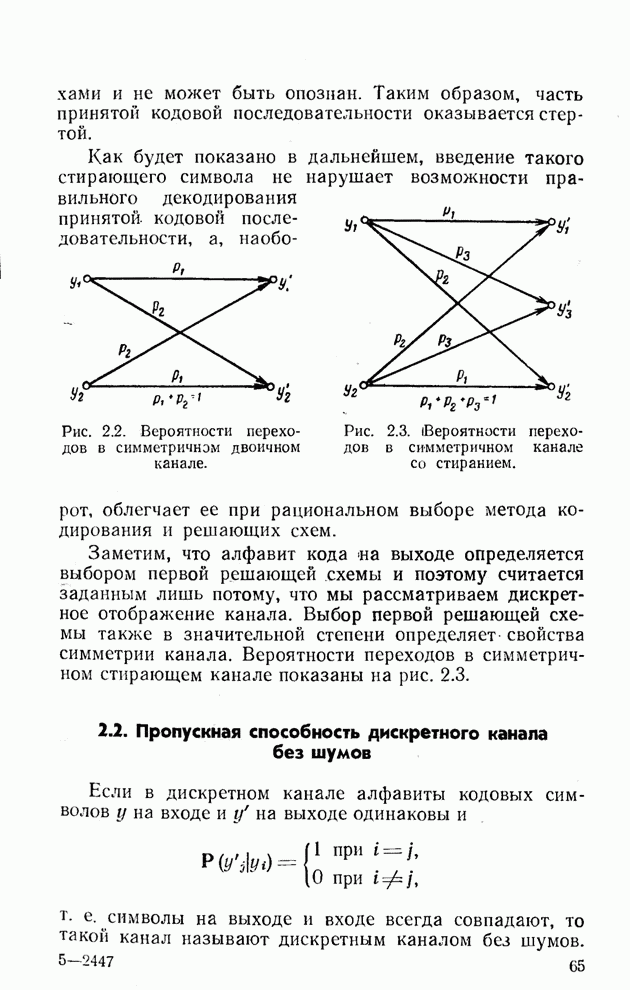
1.3. Количество информации в сообщении
Для того чтобы
иметь возможность сравнивать различные источники сообщений и различные линии и
каналы связи, необходимо ввести некоторую количественную меру, позволяющую
оценивать содержащуюся в сообщении и переносимую сигналом информацию. Такая
мера в виде количества информации была введена К. Шенноном [1] на основе концепции
выбора, что позволило ему построить достаточно общую математическую теорию
связи.
Рассмотрим основные
идеи этой теории применительно к дискретному источнику, выдающему
последовательность элементарных сообщений. Попытаемся найти удобную меру количества
информации, заключенной в некотором сообщении. Основная идея теории информации
заключается в том, что эта мера определяется не конкретным содержанием данного
сообщения, а тем фактом, что источник выбирает данное элементарной т общение
из конечного множества  . Эта идея оправдана тем, что на ее
основании удалось получить ряд далеко идущих и в то же время нетривиальных
результатов, хорошо согласующихся с интуитивными представлениями о передаче
информации. Основные из этих результатов будут изложены далее.
. Эта идея оправдана тем, что на ее
основании удалось получить ряд далеко идущих и в то же время нетривиальных
результатов, хорошо согласующихся с интуитивными представлениями о передаче
информации. Основные из этих результатов будут изложены далее.
Итак, если источник
производит выбор одного элементарного сообщения  (
( ) из множества алфавита , то выдаваемое им количество информации
зависит не от конкретного содержания этого элемента, а от того, каким образом
этот выбор осуществляется. Если выбираемый элемент сообщения заранее определен,
то естественно полагать, что заключающаяся в нем информация равна нулю. Поэтому
будем считать, что выбор буквы происходит с некоторой
вероятностью
) из множества алфавита , то выдаваемое им количество информации
зависит не от конкретного содержания этого элемента, а от того, каким образом
этот выбор осуществляется. Если выбираемый элемент сообщения заранее определен,
то естественно полагать, что заключающаяся в нем информация равна нулю. Поэтому
будем считать, что выбор буквы происходит с некоторой
вероятностью  .
Эта вероятность может, вообще говоря, зависеть от того, какая
последовательность предшествовала данной букве. Примем, что количество
информации, заключенное в элементарном сообщении является непрерывной функцией этой
вероятности
.
Эта вероятность может, вообще говоря, зависеть от того, какая
последовательность предшествовала данной букве. Примем, что количество
информации, заключенное в элементарном сообщении является непрерывной функцией этой
вероятности  ,
и попытаемся определить вид этой функции так, чтобы он удовлетворял некоторым
простейшим интуитивным представлениям об информации.
,
и попытаемся определить вид этой функции так, чтобы он удовлетворял некоторым
простейшим интуитивным представлениям об информации.
С этой целью
произведем простое преобразование сообщения, заключающееся в том, что каждую
пару «букв»  ,
создаваемых
последовательно источником, мы будем рассматривать как одну укрупненную
«букву». Такое преобразование назовем укрупнением алфавита. Множество
,
создаваемых
последовательно источником, мы будем рассматривать как одну укрупненную
«букву». Такое преобразование назовем укрупнением алфавита. Множество  укрупненных «букв»
образует алфавит объемом
укрупненных «букв»
образует алфавит объемом  ,
так как вслед за
каждым из
,
так как вслед за
каждым из  элементов
алфавита может,
вообще говоря, выбираться любой из элементов. Пусть
элементов
алфавита может,
вообще говоря, выбираться любой из элементов. Пусть  есть вероятность того, что
источник произведет последовательный выбор элементов
есть вероятность того, что
источник произведет последовательный выбор элементов  и
. Тогда, рассматривая
пару , как букву нового
алфавита можно
утверждать, что в этой паре заключено количество информации
и
. Тогда, рассматривая
пару , как букву нового
алфавита можно
утверждать, что в этой паре заключено количество информации  .
.
Естественно
потребовать, чтобы количество информации, заключенное в паре букв,
удовлетворяло условию аддитивности, т. е. равнялось сумме количеств информации,
содержащихся в каждой из букв и первоначального алфавита . Информация,
содержащаяся в букве , равна  , где
, где  — вероятность выбора буквы после всех букв, предшествовавших ей. Для
определения информации, содержащейся в букве , нужно учесть вероятность выбора буквы
после буквы с
учетом также всех букв, предшествовавших букве . Эту условную вероятность
обозначим
— вероятность выбора буквы после всех букв, предшествовавших ей. Для
определения информации, содержащейся в букве , нужно учесть вероятность выбора буквы
после буквы с
учетом также всех букв, предшествовавших букве . Эту условную вероятность
обозначим  . Тогда количество
информации в букве выразится функцией
. Тогда количество
информации в букве выразится функцией  .
.
С другой стороны,
вероятность выбора пары букв по правилу умножения вероятностей равна
 .
(1.2)
.
(1.2)
Требование
аддитивности количества информации при операции укрупнения алфавита приводит к
равенству
 .
.
Пусть  и
и  . Тогда
для любых
. Тогда
для любых  и
и

 должно
соблюдаться уравнение
должно
соблюдаться уравнение
 (1.3)
(1.3)
Случаи  или
или  мы исключаем из
рассмотрения, так как вследствие конечного числа букв алфавита эти равенства
означают, что выбор источником пары букв , является невозможным событием.
мы исключаем из
рассмотрения, так как вследствие конечного числа букв алфавита эти равенства
означают, что выбор источником пары букв , является невозможным событием.
Равенство (1.3)
является функциональным уравнением, из которого может быть определен вид
функции  .
Продифференцируем обе части уравнения (1.3) по р:
.
Продифференцируем обе части уравнения (1.3) по р:
 .
.
Умножим обе части полученного уравнения
на р и введем обозначение  , тогда
, тогда
 (1.4)
(1.4)
Это уравнение
должно быть справедливо при любом  и любом
и любом  . Последнее ограничение
. Последнее ограничение  не существенно, так
как уравнение (1.4) симметрично относительно и
не существенно, так
как уравнение (1.4) симметрично относительно и  и, следовательно, должно выполняться
для любой пары положительных значений аргументов, не превышающих единицы. Но
это возможно лишь в том случае, если обе части (1.4) представляют некоторую
постоянную величину
и, следовательно, должно выполняться
для любой пары положительных значений аргументов, не превышающих единицы. Но
это возможно лишь в том случае, если обе части (1.4) представляют некоторую
постоянную величину  , откуда
, откуда
 ,
,
 .
.
Интегрируя
полученное уравнение, найдем
 , (1.5)
, (1.5)
где  — произвольная постоянная
интегрирования.
— произвольная постоянная
интегрирования.
Формула (1.5)
определяет класс функций  , выражающих количество информации при
выборе буквы ,
имеющей вероятность
, выражающих количество информации при
выборе буквы ,
имеющей вероятность  ,
и удовлетворяющих условию аддитивности. Для определения
постоянной интегрирования воспользуемся высказанным выше условием,
по которому заранее предопределенный элемент сообщения, т. е. имеющий
вероятность
,
и удовлетворяющих условию аддитивности. Для определения
постоянной интегрирования воспользуемся высказанным выше условием,
по которому заранее предопределенный элемент сообщения, т. е. имеющий
вероятность  ,
не содержит информации. Следовательно,
,
не содержит информации. Следовательно,  , откуда сразу следует, что
, откуда сразу следует, что  .
.
Что касается
коэффициента пропорциональности , то его можно
выбрать произвольно, так как он определяет лишь систему единиц, в которых
измеряется информация. Однако, поскольку  , разумно выбирать отрицательным, для того чтобы
количество информации было положительным. Наиболее простым является выбор
, разумно выбирать отрицательным, для того чтобы
количество информации было положительным. Наиболее простым является выбор  . Тогда
. Тогда
 (1.6)
(1.6)
При
этом единица количества информации равна той информации, которая содержится в
элементарном сообщении, имеющем вероятность  (
( — основание натуральных логарифмов),
или, другими словами, равна информации, содержащейся в сообщении о том, что
наступило событие, вероятность которого равнялась . Такую единицу информации
называют натуральной единицей.
— основание натуральных логарифмов),
или, другими словами, равна информации, содержащейся в сообщении о том, что
наступило событие, вероятность которого равнялась . Такую единицу информации
называют натуральной единицей.
Чаще выбирают  . Тогда
. Тогда  или
или
 (1.6а)
(1.6а)
При таком выборе
единица
информации называется двоичной. Она равна информации, содержащейся в сообщении
о том, что наступило событие, вероятность которого равнялась ½ т. е.
которое могло с равной вероятностью наступить и не наступить. Иногда
используют и другие единицы информации, например десятичные. Мы будем применять
как двоичные, так и натуральные единицы количества информации. В тех случаях,
когда выбор единиц не играет роли, мы будем писать
 , (1.6б)
, (1.6б)
считая, что логарифм берется по
любому основанию, лишь бы это основание сохранялось на протяжении решаемой
задачи.
Благодаря свойству
аддитивности информации выражения (1.6) позволяют определить количество
информации не только в букве сообщения, но и в любом сколь угодно длинном
сообщении. Нужно лишь принять за вероятность выбора этого сообщения из
всех возможных с учетом ранее выбранных сообщений.