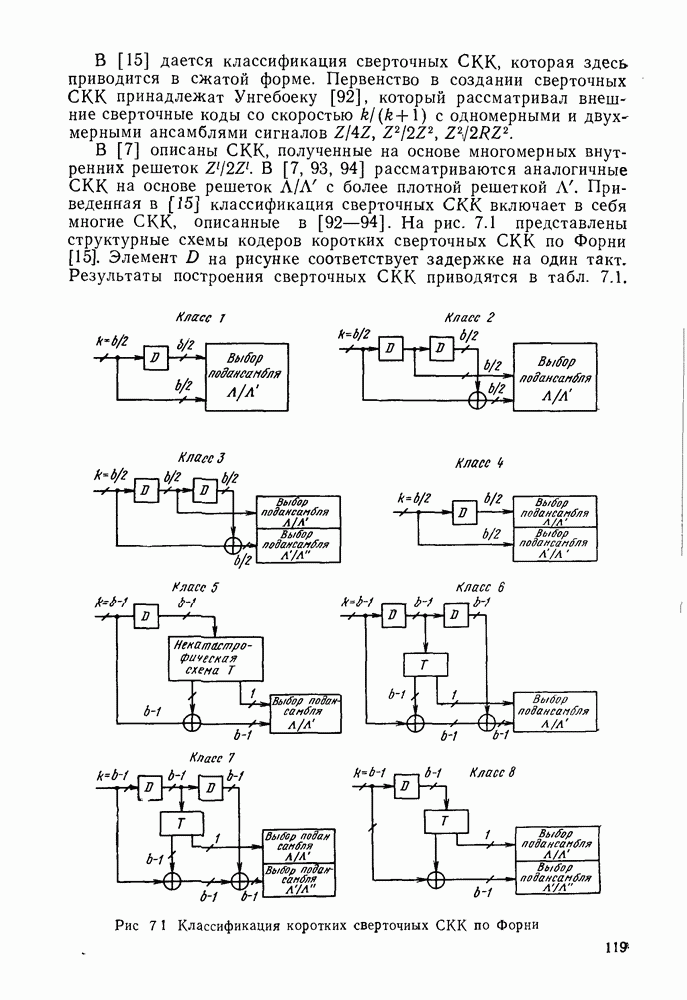
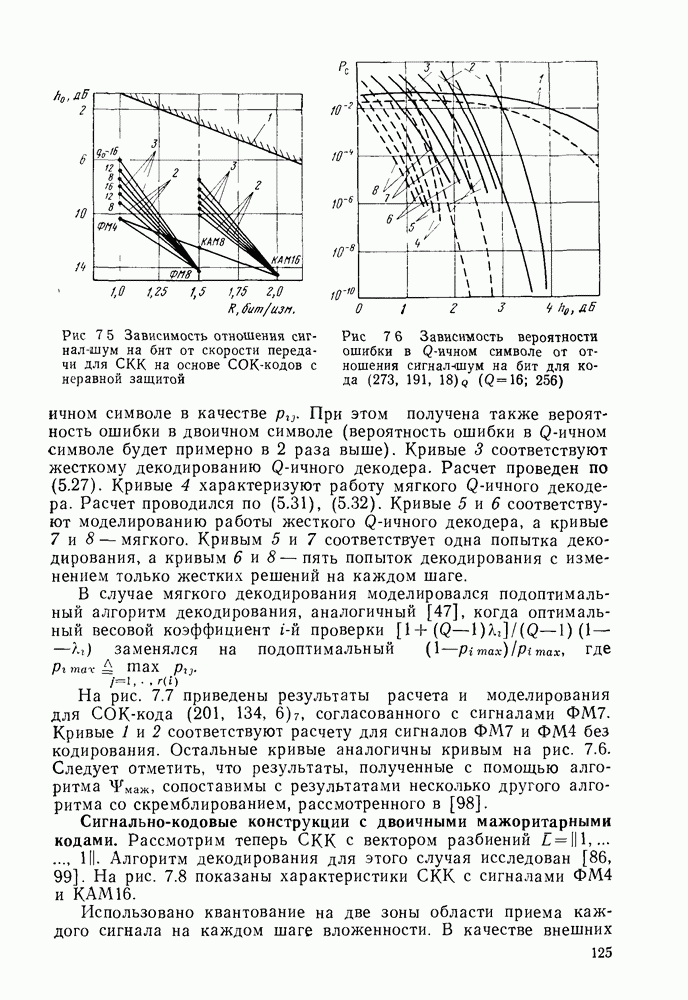
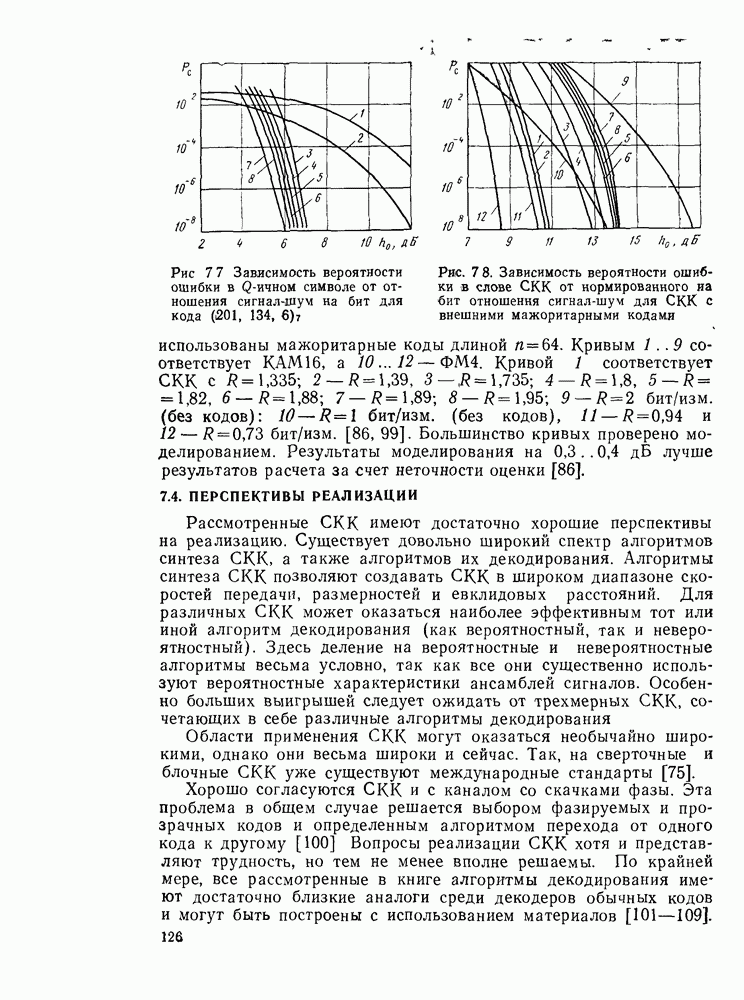
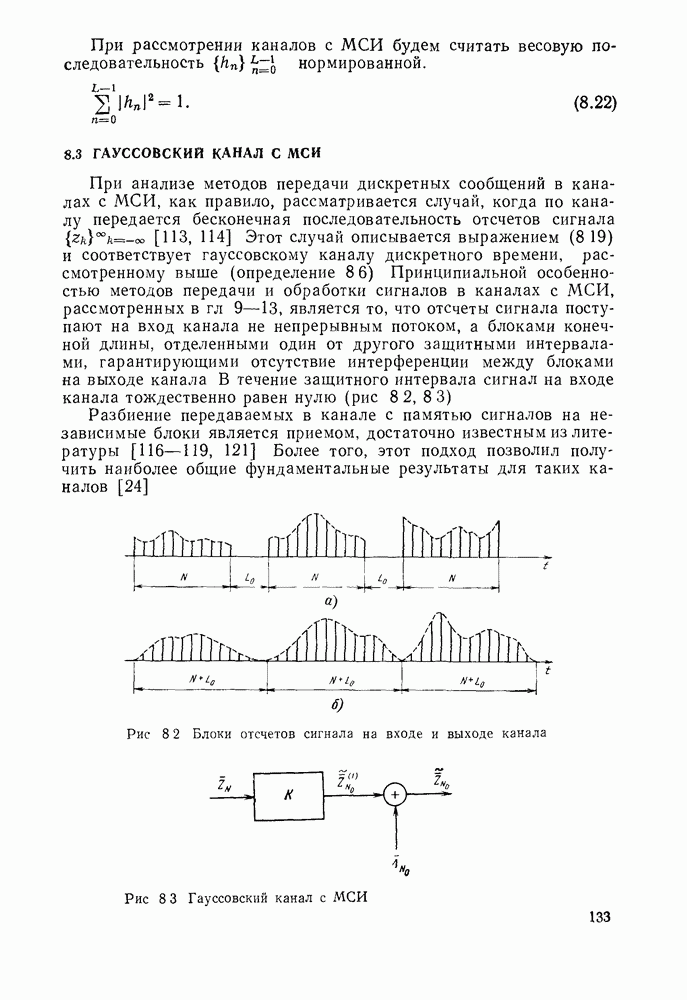
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
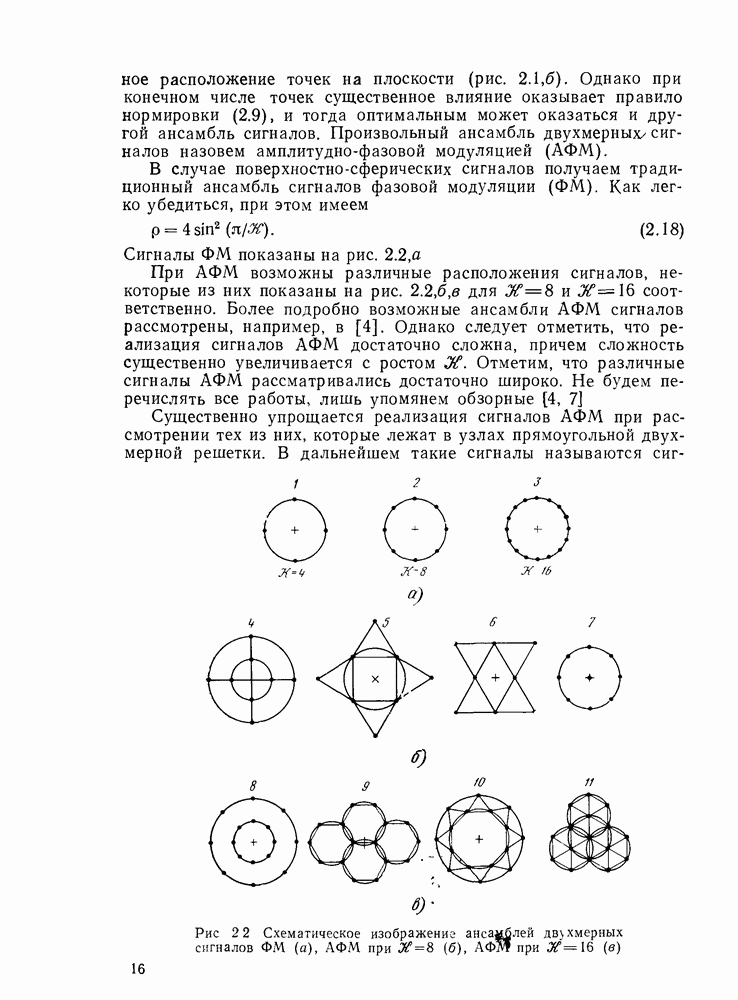
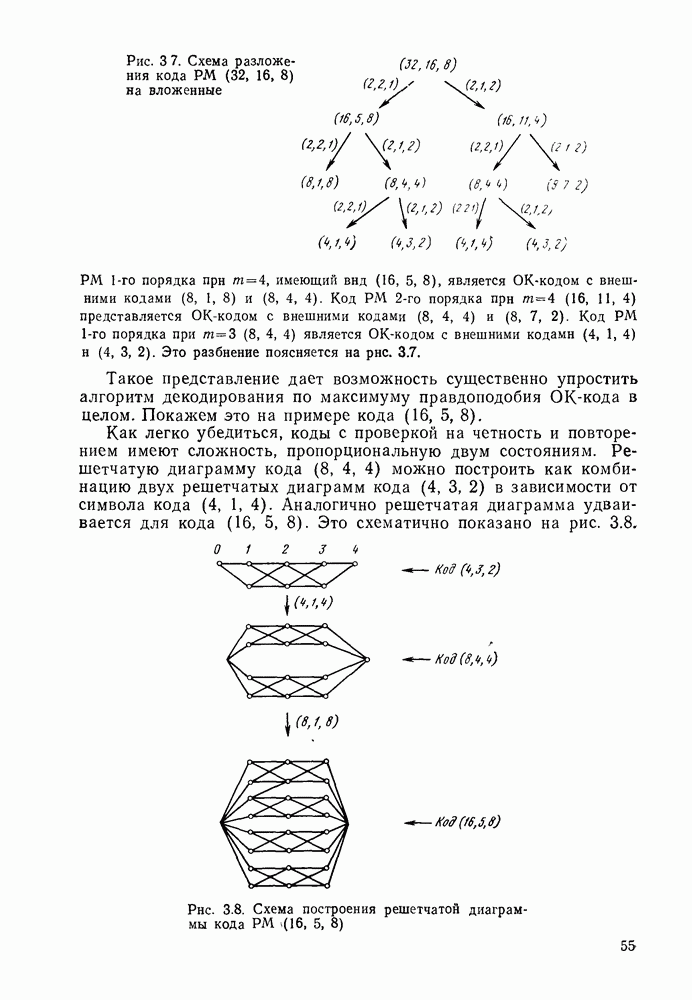
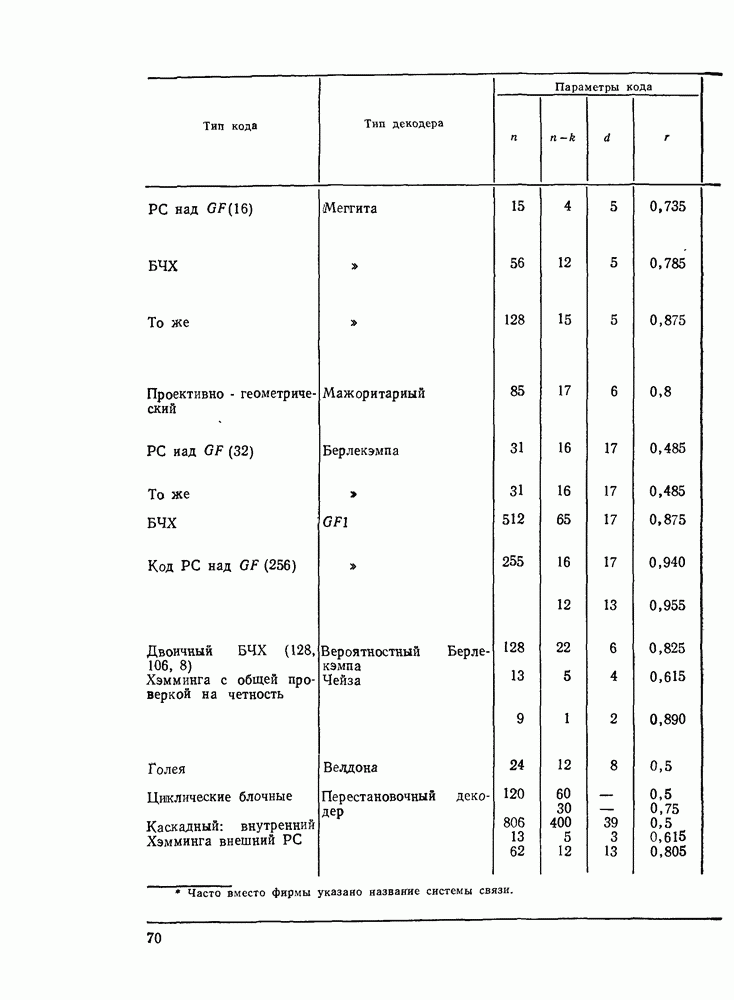
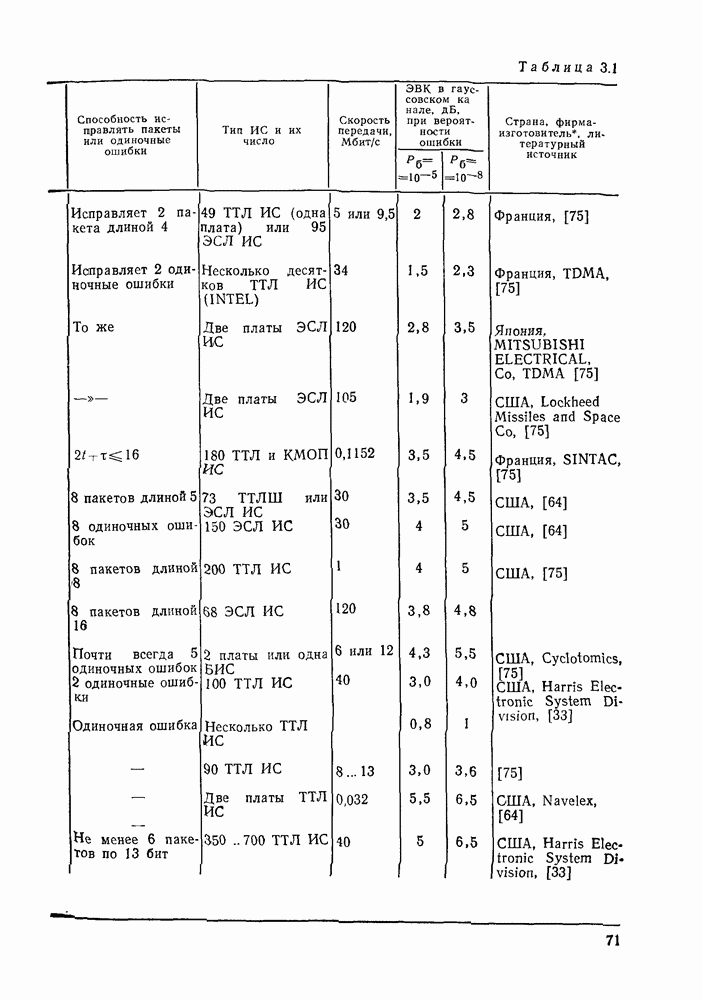
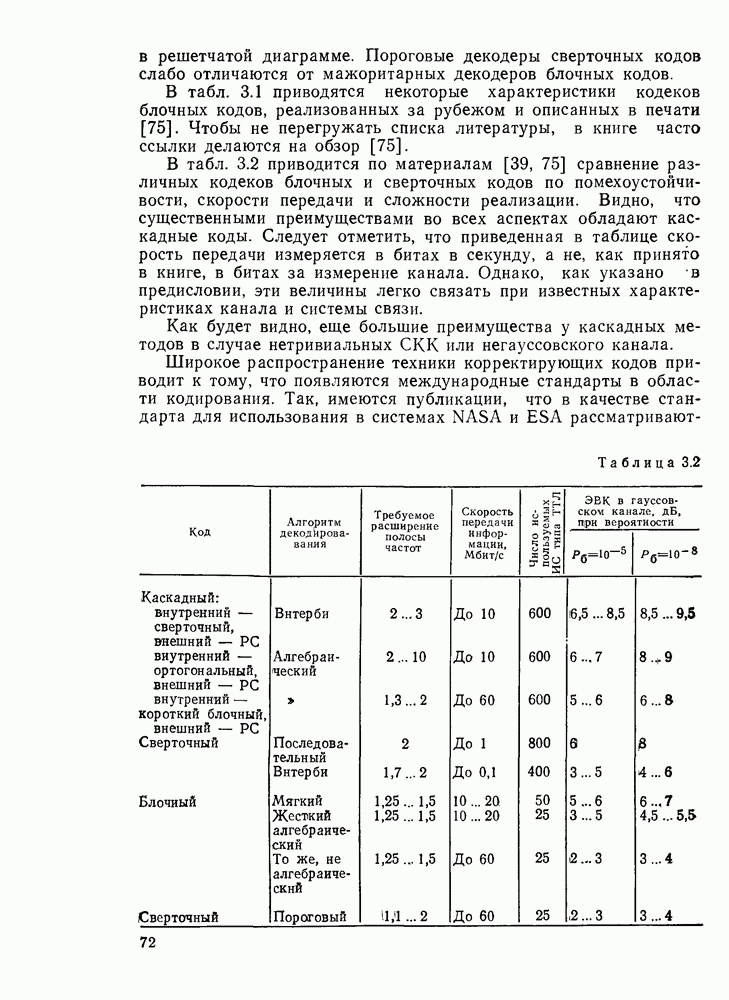
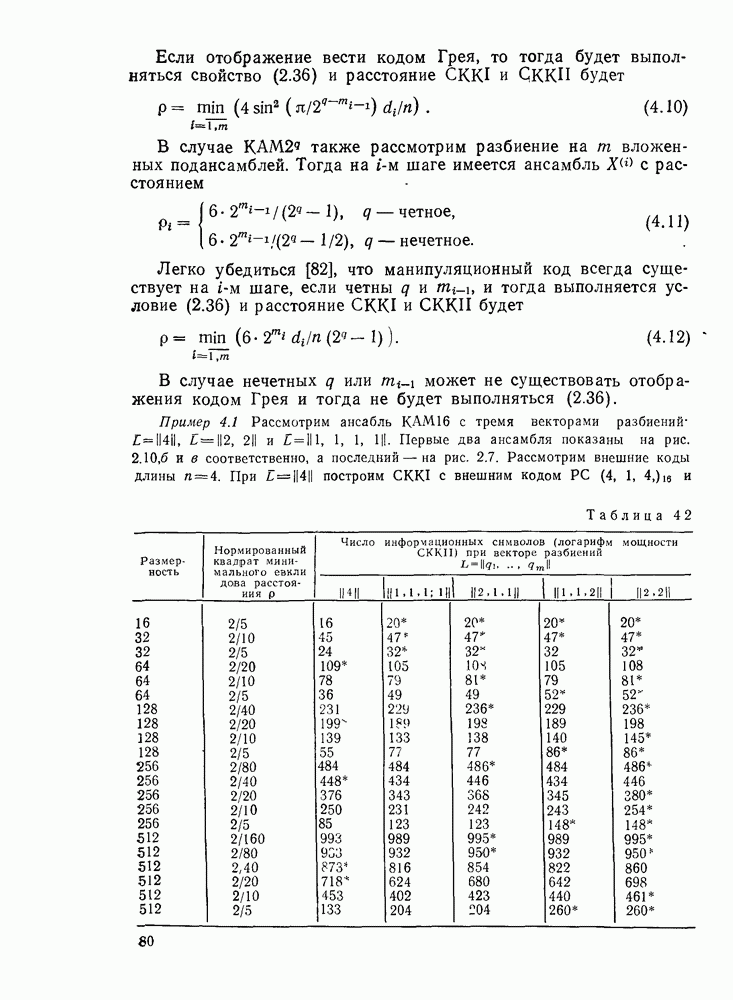
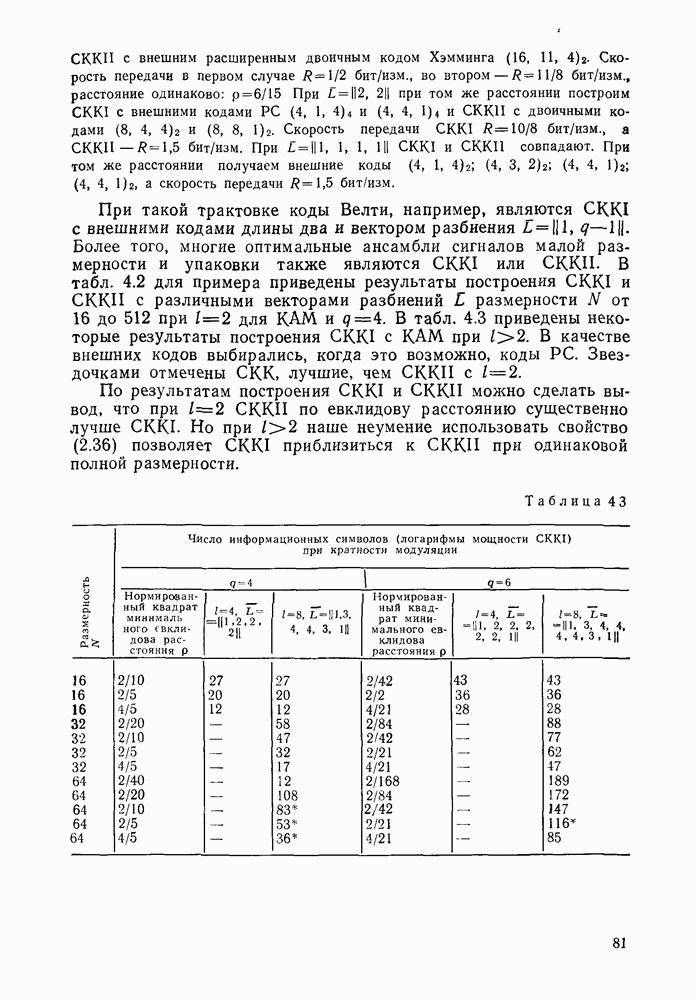
3.3. АЛГОРИТМЫ ДЕКОДИРОВАНИЯ БЛОЧНЫХ КОДОВВ данном разделе рассмотрим некоторые алгоритмы декодирования блочных кодов Пр имер невероятностных алгоритмов — декодирование только по расстоянию. Основное множество алгоритмов занимает промежуточное положение между этими двумя классами алгоритмов и является в некоторой мере и вероятностным, и невероятностным. Декодер Меггита. Предназначен для декодирования произвольного циклического или укороченного циклического кода. Сложность декодера лавинообразно возрастает с числом исправляемых ошибок, поэтому применяется для исправления небольшого числа ошибок (не более трех). Распознавание комбинаций ошибок осуществляется с помощью синдрома
Из (3.6) следует, что множество комбинаций ошибок можно разбить на непересекающиеся подмножества, в каждом из которых содержатся циклические сдвиги одной и той же комбинации. Тогда число запоминаемых комбинаций должно быть равно числу подмножеств. Алгоритм состоит из Перестановочное декодирование. Основы этого алгоритма были описаны в [42], более подробно он рассмотрен в [33]. Определение 3.13. Информационным множеством линейного Пример 3.8. У кода РС любое множество Общий алгоритм перестановочного декодирования выглядит следующим образом: 1. Выбираем несколько 2. Для каждого из 3. Сравниваем каждое полученное кодовое слово с принятой последовательностью. Выбираем ближайшее кодовое слово в качестве декодированного или отказываемся от декодирования. В данной модификации слово будет декодировано верно, если не содержит ошибок хотя бы в одном информационном множестве. Возможны и другие подходы к перестановочному декодированию, когда выбираются не информационные множества, а соответствующие им синдромы. В этом случае комбинация ошибок исправляется, если удается найти проверочное множество, целиком покрывающее данную комбинацию. Эти покрывающие множества могут выбираться как заранее с помощью комбинаторных соотношений, так и случайно [33]. Число покрывающих множество «при исправлении декодером
где Мажоритарное декодирование. Этот вид декодирования применим к кодам определенной структуры — мажоритарным кодам (имеющим разделенные проверки). Здесь для простоты будем рассматривать только двоичные коды. Обозначим
проверки на приеме. Если проверки разделенные, то коэффициент
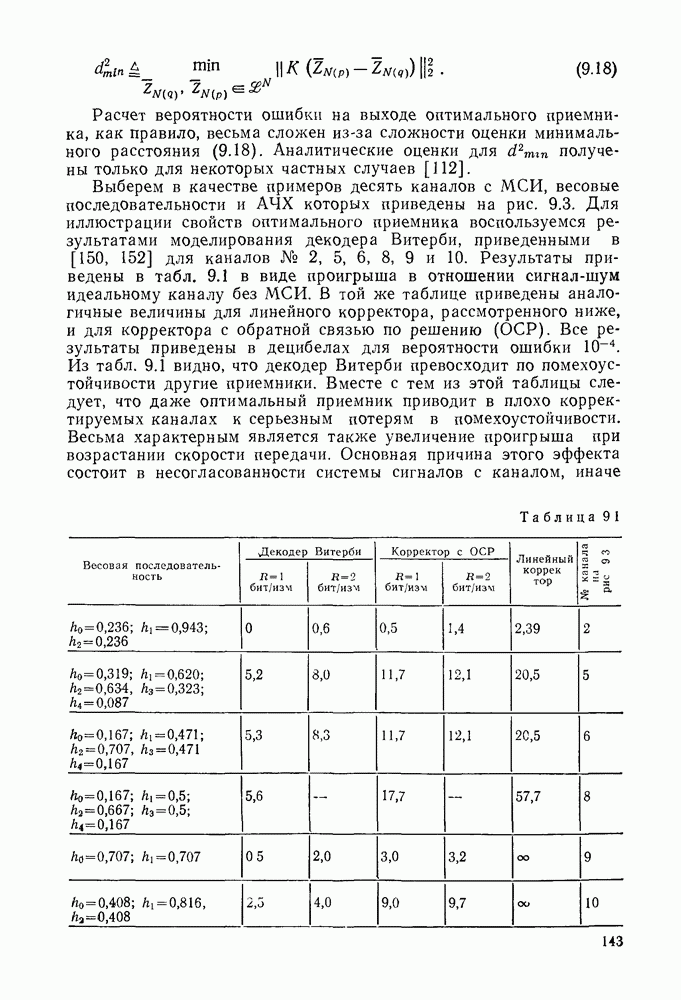
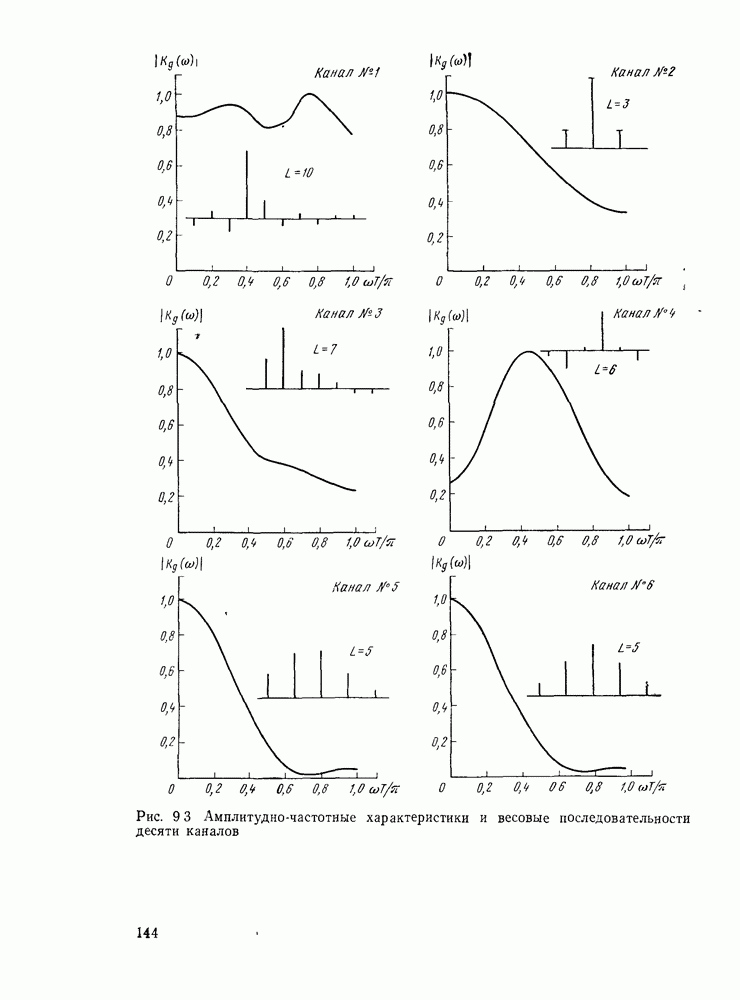
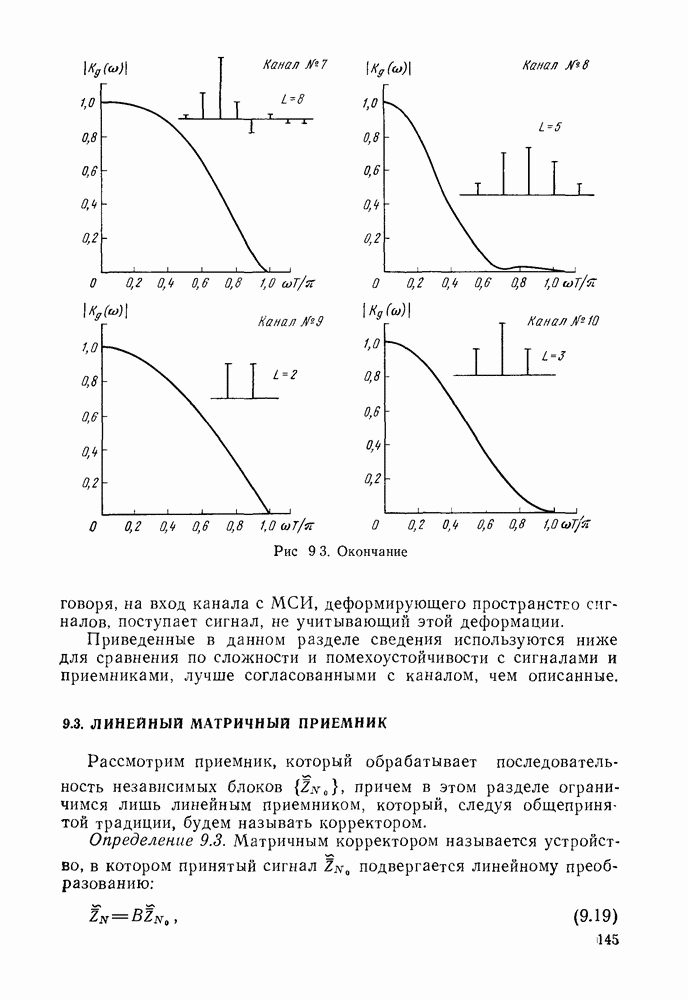
где Если у символа кодового или принятого слова двойная нумерация, то рассматриваем задание проверок в виде (3.9), а если одиночная — в виде (3.8). Запись в виде разделенных проверок позволяет легко осуществить мажоритарное декодирование. Решение о символе
Легко убедиться, что символ Для многошагового алгоритма решение относительно одного символа принимается не сразу. Сначала оно принимается относительно группы символов, а затем эти группы символов уменьшаются. На последнем шаге решение принимается относительно символа. Возможны различные модификации мажоритарного алгоритма. Например, декодированным символом можно заменять символ, принятый из канала. Кроме того, можно осуществлять повторное декодирование. Для двоичных мажоритарных кодов на основе проективной плоскости из примера Долю неисправимых комбинаций ошибок веса
Аналогичные доли для некоторых других мажоритарных кодов приведены в [45]. Мажоритарное декодирование легко осуществить и с использованием мягкого решения [46, 47]. В этом случае получается пороговое декодирование по максимуму правдоподобия проверок. Алгоритм состоит в следующем:
где
где Возможны упрощенные варианты решающего правила (3.12), когда в качестве веса вместо Алгоритм Велдона. Данный, алгоритм предназначен для использования (частичного) мягкого решения. Получается несколько оценок каждого переданного символа, каждая из которых берется с весом, соответствующим ее надежности, и вычисляется некоторая решающая функция [48]. Характеристики алгоритма декодирования не очень хороши, однако его преимуществом является использование жестких декодеров. Алгоритмы Чейза. Эти алгоритмы представляют собой способ приближения к решению по максимуму правдоподобия. Аналогично алгоритму Велдона используют многократные жесткие декодирования. В первоначальной работе Чейза [49] рассмотрены три основных алгоритма, хотя возможны и другие. Основная процедура такова: 1. Получаем вектор жестких решений а. 2. Намеренно вводим различные комбинации ошибок 3. Выбираем в качестве результата декодирования ближайшее слово к принятому. Три предложенных Чейзом варианта отличаются методом порождения «пробных» последовательностей. Метод 1. Выбираем нулевую последовательность ошибок и все комбинации ошибок веса Метод 2. Выбираем Метод 3. Находим Метод 1 имеет наибольшее число «пробных» последовательностей и наилучшие характеристики. Далее в обратной последовательности расположены методы 2 и 3 Алгоритм декодирования по минимуму обобщенного расстояния. Указанный алгоритм непосредственно связан с третьим алгоритмом Чейза и состоит в следующем Находим Алгебраические алгоритмы декодирования. Эти алгоритмы основаны на операциях в конечных полях и в основном касаются кодов БЧХ Здесь весьма коротко остановимся на основных особенностях алгоритмов Нам понадобится дискретное преобразование Фурье вектора а над конечным полем Утверждение 3.5 Пусть
где Задание корней многочлена в одной области эквивалентно выбору нулевыми соответствующих компонентов вектора в другой. Для любого слова примитивного кода Существует ряд методов алгебраического декодирования кодов БЧХ Все они связаны либо с исправлением только ошибок, либо с исправлениями ошибок и стираний, причем возможны декодирования как во временной, так и в частотной областях Для декодирования в частотной области вычисляется преобразование Фурье
Так как преобразование
где
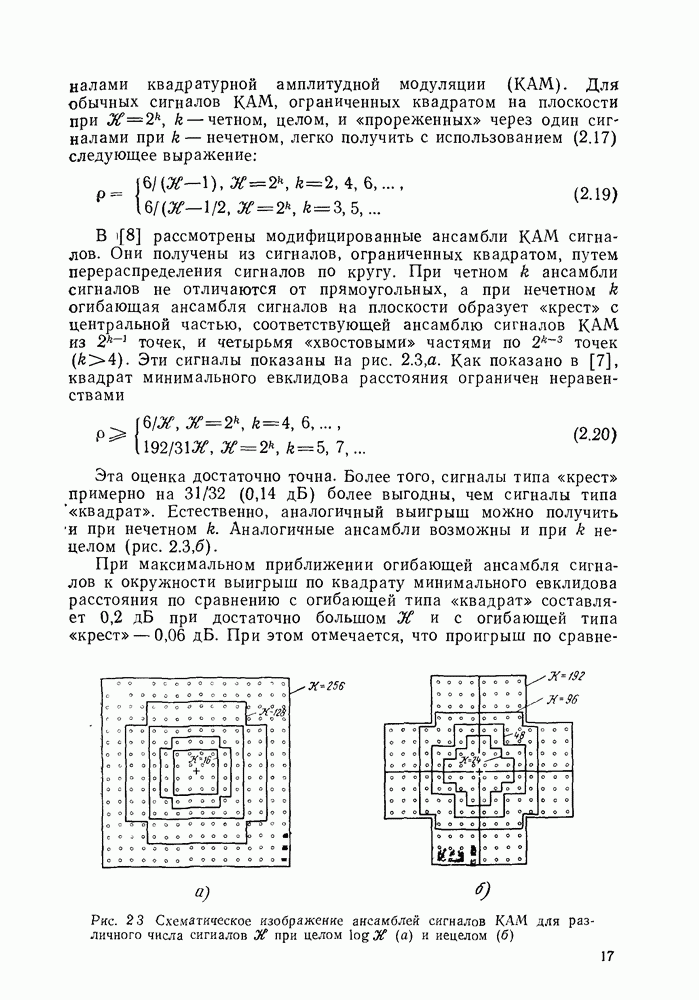
Из (3.17) можно получить Выбор схемы решения ключевого уравнения — основной этап построения декодера [33]. Наиболее употребимыми здесь являются алгоритмы Евклида (прямой) и Берлекэмпа (итеративный). Декодирование во временной области, хотя и было известно раньше и употребляется пока более широко, очень напоминает декодирование в частотной области, поэтому на нем не будем останавливаться [33]. Декодирование стираний существенно усложняет процедуру. Вводят многочлен локаторов стираний
который вычисляется по известным местам стираний. После этого вычисляют синдромы и новое ключевое уравнение, которое решается при определенных ограничениях относительно стираний. После решения ключевого уравнения получают общий многочлен локаторов ошибок и стираний и многочлен значений ошибок, при нахождении коэффициентов которых завершается декодирование. Алгоритмы декодирования по максимуму правдоподобия. Наиболее естественным алгоритмом по максимуму правдоподобия является корреляционное декодирование. При этом алгоритме для каждого входного символа вычисляются функции правдоподобия
где декодированного слова выбирается слово с номером Легко понять, что сложность этого алгоритма пропорциональна числу кодовых слов кода (экспонента от числа информационных символов линейного систематического кода). В случае Для линейных кодов возможен алгоритм, сложность которого экспоненциально зависит от числа не информационных символов, а проверочных. Это алгоритм декодирования Витерби [39], который для блочных кодов был впервые получен Вульфом [51]. Для задания алгоритма нам понадобятся следующие определения. Определение 3.1.4. Для любого принятого вектора а частичным синдромом называется вектор
где Справедлива итеративная формула
где Определение 3.15. Решетчатой диаграммой линейного блочного кода А будем называть направленный вправо граф, узлы которого состоят из Ребра соединяют только узлы Легко понять, что решетчатая диаграмма дает достаточно компактное представление кодовых слов. Каждый путь по решетке из нулевого узла в Алгоритм декодирования состоит из
Рис. 3.2 Примерный вид решетчатой диаграммы двоичного линейного кода наиболее правдоподобных префиксов длины Можно убедиться, что алгоритм требует не более Пример 3.9 Рассмотрим канал с двумя входами и четырьмя выходами (рис 3 3, а) Пусть передача по такому каналу осуществляется кодом с провер кой на четность ( При декодировании по Витерби в соответствии с решетчатой диаграммой, изображенной на рис 3 3,6, на шаге 1 для узла 0 запоминаем путь 0 с метрикой 0,75, для узла 1 запоминаем путь 1 с метрикой 0,02 На шаге 2 выбирается
Рис. 3.3 Пример канала с двумя входами и четырьмя выходами (а) и решетчатой диаграммы кода в узле 0 путь 00 с метрикой 0,06, а в узле 1 — путь В заключение отметим, что, как и в случае сверточных кодов [39], сложность алгоритма Витерби очень мало зависит от того, какой канал используется при декодировании: с мягким или жестким решением.
|
 |
Оглавление
|









































































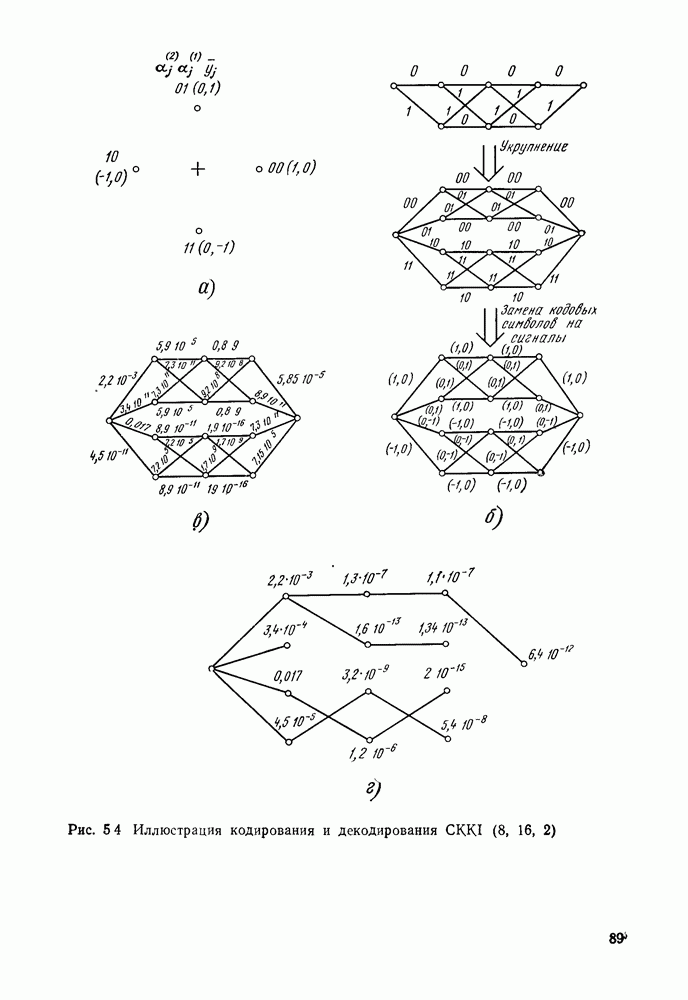























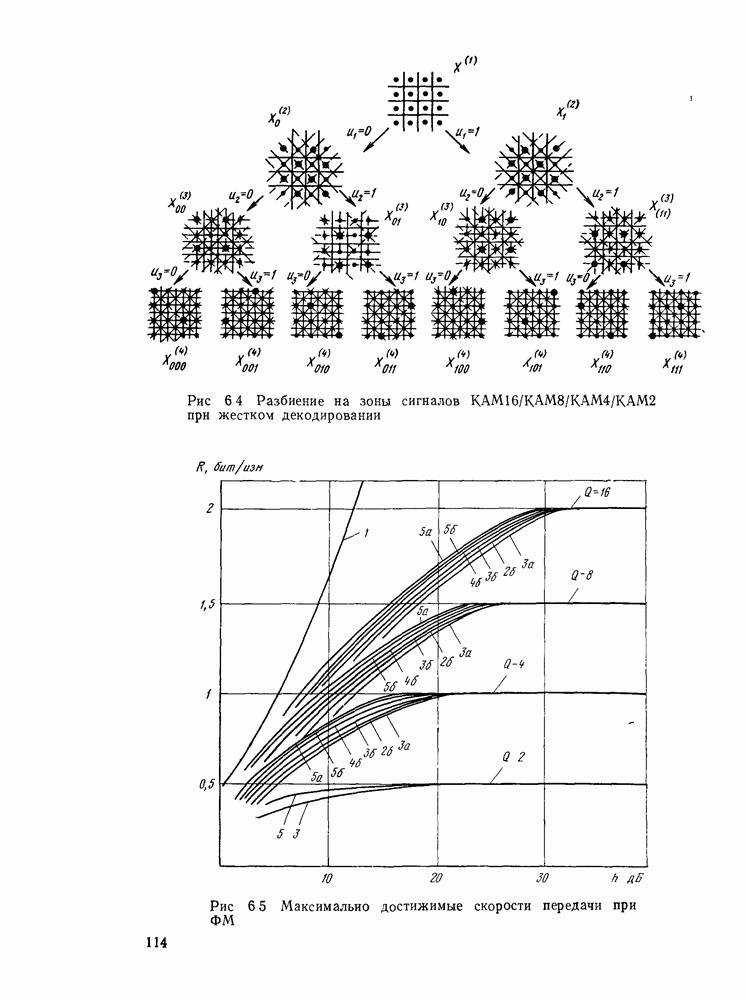
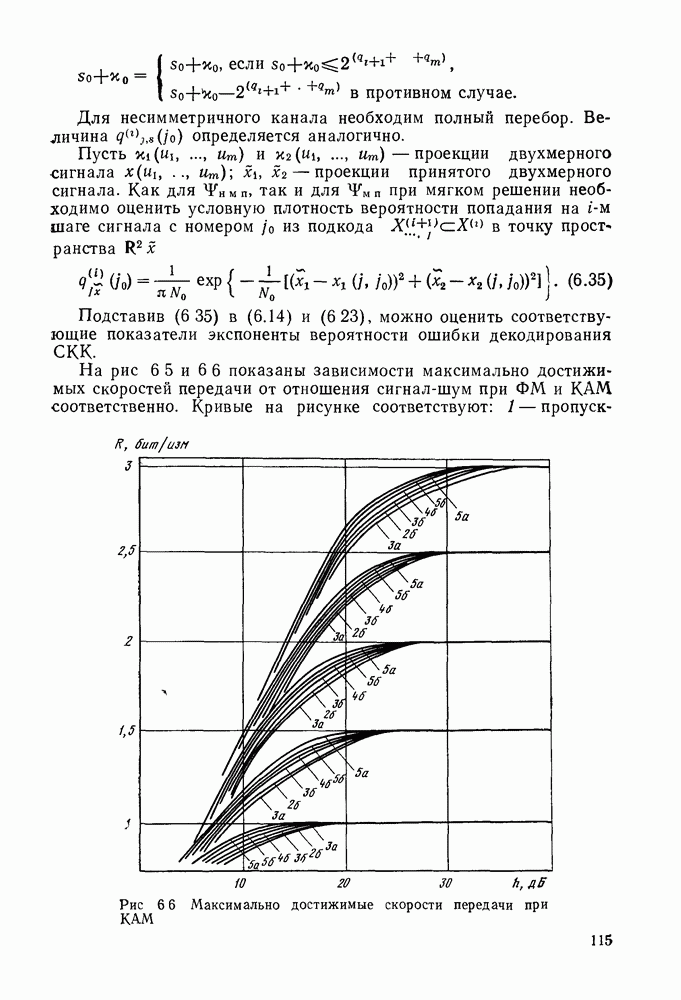
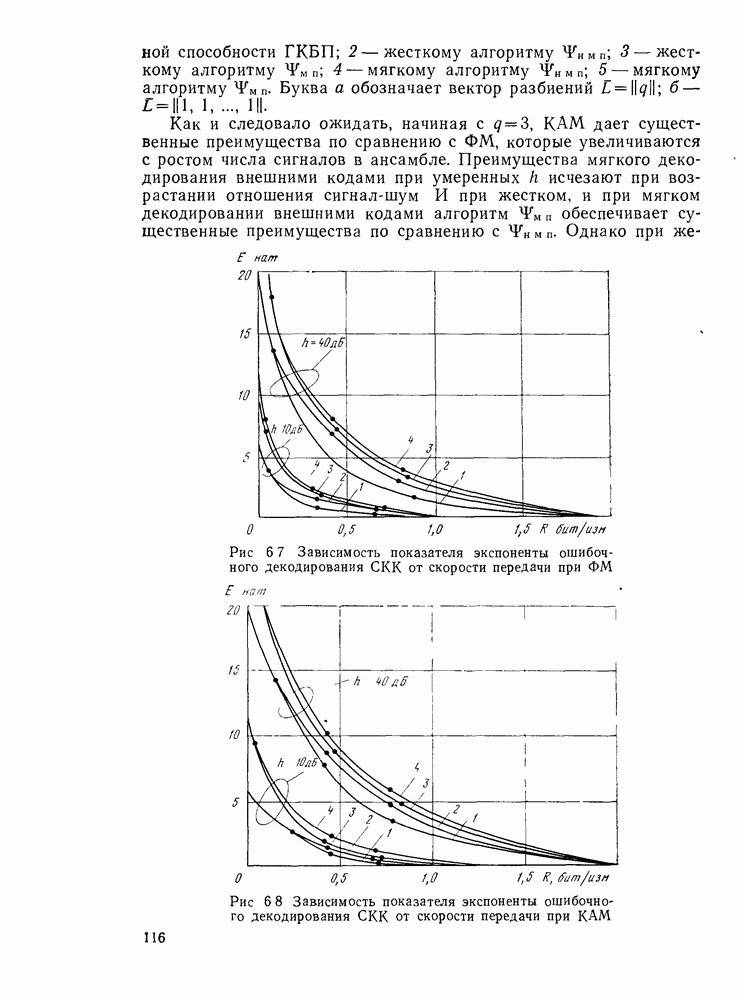

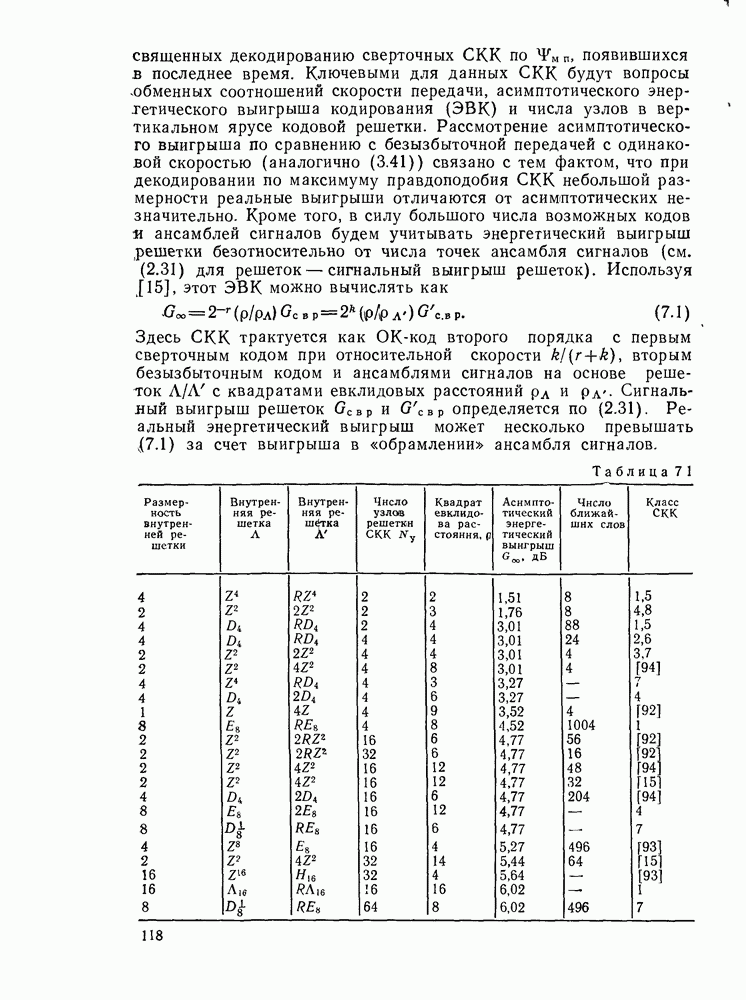



































































































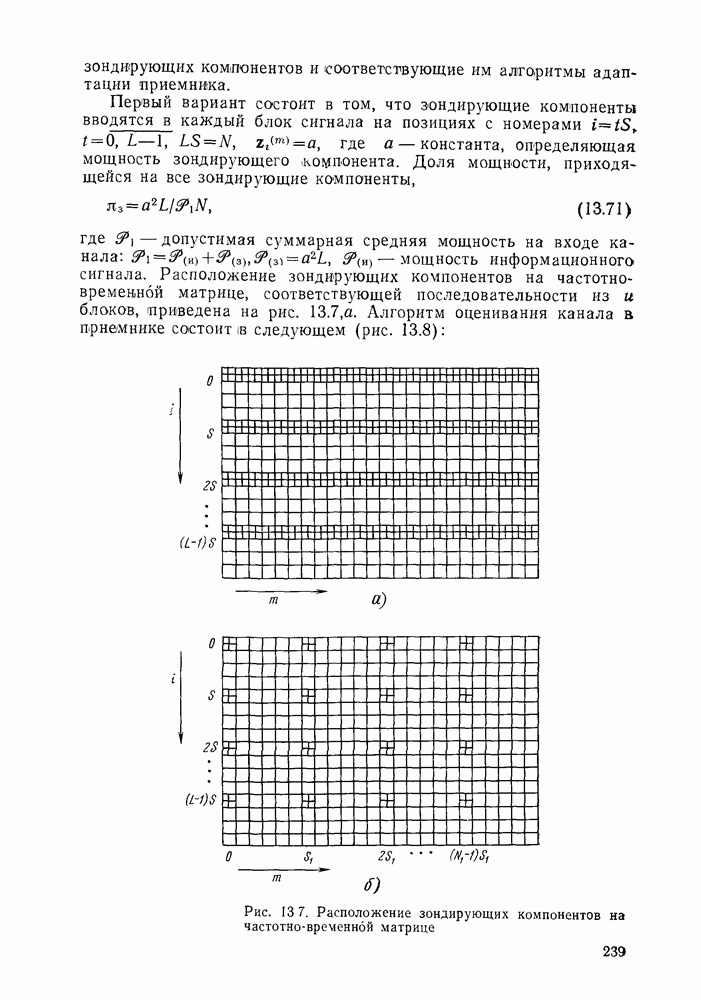

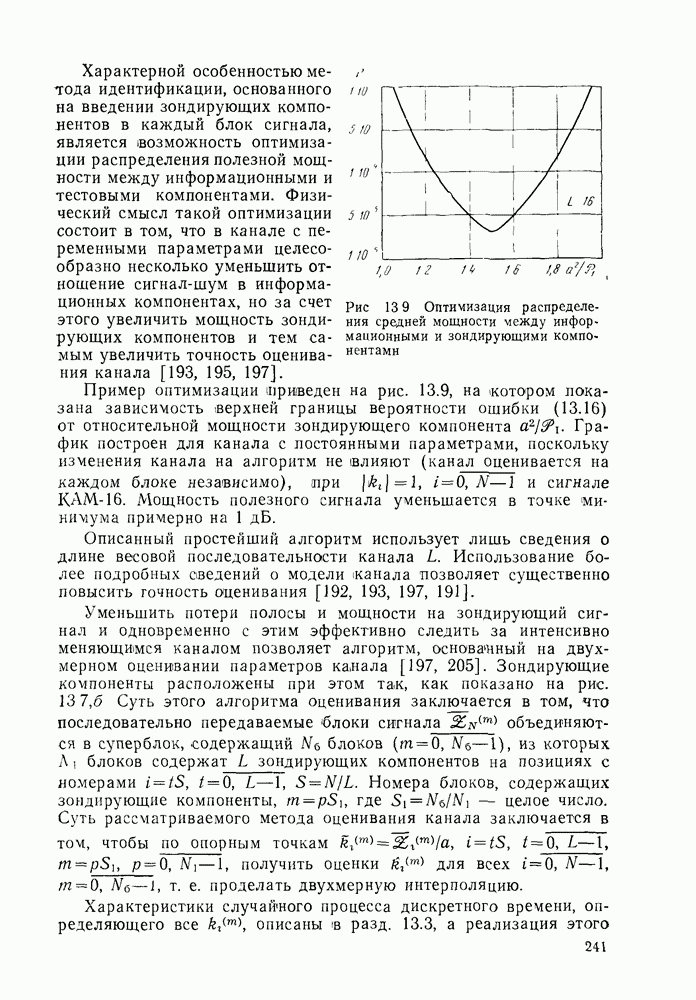



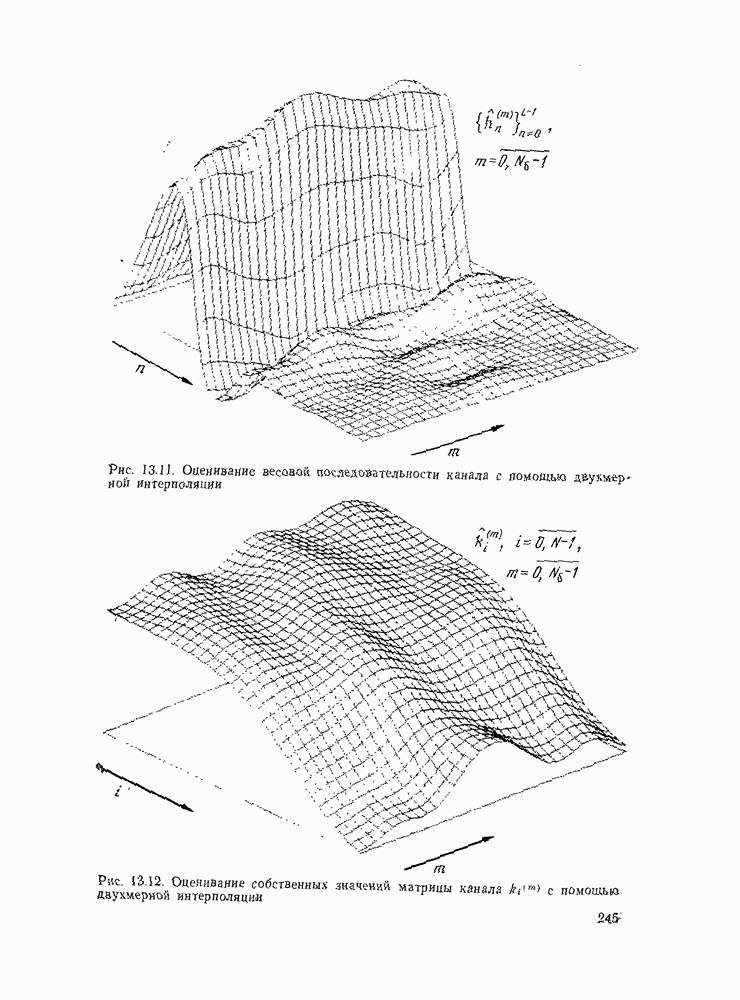
















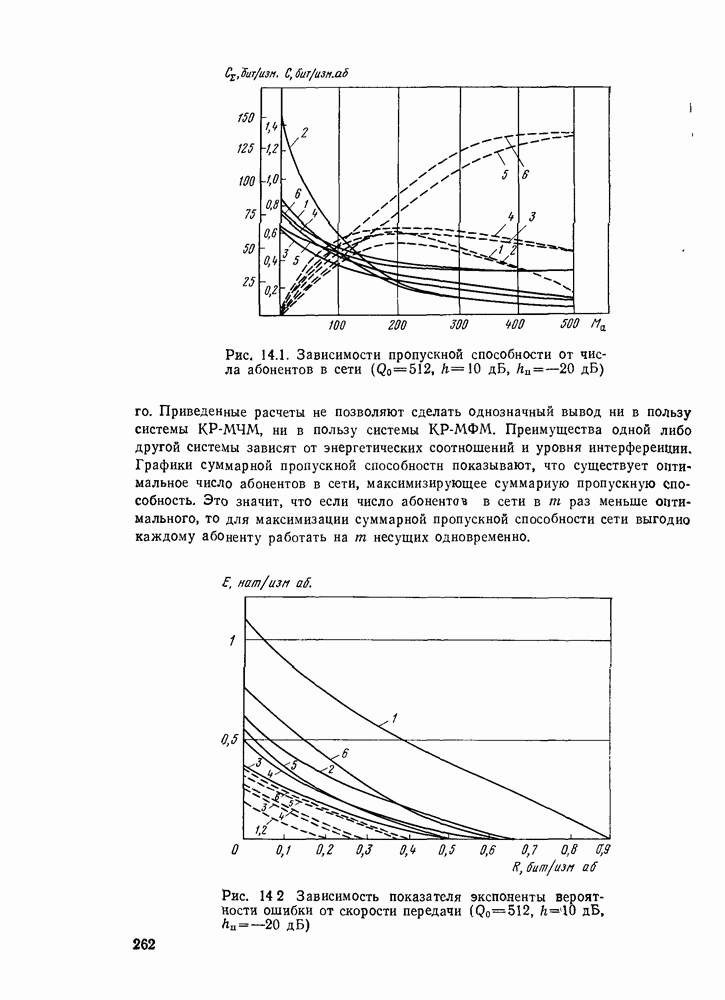






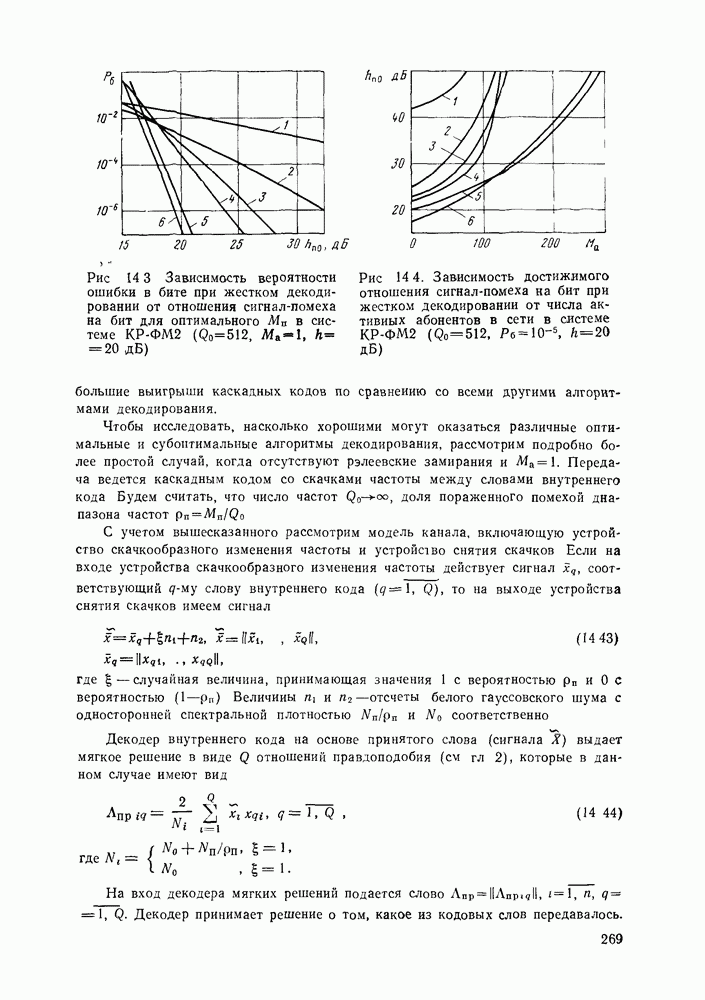















 позволяющие получить либо предполагаемое передаваемое слово, либо соответствующий информационный вектор. Как указывалось, алгоритмы декодирования могут быть вероятностными и невероятностными, полными и по расстоянию. Оптимальными алгоритмами для каналов без памяти являются алгоритмы, минимизирующие вероятность ошибки в кодовом слове
позволяющие получить либо предполагаемое передаваемое слово, либо соответствующий информационный вектор. Как указывалось, алгоритмы декодирования могут быть вероятностными и невероятностными, полными и по расстоянию. Оптимальными алгоритмами для каналов без памяти являются алгоритмы, минимизирующие вероятность ошибки в кодовом слове  либо в одном информационном двоичном символе (бите)
либо в одном информационном двоичном символе (бите)  Легко показать, что эти алгоритмы сводятся к алгоритмам, максимизирующим метрику правдоподобия кодового слова
Легко показать, что эти алгоритмы сводятся к алгоритмам, максимизирующим метрику правдоподобия кодового слова  т. е. в качестве декодированного слова
т. е. в качестве декодированного слова  выбирается то из всех кодовых слов
выбирается то из всех кодовых слов  которое максимизирует указанную метрику (это, естественно, пример вероятностного алгоритма).
которое максимизирует указанную метрику (это, естественно, пример вероятностного алгоритма).
 Алгоритм декодирования использует тот факт, что существует взаимно однозначное соответствие между всеми векторами ошибок, которые код может исправить, и значениями синдрома. Кроме того, существует очень простая связь между синдромом некоторого слова
Алгоритм декодирования использует тот факт, что существует взаимно однозначное соответствие между всеми векторами ошибок, которые код может исправить, и значениями синдрома. Кроме того, существует очень простая связь между синдромом некоторого слова  (в виде полинома от х) и синдромом его циклического сдвига
(в виде полинома от х) и синдромом его циклического сдвига 

 шагов (сдвигов), и на каждом шаге реальный синдром сверяется с записанным для каждого подмножества. В случае совпадения данная ошибка исправляется [41].
шагов (сдвигов), и на каждом шаге реальный синдром сверяется с записанным для каждого подмножества. В случае совпадения данная ошибка исправляется [41].
 -кода назовем любое множество
-кода назовем любое множество  символов кодового слова, которые можно задавать независимо Остальные
символов кодового слова, которые можно задавать независимо Остальные  символов являются проверочным множеством.
символов являются проверочным множеством.
 символов является информационным.
символов является информационным.
 различных информационных множеств в соответствии с некоторым правилом.
различных информационных множеств в соответствии с некоторым правилом.
 информационных множеств строим кодовое слово, предполагая, что в данном информационном множестве не содержатся ошибки.
информационных множеств строим кодовое слово, предполагая, что в данном информационном множестве не содержатся ошибки.
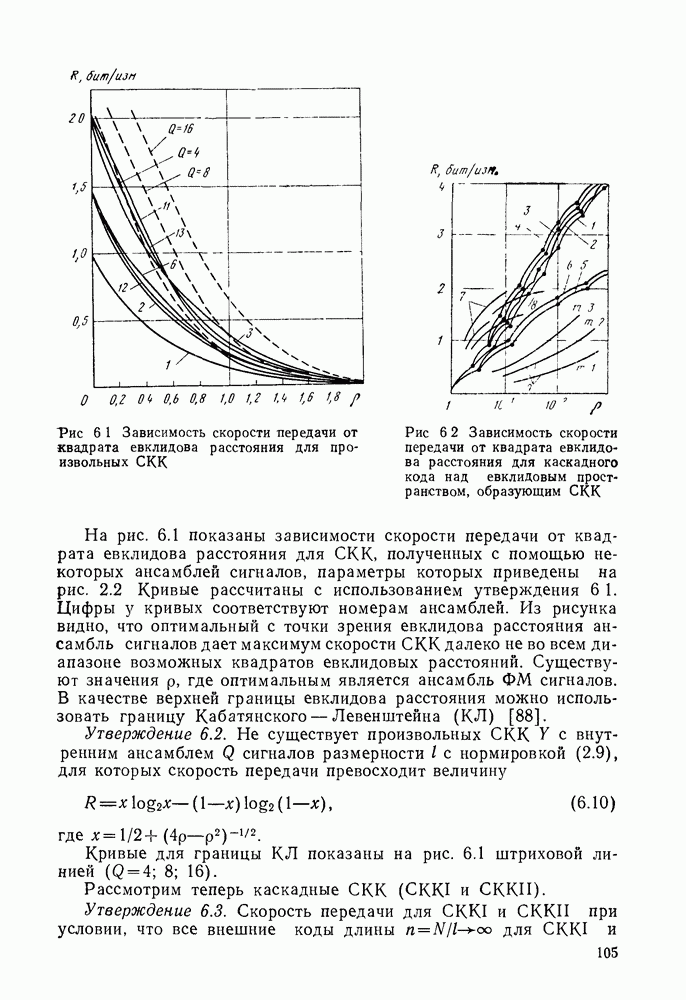
 ошибок ограничено снизу неравенством [33]
ошибок ограничено снизу неравенством [33]

 наименьшее целое, большее х.
наименьшее целое, большее х.

 при произвольном
при произвольном  равен 1 только для одного
равен 1 только для одного  для остальных
для остальных  он равен нулю. Проверки
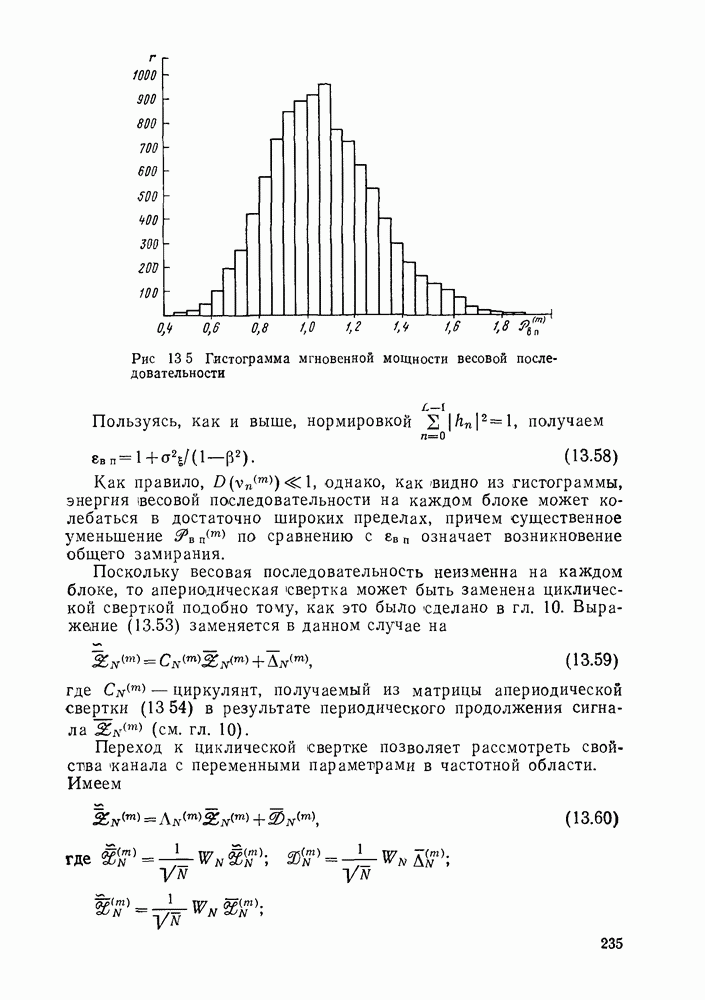
он равен нулю. Проверки  дают значения
дают значения  кодового символа. Для остальных символов проверки получаются циклическим сдвигом символа относительно коэффициентов проверок. Как правило, особенно для мажоритарных кодов, рассмотренных выше, первая проверка является тривиальной
кодового символа. Для остальных символов проверки получаются циклическим сдвигом символа относительно коэффициентов проверок. Как правило, особенно для мажоритарных кодов, рассмотренных выше, первая проверка является тривиальной  а в остальных проверках имеется
а в остальных проверках имеется  ненулевых коэффициентов. В дальнейшем будем рассматривать только такие мажоритарные коды, и для них перепишем (3.8) в виде
ненулевых коэффициентов. В дальнейшем будем рассматривать только такие мажоритарные коды, и для них перепишем (3.8) в виде

 символ
символ  проверки;
проверки; 
 принимается голосованием по большинству:
принимается голосованием по большинству:

 будет декодирован правильно, если большинство проверок правильно, а это будет, если в принятом слове не более
будет декодирован правильно, если большинство проверок правильно, а это будет, если в принятом слове не более  ошибок
ошибок  целая часть
целая часть 
 комбинация ошибок веса
комбинация ошибок веса  не будет исправлена при втором декодировании тогда и только тогда, когда прямые, проведенные в
не будет исправлена при втором декодировании тогда и только тогда, когда прямые, проведенные в  через точки, соответствующие ошибкам, образуют
через точки, соответствующие ошибкам, образуют  -дугу, т. е. никакие три точки не лежат на одной прямой [43]. Это утверждение основано на том факте, что все слова веса
-дугу, т. е. никакие три точки не лежат на одной прямой [43]. Это утверждение основано на том факте, что все слова веса  в таком коде соответствуют
в таком коде соответствуют  -дугам (овалам) [43, 44].
-дугам (овалам) [43, 44].
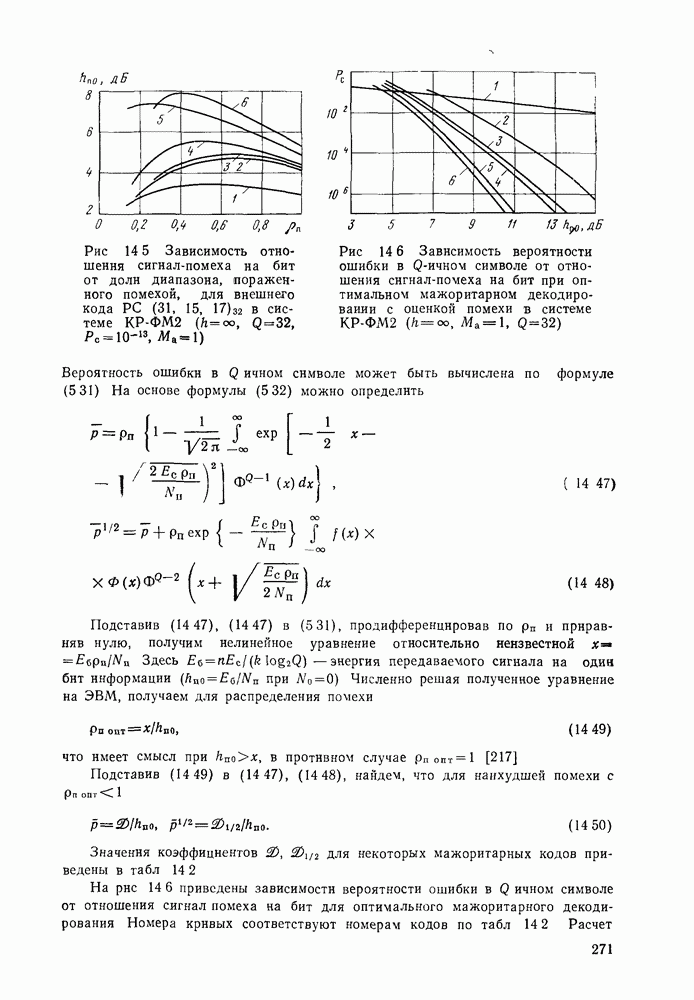
 в соответствии с [43] можно вычислить по формуле
в соответствии с [43] можно вычислить по формуле

 если
если

 — вероятность того, что ошибка в
— вероятность того, что ошибка в  проверке будет равна нулю. С использованием [47]
проверке будет равна нулю. С использованием [47]  вычисляется по формуле
вычисляется по формуле

 число символов, входящих в
число символов, входящих в  проверку;
проверку;  вероятность ошибки в
вероятность ошибки в  символе
символе  проверки.
проверки.
 берется наибольшая вероятность ошибки символа, входящего в данную проверку.
берется наибольшая вероятность ошибки символа, входящего в данную проверку.
 порождая «пробные» последовательности а
порождая «пробные» последовательности а  Декодируем каждую «пробную» последовательность жестким декодером.
Декодируем каждую «пробную» последовательность жестким декодером.

 последовательностей, имеющих всевозможные значения на
последовательностей, имеющих всевозможные значения на  достоверных позициях и нули на остальных.
достоверных позициях и нули на остальных.
 наименее достоверных символов «Пробные» последовательности имеют единицы на
наименее достоверных символов «Пробные» последовательности имеют единицы на  наименее достоверных позициях
наименее достоверных позициях  для нечетного
для нечетного  для четного
для четного  )
)
 наименее достоверных (надежных) символов и упорядочиваем их по надежности, как и в методе 3 Чейза Для
наименее достоверных (надежных) символов и упорядочиваем их по надежности, как и в методе 3 Чейза Для  «пробной» последовательности стираем
«пробной» последовательности стираем  наименее надежных символов, а далее проводим декодирование с исправлением ошибок и стираний Затем выбираем слово, ближайшее к принятому [50] Этот алгоритм далее будет описан подробнее в более общем случае
наименее надежных символов, а далее проводим декодирование с исправлением ошибок и стираний Затем выбираем слово, ближайшее к принятому [50] Этот алгоритм далее будет описан подробнее в более общем случае
 [30, 33].
[30, 33].
 последовательность
последовательность  элементов поля
элементов поля  делит
делит  для некоторого
для некоторого  и пусть
и пусть  элемент порядка
элемент порядка  Тогда вектор а и его спектр
Тогда вектор а и его спектр  связаны прямым и обратным преобразованиями Фурье
связаны прямым и обратным преобразованиями Фурье

 характеристика поля
характеристика поля 
 последовательных компонентов спектра с номерами
последовательных компонентов спектра с номерами  то
то  равны 0. Это существенно облегчает декодирование кодов БЧХ
равны 0. Это существенно облегчает декодирование кодов БЧХ
 принятого вектора а, которое выражается через преобразование Фурье переданного вектора и вектора ошибок
принятого вектора а, которое выражается через преобразование Фурье переданного вектора и вектора ошибок

 каждого кодового слова содержит
каждого кодового слова содержит  последовательных нулей, то можно получить 21 известных значений
последовательных нулей, то можно получить 21 известных значений  которые обычно называют синдромами. Если число ошибок то многочлен локаторов ошибок
которые обычно называют синдромами. Если число ошибок то многочлен локаторов ошибок

 соответствуют положениям ошибок. Тогда можно получить систему уравнений, которая называется ключевым уравнением:
соответствуют положениям ошибок. Тогда можно получить систему уравнений, которая называется ключевым уравнением:

 уравнений для
уравнений для  неизвестных коэффициентов. Эти уравнения являются линейными, и решать их можно с помощью обычной техники обращения матриц или итеративно. После нахождения многочлена
неизвестных коэффициентов. Эти уравнения являются линейными, и решать их можно с помощью обычной техники обращения матриц или итеративно. После нахождения многочлена  можно определить неизвестные компоненты
можно определить неизвестные компоненты  Затем, применив обратное преобразование Фурье, можно найти вектор ошибок.
Затем, применив обратное преобразование Фурье, можно найти вектор ошибок.

 , а затем функции правдоподобия для каждого из
, а затем функции правдоподобия для каждого из  возможных кодовых слов
возможных кодовых слов

 символ
символ  кодового слова. Далее в качестве
кодового слова. Далее в качестве
 имеющее максимальный коэффициент
имеющее максимальный коэффициент 
 -ичного кода алгоритм декодирования практически не меняется.
-ичного кода алгоритм декодирования практически не меняется.

 префикс принятого слова длины
префикс принятого слова длины  -матрица, состоящая из первых
-матрица, состоящая из первых  столбцов проверочной матрицы
столбцов проверочной матрицы 

 столбец проверочной матрицы
столбец проверочной матрицы 
 вертикальных ярусов и
вертикальных ярусов и  горизонтальных ярусов. Узел
горизонтальных ярусов. Узел  вертикального яруса и
вертикального яруса и  горизонтального яруса метится величиной
горизонтального яруса метится величиной 
 вертикальных ярусов. Каждое ребро метится символом
вертикальных ярусов. Каждое ребро метится символом  и соединяет узлы с номерами
и соединяет узлы с номерами  связанные по (3.20). Символы, выбираемые на ребрах, соответствуют словам кода А.
связанные по (3.20). Символы, выбираемые на ребрах, соответствуют словам кода А.
 соответствует кодовому слову. Число узлов сначала повышается, а затем через некоторое число узлов начинает уменьшаться. Примерный вид решетчатой диаграммы для двоичного кода показан на рис. 3.2. Отметим также, что если пути расходятся в
соответствует кодовому слову. Число узлов сначала повышается, а затем через некоторое число узлов начинает уменьшаться. Примерный вид решетчатой диаграммы для двоичного кода показан на рис. 3.2. Отметим также, что если пути расходятся в  узле, то это значит, что у соответствующих кодовых слов одинаковы префиксы, а если сходятся — суффиксы
узле, то это значит, что у соответствующих кодовых слов одинаковы префиксы, а если сходятся — суффиксы
 шагов. Входными величинами для
шагов. Входными величинами для  шага являются значения
шага являются значения 

 соответствующих узлу с номером
соответствующих узлу с номером  соответствующие этим путям частичные метрики правдоподобия
соответствующие этим путям частичные метрики правдоподобия  и метрики правдоподобия для
и метрики правдоподобия для  символа На
символа На  шаге для каждого из
шаге для каждого из  узлов устанавливаются
узлов устанавливаются  возможных путей, ведущих в этот узел, и определяются соответствующие им частичные метрики правдоподобия В качестве наиболее правдоподобного остается путь с максимальной метрикой На
возможных путей, ведущих в этот узел, и определяются соответствующие им частичные метрики правдоподобия В качестве наиболее правдоподобного остается путь с максимальной метрикой На  шаге остается один наиболее правдоподобный путь
шаге остается один наиболее правдоподобный путь
 умножений и
умножений и  сравнений Для осуществления декодирования необходимо иметь решетчатую диаграмму, у которой каждое ребро помечено кодовым символом
сравнений Для осуществления декодирования необходимо иметь решетчатую диаграмму, у которой каждое ребро помечено кодовым символом  и переходной вероятностью
и переходной вероятностью 
 Предположим, что передавалось слово (0, 0, 0), а принято
Предположим, что передавалось слово (0, 0, 0), а принято  произошла одиночная жесткая ошибка во втором символе, правильные символы находятся в «надежной» зоне а неправильный — и «нрнадежной» При корреляционном декодировании для всех слов кода
произошла одиночная жесткая ошибка во втором символе, правильные символы находятся в «надежной» зоне а неправильный — и «нрнадежной» При корреляционном декодировании для всех слов кода  вычисляем функции правдоподобия
вычисляем функции правдоподобия  Следовательно, в качестве декодированного выбирается переданное слово (0, 0, 0)
Следовательно, в качестве декодированного выбирается переданное слово (0, 0, 0)

 (б)
(б)
 с метрикой 0,1125 На шаге 3 выбирается путь 000 с метрикой 0,045
с метрикой 0,1125 На шаге 3 выбирается путь 000 с метрикой 0,045