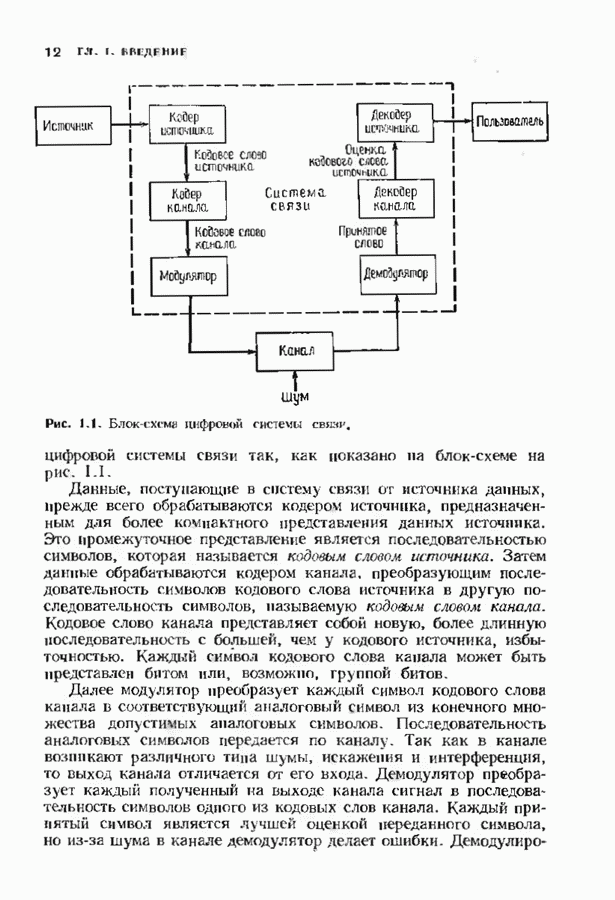
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
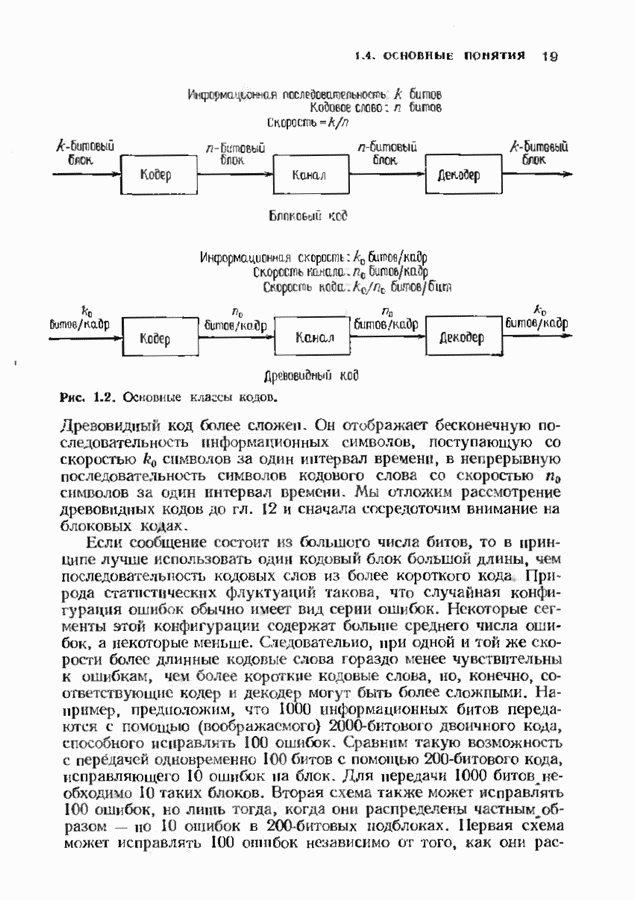
ZADANIA.TO
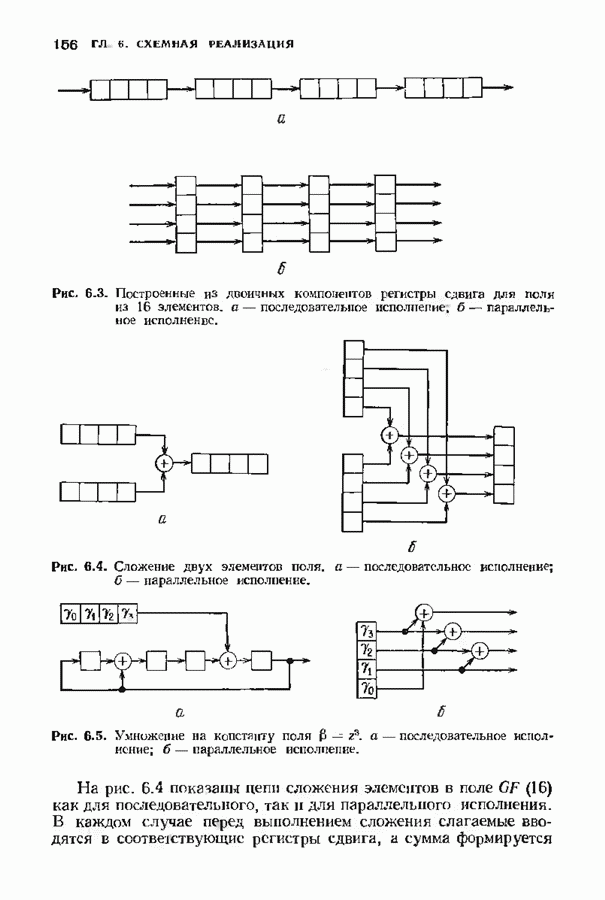
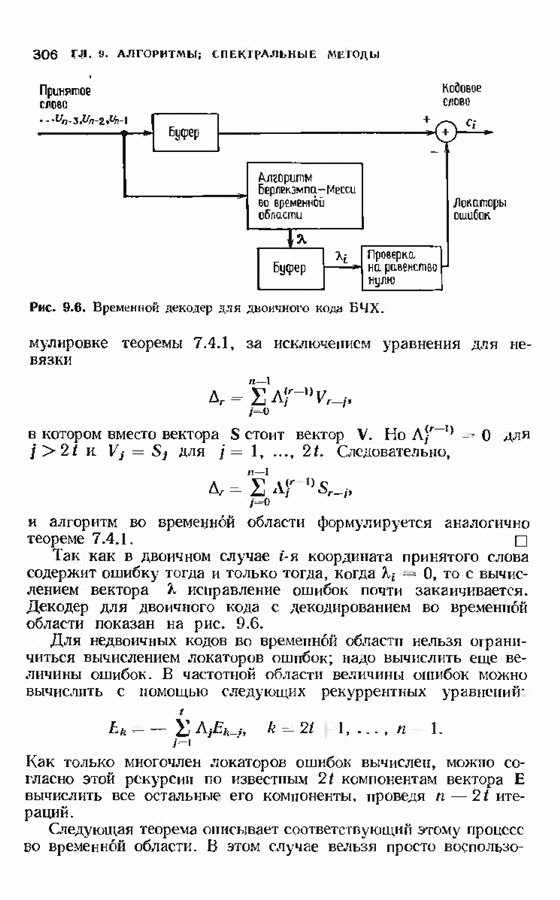
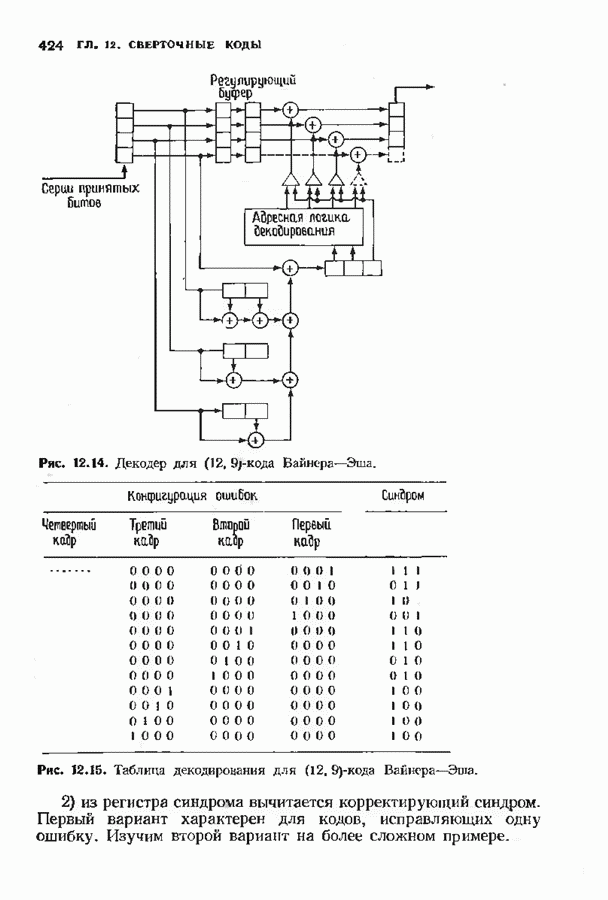
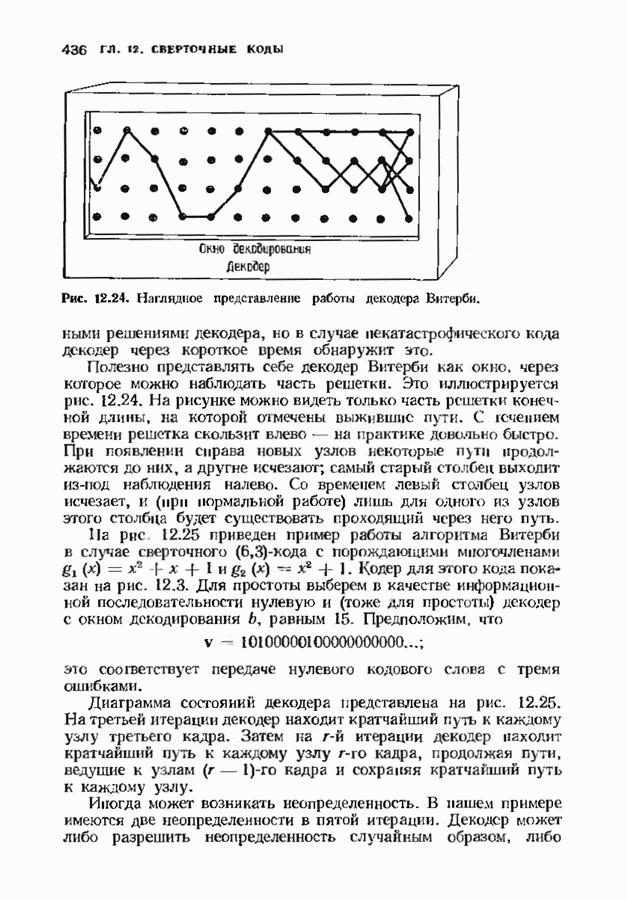
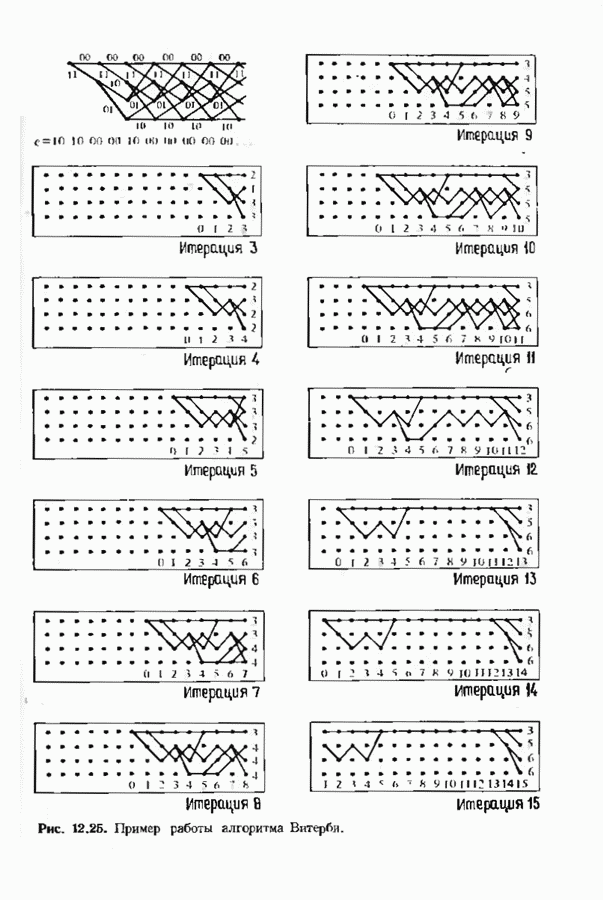
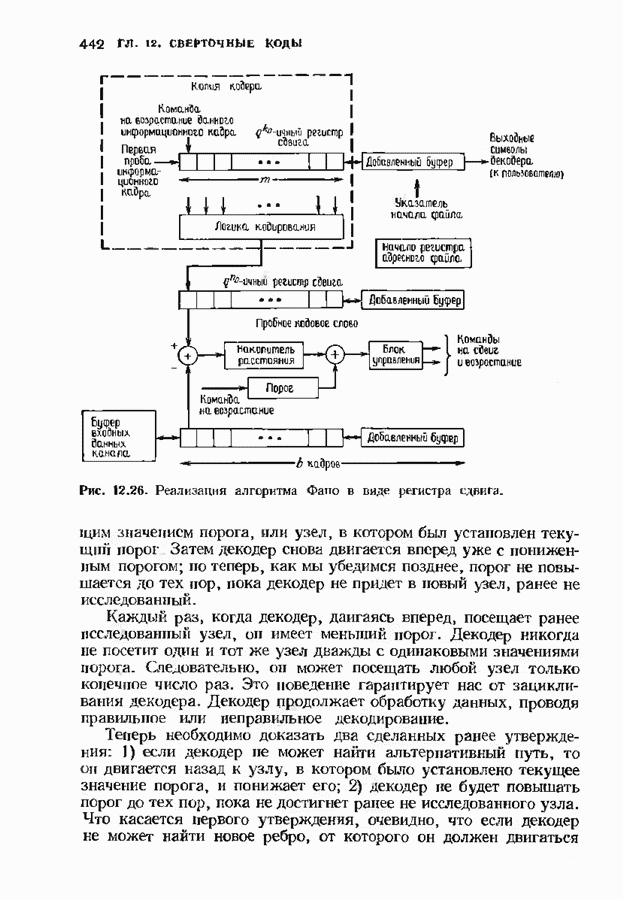
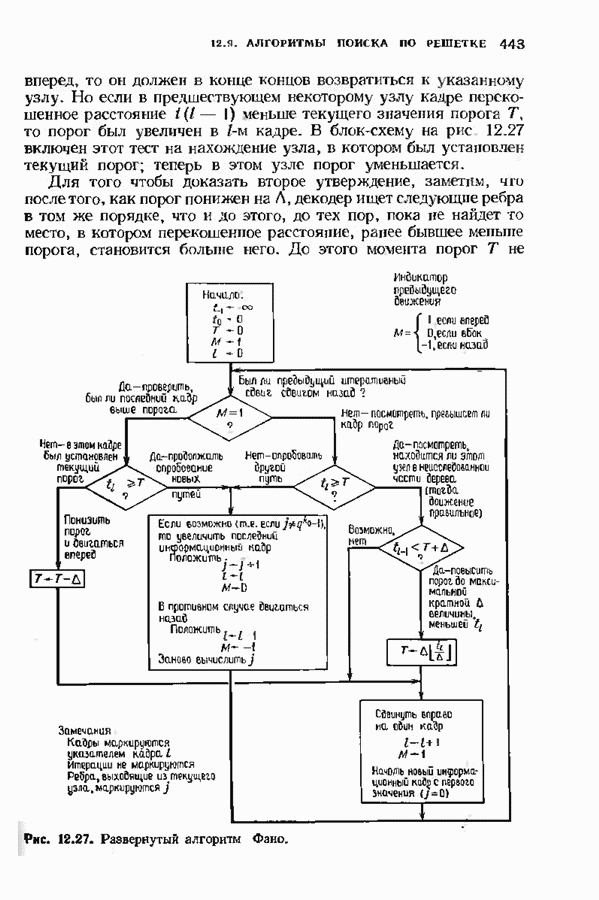
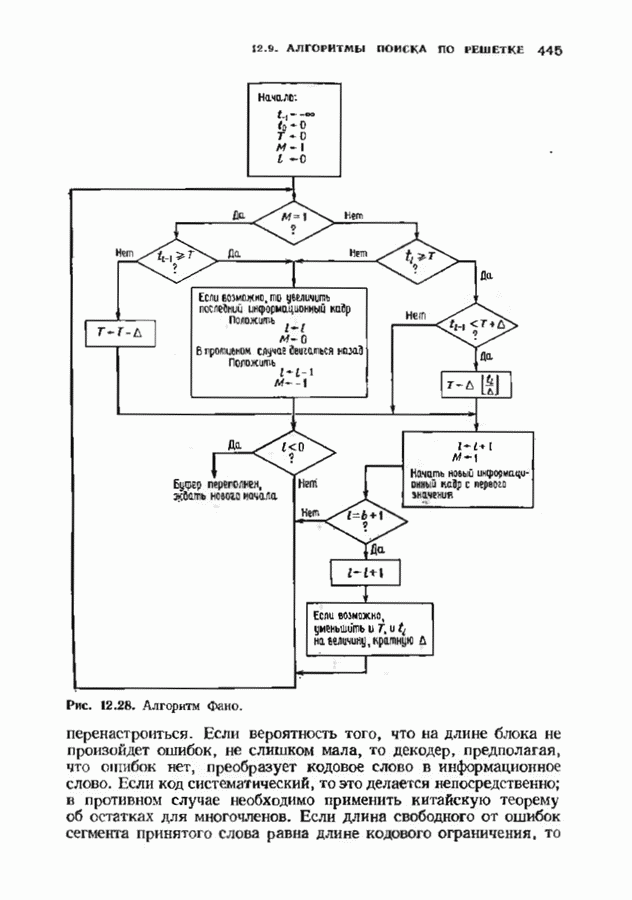
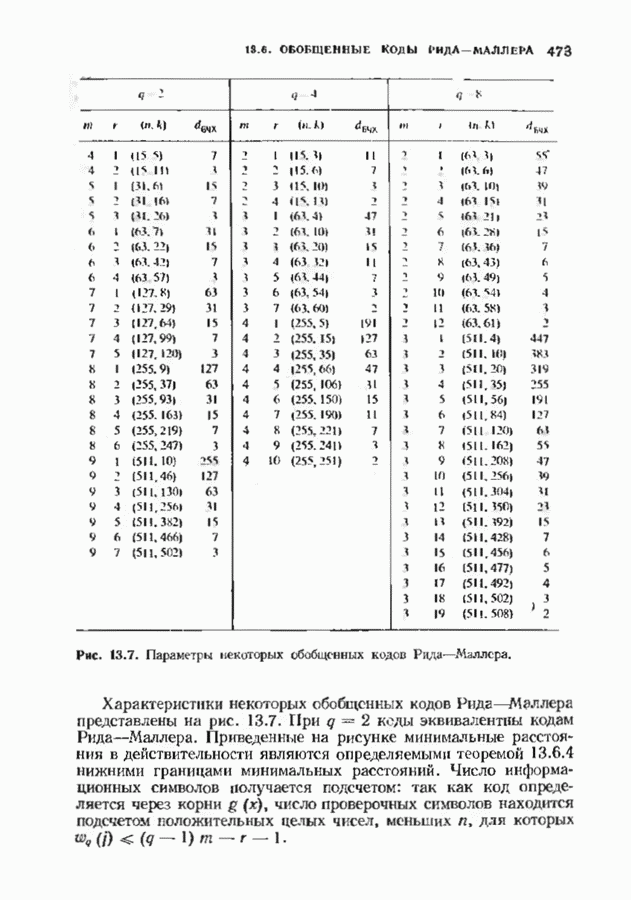
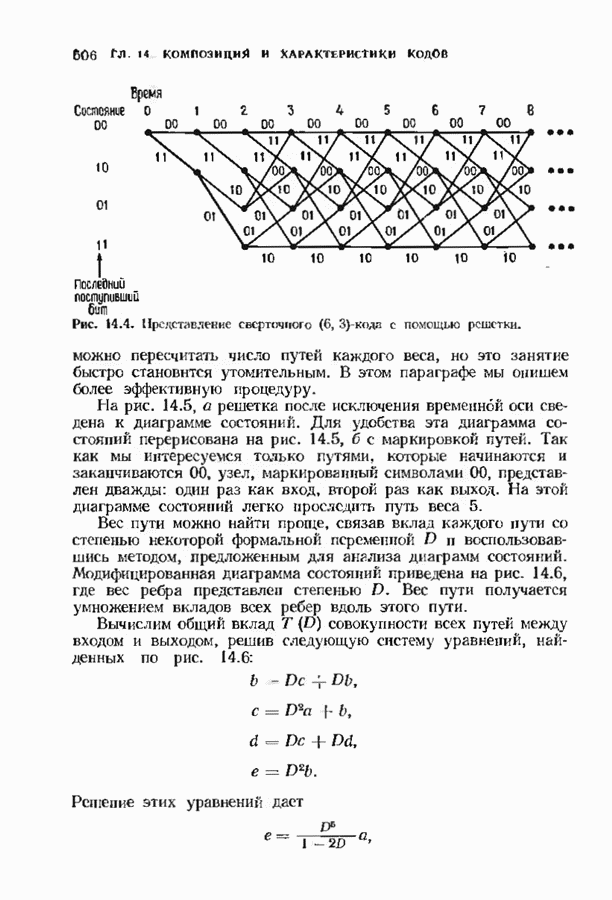
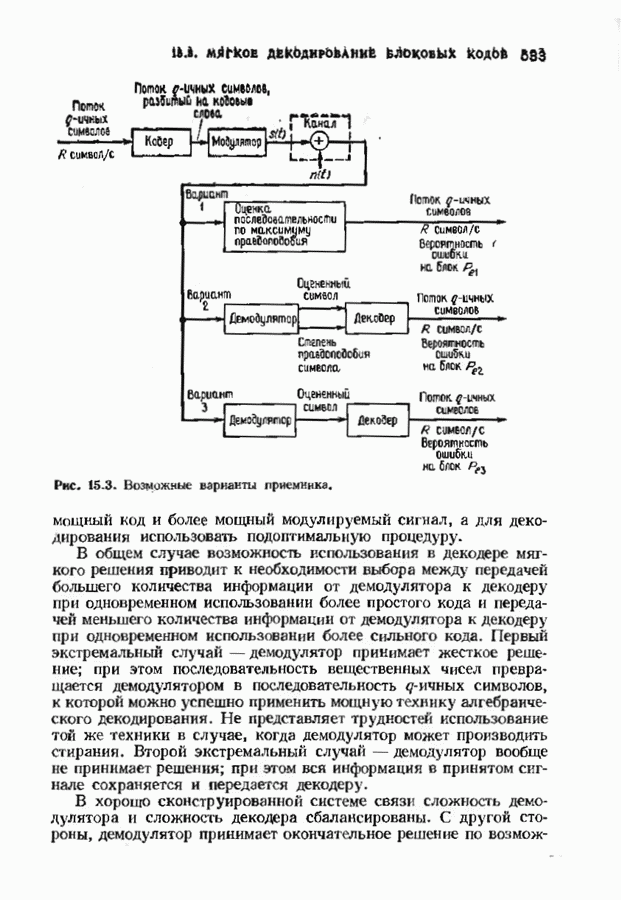
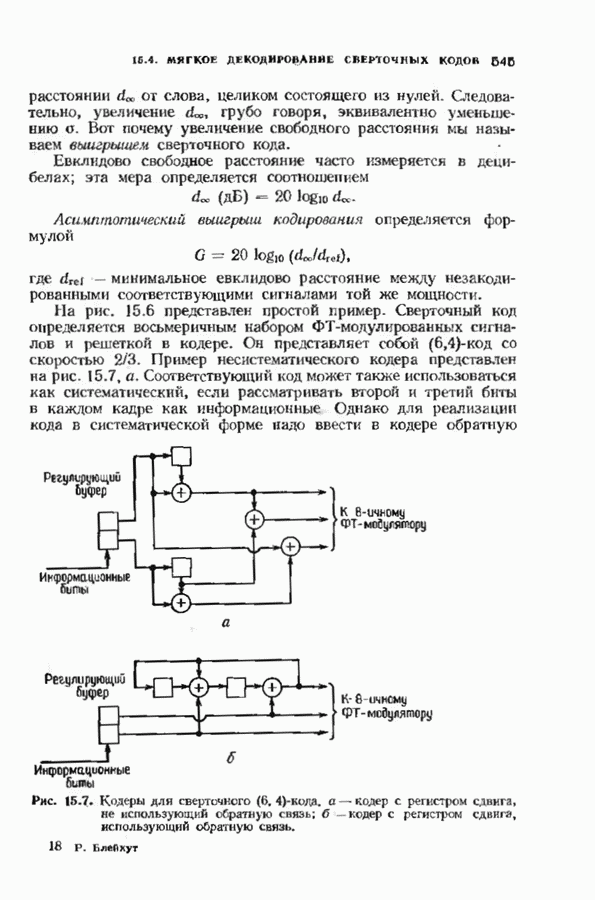
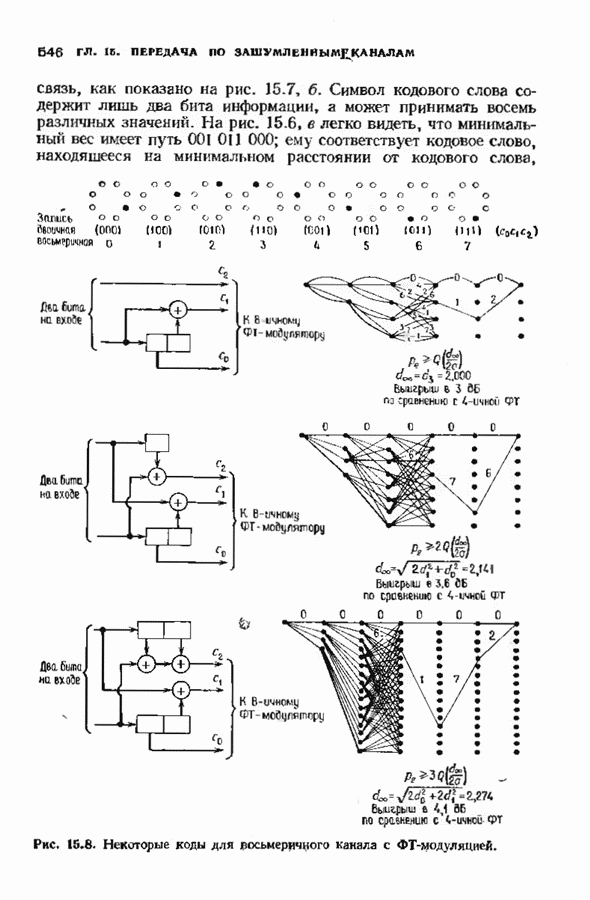
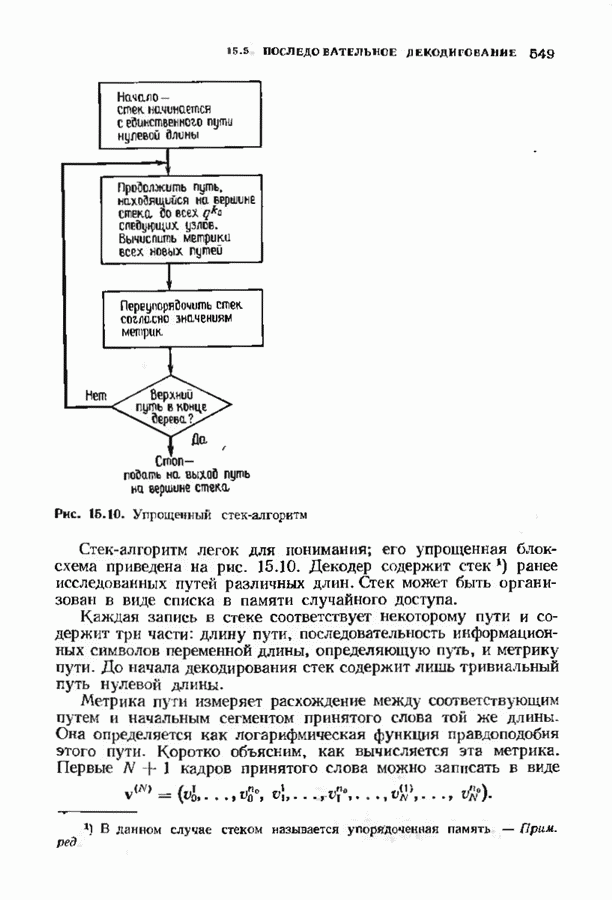
6.4. ДЕКОДЕР МЕГГИТТАНаиболее сложной частью описанного в предыдущем параграфе декодера с регистром сдвига является табулирование заранее вычисленных синдромпых многочленов Простейший декодер такого типа, так называемый декодер Меггитта, проверяет синдромы только для тех конфигураций ошибок, которые расположены в старших позициях. Декодирование ошибок в остальных позициях основано на циклической структуре кода и осуществляется позже. Соответственно таблица синдромов содержит только те синдромы, которые соответствуют многочленам ошибок с ненулевым коэффициентом Пели вычисленный синдром находится в этой таблице, то В действительности нет необходимости вычислять синдромы для всех циклических сдвигов принятого слова. Новый синдром можно легко вычислить по уже вычисленному. Основная взаимосвязь описывается следующей теоремой. Теорема 6.4.1 (Меггитт). Предположим, что
Тогда
Доказательство сводится к комбинации трех простых утверждений. (i) По определению
Согласно алгоритму деления,
однозначно, причем Комбинируя эти утверждения, получаем
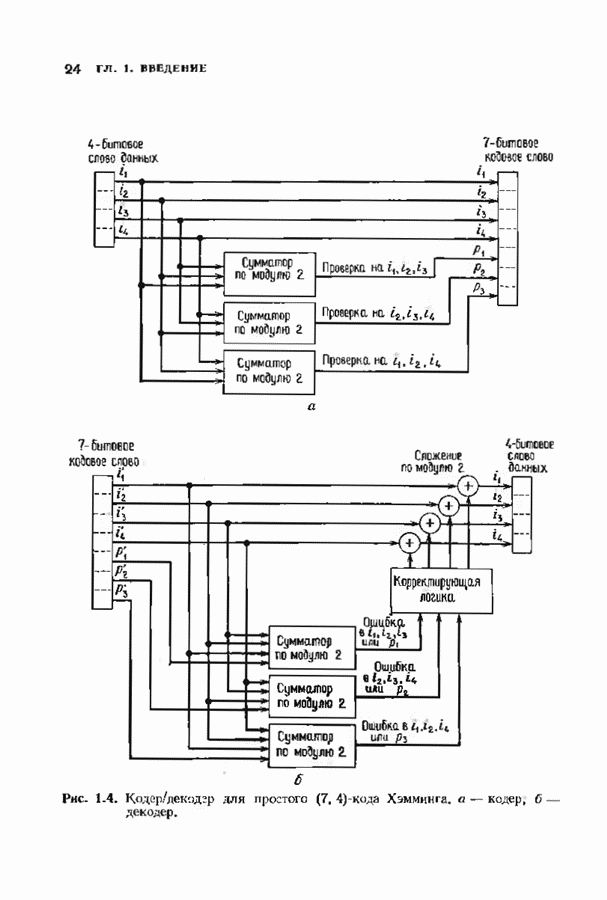
Так как
что и требовалось доказать. Из этой теоремы, в частности, следует, что многочлены ошибок и соответствующие им синдромные многочлены удовлетворяют равенству
Если
получается циклическим сдвигом многочлена
Это соотношение показывает, как вычислять синдром произвольного циклического сдвига конфигурации ошибки, синдром которой известен. Такое вычисление можно реализовать на простой цепи с регистром сдвига, что, как правило, намного проще, чем просмотр таблицы синдромов. Предположим, что
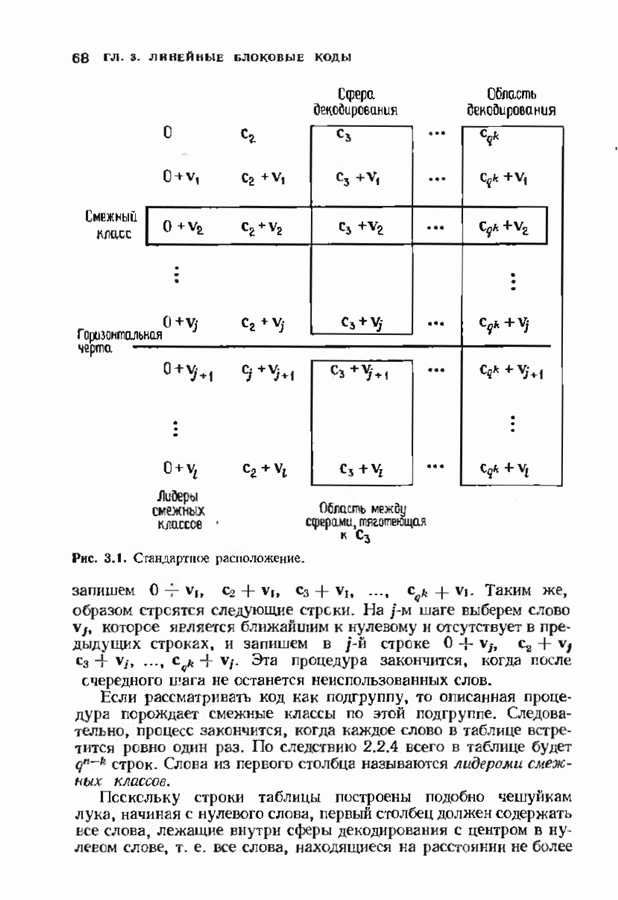
Рис. 6.16. Декодер Меггигга. представляет собой циклический сдвиг многочлена Составим таблицы из таких конфигураций ошибок, чтобы каждая исправляемая конфигурация была циклическим сдвигом одной (или нескольких) из них. Тогда в декодере необходимо запомнить только эту таблицу и таблицу соответствующих синдромных многочленов. Истинный синдром Обычно при использовании в декодере цепей с регистром сдвига в качестве табличных конфигураций ошибок выбираются такие, у которых ненулевые коэффициенты расположены в конце регистра сдвига. Это позволяет уменьшить число проводов и использовать регистры, начальные разряды которых не имеют прямого доступа. Такая реализация показана на рис. 6.18. В качестве табличных выбираются все синдромы, соответствующие исправляемым ошибкам с непулевыми старшими компонентами. В начале работы декодера содержимое всех разрядов регистра равно нулю. Сначала в декодере срабатывает цепь деления на реализует умножение синдрома на х и деление результата на Показанная на рис. 6.18 обратная связь, предназначенная для исправления записанных в буфере символов, не является необходимой; вычисленные символы можно передавать непосредственно пользователю. Мы показали эту связь на схеме для того, чтобы проиллюстрировать идею о том, что только после последнего сдвига в буфере будет записано правильное кодовое слово, а также для того, чтобы иметь отправную точку для некоторых ревлизаций декодера, которые будут описаны ниже. Приложения теоремы Меггитта лучше всего пояснить на конкретных примерах. Рассмотрим
Рис. 6.19. Декодер Меггитта для
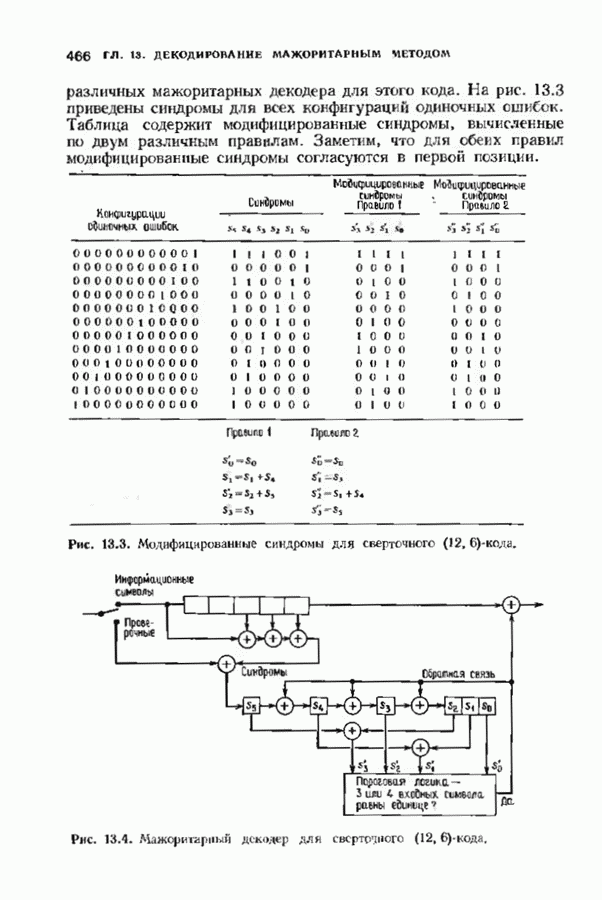
Рис. 6-20. Другой декодер Меггитта. исправления закончен. Следовательно, полный процесс работы декодера занимает 30 тактов. Обычно декодер Меггитта используют в несколько иной форме, показанной на рис. 6.20. Этот вариант декодера отличается от предыдущих наличием линии, помеченной словами «модификация синдрома». Хотя, как следует из предыдущего описания, эта линия не является необходимой для работы декодера, она необходима для тех реализаций декодера, которые будут описаны ниже. Сейчас операцию модификации синдрома следуе Чтобы понять использование модификации синдрома, предположим, что при наличии ошибки мы хотим ее исправить и полностью ликвидировать ее влияние так, как будто ее не было вообще. Согласно теореме Меггитта, необходимо позаботиться только о случае, когда ошибка произошла в старшем символе. После этого остальные компоненты будут учтены автоматически. Пусть
После исправления неудобства. Чтобы избежать этих неудобств, изменим определение синдрома, задав его равенством
Это определение отличается от первоначального, но не хуже его, и с ним можно работать точно так же, как и с первоначальным. Его преимущество состоит в том, что
так как степень многочлена Предварительное умножение На рис. 6.21 изображен модифицированный декодер Меггитта для (15, 11)-кода Хэмминга, декодер которого уже рассматривался выше (рис. 6.19). Принятый многочлен
Преимущество такой модификации ссстоит в том, что соответствующий ошибке
а это дает возможность исправления с помощью сигнала обратной связи.
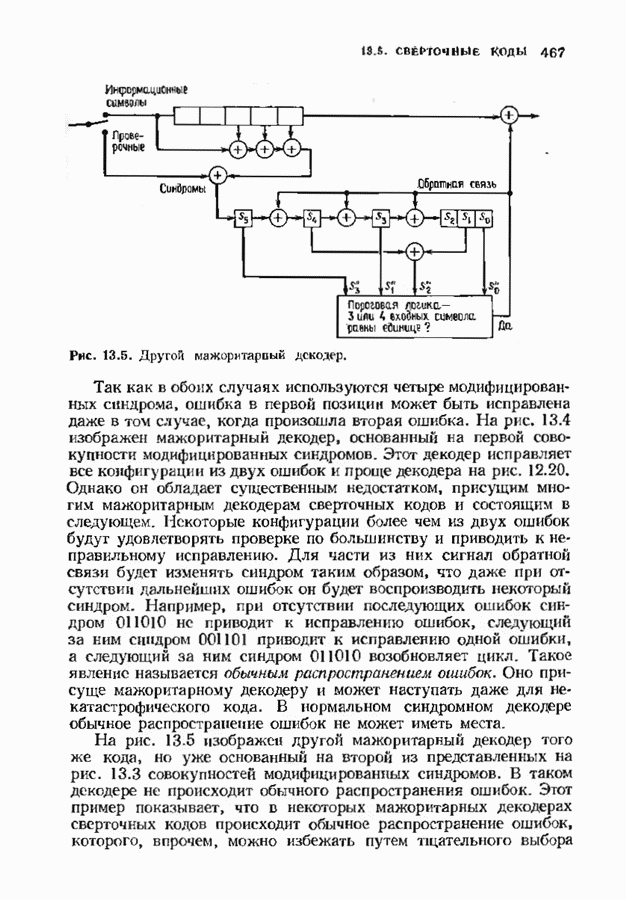
Рис. 6.21. Другой декодер Мегпггта для (15, 11)-кода Хэмминга. Следующим примером является декодер для Принятое слово умножается на
Аналогично если
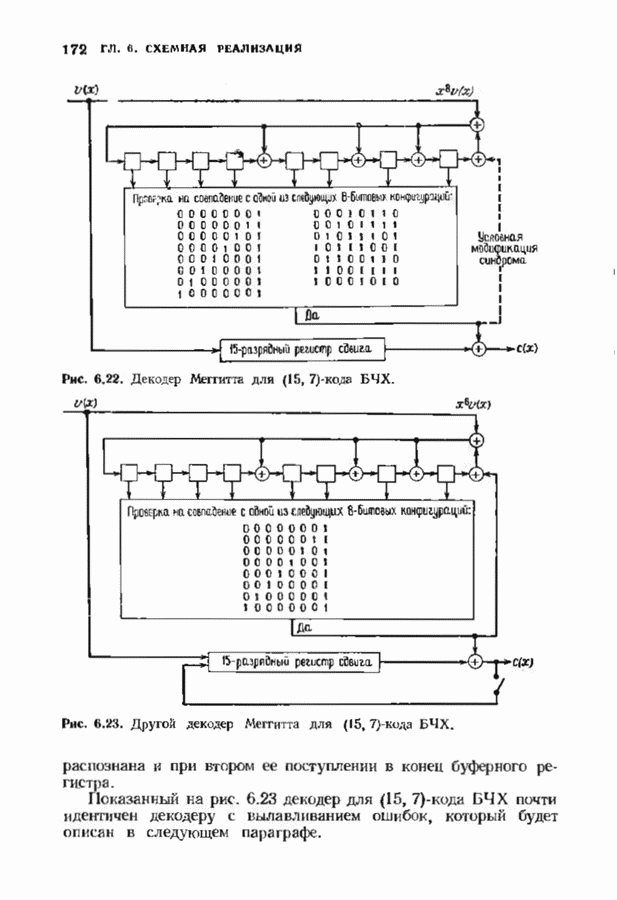
Продолжая таким образом, можно вычислить все подлежащие запоминанию синдромы. Для нахождения ошибок декодер сравнивает вычисленный по принятому слову синдром со всеми этими 15 синдромами. Такой декодер Меггитта показан на рис. 6.22. Отметим, что для нахождения ошибки в старшем разряде содержимое Можно упростить этот декодер и далее и получить схему, изображенную на рис. 6.23. Заметим, что при циклическом сдвиге принятого слова многие из 15 исправляемых конфигураций ошибок появляются дважды. Например, вектор
Рис. 6.22. Декодер Меггитта для
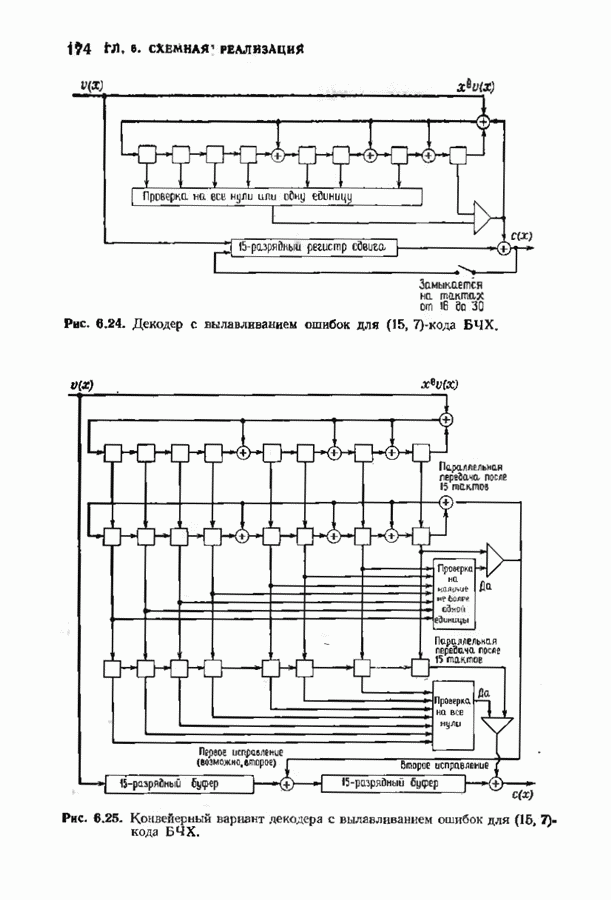
Рис. 6.23. Другой декодер Меггитта для распознана и при втором ее поступлении в конец буферного регистра. Показанный на рис. 6.23 декодер для
|
 |
Оглавление
|
























































































































































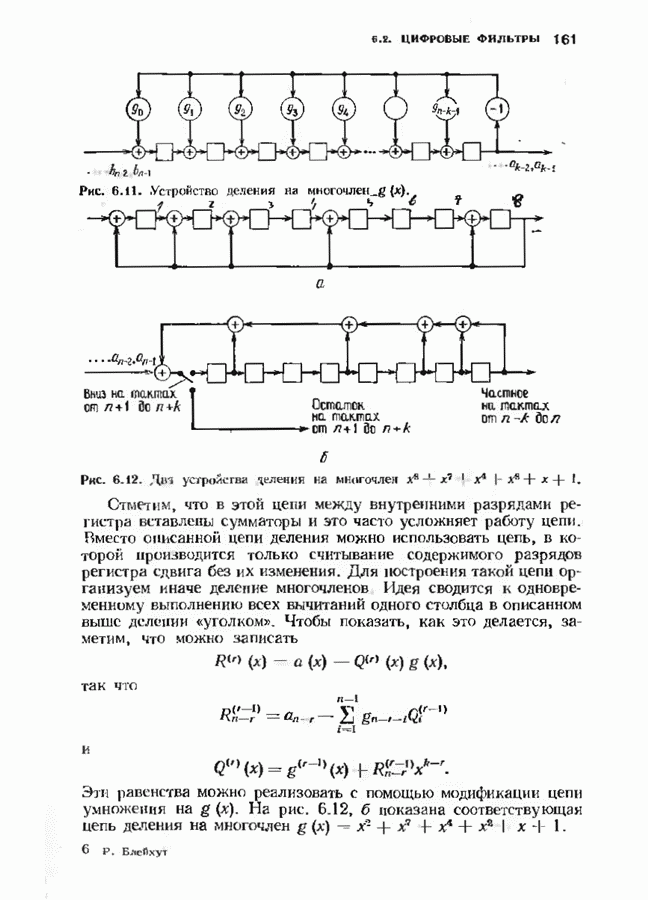

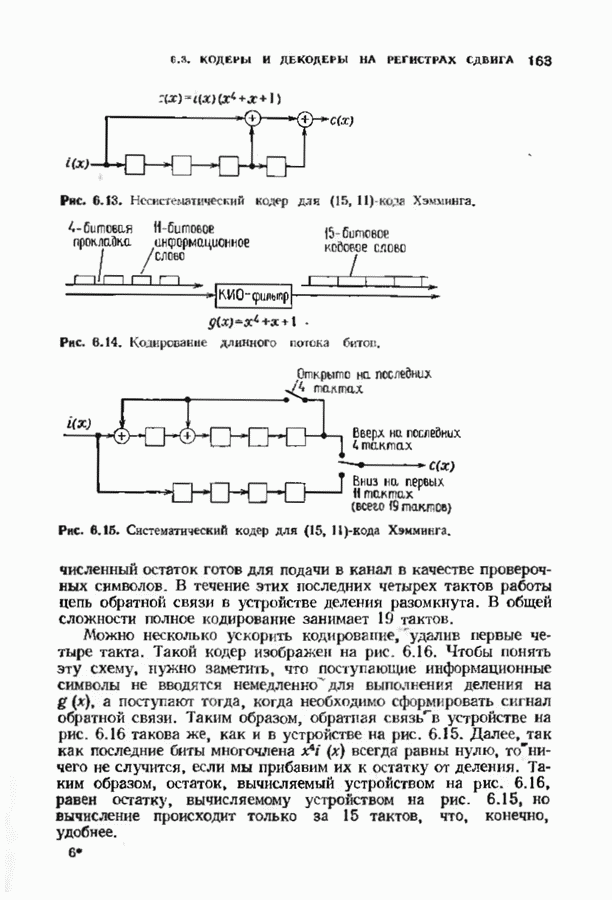
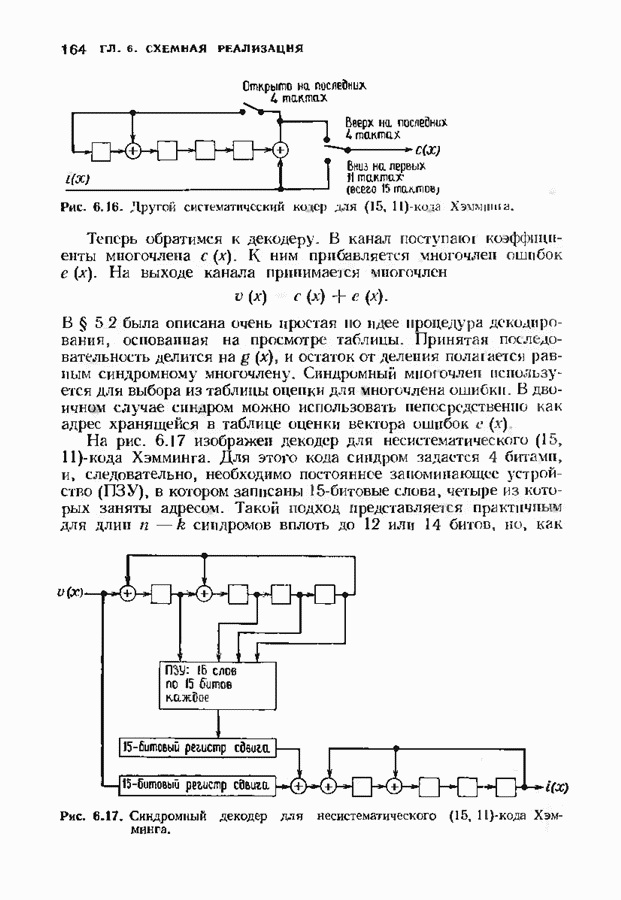






















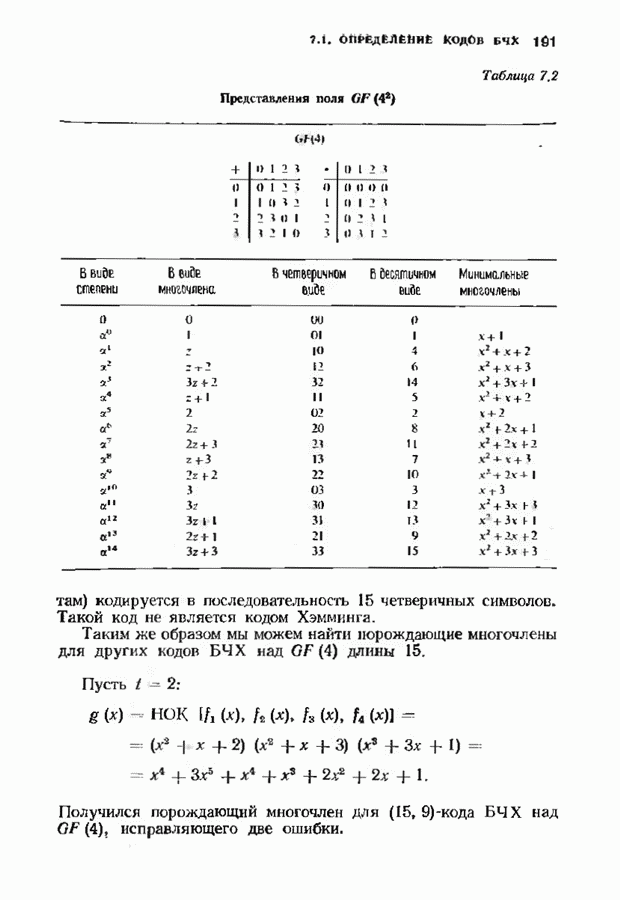







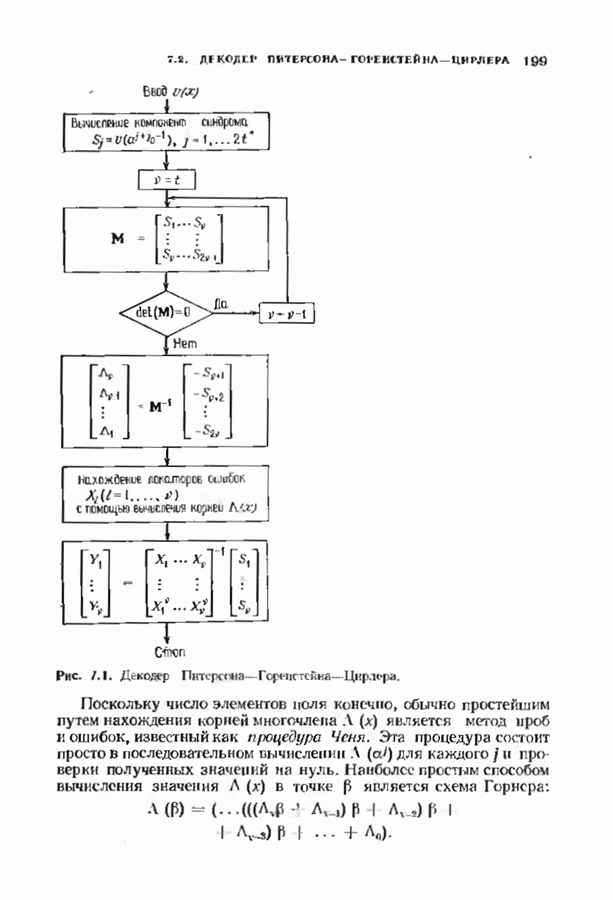







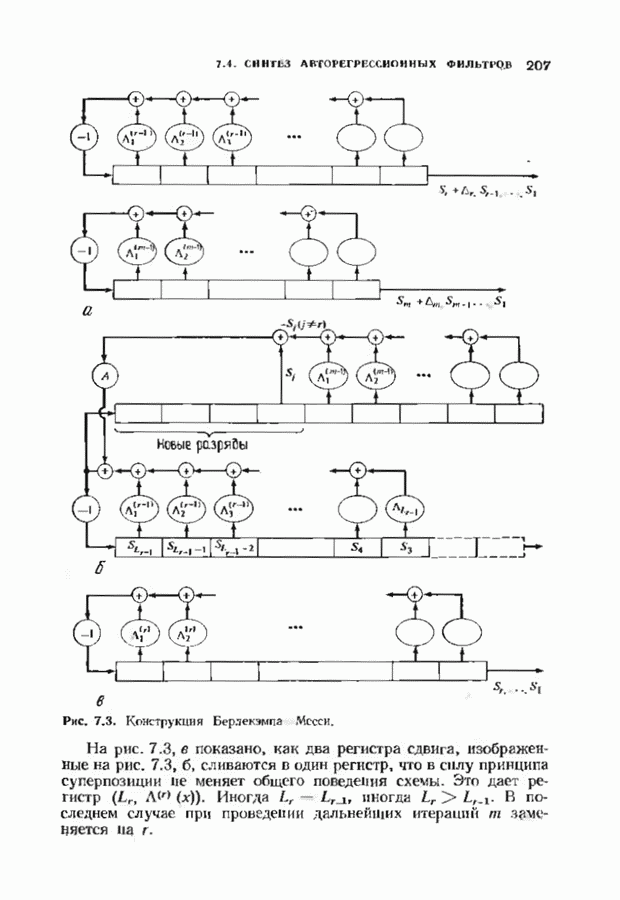






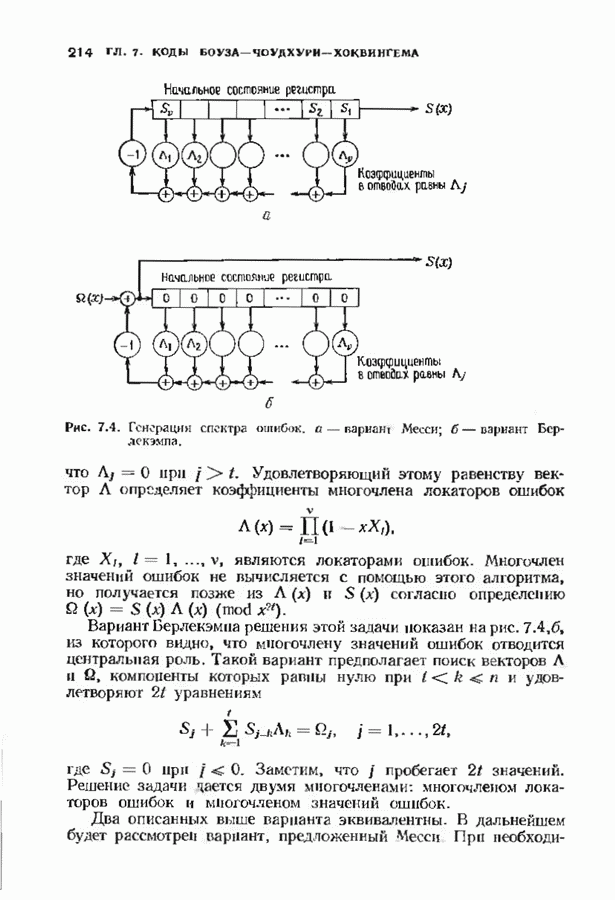
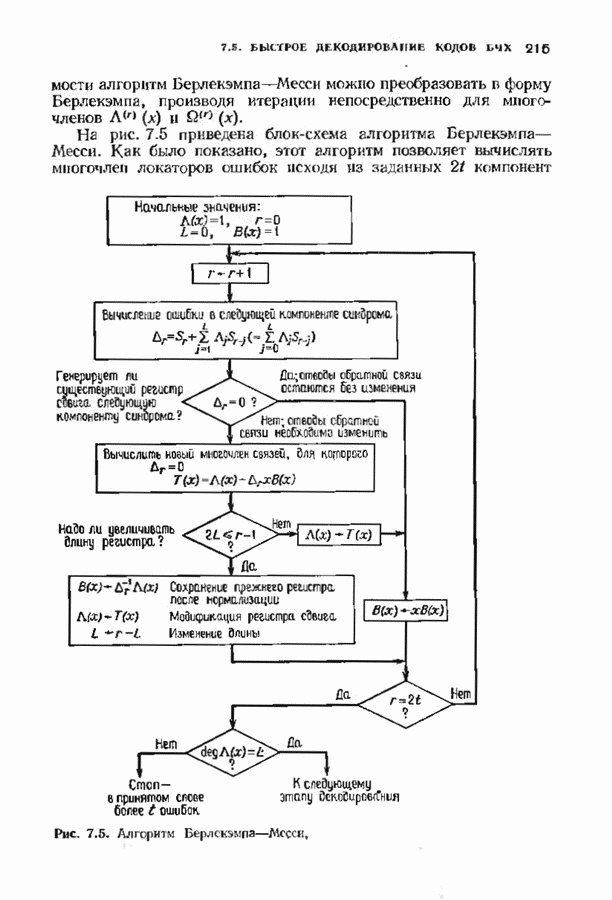


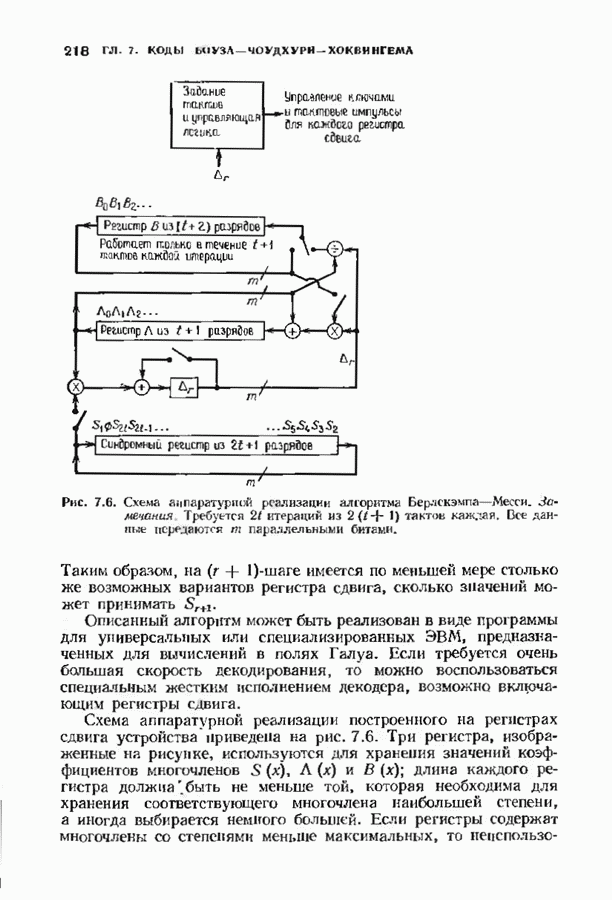









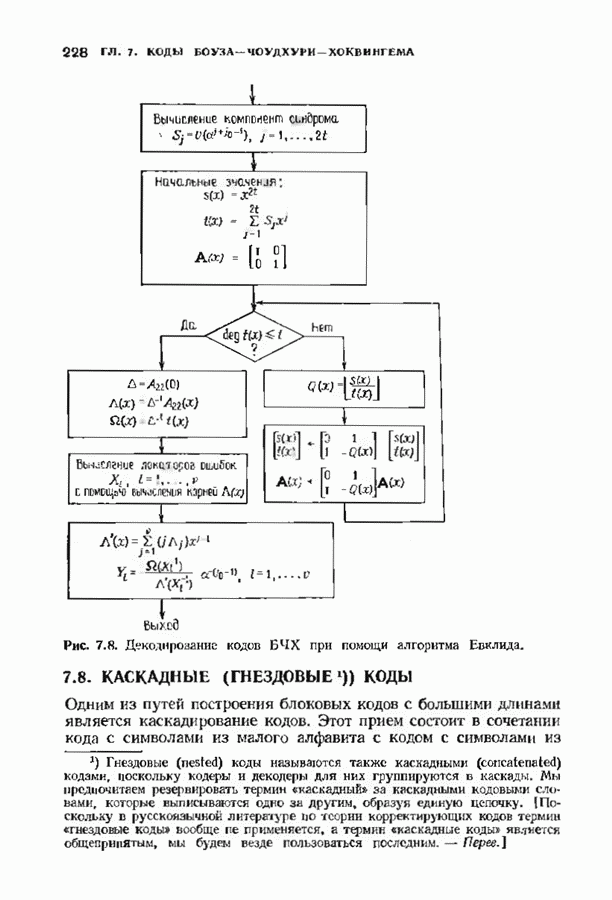

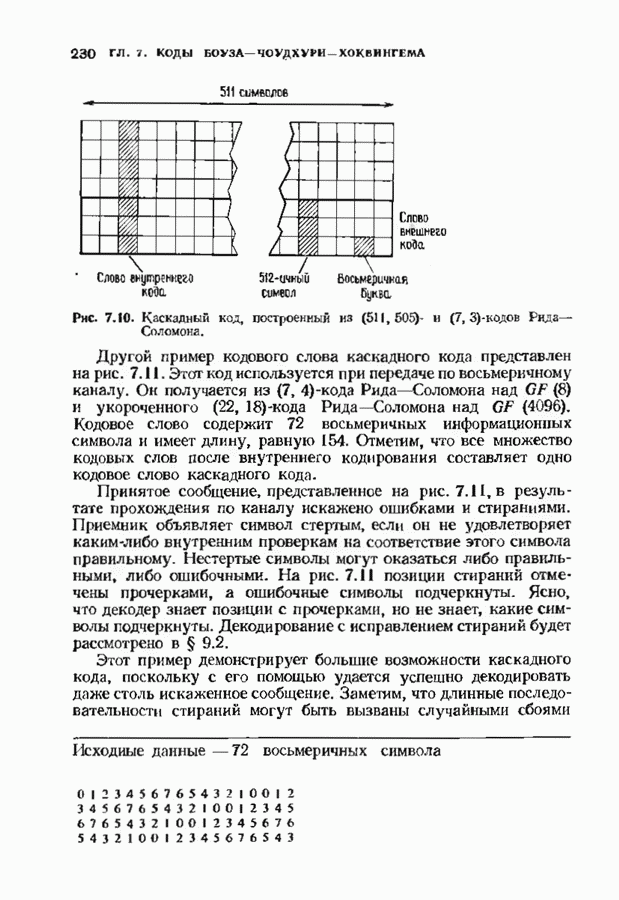














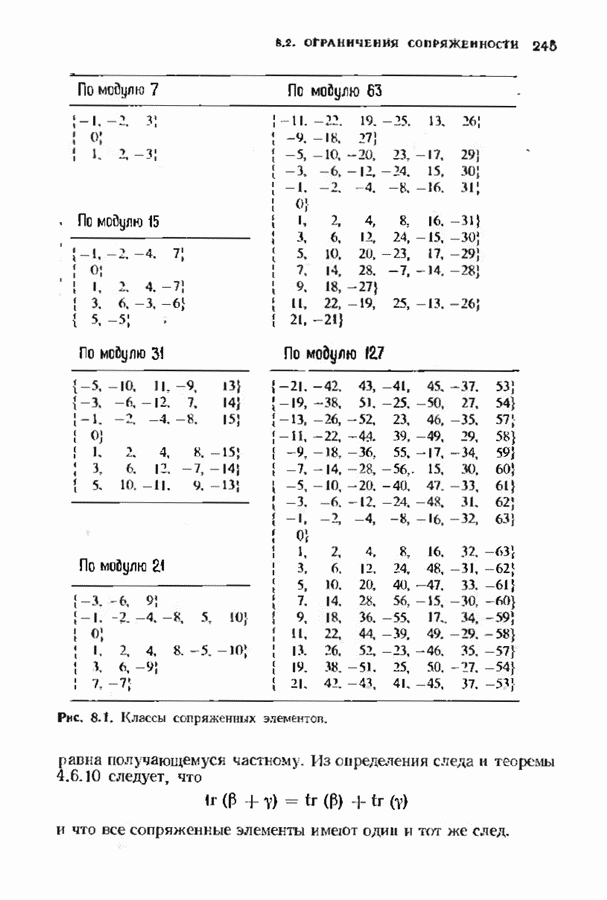





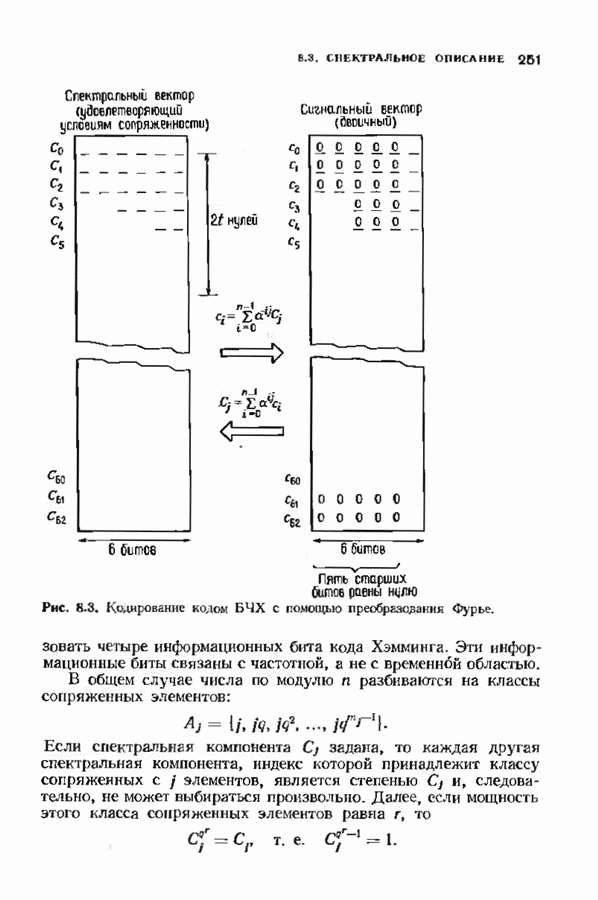








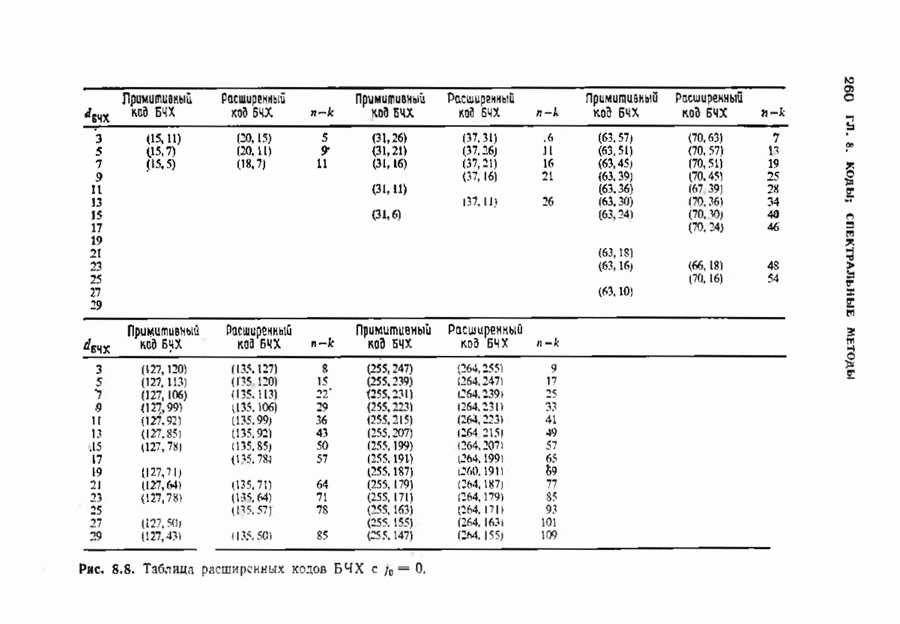

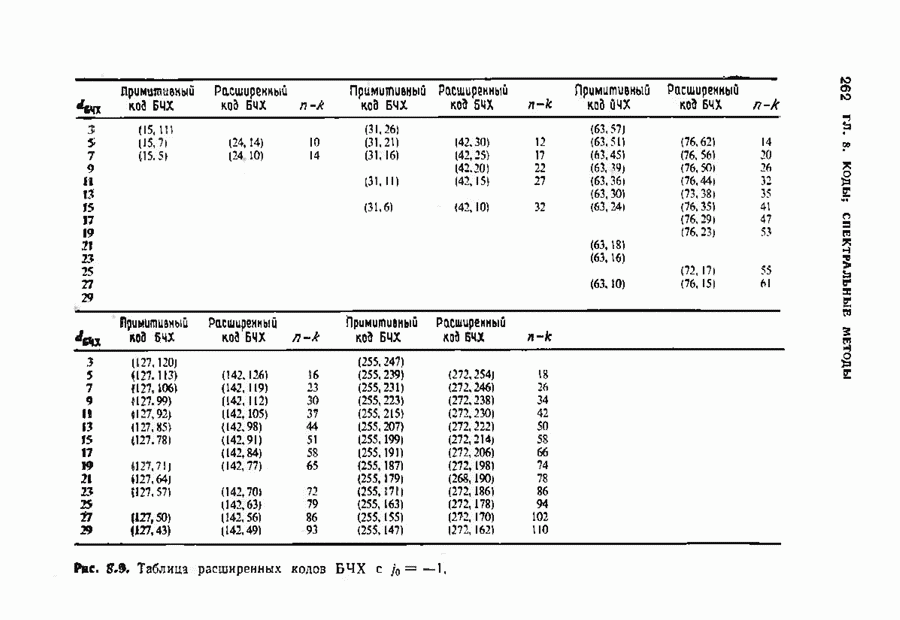
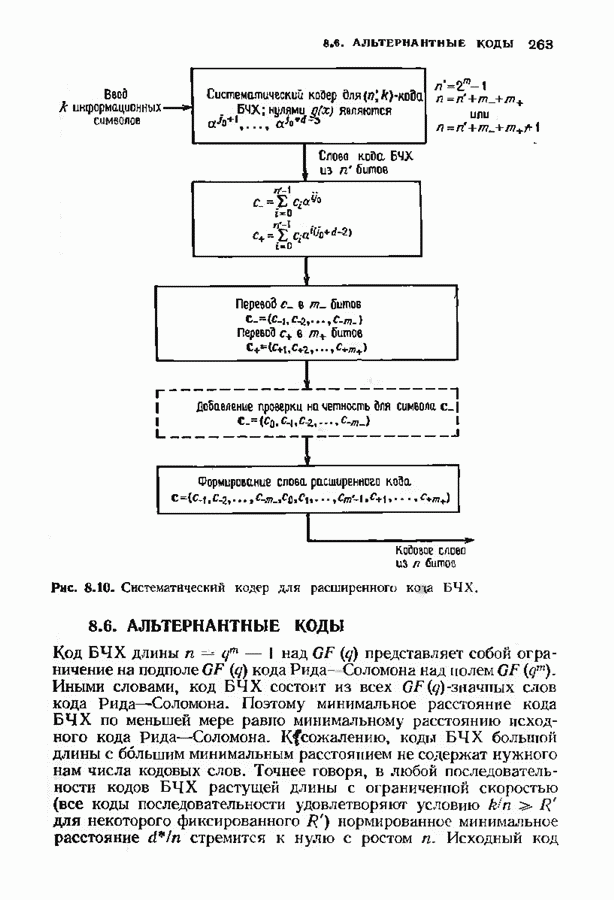







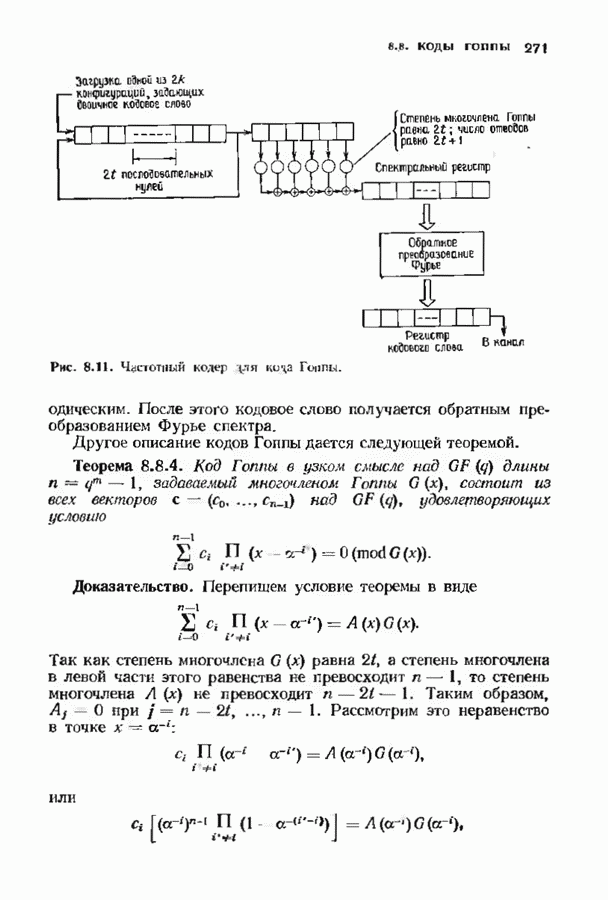



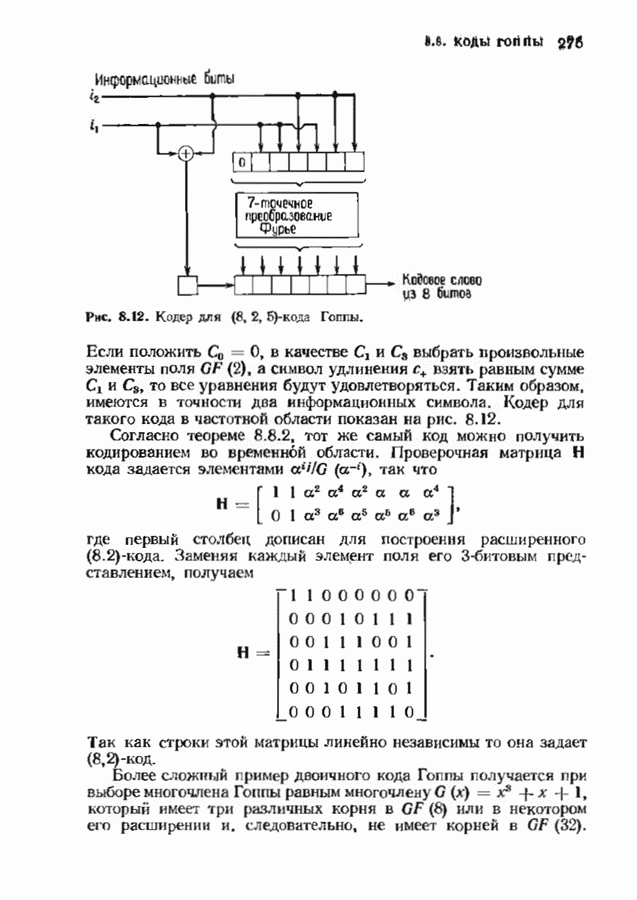












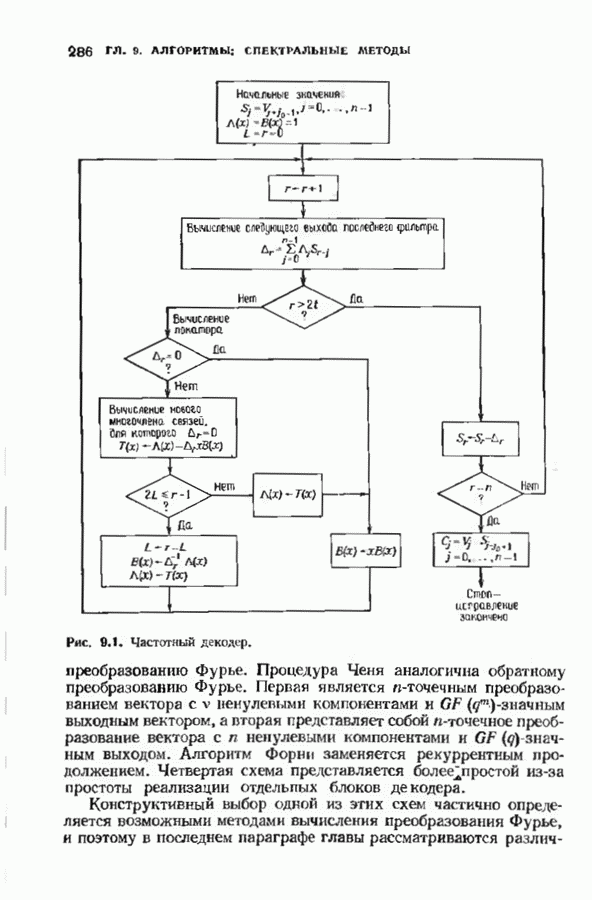
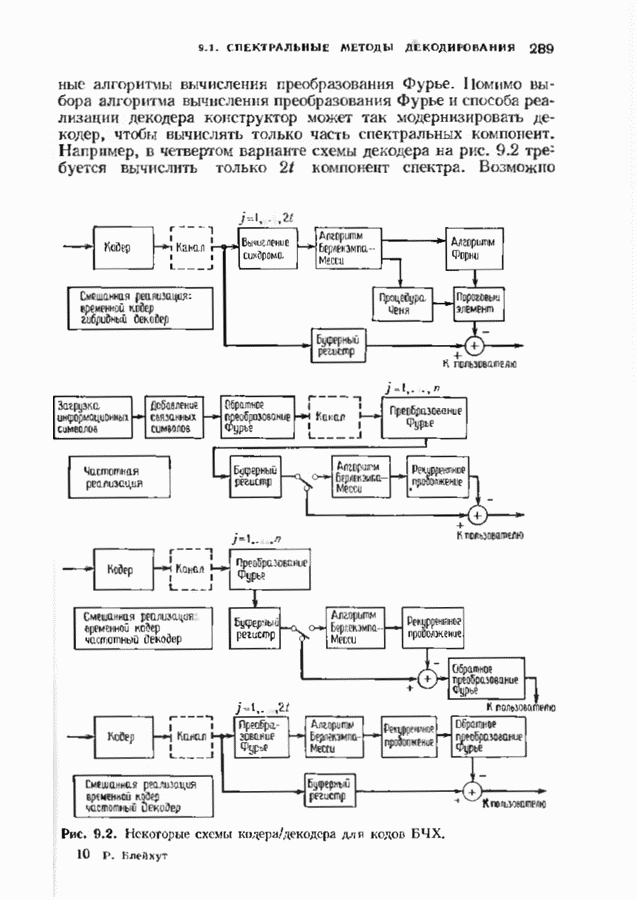



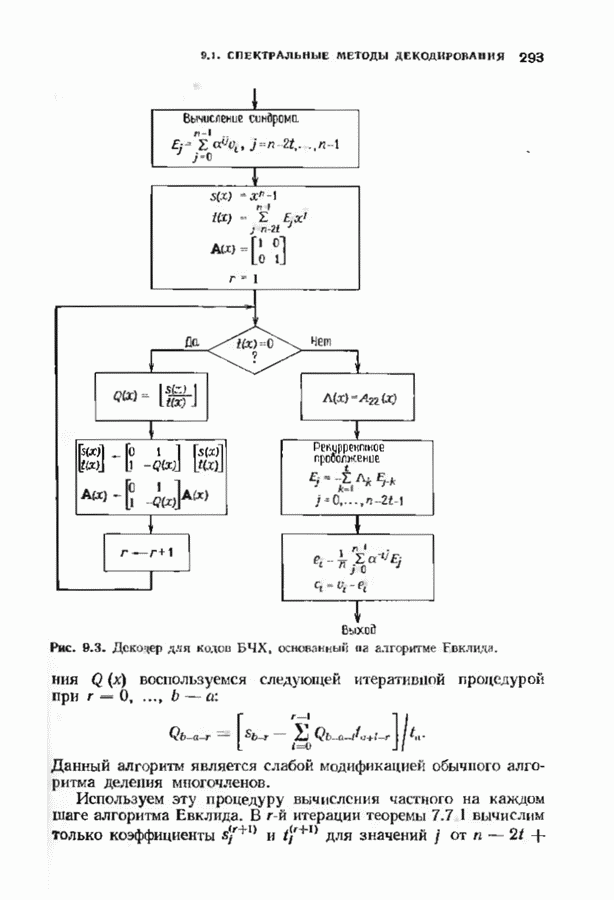





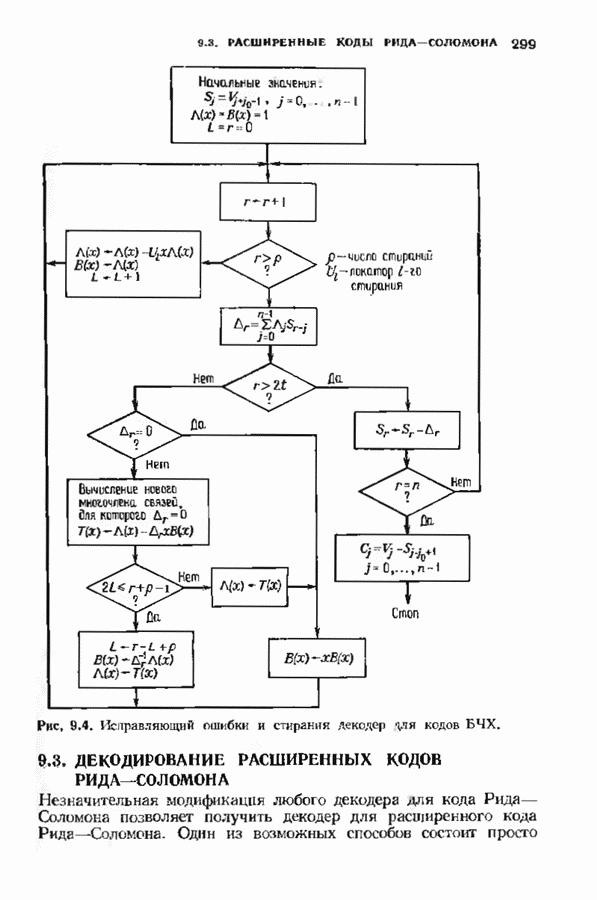


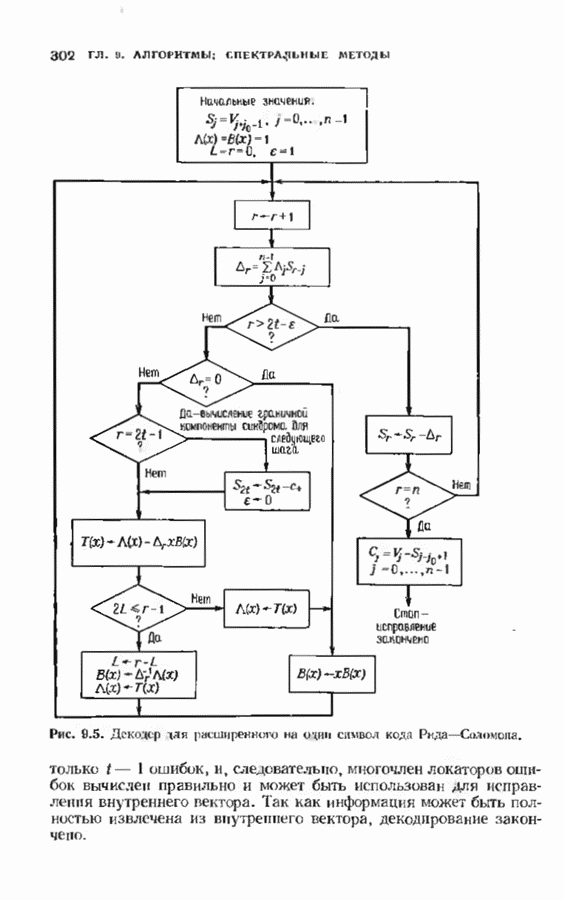






























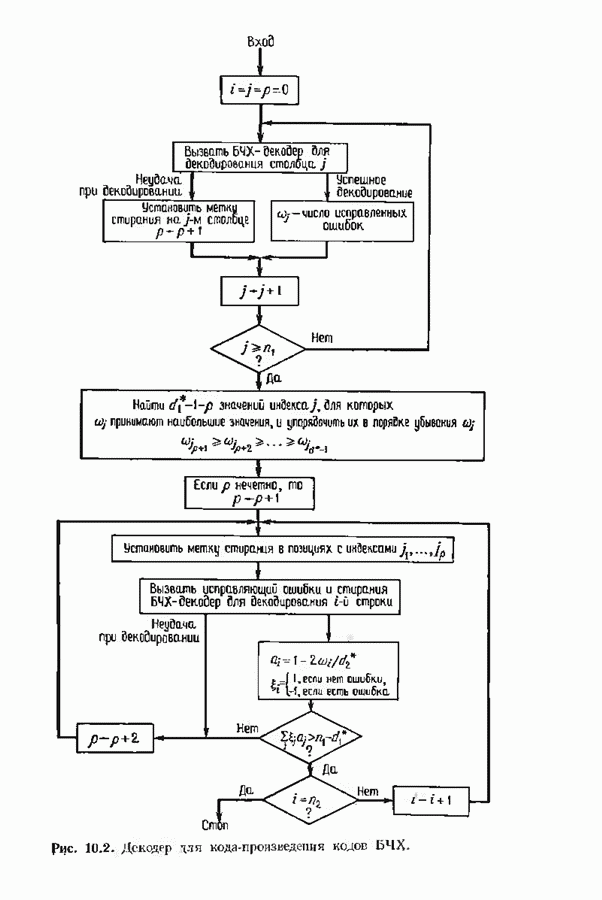















































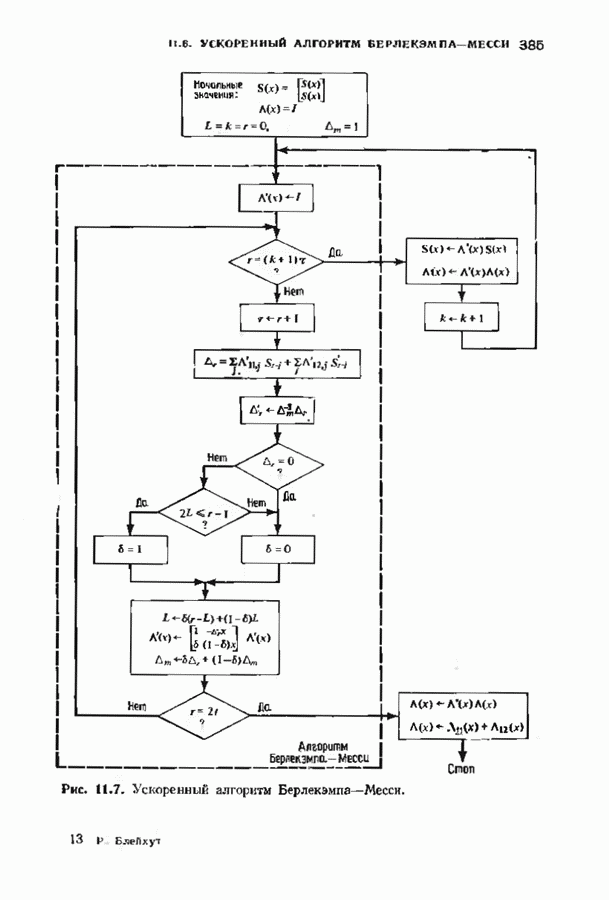



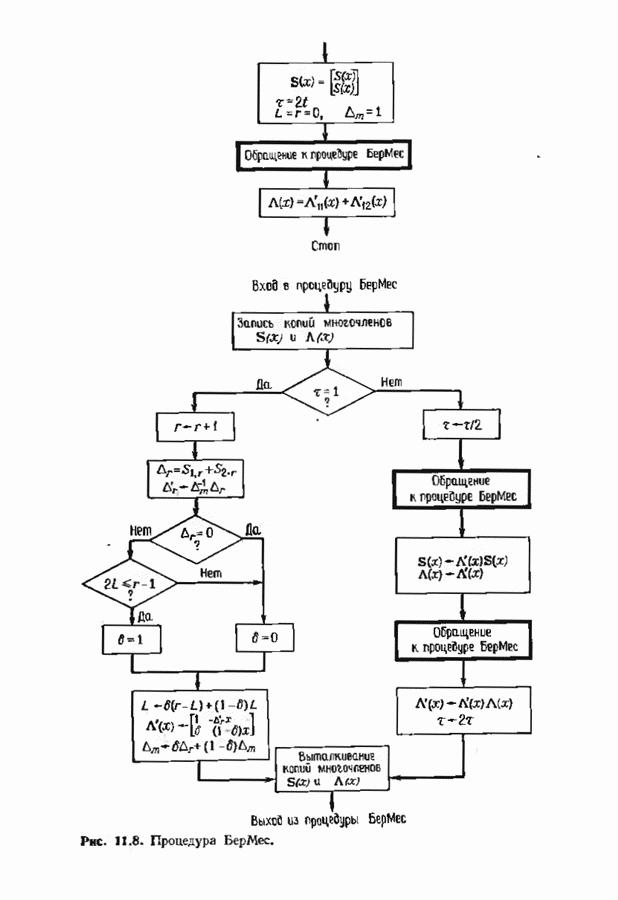













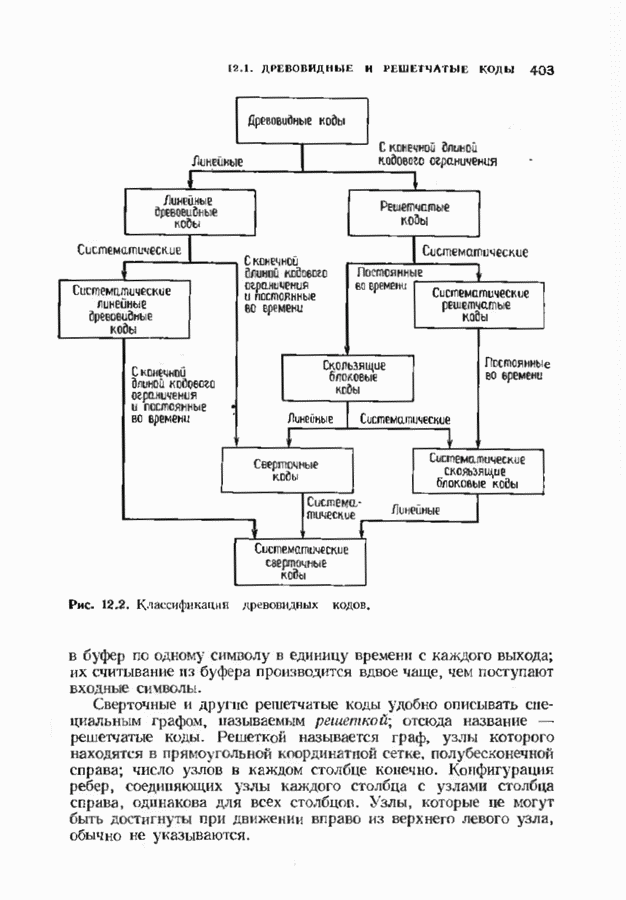

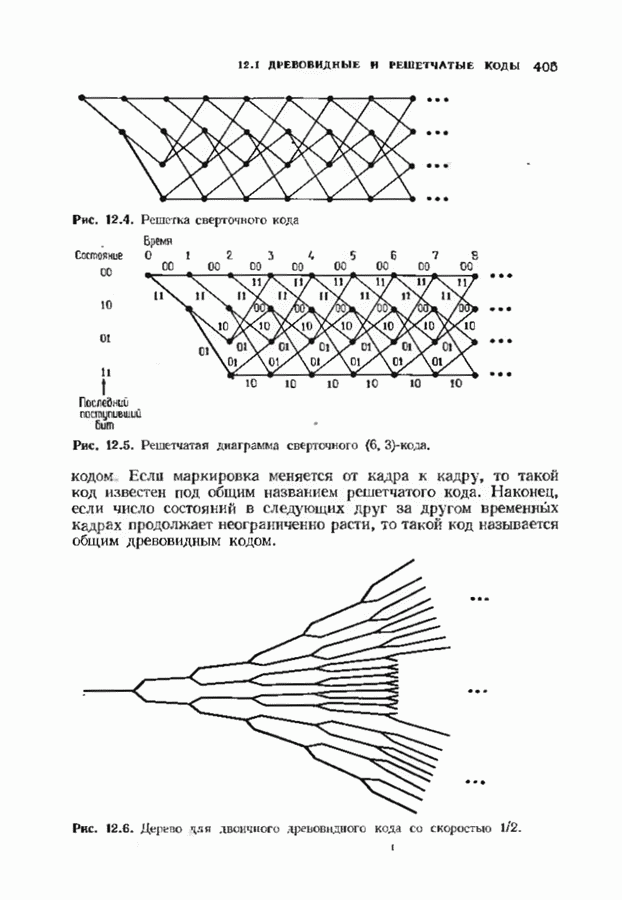

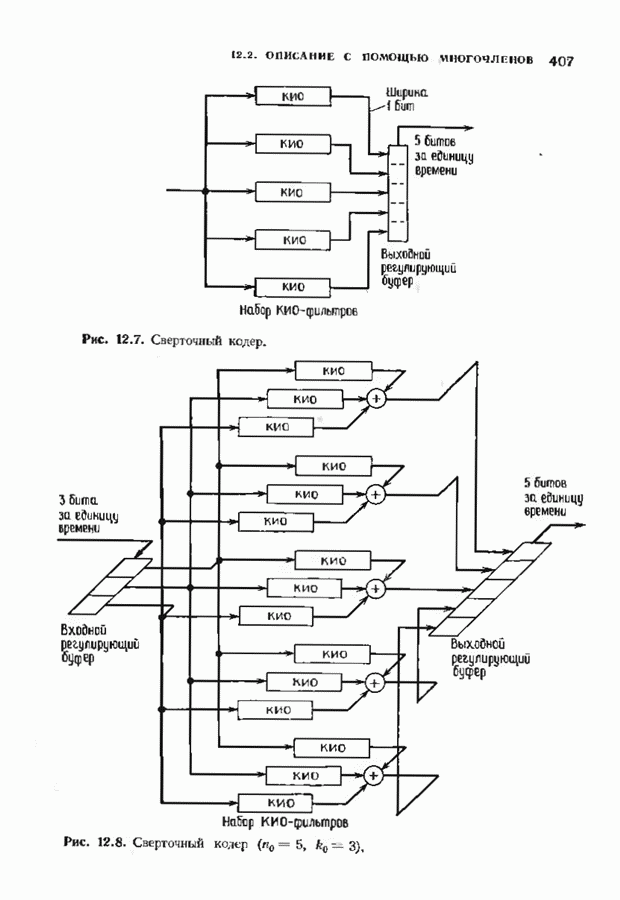




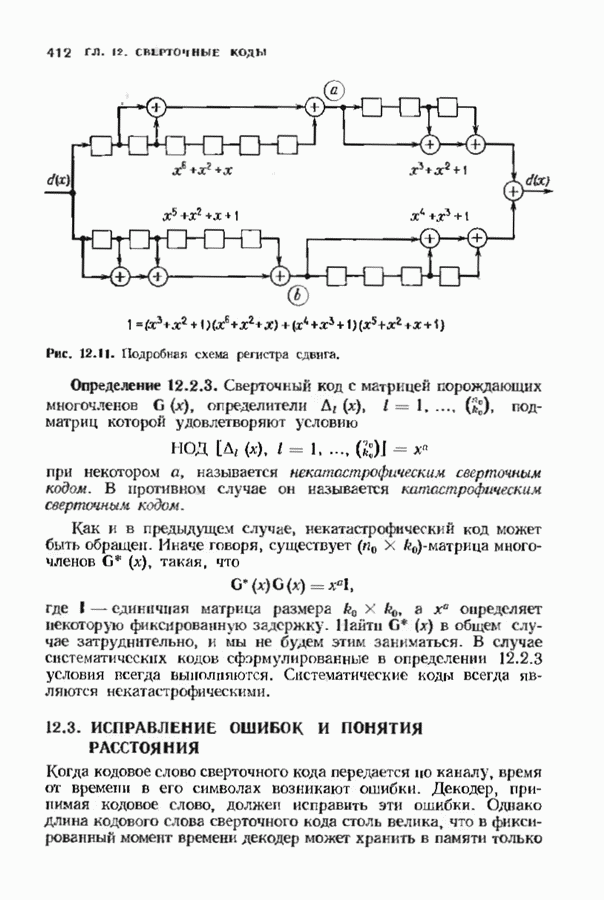




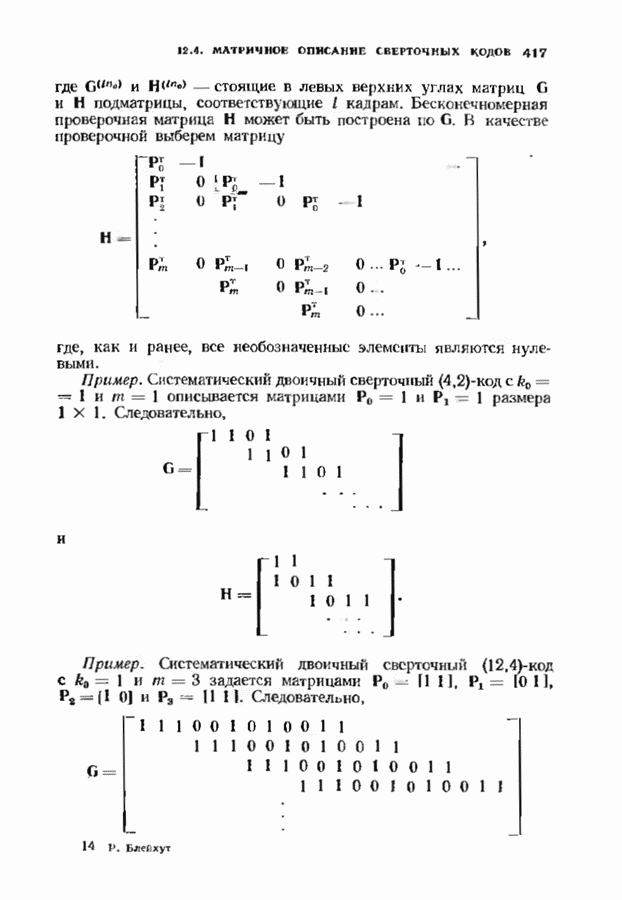


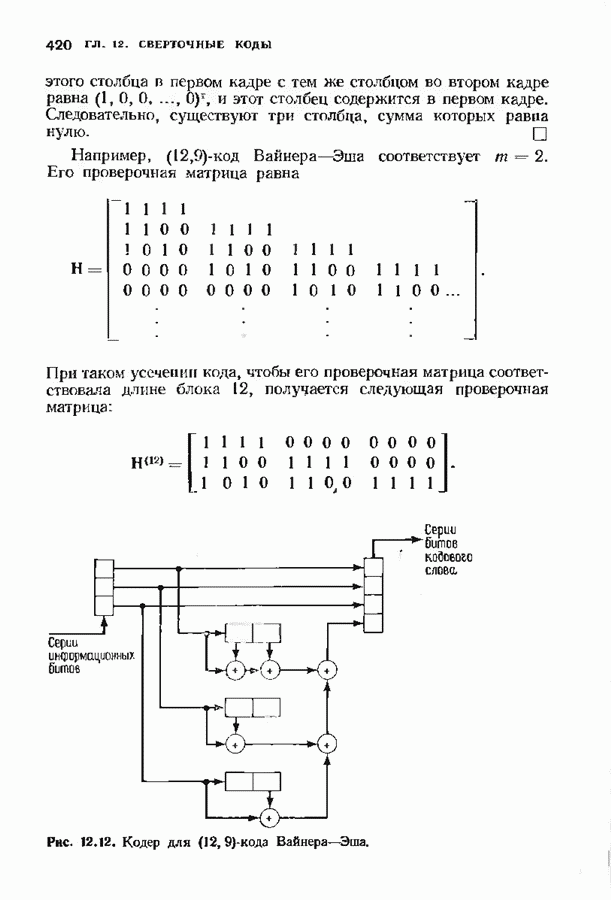
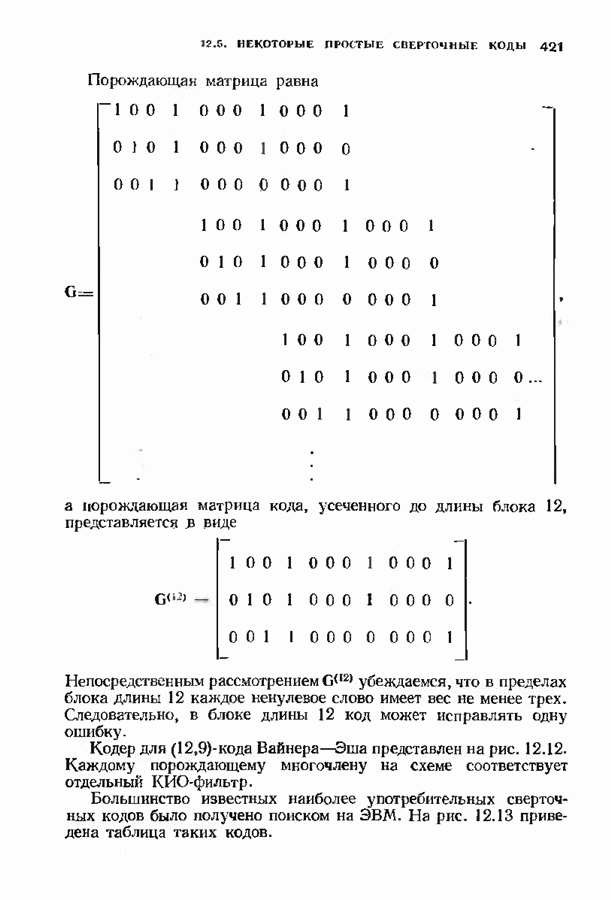


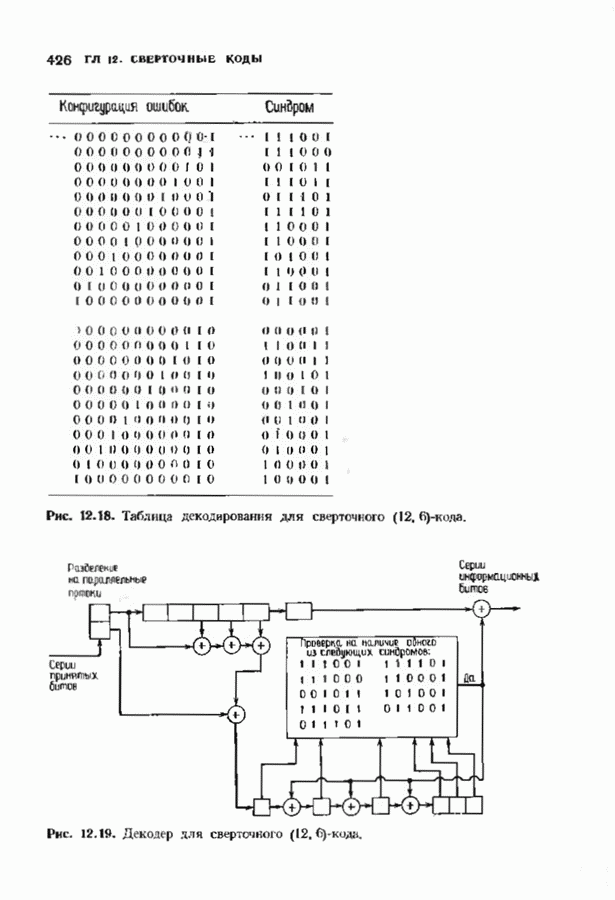
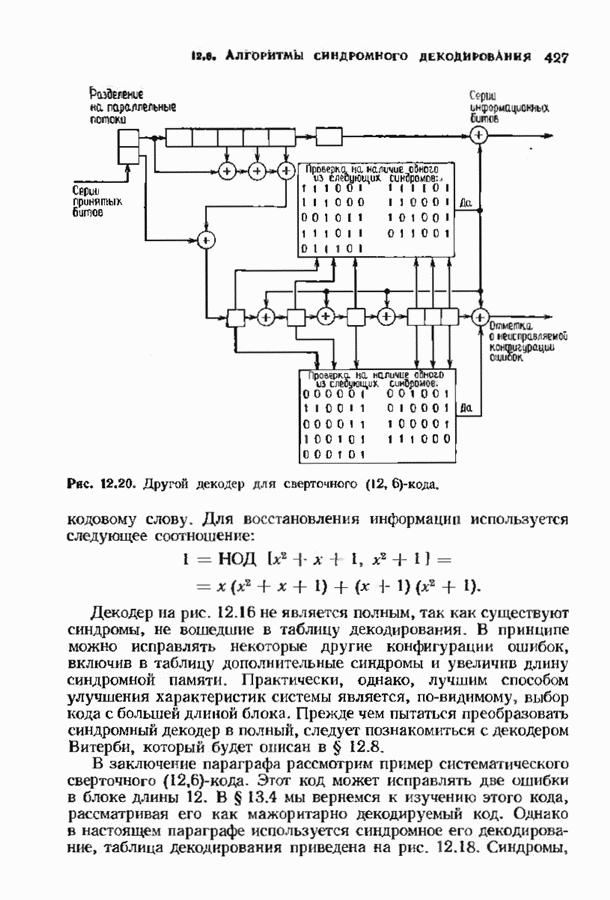



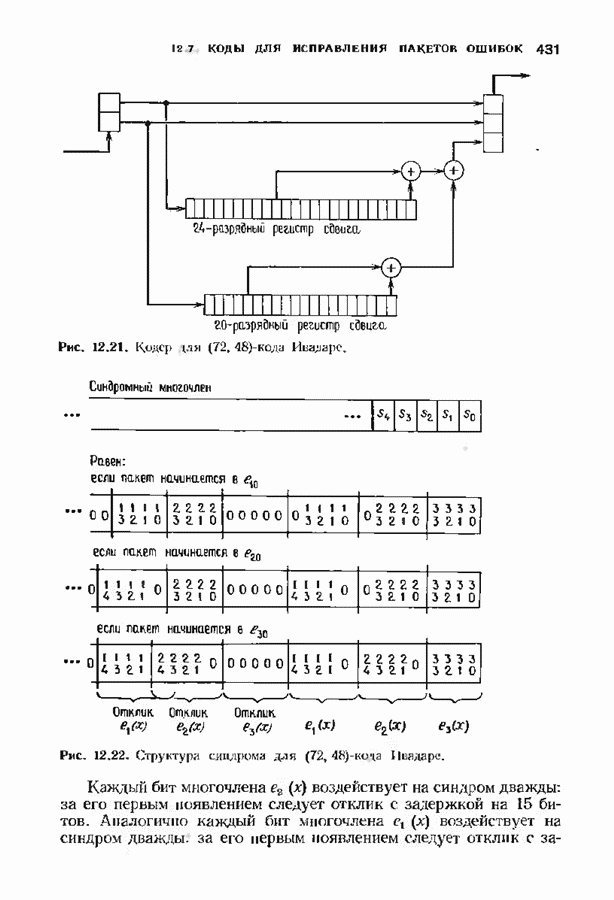
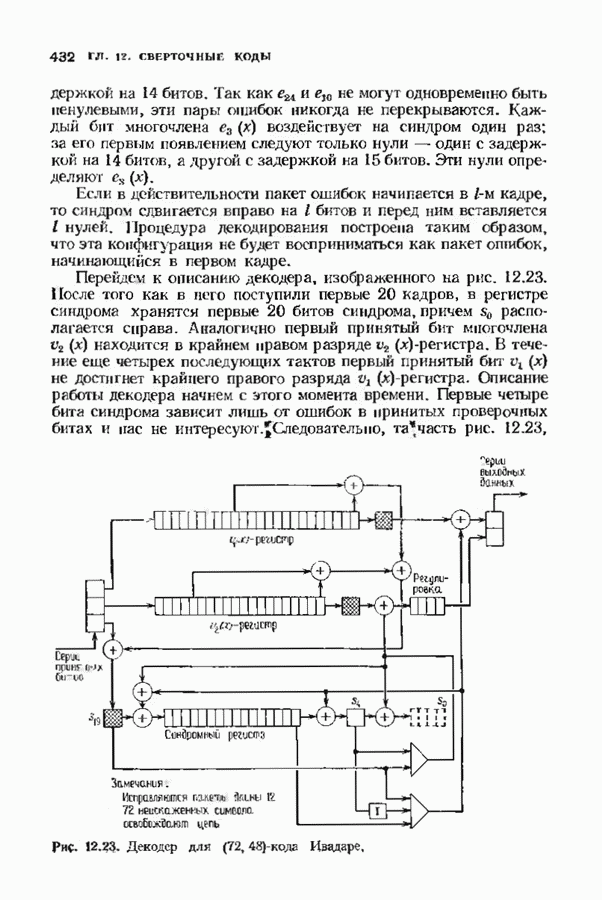



























































































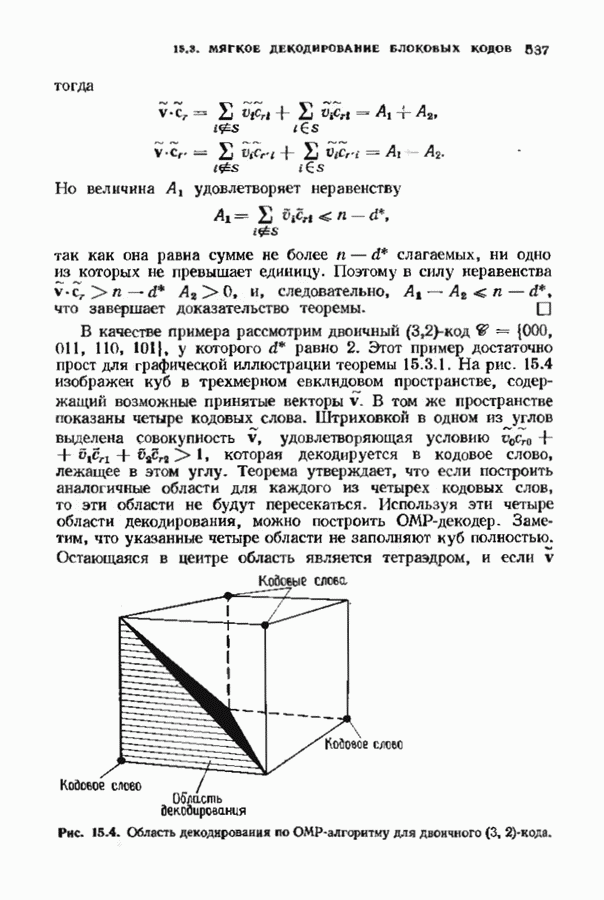

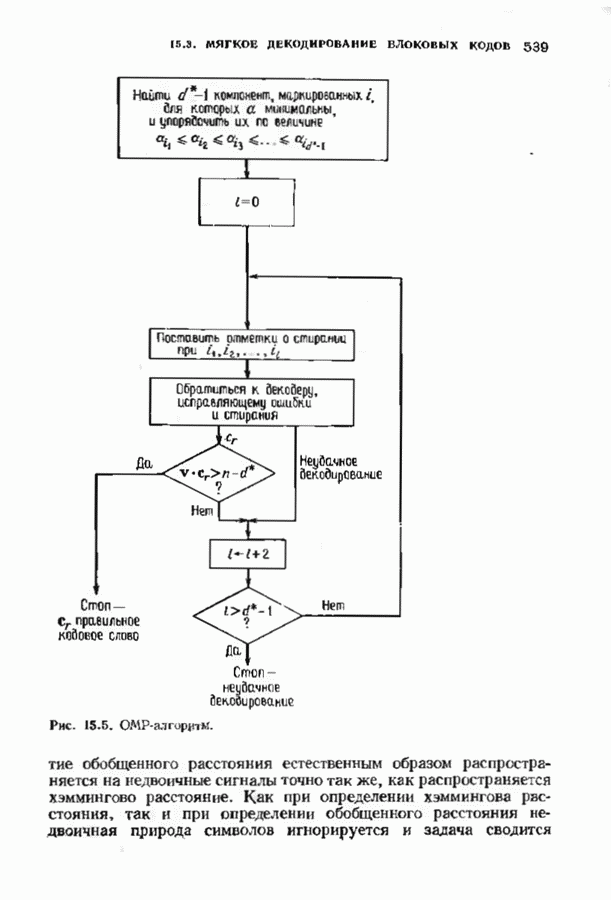




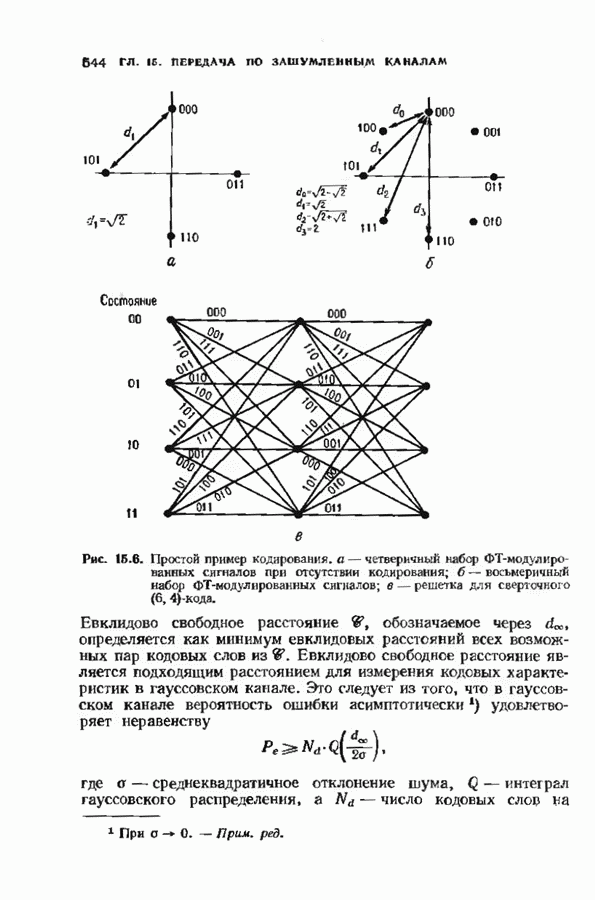
















 соответствующих им многочленов ошибок. Такой табличный декодер можно значительно упростить, воспользовавшись сильной алгебраической структурой кода для отыскания связей между синдромами. Опираясь на эти связи, можно запомнить только многочлены ошибок, соответствующие некоторым типичным синдромным многочленам. Вычисление остальных необходимых величин осуществляется затем с помощью простых вычислительных алгоритмов.
соответствующих им многочленов ошибок. Такой табличный декодер можно значительно упростить, воспользовавшись сильной алгебраической структурой кода для отыскания связей между синдромами. Опираясь на эти связи, можно запомнить только многочлены ошибок, соответствующие некоторым типичным синдромным многочленам. Вычисление остальных необходимых величин осуществляется затем с помощью простых вычислительных алгоритмов.
 исправляется. Затем принятое слово циклически сдвигается и повторяется процесс нахождения возможной ошибки в предшествующей по старшинству позиции
исправляется. Затем принятое слово циклически сдвигается и повторяется процесс нахождения возможной ошибки в предшествующей по старшинству позиции  Этот процесс повторяется последовательно для каждой компоненты; каждая компонента проверяется на наличие ошибки, и если ошибка найдена, то она исправляется.
Этот процесс повторяется последовательно для каждой компоненты; каждая компонента проверяется на наличие ошибки, и если ошибка найдена, то она исправляется.
 и
и






 то, согласно алгоритму деления,
то, согласно алгоритму деления,  определяется однозначно и
определяется однозначно и


 исправляемая конфигурация ошибок, то многочлен
исправляемая конфигурация ошибок, то многочлен

 Следовательно,
Следовательно,  также является исправляемой конфигурацией ошибки, и его синдром дается равенством
также является исправляемой конфигурацией ошибки, и его синдром дается равенством

 представляют собой вычисленные синдром и ошибку соответственно и что надо проверить, является ли
представляют собой вычисленные синдром и ошибку соответственно и что надо проверить, является ли  синдромом для многочлена ошибок
синдромом для многочлена ошибок  Проверим, выполняется ли равенство
Проверим, выполняется ли равенство  если да, то мы знаем, что
если да, то мы знаем, что  Если нет, то вычислим
Если нет, то вычислим  и сравним его с
и сравним его с  Если они совпадают, то
Если они совпадают, то


 так что мы знаем
так что мы знаем  Продолжая таким образом, вычислим
Продолжая таким образом, вычислим  в случае совпадения этого многочлена с
в случае совпадения этого многочлена с  заключаем, что
заключаем, что  равен
равен  и т. д.
и т. д.
 сравнивается со всеми синдромами, которые содержатся в таблице. Затем вычисляется
сравнивается со всеми синдромами, которые содержатся в таблице. Затем вычисляется  и тоже сравнивается со всеми содержащимися в таблице синдромами. Повторая этот процесс
и тоже сравнивается со всеми содержащимися в таблице синдромами. Повторая этот процесс  раз, находим любую исправляемую кодом ошибку.
раз, находим любую исправляемую кодом ошибку.
 В результате такой операции в регистре цепи деления записан синдром
В результате такой операции в регистре цепи деления записан синдром  а буферный регистр содержит принятое слово. Вычисленный синдром сравнивается со всеми табличными синдромами, и в случае совпадения хранящийся в старшем разряде буфера символ исправляется. После этого синдромный регистр и буферный регистр один раз циклически сдвигаются. Это
а буферный регистр содержит принятое слово. Вычисленный синдром сравнивается со всеми табличными синдромами, и в случае совпадения хранящийся в старшем разряде буфера символ исправляется. После этого синдромный регистр и буферный регистр один раз циклически сдвигаются. Это
 Содержимое разрядов синдромного регистра теперь равно многочлену
Содержимое разрядов синдромного регистра теперь равно многочлену  представляющему собой синдром ошибки
представляющему собой синдром ошибки  Если этот новый синдром совпадает с одним из табличных синдромов, то в предыдущей по старшинству позиции произошла ошибка, которая теперь появится в последнем разряде буфера. Этот бит исправляется, и производится новый циклический сдвиг на одну позицию; синдромный регистр опять ютов к проверке ошибки в позиции, отстоящей от старшей на два такта. После повторения этого процесса
Если этот новый синдром совпадает с одним из табличных синдромов, то в предыдущей по старшинству позиции произошла ошибка, которая теперь появится в последнем разряде буфера. Этот бит исправляется, и производится новый циклический сдвиг на одну позицию; синдромный регистр опять ютов к проверке ошибки в позиции, отстоящей от старшей на два такта. После повторения этого процесса  раз все биты будут исправлены.
раз все биты будут исправлены.
 -код Хэмминга, задаваемый порождающим многочленом
-код Хэмминга, задаваемый порождающим многочленом  Так как этот код исправляет только одну ошибку, то имеется только одна конфигурация ошибки с единицей в старшем разряде, а именно
Так как этот код исправляет только одну ошибку, то имеется только одна конфигурация ошибки с единицей в старшем разряде, а именно  и соответствующий ей синдром равен
и соответствующий ей синдром равен  Декодер Меггитта для этого кода изображен на рис. 6.19. Вычисленный по принятому слову синдром будет содержаться в синдромном регистре после 15 сдвигов. Из них первые 4 сдвига нужны только для того, чтобы ввести в регистр данные, без которых нельзя начать деление. Если синдром равен (1001), то
Декодер Меггитта для этого кода изображен на рис. 6.19. Вычисленный по принятому слову синдром будет содержаться в синдромном регистре после 15 сдвигов. Из них первые 4 сдвига нужны только для того, чтобы ввести в регистр данные, без которых нельзя начать деление. Если синдром равен (1001), то  и соответствующий бит исправляется. Если после одного сдвша синдром равен (1001), то
и соответствующий бит исправляется. Если после одного сдвша синдром равен (1001), то  и соответствующий бит исправляется. Таким же способом проверяется необходимость исправления каждого из битов. После 15 таких сдвигов процесс
и соответствующий бит исправляется. Таким же способом проверяется необходимость исправления каждого из битов. После 15 таких сдвигов процесс

 -кода Хэмминга.
-кода Хэмминга.

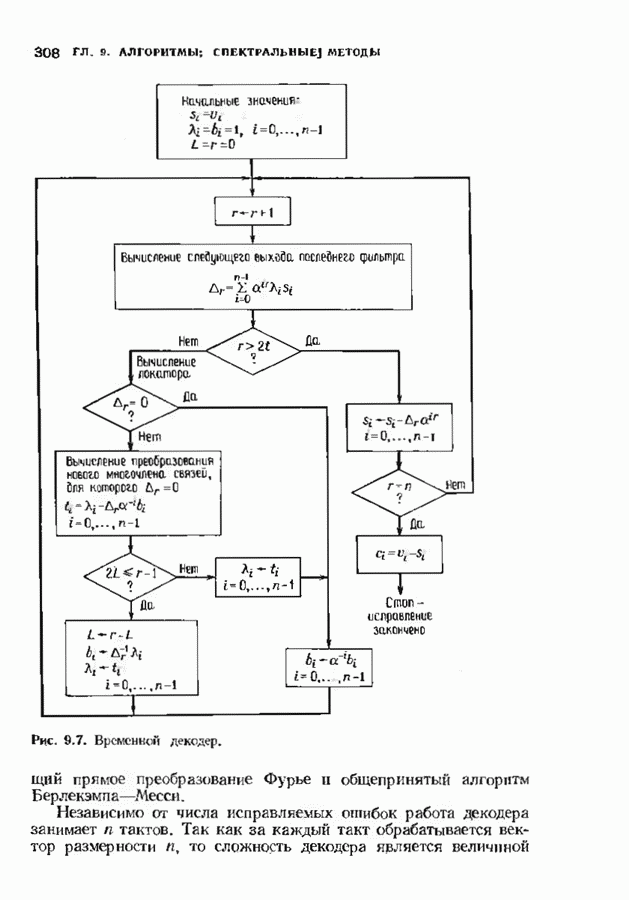
 рассматривать как своего рода попытку сделать декодер более изящным без существенного его усложнения.
рассматривать как своего рода попытку сделать декодер более изящным без существенного его усложнения.
 Тогда вклад в синдром от этой единственной компоненты вектора ошибок равен
Тогда вклад в синдром от этой единственной компоненты вектора ошибок равен

 этот вклад надо вычесть из истинного синдрома, заменив содержимое
этот вклад надо вычесть из истинного синдрома, заменив содержимое  синдромного регистра на
синдромного регистра на  Но многочлен
Но многочлен  может иметь много ненулевых коэффициентов, так что такое вычитание затрагивает многие ячейки синдромного регистра и создает дополнительные
может иметь много ненулевых коэффициентов, так что такое вычитание затрагивает многие ячейки синдромного регистра и создает дополнительные


 равна
равна  Но теперь отличен от нуля только один коэффициент многочлена
Но теперь отличен от нуля только один коэффициент многочлена  а именно старший. Соответственно после исправления
а именно старший. Соответственно после исправления  замены
замены  на
на  достаточно только вычесть
достаточно только вычесть  из старшего коэффициента синдрома. При этом полностью ликвидируется вклад, вносимый в синдром исправляемым символом.
из старшего коэффициента синдрома. При этом полностью ликвидируется вклад, вносимый в синдром исправляемым символом.
 на
на  выполняется сдвигом
выполняется сдвигом  в новую позицию синдромного регистра.
в новую позицию синдромного регистра.
 умножается на
умножается на  и делится на
и делится на  так что синдром равен
так что синдром равен

 синдром равен
синдром равен


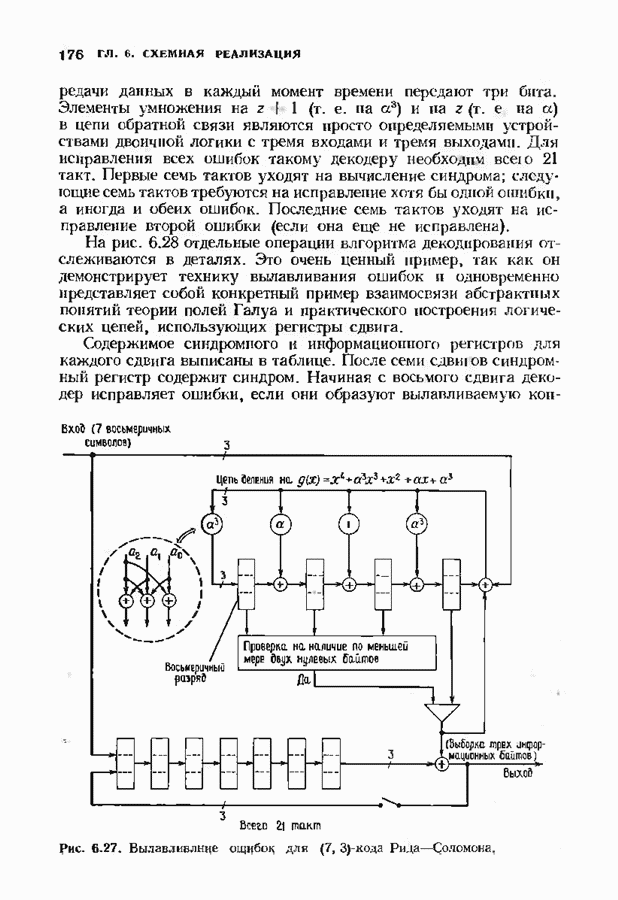
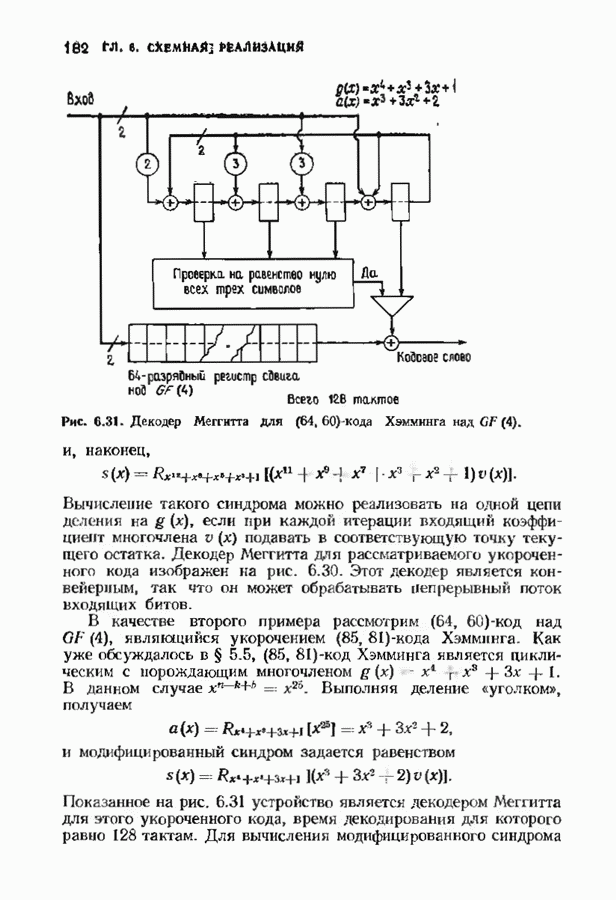
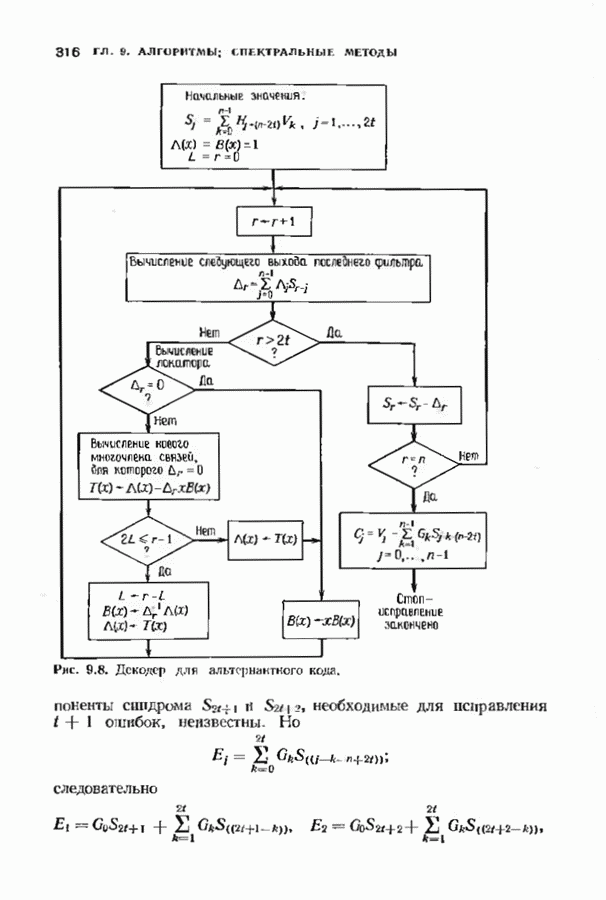
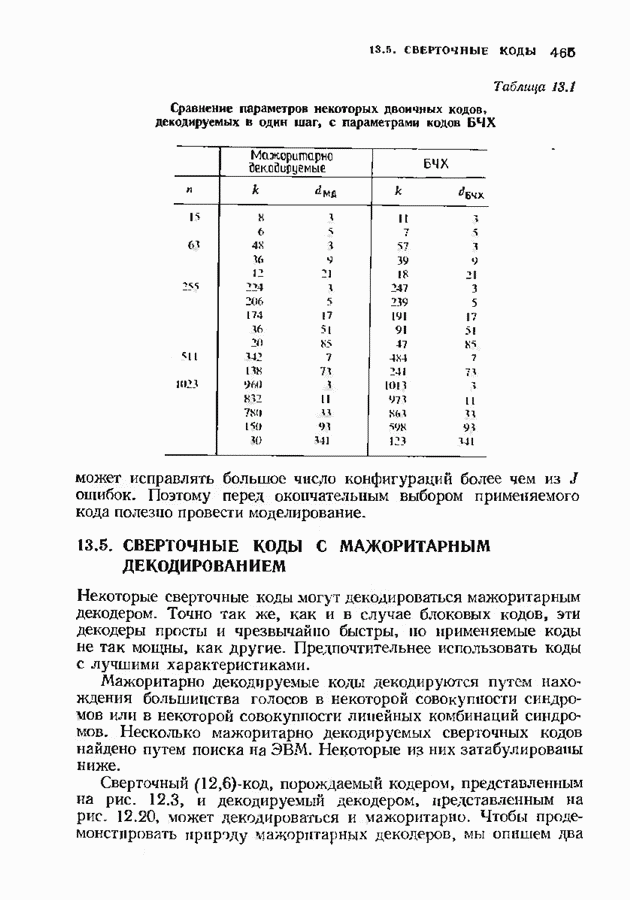
 -кода БЧХ, исправляющего две ошибки (этот код будет определен в гл. 7). Сейчас мы только укажем без доказательства, что этот код цикличен, порождается многочленом
-кода БЧХ, исправляющего две ошибки (этот код будет определен в гл. 7). Сейчас мы только укажем без доказательства, что этот код цикличен, порождается многочленом  и позволяет исправлять две ошибки. Среди них содержатся 15 конфигураций ошибок, содержащих ненулевой старший разряд: одна одиночная ошибка и 14 двойных.
и позволяет исправлять две ошибки. Среди них содержатся 15 конфигураций ошибок, содержащих ненулевой старший разряд: одна одиночная ошибка и 14 двойных.
 и делится на
и делится на  Следовательно, если
Следовательно, если  то
то

 то
то

 -битового синдромного регистра сравнивается с каждым из 15 табличных
-битового синдромного регистра сравнивается с каждым из 15 табличных  -битовых синдромов. Такое сравнение производится после каждого из 15 сдвигов, ибо каждая позиция в свою очередь проверяется на наличие ошибки в соответствующем бите. Всего декодирование занимает 30 тактов: 15 для вычисления синдрома и 15 для локализации ошибки.
-битовых синдромов. Такое сравнение производится после каждого из 15 сдвигов, ибо каждая позиция в свою очередь проверяется на наличие ошибки в соответствующем бите. Всего декодирование занимает 30 тактов: 15 для вычисления синдрома и 15 для локализации ошибки.
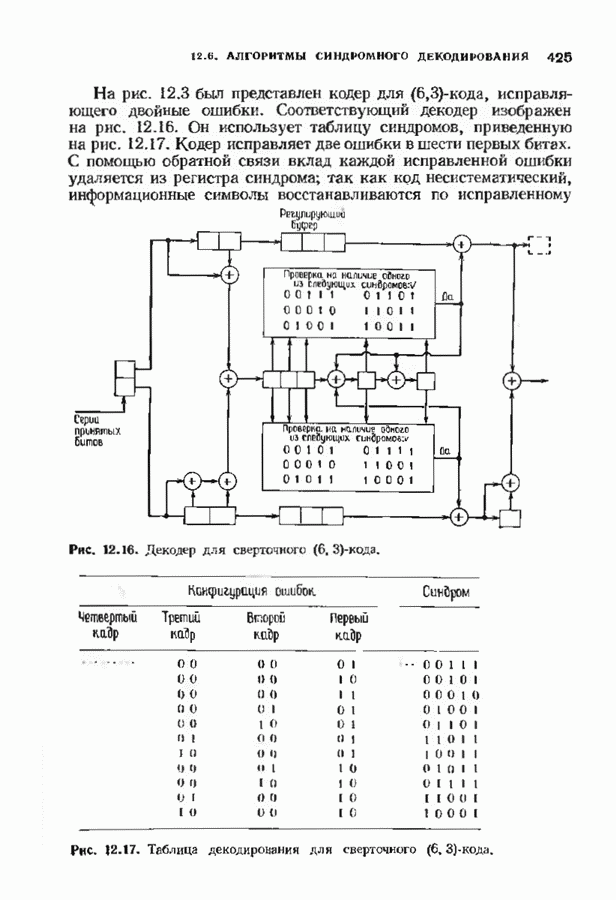
 после восьми циклических сдвигов переходит в вектор (000000010000001), где черта под единицей использвана в качестве маркера сдвигаемой единицы. Каждой из этих ошибок соответствует свой табличный синдром. Если удалить один из этих синдромов, то при соответствующем циклическом сдвиге ошибка все-таки будет найдена. Следовательно, для каждой такой пары достаточно запоминать только один синдром. В данном случае имеется только восемь снидромов, которые нужно запомнить. На рис. 6.22 они выписаны в первом столбце таблицы синдромов. Однако в тот момент, когда первая ошибка достигнет конца буфера, она может быть не исправлена, хотя в течение 15 сдвигов будет исправлена но меньшей мере одна ошибка. Для исправления обеих позиций необходимо произвести два полных цикла сдвигов, так что декодирование займет 45 тактов. Теперь необходимость модернизации синдрома очевидна, так как в противном случае ошибка не будет
после восьми циклических сдвигов переходит в вектор (000000010000001), где черта под единицей использвана в качестве маркера сдвигаемой единицы. Каждой из этих ошибок соответствует свой табличный синдром. Если удалить один из этих синдромов, то при соответствующем циклическом сдвиге ошибка все-таки будет найдена. Следовательно, для каждой такой пары достаточно запоминать только один синдром. В данном случае имеется только восемь снидромов, которые нужно запомнить. На рис. 6.22 они выписаны в первом столбце таблицы синдромов. Однако в тот момент, когда первая ошибка достигнет конца буфера, она может быть не исправлена, хотя в течение 15 сдвигов будет исправлена но меньшей мере одна ошибка. Для исправления обеих позиций необходимо произвести два полных цикла сдвигов, так что декодирование займет 45 тактов. Теперь необходимость модернизации синдрома очевидна, так как в противном случае ошибка не будет

 -кода БЧХ.
-кода БЧХ.

 -кода БЧХ.
-кода БЧХ.
 -кода БЧХ почти идентнчен декодеру с вылавливанием ошибок, который будет описан в следующем параграфе.
-кода БЧХ почти идентнчен декодеру с вылавливанием ошибок, который будет описан в следующем параграфе.