Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
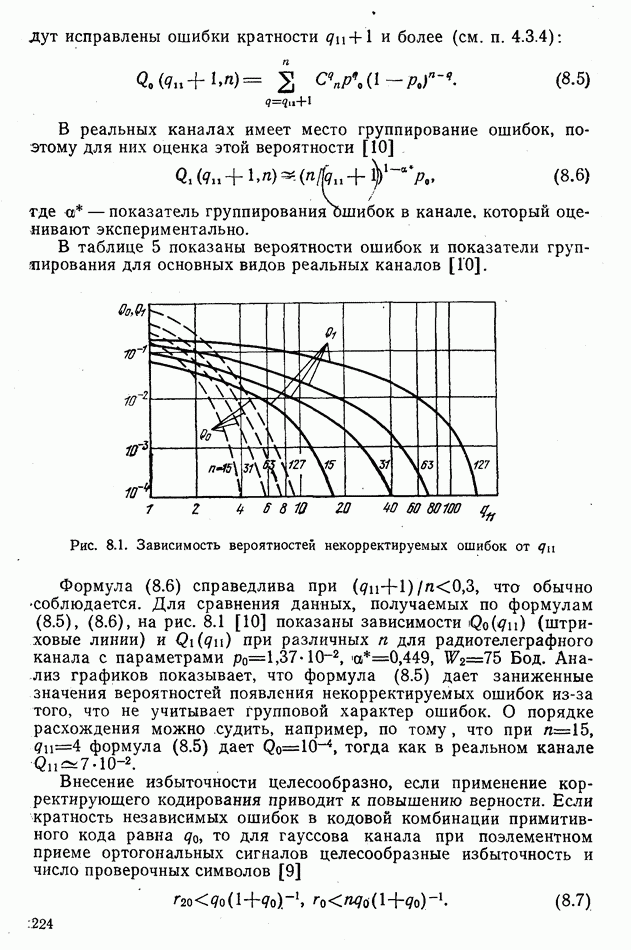
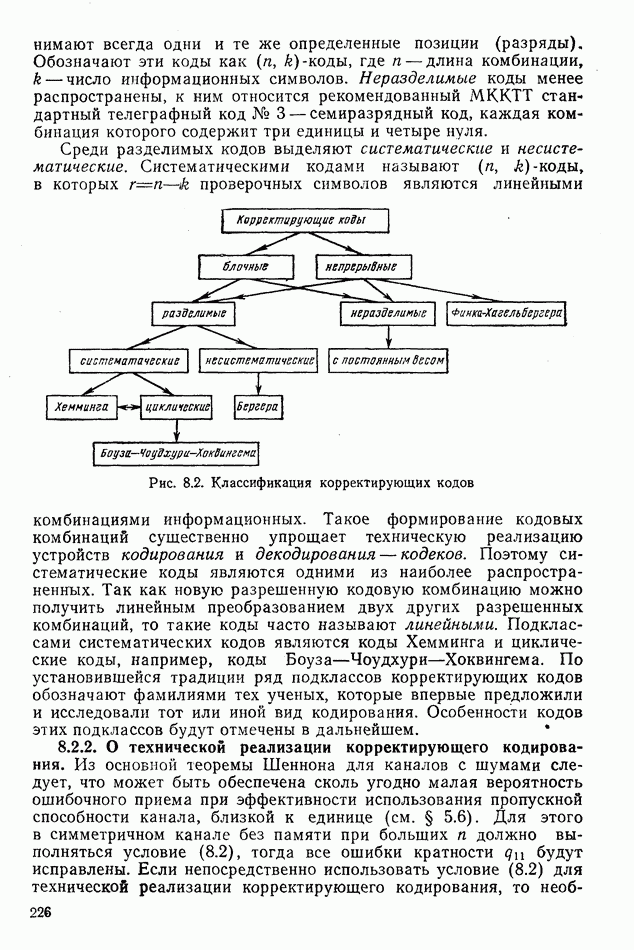
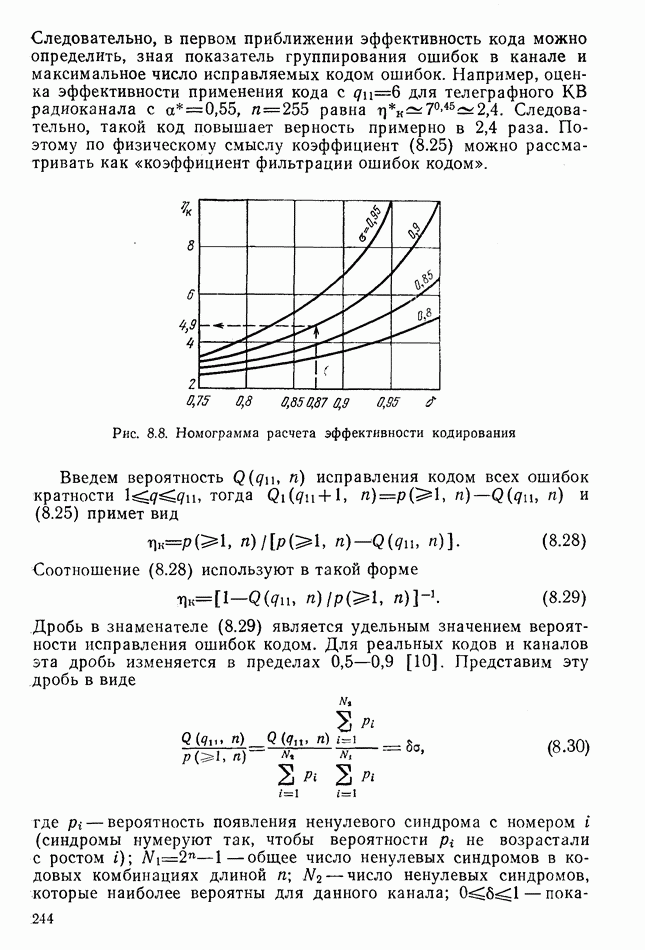
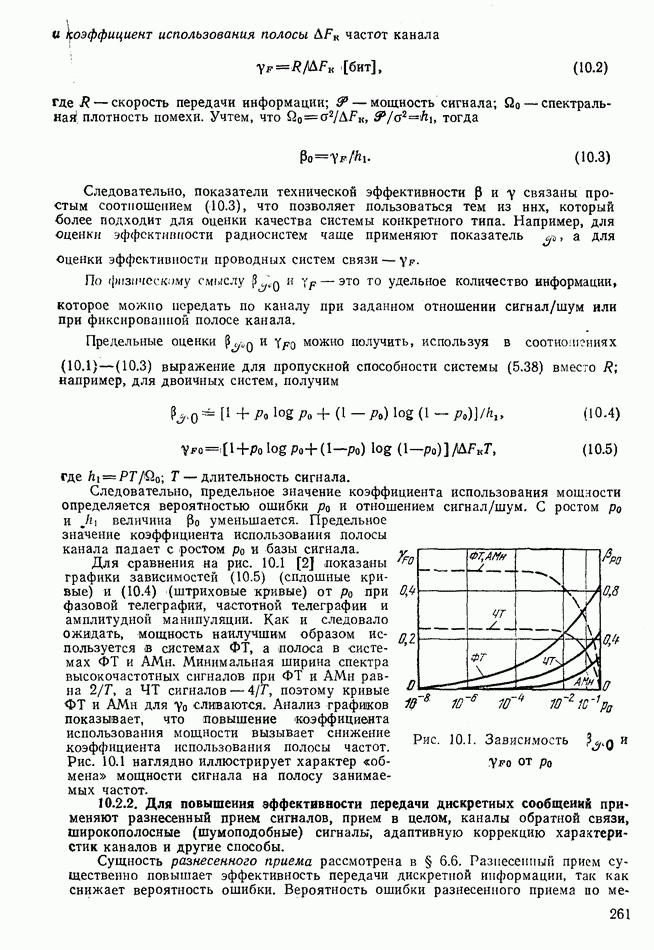
8.2. ПРИНЦИПЫ ПОСТРОЕНИЯ КОРРЕКТИРУЮЩИХ КОДОВ8.2.1. Классификация корректирующих кодов. Для коррекции ошибок нераврюмерные коды почти не применяют, поэтому в дальнейшем рассматриваются только равномерные корректирующие коды. Их общая классификация приведена на рис. 8.2. Корректирующие коды делятся на два больших класса: блочные и непрерывные. Кодовая последовательность блочных кодов состоит из отдельных кодовых комбинаций (блоков), которые кодируются и декодируются независимо. Непрерывные коды представляют непрерывную последовательность кодовых символов, ее разделение на отдельные кодовые комбинации не производится. Блочные и непрерывные коды бывают разделимые и неразделимые. В разделимых блочных кодах информационные и проверочные символы занимают всегда одни и те же определенные позиции (разряды). Обозначают эти коды как Среди разделимых кодов выделяют систематические и несистематические. Систематическими кодами называют
Рис. 8.2. Классификация корректирующих кодов Такое формирование кодовых комбинаций существенно упрощает техническую реализацию устройств кодирования и декодирования — кодеков. Поэтому систематические коды являются одними из наиболее распространенных. Так как новую разрешенную кодовую комбинацию можно получить линейным преобразованием двух других разрешенных комбинаций, то такие коды часто называют линейными. Подклассами систематических кодов являются коды Хемминга и циклические коды, например, коды Боуза-Чоудхури-Хоквингема. По установившейся традиции ряд подклассов корректирующих кодов обозначают фамилиями тех ученых, которые впервые предложили и исследовали тот или иной вид кодирования. Особенности кодов этих подклассов будут отмечены в дальнейшем. 8.2.2. О технической реализации корректирующего кодирования. Из основной теоремы Шеннона для каналов с шумами следует, что может быть обеспечена сколь угодно малая вероятность ошибочного приема при эффективности использования пропускной способности канала, близкой к единице (см. § 5.6). Для этого в симметричном канале без памяти при больших необходимо применять случайный выбор разрешенных Однако практически такое случайное корректирующее кодирование неосуществимо, так как для хранения в памяти декодера всех разрешенных комбинаций при 8.2.3. Принципы построения линейных кодов. Основным принципом построения линейных кодов является отыскание таких процедур, которые позволяют при кодировании получать все разрешенные кодовые комбинации путем конечного числа несложных линейных преобразований одной или В линейных систематических кодах разрешенные комбинации получают путем суммирования по модулю 2 различных сочетаний «сходных комбинаций. Проверочные символы получают так же, как результат суммирования по модулю 2 определенного числа информационных символов. Обнаружение ошибок основано на проверке соответствия тех проверочных символов, которые получены из принятых информационных символов, с соответствующими проверочными символами, непосредственно принятыми. Если ошибка есть, суммирование по модулю 2 проверочного символа, полученного в результате суммирования информационных символов и принятого дает единицу. Эта операция, выполненная для всех проверочных символов, даст в результате вектор ошибок — синдром кодовой комбинации. Нулевой синдром соответствует случаю отсутствия ошибок. Для исправления ошибок каждому ненулевому синдрому «приписывают» наиболее вероятные для данного канала ошибки и при появлении ненулевого синдрома декодер исправляет приписанные к нему ошибки. Если кодовая комбинация содержит 8.2.4. Условия формирования разрешенных кодовых комбинаций. В линейном коде сумма по модулю 2 любого конечного числа разрешенных кодовых комбинаций также является разрешенной кодовой комбинацией. Поэтому, выбрав
разрешенных кодов комбинаций. Чтобы каждое сочетание порождало новую разрешенную комбинацию и чтобы в конечном итоге их общее число равнялось числу, определяемому (8.8), необходимо выполнить следующие пять условий: исходные комбинации должны выбираться различными; нулевая комбинация (комбинация, состоящая из одних нулей) не должна выбираться как исходная; исходные кодовые комбинации должны быть линейно-независимы; вес каждой исходной комбинации должен быть не менее Общие методы синтеза оптимальных линейных кодов еще не созданы, но ряд оптимальных кодов при малых значениях 8.2.5. Формирование проверочных разрядов. Для линейных кодов любой проверочный разряд
где (1.19). Результат операции (8.9) может быть равен 0 или 1, так как нулевая кодовая комбинация в любом линейном коде также является разрешенной. 8.2.6. Обнаружение и исправление ошибок линейными кодами. Обнаружение ошибок основано на проверке условия (8.9). Из принятых проверочных символов
Если для всех Процедуры формирования проверочных символов из информационных и определения синдромов с помощью линейных преобразований (8.9), (8.10), получения всех разрешенных комбинаций из 8.2.7. Линейные коды (7.4). Эти коды называют кодами Хемминга, который впервые построил и исследовал характеристики кодов (7.4), обнаруживающих две и исправляющих одну ошибку. Выберем матрицу коэффициентов в (8.9) в виде
тогда пятый, шестой и седьмой проверочные символы каждой кодовой комбинации выразятся через ее информационные символы следующим образом:
Код имеет следующие характеристики:
Одна из передаваемых кодовых комбинаций имеет вид 0010110, где первые три символа являются проверочными, а последующие четыре — информационными. Обратная запись комбинации показывает, что первыми принимают информационные символы для того, чтобы из них успеть образовать проверочные символы по правилу (8.9), сравнить их с принятыми проверочными по правилу (8.10) и получить синдромы для каждой кодовой комбинации. Синдром
где Таблнца 6 (см. скан) В первом синдроме не совпадают Таким образом, сущность линейного корректирования ошибок заключается в том, что каждому синдрому приписывают наиболее вероятные ошибки, по полученным кодовым комбинациям вычисляют синдромы и по номеру синдрома исправляют «приписанные» к нему ошибки. 8.2.8. Циклические коды. Существенным недостатком линейных кодов является необходимость выбора исходных разрешенных комбинаций, проверки условий формирования разрешенных комбинаций, запоминания коэффициентов называемые регистры сдвига, и сумматоров по модулю 2. Цикл является одной из наиболее распространенных операций в вычислительной технике. Сущность циклической перестановки заключается в том, что последний символ кодовой комбинации занимает место первого, первый — второго и т. д. до тех пор, пока предпоследний символ не займет место последнего. Если циклической перестановке подвергалась разрешенная кодовая комбинация, то в результате этой операции появляется новая разрешенная комбинация. Теория циклических кодов основана на методах высшей алгебры. (С математической точки зрения циклический код является идеалом в линейной коммутативной алгебре полинома Циклическая перестановка рассматривается как умножение
поэтому полиномы Кодеры и декодеры циклических кодов строят на основе регистров сдвига, охваченных обратными связями, и сумматоров по модулю 2. Разрешенные кодовые комбинации получают из одной исходной, символами которой являются коэффициенты порождающего полинома. Сначала выполняют 8.2.9. Циклические коды (7.4). Покажем, как линейные коды (7.4) (см. п. 8.2.7) могут быть получены с помощью цикла и как строят циклические кодеры и декодеры. Теперь уже коэффициенты
В том, что (8.15) является порождающим полиномом, нетрудно убедиться, выполнив деление
Так как деление выполнено без остатка, то
является проверочным для этого кода. Произведение
Выберем исходную кодовую комбинацию
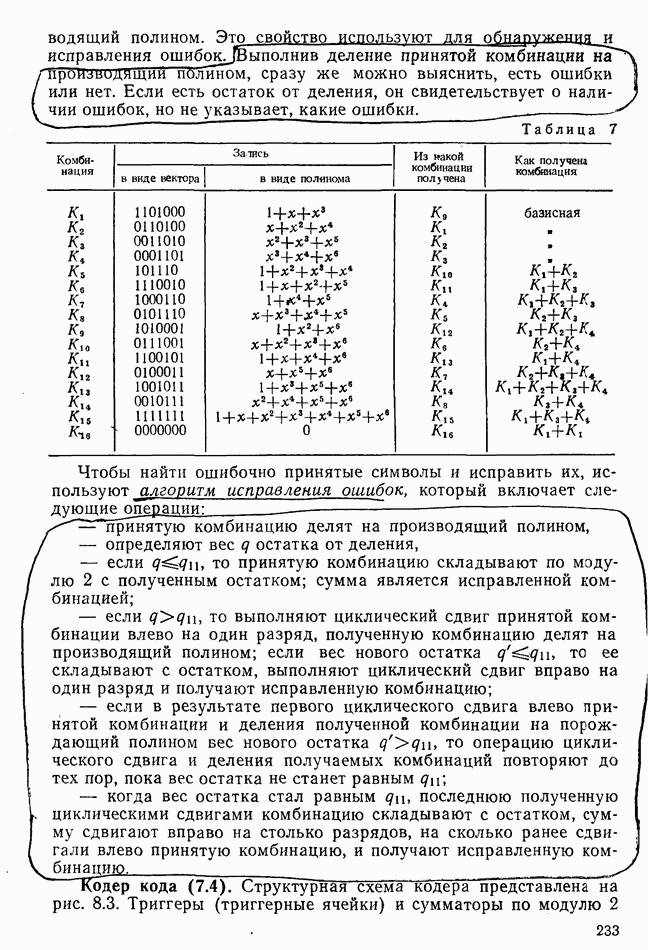
Выполнив цикл один раз, получим
второй раз —
третий раз —
где Важным свойством циклического кода является то, что каждая разрешенная кодовая комбинация делится без остатка на производящий полином. Это свойство используют для обнаружения и исправления ошибок. Выполнив деление принятой комбинациинации на производящий полином, сразу же можно выяснить, есть ошибки или нет. Если есть остаток от деления, он свидетельствует о наличии ошибок, но не указывает, какие ошибки. Таблица 7 (см. скан) Чтобы найти ошибочно принятые символы и исправить их, используют алгоритм исправления ошибок, который включает следующие операции: - принятую комбинацию делят на производящий полином, - определяют вес — если — если — если в результате первого циклического сдвига влево принятой комбинации и деления полученной комбинации на порождающий полином вес нового остатка — когда вес остатка стал равным Кодер кода (7.4). Структурная схема кодера представлена на рис. 8.3. Триггеры (триггерные ячейки) и сумматоры по модулю 2 обозначены в соответствии с ГОСТ 2.743-72 «Обозначения условные графические в схемах. Двоичные логические элементы». Действие триггерной ячейки заключается в том, что при каждом воздействии на ее вход элемента кодового сигнала (О или 1) она изменяет свое состояние на противоположное. Если в ячейке содержится символ (0) (ячейка находится в нулевом состоянии), то при появлении на ее входе символа 1 она переходит в состояние 1, а символ 0 появляется на ее выходе. Изменение состояния ячейки называют тактом или шагом. Новое состояние ячейка сохраняет до следующего шага. Сумматор по модулю 2 на каждом такте выдает суммарный сигнал 0 или 1 в зависимости от того, какие поступают входные сигналы. Таблица 8 (см. скан)
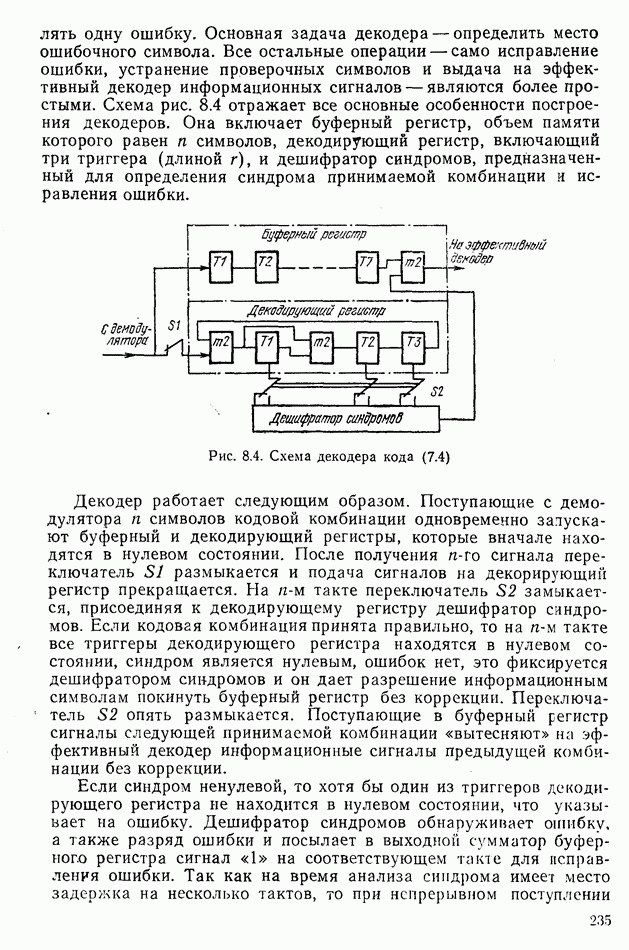
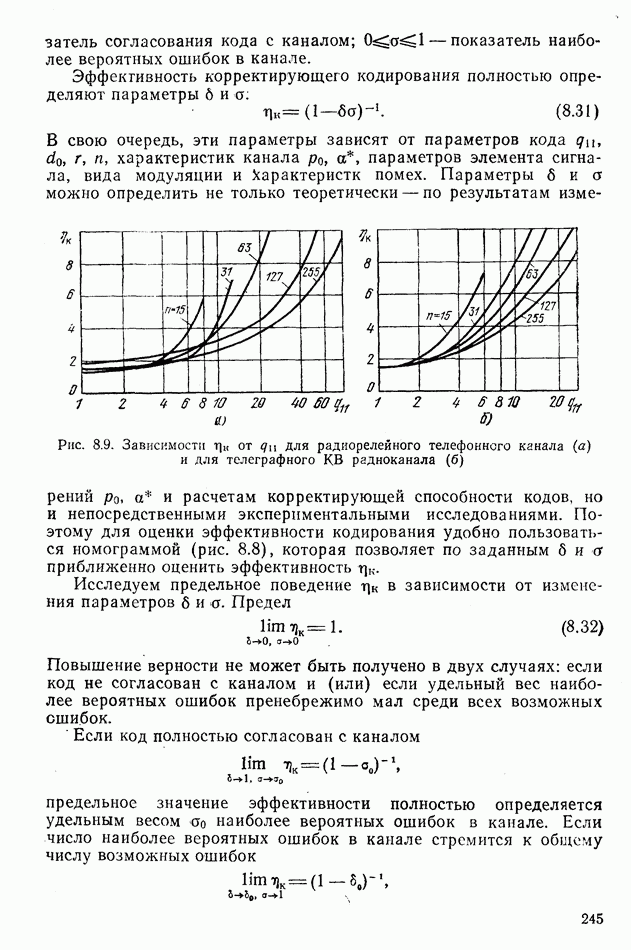
Рис. 8.3. Схема кодера кода (7.4) Рассмотрим принцип работы циклического кодера. Предположим, что с эффективного кодера поступает последовательность информационных сигналов 1001, соответствующая кодовой комбинации Декодер кода (7.4). Структурная схема декодера представлена на рис. 8.4. Его главное назначение — обнаруживать две и исправлять одну ошибку. Основная задача декодера — определить место ошибочного символа. Все остальные операции — само исправление ошибки, устранение проверочных символов и выдача на эффективный декодер информационных сигналов — являются более простыми. Схема рис. 8.4 отражает все основные особенности построения декодеров. Она включает буферный регистр, объем памяти которого равен
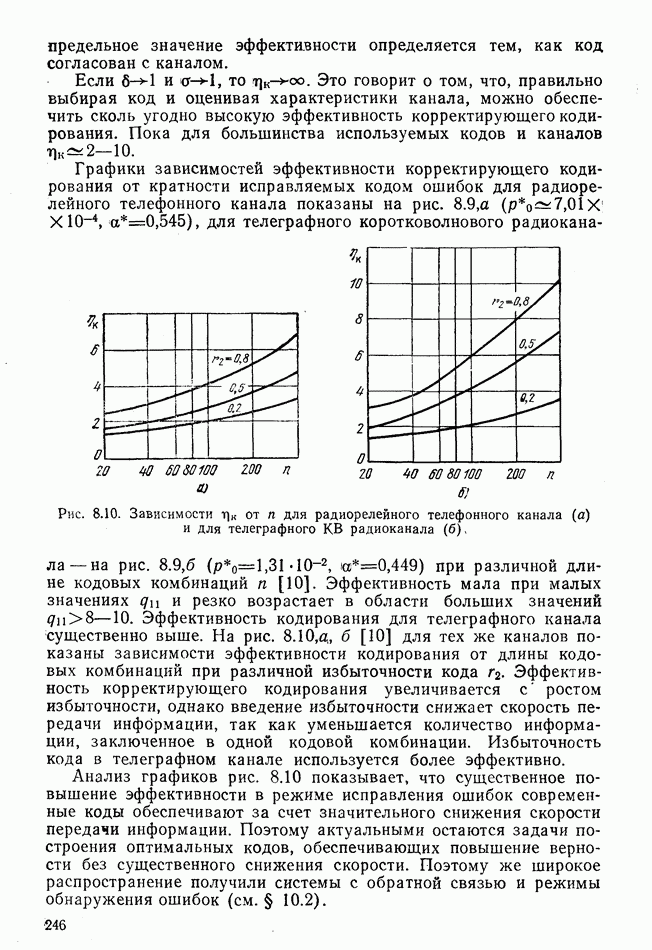
Рис. 8.4. Схема декодера кода (7.4) Декодер работает следующим образом. Поступающие с демодулятора Если синдром ненулевой, то хотя бы один из триггеров декодирующего регистра не находится в нулевом состоянии, что указывает на ошибку. Дешифратор синдромов обнаруживает ошибку, а также разряд ошибки и посылает в выходной сумматор буферного регистра сигнал «1» на соответствующем такте для исправления ошибки. Так как на время анализа синдрома имеет место задержка на несколько тактов, то при непрерывном поступлении на декодер принимаемых комбинаций предусматривается их запоминание на время задержки. После завершения анализа переключатель Таблица 9 (см. скан) Для иллюстрации конкретных особенностей работы декодера рассмотрим процесс декодирования для двух случаев: когда ошибок нет и когда они есть (табл. 9). Предположим, что принятой кодовой комбинацией является комбинация Предположим, что в принятой комбинации Декодер аппаратурно реализует общий алгоритм исправления ошибок, рассмотренный ранее. Покажем это. Разделив принятую кодовую комбинацию на образующий полином с учетом суммирования по модулю 2, получим
Остаток имеет вес
Просуммировав последнюю кодовую комбинацию с остатком, получим 1110100. Выполнив циклический сдвиг этой комбинации вправо на три разряда, получим исправленную кодовую комбинацию 1001110. Следовательно, для циклических кодов алгоритмы кодирования и декодирования относительно просто аппаратурно реализуются с помощью регистров и сумматоров: большие объемы памяти кодера и декодера не требуются. 8.2.10. Коды Боуза-Чоудхури-Хоквингема (коды БЧХ) - разработаны для увеличения минимального кодового расстояния и повышения корректирующей способности. Длина кодовой комбинации в них Рассмотрим код
Число избыточных символов
Циклические коды БЧХ получили применение в аппаратуре передачи данных. Существует рекомендация МККТТ
Многочисленные испытания кодов БЧХ подтвердили их высокую эффективность: при передаче данных по коммутируемым каналам телефонной сети общего пользования с 8.2.11. Выбор длины информационной части кодовых комбинаций при обмене информацией между ЦВМ. ЦВМ обычно обмениваются машинными словами
где
где Поэтому на практике прибегают к укороченным циклическим кодам, которые получают из полных, используя для передачи информации только те комбинации полного кода, которые содержат слева 8.2.12. При мажоритарном декодировании каждый информационный символ кодовой комбинации можно выразить через другие символы с помощью различных линейных соотношений и эти соотношения использовать для повышения верности. Из каждого соотношения определяют предполагаемое значение информационного символа, а окончательное решение о его значении принимается по большинству одинаковых символов для всех соотношений (методом голосования). Такая процедура легко реализуется с помощью регистров сдвига и сумматоров, она заметно повышает верность по отношению к обычному декодированию. 8.2.13. Код с постоянным весом относится к неразделимым несистематическим кодам. Разрешенными в нем являются кодовые комбинации, которые содержат определенное число единиц, одинаковое для всех комбинаций. МККТТ рекомендован код № 3 для передачи телеграфных сообщений по коротковолновым радиоканалам, которые обладают значительной асимметрией. Этот код содержит 35 разрешенных комбинаций длиной В последнее время предпочтение отдается циклическим кодам, так как при использовании кодов с постоянным весом резко усложняется аппаратура и возрастает стоимость кодеков из-за неразделимости информационной и проверочной части в комбинациях. 8.2.14. В кодах Бергера, которые являются разделимыми, минимальное кодовое расстояние Они также предназначены в основном для асимметричных каналов. Проверочные разряды кода Бергера представляют собой запись в двоичной форме числа единиц в информационной части кодовой комбинации. Аналогично формируются проверочные символы при декодировании. Коды Бергера обладают такой же корректирующей способностью, что и код № 3, но имеют важное достоинство — из-за разделимости кодовых комбинаций существенно упрощается построение кодеков. 8.2.15. Непрерывные коды. В простейшем непрерывном (рекуррентном) коде информационные символы а чередуются с проверочными
где
Коды этого класса называют кодами Финка-Хагельбергера.
Рис. 8.5. Схема кодера непрерывного кода
Рис. 8.6. Схема декодера непрерывного кода Рассмотрим кодирование и декодирование для такого кода. Структурная схема кодера представлена на рис. 8.5. Синхронный ключ Цепной код (8.23) позволяет исправить все одиночные ошибки при условии, что между любыми двумя ошибочно принятыми имеется по крайней мере три правильно принятых сигнала. Используя более совершенные коды и алгоритмы декодирования, можно исправлять групповые ошибки. Контрольные вопросы(см. скан) (см. скан)
|
 |
Оглавление
|






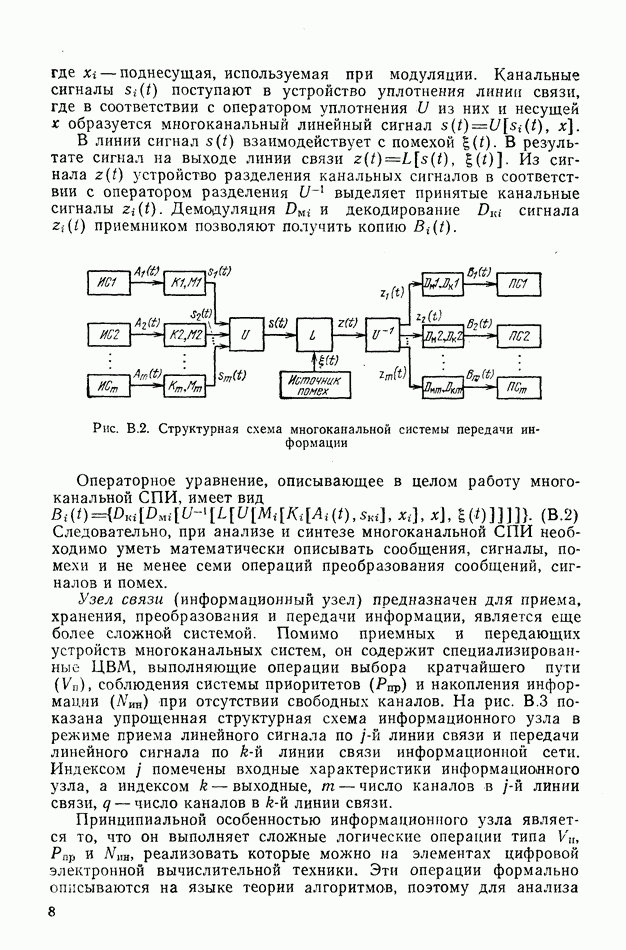
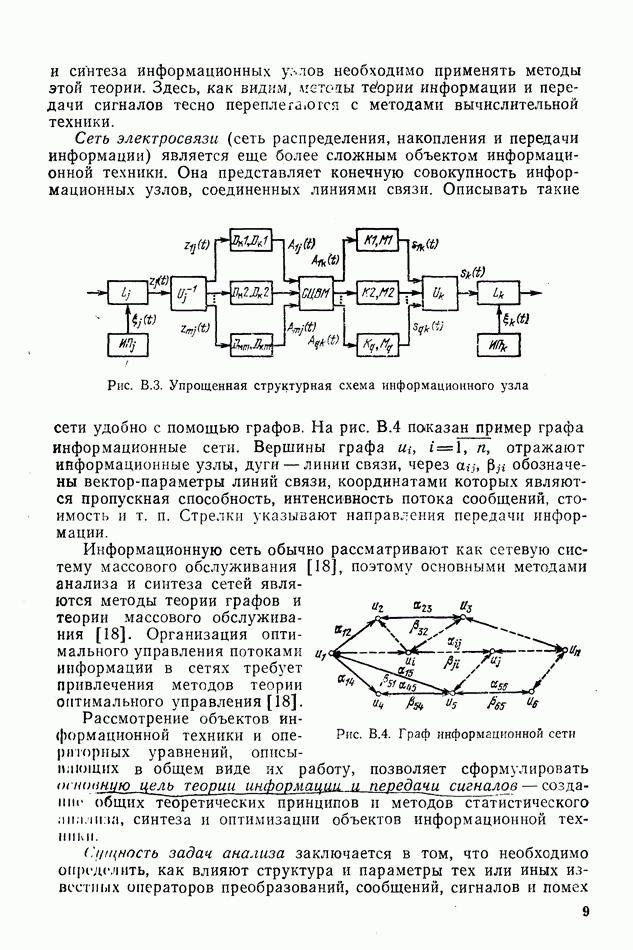



































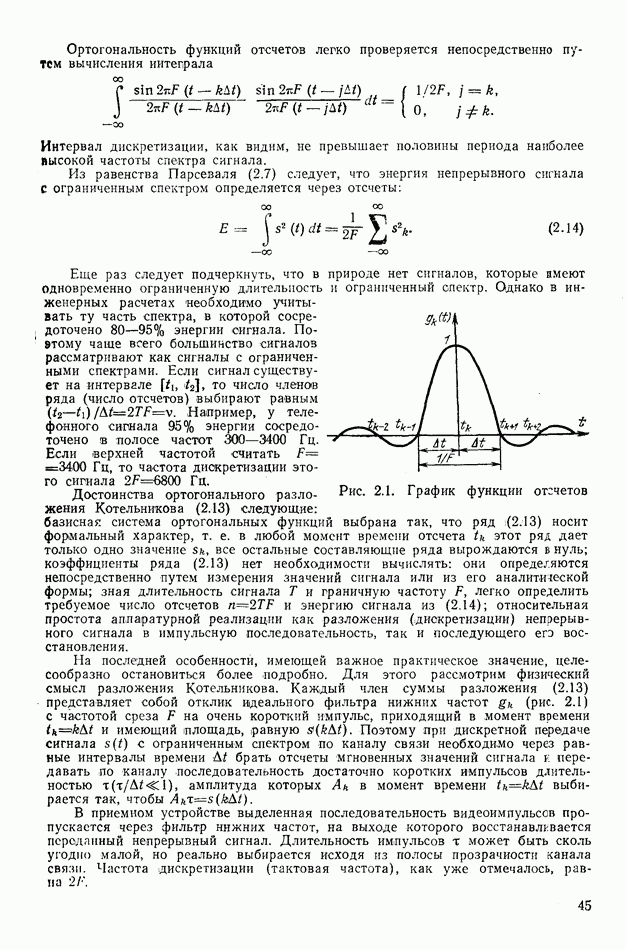




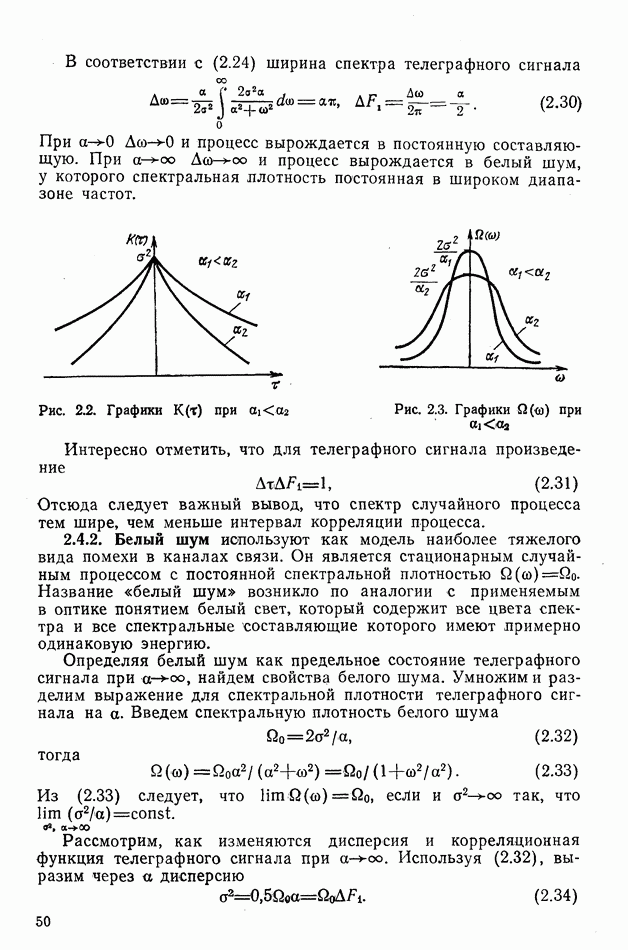
































































































































































































 -коды, где
-коды, где  - длина комбинации,
- длина комбинации,  число информационных символов. Неразделимые коды менее распространены, к ним относится рекомендованный МККТТ стандартный телеграфный код № 3 — семиразрядный код, каждая комбинация которого содержит три единицы и четыре нуля.
число информационных символов. Неразделимые коды менее распространены, к ним относится рекомендованный МККТТ стандартный телеграфный код № 3 — семиразрядный код, каждая комбинация которого содержит три единицы и четыре нуля.
 -коды, в которых
-коды, в которых  проверочных символов являются линейными комбинациями информационных.
проверочных символов являются линейными комбинациями информационных.

 должно выполняться условие (8.2), тогда все ошибки кратности
должно выполняться условие (8.2), тогда все ошибки кратности  будут исправлены. Если непосредственно использовать условие (8.2) для технической реализации корректирующего кодирования, то
будут исправлены. Если непосредственно использовать условие (8.2) для технической реализации корректирующего кодирования, то
 комбинаций из всего множества
комбинаций из всего множества  это обеспечивает и любую малую вероятность появления ошибок и сколь угодно близкую к единице эффективность использования канала.
это обеспечивает и любую малую вероятность появления ошибок и сколь угодно близкую к единице эффективность использования канала.
 обеспечивающем допустимую вероятность ошибки, требуется объем памяти декодера порядка
обеспечивающем допустимую вероятность ошибки, требуется объем памяти декодера порядка  бит [9]. Например, при
бит [9]. Например, при  объем памяти должен быть 1010 бит, что намного превышает возможности современной техники. Именно поэтому все усилия исследователей направлены на разработку и создание регулярных (детерминированных) методов построения кодов, которые по свойствам были бы близки к случайному коду, но допускали более простую техническую реализацию. Примером таких регулярных кодов являются линейные систематические коды.
объем памяти должен быть 1010 бит, что намного превышает возможности современной техники. Именно поэтому все усилия исследователей направлены на разработку и создание регулярных (детерминированных) методов построения кодов, которые по свойствам были бы близки к случайному коду, но допускали более простую техническую реализацию. Примером таких регулярных кодов являются линейные систематические коды.
 исходных разрешенных комбинаций, а при декодировании для обнаружения и исправления ошибок не хранить в памяти все разрешенные комбинации, а получать информацию об ошибках по результатам конечного числа относительно простых, также линейных преобразований над символами получаемых кодовых комбинаций. Основная задача оптимального построения корректирующего кода заключается в таком выборе числа разрешенных кодовых комбинаций заданной длины, чтобы обеспечивалось самое минимальное кодовое расстояние. Тогда получаемый код будет обладать наилучшей корректирующей способностью и минимальной вероятностью некорректируемых ошибок.
исходных разрешенных комбинаций, а при декодировании для обнаружения и исправления ошибок не хранить в памяти все разрешенные комбинации, а получать информацию об ошибках по результатам конечного числа относительно простых, также линейных преобразований над символами получаемых кодовых комбинаций. Основная задача оптимального построения корректирующего кода заключается в таком выборе числа разрешенных кодовых комбинаций заданной длины, чтобы обеспечивалось самое минимальное кодовое расстояние. Тогда получаемый код будет обладать наилучшей корректирующей способностью и минимальной вероятностью некорректируемых ошибок.
 проверочных символов, то общее число ненулевых синдромов равно
проверочных символов, то общее число ненулевых синдромов равно  и таблица исправлений включает такое число строк, которое должно храниться в памяти декодера.
и таблица исправлений включает такое число строк, которое должно храниться в памяти декодера.
 исходных разрешенных комбинаций, которые называют базисными, и суммируя их в
исходных разрешенных комбинаций, которые называют базисными, и суммируя их в  различных сочетаниях, можно построить все
различных сочетаниях, можно построить все

 (весом называют число единиц в комбинации); кодовое расстояние между любыми парами исходных комбинаций должно быть не меньше
(весом называют число единиц в комбинации); кодовое расстояние между любыми парами исходных комбинаций должно быть не меньше  Если
Если  базовых комбинаций выбраны в соответствии с этими условиями, то они за-
базовых комбинаций выбраны в соответствии с этими условиями, то они за-  дают класс кодов
дают класс кодов  который включает
который включает  линейных кодов. Для выбора определенного кода из этого класса необходимо из множества коэффициентов
линейных кодов. Для выбора определенного кода из этого класса необходимо из множества коэффициентов  (см. п. 8.2.5), определяющих условия формирования проверочных символов (разрядов), выбрать те которые минимизируют вероятность появления некорректируемых ошибок (8.6) или доставляют экстремум другому критерию оптимальности кода.
(см. п. 8.2.5), определяющих условия формирования проверочных символов (разрядов), выбрать те которые минимизируют вероятность появления некорректируемых ошибок (8.6) или доставляют экстремум другому критерию оптимальности кода.
 уже найден. К ним относятся код
уже найден. К ним относятся код  обнаруживающий одиночные ошибки, код
обнаруживающий одиночные ошибки, код  -код Хемминга, обнаруживающий две и исправляющей одну ошибку, код (14, 2), исправляющий ошибки до четвертой кратности включительно, и др. [1—3, 9, 10].
-код Хемминга, обнаруживающий две и исправляющей одну ошибку, код (14, 2), исправляющий ошибки до четвертой кратности включительно, и др. [1—3, 9, 10].
 формируется как линейная комбинация информационных
формируется как линейная комбинация информационных  поэтому
поэтому

 коэффициенты, равные 0 или 1 и выбираемые определенным образом (см. п. 8.2.4); — знак суммирования по модулю 2
коэффициенты, равные 0 или 1 и выбираемые определенным образом (см. п. 8.2.4); — знак суммирования по модулю 2
 и тех
и тех  которые получены из принятых информационных
которые получены из принятых информационных  с помощью (8.9), образуют сумму
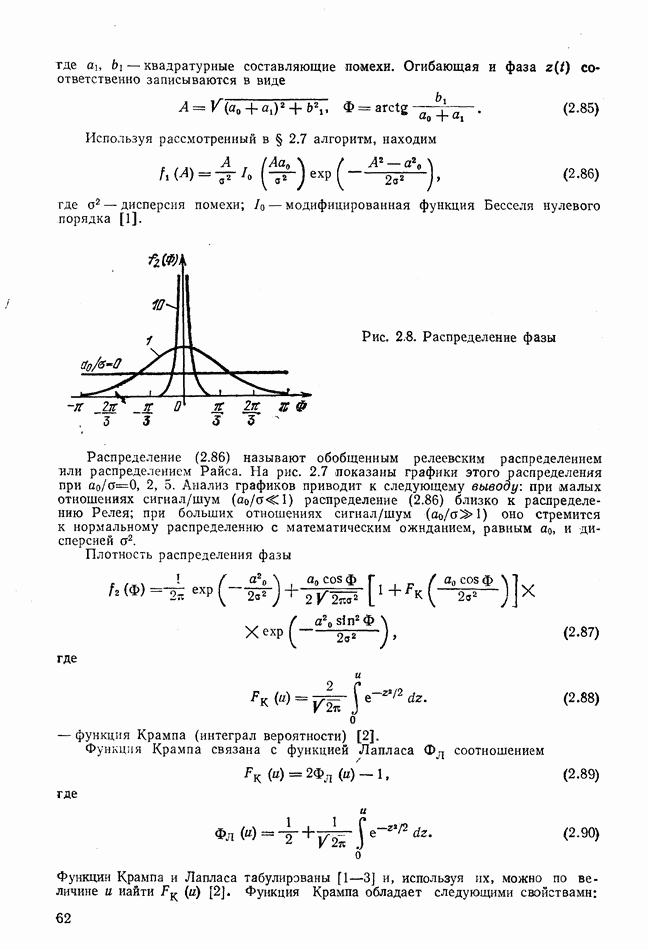
с помощью (8.9), образуют сумму

 то ошибок нет. Если хотя бы одно значение
то ошибок нет. Если хотя бы одно значение  то имеются ошибки. Вектор
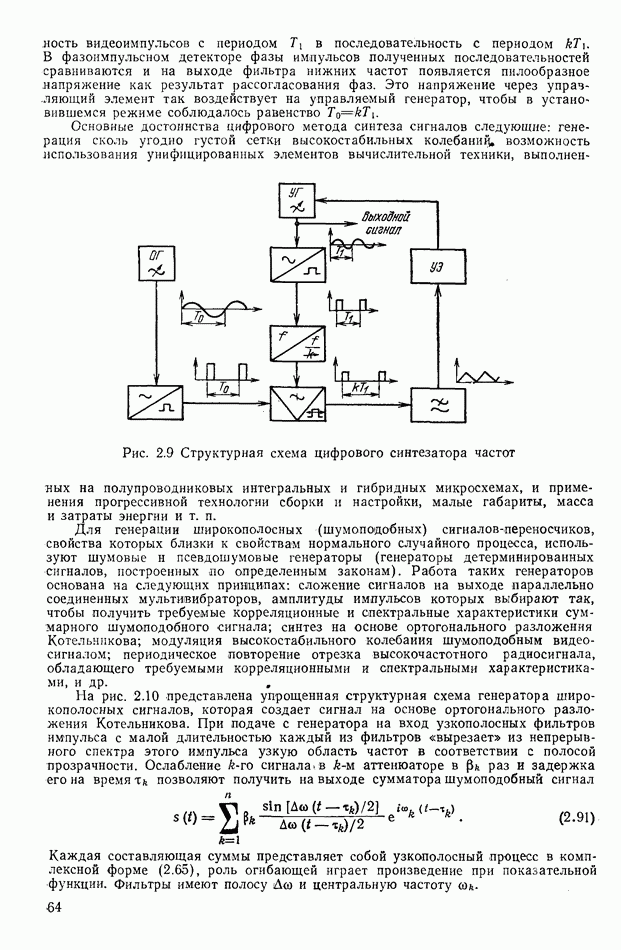
то имеются ошибки. Вектор  координатами которого служат
координатами которого служат  называют синдромом 1-й кодовой комбинации. Число различных синдромов, соответствующих различным сочетаниям ошибок в канале, равно числу всевозможных
называют синдромом 1-й кодовой комбинации. Число различных синдромов, соответствующих различным сочетаниям ошибок в канале, равно числу всевозможных  -значных перестановок двоичных чисел, т. е.
-значных перестановок двоичных чисел, т. е.  При декодировании структура синдрома (число и расположение единиц) показывает, в каких разрядах произошли ошибки, и позволяет их исправить. При определенном выборе
При декодировании структура синдрома (число и расположение единиц) показывает, в каких разрядах произошли ошибки, и позволяет их исправить. При определенном выборе  синдром, рассматриваемый как двоичное число, может указывать непосредственно номер позиции (разряда) ошибки. Таблица исправления ошибок содержит
синдром, рассматриваемый как двоичное число, может указывать непосредственно номер позиции (разряда) ошибки. Таблица исправления ошибок содержит  синдромов. Нулевой синдром в нее не включают, так как он указывает на отсутствие ошибок.
синдромов. Нулевой синдром в нее не включают, так как он указывает на отсутствие ошибок.
 исходных также путем линейных преобразований привели к значительно более простому кодированию и декодированию, обнаружению и исправлению ошибок. Существенно сокращаются объемы памяти кодера и декодера, упрощаются кодеки, алгоритмы кодирования и декодирования.
исходных также путем линейных преобразований привели к значительно более простому кодированию и декодированию, обнаружению и исправлению ошибок. Существенно сокращаются объемы памяти кодера и декодера, упрощаются кодеки, алгоритмы кодирования и декодирования.


 число разрешенных комбинаций
число разрешенных комбинаций  число синдромов
число синдромов  избыточность
избыточность  вероятность появления некорректируемых ошибок (8.6)
вероятность появления некорректируемых ошибок (8.6)

 комбинации
комбинации

 проверочный символ, полученный из (8.9);
проверочный символ, полученный из (8.9);  принятый проверочный символ. Приписывая каждому синдрому номер символа, который может быть искажен с наибольшей вероятностью, получают таблицу исправлений (табл. 6).
принятый проверочный символ. Приписывая каждому синдрому номер символа, который может быть искажен с наибольшей вероятностью, получают таблицу исправлений (табл. 6).
 поэтому наиболее вероятно, что ошибочно принят проверочный символ
поэтому наиболее вероятно, что ошибочно принят проверочный символ  так как
так как  определяются через одни и те же информационные символы, а
определяются через одни и те же информационные символы, а  приняты правильно. Аналогично определяют наиболее вероятные ошибки для других синдромов.
приняты правильно. Аналогично определяют наиболее вероятные ошибки для других синдромов.
 для формирования проверочных символов и синдромов для исправления ошибок. Поэтому поиск более простых процедур кодирования и декодирования продолжается. Он привел к появлению эффективного подкласса линейных систематических кодов — циклических кодов. Эти коды получили такое название потому, что основной операцией кодирования и декодирования является цикл. Цикл аппаратурно реализуют с помощью набора триггеров, объединенных в так
для формирования проверочных символов и синдромов для исправления ошибок. Поэтому поиск более простых процедур кодирования и декодирования продолжается. Он привел к появлению эффективного подкласса линейных систематических кодов — циклических кодов. Эти коды получили такое название потому, что основной операцией кодирования и декодирования является цикл. Цикл аппаратурно реализуют с помощью набора триггеров, объединенных в так
 порядка по модулю
порядка по модулю  над полем коэффициентов.) Кодовые комбинации (вектора) длиной
над полем коэффициентов.) Кодовые комбинации (вектора) длиной  описывают полиномами
описывают полиномами  степени, в которых коэффициентами при соответствующих степенях
степени, в которых коэффициентами при соответствующих степенях  служат символы кодовых комбинаций. Например, комбинации
служат символы кодовых комбинаций. Например, комбинации  соответствует полином
соответствует полином  (высшие степени полинома порождаются информационными символами, которые принимают первыми).
(высшие степени полинома порождаются информационными символами, которые принимают первыми).
 на
на  Так как при сложении по модулю
Так как при сложении по модулю  то замена
то замена  на 1 в произведении
на 1 в произведении  дает новый полином, коэффициенты которого образуют новую разрешенную комбинацию. Полином
дает новый полином, коэффициенты которого образуют новую разрешенную комбинацию. Полином  степени
степени  на который делится без остатка двучлен
на который делится без остатка двучлен  называют производящим (образующим) полиномом циклического кода. Результат деления называют проверочным полиномом
называют производящим (образующим) полиномом циклического кода. Результат деления называют проверочным полиномом  Произведение
Произведение

 рассматривают как ортогональные и операцию (8.14) кладут в основу построения алгоритмов декодирования.
рассматривают как ортогональные и операцию (8.14) кладут в основу построения алгоритмов декодирования.
 циклов и получают
циклов и получают  разрешенных базисных комбинаций. Затем линейным преобразованием этих
разрешенных базисных комбинаций. Затем линейным преобразованием этих  комбинаций получают оставшиеся
комбинаций получают оставшиеся  разрешенных комбинаций. Кодер и декодер циклического кода в основном выполняют операции умножения и деления полиномов. Использование цикла для кодирования и декодирования существенно упростило аппаратурную реализацию кодеров, алгоритмов кодирования и декодирования и позволило использовать в технике связи элементную базу цифровой вычислительной техники.
разрешенных комбинаций. Кодер и декодер циклического кода в основном выполняют операции умножения и деления полиномов. Использование цикла для кодирования и декодирования существенно упростило аппаратурную реализацию кодеров, алгоритмов кодирования и декодирования и позволило использовать в технике связи элементную базу цифровой вычислительной техники.
 выберем на основе порождающего полинома
выберем на основе порождающего полинома

 на
на  с учетом основной особенности суммирования по модулю:
с учетом основной особенности суммирования по модулю:  тогда
тогда

 действительно, является порождающим полиномов кода
действительно, является порождающим полиномов кода  Полученный полином
Полученный полином


 так, чтобы ее символы соответствовали значениям коэффициентов тогда
так, чтобы ее символы соответствовали значениям коэффициентов тогда




 — знак соответствия двух форм записи комбинаций. Так как
— знак соответствия двух форм записи комбинаций. Так как  полученных комбинаций уже достаточно для образования
полученных комбинаций уже достаточно для образования  остальных разрешенных комбинаций способом суммирования по модулю 2. В табл. 7 показаны все разрешенные кодовые комбинации, способ их получения и из какой комбинации можно получить выбранную, выполняя один цикл.
остальных разрешенных комбинаций способом суммирования по модулю 2. В табл. 7 показаны все разрешенные кодовые комбинации, способ их получения и из какой комбинации можно получить выбранную, выполняя один цикл.
 остатка от деления,
остатка от деления,
 то принятую комбинацию складывают по модулю 2 с полученным остатком; сумма является исправленной комбинацией;
то принятую комбинацию складывают по модулю 2 с полученным остатком; сумма является исправленной комбинацией;
 то выполняют циклический сдвиг принятой комбинации влево на один разряд, полученную комбинацию делят на производящий полином; если вес нового остатка
то выполняют циклический сдвиг принятой комбинации влево на один разряд, полученную комбинацию делят на производящий полином; если вес нового остатка  то ее складывают с остатком, выполняют циклический сдвиг вправо на один разряд и получают исправленную комбинацию;
то ее складывают с остатком, выполняют циклический сдвиг вправо на один разряд и получают исправленную комбинацию;
 то операцию циклического сдвига и деления получаемых комбинаций повторяют до тех пор, пока вес остатка не станет равным
то операцию циклического сдвига и деления получаемых комбинаций повторяют до тех пор, пока вес остатка не станет равным 
 последнюю полученную циклическими сдвигами комбинацию складывают с остатком, сумму сдвигают вправо на столько разрядов, на сколько ранее сдвигали влево принятую комбинацию, и получают исправленную комбинацию.
последнюю полученную циклическими сдвигами комбинацию складывают с остатком, сумму сдвигают вправо на столько разрядов, на сколько ранее сдвигали влево принятую комбинацию, и получают исправленную комбинацию.

 (см. табл. 7). В табл. 8 показаны положение входного переключателя
(см. табл. 7). В табл. 8 показаны положение входного переключателя  на каждом такте; сигналы, поступающие на вход регистра; состояния триггеров регистра; сигналы, поступающие на модулятор; процесс формирования проверочных сигналов в регистре такт за тактом с первого по седьмой. В начальный момент времени все триггеры регистра находятся в нулевом состоянии.
на каждом такте; сигналы, поступающие на вход регистра; состояния триггеров регистра; сигналы, поступающие на модулятор; процесс формирования проверочных сигналов в регистре такт за тактом с первого по седьмой. В начальный момент времени все триггеры регистра находятся в нулевом состоянии.
 символов, декодирующий регистр, включающий три триггера (длиной
символов, декодирующий регистр, включающий три триггера (длиной  ), и дешифратор синдромов, предназначенный для определения синдрома принимаемой комбинации и исправления ошибки.
), и дешифратор синдромов, предназначенный для определения синдрома принимаемой комбинации и исправления ошибки.

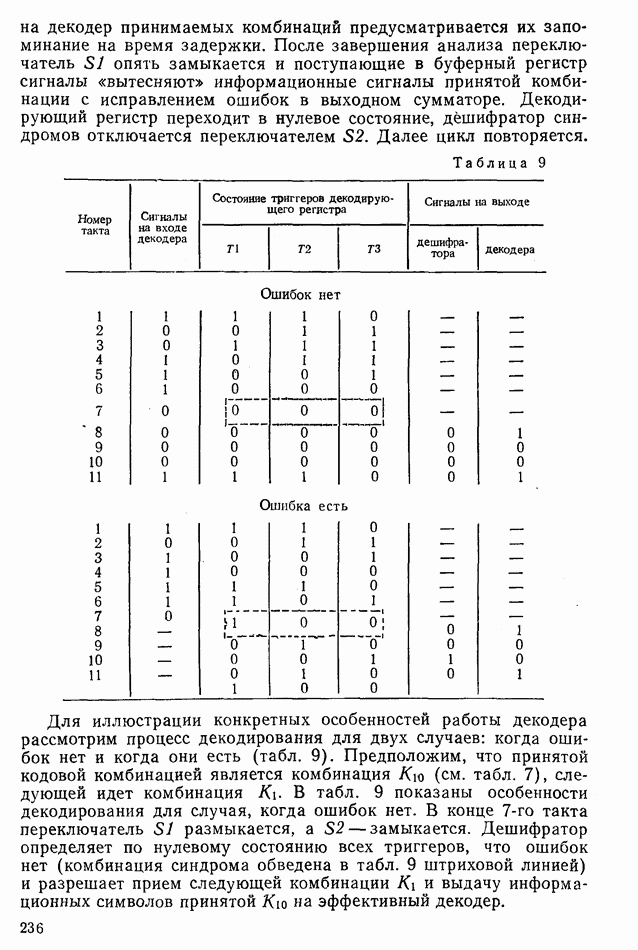
 символов кодовой комбинации одновременно запускают буферный и декодирующий регистры, которые вначале находятся в нулевом состоянии. После получения
символов кодовой комбинации одновременно запускают буферный и декодирующий регистры, которые вначале находятся в нулевом состоянии. После получения  сигнала переключатель
сигнала переключатель  размыкается и подача сигналов на декорирующий регистр прекращается. На
размыкается и подача сигналов на декорирующий регистр прекращается. На  такте переключатель
такте переключатель  замыкается, присоединяя к декодирующему регистру дешифратор синдромов. Если кодовая комбинация принята правильно, то на
замыкается, присоединяя к декодирующему регистру дешифратор синдромов. Если кодовая комбинация принята правильно, то на  такте все триггеры декодирующего регистра находятся в нулевом состоянии, синдром является нулевым, ошибок нет, это фиксируется дешифратором синдромов и он дает разрешение информационным символам покинуть буферный регистр без коррекции. Переключа-! тель
такте все триггеры декодирующего регистра находятся в нулевом состоянии, синдром является нулевым, ошибок нет, это фиксируется дешифратором синдромов и он дает разрешение информационным символам покинуть буферный регистр без коррекции. Переключа-! тель  опять размыкается. Поступающие в буферный регистр сигналы следующей принимаемой комбинации «вытесняют» на эффективный декодер информационные сигналы предыдущей комбинации без коррекции.
опять размыкается. Поступающие в буферный регистр сигналы следующей принимаемой комбинации «вытесняют» на эффективный декодер информационные сигналы предыдущей комбинации без коррекции.
 опять замыкается и поступающие в буферный регистр сигналы «вытесняют» информационные сигналы принятой комбинации с исправлением ошибок в выходном сумматоре. Декодирующий регистр переходит в нулевое состояние, дешифратор синдромов отключается переключателем
опять замыкается и поступающие в буферный регистр сигналы «вытесняют» информационные сигналы принятой комбинации с исправлением ошибок в выходном сумматоре. Декодирующий регистр переходит в нулевое состояние, дешифратор синдромов отключается переключателем  . Далее цикл повторяется.
. Далее цикл повторяется.
 (см. табл. 7), следующей идет комбинация
(см. табл. 7), следующей идет комбинация  В табл. 9 показаны особенности декодирования для случая, когда ошибок нет. В конце
В табл. 9 показаны особенности декодирования для случая, когда ошибок нет. В конце  такта переключатель
такта переключатель  размыкается,
размыкается,  замыкается. Дешифратор определяет по нулевому состоянию всех триггеров, что ошибок нет (комбинация синдрома обведена в табл. 9 штриховой линией) и разрешает прием следующей комбинации
замыкается. Дешифратор определяет по нулевому состоянию всех триггеров, что ошибок нет (комбинация синдрома обведена в табл. 9 штриховой линией) и разрешает прием следующей комбинации  и выдачу информационных символов принятой Кто на эффективный декодер.
и выдачу информационных символов принятой Кто на эффективный декодер.
 имеется ошибка в пятом разряде — третьем принятом. В табл. 9 показаны особенности декодирования в этом случае. Дешифратор синдрома на
имеется ошибка в пятом разряде — третьем принятом. В табл. 9 показаны особенности декодирования в этом случае. Дешифратор синдрома на  такте обнаружил ошибку. Для определения места ошибки он запускает буферный и декодирующий регистры и заставляет их выполнить еще несколько тактов. На
такте обнаружил ошибку. Для определения места ошибки он запускает буферный и декодирующий регистры и заставляет их выполнить еще несколько тактов. На  такте, когда третий информационный символ покидает буферный регистр и поступает на выходной сумматор (сумматор исправления ошибок), на него с дешифратора поступает сигнал коррекции «1». В результате ошибка исправляется: с выходного сумматора поступает правильный сигнал «0». На время исправления ошибки сигналы комбинации
такте, когда третий информационный символ покидает буферный регистр и поступает на выходной сумматор (сумматор исправления ошибок), на него с дешифратора поступает сигнал коррекции «1». В результате ошибка исправляется: с выходного сумматора поступает правильный сигнал «0». На время исправления ошибки сигналы комбинации  запоминаются.
запоминаются.

 что больше
что больше  Поэтому выполняем циклические сдвиги принятой комбинации влево и деление получаемых комбинаций на образующий полином до тех пор, пока не получим остаток от деления с весом
Поэтому выполняем циклические сдвиги принятой комбинации влево и деление получаемых комбинаций на образующий полином до тех пор, пока не получим остаток от деления с весом  Таких сдвигов требуется три:
Таких сдвигов требуется три:

 производящий полином находится как наименьшее общее кратное
производящий полином находится как наименьшее общее кратное  неприводимых полиномов
неприводимых полиномов  где
где  (Полином называют неприводимым, если он делится без остатка только на единицу и на самого себя. Наименьшим общим кратным совокупности неприводимых полиномов называют полином с наименьшим показателем степени, который делится на каждый из них.) Коды БЧХ обладают хорошими корректирующими способностями и позволяют обнаруживать и исправлять ошибки с учетом группирования, что очень важно для реальных каналов.
(Полином называют неприводимым, если он делится без остатка только на единицу и на самого себя. Наименьшим общим кратным совокупности неприводимых полиномов называют полином с наименьшим показателем степени, который делится на каждый из них.) Коды БЧХ обладают хорошими корректирующими способностями и позволяют обнаруживать и исправлять ошибки с учетом группирования, что очень важно для реальных каналов.
 [4]. Производящий полином
[4]. Производящий полином

 избыточность
избыточность  максимальная кратность обнаруживаемых ошибок
максимальная кратность обнаруживаемых ошибок  полностью исправляемых ошибок
полностью исправляемых ошибок  вероятность появления некорректируемых ошибок
вероятность появления некорректируемых ошибок

 , согласно которой в среднескоростных системах передачи данных предлагается применять коды
, согласно которой в среднескоростных системах передачи данных предлагается применять коды  разрядов. Производящий полином этих кодов
разрядов. Производящий полином этих кодов

 вероятность необнаруживаемых ошибок приема
вероятность необнаруживаемых ошибок приема  -разрядных знаков (байтов), из которых составлена информационная часть кодовой комбинации, не превышает
-разрядных знаков (байтов), из которых составлена информационная часть кодовой комбинации, не превышает 

 целые числа;
целые числа;  разрядов — машинный слог (байт). Поэтому длина информационной части кодовой комбинации должна быть равна или кратна байту. Следовательно, число информационных сигналов
разрядов — машинный слог (байт). Поэтому длина информационной части кодовой комбинации должна быть равна или кратна байту. Следовательно, число информационных сигналов

 целое число. Однако при выбранном кодовом расстоянии и числе проверочных разрядов циклические коды не дают возможности свободно выбирать длину информационной части.
целое число. Однако при выбранном кодовом расстоянии и числе проверочных разрядов циклические коды не дают возможности свободно выбирать длину информационной части.
 нулей, эти нулевые сигналы в канал связи не передают. Укороченные коды обладают корректирующей способностью полных кодов, но циклический сдвиг укороченных комбинаций не всегда приводит к образованию разрешенных комбинаций. Поэтому укороченные коды часто называют псевдоциклическими.
нулей, эти нулевые сигналы в канал связи не передают. Укороченные коды обладают корректирующей способностью полных кодов, но циклический сдвиг укороченных комбинаций не всегда приводит к образованию разрешенных комбинаций. Поэтому укороченные коды часто называют псевдоциклическими.
 и весом, равным 3. Минимальное кодовое расстояние
и весом, равным 3. Минимальное кодовое расстояние  поэтому код обнаруживает все одиночные ошибки и все ошибки нечетной кратности.
поэтому код обнаруживает все одиночные ошибки и все ошибки нечетной кратности.
 также равно 2.
также равно 2.
 в определенном порядке, например
в определенном порядке, например




 управляет работой кодера и чередует выдачу на модулятор информационных сигналов, которые поступают с эффективного кодера, и проверочных сигналов, которые поступают с сумматора. Триггер запоминает предыдущий информационный сигнал и выдает его на сумматор для суммирования с последующим. Структурная схема декодера представлена на рис. 8.6. Как обычно, она сложнее кодера и включает два триггера, три сумматора и одну схему совпадения. Алгоритм работы декодера такой: если (8.24) не выполняется для двух соседних поверочных символов, то находящийся между ними информационный сигнал следует изменить на противоположный.
управляет работой кодера и чередует выдачу на модулятор информационных сигналов, которые поступают с эффективного кодера, и проверочных сигналов, которые поступают с сумматора. Триггер запоминает предыдущий информационный сигнал и выдает его на сумматор для суммирования с последующим. Структурная схема декодера представлена на рис. 8.6. Как обычно, она сложнее кодера и включает два триггера, три сумматора и одну схему совпадения. Алгоритм работы декодера такой: если (8.24) не выполняется для двух соседних поверочных символов, то находящийся между ними информационный сигнал следует изменить на противоположный.