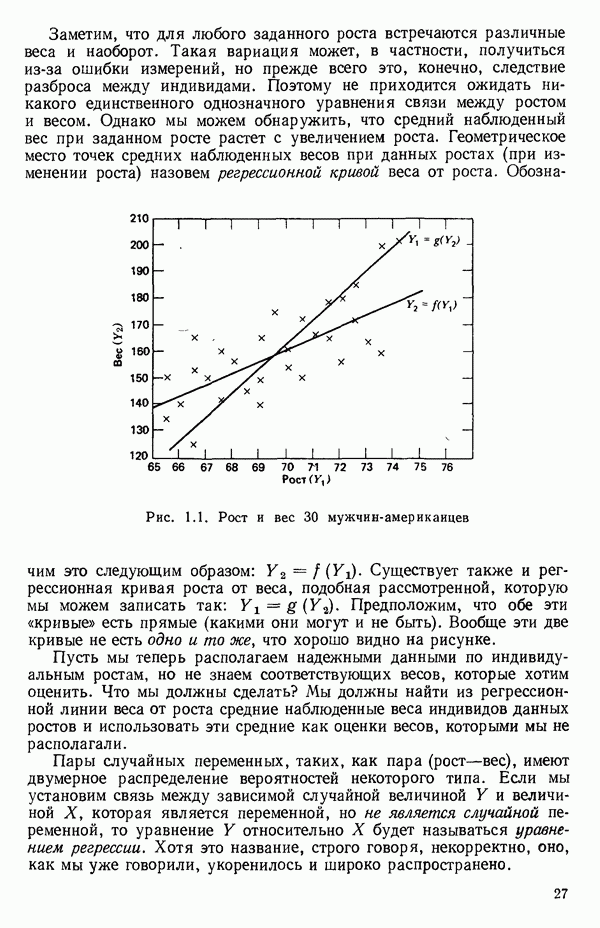
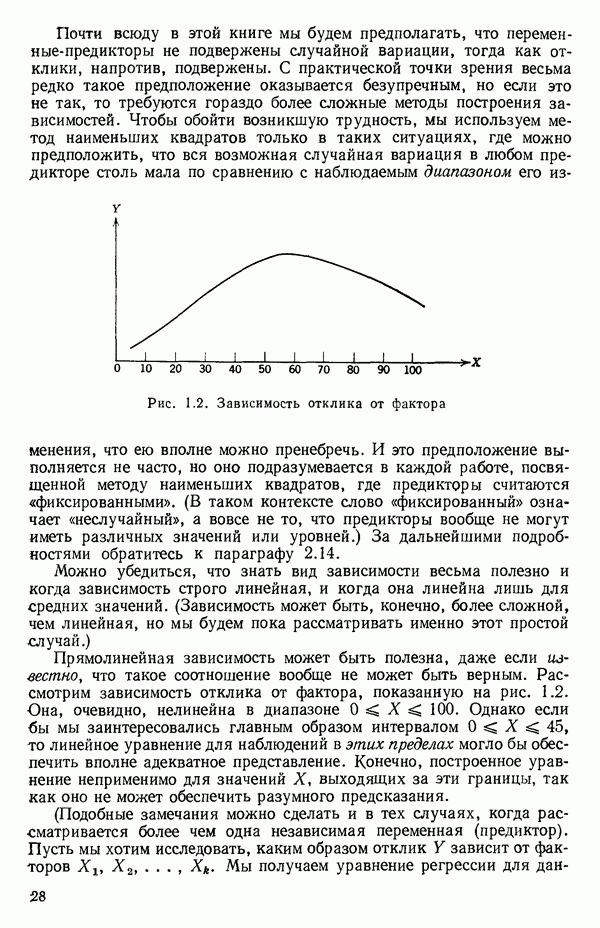
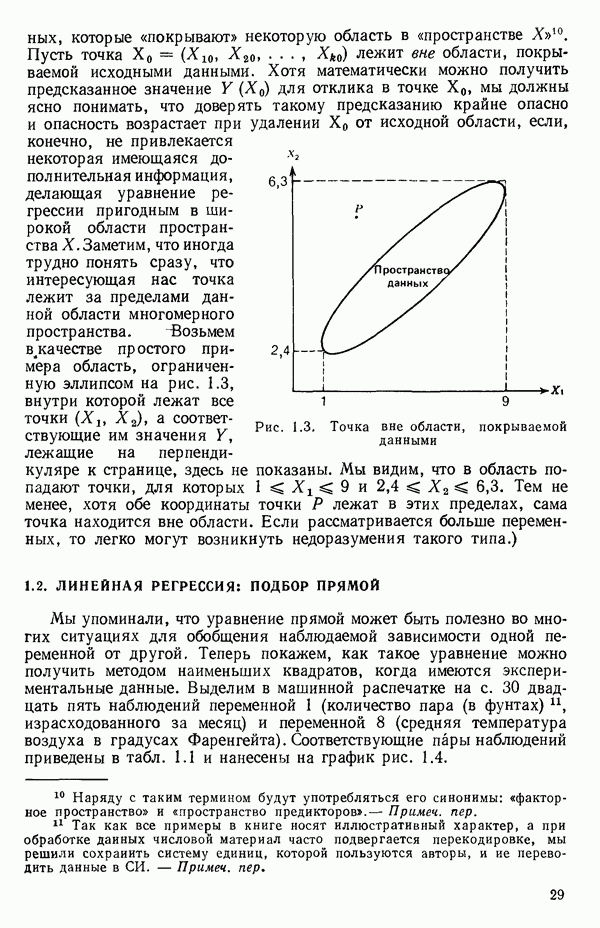
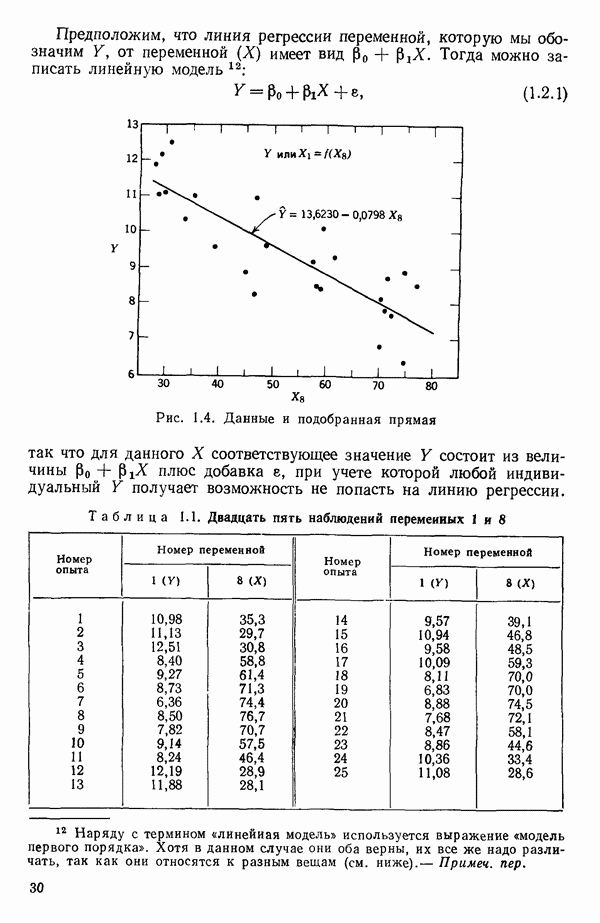
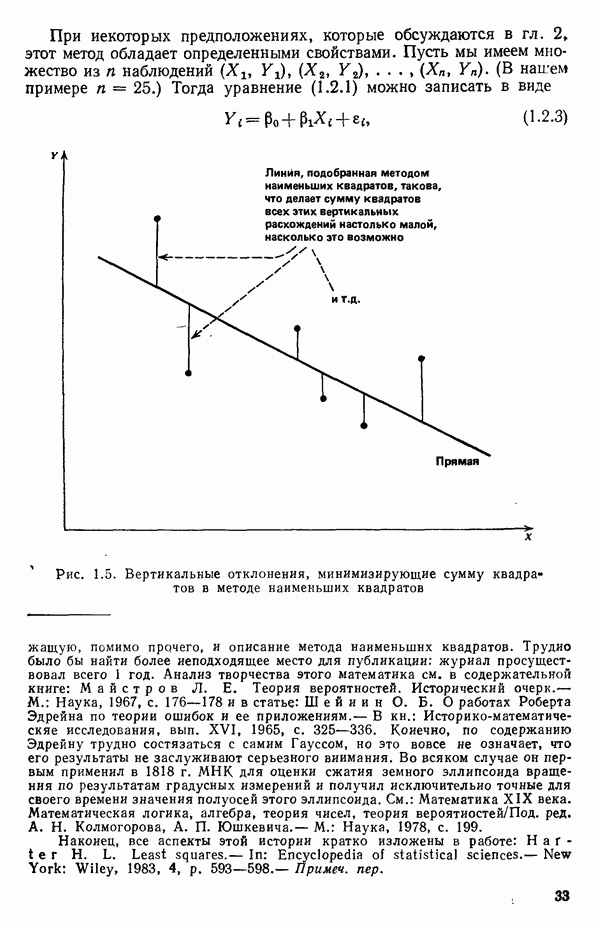
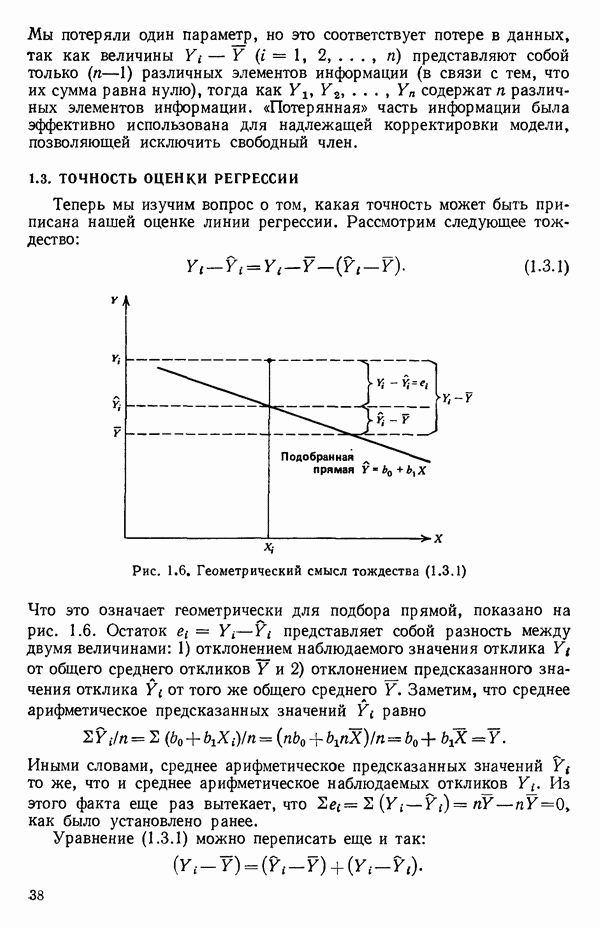
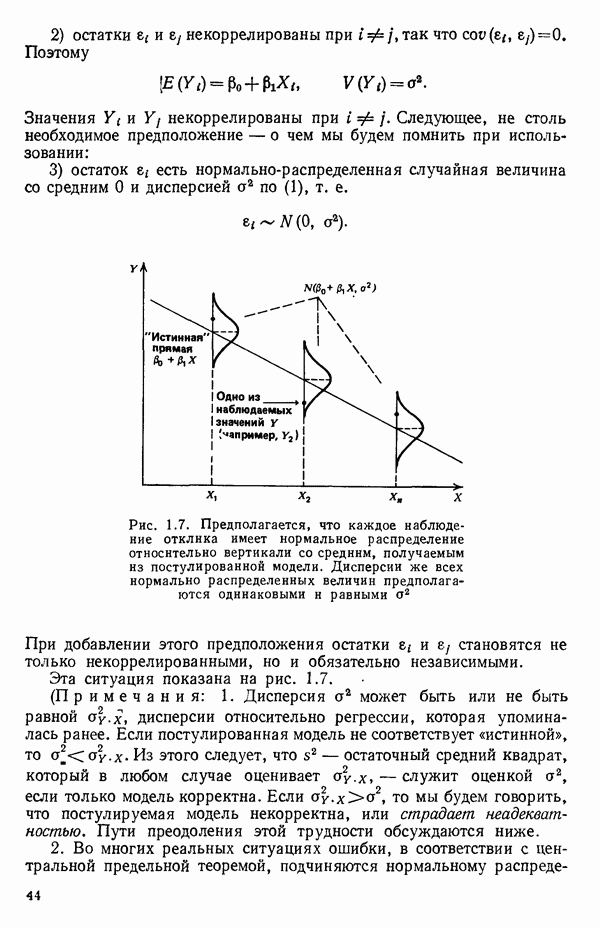
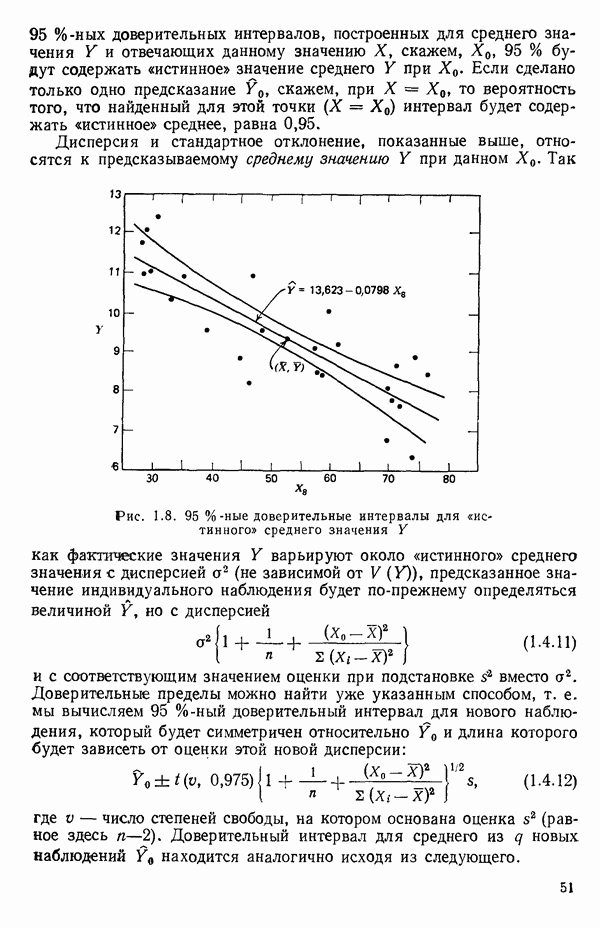
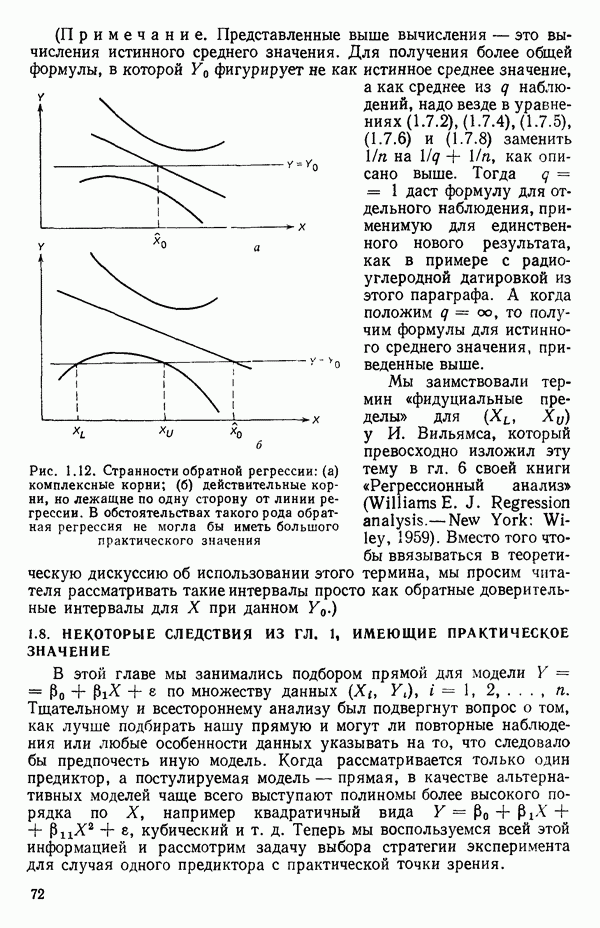
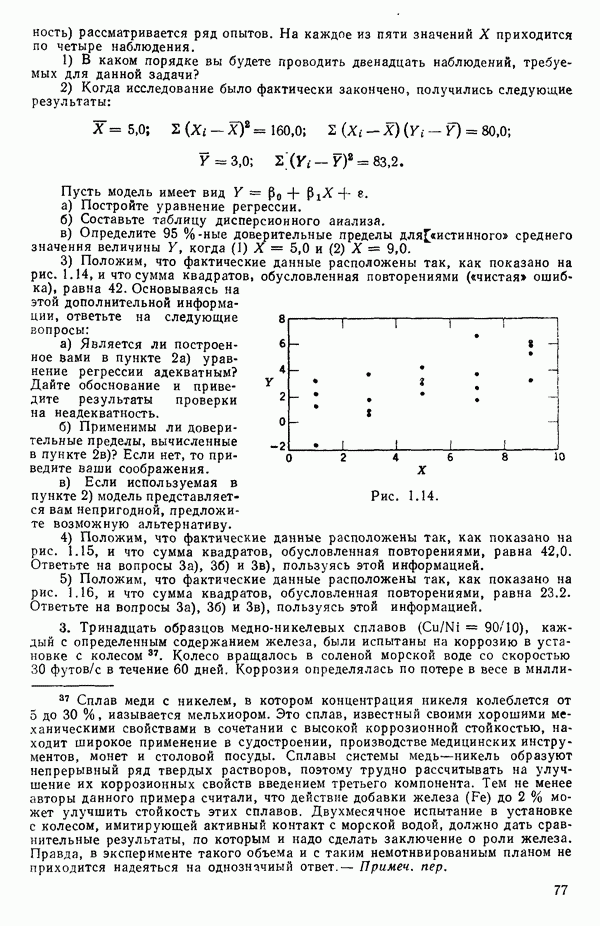
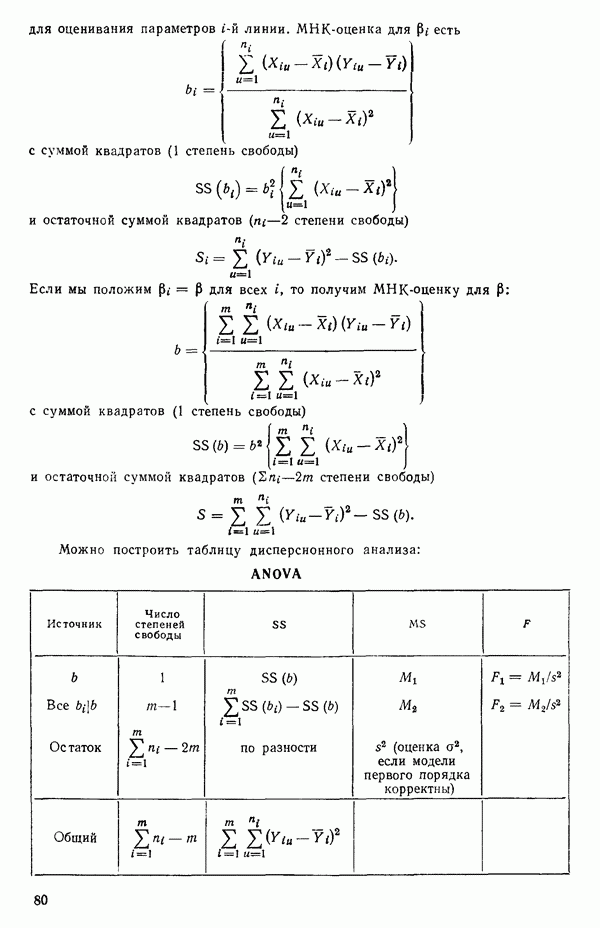
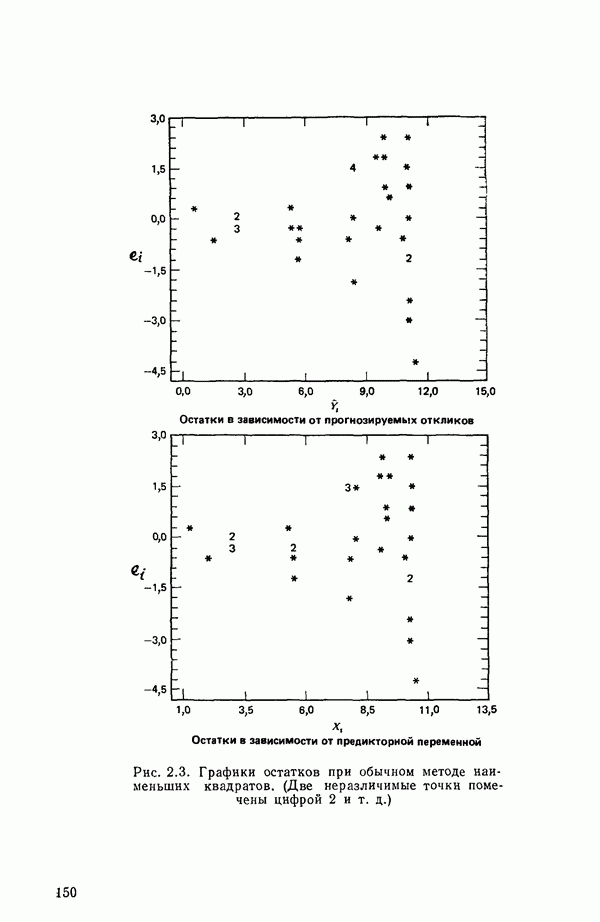
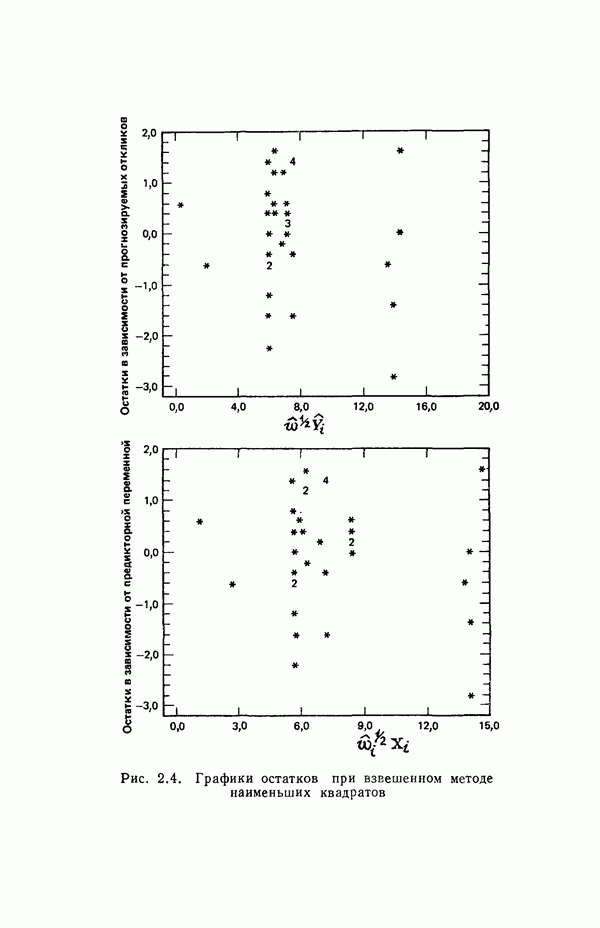
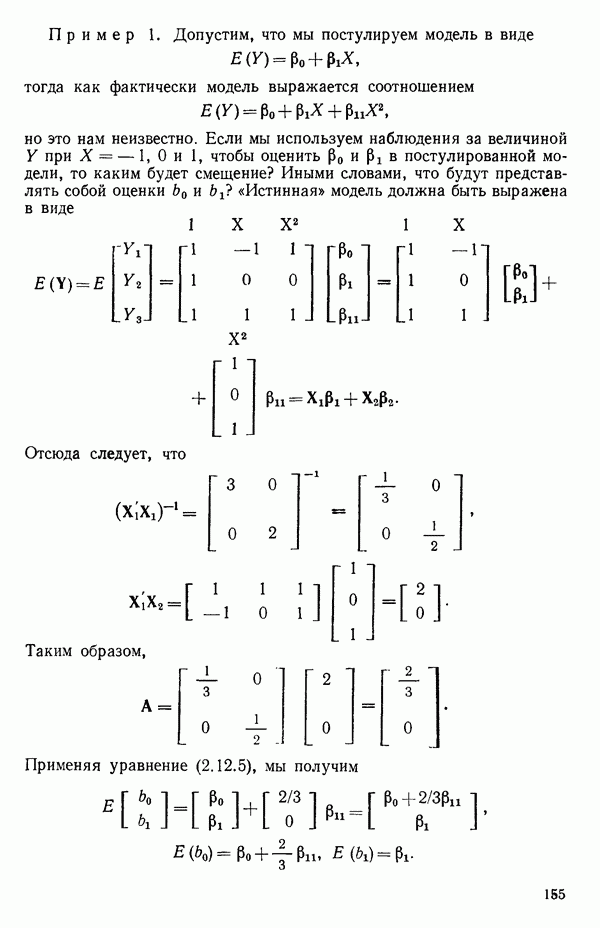
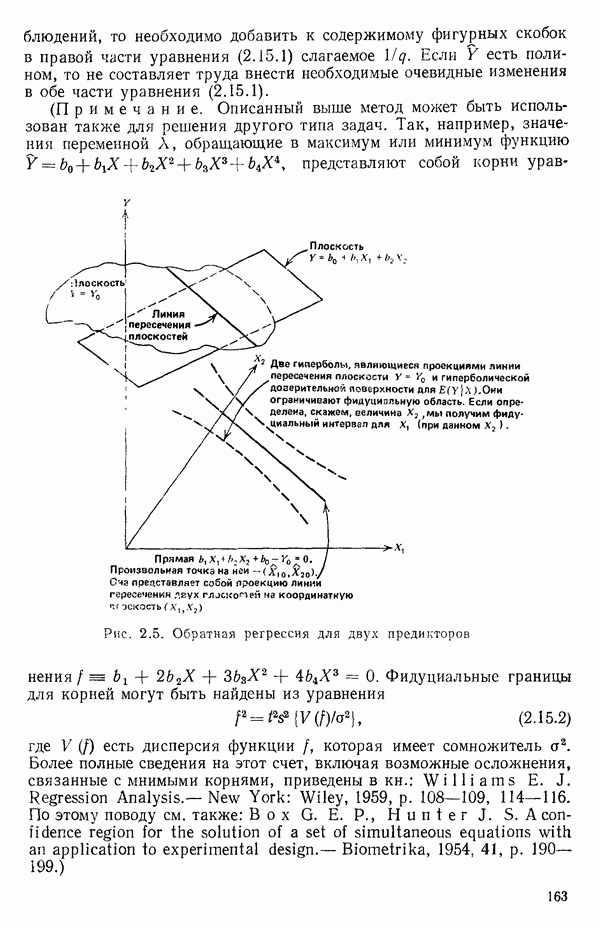
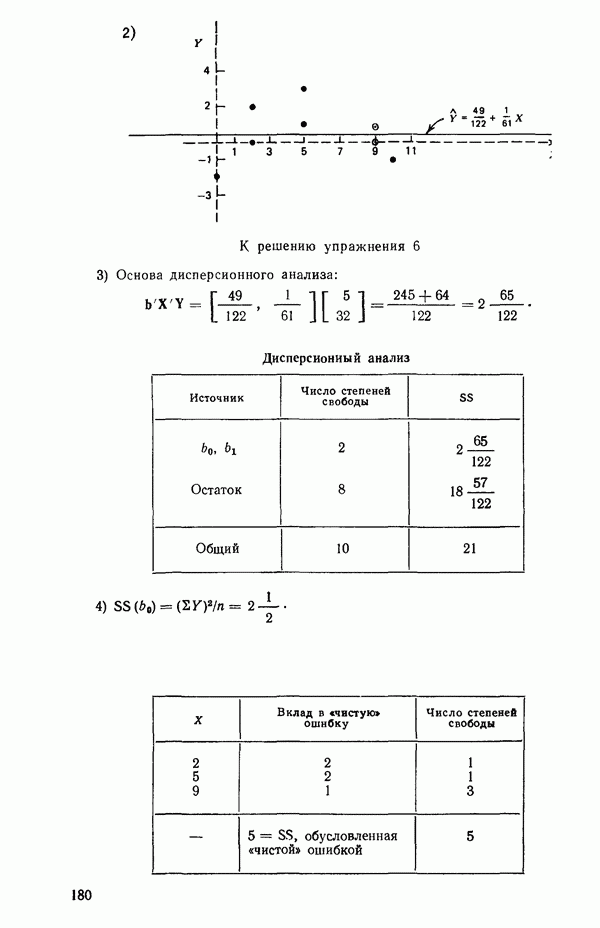
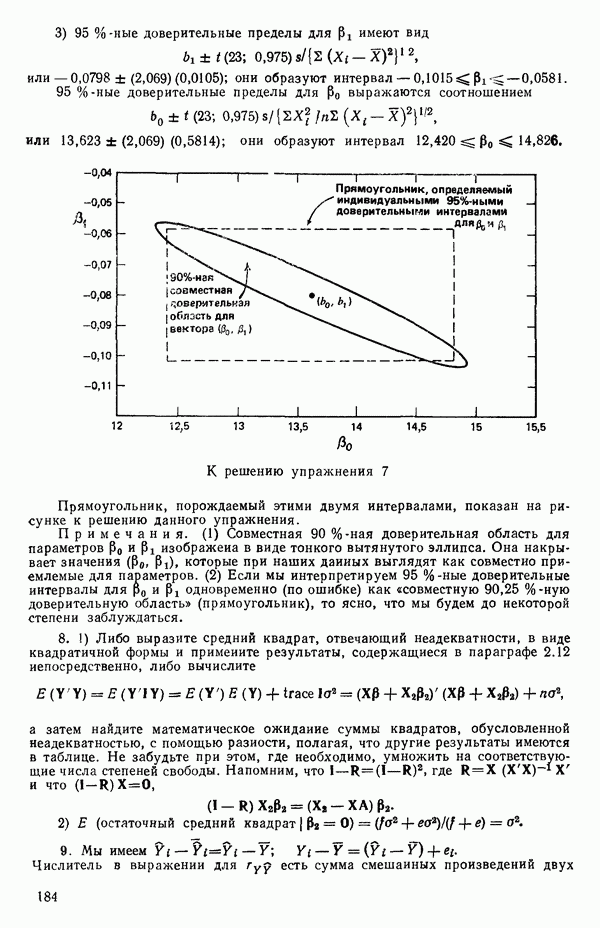
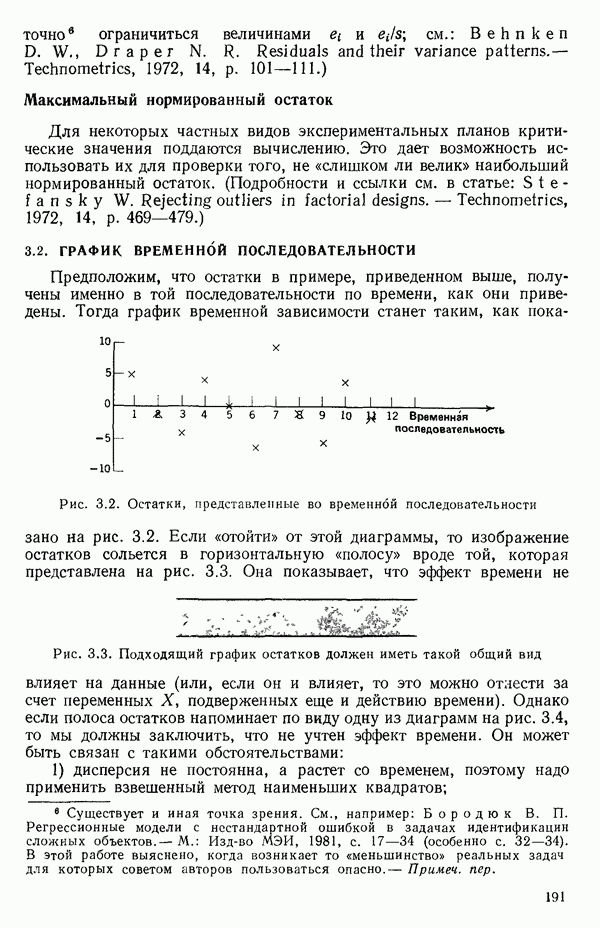
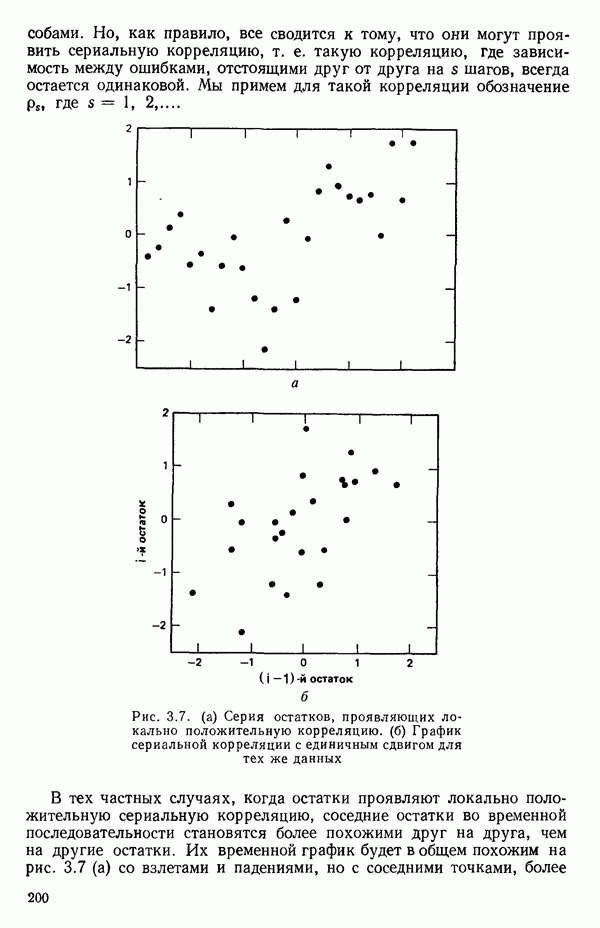
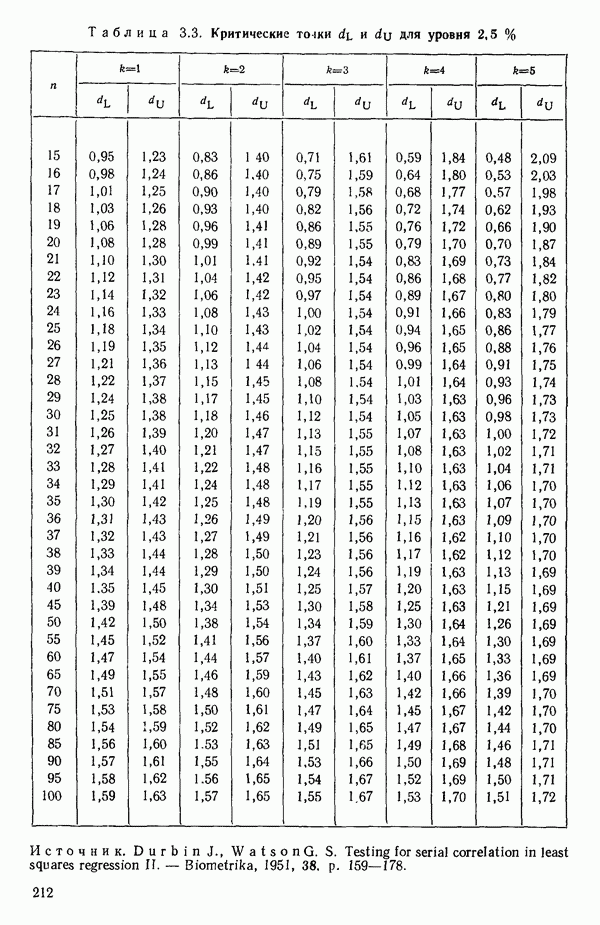
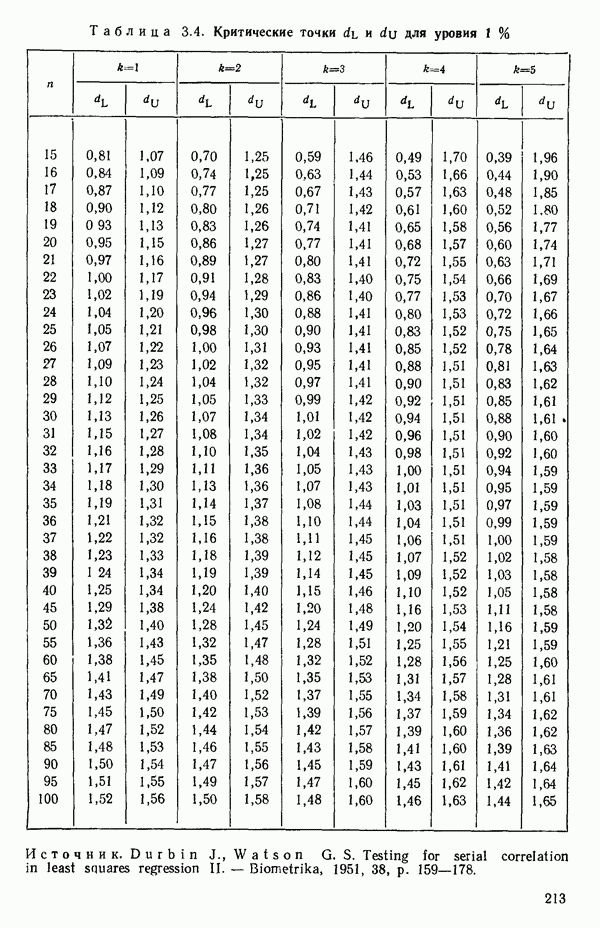
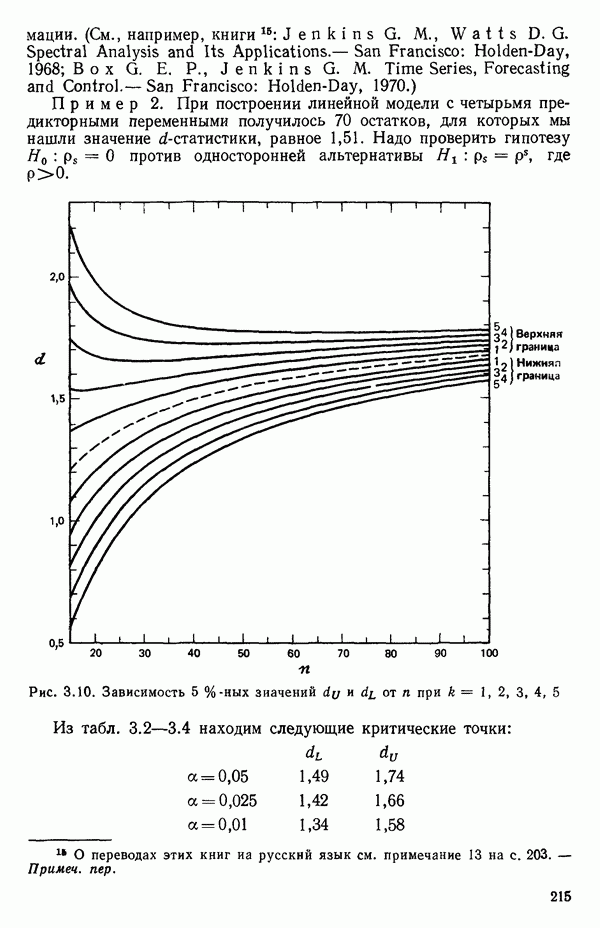
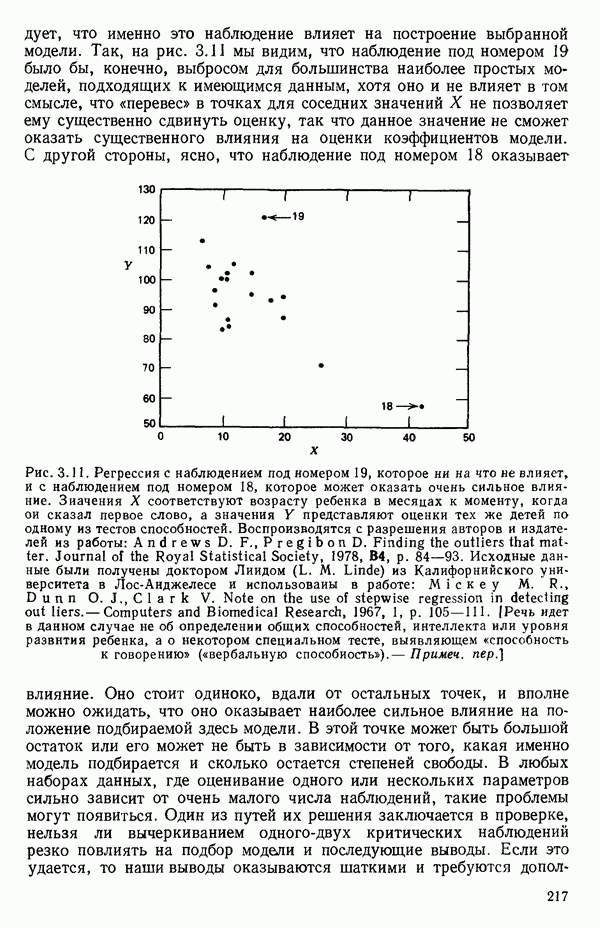
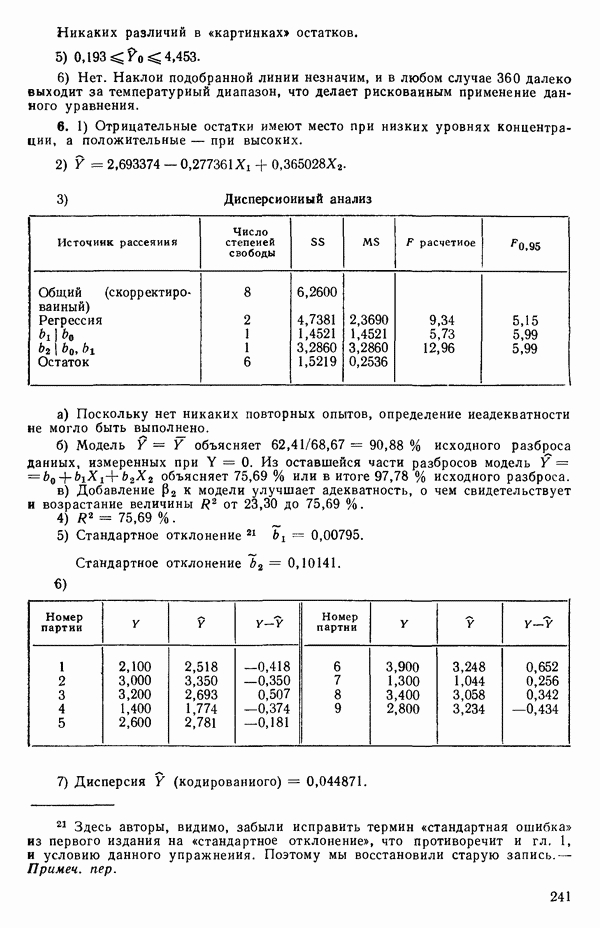
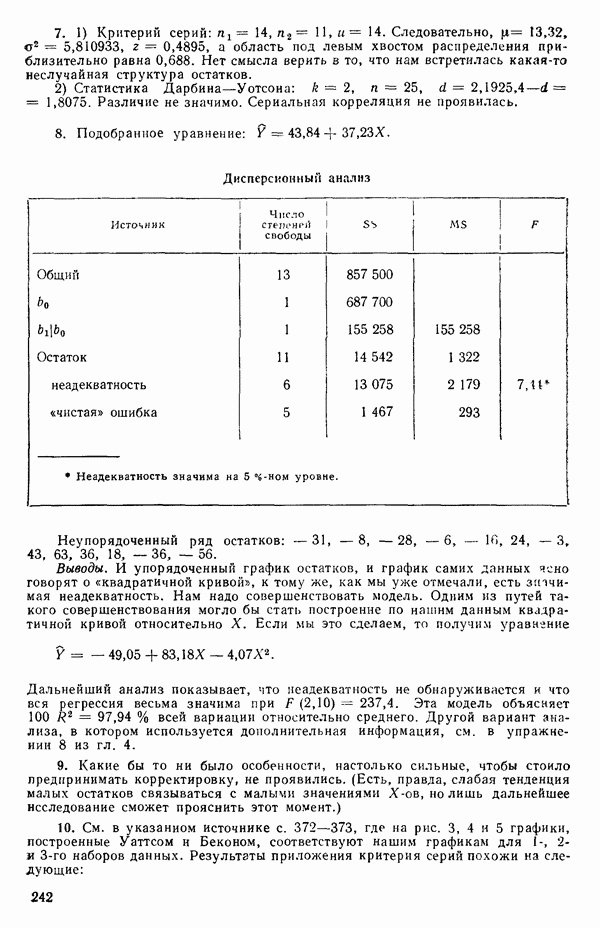
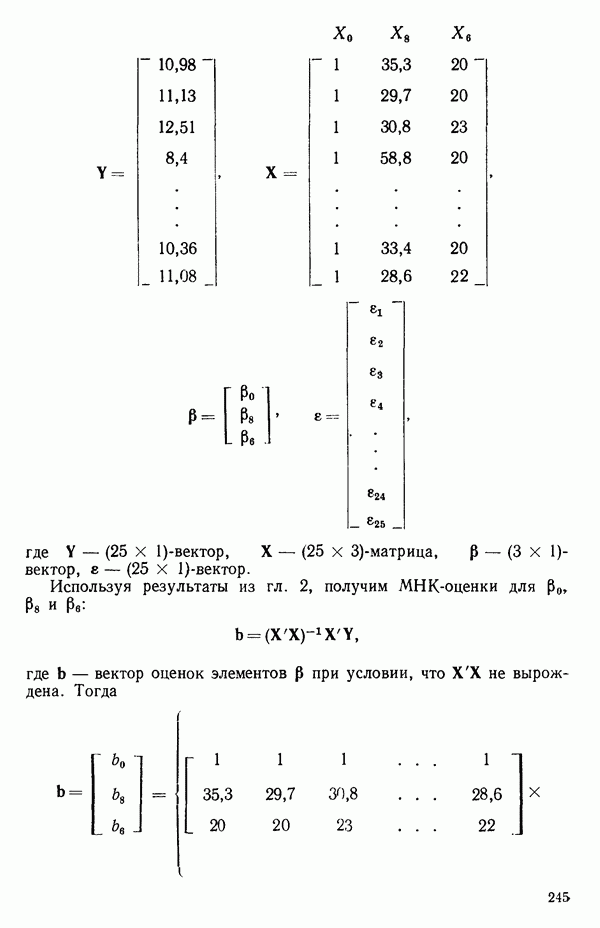
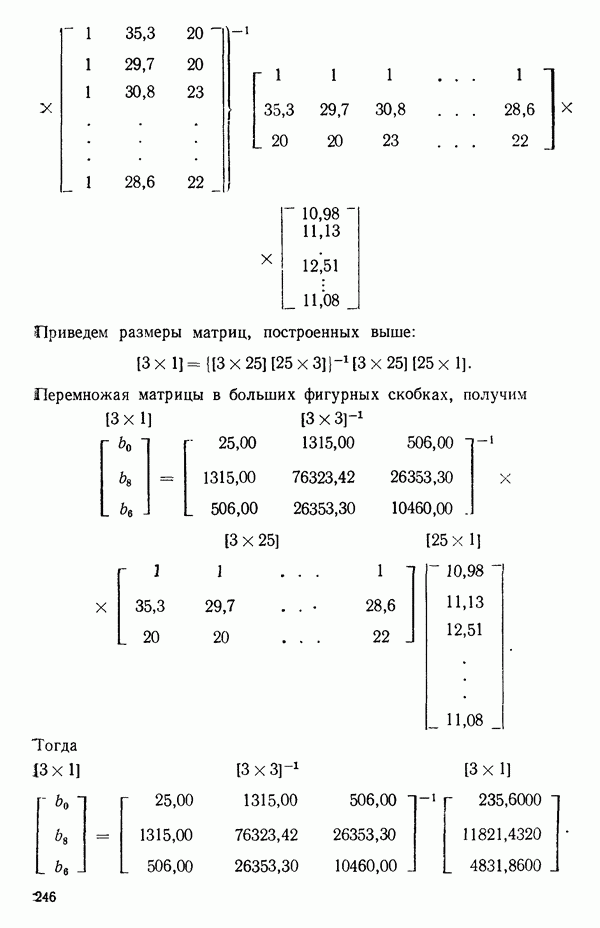
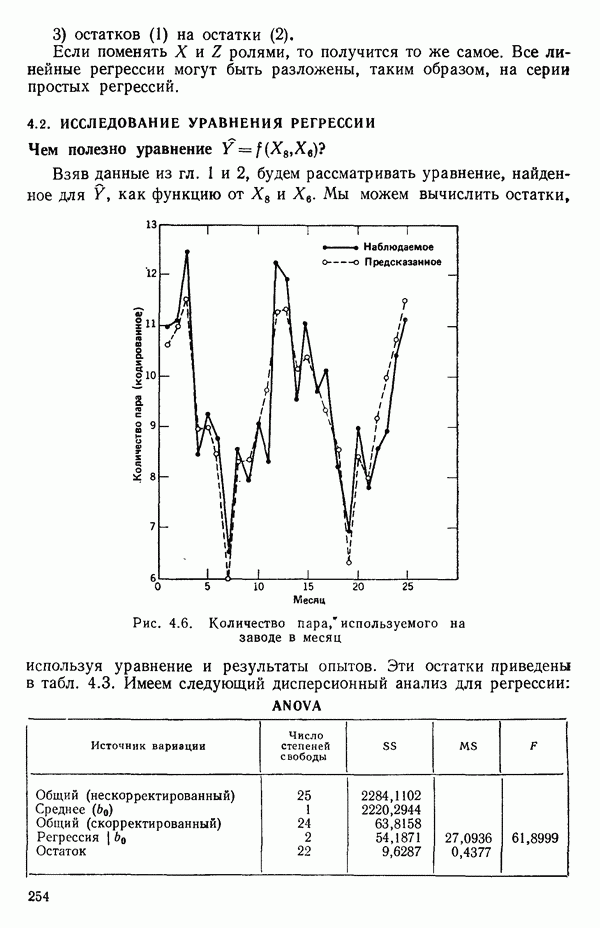
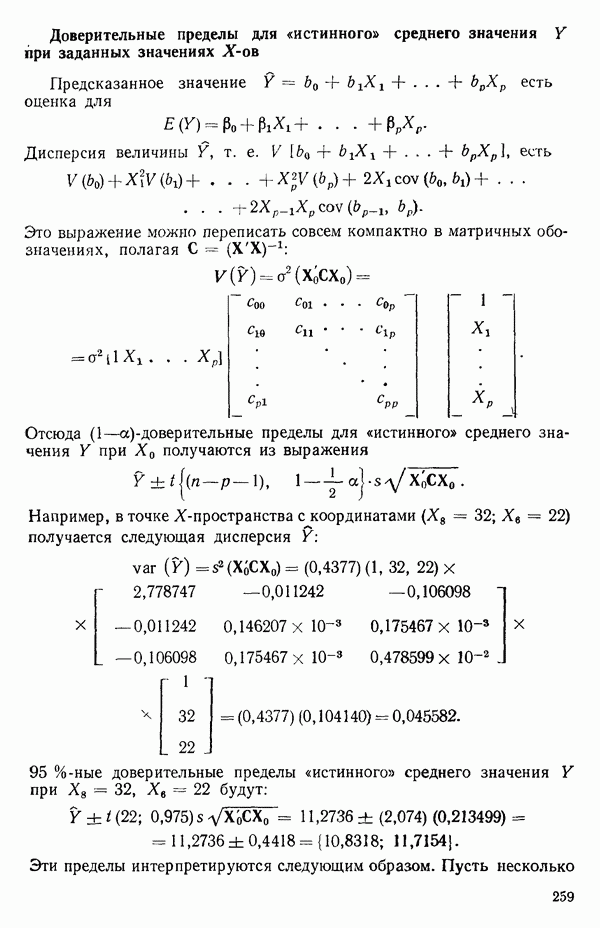
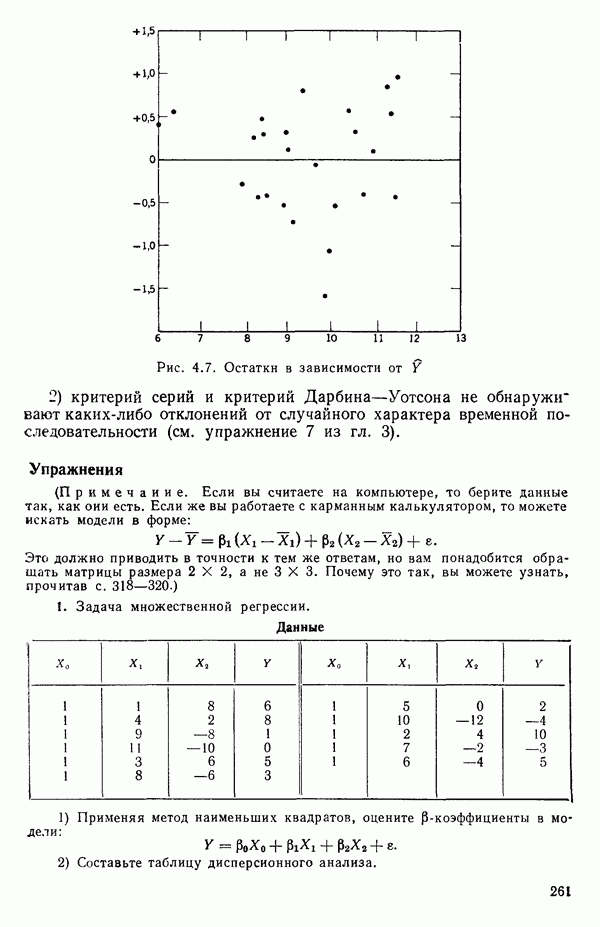
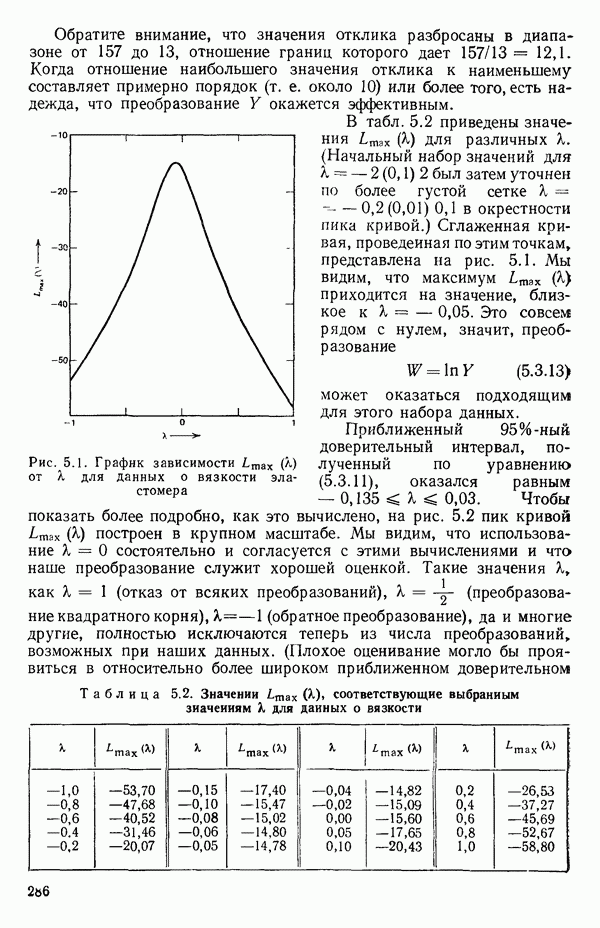
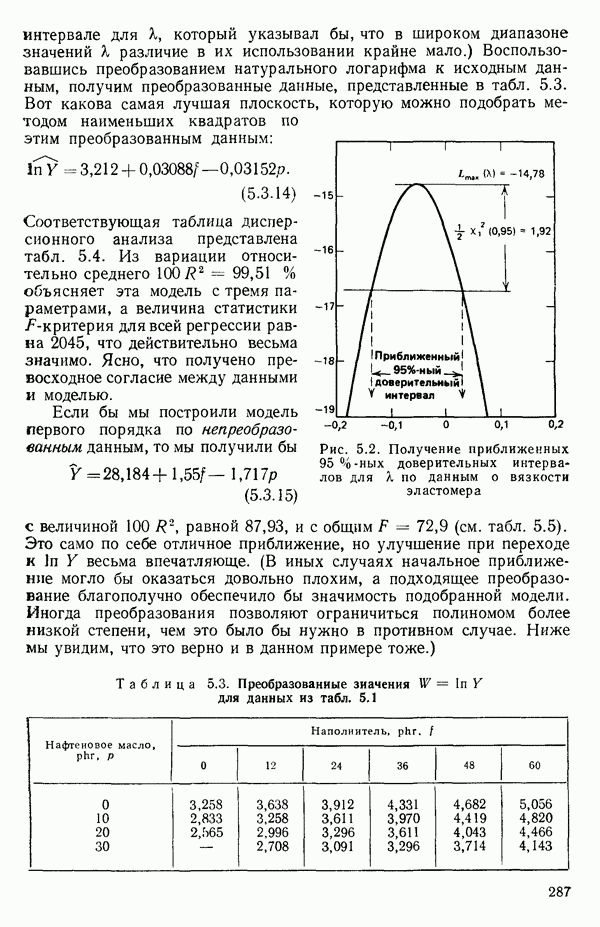
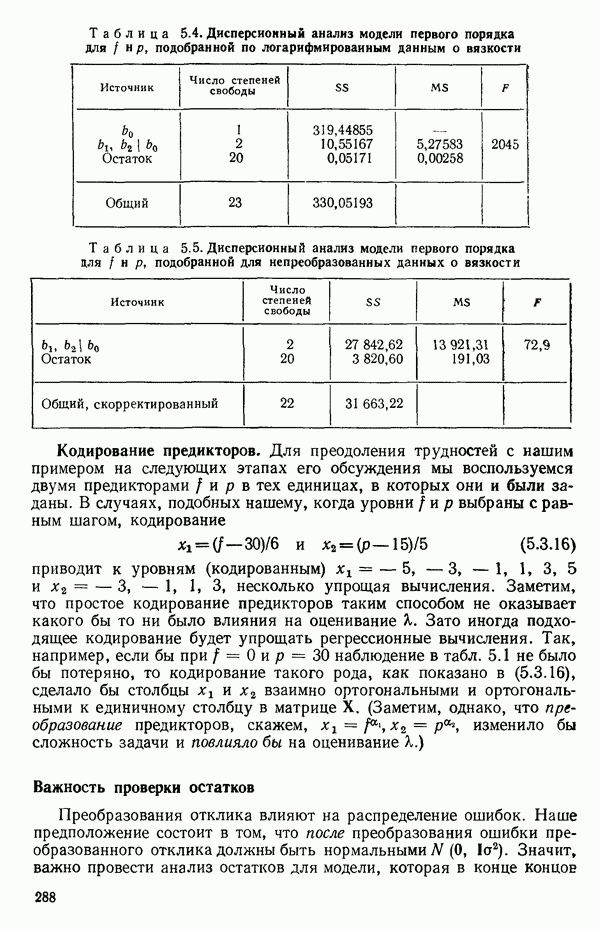
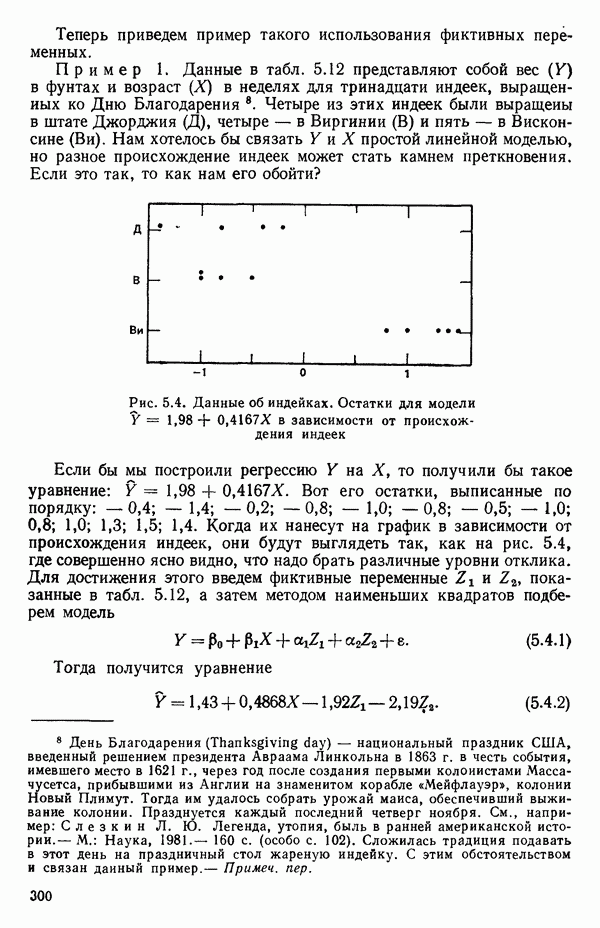
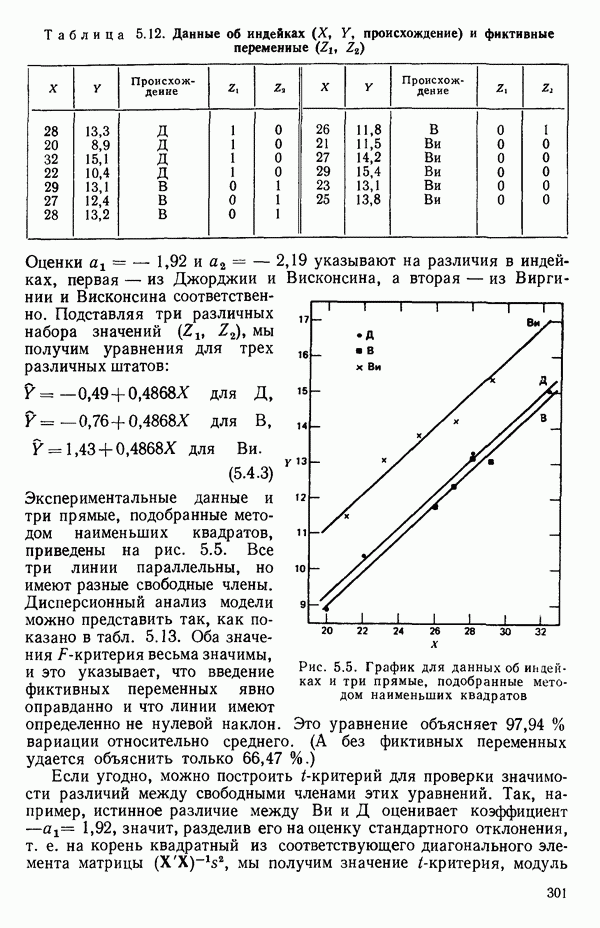
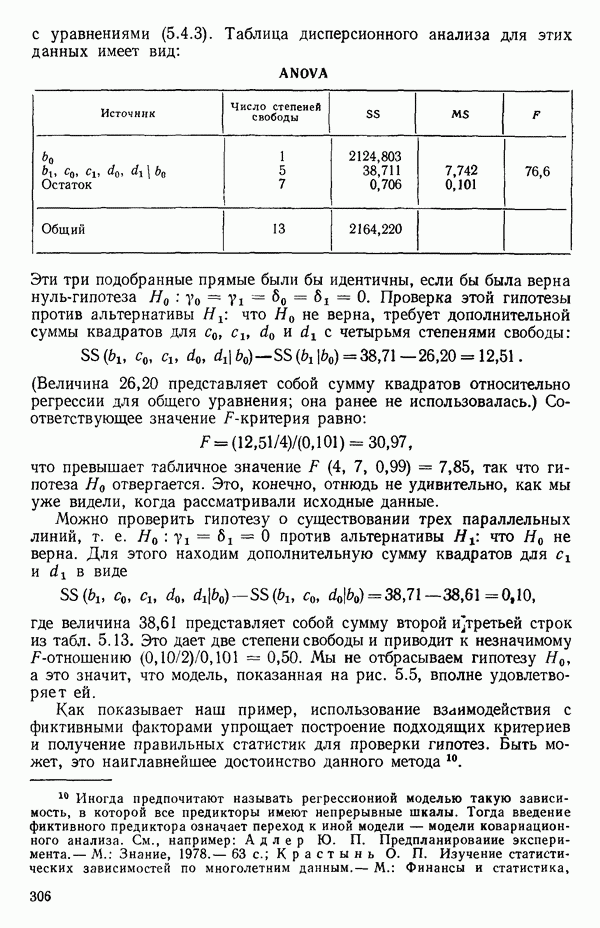
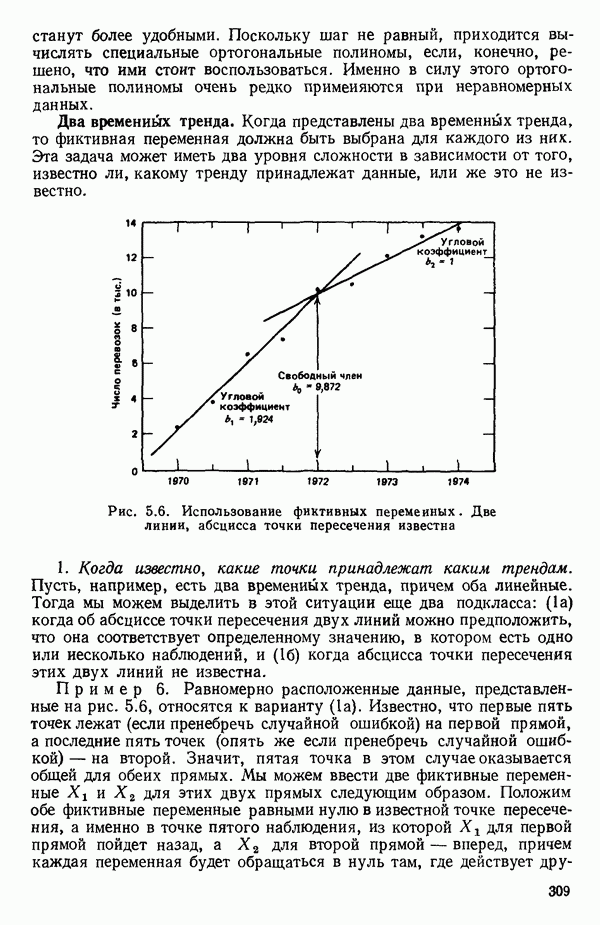
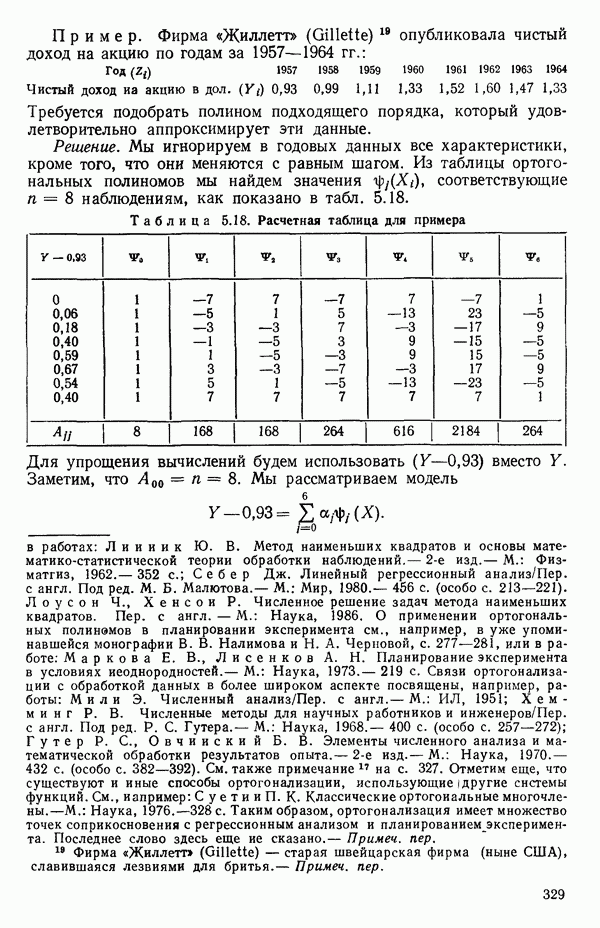
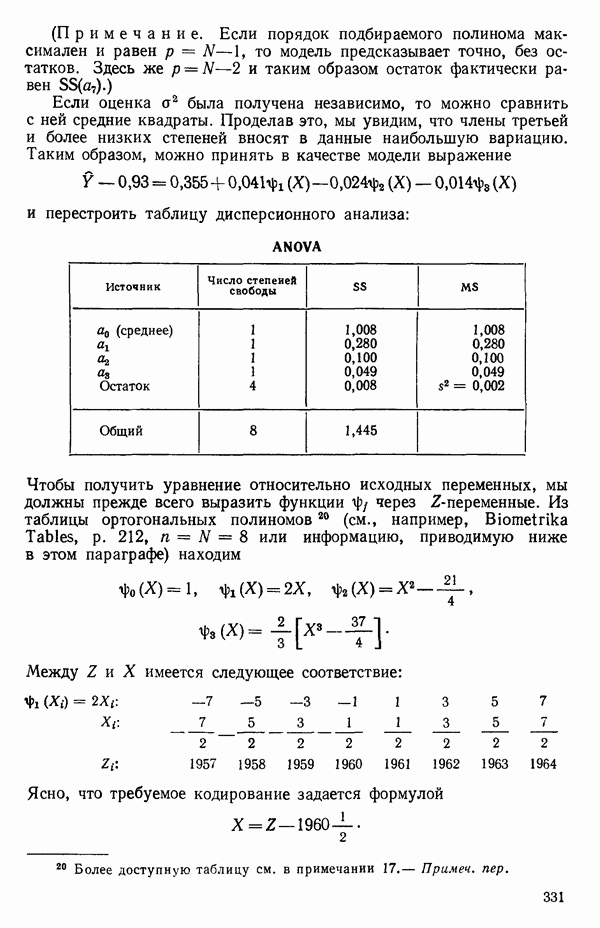
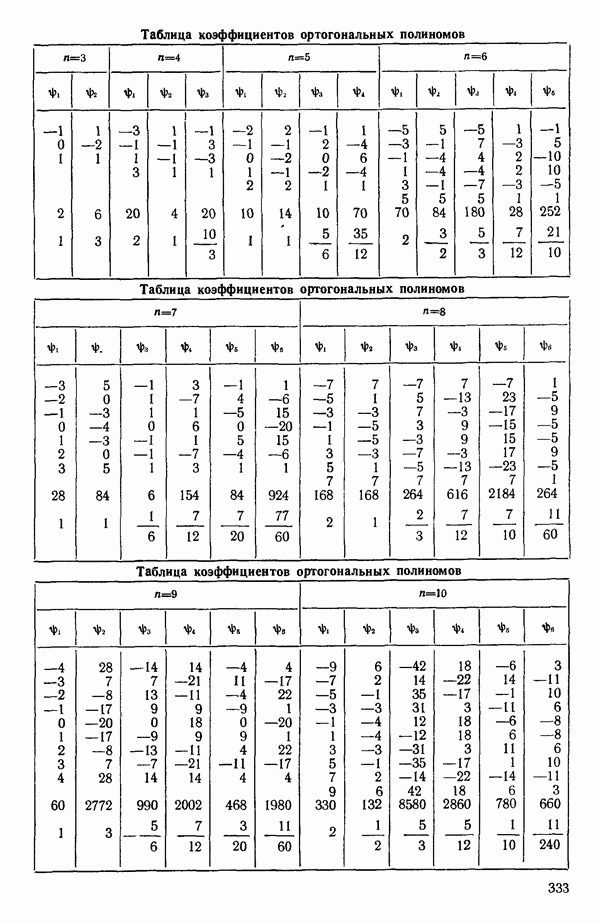
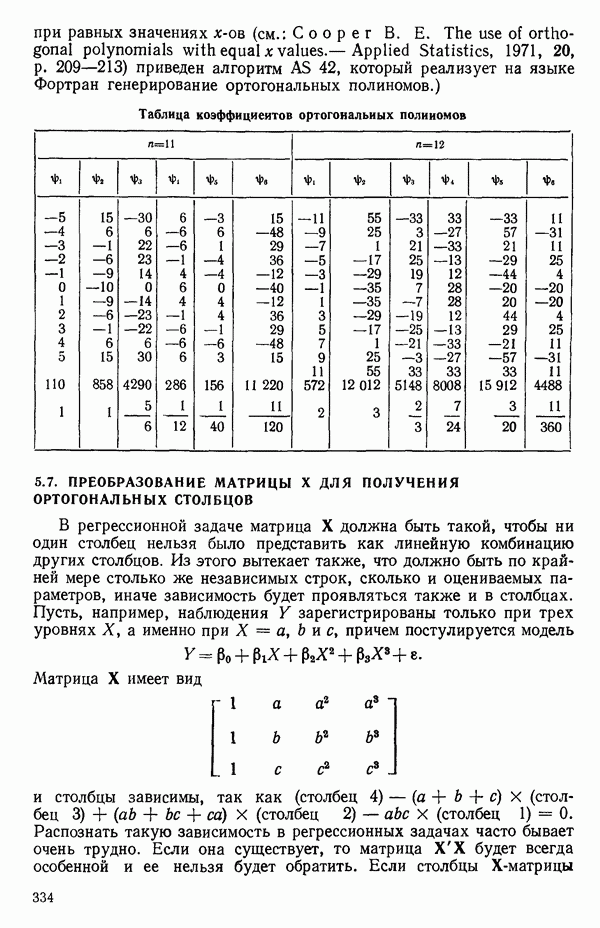
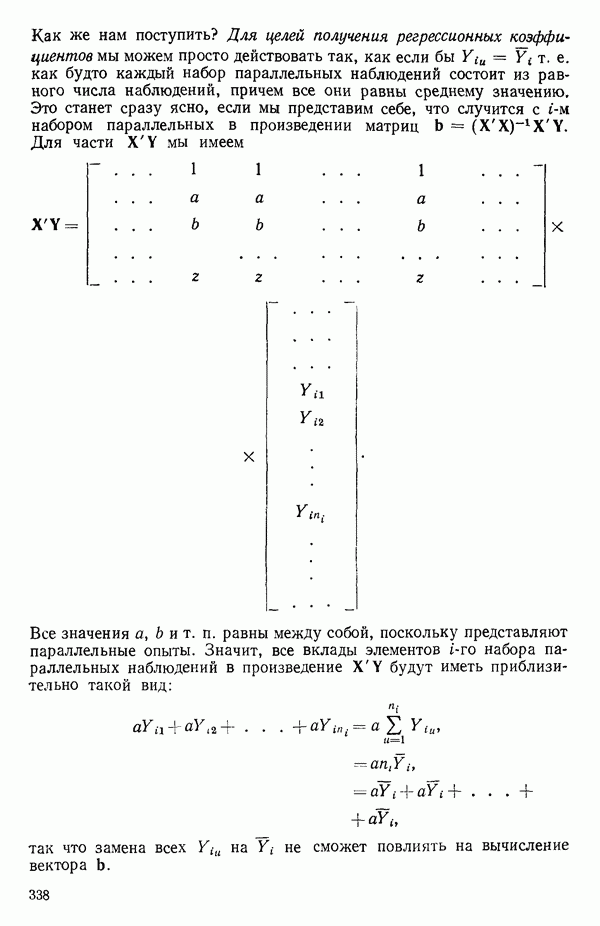
2.6. СЛУЧАЙ ОБЩЕЙ РЕГРЕССИИ
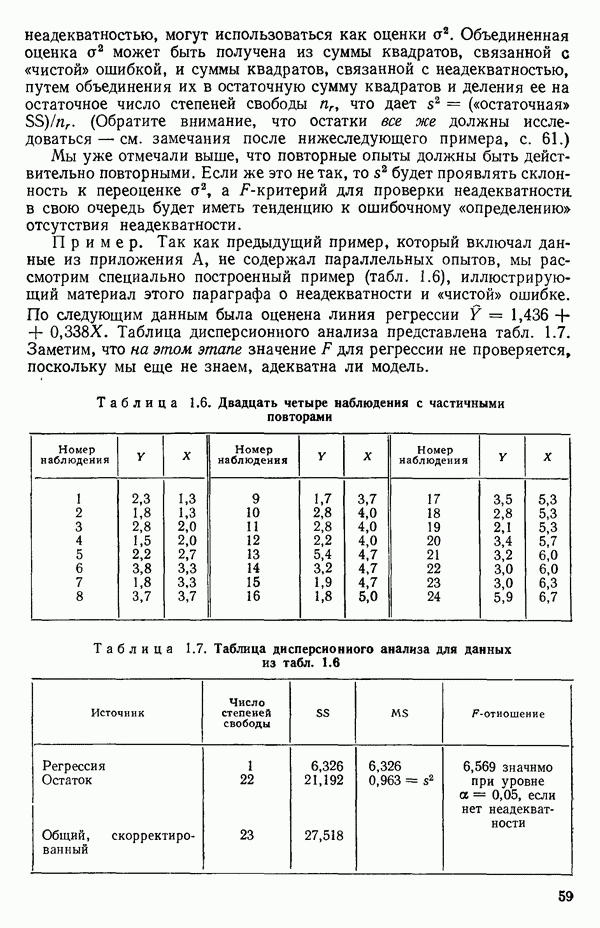
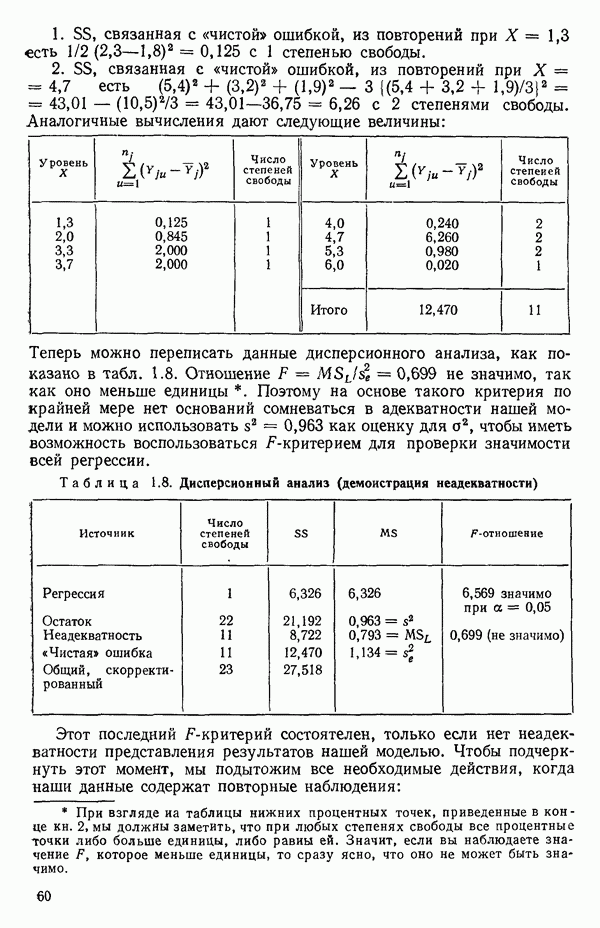
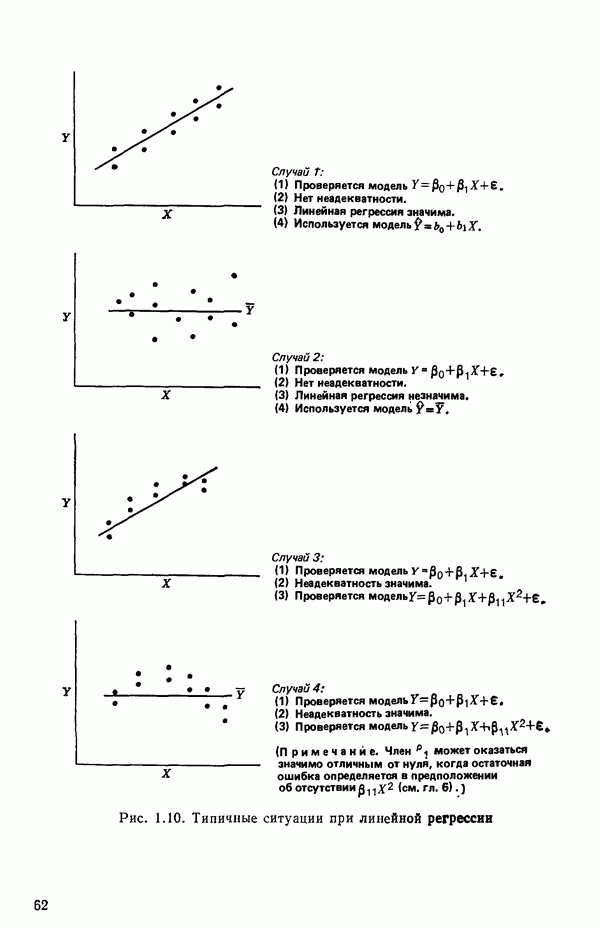
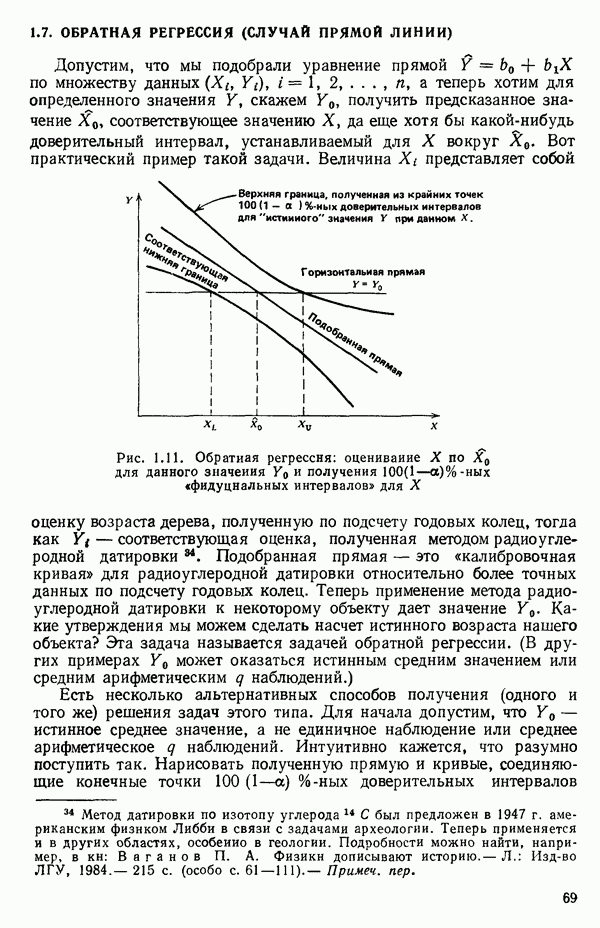
Мы показали, как можно решить проблему подбора уравнения прямой методом наименьших квадратов, используя матрицы. Этот подход важен по следующим соображениям. Если мы хотим подобрать с помощью метода наименьших квадратов любую модель, линейную по параметрам, то вычисления необходимо проводить точно по тем же матричным формулам, как и при оценивании уравнения прямой линии, содержащей лишь два параметра:  и Однако сложность вычислений с увеличением числа параметров резко возрастает. Таким образом, хотя формулы и легко запоминаются, почти во всех случаях приходится прибегать к помощи цифровых вычислительных машин. Исключение составляют случаи, когда:
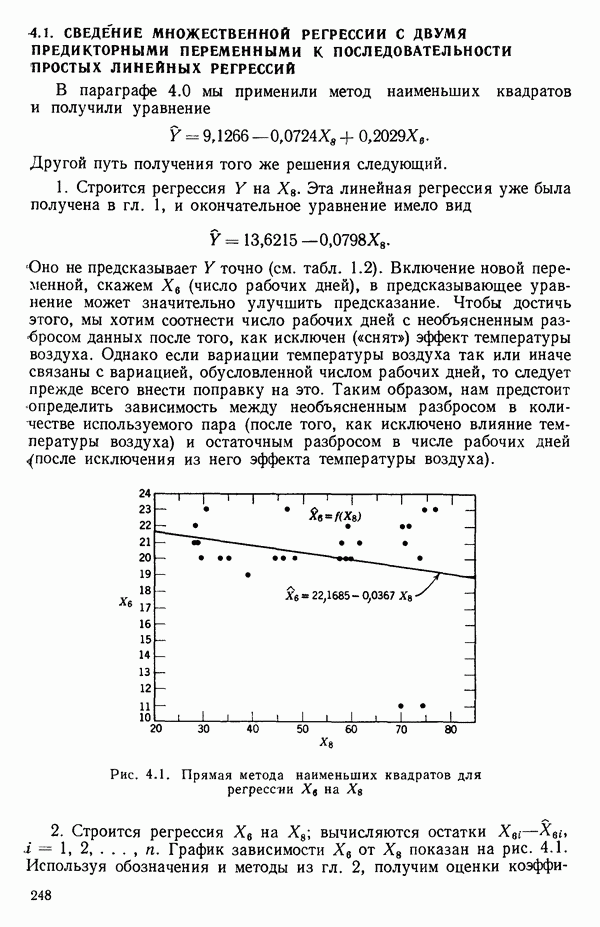
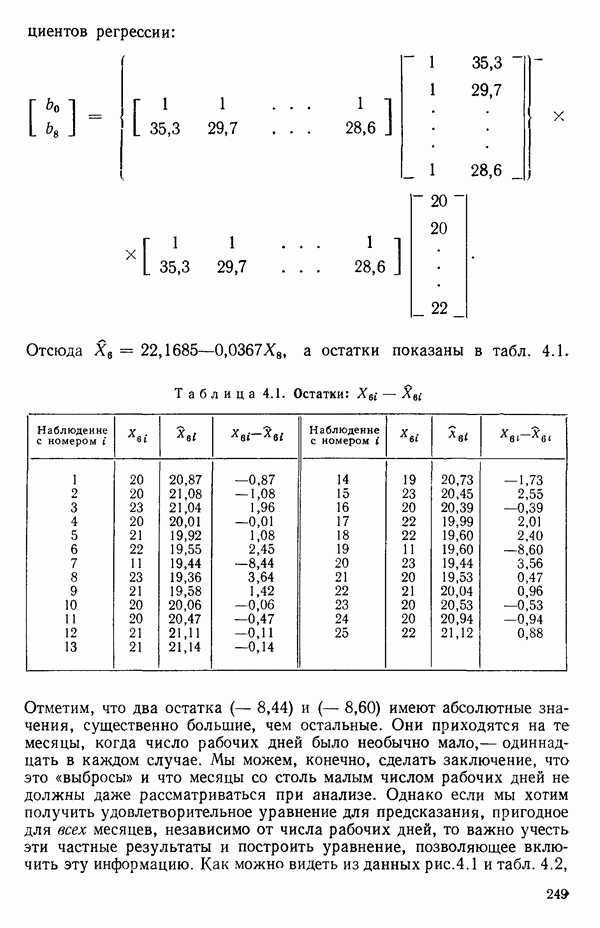
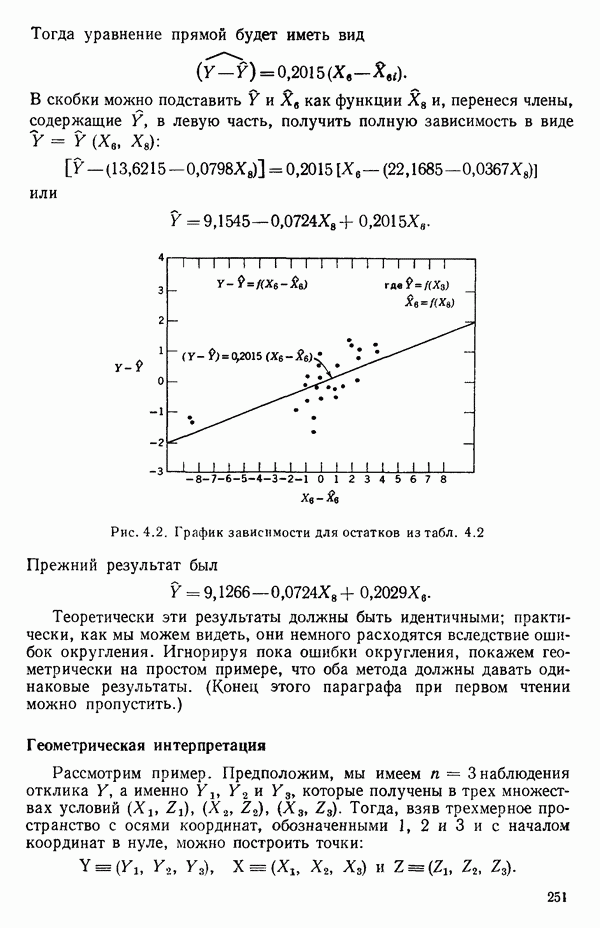
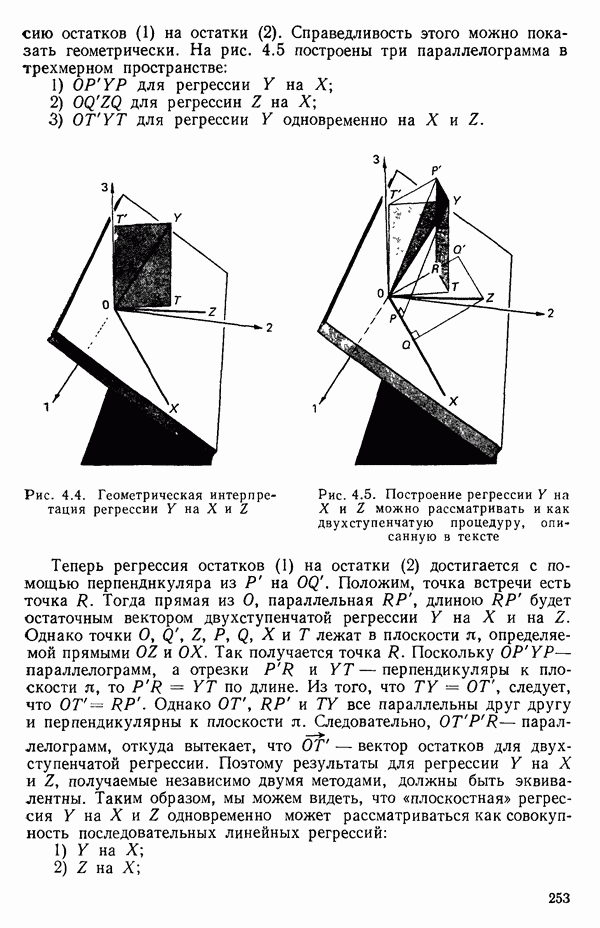
и Однако сложность вычислений с увеличением числа параметров резко возрастает. Таким образом, хотя формулы и легко запоминаются, почти во всех случаях приходится прибегать к помощи цифровых вычислительных машин. Исключение составляют случаи, когда:
1) число параметров мало, скажем, меньше пяти;
2) обрабатываемые данные получены на основе заранее спланированных экспериментов, что приводит к матрице  простого или специального вида.
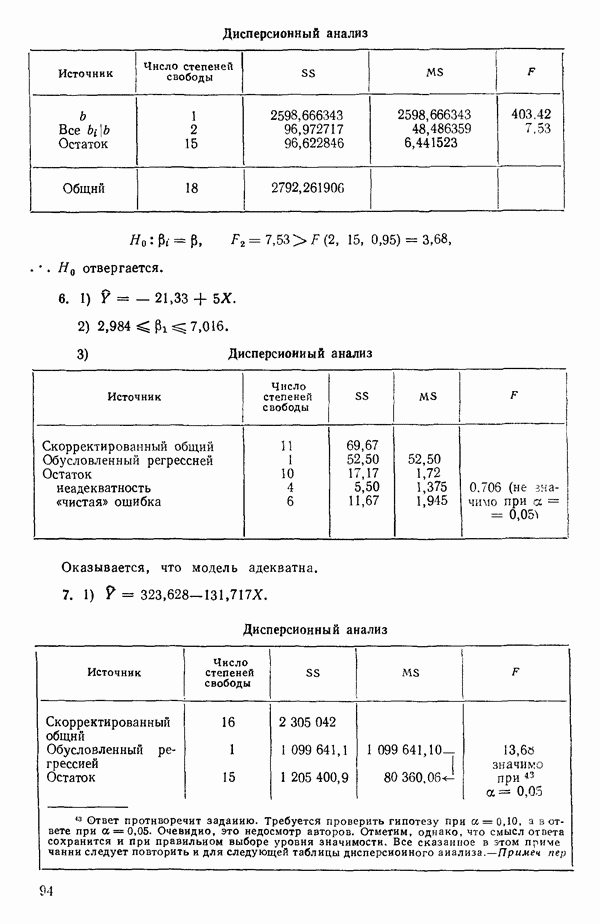
простого или специального вида.
Дадим теперь общее изложение методов линейной регрессии. Для ознакомления с теоретическим обоснованием этих результатов читатель может обратиться, например, к книге: Plackett R. L. Regression Analysis.- Oxford: Clarendon Press, 1960.
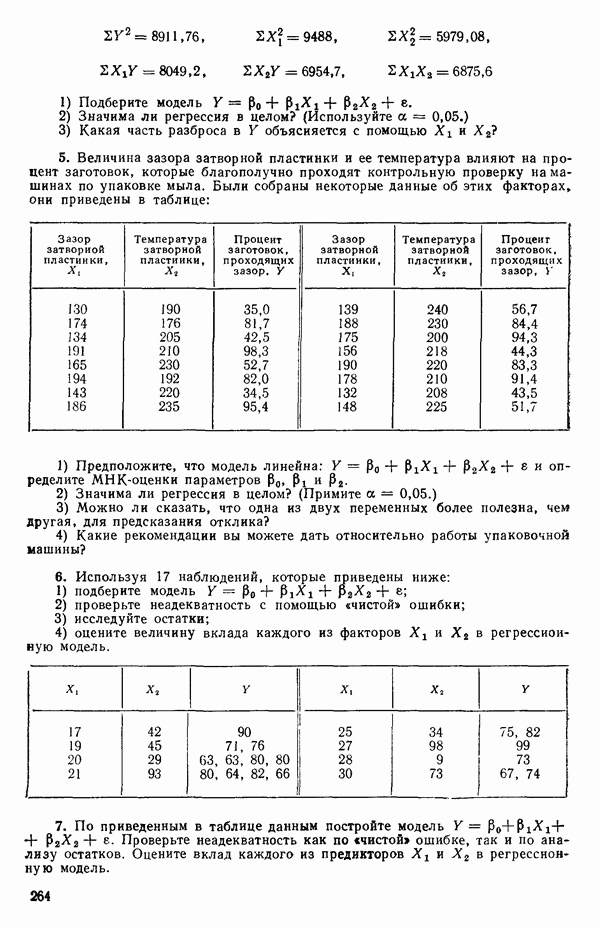
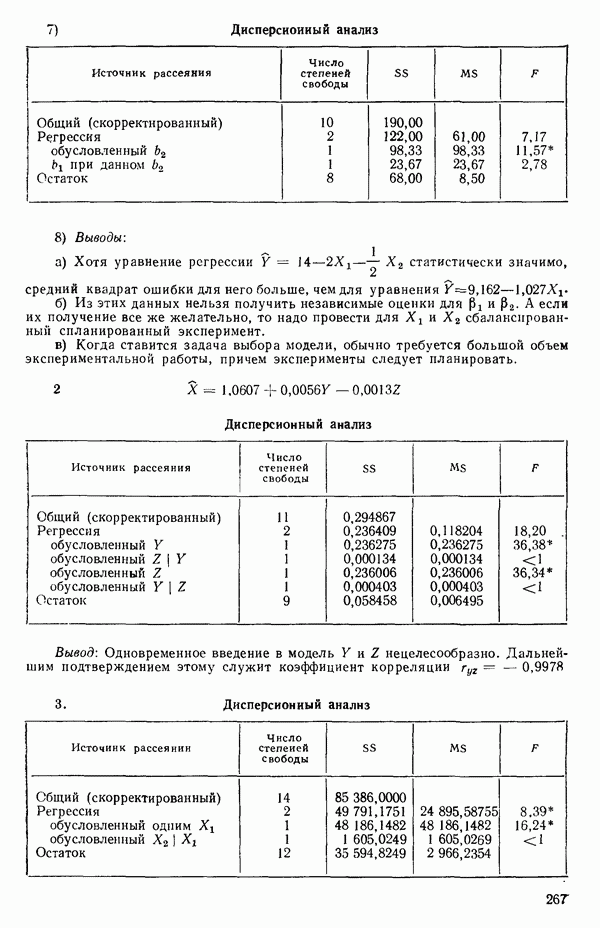
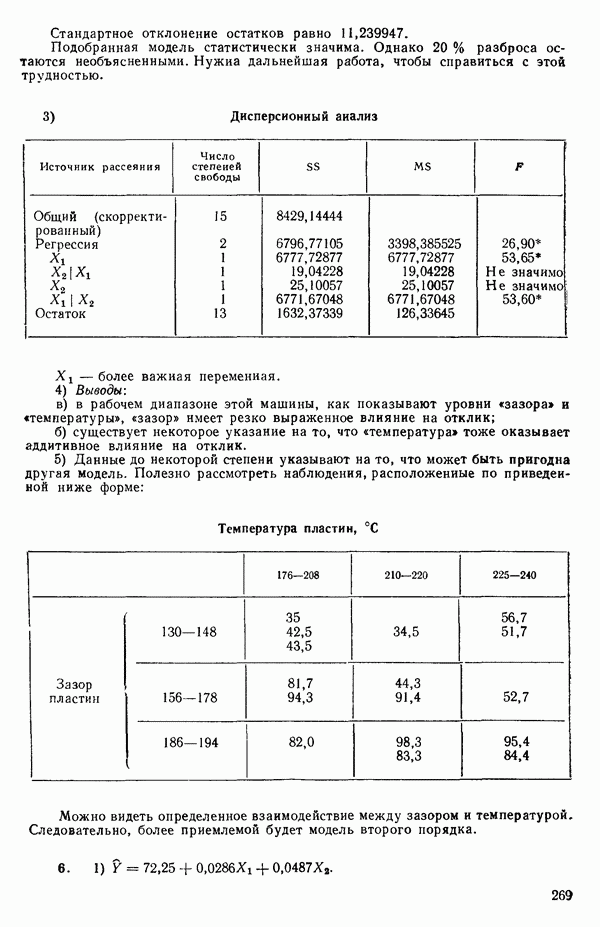
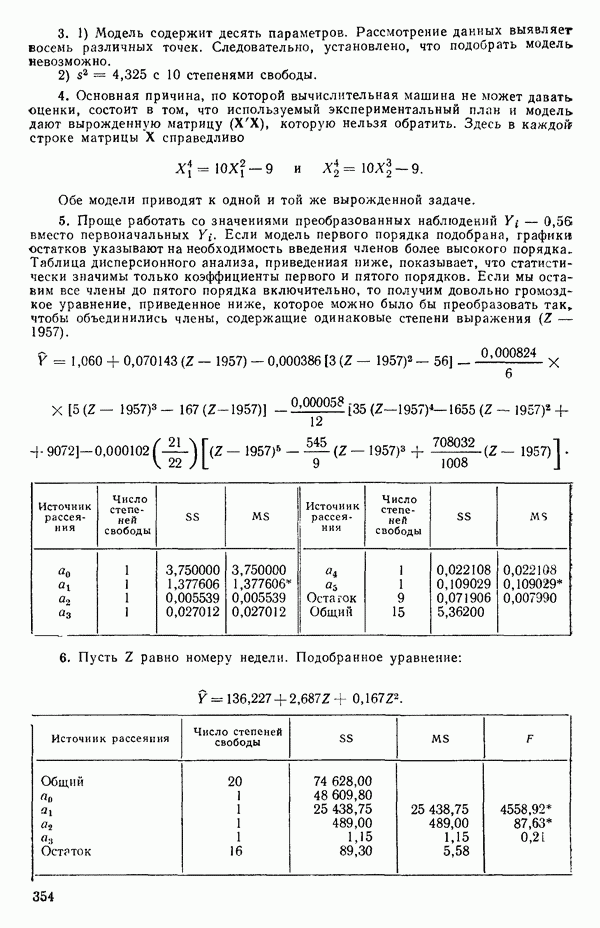
Предположим, что мы имеем модель, подлежащую исследованию, и она может быть представлена в виде

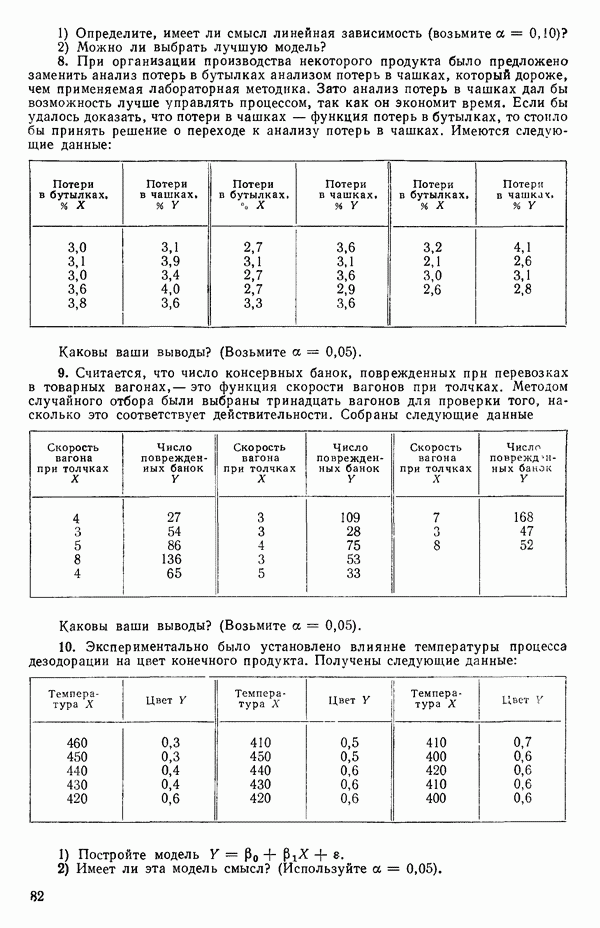
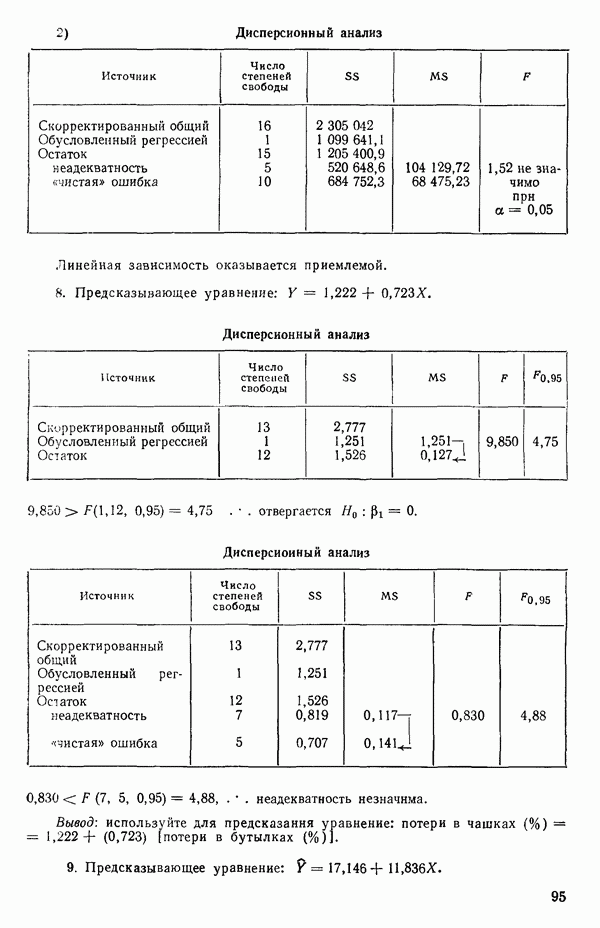
где  -вектор наблюдений;
-вектор наблюдений;  -матрица с известными численными элементами;
-матрица с известными численными элементами;  -вектор параметров;
-вектор параметров;  -вектор ошибок и где
-вектор ошибок и где  так что элементы вектора
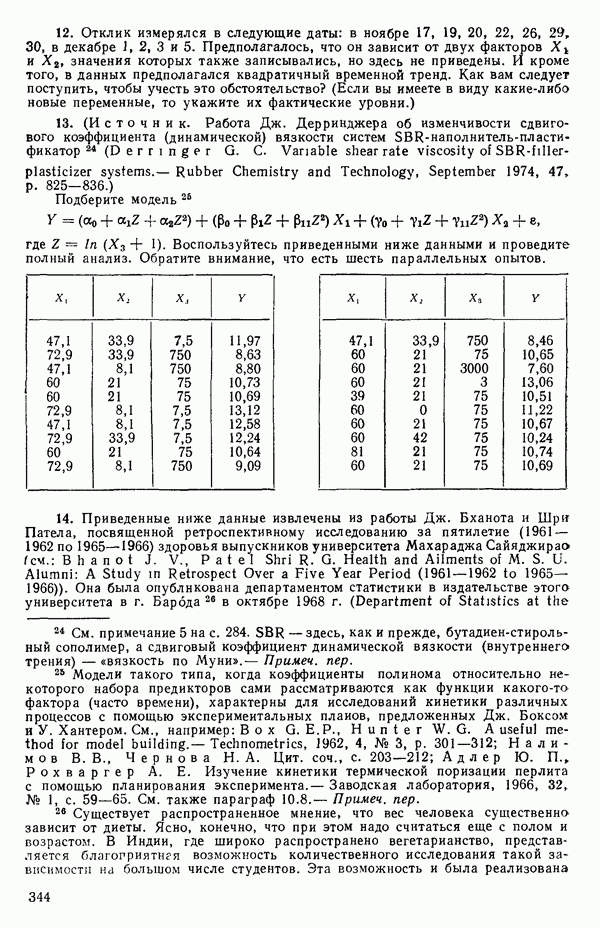
так что элементы вектора  некоррелированы.
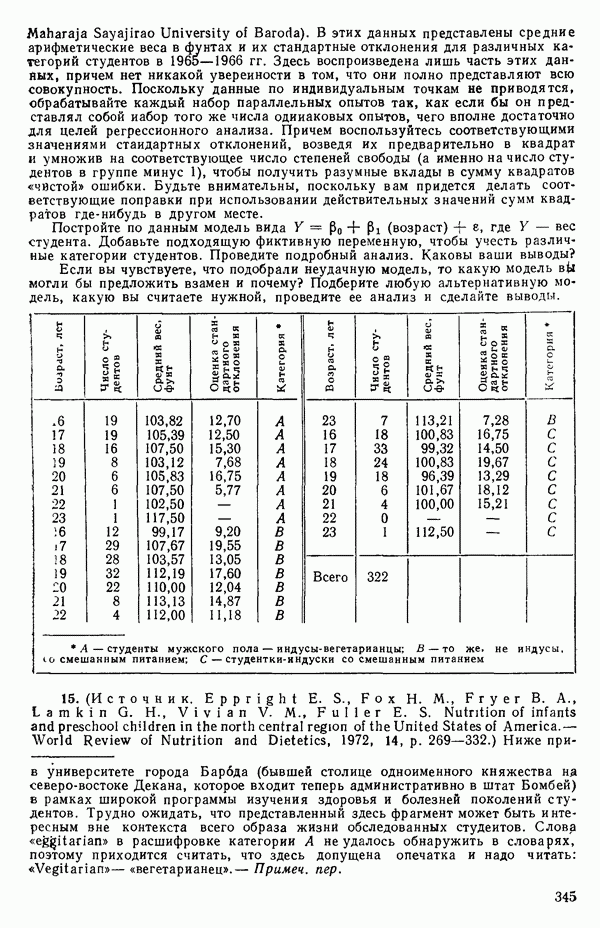
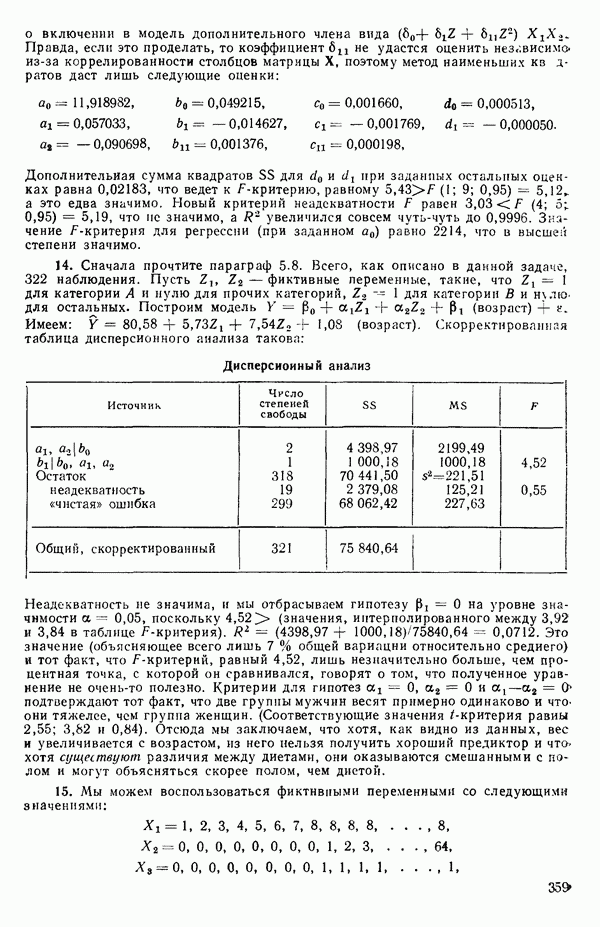
некоррелированы.
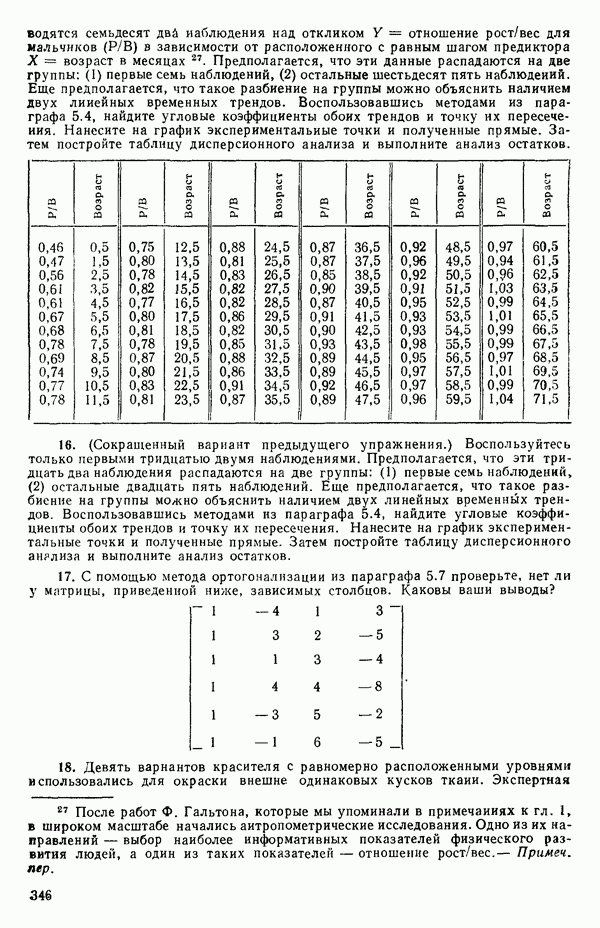
Поскольку  альтернативная форма записи модели имеет вид
альтернативная форма записи модели имеет вид

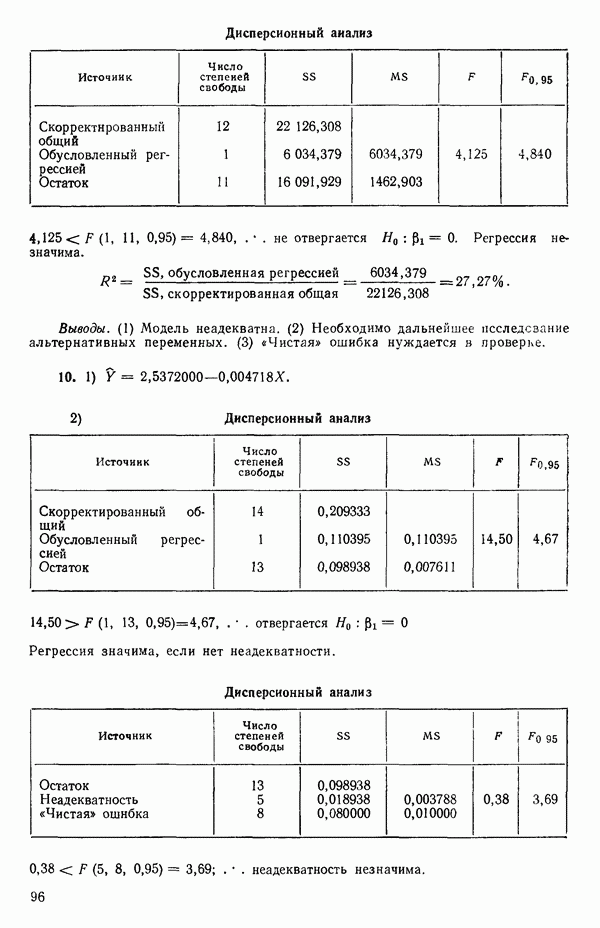
Сумма квадратов ошибок равна:

(Это вытекает из того, что  есть
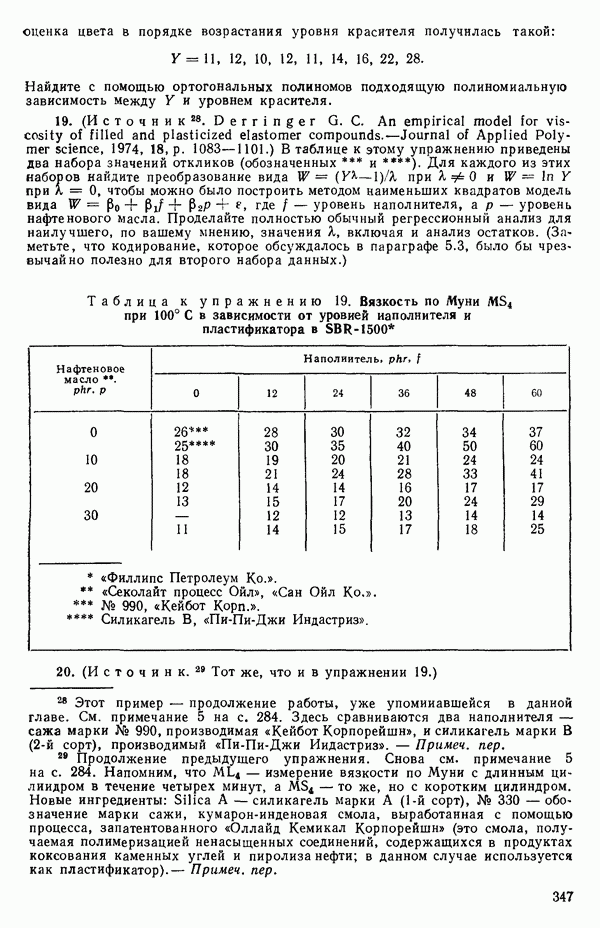
есть  -матрица или скаляр;
-матрица или скаляр;  транспонирование ничего не изменяет
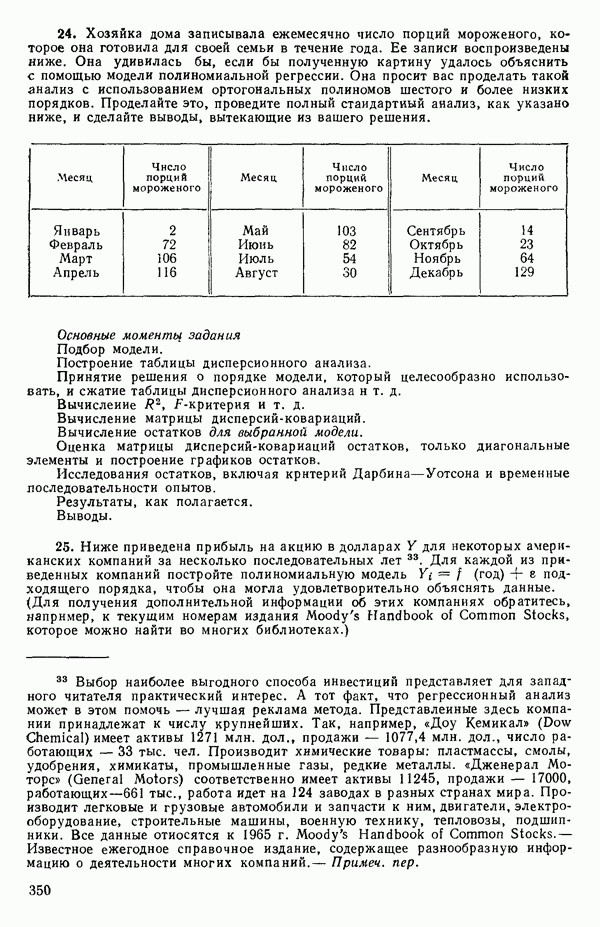
транспонирование ничего не изменяет 
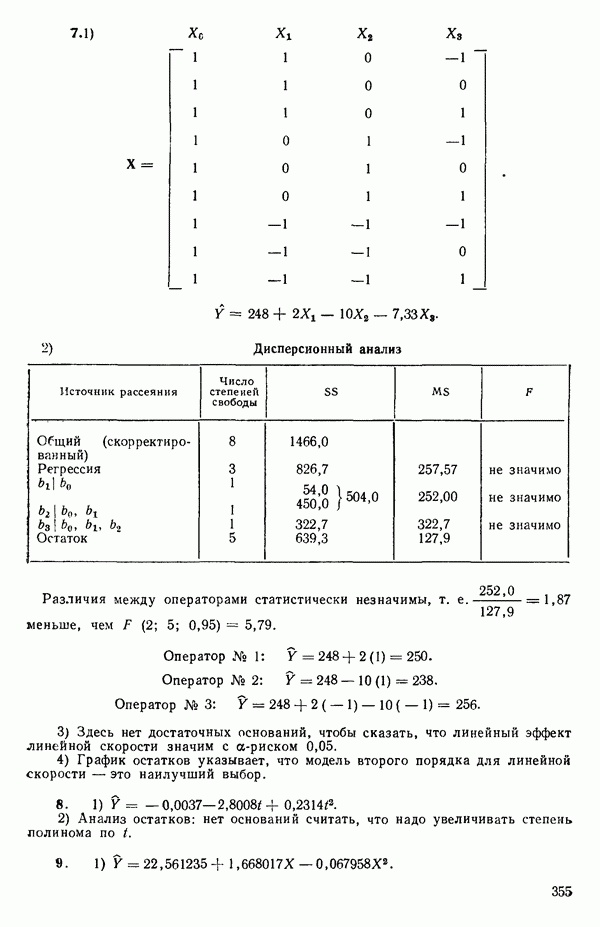
МНК-оценка вектора Р есть вектор  который при подстановке в (2.6.2) доставляет минимум величине ее. Эту оценку можно найти, дифференцируя выражение (2.6.2) по Р и приравнивая результирующее матричное выражение к нулевому вектору. Причем надо заменить
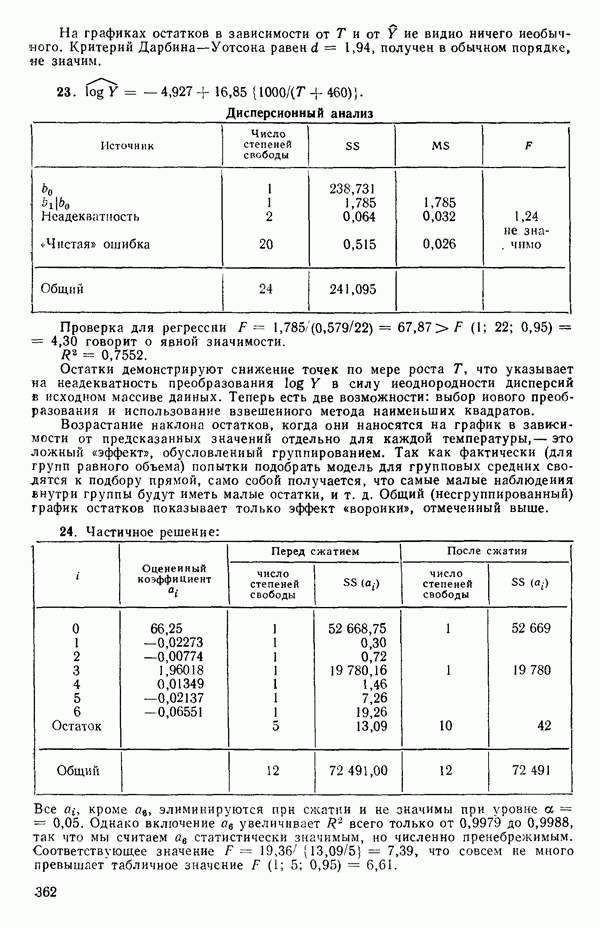
который при подстановке в (2.6.2) доставляет минимум величине ее. Эту оценку можно найти, дифференцируя выражение (2.6.2) по Р и приравнивая результирующее матричное выражение к нулевому вектору. Причем надо заменить  на
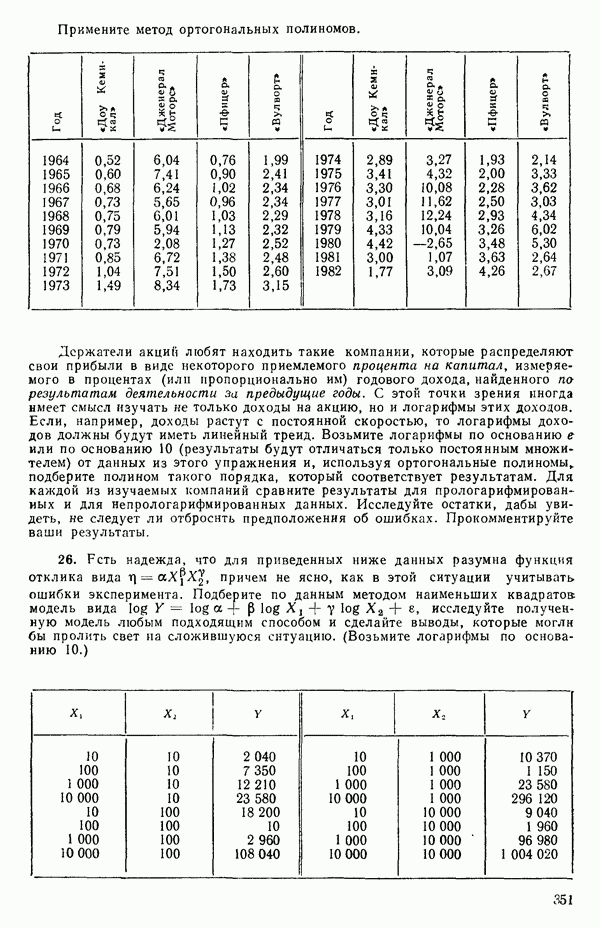
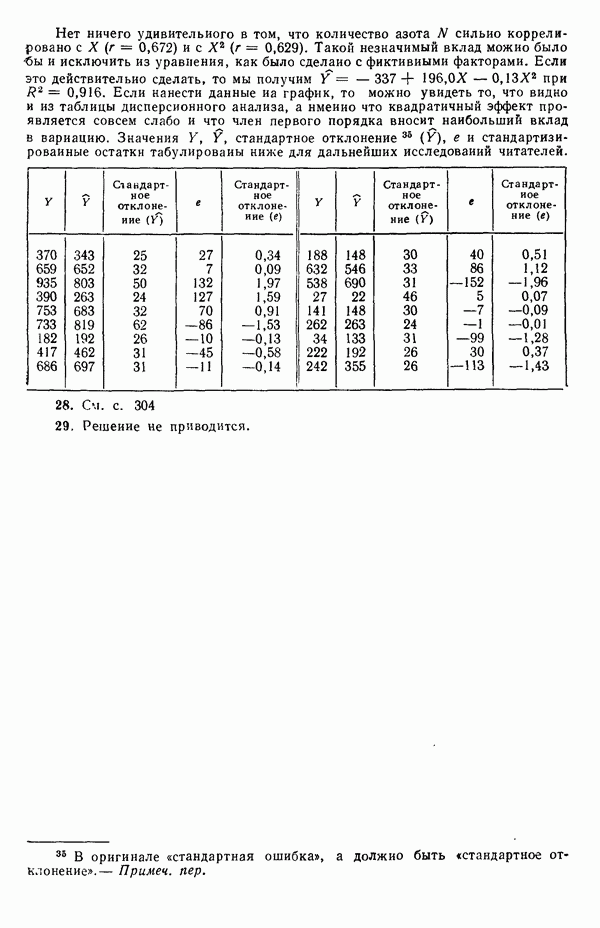
на  (Дифференцирование ее по вектору
(Дифференцирование ее по вектору  эквивалентно ее диффеоенцированию отдельно по каждому элементу вектора, последовательной записи получаемых выражений (одно под другим) с дальнейшим переписыванием последних в матричном виде.) Отсюда получаются нормальные уравнения
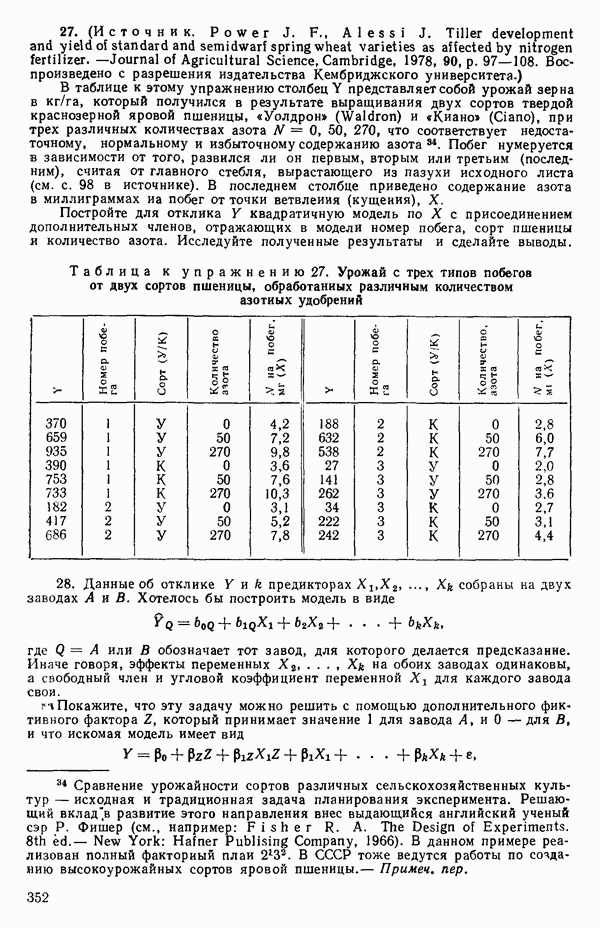
эквивалентно ее диффеоенцированию отдельно по каждому элементу вектора, последовательной записи получаемых выражений (одно под другим) с дальнейшим переписыванием последних в матричном виде.) Отсюда получаются нормальные уравнения

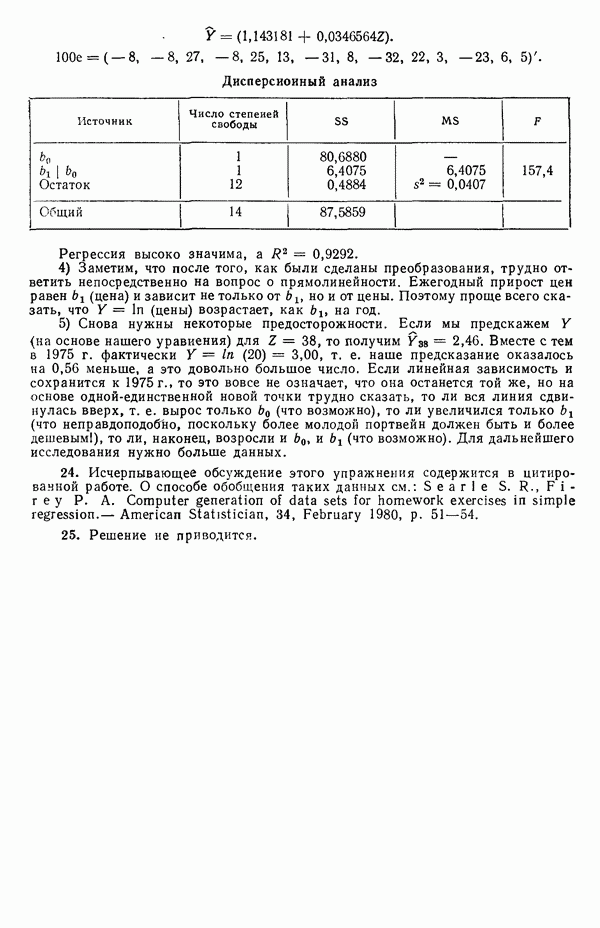
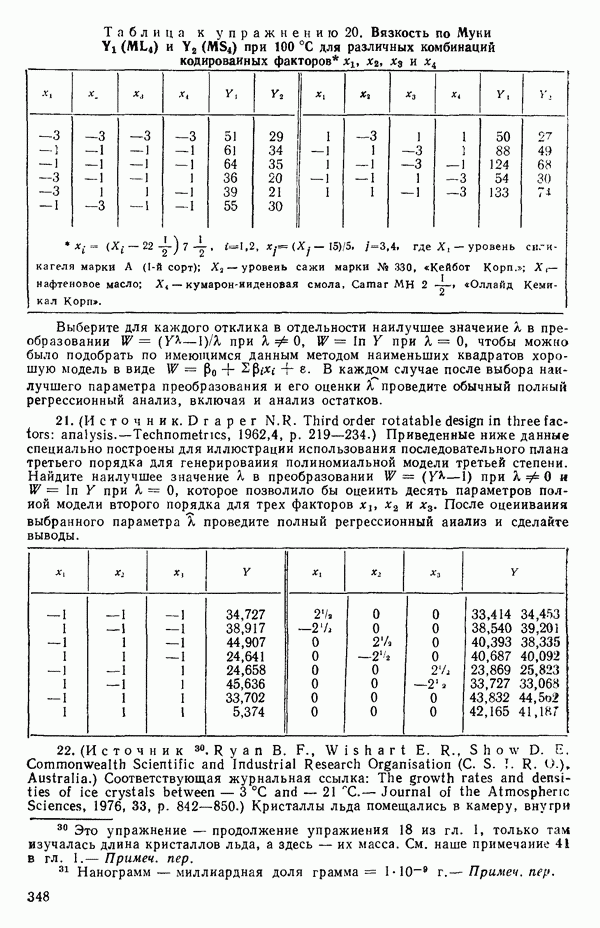
Встречаются два основных случая: либо уравнение (2.6.3) содержит  независимых уравнений относительно
независимых уравнений относительно  неизвестных параметров, либо некоторые уравнения зависят от других и тогда независимых уравнений будет меньше, чем неизвестных величин, подлежащих определению. Если некоторые нормальные уравнения зависят от других, то матрица
неизвестных параметров, либо некоторые уравнения зависят от других и тогда независимых уравнений будет меньше, чем неизвестных величин, подлежащих определению. Если некоторые нормальные уравнения зависят от других, то матрица  особенная, и потому
особенная, и потому  не существует. В таком случае надо или выразить модель через меньшее число параметров, или выдвинуть дополнительные ограничения на параметры. Некоторые примеры такого рода рассматриваются в гл. 9. Если все нормальные уравнения независимы, то матрица
не существует. В таком случае надо или выразить модель через меньшее число параметров, или выдвинуть дополнительные ограничения на параметры. Некоторые примеры такого рода рассматриваются в гл. 9. Если все нормальные уравнения независимы, то матрица  неособенная и для нее существует обратная матрица. В этом случае решение нормальных уравнений может быть записано в виде
неособенная и для нее существует обратная матрица. В этом случае решение нормальных уравнений может быть записано в виде

Решение  обладает следующими свойствами:
обладает следующими свойствами:
1. Вектор  это оценка вектора
это оценка вектора  которая минимизирует сумму квадратов ошибок независимо от того, каков характер распределения этих ошибок.
которая минимизирует сумму квадратов ошибок независимо от того, каков характер распределения этих ошибок.
(Примечание. Предположение о том, что  есть нормально-распределенный вектор, не требуется для отыскания оценки
есть нормально-распределенный вектор, не требуется для отыскания оценки  но оно
но оно
необходимо в дальнейшем для того, чтобы можно было использовать такие статистические критерии, как  и
и  -критерии, поскольку они опираются на предположение о нормальности, или для получения доверительных интервалов, которые в свою очередь базируются на
-критерии, поскольку они опираются на предположение о нормальности, или для получения доверительных интервалов, которые в свою очередь базируются на  и
и  -распределениях.)
-распределениях.)
2. Элементы вектора  линейные функции наблюдений
линейные функции наблюдений  представляют собой несмещенные оценки элементов вектора
представляют собой несмещенные оценки элементов вектора  обладающие минимальными дисперсиями (среди любых линейных функций наблюдений, являющихся несмещенными оценками) безотносительно к характеру распределения ошибок.
обладающие минимальными дисперсиями (среди любых линейных функций наблюдений, являющихся несмещенными оценками) безотносительно к характеру распределения ошибок.
(Примечание. Предположим, что мы имеем выражение  которое есть линейная функция наблюдений
которое есть линейная функция наблюдений  и что мы используем в качестве оценки параметра
и что мы используем в качестве оценки параметра  Тогда Т — случайная величина с распределением, зависящим от распределения величин
Тогда Т — случайная величина с распределением, зависящим от распределения величин  Если мы будем многократно повторять выборки из совокупности величин
Если мы будем многократно повторять выборки из совокупности величин  и вычислять соответствующие значения Т, то в результате будем генерировать распределение величин Т эмпирически. Независимо от того, есть у нас такое распределение или нет, распределение величин Т будет иметь некоторое определенное среднее значение, допускающее запись в виде
и вычислять соответствующие значения Т, то в результате будем генерировать распределение величин Т эмпирически. Независимо от того, есть у нас такое распределение или нет, распределение величин Т будет иметь некоторое определенное среднее значение, допускающее запись в виде  и дисперсию, которую можно обозначить как
и дисперсию, которую можно обозначить как  Если среднее распределения величин Т равно параметру
Если среднее распределения величин Т равно параметру  оцениваемому с помощью Т, т. е. если
оцениваемому с помощью Т, т. е. если  то мы говорим, что Т есть несмещенный «оцениватель» 0. Термином «оцениватель» обычно пользуются, если речь идет о теоретическом выражении для Т исходя из выборки величин
то мы говорим, что Т есть несмещенный «оцениватель» 0. Термином «оцениватель» обычно пользуются, если речь идет о теоретическом выражении для Т исходя из выборки величин  Конкретное численное значение величин Т следует называть несмещенной оценкой параметра
Конкретное численное значение величин Т следует называть несмещенной оценкой параметра  Хотя это определение и корректно, оно не всегда применяется в статистических работах. Если мы имеем все возможные линейные функции
Хотя это определение и корректно, оно не всегда применяется в статистических работах. Если мы имеем все возможные линейные функции  скажем, от
скажем, от  наблюдений
наблюдений  и если Т удовлетворяют условию
и если Т удовлетворяют условию

т. е. все они суть несмещенные оцениватели величины 0, то одна из них с наименьшей величиной из  есть несмещенный оцениватель параметра
есть несмещенный оцениватель параметра  с наименьшей дисперсией (результат пункта 2 — это теорема Гаусса).)
с наименьшей дисперсией (результат пункта 2 — это теорема Гаусса).)
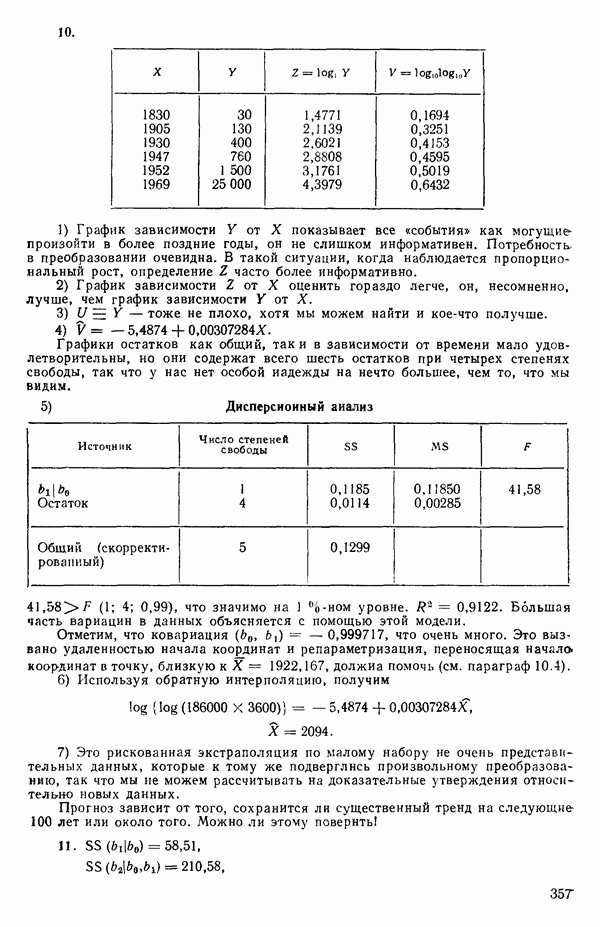
3. Если ошибки являются независимыми и  то
то  есть оценка максимального правдоподобия величины
есть оценка максимального правдоподобия величины  В векторных
В векторных
обозначениях мы можем записать  полагая, что
полагая, что  подчиняется
подчиняется  -мерному нормальному распределению с
-мерному нормальному распределению с  означает вектор, составляющие которого равны нулю, а размерность та же, что и у
означает вектор, составляющие которого равны нулю, а размерность та же, что и у  , т. е. этот вектор имеет матрицу дислерсий-ковариаций, все диагональные элементы которой
, т. е. этот вектор имеет матрицу дислерсий-ковариаций, все диагональные элементы которой  равны
равны  а внедиагональные элементы, представляющие собой ковариациисоу
а внедиагональные элементы, представляющие собой ковариациисоу  все равны нулю. Функция правдоподобия для выборки из наблюдений
все равны нулю. Функция правдоподобия для выборки из наблюдений  определяется в этом случае как произведение
определяется в этом случае как произведение

Таким образом, при фиксированной величине  максимизация функции правдоподобия эквивалентна минимизации величины ее. Отметим, что этот факт может рассматриваться как обоснование метода наименьших квадратов (т. е. процедуры минимизации суммы квадратов ошибок), поскольку во многих физических ситуациях предположение о нормальном характере распределения ошибок довольно благоразумно. Во всяком случае мы будем выяснять, не нарушается ли это предположение, исследуя остатки в рамках регрессионного анализа. Если, однако, имеются определенные априорные сведения о распределении ошибок (из теоретических соображений или из определенных знаний об изучаемом процессе), то использование принципа максимального правдоподобия для отыскания оценок может привести к критерию, отличному от суммы квадратов ошибок. Например, предположим, что ошибки
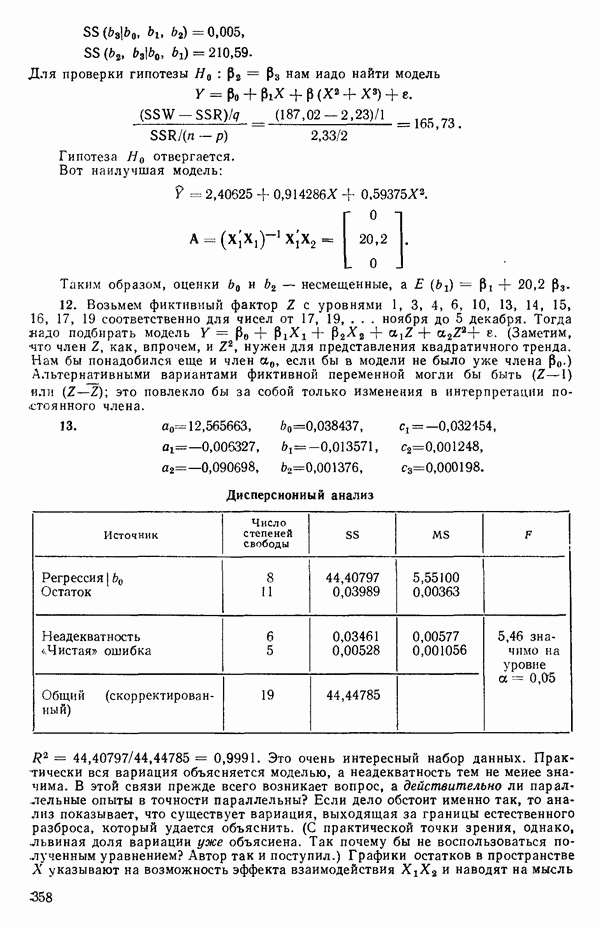
максимизация функции правдоподобия эквивалентна минимизации величины ее. Отметим, что этот факт может рассматриваться как обоснование метода наименьших квадратов (т. е. процедуры минимизации суммы квадратов ошибок), поскольку во многих физических ситуациях предположение о нормальном характере распределения ошибок довольно благоразумно. Во всяком случае мы будем выяснять, не нарушается ли это предположение, исследуя остатки в рамках регрессионного анализа. Если, однако, имеются определенные априорные сведения о распределении ошибок (из теоретических соображений или из определенных знаний об изучаемом процессе), то использование принципа максимального правдоподобия для отыскания оценок может привести к критерию, отличному от суммы квадратов ошибок. Например, предположим, что ошибки  были бы независимыми и следовали бы двустороннему экспоненциальному распределению
были бы независимыми и следовали бы двустороннему экспоненциальному распределению

а не нормальному распределению

которое обычно предполагается. Плотность двустороннего экспоненциального распределения имеет при  заостренный пик высотой
заостренный пик высотой  и убывает до нуля, когда стремится к
и убывает до нуля, когда стремится к  или —
или —  Тогда применение принципа максимума правдоподобия для оценивания вектора
Тогда применение принципа максимума правдоподобия для оценивания вектора  при фиксированном
при фиксированном  свелось бы к минимизации суммы абсолютных значений ошибок
свелось бы к минимизации суммы абсолютных значений ошибок  а не суммы квадратов ошибок
а не суммы квадратов ошибок  Для более детального ознакомления с минимизацией суммы
Для более детального ознакомления с минимизацией суммы
абсолютных значений ошибок см. статью: Gеnt1е J. Е. Communications Statistics- Simulated Computations. 1977, В 6 (4), p. 313- 328.
Вычислительные аспекты рассмотрены в публикациях: Gentle J. Е., Kennedy W. J., Sposito V. A. (Fortran) Algorithm AS 110. Lp norm fit of a straight line.- Applied Statistics, 1977, 26, p. 114-118; Naru1a S. C., We11ingtоn J. F. (Fortran) Algorithm AS 108, Multiple linear regression with minimum sum of absolute errors. - Applied Statistics, 1977, 26, p. 106-111.