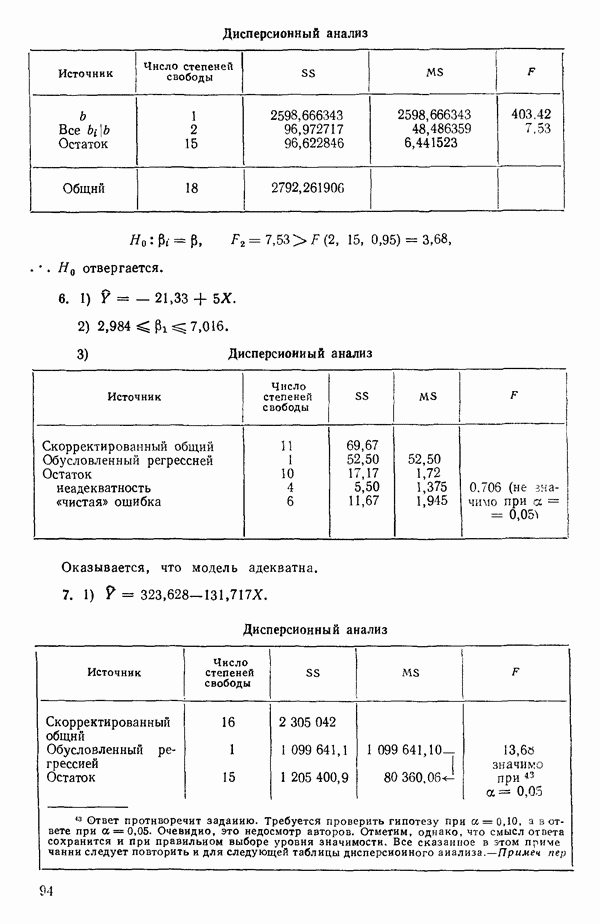
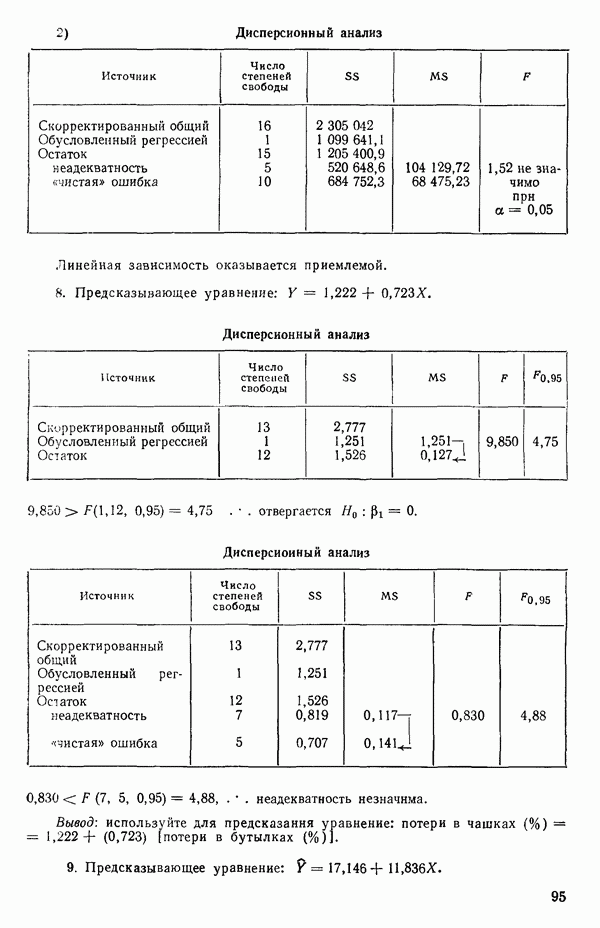
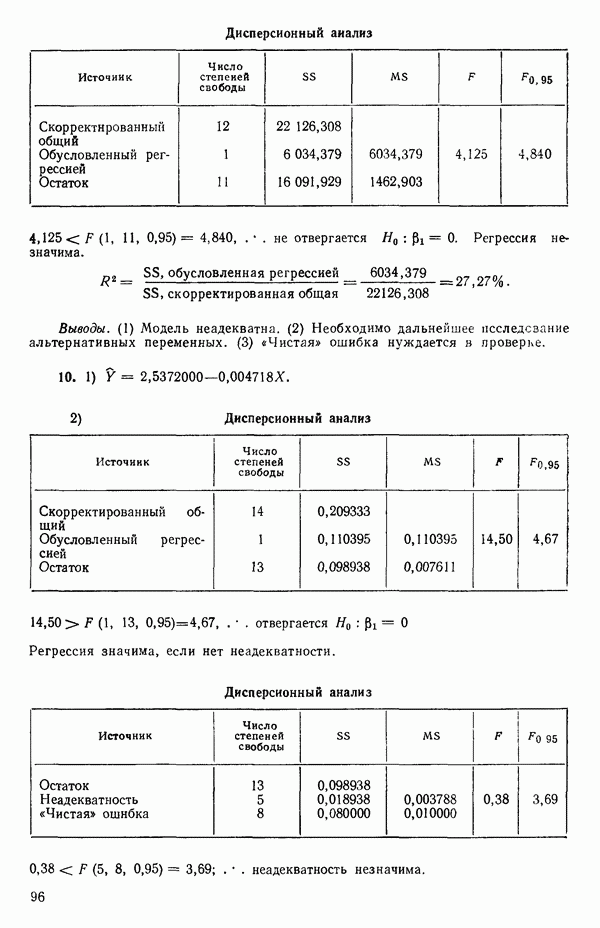
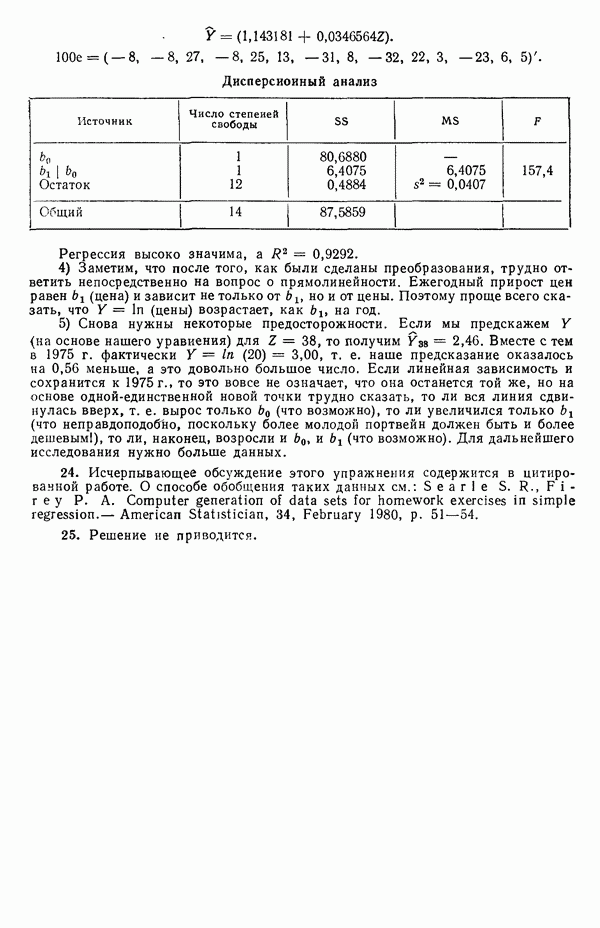
распределение вероятностей со средним  и дисперсией
и дисперсией  Если даже это для X и не совсем так, во многих практических ситуациях можно действовать так, как будто это верно. (Дальнейшее обсуждение см. в параграфе 2.14.)
Если даже это для X и не совсем так, во многих практических ситуациях можно действовать так, как будто это верно. (Дальнейшее обсуждение см. в параграфе 2.14.)
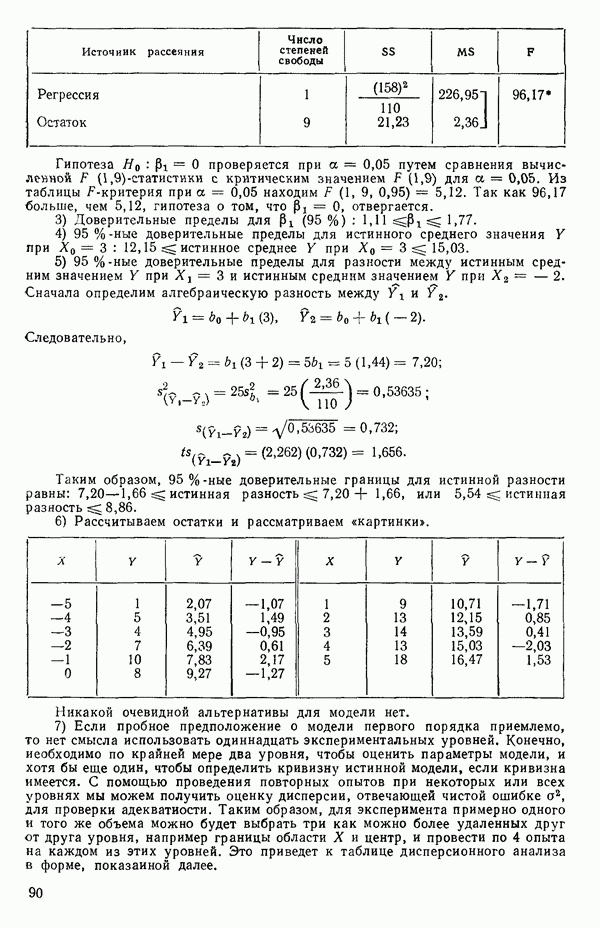
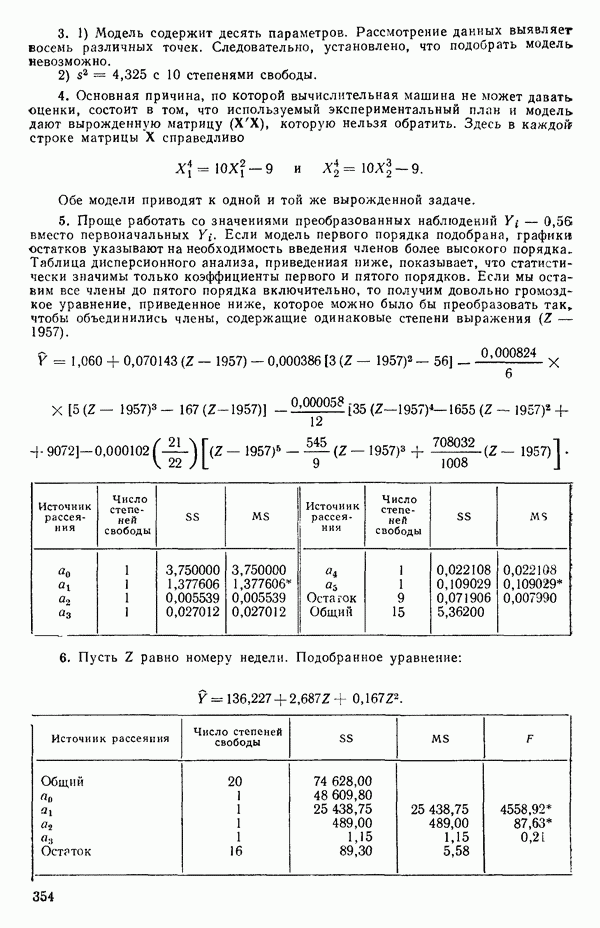
Теперь, для большей общности, рассмотрим две случайные величины, скажем,  с некоторым непрерывным совместным двумерным распределением вероятностей
с некоторым непрерывным совместным двумерным распределением вероятностей  Тогда мы определим коэффициент корреляции между
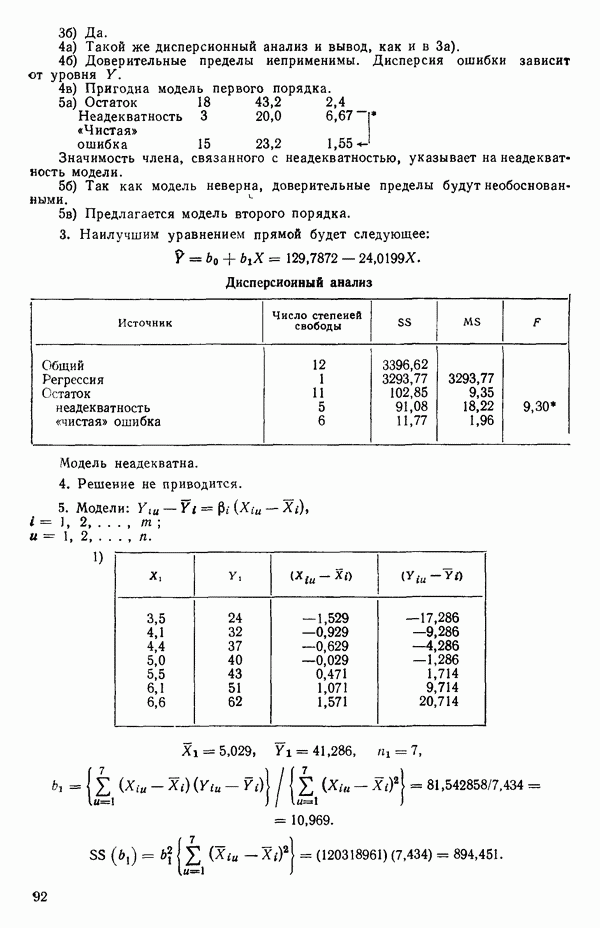
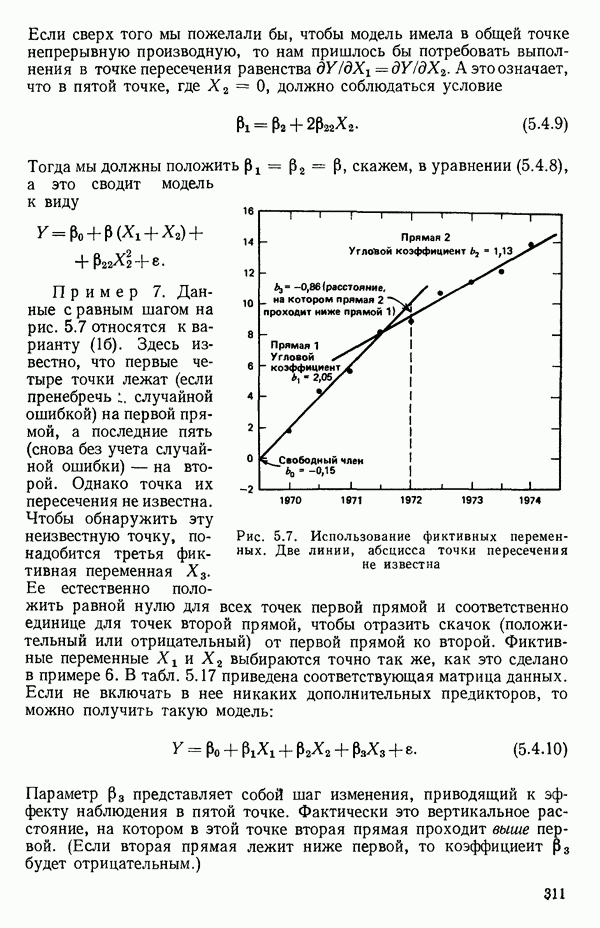
Тогда мы определим коэффициент корреляции между  как
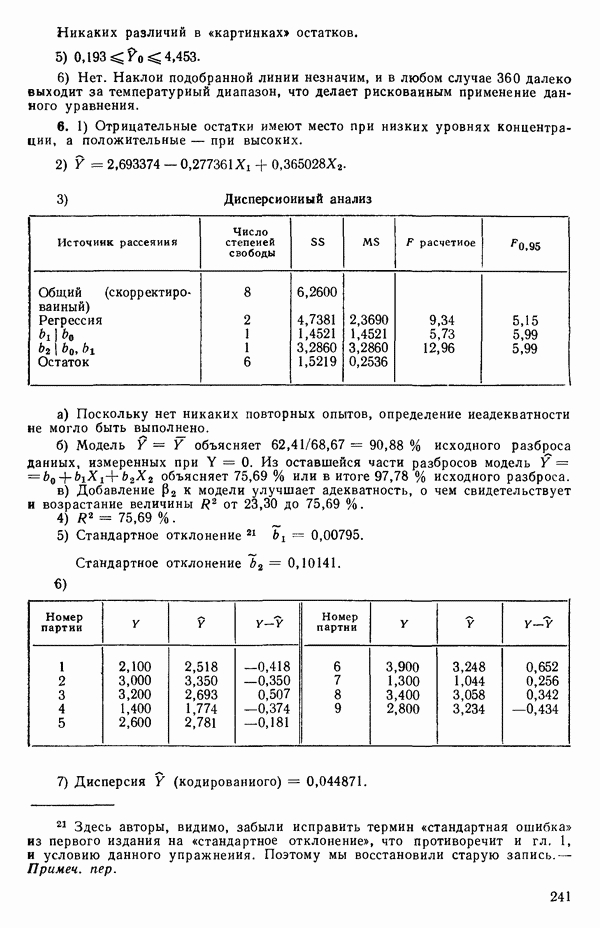
как

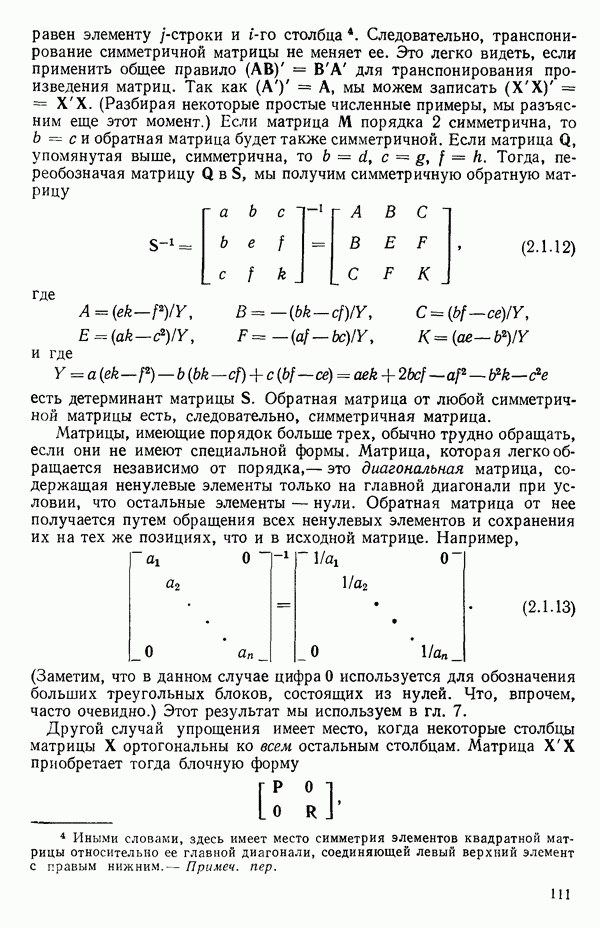
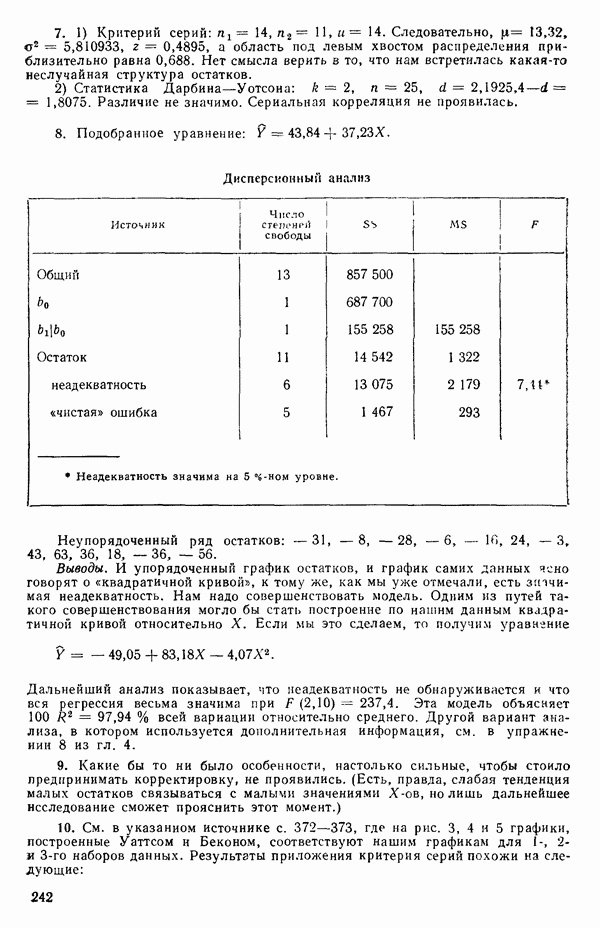
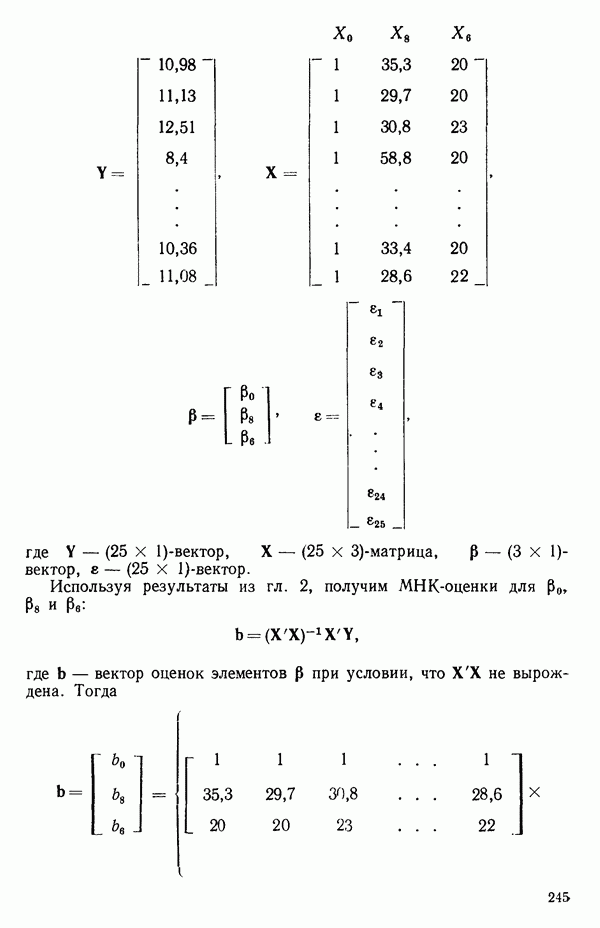
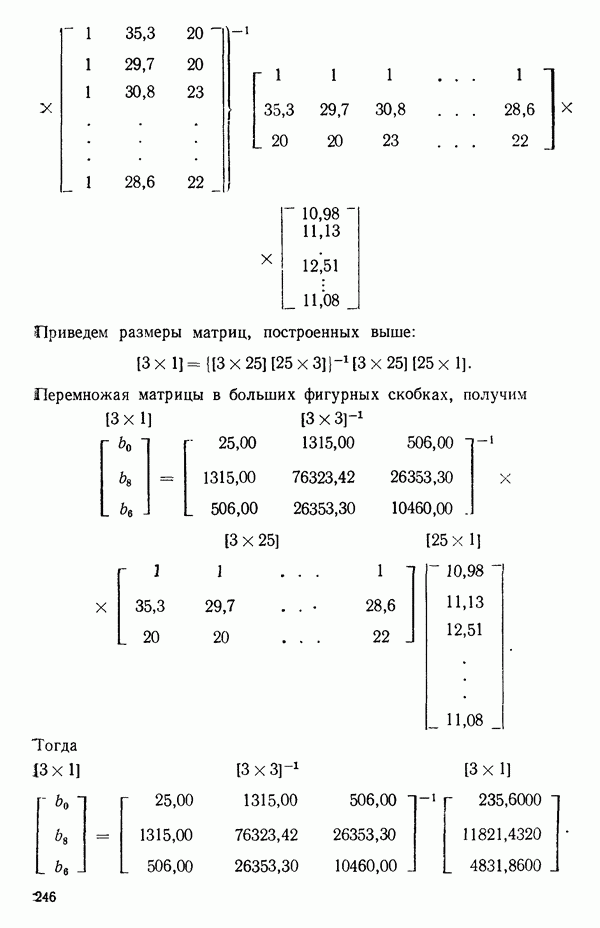
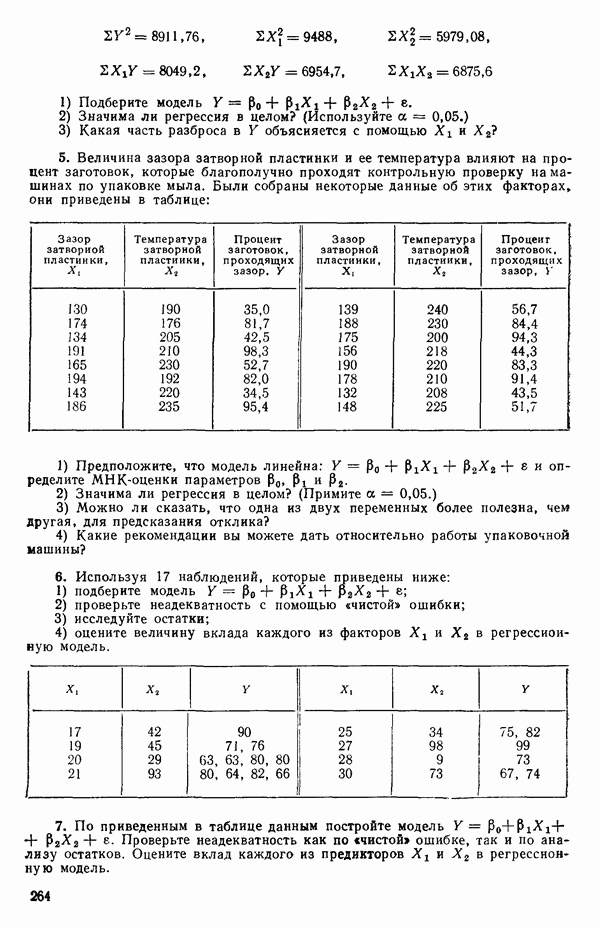
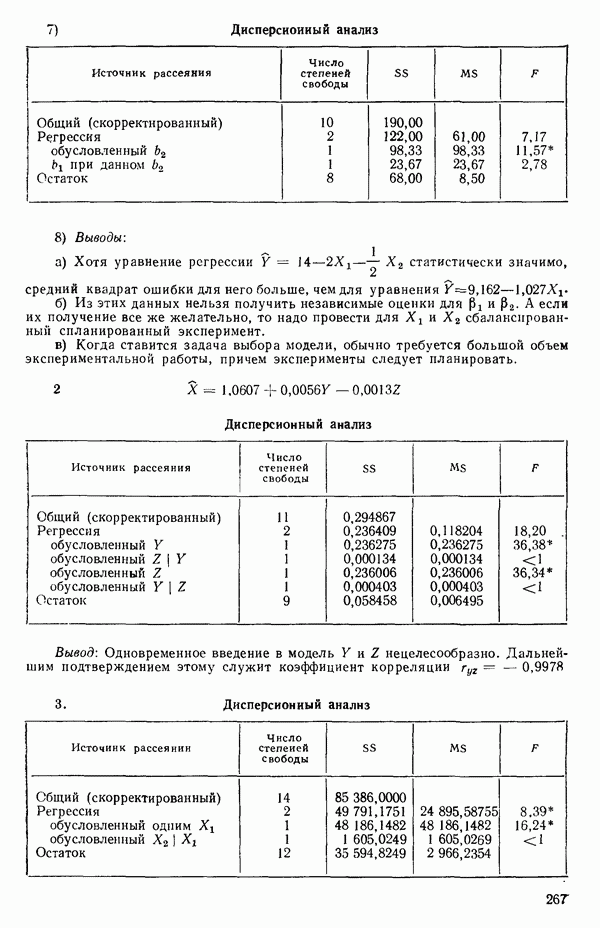
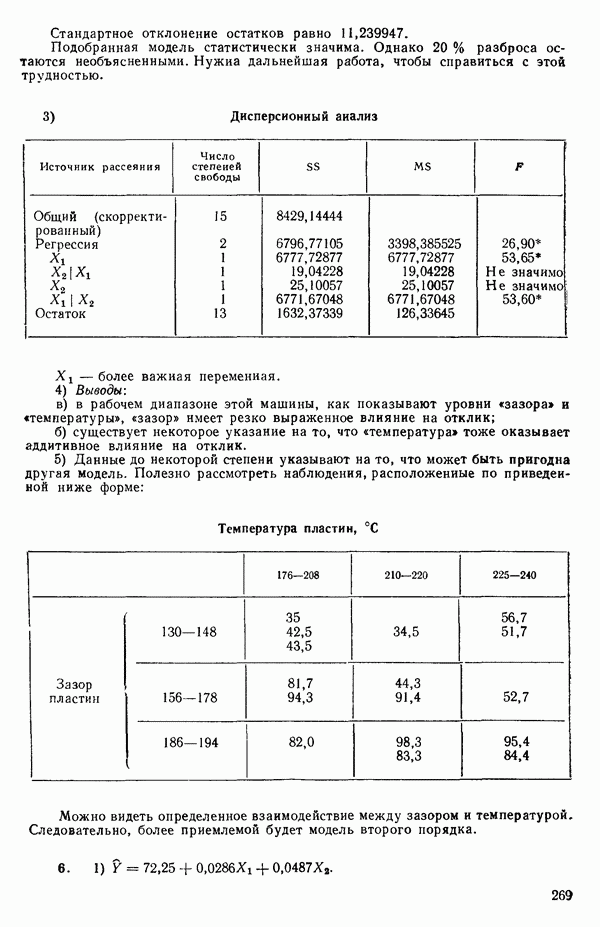
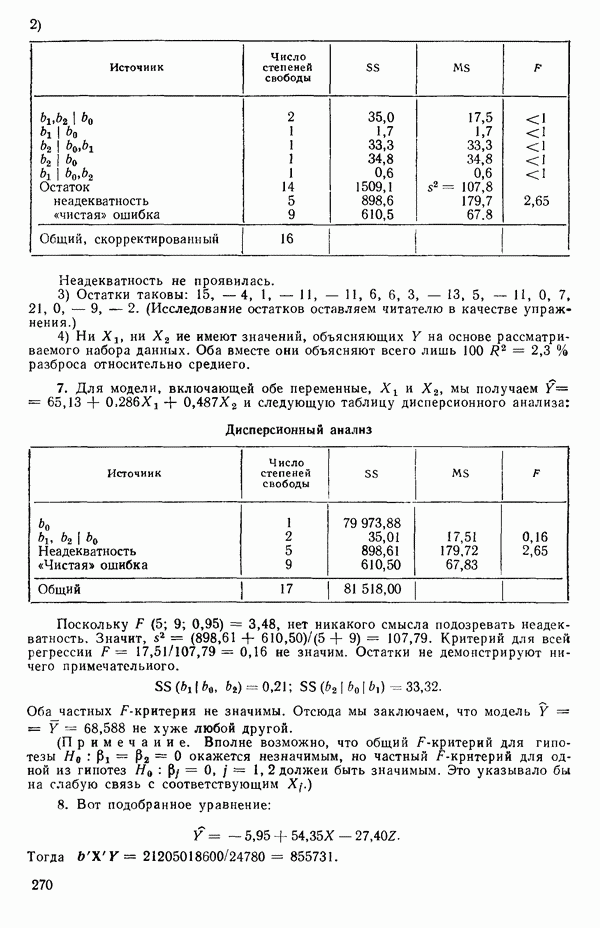
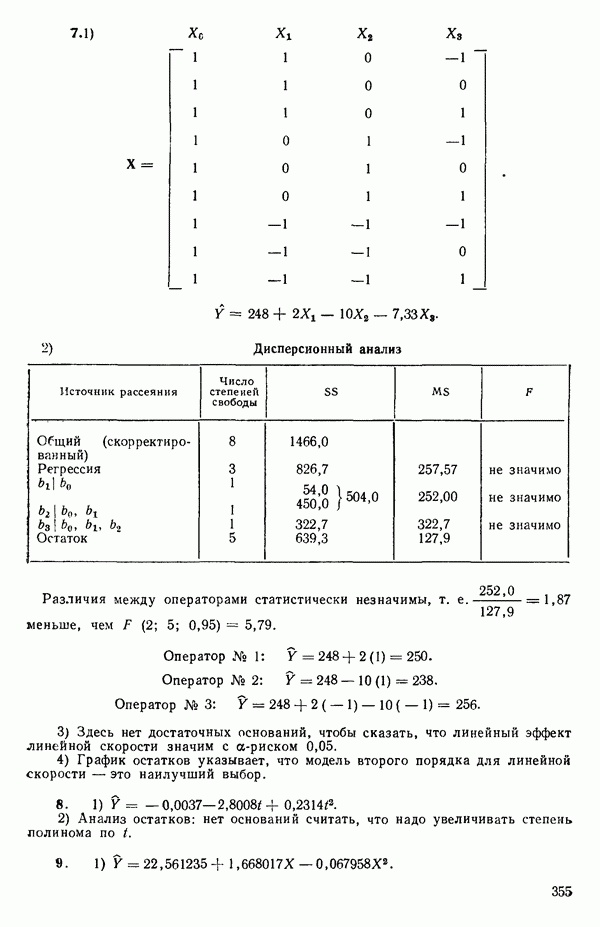
где

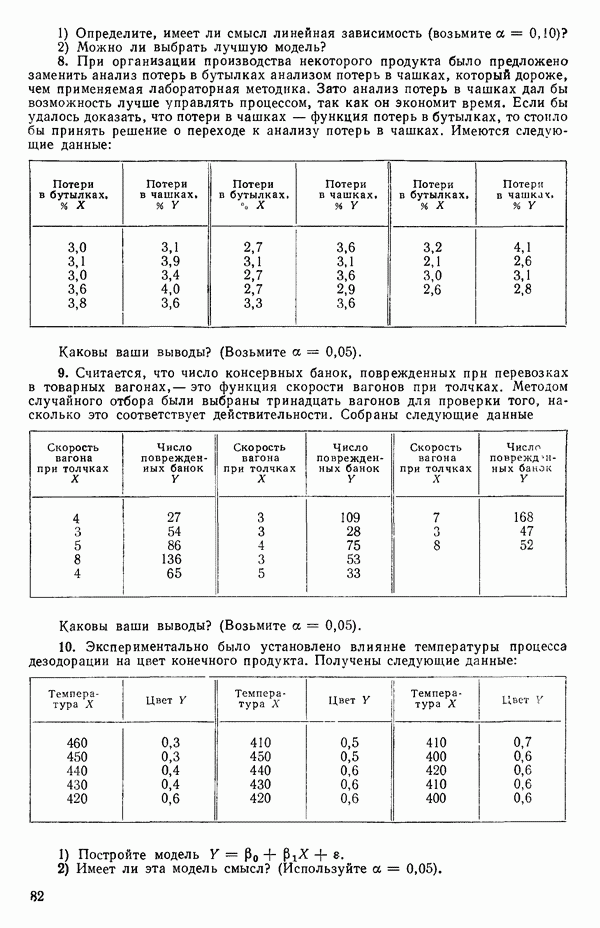
и

а

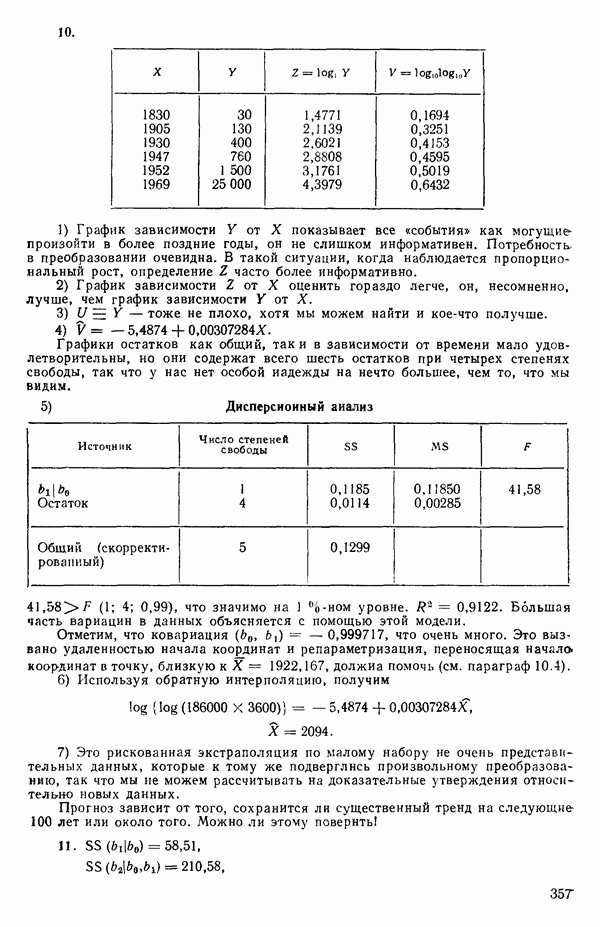
Значения  и
и  определяются аналогично в терминах
определяются аналогично в терминах  (Если распределения дискретны, то, как обычно, интегрирование заменяется суммированием.)
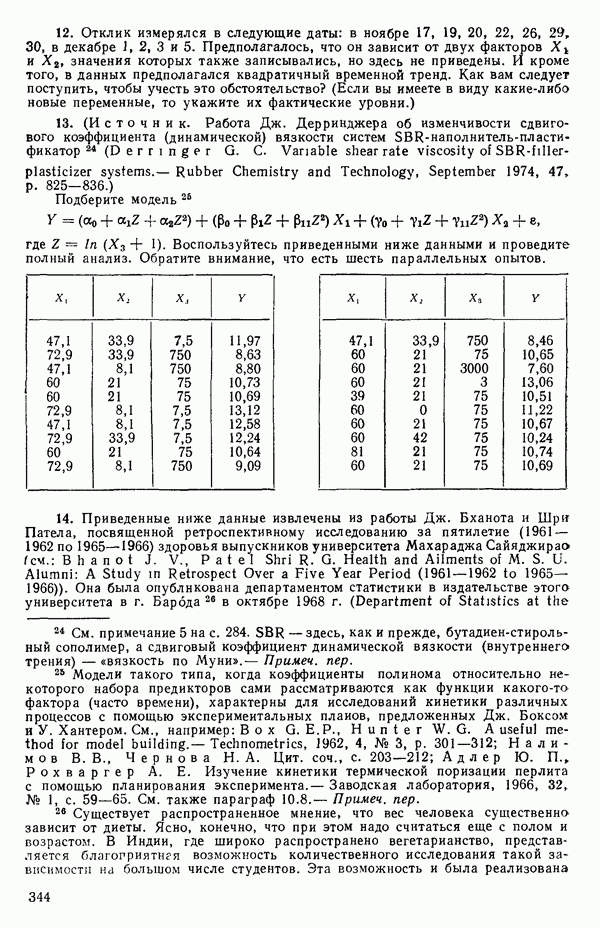
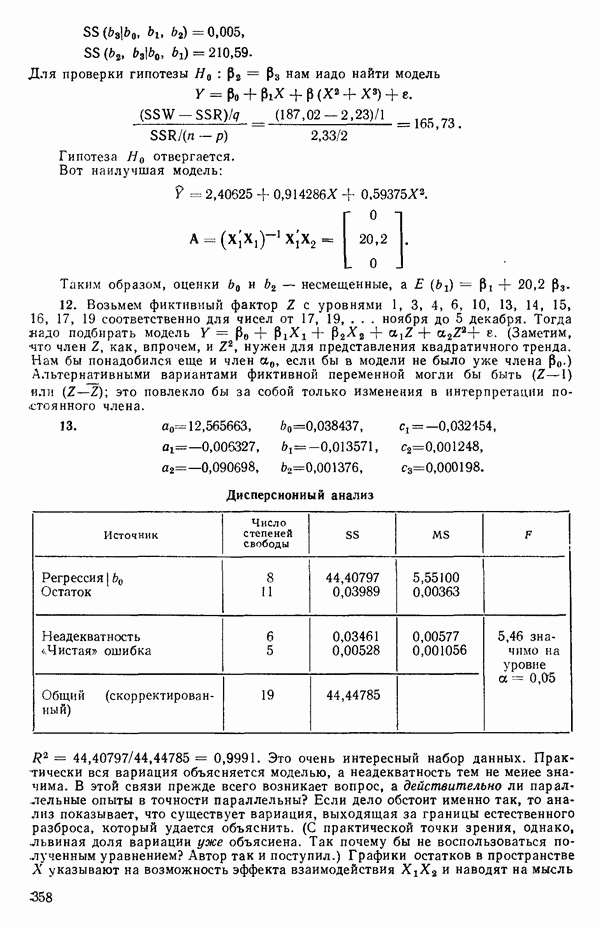
(Если распределения дискретны, то, как обычно, интегрирование заменяется суммированием.)
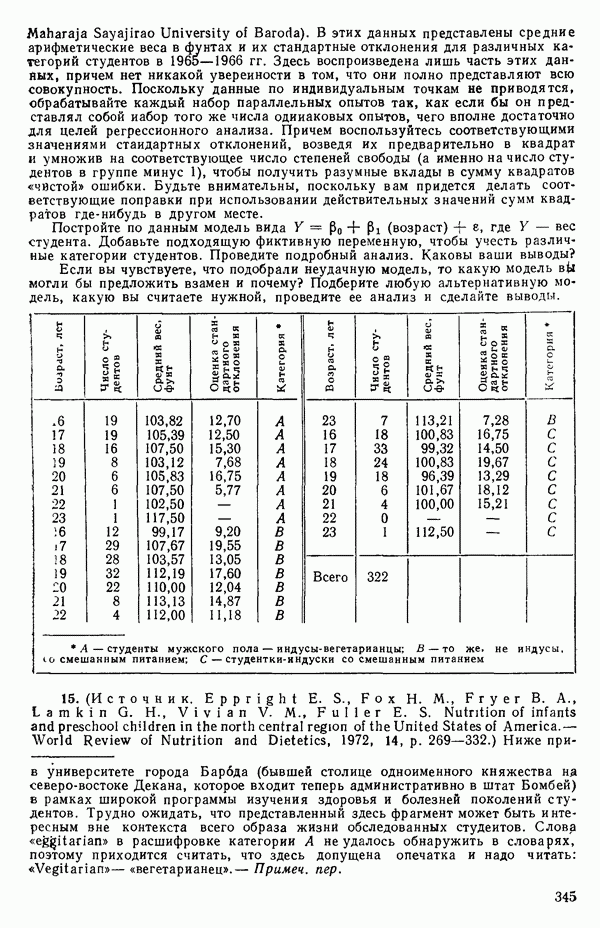
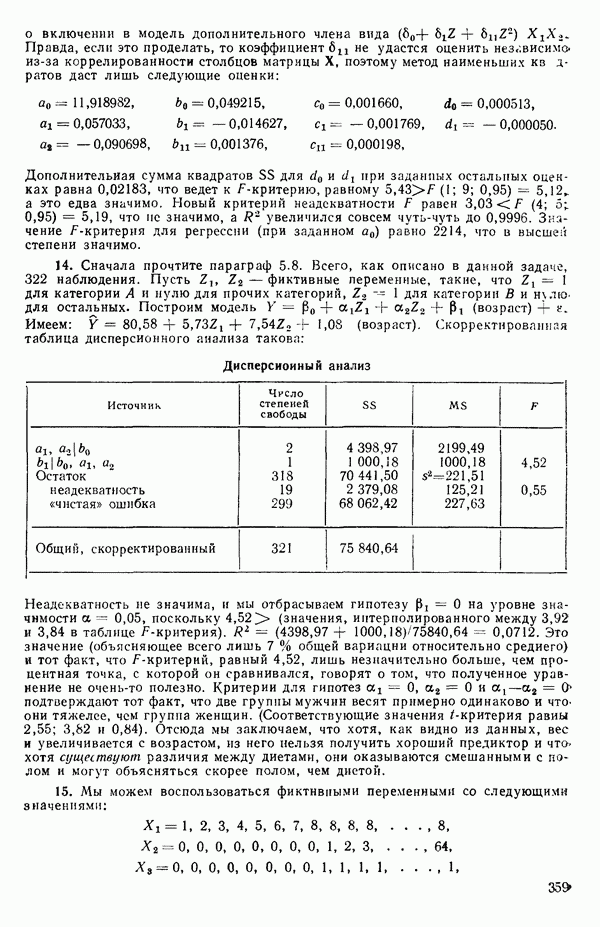
Можно показать, что —  Величина
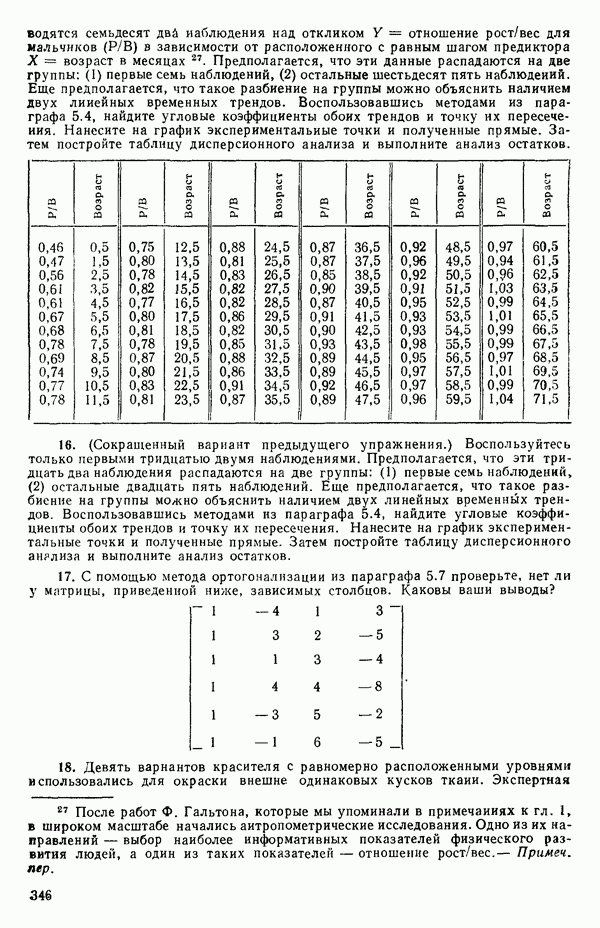
Величина  служит мерой линейной зависимости между случайными величинами
служит мерой линейной зависимости между случайными величинами  Если, например,
Если, например,  то
то  идеально положительно коррелированы и все возможные значения и
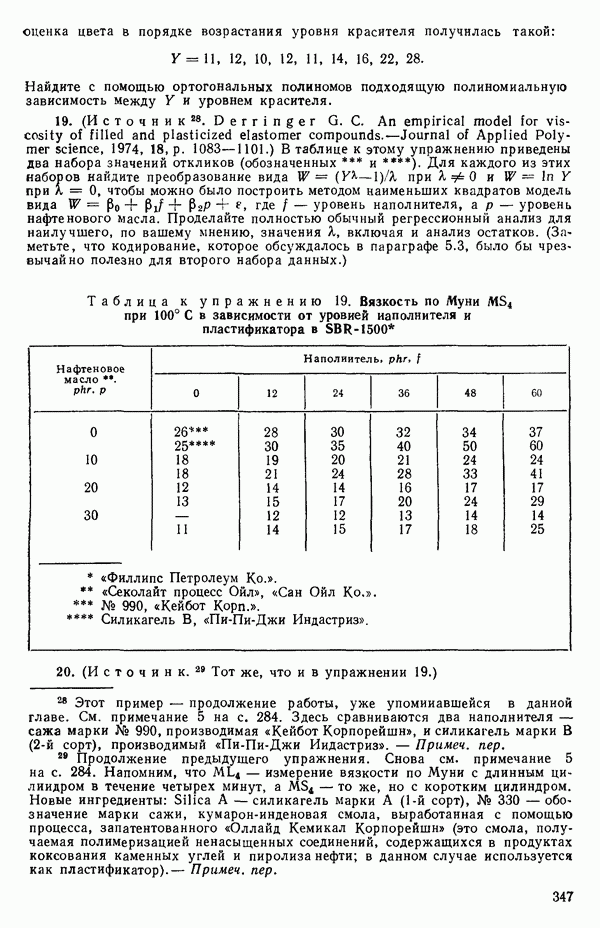
идеально положительно коррелированы и все возможные значения и  лежат на прямой с положительным наклоном в плоскости
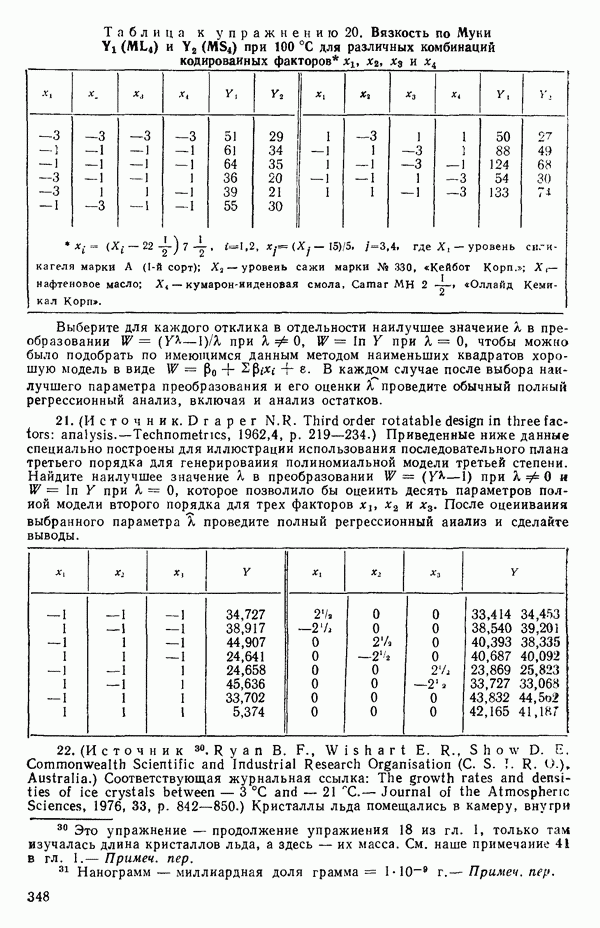
лежат на прямой с положительным наклоном в плоскости  Если же
Если же  то говорят, что величины не коррелированы, т. е. не связаны друг с другом линейно. Это не означает, что
то говорят, что величины не коррелированы, т. е. не связаны друг с другом линейно. Это не означает, что  статистически независимы, как можно узнать из любого элементарного учебника. Ну а если
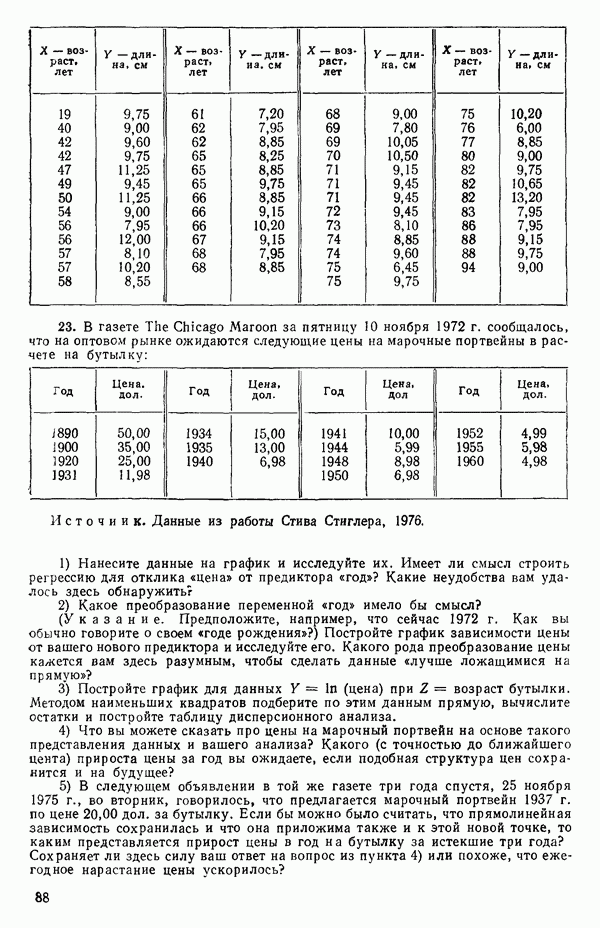
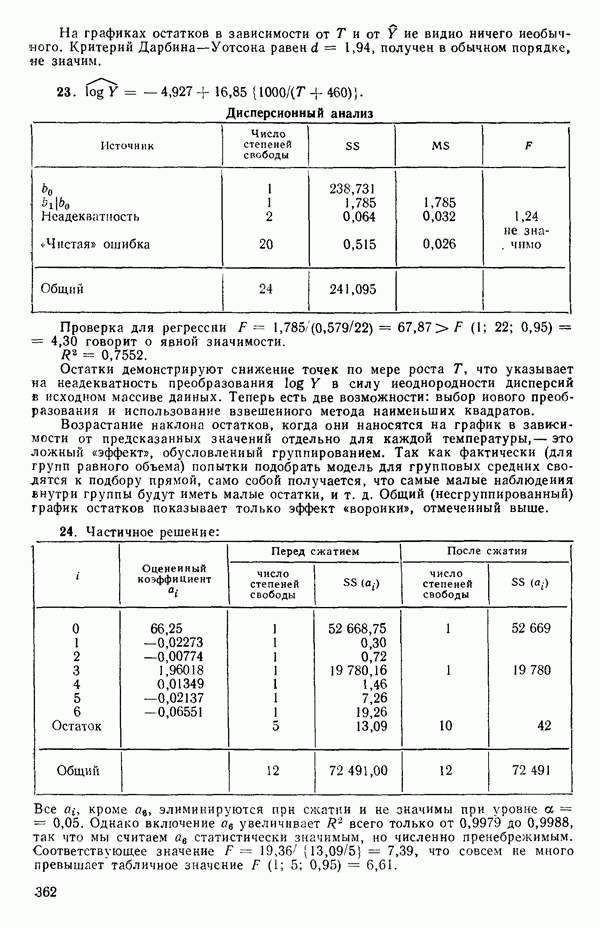
статистически независимы, как можно узнать из любого элементарного учебника. Ну а если  то
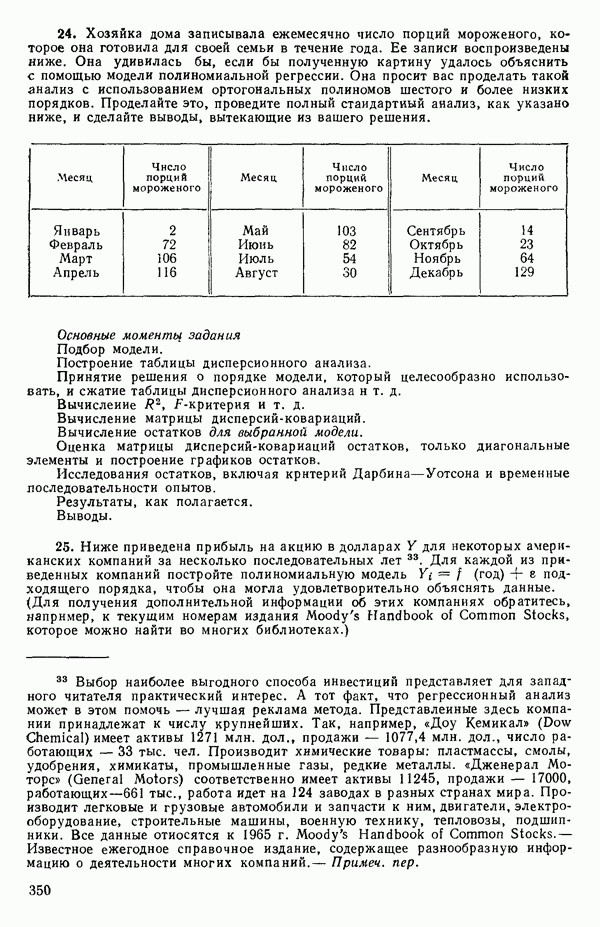
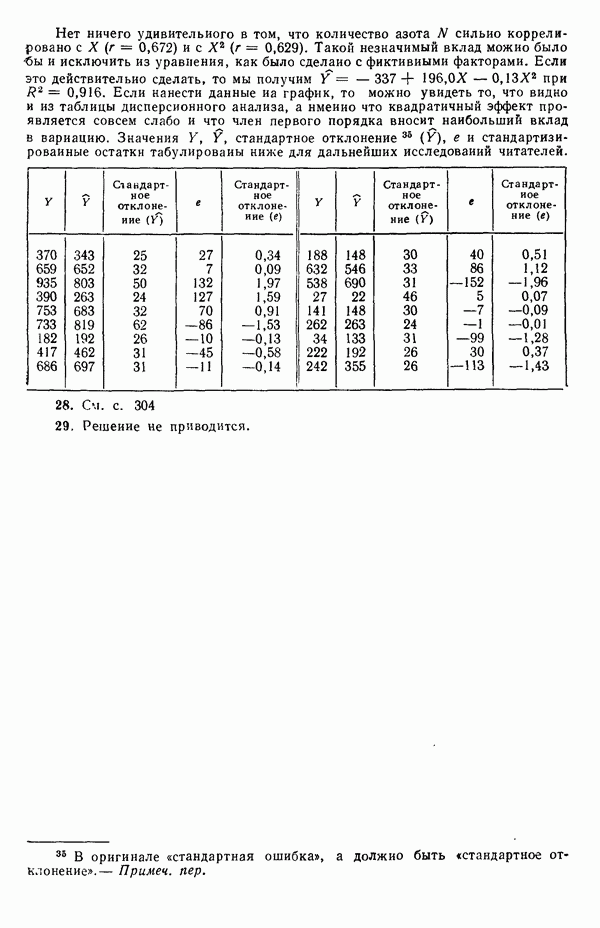
то  идеально отрицательно коррелированны и все возможные значения
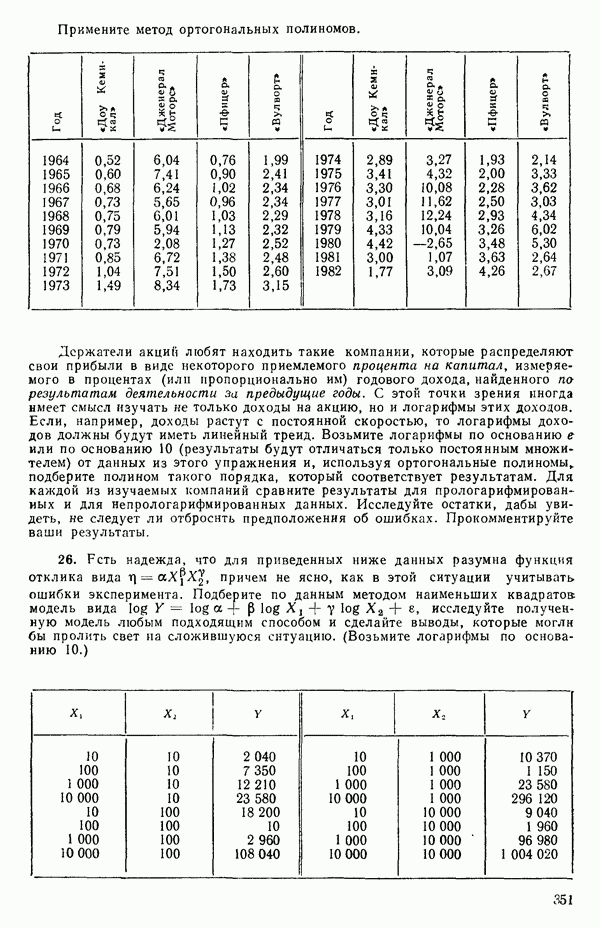
идеально отрицательно коррелированны и все возможные значения  снова лежат на прямой, на этот раз с отрицательным наклоном в плоскости
снова лежат на прямой, на этот раз с отрицательным наклоном в плоскости 
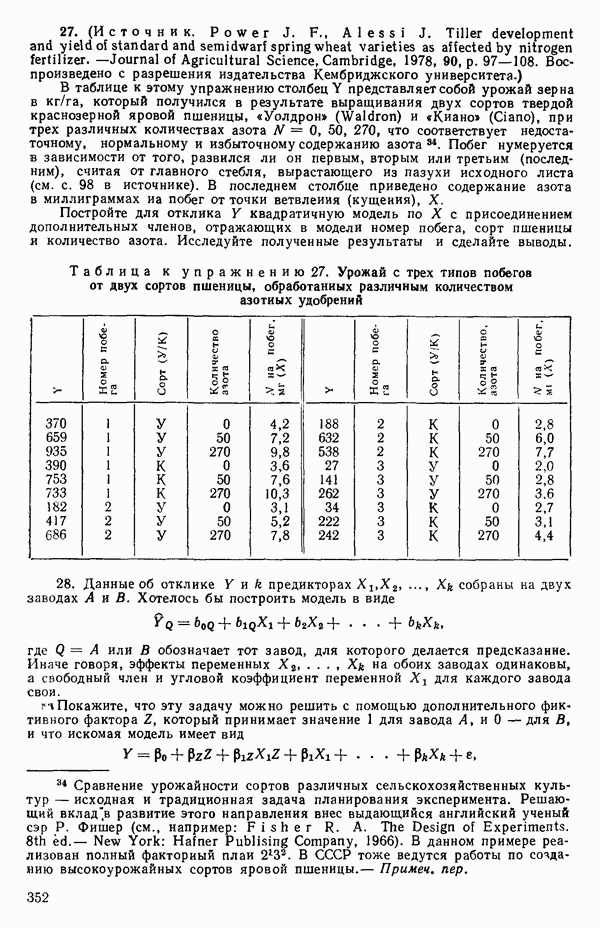
Если имеется выборка объема  из величин
из величин  с совместным распределением, то величина
с совместным распределением, то величина

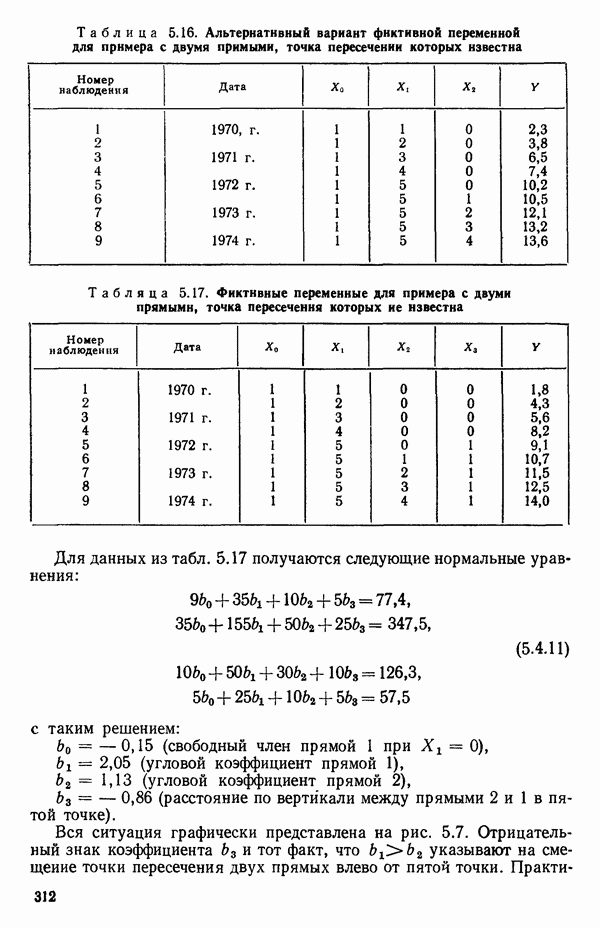
называемая выборочным коэффициентом корреляции между  оценивает
оценивает  и представляет собой эмпирическую
и представляет собой эмпирическую  линейной зависимости между
линейной зависимости между  Причем
Причем  (Если
(Если
перед всеми суммами поставить множители  то
то  примет вид
примет вид  с дисперсиями и ковариацией, замененными их выборочными оценками.) Подобно
с дисперсиями и ковариацией, замененными их выборочными оценками.) Подобно  лежит между — 1 и 1.
лежит между — 1 и 1.
Если величины  представляют собой скорее постоянные, чем выборочные значения из некоторого распределения, то
представляют собой скорее постоянные, чем выборочные значения из некоторого распределения, то  можно все же использовать как меру линейной зависимости. Поскольку множество значений
можно все же использовать как меру линейной зависимости. Поскольку множество значений  может рассматриваться как полное конечное распределение,
может рассматриваться как полное конечное распределение,  будет действительно скорее генеральным, чем выборочным, значением, т. е. в этом случае
будет действительно скорее генеральным, чем выборочным, значением, т. е. в этом случае  (Если перед всеми суммами в уравнение (1.6.5) добавить множители
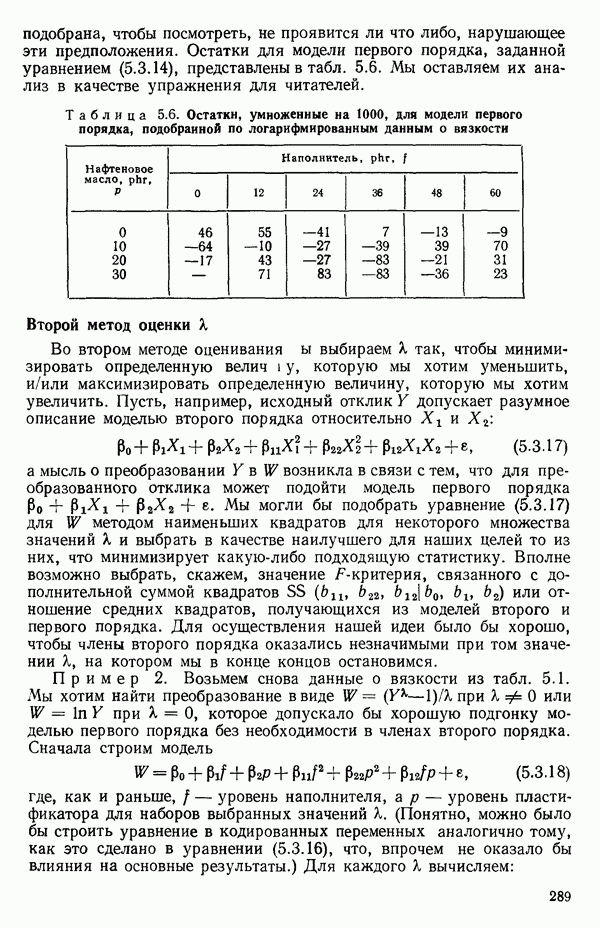
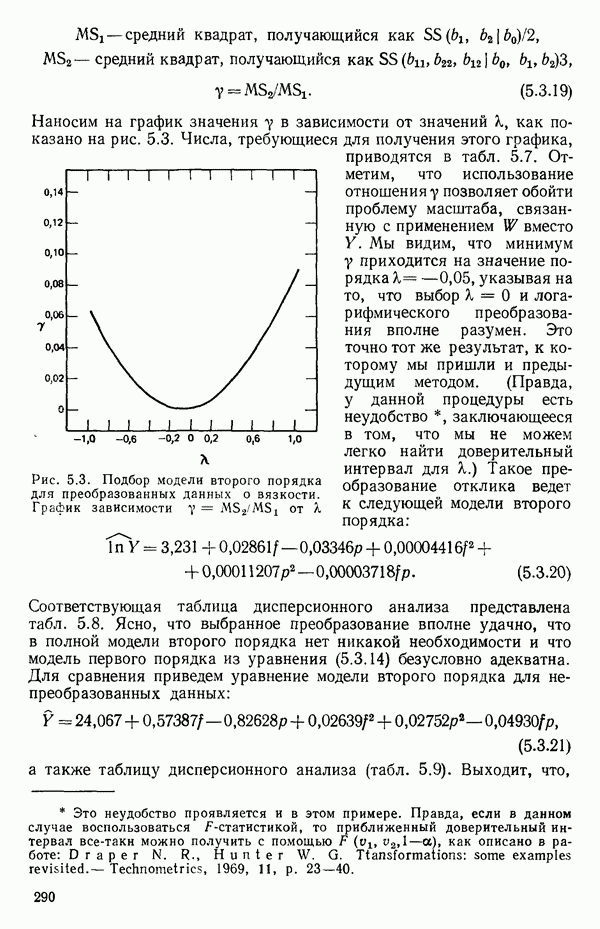
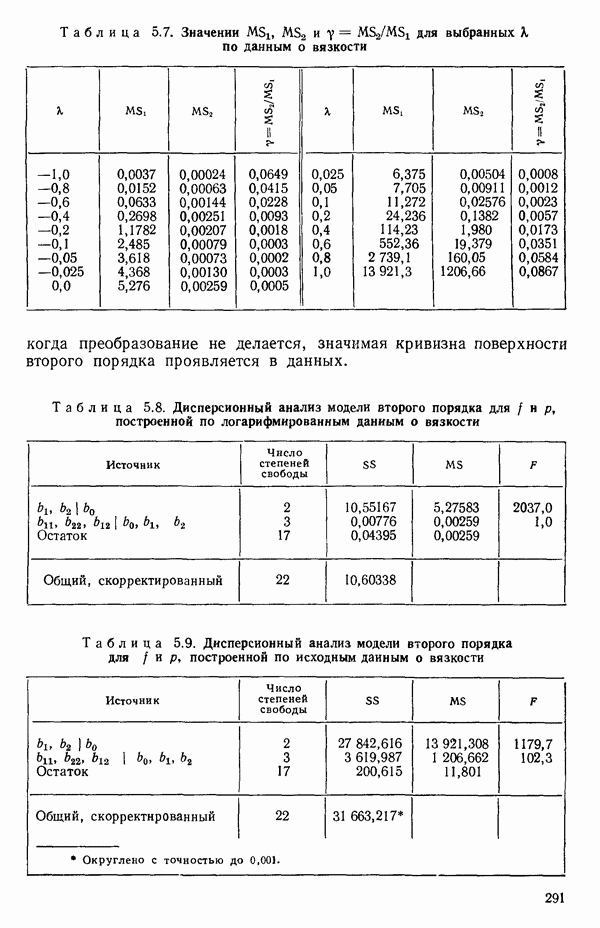
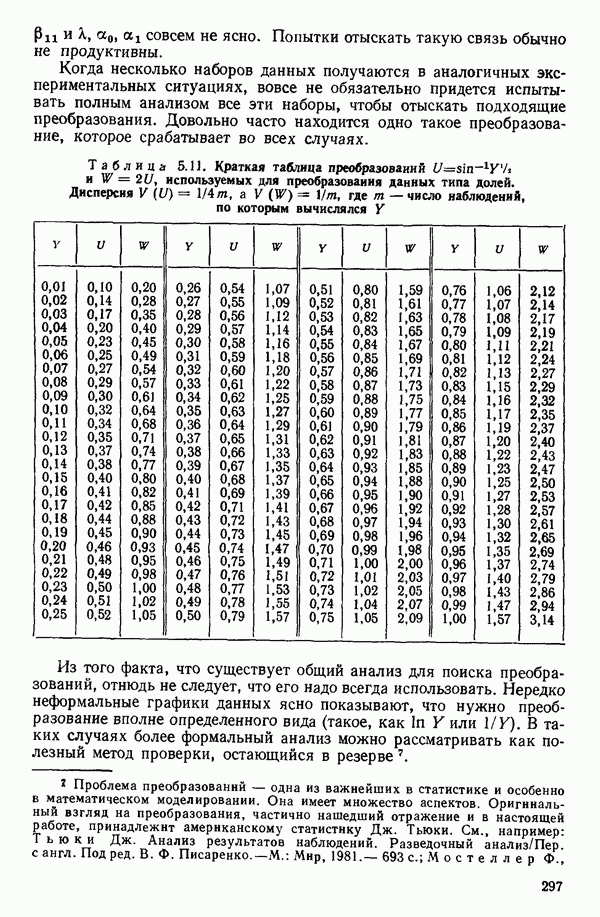
(Если перед всеми суммами в уравнение (1.6.5) добавить множители  то как раз получится уравнение (1.6.1) для дискретного случая.)
то как раз получится уравнение (1.6.1) для дискретного случая.)
Если мы сталкиваемся с ситуацией, где  представляют собой значения из конечного Х-распределения, а соответствующие им наблюдения
представляют собой значения из конечного Х-распределения, а соответствующие им наблюдения  фактические значения случайных величин, средние значения которых зависят от соответствующих
фактические значения случайных величин, средние значения которых зависят от соответствующих  (как в этой главе), то коэффициент корреляции
(как в этой главе), то коэффициент корреляции  можно все-таки определить по уравнению (1.6.1) при условии, что все интегралы по X в выражениях вроде уравнений (1.6.2) — (1.6.4) заменяются суммами по дискретным значениям
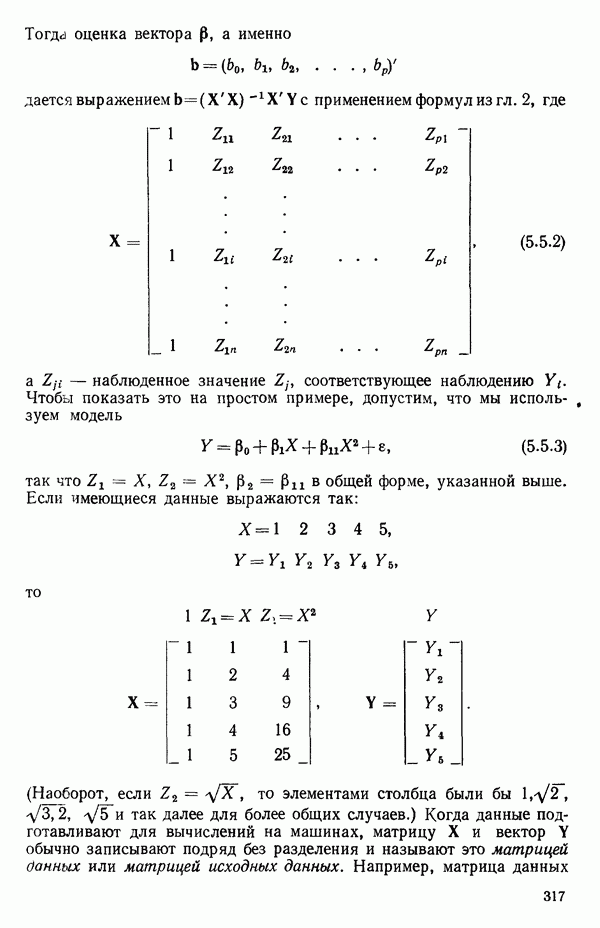
можно все-таки определить по уравнению (1.6.1) при условии, что все интегралы по X в выражениях вроде уравнений (1.6.2) — (1.6.4) заменяются суммами по дискретным значениям  Выражение (1.6.5), с заменой
Выражение (1.6.5), с заменой  на
на  можно, конечно, применить для оценки
можно, конечно, применить для оценки  по
по  если имеется выборка наблюдений
если имеется выборка наблюдений  для
для  значений
значений  соответственно.
соответственно.
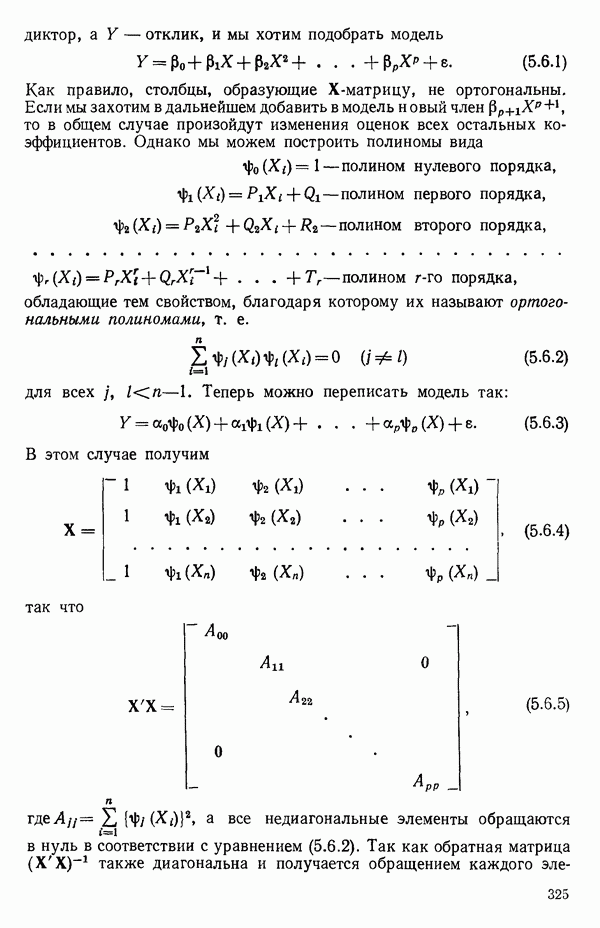
В этой книге мы будем пользоваться выражением для  из уравнения (1.6.5). Его фактические названия и роли будут зависеть от того, можно ли рассматривать величины
из уравнения (1.6.5). Его фактические названия и роли будут зависеть от того, можно ли рассматривать величины  как выборочные или как генеральные. Мы будем называть все такие величины
как выборочные или как генеральные. Мы будем называть все такие величины  корреляциями (коэффициентами корреляции) между
корреляциями (коэффициентами корреляции) между  рассматривая их как подходящие меры линейной связи, между различными величинами, представляющими интерес. Указанные выше различия зависят от того, являются ли действительные значения выборочными или же они генеральные. Это, однако, не обязательно учитывать для наших целей, и мы будем игнорировать такие различия.
рассматривая их как подходящие меры линейной связи, между различными величинами, представляющими интерес. Указанные выше различия зависят от того, являются ли действительные значения выборочными или же они генеральные. Это, однако, не обязательно учитывать для наших целей, и мы будем игнорировать такие различия.
Если корреляция  не равна нулю, это значит, что в нашем множестве данных существует некоторая линейная зависимость между конкретными значениями
не равна нулю, это значит, что в нашем множестве данных существует некоторая линейная зависимость между конкретными значениями  при
при  В рассматриваемой регрессионной ситуации мы предполагаем, что значения
В рассматриваемой регрессионной ситуации мы предполагаем, что значения  не подвержены воздействию случайных ошибок (или по крайней мере такое приближение можно считать удовлетворительным, поскольку подобные постулаты редко выполняются строго, что обсуждается в параграфе 2.14), а значения
не подвержены воздействию случайных ошибок (или по крайней мере такое приближение можно считать удовлетворительным, поскольку подобные постулаты редко выполняются строго, что обсуждается в параграфе 2.14), а значения  имеют случайный разброс относительно среднего, зависящего от модели. Позже, когда мы начнем рассматривать больше чем одну предикторную переменную, мы еще будем пользоваться коэффициентом корреляции (например, уравнение (1.6.5) с
имеют случайный разброс относительно среднего, зависящего от модели. Позже, когда мы начнем рассматривать больше чем одну предикторную переменную, мы еще будем пользоваться коэффициентом корреляции (например, уравнение (1.6.5) с  вместо
вместо  Этот коэффициент мы можем тогда назвать
Этот коэффициент мы можем тогда назвать  измерения линейной зависимости между конкретными значениями
измерения линейной зависимости между конкретными значениями  встречающимися в наборе данных. Ни в одном из этих случаев у нас нет выборки из некоторого двумерного распределения.
встречающимися в наборе данных. Ни в одном из этих случаев у нас нет выборки из некоторого двумерного распределения.
























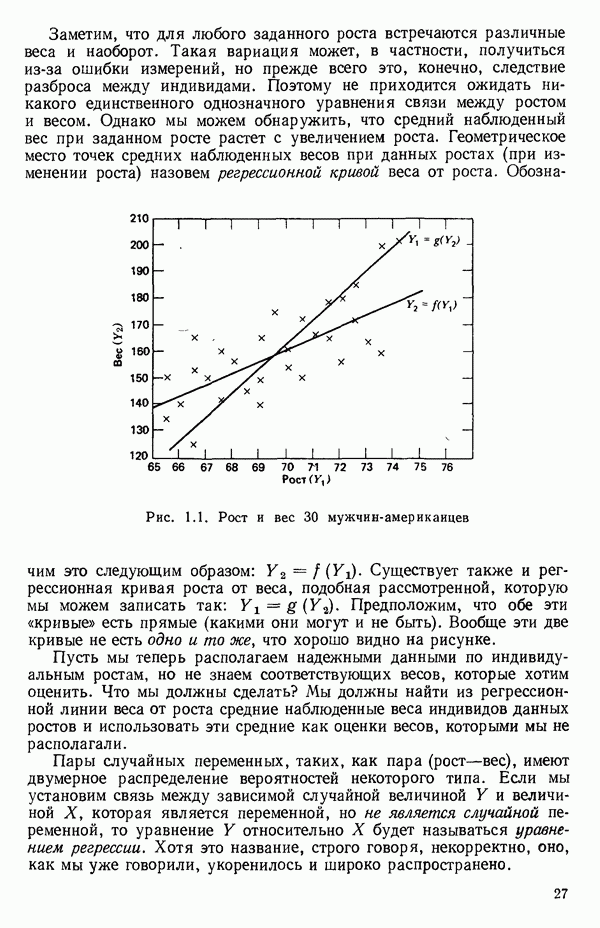
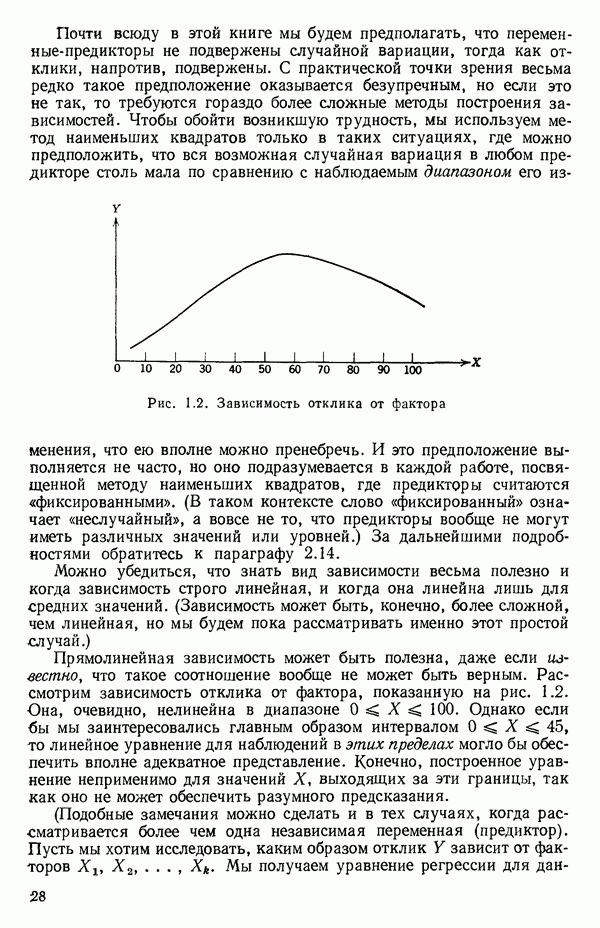
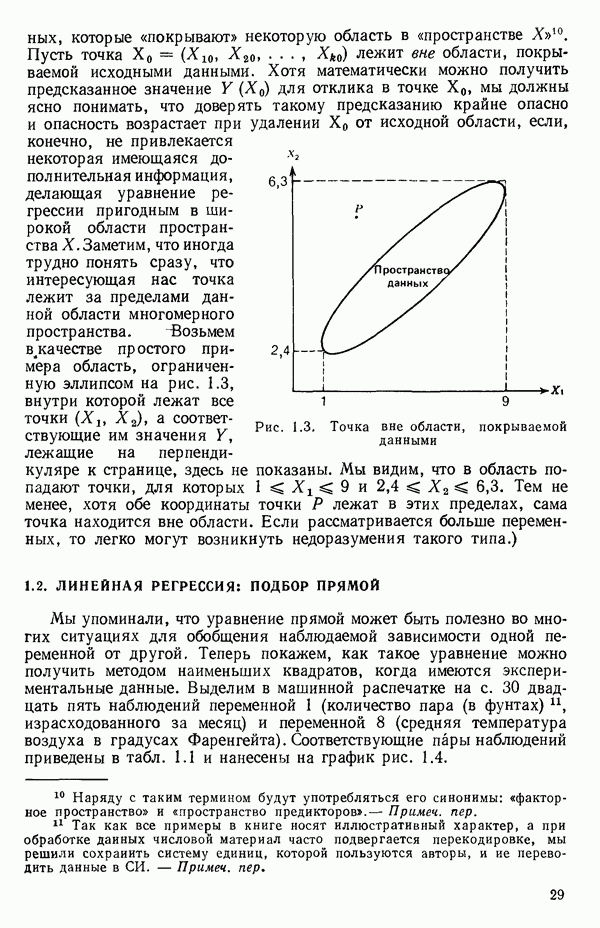
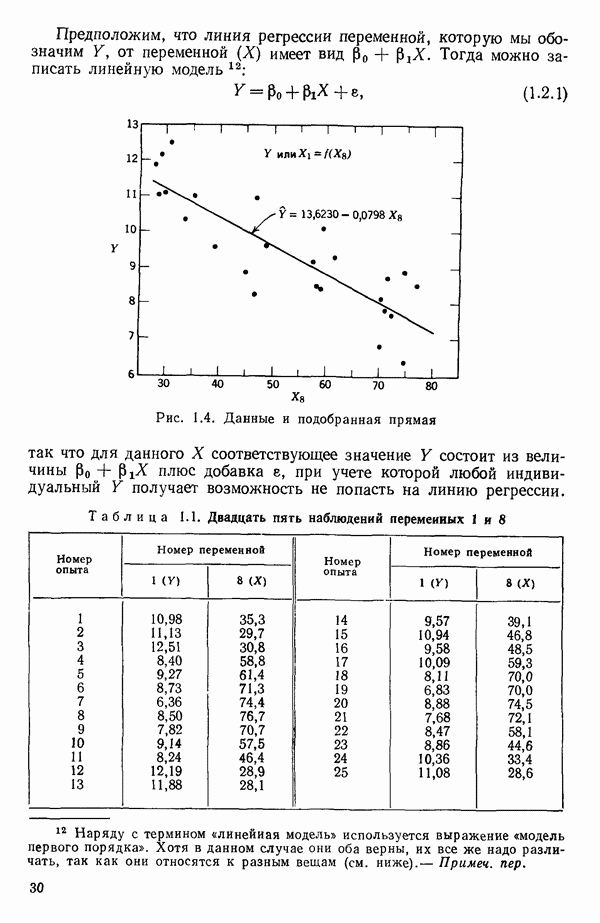

































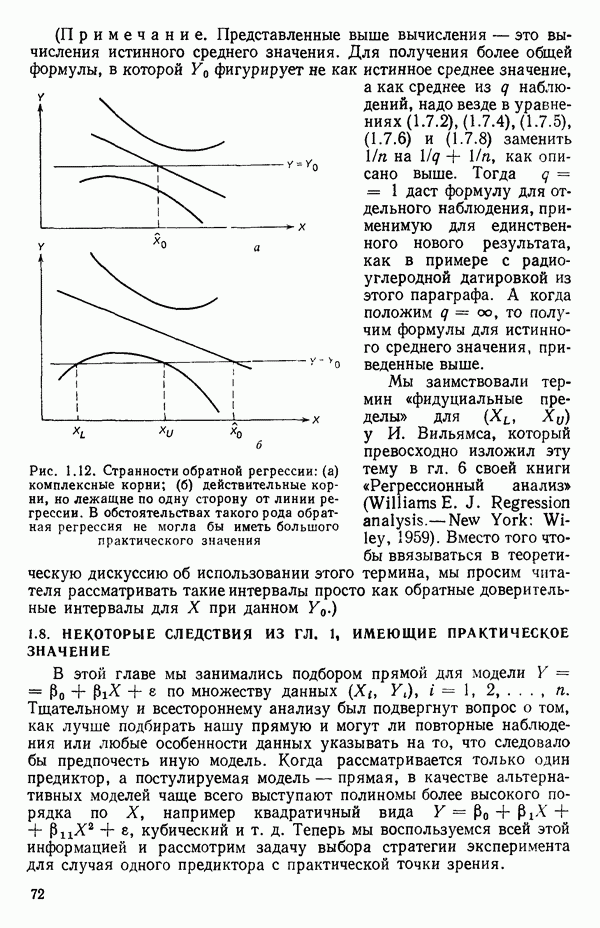






























































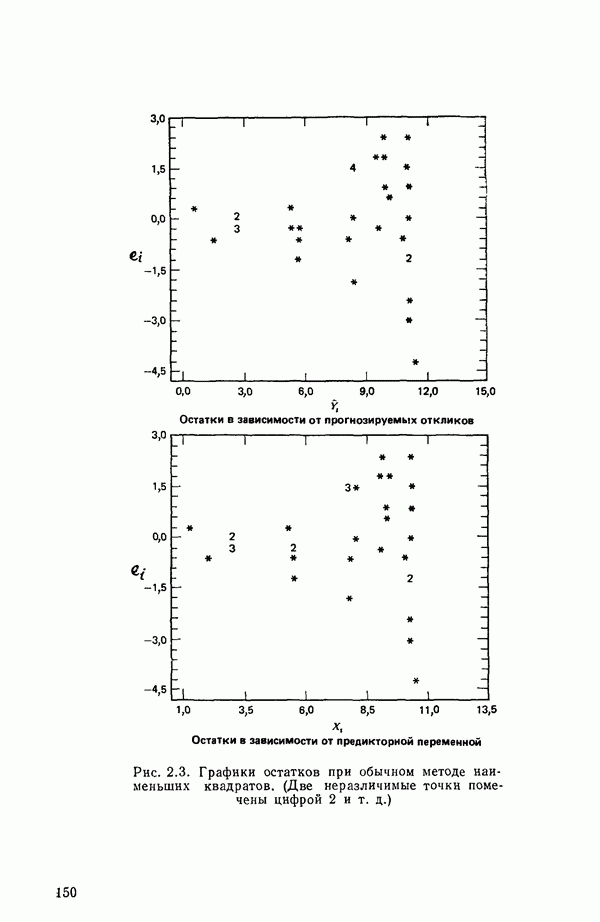

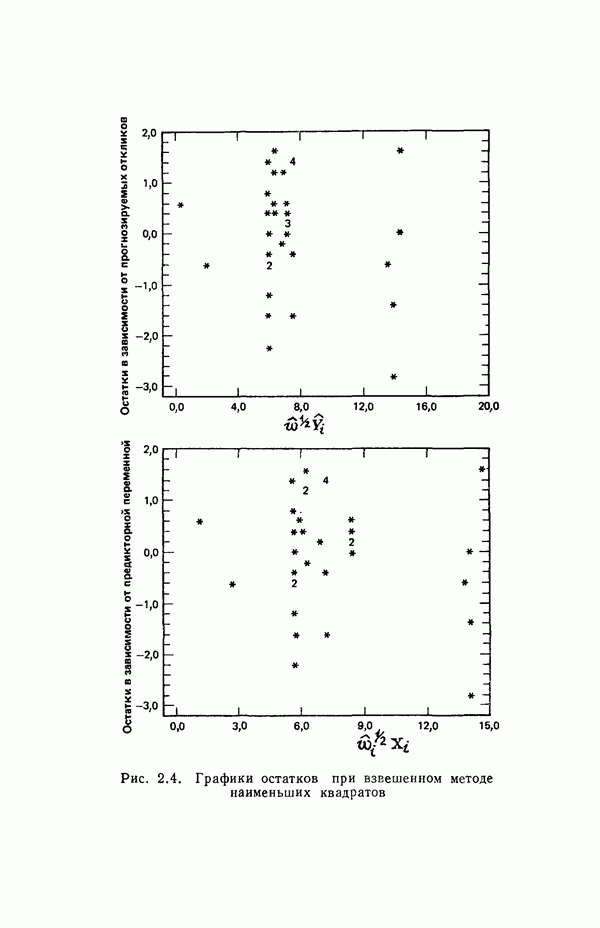














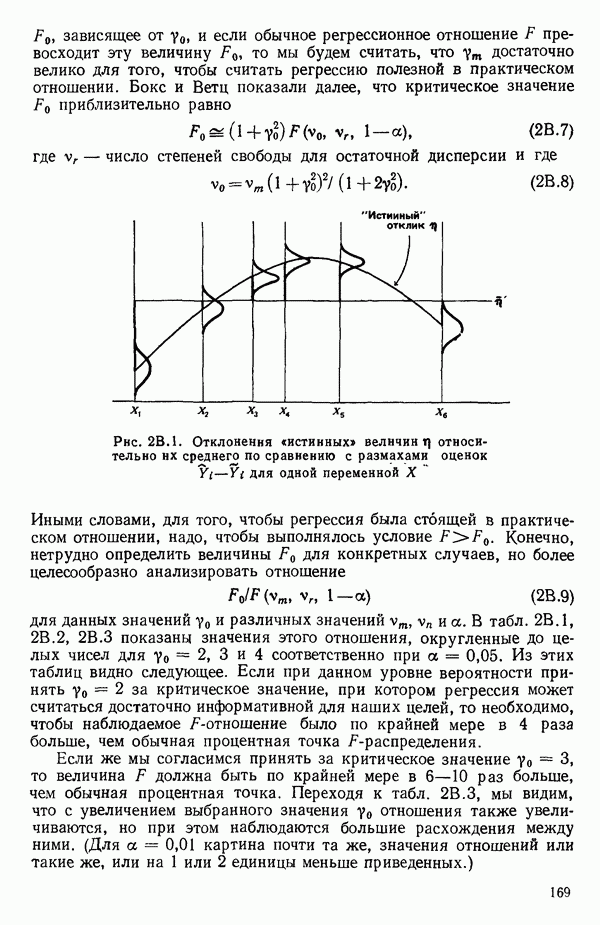
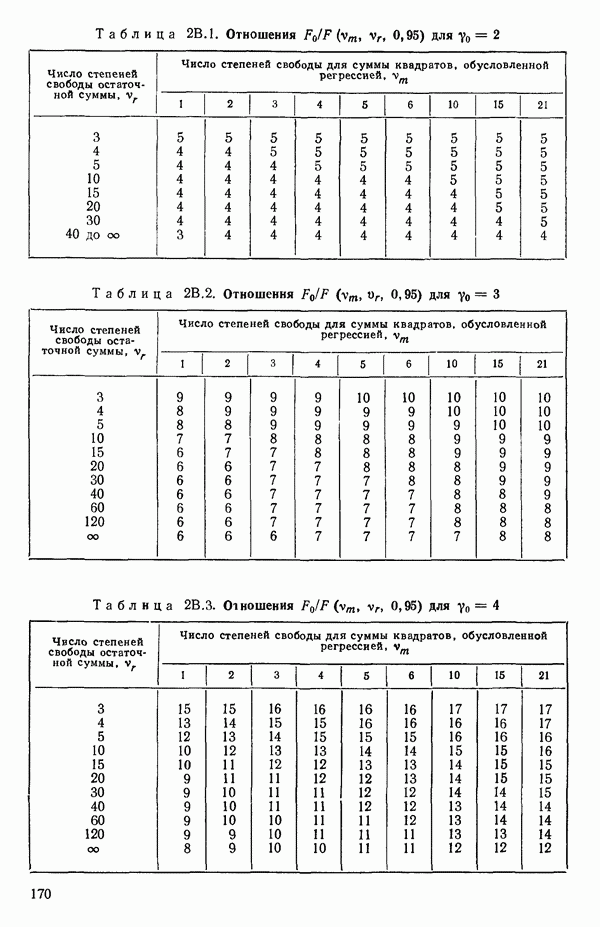








































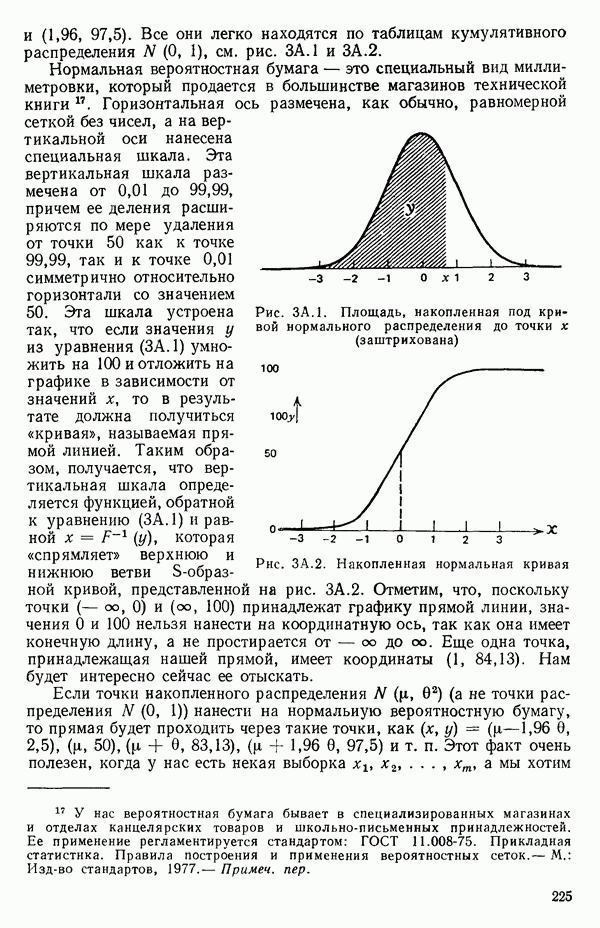
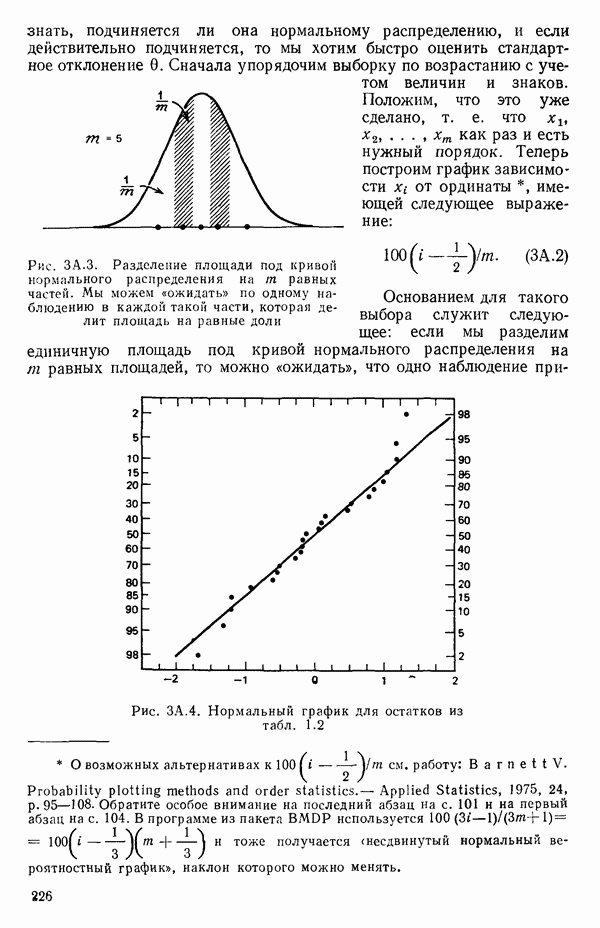


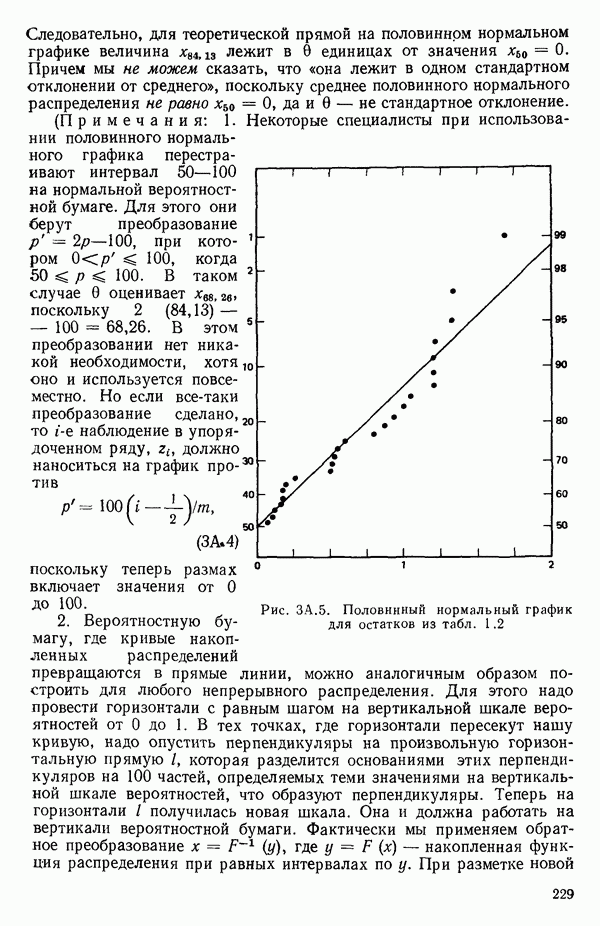





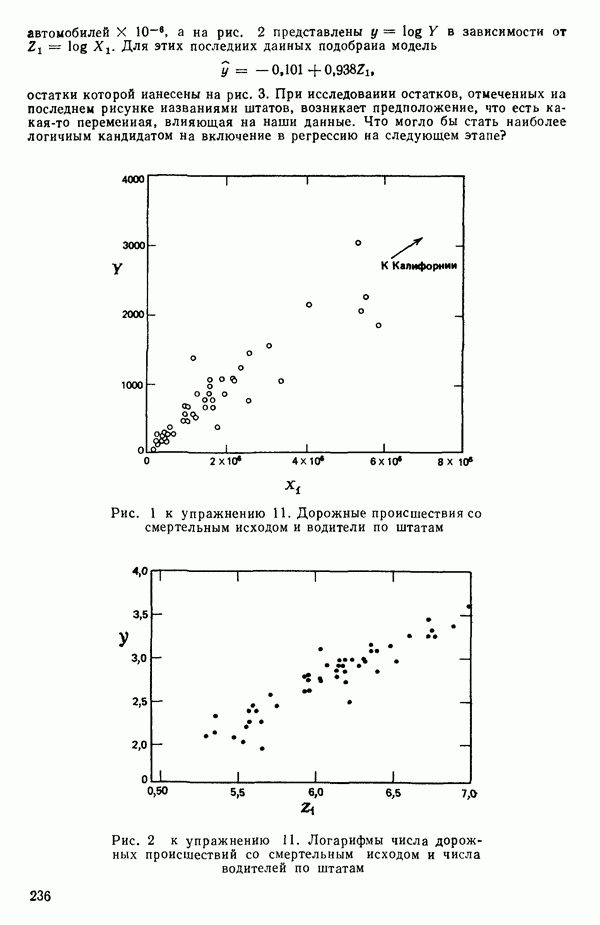
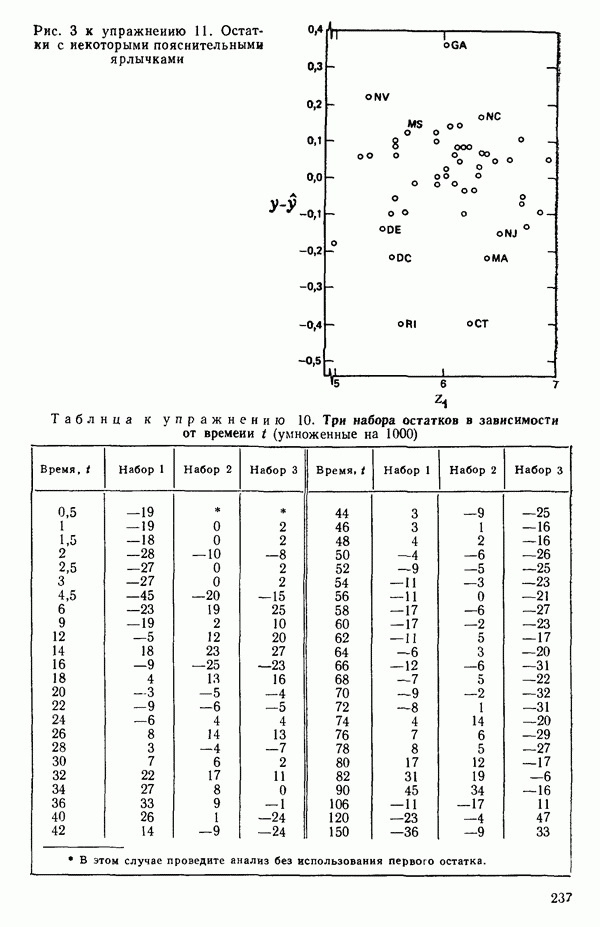
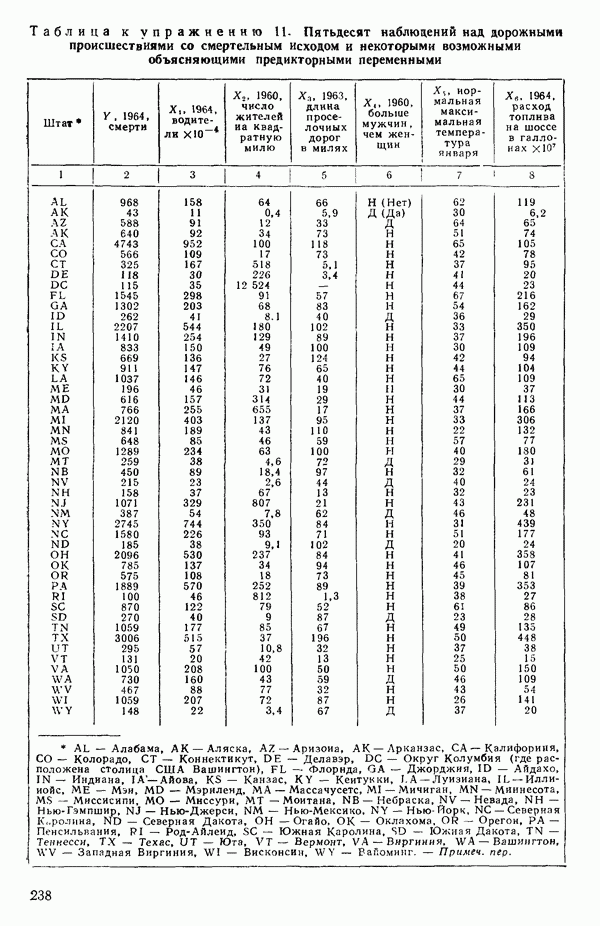

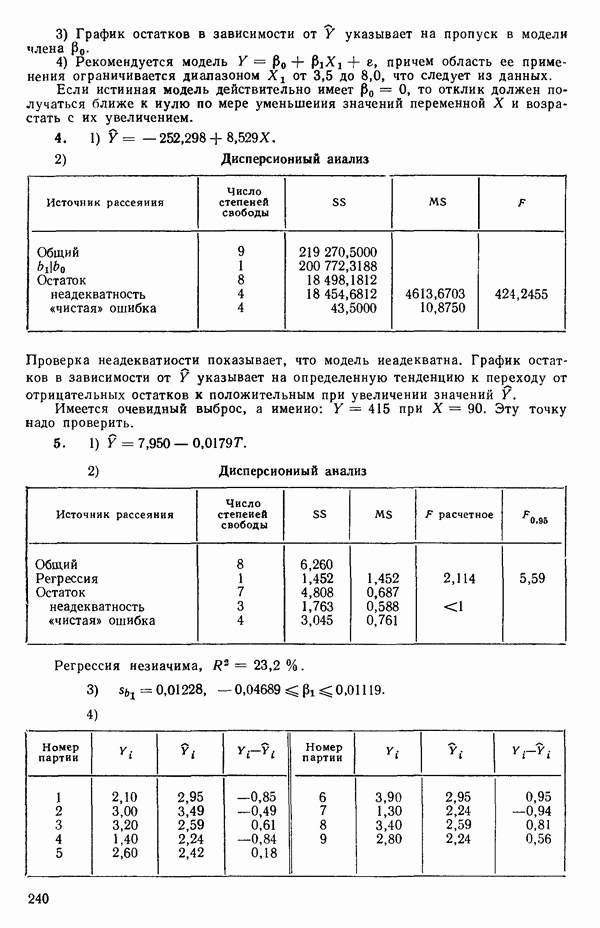





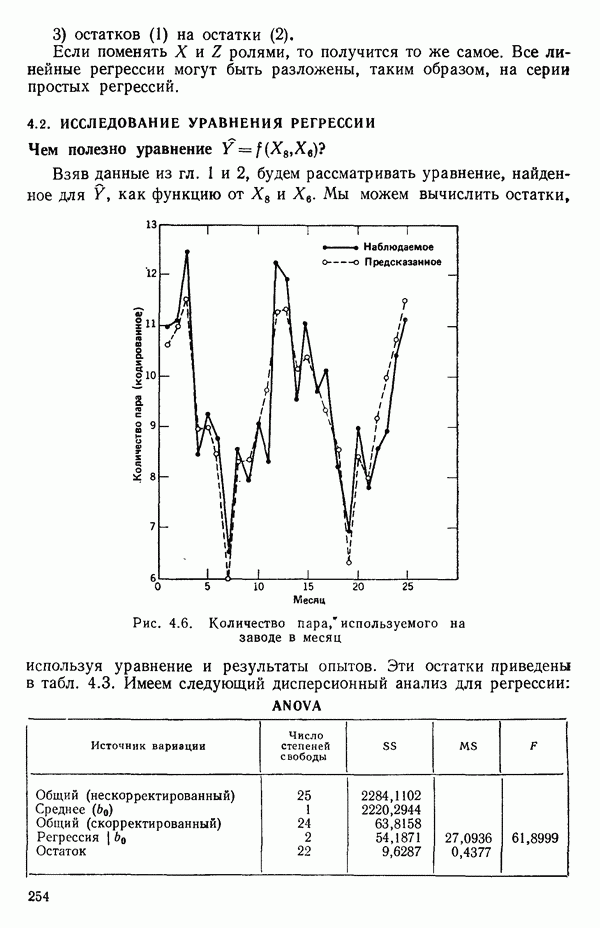




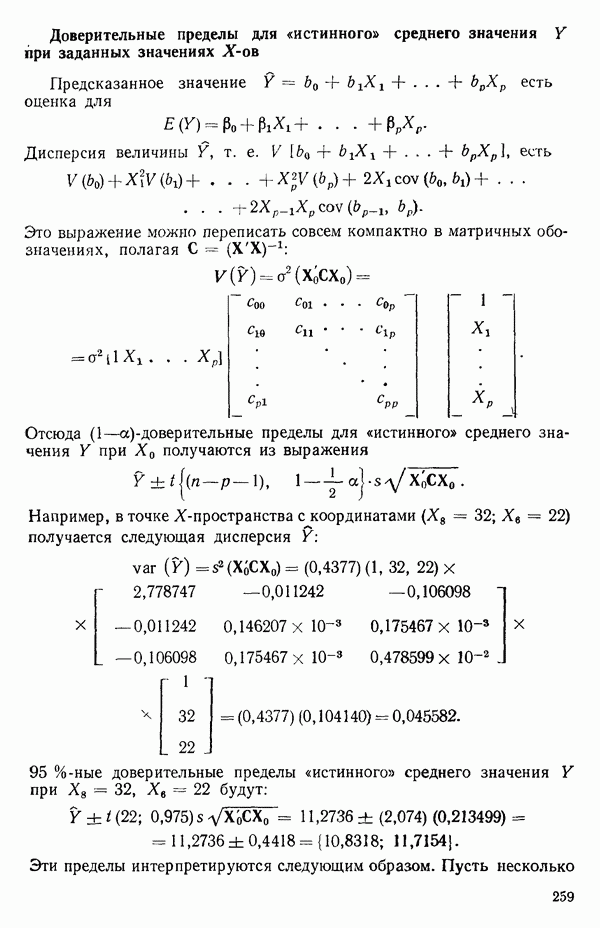

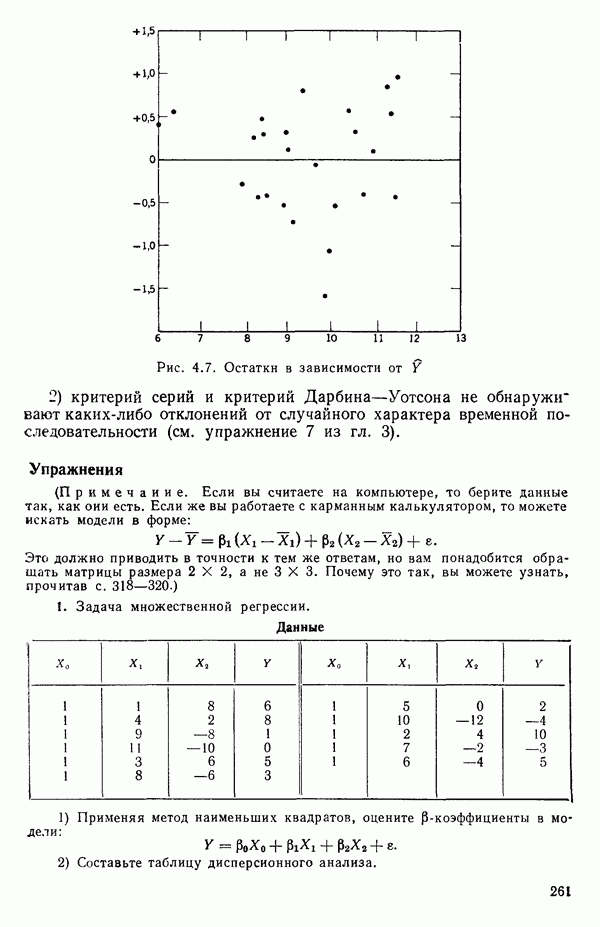

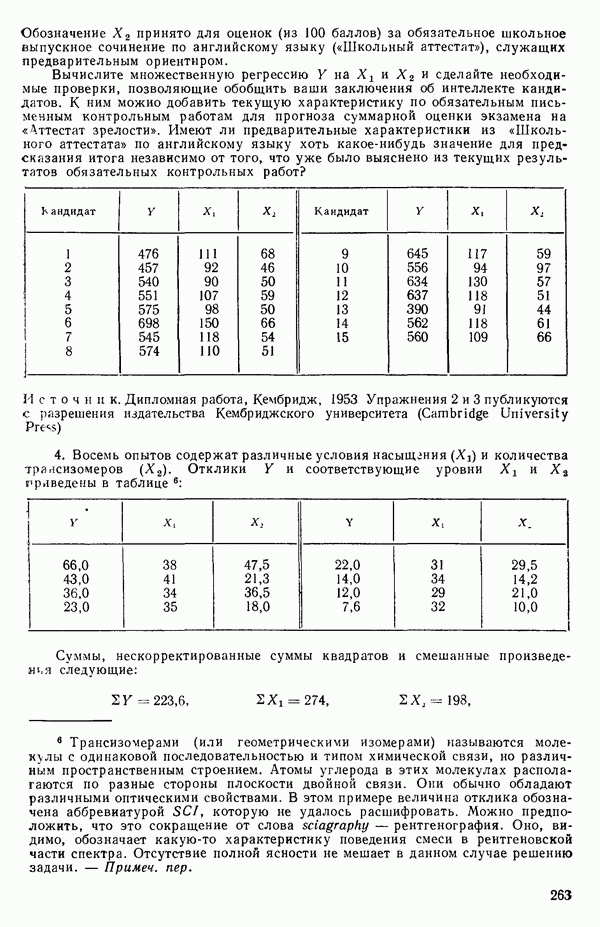

















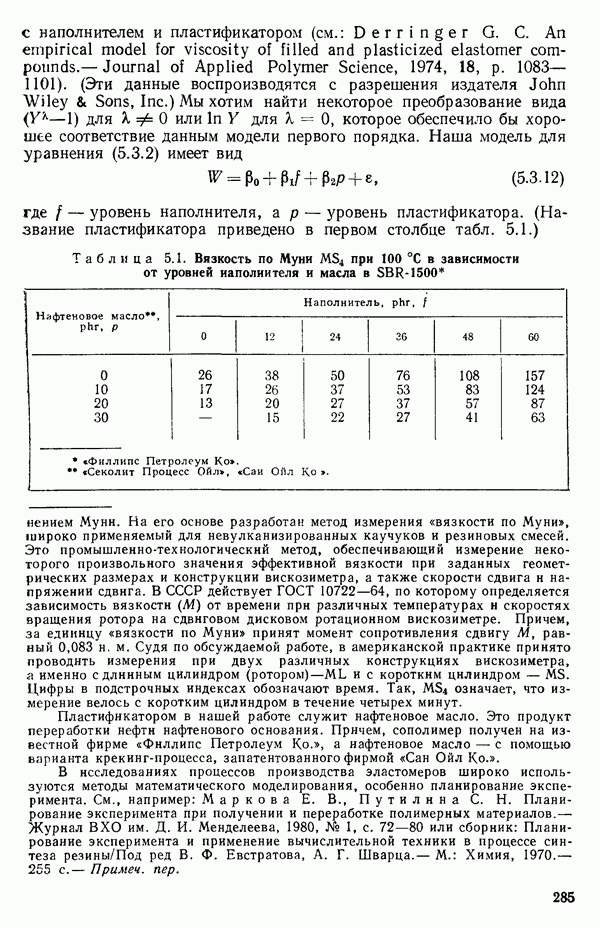
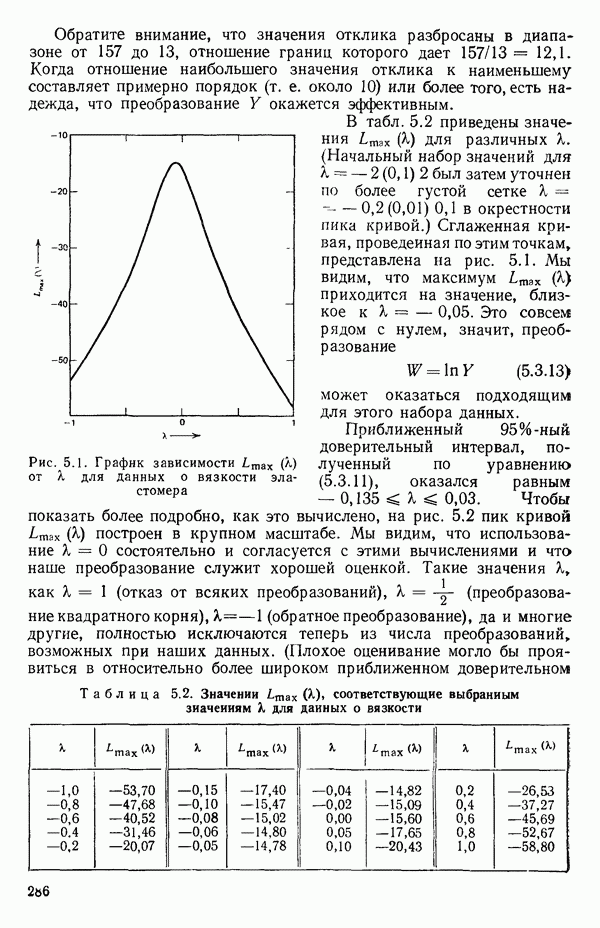
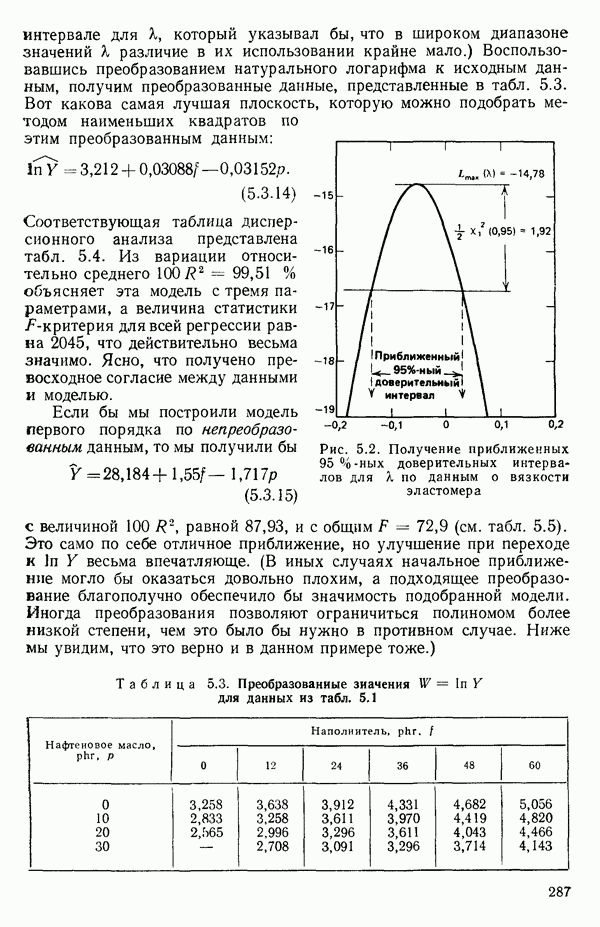
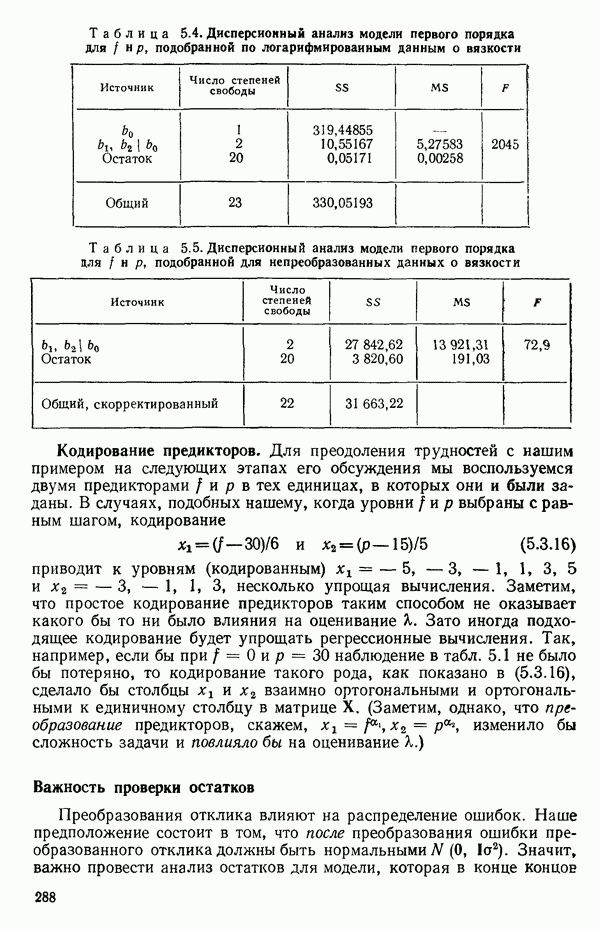




























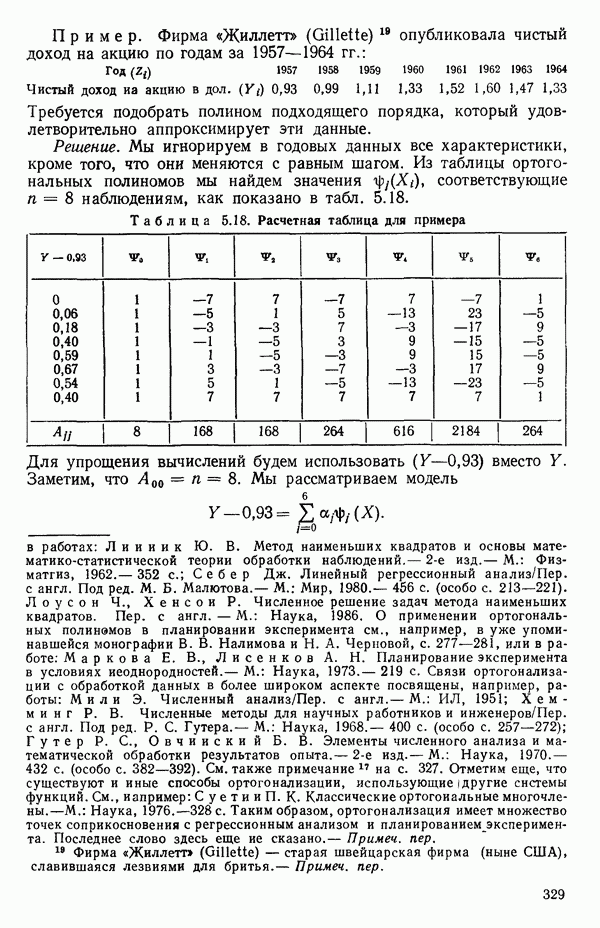

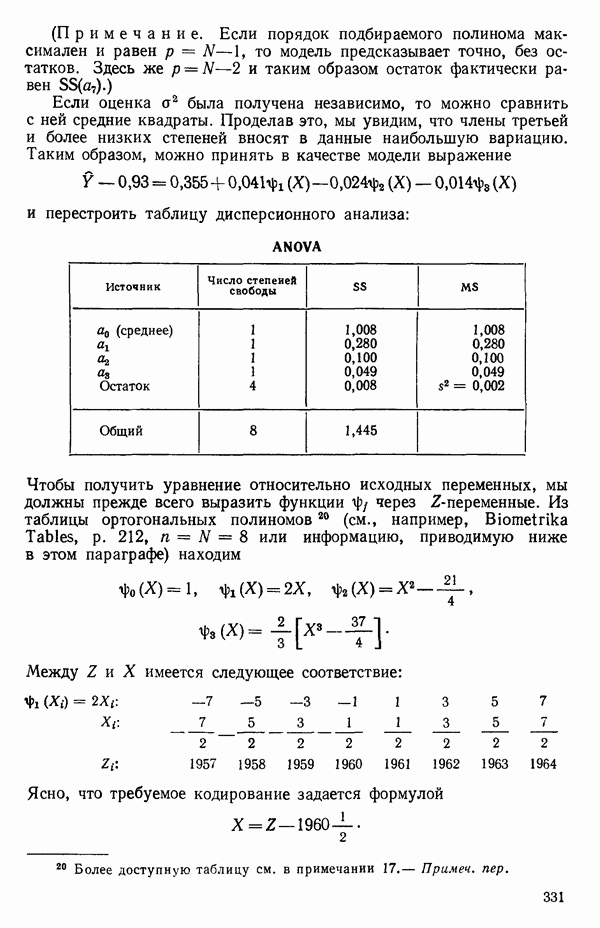

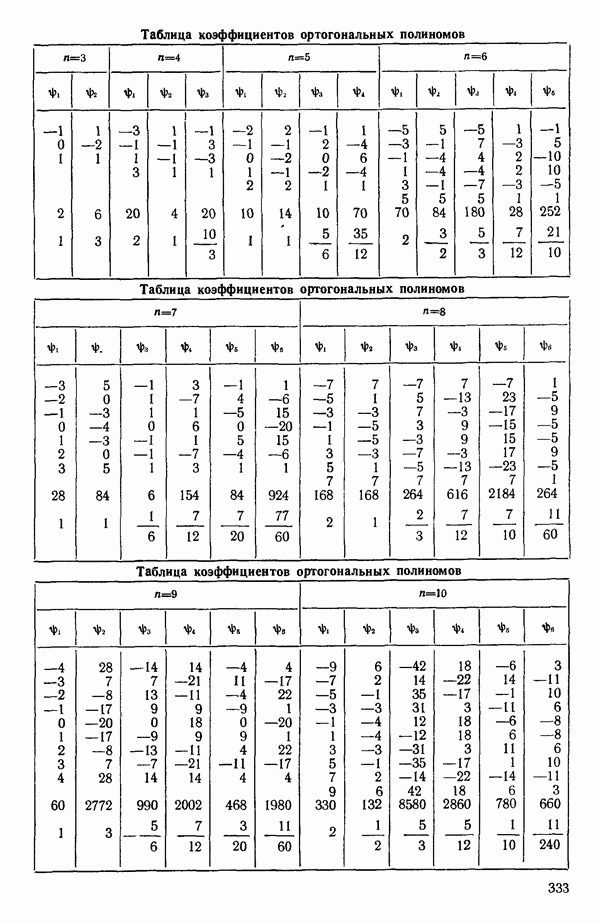
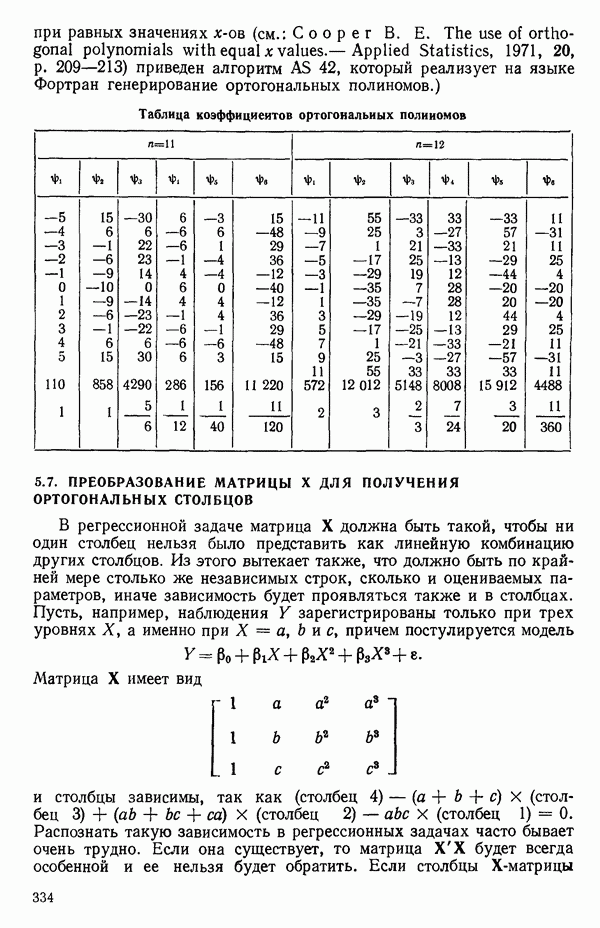



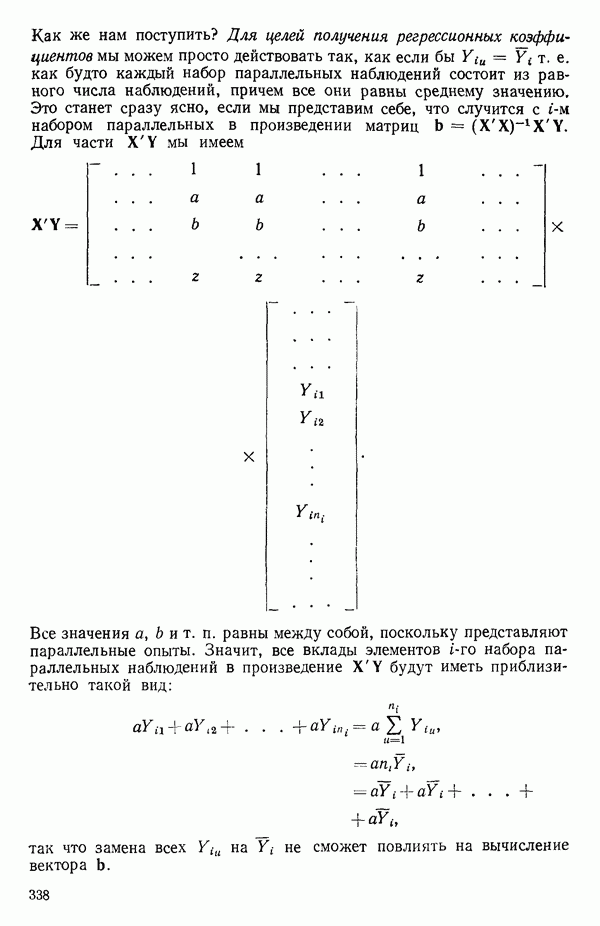








 мы предварительно полагали, что
мы предварительно полагали, что  можно без учета ошибок выразить как функцию первого порядка от
можно без учета ошибок выразить как функцию первого порядка от  . В такой зависимости X обычно предполагается «фиксированным» (неслучайным), т. е. не имеющим вероятностного распределения, в то время как
. В такой зависимости X обычно предполагается «фиксированным» (неслучайным), т. е. не имеющим вероятностного распределения, в то время как  обычно предполагается случайной величиной, имеющей
обычно предполагается случайной величиной, имеющей
 у указывает только на силу линейной зависимости между
у указывает только на силу линейной зависимости между  Из него не вытекает никакого заключения о типе причинной связи между
Из него не вытекает никакого заключения о типе причинной связи между  Такое ложное заключение во многих случаях приводит к ошибочным выводам. (Несколько примеров таких выводов, вроде: «Блохи делают человека здоровым», см. в гл. 8 книги Даррелла Хаффа «Как лгать с помощью статистики» (Huff D. How to lie with statistics.- New York: W. W. Norton, 1954). За пределами Северной Америки эта книга известна благодаря массовому изданию в мягкой обложке в серии «Пеликан».)
Такое ложное заключение во многих случаях приводит к ошибочным выводам. (Несколько примеров таких выводов, вроде: «Блохи делают человека здоровым», см. в гл. 8 книги Даррелла Хаффа «Как лгать с помощью статистики» (Huff D. How to lie with statistics.- New York: W. W. Norton, 1954). За пределами Северной Америки эта книга известна благодаря массовому изданию в мягкой обложке в серии «Пеликан».)