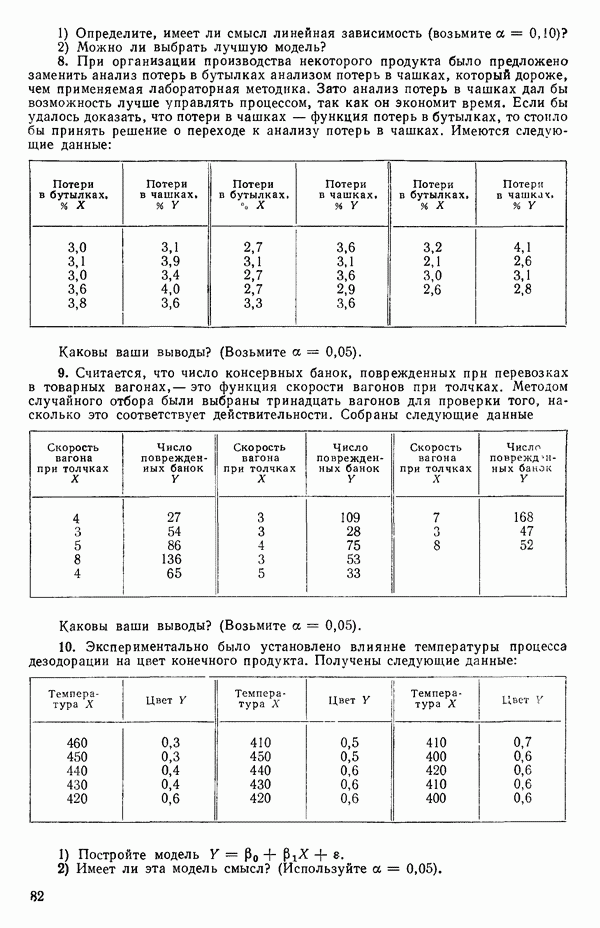
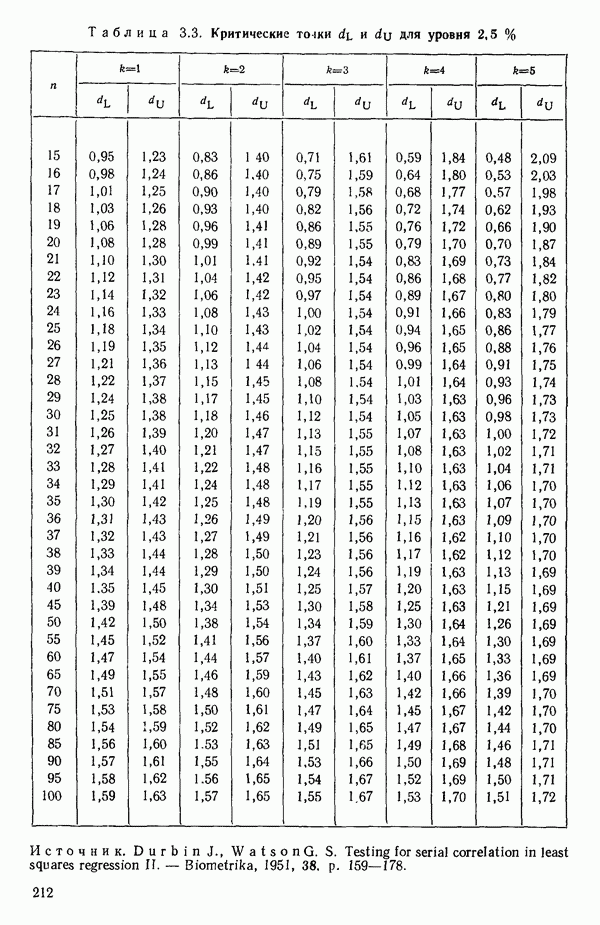
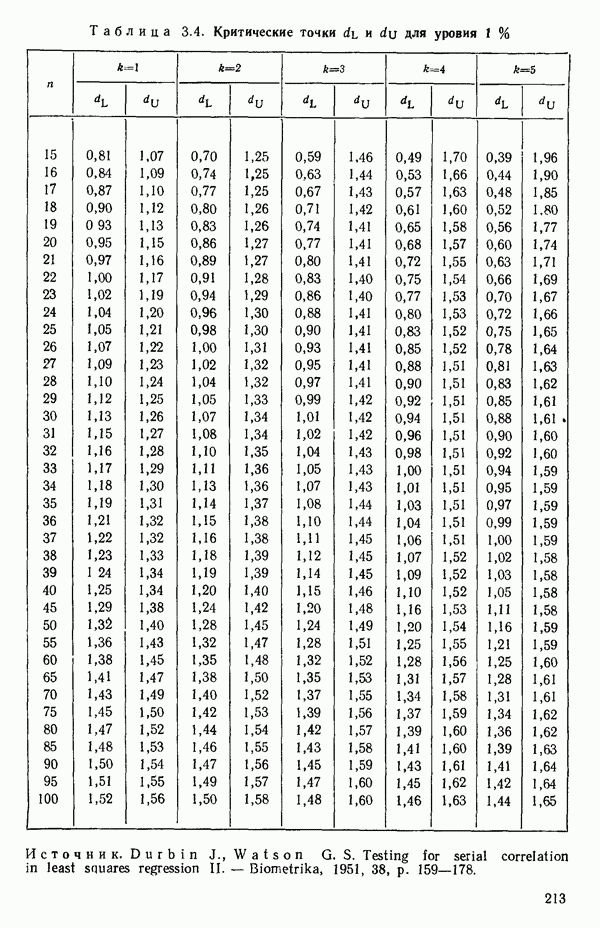
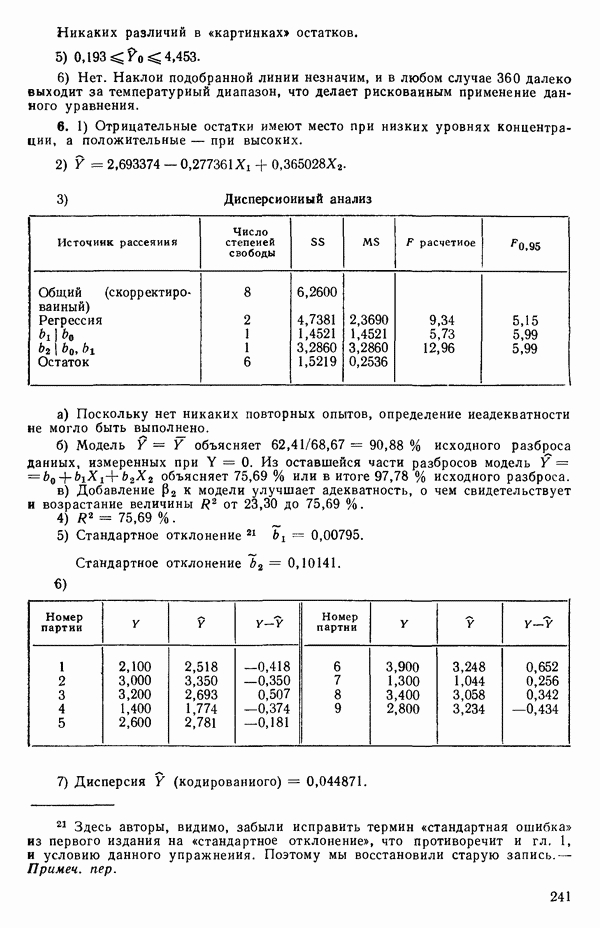
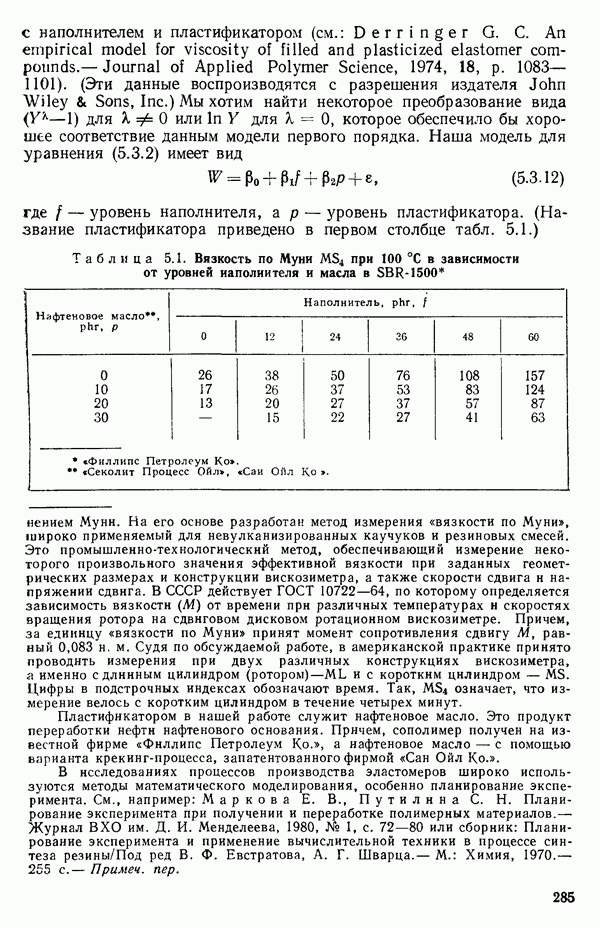
3.12. ОПРЕДЕЛЕНИЕ ВЛИЯЮЩИХ НАБЛЮДЕНИЙ
Сначала мы рассмотрим пример (в значительной мере искусственный), в котором уравнение прямой подбирается по множеству данных, включающему 5 наблюдений, причем 4 при значении  а одно при
а одно при  Если
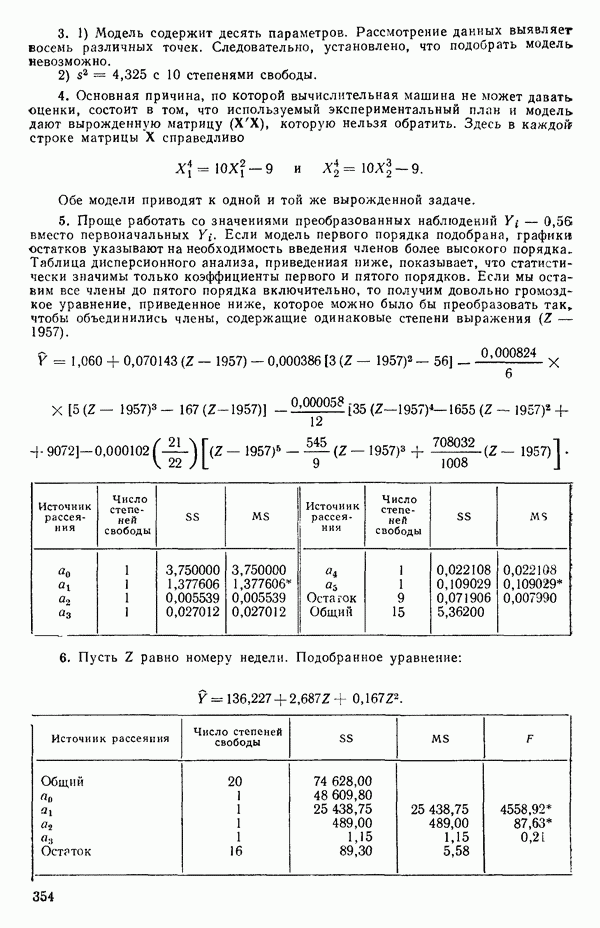
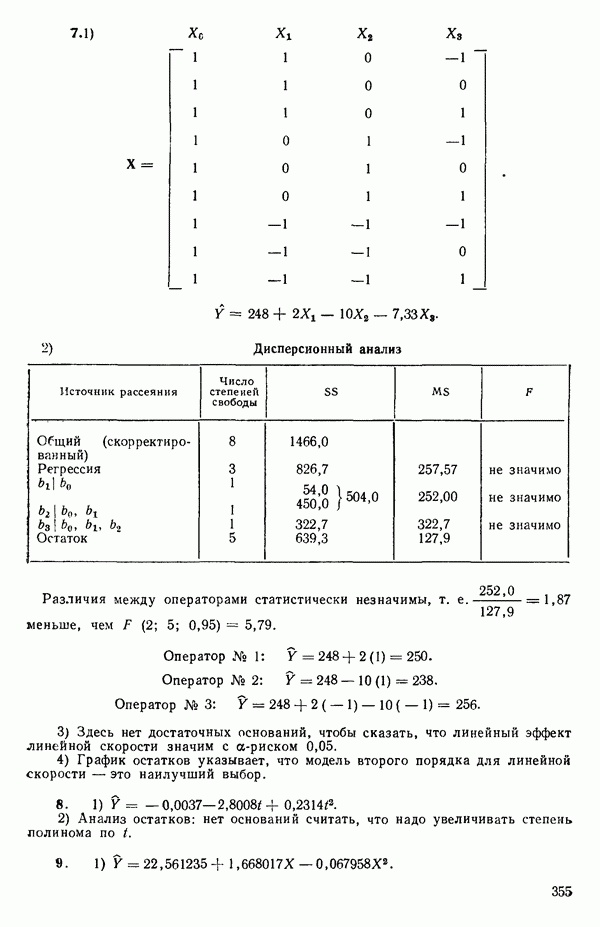
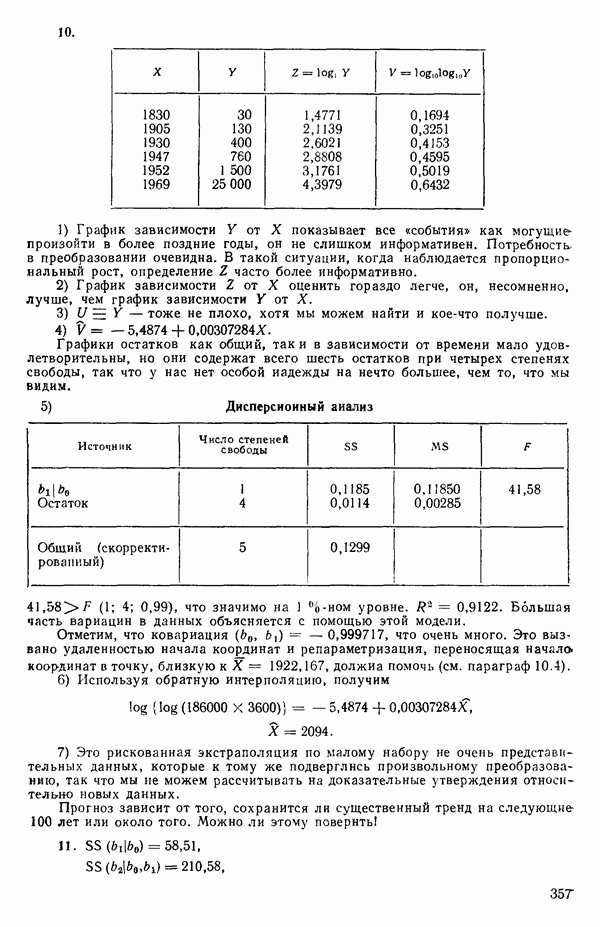
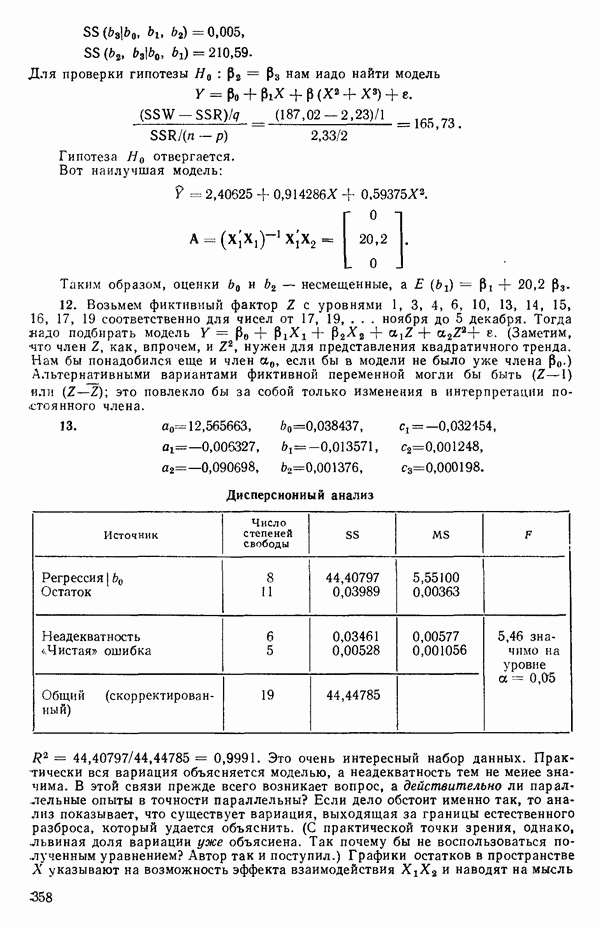
Если  то можно показать, что для
то можно показать, что для  , тогда как для
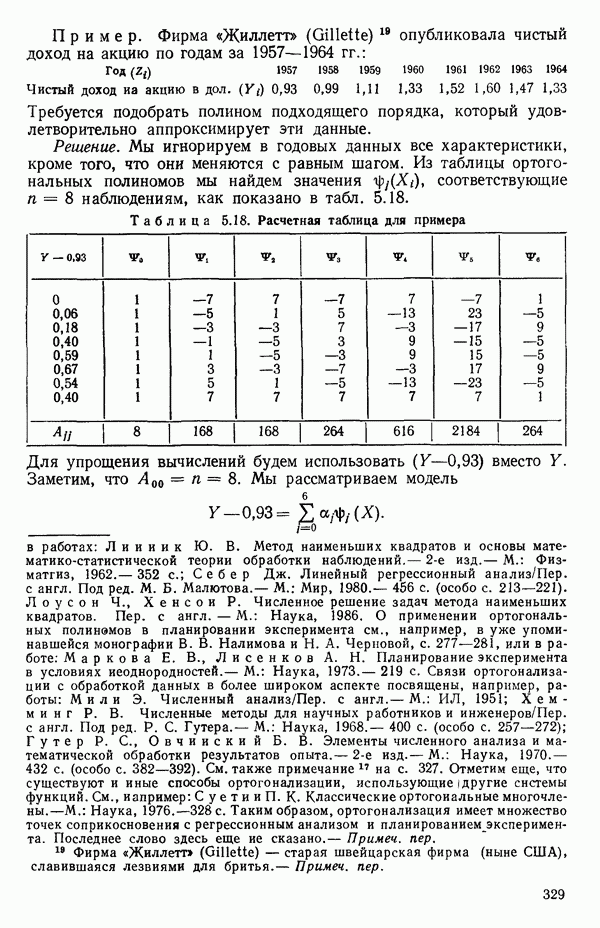
, тогда как для  На первый взгляд нулевая дисперсия кажется весьма желательной, но на самом деле это совсем не так, поскольку подбираемая прямая определяется совместно средним уровнем
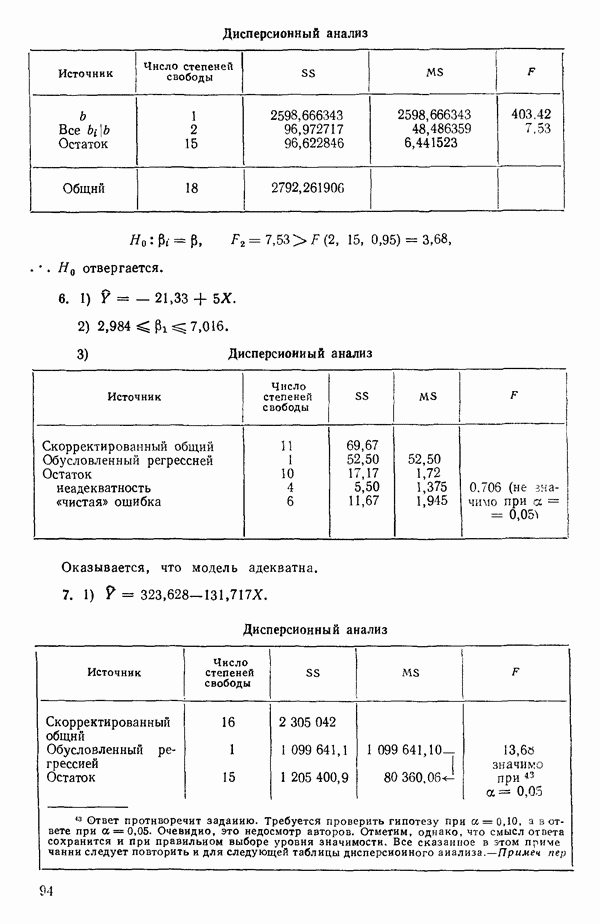
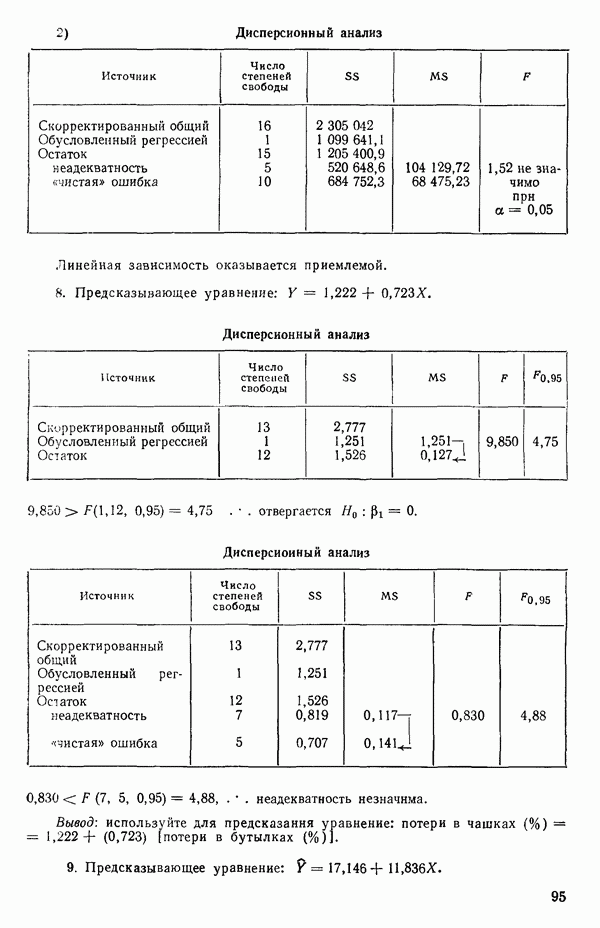
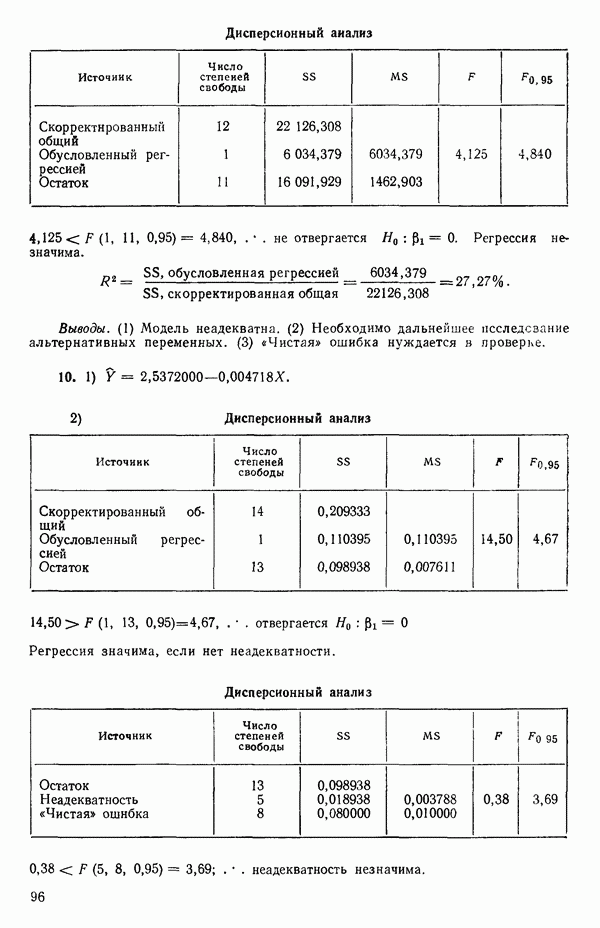
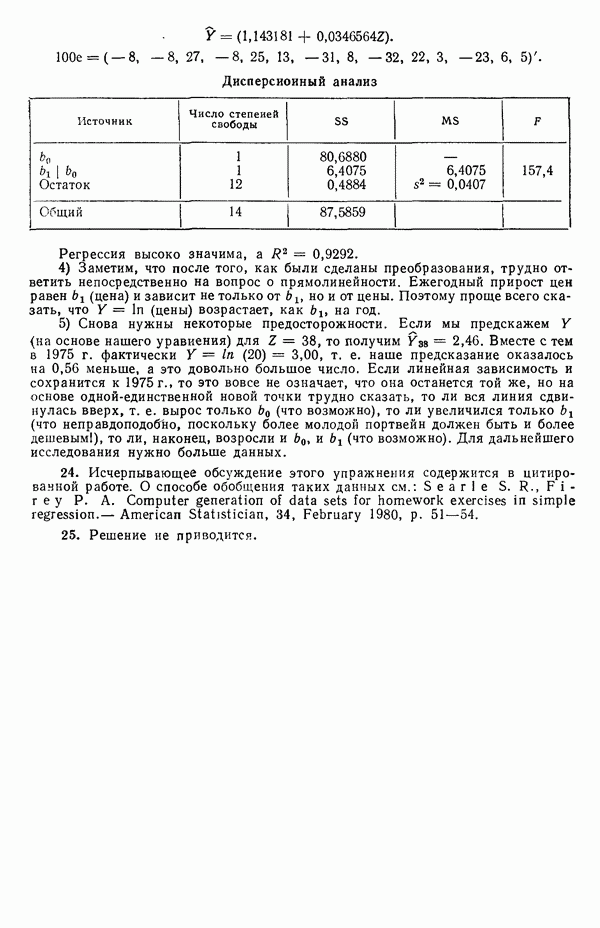
На первый взгляд нулевая дисперсия кажется весьма желательной, но на самом деле это совсем не так, поскольку подбираемая прямая определяется совместно средним уровнем  при
при  и единственным наблюдаемым значением
и единственным наблюдаемым значением  при
при  Остаток при
Остаток при  равен нулю при любом значении
равен нулю при любом значении  так что фактически параметры оцениваются в зависимости от «веса» этого единственного наблюдения. Сколь угодно большая ошибка в подобном наблюдении неопределима в процессе построения модели, да и исследование остатков не сможет ее обнаружить, даже если она и существует. Наблюдение при
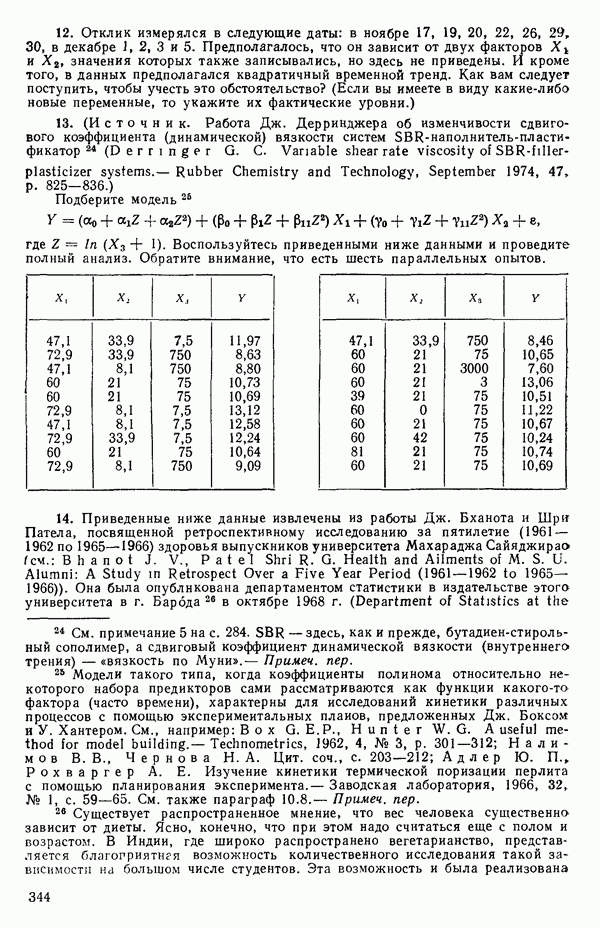
так что фактически параметры оцениваются в зависимости от «веса» этого единственного наблюдения. Сколь угодно большая ошибка в подобном наблюдении неопределима в процессе построения модели, да и исследование остатков не сможет ее обнаружить, даже если она и существует. Наблюдение при  оказывает огромное влияние на результат, безотносительно к тому, верно оно или нет.
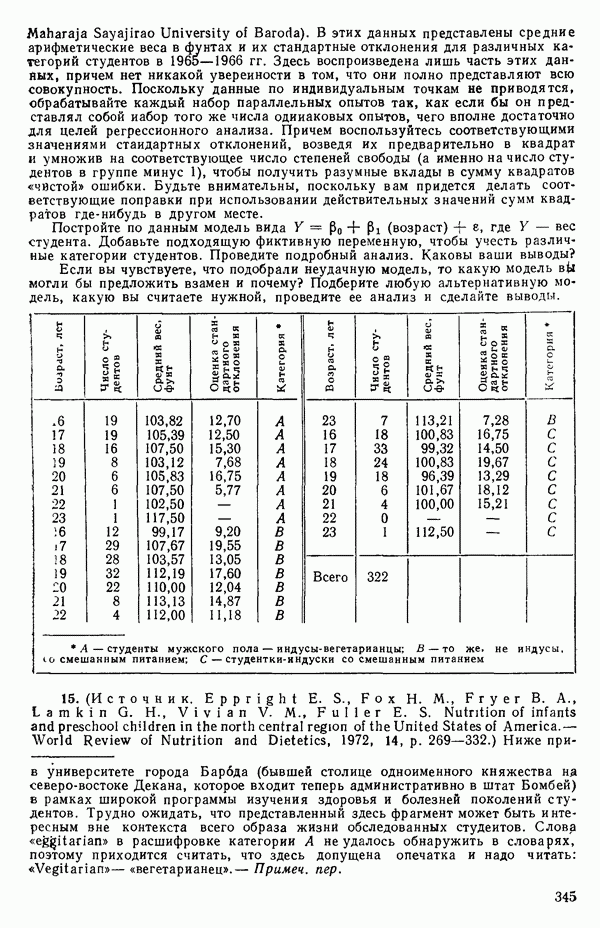
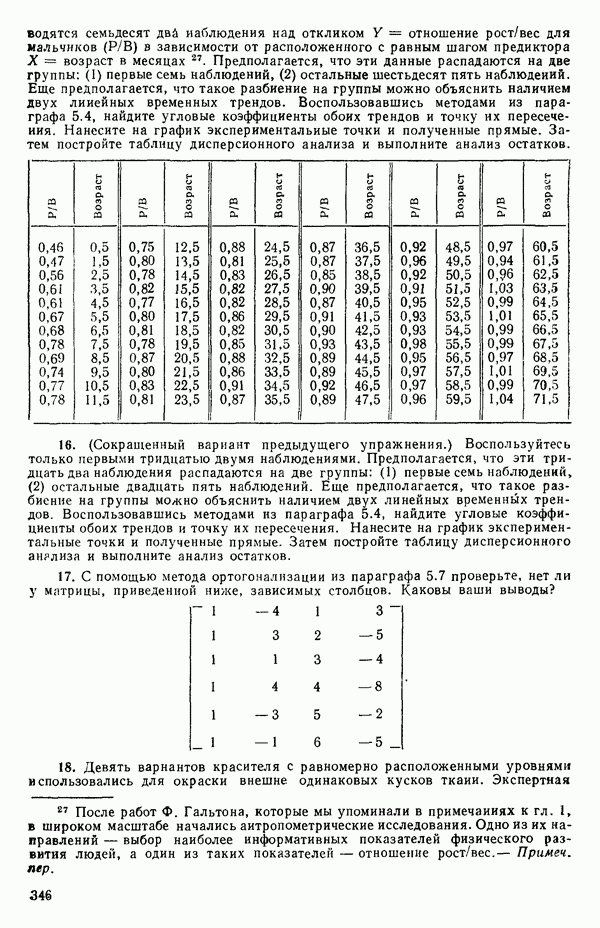
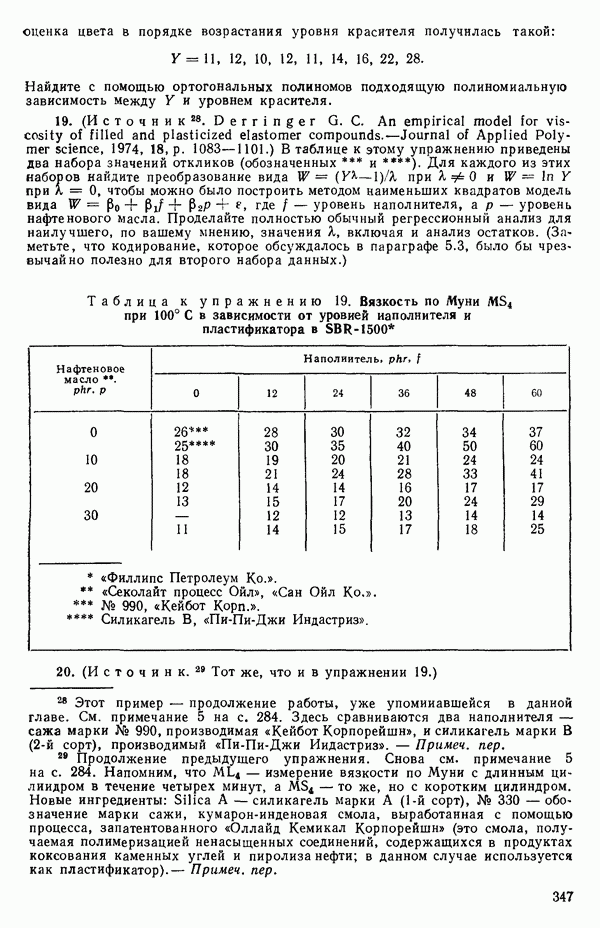
оказывает огромное влияние на результат, безотносительно к тому, верно оно или нет.
Тот факт, что какое-то наблюдение имеет большой «выброс», конечно, совсем не положителен, но из этого вовсе не обязательно
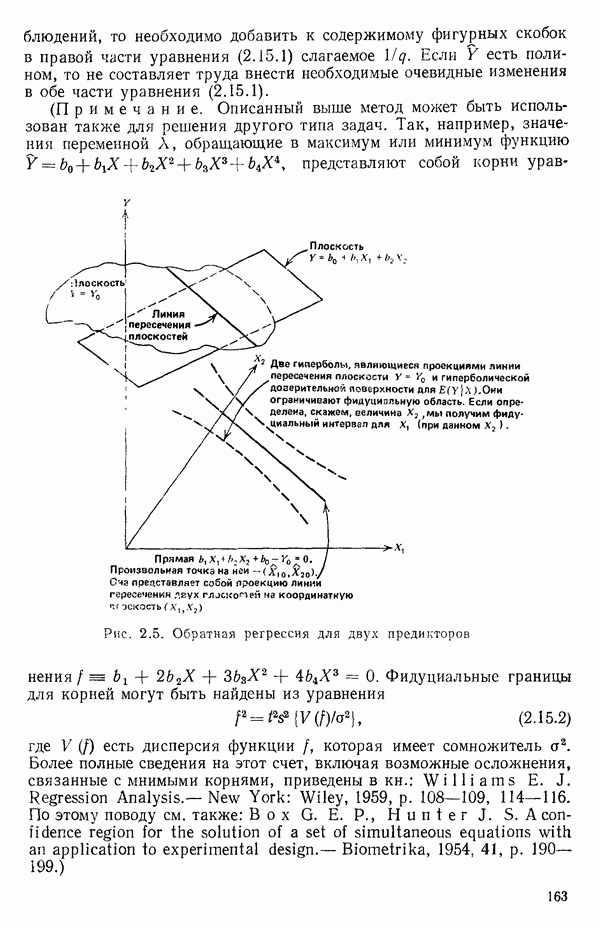
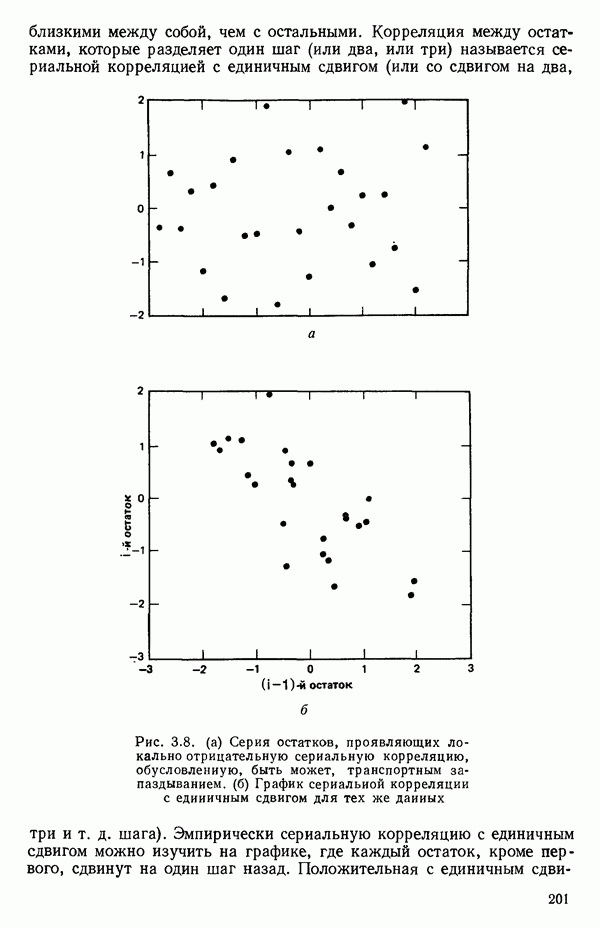
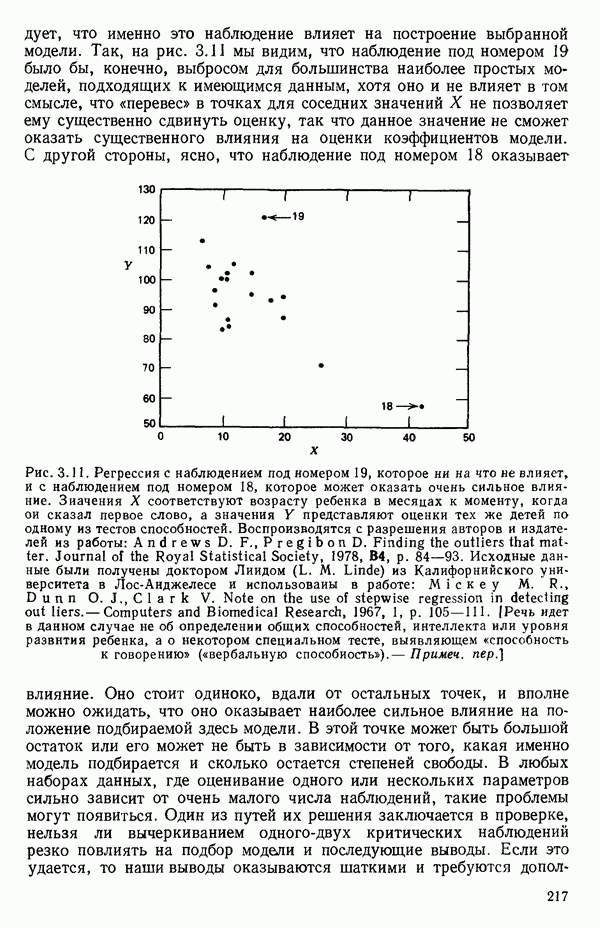
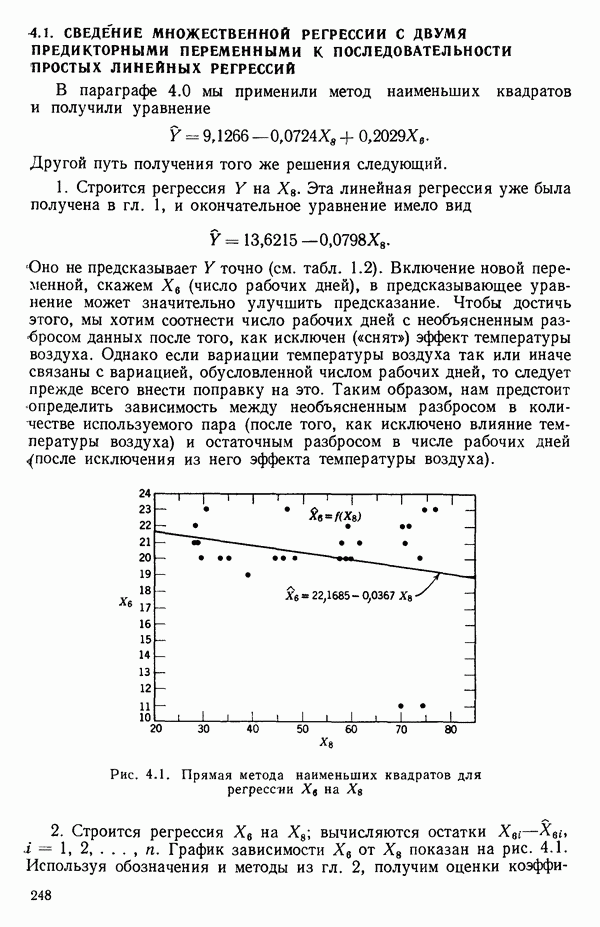
следует, что именно это наблюдение влияет на построение выбранной модели. Так, на рис. 3.11 мы видим, что наблюдение под номером 19 было бы, конечно, выбросом для большинства наиболее простых моделей, подходящих к имеющимся данным, хотя оно и не влияет в том смысле, что «перевес» в точках для соседних значений X не позволяет ему существенно сдвинуть оценку, так что данное значение не сможет оказать существенного влияния на оценки коэффициентов модели. С другой стороны, ясно, что наблюдение под номером 18 оказывает влияние.

Рис. 3.11. Регрессия с наблюдением под номером 19, которое ни на что не влияет, и с наблюдением под номером 18, которое может оказать очень сильное влияние. Значения X соответствуют возрасту ребенка в месяцах к моменту, когда он сказал первое слово, а значения  представляют оценки тех же детей по одному из тестов способностей. Воспроизводятся с разрешения авторов и издателей из работы: Andrews D. F.,PregibonD. Finding the outliers that matter. Journal of the Royal Statistical Society, 1978, B4, p. 84-93. Исходные данные были получены доктором Лиидом (L. М. Linde) из Калифорнийского университета в Лос-Анджелесе и использованы в работе: Мiскеу М. R., Dunn О. J.,Clark V. Note on the use of stepwise regression in detecting out liers.- Computers and Biomedical Research, 1967, 1, p. 105-111. [Речь идет в данном случае не об определении общих способностей, интеллекта или уровня развития ребенка, а о некотором специальном тесте, выявляющем «способность к говорению» («вербальную способность»), — Примеч. пер.]
представляют оценки тех же детей по одному из тестов способностей. Воспроизводятся с разрешения авторов и издателей из работы: Andrews D. F.,PregibonD. Finding the outliers that matter. Journal of the Royal Statistical Society, 1978, B4, p. 84-93. Исходные данные были получены доктором Лиидом (L. М. Linde) из Калифорнийского университета в Лос-Анджелесе и использованы в работе: Мiскеу М. R., Dunn О. J.,Clark V. Note on the use of stepwise regression in detecting out liers.- Computers and Biomedical Research, 1967, 1, p. 105-111. [Речь идет в данном случае не об определении общих способностей, интеллекта или уровня развития ребенка, а о некотором специальном тесте, выявляющем «способность к говорению» («вербальную способность»), — Примеч. пер.]
Оно стоит одиноко, вдали от остальных точек, и вполне можно ожидать, что оно оказывает наиболее сильное влияние на положение подбираемой здесь модели. В этой точке может быть большой остаток или его может не быть в зависимости от того, какая именно модель подбирается и сколько остается степеней свободы. В любых наборах данных, где оценивание одного или нескольких параметров сильно зависит от очень малого числа наблюдений, такие проблемы могут появиться. Один из путей их решения заключается в проверке, нельзя ли вычеркиванием одного-двух критических наблюдений резко повлиять на подбор модели и последующие выводы. Если это удается, то наши выводы оказываются шаткими и требуются
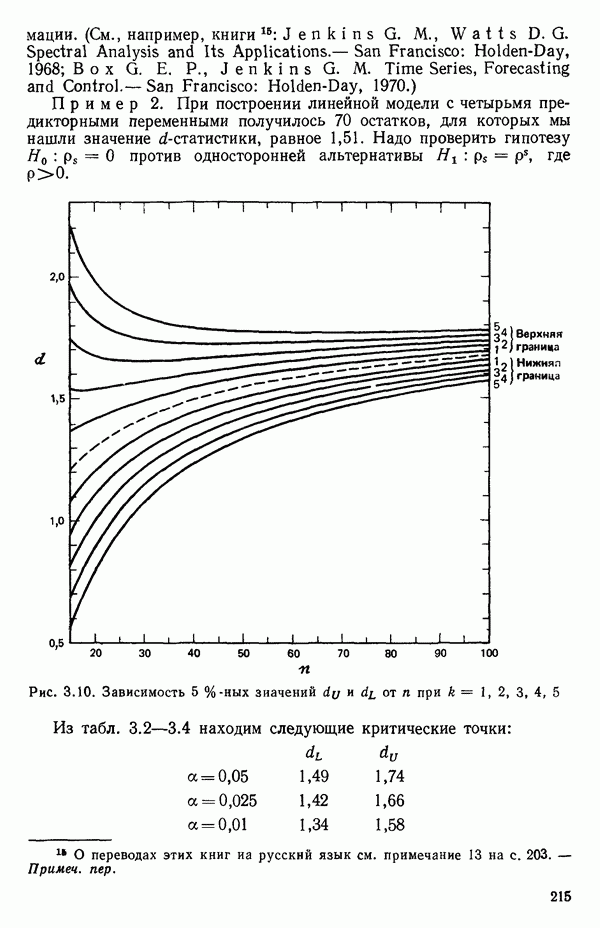
дополнительные данные. Метод ПРЕСС (PRESS), описанный в параграфе 6.8, принадлежит к методам такого рода. А вот другие предложения, высказанные в литературе.
1. Р. Кук в работе, посвященной определению влияющих наблюдений в линейной регрессии (см.: Cook R. D. Detection of influential observations in linear regression. - Technometrics, 1977, 19, p. 15-18) предположил, что влияние  точки в данных можно измерить расстоянием
точки в данных можно измерить расстоянием

где X — матрица размера  обычный векшр МНК-оценок, а
обычный векшр МНК-оценок, а  вектор МНК-оценок, полученный после того, как из данных исключена
вектор МНК-оценок, полученный после того, как из данных исключена  точка. Расстояния
точка. Расстояния  сравниваются с помощью
сравниваются с помощью  -критерия при
-критерия при  для выбранного а. Большие значения
для выбранного а. Большие значения  воспринимаются как указания на влияние
воспринимаются как указания на влияние  наблюдения. Расстояние
наблюдения. Расстояние  может быть, легче оценить, если переписать его в следующей эквивалентной форме:
может быть, легче оценить, если переписать его в следующей эквивалентной форме:

где  остаток для случая, когда используются все данные;
остаток для случая, когда используются все данные;  оценка дисперсии
оценка дисперсии  обусловленной остаточным средним квадратом, когда используются все данные, а
обусловленной остаточным средним квадратом, когда используются все данные, а  диагональный элемент матрицы
диагональный элемент матрицы  Мы видим, что первый сомножитель в уравнении (3.12.2) — «стьюдентизированный» остаток, т. е. остаток, деленный на свою стандартную ошибку (см. параграф
Мы видим, что первый сомножитель в уравнении (3.12.2) — «стьюдентизированный» остаток, т. е. остаток, деленный на свою стандартную ошибку (см. параграф
3.7), тогда как второй член представляет собой отношение (дисперсия  предсказанного значения)/(дисперсия t-го остатка). Заметим, что
предсказанного значения)/(дисперсия t-го остатка). Заметим, что  Расстояние
Расстояние  может быть большим, когда велик либо первый, либо второй сомножитель. А эти сомножители служат мерами двух различных характеристик каждой точки.
может быть большим, когда велик либо первый, либо второй сомножитель. А эти сомножители служат мерами двух различных характеристик каждой точки.
В примере, который мы привели раньше,

и

где при  каждое
каждое  причем
причем  Пятое наблюдение при
Пятое наблюдение при  таким образом, «сигнализирует» о том, что здесь есть какая-то особенность, а исследование выявляет в этих обстоятельствах огромное влияние этой точки.
таким образом, «сигнализирует» о том, что здесь есть какая-то особенность, а исследование выявляет в этих обстоятельствах огромное влияние этой точки.
Для вычисления  рекомендуется использовать машинные программы (например, такие, как
рекомендуется использовать машинные программы (например, такие, как  Вычисления привлекают своей простотой, а сама статистика обладает свойством эффективности. За дальнейшими подробностями обращайтесь к работе, указанной выше, а также к статье: Cook R. D. Influential observations
Вычисления привлекают своей простотой, а сама статистика обладает свойством эффективности. За дальнейшими подробностями обращайтесь к работе, указанной выше, а также к статье: Cook R. D. Influential observations
in linear regression.— Journal of the American Statistical Association, 1979, 74, p. 169—174.
2. Д. Эндрьюс и Д. Прегибон (см.: Andrews D. F., Pregibоn D. Finding the outliers that matter.- Journal of the Royal Statistical Society, 1978, В-40, p. 84-93) предложили статистику (называемую ниже АР):

где  т. е. это обычная матрица X, к которой справа присоединена матрица-столбец
т. е. это обычная матрица X, к которой справа присоединена матрица-столбец  и где оператор
и где оператор  означает «выполнение операции, указанной в конце, но после исключения элементов, связанных с
означает «выполнение операции, указанной в конце, но после исключения элементов, связанных с  элементами
элементами  Например,
Например,  означает «получение обратной матрицы от произведения матриц в скобках после исключения из матрицы X строк, связанных с и
означает «получение обратной матрицы от произведения матриц в скобках после исключения из матрицы X строк, связанных с и  Можно показать, что решение уравнения (3.12.4) сводится к вычислению определителя размером
Можно показать, что решение уравнения (3.12.4) сводится к вычислению определителя размером  полученного следующим образом. Вычислите
полученного следующим образом. Вычислите  Вычеркните из матрицы
Вычеркните из матрицы  все строки и столбцы, кроме тех, что связаны с
все строки и столбцы, кроме тех, что связаны с  наблюдениями, которые требуются для вычисляемой статистики, и найдите определитель той матрицы, которая останется после вычеркиваний. Используя
наблюдениями, которые требуются для вычисляемой статистики, и найдите определитель той матрицы, которая останется после вычеркиваний. Используя  для обозначения операции «вычеркнуть все, кроме элементов, связанных с
для обозначения операции «вычеркнуть все, кроме элементов, связанных с  наблюдениями
наблюдениями  мы можем переписать:
мы можем переписать:

Такой определитель размера  это безразмерная величина. Представляют интерес его малые значения, поскольку они указывают на «связь с особенностью и/или с влияющими наблюдениями» (см. с. 88 работы Д. Эндрьюса и Д. Прегибона). График функции
это безразмерная величина. Представляют интерес его малые значения, поскольку они указывают на «связь с особенностью и/или с влияющими наблюдениями» (см. с. 88 работы Д. Эндрьюса и Д. Прегибона). График функции

для самых маленьких  часто оказывается горизонтальным. В уравнении (3.12.6) величина
часто оказывается горизонтальным. В уравнении (3.12.6) величина  обозначает минимальное значение
обозначает минимальное значение  , какое только удалось наблюдать при всех возможных вычерчиваниях по
, какое только удалось наблюдать при всех возможных вычерчиваниях по  На этих горизонтальных графиках мы видим то значение
На этих горизонтальных графиках мы видим то значение  для которого самое маленькое значение в уравнении (3.12.6) отличается от всех остальных. Это и есть значение
для которого самое маленькое значение в уравнении (3.12.6) отличается от всех остальных. Это и есть значение  рассматриваемое как число влияющих наблюдений, нуждающихся в дополнительном исследовании. Относительно влияющие наблюдения — это наблюдения, приводящие к выделяющимся значениям в уравнении (3.12.6).
рассматриваемое как число влияющих наблюдений, нуждающихся в дополнительном исследовании. Относительно влияющие наблюдения — это наблюдения, приводящие к выделяющимся значениям в уравнении (3.12.6).
Легко назвать причины, по которым статистики АР вполне разумны. Величина  «соответствует той доле объема, образованного матрицей X, который обеспечивается
«соответствует той доле объема, образованного матрицей X, который обеспечивается  наблюдениями
наблюдениями  Если это подмножество наблюдений значительно удалено от остальных в факторном пространстве, то можно ожидать, что оно даст большую долю объема в пространстве, образованном матрицей
Если это подмножество наблюдений значительно удалено от остальных в факторном пространстве, то можно ожидать, что оно даст большую долю объема в пространстве, образованном матрицей  Это позволяет получить естественную интерпретацию термина «выброс». Следовательно, малые значения в уравнении
Это позволяет получить естественную интерпретацию термина «выброс». Следовательно, малые значения в уравнении
(3.12.4) связаны с особенностью и/или влияющими наблюдениями. Какова бы ни была действительная причина этого явления, стоит выделить подмножества наблюдений, дающих малые значения в уравнении (3.12.4) для дальнейшего тщательного изучения» (см. с. 88 указанной выше работы).
Можно показать, что при  АР-статистика из уравнения (3.12.4) сводится к выражению:
АР-статистика из уравнения (3.12.4) сводится к выражению:  Прилагая его к нашему примеру из этого параграфа, мы найдем такие значения АР-стати-стики:
Прилагая его к нашему примеру из этого параграфа, мы найдем такие значения АР-стати-стики:

и

И снова пятое наблюдение «сигнализирует» о том, что есть какая-то аномалия и/или что оно сильно влияет на значения МНК-оценок.
3. В статье Н. Дрейпера и Дж. Джона о влияющих наблюдениях и выбросах в регрессии (Draper N. R., John J. A. Influential observations and outliers in regression.- Technometrics, 1981, 23, p. 21-26) выявляются роли статистик Кука и  Запишем исходную регрессионную модель для
Запишем исходную регрессионную модель для  наблюдений и
наблюдений и  параметров в виде
параметров в виде

Все наблюдения разделены на две группы. В одной К наблюдений  подлежащих исследованию как подозреваемые в том, что они представляют собой выбросы или влияющие наблюдения. Во второй остальные
подлежащих исследованию как подозреваемые в том, что они представляют собой выбросы или влияющие наблюдения. Во второй остальные  наблюдений, которые ни в чем не заподозрены. Естественно, для такого разделения в уравнении (3.12.7) может понадобиться перестановка строк. Пользуясь обычным МНК-анализом, получим остатки для построенной модели в виде
наблюдений, которые ни в чем не заподозрены. Естественно, для такого разделения в уравнении (3.12.7) может понадобиться перестановка строк. Пользуясь обычным МНК-анализом, получим остатки для построенной модели в виде

где

— это подматрица матрицы 
Вычеркивая подозрительные наблюдения  получаем модель
получаем модель  . С другой стороны, можно было бы воспользоваться моделью
. С другой стороны, можно было бы воспользоваться моделью

где  — вектор размера
— вектор размера  состоящий из дополнительных
состоящий из дополнительных
параметров (см. Draper N. R. Missing values in response surface designs.- Technometrics, 1961, 3, p. 389-398). Вот окончательные оценки векторов  и с, соответствующие «истинным» значениям
и с, соответствующие «истинным» значениям  и у:
и у:

Подставив  в уравнение (3.12.7) в качестве оценок «пропущенных значений»
в уравнение (3.12.7) в качестве оценок «пропущенных значений»

и пересчитав уравнение (3.12.7), найдем новые остатки, компоненты которых и выражаются так:

причем размерности  те же, что и размерности
те же, что и размерности  в уравнении (3.12.7). Описанная выше процедура корректировки вектора
в уравнении (3.12.7). Описанная выше процедура корректировки вектора  с необходимостью требует, чтобы выполнялось условие
с необходимостью требует, чтобы выполнялось условие  тогда как
тогда как  есть не что иное, как остатки для модели
есть не что иное, как остатки для модели  Эти остатки
Эти остатки  называют «пересмотренными остатками».
называют «пересмотренными остатками».
Дополнительная сумма квадратов, обусловленная включением в модель параметров у из уравнения (3.12.10), в отличие от модели уравнения (3.12.7) равна:

Такая статистика может применяться как критерий для «выбросов», см.: Gentleman J. F., Wi1k М. В. Detecting outliers in a two-way table I. Statistical behavior of residuals.- Technometrics, 1975, 17, p. 1-14 и Detecting outliers II. Supplementing the direct analysis of residuals.- Biometrics, 1975, 31, p. 387-410, а также John J. A., Draper N. R. On testing for two outliers or one outlier in two-way tables.- Technometrics, 1978, 20, p. 69-78. Самое последнее, что появилось в печати, это работа: Draper N. R., John J. A. Testing for three or fewer outliers in two-way tables.- Technometrics, 1980, 22, p. 9-15.
В качестве приближенного критерия для одного выброса на уровне  мы вычисляем статистику
мы вычисляем статистику

где знаменатель представляет собой остаточный средний квадрат с  степенями свободы, полученный для модели такого типа, как (3.12.10) в предположении, что возможен один-единственный выброс в некотором заранее определенном месте. Величину F надо сравнивать с
степенями свободы, полученный для модели такого типа, как (3.12.10) в предположении, что возможен один-единственный выброс в некотором заранее определенном месте. Величину F надо сравнивать с  -ной точкой
-ной точкой  а не с. а
а не с. а  -ной точкой
-ной точкой  . Чтобы узнать, почему это так, обратитесь к работе о критических значениях критерия для обнаружения выбросов в факторных экспериментах: John J. A., Prescott P. Applied Statistics, 1975, 24, p. 56-59.
. Чтобы узнать, почему это так, обратитесь к работе о критических значениях критерия для обнаружения выбросов в факторных экспериментах: John J. A., Prescott P. Applied Statistics, 1975, 24, p. 56-59.
Разложение статистики Эндрьюса-Прегибона (АР) на множители
Можно показать, что статистика АР допускает следующее разложение на множители:

где  остаточная сумма квадратов, получаемая при подборе полной модели в виде (3.12.7), величина
остаточная сумма квадратов, получаемая при подборе полной модели в виде (3.12.7), величина  получается по уравнению (3.12.15),
получается по уравнению (3.12.15),  определяется по уравнению (3.12.9). Таким образом, первый сомножитель несет ту же информацию, что и
определяется по уравнению (3.12.9). Таким образом, первый сомножитель несет ту же информацию, что и  причем он тем меньше, чем больше само
причем он тем меньше, чем больше само  Вместе с тем второй сомножитель становится малым, когда К точек отбираются среди данных так, что они оказываются удаленными в факторном пространстве (это можно доказать).
Вместе с тем второй сомножитель становится малым, когда К точек отбираются среди данных так, что они оказываются удаленными в факторном пространстве (это можно доказать).
Рекомендации
H. Дрейпер и Дж. Джон в цитированной выше работе о влияющих наблюдениях и выбросах в регрессии рекомендуют выводить на печать  статистику Кука и второй множитель АР-статистики вот по каким соображениям:
статистику Кука и второй множитель АР-статистики вот по каким соображениям:
I. Значения служат мерами для остатков, их большие величины указывают на особенности.
2. Вид статистики Кука гарантирует, что она будет чувствительна к изменениям в модели при пропуске наблюдений. Значит, статистика Кука будет показывать, какие наблюдения влияют, и это влияние проявляется, в частности, в том, что изменяются коэффициенты подбираемого уравнения.
Общий вид статистики Кука таков:

где  оценка метода наименьших квадратов (МНК-оценка) для вектора Р в уравнении (3.12.7);
оценка метода наименьших квадратов (МНК-оценка) для вектора Р в уравнении (3.12.7);  МНК-оценка для Р в уравнении
МНК-оценка для Р в уравнении  обозначают К индексов, отобранных для образования подвектора
обозначают К индексов, отобранных для образования подвектора 
3. Второй сомножитель АР-статистики  это пространственная мера, показывающая, какие наблюдения «влиятельны» в том смысле, что они отделены от массы наблюдений в пространстве, образованном столбцами матрицы
это пространственная мера, показывающая, какие наблюдения «влиятельны» в том смысле, что они отделены от массы наблюдений в пространстве, образованном столбцами матрицы  Отметим, что такие наблюдения могут быть, а могут и не быть влияющими в том смысле, который обсуждался в предыдущем параграфе.
Отметим, что такие наблюдения могут быть, а могут и не быть влияющими в том смысле, который обсуждался в предыдущем параграфе.
Использование «оценок» для пропущенных значений
Обычно, когда наблюдения пропущены или забракованы, параметры можно оценивать с помощью уравнения (3.12.11). А уравнение (3.12.13) может работать нормально только в ситуациях спланированного эксперимента, когда матрица  имеет очень простую структуру, т. е. когда она легко обращается. Этот случай мы проиллюстрируем числовым примером.
имеет очень простую структуру, т. е. когда она легко обращается. Этот случай мы проиллюстрируем числовым примером.
Числовая иллюстрация
Данные в табл. 3.5 воспроизводят полный факторный эксперимент 24 из книги: Cochran W. G., Сох G. М. Experimental Designs.- New York : Wiley, 1957. План эксперимента задается столбцами  Два существовавших значения (равные 19 и 30 соответственно) были якобы потеряны и заменены буквенными обозначениями
Два существовавших значения (равные 19 и 30 соответственно) были якобы потеряны и заменены буквенными обозначениями  специально для данного примера. Это уже было сделано раньше в иллюстративных целях в работах: Нasеmen J. К., Gay lor D. W. Ап algorithm for noniterative estimation of multiple missing values for crossed classifications. - Technometrics,
специально для данного примера. Это уже было сделано раньше в иллюстративных целях в работах: Нasеmen J. К., Gay lor D. W. Ап algorithm for noniterative estimation of multiple missing values for crossed classifications. - Technometrics,
Таблица 3.5. Факторный эксперимент 24 с двумя «пропущенными» значениями

Мы хотим подобрать по данным следующую модель:

так что матрица X как раз приведена в табл. 3.5. Следовательно, матрица  включающая первую и седьмую строки матрицы X, соответствующие значениям
включающая первую и седьмую строки матрицы X, соответствующие значениям  равна:
равна:

а матрица  образуется из той части матрицы X, которая остается после вычеркивания строк, образующих матрицу
образуется из той части матрицы X, которая остается после вычеркивания строк, образующих матрицу  Вектор
Вектор 




















































































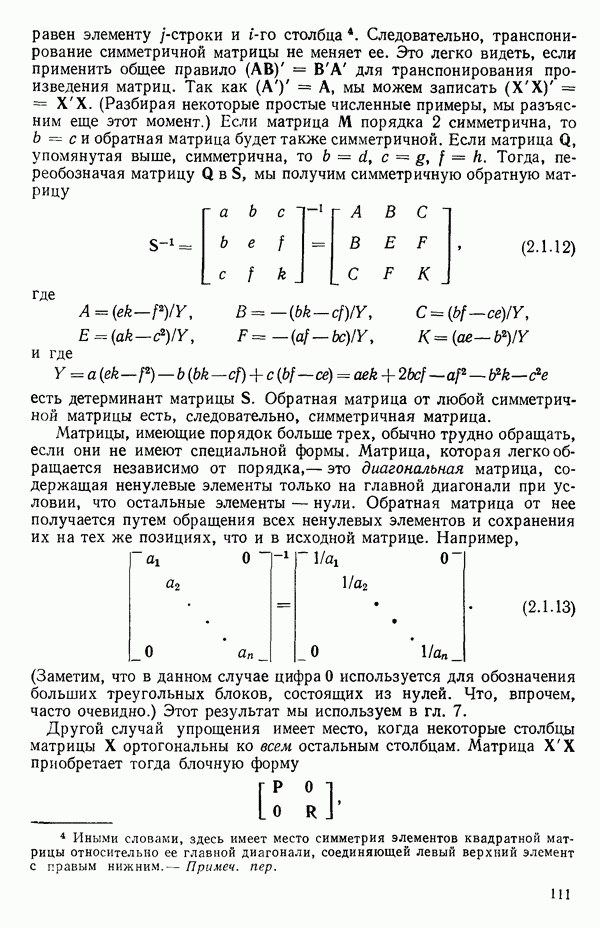



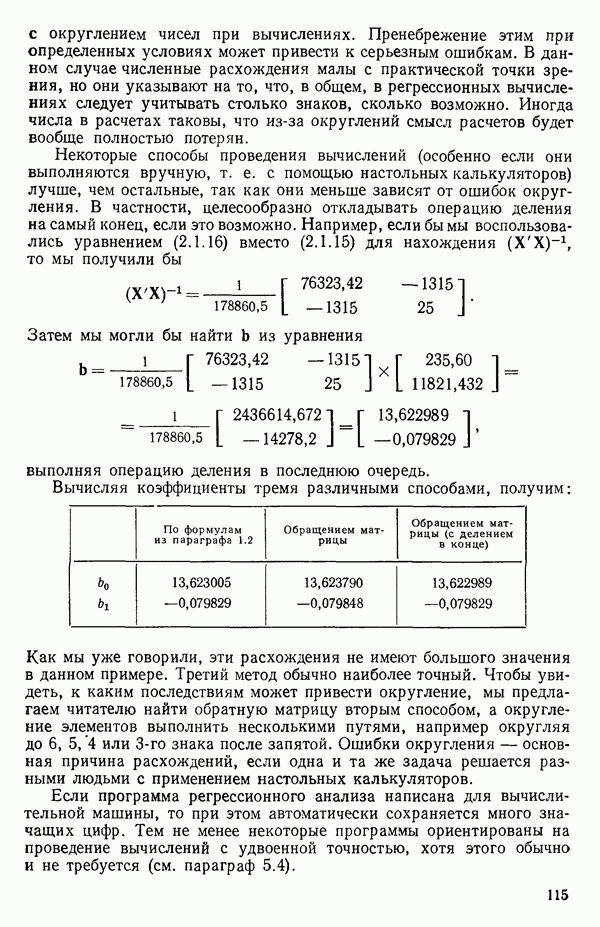
















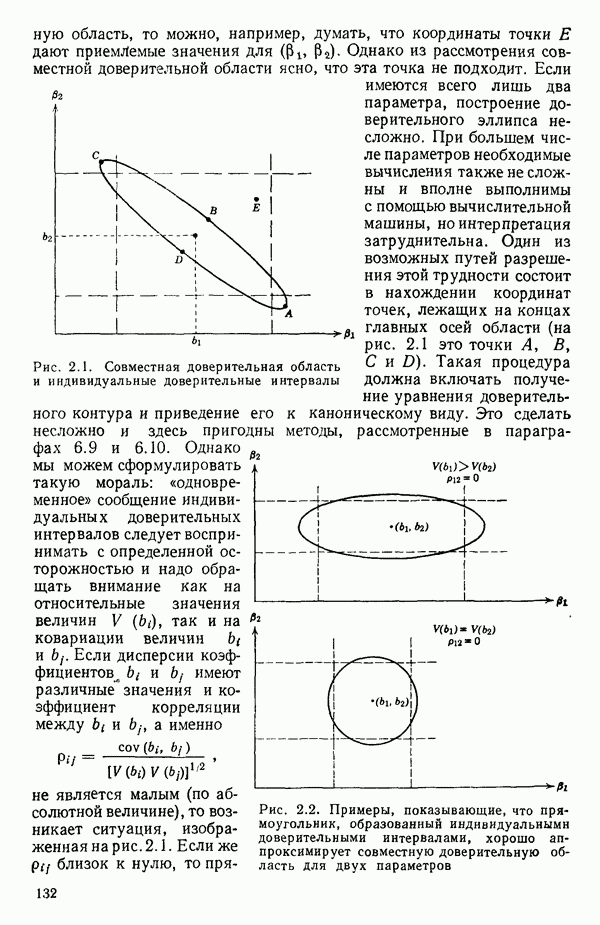










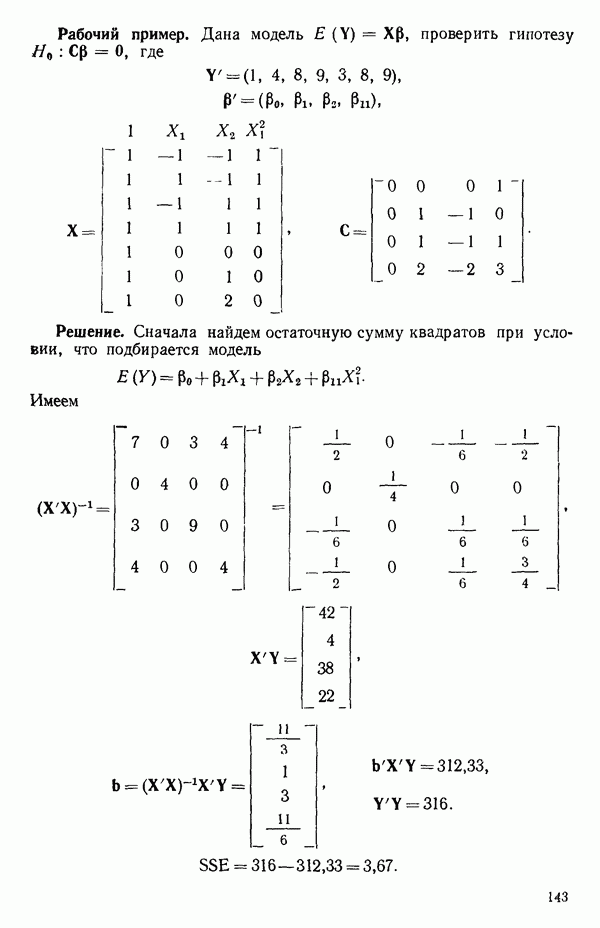
















































































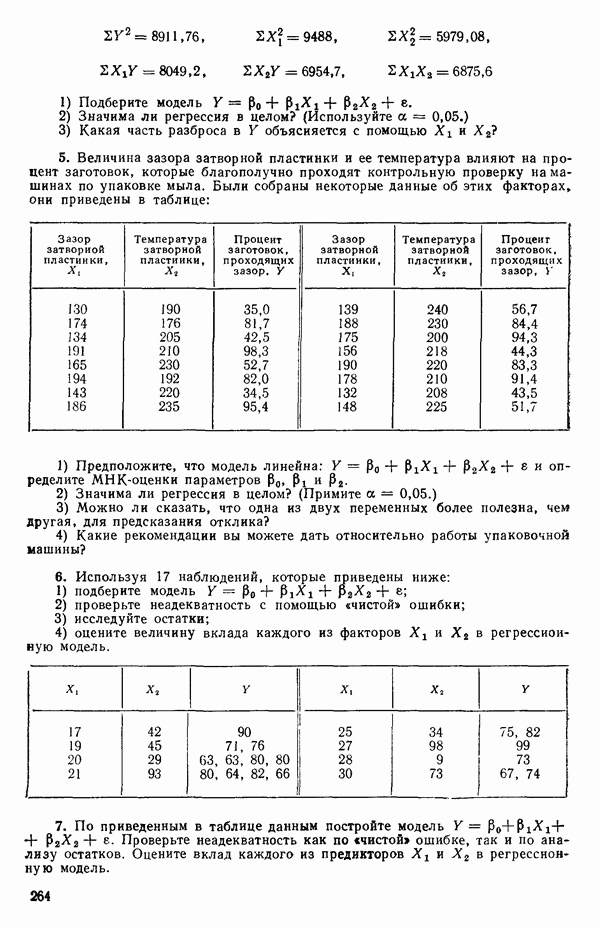


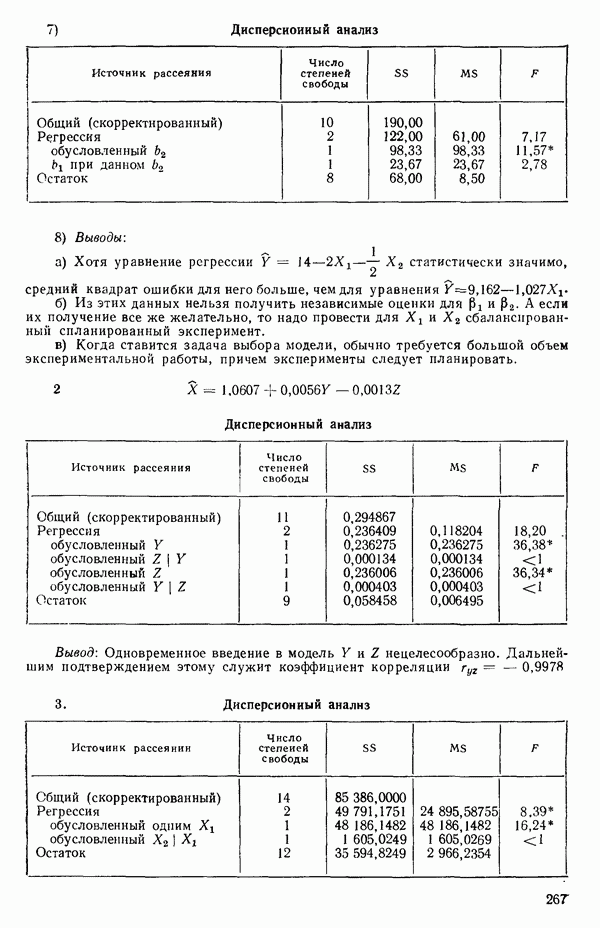

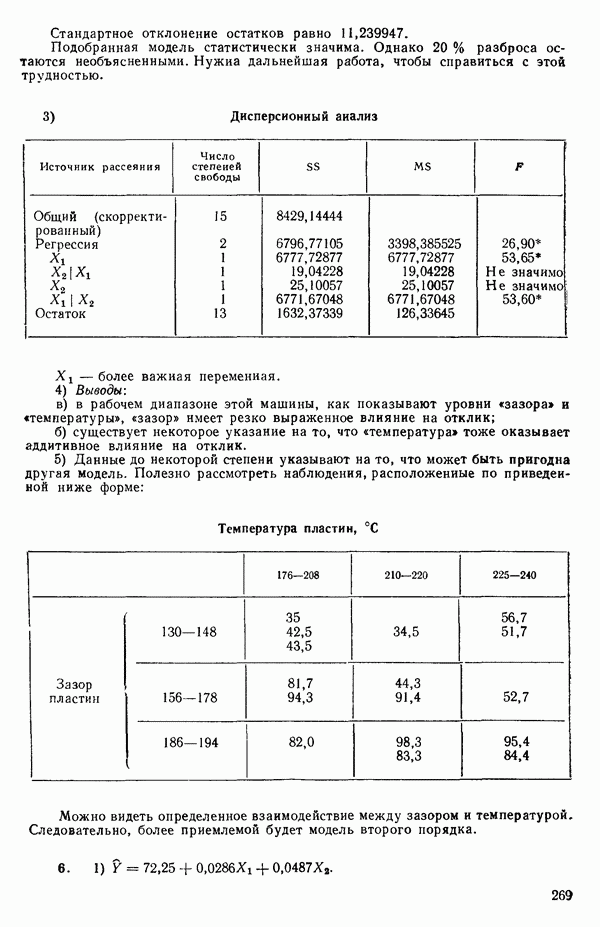
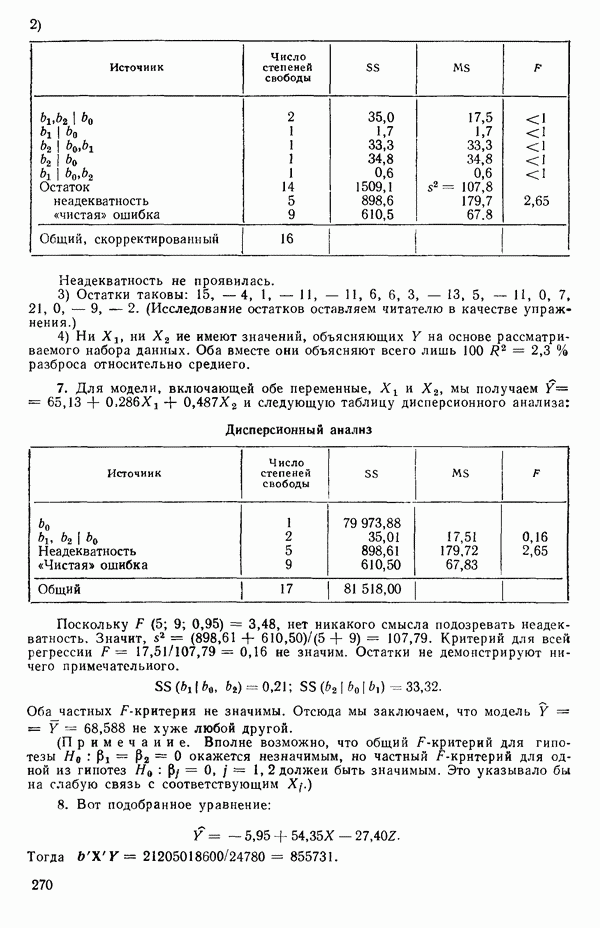

















































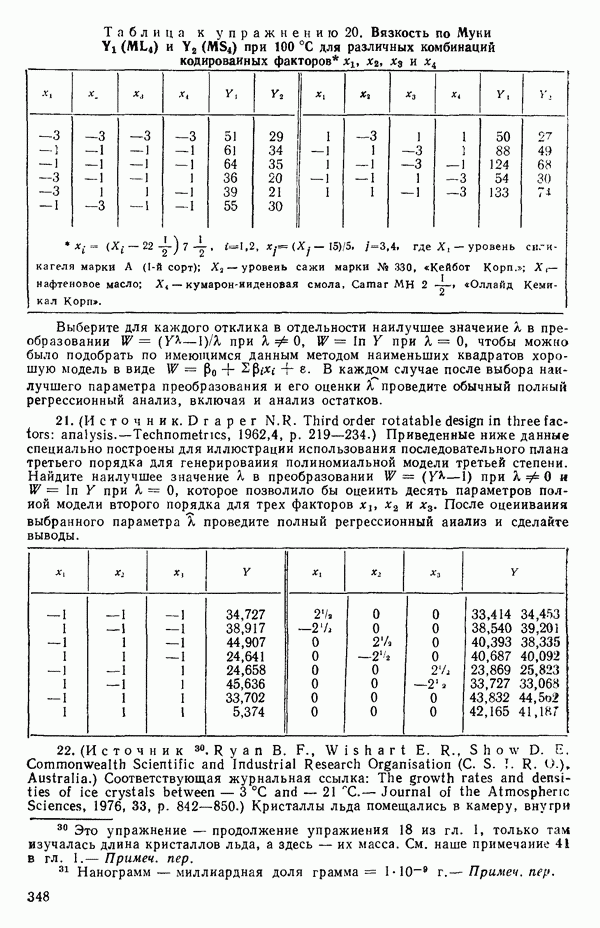

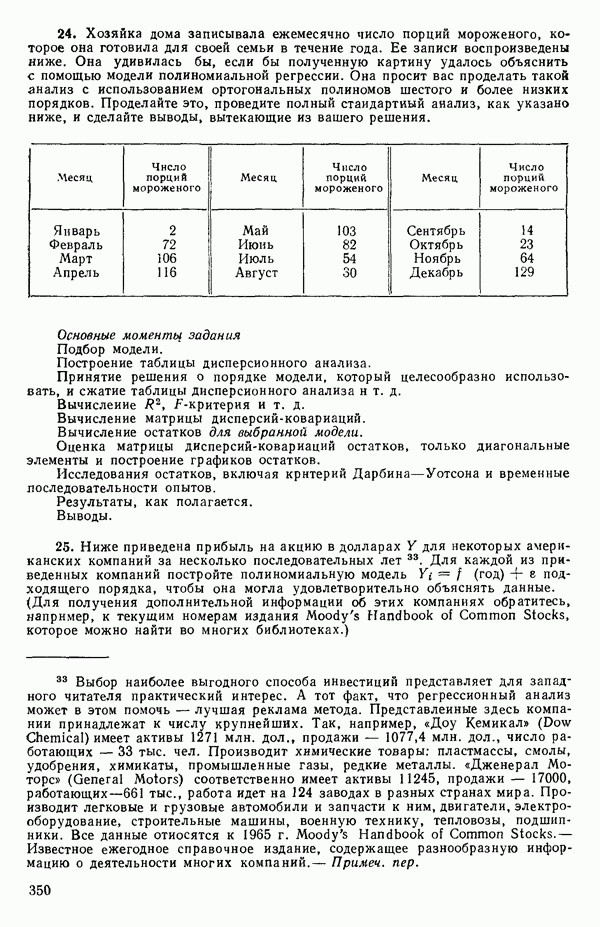
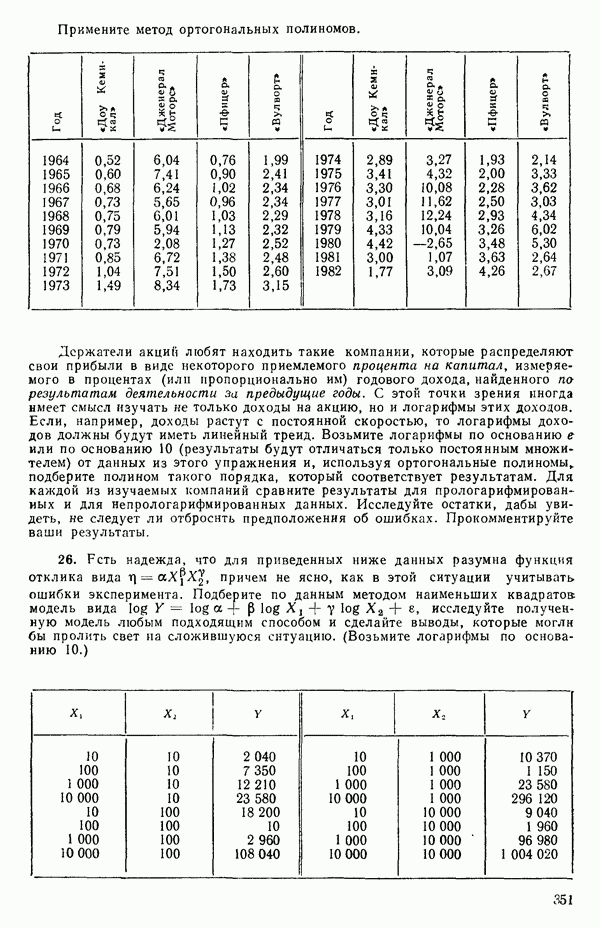
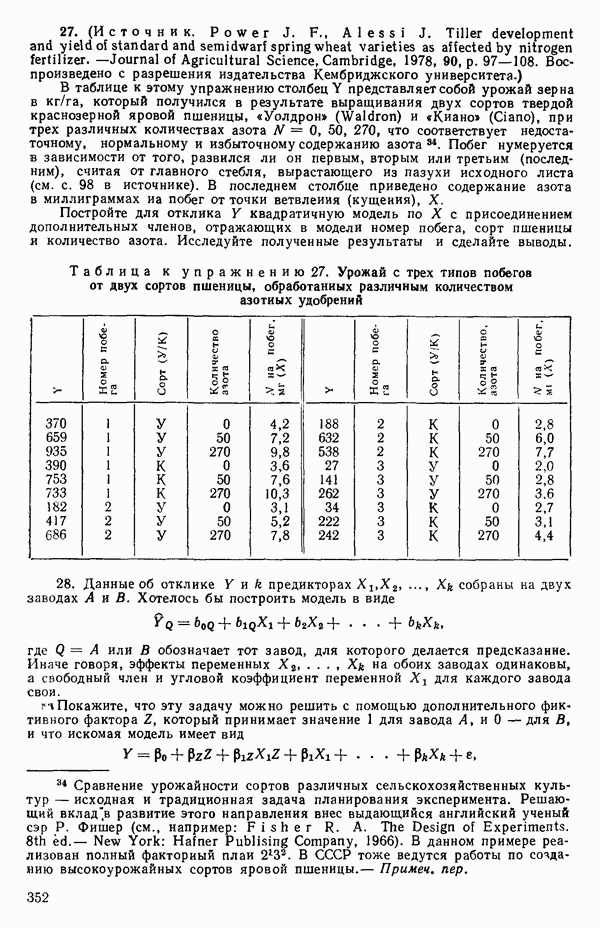


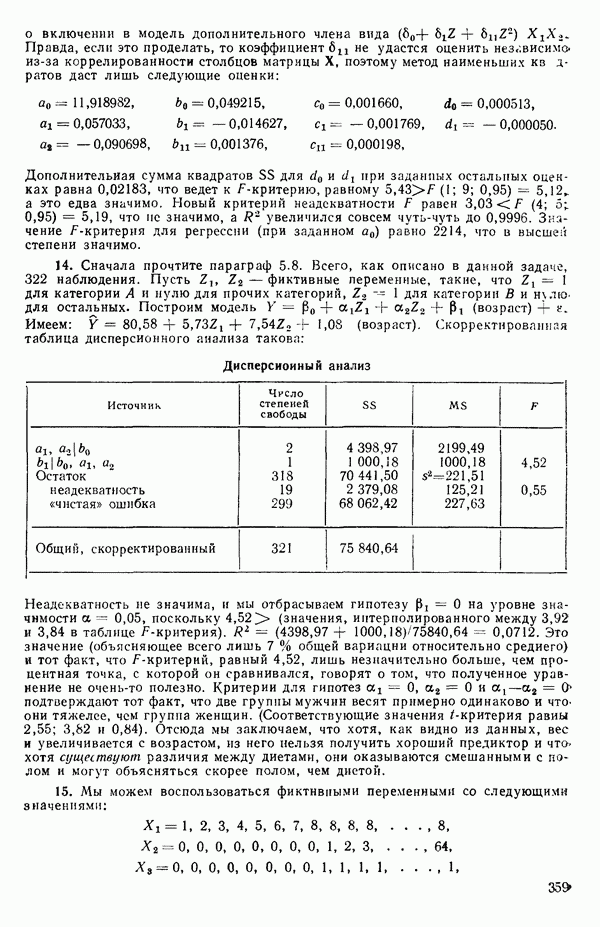



 кроме пропущенных
кроме пропущенных  Теперь мы видим, что
Теперь мы видим, что


 и вычислить вектор
и вычислить вектор  Заметим, что в данном примере
Заметим, что в данном примере  так что подобные вычисления крайне просты. Другой способ подсчета
так что подобные вычисления крайне просты. Другой способ подсчета  должен привести к тому же ответу, но он более сложен.
должен привести к тому же ответу, но он более сложен.