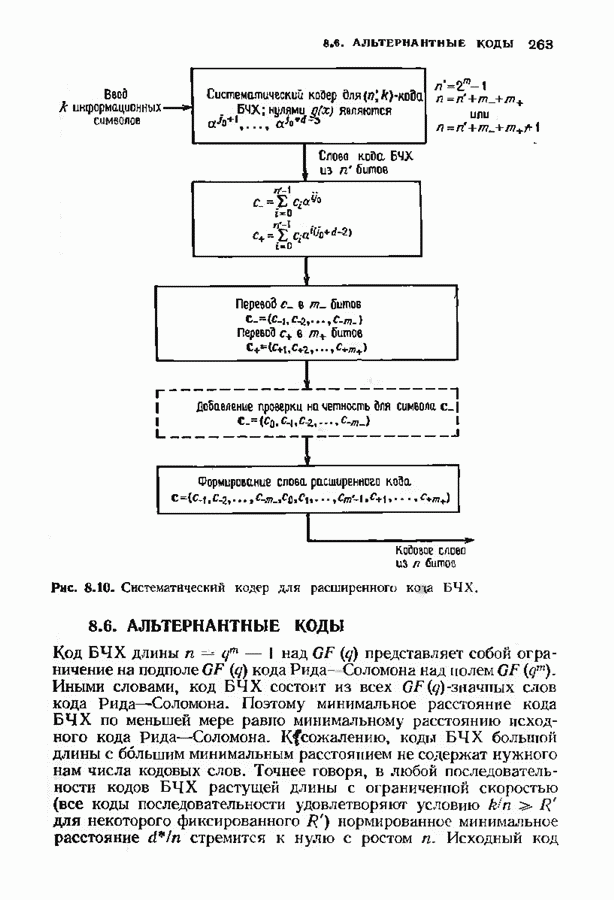
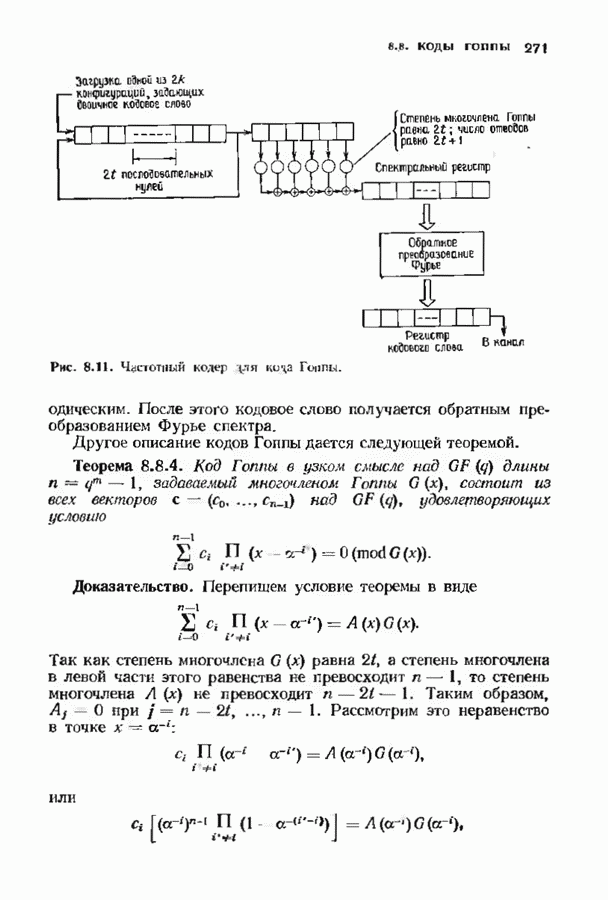
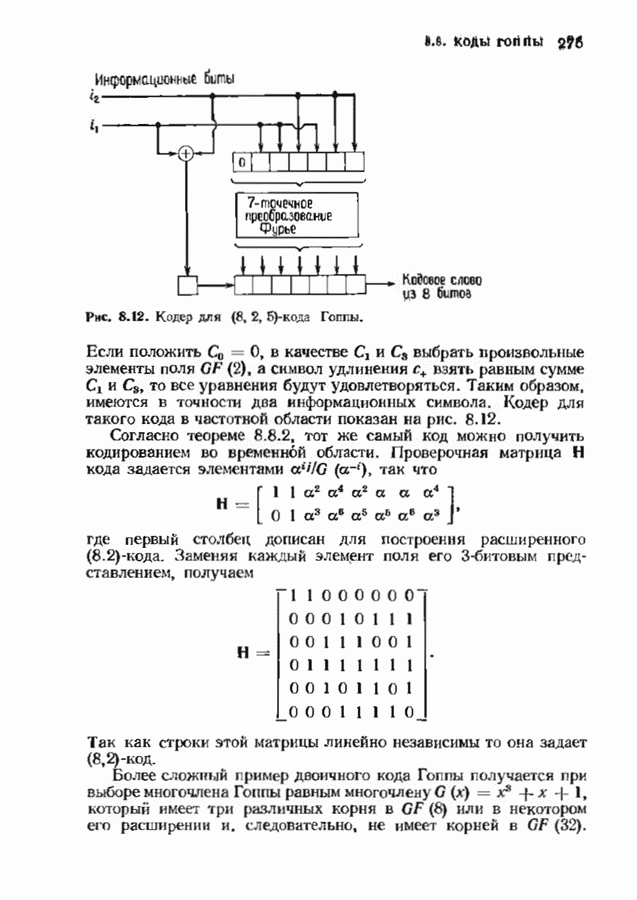
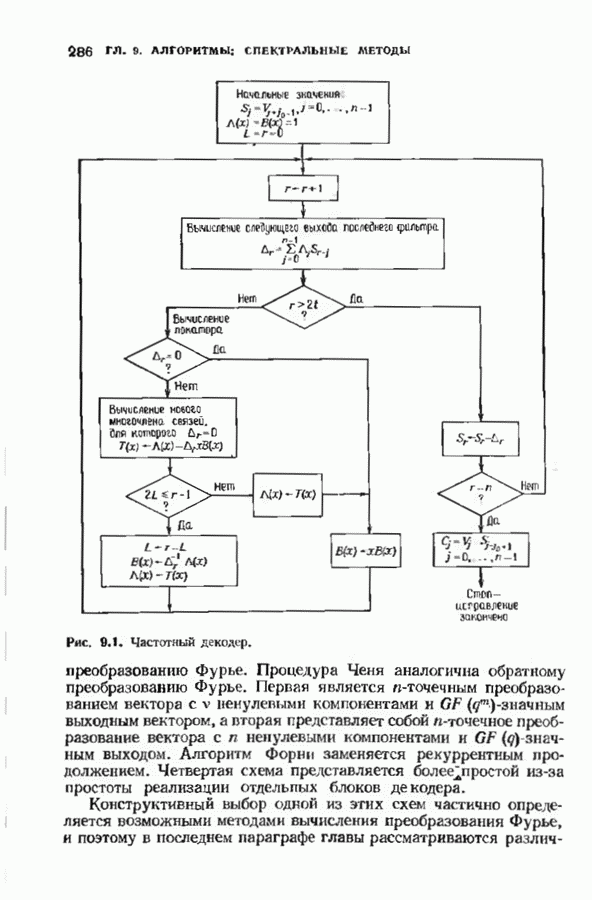
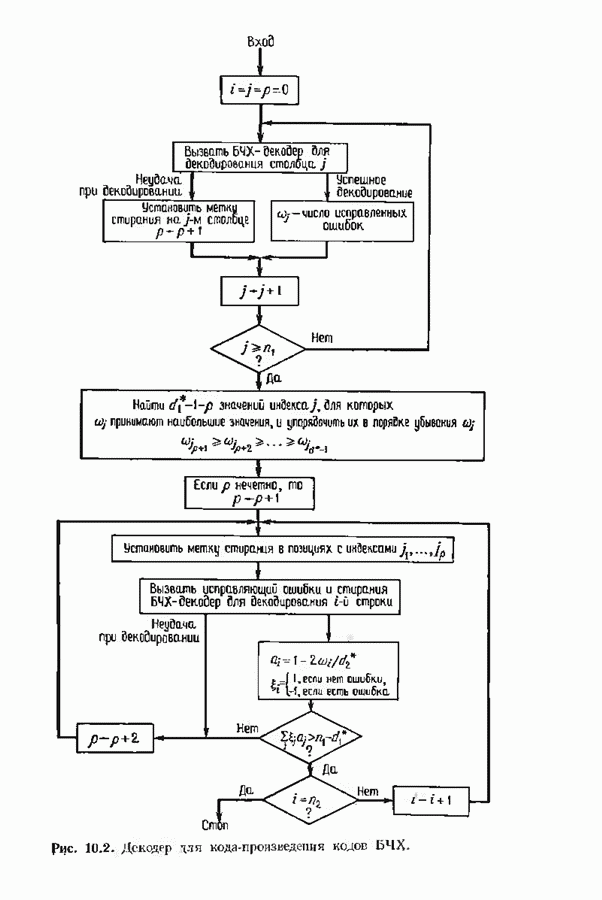
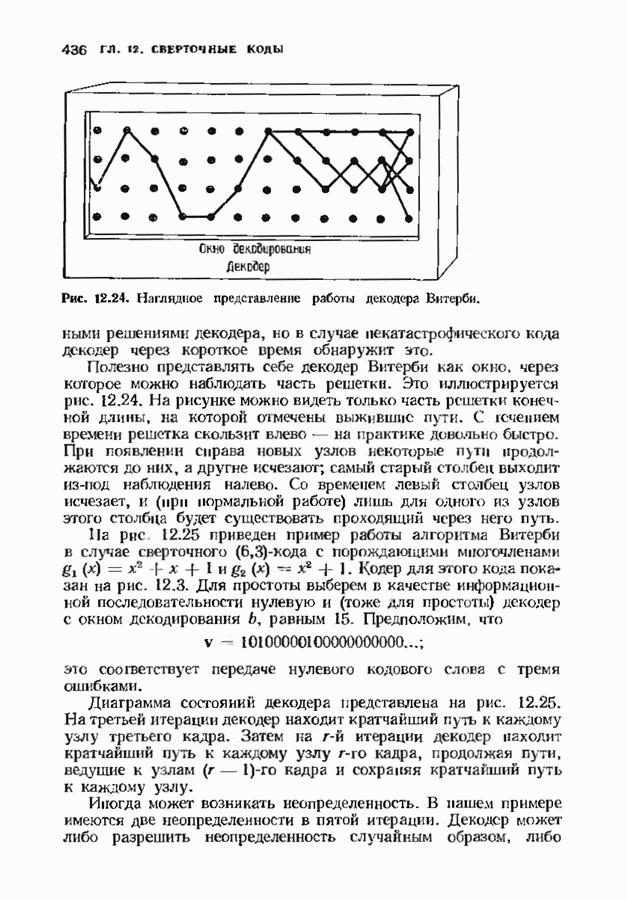
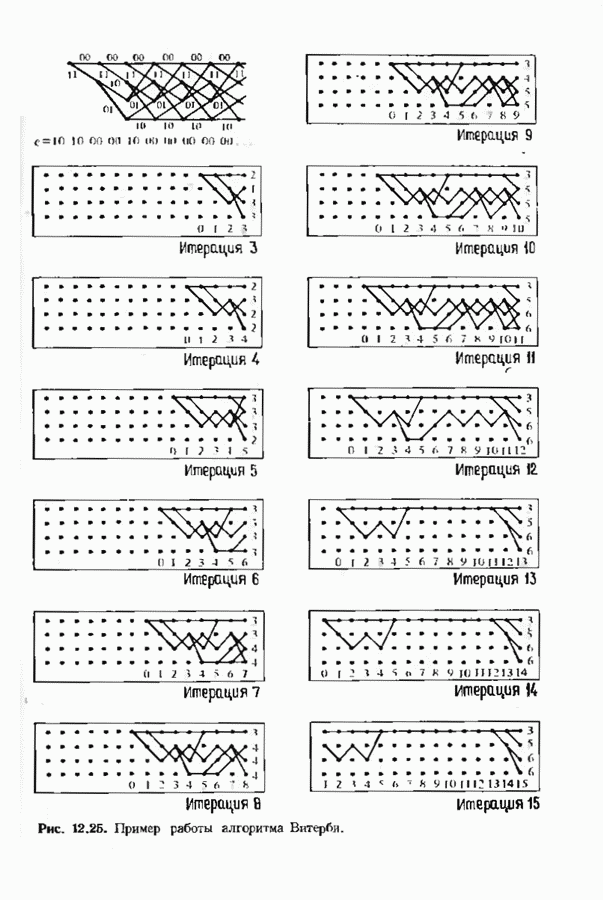
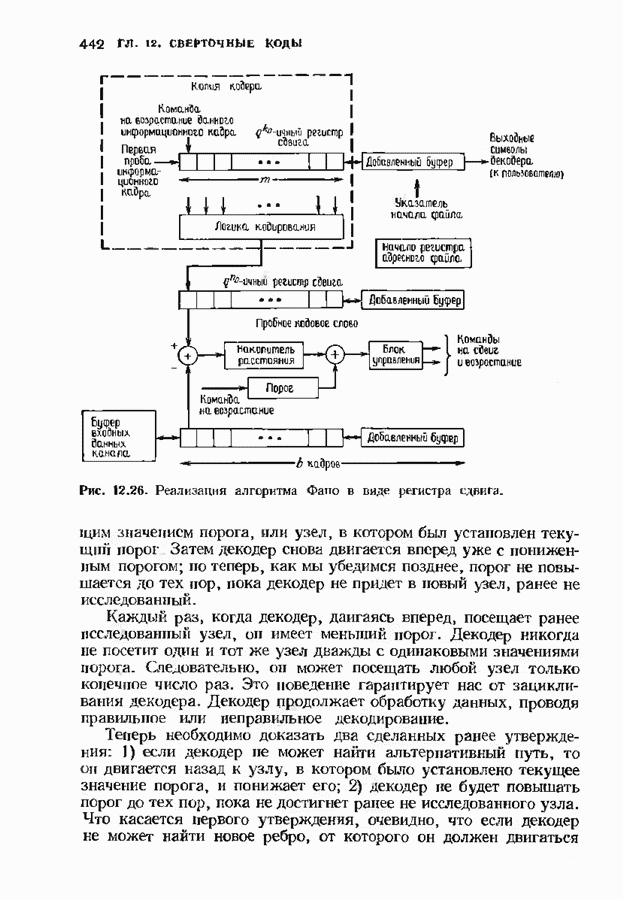
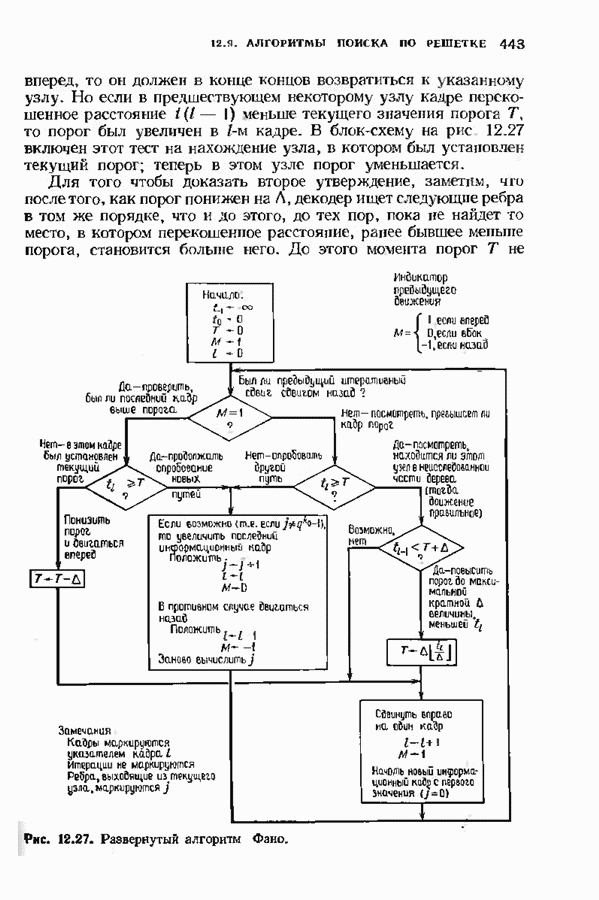
Пред.
След.
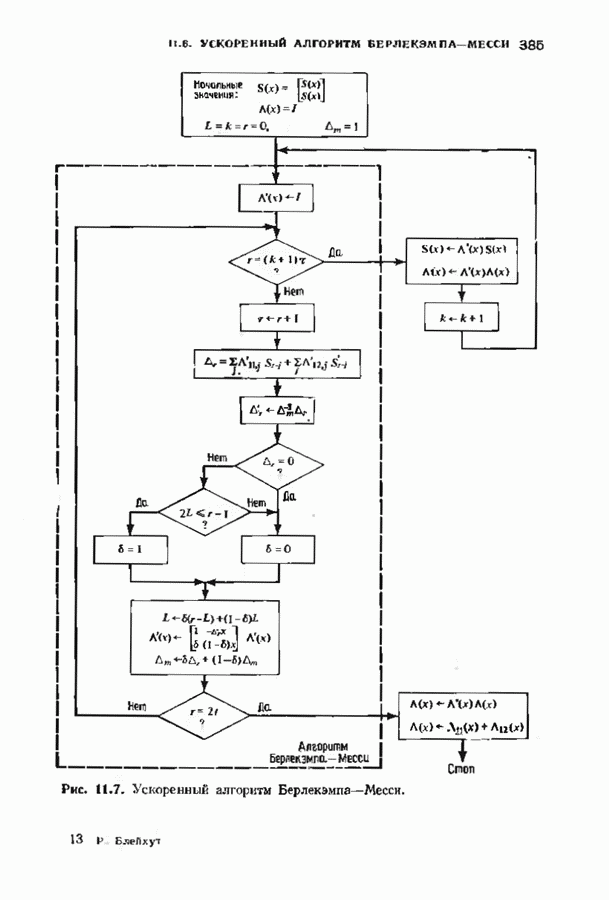
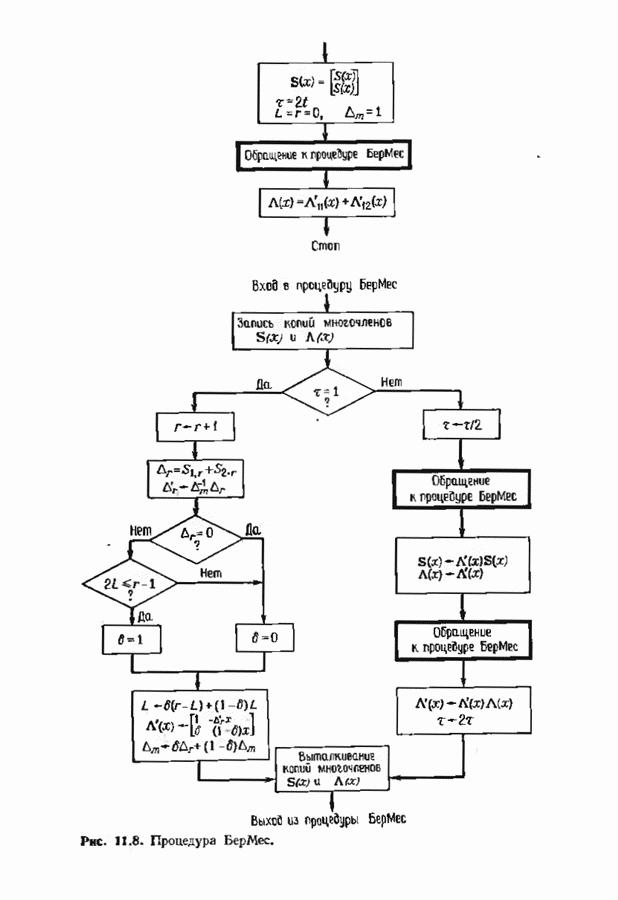
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
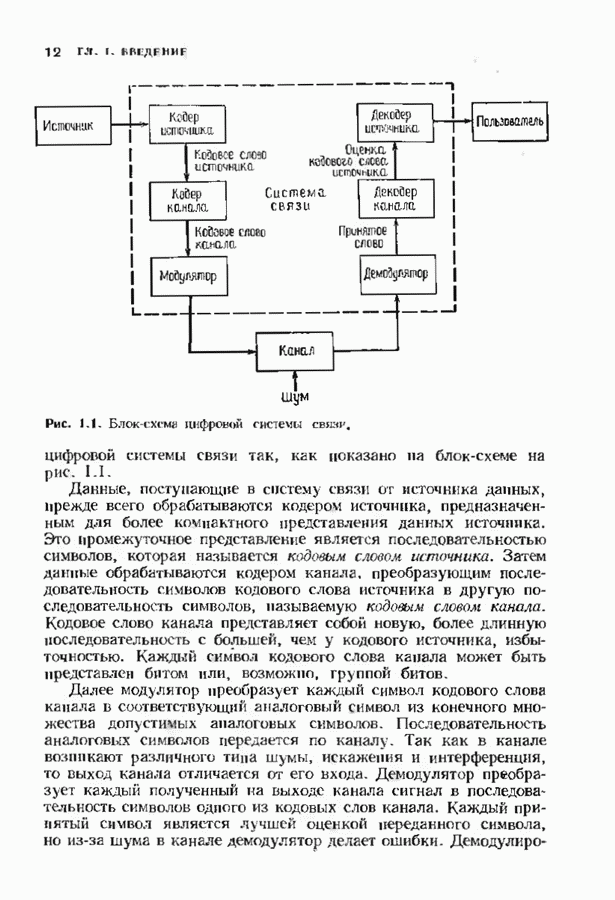
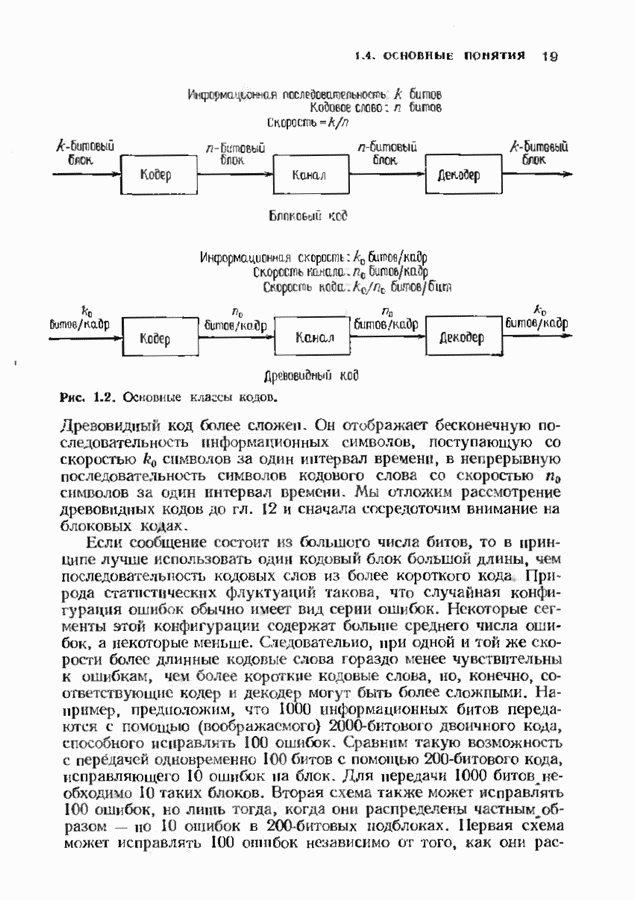
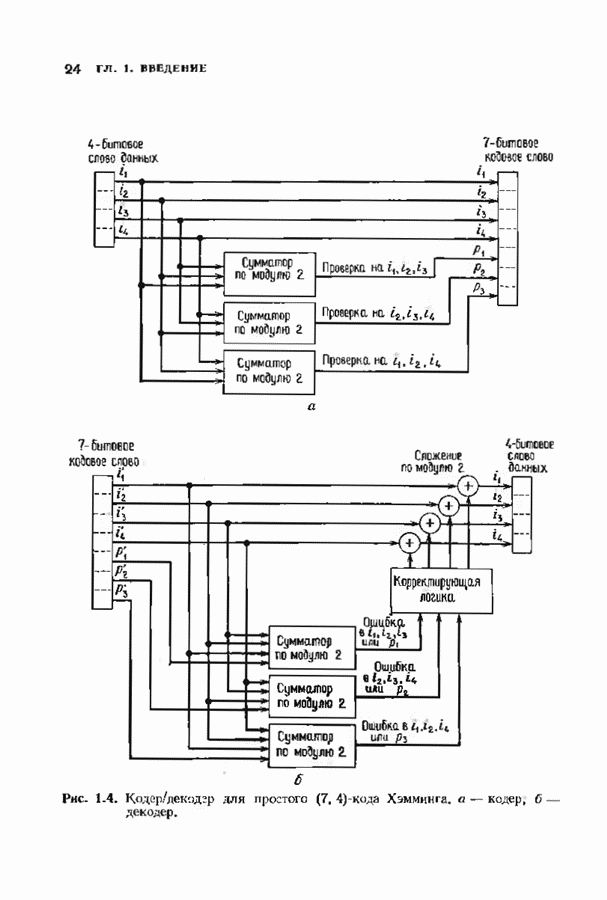
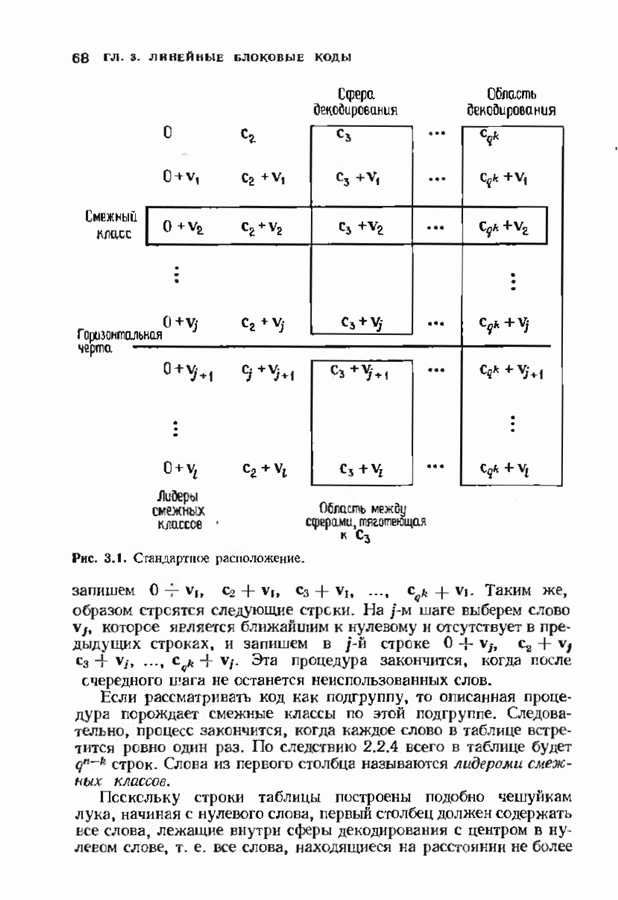
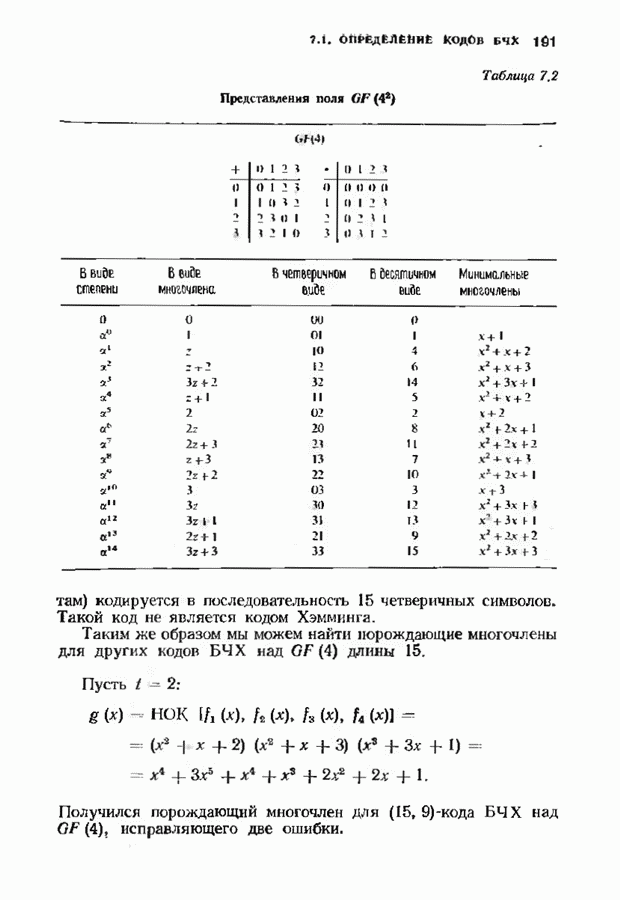
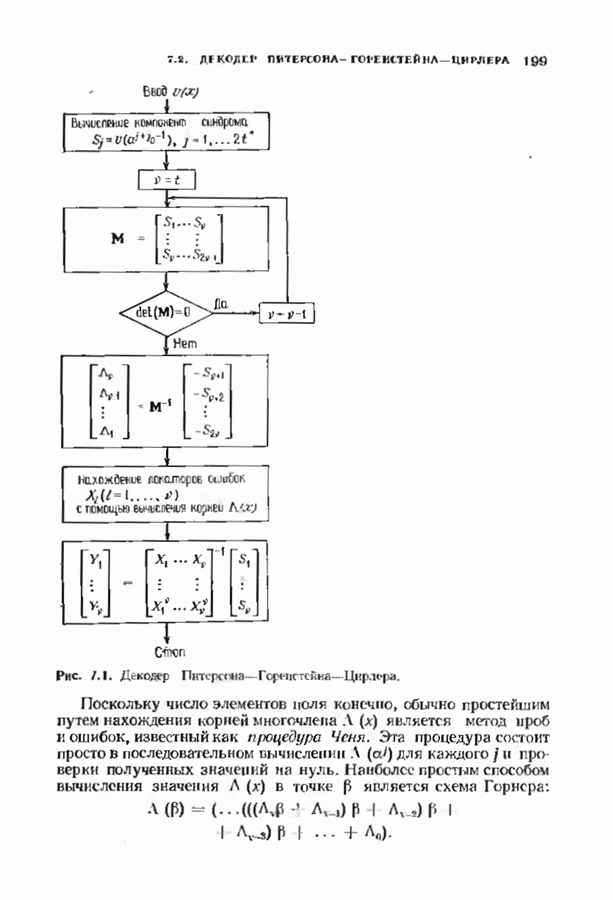
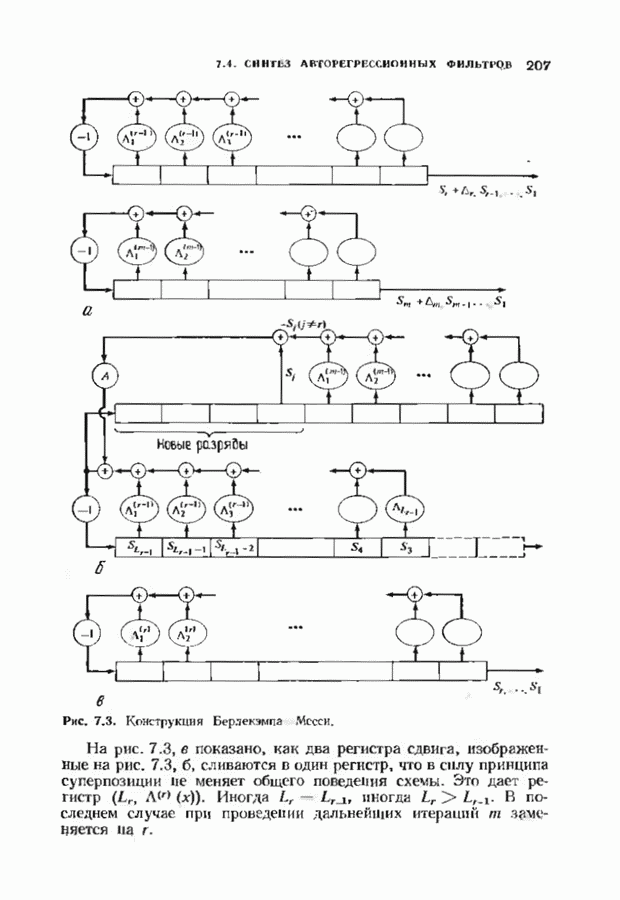
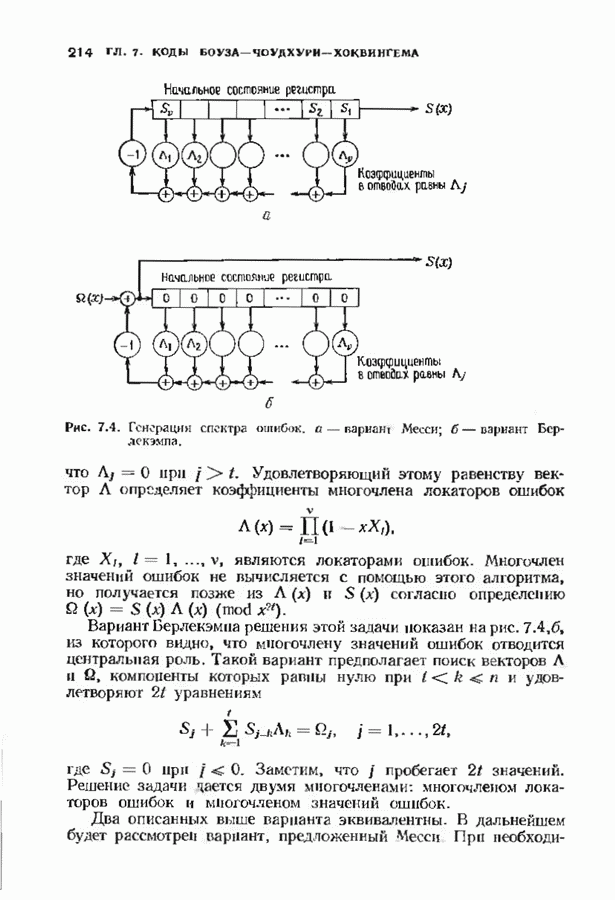
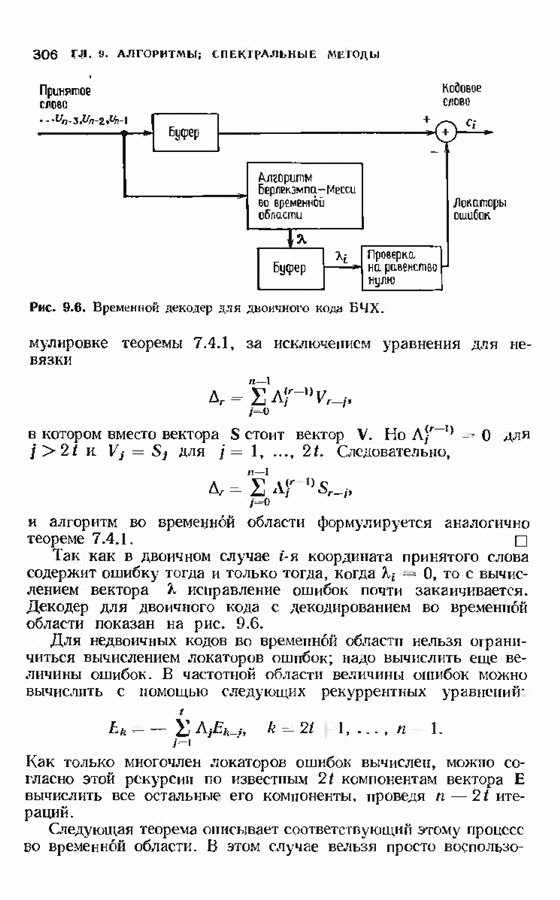
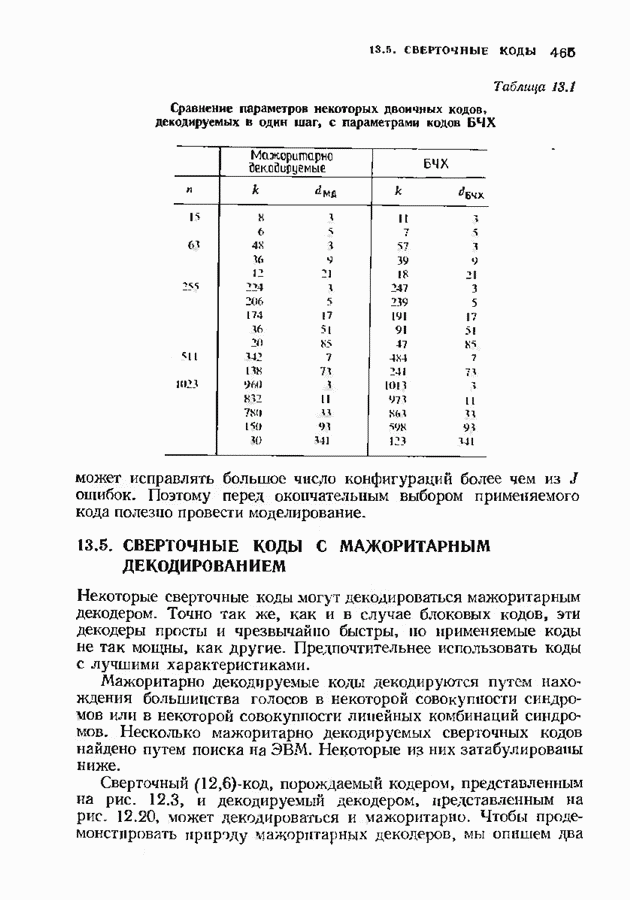
14.2. ВЕРОЯТНОСТИ ОШИБОЧНОГО ДЕКОДИРОВАНИЯ И НЕУДАЧНОГО ДЕКОДИРОВАНИЯНеполный декодер для корректирующего Рассмотрим случай использования линейных кодов в каналах, вносящих в символы ошибки независимо и симметрично. Выражения для указанных вероятностей зависят от распределения весов кода и поэтому полезны лишь в случае, когда оно известно. В предыдущем параграфе получено распределение весов для кодов Рида-Соломона, так что для этих кодов мы можем вычислить вероятности ошибочного декодирования и неудачного декодирования. Рассматриваемые каналы представляют собой
Мы рассмотрим лишь неполный декодер, который не принимает решения о декодировании вне радиуса упаковки кода. Каждое принятое слово, лежащее от ближайшего кодового слова на расстоянии, не превышающем
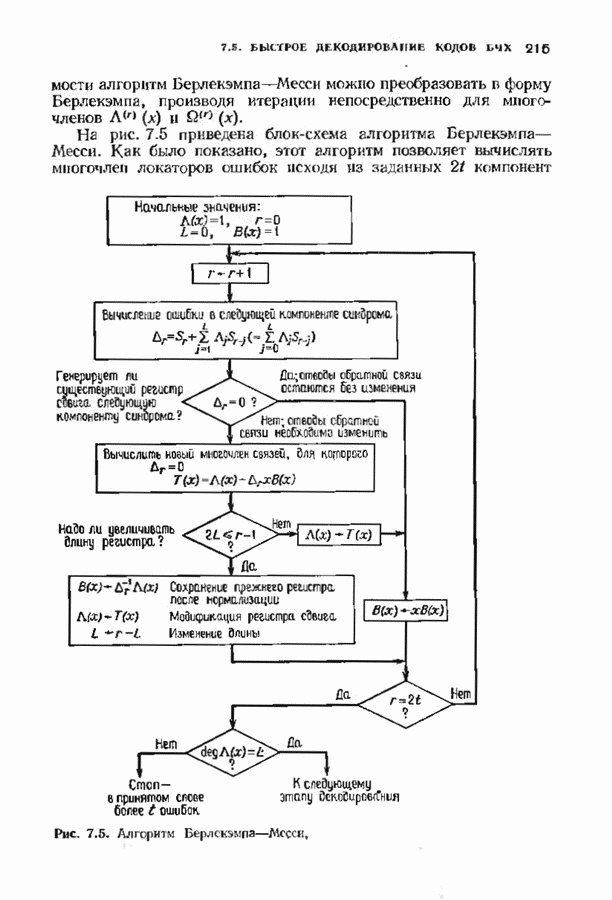
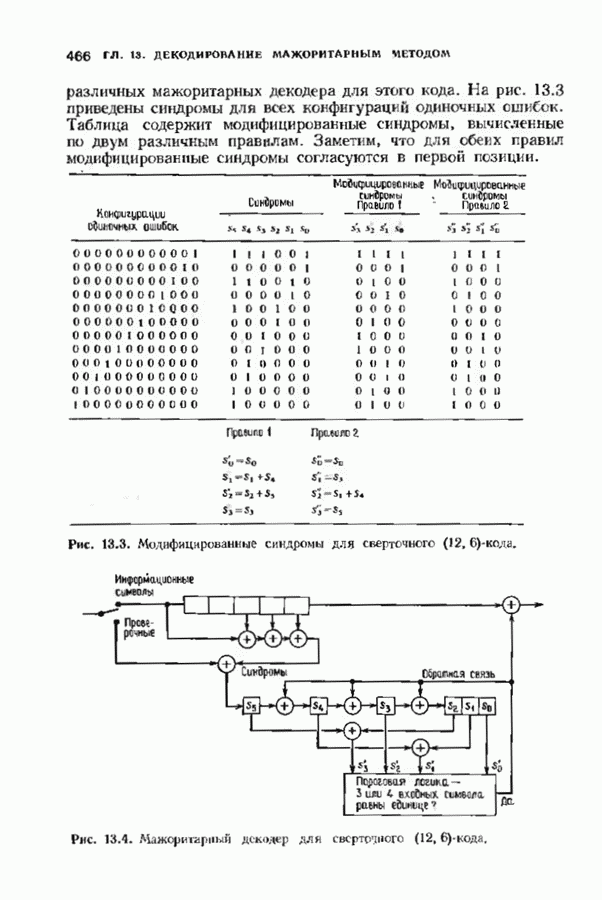
Исследуем условные вероятности ошибочного и неудачного декодирования в случае линейного кода при условии, что передано слово, целиком состоящее из нулей. Каждое другое переданное слово приводит к тем же самым условным вероятностям, так что они являются также безусловными вероятностями. На рис. 14.2 изображены три области, в которые может попасть принятое слово.
Рис. 14.2. Области декодирования. Вероятность правильного декодирования — это вероятность того, что принятое слово попадает в область, покрытую редкой штриховкой. Вероятность неправильного декодирования — это вероятность того, что принятое слово попадет в область, покрытую частой штриховкой. Вероятность неудачного декодирования - это вероятность того, что принятое слово попадет в незаштрихованную область. Сумма этих трех вероятностей равна I, поэтому достаточно найти формулы лишь для двух из них. Начнем с самого простого. Теорема 14.2.1. Вероятность правильного декодирования декодера, исправляющего ошибки в пределах радиуса упаковки кода, равна
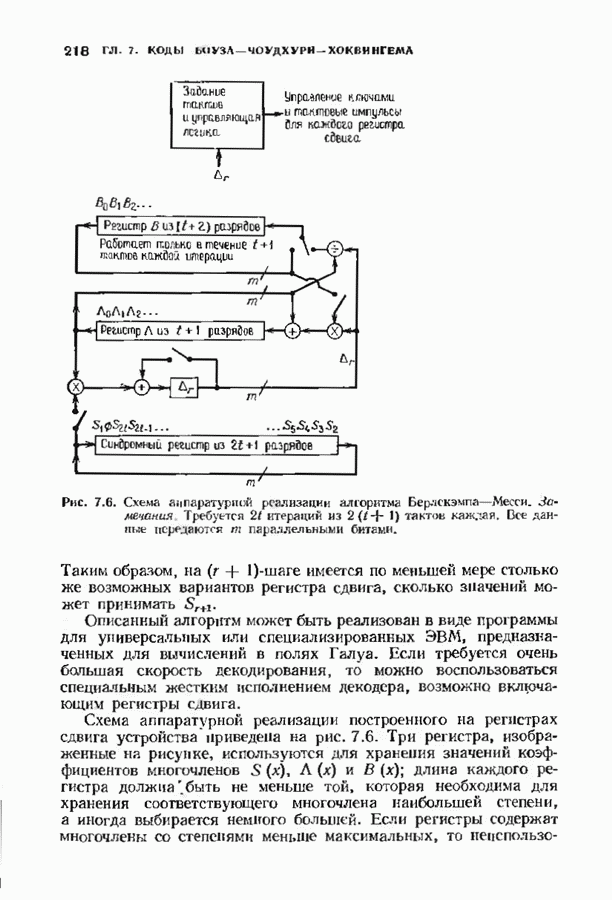
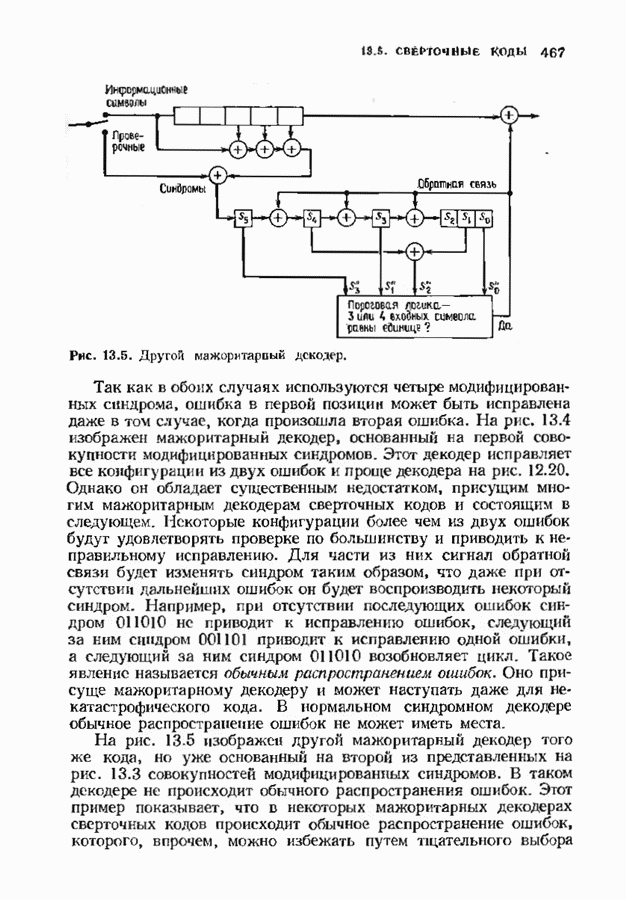
Доказательство. Число способов, которыми можно разместить конфигурации из Хотя теорема справедлива для любых объемов алфавита, в формулу входит лишь вероятность появления ошибочного символа. Не имеет значения, как она распадается на вероятности конкретных опжбочпых значений. В следующей теореме, касающейся неудачного декодировании, необходимо подсчитать число способов, которыми могут быть сделаны ошибки. Некоторые конфигурации ошибок, вероятности которых нужно просуммировать, приведены на рис. 14.3. Пусть Теорема 14.2.2. Число конфигураций ошибок веса
Доказательство. Равенству, которое требуется доказать, эквивалентно равенство
что может быть проверено подстановкой
Рис. 14.3. Некоторые слова, вызывающие ошибку декодирования. компонент на любой из оставшихся Теорема 14.2.3. Если
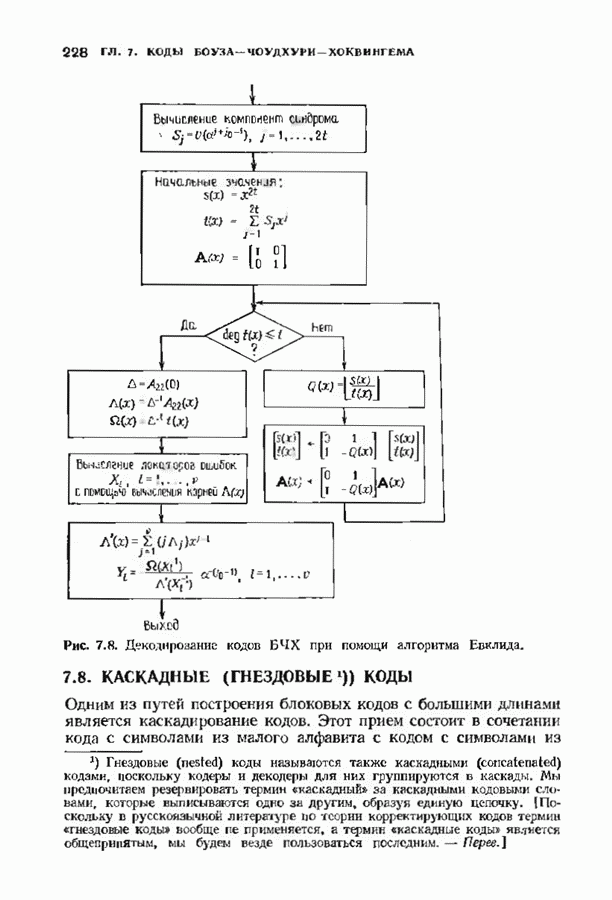
Доказательство. Число конфигураций ошибок веса Теоремы 14.2.2, 14.2.3 и 14.1.2 содержат все необходимое для нахождения вероятности ошибки кода Рида-Соломона. Эта вероятность может быть вычислена непосредственно на ЭВМ. Приведенные соотношения легко модифицировать применительно к декодеру, исправляющему ошибки и стирания. Если число стираний равно
|
 |
Оглавление
|
































































































































































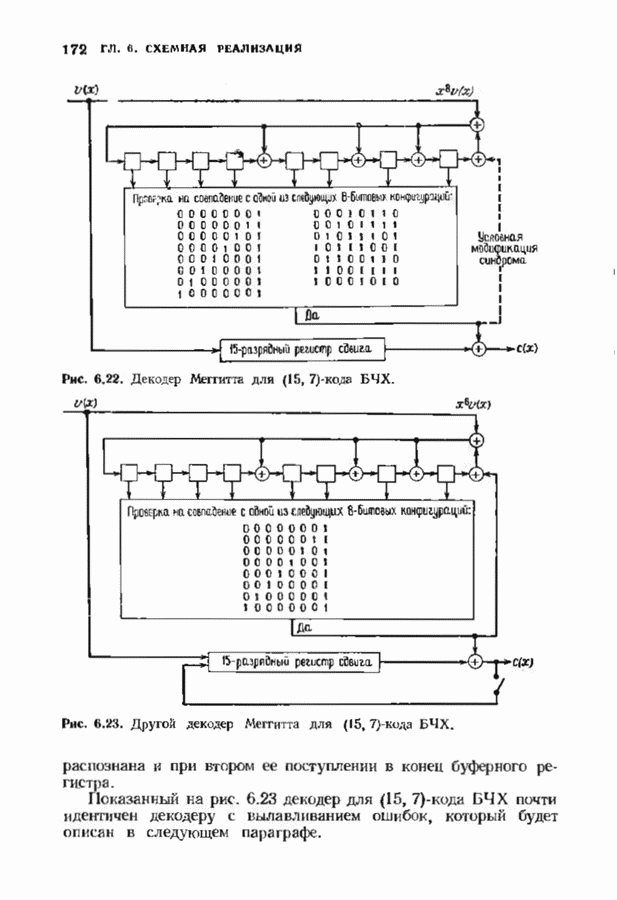

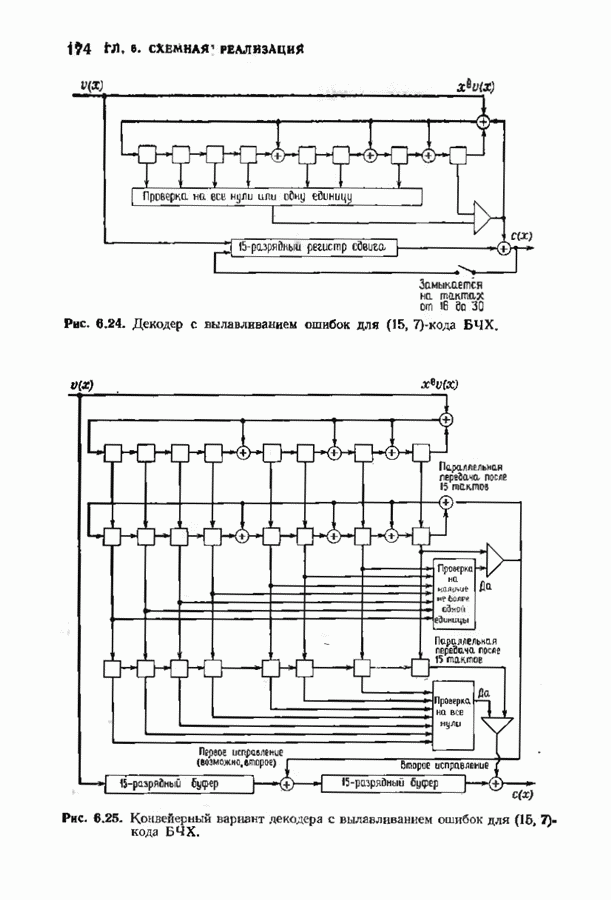

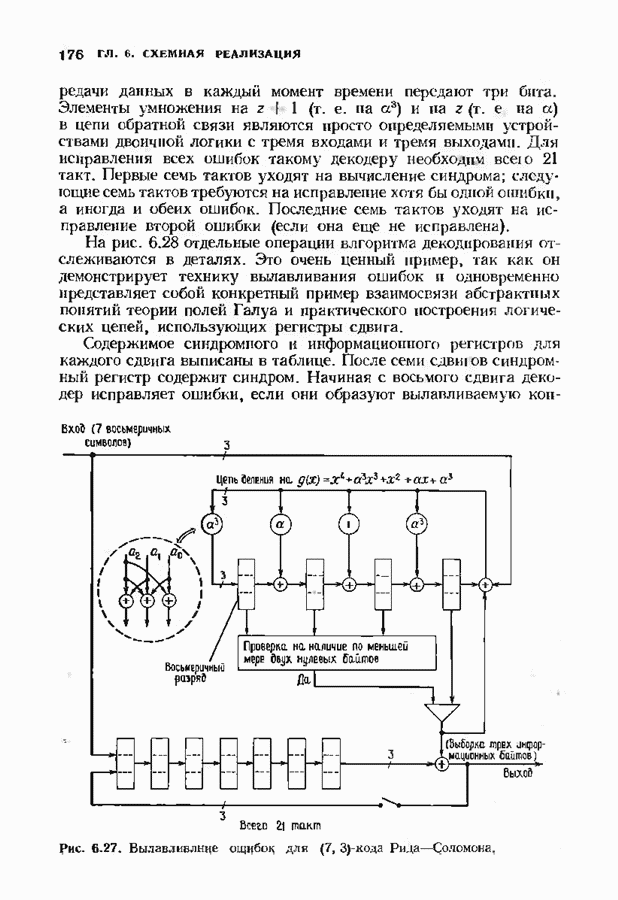





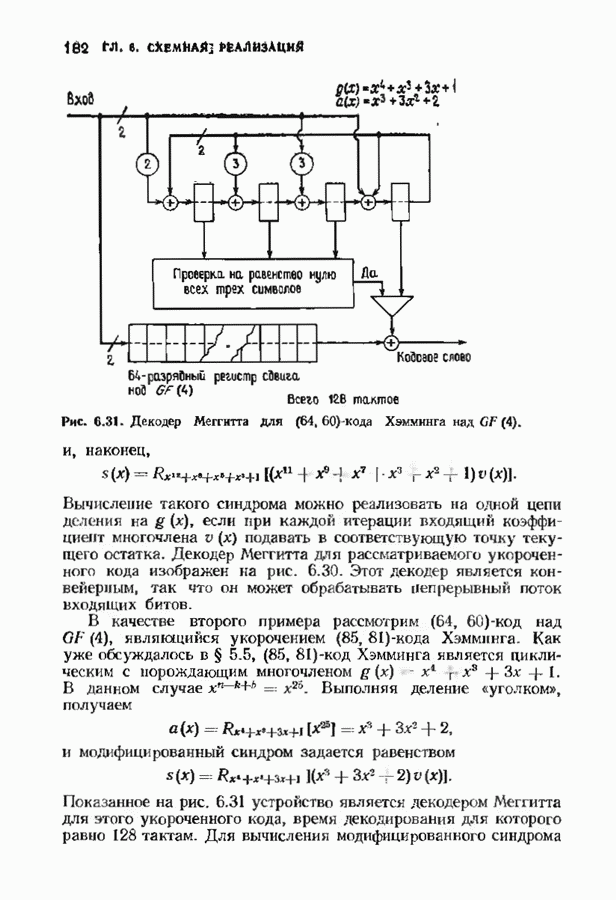


























































































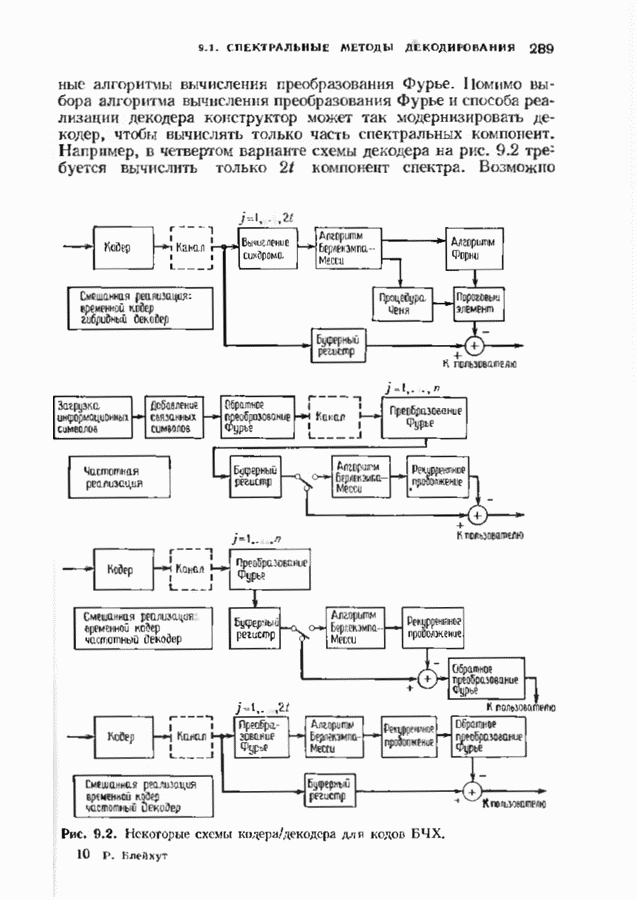



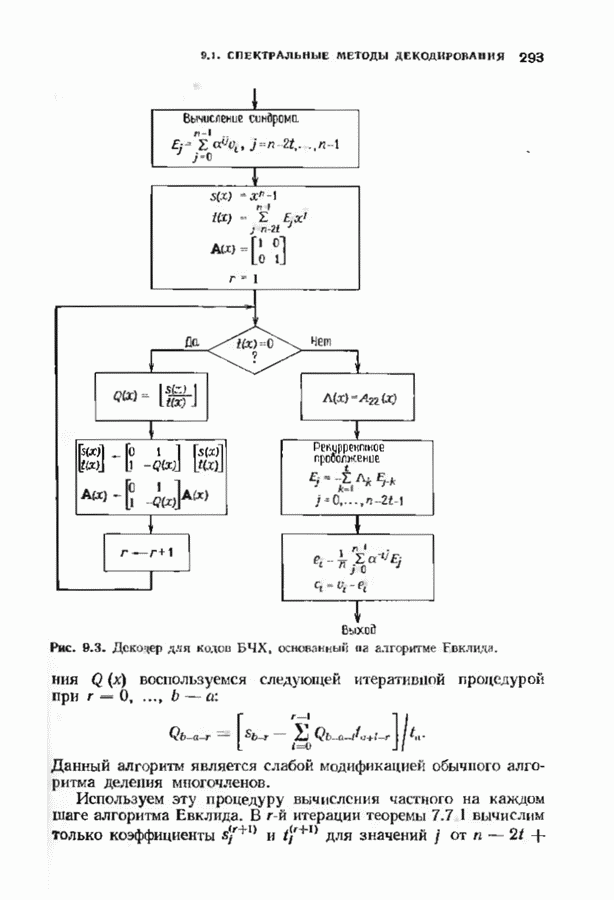





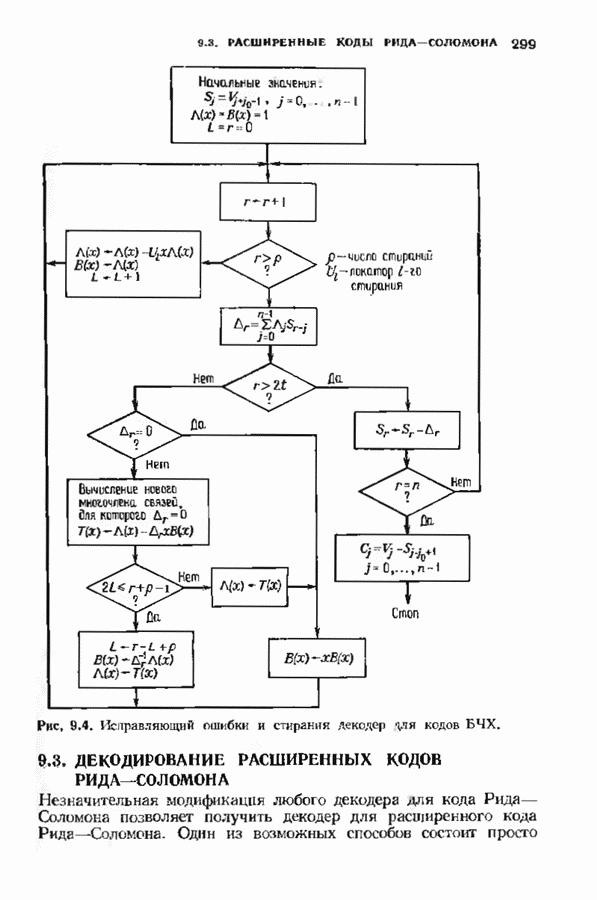


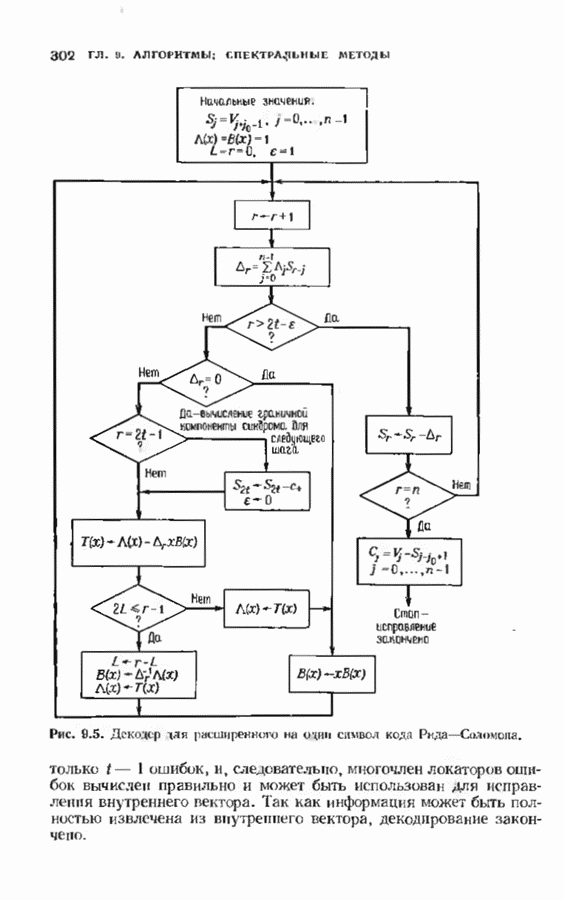






























































































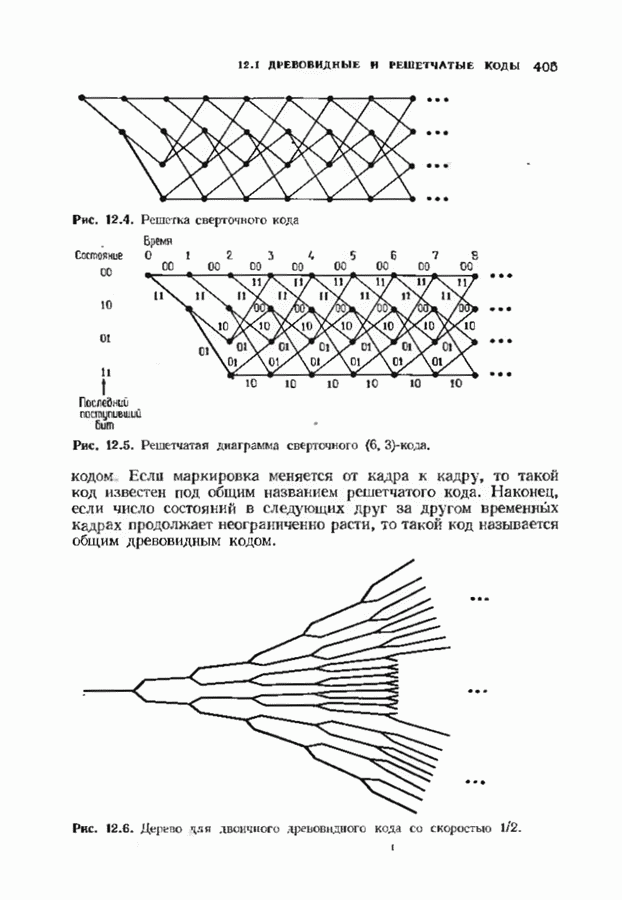

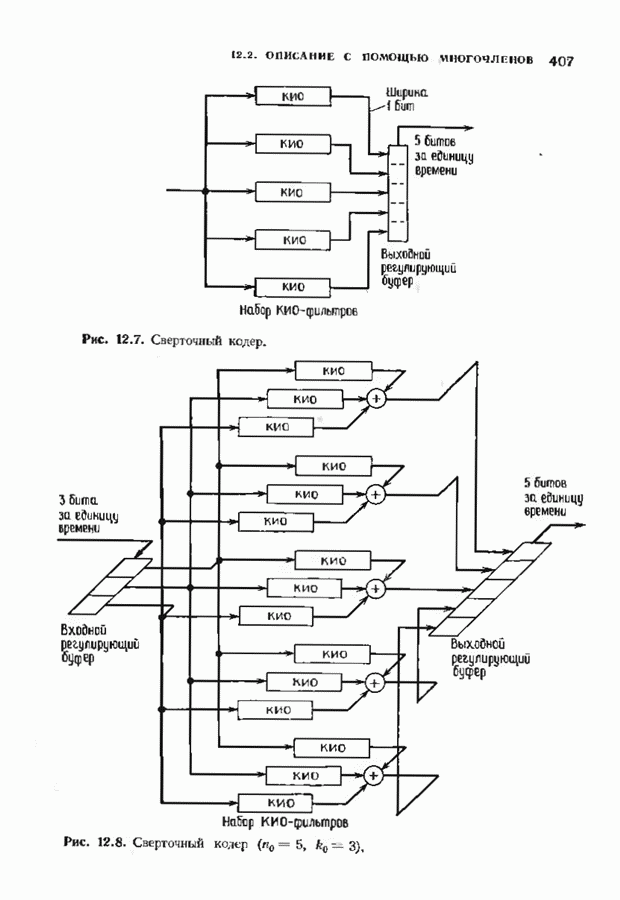




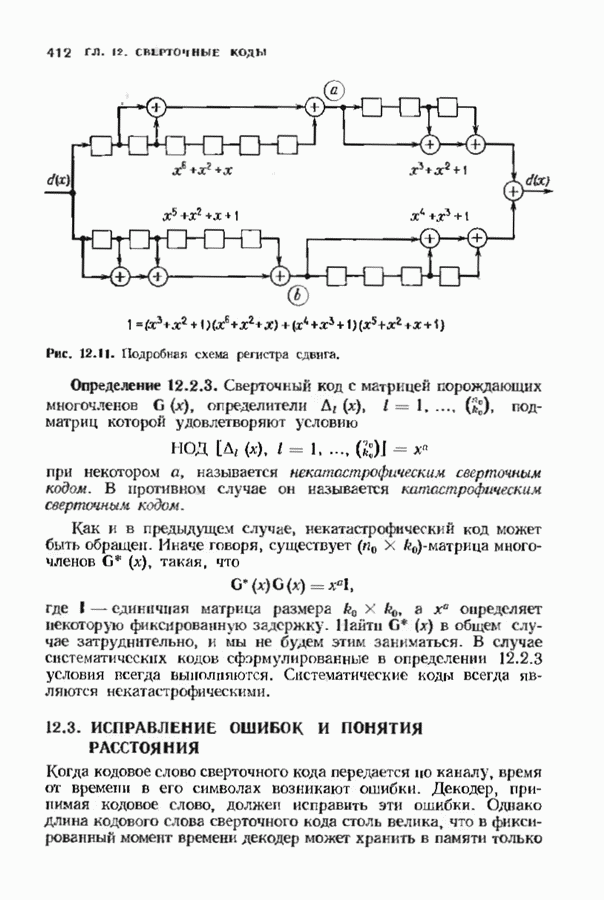




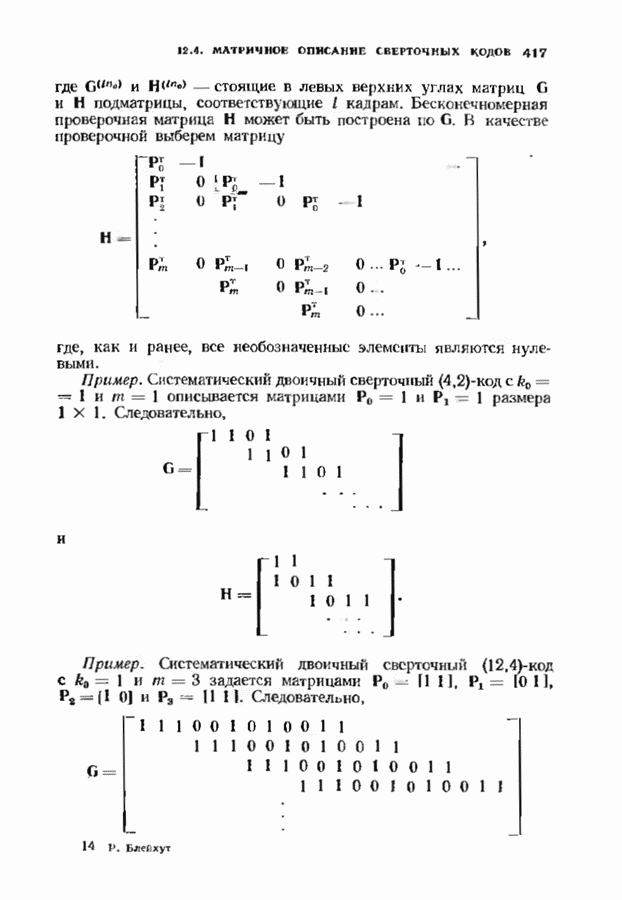




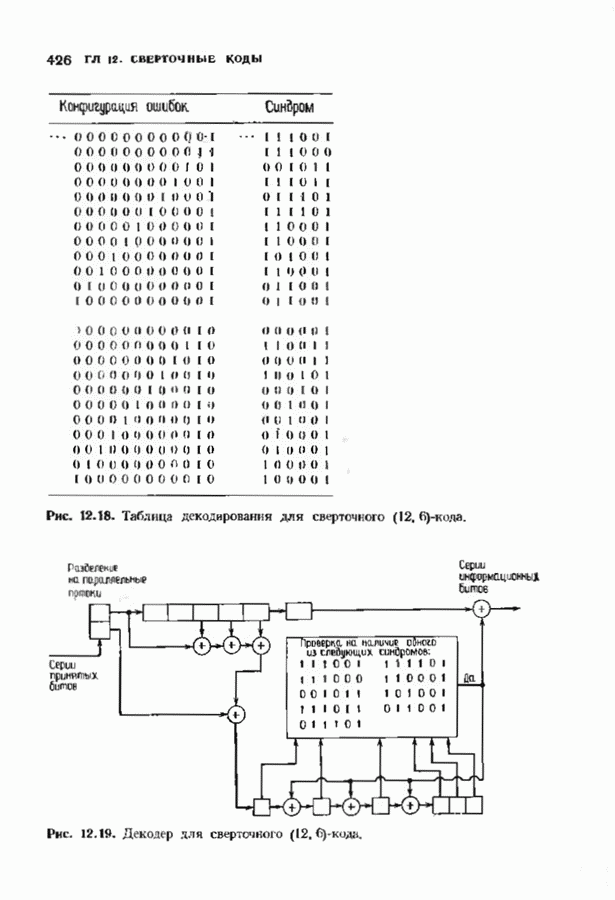
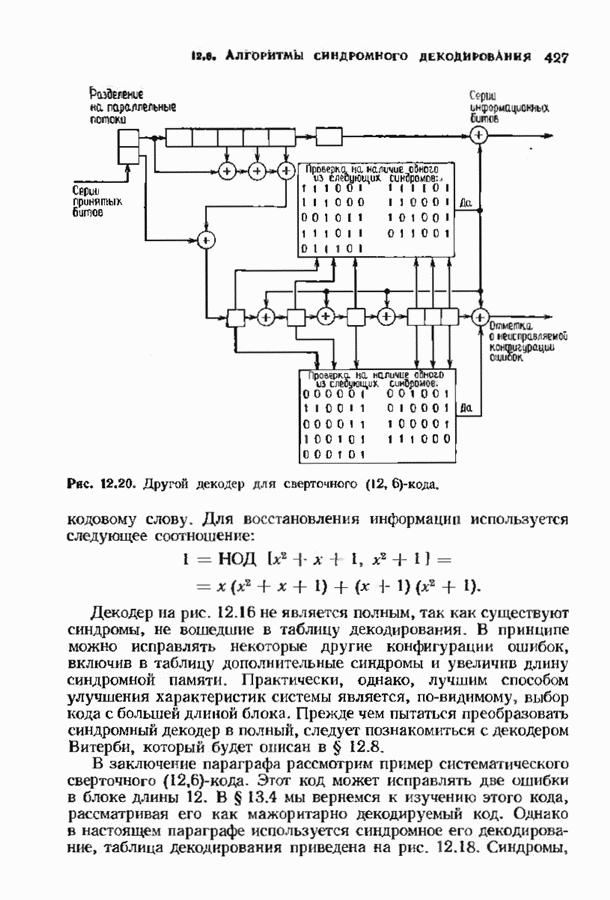



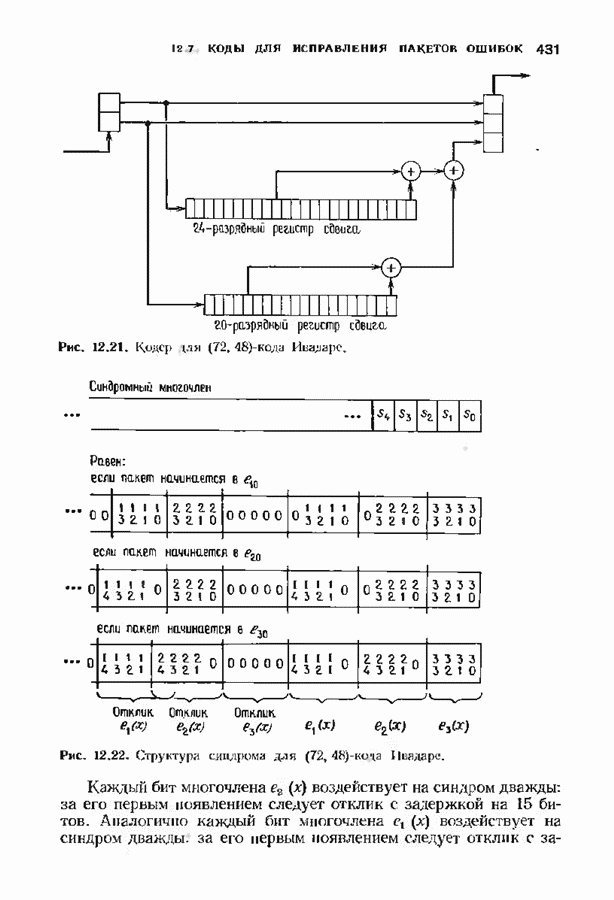
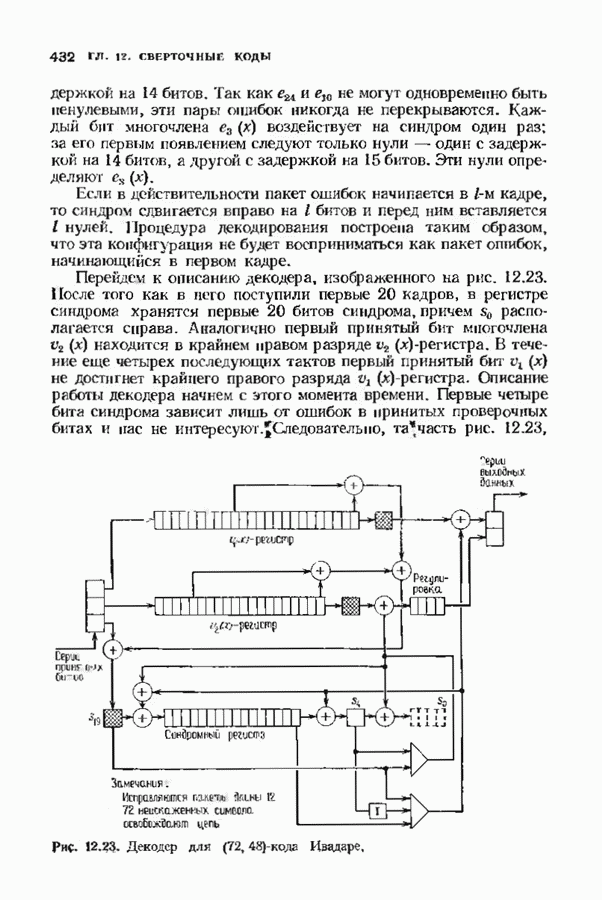








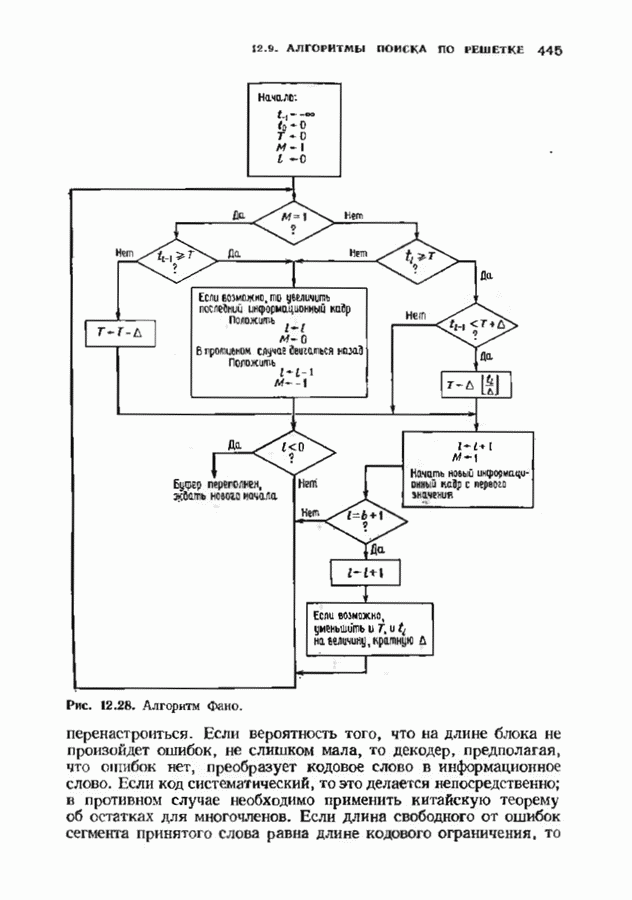
























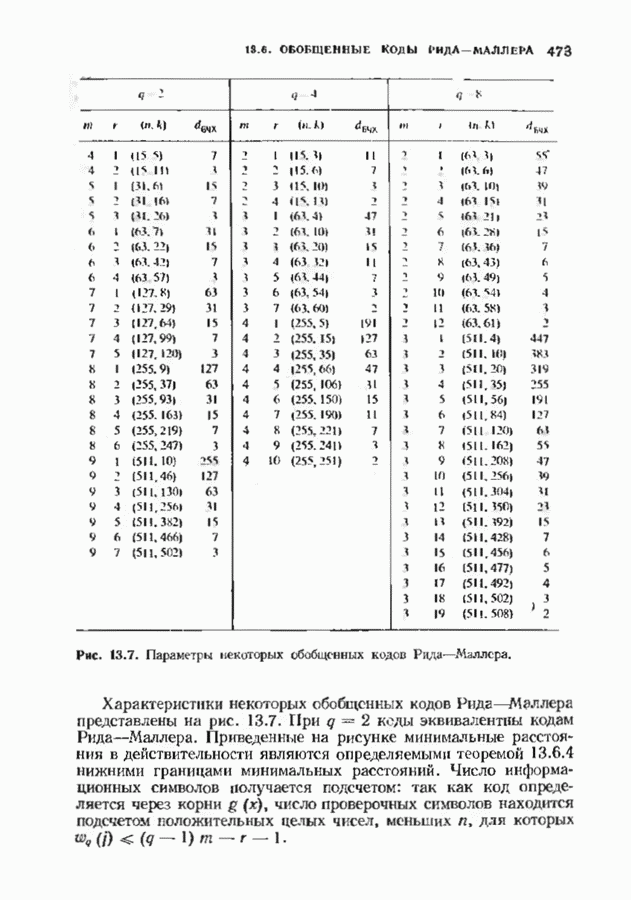
































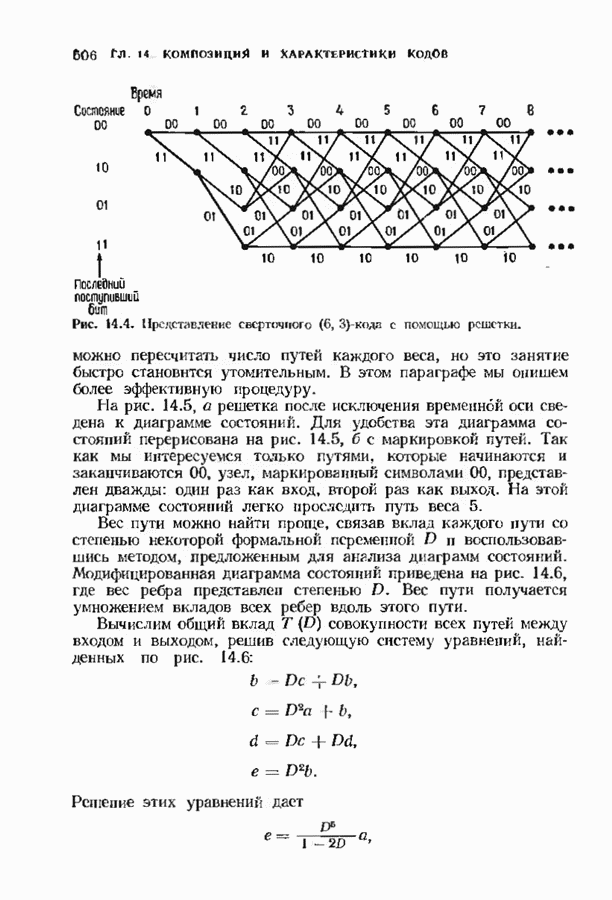
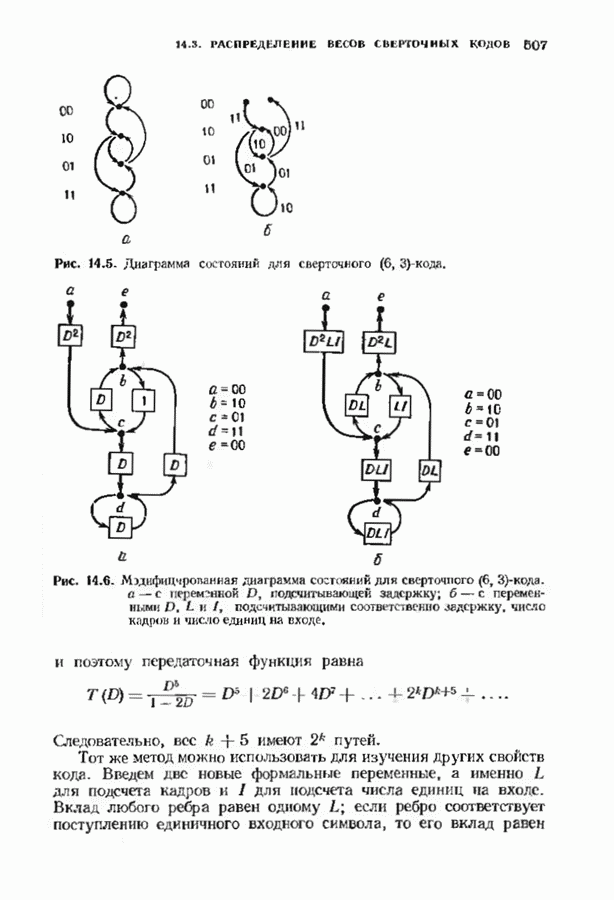




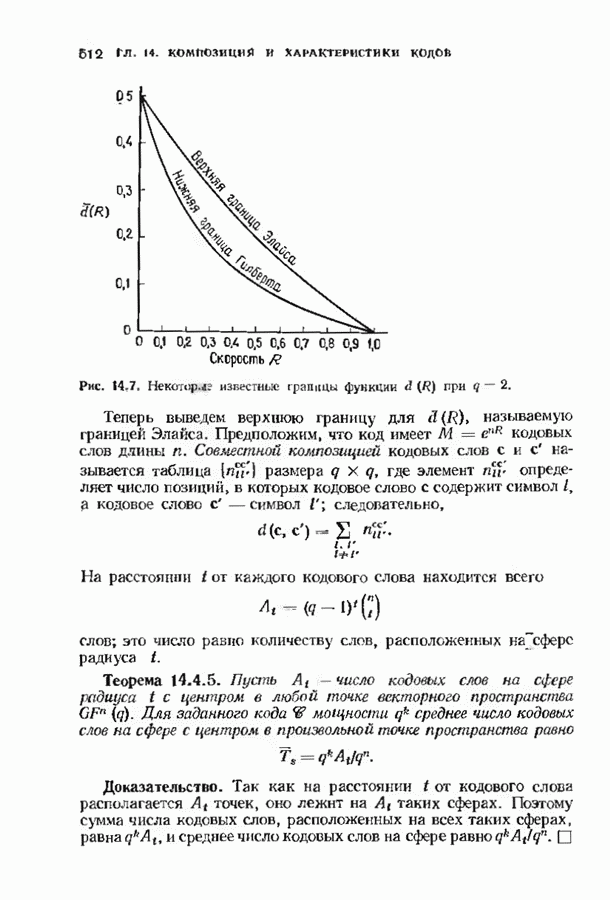




















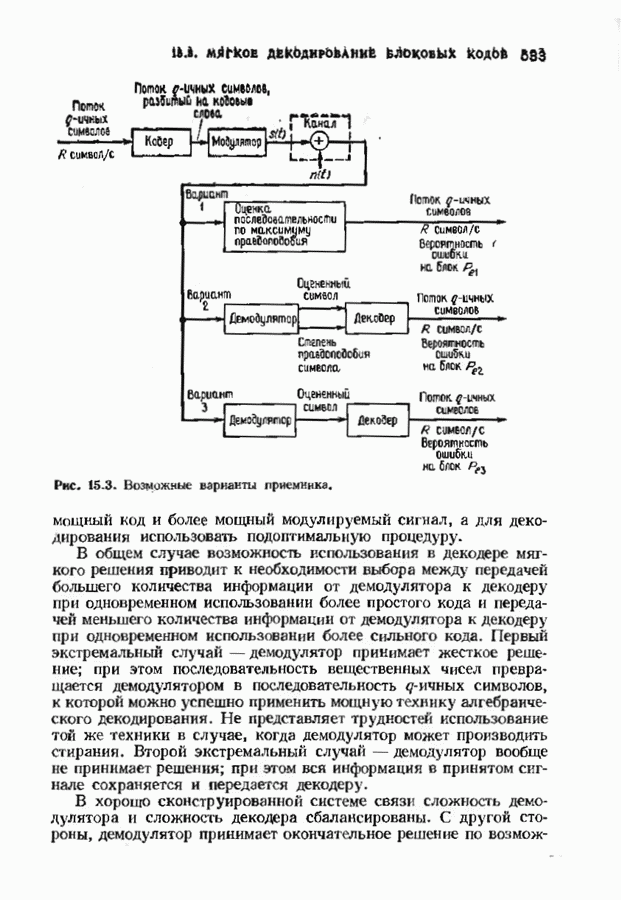



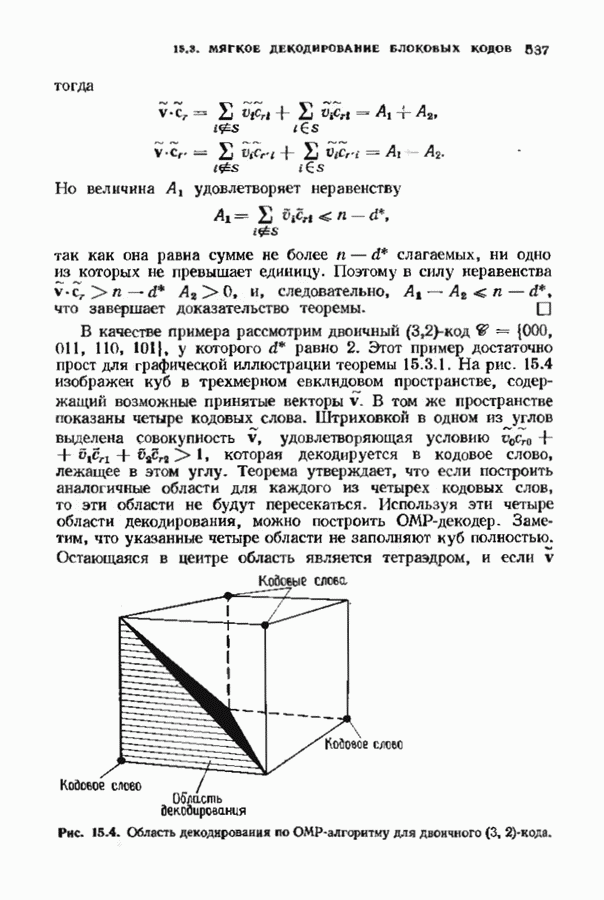

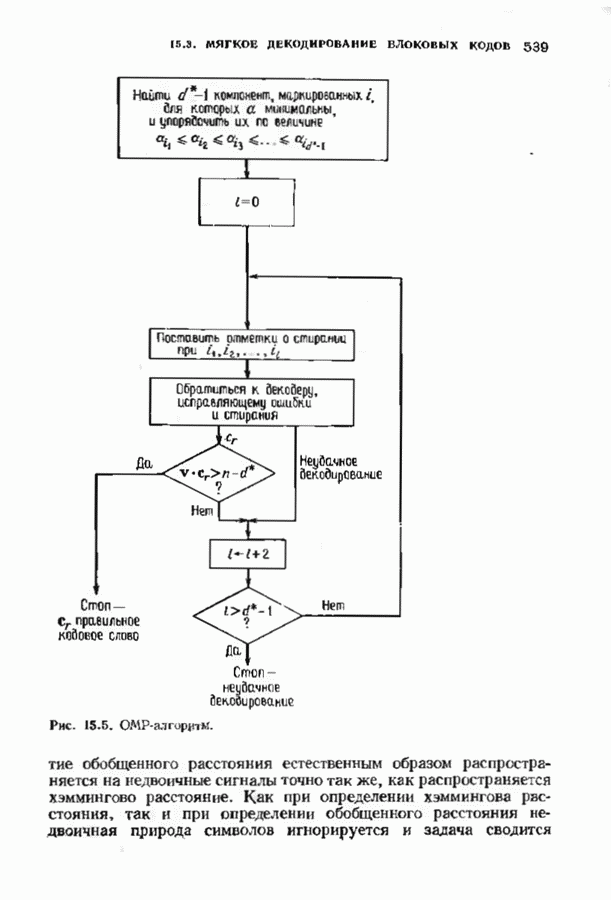




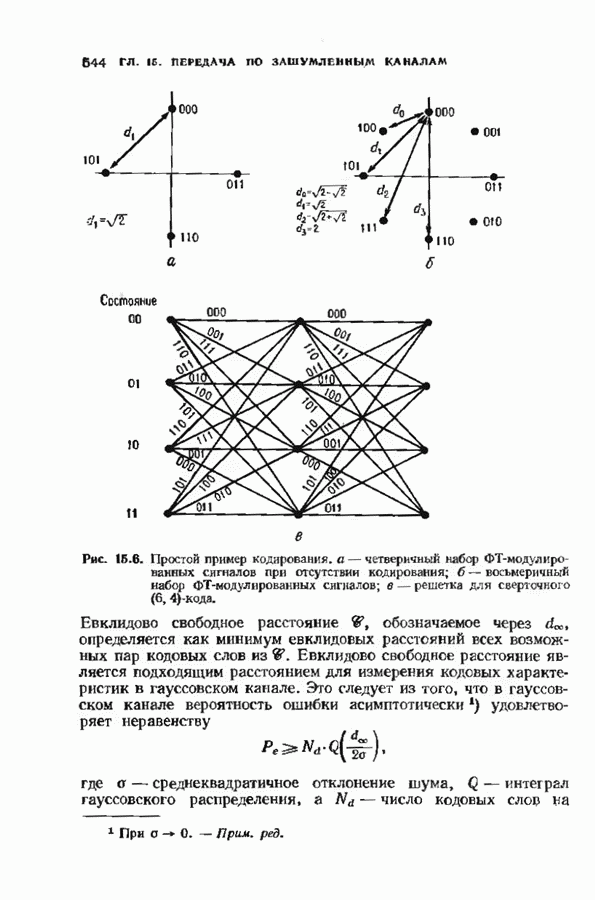
















 ошибок кода исправляет в пределах радиуса упаковки все конфигурации ошибок веса, не превышающего
ошибок кода исправляет в пределах радиуса упаковки все конфигурации ошибок веса, не превышающего  и не исправляет ни одной конфигурации ошибок веса больше
и не исправляет ни одной конфигурации ошибок веса больше  Если происходит более
Если происходит более  ошибок, то декодер иногда заявляет, что сообщение не подлежит исправлению, а иногда делает ошибку при декодировании. Следовательно, на выходе декодера может появляться правильное сообщение, неправильное сообщение или декодирование объявляется неудачным (сообщение стирается). В общем случае неизвестно, как вычислить вероятности этих событий, но в некоторых частных случаях, представляющих практический интерес, получены удовлетворительные выражения.
ошибок, то декодер иногда заявляет, что сообщение не подлежит исправлению, а иногда делает ошибку при декодировании. Следовательно, на выходе декодера может появляться правильное сообщение, неправильное сообщение или декодирование объявляется неудачным (сообщение стирается). В общем случае неизвестно, как вычислить вероятности этих событий, но в некоторых частных случаях, представляющих практический интерес, получены удовлетворительные выражения.
 -ичные каналы, вносящие ошибки в передаваемые символы независимо с вероятностью
-ичные каналы, вносящие ошибки в передаваемые символы независимо с вероятностью  и передающие символы правильно с вероятностью
и передающие символы правильно с вероятностью  Каждое из
Каждое из  ошибочных значений принимается с вероятностью
ошибочных значений принимается с вероятностью  Каждая конфшурация
Каждая конфшурация  ошибок наблюдается с вероятностью
ошибок наблюдается с вероятностью

 декодируется в это кодовое слово; здесь
декодируется в это кодовое слово; здесь  фиксированное число, удовлетворяющее неравенству
фиксированное число, удовлетворяющее неравенству



 ошибок, равно
ошибок, равно  каждая из них имеет место с вероятностью
каждая из них имеет место с вероятностью  Отсюда следует утверждение теоремы.
Отсюда следует утверждение теоремы.
 означает число конфигураций ошибок веса
означает число конфигураций ошибок веса  находящихся на расстоянии
находящихся на расстоянии  от кодового слова веса
от кодового слова веса  Ясно, что
Ясно, что  не зависит от выбора кодового слова веса
не зависит от выбора кодового слова веса  Заметим, что если
Заметим, что если  то
то  В приведенной ниже теореме это условие выполняется автоматически, так как мы условились считать
В приведенной ниже теореме это условие выполняется автоматически, так как мы условились считать  при
при  или
или 
 находящихся на расапоянии
находящихся на расапоянии  от конкретного кодового слова веса I, равно
от конкретного кодового слова веса I, равно


 нем фигурируют три индекса суммирования и два ограничения Суммируется число кодовых слов, которые могут быть получены заменой любых
нем фигурируют три индекса суммирования и два ограничения Суммируется число кодовых слов, которые могут быть получены заменой любых  из
из  нулевых компонент кодового слова на любой из
нулевых компонент кодового слова на любой из  ненулевых символов, любых
ненулевых символов, любых  из I ненулевых
из I ненулевых

 ненулевых символов и любых
ненулевых символов и любых  из оставшихся ненулевых компонент на нули. Ограничение
из оставшихся ненулевых компонент на нули. Ограничение  гарантирует, что результирующее слово находится на расстоянии
гарантирует, что результирующее слово находится на расстоянии  от кодового слова. Ограничение
от кодового слова. Ограничение  гарантирует, что результирующее слово имеет вес
гарантирует, что результирующее слово имеет вес 
 и декодер исправляет все конфигурации ошибок, вес которых не превышает
и декодер исправляет все конфигурации ошибок, вес которых не превышает  то вероятность ошибочного декодирования равна
то вероятность ошибочного декодирования равна

 которые приводят к ошибке декодирования, равно (
которые приводят к ошибке декодирования, равно ( в силу условия
в силу условия  ни одна из конфигураций ошибок не сосчитана дважды. Вероятность каждой из них равна
ни одна из конфигураций ошибок не сосчитана дважды. Вероятность каждой из них равна  что доказывает теорему.
что доказывает теорему. 
 то нужпо просто заменить
то нужпо просто заменить  на
на  на условную вероятность ошибки
на условную вероятность ошибки  Тогда если распределение вероятностей
Тогда если распределение вероятностей  числа стираний
числа стираний  известно, то
известно, то  может быть вычислено по формуле
может быть вычислено по формуле 