Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Примечания1 (к § 2.1). Термин, «канал с памятью» укалывает на то, что вероятность ошибки в таком канале зависит от того, как принимались предыдущие символы, т.е. канал как бы хранит в своей памяти предыдущие события.
Говоря о зависимости ошибок в канале с памятью,
следует учитывать, что здесь имеются в виду не причинно-следственная
зависимость, а статическая. Два события Пусть, например, в двоичном дискретном канале
ошибки возникают только под действием некоторого источника помех
Вычислим условную вероятность
Таким образом, ошибки в таком канале оказываются
зависимыми, хотя причиной ошибочного приёма В постоянном симметричном канале ошибки
независимы. Как известно, отсюда следует, что появление
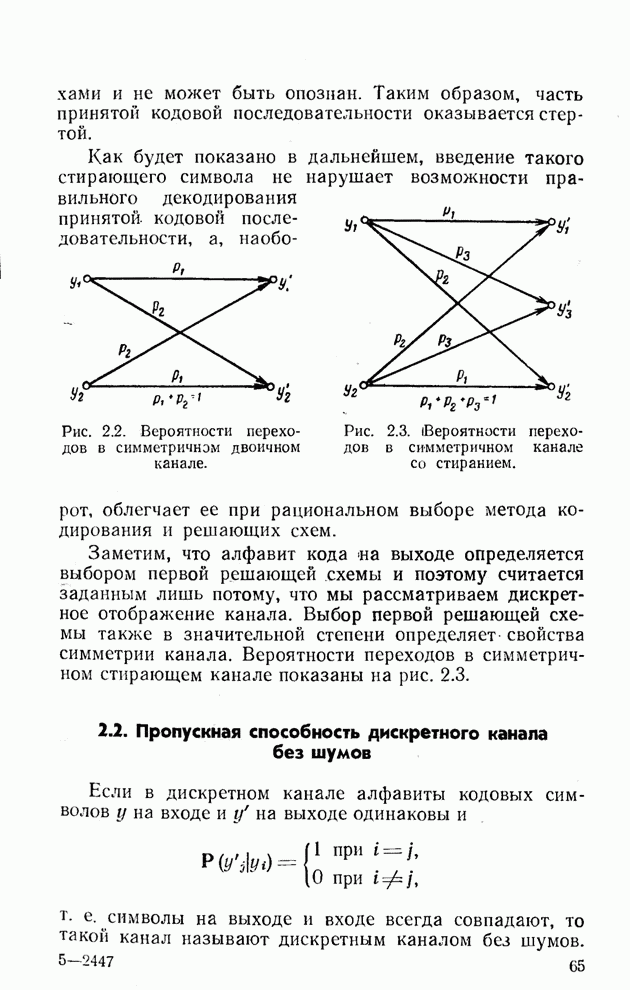
Поэтому всякий симметричный канал, в котором число ошибок в блоке не подчиняется биномиальному распределению, является каналом с памятью. 2 (к § 2.3). Можно сформулировать условие однозначной
декодируемости последовательности символов неравномерного кода. Для
существования кода, содержащего
где Из условия (2.72) можно вывести теорему кодирования для канала без шумов [7]. 3 (к § 2.3). В качестве примера практически используемого метода кодирования, приближающегося к экономичному, обычно приводят телеграфный код Морзе. Этот пример не очень удачен, так как код Морзе содержит значительную избыточность, хотя при его разработке был использован принцип выбора наиболее коротких комбинаций для наиболее часто встречающихся букв. В телеграфной практике существует другой поучительный пример использования статических свойств источника для сокращения среднего числа символов кодовой последовательности, причём использованы не столько одномерные распределения вероятностей букв, сколько вероятностные связи между передаваемыми знаками. Этот пример представляет различные равномерные коды, используемые для буквопечатающего телеграфирования с помощью телеграфных аппаратов, снабжённых «регистрами». Число букв в алфавите большинства языков не
превышает 32. Поэтому можно передавать любые телеграммы, записанные буквами, с
помощью 5-разрядного двоичного кода (так как Среднее количество символов, приходящихся на знак, существенно сокращается путём применения системы регистров. В простейшем случае телеграфный аппарат имеет два регистра, т.е. два возможных состояния. В первом состоянии (буквенном регистре) передаются и применяются 5-разрядные кодовые комбинации, соответствующие обычным буквам алфавита и пробелу между словами. Во втором состоянии (цифровом регистре) те же кодовые комбинации соответствуют цифрам и знак препинания. Две кодовые комбинации используются для перевода приёмного аппарата с одного регистра на другой. Легко убедится, что если бы все знаки (включая
цифры и знаки препинания) появлялись в телеграммах с равной вероятностью, то
применение системы регистров дало бы не экономию а, наоборот, некоторый
проигрыш по сравнению с применением примитивного 6-разрядного кода.
Действительно, если вероятность того, что очередной передаваемый знак
принадлежит к буквенному регистру, равна Математическое ожидание
Поэтому в среднем через каждые 2 информационных
знака будет передаваться знак перевода регистра. Для передачи В действительности, в текстах телеграммы цифры и знаки препинания появляются значительно реже, чем буквы. К тому же цифры часто следуют подряд одна за другой. В результате средняя длина последовательности знаков, принадлежащих к одному регистру, значительно больше двух и обычно достигает нескольких десятков. В силу этого среднее число символов на один знак оказывается лишь на немного больше пяти, т.е. применение регистров даёт заметную экономию. Заметим, что применение регистров как и другие методы сокращения избыточности, понижет помехоустойчивость. Это выражается в том, что ошибочный приём комбинации перевода регистра как знака, или наоборот, вызывает ошибки в ряде последующих знаков и даже изменяет число принятых знаков. Поэтому в современных системах передачи дискретных сообщений, к которым предъявляется требование высокой верности, регистровое кодирование, как правило, не применяется. 4 (к §
2.7 и 2.8). Простейшим способом корректирующего
кодирования является повторение информационных символов. Если каждую В частном случае, если комбинация примитивного кода
передаётся дважды, то получается код с Если повторять несколько раз комбинации
избыточного кода с минимальным хемминговым расстоянием Сущность таких методов кодирования не изменится, если длину повторяемого блока увеличить до длительности целого законченного сообщения. При этом эффективность кода может повысится благодаря декорреляции ошибок. Поэтому нельзя, как это делают некоторые авторы, противопоставлять системы с повторением системам с корректирующим кодом. Повторение сообщения – это тоже корректирующий код, мало эффективный, но зато легко реализуемый. 5 (к §
2.7 и 2.8). Говоря об ограниченных
возможностях обеспечения высокой верности в каналах с шумами путём применения
корректирующих кодов с большой длиной блока При 6 (к §
2.8). Формула (2.61) является точной, если
состояние канала известно обоим корреспондентам. В общем случае для
неоднородного канала скорость передачи информации
где Очевидно, что состояние канала
Так как
С другой стороны, в теории информации доказывается, что
где
Объединяя полученные неравенства, найдём
Пусть
И так как
неравенство (2.75) справедливо при любом распределении
Но максимум среднего значения нескольких величин не превосходит среднего значения максимумов, откуда
где Если число состояний не велико и смена их происходит
редко, то
откуда для случая двух состояний вытекает (2.58). В работе [41] показано, что при некоторых дополнительных условиях (2.79) перидотит в точное равенство.
|
 |
Оглавление
|












































































































































































































































































































































































































































































































































































































































































































































 (2.72)
(2.72)
