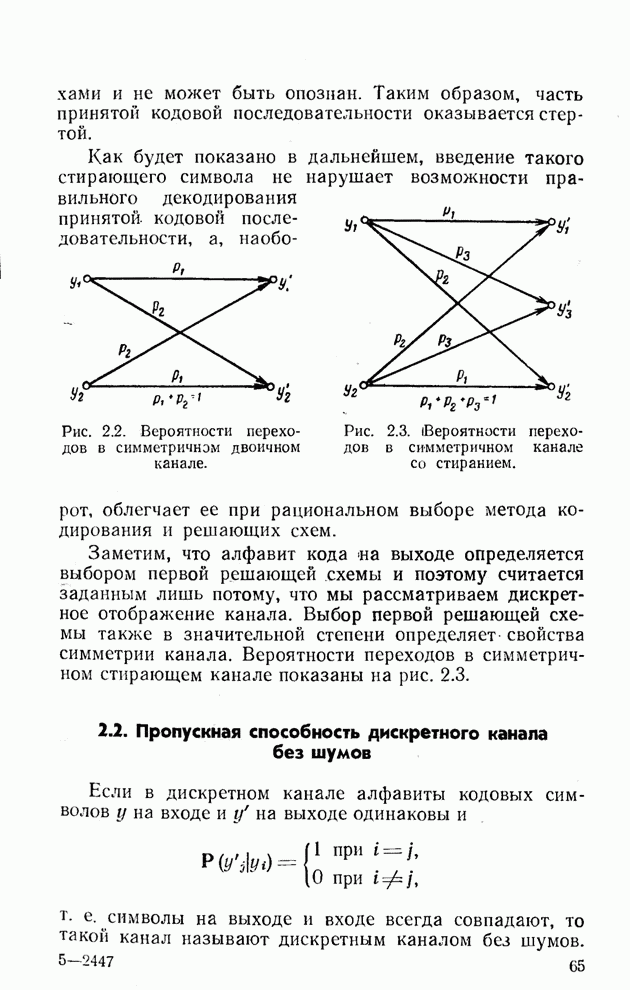
2.5. Постоянный симметричный канал. Случайное кодирование
Постоянный симметричный канал полностью характеризуется
основанием кода  ,
технической скоростью передачи символов
,
технической скоростью передачи символов  и вероятностью
и вероятностью  ошибочного приема символа
(«или, как мы будем говорить для краткости, вероятностью ошибки):
ошибочного приема символа
(«или, как мы будем говорить для краткости, вероятностью ошибки):
 . (2.25)
. (2.25)
Его
пропускная способность на основании (2.21) равна
 (2.26)
(2.26)
В этом выражении только  зависит от распределения
вероятностей
зависит от распределения
вероятностей  . Следовательно, для определения пропускной
способности симметричного постоянного канала необходимо найти такое
распределение вероятностей , которое обеспечивает максимальное
значение . Очевидно, принимает
максимальное значение, равное
. Следовательно, для определения пропускной
способности симметричного постоянного канала необходимо найти такое
распределение вероятностей , которое обеспечивает максимальное
значение . Очевидно, принимает
максимальное значение, равное  , в том случае, когда вероятности
принятых символов
, в том случае, когда вероятности
принятых символов  одинаковы и не
зависят от других принятых символов. Но из свойства симметрии канала легко
показать, что для этого необходимо и достаточно наложить такое же условие на
распределение вероятностей переданных символов .
При этом условии скорость передачи информации
одинаковы и не
зависят от других принятых символов. Но из свойства симметрии канала легко
показать, что для этого необходимо и достаточно наложить такое же условие на
распределение вероятностей переданных символов .
При этом условии скорость передачи информации  достигает
максимума, равного пропускной способности канала:
достигает
максимума, равного пропускной способности канала:
 (2.27)
(2.27)
В частном случае, при  ,
,
 (2.28)
(2.28)
Заметим, что при  пропускная способность
пропускная способность  . Поэтому в
дальнейшем, не нарушая общности можно полагать
. Поэтому в
дальнейшем, не нарушая общности можно полагать  или
или  .
.
Если в симметричном постоянном канале
передавать сообщения некоторого источника с помощью примитивного кодирования  -разрядным равномерным
кодом, то вероятность правильного декодирования
переданной буквы
-разрядным равномерным
кодом, то вероятность правильного декодирования
переданной буквы  равна
вероятности того, что все символов, входящих в кодовую
комбинацию, соответствующую данной булке, приняты правильно:
равна
вероятности того, что все символов, входящих в кодовую
комбинацию, соответствующую данной булке, приняты правильно:

 (2.29)
(2.29)
Вообще, вероятность того, что некоторое
сообщение, закодированное примитивно (без внесения избыточности)
последовательностью из  символов, будет принято
правильно, равна
символов, будет принято
правильно, равна
 (2.30)
(2.30)
Применяя кодирование с избыточностью для источников
с производительностью  , можно существенно увеличить
вероятность правильного приема.
, можно существенно увеличить
вероятность правильного приема.
В постоянном симметричном канале вероятность
ошибочного приема некоторого символа не зависит от того, как приняты другие
символы. Поэтому вероятность того, что в переданной кодовой комбинации из символов определенные
 символов
некоторым образом искажены, а остальные
символов
некоторым образом искажены, а остальные  приняты правильно, равна в
соответствии с (2.25)
приняты правильно, равна в
соответствии с (2.25)
 (2.31)
(2.31)
Легко видеть, что  является монотонной
убывающей функцией , поскольку
является монотонной
убывающей функцией , поскольку  , и не
зависит от того, какие символы приняты
ошибочно. Но можно
рассматривать как функцию правдоподобия переданной кодовой комбинации, если
она отличается от принятой в определенных разрядах.
, и не
зависит от того, какие символы приняты
ошибочно. Но можно
рассматривать как функцию правдоподобия переданной кодовой комбинации, если
она отличается от принятой в определенных разрядах.
Отсюда следует, что в постоянном симметричном
канале функция правдоподобия принимает максимальное значение для той
разрешенной кодовой комбинации, которая отличается от принятой (запрещенной) комбинации
в наименьшем числе разрядов. (Если таких комбинаций несколько, то все они
имеют одинаковые значения функции правдоподобия.)
В теории кодирования количество разрядов, в
которых кодовая комбинации  отличается от кодовой комбинации
отличается от кодовой комбинации
 , называется
хемминговым расстоянием [15]
, называется
хемминговым расстоянием [15]  между этими комбинациями. Легко
убедиться, что хемнингово расстояние удовлетворяет обычным условиям метрики, а
именно: 1)
между этими комбинациями. Легко
убедиться, что хемнингово расстояние удовлетворяет обычным условиям метрики, а
именно: 1)  тогда
и только тогда, когда комбинации и тождественно равны, 2)
тогда
и только тогда, когда комбинации и тождественно равны, 2)  и 3) для
любых трех комбинаций выполняется аксиома треугольника
и 3) для
любых трех комбинаций выполняется аксиома треугольника
 (2.32)
(2.32)
Итак, при декодировании по критерию максимального
правдоподобия принятая запрещенная комбинация должна интерпретироваться как
ближайшая к ней (в смысле хеммингова расстояния) разрешенная комбинация.
Ошибочное декодирование при этом будет иметь место лишь в том случае, когда в
результате действия шумов принятая кодовая комбинация окажется дальше от
действительно переданной, чем от какой-либо другой разрешенной комбинации.
Если между двумя разрешенными кодовыми комбинациями
и хеммингово
расстояние равно ,
то для того, чтобы переданная комбинация была декодирована как , необходимо,
чтобы в принятой комбинации  было не менее
было не менее  ошибочно
принятых символов. Поэтому чем больше , тем меньше вероятность того, что в
данном канале кодовая комбинация перейдет в при декодировании с
исправлением ошибок по критерию максимального правдоподобия.
ошибочно
принятых символов. Поэтому чем больше , тем меньше вероятность того, что в
данном канале кодовая комбинация перейдет в при декодировании с
исправлением ошибок по критерию максимального правдоподобия.
Очевидно, что при построении корректирующего кода
желательно выбирать разрешенные кодовые комбинации таким образом, чтобы
хеммннговы расстояния между ними были как можно больше. Пусть минимальное
хеммингово расстояние между двумя разрешенными кодовыми комбинациями равно  . Тогда в
устройстве с обнаружением ошибок будут обнаружены любые ошибочно принятые
кодовые комбинации, в которых число искаженных символов не превышает
. Тогда в
устройстве с обнаружением ошибок будут обнаружены любые ошибочно принятые
кодовые комбинации, в которых число искаженных символов не превышает  . Действительно, если
в принятой кодовой комбинации ошибочными являются символов, то ее хеммингово
расстояние от переданной комбинации по определению равно . Поэтому при
. Действительно, если
в принятой кодовой комбинации ошибочными являются символов, то ее хеммингово
расстояние от переданной комбинации по определению равно . Поэтому при  принятая кодовая
комбинация но может оказаться одной из разрешенных.
принятая кодовая
комбинация но может оказаться одной из разрешенных.
Если — нечетное число, то в устройство с
исправлением ошибок будут правильно декодированы вес принятые кодовые
комбинации при условии, что число ошибочно принятых символов {или, как
говорят, кратность ошибок)
не превышает  Действительно, при числе ошибочно
принятых символов
Действительно, при числе ошибочно
принятых символов  хеммингово
расстояние между принятой комбинацией и любой из разрешенных комбинаций (кроме
действительно передававшейся), согласно (2.32) не может быть
меньше
хеммингово
расстояние между принятой комбинацией и любой из разрешенных комбинаций (кроме
действительно передававшейся), согласно (2.32) не может быть
меньше  и
ошибочное декодирование не произойдет. При четном как
легко убедиться, возможно как исправление всех ошибок кратности, не превышающей
и
ошибочное декодирование не произойдет. При четном как
легко убедиться, возможно как исправление всех ошибок кратности, не превышающей
 , и так и
обнаружение ошибок кратности
, и так и
обнаружение ошибок кратности  ; в последнем случае, вообще говоря,
могут существовать две или несколько разрешенных комбинаций, одинаково
отстоящих от принятой. Можно также обеспечить гарантированное исправление всех
ошибок кратности, не превышающей , и исправление с некоторой
вероятностью ошибок кратности .
; в последнем случае, вообще говоря,
могут существовать две или несколько разрешенных комбинаций, одинаково
отстоящих от принятой. Можно также обеспечить гарантированное исправление всех
ошибок кратности, не превышающей , и исправление с некоторой
вероятностью ошибок кратности .
Таким образом, задача построения
корректирующего кода сводится к выбору  -разрядных комбинаций, имеющих
максимальное возможное расстояние .
-разрядных комбинаций, имеющих
максимальное возможное расстояние .
В связи с этим возникает вопрос, каково наибольшее
возможное значение при
заданных и
либо
каково наибольшее значение при заданных и . Точного выражения,
которое давало бы ответ на этот вопрос, не существует, однако известны некоторые
оценки.
Приведем без доказательств две наиболее важные
оценки, относящиеся к двоичным корректирующим кодам (). Как показал Хемминг [15],
для любого двоичного кода.
 (2.33)
(2.33)
Те коды, для которых в (2.23) имеет место
равенство, называются плотно упакованными. Помимо примитивных кодов известны и
некоторые плотно упакованные корректирующие коды, например код, состоящий ил
двух комбинаций;  и
и
 , для
которого
, для
которого  ,
,  и
и  .
.
С другой стороны Р. Р. Варшамов показал [11],
что при любых и
существуют
коды, для которых
 (2.34)
(2.34)
Задача конструктивного построения оптимального
(для постоянного симметричного канала) кода, имеющего при заданных и наибольшее
значение ,
в общем виде не решена. Одним из способов приближения к решению этой
задачи (при достаточно большом ), как это ни парадоксально,
является случайный выбор разрешенных кодовых комбинаций из всех  возможных
блоков символов длиной . Поясним это на примере двоичных
кодов ().
возможных
блоков символов длиной . Поясним это на примере двоичных
кодов ().
Пусть случайный образом выбрано последовательностей
символов  и
и
 длиной . Это можно
сделать, например, подбрасывая
длиной . Это можно
сделать, например, подбрасывая  раз монету и записывая , когда выпадает
герб, и в
противном случае. Рассмотрим любую пару из построенных таким образом
комбинаций. Расстояние
раз монету и записывая , когда выпадает
герб, и в
противном случае. Рассмотрим любую пару из построенных таким образом
комбинаций. Расстояние  между этими комбинациями
является случайной величиной. Определим ее математическое ожидание и дисперсию.
между этими комбинациями
является случайной величиной. Определим ее математическое ожидание и дисперсию.
Очевидно, вероятность того, что в некотором
разряде рассматриваемые комбинации будут иметь различные символы, равна  . Поскольку события,
заключающиеся в несовпадении символов в разных разрядах данных двух кодовых
комбинации, независимы, то задача сводится к схеме Бернули (последовательности
из независимых
испытаний) с вероятностью положительного исхода, равной . При этом, как известно,
математическое ожидание расстояния равно
. Поскольку события,
заключающиеся в несовпадении символов в разных разрядах данных двух кодовых
комбинации, независимы, то задача сводится к схеме Бернули (последовательности
из независимых
испытаний) с вероятностью положительного исхода, равной . При этом, как известно,
математическое ожидание расстояния равно
 ,
,
а её дисперсия
 .
.
При  , воспользовавшись интегральной предельной
теоремой Муавра — Лапласа (см. например [16]), можно оценить вероятность того,
что хеммингово расстояние между двумя случайно выбранными кодовыми
комбинациями окажется меньше, чем
, воспользовавшись интегральной предельной
теоремой Муавра — Лапласа (см. например [16]), можно оценить вероятность того,
что хеммингово расстояние между двумя случайно выбранными кодовыми
комбинациями окажется меньше, чем  , где
, где  — некоторое малое
положительное число:
— некоторое малое
положительное число:
 (2.35)
(2.35)
При увеличении функция Лапласа  быстро стремится к нулю. Поэтому
при любых положительных и
быстро стремится к нулю. Поэтому
при любых положительных и  можно найти такое , что с вероятностью,
большей
можно найти такое , что с вероятностью,
большей  ,
хеммингово расстояние между любой парой случайно выбранных кодовых комбинаций
будет больше, чем .
,
хеммингово расстояние между любой парой случайно выбранных кодовых комбинаций
будет больше, чем .
Приведенные рассуждения дают только качественное
подтверждение того, что при случайном выборе кода можно с вероятностью,
близкой к единице, получить большое хеммингово расстояние между разрешенными
кодовыми комбинациями. Для того чтобы определить скорость передачи информации
при случайном кодировании, оценим вероятность ошибочного декодирования при .
Предположим, что случайным образом выбраны , разрешенных
кодовых комбинаций, которые известны как на передающей, так и на приемной
стороне. Пусть одна из них (комбинация ) послана по каналу связи.
Принятая комбинация , вообще говоря, будет содержать
ошибочные символы. Математическое ожидание количества ошибочных символов в равно  , где — вероятность
ошибки в канале. Если
, где — вероятность
ошибки в канале. Если  и
и  — произвольно выбранные сколь угодно малые
положительные величины, то на основании закона больших чисел существует такое
значение
— произвольно выбранные сколь угодно малые
положительные величины, то на основании закона больших чисел существует такое
значение  ,
что при
,
что при  с
вероятностью
с
вероятностью  величина
не
превзойдет
величина
не
превзойдет  .
.
Ошибочное декодирование произойдет в том
случае, если существует хотя бы одна разрешенная комбинация (помимо ), расстояние
которой до принятой комбинации меньше чем . Оценим вероятность
этого. Общее число  комбинаций,
находящихся на расстоянии не большем от комбинации , равно
комбинаций,
находящихся на расстоянии не большем от комбинации , равно
 (2.36)
(2.36)
Поскольку величина очень велика, можно,
воспользовавшись приближенной формулой Стирлинга, заменять правую часть
(2.36) следующим образом:
 (2.37)
(2.37)
Но с вероятностью отношение  меньше чем
меньше чем  . Обозначим
. Обозначим  . Тогда с
вероятностью
. Тогда с
вероятностью
 (2.38)
(2.38)
Любая из этих комбинаций может быть разрешенной
с вероятностью  ,
а вероятность того, что ни одна из комбинации (кроме заведомо
известной комбинации ) не принадлежит к числу
разрешенных, равна
,
а вероятность того, что ни одна из комбинации (кроме заведомо
известной комбинации ) не принадлежит к числу
разрешенных, равна
 (2.39)
(2.39)
Таким образом, вероятность  правильного декодирования
принятой комбинации оценивается следующим
выражением:
правильного декодирования
принятой комбинации оценивается следующим
выражением:
 (2.40)
(2.40)
где логарифм борется по основанию 2.
Введем еще одно обозначение:
 (2.41)
(2.41)
Легко убедиться, что  меньше пропускной способности
канала:
меньше пропускной способности
канала:
 (2.42)
(2.42)
и стремится к ней, когда стремится к нулю. Переписав
(2.40) следующим образом:
 (2.43)
(2.43)
видим, что с увеличением вероятность правильного
декодирования стремится к при условии, что величина удовлетворяет
неравенству
 (2.44)
(2.44)
где 
В частности, это будет верно, если  Учитывая, что при достаточно
большом величина
может
быть сколь угодно малой, а величина — сколь угодно близкой к
Учитывая, что при достаточно
большом величина
может
быть сколь угодно малой, а величина — сколь угодно близкой к  , можно
утверждать, что при случайно выбранном коде вероятность правильного декодирования
принятой комбинации сколь угодно близка к единице (для достаточно большого ), если число разрешенных
комбинаций
, можно
утверждать, что при случайно выбранном коде вероятность правильного декодирования
принятой комбинации сколь угодно близка к единице (для достаточно большого ), если число разрешенных
комбинаций
 (2.45)
(2.45)
Определим, наконец, скорость передачи
информации при таком кодировании. Так как вероятность правильного
декодирования сколь угодно близка к единице, то количество переданной по каналу
информации равно энтропии кодовой комбинации. Если вес разрешенные комбинации
выбираются независимо и равновероятно, то энтропия на кодовую комбинацию равна  , а энтропия на
каждый переданный символ
, а энтропия на
каждый переданный символ
 (2.46)
(2.46)
Следовательно, скорость передачи информации

или, подставляя сюда (2.45),
 (2.47)
(2.47)
С увеличением второй член стремится к нулю, т.
е. скорость передачи информации может быть сколь угодно близкой к пропускной
способности канала.
Разумеется, при описанном случайном выборе кода
существует некоторая вероятность выбрать «плохой» код. Например, может
случиться (хотя и с очень малой вероятностью), что какие-то две комбинации и будут совпадать
друг с другом либо отличаться только в одном разряде. При передаче комбинации она с большой
вероятностью будет декодирована как , и наоборот. Если это имеет место для
нескольких пар комбинаций, то такой код не обеспечит высокой верности
декодирования.
Вероятность правильного приема, оценку которой
даст (2.45), является по существу совместной вероятностью двух событии —
выбора «хорошего» кода и правильного декодирования при этом коде. Более подробный
анализ [9] приводит к следующему результату. Среди случайно выбранных
кодов существуют «хорошие» коды, для которых вероятность ошибочного декодирования
 при
достаточно большом подчиняется неравенству
при
достаточно большом подчиняется неравенству
 (2.48)
(2.48)
где — некоторый коэффициент,
медленно меняющийся с ростом ;  — функция скорости передачи
информации
— функция скорости передачи
информации  ,
положительная при
,
положительная при  и равная нулю при
и равная нулю при  .
.
Что касается вероятности  выбрать «плохой» код, для
которого (2.48) не имеет места, то она также стремится к нулю с ростом , причем значительно
быстрее, чем вероятность ошибочного декодирования. Таким образом, если
значение выбрано
так, чтобы обеспечить достаточно малую вероятность ошибочного декодирования
(2.48), то практически с вероятностью
выбрать «плохой» код, для
которого (2.48) не имеет места, то она также стремится к нулю с ростом , причем значительно
быстрее, чем вероятность ошибочного декодирования. Таким образом, если
значение выбрано
так, чтобы обеспечить достаточно малую вероятность ошибочного декодирования
(2.48), то практически с вероятностью  случайно выбранный -разрядный код будет хорошим.
случайно выбранный -разрядный код будет хорошим.
Казалось бы, что полученные результаты
полностью решают задачу безошибочной передачи информации со скоростью, близкой
к пропускной способности постоянного симметричного двоичного канала. Однако
практическое использование чисто случайного кода сталкивается с
непреодолимыми в настоящее время, а также, по-видимому, и в ближайшие десятилетия,
трудностями. Дело в том, что единственным методом кодирования и декодирования
(при случайном коде) является хранение в памяти кодера и декодера по крайней
мере всех разрешенных комбинаций и сравнение их с принятой комбинацией. При
значениях ,
обеспечивающих достаточно малую вероятность ошибочного декодирования,
необходимый объем памяти существенно превышает все достигнутое современной
техникой.
Именно вследствие этого чисто случайное кодирование
не нашло практического применения и усилия исследователей были направлены на
поиски регулярных (или полурегулярных) методов кодирования, при которых можно
сформулировать определенные правила преобразования сообщений в кодовые
комбинации, а также правила декодирования с обнаружением и исправлением ошибок
и построить по этим правилам относительно просто реализуемые логические схемы.