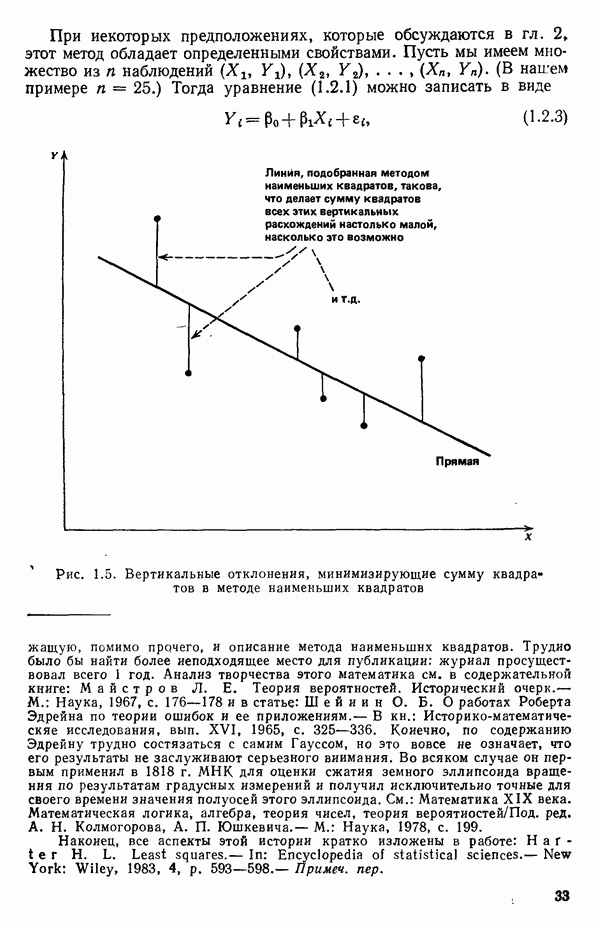
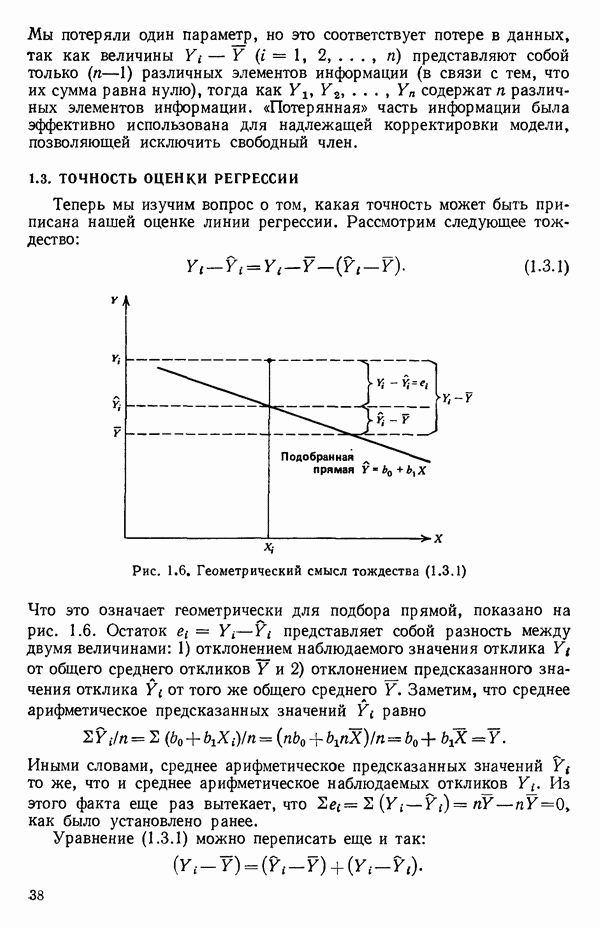
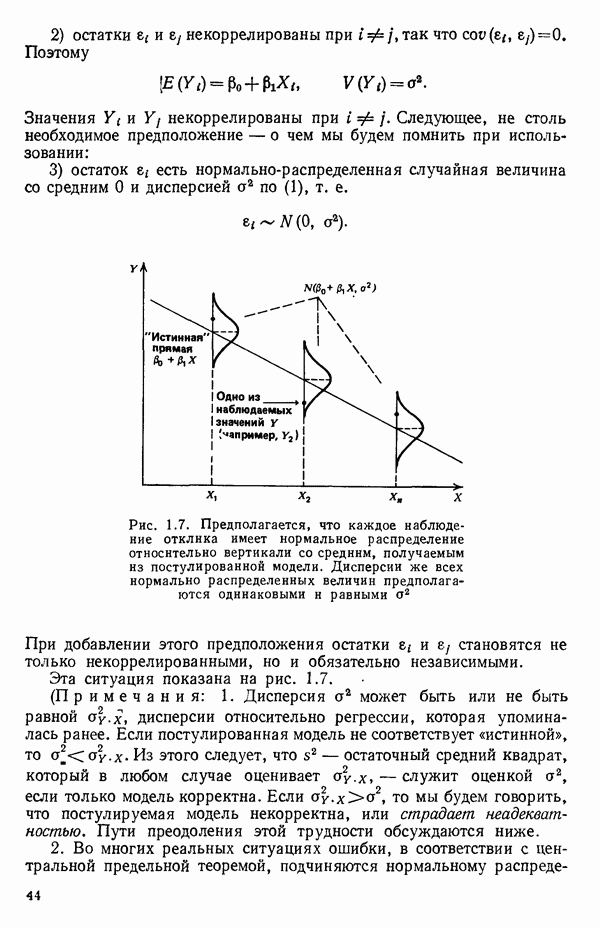
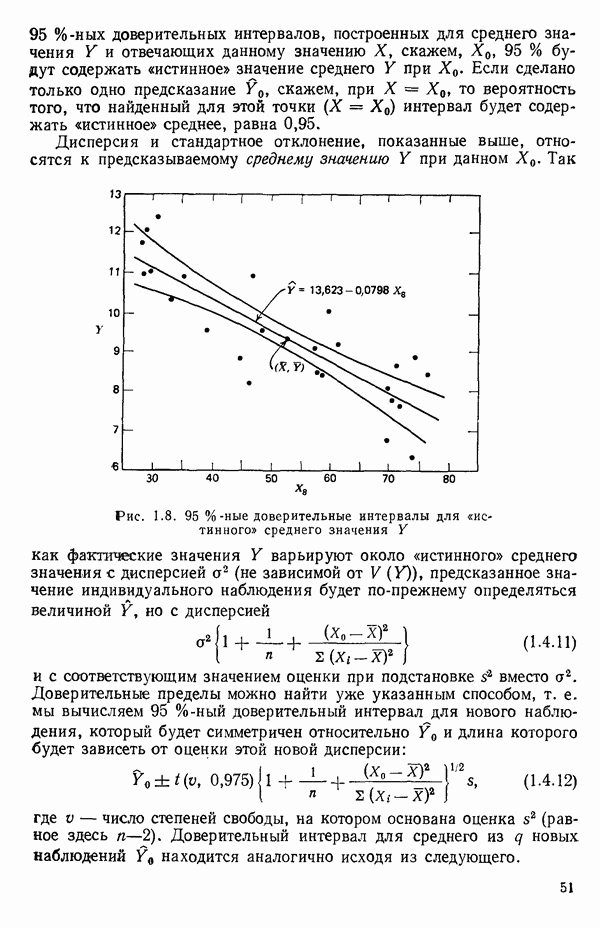
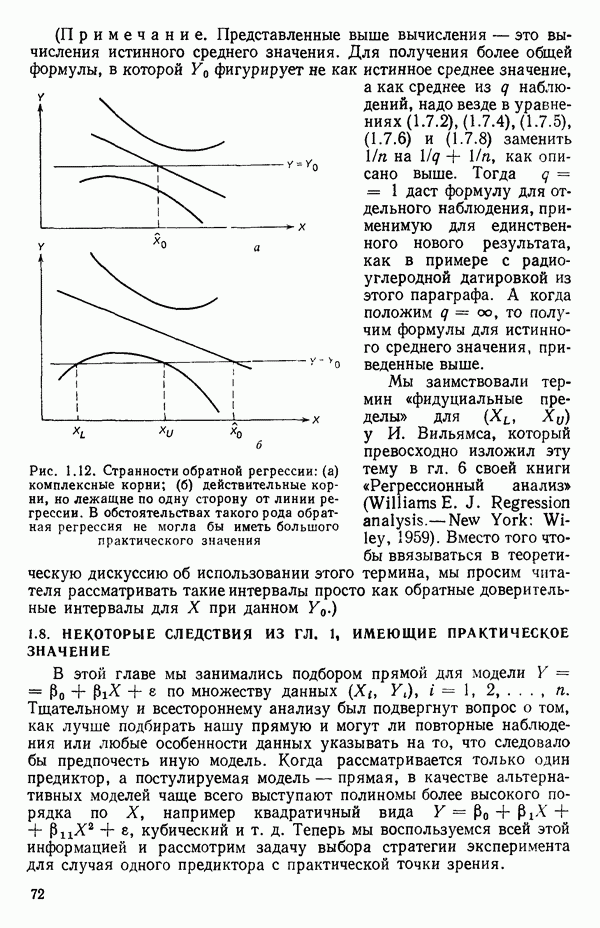
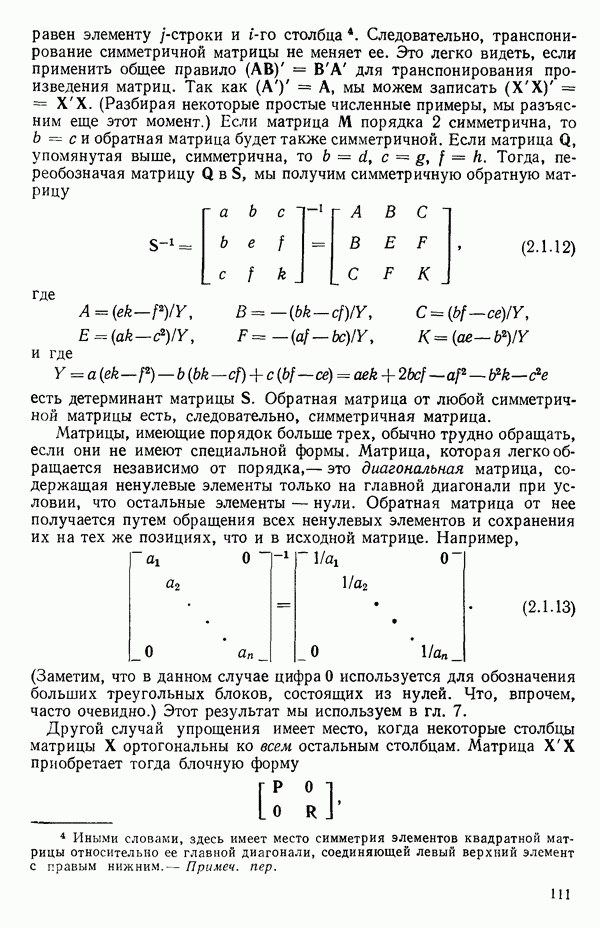
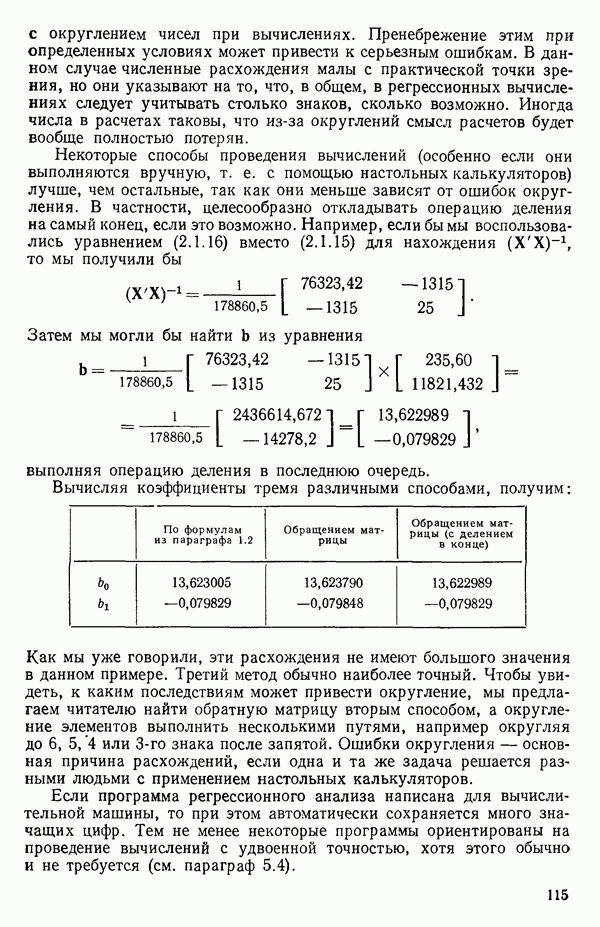
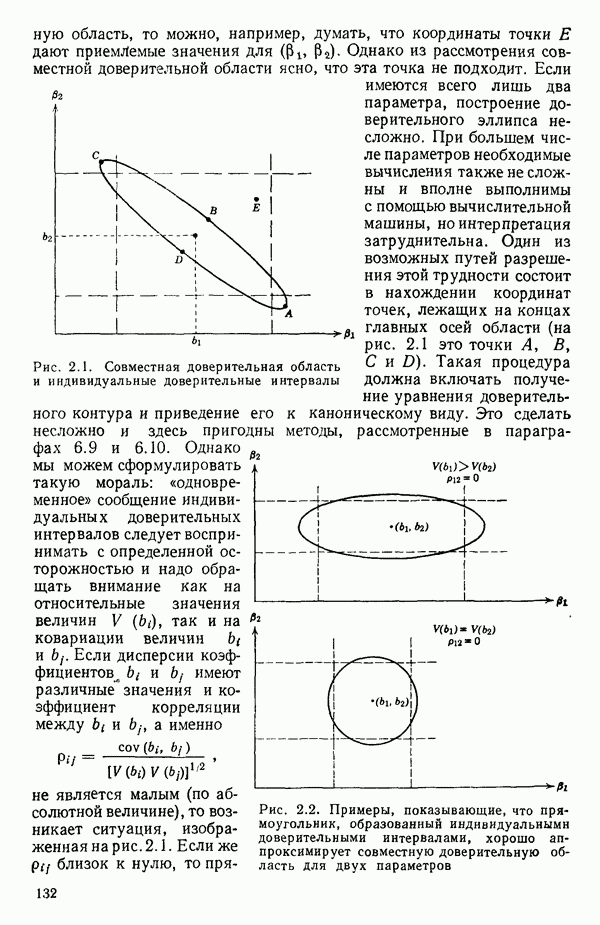
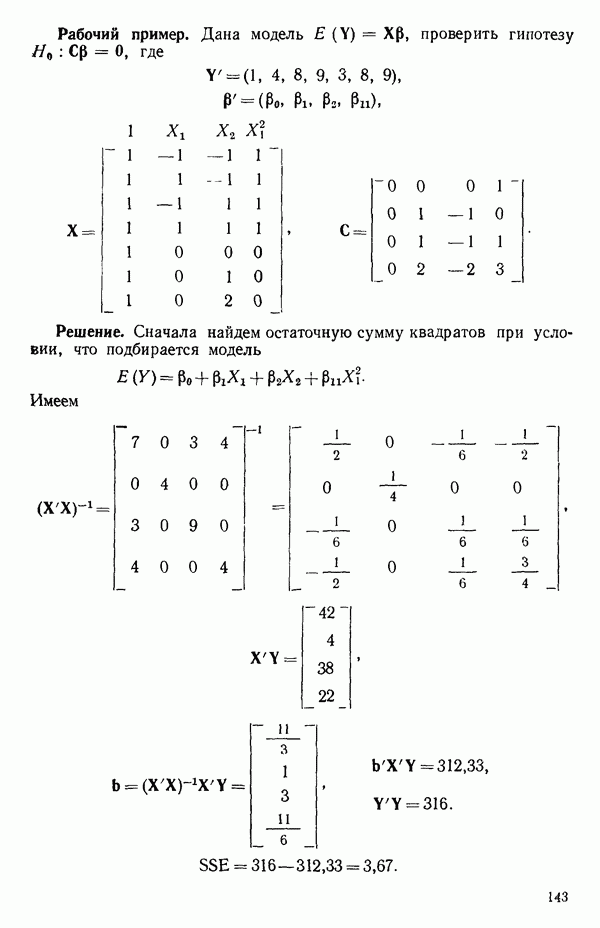
Пред.
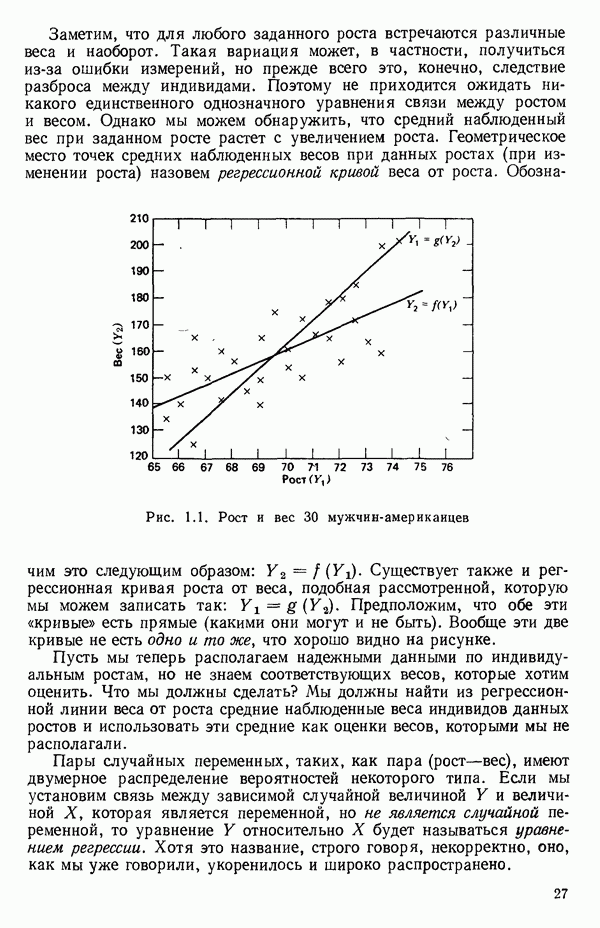
След.
Макеты страниц
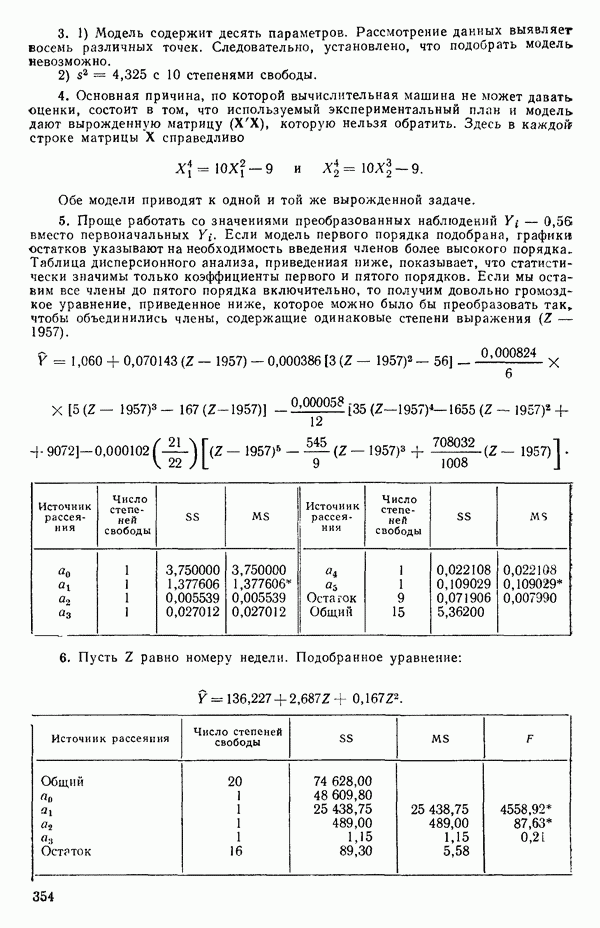
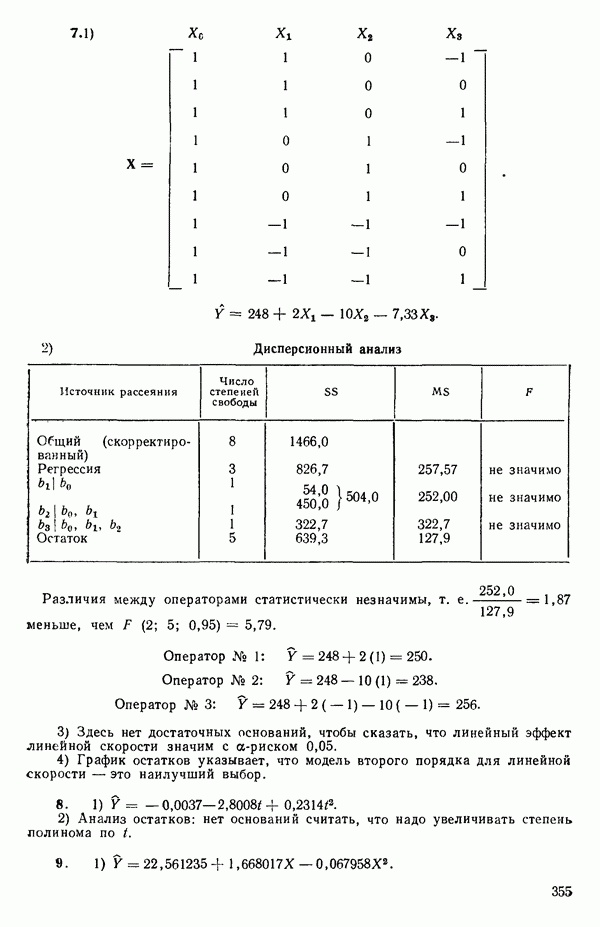
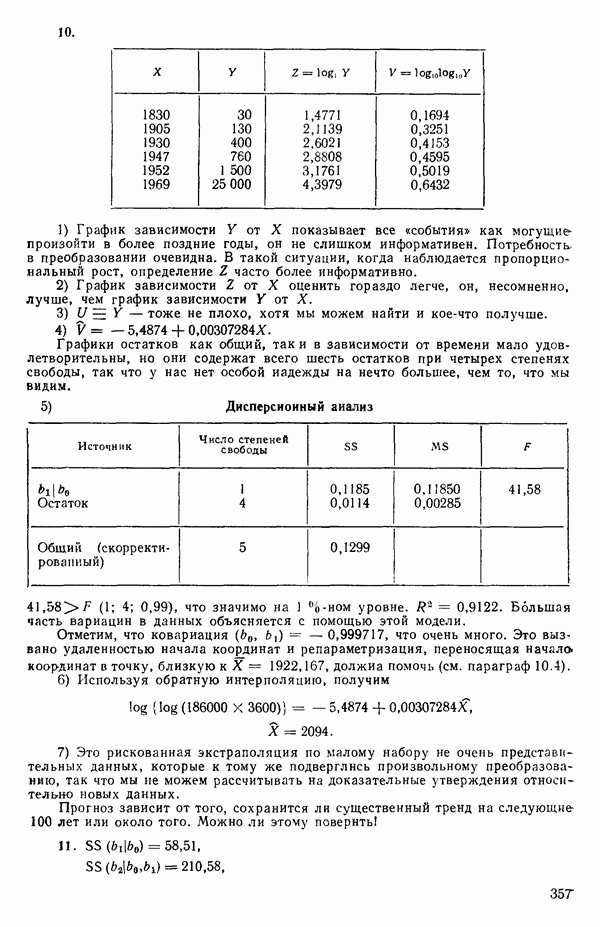
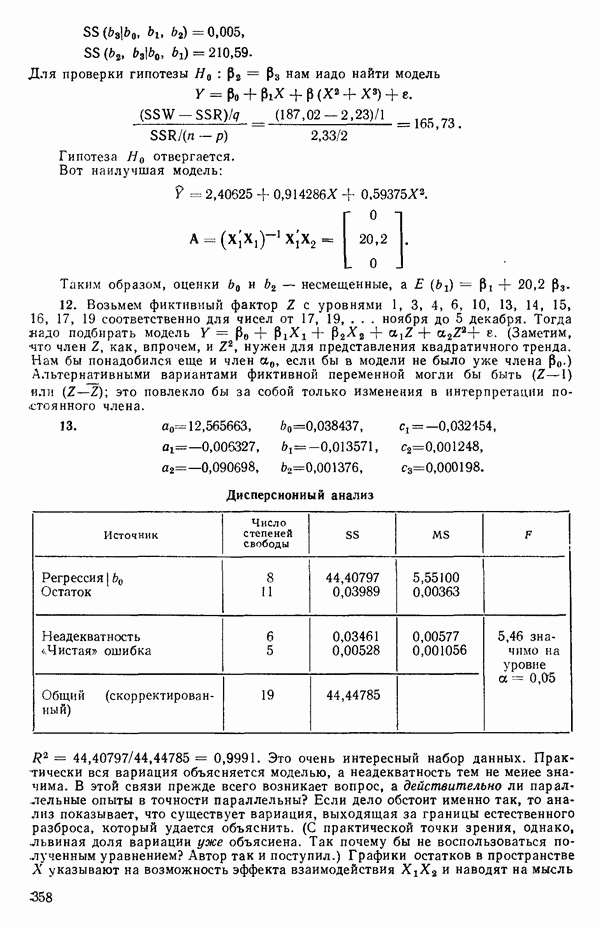
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
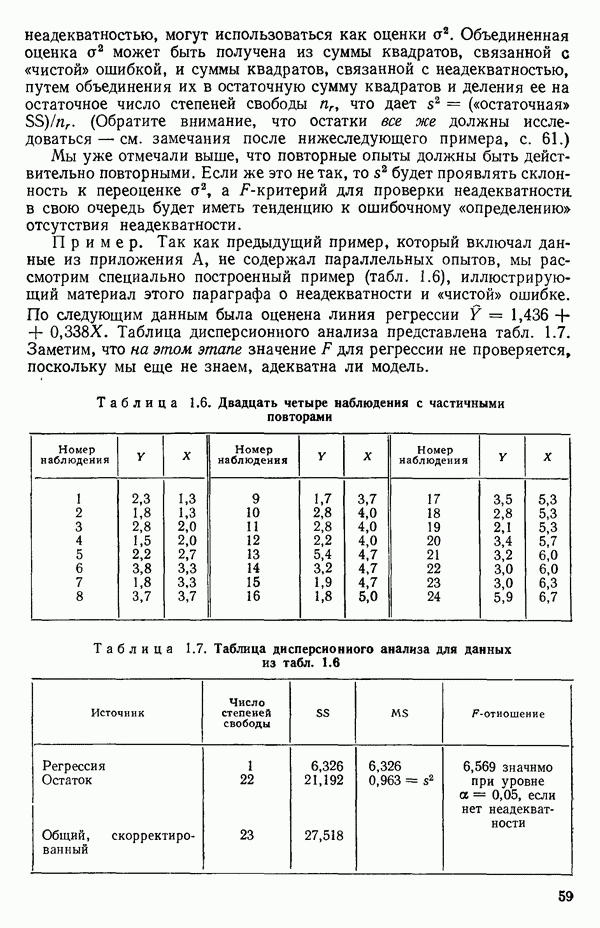
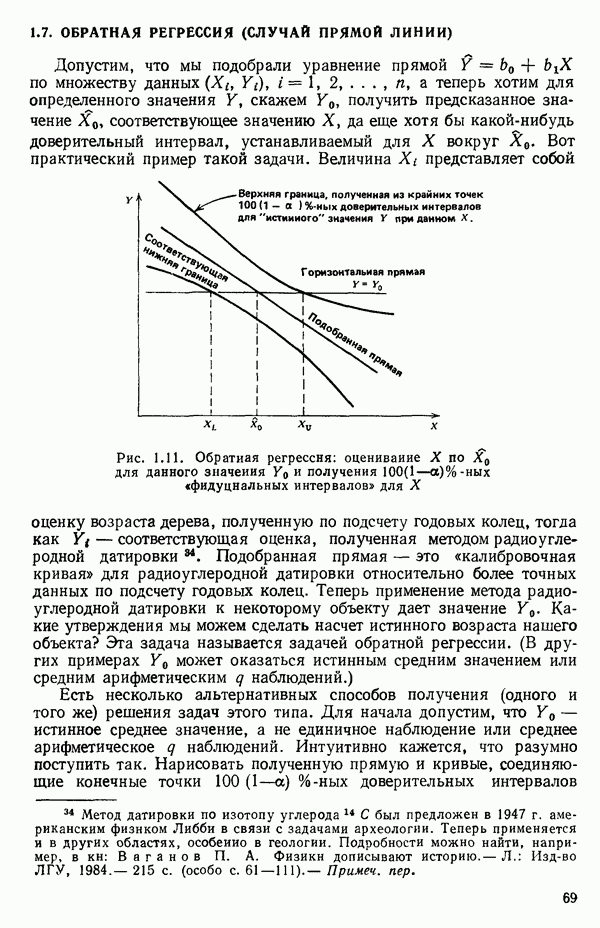
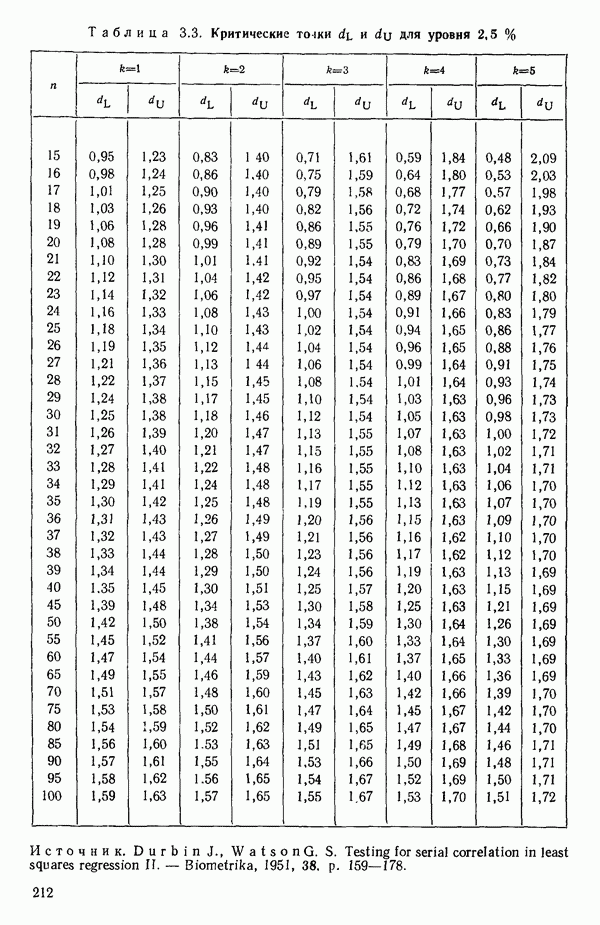
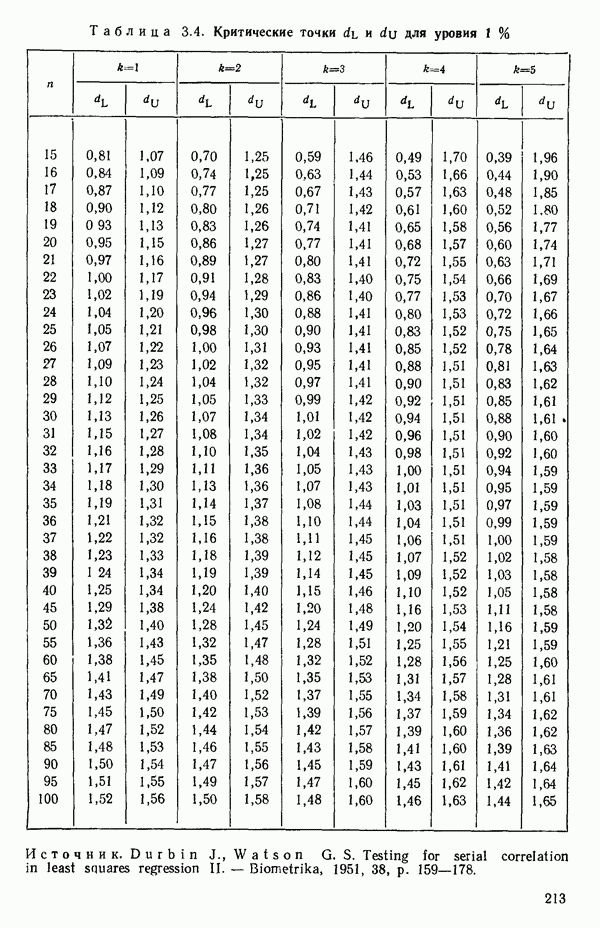
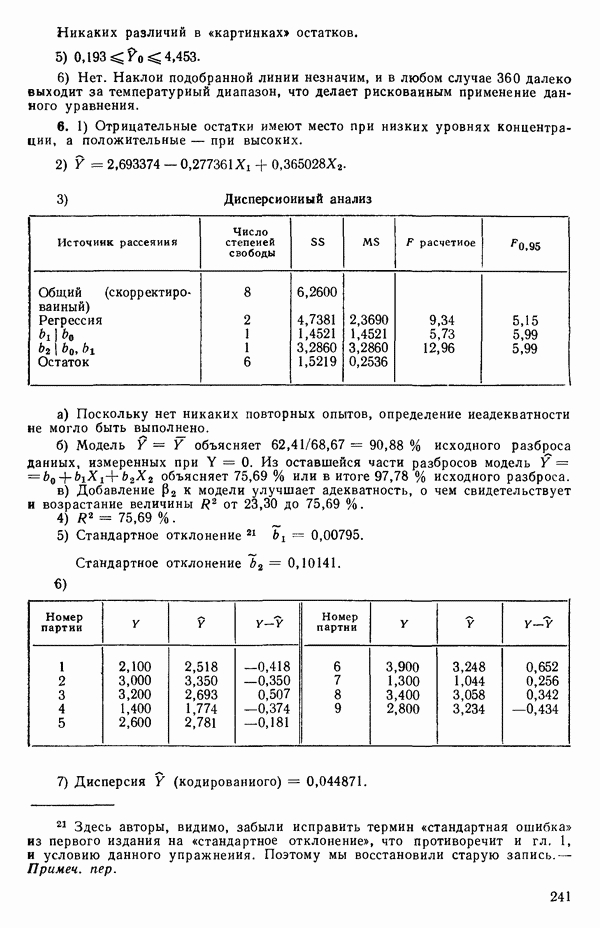
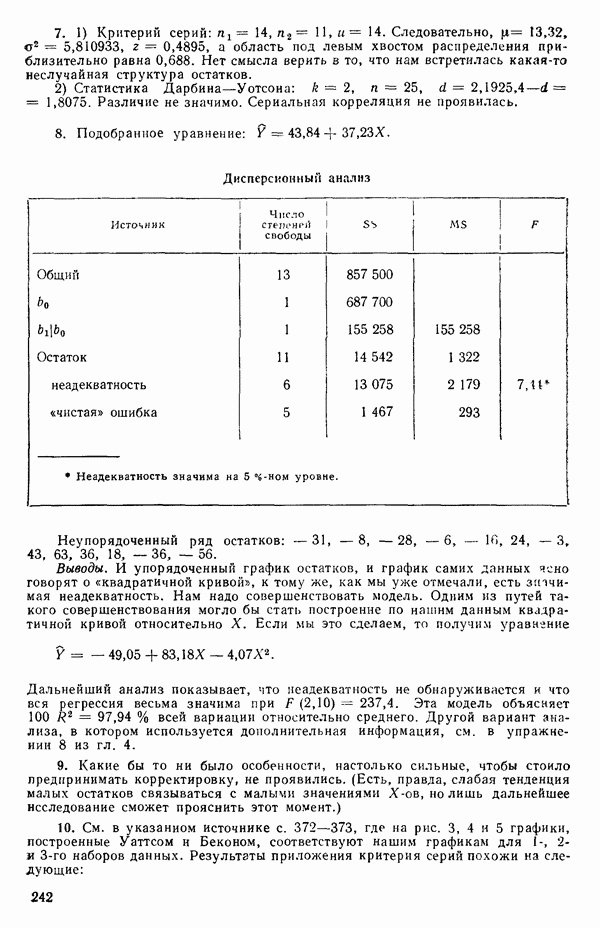
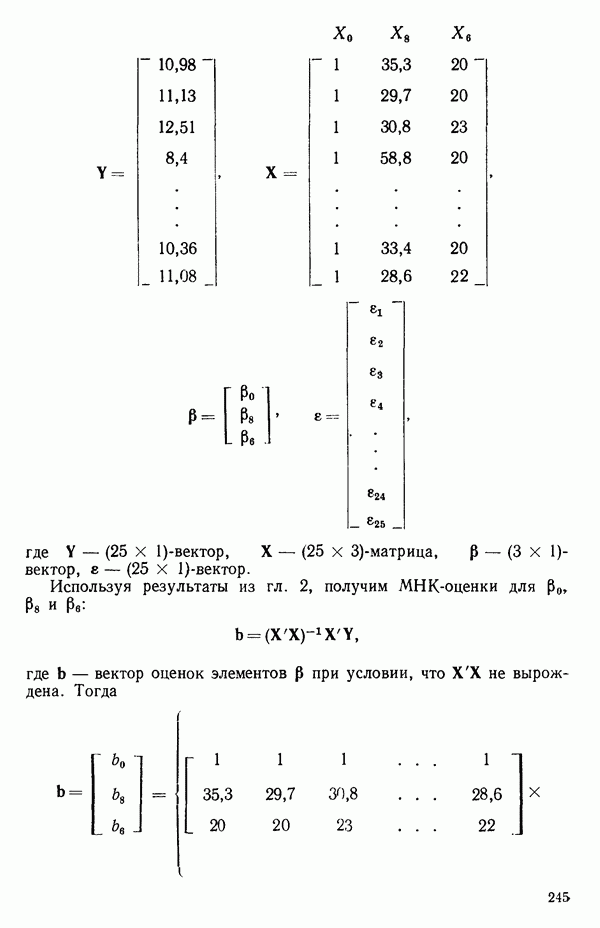
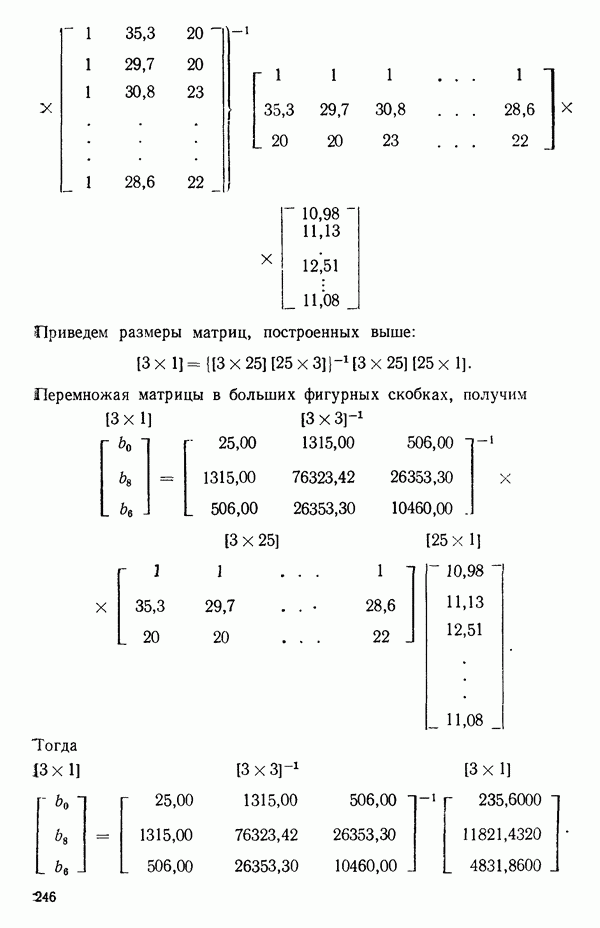
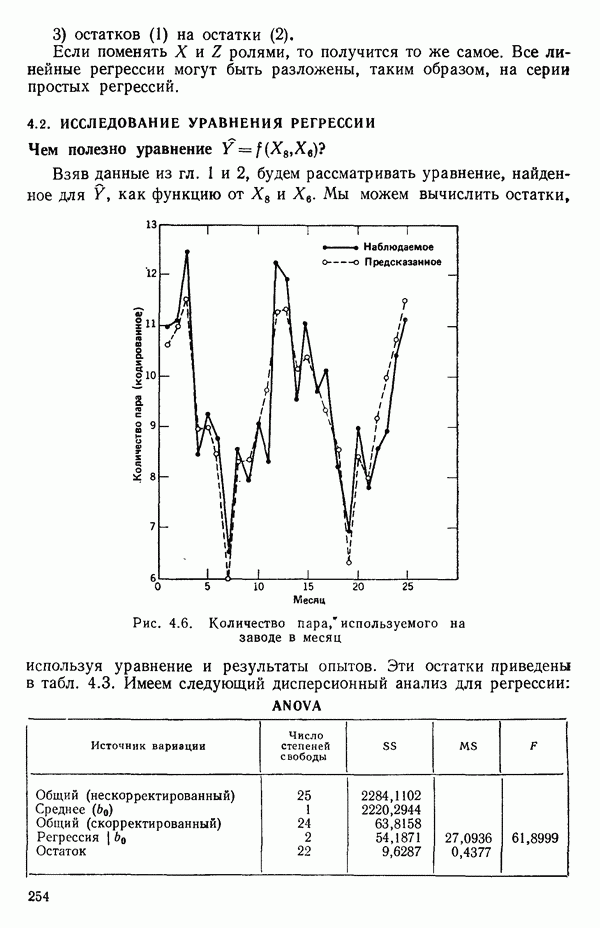
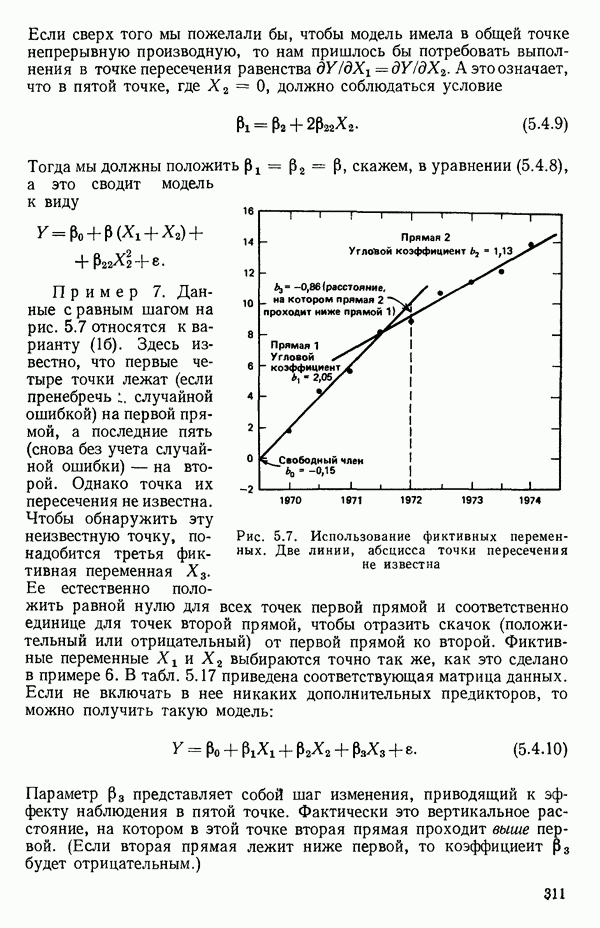
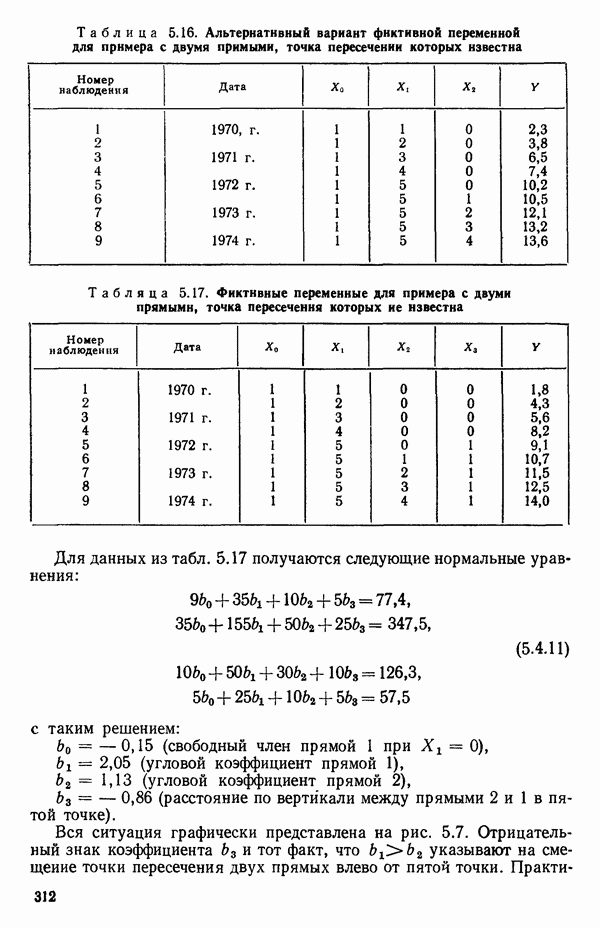
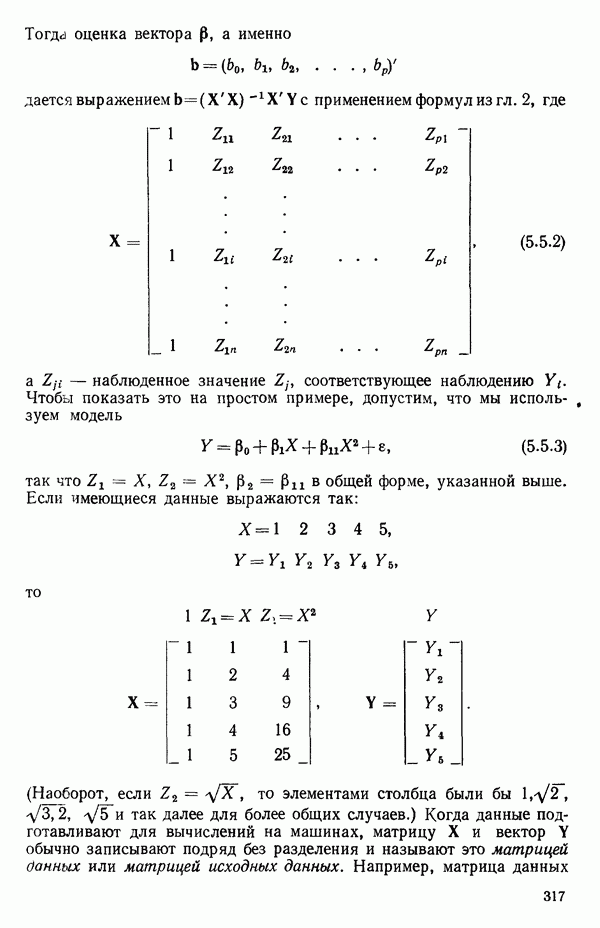
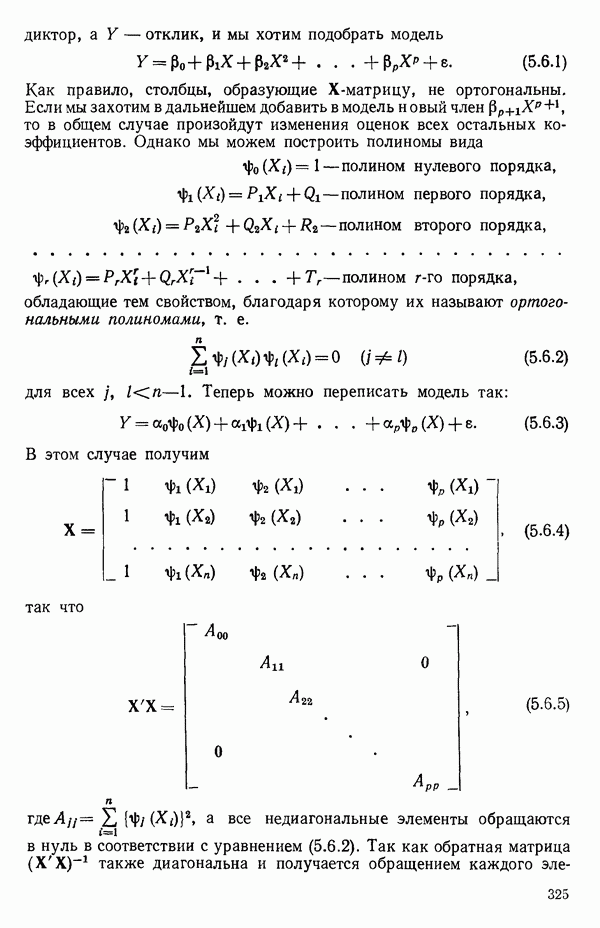
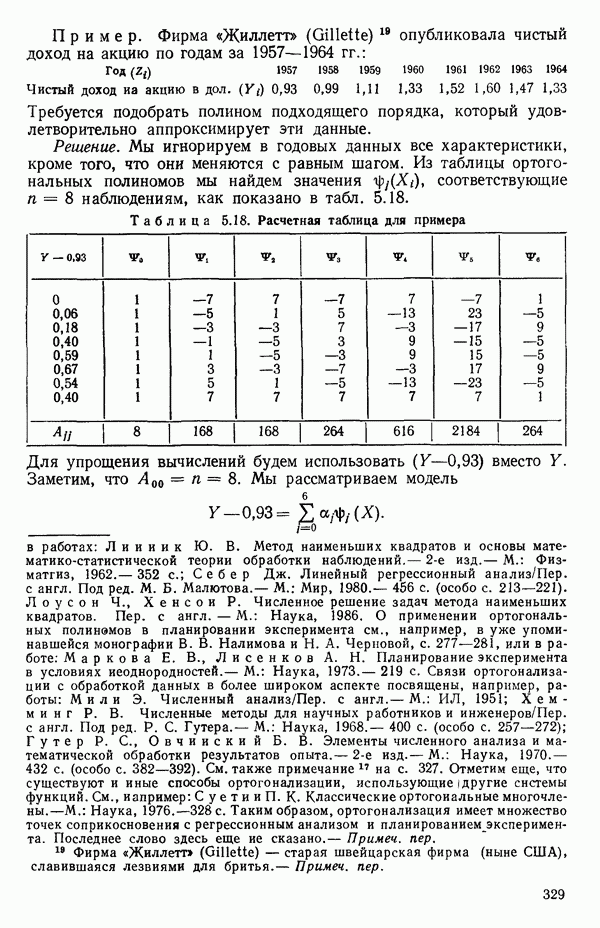
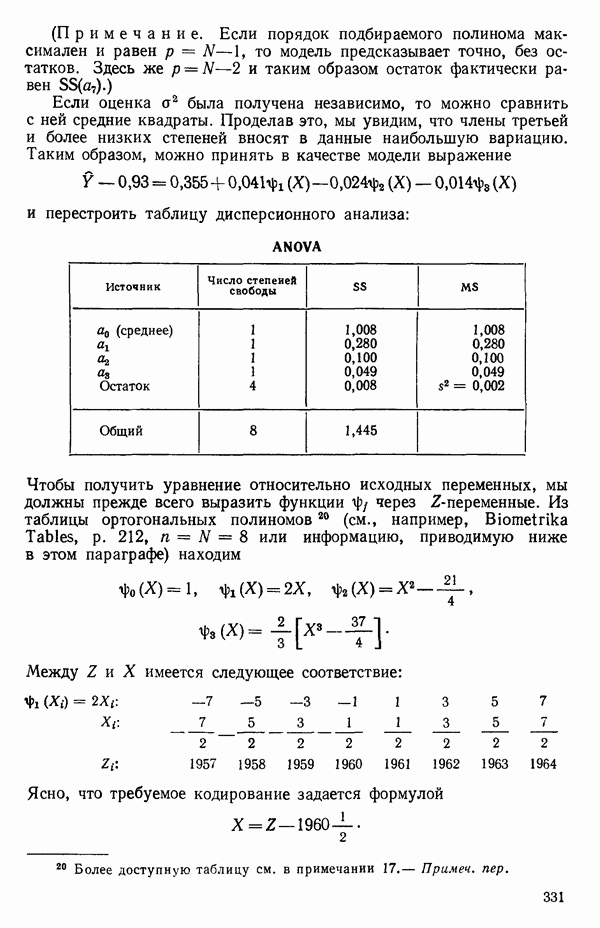
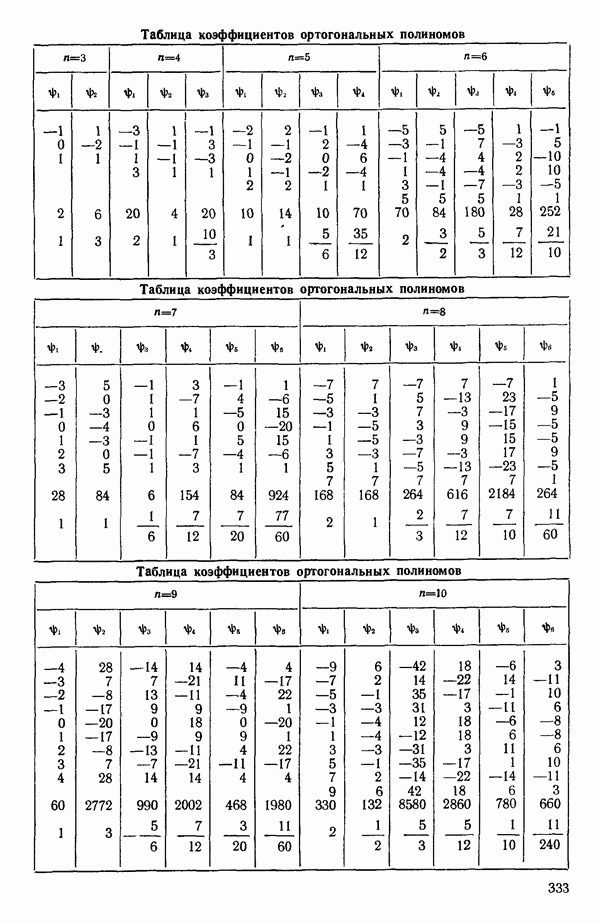
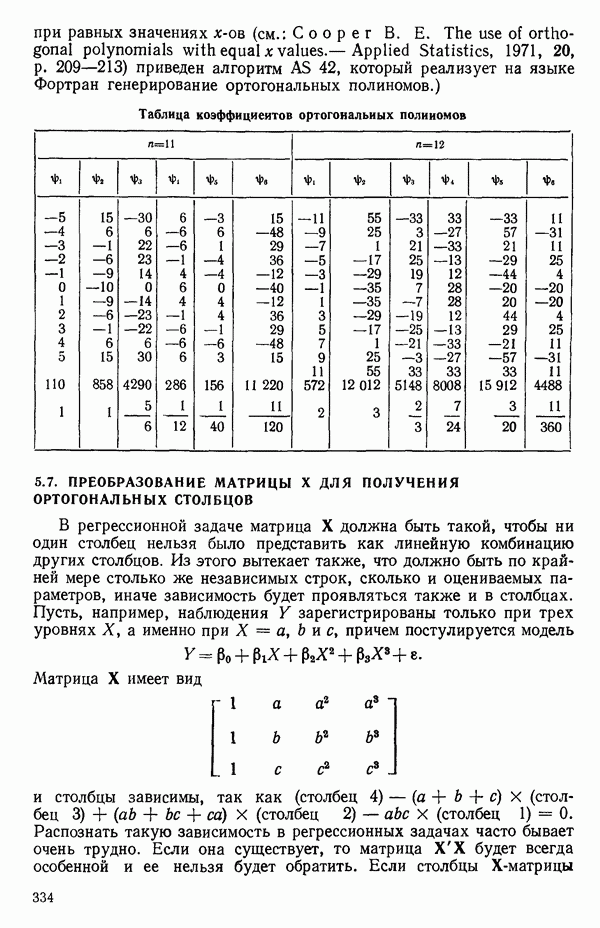
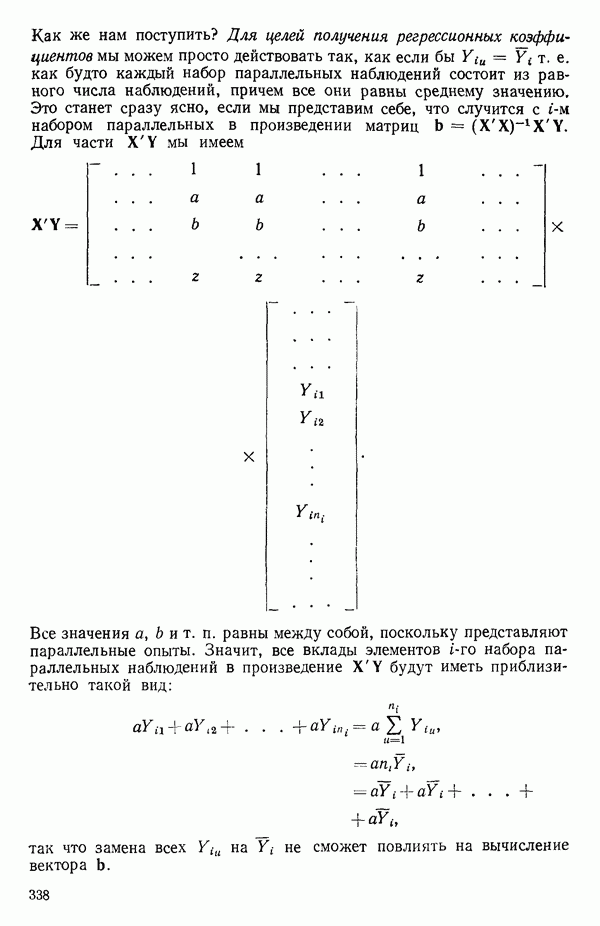
5.4. ИСПОЛЬЗОВАНИЕ «ФИКТИВНЫХ» ПЕРЕМЕННЫХ В МНОЖЕСТВЕННОЙ РЕГРЕССИИОбщая концепция «фиктивных» переменных и пример их использованияФакторы, применяемые в регрессионных задачах, обычно могут принимать значения из какого-либо непрерывного интервала. Иногда мы можем вводить фактор, который имеет два или более различных уровня. Например, данные можно получать на трех машинах, или на двух фабриках, или с помощью шести операторов. В таком случае мы не можем построить непрерывную шкалу для факторов «машина», или «фабрика», или «оператор». Мы можем приписать этим факторам некоторые уровни по порядку, учитывая тот факт, что различные машины, фабрики или операторы могут иметь независимые детерминированные эффекты в отклике. Переменные такого типа обычно называют фиктивными переменными. Обычно (но не всегда) они не связаны с физическими уровнями, которые могут существовать у факторов сами по себе. Первый пример фиктивной переменной — это дополнительная переменная Фиктивные переменные для разбиения данных на блокиДопустим, мы хотим отразить в модели представление о том, что два типа машин (скажем, тип А и тип В) дают различные уровни отклика в дополнение к вариации, обусловленной другими факторами. Один путь состоит в том, чтобы включить в модель фиктивную переменную одновременно с оцениванием
Фактически годятся любые два различных значения
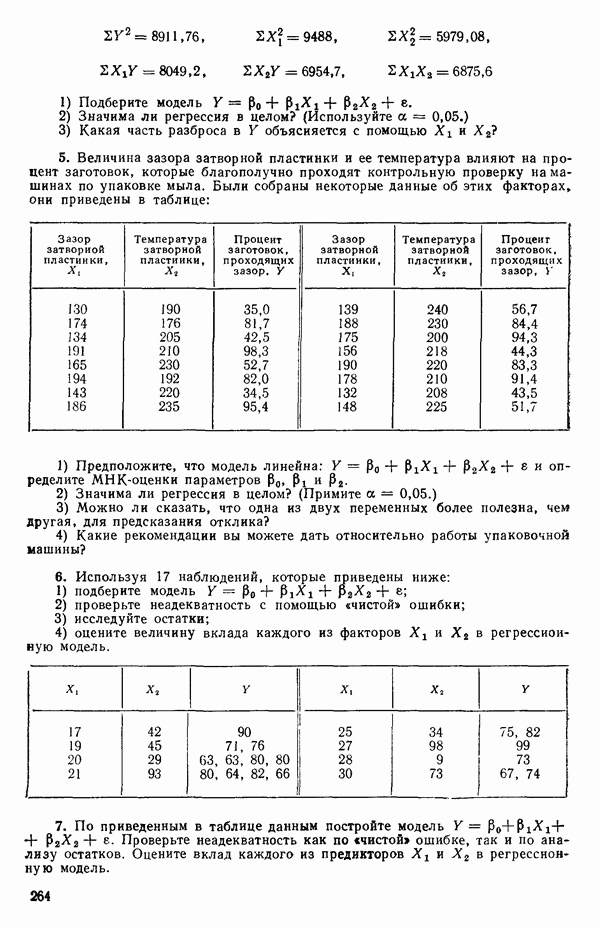
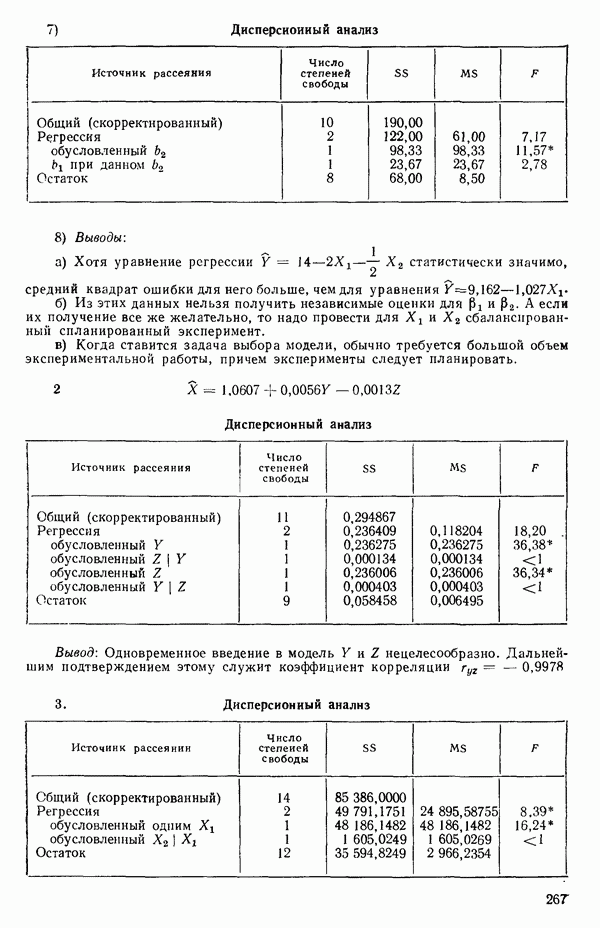
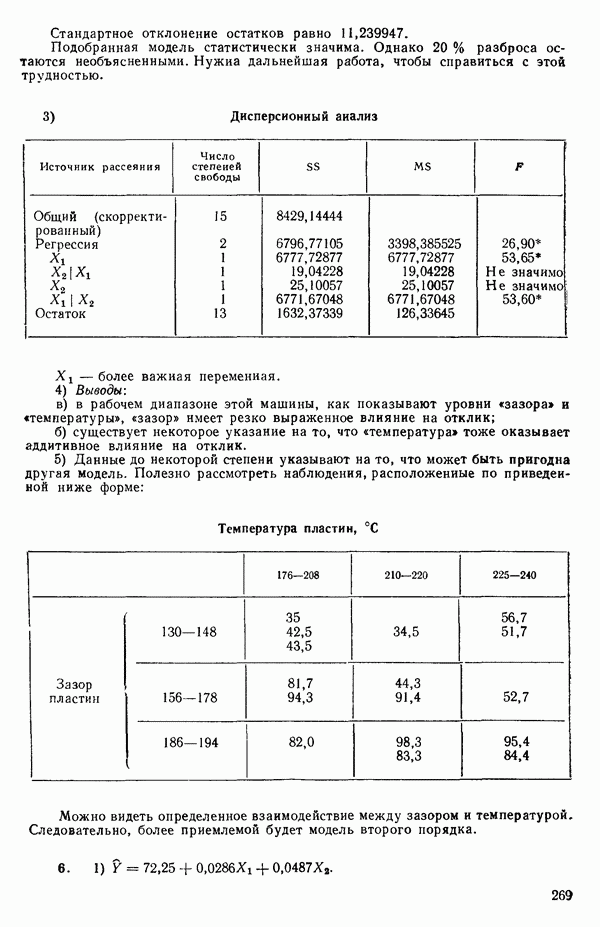
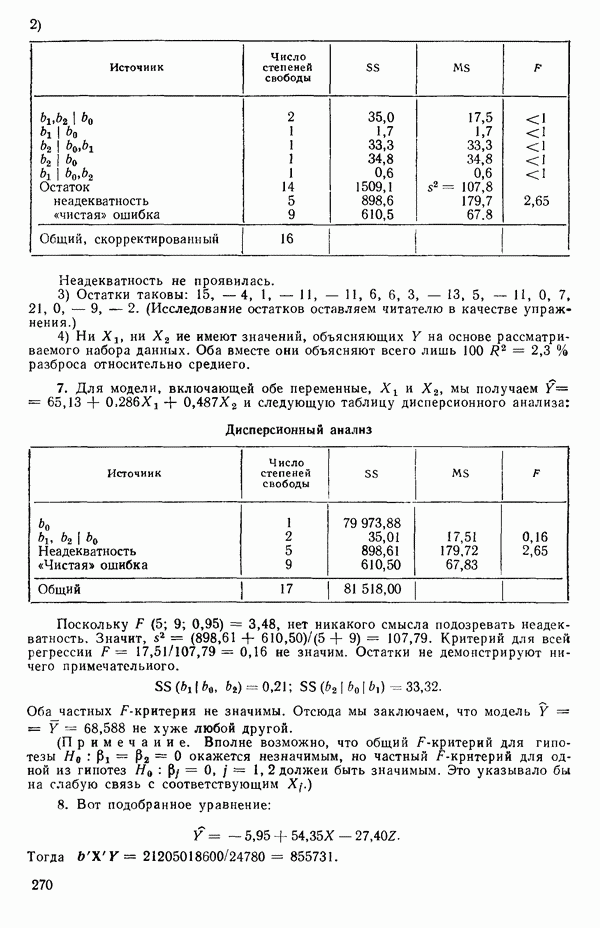
и
то соответствующие столбцы матрицы X будут ортогональны к «столбцу (Примечание. Если желательно рассматривать три разные машины, то потребуются две фиктивные переменные:
и модель будет включать дополнительные члены
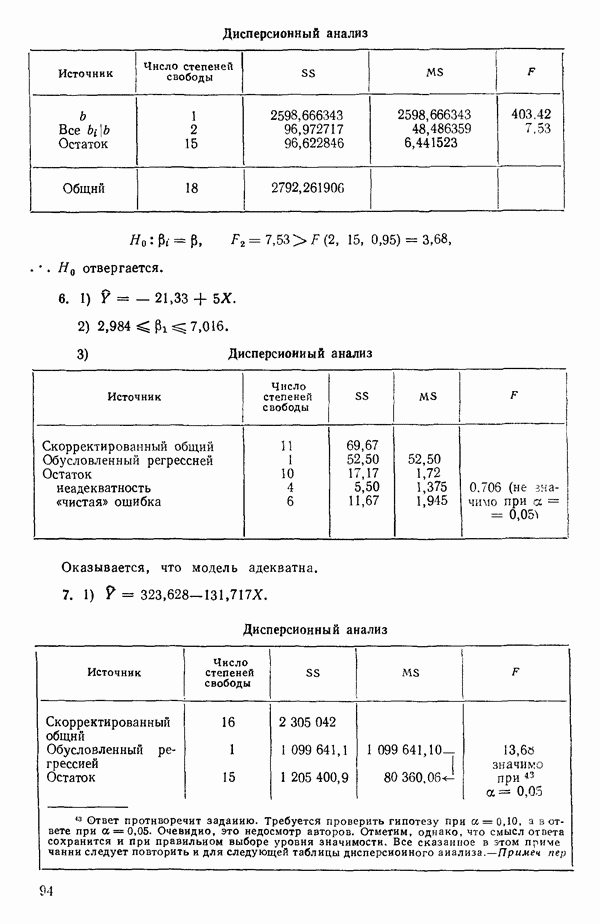
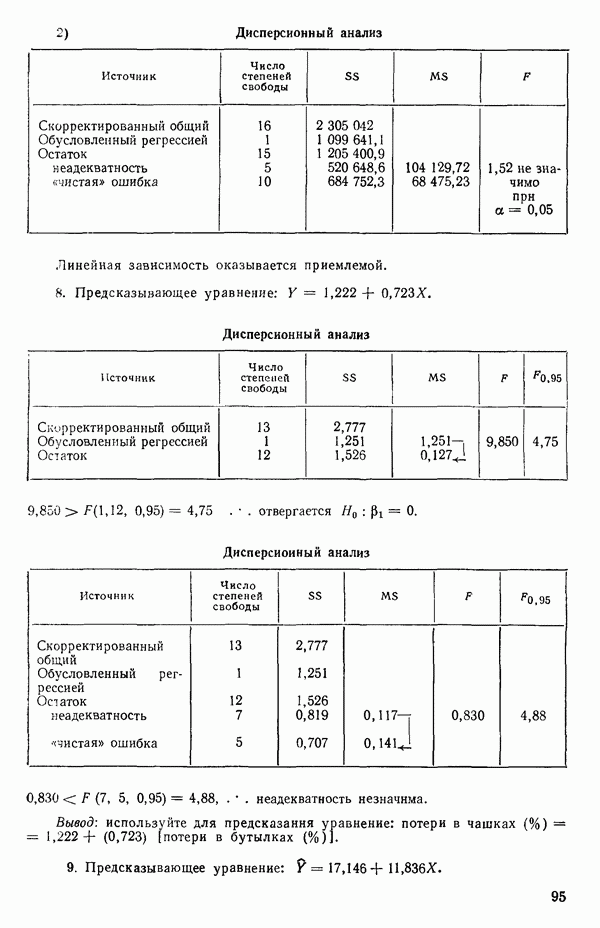
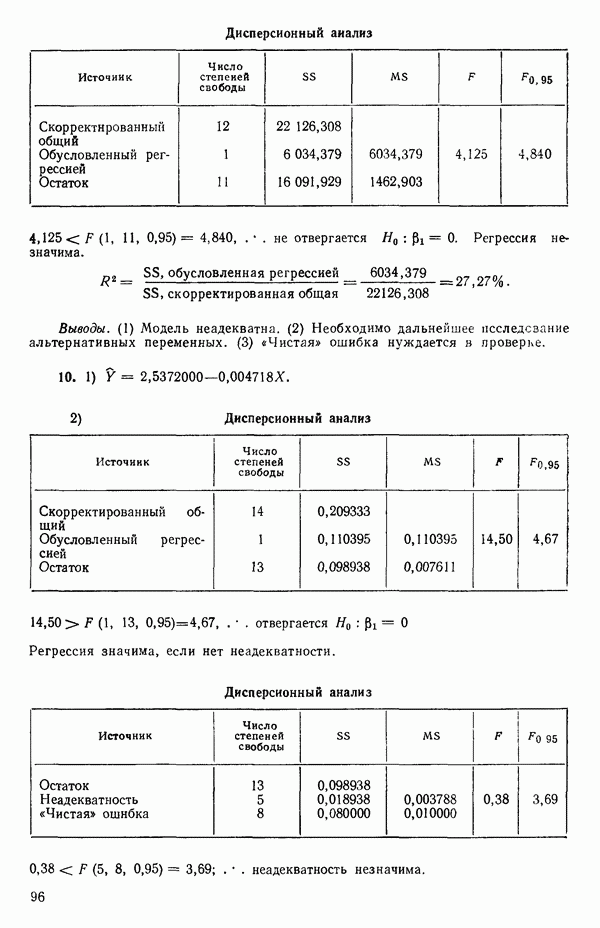
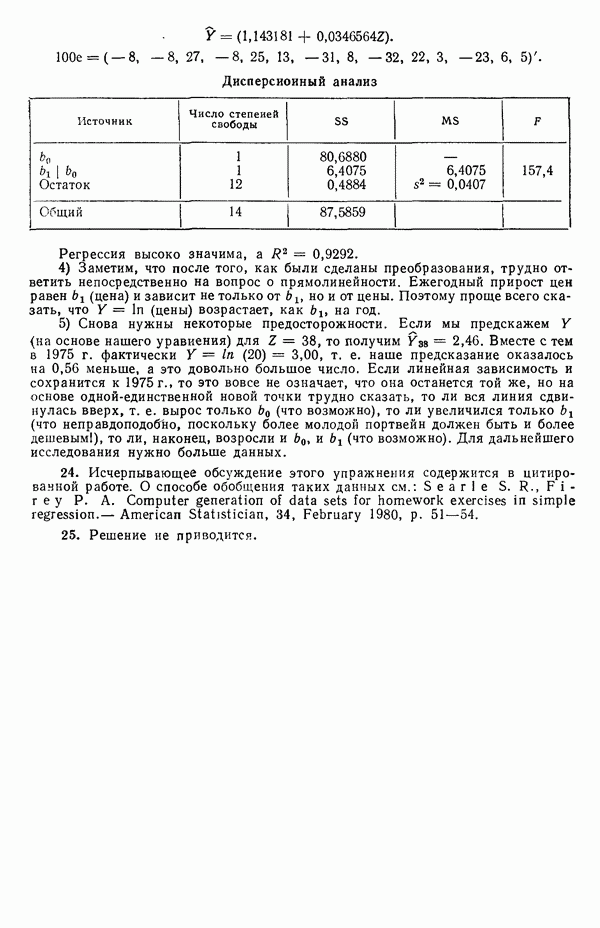
где В общем, при продолжении такой процедуры мы можем прийти к Теперь приведем пример такого использования фиктивных переменных. Пример 1. Данные в табл. 5.12 представляют собой вес
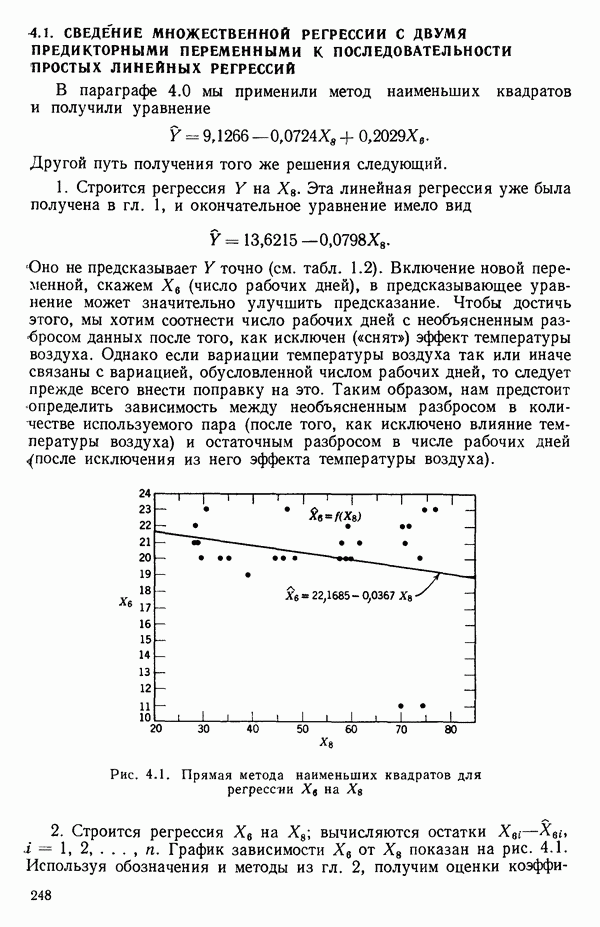
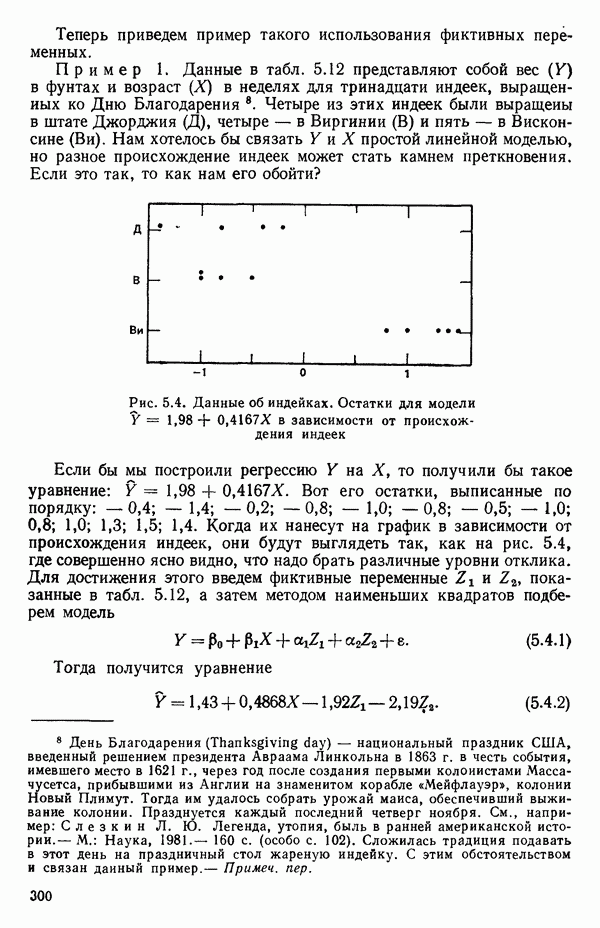
Рис. 5.4. Данные об индейках. Остатки для модели Если бы мы построили регрессию
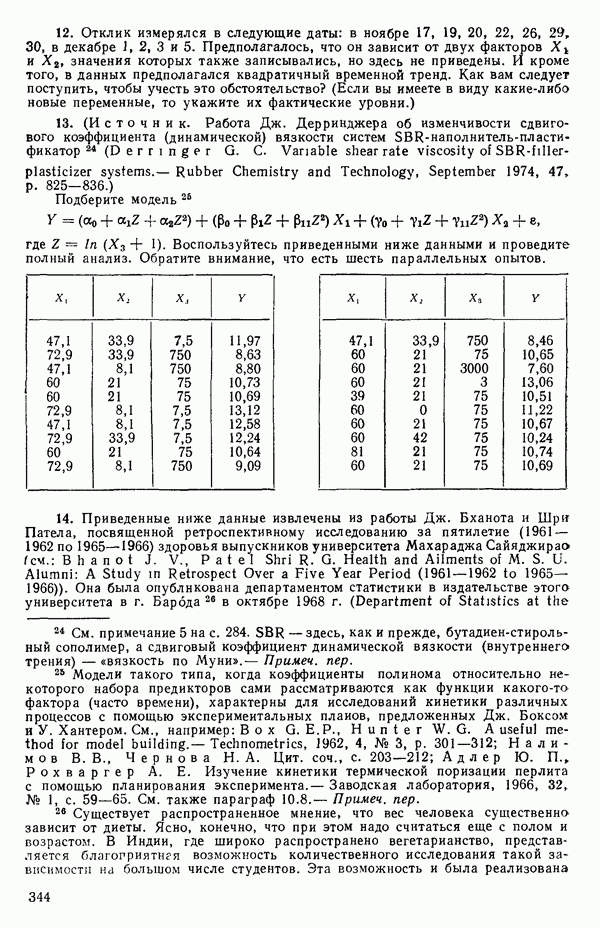
Тогда получится уравнение
Таблица 5.12. Данные об индейках
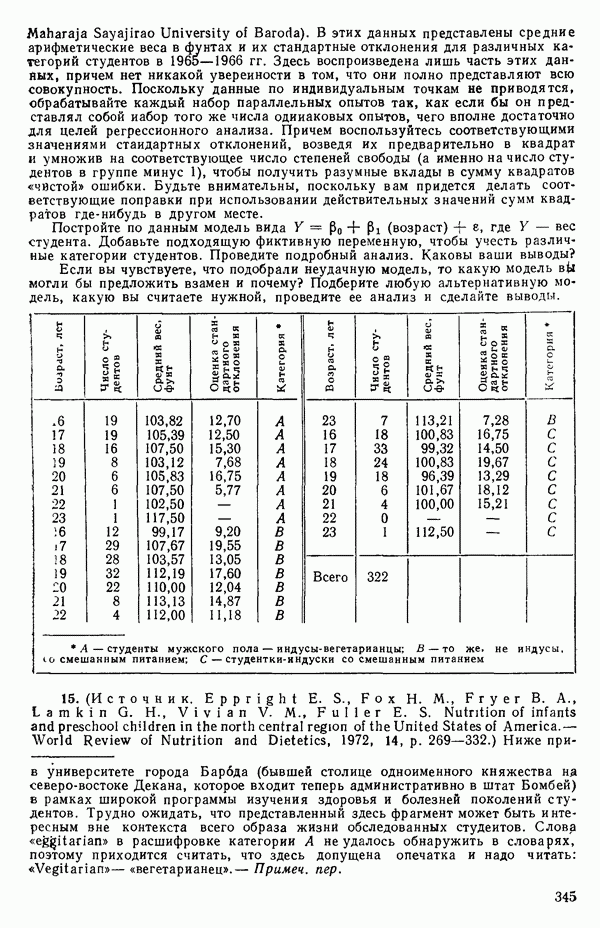
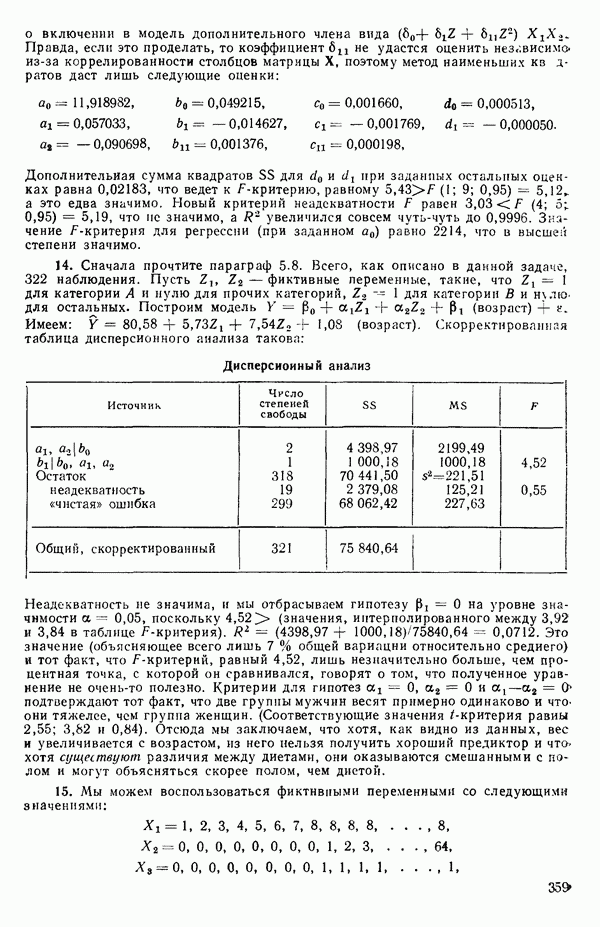
Оценки
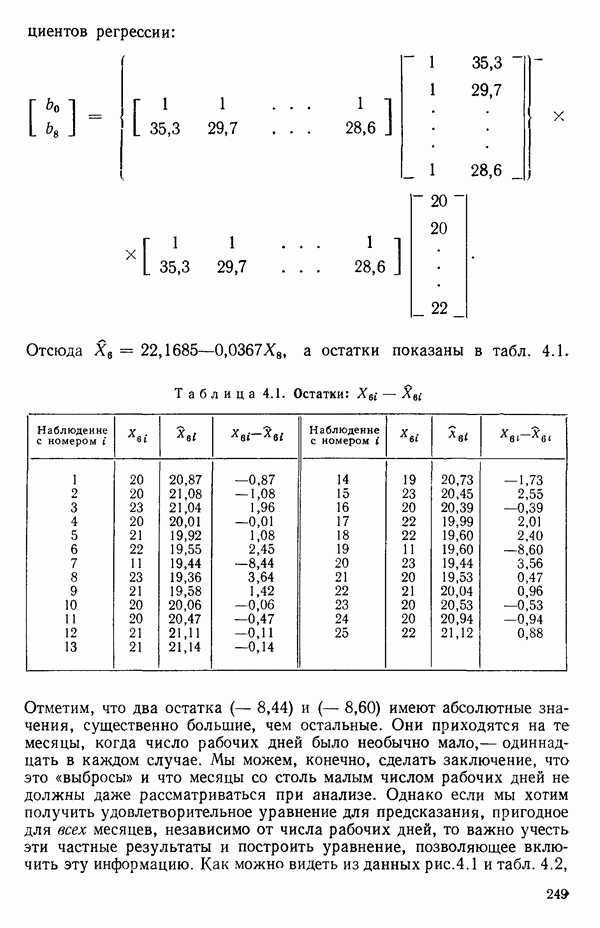
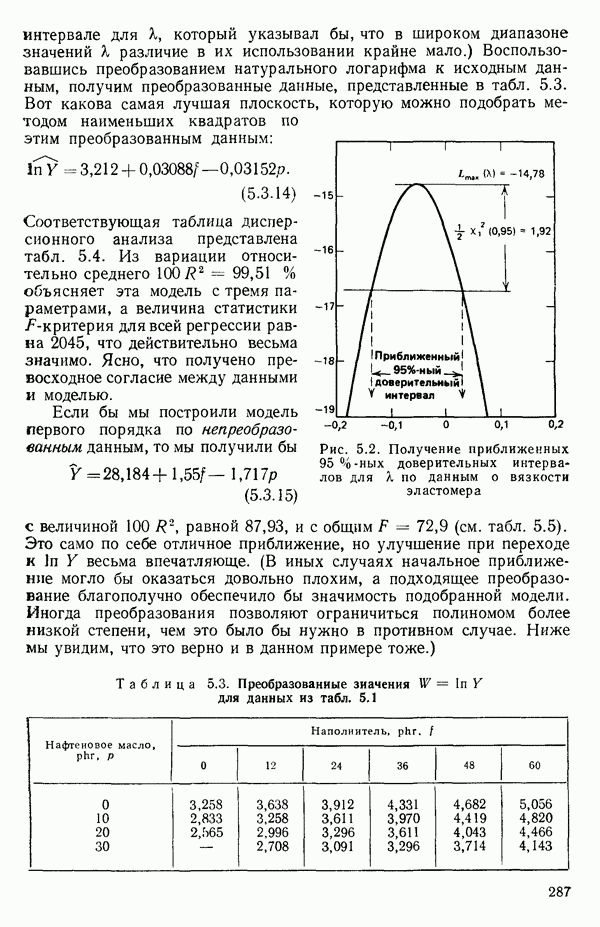
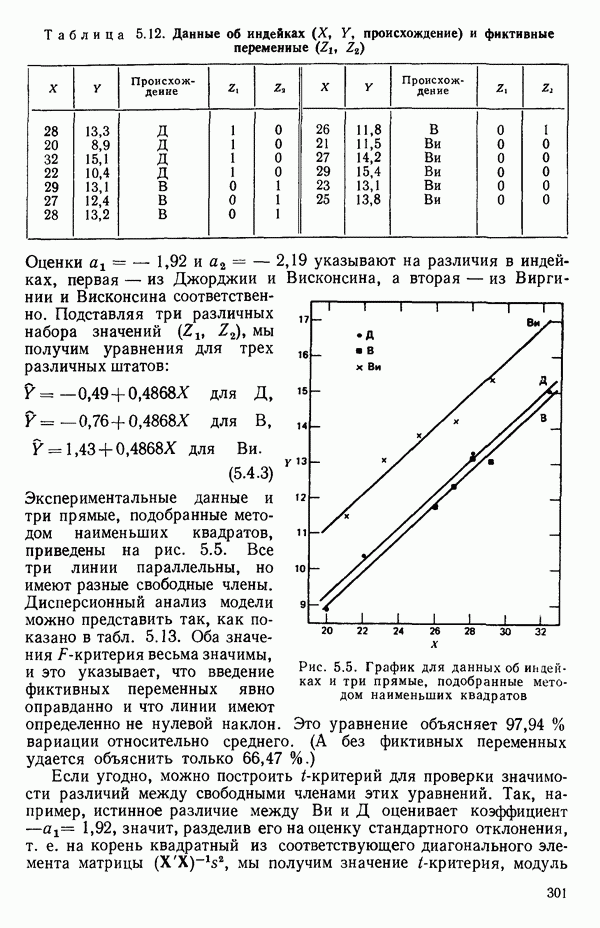
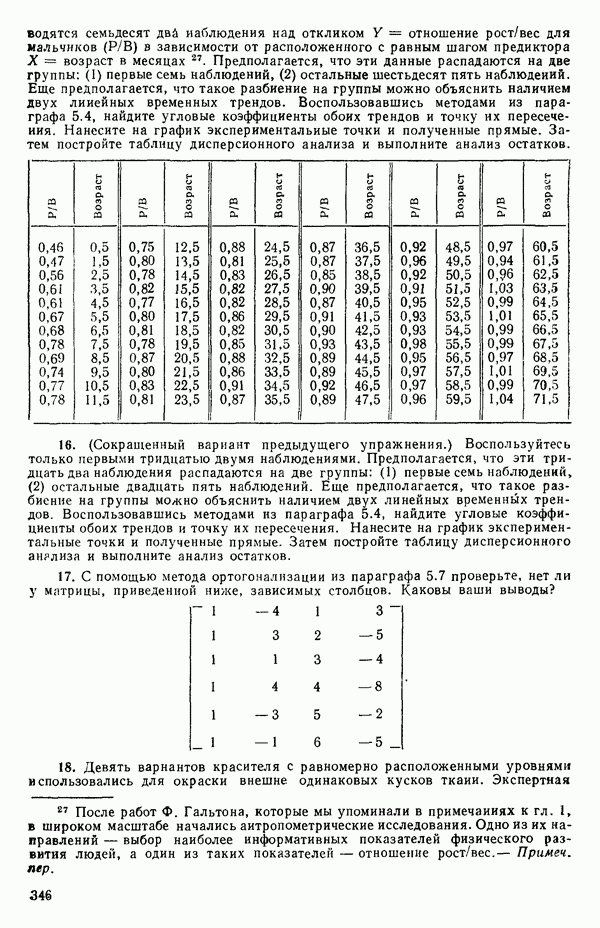
Экспериментальные данные и три прямые, подобранные методом наименьших квадратов, приведены на рис. 5.5. Все три линии параллельны, но имеют разные свободные члены. Дисперсионный анализ модели можно представить так, как показано в табл. 5.13. Оба значения F-критерия весьма значимы, и это указывает, что введение фиктивных переменных явно оправданно и что линии имеют определенно не нулевой наклон. Это уравнение объясняет
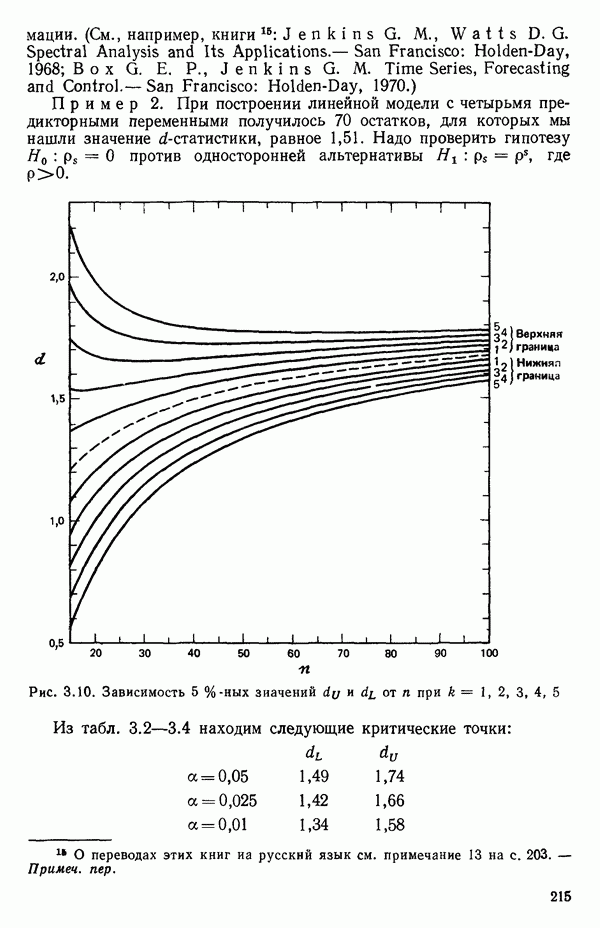
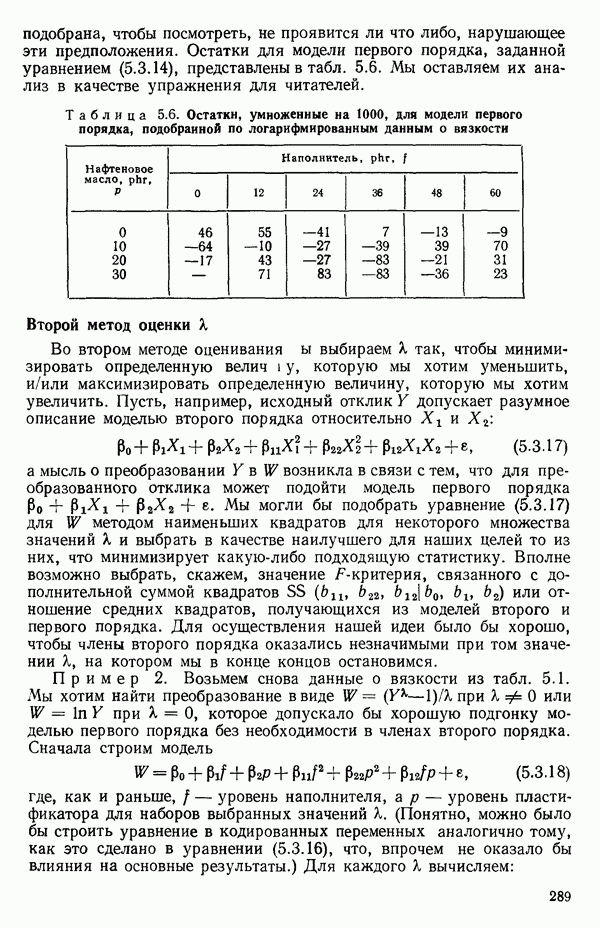
Рис. 5.5. График для данных об индейках и три прямые, подобранные методом наименьших квадратов Если угодно, можно построить (абсолютное значение) которого надо сравнить с процентной точкой
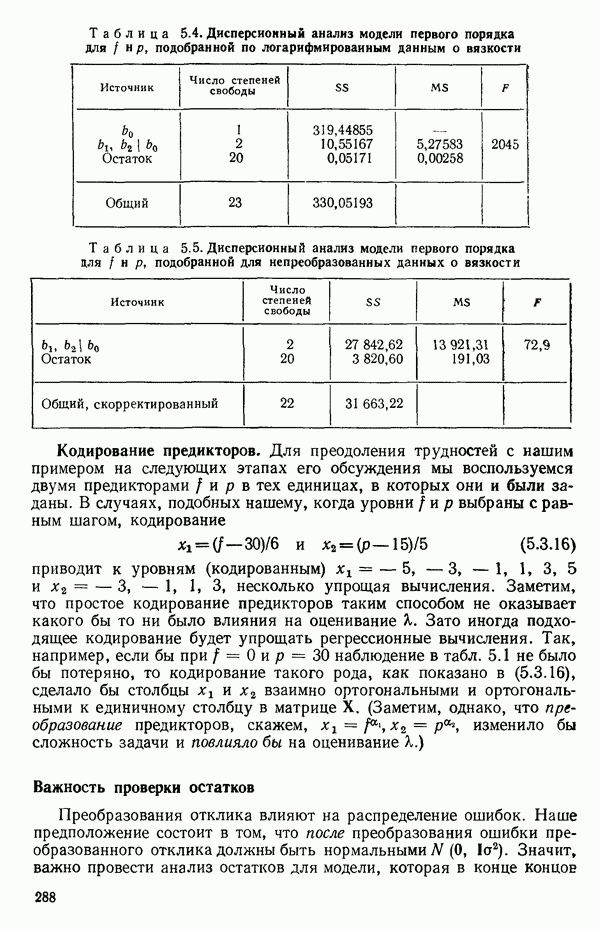
Этот результат сравнивается с Таблица 5.13. Дисперсионный анализ для примера с индейками
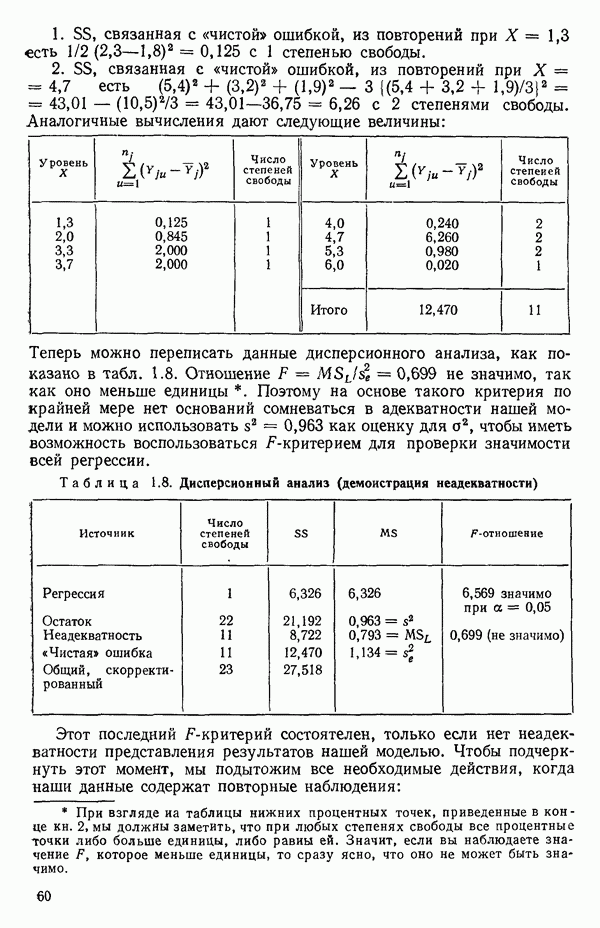
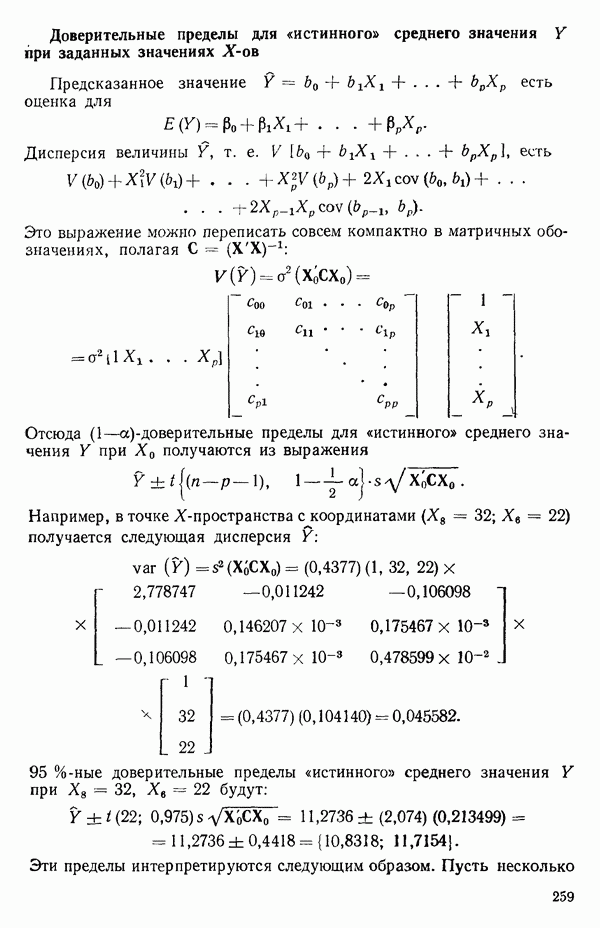
Представление фиктивных переменных не единственноКак можно понять из того, что сказано выше, для данной регрессионной задачи существует не единственный способ выбора фиктивных переменных, а в большинстве случаев путей их представления превеликое множество. Это обстоятельство может оказаться выгодным, если мы сумеем использовать его для объяснения некоторых особенностей, проявляющихся в наших данных. Правда, должна быть уверенность в том, что выбранное представление действительно сработает, т. е. даст возможность сосчитать результат для всех уровней (категорий) фиктивного фактора, не приводя к вырожденности матрицы Пример 2. Ниже приведена схема фиктивного фактора. Пригодна ли она, если иметь в виду возможные различия в уровнях для шести групп?
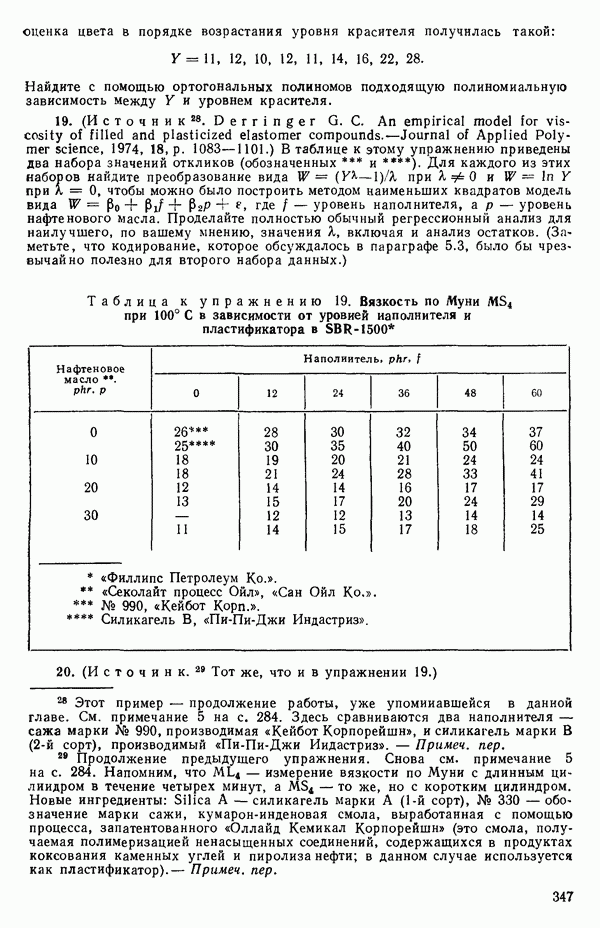
Ответ утвердительный. Вспомните, что наша схема базисных векторов для описываемого случая, записанная ниже со столбцом
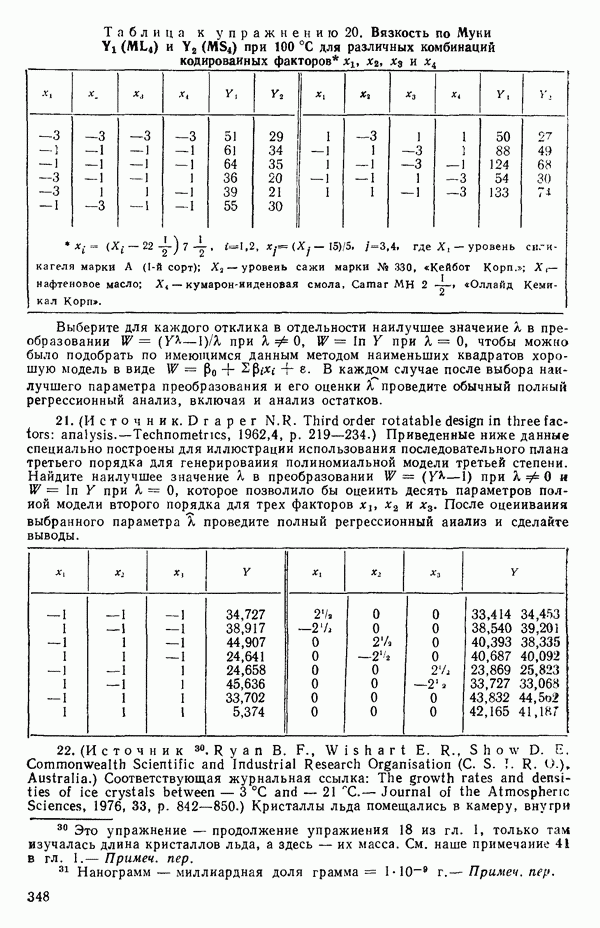
Сразу видно, что:
Таким образом, система столбцов Пример 3. Другая вполне пригодная схема в том же контексте, что и в примере 2, могла бы содержать столбцы
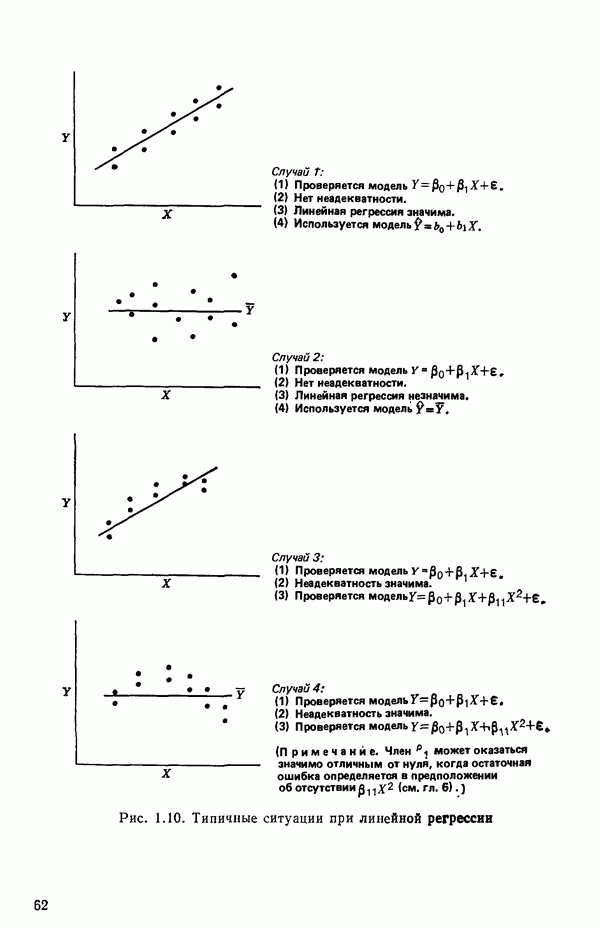
Члены с взаимодействиями, включающие фиктивные факторыПоложим, для определенности, что мы имеем два аналогичных набора данных об отклике
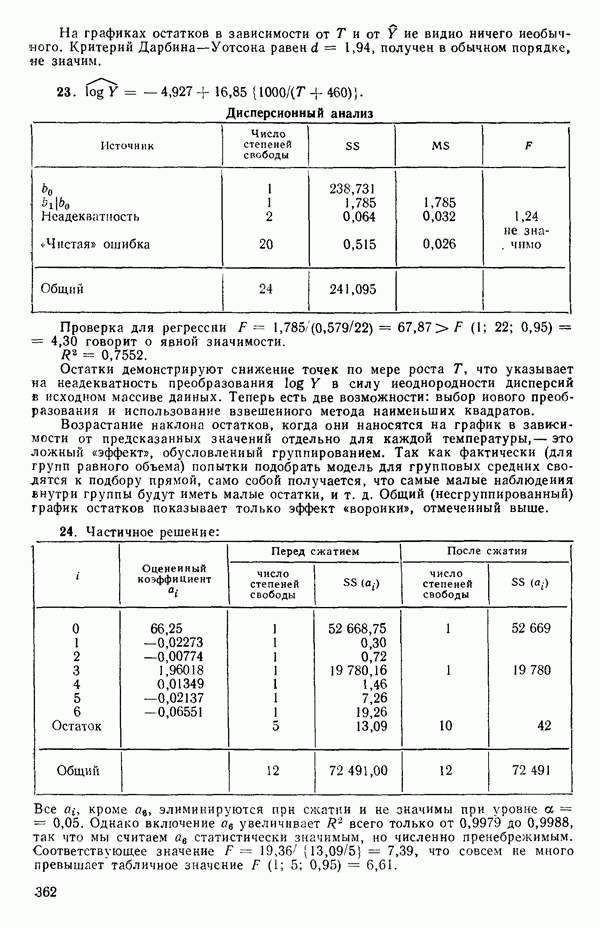
Нужно выяснить, можно ли использовать для обоих множеств данных одну и ту же модель и если можно, то как подобрать ее коэффициенты? Один из путей подхода к этой задаче заключается в том, чтобы одновременно подбирать модель для обоих наборов данных в виде
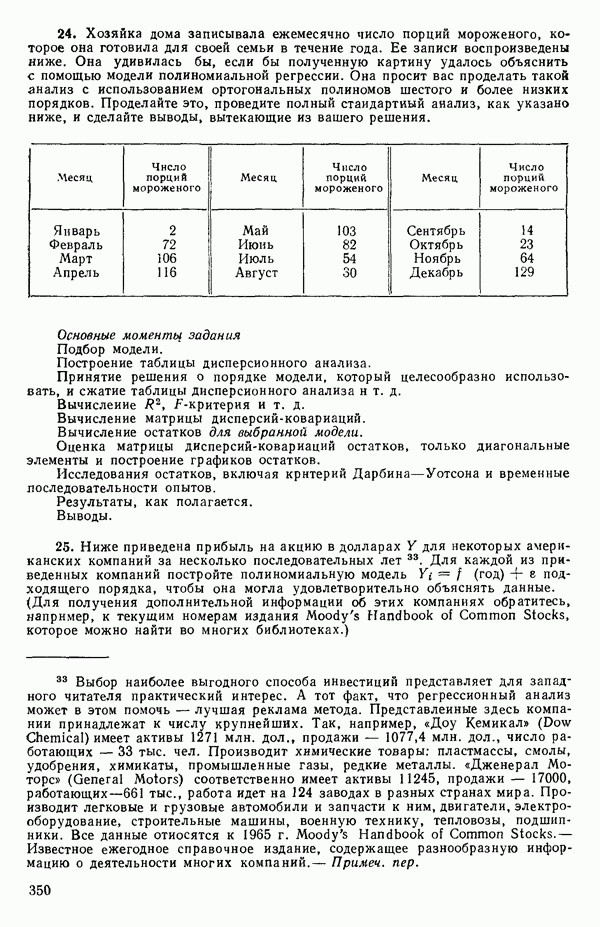
где 1. Гипотеза 2. Если гипотеза 3. Если гипотеза Могли бы быть выбраны и другие последовательности проверок, если бы это было разумно в контексте решаемой задачи. Выбранная последовательность представляет естественный порядок различий, который часто разумен. В принципе нет никаких проблем, препятствующих распространению такого подхода на ситуации с большим числом наборов данных и с другими моделями, включающими больше предикторов, Если бы для одного набора данных основная модель была бы
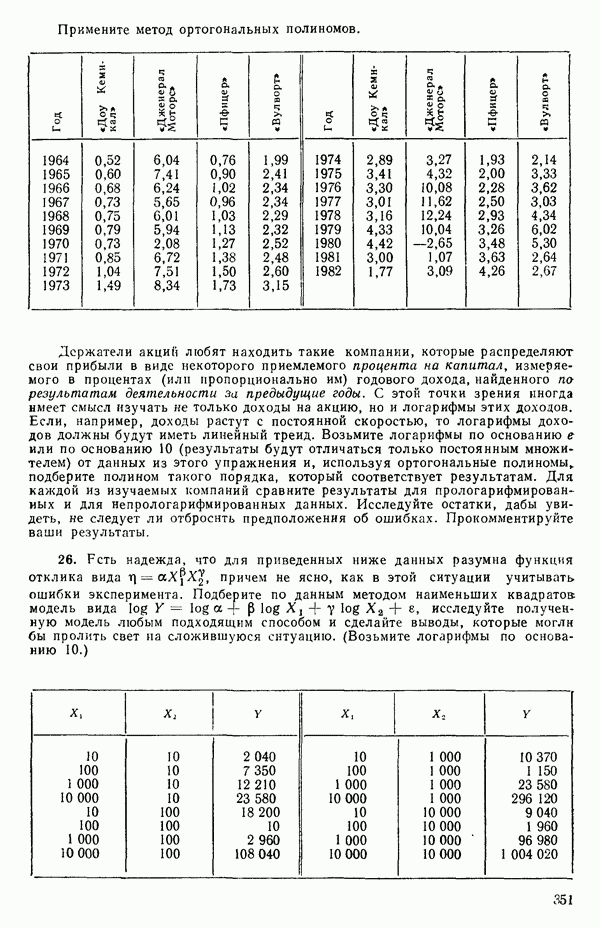
то по всем данным мы могли бы построить модель
где Мы должны получить такие же ответы, как если бы мы обрабатывали каждый набор данных отдельно. Так, если
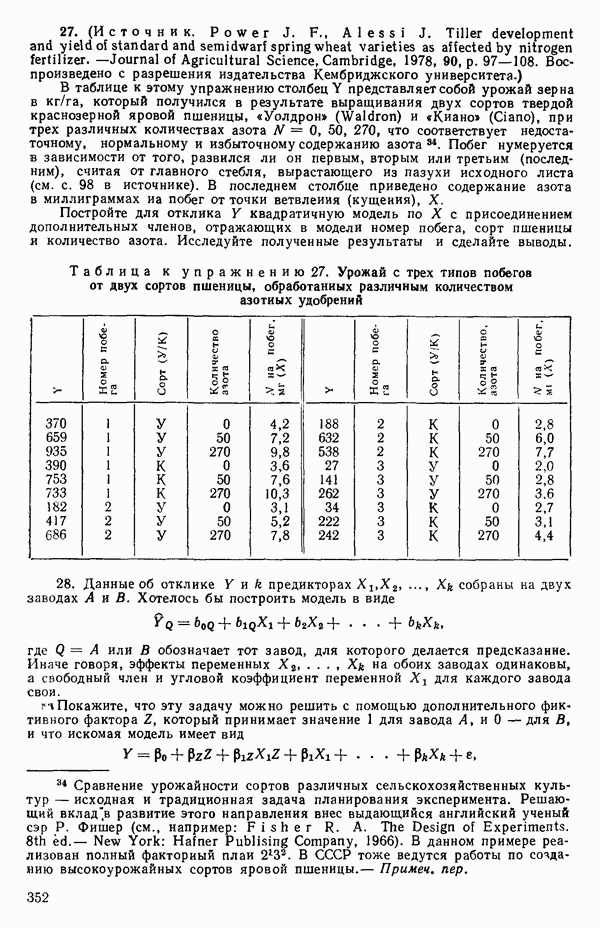
и мы можем ее представить, скажем, так:
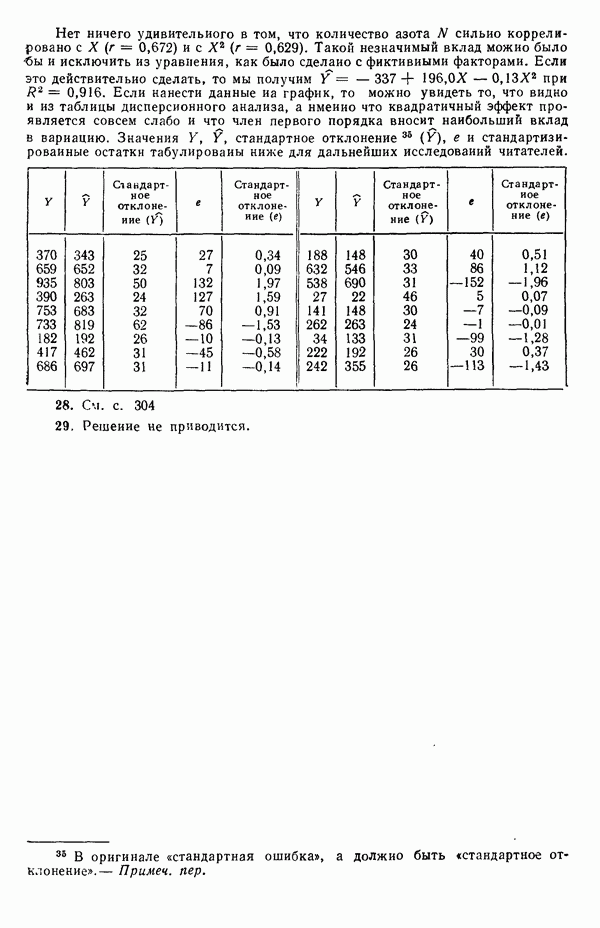
Преимущество использования взаимодействий с фиктивными факторами заключается в том, что появляется возможность простой формализации и естественный способ применения критериев дополнительной суммы квадратов. Пример 4. Проиллюстрируем сказанное на примере с индейками. Для построения трех отдельных прямых (см. табл. 5.12) мы возьмем модель
т. е.
Тогда получится следующее уравнение
А вот три отдельных уравнения прямых линий:
Эти линии, которые в точности те же, что получились бы при подборе уравнений для каждого набора данных в отдельности, несколько отличаются от тех линий, что приведены на рис. 5.5, в чем читатель может убедиться, если построит их на графике или просто сравнит с уравнениями (5.4.3). Таблица дисперсионного анализа для этих данных имеет вид:
Эти три подобранные прямые были бы идентичны, если бы была верна нуль-гипотеза
(Величина 26,20 представляет собой сумму квадратов относительно регрессии для общего уравнения; она ранее не использовалась.) Соответствующее значение
что превышает табличное значение Можно проверить гипотезу о существовании трех параллельных линий, т. е.
где величина 38,61 представляет собой сумму второй Как показывает наш пример, использование взаимодействия с фиктивными факторами упрощает построение подходящих критериев и получение правильных статистик для проверки гипотез. Быть может, это наиглавнейшее достоинство данного метода.
|
 |
Оглавление
|













































































































































































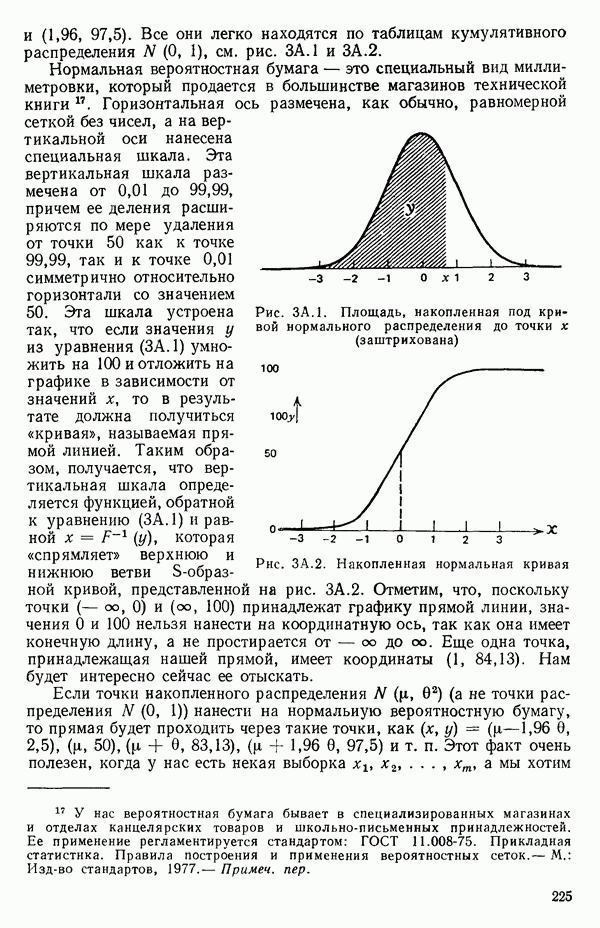
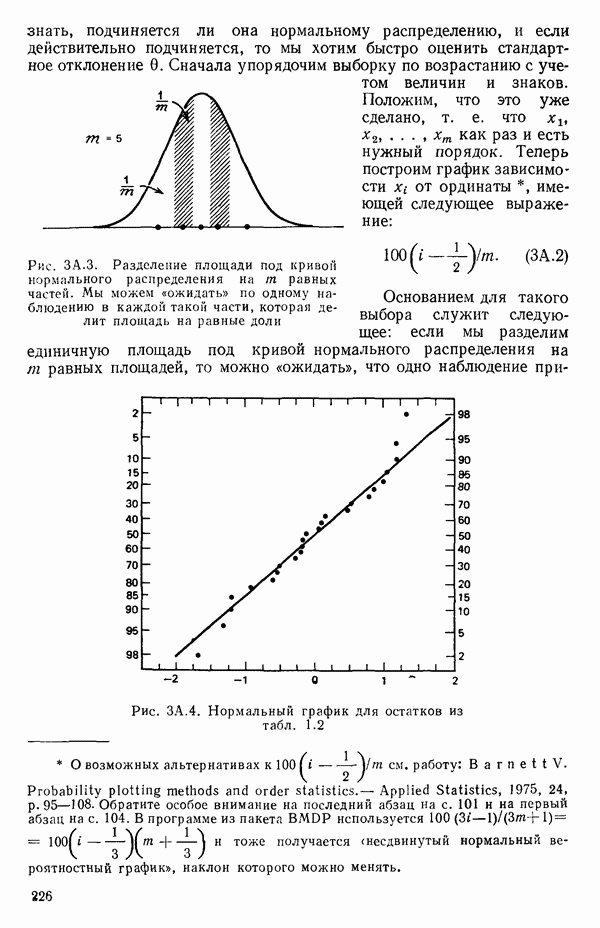


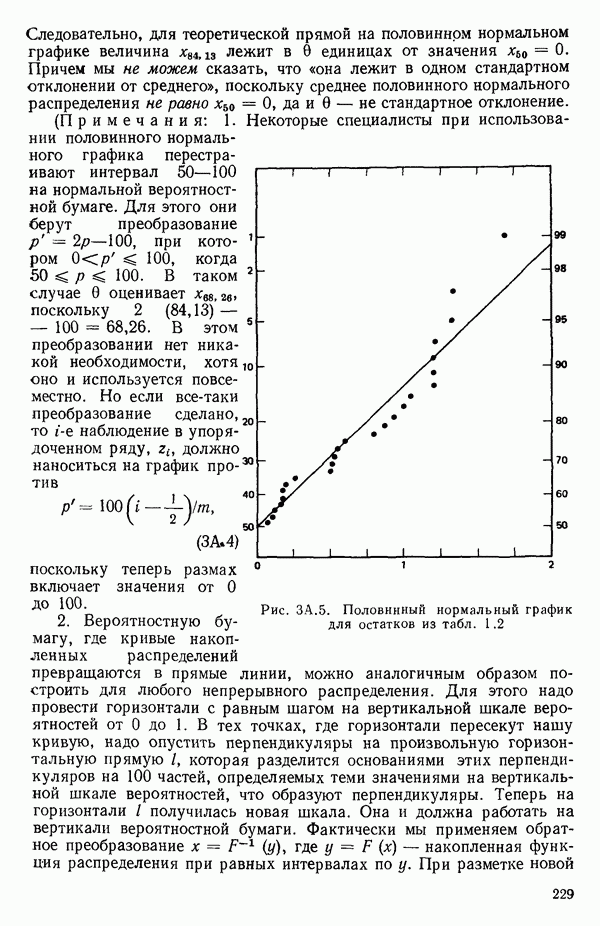





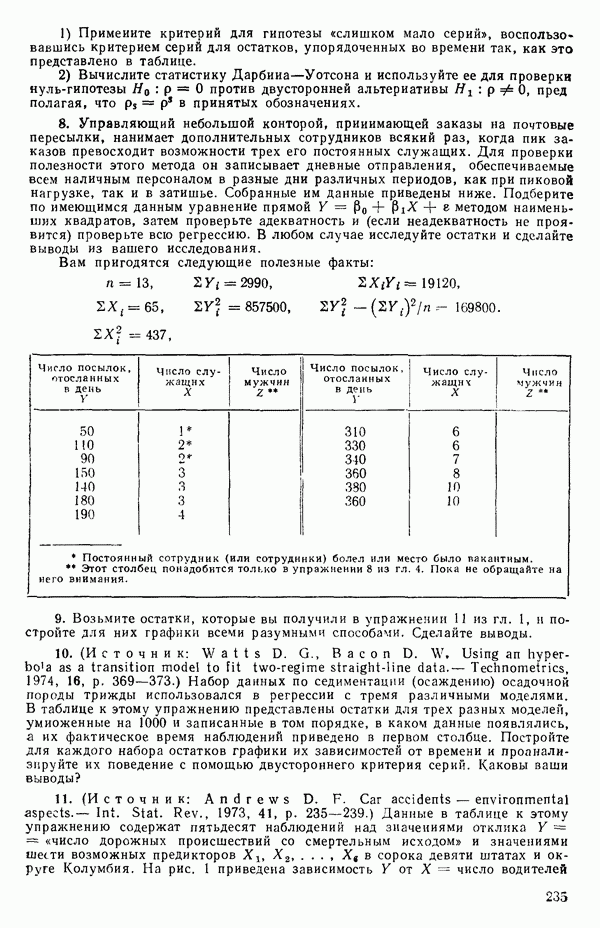






































































 при члене
при члене  в регрессионной модели (она всегда равна единице). Переменную
в регрессионной модели (она всегда равна единице). Переменную  совсем не обязательно вводить в модель, но ее использование иногда обеспечивает удобство в обозначениях. Другие фиктивные переменные вводятся, как мы увидим, из соображений, более важных, чем просто удобство обозначений, что имеет место, скажем, при применении регрессионных методов к задачам дисперсионного анализа, как это показано в гл. 9.
совсем не обязательно вводить в модель, но ее использование иногда обеспечивает удобство в обозначениях. Другие фиктивные переменные вводятся, как мы увидим, из соображений, более важных, чем просто удобство обозначений, что имеет место, скажем, при применении регрессионных методов к задачам дисперсионного анализа, как это показано в гл. 9.
 и коэффициент регрессии, скажем а, так что в модели появится дополнительный член
и коэффициент регрессии, скажем а, так что в модели появится дополнительный член  Коэффициент а можно оценить
Коэффициент а можно оценить
 -коэффициентов. Фактору
-коэффициентов. Фактору  можно приписать следующие значения:
можно приписать следующие значения:

 хотя приведенные выше обычно оказываются наилучшими. Однако иногда удобнее другие обозначения. Пусть, например, из общего числа наблюдений
хотя приведенные выше обычно оказываются наилучшими. Однако иногда удобнее другие обозначения. Пусть, например, из общего числа наблюдений  часть
часть  получена на машине типа А, а
получена на машине типа А, а  на машине типа В. Тогда если мы выберем уровни
на машине типа В. Тогда если мы выберем уровни


 и сумма их квадратов будет равна единице, что может быть также удобно.
и сумма их квадратов будет равна единице, что может быть также удобно.
 Тогда мы получим
Тогда мы получим

 с коэффициентами
с коэффициентами  требующими оценивания. Снова возможно много различных вариантов уровней. Если желательны столбцы, которые ортогональны к «столбцу
требующими оценивания. Снова возможно много различных вариантов уровней. Если желательны столбцы, которые ортогональны к «столбцу  и имеют единичную сумму квадратов, то можно достигнуть этого, положив
и имеют единичную сумму квадратов, то можно достигнуть этого, положив

 соответственно числа наблюдений на машинах
соответственно числа наблюдений на машинах 
 уровням для
уровням для  фиктивных переменных. Структура такой системы фиктивных переменных получится, если выписать единичную матрицу I размером
фиктивных переменных. Структура такой системы фиктивных переменных получится, если выписать единичную матрицу I размером  и приписать к ней строку, состоящую из
и приписать к ней строку, состоящую из  нулей. Для случая
нулей. Для случая  это показано на столбцах
это показано на столбцах  во второй таблице из примера 2.
во второй таблице из примера 2.
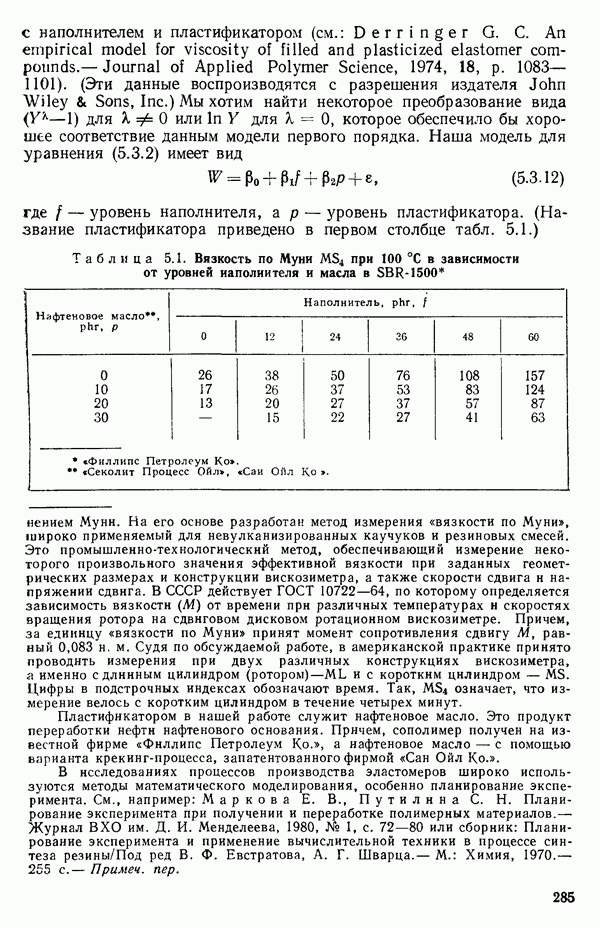
 в фунтах и возраст (X) в неделях для тринадцати индеек, выращенных ко Дню Благодарения. Четыре из этих индеек были выращены в штате Джорджия
в фунтах и возраст (X) в неделях для тринадцати индеек, выращенных ко Дню Благодарения. Четыре из этих индеек были выращены в штате Джорджия  четыре — в Виргинии
четыре — в Виргинии  и пять — в Висконсине
и пять — в Висконсине  Нам хотелось бы связать
Нам хотелось бы связать  простой линейной моделью, но разное происхождение индеек может стать камнем преткновения. Если это так, то как нам его обойти?
простой линейной моделью, но разное происхождение индеек может стать камнем преткновения. Если это так, то как нам его обойти?

 в зависимости от происхождения индеек
в зависимости от происхождения индеек
 на X, то получили бы такое уравнение:
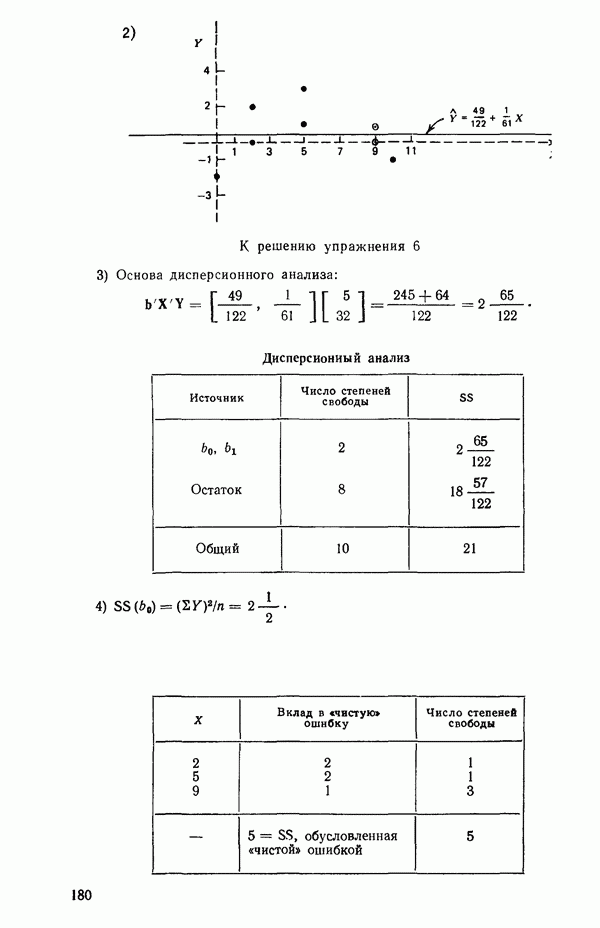
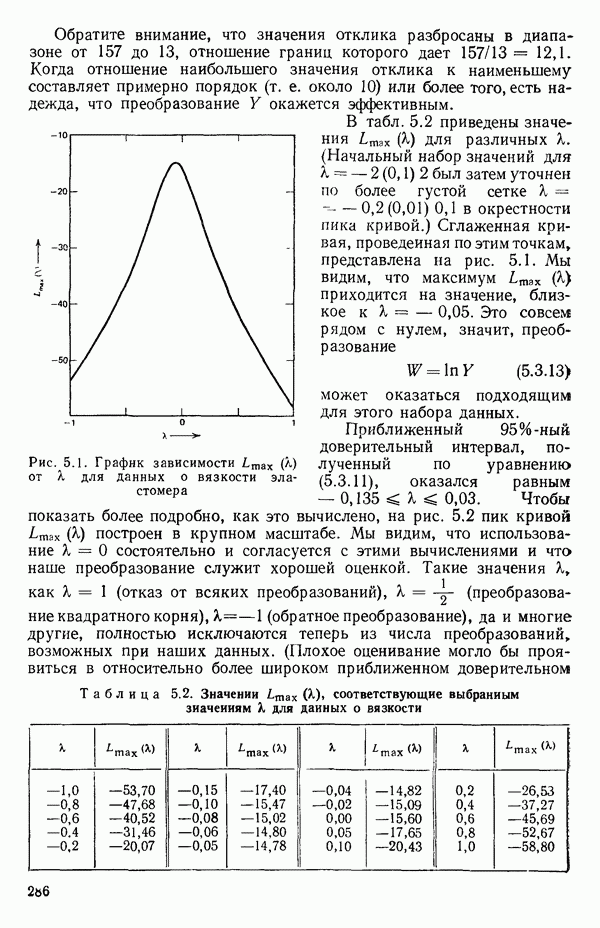
на X, то получили бы такое уравнение:  Вот его остатки, выписанные по порядку:
Вот его остатки, выписанные по порядку:  Когда их нанесут на график в зависимости от происхождения индеек, они будут выглядеть так, как на рис. 5.4, где совершенно ясно видно, что надо брать различные уровни отклика. Для достижения этого введем фиктивные переменные
Когда их нанесут на график в зависимости от происхождения индеек, они будут выглядеть так, как на рис. 5.4, где совершенно ясно видно, что надо брать различные уровни отклика. Для достижения этого введем фиктивные переменные  показанные в табл. 5.12, а затем методом наименьших квадратов подберем модель
показанные в табл. 5.12, а затем методом наименьших квадратов подберем модель


 происхождение) и фиктивные переменные
происхождение) и фиктивные переменные 

 указывают на различия в индейках, первая — из Джорджии и Висконсина, а вторая — из Виргинии и Висконсина соответственно. Подставляя три различных набора значений
указывают на различия в индейках, первая — из Джорджии и Висконсина, а вторая — из Виргинии и Висконсина соответственно. Подставляя три различных набора значений  мы получим уравнения для трех различных штатов:
мы получим уравнения для трех различных штатов:

 вариации относительно среднего. (А без фиктивных переменных удается объяснить только 66,47 %.)
вариации относительно среднего. (А без фиктивных переменных удается объяснить только 66,47 %.)

 -критерий для проверки значимости различий между свободными членами этих уравнений. Так, например, истинное различие между
-критерий для проверки значимости различий между свободными членами этих уравнений. Так, например, истинное различие между  оценивает коэффициент
оценивает коэффициент  значит, разделив его на оценку стандартного отклонения, т. е. на корень квадратный из соответствующего диагонального элемента матрицы
значит, разделив его на оценку стандартного отклонения, т. е. на корень квадратный из соответствующего диагонального элемента матрицы  мы получим значение
мы получим значение  -критерия, модуль
-критерия, модуль
 двустороннего критерия, проверяющего нуль-гипотезу
двустороннего критерия, проверяющего нуль-гипотезу  против альтернативы Ф 0. Пользуясь нашими данными, получим:
против альтернативы Ф 0. Пользуясь нашими данными, получим:  что значимо на уровне
что значимо на уровне  Другой, но равноценный критерий получится, если воспользоваться соотношением
Другой, но равноценный критерий получится, если воспользоваться соотношением

 для критерия с тем же уровнем значимости. Результат идентичен предыдущему, поскольку теоретически величина
для критерия с тем же уровнем значимости. Результат идентичен предыдущему, поскольку теоретически величина  -критерия должна равняться квадрату величины
-критерия должна равняться квадрату величины  -критерия, полученного выше. В данном случае
-критерия, полученного выше. В данном случае  что должно было бы быть равно:
что должно было бы быть равно:  То, что нет полного совпадения, объясняется ошибками округления. Критерий для нуль-гипотезы
То, что нет полного совпадения, объясняется ошибками округления. Критерий для нуль-гипотезы  где
где  представляет собой истинную разность между
представляет собой истинную разность между  можно построить точно так же. Величина
можно построить точно так же. Величина  -критерия окажется равной —
-критерия окажется равной —  что также значимо на уровне
что также значимо на уровне  Оценкой различия между
Оценкой различия между  служит разность
служит разность  оценкой дисперсии которой в свою очередь служит выражение:
оценкой дисперсии которой в свою очередь служит выражение:  все три члена которого можно извлечь из матрицы
все три члена которого можно извлечь из матрицы  В результате получим:
В результате получим:  Тогда величина
Тогда величина  -критерия, равная
-критерия, равная  окажется незначимой. Таким образом, фактические различия существуют между
окажется незначимой. Таким образом, фактические различия существуют между  и между
и между  но не проявляются между
но не проявляются между 

 Основные представления мы советуем брать среди простейших. Все другие представления должны обязательно обеспечить такое же число линейно независимых столбцов матрицы X, причем так, чтобы они были линейными комбинациями исходных столбцов.
Основные представления мы советуем брать среди простейших. Все другие представления должны обязательно обеспечить такое же число линейно независимых столбцов матрицы X, причем так, чтобы они были линейными комбинациями исходных столбцов.

 была вот какой:
была вот какой:


 представляет собой независимые линейные комбинации столбцов системы
представляет собой независимые линейные комбинации столбцов системы 
 Это привело бы к схеме:
Это привело бы к схеме:

 и предикторе X и что для каждого из этих наборов мы имеем в виду модель в форме
и предикторе X и что для каждого из этих наборов мы имеем в виду модель в форме


 фиктивный фактор, принимающий уровень 0 для одного набора данных и 1 — для другого. Тогда критерий дополнительной суммы квадратов позволяет нам проверять различные варианты гипотез, такие, например, как:
фиктивный фактор, принимающий уровень 0 для одного набора данных и 1 — для другого. Тогда критерий дополнительной суммы квадратов позволяет нам проверять различные варианты гипотез, такие, например, как:
 против альтернативы
против альтернативы  что это не так. Если эта гипотеза будет отвергнута, то мы придем к выводу, что модели не одинаковы, ну а если нет, то мы будем пользоваться одной моделью.
что это не так. Если эта гипотеза будет отвергнута, то мы придем к выводу, что модели не одинаковы, ну а если нет, то мы будем пользоваться одной моделью.
 окажется отвергнутой, то мы можем рассмотреть подмножества значений а. Так, например, мы моглн бы проверить гипотезу
окажется отвергнутой, то мы можем рассмотреть подмножества значений а. Так, например, мы моглн бы проверить гипотезу  против альтернативы
против альтернативы  что это не так. Если бы
что это не так. Если бы  не была отвергнута, то мы могли бы заключить, что имеющиеся два набора данных отличаются только уровнем отклика, но имеют одинаковые углы наклона и кривизну.
не была отвергнута, то мы могли бы заключить, что имеющиеся два набора данных отличаются только уровнем отклика, но имеют одинаковые углы наклона и кривизну.
 окажется отвергнутой, то мы сможем проверить новую гипотезу
окажется отвергнутой, то мы сможем проверить новую гипотезу  против альтернативы
против альтернативы  чтобы увидеть, не отличаются ли модели только членами нулевого и первого порядка, на что указывало бы не отбрасывание
чтобы увидеть, не отличаются ли модели только членами нулевого и первого порядка, на что указывало бы не отбрасывание 
 Если бы было
Если бы было  наборов данных, нам пришлось бы образовать
наборов данных, нам пришлось бы образовать  фиктивных факторов
фиктивных факторов  с уровнями, задаваемыми элементами матрицы
с уровнями, задаваемыми элементами матрицы  к которой снизу приписана строка с
к которой снизу приписана строка с  нулями. Тогда строки будут соответствовать группам, а столбцы — фиктивным факторам.
нулями. Тогда строки будут соответствовать группам, а столбцы — фиктивным факторам.


 вектор параметров такого же размера, что и
вектор параметров такого же размера, что и  как в приведенном выше примере для
как в приведенном выше примере для 
 матрица: X для
матрица: X для  набора данных, а всего имеются два набора, то модель имеет вид:
набора данных, а всего имеются два набора, то модель имеет вид:








 Проверка этой гипотезы против альтернативы
Проверка этой гипотезы против альтернативы  что
что  не верна, требует дополнительной суммы квадратов для
не верна, требует дополнительной суммы квадратов для  и с четырьмя степенями свободы:
и с четырьмя степенями свободы:

 -критерия равно:
-критерия равно:

 так что гипотеза
так что гипотеза  отвергается. Это, конечно, отнюдь не удивительно, как мы уже видели, когда рассматривали исходные данные.
отвергается. Это, конечно, отнюдь не удивительно, как мы уже видели, когда рассматривали исходные данные.
 против альтернативы
против альтернативы  что
что  не верна. Для этого находим дополнительную сумму квадратов для
не верна. Для этого находим дополнительную сумму квадратов для  в виде
в виде

 строк из табл. 5.13. Это дает две степени свободы и приводит к незначимому
строк из табл. 5.13. Это дает две степени свободы и приводит к незначимому  -отношению
-отношению  Мы не отбрасываем гипотезу
Мы не отбрасываем гипотезу  а это значит, что модель, показанная на рис. 5.5, вполне удовлетворяет ей.
а это значит, что модель, показанная на рис. 5.5, вполне удовлетворяет ей.