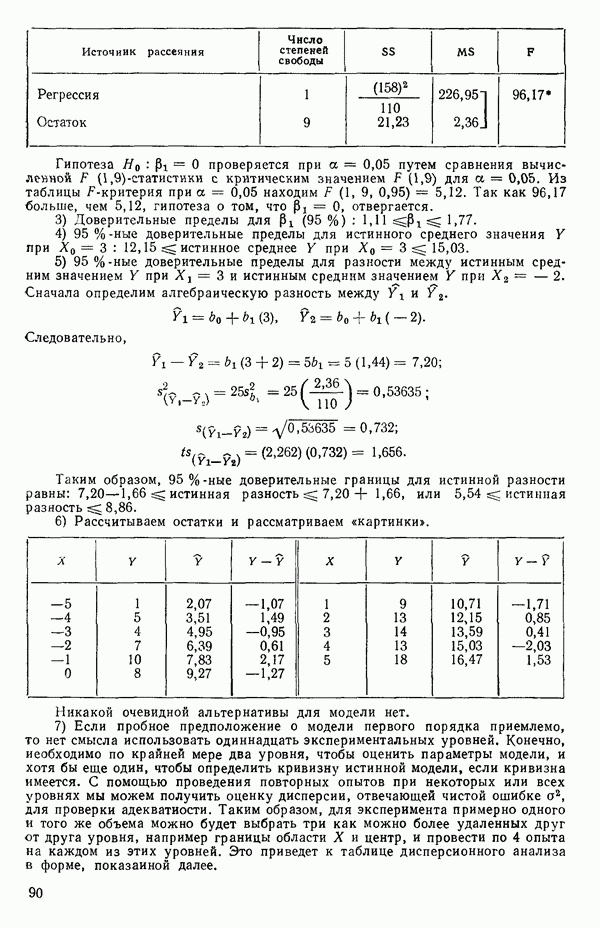
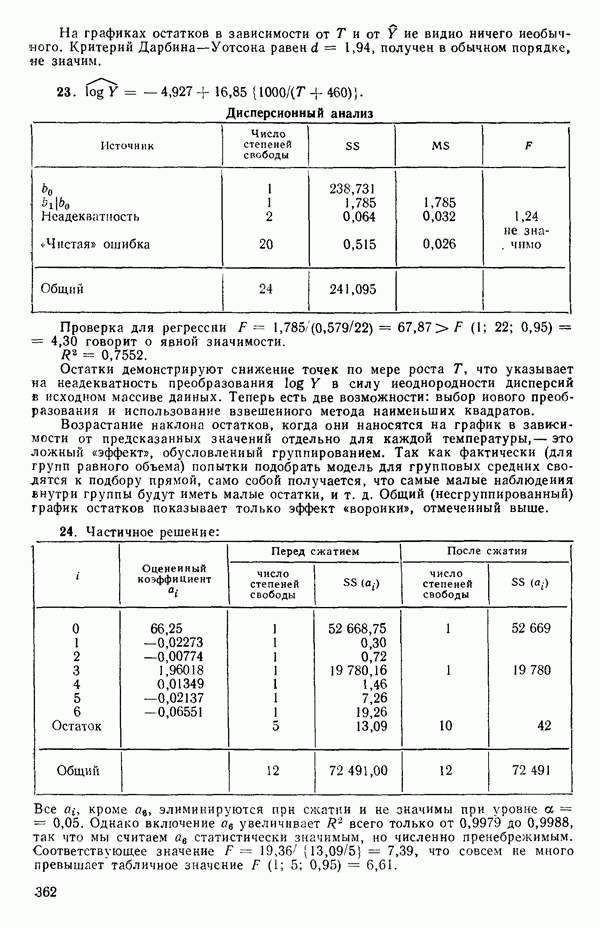
т.е.

Подставляя все это в уравнение (5.3.3), получим

для каждого значения  , которое мы выбрали. (Не забывайте использовать
, которое мы выбрали. (Не забывайте использовать  когда
когда  Или же вообще избегайте применения значения
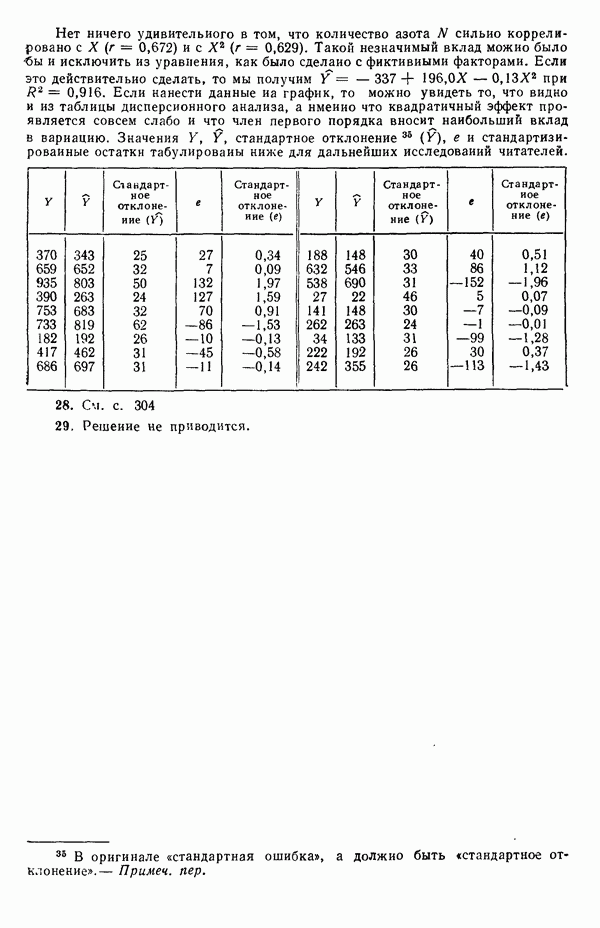
Или же вообще избегайте применения значения  , точно равного нулю, когда покрываете заданный диапазон значений
, точно равного нулю, когда покрываете заданный диапазон значений  )
)
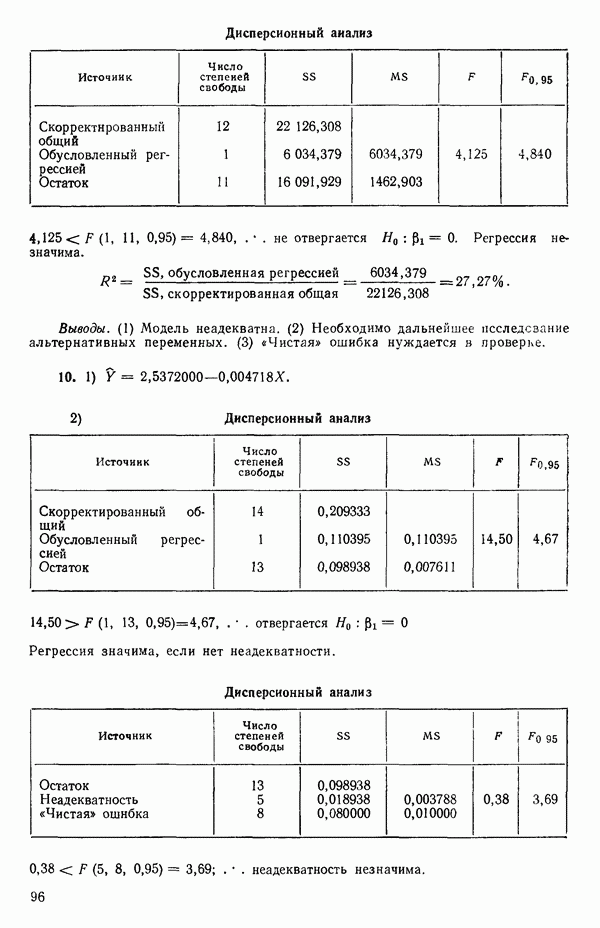
3. После того как уравнение (5.3.6) вычислено для нескольких значений  в заданном диапазоне, постройте график значений
в заданном диапазоне, постройте график значений  в зависимости от
в зависимости от  и соедините точки гладкой кривой. Отыщите то значение
и соедините точки гладкой кривой. Отыщите то значение  , которое максимизирует величину
, которое максимизирует величину  Это и будет
Это и будет  , оценка метода максимума правдоподобия для
, оценка метода максимума правдоподобия для  . Чаще всего мы предпочитаем не использовать такого точного значения
. Чаще всего мы предпочитаем не использовать такого точного значения  в дальнейших вычислениях. Вместо этого мы берем ближайшее удобное значение в последовательности
в дальнейших вычислениях. Вместо этого мы берем ближайшее удобное значение в последовательности  после первоначальной прикидки, так что искомое значение попадает в заданный доверительный интервал (см. ниже). Если, например, вычисленное значение Я окажется порядка
после первоначальной прикидки, так что искомое значение попадает в заданный доверительный интервал (см. ниже). Если, например, вычисленное значение Я окажется порядка  то мы, по-видимому, сможем воспользоваться величиной
то мы, по-видимому, сможем воспользоваться величиной  А если бы
А если бы  оказалась примерно 0,94, то мы могли бы взять
оказалась примерно 0,94, то мы могли бы взять  и т. д. (Правда, существует масса вариантов персональных решений при выборе
и т. д. (Правда, существует масса вариантов персональных решений при выборе  после того, как вычисления уже закончены. Так в некоторых случаях могут пригодиться значения вроде
после того, как вычисления уже закончены. Так в некоторых случаях могут пригодиться значения вроде  Некоторые специалисты предпочитают округлять до ближайшей четверти, а не до половины. Другие чувствуют себя неуютно при любом округлении и продолжают пользоваться теми значениями, какие они получили без всяких
Некоторые специалисты предпочитают округлять до ближайшей четверти, а не до половины. Другие чувствуют себя неуютно при любом округлении и продолжают пользоваться теми значениями, какие они получили без всяких
округлений.) Итак, мы анализируем преобразованные данные, т. е. данные, преобразованные с помощью выбора какого бы то ни былоконечного значения X, и описываем результаты.
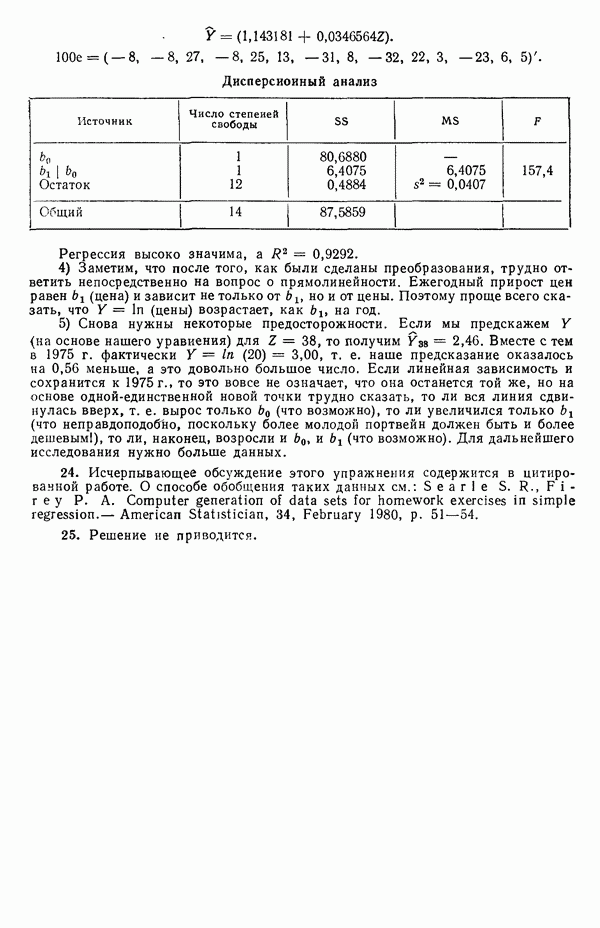
Альтернативный подход
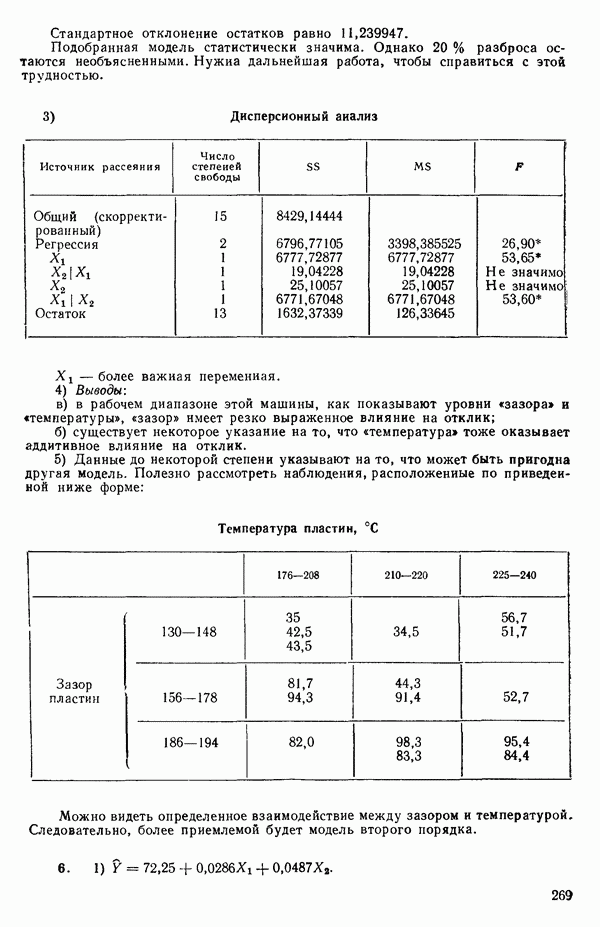
Альтернативный, но эквивалентный способ вычислений, который предпочитают отдельные специалисты, сводится к преобразованию наблюдений к виду

и максимизации выражения

где

а величина  остаточная сумма квадратов, полученная для модели
остаточная сумма квадратов, полученная для модели  Проще говоря, это означает, что мы можем минимизировать функцию
Проще говоря, это означает, что мы можем минимизировать функцию  Заметим, что с учетом уравнения (5.3.5) величина
Заметим, что с учетом уравнения (5.3.5) величина  в уравнении (5.3.7) может быть переписана:
в уравнении (5.3.7) может быть переписана:

где

— среднее геометрическое значений  Форма, в которой представлено уравнение
Форма, в которой представлено уравнение  одна из тех, что обычно приводится. У нее несколько преимуществ. Она гораздо проще (см. указанную выше статью Дж. Бокса и Д. Кокса 1964 г., с. 216) благодаря изменению масштаба обеспечивает большую точность вычислений, особенно для больших значений X, и позволяет выполнять все вычисления с помощью любой стандартной программы регрессионного анализа. А еще она допускает прямое сравнение остаточных сумм квадратов, поскольку масштабный делитель
одна из тех, что обычно приводится. У нее несколько преимуществ. Она гораздо проще (см. указанную выше статью Дж. Бокса и Д. Кокса 1964 г., с. 216) благодаря изменению масштаба обеспечивает большую точность вычислений, особенно для больших значений X, и позволяет выполнять все вычисления с помощью любой стандартной программы регрессионного анализа. А еще она допускает прямое сравнение остаточных сумм квадратов, поскольку масштабный делитель  фактически возвращает значения
фактически возвращает значения  назад к исходным величинам в выражении (5.3.7а). Пример, который мы приводим ниже, рассчитан в терминах
назад к исходным величинам в выражении (5.3.7а). Пример, который мы приводим ниже, рассчитан в терминах  но если читатель пожелает, он может для сравнения вести параллельные вычисления через
но если читатель пожелает, он может для сравнения вести параллельные вычисления через 
Приближенный доверительный интервал для «лямбда»
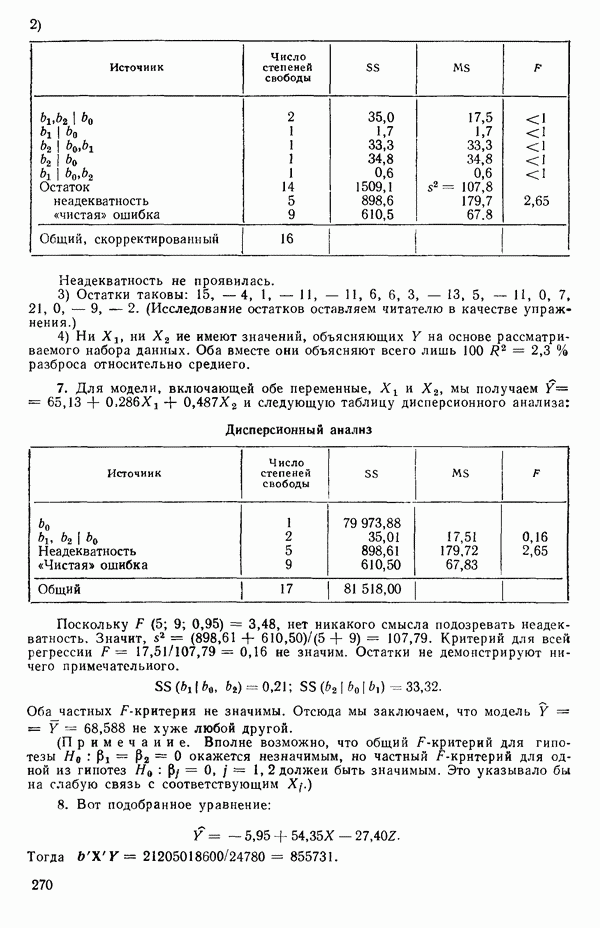
Приближенный 
 -ный доверительный интервал для А, включает те значения X, которые удовлетворяют неравенству
-ный доверительный интервал для А, включает те значения X, которые удовлетворяют неравенству

где  — процентная точка распределения
— процентная точка распределения  -квадрат с одной степенью свободы, которая отсекает площадь, равную а, от верхнего хвоста этого распределения. Вот некоторые из этих значений:
-квадрат с одной степенью свободы, которая отсекает площадь, равную а, от верхнего хвоста этого распределения. Вот некоторые из этих значений:

Чтобы удовлетворить неравенству (5.3.10), мы просто нанесем на график зависимости  от
от  некоторую горизонтальную линию «а уровне
некоторую горизонтальную линию «а уровне

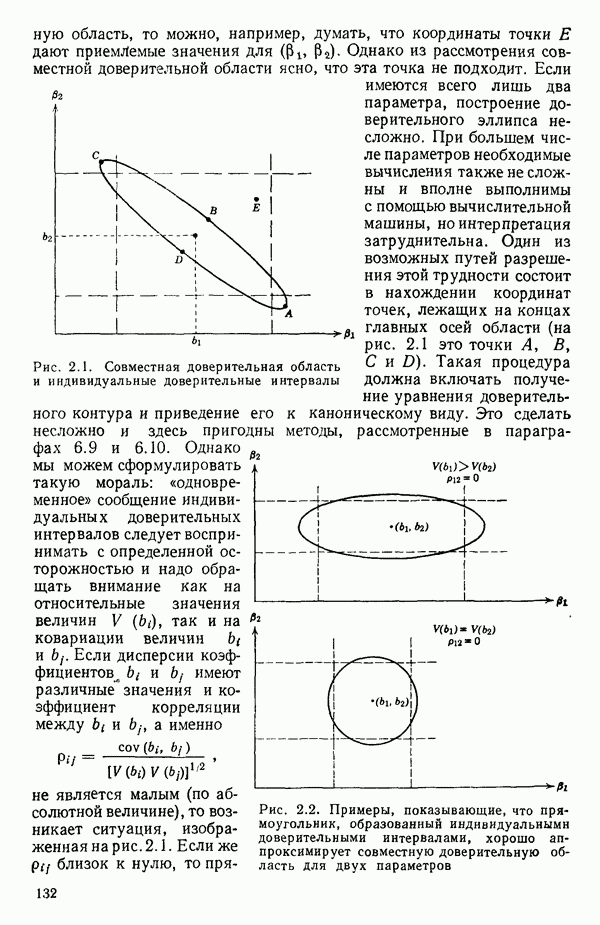
вертикальной шкалы. Эта линия пересечет кривую в двух точках <при двух значениях А). Они и будут крайними точками приближенного доверительного интервала.
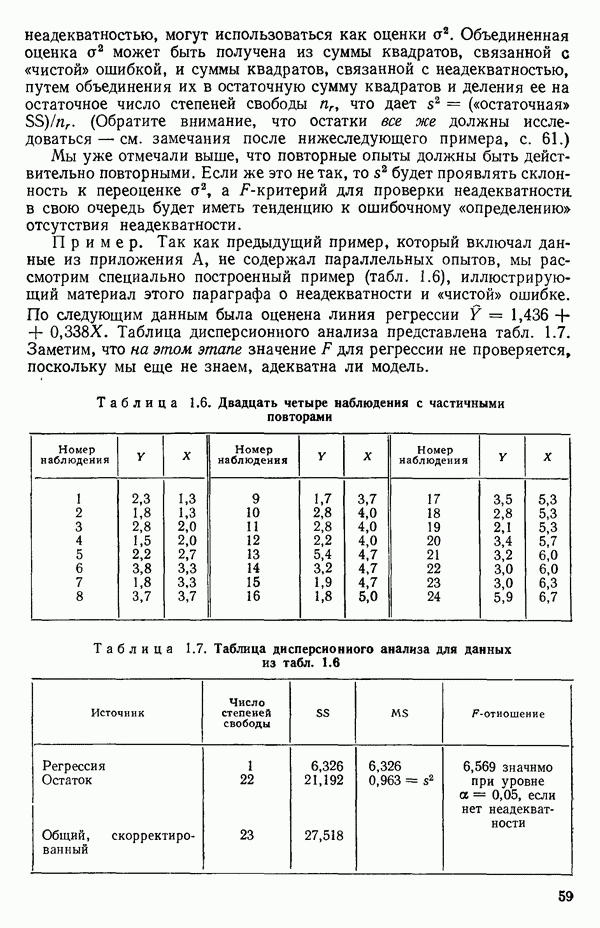
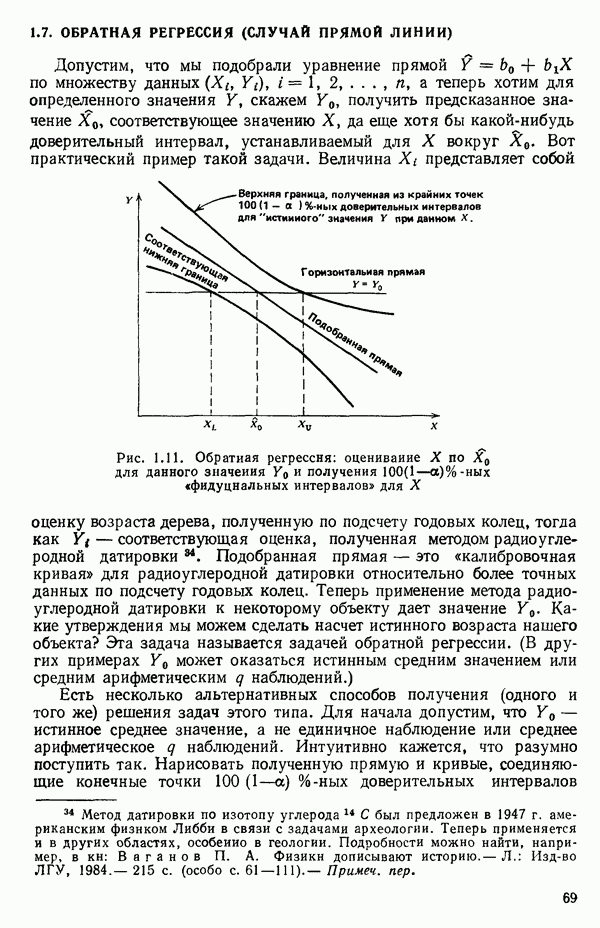
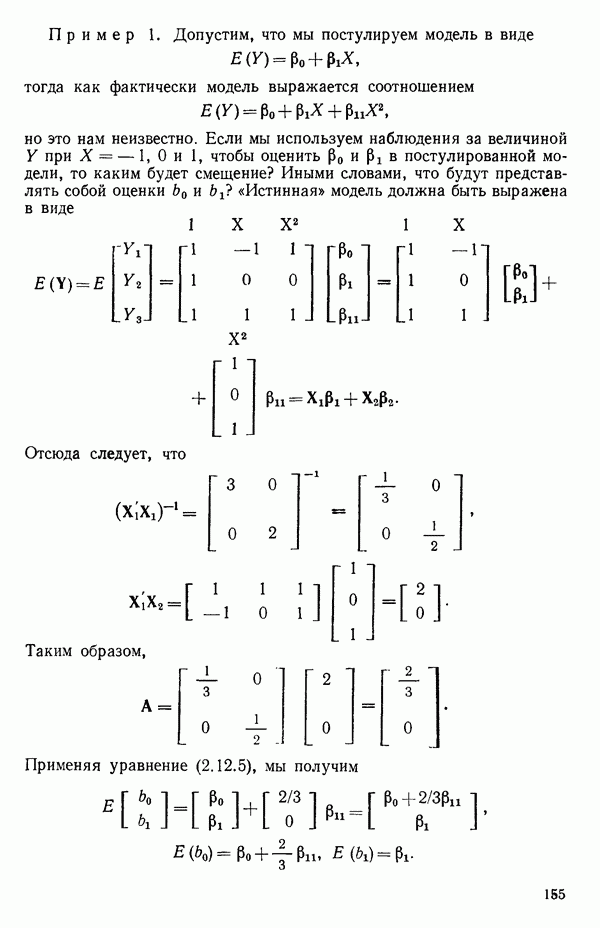
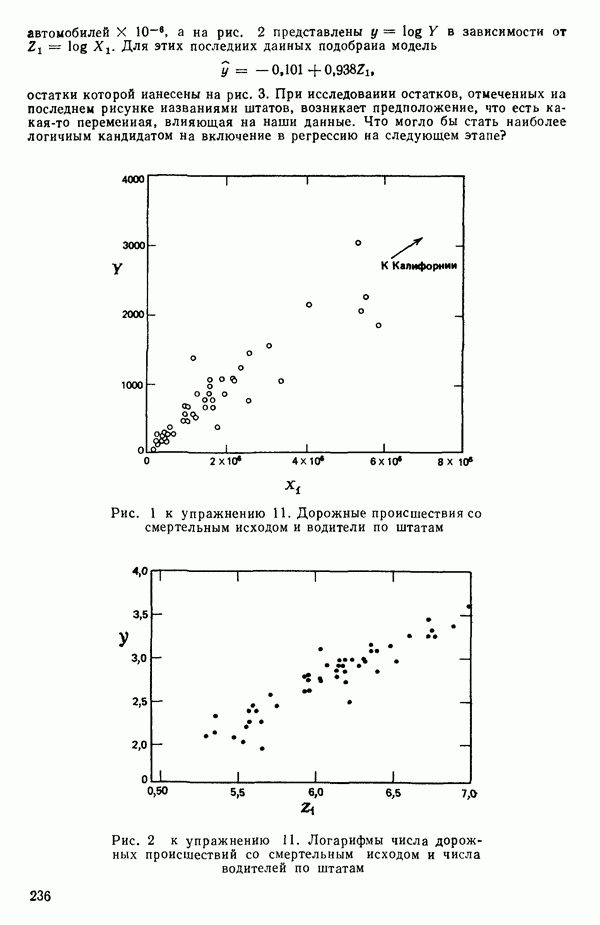
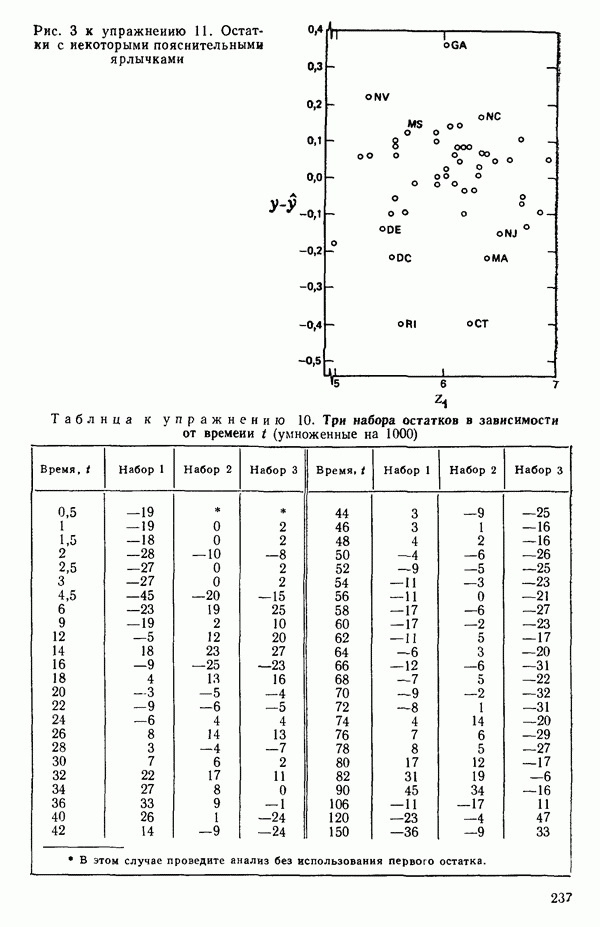
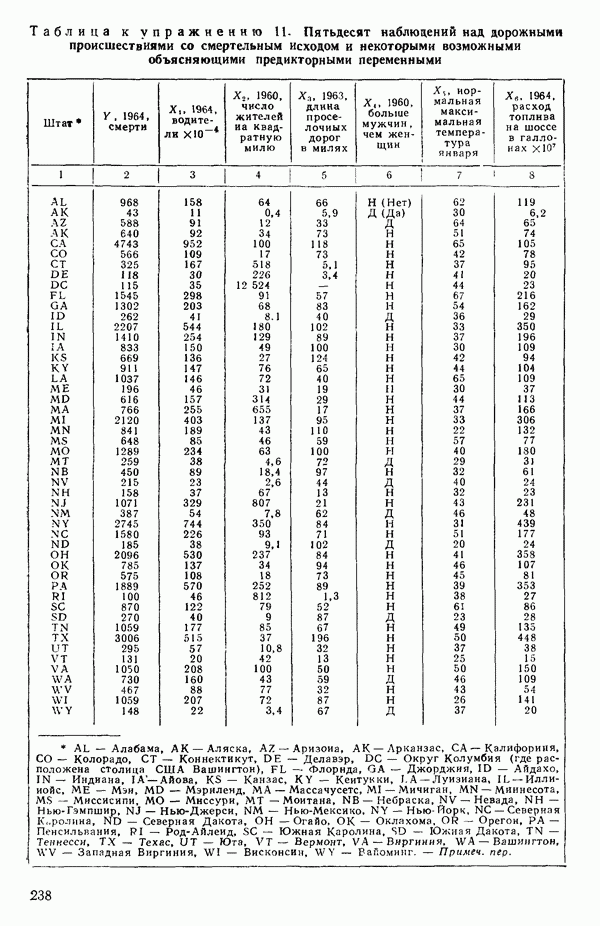
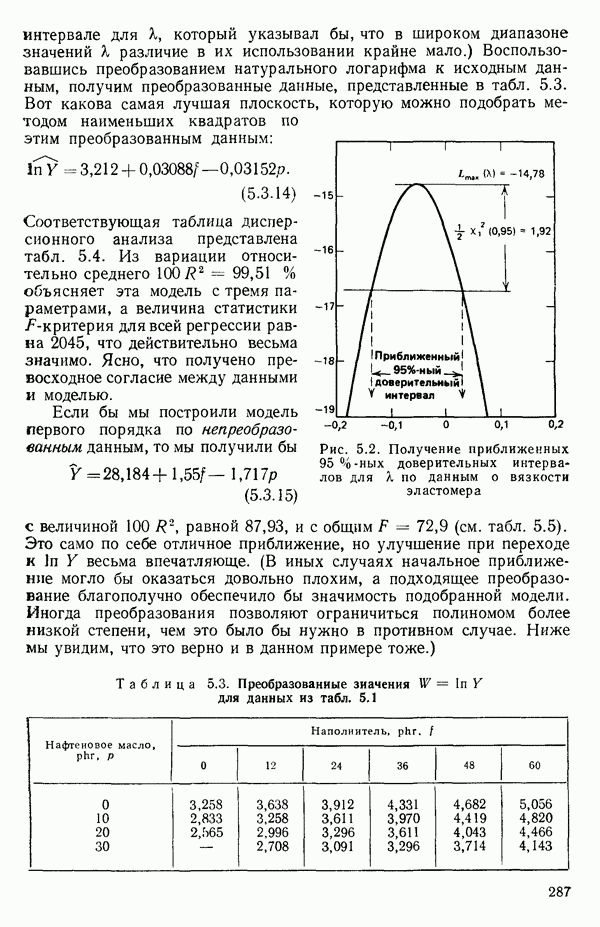
Пример 1. Данные в табл. 5.1 представляют собой фрагмент «более обширного набора, приведенного в работе Дж. Дерринджера, где обсуждается эмпирическая модель вязкости сложного эластомера
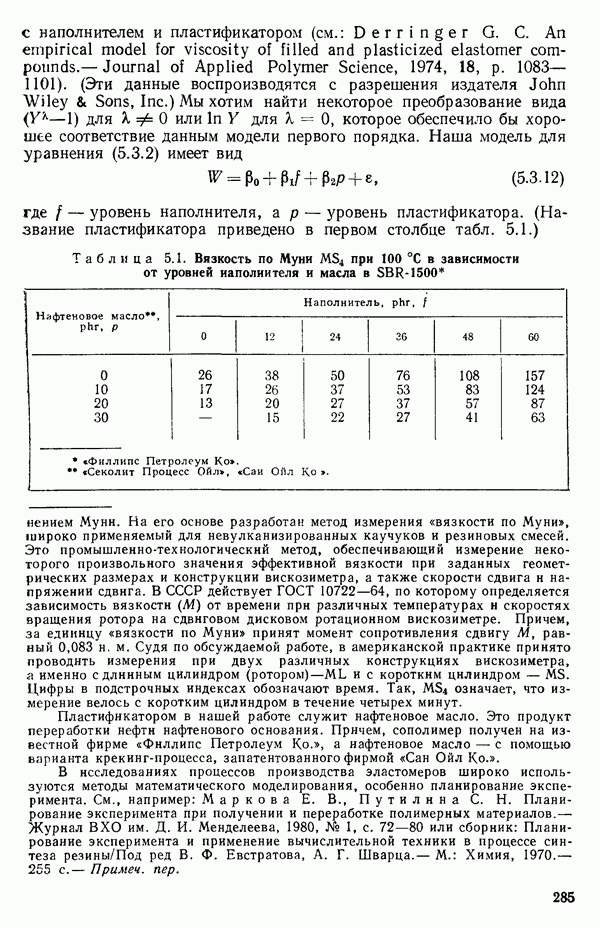
Обратите внимание, что значения отклика разбросаны в диапазоне от 157 до 13, отношение границ которого дает  Когда отношение наибольшего значения отклика к наименьшему составляет примерно порядок (т. е. около 10) или более того, есть надежда, что преобразование
Когда отношение наибольшего значения отклика к наименьшему составляет примерно порядок (т. е. около 10) или более того, есть надежда, что преобразование  окажется эффективным.
окажется эффективным.
В табл. 5.2 приведены значения  для различных
для различных  (Начальный набор значений для
(Начальный набор значений для  был затем уточнен по более густой сетке
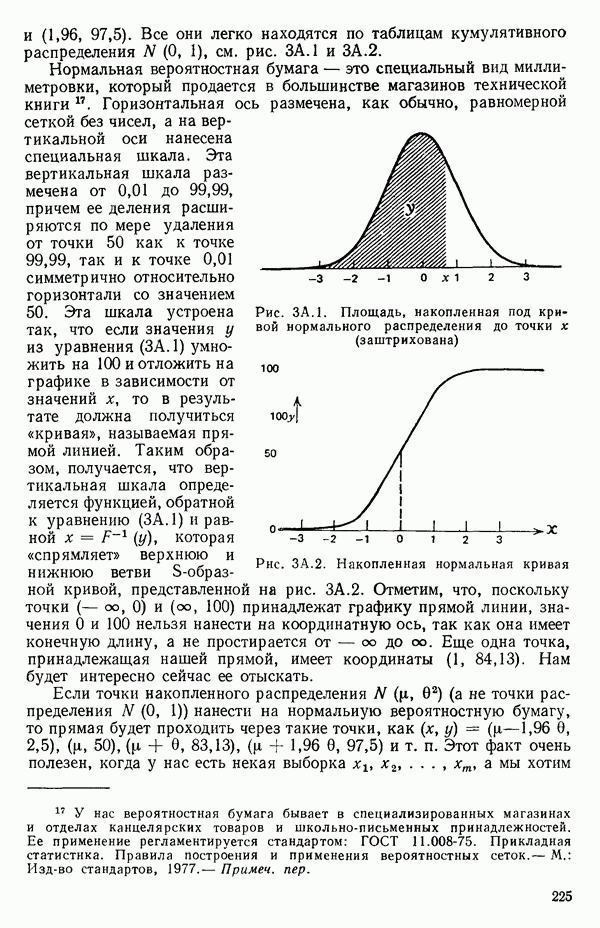
был затем уточнен по более густой сетке  в окрестности пика кривой.) Сглаженная кривая, проведенная по этим точкам, представлена на рис. 5.1. Мы видим, что максимум
в окрестности пика кривой.) Сглаженная кривая, проведенная по этим точкам, представлена на рис. 5.1. Мы видим, что максимум  приходится на значение, близкое к
приходится на значение, близкое к  Это совсем рядом с нулем, значит, преобразование
Это совсем рядом с нулем, значит, преобразование

может оказаться подходящим для этого набора данных.

Рис. 5.1. График зависимости  от Я для данных о вязкости эластомера
от Я для данных о вязкости эластомера
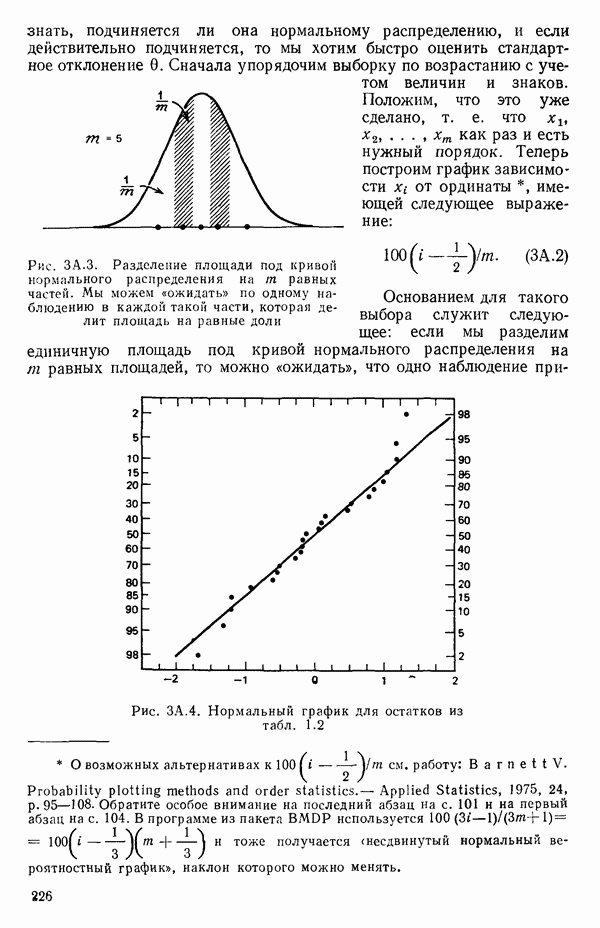
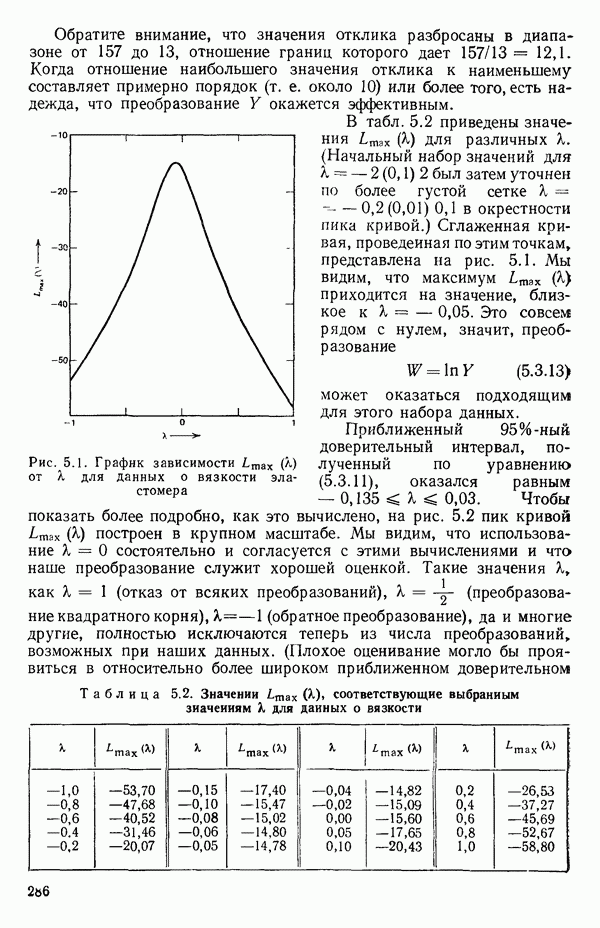
Приближенный 95%-ный доверительный интервал, полученный по уравнению (5.3.11), оказался равным  Чтобы показать более подробно, как это вычислено, на рис. 5.2 пик кривой
Чтобы показать более подробно, как это вычислено, на рис. 5.2 пик кривой  построен в крупном масштабе. Мы видим, что использование
построен в крупном масштабе. Мы видим, что использование  состоятельно и согласуется с этими вычислениями и что наше преобразование служит хорошей оценкой. Такие значения X, как
состоятельно и согласуется с этими вычислениями и что наше преобразование служит хорошей оценкой. Такие значения X, как  (отказ от всяких преобразований),
(отказ от всяких преобразований),  (преобразование квадратного корня),
(преобразование квадратного корня),  (обратное преобразование), да и многие другие, полностью исключаются теперь из числа преобразований, возможных при наших данных. (Плохое оценивание могло бы проявиться в относительно более широком приближенном доверительном
(обратное преобразование), да и многие другие, полностью исключаются теперь из числа преобразований, возможных при наших данных. (Плохое оценивание могло бы проявиться в относительно более широком приближенном доверительном
Таблица 5.2. Значении  соответствующие выбранным значениям X для данных о вязкости
соответствующие выбранным значениям X для данных о вязкости

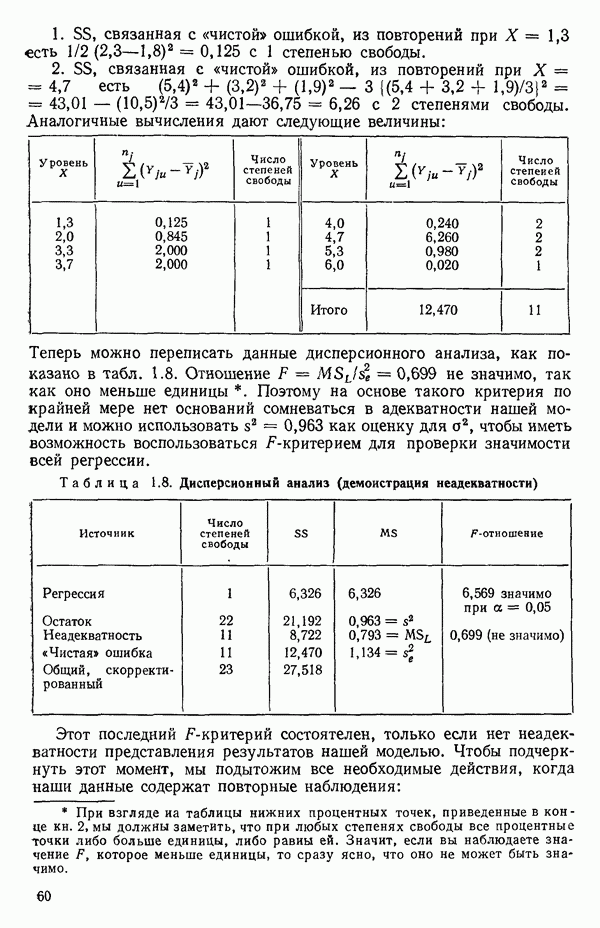
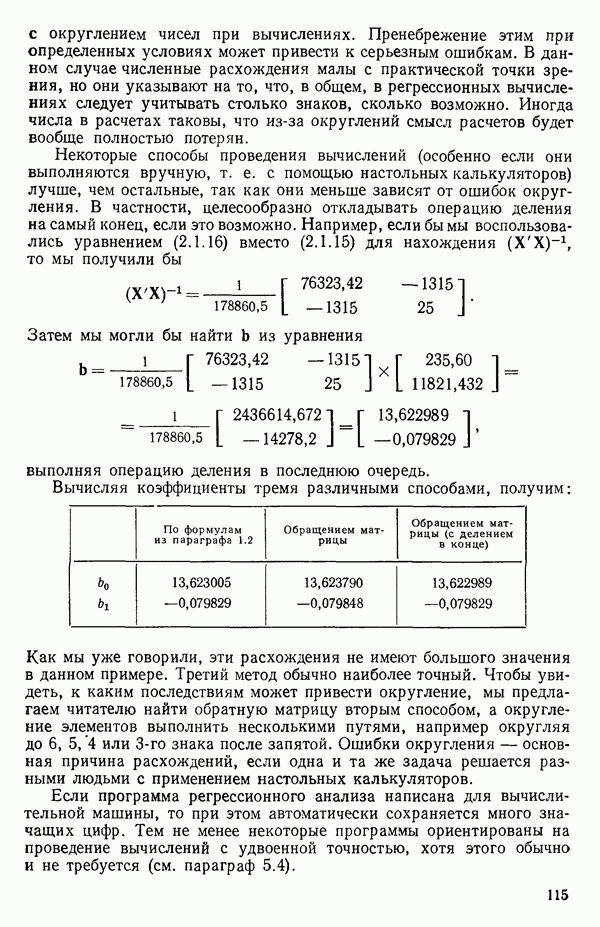
интервале для X, который указывал бы, что в широком диапазоне значений X различие в их использовании крайне мало.) Воспользовавшись преобразованием натурального логарифма к исходным данным, получим преобразованные данные, представленные в табл. 5.3. Вот какова самая лучшая плоскость, которую можно подобрать методом наименьших квадратов по этим преобразованным данным:

Соответствующая таблица дисперсионного анализа представлена табл. 5.4. Из вариации относительно среднего  объясняет эта модель с тремя параметрами, а величина статистики
объясняет эта модель с тремя параметрами, а величина статистики  -критерия для всей регрессии равна 2045, что действительно весьма значимо. Ясно, что получено превосходное согласие между данными и моделью.
-критерия для всей регрессии равна 2045, что действительно весьма значимо. Ясно, что получено превосходное согласие между данными и моделью.

Рис. 5.2. Получение приближенных  -ных доверительных интервалов для
-ных доверительных интервалов для  по данным о вязкости эластомера
по данным о вязкости эластомера
Если бы мы построили модель первого порядка по непреобразованным данным, то мы получили бы

с величиной  равной 87,93, и с общим
равной 87,93, и с общим  (см. табл. 5.5). Это само по себе отличное приближение, но улучшение при переходе
(см. табл. 5.5). Это само по себе отличное приближение, но улучшение при переходе  весьма впечатляюще. (В иных случаях начальное приближение могло бы оказаться довольно плохим, а подходящее преобразование благополучно обеспечило бы значимость подобранной модели. Иногда преобразования позволяют ограничиться полиномом более низкой степени, чем это было бы нужно в противном случае. Ниже мы увидим, что это верно и в данном примере тоже.)
весьма впечатляюще. (В иных случаях начальное приближение могло бы оказаться довольно плохим, а подходящее преобразование благополучно обеспечило бы значимость подобранной модели. Иногда преобразования позволяют ограничиться полиномом более низкой степени, чем это было бы нужно в противном случае. Ниже мы увидим, что это верно и в данном примере тоже.)
Таблица 5.3. Преобразованные значения  для данных из табл. 5.1
для данных из табл. 5.1

Таблица 5.4. Дисперсионный анализ модели первого порядка для  подобранной по логарифмированным данным о вязкости
подобранной по логарифмированным данным о вязкости

Таблица 5.5. Дисперсионный анализ модели первого порядка для  подобранной для непреобразованных данных о вязкости
подобранной для непреобразованных данных о вязкости

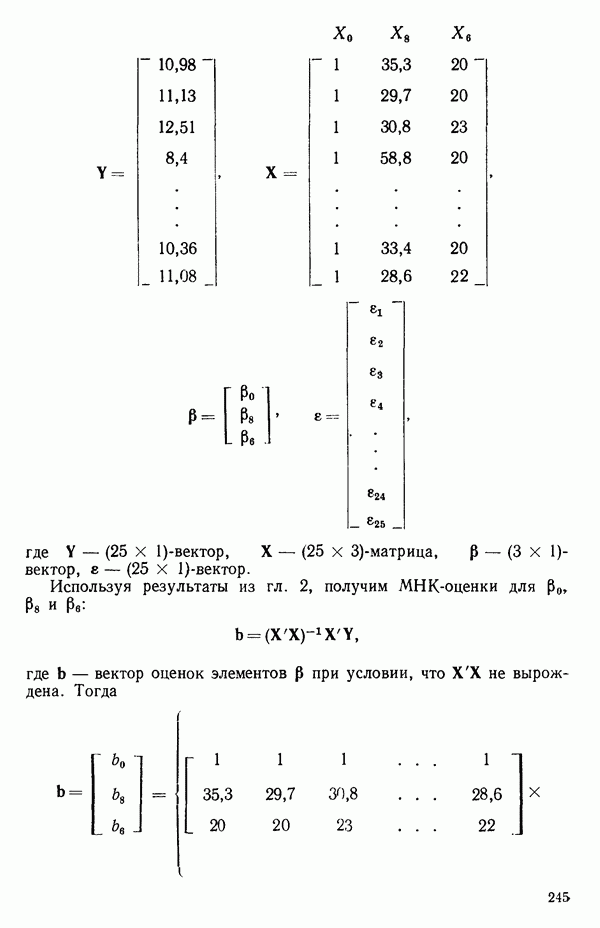
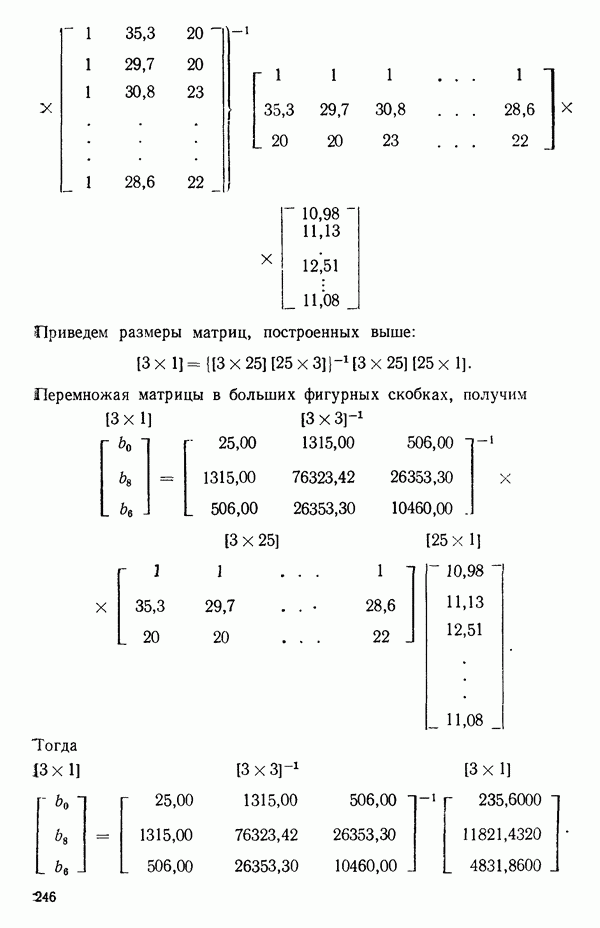
Кодирование предикторов. Для преодоления трудностей с нашим примером на следующих этапах его обсуждения мы воспользуемся двумя предикторами  в тех единицах, в которых они и были заданы. В случаях, подобных нашему, когда уровни
в тех единицах, в которых они и были заданы. В случаях, подобных нашему, когда уровни  выбраны с равным шагом, кодирование
выбраны с равным шагом, кодирование

приводит к уровням (кодированным)  несколько упрощая вычисления. Заметим, что простое кодирование предикторов таким способом не оказывает какого бы то ни было влияния на оценивание К. Зато иногда подходящее кодирование будет упрощать регрессионные вычисления. Так, например, если бы при
несколько упрощая вычисления. Заметим, что простое кодирование предикторов таким способом не оказывает какого бы то ни было влияния на оценивание К. Зато иногда подходящее кодирование будет упрощать регрессионные вычисления. Так, например, если бы при  наблюдение в табл. 5.1 не было бы потеряно, то кодирование такого рода, как показано в (5.3.16), сделало бы столбцы
наблюдение в табл. 5.1 не было бы потеряно, то кодирование такого рода, как показано в (5.3.16), сделало бы столбцы  взаимно ортогональными и ортогональными к единичному столбцу в матрице
взаимно ортогональными и ортогональными к единичному столбцу в матрице  (Заметим, однако, что преобразование предикторов, скажем,
(Заметим, однако, что преобразование предикторов, скажем,  изменило бы сложность задачи и повлияло бы на оценивание
изменило бы сложность задачи и повлияло бы на оценивание 
Важность проверки остатков
Преобразования отклика влияют на распределение ошибок. Наше предположение состоит в том, что после преобразования ошибки преобразованного отклика должны быть нормальными  Значит, важно провести анализ остатков для модели, которая в конце концов
Значит, важно провести анализ остатков для модели, которая в конце концов
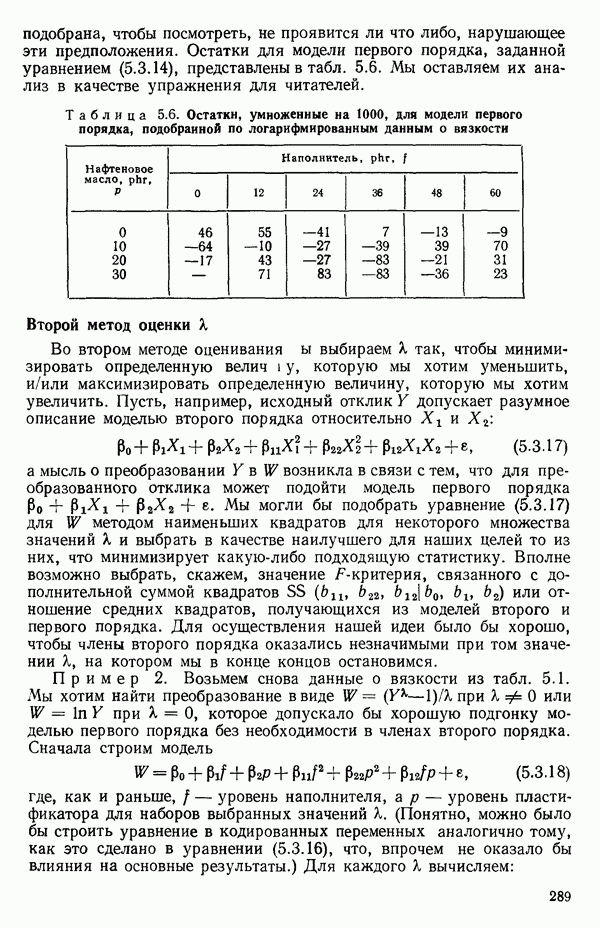
подобрана, чтобы посмотреть, не проявится ли что либо, нарушающее эти предположения. Остатки для модели первого порядка, заданной уравнением (5.3.14), представлены в табл. 5.6. Мы оставляем их анализ в качестве упражнения для читателей.
Таблица 5.6. Остатки, умноженные на 1000, для модели первого порядка, подобранной по логарифмированным данным о вязкости

Второй метод оценки X
Во втором методе оценивания  выбираем X так, чтобы минимизировать определенную велич
выбираем X так, чтобы минимизировать определенную велич  которую мы хотим уменьшить, и/или максимизировать определенную величину, которую мы хотим увеличить. Пусть, например, исходный отклик
которую мы хотим уменьшить, и/или максимизировать определенную величину, которую мы хотим увеличить. Пусть, например, исходный отклик  допускает разумное описание моделью второго порядка относительно
допускает разумное описание моделью второго порядка относительно 

а мысль о преобразовании  возникла в связи с тем, что для преобразованного отклика может подойти модель первого порядка
возникла в связи с тем, что для преобразованного отклика может подойти модель первого порядка  Мы могли бы подобрать уравнение (5.3.17) для
Мы могли бы подобрать уравнение (5.3.17) для  методом наименьших квадратов для некоторого множества значений X и выбрать в качестве наилучшего для наших целей то из них, что минимизирует какую-либо подходящую статистику. Вполне возможно выбрать, скажем, значение F-критерия, связанного с дополнительной суммой квадратов
методом наименьших квадратов для некоторого множества значений X и выбрать в качестве наилучшего для наших целей то из них, что минимизирует какую-либо подходящую статистику. Вполне возможно выбрать, скажем, значение F-критерия, связанного с дополнительной суммой квадратов  или отношение средних квадратов, получающихся из моделей второго и первого порядка. Для осуществления нашей идеи было бы хорошо, чтобы члены второго порядка оказались незначимыми при том значении X, на котором мы в конце концов остановимся.
или отношение средних квадратов, получающихся из моделей второго и первого порядка. Для осуществления нашей идеи было бы хорошо, чтобы члены второго порядка оказались незначимыми при том значении X, на котором мы в конце концов остановимся.
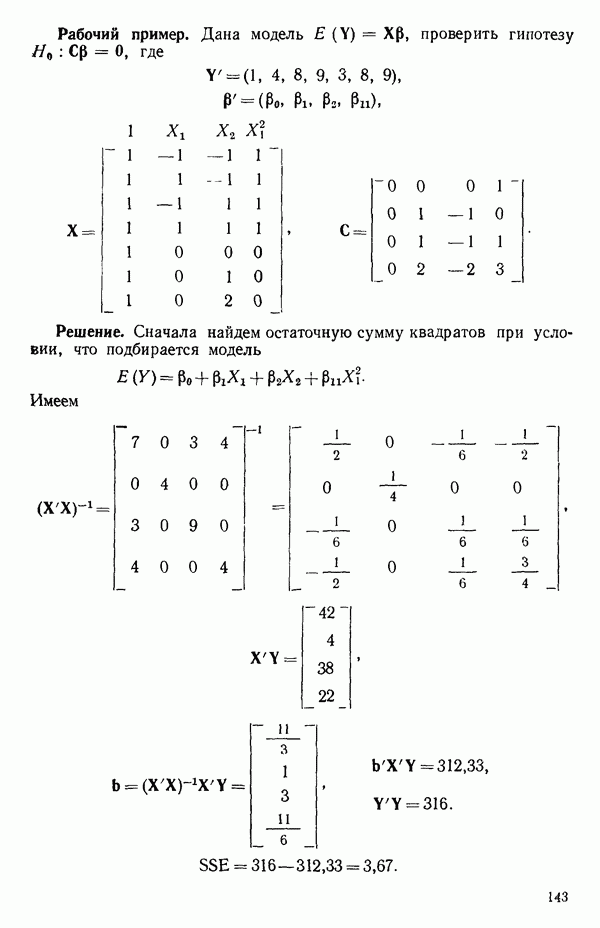
Пример 2. Возьмем снова данные о вязкости из табл. 5.1. Мы хотим найти преобразование в виде  при
при  или
или  при
при  которое допускало бы хорошую подгонку моделью первого порядка без необходимости в членах второго порядка. Сначала строим модель
которое допускало бы хорошую подгонку моделью первого порядка без необходимости в членах второго порядка. Сначала строим модель

где, как и раньше,  уровень наполнителя,
уровень наполнителя,  уровень пластификатора для наборов выбранных значений
уровень пластификатора для наборов выбранных значений  (Понятно, можно было бы строить уравнение в кодированных переменных аналогично тому, как это сделано в уравнении (5.3.16), что, впрочем не оказало бы влияния на основные результаты.) Для каждого X вычисляем:
(Понятно, можно было бы строить уравнение в кодированных переменных аналогично тому, как это сделано в уравнении (5.3.16), что, впрочем не оказало бы влияния на основные результаты.) Для каждого X вычисляем:
 средний квадрат, получающийся как
средний квадрат, получающийся как  — средний квадрат, получающийся как
— средний квадрат, получающийся как 

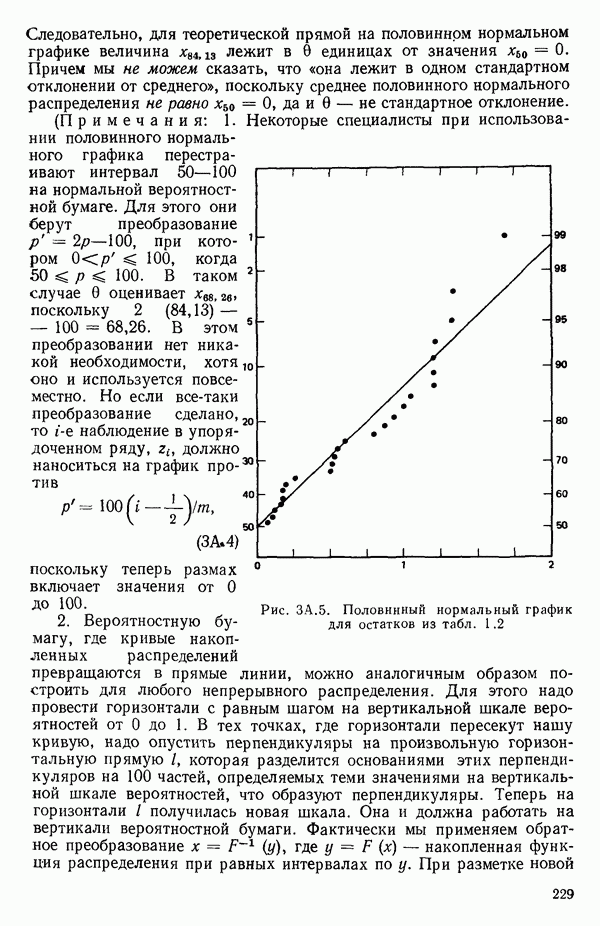
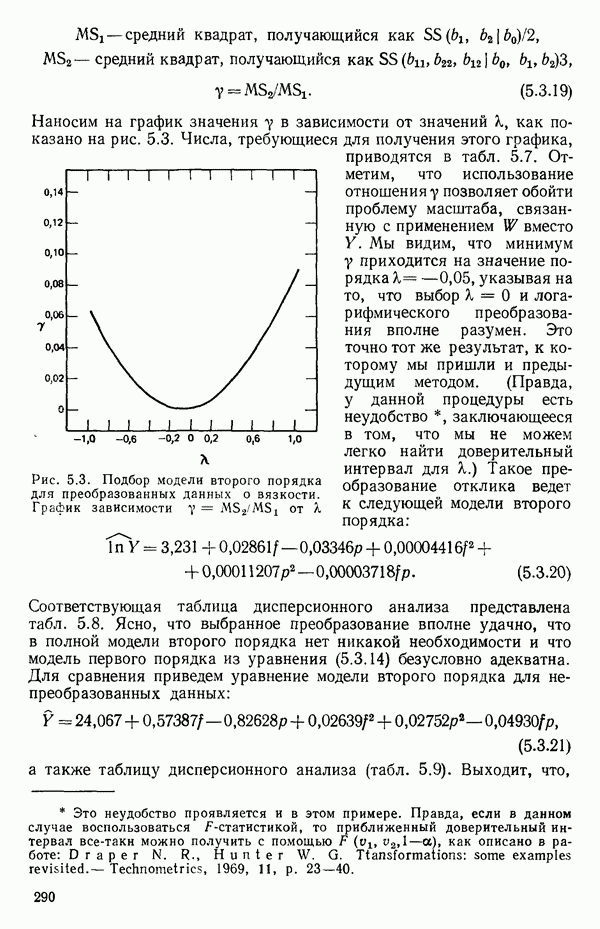
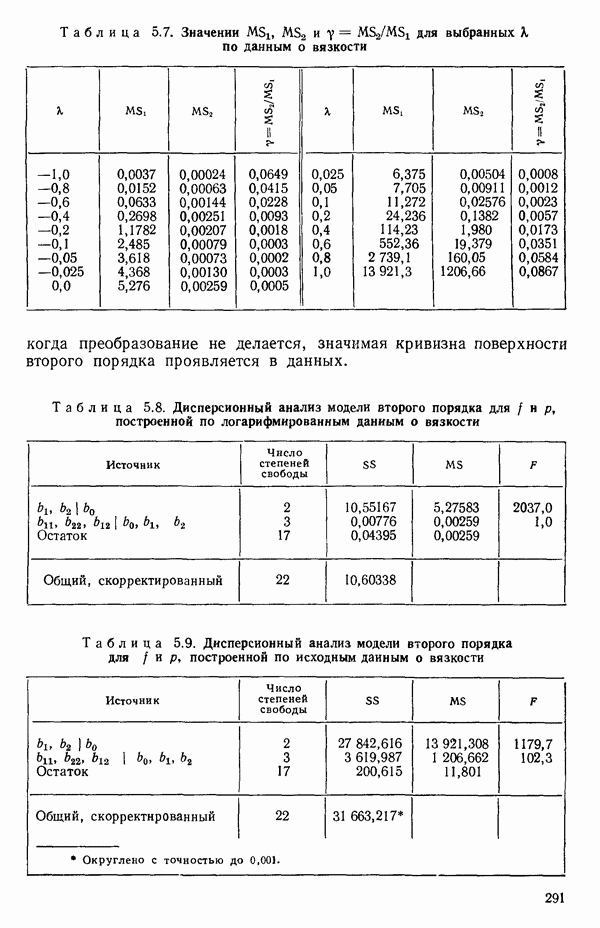
Наносим на график значения у в зависимости от значений к, как показано на рис. 5.3. Числа, требующиеся для получения этого графика, приводятся в табл. 5.7. Отметим, что использование отношения у позволяет обойти проблему масштаба, связанную с применением  вместо
вместо  Мы видим, что минимум у приходится на значение порядка
Мы видим, что минимум у приходится на значение порядка  , указывая на то, что выбор
, указывая на то, что выбор  и логарифмического преобразования вполне разумен. Это точно тот же результат, к которому мы пришли и предыдущим методом. (Правда, у данной процедуры есть неудобство, заключающееся в том, что мы не можем легко найти доверительный интервал для к.) Такое преобразование отклика ведет к следующей модели второго порядка:
и логарифмического преобразования вполне разумен. Это точно тот же результат, к которому мы пришли и предыдущим методом. (Правда, у данной процедуры есть неудобство, заключающееся в том, что мы не можем легко найти доверительный интервал для к.) Такое преобразование отклика ведет к следующей модели второго порядка:

Соответствующая таблица дисперсионного анализа представлена табл. 5.8. Ясно, что выбранное преобразование вполне удачно, что в полной модели второго порядка нет никакой необходимости и что модель первого порядка из уравнения (5.3.14) безусловно адекватна. Для сравнения приведем уравнение модели второго порядка для непреобразованных данных:

а также таблицу дисперсионного анализа (табл. 5.9). Выходит, что,

Рис. 5.3. Подбор модели второго порядка для преобразованных данных о вязкости. График зависимости  от
от 
Таблица 5.7. Значении  для выбранных к по данным о вязкости
для выбранных к по данным о вязкости

когда преобразование не делается, значимая кривизна поверхности второго порядка проявляется в данных.
Таблица 5.8. Дисперсионный анализ модели второго порядка для  построенной по логарифмированным данным о вязкости
построенной по логарифмированным данным о вязкости

Таблица 5.9. Дисперсионный анализ модели второго порядка для  построенной по исходным данным о вязкости
построенной по исходным данным о вязкости

Преимущества метода максимума правдоподобия
Из двух методов, предназначенных для оценивания параметров преобразования, в большинстве практических ситуаций мы предпочли бы метод максимума правдоподобия. С его помощью мы всегда можем получить приближенный доверительный интервал или область, а, кроме того, здесь нужно только подобрать ту самую модель, которой мы интересуемся, без всяких дополнительных сложностей, обычно возникающих при втором методе. (Действительно, в некоторых случаях данные могут оказаться неадекватными альтернативной модели более высокого порядка.) Правда, второй метод может оказаться полезным, когда нам понадобится исследовать ряд критериев. Тогда можно одновременно построить графики зависимостей каждого критерия от X и сравнить значения X, получающиеся на каждом из графиков.
Приближенный метод оценивания
Относительно простой приближенный метод оценки X в больших массивах данных, когда множество остаточных средних квадратов само собой возникает в ходе анализа, описан в работе: Нiпz P. N., Eagles Н. A. Estimation of a transformation for the analysis of some agronomic and genetic experiments.- Crop Science, 1976, 16, p. 280-283.
Семейство преобразований отклика с большими возможностями
Вводя новый параметр, мы можем расширить диапазон допустимых преобразований сверх того, что обсуждалось выше. Рассмотрим двухпараметрическое семейство:

где обязательно  Методы, применяемые для однопараметрического семейства (когда
Методы, применяемые для однопараметрического семейства (когда  можно распространить и на этот случай. Теперь вместо
можно распространить и на этот случай. Теперь вместо  мы имеем
мы имеем  и вынуждены искать оценки метода максимума правдоподобия
и вынуждены искать оценки метода максимума правдоподобия  на двумерной сетке. Точно так же и при вычислениях, связанных с получением доверительной области для
на двумерной сетке. Точно так же и при вычислениях, связанных с получением доверительной области для  мы берем теперь
мы берем теперь  -квадрат с двумя степенями свободы, вместо одной поскольку имеются два параметра преобразования. Работают в точности те же идеи, только вычисления становятся более сложными. Пример такого рода кратко обсуждается в упомянутой выше работе Дж. Бокса и Д. Кокса 1964 г. на с. 225— 226.
-квадрат с двумя степенями свободы, вместо одной поскольку имеются два параметра преобразования. Работают в точности те же идеи, только вычисления становятся более сложными. Пример такого рода кратко обсуждается в упомянутой выше работе Дж. Бокса и Д. Кокса 1964 г. на с. 225— 226.
Нормирующее преобразование (аналогичное уравнению (5.3.7а), когда  в этом случае таково:
в этом случае таково:

где

есть среднее геометрическое значений 
Заметим, что поскольку  мы должны избегать выбора значений X, удовлетворяющих неравенству
мы должны избегать выбора значений X, удовлетворяющих неравенству  Хотя и проще всего отбрасывать те значения
Хотя и проще всего отбрасывать те значения  которые нарушают ограничение, — это не годится. Требуется локальный максимум, удовлетворяющий данному ограничению.
которые нарушают ограничение, — это не годится. Требуется локальный максимум, удовлетворяющий данному ограничению.
Альтернативное семейство преобразований откликов
Когда графики остатков явно свидетельствуют о симметричном, но не нормальном распределении ошибок, может оказаться полезным однопараметрическое семейство степенных функций от модулей.

За примером обратитесь к работе: John J. A., Draper N. R. An alternative family of transformations.- Applied Statistics, 1980, 29, p. 190-197.
Семейство стеленных функций для долей
Все то же самое можно использовать и для оценки параметра X в семействе

где  наблюдаемая доля случаев, когда некоторое событие имеет место. Вообще говоря, наблюдаемые значения
наблюдаемая доля случаев, когда некоторое событие имеет место. Вообще говоря, наблюдаемые значения  могут зависеть от массы предикторов
могут зависеть от массы предикторов  и следовало бы постулировать модель в общем виде:
и следовало бы постулировать модель в общем виде:

где  вектор параметров. Значение X следовало бы выбирать так, чтобы получилась наилучшая подгонка к имеющимся данным в предположении, что
вектор параметров. Значение X следовало бы выбирать так, чтобы получилась наилучшая подгонка к имеющимся данным в предположении, что 
Степенное преобразование (5.3.23) было предложено Дж. Тьюки. Для работы со статистическим распределением величины  когда
когда  имеет равномерное распределение, хорошей предварительной подготовкой будет чтение статьи Б. Джойнера и Дж. Розенблатта о некоторых свойствах размаха в выборках из симметричного Я-распреде-ления Тьюки (см.: Joiner В. L., Rosenblatt J. R. Some properties of the range in samples from Turkeys symmetric X distributions.- J. Amer. Statist. Assoc., 1971, 66, p. 394—399; см. также ссылки на литературу в этой статье).
имеет равномерное распределение, хорошей предварительной подготовкой будет чтение статьи Б. Джойнера и Дж. Розенблатта о некоторых свойствах размаха в выборках из симметричного Я-распреде-ления Тьюки (см.: Joiner В. L., Rosenblatt J. R. Some properties of the range in samples from Turkeys symmetric X distributions.- J. Amer. Statist. Assoc., 1971, 66, p. 394—399; см. также ссылки на литературу в этой статье).
Два примера преобразования долей приведены ниже на с. 294—296. Одно из них — частный случай обсуждавшегося выше семейства, а второе — приближение к некоторому частному случаю.
Преобразования для стабилизации дисперсии
Если преобразованные данные анализируются методом наименьших квадратов, то важно, чтобы дисперсия отклика оказалась независимой от его среднего значения. Там, где известно заранее или где можно установить эмпирически, что стандартное отклонение непреобразованного отклика  скажем
скажем  связано некоторой определенной функцией
связано некоторой определенной функцией  со своим средним значением,
со своим средним значением,  мы можем получить подходящее преобразование непосредственно, воспользовавшись преобразованным значением
мы можем получить подходящее преобразование непосредственно, воспользовавшись преобразованным значением  из выражения:
из выражения:

Иными словами, мы получим  , интегрируя
, интегрируя  по
по  Несколько хорошо известных преобразований, получающихся таким образом, приведено в табл. 5.10. Отметим, что некоторые из членов этого семейства определяются по уравнению (5.3.1).
Несколько хорошо известных преобразований, получающихся таким образом, приведено в табл. 5.10. Отметим, что некоторые из членов этого семейства определяются по уравнению (5.3.1).
Таблица 5.10. Преобразования, подходящие для стабилизации дисперсий, когда 

Преобразования откликов, задаваемых долями
Многие виды данных об откликах представляют собой доли,  получаемые как числа «успехов» (они могут быть и неудачами), появляющихся при большом числе «опытов». Так, например, шесть крыс из десяти, справившихся с поставленной задачей, дают
получаемые как числа «успехов» (они могут быть и неудачами), появляющихся при большом числе «опытов». Так, например, шесть крыс из десяти, справившихся с поставленной задачей, дают  Данные, представленные в виде долей, как правило, не имеют одинаковых дисперсий, так как
Данные, представленные в виде долей, как правило, не имеют одинаковых дисперсий, так как  где
где  число опытов. Вот два наиболее распространенных преобразования для данных такого рода.
число опытов. Вот два наиболее распространенных преобразования для данных такого рода.
1. Преобразование логарифма преобладания. Положим

Тогда  будет натуральным логарифмом «отношения преобладания»
будет натуральным логарифмом «отношения преобладания»  отношения доли успехов к доле неудач. При подборе модели
отношения доли успехов к доле неудач. При подборе модели

по нашим данным  мы возьмем взвешенный метод наименьших квадратов, так как приближенно
мы возьмем взвешенный метод наименьших квадратов, так как приближенно  и это — отнюдь не константа. Для демонстрации такого утверждения воспользуемся тем фактом, что при малых
и это — отнюдь не константа. Для демонстрации такого утверждения воспользуемся тем фактом, что при малых  Тогда, опуская на минуту подстрочный индекс
Тогда, опуская на минуту подстрочный индекс  мы увидим, что (все результаты приближенные)
мы увидим, что (все результаты приближенные)

т. е.

Аналогично

а

Отсюда следует, что  Понятно, что эти
Понятно, что эти  дисперсий
дисперсий  не известны, но их оценками служат соответствующие значения
не известны, но их оценками служат соответствующие значения  для
для  а само оценивание происходит так же, как в параграфе 2.11. В этом случае матрица V диагональна с оцененными диагональными элементами
а само оценивание происходит так же, как в параграфе 2.11. В этом случае матрица V диагональна с оцененными диагональными элементами 
2. Преобразование арксинуса. Как показано в табл. 5.10, преобразование  будет стабилизировать дисперсию, если все те выборки, по которым определяются наблюдаемые значения
будет стабилизировать дисперсию, если все те выборки, по которым определяются наблюдаемые значения  будут иметь одинаковый объем, допустим
будут иметь одинаковый объем, допустим  На самом деле несколько лучше преобразование
На самом деле несколько лучше преобразование  поскольку оно дает постоянную теоретическую дисперсию, равную
поскольку оно дает постоянную теоретическую дисперсию, равную  Заметим, что если только
Заметим, что если только  не постоянно для наших данных, это преобразование не будет стабилизировать дисперсию. В таком случае нужно преобразование
не постоянно для наших данных, это преобразование не будет стабилизировать дисперсию. В таком случае нужно преобразование  где
где  определяется по
определяется по  опытам. Еще отметим, что данные в середине диапазона долей (скажем, между 0,30 и 0,70) не будут слишком меняться под воздействием такого преобразования,
опытам. Еще отметим, что данные в середине диапазона долей (скажем, между 0,30 и 0,70) не будут слишком меняться под воздействием такого преобразования,
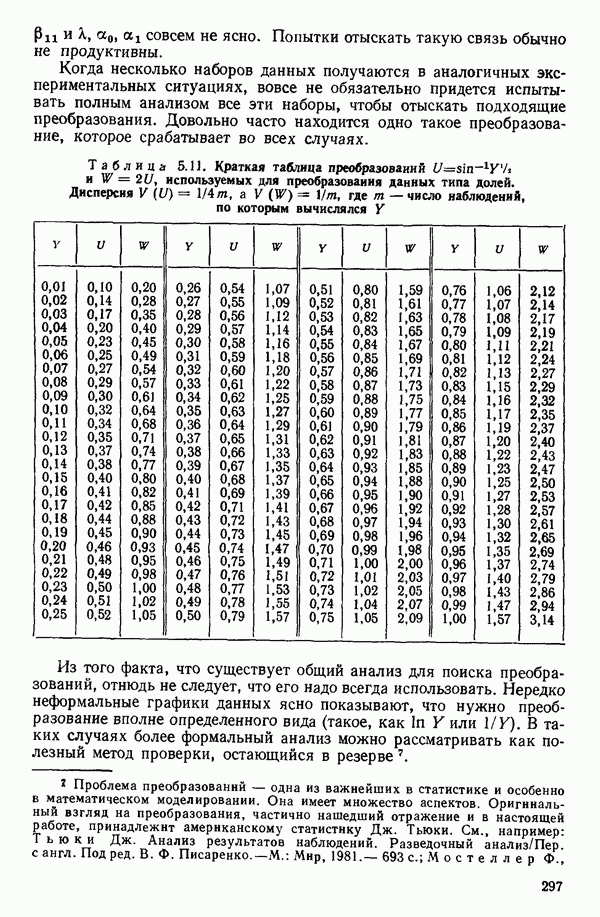
так как само преобразование, в этом интервале значений приблизительно линейно. Табл. 5.11 представляет собой краткое извлечение из таблиц преобразований  Обратите внимание, что и
Обратите внимание, что и  приведены не в градусах, а в радианах. Если же использовались градусы, то следует умножить значение
приведены не в градусах, а в радианах. Если же использовались градусы, то следует умножить значение  на
на  на
на  Кроме того, для перевода в градусы дисперсии
Кроме того, для перевода в градусы дисперсии  равной
равной  в радианах, следует умножить ее на
в радианах, следует умножить ее на 
В общем, всегда надо помнить, что не существует гарантии того, что использование этих преобразований всегда лучше, чем прямой анализ непреобразованных долей. Многое зависит от данных. Эффективность преобразования лучше всего оценить, осуществив это преобразование, затем проверив адекватность модели и исследовав структуру остатков, которые получатся в результате.
Преобразование предикторов
Известно очень много возможных преобразований предикторов. Один из полезных типов преобразований, применяемых во множестве случаев, это степенные преобразования:

для  где
где  исходные (непреобра-зованные) предикторы, а а; — параметры, подлежащие оценке. Самый лучший способ оценки а — это оценка их одновременно с параметрами постулируемой модели с помощью методов нелинейного оценивания (см. гл. 10). Или же можно воспользоваться итеративным методом, описанным в работе: Box G. Е., Tidwell P. W. Transformation of the independent variables.- Technometrics, 1962, 4, p. 531-550.
исходные (непреобра-зованные) предикторы, а а; — параметры, подлежащие оценке. Самый лучший способ оценки а — это оценка их одновременно с параметрами постулируемой модели с помощью методов нелинейного оценивания (см. гл. 10). Или же можно воспользоваться итеративным методом, описанным в работе: Box G. Е., Tidwell P. W. Transformation of the independent variables.- Technometrics, 1962, 4, p. 531-550.
Важно иметь в виду, что преобразования предикторов не влияют на распределения ошибок отклика. Но, конечно, они воздействуют на исследование остатков после подбора заданной модели, что, впрочем, верно для построения любой регрессионной модели.
Комбинируя оба множества методов, описанных выше, мы можем одновременно преобразовывать и отклик, и предикторы, или же делать это в последовательных итерациях. В общем вычисления получаются более сложными.
Комментарии
Когда мы делаем преобразование, невозможно соотносить параметры модели, построенной по преобразованным данным, с параметрами первоначальной модели для непреобразованных данных. Обычно здесь нет математической эквивалентности, если не принимать во внимание приближения такого типа, как разложение в ряд Тейлора. Так, например, если вместо модели  мы построим модель
мы построим модель  то соотношение между
то соотношение между 
 совсем не ясно. Попытки отыскать такую связь обычно не продуктивны.
совсем не ясно. Попытки отыскать такую связь обычно не продуктивны.
Когда несколько наборов данных получаются в аналогичных экспериментальных ситуациях, вовсе не обязательно придется испытывать полным анализом все эти наборы, чтобы отыскать подходящие преобразования. Довольно часто находится одно такое преобразование, которое срабатывает во всех случаях.
Таблица 5.11. Краткая таблица преобразований  используемых для преобразования данных типа долей. Дисперсия
используемых для преобразования данных типа долей. Дисперсия  а
а  где
где  число наблюдений, по которым вычислялся
число наблюдений, по которым вычислялся 

Из того факта, что существует общий анализ для поиска преобразований, отнюдь не следует, что его надо всегда использовать. Нередко неформальные графики данных ясно показывают, что нужно преобразование вполне определенного вида (такое, как  или
или  В таких случаях более формальный анализ можно рассматривать как полезный метод проверки, остающийся в резерве.
В таких случаях более формальный анализ можно рассматривать как полезный метод проверки, остающийся в резерве.























































































































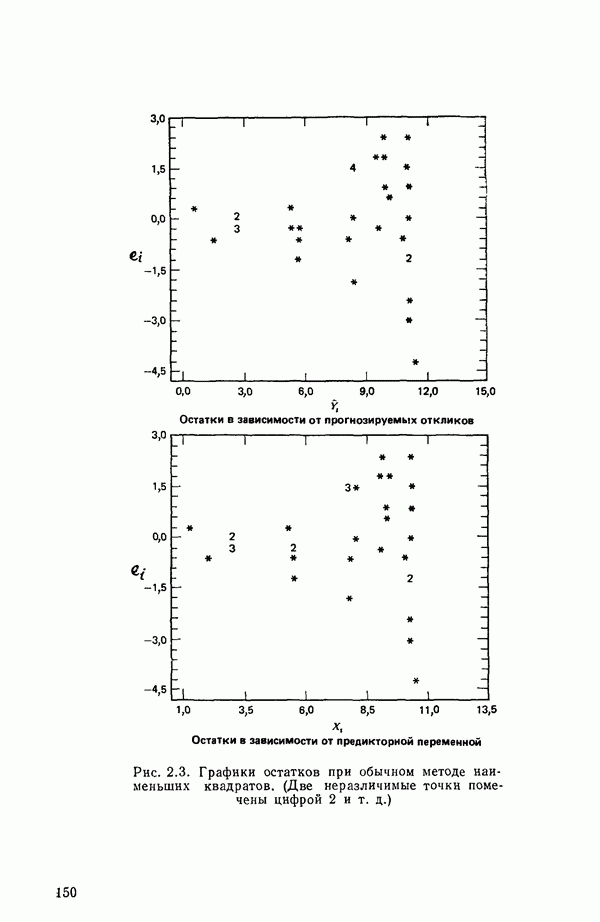

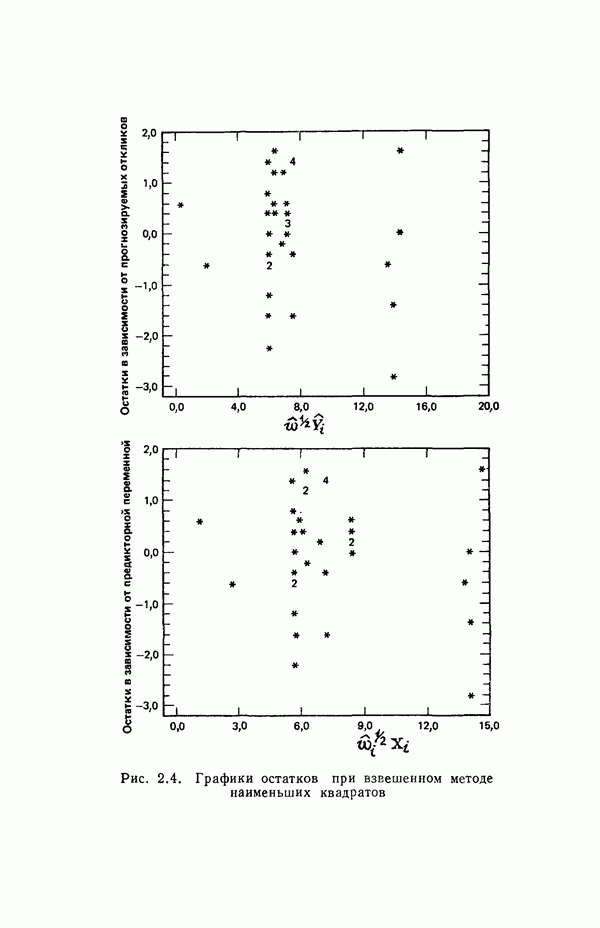

































































































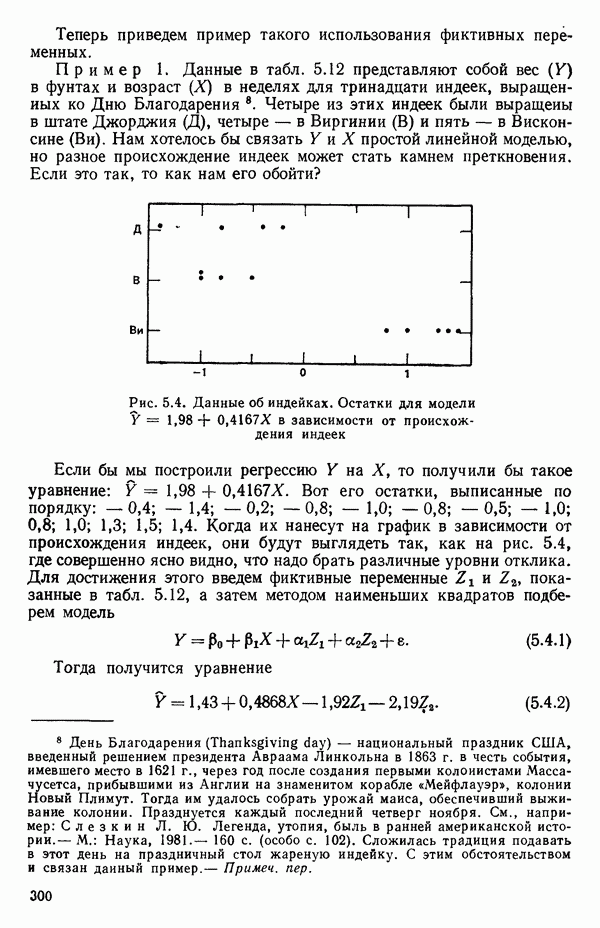


































 или
или  для
для  которое обеспечило бы хорошее соответствие данным модели первого порядка. Наша модель для уравнения (5.3.2) имеет вид
которое обеспечило бы хорошее соответствие данным модели первого порядка. Наша модель для уравнения (5.3.2) имеет вид

 уровень наполнителя,
уровень наполнителя,  уровень пластификатора. (Название пластификатора приведено в первом столбце табл. 5.1.)
уровень пластификатора. (Название пластификатора приведено в первом столбце табл. 5.1.)
 при 100 °С в зависимости от уровней наполнителя и масла в
при 100 °С в зависимости от уровней наполнителя и масла в 
