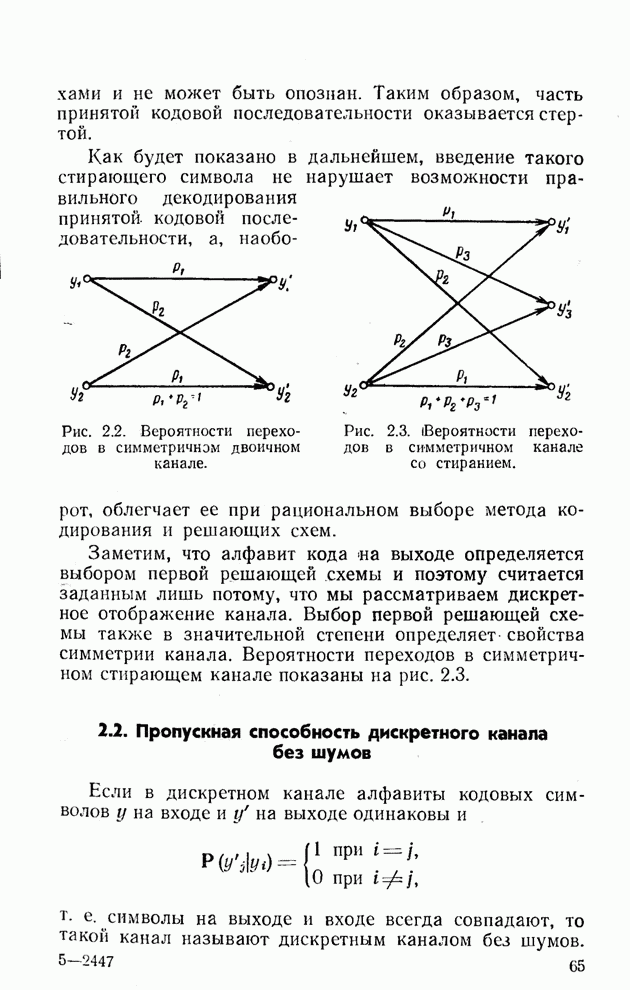
2.8. Кодирование в несимметричных каналах и каналах с памятью
Несимметричные постоянные каналы редко встречаются
на практике и теория кодирования для них мало разработана. При кодировании без
избыточности максимум скорости передачи информации в несимметричном канале
имеет место при неравномерном распределении априорных вероятностей, когда чаще
используются те символы, которые принимаются более правильно.
Ограничимся кратким рассмотрением двоичного несимметричного
постоянного канала. Пусть используются символы 0 и 1, причем  и
и  . Обозначим
априорные вероятности этих символов соответственно
. Обозначим
априорные вероятности этих символов соответственно  и
и  .
.
Тогда среднее количество переданной
информации на каждый символ равно
 (2.55)
(2.55)
Дифференцируя это выражение по с учетом того, что , и приравнивая
производную к нулю, можно найти оптимальное априорное распределение
вероятностей символов, обеспечивающее максимум передаваемой информации.
Оптимальное значение оказывается равным
 (2.56)
(2.56)
где

Найдя  и подставив его в (2.55), можно найти
максимальное количество передаваемой в таком канале информации
и подставив его в (2.55), можно найти
максимальное количество передаваемой в таком канале информации  и его пропускную способность
и его пропускную способность
 .
.
В частном случае симметричного канала  величина
величина  равна нулю и
оптимальное значение , как и следовало ожидать, равно 0,5.
равна нулю и
оптимальное значение , как и следовало ожидать, равно 0,5.
В предельном случае, когда один из символов, например
«1», всегда принимается правильно  , a другой символ «0» может
приниматься как «1» с вероятностью
, a другой символ «0» может
приниматься как «1» с вероятностью  , выражение (2.56) упрощается
, выражение (2.56) упрощается
 (2.56а)
(2.56а)
Заметны, что в этом случае символ «1» является
«надежным» передаваемым символом, так как он всегда принимается верно. Однако
«достоверным» принятым символом является (0), так как приняв его, можно с
полной достоверностью утверждать, что именно этот символ передавался.
В частном случае, когда  , а
, а  , оптимальным распределением
вероятностей символов оказывается
, оптимальным распределением
вероятностей символов оказывается  и
и  . Пропускная способность такого
канала равна
. Пропускная способность такого
канала равна  .
Заметим, что эта пропускная способность
значительно выше, чем у симметричного канала с той же средней вероятностью ошибок
(
.
Заметим, что эта пропускная способность
значительно выше, чем у симметричного канала с той же средней вероятностью ошибок
( ),
которая равна
),
которая равна  .
.
Пропускная способность несимметричного канала
равна пулю, когда  .
При этом принятые символы не содержат никакой информации о переданных, так
как апостериорные вероятности символов «0» и «1» совпадают с априорными.
.
При этом принятые символы не содержат никакой информации о переданных, так
как апостериорные вероятности символов «0» и «1» совпадают с априорными.
Для несимметричного канала, в котором (или  так что
практически величиной
так что
практически величиной  можно пренебречь), можно применить
эффективные корректирующие коды, позволяющие обнаруживать и исправлять ошибки
[14]. Однако теория таких кодов мало разработана и существенно отличается от
теории кодирования в симметричных каналах. Так, например, код, состоящий из
кодовых комбинаций 00 и 11, позволяет исправлять одну ошибку (переход 0 в 1),
если условиться декодировать принятые комбинации 01 и 10 как 00. В то же время
код, состоящий из комбинации 01 и 10 не даст возможности исправлять ошибку, а
позволяет только ее обнаруживать, хотя оба эти кода характеризуются одинаковым
хемминговым расстоянием, равным 2. Заметим, что в симметричном канале оба эти
кода позволяют только обнаружить одиночную ошибку.
можно пренебречь), можно применить
эффективные корректирующие коды, позволяющие обнаруживать и исправлять ошибки
[14]. Однако теория таких кодов мало разработана и существенно отличается от
теории кодирования в симметричных каналах. Так, например, код, состоящий из
кодовых комбинаций 00 и 11, позволяет исправлять одну ошибку (переход 0 в 1),
если условиться декодировать принятые комбинации 01 и 10 как 00. В то же время
код, состоящий из комбинации 01 и 10 не даст возможности исправлять ошибку, а
позволяет только ее обнаруживать, хотя оба эти кода характеризуются одинаковым
хемминговым расстоянием, равным 2. Заметим, что в симметричном канале оба эти
кода позволяют только обнаружить одиночную ошибку.
Значительно больший практический интерес представляют
непостоянные каналы пли каналы с памятью. К ним относится подавляющее большинство
каналов, с которыми приходится встречаться в технике связи. Симметричные каналы
с памятью отличаются от симметричных постоянных каналов тем, что распределение
числа ошибок на протяжении некоторого блока символов с любой длиной  не всегда
подчиняется биноминальному распределению. Если в постоянном канале условная
вероятность ошибочного приема
не всегда
подчиняется биноминальному распределению. Если в постоянном канале условная
вероятность ошибочного приема  -го символа при условии, что
-го символа при условии, что  -й символ принят
ошибочно, равна безусловной вероятности ошибки
-й символ принят
ошибочно, равна безусловной вероятности ошибки
 , (2.57)
, (2.57)
то в канале с памятью она может бить больше или
меньше этой величины.
Отклонение распределения ошибок от биномиального
в реальных каналах вызывается различными причинами. Так, дискретным отображением
большинства радиоканалов является канал с памятью вследствие обычно имеющих
место замираний, которые будут рассмотрены в пятой главе. Другой причиной
могут являться атмосферные и взаимные помехи. Иногда отклонение от
биномиального распределения вызывается особенностями примененного метода
модуляции и демодуляции. В уплотненных кабельных линиях связи причиной «памяти»
обычно считают наличие коммутационных помех, возникающих
при переключениях отдельных элементов канала и по существу выводящих па
короткое время канал из строя.
Изучение каналов с памятью, разработка корректирующих
кодов для них и оценка их эффективности затрудняются тем, что для описания
такого канала недостаточно знать один параметр (каким является вероятность
ошибки в постоянном симметричном канале). Для этого нужно уметь определять
вероятности любых сочетаний ошибок в пределах блока любой длины п. С
целью получения таких данных прибегают к экспериментальному исследованию
различных реальных каналов. Однако обобщение полученных экспериментальных
результатов затрудняется тем, что не всегда удается, подобрать удобное
аналитическое представление, тем более, что различные каналы ведут себя
по-разному. Поэтому исследователи пытаются построить такие математические
модели дискретного канала с памятью, которые определяются лишь небольшим числом
параметров, соответствующий подбор которых позволяет хотя бы в общих чертах
описать поведение реальных каналов.
Отметим прежде всего основные особенности, по
которым можно классифицировать каналы с памятью. Подавляющее большинство
каналов, встречающихся на практике, удовлетворяет
условию
 (2.58)
(2.58)
Это означает, что по сравнению с постоянным
каналом в таком канале ошибки имеют тенденцию группироваться. С увеличением  неравенство
(2.58) обычно приближается к равенству. Такие каналы будем называть каналами
с группированием ошибок.
неравенство
(2.58) обычно приближается к равенству. Такие каналы будем называть каналами
с группированием ошибок.
В большей части каналов с
группированием ошибок  ; в частности, в двоичном канале
; в частности, в двоичном канале  . Такие каналы можно назвать нормальными каналами с группированием ошибок в отличие от аномальных
каналов, в которых
. Такие каналы можно назвать нормальными каналами с группированием ошибок в отличие от аномальных
каналов, в которых  может превышать
может превышать  .
.
|
Значительно реже встречаются каналы с
рассредоточенными ошибками, в которых
 (2.59) (2.59)
Примером может служить канал, в котором
причиной ошибок являются импульсные помехи, если каждый импульс поражает
только один символ, а источник помехи обладает тем свойством, что вероятность
появления следующего импульса непосредственно после предыдущего очень мала и
со временем возрастает.
Возможны также каналы с памятью, для которых
при одних значениях справедливо (2.58), а при других
значениях – (2.59). Так, если (2.58) выполняется при нечётных , а (2.59) - при
чётных ,
то в канале имеется тенденция к сдваиванию ошибок. Пример такого канала будет
приведён несколько ниже.
|
Все известные математические модели каналов с
памятью построены почти исключительно для описания нормальных каналов с
группированием ошибок. Простейшей моделью канала с памятью является марковская,
т.е. представление последовательности ошибок в виде простой цепи Маркова
|2]. При этом вероятность того, что данный символ будет принят ошибочно, равна
некоторой величине ,
если предыдущий символ был принят верно, и некоторой другой величине , если предыдущий
символ был принят ошибочно.
При  марковская модель представляет
нормальный канал с группированием ошибок, при
марковская модель представляет
нормальный канал с группированием ошибок, при  — канал с рассредоточенными
ошибками. Безусловная (средняя) вероятность ошибки
— канал с рассредоточенными
ошибками. Безусловная (средняя) вероятность ошибки  в таком канале должна
удовлетворять уравнению
в таком канале должна
удовлетворять уравнению

откуда
 (2.60)
(2.60)
При такой модели чрезвычайно просто вычисляется
вероятность любого сочетания ошибок и легко оценивается эффективность любого
кода. К сожалению, однако, эта модель очень грубо воспроизводит свойства
реальных каналов с группированием ошибок. Поэтому в настоящее время ею не
пользуются.
Попытки описать канал цепью Маркова более высокого
порядка (т. е. считать, что вероятность ошибочного приема символа однозначно
определяется тем, как приняты предыдущие  символов) также не увенчались
успехом. При малых такая
модель плохо согласуется с экспериментом, при больших она неудобна для расчетов.
символов) также не увенчались
успехом. При малых такая
модель плохо согласуется с экспериментом, при больших она неудобна для расчетов.
Несколько более успешно используется модель
Гильберта (точнее, Джильберта) [23]. Согласно этой модели канал
может находиться в двух состояниях  и
и  . В состоянии ошибок не происходит, в
состоянии ошибки
возникают независимо с вероятностью . Известна вероятность
. В состоянии ошибок не происходит, в
состоянии ошибки
возникают независимо с вероятностью . Известна вероятность  -перехода (при передаче
очередного символа) из состояния в состояние и вероятность
-перехода (при передаче
очередного символа) из состояния в состояние и вероятность  -перехода из в . Таким образом,
здесь простую марковскую цепь образует не последовательность ошибок, а
последовательность состояний.
-перехода из в . Таким образом,
здесь простую марковскую цепь образует не последовательность ошибок, а
последовательность состояний.
Вероятности пребывания канала в состояниях и , как легко
подсчитать, равны


а безусловная вероятность ошибки
 .
.
Чаще
всего, при использовании модели Гильберта для двоичного канала полагают  . Другими словами, состояние
рассматривается
как полный обрыв связи, тогда как в состоянии шумы в канале отсутствуют. Это довольно
хорошо согласуется с представлением о канале, в котором действуют только
коммутационные помехи.
. Другими словами, состояние
рассматривается
как полный обрыв связи, тогда как в состоянии шумы в канале отсутствуют. Это довольно
хорошо согласуется с представлением о канале, в котором действуют только
коммутационные помехи.
Более
общей, но менее удобной для расчетов является модель Беннета—Фрелиха [24]. Согласно этой модели ошибки возникают в
виде более или менее продолжительных всплесков или пачек. Под пачкой подразумевается последовательность
символов, в которой первый и последний приняты ошибочно, а между ними могут
быть как правильно, так и ошибочно принятые символы. Предполагается, что пачки
возникают независимо друг от друга с вероятностью  . Помимо этой вероятности канал характеризуется вероятностью ошибок внутри пачки и распределением
. Помимо этой вероятности канал характеризуется вероятностью ошибок внутри пачки и распределением  вероятностей
длины (числа символов) пачки
вероятностей
длины (числа символов) пачки  . Подбирая
значения и , а также вид функции , в ряде случаев удастся
получить описание канала, согласующееся с экспериментальными результатами.
Вычисления вероятностей различных сочетаний ошибок и результата их исправления
корректирующими кодами по модели Беннета—Фрелиха довольно сложны и обычно
заменяются моделированием на цифровых вычислительных машинах.
. Подбирая
значения и , а также вид функции , в ряде случаев удастся
получить описание канала, согласующееся с экспериментальными результатами.
Вычисления вероятностей различных сочетаний ошибок и результата их исправления
корректирующими кодами по модели Беннета—Фрелиха довольно сложны и обычно
заменяются моделированием на цифровых вычислительных машинах.
Заметим,
что понятие пачки ошибок не совпадает с понятием состояния в модели Гильберта. Состояние , как и пачка, характеризуется ненулевой вероятностью
ошибок , но в
отличие от пачки не ставится условие, чтобы состояние начиналось и заканчивалось ошибочно принятыми
символами.
Модель
Беннета—Фрелиха более гибка, чем модель Гильберта, так как она допускает весьма
свободный выбор функции , на которую наложено только обычное условие
нормирования, тогда как в модели Гильберта распределение вероятностей
длительности состояния всегда выражается формулой  , т. е. однозначно определяется
величиной .
Тем не менее для многих экспериментально исследованных каналов не удастся
удовлетворительно подобрать параметры модели Беннета—Фрелиха, а тем более
модели Гильберта. Ввиду этого О.В.Попов предложил [25] более сложную модель
дискретного канала, отличающуюся от модели Беннета—Фрелиха тем, что пачки
ошибок считаются не независимыми. Согласно этой модели канал может находиться в
двух состояниях, причем в первом состоянии ошибки не возникают, а во втором
состоянии с определенной вероятностью возникают пачки ошибок; параметрами
являются вероятности переходов из одного состояния в другое; вероятность
возникновения пачки во втором состоянии, вероятность ошибки внутри пачки
(которая обычно равна 0,5) и распределение вероятностей длины пачки. В большинстве
случаев удается этими параметрами достаточно хорошо характеризовать реальные
каналы.
, т. е. однозначно определяется
величиной .
Тем не менее для многих экспериментально исследованных каналов не удастся
удовлетворительно подобрать параметры модели Беннета—Фрелиха, а тем более
модели Гильберта. Ввиду этого О.В.Попов предложил [25] более сложную модель
дискретного канала, отличающуюся от модели Беннета—Фрелиха тем, что пачки
ошибок считаются не независимыми. Согласно этой модели канал может находиться в
двух состояниях, причем в первом состоянии ошибки не возникают, а во втором
состоянии с определенной вероятностью возникают пачки ошибок; параметрами
являются вероятности переходов из одного состояния в другое; вероятность
возникновения пачки во втором состоянии, вероятность ошибки внутри пачки
(которая обычно равна 0,5) и распределение вероятностей длины пачки. В большинстве
случаев удается этими параметрами достаточно хорошо характеризовать реальные
каналы.
Попытка
описать двоичный канал с группированием ошибок при помощи всего лишь двух
параметров — вероятности ошибок и показателя группирования , сделана в [37]. С
этой целью рассматривается условное математическое ожидание  числа ошибок в блоке длиной при условии, что
произошло не менее ошибок.
Величина
числа ошибок в блоке длиной при условии, что
произошло не менее ошибок.
Величина  при
при
 согласно
проведенным экспериментам достаточно хорошо аппроксимируется для некоторых
каналов эмпирическими выражениями
согласно
проведенным экспериментам достаточно хорошо аппроксимируется для некоторых
каналов эмпирическими выражениями
 при
при 
 при
при 
где
—
параметр, зависящий от характеристик канала. Для постоянных каналов  ; чем значительнее
группируются ошибки, тем больше . При
; чем значительнее
группируются ошибки, тем больше . При  ошибки следуют сплошными потоками.
Заметим, что
ошибки следуют сплошными потоками.
Заметим, что  по
определению. Зная и
, можно
вычислить вероятности различного числа ошибок в блоках любой длины, не
задумываясь о механизме, вызывающем группирование.
по
определению. Зная и
, можно
вычислить вероятности различного числа ошибок в блоках любой длины, не
задумываясь о механизме, вызывающем группирование.
Все
описанные модели дискретного канала с памятью также являются в значительной
мере формальными. При их построении не учитываются причины, вызывающие
группирование ошибок, а попросту подбирается вероятностная схема, которая
должна описывать наблюдаемые факты. Правда, для некоторых моделей (например,
Беннета—Фрелиха) часто подводят «физическую базу», говоря о том, что
источником ошибок являются только коммутационные помехи или всплески импульсных
помех, возникающие независимо (в модели Попова зависимо) друг от друга и
поражающие более или менее длительный отрезок сигнала. По эти модели применяют,
и довольно успешно, также к таким каналам, в которых заведомо существуют и
другие виды помех [44].
В
отличие от формальных математических моделей дискретных каналов в последнее
время уделяется внимание построению физических моделей. В этих моделях
дискретный канал рассматривается как отображение непрерывного канала и
распределение ошибок выводится из вероятностных свойств сигнала и помехи в непрерывном
канале. Так, например, В. И. Коржик [26] рассмотрел распределение ошибок в
канале с флюктуационной помехой, когда сигнал подвержен релеевским замираниям
(см. гл. 5). С некоторыми из таких моделей мы познакомимся в последующих
главах.
Вычисление
пропускной способности различных моделей дискретного канала с памятью
представляет собой сложную задачу. Для модели Гильберта она решена в [23].
Впрочем, в случае, когда состояния канала меняются очень редко, можно
приближенно определить пропускную способность, зная пропускную способность
постоянных каналов, соответствующих этим состояниям. Рассмотрим, например,
обобщение модели Гильберта, полагая, что канал может находиться в состояниях с вероятностью
ошибки и с
вероятностью ошибки, причем вероятности - и -переходов
из одного состояния в другое очень малы, вследствие чего состояния изменяются
редко. Для определенности предположим, что  .
.
Пропускную
способность такого канала можно приближенно определить, усредняя «частичные»
пропускные способности по состояниям и :
 (2.61)
(2.61)
где
 и
и  — соответственно
вероятности состояний и
— соответственно
вероятности состояний и 
 и
и  — пропускные способности для симметричных
каналов с вероятностями ошибок и .
— пропускные способности для симметричных
каналов с вероятностями ошибок и .
Если
бы состояние канала было в каждый момент известно обоим корреспондентам, то
формула (2.61) была бы точной и можно было бы в каждом состоянии применять
свой корректирующий код, приспособленный к данному значению вероятности ошибки.
Но для этого нужно, чтобы на передающее устройство поступала информация с
приемного устройства, но которой можно было бы судить о состоянии канала. Этот
случай будет рассмотрен в гл. 11.
Очевидно,
что применение кода, рассчитанного на постоянный симметричный канал с
вероятностью ошибки равной средней вероятности ошибок в
канале с памятью:

не
приводит к цели. Действительно, пусть применен -разрядный корректирующий код,
позволяющий исправлять ошибок в кодовой комбинации. В постоянном канале,
если  вероятность
того, что в кодовой комбинации будет больше чем ошибочно принятых символов, может быть
сдана очень малой. Такой код в постоянном канале обеспечивает высокую верность
принятых сообщений. В рассматриваемом же канале такой код, если больше
вероятность
того, что в кодовой комбинации будет больше чем ошибочно принятых символов, может быть
сдана очень малой. Такой код в постоянном канале обеспечивает высокую верность
принятых сообщений. В рассматриваемом же канале такой код, если больше  но меньше
но меньше  , не обеспечит верности, так как те комбинации,
которые передаются в худших условиях (в состоянии ) с большой вероятностью будут приняты с числом ошибок, превышающим ,
и, следовательно, не будут исправлены. В то же время тс комбинации, которые
переданы в состоянии , будут иметь, как правило, значительно
меньше чем ошибочно принятых символов (так как
, не обеспечит верности, так как те комбинации,
которые передаются в худших условиях (в состоянии ) с большой вероятностью будут приняты с числом ошибок, превышающим ,
и, следовательно, не будут исправлены. В то же время тс комбинации, которые
переданы в состоянии , будут иметь, как правило, значительно
меньше чем ошибочно принятых символов (так как  ), и для них
исправляющая способность кода чрезмерно велика, т. е. код имеет чересчур
большую избыточность. Другими словами, хотя среднее количество ошибок в кодовой
комбинации равно но эти ошибки расположены не равномерно, а появляются чаще всего
пачками, когда канал находится в состоянии .
), и для них
исправляющая способность кода чрезмерно велика, т. е. код имеет чересчур
большую избыточность. Другими словами, хотя среднее количество ошибок в кодовой
комбинации равно но эти ошибки расположены не равномерно, а появляются чаще всего
пачками, когда канал находится в состоянии .
Конечно,
в этом случае можно было бы применить корректирующий код, рассчитанный на худшие
условия (состояние ),
и ценой большой избыточности (т. е. замедления передачи информации) обеспечить
требуемую верность. Но для состояния такая избыточность была бы непомерно
велика. При этом используемая пропускная способность канала сводится по
существу к —
пропускной способности в наихудших условиях. Поэтому такой метод кодирования
весьма невыгоден. В некоторых случаях (например, при радиосвязи с отражением
от метеорных следов) такое кодирование вообще невозможно, так как в состоянии пропускная способность
практически снижается до нуля.
Одним
из возможных решений может быть следующее. Применим код, содержащий столь
длинные комбинации, что на протяжении каждой такой комбинации канал с большой
вероятностью несколько раз сменит свое состояние. При этом условии ожидаемое
количество ошибок в комбинации определяется средней вероятностью ошибок  . Если количество
исправляемых ошибок в комбинации значительно превосходит то в этом случае все
комбинации с большой вероятностью будут правильно декодированы. Однако и этот
метод кодирования имеет два существенных недостатка. Во-первых, в реальных
условиях (например, при замираниях) длина кодовой комбинации должна быть столь
велика (порядка тысяч разрядов), что практическая реализация схем кодирования
и декодирования наталкивается на непреодолимые трудности. Во-вторых, такой
метод кодирования по существу рассчитан на постоянный симметричный канал с
вероятностью ошибок
. Если количество
исправляемых ошибок в комбинации значительно превосходит то в этом случае все
комбинации с большой вероятностью будут правильно декодированы. Однако и этот
метод кодирования имеет два существенных недостатка. Во-первых, в реальных
условиях (например, при замираниях) длина кодовой комбинации должна быть столь
велика (порядка тысяч разрядов), что практическая реализация схем кодирования
и декодирования наталкивается на непреодолимые трудности. Во-вторых, такой
метод кодирования по существу рассчитан на постоянный симметричный канал с
вероятностью ошибок  . Но пропускная способность такого
канала, как можно доказать, всегда меньше пропускной способности канала с
памятью при той же средней вероятности ошибки. Поэтому в принципе должны
существовать более экономные коды, обеспечивающие в канале с памятью такую же
верность при меньшей избыточности.
. Но пропускная способность такого
канала, как можно доказать, всегда меньше пропускной способности канала с
памятью при той же средней вероятности ошибки. Поэтому в принципе должны
существовать более экономные коды, обеспечивающие в канале с памятью такую же
верность при меньшей избыточности.
Первый
из этих недостатков можно в значительной степени преодолеть, применяя
корректирующие коды с относительно короткими комбинациями в сочетании с
системой «декорреляции ошибок». Эта система заключается в том, что сообщения
колируются обычным образом с помощью, например, систематического кеда, причем
длина комбинации и число исправляемых ошибок (а следовательно, избыточность кода)
выбираются исходя из условий получения требуемой верности в постоянном
симметричном канале с вероятностью ошибок . Полученные при этом символы кодовой
комбинации передаются в канал не непосредственно один за другим, а со
значительными промежутками времени. В этих промежутках передаются символы других
кодовых комбинаций. Этот процесс можно наглядно представить следующим образом
[27]. Запишем  кодовых
комбинаций в виде таблицы:
кодовых
комбинаций в виде таблицы:

Здесь
каждая строка представляет -разрядную комбинацию корректирующего
кода. Будем осуществлять передачу этих символов не по строчкам, а по столбцам,
т. е. сначала передадим поочередно 1-е разряды всех комбинаций,
затем все 2-е разряды и т. д. Если количество комбинаций в таблице достаточно
велико, то за время ее передачи канал успеет несколько раз сменить свое
состояние, и среднее количество ошибок в каждой кодовой комбинация будет
определяться средней вероятностью ошибки . Пачки ошибок при этом распределятся
между различными кодовыми комбинациями, а не будут сосредоточены в отдельных
комбинациях, как это имеет место при обычной последовательной передаче.
Принятые символы аналогичным образом расставляются по своим местам, после чего
производится декодирование. При этом устройства кодирования и декодирования
оказываются не более сложными, чем в постоянных каналах, но требуются дополнительные
запоминающие устройства значительной емкости на передатчике и приемнике.
Декорреляция
ошибок сравнительно просто осуществляется при применении цепного кода,
описанного в § 2.6. Именно с этой целью там применен отличный от нуля «шаг»
кода  . При достаточно большом значении символы, входящие в одну и ту же
проверку на четность (2.51), будут разнесены по времени настолько, что
состояние канала за это время успеет измениться. Другими словами, пачка ошибок
будет, как правило, захватывать только символы, не связанные друг с другом
проверками на четность. Для этого необходимо, чтобы шаг превышал количество ошибок в
самом длинном из ожидаемых всплесков.
. При достаточно большом значении символы, входящие в одну и ту же
проверку на четность (2.51), будут разнесены по времени настолько, что
состояние канала за это время успеет измениться. Другими словами, пачка ошибок
будет, как правило, захватывать только символы, не связанные друг с другом
проверками на четность. Для этого необходимо, чтобы шаг превышал количество ошибок в
самом длинном из ожидаемых всплесков.
Хотя
кодирование с декорреляцией ошибок позволяет применить обычные корректирующие
коды в канале с памятью, однако, как уже указывалось, этот метод остается
неэкономичным, поскольку он не использует повышения пропускной способности
такого канала но сравнению с постоянным, имеющим ту же среднюю вероятность
ошибки.
В
связи с этим большой интерес представляют коды, позволяющие исправлять пачки
ошибок. Если в постоянном симметричном канале вероятность того, что в блоке из
символов
произойдет ошибок,
не зависит от того, как расположены ошибочно принятые символы в блоке, то в
канале с группированием ошибок значительно более вероятно ошибочно принять близко отстоящих
друг от друга символов, чем равномерно распределенных по всему блоку. Поэтому
имеет смысл строить корректирующий код таким образом, чтобы исправлять не все
ошибки определенной кратности, а такие, которые представляют пачку некоторой
определенной длины  . Такой код исправляет любое сочетание
ошибок, если между первые и последним ошибочно принятыми символами находится не
более
. Такой код исправляет любое сочетание
ошибок, если между первые и последним ошибочно принятыми символами находится не
более  разрядов,
среди которых может быть сколько угодно ошибочных. При этом величина может быть значительно
большей, чем число независимых ошибок, которое мог бы исправить код при той же
избыточности.
разрядов,
среди которых может быть сколько угодно ошибочных. При этом величина может быть значительно
большей, чем число независимых ошибок, которое мог бы исправить код при той же
избыточности.
В
1959 г. Н. Абрамсон [28] предложил циклический код, позволяющий исправлять как
одиночные, так и двойные смежные ошибки  . Вскоре П. Файр [29] излучил обобщение
этого результата, построив коды, позволяющие обнаруживать и исправлять пачки
ошибок при
. Вскоре П. Файр [29] излучил обобщение
этого результата, построив коды, позволяющие обнаруживать и исправлять пачки
ошибок при  .
Эти коды оказались циклическими или укороченными циклическими кодами [11].
Найдены также и другие коды, исправляющие пачки ошибок. Практическое
применение их затрудняется тем, что при не очень большой избыточности, как
правило,
.
Эти коды оказались циклическими или укороченными циклическими кодами [11].
Найдены также и другие коды, исправляющие пачки ошибок. Практическое
применение их затрудняется тем, что при не очень большой избыточности, как
правило,  . Так,
например, код Файра (279, 265), содержащий 265 информационных и 14
проверочных разрядов, позволяет исправить только одну пачку ошибок длиной
. Так,
например, код Файра (279, 265), содержащий 265 информационных и 14
проверочных разрядов, позволяет исправить только одну пачку ошибок длиной  . Другой код со
значительно большей избыточностью (44, 22) исправляет пачки длиной
. Другой код со
значительно большей избыточностью (44, 22) исправляет пачки длиной  . Заметим, что этот
же код в условиях постоянного канала позволяет исправить только одиночные,
двойные и в отдельных случаях тройные ошибки. Значительно более успешно осуществляется
в циклических кодах обнаружение пачек ошибок [18].
. Заметим, что этот
же код в условиях постоянного канала позволяет исправить только одиночные,
двойные и в отдельных случаях тройные ошибки. Значительно более успешно осуществляется
в циклических кодах обнаружение пачек ошибок [18].
Поскольку
в реальных каналах часто наблюдаются пачки ошибок длиной в несколько десятков и
даже сотен символов, для их исправления потребовался бы код с длиной кодовой
комбинации, измеряемой тысячами и даже десятками тысяч разрядов, что в
настоящее время технически почти неосуществимо. Поэтому предпочитают
использовать циклические коды не для исправления, а для обнаружения пачек
ошибок в системах с обратной связью (см. гл. 11).
В
качестве примера симметричного аномального марковского канала рассмотрим
двоичный канал с двумя состояниями, где в состоянии вероятность
ошибки  , а
в состоянии вероятность ошибки
, а
в состоянии вероятность ошибки  , причем после правильного приема символа канал находится
в состоянии , а после ошибочного приема — в состоянии . Другими словами, в
состоянии все
символы принимаются правильно, пока не произойдет ошибка, имеющая вероятность , после чего все
последующие символы принимаются «в негативе» т. е. вместо «0» принимается «1»
и наоборот, пока символ не будет принят правильно, что в состоянии произойдет
с вероятностью .
После этого канал перейдет в состояние . Легко убедиться, что оба состояния
равновероятны и средняя вероятность ошибки
, причем после правильного приема символа канал находится
в состоянии , а после ошибочного приема — в состоянии . Другими словами, в
состоянии все
символы принимаются правильно, пока не произойдет ошибка, имеющая вероятность , после чего все
последующие символы принимаются «в негативе» т. е. вместо «0» принимается «1»
и наоборот, пока символ не будет принят правильно, что в состоянии произойдет
с вероятностью .
После этого канал перейдет в состояние . Легко убедиться, что оба состояния
равновероятны и средняя вероятность ошибки  . При такой вероятности ошибки
пропускная способность постоянного канала равна нулю, тогда как рассматриваемый
канал согласно (2.58) и (2.28) имеет относительно большую пропускную
способность
. При такой вероятности ошибки
пропускная способность постоянного канала равна нулю, тогда как рассматриваемый
канал согласно (2.58) и (2.28) имеет относительно большую пропускную
способность
 .
.
Такой
канал является несколько идеализированным дискретным отображением реального
канала, в котором применена двоичная фазовая модуляция на 180° при небольшом
уровне аддитивных помех. Для преодоления тенденции «перескока в негатив» в
настоящее время широко используется метод так называемой относительной фазовой
манипуляции, сущность которого сводится к перекодированию передаваемой
последовательности символов.
Пусть
сообщение закодировано каким угодно образом в виде последовательности двоичных
символов  .
Произведем посимвольное перекодирование этой последовательности без внесения
дополнительной избыточности в новую последовательность
.
Произведем посимвольное перекодирование этой последовательности без внесения
дополнительной избыточности в новую последовательность  по следующему закону:
по следующему закону:

Принятые
символы  , если
при их передаче не произошло перехода в негатив, аналогичным образом преобразуются
в символы по закону
, если
при их передаче не произошло перехода в негатив, аналогичным образом преобразуются
в символы по закону  (так как вычитание но модулю 2
совпадает со сложением).
(так как вычитание но модулю 2
совпадает со сложением).
Предположим
теперь, что при приеме символа  произошел переход в негатив,
т. е. начиная с все
остальные переданные символы принимаются как
произошел переход в негатив,
т. е. начиная с все
остальные переданные символы принимаются как  (до очередного перехода в
позитив). Тогда вместо символа
(до очередного перехода в
позитив). Тогда вместо символа  будет восстановлен символ
будет восстановлен символ  а вместо символа
а вместо символа  — символ
— символ  . Легко видеть, что
все последующие символы (до перехода канала в позитив) будут также
восстановлены правильно, а в момент перехода в позитив один символ будет
восстановлен ошибочно. Таким образом, при каждом переходе канала из одного состояния
в другое один из передаваемых символов будет принят с ошибкой. В результате
примененное перекодирование превращает этот марковский канал в однородный
канал с вероятностью ошибки
. Легко видеть, что
все последующие символы (до перехода канала в позитив) будут также
восстановлены правильно, а в момент перехода в позитив один символ будет
восстановлен ошибочно. Таким образом, при каждом переходе канала из одного состояния
в другое один из передаваемых символов будет принят с ошибкой. В результате
примененное перекодирование превращает этот марковский канал в однородный
канал с вероятностью ошибки  . Если при первоначальном кодировании сообщения в
символы
. Если при первоначальном кодировании сообщения в
символы  применить
код, исправляющий одиночные ошибки, то можно получить высокую верность приема в
таком канале.
применить
код, исправляющий одиночные ошибки, то можно получить высокую верность приема в
таком канале.
Следует
заметить, что если вместо описанного канала рассмотреть более сложный (и более
близкий к отображению реального канала с фазовой модуляцией), в котором наряду
с вероятностью перехода
из одного состояния в другое существует также вероятность  ошибочного приема символа без изменения состояния канала, то описанный
метод перекодирования приведет к тому, что с вероятностью два
последовательных символа будут восстановлены ошибочно. Действительно, если
вместо символа принят символ
ошибочного приема символа без изменения состояния канала, то описанный
метод перекодирования приведет к тому, что с вероятностью два
последовательных символа будут восстановлены ошибочно. Действительно, если
вместо символа принят символ  , а последующие символы приняты верно, то при
восстановлении символов получим:
, а последующие символы приняты верно, то при
восстановлении символов получим:

и
т. д.
Для
того чтобы обеспечить высокую верность приема в этом случае, следует при
составлении последовательности символов применить код, исправляющий пакеты
ошибок длиной в два разряда [28].
В
качестве примера несимметричного, но симметричного в среднем канала укажем на
дискретное отображение реального канала с частотной модуляцией (ЧТ) при
узкополосной помехе, которая может попасть в тракт нажатия, в тракт отжатия,
либо вообще не попасть в полосу пропускания приемного устройства. Такой канал
имеет три состояния. В состоянии канал симметричен и вероятность ошибок. В состоянии вероятность
 приема
символа «0», когда передан символ «1», пренебрежимо мала, но вероятность
приема
символа «0», когда передан символ «1», пренебрежимо мала, но вероятность  приема «1», когда
передан «0», равна .
В состоянии
приема «1», когда
передан «0», равна .
В состоянии  , наоборот,
вероятностью можно
пренебречь, а вероятность
, наоборот,
вероятностью можно
пренебречь, а вероятность  . Очевидно, что принятые кодовые
последовательности в таком канале будут содержать пакеты односторонних ошибок
либо замен нулей на единицы, либо наоборот. Вероятность того, что в
одной кодовой комбинации символ «0» будет принят как «1», а символ «1» — как
«0» (такие ошибки называют «ошибками смещения»), очень мала. Действительно, в
состоянии вероятность
двух ошибок в не очень длинной кодовой комбинации вообще мала, поскольку
. Очевидно, что принятые кодовые
последовательности в таком канале будут содержать пакеты односторонних ошибок
либо замен нулей на единицы, либо наоборот. Вероятность того, что в
одной кодовой комбинации символ «0» будет принят как «1», а символ «1» — как
«0» (такие ошибки называют «ошибками смещения»), очень мала. Действительно, в
состоянии вероятность
двух ошибок в не очень длинной кодовой комбинации вообще мала, поскольку  , а в состояниях и ошибки смещения практически
невозможны. Переход же от состояния к состоянию (или
наоборот) на протяжении передачи кодовой комбинации тоже маловероятен, если
состояния изменяются сравнительно медленно.
, а в состояниях и ошибки смещения практически
невозможны. Переход же от состояния к состоянию (или
наоборот) на протяжении передачи кодовой комбинации тоже маловероятен, если
состояния изменяются сравнительно медленно.
Существуют методы кодирования для
таких двоичных каналов, позволяющие если не исправлять, то обнаруживать любые
ошибки, кроме ошибок смещения. Один из этих методов заключается в применении несистематического
кода с
постоянным весом. Весом кодовой комбинации называется количество
входящих в нее ненулевых символов, в частности для двоичных кодов - количество
единиц. Если в -разрядном
коде все комбинации имеют вес , то, как легко
убедиться, число разрешенных комбинаций
 .
.
Так, например, при  и
и 
 , при
, при  и
и 
 и т. д.
и т. д.
Любые ошибки, кроме ошибок смещения,
изменяют вес кодовой комбинации и легко могут быть обнаружены простым счетчиком
единиц.
Другой класс кодов для таких же
каналов был предложен Бергером [30]. Эти коды, хотя и не являются
систематическими, относятся к разделимым, так как в каждой кодовой комбинации
можно выделить разряды, занятые информационными символами. К ним приписываются
проверочные разряды, представляющие собой инвертированную двоичную запись количества
единиц, содержащихся в информационных разрядах. При информационных разрядах число
проверочных разрядов должно быть не менее  , откуда
, откуда

Такие коды также обнаруживают все ошибки, кроме части ошибок
смещения.
Рассмотренные каналы с памятью далеко не исчерпывают всех
возможных случаев. К тому же они являются лишь очень грубыми моделями реальных
каналов. Тем не менее приведенные рассуждения позволили в общих чертах
пояснить особенности задачи кодирования в таких каналах и показать, что
непосредственное применение корректирующих кодов, разработанных для постоянных
каналов, как правило, не приводит к положительным результатам.