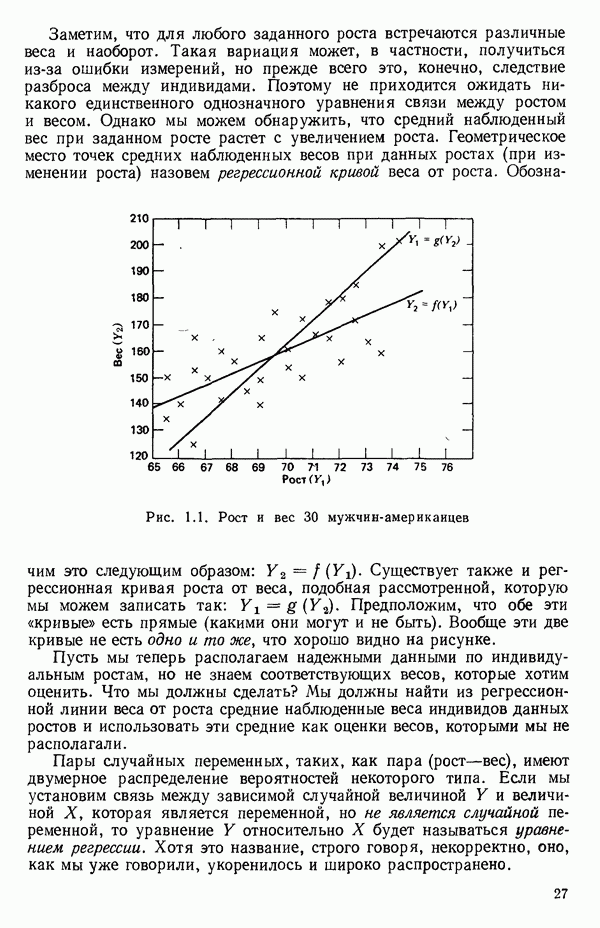
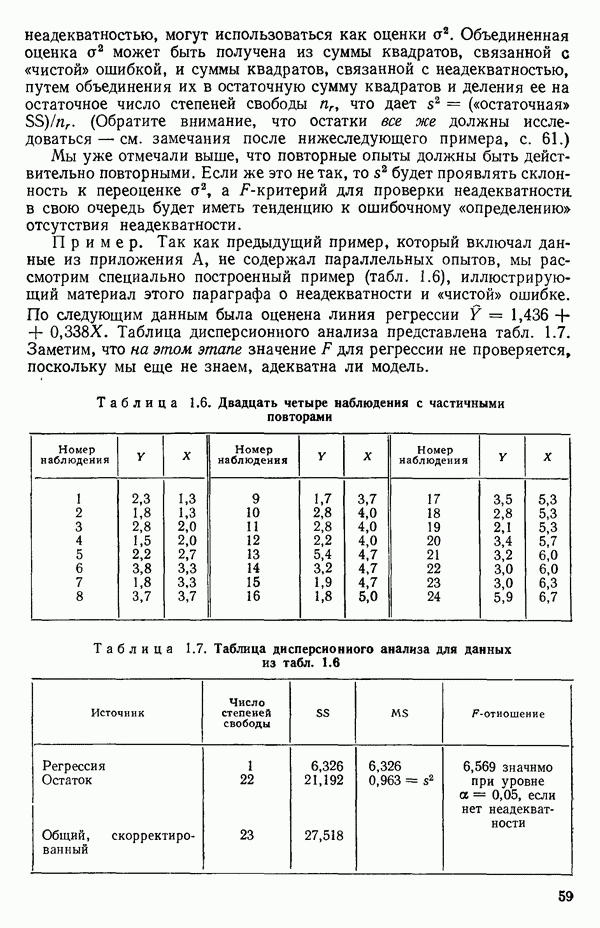
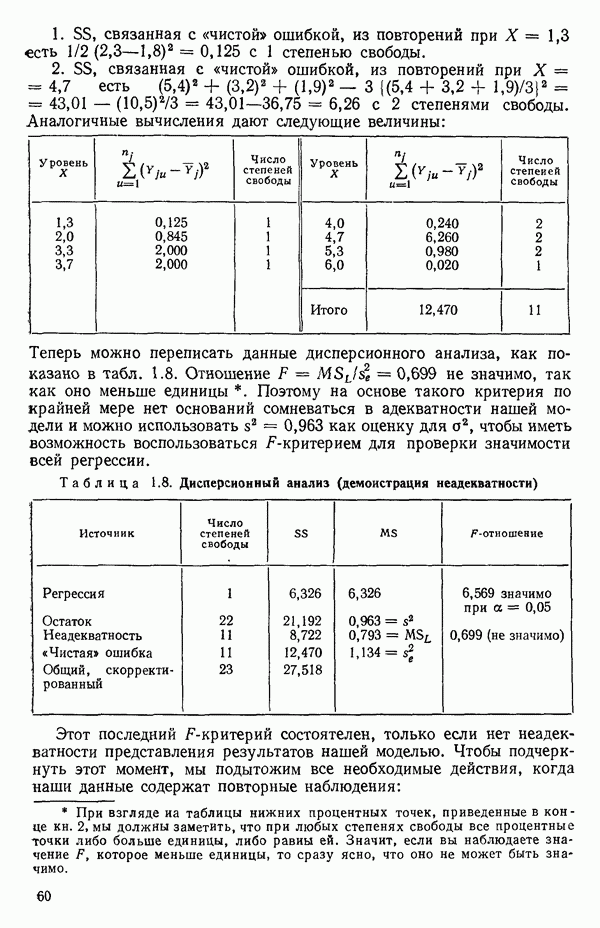
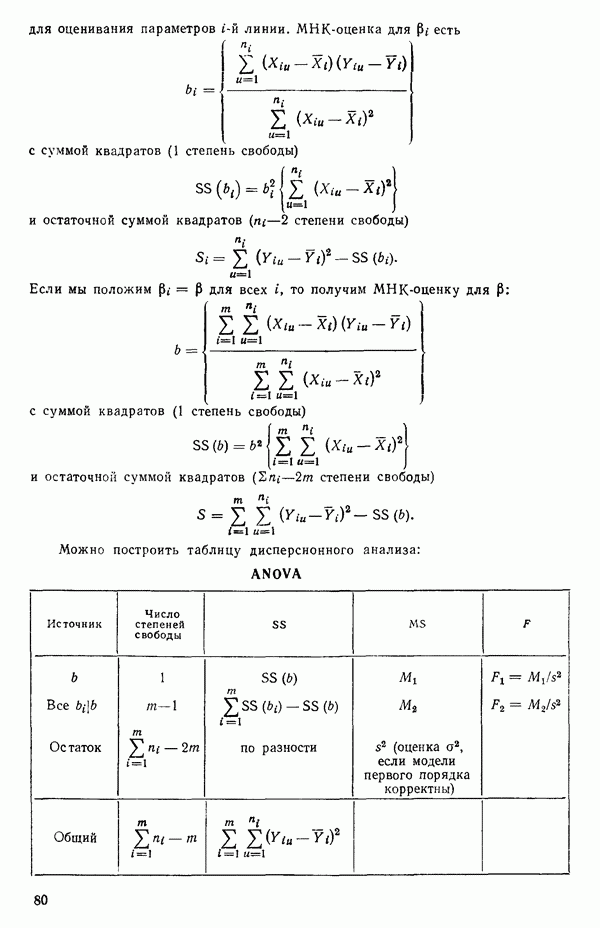
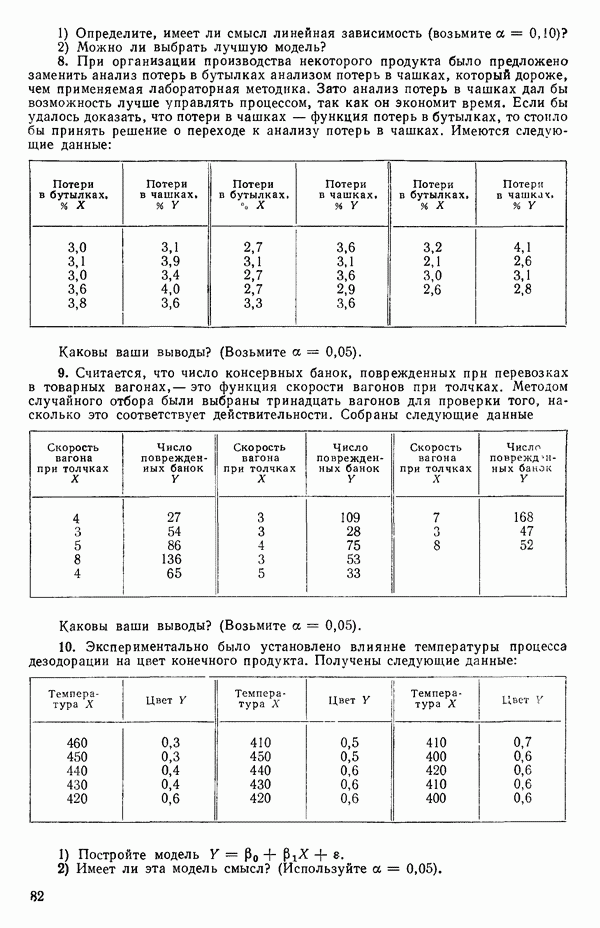
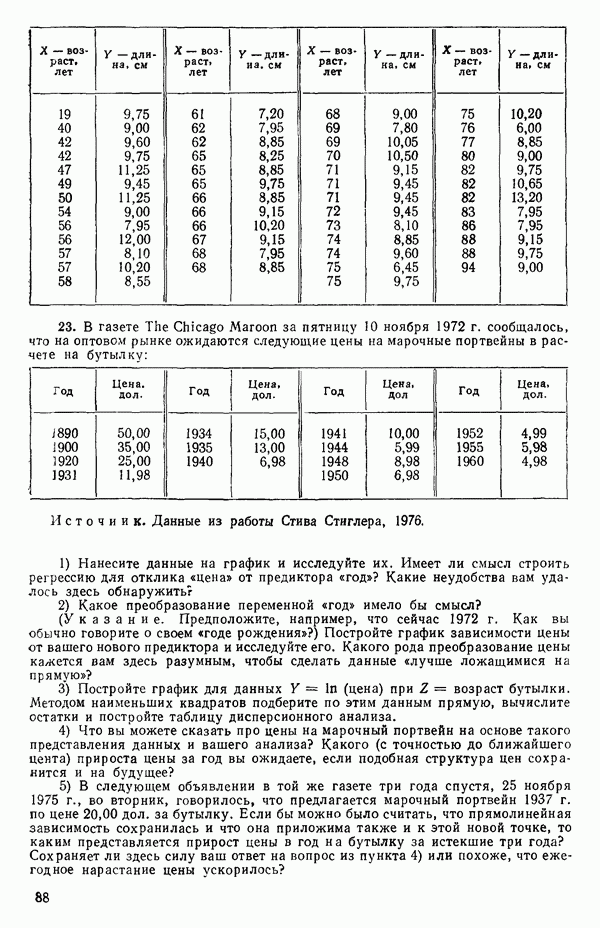
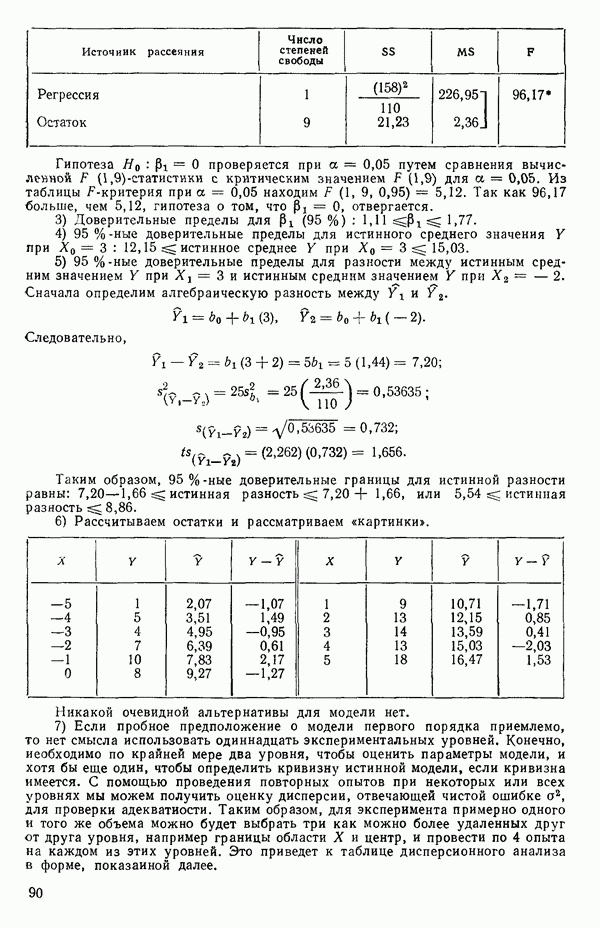
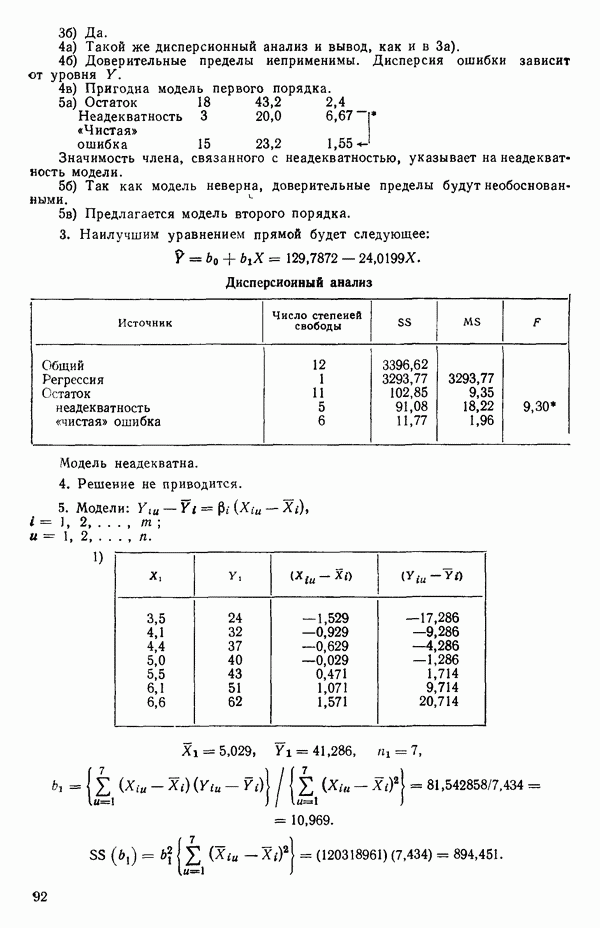
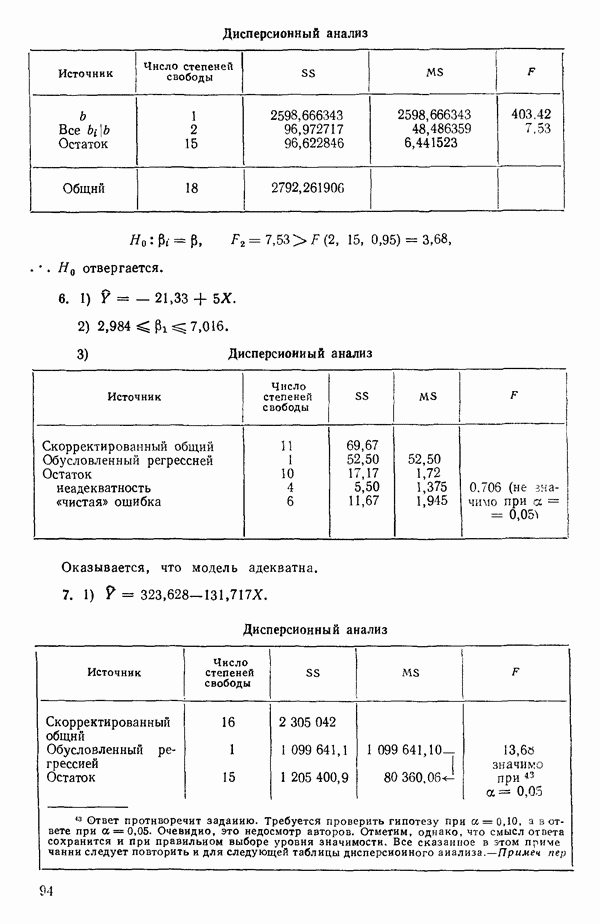
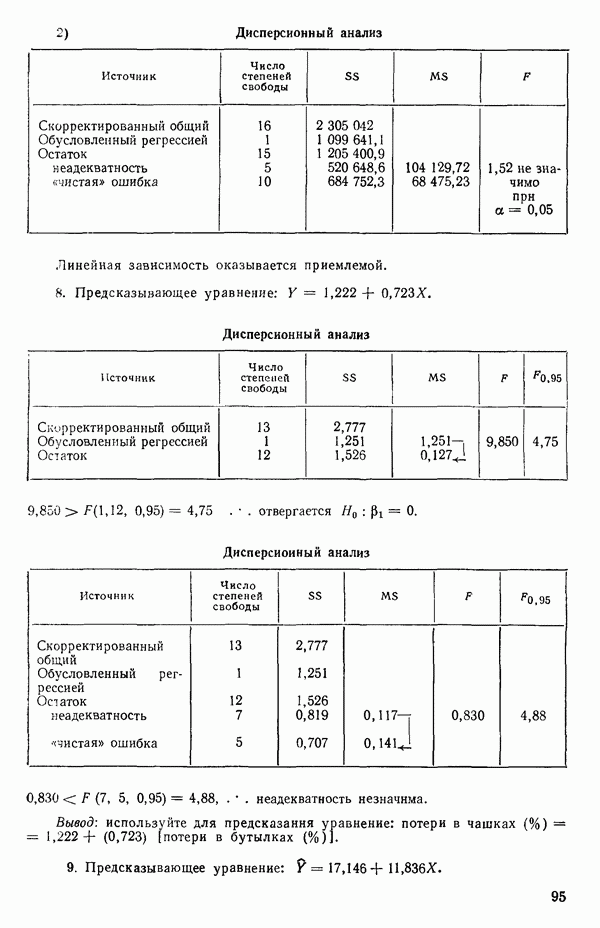
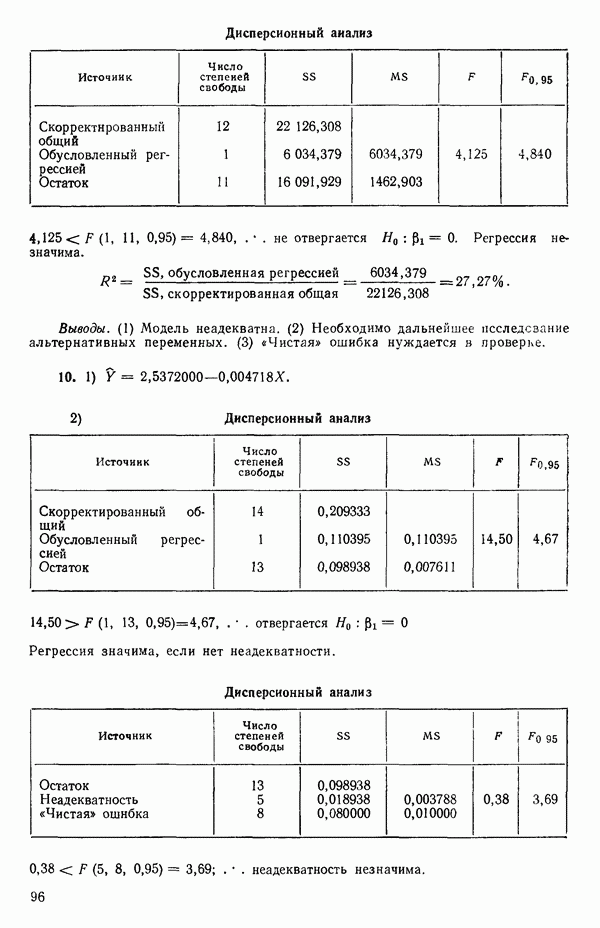
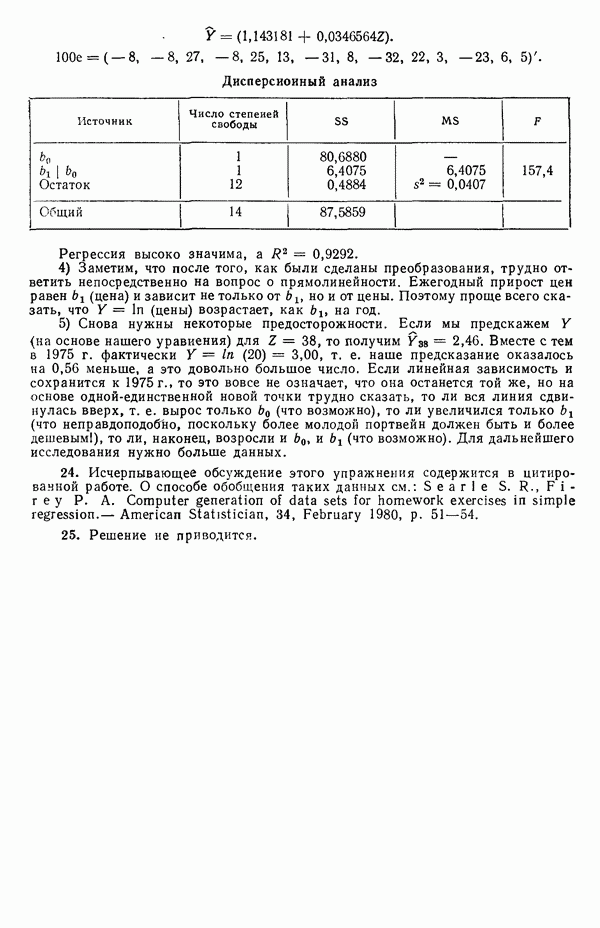
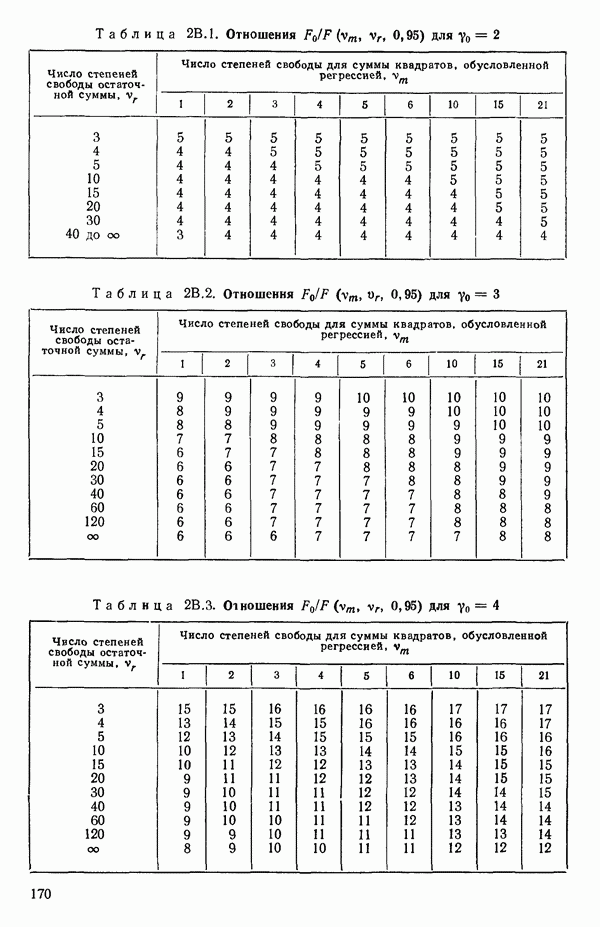
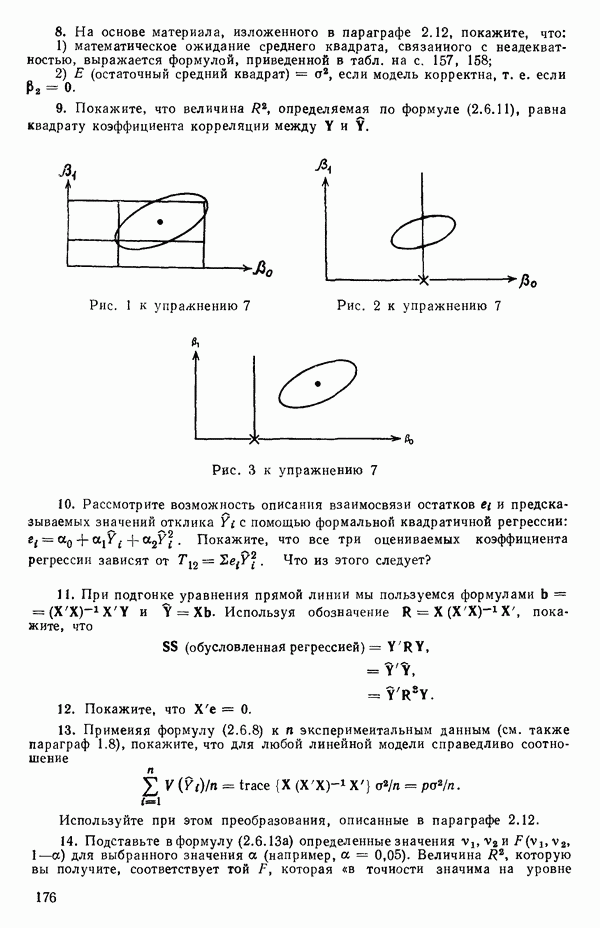
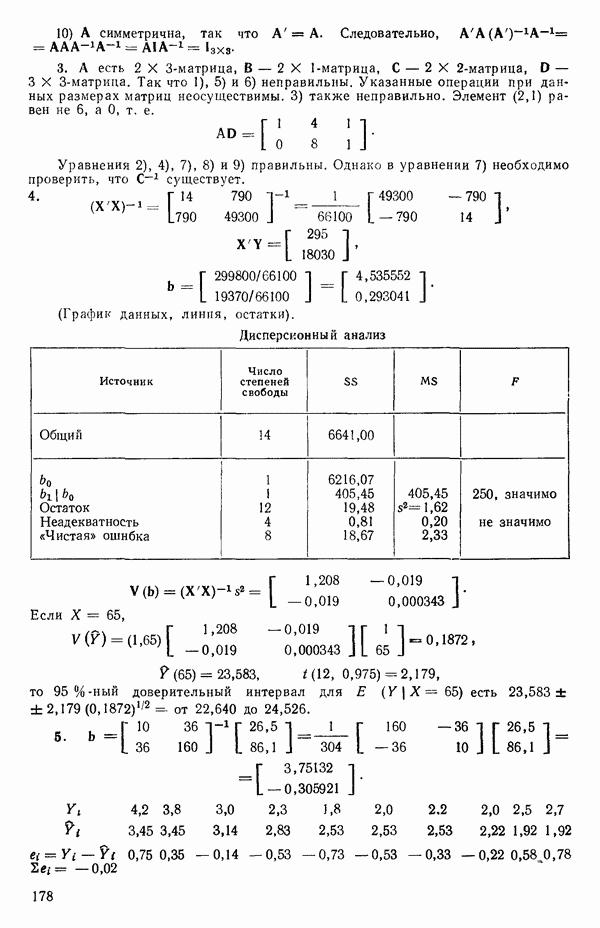
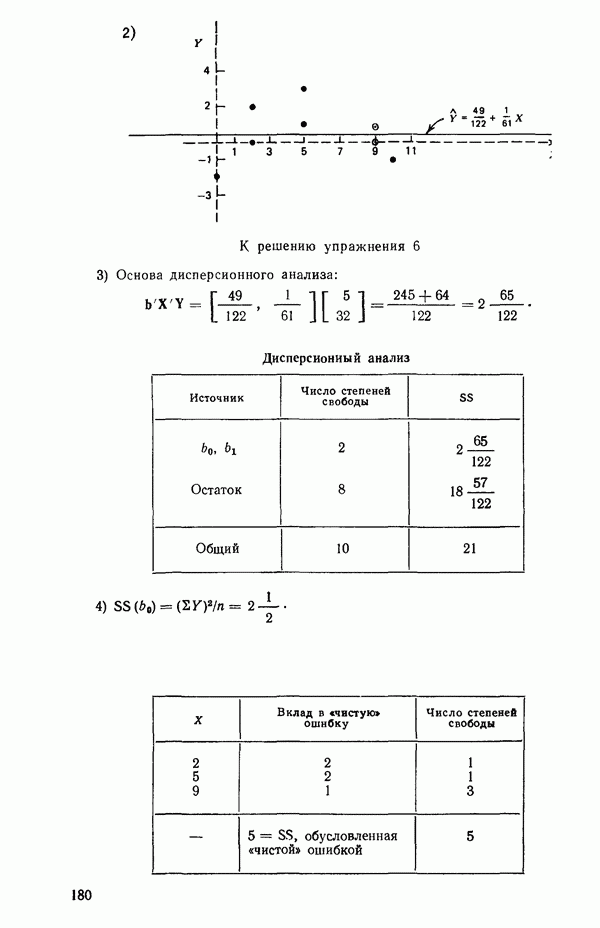
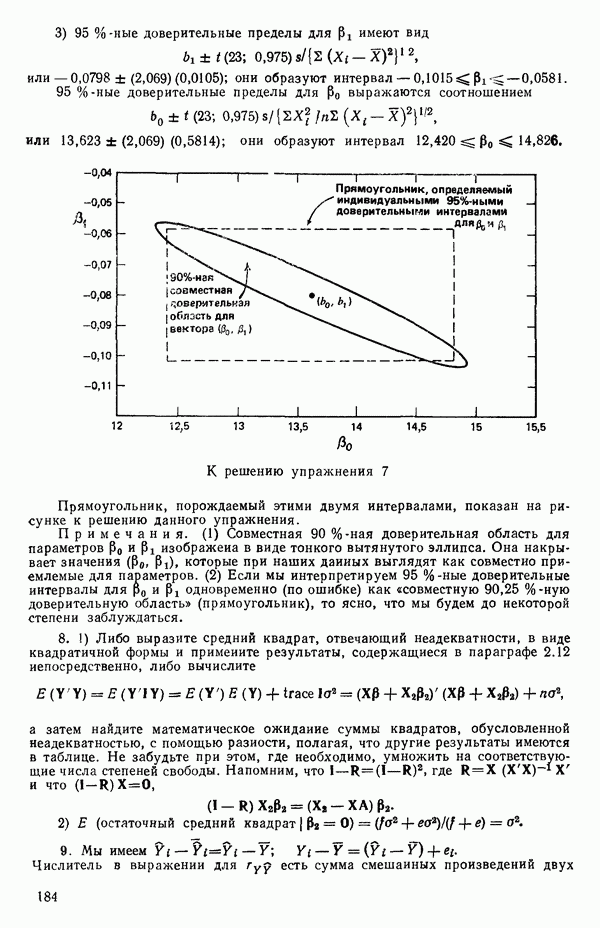
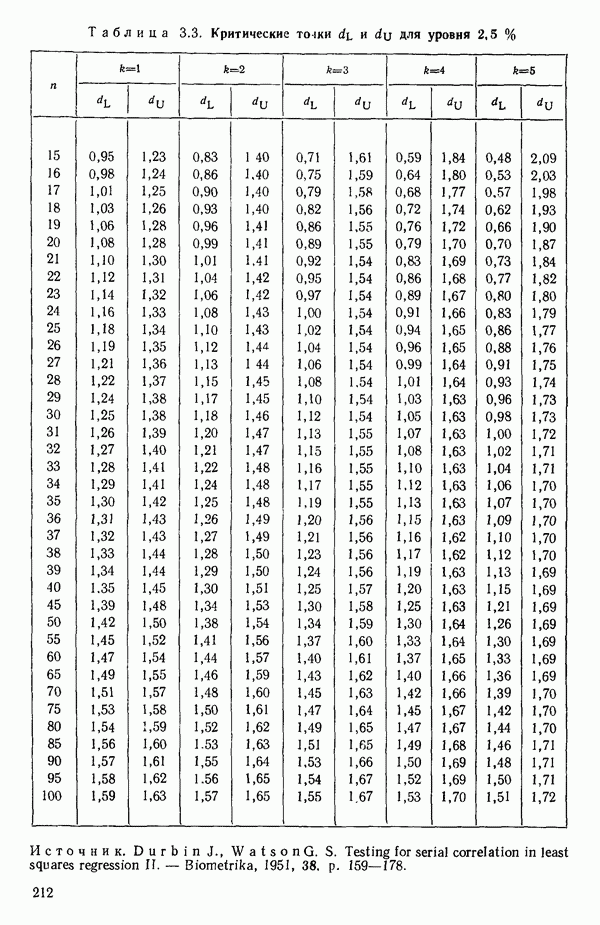
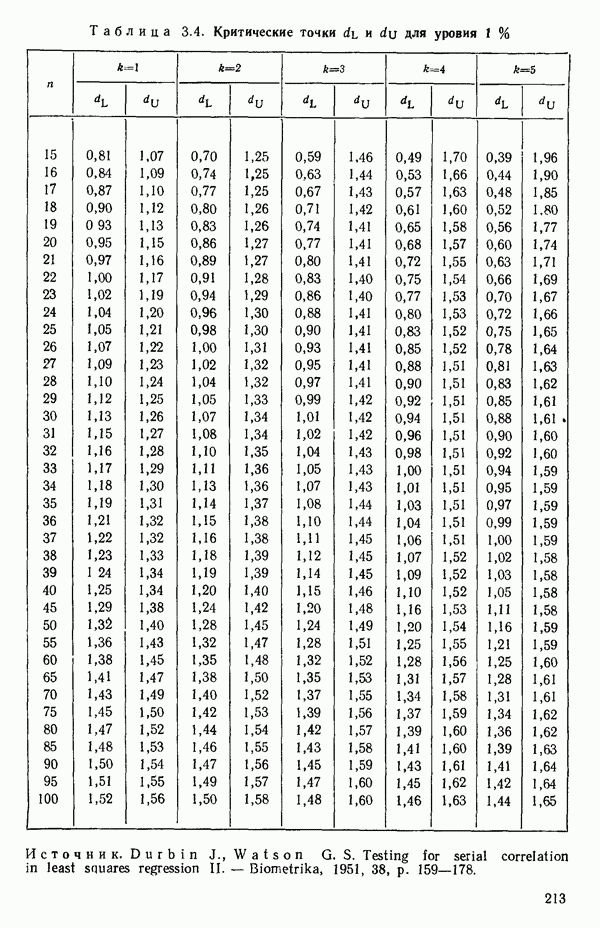
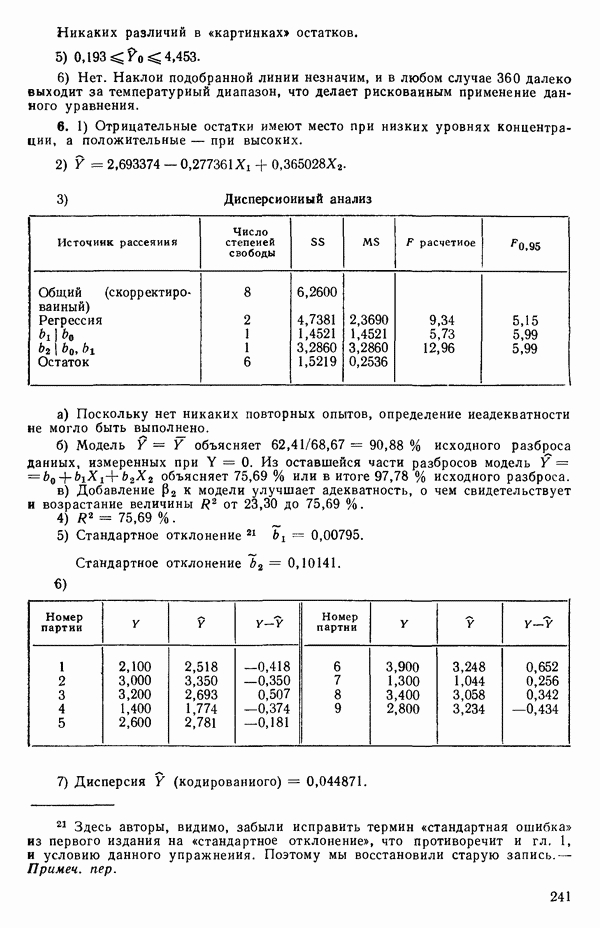
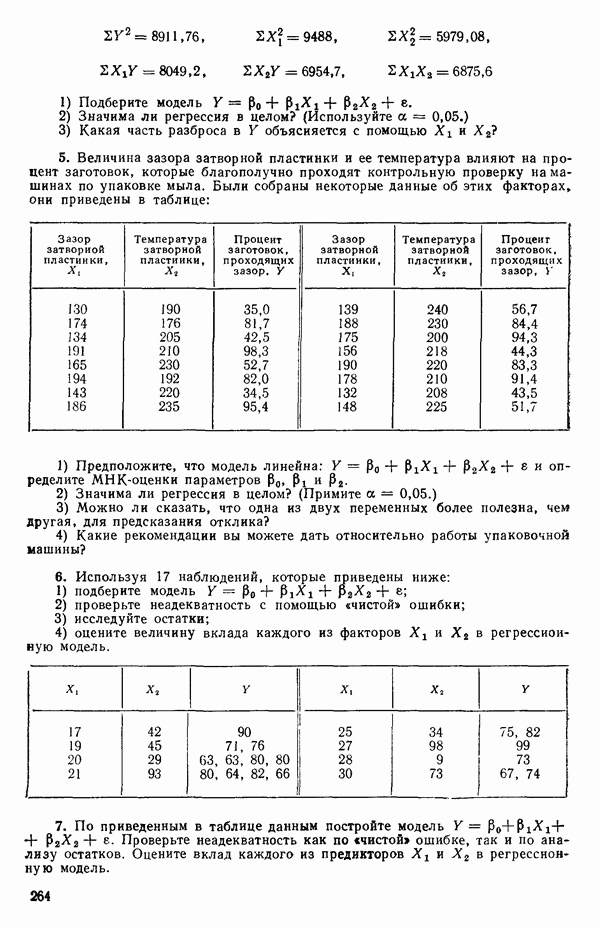
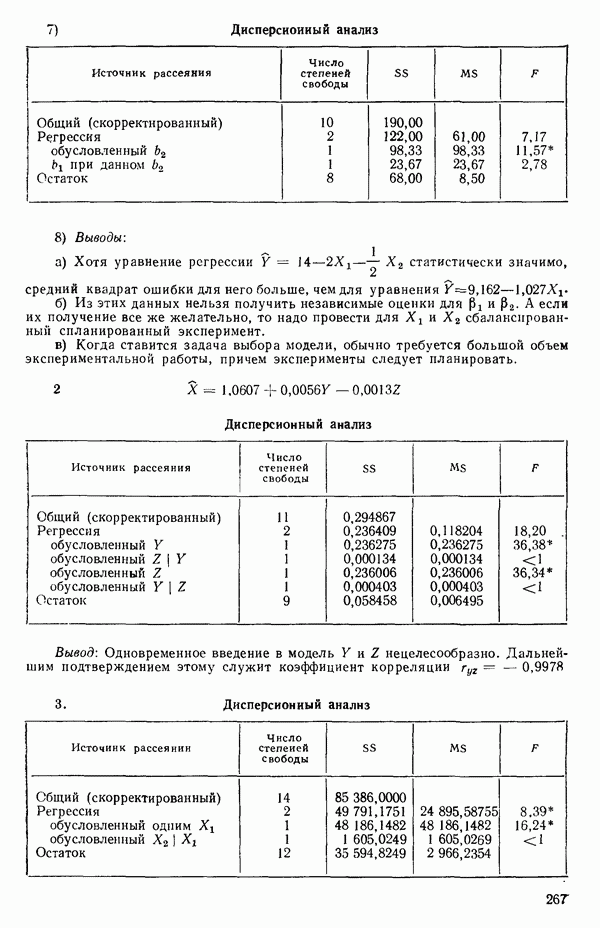
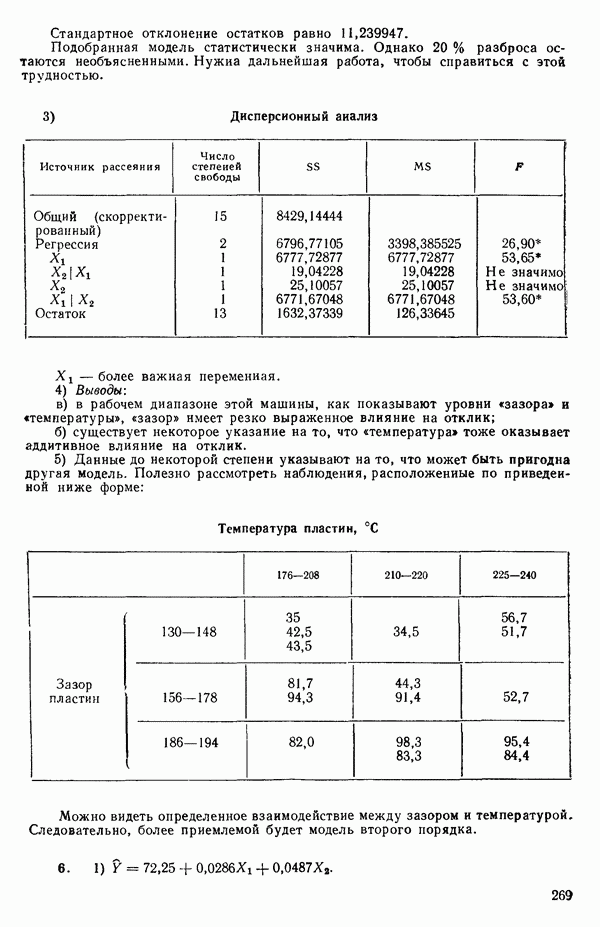
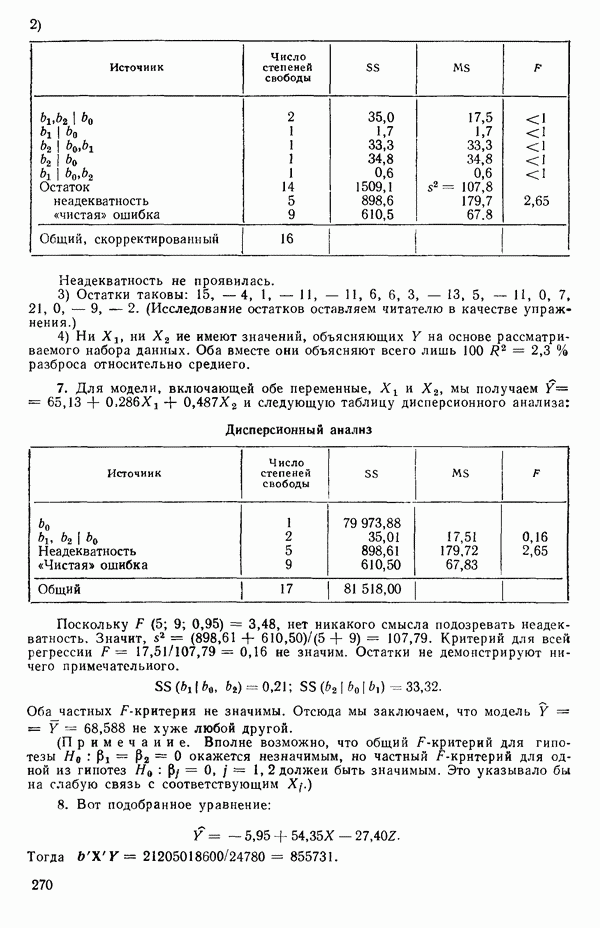
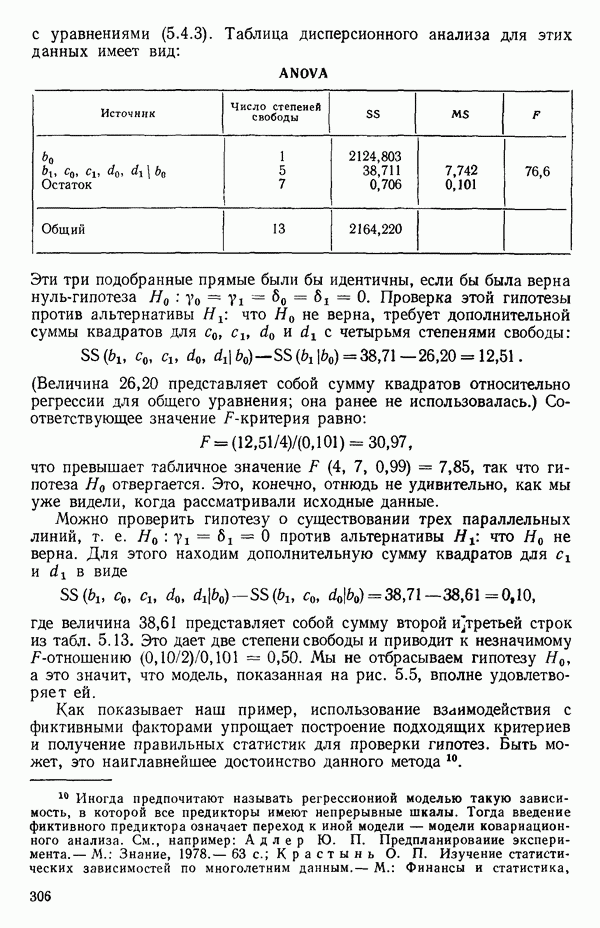
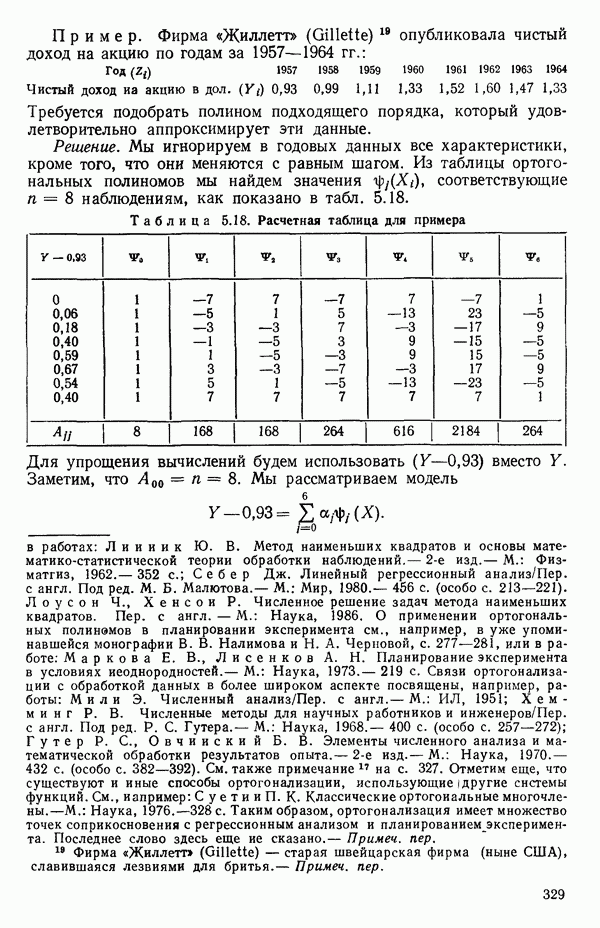
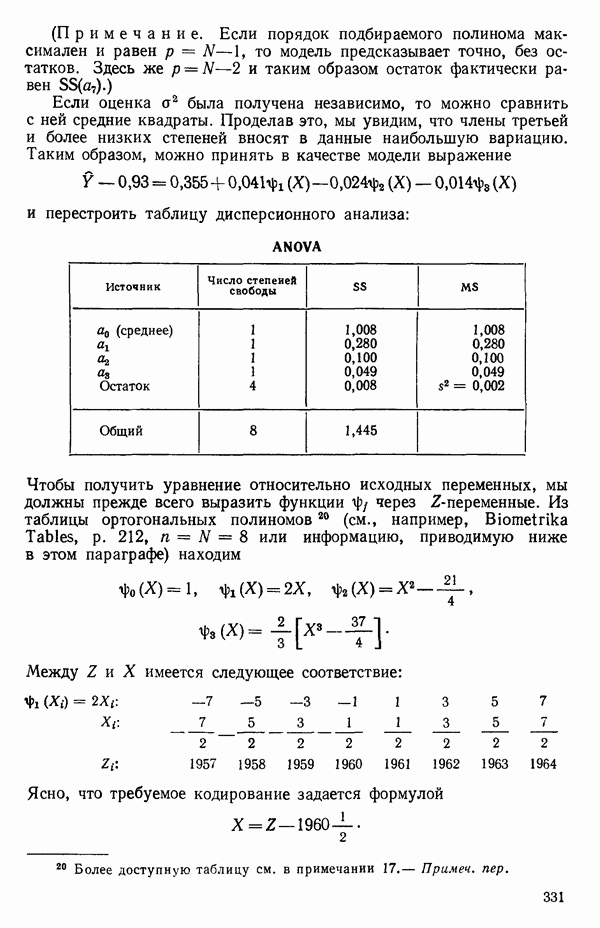
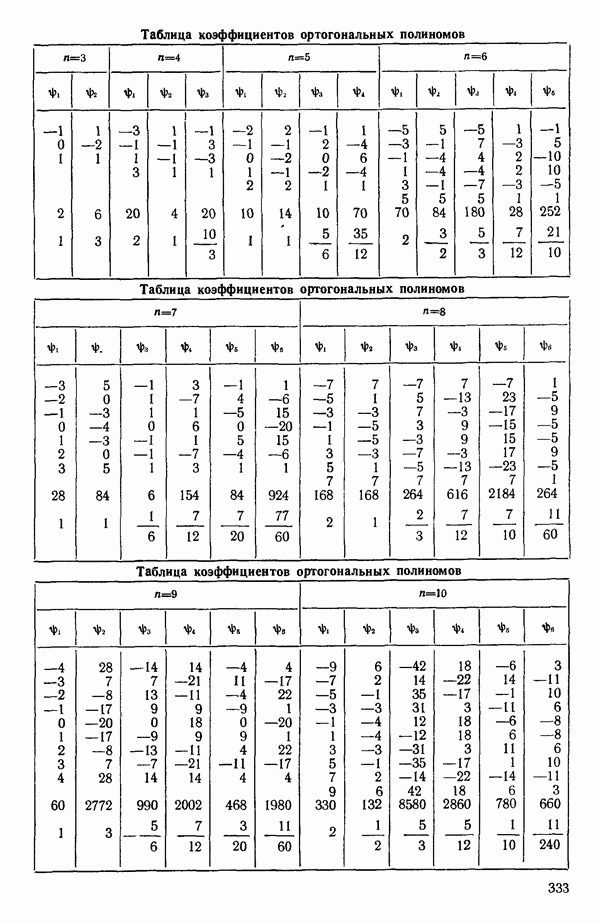
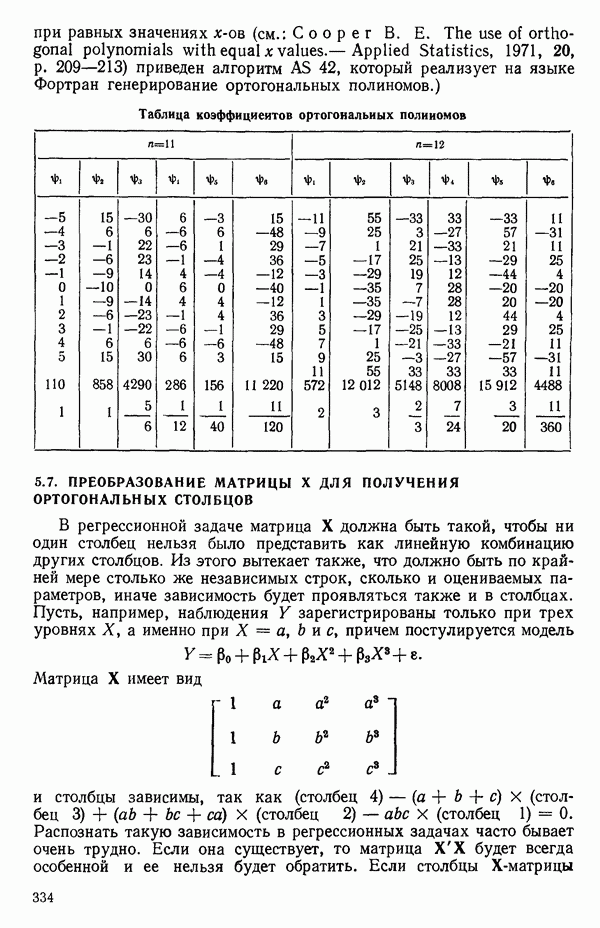
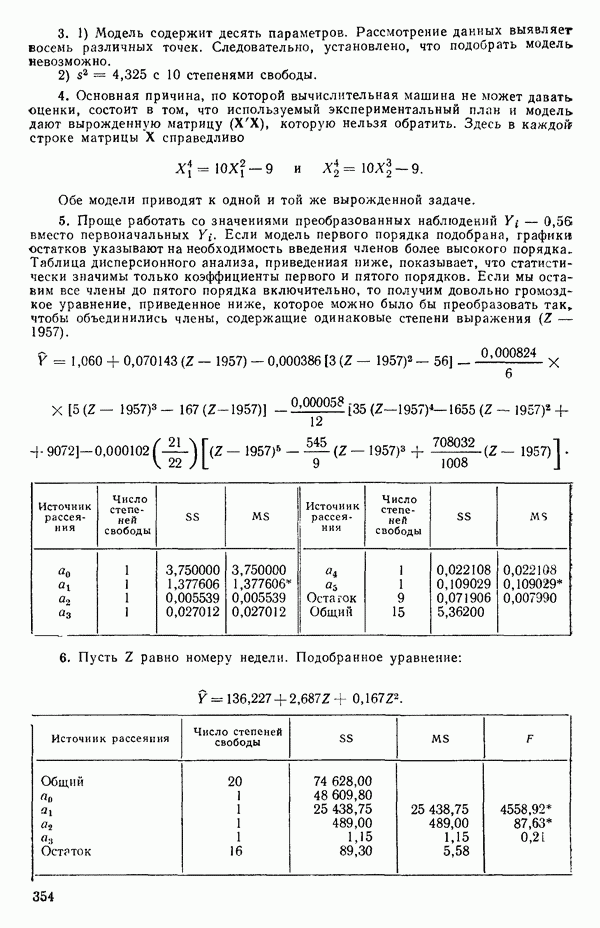
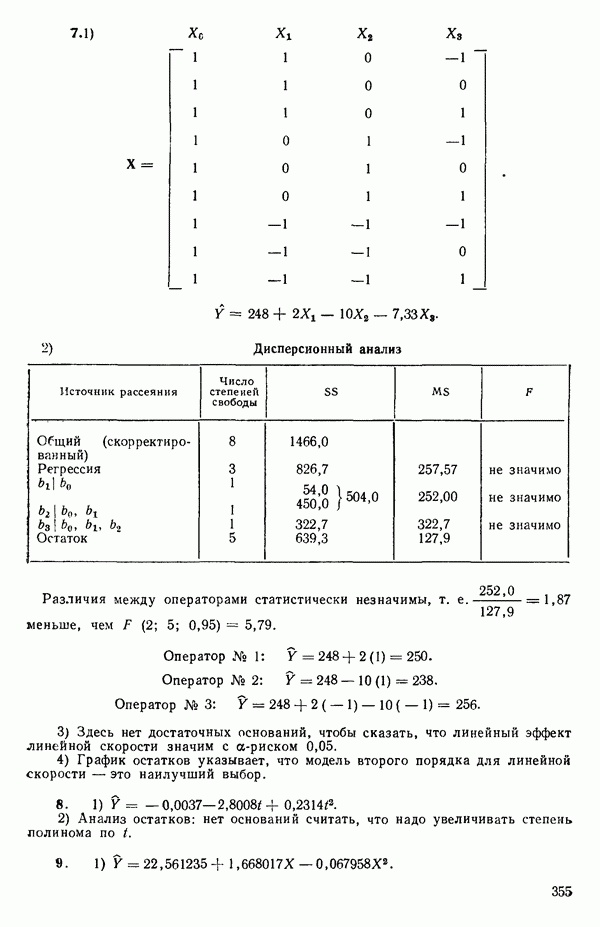
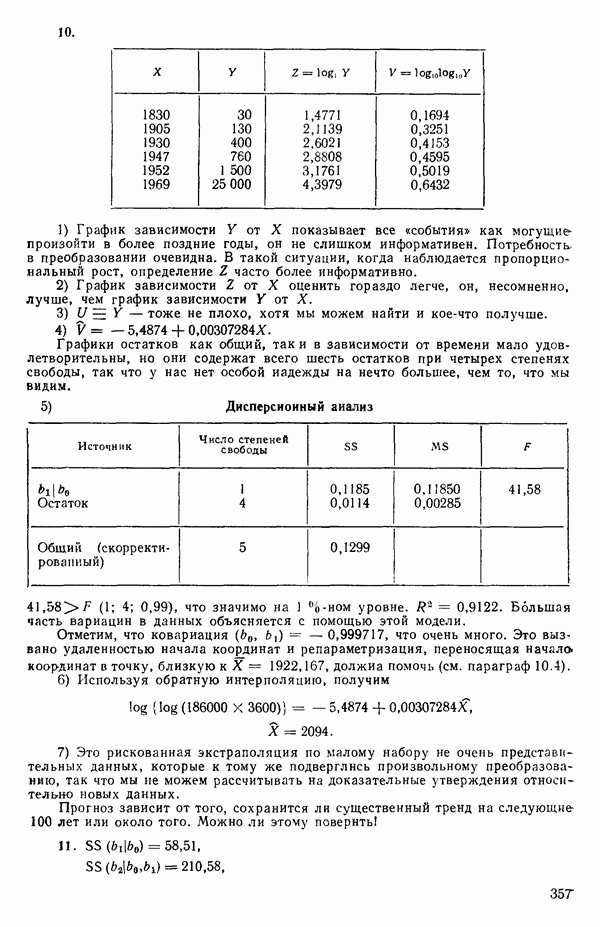
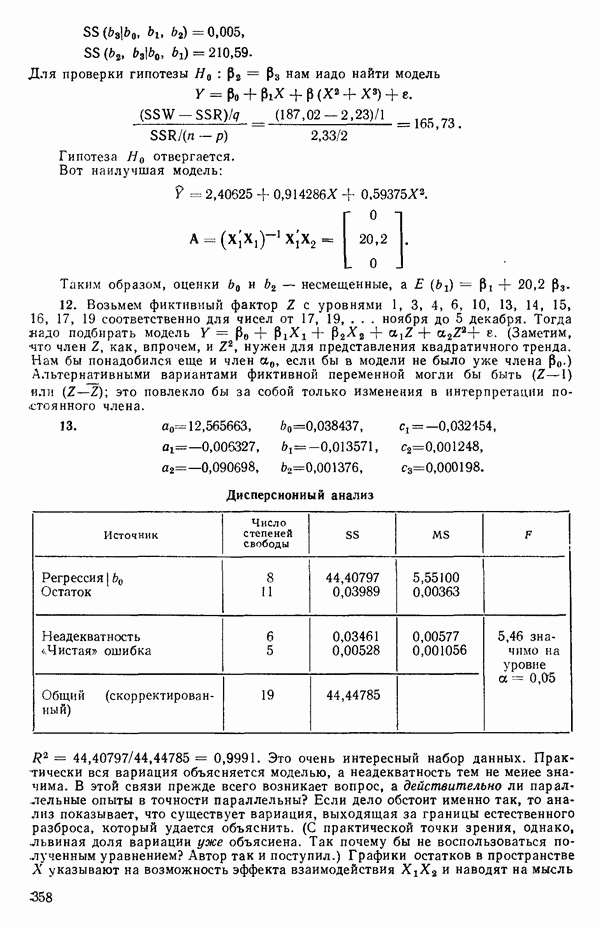
5. Основная таблица дисперсионного анализа может быть составлена так:

Дальнейшее разбиение таблицы дисперсионного анализа на части может быть выполнено следующим образом:
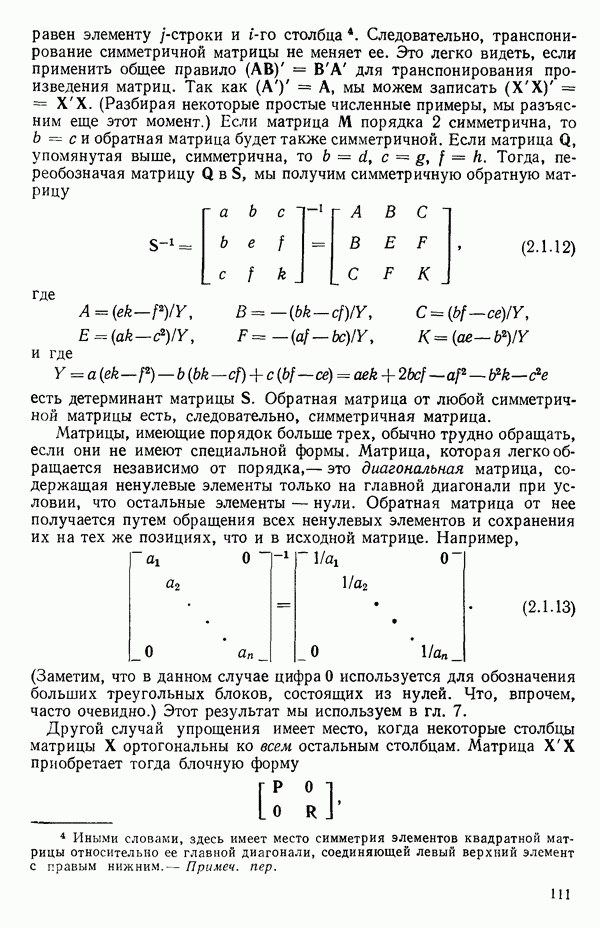
5а. Если в модели имеется коэффициент  то сумму квадратов, обусловленную регрессией, можно разбить на слагаемые:
то сумму квадратов, обусловленную регрессией, можно разбить на слагаемые:

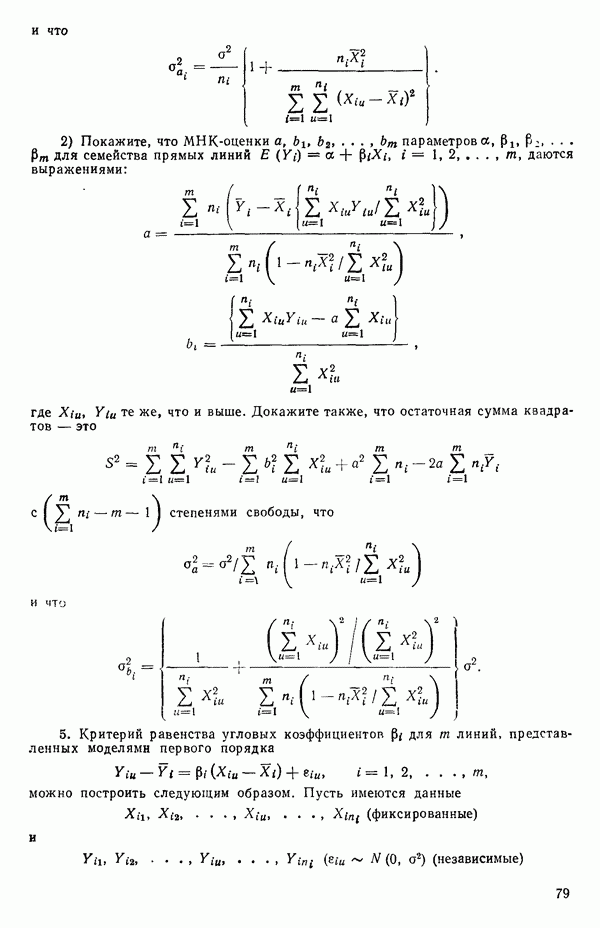
Эти суммы имеют соответственно  степеней свободы. Разбиение суммы квадратов, связанной с регрессией, на составные части будет обсуждаться более детально в параграфе 2.7.
степеней свободы. Разбиение суммы квадратов, связанной с регрессией, на составные части будет обсуждаться более детально в параграфе 2.7.
56. Если имеются повторные наблюдения, то мы можем расщепить остаточную  на
на  («чистой» ошибки), связанную с «чистой» ошибкой и имеющую
(«чистой» ошибки), связанную с «чистой» ошибкой и имеющую  степеней свободы, которая оценивает
степеней свободы, которая оценивает  и
и  (неадекватности) — сумму квадратов, связанную с неадекватностью модели и имеющую
(неадекватности) — сумму квадратов, связанную с неадекватностью модели и имеющую  степеней свободы. При проведении повторных опытов должны выдерживаться уровни всех независимых переменных (хотя на практике иногда используются «очень близкие» точки). Это приводит к следующей таблице дисперсионного анализа:
степеней свободы. При проведении повторных опытов должны выдерживаться уровни всех независимых переменных (хотя на практике иногда используются «очень близкие» точки). Это приводит к следующей таблице дисперсионного анализа:

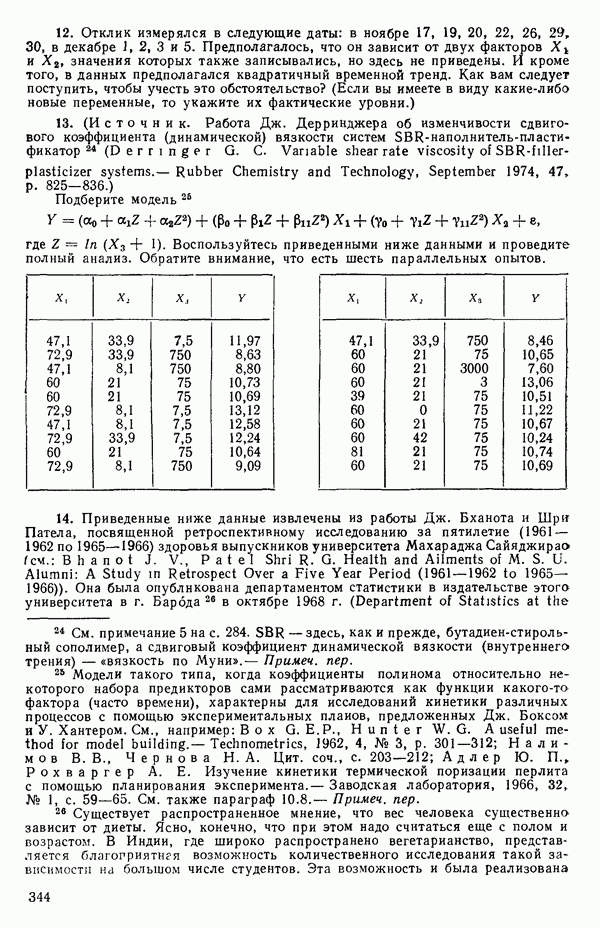
(Примечание. Порядок, в котором расположены члены в этой таблице, не играет роли. Большинство таблиц в данной книге имеет такое расположение, которое зачастую можно видеть в машинных программах.)
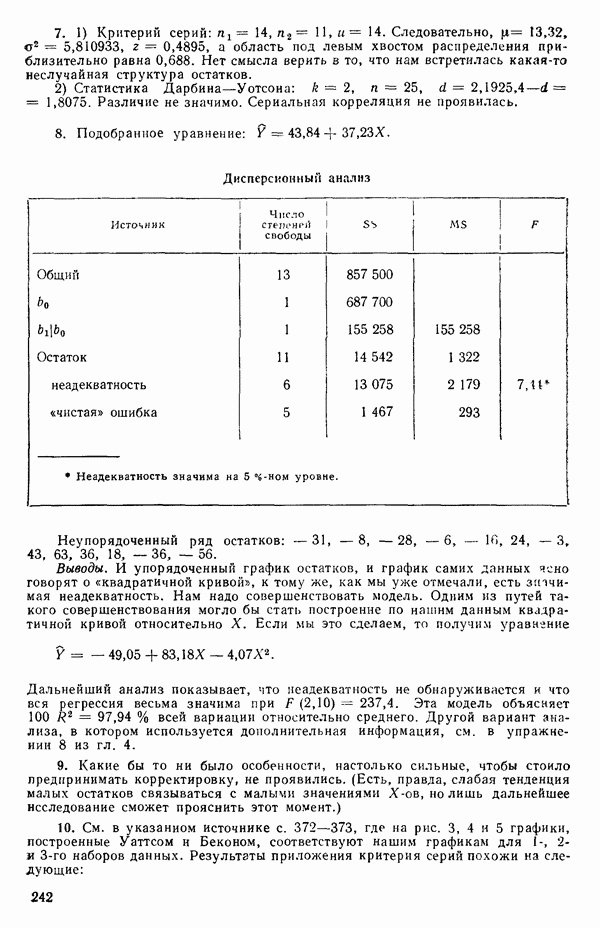
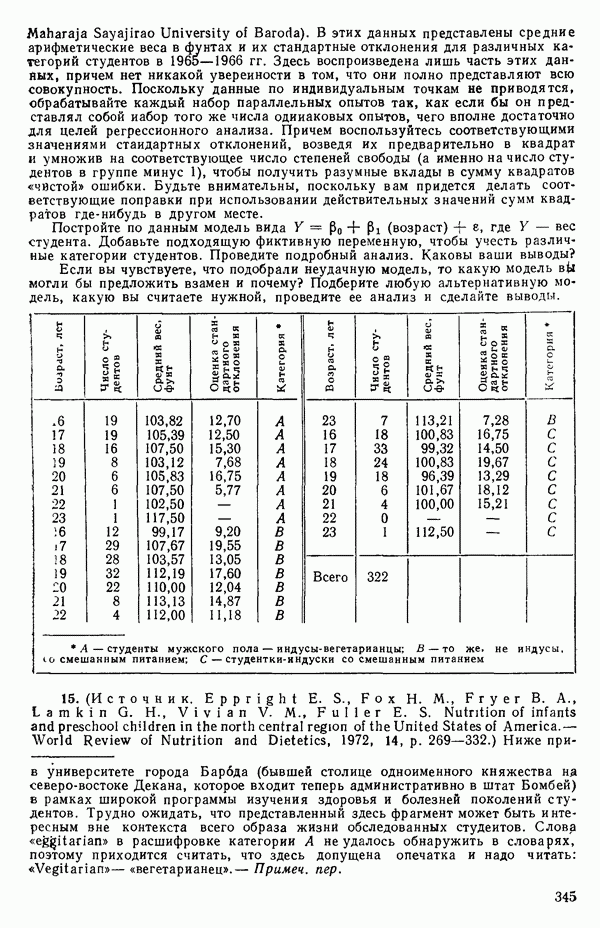
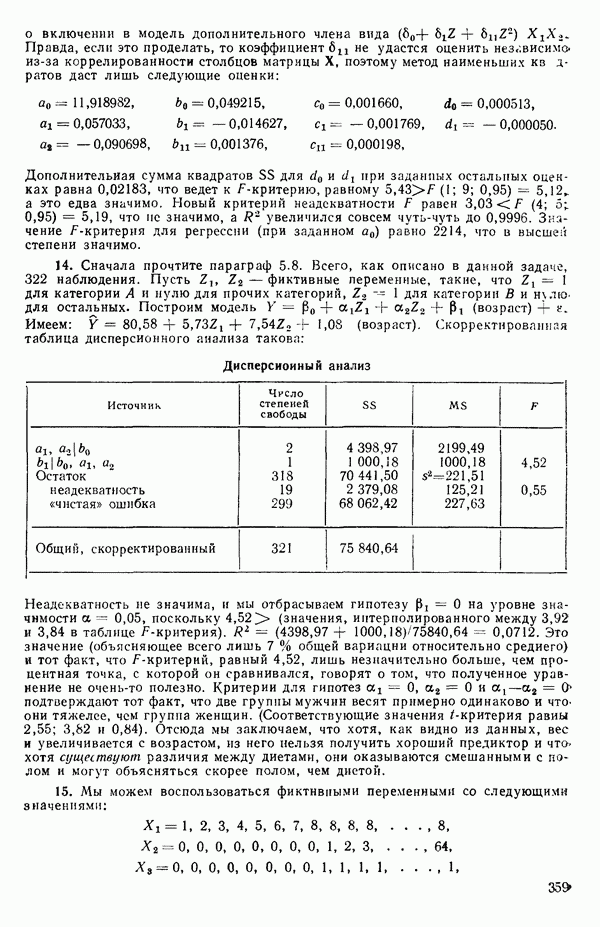
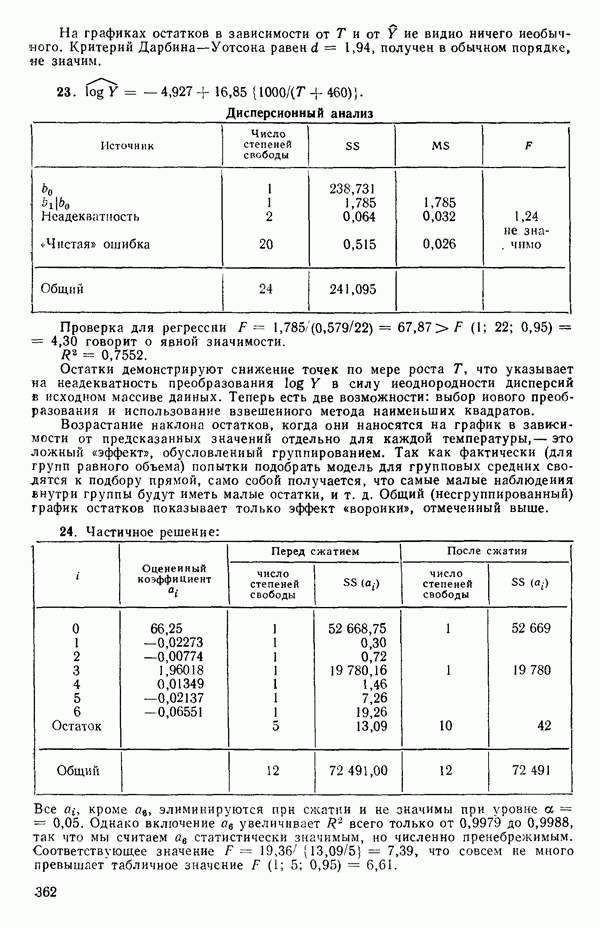
-статистика. Отношение

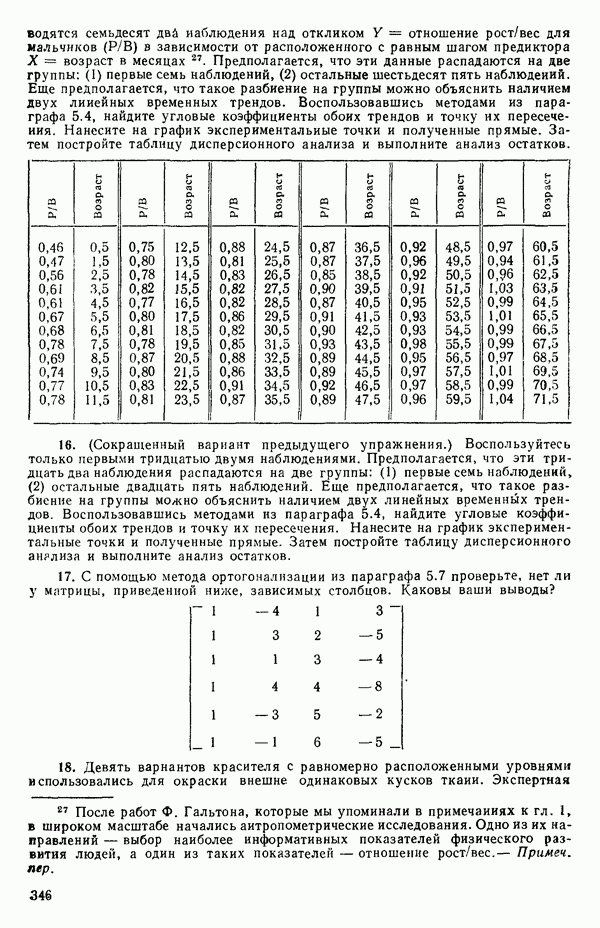
есть обобщение величины, введенной ранее при рассмотрении линейной регрессии, и представляет собой квадрат множественного коэффициента корреляции. Другое название величины  множественный коэффициент детерминации. Величину
множественный коэффициент детерминации. Величину  не следует путать с буквой
не следует путать с буквой  в выражениях
в выражениях  где буква
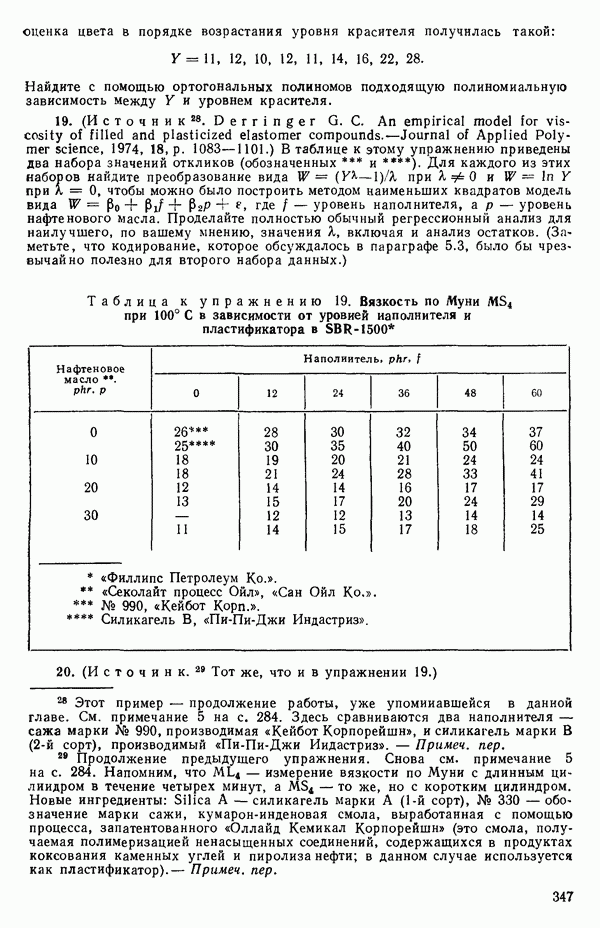
где буква  отражает вклад регрессии.
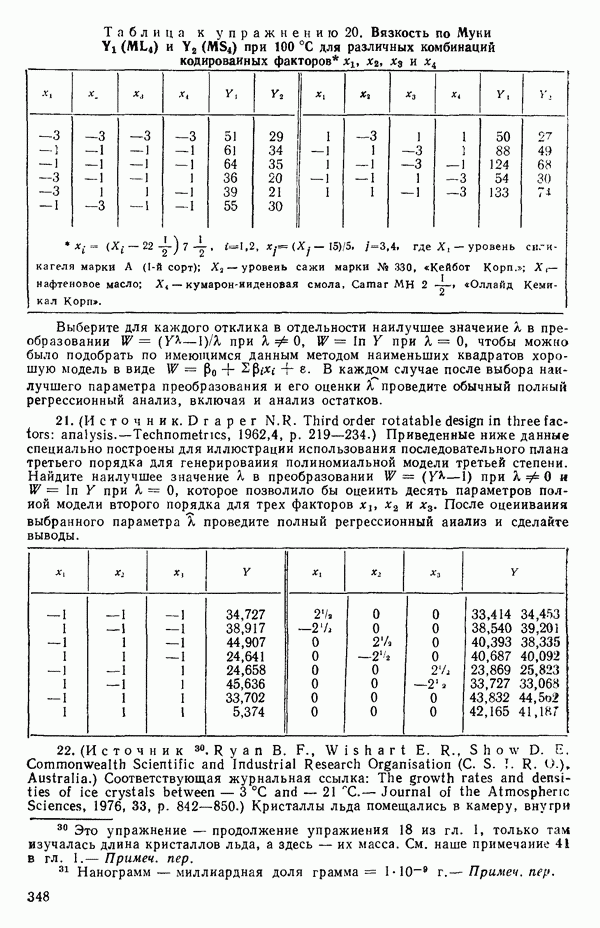
отражает вклад регрессии.  есть квадрат коэффициента корреляции между
есть квадрат коэффициента корреляции между  при этом
при этом  Если есть повторные опыты, то
Если есть повторные опыты, то  не может достигать 1; см. замечания на с. 54, 61—62, 84, 98—99.
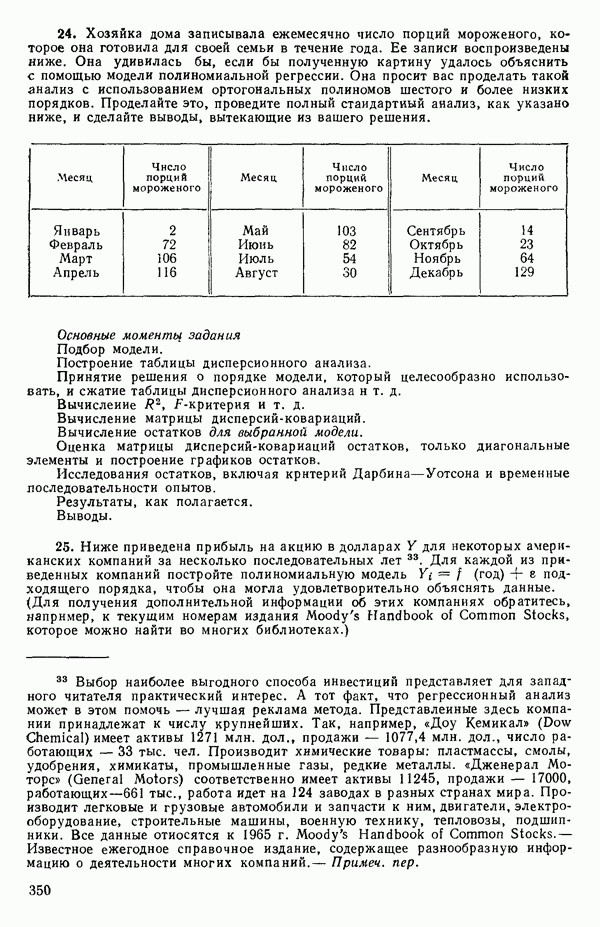
не может достигать 1; см. замечания на с. 54, 61—62, 84, 98—99.  при полном согласии экспериментальных и расчетных данных
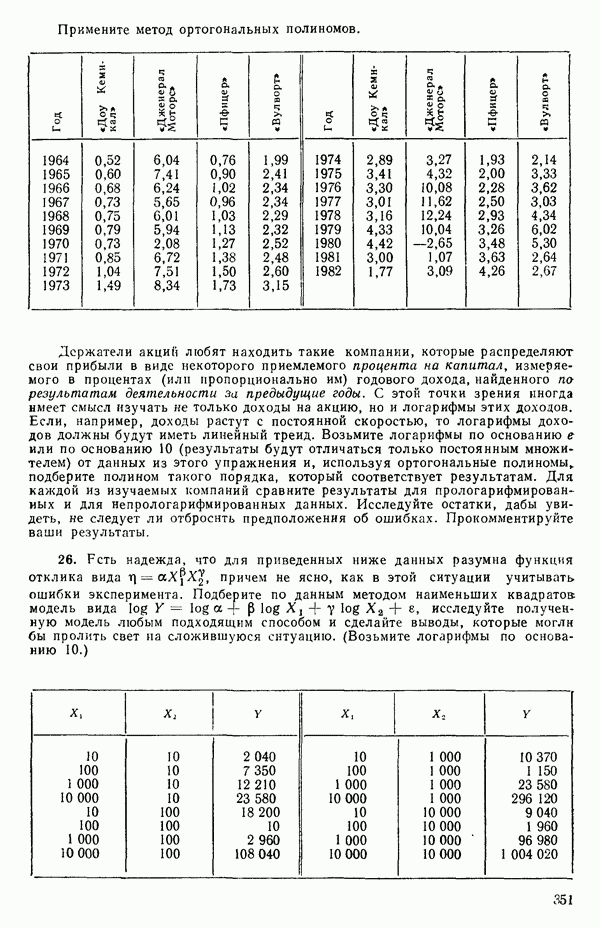
при полном согласии экспериментальных и расчетных данных  но это маловероятный случай.
но это маловероятный случай.
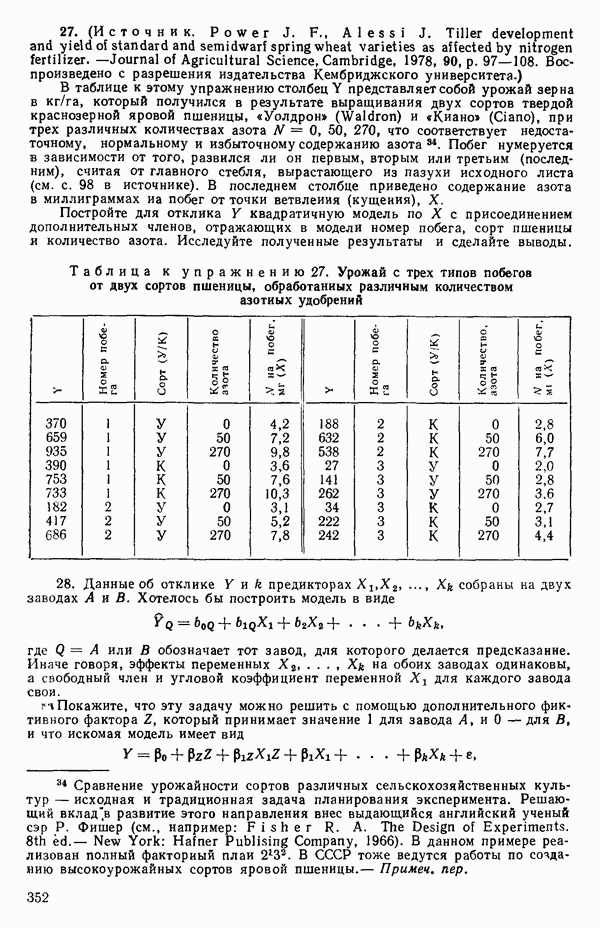
Если  т. е.
т. е.  (или адекватна модель
(или адекватна модель  Следовательно,
Следовательно,  есть мера полезности параметров кроме
есть мера полезности параметров кроме  в модели. Важно понимать, что величина
в модели. Важно понимать, что величина  может принимать значение 1 только при соответствующем выборе коэффициентов модели, включая
может принимать значение 1 только при соответствующем выборе коэффициентов модели, включая  поскольку в этом случае может быть подобрана модель, которая описывает экспериментальные результаты точно. (Например, если мы имеем наблюдения
поскольку в этом случае может быть подобрана модель, которая описывает экспериментальные результаты точно. (Например, если мы имеем наблюдения  для четырех различных значений X, то кубический полином
для четырех различных значений X, то кубический полином

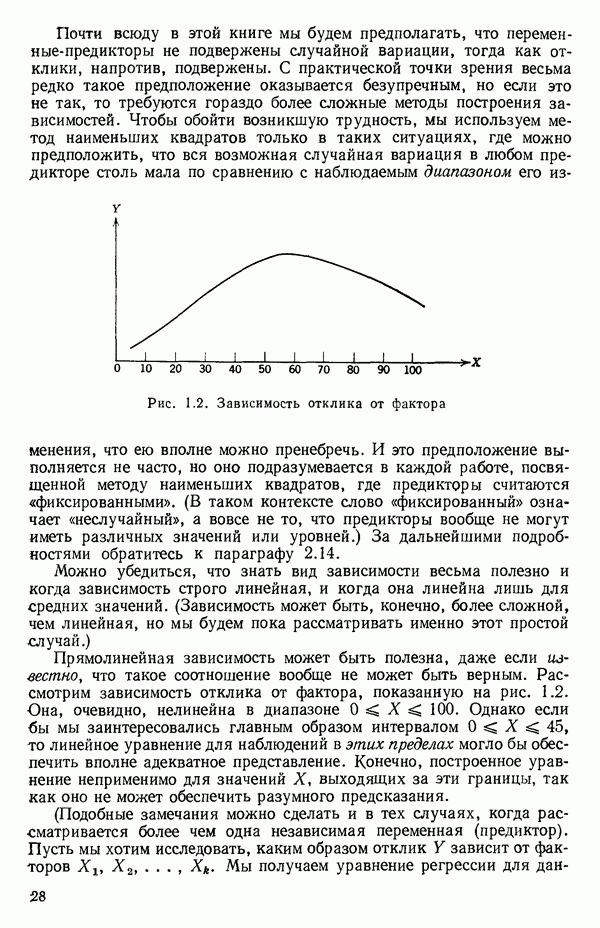
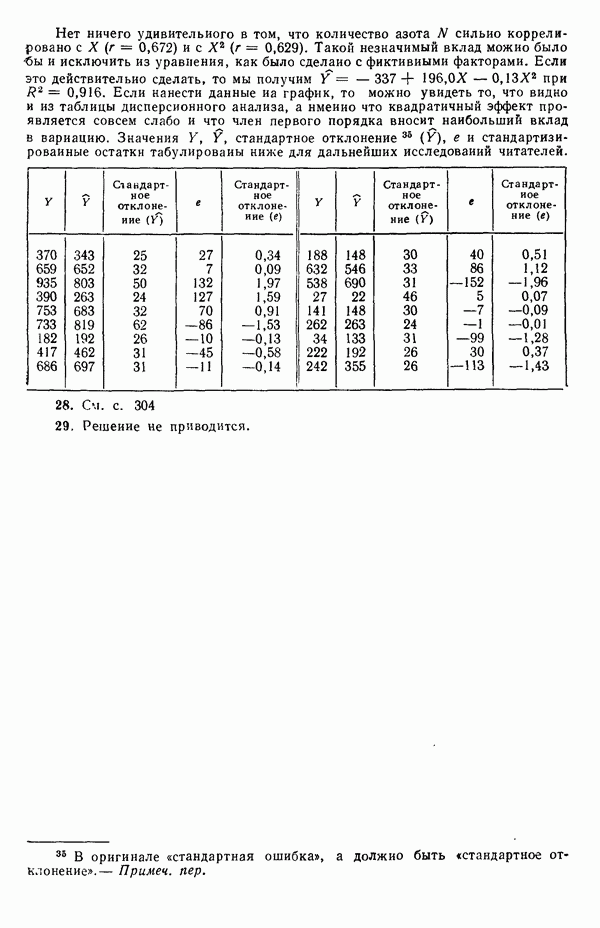
пройдет точно через все четыре точки.) Поскольку величина  используется часто в качестве меры эффективности регрессионной модели при объяснении вариации в данных, мы должны быть уверены, что увеличение
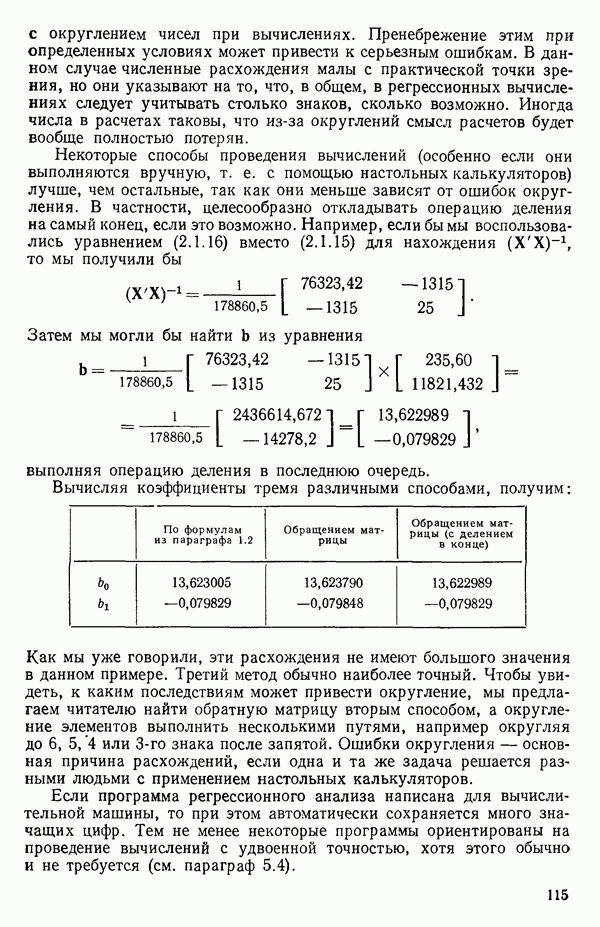
используется часто в качестве меры эффективности регрессионной модели при объяснении вариации в данных, мы должны быть уверены, что увеличение  благодаря введению новых слагаемых в модель имеет некоторый реальный смысл, а не обусловлено всего лишь тем фактом, что число параметров в модели становится ближе к состоянию насыщения, т. е. к числу наблюдений. Это особенно опасно, когда имеются повторные наблюдения. Например, если мы имеем сто наблюдений, состоящих из пяти групп, содержащих по двадцать повторных наблюдений, то фактически мы имеем лишь пять величин, несущих содержательную информацию, и они представляются пятью средними значениями, а также 95 степеней свободы для суммы квадратов, связанной с «чистой» ошибкой, по 19 для каждой точки, где проводятся повторные опыты. Следовательно, модель, содержащая пять параметров, дает очень хорошее согласие с пятью средними и может дать величину
благодаря введению новых слагаемых в модель имеет некоторый реальный смысл, а не обусловлено всего лишь тем фактом, что число параметров в модели становится ближе к состоянию насыщения, т. е. к числу наблюдений. Это особенно опасно, когда имеются повторные наблюдения. Например, если мы имеем сто наблюдений, состоящих из пяти групп, содержащих по двадцать повторных наблюдений, то фактически мы имеем лишь пять величин, несущих содержательную информацию, и они представляются пятью средними значениями, а также 95 степеней свободы для суммы квадратов, связанной с «чистой» ошибкой, по 19 для каждой точки, где проводятся повторные опыты. Следовательно, модель, содержащая пять параметров, дает очень хорошее согласие с пятью средними и может дать величину  очень близкую к 1, особенно, если экспериментальная ошибка мала по сравнению с размахом для пяти средних. В этом случае тот факт, что сотня наблюдений может хорошо предсказываться с помощью модели, содержащей лишь пять параметров, не является удивительным, так как на самом деле модель предсказывает только пять различных определенных экспериментальных
очень близкую к 1, особенно, если экспериментальная ошибка мала по сравнению с размахом для пяти средних. В этом случае тот факт, что сотня наблюдений может хорошо предсказываться с помощью модели, содержащей лишь пять параметров, не является удивительным, так как на самом деле модель предсказывает только пять различных определенных экспериментальных
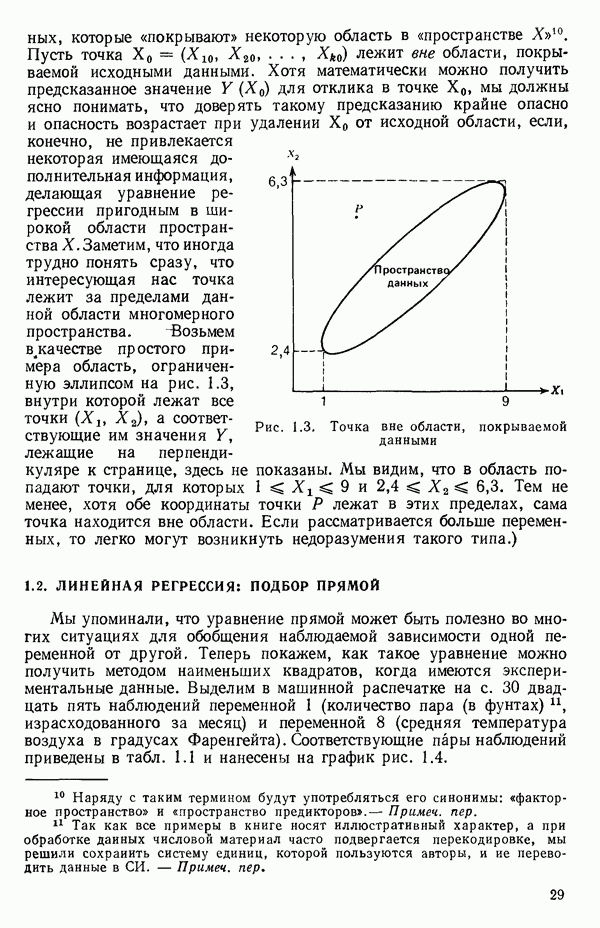
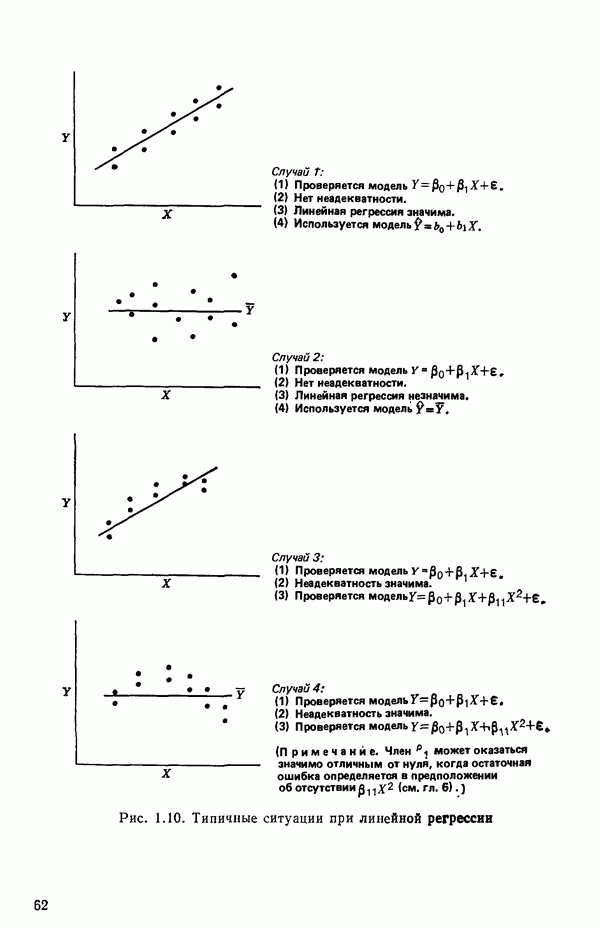
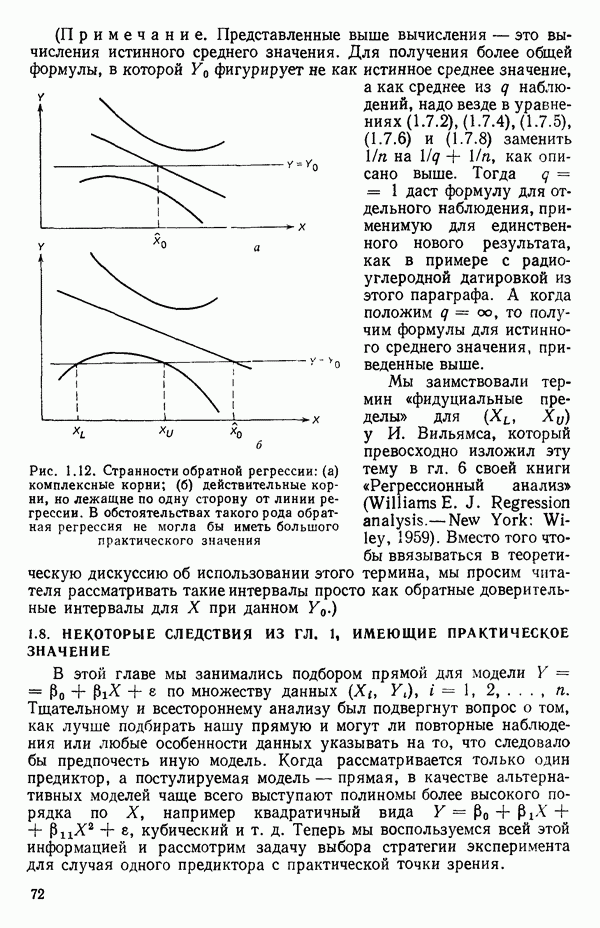
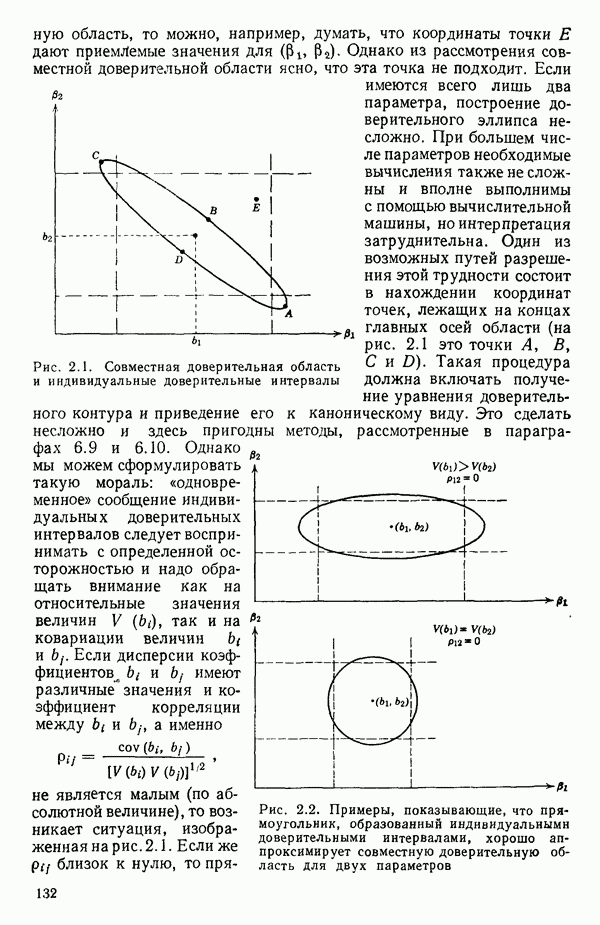
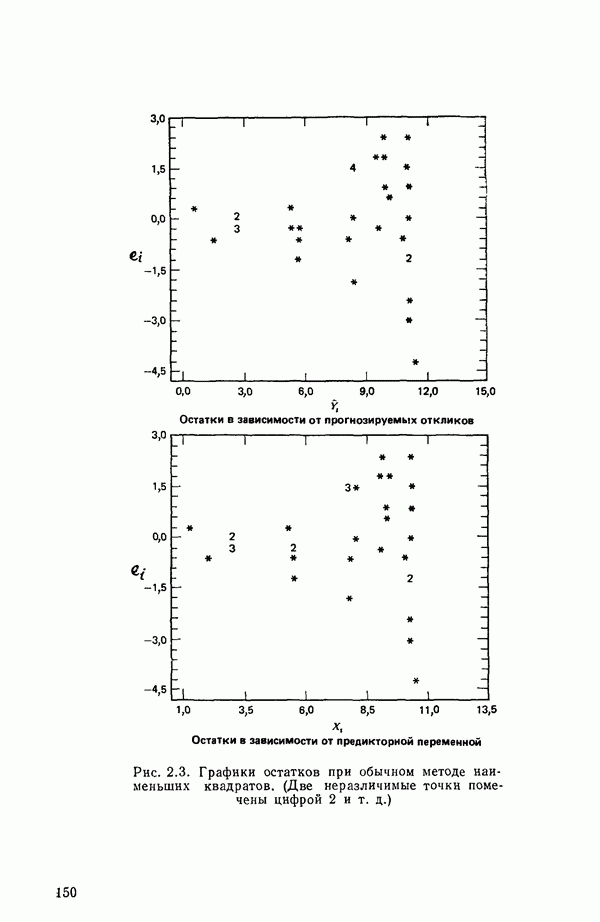
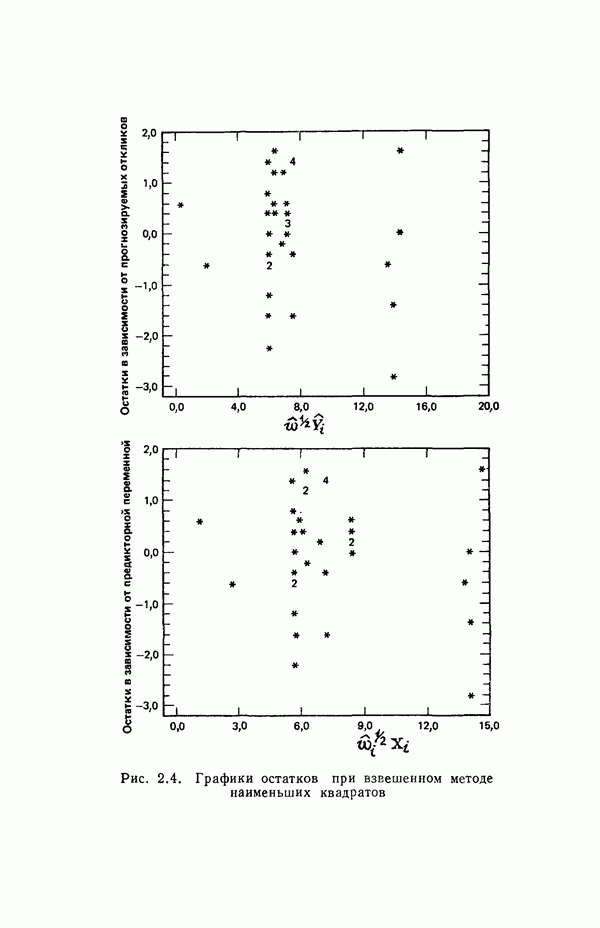
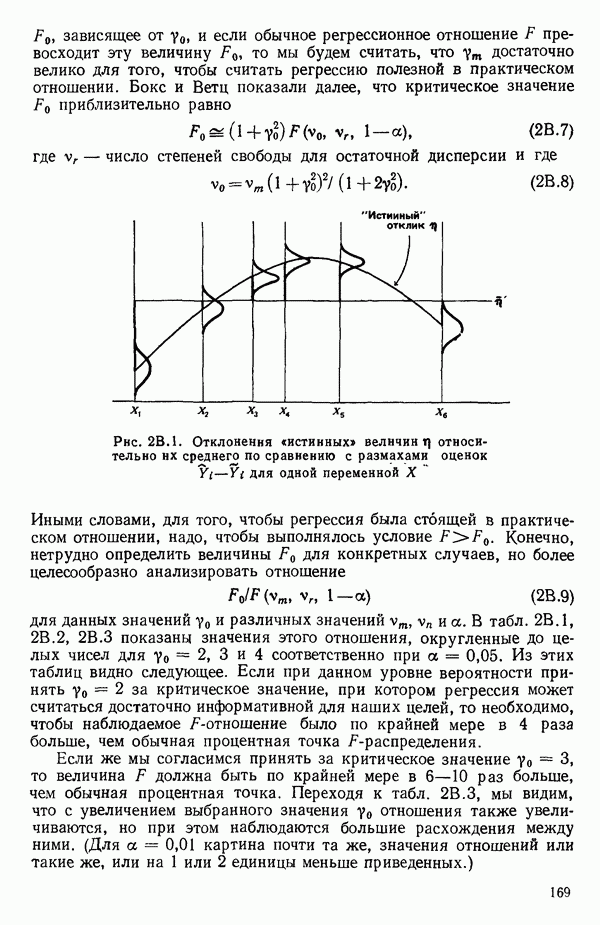
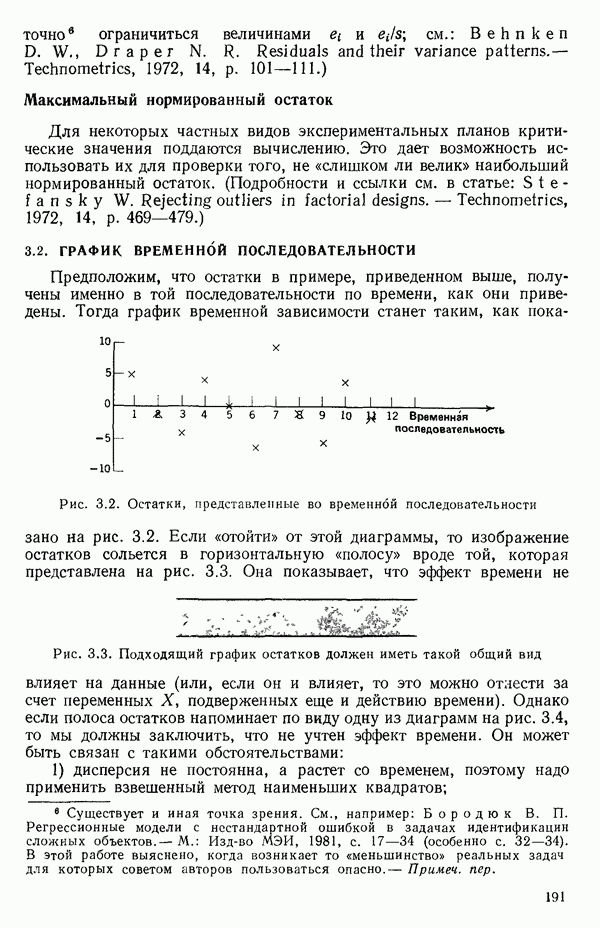
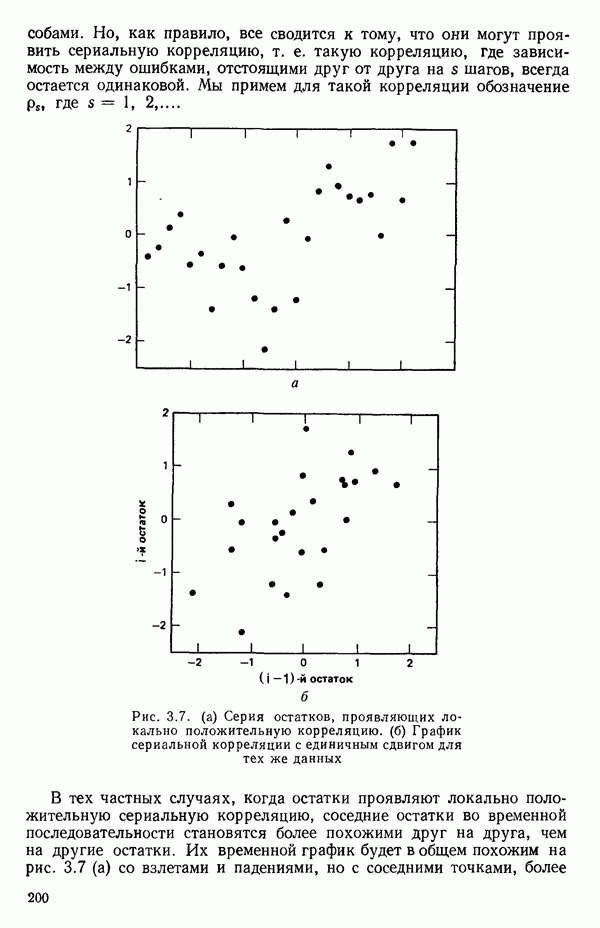
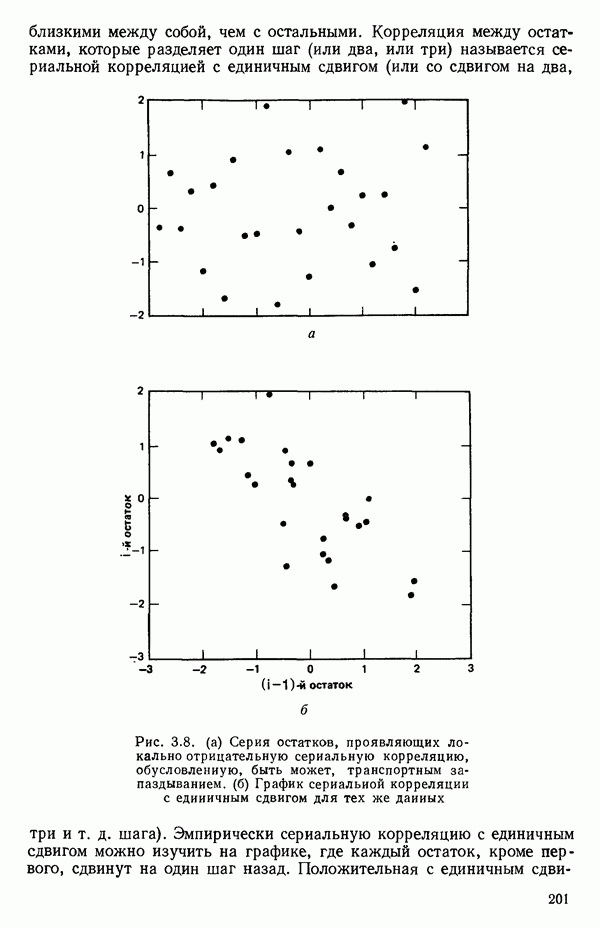
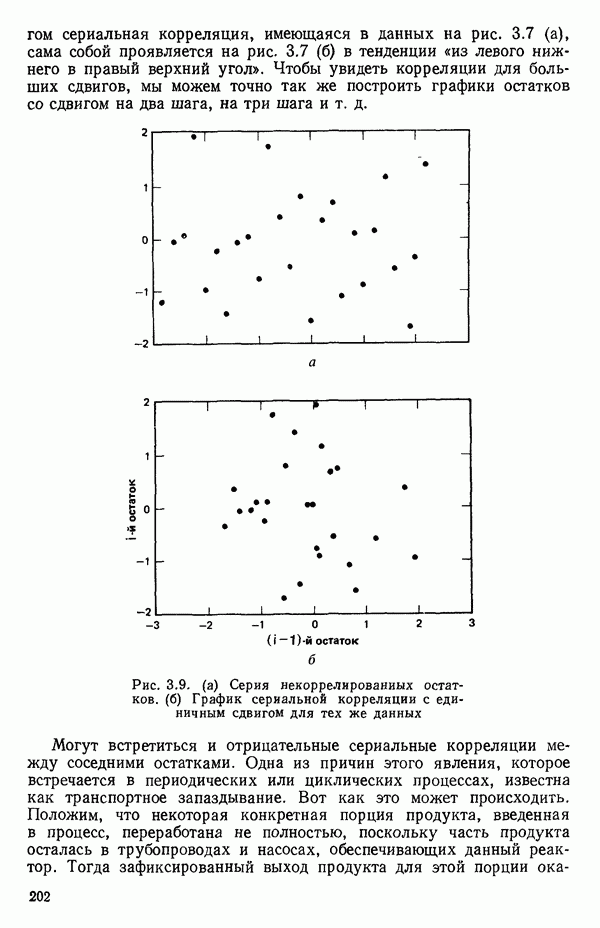
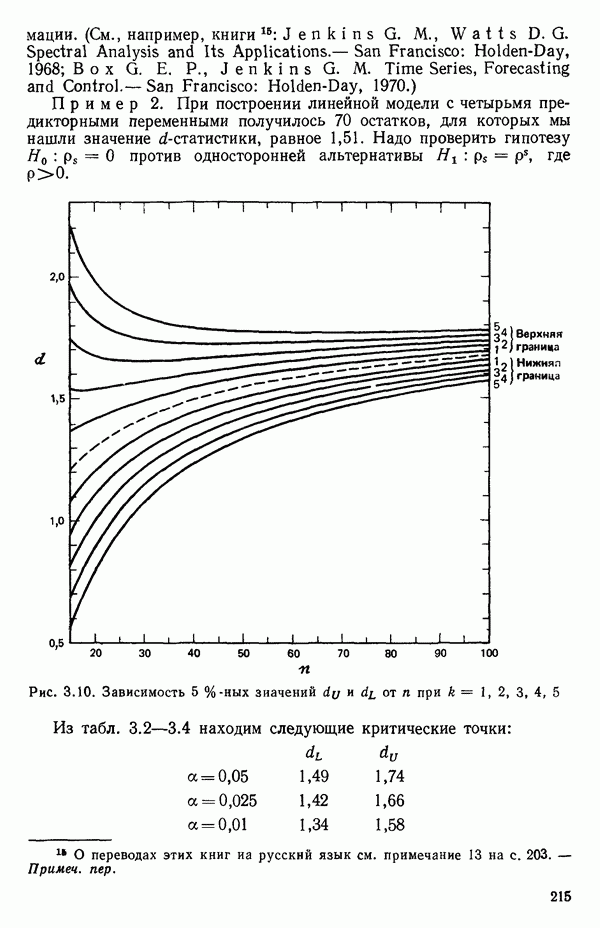
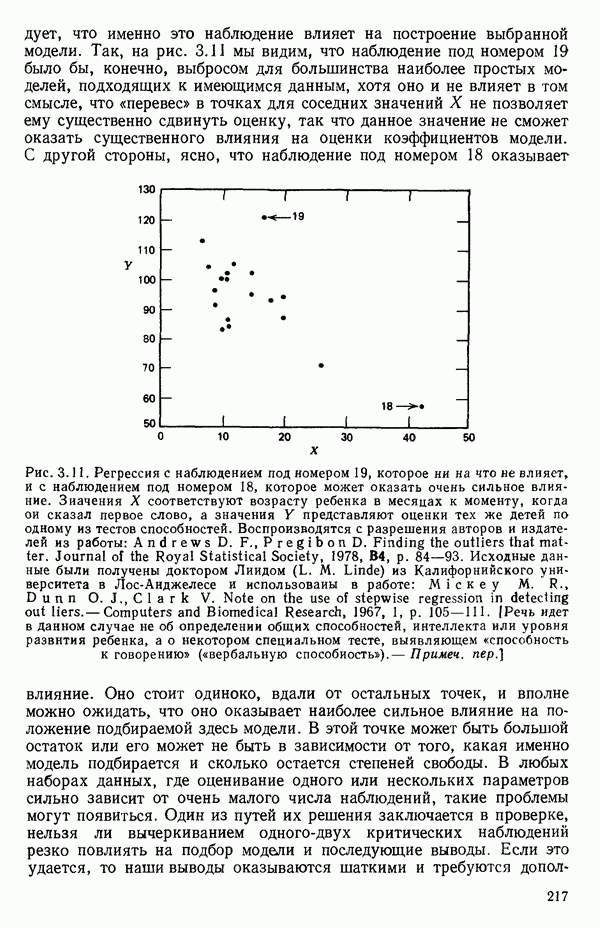
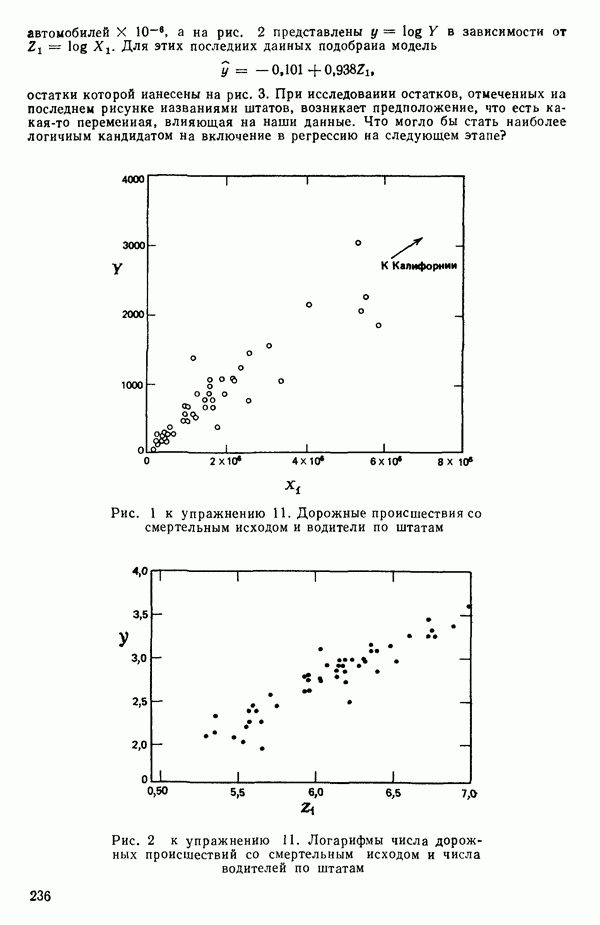
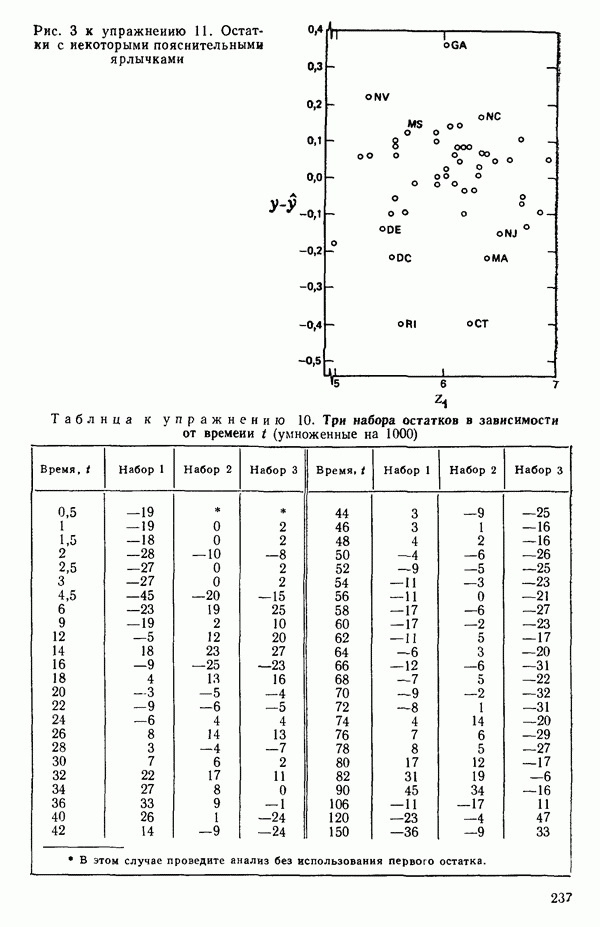
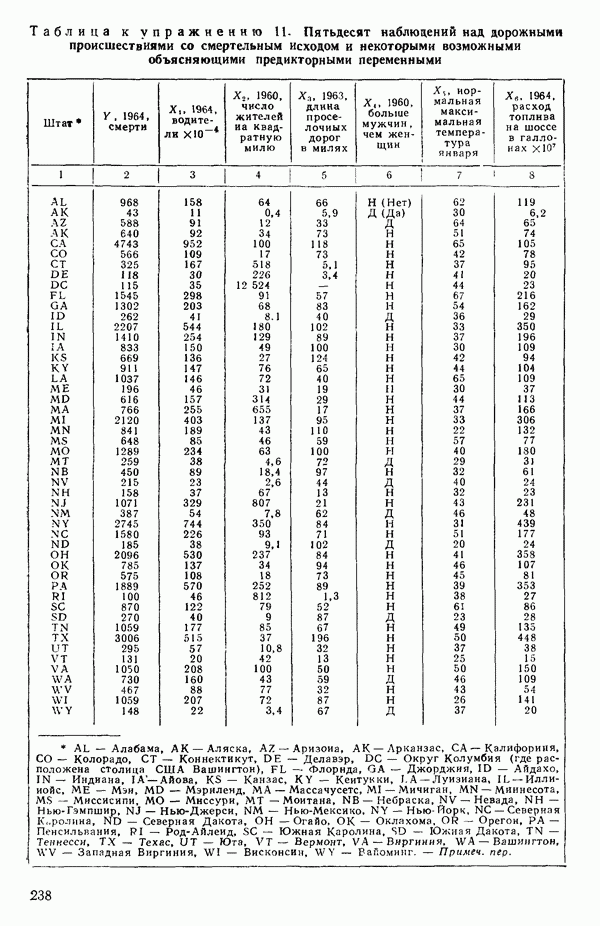
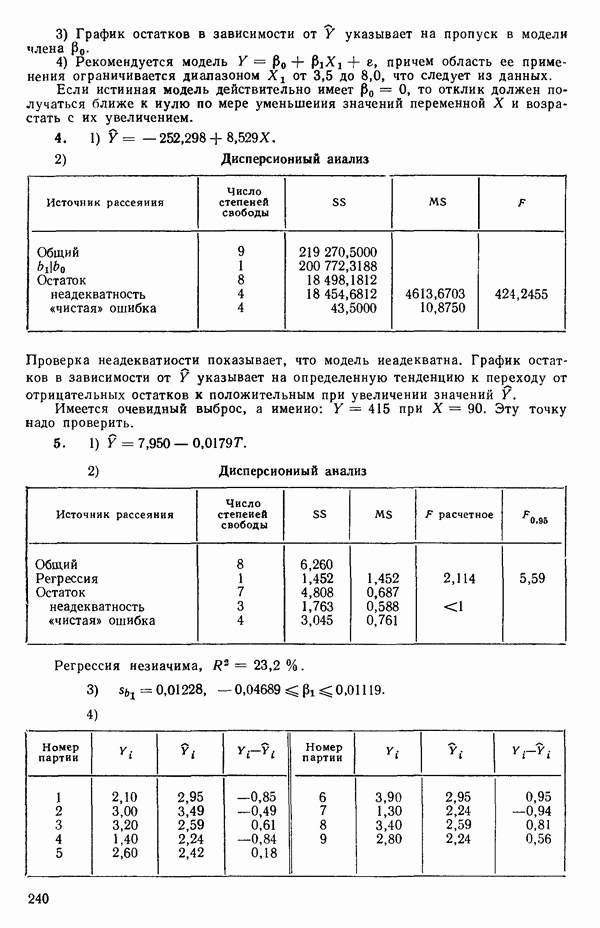
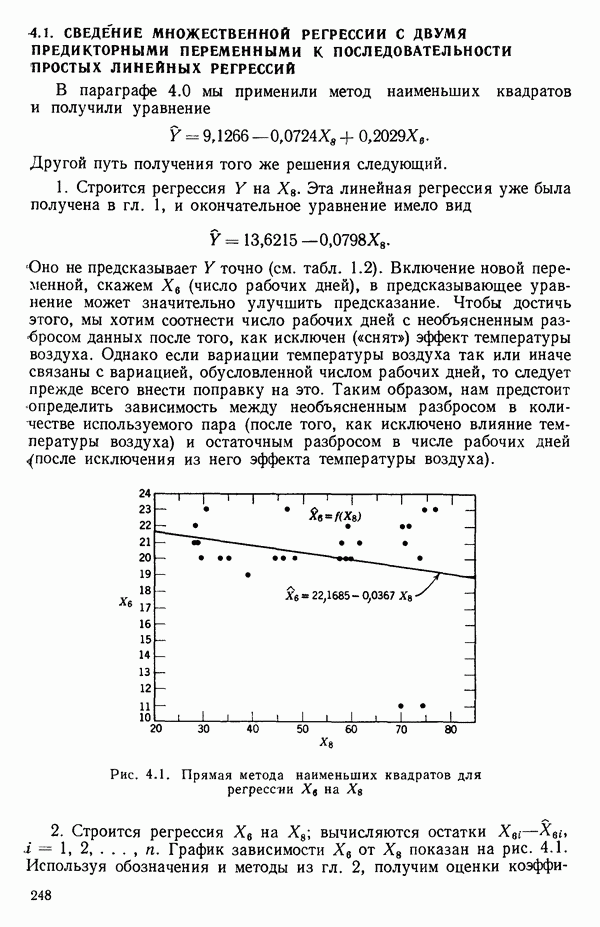
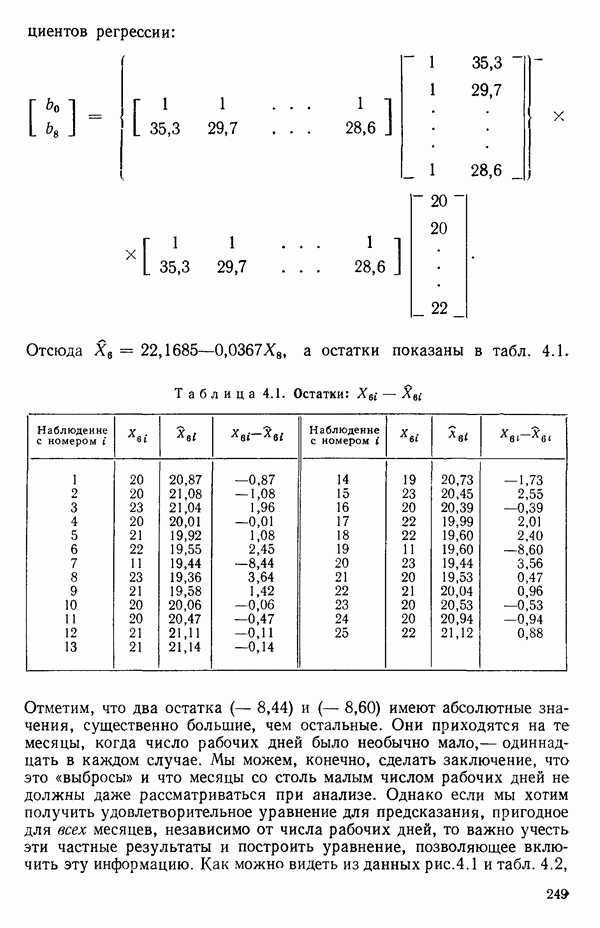
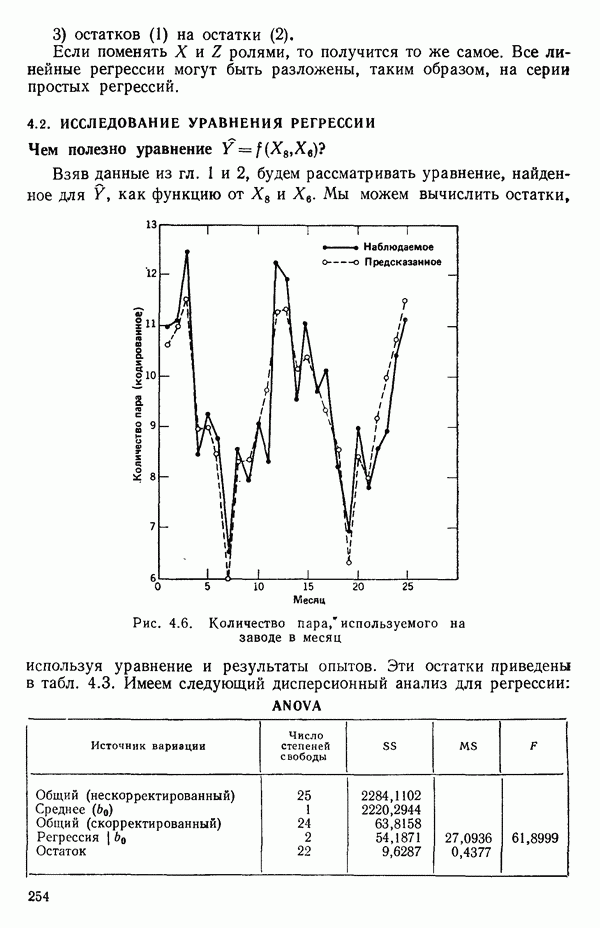
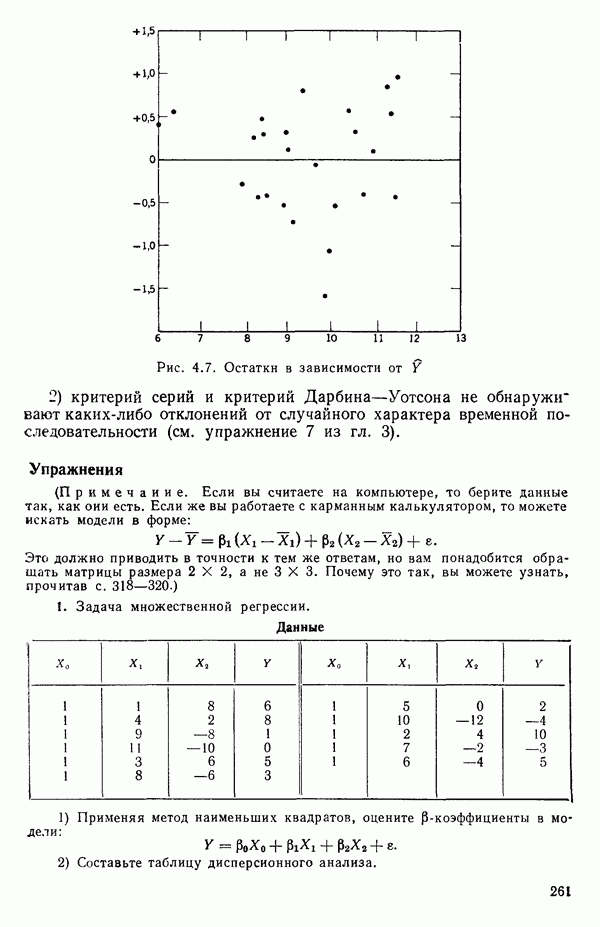
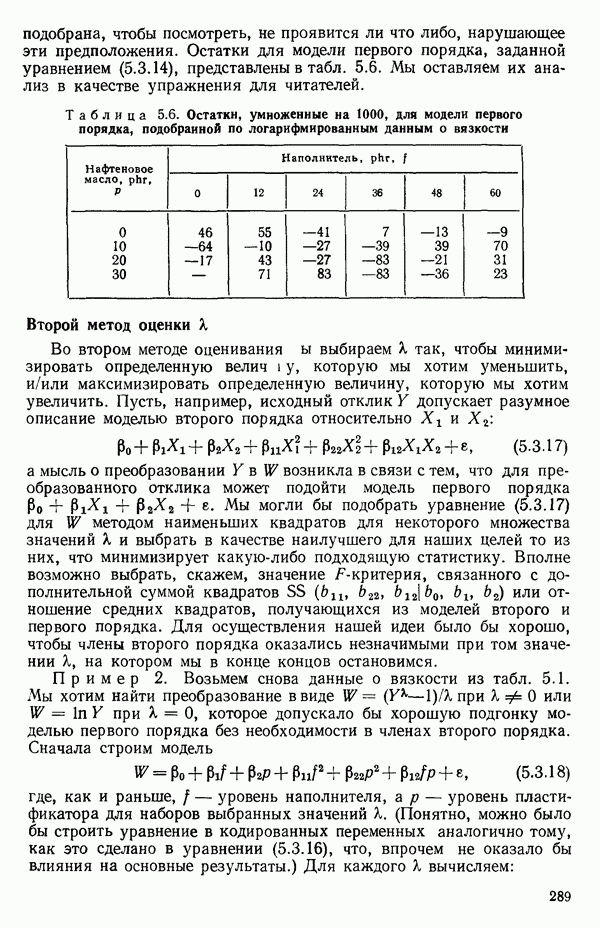
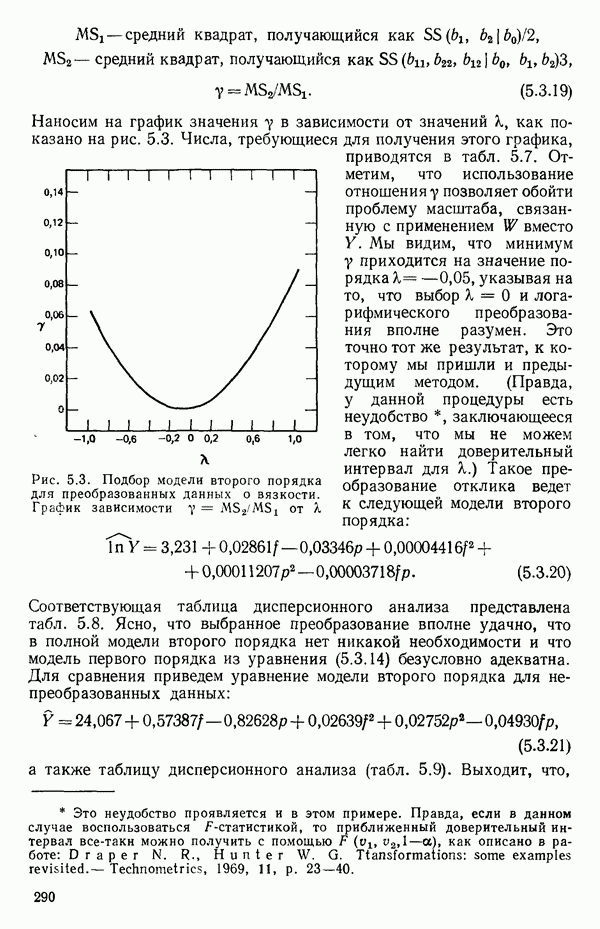
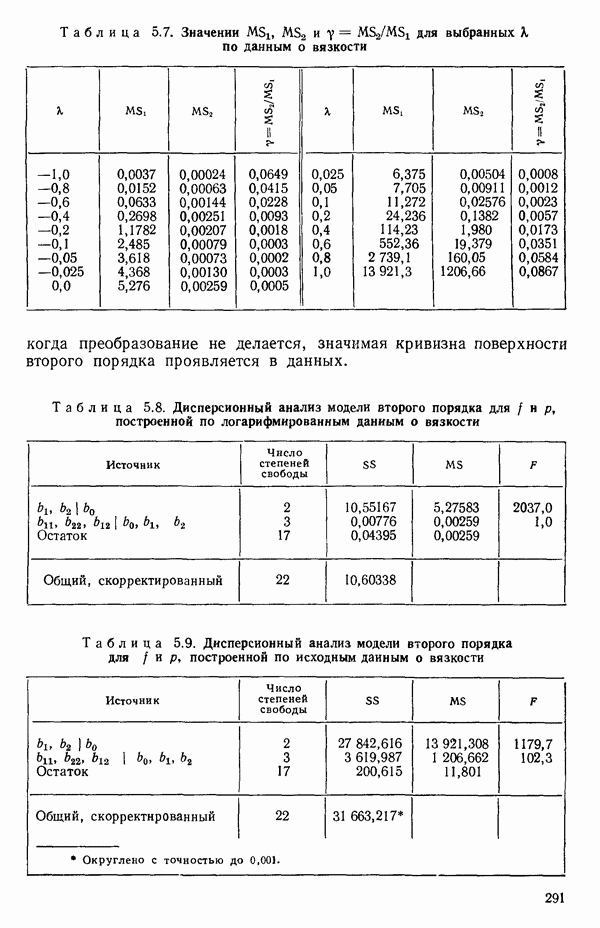
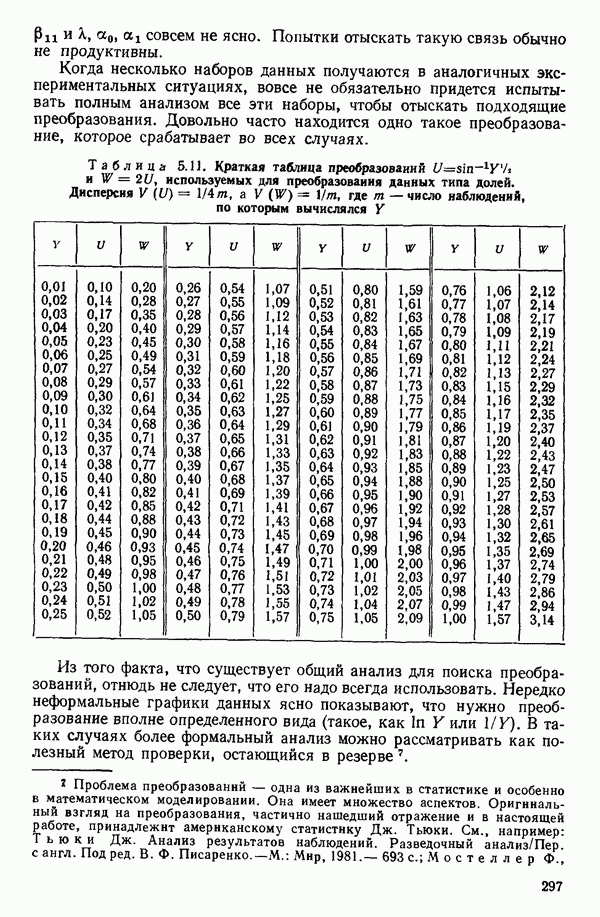
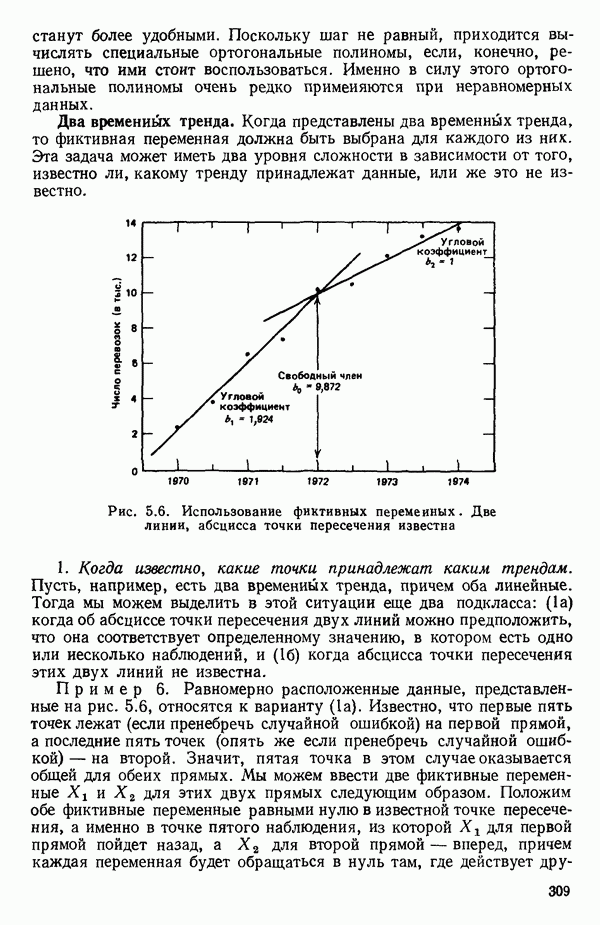
точек, а не сто, как это могло показаться вначале. Может быть и так, что точных повторений нет, но точки в Х-пространстве (для которых имеются наблюдения  расположены близко друг к другу. Такая ситуация может быть, однако, не очевидной, хорошо скрытой благодаря определенному подбору экспериментальных данных. Графики данных и остатки (см. гл. 3 обычно позволяют обнаруживать такие «скопления» (кластеры — clasters) точек.
расположены близко друг к другу. Такая ситуация может быть, однако, не очевидной, хорошо скрытой благодаря определенному подбору экспериментальных данных. Графики данных и остатки (см. гл. 3 обычно позволяют обнаруживать такие «скопления» (кластеры — clasters) точек.

















































































































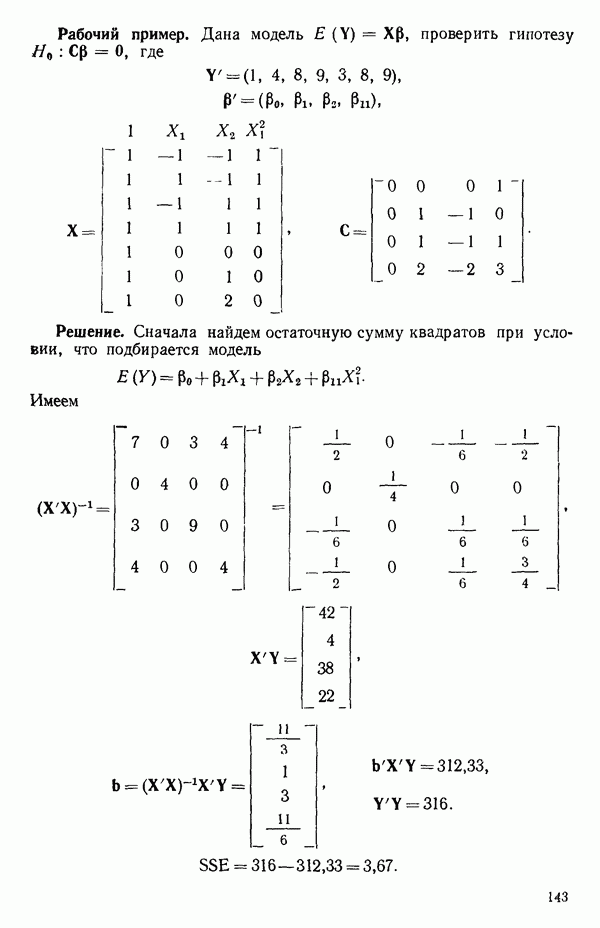





























































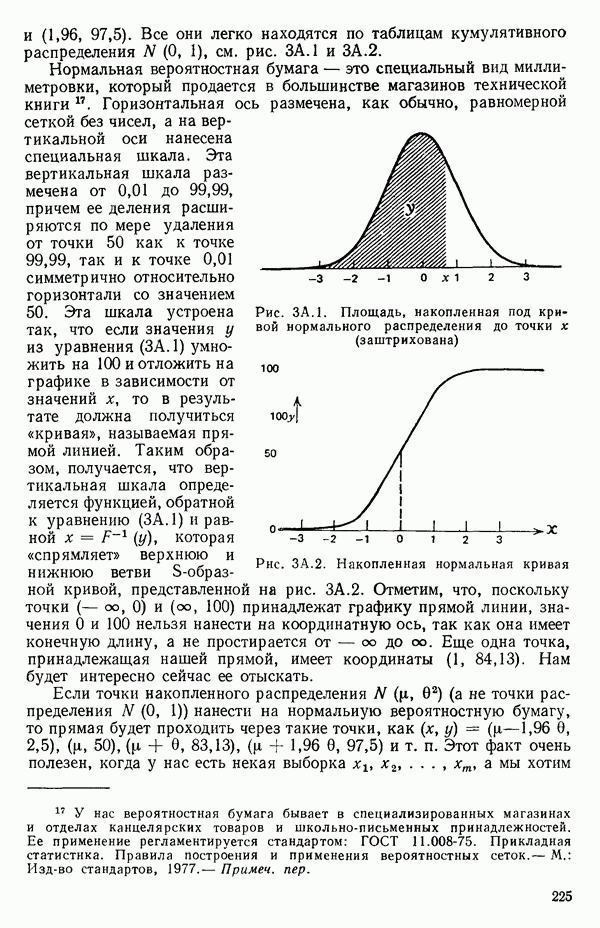
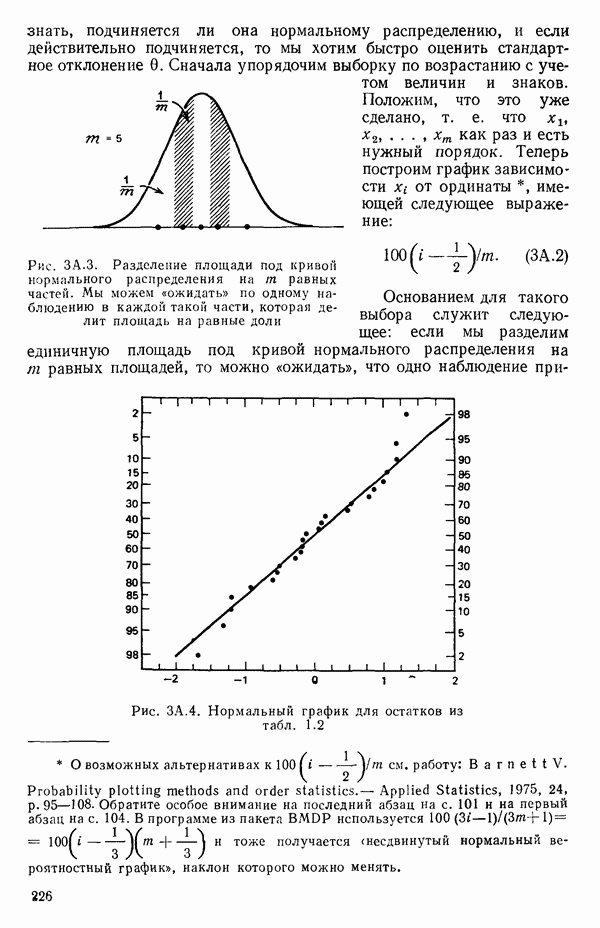


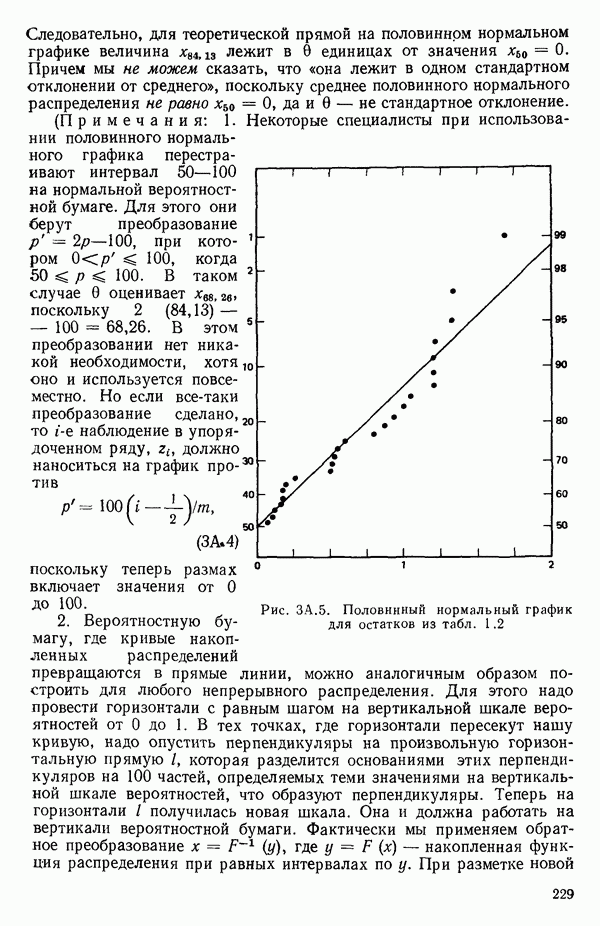





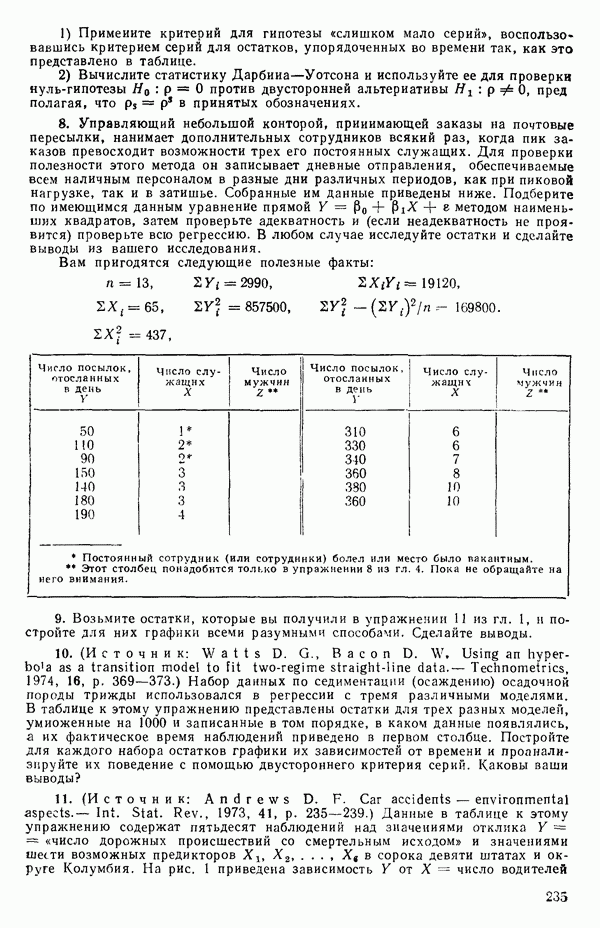



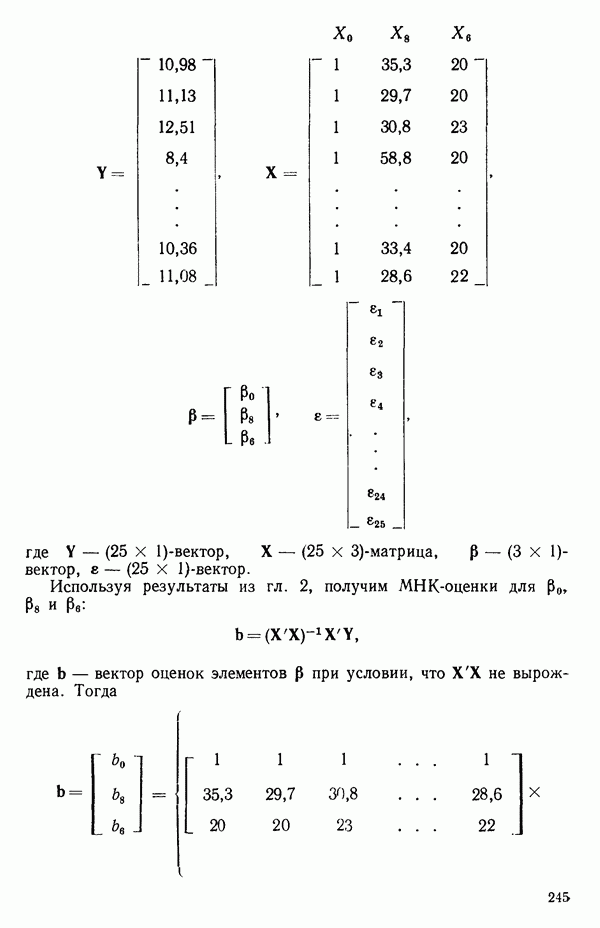
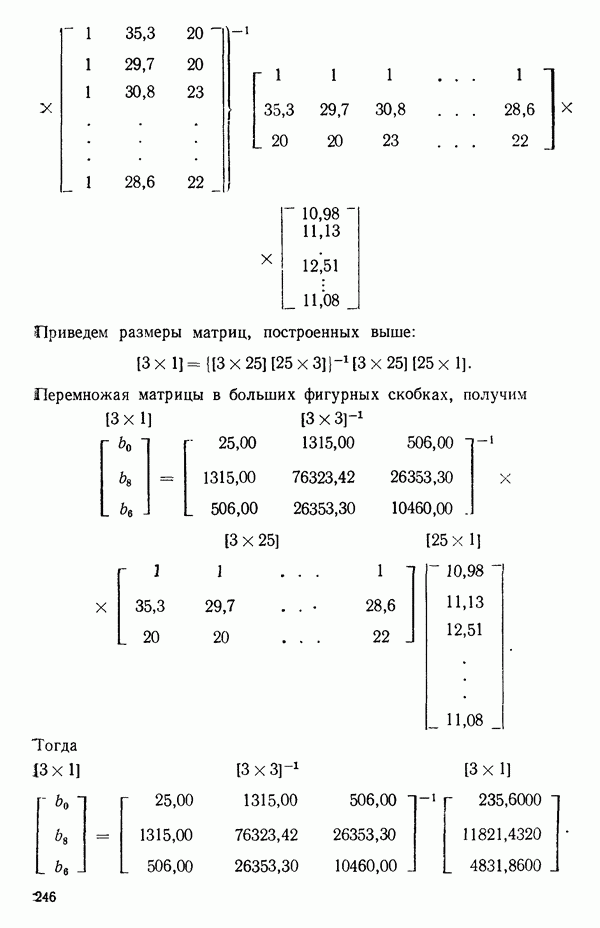








































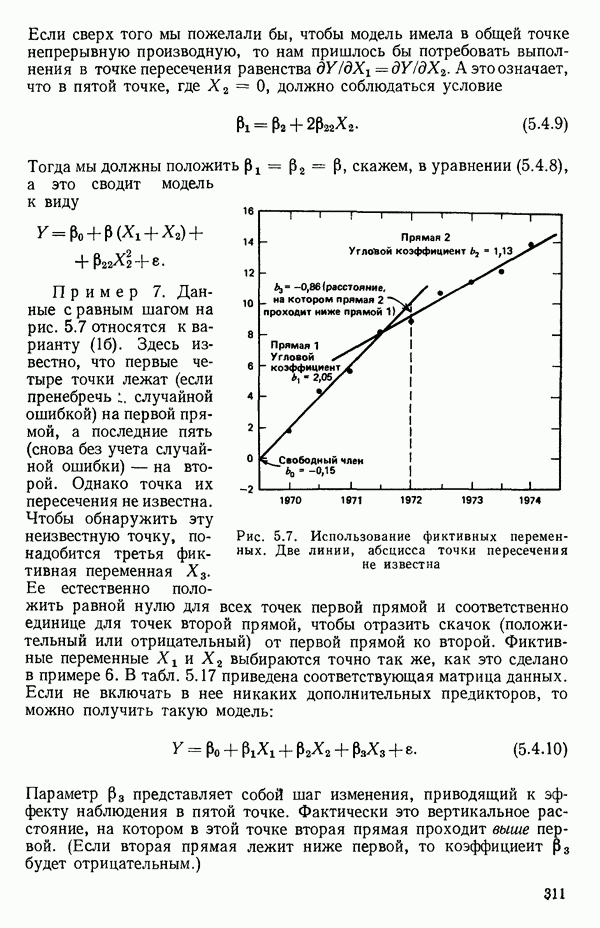
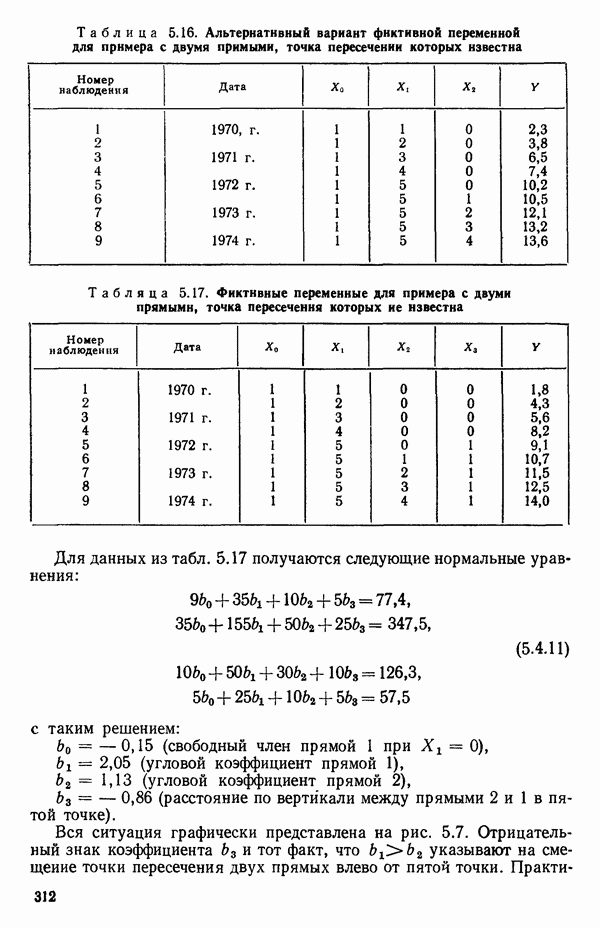




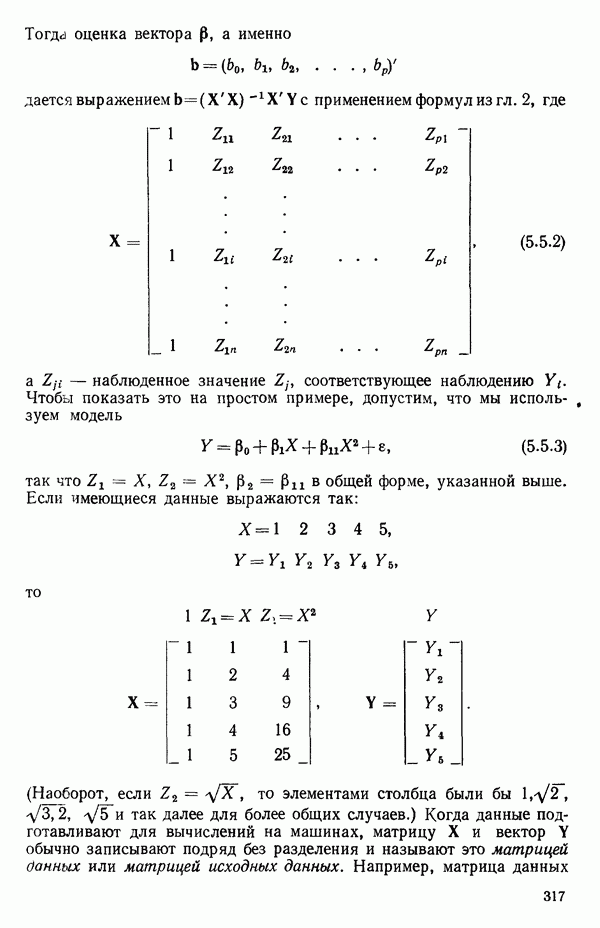







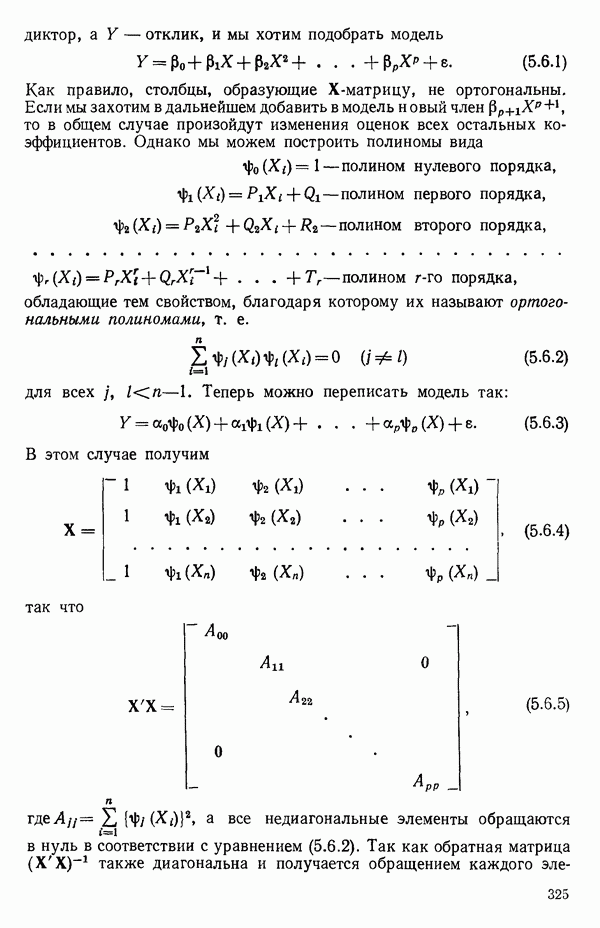








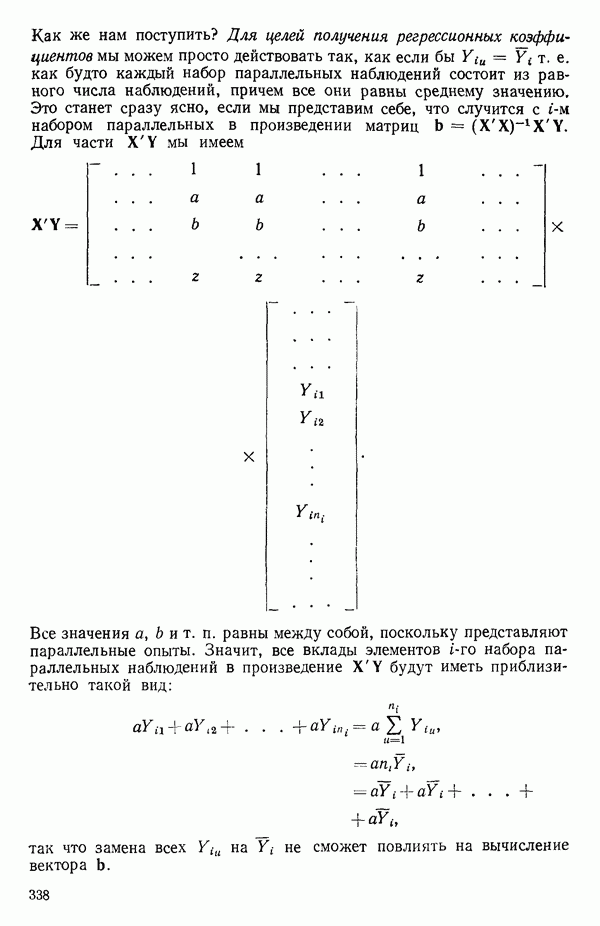








 вектора
вектора  Можно перейти к следующим стадиям (этапам) анализа независимо от того, являются ли ошибки нормально-распределенными.
Можно перейти к следующим стадиям (этапам) анализа независимо от того, являются ли ошибки нормально-распределенными.

 (об исследовании остатков см. гл. 3). Верно, что
(об исследовании остатков см. гл. 3). Верно, что  какой бы ни была модель. В этом можно убедиться, умножая каждое
какой бы ни была модель. В этом можно убедиться, умножая каждое  нормальное уравнение на
нормальное уравнение на  и складывая результаты. Если модель содержит член
и складывая результаты. Если модель содержит член  то справедливо соотношение
то справедливо соотношение  (Здесь
(Здесь  - соответственно
- соответственно  элементы векторов
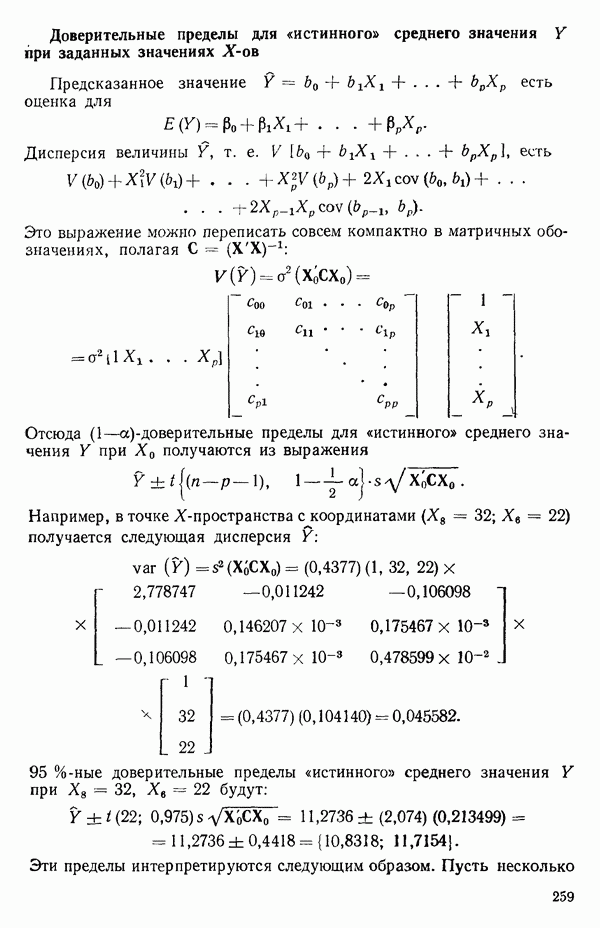
элементы векторов  дает дисперсии (диагональные элементы) и ковариации (внедиагональные элементы) оценок параметров (получение оценки параметра
дает дисперсии (диагональные элементы) и ковариации (внедиагональные элементы) оценок параметров (получение оценки параметра  описано ниже).
описано ниже).
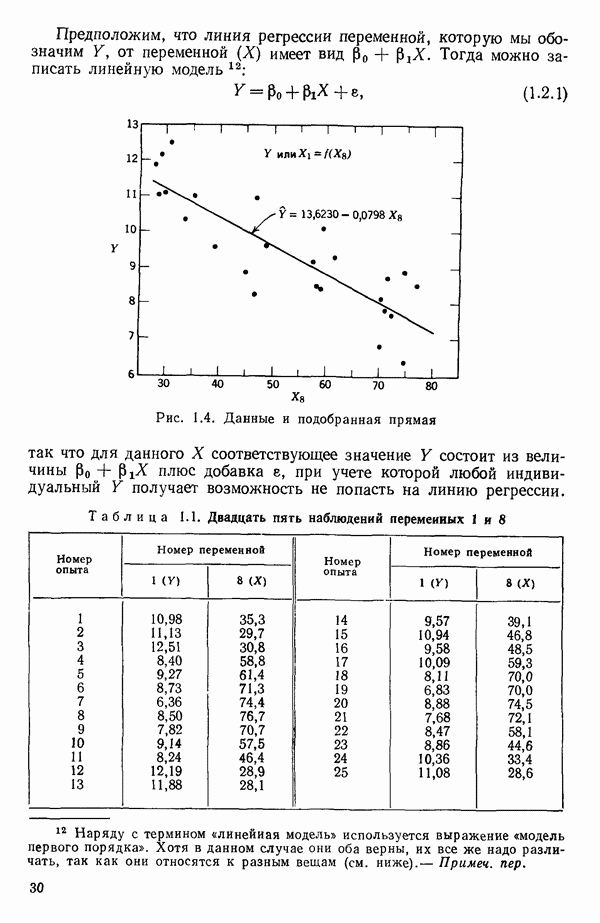
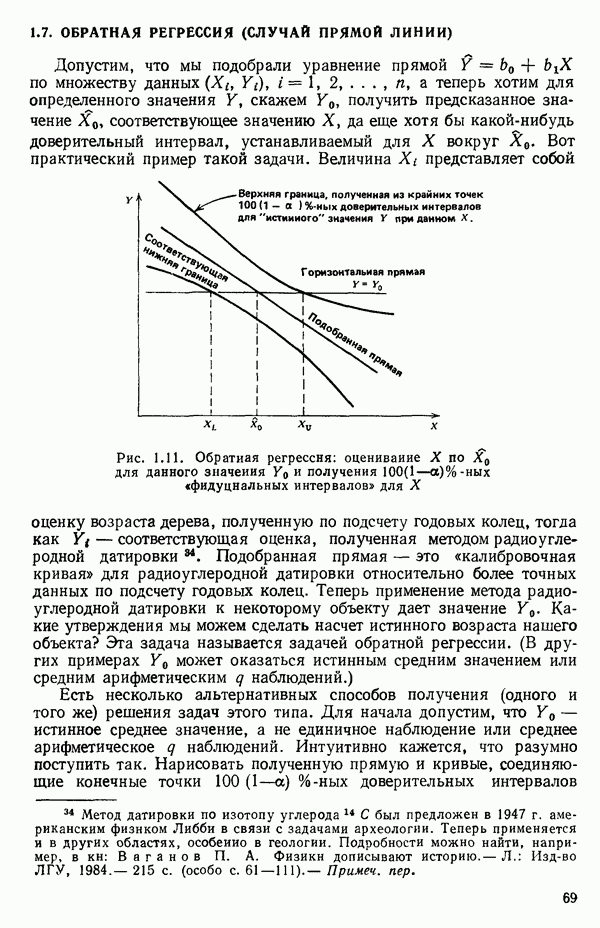
 есть
есть  -вектор, являющийся некоторой строкой матрицы X, так что
-вектор, являющийся некоторой строкой матрицы X, так что  есть предсказываемое значение отклика в точке
есть предсказываемое значение отклика в точке  Например, если модель имела бы вид
Например, если модель имела бы вид  то для данного значения
то для данного значения  вектор
вектор  имел бы вид
имел бы вид  Тогда
Тогда  есть величина отклика при
есть величина отклика при  предсказываемая с помощью уравнения регрессии; она имеет дисперсию
предсказываемая с помощью уравнения регрессии; она имеет дисперсию
