Пред.
След.
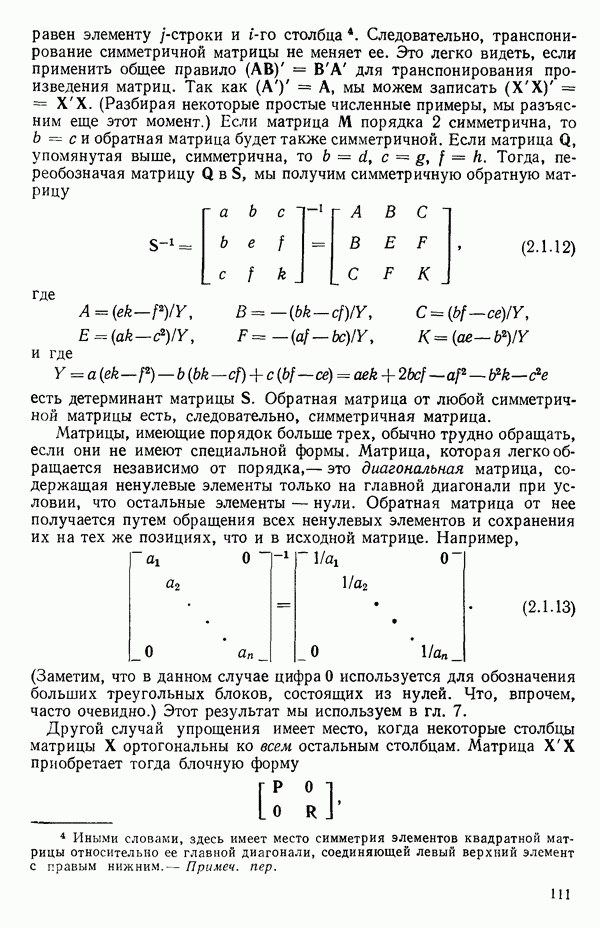
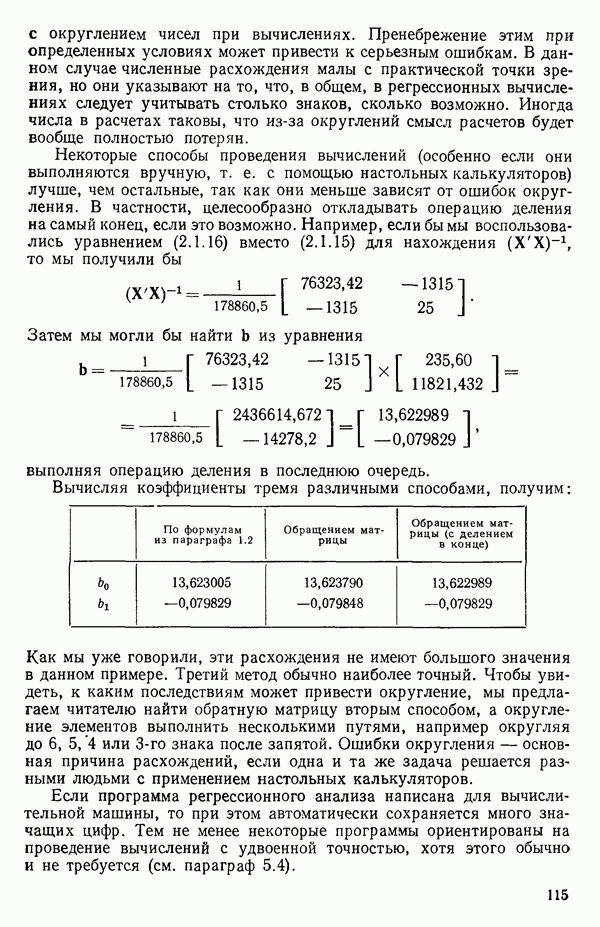
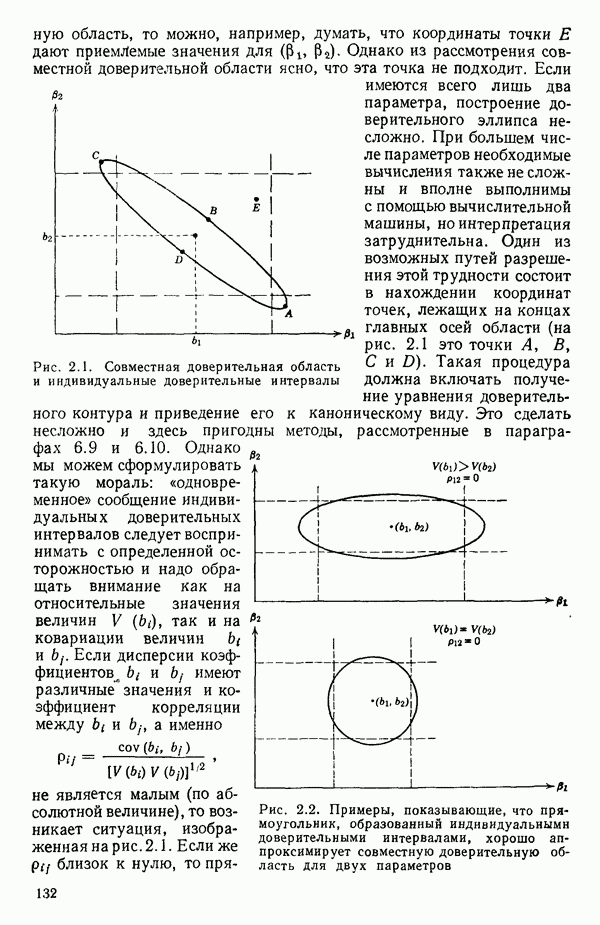
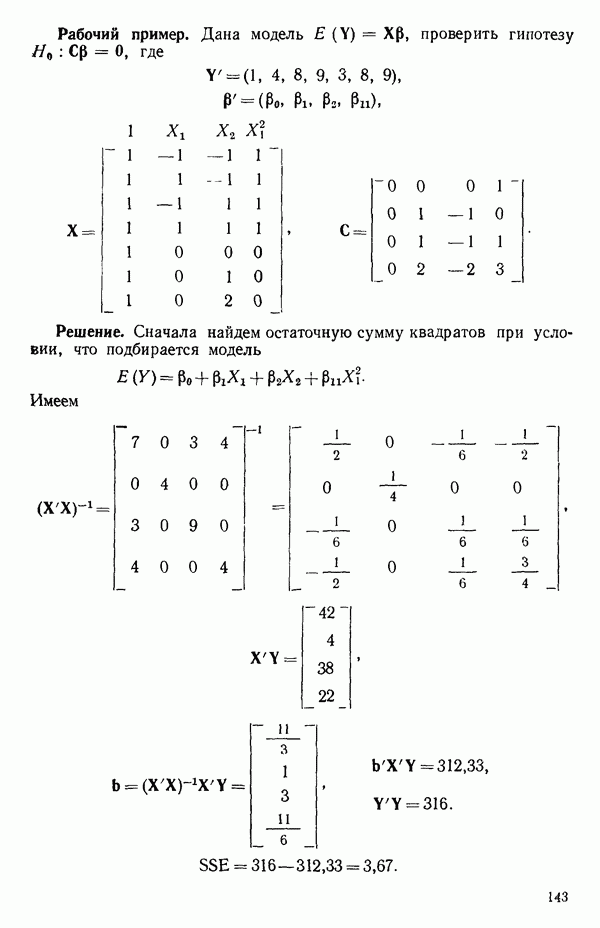
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
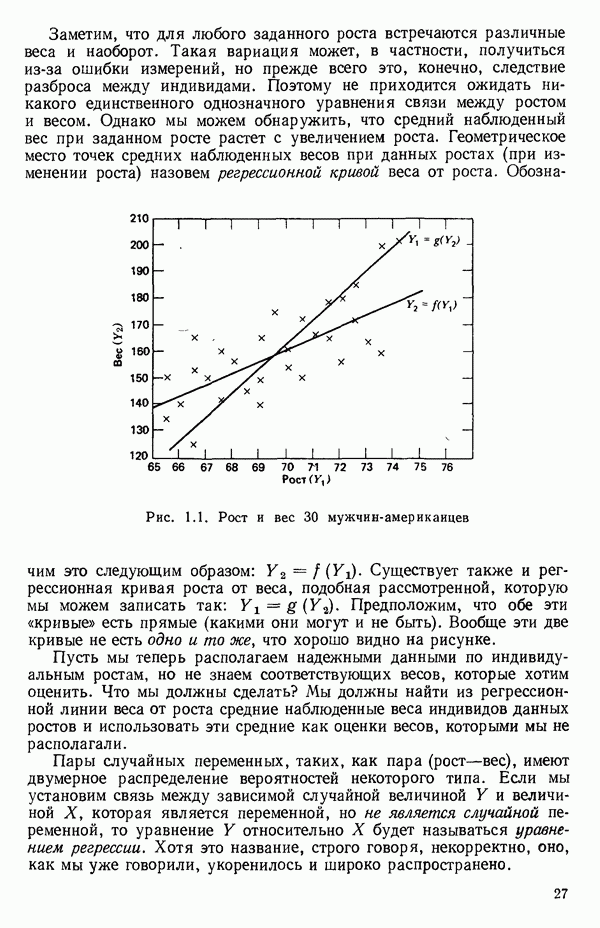
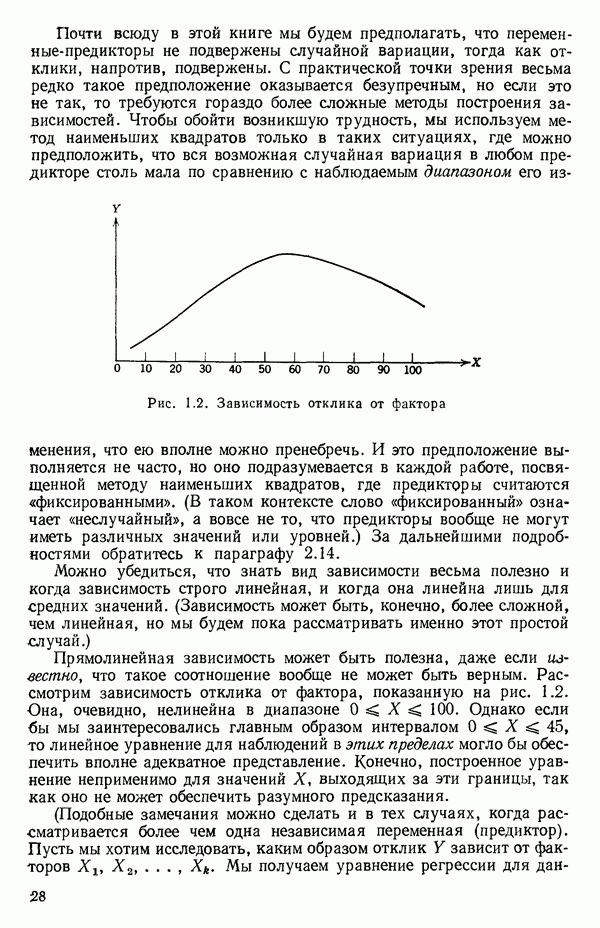
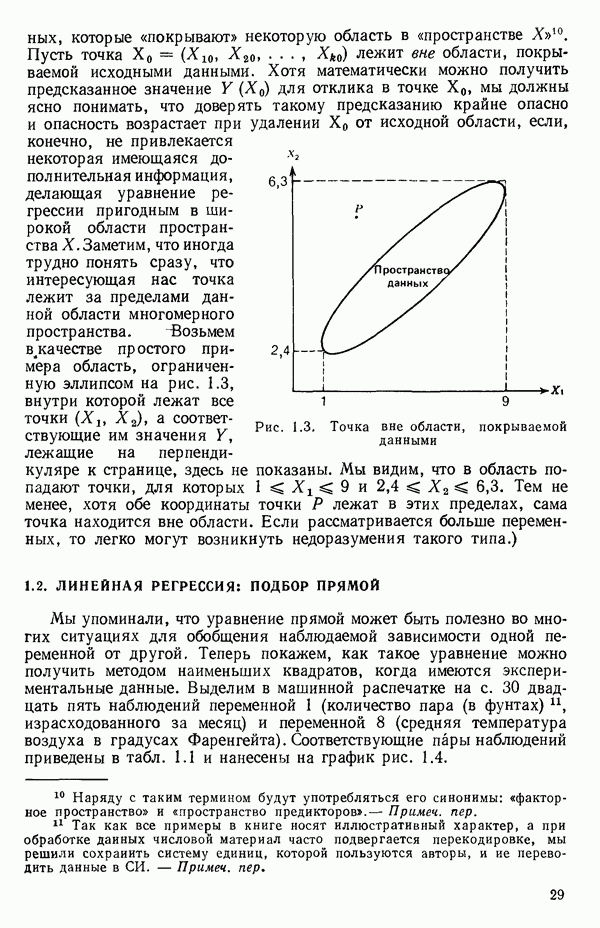
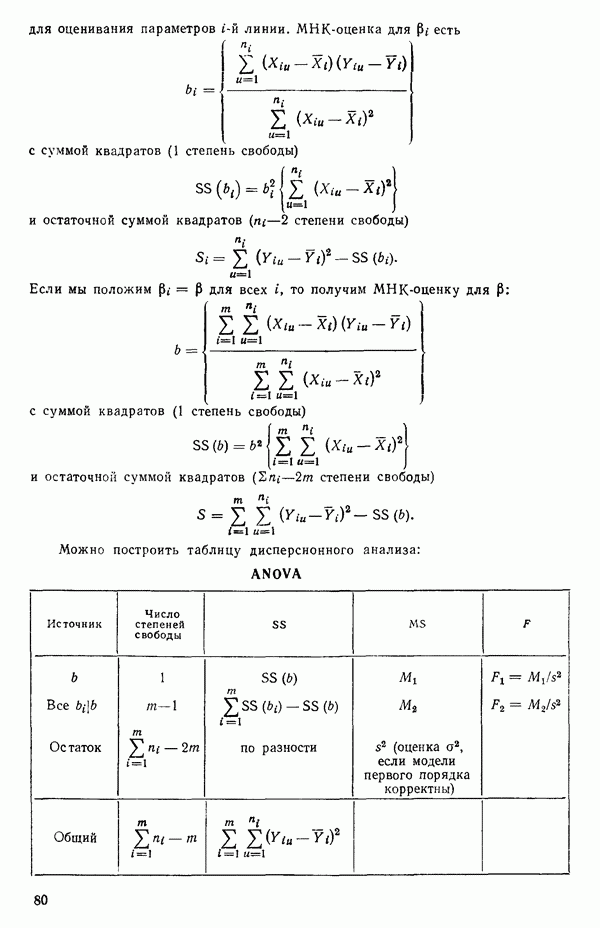
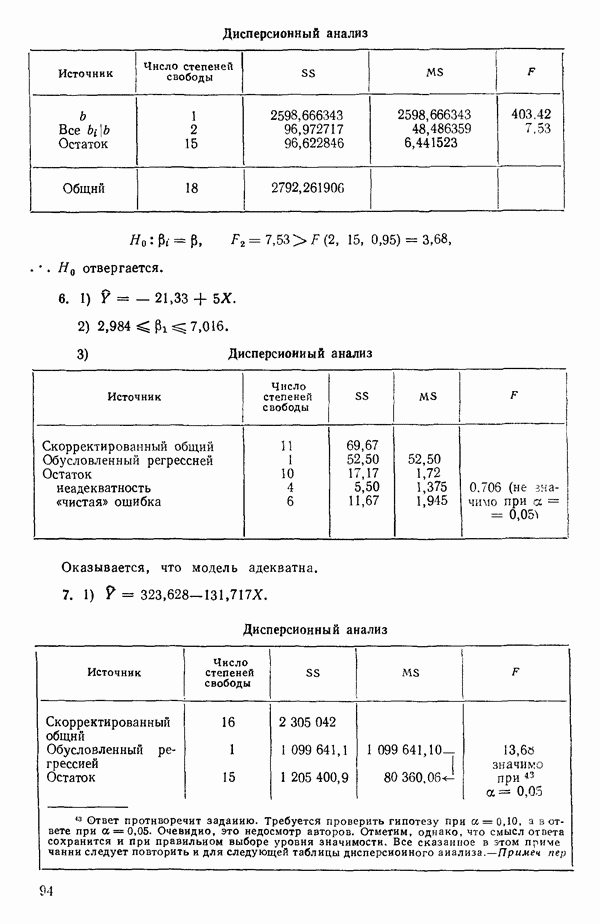
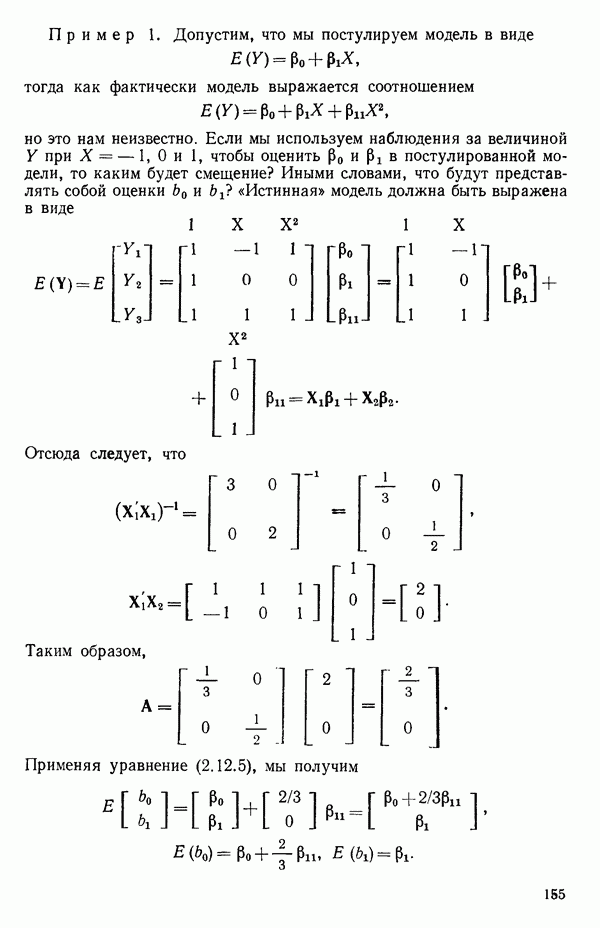
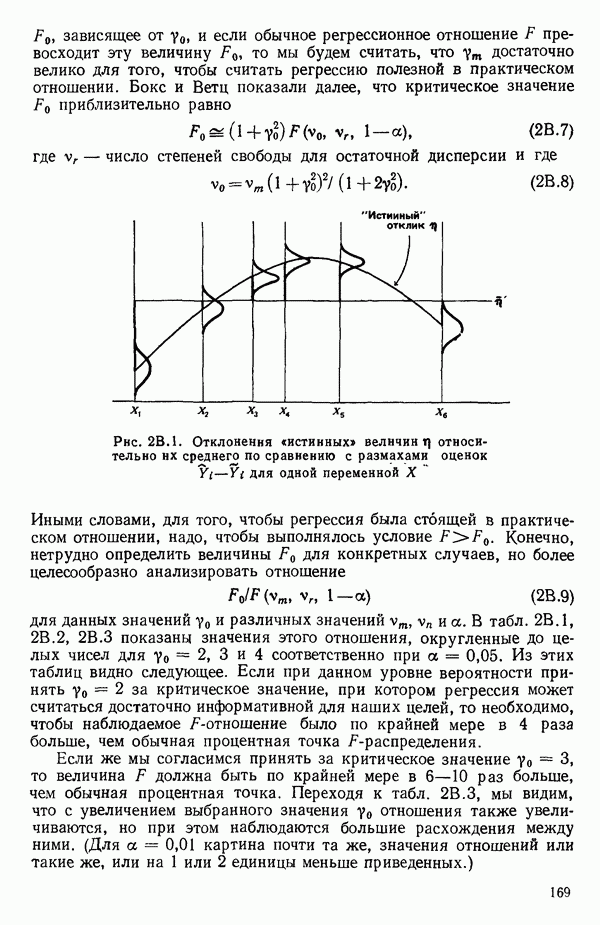
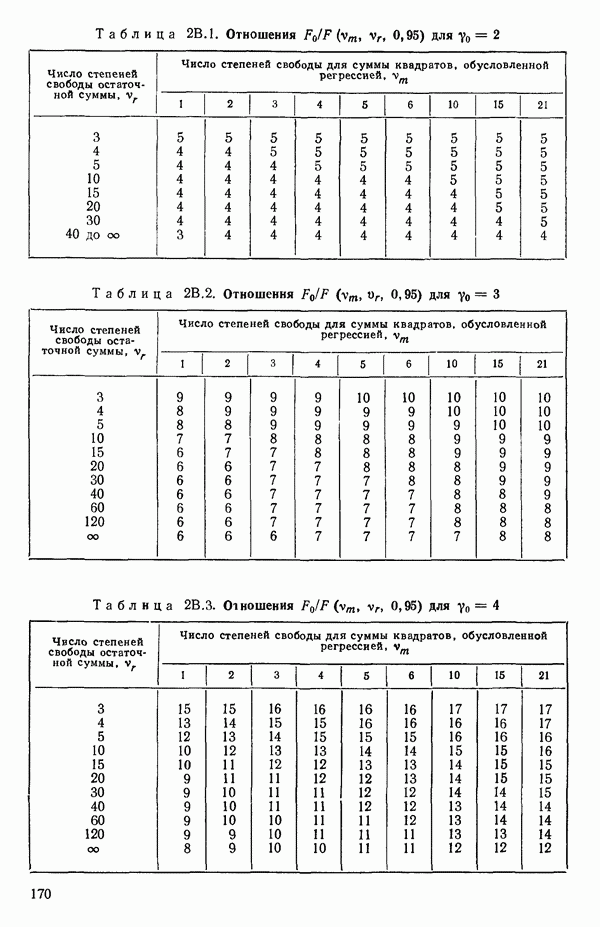
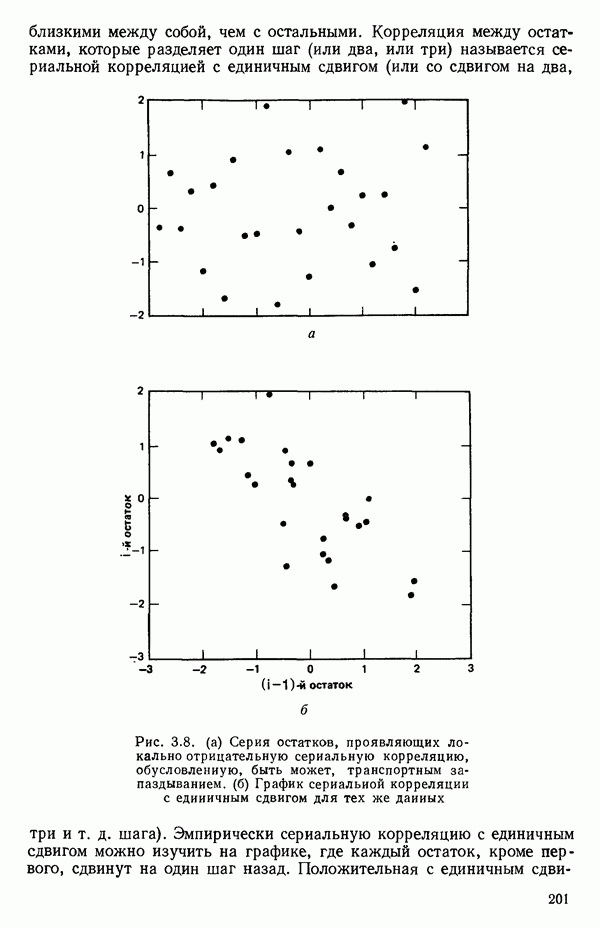
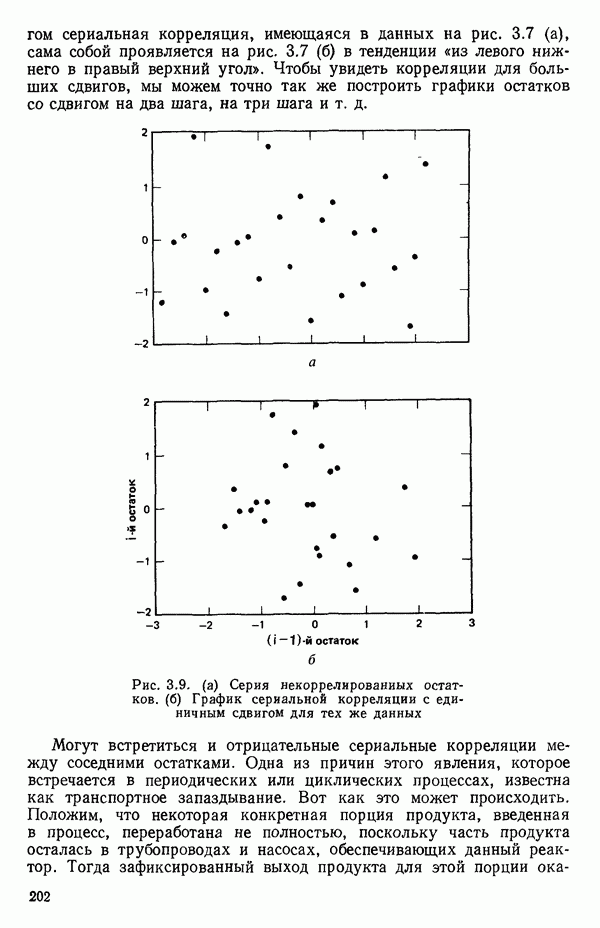
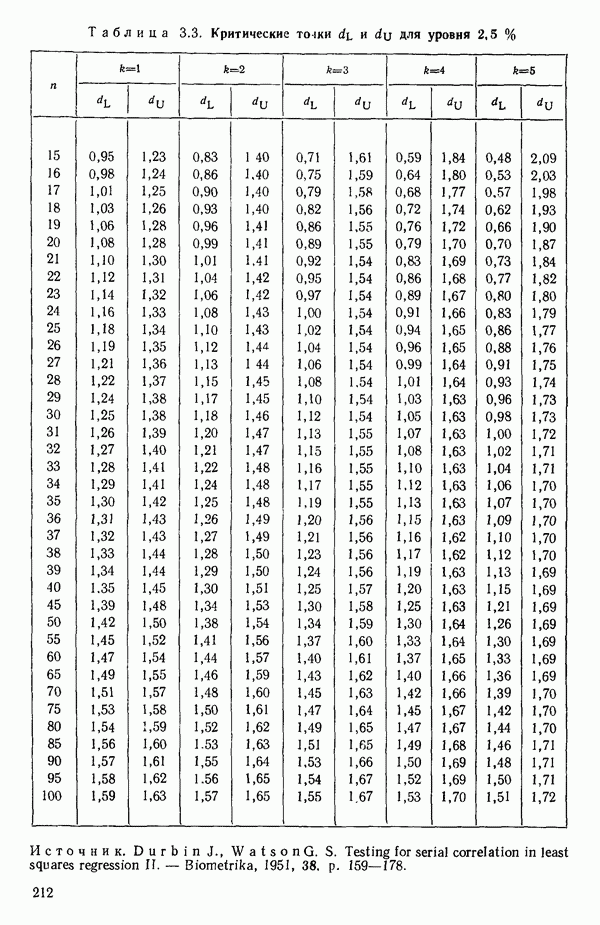
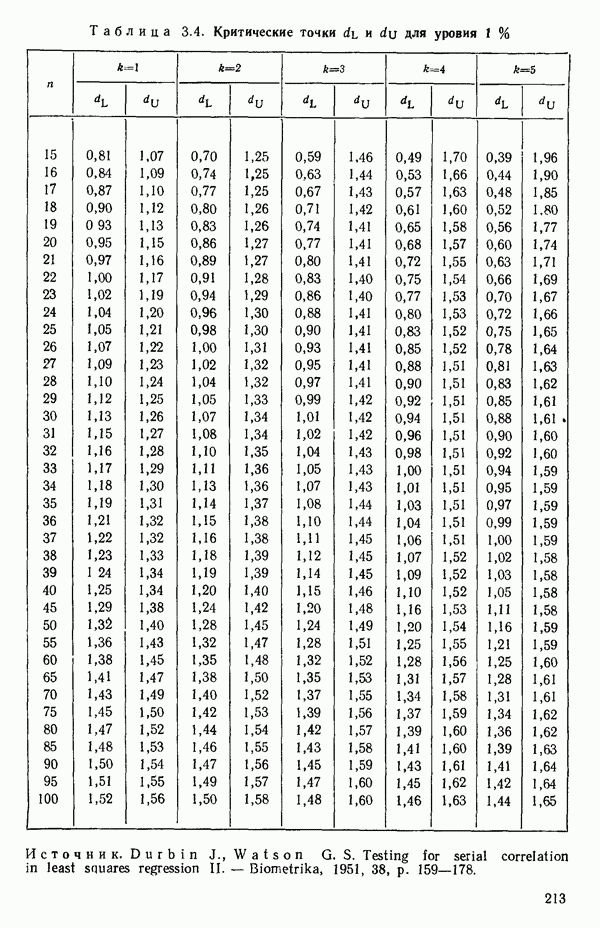
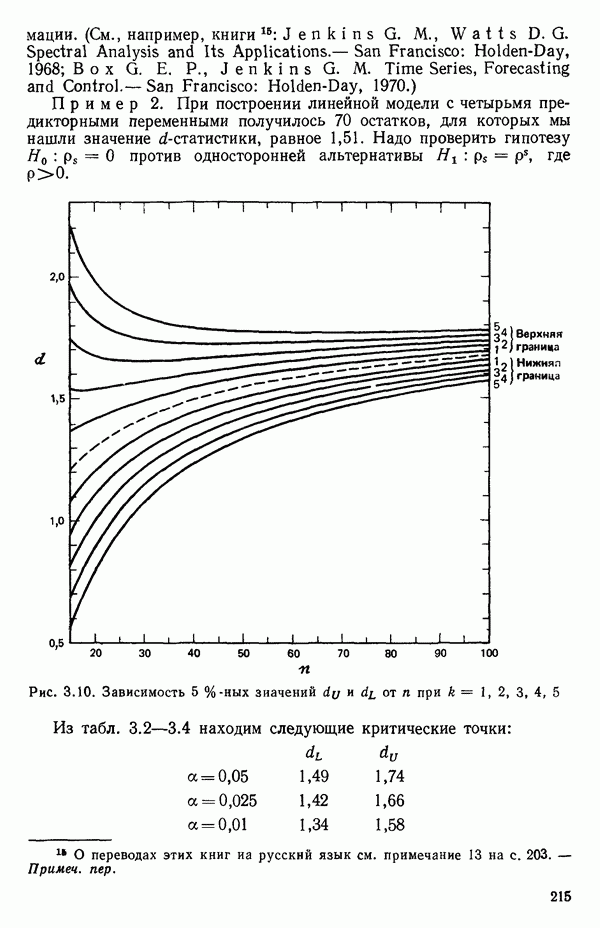
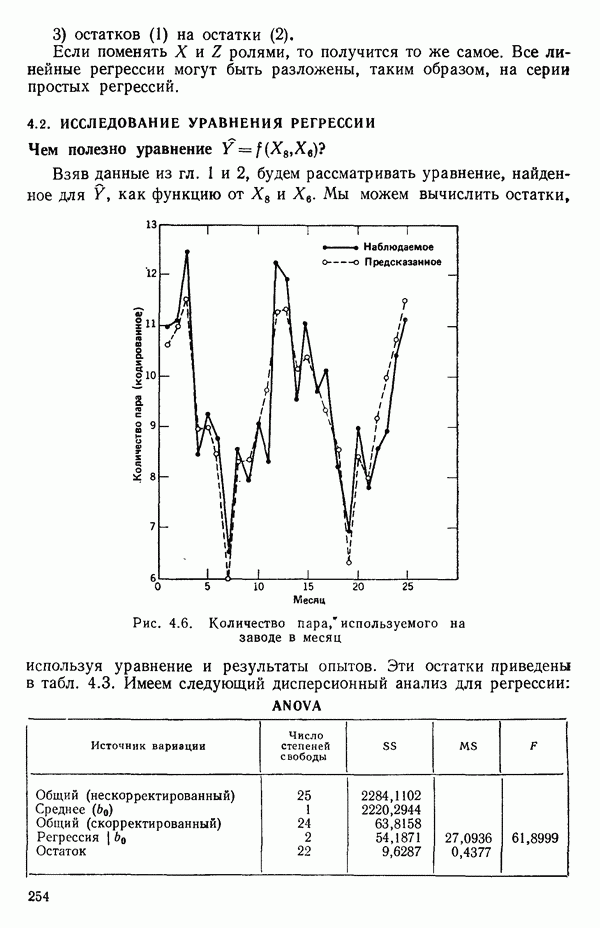
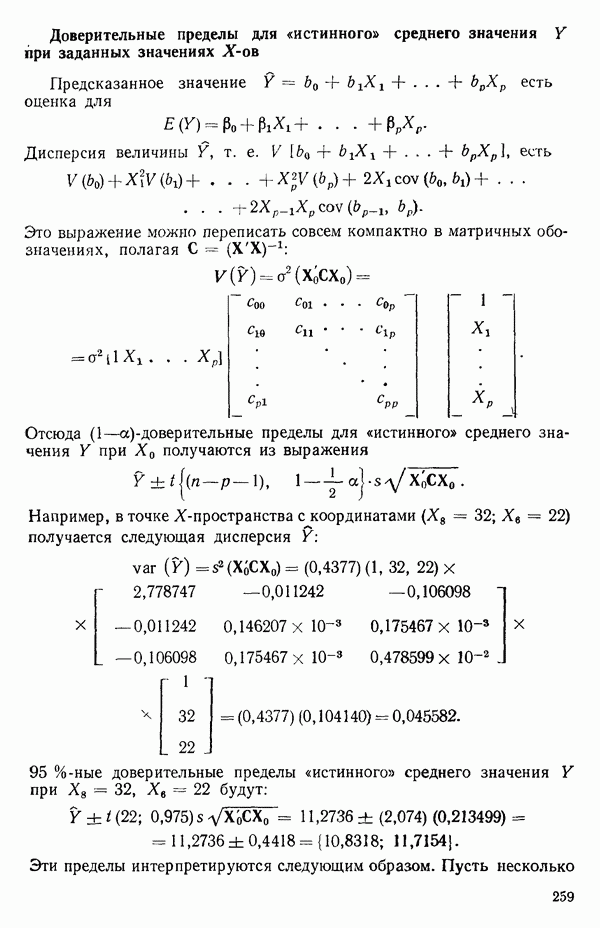
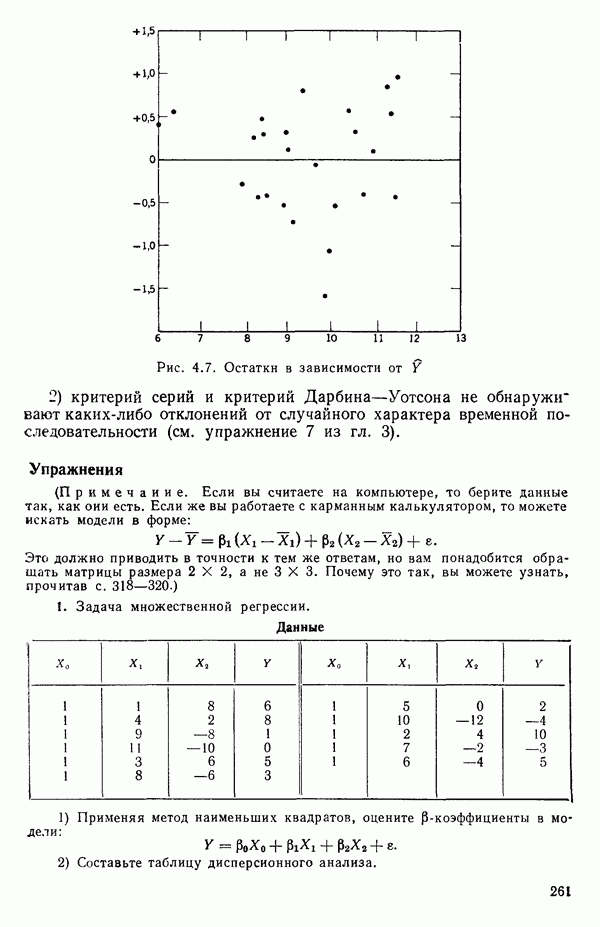
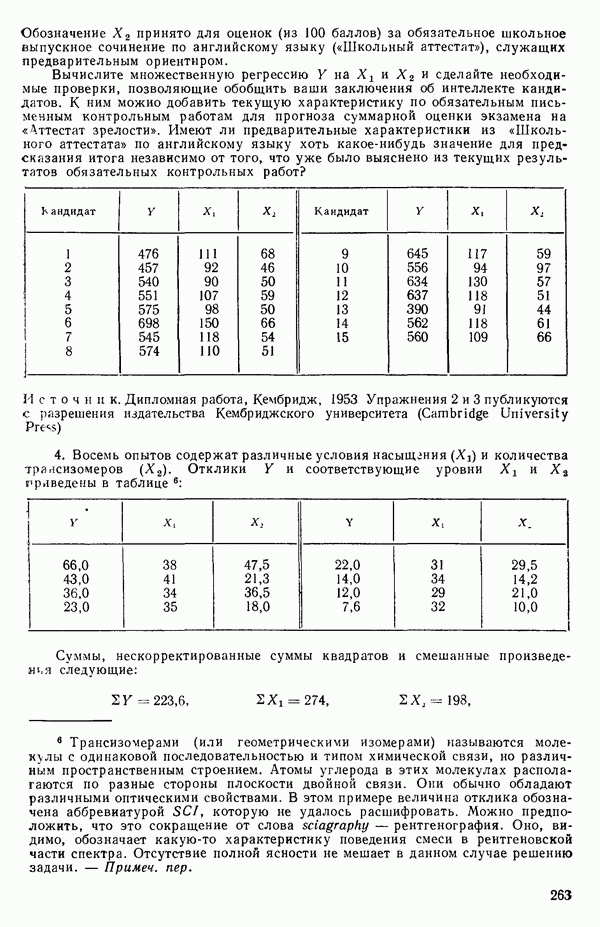
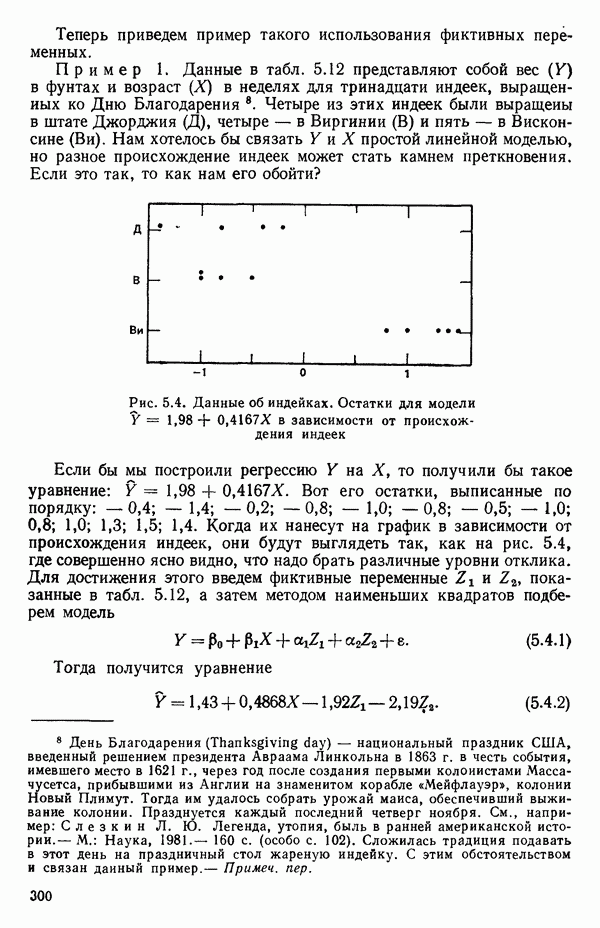
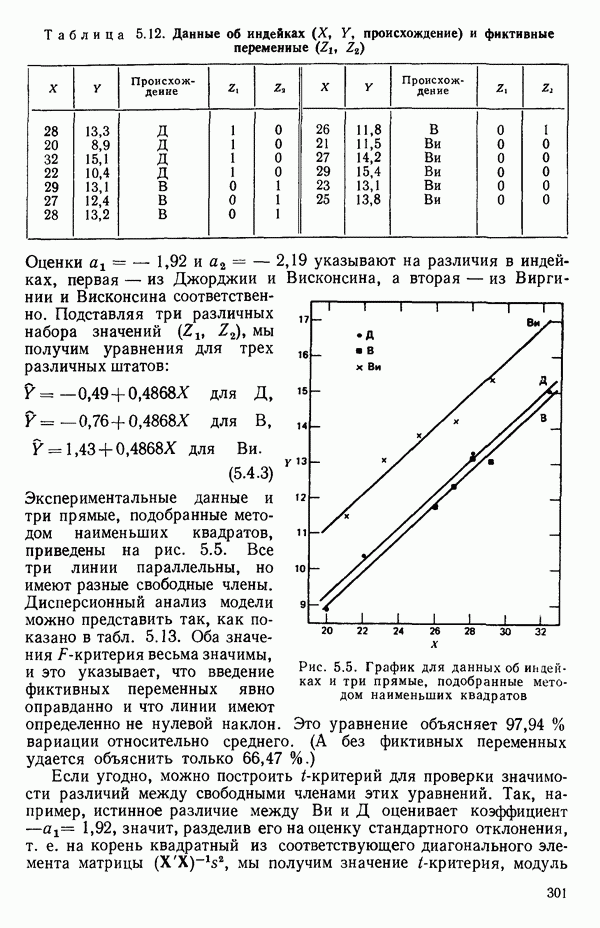
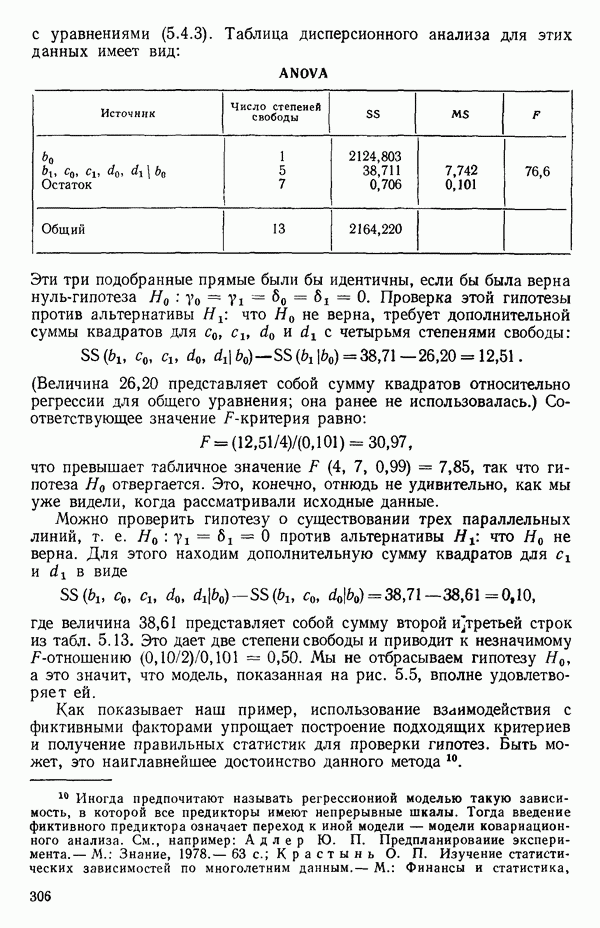
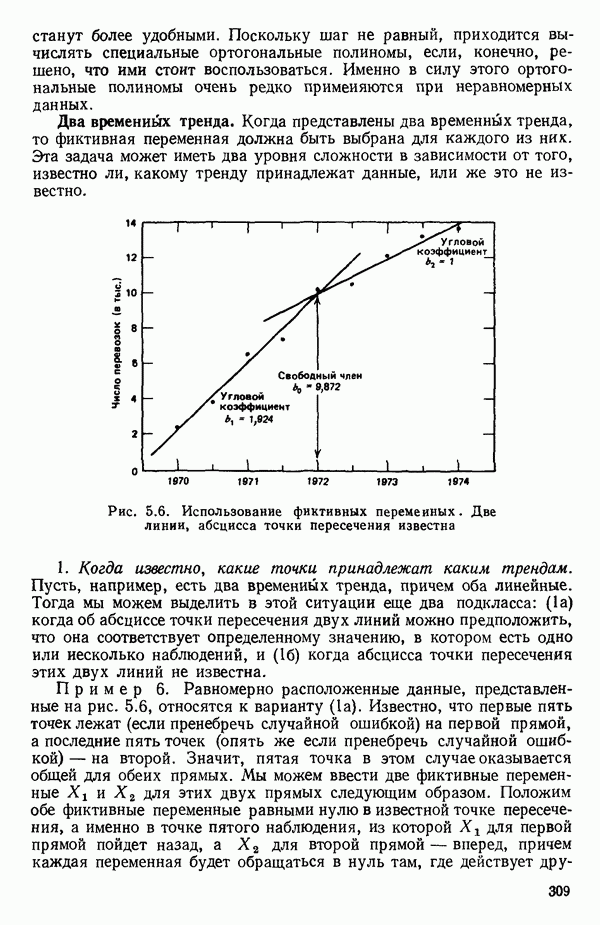
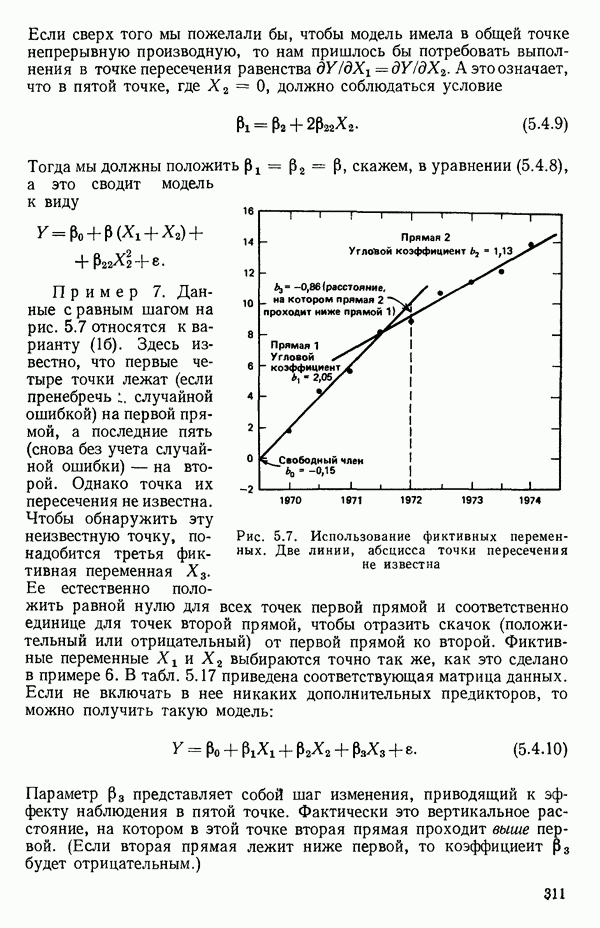
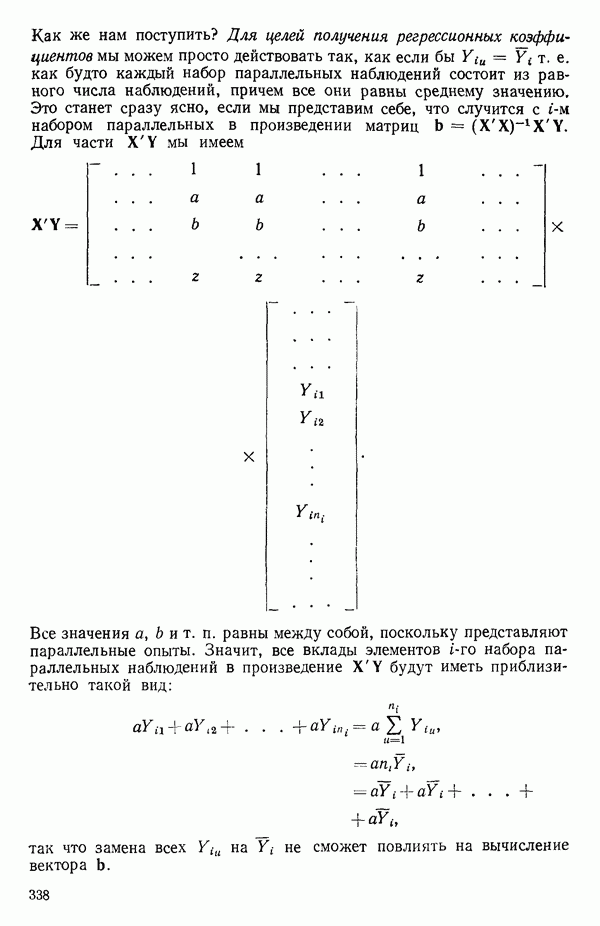
5.5. ЦЕНТРИРОВАНИЕ И МАСШТАБИРОВАНИЕ. ПРЕДСТАВЛЕНИЕ РЕГРЕССИИ В КОРРЕЛЯЦИОННОЙ ФОРМЕЕсли в регрессионную модель включены только одна или две предикторные переменные, то непосредственное вычисление по формуле Пример, Хотя цифровая машина перерабатывает значительно больше цифр, чем человеческая «вычислительная машина», ошибки такого типа нередко происходят и часто приводят к совершенно не верным результатам или к увеличению времени счета. Заключения, которые, по общему мнению, логичны, иногда базируются целиком на капризах ошибок округления. В работе Р. Фройнда о предупреждении ошибок округления в регрессионном анализе (Freund R.J. A warning of round-off errors in regression.- American Statistician, December, 1963, 17, p. 13-15) приведен пример, в котором пять различных регрессионных вычислений с использованием четырех разных регрессионных программ привели к значительным различиям в оцениваемых коэффициентах, обусловленным ошибками округления. Для преодоления этого некоторые программы позволяют получать результаты с удвоенной точностью. Это означает, что машина (по требованию) работает с числами, вдвое более длинными, чем обычно. Применение такого приема как стандартного способа приводит к излишнему расходованию машинного времени и часто оказывается неоправданной предосторожностью. Гораздо лучше сначала выяснить, что ошибки округления могут иметь место, и лишь тогда предпринимать шаги, позволяющие уменьшить ошибки, а возможно, и исключить их полностью. Две основные причины ошибок округления таковы: 1. Числа, включенные в регрессионные вычисления, могут резко различаться по порядку, как, например, если включить в расчет числа вроде 2. Матрица, которую надо обращать, может оказаться очень близкой к вырожденной. Из уравнений (2.1.10) и (2.1.11) мы можем видеть, что определитель матрицы входит в каждый элемент обратной матрицы. Если определитель матрицы мал по сравнению с остальными числами в расчете, то помехи от округления, вероятно, будут иметь место, и это справедливо не только для матриц Плохая обусловленностьКогда существуют строгие зависимости между столбцами матрицы X, т. е. когда один (или более) столбцов можно строго выразить как линейную комбинацию (с различными численными коэффициентами) других столбцов, определитель ложится либо на «модельера», либо на «сборщика данных») Дело, по существу, сводится к выбору между простотой модели и охватом, если, конечно, можно собрать данные, позволяющие оценить такую модель. Когда же зависимости проявляются лишь приближенно, в матрице Допустим, что мы хотим подобрать общую линейную модель методом наименьших квадратов в виде
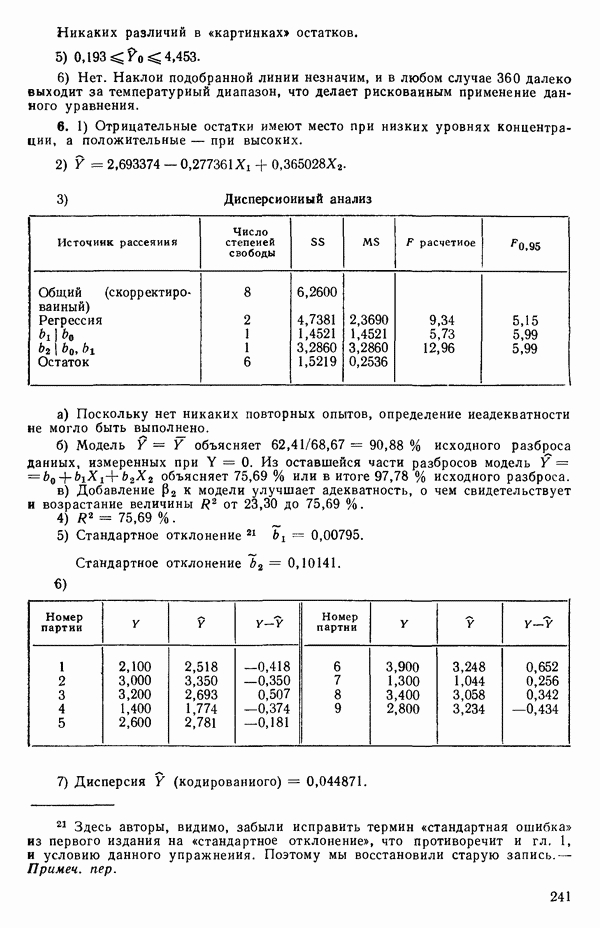
где
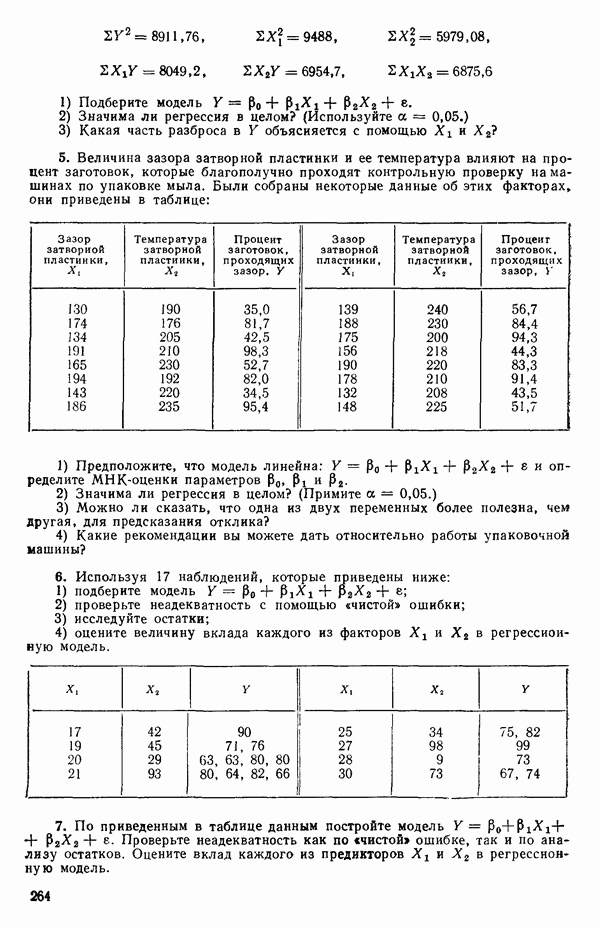
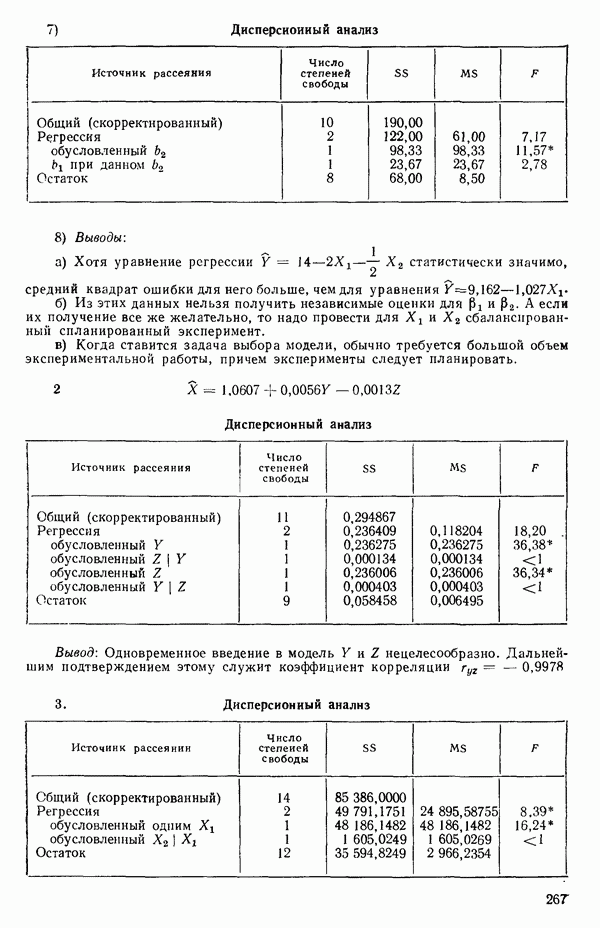
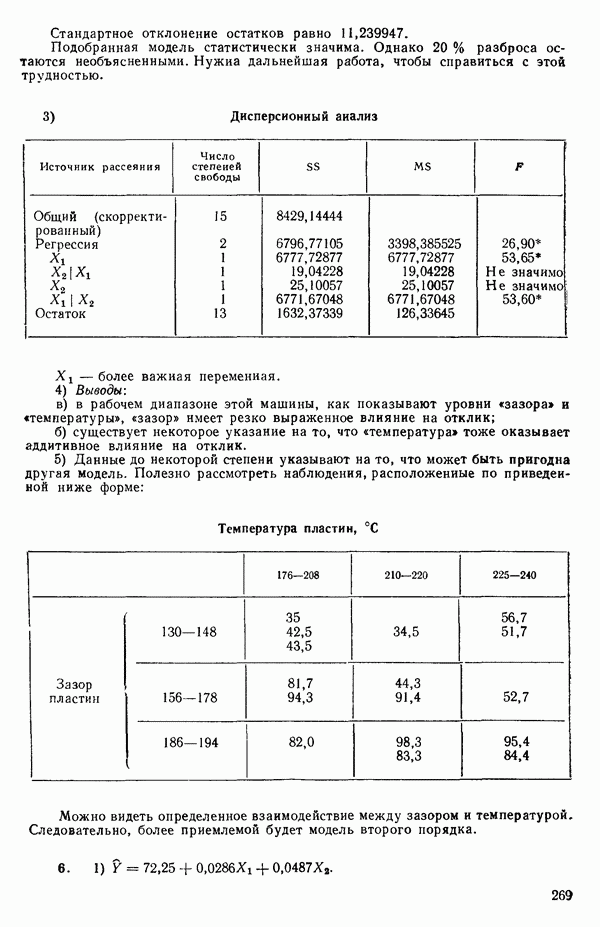
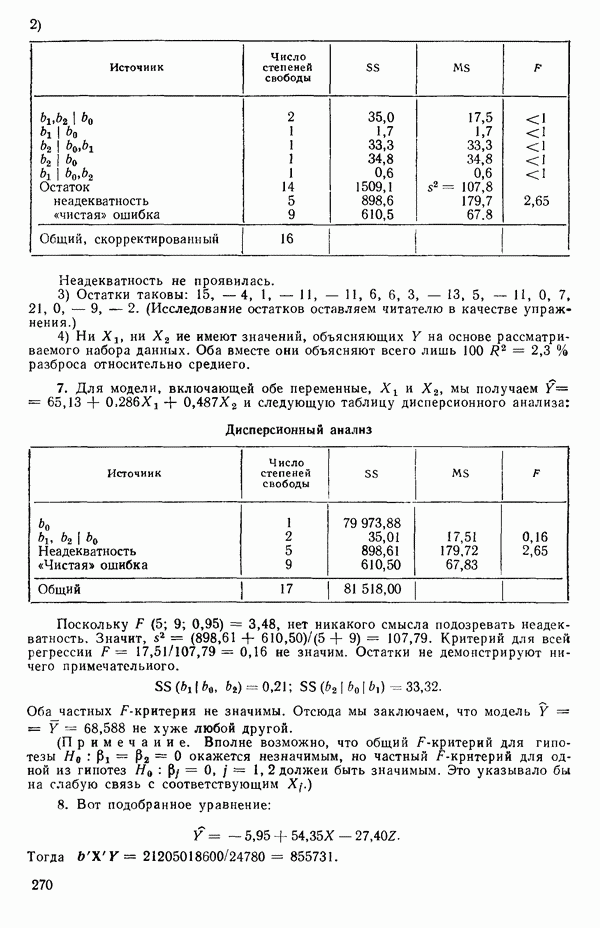
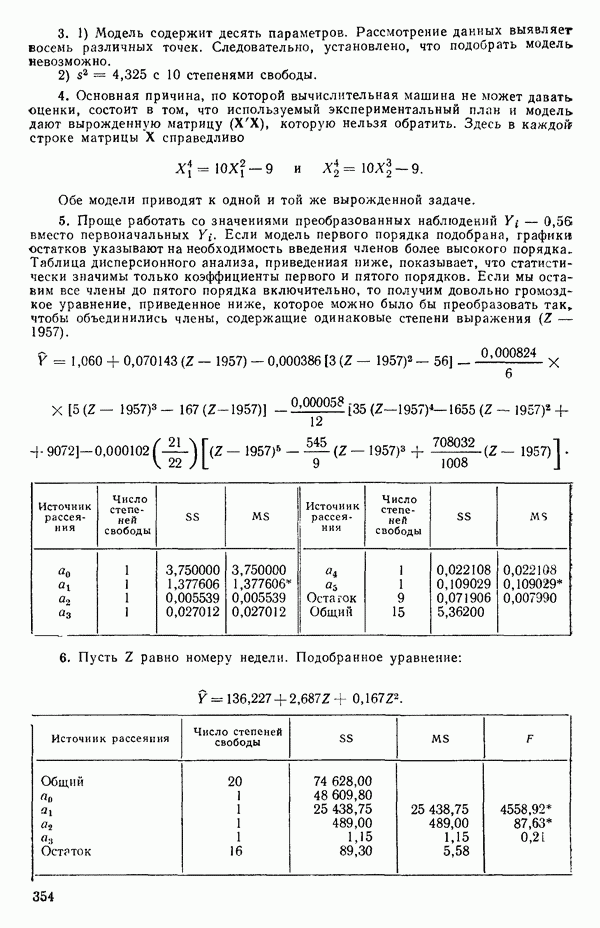
и вектор
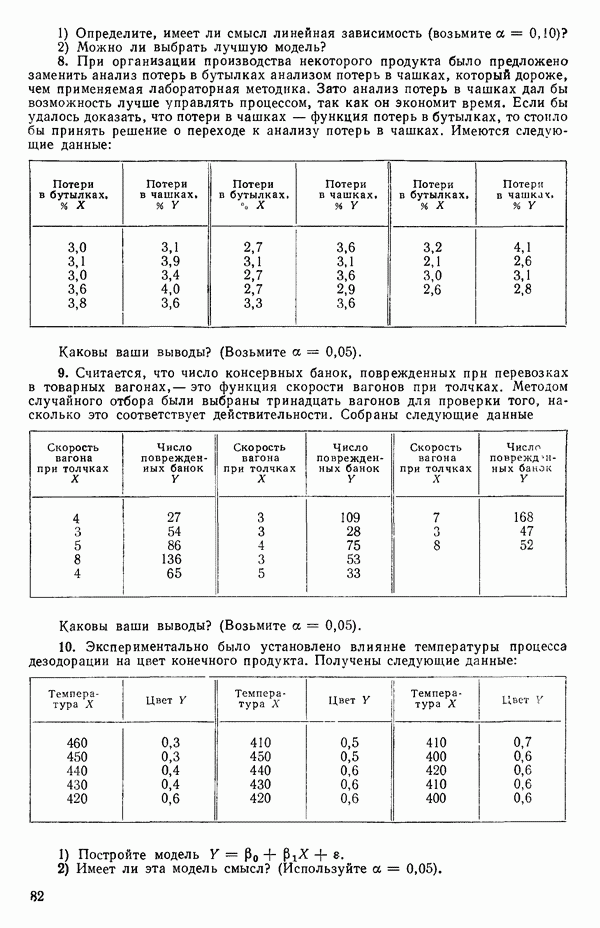
Тогдс! оценка вектора Р, а именно
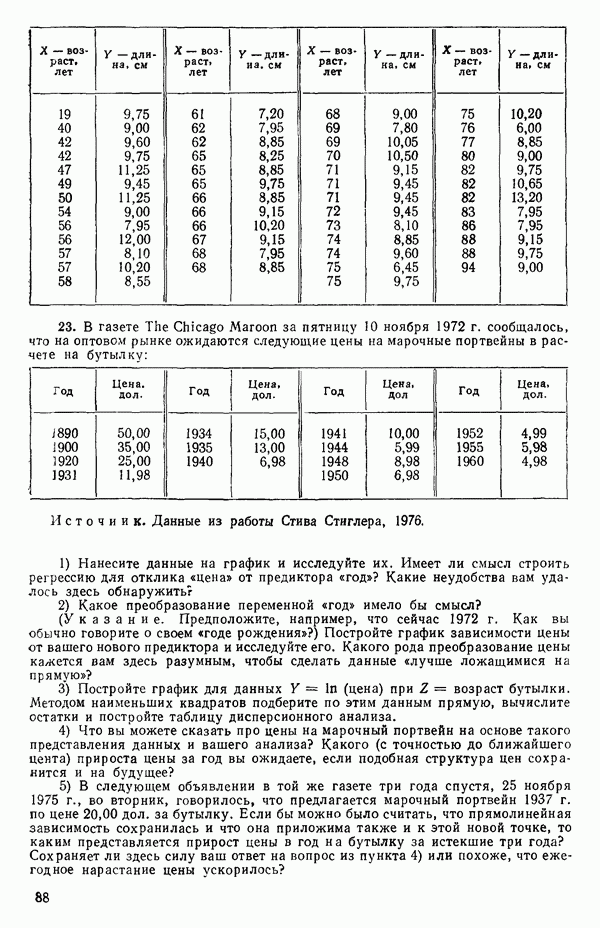
дается выражением
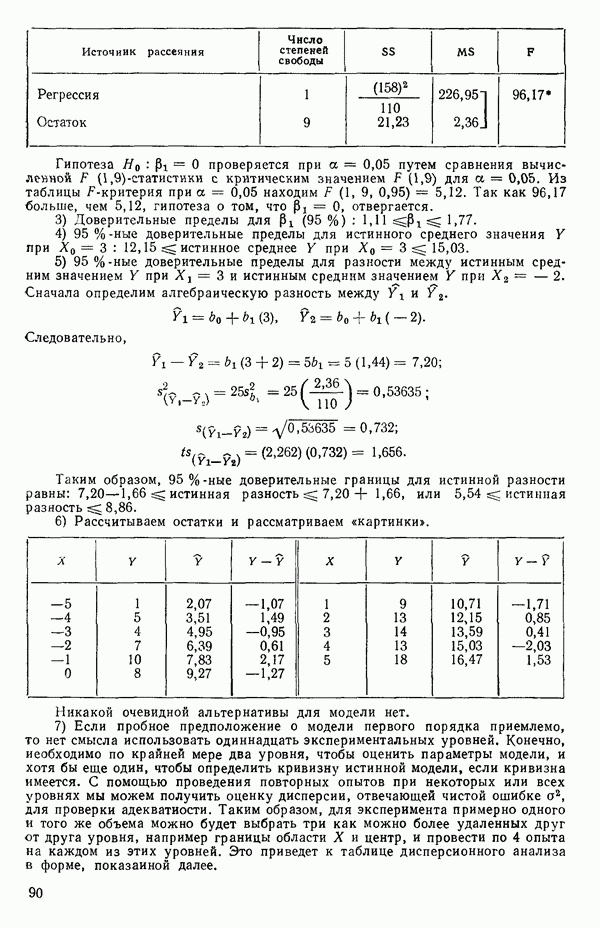
а
так что
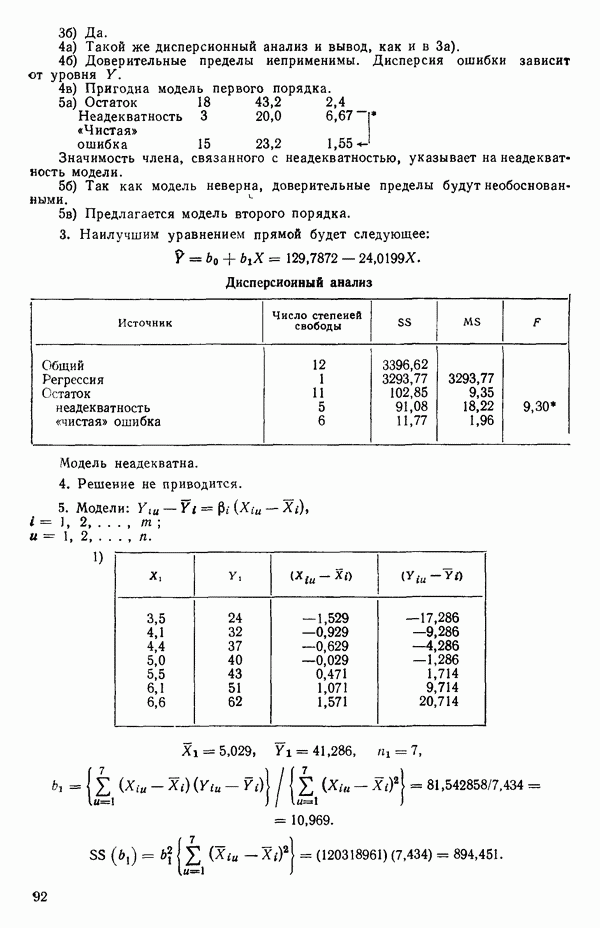
то
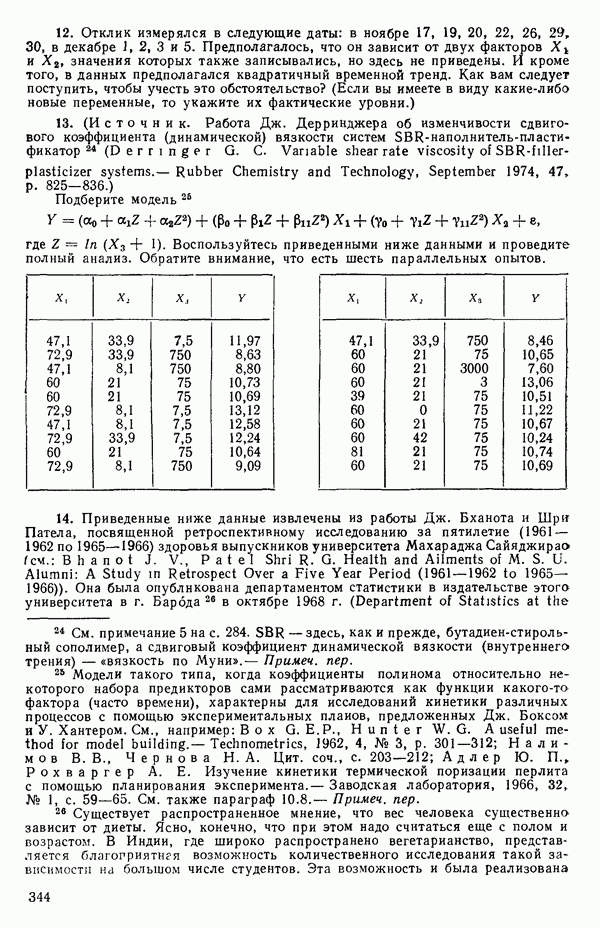
(Наоборот, если для приведенного выше простого примера имеет вид:
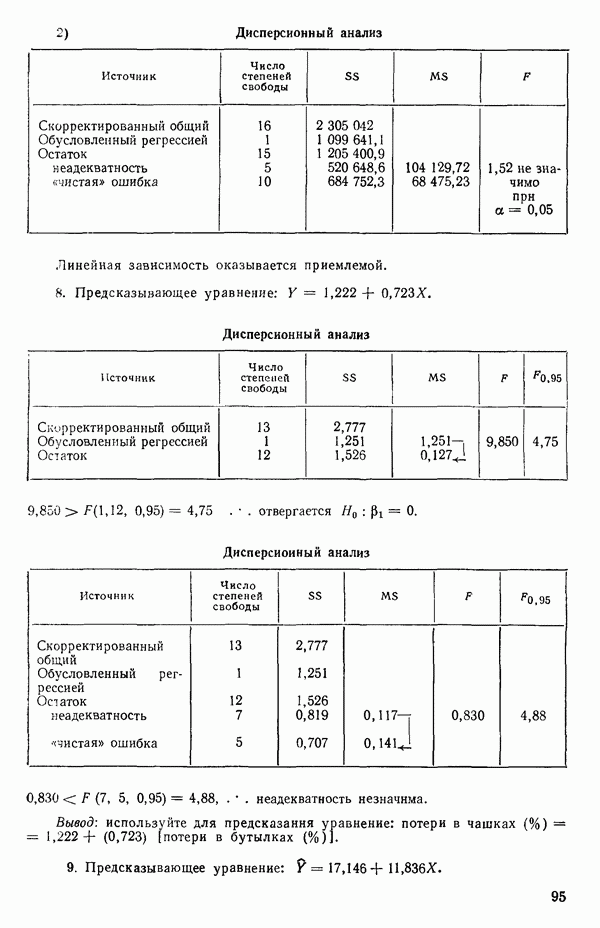
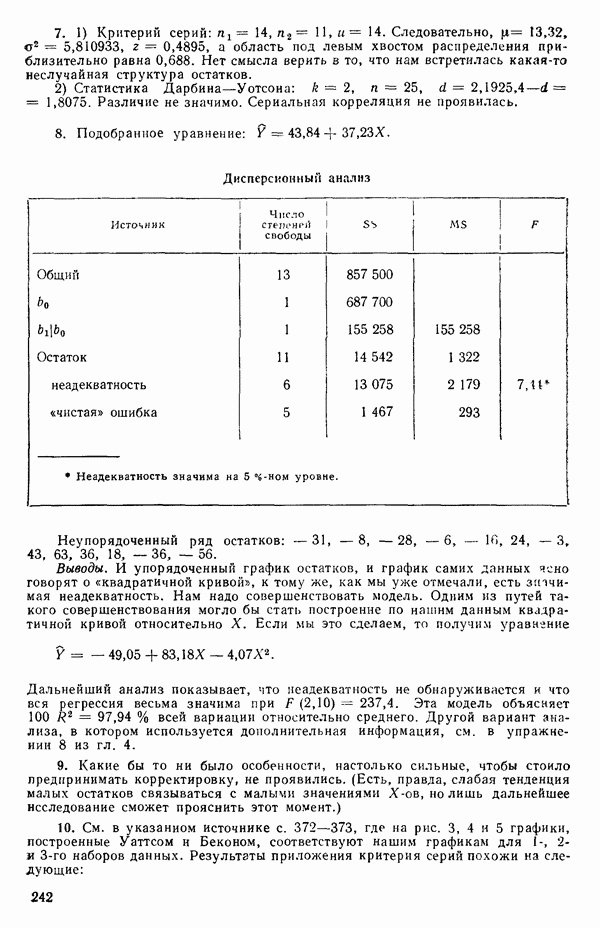
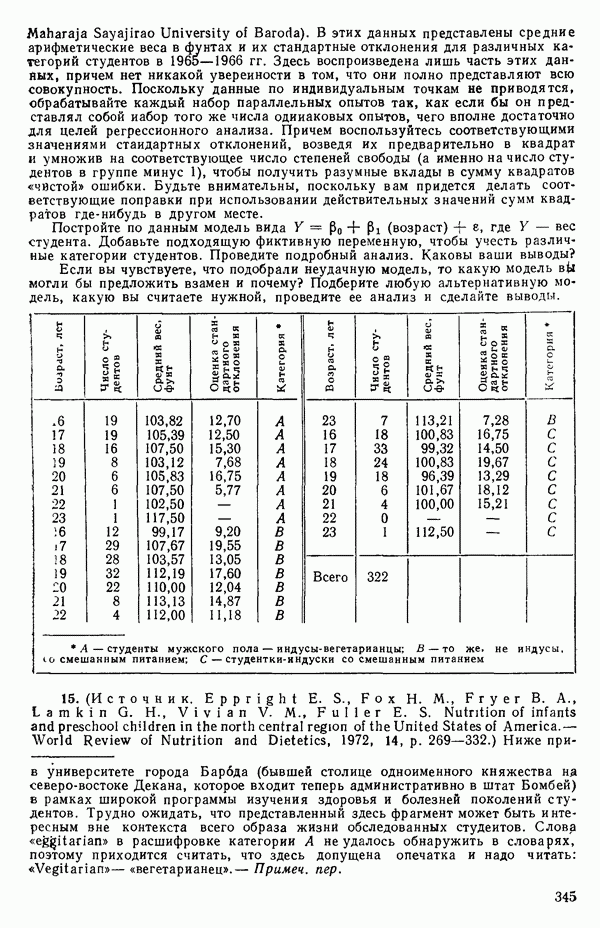
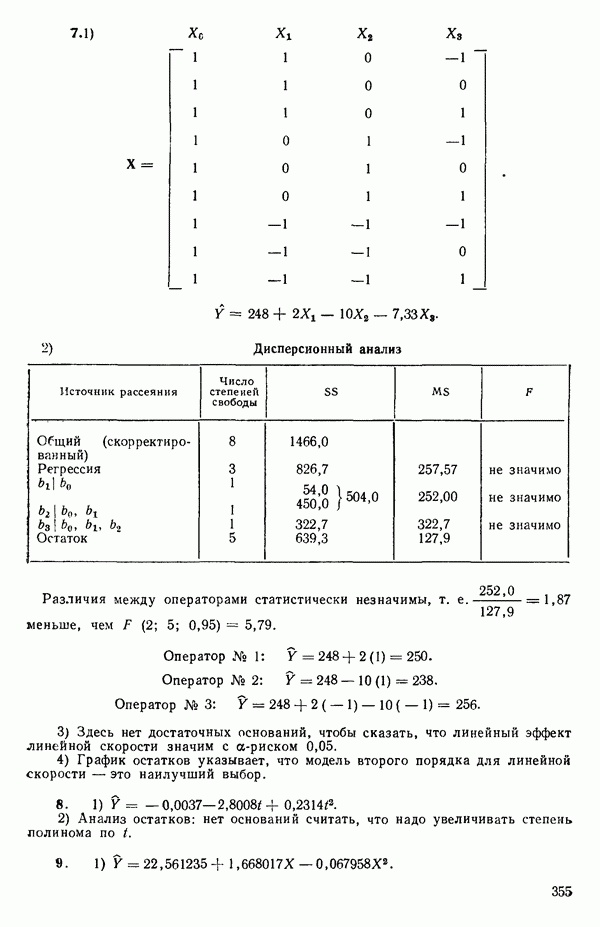
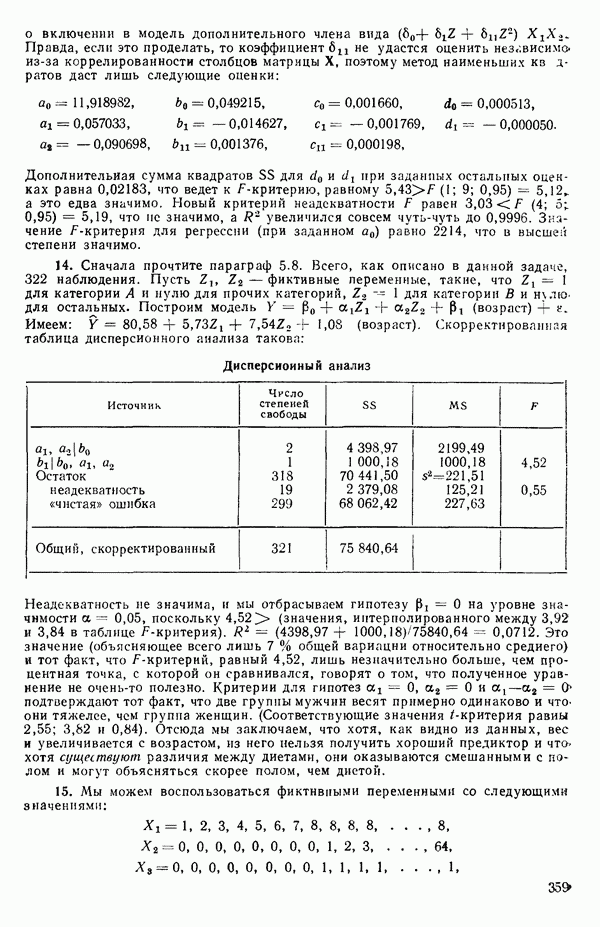
«Центрирование» данныхПусть мы имеем следующую матрицу исходных данных вместе со средними по столбцам:
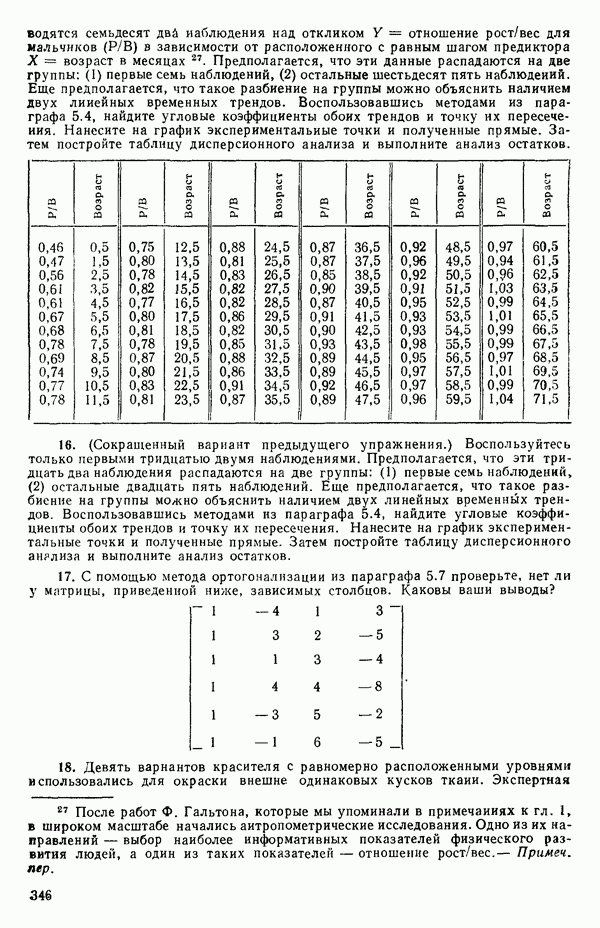
Наша модель такова:
Мы можем переписать ее в виде
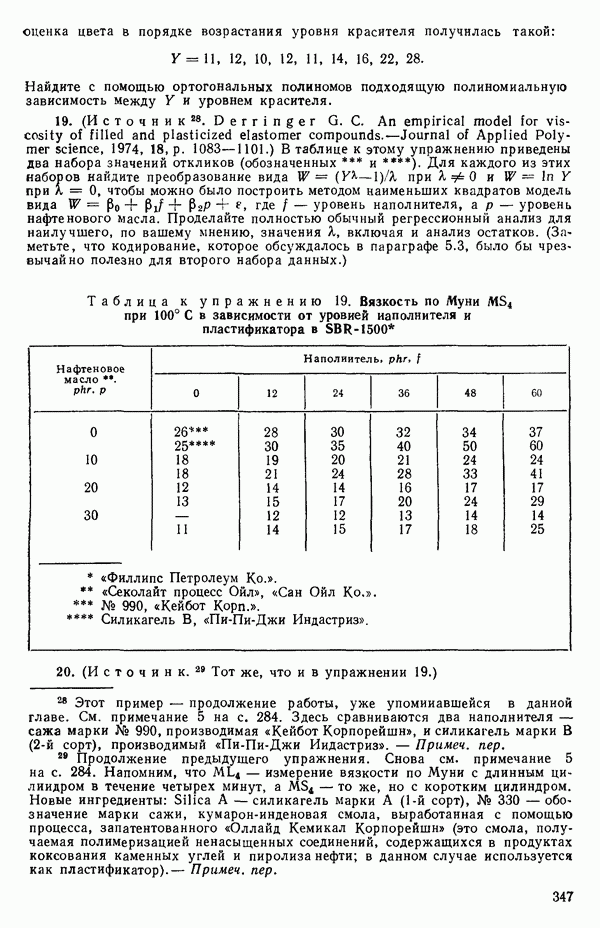
где
то модель можно будет выразить так:
Теперь можно преобразовать данные, как мы сделали раньше с переменными, так что
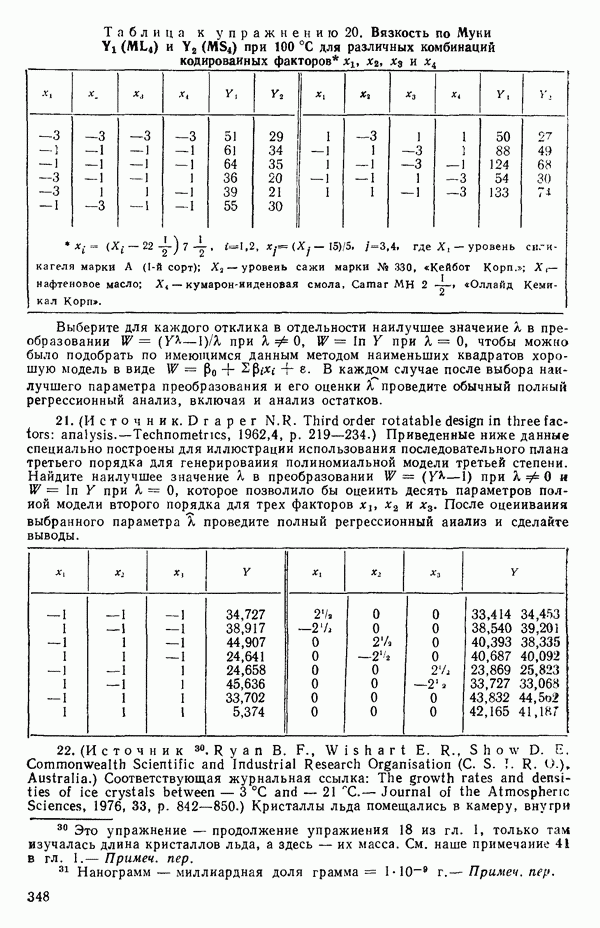
или
независимо от того, какими могут быть значения Поскольку это будет верно всегда, мы можем исключить
для оценивания методом наименьших квадратов. И она будет давать точно те же оценки параметров и предсказанные значения, какие мы получили бы, если бы воспользовались МНК для уравнения (5.5.6). (При вычислениях на карманном калькуляторе это иногда полезно, так как уменьшает на единицу размер матрицы, которую требуется обратить.) Кажущийся выигрыш, состоящий в том, что теперь надо оценивать на один параметр меньше, компенсируется тем, что
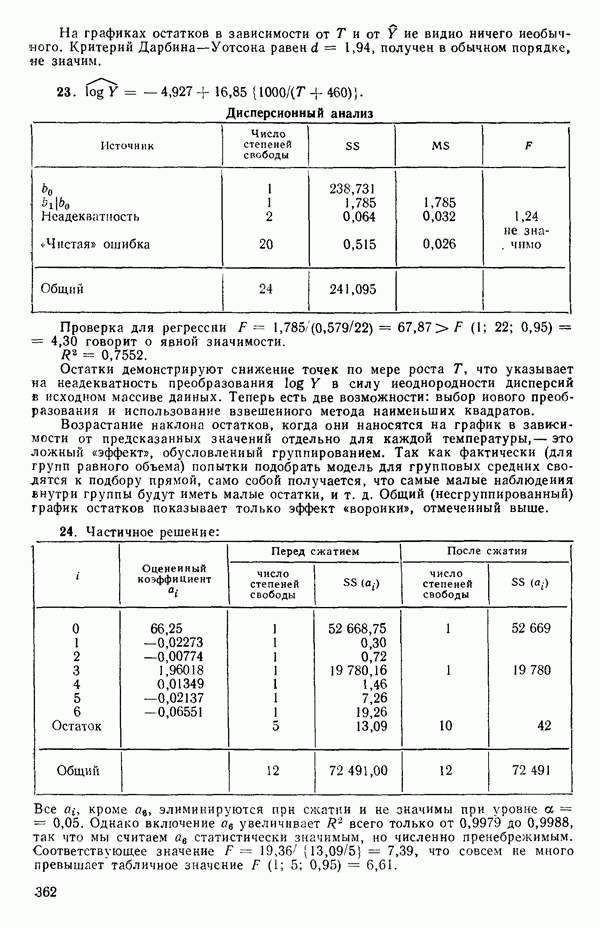
и поэтому одна степень свободы исключается из общего числа. Матрица данных для уравнения (5.5.8) будет иметь следующий вид:
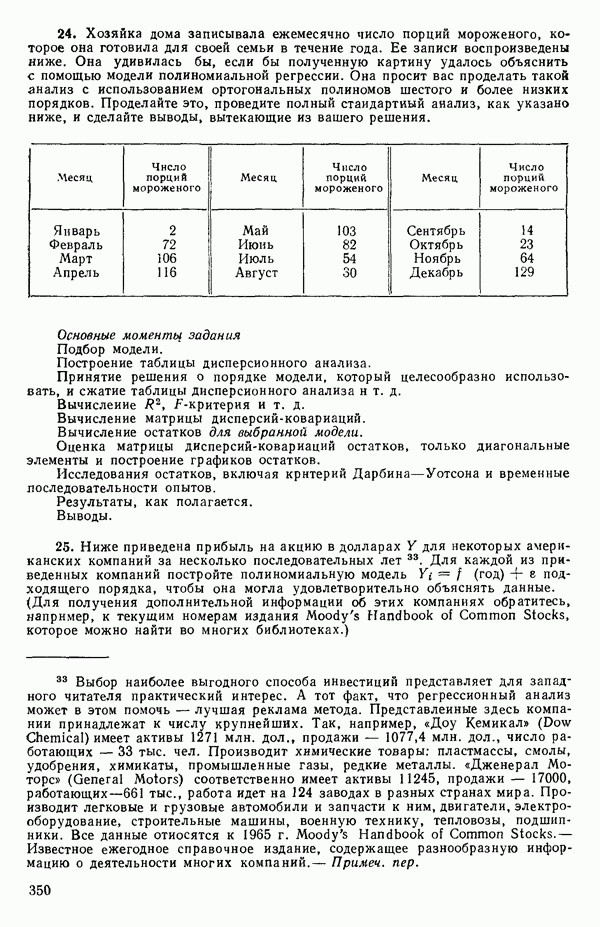
Для иллюстрации ситуации в очень простом случае мы воспользуемся примером, построенным выше, с матрицей исходных данных (5.5.4). Положим
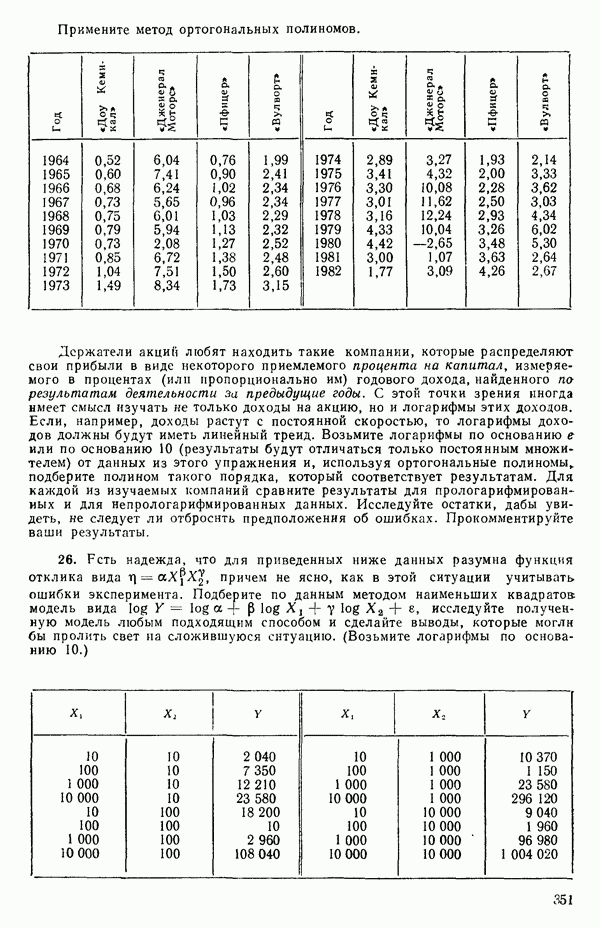
Заметим, что благодаря центрированию столбцов
|
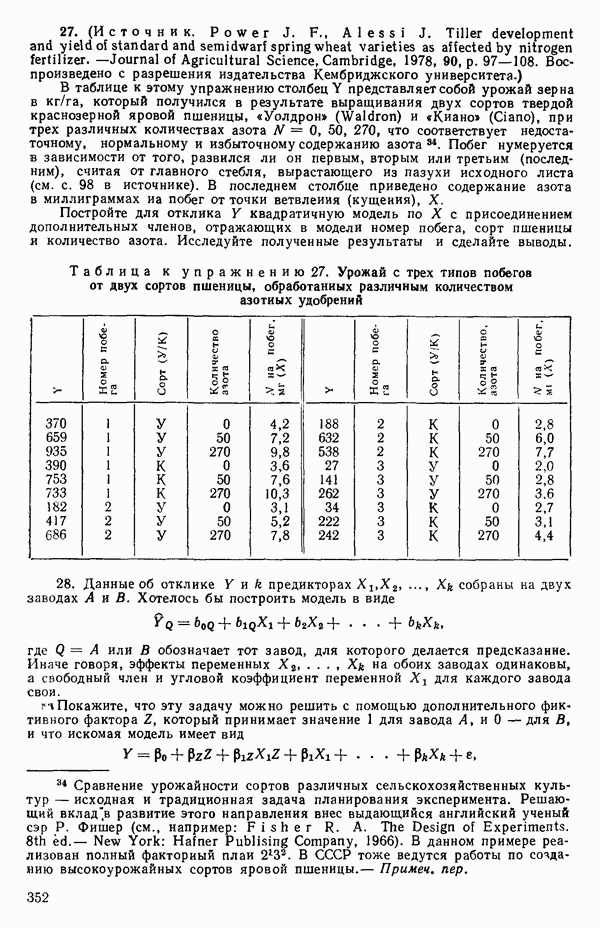
 |
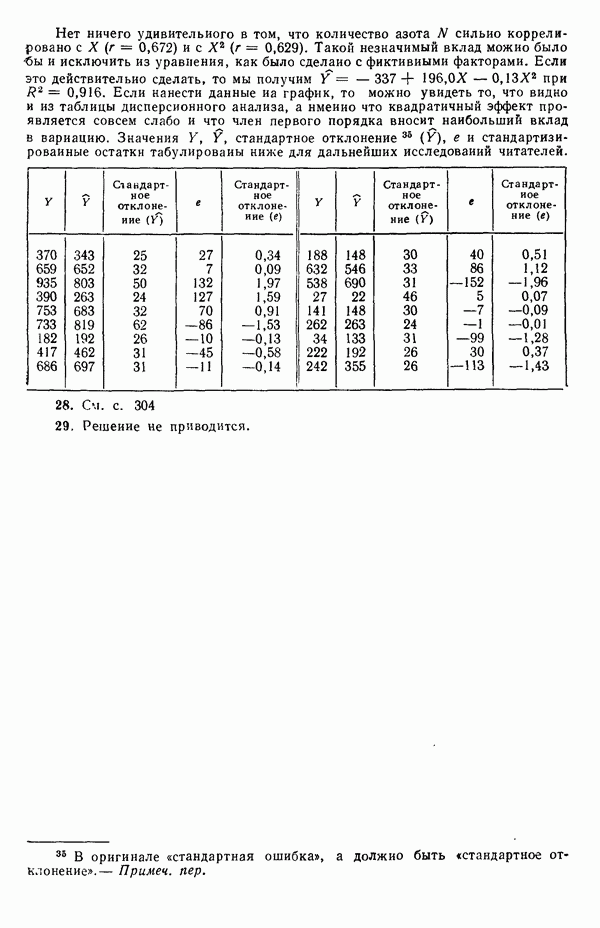
Оглавление
|























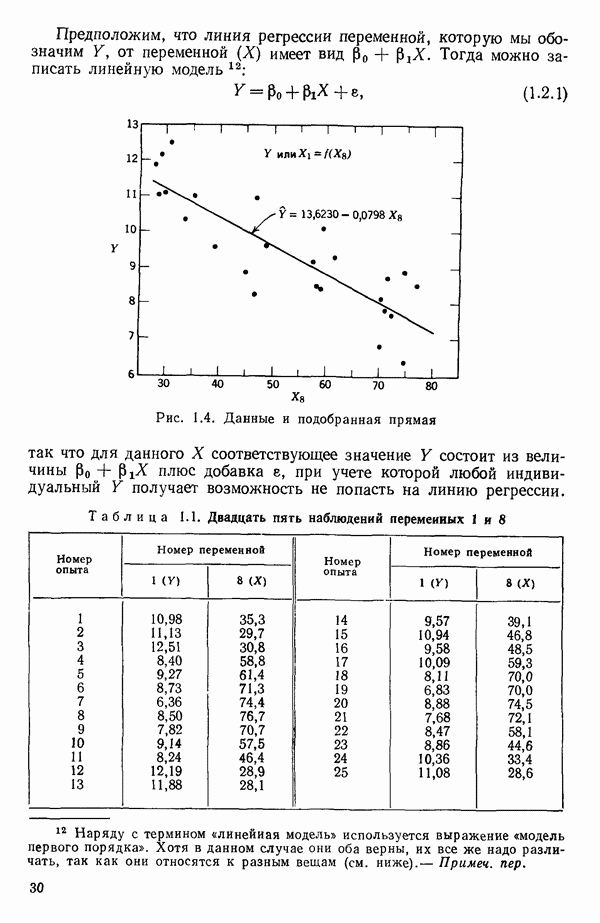


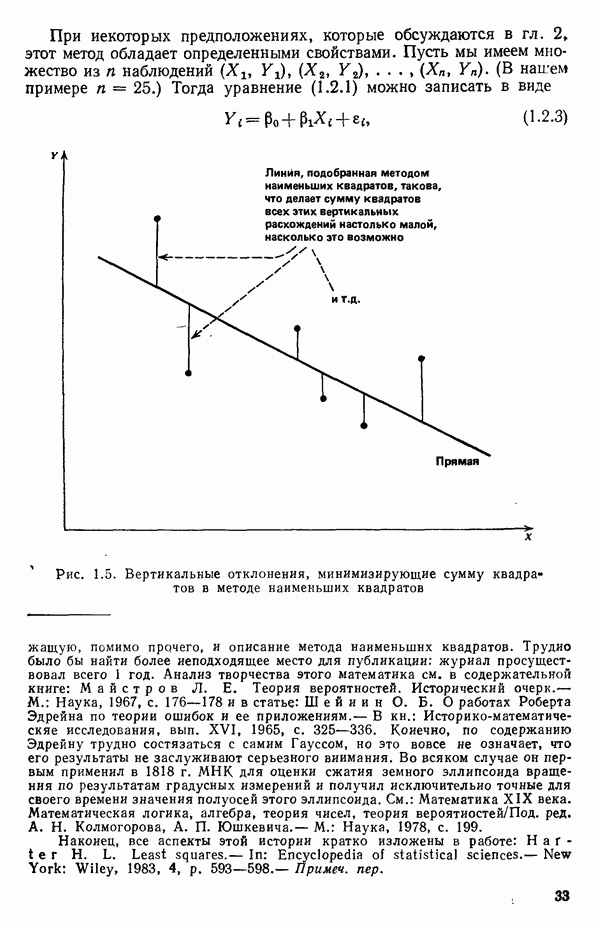






















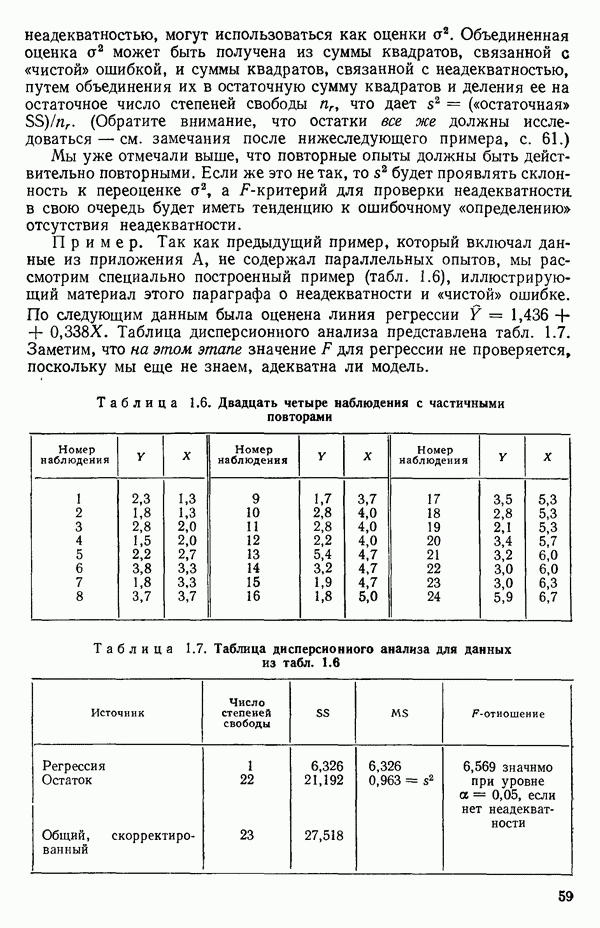
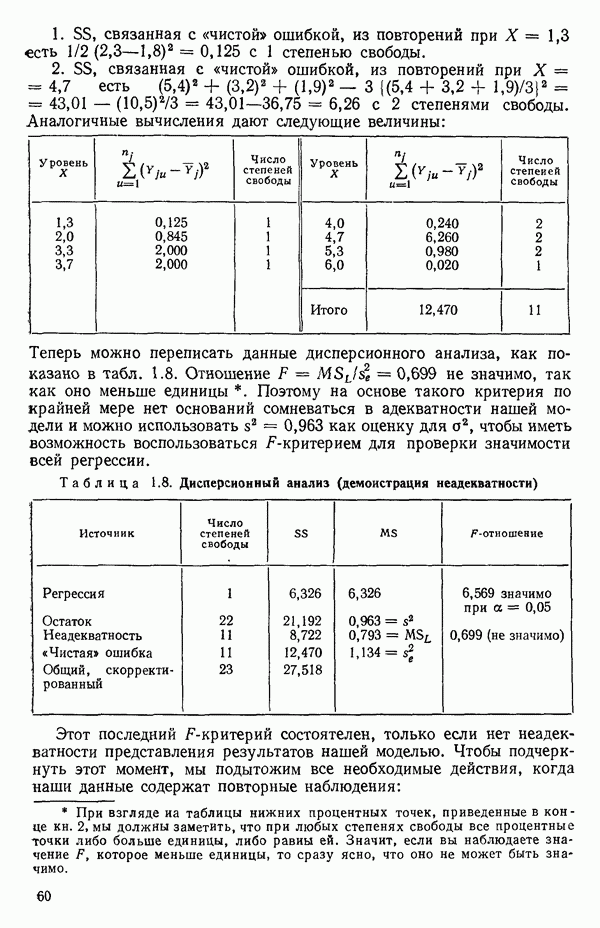

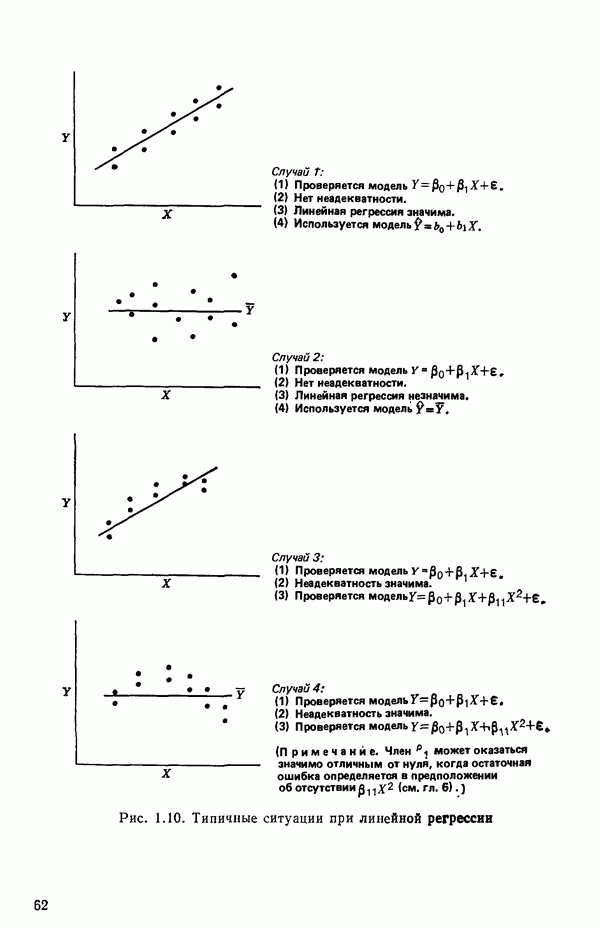






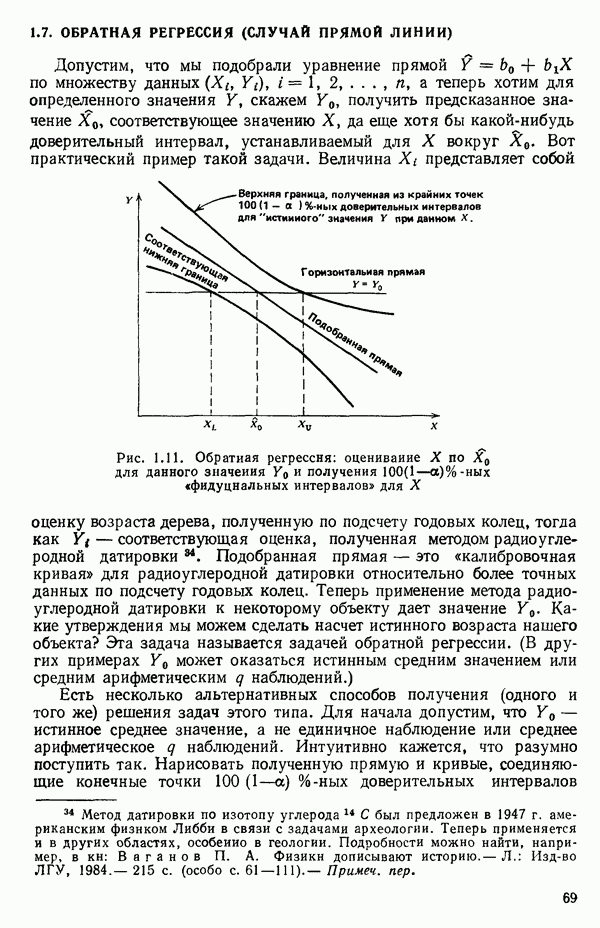


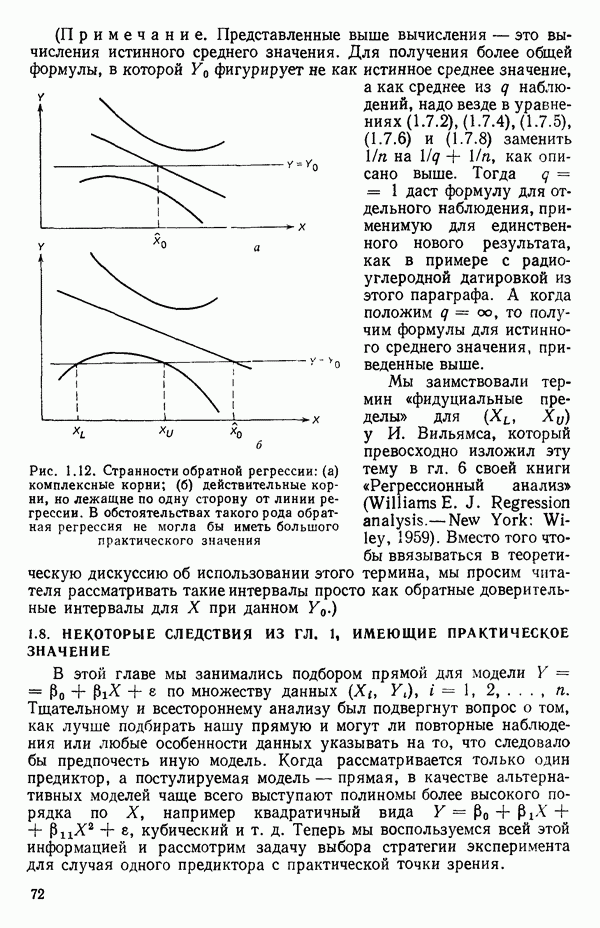














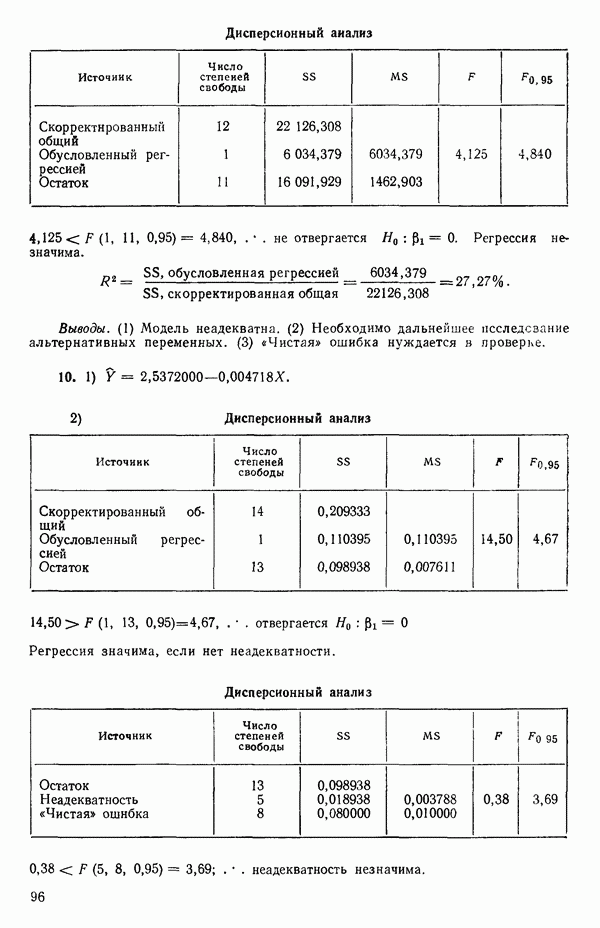
















































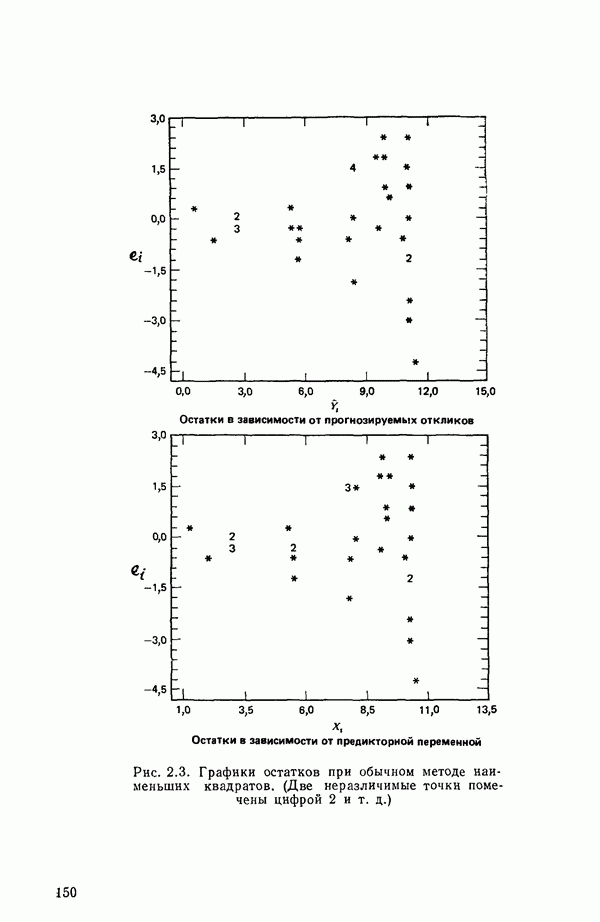

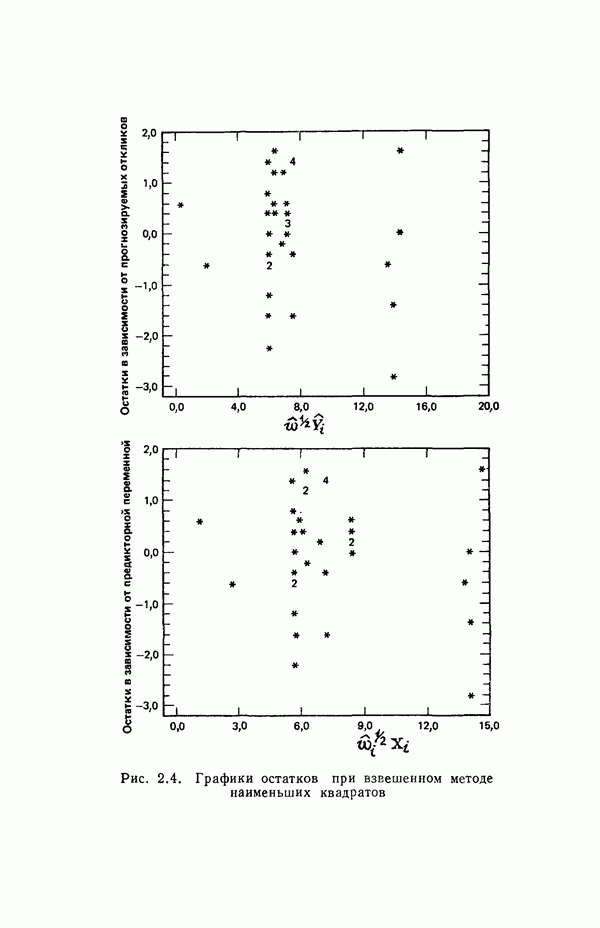





















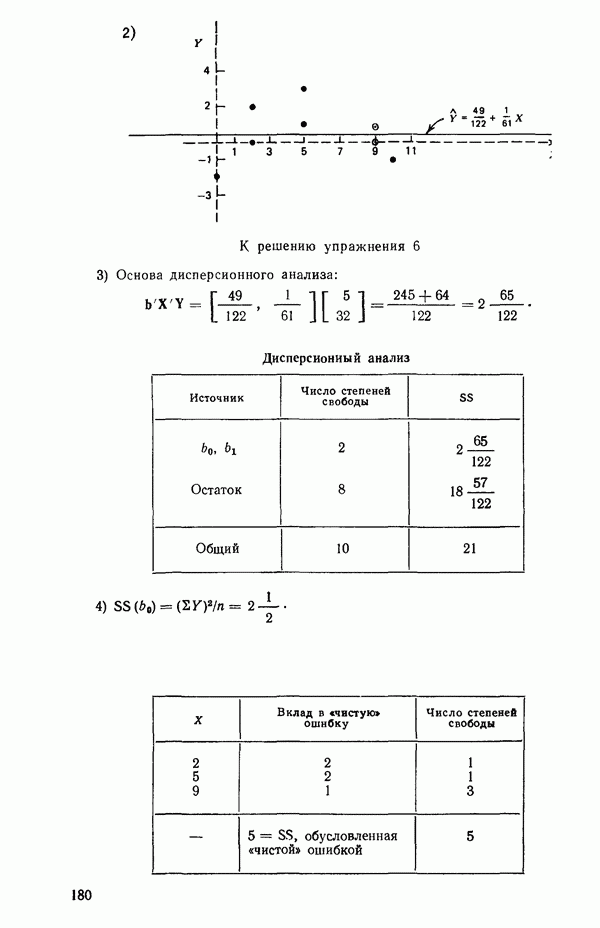



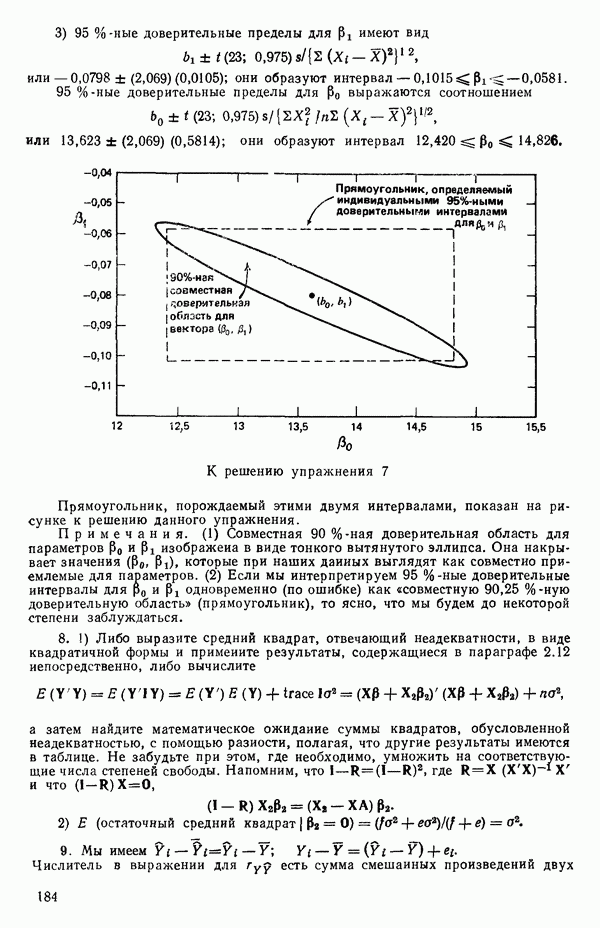






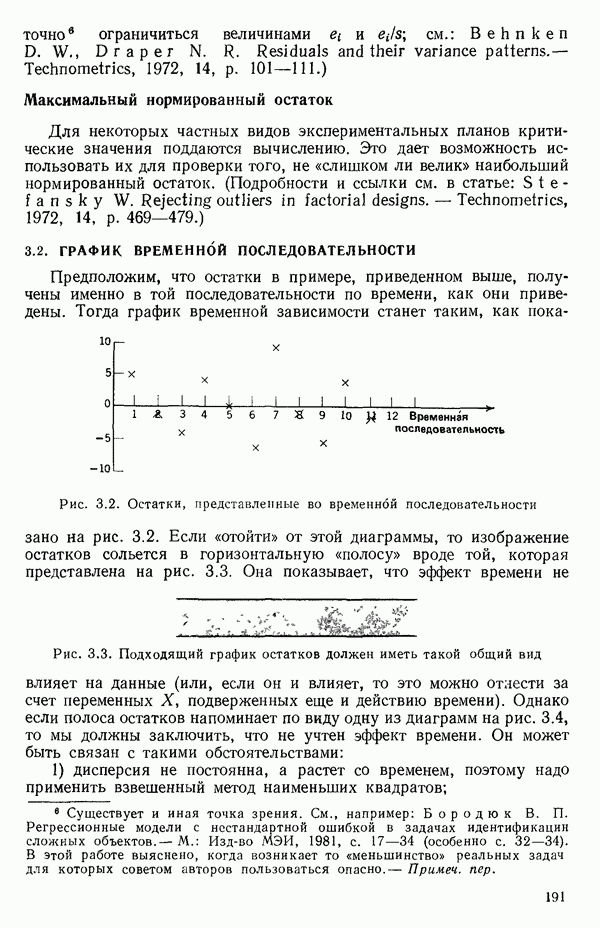








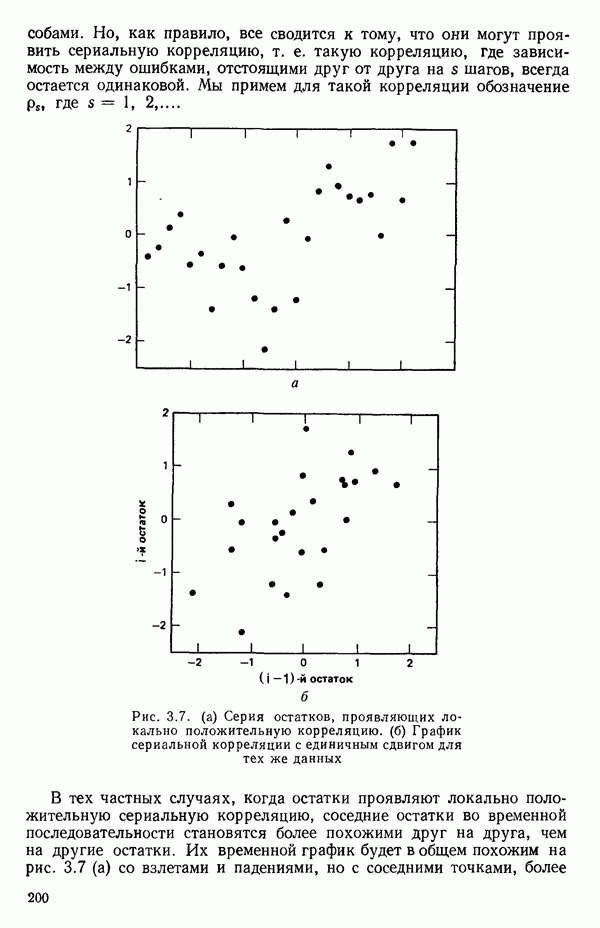
















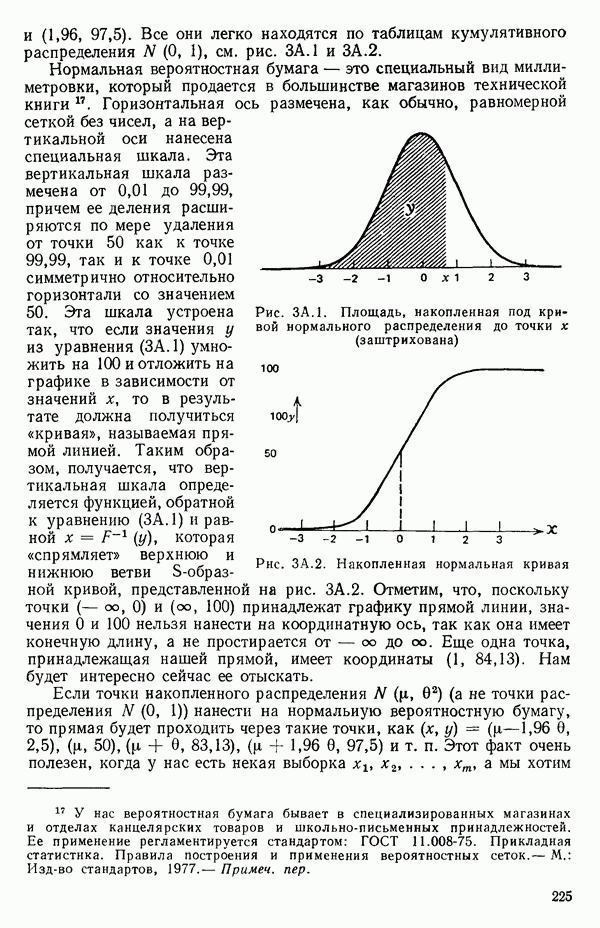
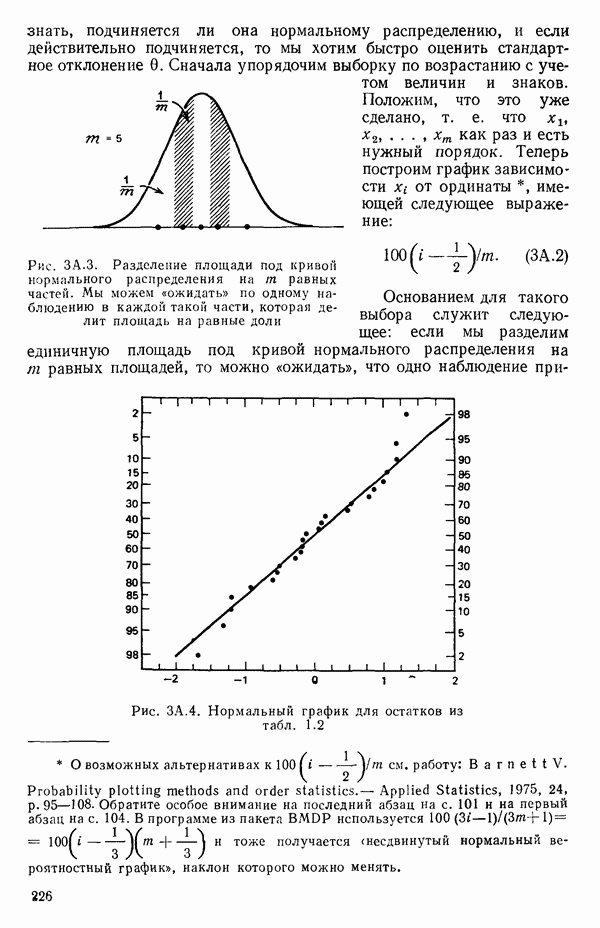


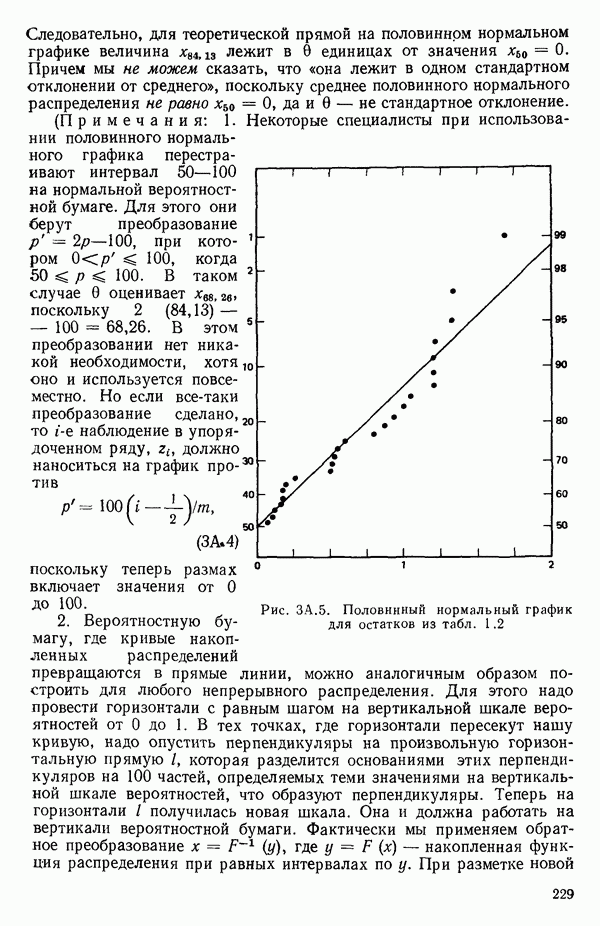





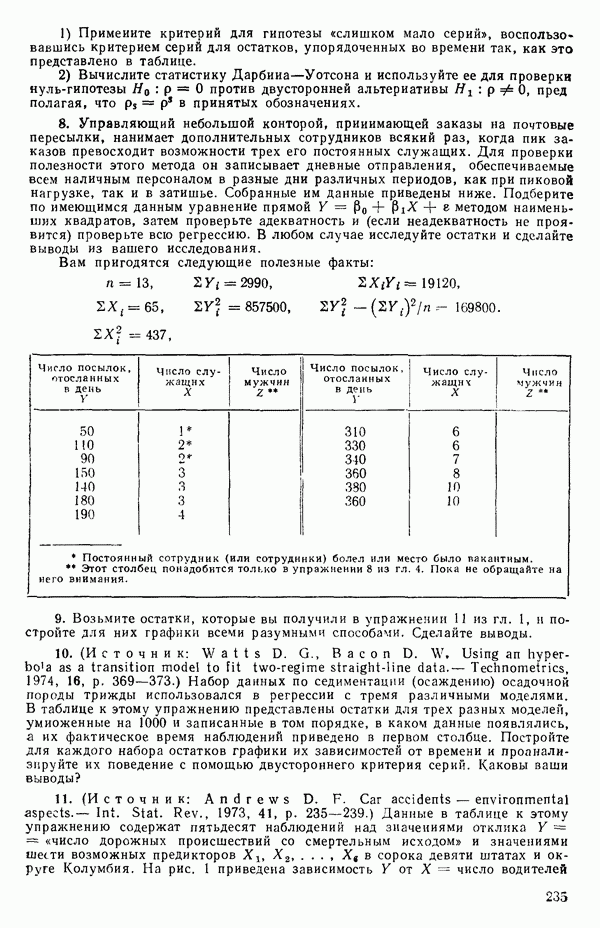
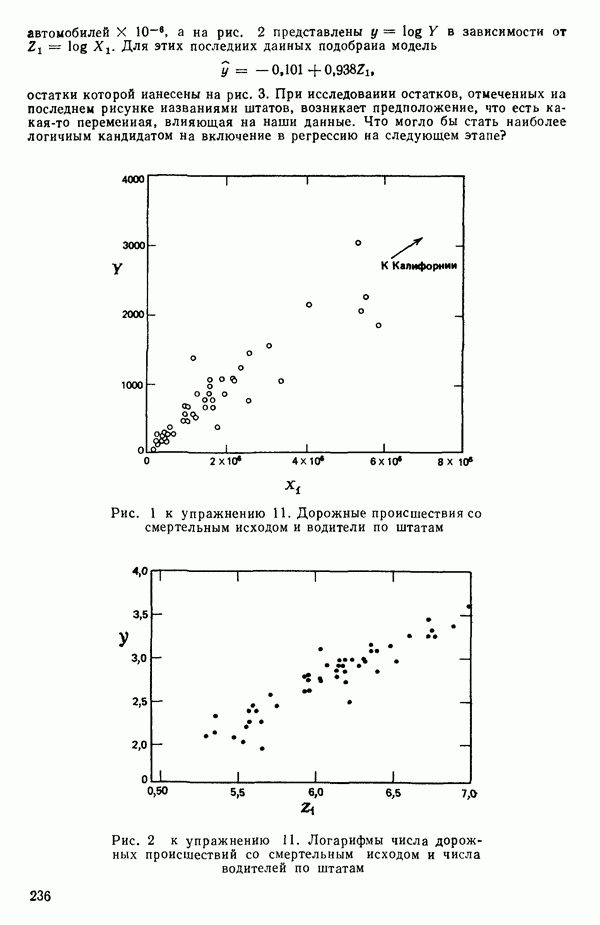
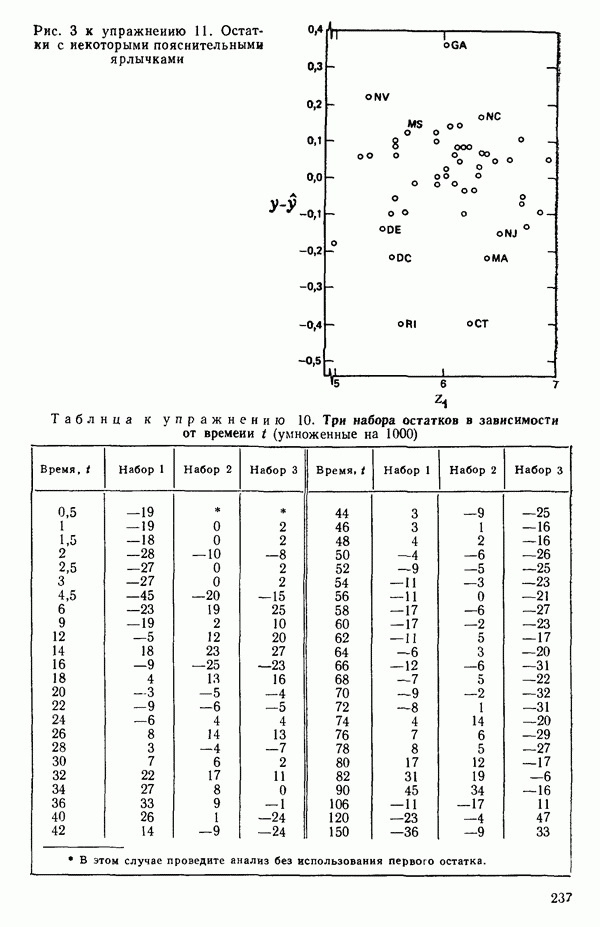
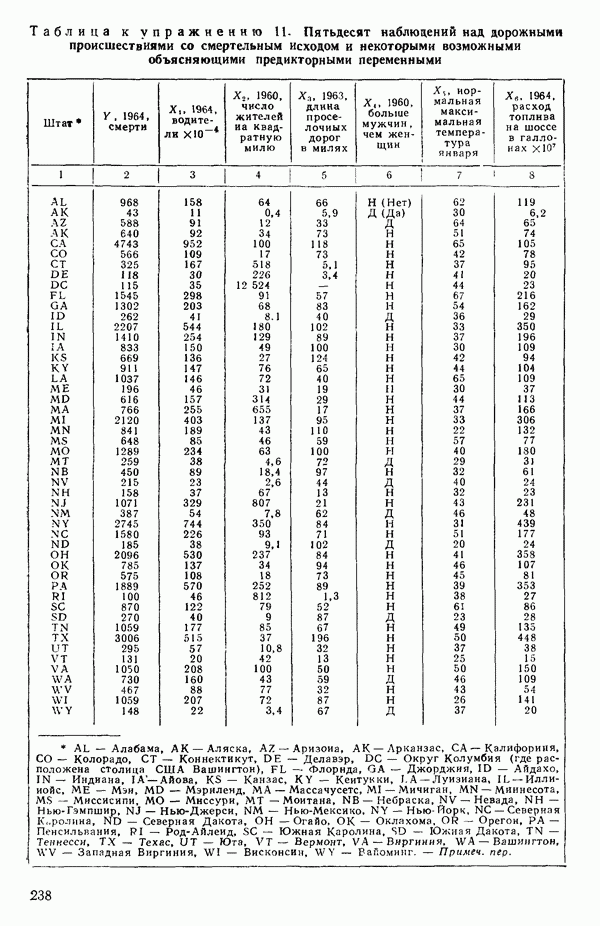

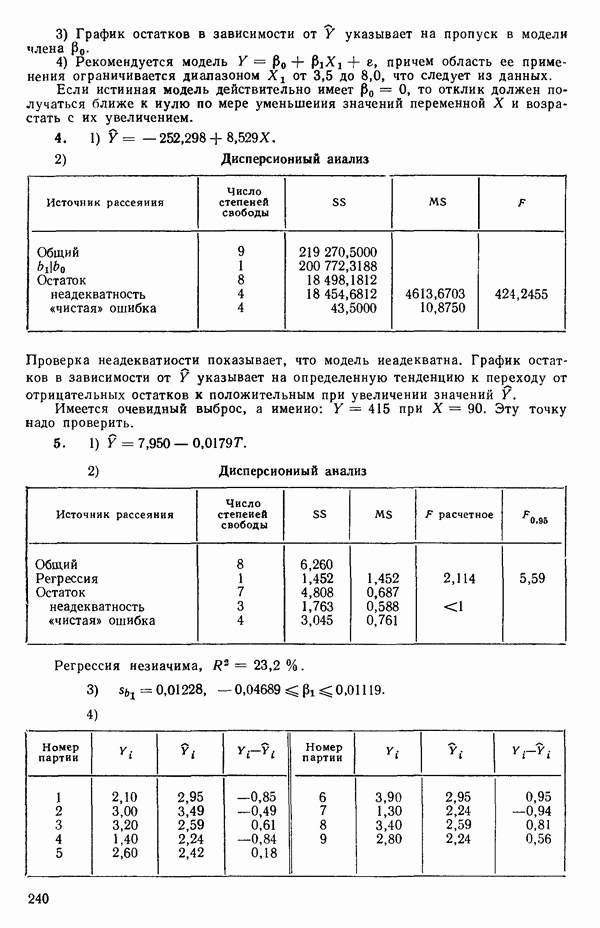



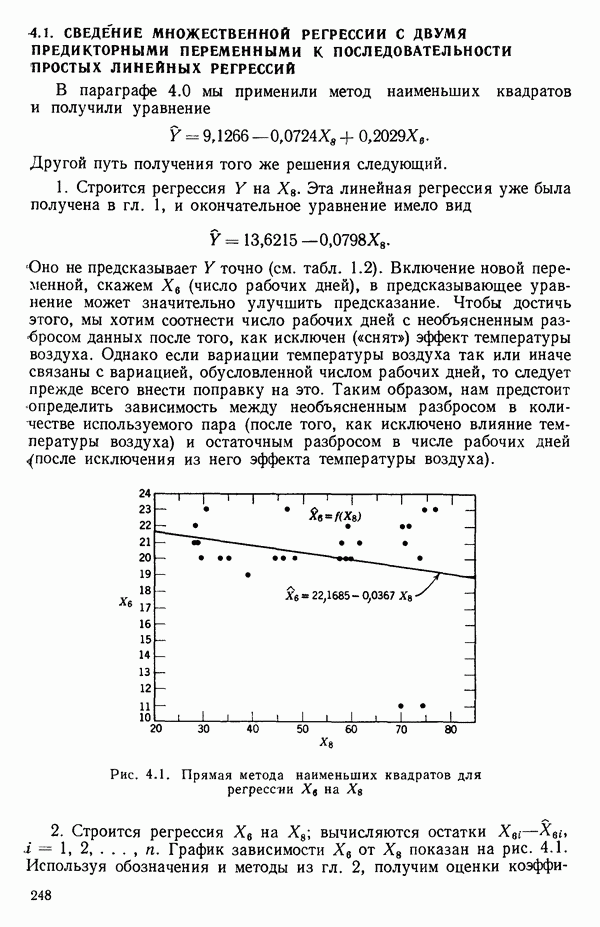
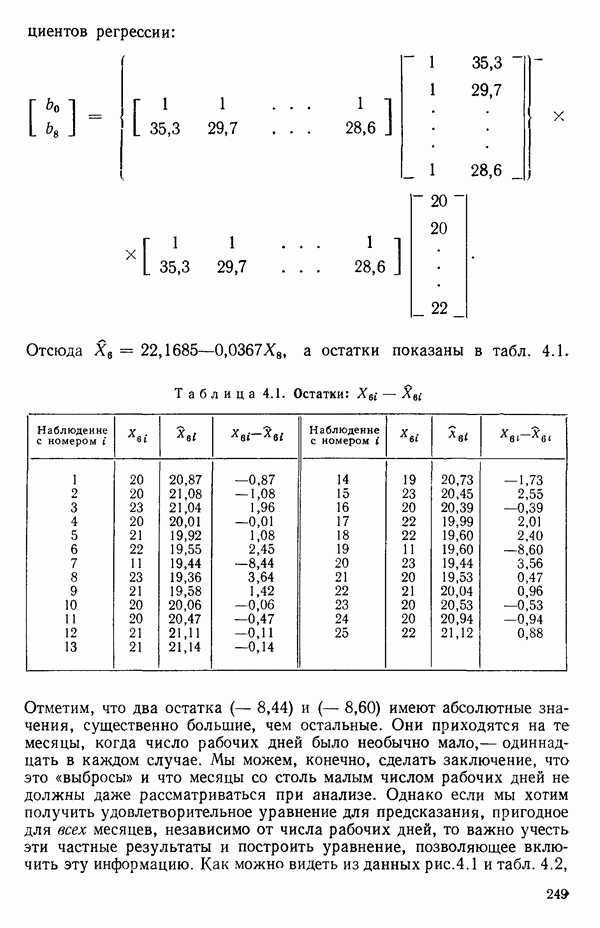

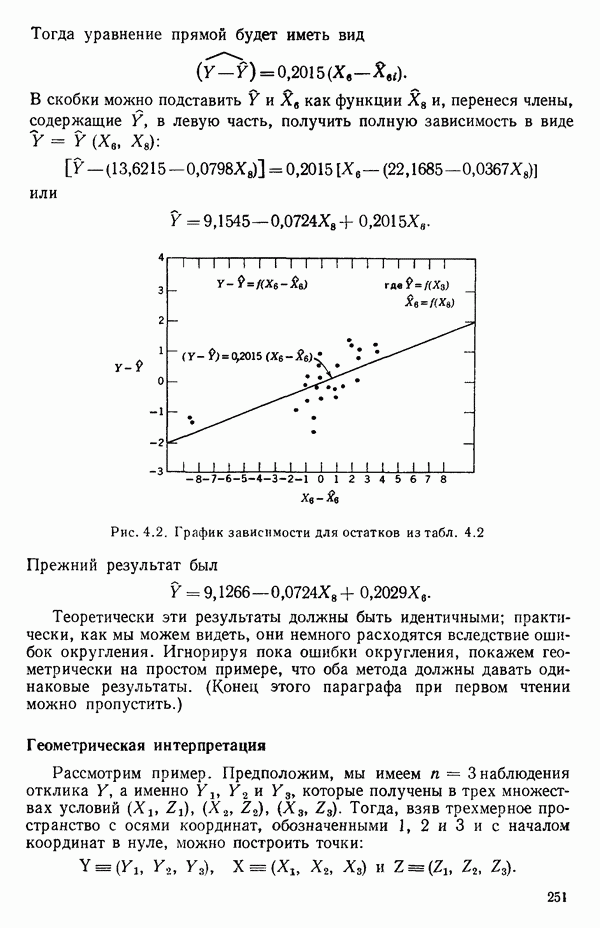

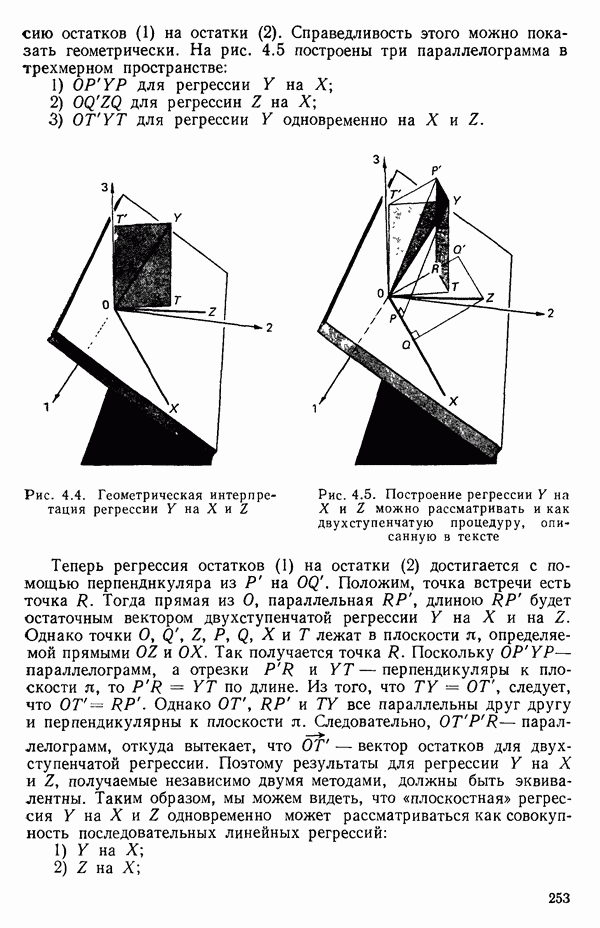























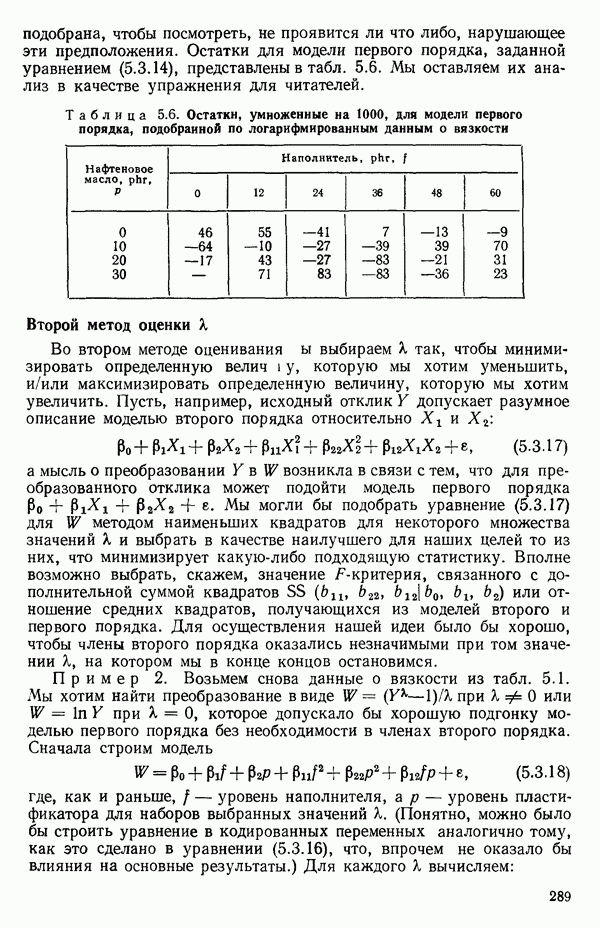
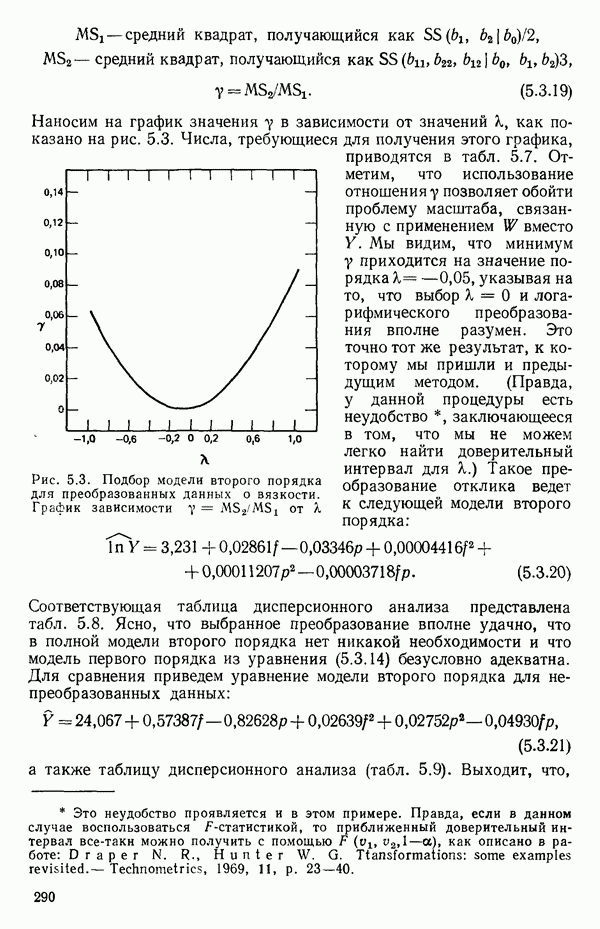
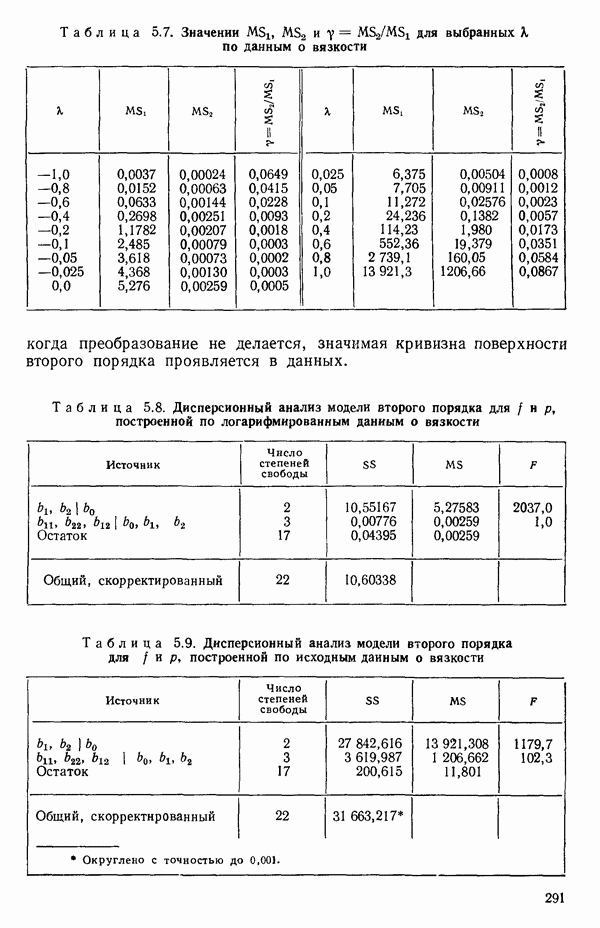





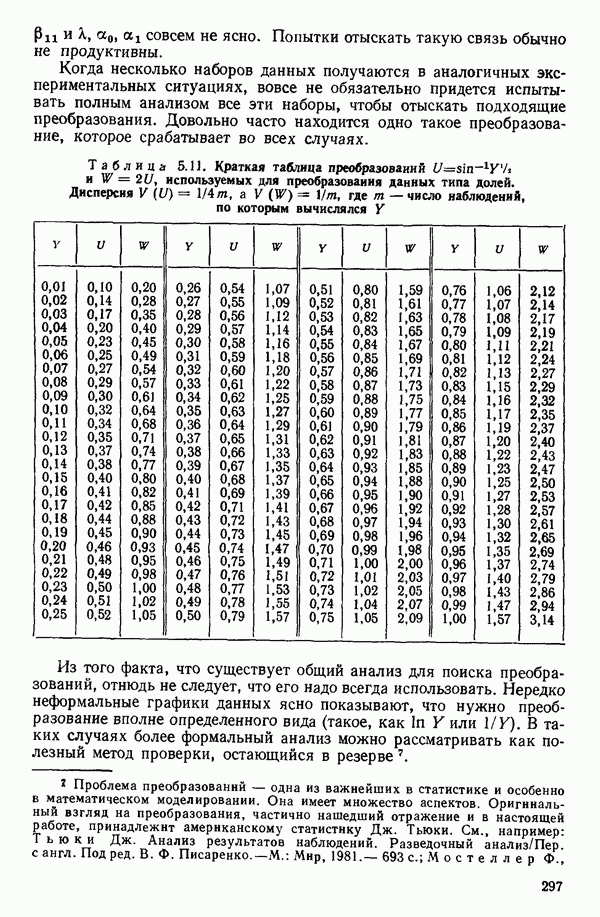























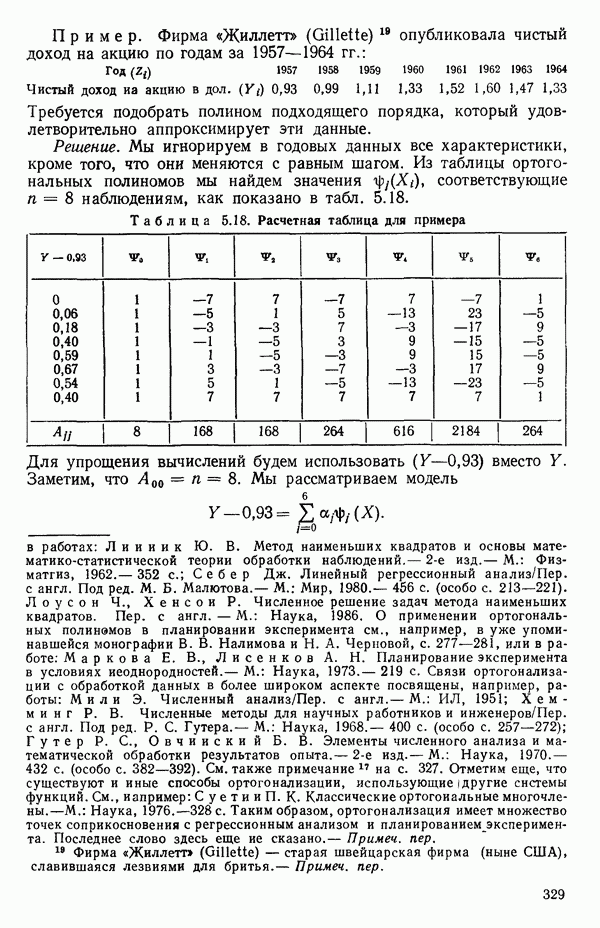










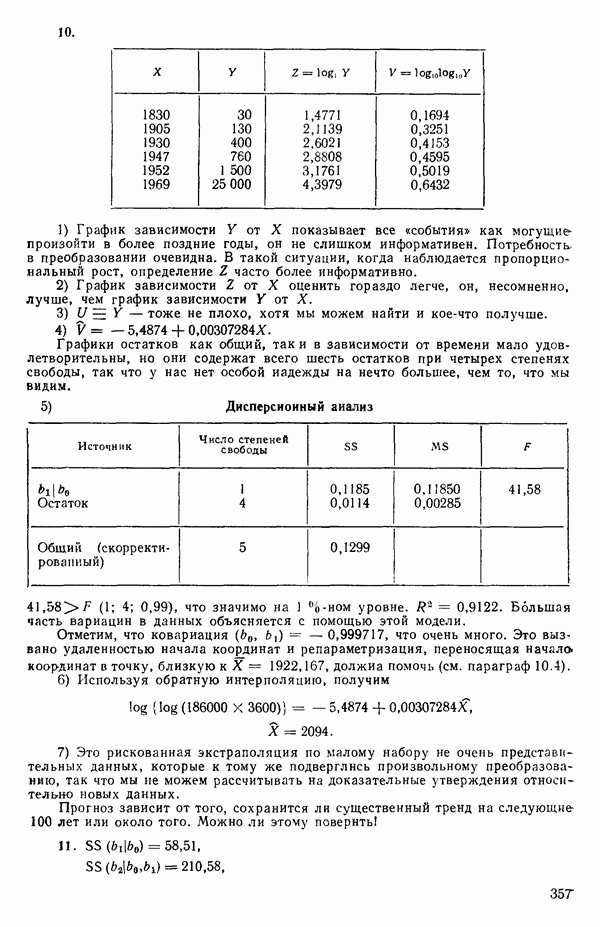
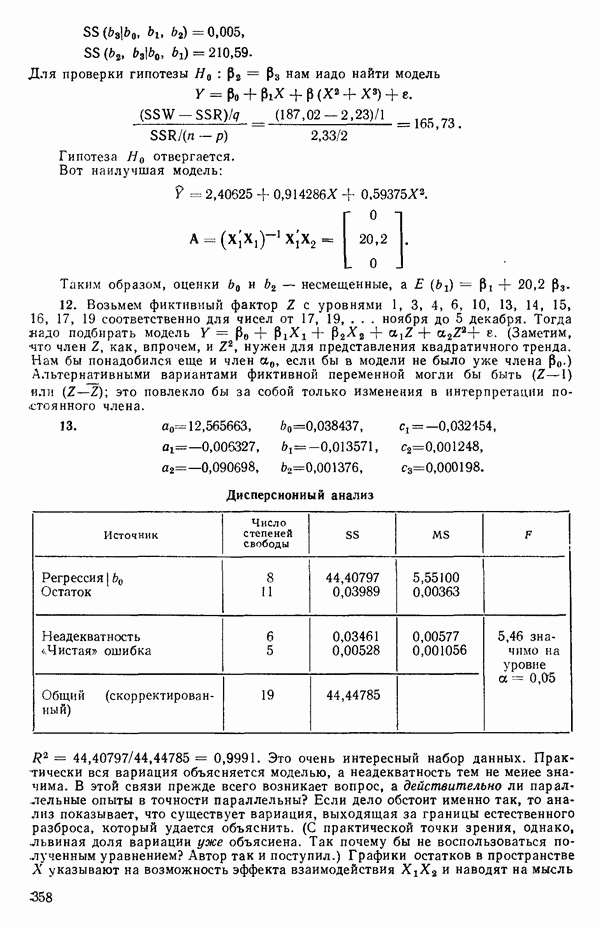



 как показано в примере для двух переменных в гл. 4, обычно не вызывает затруднений при условии, что вычисления проводятся с достаточным числом значащих цифр. В задачах с несколькими предикторами и с большим объемом данных результаты могут оказаться совершенно не верными вследствие ошибок округления. Вот типичный пример, когда возникают ошибки округления: допустим, требуется вычислить
как показано в примере для двух переменных в гл. 4, обычно не вызывает затруднений при условии, что вычисления проводятся с достаточным числом значащих цифр. В задачах с несколькими предикторами и с большим объемом данных результаты могут оказаться совершенно не верными вследствие ошибок округления. Вот типичный пример, когда возникают ошибки округления: допустим, требуется вычислить  Если
Если  велики, а
велики, а  мало, то слишком большое округление чисел
мало, то слишком большое округление чисел  может привести к тому, что все значащие цифры в числе
может привести к тому, что все значащие цифры в числе  будут потеряны.
будут потеряны.
 Допустим, что вычисления ведутся вручную и мы округляем числа до трех значащих цифр после запятой. Тогда
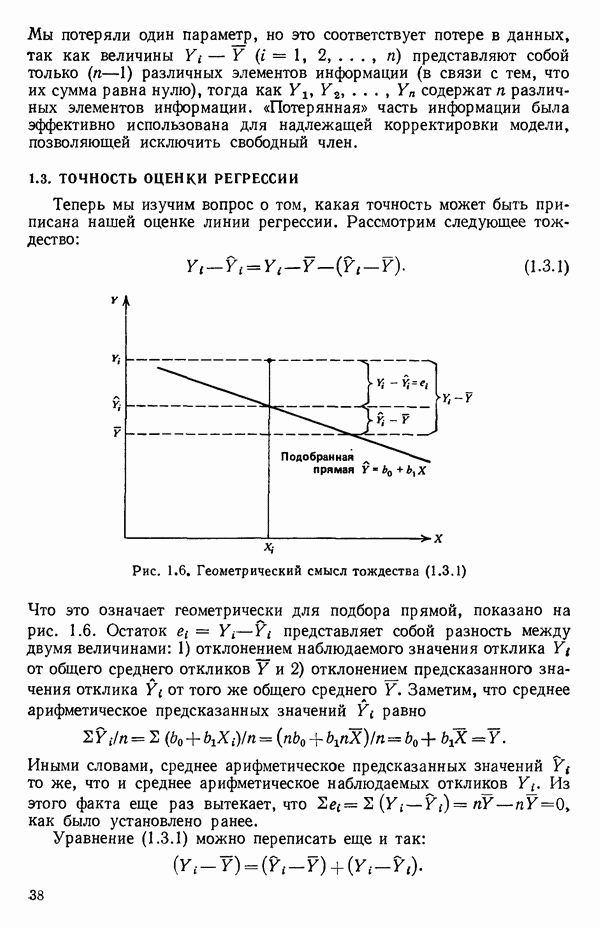
Допустим, что вычисления ведутся вручную и мы округляем числа до трех значащих цифр после запятой. Тогда  , так что
, так что  (Более точно
(Более точно  Поэтому если умножить
Поэтому если умножить  на последней стадии, скажем, на
на последней стадии, скажем, на  то в результате будет нуль (вместо правильного
то в результате будет нуль (вместо правильного  огромная разница.)
огромная разница.)
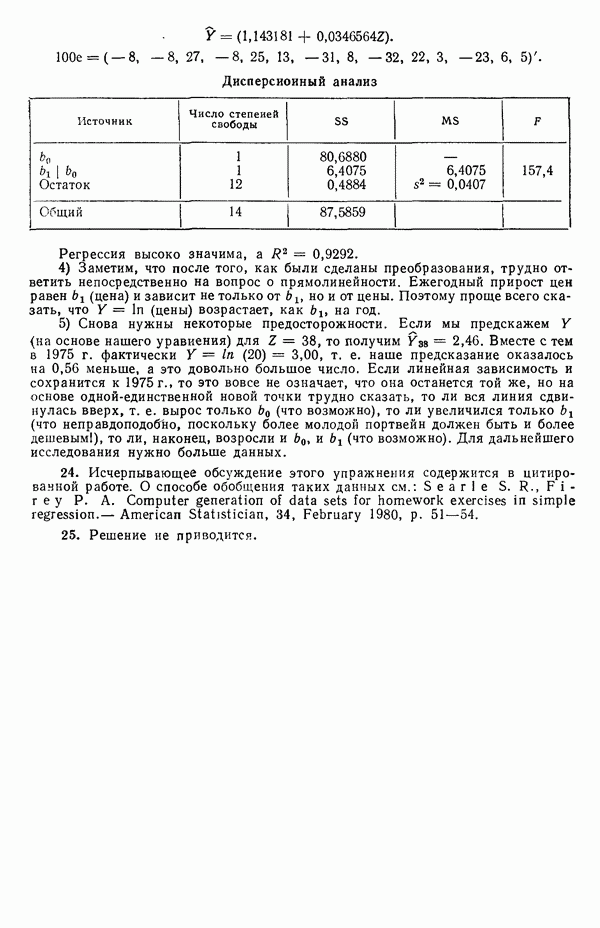
 и 6.
и 6.
 и
и  но и в общем случае. Когда
но и в общем случае. Когда  очень мал по сравнению с другими числами в расчете, о матрице
очень мал по сравнению с другими числами в расчете, о матрице  говорят, что она плохо (или слабо) обусловлена. Когда же
говорят, что она плохо (или слабо) обусловлена. Когда же  о матрице
о матрице  говорят, что она сингулярная (вырожденная), если это случается при машинном счете, то возникает переполнение и машина останавливается. (Точнее говоря, мы обычно имеем дело с величиной определителя корреляционной матрицы, которая обсуждается ниже в этом параграфе.)
говорят, что она сингулярная (вырожденная), если это случается при машинном счете, то возникает переполнение и машина останавливается. (Точнее говоря, мы обычно имеем дело с величиной определителя корреляционной матрицы, которая обсуждается ниже в этом параграфе.)
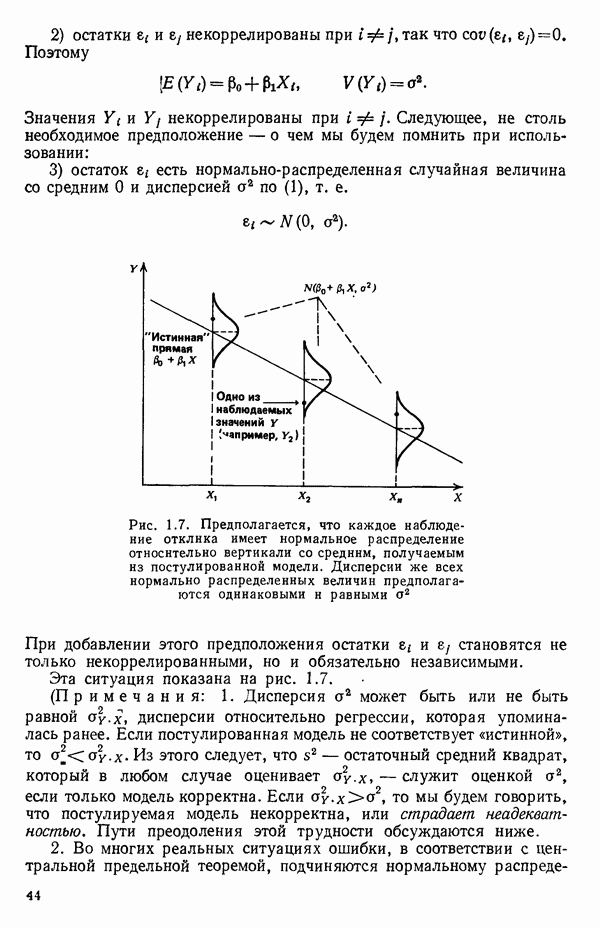
 Мы можем рассуждать об этом двумя способами. Либо модель переопределена, т. е. постулировалось больше параметров, чем действительно нужно для описания данных, либо наши данные приводят к неадекватной оценке выбранной модели. (Конечно, у всякой монеты есть две стороны, но и «вина»
Мы можем рассуждать об этом двумя способами. Либо модель переопределена, т. е. постулировалось больше параметров, чем действительно нужно для описания данных, либо наши данные приводят к неадекватной оценке выбранной модели. (Конечно, у всякой монеты есть две стороны, но и «вина»
 может встретиться плохая обусловленность, и тогда потребуются те же самые выборы или, быть может, использование ридж-регрессии, которая описана в параграфе 6.7. Полезное обсуждение того, что же такое плохая обусловленность (она обычно называется мультиколлинеарностью предикторов), можно найти в работе: Lilian A. W., Watts D. G. Meaningful multicollinearity measures.- Technometrics, 1978, 20, p. 407-412. Мы обсудим теперь шаги, которые можно сделать для улучшения метода вычислений. Это — центрирование данных и использование корреляционной матрицы вместо матрицы
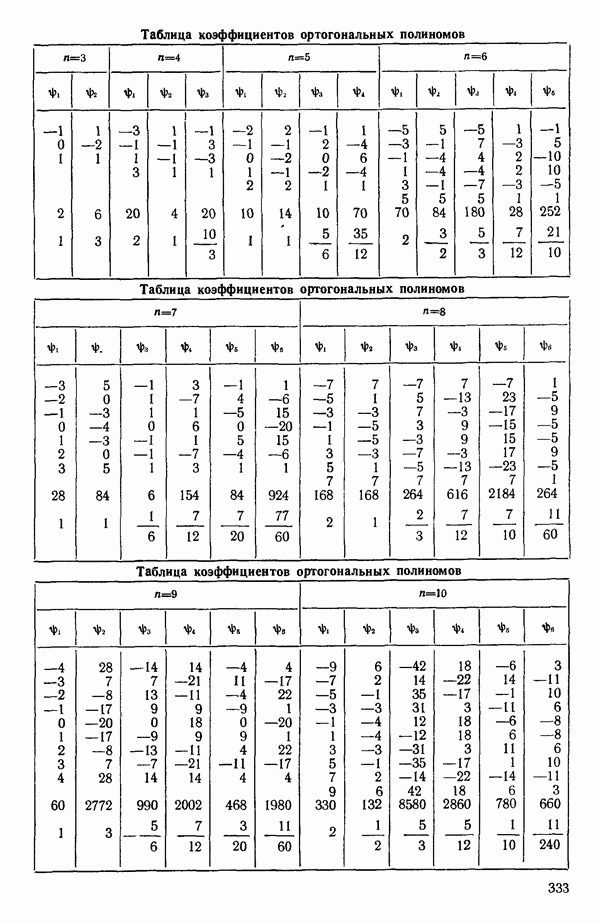
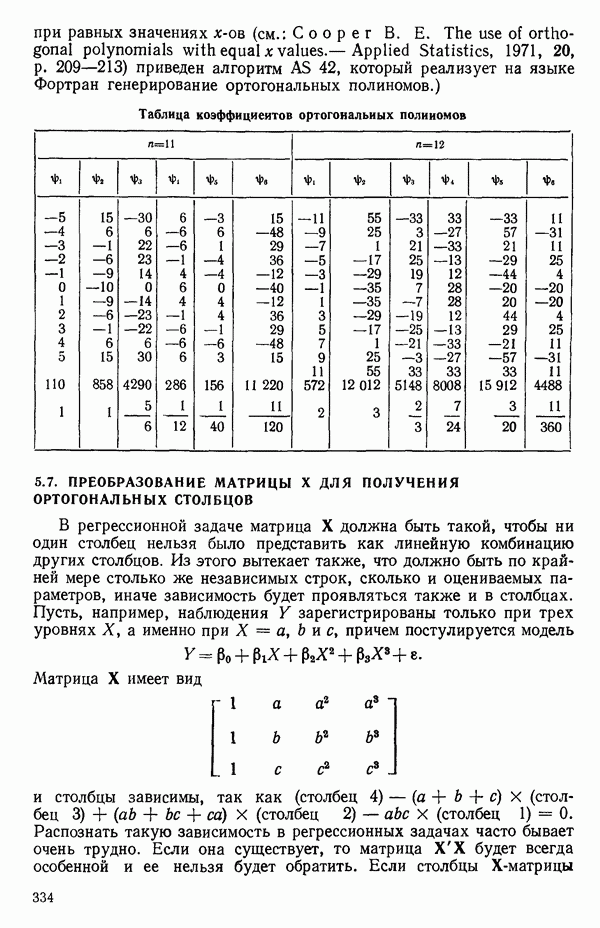
может встретиться плохая обусловленность, и тогда потребуются те же самые выборы или, быть может, использование ридж-регрессии, которая описана в параграфе 6.7. Полезное обсуждение того, что же такое плохая обусловленность (она обычно называется мультиколлинеарностью предикторов), можно найти в работе: Lilian A. W., Watts D. G. Meaningful multicollinearity measures.- Technometrics, 1978, 20, p. 407-412. Мы обсудим теперь шаги, которые можно сделать для улучшения метода вычислений. Это — центрирование данных и использование корреляционной матрицы вместо матрицы  Ортогонализация столбцов Х-матрицы методом Грама-Шмидта будет обсуждаться в параграфе 5.7 после краткого обсуждения ортогональных полиномов в параграфе 5.6. Центрирование и использование корреляционной матрицы стандартны для большинства программ линейной регрессии. Ортогонализация — полезная процедура, которая может применяться для проверки матрицы
Ортогонализация столбцов Х-матрицы методом Грама-Шмидта будет обсуждаться в параграфе 5.7 после краткого обсуждения ортогональных полиномов в параграфе 5.6. Центрирование и использование корреляционной матрицы стандартны для большинства программ линейной регрессии. Ортогонализация — полезная процедура, которая может применяться для проверки матрицы  на вырожденность.
на вырожденность.

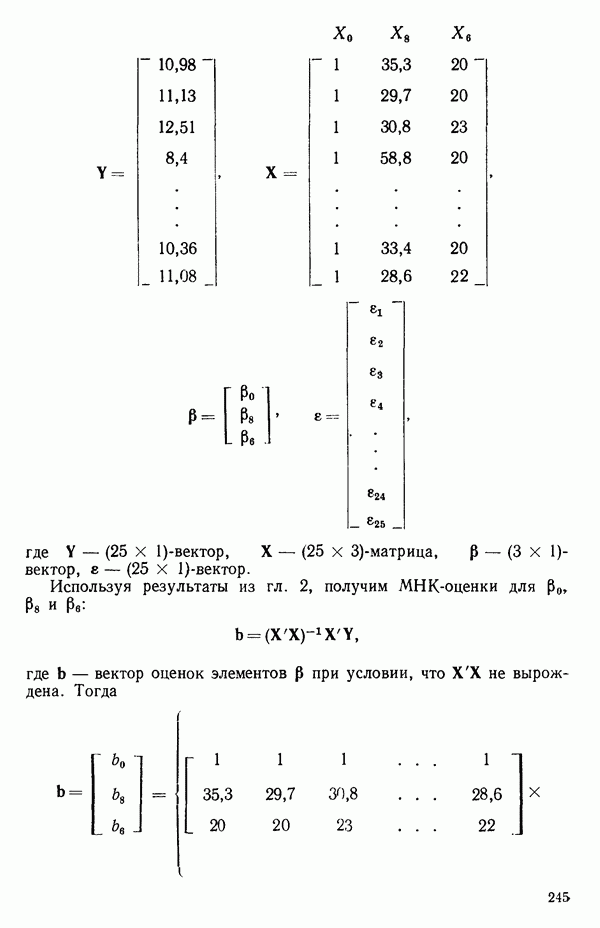
 некоторые (определенные) функции предикторов
некоторые (определенные) функции предикторов  Запишем вектор параметров:
Запишем вектор параметров:

 наблюдений
наблюдений


 с применением формул из гл. 2, где
с применением формул из гл. 2, где

 наблюденное значение
наблюденное значение  соответствующее наблюдению
соответствующее наблюдению  Чтобы показать это на простом примере, допустим, что мы используем модель
Чтобы показать это на простом примере, допустим, что мы используем модель

 в общей форме, указанной выше. Если имеющиеся данные выражаются так:
в общей форме, указанной выше. Если имеющиеся данные выражаются так:


 элементами столбца были бы
элементами столбца были бы  и так далее для более общих случаев.) Когда данные подготавливают для вычислений на машинах, матрицу X и вектор
и так далее для более общих случаев.) Когда данные подготавливают для вычислений на машинах, матрицу X и вектор  обычно записывают подряд без разделения и называют это матрицей банных или матрицей исходных данных. Например, матрица данных
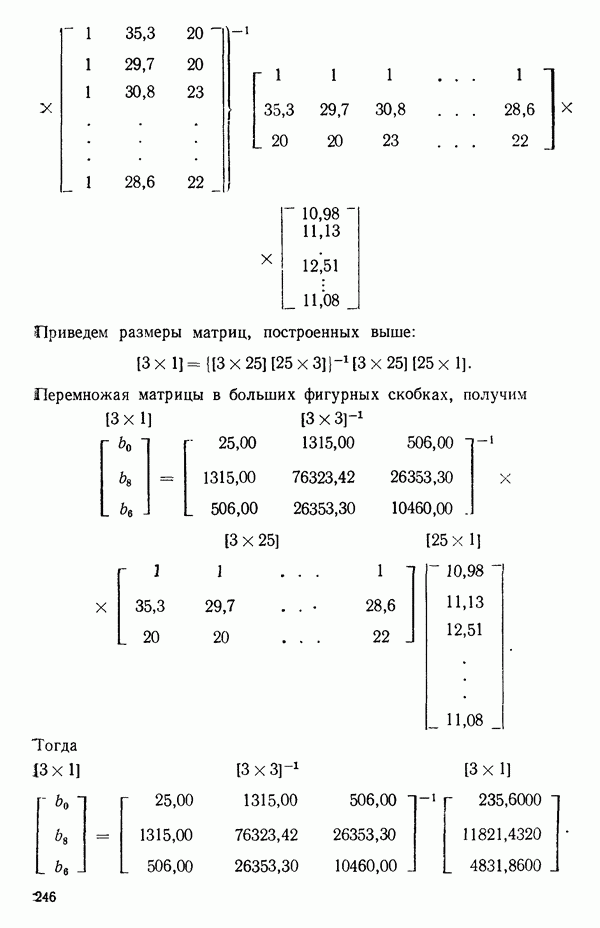
обычно записывают подряд без разделения и называют это матрицей банных или матрицей исходных данных. Например, матрица данных


 )
)

 - фактические численные значения, полученные на основании данных. Если обозначить
- фактические численные значения, полученные на основании данных. Если обозначить


 при
при  Отсюда
Отсюда  И таким образом, первое нормальное уравнение, получаемое путем дифференцирования остаточной суммы квадратов по
И таким образом, первое нормальное уравнение, получаемое путем дифференцирования остаточной суммы квадратов по  сводится к
сводится к



 из модели и применять ее в виде
из модели и применять ее в виде

 (новых) значений зависимой переменной, а именно
(новых) значений зависимой переменной, а именно  теперь связаны ограничением
теперь связаны ограничением


 что приведет к новой матрице исходных данных:
что приведет к новой матрице исходных данных:

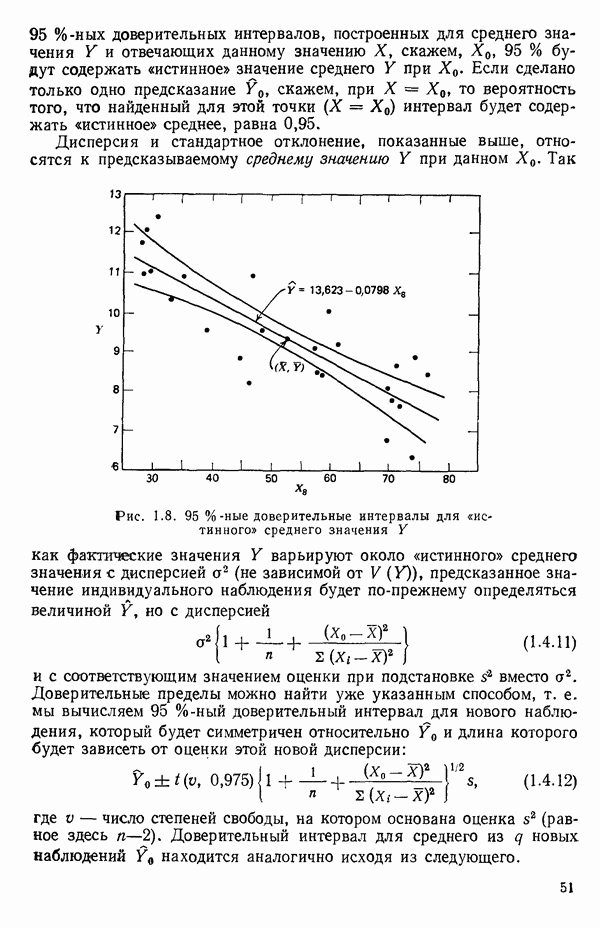
 уменьшаются абсолютные значения чисел, участвующих в вычислениях, и подчеркиваются не столько абсолютные значения, сколько разброс и распределение элементов
уменьшаются абсолютные значения чисел, участвующих в вычислениях, и подчеркиваются не столько абсолютные значения, сколько разброс и распределение элементов  -столбца относительно их среднего. Центрирование также необходимо для получения корреляционной матрицы переменных, которая очень важна далее в процедурах отбора, обсуждаемых в гл. 6.
-столбца относительно их среднего. Центрирование также необходимо для получения корреляционной матрицы переменных, которая очень важна далее в процедурах отбора, обсуждаемых в гл. 6.